---
license: creativeml-openrail-m
base_model: "PixArt-alpha/PixArt-Sigma-XL-2-1024-MS"
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- full
inference: true
widget:
- text: 'A blonde sexy girl, wearing glasses at latex shirt and a blue beanie with a tattoo, blue and white, highly detailed, sublime, extremely beautiful, sharp focus, refined, cinematic, intricate, elegant, dynamic, rich deep colors, bright color, shining light, attractive, cute, pretty, background full, epic composition, dramatic atmosphere, radiant, professional, stunning'
parameters:
negative_prompt: 'blurry, cropped, ugly'
output:
url: ./assets/1.png
- text: 'a wizard with a glowing staff and a glowing hat, colorful magic, dramatic atmosphere, sharp focus, highly detailed, cinematic, original composition, fine detail, intricate, elegant, creative, color spread, shiny, amazing, symmetry, illuminated, inspired, pretty, attractive, artistic, dynamic background, relaxed, professional, extremely inspirational, beautiful, determined, cute, adorable, best'
parameters:
negative_prompt: 'blurry, cropped, ugly'
output:
url: ./assets/2.png
- text: 'girl in modern car, intricate, elegant, highly detailed, extremely complimentary colors, beautiful, glowing aesthetic, pretty, dramatic light, sharp focus, perfect composition, clear artistic color, calm professional background, precise, joyful, emotional, unique, cute, best, gorgeous, great delicate, expressive, thought, iconic, fine, awesome, creative, winning, charming, enhanced'
parameters:
negative_prompt: 'blurry, cropped, ugly'
output:
url: ./assets/3.png
- text: 'girl in modern car, intricate, elegant, highly detailed, extremely complimentary colors, beautiful, glowing aesthetic, pretty, dramatic light, sharp focus, perfect composition, clear artistic color, calm professional background, precise, joyful, emotional, unique, cute, best, gorgeous, great delicate, expressive, thought, iconic, fine, awesome, creative, winning, charming, enhanced'
parameters:
negative_prompt: 'blurry, cropped, ugly'
output:
url: ./assets/3.png
- text: 'A girl stands amidst scattered glass shards, surrounded by a beautifully crafted and expansive world. The scene is depicted from a dynamic angle, emphasizing her determined expression. The background features vast landscapes with floating crystals and soft, glowing lights that create a mystical and grand atmosphere.'
parameters:
negative_prompt: 'blurry, cropped, ugly'
output:
url: ./assets/ComfyUI_PixArt_00036_.png
---
# SigmaJourney: PixartSigma + MidJourney v6
## Inference
- Duplicated from [TensorFamily/SigmaJourney](https://huggingface.co/TensorFamily/SigmaJourney) and combined with [PixArt-alpha/PixArt-Sigma-XL-2-1024-MS](https://huggingface.co/PixArt-alpha/PixArt-Sigma-XL-2-1024-MS) for easier use with Diffusers PixArtSigmaPipeline.
### ComfyUI
- Download model file `transformer/diffusion_pytorch_model.safetensors` and put into `ComfyUI/models/checkpoints`
- Use ExtraModels node: https://github.com/city96/ComfyUI_ExtraModels?tab=readme-ov-file#pixart

```python
import torch
from diffusers import DiffusionPipeline, EulerAncestralDiscreteScheduler
from diffusers.models import PixArtTransformer2DModel
model_id = "toilaluan/SigmaJourney"
negative_prompt = "malformed, disgusting, overexposed, washed-out"
pipeline = DiffusionPipeline.from_pretrained("PixArt-alpha/PixArt-Sigma-XL-2-1024-MS", torch_dtype=torch.float16)
pipeline.transformer = PixArtTransformer2DModel.from_pretrained(model_id, subfolder="transformer", torch_dtype=torch.float16)
pipeline.scheduler = EulerAncestralDiscreteScheduler.from_config(pipeline.scheduler.config)
pipeline.to('cuda' if torch.cuda.is_available() else 'cpu')
prompt = "On the left, there is a red cube. On the right, there is a blue sphere. On top of the red cube is a dog. On top of the blue sphere is a cat"
image = pipeline(
prompt=prompt,
negative_prompt='blurry, cropped, ugly',
