

Upload folder using huggingface_hub (#1)
Browse files- 900bfdc3cf819b9694cb301745ead297a7353ac90a4be01e85fe38219ddce00a (09287a67901b2919c4876a081d914200bdbebf52)
- 5a656c7a2c81617685ca6a7334cc74ac6acda66357890ea5ae7c71c74079dace (c62bdec7ce75a84223836bd7dc049bdb369ef872)
- d3fc011bca4352d0b5fc0ad764cc6d4f698f326d0fdd418cf6ed91eb1048581d (38b661b133aa5a8adae35e70e00784ae50c6b628)
- README.md +83 -0
- config.json +46 -0
- generation_config.json +6 -0
- model-00001-of-00002.safetensors +3 -0
- model-00002-of-00002.safetensors +3 -0
- model.safetensors.index.json +330 -0
- plots.png +0 -0
- smash_config.json +27 -0
README.md
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: pruna-engine
|
| 3 |
+
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
|
| 4 |
+
metrics:
|
| 5 |
+
- memory_disk
|
| 6 |
+
- memory_inference
|
| 7 |
+
- inference_latency
|
| 8 |
+
- inference_throughput
|
| 9 |
+
- inference_CO2_emissions
|
| 10 |
+
- inference_energy_consumption
|
| 11 |
+
---
|
| 12 |
+
<!-- header start -->
|
| 13 |
+
<!-- 200823 -->
|
| 14 |
+
<div style="width: auto; margin-left: auto; margin-right: auto">
|
| 15 |
+
<a href="https://www.pruna.ai/" target="_blank" rel="noopener noreferrer">
|
| 16 |
+
<img src="https://i.imgur.com/eDAlcgk.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
|
| 17 |
+
</a>
|
| 18 |
+
</div>
|
| 19 |
+
<!-- header end -->
|
| 20 |
+
|
| 21 |
+
[](https://twitter.com/PrunaAI)
|
| 22 |
+
[](https://github.com/PrunaAI)
|
| 23 |
+
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
|
| 24 |
+
[](https://discord.gg/CP4VSgck)
|
| 25 |
+
|
| 26 |
+
# Simply make AI models cheaper, smaller, faster, and greener!
|
| 27 |
+
|
| 28 |
+
- Give a thumbs up if you like this model!
|
| 29 |
+
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
|
| 30 |
+
