

Upload endoscopic_tool_segmentation version 0.6.1
Browse files- .gitattributes +1 -0
- LICENSE +201 -0
- configs/evaluate.json +75 -0
- configs/inference.json +149 -0
- configs/inference_trt.json +12 -0
- configs/logging.conf +21 -0
- configs/metadata.json +108 -0
- configs/multi_gpu_evaluate.json +31 -0
- configs/multi_gpu_train.json +43 -0
- configs/train.json +287 -0
- docs/README.md +171 -0
- docs/data_license.txt +1 -0
- models/model.pt +3 -0
- models/model.ts +3 -0
- scripts/export_to_onnx.py +122 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
models/model.ts filter=lfs diff=lfs merge=lfs -text
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
configs/evaluate.json
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"validate#postprocessing": {
|
| 3 |
+
"_target_": "Compose",
|
| 4 |
+
"transforms": [
|
| 5 |
+
{
|
| 6 |
+
"_target_": "Invertd",
|
| 7 |
+
"keys": [
|
| 8 |
+
"pred",
|
| 9 |
+
"label"
|
| 10 |
+
],
|
| 11 |
+
"transform": "@validate#preprocessing",
|
| 12 |
+
"orig_keys": "image",
|
| 13 |
+
"meta_key_postfix": "meta_dict",
|
| 14 |
+
"nearest_interp": [
|
| 15 |
+
false,
|
| 16 |
+
true
|
| 17 |
+
],
|
| 18 |
+
"to_tensor": true
|
| 19 |
+
},
|
| 20 |
+
{
|
| 21 |
+
"_target_": "AsDiscreted",
|
| 22 |
+
"keys": [
|
| 23 |
+
"pred",
|
| 24 |
+
"label"
|
| 25 |
+
],
|
| 26 |
+
"argmax": [
|
| 27 |
+
true,
|
| 28 |
+
false
|
| 29 |
+
],
|
| 30 |
+
"to_onehot": 2
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"_target_": "SaveImaged",
|
| 34 |
+
"_disabled_": true,
|
| 35 |
+
"keys": "pred",
|
| 36 |
+
"meta_keys": "pred_meta_dict",
|
| 37 |
+
"output_dir": "@output_dir",
|
| 38 |
+
"output_ext": ".png",
|
| 39 |
+
"resample": false,
|
| 40 |
+
"squeeze_end_dims": true
|
| 41 |
+
}
|
| 42 |
+
]
|
| 43 |
+
},
|
| 44 |
+
"validate#handlers": [
|
| 45 |
+
{
|
| 46 |
+
"_target_": "CheckpointLoader",
|
| 47 |
+
"load_path": "$@ckpt_dir + '/model.pt'",
|
| 48 |
+
"load_dict": {
|
| 49 |
+
"model": "@network"
|
| 50 |
+
},
|
| 51 |
+
"map_location": "@device"
|
| 52 |
+
},
|
| 53 |
+
{
|
| 54 |
+
"_target_": "StatsHandler",
|
| 55 |
+
"iteration_log": false
|
| 56 |
+
},
|
| 57 |
+
{
|
| 58 |
+
"_target_": "MetricsSaver",
|
| 59 |
+
"save_dir": "@output_dir",
|
| 60 |
+
"metrics": [
|
| 61 |
+
"val_iou",
|
| 62 |
+
"val_mean_dice"
|
| 63 |
+
],
|
| 64 |
+
"metric_details": [
|
| 65 |
+
"val_iou",
|
| 66 |
+
"val_mean_dice"
|
| 67 |
+
],
|
| 68 |
+
"batch_transform": "$monai.handlers.from_engine(['image_meta_dict'])",
|
| 69 |
+
"summary_ops": "*"
|
| 70 |
+
}
|
| 71 |
+
],
|
| 72 |
+
"run": [
|
| 73 |
+
"$@validate#evaluator.run()"
|
| 74 |
+
]
|
| 75 |
+
}
|
configs/inference.json
ADDED
|
@@ -0,0 +1,149 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"imports": [
|
| 3 |
+
"$import glob",
|
| 4 |
+
"$import numpy",
|
| 5 |
+
"$import os"
|
| 6 |
+
],
|
| 7 |
+
"bundle_root": ".",
|
| 8 |
+
"image_key": "image",
|
| 9 |
+
"output_dir": "$@bundle_root + '/eval'",
|
| 10 |
+
"output_ext": ".png",
|
| 11 |
+
"output_dtype": "$numpy.float32",
|
| 12 |
+
"output_postfix": "trans",
|
| 13 |
+
"separate_folder": true,
|
| 14 |
+
"load_pretrain": true,
|
| 15 |
+
"dataset_dir": "/workspace/data/endoscopic_tool_dataset",
|
| 16 |
+
"datalist": "$list(sorted(glob.glob(os.path.join(@dataset_dir,'test', '*', '*[!seg].jpg'))))",
|
| 17 |
+
"device": "$torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')",
|
| 18 |
+
"network_def": {
|
| 19 |
+
"_target_": "FlexibleUNet",
|
| 20 |
+
"in_channels": 3,
|
| 21 |
+
"out_channels": 2,
|
| 22 |
+
"backbone": "efficientnet-b2",
|
| 23 |
+
"spatial_dims": 2,
|
| 24 |
+
"pretrained": false,
|
| 25 |
+
"is_pad": false,
|
| 26 |
+
"pre_conv": null
|
| 27 |
+
},
|
| 28 |
+
"network": "$@network_def.to(@device)",
|
| 29 |
+
"preprocessing": {
|
| 30 |
+
"_target_": "Compose",
|
| 31 |
+
"transforms": [
|
| 32 |
+
{
|
| 33 |
+
"_target_": "LoadImaged",
|
| 34 |
+
"keys": "@image_key",
|
| 35 |
+
"image_only": false
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
"_target_": "EnsureChannelFirstd",
|
| 39 |
+
"keys": "@image_key",
|
| 40 |
+
"channel_dim": -1
|
| 41 |
+
},
|
| 42 |
+
{
|
| 43 |
+
"_target_": "Resized",
|
| 44 |
+
"keys": [
|
| 45 |
+
"@image_key"
|
| 46 |
+
],
|
| 47 |
+
"spatial_size": [
|
| 48 |
+
736,
|
| 49 |
+
480
|
| 50 |
+
],
|
| 51 |
+
"mode": [
|
| 52 |
+
"bilinear"
|
| 53 |
+
]
|
| 54 |
+
},
|
| 55 |
+
{
|
| 56 |
+
"_target_": "ScaleIntensityd",
|
| 57 |
+
"keys": [
|
| 58 |
+
"@image_key"
|
| 59 |
+
]
|
| 60 |
+
}
|
| 61 |
+
]
|
| 62 |
+
},
|
| 63 |
+
"dataset": {
|
| 64 |
+
"_target_": "Dataset",
|
| 65 |
+
"data": "$[{'image': i} for i in @datalist]",
|
| 66 |
+
"transform": "@preprocessing"
|
| 67 |
+
},
|
| 68 |
+
"dataloader": {
|
| 69 |
+
"_target_": "DataLoader",
|
| 70 |
+
"dataset": "@dataset",
|
| 71 |
+
"batch_size": 1,
|
| 72 |
+
"shuffle": false,
|
| 73 |
+
"num_workers": 4
|
| 74 |
+
},
|
| 75 |
+
"inferer": {
|
| 76 |
+
"_target_": "SimpleInferer"
|
| 77 |
+
},
|
| 78 |
+
"postprocessing": {
|
| 79 |
+
"_target_": "Compose",
|
| 80 |
+
"transforms": [
|
| 81 |
+
{
|
