
Ubuntu
commited on
Commit
•
5bac540
1
Parent(s):
f762044
readme update
Browse files- README.md +9 -5
- README_en.md +131 -0
- generation_config.json +13 -0
README.md
CHANGED
|
@@ -15,11 +15,15 @@ inference: false
|
|
| 15 |
|
| 16 |
# GLM-4-9B-Chat-1M
|
| 17 |
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 23 |
|
| 24 |
## 评测结果
|
| 25 |
|
|
|
|
| 15 |
|
| 16 |
# GLM-4-9B-Chat-1M
|
| 17 |
|
| 18 |
+
Read this in [English](README_en.md)
|
| 19 |
+
|
| 20 |
+
GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。 在语义、数学、推理、代码和知识等多方面的数据集测评中,
|
| 21 |
+
**GLM-4-9B** 及其人类偏好对齐的版本 **GLM-4-9B-Chat** 均表现出超越 Llama-3-8B 的卓越性能。除了能进行多轮对话,GLM-4-9B-Chat
|
| 22 |
+
还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等高级功能。本代模型增加了多语言支持,支持包括日语,韩语,德语在内的
|
| 23 |
+
26 种语言。我们还推出了支持 1M 上下文长度(约 200 万中文字符)的 **GLM-4-9B-Chat-1M** 模型和基于 GLM-4-9B 的多模态模型
|
| 24 |
+
GLM-4V-9B。**GLM-4V-9B** 具备 1120 * 1120 高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中,GLM-4V-9B
|
| 25 |
+
表现出超越 GPT-4-turbo-2024-04-09、Gemini
|
| 26 |
+
1.0 Pro、Qwen-VL-Max 和 Claude 3 Opus 的卓越性能。
|
| 27 |
|
| 28 |
## 评测结果
|
| 29 |
|
README_en.md
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# GLM-4-9B-Chat-1M
|
| 2 |
+
|
| 3 |
+
## Model Introduction
|
| 4 |
+
|
| 5 |
+
GLM-4-9B is the open-source version of the latest generation of pre-trained models in the GLM-4 series launched by Zhipu
|
| 6 |
+
AI. In the evaluation of data sets in semantics, mathematics, reasoning, code, and knowledge, **GLM-4-9B**
|
| 7 |
+
and its human preference-aligned version **GLM-4-9B-Chat** have shown superior performance beyond Llama-3-8B. In
|
| 8 |
+
addition to multi-round conversations, GLM-4-9B-Chat also has advanced features such as web browsing, code execution,
|
| 9 |
+
custom tool calls (Function Call), and long text
|
| 10 |
+
reasoning (supporting up to 128K context). This generation of models has added multi-language support, supporting 26
|
| 11 |
+
languages including Japanese, Korean, and German. We have also launched the **GLM-4-9B-Chat-1M** model that supports 1M
|
| 12 |
+
context length (about 2 million Chinese characters) and the multimodal model GLM-4V-9B based on GLM-4-9B.
|
| 13 |
+
**GLM-4V-9B** possesses dialogue capabilities in both Chinese and English at a high resolution of 1120*1120.
|
| 14 |
+
In various multimodal evaluations, including comprehensive abilities in Chinese and English, perception & reasoning,
|
| 15 |
+
text recognition, and chart understanding, GLM-4V-9B demonstrates superior performance compared to
|
| 16 |
+
GPT-4-turbo-2024-04-09, Gemini 1.0 Pro, Qwen-VL-Max, and Claude 3 Opus.
