
Upload folder using huggingface_hub
Browse files- adapter_config.json +21 -0
- all_results.json +7 -0
- special_tokens_map.json +24 -0
- tokenizer.json +0 -0
- tokenizer.model +3 -0
- tokenizer_config.json +35 -0
- train_results.json +7 -0
- trainer_log.jsonl +21 -0
- trainer_state.json +145 -0
- training_args.bin +3 -0
- training_loss.png +0 -0
adapter_config.json
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"auto_mapping": null,
|
| 3 |
+
"base_model_name_or_path": "/data/lizongyue/llm_factory/model/meta-llama/Llama-2-7b-chat-hf",
|
| 4 |
+
"bias": "none",
|
| 5 |
+
"fan_in_fan_out": false,
|
| 6 |
+
"inference_mode": true,
|
| 7 |
+
"init_lora_weights": true,
|
| 8 |
+
"layers_pattern": null,
|
| 9 |
+
"layers_to_transform": null,
|
| 10 |
+
"lora_alpha": 32.0,
|
| 11 |
+
"lora_dropout": 0.1,
|
| 12 |
+
"modules_to_save": null,
|
| 13 |
+
"peft_type": "LORA",
|
| 14 |
+
"r": 8,
|
| 15 |
+
"revision": null,
|
| 16 |
+
"target_modules": [
|
| 17 |
+
"q_proj",
|
| 18 |
+
"v_proj"
|
| 19 |
+
],
|
| 20 |
+
"task_type": "CAUSAL_LM"
|
| 21 |
+
}
|
all_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 80.0,
|
| 3 |
+
"train_loss": 0.4674161618947983,
|
| 4 |
+
"train_runtime": 1650.9942,
|
| 5 |
+
"train_samples_per_second": 4.846,
|
| 6 |
+
"train_steps_per_second": 0.121
|
| 7 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "</s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": "</s>",
|
| 17 |
+
"unk_token": {
|
| 18 |
+
"content": "<unk>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
}
|
| 24 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9e556afd44213b6bd1be2b850ebbbd98f5481437a8021afaf58ee7fb1818d347
|
| 3 |
+
size 499723
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"__type": "AddedToken",
|
| 4 |
+
"content": "<s>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false
|
| 9 |
+
},
|
| 10 |
+
"chat_template": "{% if messages[0]['role'] == 'system' %}{% set loop_messages = messages[1:] %}{% set system_message = messages[0]['content'] %}{% else %}{% set loop_messages = messages %}{% set system_message = false %}{% endif %}{% for message in loop_messages %}{% if (message['role'] == 'user') != (loop.index0 % 2 == 0) %}{{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }}{% endif %}{% if loop.index0 == 0 and system_message != false %}{% set content = '<<SYS>>\\n' + system_message + '\\n<</SYS>>\\n\\n' + message['content'] %}{% else %}{% set content = message['content'] %}{% endif %}{% if message['role'] == 'user' %}{{ bos_token + '[INST] ' + content.strip() + ' [/INST]' }}{% elif message['role'] == 'assistant' %}{{ ' ' + content.strip() + ' ' + eos_token }}{% endif %}{% endfor %}",
|
| 11 |
+
"clean_up_tokenization_spaces": false,
|
| 12 |
+
"eos_token": {
|
| 13 |
+
"__type": "AddedToken",
|
| 14 |
+
"content": "</s>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false
|
| 19 |
+
},
|
| 20 |
+
"legacy": false,
|
| 21 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 22 |
+
"pad_token": null,
|
| 23 |
+
"padding_side": "right",
|
| 24 |
+
"sp_model_kwargs": {},
|
| 25 |
+
"split_special_tokens": false,
|
| 26 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 27 |
