
Commit
·
c448da8
1
Parent(s):
785a186
Upload 12 files
Browse files- MODEL_LICENSE.txt +65 -0
- config.json +47 -0
- configuration_chatglm.py +61 -0
- flowchart V2.png +0 -0
- generation_config.json +6 -0
- modeling_chatglm.py +1281 -0
- pytorch_model.bin.index.json +208 -0
- quantization.py +188 -0
- special_tokens_map.json +1 -0
- tokenizer.model +3 -0
- tokenizer_config.json +14 -0
- training_loss.png +0 -0
MODEL_LICENSE.txt
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
The ChatGLM2-6B License
|
| 2 |
+
|
| 3 |
+
1. 定义
|
| 4 |
+
|
| 5 |
+
“许可方”是指分发其软件的 ChatGLM2-6B 模型团队。
|
| 6 |
+
|
| 7 |
+
“软件”是指根据本许可提供的 ChatGLM2-6B 模型参数。
|
| 8 |
+
|
| 9 |
+
2. 许可授予
|
| 10 |
+
|
| 11 |
+
根据本许可的条款和条件,许可方特此授予您非排他性、全球性、不可转让、不可再许可、可撤销、免版税的版权许可。
|
| 12 |
+
|
| 13 |
+
上述版权声明和本许可声明应包含在本软件的所有副本或重要部分中。
|
| 14 |
+
|
| 15 |
+
3.限制
|
| 16 |
+
|
| 17 |
+
您不得出于任何军事或非法目的使用、复制、修改、合并、发布、分发、复制或创建本软件的全部或部分衍生作品。
|
| 18 |
+
|
| 19 |
+
您不得利用本软件从事任何危害国家安全和国家统一、危害社会公共利益、侵犯人身权益的行为。
|
| 20 |
+
|
| 21 |
+
4.免责声明
|
| 22 |
+
|
| 23 |
+
本软件“按原样”提供,不提供任何明示或暗示的保证,包括但不限于对适销性、特定用途的适用性和非侵权性的保证。 在任何情况下,作者或版权持有人均不对任何索赔、损害或其他责任负责,无论是在合同诉讼、侵权行为还是其他方面,由软件或软件的使用或其他交易引起、由软件引起或与之相关 软件。
|
| 24 |
+
|
| 25 |
+
5. 责任限制
|
| 26 |
+
|
| 27 |
+
除适用法律禁止的范围外,在任何情况下且根据任何法律理论,无论是基于侵权行为、疏忽、合同、责任或其他原因,任何许可方均不对您承担任何直接、间接、特殊、偶然、示范性、 或间接损害,或任何其他商业损失,即使许可人已被告知此类损害的可能性。
|
| 28 |
+
|
| 29 |
+
6.争议解决
|
| 30 |
+
|
| 31 |
+
本许可受中华人民共和国法律管辖并按其解释。 因本许可引起的或与本许可有关的任何争议应提交北京市海淀区人民法院。
|
| 32 |
+
|
| 33 |
+
请注意,许可证可能会更新到更全面的版本。 有关许可和版权的任何问题,请通过 [email protected] 与我们联系。
|
| 34 |
+
|
| 35 |
+
1. Definitions
|
| 36 |
+
|
| 37 |
+
“Licensor” means the ChatGLM2-6B Model Team that distributes its Software.
|
| 38 |
+
|
| 39 |
+
“Software” means the ChatGLM2-6B model parameters made available under this license.
|
| 40 |
+
|
| 41 |
+
2. License Grant
|
| 42 |
+
|
| 43 |
+
Subject to the terms and conditions of this License, the Licensor hereby grants to you a non-exclusive, worldwide, non-transferable, non-sublicensable, revocable, royalty-free copyright license to use the Software.
|
| 44 |
+
|
| 45 |
+
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
|
| 46 |
+
|
| 47 |
+
3. Restriction
|
| 48 |
+
|
| 49 |
+
You will not use, copy, modify, merge, publish, distribute, reproduce, or create derivative works of the Software, in whole or in part, for any military, or illegal purposes.
|
| 50 |
+
|
| 51 |
+
You will not use the Software for any act that may undermine China's national security and national unity, harm the public interest of society, or infringe upon the rights and interests of human beings.
|
| 52 |
+
|
| 53 |
+
4. Disclaimer
|
| 54 |
+
|
| 55 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 56 |
+
|
| 57 |
+
5. Limitation of Liability
|
| 58 |
+
|
| 59 |
+
EXCEPT TO THE EXTENT PROHIBITED BY APPLICABLE LAW, IN NO EVENT AND UNDER NO LEGAL THEORY, WHETHER BASED IN TORT, NEGLIGENCE, CONTRACT, LIABILITY, OR OTHERWISE WILL ANY LICENSOR BE LIABLE TO YOU FOR ANY DIRECT, INDIRECT, SPECIAL, INCIDENTAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES, OR ANY OTHER COMMERCIAL LOSSES, EVEN IF THE LICENSOR HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
|
| 60 |
+
|
| 61 |
+
6. Dispute Resolution
|
| 62 |
+
|
| 63 |
+
This license shall be governed and construed in accordance with the laws of People’s Republic of China. Any dispute arising from or in connection with this License shall be submitted to Haidian District People's Court in Beijing.
|
| 64 |
+
|
| 65 |
+
Note that the license is subject to update to a more comprehensive version. For any questions related to the license and copyright, please contact us at [email protected].
|
config.json
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "THUDM/chatglm2-6b",
|
| 3 |
+
"add_bias_linear": false,
|
| 4 |
+
"add_qkv_bias": true,
|
| 5 |
+
"apply_query_key_layer_scaling": true,
|
| 6 |
+
"apply_residual_connection_post_layernorm": false,
|
| 7 |
+
"architectures": [
|
| 8 |
+
"ChatGLMForConditionalGeneration"
|
| 9 |
+
],
|
| 10 |
+
"attention_dropout": 0.0,
|
| 11 |
+
"attention_softmax_in_fp32": true,
|
| 12 |
+
"auto_map": {
|
| 13 |
+
"AutoConfig": "configuration_chatglm.ChatGLMConfig",
|
| 14 |
+
"AutoModel": "modeling_chatglm.ChatGLMForConditionalGeneration",
|
| 15 |
+
"AutoModelForCausalLM": "THUDM/chatglm2-6b--modeling_chatglm.ChatGLMForConditionalGeneration",
|
| 16 |
+
"AutoModelForSeq2SeqLM": "THUDM/chatglm2-6b--modeling_chatglm.ChatGLMForConditionalGeneration",
|
| 17 |
+
"AutoModelForSequenceClassification": "THUDM/chatglm2-6b--modeling_chatglm.ChatGLMForSequenceClassification"
|
| 18 |
+
},
|
| 19 |
+
"bias_dropout_fusion": true,
|
| 20 |
+
"classifier_dropout": null,
|
| 21 |
+
"eos_token_id": 2,
|
| 22 |
+
"ffn_hidden_size": 13696,
|
| 23 |
+
"fp32_residual_connection": false,
|
| 24 |
+
"hidden_dropout": 0.0,
|
| 25 |
+
"hidden_size": 4096,
|
| 26 |
+
"kv_channels": 128,
|
| 27 |
+
"layernorm_epsilon": 1e-05,
|
| 28 |
+
"model_type": "chatglm",
|
| 29 |
+
"multi_query_attention": true,
|
| 30 |
+
"multi_query_group_num": 2,
|
| 31 |
+
"num_attention_heads": 32,
|
| 32 |
+
"num_layers": 28,
|
| 33 |
+
"original_rope": true,
|
| 34 |
+
"pad_token_id": 0,
|
| 35 |
+
"padded_vocab_size": 65024,
|
| 36 |
+
"post_layer_norm": true,
|
| 37 |
+
"pre_seq_len": null,
|
| 38 |
+
"prefix_projection": false,
|
| 39 |
+
"quantization_bit": 0,
|
| 40 |
+
"rmsnorm": true,
|
| 41 |
+
"seq_length": 32768,
|
| 42 |
+
"tie_word_embeddings": false,
|
| 43 |
+
"torch_dtype": "float32",
|
| 44 |
+
"transformers_version": "4.33.2",
|
| 45 |
+
"use_cache": true,
|
| 46 |
+
"vocab_size": 65024
|
| 47 |
+
}
|
configuration_chatglm.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import PretrainedConfig
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class ChatGLMConfig(PretrainedConfig):
|
| 5 |
+
model_type = "chatglm"
|
| 6 |
+
def __init__(
|
| 7 |
+
self,
|
| 8 |
+
num_layers=28,
|
| 9 |
+
padded_vocab_size=65024,
|
| 10 |
+
hidden_size=4096,
|
| 11 |
+
ffn_hidden_size=13696,
|
| 12 |
+
kv_channels=128,
|
| 13 |
+
num_attention_heads=32,
|
| 14 |
+
seq_length=2048,
|
| 15 |
+
hidden_dropout=0.0,
|
| 16 |
+
classifier_dropout=None,
|
| 17 |
+
attention_dropout=0.0,
|
| 18 |
+
layernorm_epsilon=1e-5,
|
| 19 |
+
rmsnorm=True,
|
| 20 |
+
apply_residual_connection_post_layernorm=False,
|
| 21 |
+
post_layer_norm=True,
|
| 22 |
+
add_bias_linear=False,
|
| 23 |
+
add_qkv_bias=False,
|
| 24 |
+
bias_dropout_fusion=True,
|
| 25 |
+
multi_query_attention=False,
|
| 26 |
+
multi_query_group_num=1,
|
| 27 |
+
apply_query_key_layer_scaling=True,
|
| 28 |
+
attention_softmax_in_fp32=True,
|
| 29 |
+
fp32_residual_connection=False,
|
| 30 |
+
quantization_bit=0,
|
| 31 |
+
pre_seq_len=None,
|
| 32 |
+
prefix_projection=False,
|
| 33 |
+
**kwargs
|
| 34 |
+
):
|
| 35 |
+
self.num_layers = num_layers
|
| 36 |
+
self.vocab_size = padded_vocab_size
|
| 37 |
+
self.padded_vocab_size = padded_vocab_size
|
| 38 |
+
self.hidden_size = hidden_size
|
| 39 |
+
self.ffn_hidden_size = ffn_hidden_size
|
| 40 |
+
self.kv_channels = kv_channels
|
| 41 |
+
self.num_attention_heads = num_attention_heads
|
| 42 |
+
self.seq_length = seq_length
|
| 43 |
+
self.hidden_dropout = hidden_dropout
|
| 44 |
+
self.classifier_dropout = classifier_dropout
|
| 45 |
+
self.attention_dropout = attention_dropout
|
| 46 |
+
self.layernorm_epsilon = layernorm_epsilon
|
| 47 |
+
self.rmsnorm = rmsnorm
|
| 48 |
+
self.apply_residual_connection_post_layernorm = apply_residual_connection_post_layernorm
|
| 49 |
+
self.post_layer_norm = post_layer_norm
|
| 50 |
+
self.add_bias_linear = add_bias_linear
|
| 51 |
+
self.add_qkv_bias = add_qkv_bias
|
| 52 |
+
self.bias_dropout_fusion = bias_dropout_fusion
|
| 53 |
+
self.multi_query_attention = multi_query_attention
|
| 54 |
+
self.multi_query_group_num = multi_query_group_num
|
| 55 |
+
self.apply_query_key_layer_scaling = apply_query_key_layer_scaling
|
| 56 |
+
self.attention_softmax_in_fp32 = attention_softmax_in_fp32
|
| 57 |
+
self.fp32_residual_connection = fp32_residual_connection
|
| 58 |
+
self.quantization_bit = quantization_bit
|
| 59 |
+
self.pre_seq_len = pre_seq_len
|
| 60 |
+
self.prefix_projection = prefix_projection
|
| 61 |
+
super().__init__(**kwargs)
|
flowchart V2.png
ADDED

|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"eos_token_id": 2,
|
| 4 |
+
"pad_token_id": 0,
|
| 5 |
+
"transformers_version": "4.33.2"
|
| 6 |
+
}
|
modeling_chatglm.py
ADDED
|
@@ -0,0 +1,1281 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" PyTorch ChatGLM model. """
|
| 2 |
+
|
| 3 |
+
import math
|
| 4 |
+
import copy
|
| 5 |
+
import warnings
|
| 6 |
+
import re
|
| 7 |
+
import sys
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
import torch.utils.checkpoint
|
| 11 |
+
import torch.nn.functional as F
|
| 12 |
+
from torch import nn
|
| 13 |
+
from torch.nn import CrossEntropyLoss, LayerNorm
|
| 14 |
+
from torch.nn import CrossEntropyLoss, LayerNorm, MSELoss, BCEWithLogitsLoss
|
| 15 |
+
from torch.nn.utils import skip_init
|
| 16 |
+
from typing import Optional, Tuple, Union, List, Callable, Dict, Any
|
| 17 |
+
|
| 18 |
+
from transformers.modeling_outputs import (
|
| 19 |
+
BaseModelOutputWithPast,
|
| 20 |
+
CausalLMOutputWithPast,
|
| 21 |
+
SequenceClassifierOutputWithPast,
|
| 22 |
+
)
|
| 23 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 24 |
+
from transformers.utils import logging
|
| 25 |
+
from transformers.generation.logits_process import LogitsProcessor
|
| 26 |
+
from transformers.generation.utils import LogitsProcessorList, StoppingCriteriaList, GenerationConfig, ModelOutput
|
| 27 |
+
|
| 28 |
+
from .configuration_chatglm import ChatGLMConfig
|
| 29 |
+
|
| 30 |
+
# flags required to enable jit fusion kernels
|
| 31 |
+
|
| 32 |
+
if sys.platform != 'darwin':
|
| 33 |
+
torch._C._jit_set_profiling_mode(False)
|
| 34 |
+
torch._C._jit_set_profiling_executor(False)
|
| 35 |
+
torch._C._jit_override_can_fuse_on_cpu(True)
|
| 36 |
+
torch._C._jit_override_can_fuse_on_gpu(True)
|
| 37 |
+
|
| 38 |
+
logger = logging.get_logger(__name__)
|
| 39 |
+
|
| 40 |
+
_CHECKPOINT_FOR_DOC = "THUDM/ChatGLM2-6B"
|
| 41 |
+
_CONFIG_FOR_DOC = "ChatGLM6BConfig"
|
| 42 |
+
|
| 43 |
+
CHATGLM_6B_PRETRAINED_MODEL_ARCHIVE_LIST = [
|
| 44 |
+
"THUDM/chatglm2-6b",
|
| 45 |
+
# See all ChatGLM models at https://huggingface.co/models?filter=chatglm
|
| 46 |
+
]
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def default_init(cls, *args, **kwargs):
|
| 50 |
+
return cls(*args, **kwargs)
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
class InvalidScoreLogitsProcessor(LogitsProcessor):
|
| 54 |
+
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
|
| 55 |
+
if torch.isnan(scores).any() or torch.isinf(scores).any():
|
| 56 |
+
scores.zero_()
|
| 57 |
+
scores[..., 5] = 5e4
|
| 58 |
+
return scores
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
class PrefixEncoder(torch.nn.Module):
|
| 62 |
+
"""
|
| 63 |
+
The torch.nn model to encode the prefix
|
| 64 |
+
Input shape: (batch-size, prefix-length)
|
| 65 |
+
Output shape: (batch-size, prefix-length, 2*layers*hidden)
|
| 66 |
+
"""
|
| 67 |
+
|
| 68 |
+
def __init__(self, config: ChatGLMConfig):
|
| 69 |
+
super().__init__()
|
| 70 |
+
self.prefix_projection = config.prefix_projection
|
| 71 |
+
if self.prefix_projection:
|
| 72 |
+
# Use a two-layer MLP to encode the prefix
|
| 73 |
+
kv_size = config.num_layers * config.kv_channels * config.multi_query_group_num * 2
|
| 74 |
+
self.embedding = torch.nn.Embedding(config.pre_seq_len, kv_size)
|
| 75 |
+
self.trans = torch.nn.Sequential(
|
| 76 |
+
torch.nn.Linear(kv_size, config.hidden_size),
|
| 77 |
+
torch.nn.Tanh(),
|
| 78 |
+
torch.nn.Linear(config.hidden_size, kv_size)
|
| 79 |
+
)
|
| 80 |
+
else:
|
| 81 |
+
self.embedding = torch.nn.Embedding(config.pre_seq_len,
|
| 82 |
+
config.num_layers * config.kv_channels * config.multi_query_group_num * 2)
|
| 83 |
+
|
| 84 |
+
def forward(self, prefix: torch.Tensor):
|
| 85 |
+
if self.prefix_projection:
|
| 86 |
+
prefix_tokens = self.embedding(prefix)
|
| 87 |
+
past_key_values = self.trans(prefix_tokens)
|
| 88 |
+
else:
|
| 89 |
+
past_key_values = self.embedding(prefix)
|
| 90 |
+
return past_key_values
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def split_tensor_along_last_dim(
|
| 94 |
+
tensor: torch.Tensor,
|
| 95 |
+
num_partitions: int,
|
| 96 |
+
contiguous_split_chunks: bool = False,
|
| 97 |
+
) -> List[torch.Tensor]:
|
| 98 |
+
"""Split a tensor along its last dimension.