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 31 |
+
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
|
| 32 |
+
- Join Pruna AI community on Discord [here](https://discord.gg/CP4VSgck) to share feedback/suggestions or get help.
|
| 33 |
+
|
| 34 |
+
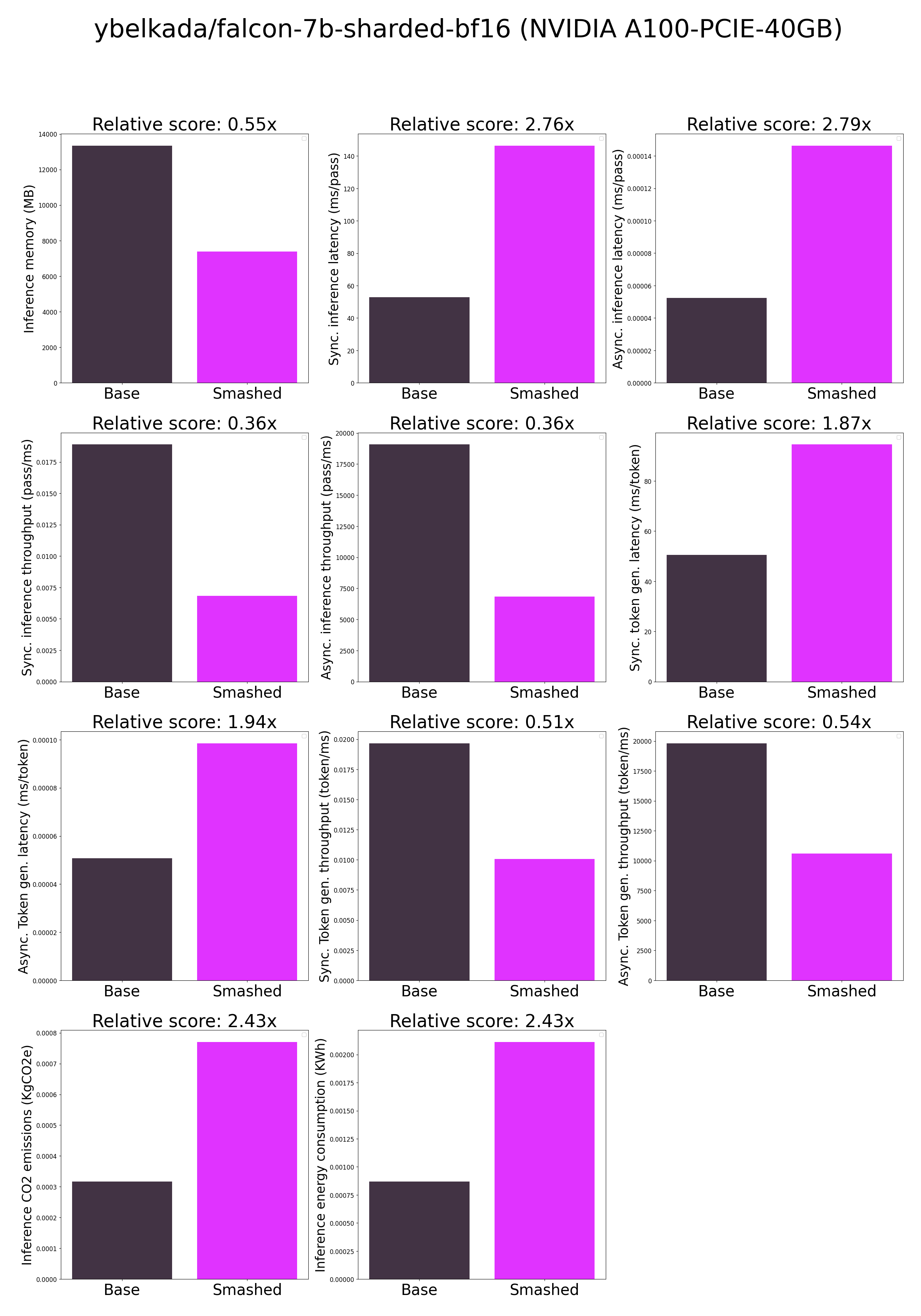
## Results
|
| 35 |
+
|
| 36 |
+

|
| 37 |
+
|
| 38 |
+
**Frequently Asked Questions**
|
| 39 |
+
- ***How does the compression work?*** The model is compressed with llm-int8.
|
| 40 |
+
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
|
| 41 |
+
- ***How is the model efficiency evaluated?*** These results were obtained on NVIDIA A100-PCIE-40GB with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
|
| 42 |
+
- ***What is the model format?*** We use safetensors.
|
| 43 |
+
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
|
| 44 |
+
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append "turbo", "tiny", or "green" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
|
| 45 |
+
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 46 |
+
- ***What are "first" metrics?*** Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
|
| 47 |
+
- ***What are "Sync" and "Async" metrics?*** "Sync" metrics are obtained by syncing all GPU processes and stop measurement when all of them are executed. "Async" metrics are obtained without syncing all GPU processes and stop when the model output can be used by the CPU. We provide both metrics since both could be relevant depending on the use-case. We recommend to test the efficiency gains directly in your use-cases.
|
| 48 |
+
|
| 49 |
+
## Setup
|
| 50 |
+
|
| 51 |
+
You can run the smashed model with these steps:
|
| 52 |
+
|
| 53 |
+
0. Check requirements from the original repo ybelkada/falcon-7b-sharded-bf16 installed. In particular, check python, cuda, and transformers versions.
