

Commit
·
054e6fd
1
Parent(s):
4871737
readme: Add model intro and testset rename
Browse filesSigned-off-by: eric <[email protected]>
- README.md +81 -51
- README_zh.md +81 -55
- assets/imgs/data_src_dist.png +0 -0
- config.json +3 -3
- configuration_orion.py +4 -4
- modeling_orion.py +46 -46
README.md
CHANGED
|
@@ -48,9 +48,35 @@ tags:
|
|
| 48 |
|
| 49 |
- Orion-MOE8x7B-Base Large Language Model(LLM) is a pretrained generative Sparse Mixture of Experts, trained from scratch by OrionStarAI. The base model is trained on multilingual corpus, including Chinese, English, Japanese, Korean, etc, and it exhibits superior performance in these languages.
|
| 50 |
|
| 51 |
-
- The Orion-MOE8x7B series models exhibit the following features
|
| 52 |
- The model demonstrates excellent performance in comprehensive evaluations compared to other base models of the same parameter scale.
|
| 53 |
- It has strong multilingual capabilities, significantly leading in Japanese and Korean test sets, and also performing comprehensively better in Arabic, German, French, and Spanish test sets.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 54 |
|
| 55 |
|
| 56 |
<a name="model-download"></a><br>
|
|
@@ -68,69 +94,71 @@ Model release and download links are provided in the table below:
|
|
| 68 |
|
| 69 |
## 3.1. Base Model Orion-MOE8x7B-Base Benchmarks
|
| 70 |
### 3.1.1. LLM evaluation results on examination and professional knowledge
|
| 71 |
-
|TestSet
|
| 72 |
-
|
|
| 73 |
-
|
|
| 74 |
-
|
|
| 75 |
-
|
|
| 76 |
-
|
|
| 77 |
-
|ARC_c
|
| 78 |
-
|
|
| 79 |
-
|
|
| 80 |
-
|
|
| 81 |
-
|
|
| 82 |
-
|
|
| 83 |
-
|
|
| 84 |
-
|IFEval
|
| 85 |
-
|
|
| 86 |
-
|
|
| 87 |
-
|MBPP
|
| 88 |
-
|
|
| 89 |
-
|
|
| 90 |
-
|
|
| 91 |
|
| 92 |
### 3.1.2. Comparison of LLM performances on Japanese testsets
|
| 93 |
-
| Model |
|
| 94 |
-
|
| 95 |
-
|Mixtral-8x7B
|
| 96 |
-
|Qwen1.5-32B
|
| 97 |
-
|Qwen2.5-32B
|
| 98 |
-
|Orion-14B-Base
|
| 99 |
-
|Orion 8x7B
|
| 100 |
|
| 101 |
### 3.1.3. Comparison of LLM performances on Korean testsets
|
| 102 |
-
|Model |
|
| 103 |
-
|
| 104 |
-
|Mixtral-8x7B
|
| 105 |
-
|Qwen1.5-32B
|
| 106 |
-
|Qwen2.5-32B
|
| 107 |
-
|Orion-14B-Base
|
| 108 |
-
|Orion 8x7B
|
| 109 |
|
| 110 |
### 3.1.4. Comparison of LLM performances on Arabic, German, French, and Spanish testsets
|
| 111 |
| Lang | ar | | de | | fr | | es | |
|
| 112 |
|----|----|----|----|----|----|----|----|----|
|
| 113 |
-
|**
|
| 114 |
-
|Mixtral-8x7B
|
| 115 |
-
|Qwen1.5-32B
|
| 116 |
-
|Qwen2.5-32B
|
| 117 |
-
|Orion-14B-Base
|
| 118 |
-
|Orion 8x7B
|
| 119 |
|
| 120 |
### 3.1.5. Leakage Detection Benchmark
|
| 121 |
-
|
| 122 |
-
|
| 123 |
-
|
| 124 |
-
- English Test: mmlu
|
| 125 |
-
- Chinese Test: ceval, cmmlu
|
| 126 |
|
| 127 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 128 |
|------|------|------|------|------|------|
|
| 129 |
-
|
|
| 130 |
-
|
|
| 131 |
-
|
|
| 132 |
|
| 133 |
-
### 3.1.6. Inference speed
|
| 134 |
Based on 8x Nvidia RTX3090, in unit of tokens per second.
|
| 135 |
|OrionLLM_V2.4.6.1 | 1para_out62 | 1para_out85 | 1para_out125 | 1para_out210 |
|
| 136 |
|----|----|----|----|----|
|
|
@@ -197,6 +225,8 @@ device, you can use something like `export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7`
|
|
| 197 |
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python demo/text_generation_base.py --model OrionStarAI/Orion-MOE8x7B-Base --tokenizer OrionStarAI/Orion-MOE8x7B-Base --prompt hello
|
| 198 |
|
| 199 |
```
|
|
|
|
|
|
|
| 200 |
|
| 201 |
<a name="declarations-license"></a><br>
|
| 202 |
# 5. Declarations, License
|
|
|
|
| 48 |
|
| 49 |
- Orion-MOE8x7B-Base Large Language Model(LLM) is a pretrained generative Sparse Mixture of Experts, trained from scratch by OrionStarAI. The base model is trained on multilingual corpus, including Chinese, English, Japanese, Korean, etc, and it exhibits superior performance in these languages.
|
| 50 |
|
| 51 |
+
- The Orion-MOE8x7B series models exhibit the following features
|
| 52 |
- The model demonstrates excellent performance in comprehensive evaluations compared to other base models of the same parameter scale.
|
| 53 |
- It has strong multilingual capabilities, significantly leading in Japanese and Korean test sets, and also performing comprehensively better in Arabic, German, French, and Spanish test sets.
|
| 54 |
+
- Model Hyper-Parameters
|
| 55 |
+
- The architecture of the OrionMOE 8*7B models closely resembles that of Mixtral 8*7B, with specific details shown in the table below.
|
| 56 |
+
|
| 57 |
+
|Configuration |OrionMOE 8*7B|
|
| 58 |
+
|-------------------|-------------|
|
| 59 |
+
|Hidden Size | 4096 |
|
| 60 |
+
|# Layers | 32 |
|
| 61 |
+
|# Query Heads | 32 |
|
| 62 |
+
|# KV Heads | 8 |
|
| 63 |
+
|Intermediate Size | 14592 |
|
| 64 |
+
|# Experts | 8 |
|
| 65 |
+
|# Activated Experts| 2 |
|
| 66 |
+
|Embedding Tying | False |
|
| 67 |
+
|Position embedding | RoPE |
|
| 68 |
+
|seq_len | 8192 |
|
| 69 |
+
|Vocabulary Size | 1136664 |
|
| 70 |
+
|
| 71 |
+
- Model pretrain hyper-parameters
|
| 72 |
+
- We use the AdamW optimizer with hyperparameters set to 𝛽1 = 0.9, 𝛽2 = 0.95, and a weight decay of 0.1.
|
| 73 |
+
- Training begins with a learning rate warm-up phase over 2000 iterations, where the learning rate is linearly increased to a peak of 3e-4. Afterward, a cosine schedule is applied to gradually reduce the learning rate to 3e-5 over the course of training.
|
| 74 |
+
- The model is trained using BF16/FP32 mixed precision, with a batch size of 2600, processing approximately 22 million tokens per step.