|
| 99 |
+
|
| 100 |
+
Arguments:
|
| 101 |
+
tensor: input tensor.
|
| 102 |
+
num_partitions: number of partitions to split the tensor
|
| 103 |
+
contiguous_split_chunks: If True, make each chunk contiguous
|
| 104 |
+
in memory.
|
| 105 |
+
|
| 106 |
+
Returns:
|
| 107 |
+
A list of Tensors
|
| 108 |
+
"""
|
| 109 |
+
# Get the size and dimension.
|
| 110 |
+
last_dim = tensor.dim() - 1
|
| 111 |
+
last_dim_size = tensor.size()[last_dim] // num_partitions
|
| 112 |
+
# Split.
|
| 113 |
+
tensor_list = torch.split(tensor, last_dim_size, dim=last_dim)
|
| 114 |
+
# Note: torch.split does not create contiguous tensors by default.
|
| 115 |
+
if contiguous_split_chunks:
|
| 116 |
+
return tuple(chunk.contiguous() for chunk in tensor_list)
|
| 117 |
+
|
| 118 |
+
return tensor_list
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
class RotaryEmbedding(nn.Module):
|
| 122 |
+
def __init__(self, dim, original_impl=False, device=None, dtype=None):
|
| 123 |
+
super().__init__()
|
| 124 |
+
inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2, device=device).to(dtype=dtype) / dim))
|
| 125 |
+
self.register_buffer("inv_freq", inv_freq)
|
| 126 |
+
self.dim = dim
|
| 127 |
+
self.original_impl = original_impl
|
| 128 |
+
|
| 129 |
+
def forward_impl(
|
| 130 |
+
self, seq_len: int, n_elem: int, dtype: torch.dtype, device: torch.device, base: int = 10000
|
| 131 |
+
):
|
| 132 |
+
"""Enhanced Transformer with Rotary Position Embedding.
|
| 133 |
+
|
| 134 |
+
Derived from: https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/labml_nn/
|
| 135 |
+
transformers/rope/__init__.py. MIT License:
|
| 136 |
+
https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/license.
|
| 137 |
+
"""
|
| 138 |
+
# $\Theta = {\theta_i = 10000^{\frac{2(i-1)}{d}}, i \in [1, 2, ..., \frac{d}{2}]}$
|
| 139 |
+
theta = 1.0 / (base ** (torch.arange(0, n_elem, 2, dtype=dtype, device=device) / n_elem))
|
| 140 |
+
|
| 141 |
+
# Create position indexes `[0, 1, ..., seq_len - 1]`
|
| 142 |
+
seq_idx = torch.arange(seq_len, dtype=dtype, device=device)
|
| 143 |
+
|
| 144 |
+
# Calculate the product of position index and $\theta_i$
|
| 145 |
+
idx_theta = torch.outer(seq_idx, theta).float()
|
| 146 |
+
|
| 147 |
+
cache = torch.stack([torch.cos(idx_theta), torch.sin(idx_theta)], dim=-1)
|
| 148 |
+
|
| 149 |
+
# this is to mimic the behaviour of complex32, else we will get different results
|
| 150 |
+
if dtype in (torch.float16, torch.bfloat16, torch.int8):
|
| 151 |
+
cache = cache.bfloat16() if dtype == torch.bfloat16 else cache.half()
|
| 152 |
+
return cache
|
| 153 |
+
|
| 154 |
+
def forward(self, max_seq_len, offset=0):
|
| 155 |
+
return self.forward_impl(
|
| 156 |
+
max_seq_len, self.dim, dtype=self.inv_freq.dtype, device=self.inv_freq.device
|
| 157 |
+
)
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
@torch.jit.script
|
| 161 |
+
def apply_rotary_pos_emb(x: torch.Tensor, rope_cache: torch.Tensor) -> torch.Tensor:
|
| 162 |
+
# x: [sq, b, np, hn]
|
| 163 |
+
sq, b, np, hn = x.size(0), x.size(1), x.size(2), x.size(3)
|
| 164 |
+
rot_dim = rope_cache.shape[-2] * 2
|
| 165 |
+
x, x_pass = x[..., :rot_dim], x[..., rot_dim:]
|
| 166 |
+
# truncate to support variable sizes
|
| 167 |
+
rope_cache = rope_cache[:sq]
|
| 168 |
+
xshaped = x.reshape(sq, -1, np, rot_dim // 2, 2)
|
| 169 |
+
rope_cache = rope_cache.view(sq, -1, 1, xshaped.size(3), 2)
|
| 170 |
+
x_out2 = torch.stack(
|
| 171 |
+
[
|
| 172 |
+
xshaped[..., 0] * rope_cache[..., 0] - xshaped[..., 1] * rope_cache[..., 1],
|
| 173 |
+
xshaped[..., 1] * rope_cache[..., 0] + xshaped[..., 0] * rope_cache[..., 1],
|
| 174 |
+
],
|
| 175 |
+
-1,
|
| 176 |
+
)
|
| 177 |
+
x_out2 = x_out2.flatten(3)
|
| 178 |
+
return torch.cat((x_out2, x_pass), dim=-1)
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
class RMSNorm(torch.nn.Module):
|
| 182 |
+
def __init__(self, normalized_shape, eps=1e-5, device=None, dtype=None, **kwargs):
|
| 183 |
+
super().__init__()
|
| 184 |
+
self.weight = torch.nn.Parameter(torch.empty(normalized_shape, device=device, dtype=dtype))
|
| 185 |
+
self.eps = eps
|
| 186 |
+
|
| 187 |
+
def forward(self, hidden_states: torch.Tensor):
|
| 188 |
+
input_dtype = hidden_states.dtype
|
| 189 |
+
variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
|
| 190 |
+
hidden_states = hidden_states * torch.rsqrt(variance + self.eps)
|
| 191 |
+
|
| 192 |
+
return (self.weight * hidden_states).to(input_dtype)
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
class CoreAttention(torch.nn.Module):
|
| 196 |
+
def __init__(self, config: ChatGLMConfig, layer_number):
|
| 197 |
+
super(CoreAttention, self).__init__()
|
| 198 |
+
|
| 199 |
+
self.apply_query_key_layer_scaling = config.apply_query_key_layer_scaling
|
| 200 |
+
self.attention_softmax_in_fp32 = config.attention_softmax_in_fp32
|
| 201 |
+
if self.apply_query_key_layer_scaling:
|
| 202 |
+
self.attention_softmax_in_fp32 = True
|
| 203 |
+
self.layer_number = max(1, layer_number)
|
| 204 |
+
|
| 205 |
+
projection_size = config.kv_channels * config.num_attention_heads
|
| 206 |
+
|
| 207 |
+
# Per attention head and per partition values.
|
| 208 |
+
self.hidden_size_per_partition = projection_size
|
| 209 |
+
self.hidden_size_per_attention_head = projection_size // config.num_attention_heads
|
| 210 |
+
self.num_attention_heads_per_partition = config.num_attention_heads
|
| 211 |
+
|
| 212 |
+
coeff = None
|
| 213 |
+
self.norm_factor = math.sqrt(self.hidden_size_per_attention_head)
|
| 214 |
+
if self.apply_query_key_layer_scaling:
|
| 215 |
+
coeff = self.layer_number
|
| 216 |
+
self.norm_factor *= coeff
|
| 217 |
+
self.coeff = coeff
|
| 218 |
+
|
| 219 |
+
self.attention_dropout = torch.nn.Dropout(config.attention_dropout)
|
| 220 |
+
|
| 221 |
+
def forward(self, query_layer, key_layer, value_layer, attention_mask):
|
| 222 |
+
pytorch_major_version = int(torch.__version__.split('.')[0])
|
| 223 |
+
if pytorch_major_version >= 2:
|
| 224 |
+
query_layer, key_layer, value_layer = [k.permute(1, 2, 0, 3) for k in [query_layer, key_layer, value_layer]]
|
| 225 |
+
if attention_mask is None and query_layer.shape[2] == key_layer.shape[2]:
|
| 226 |
+
context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer, key_layer, value_layer,
|
| 227 |
+
is_causal=True)
|
| 228 |
+
else:
|
| 229 |
+
if attention_mask is not None:
|
| 230 |
+
attention_mask = ~attention_mask
|
| 231 |
+
context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer, key_layer, value_layer,
|
| 232 |
+
attention_mask)
|
| 233 |
+
context_layer = context_layer.permute(2, 0, 1, 3)
|
| 234 |
+
new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size_per_partition,)
|
| 235 |
+
context_layer = context_layer.reshape(*new_context_layer_shape)
|
| 236 |
+
else:
|
| 237 |
+
# Raw attention scores
|
| 238 |
+
|
| 239 |
+
# [b, np, sq, sk]
|
| 240 |
+
output_size = (query_layer.size(1), query_layer.size(2), query_layer.size(0), key_layer.size(0))
|
| 241 |
+
|
| 242 |
+
# [sq, b, np, hn] -> [sq, b * np, hn]
|
| 243 |
+
query_layer = query_layer.view(output_size[2], output_size[0] * output_size[1], -1)
|
| 244 |
+
# [sk, b, np, hn] -> [sk, b * np, hn]
|
| 245 |
+
key_layer = key_layer.view(output_size[3], output_size[0] * output_size[1], -1)
|
| 246 |
+
|
| 247 |
+
# preallocting input tensor: [b * np, sq, sk]
|
| 248 |
+
matmul_input_buffer = torch.empty(
|
| 249 |
+
output_size[0] * output_size[1], output_size[2], output_size[3], dtype=query_layer.dtype,
|
| 250 |
+
device=query_layer.device
|
| 251 |
+
)
|
| 252 |
+
|
| 253 |
+
# Raw attention scores. [b * np, sq, sk]
|
| 254 |
+
matmul_result = torch.baddbmm(
|
| 255 |
+
matmul_input_buffer,
|
| 256 |
+
query_layer.transpose(0, 1), # [b * np, sq, hn]
|
| 257 |
+
key_layer.transpose(0, 1).transpose(1, 2), # [b * np, hn, sk]
|
| 258 |
+
beta=0.0,
|
| 259 |
+
alpha=(1.0 / self.norm_factor),
|
| 260 |
+
)
|
| 261 |
+
|
| 262 |
+
# change view to [b, np, sq, sk]
|
| 263 |
+
attention_scores = matmul_result.view(*output_size)
|
| 264 |
+
|
| 265 |
+
# ===========================
|
| 266 |
+
# Attention probs and dropout
|
| 267 |
+
# ===========================
|
| 268 |
+
|
| 269 |
+
# attention scores and attention mask [b, np, sq, sk]
|
| 270 |
+
if self.attention_softmax_in_fp32:
|
| 271 |
+
attention_scores = attention_scores.float()
|
| 272 |
+
if self.coeff is not None:
|
| 273 |
+
attention_scores = attention_scores * self.coeff
|
| 274 |
+
if attention_mask is None and attention_scores.shape[2] == attention_scores.shape[3]:
|
| 275 |
+
attention_mask = torch.ones(output_size[0], 1, output_size[2], output_size[3],
|
| 276 |
+
device=attention_scores.device, dtype=torch.bool)
|
| 277 |
+
attention_mask.tril_()
|
| 278 |
+
attention_mask = ~attention_mask
|
| 279 |
+
if attention_mask is not None:
|
| 280 |
+
attention_scores = attention_scores.masked_fill(attention_mask, float("-inf"))
|
| 281 |
+
attention_probs = F.softmax(attention_scores, dim=-1)
|
| 282 |
+
attention_probs = attention_probs.type_as(value_layer)
|
| 283 |
+
|
| 284 |
+
# This is actually dropping out entire tokens to attend to, which might
|
| 285 |
+
# seem a bit unusual, but is taken from the original Transformer paper.
|
| 286 |
+
attention_probs = self.attention_dropout(attention_probs)
|
| 287 |
+
# =========================
|
| 288 |
+
# Context layer. [sq, b, hp]
|
| 289 |
+
# =========================
|
| 290 |
+
|
| 291 |
+
# value_layer -> context layer.
|
| 292 |
+
# [sk, b, np, hn] --> [b, np, sq, hn]
|
| 293 |
+
|
| 294 |
+
# context layer shape: [b, np, sq, hn]
|
| 295 |
+
output_size = (value_layer.size(1), value_layer.size(2), query_layer.size(0), value_layer.size(3))
|
| 296 |
+
# change view [sk, b * np, hn]
|
| 297 |
+
value_layer = value_layer.view(value_layer.size(0), output_size[0] * output_size[1], -1)
|
| 298 |
+
# change view [b * np, sq, sk]
|
| 299 |
+
attention_probs = attention_probs.view(output_size[0] * output_size[1], output_size[2], -1)
|
| 300 |
+
# matmul: [b * np, sq, hn]
|
| 301 |
+
context_layer = torch.bmm(attention_probs, value_layer.transpose(0, 1))
|
| 302 |
+
# change view [b, np, sq, hn]
|
| 303 |
+
context_layer = context_layer.view(*output_size)
|
| 304 |
+
# [b, np, sq, hn] --> [sq, b, np, hn]
|
| 305 |
+
context_layer = context_layer.permute(2, 0, 1, 3).contiguous()
|
| 306 |
+
# [sq, b, np, hn] --> [sq, b, hp]
|
| 307 |
+
new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size_per_partition,)
|
| 308 |
+
context_layer = context_layer.view(*new_context_layer_shape)
|
| 309 |
+
|
| 310 |
+
return context_layer
|
| 311 |
+
|
| 312 |
+
|
| 313 |
+
class SelfAttention(torch.nn.Module):
|
| 314 |
+
"""Parallel self-attention layer abstract class.
|
| 315 |
+
|
| 316 |
+
Self-attention layer takes input with size [s, b, h]
|
| 317 |
+
and returns output of the same size.
