

Commit
·
8280bef
1
Parent(s):
52e4020
added plots
Browse files
README.md
CHANGED
|
@@ -17,11 +17,11 @@ This base model was able to attain class-leading Japanese performance in standar
|
|
| 17 |
|
| 18 |
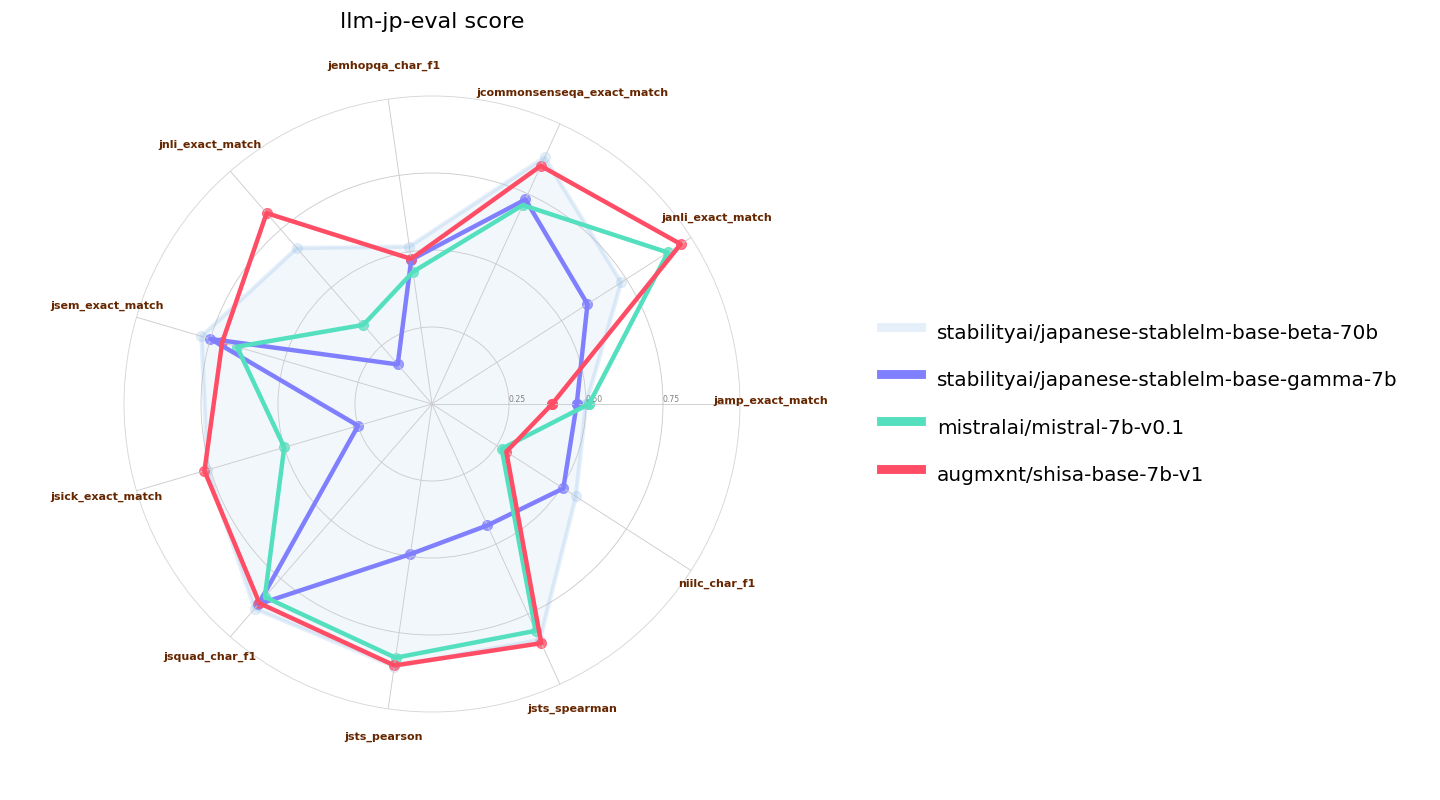
We used a slightly modified [llm-jp-eval](https://github.com/llm-jp/llm-jp-eval) (our base model requires a `bos_token` to be prepended to the prompt; we tested other models with and without the modification and took the higher results for all models tested). Here we validate versus the original Mistral 7B base model as well as [Japanese Stable LM Instruct Gamma 7B](https://huggingface.co/stabilityai/japanese-stablelm-instruct-gamma-7b), which is a Mistral 7B base with an additional 100B tokens of JA/EN pre-training. We also include [Japanese-StableLM-Base-Beta-70B](https://huggingface.co/stabilityai/japanese-stablelm-base-beta-70b), which is a Llama 2 70B that also has an additional 100B tokens of JA/EN pre-training as a reference:
|
| 19 |
|
| 20 |
-
![Mistral llm-jp-eval Comparison]()
|
| 21 |
|
| 22 |
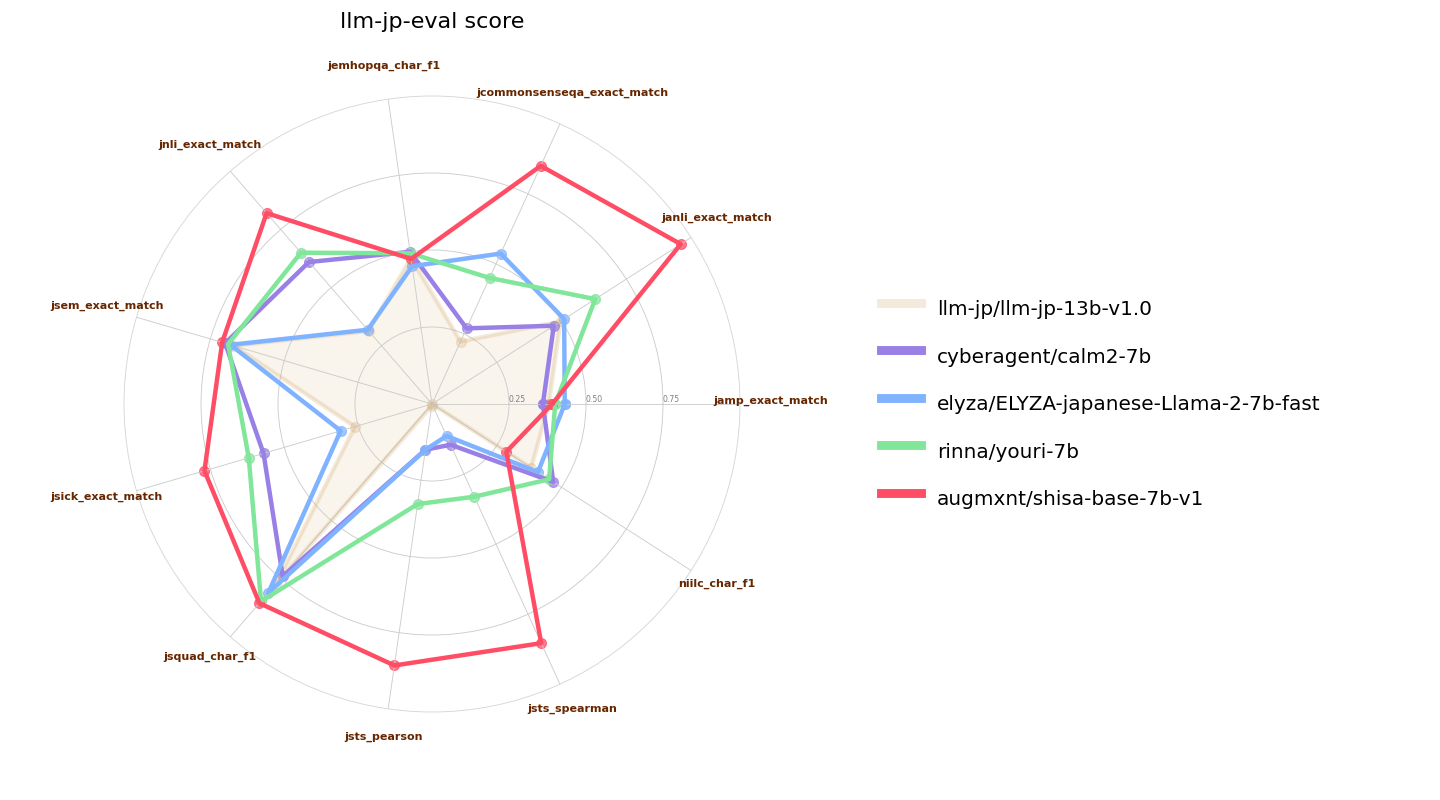
Here we also compare `mistral-7b-ja-v0.1` to other recently-released similar classed (7B parameter) Japanese-tuned models. [ELYZA 7B fast model](https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-fast) and [Youri 7B](https://huggingface.co/rinna/youri-7b) are Llama 2 7B models with 18B and 40B of additional pre-training respectively, and [CALM2-7B](https://huggingface.co/cyberagent/calm2-7b) and [llm-jp-13b]() are pretrained models with 1.3T and 300B JA/EN tokens of pre-training:
|
| 23 |
|
| 24 |
-
![7B llm-jp-eval Performance]()
|
| 25 |
|
| 26 |
## Tokenizer
|
| 27 |
