

Upload endoscopic_inbody_classification version 0.5.0
Browse files- .gitattributes +1 -0
- LICENSE +201 -0
- configs/evaluate.json +47 -0
- configs/inference.json +131 -0
- configs/inference_trt.json +12 -0
- configs/logging.conf +21 -0
- configs/metadata.json +104 -0
- configs/multi_gpu_train.json +41 -0
- configs/train.json +264 -0
- docs/README.md +175 -0
- docs/data_license.txt +1 -0
- models/model.pt +3 -0
- models/model.ts +3 -0
- scripts/data_process.py +69 -0
- scripts/export_to_onnx.py +118 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
models/model.ts filter=lfs diff=lfs merge=lfs -text
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
configs/evaluate.json
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"validate#postprocessing": {
|
| 3 |
+
"_target_": "Compose",
|
| 4 |
+
"transforms": [
|
| 5 |
+
{
|
| 6 |
+
"_target_": "AsDiscreted",
|
| 7 |
+
"keys": [
|
| 8 |
+
"pred",
|
| 9 |
+
"label"
|
| 10 |
+
],
|
| 11 |
+
"argmax": [
|
| 12 |
+
true,
|
| 13 |
+
false
|
| 14 |
+
],
|
| 15 |
+
"to_onehot": 2
|
| 16 |
+
}
|
| 17 |
+
]
|
| 18 |
+
},
|
| 19 |
+
"validate#handlers": [
|
| 20 |
+
{
|
| 21 |
+
"_target_": "CheckpointLoader",
|
| 22 |
+
"load_path": "$@ckpt_dir + '/model.pt'",
|
| 23 |
+
"load_dict": {
|
| 24 |
+
"model": "@network"
|
| 25 |
+
}
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
"_target_": "StatsHandler",
|
| 29 |
+
"iteration_log": false
|
| 30 |
+
},
|
| 31 |
+
{
|
| 32 |
+
"_target_": "MetricsSaver",
|
| 33 |
+
"save_dir": "@output_dir",
|
| 34 |
+
"metrics": [
|
| 35 |
+
"val_accu"
|
| 36 |
+
],
|
| 37 |
+
"metric_details": [
|
| 38 |
+
"val_accu"
|
| 39 |
+
],
|
| 40 |
+
"batch_transform": "$lambda x: [xx['image'].meta for xx in x]",
|
| 41 |
+
"summary_ops": "*"
|
| 42 |
+
}
|
| 43 |
+
],
|
| 44 |
+
"run": [
|
| 45 |
+
"$@validate#evaluator.run()"
|
| 46 |
+
]
|
| 47 |
+
}
|
configs/inference.json
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"imports": [
|
| 3 |
+
"$import json",
|
| 4 |
+
"$import os",
|
| 5 |
+
"$import numpy",
|
| 6 |
+
"$import torch"
|
| 7 |
+
],
|
| 8 |
+
"bundle_root": ".",
|
| 9 |
+
"image_key": "image",
|
| 10 |
+
"load_pretrain": true,
|
| 11 |
+
"output_dir": "$@bundle_root + '/eval'",
|
| 12 |
+
"output_filename": "predictions.csv",
|
| 13 |
+
"dataset_dir": "/workspace/data/endoscopic_inbody_classification",
|
| 14 |
+
"test_json": "$@bundle_root+'/label/test_samples.json'",
|
| 15 |
+
"test_fp": "$open(@test_json,'r', encoding='utf8')",
|
| 16 |
+
"test_dict": "$json.load(@test_fp)",
|
| 17 |
+
"device": "$torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')",
|
| 18 |
+
"network_def": {
|
| 19 |
+
"_target_": "SEResNet50",
|
| 20 |
+
"spatial_dims": 2,
|
| 21 |
+
"in_channels": 3,
|
| 22 |
+
"num_classes": 2
|
| 23 |
+
},
|
| 24 |
+
"network": "$@network_def.to(@device)",
|
| 25 |
+
"preprocessing": {
|
| 26 |
+
"_target_": "Compose",
|
| 27 |
+
"transforms": [
|
| 28 |
+
{
|
| 29 |
+
"_target_": "LoadImaged",
|
| 30 |
+
"keys": "@image_key",
|
| 31 |
+
"image_only": false
|
| 32 |
+
},
|
| 33 |
+
{
|
| 34 |
+
"_target_": "EnsureChannelFirstd",
|
| 35 |
+
"keys": "@image_key",
|
| 36 |
+
"channel_dim": -1
|
| 37 |
+
},
|
| 38 |
+
{
|
| 39 |
+
"_target_": "Resized",
|
| 40 |
+
"keys": "@image_key",
|
| 41 |
+
"spatial_size": [
|
| 42 |
+
256,
|
| 43 |
+
256
|
| 44 |
+
],
|
| 45 |
+
"mode": "bilinear"
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"_target_": "CastToTyped",
|
| 49 |
+
"dtype": "$torch.float32",
|
| 50 |
+
"keys": "@image_key"
|
| 51 |
+
},
|
| 52 |
+
{
|
| 53 |
+
"_target_": "NormalizeIntensityd",
|
| 54 |
+
"nonzero": true,
|
| 55 |
+
"channel_wise": true,
|
| 56 |
+
"keys": "@image_key"
|
| 57 |
+
},
|
| 58 |
+
{
|
| 59 |
+
"_target_": "EnsureTyped",
|
| 60 |
+
"keys": "@image_key"
|
| 61 |
+
}
|
| 62 |
+
]
|
| 63 |
+
},
|
| 64 |
+
"dataset": {
|
| 65 |
+
"_target_": "Dataset",
|
| 66 |
+
"data": "@test_dict",
|
| 67 |
+
"transform": "@preprocessing"
|
| 68 |
+
},
|
| 69 |
+
"dataloader": {
|
| 70 |
+
"_target_": "DataLoader",
|
| 71 |
+
"dataset": "@dataset",
|
| 72 |
+
"batch_size": 1,
|
| 73 |
+
"shuffle": false,
|
| 74 |
+
"num_workers": 4
|
| 75 |
+
},
|
| 76 |
+
"inferer": {
|
| 77 |
+
"_target_": "SimpleInferer"
|
| 78 |
+
},
|
| 79 |
+
"postprocessing": {
|
| 80 |
+
"_target_": "Compose",
|
| 81 |
+
"transforms": [
|
| 82 |
