
File size: 6,603 Bytes
05efeba e9be23d 56b2510 05efeba |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 |
---
license: apache-2.0
library_name: PaddleOCR
language:
- en
- zh
pipeline_tag: image-to-text
tags:
- OCR
- PaddlePaddle
- PaddleOCR
- layout_detection
---
# PicoDet_layout_1x
## Introduction
A high-efficiency layout area localization model trained on a self-built dataset using PicoDet-1x, capable of detecting 5-Class english document area, including Text, Title, Table, Figure, and List. The key metrics are as follow:
| Model| mAP(0.5) (%) |
| --- | --- |
|PicoDet_layout_1x | 97.8 |
## Quick Start
### Installation
1. PaddlePaddle
Please refer to the following commands to install PaddlePaddle using pip:
```bash
# for CUDA11.8
python -m pip install paddlepaddle-gpu==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
# for CUDA12.6
python -m pip install paddlepaddle-gpu==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
# for CPU
python -m pip install paddlepaddle==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/
```
For details about PaddlePaddle installation, please refer to the [PaddlePaddle official website](https://www.paddlepaddle.org.cn/en/install/quick).
2. PaddleOCR
Install the latest version of the PaddleOCR inference package from PyPI:
```bash
python -m pip install paddleocr
```
### Model Usage
You can quickly experience the functionality with a single command:
```bash
paddleocr layout_detection \
--model_name PicoDet_layout_1x \
-i https://cdn-uploads.huggingface.co/production/uploads/63d7b8ee07cd1aa3c49a2026/-oU2IpNLcA0gTMJ34wDBR.png
```
You can also integrate the model inference of the layout detection module into your project. Before running the following code, please download the sample image to your local machine.
```python
from paddleocr import LayoutDetection
model = LayoutDetection(model_name="PicoDet_layout_1x")
output = model.predict("-oU2IpNLcA0gTMJ34wDBR.png", batch_size=1, layout_nms=True)
for res in output:
res.print()
res.save_to_img(save_path="./output/")
res.save_to_json(save_path="./output/res.json")
```
After running, the obtained result is as follows:
```json
{'res': {'input_path': '-oU2IpNLcA0gTMJ34wDBR.png', 'page_index': None, 'boxes': [{'cls_id': 0, 'label': 'Text', 'score': 0.9922339916229248, 'coordinate': [84.18926, 1248.3407, 583.2205, 1582.3639]}, {'cls_id': 0, 'label': 'Text', 'score': 0.991148829460144, 'coordinate': [606.0175, 1209.0277, 1105.669, 1538.559]}, {'cls_id': 0, 'label': 'Text', 'score': 0.989486813545227, 'coordinate': [84.11199, 710.821, 582.4992, 1208.4802]}, {'cls_id': 0, 'label': 'Text', 'score': 0.9823781847953796, 'coordinate': [605.9509, 951.964, 1105.8907, 1089.925]}, {'cls_id': 3, 'label': 'Table', 'score': 0.98123699426651, 'coordinate': [608.91614, 301.1981, 1111.2635, 805.45233]}, {'cls_id': 4, 'label': 'Figure', 'score': 0.971710741519928, 'coordinate': [84.329, 200.35394, 577.5106, 681.766]}, {'cls_id': 0, 'label': 'Text', 'score': 0.950641930103302, 'coordinate': [607.27435, 826.2146, 1107.0017, 911.43726]}, {'cls_id': 0, 'label': 'Text', 'score': 0.9468774795532227, 'coordinate': [605.6758, 197.66481, 1105.3107, 265.3606]}, {'cls_id': 1, 'label': 'Title', 'score': 0.86313396692276, 'coordinate': [606.6188, 1170.0265, 827.1196, 1192.0656]}, {'cls_id': 1, 'label': 'Title', 'score': 0.8427881002426147, 'coordinate': [605.2791, 1131.709, 823.0802, 1152.363]}, {'cls_id': 0, 'label': 'Text', 'score': 0.5990690588951111, 'coordinate': [625.3928, 1558.7576, 849.12946, 1583.5391]}]}}
