

Commit
·
3257e9c
1
Parent(s):
46b2d01
Update README.md
Browse files
README.md
CHANGED
|
@@ -29,7 +29,7 @@ Here we also compare `shisa-base-7b-v1` to other recently-released similar class
|
|
| 29 |
|
| 30 |
|
| 31 |
## Tokenizer
|
| 32 |
-
As mentioned in the introduction, our tokenizer is an extended version of the Mistral 7B tokenizer, with a vocab size of 120073 and aligned to 120128 for better performance. The remaining unused tokens are assigned as
|
| 33 |
|
| 34 |
We use the "Fast" tokenizer, which should be the default for `AutoTokenizer`, but if you have problems, make sure to check `tokenizer.is_fast` or to initialize with `use_fast=True`.
|
| 35 |
|
|
@@ -83,6 +83,9 @@ Thanks to the [ELYZA](https://huggingface.co/elyza) team for publishing the deta
|
|
| 83 |
And of course, thanks to the [Mistral AI](https://huggingface.co/mistralai) for releasing such a strong base model!
|
| 84 |
|
| 85 |
---
|
|
|
|
|
|
|
|
|
|
| 86 |
|
| 87 |
`shisa-base-7b-v1`は、[Mistral 7B](https://huggingface.co/mistralai/Mistral-7B-v0.1)を基にして、主に日本語の事前トレーニングのために追加で80億トークンを追加しています。日本語トークンは、[MADLAD-400](https://github.com/google-research/google-research/tree/master/madlad_400)から取得し、[DSIR](https://github.com/p-lambda/dsir)を使用しています。さらに、MADLAD-400 ENと様々なオープンデータソースからの英語トークンの10%を追加し、壊滅的忘却を防ぐために組み込んでいます。
|
| 88 |
|
|
@@ -104,7 +107,7 @@ Mistralのトークン化器を12万トークンまで拡張し、日本語の
|
|
| 104 |
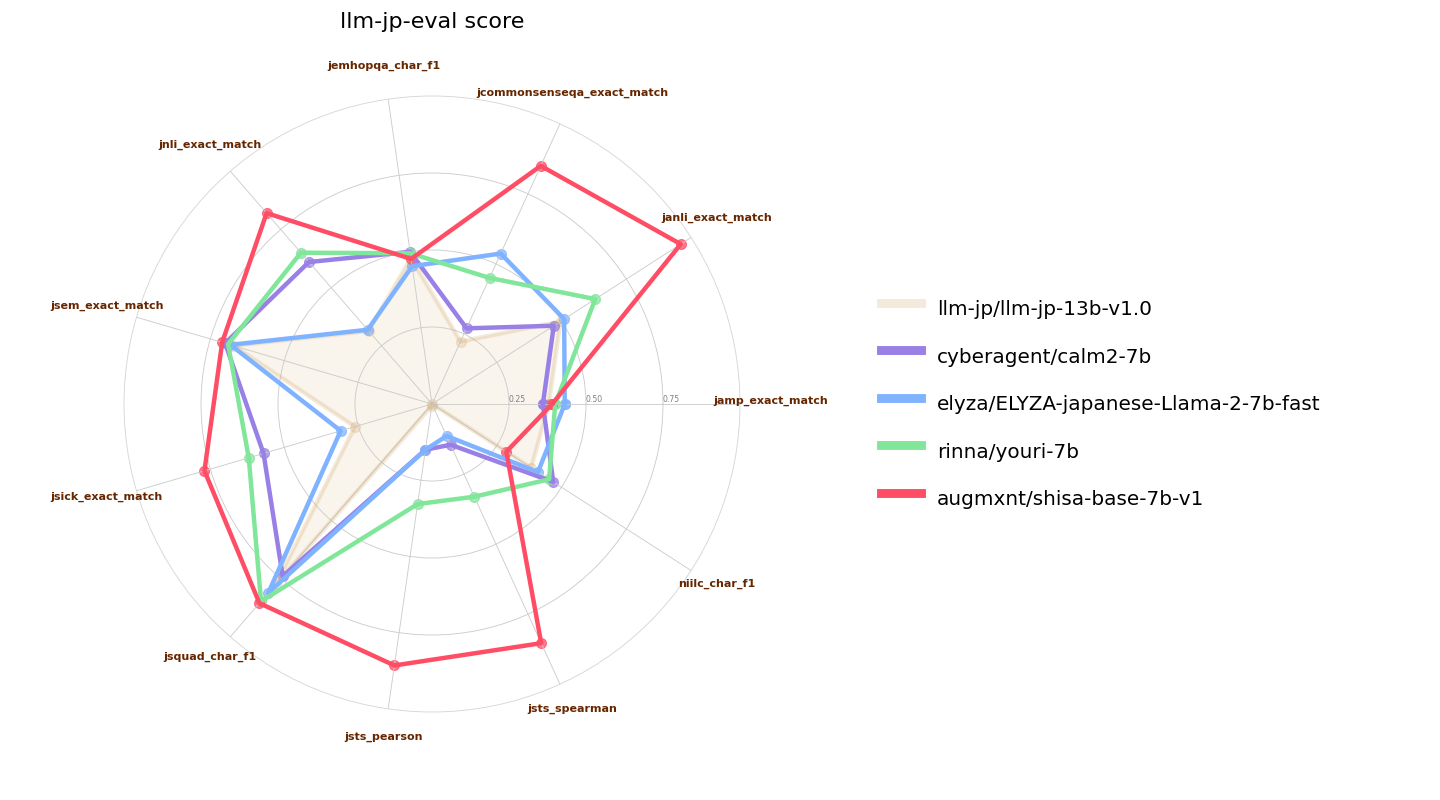
![7B llm-jp-eval パフォーマンス]()
|
| 105 |
|
| 106 |
## トークン化器
|
| 107 |
-
序文で触れたように、私たちのトークン化器はMistral 7Bトークン化器の拡張版で、語彙サイズは120073であり、120128
|
| 108 |
|
| 109 |
