

Update README.md
Browse files
README.md
CHANGED
|
@@ -17,7 +17,7 @@ The **'inappropriateness'** substance we tried to collect in the dataset and det
|
|
| 17 |
|
| 18 |
|
| 19 |
|
| 20 |
-
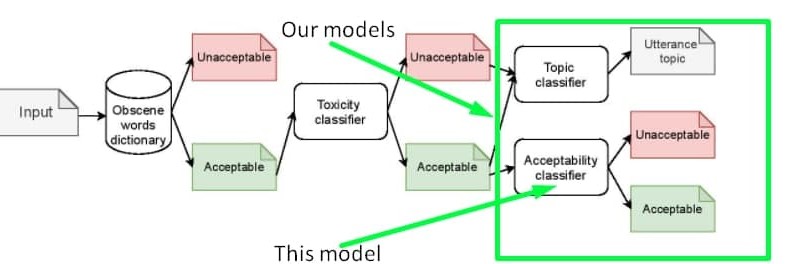
You can also train one classifier for both toxicity and inappropriateness detection. The data could be found on our [GitHub](https://github.com/skoltech-nlp/inappropriate-sensitive-topics/blob/main/Version2/appropriateness/Appropriateness.csv) or on [kaggle](https://www.kaggle.com/nigula/russianinappropriatemessages)
|
| 21 |
|
| 22 |
#### Inappropraiteness intuition
|
| 23 |
This model is trained on the dataset of inappropriate messages of the Russian language. Generally, an inappropriate utterance is an utterance that has not obscene words or any kind of toxic intent, but can still harm the reputation of the speaker. Find some sample for more intuition in the table below. Learn more about the concept of inappropriateness [in this article ](https://www.aclweb.org/anthology/2021.bsnlp-1.4/) presented at the workshop for Balto-Slavic NLP at the EACL-2021 conference. Please note that this article describes the first version of the dataset, while the model is trained on the extended version of the dataset open-sourced on our [GitHub](https://github.com/skoltech-nlp/inappropriate-sensitive-topics/blob/main/Version2/appropriateness/Appropriateness.csv) or on [kaggle](https://www.kaggle.com/nigula/russianinappropriatemessages). The properties of the dataset are the same as the one described in the article, the only difference is the size.
|
|
|
|
| 17 |
|
| 18 |

|
| 19 |
|
| 20 |
+
You can also train one classifier for both toxicity and inappropriateness detection. The data to be mixed with toxic labelled samples could be found on our [GitHub](https://github.com/skoltech-nlp/inappropriate-sensitive-topics/blob/main/Version2/appropriateness/Appropriateness.csv) or on [kaggle](https://www.kaggle.com/nigula/russianinappropriatemessages)
|
| 21 |
|
| 22 |
#### Inappropraiteness intuition
|
| 23 |
This model is trained on the dataset of inappropriate messages of the Russian language. Generally, an inappropriate utterance is an utterance that has not obscene words or any kind of toxic intent, but can still harm the reputation of the speaker. Find some sample for more intuition in the table below. Learn more about the concept of inappropriateness [in this article ](https://www.aclweb.org/anthology/2021.bsnlp-1.4/) presented at the workshop for Balto-Slavic NLP at the EACL-2021 conference. Please note that this article describes the first version of the dataset, while the model is trained on the extended version of the dataset open-sourced on our [GitHub](https://github.com/skoltech-nlp/inappropriate-sensitive-topics/blob/main/Version2/appropriateness/Appropriateness.csv) or on [kaggle](https://www.kaggle.com/nigula/russianinappropriatemessages). The properties of the dataset are the same as the one described in the article, the only difference is the size.
|