| 82 |
+
"_target_": "Invertd",
|
| 83 |
+
"keys": "pred",
|
| 84 |
+
"transform": "@preprocessing",
|
| 85 |
+
"orig_keys": "@image_key",
|
| 86 |
+
"meta_key_postfix": "meta_dict",
|
| 87 |
+
"nearest_interp": false,
|
| 88 |
+
"to_tensor": true
|
| 89 |
+
},
|
| 90 |
+
{
|
| 91 |
+
"_target_": "AsDiscreted",
|
| 92 |
+
"argmax": true,
|
| 93 |
+
"to_onehot": 2,
|
| 94 |
+
"keys": [
|
| 95 |
+
"pred"
|
| 96 |
+
]
|
| 97 |
+
},
|
| 98 |
+
{
|
| 99 |
+
"_target_": "Lambdad",
|
| 100 |
+
"keys": [
|
| 101 |
+
"pred"
|
| 102 |
+
],
|
| 103 |
+
"func": "$lambda x : x[1:]"
|
| 104 |
+
},
|
| 105 |
+
{
|
| 106 |
+
"_target_": "SaveImaged",
|
| 107 |
+
"keys": "pred",
|
| 108 |
+
"meta_keys": "pred_meta_dict",
|
| 109 |
+
"output_dir": "@output_dir",
|
| 110 |
+
"output_ext": "@output_ext",
|
| 111 |
+
"output_dtype": "@output_dtype",
|
| 112 |
+
"output_postfix": "@output_postfix",
|
| 113 |
+
"separate_folder": "@separate_folder",
|
| 114 |
+
"scale": 255,
|
| 115 |
+
"squeeze_end_dims": true
|
| 116 |
+
}
|
| 117 |
+
]
|
| 118 |
+
},
|
| 119 |
+
"handlers": [
|
| 120 |
+
{
|
| 121 |
+
"_target_": "StatsHandler",
|
| 122 |
+
"iteration_log": false
|
| 123 |
+
}
|
| 124 |
+
],
|
| 125 |
+
"evaluator": {
|
| 126 |
+
"_target_": "SupervisedEvaluator",
|
| 127 |
+
"device": "@device",
|
| 128 |
+
"val_data_loader": "@dataloader",
|
| 129 |
+
"network": "@network",
|
| 130 |
+
"inferer": "@inferer",
|
| 131 |
+
"postprocessing": "@postprocessing",
|
| 132 |
+
"val_handlers": "@handlers"
|
| 133 |
+
},
|
| 134 |
+
"checkpointloader": {
|
| 135 |
+
"_target_": "CheckpointLoader",
|
| 136 |
+
"load_path": "$@bundle_root + '/models/model.pt'",
|
| 137 |
+
"load_dict": {
|
| 138 |
+
"model": "@network"
|
| 139 |
+
},
|
| 140 |
+
"map_location": "@device"
|
| 141 |
+
},
|
| 142 |
+
"initialize": [
|
| 143 |
+
"$monai.utils.set_determinism(seed=123)",
|
| 144 |
+
"$@checkpointloader(@evaluator) if @load_pretrain else None"
|
| 145 |
+
],
|
| 146 |
+
"run": [
|
| 147 |
+
"[email protected]()"
|
| 148 |
+
]
|
| 149 |
+
}
|
configs/inference_trt.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"imports": [
|
| 3 |
+
"$import glob",
|
| 4 |
+
"$import os",
|
| 5 |
+
"$import torch_tensorrt"
|
| 6 |
+
],
|
| 7 |
+
"network_def": "$torch.jit.load(@bundle_root + '/models/model_trt.ts')",
|
| 8 |
+
"evaluator#amp": false,
|
| 9 |
+
"initialize": [
|
| 10 |
+
"$monai.utils.set_determinism(seed=123)"
|
| 11 |
+
]
|
| 12 |
+
}
|
configs/logging.conf
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[loggers]
|
| 2 |
+
keys=root
|
| 3 |
+
|
| 4 |
+
[handlers]
|
| 5 |
+
keys=consoleHandler
|
| 6 |
+
|
| 7 |
+
[formatters]
|
| 8 |
+
keys=fullFormatter
|
| 9 |
+
|
| 10 |
+
[logger_root]
|
| 11 |
+
level=INFO
|
| 12 |
+
handlers=consoleHandler
|
| 13 |
+
|
| 14 |
+
[handler_consoleHandler]
|
| 15 |
+
class=StreamHandler
|
| 16 |
+
level=INFO
|
| 17 |
+
formatter=fullFormatter
|
| 18 |
+
args=(sys.stdout,)
|
| 19 |
+
|
| 20 |
+
[formatter_fullFormatter]
|
| 21 |
+
format=%(asctime)s - %(name)s - %(levelname)s - %(message)s
|
configs/metadata.json
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_20240725.json",
|
| 3 |
+
"version": "0.6.1",
|
| 4 |
+
"changelog": {
|
| 5 |
+
"0.6.1": "update to huggingface hosting and fix missing dependencies",
|
| 6 |
+
"0.6.0": "use monai 1.4 and update large files",
|
| 7 |
+
"0.5.9": "update to use monai 1.3.1",
|
| 8 |
+
"0.5.8": "add load_pretrain flag for infer",
|
| 9 |
+
"0.5.7": "add checkpoint loader for infer",
|
| 10 |
+
"0.5.6": "update to use monai 1.3.0",
|
| 11 |
+
"0.5.5": "update AddChanneld with EnsureChannelFirstd and set image_only to False",
|
| 12 |
+
"0.5.4": "fix the wrong GPU index issue of multi-node",
|
| 13 |
+
"0.5.3": "remove error dollar symbol in readme",
|
| 14 |
+
"0.5.2": "remove the CheckpointLoader from the train.json",
|
| 15 |
+
"0.5.1": "add RAM warning",
|
| 16 |
+
"0.5.0": "update TensorRT descriptions",
|
| 17 |
+
"0.4.9": "update the model weights",
|
| 18 |
+
"0.4.8": "update the TensorRT part in the README file",
|
| 19 |
+
"0.4.7": "fix mgpu finalize issue",
|
| 20 |
+
"0.4.6": "enable deterministic training",
|
| 21 |
+
"0.4.5": "add the command of executing inference with TensorRT models",
|
| 22 |
+
"0.4.4": "adapt to BundleWorkflow interface",
|
| 23 |
+
"0.4.3": "update this bundle to support TensorRT convert",
|
| 24 |
+
"0.4.2": "support monai 1.2 new FlexibleUNet",
|
| 25 |
+
"0.4.1": "add name tag",
|
| 26 |
+
"0.4.0": "add support for multi-GPU training and evaluation",
|
| 27 |
+
"0.3.2": "restructure readme to match updated template",
|
| 28 |
+
"0.3.1": "add figures of workflow and metrics, add invert transform",
|
| 29 |
+
"0.3.0": "update dataset processing",
|
| 30 |
+
"0.2.1": "update to use monai 1.0.1",
|
| 31 |
+
"0.2.0": "update license files",
|
| 32 |
+
"0.1.0": "complete the first version model package",
|
| 33 |
+
"0.0.1": "initialize the model package structure"
|
| 34 |
+
},
|
| 35 |
+
"monai_version": "1.4.0",
|
| 36 |
+
"pytorch_version": "2.4.0",
|
| 37 |
+
"numpy_version": "1.24.4",
|
| 38 |