|
| 54 |
+
1. Make sure that you have installed quantization related packages.
|
| 55 |
+
```bash
|
| 56 |
+
pip install transformers accelerate bitsandbytes>0.37.0
|
| 57 |
+
```
|
| 58 |
+
2. Load & run the model.
|
| 59 |
+
```python
|
| 60 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 61 |
+
|
| 62 |
+
model = AutoModelForCausalLM.from_pretrained("PrunaAI/ybelkada-falcon-7b-sharded-bf16-bnb-8bit-smashed",
|
| 63 |
+
trust_remote_code=True)
|
| 64 |
+
tokenizer = AutoTokenizer.from_pretrained("ybelkada/falcon-7b-sharded-bf16")
|
| 65 |
+
|
| 66 |
+
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
|
| 67 |
+
|
| 68 |
+
outputs = model.generate(input_ids, max_new_tokens=216)
|
| 69 |
+
tokenizer.decode(outputs[0])
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
## Configurations
|
| 73 |
+
|
| 74 |
+
The configuration info are in `smash_config.json`.
|
| 75 |
+
|
| 76 |
+
## Credits & License
|
| 77 |
+
|
| 78 |
+
The license of the smashed model follows the license of the original model. Please check the license of the original model ybelkada/falcon-7b-sharded-bf16 before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
|
| 79 |
+
|
| 80 |
+
## Want to compress other models?
|
| 81 |
+
|
| 82 |
+
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
|
| 83 |
+
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
config.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/tmp/tmp4qhbr9ev",
|
| 3 |
+
"alibi": false,
|
| 4 |
+
"apply_residual_connection_post_layernorm": false,
|
| 5 |
+
"architectures": [
|
| 6 |
+
"FalconForCausalLM"
|
| 7 |
+
],
|
| 8 |
+
"attention_dropout": 0.0,
|
| 9 |
+
"bias": false,
|
| 10 |
+
"bos_token_id": 11,
|
| 11 |
+
"eos_token_id": 11,
|
| 12 |
+
"hidden_dropout": 0.0,
|
| 13 |
+
"hidden_size": 4544,
|
| 14 |
+
"initializer_range": 0.02,
|
| 15 |
+
"layer_norm_epsilon": 1e-05,
|
| 16 |
+
"max_position_embeddings": 2048,
|
| 17 |
+
"model_type": "falcon",
|
| 18 |
+
"multi_query": true,
|
| 19 |
+
"n_head": 71,
|
| 20 |
+
"n_layer": 32,
|
| 21 |
+
"new_decoder_architecture": false,
|
| 22 |
+
"num_attention_heads": 71,
|
| 23 |
+
"num_hidden_layers": 32,
|
| 24 |
+
"num_kv_heads": 71,
|
| 25 |
+
"parallel_attn": true,
|
| 26 |
+
"quantization_config": {
|
| 27 |
+
"bnb_4bit_compute_dtype": "bfloat16",
|
| 28 |
+
"bnb_4bit_quant_type": "fp4",
|
| 29 |
+
"bnb_4bit_use_double_quant": true,
|
| 30 |
+
"llm_int8_enable_fp32_cpu_offload": false,
|
| 31 |
+
"llm_int8_has_fp16_weight": false,
|
| 32 |
+
"llm_int8_skip_modules": [
|
| 33 |
+
"lm_head"
|
| 34 |
+
],
|
| 35 |
+
"llm_int8_threshold": 6.0,
|
| 36 |
+
"load_in_4bit": false,
|
| 37 |
+
"load_in_8bit": true,
|
| 38 |
+
"quant_method": "bitsandbytes"
|
| 39 |
+
},
|
| 40 |
+
"rope_scaling": null,
|
| 41 |
+
"rope_theta": 10000.0,
|
| 42 |
+
"torch_dtype": "float16",
|
| 43 |
+
"transformers_version": "4.37.1",
|
| 44 |
+
"use_cache": true,
|
| 45 |
+
"vocab_size": 65024
|
| 46 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": 2,
|
| 5 |
+
"transformers_version": "4.37.1"
|
| 6 |
+
}
|
model-00001-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6eab2b9a9857814efd5df05a1c862805e1bf4a8df477af02576f0b34cf8c2c53
|
| 3 |
+
size 4984221952
|
model-00002-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:40320fc752b97e007b53284aac41dbfb043dc8af371439097fc6e08fa02dcd1e
|
| 3 |
+
size 2237391976
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,330 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 7221577472
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"transformer.h.0.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 7 |
+
"transformer.h.0.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 8 |
+
"transformer.h.0.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 9 |
+
"transformer.h.0.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 10 |
+
"transformer.h.0.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 11 |
+
"transformer.h.0.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 12 |
+
"transformer.h.0.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 13 |
+
"transformer.h.0.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 14 |
+
"transformer.h.0.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 15 |
+
"transformer.h.0.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 16 |
+
"transformer.h.1.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 17 |
+
"transformer.h.1.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 18 |
+
"transformer.h.1.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 19 |
+
"transformer.h.1.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 20 |
+
"transformer.h.1.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 21 |
+
"transformer.h.1.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 22 |
+
"transformer.h.1.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 23 |
+
"transformer.h.1.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 24 |
+
"transformer.h.1.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 25 |
+
"transformer.h.1.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 26 |
+
"transformer.h.10.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 27 |
+
"transformer.h.10.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 28 |
+
"transformer.h.10.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 29 |
+
"transformer.h.10.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 30 |
+
"transformer.h.10.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 31 |
+
"transformer.h.10.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 32 |
+
"transformer.h.10.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 33 |
+
"transformer.h.10.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 34 |
+
"transformer.h.10.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 35 |
+
"transformer.h.10.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 36 |
+
"transformer.h.11.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 37 |
+
"transformer.h.11.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 38 |
+