+
{
|
| 83 |
+
"_target_": "AsDiscreted",
|
| 84 |
+
"argmax": true,
|
| 85 |
+
"to_onehot": 2,
|
| 86 |
+
"keys": [
|
| 87 |
+
"pred"
|
| 88 |
+
]
|
| 89 |
+
},
|
| 90 |
+
{
|
| 91 |
+
"_target_": "SaveClassificationd",
|
| 92 |
+
"keys": "pred",
|
| 93 |
+
"meta_keys": "$@image_key + '_meta_dict'",
|
| 94 |
+
"output_dir": "@output_dir",
|
| 95 |
+
"filename": "@output_filename"
|
| 96 |
+
}
|
| 97 |
+
]
|
| 98 |
+
},
|
| 99 |
+
"handlers": [
|
| 100 |
+
{
|
| 101 |
+
"_target_": "StatsHandler",
|
| 102 |
+
"iteration_log": true
|
| 103 |
+
}
|
| 104 |
+
],
|
| 105 |
+
"evaluator": {
|
| 106 |
+
"_target_": "SupervisedEvaluator",
|
| 107 |
+
"device": "@device",
|
| 108 |
+
"val_data_loader": "@dataloader",
|
| 109 |
+
"network": "@network",
|
| 110 |
+
"inferer": "@inferer",
|
| 111 |
+
"postprocessing": "@postprocessing",
|
| 112 |
+
"val_handlers": "@handlers"
|
| 113 |
+
},
|
| 114 |
+
"checkpointloader": {
|
| 115 |
+
"_target_": "CheckpointLoader",
|
| 116 |
+
"load_path": "$@bundle_root + '/models/model.pt'",
|
| 117 |
+
"load_dict": {
|
| 118 |
+
"model": "@network"
|
| 119 |
+
}
|
| 120 |
+
},
|
| 121 |
+
"initialize": [
|
| 122 |
+
"$monai.utils.set_determinism(seed=123)",
|
| 123 |
+
"$@checkpointloader(@evaluator) if @load_pretrain else None"
|
| 124 |
+
],
|
| 125 |
+
"run": [
|
| 126 |
+
"[email protected]()"
|
| 127 |
+
],
|
| 128 |
+
"finalize": [
|
| 129 |
+
"$@test_fp.close()"
|
| 130 |
+
]
|
| 131 |
+
}
|
configs/inference_trt.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"imports": [
|
| 3 |
+
"$import os",
|
| 4 |
+
"$import json",
|
| 5 |
+
"$import torch_tensorrt"
|
| 6 |
+
],
|
| 7 |
+
"network_def": "$torch.jit.load(@bundle_root + '/models/model_trt.ts')",
|
| 8 |
+
"evaluator#amp": false,
|
| 9 |
+
"initialize": [
|
| 10 |
+
"$monai.utils.set_determinism(seed=123)"
|
| 11 |
+
]
|
| 12 |
+
}
|
configs/logging.conf
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[loggers]
|
| 2 |
+
keys=root
|
| 3 |
+
|
| 4 |
+
[handlers]
|
| 5 |
+
keys=consoleHandler
|
| 6 |
+
|
| 7 |
+
[formatters]
|
| 8 |
+
keys=fullFormatter
|
| 9 |
+
|
| 10 |
+
[logger_root]
|
| 11 |
+
level=INFO
|
| 12 |
+
handlers=consoleHandler
|
| 13 |
+
|
| 14 |
+
[handler_consoleHandler]
|
| 15 |
+
class=StreamHandler
|
| 16 |
+
level=INFO
|
| 17 |
+
formatter=fullFormatter
|
| 18 |
+
args=(sys.stdout,)
|
| 19 |
+
|
| 20 |
+
[formatter_fullFormatter]
|
| 21 |
+
format=%(asctime)s - %(name)s - %(levelname)s - %(message)s
|
configs/metadata.json
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_20240725.json",
|
| 3 |
+
"version": "0.5.0",
|
| 4 |
+
"changelog": {
|
| 5 |
+
"0.5.0": "update to huggingface hosting and fix missing dependencies",
|
| 6 |
+
"0.4.9": "use monai 1.4 and update large files",
|
| 7 |
+
"0.4.8": "update to use monai 1.3.1",
|
| 8 |
+
"0.4.7": "add load_pretrain flag for infer",
|
| 9 |
+
"0.4.6": "add output for inference",
|
| 10 |
+
"0.4.5": "update with EnsureChannelFirstd and remove meta dict usage",
|
| 11 |
+
"0.4.4": "fix the wrong GPU index issue of multi-node",
|
| 12 |
+
"0.4.3": "add dataset dir example",
|
| 13 |
+
"0.4.2": "update ONNX-TensorRT descriptions",
|
| 14 |
+
"0.4.1": "update the model weights with the deterministic training",
|
| 15 |
+
"0.4.0": "add the ONNX-TensorRT way of model conversion",
|
| 16 |
+
"0.3.9": "fix mgpu finalize issue",
|
| 17 |
+
"0.3.8": "enable deterministic training",
|
| 18 |
+
"0.3.7": "adapt to BundleWorkflow interface",
|
| 19 |
+
"0.3.6": "add name tag",
|
| 20 |
+
"0.3.5": "fix a comment issue in the data_process script",
|
| 21 |
+
"0.3.4": "add note for multi-gpu training with example dataset",
|
| 22 |
+
"0.3.3": "enhance data preprocess script and readme file",
|
| 23 |
+
"0.3.2": "restructure readme to match updated template",
|
| 24 |
+
"0.3.1": "add workflow, train loss and validation accuracy figures",
|
| 25 |
+
"0.3.0": "update dataset processing",
|
| 26 |
+
"0.2.2": "update to use monai 1.0.1",
|
| 27 |
+
"0.2.1": "enhance readme on commands example",
|
| 28 |
+
"0.2.0": "update license files",
|
| 29 |
+
"0.1.0": "complete the first version model package",
|
| 30 |
+
"0.0.1": "initialize the model package structure"
|
| 31 |
+
},
|
| 32 |
+
"monai_version": "1.4.0",
|
| 33 |
+
"pytorch_version": "2.4.0",
|
| 34 |
+
"numpy_version": "1.24.4",
|
| 35 |
+