|
| 17 |
+
|
| 18 |
+
### Long Context
|
| 19 |
+
|
| 20 |
+
The [eval_needle experiment](https://github.com/LargeWorldModel/LWM/blob/main/scripts/eval_needle.py) was conducted with
|
| 21 |
+
a context length of 1M, and the results are as follows:
|
| 22 |
+
|
| 23 |
+
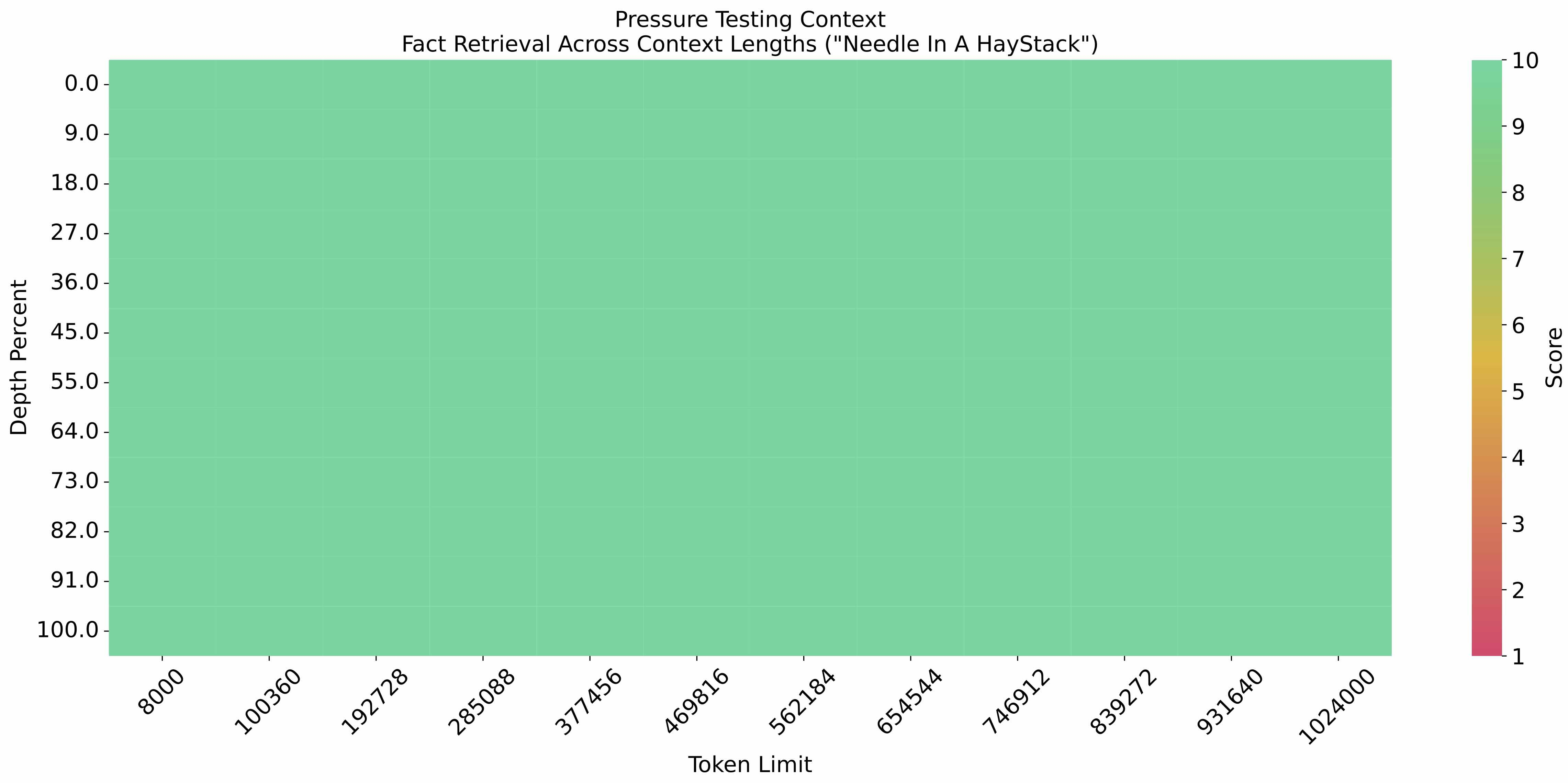
|
| 24 |
+
|
| 25 |
+
The long text capability was further evaluated on LongBench, and the results are as follows:
|
| 26 |
+
|
| 27 |
+
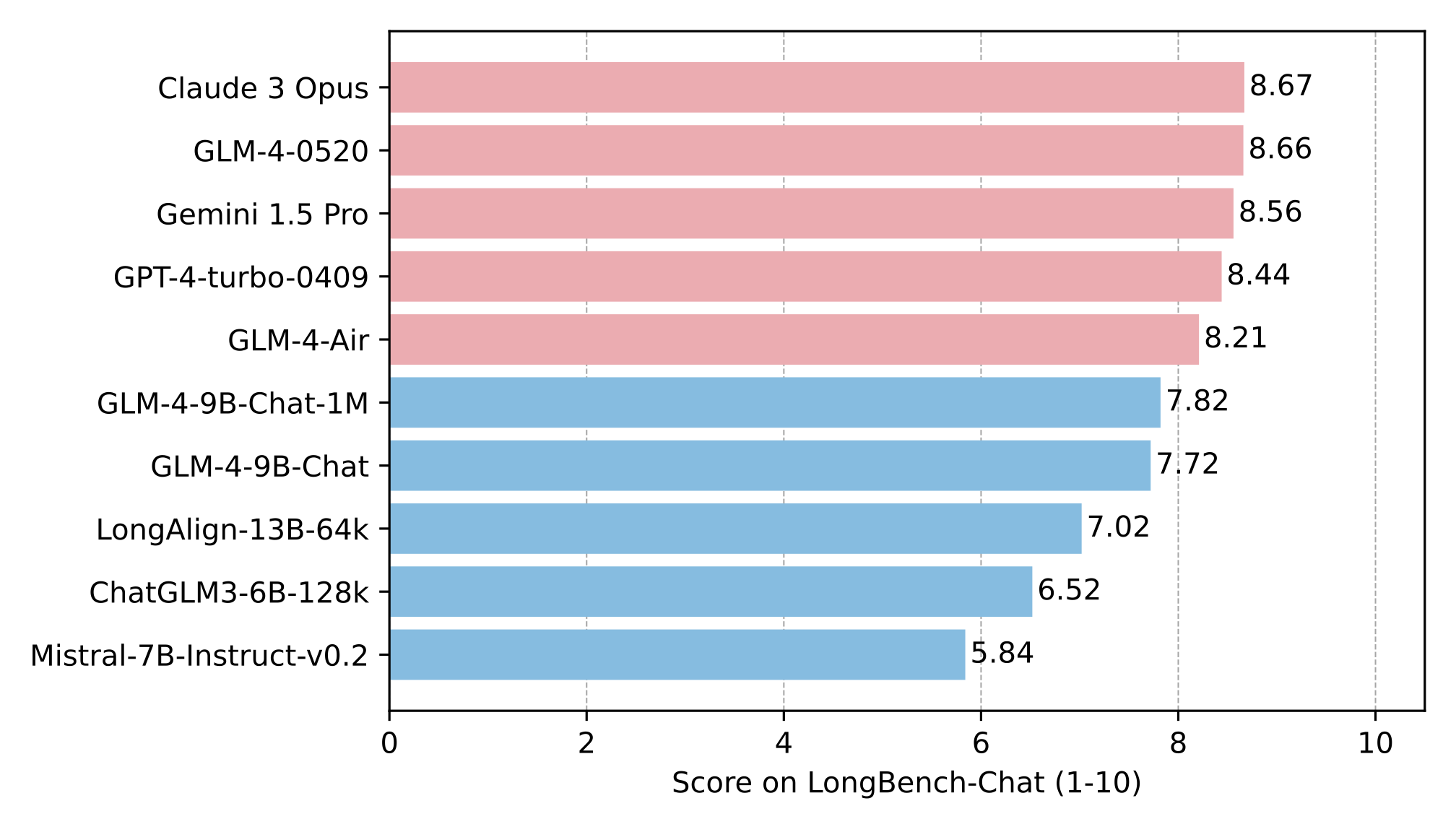
|
| 28 |
+
|
| 29 |
+
**This repository is the model repository of GLM-4-9B-Chat-1M, supporting `1M` context length.**
|
| 30 |
+
|
| 31 |
+
## Quick call
|
| 32 |
+
|
| 33 |
+
**For hardware configuration and system requirements, please check [here](basic_demo/README_en.md).**
|
| 34 |
+
|
| 35 |
+
### Use the following method to quickly call the GLM-4-9B-Chat language model
|
| 36 |
+
|
| 37 |
+
Use the transformers backend for inference:
|
| 38 |
+
|
| 39 |
+
```python
|
| 40 |
+
import torch
|
| 41 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 42 |
+
|
| 43 |
+
device = "cuda"
|
| 44 |
+
|
| 45 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4-9b-chat-1m",trust_remote_code=True)
|
| 46 |
+
|
| 47 |
+
query = "hello"
|
| 48 |
+
|
| 49 |
+
inputs = tokenizer.apply_chat_template([{"role": "user", "content": query}],
|
| 50 |
+
add_generation_prompt=True,
|
| 51 |
+
tokenize=True,
|
| 52 |
+
return_tensors="pt",
|
| 53 |
+
return_dict=True
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
inputs = inputs.to(device)
|
| 57 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 58 |
+
"THUDM/glm-4-9b-chat-1m",
|