+
"required_packages_version": {
|
| 39 |
+
"nibabel": "5.2.1",
|
| 40 |
+
"pytorch-ignite": "0.4.11",
|
| 41 |
+
"pillow": "10.4.0",
|
| 42 |
+
"tensorboard": "2.17.0"
|
| 43 |
+
},
|
| 44 |
+
"supported_apps": {},
|
| 45 |
+
"name": "Endoscopic tool segmentation",
|
| 46 |
+
"task": "Endoscopic tool segmentation",
|
| 47 |
+
"description": "A pre-trained binary segmentation model for endoscopic tool segmentation",
|
| 48 |
+
"authors": "NVIDIA DLMED team",
|
| 49 |
+
"copyright": "Copyright (c) 2021-2022, NVIDIA CORPORATION",
|
| 50 |
+
"data_source": "private dataset",
|
| 51 |
+
"data_type": "RGB",
|
| 52 |
+
"image_classes": "three channel data, intensity [0-255]",
|
| 53 |
+
"label_classes": "single channel data, 1/255 is tool, 0 is background",
|
| 54 |
+
"pred_classes": "2 channels OneHot data, channel 1 is tool, channel 0 is background",
|
| 55 |
+
"eval_metrics": {
|
| 56 |
+
"mean_iou": 0.86
|
| 57 |
+
},
|
| 58 |
+
"references": [
|
| 59 |
+
"Tan, M. and Le, Q. V. Efficientnet: Rethinking model scaling for convolutional neural networks. ICML, 2019a. https://arxiv.org/pdf/1905.11946.pdf",
|
| 60 |
+
"O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234\u2013241. Springer, 2015. https://arxiv.org/pdf/1505.04597.pdf"
|
| 61 |
+
],
|
| 62 |
+
"network_data_format": {
|
| 63 |
+
"inputs": {
|
| 64 |
+
"image": {
|
| 65 |
+
"type": "magnitude",
|
| 66 |
+
"format": "RGB",
|
| 67 |
+
"modality": "regular",
|
| 68 |
+
"num_channels": 3,
|
| 69 |
+
"spatial_shape": [
|
| 70 |
+
736,
|
| 71 |
+
480
|
| 72 |
+
],
|
| 73 |
+
"dtype": "float32",
|
| 74 |
+
"value_range": [
|
| 75 |
+
0,
|
| 76 |
+
1
|
| 77 |
+
],
|
| 78 |
+
"is_patch_data": false,
|
| 79 |
+
"channel_def": {
|
| 80 |
+
"0": "R",
|
| 81 |
+
"1": "G",
|
| 82 |
+
"2": "B"
|
| 83 |
+
}
|
| 84 |
+
}
|
| 85 |
+
},
|
| 86 |
+
"outputs": {
|
| 87 |
+
"pred": {
|
| 88 |
+
"type": "image",
|
| 89 |
+
"format": "segmentation",
|
| 90 |
+
"num_channels": 2,
|
| 91 |
+
"spatial_shape": [
|
| 92 |
+
736,
|
| 93 |
+
480
|
| 94 |
+
],
|
| 95 |
+
"dtype": "float32",
|
| 96 |
+
"value_range": [
|
| 97 |
+
0,
|
| 98 |
+
1
|
| 99 |
+
],
|
| 100 |
+
"is_patch_data": false,
|
| 101 |
+
"channel_def": {
|
| 102 |
+
"0": "background",
|
| 103 |
+
"1": "tools"
|
| 104 |
+
}
|
| 105 |
+
}
|
| 106 |
+
}
|
| 107 |
+
}
|
| 108 |
+
}
|
configs/multi_gpu_evaluate.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"device": "$torch.device('cuda:' + os.environ['LOCAL_RANK'])",
|
| 3 |
+
"network": {
|
| 4 |
+
"_target_": "torch.nn.parallel.DistributedDataParallel",
|
| 5 |
+
"module": "$@network_def.to(@device)",
|
| 6 |
+
"device_ids": [
|
| 7 |
+
"@device"
|
| 8 |
+
]
|
| 9 |
+
},
|
| 10 |
+
"validate#sampler": {
|
| 11 |
+
"_target_": "DistributedSampler",
|
| 12 |
+
"dataset": "@validate#dataset",
|
| 13 |
+
"even_divisible": false,
|
| 14 |
+
"shuffle": false
|
| 15 |
+
},
|
| 16 |
+
"validate#dataloader#sampler": "@validate#sampler",
|
| 17 |
+
"validate#handlers#1#_disabled_": "$dist.get_rank() > 0",
|
| 18 |
+
"initialize": [
|
| 19 |
+
"$import torch.distributed as dist",
|
| 20 |
+
"$dist.is_initialized() or dist.init_process_group(backend='nccl')",
|
| 21 |
+
"$torch.cuda.set_device(@device)",
|
| 22 |
+
"$import logging",
|
| 23 |
+
"$@validate#evaluator.logger.setLevel(logging.WARNING if dist.get_rank() > 0 else logging.INFO)"
|
| 24 |
+
],
|
| 25 |
+
"run": [
|
| 26 |
+
"$@validate#evaluator.run()"
|
| 27 |
+
],
|
| 28 |
+
"finalize": [
|
| 29 |
+
"$dist.is_initialized() and dist.destroy_process_group()"
|
| 30 |
+
]
|
| 31 |
+
}
|
configs/multi_gpu_train.json
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"device": "$torch.device('cuda:' + os.environ['LOCAL_RANK'])",
|
| 3 |
+
"network": {
|
| 4 |
+
"_target_": "torch.nn.parallel.DistributedDataParallel",
|
| 5 |
+
"module": "$@network_def.to(@device)",
|
| 6 |
+
"device_ids": [
|
| 7 |
+
"@device"
|
| 8 |
+
],
|
| 9 |
+
"find_unused_parameters": true
|
| 10 |
+
},
|
| 11 |
+
"train#sampler": {
|
| 12 |
+
"_target_": "DistributedSampler",
|
| 13 |
+
"dataset": "@train#dataset",
|
| 14 |
+
"even_divisible": true,
|
| 15 |
+
"shuffle": true
|
| 16 |
+
},
|
| 17 |
+
"train#dataloader#sampler": "@train#sampler",
|
| 18 |
+
"train#dataloader#shuffle": false,
|
| 19 |
+
"train#trainer#train_handlers": "$@train#handlers[: -2 if dist.get_rank() > 0 else None]",
|
| 20 |
+
"validate#sampler": {
|
| 21 |
+
"_target_": "DistributedSampler",
|
| 22 |
+
"dataset": "@validate#dataset",
|
| 23 |
+
"even_divisible": false,
|
| 24 |
+
"shuffle": false
|
| 25 |
+
},
|
| 26 |
+
"validate#dataloader#sampler": "@validate#sampler",
|
| 27 |
+
"validate#evaluator#val_handlers": "$None if dist.get_rank() > 0 else @validate#handlers",
|
| 28 |
+
"initialize": [
|
| 29 |
+
"$import torch.distributed as dist",
|
| 30 |
+
"$dist.is_initialized() or dist.init_process_group(backend='nccl')",
|
| 31 |
+
"$torch.cuda.set_device(@device)",
|
| 32 |
+
"$monai.utils.set_determinism(seed=123)",
|
| 33 |
+
"$import logging",
|
| 34 |
+
"$@train#trainer.logger.setLevel(logging.WARNING if dist.get_rank() > 0 else logging.INFO)",