"required_packages_version": {
|
| 36 |
+
"nibabel": "5.2.1",
|
| 37 |
+
"pytorch-ignite": "0.4.11",
|
| 38 |
+
"pillow": "10.4.0",
|
| 39 |
+
"tensorboard": "2.17.0"
|
| 40 |
+
},
|
| 41 |
+
"supported_apps": {},
|
| 42 |
+
"name": "Endoscopic inbody classification",
|
| 43 |
+
"task": "Endoscopic inbody classification",
|
| 44 |
+
"description": "A pre-trained binary classification model for endoscopic inbody classification task",
|
| 45 |
+
"authors": "NVIDIA DLMED team",
|
| 46 |
+
"copyright": "Copyright (c) 2021-2022, NVIDIA CORPORATION",
|
| 47 |
+
"data_source": "private dataset",
|
| 48 |
+
"data_type": "RGB",
|
| 49 |
+
"image_classes": "three channel data, intensity [0-255]",
|
| 50 |
+
"label_classes": "0: inbody, 1: outbody",
|
| 51 |
+
"pred_classes": "vector whose length equals to 2, [1,0] means in body, [0,1] means out body",
|
| 52 |
+
"eval_metrics": {
|
| 53 |
+
"accuracy": 0.99
|
| 54 |
+
},
|
| 55 |
+
"references": [
|
| 56 |
+
"J. Hu, L. Shen and G. Sun, Squeeze-and-Excitation Networks, 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 7132-7141. https://arxiv.org/pdf/1709.01507.pdf"
|
| 57 |
+
],
|
| 58 |
+
"network_data_format": {
|
| 59 |
+
"inputs": {
|
| 60 |
+
"image": {
|
| 61 |
+
"type": "magnitude",
|
| 62 |
+
"format": "RGB",
|
| 63 |
+
"modality": "regular",
|
| 64 |
+
"num_channels": 3,
|
| 65 |
+
"spatial_shape": [
|
| 66 |
+
256,
|
| 67 |
+
256
|
| 68 |
+
],
|
| 69 |
+
"dtype": "float32",
|
| 70 |
+
"value_range": [
|
| 71 |
+
0,
|
| 72 |
+
1
|
| 73 |
+
],
|
| 74 |
+
"is_patch_data": false,
|
| 75 |
+
"channel_def": {
|
| 76 |
+
"0": "R",
|
| 77 |
+
"1": "G",
|
| 78 |
+
"2": "B"
|
| 79 |
+
}
|
| 80 |
+
}
|
| 81 |
+
},
|
| 82 |
+
"outputs": {
|
| 83 |
+
"pred": {
|
| 84 |
+
"type": "probabilities",
|
| 85 |
+
"format": "classes",
|
| 86 |
+
"num_channels": 2,
|
| 87 |
+
"spatial_shape": [
|
| 88 |
+
1,
|
| 89 |
+
2
|
| 90 |
+
],
|
| 91 |
+
"dtype": "float32",
|
| 92 |
+
"value_range": [
|
| 93 |
+
0,
|
| 94 |
+
1
|
| 95 |
+
],
|
| 96 |
+
"is_patch_data": false,
|
| 97 |
+
"channel_def": {
|
| 98 |
+
"0": "in body",
|
| 99 |
+
"1": "out body"
|
| 100 |
+
}
|
| 101 |
+
}
|
| 102 |
+
}
|
| 103 |
+
}
|
| 104 |
+
}
|
configs/multi_gpu_train.json
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"device": "$torch.device('cuda:' + os.environ['LOCAL_RANK'])",
|
| 3 |
+
"network": {
|
| 4 |
+
"_target_": "torch.nn.parallel.DistributedDataParallel",
|
| 5 |
+
"module": "$@network_def.to(@device)",
|
| 6 |
+
"device_ids": [
|
| 7 |
+
"@device"
|
| 8 |
+
]
|
| 9 |
+
},
|
| 10 |
+
"train#sampler": {
|
| 11 |
+
"_target_": "DistributedSampler",
|
| 12 |
+
"dataset": "@train#dataset",
|
| 13 |
+
"even_divisible": true,
|
| 14 |
+
"shuffle": true
|
| 15 |
+
},
|
| 16 |
+
"train#dataloader#sampler": "@train#sampler",
|
| 17 |
+
"train#dataloader#shuffle": false,
|
| 18 |
+
"train#trainer#train_handlers": "$@train#handlers[: -2 if dist.get_rank() > 0 else None]",
|
| 19 |
+
"validate#sampler": {
|
| 20 |
+
"_target_": "DistributedSampler",
|
| 21 |
+
"dataset": "@validate#dataset",
|
| 22 |
+
"even_divisible": false,
|
| 23 |
+
"shuffle": false
|
| 24 |
+
},
|
| 25 |
+
"validate#dataloader#sampler": "@validate#sampler",
|
| 26 |
+
"validate#evaluator#val_handlers": "$None if dist.get_rank() > 0 else @validate#handlers",
|
| 27 |
+
"initialize": [
|
| 28 |
+
"$import torch.distributed as dist",
|
| 29 |
+
"$dist.is_initialized() or dist.init_process_group(backend='nccl')",
|
| 30 |
+
"$torch.cuda.set_device(@device)",
|
| 31 |
+
"$monai.utils.set_determinism(seed=123)"
|
| 32 |
+
],
|
| 33 |
+
"run": [
|
| 34 |
+
"$@train#trainer.run()"
|
| 35 |
+
],
|
| 36 |
+
"finalize": [
|
| 37 |
+
"$dist.is_initialized() and dist.destroy_process_group()",
|
| 38 |
+
"$@train_fp.close()",
|
| 39 |
+
"$@val_fp.close()"
|
| 40 |
+
]
|
| 41 |
+
}
|
configs/train.json
ADDED
|
@@ -0,0 +1,264 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"imports": [
|
| 3 |
+
"$import torch",
|
| 4 |
+
"$import json",
|
| 5 |
+
"$import ignite",
|
| 6 |
+
"$import os"
|
| 7 |
+
],
|
| 8 |
+
"bundle_root": ".",
|
| 9 |
+
"ckpt_dir": "$@bundle_root + '/models'",
|
| 10 |
+
"output_dir": "$@bundle_root + '/eval'",
|
| 11 |
+
"dataset_dir": "/workspace/data/endoscopic_inbody_classification",
|
| 12 |
+
"train_json": "$@bundle_root+'/label/train_samples.json'",
|
| 13 |
+
