Context Is Gold to Find the Gold Passage: Evaluating and Training Contextual Document Embeddings








 Traditional embedding methods (right, top) produce embeddings that do not include essential contextual information. Our light-weight training recipe (InSeNT) trains Contextualized Embedding Models that are aware of document-wide context when encoding a passage (right, bottom) and can integrate document-wide information in individual chunk representations, augmenting embedding relevance and improving downstream retrieval performance without increasing inference cost.
Traditional embedding methods (right, top) produce embeddings that do not include essential contextual information. Our light-weight training recipe (InSeNT) trains Contextualized Embedding Models that are aware of document-wide context when encoding a passage (right, bottom) and can integrate document-wide information in individual chunk representations, augmenting embedding relevance and improving downstream retrieval performance without increasing inference cost.
TL;DR
Dense retrievers typically embed each passage in isolation. When the relevant clues spill across passages, those models mis-rank results. ConTEB (the Contextual Text Embedding Benchmark) quantifies this weakness; InSeNT + late-chunking pooling is a promising way to fix it, with a minor fine-tuning phase and almost no runtime overhead, delivering large gains on ConTEB.
Why does context matter ?
Search applications rarely deal with tweet-length texts. Technical manuals, contracts, scientific papers, and support tickets easily run into thousands of tokens. Users, however, still expect an answer at the passage level. When the decisive evidence sits partially outside the passage boundary, a model that “sees” only a single chunk is likely to fail. Context can help resolve ambiguity, such as distinguishing between multiple meanings of a word or resolving pronouns and entity references. It is also crucial when documents have a structured format, commonly found in legal or scientific texts for instance, and knowing where the passage is within the table of content is essential to understanding.

In the example above, embedding the sentence in bold "They extended [...]" without leveraging document context will be ambiguous: are we talking about Napoleonic armies or Brazilian football?
How retrieval systems actually chunk documents
Before embedding, virtually every production pipeline breaks each document into smaller, model and reader-friendly units. Common strategies include:
| Strategy | Typical parameters | Rationale & trade-offs |
|---|---|---|
| Fixed-length sliding window | k ≈ 128–1024 tokens, some overlap |
Simple to implement; overlap reduces boundary effects but multiplies index size. |
| Structure-aware blocks | Headings, paragraphs, list items | Preserves semantic units but yields highly variable lengths. |
| Hybrid | Fixed window inside structural blocks | Combines predictability with some respect for discourse structure. |
Designers must balance (i) respecting the Transformer’s maximum input, (ii) keeping enough context for downstream reading comprehension, and (iii) controlling index growth and latency. In practice, no chunking scheme can guarantee that every question’s evidence is entirely self-contained.
ConTEB: a benchmark that penalises context blindness
ConTEB introduces eight retrieval tasks where answering requires information beyond any single chunk. Some datasets are synthetic and controlled (e.g. Football, Geography); others are derived from realistic RAG workloads such as NarrativeQA or Covid-QA. A “sanity test” (NanoBEIR) ensures that improvements do not come at the expense of traditional self-contained tasks.

Getting into the gist of it: How can we add context to embeddings ?
Early results on ConTEB showcase context standard retrieval methods struggle in settings in which context is key! Our approach attempts to integrate contextual information through two key components: the recently proposed Late Chunking technique, and a custom training recipe we call InSeNT.
Late chunking: pooling after embedding the full document
As previously stated, dense retrievers usually break a long document d into smaller, fixed-length chunks
encode each chunk independently, and later treat the set of chunk vectors as the “representation” of the document:
That early chunking strategy prevents any token in $c_i$ from seeing tokens from other chunks during encoding.
The Late Chunking Idea
- One long forward pass. Concatenate all chunks and let the encoder contextualize across the entire document:
- Recover chunk-level vectors after the fact. For each original chunk $c_i$, average its token embeddings inside $H$:
The resulting set
retains the same shape expected by downstream retrieval code, but each chunk vector now benefits from full-document context: tokens in earlier paragraphs can influence the representation of later ones (and vice-versa), capturing long-range dependencies without any training changes.
Late Chunking computes token embeddings over the full document first and then pools back to chunk vectors, letting every chunk “know” about every other chunk before it ever meets the retrieval engine.
InSeNT: In-Sequence Negative Training
Late Chunking is primarly designed to be used without retraining the underlying embedding model. We find that while it often enables information propagation between chunks, this information flow can be largely optimized through a well-designed lightweight training phase.