"transformer.h.11.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 39 |
+
"transformer.h.11.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 40 |
+
"transformer.h.11.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 41 |
+
"transformer.h.11.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 42 |
+
"transformer.h.11.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 43 |
+
"transformer.h.11.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 44 |
+
"transformer.h.11.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 45 |
+
"transformer.h.11.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 46 |
+
"transformer.h.12.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 47 |
+
"transformer.h.12.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 48 |
+
"transformer.h.12.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 49 |
+
"transformer.h.12.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 50 |
+
"transformer.h.12.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 51 |
+
"transformer.h.12.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 52 |
+
"transformer.h.12.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 53 |
+
"transformer.h.12.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 54 |
+
"transformer.h.12.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 55 |
+
"transformer.h.12.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 56 |
+
"transformer.h.13.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 57 |
+
"transformer.h.13.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 58 |
+
"transformer.h.13.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 59 |
+
"transformer.h.13.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 60 |
+
"transformer.h.13.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 61 |
+
"transformer.h.13.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 62 |
+
"transformer.h.13.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 63 |
+
"transformer.h.13.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 64 |
+
"transformer.h.13.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 65 |
+
"transformer.h.13.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 66 |
+
"transformer.h.14.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 67 |
+
"transformer.h.14.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 68 |
+
"transformer.h.14.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 69 |
+
"transformer.h.14.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 70 |
+
"transformer.h.14.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 71 |
+
"transformer.h.14.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 72 |
+
"transformer.h.14.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 73 |
+
"transformer.h.14.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 74 |
+
"transformer.h.14.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 75 |
+
"transformer.h.14.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 76 |
+
"transformer.h.15.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 77 |
+
"transformer.h.15.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 78 |
+
"transformer.h.15.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 79 |
+
"transformer.h.15.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 80 |
+
"transformer.h.15.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 81 |
+
"transformer.h.15.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 82 |
+
"transformer.h.15.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 83 |
+
"transformer.h.15.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 84 |
+
"transformer.h.15.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 85 |
+
"transformer.h.15.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 86 |
+
"transformer.h.16.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 87 |
+
"transformer.h.16.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 88 |
+
"transformer.h.16.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 89 |
+
"transformer.h.16.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 90 |
+
"transformer.h.16.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 91 |
+
"transformer.h.16.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 92 |
+
"transformer.h.16.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 93 |
+
"transformer.h.16.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 94 |
+
"transformer.h.16.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 95 |
+
"transformer.h.16.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 96 |
+
"transformer.h.17.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 97 |
+
"transformer.h.17.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 98 |
+
"transformer.h.17.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 99 |
+
"transformer.h.17.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 100 |
+
"transformer.h.17.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 101 |
+
"transformer.h.17.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 102 |
+
"transformer.h.17.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 103 |
+
"transformer.h.17.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 104 |
+
"transformer.h.17.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 105 |
+
"transformer.h.17.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 106 |
+
"transformer.h.18.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 107 |
+
"transformer.h.18.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 108 |
+
"transformer.h.18.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 109 |
+
"transformer.h.18.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 110 |
+
"transformer.h.18.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 111 |
+
"transformer.h.18.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 112 |
+
"transformer.h.18.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 113 |
+
"transformer.h.18.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 114 |
+
"transformer.h.18.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 115 |
