

Add files (#1)
Browse files- Add files (4c64221df87e5c2599c8d3a616943e5d23ed29de)
- .gitattributes +1 -0
- LICENSE +664 -0
- README.md +157 -0
- assets/demo-preview.png +0 -0
- assets/github-banner.png +0 -0
- docs/architecture.md +103 -0
- docs/assets/NAR_inpainting_diagram.png +0 -0
- docs/assets/example_ref.wav +0 -0
- docs/assets/intro_vid.mp4 +3 -0
- docs/assets/mars5_AR_arch.png +0 -0
- docs/assets/mars5_NAR_arch.png +0 -0
- docs/assets/simplified_diagram.png +0 -0
- hubconf.py +33 -0
- inference.py +236 -0
- mars5/ar_generate.py +165 -0
- mars5/diffuser.py +472 -0
- mars5/minbpe/base.py +166 -0
- mars5/minbpe/codebook.py +210 -0
- mars5/minbpe/regex.py +164 -0
- mars5/model.py +344 -0
- mars5/nn_future.py +400 -0
- mars5/samplers.py +122 -0
- mars5/trim.py +741 -0
- mars5/utils.py +62 -0
- mars5_demo.ipynb +140 -0
- requirements.txt +8 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
docs/assets/intro_vid.mp4 filter=lfs diff=lfs merge=lfs -text
|
LICENSE
ADDED
|
@@ -0,0 +1,664 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
GNU AFFERO GENERAL PUBLIC LICENSE
|
| 2 |
+
Version 3, 19 November 2007
|
| 3 |
+
|
| 4 |
+
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
|
| 5 |
+
Everyone is permitted to copy and distribute verbatim copies
|
| 6 |
+
of this license document, but changing it is not allowed.
|
| 7 |
+
|
| 8 |
+
Preamble
|
| 9 |
+
|
| 10 |
+
The GNU Affero General Public License is a free, copyleft license for
|
| 11 |
+
software and other kinds of works, specifically designed to ensure
|
| 12 |
+
cooperation with the community in the case of network server software.
|
| 13 |
+
|
| 14 |
+
The licenses for most software and other practical works are designed
|
| 15 |
+
to take away your freedom to share and change the works. By contrast,
|
| 16 |
+
our General Public Licenses are intended to guarantee your freedom to
|
| 17 |
+
share and change all versions of a program--to make sure it remains free
|
| 18 |
+
software for all its users.
|
| 19 |
+
|
| 20 |
+
When we speak of free software, we are referring to freedom, not
|
| 21 |
+
price. Our General Public Licenses are designed to make sure that you
|
| 22 |
+
have the freedom to distribute copies of free software (and charge for
|
| 23 |
+
them if you wish), that you receive source code or can get it if you
|
| 24 |
+
want it, that you can change the software or use pieces of it in new
|
| 25 |
+
free programs, and that you know you can do these things.
|
| 26 |
+
|
| 27 |
+
Developers that use our General Public Licenses protect your rights
|
| 28 |
+
with two steps: (1) assert copyright on the software, and (2) offer
|
| 29 |
+
you this License which gives you legal permission to copy, distribute
|
| 30 |
+
and/or modify the software.
|
| 31 |
+
|
| 32 |
+
A secondary benefit of defending all users' freedom is that
|
| 33 |
+
improvements made in alternate versions of the program, if they
|
| 34 |
+
receive widespread use, become available for other developers to
|
| 35 |
+
incorporate. Many developers of free software are heartened and
|
| 36 |
+
encouraged by the resulting cooperation. However, in the case of
|
| 37 |
+
software used on network servers, this result may fail to come about.
|
| 38 |
+
The GNU General Public License permits making a modified version and
|
| 39 |
+
letting the public access it on a server without ever releasing its
|
| 40 |
+
source code to the public.
|
| 41 |
+
|
| 42 |
+
The GNU Affero General Public License is designed specifically to
|
| 43 |
+
ensure that, in such cases, the modified source code becomes available
|
| 44 |
+
to the community. It requires the operator of a network server to
|
| 45 |
+
provide the source code of the modified version running there to the
|
| 46 |
+
users of that server. Therefore, public use of a modified version, on
|
| 47 |
+
a publicly accessible server, gives the public access to the source
|
| 48 |
+
code of the modified version.
|
| 49 |
+
|
| 50 |
+
An older license, called the Affero General Public License and
|
| 51 |
+
published by Affero, was designed to accomplish similar goals. This is
|
| 52 |
+
a different license, not a version of the Affero GPL, but Affero has
|
| 53 |
+
released a new version of the Affero GPL which permits relicensing under
|
| 54 |
+
this license.
|
| 55 |
+
|
| 56 |
+
The precise terms and conditions for copying, distribution and
|
| 57 |
+
modification follow.
|
| 58 |
+
|
| 59 |
+
TERMS AND CONDITIONS
|
| 60 |
+
|
| 61 |
+
0. Definitions.
|
| 62 |
+
|
| 63 |
+
"This License" refers to version 3 of the GNU Affero General Public License.
|
| 64 |
+
|
| 65 |
+
"Copyright" also means copyright-like laws that apply to other kinds of
|
| 66 |
+
works, such as semiconductor masks.
|
| 67 |
+
|
| 68 |
+
"The Program" refers to any copyrightable work licensed under this
|
| 69 |
+
License. Each licensee is addressed as "you". "Licensees" and
|
| 70 |
+
"recipients" may be individuals or organizations.
|
| 71 |
+
|
| 72 |
+
To "modify" a work means to copy from or adapt all or part of the work
|
| 73 |
+
in a fashion requiring copyright permission, other than the making of an
|
| 74 |
+
exact copy. The resulting work is called a "modified version" of the
|
| 75 |
+
earlier work or a work "based on" the earlier work.
|
| 76 |
+
|
| 77 |
+
A "covered work" means either the unmodified Program or a work based
|
| 78 |
+
on the Program.
|
| 79 |
+
|
| 80 |
+
To "propagate" a work means to do anything with it that, without
|
| 81 |
+
permission, would make you directly or secondarily liable for
|
| 82 |
+
infringement under applicable copyright law, except executing it on a
|
| 83 |
+
computer or modifying a private copy. Propagation includes copying,
|
| 84 |
+
distribution (with or without modification), making available to the
|
| 85 |
+
public, and in some countries other activities as well.
|
| 86 |
+
|
| 87 |
+
To "convey" a work means any kind of propagation that enables other
|
| 88 |
+
parties to make or receive copies. Mere interaction with a user through
|
| 89 |
+
a computer network, with no transfer of a copy, is not conveying.
|
| 90 |
+
|
| 91 |
+
An interactive user interface displays "Appropriate Legal Notices"
|
| 92 |
+
to the extent that it includes a convenient and prominently visible
|
| 93 |
+
feature that (1) displays an appropriate copyright notice, and (2)
|
| 94 |
+
tells the user that there is no warranty for the work (except to the
|
| 95 |
+
extent that warranties are provided), that licensees may convey the
|
| 96 |
+
work under this License, and how to view a copy of this License. If
|
| 97 |
+
the interface presents a list of user commands or options, such as a
|
| 98 |
+
menu, a prominent item in the list meets this criterion.
|
| 99 |
+
|
| 100 |
+
1. Source Code.
|
| 101 |
+
|
| 102 |
+
The "source code" for a work means the preferred form of the work
|
| 103 |
+
for making modifications to it. "Object code" means any non-source
|
| 104 |
+
form of a work.
|
| 105 |
+
|
| 106 |
+
A "Standard Interface" means an interface that either is an official
|
| 107 |
+
standard defined by a recognized standards body, or, in the case of
|
| 108 |
+
interfaces specified for a particular programming language, one that
|
| 109 |
+
is widely used among developers working in that language.
|
| 110 |
+
|
| 111 |
+
The "System Libraries" of an executable work include anything, other
|
| 112 |
+
than the work as a whole, that (a) is included in the normal form of
|
| 113 |
+
packaging a Major Component, but which is not part of that Major
|
| 114 |
+
Component, and (b) serves only to enable use of the work with that
|
| 115 |
+
Major Component, or to implement a Standard Interface for which an
|
| 116 |
+
implementation is available to the public in source code form. A
|
| 117 |
+
"Major Component", in this context, means a major essential component
|
| 118 |
+
(kernel, window system, and so on) of the specific operating system
|
| 119 |
+
(if any) on which the executable work runs, or a compiler used to
|
| 120 |
+
produce the work, or an object code interpreter used to run it.
|
| 121 |
+
|
| 122 |
+
The "Corresponding Source" for a work in object code form means all
|
| 123 |
+
the source code needed to generate, install, and (for an executable
|
| 124 |
+
work) run the object code and to modify the work, including scripts to
|
| 125 |
+
control those activities. However, it does not include the work's
|
| 126 |
+
System Libraries, or general-purpose tools or generally available free
|
| 127 |
+
programs which are used unmodified in performing those activities but
|
| 128 |
+
which are not part of the work. For example, Corresponding Source
|
| 129 |
+
includes interface definition files associated with source files for
|
| 130 |
+
the work, and the source code for shared libraries and dynamically
|
| 131 |
+
linked subprograms that the work is specifically designed to require,
|
| 132 |
+
such as by intimate data communication or control flow between those
|
| 133 |
+
subprograms and other parts of the work.
|
| 134 |
+
|
| 135 |
+
The Corresponding Source need not include anything that users
|
| 136 |
+
can regenerate automatically from other parts of the Corresponding
|
| 137 |
+
Source.
|
| 138 |
+
|
| 139 |
+
The Corresponding Source for a work in source code form is that
|
| 140 |
+
same work.
|
| 141 |
+
|
| 142 |
+
2. Basic Permissions.
|
| 143 |
+
|
| 144 |
+
All rights granted under this License are granted for the term of
|
| 145 |
+
copyright on the Program, and are irrevocable provided the stated
|
| 146 |
+
conditions are met. This License explicitly affirms your unlimited
|
| 147 |
+
permission to run the unmodified Program. The output from running a
|
| 148 |
+
covered work is covered by this License only if the output, given its
|
| 149 |
+
content, constitutes a covered work. This License acknowledges your
|
| 150 |
+
rights of fair use or other equivalent, as provided by copyright law.
|
| 151 |
+
|
| 152 |
+
You may make, run and propagate covered works that you do not
|
| 153 |
+
convey, without conditions so long as your license otherwise remains
|
| 154 |
+
in force. You may convey covered works to others for the sole purpose
|
| 155 |
+
of having them make modifications exclusively for you, or provide you
|
| 156 |
+
with facilities for running those works, provided that you comply with
|
| 157 |
+
the terms of this License in conveying all material for which you do
|
| 158 |
+
not control copyright. Those thus making or running the covered works
|
| 159 |
+
for you must do so exclusively on your behalf, under your direction
|
| 160 |
+
and control, on terms that prohibit them from making any copies of
|
| 161 |
+
your copyrighted material outside their relationship with you.
|
| 162 |
+
|
| 163 |
+
Conveying under any other circumstances is permitted solely under
|
| 164 |
+
the conditions stated below. Sublicensing is not allowed; section 10
|
| 165 |
+
makes it unnecessary.
|
| 166 |
+
|
| 167 |
+
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
| 168 |
+
|
| 169 |
+
No covered work shall be deemed part of an effective technological
|
| 170 |
+
measure under any applicable law fulfilling obligations under article
|
| 171 |
+
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
| 172 |
+
similar laws prohibiting or restricting circumvention of such
|
| 173 |
+
measures.
|
| 174 |
+
|
| 175 |
+
When you convey a covered work, you waive any legal power to forbid
|
| 176 |
+
circumvention of technological measures to the extent such circumvention
|
| 177 |
+
is effected by exercising rights under this License with respect to
|
| 178 |
+
the covered work, and you disclaim any intention to limit operation or
|
| 179 |
+
modification of the work as a means of enforcing, against the work's
|
| 180 |
+
users, your or third parties' legal rights to forbid circumvention of
|
| 181 |
+
technological measures.
|
| 182 |
+
|
| 183 |
+
4. Conveying Verbatim Copies.
|
| 184 |
+
|
| 185 |
+
You may convey verbatim copies of the Program's source code as you
|
| 186 |
+
receive it, in any medium, provided that you conspicuously and
|
| 187 |
+
appropriately publish on each copy an appropriate copyright notice;
|
| 188 |
+
keep intact all notices stating that this License and any
|
| 189 |
+
non-permissive terms added in accord with section 7 apply to the code;
|
| 190 |
+
keep intact all notices of the absence of any warranty; and give all
|
| 191 |
+
recipients a copy of this License along with the Program.
|
| 192 |
+
|
| 193 |
+
You may charge any price or no price for each copy that you convey,
|
| 194 |
+
and you may offer support or warranty protection for a fee.
|
| 195 |
+
|
| 196 |
+
5. Conveying Modified Source Versions.
|
| 197 |
+
|
| 198 |
+
You may convey a work based on the Program, or the modifications to
|
| 199 |
+
produce it from the Program, in the form of source code under the
|
| 200 |
+
terms of section 4, provided that you also meet all of these conditions:
|
| 201 |
+
|
| 202 |
+
a) The work must carry prominent notices stating that you modified
|
| 203 |
+
it, and giving a relevant date.
|
| 204 |
+
|
| 205 |
+
b) The work must carry prominent notices stating that it is
|
| 206 |
+
released under this License and any conditions added under section
|
| 207 |
+
7. This requirement modifies the requirement in section 4 to
|
| 208 |
+
"keep intact all notices".
|
| 209 |
+
|
| 210 |
+
c) You must license the entire work, as a whole, under this
|
| 211 |
+
License to anyone who comes into possession of a copy. This
|
| 212 |
+
License will therefore apply, along with any applicable section 7
|
| 213 |
+
additional terms, to the whole of the work, and all its parts,
|
| 214 |
+
regardless of how they are packaged. This License gives no
|
| 215 |
+
permission to license the work in any other way, but it does not
|
| 216 |
+
invalidate such permission if you have separately received it.
|
| 217 |
+
|
| 218 |
+
d) If the work has interactive user interfaces, each must display
|
| 219 |
+
Appropriate Legal Notices; however, if the Program has interactive
|
| 220 |
+
interfaces that do not display Appropriate Legal Notices, your
|
| 221 |
+
work need not make them do so.
|
| 222 |
+
|
| 223 |
+
A compilation of a covered work with other separate and independent
|
| 224 |
+
works, which are not by their nature extensions of the covered work,
|
| 225 |
+
and which are not combined with it such as to form a larger program,
|
| 226 |
+
in or on a volume of a storage or distribution medium, is called an
|
| 227 |
+
"aggregate" if the compilation and its resulting copyright are not
|
| 228 |
+
used to limit the access or legal rights of the compilation's users
|
| 229 |
+
beyond what the individual works permit. Inclusion of a covered work
|
| 230 |
+
in an aggregate does not cause this License to apply to the other
|
| 231 |
+
parts of the aggregate.
|
| 232 |
+
|
| 233 |
+
6. Conveying Non-Source Forms.
|
| 234 |
+
|
| 235 |
+
You may convey a covered work in object code form under the terms
|
| 236 |
+
of sections 4 and 5, provided that you also convey the
|
| 237 |
+
machine-readable Corresponding Source under the terms of this License,
|
| 238 |
+
in one of these ways:
|
| 239 |
+
|
| 240 |
+
a) Convey the object code in, or embodied in, a physical product
|
| 241 |
+
(including a physical distribution medium), accompanied by the
|
| 242 |
+
Corresponding Source fixed on a durable physical medium
|
| 243 |
+
customarily used for software interchange.
|
| 244 |
+
|
| 245 |
+
b) Convey the object code in, or embodied in, a physical product
|
| 246 |
+
(including a physical distribution medium), accompanied by a
|
| 247 |
+
written offer, valid for at least three years and valid for as
|
| 248 |
+
long as you offer spare parts or customer support for that product
|
| 249 |
+
model, to give anyone who possesses the object code either (1) a
|
| 250 |
+
copy of the Corresponding Source for all the software in the
|
| 251 |
+
product that is covered by this License, on a durable physical
|
| 252 |
+
medium customarily used for software interchange, for a price no
|
| 253 |
+
more than your reasonable cost of physically performing this
|
| 254 |
+
conveying of source, or (2) access to copy the
|
| 255 |
+
Corresponding Source from a network server at no charge.
|
| 256 |
+
|
| 257 |
+
c) Convey individual copies of the object code with a copy of the
|
| 258 |
+
written offer to provide the Corresponding Source. This
|
| 259 |
+
alternative is allowed only occasionally and noncommercially, and
|
| 260 |
+
only if you received the object code with such an offer, in accord
|
| 261 |
+
with subsection 6b.
|
| 262 |
+
|
| 263 |
+
d) Convey the object code by offering access from a designated
|
| 264 |
+
place (gratis or for a charge), and offer equivalent access to the
|
| 265 |
+
Corresponding Source in the same way through the same place at no
|
| 266 |
+
further charge. You need not require recipients to copy the
|
| 267 |
+
Corresponding Source along with the object code. If the place to
|
| 268 |
+
copy the object code is a network server, the Corresponding Source
|
| 269 |
+
may be on a different server (operated by you or a third party)
|
| 270 |
+
that supports equivalent copying facilities, provided you maintain
|
| 271 |
+
clear directions next to the object code saying where to find the
|
| 272 |
+
Corresponding Source. Regardless of what server hosts the
|
| 273 |
+
Corresponding Source, you remain obligated to ensure that it is
|
| 274 |
+
available for as long as needed to satisfy these requirements.
|
| 275 |
+
|
| 276 |
+
e) Convey the object code using peer-to-peer transmission, provided
|
| 277 |
+
you inform other peers where the object code and Corresponding
|
| 278 |
+
Source of the work are being offered to the general public at no
|
| 279 |
+
charge under subsection 6d.
|
| 280 |
+
|
| 281 |
+
A separable portion of the object code, whose source code is excluded
|
| 282 |
+
from the Corresponding Source as a System Library, need not be
|
| 283 |
+
included in conveying the object code work.
|
| 284 |
+
|
| 285 |
+
A "User Product" is either (1) a "consumer product", which means any
|
| 286 |
+
tangible personal property which is normally used for personal, family,
|
| 287 |
+
or household purposes, or (2) anything designed or sold for incorporation
|
| 288 |
+
into a dwelling. In determining whether a product is a consumer product,
|
| 289 |
+
doubtful cases shall be resolved in favor of coverage. For a particular
|
| 290 |
+
product received by a particular user, "normally used" refers to a
|
| 291 |
+
typical or common use of that class of product, regardless of the status
|
| 292 |
+
of the particular user or of the way in which the particular user
|
| 293 |
+
actually uses, or expects or is expected to use, the product. A product
|
| 294 |
+
is a consumer product regardless of whether the product has substantial
|
| 295 |
+
commercial, industrial or non-consumer uses, unless such uses represent
|
| 296 |
+
the only significant mode of use of the product.
|
| 297 |
+
|
| 298 |
+
"Installation Information" for a User Product means any methods,
|
| 299 |
+
procedures, authorization keys, or other information required to install
|
| 300 |
+
and execute modified versions of a covered work in that User Product from
|
| 301 |
+
a modified version of its Corresponding Source. The information must
|
| 302 |
+
suffice to ensure that the continued functioning of the modified object
|
| 303 |
+
code is in no case prevented or interfered with solely because
|
| 304 |
+
modification has been made.
|
| 305 |
+
|
| 306 |
+
If you convey an object code work under this section in, or with, or
|
| 307 |
+
specifically for use in, a User Product, and the conveying occurs as
|
| 308 |
+
part of a transaction in which the right of possession and use of the
|
| 309 |
+
User Product is transferred to the recipient in perpetuity or for a
|
| 310 |
+
fixed term (regardless of how the transaction is characterized), the
|
| 311 |
+
Corresponding Source conveyed under this section must be accompanied
|
| 312 |
+
by the Installation Information. But this requirement does not apply
|
| 313 |
+
if neither you nor any third party retains the ability to install
|
| 314 |
+
modified object code on the User Product (for example, the work has
|
| 315 |
+
been installed in ROM).
|
| 316 |
+
|
| 317 |
+
The requirement to provide Installation Information does not include a
|
| 318 |
+
requirement to continue to provide support service, warranty, or updates
|
| 319 |
+
for a work that has been modified or installed by the recipient, or for
|
| 320 |
+
the User Product in which it has been modified or installed. Access to a
|
| 321 |
+
network may be denied when the modification itself materially and
|
| 322 |
+
adversely affects the operation of the network or violates the rules and
|
| 323 |
+
protocols for communication across the network.
|
| 324 |
+
|
| 325 |
+
Corresponding Source conveyed, and Installation Information provided,
|
| 326 |
+
in accord with this section must be in a format that is publicly
|
| 327 |
+
documented (and with an implementation available to the public in
|
| 328 |
+
source code form), and must require no special password or key for
|
| 329 |
+
unpacking, reading or copying.
|
| 330 |
+
|
| 331 |
+
7. Additional Terms.
|
| 332 |
+
|
| 333 |
+
"Additional permissions" are terms that supplement the terms of this
|
| 334 |
+
License by making exceptions from one or more of its conditions.
|
| 335 |
+
Additional permissions that are applicable to the entire Program shall
|
| 336 |
+
be treated as though they were included in this License, to the extent
|
| 337 |
+
that they are valid under applicable law. If additional permissions
|
| 338 |
+
apply only to part of the Program, that part may be used separately
|
| 339 |
+
under those permissions, but the entire Program remains governed by
|
| 340 |
+
this License without regard to the additional permissions.
|
| 341 |
+
|
| 342 |
+
When you convey a copy of a covered work, you may at your option
|
| 343 |
+
remove any additional permissions from that copy, or from any part of
|
| 344 |
+
it. (Additional permissions may be written to require their own
|
| 345 |
+
removal in certain cases when you modify the work.) You may place
|
| 346 |
+
additional permissions on material, added by you to a covered work,
|
| 347 |
+
for which you have or can give appropriate copyright permission.
|
| 348 |
+
|
| 349 |
+
Notwithstanding any other provision of this License, for material you
|
| 350 |
+
add to a covered work, you may (if authorized by the copyright holders of
|
| 351 |
+
that material) supplement the terms of this License with terms:
|
| 352 |
+
|
| 353 |
+
a) Disclaiming warranty or limiting liability differently from the
|
| 354 |
+
terms of sections 15 and 16 of this License; or
|
| 355 |
+
|
| 356 |
+
b) Requiring preservation of specified reasonable legal notices or
|
| 357 |
+
author attributions in that material or in the Appropriate Legal
|
| 358 |
+
Notices displayed by works containing it; or
|
| 359 |
+
|
| 360 |
+
c) Prohibiting misrepresentation of the origin of that material, or
|
| 361 |
+
requiring that modified versions of such material be marked in
|
| 362 |
+
reasonable ways as different from the original version; or
|
| 363 |
+
|
| 364 |
+
d) Limiting the use for publicity purposes of names of licensors or
|
| 365 |
+
authors of the material; or
|
| 366 |
+
|
| 367 |
+
e) Declining to grant rights under trademark law for use of some
|
| 368 |
+
trade names, trademarks, or service marks; or
|
| 369 |
+
|
| 370 |
+
f) Requiring indemnification of licensors and authors of that
|
| 371 |
+
material by anyone who conveys the material (or modified versions of
|
| 372 |
+
it) with contractual assumptions of liability to the recipient, for
|
| 373 |
+
any liability that these contractual assumptions directly impose on
|
| 374 |
+
those licensors and authors.
|
| 375 |
+
|
| 376 |
+
All other non-permissive additional terms are considered "further
|
| 377 |
+
restrictions" within the meaning of section 10. If the Program as you
|
| 378 |
+
received it, or any part of it, contains a notice stating that it is
|
| 379 |
+
governed by this License along with a term that is a further
|
| 380 |
+
restriction, you may remove that term. If a license document contains
|
| 381 |
+
a further restriction but permits relicensing or conveying under this
|
| 382 |
+
License, you may add to a covered work material governed by the terms
|
| 383 |
+
of that license document, provided that the further restriction does
|
| 384 |
+
not survive such relicensing or conveying.
|
| 385 |
+
|
| 386 |
+
If you add terms to a covered work in accord with this section, you
|
| 387 |
+
must place, in the relevant source files, a statement of the
|
| 388 |
+
additional terms that apply to those files, or a notice indicating
|
| 389 |
+
where to find the applicable terms.
|
| 390 |
+
|
| 391 |
+
Additional terms, permissive or non-permissive, may be stated in the
|
| 392 |
+
form of a separately written license, or stated as exceptions;
|
| 393 |
+
the above requirements apply either way.
|
| 394 |
+
|
| 395 |
+
8. Termination.
|
| 396 |
+
|
| 397 |
+
You may not propagate or modify a covered work except as expressly
|
| 398 |
+
provided under this License. Any attempt otherwise to propagate or
|
| 399 |
+
modify it is void, and will automatically terminate your rights under
|
| 400 |
+
this License (including any patent licenses granted under the third
|
| 401 |
+
paragraph of section 11).
|
| 402 |
+
|
| 403 |
+
However, if you cease all violation of this License, then your
|
| 404 |
+
license from a particular copyright holder is reinstated (a)
|
| 405 |
+
provisionally, unless and until the copyright holder explicitly and
|
| 406 |
+
finally terminates your license, and (b) permanently, if the copyright
|
| 407 |
+
holder fails to notify you of the violation by some reasonable means
|
| 408 |
+
prior to 60 days after the cessation.
|
| 409 |
+
|
| 410 |
+
Moreover, your license from a particular copyright holder is
|
| 411 |
+
reinstated permanently if the copyright holder notifies you of the
|
| 412 |
+
violation by some reasonable means, this is the first time you have
|
| 413 |
+
received notice of violation of this License (for any work) from that
|
| 414 |
+
copyright holder, and you cure the violation prior to 30 days after
|
| 415 |
+
your receipt of the notice.
|
| 416 |
+
|
| 417 |
+
Termination of your rights under this section does not terminate the
|
| 418 |
+
licenses of parties who have received copies or rights from you under
|
| 419 |
+
this License. If your rights have been terminated and not permanently
|
| 420 |
+
reinstated, you do not qualify to receive new licenses for the same
|
| 421 |
+
material under section 10.
|
| 422 |
+
|
| 423 |
+
9. Acceptance Not Required for Having Copies.
|
| 424 |
+
|
| 425 |
+
You are not required to accept this License in order to receive or
|
| 426 |
+
run a copy of the Program. Ancillary propagation of a covered work
|
| 427 |
+
occurring solely as a consequence of using peer-to-peer transmission
|
| 428 |
+
to receive a copy likewise does not require acceptance. However,
|
| 429 |
+
nothing other than this License grants you permission to propagate or
|
| 430 |
+
modify any covered work. These actions infringe copyright if you do
|
| 431 |
+
not accept this License. Therefore, by modifying or propagating a
|
| 432 |
+
covered work, you indicate your acceptance of this License to do so.
|
| 433 |
+
|
| 434 |
+
10. Automatic Licensing of Downstream Recipients.
|
| 435 |
+
|
| 436 |
+
Each time you convey a covered work, the recipient automatically
|
| 437 |
+
receives a license from the original licensors, to run, modify and
|
| 438 |
+
propagate that work, subject to this License. You are not responsible
|
| 439 |
+
for enforcing compliance by third parties with this License.
|
| 440 |
+
|
| 441 |
+
An "entity transaction" is a transaction transferring control of an
|
| 442 |
+
organization, or substantially all assets of one, or subdividing an
|
| 443 |
+
organization, or merging organizations. If propagation of a covered
|
| 444 |
+
work results from an entity transaction, each party to that
|
| 445 |
+
transaction who receives a copy of the work also receives whatever
|
| 446 |
+
licenses to the work the party's predecessor in interest had or could
|
| 447 |
+
give under the previous paragraph, plus a right to possession of the
|
| 448 |
+
Corresponding Source of the work from the predecessor in interest, if
|
| 449 |
+
the predecessor has it or can get it with reasonable efforts.
|
| 450 |
+
|
| 451 |
+
You may not impose any further restrictions on the exercise of the
|
| 452 |
+
rights granted or affirmed under this License. For example, you may
|
| 453 |
+
not impose a license fee, royalty, or other charge for exercise of
|
| 454 |
+
rights granted under this License, and you may not initiate litigation
|
| 455 |
+
(including a cross-claim or counterclaim in a lawsuit) alleging that
|
| 456 |
+
any patent claim is infringed by making, using, selling, offering for
|
| 457 |
+
sale, or importing the Program or any portion of it.
|
| 458 |
+
|
| 459 |
+
11. Patents.
|
| 460 |
+
|
| 461 |
+
A "contributor" is a copyright holder who authorizes use under this
|
| 462 |
+
License of the Program or a work on which the Program is based. The
|
| 463 |
+
work thus licensed is called the contributor's "contributor version".
|
| 464 |
+
|
| 465 |
+
A contributor's "essential patent claims" are all patent claims
|
| 466 |
+
owned or controlled by the contributor, whether already acquired or
|
| 467 |
+
hereafter acquired, that would be infringed by some manner, permitted
|
| 468 |
+
by this License, of making, using, or selling its contributor version,
|
| 469 |
+
but do not include claims that would be infringed only as a
|
| 470 |
+
consequence of further modification of the contributor version. For
|
| 471 |
+
purposes of this definition, "control" includes the right to grant
|
| 472 |
+
patent sublicenses in a manner consistent with the requirements of
|
| 473 |
+
this License.
|
| 474 |
+
|
| 475 |
+
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
| 476 |
+
patent license under the contributor's essential patent claims, to
|
| 477 |
+
make, use, sell, offer for sale, import and otherwise run, modify and
|
| 478 |
+
propagate the contents of its contributor version.
|
| 479 |
+
|
| 480 |
+
In the following three paragraphs, a "patent license" is any express
|
| 481 |
+
agreement or commitment, however denominated, not to enforce a patent
|
| 482 |
+
(such as an express permission to practice a patent or covenant not to
|
| 483 |
+
sue for patent infringement). To "grant" such a patent license to a
|
| 484 |
+
party means to make such an agreement or commitment not to enforce a
|
| 485 |
+
patent against the party.
|
| 486 |
+
|
| 487 |
+
If you convey a covered work, knowingly relying on a patent license,
|
| 488 |
+
and the Corresponding Source of the work is not available for anyone
|
| 489 |
+
to copy, free of charge and under the terms of this License, through a
|
| 490 |
+
publicly available network server or other readily accessible means,
|
| 491 |
+
then you must either (1) cause the Corresponding Source to be so
|
| 492 |
+
available, or (2) arrange to deprive yourself of the benefit of the
|
| 493 |
+
patent license for this particular work, or (3) arrange, in a manner
|
| 494 |
+
consistent with the requirements of this License, to extend the patent
|
| 495 |
+
license to downstream recipients. "Knowingly relying" means you have
|
| 496 |
+
actual knowledge that, but for the patent license, your conveying the
|
| 497 |
+
covered work in a country, or your recipient's use of the covered work
|
| 498 |
+
in a country, would infringe one or more identifiable patents in that
|
| 499 |
+
country that you have reason to believe are valid.
|
| 500 |
+
|
| 501 |
+
If, pursuant to or in connection with a single transaction or
|
| 502 |
+
arrangement, you convey, or propagate by procuring conveyance of, a
|
| 503 |
+
covered work, and grant a patent license to some of the parties
|
| 504 |
+
receiving the covered work authorizing them to use, propagate, modify
|
| 505 |
+
or convey a specific copy of the covered work, then the patent license
|
| 506 |
+
you grant is automatically extended to all recipients of the covered
|
| 507 |
+
work and works based on it.
|
| 508 |
+
|
| 509 |
+
A patent license is "discriminatory" if it does not include within
|
| 510 |
+
the scope of its coverage, prohibits the exercise of, or is
|
| 511 |
+
conditioned on the non-exercise of one or more of the rights that are
|
| 512 |
+
specifically granted under this License. You may not convey a covered
|
| 513 |
+
work if you are a party to an arrangement with a third party that is
|
| 514 |
+
in the business of distributing software, under which you make payment
|
| 515 |
+
to the third party based on the extent of your activity of conveying
|
| 516 |
+
the work, and under which the third party grants, to any of the
|
| 517 |
+
parties who would receive the covered work from you, a discriminatory
|
| 518 |
+
patent license (a) in connection with copies of the covered work
|
| 519 |
+
conveyed by you (or copies made from those copies), or (b) primarily
|
| 520 |
+
for and in connection with specific products or compilations that
|
| 521 |
+
contain the covered work, unless you entered into that arrangement,
|
| 522 |
+
or that patent license was granted, prior to 28 March 2007.
|
| 523 |
+
|
| 524 |
+
Nothing in this License shall be construed as excluding or limiting
|
| 525 |
+
any implied license or other defenses to infringement that may
|
| 526 |
+
otherwise be available to you under applicable patent law.
