

update v1
Browse files- README.md +11 -9
- images/bird.jpg +0 -0
- images/evaluation.png +0 -0
- model-00001-of-00007.safetensors +1 -1
- model-00002-of-00007.safetensors +1 -1
- model-00003-of-00007.safetensors +1 -1
- model-00004-of-00007.safetensors +1 -1
- model-00005-of-00007.safetensors +1 -1
- model-00006-of-00007.safetensors +1 -1
- model-00007-of-00007.safetensors +2 -2
- model.safetensors.index.json +2 -4
- test.py +29 -0
- vision_encoder.py +1 -0
README.md
CHANGED
|
@@ -18,7 +18,9 @@ datasets:
|
|
| 18 |
|
| 19 |
The Imp project aims to provide a family of a strong multimodal `small` language models (MSLMs). Our `imp-v1-3b` is a strong MSLM with only **3B** parameters, which is build upon a small yet powerful SLM [Phi-2 ](https://huggingface.co/microsoft/phi-2)(2.7B) and a powerful visual encoder [SigLIP ](https://huggingface.co/google/siglip-so400m-patch14-384)(0.4B), and trained on the [LLaVA-v1.5](https://github.com/haotian-liu/LLaVA) training set.
|
| 20 |
|
| 21 |
-
As shown in the
|
|
|
|
|
|
|
| 22 |
|
| 23 |
We release our model weights and provide an example below to run our model . Detailed technical report and corresponding training/evaluation code will be released soon on our [GitHub repo](https://github.com/MILVLG/imp). We will persistently improve our model and release the next versions to further improve model performance :)
|
| 24 |
|
|
@@ -68,14 +70,14 @@ print(tokenizer.decode(output_ids[input_ids.shape[1]:], skip_special_tokens=True
|
|
| 68 |
## Model evaluation
|
| 69 |
We conduct evaluation on 9 commonly-used benchmarks, including 5 academic VQA benchmarks and 4 popular MLLM benchmarks, to compare our Imp model with LLaVA (7B) and existing MSLMs of similar model sizes.
|
| 70 |
|
| 71 |
-
| Models | Size | VQAv2 | GQA |
|
| 72 |
-
|
| 73 |
-
| [LLaVA-v1.5-lora](https://huggingface.co/liuhaotian/llava-v1.5-7b) | 7B |79.10 |
|
| 74 |
-
| [TinyGPT-V](https://huggingface.co/Tyrannosaurus/TinyGPT-V) | 3B | - | 33.60 |
|
| 75 |
-
| [LLaVA-Phi](https://github.com/zhuyiche/llava-phi) | 3B | 71.40 | - |
|
| 76 |
-
| [MobileVLM](https://huggingface.co/mtgv/MobileVLM-3B) | 3B | - | 59.00 |
|
| 77 |
-
| [MC-LLaVA-3b](https://huggingface.co/visheratin/MC-LLaVA-3b) | 3B | 64.24 | 49.60 |
|
| 78 |
-
| **Imp-v1 (ours)** | 3B | **
|
| 79 |
|
| 80 |
### Examples
|
| 81 |
|
|
|
|
| 18 |
|
| 19 |
The Imp project aims to provide a family of a strong multimodal `small` language models (MSLMs). Our `imp-v1-3b` is a strong MSLM with only **3B** parameters, which is build upon a small yet powerful SLM [Phi-2 ](https://huggingface.co/microsoft/phi-2)(2.7B) and a powerful visual encoder [SigLIP ](https://huggingface.co/google/siglip-so400m-patch14-384)(0.4B), and trained on the [LLaVA-v1.5](https://github.com/haotian-liu/LLaVA) training set.