|
| 75 |
+
- Model pretrain data distribution
|
| 76 |
+
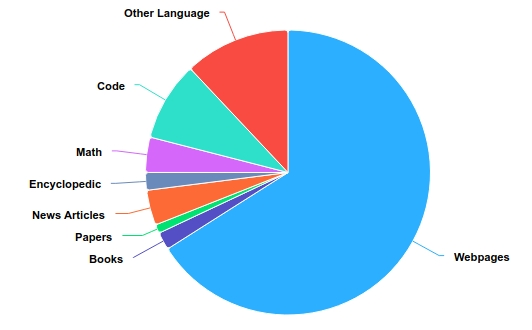
- The training dataset is primarily composed of English, Chinese, and other languages, accounting for 50%, 25%, and 12% of the data, respectively. Additionally, code makes up 9%, while mathematical text accounts for 4%. The distribution by topics is detailed in the table below.
|
| 77 |
+
<div align="center">
|
| 78 |
+
<img src="./assets/imgs/data_src_dist.png" alt="logo" width="80%" />
|
| 79 |
+
</div>
|
| 80 |
|
| 81 |
|
| 82 |
<a name="model-download"></a><br>
|
|
|
|
| 94 |
|
| 95 |
## 3.1. Base Model Orion-MOE8x7B-Base Benchmarks
|
| 96 |
### 3.1.1. LLM evaluation results on examination and professional knowledge
|
| 97 |
+
|TestSet|Mixtral 8*7B|Qwen1.5-32b|Qwen2.5-32b|Orion 14B|Orion 8*7B|
|
| 98 |
+
| ----------- | ----- | ----- | ----- | ----- | ----- |
|
| 99 |
+
|CEval | 54.09 | 83.50 | 87.74 | 72.80 | 89.74 |
|
| 100 |
+
|CMMLU | 53.21 | 82.30 | 89.01 | 70.57 | 89.16 |
|
| 101 |
+
|MMLU | 70.40 | 73.40 | 82.90 | 69.94 | 85.90 |
|
| 102 |
+
|MMLU Pro | 38.50 | 45.25 | 58.01 | 33.95 | 58.31 |
|
| 103 |
+
|ARC_c | 85.08 | 90.17 | 94.24 | 79.66 | 91.86 |
|
| 104 |
+
|HellaSwag | 81.95 | 81.98 | 82.51 | 78.53 | 89.19 |
|
| 105 |
+
|LAMBADA | 76.79 | 73.74 | 75.37 | 78.83 | 79.74 |
|
| 106 |
+
|BBH | 50.87 | 57.28 | 67.69 | 50.35 | 55.82 |
|
| 107 |
+
|MuSR | 43.21 | 42.65 | 49.78 | 43.61 | 49.93 |
|
| 108 |
+
|PIQA | 83.41 | 82.15 | 80.05 | 79.54 | 87.32 |
|
| 109 |
+
|CommonSenseQA| 69.62 | 74.69 | 72.97 | 66.91 | 73.05 |
|
| 110 |
+
|IFEval | 24.15 | 32.97 | 41.59 | 29.08 | 30.06 |
|
| 111 |
+
|GPQA | 30.90 | 33.49 | 49.50 | 28.53 | 52.17 |
|
| 112 |
+
|HumanEval | 33.54 | 35.98 | 46.95 | 20.12 | 44.51 |
|
| 113 |
+
|MBPP | 60.70 | 49.40 | 71.00 | 30.00 | 43.40 |
|
| 114 |
+
|MATH Lv5 | 9.00 | 25.00 | 31.72 | 2.54 | 5.07 |
|
| 115 |
+
|GSM8K | 47.50 | 77.40 | 80.36 | 52.01 | 59.82 |
|
| 116 |
+
|MATH | 28.40 | 36.10 | 48.88 | 7.84 | 23.68 |
|
| 117 |
|
| 118 |
### 3.1.2. Comparison of LLM performances on Japanese testsets
|
| 119 |
+
| Model | JSQuAD | JCommonSenseQA | JNLI | MARC-ja | JAQKET v2 | PAWS-ja | avg |
|
| 120 |
+
|--------------|-------|-------|-------|-------|-------|-------|-------|
|
| 121 |
+
|Mixtral-8x7B | 89.00 | 78.73 | 32.13 | 95.44 | 78.86 | 44.50 | 69.78 |
|
| 122 |
+
|Qwen1.5-32B | 89.86 | 84.54 | 50.99 | 97.08 | 82.14 | 43.80 | 74.74 |
|
| 123 |
+
|Qwen2.5-32B | 89.09 | 93.83 | 72.14 | 97.86 | 89.27 | 42.15 | 80.73 |
|
| 124 |
+
|Orion-14B-Base| 74.22 | 88.20 | 72.85 | 94.06 | 66.20 | 49.90 | 74.24 |
|
| 125 |
+
|Orion 8x7B | 91.77 | 90.43 | 90.46 | 96.40 | 81.19 | 47.35 | 82.93 |
|
| 126 |
|
| 127 |
### 3.1.3. Comparison of LLM performances on Korean testsets
|
| 128 |
+
|Model | HAE-RAE | KoBEST BoolQ | KoBEST COPA | KoBEST HellaSwag | KoBEST SentiNeg | KoBEST WiC | PAWS-ko | avg |
|
| 129 |
+
|--------------|-------|-------|-------|-------|-------|-------|-------|-------|
|
| 130 |
+
|Mixtral-8x7B | 53.16 | 78.56 | 66.20 | 56.60 | 77.08 | 49.37 | 44.05 | 60.72 |
|
| 131 |
+
|Qwen1.5-32B | 46.38 | 76.28 | 60.40 | 53.00 | 78.34 | 52.14 | 43.40 | 58.56 |
|
| 132 |
+
|Qwen2.5-32B | 70.67 | 80.27 | 76.70 | 61.20 | 96.47 | 77.22 | 37.05 | 71.37 |
|
| 133 |
+
|Orion-14B-Base| 69.66 | 80.63 | 77.10 | 58.20 | 92.44 | 51.19 | 44.55 | 67.68 |
|
| 134 |
+
|Orion 8x7B | 65.17 | 85.40 | 80.40 | 56.00 | 96.98 | 73.57 | 46.35 | 71.98 |
|
| 135 |
|
| 136 |
### 3.1.4. Comparison of LLM performances on Arabic, German, French, and Spanish testsets
|
| 137 |
| Lang | ar | | de | | fr | | es | |
|
| 138 |
|----|----|----|----|----|----|----|----|----|
|
| 139 |
+
|**Model**|**HellaSwag**|**ARC**|**HellaSwag**|**ARC**|**HellaSwag**|**ARC**|**HellaSwag**|**ARC**|
|
| 140 |
+
|Mixtral-8x7B | 53.16 | 78.56 | 66.20 | 56.60 | 77.08 | 49.37 | 44.05 | 60.72 |
|
| 141 |
+
|Qwen1.5-32B | 46.38 | 76.28 | 60.40 | 53.00 | 78.34 | 52.14 | 43.40 | 58.56 |
|
| 142 |
+
|Qwen2.5-32B | 70.67 | 80.27 | 76.70 | 61.20 | 96.47 | 77.22 | 37.05 | 71.37 |
|
| 143 |
+
|Orion-14B-Base| 69.66 | 80.63 | 77.10 | 58.20 | 92.44 | 51.19 | 44.55 | 67.68 |
|
| 144 |
+
|Orion 8x7B | 65.17 | 85.40 | 80.40 | 56.00 | 96.98 | 73.57 | 46.35 | 71.98 |
|
| 145 |
|
| 146 |
### 3.1.5. Leakage Detection Benchmark
|
| 147 |
+
When the pre-training data of a large language model contains content from a specific dataset, the model’s performance on that dataset may be artificially enhanced, leading to inaccurate performance evaluations. To address this issue, researchers from the Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences, and other institutions have proposed a simple and effective method for detecting data leakage. This method leverages the interchangeable nature of multiple-choice options by shuffling the options in the original dataset to generate derived data. The log-probability distribution of the derived dataset is then computed using the model to detect whether the original dataset has been leaked.
