

Update README.md
Browse filesUpdate with official HF Leaderboard scores.
README.md
CHANGED
|
@@ -24,7 +24,7 @@ We use [OpenChat](https://huggingface.co/openchat) packing, trained with [Axolot
|
|
| 24 |
This release is trained on a curated filtered subset of most of our GPT-4 augmented data.
|
| 25 |
It is the same subset of our data as was used in our [OpenOrcaxOpenChat-Preview2-13B model](https://huggingface.co/Open-Orca/OpenOrcaxOpenChat-Preview2-13B).
|
| 26 |
|
| 27 |
-
**HF Leaderboard evals place this model as #
|
| 28 |
|
| 29 |
This release provides a first: a fully open model with class-breaking performance, capable of running fully accelerated on even moderate consumer GPUs.
|
| 30 |
Our thanks to the Mistral team for leading the way here.
|
|
@@ -112,20 +112,20 @@ pip install git+https://github.com/huggingface/transformers
|
|
| 112 |
## HuggingFace Leaderboard Performance
|
| 113 |
|
| 114 |
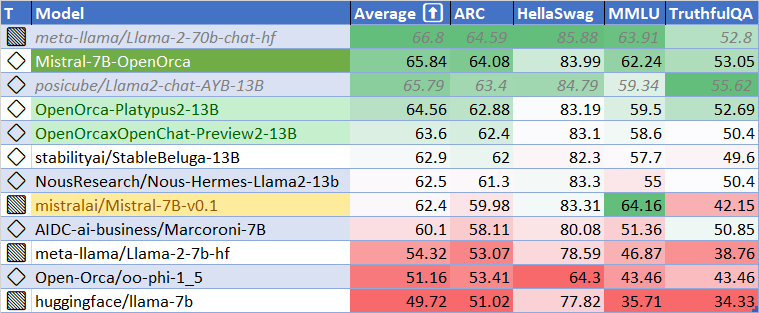
We have evaluated using the methodology and tools for the HuggingFace Leaderboard, and find that we have dramatically improved upon the base model.
|
| 115 |
-
We find **
|
| 116 |
|
| 117 |
-
At release time, this beats all 7B
|
| 118 |
|
| 119 |
|
| 120 |
|
| 121 |
|
| 122 |
| Metric | Value |
|
| 123 |
|-----------------------|-------|
|
| 124 |
-
| MMLU (5-shot) |
|
| 125 |
-
| ARC (25-shot) |
|
| 126 |
-
| HellaSwag (10-shot) | 83.
|
| 127 |
-
| TruthfulQA (0-shot) |
|
| 128 |
-
| Avg. | 65.
|
| 129 |
|
| 130 |
We use [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) to run the benchmark tests above, using the same version as the HuggingFace LLM Leaderboard.
|
| 131 |
|
|
|
|
| 24 |
This release is trained on a curated filtered subset of most of our GPT-4 augmented data.
|
| 25 |
It is the same subset of our data as was used in our [OpenOrcaxOpenChat-Preview2-13B model](https://huggingface.co/Open-Orca/OpenOrcaxOpenChat-Preview2-13B).
|
| 26 |
|
| 27 |
+
**HF Leaderboard evals place this model as #1 for all models smaller than 30B at release time, outperforming all other 7B and 13B models!**
|
| 28 |
|
| 29 |
This release provides a first: a fully open model with class-breaking performance, capable of running fully accelerated on even moderate consumer GPUs.
|
| 30 |
Our thanks to the Mistral team for leading the way here.
|
|
|
|
| 112 |
## HuggingFace Leaderboard Performance
|
| 113 |
|
| 114 |
We have evaluated using the methodology and tools for the HuggingFace Leaderboard, and find that we have dramatically improved upon the base model.
|
| 115 |
+
We find **106%** of the base model's performance on HF Leaderboard evals, averaging **65.84**.
|
| 116 |
|
| 117 |
+
At release time, this beats all 7B and 13B models!
|
| 118 |
|
| 119 |

|
| 120 |
|
| 121 |
|
| 122 |
| Metric | Value |
|
| 123 |
|-----------------------|-------|
|
| 124 |
+
| MMLU (5-shot) | 62.24 |
|
| 125 |
+
| ARC (25-shot) | 64.08 |
|
| 126 |
+
| HellaSwag (10-shot) | 83.99 |
|
| 127 |
+
| TruthfulQA (0-shot) | 53.05 |
|
| 128 |
+
| Avg. | 65.84 |
|
| 129 |
|
| 130 |
We use [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) to run the benchmark tests above, using the same version as the HuggingFace LLM Leaderboard.
|
| 131 |
|