+
"transformer.h.18.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 116 |
+
"transformer.h.19.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 117 |
+
"transformer.h.19.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 118 |
+
"transformer.h.19.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 119 |
+
"transformer.h.19.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 120 |
+
"transformer.h.19.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 121 |
+
"transformer.h.19.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 122 |
+
"transformer.h.19.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 123 |
+
"transformer.h.19.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 124 |
+
"transformer.h.19.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 125 |
+
"transformer.h.19.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 126 |
+
"transformer.h.2.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 127 |
+
"transformer.h.2.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 128 |
+
"transformer.h.2.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 129 |
+
"transformer.h.2.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 130 |
+
"transformer.h.2.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 131 |
+
"transformer.h.2.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 132 |
+
"transformer.h.2.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 133 |
+
"transformer.h.2.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 134 |
+
"transformer.h.2.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 135 |
+
"transformer.h.2.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 136 |
+
"transformer.h.20.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 137 |
+
"transformer.h.20.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 138 |
+
"transformer.h.20.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 139 |
+
"transformer.h.20.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 140 |
+
"transformer.h.20.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 141 |
+
"transformer.h.20.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 142 |
+
"transformer.h.20.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 143 |
+
"transformer.h.20.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 144 |
+
"transformer.h.20.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 145 |
+
"transformer.h.20.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 146 |
+
"transformer.h.21.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 147 |
+
"transformer.h.21.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 148 |
+
"transformer.h.21.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 149 |
+
"transformer.h.21.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 150 |
+
"transformer.h.21.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 151 |
+
"transformer.h.21.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 152 |
+
"transformer.h.21.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 153 |
+
"transformer.h.21.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 154 |
+
"transformer.h.21.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 155 |
+
"transformer.h.21.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 156 |
+
"transformer.h.22.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 157 |
+
"transformer.h.22.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 158 |
+
"transformer.h.22.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 159 |
+
"transformer.h.22.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 160 |
+
"transformer.h.22.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 161 |
+
"transformer.h.22.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 162 |
+
"transformer.h.22.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 163 |
+
"transformer.h.22.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 164 |
+
"transformer.h.22.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 165 |
+
"transformer.h.22.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 166 |
+
"transformer.h.23.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 167 |
+
"transformer.h.23.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 168 |
+
"transformer.h.23.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 169 |
+
"transformer.h.23.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 170 |
+
"transformer.h.23.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 171 |
+
"transformer.h.23.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 172 |
+
"transformer.h.23.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 173 |
+
"transformer.h.23.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 174 |
+
"transformer.h.23.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 175 |
+
"transformer.h.23.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 176 |
+
"transformer.h.24.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 177 |
+
"transformer.h.24.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 178 |
+
"transformer.h.24.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 179 |
+
"transformer.h.24.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 180 |
+
"transformer.h.24.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 181 |
+
"transformer.h.24.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 182 |
+
"transformer.h.24.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 183 |
+
"transformer.h.24.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 184 |
+
"transformer.h.24.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 185 |
+
"transformer.h.24.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 186 |
+
"transformer.h.25.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 187 |
+
"transformer.h.25.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 188 |
+
"transformer.h.25.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 189 |
+
"transformer.h.25.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 190 |
+
