Orion-MoE8x7B
# 目录
- [📖 模型介绍](#zh_model-introduction)
- [🔗 下载路径](#zh_model-download)
- [🔖 评估结果](#zh_model-benchmark)
- [📊 模型推理](#zh_model-inference)
- [📜 声明协议](#zh_declarations-license)
- [🥇 企业介绍](#zh_company-introduction)
# 1. 模型介绍
- Orion-MoE8x7B是一个具有8乘以70亿参数的生成式稀疏混合专家大语言模型,该模型在训练数据语言上涵盖了中文、英语、日语、韩语等多种语言。在多语言环境下的一系列任务中展现出卓越的性能。在主流的公开基准评测中,Orion-MoE8x7B模型表现优异,多项指标显著超越同等参数基本的其他模型。
- Orion-MoE8x7B模型有以下几个特点:
- 同规模参数级别基座大模型综合评测效果表现优异
- 多语言能力强,在日语、韩语测试集上显著领先,在阿拉伯语、德语、法语、西班牙语测试集上也全面领先
- Orion-MoE8x7B模型超参
- Orion-MoE8x7B模型架构接近Mixtral 8x7B,超参细节请参考下表
|Configuration |OrionMOE 8x7B|
|-------------------|-------------|
|Hidden Size | 4096 |
|# Layers | 32 |
|# Query Heads | 32 |
|# KV Heads | 8 |
|Intermediate Size | 14592 |
|# Experts | 8 |
|# Activated Experts| 2 |
|Embedding Tying | False |
|Position embedding | RoPE |
|seq_len | 8192 |
|Vocabulary Size | 113664 |
- Orion-MoE8x7B训练超参
- 我们使用AdamW优化器将超参数设置为 𝛽1 = 0.9, 𝛽2 = 0.95,权重衰减为0.1。
- 训练开始时进行2000次预热阶段迭代,学习率线性增加至峰值3e-4,之后采用余弦调度,逐渐将学习率降低到3e-5以完成整个训练过程。
- 模型训练采用BF16/FP32混合精度,批量大小为2600,每步处理大约2200万个token。
- Orion-MoE8x7B训练数据组成
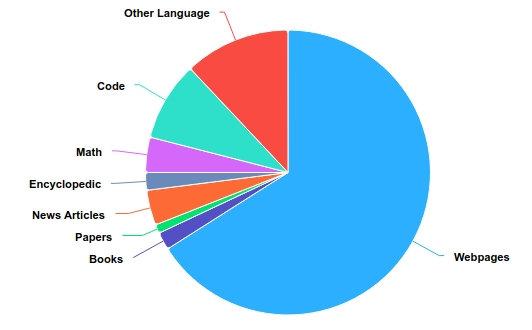
- 预训练数据语种上主要由英语、中文和其他多语言语言组成,分别占比50%、25%和12%。数据分类上,代码占9%,数学文本占4%,分布参考下图。
# 2. 下载路径
发布模型和下载链接见下表:
| 模型名称 | HuggingFace下载链接 | ModelScope下载链接 |
|---------|-------------------|-------------------|
| ⚾ 基座模型 | [Orion-MoE8x7B](https://huggingface.co/OrionStarAI/Orion-MoE8x7B) | [Orion-MoE8x7B](https://modelscope.cn/models/OrionStarAI/Orion-MoE8x7B-Base/summary) |
# 3. 评估结果
### 3.1. 基座模型基准测试对比
|TestSet|Mixtral 8x7B|Qwen1.5-32b|Qwen2.5-32b|Orion 14B |Qwen2-57B-A14 Orion MoE8x7B |
| -------------- | ---- | ---- | ---- | ---- | ----
| MMLU | 70.4 | 73.4 | 82.9 | 69.9 | 76.5 **85.9** |
| MMLU Pro | 38.5 | 45.3 | 58.0 | 34.0 |48.6 **58.3** |
| CEval | 54.1 | 83.5 | 87.7 | 72.8 | 87.7 **89.7** |
| CMMLU | 53.2 | 82.3 | 89.0 | 70.6 | 88.5 **89.2** |
| ARC_c | 85.1 | 90.2 | **94.2** | 79.7 |91.5 91.9 |
| HellaSwag | 81.9 | 82.0 | 82.5 | 78.5 | 85.2 **89.2** |
| LAMBADA | 76.8 | 73.7 | 75.4 | 78.8 | 72.6 **79.7** |
| BBH | 50.9 | 57.3 | **67.7** | 50.4 | 55.1 55.8 |
| MuSR | 43.2 | 42.7 | 49.8 | 43.6 | 39.0 **49.9** |
| PIQA | 83.4 | 82.2 | 80.1 | 79.5 | 81.9 **87.3** |
| CommonSenseQA | 69.6 | **74.7** | 73.0 | 66.9 | 69.9 73.1 |
| IFEval | 24.2 | 33.0 | **41.6** | 29.1 | 31.2 30.1 |
| GQPA | 30.9 | 33.5 | 49.5 | 28.5 | 32.6 **52.2** |
| HumanEval | 33.5 | 36.0 | **47.0** | 20.1 | 53.0 44.5 |
### 3.2. 小语种: 日文
|Model Average | |JSQuAD|JCommonSenseQA|JNLI|MARC-ja|JAQKET v2|PAWS-ja|
|-------------|-------|-------|---------------|-----|-------|---------|
|Mixtral-8x7B 69.8 | |89.0 |78.7 |32.1 |95.4 |78.9 |44.5 |
|Qwen1.5-32B 74.7 | |89.9 |84.5 |51.0 |97.1 |82.1 |43.8 |