|
| 35 |
+
"$@validate#evaluator.logger.setLevel(logging.WARNING if dist.get_rank() > 0 else logging.INFO)"
|
| 36 |
+
],
|
| 37 |
+
"run": [
|
| 38 |
+
"$@train#trainer.run()"
|
| 39 |
+
],
|
| 40 |
+
"finalize": [
|
| 41 |
+
"$dist.is_initialized() and dist.destroy_process_group()"
|
| 42 |
+
]
|
| 43 |
+
}
|
configs/train.json
ADDED
|
@@ -0,0 +1,287 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"imports": [
|
| 3 |
+
"$import glob",
|
| 4 |
+
"$import os",
|
| 5 |
+
"$import torch",
|
| 6 |
+
"$import numpy as np"
|
| 7 |
+
],
|
| 8 |
+
"bundle_root": ".",
|
| 9 |
+
"use_imagenet_pretrain": false,
|
| 10 |
+
"ckpt_dir": "$@bundle_root + '/models'",
|
| 11 |
+
"output_dir": "$@bundle_root + '/eval'",
|
| 12 |
+
"dataset_dir": "/workspace/data/endoscopic_tool_dataset",
|
| 13 |
+
"images": "$list(sorted(glob.glob(os.path.join(@dataset_dir,'train', '*', '*[!seg].jpg'))))",
|
| 14 |
+
"labels": "$[x.replace('.jpg', '_seg.jpg') for x in @images]",
|
| 15 |
+
"val_images": "$list(sorted(glob.glob(os.path.join(@dataset_dir,'val', '*', '*[!seg].jpg'))))",
|
| 16 |
+
"val_labels": "$[x.replace('.jpg', '_seg.jpg') for x in @val_images]",
|
| 17 |
+
"val_interval": 1,
|
| 18 |
+
"device": "$torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')",
|
| 19 |
+
"network_def": {
|
| 20 |
+
"_target_": "FlexibleUNet",
|
| 21 |
+
"in_channels": 3,
|
| 22 |
+
"out_channels": 2,
|
| 23 |
+
"backbone": "efficientnet-b2",
|
| 24 |
+
"spatial_dims": 2,
|
| 25 |
+
"dropout": 0.6,
|
| 26 |
+
"pretrained": "@use_imagenet_pretrain",
|
| 27 |
+
"is_pad": false,
|
| 28 |
+
"pre_conv": null
|
| 29 |
+
},
|
| 30 |
+
"network": "$@network_def.to(@device)",
|
| 31 |
+
"loss": {
|
| 32 |
+
"_target_": "DiceFocalLoss",
|
| 33 |
+
"include_background": false,
|
| 34 |
+
"to_onehot_y": true,
|
| 35 |
+
"softmax": true,
|
| 36 |
+
"jaccard": true
|
| 37 |
+
},
|
| 38 |
+
"optimizer": {
|
| 39 |
+
"_target_": "torch.optim.Adam",
|
| 40 |
+
"params": "[email protected]()",
|
| 41 |
+
"lr": 0.0001
|
| 42 |
+
},
|
| 43 |
+
"lr_scheduler": {
|
| 44 |
+
"_target_": "torch.optim.lr_scheduler.CosineAnnealingWarmRestarts",
|
| 45 |
+
"optimizer": "@optimizer",
|
| 46 |
+
"T_0": 100,
|
| 47 |
+
"T_mult": 1
|
| 48 |
+
},
|
| 49 |
+
"train": {
|
| 50 |
+
"deterministic_transforms": [
|
| 51 |
+
{
|
| 52 |
+
"_target_": "LoadImaged",
|
| 53 |
+
"keys": [
|
| 54 |
+
"image",
|
| 55 |
+
"label"
|
| 56 |
+
],
|
| 57 |
+
"image_only": false
|
| 58 |
+
},
|
| 59 |
+
{
|
| 60 |
+
"_target_": "EnsureChannelFirstd",
|
| 61 |
+
"keys": "image",
|
| 62 |
+
"channel_dim": -1
|
| 63 |
+
},
|
| 64 |
+
{
|
| 65 |
+
"_target_": "EnsureChannelFirstd",
|
| 66 |
+
"keys": "label",
|
| 67 |
+
"channel_dim": "no_channel"
|
| 68 |
+
},
|
| 69 |
+
{
|
| 70 |
+
"_target_": "Resized",
|
| 71 |
+
"keys": [
|
| 72 |
+
"image",
|
| 73 |
+
"label"
|
| 74 |
+
],
|
| 75 |
+
"spatial_size": [
|
| 76 |
+
736,
|
| 77 |
+
480
|
| 78 |
+
],
|
| 79 |
+
"mode": [
|
| 80 |
+
"bilinear",
|
| 81 |
+
"nearest"
|
| 82 |
+
]
|
| 83 |
+
},
|
| 84 |
+
{
|
| 85 |
+
"_target_": "ScaleIntensityd",
|
| 86 |
+
"keys": [
|
| 87 |
+
"image",
|
| 88 |
+
"label"
|
| 89 |
+
]
|
| 90 |
+
}
|
| 91 |
+
],
|
| 92 |
+
"random_transforms": [
|
| 93 |
+
{
|
| 94 |
+
"_target_": "RandRotated",
|
| 95 |
+
"keys": [
|
| 96 |
+
"image",
|
| 97 |
+
"label"
|
| 98 |
+
],
|
| 99 |
+
"range_x": "$np.pi",
|
| 100 |
+
"prob": 0.8,
|
| 101 |
+
"mode": [
|
| 102 |
+
"bilinear",
|
| 103 |
+
"nearest"
|
| 104 |
+
]
|
| 105 |
+
},
|
| 106 |
+
{
|
| 107 |
+
"_target_": "RandZoomd",
|
| 108 |
+
"keys": [
|
| 109 |
+
"image",
|
| 110 |
+
"label"
|
| 111 |
+
],
|
| 112 |
+
"min_zoom": 0.8,
|
| 113 |
+
"max_zoom": 1.2,
|
| 114 |
+
"prob": 0.2,
|
| 115 |
+
"mode": [
|
| 116 |
+
"bilinear",
|
| 117 |
+
"nearest"
|
| 118 |
+
]
|
| 119 |
+
}
|
| 120 |
+
],
|
| 121 |
+
"preprocessing": {
|
| 122 |
+
"_target_": "Compose",
|
| 123 |
+
"transforms": "$@train#deterministic_transforms + @train#random_transforms"
|
| 124 |
+
},
|
| 125 |
+
"dataset": {
|
| 126 |
+
"_target_": "CacheDataset",
|
| 127 |
+
"data": "$[{'image': i, 'label': l} for i, l in zip(@images, @labels)]",
|
| 128 |
+
"transform": "@train#preprocessing",
|
| 129 |
+
"cache_rate": 0.5,
|
| 130 |
+
"num_workers": 4
|
| 131 |
+
},
|
| 132 |
+
"dataloader": {
|
| 133 |
+
"_target_": "DataLoader",
|
| 134 |
+
"dataset": "@train#dataset",
|
| 135 |
+
"batch_size": 8,
|
| 136 |
+
"shuffle": true,
|
| 137 |
+
"num_workers": 4
|
| 138 |
+
},
|
| 139 |
+
"inferer": {
|
| 140 |
+
"_target_": "SimpleInferer"
|
| 141 |
+
},
|
| 142 |
+
"handlers": [
|
| 143 |
+
{
|
| 144 |
+
"_target_": "ValidationHandler",
|
| 145 |
+
"validator": "@validate#evaluator",
|
| 146 |
+
"epoch_level": true,
|
| 147 |
+
"interval": "@val_interval"
|
| 148 |
+
},
|
| 149 |
+
{
|
| 150 |
+
"_target_": "StatsHandler",
|
| 151 |
+
"tag_name": "train_loss",
|
| 152 |
+
"output_transform": "$monai.handlers.from_engine(['loss'], first=True)"
|
| 153 |
+
},
|
| 154 |
+
{
|
| 155 |
+
"_target_": "TensorBoardStatsHandler",
|
| 156 |
+
"log_dir": "@output_dir",