|
| 527 |
+
|
| 528 |
+
12. No Surrender of Others' Freedom.
|
| 529 |
+
|
| 530 |
+
If conditions are imposed on you (whether by court order, agreement or
|
| 531 |
+
otherwise) that contradict the conditions of this License, they do not
|
| 532 |
+
excuse you from the conditions of this License. If you cannot convey a
|
| 533 |
+
covered work so as to satisfy simultaneously your obligations under this
|
| 534 |
+
License and any other pertinent obligations, then as a consequence you may
|
| 535 |
+
not convey it at all. For example, if you agree to terms that obligate you
|
| 536 |
+
to collect a royalty for further conveying from those to whom you convey
|
| 537 |
+
the Program, the only way you could satisfy both those terms and this
|
| 538 |
+
License would be to refrain entirely from conveying the Program.
|
| 539 |
+
|
| 540 |
+
13. Remote Network Interaction; Use with the GNU General Public License.
|
| 541 |
+
|
| 542 |
+
Notwithstanding any other provision of this License, if you modify the
|
| 543 |
+
Program, your modified version must prominently offer all users
|
| 544 |
+
interacting with it remotely through a computer network (if your version
|
| 545 |
+
supports such interaction) an opportunity to receive the Corresponding
|
| 546 |
+
Source of your version by providing access to the Corresponding Source
|
| 547 |
+
from a network server at no charge, through some standard or customary
|
| 548 |
+
means of facilitating copying of software. This Corresponding Source
|
| 549 |
+
shall include the Corresponding Source for any work covered by version 3
|
| 550 |
+
of the GNU General Public License that is incorporated pursuant to the
|
| 551 |
+
following paragraph.
|
| 552 |
+
|
| 553 |
+
Notwithstanding any other provision of this License, you have
|
| 554 |
+
permission to link or combine any covered work with a work licensed
|
| 555 |
+
under version 3 of the GNU General Public License into a single
|
| 556 |
+
combined work, and to convey the resulting work. The terms of this
|
| 557 |
+
License will continue to apply to the part which is the covered work,
|
| 558 |
+
but the work with which it is combined will remain governed by version
|
| 559 |
+
3 of the GNU General Public License.
|
| 560 |
+
|
| 561 |
+
14. Revised Versions of this License.
|
| 562 |
+
|
| 563 |
+
The Free Software Foundation may publish revised and/or new versions of
|
| 564 |
+
the GNU Affero General Public License from time to time. Such new versions
|
| 565 |
+
will be similar in spirit to the present version, but may differ in detail to
|
| 566 |
+
address new problems or concerns.
|
| 567 |
+
|
| 568 |
+
Each version is given a distinguishing version number. If the
|
| 569 |
+
Program specifies that a certain numbered version of the GNU Affero General
|
| 570 |
+
Public License "or any later version" applies to it, you have the
|
| 571 |
+
option of following the terms and conditions either of that numbered
|
| 572 |
+
version or of any later version published by the Free Software
|
| 573 |
+
Foundation. If the Program does not specify a version number of the
|
| 574 |
+
GNU Affero General Public License, you may choose any version ever published
|
| 575 |
+
by the Free Software Foundation.
|
| 576 |
+
|
| 577 |
+
If the Program specifies that a proxy can decide which future
|
| 578 |
+
versions of the GNU Affero General Public License can be used, that proxy's
|
| 579 |
+
public statement of acceptance of a version permanently authorizes you
|
| 580 |
+
to choose that version for the Program.
|
| 581 |
+
|
| 582 |
+
Later license versions may give you additional or different
|
| 583 |
+
permissions. However, no additional obligations are imposed on any
|
| 584 |
+
author or copyright holder as a result of your choosing to follow a
|
| 585 |
+
later version.
|
| 586 |
+
|
| 587 |
+
15. Disclaimer of Warranty.
|
| 588 |
+
|
| 589 |
+
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
| 590 |
+
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
| 591 |
+
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
| 592 |
+
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
| 593 |
+
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
| 594 |
+
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
| 595 |
+
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
| 596 |
+
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
| 597 |
+
|
| 598 |
+
16. Limitation of Liability.
|
| 599 |
+
|
| 600 |
+
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
| 601 |
+
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
| 602 |
+
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
| 603 |
+
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
| 604 |
+
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
|
| 605 |
+
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
|
| 606 |
+
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
| 607 |
+
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
| 608 |
+
SUCH DAMAGES.
|
| 609 |
+
|
| 610 |
+
17. Interpretation of Sections 15 and 16.
|
| 611 |
+
|
| 612 |
+
If the disclaimer of warranty and limitation of liability provided
|
| 613 |
+
above cannot be given local legal effect according to their terms,
|
| 614 |
+
reviewing courts shall apply local law that most closely approximates
|
| 615 |
+
an absolute waiver of all civil liability in connection with the
|
| 616 |
+
Program, unless a warranty or assumption of liability accompanies a
|
| 617 |
+
copy of the Program in return for a fee.
|
| 618 |
+
|
| 619 |
+
END OF TERMS AND CONDITIONS
|
| 620 |
+
|
| 621 |
+
How to Apply These Terms to Your New Programs
|
| 622 |
+
|
| 623 |
+
If you develop a new program, and you want it to be of the greatest
|
| 624 |
+
possible use to the public, the best way to achieve this is to make it
|
| 625 |
+
free software which everyone can redistribute and change under these terms.
|
| 626 |
+
|
| 627 |
+
To do so, attach the following notices to the program. It is safest
|
| 628 |
+
to attach them to the start of each source file to most effectively
|
| 629 |
+
state the exclusion of warranty; and each file should have at least
|
| 630 |
+
the "copyright" line and a pointer to where the full notice is found.
|
| 631 |
+
|
| 632 |
+
<one line to give the program's name and a brief idea of what it does.>
|
| 633 |
+
Copyright (C) <year> <name of author>
|
| 634 |
+
|
| 635 |
+
This program is free software: you can redistribute it and/or modify
|
| 636 |
+
it under the terms of the GNU Affero General Public License as published
|
| 637 |
+
by the Free Software Foundation, either version 3 of the License, or
|
| 638 |
+
(at your option) any later version.
|
| 639 |
+
|
| 640 |
+
This program is distributed in the hope that it will be useful,
|
| 641 |
+
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
| 642 |
+
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
| 643 |
+
GNU Affero General Public License for more details.
|
| 644 |
+
|
| 645 |
+
You should have received a copy of the GNU Affero General Public License
|
| 646 |
+
along with this program. If not, see <https://www.gnu.org/licenses/>.
|
| 647 |
+
|
| 648 |
+
Also add information on how to contact you by electronic and paper mail.
|
| 649 |
+
|
| 650 |
+
If your software can interact with users remotely through a computer
|
| 651 |
+
network, you should also make sure that it provides a way for users to
|
| 652 |
+
get its source. For example, if your program is a web application, its
|
| 653 |
+
interface could display a "Source" link that leads users to an archive
|
| 654 |
+
of the code. There are many ways you could offer source, and different
|
| 655 |
+
solutions will be better for different programs; see section 13 for the
|
| 656 |
+
specific requirements.
|
| 657 |
+
|
| 658 |
+
You should also get your employer (if you work as a programmer) or school,
|
| 659 |
+
if any, to sign a "copyright disclaimer" for the program,
|
| 660 |
+
if necessary. For more information on this, and how to apply and follow the GNU AGPL, see <https://www.gnu.org/licenses/>.
|
| 661 |
+
|
| 662 |
+
If you would like to obtain a copy of the software under a different license (e.g. Apache),
|
| 663 |
+
please send an email to Camb.AI at [email protected] indicating that
|
| 664 |
+
you would like a copy of the software under a different license.
|
README.md
ADDED
|
@@ -0,0 +1,157 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+

|
| 2 |
+
|
| 3 |
+
# MARS5: A novel speech model for insane prosody.
|
| 4 |
+
|
| 5 |
+
This is the repo for the MARS5 English speech model (TTS) from CAMB.AI.
|
| 6 |
+
|
| 7 |
+
The model follows a two-stage AR-NAR pipeline with a distinctively novel NAR component (see more info in the [docs](docs/architecture.md)).
|
| 8 |
+
|
| 9 |
+
With just 5 seconds of audio and a snippet of text, MARS5 can generate speech even for prosodically hard and diverse scenarios like sports commentary, anime and more. Check out our demo:
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
https://github.com/Camb-ai/MARS5-TTS/assets/23717819/3e191508-e03c-4ff9-9b02-d73ae0ebefdd
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
**Quick links**:
|
| 20 |
+
- [CAMB.AI website](https://camb.ai/) (access MARS5 in 140+ languages for TTS and dubbing)
|
| 21 |
+
- Technical docs: [in the docs folder](docs/architecture.md)
|
| 22 |
+
- Colab quickstart: <a target="_blank" href="https://colab.research.google.com/github/Camb-ai/mars5-tts/blob/master/mars5_demo.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
|
| 23 |
+
- Demo page with samples: [here](https://179c54d254f7.ngrok.app/)
|
| 24 |
+
|
| 25 |
+

|
| 26 |
+
|
| 27 |
+
**Figure**: the high-level architecture flow of Mars 5. Given text and a reference audio, coarse (L0) encodec speech features are obtained through an autoregressive transformer model. Then, the text, reference, and coarse features are refined in a multinomial DDPM model to produce the remaining encodec codebook values. The output of the DDPM is then vocoded to produce the final audio.
|
| 28 |
+
|
| 29 |
+
Because the model is trained on raw audio together with byte-pair-encoded text, it can be steered with things like punctuation and capitalization.
|
| 30 |
+
E.g. to add a pause, add a comma to that part in the transcript. Or, to emphasize a word, put it in capital letters in the transcript.
|
| 31 |
+
This enables a fairly natural way for guiding the prosody of the generated output.
|
| 32 |
+
|
| 33 |
+
Speaker identity is specified using an audio reference file between 2-12 seconds, with lengths around 6s giving optimal results.
|
| 34 |
+
Further, by providing the transcript of the reference, MARS5 enables one to do a '_deep clone_' which improves the quality of the cloning and output, at the cost of taking a bit longer to produce the audio.
|
| 35 |
+
For more details on this and other performance and model details, please see inside the [docs folder](docs/architecture.md).
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
## Quickstart
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
We use `torch.hub` to make loading the model easy -- no cloning of the repo needed. The steps to perform inference are simple:
|
| 42 |
+
|
| 43 |
+
1. **Install pip dependencies**: we have 3 inference dependencies only `torch`, `torchaudio`, `librosa`, `vocos`, and `encodec`. Python must be at version 3.10 or greater, and torch must be v2.0 or greater.
|
| 44 |
+
|
| 45 |
+
```bash
|
| 46 |
+
pip install --upgrade torch torchaudio librosa vocos encodec
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
2. **Load models**: load the Mars 5 AR and NAR model from torch hub:
|
| 50 |
+
|
| 51 |
+
```python
|
| 52 |
+
import torch, librosa
|
| 53 |
+
|
| 54 |
+
mars5, config_class = torch.hub.load('Camb-ai/mars5-tts', 'mars5_english', trust_repo=True)
|
| 55 |
+
# The `mars5` contains the AR and NAR model, as well as inference code.
|
| 56 |
+
# The `config_class` contains tunable inference config settings like temperature.
|
| 57 |
+
```
|
| 58 |
+
3. **Pick a reference** and optionally its transcript:
|
| 59 |
+
|
| 60 |
+
```python
|
| 61 |
+
# load reference audio between 1-12 seconds.
|
| 62 |
+
wav, sr = librosa.load('<path to arbitrary 24kHz waveform>.wav',
|
| 63 |
+
sr=mars5.sr, mono=True)
|
| 64 |
+
wav = torch.from_numpy(wav)
|
| 65 |
+
ref_transcript = "<transcript of the reference audio>"
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
The reference transcript is an optional piece of info you need if you wish to do a deep clone.
|
| 69 |
+
Mars5 supports 2 kinds of inference: a shallow, fast inference whereby you do not need the transcript of the reference (we call this a _shallow clone_), and a second slower, but typically higher quality way, which we call a _deep clone_.
|
| 70 |
+
To use the deep clone, you need the prompt transcript. See the [model docs](docs/architecture.md) for more info on this.
|
| 71 |
+
|
| 72 |
+
4. **Perform the synthesis**:
|
| 73 |
+
|
| 74 |
+
```python
|
| 75 |
+
# Pick whether you want a deep or shallow clone. Set to False if you don't know prompt transcript or want fast inference. Set to True if you know transcript and want highest quality.
|
| 76 |
+
deep_clone = True
|
| 77 |
+
# Below you can tune other inference settings, like top_k, temperature, top_p, etc...
|
| 78 |
+
cfg = config_class(deep_clone=deep_clone, rep_penalty_window=100,
|
| 79 |
+
top_k=100, temperature=0.7, freq_penalty=3)
|
| 80 |
+
|
| 81 |
+
ar_codes, output_audio = mars5.tts("The quick brown rat.", wav,
|
| 82 |
+
ref_transcript,
|
| 83 |
+
cfg=cfg)
|
| 84 |
+
# output_audio is (T,) shape float tensor corresponding to the 24kHz output audio.
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
That's it! These default settings provide pretty good results, but feel free to tune the inference settings to optimize the output for your particular example. See the [`InferenceConfig`](inference.py) code or the demo notebook for info and docs on all the different inference settings.
|
| 88 |
+
|
| 89 |
+
_Some tips for best quality:_
|
| 90 |
+
- Make sure reference audio is clean and between 1 second and 12 seconds.
|
| 91 |
+
- Use deep clone and provide an accurate transcript for the reference.
|
| 92 |
+
- Use proper punctuation -- the model can be guided and made better or worse with proper use of punctuation and capitalization.
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
## Model details
|
| 96 |
+
|
| 97 |
+
**Checkpoints**
|
| 98 |
+
|
| 99 |
+
The checkpoints for MARS5 are provided under the releases tab of this github repo. We provide two checkpoints:
|
| 100 |
+
|
| 101 |
+
- AR fp16 checkpoint [~750M parameters], along with config embedded in the checkpoint.
|
| 102 |
+
- NAR fp16 checkpoint [~450M parameters], along with config embedded in the checkpoint.
|
| 103 |
+
- The byte-pair encoding tokenizer used for the L0 encodec codes and the English text is embedded in each checkpoint under the `'vocab'` key, and follows roughly the same format of a saved minbpe tokenizer.
|
| 104 |
+
|
| 105 |
+
**Hardware requirements**:
|
| 106 |
+
|
| 107 |
+
You must be able to store at least 750M+450M params on GPU, and do inference with 750M of active parameters. In general, at least **20GB of GPU VRAM** is needed to run the model on GPU (we plan to further optimize this in the future).
|
| 108 |
+
|
| 109 |
+
If you do not have the necessary hardware requirements and just want to use MARS5 in your applications, you can use it via our API: see [docs.camb.ai](https://docs.camb.ai/). If you need some more credits to test it for your use case, feel free to reach out to `[email protected]` for help.
|
| 110 |
+
|
| 111 |
+
## Roadmap
|
| 112 |
+
|
| 113 |
+
Mars 5 is not perfect at the moment, and we are working on a few efforts to improve its quality, stability, and performance.
|
| 114 |
+
Rough areas we are looking to improve, and welcome any contributions:
|
| 115 |
+
|
| 116 |
+
- Improving inference stability and consistency
|
| 117 |
+
- Speed/performance optimizations
|
| 118 |
+
- Improving reference audio selection when given long references.
|
| 119 |
+
- Benchmark performance numbers for Mars 5 on standard speech datasets.
|
| 120 |
+
|
| 121 |
+
If you would like to contribute any improvement to MARS, please feel free to contribute (guidelines below).
|
| 122 |
+
|
| 123 |
+
## Contributions
|
| 124 |
+
|
| 125 |
+
We welcome any contributions to improving the model. As you may find when experimenting, it can produce really great results, it can still be further improved to create excellent outputs _consistently_.
|
| 126 |
+
|
| 127 |
+
**Contribution format**:
|
| 128 |
+
|
| 129 |
+
The preferred way to contribute to our repo is to fork the [master repository](https://github.com/Camb-ai/mars5-tts) on GitHub:
|
| 130 |
+
|
| 131 |
+
1. Fork the repo on github
|
| 132 |
+
2. Clone the repo, set upstream as this repo: `git remote add upstream [email protected]:Camb-ai/mars5-tts.git`
|
| 133 |
+
3. Make to a new local branch and make your changes, commit changes.
|
| 134 |
+
4. Push changes to new upstream branch: `git push --set-upstream origin <NAME-NEW-BRANCH>`
|
| 135 |
+
5. On github, go to your fork and click 'Pull request' to begin the PR process. Please make sure to include a description of what you did/fixed.
|
| 136 |
+
|
| 137 |
+
## License
|
| 138 |
+
|
| 139 |
+
We are open-sourcing MARS in English under GNU AGPL 3.0, but you can request to use it under a different license by emailing [email protected]
|
| 140 |
+
|
| 141 |
+
## Join our team
|
| 142 |
+
|
| 143 |
+
We're an ambitious team, globally distributed, with a singular aim of making everyone's voice count. At CAMB.AI, we're a research team of Interspeech-published, Carnegie Mellon, ex-Siri engineers and we're looking for you to join our team.
|
| 144 |
+
|
| 145 |
+
We're actively hiring; please drop us an email at [email protected] if you're interested. Visit our [careers page](https://www.camb.ai/careers) for more info.
|
| 146 |
+
|
| 147 |
+
## Acknowledgements
|
| 148 |
+
|
| 149 |
+
Parts of code for this project are adapted from the following repositories -- please make sure to check them out! Thank you to the authors of:
|
| 150 |
+
|
| 151 |
+
- AWS: For providing much needed compute resources (NVIDIA H100s) to enable training of the model.
|
| 152 |
+
- TransFusion: [https://github.com/RF5/transfusion-asr](https://github.com/RF5/transfusion-asr)
|
| 153 |
+
- Multinomial diffusion: [https://github.com/ehoogeboom/multinomial_diffusion](https://github.com/ehoogeboom/multinomial_diffusion)
|
| 154 |
+
- Mistral-src: [https://github.com/mistralai/mistral-src](https://github.com/mistralai/mistral-src)
|
| 155 |
+
- minbpe: [https://github.com/karpathy/minbpe](https://github.com/karpathy/minbpe)
|
| 156 |
+
- gemelo-ai's encodec Vocos: [https://github.com/gemelo-ai/vocos](https://github.com/gemelo-ai/vocos)
|
| 157 |
+
- librosa for their `.trim()` code: [https://librosa.org/doc/main/generated/librosa.effects.trim.html](https://librosa.org/doc/main/generated/librosa.effects.trim.html)
|
assets/demo-preview.png
ADDED

|
assets/github-banner.png
ADDED

|
docs/architecture.md
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Mars 5 technical details
|
| 2 |
+
|
| 3 |
+
While we do not have the time for a proper full writeup of the details of Mars5, its design, training, and implementation, we at least try give a more detailed overview here of how Mars5 works.
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
## hubconf object/api
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
After loading the model with `torch.hub.load`, two objects are returned, a Mars5TTS, and the dataclass of the inference config to use when calling the `mars5.tts()` method.
|
| 10 |
+
Concretely, the main methods of the mars5 object are:
|
| 11 |
+
|
| 12 |
+
```python
|
| 13 |
+
|
| 14 |
+
# The init function, called automatically when you initialize the
|
| 15 |
+
# model from torch.hub.load(). If you want, you can pass in your
|
| 16 |
+
# own custom checkpoints here to initalize the model with your
|
| 17 |
+
# own model, tokenizer, etc...
|
| 18 |
+
def __init__(self, ar_ckpt, nar_ckpt, device: str = None) -> None:
|
| 19 |
+
# ... initialization code ...
|
| 20 |
+
|
| 21 |
+
# Main text-to-speech function, converting text and a reference
|
| 22 |
+
# audio to speech.
|
| 23 |
+
def tts(self, text: str, ref_audio: Tensor, ref_transcript: str | None,
|
| 24 |
+
cfg: InferenceConfig) -> Tensor:
|
| 25 |
+
""" Perform TTS for `text`, given a reference audio `ref_audio` (of shape [sequence_length,], sampled at 24kHz)
|
| 26 |
+
which has an associated `ref_transcript`. Perform inference using the inference
|
| 27 |
+
config given by `cfg`, which controls the temperature, top_p, etc...
|
| 28 |
+
Returns:
|
| 29 |
+
- `ar_codes`: (seq_len,) long tensor of discrete coarse code outputs from the AR model.
|
| 30 |
+
- `out_wav`: (T,) float output audio tensor sampled at 24kHz.
|
| 31 |
+
"""
|
| 32 |
+
|
| 33 |
+
# Utility function to vocode encodec tokens, if one wishes
|
| 34 |
+
# to hear the raw AR model ouput by vocoding the `ar_codes`
|
| 35 |
+
# returned above.
|
| 36 |
+
def vocode(self, tokens: Tensor) -> Tensor:
|
| 37 |
+
""" Vocodes tokens of shape (seq_len, n_q) """
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
## Model design
|
| 42 |
+
|
| 43 |
+
Mars 5 follows a two-stage AR-NAR design according to the diagram on the main page.
|
| 44 |
+
|
| 45 |
+
#### AR component
|
| 46 |
+
|
| 47 |
+
The AR model follows a Mistral-style encoder-only transformer model to predict Encodec L0 codes (the lowest/most coarse level quantization codes).
|
| 48 |
+
Overall, the AR and NAR model is going to predict all 8 codebook entries of the Encodec 6kbps codec.
|
| 49 |
+
The AR model design is given below:
|
| 50 |
+
|
| 51 |
+

|
| 52 |
+
|
| 53 |
+
**Figure**: autoregressive component of Mars 5. During training, the initial 6kbps encodec tokens of the speech are fed through a small encoder-only transformer, producing a single output vector corresponding to an implicit speaker embedding.
|
| 54 |
+
This vector is concatenated with learnt embeddings corresponding to the text tokens, and L0 speech tokens, after byte-pair encoding tokenization.
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
The AR model is trained using the standard next-token prediction task of language models with a cross-entropy loss with the next token, given a smaller weight to text tokens.
|
| 58 |
+
During inference, we iteratively sample from the transformer to produce the desiged L0 codes.
|
| 59 |
+
When we use a _shallow clone_, then the reference audio is fed into the transcript to make the implicit speaker embedding used in the input sequence.
|
| 60 |
+
When we use a _deep clone_, the above is done, but we also concatenate the reference transcript with the desired text, and the reference audio tokens with the input sequence before we start sampling the output.
|
| 61 |
+
In pseudocode:
|
| 62 |
+
|
| 63 |
+
```
|
| 64 |
+
speaker_embedding <- speaker_conditioning_transformer(ref audio)
|
| 65 |
+
if deep_clone:
|
| 66 |
+
prompt = concatenate( speaker embedding, reference text, target text, reference L0 speech codes )
|
| 67 |
+
else:
|
| 68 |
+
prompt = concatenate( speaker embedding, target text )
|
| 69 |
+
|
| 70 |
+
ar output <- autoregressively sample from prompt
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
While a deep clone provides a more accurate cloning of the reference speaker identity and prosody, it requires knowledge of the reference transcript and takes longer to do inference.
|
| 74 |
+
|
| 75 |
+
#### NAR component
|
| 76 |
+
|
| 77 |
+
After the AR model has predicted the L0 encodec codes, we need a way to predict the remaining 7 codebooks of the 6kbps Encodec codec.
|
| 78 |
+
This is what the NAR model is trained to do, using a multinomial diffusion framework.
|
| 79 |
+
Concretely, the diffusion process is a discrete DDPM, whereby at each timestep in the diffusion process, it takes in a sequence of `(batch size, sequence length, n_codebooks)` and produces an output categorical distribution over each codebook, i.e. an output of shape `(batch size, sequence length, n_codebooks, 1024)`, since each encodec codebook has 1024 possible values.
|
| 80 |
+
The architecture of the model looks as follows:
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+

|
| 84 |
+
|
| 85 |
+
**Figure**: Mars 5 non-autoregressive component. It follows an encoder-decoder transformer architecture, whereby the encoder computes an implicit speaker embedding like the AR model, and concatenates that along with the target to form an input sequence to a transformer encoder. The transformer decoder predicts the distribution of all 8 encodec codebook tokens given a partly noised input at some diffusion timestep `t`.
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
The encoder and decoder transformers are simple `nn.Transformer` variants with sinusoidal positional embeddings and SwiGLU activations.
|
| 89 |
+
A multinomial diffusion manager controls the forward and reference diffusion processes during inference and training according to a cosine diffusion schedule.
|
| 90 |
+
Diffusion is performed independently of the sequence length or codebook index.
|
| 91 |
+
|
| 92 |
+
During training and inference, the L0 codebooks of the input at timestep $t$ are overridden (i.e. not noised in the forward diffusion process) with either the ground truth L0 codes (during training) or the AR model's predictions (during inference).
|
| 93 |
+
Like the AR model, the NAR model can perform inference in either a _shallow clone_ way or a _deep clone_ way.
|
| 94 |
+
And, like the AR model, the difference between the two is, with a _deep clone_, we concatenate the reference text to the input text sequence, and the reference speech codes (the full values for all 8 codebooks) to the decoder input sequence $x$.
|
| 95 |
+
During inference, we then treat the portion of $x$ corresponding to the reference codec codes, and all the AR L0 codes, as 'fixed' and effectively perform diffusion inpainting for the remaining missing codec codes.
|
| 96 |
+
The figure below explains what the input to the decoder looks like for a deep clone:
|
| 97 |
+
|
| 98 |
+

|
| 99 |
+
|
| 100 |
+
This allows us to use diffusion inpainting techniques like [RePaint](https://arxiv.org/abs/2201.09865) to improve the quality of the output at the cost of more inference time.
|
| 101 |
+
We've implemented this in the the diffusion config used in the NAR inference code (see it [here](/mars5/diffuser.py)), and you can simply increase the `jump_len` and `jump_n_sample` to greater than 1 to use RePaint inpainting to improve NAR performance.
|
| 102 |
+
|
| 103 |
+
|
docs/assets/NAR_inpainting_diagram.png
ADDED
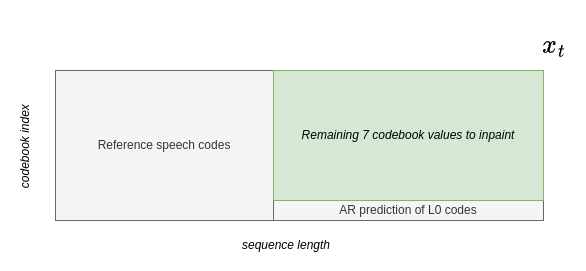
|
docs/assets/example_ref.wav
ADDED
|
Binary file (137 kB). View file
|
|
|
docs/assets/intro_vid.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cabbb40186fd5599282b4ada76643b1d1b34c513af1977861513f9d2f1220ad6
|
| 3 |
+
size 2105962
|
docs/assets/mars5_AR_arch.png
ADDED
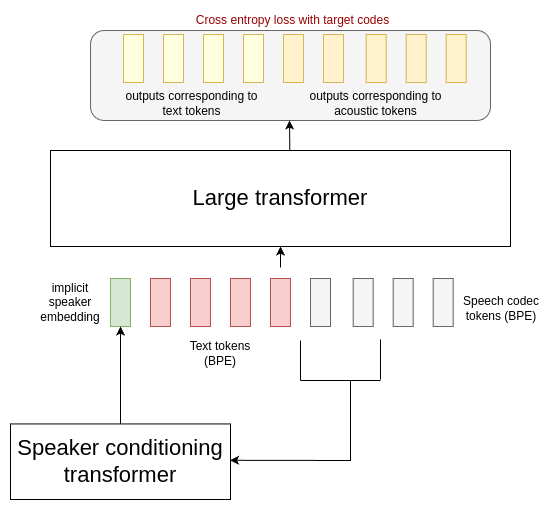
|
docs/assets/mars5_NAR_arch.png
ADDED
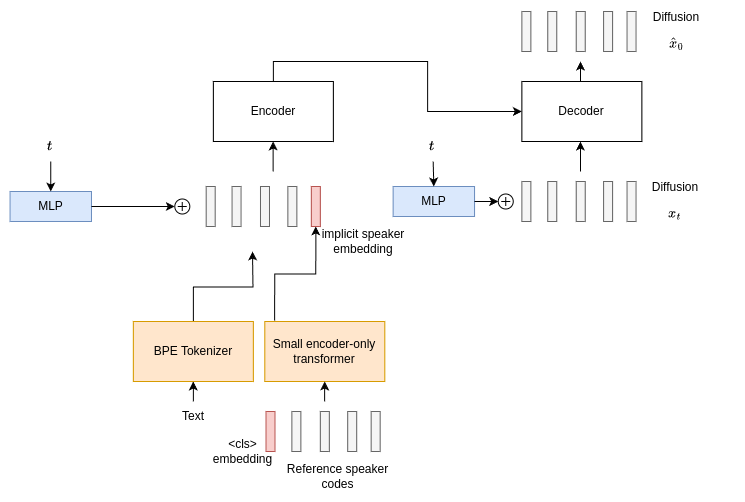
|
docs/assets/simplified_diagram.png
ADDED
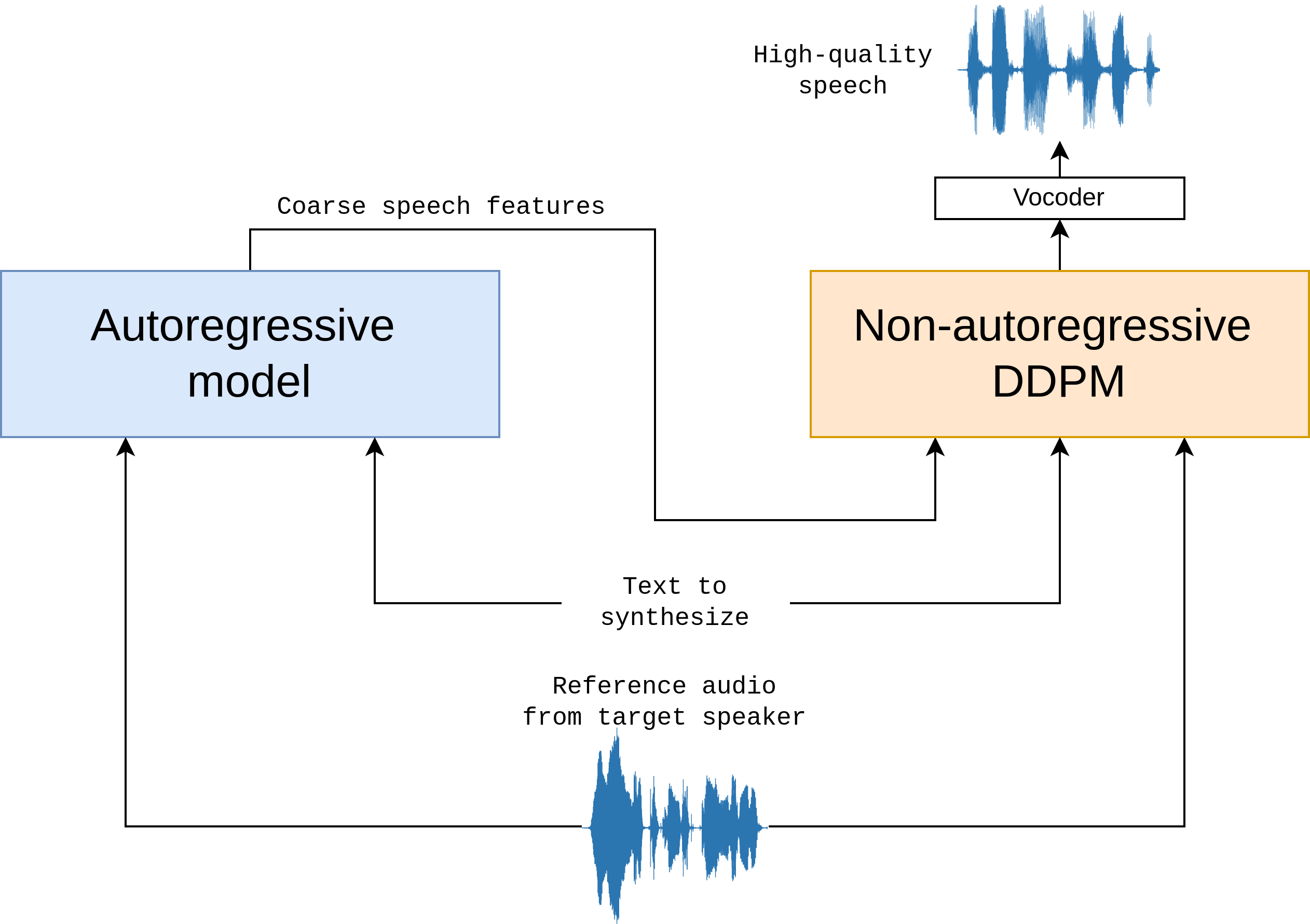
|
hubconf.py
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
dependencies = ['torch', 'torchaudio', 'numpy', 'vocos']
|
| 2 |
+
|
| 3 |
+
import logging
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
from inference import Mars5TTS, InferenceConfig
|
| 8 |
+
|
| 9 |
+
ar_url = "https://github.com/Camb-ai/mars5-tts/releases/download/v0.1-checkpoints/mars5_en_checkpoints_ar-1680000.pt"
|
| 10 |
+
nar_url = "https://github.com/Camb-ai/mars5-tts/releases/download/v0.1-checkpoints/mars5_en_checkpoints_nar-1260000.pt"
|
| 11 |
+
|
| 12 |
+
def mars5_english(pretrained=True, progress=True, device=None, ar_path=None, nar_path=None) -> Mars5TTS:
|
| 13 |
+
""" Load mars5 english model on `device`, optionally show `progress`. """
|
| 14 |
+
if device is None: device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 15 |
+
logging.info(f"Using device: {device}")
|
| 16 |
+
if pretrained == False: raise AssertionError('Only pretrained model currently supported.')