私たちは「Fast」トークン化器を使用しており、これは`AutoTokenizer`のデフォルトであるべきですが、問題がある場合は`tokenizer.is_fast`をチェックするか、`use_fast=True`で初期化することを確認してください。
|
| 110 |
|
|
|
|
| 29 |

|
| 30 |
|
| 31 |
## Tokenizer
|
| 32 |
+
As mentioned in the introduction, our tokenizer is an extended version of the Mistral 7B tokenizer, with a vocab size of 120073 and aligned to 120128 for better performance. The remaining unused tokens are assigned as zero-weighted `<|extra_{idx}|>` tokens.
|
| 33 |
|
| 34 |
We use the "Fast" tokenizer, which should be the default for `AutoTokenizer`, but if you have problems, make sure to check `tokenizer.is_fast` or to initialize with `use_fast=True`.
|
| 35 |
|
|
|
|
| 83 |
And of course, thanks to the [Mistral AI](https://huggingface.co/mistralai) for releasing such a strong base model!
|
| 84 |
|
| 85 |
---
|
| 86 |
+
*(GPT-4によって翻訳されました)*
|
| 87 |
+
|
| 88 |
+
# shisa-base-7b-v1
|
| 89 |
|
| 90 |
`shisa-base-7b-v1`は、[Mistral 7B](https://huggingface.co/mistralai/Mistral-7B-v0.1)を基にして、主に日本語の事前トレーニングのために追加で80億トークンを追加しています。日本語トークンは、[MADLAD-400](https://github.com/google-research/google-research/tree/master/madlad_400)から取得し、[DSIR](https://github.com/p-lambda/dsir)を使用しています。さらに、MADLAD-400 ENと様々なオープンデータソースからの英語トークンの10%を追加し、壊滅的忘却を防ぐために組み込んでいます。
|
| 91 |
|
|
|
|
| 107 |
![7B llm-jp-eval パフォーマンス]()
|
| 108 |
|
| 109 |
## トークン化器
|
| 110 |
+
序文で触れたように、私たちのトークン化器はMistral 7Bトークン化器の拡張版で、語彙サイズは120073であり、120128に合わせられています。残りの未使用トークンは、ゼロ重み付けされた`<|extra_{idx}|>`トークンとして割り当てられています。
|
| 111 |
|
| 112 |
私たちは「Fast」トークン化器を使用しており、これは`AutoTokenizer`のデフォルトであるべきですが、問題がある場合は`tokenizer.is_fast`をチェックするか、`use_fast=True`で初期化することを確認してください。
|
| 113 |
|