Introducing ColQwen-Omni: Retrieve in every modality











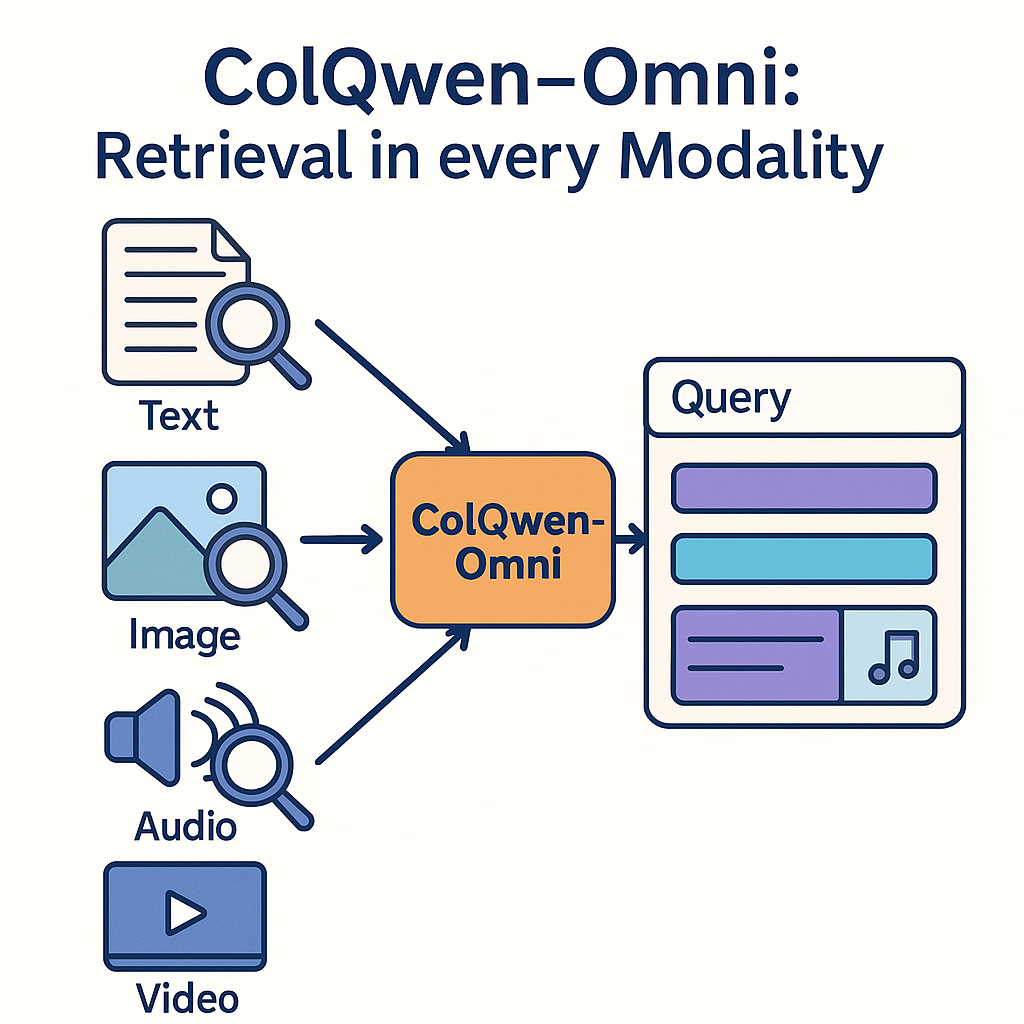
Remember ColPali, ColQwen, DSE ? These models introduced the concept of visual document retrieval: instead of painfully extracting text from a document in order to process it, it is possible to just treat document pages as a series of images (screenshots), and train Vision Language Models (VLMs) to represent their content directly as vectors. ColPali has shown this strategy to often be much quicker, simpler, and yield better retrieval perfomance than alternative methods. The ColPali and ColQwen model series have since their release about a year ago been downloaded millions of times, been mentionned as a top AI innovation of 2024, and have inspired many follow up work! Models actually became so good our first benchmark (Vidore v1) is now too easy!

Rapid progress in VLMs has led to top models being able to process more modalities. The amazing Qwen-Omni series is typically able to process audio and video inputs on top of images and text! Upon seeing this, we were immediately interested in seeing whether we could generalize the ColQwen series to embed and retrieve not only document images, but also audio chunks and short videos. After VisionRAG, is AudioRAG possible ? Introducing ColQwen-Omni (3B), an extension of ColQwen2 that embeds basically anything you throw at it!
