

Upload folder using huggingface_hub (#1)
Browse files- 36c3c01637c938adecb7c9f908278cc32e472697e4f72ae1d46d0ea5c7b567d8 (f0c912f9e3edc9c7af33aeebe2ac46bdac021d22)
- README.md +59 -0
- config.json +1 -0
- model/config.json +6 -0
- model/model.bin +3 -0
- model/smasher_config.json +1 -0
- model/special_tokens_map.json +30 -0
- model/tokenizer.json +0 -0
- model/tokenizer.model +3 -0
- model/tokenizer_config.json +37 -0
- model/vocabulary.json +0 -0
- plots.png +0 -0
README.md
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
library_name: pruna-engine
|
| 4 |
+
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
|
| 5 |
+
metrics:
|
| 6 |
+
- memory_disk
|
| 7 |
+
- memory_inference
|
| 8 |
+
- inference_latency
|
| 9 |
+
- inference_throughput
|
| 10 |
+
- inference_CO2_emissions
|
| 11 |
+
- inference_energy_consumption
|
| 12 |
+
---
|
| 13 |
+
<!-- header start -->
|
| 14 |
+
<!-- 200823 -->
|
| 15 |
+
<div style="width: auto; margin-left: auto; margin-right: auto">
|
| 16 |
+
<a href="https://www.pruna.ai/" target="_blank" rel="noopener noreferrer">
|
| 17 |
+
<img src="https://i.imgur.com/eDAlcgk.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
|
| 18 |
+
</a>
|
| 19 |
+
</div>
|
| 20 |
+
<!-- header end -->
|
| 21 |
+
|
| 22 |
+
# Simply make AI models cheaper, smaller, faster, and greener!
|
| 23 |
+
|
| 24 |
+
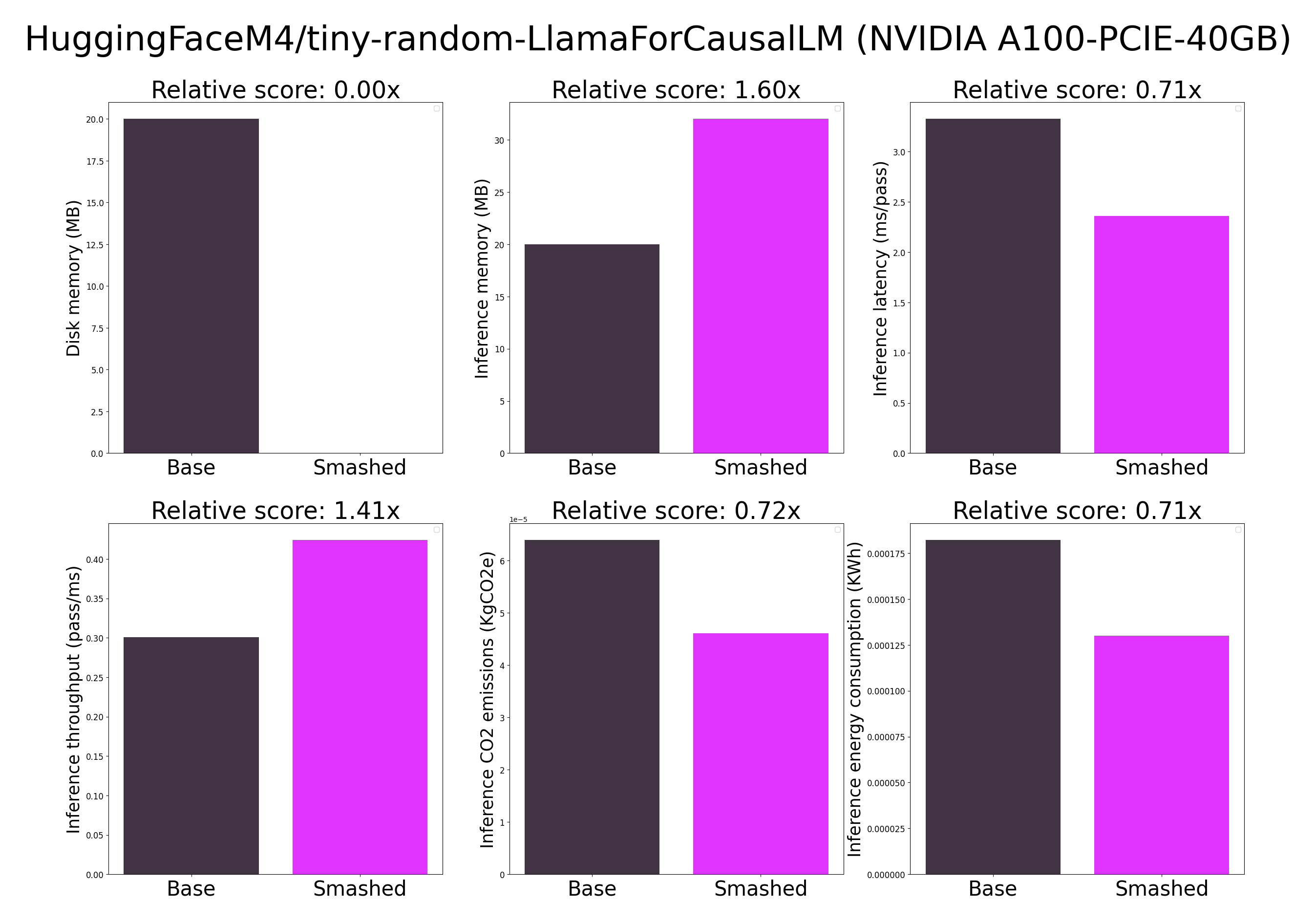
## Results
|
| 25 |
+
|
| 26 |
+

|
| 27 |
+
|
| 28 |
+
## Setup
|
| 29 |
+
|
| 30 |
+
You can run the smashed model by:
|
| 31 |
+
1. Installing and importing the `pruna-engine` (version 0.2.6) package. Use `pip install pruna --extra-index-url https://pypi.nvidia.com --extra-index-url https://pypi.ngc.nvidia.com` for installation. See [Pypi](https://pypi.org/project/pruna-engine/) for detailed on the package.