num_inference_steps=30,
generator=torch.Generator(device='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu').manual_seed(1641421826),
width=1024,
height=1024,
guidance_scale=5.5,
).images[0]
image.save("output.png", format="JPEG")
```

# 🐱 PixArt-Σ Model Card

## Model
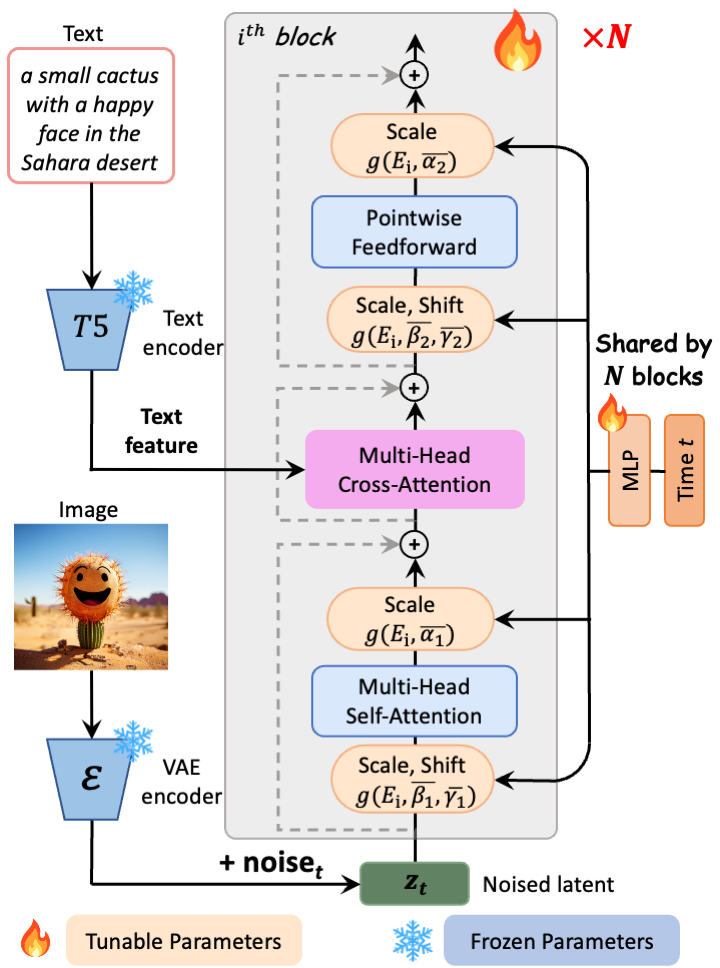
[PixArt-Σ](https://arxiv.org/abs/2403.04692) consists of pure transformer blocks for latent diffusion:
It can directly generate 1024px, 2K and 4K images from text prompts within a single sampling process.
Source code is available at https://github.com/PixArt-alpha/PixArt-sigma.
### Model Description
- **Developed by:** PixArt-Σ
- **Model type:** Diffusion-Transformer-based text-to-image generative model
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/LICENSE.md)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts.
It is a [Transformer Latent Diffusion Model](https://arxiv.org/abs/2310.00426) that uses one fixed, pretrained text encoders ([T5](
https://huggingface.co/DeepFloyd/t5-v1_1-xxl))
and one latent feature encoder ([VAE](https://arxiv.org/abs/2112.10752)).
- **Resources for more information:** Check out our [GitHub Repository](https://github.com/PixArt-alpha/PixArt-sigma) and the [PixArt-Σ report on arXiv](https://arxiv.org/abs/2403.04692).
### Model Sources
For research purposes, we recommend our `generative-models` Github repository (https://github.com/PixArt-alpha/PixArt-sigma),
which is more suitable for both training and inference and for which most advanced diffusion sampler like [SA-Solver](https://arxiv.org/abs/2309.05019) will be added over time.
[Hugging Face](https://huggingface.co/spaces/PixArt-alpha/PixArt-Sigma) provides free PixArt-Σ inference.
- **Repository:** https://github.com/PixArt-alpha/PixArt-sigma
- **Demo:** https://huggingface.co/spaces/PixArt-alpha/PixArt-Sigma
### 🧨 Diffusers
> [!IMPORTANT]
> Make sure to upgrade diffusers to >= 0.28.0:
> ```bash
> pip install -U diffusers --upgrade
> ```
> In addition make sure to install `transformers`, `safetensors`, `sentencepiece`, and `accelerate`:
> ```
> pip install transformers accelerate safetensors sentencepiece
> ```
> For `diffusers<0.28.0`, check this [script](https://github.com/PixArt-alpha/PixArt-sigma#2-integration-in-diffusers) for help.
To just use the base model, you can run:
```python
import torch
from diffusers import Transformer2DModel, PixArtSigmaPipeline
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
weight_dtype = torch.float16
pipe = PixArtSigmaPipeline.from_pretrained(
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS",
torch_dtype=weight_dtype,
use_safetensors=True,
)
pipe.to(device)
# Enable memory optimizations.
# pipe.enable_model_cpu_offload()
prompt = "A small cactus with a happy face in the Sahara desert."
image = pipe(prompt).images[0]
image.save("./catcus.png")
```
When using `torch >= 2.0`, you can improve the inference speed by 20-30% with torch.compile. Simple wrap the unet with torch compile before running the pipeline:
```py
pipe.transformer = torch.compile(pipe.transformer, mode="reduce-overhead", fullgraph=True)
```
If you are limited by GPU VRAM, you can enable *cpu offloading* by calling `pipe.enable_model_cpu_offload`
instead of `.to("cuda")`:
```diff
- pipe.to("cuda")
+ pipe.enable_model_cpu_offload()
```
For more information on how to use PixArt-Σ with `diffusers`, please have a look at [the PixArt-Σ Docs](https://huggingface.co/docs/diffusers/main/en/api/pipelines/pixart_sigma.md).
## Uses
### Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
Excluded uses are described below.
### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model struggles with more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- fingers, .etc in general may not be generated properly.
- The autoencoding part of the model is lossy.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.



