

Update README and scripts
Browse files- README.md +12 -10
- configuration_qwen2.py +0 -5
- figures/chat_example.png +0 -0
- modeling_qwen2.py +4 -83
README.md
CHANGED
|
@@ -1,20 +1,22 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
base_model:
|
| 4 |
-
- Qwen/Qwen2.5-14B-Instruct
|
| 5 |
-
---
|
| 6 |
# ChatTS-14B Model
|
| 7 |
-
|
|
|
|
| 8 |
|
| 9 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 10 |
- QWen2.5-14B-Instruct (https://huggingface.co/Qwen/Qwen2.5-14B-Instruct)
|
| 11 |
- transformers (https://github.com/huggingface/transformers.git)
|
| 12 |
- [ChatTS Paper](https://arxiv.org/pdf/2412.03104)
|
| 13 |
|
| 14 |
-
|
| 15 |
This model is licensed under the [Apache License 2.0](LICENSE).
|
| 16 |
|
| 17 |
-
|
| 18 |
```
|
| 19 |
@article{xie2024chatts,
|
| 20 |
title={ChatTS: Aligning Time Series with LLMs via Synthetic Data for Enhanced Understanding and Reasoning},
|
|
@@ -22,4 +24,4 @@ This model is licensed under the [Apache License 2.0](LICENSE).
|
|
| 22 |
journal={arXiv preprint arXiv:2412.03104},
|
| 23 |
year={2024}
|
| 24 |
}
|
| 25 |
-
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
# ChatTS-14B Model
|
| 2 |
+
`ChatTS` focuses on **Understanding and Reasoning** about time series, much like what vision/video/audio-MLLMs do.
|
| 3 |
+
This repo provides code, datasets and model for `ChatTS`: [ChatTS: Aligning Time Series with LLMs via Synthetic Data for Enhanced Understanding and Reasoning](https://arxiv.org/pdf/2412.03104).
|
| 4 |
|
| 5 |
+
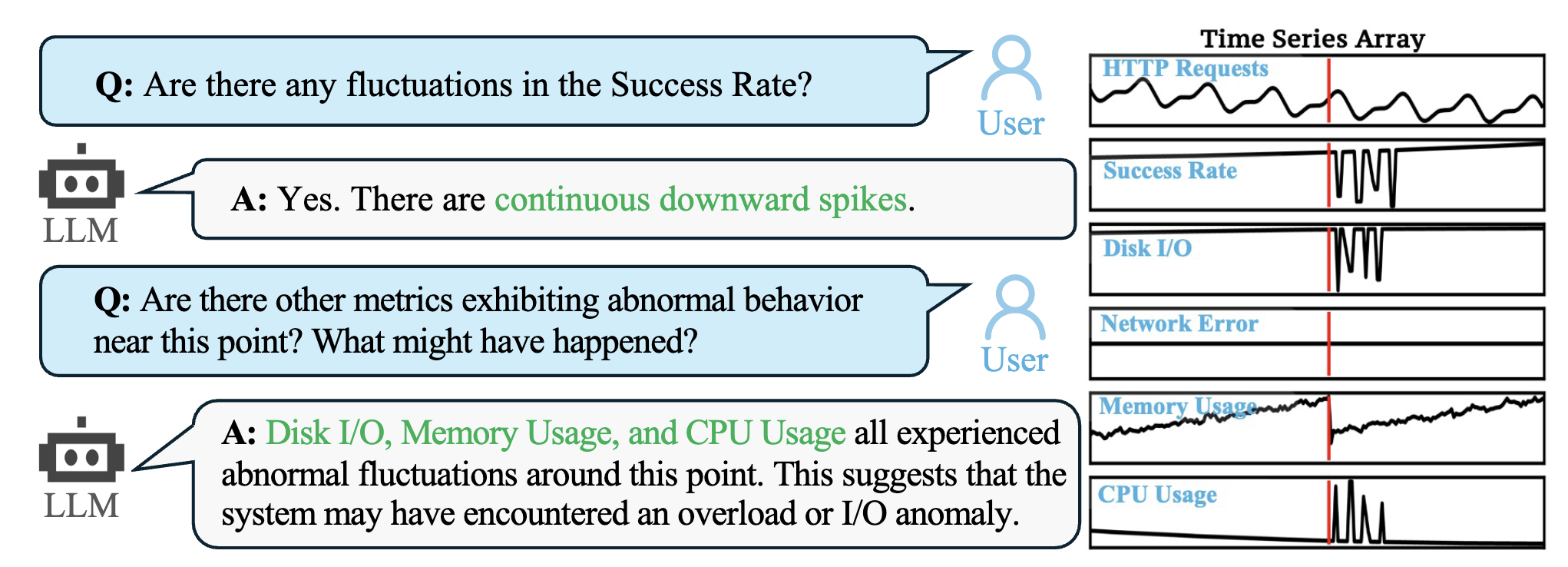
Here is an example of a ChatTS application, which allows users to interact with a LLM to understand and reason about time series data:
|
| 6 |
+

|
| 7 |
+
|
| 8 |
+
## Usage
|
| 9 |
+
This model is fine-tuned on the QWen2.5-14B-Instruct (https://huggingface.co/Qwen/Qwen2.5-14B-Instruct) model. For more usage details, please refer to the `README.md` in the ChatTS repository.