|
| 318 |
+
"""
|
| 319 |
+
|
| 320 |
+
def __init__(self, config: ChatGLMConfig, layer_number, device=None):
|
| 321 |
+
super(SelfAttention, self).__init__()
|
| 322 |
+
self.layer_number = max(1, layer_number)
|
| 323 |
+
|
| 324 |
+
self.projection_size = config.kv_channels * config.num_attention_heads
|
| 325 |
+
|
| 326 |
+
# Per attention head and per partition values.
|
| 327 |
+
self.hidden_size_per_attention_head = self.projection_size // config.num_attention_heads
|
| 328 |
+
self.num_attention_heads_per_partition = config.num_attention_heads
|
| 329 |
+
|
| 330 |
+
self.multi_query_attention = config.multi_query_attention
|
| 331 |
+
self.qkv_hidden_size = 3 * self.projection_size
|
| 332 |
+
if self.multi_query_attention:
|
| 333 |
+
self.num_multi_query_groups_per_partition = config.multi_query_group_num
|
| 334 |
+
self.qkv_hidden_size = (
|
| 335 |
+
self.projection_size + 2 * self.hidden_size_per_attention_head * config.multi_query_group_num
|
| 336 |
+
)
|
| 337 |
+
self.query_key_value = nn.Linear(config.hidden_size, self.qkv_hidden_size,
|
| 338 |
+
bias=config.add_bias_linear or config.add_qkv_bias,
|
| 339 |
+
device=device, **_config_to_kwargs(config)
|
| 340 |
+
)
|
| 341 |
+
|
| 342 |
+
self.core_attention = CoreAttention(config, self.layer_number)
|
| 343 |
+
|
| 344 |
+
# Output.
|
| 345 |
+
self.dense = nn.Linear(self.projection_size, config.hidden_size, bias=config.add_bias_linear,
|
| 346 |
+
device=device, **_config_to_kwargs(config)
|
| 347 |
+
)
|
| 348 |
+
|
| 349 |
+
def _allocate_memory(self, inference_max_sequence_len, batch_size, device=None, dtype=None):
|
| 350 |
+
if self.multi_query_attention:
|
| 351 |
+
num_attention_heads = self.num_multi_query_groups_per_partition
|
| 352 |
+
else:
|
| 353 |
+
num_attention_heads = self.num_attention_heads_per_partition
|
| 354 |
+
return torch.empty(
|
| 355 |
+
inference_max_sequence_len,
|
| 356 |
+
batch_size,
|
| 357 |
+
num_attention_heads,
|
| 358 |
+
self.hidden_size_per_attention_head,
|
| 359 |
+
dtype=dtype,
|
| 360 |
+
device=device,
|
| 361 |
+
)
|
| 362 |
+
|
| 363 |
+
def forward(
|
| 364 |
+
self, hidden_states, attention_mask, rotary_pos_emb, kv_cache=None, use_cache=True
|
| 365 |
+
):
|
| 366 |
+
# hidden_states: [sq, b, h]
|
| 367 |
+
|
| 368 |
+
# =================================================
|
| 369 |
+
# Pre-allocate memory for key-values for inference.
|
| 370 |
+
# =================================================
|
| 371 |
+
# =====================
|
| 372 |
+
# Query, Key, and Value
|
| 373 |
+
# =====================
|
| 374 |
+
|
| 375 |
+
# Attention heads [sq, b, h] --> [sq, b, (np * 3 * hn)]
|
| 376 |
+
mixed_x_layer = self.query_key_value(hidden_states)
|
| 377 |
+
|
| 378 |
+
if self.multi_query_attention:
|
| 379 |
+
(query_layer, key_layer, value_layer) = mixed_x_layer.split(
|
| 380 |
+
[
|
| 381 |
+
self.num_attention_heads_per_partition * self.hidden_size_per_attention_head,
|
| 382 |
+
self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
|
| 383 |
+
self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
|
| 384 |
+
],
|
| 385 |
+
dim=-1,
|
| 386 |
+
)
|
| 387 |
+
query_layer = query_layer.view(
|
| 388 |
+
query_layer.size()[:-1] + (self.num_attention_heads_per_partition, self.hidden_size_per_attention_head)
|
| 389 |
+
)
|
| 390 |
+
key_layer = key_layer.view(
|
| 391 |
+
key_layer.size()[:-1] + (self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head)
|
| 392 |
+
)
|
| 393 |
+
value_layer = value_layer.view(
|
| 394 |
+
value_layer.size()[:-1]
|
| 395 |
+
+ (self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head)
|
| 396 |
+
)
|
| 397 |
+
else:
|
| 398 |
+
new_tensor_shape = mixed_x_layer.size()[:-1] + \
|
| 399 |
+
(self.num_attention_heads_per_partition,
|
| 400 |
+
3 * self.hidden_size_per_attention_head)
|
| 401 |
+
mixed_x_layer = mixed_x_layer.view(*new_tensor_shape)
|
| 402 |
+
|
| 403 |
+
# [sq, b, np, 3 * hn] --> 3 [sq, b, np, hn]
|
| 404 |
+
(query_layer, key_layer, value_layer) = split_tensor_along_last_dim(mixed_x_layer, 3)
|
| 405 |
+
|
| 406 |
+
# apply relative positional encoding (rotary embedding)
|
| 407 |
+
if rotary_pos_emb is not None:
|
| 408 |
+
query_layer = apply_rotary_pos_emb(query_layer, rotary_pos_emb)
|
| 409 |
+
key_layer = apply_rotary_pos_emb(key_layer, rotary_pos_emb)
|
| 410 |
+
|
| 411 |
+
# adjust key and value for inference
|
| 412 |
+
if kv_cache is not None:
|
| 413 |
+
cache_k, cache_v = kv_cache
|
| 414 |
+
key_layer = torch.cat((cache_k, key_layer), dim=0)
|
| 415 |
+
value_layer = torch.cat((cache_v, value_layer), dim=0)
|
| 416 |
+
if use_cache:
|
| 417 |
+
kv_cache = (key_layer, value_layer)
|
| 418 |
+
else:
|
| 419 |
+
kv_cache = None
|
| 420 |
+
|
| 421 |
+
if self.multi_query_attention:
|
| 422 |
+
key_layer = key_layer.unsqueeze(-2)
|
| 423 |
+
key_layer = key_layer.expand(
|
| 424 |
+
-1, -1, -1, self.num_attention_heads_per_partition // self.num_multi_query_groups_per_partition, -1
|
| 425 |
+
)
|
| 426 |
+
key_layer = key_layer.contiguous().view(
|
| 427 |
+
key_layer.size()[:2] + (self.num_attention_heads_per_partition, self.hidden_size_per_attention_head)
|
| 428 |
+
)
|
| 429 |
+
value_layer = value_layer.unsqueeze(-2)
|
| 430 |
+
value_layer = value_layer.expand(
|
| 431 |
+
-1, -1, -1, self.num_attention_heads_per_partition // self.num_multi_query_groups_per_partition, -1
|
| 432 |
+
)
|
| 433 |
+
value_layer = value_layer.contiguous().view(
|
| 434 |
+
value_layer.size()[:2] + (self.num_attention_heads_per_partition, self.hidden_size_per_attention_head)
|
| 435 |
+
)
|
| 436 |
+
|
| 437 |
+
# ==================================
|
| 438 |
+
# core attention computation
|
| 439 |
+
# ==================================
|
| 440 |
+
|
| 441 |
+
context_layer = self.core_attention(query_layer, key_layer, value_layer, attention_mask)
|
| 442 |
+
|
| 443 |
+
# =================
|
| 444 |
+
# Output. [sq, b, h]
|
| 445 |
+
# =================
|
| 446 |
+
|
| 447 |
+
output = self.dense(context_layer)
|
| 448 |
+
|
| 449 |
+
return output, kv_cache
|
| 450 |
+
|
| 451 |
+
|
| 452 |
+
def _config_to_kwargs(args):
|
| 453 |
+
common_kwargs = {
|
| 454 |
+
"dtype": args.torch_dtype,
|
| 455 |
+
}
|
| 456 |
+
return common_kwargs
|
| 457 |
+
|
| 458 |
+
|
| 459 |
+
class MLP(torch.nn.Module):
|
| 460 |
+
"""MLP.
|
| 461 |
+
|
| 462 |
+
MLP will take the input with h hidden state, project it to 4*h
|
| 463 |
+
hidden dimension, perform nonlinear transformation, and project the
|
| 464 |
+
state back into h hidden dimension.
|
| 465 |
+
"""
|
| 466 |
+
|
| 467 |
+
def __init__(self, config: ChatGLMConfig, device=None):
|
| 468 |
+
super(MLP, self).__init__()
|
| 469 |
+
|
| 470 |
+
self.add_bias = config.add_bias_linear
|
| 471 |
+
|
| 472 |
+
# Project to 4h. If using swiglu double the output width, see https://arxiv.org/pdf/2002.05202.pdf
|
| 473 |
+
self.dense_h_to_4h = nn.Linear(
|
| 474 |
+
config.hidden_size,
|
| 475 |
+
config.ffn_hidden_size * 2,
|
| 476 |
+
bias=self.add_bias,
|
| 477 |
+
device=device,
|
| 478 |
+
**_config_to_kwargs(config)
|
| 479 |
+
)
|
| 480 |
+
|
| 481 |
+
def swiglu(x):
|
| 482 |
+
x = torch.chunk(x, 2, dim=-1)
|
| 483 |
+
return F.silu(x[0]) * x[1]
|
| 484 |
+
|
| 485 |
+
self.activation_func = swiglu
|
| 486 |
+
|
| 487 |
+
# Project back to h.
|
| 488 |
+
self.dense_4h_to_h = nn.Linear(
|
| 489 |
+
config.ffn_hidden_size,
|
| 490 |
+
config.hidden_size,
|
| 491 |
+
bias=self.add_bias,
|
| 492 |
+
device=device,
|
| 493 |
+
**_config_to_kwargs(config)
|
| 494 |
+
)
|
| 495 |
+
|
| 496 |
+
def forward(self, hidden_states):
|
| 497 |
+
# [s, b, 4hp]
|
| 498 |
+
intermediate_parallel = self.dense_h_to_4h(hidden_states)
|
| 499 |
+
intermediate_parallel = self.activation_func(intermediate_parallel)
|
| 500 |
+
# [s, b, h]
|
| 501 |
+
output = self.dense_4h_to_h(intermediate_parallel)
|
| 502 |
+
return output
|
| 503 |
+
|
| 504 |
+
|
| 505 |
+
class GLMBlock(torch.nn.Module):
|
| 506 |
+
"""A single transformer layer.
|
| 507 |
+
|
| 508 |
+
Transformer layer takes input with size [s, b, h] and returns an
|
| 509 |
+
output of the same size.
|
| 510 |
+
"""
|
| 511 |
+
|
| 512 |
+
def __init__(self, config: ChatGLMConfig, layer_number, device=None):
|
| 513 |
+
super(GLMBlock, self).__init__()
|
| 514 |
+
self.layer_number = layer_number
|
| 515 |
+
|
| 516 |
+
self.apply_residual_connection_post_layernorm = config.apply_residual_connection_post_layernorm
|
| 517 |
+
|
| 518 |
+
self.fp32_residual_connection = config.fp32_residual_connection
|
| 519 |
+
|
| 520 |
+
LayerNormFunc = RMSNorm if config.rmsnorm else LayerNorm
|
| 521 |
+
# Layernorm on the input data.
|
| 522 |
+
self.input_layernorm = LayerNormFunc(config.hidden_size, eps=config.layernorm_epsilon, device=device,
|
| 523 |
+
dtype=config.torch_dtype)
|
| 524 |
+
|
| 525 |
+
# Self attention.
|
| 526 |
+
self.self_attention = SelfAttention(config, layer_number, device=device)
|
| 527 |
+
self.hidden_dropout = config.hidden_dropout
|
| 528 |
+
|
| 529 |
+
# Layernorm on the attention output
|
| 530 |
+
self.post_attention_layernorm = LayerNormFunc(config.hidden_size, eps=config.layernorm_epsilon, device=device,
|
| 531 |
+
dtype=config.torch_dtype)
|
| 532 |
+
|
| 533 |
+
# MLP
|
| 534 |
+
self.mlp = MLP(config, device=device)
|
| 535 |
+
|
| 536 |
+
def forward(
|
| 537 |
+
self, hidden_states, attention_mask, rotary_pos_emb, kv_cache=None, use_cache=True,
|
| 538 |
+
):
|
| 539 |
+
# hidden_states: [s, b, h]
|
| 540 |
+
|
| 541 |
+
# Layer norm at the beginning of the transformer layer.
|
| 542 |
+
layernorm_output = self.input_layernorm(hidden_states)
|
| 543 |
+
# Self attention.
|
| 544 |
+
attention_output, kv_cache = self.self_attention(
|
| 545 |
+
layernorm_output,
|
| 546 |
+
attention_mask,
|
| 547 |
+
rotary_pos_emb,
|
| 548 |
+
kv_cache=kv_cache,
|
| 549 |
+
use_cache=use_cache
|
| 550 |
+
)
|
| 551 |
+
|
| 552 |
+
# Residual connection.
|
| 553 |
+
if self.apply_residual_connection_post_layernorm:
|
| 554 |
+
residual = layernorm_output
|
| 555 |
+
else:
|
| 556 |
+
residual = hidden_states
|
| 557 |
+
|
| 558 |
+
layernorm_input = torch.nn.functional.dropout(attention_output, p=self.hidden_dropout, training=self.training)
|
| 559 |
+
layernorm_input = residual + layernorm_input
|
| 560 |
+
|
| 561 |
+
# Layer norm post the self attention.
|
| 562 |
+
layernorm_output = self.post_attention_layernorm(layernorm_input)
|
| 563 |
+
|
| 564 |
+
# MLP.
|
| 565 |
+
mlp_output = self.mlp(layernorm_output)
|
| 566 |
+
|
| 567 |
+
# Second residual connection.
|
| 568 |
+
if self.apply_residual_connection_post_layernorm:
|
| 569 |
+
residual = layernorm_output
|
| 570 |
+
else:
|
| 571 |
+
residual = layernorm_input
|
| 572 |
+
|
| 573 |
+
output = torch.nn.functional.dropout(mlp_output, p=self.hidden_dropout, training=self.training)
|
| 574 |
+
output = residual + output
|
| 575 |
+
|
| 576 |
+
return output, kv_cache
|
| 577 |
+
|
| 578 |
+
|
| 579 |
+
class GLMTransformer(torch.nn.Module):
|
| 580 |
+
"""Transformer class."""
|
| 581 |
+
|
| 582 |
+
def __init__(self, config: ChatGLMConfig, device=None):
|
| 583 |
+
super(GLMTransformer, self).__init__()
|
| 584 |
+
|
| 585 |
+
self.fp32_residual_connection = config.fp32_residual_connection
|
| 586 |
+
self.post_layer_norm = config.post_layer_norm
|
| 587 |
+
|
| 588 |
+
# Number of layers.
|
| 589 |
+
self.num_layers = config.num_layers
|
| 590 |
+
|
| 591 |
+
# Transformer layers.
|
| 592 |
+
def build_layer(layer_number):
|
| 593 |
+
return GLMBlock(config, layer_number, device=device)
|
| 594 |
+
|
| 595 |
+
self.layers = torch.nn.ModuleList([build_layer(i + 1) for i in range(self.num_layers)])
|
| 596 |
+
|
| 597 |
+
if self.post_layer_norm:
|
| 598 |
+
LayerNormFunc = RMSNorm if config.rmsnorm else LayerNorm
|
| 599 |
+
# Final layer norm before output.
|
| 600 |
+
self.final_layernorm = LayerNormFunc(config.hidden_size, eps=config.layernorm_epsilon, device=device,
|
| 601 |
+
dtype=config.torch_dtype)
|
| 602 |
+
|
| 603 |
+
self.gradient_checkpointing = False
|
| 604 |
+
|
| 605 |
+
def _get_layer(self, layer_number):
|
| 606 |
+
return self.layers[layer_number]
|
| 607 |
+
|
| 608 |
+
def forward(
|
| 609 |
+
self, hidden_states, attention_mask, rotary_pos_emb, kv_caches=None,
|
| 610 |
+
use_cache: Optional[bool] = True,
|
| 611 |
+
output_hidden_states: Optional[bool] = False,
|
| 612 |
+
):
|
| 613 |
+
if not kv_caches:
|
| 614 |
+
kv_caches = [None for _ in range(self.num_layers)]
|
| 615 |
+
presents = () if use_cache else None
|
| 616 |
+
if self.gradient_checkpointing and self.training:
|
| 617 |
+
if use_cache:
|
| 618 |
+
logger.warning_once(
|
| 619 |
+
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
| 620 |
+
)
|
| 621 |
+
use_cache = False
|
| 622 |
+
|
| 623 |
+
all_self_attentions = None
|
| 624 |
+
all_hidden_states = () if output_hidden_states else None
|
| 625 |
+
for index in range(self.num_layers):
|
| 626 |
+
if output_hidden_states:
|
| 627 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 628 |
+
|
| 629 |
+
layer = self._get_layer(index)
|
| 630 |
+
if self.gradient_checkpointing and self.training:
|
| 631 |
+
layer_ret = torch.utils.checkpoint.checkpoint(
|
| 632 |
+
layer,
|
| 633 |
+
hidden_states,
|
| 634 |
+
attention_mask,
|
| 635 |
+
rotary_pos_emb,
|
| 636 |
+
kv_caches[index],
|
| 637 |
+
use_cache
|
| 638 |
+
)
|
| 639 |
+
else:
|
| 640 |
+
layer_ret = layer(
|
| 641 |
+
hidden_states,
|
| 642 |
+
attention_mask,
|
| 643 |
+
rotary_pos_emb,
|
| 644 |
+
kv_cache=kv_caches[index],
|
| 645 |
+
use_cache=use_cache
|
| 646 |
+
)
|
| 647 |
+
hidden_states, kv_cache = layer_ret
|
| 648 |
+
if use_cache:
|
| 649 |
+
presents = presents + (kv_cache,)
|
| 650 |
+
|
| 651 |
+
if output_hidden_states:
|
| 652 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 653 |
+
|
| 654 |
+
# Final layer norm.
|
| 655 |
+
if self.post_layer_norm:
|
| 656 |
+
hidden_states = self.final_layernorm(hidden_states)
|
| 657 |
+
|
| 658 |
+
return hidden_states, presents, all_hidden_states, all_self_attentions
|
| 659 |
+
|
| 660 |
+
|
| 661 |
+
class ChatGLMPreTrainedModel(PreTrainedModel):
|
| 662 |
+
"""
|
| 663 |
+
An abstract class to handle weights initialization and
|
| 664 |
+
a simple interface for downloading and loading pretrained models.
|
| 665 |
+
"""
|
| 666 |
+
|
| 667 |
+
is_parallelizable = False
|
| 668 |
+
supports_gradient_checkpointing = True
|
| 669 |
+
config_class = ChatGLMConfig
|
| 670 |
+
base_model_prefix = "transformer"
|
| 671 |
+
_no_split_modules = ["GLMBlock"]
|
| 672 |
+
|
| 673 |
+
def _init_weights(self, module: nn.Module):
|
| 674 |
+
"""Initialize the weights."""
