

Update README.md
Browse files
README.md
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
# Dolphin
|
| 2 |
|
| 3 |
-
[Paper]
|
| 4 |
[Github](https://github.com/DataoceanAI/Dolphin)
|
| 5 |
[Huggingface](https://huggingface.co/DataoceanAI)
|
| 6 |
[Modelscope](https://www.modelscope.cn/organization/DataoceanAI)
|
|
@@ -12,7 +12,7 @@ Dolphin is a multilingual, multitask ASR model developed through a collaboration
|
|
| 12 |
|
| 13 |
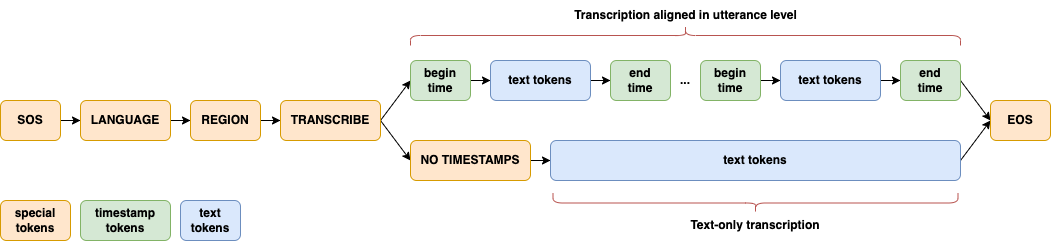
Dolphin largely follows the innovative design approach of [Whisper](https://github.com/openai/whisper) and [OWSM](https://github.com/espnet/espnet/tree/master/egs2/owsm_v3.1/s2t1). A joint CTC-Attention architecture is adopted, with encoder based on E-Branchformer and decoder based on standard Transformer. Several key modifications are introduced for its specific focus on ASR. Dolphin does not support translation tasks, and eliminates the use of previous text and its related tokens.
|
| 14 |
|
| 15 |
-
A significant enhancement in Dolphin is the introduction of a two-level language token system to better handle linguistic and regional diversity, especially in Dataocean AI dataset. The first token specifies the language (e.g., `<zh>`, `<ja>`), while the second token indicates the region (e.g., `<CN>`, `<JP>`). See details in [paper].
|
| 16 |
|
| 17 |
|
| 18 |
## Setup
|
|
@@ -43,7 +43,7 @@ pip install git+https://github.com/SpeechOceanTech/Dolphin.git
|
|
| 43 |
|
| 44 |
### Models
|
| 45 |
|
| 46 |
-
There are 4 models in Dolphin, and 2 of them are available now. See details in [paper].
|
| 47 |
|
| 48 |
| Model | Parameters | Average WER | Publicly Available |
|
| 49 |
|:------:|:----------:|:------------------:|:------------------:|
|
|
|
|
| 1 |
# Dolphin
|
| 2 |
|
| 3 |
+
[Paper](https://arxiv.org/abs/2503.20212)
|
| 4 |
[Github](https://github.com/DataoceanAI/Dolphin)
|
| 5 |
[Huggingface](https://huggingface.co/DataoceanAI)
|
| 6 |
[Modelscope](https://www.modelscope.cn/organization/DataoceanAI)
|
|
|
|
| 12 |

|
| 13 |
Dolphin largely follows the innovative design approach of [Whisper](https://github.com/openai/whisper) and [OWSM](https://github.com/espnet/espnet/tree/master/egs2/owsm_v3.1/s2t1). A joint CTC-Attention architecture is adopted, with encoder based on E-Branchformer and decoder based on standard Transformer. Several key modifications are introduced for its specific focus on ASR. Dolphin does not support translation tasks, and eliminates the use of previous text and its related tokens.
|
| 14 |
|
| 15 |
+
A significant enhancement in Dolphin is the introduction of a two-level language token system to better handle linguistic and regional diversity, especially in Dataocean AI dataset. The first token specifies the language (e.g., `<zh>`, `<ja>`), while the second token indicates the region (e.g., `<CN>`, `<JP>`). See details in [paper](https://arxiv.org/abs/2503.20212).
|
| 16 |
|
| 17 |
|
| 18 |
## Setup
|
|
|
|
| 43 |
|
| 44 |
### Models
|
| 45 |
|
| 46 |
+
There are 4 models in Dolphin, and 2 of them are available now. See details in [paper](https://arxiv.org/abs/2503.20212).
|
| 47 |
|
| 48 |
| Model | Parameters | Average WER | Publicly Available |
|
| 49 |
|:------:|:----------:|:------------------:|:------------------:|
|