|
| 10 |
+
|
| 11 |
+
## Reference
|
| 12 |
- QWen2.5-14B-Instruct (https://huggingface.co/Qwen/Qwen2.5-14B-Instruct)
|
| 13 |
- transformers (https://github.com/huggingface/transformers.git)
|
| 14 |
- [ChatTS Paper](https://arxiv.org/pdf/2412.03104)
|
| 15 |
|
| 16 |
+
## License
|
| 17 |
This model is licensed under the [Apache License 2.0](LICENSE).
|
| 18 |
|
| 19 |
+
## Cite
|
| 20 |
```
|
| 21 |
@article{xie2024chatts,
|
| 22 |
title={ChatTS: Aligning Time Series with LLMs via Synthetic Data for Enhanced Understanding and Reasoning},
|
|
|
|
| 24 |
journal={arXiv preprint arXiv:2412.03104},
|
| 25 |
year={2024}
|
| 26 |
}
|
| 27 |
+
```
|
configuration_qwen2.py
CHANGED
|
@@ -1,5 +1,4 @@
|
|
| 1 |
# coding=utf-8
|
| 2 |
-
# The following code are reused from the QWen project (https://huggingface.co/Qwen/Qwen2.5-14B-Instruct) of Alibaba Cloud.
|
| 3 |
# Copyright 2024 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
|
| 4 |
#
|
| 5 |
# Licensed under the Apache License, Version 2.0 (the "License");
|
|
@@ -13,10 +12,6 @@
|
|
| 13 |
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
# See the License for the specific language governing permissions and
|
| 15 |
# limitations under the License.
|
| 16 |
-
|
| 17 |
-
# The code is modified by ByteDance and Tsinghua University from the original implementation of Qwen:
|
| 18 |
-
# - We changed Qwen2Config to Qwen2TSConfig to support time series modeling.
|
| 19 |
-
|
| 20 |
""" Qwen2 model configuration"""
|
| 21 |
|
| 22 |
from transformers import PretrainedConfig
|
|
|
|
| 1 |
# coding=utf-8
|
|
|
|
| 2 |
# Copyright 2024 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
|
| 3 |
#
|
| 4 |
# Licensed under the Apache License, Version 2.0 (the "License");
|
|
|
|
| 12 |
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
# See the License for the specific language governing permissions and
|
| 14 |
# limitations under the License.
|
|
|
|
|
|
|
|
|
|
|
|
|
| 15 |
""" Qwen2 model configuration"""
|
| 16 |
|
| 17 |
from transformers import PretrainedConfig
|
figures/chat_example.png
ADDED
|
modeling_qwen2.py
CHANGED
|
@@ -1,5 +1,4 @@
|
|
| 1 |
# coding=utf-8
|
| 2 |
-
# The following code are reused from the QWen project (https://huggingface.co/Qwen/Qwen2.5-14B-Instruct) of Alibaba Cloud.
|
| 3 |
# Copyright 2024 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
|
| 4 |
#
|
| 5 |
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
|
|
@@ -18,10 +17,6 @@
|
|
| 18 |
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 19 |
# See the License for the specific language governing permissions and
|
| 20 |
# limitations under the License.
|
| 21 |
-
|
| 22 |
-
# The code is modified by ByteDance and Tsinghua University from the original implementation of Qwen:
|
| 23 |
-
# - Support time series modality for Qwen2 model.
|
| 24 |
-
|
| 25 |
""" PyTorch Qwen2 model."""