During contrastive fine-tuning, InSeNT mixes the usual in-batch negatives (text sequences from other documents) with in-sequence negatives — other chunks from the same (late-chunked) document.
Intuitively, training Late Chunking models contrastively with chunks from different documents encourages information propagation within each document and improves document identification. On the other hand, the contrastive term between same-document chunks ensures each chunk retains its specificity, and remains identifiable w.r.t. to its neighbors.
A small mixing weight (λ ≈ 0.1) balances these two complementary yet somewhat contradictory objectives.

An interesting finding of this work is that having both in-sequence and in-batch negatives during training is absolutely crucial to good downstream performance.
Empirical gains
Results are clear! Context is gold when it comes to constructing relevant embeddings on ConTEB documents. Late Chunking alone yields large nDCG gains (+ 9.0), and InSeNT further largely improves performance, resulting in a 23.6 nDCG@10 boost on average w.r.t. standard embedding methods. Performance on NanoBEIR (self-contained queries) slightly decreases, indicating minor regression on conventional benchmarks that could be corrected by adding replay data in the training mix.

We further show contextualized embeddings are able to better scale with corpus size, and are more robust to sub-optimal chunking stategies.
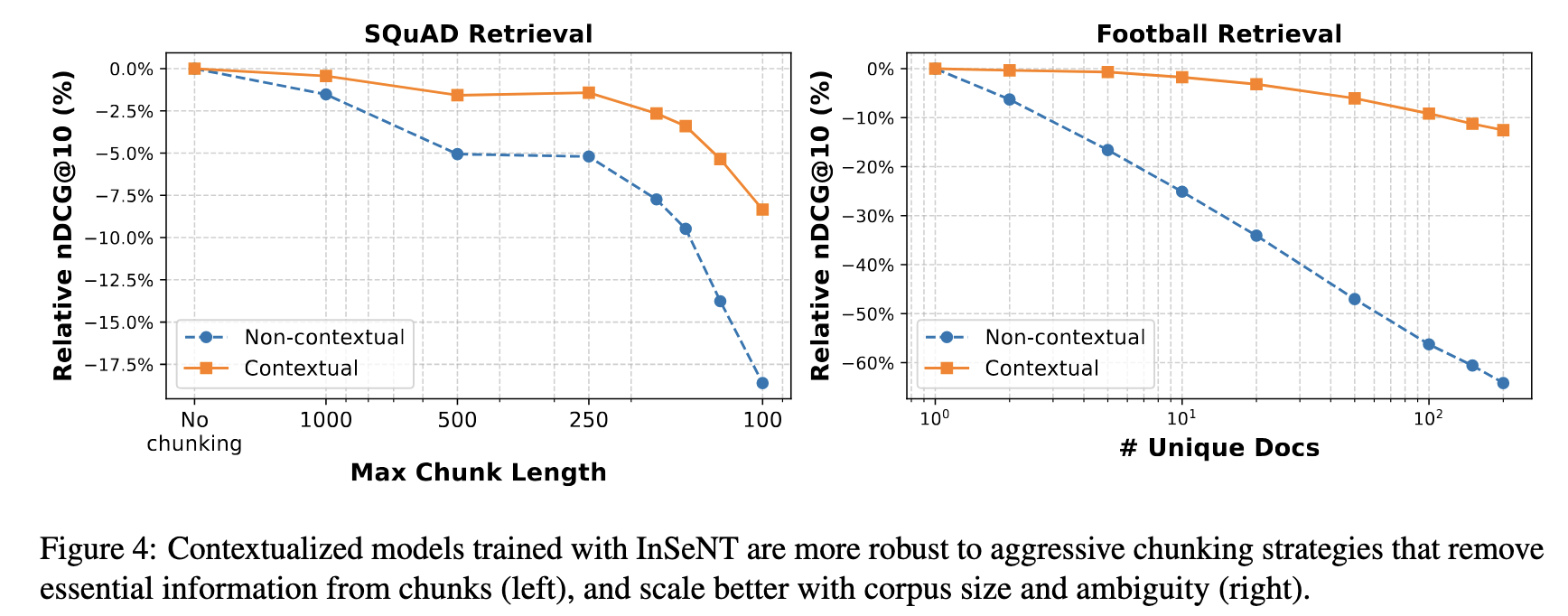 Contextualized models trained with InSeNT are more robust to aggressive chunking strategies that remove essential information from chunks (left), and scale better with corpus size and ambiguity (right).
Contextualized models trained with InSeNT are more robust to aggressive chunking strategies that remove essential information from chunks (left), and scale better with corpus size and ambiguity (right).
What about Late Interaction models ?
Late Interaction models (ColBERT-style) keep multiple vectors per passage (usually one per token), and use a multi-vector to multi-vector matching operation called MaxSim to obtain a scalar query-document relevance score. Those familiar with the work from our group know we are big fans ! These models tend to perform better than their dense counterparts at the expense of increased storage cost, and especially shine in long-context settings.