|
| 20 |
|
| 21 |
+
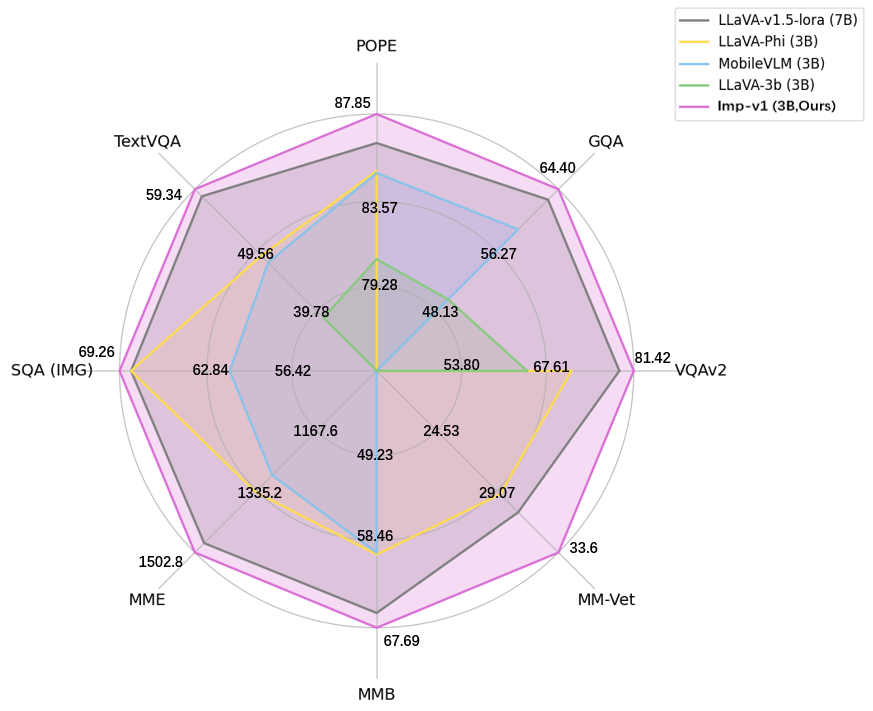
As shown in the image below, `imp-v1-3b` significantly outperforms the counterparts of similar model sizes, and even achieves slightly better performance than the strong LLaVA-7B model on various multimodal benchmarks.
|
| 22 |
+
|
| 23 |
+

|
| 24 |
|
| 25 |
We release our model weights and provide an example below to run our model . Detailed technical report and corresponding training/evaluation code will be released soon on our [GitHub repo](https://github.com/MILVLG/imp). We will persistently improve our model and release the next versions to further improve model performance :)
|
| 26 |
|
|
|
|
| 70 |
## Model evaluation
|
| 71 |
We conduct evaluation on 9 commonly-used benchmarks, including 5 academic VQA benchmarks and 4 popular MLLM benchmarks, to compare our Imp model with LLaVA (7B) and existing MSLMs of similar model sizes.
|
| 72 |
|
| 73 |
+
| Models | Size | VQAv2 | GQA | SQA(IMG) | TextVQA | POPE | MME(P) | MMB |MM-Vet|
|
| 74 |
+
|:--------:|:-----:|:----:|:-------------:|:--------:|:-----:|:----:|:-------:|:-------:|:-------:|
|
| 75 |
+
| [LLaVA-v1.5-lora](https://huggingface.co/liuhaotian/llava-v1.5-7b) | 7B |79.10 | 63.00| 68.40 |58.20| 86.40 | 1476.9 | 66.10 |30.2|
|
| 76 |
+
| [TinyGPT-V](https://huggingface.co/Tyrannosaurus/TinyGPT-V) | 3B | - | 33.60 | - | - | -| - | - |-|
|
| 77 |
+
| [LLaVA-Phi](https://github.com/zhuyiche/llava-phi) | 3B | 71.40 | - | 68.40 | 48.60 | 85.00 | 1335.1 | 59.80 |28.9|
|
| 78 |
+
| [MobileVLM](https://huggingface.co/mtgv/MobileVLM-3B) | 3B | - | 59.00 | 61.00 | 47.50 | 84.90 | 1288.9 | 59.60 |-|
|
| 79 |
+
| [MC-LLaVA-3b](https://huggingface.co/visheratin/MC-LLaVA-3b) | 3B | 64.24 | 49.60 | - | 38.59 | 80.59 | - | - |-|
|
| 80 |
+
| **Imp-v1 (ours)** | 3B | **81.42** | **64.40** | **69.26**| **59.34** | **87.85**| **1502.8** | **67.69** |**33.6**|
|
| 81 |
|
| 82 |
### Examples
|
| 83 |
|
images/bird.jpg
ADDED

|
images/evaluation.png
ADDED
|
model-00001-of-00007.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 996428776
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:166a9e057252c25fa569d6337d171f4ad9fa5215ca066ce2689db968b59a1aeb
|
| 3 |
size 996428776
|
model-00002-of-00007.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 996507088
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ac8936c5f7c1992673ff7c56841430b064a0a5874821c2df9a3f6f5d7713df9d
|
| 3 |
size 996507088
|
model-00003-of-00007.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 996512312
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:75f41aff80125fc02600c56583b630ce414c9f4c9c15002e4db2aa103110446d
|
| 3 |
size 996512312
|
model-00004-of-00007.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 996512088
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f0008d0798eb81eea3c915894230d3aa7854b18f492344715c10ef4b80919e85
|
| 3 |
size 996512088
|
model-00005-of-00007.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 996507152
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5d692152683b3597b34215209270cd9ece3bde5340883a6649e2a226674b84fc
|
| 3 |
size 996507152
|
model-00006-of-00007.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 1021447256
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b37dd972e5111ccb1609e70215e5b9806d12dd573ab23f54f790252e715f4390
|
| 3 |
size 1021447256
|
model-00007-of-00007.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:93604db012439a7fdd71718433aac7941daf7eeafcb6fb3298aee6e0a15c08c9
|
| 3 |
+
size 370061024
|
model.safetensors.index.json
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
{
|
| 2 |
"metadata": {
|
| 3 |
-
"total_size":
