

Upload folder using huggingface_hub (#2)
Browse files- 3c04afac993e32df3f34cb20ffea540ea2a3f8de432ce27a11448ee87a0c5692 (4b87a0a936829d7d76fd9241c0b2377c37d404f4)
- dffc055384d798c24da3e3cff13366bbcd6e7a463fb21c4059642d55da04c548 (337a3cd0dbb0f0585cbccd86bcbc3bd2d5ce79e0)
- config.json +1 -1
- plots.png +0 -0
- results.json +24 -24
- smash_config.json +5 -5
config.json
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
{
|
| 2 |
-
"_name_or_path": "/tmp/
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
|
|
|
| 1 |
{
|
| 2 |
+
"_name_or_path": "/tmp/tmptqw5iwk9",
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
plots.png
CHANGED

|
|
results.json
CHANGED
|
@@ -1,30 +1,30 @@
|
|
| 1 |
{
|
| 2 |
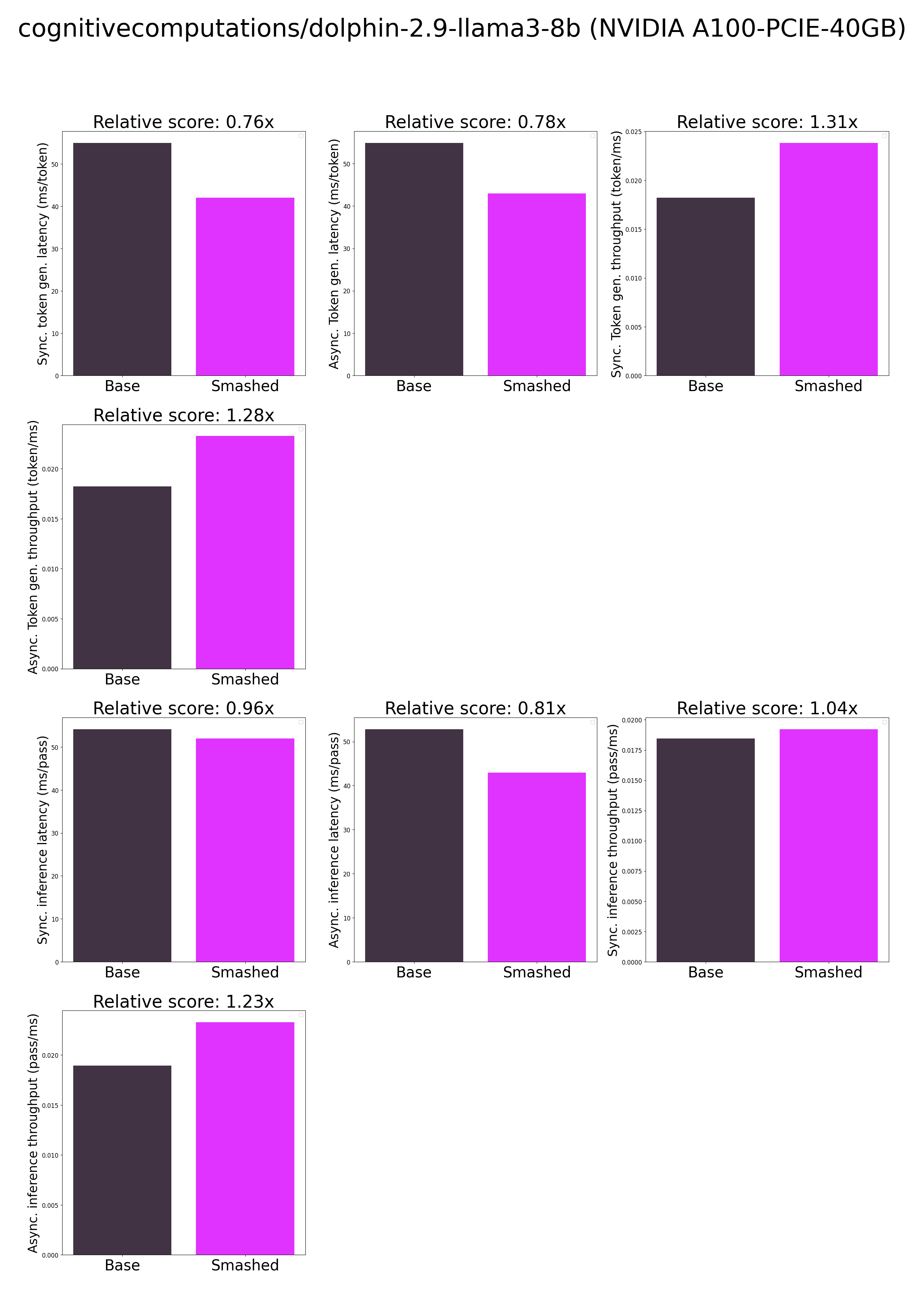
"base_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 3 |
"base_current_gpu_total_memory": 40339.3125,
|
| 4 |
-
"base_token_generation_latency_sync":
|
| 5 |
-
"base_token_generation_latency_async":
|
| 6 |
-
"base_token_generation_throughput_sync": 0.
|
| 7 |
-
"base_token_generation_throughput_async": 0.
|
| 8 |
-
"base_token_generation_CO2_emissions":
|
| 9 |
-
"base_token_generation_energy_consumption":
|
| 10 |
-
"base_inference_latency_sync":
|
| 11 |
-
"base_inference_latency_async":
|
| 12 |
-
"base_inference_throughput_sync": 0.