|
| 157 |
+
"tag_name": "train_loss",
|
| 158 |
+
"output_transform": "$monai.handlers.from_engine(['loss'], first=True)"
|
| 159 |
+
},
|
| 160 |
+
{
|
| 161 |
+
"_target_": "LrScheduleHandler",
|
| 162 |
+
"lr_scheduler": "@lr_scheduler",
|
| 163 |
+
"print_lr": true
|
| 164 |
+
}
|
| 165 |
+
],
|
| 166 |
+
"key_metric": {
|
| 167 |
+
"train_iou": {
|
| 168 |
+
"_target_": "MeanIoUHandler",
|
| 169 |
+
"include_background": false,
|
| 170 |
+
"reduction": "mean",
|
| 171 |
+
"output_transform": "$monai.handlers.from_engine(['pred', 'label'])"
|
| 172 |
+
}
|
| 173 |
+
},
|
| 174 |
+
"postprocessing": {
|
| 175 |
+
"_target_": "Compose",
|
| 176 |
+
"transforms": [
|
| 177 |
+
{
|
| 178 |
+
"_target_": "AsDiscreted",
|
| 179 |
+
"argmax": [
|
| 180 |
+
true,
|
| 181 |
+
false
|
| 182 |
+
],
|
| 183 |
+
"to_onehot": [
|
| 184 |
+
2,
|
| 185 |
+
2
|
| 186 |
+
],
|
| 187 |
+
"keys": [
|
| 188 |
+
"pred",
|
| 189 |
+
"label"
|
| 190 |
+
]
|
| 191 |
+
}
|
| 192 |
+
]
|
| 193 |
+
},
|
| 194 |
+
"trainer": {
|
| 195 |
+
"_target_": "SupervisedTrainer",
|
| 196 |
+
"max_epochs": 100,
|
| 197 |
+
"device": "@device",
|
| 198 |
+
"train_data_loader": "@train#dataloader",
|
| 199 |
+
"network": "@network",
|
| 200 |
+
"loss_function": "@loss",
|
| 201 |
+
"optimizer": "@optimizer",
|
| 202 |
+
"inferer": "@train#inferer",
|
| 203 |
+
"postprocessing": "@train#postprocessing",
|
| 204 |
+
"key_train_metric": "@train#key_metric",
|
| 205 |
+
"train_handlers": "@train#handlers"
|
| 206 |
+
}
|
| 207 |
+
},
|
| 208 |
+
"validate": {
|
| 209 |
+
"preprocessing": {
|
| 210 |
+
"_target_": "Compose",
|
| 211 |
+
"transforms": "%train#deterministic_transforms"
|
| 212 |
+
},
|
| 213 |
+
"dataset": {
|
| 214 |
+
"_target_": "CacheDataset",
|
| 215 |
+
"data": "$[{'image': i, 'label': l} for i, l in zip(@val_images, @val_labels)]",
|
| 216 |
+
"transform": "@validate#preprocessing",
|
| 217 |
+
"cache_rate": 1.0
|
| 218 |
+
},
|
| 219 |
+
"dataloader": {
|
| 220 |
+
"_target_": "DataLoader",
|
| 221 |
+
"dataset": "@validate#dataset",
|
| 222 |
+
"batch_size": 8,
|
| 223 |
+
"shuffle": false,
|
| 224 |
+
"num_workers": 4
|
| 225 |
+
},
|
| 226 |
+
"inferer": {
|
| 227 |
+
"_target_": "SimpleInferer"
|
| 228 |
+
},
|
| 229 |
+
"postprocessing": {
|
| 230 |
+
"_target_": "Compose",
|
| 231 |
+
"transforms": "%train#postprocessing"
|
| 232 |
+
},
|
| 233 |
+
"handlers": [
|
| 234 |
+
{
|
| 235 |
+
"_target_": "StatsHandler",
|
| 236 |
+
"iteration_log": false
|
| 237 |
+
},
|
| 238 |
+
{
|
| 239 |
+
"_target_": "TensorBoardStatsHandler",
|
| 240 |
+
"log_dir": "@output_dir",
|
| 241 |
+
"iteration_log": false
|
| 242 |
+
},
|
| 243 |
+
{
|
| 244 |
+
"_target_": "CheckpointSaver",
|
| 245 |
+
"save_dir": "@ckpt_dir",
|
| 246 |
+
"save_dict": {
|
| 247 |
+
"model": "@network"
|
| 248 |
+
},
|
| 249 |
+
"save_key_metric": true,
|
| 250 |
+
"key_metric_filename": "model.pt"
|
| 251 |
+
}
|
| 252 |
+
],
|
| 253 |
+
"additional_metrics": {
|
| 254 |
+
"val_mean_dice": {
|
| 255 |
+
"_target_": "MeanDice",
|
| 256 |
+
"include_background": false,
|
| 257 |
+
"reduction": "mean",
|
| 258 |
+
"output_transform": "$monai.handlers.from_engine(['pred', 'label'])"
|
| 259 |
+
}
|
| 260 |
+
},
|
| 261 |
+
"key_metric": {
|
| 262 |
+
"val_iou": {
|
| 263 |
+
"_target_": "MeanIoUHandler",
|
| 264 |
+
"include_background": false,
|
| 265 |
+
"reduction": "mean",
|
| 266 |
+
"output_transform": "$monai.handlers.from_engine(['pred', 'label'])"
|
| 267 |
+
}
|
| 268 |
+
},
|
| 269 |
+
"evaluator": {
|
| 270 |
+
"_target_": "SupervisedEvaluator",
|
| 271 |
+
"device": "@device",
|
| 272 |
+
"val_data_loader": "@validate#dataloader",
|
| 273 |
+
"network": "@network",
|
| 274 |
+
"inferer": "@validate#inferer",
|
| 275 |
+
"postprocessing": "@validate#postprocessing",
|
| 276 |
+
"key_val_metric": "@validate#key_metric",
|
| 277 |
+
"additional_metrics": "@validate#additional_metrics",
|
| 278 |
+
"val_handlers": "@validate#handlers"
|
| 279 |
+
}
|
| 280 |
+
},
|
| 281 |
+
"initialize": [
|
| 282 |
+
"$monai.utils.set_determinism(seed=123)"
|
| 283 |
+
],
|
| 284 |
+
"run": [
|
| 285 |
+
"$@train#trainer.run()"
|
| 286 |
+
]
|
| 287 |
+
}
|
docs/README.md
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Model Overview
|
| 2 |
+
A pre-trained model for the endoscopic tool segmentation task, trained using a flexible unet structure with an efficientnet-b2 [1] as the backbone and a UNet architecture [2] as the decoder. Datasets use private samples from [Activ Surgical](https://www.activsurgical.com/).
|
| 3 |
+
|
| 4 |
+
The [PyTorch model](https://drive.google.com/file/d/1I7UtWDKDEcezMqYiA-i_hsRTCrvWwJ61/view?usp=sharing) and [torchscript model](https://drive.google.com/file/d/1e_wYd1HjJQ0dz_HKdbthRcMOyUL02aLG/view?usp=sharing) are shared in google drive. Details can be found in `large_files.yml` file. Modify the "bundle_root" parameter specified in configs/train.json and configs/inference.json to reflect where models are downloaded. Expected directory path to place downloaded models is "models/" under "bundle_root".