|
| 675 |
+
return
|
| 676 |
+
|
| 677 |
+
def get_masks(self, input_ids, past_key_values, padding_mask=None):
|
| 678 |
+
batch_size, seq_length = input_ids.shape
|
| 679 |
+
full_attention_mask = torch.ones(batch_size, seq_length, seq_length, device=input_ids.device)
|
| 680 |
+
full_attention_mask.tril_()
|
| 681 |
+
past_length = 0
|
| 682 |
+
if past_key_values:
|
| 683 |
+
past_length = past_key_values[0][0].shape[0]
|
| 684 |
+
if past_length:
|
| 685 |
+
full_attention_mask = torch.cat((torch.ones(batch_size, seq_length, past_length,
|
| 686 |
+
device=input_ids.device), full_attention_mask), dim=-1)
|
| 687 |
+
if padding_mask is not None:
|
| 688 |
+
full_attention_mask = full_attention_mask * padding_mask.unsqueeze(1)
|
| 689 |
+
if not past_length and padding_mask is not None:
|
| 690 |
+
full_attention_mask -= padding_mask.unsqueeze(-1) - 1
|
| 691 |
+
full_attention_mask = (full_attention_mask < 0.5).bool()
|
| 692 |
+
full_attention_mask.unsqueeze_(1)
|
| 693 |
+
return full_attention_mask
|
| 694 |
+
|
| 695 |
+
def get_position_ids(self, input_ids, device):
|
| 696 |
+
batch_size, seq_length = input_ids.shape
|
| 697 |
+
position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)
|
| 698 |
+
return position_ids
|
| 699 |
+
|
| 700 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 701 |
+
if isinstance(module, GLMTransformer):
|
| 702 |
+
module.gradient_checkpointing = value
|
| 703 |
+
|
| 704 |
+
|
| 705 |
+
class Embedding(torch.nn.Module):
|
| 706 |
+
"""Language model embeddings."""
|
| 707 |
+
|
| 708 |
+
def __init__(self, config: ChatGLMConfig, device=None):
|
| 709 |
+
super(Embedding, self).__init__()
|
| 710 |
+
|
| 711 |
+
self.hidden_size = config.hidden_size
|
| 712 |
+
# Word embeddings (parallel).
|
| 713 |
+
self.word_embeddings = nn.Embedding(
|
| 714 |
+
config.padded_vocab_size,
|
| 715 |
+
self.hidden_size,
|
| 716 |
+
dtype=config.torch_dtype,
|
| 717 |
+
device=device
|
| 718 |
+
)
|
| 719 |
+
self.fp32_residual_connection = config.fp32_residual_connection
|
| 720 |
+
|
| 721 |
+
def forward(self, input_ids):
|
| 722 |
+
# Embeddings.
|
| 723 |
+
words_embeddings = self.word_embeddings(input_ids)
|
| 724 |
+
embeddings = words_embeddings
|
| 725 |
+
# Data format change to avoid explicit tranposes : [b s h] --> [s b h].
|
| 726 |
+
embeddings = embeddings.transpose(0, 1).contiguous()
|
| 727 |
+
# If the input flag for fp32 residual connection is set, convert for float.
|
| 728 |
+
if self.fp32_residual_connection:
|
| 729 |
+
embeddings = embeddings.float()
|
| 730 |
+
return embeddings
|
| 731 |
+
|
| 732 |
+
|
| 733 |
+
class ChatGLMModel(ChatGLMPreTrainedModel):
|
| 734 |
+
def __init__(self, config: ChatGLMConfig, device=None, empty_init=True):
|
| 735 |
+
super().__init__(config)
|
| 736 |
+
if empty_init:
|
| 737 |
+
init_method = skip_init
|
| 738 |
+
else:
|
| 739 |
+
init_method = default_init
|
| 740 |
+
init_kwargs = {}
|
| 741 |
+
if device is not None:
|
| 742 |
+
init_kwargs["device"] = device
|
| 743 |
+
self.embedding = init_method(Embedding, config, **init_kwargs)
|
| 744 |
+
self.num_layers = config.num_layers
|
| 745 |
+
self.multi_query_group_num = config.multi_query_group_num
|
| 746 |
+
self.kv_channels = config.kv_channels
|
| 747 |
+
|
| 748 |
+
# Rotary positional embeddings
|
| 749 |
+
self.seq_length = config.seq_length
|
| 750 |
+
rotary_dim = (
|
| 751 |
+
config.hidden_size // config.num_attention_heads if config.kv_channels is None else config.kv_channels
|
| 752 |
+
)
|
| 753 |
+
|
| 754 |
+
self.rotary_pos_emb = RotaryEmbedding(rotary_dim // 2, original_impl=config.original_rope, device=device,
|
| 755 |
+
dtype=config.torch_dtype)
|
| 756 |
+
self.encoder = init_method(GLMTransformer, config, **init_kwargs)
|
| 757 |
+
self.output_layer = init_method(nn.Linear, config.hidden_size, config.padded_vocab_size, bias=False,
|
| 758 |
+
dtype=config.torch_dtype, **init_kwargs)
|
| 759 |
+
self.pre_seq_len = config.pre_seq_len
|
| 760 |
+
self.prefix_projection = config.prefix_projection
|
| 761 |
+
if self.pre_seq_len is not None:
|
| 762 |
+
for param in self.parameters():
|
| 763 |
+
param.requires_grad = False
|
| 764 |
+
self.prefix_tokens = torch.arange(self.pre_seq_len).long()
|
| 765 |
+
self.prefix_encoder = PrefixEncoder(config)
|
| 766 |
+
self.dropout = torch.nn.Dropout(0.1)
|
| 767 |
+
|
| 768 |
+
def get_input_embeddings(self):
|
| 769 |
+
return self.embedding.word_embeddings
|
| 770 |
+
|
| 771 |
+
def get_prompt(self, batch_size, device, dtype=torch.half):
|
| 772 |
+
prefix_tokens = self.prefix_tokens.unsqueeze(0).expand(batch_size, -1).to(device)
|
| 773 |
+
past_key_values = self.prefix_encoder(prefix_tokens).type(dtype)
|
| 774 |
+
past_key_values = past_key_values.view(
|
| 775 |
+
batch_size,
|
| 776 |
+
self.pre_seq_len,
|
| 777 |
+
self.num_layers * 2,
|
| 778 |
+
self.multi_query_group_num,
|
| 779 |
+
self.kv_channels
|
| 780 |
+
)
|
| 781 |
+
# seq_len, b, nh, hidden_size
|
| 782 |
+
past_key_values = self.dropout(past_key_values)
|
| 783 |
+
past_key_values = past_key_values.permute([2, 1, 0, 3, 4]).split(2)
|
| 784 |
+
return past_key_values
|
| 785 |
+
|
| 786 |
+
def forward(
|
| 787 |
+
self,
|
| 788 |
+
input_ids,
|
| 789 |
+
position_ids: Optional[torch.Tensor] = None,
|
| 790 |
+
attention_mask: Optional[torch.BoolTensor] = None,
|
| 791 |
+
full_attention_mask: Optional[torch.BoolTensor] = None,
|
| 792 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
|
| 793 |
+
inputs_embeds: Optional[torch.Tensor] = None,
|
| 794 |
+
use_cache: Optional[bool] = None,
|
| 795 |
+
output_hidden_states: Optional[bool] = None,
|
| 796 |
+
return_dict: Optional[bool] = None,
|
| 797 |
+
):
|
| 798 |
+
output_hidden_states = (
|
| 799 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 800 |
+
)
|
| 801 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 802 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 803 |
+
|
| 804 |
+
batch_size, seq_length = input_ids.shape
|
| 805 |
+
|
| 806 |
+
if inputs_embeds is None:
|
| 807 |
+
inputs_embeds = self.embedding(input_ids)
|
| 808 |
+
|
| 809 |
+
if self.pre_seq_len is not None:
|
| 810 |
+
if past_key_values is None:
|
| 811 |
+
past_key_values = self.get_prompt(batch_size=batch_size, device=input_ids.device,
|
| 812 |
+
dtype=inputs_embeds.dtype)
|
| 813 |
+
if attention_mask is not None:
|
| 814 |
+
attention_mask = torch.cat([attention_mask.new_ones((batch_size, self.pre_seq_len)),
|
| 815 |
+
attention_mask], dim=-1)
|
| 816 |
+
|
| 817 |
+
if full_attention_mask is None:
|
| 818 |
+
if (attention_mask is not None and not attention_mask.all()) or (past_key_values and seq_length != 1):
|
| 819 |
+
full_attention_mask = self.get_masks(input_ids, past_key_values, padding_mask=attention_mask)
|
| 820 |
+
|
| 821 |
+
# Rotary positional embeddings
|
| 822 |
+
rotary_pos_emb = self.rotary_pos_emb(self.seq_length)
|
| 823 |
+
if position_ids is not None:
|
| 824 |
+
rotary_pos_emb = rotary_pos_emb[position_ids]
|
| 825 |
+
else:
|
| 826 |
+
rotary_pos_emb = rotary_pos_emb[None, :seq_length]
|
| 827 |
+
rotary_pos_emb = rotary_pos_emb.transpose(0, 1).contiguous()
|
| 828 |
+
|
| 829 |
+
# Run encoder.
|
| 830 |
+
hidden_states, presents, all_hidden_states, all_self_attentions = self.encoder(
|
| 831 |
+
inputs_embeds, full_attention_mask, rotary_pos_emb=rotary_pos_emb,
|
| 832 |
+
kv_caches=past_key_values, use_cache=use_cache, output_hidden_states=output_hidden_states
|
| 833 |
+
)
|
| 834 |
+
|
| 835 |
+
if not return_dict:
|
| 836 |
+
return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
|
| 837 |
+
|
| 838 |
+
return BaseModelOutputWithPast(
|
| 839 |
+
last_hidden_state=hidden_states,
|
| 840 |
+
past_key_values=presents,
|
| 841 |
+
hidden_states=all_hidden_states,
|
| 842 |
+
attentions=all_self_attentions,
|
| 843 |
+
)
|
| 844 |
+
|
| 845 |
+
def quantize(self, weight_bit_width: int):
|
| 846 |
+
from .quantization import quantize
|
| 847 |
+
quantize(self.encoder, weight_bit_width)
|
| 848 |
+
return self
|
| 849 |
+
|
| 850 |
+
|
| 851 |
+
class ChatGLMForConditionalGeneration(ChatGLMPreTrainedModel):
|
| 852 |
+
def __init__(self, config: ChatGLMConfig, empty_init=True, device=None):
|
| 853 |
+
super().__init__(config)
|
| 854 |
+
|
| 855 |
+
self.max_sequence_length = config.max_length
|
| 856 |
+
self.transformer = ChatGLMModel(config, empty_init=empty_init, device=device)
|
| 857 |
+
self.config = config
|
| 858 |
+
self.quantized = False
|
| 859 |
+
|
| 860 |
+
if self.config.quantization_bit:
|
| 861 |
+
self.quantize(self.config.quantization_bit, empty_init=True)
|
| 862 |
+
|
| 863 |
+
def _update_model_kwargs_for_generation(
|
| 864 |
+
self,
|
| 865 |
+
outputs: ModelOutput,
|
| 866 |
+
model_kwargs: Dict[str, Any],
|
| 867 |
+
is_encoder_decoder: bool = False,
|
| 868 |
+
standardize_cache_format: bool = False,
|
| 869 |
+
) -> Dict[str, Any]:
|
| 870 |
+
# update past_key_values
|
| 871 |
+
model_kwargs["past_key_values"] = self._extract_past_from_model_output(
|
| 872 |
+
outputs, standardize_cache_format=standardize_cache_format
|
| 873 |
+
)
|
| 874 |
+
|
| 875 |
+
# update attention mask
|
| 876 |
+
if "attention_mask" in model_kwargs:
|
| 877 |
+
attention_mask = model_kwargs["attention_mask"]
|
| 878 |
+
model_kwargs["attention_mask"] = torch.cat(
|
| 879 |
+
[attention_mask, attention_mask.new_ones((attention_mask.shape[0], 1))], dim=-1
|
| 880 |
+
)
|
| 881 |
+
|
| 882 |
+
# update position ids
|
| 883 |
+
if "position_ids" in model_kwargs:
|
| 884 |
+
position_ids = model_kwargs["position_ids"]
|
| 885 |
+
new_position_id = position_ids[..., -1:].clone()
|
| 886 |
+
new_position_id += 1
|
| 887 |
+
model_kwargs["position_ids"] = torch.cat(
|
| 888 |
+
[position_ids, new_position_id], dim=-1
|
| 889 |
+
)
|
| 890 |
+
|
| 891 |
+
model_kwargs["is_first_forward"] = False
|
| 892 |
+
return model_kwargs
|
| 893 |
+
|
| 894 |
+
def prepare_inputs_for_generation(
|
| 895 |
+
self,
|
| 896 |
+
input_ids: torch.LongTensor,
|
| 897 |
+
past_key_values: Optional[torch.Tensor] = None,
|
| 898 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 899 |
+
position_ids: Optional[torch.Tensor] = None,
|
| 900 |
+
is_first_forward: bool = True,
|
| 901 |
+
**kwargs
|
| 902 |
+
) -> dict:
|
| 903 |
+
# only last token for input_ids if past is not None
|
| 904 |
+
if position_ids is None:
|
| 905 |
+
position_ids = self.get_position_ids(input_ids, device=input_ids.device)
|
| 906 |
+
if not is_first_forward:
|
| 907 |
+
position_ids = position_ids[..., -1:]
|
| 908 |
+
input_ids = input_ids[:, -1:]
|
| 909 |
+
return {
|
| 910 |
+
"input_ids": input_ids,
|
| 911 |
+
"past_key_values": past_key_values,
|
| 912 |
+
"position_ids": position_ids,
|
| 913 |
+
"attention_mask": attention_mask,
|
| 914 |
+
"return_last_logit": True
|
| 915 |
+
}
|
| 916 |
+
|
| 917 |
+
def forward(
|
| 918 |
+
self,
|
| 919 |
+
input_ids: Optional[torch.Tensor] = None,
|
| 920 |
+
position_ids: Optional[torch.Tensor] = None,
|
| 921 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 922 |
+
past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
|
| 923 |
+
inputs_embeds: Optional[torch.Tensor] = None,
|
| 924 |
+
labels: Optional[torch.Tensor] = None,
|
| 925 |
+
use_cache: Optional[bool] = None,
|
| 926 |
+
output_attentions: Optional[bool] = None,
|
| 927 |
+
output_hidden_states: Optional[bool] = None,
|
| 928 |
+
return_dict: Optional[bool] = None,
|
| 929 |
+
return_last_logit: Optional[bool] = False,
|
| 930 |
+
):
|
| 931 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 932 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 933 |
+
|
| 934 |
+
transformer_outputs = self.transformer(
|
| 935 |
+
input_ids=input_ids,
|
| 936 |
+
position_ids=position_ids,
|
| 937 |
+
attention_mask=attention_mask,
|
| 938 |
+
past_key_values=past_key_values,
|
| 939 |
+
inputs_embeds=inputs_embeds,
|
| 940 |
+
use_cache=use_cache,
|
| 941 |
+
output_hidden_states=output_hidden_states,
|
| 942 |
+
return_dict=return_dict,
|
| 943 |
+
)
|
| 944 |
+
|
| 945 |
+
hidden_states = transformer_outputs[0]
|
| 946 |
+
if return_last_logit:
|
| 947 |
+
hidden_states = hidden_states[-1:]
|
| 948 |
+
lm_logits = self.transformer.output_layer(hidden_states)
|
| 949 |
+
lm_logits = lm_logits.transpose(0, 1).contiguous()
|
| 950 |
+
|
| 951 |
+
loss = None
|
| 952 |
+
if labels is not None:
|
| 953 |
+
lm_logits = lm_logits.to(torch.float32)
|
| 954 |
+
|
| 955 |
+
# Shift so that tokens < n predict n
|
| 956 |
+
shift_logits = lm_logits[..., :-1, :].contiguous()
|
| 957 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 958 |
+
# Flatten the tokens
|
| 959 |
+
loss_fct = CrossEntropyLoss(ignore_index=-100)
|
| 960 |
+
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
|
| 961 |
+
|
| 962 |
+
lm_logits = lm_logits.to(hidden_states.dtype)
|
| 963 |
+
loss = loss.to(hidden_states.dtype)
|
| 964 |
+
|
| 965 |
+
if not return_dict:
|
| 966 |
+
output = (lm_logits,) + transformer_outputs[1:]
|
| 967 |
+
return ((loss,) + output) if loss is not None else output
|
| 968 |
+
|
| 969 |
+
return CausalLMOutputWithPast(
|
| 970 |
+
loss=loss,
|
| 971 |
+
logits=lm_logits,
|
| 972 |
+
past_key_values=transformer_outputs.past_key_values,
|
| 973 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 974 |
+
attentions=transformer_outputs.attentions,
|
| 975 |
+
)
|
| 976 |
+
|
| 977 |
+
@staticmethod
|
| 978 |
+
def _reorder_cache(
|
| 979 |
+
past: Tuple[Tuple[torch.Tensor, torch.Tensor], ...], beam_idx: torch.LongTensor
|
| 980 |
+
) -> Tuple[Tuple[torch.Tensor, torch.Tensor], ...]:
|
| 981 |
+
"""
|
| 982 |
+
This function is used to re-order the `past_key_values` cache if [`~PreTrainedModel.beam_search`] or
|
| 983 |
+
[`~PreTrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
|
| 984 |
+
beam_idx at every generation step.