"transformer.h.25.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 191 |
+
"transformer.h.25.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 192 |
+
"transformer.h.25.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 193 |
+
"transformer.h.25.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 194 |
+
"transformer.h.25.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 195 |
+
"transformer.h.25.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 196 |
+
"transformer.h.26.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 197 |
+
"transformer.h.26.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 198 |
+
"transformer.h.26.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 199 |
+
"transformer.h.26.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 200 |
+
"transformer.h.26.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 201 |
+
"transformer.h.26.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 202 |
+
"transformer.h.26.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 203 |
+
"transformer.h.26.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 204 |
+
"transformer.h.26.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 205 |
+
"transformer.h.26.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 206 |
+
"transformer.h.27.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 207 |
+
"transformer.h.27.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 208 |
+
"transformer.h.27.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 209 |
+
"transformer.h.27.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 210 |
+
"transformer.h.27.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 211 |
+
"transformer.h.27.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 212 |
+
"transformer.h.27.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 213 |
+
"transformer.h.27.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 214 |
+
"transformer.h.27.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 215 |
+
"transformer.h.27.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 216 |
+
"transformer.h.28.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 217 |
+
"transformer.h.28.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 218 |
+
"transformer.h.28.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 219 |
+
"transformer.h.28.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 220 |
+
"transformer.h.28.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 221 |
+
"transformer.h.28.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 222 |
+
"transformer.h.28.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 223 |
+
"transformer.h.28.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 224 |
+
"transformer.h.28.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 225 |
+
"transformer.h.28.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 226 |
+
"transformer.h.29.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 227 |
+
"transformer.h.29.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 228 |
+
"transformer.h.29.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 229 |
+
"transformer.h.29.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 230 |
+
"transformer.h.29.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 231 |
+
"transformer.h.29.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 232 |
+
"transformer.h.29.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 233 |
+
"transformer.h.29.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 234 |
+
"transformer.h.29.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 235 |
+
"transformer.h.29.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 236 |
+
"transformer.h.3.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 237 |
+
"transformer.h.3.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 238 |
+
"transformer.h.3.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 239 |
+
"transformer.h.3.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 240 |
+
"transformer.h.3.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 241 |
+
"transformer.h.3.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 242 |
+
"transformer.h.3.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 243 |
+
"transformer.h.3.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 244 |
+
"transformer.h.3.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 245 |
+
"transformer.h.3.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 246 |
+
"transformer.h.30.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 247 |
+
"transformer.h.30.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 248 |
+
"transformer.h.30.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 249 |
+
"transformer.h.30.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 250 |
+
"transformer.h.30.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 251 |
+
"transformer.h.30.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 252 |
+
"transformer.h.30.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 253 |
+
"transformer.h.30.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 254 |
+
"transformer.h.30.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 255 |
+
"transformer.h.30.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 256 |
+
"transformer.h.31.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 257 |
+
"transformer.h.31.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 258 |
+
"transformer.h.31.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 259 |
+
"transformer.h.31.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 260 |
+
"transformer.h.31.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 261 |
+
"transformer.h.31.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 262 |
+
"transformer.h.31.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 263 |
+
"transformer.h.31.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 264 |
+
"transformer.h.31.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 265 |
+
"transformer.h.31.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 266 |
+