|
| 17 |
+
logging.info("Loading AR checkpoint...")
|
| 18 |
+
if ar_path is None:
|
| 19 |
+
ar_ckpt = torch.hub.load_state_dict_from_url(
|
| 20 |
+
ar_url, progress=progress, check_hash=False, map_location='cpu'
|
| 21 |
+
)
|
| 22 |
+
else: ar_ckpt = torch.load(str(ar_path), map_location='cpu')
|
| 23 |
+
|
| 24 |
+
logging.info("Loading NAR checkpoint...")
|
| 25 |
+
if nar_path is None:
|
| 26 |
+
nar_ckpt = torch.hub.load_state_dict_from_url(
|
| 27 |
+
nar_url, progress=progress, check_hash=False, map_location='cpu'
|
| 28 |
+
)
|
| 29 |
+
else: nar_ckpt = torch.load(str(nar_path), map_location='cpu')
|
| 30 |
+
logging.info("Initializing modules...")
|
| 31 |
+
mars5 = Mars5TTS(ar_ckpt, nar_ckpt, device=device)
|
| 32 |
+
return mars5, InferenceConfig
|
| 33 |
+
|
inference.py
ADDED
|
@@ -0,0 +1,236 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import Tensor
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
import logging
|
| 6 |
+
import json
|
| 7 |
+
from typing import Optional
|
| 8 |
+
from pathlib import Path
|
| 9 |
+
from dataclasses import dataclass
|
| 10 |
+
import os
|
| 11 |
+
|
| 12 |
+
from mars5.model import CodecLM, ResidualTransformer
|
| 13 |
+
from vocos import Vocos
|
| 14 |
+
from encodec import EncodecModel
|
| 15 |
+
from mars5.diffuser import MultinomialDiffusion, DSH, perform_simple_inference
|
| 16 |
+
from mars5.minbpe.regex import RegexTokenizer, GPT4_SPLIT_PATTERN
|
| 17 |
+
from mars5.minbpe.codebook import CodebookTokenizer
|
| 18 |
+
from mars5.ar_generate import ar_generate
|
| 19 |
+
from mars5.utils import nuke_weight_norm
|
| 20 |
+
from mars5.trim import trim
|
| 21 |
+
import tempfile
|
| 22 |
+
import logging
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
@dataclass
|
| 26 |
+
class InferenceConfig():
|
| 27 |
+
""" The defaults configuration variables for TTS inference. """
|
| 28 |
+
|
| 29 |
+
## >>>> AR CONFIG
|
| 30 |
+
temperature: float = 0.7
|
| 31 |
+
top_k: int = 200 # 0 disables it
|
| 32 |
+
top_p: float = 0.2
|
| 33 |
+
typical_p: float = 1.0
|
| 34 |
+
freq_penalty: float = 3
|
| 35 |
+
presence_penalty: float = 0.4
|
| 36 |
+
rep_penalty_window: int = 80 # how far in the past to consider when penalizing repetitions. Equates to 5s
|
| 37 |
+
|
| 38 |
+
eos_penalty_decay: float = 0.5 # how much to penalize <eos>
|
| 39 |
+
eos_penalty_factor: float = 1 # overal penalty weighting
|
| 40 |
+
eos_estimated_gen_length_factor: float = 1.0 # multiple of len(text_phones) to assume an approximate output length is
|
| 41 |
+
|
| 42 |
+
## >>>> NAR CONFIG
|
| 43 |
+
# defaults, that can be overridden with user specified inputs
|
| 44 |
+
timesteps: int = 200
|
| 45 |
+
x_0_temp: float = 0.7
|
| 46 |
+
q0_override_steps: int = 20 # number of diffusion steps where NAR L0 predictions overrides AR L0 predictions.
|
| 47 |
+
nar_guidance_w: float = 3
|
| 48 |
+
|
| 49 |
+
max_prompt_dur: float = 12 # maximum length prompt is allowed, in seconds.
|
| 50 |
+
|
| 51 |
+
# Maximum AR codes to generate in 1 inference.
|
| 52 |
+
# Default of -1 leaves it same as training time max AR tokens.
|
| 53 |
+
# Typical values up to ~2x training time can be tolerated,
|
| 54 |
+
# with ~1.5x trianing time tokens having still mostly ok performance.
|
| 55 |
+
generate_max_len_override: int = -1
|
| 56 |
+
|
| 57 |
+
# Whether to deep clone from the reference.
|
| 58 |
+
# Pros: improves intelligibility and speaker cloning performance.
|
| 59 |
+
# Cons: requires reference transcript, and inference takes a bit longer.
|
| 60 |
+
deep_clone: bool = True
|
| 61 |
+
|
| 62 |
+
use_kv_cache: bool = True
|
| 63 |
+
trim_db: float = 27
|
| 64 |
+
beam_width: int = 1 # only beam width of 1 is currently supported
|
| 65 |
+
ref_audio_pad: float = 0
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
class Mars5TTS(nn.Module):
|
| 69 |
+
|
| 70 |
+
def __init__(self, ar_ckpt, nar_ckpt, device: str = None) -> None:
|
| 71 |
+
super().__init__()
|
| 72 |
+
|
| 73 |
+
if device is None:
|
| 74 |
+
device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 75 |
+
self.device = torch.device(device)
|
| 76 |
+
|
| 77 |
+
self.codec = EncodecModel.encodec_model_24khz().to(device).eval()
|
| 78 |
+
self.codec.set_target_bandwidth(6.0)
|
| 79 |
+
|
| 80 |
+
# save and load text tokenize
|
| 81 |
+
self.texttok = RegexTokenizer(GPT4_SPLIT_PATTERN)
|
| 82 |
+
tfn = tempfile.mkstemp(suffix='texttok.model')[1]
|
| 83 |
+
Path(tfn).write_text(ar_ckpt['vocab']['texttok.model'])
|
| 84 |
+
self.texttok.load(tfn)
|
| 85 |
+
os.remove(tfn)
|
| 86 |
+
# save and load speech tokenizer
|
| 87 |
+
sfn = tempfile.mkstemp(suffix='speechtok.model')[1]
|
| 88 |
+
self.speechtok = CodebookTokenizer(GPT4_SPLIT_PATTERN)
|
| 89 |
+
Path(sfn).write_text(ar_ckpt['vocab']['speechtok.model'])
|
| 90 |
+
self.speechtok.load(sfn)
|
| 91 |
+
os.remove(sfn)
|
| 92 |
+
# keep track of tokenization things.
|
| 93 |
+
self.n_vocab = len(self.texttok.vocab) + len(self.speechtok.vocab)
|
| 94 |
+
self.n_text_vocab = len(self.texttok.vocab) + 1
|
| 95 |
+
self.diffusion_n_classes: int = 1025 # 1 for padding idx
|
| 96 |
+
# load AR model
|
| 97 |
+
self.codeclm = CodecLM(n_vocab=self.n_vocab, dim=1536, dim_ff_scale=7/3)
|
| 98 |
+
self.codeclm.load_state_dict(ar_ckpt['model'])
|
| 99 |
+
self.codeclm = self.codeclm.to(self.device).eval()
|
| 100 |
+
# load NAR model
|
| 101 |
+
self.codecnar = ResidualTransformer(n_text_vocab=self.n_text_vocab, n_quant=self.diffusion_n_classes,
|
| 102 |
+
p_cond_drop=0, dropout=0)
|
| 103 |
+
self.codecnar.load_state_dict(nar_ckpt['model'])
|
| 104 |
+
self.codecnar = self.codecnar.to(self.device).eval()
|
| 105 |
+
self.default_T = 200
|
| 106 |
+
|
| 107 |
+
self.sr = 24000
|
| 108 |
+
self.latent_sr = 75
|
| 109 |
+
|
| 110 |
+
# load vocoder
|
| 111 |
+
self.vocos = Vocos.from_pretrained("charactr/vocos-encodec-24khz").to(self.device).eval()
|
| 112 |
+
nuke_weight_norm(self.codec)
|
| 113 |
+
nuke_weight_norm(self.vocos)
|
| 114 |
+
|
| 115 |
+
@torch.inference_mode
|
| 116 |
+
def vocode(self, tokens: Tensor) -> Tensor:
|
| 117 |
+
""" Vocodes tokens of shape (seq_len, n_q) """
|
| 118 |
+
tokens = tokens.T.to(self.device)
|
| 119 |
+
features = self.vocos.codes_to_features(tokens)
|
| 120 |
+
# A cool hidden feature of vocos vocoding:
|
| 121 |
+
# setting the bandwidth below to 1 (corresponding to 3 kbps)
|
| 122 |
+
# actually still works on 6kbps input tokens, but *smooths* the output
|
| 123 |
+
# audio a bit, which can help improve quality if its a bit noisy.
|
| 124 |
+
# Hence we use [1] and not [2] below.
|
| 125 |
+
bandwidth_id = torch.tensor([1], device=self.device) # 6 kbps
|
| 126 |
+
wav_diffusion = self.vocos.decode(features, bandwidth_id=bandwidth_id)
|
| 127 |
+
return wav_diffusion.cpu().squeeze()[None]
|
| 128 |
+
|
| 129 |
+
@torch.inference_mode
|
| 130 |
+
def tts(self, text: str, ref_audio: Tensor, ref_transcript: Optional[str] = None,
|
| 131 |
+
cfg: Optional[InferenceConfig] = InferenceConfig()) -> Tensor:
|
| 132 |
+
""" Perform TTS for `text`, given a reference audio `ref_audio` (of shape [sequence_length,], sampled at 24kHz)
|
| 133 |
+
which has an associated `ref_transcript`. Perform inference using the inference
|
| 134 |
+
config given by `cfg`, which controls the temperature, top_p, etc...
|
| 135 |
+
Returns:
|
| 136 |
+
- `ar_codes`: (seq_len,) long tensor of discrete coarse code outputs from the AR model.
|
| 137 |
+
- `out_wav`: (T,) float output audio tensor sampled at 24kHz.
|
| 138 |
+
"""
|
| 139 |
+
|
| 140 |
+
if cfg.deep_clone and ref_transcript is None:
|
| 141 |
+
raise AssertionError(
|
| 142 |
+
("Inference config deep clone is set to true, but reference transcript not specified! "
|
| 143 |
+
"Please specify the transcript of the prompt, or set deep_clone=False in the inference `cfg` argument."
|
| 144 |
+
))
|
| 145 |
+
ref_dur = ref_audio.shape[-1]/self.sr
|
| 146 |
+
if ref_dur > cfg.max_prompt_dur:
|
| 147 |
+
logging.warning((f"Reference audio duration is {ref_dur:.2f} > max suggested ref audio. "
|
| 148 |
+
f"Expect quality degradations. We recommend you trim prompt to be shorter than max prompt length."))
|
| 149 |
+
|
| 150 |
+
# get text codes.
|
| 151 |
+
text_tokens = self.texttok.encode("<|startoftext|>"+text.strip()+"<|endoftext|>",
|
| 152 |
+
allowed_special='all')
|
| 153 |
+
|
| 154 |
+
text_tokens_full = self.texttok.encode("<|startoftext|>"+ ref_transcript + ' ' + str(text).strip()+"<|endoftext|>",
|
| 155 |
+
allowed_special='all')
|
| 156 |
+
|
| 157 |
+
if ref_audio.dim() == 1: ref_audio = ref_audio[None]
|
| 158 |
+
if ref_audio.shape[0] != 1: ref_audio = ref_audio.mean(dim=0, keepdim=True)
|
| 159 |
+
ref_audio = F.pad(ref_audio, (int(self.sr*cfg.ref_audio_pad), 0))
|
| 160 |
+
# get reference audio codec tokens
|
| 161 |
+
prompt_codec = self.codec.encode(ref_audio[None].to(self.device))[0][0] # (bs, n_q, seq_len)
|
| 162 |
+
|
| 163 |
+
n_speech_inp = 0
|
| 164 |
+
n_start_skip = 0
|
| 165 |
+
q0_str = ' '.join([str(t) for t in prompt_codec[0, 0].tolist()])
|
| 166 |
+
# Note, in the below, we do NOT want to encode the <eos> token as a part of it, since we will be continuing it!!!
|
| 167 |
+
speech_tokens = self.speechtok.encode(q0_str.strip()) # + "<|endofspeech|>", allowed_special='all')
|
| 168 |
+
spk_ref_codec = prompt_codec[0, :, :].T # (seq_len, n_q)
|
| 169 |
+
|
| 170 |
+
raw_prompt_acoustic_len = len(prompt_codec[0,0].squeeze())
|
| 171 |
+
offset_speech_codes = [p+len(self.texttok.vocab) for p in speech_tokens]
|
| 172 |
+
if not cfg.deep_clone:
|
| 173 |
+
# shallow clone, so
|
| 174 |
+
# 1. clip existing speech codes to be empty (n_speech_inp = 0)
|
| 175 |
+
offset_speech_codes = offset_speech_codes[:n_speech_inp]
|
| 176 |
+
else:
|
| 177 |
+
# Deep clone, so
|
| 178 |
+
# 1. set text to be text of prompt + target text
|
| 179 |
+
text_tokens = text_tokens_full
|
| 180 |
+
# 2. update n_speech_inp to be length of prompt, so we only display from ths `n_speech_inp` onwards in the final output.
|
| 181 |
+
n_speech_inp = len(offset_speech_codes)
|
| 182 |
+
prompt = torch.tensor(text_tokens + offset_speech_codes, dtype=torch.long, device=self.device)
|
| 183 |
+
first_codec_idx = prompt.shape[-1] - n_speech_inp + 1
|
| 184 |
+
|
| 185 |
+
# ---> perform AR code generation
|
| 186 |
+
|
| 187 |
+
logging.debug(f"Raw acoustic prompt length: {raw_prompt_acoustic_len}")
|
| 188 |
+
|
| 189 |
+
ar_codes = ar_generate(self.texttok, self.speechtok, self.codeclm,
|
| 190 |
+
prompt, spk_ref_codec, first_codec_idx,
|
| 191 |
+
max_len=cfg.generate_max_len_override if cfg.generate_max_len_override > 1 else 2000,
|
| 192 |
+
temperature=cfg.temperature, topk=cfg.top_k, top_p=cfg.top_p, typical_p=cfg.typical_p,
|
| 193 |
+
alpha_frequency=cfg.freq_penalty, alpha_presence=cfg.presence_penalty, penalty_window=cfg.rep_penalty_window,
|
| 194 |
+
eos_penalty_decay=cfg.eos_penalty_decay, eos_penalty_factor=cfg.eos_penalty_factor,
|
| 195 |
+
beam_width=cfg.beam_width, beam_length_penalty=1,
|
| 196 |
+
n_phones_gen=round(cfg.eos_estimated_gen_length_factor*len(text)),
|
| 197 |
+
vocode=False, use_kv_cache=cfg.use_kv_cache)
|
| 198 |
+
|
| 199 |
+
# Parse AR output
|
| 200 |
+
output_tokens = ar_codes - len(self.texttok.vocab)
|
| 201 |
+
output_tokens = output_tokens.clamp(min=0).squeeze()[first_codec_idx:].cpu().tolist()
|
| 202 |
+
gen_codes_decoded = self.speechtok.decode_int(output_tokens)
|
| 203 |
+
gen_codes_decoded = torch.tensor([s for s in gen_codes_decoded if type(s) == int], dtype=torch.long, device=self.device)
|
| 204 |
+
|
| 205 |
+
c_text = torch.tensor(text_tokens, dtype=torch.long, device=self.device)[None]
|
| 206 |
+
c_codes = prompt_codec.permute(0, 2, 1)
|
| 207 |
+
c_texts_lengths = torch.tensor([len(text_tokens)], dtype=torch.long, device=self.device)
|
| 208 |
+
c_codes_lengths = torch.tensor([c_codes.shape[1],], dtype=torch.long, device=self.device)
|
| 209 |
+
|
| 210 |
+
_x = gen_codes_decoded[None, n_start_skip:, None].repeat(1, 1, 8) # (seq_len) -> (1, seq_len, 8)
|
| 211 |
+
x_padding_mask = torch.zeros((1, _x.shape[1]), dtype=torch.bool, device=_x.device)
|
| 212 |
+
|
| 213 |
+
# ---> perform DDPM NAR inference
|
| 214 |
+
|
| 215 |
+
T = self.default_T
|
| 216 |
+
diff = MultinomialDiffusion(self.diffusion_n_classes, timesteps=T, device=self.device)
|
| 217 |
+
|
| 218 |
+
dsh_cfg = DSH(last_greedy=True, x_0_temp=cfg.x_0_temp,
|
| 219 |
+
guidance_w=cfg.nar_guidance_w,
|
| 220 |
+
deep_clone=cfg.deep_clone, jump_len=1, jump_n_sample=1,
|
| 221 |
+
q0_override_steps=cfg.q0_override_steps,
|
| 222 |
+
enable_kevin_scaled_inference=True, # see TransFusion ASR for explanation of this
|
| 223 |
+
progress=False)
|
| 224 |
+
|
| 225 |
+
final_output = perform_simple_inference(self.codecnar,(
|
| 226 |
+
c_text, c_codes, c_texts_lengths, c_codes_lengths, _x, x_padding_mask
|
| 227 |
+
), diff, diff.num_timesteps, torch.float16, dsh=dsh_cfg, retain_quant0=True) # (bs, seq_len, n_quant)
|
| 228 |
+
|
| 229 |
+
skip_front = raw_prompt_acoustic_len if cfg.deep_clone else 0
|
| 230 |
+
final_output = final_output[0, skip_front:].to(self.device) # (seq_len, n_quant)
|
| 231 |
+
|
| 232 |
+
# vocode final output and trim silences
|
| 233 |
+
final_audio = self.vocode(final_output).squeeze()
|
| 234 |
+
final_audio, _ = trim(final_audio.cpu(), top_db=cfg.trim_db)
|
| 235 |
+
|
| 236 |
+
return gen_codes_decoded, final_audio
|
mars5/ar_generate.py
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn.functional as F
|
| 3 |
+
import torchaudio
|
| 4 |
+
import copy
|
| 5 |
+
from torch import Tensor, nn
|
| 6 |
+
import logging
|
| 7 |
+
from .model import length_to_mask
|
| 8 |
+
from .samplers import (apply_typical_p, early_eos_penalty,
|
| 9 |
+
top_k_top_p_filtering, freq_rep_penalty)
|
| 10 |
+
from .nn_future import RotatingBufferCache
|
| 11 |
+
from .minbpe.codebook import CodebookTokenizer
|
| 12 |
+
from .minbpe.regex import RegexTokenizer
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
@torch.inference_mode()
|
| 16 |
+
def ar_generate(texttok: RegexTokenizer, speechtok: CodebookTokenizer,
|
| 17 |
+
codeclm: nn.Module, xx: Tensor, ss_gen: Tensor, first_codex_idx: int,
|
| 18 |
+
max_len: int = 1500, fp16: bool = True, temperature: float = 1.0, topk: int = None,
|
| 19 |
+
top_p=1.0, alpha_frequency=0, alpha_presence=0, penalty_window=100,
|
| 20 |
+
typical_p=1.0, eos_penalty_factor=1.0, eos_penalty_decay=0, n_phones_gen=None, vocode=True,
|
| 21 |
+
beam_width: int = 1, beam_length_penalty=2, use_kv_cache: bool = True) -> tuple[Tensor, Tensor]:
|
| 22 |
+
""" Use the `codeclm` language model to autoregressively generate a completion of `xx` (seq_len), where the first `first_codex_idx`-1
|
| 23 |
+
indices correspond to the input phones. The output generation is limited to at most `max_len` (measured as num latent codes).
|
| 24 |
+
Returns both output first quantizer codes and synthesized audio using `codec`. Use decoding with `beam_width` to keep
|
| 25 |
+
track of top `beam_width` outcomes, selecting the top one among them.
|
| 26 |
+
|
| 27 |
+
- Optionally vocode if `vocode` (default True).
|
| 28 |
+
- See `InferenceConfig` for other inference docs.
|
| 29 |
+
"""
|
| 30 |
+
assert xx.dim() == 1, "Only batch size of 1 is currently supported."
|
| 31 |
+
assert beam_width == 1, "Only beam size of 1 is currently supported."
|
| 32 |
+
# internally our batch size will be the beam width
|
| 33 |
+
bs = beam_width
|
| 34 |
+
x_inp = xx[None].repeat(bs, 1) # (bs, seq_len)
|
| 35 |
+
ss_gen = ss_gen[None].repeat(bs, 1, 1)
|
| 36 |
+
# We must subtract 1 in the line below so that we match the train-time conditions of having a
|
| 37 |
+
# False padding value for the <bos> token position. This is needed so that we correctly use the
|
| 38 |
+
# _acoustic_ and not the linguistic language embedding for the <bos> token.
|
| 39 |
+
offsets = torch.tensor([first_codex_idx - 1 for _ in range(bs)], dtype=torch.long, device=xx.device)
|
| 40 |
+
valid_logit_idx_start = len(texttok.vocab) # vocab['s2i']['quant0-0000']
|
| 41 |
+
valid_logit_idx_end = len(texttok.vocab) + len(speechtok.vocab) + 1 # vocab['s2i']['quant1-0000']
|
| 42 |
+
# Make mask that is True where we have valid outputs, False otherwise (where we have text outputs).
|
| 43 |
+
# logit_mask = torch.zeros(n_vocab, dtype=bool, device=x_inp.device)
|
| 44 |
+
# logit_mask[valid_logit_idx_start:valid_logit_idx_end] = True
|
| 45 |
+
# logit_mask[vocab['s2i']['<eos>']] = True
|
| 46 |
+
cum_logprobs = torch.zeros(bs, dtype=torch.float, device=x_inp.device)
|
| 47 |
+
eos_idx = len(texttok.vocab) + speechtok.special_tokens['<|endofspeech|>']
|
| 48 |
+
n_vocab = len(texttok.vocab) + len(speechtok.vocab)
|
| 49 |
+
|
| 50 |
+
logging.info(f"Starting beam decoding with beam_width={beam_width}")
|
| 51 |
+
|
| 52 |
+
prev_ids = [[] for _ in range(bs)]
|
| 53 |
+
|
| 54 |
+
cache = None
|
| 55 |
+
if use_kv_cache:
|
| 56 |
+
# Initialise kv cache
|
| 57 |
+
cache_window = min(codeclm.ar.args.sliding_window, x_inp.shape[-1] + max_len)
|
| 58 |
+
cache = RotatingBufferCache(codeclm.ar.args.n_layers, bs, cache_window, codeclm.ar.args.n_kv_heads, codeclm.ar.args.head_dim)
|
| 59 |
+
cache.to(device=x_inp.device, dtype=torch.float16)
|
| 60 |
+
|
| 61 |
+
counter = 0
|
| 62 |
+
while x_inp.shape[-1] < max_len:
|
| 63 |
+
counter += 1
|
| 64 |
+
gen_length = torch.tensor([x_inp.shape[-1] for _ in range(bs)], dtype=torch.long, device=xx.device)
|
| 65 |
+
padding_mask = length_to_mask(gen_length, offsets)
|
| 66 |
+
|
| 67 |
+
with torch.autocast('cuda', enabled=fp16):
|
| 68 |
+
logits: Tensor = codeclm(x_inp, padding_mask, spk_reference=ss_gen, cache=cache, counter=counter)
|
| 69 |
+
logits = logits.float()
|
| 70 |
+
|
| 71 |
+
logits = logits[:, -1] # select last index, now (bs, logit_dim)
|
| 72 |
+
|
| 73 |
+
# <---------------------- logit filtering ---------------------->
|
| 74 |
+
filtered_logits = logits.clone()
|
| 75 |
+
|
| 76 |
+
# apply repetition penalty before logit mask if any item in the beam has more than 1 prior token.
|
| 77 |
+
if len(prev_ids[0]) > 1:
|
| 78 |
+
filtered_logits = freq_rep_penalty(filtered_logits, previous=torch.tensor(prev_ids, dtype=torch.long),
|
| 79 |
+
alpha_frequency=alpha_frequency, alpha_presence=alpha_presence,
|
| 80 |
+
penalty_window=penalty_window)
|
| 81 |
+
|
| 82 |
+
filtered_logits[..., :valid_logit_idx_start-1] = float('-inf')
|
| 83 |
+
filtered_logits[..., valid_logit_idx_end:] = float('-inf')
|
| 84 |
+
|
| 85 |
+
if n_phones_gen is not None:
|
| 86 |
+
# apply eos penalty
|
| 87 |
+
filtered_logits = early_eos_penalty(filtered_logits, len(prev_ids[0]), n_phones_gen,
|
| 88 |
+
eos_penalty_decay, eos_penalty_factor,
|
| 89 |
+
eos_index=eos_idx)
|
| 90 |
+
|
| 91 |
+
filtered_logits = filtered_logits / temperature
|
| 92 |
+
filtered_logits = top_k_top_p_filtering(filtered_logits, top_k=topk, top_p=top_p)
|
| 93 |
+
filtered_logits = apply_typical_p(filtered_logits, mass=typical_p)
|
| 94 |
+
|
| 95 |
+
# mask out anything that isn't first quantizer output codes
|
| 96 |
+
filtered_logits[..., :valid_logit_idx_start-1] = float('-inf')
|
| 97 |
+
filtered_logits[..., valid_logit_idx_end:] = float('-inf')
|
| 98 |
+
logits = filtered_logits
|
| 99 |
+
|
| 100 |
+
# <---------------------- next frame prediction --------------------->
|
| 101 |
+
|
| 102 |
+
logprobs = logits.log_softmax(dim=-1)
|
| 103 |
+
|
| 104 |
+
# update assignments: if any beam ended in <eos> last step, it MUST also end in <eos> this step.
|
| 105 |
+
# so, below we multiply the logits with a True/False mask, setting to
|
| 106 |
+
for j in range(bs):
|
| 107 |
+
if x_inp[j, -1] == eos_idx:
|
| 108 |
+
# do not add any additional probability to it, keeping it the same for all vocab idxs
|
| 109 |
+
logprobs[j] = float('-inf') # zero probability of anything non-eos after 1 eos
|
| 110 |
+
logprobs[j, eos_idx] = 0 # probability=1 of <eos> after <eos>
|
| 111 |
+
|
| 112 |
+
candidate_cum_logprobs = cum_logprobs[:, None] + logprobs # (bs, 1) + (bs, vocab) -> (bs, vocab)
|
| 113 |
+
|
| 114 |
+
logp_flat = logprobs.flatten()
|
| 115 |
+
candidates = torch.multinomial(logp_flat.exp(), num_samples=beam_width, replacement=False) # (bs,)
|
| 116 |
+
# Ravel it up:
|
| 117 |
+
beam_idxs = candidates // n_vocab # (bs,)
|
| 118 |
+
tok_inds_in_each_beam = candidates % n_vocab # (bs,)
|
| 119 |
+
|
| 120 |
+
# check for breaks
|
| 121 |
+
if torch.all(tok_inds_in_each_beam == eos_idx):
|
| 122 |
+
# apply length penalty:
|
| 123 |
+
non_eos_toks = (x_inp != eos_idx).sum(dim=-1) # (bs,) number of non eos toks
|
| 124 |
+
gen_length = non_eos_toks - first_codex_idx
|
| 125 |
+
penalties = (gen_length**beam_length_penalty)
|
| 126 |
+
penalized_cum_tok_logp = candidate_cum_logprobs / penalties[:, None]
|
| 127 |
+
|
| 128 |
+
eos_avg_logps = penalized_cum_tok_logp[:, eos_idx]
|
| 129 |
+
best_beam_idx = eos_avg_logps.argmax()
|
| 130 |
+
best_avg_logp = eos_avg_logps[best_beam_idx]
|
| 131 |
+
best_beam = x_inp[best_beam_idx]
|
| 132 |
+
logging.info((f"best beam = {best_beam_idx} @ penalized_cum_tok_logp = {best_avg_logp.item():.3f} |\n num toks: {non_eos_toks.cpu().tolist()}. "
|
| 133 |
+
f"Candidates: {eos_avg_logps.cpu()} |\n non-eos toks: {non_eos_toks.cpu().tolist()} |\n penalties: {penalties.cpu().tolist()} | "
|
| 134 |
+
f"raw cumulative probs: {candidate_cum_logprobs[:, eos_idx].cpu().tolist()}"))
|
| 135 |
+
break
|
| 136 |
+
|
| 137 |
+
# update beam histories:
|
| 138 |
+
x_inp = x_inp[beam_idxs]
|
| 139 |
+
# update next token
|
| 140 |
+
next_sample = tok_inds_in_each_beam
|
| 141 |
+
# update cum logprob
|
| 142 |
+
cum_logprobs = cum_logprobs[beam_idxs] + logprobs[beam_idxs, tok_inds_in_each_beam]
|
| 143 |
+
# update prior inds to point to correct beam
|
| 144 |
+
prev_ids = [copy.deepcopy(prev_ids[beam_idx.item()]) for beam_idx in beam_idxs]
|
| 145 |
+
# add new tokens to previous ids
|
| 146 |
+
for j in range(bs):
|
| 147 |
+
prev_ids[j].append(tok_inds_in_each_beam[j].item())
|
| 148 |
+
|
| 149 |
+
logging.debug("L%d | next sample: %s | beam: %s | cum_logp: %s", len(x_inp[0]), next_sample.cpu().tolist(), beam_idxs.cpu().tolist(), cum_logprobs.cpu())
|
| 150 |
+
|
| 151 |
+
# update cache with beam indexes
|
| 152 |
+
if cache is not None:
|
| 153 |
+
cache.cache_k = cache.cache_k[:, beam_idxs]
|
| 154 |
+
cache.cache_v = cache.cache_v[:, beam_idxs]
|
| 155 |
+
|
| 156 |
+
# add 1 None below to make (bs,) -> (bs, 1) so we can concat along seq len dim.
|
| 157 |
+
x_inp = torch.cat([x_inp, next_sample[:, None]], dim=-1)
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
if x_inp.shape[-1] >= max_len - 1:
|
| 161 |
+
logging.warning(f"[autoregressive generation] output length = {x_inp.shape[-1]} -- inference likely failed or input too long!")
|
| 162 |
+
best_beam = x_inp[0]
|
| 163 |
+
|
| 164 |
+
if not vocode: return best_beam # (seq_len,)
|
| 165 |
+
else: raise AssertionError()
|
mars5/diffuser.py
ADDED
|
@@ -0,0 +1,472 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Discrete multinomial diffusion code adapted from https://github.com/RF5/transfusion-asr,
|
| 3 |
+
which in turn is adapted from https://github.com/ehoogeboom/multinomial_diffusion.
|
| 4 |
+
|
| 5 |
+
Please see the original repo (https://github.com/ehoogeboom/multinomial_diffusion) and paper for full
|
| 6 |
+
details on how multinomial diffusion works -- thanks to the original authors!
|
| 7 |
+
"""
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
from torch import Tensor
|
| 11 |
+
from torch.functional import F
|
| 12 |
+
import numpy as np
|
| 13 |
+
from dataclasses import dataclass
|
| 14 |
+
from typing import Union
|
| 15 |
+
|
| 16 |
+
# -------------- Multinomial utility functions -----------
|
| 17 |
+
|
| 18 |
+
MIN_LOG_ARG = 1e-7 # originally was 1e-40
|
| 19 |
+
|
| 20 |
+
def log_1_min_a(a): return torch.log((1 - a.exp()).clamp_(min=1e-30))
|
| 21 |
+
|
| 22 |
+
def log_add_exp(a, b):
|
| 23 |
+
maximum = torch.max(a, b)
|
| 24 |
+
return maximum + torch.log(torch.exp(a - maximum) + torch.exp(b - maximum))
|
| 25 |
+
|
| 26 |
+
def extract(a: Tensor, t, x_shape):
|
| 27 |
+
""" Given 1D vector of alpha/alpha_cum/betas, get index at `t` of shape (bs,), and then
|
| 28 |
+
broadcast it to number of dims in `x_shape`.
