---
license: gpl-3.0
---
# Hybrid Depth: Robust Depth Fusion for Mobile AR By Leveraging Depth from Focus and Single-Image Priors
This work presents HybridDepth. HybridDepth is a practical depth estimation solution based on focal stack images captured from a camera. This approach outperforms state-of-the-art models across several well-known datasets, including NYU V2, DDFF12, and ARKitScenes.

## Abstract of paper
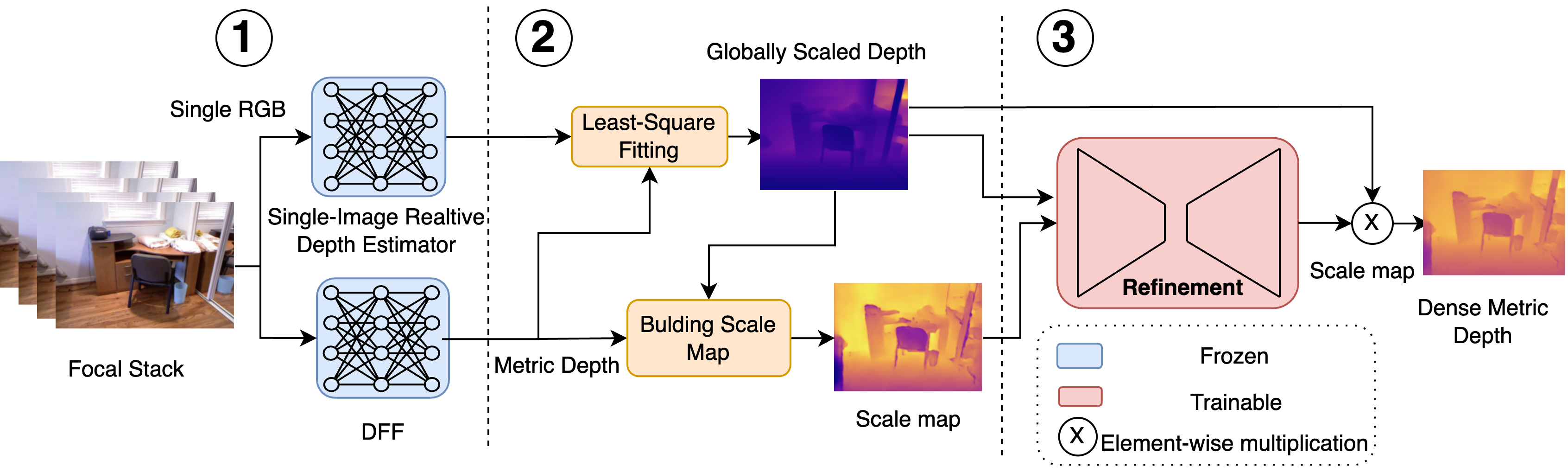
We propose HYBRIDDEPTH, a robust depth estimation pipeline that addresses the unique challenges of depth estimation for mobile AR, such as scale ambiguity, hardware heterogeneity, and generalizability. HYBRIDDEPTH leverages the camera features available on mobile devices. It effectively combines the scale accuracy inherent in Depth from Focus (DFF) methods with the generalization capabilities enabled by strong single-image depth priors. By utilizing the focal planes of a mobile camera, our approach accurately captures depth values from focused pixels and applies these values to compute scale and shift parameters for transforming relative depths into metric depths. We test our pipeline as an end-to-end system, with a newly developed mobile client to capture focal stacks, which are then sent to a GPU-powered server for depth estimation.
Through comprehensive quantitative and qualitative analyses, we demonstrate that HYBRIDDEPTH not only outperforms state-ofthe-art (SOTA) models in common datasets (DDFF12, NYU Depth v2) and a real-world AR dataset ARKitScenes but also demonstrates strong zero-shot generalization. For example, HYBRIDDEPTH trained on NYU Depth v2 achieves comparable performance on the DDFF12 to existing models trained on DDFF12; it also outperforms all the SOTA models in zero-shot performance on the ARKitScenes dataset. Additionally, we conduct a qualitative comparison between our model and the ARCore framework, demonstrating that our model’s output depth maps are significantly more accurate in terms of structural details and metric accuracy. The source code of this project is available at https://github.com/cake-lab/HybridDepth.