|
| 5 |
+
|
| 6 |
+
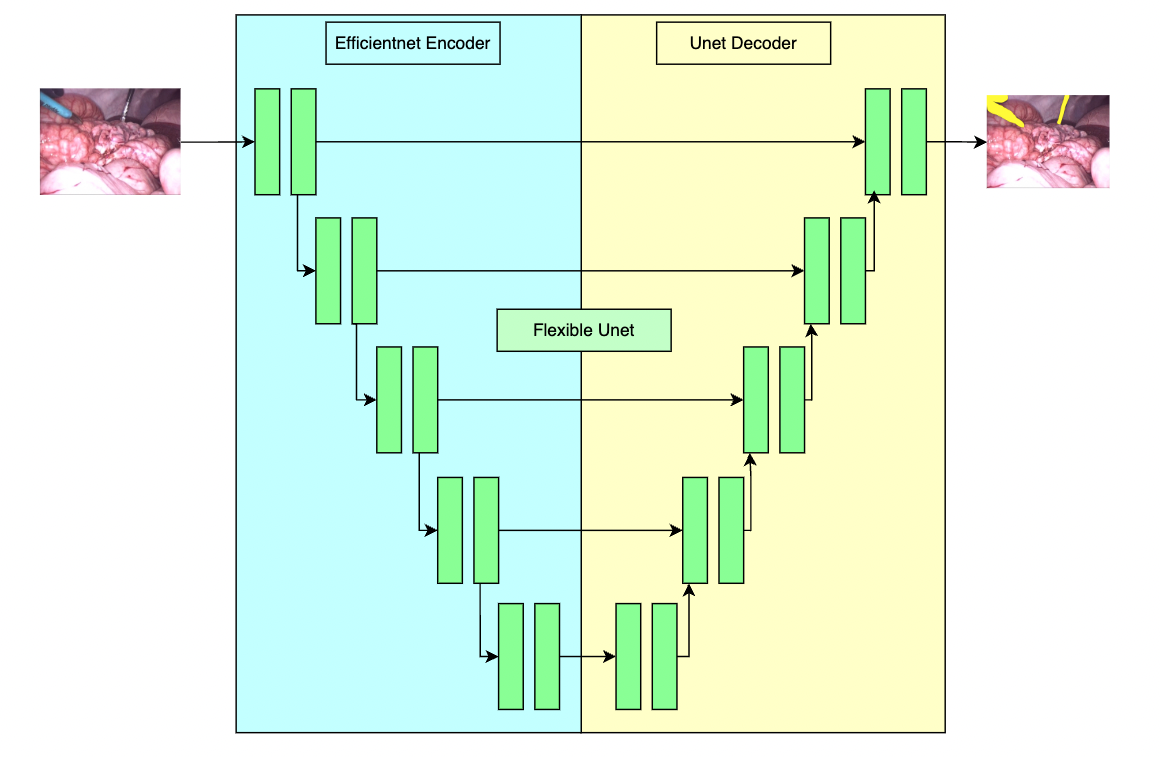
|
| 7 |
+
|
| 8 |
+
## Pre-trained weights
|
| 9 |
+
A pre-trained encoder weights would benefit the model training. In this bundle, the encoder is trained with pre-trained weights from some internal data. We provide two options to enable users to load pre-trained weights:
|
| 10 |
+
|
| 11 |
+
1. Via setting the `use_imagenet_pretrain` parameter in the config file to `True`, [ImageNet](https://ieeexplore.ieee.org/document/5206848) pre-trained weights from the [EfficientNet-PyTorch repo](https://github.com/lukemelas/EfficientNet-PyTorch) can be loaded. Please note that these weights are for non-commercial use. Each user is responsible for checking the content of the models/datasets and the applicable licenses and determining if suitable for the intended use.
|
| 12 |
+
2. Via adding a `CheckpointLoader` as the first handler to the `handlers` section of the `train.json` config file, weights from a local path can be loaded. Here is an example `CheckpointLoader`:
|
| 13 |
+
|
| 14 |
+
```json
|
| 15 |
+
{
|
| 16 |
+
"_target_": "CheckpointLoader",
|
| 17 |
+
"load_path": "/path/to/local/weight/model.pt",
|
| 18 |
+
"load_dict": {
|
| 19 |
+
"model": "@network"
|
| 20 |
+
},
|
| 21 |
+
"strict": false,
|
| 22 |
+
"map_location": "@device"
|
| 23 |
+
}
|
| 24 |
+
```
|
| 25 |
+
|
| 26 |
+
When executing the training command, if neither adding the `CheckpointLoader` to the `train.json` nor setting the `use_imagenet_pretrain` parameter to `True`, a training process would start from scratch.
|
| 27 |
+
|
| 28 |
+
## Data
|
| 29 |
+
Datasets used in this work were provided by [Activ Surgical](https://www.activsurgical.com/).
|
| 30 |
+
|
| 31 |
+
Since datasets are private, existing public datasets like [EndoVis 2017](https://endovissub2017-roboticinstrumentsegmentation.grand-challenge.org/Data/) can be used to train a similar model.
|
| 32 |
+
|
| 33 |
+
### Preprocessing
|
| 34 |
+
When using EndoVis or any other dataset, it should be divided into "train", "valid" and "test" folders. Samples in each folder would better be images and converted to jpg format. Otherwise, "images", "labels", "val_images" and "val_labels" parameters in `configs/train.json` and "datalist" in `configs/inference.json` should be modified to fit given dataset. After that, "dataset_dir" parameter in `configs/train.json` and `configs/inference.json` should be changed to root folder which contains "train", "valid" and "test" folders.
|
| 35 |
+
|
| 36 |
+
Please notice that loading data operation in this bundle is adaptive. If images and labels are not in the same format, it may lead to a mismatching problem. For example, if images are in jpg format and labels are in npy format, PIL and Numpy readers will be used separately to load images and labels. Since these two readers have their own way to parse file's shape, loaded labels will be transpose of the correct ones and incur a missmatching problem.
|
| 37 |
+
|
| 38 |
+
## Training configuration
|
| 39 |
+
The training as performed with the following:
|
| 40 |
+
- GPU: At least 12GB of GPU memory
|
| 41 |
+
- Actual Model Input: 736 x 480 x 3
|
| 42 |
+
- Optimizer: Adam
|
| 43 |
+
- Learning Rate: 1e-4
|
| 44 |
+
- Dataset Manager: CacheDataset
|
| 45 |
+
|
| 46 |
+
### Memory Consumption Warning
|
| 47 |
+
|
| 48 |
+
If you face memory issues with CacheDataset, you can either switch to a regular Dataset class or lower the caching rate `cache_rate` in the configurations within range [0, 1] to minimize the System RAM requirements.
|
| 49 |
+
|
| 50 |
+
### Input
|
| 51 |
+
A three channel video frame
|
| 52 |
+
|
| 53 |
+
### Output
|
| 54 |
+
Two channels:
|
| 55 |
+
- Label 1: tools
|
| 56 |
+
- Label 0: everything else
|
| 57 |
+
|
| 58 |
+
## Performance
|
| 59 |
+
IoU was used for evaluating the performance of the model. This model achieves a mean IoU score of 0.86.