+
"unk_token": {
|
| 28 |
+
"__type": "AddedToken",
|
| 29 |
+
"content": "<unk>",
|
| 30 |
+
"lstrip": false,
|
| 31 |
+
"normalized": false,
|
| 32 |
+
"rstrip": false,
|
| 33 |
+
"single_word": false
|
| 34 |
+
}
|
| 35 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 80.0,
|
| 3 |
+
"train_loss": 0.4674161618947983,
|
| 4 |
+
"train_runtime": 1650.9942,
|
| 5 |
+
"train_samples_per_second": 4.846,
|
| 6 |
+
"train_steps_per_second": 0.121
|
| 7 |
+
}
|
trainer_log.jsonl
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
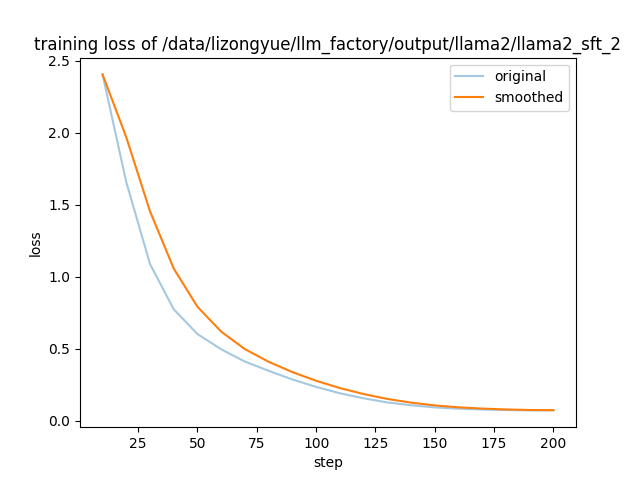
{"current_steps": 10, "total_steps": 200, "loss": 2.4048, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.9692208514878444e-05, "epoch": 4.0, "percentage": 5.0, "elapsed_time": "0:01:23", "remaining_time": "0:26:25"}
|
| 2 |
+
{"current_steps": 20, "total_steps": 200, "loss": 1.6571, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.877641290737884e-05, "epoch": 8.0, "percentage": 10.0, "elapsed_time": "0:02:47", "remaining_time": "0:25:03"}
|
| 3 |
+
{"current_steps": 30, "total_steps": 200, "loss": 1.088, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.72751631047092e-05, "epoch": 12.0, "percentage": 15.0, "elapsed_time": "0:04:09", "remaining_time": "0:23:34"}
|
| 4 |
+
{"current_steps": 40, "total_steps": 200, "loss": 0.7735, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.522542485937369e-05, "epoch": 16.0, "percentage": 20.0, "elapsed_time": "0:05:31", "remaining_time": "0:22:07"}
|
| 5 |
+
{"current_steps": 50, "total_steps": 200, "loss": 0.6017, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.267766952966369e-05, "epoch": 20.0, "percentage": 25.0, "elapsed_time": "0:06:54", "remaining_time": "0:20:44"}
|
| 6 |
+
{"current_steps": 60, "total_steps": 200, "loss": 0.4956, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.969463130731183e-05, "epoch": 24.0, "percentage": 30.0, "elapsed_time": "0:08:16", "remaining_time": "0:19:17"}
|
| 7 |
+
{"current_steps": 70, "total_steps": 200, "loss": 0.4105, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.634976249348867e-05, "epoch": 28.0, "percentage": 35.0, "elapsed_time": "0:09:38", "remaining_time": "0:17:53"}
|
| 8 |
+
{"current_steps": 80, "total_steps": 200, "loss": 0.3463, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.272542485937369e-05, "epoch": 32.0, "percentage": 40.0, "elapsed_time": "0:11:00", "remaining_time": "0:16:31"}
|
| 9 |
+
{"current_steps": 90, "total_steps": 200, "loss": 0.2862, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.8910861626005776e-05, "epoch": 36.0, "percentage": 45.0, "elapsed_time": "0:12:24", "remaining_time": "0:15:09"}
|
| 10 |
+
{"current_steps": 100, "total_steps": 200, "loss": 0.2345, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.5e-05, "epoch": 40.0, "percentage": 50.0, "elapsed_time": "0:13:46", "remaining_time": "0:13:46"}
|
| 11 |
+
{"current_steps": 110, "total_steps": 200, "loss": 0.1905, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.1089138373994223e-05, "epoch": 44.0, "percentage": 55.0, "elapsed_time": "0:15:08", "remaining_time": "0:12:23"}
|
| 12 |
+