```
The visualized image is as follows:
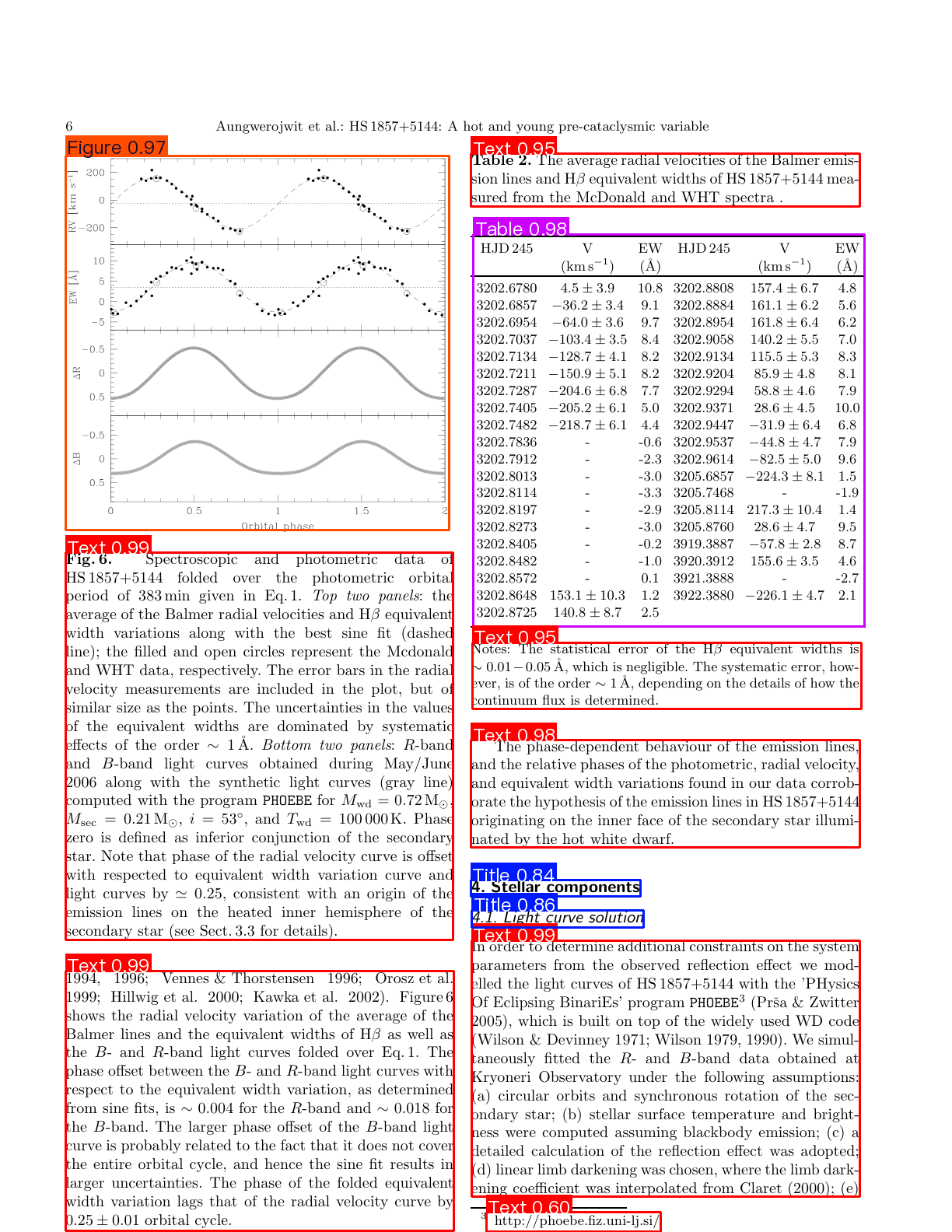
For details about usage command and descriptions of parameters, please refer to the [Document](https://paddlepaddle.github.io/PaddleOCR/latest/en/version3.x/module_usage/layout_detection.html#iii-quick-integration).
### Pipeline Usage
The ability of a single model is limited. But the pipeline consists of several models can provide more capacity to resolve difficult problems in real-world scenJust a few lines of code can experience the inference of the pipelinearios.
#### PP-TableMagic (table_recognition_v2)
The General Table Recognition v2 pipeline (PP-TableMagic) is designed to tackle table recognition tasks, identifying tables in images and outputting them in HTML format. PP-TableMagic includes the following 8 modules:
* Table Structure Recognition Module
* Table Classification Module
* Table Cell Detection Module
* Text Detection Module
* Text Recognition Module
* Layout Region Detection Module (optional)
* Document Image Orientation Classification Module (optional)
* Text Image Unwarping Module (optional)
You can quickly experience the PP-TableMagic pipeline with a single command.
```bash
paddleocr table_recognition_v2 -i https://cdn-uploads.huggingface.co/production/uploads/63d7b8ee07cd1aa3c49a2026/-oU2IpNLcA0gTMJ34wDBR.png \
--layout_detection_model_name PicoDet_layout_1x \
--use_doc_orientation_classify False \
--use_doc_unwarping False \
--save_path ./output \
--device gpu:0
```
You can also integrate the PP-TableMagic pipeline into your project. Before running the following code, please download the sample image to your local machine.
```python
from paddleocr import TableRecognitionPipelineV2
pipeline = TableRecognitionPipelineV2(
layout_detection_model_name=PicoDet_layout_1x,
use_doc_orientation_classify=False, # Use use_doc_orientation_classify to enable/disable document orientation classification model
use_doc_unwarping=False, # Use use_doc_unwarping to enable/disable document unwarping module
device="gpu:0", # Use device to specify GPU for model inference
)
output = pipeline.predict("-oU2IpNLcA0gTMJ34wDBR.png")
for res in output:
res.print() ## Print the predicted structured output
res.save_to_img("./output/")
res.save_to_xlsx("./output/")
res.save_to_html("./output/")
res.save_to_json("./output/")
```
The default model used in pipeline is `PP-DocLayout-L`, so it is needed that specifing to `PicoDet_layout_1x` by argument `layout_detection_model_name`. And you can also use the local model file by argument `layout_detection_model_dir`. For details about usage command and descriptions of parameters, please refer to the [Document](https://paddlepaddle.github.io/PaddleOCR/main/en/version3.x/pipeline_usage/table_recognition_v2.html#2-quick-start).
## Links
[PaddleOCR Repo](https://github.com/paddlepaddle/paddleocr)
[PaddleOCR Documentation](https://paddlepaddle.github.io/PaddleOCR/latest/en/index.html)
|