Interestingly, while LI models are good at long-context retrieving, they are poorly suited to out-of-the-box late chunking (-0.3 nDCG@10 w.r.t. ModernColBERT without LI). We posit that since token embeddings are trained without pooling, these models learn very local features and cannot leverage information from neighboring tokens. Once trained with our method, ModernColBERT+InSeNT displays large performance gains across the board (+11.5 nDCG@10 w.r.t. ModernColBERT + Late Chunking), showcasing an increased ability to leverage external context.
In practice, this means that to perform late-chunking contextualization with LI models, you really need to train them!
As a sidenote, this project stems from disappointing attempts to contextualize documents using late chunking with ColPali models without retraining. The results obtained throught this work are a promising avenue to improve visual retrievers such as ColPali by enabling them to integrate information beyond the single page they embed.
Ressources
- HuggingFace Project Page: The HF page centralizing everything!
- (Model) ModernBERT: The Contextualized ModernBERT bi-encoder trained with InSENT loss and Late Chunking
- (Model) ModernColBERT: The Contextualized ModernColBERT trained with InSENT loss and Late Chunking
- Leaderboard: Coming Soon
- (Data) ConTEB Benchmark Datasets: Datasets included in ConTEB.
- (Code) Contextual Document Engine: The code used to train and run inference with our architecture.
- (Code) ConTEB Benchmarkk: A Python package/CLI tool to evaluate document retrieval systems on the ConTEB benchmark.
- Preprint: The paper with all details !
Contact of the first-authors
- Manuel Faysse: [email protected]
- Max Conti: [email protected]
Citation
If you use any datasets or models from this organization in your research, please cite the original work as follows:
@misc{conti2025contextgoldgoldpassage,
title={Context is Gold to find the Gold Passage: Evaluating and Training Contextual Document Embeddings},
author={Max Conti and Manuel Faysse and Gautier Viaud and Antoine Bosselut and Céline Hudelot and Pierre Colombo},
year={2025},
eprint={2505.24782},
archivePrefix={arXiv},
primaryClass={cs.IR},
url={https://arxiv.org/abs/2505.24782},
}
Acknowledgments
This work is partially supported by ILLUIN Technology, and by a grant from ANRT France. This work was performed using HPC resources from the GENCI Jeanzay supercomputer with grant AD011016393.