|
| 148 |
+
|
| 149 |
+
We conducted data leakage detection experiments on three benchmark datasets: MMLU, CMMLU, and C-Eval.
|
|
|
|
|
|
|
| 150 |
|
| 151 |
+
More details can be found in the paper: https://web3.arxiv.org/pdf/2409.01790.
|
| 152 |
+
|
| 153 |
+
Test code: https://github.com/nishiwen1214/Benchmark-leakage-detection.
|
| 154 |
+
|
| 155 |
+
|Threshold 0.2|Qwen2.5 32B|Qwen1.5 32B|Orion 8x7B|Orion 14B|Mixtral 8x7B|
|
| 156 |
|------|------|------|------|------|------|
|
| 157 |
+
|MMLU | 0.30 | 0.27 | 0.22 | 0.28 | 0.25 |
|
| 158 |
+
|CEval | 0.39 | 0.38 | 0.27 | 0.26 | 0.26 |
|
| 159 |
+
|CMMLU | 0.38 | 0.39 | 0.23 | 0.27 | 0.22 |
|
| 160 |
|
| 161 |
+
### 3.1.6. Inference speed[Todo]
|
| 162 |
Based on 8x Nvidia RTX3090, in unit of tokens per second.
|
| 163 |
|OrionLLM_V2.4.6.1 | 1para_out62 | 1para_out85 | 1para_out125 | 1para_out210 |
|
| 164 |
|----|----|----|----|----|
|
|
|
|
| 225 |
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python demo/text_generation_base.py --model OrionStarAI/Orion-MOE8x7B-Base --tokenizer OrionStarAI/Orion-MOE8x7B-Base --prompt hello
|
| 226 |
|
| 227 |
```
|
| 228 |
+
## 4.3. [Todo] vLLM inference code
|
| 229 |
+
|
| 230 |
|
| 231 |
<a name="declarations-license"></a><br>
|
| 232 |
# 5. Declarations, License
|
README_zh.md
CHANGED
|
@@ -44,8 +44,32 @@
|
|
| 44 |
- 同规模参数级别基座大模型综合评测效果表现优异
|
| 45 |
- 多语言能力强,在日语、韩语测试集上显著领先,在阿拉伯语、德语、法语、西班牙语测试集上也全面领先
|
| 46 |
|
| 47 |
-
|
| 48 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 49 |
|
| 50 |
|
| 51 |
<a name="zh_model-download"></a><br>
|
|
@@ -65,76 +89,78 @@
|
|
| 65 |
## 3.1. 基座模型Orion-MOE8x7B-Base评估
|
| 66 |
|
| 67 |
### 3.1.1. 基座模型基准测试对比
|
| 68 |
-
|TestSet
|
| 69 |
-
|
|
| 70 |
-
|
|
| 71 |
-
|
|
| 72 |
-
|
|
| 73 |
-
|
|
| 74 |
-
|ARC_c
|
| 75 |
-
|
|
| 76 |
-
|
|
| 77 |
-
|
|
| 78 |
-
|
|
| 79 |
-
|
|
| 80 |
-
|
|
| 81 |
-
|IFEval
|
| 82 |
-
|
|
| 83 |
-
|
|
| 84 |
-
|MBPP
|
| 85 |
-
|
|
| 86 |
-
|
|
| 87 |
-
|
|
| 88 |
|
| 89 |
|
| 90 |
|
| 91 |
### 3.1.2. 小语种: 日文
|
| 92 |
-
| Model |
|
| 93 |
-
|
| 94 |
-
|Mixtral-8x7B
|
| 95 |
-
|Qwen1.5-32B
|
| 96 |
-
|Qwen2.5-32B
|
| 97 |
-
|Orion-14B-Base
|
| 98 |
-
|Orion 8x7B
|
| 99 |
|
| 100 |
|
| 101 |
### 3.1.3. 小语种�� 韩文
|
| 102 |
-
|Model |
|
| 103 |
-
|
| 104 |
-
|Mixtral-8x7B
|
| 105 |
-
|Qwen1.5-32B
|
| 106 |
-
|Qwen2.5-32B
|
| 107 |
-
|Orion-14B-Base
|
| 108 |
-
|Orion 8x7B
|
| 109 |
|
| 110 |
|
| 111 |
|
| 112 |
### 3.1.4. 小语种: 阿拉伯语,德语,法语,西班牙语
|
| 113 |
| Lang | ar | | de | | fr | | es | |
|
| 114 |
-
|
| 115 |
-
|**
|
| 116 |
-
|Mixtral-8x7B
|
| 117 |
-
|Qwen1.5-32B
|
| 118 |
-
|Qwen2.5-32B
|
| 119 |
-
|Orion-14B-Base
|
| 120 |
-
|Orion 8x7B
|
| 121 |
|
| 122 |
|
| 123 |
### 3.1.5. 泄漏检测结果
|
| 124 |
-
|
| 125 |
-
- 检测代码: https://github.com/nishiwen1214/Benchmark-leakage-detection
|
| 126 |
-
- 论文: https://web3.arxiv.org/pdf/2409.01790
|
| 127 |
-
- 英文测试:mmlu
|
| 128 |
-
- 中文测试:ceval, cmmlu
|
| 129 |
|
| 130 |
-
|
| 131 |
-
|----|----|----|----|----|----|
|
| 132 |
-
|mmlu | 0.3 | 0.27 | 0.22 | 0.28 | 0.25 |
|
| 133 |
-
|ceval | 0.39 | 0.38 | 0.27 | 0.26 | 0.26 |
|
| 134 |
-
|cmmlu | 0.38 | 0.39 | 0.23 | 0.27 | 0.22 |
|
| 135 |
|
|
|
|
| 136 |
|
| 137 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 138 |
基于8卡Nvidia RTX3090,单位是令牌每秒
|
| 139 |
|OrionLLM_V2.4.6.1 | 1并发_输出62 | 1并发_输出85 | 1并发_输出125 | 1并发_输出210 |
|
| 140 |
|----|----|----|----|----|
|
|
@@ -198,7 +224,7 @@ print(response)
|
|
| 198 |
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python demo/text_generation_base.py --model OrionStarAI/Orion-MOE8x7B-Base --tokenizer OrionStarAI/Orion-MOE8x7B-Base --prompt 你好,你叫什么名字
|
| 199 |
|
| 200 |
```
|
| 201 |
-
|
| 202 |
|
| 203 |
|
| 204 |
<a name="zh_declarations-license"></a><br>
|
|
|
|
| 44 |
- 同规模参数级别基座大模型综合评测效果表现优异
|
| 45 |
- 多语言能力强,在日语、韩语测试集上显著领先,在阿拉伯语、德语、法语、西班牙语测试集上也全面领先
|
| 46 |
|
| 47 |
+
- Orion-MOE8x7B-Base模型超参
|
| 48 |
+
- Orion-MOE8x7B-Base模型架构接近Mixtral 8x7B,超参细节请参考下表
|
| 49 |
+
|
| 50 |
+
|Configuration |OrionMOE 8*7B|
|
| 51 |
+
|-------------------|-------------|
|
| 52 |
+
|Hidden Size | 4096 |
|
| 53 |
+
|# Layers | 32 |
|
| 54 |
+
|# Query Heads | 32 |
|
| 55 |
+
|# KV Heads | 8 |
|
| 56 |
+
|Intermediate Size | 14592 |
|
| 57 |
+
|# Experts | 8 |
|
| 58 |
+
|# Activated Experts| 2 |