|
| 985 |
+
|
| 986 |
+
Output shares the same memory storage as `past`.
|
| 987 |
+
"""
|
| 988 |
+
return tuple(
|
| 989 |
+
(
|
| 990 |
+
layer_past[0].index_select(1, beam_idx.to(layer_past[0].device)),
|
| 991 |
+
layer_past[1].index_select(1, beam_idx.to(layer_past[1].device)),
|
| 992 |
+
)
|
| 993 |
+
for layer_past in past
|
| 994 |
+
)
|
| 995 |
+
|
| 996 |
+
def process_response(self, response):
|
| 997 |
+
response = response.strip()
|
| 998 |
+
response = response.replace("[[训练时间]]", "2023年")
|
| 999 |
+
return response
|
| 1000 |
+
|
| 1001 |
+
def build_inputs(self, tokenizer, query: str, history: List[Tuple[str, str]] = None):
|
| 1002 |
+
prompt = tokenizer.build_prompt(query, history=history)
|
| 1003 |
+
inputs = tokenizer([prompt], return_tensors="pt")
|
| 1004 |
+
inputs = inputs.to(self.device)
|
| 1005 |
+
return inputs
|
| 1006 |
+
|
| 1007 |
+
def build_stream_inputs(self, tokenizer, query: str, history: List[Tuple[str, str]] = None):
|
| 1008 |
+
if history:
|
| 1009 |
+
prompt = "\n\n[Round {}]\n\n问:{}\n\n答:".format(len(history) + 1, query)
|
| 1010 |
+
input_ids = tokenizer.encode(prompt, add_special_tokens=False)
|
| 1011 |
+
input_ids = input_ids[1:]
|
| 1012 |
+
inputs = tokenizer.batch_encode_plus([(input_ids, None)], return_tensors="pt", add_special_tokens=False)
|
| 1013 |
+
else:
|
| 1014 |
+
prompt = "[Round {}]\n\n问:{}\n\n答:".format(len(history) + 1, query)
|
| 1015 |
+
inputs = tokenizer([prompt], return_tensors="pt")
|
| 1016 |
+
inputs = inputs.to(self.device)
|
| 1017 |
+
return inputs
|
| 1018 |
+
|
| 1019 |
+
@torch.inference_mode()
|
| 1020 |
+
def chat(self, tokenizer, query: str, history: List[Tuple[str, str]] = None, max_length: int = 8192, num_beams=1,
|
| 1021 |
+
do_sample=True, top_p=0.8, temperature=0.8, logits_processor=None, **kwargs):
|
| 1022 |
+
if history is None:
|
| 1023 |
+
history = []
|
| 1024 |
+
if logits_processor is None:
|
| 1025 |
+
logits_processor = LogitsProcessorList()
|
| 1026 |
+
logits_processor.append(InvalidScoreLogitsProcessor())
|
| 1027 |
+
gen_kwargs = {"max_length": max_length, "num_beams": num_beams, "do_sample": do_sample, "top_p": top_p,
|
| 1028 |
+
"temperature": temperature, "logits_processor": logits_processor, **kwargs}
|
| 1029 |
+
inputs = self.build_inputs(tokenizer, query, history=history)
|
| 1030 |
+
outputs = self.generate(**inputs, **gen_kwargs)
|
| 1031 |
+
outputs = outputs.tolist()[0][len(inputs["input_ids"][0]):]
|
| 1032 |
+
response = tokenizer.decode(outputs)
|
| 1033 |
+
response = self.process_response(response)
|
| 1034 |
+
history = history + [(query, response)]
|
| 1035 |
+
return response, history
|
| 1036 |
+
|
| 1037 |
+
@torch.inference_mode()
|
| 1038 |
+
def stream_chat(self, tokenizer, query: str, history: List[Tuple[str, str]] = None, past_key_values=None,
|
| 1039 |
+
max_length: int = 8192, do_sample=True, top_p=0.8, temperature=0.8, logits_processor=None,
|
| 1040 |
+
return_past_key_values=False, **kwargs):
|
| 1041 |
+
if history is None:
|
| 1042 |
+
history = []
|
| 1043 |
+
if logits_processor is None:
|
| 1044 |
+
logits_processor = LogitsProcessorList()
|
| 1045 |
+
logits_processor.append(InvalidScoreLogitsProcessor())
|
| 1046 |
+
gen_kwargs = {"max_length": max_length, "do_sample": do_sample, "top_p": top_p,
|
| 1047 |
+
"temperature": temperature, "logits_processor": logits_processor, **kwargs}
|
| 1048 |
+
if past_key_values is None and not return_past_key_values:
|
| 1049 |
+
inputs = self.build_inputs(tokenizer, query, history=history)
|
| 1050 |
+
else:
|
| 1051 |
+
inputs = self.build_stream_inputs(tokenizer, query, history=history)
|
| 1052 |
+
if past_key_values is not None:
|
| 1053 |
+
past_length = past_key_values[0][0].shape[0]
|
| 1054 |
+
if self.transformer.pre_seq_len is not None:
|
| 1055 |
+
past_length -= self.transformer.pre_seq_len
|
| 1056 |
+
inputs.position_ids += past_length
|
| 1057 |
+
attention_mask = inputs.attention_mask
|
| 1058 |
+
attention_mask = torch.cat((attention_mask.new_ones(1, past_length), attention_mask), dim=1)
|
| 1059 |
+
inputs['attention_mask'] = attention_mask
|
| 1060 |
+
for outputs in self.stream_generate(**inputs, past_key_values=past_key_values,
|
| 1061 |
+
return_past_key_values=return_past_key_values, **gen_kwargs):
|
| 1062 |
+
if return_past_key_values:
|
| 1063 |
+
outputs, past_key_values = outputs
|
| 1064 |
+
outputs = outputs.tolist()[0][len(inputs["input_ids"][0]):]
|
| 1065 |
+
response = tokenizer.decode(outputs)
|
| 1066 |
+
if response and response[-1] != "�":
|
| 1067 |
+
response = self.process_response(response)
|
| 1068 |
+
new_history = history + [(query, response)]
|
| 1069 |
+
if return_past_key_values:
|
| 1070 |
+
yield response, new_history, past_key_values
|
| 1071 |
+
else:
|
| 1072 |
+
yield response, new_history
|
| 1073 |
+
|
| 1074 |
+
@torch.inference_mode()
|
| 1075 |
+
def stream_generate(
|
| 1076 |
+
self,
|
| 1077 |
+
input_ids,
|
| 1078 |
+
generation_config: Optional[GenerationConfig] = None,
|
| 1079 |
+
logits_processor: Optional[LogitsProcessorList] = None,
|
| 1080 |
+
stopping_criteria: Optional[StoppingCriteriaList] = None,
|
| 1081 |
+
prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor], List[int]]] = None,
|
| 1082 |
+
return_past_key_values=False,
|
| 1083 |
+
**kwargs,
|
| 1084 |
+
):
|
| 1085 |
+
batch_size, input_ids_seq_length = input_ids.shape[0], input_ids.shape[-1]
|
| 1086 |
+
|
| 1087 |
+
if generation_config is None:
|
| 1088 |
+
generation_config = self.generation_config
|
| 1089 |
+
generation_config = copy.deepcopy(generation_config)
|
| 1090 |
+
model_kwargs = generation_config.update(**kwargs)
|
| 1091 |
+
bos_token_id, eos_token_id = generation_config.bos_token_id, generation_config.eos_token_id
|
| 1092 |
+
|
| 1093 |
+
if isinstance(eos_token_id, int):
|
| 1094 |
+
eos_token_id = [eos_token_id]
|
| 1095 |
+
|
| 1096 |
+
has_default_max_length = kwargs.get("max_length") is None and generation_config.max_length is not None
|
| 1097 |
+
if has_default_max_length and generation_config.max_new_tokens is None:
|
| 1098 |
+
warnings.warn(
|
| 1099 |
+
f"Using `max_length`'s default ({generation_config.max_length}) to control the generation length. "
|
| 1100 |
+
"This behaviour is deprecated and will be removed from the config in v5 of Transformers -- we"
|
| 1101 |
+
" recommend using `max_new_tokens` to control the maximum length of the generation.",
|
| 1102 |
+
UserWarning,
|
| 1103 |
+
)
|
| 1104 |
+
elif generation_config.max_new_tokens is not None:
|
| 1105 |
+
generation_config.max_length = generation_config.max_new_tokens + input_ids_seq_length
|
| 1106 |
+
if not has_default_max_length:
|
| 1107 |
+
logger.warn(
|
| 1108 |
+
f"Both `max_new_tokens` (={generation_config.max_new_tokens}) and `max_length`(="
|
| 1109 |
+
f"{generation_config.max_length}) seem to have been set. `max_new_tokens` will take precedence. "
|
| 1110 |
+
"Please refer to the documentation for more information. "
|
| 1111 |
+
"(https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)",
|
| 1112 |
+
UserWarning,
|
| 1113 |
+
)
|
| 1114 |
+
|
| 1115 |
+
if input_ids_seq_length >= generation_config.max_length:
|
| 1116 |
+
input_ids_string = "decoder_input_ids" if self.config.is_encoder_decoder else "input_ids"
|
| 1117 |
+
logger.warning(
|
| 1118 |
+
f"Input length of {input_ids_string} is {input_ids_seq_length}, but `max_length` is set to"
|
| 1119 |
+
f" {generation_config.max_length}. This can lead to unexpected behavior. You should consider"
|
| 1120 |
+
" increasing `max_new_tokens`."
|
| 1121 |
+
)
|
| 1122 |
+
|
| 1123 |
+
# 2. Set generation parameters if not already defined
|
| 1124 |
+
logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
|
| 1125 |
+
stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
|
| 1126 |
+
|
| 1127 |
+
logits_processor = self._get_logits_processor(
|
| 1128 |
+
generation_config=generation_config,
|
| 1129 |
+
input_ids_seq_length=input_ids_seq_length,
|
| 1130 |
+
encoder_input_ids=input_ids,
|
| 1131 |
+
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
|
| 1132 |
+
logits_processor=logits_processor,
|
| 1133 |
+
)
|
| 1134 |
+
|
| 1135 |
+
stopping_criteria = self._get_stopping_criteria(
|
| 1136 |
+
generation_config=generation_config, stopping_criteria=stopping_criteria
|
| 1137 |
+
)
|
| 1138 |
+
logits_warper = self._get_logits_warper(generation_config)
|
| 1139 |
+
|
| 1140 |
+
unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
|
| 1141 |
+
scores = None
|
| 1142 |
+
while True:
|
| 1143 |
+
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
|
| 1144 |
+
# forward pass to get next token
|
| 1145 |
+
outputs = self(
|
| 1146 |
+
**model_inputs,
|
| 1147 |
+
return_dict=True,
|
| 1148 |
+
output_attentions=False,
|
| 1149 |
+
output_hidden_states=False,
|
| 1150 |
+
)
|
| 1151 |
+
|
| 1152 |
+
next_token_logits = outputs.logits[:, -1, :]
|
| 1153 |
+
|
| 1154 |
+
# pre-process distribution
|
| 1155 |
+
next_token_scores = logits_processor(input_ids, next_token_logits)
|
| 1156 |
+
next_token_scores = logits_warper(input_ids, next_token_scores)
|
| 1157 |
+
|
| 1158 |
+
# sample
|
| 1159 |
+
probs = nn.functional.softmax(next_token_scores, dim=-1)
|
| 1160 |
+
if generation_config.do_sample:
|
| 1161 |
+
next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
|
| 1162 |
+
else:
|
| 1163 |
+
next_tokens = torch.argmax(probs, dim=-1)
|
| 1164 |
+
|
| 1165 |
+
# update generated ids, model inputs, and length for next step
|
| 1166 |
+
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
|
| 1167 |
+
model_kwargs = self._update_model_kwargs_for_generation(
|
| 1168 |
+
outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
|
| 1169 |
+
)
|
| 1170 |
+
unfinished_sequences = unfinished_sequences.mul((sum(next_tokens != i for i in eos_token_id)).long())
|
| 1171 |
+
if return_past_key_values:
|
| 1172 |
+
yield input_ids, outputs.past_key_values
|
| 1173 |
+
else:
|
| 1174 |
+
yield input_ids
|
| 1175 |
+
# stop when each sentence is finished, or if we exceed the maximum length
|
| 1176 |
+
if unfinished_sequences.max() == 0 or stopping_criteria(input_ids, scores):
|
| 1177 |
+
break
|
| 1178 |
+
|
| 1179 |
+
def quantize(self, bits: int, empty_init=False, device=None, **kwargs):
|
| 1180 |
+
if bits == 0:
|
| 1181 |
+
return
|
| 1182 |
+
|
| 1183 |
+
from .quantization import quantize
|
| 1184 |
+
|
| 1185 |
+
if self.quantized:
|
| 1186 |
+
logger.info("Already quantized.")