|
| 26 |
import inspect
|
| 27 |
import math
|
|
@@ -78,7 +73,6 @@ class TimeSeriesEmbedding(nn.Module):
|
|
| 78 |
self.num_features = config['num_features']
|
| 79 |
|
| 80 |
layers = []
|
| 81 |
-
# 调整输入大小以包含掩码通道
|
| 82 |
input_size = 1 * self.patch_size
|
| 83 |
|
| 84 |
for _ in range(self.num_layers - 1):
|
|
@@ -97,7 +91,6 @@ class TimeSeriesEmbedding(nn.Module):
|
|
| 97 |
valid_lengths = mask.sum(dim=1).long() # Shape: (batch_size)
|
| 98 |
|
| 99 |
patch_cnt = (valid_lengths + self.patch_size - 1) // self.patch_size # 向上取整
|
| 100 |
-
# print(f"[DEBUG] TimeSeriesEmbedding: {valid_lengths=}, {patch_cnt=}, {mask.shape=}")
|
| 101 |
|
| 102 |
patches_list = []
|
| 103 |
for i in range(batch_size):
|
|
@@ -118,9 +111,7 @@ class TimeSeriesEmbedding(nn.Module):
|
|
| 118 |
x_patches = torch.cat(patches_list, dim=0) # Shape: (total_patch_cnt, patch_size * num_features)
|
| 119 |
x = self.mlp(x_patches)
|
| 120 |
else:
|
| 121 |
-
# 如果没有有效的 patches,返回空 tensor
|
| 122 |
x = torch.empty(0, self.hidden_size, device=x.device)
|
| 123 |
-
# print(f"[DEBUG] TimeSeriesEmbedding OUTPUT: {x.shape=}, {patch_cnt=}")
|
| 124 |
|
| 125 |
return x, patch_cnt
|
| 126 |
|
|
@@ -1204,21 +1195,7 @@ class Qwen2TSForCausalLM(Qwen2PreTrainedModel):
|
|
| 1204 |
return num_special_ts_tokens * (num_patches - 2) + input_ids.size(1)
|
| 1205 |
|
| 1206 |
def _get_original_length(self, timeseries, input_ids, past_length):
|
| 1207 |
-
"""
|
| 1208 |
-
根据转换后的 past_length 计算对应的原始序列长度,并返回包含的 <ts> 标记数量。
|
| 1209 |
-
|
| 1210 |
-
Args:
|
| 1211 |
-
timeseries (Tensor): 时间序列数据张量,形状为 (batch_size, num_time_steps)。
|
| 1212 |
-
input_ids (Tensor): 原始输入 IDs 张量,形状为 (batch_size, seq_length)。
|
| 1213 |
-
past_length (int 或 Tensor): 转换后的序列长度(包含插入的时间序列特征 token),可以是标量或形状为 (batch_size,) 的张量。
|
| 1214 |
-
|
| 1215 |
-
Returns:
|
| 1216 |
-
Tuple[Tensor, Tensor]:
|
| 1217 |
-
- original_length (Tensor): 每个样本对应的原始序列长度,形状为 (batch_size,)。
|
| 1218 |
-
- num_special_ts_tokens_within_past (Tensor): 每个样本在 past_length 范围内包含的 <ts> 标记数量,形状为 (batch_size,)。
|
| 1219 |
-
"""
|
| 1220 |
if timeseries is None:
|
| 1221 |
-
# 如果没有时间序列特征插入,原始长度等于 past_length
|
| 1222 |
if isinstance(past_length, int):
|
| 1223 |
original_length = torch.full((input_ids.size(0),), past_length, dtype=torch.long, device=input_ids.device)
|
| 1224 |
else:
|
|
@@ -1226,45 +1203,32 @@ class Qwen2TSForCausalLM(Qwen2PreTrainedModel):
|
|
| 1226 |
num_special_ts_tokens_within_past = torch.zeros(input_ids.size(0), dtype=torch.long, device=input_ids.device)
|
| 1227 |
return original_length, num_special_ts_tokens_within_past
|
| 1228 |
|
| 1229 |
-
# 获取配置参数
|
| 1230 |
patch_size = self.config.ts['patch_size']
|
| 1231 |
num_patches = timeseries.size(1) * timeseries.size(2) // patch_size // self.config.ts['num_features']
|
| 1232 |
ts_token_start_index = self.config.ts_token_start_index
|
| 1233 |
|
| 1234 |
-
# 生成 mask,标识 <ts> token 的位置
|
| 1235 |