"val_json": "$@bundle_root+'/label/val_samples.json'",
|
| 14 |
+
"train_fp": "$open(@train_json,'r', encoding='utf8')",
|
| 15 |
+
"train_dict": "$json.load(@train_fp)",
|
| 16 |
+
"val_fp": "$open(@val_json,'r', encoding='utf8')",
|
| 17 |
+
"val_dict": "$json.load(@val_fp)",
|
| 18 |
+
"val_interval": 1,
|
| 19 |
+
"device": "$torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')",
|
| 20 |
+
"network_def": {
|
| 21 |
+
"_target_": "SEResNet50",
|
| 22 |
+
"spatial_dims": 2,
|
| 23 |
+
"in_channels": 3,
|
| 24 |
+
"num_classes": 2
|
| 25 |
+
},
|
| 26 |
+
"network": "$@network_def.to(@device)",
|
| 27 |
+
"loss": {
|
| 28 |
+
"_target_": "torch.nn.CrossEntropyLoss",
|
| 29 |
+
"reduction": "sum"
|
| 30 |
+
},
|
| 31 |
+
"optimizer": {
|
| 32 |
+
"_target_": "torch.optim.Adam",
|
| 33 |
+
"params": "[email protected]()",
|
| 34 |
+
"lr": 0.001
|
| 35 |
+
},
|
| 36 |
+
"train": {
|
| 37 |
+
"deterministic_transforms": [
|
| 38 |
+
{
|
| 39 |
+
"_target_": "LoadImaged",
|
| 40 |
+
"keys": "image"
|
| 41 |
+
},
|
| 42 |
+
{
|
| 43 |
+
"_target_": "ToTensord",
|
| 44 |
+
"keys": "label"
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
"_target_": "EnsureChannelFirstd",
|
| 48 |
+
"keys": "image",
|
| 49 |
+
"channel_dim": -1
|
| 50 |
+
},
|
| 51 |
+
{
|
| 52 |
+
"_target_": "Resized",
|
| 53 |
+
"keys": "image",
|
| 54 |
+
"spatial_size": [
|
| 55 |
+
256,
|
| 56 |
+
256
|
| 57 |
+
],
|
| 58 |
+
"mode": "bilinear"
|
| 59 |
+
},
|
| 60 |
+
{
|
| 61 |
+
"_target_": "CastToTyped",
|
| 62 |
+
"dtype": "$torch.float32",
|
| 63 |
+
"keys": "image"
|
| 64 |
+
},
|
| 65 |
+
{
|
| 66 |
+
"_target_": "NormalizeIntensityd",
|
| 67 |
+
"nonzero": true,
|
| 68 |
+
"channel_wise": true,
|
| 69 |
+
"keys": "image"
|
| 70 |
+
},
|
| 71 |
+
{
|
| 72 |
+
"_target_": "EnsureTyped",
|
| 73 |
+
"keys": "image"
|
| 74 |
+
}
|
| 75 |
+
],
|
| 76 |
+
"random_transforms": [
|
| 77 |
+
{
|
| 78 |
+
"_target_": "RandRotated",
|
| 79 |
+
"range_x": 0.3,
|
| 80 |
+
"prob": 0.2,
|
| 81 |
+
"mode": "bilinear",
|
| 82 |
+
"keys": "image"
|
| 83 |
+
},
|
| 84 |
+
{
|
| 85 |
+
"_target_": "RandScaleIntensityd",
|
| 86 |
+
"factors": 0.3,
|
| 87 |
+
"prob": 0.5,
|
| 88 |
+
"keys": "image"
|
| 89 |
+
},
|
| 90 |
+
{
|
| 91 |
+
"_target_": "RandShiftIntensityd",
|
| 92 |
+
"offsets": 0.1,
|
| 93 |
+
"prob": 0.5,
|
| 94 |
+
"keys": "image"
|
| 95 |
+
},
|
| 96 |
+
{
|
| 97 |
+
"_target_": "RandGaussianNoised",
|
| 98 |
+
"std": 0.01,
|
| 99 |
+
"prob": 0.15,
|
| 100 |
+
"keys": "image"
|
| 101 |
+
},
|
| 102 |
+
{
|
| 103 |
+
"_target_": "RandFlipd",
|
| 104 |
+
"spatial_axis": 0,
|
| 105 |
+
"prob": 0.5,
|
| 106 |
+
"keys": "image"
|
| 107 |
+
},
|
| 108 |
+
{
|
| 109 |
+
"_target_": "RandFlipd",
|
| 110 |
+
"spatial_axis": 1,
|
| 111 |
+
"prob": 0.5,
|
| 112 |
+
"keys": "image"
|
| 113 |
+
}
|
| 114 |
+
],
|
| 115 |
+
"preprocessing": {
|
| 116 |
+
"_target_": "Compose",
|
| 117 |
+
"transforms": "$@train#deterministic_transforms + @train#random_transforms"
|
| 118 |
+
},
|
| 119 |
+
"dataset": {
|
| 120 |
+
"_target_": "Dataset",
|
| 121 |
+
"data": "@train_dict",
|
| 122 |
+
"transform": "@train#preprocessing"
|
| 123 |
+
},
|
| 124 |
+
"dataloader": {
|
| 125 |
+
"_target_": "DataLoader",
|
| 126 |
+
"dataset": "@train#dataset",
|
| 127 |
+
"batch_size": 64,
|
| 128 |
+
"shuffle": true,
|
| 129 |
+
"num_workers": 4
|
| 130 |
+
},
|
| 131 |
+
"inferer": {
|
| 132 |
+
"_target_": "SimpleInferer"
|
| 133 |
+
},
|
| 134 |
+
"handlers": [
|
| 135 |
+
{
|
| 136 |
+
"_target_": "ValidationHandler",
|
| 137 |
+
"validator": "@validate#evaluator",
|
| 138 |
+
"epoch_level": true,
|
| 139 |
+
"interval": "@val_interval"
|
| 140 |
+
},
|
| 141 |
+
{
|
| 142 |
+
"_target_": "StatsHandler",
|
| 143 |
+
"tag_name": "train_loss",
|
| 144 |
+
"output_transform": "$monai.handlers.from_engine(['loss'], first=True)"
|
| 145 |
+
},
|
| 146 |
+
{
|
| 147 |
+
"_target_": "TensorBoardStatsHandler",
|
| 148 |
+
"log_dir": "@output_dir",
|
| 149 |
+
"tag_name": "train_loss",
|
| 150 |
+
"output_transform": "$monai.handlers.from_engine(['loss'], first=True)"
|
| 151 |
+
}
|
| 152 |
+
],
|
| 153 |
+
"key_metric": {
|
| 154 |
+
"train_accu": {
|
| 155 |
+
"_target_": "ignite.metrics.Accuracy",
|
| 156 |
+
"output_transform": "$monai.handlers.from_engine(['pred', 'label'])"
|
| 157 |
+
}
|
| 158 |
+
},
|