|
| 60 |
+
|
| 61 |
+
#### Training Loss
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
#### Validation IoU
|
| 65 |
+
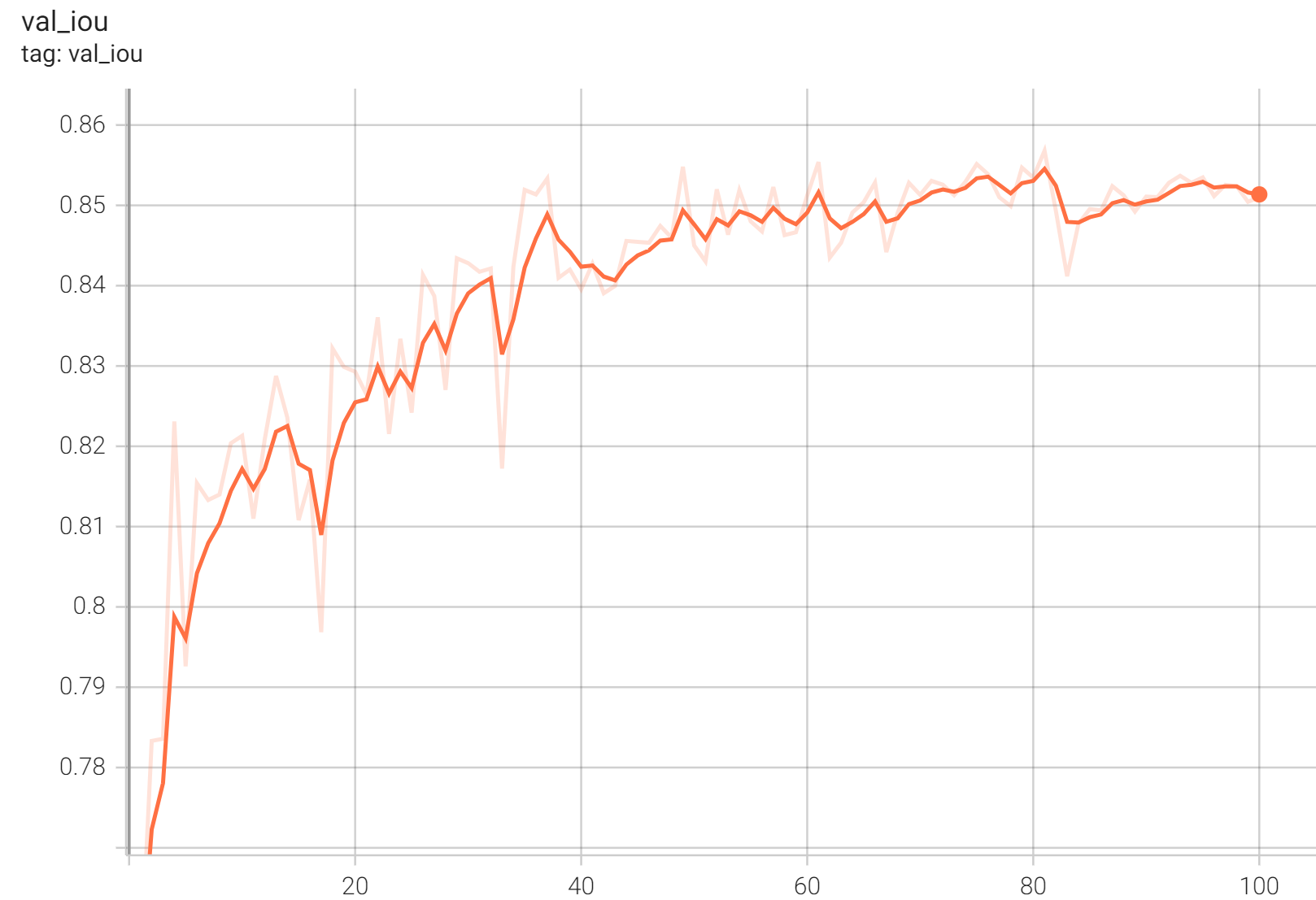
|
| 66 |
+
|
| 67 |
+
#### TensorRT speedup
|
| 68 |
+
The `endoscopic_tool_segmentation` bundle supports acceleration with TensorRT. The table below displays the speedup ratios observed on an A100 80G GPU.
|
| 69 |
+
|
| 70 |
+
| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
|
| 71 |
+
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
|
| 72 |
+
| model computation | 12.00 | 14.06 | 6.59 | 5.20 | 0.85 | 1.82 | 2.31 | 2.70 |
|
| 73 |
+
| end2end |170.04 | 172.20 | 155.26 | 155.57 | 0.99 | 1.10 | 1.09 | 1.11 |
|
| 74 |
+
|
| 75 |
+
Where:
|
| 76 |
+
- `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing
|
| 77 |
+
- `end2end` means run the bundle end-to-end with the TensorRT based model.
|
| 78 |
+
- `torch_fp32` and `torch_amp` are for the PyTorch models with or without `amp` mode.
|
| 79 |
+
- `trt_fp32` and `trt_fp16` are for the TensorRT based models converted in corresponding precision.
|
| 80 |
+
- `speedup amp`, `speedup fp32` and `speedup fp16` are the speedup ratios of corresponding models versus the PyTorch float32 model
|
| 81 |
+
- `amp vs fp16` is the speedup ratio between the PyTorch amp model and the TensorRT float16 based model.
|
| 82 |
+
|
| 83 |
+
This result is benchmarked under:
|
| 84 |
+
- TensorRT: 8.5.3+cuda11.8
|
| 85 |
+
- Torch-TensorRT Version: 1.4.0
|
| 86 |
+
- CPU Architecture: x86-64
|
| 87 |
+
- OS: ubuntu 20.04
|
| 88 |
+
- Python version:3.8.10
|
| 89 |
+
- CUDA version: 12.0
|
| 90 |
+
- GPU models and configuration: A100 80G
|
| 91 |
+
|
| 92 |
+
## MONAI Bundle Commands
|
| 93 |
+
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
|
| 94 |
+
|
| 95 |
+
For more details usage instructions, visit the [MONAI Bundle Configuration Page](https://docs.monai.io/en/latest/config_syntax.html).
|
| 96 |
+
|
| 97 |
+
#### Execute training:
|
| 98 |
+
|
| 99 |
+
```
|
| 100 |
+
python -m monai.bundle run --config_file configs/train.json
|
| 101 |
+
```
|
| 102 |
+
|
| 103 |
+
Please note that if the default dataset path is not modified with the actual path in the bundle config files, you can also override it by using `--dataset_dir`:
|
| 104 |
+
|
| 105 |
+
```
|
| 106 |
+
python -m monai.bundle run --config_file configs/train.json --dataset_dir <actual dataset path>
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
#### Override the `train` config to execute multi-GPU training:
|
| 110 |
+
|
| 111 |
+
```
|
| 112 |
+
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']"
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
Please note that the distributed training-related options depend on the actual running environment; thus, users may need to remove `--standalone`, modify `--nnodes`, or do some other necessary changes according to the machine used. For more details, please refer to [pytorch's official tutorial](https://pytorch.org/tutorials/intermediate/ddp_tutorial.html).
|
| 116 |
+
|
| 117 |
+
#### Override the `train` config to execute evaluation with the trained model:
|
| 118 |
+
|
| 119 |
+
```
|
| 120 |
+
python -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json']"
|
| 121 |
+
```
|
| 122 |
+
|
| 123 |
+
#### Override the `train` config and `evaluate` config to execute multi-GPU evaluation:
|
| 124 |
+
|
| 125 |
+
```
|
| 126 |
+
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json','configs/multi_gpu_evaluate.json']"
|
| 127 |
+
```
|
| 128 |
+
|
| 129 |
+
#### Execute inference:
|
| 130 |
+
|
| 131 |
+
```
|
| 132 |
+
python -m monai.bundle run --config_file configs/inference.json
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
#### Export checkpoint to TorchScript file:
|
| 136 |
+
|
| 137 |
+
```
|
| 138 |
+
python -m monai.bundle ckpt_export network_def --filepath models/model.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json
|
| 139 |
+
```
|
| 140 |
+
|
| 141 |
+
#### Export checkpoint to TensorRT based models with fp32 or fp16 precision:
|
| 142 |
+
|
| 143 |
+
```
|
| 144 |
+
python -m monai.bundle trt_export --net_id network_def --filepath models/model_trt.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json --precision <fp32/fp16>
|
| 145 |
+
```
|
| 146 |
+
|
| 147 |
+
#### Execute inference with the TensorRT model:
|
| 148 |
+
|
| 149 |
+
```
|
| 150 |
+
python -m monai.bundle run --config_file "['configs/inference.json', 'configs/inference_trt.json']"
|
| 151 |
+
```
|
| 152 |
+
|
| 153 |
+
# References
|
| 154 |
+
[1] Tan, M. and Le, Q. V. Efficientnet: Rethinking model scaling for convolutional neural networks. ICML, 2019a. https://arxiv.org/pdf/1905.11946.pdf
|
| 155 |
+
|
| 156 |
+
[2] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015. https://arxiv.org/pdf/1505.04597.pdf
|
| 157 |
+
|
| 158 |
+
# License
|
| 159 |
+
Copyright (c) MONAI Consortium
|
| 160 |
+
|
| 161 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 162 |
+
you may not use this file except in compliance with the License.