|
| 59 |
+
|Embedding Tying | False |
|
| 60 |
+
|Position embedding | RoPE |
|
| 61 |
+
|seq_len | 8192 |
|
| 62 |
+
|Vocabulary Size | 1136664 |
|
| 63 |
+
|
| 64 |
+
- Orion-MOE8x7B-Base训练超参
|
| 65 |
+
- 我们使用AdamW优化器将超参数设置为 𝛽1 = 0.9, 𝛽2 = 0.95,权重衰减为0.1。
|
| 66 |
+
- 训练开始时进行2000次预热阶段迭代,学习率线性增加至峰值3e-4,之后采用余弦调度,逐渐将学习率降低到3e-5以完成整个训练过程。
|
| 67 |
+
- 模型训练采用BF16/FP32混合精度,批量大小为2600,每步处理大约2200万个token。
|
| 68 |
+
- Orion-MOE8x7B-Base训练数据组成
|
| 69 |
+
- 预训练数据语种上主要由英语、中文和其他多语言语言组成,分别占比50%、25%和12%。数据分类上,代码占9%,数学文本占4%,分布参考下图。
|
| 70 |
+
<div align="center">
|
| 71 |
+
<img src="./assets/imgs/data_src_dist.png" alt="logo" width="80%" />
|
| 72 |
+
</div>
|
| 73 |
|
| 74 |
|
| 75 |
<a name="zh_model-download"></a><br>
|
|
|
|
| 89 |
## 3.1. 基座模型Orion-MOE8x7B-Base评估
|
| 90 |
|
| 91 |
### 3.1.1. 基座模型基准测试对比
|
| 92 |
+
|TestSet|Mixtral 8*7B|Qwen1.5-32b|Qwen2.5-32b|Orion 14B|Orion 8*7B|
|
| 93 |
+
| ----------- | ----- | ----- | ----- | ----- | ----- |
|
| 94 |
+
|CEval | 54.09 | 83.50 | 87.74 | 72.80 | 89.74 |
|
| 95 |
+
|CMMLU | 53.21 | 82.30 | 89.01 | 70.57 | 89.16 |
|
| 96 |
+
|MMLU | 70.40 | 73.40 | 82.90 | 69.94 | 85.90 |
|
| 97 |
+
|MMLU Pro | 38.50 | 45.25 | 58.01 | 33.95 | 58.31 |
|
| 98 |
+
|ARC_c | 85.08 | 90.17 | 94.24 | 79.66 | 91.86 |
|
| 99 |
+
|HellaSwag | 81.95 | 81.98 | 82.51 | 78.53 | 89.19 |
|
| 100 |
+
|LAMBADA | 76.79 | 73.74 | 75.37 | 78.83 | 79.74 |
|
| 101 |
+
|BBH | 50.87 | 57.28 | 67.69 | 50.35 | 55.82 |
|
| 102 |
+
|MuSR | 43.21 | 42.65 | 49.78 | 43.61 | 49.93 |
|
| 103 |
+
|PIQA | 83.41 | 82.15 | 80.05 | 79.54 | 87.32 |
|
| 104 |
+
|CommonSenseQA| 69.62 | 74.69 | 72.97 | 66.91 | 73.05 |
|
| 105 |
+
|IFEval | 24.15 | 32.97 | 41.59 | 29.08 | 30.06 |
|
| 106 |
+
|GPQA | 30.90 | 33.49 | 49.50 | 28.53 | 52.17 |
|
| 107 |
+
|HumanEval | 33.54 | 35.98 | 46.95 | 20.12 | 44.51 |
|
| 108 |
+
|MBPP | 60.70 | 49.40 | 71.00 | 30.00 | 43.40 |
|
| 109 |
+
|MATH Lv5 | 9.00 | 25.00 | 31.72 | 2.54 | 5.07 |
|
| 110 |
+
|GSM8K | 47.50 | 77.40 | 80.36 | 52.01 | 59.82 |
|
| 111 |
+
|MATH | 28.40 | 36.10 | 48.88 | 7.84 | 23.68 |
|
| 112 |
|
| 113 |
|
| 114 |
|
| 115 |
### 3.1.2. 小语种: 日文
|
| 116 |
+
| Model | JSQuAD | JCommonSenseQA | JNLI | MARC-ja | JAQKET v2 | PAWS-ja | avg |
|
| 117 |
+
|--------------|-------|-------|-------|-------|-------|-------|-------|
|
| 118 |
+
|Mixtral-8x7B | 89.00 | 78.73 | 32.13 | 95.44 | 78.86 | 44.50 | 69.78 |
|
| 119 |
+
|Qwen1.5-32B | 89.86 | 84.54 | 50.99 | 97.08 | 82.14 | 43.80 | 74.74 |
|
| 120 |
+
|Qwen2.5-32B | 89.09 | 93.83 | 72.14 | 97.86 | 89.27 | 42.15 | 80.73 |
|
| 121 |
+
|Orion-14B-Base| 74.22 | 88.20 | 72.85 | 94.06 | 66.20 | 49.90 | 74.24 |
|
| 122 |
+
|Orion 8x7B | 91.77 | 90.43 | 90.46 | 96.40 | 81.19 | 47.35 | 82.93 |
|
| 123 |
|
| 124 |
|
| 125 |
### 3.1.3. 小语种�� 韩文
|
| 126 |
+
|Model | HAE-RAE | KoBEST BoolQ | KoBEST COPA | KoBEST HellaSwag | KoBEST SentiNeg | KoBEST WiC | PAWS-ko | avg |
|
| 127 |
+
|--------------|-------|-------|-------|-------|-------|-------|-------|-------|
|
| 128 |
+
|Mixtral-8x7B | 53.16 | 78.56 | 66.20 | 56.60 | 77.08 | 49.37 | 44.05 | 60.72 |
|
| 129 |
+
|Qwen1.5-32B | 46.38 | 76.28 | 60.40 | 53.00 | 78.34 | 52.14 | 43.40 | 58.56 |
|
| 130 |
+
|Qwen2.5-32B | 70.67 | 80.27 | 76.70 | 61.20 | 96.47 | 77.22 | 37.05 | 71.37 |
|
| 131 |
+
|Orion-14B-Base| 69.66 | 80.63 | 77.10 | 58.20 | 92.44 | 51.19 | 44.55 | 67.68 |
|
| 132 |
+
|Orion 8x7B | 65.17 | 85.40 | 80.40 | 56.00 | 96.98 | 73.57 | 46.35 | 71.98 |
|
| 133 |
|
| 134 |
|
| 135 |
|
| 136 |
### 3.1.4. 小语种: 阿拉伯语,德语,法语,西班牙语
|
| 137 |
| Lang | ar | | de | | fr | | es | |
|
| 138 |
+
|----|----|----|----|----|----|----|----|----|
|
| 139 |
+
|**Model**|**HellaSwag**|**ARC**|**HellaSwag**|**ARC**|**HellaSwag**|**ARC**|**HellaSwag**|**ARC**|
|
| 140 |
+
|Mixtral-8x7B | 53.16 | 78.56 | 66.20 | 56.60 | 77.08 | 49.37 | 44.05 | 60.72 |
|
| 141 |
+
|Qwen1.5-32B | 46.38 | 76.28 | 60.40 | 53.00 | 78.34 | 52.14 | 43.40 | 58.56 |
|
| 142 |
+
|Qwen2.5-32B | 70.67 | 80.27 | 76.70 | 61.20 | 96.47 | 77.22 | 37.05 | 71.37 |
|
| 143 |
+
|Orion-14B-Base| 69.66 | 80.63 | 77.10 | 58.20 | 92.44 | 51.19 | 44.55 | 67.68 |
|
| 144 |
+
|Orion 8x7B | 65.17 | 85.40 | 80.40 | 56.00 | 96.98 | 73.57 | 46.35 | 71.98 |
|
| 145 |
|
| 146 |
|
| 147 |
### 3.1.5. 泄漏检测结果
|
| 148 |
+