| 159 |
+
"postprocessing": {
|
| 160 |
+
"_target_": "Compose",
|
| 161 |
+
"transforms": [
|
| 162 |
+
{
|
| 163 |
+
"_target_": "AsDiscreted",
|
| 164 |
+
"argmax": [
|
| 165 |
+
true,
|
| 166 |
+
false
|
| 167 |
+
],
|
| 168 |
+
"to_onehot": [
|
| 169 |
+
2,
|
| 170 |
+
2
|
| 171 |
+
],
|
| 172 |
+
"keys": [
|
| 173 |
+
"pred",
|
| 174 |
+
"label"
|
| 175 |
+
]
|
| 176 |
+
}
|
| 177 |
+
]
|
| 178 |
+
},
|
| 179 |
+
"trainer": {
|
| 180 |
+
"_target_": "SupervisedTrainer",
|
| 181 |
+
"max_epochs": 25,
|
| 182 |
+
"device": "@device",
|
| 183 |
+
"train_data_loader": "@train#dataloader",
|
| 184 |
+
"network": "@network",
|
| 185 |
+
"loss_function": "@loss",
|
| 186 |
+
"optimizer": "@optimizer",
|
| 187 |
+
"inferer": "@train#inferer",
|
| 188 |
+
"postprocessing": "@train#postprocessing",
|
| 189 |
+
"key_train_metric": "@train#key_metric",
|
| 190 |
+
"train_handlers": "@train#handlers"
|
| 191 |
+
}
|
| 192 |
+
},
|
| 193 |
+
"validate": {
|
| 194 |
+
"preprocessing": {
|
| 195 |
+
"_target_": "Compose",
|
| 196 |
+
"transforms": "%train#deterministic_transforms"
|
| 197 |
+
},
|
| 198 |
+
"dataset": {
|
| 199 |
+
"_target_": "Dataset",
|
| 200 |
+
"data": "@val_dict",
|
| 201 |
+
"transform": "@validate#preprocessing"
|
| 202 |
+
},
|
| 203 |
+
"dataloader": {
|
| 204 |
+
"_target_": "DataLoader",
|
| 205 |
+
"dataset": "@validate#dataset",
|
| 206 |
+
"batch_size": 64,
|
| 207 |
+
"shuffle": false,
|
| 208 |
+
"num_workers": 4
|
| 209 |
+
},
|
| 210 |
+
"inferer": {
|
| 211 |
+
"_target_": "SimpleInferer"
|
| 212 |
+
},
|
| 213 |
+
"postprocessing": {
|
| 214 |
+
"_target_": "Compose",
|
| 215 |
+
"transforms": "%train#postprocessing"
|
| 216 |
+
},
|
| 217 |
+
"handlers": [
|
| 218 |
+
{
|
| 219 |
+
"_target_": "StatsHandler",
|
| 220 |
+
"iteration_log": false
|
| 221 |
+
},
|
| 222 |
+
{
|
| 223 |
+
"_target_": "TensorBoardStatsHandler",
|
| 224 |
+
"log_dir": "@output_dir",
|
| 225 |
+
"iteration_log": false
|
| 226 |
+
},
|
| 227 |
+
{
|
| 228 |
+
"_target_": "CheckpointSaver",
|
| 229 |
+
"save_dir": "@ckpt_dir",
|
| 230 |
+
"save_dict": {
|
| 231 |
+
"model": "@network"
|
| 232 |
+
},
|
| 233 |
+
"save_key_metric": true,
|
| 234 |
+
"key_metric_filename": "model.pt"
|
| 235 |
+
}
|
| 236 |
+
],
|
| 237 |
+
"key_metric": {
|
| 238 |
+
"val_accu": {
|
| 239 |
+
"_target_": "ignite.metrics.Accuracy",
|
| 240 |
+
"output_transform": "$monai.handlers.from_engine(['pred', 'label'])"
|
| 241 |
+
}
|
| 242 |
+
},
|
| 243 |
+
"evaluator": {
|
| 244 |
+
"_target_": "SupervisedEvaluator",
|
| 245 |
+
"device": "@device",
|
| 246 |
+
"val_data_loader": "@validate#dataloader",
|
| 247 |
+
"network": "@network",
|
| 248 |
+
"inferer": "@validate#inferer",
|
| 249 |
+
"postprocessing": "@validate#postprocessing",
|
| 250 |
+
"key_val_metric": "@validate#key_metric",
|
| 251 |
+
"val_handlers": "@validate#handlers"
|
| 252 |
+
}
|
| 253 |
+
},
|
| 254 |
+
"initialize": [
|
| 255 |
+
"$monai.utils.set_determinism(seed=123)"
|
| 256 |
+
],
|
| 257 |
+
"run": [
|
| 258 |
+
"$@train#trainer.run()"
|
| 259 |
+
],
|
| 260 |
+
"finalize": [
|
| 261 |
+
"$@train_fp.close()",
|
| 262 |
+
"$@val_fp.close()"
|
| 263 |
+
]
|
| 264 |
+
}
|
docs/README.md
ADDED
|
@@ -0,0 +1,175 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Model Overview
|
| 2 |
+
A pre-trained model for the endoscopic inbody classification task and trained using the SEResNet50 structure, whose details can be found in [1]. All datasets are from private samples of [Activ Surgical](https://www.activsurgical.com/). Samples in training and validation dataset are from the same 4 videos, while test samples are from different two videos.
|
| 3 |
+
|
| 4 |
+
The [PyTorch model](https://drive.google.com/file/d/14CS-s1uv2q6WedYQGeFbZeEWIkoyNa-x/view?usp=sharing) and [torchscript model](https://drive.google.com/file/d/1fOoJ4n5DWKHrt9QXTZ2sXwr9C-YvVGCM/view?usp=sharing) are shared in google drive. Modify the `bundle_root` parameter specified in `configs/train.json` and `configs/inference.json` to reflect where models are downloaded. Expected directory path to place downloaded models is `models/` under `bundle_root`.
|
| 5 |
+
|
| 6 |
+
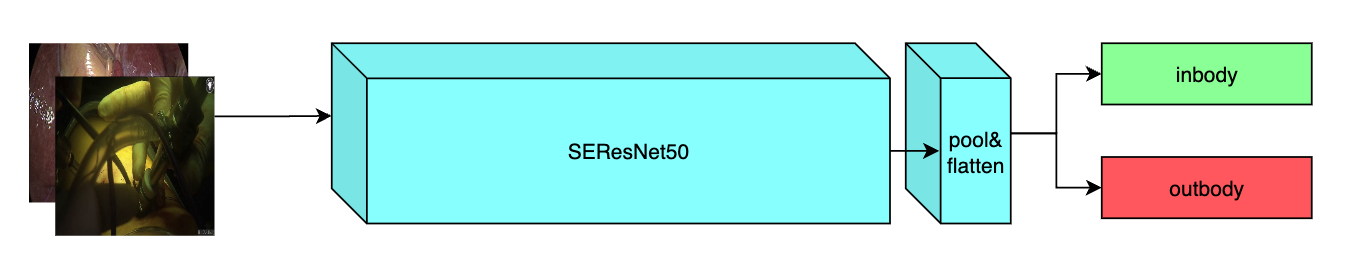
|
| 7 |
+
|
| 8 |
+
## Data
|
| 9 |
+
The datasets used in this work were provided by [Activ Surgical](https://www.activsurgical.com/).