| 59 |
+
torch_dtype=torch.bfloat16,
|
| 60 |
+
low_cpu_mem_usage=True,
|
| 61 |
+
trust_remote_code=True
|
| 62 |
+
).to(device).eval()
|
| 63 |
+
|
| 64 |
+
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
|
| 65 |
+
with torch.no_grad():
|
| 66 |
+
outputs = model.generate(**inputs, **gen_kwargs)
|
| 67 |
+
outputs = outputs[:, inputs['input_ids'].shape[1]:]
|
| 68 |
+
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
|
| 69 |
+
```
|
| 70 |
+
|
| 71 |
+
Use the vLLM backend for inference:
|
| 72 |
+
|
| 73 |
+
```python
|
| 74 |
+
from transformers import AutoTokenizer
|
| 75 |
+
from vllm import LLM, SamplingParams
|
| 76 |
+
|
| 77 |
+
# GLM-4-9B-Chat-1M
|
| 78 |
+
|
| 79 |
+
# If you encounter OOM, it is recommended to reduce max_model_len or increase tp_size
|
| 80 |
+
|
| 81 |
+
max_model_len, tp_size = 1048576, 4
|
| 82 |
+
|
| 83 |
+
model_name = "THUDM/glm-4-9b-chat-1m"
|
| 84 |
+
prompt = [{"role": "user", "content": "你好"}]
|
| 85 |
+
|
| 86 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
|
| 87 |
+
llm = LLM(
|
| 88 |
+
model=model_name,
|
| 89 |
+
tensor_parallel_size=tp_size,
|
| 90 |
+
max_model_len=max_model_len,
|
| 91 |
+
trust_remote_code=True,
|
| 92 |
+
enforce_eager=True,
|
| 93 |
+
# GLM-4-9B-Chat-1M If you encounter OOM phenomenon, it is recommended to turn on the following parameters
|
| 94 |
+
# enable_chunked_prefill=True,
|
| 95 |
+
# max_num_batched_tokens=8192
|
| 96 |
+
)
|
| 97 |
+
stop_token_ids = [151329, 151336, 151338]
|
| 98 |
+
sampling_params = SamplingParams(temperature=0.95, max_tokens=1024, stop_token_ids=stop_token_ids)
|
| 99 |
+
|
| 100 |
+