Example Usage
Let's walk through how to use it to retrieve audio chunks ! You can follow along in Google Colab. First, let's load the model:
# !pip install git+https://github.com/illuin-tech/colpali
from colpali_engine.models import ColQwen2_5Omni, ColQwen2_5OmniProcessor
model = ColQwen2_5Omni.from_pretrained(
"vidore/colqwen-omni-v0.1",
torch_dtype=torch.bfloat16,
device_map="cuda",
attn_implementation="flash_attention_2").eval()
processor = ColQwen2_5OmniProcessor.from_pretrained("vidore/colqwen-omni-v0.1")
Let's say our goal is to be able to query a 30 minute long podcast. Let's split the podcast into 30 second chunks, and store each chunk in WAV format in a python list.
from pydub import AudioSegment
audio = AudioSegment.from_wav("<my_legally_downloaded_podcast>.wav")
# Set target frame rate
target_rate = 16000
chunk_length_ms = 30 * 1000 # 30 seconds
audios = []
for i in range(0, len(audio), chunk_length_ms):
chunk = audio[i:i + chunk_length_ms]
# Convert stereo to mono, sample at 16k Hz
chunk = chunk.set_channels(1).set_frame_rate(target_rate)
# Export and convert to numpy array
buf = io.BytesIO()
chunk.export(buf, format="wav")
buf.seek(0)
rate, data = wavfile.read(buf)
audios.append(data)
We now have everything in place to embed all audios.
from torch.utils.data import DataLoader
# Process the inputs by batches of 4
dataloader = DataLoader(
dataset=audios,
batch_size=4,
shuffle=False,
collate_fn=lambda x: processor.process_audios(x))
ds = []
for batch_doc in tqdm(dataloader):
with torch.no_grad():
batch_doc = {k: v.to(model.device) for k, v in batch_doc.items()}
embeddings_doc = model(**batch_doc)
ds.extend(list(torch.unbind(embeddings_doc.to("cpu"))))
Here, a 30 minute audio can be embedded in under 10 seconds, and we get about 800 audio tokens for 30s of audio ! Let's give it a test:
def get_results(query: str, k=3):
batch_queries = processor.process_queries([query]).to(model.device)
# Forward pass
with torch.no_grad():
query_embeddings = model(**batch_queries)
scores = processor.score_multi_vector(query_embeddings, ds)
return scores[0].topk(k).indices.tolist()
res = get_results("<YOUR QUERY>")
print(f"The best audio chunks are: {res}")
#> The best audio chunks are: [102, 96, 35]
Audio chunks #102 and 96 are perfectly relevant in my case! It's even possible to send the top most relevant audio chunks to GPT-4o to do end-to-end AudioRAG !
Let's demonstrate everything end-to-end with a 30 minute audio about the Hannibal and the punic wars:
The complete notebook can be found here.
When is it Useful to Retrieve Audios?
Many use cases may require audio retrieval. For example, you might want to find specific information within an educational video, recorded class, or podcast. You might need to locate the one voice note amongst dozens from a friend mentioning the address of their birthday party. Call center managers might attempt to find a few instances of customers laughing or expressing anger within millions of recorded calls. Numerous use cases exist, and although it's possible to transcribe audio to text using a Speech-to-Text (STT) system and then search the transcription, retrieving audio directly is orders of magnitude faster and direct audio retrieval better captures information such as emotions, ambient sounds, and voice tones, opening up entirely new possibilities!
What About Videos?
Videos also work with ColQwen-Omni. Note, however, that video processing is very memory-intensive, so it's best suited for short clips.
batch_videos = processor.process_videos(videos).to(model.device)
# Forward pass
with torch.no_grad():
video_embeddings = model(**batch_videos)
Here's a fun demo featuring the Mother of Dragons.
Training
The first iteration of this model is the result of a scientific experiment. We explored whether a model trained purely on visual document retrieval, without exposure to audio or videos during training, could effectively transfer its embedding capabilities to other modalities. The answer turned out to be: fairly well! By training strictly on the Vidore train set, the model matched the performance of current top models on visual document retrieval and while we don't recomment using the model in production yet, it demonstrated strong performance in audio retrieval as well.
In future iterations, we plan to specifically incorporate audio clips into the contrastive training set to further optimize the model for audio retrieval, potentially significantly boosting performance. The current model is great at understanding spoken content but shows some limitations in grasping accents, emotions, and ambient sounds. We are confident that focused training can address these areas effectively, and welcome any feedback on v0.1 to know what data to integrate in future runs! In the meantime, training code for colqwen-omni is available on our Github and is ready to take in your custom datasets! Our goal will also be to improve the model on natural images and text retrieval - paving the way for a truly modality agnostic retriever!
Some Links
📝 The paper
🗃️ The HF organization
👀 The model
💻 The code
📝 The Single-Vector DSE Version
@misc{faysse2024colpaliefficientdocumentretrieval,
title={ColPali: Efficient Document Retrieval with Vision Language Models},
author={Manuel Faysse and Hugues Sibille and Tony Wu and Bilel Omrani and Gautier Viaud and Céline Hudelot and Pierre Colombo},
year={2024},
eprint={2407.01449},
archivePrefix={arXiv},
primaryClass={cs.IR},
url={https://arxiv.org/abs/2407.01449},
}