|
| 10 |
+
|
| 11 |
+
Since datasets are private, we provide a [link](https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/inbody_outbody_samples.zip) of 20 samples (10 in-body and 10 out-body) to show what they look like.
|
| 12 |
+
|
| 13 |
+
### Preprocessing
|
| 14 |
+
After downloading this dataset, python script in `scripts` folder named `data_process` can be used to generate label json files by running the command below and modifying `datapath` to path of unziped downloaded data. Generated label json files will be stored in `label` folder under the bundle path.
|
| 15 |
+
|
| 16 |
+
```
|
| 17 |
+
python scripts/data_process.py --datapath /path/to/data/root
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
By default, label path parameter in `train.json` and `inference.json` of this bundle is point to the generated `label` folder under bundle path. If you move these generated label files to another place, please modify the `train_json`, `val_json` and `test_json` parameters specified in `configs/train.json` and `configs/inference.json` to where these label files are.
|
| 21 |
+
|
| 22 |
+
The input label json should be a list made up by dicts which includes `image` and `label` keys. An example format is shown below.
|
| 23 |
+
|
| 24 |
+
```
|
| 25 |
+
[
|
| 26 |
+
{
|
| 27 |
+
"image":"/path/to/image/image_name0.jpg",
|
| 28 |
+
"label": 0
|
| 29 |
+
},
|
| 30 |
+
{
|
| 31 |
+
"image":"/path/to/image/image_name1.jpg",
|
| 32 |
+
"label": 0
|
| 33 |
+
},
|
| 34 |
+
{
|
| 35 |
+
"image":"/path/to/image/image_name2.jpg",
|
| 36 |
+
"label": 1
|
| 37 |
+
},
|
| 38 |
+
....
|
| 39 |
+
{
|
| 40 |
+
"image":"/path/to/image/image_namek.jpg",
|
| 41 |
+
"label": 0
|
| 42 |
+
},
|
| 43 |
+
]
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
## Training configuration
|
| 47 |
+
The training as performed with the following:
|
| 48 |
+
- GPU: At least 12GB of GPU memory
|
| 49 |
+
- Actual Model Input: 256 x 256 x 3
|
| 50 |
+
- Optimizer: Adam
|
| 51 |
+
- Learning Rate: 1e-3
|
| 52 |
+
|
| 53 |
+
### Input
|
| 54 |
+
A three channel video frame
|
| 55 |
+
|
| 56 |
+
### Output
|
| 57 |
+
Two Channels
|
| 58 |
+
- Label 0: in body
|
| 59 |
+
- Label 1: out body
|
| 60 |
+
|
| 61 |
+
## Performance
|
| 62 |
+
Accuracy was used for evaluating the performance of the model. This model achieves an accuracy score of 0.99
|
| 63 |
+
|
| 64 |
+
#### Training Loss
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
#### Validation Accuracy
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
#### TensorRT speedup
|
| 71 |
+
The `endoscopic_inbody_classification` bundle supports acceleration with TensorRT through the ONNX-TensorRT method. The table below displays the speedup ratios observed on an A100 80G GPU.
|
| 72 |
+
|
| 73 |
+
| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
|
| 74 |
+
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
|
| 75 |
+
| model computation | 6.50 | 9.23 | 2.78 | 2.31 | 0.70 | 2.34 | 2.81 | 4.00 |
|
| 76 |
+
| end2end | 23.54 | 23.78 | 7.37 | 7.14 | 0.99 | 3.19 | 3.30 | 3.33 |
|
| 77 |
+
|
| 78 |
+
Where:
|
| 79 |
+
- `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing
|
| 80 |
+
- `end2end` means run the bundle end-to-end with the TensorRT based model.
|
| 81 |
+
- `torch_fp32` and `torch_amp` are for the PyTorch models with or without `amp` mode.
|
| 82 |
+
- `trt_fp32` and `trt_fp16` are for the TensorRT based models converted in corresponding precision.
|
| 83 |
+
- `speedup amp`, `speedup fp32` and `speedup fp16` are the speedup ratios of corresponding models versus the PyTorch float32 model
|
| 84 |
+
- `amp vs fp16` is the speedup ratio between the PyTorch amp model and the TensorRT float16 based model.
|
| 85 |
+
|
| 86 |
+
Currently, the only available method to accelerate this model is through ONNX-TensorRT. However, the Torch-TensorRT method is under development and will be available in the near future.
|
| 87 |
+
|
| 88 |
+
This result is benchmarked under:
|
| 89 |
+
- TensorRT: 8.5.3+cuda11.8
|
| 90 |
+
- Torch-TensorRT Version: 1.4.0
|
| 91 |
+
- CPU Architecture: x86-64
|
| 92 |
+
- OS: ubuntu 20.04
|
| 93 |
+
- Python version:3.8.10
|
| 94 |
+
- CUDA version: 12.0
|
| 95 |
+
- GPU models and configuration: A100 80G
|
| 96 |
+
|
| 97 |
+
## MONAI Bundle Commands
|
| 98 |
+
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
|
| 99 |
+
|
| 100 |
+
For more details usage instructions, visit the [MONAI Bundle Configuration Page](https://docs.monai.io/en/latest/config_syntax.html).
|
| 101 |
+
|
| 102 |
+
#### Execute training:
|
| 103 |
+
|
| 104 |
+
```
|
| 105 |
+
python -m monai.bundle run --config_file configs/train.json
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
Please note that if the default dataset path is not modified with the actual path in the bundle config files, you can also override it by using `--dataset_dir`:
|
| 109 |
+
|
| 110 |
+
```
|
| 111 |
+
python -m monai.bundle run --config_file configs/train.json --dataset_dir <actual dataset path>
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
#### Override the `train` config to execute multi-GPU training:
|
| 115 |
+
|
| 116 |
+
```
|
| 117 |
+
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run \
|
| 118 |
+
--config_file "['configs/train.json','configs/multi_gpu_train.json']"
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
+
Please note that the distributed training-related options depend on the actual running environment; thus, users may need to remove `--standalone`, modify `--nnodes`, or do some other necessary changes according to the machine used. For more details, please refer to [pytorch's official tutorial](https://pytorch.org/tutorials/intermediate/ddp_tutorial.html).