|
| 29 |
+
"""
|
| 30 |
+
b, *_ = t.shape
|
| 31 |
+
out = a.gather(-1, t)
|
| 32 |
+
return out.reshape(b, *((1,) * (len(x_shape) - 1)))
|
| 33 |
+
|
| 34 |
+
def index_to_log_onehot(x, num_classes, dim=-1, dtype=torch.float32):
|
| 35 |
+
""" Convert indices `x` (bs, ...) to approx one-hot log-probs of shape (bs, ..., num_classes) """
|
| 36 |
+
assert x.max().item() < num_classes, \
|
| 37 |
+
f'Error: {x.max().item()} >= {num_classes}'
|
| 38 |
+
x_onehot = F.one_hot(x, num_classes)
|
| 39 |
+
if dim == 1:
|
| 40 |
+
permute_order = (0, -1) + tuple(range(1, len(x.size())))
|
| 41 |
+
x_onehot = x_onehot.permute(permute_order)
|
| 42 |
+
else:
|
| 43 |
+
pass
|
| 44 |
+
|
| 45 |
+
log_x = torch.log(x_onehot.to(dtype).clamp(min=MIN_LOG_ARG)) # so min(log_x) will be -30
|
| 46 |
+
|
| 47 |
+
return log_x
|
| 48 |
+
|
| 49 |
+
def sum_except_batch(x: Tensor, num_dims=1) -> Tensor:
|
| 50 |
+
'''
|
| 51 |
+
Sums all dimensions except the first.
|
| 52 |
+
Args:
|
| 53 |
+
x: Tensor, shape (batch_size, ...)
|
| 54 |
+
num_dims: int, number of batch dims (default=1)
|
| 55 |
+
Returns:
|
| 56 |
+
x_sum: Tensor, shape (batch_size,)
|
| 57 |
+
'''
|
| 58 |
+
return x.reshape(*x.shape[:num_dims], -1).sum(-1)
|
| 59 |
+
|
| 60 |
+
# -------------- Multinomial diffusion class -------------
|
| 61 |
+
|
| 62 |
+
class MultinomialDiffusion():
|
| 63 |
+
def __init__(self, num_classes, timesteps=100, diffusion_s=0.008,
|
| 64 |
+
loss_type='vb_stochastic', parametrization='x0',
|
| 65 |
+
dtype=torch.float32,
|
| 66 |
+
device='cpu'):
|
| 67 |
+
super(MultinomialDiffusion, self).__init__()
|
| 68 |
+
assert loss_type in ('vb_stochastic',)
|
| 69 |
+
assert parametrization in ('x0', 'direct')
|
| 70 |
+
|
| 71 |
+
self.num_classes = num_classes
|
| 72 |
+
self.loss_type = loss_type
|
| 73 |
+
self.num_timesteps = timesteps
|
| 74 |
+
self.parametrization = parametrization
|
| 75 |
+
|
| 76 |
+
alphas = self.cosine_beta_schedule(timesteps, diffusion_s)
|
| 77 |
+
|
| 78 |
+
alphas = alphas.to(torch.float64)
|
| 79 |
+
log_alpha = alphas.log()
|
| 80 |
+
log_cumprod_alpha = torch.cumsum(log_alpha, dim=-1)
|
| 81 |
+
|
| 82 |
+
log_1_min_alpha = log_1_min_a(log_alpha) # = log(betas)
|
| 83 |
+
|
| 84 |
+
log_1_min_cumprod_alpha = log_1_min_a(log_cumprod_alpha) # = log(1- \bar{a})
|
| 85 |
+
a = log_add_exp(log_alpha, log_1_min_alpha) # log(1-beta + beta) = log(1) = 0
|
| 86 |
+
|
| 87 |
+
assert log_add_exp(log_alpha, log_1_min_alpha).abs().sum().item() < 1.e-5
|
| 88 |
+
assert log_add_exp(log_cumprod_alpha, log_1_min_cumprod_alpha).abs().sum().item() < 1e-5
|
| 89 |
+
assert (torch.cumsum(log_alpha, dim=-1) - log_cumprod_alpha).abs().sum().item() < 1.e-5
|
| 90 |
+
|
| 91 |
+
# Convert to float32 and register buffers.
|
| 92 |
+
self.log_alpha = log_alpha.to(dtype).to(device)
|
| 93 |
+
self.log_1_min_alpha = log_1_min_alpha.to(dtype).to(device)
|
| 94 |
+
self.log_cumprod_alpha = log_cumprod_alpha.to(dtype).to(device)
|
| 95 |
+
self.log_1_min_cumprod_alpha = log_1_min_cumprod_alpha.to(dtype).to(device)
|
| 96 |
+
|
| 97 |
+
@staticmethod
|
| 98 |
+
def cosine_beta_schedule(timesteps, s=0.008) -> Tensor:
|
| 99 |
+
"""
|
| 100 |
+
cosine schedule as proposed in https://arxiv.org/abs/2102.09672 .
|
| 101 |
+
Returns alpha parameters, NOT Beta
|
| 102 |
+
"""
|
| 103 |
+
steps = timesteps + 1
|
| 104 |
+
x = torch.linspace(0, timesteps, steps)
|
| 105 |
+
alphas_cumprod = torch.cos(((x / timesteps) + s) / (1 + s) * torch.pi * 0.5) ** 2
|
| 106 |
+
alphas_cumprod = alphas_cumprod / alphas_cumprod[0]
|
| 107 |
+
alphas = (alphas_cumprod[1:] / alphas_cumprod[:-1])
|
| 108 |
+
alphas = torch.clamp(alphas, 0.001, 1.0)
|
| 109 |
+
return torch.sqrt(alphas)
|
| 110 |
+
|
| 111 |
+
def multinomial_kl(self, log_prob1: Tensor, log_prob2: Tensor, dim=-1) -> Tensor:
|
| 112 |
+
""" Get KL divergence between two categorical distributions specified with `log_prob1` and `log_prob2`.
|
| 113 |
+
Assumed probability dim is `dim` (i.e. log_prob1.exp().sum(dim=`dim`) should be tensor of ones)
|
| 114 |
+
"""
|
| 115 |
+
kl = (log_prob1.exp() * (log_prob1 - log_prob2)).sum(dim=dim)
|
| 116 |
+
return kl
|
| 117 |
+
|
| 118 |
+
def q_pred_one_timestep(self, log_x_t: Tensor, t: Tensor) -> Tensor:
|
| 119 |
+
""" Compute q(x_t | x_{t-1}) = C(x_t | alpha_t * x_{t-1} + (1-alpha_t)/K in the log-domain
|
| 120 |
+
given `log_x_t` as log one-hot encoding of x_t.
|
| 121 |
+
|
| 122 |
+
Recall due to symmetry property we can compute
|
| 123 |
+
this value using x_t instead of x_{t-1} (se appendix A of https://arxiv.org/pdf/2102.05379.pdf)
|
| 124 |
+
"""
|
| 125 |
+
dt = log_x_t.dtype
|
| 126 |
+
log_alpha_t = extract(self.log_alpha, t, log_x_t.shape).to(dt)
|
| 127 |
+
log_1_min_alpha_t = extract(self.log_1_min_alpha, t, log_x_t.shape).to(dt)
|
| 128 |
+
|
| 129 |
+
# alpha_t * E[xt] + (1 - alpha_t) 1 / K
|
| 130 |
+
log_probs = log_add_exp(
|
| 131 |
+
log_x_t + log_alpha_t,
|
| 132 |
+
log_1_min_alpha_t - np.log(self.num_classes)
|
| 133 |
+
)
|
| 134 |
+
return log_probs
|
| 135 |
+
|
| 136 |
+
def q_pred_one_timestep_scaled(self, log_x_t: Tensor, t: Tensor, c: int, jump_len: int) -> Tensor:
|
| 137 |
+
""" Compute q(x_t | x_{t-1}) = C(x_t | alpha_t * x_{t-1} + (1-alpha_t)/K in the log-domain
|
| 138 |
+
given `log_x_t` as log one-hot encoding of x_t.
|
| 139 |
+
|
| 140 |
+
Recall due to symmetry property we can compute
|
| 141 |
+
this value using x_t instead of x_{t-1} (se appendix A of https://arxiv.org/pdf/2102.05379.pdf)
|
| 142 |
+
"""
|
| 143 |
+
dt = log_x_t.dtype
|
| 144 |
+
log_alpha_t = extract(self.log_alpha, t, log_x_t.shape).to(dt)
|
| 145 |
+
log_1_min_alpha_t = extract(self.log_1_min_alpha, t, log_x_t.shape).to(dt)
|
| 146 |
+
|
| 147 |
+
# Magic
|
| 148 |
+
xax = torch.arange(0,log_x_t.shape[1],1).to(log_x_t.device)
|
| 149 |
+
aa=log_x_t.shape[1]*(c/jump_len)
|
| 150 |
+
sig = 1/(1+torch.exp(-(xax-aa+20)/8))
|
| 151 |
+
log_alpha_t = (torch.log(1/sig)[None,:,None] + log_alpha_t).clamp(-torch.inf, 0)
|
| 152 |
+
log_1_min_alpha_t = torch.log(sig)[None,:,None] + log_1_min_alpha_t
|
| 153 |
+
|
| 154 |
+
# alpha_t * E[xt] + (1 - alpha_t) 1 / K
|
| 155 |
+
log_probs = log_add_exp(
|
| 156 |
+
log_x_t + log_alpha_t,
|
| 157 |
+
log_1_min_alpha_t - np.log(self.num_classes)
|
| 158 |
+
)
|
| 159 |
+
return log_probs
|
| 160 |
+
|
| 161 |
+
def q_pred(self, log_x_start: Tensor, t) -> Tensor:
|
| 162 |
+
""" Compute q(x_t | x_0) = C(x_t | bar{alpha}_t * x_0 + (1 - bar{alpha}_t)/K ) in log domain,
|
| 163 |
+
given `log_x_start` of log probs of x_0.
|
| 164 |
+
"""
|
| 165 |
+
dt = log_x_start.dtype
|
| 166 |
+
log_cumprod_alpha_t = extract(self.log_cumprod_alpha, t, log_x_start.shape).to(dt)
|
| 167 |
+
log_1_min_cumprod_alpha = extract(self.log_1_min_cumprod_alpha, t, log_x_start.shape).to(dt)
|
| 168 |
+
|
| 169 |
+
log_probs = log_add_exp(
|
| 170 |
+
log_x_start + log_cumprod_alpha_t,
|
| 171 |
+
log_1_min_cumprod_alpha - np.log(self.num_classes)
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
return log_probs
|
| 175 |
+
|
| 176 |
+
def q_posterior(self, log_x_start, log_x_t, t):
|
| 177 |
+
""" Compute `q(xt-1 | xt, x0) = q(xt | xt-1, x0) * q(xt-1 | x0) / q(xt | x0)`
|
| 178 |
+
where q(xt | xt-1, x0) = q(xt | xt-1).
|
| 179 |
+
"""
|
| 180 |
+
# q(xt-1 | xt, x0) = q(xt | xt-1, x0) * q(xt-1 | x0) / q(xt | x0)
|
| 181 |
+
# where q(xt | xt-1, x0) = q(xt | xt-1).
|
| 182 |
+
|
| 183 |
+
t_minus_1 = t - 1
|
| 184 |
+
# Remove negative values, will not be used anyway for final decoder
|
| 185 |
+
t_minus_1 = torch.where(t_minus_1 < 0, torch.zeros_like(t_minus_1), t_minus_1)
|
| 186 |
+
log_EV_qxtmin_x0 = self.q_pred(log_x_start, t_minus_1) # log( q(x_{t-1} | x_0) )
|
| 187 |
+
# if t == 0, then log( q(x_0 | x_0) ) = log( one_hot(x_0) ), not even random at that point.
|
| 188 |
+
# so, where t == 0
|
| 189 |
+
num_axes = (1,) * (len(log_x_start.size()) - 1)
|
| 190 |
+
t_broadcast = t.view(-1, *num_axes) * torch.ones_like(log_x_start) # broadcast to non-batch axes
|
| 191 |
+
log_EV_qxtmin_x0 = torch.where(t_broadcast == 0, log_x_start, log_EV_qxtmin_x0)
|
| 192 |
+
# where it is zero, replace
|
| 193 |
+
# with log one-hot encoding of x0.
|
| 194 |
+
|
| 195 |
+
# Note: _NOT_ x_tmin1, which is how the formula is typically used!!!
|
| 196 |
+
# Not very easy to see why this is true. But it is :)
|
| 197 |
+
# log_EV_qxtmin_x0 ~ q(x_{t-1} | x_0)
|
| 198 |
+
# q_pred_one_timestep(log_x_t, t) ~ q(x_t | x_{t-1}) (which due to symmetry can be computed using x_t)
|
| 199 |
+
unnormed_logprobs = log_EV_qxtmin_x0 + self.q_pred_one_timestep(log_x_t, t) # numerator of bayes
|
| 200 |
+
|
| 201 |
+
# approximate denominator with just a normalizing sum.
|
| 202 |
+
log_EV_xtmin_given_xt_given_xstart = \
|
| 203 |
+
unnormed_logprobs \
|
| 204 |
+
- torch.logsumexp(unnormed_logprobs, dim=-1, keepdim=True)
|
| 205 |
+
|
| 206 |
+
return log_EV_xtmin_given_xt_given_xstart
|
| 207 |
+
|
| 208 |
+
def p_pred(self, log_x_t, t, log_x0_pred):
|
| 209 |
+
""" Predict `p(x_{t-1} | x_t)` using `q(xt-1 | xt, hat{x0})`, where `hat{x0}` is given by
|
| 210 |
+
log probabilities from model as `log_x0_pred` (bs, ...., K) and x_t is given by
|
| 211 |
+
`log_x_t` of shape `(bs, ..., K)`
|
| 212 |
+
"""
|
| 213 |
+
# log_x_recon = self.predict_start(log_x, t=t) # model itself predicts x_0
|
| 214 |
+
# log_x0_pred
|
| 215 |
+
log_model_pred = self.q_posterior(
|
| 216 |
+
log_x_start=log_x0_pred, log_x_t=log_x_t, t=t)
|
| 217 |
+
return log_model_pred
|
| 218 |
+
|
| 219 |
+
def log_sample_categorical(self, logprobs: Tensor, dim=-1) -> Tensor:
|
| 220 |
+
""" Sample from categorical `logprobs` (bs, ..., probs), where position of probs is specified
|
| 221 |
+
by `dim`.
|
| 222 |
+
|
| 223 |
+
Returns sampled long indices of shape `(bs, ...)`
|
| 224 |
+
"""
|
| 225 |
+
uniform = torch.rand_like(logprobs)
|
| 226 |
+
gumbel_noise = -torch.log( (-torch.log(uniform.clamp_(min=MIN_LOG_ARG)) ).clamp_(min=MIN_LOG_ARG))
|
| 227 |
+
sample = (gumbel_noise + logprobs).argmax(dim=dim)
|
| 228 |
+
return sample
|
| 229 |
+
|
| 230 |
+
def q_sample(self, log_x_start, t):
|
| 231 |
+
""" Draw `x_t` ~ q(x_t | x_0) . `log_x_start` is of shape `(bs, ..., K)`, returns result of same shape """
|
| 232 |
+
log_EV_qxt_x0 = self.q_pred(log_x_start, t)
|
| 233 |
+
sample = self.log_sample_categorical(log_EV_qxt_x0)
|
| 234 |
+
# log_sample = index_to_log_onehot(sample, self.num_classes)
|
| 235 |
+
|
| 236 |
+
return sample #log_sample
|
| 237 |
+
|
| 238 |
+
def compute_Lt(self, log_x_start: Tensor, log_x_t: Tensor, log_x0_pred: Tensor, t,
|
| 239 |
+
detach_mean=False, include_kl_prior=True):
|
| 240 |
+
""" Get loss given one-hot log x_0, one-hot log x_t, t, and model prediction `log_x0_pred`.
|
| 241 |
+
Parameters:
|
| 242 |
+
- `log_x_start`: ground-truth input x0, converted to log one-hot (bs, ..., K)
|
| 243 |
+
- `log_x_t`: sampled noisy input at `x_t`, converted to log one-hot (bs, ..., K)
|
| 244 |
+
- `t`: diffusion timestep (bs,)
|
| 245 |
+
- `log_x0_pred`: model prediction of log probabilities of x0, i.e. hat{x0}.
|
| 246 |
+
- `include_kl_prior`: add last two terms to model loss (does not change optimization problem).
|
| 247 |
+
"""
|
| 248 |
+
dtype = log_x_start.dtype
|
| 249 |
+
log_true_prob = self.q_posterior(
|
| 250 |
+
log_x_start=log_x_start, log_x_t=log_x_t, t=t)
|
| 251 |
+
|
| 252 |
+
log_model_prob = self.p_pred(log_x_t=log_x_t, t=t, log_x0_pred=log_x0_pred)
|
| 253 |
+
|
| 254 |
+
if detach_mean:
|
| 255 |
+
log_model_prob = log_model_prob.detach()
|
| 256 |
+
|
| 257 |
+
kl = self.multinomial_kl(log_true_prob, log_model_prob)
|
| 258 |
+
kl = sum_except_batch(kl)
|
| 259 |
+
|
| 260 |
+
# Add L_0, -log(p(x_0 | x_1))
|
| 261 |
+
decoder_nll = - (log_x_start.exp() * log_model_prob).sum(dim=-1)
|
| 262 |
+
decoder_nll = sum_except_batch(decoder_nll)
|
| 263 |
+
|
| 264 |
+
mask = (t == torch.zeros_like(t)).to(dtype)
|
| 265 |
+
loss = mask * decoder_nll + (1. - mask) * kl # only add L0 if t == 0.
|
| 266 |
+
|
| 267 |
+
if include_kl_prior:
|
| 268 |
+
pt = torch.ones_like(t, dtype=dtype)
|
| 269 |
+
kl_prior = self.kl_prior(log_x_start)
|
| 270 |
+
loss = (kl) + kl_prior
|
| 271 |
+
|
| 272 |
+
return loss
|
| 273 |
+
|
| 274 |
+
def kl_prior(self, log_x_start: Tensor) -> Tensor:
|
| 275 |
+
""" This function computes -H_{q}(x_T | x_0)+H_{p}(x_T), which
|
| 276 |
+
by some math (see wiki for KL div relation to conditional entropy).
|
| 277 |
+
So KL(q(x_T | x_0) || 1/K) = -H_{q}(x_T | x_0)+H_{p}(x_T) for categorical distribution.
|
| 278 |
+
|
| 279 |
+
Given `log_x_start` (bs, ..., probs), return KL prior of shape (bs,)
|
| 280 |
+
"""
|
| 281 |
+
b = log_x_start.size(0)
|
| 282 |
+
device = log_x_start.device
|
| 283 |
+
ones = torch.ones(b, device=device, dtype=torch.long)
|
| 284 |
+
|
| 285 |
+
log_qxT_prob = self.q_pred(log_x_start, t=(self.num_timesteps - 1) * ones) # q(x_T | x_0)
|
| 286 |
+
log_half_prob = -torch.log(self.num_classes * torch.ones_like(log_qxT_prob)) # log(1/K), broadcast to q(x_T|x_0) shape
|
| 287 |
+
|
| 288 |
+
kl_prior = self.multinomial_kl(log_qxT_prob, log_half_prob)
|
| 289 |
+
return sum_except_batch(kl_prior)
|
| 290 |
+
|
| 291 |
+
|
| 292 |
+
def index2logit(x: Tensor, vocab_size: int, dtype=torch.float32):
|
| 293 |
+
x = F.one_hot(x, num_classes=vocab_size).to(dtype)
|
| 294 |
+
x = x * (vocab_size/(vocab_size - 1)) - 1/(vocab_size - 1)
|
| 295 |
+
return x
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
# ------------------------------
|
| 299 |
+
# Functions adapted from the full
|
| 300 |
+
|
| 301 |
+
|
| 302 |
+
@dataclass
|
| 303 |
+
class DSH():
|
| 304 |
+
# Diffusion Sampling Hyperparameters [DSH] (Section 4)
|
| 305 |
+
jump_len: int = 1 # j in RePaint paper [default 10] (Section 4.1)
|
| 306 |
+
jump_n_sample: int = 1 # r in RePaint paper [default 10] (Section 4.1)
|
| 307 |
+
last_greedy: bool = False # whether to not sample at t=0, but take argmax prediction. [default False]
|
| 308 |
+
x_0_temp: float = 1.0 # reweight temp for model prediction of x0
|
| 309 |
+
guidance_w: float = 1.0 # classifier free guidance weight [default 1.5] (Section 4.3)
|
| 310 |
+
enable_kevin_scaled_inference: bool = True # sequentially progressive diffusion [default True] (Section 4.2)
|
| 311 |
+
T_override: Union[None, int] = None # allow variable transcription sizes during inference (Section 4.4)
|
| 312 |
+
|
| 313 |
+
deep_clone: bool = False # whether to do deep clone.
|
| 314 |
+
q0_override_steps: int = 0 # number of steps that we allow overriding the input quant level 0 inputs.
|
| 315 |
+
progress: bool = False # whether to show progress bar
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
def get_schedule(t_T, jump_len=10, jump_n_sample=10):
|
| 319 |
+
jumps = {}
|
| 320 |
+
for j in range(0, t_T - jump_len, jump_len):
|
| 321 |
+
jumps[j] = jump_n_sample - 1
|
| 322 |
+
t = t_T
|
| 323 |
+
ts = []
|
| 324 |
+
while t >= 1:
|
| 325 |
+
t = t-1
|
| 326 |
+
ts.append(t)
|
| 327 |
+
if jumps.get(t, 0) > 0:
|
| 328 |
+
jumps[t] = jumps[t] - 1
|
| 329 |
+
for _ in range(jump_len):
|
| 330 |
+
t = t + 1
|
| 331 |
+
ts.append(t)
|
| 332 |
+
ts.append(-1)
|
| 333 |
+
return ts
|
| 334 |
+
|
| 335 |
+
|
| 336 |
+
def forward_diffusion(diff: MultinomialDiffusion, dtype, x, t, c=None, dsh=DSH):
|
| 337 |
+
"""Simple forward diffusion process p"""
|
| 338 |
+
log_x_t = index_to_log_onehot(x, diff.num_classes, dtype=dtype)
|
| 339 |
+
if c is not None: x = diff.q_pred_one_timestep_scaled(log_x_t, t, c, dsh.jump_len)
|
| 340 |
+
else: x = diff.q_pred_one_timestep(log_x_t, t)
|
| 341 |
+
x = diff.log_sample_categorical(x)
|
| 342 |
+
return x
|
| 343 |
+
|
| 344 |
+
|
| 345 |
+
def reverse_diffusion(diff: MultinomialDiffusion, model, batch, x_known=None, m=None,
|
| 346 |
+
last_greedy=False, temperature=1.0, alphas=None, ensemble_size=1, dsh=DSH):
|
| 347 |
+
"""Reverse diffusion process q: predict x_{t-1} given x, t, x_known, m. Optionally do not sample model output
|
| 348 |
+
for t=0, but rather use the greedy argmax with `last_greedy`.
|
| 349 |
+
"""
|
| 350 |
+
x = batch[4]
|
| 351 |
+
t = batch[-1]
|
| 352 |
+
if x_known is None: x_known = torch.zeros_like(x)
|
| 353 |
+
if m is None: m = torch.zeros_like(x)
|
| 354 |
+
|
| 355 |
+
# Equation 8b
|
| 356 |
+
# for b in batch:
|
| 357 |
+
# print(f"{b.shape}: {b}")
|
| 358 |
+
x_0_pred = model(*batch) # (bs, seq_len, logit_dim, n_quant)
|
| 359 |
+
x_0_pred = x_0_pred.permute(0, 1, 3, 2) # (bs, seq_len, n_quant, dim)
|
| 360 |
+
|
| 361 |
+
if dsh.guidance_w != 1:
|
| 362 |
+
uncond_x_0_pred = model(*(c.clone() if c is not None else None for c in batch), drop_cond=True)
|
| 363 |
+
uncond_x_0_pred = uncond_x_0_pred.permute(0, 1, 3, 2)
|
| 364 |
+
x_0_pred = dsh.guidance_w*x_0_pred + (1-dsh.guidance_w)*uncond_x_0_pred
|
| 365 |
+
|
| 366 |
+
x_0_pred = x_0_pred / temperature
|
| 367 |
+
log_x_0_pred = F.log_softmax(x_0_pred, dim=-1)
|
| 368 |
+
log_x_t = index_to_log_onehot(x, diff.num_classes, dtype=x_0_pred.dtype)
|
| 369 |
+
|
| 370 |
+
# print("PRE: ", log_x_t.shape, t.shape, log_x_0_pred.shape)
|
| 371 |
+
log_model_pred = diff.p_pred(log_x_t, t, log_x_0_pred) # p(x_{t-1} | x_{t})
|
| 372 |
+
|
| 373 |
+
a_t = alphas[t[0]] if alphas is not None else 0
|
| 374 |
+
mat = torch.eye(ensemble_size, device=x.device)*(1-a_t)
|
| 375 |
+
mat += 1/ensemble_size * a_t
|
| 376 |
+
mat = torch.block_diag(*([mat]*(x.shape[0]//ensemble_size)))
|
| 377 |
+
log_model_pred = ( (mat[..., None, None] ).log().to(x.dtype) + log_model_pred[None])
|
| 378 |
+
log_model_pred = torch.logsumexp(log_model_pred, dim=1)
|
| 379 |
+
|
| 380 |
+
if (t==0).all() and last_greedy: # Do not sample at t=0
|
| 381 |
+
x_tm1_unknown = log_model_pred.argmax(dim=-1)
|
| 382 |
+
else:
|
| 383 |
+
x_tm1_unknown = diff.log_sample_categorical(log_model_pred)
|
| 384 |
+
|
| 385 |
+
# Equation 8a
|
| 386 |
+
x_known_log = index_to_log_onehot(x_known, diff.num_classes, dtype=x_0_pred.dtype)
|
| 387 |
+
if (t==0).all(): # Do not sample at t=0
|
| 388 |
+
x_tm1_known = x_known
|
| 389 |
+
else:
|
| 390 |
+
x_tm1_known = diff.q_sample(x_known_log, t)
|
| 391 |
+
|
| 392 |
+
# Equation 8c
|
| 393 |
+
x_tm1 = x_tm1_known * m.long() + x_tm1_unknown * (1 - m.long())
|
| 394 |
+
return x_tm1, x_0_pred
|
| 395 |
+
|
| 396 |
+
|
| 397 |
+
|
| 398 |
+
@torch.inference_mode()
|
| 399 |
+
def perform_simple_inference(model: torch.nn.Module, batch: tuple, diff: MultinomialDiffusion, T, dtype=torch.float16,
|
| 400 |
+
retain_quant0: bool = True, dsh=DSH):
|
| 401 |
+
""" If `retain_quant0`, then do not sample quant0 in each forward or reverse diffusion step. """
|
| 402 |
+
|
| 403 |
+
# (bs=1, N), (bs, seq_len2, 8), (bs,)
|
| 404 |
+
c_text, c_codes, c_text_lengths, c_codes_lengths, x, x_padding_mask = batch
|
| 405 |
+
|
| 406 |
+
device = c_text.device
|
| 407 |
+
bs = c_text.shape[0]
|
| 408 |
+
x_quant0 = x[..., 0].clone() # (bs, seq_len) 0th quant level
|
| 409 |
+
x = torch.randint(0, diff.num_classes, x.shape, dtype=x.dtype, device=device)
|
| 410 |
+
# CRITICAL LINE: override quantization level 0 with provided quant0 level.
|
| 411 |
+
x[..., 0] = x_quant0
|
| 412 |
+
|
| 413 |
+
# RePaint paper resample scheduling
|
| 414 |
+
times = get_schedule(T, jump_n_sample=dsh.jump_n_sample, jump_len=dsh.jump_len)
|
| 415 |
+
|
| 416 |
+
x_known = torch.zeros_like(x)
|
| 417 |
+
x_known[..., 0] = x[..., 0] # override L0 codes
|
| 418 |
+
m = torch.zeros_like(x).bool()
|
| 419 |
+
# (bs, seq_len, 8)
|
| 420 |
+
m[..., 0] = True
|
| 421 |
+
|
| 422 |
+
offset = 0
|
| 423 |
+
if dsh.deep_clone:
|
| 424 |
+
print(f"Note: using deep clone. Assuming input `c_phones` is concatenated prompt and output phones.",
|
| 425 |
+
"Also assuming no padded indices in `c_codes`.")
|
| 426 |
+
prompt = c_codes
|
| 427 |
+
x = torch.cat((prompt, x), dim=1) # (bs=1, sl1 + sl2, 8)
|
| 428 |
+
x_known = torch.cat((prompt, x_known), dim=1)
|
| 429 |
+
x_padding_mask = torch.cat((
|
| 430 |
+
torch.zeros(x_padding_mask.shape[0], c_codes_lengths[0], dtype=torch.bool, device=x_padding_mask.device),
|
| 431 |
+
x_padding_mask), dim=-1
|
| 432 |
+
)
|
| 433 |
+
# (bs=1, :up to prompt duration, all 8 codebooks) = True/masked.
|
| 434 |
+
m = torch.cat((torch.ones_like(prompt), m), dim=1)
|
| 435 |
+
x_quant0 = torch.cat((prompt[..., 0], x_quant0), dim=-1)
|
| 436 |
+
offset = c_codes_lengths[0]
|
| 437 |
+
|
| 438 |
+
print(f"New x: {x.shape} | new x_known: {x_known.shape} . Base prompt: {prompt.shape}. New padding mask: {x_padding_mask.shape} | m shape: {m.shape}")
|
| 439 |
+
|
| 440 |
+
c = 0 # sequentially progressive diffusion offset (Section 4.2)
|
| 441 |
+
|
| 442 |
+
# ensemble bs (not in paper)
|
| 443 |
+
alphas = torch.linspace(1, 0, T).to(device)
|
| 444 |
+
|
| 445 |
+
pb = zip(times[:-1], times[1:])
|
| 446 |
+
if dsh.progress:
|
| 447 |
+
from fastprogress import progress_bar
|
| 448 |
+
pb = progress_bar(pb, total=len(times)-1)
|
| 449 |
+
|
| 450 |
+
# See RePaint paper algorithm
|
| 451 |
+
for t_last, t_cur in pb:
|
| 452 |
+
|
| 453 |
+
t = torch.ones((bs,), dtype=torch.long, device=x.device) * (t_last)
|
| 454 |
+
if t_cur < t_last:
|
| 455 |
+
if c > dsh.jump_n_sample:
|
| 456 |
+
c = 0
|
| 457 |
+
c += 1/dsh.jump_len
|
| 458 |
+
|
| 459 |
+
# Reverse diffusion: q
|
| 460 |
+
cbatch = (c_text, c_codes, c_text_lengths, c_codes_lengths, x, x_padding_mask, t)
|
| 461 |
+
x, x_0_pred = reverse_diffusion(diff, model, cbatch, x_known, m, temperature=dsh.x_0_temp, alphas=alphas, ensemble_size=1, dsh=dsh)
|
| 462 |
+
else:
|
| 463 |
+
# Forward diffusion: p
|
| 464 |
+
if dsh.enable_kevin_scaled_inference: x = forward_diffusion(diff, dtype, x, t, c=c, dsh=dsh)
|
| 465 |
+
else: x = forward_diffusion(diff, dtype, x, t, c=None, dsh=dsh)
|
| 466 |
+
|
| 467 |
+
if retain_quant0 and dsh.q0_override_steps < t_last:
|
| 468 |
+
x[..., 0] = x_quant0
|
| 469 |
+
|
| 470 |
+
# crop offset:
|
| 471 |
+
x = x[:, offset:]
|
| 472 |
+
return x
|
mars5/minbpe/base.py
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Contains the base Tokenizer class and a few common helper functions.
|
| 3 |
+
The base class also contains the (common) save/load functionality.
|
| 4 |
+
It would be possible to be a lot more strict about the interface and
|
| 5 |
+
e.g. isolating all regex/pattern parts to the RegexTokenizer, but
|
| 6 |
+
some concessions are made for simplicity.