|Qwen2.5-32B 80.7 | |89.1 |93.8 |72.1 |**97.9** |**89.3** |42.2 |
|Orion-14B 74.2 | |74.2 |88.2 |72.8 |94.1 |66.2 |49.9 |
|Orion-MoE8x7B **82.9** | | **91.8** | 90.4 | **90.5** | 96.4 | 81.2 | **47.4** |
### 3.3. 小语种: 韩文
|Model Average | |HAE-RAE|KoBEST BoolQ|KoBEST COPA|KoBEST HellaSwag|KoBEST SentiNeg|KoBEST WiC|PAWS-ko|
|-----|-------|-------|------------|-----------|----------------|---------------|----------|
|Mixtral-8x7B 60.7 | |53.2 |78.6 |66.2 |56.6 |77.1 |49.4 |44.1 |
|Qwen1.5-32B 58.6 | |46.4 |76.3 |60.4 |53.0 |78.3 |52.1 |43.4 |
|Qwen2.5-32B 71.4 | |**70.7** |80.3 |76.7 |**61.2** |96.5 |**77.2** |37.1 |
|Orion-14B 67.7 | |69.7 |80.6 |77.1 |58.2 |92.4 |51.2 |44.6 |
|Orion-MoE8x7B **72.0** | | 65.2 | **85.4** | **80.4** | 56.0 | **97.0** | 73.6 | **46.4** |
### 3.4. 小语种: 阿拉伯语,德语,法语,西班牙语
| Language | Spanish | | French | | German | | Arabic | |
|----|----|----|----|----|----|----|----|----|
|**Model**|**HellaSwag**|**ARC**|**HellaSwag**|**ARC**|**HellaSwag**|**ARC**|**HellaSwag**|**ARC**|
|Mixtral-8x7B |74.3 |54.8 |73.9 |55.9 |69.2 |52.4 |47.9 |36.3 |
|Qwen1.5-32B |70.5 |55.1 |68.9 |56.0 |63.8 |50.8 |50.1 |40.0 |
|Qwen2.5-32B |75.0 |65.3 |74.2 |62.7 |69.8 |61.8 |59.8 |52.9 |
|Orion-14B |62.0 |44.6 |60.2 |42.3 |54.7 |38.9 |42.3 |33.9 | Orion-MoE8x7B | **87.4** | **70.1** | **85.6** | **68.8** | **80.6** | **63.5** | **69.4** | **54.3 | **
### 3.5. 泄漏检测结果
当大型语言模型的预训练数据包含特定数据集的内容时,该模型在该数据集上的表现可能会被人为提高,从而导致不准确的性能评估。为了解决这个问题,来自中国科学院深圳先进技术研究院和其他机构的研究人员提出了一种简单有效的数据泄露检测方法。该方法利用多选项的可互换性,通过打乱原始数据集中的选项生成派生数据。然后,使用模型计算派生数据集的对数概率分布,以检测原始数据集是否存在泄露。
我们在三个基准数据集上进行了数据泄露检测实验:MMLU、CMMLU 和 C-Eval。
更多细节可以在论文中找到:https://web3.arxiv.org/pdf/2409.01790。
测试代码:https://github.com/nishiwen1214/Benchmark-leakage-detection。
|Threshold 0.2|Qwen2.5 32B|Qwen1.5 32B| Orion MoE8x7B |Orion 14B|Mixtral 8x7B|
|------|------|------|------|------|------|
|MMLU | 0.30 | 0.27 | 0.22 | 0.28 | 0.25 |
|CEval | 0.39 | 0.38 | 0.27 | 0.26 | 0.26 |
|CMMLU | 0.38 | 0.39 | 0.23 | 0.27 | 0.22 |
### 3.6. 推理速度
搭建基于8卡Nvidia RTX3090以及4卡Nvidia A100,采用"token/秒"为单位,从客户端统计测试结果。
|Models | 8x3090 1 concurrent | 8x3090 4 concurrent | 4xA100 1 concurrent | 4xA100 4 concurrent|
|---------|--------|-------|--------|-------|
|Qwen32 | 52.93 | 46.06 | 62.43 | 56.81 | Orion-MoE | **102.77** | **54.61** | **107.76** | **61.83** |
同时测试了4卡A100上,基于不同输入长度(tokens)的推理速度比较,采用"token/秒"为单位,从客户端统计测试结果。
| Input | 4k | 8k | 12k | 16k | 32k | 64k |
|---------|-------|-------|-------|-------|-------|-------|
|Qwen32 | 53.99 | 47.59 | 25.98 | 24.35 | 18.64 | 11.86 | Orion-MoE | **90.86** | **54.40** | **31.08** | **29.04** | **22.69** | **14.51** |
# 4. 模型推理
推理所需的模型权重、源码、配置已发布在 Hugging Face,下载链接见本文档最开始的表格。我们在此示范多种推理方式。程序会自动从
Hugging Face 下载所需资源。