As mentioned in the introduction, our tokenizer is an extended version of the Mistral 7B tokenizer, with a vocab size of 120073 and aligned to 128K. The remaining unused tokens are assigned as average-weighted `<|extra_{idx}|>` tokens.
|
|
|
|
| 17 |
|
| 18 |
We used a slightly modified [llm-jp-eval](https://github.com/llm-jp/llm-jp-eval) (our base model requires a `bos_token` to be prepended to the prompt; we tested other models with and without the modification and took the higher results for all models tested). Here we validate versus the original Mistral 7B base model as well as [Japanese Stable LM Instruct Gamma 7B](https://huggingface.co/stabilityai/japanese-stablelm-instruct-gamma-7b), which is a Mistral 7B base with an additional 100B tokens of JA/EN pre-training. We also include [Japanese-StableLM-Base-Beta-70B](https://huggingface.co/stabilityai/japanese-stablelm-base-beta-70b), which is a Llama 2 70B that also has an additional 100B tokens of JA/EN pre-training as a reference:
|
| 19 |
|
| 20 |
+
|
| 21 |
|
| 22 |
Here we also compare `mistral-7b-ja-v0.1` to other recently-released similar classed (7B parameter) Japanese-tuned models. [ELYZA 7B fast model](https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-fast) and [Youri 7B](https://huggingface.co/rinna/youri-7b) are Llama 2 7B models with 18B and 40B of additional pre-training respectively, and [CALM2-7B](https://huggingface.co/cyberagent/calm2-7b) and [llm-jp-13b]() are pretrained models with 1.3T and 300B JA/EN tokens of pre-training:
|
| 23 |
|
| 24 |
+
|
| 25 |
|
| 26 |
## Tokenizer
|
| 27 |
As mentioned in the introduction, our tokenizer is an extended version of the Mistral 7B tokenizer, with a vocab size of 120073 and aligned to 128K. The remaining unused tokens are assigned as average-weighted `<|extra_{idx}|>` tokens.
|