
Update README.md
Browse files
README.md
CHANGED
|
@@ -15,13 +15,13 @@ tags:
|
|
| 15 |
|
| 16 |
El modelo fue entrenado usando el modelo base de VisionTransformer junto con el optimizador SAM de Google y la función de perdida Negative log likelihood, sobre los datos [Wildfire](https://drive.google.com/file/d/1TlF8DIBLAccd0AredDUimQQ54sl_DwCE/view?usp=sharing). Los resultados muestran que el clasificador alcanzó una precisión del 97% con solo 10 épocas de entrenamiento.
|
| 17 |
La teoría de se muestra a continuación.
|
| 18 |
-
|
| 19 |
|
| 20 |
# VisionTransformer
|
| 21 |
|
| 22 |
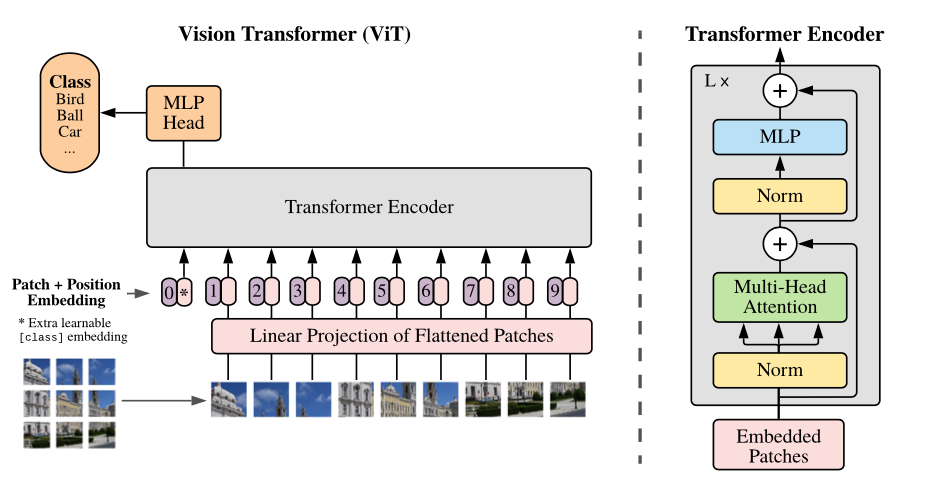
**Attention-based neural networks such as the Vision Transformer** (ViT) have recently attained state-of-the-art results on many computer vision benchmarks. Scale is a primary ingredient in attaining excellent results, therefore, understanding a model's scaling properties is a key to designing future generations effectively. While the laws for scaling Transformer language models have been studied, it is unknown how Vision Transformers scale. To address this, we scale ViT models and data, both up and down, and characterize the relationships between error rate, data, and compute. Along the way, we refine the architecture and training of ViT, reducing memory consumption and increasing accuracy of the resulting models. As a result, we successfully train a ViT model with two billion parameters, which attains a new state-of-the-art on ImageNet of 90.45% top-1 accuracy. The model also performs well for few-shot transfer, for example, reaching 84.86% top-1 accuracy on ImageNet with only 10 examples per class.
|
| 23 |
|
| 24 |
-
|
| 25 |
|
| 26 |
[1] A. Dosovitskiy et al., “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”. arXiv, el 3 de junio de 2021. Consultado: el 12 de noviembre de 2023. [En línea]. Disponible en: http://arxiv.org/abs/2010.11929
|
| 27 |
|
|
|
|
| 15 |
|
| 16 |
El modelo fue entrenado usando el modelo base de VisionTransformer junto con el optimizador SAM de Google y la función de perdida Negative log likelihood, sobre los datos [Wildfire](https://drive.google.com/file/d/1TlF8DIBLAccd0AredDUimQQ54sl_DwCE/view?usp=sharing). Los resultados muestran que el clasificador alcanzó una precisión del 97% con solo 10 épocas de entrenamiento.
|
| 17 |
La teoría de se muestra a continuación.
|
| 18 |
+
|
| 19 |
|
| 20 |
# VisionTransformer
|
| 21 |
|
| 22 |
**Attention-based neural networks such as the Vision Transformer** (ViT) have recently attained state-of-the-art results on many computer vision benchmarks. Scale is a primary ingredient in attaining excellent results, therefore, understanding a model's scaling properties is a key to designing future generations effectively. While the laws for scaling Transformer language models have been studied, it is unknown how Vision Transformers scale. To address this, we scale ViT models and data, both up and down, and characterize the relationships between error rate, data, and compute. Along the way, we refine the architecture and training of ViT, reducing memory consumption and increasing accuracy of the resulting models. As a result, we successfully train a ViT model with two billion parameters, which attains a new state-of-the-art on ImageNet of 90.45% top-1 accuracy. The model also performs well for few-shot transfer, for example, reaching 84.86% top-1 accuracy on ImageNet with only 10 examples per class.
|
| 23 |
|
| 24 |
+
|
| 25 |
|
| 26 |
[1] A. Dosovitskiy et al., “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”. arXiv, el 3 de junio de 2021. Consultado: el 12 de noviembre de 2023. [En línea]. Disponible en: http://arxiv.org/abs/2010.11929
|
| 27 |
|