|
| 122 |
+
|
| 123 |
+
In addition, if using the 20 samples example dataset, the preprocessing script will divide the samples to 16 training samples, 2 validation samples and 2 test samples. However, pytorch multi-gpu training requires number of samples in dataloader larger than gpu numbers. Therefore, please use no more than 2 gpus to run this bundle if using the 20 samples example dataset.
|
| 124 |
+
|
| 125 |
+
#### Override the `train` config to execute evaluation with the trained model:
|
| 126 |
+
|
| 127 |
+
```
|
| 128 |
+
python -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json']"
|
| 129 |
+
```
|
| 130 |
+
|
| 131 |
+
#### Execute inference:
|
| 132 |
+
|
| 133 |
+
```
|
| 134 |
+
python -m monai.bundle run --config_file configs/inference.json
|
| 135 |
+
```
|
| 136 |
+
The classification result of every images in `test.json` will be printed to the screen.
|
| 137 |
+
|
| 138 |
+
#### Export checkpoint to TorchScript file:
|
| 139 |
+
|
| 140 |
+
```
|
| 141 |
+
python -m monai.bundle ckpt_export network_def --filepath models/model.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json
|
| 142 |
+
```
|
| 143 |
+
|
| 144 |
+
#### Export checkpoint to TensorRT based models with fp32 or fp16 precision:
|
| 145 |
+
|
| 146 |
+
```bash
|
| 147 |
+
python -m monai.bundle trt_export --net_id network_def \
|
| 148 |
+
--filepath models/model_trt.ts --ckpt_file models/model.pt \
|
| 149 |
+
--meta_file configs/metadata.json --config_file configs/inference.json \
|
| 150 |
+
--precision <fp32/fp16> --use_onnx "True" --use_trace "True"
|
| 151 |
+
```
|
| 152 |
+
|
| 153 |
+
#### Execute inference with the TensorRT model:
|
| 154 |
+
|
| 155 |
+
```
|
| 156 |
+
python -m monai.bundle run --config_file "['configs/inference.json', 'configs/inference_trt.json']"
|
| 157 |
+
```
|
| 158 |
+
|
| 159 |
+
# References
|
| 160 |
+
[1] J. Hu, L. Shen and G. Sun, Squeeze-and-Excitation Networks, 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 7132-7141. https://arxiv.org/pdf/1709.01507.pdf
|
| 161 |
+
|
| 162 |
+
# License
|
| 163 |
+
Copyright (c) MONAI Consortium
|
| 164 |
+
|
| 165 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 166 |
+
you may not use this file except in compliance with the License.
|
| 167 |
+
You may obtain a copy of the License at
|
| 168 |
+
|
| 169 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 170 |
+
|
| 171 |
+
Unless required by applicable law or agreed to in writing, software
|
| 172 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 173 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 174 |
+
See the License for the specific language governing permissions and
|
| 175 |
+
limitations under the License.
|
docs/data_license.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Datasets used in this work were provided by Activ Surgical.
|
models/model.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dc8d874efa195e4416124aad4e1469e0b3ef873753e20948d762e7bfdb37b929
|
| 3 |
+
size 104502013
|
models/model.ts
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ba8c62eca55d37044d6d7631b1b0444709ac9009c202839dc054ca38bf732edf
|
| 3 |
+
size 104609651
|
scripts/data_process.py
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
train_rate = 0.6
|
| 6 |
+
val_rate = 0.2
|
| 7 |
+
test_rate = 0.2
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def save_json(content, path, filename):
|
| 11 |
+
if not os.path.exists(path):
|
| 12 |
+
os.makedirs(path, exist_ok=True)
|
| 13 |
+
dst_file_name = os.path.join(path, filename)
|
| 14 |
+
with open(dst_file_name, "w+") as fp:
|
| 15 |
+
json.dump(content, fp, indent=4, separators=(",", ":"))
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def generate_labels(data_path, output_path):
|
| 19 |
+
"""
|
| 20 |
+
Loading a model by name.
|
| 21 |
+
|
| 22 |
+
Args:
|
| 23 |
+
data_path: path to classification dataset, which must contain `inbody` and `outbody` directories.
|
| 24 |
+
output_path: path to save labels
|
| 25 |
+
"""
|
| 26 |
+
|
| 27 |
+
data_list = [os.path.join(root, x) for root, _, filenames in os.walk(data_path) for x in filenames if "jpg" in x]
|
| 28 |
+
label_list = [int("outbody" in os.path.basename(os.path.dirname(x))) for x in data_list]
|
| 29 |
+
data_label_json = [{"image": x, "label": y} for x, y in zip(data_list, label_list)]
|
| 30 |
+
inbody_list = list(filter(lambda x: x["label"] == 0, data_label_json))
|
| 31 |
+
outbody_list = list(filter(lambda x: not (x["label"] == 0), data_label_json))
|
| 32 |
+
inbody_train_len = int(len(inbody_list) * train_rate)
|
| 33 |
+
outbody_train_len = int(len(outbody_list) * train_rate)
|
| 34 |
+
inbody_val_len = int(len(inbody_list) * (train_rate + val_rate))
|
| 35 |
+
outbody_val_len = int(len(outbody_list) * (train_rate + val_rate))
|
| 36 |
+
inbody_train_list = inbody_list[:inbody_train_len]
|
| 37 |
+
outbody_train_list = outbody_list[:outbody_train_len]
|
| 38 |
+
inbody_val_list = inbody_list[inbody_train_len:inbody_val_len]
|
| 39 |
+
outbody_val_list = outbody_list[outbody_train_len:outbody_val_len]
|
| 40 |
+
inbody_test_list = inbody_list[inbody_val_len:]
|
| 41 |
+
outbody_test_list = outbody_list[outbody_val_len:]
|
| 42 |
+
train_list = inbody_train_list + outbody_train_list
|
| 43 |
+
val_list = inbody_val_list + outbody_val_list
|
| 44 |
+
test_list = inbody_test_list + outbody_test_list
|
| 45 |
+
save_json(train_list, out_path, "train_samples.json")
|
| 46 |
+
save_json(val_list, out_path, "val_samples.json")
|
| 47 |
+
save_json(test_list, out_path, "test_samples.json")
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
if __name__ == "__main__":
|
| 51 |
+
parser = argparse.ArgumentParser()
|
| 52 |
+
# path to downloaded dataset.
|
| 53 |
+
parser.add_argument(
|
| 54 |
+
"--datapath",
|
| 55 |
+
type=str,
|
| 56 |
+
default=r"/workspace/data/endoscopic_inbody_classification",
|
| 57 |
+
help="The root path of the inbody classification dataset.",
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
# path to save label json.
|
| 61 |
+
parser.add_argument("--outpath", type=str, default=r"./label", help="The output path of labels.")