|
| 7 |
+
"""
|
| 8 |
+
import unicodedata
|
| 9 |
+
|
| 10 |
+
# -----------------------------------------------------------------------------
|
| 11 |
+
# a few helper functions useful for both BasicTokenizer and RegexTokenizer
|
| 12 |
+
|
| 13 |
+
def get_stats(ids, counts=None):
|
| 14 |
+
"""
|
| 15 |
+
Given a list of integers, return a dictionary of counts of consecutive pairs
|
| 16 |
+
Example: [1, 2, 3, 1, 2] -> {(1, 2): 2, (2, 3): 1, (3, 1): 1}
|
| 17 |
+
Optionally allows to update an existing dictionary of counts
|
| 18 |
+
"""
|
| 19 |
+
counts = {} if counts is None else counts
|
| 20 |
+
for pair in zip(ids, ids[1:]): # iterate consecutive elements
|
| 21 |
+
counts[pair] = counts.get(pair, 0) + 1
|
| 22 |
+
return counts
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def merge(ids, pair, idx):
|
| 26 |
+
"""
|
| 27 |
+
In the list of integers (ids), replace all consecutive occurrences
|
| 28 |
+
of pair with the new integer token idx
|
| 29 |
+
Example: ids=[1, 2, 3, 1, 2], pair=(1, 2), idx=4 -> [4, 3, 4]
|
| 30 |
+
"""
|
| 31 |
+
newids = []
|
| 32 |
+
i = 0
|
| 33 |
+
while i < len(ids):
|
| 34 |
+
# if not at the very last position AND the pair matches, replace it
|
| 35 |
+
if ids[i] == pair[0] and i < len(ids) - 1 and ids[i+1] == pair[1]:
|
| 36 |
+
newids.append(idx)
|
| 37 |
+
i += 2
|
| 38 |
+
else:
|
| 39 |
+
newids.append(ids[i])
|
| 40 |
+
i += 1
|
| 41 |
+
return newids
|
| 42 |
+
|
| 43 |
+
# first two helper functions...
|
| 44 |
+
def replace_control_characters(s: str) -> str:
|
| 45 |
+
# we don't want to print control characters
|
| 46 |
+
# which distort the output (e.g. \n or much worse)
|
| 47 |
+
# https://stackoverflow.com/questions/4324790/removing-control-characters-from-a-string-in-python/19016117#19016117
|
| 48 |
+
# http://www.unicode.org/reports/tr44/#GC_Values_Table
|
| 49 |
+
chars = []
|
| 50 |
+
for ch in s:
|
| 51 |
+
if unicodedata.category(ch)[0] != "C":
|
| 52 |
+
chars.append(ch) # this character is ok
|
| 53 |
+
else:
|
| 54 |
+
chars.append(f"\\u{ord(ch):04x}") # escape
|
| 55 |
+
return "".join(chars)
|
| 56 |
+
|
| 57 |
+
def render_token(t: bytes) -> str:
|
| 58 |
+
# pretty print a token, escaping control characters
|
| 59 |
+
s = t.decode('utf-8', errors='replace')
|
| 60 |
+
s = replace_control_characters(s)
|
| 61 |
+
return s
|
| 62 |
+
|
| 63 |
+
# -----------------------------------------------------------------------------
|
| 64 |
+
# the base Tokenizer class
|
| 65 |
+
|
| 66 |
+
class Tokenizer:
|
| 67 |
+
"""Base class for Tokenizers"""
|
| 68 |
+
|
| 69 |
+
def __init__(self):
|
| 70 |
+
# default: vocab size of 256 (all bytes), no merges, no patterns
|
| 71 |
+
self.merges = {} # (int, int) -> int
|
| 72 |
+
self.pattern = "" # str
|
| 73 |
+
self.special_tokens = {} # str -> int, e.g. {'<|endoftext|>': 100257}
|
| 74 |
+
self.vocab = self._build_vocab() # int -> bytes
|
| 75 |
+
|
| 76 |
+
def train(self, text, vocab_size, verbose=False):
|
| 77 |
+
# Tokenizer can train a vocabulary of size vocab_size from text
|
| 78 |
+
raise NotImplementedError
|
| 79 |
+
|
| 80 |
+
def encode(self, text):
|
| 81 |
+
# Tokenizer can encode a string into a list of integers
|
| 82 |
+
raise NotImplementedError
|
| 83 |
+
|
| 84 |
+
def decode(self, ids):
|
| 85 |
+
# Tokenizer can decode a list of integers into a string
|
| 86 |
+
raise NotImplementedError
|
| 87 |
+
|
| 88 |
+
def _build_vocab(self):
|
| 89 |
+
# vocab is simply and deterministically derived from merges
|
| 90 |
+
vocab = {idx: bytes([idx]) for idx in range(256)}
|
| 91 |
+
for (p0, p1), idx in self.merges.items():
|
| 92 |
+
vocab[idx] = vocab[p0] + vocab[p1]
|
| 93 |
+
for special, idx in self.special_tokens.items():
|
| 94 |
+
vocab[idx] = special.encode("utf-8")
|
| 95 |
+
return vocab
|
| 96 |
+
|
| 97 |
+
def save(self, file_prefix):
|
| 98 |
+
"""
|
| 99 |
+
Saves two files: file_prefix.vocab and file_prefix.model
|
| 100 |
+
This is inspired (but not equivalent to!) sentencepiece's model saving:
|
| 101 |
+
- model file is the critical one, intended for load()
|
| 102 |
+
- vocab file is just a pretty printed version for human inspection only
|
| 103 |
+
"""
|
| 104 |
+
# write the model: to be used in load() later
|
| 105 |
+
model_file = file_prefix + ".model"
|
| 106 |
+
with open(model_file, 'w') as f:
|
| 107 |
+
# write the version, pattern and merges, that's all that's needed
|
| 108 |
+
f.write("minbpe v1\n")
|
| 109 |
+
f.write(f"{self.pattern}\n")
|
| 110 |
+
# write the special tokens, first the number of them, then each one
|
| 111 |
+
f.write(f"{len(self.special_tokens)}\n")
|
| 112 |
+
for special, idx in self.special_tokens.items():
|
| 113 |
+
f.write(f"{special} {idx}\n")
|
| 114 |
+
# the merges dict
|
| 115 |
+
for idx1, idx2 in self.merges:
|
| 116 |
+
f.write(f"{idx1} {idx2}\n")
|
| 117 |
+
# write the vocab: for the human to look at
|
| 118 |
+
vocab_file = file_prefix + ".vocab"
|
| 119 |
+
inverted_merges = {idx: pair for pair, idx in self.merges.items()}
|
| 120 |
+
with open(vocab_file, "w", encoding="utf-8") as f:
|
| 121 |
+
for idx, token in self.vocab.items():
|
| 122 |
+
# note: many tokens may be partial utf-8 sequences
|
| 123 |
+
# and cannot be decoded into valid strings. Here we're using
|
| 124 |
+
# errors='replace' to replace them with the replacement char �.
|
| 125 |
+
# this also means that we couldn't possibly use .vocab in load()
|
| 126 |
+
# because decoding in this way is a lossy operation!
|
| 127 |
+
s = render_token(token)
|
| 128 |
+
# find the children of this token, if any
|
| 129 |
+
if idx in inverted_merges:
|
| 130 |
+
# if this token has children, render it nicely as a merge
|
| 131 |
+
idx0, idx1 = inverted_merges[idx]
|
| 132 |
+
s0 = render_token(self.vocab[idx0])
|
| 133 |
+
s1 = render_token(self.vocab[idx1])
|
| 134 |
+
f.write(f"[{s0}][{s1}] -> [{s}] {idx}\n")
|
| 135 |
+
else:
|
| 136 |
+
# otherwise this is leaf token, just print it
|
| 137 |
+
# (this should just be the first 256 tokens, the bytes)
|
| 138 |
+
f.write(f"[{s}] {idx}\n")
|
| 139 |
+
|
| 140 |
+
def load(self, model_file):
|
| 141 |
+
"""Inverse of save() but only for the model file"""
|
| 142 |
+
model_file = str(model_file)
|
| 143 |
+
assert model_file.endswith(".model")
|
| 144 |
+
# read the model file
|
| 145 |
+
merges = {}
|
| 146 |
+
special_tokens = {}
|
| 147 |
+
idx = 256
|
| 148 |
+
with open(model_file, 'r', encoding="utf-8") as f:
|
| 149 |
+
# read the version
|
| 150 |
+
version = f.readline().strip()
|
| 151 |
+
assert version == "minbpe v1"
|
| 152 |
+
# read the pattern
|
| 153 |
+
self.pattern = f.readline().strip()
|
| 154 |
+
# read the special tokens
|
| 155 |
+
num_special = int(f.readline().strip())
|
| 156 |
+
for _ in range(num_special):
|
| 157 |
+
special, special_idx = f.readline().strip().split()
|
| 158 |
+
special_tokens[special] = int(special_idx)
|
| 159 |
+
# read the merges
|
| 160 |
+
for line in f:
|
| 161 |
+
idx1, idx2 = map(int, line.split())
|
| 162 |
+
merges[(idx1, idx2)] = idx
|
| 163 |
+
idx += 1
|
| 164 |
+
self.merges = merges
|
| 165 |
+
self.special_tokens = special_tokens
|
| 166 |
+
self.vocab = self._build_vocab()
|
mars5/minbpe/codebook.py
ADDED
|
@@ -0,0 +1,210 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Minimal (byte-level) Byte Pair Encoding tokenizer.
|
| 3 |
+
|
| 4 |
+
Unlike RegexTokenizer:
|
| 5 |
+
- Operates on integer codes from an encodec codebook.
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import regex as re
|
| 9 |
+
from .base import Tokenizer, get_stats, merge
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class CodebookTokenizer(Tokenizer):
|
| 13 |
+
|
| 14 |
+
def __init__(self, pattern=None, codebook_size=1024):
|
| 15 |
+
"""
|
| 16 |
+
- pattern: optional string to override the default (GPT-4 split pattern)
|
| 17 |
+
- special_tokens: str -> int dictionary of special tokens
|
| 18 |
+
example: {'<|endoftext|>': 100257}
|
| 19 |
+
"""
|
| 20 |
+
self.merges = {} # (int, int) -> int
|
| 21 |
+
self.pattern = pattern
|
| 22 |
+
self.compiled_pattern = re.compile(self.pattern)
|
| 23 |
+
self.special_tokens = {} # str -> int, e.g. {'<|endoftext|>': 100257}
|
| 24 |
+
self.inverse_special_tokens = {}
|
| 25 |
+
self.codebook_size = codebook_size
|
| 26 |
+
self.vocab = self._build_vocab() # int -> bytes
|
| 27 |
+
|
| 28 |
+
def train(self, text, vocab_size, verbose=False):
|
| 29 |
+
assert vocab_size >= self.codebook_size
|
| 30 |
+
num_merges = vocab_size - self.codebook_size
|
| 31 |
+
|
| 32 |
+
# split the text up into text chunks
|
| 33 |
+
# text is a continuous signal, there is no splitting it up.
|
| 34 |
+
text_chunks = [text,] # re.findall(self.compiled_pattern, text)
|
| 35 |
+
|
| 36 |
+
# input text preprocessing
|
| 37 |
+
ids = [[int(idx) for idx in ch.split(' ')] for ch in text_chunks]
|
| 38 |
+
|
| 39 |
+
# iteratively merge the most common pairs to create new tokens
|
| 40 |
+
merges = {} # (int, int) -> int
|
| 41 |
+
# vocab = {idx: bytes([idx]) for idx in range(self.codebook_size)} # idx -> bytes
|
| 42 |
+
vocab = {idx: f" {idx:04d}".encode('utf-8') for idx in range(self.codebook_size)} # idx -> bytes
|
| 43 |
+
|
| 44 |
+
for i in range(num_merges):
|
| 45 |
+
# count the number of times every consecutive pair appears
|
| 46 |
+
stats = {}
|
| 47 |
+
for chunk_ids in ids:
|
| 48 |
+
# passing in stats will update it in place, adding up counts
|
| 49 |
+
get_stats(chunk_ids, stats)
|
| 50 |
+
# find the pair with the highest count
|
| 51 |
+
pair = max(stats, key=stats.get)
|
| 52 |
+
# mint a new token: assign it the next available id
|
| 53 |
+
idx = self.codebook_size + i
|
| 54 |
+
# replace all occurrences of pair in ids with idx
|
| 55 |
+
ids = [merge(chunk_ids, pair, idx) for chunk_ids in ids]
|
| 56 |
+
# save the merge
|
| 57 |
+
merges[pair] = idx
|
| 58 |
+
vocab[idx] = vocab[pair[0]] + vocab[pair[1]]
|
| 59 |
+
# prints
|
| 60 |
+
if verbose:
|
| 61 |
+
print(f"merge {i+1}/{num_merges}: {pair} -> {idx} ({vocab[idx]}) had {stats[pair]} occurrences")
|
| 62 |
+
|
| 63 |
+
# save class variables
|
| 64 |
+
self.merges = merges # used in encode()
|
| 65 |
+
self.vocab = vocab # used in decode()
|
| 66 |
+
|
| 67 |
+
def register_special_tokens(self, special_tokens):
|
| 68 |
+
# special_tokens is a dictionary of str -> int
|
| 69 |
+
# example: {"<|endoftext|>": 100257}
|
| 70 |
+
self.special_tokens = special_tokens
|
| 71 |
+
self.inverse_special_tokens = {v: k for k, v in special_tokens.items()}
|
| 72 |
+
|
| 73 |
+
def decode(self, ids):
|
| 74 |
+
# given ids (list of integers), return Python string
|
| 75 |
+
part_bytes = []
|
| 76 |
+
for idx in ids:
|
| 77 |
+
if idx in self.vocab:
|
| 78 |
+
part_bytes.append(self.vocab[idx])
|
| 79 |
+
elif idx in self.inverse_special_tokens:
|
| 80 |
+
part_bytes.append(self.inverse_special_tokens[idx].encode("utf-8"))
|
| 81 |
+
else:
|
| 82 |
+
raise ValueError(f"invalid token id: {idx}")
|
| 83 |
+
text_bytes = b"".join(part_bytes)
|
| 84 |
+
text = text_bytes.decode("utf-8", errors="replace")
|
| 85 |
+
return text
|
| 86 |
+
|
| 87 |
+
def decode_int(self, ids) -> list[int]:
|
| 88 |
+
ret: str = self.decode(ids)
|
| 89 |
+
for s in self.special_tokens:
|
| 90 |
+
ret = ret.replace(s, ' ' + s + ' ')
|
| 91 |
+
ret = ret.strip()
|
| 92 |
+
ret = [int(t) if t[0].isnumeric() else t for t in ret.split(' ') if len(t) > 0]
|
| 93 |
+
return ret
|
| 94 |
+
|
| 95 |
+
def _encode_chunk(self, text_bytes):
|
| 96 |
+
# return the token ids
|
| 97 |
+
# let's begin. first, convert all bytes to integers in range 0..255
|
| 98 |
+
ids = list(text_bytes)
|
| 99 |
+
while len(ids) >= 2:
|
| 100 |
+
# find the pair with the lowest merge index
|
| 101 |
+
stats = get_stats(ids)
|
| 102 |
+
pair = min(stats, key=lambda p: self.merges.get(p, float("inf")))
|
| 103 |
+
# subtle: if there are no more merges available, the key will
|
| 104 |
+
# result in an inf for every single pair, and the min will be
|
| 105 |
+
# just the first pair in the list, arbitrarily
|
| 106 |
+
# we can detect this terminating case by a membership check
|
| 107 |
+
if pair not in self.merges:
|
| 108 |
+
break # nothing else can be merged anymore
|
| 109 |
+
# otherwise let's merge the best pair (lowest merge index)
|
| 110 |
+
idx = self.merges[pair]
|
| 111 |
+
ids = merge(ids, pair, idx)
|
| 112 |
+
return ids
|
| 113 |
+
|
| 114 |
+
def encode_ordinary(self, text):
|
| 115 |
+
"""Encoding that ignores any special tokens."""
|
| 116 |
+
# split text into chunks of text by categories defined in regex pattern
|
| 117 |
+
text_chunks = [text,] #re.findall(self.compiled_pattern, text)
|
| 118 |
+
# all chunks of text are encoded separately, then results are joined
|
| 119 |
+
ids = []
|
| 120 |
+
for chunk in text_chunks:
|
| 121 |
+
# chunk_bytes = chunk.encode("utf-8") # raw bytes
|
| 122 |
+
chunk_ids = [int(idx) for idx in chunk.split(' ')]
|
| 123 |
+
chunk_ids = self._encode_chunk(chunk_ids)
|
| 124 |
+
ids.extend(chunk_ids)
|
| 125 |
+
return ids
|
| 126 |
+
|
| 127 |
+
def encode(self, text, allowed_special="none_raise"):
|
| 128 |
+
"""
|
| 129 |
+
Unlike encode_ordinary, this function handles special tokens.
|
| 130 |
+
allowed_special: can be "all"|"none"|"none_raise" or a custom set of special tokens
|
| 131 |
+
if none_raise, then an error is raised if any special token is encountered in text
|
| 132 |
+
this is the default tiktoken behavior right now as well
|
| 133 |
+
any other behavior is either annoying, or a major footgun
|
| 134 |
+
"""
|
| 135 |
+
# decode the user desire w.r.t. handling of special tokens
|
| 136 |
+
special = None
|
| 137 |
+
if allowed_special == "all":
|
| 138 |
+
special = self.special_tokens
|
| 139 |
+
elif allowed_special == "none":
|
| 140 |
+
special = {}
|
| 141 |
+
elif allowed_special == "none_raise":
|
| 142 |
+
special = {}
|
| 143 |
+
assert all(token not in text for token in self.special_tokens)
|
| 144 |
+
elif isinstance(allowed_special, set):
|
| 145 |
+
special = {k: v for k, v in self.special_tokens.items() if k in allowed_special}
|
| 146 |
+
else:
|
| 147 |
+
raise ValueError(f"allowed_special={allowed_special} not understood")
|
| 148 |
+
if not special:
|
| 149 |
+
# shortcut: if no special tokens, just use the ordinary encoding
|
| 150 |
+
return self.encode_ordinary(text)
|
| 151 |
+
# otherwise, we have to be careful with potential special tokens in text
|
| 152 |
+
# we handle special tokens by splitting the text
|
| 153 |
+
# based on the occurrence of any exact match with any of the special tokens
|
| 154 |
+
# we can use re.split for this. note that surrounding the pattern with ()
|
| 155 |
+
# makes it into a capturing group, so the special tokens will be included
|
| 156 |
+
special_pattern = "(" + "|".join(re.escape(k) for k in special) + ")"
|
| 157 |
+
special_chunks = re.split(special_pattern, text)
|
| 158 |
+
# now all the special characters are separated from the rest of the text
|
| 159 |
+
# all chunks of text are encoded separately, then results are joined
|
| 160 |
+
ids = []
|
| 161 |
+
for part in special_chunks:
|
| 162 |
+
part = part.strip()
|
| 163 |
+
if len(part) == 0: continue
|
| 164 |
+
if part in special:
|
| 165 |
+
# this is a special token, encode it separately as a special case
|
| 166 |
+
ids.append(special[part])
|
| 167 |
+
else:
|
| 168 |
+
# this is an ordinary sequence, encode it normally
|
| 169 |
+
ids.extend(self.encode_ordinary(part))
|
| 170 |
+
return ids
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
def load(self, model_file):
|
| 174 |
+
"""Inverse of save() but only for the model file"""
|
| 175 |
+
model_file = str(model_file)
|
| 176 |
+
assert model_file.endswith(".model")
|
| 177 |
+
# read the model file
|
| 178 |
+
merges = {}
|
| 179 |
+
special_tokens = {}
|
| 180 |
+
idx = self.codebook_size
|
| 181 |
+
with open(model_file, 'r', encoding="utf-8") as f:
|
| 182 |
+
# read the version
|
| 183 |
+
version = f.readline().strip()
|
| 184 |
+
assert version == "minbpe v1"
|
| 185 |
+
# read the pattern
|
| 186 |
+
self.pattern = f.readline().strip()
|
| 187 |
+
# read the special tokens
|
| 188 |
+
num_special = int(f.readline().strip())
|
| 189 |
+
for _ in range(num_special):
|
| 190 |
+
special, special_idx = f.readline().strip().split()
|
| 191 |
+
special_tokens[special] = int(special_idx)
|
| 192 |
+
# read the merges
|
| 193 |
+
for line in f:
|
| 194 |
+
# print(line)
|
| 195 |
+
idx1, idx2 = map(int, line.split())
|
| 196 |
+
merges[(idx1, idx2)] = idx
|
| 197 |
+
idx += 1
|
| 198 |
+
self.merges = merges
|
| 199 |
+
self.special_tokens = special_tokens
|
| 200 |
+
self.vocab = self._build_vocab()
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
def _build_vocab(self):
|
| 204 |
+
# vocab is simply and deterministically derived from merges
|
| 205 |
+
vocab = {idx: f" {idx:04d}".encode('utf-8') for idx in range(self.codebook_size)}
|
| 206 |
+
for (p0, p1), idx in self.merges.items():
|
| 207 |
+
vocab[idx] = vocab[p0] + vocab[p1]
|
| 208 |
+
for special, idx in self.special_tokens.items():
|
| 209 |
+
vocab[idx] = special.encode("utf-8")
|
| 210 |
+
return vocab
|
mars5/minbpe/regex.py
ADDED
|
@@ -0,0 +1,164 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Minimal (byte-level) Byte Pair Encoding tokenizer.
|
| 3 |
+
|
| 4 |
+
Algorithmically follows along the GPT tokenizer:
|
| 5 |
+
https://github.com/openai/gpt-2/blob/master/src/encoder.py
|
| 6 |
+
|
| 7 |
+
Unlike BasicTokenizer:
|
| 8 |
+
- RegexTokenizer handles an optional regex splitting pattern.
|
| 9 |
+
- RegexTokenizer handles optional special tokens.
|
| 10 |
+
"""
|
| 11 |
+
|
| 12 |
+
import regex as re
|
| 13 |
+
from .base import Tokenizer, get_stats, merge
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
# the main GPT text split patterns, see
|
| 17 |
+
# https://github.com/openai/tiktoken/blob/main/tiktoken_ext/openai_public.py
|
| 18 |
+
GPT2_SPLIT_PATTERN = r"""'(?:[sdmt]|ll|ve|re)| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""
|
| 19 |
+
GPT4_SPLIT_PATTERN = r"""'(?i:[sdmt]|ll|ve|re)|[^\r\n\p{L}\p{N}]?+\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]++[\r\n]*|\s*[\r\n]|\s+(?!\S)|\s+"""
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class RegexTokenizer(Tokenizer):
|
| 23 |
+
|
| 24 |
+
def __init__(self, pattern=None):
|
| 25 |
+
"""
|
| 26 |
+
- pattern: optional string to override the default (GPT-4 split pattern)
|
| 27 |
+
- special_tokens: str -> int dictionary of special tokens
|
| 28 |
+
example: {'<|endoftext|>': 100257}
|
| 29 |
+
"""
|
| 30 |
+
super().__init__()
|
| 31 |
+
self.pattern = GPT4_SPLIT_PATTERN if pattern is None else pattern
|
| 32 |
+
self.compiled_pattern = re.compile(self.pattern)
|
| 33 |
+
self.special_tokens = {}
|
| 34 |
+
self.inverse_special_tokens = {}
|
| 35 |
+
|
| 36 |
+
def train(self, text, vocab_size, verbose=False):
|
| 37 |
+
assert vocab_size >= 256
|
| 38 |
+
num_merges = vocab_size - 256
|
| 39 |
+
|
| 40 |
+
# split the text up into text chunks
|
| 41 |
+
text_chunks = re.findall(self.compiled_pattern, text)
|
| 42 |
+
|
| 43 |
+
# input text preprocessing
|
| 44 |
+
ids = [list(ch.encode("utf-8")) for ch in text_chunks]
|
| 45 |
+
|
| 46 |
+
# iteratively merge the most common pairs to create new tokens
|
| 47 |
+
merges = {} # (int, int) -> int
|
| 48 |
+
vocab = {idx: bytes([idx]) for idx in range(256)} # idx -> bytes
|
| 49 |
+
for i in range(num_merges):
|
| 50 |
+
# count the number of times every consecutive pair appears
|
| 51 |
+
stats = {}
|
| 52 |
+
for chunk_ids in ids:
|
| 53 |
+
# passing in stats will update it in place, adding up counts
|
| 54 |
+
get_stats(chunk_ids, stats)
|
| 55 |
+
# find the pair with the highest count
|
| 56 |
+
pair = max(stats, key=stats.get)
|
| 57 |
+
# mint a new token: assign it the next available id
|
| 58 |
+
idx = 256 + i
|
| 59 |
+
# replace all occurrences of pair in ids with idx
|
| 60 |
+
ids = [merge(chunk_ids, pair, idx) for chunk_ids in ids]
|
| 61 |
+
# save the merge
|
| 62 |
+
merges[pair] = idx
|
| 63 |
+
vocab[idx] = vocab[pair[0]] + vocab[pair[1]]
|
| 64 |
+
# prints
|
| 65 |
+
if verbose:
|
| 66 |
+
print(f"merge {i+1}/{num_merges}: {pair} -> {idx} ({vocab[idx]}) had {stats[pair]} occurrences")
|
| 67 |
+
|
| 68 |
+
# save class variables
|
| 69 |
+
self.merges = merges # used in encode()
|
| 70 |
+
self.vocab = vocab # used in decode()
|
| 71 |
+
|
| 72 |
+
def register_special_tokens(self, special_tokens):
|
| 73 |
+
# special_tokens is a dictionary of str -> int
|
| 74 |
+
# example: {"<|endoftext|>": 100257}
|
| 75 |
+
self.special_tokens = special_tokens
|
| 76 |
+
self.inverse_special_tokens = {v: k for k, v in special_tokens.items()}
|
| 77 |
+
|
| 78 |
+
def decode(self, ids):
|
| 79 |
+
# given ids (list of integers), return Python string
|
| 80 |
+
part_bytes = []
|
| 81 |
+
for idx in ids:
|
| 82 |
+
if idx in self.vocab:
|
| 83 |
+
part_bytes.append(self.vocab[idx])
|
| 84 |
+
elif idx in self.inverse_special_tokens:
|
| 85 |
+
part_bytes.append(self.inverse_special_tokens[idx].encode("utf-8"))
|
| 86 |
+
else:
|
| 87 |
+
raise ValueError(f"invalid token id: {idx}")
|
| 88 |
+
text_bytes = b"".join(part_bytes)
|
| 89 |
+
text = text_bytes.decode("utf-8", errors="replace")
|
| 90 |
+
return text
|
| 91 |
+
|
| 92 |
+
def _encode_chunk(self, text_bytes):
|
| 93 |
+
# return the token ids
|
| 94 |
+
# let's begin. first, convert all bytes to integers in range 0..255
|
| 95 |
+
ids = list(text_bytes)
|
| 96 |
+
while len(ids) >= 2:
|
| 97 |
+
# find the pair with the lowest merge index
|
| 98 |
+
stats = get_stats(ids)
|
| 99 |
+
pair = min(stats, key=lambda p: self.merges.get(p, float("inf")))
|
| 100 |
+
# subtle: if there are no more merges available, the key will
|
| 101 |
+
# result in an inf for every single pair, and the min will be
|
| 102 |
+
# just the first pair in the list, arbitrarily
|
| 103 |
+
# we can detect this terminating case by a membership check
|
| 104 |
+
if pair not in self.merges:
|
| 105 |
+
break # nothing else can be merged anymore
|
| 106 |
+
# otherwise let's merge the best pair (lowest merge index)
|
| 107 |
+
idx = self.merges[pair]
|
| 108 |
+
ids = merge(ids, pair, idx)
|
| 109 |
+
return ids
|
| 110 |
+
|
| 111 |
+
def encode_ordinary(self, text):
|
| 112 |
+
"""Encoding that ignores any special tokens."""
|
| 113 |
+
# split text into chunks of text by categories defined in regex pattern
|
| 114 |
+
text_chunks = re.findall(self.compiled_pattern, text)
|
| 115 |
+
# all chunks of text are encoded separately, then results are joined
|
| 116 |
+
ids = []
|
| 117 |
+
for chunk in text_chunks:
|
| 118 |
+
chunk_bytes = chunk.encode("utf-8") # raw bytes
|
| 119 |
+
chunk_ids = self._encode_chunk(chunk_bytes)
|
| 120 |
+
ids.extend(chunk_ids)
|
| 121 |
+
return ids
|
| 122 |
+
|
| 123 |
+
def encode(self, text, allowed_special="none_raise"):
|
| 124 |
+
"""
|
| 125 |
+
Unlike encode_ordinary, this function handles special tokens.
|
| 126 |
+
allowed_special: can be "all"|"none"|"none_raise" or a custom set of special tokens
|
| 127 |
+
if none_raise, then an error is raised if any special token is encountered in text
|
| 128 |
+
this is the default tiktoken behavior right now as well
|
| 129 |
+
any other behavior is either annoying, or a major footgun
|
| 130 |
+
"""
|
| 131 |
+
# decode the user desire w.r.t. handling of special tokens
|
| 132 |
+
special = None
|
| 133 |
+
if allowed_special == "all":
|
| 134 |
+
special = self.special_tokens
|
| 135 |
+
elif allowed_special == "none":
|
| 136 |
+
special = {}
|
| 137 |
+
elif allowed_special == "none_raise":
|
| 138 |
+
special = {}
|
| 139 |
+
assert all(token not in text for token in self.special_tokens)
|
| 140 |
+
elif isinstance(allowed_special, set):
|
| 141 |
+
special = {k: v for k, v in self.special_tokens.items() if k in allowed_special}
|
| 142 |
+
else:
|
| 143 |
+
raise ValueError(f"allowed_special={allowed_special} not understood")
|
| 144 |
+
if not special:
|
| 145 |
+
# shortcut: if no special tokens, just use the ordinary encoding
|
| 146 |
+
return self.encode_ordinary(text)
|
| 147 |
+
# otherwise, we have to be careful with potential special tokens in text
|
| 148 |
+
# we handle special tokens by splitting the text
|
| 149 |
+
# based on the occurrence of any exact match with any of the special tokens
|
| 150 |
+
# we can use re.split for this. note that surrounding the pattern with ()
|
| 151 |
+
# makes it into a capturing group, so the special tokens will be included
|
| 152 |
+
special_pattern = "(" + "|".join(re.escape(k) for k in special) + ")"
|
| 153 |
+
special_chunks = re.split(special_pattern, text)
|
| 154 |
+
# now all the special characters are separated from the rest of the text
|
| 155 |
+
# all chunks of text are encoded separately, then results are joined
|
| 156 |
+
ids = []
|
| 157 |
+
for part in special_chunks:
|
| 158 |
+
if part in special:
|
| 159 |
+
# this is a special token, encode it separately as a special case
|
| 160 |
+
ids.append(special[part])
|
| 161 |
+
else:
|
| 162 |
+
# this is an ordinary sequence, encode it normally
|
| 163 |
+
ids.extend(self.encode_ordinary(part))
|
| 164 |
+
return ids
|
mars5/model.py
ADDED
|
@@ -0,0 +1,344 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from typing import Optional
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
from torch import Tensor
|
| 8 |
+
|
| 9 |
+
from .nn_future import (FNNSwiGLU, MistralTransformer, ModelArgs,
|
| 10 |
+
RotatingBufferCache, SinePositionalEmbedding)
|
| 11 |
+
from .utils import construct_padding_mask, length_to_mask
|
| 12 |
+
|
| 13 |
+
LAYERNORM_EPS = 4e-5
|
| 14 |
+
|
| 15 |
+
# ------------------------
|
| 16 |
+
# Code adapted from OpenAI guided diffusion repo
|
| 17 |
+
|
| 18 |
+
def timestep_embedding(timesteps, dim, max_period=10000, dtype=torch.float32):
|
| 19 |
+
"""
|
| 20 |
+
Create sinusoidal timestep embeddings.
|
| 21 |
+
:param timesteps: a 1-D Tensor of N indices, one per batch element.
|
| 22 |
+
These may be fractional.
|
| 23 |
+
:param dim: the dimension of the output.
|
| 24 |
+
:param max_period: controls the minimum frequency of the embeddings.
|
| 25 |
+
:return: an [N x dim] Tensor of positional embeddings.
|
| 26 |
+
"""
|
| 27 |
+
half = dim // 2
|
| 28 |
+
freqs = torch.exp(
|
| 29 |
+
-math.log(max_period) * torch.arange(start=0, end=half) / half
|
| 30 |
+
).to(device=timesteps.device)
|
| 31 |
+
args = timesteps[:, None].float() * freqs[None]
|
| 32 |
+
embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1).to(dtype)
|
| 33 |
+
if dim % 2:
|
| 34 |
+
embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
|
| 35 |
+
return embedding
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
# --------------------------------
|
| 39 |
+
# autoregressive codec language model
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class CodecLM(nn.Module):
|
| 43 |
+
|
| 44 |
+
def __init__(self, n_vocab, dim=1536, nhead=24, n_layers=26, n_spk_layers=2, dim_ff_scale=None, sliding_window=3000) -> None:
|
| 45 |
+
super().__init__()
|
| 46 |
+
|
| 47 |
+
if dim_ff_scale is None: hidden_dim = int(dim*4*(3/4))
|
| 48 |
+
else: hidden_dim = int(dim*dim_ff_scale)
|
| 49 |
+
|
| 50 |
+
self.cfg = ModelArgs(n_vocab, dim=dim, n_layers=n_layers, n_heads=nhead, n_kv_heads=nhead, hidden_dim=hidden_dim, sliding_window=sliding_window)
|
| 51 |
+
self.ar = MistralTransformer(self.cfg)
|
| 52 |
+
|
| 53 |
+
self.embed = nn.Embedding(n_vocab, dim)
|
| 54 |
+
|
| 55 |
+
# --- spk embedding network
|
| 56 |
+
dim_ff = int(dim*4*(3/4))
|
| 57 |
+
self.pos_embedding = SinePositionalEmbedding(dim, scale=False, alpha=True)
|
| 58 |
+
self.ref_chunked_emb = ChunkedEmbedding(1024 + 1, 8, dim) # add 1 for pad idx
|
| 59 |
+
self.spk_identity_emb = nn.Embedding(1, dim)
|
| 60 |
+
# define custom decoder
|
| 61 |
+
encoder_layer = nn.TransformerEncoderLayer(dim, nhead, dim_ff,
|
| 62 |
+
activation=FNNSwiGLU(dim, dim_ff), dropout=0,
|
| 63 |
+
batch_first=True, norm_first=True, layer_norm_eps=LAYERNORM_EPS)
|
| 64 |
+
encoder_layer.linear1 = nn.Identity()
|
| 65 |
+
self.spk_encoder = nn.TransformerEncoder(encoder_layer, n_spk_layers, norm=nn.LayerNorm(dim, eps=LAYERNORM_EPS))
|
| 66 |
+
# monkeypatch for broken copy.deepcopy of nn.Modules in nn.TransformerDecoder
|
| 67 |
+
for l in self.spk_encoder.layers: l.activation = FNNSwiGLU(dim, dim_ff)
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
@torch.inference_mode
|
| 71 |
+
def get_spk_embedding(self, spk_reference, c_codes_lengths=None) -> Tensor:
|
| 72 |
+
""" Gets speaker reference embeddings using `spk_reference` codes of shape (bs, seq_len, n_codebooks). """
|
| 73 |
+
bs = spk_reference.shape[0]
|
| 74 |
+
if bs != 1:
|
| 75 |
+
raise AssertionError(f"Speaker embedding extraction only implemented using for bs=1 currently.")