{"current_steps": 120, "total_steps": 200, "loss": 0.1554, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.7274575140626318e-05, "epoch": 48.0, "percentage": 60.0, "elapsed_time": "0:16:30", "remaining_time": "0:11:00"}
|
| 13 |
+
{"current_steps": 130, "total_steps": 200, "loss": 0.1269, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.3650237506511331e-05, "epoch": 52.0, "percentage": 65.0, "elapsed_time": "0:17:53", "remaining_time": "0:09:37"}
|
| 14 |
+
{"current_steps": 140, "total_steps": 200, "loss": 0.1071, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.0305368692688174e-05, "epoch": 56.0, "percentage": 70.0, "elapsed_time": "0:19:15", "remaining_time": "0:08:15"}
|
| 15 |
+
{"current_steps": 150, "total_steps": 200, "loss": 0.0921, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 7.3223304703363135e-06, "epoch": 60.0, "percentage": 75.0, "elapsed_time": "0:20:38", "remaining_time": "0:06:52"}
|
| 16 |
+
{"current_steps": 160, "total_steps": 200, "loss": 0.0832, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.7745751406263165e-06, "epoch": 64.0, "percentage": 80.0, "elapsed_time": "0:22:01", "remaining_time": "0:05:30"}
|
| 17 |
+
{"current_steps": 170, "total_steps": 200, "loss": 0.0777, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.7248368952908053e-06, "epoch": 68.0, "percentage": 85.0, "elapsed_time": "0:23:24", "remaining_time": "0:04:07"}
|
| 18 |
+
{"current_steps": 180, "total_steps": 200, "loss": 0.0739, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.2235870926211619e-06, "epoch": 72.0, "percentage": 90.0, "elapsed_time": "0:24:46", "remaining_time": "0:02:45"}
|
| 19 |
+
{"current_steps": 190, "total_steps": 200, "loss": 0.0714, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.077914851215585e-07, "epoch": 76.0, "percentage": 95.0, "elapsed_time": "0:26:08", "remaining_time": "0:01:22"}
|
| 20 |
+
{"current_steps": 200, "total_steps": 200, "loss": 0.072, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 0.0, "epoch": 80.0, "percentage": 100.0, "elapsed_time": "0:27:30", "remaining_time": "0:00:00"}
|
| 21 |
+
{"current_steps": 200, "total_steps": 200, "loss": null, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": null, "epoch": 80.0, "percentage": 100.0, "elapsed_time": "0:27:30", "remaining_time": "0:00:00"}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 80.0,
|
| 5 |
+
"global_step": 200,
|
| 6 |
+
"is_hyper_param_search": false,
|
| 7 |
+
"is_local_process_zero": true,
|
| 8 |
+
"is_world_process_zero": true,
|
| 9 |
+
"log_history": [
|
| 10 |
+
{
|
| 11 |
+
"epoch": 4.0,
|
| 12 |
+
"learning_rate": 4.9692208514878444e-05,
|
| 13 |
+
"loss": 2.4048,
|
| 14 |
+
"step": 10
|
| 15 |
+
},
|
| 16 |
+
{
|
| 17 |
+
"epoch": 8.0,
|
| 18 |
+
"learning_rate": 4.877641290737884e-05,
|
| 19 |
+
"loss": 1.6571,
|
| 20 |
+
"step": 20
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
"epoch": 12.0,
|
| 24 |
+
"learning_rate": 4.72751631047092e-05,
|
| 25 |
+
"loss": 1.088,
|
| 26 |
+
"step": 30
|
| 27 |
+
},
|
| 28 |
+
{
|
| 29 |
+
"epoch": 16.0,
|
| 30 |
+
"learning_rate": 4.522542485937369e-05,
|
| 31 |
+
"loss": 0.7735,
|
| 32 |
+
"step": 40
|
| 33 |
+
},
|
| 34 |
