

Update README.md
Browse files
README.md
CHANGED
|
@@ -8,7 +8,7 @@ pipeline_tag: text-generation
|
|
| 8 |
license: apache-2.0
|
| 9 |
---
|
| 10 |
|
| 11 |
-
<p><h1>🐋
|
| 12 |
|
| 13 |
|
| 14 |

|
|
@@ -26,7 +26,8 @@ It is the same subset of our data as was used in our [OpenOrcaxOpenChat-Preview2
|
|
| 26 |
|
| 27 |
HF Leaderboard evals place this model as #2 for all models smaller than 30B at release time, outperforming all but one 13B model.
|
| 28 |
|
| 29 |
-
|
|
|
|
| 30 |
|
| 31 |
Want to visualize our full (pre-filtering) dataset? Check out our [Nomic Atlas Map](https://atlas.nomic.ai/map/c1b88b47-2d9b-47e0-9002-b80766792582/2560fd25-52fe-42f1-a58f-ff5eccc890d2).
|
| 32 |
|
|
@@ -39,31 +40,68 @@ We will also give sneak-peak announcements on our Discord, which you can find he
|
|
| 39 |
|
| 40 |
https://AlignmentLab.ai
|
| 41 |
|
| 42 |
-
or
|
| 43 |
|
| 44 |
https://discord.gg/5y8STgB3P3
|
| 45 |
|
|
|
|
| 46 |
# Prompt Template
|
| 47 |
|
| 48 |
We used [OpenAI's Chat Markup Language (ChatML)](https://github.com/openai/openai-python/blob/main/chatml.md) format, with `<|im_start|>` and `<|im_end|>` tokens added to support this.
|
| 49 |
|
| 50 |
## Example Prompt Exchange
|
| 51 |
|
| 52 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 53 |
|
| 54 |
# Evaluation
|
| 55 |
|
| 56 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 57 |
|
| 58 |
-
TBD
|
| 59 |
|
| 60 |
-
##
|
| 61 |
|
| 62 |
-
|
| 63 |
|
| 64 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 65 |
|
| 66 |
-
TBD
|
| 67 |
|
| 68 |
# Dataset
|
| 69 |
|
|
@@ -75,6 +113,7 @@ We used a curated, filtered selection of most of the GPT-4 augmented data from o
|
|
| 75 |
We trained with 8x A6000 GPUs for 62 hours, completing 4 epochs of full fine tuning on our dataset in one training run.
|
| 76 |
Commodity cost was ~$400.
|
| 77 |
|
|
|
|
| 78 |
# Citation
|
| 79 |
|
| 80 |
```bibtex
|
|
|
|
| 8 |
license: apache-2.0
|
| 9 |
---
|
| 10 |
|
| 11 |
+
<p><h1>🐋 Mistral-7B-OpenOrca 🐋</h1></p>
|
| 12 |
|
| 13 |
|
| 14 |

|
|
|
|
| 26 |
|
| 27 |
HF Leaderboard evals place this model as #2 for all models smaller than 30B at release time, outperforming all but one 13B model.
|
| 28 |
|
| 29 |
+
This release provides a first: a fully open model with class-breaking performance, capable of running fully accelerated on even moderate consumer GPUs.
|
| 30 |
+
Our thanks to the Mistral team for leading the way here.
|
| 31 |
|
| 32 |
Want to visualize our full (pre-filtering) dataset? Check out our [Nomic Atlas Map](https://atlas.nomic.ai/map/c1b88b47-2d9b-47e0-9002-b80766792582/2560fd25-52fe-42f1-a58f-ff5eccc890d2).
|
| 33 |
|
|
|
|
| 40 |
|
| 41 |
https://AlignmentLab.ai
|
| 42 |
|
| 43 |
+
or check the OpenAccess AI Collective Discord for more information about Axolotl trainer here:
|
| 44 |
|
| 45 |
https://discord.gg/5y8STgB3P3
|
| 46 |
|
| 47 |
+
|
| 48 |
# Prompt Template
|
| 49 |
|
| 50 |
We used [OpenAI's Chat Markup Language (ChatML)](https://github.com/openai/openai-python/blob/main/chatml.md) format, with `<|im_start|>` and `<|im_end|>` tokens added to support this.
|
| 51 |
|
| 52 |
## Example Prompt Exchange
|
| 53 |
|
| 54 |
+
```
|
| 55 |
+
<|im_start|>system
|
| 56 |
+
You are MistralOrca, a large language model trained by Alignment Lab AI. Write out your reasoning step-by-step to be sure you get the right answers!
|
| 57 |
+
<|im_end|>
|
| 58 |
+
<|im_start|>user
|
| 59 |
+
How are you<|im_end|>
|
| 60 |
+
<|im_start|>assistant
|
| 61 |
+
I am doing well!<|im_end|>
|
| 62 |
+
<|im_start|>user
|
| 63 |
+
Please tell me about how mistral winds have attracted super-orcas.<|im_end|>
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
|
| 67 |
# Evaluation
|
| 68 |
|
| 69 |
+
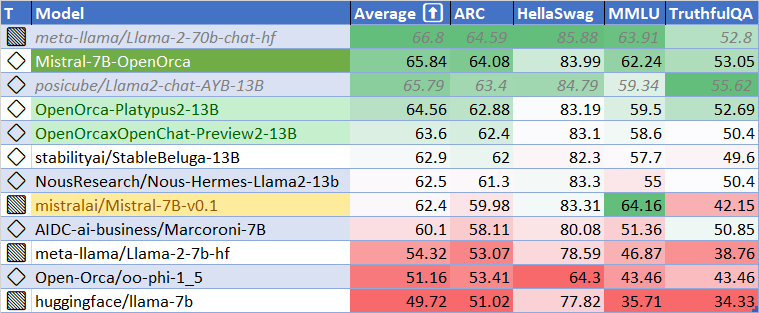
## HuggingFace Leaderboard Performance
|
| 70 |
+
|
| 71 |
+
We have evaluated using the methodology and tools for the HuggingFace Leaderboard, and find that we have dramatically improved upon the base model.
|
| 72 |
+
We find **105%** of the base model's performance on HF Leaderboard evals, averaging **65.33**.
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
| Metric | Value |
|
| 78 |
+
|-----------------------|-------|
|
| 79 |
+
| MMLU (5-shot) | 61.73 |
|
| 80 |
+
| ARC (25-shot) | 63.57 |
|
| 81 |
+
| HellaSwag (10-shot) | 83.79 |
|
| 82 |
+
| TruthfulQA (0-shot) | 52.24 |
|
| 83 |
+
| Avg. | 65.33 |
|
| 84 |
+
|
| 85 |
+
We use [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) to run the benchmark tests above, using the same version as the HuggingFace LLM Leaderboard.
|
| 86 |
|
|
|
|
| 87 |
|
| 88 |
+
## AGIEval Performance
|
| 89 |
|
| 90 |
+
We compare our results to our base Preview2 model (using LM Evaluation Harness).
|
| 91 |
|
| 92 |
+
We find **129%** of the base model's performance on AGI Eval, averaging **0.397**.
|
| 93 |
+
As well, we significantly improve upon the official `mistralai/Mistral-7B-Instruct-v0.1` finetuning, achieving **119%** of their performance.
|
| 94 |
+
|
| 95 |
+

|
| 96 |
+
|
| 97 |
+
## BigBench-Hard Performance
|
| 98 |
+
|
| 99 |
+
We compare our results to our base Preview2 model (using LM Evaluation Harness).
|
| 100 |
+
|
| 101 |
+
We find **119%** of the base model's performance on BigBench-Hard, averaging **0.416**.
|
| 102 |
+
|
| 103 |
+

|
| 104 |
|
|
|
|
| 105 |
|
| 106 |
# Dataset
|
| 107 |
|
|
|
|
| 113 |
We trained with 8x A6000 GPUs for 62 hours, completing 4 epochs of full fine tuning on our dataset in one training run.
|
| 114 |
Commodity cost was ~$400.
|
| 115 |
|
| 116 |
+
|
| 117 |
# Citation
|
| 118 |
|
| 119 |
```bibtex
|