"transformer.h.4.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 267 |
+
"transformer.h.4.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 268 |
+
"transformer.h.4.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 269 |
+
"transformer.h.4.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 270 |
+
"transformer.h.4.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 271 |
+
"transformer.h.4.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 272 |
+
"transformer.h.4.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 273 |
+
"transformer.h.4.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 274 |
+
"transformer.h.4.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 275 |
+
"transformer.h.4.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 276 |
+
"transformer.h.5.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 277 |
+
"transformer.h.5.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 278 |
+
"transformer.h.5.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 279 |
+
"transformer.h.5.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 280 |
+
"transformer.h.5.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 281 |
+
"transformer.h.5.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 282 |
+
"transformer.h.5.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 283 |
+
"transformer.h.5.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 284 |
+
"transformer.h.5.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 285 |
+
"transformer.h.5.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 286 |
+
"transformer.h.6.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 287 |
+
"transformer.h.6.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 288 |
+
"transformer.h.6.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 289 |
+
"transformer.h.6.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 290 |
+
"transformer.h.6.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 291 |
+
"transformer.h.6.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 292 |
+
"transformer.h.6.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 293 |
+
"transformer.h.6.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 294 |
+
"transformer.h.6.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 295 |
+
"transformer.h.6.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 296 |
+
"transformer.h.7.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 297 |
+
"transformer.h.7.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 298 |
+
"transformer.h.7.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 299 |
+
"transformer.h.7.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 300 |
+
"transformer.h.7.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 301 |
+
"transformer.h.7.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 302 |
+
"transformer.h.7.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 303 |
+
"transformer.h.7.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 304 |
+
"transformer.h.7.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 305 |
+
"transformer.h.7.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 306 |
+
"transformer.h.8.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 307 |
+
"transformer.h.8.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 308 |
+
"transformer.h.8.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 309 |
+
"transformer.h.8.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 310 |
+
"transformer.h.8.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 311 |
+
"transformer.h.8.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 312 |
+
"transformer.h.8.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 313 |
+
"transformer.h.8.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 314 |
+
"transformer.h.8.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 315 |
+
"transformer.h.8.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 316 |
+
"transformer.h.9.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 317 |
+
"transformer.h.9.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 318 |
+
"transformer.h.9.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 319 |
+
"transformer.h.9.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 320 |
+
"transformer.h.9.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 321 |
+
"transformer.h.9.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 322 |
+
"transformer.h.9.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 323 |
+
"transformer.h.9.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 324 |
+
"transformer.h.9.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 325 |
+
"transformer.h.9.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 326 |
+
"transformer.ln_f.bias": "model-00002-of-00002.safetensors",
|
| 327 |
+
"transformer.ln_f.weight": "model-00002-of-00002.safetensors",
|
| 328 |
+
"transformer.word_embeddings.weight": "model-00001-of-00002.safetensors"
|
| 329 |
+
}
|
| 330 |
+
}
|
plots.png
ADDED
|
smash_config.json
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"api_key": null,
|
| 3 |
+
"verify_url": "http://johnrachwan.pythonanywhere.com",
|
| 4 |
+
"smash_config": {
|
| 5 |
+
"pruners": "None",
|
| 6 |
+
"factorizers": "None",
|
| 7 |
+
"quantizers": "['llm-int8']",
|
| 8 |
+
"compilers": "None",
|
| 9 |
+
"task": "text_text_generation",
|
| 10 |
+
"device": "cuda",
|
| 11 |
+
"cache_dir": "/ceph/hdd/staff/charpent/.cache/modelsgin8pykn",
|
| 12 |
+
"batch_size": 1,
|
| 13 |
+
"model_name": "ybelkada/falcon-7b-sharded-bf16",
|
| 14 |
+
"pruning_ratio": 0.0,
|
| 15 |
+
"n_quantization_bits": 8,
|
| 16 |
+
"output_deviation": 0.005,
|
| 17 |
+
"max_batch_size": 1,
|
| 18 |
+
"qtype_weight": "torch.qint8",
|
| 19 |
+
"qtype_activation": "torch.quint8",
|
| 20 |
+
"qobserver": "<class 'torch.ao.quantization.observer.MinMaxObserver'>",
|
| 21 |
+
"qscheme": "torch.per_tensor_symmetric",
|
| 22 |
+
"qconfig": "x86",
|
| 23 |
+
"group_size": 128,
|
| 24 |
+
"damp_percent": 0.1,
|
| 25 |
+
"save_load_fn": "bitsandbytes"
|
| 26 |
+
}
|
| 27 |
+
}
|