|
| 4 |
},
|
| 5 |
"weight_map": {
|
| 6 |
"lm_head.linear.bias": "model-00007-of-00007.safetensors",
|
|
@@ -750,8 +750,6 @@
|
|
| 750 |
"transformer.vision_tower.vision_tower.vision_model.encoder.layers.9.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
| 751 |
"transformer.vision_tower.vision_tower.vision_model.encoder.layers.9.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
| 752 |
"transformer.vision_tower.vision_tower.vision_model.encoder.layers.9.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
| 753 |
-
"transformer.vision_tower.vision_tower.vision_model.encoder.layers.9.self_attn.v_proj.weight": "model-00006-of-00007.safetensors"
|
| 754 |
-
"transformer.vision_tower.vision_tower.vision_model.post_layernorm.bias": "model-00007-of-00007.safetensors",
|
| 755 |
-
"transformer.vision_tower.vision_tower.vision_model.post_layernorm.weight": "model-00007-of-00007.safetensors"
|
| 756 |
}
|
| 757 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"metadata": {
|
| 3 |
+
"total_size": 6373874240
|
| 4 |
},
|
| 5 |
"weight_map": {
|
| 6 |
"lm_head.linear.bias": "model-00007-of-00007.safetensors",
|
|
|
|
| 750 |
"transformer.vision_tower.vision_tower.vision_model.encoder.layers.9.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
| 751 |
"transformer.vision_tower.vision_tower.vision_model.encoder.layers.9.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
| 752 |
"transformer.vision_tower.vision_tower.vision_model.encoder.layers.9.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
| 753 |
+
"transformer.vision_tower.vision_tower.vision_model.encoder.layers.9.self_attn.v_proj.weight": "model-00006-of-00007.safetensors"
|
|
|
|
|
|
|
| 754 |
}
|
| 755 |
}
|
test.py
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 3 |
+
from PIL import Image
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
torch.set_default_device("cuda")
|
| 7 |
+
|
| 8 |
+
#Create model
|
| 9 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 10 |
+
"/data/ouyangxc/labs/hg/imp-v1-3b",
|
| 11 |
+
torch_dtype=torch.float16,
|
| 12 |
+
device_map="auto",
|
| 13 |
+
trust_remote_code=True)
|
| 14 |
+
tokenizer = AutoTokenizer.from_pretrained("/data/ouyangxc/labs/hg/imp-v1-3b", trust_remote_code=True)
|
| 15 |
+
|
| 16 |
+
#Set inputs
|
| 17 |
+
text = "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: <image>\nWhat's the color of the car? ASSISTANT:"
|
| 18 |
+
image = Image.open("images/car.jpg")
|
| 19 |
+
|
| 20 |
+
input_ids = tokenizer(text, return_tensors='pt').input_ids
|
| 21 |
+
image_tensor = model.image_preprocess(image)
|
| 22 |
+
|
| 23 |
+
#Generate the answer
|
| 24 |
+
output_ids = model.generate(
|
| 25 |
+
input_ids,
|
| 26 |
+
max_new_tokens=150,
|
| 27 |
+
images=image_tensor,
|
| 28 |
+
use_cache=True)[0]
|
| 29 |
+
print(tokenizer.decode(output_ids[input_ids.shape[1]:], skip_special_tokens=True).strip())
|
vision_encoder.py
CHANGED
|
@@ -549,6 +549,7 @@ class VisionTower(nn.Module):
|
|
| 549 |
self.vision_tower = SiglipVisionModel(self.config)
|
| 550 |
del self.vision_tower.vision_model.encoder.layers[(self.select_layer + 1):]
|
| 551 |
self.vision_tower.vision_model.head = nn.Identity()
|
|
|
|
| 552 |
self.vision_tower.requires_grad_(False)
|
| 553 |
self.vision_tower.eval()
|
| 554 |
|
|
|
|
| 549 |
self.vision_tower = SiglipVisionModel(self.config)
|
| 550 |
del self.vision_tower.vision_model.encoder.layers[(self.select_layer + 1):]
|
| 551 |
self.vision_tower.vision_model.head = nn.Identity()
|
| 552 |
+
self.vision_tower.vision_model.post_layernorm=nn.Identity()
|
| 553 |
self.vision_tower.requires_grad_(False)
|
| 554 |
self.vision_tower.eval()
|
| 555 |
|