

Upload folder using huggingface_hub (#2)
Browse files- d109159cc389e09a0aff571a30bddb3741c6f9cfc9817678e80025aded6a85fc (535f11a29c5e1c89e01650044b67e0976214c8b8)
- plots.png +0 -0
- smash_config.json +2 -2
plots.png
CHANGED

|
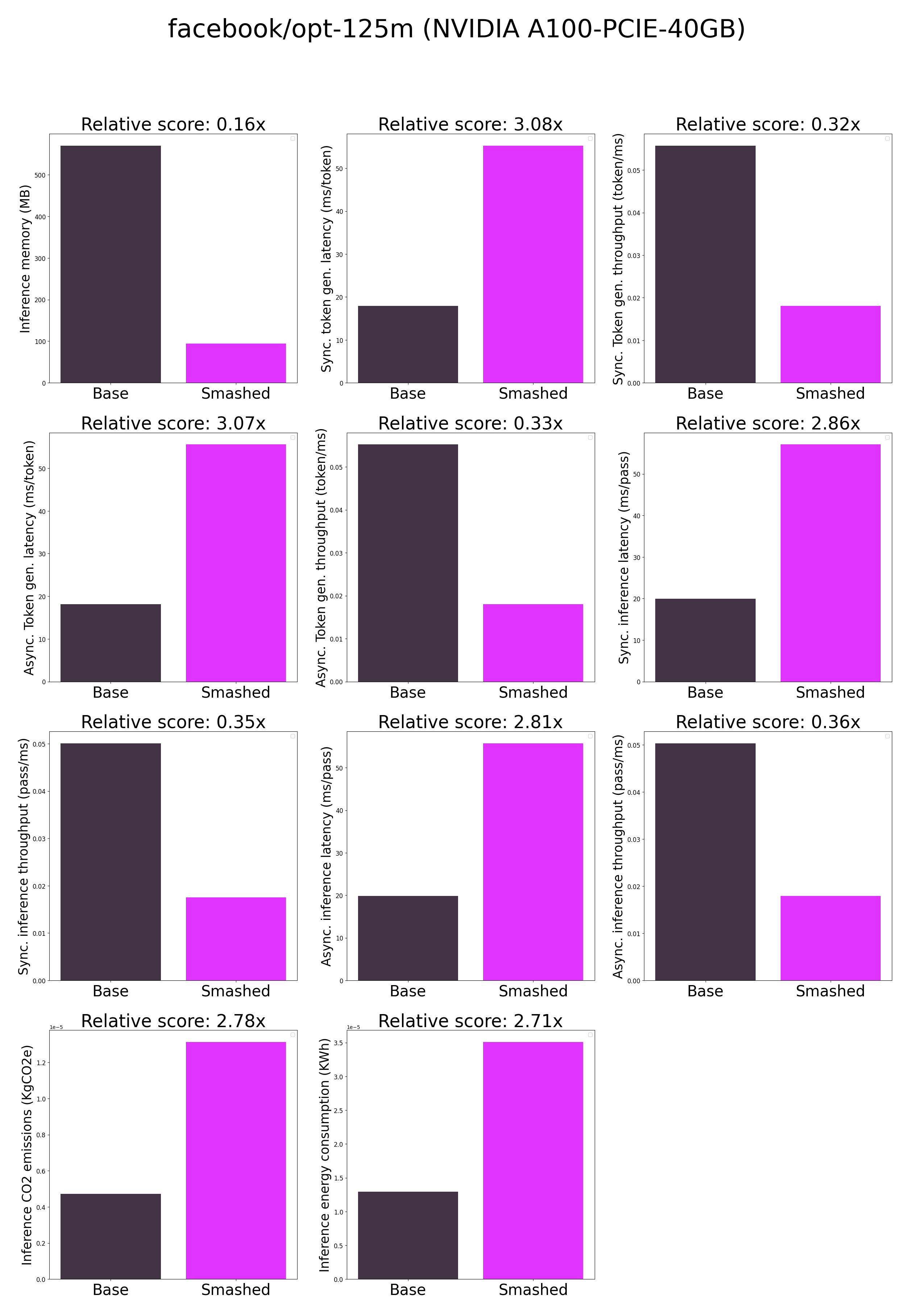
|
smash_config.json
CHANGED
|
@@ -6,7 +6,7 @@
|
|
| 6 |
"pruning_ratio": 0.0,
|
| 7 |
"factorizers": "[]",
|
| 8 |
"quantizers": "['hqq']",
|
| 9 |
-
"
|
| 10 |
"output_deviation": 0.01,
|
| 11 |
"compilers": "[]",
|
| 12 |
"static_batch": true,
|
|
@@ -14,7 +14,7 @@
|
|
| 14 |
"controlnet": "None",
|
| 15 |
"unet_dim": 4,
|
| 16 |
"device": "cuda",
|
| 17 |
-
"cache_dir": "/ceph/hdd/staff/charpent/.cache/
|
| 18 |
"batch_size": 1,
|
| 19 |
"tokenizer": "GPT2TokenizerFast(name_or_path='facebook/opt-125m', vocab_size=50265, model_max_length=1000000000000000019884624838656, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'bos_token': '</s>', 'eos_token': '</s>', 'unk_token': '</s>', 'pad_token': '<pad>'}, clean_up_tokenization_spaces=True), added_tokens_decoder={\n\t1: AddedToken(\"<pad>\", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),\n\t2: AddedToken(\"</s>\", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),\n}",
|
| 20 |
"task": "text_text_generation",
|
|
|
|
| 6 |
"pruning_ratio": 0.0,
|
| 7 |
"factorizers": "[]",
|
| 8 |
"quantizers": "['hqq']",
|
| 9 |
+
"weight_quantization_bits": 1,
|
| 10 |
"output_deviation": 0.01,
|
| 11 |
"compilers": "[]",
|
| 12 |
"static_batch": true,
|
|
|
|
| 14 |
"controlnet": "None",
|
| 15 |
"unet_dim": 4,
|
| 16 |
"device": "cuda",
|
| 17 |
+
"cache_dir": "/ceph/hdd/staff/charpent/.cache/models57sm9wv8",
|
| 18 |
"batch_size": 1,
|
| 19 |
"tokenizer": "GPT2TokenizerFast(name_or_path='facebook/opt-125m', vocab_size=50265, model_max_length=1000000000000000019884624838656, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'bos_token': '</s>', 'eos_token': '</s>', 'unk_token': '</s>', 'pad_token': '<pad>'}, clean_up_tokenization_spaces=True), added_tokens_decoder={\n\t1: AddedToken(\"<pad>\", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),\n\t2: AddedToken(\"</s>\", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),\n}",
|
| 20 |
"task": "text_text_generation",
|