ts_mask = (input_ids == ts_token_start_index).long() # (batch_size, seq_length)
|
| 1236 |
|
| 1237 |
-
# 计算每个位置之前的 <ts> token 数量的累积和
|
| 1238 |
cumsum_ts = torch.cumsum(ts_mask, dim=1) # (batch_size, seq_length)
|
| 1239 |
|
| 1240 |
-
# 生成位置索引,从 1 开始
|
| 1241 |
seq_length = input_ids.size(1)
|
| 1242 |
positions = torch.arange(1, seq_length + 1, device=input_ids.device).unsqueeze(0).expand_as(input_ids) # (batch_size, seq_length)
|
| 1243 |
|
| 1244 |
-
# 计算转换后的位置
|
| 1245 |
transformed_length = positions + cumsum_ts * (num_patches - 2) # (batch_size, seq_length)
|
| 1246 |
|
| 1247 |
-
# 处理 past_length,可以是标量或张量
|
| 1248 |
if isinstance(past_length, int):
|
| 1249 |
past_length_tensor = torch.full((input_ids.size(0),), past_length, dtype=torch.long, device=input_ids.device)
|
| 1250 |
else:
|
| 1251 |
past_length_tensor = past_length.to(input_ids.device)
|
| 1252 |
|
| 1253 |
-
# 创建一个 mask,标识哪些原始位置在转换后不超过 past_length
|
| 1254 |
mask = transformed_length <= past_length_tensor.unsqueeze(1) # (batch_size, seq_length)
|
| 1255 |
|
| 1256 |
-
# 对每个样本,计算满足条件的位置数量,即原始长度
|
| 1257 |
original_length = torch.sum(mask, dim=1) # (batch_size,)
|
| 1258 |
-
|
| 1259 |
-
# 计算在 original_length 范围内包含的 <ts> 标记数量
|
| 1260 |
-
# 生成一个 mask,标识 original_length 范围内的 <ts> token
|
| 1261 |
-
# 首先生成一个位置索引
|
| 1262 |
original_positions = torch.arange(1, seq_length + 1, device=input_ids.device).unsqueeze(0).expand_as(input_ids) # (batch_size, seq_length)
|
| 1263 |
original_mask = original_positions <= original_length.unsqueeze(1) # (batch_size, seq_length)
|
| 1264 |
ts_within_original_mask = ts_mask.bool() & original_mask.bool() # (batch_size, seq_length)
|
| 1265 |
num_special_ts_tokens_within_past = torch.sum(ts_within_original_mask, dim=1) # (batch_size,)
|
| 1266 |
|
| 1267 |
-
# 确保 original_length 不为负数
|
| 1268 |
original_length = torch.clamp(original_length, min=0)
|
| 1269 |
|
| 1270 |
return original_length, num_special_ts_tokens_within_past
|
|
@@ -1280,7 +1244,6 @@ class Qwen2TSForCausalLM(Qwen2PreTrainedModel):
|
|
| 1280 |
special_ts_token_mask_start = input_ids == self.config.ts_token_start_index
|
| 1281 |
special_ts_token_mask_end = input_ids == self.config.ts_token_end_index
|
| 1282 |
special_ts_token_mask = special_ts_token_mask_start | special_ts_token_mask_end
|
| 1283 |
-
# print("Special ts token mask:", special_ts_token_mask)
|
| 1284 |
num_special_ts_tokens = torch.sum(special_ts_token_mask_start, dim=-1)
|
| 1285 |
# Correctly calculate the total number of patches per batch
|
| 1286 |
num_total_patches = torch.zeros(batch_size, dtype=patch_cnt.dtype, device=patch_cnt.device)
|
|
@@ -1291,8 +1254,8 @@ class Qwen2TSForCausalLM(Qwen2PreTrainedModel):
|
|
| 1291 |
num_ts_in_batch = num_special_ts_tokens[i]
|
| 1292 |
num_total_patches[i] = patch_cnt[patch_index:patch_index + num_ts_in_batch].sum() - 2 * num_ts_in_batch
|
| 1293 |
for idx in range(patch_index, patch_index + num_ts_in_batch):
|
| 1294 |
-
batch_idx,
|
| 1295 |