|
| 76 |
+
spk_seq = self.ref_chunked_emb(spk_reference) # (bs, sl, dim)
|
| 77 |
+
spk_ref_emb = self.spk_identity_emb.weight[None].expand(bs, -1, -1) # (bs, 1, dim)
|
| 78 |
+
|
| 79 |
+
spk_seq = torch.cat([spk_ref_emb, spk_seq], dim=1) # (bs, 1+sl, dim)
|
| 80 |
+
# add pos encoding
|
| 81 |
+
spk_seq = self.pos_embedding(spk_seq)
|
| 82 |
+
# codebook goes from indices 0->1023, padding is idx 1024 (the 1025th entry)
|
| 83 |
+
src_key_padding_mask = construct_padding_mask(spk_reference[:, :, 0], 1024)
|
| 84 |
+
src_key_padding_mask = torch.cat((
|
| 85 |
+
# append a zero here since we DO want to attend to initial position.
|
| 86 |
+
torch.zeros(src_key_padding_mask.shape[0], 1, dtype=bool, device=src_key_padding_mask.device),
|
| 87 |
+
src_key_padding_mask
|
| 88 |
+
),
|
| 89 |
+
dim=1)
|
| 90 |
+
# pass through transformer
|
| 91 |
+
res = self.spk_encoder(spk_seq, is_causal=False, src_key_padding_mask=src_key_padding_mask)[:, :1] # select first element -> now (bs, 1, dim).
|
| 92 |
+
return res.squeeze(1)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def forward(self, x: Tensor, x_padding_mask: Optional[Tensor] = None, spk_reference: Optional[Tensor] = None,
|
| 96 |
+
cache: Optional[RotatingBufferCache] = None, counter: int = 0) -> Tensor:
|
| 97 |
+
""" Inputs:
|
| 98 |
+
- `x`: (bs, seq_len, vocab_size)
|
| 99 |
+
- `x_padding_mask`: (bs, seq_len) mask for each input, True for positions to *ignore*, False otherwise.
|
| 100 |
+
Note that since this is an autoregressive model, this doesn't actually matter for infernece, so it is ignored at inference.
|
| 101 |
+
- `spk_reference`: (bs, seq_len, n_codebooks) corresponding to the speaker reference to clone from.
|
| 102 |
+
- `cache` and `counter`: used for kv caching, optional.
|
| 103 |
+
|
| 104 |
+
Returns `x` of same shape (bs, seq_len, dim)
|
| 105 |
+
"""
|
| 106 |
+
x = self.embed(x)
|
| 107 |
+
|
| 108 |
+
# --- speaker reference/embedding
|
| 109 |
+
if spk_reference is not None:
|
| 110 |
+
# compute ref
|
| 111 |
+
bs = spk_reference.shape[0]
|
| 112 |
+
spk_seq = self.ref_chunked_emb(spk_reference) # (bs, sl, dim)
|
| 113 |
+
spk_ref_emb = self.spk_identity_emb.weight[None].expand(bs, -1, -1) # (bs, 1, dim)
|
| 114 |
+
|
| 115 |
+
spk_seq = torch.cat([spk_ref_emb, spk_seq], dim=1) # (bs, 1+sl, dim)
|
| 116 |
+
# add pos encoding
|
| 117 |
+
spk_seq = self.pos_embedding(spk_seq)
|
| 118 |
+
# codebook goes from indices 0->1023, padding is idx 1024 (the 1025th entry)
|
| 119 |
+
src_key_padding_mask = construct_padding_mask(spk_reference[:, :, 0], 1024)
|
| 120 |
+
src_key_padding_mask = torch.cat((
|
| 121 |
+
# append a zero here since we DO want to attend to initial position.
|
| 122 |
+
torch.zeros(src_key_padding_mask.shape[0], 1, dtype=bool, device=src_key_padding_mask.device),
|
| 123 |
+
src_key_padding_mask
|
| 124 |
+
),
|
| 125 |
+
dim=1)
|
| 126 |
+
# pass through transformer
|
| 127 |
+
res = self.spk_encoder(spk_seq, is_causal=False, src_key_padding_mask=src_key_padding_mask)[:, :1] # select first element -> now (bs, 1, dim).
|
| 128 |
+
|
| 129 |
+
x = torch.cat([res, x], dim=1)
|
| 130 |
+
|
| 131 |
+
positions = torch.arange(0, x.shape[1], device=x.device, dtype=torch.long)
|
| 132 |
+
if cache is not None and counter != 1:
|
| 133 |
+
# using only the last token to predict the next one
|
| 134 |
+
x = x[:,-1,:].unsqueeze(1)
|
| 135 |
+
positions = positions[-1:]
|
| 136 |
+
|
| 137 |
+
x = self.ar(x, positions, cache) # (bs, seq_len, vocab)
|
| 138 |
+
if spk_reference is not None and (cache is None or counter == 1):
|
| 139 |
+
x = x[:, 1:] # strip out the first output token corresponding to the speaker embedding token.
|
| 140 |
+
|
| 141 |
+
return x
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
# -------------------------
|
| 145 |
+
# residual discrete diffusion model
|
| 146 |
+
|
| 147 |
+
class ChunkedEmbedding(nn.Module):
|
| 148 |
+
|
| 149 |
+
def __init__(self, codebook_size: int, n_quantizer: int, dim: int) -> None:
|
| 150 |
+
super().__init__()
|
| 151 |
+
assert dim % n_quantizer == 0, f"ChunkedEmbedding output dim ({dim}) must be divisible by n_quant {n_quantizer}"
|
| 152 |
+
self.embs = nn.ModuleList([nn.Embedding(codebook_size, dim//n_quantizer) for _ in range(n_quantizer)])
|
| 153 |
+
|
| 154 |
+
def forward(self, x: Tensor) -> Tensor:
|
| 155 |
+
""" Embeds each codebook index in `x` (bs, seq_len, n_quantizer) to an embedding vector, concatenating results.
|
| 156 |
+
Returns output of shape (bs, seq_len, dim)
|
| 157 |
+
"""
|
| 158 |
+
y = torch.cat([self.embs[i](x[..., i]) for i in range(x.shape[-1])], dim=-1)
|
| 159 |
+
return y
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
class ResidualTransformer(nn.Module):
|
| 164 |
+
|
| 165 |
+
def __init__(self, n_text_vocab, n_quant=1024, dim=1024, nhead=16,
|
| 166 |
+
enc_layers=8, dec_layers=16, n_spk_layers=3,
|
| 167 |
+
c_quant_levels=8, pred_quant_levels=8,
|
| 168 |
+
t_emb_dim=1024, norm_first=True, p_cond_drop=0.1, dropout=0) -> None:
|
| 169 |
+
super().__init__()
|
| 170 |
+
|
| 171 |
+
self.cond_pos_embedding = SinePositionalEmbedding(dim, scale=False, alpha=True)
|
| 172 |
+
self.pos_embedding = SinePositionalEmbedding(dim, scale=False, alpha=True)
|
| 173 |
+
|
| 174 |
+
# *4 from heuristic, *2/3 from swiglu, since there are 3 linear matrices not 2.
|
| 175 |
+
# so we must keep # params the same.
|
| 176 |
+
dim_ff = int(dim*4*(3/4))
|
| 177 |
+
|
| 178 |
+
# define custom encoder
|
| 179 |
+
encoder_layer = nn.TransformerEncoderLayer(dim, nhead, dim_ff,
|
| 180 |
+
activation=FNNSwiGLU(dim, dim_ff), dropout=dropout,
|
| 181 |
+
batch_first=True, norm_first=norm_first, layer_norm_eps=LAYERNORM_EPS)
|
| 182 |
+
encoder_layer.linear1 = nn.Identity()
|
| 183 |
+
encoder = nn.TransformerEncoder(encoder_layer, enc_layers, norm=nn.LayerNorm(dim, eps=LAYERNORM_EPS) if norm_first else None)
|
| 184 |
+
|
| 185 |
+
# define custom decoder
|
| 186 |
+
decoder_layer = nn.TransformerDecoderLayer(dim, nhead, dim_ff,
|
| 187 |
+
activation=FNNSwiGLU(dim, dim_ff), dropout=dropout,
|
| 188 |
+
batch_first=True, norm_first=norm_first, layer_norm_eps=LAYERNORM_EPS)
|
| 189 |
+
decoder_layer.linear1 = nn.Identity()
|
| 190 |
+
decoder = nn.TransformerDecoder(decoder_layer, dec_layers, norm=nn.LayerNorm(dim, eps=LAYERNORM_EPS) if norm_first else None)
|
| 191 |
+
|
| 192 |
+
# monkeypatch for broken copy.deepcopy of nn.Modules in nn.TransformerDecoder
|
| 193 |
+
for l in decoder.layers: l.activation = FNNSwiGLU(dim, dim_ff)
|
| 194 |
+
|
| 195 |
+
self.tfm = nn.Transformer(dim, nhead, dim_feedforward=dim_ff, batch_first=True,
|
| 196 |
+
norm_first=norm_first,
|
| 197 |
+
num_encoder_layers=enc_layers,
|
| 198 |
+
num_decoder_layers=dec_layers,
|
| 199 |
+
custom_encoder=encoder,
|
| 200 |
+
custom_decoder=decoder,
|
| 201 |
+
layer_norm_eps=LAYERNORM_EPS,
|
| 202 |
+
dropout=dropout
|
| 203 |
+
)
|
| 204 |
+
# Timestep embedding network
|
| 205 |
+
self.t_emb_dim = t_emb_dim
|
| 206 |
+
self.timestep_encoder_emb = nn.Sequential(
|
| 207 |
+
nn.Linear(t_emb_dim, dim),
|
| 208 |
+
nn.SiLU(),
|
| 209 |
+
nn.Linear(dim, dim)
|
| 210 |
+
)
|
| 211 |
+
self.timestep_decoder_emb = nn.Sequential(
|
| 212 |
+
nn.Linear(t_emb_dim, dim),
|
| 213 |
+
nn.SiLU(),
|
| 214 |
+
nn.Linear(dim, dim)
|
| 215 |
+
)
|
| 216 |
+
|
| 217 |
+
self.text_embed = nn.Embedding(n_text_vocab, dim)
|
| 218 |
+
|
| 219 |
+
## ----> reference / conditioning encoder:
|
| 220 |
+
self.ref_embedder = ChunkedEmbedding(n_quant, c_quant_levels, dim)
|
| 221 |
+
self.ref_pos_embedding = SinePositionalEmbedding(dim, scale=False, alpha=True)
|
| 222 |
+
self.spk_identity_emb = nn.Embedding(1, dim)
|
| 223 |
+
spk_encoder_layer = nn.TransformerEncoderLayer(dim, nhead, dim_ff,
|
| 224 |
+
activation=FNNSwiGLU(dim, dim_ff), dropout=dropout,
|
| 225 |
+
batch_first=True, norm_first=True, layer_norm_eps=LAYERNORM_EPS)
|
| 226 |
+
spk_encoder_layer.linear1 = nn.Identity()
|
| 227 |
+
self.spk_encoder = nn.TransformerEncoder(spk_encoder_layer, n_spk_layers, norm=nn.LayerNorm(dim, eps=LAYERNORM_EPS))
|
| 228 |
+
# monkeypatch for broken copy.deepcopy of nn.Modules in nn.TransformerDecoder
|
| 229 |
+
for l in self.spk_encoder.layers: l.activation = FNNSwiGLU(dim, dim_ff)
|
| 230 |
+
# ----> end speaker encoder network
|
| 231 |
+
|
| 232 |
+
# self.residual_encoder = nn.Embedding(n_quant, dim) # only encode first quantization level of decoder input.
|
| 233 |
+
self.residual_encoder = ChunkedEmbedding(n_quant, c_quant_levels, dim)
|
| 234 |
+
|
| 235 |
+
self.residual_decoder = nn.ModuleList([
|
| 236 |
+
nn.Sequential(
|
| 237 |
+
nn.LayerNorm(dim),
|
| 238 |
+
nn.Linear(dim, n_quant)
|
| 239 |
+
) for i in range(pred_quant_levels)
|
| 240 |
+
])
|
| 241 |
+
self.n_quantizer = pred_quant_levels
|
| 242 |
+
self.p_cond_drop = p_cond_drop
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
@torch.inference_mode
|
| 246 |
+
def get_spk_embedding(self, c_codes, c_codes_length) -> Tensor:
|
| 247 |
+
""" Obtain speaker embedding vectors using `c_codes` from reference encodec sequences, and `c_codes_length` of lengths for each sequence """
|
| 248 |
+
bs = c_codes.shape[0]
|
| 249 |
+
spk_seq = self.ref_embedder(c_codes) # (bs, sl, dim)
|
| 250 |
+
spk_ref_emb = self.spk_identity_emb.weight[None].expand(bs, -1, -1) # (bs, 1, dim)
|
| 251 |
+
spk_seq = torch.cat([spk_ref_emb, spk_seq], dim=1) # (bs, 1+sl, dim)
|
| 252 |
+
# add pos encoding
|
| 253 |
+
spk_seq = self.ref_pos_embedding(spk_seq)
|
| 254 |
+
|
| 255 |
+
# add 1 to c_codes_length to account for the fact that we concatenate the spk_ref_emb to it.
|
| 256 |
+
src_key_padding_mask = length_to_mask(c_codes_length+1, torch.zeros_like(c_codes_length), max_len=spk_seq.shape[1])
|
| 257 |
+
src_key_padding_mask = src_key_padding_mask.to(dtype=torch.bool, device=spk_seq.device)
|
| 258 |
+
|
| 259 |
+
# pass through transformer
|
| 260 |
+
res = self.spk_encoder(spk_seq, is_causal=False, src_key_padding_mask=src_key_padding_mask)[:, :1] # select first element -> now (bs, 1, dim).
|
| 261 |
+
return res.squeeze(1)
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
def forward(self, c_text: Tensor, c_codes: Tensor, c_texts_length: Tensor, c_codes_length: Tensor,
|
| 265 |
+
x: Tensor, x_padding_mask: Tensor, t: Tensor, drop_cond=False):
|
| 266 |
+
""" Input:
|
| 267 |
+
- `c_text`: (bs, seq_len1) the prompt text (BPE encoded)
|
| 268 |
+
- `c_codes`: (bs, seq_len2, n_quant) the full tokenized codes of the reference speech
|
| 269 |
+
- `c_texts_length`: (bs, ) the length of the codes in the text prompt
|
| 270 |
+
- `c_codes_length`: (bs, ) the length of the prompt acoustic token codes in `c_codes`.
|
| 271 |
+
- `x`: (bs, seq_len3) L0 residual codes
|
| 272 |
+
- `x`: (bs, seq_len3, n_quant) L0 residual codes
|
| 273 |
+
- `x_padding_mask`: (bs, seq_len3) masking for residual codes
|
| 274 |
+
- `t`: (bs) timestep
|
| 275 |
+
- `drop_cond`: bool, whether or not to forcibly drop the conditioning information.
|
| 276 |
+
Returns:
|
| 277 |
+
- outs: (bs, seq_len, n_quantizer, codebook_size)
|
| 278 |
+
"""
|
| 279 |
+
|
| 280 |
+
c_text = self.text_embed(c_text) # (bs, seq_len1, dim)
|
| 281 |
+
|
| 282 |
+
## ----> reference / conditioning encoder:
|
| 283 |
+
bs = c_codes.shape[0]
|
| 284 |
+
|
| 285 |
+
|
| 286 |
+
if self.training:
|
| 287 |
+
zero_cond_inds = torch.rand_like(t, dtype=c_text.dtype) < self.p_cond_drop
|
| 288 |
+
else:
|
| 289 |
+
# never randomly zero when in eval mode
|
| 290 |
+
zero_cond_inds = torch.zeros_like(t, dtype=torch.bool)
|
| 291 |
+
if drop_cond:
|
| 292 |
+
# force drop conditioning
|
| 293 |
+
zero_cond_inds = torch.ones_like(t, dtype=torch.bool)
|
| 294 |
+
|
| 295 |
+
c_codes_length[zero_cond_inds] = 0
|
| 296 |
+
c_codes[zero_cond_inds] = 1024
|
| 297 |
+
|
| 298 |
+
spk_seq = self.ref_embedder(c_codes) # (bs, sl, dim)
|
| 299 |
+
spk_ref_emb = self.spk_identity_emb.weight[None].expand(bs, -1, -1) # (bs, 1, dim)
|
| 300 |
+
spk_seq = torch.cat([spk_ref_emb, spk_seq], dim=1) # (bs, 1+sl, dim)
|
| 301 |
+
# add pos encoding
|
| 302 |
+
spk_seq = self.ref_pos_embedding(spk_seq)
|
| 303 |
+
|
| 304 |
+
# add 1 to c_codes_length to account for the fact that we concatenate the spk_ref_emb to it.
|
| 305 |
+
src_key_padding_mask = length_to_mask(c_codes_length+1, torch.zeros_like(c_codes_length), max_len=spk_seq.shape[1])
|
| 306 |
+
src_key_padding_mask = src_key_padding_mask.to(dtype=torch.bool, device=spk_seq.device)
|
| 307 |
+
|
| 308 |
+
# pass through transformer
|
| 309 |
+
res = self.spk_encoder(spk_seq, is_causal=False, src_key_padding_mask=src_key_padding_mask)[:, :1] # select first element -> now (bs, 1, dim).
|
| 310 |
+
c_codes = res # (bs, 1, dim)
|
| 311 |
+
c_codes_lengths_extract = torch.ones_like(c_codes_length) # manually override all the code lengths to equal 1, since we only have 1 spk embedding.
|
| 312 |
+
## ----> end reference / conditioning encoder:
|
| 313 |
+
|
| 314 |
+
## ----> timestep embeddings and parsing
|
| 315 |
+
t_emb = timestep_embedding(t, self.t_emb_dim, dtype=c_text.dtype)
|
| 316 |
+
t_emb_encoder = self.timestep_encoder_emb(t_emb) # (bs, t_dim)
|
| 317 |
+
t_emb_decoder = self.timestep_decoder_emb(t_emb)
|
| 318 |
+
|
| 319 |
+
## ----> concatenating text/phone inputs and implicit speaker embedding.
|
| 320 |
+
c_phones_unpacked = nn.utils.rnn.unpad_sequence(c_text, c_texts_length.cpu(), batch_first=True)
|
| 321 |
+
c_codes_unpacked = nn.utils.rnn.unpad_sequence(c_codes, c_codes_lengths_extract.cpu(), batch_first=True)
|
| 322 |
+
# >>> Concat [speaker codes, text codes]
|
| 323 |
+
assert all(b.shape[0] == 1 for b in c_codes_unpacked)
|
| 324 |
+
c_joined = [torch.cat((b, a), dim=0) for a, b in zip(c_phones_unpacked, c_codes_unpacked)]
|
| 325 |
+
|
| 326 |
+
c = nn.utils.rnn.pad_sequence(c_joined, batch_first=True)
|
| 327 |
+
c_joined_lengths = torch.tensor([p.shape[0] for p in c_joined], device=c.device, dtype=torch.long)
|
| 328 |
+
c_padding_mask = length_to_mask(c_joined_lengths, torch.zeros_like(c_joined_lengths))
|
| 329 |
+
c = self.cond_pos_embedding(c)
|
| 330 |
+
|
| 331 |
+
## Format input:
|
| 332 |
+
x = self.residual_encoder(x) # (bs, seq_len3, dim)
|
| 333 |
+
|
| 334 |
+
x = self.pos_embedding(x)
|
| 335 |
+
|
| 336 |
+
x = x + t_emb_decoder[:, None]
|
| 337 |
+
c = c + t_emb_encoder[:, None]
|
| 338 |
+
## Perform prediction:
|
| 339 |
+
output = self.tfm(c, x, src_key_padding_mask=c_padding_mask,
|
| 340 |
+
tgt_key_padding_mask=x_padding_mask,
|
| 341 |
+
memory_key_padding_mask=c_padding_mask) # (bs, seq_len, dim)
|
| 342 |
+
outs = torch.stack([self.residual_decoder[i](output) for i in range(self.n_quantizer)], dim=-1) # (bs, seq_len, logit_dim, n_quant)
|
| 343 |
+
return outs
|
| 344 |
+
|
mars5/nn_future.py
ADDED
|
@@ -0,0 +1,400 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
from torch import Tensor
|
| 5 |
+
import math
|
| 6 |
+
from dataclasses import dataclass
|
| 7 |
+
from typing import Optional
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
# --------------------------
|
| 11 |
+
# activation functions
|
| 12 |
+
|
| 13 |
+
class FNNSwiGLU(nn.Module):
|
| 14 |
+
|
| 15 |
+
def __init__(self, dim, dim_ff) -> None:
|
| 16 |
+
super().__init__()
|
| 17 |
+
|
| 18 |
+
# we will receive in xW
|
| 19 |
+
self.V = nn.Linear(dim, dim_ff, bias=False)
|
| 20 |
+
self.W = nn.Linear(dim, dim_ff, bias=False)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def forward(self, x: Tensor) -> Tensor:
|
| 24 |
+
""" Compute SwiGLU output of x, the output of the first linear layer. i.e.
|
| 25 |
+
FFNSwiGLU(x, W, V, W2) = (Swish1(xW) ⊗ xV )W2.
|
| 26 |
+
NOTE: the transformer linear1 layer must be overwritten to identity. This layer only applies
|
| 27 |
+
the Swish(xW) * xV. The W2 multiplication is done in the main transformer layer
|
| 28 |
+
"""
|
| 29 |
+
return F.silu(self.W(x)) * self.V(x)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
# ---------------------------------
|
| 33 |
+
# padding and position layers
|
| 34 |
+
|
| 35 |
+
class SinePositionalEmbedding(nn.Module):
|
| 36 |
+
def __init__(
|
| 37 |
+
self,
|
| 38 |
+
dim_model: int,
|
| 39 |
+
dropout: float = 0.0,
|
| 40 |
+
scale: bool = False,
|
| 41 |
+
alpha: bool = False,
|
| 42 |
+
):
|
| 43 |
+
super().__init__()
|
| 44 |
+
self.dim_model = dim_model
|
| 45 |
+
self.x_scale = math.sqrt(dim_model) if scale else 1.0
|
| 46 |
+
self.alpha = nn.Parameter(torch.ones(1), requires_grad=alpha)
|
| 47 |
+
self.dropout = torch.nn.Dropout(p=dropout)
|
| 48 |
+
|
| 49 |
+
self.reverse = False
|
| 50 |
+
self.pe = None
|
| 51 |
+
self.extend_pe(torch.tensor(0.0).expand(1, 4000))
|
| 52 |
+
|
| 53 |
+
def extend_pe(self, x):
|
| 54 |
+
"""Reset the positional encodings."""
|
| 55 |
+
if self.pe is not None:
|
| 56 |
+
if self.pe.size(1) >= x.size(1):
|
| 57 |
+
if self.pe.dtype != x.dtype or self.pe.device != x.device:
|
| 58 |
+
self.pe = self.pe.to(dtype=x.dtype, device=x.device)
|
| 59 |
+
return
|
| 60 |
+
pe = torch.zeros(x.size(1), self.dim_model)
|
| 61 |
+
if self.reverse:
|
| 62 |
+
position = torch.arange(
|
| 63 |
+
x.size(1) - 1, -1, -1.0, dtype=torch.float32
|
| 64 |
+
).unsqueeze(1)
|
| 65 |
+
else:
|
| 66 |
+
position = torch.arange(
|
| 67 |
+
0, x.size(1), dtype=torch.float32
|
| 68 |
+
).unsqueeze(1)
|
| 69 |
+
div_term = torch.exp(
|
| 70 |
+
torch.arange(0, self.dim_model, 2, dtype=torch.float32)
|
| 71 |
+
* -(math.log(10000.0) / self.dim_model)
|
| 72 |
+
)
|
| 73 |
+
pe[:, 0::2] = torch.sin(position * div_term)
|
| 74 |
+
pe[:, 1::2] = torch.cos(position * div_term)
|
| 75 |
+
pe = pe.unsqueeze(0)
|
| 76 |
+
self.pe = pe.to(device=x.device, dtype=x.dtype).detach()
|
| 77 |
+
|
| 78 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 79 |
+
""" Assumes x of shape (bs, seq_len, dim) """
|
| 80 |
+
self.extend_pe(x)
|
| 81 |
+
output = x.unsqueeze(-1) if x.ndim == 2 else x
|
| 82 |
+
output = output * self.x_scale + self.alpha * self.pe[:, : x.size(1)]
|
| 83 |
+
return self.dropout(output)
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
# --------------------------------
|
| 87 |
+
# kv cache blocks
|
| 88 |
+
|
| 89 |
+
class CacheView:
|
| 90 |
+
def __init__(self, cache_k: torch.Tensor, cache_v: torch.Tensor):
|
| 91 |
+
self.cache_k = cache_k
|
| 92 |
+
self.cache_v = cache_v
|
| 93 |
+
|
| 94 |
+
@property
|
| 95 |
+
def sliding_window(self):
|
| 96 |
+
return self.cache_k.shape[1]
|
| 97 |
+
|
| 98 |
+
class RotatingBufferCache:
|
| 99 |
+
"""
|
| 100 |
+
This is an example that implements a less naive rotating buffer cache, allowing for variable length sequences.
|
| 101 |
+
Allocated cache is rectangular which is wasteful (see PagedAttention for better mechanisms)
|
| 102 |
+
"""
|
| 103 |
+
def __init__(self, n_layers: int, max_batch_size: int, sliding_window: int, n_kv_heads: int, head_dim: int):
|
| 104 |
+
|
| 105 |
+
self.sliding_window = sliding_window
|
| 106 |
+
self.n_kv_heads = n_kv_heads
|
| 107 |
+
self.head_dim = head_dim
|
| 108 |
+
|
| 109 |
+
self.cache_k = torch.empty((
|
| 110 |
+
n_layers,
|
| 111 |
+
max_batch_size,
|
| 112 |
+
sliding_window,
|
| 113 |
+
n_kv_heads,
|
| 114 |
+
head_dim
|
| 115 |
+
))
|
| 116 |
+
self.cache_v = torch.empty((
|
| 117 |
+
n_layers,
|
| 118 |
+
max_batch_size,
|
| 119 |
+
sliding_window,
|
| 120 |
+
n_kv_heads,
|
| 121 |
+
head_dim
|
| 122 |
+
))
|
| 123 |
+
|
| 124 |
+
def get_view(self, layer_id: int) -> CacheView:
|
| 125 |
+
return CacheView(self.cache_k[layer_id], self.cache_v[layer_id])
|
| 126 |
+
|
| 127 |
+
@property
|
| 128 |
+
def device(self):
|
| 129 |
+
return self.cache_k.device
|
| 130 |
+
|
| 131 |
+
def to(self, device: torch.device, dtype: torch.dtype):
|
| 132 |
+
self.cache_k = self.cache_k.to(device=device, dtype=dtype)
|
| 133 |
+
self.cache_v = self.cache_v.to(device=device, dtype=dtype)