|
| 13 |
-
"base_inference_throughput_async": 0.
|
| 14 |
-
"base_inference_CO2_emissions":
|
| 15 |
-
"base_inference_energy_consumption":
|
| 16 |
"smashed_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 17 |
"smashed_current_gpu_total_memory": 40339.3125,
|
| 18 |
-
"smashed_token_generation_latency_sync":
|
| 19 |
-
"smashed_token_generation_latency_async":
|
| 20 |
-
"smashed_token_generation_throughput_sync": 0.
|
| 21 |
-
"smashed_token_generation_throughput_async": 0.
|
| 22 |
-
"smashed_token_generation_CO2_emissions":
|
| 23 |
-
"smashed_token_generation_energy_consumption":
|
| 24 |
-
"smashed_inference_latency_sync":
|
| 25 |
-
"smashed_inference_latency_async":
|
| 26 |
-
"smashed_inference_throughput_sync": 0.
|
| 27 |
-
"smashed_inference_throughput_async": 0.
|
| 28 |
-
"smashed_inference_CO2_emissions":
|
| 29 |
-
"smashed_inference_energy_consumption":
|
| 30 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"base_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 3 |
"base_current_gpu_total_memory": 40339.3125,
|
| 4 |
+
"base_token_generation_latency_sync": 54.95326919555664,
|
| 5 |
+
"base_token_generation_latency_async": 54.871915467083454,
|
| 6 |
+
"base_token_generation_throughput_sync": 0.018197279518374077,
|
| 7 |
+
"base_token_generation_throughput_async": 0.01822425901278915,
|
| 8 |
+
"base_token_generation_CO2_emissions": null,
|
| 9 |
+
"base_token_generation_energy_consumption": null,
|
| 10 |
+
"base_inference_latency_sync": 54.171545791625974,
|
| 11 |
+
"base_inference_latency_async": 52.81825065612793,
|
| 12 |
+
"base_inference_throughput_sync": 0.018459875666951772,
|
| 13 |
+
"base_inference_throughput_async": 0.01893284967937462,
|
| 14 |
+
"base_inference_CO2_emissions": null,
|
| 15 |
+
"base_inference_energy_consumption": null,
|
| 16 |
"smashed_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 17 |
"smashed_current_gpu_total_memory": 40339.3125,
|
| 18 |
+
"smashed_token_generation_latency_sync": 41.98579063415527,
|
| 19 |
+
"smashed_token_generation_latency_async": 42.9755836725235,
|
| 20 |
+
"smashed_token_generation_throughput_sync": 0.023817581731722923,
|
| 21 |
+
"smashed_token_generation_throughput_async": 0.023269026608691564,
|
| 22 |
+
"smashed_token_generation_CO2_emissions": null,
|
| 23 |
+
"smashed_token_generation_energy_consumption": null,
|
| 24 |
+
"smashed_inference_latency_sync": 52.003635787963866,
|
| 25 |
+
"smashed_inference_latency_async": 42.94884204864502,
|
| 26 |
+
"smashed_inference_throughput_sync": 0.01922942472863499,
|
| 27 |
+
"smashed_inference_throughput_async": 0.023283514812049485,
|
| 28 |
+
"smashed_inference_CO2_emissions": null,
|
| 29 |
+
"smashed_inference_energy_consumption": null
|
| 30 |
}
|
smash_config.json
CHANGED
|
@@ -2,19 +2,19 @@
|
|
| 2 |
"api_key": null,
|
| 3 |
"verify_url": "http://johnrachwan.pythonanywhere.com",
|
| 4 |
"smash_config": {
|
| 5 |
-
"pruners": "
|
| 6 |
"pruning_ratio": 0.0,
|
| 7 |
-
"factorizers": "
|
| 8 |
"quantizers": "['awq']",
|
| 9 |
"weight_quantization_bits": 4,
|
| 10 |
-
"output_deviation": 0.
|
| 11 |
-
"compilers": "
|
| 12 |
"static_batch": true,
|
| 13 |
"static_shape": true,
|
| 14 |
"controlnet": "None",
|
| 15 |
"unet_dim": 4,
|
| 16 |
"device": "cuda",
|
| 17 |
-
"cache_dir": "/ceph/hdd/staff/charpent/.cache/
|
| 18 |
"batch_size": 1,
|
| 19 |
"model_name": "cognitivecomputations/dolphin-2.9-llama3-8b",
|
| 20 |
"task": "text_text_generation",
|
|
|
|
| 2 |
"api_key": null,
|
| 3 |
"verify_url": "http://johnrachwan.pythonanywhere.com",
|
| 4 |
"smash_config": {
|
| 5 |
+
"pruners": "None",
|
| 6 |
"pruning_ratio": 0.0,
|
| 7 |
+
"factorizers": "None",
|
| 8 |
"quantizers": "['awq']",
|
| 9 |
"weight_quantization_bits": 4,
|
| 10 |
+
"output_deviation": 0.005,
|
| 11 |
+
"compilers": "None",
|
| 12 |
"static_batch": true,
|
| 13 |
"static_shape": true,
|
| 14 |
"controlnet": "None",
|
| 15 |
"unet_dim": 4,
|
| 16 |
"device": "cuda",
|
| 17 |
+
"cache_dir": "/ceph/hdd/staff/charpent/.cache/models8pfyzfi3",
|
| 18 |
"batch_size": 1,
|
| 19 |
"model_name": "cognitivecomputations/dolphin-2.9-llama3-8b",
|
| 20 |
"task": "text_text_generation",
|