|
| 1187 |
+
return self
|
| 1188 |
+
|
| 1189 |
+
self.quantized = True
|
| 1190 |
+
|
| 1191 |
+
self.config.quantization_bit = bits
|
| 1192 |
+
|
| 1193 |
+
self.transformer.encoder = quantize(self.transformer.encoder, bits, empty_init=empty_init, device=device,
|
| 1194 |
+
**kwargs)
|
| 1195 |
+
return self
|
| 1196 |
+
|
| 1197 |
+
|
| 1198 |
+
class ChatGLMForSequenceClassification(ChatGLMPreTrainedModel):
|
| 1199 |
+
def __init__(self, config: ChatGLMConfig, empty_init=True, device=None):
|
| 1200 |
+
super().__init__(config)
|
| 1201 |
+
|
| 1202 |
+
self.num_labels = config.num_labels
|
| 1203 |
+
self.transformer = ChatGLMModel(config, empty_init=empty_init, device=device)
|
| 1204 |
+
|
| 1205 |
+
self.classifier_head = nn.Linear(config.hidden_size, config.num_labels, bias=True, dtype=torch.half)
|
| 1206 |
+
if config.classifier_dropout is not None:
|
| 1207 |
+
self.dropout = nn.Dropout(config.classifier_dropout)
|
| 1208 |
+
else:
|
| 1209 |
+
self.dropout = None
|
| 1210 |
+
self.config = config
|
| 1211 |
+
|
| 1212 |
+
if self.config.quantization_bit:
|
| 1213 |
+
self.quantize(self.config.quantization_bit, empty_init=True)
|
| 1214 |
+
|
| 1215 |
+
def forward(
|
| 1216 |
+
self,
|
| 1217 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 1218 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1219 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1220 |
+
full_attention_mask: Optional[torch.Tensor] = None,
|
| 1221 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
|
| 1222 |
+
inputs_embeds: Optional[torch.LongTensor] = None,
|
| 1223 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1224 |
+
use_cache: Optional[bool] = None,
|
| 1225 |
+
output_hidden_states: Optional[bool] = None,
|
| 1226 |
+
return_dict: Optional[bool] = None,
|
| 1227 |
+
) -> Union[Tuple[torch.Tensor, ...], SequenceClassifierOutputWithPast]:
|
| 1228 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1229 |
+
|
| 1230 |
+
transformer_outputs = self.transformer(
|
| 1231 |
+
input_ids=input_ids,
|
| 1232 |
+
position_ids=position_ids,
|
| 1233 |
+
attention_mask=attention_mask,
|
| 1234 |
+
full_attention_mask=full_attention_mask,
|
| 1235 |
+
past_key_values=past_key_values,
|
| 1236 |
+
inputs_embeds=inputs_embeds,
|
| 1237 |
+
use_cache=use_cache,
|
| 1238 |
+
output_hidden_states=output_hidden_states,
|
| 1239 |
+
return_dict=return_dict,
|
| 1240 |
+
)
|
| 1241 |
+
|
| 1242 |
+
hidden_states = transformer_outputs[0]
|
| 1243 |
+
pooled_hidden_states = hidden_states[-1]
|
| 1244 |
+
if self.dropout is not None:
|
| 1245 |
+
pooled_hidden_states = self.dropout(pooled_hidden_states)
|
| 1246 |
+
logits = self.classifier_head(pooled_hidden_states)
|
| 1247 |
+
|
| 1248 |
+
loss = None
|
| 1249 |
+
if labels is not None:
|
| 1250 |
+
if self.config.problem_type is None:
|
| 1251 |
+
if self.num_labels == 1:
|
| 1252 |
+
self.config.problem_type = "regression"
|
| 1253 |
+
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
|
| 1254 |
+
self.config.problem_type = "single_label_classification"
|
| 1255 |
+
else:
|
| 1256 |
+
self.config.problem_type = "multi_label_classification"
|
| 1257 |
+
|
| 1258 |
+
if self.config.problem_type == "regression":
|
| 1259 |
+
loss_fct = MSELoss()
|
| 1260 |
+
if self.num_labels == 1:
|
| 1261 |
+
loss = loss_fct(logits.squeeze().float(), labels.squeeze())
|
| 1262 |
+
else:
|
| 1263 |
+
loss = loss_fct(logits.float(), labels)
|
| 1264 |
+
elif self.config.problem_type == "single_label_classification":
|
| 1265 |
+
loss_fct = CrossEntropyLoss()
|
| 1266 |
+
loss = loss_fct(logits.view(-1, self.num_labels).float(), labels.view(-1))
|
| 1267 |
+
elif self.config.problem_type == "multi_label_classification":
|
| 1268 |
+
loss_fct = BCEWithLogitsLoss()
|
| 1269 |
+
loss = loss_fct(logits.float(), labels.view(-1, self.num_labels))
|
| 1270 |
+
|
| 1271 |
+
if not return_dict:
|
| 1272 |
+
output = (logits,) + transformer_outputs[1:]
|
| 1273 |
+
return ((loss,) + output) if loss is not None else output
|
| 1274 |
+
|
| 1275 |
+
return SequenceClassifierOutputWithPast(
|
| 1276 |
+
loss=loss,
|
| 1277 |
+
logits=logits,
|
| 1278 |
+
past_key_values=transformer_outputs.past_key_values,
|
| 1279 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 1280 |
+
attentions=transformer_outputs.attentions,
|
| 1281 |
+
)
|
pytorch_model.bin.index.json
ADDED
|
@@ -0,0 +1,208 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 24974336128
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "pytorch_model-00003-of-00003.bin",
|
| 7 |
+
"transformer.embedding.word_embeddings.weight": "pytorch_model-00001-of-00003.bin",
|
| 8 |
+
"transformer.encoder.final_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 9 |
+
"transformer.encoder.layers.0.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 10 |
+
"transformer.encoder.layers.0.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 11 |
+
"transformer.encoder.layers.0.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 12 |
+
"transformer.encoder.layers.0.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 13 |
+
"transformer.encoder.layers.0.self_attention.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 14 |
+
"transformer.encoder.layers.0.self_attention.query_key_value.bias": "pytorch_model-00001-of-00003.bin",
|
| 15 |
+
"transformer.encoder.layers.0.self_attention.query_key_value.weight": "pytorch_model-00001-of-00003.bin",
|
| 16 |
+
"transformer.encoder.layers.1.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 17 |
+
"transformer.encoder.layers.1.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 18 |
+
"transformer.encoder.layers.1.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 19 |
+
"transformer.encoder.layers.1.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 20 |
+
"transformer.encoder.layers.1.self_attention.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 21 |
+
"transformer.encoder.layers.1.self_attention.query_key_value.bias": "pytorch_model-00001-of-00003.bin",
|
| 22 |
+
"transformer.encoder.layers.1.self_attention.query_key_value.weight": "pytorch_model-00001-of-00003.bin",
|
| 23 |
+
"transformer.encoder.layers.10.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 24 |
+
"transformer.encoder.layers.10.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 25 |
+
"transformer.encoder.layers.10.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 26 |
+
"transformer.encoder.layers.10.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 27 |
+
"transformer.encoder.layers.10.self_attention.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 28 |
+
"transformer.encoder.layers.10.self_attention.query_key_value.bias": "pytorch_model-00001-of-00003.bin",
|
| 29 |
+
"transformer.encoder.layers.10.self_attention.query_key_value.weight": "pytorch_model-00001-of-00003.bin",
|
| 30 |
+
"transformer.encoder.layers.11.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 31 |
+
"transformer.encoder.layers.11.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 32 |
+
"transformer.encoder.layers.11.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 33 |
+
"transformer.encoder.layers.11.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 34 |
+
"transformer.encoder.layers.11.self_attention.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 35 |
+
"transformer.encoder.layers.11.self_attention.query_key_value.bias": "pytorch_model-00002-of-00003.bin",
|
| 36 |
+
"transformer.encoder.layers.11.self_attention.query_key_value.weight": "pytorch_model-00002-of-00003.bin",
|
| 37 |
+
"transformer.encoder.layers.12.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 38 |
+
"transformer.encoder.layers.12.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 39 |
+
"transformer.encoder.layers.12.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 40 |
+
"transformer.encoder.layers.12.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 41 |
+
"transformer.encoder.layers.12.self_attention.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 42 |
+
"transformer.encoder.layers.12.self_attention.query_key_value.bias": "pytorch_model-00002-of-00003.bin",
|
| 43 |
+
"transformer.encoder.layers.12.self_attention.query_key_value.weight": "pytorch_model-00002-of-00003.bin",
|
| 44 |
+
"transformer.encoder.layers.13.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 45 |
+
"transformer.encoder.layers.13.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 46 |
+
"transformer.encoder.layers.13.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 47 |
+
"transformer.encoder.layers.13.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 48 |
+
"transformer.encoder.layers.13.self_attention.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 49 |
+
"transformer.encoder.layers.13.self_attention.query_key_value.bias": "pytorch_model-00002-of-00003.bin",
|
| 50 |
+
"transformer.encoder.layers.13.self_attention.query_key_value.weight": "pytorch_model-00002-of-00003.bin",
|
| 51 |
+
"transformer.encoder.layers.14.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 52 |
+
"transformer.encoder.layers.14.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 53 |
+
"transformer.encoder.layers.14.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 54 |
+
"transformer.encoder.layers.14.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 55 |
+
"transformer.encoder.layers.14.self_attention.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 56 |
+
"transformer.encoder.layers.14.self_attention.query_key_value.bias": "pytorch_model-00002-of-00003.bin",
|
| 57 |
+
"transformer.encoder.layers.14.self_attention.query_key_value.weight": "pytorch_model-00002-of-00003.bin",
|
| 58 |
+
"transformer.encoder.layers.15.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 59 |
+
"transformer.encoder.layers.15.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 60 |
+
"transformer.encoder.layers.15.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 61 |
+
"transformer.encoder.layers.15.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 62 |
+
"transformer.encoder.layers.15.self_attention.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 63 |
+
"transformer.encoder.layers.15.self_attention.query_key_value.bias": "pytorch_model-00002-of-00003.bin",
|
| 64 |
+
"transformer.encoder.layers.15.self_attention.query_key_value.weight": "pytorch_model-00002-of-00003.bin",
|
| 65 |
+
"transformer.encoder.layers.16.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 66 |
+
"transformer.encoder.layers.16.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 67 |
+
"transformer.encoder.layers.16.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 68 |
+
"transformer.encoder.layers.16.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 69 |
+
"transformer.encoder.layers.16.self_attention.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 70 |
+
"transformer.encoder.layers.16.self_attention.query_key_value.bias": "pytorch_model-00002-of-00003.bin",
|
| 71 |
+
"transformer.encoder.layers.16.self_attention.query_key_value.weight": "pytorch_model-00002-of-00003.bin",
|
| 72 |
+
"transformer.encoder.layers.17.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 73 |
+
"transformer.encoder.layers.17.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 74 |
+
"transformer.encoder.layers.17.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 75 |
+
"transformer.encoder.layers.17.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 76 |
+
"transformer.encoder.layers.17.self_attention.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 77 |
+
"transformer.encoder.layers.17.self_attention.query_key_value.bias": "pytorch_model-00002-of-00003.bin",
|
| 78 |
+
"transformer.encoder.layers.17.self_attention.query_key_value.weight": "pytorch_model-00002-of-00003.bin",
|
| 79 |
+
"transformer.encoder.layers.18.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 80 |
+
"transformer.encoder.layers.18.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 81 |
+
"transformer.encoder.layers.18.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 82 |
+
"transformer.encoder.layers.18.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 83 |
+
"transformer.encoder.layers.18.self_attention.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 84 |
+
"transformer.encoder.layers.18.self_attention.query_key_value.bias": "pytorch_model-00002-of-00003.bin",
|
| 85 |
+
"transformer.encoder.layers.18.self_attention.query_key_value.weight": "pytorch_model-00002-of-00003.bin",
|
| 86 |
+
"transformer.encoder.layers.19.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 87 |
+
"transformer.encoder.layers.19.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 88 |
+
"transformer.encoder.layers.19.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 89 |
+
"transformer.encoder.layers.19.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 90 |
+
"transformer.encoder.layers.19.self_attention.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 91 |
+
"transformer.encoder.layers.19.self_attention.query_key_value.bias": "pytorch_model-00002-of-00003.bin",
|
| 92 |
+
"transformer.encoder.layers.19.self_attention.query_key_value.weight": "pytorch_model-00002-of-00003.bin",
|
| 93 |
+
"transformer.encoder.layers.2.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 94 |
+
"transformer.encoder.layers.2.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 95 |
+
"transformer.encoder.layers.2.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 96 |
+
"transformer.encoder.layers.2.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 97 |
+
"transformer.encoder.layers.2.self_attention.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 98 |
+
"transformer.encoder.layers.2.self_attention.query_key_value.bias": "pytorch_model-00001-of-00003.bin",