|
| 134 |
+
return self
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
# --------------------------------
|
| 138 |
+
# Mistral transformer blocks
|
| 139 |
+
# Code for the follow blocks are adapted from
|
| 140 |
+
# https://github.com/mistralai/mistral-src
|
| 141 |
+
# Thank you Mistral team!
|
| 142 |
+
|
| 143 |
+
@dataclass
|
| 144 |
+
class ModelArgs:
|
| 145 |
+
vocab_size: int
|
| 146 |
+
|
| 147 |
+
dim: int = 1152 # default for mars3 and before: 1024
|
| 148 |
+
n_layers: int = 24
|
| 149 |
+
head_dim: int = 64 # = dim/n_heads
|
| 150 |
+
hidden_dim: int = 3584
|
| 151 |
+
n_heads: int = 16
|
| 152 |
+
n_kv_heads: int = 16 # default: 8
|
| 153 |
+
sliding_window: int = 1792
|
| 154 |
+
norm_eps: float = 1e-5
|
| 155 |
+
|
| 156 |
+
max_batch_size: int = 256
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
def repeat_kv(keys: torch.Tensor, values: torch.Tensor, repeats: int):
|
| 160 |
+
if repeats == 1: return keys, values
|
| 161 |
+
keys = torch.repeat_interleave(keys, repeats=repeats, dim=2)
|
| 162 |
+
values = torch.repeat_interleave(values, repeats=repeats, dim=2)
|
| 163 |
+
return keys, values
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def _reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor) -> torch.Tensor:
|
| 167 |
+
"""
|
| 168 |
+
freqs_cis: complex - (seq_len, head_dim / 2)
|
| 169 |
+
x: complex - (bsz, seq_len, head_dim / 2)
|
| 170 |
+
"""
|
| 171 |
+
ndim = x.ndim
|
| 172 |
+
assert 1 < ndim
|
| 173 |
+
assert freqs_cis.shape == (x.shape[1], x.shape[-1]), (
|
| 174 |
+
freqs_cis.shape,
|
| 175 |
+
(x.shape[1], x.shape[-1]),
|
| 176 |
+
)
|
| 177 |
+
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]
|
| 178 |
+
return freqs_cis.view(*shape)
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
def apply_rotary_emb(
|
| 182 |
+
xq: torch.Tensor,
|
| 183 |
+
xk: torch.Tensor,
|
| 184 |
+
freqs_cis: torch.Tensor,
|
| 185 |
+
) -> tuple[torch.Tensor, torch.Tensor]:
|
| 186 |
+
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
|
| 187 |
+
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
|
| 188 |
+
freqs_cis = _reshape_for_broadcast(freqs_cis, xq_)
|
| 189 |
+
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)
|
| 190 |
+
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)
|
| 191 |
+
return xq_out.type_as(xq), xk_out.type_as(xk)
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0) -> torch.Tensor:
|
| 195 |
+
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
|
| 196 |
+
t = torch.arange(end, device=freqs.device) # type: ignore
|
| 197 |
+
freqs = torch.outer(t, freqs).float() # type: ignore
|
| 198 |
+
return torch.polar(torch.ones_like(freqs), freqs) # complex64
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
class Attention(nn.Module):
|
| 202 |
+
def __init__(self, args: ModelArgs):
|
| 203 |
+
super().__init__()
|
| 204 |
+
self.args = args
|
| 205 |
+
|
| 206 |
+
self.n_heads: int = args.n_heads
|
| 207 |
+
self.n_kv_heads: int = args.n_kv_heads
|
| 208 |
+
|
| 209 |
+
self.repeats = self.n_heads // self.n_kv_heads
|
| 210 |
+
self.sliding_window = self.args.sliding_window
|
| 211 |
+
|
| 212 |
+
self.scale = self.args.head_dim**-0.5
|
| 213 |
+
|
| 214 |
+
self.wq = nn.Linear(
|
| 215 |
+
args.dim,
|
| 216 |
+
args.n_heads * args.head_dim,
|
| 217 |
+
bias=False
|
| 218 |
+
)
|
| 219 |
+
self.wk = nn.Linear(
|
| 220 |
+
args.dim,
|
| 221 |
+
args.n_kv_heads * args.head_dim,
|
| 222 |
+
bias=False
|
| 223 |
+
)
|
| 224 |
+
self.wv = nn.Linear(
|
| 225 |
+
args.dim,
|
| 226 |
+
args.n_kv_heads * args.head_dim,
|
| 227 |
+
bias=False
|
| 228 |
+
)
|
| 229 |
+
self.wo = nn.Linear(
|
| 230 |
+
args.n_heads * args.head_dim,
|
| 231 |
+
args.dim,
|
| 232 |
+
bias=False
|
| 233 |
+
)
|
| 234 |
+
|
| 235 |
+
def forward(
|
| 236 |
+
self, x: torch.Tensor, freqs_cis: torch.Tensor, positions: torch.Tensor, mask: Optional[torch.Tensor], cache: Optional[CacheView]
|
| 237 |
+
) -> torch.Tensor:
|
| 238 |
+
|
| 239 |
+
bsz, seqlen, _ = x.shape
|
| 240 |
+
|
| 241 |
+
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
|
| 242 |
+
xq = xq.view(bsz, seqlen, self.n_heads, self.args.head_dim)
|
| 243 |
+
xk = xk.view(bsz, seqlen, self.n_kv_heads, self.args.head_dim)
|
| 244 |
+
xv = xv.view(bsz, seqlen, self.n_kv_heads, self.args.head_dim)
|
| 245 |
+
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
|
| 246 |
+
|
| 247 |
+
# The cache is a rotating buffer
|
| 248 |
+
if cache is not None:
|
| 249 |
+
scatter_pos = (positions[-self.sliding_window:] % self.sliding_window)[None, :, None, None]
|
| 250 |
+
scatter_pos = scatter_pos.repeat(bsz, 1, self.n_kv_heads, self.args.head_dim)
|
| 251 |
+
cache.cache_k[:bsz].scatter_(dim=1, index=scatter_pos, src=xk[:, -self.sliding_window:])
|
| 252 |
+
cache.cache_v[:bsz].scatter_(dim=1, index=scatter_pos, src=xv[:, -self.sliding_window:])
|
| 253 |
+
|
| 254 |
+
if positions.shape[0] > 1:
|
| 255 |
+
# prefill
|
| 256 |
+
key, value = repeat_kv(xk, xv, self.repeats)
|
| 257 |
+
else:
|
| 258 |
+
cur_pos = positions[-1].item() + 1
|
| 259 |
+
key, value = repeat_kv(cache.cache_k[:bsz, :cur_pos, ...], cache.cache_v[:bsz, :cur_pos, ...], self.repeats)
|
| 260 |
+
|
| 261 |
+
# print(f"Internal: {xq.shape}, key: {key.shape}, mask: {mask.shape} | {mask.dtype} | xq: {xq.dtype} | mask: {mask} ")
|
| 262 |
+
# if mask is not None:
|
| 263 |
+
# mask = mask[None, None, ...].expand(bsz, self.n_heads, -1, -1)
|
| 264 |
+
# mask = mask.to(key.dtype)
|
| 265 |
+
|
| 266 |
+
query = xq.transpose(1, 2)
|
| 267 |
+
key = key.transpose(1, 2)
|
| 268 |
+
value = value.transpose(1, 2)
|
| 269 |
+
# # scores : [bsz, n_heads, seqlen | 1, seqlen]
|
| 270 |
+
# scores = torch.matmul(query, key.transpose(2, 3)) * self.scale
|
| 271 |
+
|
| 272 |
+
output = F.scaled_dot_product_attention(query, key, value, mask) # (bs, n_local_heads, slen, head_dim)
|
| 273 |
+
output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
|
| 274 |
+
return self.wo(output)
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
class FeedForward(nn.Module):
|
| 278 |
+
def __init__(self, args: ModelArgs):
|
| 279 |
+
super().__init__()
|
| 280 |
+
|
| 281 |
+
self.w1 = nn.Linear(
|
| 282 |
+
args.dim,
|
| 283 |
+
args.hidden_dim,
|
| 284 |
+
bias=False
|
| 285 |
+
)
|
| 286 |
+
self.w2 = nn.Linear(
|
| 287 |
+
args.hidden_dim,
|
| 288 |
+
args.dim,
|
| 289 |
+
bias=False
|
| 290 |
+
)
|
| 291 |
+
self.w3 = nn.Linear(
|
| 292 |
+
args.dim,
|
| 293 |
+
args.hidden_dim,
|
| 294 |
+
bias=False
|
| 295 |
+
)
|
| 296 |
+
|
| 297 |
+
def forward(self, x) -> torch.Tensor:
|
| 298 |
+
return self.w2(nn.functional.silu(self.w1(x)) * self.w3(x))
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
class RMSNorm(torch.nn.Module):
|
| 302 |
+
def __init__(self, dim: int, eps: float = 1e-6):
|
| 303 |
+
super().__init__()
|
| 304 |
+
self.eps = eps
|
| 305 |
+
self.weight = nn.Parameter(torch.ones(dim))
|
| 306 |
+
|
| 307 |
+
def _norm(self, x):
|
| 308 |
+
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
|
| 309 |
+
|
| 310 |
+
def forward(self, x):
|
| 311 |
+
output = self._norm(x.float()).type_as(x)
|
| 312 |
+
return output * self.weight
|
| 313 |
+
|
| 314 |
+
|
| 315 |
+
class TransformerBlock(nn.Module):
|
| 316 |
+
def __init__(self, args: ModelArgs):
|
| 317 |
+
super().__init__()
|
| 318 |
+
self.n_heads = args.n_heads
|
| 319 |
+
self.dim = args.dim
|
| 320 |
+
self.attention = Attention(args)
|
| 321 |
+
self.feed_forward = FeedForward(args=args)
|
| 322 |
+
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
|
| 323 |
+
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
|
| 324 |
+
self.args = args
|
| 325 |
+
|
| 326 |
+
def forward(
|
| 327 |
+
self, x: torch.Tensor, freqs_cis: torch.Tensor, positions: torch.Tensor, mask: Optional[torch.Tensor], cache: Optional[CacheView]
|
| 328 |
+
) -> torch.Tensor:
|
| 329 |
+
r = self.attention.forward(self.attention_norm(x), freqs_cis, positions, mask, cache)
|
| 330 |
+
h = x + r
|
| 331 |
+
r = self.feed_forward.forward(self.ffn_norm(h))
|
| 332 |
+
out = h + r
|
| 333 |
+
return out
|
| 334 |
+
|
| 335 |
+
|
| 336 |
+
class MistralTransformer(nn.Module):
|
| 337 |
+
def __init__(self, args: ModelArgs):
|
| 338 |
+
super().__init__()
|
| 339 |
+
self.args = args
|
| 340 |
+
self.vocab_size = args.vocab_size
|
| 341 |
+
self.n_layers = args.n_layers
|
| 342 |
+
assert self.vocab_size > 0
|
| 343 |
+
|
| 344 |
+
# self.tok_embeddings = nn.Embedding(args.vocab_size, args.dim)
|
| 345 |
+
|
| 346 |
+
self.layers = torch.nn.ModuleList(
|
| 347 |
+
[TransformerBlock(args=args) for _ in range(args.n_layers)]
|
| 348 |
+
)
|
| 349 |
+
|
| 350 |
+
self.norm = RMSNorm(args.dim, eps=args.norm_eps)
|
| 351 |
+
|
| 352 |
+
self.output = nn.Linear(
|
| 353 |
+
args.dim,
|
| 354 |
+
args.vocab_size,
|
| 355 |
+
bias=False
|
| 356 |
+
)
|
| 357 |
+
|
| 358 |
+
# self.freqs_cis
|
| 359 |
+
self.freqs_cis = precompute_freqs_cis(self.args.head_dim, 128_000)
|
| 360 |
+
|
| 361 |
+
@property
|
| 362 |
+
def dtype(self) -> torch.dtype:
|
| 363 |
+
return self.tok_embeddings.weight.dtype
|
| 364 |
+
|
| 365 |
+
@property
|
| 366 |
+
def device(self) -> torch.device:
|
| 367 |
+
return self.tok_embeddings.weight.device
|
| 368 |
+
|
| 369 |
+
def forward(
|
| 370 |
+
self,
|
| 371 |
+
input_ids: torch.Tensor,
|
| 372 |
+
positions: torch.Tensor,
|
| 373 |
+
cache: Optional[RotatingBufferCache]
|
| 374 |
+
):
|
| 375 |
+
h = input_ids
|
| 376 |
+
if self.freqs_cis.device != h.device:
|
| 377 |
+
self.freqs_cis = self.freqs_cis.to(h.device)
|
| 378 |
+
freqs_cis = self.freqs_cis[positions]
|
| 379 |
+
|
| 380 |
+
mask: Optional[torch.Tensor] = None
|
| 381 |
+
if input_ids.shape[1] > 1:
|
| 382 |
+
seqlen = input_ids.shape[1]
|
| 383 |
+
tensor = torch.full(
|
| 384 |
+
(seqlen, seqlen),
|
| 385 |
+
dtype=h.dtype,
|
| 386 |
+
fill_value=1,
|
| 387 |
+
device=h.device,
|
| 388 |
+
)
|
| 389 |
+
mask = torch.tril(tensor, diagonal=0).to(h.dtype)
|
| 390 |
+
# make the mask banded to account for sliding window
|
| 391 |
+
mask = torch.triu(mask, diagonal=-self.args.sliding_window)
|
| 392 |
+
mask = torch.log(mask)
|
| 393 |
+
|
| 394 |
+
for layer_id, layer in enumerate(self.layers):
|
| 395 |
+
cache_view = None if cache is None else cache.get_view(layer_id)
|
| 396 |
+
h = layer(h, freqs_cis, positions, mask, cache_view)
|
| 397 |
+
|
| 398 |
+
return self.output(self.norm(h))
|
| 399 |
+
|
| 400 |
+
|
mars5/samplers.py
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Code for modifying categorical distributions to improve quality of sampling.
|
| 3 |
+
|
| 4 |
+
Adapted from:
|
| 5 |
+
- https://github.com/e-c-k-e-r/vall-e/blob/master/vall_e/samplers.py
|
| 6 |
+
- Mirosoft UniLM
|
| 7 |
+
- Matthew Baas's typical sampling code.
|
| 8 |
+
- https://github.com/LostRuins/koboldcpp
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
import math
|
| 12 |
+
import torch
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
import numpy as np
|
| 15 |
+
import logging
|
| 16 |
+
|
| 17 |
+
from torch import Tensor, nn
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def freq_rep_penalty(logits: Tensor, previous: Tensor, alpha_frequency: float, alpha_presence: float, penalty_window: int = 100) -> Tensor:
|
| 21 |
+
""" Apply frequency and presence penalty according to openai's formuation.
|
| 22 |
+
Concretely: given `logits` (bs, vocab_size) and `previous` (bs, seq_len,)
|
| 23 |
+
|
| 24 |
+
Modified to support batched inference.
|
| 25 |
+
|
| 26 |
+
See: https://platform.openai.com/docs/guides/text-generation/parameter-details
|
| 27 |
+
"""
|
| 28 |
+
bs = logits.shape[0]
|
| 29 |
+
previous = previous[..., -penalty_window:]
|
| 30 |
+
c = torch.zeros_like(logits, device=logits.device, dtype=torch.long) # (1, vocab_size)
|
| 31 |
+
for i in range(bs):
|
| 32 |
+
vals, cnts = previous[i].unique(return_counts=True)
|
| 33 |
+
c[i, vals] = cnts.to(c.device)
|
| 34 |
+
|
| 35 |
+
logits = logits - c * alpha_frequency - (c > 0).to(logits.dtype) * alpha_presence
|
| 36 |
+
return logits
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def early_eos_penalty(logits: Tensor, n_generated: int, estimated_gen_length: int, decay: float, factor: float = 1, eos_index: int = 0) -> Tensor:
|
| 40 |
+
""" Penalize the `eos_index` of `logits` (bs, vocab_size) up to `estimated_gen_length`,
|
| 41 |
+
whereby we reduce the logit value by `factor`*(expected_length - current_length)^decay,
|
| 42 |
+
`n_generated` is the current number of generated samples. `decay` anneals the penalty relative to the distance.
|
| 43 |
+
|
| 44 |
+
Good values for decay are between 0 and 1. 0 = hard always apply penalty of 1, 1 = linearly scale penalty relative to distance.
|
| 45 |
+
Setting factor = 0 disabled penatly. Increasing factor increases penalty.
|
| 46 |
+
"""
|
| 47 |
+
if n_generated > estimated_gen_length: return logits
|
| 48 |
+
penalty = max(estimated_gen_length - n_generated, 1)
|
| 49 |
+
|
| 50 |
+
bigger = logits[:, eos_index] > 0
|
| 51 |
+
|
| 52 |
+
modifier = factor*(penalty ** decay)
|
| 53 |
+
# logits[bigger, eos_index] /= modifier
|
| 54 |
+
# logits[~bigger, eos_index] *= modifier
|
| 55 |
+
logits[:, eos_index] -= modifier
|
| 56 |
+
return logits
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
# Credit to https://github.com/microsoft/unilm/blob/master/xtune/src/transformers/modeling_utils.py#L1145 /
|
| 60 |
+
# https://gist.github.com/thomwolf/1a5a29f6962089e871b94cbd09daf317
|
| 61 |
+
def top_k_top_p_filtering( logits: Tensor, top_k=0, top_p=1.0, filter_value=-float("Inf"), min_tokens=1 ) -> Tensor:
|
| 62 |
+
"""Filter a distribution of logits using top-k and/or nucleus (top-p) filtering
|
| 63 |
+
Args:
|
| 64 |
+
logits: logits distribution shape (batch size, vocabulary size)
|
| 65 |
+
if top_k > 0: keep only top k tokens with highest probability (top-k filtering).
|
| 66 |
+
if top_p < 1.0: keep the top tokens with cumulative probability >= top_p (nucleus filtering).
|
| 67 |
+
Nucleus filtering is described in Holtzman et al. (http://arxiv.org/abs/1904.09751)
|
| 68 |
+
Make sure we keep at least min_tokens per batch example in the output
|
| 69 |
+
"""
|
| 70 |
+
if top_k > 0:
|
| 71 |
+
top_k = min(max(top_k, min_tokens), logits.size(-1)) # Safety check
|
| 72 |
+
# Remove all tokens with a probability less than the last token of the top-k
|
| 73 |
+
indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None]
|
| 74 |
+
logits[indices_to_remove] = filter_value
|
| 75 |
+
|
| 76 |
+
if top_p < 1.0:
|
| 77 |
+
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
|
| 78 |
+
cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
|
| 79 |
+
|
| 80 |
+
# Remove tokens with cumulative probability above the threshold (token with 0 are kept)
|
| 81 |
+
sorted_indices_to_remove = cumulative_probs > top_p
|
| 82 |
+
if min_tokens > 1:
|
| 83 |
+
# Keep at least min_tokens (set to min_tokens-1 because we add the first one below)
|
| 84 |
+
sorted_indices_to_remove[..., :min_tokens] = 0
|
| 85 |
+
# Shift the indices to the right to keep also the first token above the threshold
|
| 86 |
+
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
|
| 87 |
+
sorted_indices_to_remove[..., 0] = 0
|
| 88 |
+
|
| 89 |
+
# scatter sorted tensors to original indexing
|
| 90 |
+
indices_to_remove = sorted_indices_to_remove.scatter(1, sorted_indices, sorted_indices_to_remove)
|
| 91 |
+
logits[indices_to_remove] = filter_value
|
| 92 |
+
|
| 93 |
+
return logits
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def apply_typical_p(logprobs: Tensor, mass: float) -> Tensor:
|
| 97 |
+
""" Warp categorical logprobs associated with `x` to be in line with `mass`. Last dimension is the bin dimension.
|
| 98 |
+
`mass` corresponds to `tau` in the paper.
|
| 99 |
+
"""
|
| 100 |
+
if mass > 0.999: return logprobs
|
| 101 |
+
# see: https://arxiv.org/abs/2202.00666
|
| 102 |
+
# calculate entropy
|
| 103 |
+
# normalized = logprobs #torch.nn.functional.log_softmax(scores, dim=-1)
|
| 104 |
+
normalized = torch.nn.functional.log_softmax(logprobs, dim=-1)
|
| 105 |
+
p = torch.exp(normalized)
|
| 106 |
+
ent = -(normalized * p).nansum(-1, keepdim=True)
|
| 107 |
+
|
| 108 |
+
# shift and sort
|
| 109 |
+
shifted_scores = torch.abs((-normalized) - ent)
|
| 110 |
+
sorted_scores, sorted_indices = torch.sort(shifted_scores, descending=False)
|
| 111 |
+
sorted_logits = logprobs.gather(-1, sorted_indices)
|
| 112 |
+
cumulative_probs = sorted_logits.softmax(dim=-1).cumsum(dim=-1)
|
| 113 |
+
|
| 114 |
+
# Remove tokens with cumulative mass above the threshold
|
| 115 |
+
last_ind = (cumulative_probs < mass).sum(dim=1)
|
| 116 |
+
last_ind[last_ind < 0] = 0
|
| 117 |
+
sorted_indices_to_remove = sorted_scores > sorted_scores.gather(1, last_ind.view(-1, 1))
|
| 118 |
+
|
| 119 |
+
indices_to_remove = sorted_indices_to_remove.scatter(1, sorted_indices, sorted_indices_to_remove)
|
| 120 |
+
|
| 121 |
+
scores = logprobs.masked_fill(indices_to_remove, -float('Inf'))
|
| 122 |
+
return scores
|
mars5/trim.py
ADDED
|
@@ -0,0 +1,741 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" Custom port of librosa trim code, to remove numba dependency.
|
| 2 |
+
This allows us to use librosa.trim effect without the librosa or numba dependancy.
|
| 3 |
+
|
| 4 |
+
All code below adapted from librosa open source github:
|
| 5 |
+
"""
|
| 6 |
+
|
| 7 |
+
import numpy as np
|
| 8 |
+
import torch
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
import warnings
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def amplitude_to_db(S, ref=1.0, amin=1e-5, top_db=80.0):
|
| 14 |
+
"""Convert an amplitude spectrogram to dB-scaled spectrogram.
|
| 15 |
+
|
| 16 |
+
This is equivalent to ``power_to_db(S**2)``, but is provided for convenience.
|
| 17 |
+
|
| 18 |
+
Parameters
|
| 19 |
+
----------
|
| 20 |
+
S : np.ndarray
|
| 21 |
+
input amplitude
|
| 22 |
+
|
| 23 |
+
ref : scalar or callable
|
| 24 |
+
If scalar, the amplitude ``abs(S)`` is scaled relative to ``ref``:
|
| 25 |
+
``20 * log10(S / ref)``.
|
| 26 |
+
Zeros in the output correspond to positions where ``S == ref``.
|
| 27 |
+
|
| 28 |
+
If callable, the reference value is computed as ``ref(S)``.
|
| 29 |
+
|
| 30 |
+
amin : float > 0 [scalar]
|
| 31 |
+
minimum threshold for ``S`` and ``ref``
|
| 32 |
+
|
| 33 |
+
top_db : float >= 0 [scalar]
|
| 34 |
+
threshold the output at ``top_db`` below the peak:
|
| 35 |
+
``max(20 * log10(S)) - top_db``
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
Returns
|
| 39 |
+
-------
|
| 40 |
+
S_db : np.ndarray
|
| 41 |
+
``S`` measured in dB
|
| 42 |
+
|
| 43 |
+
See Also
|
| 44 |
+
--------
|
| 45 |
+
power_to_db, db_to_amplitude
|
| 46 |
+
|
| 47 |
+
Notes
|
| 48 |
+
-----
|
| 49 |
+
This function caches at level 30.
|
| 50 |
+
"""
|
| 51 |
+
|
| 52 |
+
# S = np.asarray(S)
|
| 53 |
+
S = torch.asarray(S)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
magnitude = S.abs()
|
| 57 |
+
|
| 58 |
+
if callable(ref):
|
| 59 |
+
# User supplied a function to calculate reference power
|
| 60 |
+
ref_value = ref(magnitude)
|
| 61 |
+
else:
|
| 62 |
+
ref_value = torch.abs(ref)
|
| 63 |
+
|
| 64 |
+
power = torch.square(magnitude, out=magnitude)
|
| 65 |
+
|
| 66 |
+
return power_to_db(power, ref=ref_value ** 2, amin=amin ** 2, top_db=top_db)
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def _signal_to_frame_nonsilent(
|
| 70 |
+
y, frame_length=2048, hop_length=512, top_db=60, ref=torch.max
|
| 71 |
+
):
|
| 72 |
+
"""Frame-wise non-silent indicator for audio input.
|
| 73 |
+
|
| 74 |
+
This is a helper function for `trim` and `split`.
|
| 75 |
+
|
| 76 |
+
Parameters
|
| 77 |
+
----------
|
| 78 |
+
y : np.ndarray, shape=(n,) or (2,n)
|
| 79 |
+
Audio signal, mono or stereo
|
| 80 |
+
|
| 81 |
+
frame_length : int > 0
|
| 82 |
+
The number of samples per frame
|
| 83 |
+
|
| 84 |
+
hop_length : int > 0
|
| 85 |
+
The number of samples between frames
|
| 86 |
+
|
| 87 |
+
top_db : number > 0
|
| 88 |
+
The threshold (in decibels) below reference to consider as
|
| 89 |
+
silence
|
| 90 |
+
|
| 91 |
+
ref : callable or float
|
| 92 |
+
The reference power
|
| 93 |
+
|
| 94 |
+
Returns
|
| 95 |
+
-------
|
| 96 |
+
non_silent : np.ndarray, shape=(m,), dtype=bool
|
| 97 |
+
Indicator of non-silent frames
|
| 98 |
+
"""
|
| 99 |
+
# Convert to mono
|
| 100 |
+
if y.ndim > 1:
|
| 101 |
+
y_mono = torch.mean(y, dim=0)
|
| 102 |
+
else: y_mono = y
|
| 103 |
+
|
| 104 |
+
# Compute the MSE for the signal
|
| 105 |
+
mse = rms(y=y_mono, frame_length=frame_length, hop_length=hop_length) ** 2
|
| 106 |
+
|
| 107 |
+
return power_to_db(mse.squeeze(), ref=ref, top_db=None) > -top_db
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def trim(y, top_db=60, ref=torch.max, frame_length=2048, hop_length=512):
|
| 111 |
+
"""Trim leading and trailing silence from an audio signal.
|
| 112 |
+
|
| 113 |
+
Parameters
|
| 114 |
+
----------
|
| 115 |
+
y : np.ndarray, shape=(n,) or (2,n)
|
| 116 |
+
Audio signal, can be mono or stereo
|
| 117 |
+
|
| 118 |
+
top_db : number > 0
|
| 119 |
+
The threshold (in decibels) below reference to consider as
|
| 120 |
+
silence
|
| 121 |
+
|
| 122 |
+
ref : number or callable
|
| 123 |
+
The reference power. By default, it uses `np.max` and compares
|
| 124 |
+
to the peak power in the signal.
|
| 125 |
+
|
| 126 |
+
frame_length : int > 0
|
| 127 |
+
The number of samples per analysis frame
|
| 128 |
+
|
| 129 |
+
hop_length : int > 0
|
| 130 |
+
The number of samples between analysis frames
|
| 131 |
+
|
| 132 |
+
Returns
|
| 133 |
+
-------
|
| 134 |
+
y_trimmed : np.ndarray, shape=(m,) or (2, m)
|
| 135 |
+
The trimmed signal
|
| 136 |
+
|
| 137 |
+
index : np.ndarray, shape=(2,)
|
| 138 |
+
the interval of ``y`` corresponding to the non-silent region:
|
| 139 |
+
``y_trimmed = y[index[0]:index[1]]`` (for mono) or
|
| 140 |
+
``y_trimmed = y[:, index[0]:index[1]]`` (for stereo).
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
Examples
|
| 144 |
+
--------
|
| 145 |
+
>>> # Load some audio
|
| 146 |
+
>>> y, sr = librosa.load(librosa.ex('choice'))
|
| 147 |
+
>>> # Trim the beginning and ending silence
|
| 148 |
+
>>> yt, index = librosa.effects.trim(y)
|
| 149 |
+
>>> # Print the durations
|
| 150 |
+
>>> print(librosa.get_duration(y), librosa.get_duration(yt))
|
| 151 |
+
25.025986394557822 25.007891156462584
|
| 152 |
+
"""
|
| 153 |
+
|
| 154 |
+
non_silent = _signal_to_frame_nonsilent(
|
| 155 |
+
y, frame_length=frame_length, hop_length=hop_length, ref=ref, top_db=top_db
|
| 156 |
+
)
|
| 157 |
+
|
| 158 |
+
# nonzero = np.flatnonzero(non_silent)
|
| 159 |
+
nonzero = torch.nonzero(torch.ravel(non_silent)).squeeze()#[0]
|
| 160 |
+
|
| 161 |
+
if nonzero.numel() > 0:
|
| 162 |
+
# Compute the start and end positions
|
| 163 |
+
# End position goes one frame past the last non-zero
|
| 164 |
+
start = int(frames_to_samples(nonzero[0], hop_length))
|
| 165 |
+
end = min(y.shape[-1], int(frames_to_samples(nonzero[-1] + 1, hop_length)))
|
| 166 |
+
else:
|
| 167 |
+
# The signal only contains zeros
|
| 168 |
+
start, end = 0, 0
|
| 169 |
+
|
| 170 |
+
# Build the mono/stereo index
|
| 171 |
+
full_index = [slice(None)] * y.ndim
|
| 172 |
+
full_index[-1] = slice(start, end)
|
| 173 |
+
|
| 174 |
+
# print(non_silent)
|
| 175 |
+
# print(non_silent.shape, nonzero.shape)
|
| 176 |
+
|
| 177 |
+
return y[tuple(full_index)], torch.asarray([start, end])
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
def rms(
|
| 181 |
+
y=None, S=None, frame_length=2048, hop_length=512, center=True, pad_mode="reflect"
|
| 182 |
+
):
|
| 183 |
+
"""Compute root-mean-square (RMS) value for each frame, either from the
|
| 184 |
+
audio samples ``y`` or from a spectrogram ``S``.
|
| 185 |
+
|
| 186 |
+
Computing the RMS value from audio samples is faster as it doesn't require
|
| 187 |
+
a STFT calculation. However, using a spectrogram will give a more accurate
|
| 188 |
+
representation of energy over time because its frames can be windowed,
|
| 189 |
+
thus prefer using ``S`` if it's already available.
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
Parameters
|
| 193 |
+
----------
|
| 194 |
+
y : np.ndarray [shape=(n,)] or None
|
| 195 |
+
(optional) audio time series. Required if ``S`` is not input.
|
| 196 |
+
|
| 197 |
+
S : np.ndarray [shape=(d, t)] or None
|
| 198 |
+
(optional) spectrogram magnitude. Required if ``y`` is not input.
|
| 199 |
+
|
| 200 |
+
frame_length : int > 0 [scalar]
|
| 201 |
+
length of analysis frame (in samples) for energy calculation
|
| 202 |
+
|
| 203 |
+
hop_length : int > 0 [scalar]
|
| 204 |
+
hop length for STFT. See `librosa.stft` for details.
|
| 205 |
+
|
| 206 |
+
center : bool
|
| 207 |
+
If `True` and operating on time-domain input (``y``), pad the signal
|
| 208 |
+
by ``frame_length//2`` on either side.
|
| 209 |
+
|
| 210 |
+
If operating on spectrogram input, this has no effect.
|
| 211 |
+
|
| 212 |
+
pad_mode : str
|
| 213 |
+
Padding mode for centered analysis. See `numpy.pad` for valid
|
| 214 |
+
values.
|
| 215 |
+
|
| 216 |
+
Returns
|
| 217 |
+
-------
|
| 218 |
+
rms : np.ndarray [shape=(1, t)]
|
| 219 |
+
RMS value for each frame
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
Examples
|
| 223 |
+
--------
|
| 224 |
+
>>> y, sr = librosa.load(librosa.ex('trumpet'))
|
| 225 |
+
>>> librosa.feature.rms(y=y)
|
| 226 |
+
array([[1.248e-01, 1.259e-01, ..., 1.845e-05, 1.796e-05]],
|
| 227 |
+
dtype=float32)
|
| 228 |
+
|
| 229 |
+
Or from spectrogram input
|
| 230 |
+
|
| 231 |
+
>>> S, phase = librosa.magphase(librosa.stft(y))
|
| 232 |
+
>>> rms = librosa.feature.rms(S=S)
|
| 233 |
+
|
| 234 |
+
>>> import matplotlib.pyplot as plt
|
| 235 |
+
>>> fig, ax = plt.subplots(nrows=2, sharex=True)
|
| 236 |
+
>>> times = librosa.times_like(rms)
|
| 237 |
+
>>> ax[0].semilogy(times, rms[0], label='RMS Energy')
|
| 238 |
+
>>> ax[0].set(xticks=[])
|
| 239 |
+
>>> ax[0].legend()
|
| 240 |
+
>>> ax[0].label_outer()
|
| 241 |
+
>>> librosa.display.specshow(librosa.amplitude_to_db(S, ref=np.max),
|
| 242 |
+
... y_axis='log', x_axis='time', ax=ax[1])
|
| 243 |
+
>>> ax[1].set(title='log Power spectrogram')
|
| 244 |
+
|
| 245 |
+
Use a STFT window of constant ones and no frame centering to get consistent
|
| 246 |
+
results with the RMS computed from the audio samples ``y``
|
| 247 |
+
|
| 248 |
+
>>> S = librosa.magphase(librosa.stft(y, window=np.ones, center=False))[0]
|
| 249 |
+
>>> librosa.feature.rms(S=S)
|
| 250 |
+
>>> plt.show()
|
| 251 |
+
|
| 252 |
+
"""
|
| 253 |
+
if y is not None:
|
| 254 |
+
if y.dim() > 1:
|
| 255 |
+
y = torch.mean(y, dim=0)
|
| 256 |
+
|
| 257 |
+
if center:
|
| 258 |
+
y = F.pad(y[None, None], (int(frame_length//2), int(frame_length//2)), mode=pad_mode)[0, 0]
|
| 259 |
+
# y = np.pad(y, int(frame_length // 2), mode=pad_mode)
|
| 260 |
+
|
| 261 |
+
x = frame(y, frame_length=frame_length, hop_length=hop_length)
|
| 262 |
+
# print(y.shape, x.shape, x)
|
| 263 |
+
# Calculate power
|
| 264 |
+
power = torch.mean(x.abs() ** 2, dim=0, keepdim=True)
|
| 265 |
+
elif S is not None:
|
| 266 |
+
# Check the frame length
|
| 267 |
+
if S.shape[0] != frame_length // 2 + 1:
|
| 268 |
+
raise AssertionError(
|
| 269 |
+
"Since S.shape[0] is {}, "
|
| 270 |
+
"frame_length is expected to be {} or {}; "
|
| 271 |
+
"found {}".format(
|
| 272 |
+
S.shape[0], S.shape[0] * 2 - 2, S.shape[0] * 2 - 1, frame_length
|
| 273 |
+
)
|
| 274 |
+
)
|
| 275 |
+
|
| 276 |
+
# power spectrogram
|
| 277 |
+
x = torch.abs(S) ** 2
|
| 278 |
+
|
| 279 |
+
# Adjust the DC and sr/2 component
|
| 280 |
+
x[0] *= 0.5
|
| 281 |
+
if frame_length % 2 == 0:
|
| 282 |
+
x[-1] *= 0.5
|
| 283 |
+
|
| 284 |
+
# Calculate power
|
| 285 |
+
power = 2 * torch.sum(x, dim=0, keepdim=True) / frame_length ** 2
|
| 286 |
+
else:
|
| 287 |
+
raise AssertionError("Either `y` or `S` must be input.")
|
| 288 |
+
|
| 289 |
+
return torch.sqrt(power)
|
| 290 |
+
|
| 291 |
+
|
| 292 |
+
def frame(x, frame_length, hop_length, axis=-1):
|
| 293 |
+
"""Slice a data array into (overlapping) frames.
|
| 294 |
+
|
| 295 |
+
This implementation uses low-level stride manipulation to avoid
|
| 296 |
+
making a copy of the data. The resulting frame representation
|
| 297 |
+
is a new view of the same input data.
|
| 298 |
+
|
| 299 |
+
However, if the input data is not contiguous in memory, a warning
|
| 300 |
+
will be issued and the output will be a full copy, rather than
|
| 301 |
+
a view of the input data.
|
| 302 |
+
|
| 303 |
+
For example, a one-dimensional input ``x = [0, 1, 2, 3, 4, 5, 6]``
|
| 304 |
+
can be framed with frame length 3 and hop length 2 in two ways.
|
| 305 |
+
The first (``axis=-1``), results in the array ``x_frames``::
|
| 306 |
+
|
| 307 |
+
[[0, 2, 4],
|
| 308 |
+
[1, 3, 5],
|
| 309 |
+
[2, 4, 6]]
|
| 310 |
+
|
| 311 |
+
where each column ``x_frames[:, i]`` contains a contiguous slice of
|
| 312 |
+
the input ``x[i * hop_length : i * hop_length + frame_length]``.
|
| 313 |
+
|
| 314 |
+
The second way (``axis=0``) results in the array ``x_frames``::
|
| 315 |
+
|
| 316 |
+
[[0, 1, 2],
|
| 317 |
+
[2, 3, 4],
|
| 318 |
+
[4, 5, 6]]
|
| 319 |
+
|
| 320 |
+
where each row ``x_frames[i]`` contains a contiguous slice of the input.
|
| 321 |
+
|
| 322 |
+
This generalizes to higher dimensional inputs, as shown in the examples below.
|
| 323 |
+
In general, the framing operation increments by 1 the number of dimensions,
|
| 324 |
+
adding a new "frame axis" either to the end of the array (``axis=-1``)
|
| 325 |
+
or the beginning of the array (``axis=0``).