|
| 62 |
+
|
| 63 |
+
args = parser.parse_args()
|
| 64 |
+
data_path = args.datapath
|
| 65 |
+
out_path = args.outpath
|
| 66 |
+
|
| 67 |
+
if not os.path.exists(out_path):
|
| 68 |
+
os.makedirs(out_path, exist_ok=True)
|
| 69 |
+
generate_labels(data_path, out_path)
|
scripts/export_to_onnx.py
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import onnx
|
| 6 |
+
import onnxruntime
|
| 7 |
+
import torch
|
| 8 |
+
from monai.networks.nets import SEResNet50
|
| 9 |
+
|
| 10 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def load_model_and_export(modelname, outname, out_channels, height, width, multigpu=False, in_channels=3):
|
| 14 |
+
"""
|
| 15 |
+
Loading a model by name.
|
| 16 |
+
|
| 17 |
+
Args:
|
| 18 |
+
modelname: a whole path name of the model that need to be loaded.
|
| 19 |
+
outname: a name for output onnx model.
|
| 20 |
+
out_channels: output channels, which usually equals to 1 + class_number.
|
| 21 |
+
height: input images' height.
|
| 22 |
+
width: input images' width.
|
| 23 |
+
multigpu: if the pre-trained model trained on a multigpu environment.
|
| 24 |
+
in_channels: input images' channel number.
|
| 25 |
+
"""
|
| 26 |
+
isopen = os.path.exists(modelname)
|
| 27 |
+
if not isopen:
|
| 28 |
+
raise Exception("The specified model to load does not exist!")
|
| 29 |
+
|
| 30 |
+
model = SEResNet50(spatial_dims=2, in_channels=in_channels, num_classes=out_channels)
|
| 31 |
+
|
| 32 |
+
if multigpu:
|
| 33 |
+
model = torch.nn.DataParallel(model)
|
| 34 |
+
model = model.cuda()
|
| 35 |
+
model.load_state_dict(torch.load(modelname, map_location=device)) # if the model is trained on multi gpu
|
| 36 |
+
model = model.eval()
|
| 37 |
+
|
| 38 |
+
np.random.seed(0)
|
| 39 |
+
x = np.random.random((1, 3, width, height))
|
| 40 |
+
x = torch.tensor(x, dtype=torch.float32)
|
| 41 |
+
x = x.cuda()
|
| 42 |
+
torch_out = model(x)
|
| 43 |
+
input_names = ["INPUT__0"]
|
| 44 |
+
output_names = ["OUTPUT__0"]
|
| 45 |
+
# Export the model
|
| 46 |
+
if multigpu:
|
| 47 |
+
model_trans = model.module
|
| 48 |
+
else:
|
| 49 |
+
model_trans = model
|
| 50 |
+
torch.onnx.export(
|
| 51 |
+
model_trans, # model to save
|
| 52 |
+
x, # model input
|
| 53 |
+
outname, # model save path
|
| 54 |
+
export_params=True,
|
| 55 |
+
verbose=True,
|
| 56 |
+
do_constant_folding=True,
|
| 57 |
+
input_names=input_names,
|
| 58 |
+
output_names=output_names,
|
| 59 |
+
opset_version=15,
|
| 60 |
+
dynamic_axes={"INPUT__0": {0: "batch_size"}, "OUTPUT__0": {0: "batch_size"}},
|
| 61 |
+
)
|
| 62 |
+
onnx_model = onnx.load(outname)
|
| 63 |
+
onnx.checker.check_model(onnx_model, full_check=True)
|
| 64 |
+
ort_session = onnxruntime.InferenceSession(outname)
|
| 65 |
+
|
| 66 |
+
def to_numpy(tensor):
|
| 67 |
+
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
|
| 68 |
+
|
| 69 |
+
# compute ONNX Runtime output prediction
|
| 70 |
+
ort_inputs = {ort_session.get_inputs()[0].name: to_numpy(x)}
|
| 71 |
+
ort_outs = ort_session.run(["OUTPUT__0"], ort_inputs)
|
| 72 |
+
numpy_torch_out = to_numpy(torch_out)
|
| 73 |
+
# compare ONNX Runtime and PyTorch results
|
| 74 |
+
np.testing.assert_allclose(numpy_torch_out, ort_outs[0], rtol=1e-03, atol=1e-05)
|
| 75 |
+
print("Exported model has been tested with ONNXRuntime, and the result looks good!")
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
if __name__ == "__main__":
|
| 79 |
+
parser = argparse.ArgumentParser()
|
| 80 |
+
# the original model for converting.
|
| 81 |
+
parser.add_argument(
|
| 82 |
+
"--model",
|
| 83 |
+
type=str,
|
| 84 |
+
default=r"/workspace/bundle/endoscopic_inbody_classification/models/model.pt",
|
| 85 |
+
help="Input an existing model weight",
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
# path to save the onnx model.
|
| 89 |
+
parser.add_argument(
|
| 90 |
+
"--outpath",
|
| 91 |
+
type=str,
|
| 92 |
+
default=r"/workspace/bundle/endoscopic_inbody_classification/models/model.onnx",
|
| 93 |
+
help="A path to save the onnx model.",
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
parser.add_argument("--width", type=int, default=256, help="Width for exporting onnx model.")
|
| 97 |
+
|
| 98 |
+
parser.add_argument("--height", type=int, default=256, help="Height for exporting onnx model.")
|
| 99 |
+
|
| 100 |
+
parser.add_argument(
|
| 101 |
+
"--out_channels", type=int, default=2, help="Number of expected out_channels in model for exporting to onnx."
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
parser.add_argument("--multigpu", type=bool, default=False, help="If loading model trained with multi gpu.")
|
| 105 |
+
|
| 106 |
+
args = parser.parse_args()
|
| 107 |
+
modelname = args.model
|
| 108 |
+
outname = args.outpath
|
| 109 |
+
out_channels = args.out_channels
|
| 110 |
+
height = args.height
|
| 111 |
+
width = args.width
|
| 112 |
+
multigpu = args.multigpu
|
| 113 |
+
|
| 114 |
+
if os.path.exists(outname):
|
| 115 |
+
raise Exception(
|
| 116 |
+
"The specified outpath already exists! Change the outpath to avoid overwriting your saved model. "
|
| 117 |
+
)
|
| 118 |
+
model = load_model_and_export(modelname, outname, out_channels, height, width, multigpu)
|