|
| 99 |
+
"transformer.encoder.layers.2.self_attention.query_key_value.weight": "pytorch_model-00001-of-00003.bin",
|
| 100 |
+
"transformer.encoder.layers.20.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 101 |
+
"transformer.encoder.layers.20.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 102 |
+
"transformer.encoder.layers.20.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 103 |
+
"transformer.encoder.layers.20.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 104 |
+
"transformer.encoder.layers.20.self_attention.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 105 |
+
"transformer.encoder.layers.20.self_attention.query_key_value.bias": "pytorch_model-00002-of-00003.bin",
|
| 106 |
+
"transformer.encoder.layers.20.self_attention.query_key_value.weight": "pytorch_model-00002-of-00003.bin",
|
| 107 |
+
"transformer.encoder.layers.21.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 108 |
+
"transformer.encoder.layers.21.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 109 |
+
"transformer.encoder.layers.21.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 110 |
+
"transformer.encoder.layers.21.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 111 |
+
"transformer.encoder.layers.21.self_attention.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 112 |
+
"transformer.encoder.layers.21.self_attention.query_key_value.bias": "pytorch_model-00002-of-00003.bin",
|
| 113 |
+
"transformer.encoder.layers.21.self_attention.query_key_value.weight": "pytorch_model-00002-of-00003.bin",
|
| 114 |
+
"transformer.encoder.layers.22.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 115 |
+
"transformer.encoder.layers.22.mlp.dense_4h_to_h.weight": "pytorch_model-00003-of-00003.bin",
|
| 116 |
+
"transformer.encoder.layers.22.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 117 |
+
"transformer.encoder.layers.22.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 118 |
+
"transformer.encoder.layers.22.self_attention.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 119 |
+
"transformer.encoder.layers.22.self_attention.query_key_value.bias": "pytorch_model-00002-of-00003.bin",
|
| 120 |
+
"transformer.encoder.layers.22.self_attention.query_key_value.weight": "pytorch_model-00002-of-00003.bin",
|
| 121 |
+
"transformer.encoder.layers.23.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 122 |
+
"transformer.encoder.layers.23.mlp.dense_4h_to_h.weight": "pytorch_model-00003-of-00003.bin",
|
| 123 |
+
"transformer.encoder.layers.23.mlp.dense_h_to_4h.weight": "pytorch_model-00003-of-00003.bin",
|
| 124 |
+
"transformer.encoder.layers.23.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 125 |
+
"transformer.encoder.layers.23.self_attention.dense.weight": "pytorch_model-00003-of-00003.bin",
|
| 126 |
+
"transformer.encoder.layers.23.self_attention.query_key_value.bias": "pytorch_model-00003-of-00003.bin",
|
| 127 |
+
"transformer.encoder.layers.23.self_attention.query_key_value.weight": "pytorch_model-00003-of-00003.bin",
|
| 128 |
+
"transformer.encoder.layers.24.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 129 |
+
"transformer.encoder.layers.24.mlp.dense_4h_to_h.weight": "pytorch_model-00003-of-00003.bin",
|
| 130 |
+
"transformer.encoder.layers.24.mlp.dense_h_to_4h.weight": "pytorch_model-00003-of-00003.bin",
|
| 131 |
+
"transformer.encoder.layers.24.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 132 |
+
"transformer.encoder.layers.24.self_attention.dense.weight": "pytorch_model-00003-of-00003.bin",
|
| 133 |
+
"transformer.encoder.layers.24.self_attention.query_key_value.bias": "pytorch_model-00003-of-00003.bin",
|
| 134 |
+
"transformer.encoder.layers.24.self_attention.query_key_value.weight": "pytorch_model-00003-of-00003.bin",
|
| 135 |
+
"transformer.encoder.layers.25.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 136 |
+
"transformer.encoder.layers.25.mlp.dense_4h_to_h.weight": "pytorch_model-00003-of-00003.bin",
|
| 137 |
+
"transformer.encoder.layers.25.mlp.dense_h_to_4h.weight": "pytorch_model-00003-of-00003.bin",
|
| 138 |
+
"transformer.encoder.layers.25.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 139 |
+
"transformer.encoder.layers.25.self_attention.dense.weight": "pytorch_model-00003-of-00003.bin",
|
| 140 |
+
"transformer.encoder.layers.25.self_attention.query_key_value.bias": "pytorch_model-00003-of-00003.bin",
|
| 141 |
+
"transformer.encoder.layers.25.self_attention.query_key_value.weight": "pytorch_model-00003-of-00003.bin",
|
| 142 |
+
"transformer.encoder.layers.26.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 143 |
+
"transformer.encoder.layers.26.mlp.dense_4h_to_h.weight": "pytorch_model-00003-of-00003.bin",
|
| 144 |
+
"transformer.encoder.layers.26.mlp.dense_h_to_4h.weight": "pytorch_model-00003-of-00003.bin",
|
| 145 |
+
"transformer.encoder.layers.26.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 146 |
+
"transformer.encoder.layers.26.self_attention.dense.weight": "pytorch_model-00003-of-00003.bin",
|
| 147 |
+
"transformer.encoder.layers.26.self_attention.query_key_value.bias": "pytorch_model-00003-of-00003.bin",
|
| 148 |
+
"transformer.encoder.layers.26.self_attention.query_key_value.weight": "pytorch_model-00003-of-00003.bin",
|
| 149 |
+
"transformer.encoder.layers.27.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 150 |
+
"transformer.encoder.layers.27.mlp.dense_4h_to_h.weight": "pytorch_model-00003-of-00003.bin",
|
| 151 |
+
"transformer.encoder.layers.27.mlp.dense_h_to_4h.weight": "pytorch_model-00003-of-00003.bin",
|
| 152 |
+
"transformer.encoder.layers.27.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 153 |
+
"transformer.encoder.layers.27.self_attention.dense.weight": "pytorch_model-00003-of-00003.bin",
|
| 154 |
+
"transformer.encoder.layers.27.self_attention.query_key_value.bias": "pytorch_model-00003-of-00003.bin",
|
| 155 |
+
"transformer.encoder.layers.27.self_attention.query_key_value.weight": "pytorch_model-00003-of-00003.bin",
|
| 156 |
+
"transformer.encoder.layers.3.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 157 |
+
"transformer.encoder.layers.3.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 158 |
+
"transformer.encoder.layers.3.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 159 |
+
"transformer.encoder.layers.3.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 160 |
+
"transformer.encoder.layers.3.self_attention.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 161 |
+
"transformer.encoder.layers.3.self_attention.query_key_value.bias": "pytorch_model-00001-of-00003.bin",
|
| 162 |
+
"transformer.encoder.layers.3.self_attention.query_key_value.weight": "pytorch_model-00001-of-00003.bin",
|
| 163 |
+
"transformer.encoder.layers.4.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 164 |
+
"transformer.encoder.layers.4.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 165 |
+
"transformer.encoder.layers.4.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 166 |
+
"transformer.encoder.layers.4.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 167 |
+
"transformer.encoder.layers.4.self_attention.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 168 |
+
"transformer.encoder.layers.4.self_attention.query_key_value.bias": "pytorch_model-00001-of-00003.bin",
|
| 169 |
+
"transformer.encoder.layers.4.self_attention.query_key_value.weight": "pytorch_model-00001-of-00003.bin",
|
| 170 |
+
"transformer.encoder.layers.5.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 171 |
+
"transformer.encoder.layers.5.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 172 |
+
"transformer.encoder.layers.5.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 173 |
+
"transformer.encoder.layers.5.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 174 |
+
"transformer.encoder.layers.5.self_attention.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 175 |
+
"transformer.encoder.layers.5.self_attention.query_key_value.bias": "pytorch_model-00001-of-00003.bin",
|
| 176 |
+
"transformer.encoder.layers.5.self_attention.query_key_value.weight": "pytorch_model-00001-of-00003.bin",
|
| 177 |
+
"transformer.encoder.layers.6.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 178 |
+
"transformer.encoder.layers.6.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 179 |
+
"transformer.encoder.layers.6.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 180 |
+
"transformer.encoder.layers.6.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 181 |
+
"transformer.encoder.layers.6.self_attention.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 182 |
+
"transformer.encoder.layers.6.self_attention.query_key_value.bias": "pytorch_model-00001-of-00003.bin",
|
| 183 |
+
"transformer.encoder.layers.6.self_attention.query_key_value.weight": "pytorch_model-00001-of-00003.bin",
|
| 184 |
+
"transformer.encoder.layers.7.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 185 |
+
"transformer.encoder.layers.7.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 186 |
+
"transformer.encoder.layers.7.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 187 |
+
"transformer.encoder.layers.7.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 188 |
+
"transformer.encoder.layers.7.self_attention.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 189 |
+
"transformer.encoder.layers.7.self_attention.query_key_value.bias": "pytorch_model-00001-of-00003.bin",
|
| 190 |
+
"transformer.encoder.layers.7.self_attention.query_key_value.weight": "pytorch_model-00001-of-00003.bin",
|
| 191 |
+
"transformer.encoder.layers.8.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 192 |
+
"transformer.encoder.layers.8.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 193 |
+
"transformer.encoder.layers.8.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 194 |
+
"transformer.encoder.layers.8.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 195 |
+
"transformer.encoder.layers.8.self_attention.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 196 |
+
"transformer.encoder.layers.8.self_attention.query_key_value.bias": "pytorch_model-00001-of-00003.bin",
|
| 197 |
+
"transformer.encoder.layers.8.self_attention.query_key_value.weight": "pytorch_model-00001-of-00003.bin",
|
| 198 |
+
"transformer.encoder.layers.9.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 199 |
+
"transformer.encoder.layers.9.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 200 |
+
"transformer.encoder.layers.9.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 201 |
+
"transformer.encoder.layers.9.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 202 |
+
"transformer.encoder.layers.9.self_attention.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 203 |
+
"transformer.encoder.layers.9.self_attention.query_key_value.bias": "pytorch_model-00001-of-00003.bin",
|
| 204 |
+
"transformer.encoder.layers.9.self_attention.query_key_value.weight": "pytorch_model-00001-of-00003.bin",
|
| 205 |
+
"transformer.output_layer.weight": "pytorch_model-00003-of-00003.bin",
|
| 206 |
+
"transformer.rotary_pos_emb.inv_freq": "pytorch_model-00001-of-00003.bin"
|
| 207 |
+
}
|
| 208 |
+
}
|
quantization.py
ADDED
|
@@ -0,0 +1,188 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch.nn import Linear
|
| 2 |
+
from torch.nn.parameter import Parameter
|
| 3 |
+
|
| 4 |
+
import bz2
|
| 5 |
+
import torch
|
| 6 |
+
import base64
|
| 7 |
+
import ctypes
|
| 8 |
+
from transformers.utils import logging
|
| 9 |
+
|
| 10 |
+
from typing import List
|
| 11 |
+
from functools import partial
|
| 12 |
+
|
| 13 |
+
logger = logging.get_logger(__name__)
|
| 14 |
+
|
| 15 |
+
try:
|
| 16 |
+
from cpm_kernels.kernels.base import LazyKernelCModule, KernelFunction, round_up
|
| 17 |
+
|
| 18 |
+
class Kernel:
|
| 19 |
+
def __init__(self, code: bytes, function_names: List[str]):
|
| 20 |
+
self.code = code
|
| 21 |
+
self._function_names = function_names
|
| 22 |
+
self._cmodule = LazyKernelCModule(self.code)
|
| 23 |
+
|
| 24 |
+
for name in self._function_names:
|
| 25 |
+
setattr(self, name, KernelFunction(self._cmodule, name))
|
| 26 |
+
|
| 27 |
+