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
Parameters
|
| 329 |
+
----------
|
| 330 |
+
x : np.ndarray
|
| 331 |
+
Array to frame
|
| 332 |
+
|
| 333 |
+
frame_length : int > 0 [scalar]
|
| 334 |
+
Length of the frame
|
| 335 |
+
|
| 336 |
+
hop_length : int > 0 [scalar]
|
| 337 |
+
Number of steps to advance between frames
|
| 338 |
+
|
| 339 |
+
axis : 0 or -1
|
| 340 |
+
The axis along which to frame.
|
| 341 |
+
|
| 342 |
+
If ``axis=-1`` (the default), then ``x`` is framed along its last dimension.
|
| 343 |
+
``x`` must be "F-contiguous" in this case.
|
| 344 |
+
|
| 345 |
+
If ``axis=0``, then ``x`` is framed along its first dimension.
|
| 346 |
+
``x`` must be "C-contiguous" in this case.
|
| 347 |
+
|
| 348 |
+
Returns
|
| 349 |
+
-------
|
| 350 |
+
x_frames : np.ndarray [shape=(..., frame_length, N_FRAMES) or (N_FRAMES, frame_length, ...)]
|
| 351 |
+
A framed view of ``x``, for example with ``axis=-1`` (framing on the last dimension)::
|
| 352 |
+
|
| 353 |
+
x_frames[..., j] == x[..., j * hop_length : j * hop_length + frame_length]
|
| 354 |
+
|
| 355 |
+
If ``axis=0`` (framing on the first dimension), then::
|
| 356 |
+
|
| 357 |
+
x_frames[j] = x[j * hop_length : j * hop_length + frame_length]
|
| 358 |
+
|
| 359 |
+
Raises
|
| 360 |
+
------
|
| 361 |
+
ParameterError
|
| 362 |
+
If ``x`` is not an `np.ndarray`.
|
| 363 |
+
|
| 364 |
+
If ``x.shape[axis] < frame_length``, there is not enough data to fill one frame.
|
| 365 |
+
|
| 366 |
+
If ``hop_length < 1``, frames cannot advance.
|
| 367 |
+
|
| 368 |
+
If ``axis`` is not 0 or -1. Framing is only supported along the first or last axis.
|
| 369 |
+
|
| 370 |
+
|
| 371 |
+
See Also
|
| 372 |
+
--------
|
| 373 |
+
numpy.asfortranarray : Convert data to F-contiguous representation
|
| 374 |
+
numpy.ascontiguousarray : Convert data to C-contiguous representation
|
| 375 |
+
numpy.ndarray.flags : information about the memory layout of a numpy `ndarray`.
|
| 376 |
+
|
| 377 |
+
Examples
|
| 378 |
+
--------
|
| 379 |
+
Extract 2048-sample frames from monophonic signal with a hop of 64 samples per frame
|
| 380 |
+
|
| 381 |
+
>>> y, sr = librosa.load(librosa.ex('trumpet'))
|
| 382 |
+
>>> frames = librosa.util.frame(y, frame_length=2048, hop_length=64)
|
| 383 |
+
>>> frames
|
| 384 |
+
array([[-1.407e-03, -2.604e-02, ..., -1.795e-05, -8.108e-06],
|
| 385 |
+
[-4.461e-04, -3.721e-02, ..., -1.573e-05, -1.652e-05],
|
| 386 |
+
...,
|
| 387 |
+
[ 7.960e-02, -2.335e-01, ..., -6.815e-06, 1.266e-05],
|
| 388 |
+
[ 9.568e-02, -1.252e-01, ..., 7.397e-06, -1.921e-05]],
|
| 389 |
+
dtype=float32)
|
| 390 |
+
>>> y.shape
|
| 391 |
+
(117601,)
|
| 392 |
+
|
| 393 |
+
>>> frames.shape
|
| 394 |
+
(2048, 1806)
|
| 395 |
+
|
| 396 |
+
Or frame along the first axis instead of the last:
|
| 397 |
+
|
| 398 |
+
>>> frames = librosa.util.frame(y, frame_length=2048, hop_length=64, axis=0)
|
| 399 |
+
>>> frames.shape
|
| 400 |
+
(1806, 2048)
|
| 401 |
+
|
| 402 |
+
Frame a stereo signal:
|
| 403 |
+
|
| 404 |
+
>>> y, sr = librosa.load(librosa.ex('trumpet', hq=True), mono=False)
|
| 405 |
+
>>> y.shape
|
| 406 |
+
(2, 117601)
|
| 407 |
+
>>> frames = librosa.util.frame(y, frame_length=2048, hop_length=64)
|
| 408 |
+
(2, 2048, 1806)
|
| 409 |
+
|
| 410 |
+
Carve an STFT into fixed-length patches of 32 frames with 50% overlap
|
| 411 |
+
|
| 412 |
+
>>> y, sr = librosa.load(librosa.ex('trumpet'))
|
| 413 |
+
>>> S = np.abs(librosa.stft(y))
|
| 414 |
+
>>> S.shape
|
| 415 |
+
(1025, 230)
|
| 416 |
+
>>> S_patch = librosa.util.frame(S, frame_length=32, hop_length=16)
|
| 417 |
+
>>> S_patch.shape
|
| 418 |
+
(1025, 32, 13)
|
| 419 |
+
>>> # The first patch contains the first 32 frames of S
|
| 420 |
+
>>> np.allclose(S_patch[:, :, 0], S[:, :32])
|
| 421 |
+
True
|
| 422 |
+
>>> # The second patch contains frames 16 to 16+32=48, and so on
|
| 423 |
+
>>> np.allclose(S_patch[:, :, 1], S[:, 16:48])
|
| 424 |
+
True
|
| 425 |
+
"""
|
| 426 |
+
|
| 427 |
+
# if not isinstance(x, np.ndarray):
|
| 428 |
+
# raise AssertionError(
|
| 429 |
+
# "Input must be of type numpy.ndarray, " "given type(x)={}".format(type(x))
|
| 430 |
+
# )
|
| 431 |
+
x: torch.Tensor = x
|
| 432 |
+
|
| 433 |
+
if x.shape[axis] < frame_length:
|
| 434 |
+
raise AssertionError(
|
| 435 |
+
"Input is too short (n={:d})"
|
| 436 |
+
" for frame_length={:d}".format(x.shape[axis], frame_length)
|
| 437 |
+
)
|
| 438 |
+
|
| 439 |
+
if hop_length < 1:
|
| 440 |
+
raise AssertionError("Invalid hop_length: {:d}".format(hop_length))
|
| 441 |
+
|
| 442 |
+
if axis == -1 and not x.is_contiguous():
|
| 443 |
+
warnings.warn(
|
| 444 |
+
"librosa.util.frame called with axis={} "
|
| 445 |
+
"on a non-contiguous input. This will result in a copy.".format(axis)
|
| 446 |
+
)
|
| 447 |
+
x = x.contiguous()
|
| 448 |
+
elif axis == 0 and not x.is_contiguous():
|
| 449 |
+
warnings.warn(
|
| 450 |
+
"librosa.util.frame called with axis={} "
|
| 451 |
+
"on a non-contiguous input. This will result in a copy.".format(axis)
|
| 452 |
+
)
|
| 453 |
+
x = x.contiguous()
|
| 454 |
+
|
| 455 |
+
n_frames = 1 + (x.shape[axis] - frame_length) // hop_length
|
| 456 |
+
strides = torch.asarray(x.numpy().strides)
|
| 457 |
+
# print(strides, x)
|
| 458 |
+
new_stride = torch.prod(strides[strides > 0] // x.itemsize) * x.itemsize
|
| 459 |
+
|
| 460 |
+
if axis == -1:
|
| 461 |
+
shape = list(x.shape)[:-1] + [frame_length, n_frames]
|
| 462 |
+
strides = list(strides) + [hop_length * new_stride]
|
| 463 |
+
|
| 464 |
+
elif axis == 0:
|
| 465 |
+
shape = [n_frames, frame_length] + list(x.shape)[1:]
|
| 466 |
+
strides = [hop_length * new_stride] + list(strides)
|
| 467 |
+
|
| 468 |
+
else:
|
| 469 |
+
raise AssertionError("Frame axis={} must be either 0 or -1".format(axis))
|
| 470 |
+
|
| 471 |
+
return torch.from_numpy(as_strided(x, shape=shape, strides=strides))
|
| 472 |
+
# return x.as_strided(size=shape, stride=strides)
|
| 473 |
+
|
| 474 |
+
|
| 475 |
+
|
| 476 |
+
class DummyArray:
|
| 477 |
+
"""Dummy object that just exists to hang __array_interface__ dictionaries
|
| 478 |
+
and possibly keep alive a reference to a base array.
|
| 479 |
+
"""
|
| 480 |
+
|
| 481 |
+
def __init__(self, interface, base=None):
|
| 482 |
+
self.__array_interface__ = interface
|
| 483 |
+
self.base = base
|
| 484 |
+
|
| 485 |
+
|
| 486 |
+
|
| 487 |
+
def as_strided(x, shape=None, strides=None, subok=False, writeable=True):
|
| 488 |
+
"""
|
| 489 |
+
Create a view into the array with the given shape and strides.
|
| 490 |
+
|
| 491 |
+
.. warning:: This function has to be used with extreme care, see notes.
|
| 492 |
+
|
| 493 |
+
Parameters
|
| 494 |
+
----------
|
| 495 |
+
x : ndarray
|
| 496 |
+
Array to create a new.
|
| 497 |
+
shape : sequence of int, optional
|
| 498 |
+
The shape of the new array. Defaults to ``x.shape``.
|
| 499 |
+
strides : sequence of int, optional
|
| 500 |
+
The strides of the new array. Defaults to ``x.strides``.
|
| 501 |
+
subok : bool, optional
|
| 502 |
+
.. versionadded:: 1.10
|
| 503 |
+
|
| 504 |
+
If True, subclasses are preserved.
|
| 505 |
+
writeable : bool, optional
|
| 506 |
+
.. versionadded:: 1.12
|
| 507 |
+
|
| 508 |
+
If set to False, the returned array will always be readonly.
|
| 509 |
+
Otherwise it will be writable if the original array was. It
|
| 510 |
+
is advisable to set this to False if possible (see Notes).
|
| 511 |
+
|
| 512 |
+
Returns
|
| 513 |
+
-------
|
| 514 |
+
view : ndarray
|
| 515 |
+
|
| 516 |
+
See also
|
| 517 |
+
--------
|
| 518 |
+
broadcast_to : broadcast an array to a given shape.
|
| 519 |
+
reshape : reshape an array.
|
| 520 |
+
lib.stride_tricks.sliding_window_view :
|
| 521 |
+
userfriendly and safe function for the creation of sliding window views.
|
| 522 |
+
|
| 523 |
+
Notes
|
| 524 |
+
-----
|
| 525 |
+
``as_strided`` creates a view into the array given the exact strides
|
| 526 |
+
and shape. This means it manipulates the internal data structure of
|
| 527 |
+
ndarray and, if done incorrectly, the array elements can point to
|
| 528 |
+
invalid memory and can corrupt results or crash your program.
|
| 529 |
+
It is advisable to always use the original ``x.strides`` when
|
| 530 |
+
calculating new strides to avoid reliance on a contiguous memory
|
| 531 |
+
layout.
|
| 532 |
+
|
| 533 |
+
Furthermore, arrays created with this function often contain self
|
| 534 |
+
overlapping memory, so that two elements are identical.
|
| 535 |
+
Vectorized write operations on such arrays will typically be
|
| 536 |
+
unpredictable. They may even give different results for small, large,
|
| 537 |
+
or transposed arrays.
|
| 538 |
+
Since writing to these arrays has to be tested and done with great
|
| 539 |
+
care, you may want to use ``writeable=False`` to avoid accidental write
|
| 540 |
+
operations.
|
| 541 |
+
|
| 542 |
+
For these reasons it is advisable to avoid ``as_strided`` when
|
| 543 |
+
possible.
|
| 544 |
+
"""
|
| 545 |
+
# first convert input to array, possibly keeping subclass
|
| 546 |
+
x = np.array(x, copy=False, subok=subok)
|
| 547 |
+
interface = dict(x.__array_interface__)
|
| 548 |
+
if shape is not None:
|
| 549 |
+
interface['shape'] = tuple(shape)
|
| 550 |
+
if strides is not None:
|
| 551 |
+
interface['strides'] = tuple(strides)
|
| 552 |
+
|
| 553 |
+
array = np.asarray(DummyArray(interface, base=x))
|
| 554 |
+
# The route via `__interface__` does not preserve structured
|
| 555 |
+
# dtypes. Since dtype should remain unchanged, we set it explicitly.
|
| 556 |
+
array.dtype = x.dtype
|
| 557 |
+
|
| 558 |
+
view = _maybe_view_as_subclass(x, array)
|
| 559 |
+
|
| 560 |
+
if view.flags.writeable and not writeable:
|
| 561 |
+
view.flags.writeable = False
|
| 562 |
+
|
| 563 |
+
return view
|
| 564 |
+
|
| 565 |
+
|
| 566 |
+
def _maybe_view_as_subclass(original_array, new_array):
|
| 567 |
+
if type(original_array) is not type(new_array):
|
| 568 |
+
# if input was an ndarray subclass and subclasses were OK,
|
| 569 |
+
# then view the result as that subclass.
|
| 570 |
+
new_array = new_array.view(type=type(original_array))
|
| 571 |
+
# Since we have done something akin to a view from original_array, we
|
| 572 |
+
# should let the subclass finalize (if it has it implemented, i.e., is
|
| 573 |
+
# not None).
|
| 574 |
+
if new_array.__array_finalize__:
|
| 575 |
+
new_array.__array_finalize__(original_array)
|
| 576 |
+
return new_array
|
| 577 |
+
|
| 578 |
+
|
| 579 |
+
def power_to_db(S, ref=1.0, amin=1e-10, top_db=80.0):
|
| 580 |
+
"""Convert a power spectrogram (amplitude squared) to decibel (dB) units
|
| 581 |
+
|
| 582 |
+
This computes the scaling ``10 * log10(S / ref)`` in a numerically
|
| 583 |
+
stable way.
|
| 584 |
+
|
| 585 |
+
Parameters
|
| 586 |
+
----------
|
| 587 |
+
S : np.ndarray
|
| 588 |
+
input power
|
| 589 |
+
|
| 590 |
+
ref : scalar or callable
|
| 591 |
+
If scalar, the amplitude ``abs(S)`` is scaled relative to ``ref``::
|
| 592 |
+
|
| 593 |
+
10 * log10(S / ref)
|
| 594 |
+
|
| 595 |
+
Zeros in the output correspond to positions where ``S == ref``.
|
| 596 |
+
|
| 597 |
+
If callable, the reference value is computed as ``ref(S)``.
|
| 598 |
+
|
| 599 |
+
amin : float > 0 [scalar]
|
| 600 |
+
minimum threshold for ``abs(S)`` and ``ref``
|
| 601 |
+
|
| 602 |
+
top_db : float >= 0 [scalar]
|
| 603 |
+
threshold the output at ``top_db`` below the peak:
|
| 604 |
+
``max(10 * log10(S)) - top_db``
|
| 605 |
+
|
| 606 |
+
Returns
|
| 607 |
+
-------
|
| 608 |
+
S_db : np.ndarray
|
| 609 |
+
``S_db ~= 10 * log10(S) - 10 * log10(ref)``
|
| 610 |
+
|
| 611 |
+
See Also
|
| 612 |
+
--------
|
| 613 |
+
perceptual_weighting
|
| 614 |
+
db_to_power
|
| 615 |
+
amplitude_to_db
|
| 616 |
+
db_to_amplitude
|
| 617 |
+
|
| 618 |
+
Notes
|
| 619 |
+
-----
|
| 620 |
+
This function caches at level 30.
|
| 621 |
+
|
| 622 |
+
|
| 623 |
+
Examples
|
| 624 |
+
--------
|
| 625 |
+
Get a power spectrogram from a waveform ``y``
|
| 626 |
+
|
| 627 |
+
>>> y, sr = librosa.load(librosa.ex('trumpet'))
|
| 628 |
+
>>> S = np.abs(librosa.stft(y))
|
| 629 |
+
>>> librosa.power_to_db(S**2)
|
| 630 |
+
array([[-41.809, -41.809, ..., -41.809, -41.809],
|
| 631 |
+
[-41.809, -41.809, ..., -41.809, -41.809],
|
| 632 |
+
...,
|
| 633 |
+
[-41.809, -41.809, ..., -41.809, -41.809],
|
| 634 |
+
[-41.809, -41.809, ..., -41.809, -41.809]], dtype=float32)
|
| 635 |
+
|
| 636 |
+
Compute dB relative to peak power
|
| 637 |
+
|
| 638 |
+
>>> librosa.power_to_db(S**2, ref=np.max)
|
| 639 |
+
array([[-80., -80., ..., -80., -80.],
|
| 640 |
+
[-80., -80., ..., -80., -80.],
|
| 641 |
+
...,
|
| 642 |
+
[-80., -80., ..., -80., -80.],
|
| 643 |
+
[-80., -80., ..., -80., -80.]], dtype=float32)
|
| 644 |
+
|
| 645 |
+
Or compare to median power
|
| 646 |
+
|
| 647 |
+
>>> librosa.power_to_db(S**2, ref=np.median)
|
| 648 |
+
array([[16.578, 16.578, ..., 16.578, 16.578],
|
| 649 |
+
[16.578, 16.578, ..., 16.578, 16.578],
|
| 650 |
+
...,
|
| 651 |
+
[16.578, 16.578, ..., 16.578, 16.578],
|
| 652 |
+
[16.578, 16.578, ..., 16.578, 16.578]], dtype=float32)
|
| 653 |
+
|
| 654 |
+
|
| 655 |
+
And plot the results
|
| 656 |
+
|
| 657 |
+
>>> import matplotlib.pyplot as plt
|
| 658 |
+
>>> fig, ax = plt.subplots(nrows=2, sharex=True, sharey=True)
|
| 659 |
+
>>> imgpow = librosa.display.specshow(S**2, sr=sr, y_axis='log', x_axis='time',
|
| 660 |
+
... ax=ax[0])
|
| 661 |
+
>>> ax[0].set(title='Power spectrogram')
|
| 662 |
+
>>> ax[0].label_outer()
|
| 663 |
+
>>> imgdb = librosa.display.specshow(librosa.power_to_db(S**2, ref=np.max),
|
| 664 |
+
... sr=sr, y_axis='log', x_axis='time', ax=ax[1])
|
| 665 |
+
>>> ax[1].set(title='Log-Power spectrogram')
|
| 666 |
+
>>> fig.colorbar(imgpow, ax=ax[0])
|
| 667 |
+
>>> fig.colorbar(imgdb, ax=ax[1], format="%+2.0f dB")
|
| 668 |
+
"""
|
| 669 |
+
|
| 670 |
+
S = torch.asarray(S)
|
| 671 |
+
|
| 672 |
+
if amin <= 0:
|
| 673 |
+
raise AssertionError("amin must be strictly positive")
|
| 674 |
+
|
| 675 |
+
# if np.issubdtype(S.dtype, np.complexfloating):
|
| 676 |
+
# warnings.warn(
|
| 677 |
+
# "power_to_db was called on complex input so phase "
|
| 678 |
+
# "information will be discarded. To suppress this warning, "
|
| 679 |
+
# "call power_to_db(np.abs(D)**2) instead."
|
| 680 |
+
# )
|
| 681 |
+
# magnitude = np.abs(S)
|
| 682 |
+
# else:
|
| 683 |
+
magnitude = S
|
| 684 |
+
|
| 685 |
+
if callable(ref):
|
| 686 |
+
# User supplied a function to calculate reference power
|
| 687 |
+
ref_value = ref(magnitude)
|
| 688 |
+
else:
|
| 689 |
+
ref_value = torch.abs(ref)
|
| 690 |
+
|
| 691 |
+
log_spec = 10.0 * torch.log10(torch.maximum(torch.tensor(amin), magnitude))
|
| 692 |
+
log_spec -= 10.0 * torch.log10(torch.maximum(torch.tensor(amin), ref_value))
|
| 693 |
+
|
| 694 |
+
if top_db is not None:
|
| 695 |
+
if top_db < 0:
|
| 696 |
+
raise AssertionError("top_db must be non-negative")
|
| 697 |
+
log_spec = torch.maximum(log_spec, log_spec.max() - top_db)
|
| 698 |
+
|
| 699 |
+
return log_spec
|
| 700 |
+
|
| 701 |
+
|
| 702 |
+
def frames_to_samples(frames, hop_length=512, n_fft=None):
|
| 703 |
+
"""Converts frame indices to audio sample indices.
|
| 704 |
+
|
| 705 |
+
Parameters
|
| 706 |
+
----------
|
| 707 |
+
frames : number or np.ndarray [shape=(n,)]
|
| 708 |
+
frame index or vector of frame indices
|
| 709 |
+
|
| 710 |
+
hop_length : int > 0 [scalar]
|
| 711 |
+
number of samples between successive frames
|
| 712 |
+
|
| 713 |
+
n_fft : None or int > 0 [scalar]
|
| 714 |
+
Optional: length of the FFT window.
|
| 715 |
+
If given, time conversion will include an offset of ``n_fft // 2``
|
| 716 |
+
to counteract windowing effects when using a non-centered STFT.
|
| 717 |
+
|
| 718 |
+
Returns
|
| 719 |
+
-------
|
| 720 |
+
times : number or np.ndarray
|
| 721 |
+
time (in samples) of each given frame number::
|
| 722 |
+
|
| 723 |
+
times[i] = frames[i] * hop_length
|
| 724 |
+
|
| 725 |
+
See Also
|
| 726 |
+
--------
|
| 727 |
+
frames_to_time : convert frame indices to time values
|
| 728 |
+
samples_to_frames : convert sample indices to frame indices
|
| 729 |
+
|
| 730 |
+
Examples
|
| 731 |
+
--------
|
| 732 |
+
>>> y, sr = librosa.load(librosa.ex('choice'))
|
| 733 |
+
>>> tempo, beats = librosa.beat.beat_track(y, sr=sr)
|
| 734 |
+
>>> beat_samples = librosa.frames_to_samples(beats)
|
| 735 |
+
"""
|
| 736 |
+
|
| 737 |
+
offset = 0
|
| 738 |
+
if n_fft is not None:
|
| 739 |
+
offset = int(n_fft // 2)
|
| 740 |
+
|
| 741 |
+
return (torch.asarray(frames) * hop_length + offset).to(torch.int)
|
mars5/utils.py
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import logging
|
| 3 |
+
|
| 4 |
+
def length_to_mask(length, offsets, max_len=None):
|
| 5 |
+
"""
|
| 6 |
+
Convert tensor of lengths into a mask.
|
| 7 |
+
|
| 8 |
+
Args:
|
| 9 |
+
length (Tensor): a tensor of lengths, shape = (batch_size,)
|
| 10 |
+
offsets (Tensor): a tensor of offsets, shape = (batch_size,)
|
| 11 |
+
max_len (int, optional): maximum length to be considered
|
| 12 |
+
|
| 13 |
+
Returns:
|
| 14 |
+
mask (Tensor): a mask tensor, shape = (batch_size, max_len),
|
| 15 |
+
True in masked positions, False otherwise.
|
| 16 |
+
"""
|
| 17 |
+
# get the batch size
|
| 18 |
+
batch_size = length.size(0)
|
| 19 |
+
|
| 20 |
+
# if maximum length is not provided, then compute it from the 'length' tensor.
|
| 21 |
+
if max_len is None:
|
| 22 |
+
max_len = length.max().item()
|
| 23 |
+
|
| 24 |
+
# Create a tensor of size `(batch_size, max_len)` filled with `True`.
|
| 25 |
+
mask = torch.ones(size=(batch_size, max_len), dtype=torch.bool, device=length.device)
|
| 26 |
+
|
| 27 |
+
# Create a tensor with consecutive numbers.
|
| 28 |
+
range_tensor = torch.arange(max_len, device=length.device)
|
| 29 |
+
|
| 30 |
+
# Expand the dim of 'length' tensor and 'offset' tensor to make it `(batch_size, max_len)`.
|
| 31 |
+
# The added dimension will be used for broadcasting.
|
| 32 |
+
length_exp = length.unsqueeze(-1)
|
| 33 |
+
offsets_exp = offsets.unsqueeze(-1)
|
| 34 |
+
|
| 35 |
+
# Create a boolean mask where `False` represents valid positions and `True` represents padding.
|
| 36 |
+
mask = (range_tensor < offsets_exp) | (~(range_tensor < length_exp))
|
| 37 |
+
|
| 38 |
+
return mask
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def construct_padding_mask(input_tensor, pad_token):
|
| 42 |
+
return (input_tensor == pad_token).cumsum(dim=1) > 0
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def nuke_weight_norm(module):
|
| 46 |
+
"""
|
| 47 |
+
Recursively remove weight normalization from a module and its children.
|
| 48 |
+
|
| 49 |
+
Args:
|
| 50 |
+
module (torch.nn.Module): The module from which to remove weight normalization.
|
| 51 |
+
"""
|
| 52 |
+
# Remove weight norm from current module if it exists
|
| 53 |
+
try:
|
| 54 |
+
torch.nn.utils.remove_weight_norm(module)
|
| 55 |
+
logging.debug(f"Removed weight norm from {module.__class__.__name__}")
|
| 56 |
+
except ValueError:
|
| 57 |
+
# Ignore if the module does not have weight norm applied.
|
| 58 |
+
pass
|
| 59 |
+
|
| 60 |
+
# Recursively call the function on children modules
|
| 61 |
+
for child in module.children():
|
| 62 |
+
nuke_weight_norm(child)
|
mars5_demo.ipynb
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"!pip install --upgrade vocos encodec librosa"
|
| 10 |
+
]
|
| 11 |
+
},
|
| 12 |
+
{
|
| 13 |
+
"cell_type": "code",
|
| 14 |
+
"execution_count": 16,
|
| 15 |
+
"metadata": {},
|
| 16 |
+
"outputs": [],
|
| 17 |
+
"source": [
|
| 18 |
+
"import pprint\n",
|
| 19 |
+
"import IPython.display as ipd\n",
|
| 20 |
+
"import torch\n",
|
| 21 |
+
"import librosa"
|
| 22 |
+
]
|
| 23 |
+
},
|
| 24 |
+
{
|
| 25 |
+
"cell_type": "code",
|
| 26 |
+
"execution_count": null,
|
| 27 |
+
"metadata": {},
|
| 28 |
+
"outputs": [],
|
| 29 |
+
"source": [
|
| 30 |
+
"# load model\n",
|
| 31 |
+
"mars5, config_class = torch.hub.load('Camb-ai/mars5-tts', 'mars5_english', trust_repo=True)"
|
| 32 |
+
]
|
| 33 |
+
},
|
| 34 |
+
{
|
| 35 |
+
"cell_type": "markdown",
|
| 36 |
+
"metadata": {},
|
| 37 |
+
"source": [
|
| 38 |
+
"Now that the model is loaded, pick a reference audio to clone from. If you want to use deep clone, also specify its transcript. "
|
| 39 |
+
]
|
| 40 |
+
},
|
| 41 |
+
{
|
| 42 |
+
"cell_type": "code",
|
| 43 |
+
"execution_count": null,
|
| 44 |
+
"metadata": {},
|
| 45 |
+
"outputs": [],
|
| 46 |
+
"source": [
|
| 47 |
+
"# download example ref audio\n",
|
| 48 |
+
"!wget -O example.wav https://github.com/Camb-ai/mars5-tts/raw/master/docs/assets/example_ref.wav "
|
| 49 |
+
]
|
| 50 |
+
},
|
| 51 |
+
{
|
| 52 |
+
"cell_type": "code",
|
| 53 |
+
"execution_count": null,
|
| 54 |
+
"metadata": {},
|
| 55 |
+
"outputs": [],
|
| 56 |
+
"source": [
|
| 57 |
+
"wav, sr = librosa.load('./example.wav', \n",
|
| 58 |
+
" sr=mars5.sr, mono=True)\n",
|
| 59 |
+
"wav = torch.from_numpy(wav)\n",
|
| 60 |
+
"ref_transcript = \"We actually haven't managed to meet demand.\"\n",
|
| 61 |
+
"print(\"Reference audio:\")\n",
|
| 62 |
+
"ipd.display(ipd.Audio(wav.numpy(), rate=mars5.sr))\n",
|
| 63 |
+
"print(f\"Reference transcript: {ref_transcript}\")"
|
| 64 |
+
]
|
| 65 |
+
},
|
| 66 |
+
{
|
| 67 |
+
"cell_type": "code",
|
| 68 |
+
"execution_count": null,
|
| 69 |
+
"metadata": {},
|
| 70 |
+
"outputs": [],
|
| 71 |
+
"source": [
|
| 72 |
+
"deep_clone = True # set to False if you don't know prompt transcript or want fast inference.\n",
|
| 73 |
+
"# Below you can tune other inference settings, like top_k, temperature, top_p, etc...\n",
|
| 74 |
+
"cfg = config_class(deep_clone=deep_clone, rep_penalty_window=100,\n",
|
| 75 |
+
" top_k=100, temperature=0.7, freq_penalty=3)\n",
|
| 76 |
+
"\n",
|
| 77 |
+
"ar_codes, wav_out = mars5.tts(\"The quick brown rat.\", wav, \n",
|
| 78 |
+
" ref_transcript,\n",
|
| 79 |
+
" cfg=cfg)\n",
|
| 80 |
+
"\n",
|
| 81 |
+
"print('Synthesized output audio:')\n",
|
| 82 |
+
"ipd.Audio(wav_out.numpy(), rate=mars5.sr)"
|
| 83 |
+
]
|
| 84 |
+
},
|
| 85 |
+
{
|
| 86 |
+
"cell_type": "markdown",
|
| 87 |
+
"metadata": {},
|
| 88 |
+
"source": [
|
| 89 |
+
"You can see all the inference settings available to tune in the inference config here:"
|
| 90 |
+
]
|
| 91 |
+
},
|
| 92 |
+
{
|
| 93 |
+
"cell_type": "code",
|
| 94 |
+
"execution_count": null,
|
| 95 |
+
"metadata": {},
|
| 96 |
+
"outputs": [],
|
| 97 |
+
"source": [
|
| 98 |
+
"pprint.pprint(config_class())"
|
| 99 |
+
]
|
| 100 |
+
},
|
| 101 |
+
{
|
| 102 |
+
"cell_type": "markdown",
|
| 103 |
+
"metadata": {},
|
| 104 |
+
"source": [
|
| 105 |
+
"You can also listen to the vocoded raw coarse codes, for debugging purposes:"
|
| 106 |
+
]
|
| 107 |
+
},
|
| 108 |
+
{
|
| 109 |
+
"cell_type": "code",
|
| 110 |
+
"execution_count": null,
|
| 111 |
+
"metadata": {},
|
| 112 |
+
"outputs": [],
|
| 113 |
+
"source": [
|
| 114 |
+
"ar_wav = mars5.vocode(ar_codes.cpu()[:, None])\n",
|
| 115 |
+
"ipd.Audio(ar_wav.numpy(), rate=mars5.sr)"
|
| 116 |
+
]
|
| 117 |
+
}
|
| 118 |
+
],
|
| 119 |
+
"metadata": {
|
| 120 |
+
"kernelspec": {
|
| 121 |
+
"display_name": "matt-py311",
|
| 122 |
+
"language": "python",
|
| 123 |
+
"name": "python3"
|
| 124 |
+
},
|
| 125 |
+
"language_info": {
|
| 126 |
+
"codemirror_mode": {
|
| 127 |
+
"name": "ipython",
|
| 128 |
+
"version": 3
|
| 129 |
+
},
|
| 130 |
+
"file_extension": ".py",
|
| 131 |
+
"mimetype": "text/x-python",
|
| 132 |
+
"name": "python",
|
| 133 |
+
"nbconvert_exporter": "python",
|
| 134 |
+
"pygments_lexer": "ipython3",
|
| 135 |
+
"version": "3.11.9"
|
| 136 |
+
}
|
| 137 |
+
},
|
| 138 |
+
"nbformat": 4,
|
| 139 |
+
"nbformat_minor": 2
|
| 140 |
+
}
|
requirements.txt
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch
|
| 2 |
+
torchvision
|
| 3 |
+
torchaudio
|
| 4 |
+
numpy
|
| 5 |
+
regex
|
| 6 |
+
librosa
|
| 7 |
+
vocos
|
| 8 |
+
encodec
|