---
license: mit
---
Images Speak in Images:
A Generalist Painter for In-Context Visual Learning
[Xinlong Wang](https://www.xloong.wang/)1*, [Wen Wang](https://scholar.google.com/citations?user=1ks0R04AAAAJ&hl)1,2*, [Yue Cao](http://yue-cao.me/)1*, [Chunhua Shen](https://cshen.github.io/)2, [Tiejun Huang](https://scholar.google.com/citations?user=knvEK4AAAAAJ&hl=en)1,3
1[BAAI](https://www.baai.ac.cn/english.html), 2[ZJU](https://www.zju.edu.cn/english/), 3[PKU](https://english.pku.edu.cn/)
CVPR 2023
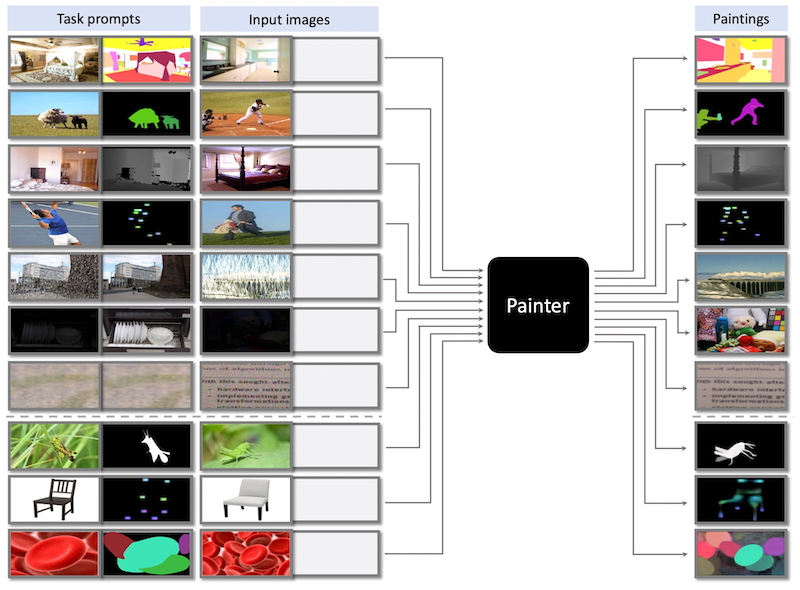
We present Painter, a generalist model using an "image"-centric solution for in-context visual learning, that is, to redefine the output of core vision tasks as images, and specify task prompts as also images. With this idea, our training process is extremely simple, which performs standard masked image modeling on the stitch of input and output image pairs. This makes the model capable of performing tasks conditioned on visible image patches. Thus, during inference, we can adopt a pair of input and output images from the same task as the input condition, to indicate which task to perform. Examples of in-context inference are illustrated in the figure above, consisting of seven in-domain examples (seven rows at top) and three out-of-domain examples (three rows at bottom).
Without bells and whistles, our generalist Painter can achieve competitive performance compared to well-established task-specific models, on seven representative vision tasks ranging from high-level visual understanding to low-level image processing.
In addition, Painter significantly outperforms recent generalist models on several challenging tasks.
[[Paper]](https://arxiv.org/abs/2212.02499)
A pre-trained Painter is available at [🤗 HF link](https://huggingface.co/BAAI/Painter/blob/main/painter_vit_large.pth). The results on various tasks are summarized below:
| depth estimation | semantic seg. | panoptic seg. | keypoint det. | denoising | deraining | enhance. |
| NYU v2 | ADE20k | COCO 2017 | COCO 2017 | SIDD | 5 datasets | LoL |
| RMSE | A.Rel | d1 | mIoU | PQ | AP | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM |
| 0.288 | 0.080 | 0.950 | 49.9 | 43.4 | 72.1 | 38.66 | 0.954 | 29.42 | 0.867 | 22.34 | 0.872 |
## Citation
```
@article{Painter,
title={Images Speak in Images: A Generalist Painter for In-Context Visual Learning},
author={Wang, Xinlong and Wang, Wen and Cao, Yue and Shen, Chunhua and Huang, Tiejun},
journal={arXiv preprint arXiv:2212.02499},
year={2022}
}
```
## Contact
**We are hiring** at all levels at BAAI Vision Team, including full-time researchers, engineers and interns.
If you are interested in working with us on **foundation model, visual perception and multimodal learning**, please contact [Xinlong Wang](https://www.xloong.wang/) (`wangxinlong@baai.ac.cn`) and [Yue Cao](http://yue-cao.me/) (`caoyue@baai.ac.cn`).