


Update architecture image (#13)
Browse files- Update architecture image (4980e89919e262e12442b4152164fe4f048db087)
Co-authored-by: Kenneth Hamilton <[email protected]>
- docs/architecture.md +1 -1
docs/architecture.md
CHANGED
|
@@ -48,7 +48,7 @@ The AR model follows a Mistral-style decoder-only transformer model to predict E
|
|
| 48 |
Overall, the AR and NAR model is going to predict all 8 codebook entries of the Encodec 6kbps codec.
|
| 49 |
The AR model design is given below:
|
| 50 |
|
| 51 |
-

|
| 52 |
|
| 53 |
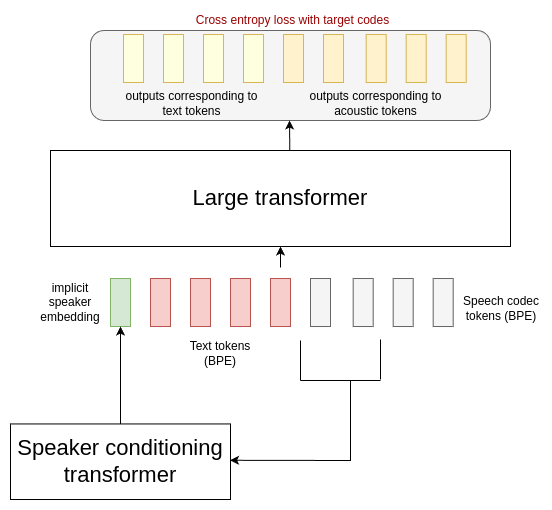
**Figure**: autoregressive component of Mars 5. During training, the initial 6kbps encodec tokens of the speech are fed through a small encoder-only transformer, producing a single output vector corresponding to an implicit speaker embedding.
|
| 54 |
This vector is concatenated with learnt embeddings corresponding to the text tokens, and L0 speech tokens, after byte-pair encoding tokenization.
|
|
|
|
| 48 |
Overall, the AR and NAR model is going to predict all 8 codebook entries of the Encodec 6kbps codec.
|
| 49 |
The AR model design is given below:
|
| 50 |
|
| 51 |
+
|
| 52 |
|
| 53 |
**Figure**: autoregressive component of Mars 5. During training, the initial 6kbps encodec tokens of the speech are fed through a small encoder-only transformer, producing a single output vector corresponding to an implicit speaker embedding.
|
| 54 |
This vector is concatenated with learnt embeddings corresponding to the text tokens, and L0 speech tokens, after byte-pair encoding tokenization.
|