当大型语言模型的预训练数据包含特定数据集的内容时,该模型在该数据集上的表现可能会被人为提高,从而导致不准确的性能评估。为了解决这个问题,来自中国科学院深圳先进技术研究院和其他机构的研究人员提出了一种简单有效的数据泄露检测方法。该方法利用多选项的可互换性,通过打乱原始数据集中的选项生成派生数据。然后,使用模型计算派生数据集的对数概率分布,以检测原始数据集是否存在泄露。
|
|
|
|
|
|
|
|
|
|
|
|
|
| 149 |
|
| 150 |
+
我们在三个基准数据集上进行了数据泄露检测实验:MMLU、CMMLU 和 C-Eval。
|
|
|
|
|
|
|
|
|
|
|
|
|
| 151 |
|
| 152 |
+
更多细节可以在论文中找到:https://web3.arxiv.org/pdf/2409.01790。
|
| 153 |
|
| 154 |
+
测试代码:https://github.com/nishiwen1214/Benchmark-leakage-detection。
|
| 155 |
+
|
| 156 |
+
|Threshold 0.2|Qwen2.5 32B|Qwen1.5 32B|Orion 8x7B|Orion 14B|Mixtral 8x7B|
|
| 157 |
+
|------|------|------|------|------|------|
|
| 158 |
+
|MMLU | 0.30 | 0.27 | 0.22 | 0.28 | 0.25 |
|
| 159 |
+
|CEval | 0.39 | 0.38 | 0.27 | 0.26 | 0.26 |
|
| 160 |
+
|CMMLU | 0.38 | 0.39 | 0.23 | 0.27 | 0.22 |
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
### 3.1.6. 推理速度[Todo: Remove result of 14B, add more description of result]
|
| 164 |
基于8卡Nvidia RTX3090,单位是令牌每秒
|
| 165 |
|OrionLLM_V2.4.6.1 | 1并发_输出62 | 1并发_输出85 | 1并发_输出125 | 1并发_输出210 |
|
| 166 |
|----|----|----|----|----|
|
|
|
|
| 224 |
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python demo/text_generation_base.py --model OrionStarAI/Orion-MOE8x7B-Base --tokenizer OrionStarAI/Orion-MOE8x7B-Base --prompt 你好,你叫什么名字
|
| 225 |
|
| 226 |
```
|
| 227 |
+
## 4.3. [Todo] vLLM推理代码
|
| 228 |
|
| 229 |
|
| 230 |
<a name="zh_declarations-license"></a><br>
|
assets/imgs/data_src_dist.png
ADDED
|
config.json
CHANGED
|
@@ -1,13 +1,13 @@
|
|
| 1 |
{
|
| 2 |
"_name_or_path": "Orion-MoE 8x7b",
|
| 3 |
"architectures": [
|
| 4 |
-
"
|
| 5 |
],
|
| 6 |
"attention_bias": false,
|
| 7 |
"attention_dropout": 0.0,
|
| 8 |
"auto_map": {
|
| 9 |
-
"AutoConfig": "configuration_orion.
|
| 10 |
-
"AutoModelForCausalLM": "modeling_orion.
|
| 11 |
},
|
| 12 |
"bos_token_id": 1,
|
| 13 |
"eos_token_id": 2,
|
|
|
|
| 1 |
{
|
| 2 |
"_name_or_path": "Orion-MoE 8x7b",
|
| 3 |
"architectures": [
|
| 4 |
+
"OrionMOECausalLM"
|
| 5 |
],
|
| 6 |
"attention_bias": false,
|
| 7 |
"attention_dropout": 0.0,
|
| 8 |
"auto_map": {
|
| 9 |
+
"AutoConfig": "configuration_orion.OrionMOEConfig",
|
| 10 |
+
"AutoModelForCausalLM": "modeling_orion.OrionMOEForCausalLM"
|
| 11 |
},
|
| 12 |
"bos_token_id": 1,
|
| 13 |
"eos_token_id": 2,
|
configuration_orion.py
CHANGED
|
@@ -8,12 +8,12 @@ from transformers.utils import logging
|
|
| 8 |
logger = logging.get_logger(__name__)
|
| 9 |
|
| 10 |
|
| 11 |
-
class
|
| 12 |
"""
|
| 13 |
Args:
|
| 14 |
vocab_size (`int`, *optional*, defaults to 113664):
|
| 15 |
-
Vocabulary size of the
|
| 16 |
-
`inputs_ids` passed when calling [`
|
| 17 |
hidden_size (`int`, *optional*, defaults to 4096):
|
| 18 |
Dimension of the hidden representations.
|
| 19 |
intermediate_size (`int`, *optional*, defaults to 14592):
|
|
@@ -32,7 +32,7 @@ class OrionConfig(PretrainedConfig):
|
|
| 32 |
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
|
| 33 |
The non-linear activation function (function or string) in the decoder.
|
| 34 |
max_position_embeddings (`int`, *optional*, defaults to `8192`):
|
| 35 |
-
The maximum sequence length that this model might ever be used with.
|
| 36 |
allows sequence of up to 4096*32 tokens.
|
| 37 |
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 38 |
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
|
|
|
| 8 |
logger = logging.get_logger(__name__)
|
| 9 |
|
| 10 |
|
| 11 |
+
class OrionMOEConfig(PretrainedConfig):
|
| 12 |
"""
|
| 13 |
Args:
|
| 14 |
vocab_size (`int`, *optional*, defaults to 113664):
|
| 15 |
+
Vocabulary size of the OrionMOE model. Defines the number of different tokens that can be represented by the
|
| 16 |
+
`inputs_ids` passed when calling [`OrionMOEModel`]
|
| 17 |
hidden_size (`int`, *optional*, defaults to 4096):
|
| 18 |
Dimension of the hidden representations.
|
| 19 |
intermediate_size (`int`, *optional*, defaults to 14592):
|
|
|
|
| 32 |
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
|
| 33 |
The non-linear activation function (function or string) in the decoder.
|
| 34 |
max_position_embeddings (`int`, *optional*, defaults to `8192`):
|
| 35 |
+
The maximum sequence length that this model might ever be used with. OrionMOE's sliding window attention
|
| 36 |
allows sequence of up to 4096*32 tokens.