quantization_code = "$QlpoOTFBWSZTWU9yuJUAQHN//////////f/n/8/n///n//bt4dTidcVx8X3V9FV/92/v4B7/AD5FBQFAAAChSgKpFCFAFVSigUAAAEKhSgUUqgFBKigqVREQAABQBQIANDTTIGI00BkZBkNGE0A0BkBkGQGRkaNAaAGQNBoGgDIAAYIGTI0DQAQAaGmmQMRpoDIyDIaMJoBoDIDIMgMjI0aA0AMgaDQNAGQAAwQMmRoGgAgA0NNMgYjTQGRkGQ0YTQDQGQGQZAZGRo0BoAZA0GgaAMgABggZMjQNABABoaaZAxGmgMjIMhowmgGgMgMgyAyMjRoDQAyBoNA0AZAADBAyZGgaAAmqU1NEgJqnptU/Sn4jRR6J6epk2pqb1Q/SgAPUGgyNNGjQ2SBpoAZAAGg0NB6mgDIAAAAA2oaApSREBNAARhGiYEaEwU8pvImlP0k2aam1GaGqbFNM1MHpTwmkepmyU9R6nqPKekHqNNPUxNGhp6n6p6QaZ6o9TG1GMqcoV9ly6nRanHlq6zPNbnGZNi6HSug+2nPiZ13XcnFYZW+45W11CumhzYhchOJ2GLLV1OBjBjGf4TptOddTSOcVxhqYZMYwZXZZY00zI1paX5X9J+b+f4e+x43RXSxXPOdquiGpduatGyXneN696M9t4HU2eR5XX/kPhP261NTx3JO1Ow7LyuDmeo9a7d351T1ZxnvnrvYnrXv/hXxPCeuYx2XsNmO003eg9J3Z6U7b23meJ4ri01OdzTk9BNO96brz+qT5nuvvH3ds/G+m/JcG/F2XYuhXlvO+jP7U3XgrzPN/lr8Sf1n6j4j7jZs+s/T0tNaNNYzTs12rxjwztHlnire3Nzc3N1wuBwOBwXBvZfoHpD7rFmR99V5vj3aXza3xdBbXMalubTg/jIv5dfAi54Pdc75j4z412n3Npj3Ld/ENm7a3b/Cod6h/ret1/5vn/C+l+gdslMvgPSLJ8d8q+U66fevYn/tW1chleEtNTGlcHCbLRlq0tHzF5tsbbZZfHjjLgZu42XCuC3NrdjTasZGNzgxPIrGqp7r3p7L2p5XjnpPSmTd5XtzqnB6U87zzg1Ol0zd0zsLszxR6lkxp35u6/teL0L0W922cR7Lu1lpL9CsHirzuM2T+BgsyViT6LHcm0/Vr6U/7LGGyJeqTEjt0PHWhF5mCT7R9mtlDwriYv0Tyr/OxYt6qp5r0mPVT0608TqnqMZaarU2nFwrTzzlrs1ed7z1ux60wyr4ydCaTi3enW8x68x0zU7tXSlcmPSW1mGpWJMg4zmPC2lK96tp0OE80y4MfEvnZj8zGluR6b22ki1Ou9V2nCd9xovcPvcYMZYy0lvN60ScZ45vN6yeCeeXFb1lVjnnCar5fwXwE2bzJ4HI1XVPXfXZMm44GUsMpYsmLB65TuVdm0cl0b+i/wGNN66XjeV7zuPpHcnK/juhhjdfId5jMdE5nN0dGmmm2zZs2cexD5n9p/dY352XsvXHaZNWWsmmS1atjR452nYudzvqv2HMRyvNNnlMcDl3R2+yx2uVrBubTW9icHDVtbNXlZm7jma1rM4VurZZd2y6nUau7ZXZ7bVU+mnoOVxZGMrVmvX60605JwmzGZhhhjTWtaaaMaaGTGmNMZasY0iX8VMUl8eepaIrzGSpemWOQyZORk2bNpjUybMmxqYmknCGCFynutfksaZpjTNMaaatM0xsxcGR0sociNqxNSmhhR1ZJPbsn8qyF0t2qH6iYBclclalbtTTcHTDsPaX6rlnElph2Jyumumtynv2Kk8GI7rsvXbIcJgHJOSaSXnnGaI3m87RtVXJOZ/YtgdTE6Wpha6ZlE8ayXkef1fh602r2WwvfMXtMdLlkfnLFdYYwYso+bWqm7yJqHXZGw2nrS5ZanSYnWlxBxMF1V940K2wdrI7R6OYf7DGGamMmTSbRhlS45xmVOumF1EyPCmHrrN8wwZOOrdNtLeMtzFzDlWnfTBxMk2NaXIZHBYxYLD4w8yju0ao65Vz1OIXoS9dLanwCe1PWrYuWMqf1if1z2k2yYfKJ741PDgno1ZQ8DRqvUny3mNoWTzGO6m1DkrJI8JiR5cSd+vZdGOO8nrMoc5+NDUFsMSXaZJeNlMmGLtJsovOsUp7I9S5VojKxF6bTVEelXqlfJobQr3LozSh2Jk7VcrVMfhXqszGWMzNqGhqZY0OadxkyyMssKugZR0KNFXBHlqwmJgTE/BNVMk6ItJXZMR0H47GpXv/DMOvNkmVuaV1PRfEdxuqc7Hcd+ZV/zTLaRxWk0nl9CdCeM6mn5rstHIBcpiuwmUZXeq81DacHI2rmrZ5SuE5mOZd6LQrZg9mx32TprA8BMo5jKN6yLTCi3WzQaZSuhzTtM1fUTGVpG8Tw+KXI0tjEpiWxtLYynOlktSbVlaI5kxP8TDH8kx50xoxi5KcA4pcja8KWLRlO/Ks6q06ergnvm1ca3Tq8Uw7LTUsmWyctXPWmpitl/uvGcWTGXGuAXDfhqazGmjkxcJW5hMMMMpYsXl2TZYtVOddG3XCarUt6Ptq9CZXSNzyuRzqRZOjsxdBbFVz6OA5HI43r1jityVlVpVkxmOsyaYWE1NTGq1sOVh36mHMcxtSvcy70edG0ZGR3I1Go1GRlV7mWWo1G0ZGRqlvH40l7o4m5xMWLLLYyNjnqc8556mdPqLJ31n/1nWOncxzG1tizrHs/Z+d2vP/B/l8wdJ6rHUn2nbbDq4p6htFtYzMMMTaZis1K5GKzGNmxhmUx2DDlZ/qNnIx41xnaMfCZWYaZWtNLTNW8ND4Fw1MyZOCdM428suKG1ehW8TesOydg7J+YYcD4cYR+8dFK6M4E3HM9ZfRNNL+Sn6rsl4DsrDl2HpPCnfxjGXtbZtYys1ttlyJ4T+BvexjGWRjMszK4Jpc77D3GyuVD7q0+G8m9G+2+rGm7cOR2y7FdtY2XUYx/oNlfRYxhMYyYZkyyg55enna9Kt/FFi6GMMwYwdwxWgxGMLKYmUyGExTKMZkMFhkymKuh0NOBNnBu+23LdwDoZYYzGGMxtORaTU1pjTGWTTGGtMrNWUsyyTTLLG1qy2ZjbK2DBllWqxMtBMaYZQmcE7zvvRcTkclUwdkxTaSdyySt/7fpL+T1v516Ji97fwr5JbLu305zMn5+GMTTZ9F+y7ExwmGVfG44yxn3dLv6l5i+Wth1jCrDq21nW9LqvvDzz3Vf3LLH/O/32TJ/erx3bXftO4eF+G956D952K/An4NfvOpjFjExjevP/UmE0fIoZXx6/w6lX/no3D0bLt+ixjieBM6ksRd0yB4Lt2SwYNE+gd1detlZWUnpiZfGfFaK+4PyCa/v18V8X75pe9fLXzp7l3VjF76vWZmHwGz1IZNWT7b8yddJ4q5kyrVdfru6atWc7bVYztL9Jf4GXvT+Y8m9/YsXP6H018a8D4XVOqvfzqeR+6yZOD8dPv0+U7/q5Pl+2dNb0MjzGVH5p6MNQ7cOWvw62U9aHE8DprDek+McLyvDz+te+9Zhq5+YTruufMcWMabqysTmZVWjKPfnK0wyVcrsuhjZRdLkHNvD72b9abriOSGIxiLixMOoalNPXzy+wT/tf+U6HHONfsz+xe8ufHBdQWWGWLA9if0rsnmrxK5LvRZQeWsTCsrmOYy8VteVfuRfcVTtDLItLIsMYxZLdU/DbtSemxF6Z6Zo5WBXE4tFdCyVMMXMTEMZXVlS6Xec2T4e0tHsRcEuWshcJ2YsNF5rUx1E8ifCq6Z+ZP7qdCeu/aTwFd53l16/o0NOw6O3dLavP4Hbi4RdmuDk6DoYaninC0+o4uZjbJ7Rxeu0/FbuFg+q7DVS6fQe0rZ6NDGUNNU6DEqOaLTicKnYZMnBWruljQxoaS3dZhocDge0bSTyOvdAbG5hxe2xji7E/L55xX13wWNDi6HCekcFxfCPGxY0MXC+s7afWaMdDyjyr+o8Rudm/NabOZvdl274zH4f5XK9z6On1Pe/K5TdPAslg77BjuO6Y3eO7GqvOPG/stknp1leyvLL0Z7bl9I4noMvLkzytLhWYzrOZzLXCORe028rORzOg4N/L0HlMOQ3Pgmnbb6KczlabORpu980q37TBqRu0/p3PO6234Bl03Ynuz+9W7gnsEcmvYaYY3aMYY0wx3pYd+ujsXauWdaY5Xkbtl23fPzFHiDB/QMo0yFjBllYxTQYYyxkrwn7JufwJ/PfgJ+C83X69ni6zvXcnyXabv0ncbLwsceS+RNlyN2mnneJtX0ngYO0+e+0+UnA+Wch3ji8hj5an4h+i6XBySU4n+R0roVcbw5yvHrmr4Yw8Y7x6c+9POPYHI5HI5HI5HI5HGXGww4nE4nrVyOR8XeqPEO7PLOiukYa3Novk5hV4cdtYZLI93e+uxff2jRo0aNGjRo0aNG1bVtW1dy3m83m8+tQ5ZzHw3nObwOu8La9Rc1dtkdS8A3eTk823tnktXWlxN6Oixe06zrN70Isd9jiOgZFq9yfkPqP/SLhN2Myl8jDM43bl1nbcb4cO57jlh8Jow6pzXZdL4dyODTuuhu77FyO27DdwdRxmvO+O+3N2+BdqyTwLHVczDVY4UPE4O66/ZO2cx1LFzVdSXtF7G4HMbrauOHRw6c8FdZ5m9fHZHYZXfTlZquyynSyTTKke6vcffSD9pzPA/G7n7jxPmuhc1DHMynPMrGL6AdewYmwu5ko+UUyTwrMv27rPH1v1nGqd87+p6N6LU8k3NEng53xXyHS97+44OSg/sy/hn+Se6yfYNjW0/uTgP+PvWYzLMmjhcLB/gGpri6H83/84eUXWT6T9Hsv7785z/7z4icpW+zfXypuR7rx/gMdZb1/wC678pcs8/2a3mDitGHxl9mfPlll5MafWWqxk/eYuTDgcNMzDGWLWvsuglNxs53GtN6uWpktlW1tZZYcuinMMWmnNnJydze3b2Y1McBxrBkXw799izLMZZYyy0TkbsGM4p03S2uVu5s/XXUdSdec6smVxZYYGpVmT8A+8ajuEyV5FatkvVru2x6uxGXXbH4A+jvgP4GMYy3iPLXzq/6z65+E005ey+cwMZD3fZcqc6xpjTFjQ0P3U+e++cPYmTIwj0nrK5NPTfl3WvpfLtXDcb2HQMudYOxFXQBor4L4T6vrOauFctYXJQ++NUWmJe5bmx1jDiZS1dTqWxo4GR8jm3fttpmPHppk9PEyv4/y8/sO07XacOmcqc0x2Vi9BvNJvN5oW8x4mOsydpidRxMYJPx06m1bqPzq9KtK8sxXNXFodD/+MYYaJTLwOhc9brCsV18oOR1i4tXChyTkq4lf4y1Ke+9axjDHqs1mfBbMXuP4Hzi+X7t8vzv7bHerrUPgPCxhjre4fXdfLNtNM+Jd+Zdh8xd8wP87uNPoPgv4W7/5P2BuxfsMabNnMnza+54Pdi5U671GPZY8CehX8Voeoo7FHpkeEc6715FwHZrIrUrHaviPUbPZHND+IhczrP6FcYvhOZ0Di/ETt0OI+YwNWR9r7tpf6WDeZKZDB1+z2IthOl1mPyb5FluvEx9h9d0NnM0Y1XPFkWIsk1WotJ0PBMmkvjvQTd0e71tfeV+8r8lQ/tpzpsmxJ+InrI/dj2UajUajVTUajatRqNRtGo1Go1Go4wjeMpZFMVV9CHbofPraLsJ3JpWV2XOoanCuFky4y3PPNxucK2uKC1Lbdb1eo+m5XomN6HfeZsabHLHRX/K+offtNGGmHWctcVcG44MdSqsOLY9VzX+Zxfxn2HPdWTpzWvkrtJ8M5zorrKcquRytJ5N5DZmcaW02l76nWO+BqPXm1A2Ry/0q71dH/mqrqeFjkYxjEXtsX8qubTk67rGycyqsdm4tZx5D6D5hhi0waaWmiaMP81Yjii5qxPlPuU/GfTL1Y5E6Jyfiq63qTa39A4J0sOGDgO9WF9bOXl0XfPRbsY2bPNKPy1YrFYrFYmRhhlTIyMjJWJYZHXuCXI8OoXsvfljGLFicNifpp2XunoPiG1wtx3p1Tah+/DD66OnVtVXP9rKbVxOnL0tR/rHtqB5UDErUVcl11D4qqvjpOcxX7armUNJB3LpW6bxVvD08e8h3odKKvyCFZBdSh2FVcST9xV3n3T8t1j7Kr9qgrqXg+13Pt5U7JCvFXVIV1YG5lRhkVYZJYYDDD4KOIMoHCp26WS8GB7uBh2zIdgq/PKyInjV2STShuoapUdCpX1yTwqq/z1VvET7Kh5nVPkO8YyxjLt2MaaMmWTLQvx3qnzltnXW0p2jxgbEtSny/Osv8Y9pLMXYoHVPAhkVdWVeODhR6q9/Sxe2liwwZWMVvFXfRkeIDxAePUPIrdJ4ey6yquzH+PD/bUOWAu05qVHtFd8rrKHSoeNIOUqrYr3FXyToqfYJgwmJdKpXXOwYYegNNGMzfZPp/t3t/DVs4zjNTN61rRqaWaa4NYbRjTa0tWwy2Y2tGN8ZO8ofNKq4j9SL7I+cSm4/6ovLV5HNXLI0jJidwrtk6ynCaP6Z++GjRlWS3tLeW129Mi9evxU9mtz6s5J3Z7M2ngTgnKvmpomxpaLCzPfmx0JWE+m3NLDDGOX47RctdYYNK5jakdqLkRlI39n590T5zctGSwwZZDJj6kW8XSi6ot2MmWWJ0DUT3nuvebBudScjZ79g8cWJ8av0k+/bE5WKd5MdbFpbDVMxu1DVMmtNZGJvq1mtRbn6M+g/kP0FwDwr7quZs7xosNGpbscyxhhd9TyJyFwbLcxlTasg75vW7TsV5K7ji44XPMMrdoj+Y3rT0Hie62nlYV/pwczzOmdLqLhYkzGMzCZWGMQzGMSsZYY6Di1t4nlJ+Em63mJxrVLxPbYxNEdgc1dU2iOKyoYYWjNrEeHTYybVk0atSa7ehuwsWMWTqn1TrnS6hYsi71d1+s+k+ic70e20fzE/VaTdxT9ZtU4GIXdeNx3X77guYYfpHeTQjaMX6brOu4OY4K7Y2d9mbHarI5ox3p4GpJ2Vd/Tst60f7j999pppjR+Q/Qf8J/VaORs3cji7FfFuN61+ui9s8hix1OCh5KGVV23BPXvZfz3CLyHpix+exi8z/KnCnosY2eunor+cxyPO/xJ0vKey9OvE9VjqaYu0x3Z3jd6o2b1T12D+F8l232lwaaacD5LE8LBxu7WTlbWraWpew8Xexjel3E+wWD4APITdNqR8F3R3T0lunCQ4GaE9R37DxeCYfcHi4xci5ovKfxVs55y2hf+65E/Xdp6jR5nrebTmi5incpkyOjs50JvrZwstbbW6kfuuQw+2mykf/EXNFzxfKTrxew929TR6bWnGL//F3JFOFCQT3K4lQ"
|
| 28 |
+
|
| 29 |
+
kernels = Kernel(
|
| 30 |
+
bz2.decompress(base64.b64decode(quantization_code)),
|
| 31 |
+
[
|
| 32 |
+
"int4WeightCompression",
|
| 33 |
+
"int4WeightExtractionFloat",
|
| 34 |
+
"int4WeightExtractionHalf",
|
| 35 |
+
"int8WeightExtractionFloat",
|
| 36 |
+
"int8WeightExtractionHalf",
|
| 37 |
+
],
|
| 38 |
+
)
|
| 39 |
+
except Exception as exception:
|
| 40 |
+
kernels = None
|
| 41 |
+
logger.warning("Failed to load cpm_kernels:" + str(exception))
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
class W8A16Linear(torch.autograd.Function):
|
| 45 |
+
@staticmethod
|
| 46 |
+
def forward(ctx, inp: torch.Tensor, quant_w: torch.Tensor, scale_w: torch.Tensor, weight_bit_width):
|
| 47 |
+
ctx.inp_shape = inp.size()
|
| 48 |
+
ctx.weight_bit_width = weight_bit_width
|
| 49 |
+
out_features = quant_w.size(0)
|
| 50 |
+
inp = inp.contiguous().view(-1, inp.size(-1))
|
| 51 |
+
weight = extract_weight_to_half(quant_w, scale_w, weight_bit_width)
|
| 52 |
+
ctx.weight_shape = weight.size()
|
| 53 |
+
output = inp.mm(weight.t())
|
| 54 |
+
ctx.save_for_backward(inp, quant_w, scale_w)
|
| 55 |
+
return output.view(*(ctx.inp_shape[:-1] + (out_features,)))
|
| 56 |
+
|
| 57 |
+
@staticmethod
|
| 58 |
+
def backward(ctx, grad_output: torch.Tensor):
|
| 59 |
+
inp, quant_w, scale_w = ctx.saved_tensors
|
| 60 |
+
weight = extract_weight_to_half(quant_w, scale_w, ctx.weight_bit_width)
|
| 61 |
+
grad_output = grad_output.contiguous().view(-1, weight.size(0))
|
| 62 |
+
grad_input = grad_output.mm(weight)
|
| 63 |
+
grad_weight = grad_output.t().mm(inp)
|
| 64 |
+
return grad_input.view(ctx.inp_shape), grad_weight.view(ctx.weight_shape), None, None
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def compress_int4_weight(weight: torch.Tensor): # (n, m)
|
| 68 |
+
with torch.cuda.device(weight.device):
|
| 69 |
+
n, m = weight.size(0), weight.size(1)
|
| 70 |
+
assert m % 2 == 0
|
| 71 |
+
m = m // 2
|
| 72 |
+
out = torch.empty(n, m, dtype=torch.int8, device="cuda")
|
| 73 |
+
stream = torch.cuda.current_stream()
|
| 74 |
+
|
| 75 |
+
gridDim = (n, 1, 1)
|
| 76 |
+
blockDim = (min(round_up(m, 32), 1024), 1, 1)
|
| 77 |
+
|
| 78 |
+
kernels.int4WeightCompression(
|
| 79 |
+
gridDim,
|
| 80 |
+
blockDim,
|
| 81 |
+
0,
|
| 82 |
+
stream,
|
| 83 |
+
[ctypes.c_void_p(weight.data_ptr()), ctypes.c_void_p(out.data_ptr()), ctypes.c_int32(n), ctypes.c_int32(m)],
|
| 84 |
+
)
|
| 85 |
+
return out
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def extract_weight_to_half(weight: torch.Tensor, scale_list: torch.Tensor, source_bit_width: int):
|
| 89 |
+
assert scale_list.dtype in [torch.half, torch.bfloat16]
|
| 90 |
+
assert weight.dtype in [torch.int8]
|
| 91 |
+
if source_bit_width == 8:
|
| 92 |
+
return weight.to(scale_list.dtype) * scale_list[:, None]
|
| 93 |
+
elif source_bit_width == 4:
|
| 94 |
+
func = (
|
| 95 |
+
kernels.int4WeightExtractionHalf if scale_list.dtype == torch.half else kernels.int4WeightExtractionBFloat16
|
| 96 |
+
)
|
| 97 |
+
else:
|
| 98 |
+
assert False, "Unsupported bit-width"
|
| 99 |
+
|
| 100 |
+
with torch.cuda.device(weight.device):
|
| 101 |
+
n, m = weight.size(0), weight.size(1)
|
| 102 |
+
out = torch.empty(n, m * (8 // source_bit_width), dtype=scale_list.dtype, device="cuda")
|
| 103 |
+
stream = torch.cuda.current_stream()
|
| 104 |
+
|
| 105 |
+
gridDim = (n, 1, 1)
|
| 106 |
+
blockDim = (min(round_up(m, 32), 1024), 1, 1)
|
| 107 |
+
|
| 108 |
+
func(
|
| 109 |
+
gridDim,
|
| 110 |
+
blockDim,
|
| 111 |
+
0,
|
| 112 |
+
stream,
|
| 113 |
+
[
|
| 114 |
+
ctypes.c_void_p(weight.data_ptr()),
|
| 115 |
+
ctypes.c_void_p(scale_list.data_ptr()),
|
| 116 |
+
ctypes.c_void_p(out.data_ptr()),
|
| 117 |
+
ctypes.c_int32(n),
|
| 118 |
+
ctypes.c_int32(m),
|
| 119 |
+
],
|
| 120 |
+
)
|
| 121 |
+
return out
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
class QuantizedLinear(torch.nn.Module):
|
| 125 |
+
def __init__(self, weight_bit_width: int, weight, bias=None, device="cpu", dtype=None, empty_init=False, *args,
|
| 126 |
+
**kwargs):
|
| 127 |
+
super().__init__()
|
| 128 |
+
self.weight_bit_width = weight_bit_width
|
| 129 |
+
|
| 130 |
+
shape = weight.shape
|
| 131 |
+
|
| 132 |
+
if weight is None or empty_init:
|
| 133 |
+
self.weight = torch.empty(shape[0], shape[1] * weight_bit_width // 8, dtype=torch.int8, device=device)
|
| 134 |
+
self.weight_scale = torch.empty(shape[0], dtype=dtype, device=device)
|
| 135 |
+
else:
|
| 136 |
+
self.weight_scale = weight.abs().max(dim=-1).values / ((2 ** (weight_bit_width - 1)) - 1)
|
| 137 |
+
self.weight = torch.round(weight / self.weight_scale[:, None]).to(torch.int8)
|
| 138 |
+
if weight_bit_width == 4:
|
| 139 |
+
self.weight = compress_int4_weight(self.weight)
|
| 140 |
+
|
| 141 |
+
self.weight = Parameter(self.weight.to(device), requires_grad=False)
|
| 142 |
+
self.weight_scale = Parameter(self.weight_scale.to(device), requires_grad=False)
|
| 143 |
+
self.bias = Parameter(bias.to(device), requires_grad=False) if bias is not None else None
|
| 144 |
+
|
| 145 |
+
def forward(self, input):
|
| 146 |
+
output = W8A16Linear.apply(input, self.weight, self.weight_scale, self.weight_bit_width)
|
| 147 |
+
if self.bias is not None:
|
| 148 |
+
output = output + self.bias
|
| 149 |
+
return output
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
def quantize(model, weight_bit_width, empty_init=False, device=None):
|
| 153 |
+
"""Replace fp16 linear with quantized linear"""
|
| 154 |
+
for layer in model.layers:
|
| 155 |
+
layer.self_attention.query_key_value = QuantizedLinear(
|
| 156 |
+
weight_bit_width=weight_bit_width,
|
| 157 |
+
weight=layer.self_attention.query_key_value.weight.to(torch.cuda.current_device()),
|
| 158 |
+
bias=layer.self_attention.query_key_value.bias,
|
| 159 |
+
dtype=layer.self_attention.query_key_value.weight.dtype,
|
| 160 |
+
device=layer.self_attention.query_key_value.weight.device if device is None else device,
|
| 161 |
+
empty_init=empty_init
|
| 162 |
+
)
|
| 163 |
+
layer.self_attention.dense = QuantizedLinear(
|
| 164 |
+
weight_bit_width=weight_bit_width,
|
| 165 |
+
weight=layer.self_attention.dense.weight.to(torch.cuda.current_device()),
|
| 166 |
+
bias=layer.self_attention.dense.bias,
|
| 167 |
+
dtype=layer.self_attention.dense.weight.dtype,
|
| 168 |
+
device=layer.self_attention.dense.weight.device if device is None else device,
|
| 169 |
+
empty_init=empty_init
|
| 170 |
+
)
|
| 171 |
+
layer.mlp.dense_h_to_4h = QuantizedLinear(
|
| 172 |
+
weight_bit_width=weight_bit_width,
|
| 173 |
+
weight=layer.mlp.dense_h_to_4h.weight.to(torch.cuda.current_device()),
|
| 174 |
+
bias=layer.mlp.dense_h_to_4h.bias,
|
| 175 |
+
dtype=layer.mlp.dense_h_to_4h.weight.dtype,
|
| 176 |
+
device=layer.mlp.dense_h_to_4h.weight.device if device is None else device,
|
| 177 |
+
empty_init=empty_init
|
| 178 |
+
)
|
| 179 |
+
layer.mlp.dense_4h_to_h = QuantizedLinear(
|
| 180 |
+
weight_bit_width=weight_bit_width,
|
| 181 |
+
weight=layer.mlp.dense_4h_to_h.weight.to(torch.cuda.current_device()),
|
| 182 |
+
bias=layer.mlp.dense_4h_to_h.bias,
|
| 183 |
+
dtype=layer.mlp.dense_4h_to_h.weight.dtype,
|
| 184 |
+
device=layer.mlp.dense_4h_to_h.weight.device if device is None else device,
|
| 185 |
+
empty_init=empty_init
|
| 186 |
+
)
|
| 187 |
+
|
| 188 |
+
return model
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{}
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e7dc4c393423b76e4373e5157ddc34803a0189ba96b21ddbb40269d31468a6f2
|
| 3 |
+
size 1018370
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"auto_map": {
|
| 3 |
+
"AutoTokenizer": [
|
| 4 |
+
"tokenization_chatglm.ChatGLMTokenizer",
|
| 5 |
+
null
|
| 6 |
+
]
|
| 7 |
+
},
|
| 8 |
+
"clean_up_tokenization_spaces": false,
|
| 9 |
+
"do_lower_case": false,
|
| 10 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 11 |
+
"padding_side": "right",
|
| 12 |
+
"remove_space": false,
|
| 13 |
+
"tokenizer_class": "ChatGLMTokenizer"
|
| 14 |
+
}
|
training_loss.png
ADDED
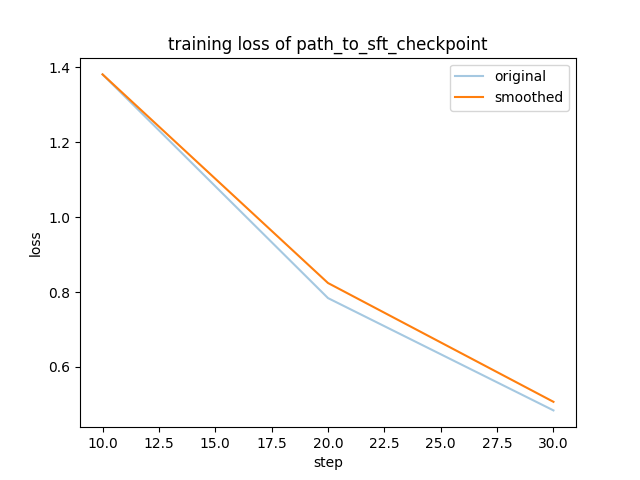
|