|
| 32 |
+
2. Downloading the model files at `model_path`. This can be done using huggingface with this repository name or with manual downloading.
|
| 33 |
+
3. Loading the model
|
| 34 |
+
4. Running the model.
|
| 35 |
+
|
| 36 |
+
You can achieve this by running the following code:
|
| 37 |
+
|
| 38 |
+
```python
|
| 39 |
+
from transformers.utils.hub import cached_file
|
| 40 |
+
from pruna_engine.PrunaModel import PrunaModel # Step (1): install and import `pruna-engine` package.
|
| 41 |
+
|
| 42 |
+
...
|
| 43 |
+
model_path = cached_file("PrunaAI/REPO", "model") # Step (2): download the model files at `model_path`.
|
| 44 |
+
smashed_model = PrunaModel.load_model(model_path) # Step (3): load the model.
|
| 45 |
+
y = smashed_model(x) # Step (4): run the model.
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
## Configurations
|
| 49 |
+
|
| 50 |
+
The configuration info are in `config.json`.
|
| 51 |
+
|
| 52 |
+
## License
|
| 53 |
+
|
| 54 |
+
We follow the same license as the original model. Please check the license of the original model before using this model.
|
| 55 |
+
|
| 56 |
+
## Want to compress other models?
|
| 57 |
+
|
| 58 |
+
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
|
| 59 |
+
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"pruner": "None", "pruning_ratio": 0.0, "factorizer": "None", "quantizer": "None", "n_quantization_bits": 8, "output_deviation": 0.005, "compiler": "ctranslate2_generation", "static_batch": true, "static_shape": true, "controlnet": "None", "unet_dim": 4, "device": "cuda", "cache_dir": "/ceph/hdd/staff/charpent/.cache/models", "max_batch_size": 1, "image_height": "None", "image_width": "None", "version": "None", "tokenizer_name": "placeholder"}
|
model/config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": "<s>",
|
| 3 |
+
"eos_token": "</s>",
|
| 4 |
+
"layer_norm_epsilon": 1e-06,
|
| 5 |
+
"unk_token": "<unk>"
|
| 6 |
+
}
|
model/model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ede1e8a6b58decc28d91af066747f8e51ded096b2ae7318d662fa50f67159334
|
| 3 |
+
size 1292303
|
model/smasher_config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"load_function": "ctranslate2", "api_key": "pruna_c4c77860c62a2965f6bc281841ee1d7bd3", "verify_url": "http://johnrachwan.pythonanywhere.com", "model_specific": {}}
|
model/special_tokens_map.json
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "</s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "<unk>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"unk_token": {
|
| 24 |
+
"content": "<unk>",
|
| 25 |
+
"lstrip": false,
|
| 26 |
+
"normalized": false,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
}
|
| 30 |
+
}
|
model/tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model/tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9e556afd44213b6bd1be2b850ebbbd98f5481437a8021afaf58ee7fb1818d347
|
| 3 |
+
size 499723
|
model/tokenizer_config.json
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "<unk>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"1": {
|
| 12 |
+
"content": "<s>",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"2": {
|
| 20 |
+
"content": "</s>",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
}
|
| 27 |
+
},
|
| 28 |
+
"bos_token": "<s>",
|
| 29 |
+
"clean_up_tokenization_spaces": false,
|
| 30 |
+
"eos_token": "</s>",
|
| 31 |
+
"legacy": false,
|
| 32 |
+
"model_max_length": 2048,
|
| 33 |
+
"pad_token": "<unk>",
|
| 34 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 35 |
+
"unk_token": "<unk>",
|
| 36 |
+
"use_default_system_prompt": true
|
| 37 |
+
}
|
model/vocabulary.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
plots.png
ADDED
|