+
{
|
| 35 |
+
"epoch": 20.0,
|
| 36 |
+
"learning_rate": 4.267766952966369e-05,
|
| 37 |
+
"loss": 0.6017,
|
| 38 |
+
"step": 50
|
| 39 |
+
},
|
| 40 |
+
{
|
| 41 |
+
"epoch": 24.0,
|
| 42 |
+
"learning_rate": 3.969463130731183e-05,
|
| 43 |
+
"loss": 0.4956,
|
| 44 |
+
"step": 60
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
"epoch": 28.0,
|
| 48 |
+
"learning_rate": 3.634976249348867e-05,
|
| 49 |
+
"loss": 0.4105,
|
| 50 |
+
"step": 70
|
| 51 |
+
},
|
| 52 |
+
{
|
| 53 |
+
"epoch": 32.0,
|
| 54 |
+
"learning_rate": 3.272542485937369e-05,
|
| 55 |
+
"loss": 0.3463,
|
| 56 |
+
"step": 80
|
| 57 |
+
},
|
| 58 |
+
{
|
| 59 |
+
"epoch": 36.0,
|
| 60 |
+
"learning_rate": 2.8910861626005776e-05,
|
| 61 |
+
"loss": 0.2862,
|
| 62 |
+
"step": 90
|
| 63 |
+
},
|
| 64 |
+
{
|
| 65 |
+
"epoch": 40.0,
|
| 66 |
+
"learning_rate": 2.5e-05,
|
| 67 |
+
"loss": 0.2345,
|
| 68 |
+
"step": 100
|
| 69 |
+
},
|
| 70 |
+
{
|
| 71 |
+
"epoch": 44.0,
|
| 72 |
+
"learning_rate": 2.1089138373994223e-05,
|
| 73 |
+
"loss": 0.1905,
|
| 74 |
+
"step": 110
|
| 75 |
+
},
|
| 76 |
+
{
|
| 77 |
+
"epoch": 48.0,
|
| 78 |
+
"learning_rate": 1.7274575140626318e-05,
|
| 79 |
+
"loss": 0.1554,
|
| 80 |
+
"step": 120
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
"epoch": 52.0,
|
| 84 |
+
"learning_rate": 1.3650237506511331e-05,
|
| 85 |
+
"loss": 0.1269,
|
| 86 |
+
"step": 130
|
| 87 |
+
},
|
| 88 |
+
{
|
| 89 |
+
"epoch": 56.0,
|
| 90 |
+
"learning_rate": 1.0305368692688174e-05,
|
| 91 |
+
"loss": 0.1071,
|
| 92 |
+
"step": 140
|
| 93 |
+
},
|
| 94 |
+
{
|
| 95 |
+
"epoch": 60.0,
|
| 96 |
+
"learning_rate": 7.3223304703363135e-06,
|
| 97 |
+
"loss": 0.0921,
|
| 98 |
+
"step": 150
|
| 99 |
+
},
|
| 100 |
+
{
|
| 101 |
+
"epoch": 64.0,
|
| 102 |
+
"learning_rate": 4.7745751406263165e-06,
|
| 103 |
+
"loss": 0.0832,
|
| 104 |
+
"step": 160
|
| 105 |
+
},
|
| 106 |
+
{
|
| 107 |
+
"epoch": 68.0,
|
| 108 |
+
"learning_rate": 2.7248368952908053e-06,
|
| 109 |
+
"loss": 0.0777,
|
| 110 |
+
"step": 170
|
| 111 |
+
},
|
| 112 |
+
{
|
| 113 |
+
"epoch": 72.0,
|
| 114 |
+
"learning_rate": 1.2235870926211619e-06,
|
| 115 |
+
"loss": 0.0739,
|
| 116 |
+
"step": 180
|
| 117 |
+
},
|
| 118 |
+
{
|
| 119 |
+
"epoch": 76.0,
|
| 120 |
+
"learning_rate": 3.077914851215585e-07,
|
| 121 |
+
"loss": 0.0714,
|
| 122 |
+
"step": 190
|
| 123 |
+
},
|
| 124 |
+
{
|
| 125 |
+
"epoch": 80.0,
|
| 126 |
+
"learning_rate": 0.0,
|
| 127 |
+
"loss": 0.072,
|
| 128 |
+
"step": 200
|
| 129 |
+
},
|
| 130 |
+
{
|
| 131 |
+
"epoch": 80.0,
|
| 132 |
+
"step": 200,
|
| 133 |
+
"total_flos": 3.758484756417741e+16,
|
| 134 |
+
"train_loss": 0.4674161618947983,
|
| 135 |
+
"train_runtime": 1650.9942,
|
| 136 |
+
"train_samples_per_second": 4.846,
|
| 137 |
+
"train_steps_per_second": 0.121
|
| 138 |
+
}
|
| 139 |
+
],
|
| 140 |
+
"max_steps": 200,
|
| 141 |
+
"num_train_epochs": 100,
|
| 142 |
+
"total_flos": 3.758484756417741e+16,
|
| 143 |
+
"trial_name": null,
|
| 144 |
+
"trial_params": null
|
| 145 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:04af69d64033227c400b4e671a8f03858f8738666ac1b19e83577ed306cf5f52
|
| 3 |
+
size 4219
|
training_loss.png
ADDED
|