|
| 37 |
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 38 |
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
modeling_orion.py
CHANGED
|
@@ -34,7 +34,7 @@ from transformers.utils import (
|
|
| 34 |
replace_return_docstrings,
|
| 35 |
)
|
| 36 |
from transformers.utils.import_utils import is_torch_fx_available
|
| 37 |
-
from .configuration_orion import
|
| 38 |
|
| 39 |
|
| 40 |
if is_flash_attn_2_available():
|
|
@@ -54,7 +54,7 @@ if is_torch_fx_available():
|
|
| 54 |
|
| 55 |
logger = logging.get_logger(__name__)
|
| 56 |
|
| 57 |
-
_CONFIG_FOR_DOC = "
|
| 58 |
|
| 59 |
def load_balancing_loss_func(
|
| 60 |
gate_logits: torch.Tensor, num_experts: torch.Tensor = None, top_k=2, attention_mask: Optional[torch.Tensor] = None
|
|
@@ -145,10 +145,10 @@ def _get_unpad_data(attention_mask):
|
|
| 145 |
)
|
| 146 |
|
| 147 |
|
| 148 |
-
class
|
| 149 |
def __init__(self, hidden_size, eps=1e-6):
|
| 150 |
"""
|
| 151 |
-
|
| 152 |
"""
|
| 153 |
super().__init__()
|
| 154 |
self.weight = nn.Parameter(torch.ones(hidden_size))
|
|
@@ -162,7 +162,7 @@ class OrionRMSNorm(nn.Module):
|
|
| 162 |
return self.weight * hidden_states.to(input_dtype)
|
| 163 |
|
| 164 |
|
| 165 |
-
class
|
| 166 |
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
|
| 167 |
super().__init__()
|
| 168 |
|
|
@@ -248,13 +248,13 @@ def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
|
|
| 248 |
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
|
| 249 |
|
| 250 |
|
| 251 |
-
class
|
| 252 |
"""
|
| 253 |
Multi-headed attention from 'Attention Is All You Need' paper. Modified to use sliding window attention: Longformer
|
| 254 |
and "Generating Long Sequences with Sparse Transformers".
|
| 255 |
"""
|
| 256 |
|
| 257 |
-
def __init__(self, config:
|
| 258 |
super().__init__()
|
| 259 |
self.config = config
|
| 260 |
self.layer_idx = layer_idx
|
|
@@ -285,7 +285,7 @@ class OrionAttention(nn.Module):
|
|
| 285 |
self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
|
| 286 |
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
|
| 287 |
|
| 288 |
-
self.rotary_emb =
|
| 289 |
self.head_dim,
|
| 290 |
max_position_embeddings=self.max_position_embeddings,
|
| 291 |
base=self.rope_theta,
|
|
@@ -376,9 +376,9 @@ class OrionAttention(nn.Module):
|
|
| 376 |
return attn_output, attn_weights, past_key_value
|
| 377 |
|
| 378 |
|
| 379 |
-
class
|
| 380 |
"""
|
| 381 |
-
|
| 382 |
untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
|
| 383 |
flash attention and deal with padding tokens in case the input contains any of them.
|
| 384 |
"""
|
|
@@ -670,14 +670,14 @@ class OrionFlashAttention2(OrionAttention):
|
|
| 670 |
)
|
| 671 |
|
| 672 |
|
| 673 |
-
class
|
| 674 |
"""
|
| 675 |
-
|
| 676 |
-
`
|
| 677 |
SDPA API.
|
| 678 |
"""
|
| 679 |
|
| 680 |
-
# Adapted from
|
| 681 |
def forward(
|
| 682 |
self,
|
| 683 |
hidden_states: torch.Tensor,
|
|
@@ -690,7 +690,7 @@ class OrionSdpaAttention(OrionAttention):
|
|
| 690 |
if output_attentions:
|
| 691 |
# TODO: Improve this warning with e.g. `model.config.attn_implementation = "manual"` once this is implemented.
|
| 692 |
logger.warning_once(
|
| 693 |
-
"
|
| 694 |
'but specifying the manual implementation will be required from Transformers version v5.0.0 onwards. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
|
| 695 |
)
|
| 696 |
return super().forward(
|
|
@@ -758,14 +758,14 @@ class OrionSdpaAttention(OrionAttention):
|
|
| 758 |
|
| 759 |
|
| 760 |
ORION_ATTENTION_CLASSES = {
|
| 761 |
-
"eager":
|
| 762 |
-
"flash_attention_2":
|
| 763 |
-
"sdpa":
|
| 764 |
}
|
| 765 |
|
| 766 |
|
| 767 |
-
class
|
| 768 |
-
def __init__(self, config:
|
| 769 |
super().__init__()
|
| 770 |
self.ffn_dim = config.intermediate_size
|
| 771 |
self.hidden_dim = config.hidden_size
|
|
@@ -782,7 +782,7 @@ class OrionBlockSparseTop2MLP(nn.Module):
|
|
| 782 |
return current_hidden_states
|
| 783 |
|
| 784 |
|
| 785 |
-
class
|
| 786 |
"""
|
| 787 |
This implementation is
|
| 788 |
strictly equivalent to standard MoE with full capacity (no
|
|
@@ -804,7 +804,7 @@ class OrionSparseMoeBlock(nn.Module):
|
|
| 804 |
# gating
|
| 805 |
self.gate = nn.Linear(self.hidden_dim, self.num_experts, bias=False)
|
| 806 |
|
| 807 |
-
self.experts = nn.ModuleList([
|
| 808 |
|
| 809 |
# Jitter parameters
|
| 810 |
self.jitter_noise = config.router_jitter_noise
|
|
@@ -847,16 +847,16 @@ class OrionSparseMoeBlock(nn.Module):
|
|
| 847 |
return final_hidden_states, router_logits
|
| 848 |
|
| 849 |
|
| 850 |
-
class
|
| 851 |
-
def __init__(self, config:
|
| 852 |
super().__init__()
|
| 853 |
self.hidden_size = config.hidden_size
|
| 854 |
|
| 855 |
self.self_attn = ORION_ATTENTION_CLASSES[config._attn_implementation](config, layer_idx)
|
| 856 |
|
| 857 |
-
self.block_sparse_moe =
|
| 858 |
-
self.input_layernorm =
|
| 859 |
-
self.post_attention_layernorm =
|
| 860 |
|
| 861 |
def forward(
|
| 862 |
self,
|
|
@@ -935,7 +935,7 @@ ORION_START_DOCSTRING = r"""
|
|
| 935 |
and behavior.