inputs = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
|
| 101 |
+
outputs = llm.generate(prompts=inputs, sampling_params=sampling_params)
|
| 102 |
+
|
| 103 |
+
print(outputs[0].outputs[0].text)
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
## LICENSE
|
| 107 |
+
|
| 108 |
+
The weights of the GLM-4 model are available under the terms of [LICENSE](LICENSE).
|
| 109 |
+
|
| 110 |
+
## Citations
|
| 111 |
+
|
| 112 |
+
If you find our work useful, please consider citing the following paper.
|
| 113 |
+
|
| 114 |
+
```
|
| 115 |
+
@article{zeng2022glm,
|
| 116 |
+
title={Glm-130b: An open bilingual pre-trained model},
|
| 117 |
+
author={Zeng, Aohan and Liu, Xiao and Du, Zhengxiao and Wang, Zihan and Lai, Hanyu and Ding, Ming and Yang, Zhuoyi and Xu, Yifan and Zheng, Wendi and Xia, Xiao and others},
|
| 118 |
+
journal={arXiv preprint arXiv:2210.02414},
|
| 119 |
+
year={2022}
|
| 120 |
+
}
|
| 121 |
+
```
|
| 122 |
+
|
| 123 |
+
```
|
| 124 |
+
@inproceedings{du2022glm,
|
| 125 |
+
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
|
| 126 |
+
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
|
| 127 |
+
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
|
| 128 |
+
pages={320--335},
|
| 129 |
+
year={2022}
|
| 130 |
+
}
|
| 131 |
+
```
|
generation_config.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"eos_token_id": [
|
| 3 |
+
151329,
|
| 4 |
+
151336,
|
| 5 |
+
151338
|
| 6 |
+
],
|
| 7 |
+
"pad_token_id": 151329,
|
| 8 |
+
"do_sample": true,
|
| 9 |
+
"temperature": 0.8,
|
| 10 |
+
"max_length": 1024000,
|
| 11 |
+
"top_p": 0.8,
|
| 12 |
+
"transformers_version": "4.38.2"
|
| 13 |
+
}
|