|
| 163 |
+
You may obtain a copy of the License at
|
| 164 |
+
|
| 165 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 166 |
+
|
| 167 |
+
Unless required by applicable law or agreed to in writing, software
|
| 168 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 169 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 170 |
+
See the License for the specific language governing permissions and
|
| 171 |
+
limitations under the License.
|
docs/data_license.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Datasets used in this work were provided by Activ Surgical.
|
models/model.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1a24d5f1d30a44474e8bb87abb62f289add2c40a291eac67138242679e928729
|
| 3 |
+
size 46290573
|
models/model.ts
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:149ac9473dee60737957505a59a24c6d816092c6aa2ff89e13c8bfc8e9831059
|
| 3 |
+
size 46500237
|
scripts/export_to_onnx.py
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import onnx
|
| 6 |
+
import onnxruntime
|
| 7 |
+
import torch
|
| 8 |
+
from monai.networks.nets import FlexibleUNet
|
| 9 |
+
|
| 10 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def load_model_and_export(
|
| 14 |
+
modelname, outname, out_channels, height, width, multigpu=False, in_channels=3, backbone="efficientnet-b0"
|
| 15 |
+
):
|
| 16 |
+
"""
|
| 17 |
+
Loading a model by name.
|
| 18 |
+
|
| 19 |
+
Args:
|
| 20 |
+
modelname: a whole path name of the model that need to be loaded.
|
| 21 |
+
outname: a name for output onnx model.
|
| 22 |
+
out_channels: output channels, which usually equals to 1 + class_number.
|
| 23 |
+
height: input images' height.
|
| 24 |
+
width: input images' width.
|
| 25 |
+
multigpu: if the pre-trained model trained on a multigpu environment.
|
| 26 |
+
in_channels: input images' channel number.
|
| 27 |
+
backbone: a name of backbone used by the flexible unet.
|
| 28 |
+
"""
|
| 29 |
+
isopen = os.path.exists(modelname)
|
| 30 |
+
if not isopen:
|
| 31 |
+
raise Exception("The specified model to load does not exist!")
|
| 32 |
+
|
| 33 |
+
model = FlexibleUNet(
|
| 34 |
+
in_channels=in_channels,
|
| 35 |
+
out_channels=out_channels,
|
| 36 |
+
backbone=backbone,
|
| 37 |
+
is_pad=False,
|
| 38 |
+
pretrained=False,
|
| 39 |
+
dropout=None,
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
if multigpu:
|
| 43 |
+
model = torch.nn.DataParallel(model)
|
| 44 |
+
model = model.cuda()
|
| 45 |
+
model.load_state_dict(torch.load(modelname, map_location=device)) # if the model is trained on multi gpu
|
| 46 |
+
model = model.eval()
|
| 47 |
+
|
| 48 |
+
np.random.seed(0)
|
| 49 |
+
x = np.random.random((1, 3, width, height))
|
| 50 |
+
x = torch.tensor(x, dtype=torch.float32)
|
| 51 |
+
x = x.cuda()
|
| 52 |
+
torch_out = model(x)
|
| 53 |
+
input_names = ["INPUT__0"]
|
| 54 |
+
output_names = ["OUTPUT__0"]
|
| 55 |
+
# Export the model
|
| 56 |
+
if multigpu:
|
| 57 |
+
model_trans = model.module
|
| 58 |
+
else:
|
| 59 |
+
model_trans = model
|
| 60 |
+
torch.onnx.export(
|
| 61 |
+
model_trans, # model to save
|
| 62 |
+
x, # model input
|
| 63 |
+
outname, # model save path
|
| 64 |
+
export_params=True,
|
| 65 |
+
verbose=True,
|
| 66 |
+
do_constant_folding=True,
|
| 67 |
+
input_names=input_names,
|
| 68 |
+
output_names=output_names,
|
| 69 |
+
opset_version=15,
|
| 70 |
+
dynamic_axes={"INPUT__0": {0: "batch_size"}, "OUTPUT__0": {0: "batch_size"}},
|
| 71 |
+
)
|
| 72 |
+
onnx_model = onnx.load(outname)
|
| 73 |
+
onnx.checker.check_model(onnx_model, full_check=True)
|
| 74 |
+
ort_session = onnxruntime.InferenceSession(outname)
|
| 75 |
+
|
| 76 |
+
def to_numpy(tensor):
|
| 77 |
+
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
|
| 78 |
+
|
| 79 |
+
# compute ONNX Runtime output prediction
|
| 80 |
+
ort_inputs = {ort_session.get_inputs()[0].name: to_numpy(x)}
|
| 81 |
+
ort_outs = ort_session.run(["OUTPUT__0"], ort_inputs)
|
| 82 |
+
numpy_torch_out = to_numpy(torch_out)
|
| 83 |
+
# compare ONNX Runtime and PyTorch results
|
| 84 |
+
np.testing.assert_allclose(numpy_torch_out, ort_outs[0], rtol=1e-03, atol=1e-05)
|
| 85 |
+
print("Exported model has been tested with ONNXRuntime, and the result looks good!")
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
if __name__ == "__main__":
|
| 89 |
+
parser = argparse.ArgumentParser()
|
| 90 |
+
# the original model for converting.
|
| 91 |
+
parser.add_argument(
|
| 92 |
+
"--model", type=str, default=r"/workspace/models/model.pt", help="Input an existing model weight"
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
# path to save the onnx model.
|
| 96 |
+
parser.add_argument(
|
| 97 |
+
"--outpath", type=str, default=r"/workspace/models/model.onnx", help="A path to save the onnx model."
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
parser.add_argument("--width", type=int, default=736, help="Width for exporting onnx model.")
|
| 101 |
+
|
| 102 |
+
parser.add_argument("--height", type=int, default=480, help="Height for exporting onnx model.")
|
| 103 |
+
|
| 104 |
+
parser.add_argument(
|
| 105 |
+
"--out_channels", type=int, default=2, help="Number of expected out_channels in model for exporting to onnx."
|
| 106 |
+
)
|
| 107 |
+
|
| 108 |
+
parser.add_argument("--multigpu", type=bool, default=False, help="If loading model trained with multi gpu.")
|
| 109 |
+
|
| 110 |
+
args = parser.parse_args()
|
| 111 |
+
modelname = args.model
|
| 112 |
+
outname = args.outpath
|
| 113 |
+
out_channels = args.out_channels
|
| 114 |
+
height = args.height
|
| 115 |
+
width = args.width
|
| 116 |
+
multigpu = args.multigpu
|
| 117 |
+
|
| 118 |
+
if os.path.exists(outname):
|
| 119 |
+
raise Exception(
|
| 120 |
+
"The specified outpath already exists! Change the outpath to avoid overwriting your saved model. "
|
| 121 |
+
)
|
| 122 |
+
model = load_model_and_export(modelname, outname, out_channels, height, width, multigpu)
|