|
| 936 |
|
| 937 |
Parameters:
|
| 938 |
-
config ([`
|
| 939 |
Model configuration class with all the parameters of the model. Initializing with a config file does not
|
| 940 |
load the weights associated with the model, only the configuration. Check out the
|
| 941 |
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
|
|
@@ -943,15 +943,15 @@ ORION_START_DOCSTRING = r"""
|
|
| 943 |
|
| 944 |
|
| 945 |
@add_start_docstrings(
|
| 946 |
-
"The bare
|
| 947 |
ORION_START_DOCSTRING,
|
| 948 |
)
|
| 949 |
|
| 950 |
-
class
|
| 951 |
-
config_class =
|
| 952 |
base_model_prefix = "model"
|
| 953 |
supports_gradient_checkpointing = True
|
| 954 |
-
_no_split_modules = ["
|
| 955 |
_skip_keys_device_placement = "past_key_values"
|
| 956 |
_supports_flash_attn_2 = True
|
| 957 |
_supports_sdpa = True
|
|
@@ -1037,28 +1037,28 @@ ORION_INPUTS_DOCSTRING = r"""
|
|
| 1037 |
|
| 1038 |
|
| 1039 |
@add_start_docstrings(
|
| 1040 |
-
"The bare
|
| 1041 |
ORION_START_DOCSTRING,
|
| 1042 |
)
|
| 1043 |
-
class
|
| 1044 |
"""
|
| 1045 |
-
Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`
|
| 1046 |
|
| 1047 |
Args:
|
| 1048 |
-
config:
|
| 1049 |
"""
|
| 1050 |
|
| 1051 |
-
def __init__(self, config:
|
| 1052 |
super().__init__(config)
|
| 1053 |
self.padding_idx = config.pad_token_id
|
| 1054 |
self.vocab_size = config.vocab_size
|
| 1055 |
|
| 1056 |
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
| 1057 |
self.layers = nn.ModuleList(
|
| 1058 |
-
[
|
| 1059 |
)
|
| 1060 |
self._attn_implementation = config._attn_implementation
|
| 1061 |
-
self.norm =
|
| 1062 |
|
| 1063 |
self.gradient_checkpointing = False
|
| 1064 |
# Initialize weights and apply final processing
|
|
@@ -1138,7 +1138,7 @@ class OrionModel(OrionPreTrainedModel):
|
|
| 1138 |
if is_padding_right:
|
| 1139 |
raise ValueError(
|
| 1140 |
"You are attempting to perform batched generation with padding_side='right'"
|
| 1141 |
-
" this may lead to unexpected behaviour for Flash Attention version of
|
| 1142 |
" call `tokenizer.padding_side = 'left'` before tokenizing the input. "
|
| 1143 |
)
|
| 1144 |
|
|
@@ -1235,12 +1235,12 @@ class OrionModel(OrionPreTrainedModel):
|
|
| 1235 |
)
|
| 1236 |
|
| 1237 |
|
| 1238 |
-
class
|
| 1239 |
_tied_weights_keys = ["lm_head.weight"]
|
| 1240 |
|
| 1241 |
def __init__(self, config):
|
| 1242 |
super().__init__(config)
|
| 1243 |
-
self.model =
|
| 1244 |
self.vocab_size = config.vocab_size
|
| 1245 |
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
| 1246 |
self.router_aux_loss_coef = config.router_aux_loss_coef
|
|
@@ -1438,9 +1438,9 @@ class OrionForCausalLM(OrionPreTrainedModel):
|
|
| 1438 |
|
| 1439 |
@add_start_docstrings(
|
| 1440 |
"""
|
| 1441 |
-
The
|
| 1442 |
|
| 1443 |
-
[`
|
| 1444 |
(e.g. GPT-2) do.
|
| 1445 |
|
| 1446 |
Since it does classification on the last token, it requires to know the position of the last token. If a
|
|
@@ -1451,11 +1451,11 @@ class OrionForCausalLM(OrionPreTrainedModel):
|
|
| 1451 |
""",
|
| 1452 |
ORION_START_DOCSTRING,
|
| 1453 |
)
|
| 1454 |
-
class
|
| 1455 |
def __init__(self, config):
|
| 1456 |
super().__init__(config)
|
| 1457 |
self.num_labels = config.num_labels
|
| 1458 |
-
self.model =
|
| 1459 |
self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
|
| 1460 |
|
| 1461 |
# Initialize weights and apply final processing
|
|
|
|
| 34 |
replace_return_docstrings,
|
| 35 |
)
|
| 36 |
from transformers.utils.import_utils import is_torch_fx_available
|
| 37 |
+
from .configuration_orion import OrionMOEConfig
|
| 38 |
|
| 39 |
|
| 40 |
if is_flash_attn_2_available():
|
|
|
|
| 54 |
|
| 55 |
logger = logging.get_logger(__name__)
|
| 56 |
|
| 57 |
+
_CONFIG_FOR_DOC = "OrionMOEConfig"
|
| 58 |
|
| 59 |
def load_balancing_loss_func(
|
| 60 |
gate_logits: torch.Tensor, num_experts: torch.Tensor = None, top_k=2, attention_mask: Optional[torch.Tensor] = None
|
|
|
|
| 145 |
)
|
| 146 |
|
| 147 |
|
| 148 |
+
class OrionMOERMSNorm(nn.Module):
|
| 149 |
def __init__(self, hidden_size, eps=1e-6):
|
| 150 |
"""
|
| 151 |
+
OrionMOERMSNorm is equivalent to T5LayerNorm
|
| 152 |
"""
|
| 153 |
super().__init__()
|
| 154 |
self.weight = nn.Parameter(torch.ones(hidden_size))
|
|
|
|
| 162 |
return self.weight * hidden_states.to(input_dtype)
|
| 163 |
|
| 164 |
|
| 165 |
+
class OrionMOERotaryEmbedding(nn.Module):
|
| 166 |
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
|
| 167 |
super().__init__()
|
| 168 |
|
|
|
|
| 248 |
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
|
| 249 |
|
| 250 |
|
| 251 |
+
class OrionMOEAttention(nn.Module):
|
| 252 |
"""
|
| 253 |
Multi-headed attention from 'Attention Is All You Need' paper. Modified to use sliding window attention: Longformer
|
| 254 |
and "Generating Long Sequences with Sparse Transformers".
|
| 255 |
"""
|
| 256 |
|
| 257 |
+
def __init__(self, config: OrionMOEConfig, layer_idx: Optional[int] = None):
|
| 258 |
super().__init__()
|
| 259 |
self.config = config
|
| 260 |
self.layer_idx = layer_idx
|
|
|
|
| 285 |
self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
|
| 286 |
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
|
| 287 |
|
| 288 |
+
self.rotary_emb = OrionMOERotaryEmbedding(
|
| 289 |
self.head_dim,
|
| 290 |
max_position_embeddings=self.max_position_embeddings,
|
| 291 |
base=self.rope_theta,
|
|
|
|
| 376 |
return attn_output, attn_weights, past_key_value
|
| 377 |
|
| 378 |
|
| 379 |
+
class OrionMOEFlashAttention2(OrionMOEAttention):
|
| 380 |
"""
|
| 381 |
+
OrionMOE flash attention module. This module inherits from `OrionMOEAttention` as the weights of the module stays
|
| 382 |
untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
|
| 383 |
flash attention and deal with padding tokens in case the input contains any of them.
|
| 384 |
"""
|
|
|
|
| 670 |
)
|
| 671 |
|
| 672 |
|
| 673 |
+
class OrionMOESdpaAttention(OrionMOEAttention):
|
| 674 |
"""
|
| 675 |
+
OrionMOE attention module using torch.nn.functional.scaled_dot_product_attention. This module inherits from
|
| 676 |
+
`OrionMOEAttention` as the weights of the module stays untouched. The only changes are on the forward pass to adapt to
|
| 677 |
SDPA API.