## Usage
### Prepraration
1. **Clone the repository and install the dependencies:**
```bash
git clone https://github.com/cake-lab/HybridDepth.git
cd HybridDepth
conda env create -f environment.yml
conda activate hybriddepth
```
2. **Download Necessary Files:**
* Download the necessary file [here](https://github.com/cake-lab/HybridDepth/releases/download/v1.0/DFF-DFV.tar) and place it in the checkpoints directory.
* Download the checkpoints listed [here](#pre-trained-models) and put them under the `checkpoints` directory.
#### Dataset Preparation
1. **NYU:**
Download dataset as per instructions given [here](https://github.com/cleinc/bts/tree/master/pytorch#nyu-depvh-v2).
1. **DDFF12:**
Download dataset as per instructions given [here](https://github.com/fuy34/DFV).
1. **ARKitScenes:**
Download dataset as per instructions given [here](https://github.com/cake-lab/Mobile-AR-Depth-Estimation).
### Using HybridDepth model for prediction
For inference you can run the provided notebook `test.ipynb` or use the following command:
```python
# Load the model checkpoint
model_path = './checkpoints/checkpoint.ckpt'
model = DepthNetModule()
# Load the weights
model.load_state_dict(torch.load(model_path))
model.eval()
model = model.to('cuda')
```
After loading the model, you can use the following code to process the input images and get the depth map:
```python
from utils.io import prepare_input_image
data_dir = 'focal stack images directory'
# Load the focal stack images
focal_stack, rgb_img, focus_dist = prepare_input_image(data_dir)
# inference
with torch.no_grad():
out = model(rgb_img, focal_stack, focus_dist)
metric_depth = out[0].squeeze().cpu().numpy() # The metric depth
```
### Evaluation
First setup the configuration file `config.yaml` in the `configs` directory. We already provide the configuration files for the three datasets in the `configs` directory. In the configuration file, you can specify the path to the dataloader, the path to the model, and other hyperparameters. Here is an example of the configuration file:
```yaml
data:
class_path: dataloader.dataset.NYUDataModule # Path to your dataloader Module in dataset.py
init_args:
nyuv2_data_root: 'root to the NYUv2 dataset or other datasets' # path to the specific dataset
img_size: [480, 640] # Adjust if your DataModule expects a tuple for img_size
remove_white_border: True
num_workers: 0 # if you are using synthetic data, you don't need multiple workers
use_labels: True
model:
invert_depth: True # If the model outputs inverted depth
ckpt_path: checkpoints/checkpoint.ckpt
```
Then specify the configuration file in the `test.sh` script.
```bash
python cli_run.py test --config configs/config_file_name.yaml
```
Finally, run the following command:
```bash
cd scripts
sh evaluate.sh
```
### Training
First setup the configuration file `config.yaml` in the `configs` directory. You only need to specify the path to the dataset and the batch size. The rest of the hyperparameters are already set.
For example, you can use the following configuration file for training on the NYUv2 dataset:
```yaml
...
model:
invert_depth: True
# learning rate
lr: 3e-4 # you can adjust this value
# weight decay
wd: 0.001 # you can adjust this value
data:
class_path: dataloader.dataset.NYUDataModule # Path to your dataloader Module in dataset.py
init_args:
nyuv2_data_root: 'root to the NYUv2 dataset or other datasets' # path to the specific dataset
img_size: [480, 640] # Adjust if your NYUDataModule expects a tuple for img_size
remove_white_border: True
batch_size: 24 # Adjust the batch size
num_workers: 0 # if you are using synthetic data, you don't need multiple workers
use_labels: True
ckpt_path: null
```
Then specify the configuration file in the `train.sh` script.
```bash
python cli_run.py train --config configs/config_file_name.yaml
```
Finally, run the following command:
```bash
cd scripts
sh train.sh
```
## Citation
If our work assists you in your research, please cite it as follows:
```Bibtex
@misc{ganj2024hybriddepthrobustdepthfusion,
title={HybridDepth: Robust Depth Fusion for Mobile AR by Leveraging Depth from Focus and Single-Image Priors},
author={Ashkan Ganj and Hang Su and Tian Guo},
year={2024},
eprint={2407.18443},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.18443},
}
```