## 4.1. Python 代码方式
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("OrionStarAI/Orion-MoE8x7B",
use_fast=False,
trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("OrionStarAI/Orion-MoE8x7B",
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained("OrionStarAI/Orion-MoE8x7B")
messages = [{"role": "user", "content": "你好! 你叫什么名字!"}]
response = model.chat(tokenizer, messages, streaming=Flase)
print(response)
```
在上述两段代码中,模型加载指定 `device_map='auto'`
,会使用所有可用显卡。如需指定使用的设备,可以使用类似 `export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7`(使用了0、1、2、3、4、5、6、7号显卡)的方式控制。
## 4.2. 脚本直接推理
```shell
# base model
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python demo/text_generation_base.py --model OrionStarAI/Orion-MoE8x7B --tokenizer OrionStarAI/Orion-MoE8x7B --prompt 你好,你叫什么名字
```
## 4.3. vLLM推理服务
下载工程(https://github.com/OrionStarAI/vllm_server), 搭建基于vLLM的推理服务镜像.
```shell
git clone git@github.com:OrionStarAI/vllm_server.git
cd vllm_server
docker build -t vllm_server:0.0.0.0 -f Dockerfile .
```
开启docker镜像服务
```shell
docker run --gpus all -it -p 9999:9999 -v $(pwd)/logs:/workspace/logs:rw -v $HOME/Downloads:/workspace/models -e CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 -e MODEL_DIR=Orion-MoE8x7B -e MODEL_NAME=orion-moe vllm_server:0.0.0.0
```
运行推理
```shell
curl http://0.0.0.0:9999/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "orion-moe","temperature": 0.2,"stream": false, "messages": [{"role": "user", "content":"Which company developed you as an AI agent?"}]}'
```
# 5. 声明、协议
## 5.1. 声明
我们强烈呼吁所有使用者,不要利用 Orion-MoE8x7B 模型进行任何危害国家社会安全或违法的活动。另外,我们也要求使用者不要将
Orion-MoE8x7B 模型用于未经适当安全审查和备案的互联网服务。
我们希望所有的使用者都能遵守这个原则,确保科技的发展能在规范和合法的环境下进行。
我们已经尽我们所能,来确保模型训练过程中使用的数据的合规性。然而,尽管我们已经做出了巨大的努力,但由于模型和数据的复杂性,仍有可能存在一些无法预见的问题。因此,如果由于使用
Orion-14B 开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
## 5.2. 协议
社区使用Orion-MoE8x7B系列模型
- 代码请遵循 [Apache License Version 2.0](./LICENSE)
- 模型请遵循 [Orion系列模型社区许可协议](./ModelsCommunityLicenseAgreement)
# 6. 企业介绍
猎户星空(OrionStar)是一家全球领先的服务机器人解决方案公司,成立于2016年9月。猎户星空致力于基于人工智能技术打造下一代革命性机器人,使人们能够摆脱重复的体力劳动,使人类的工作和生活更加智能和有趣,通过技术使社会和世界变得更加美好。
猎户星空拥有完全自主开发的全链条人工智能技术,如语音交互和视觉导航。它整合了产品开发能力和技术应用能力。基于Orion机械臂平台,它推出了ORION
STAR AI Robot Greeting、AI Robot Greeting Mini、Lucki、Coffee
Master等产品,并建立了Orion机器人的开放平台OrionOS。通过为 **真正有用的机器人而生** 的理念实践,它通过AI技术为更多人赋能。
凭借7年AI经验积累,猎户星空已推出的大模型深度应用“聚言”,并陆续面向行业客户提供定制化AI大模型咨询与服务解决方案,真正帮助客户实现企业经营效率领先同行目标。
**猎户星空具备全链条大模型应用能力的核心优势**,包括拥有从海量数据处理、大模型预训练、二次预训练、微调(Fine-tune)、Prompt
Engineering 、Agent开发的全链条能力和经验积累;拥有完整的端到端模型训练能力,包括系统化的数据处理流程和数百张GPU的并行模型训练能力,现已在大政务、云服务、出海电商、快消等多个行业场景落地。
***欢迎有大模型应用落地需求的企业联系我们进行商务合作***
**咨询电话:** 400-898-7779
**电子邮箱:** ai@orionstar.com
**Discord社区链接: https://discord.gg/zumjDWgdAs**