|
| 678 |
"""
|
| 679 |
|
| 680 |
+
# Adapted from OrionMOEAttention.forward
|
| 681 |
def forward(
|
| 682 |
self,
|
| 683 |
hidden_states: torch.Tensor,
|
|
|
|
| 690 |
if output_attentions:
|
| 691 |
# TODO: Improve this warning with e.g. `model.config.attn_implementation = "manual"` once this is implemented.
|
| 692 |
logger.warning_once(
|
| 693 |
+
"OrionMOEModel is using OrionMOESdpaAttention, but `torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to the manual attention implementation, "
|
| 694 |
'but specifying the manual implementation will be required from Transformers version v5.0.0 onwards. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
|
| 695 |
)
|
| 696 |
return super().forward(
|
|
|
|
| 758 |
|
| 759 |
|
| 760 |
ORION_ATTENTION_CLASSES = {
|
| 761 |
+
"eager": OrionMOEAttention,
|
| 762 |
+
"flash_attention_2": OrionMOEFlashAttention2,
|
| 763 |
+
"sdpa": OrionMOESdpaAttention,
|
| 764 |
}
|
| 765 |
|
| 766 |
|
| 767 |
+
class OrionMOEBlockSparseTop2MLP(nn.Module):
|
| 768 |
+
def __init__(self, config: OrionMOEConfig):
|
| 769 |
super().__init__()
|
| 770 |
self.ffn_dim = config.intermediate_size
|
| 771 |
self.hidden_dim = config.hidden_size
|
|
|
|
| 782 |
return current_hidden_states
|
| 783 |
|
| 784 |
|
| 785 |
+
class OrionMOESparseMoeBlock(nn.Module):
|
| 786 |
"""
|
| 787 |
This implementation is
|
| 788 |
strictly equivalent to standard MoE with full capacity (no
|
|
|
|
| 804 |
# gating
|
| 805 |
self.gate = nn.Linear(self.hidden_dim, self.num_experts, bias=False)
|
| 806 |
|
| 807 |
+
self.experts = nn.ModuleList([OrionMOEBlockSparseTop2MLP(config) for _ in range(self.num_experts)])
|
| 808 |
|
| 809 |
# Jitter parameters
|
| 810 |
self.jitter_noise = config.router_jitter_noise
|
|
|
|
| 847 |
return final_hidden_states, router_logits
|
| 848 |
|
| 849 |
|
| 850 |
+
class OrionMOEDecoderLayer(nn.Module):
|
| 851 |
+
def __init__(self, config: OrionMOEConfig, layer_idx: int):
|
| 852 |
super().__init__()
|
| 853 |
self.hidden_size = config.hidden_size
|
| 854 |
|
| 855 |
self.self_attn = ORION_ATTENTION_CLASSES[config._attn_implementation](config, layer_idx)
|
| 856 |
|
| 857 |
+
self.block_sparse_moe = OrionMOESparseMoeBlock(config)
|
| 858 |
+
self.input_layernorm = OrionMOERMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 859 |
+
self.post_attention_layernorm = OrionMOERMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 860 |
|
| 861 |
def forward(
|
| 862 |
self,
|
|
|
|
| 935 |
and behavior.
|
| 936 |
|
| 937 |
Parameters:
|
| 938 |
+
config ([`OrionMOEConfig`]):
|
| 939 |
Model configuration class with all the parameters of the model. Initializing with a config file does not
|
| 940 |
load the weights associated with the model, only the configuration. Check out the
|
| 941 |
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
|
|
|
|
| 943 |
|
| 944 |
|
| 945 |
@add_start_docstrings(
|
| 946 |
+
"The bare OrionMOE Model outputting raw hidden-states without any specific head on top.",
|
| 947 |
ORION_START_DOCSTRING,
|
| 948 |
)
|
| 949 |
|
| 950 |
+
class OrionMOEPreTrainedModel(PreTrainedModel):
|
| 951 |
+
config_class = OrionMOEConfig
|
| 952 |
base_model_prefix = "model"
|
| 953 |
supports_gradient_checkpointing = True
|
| 954 |
+
_no_split_modules = ["OrionMOEDecoderLayer"]
|
| 955 |
_skip_keys_device_placement = "past_key_values"
|
| 956 |
_supports_flash_attn_2 = True
|
| 957 |
_supports_sdpa = True
|
|
|
|
| 1037 |
|
| 1038 |
|
| 1039 |
@add_start_docstrings(
|
| 1040 |
+
"The bare OrionMOE Model outputting raw hidden-states without any specific head on top.",
|
| 1041 |
ORION_START_DOCSTRING,
|
| 1042 |
)
|
| 1043 |
+
class OrionMOEModel(OrionMOEPreTrainedModel):
|
| 1044 |
"""
|
| 1045 |
+
Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`OrionMOEDecoderLayer`]
|
| 1046 |
|
| 1047 |
Args:
|
| 1048 |
+
config: OrionMOEConfig
|
| 1049 |
"""
|
| 1050 |
|
| 1051 |
+
def __init__(self, config: OrionMOEConfig):
|
| 1052 |
super().__init__(config)
|
| 1053 |
self.padding_idx = config.pad_token_id
|
| 1054 |
self.vocab_size = config.vocab_size
|
| 1055 |
|
| 1056 |
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
| 1057 |
self.layers = nn.ModuleList(
|
| 1058 |
+
[OrionMOEDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
|
| 1059 |
)
|
| 1060 |
self._attn_implementation = config._attn_implementation
|
| 1061 |
+
self.norm = OrionMOERMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 1062 |
|
| 1063 |
self.gradient_checkpointing = False
|
| 1064 |
# Initialize weights and apply final processing
|
|
|
|
| 1138 |
if is_padding_right:
|
| 1139 |
raise ValueError(
|
| 1140 |
"You are attempting to perform batched generation with padding_side='right'"
|
| 1141 |
+
" this may lead to unexpected behaviour for Flash Attention version of OrionMOE. Make sure to "
|
| 1142 |
" call `tokenizer.padding_side = 'left'` before tokenizing the input. "
|
| 1143 |
)
|
| 1144 |
|
|
|
|
| 1235 |
)
|
| 1236 |
|
| 1237 |
|
| 1238 |
+
class OrionMOEForCausalLM(OrionMOEPreTrainedModel):
|
| 1239 |
_tied_weights_keys = ["lm_head.weight"]
|
| 1240 |
|
| 1241 |
def __init__(self, config):
|
| 1242 |
super().__init__(config)
|
| 1243 |
+
self.model = OrionMOEModel(config)
|
| 1244 |
self.vocab_size = config.vocab_size
|
| 1245 |
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
| 1246 |
self.router_aux_loss_coef = config.router_aux_loss_coef
|
|
|
|
| 1438 |
|
| 1439 |
@add_start_docstrings(
|
| 1440 |
"""
|
| 1441 |
+
The OrionMOE Model transformer with a sequence classification head on top (linear layer).
|
| 1442 |
|
| 1443 |
+
[`OrionMOEForSequenceClassification`] uses the last token in order to do the classification, as other causal models
|
| 1444 |
(e.g. GPT-2) do.
|
| 1445 |
|
| 1446 |
Since it does classification on the last token, it requires to know the position of the last token. If a
|
|
|
|
| 1451 |
""",
|
| 1452 |
ORION_START_DOCSTRING,
|
| 1453 |
)
|
| 1454 |
+
class OrionMOEForSequenceClassification(OrionMOEPreTrainedModel):
|
| 1455 |
def __init__(self, config):
|
| 1456 |
super().__init__(config)
|
| 1457 |
self.num_labels = config.num_labels
|
| 1458 |
+
self.model = OrionMOEModel(config)
|
| 1459 |
self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
|
| 1460 |
|
| 1461 |
# Initialize weights and apply final processing
|