-
special_ts_token_mask_start_with_size[batch_idx,
|
| 1296 |
patch_index += num_ts_in_batch
|
| 1297 |
|
| 1298 |
# Compute the maximum embed dimension, considering both start and end tokens
|
|
@@ -1300,17 +1263,13 @@ class Qwen2TSForCausalLM(Qwen2PreTrainedModel):
|
|
| 1300 |
|
| 1301 |
# batch_indices, non_ts_indices = torch.where(~special_ts_token_mask)
|
| 1302 |
batch_indices, non_ts_indices = torch.where(~special_ts_token_mask)
|
| 1303 |
-
|
| 1304 |
-
# print("batch_indices:", batch_indices)
|
| 1305 |
-
|
| 1306 |
# 2. Compute the positions where text should be written
|
| 1307 |
new_token_positions = torch.cumsum((special_ts_token_mask_start_with_size + 1), dim=-1) - 1
|
| 1308 |
-
# print("new_token_positions", new_token_positions)
|
| 1309 |
nb_ts_pad = max_embed_dim - 1 - new_token_positions[:, -1]
|
| 1310 |
if left_padding:
|
| 1311 |
new_token_positions += nb_ts_pad[:, None] # offset for left padding
|
| 1312 |
text_to_overwrite = new_token_positions[batch_indices, non_ts_indices]
|
| 1313 |
-
# print('nb_ts_pad', nb_ts_pad)
|
| 1314 |
|
| 1315 |
# 3. Create the full embedding, already padded to the maximum position
|
| 1316 |
final_embedding = torch.zeros(
|
|
@@ -1334,7 +1293,6 @@ class Qwen2TSForCausalLM(Qwen2PreTrainedModel):
|
|
| 1334 |
# 4. Fill the embeddings based on the mask
|
| 1335 |
final_embedding[batch_indices, text_to_overwrite] = inputs_embeds[batch_indices, non_ts_indices]
|
| 1336 |
final_attention_mask[batch_indices, text_to_overwrite] = attention_mask[batch_indices, non_ts_indices]
|
| 1337 |
-
# print('final_attention_mask=', final_attention_mask)
|
| 1338 |
if labels is not None:
|
| 1339 |
final_labels[batch_indices, text_to_overwrite] = labels[batch_indices, non_ts_indices]
|
| 1340 |
|
|
@@ -1343,11 +1301,8 @@ class Qwen2TSForCausalLM(Qwen2PreTrainedModel):
|
|
| 1343 |
(batch_size, max_embed_dim), True, dtype=torch.bool, device=inputs_embeds.device
|
| 1344 |
)
|
| 1345 |
ts_to_overwrite[batch_indices, text_to_overwrite] = False
|
| 1346 |
-
# print('ts_to_overwrite.long().cumsum(-1) - 1=', ts_to_overwrite.long().cumsum(-1) - 1)
|
| 1347 |
-
# print('nb_ts_pad=', nb_ts_pad[:, None])
|
| 1348 |
reversed_cumsum = ts_to_overwrite.flip(dims=[-1]).cumsum(-1).flip(dims=[-1]) - 1
|
| 1349 |
ts_to_overwrite &= reversed_cumsum >= nb_ts_pad[:, None].to(target_device)
|
| 1350 |
-
# print('ts_to_overwrite=', ts_to_overwrite)
|
| 1351 |
|
| 1352 |
if ts_to_overwrite.sum() != time_series_features.shape[:-1].numel():
|
| 1353 |
raise ValueError(
|
|
@@ -1356,7 +1311,6 @@ class Qwen2TSForCausalLM(Qwen2PreTrainedModel):
|
|
| 1356 |
)
|
| 1357 |
|
| 1358 |
final_embedding[ts_to_overwrite] = time_series_features.contiguous().reshape(-1, embed_dim).to(target_device)
|
| 1359 |
-
# logger.warning(f"[DEBUG] {final_embedding[ts_to_overwrite][:, 0]=}")
|
| 1360 |
final_attention_mask |= ts_to_overwrite
|
| 1361 |
position_ids = (final_attention_mask.cumsum(-1) - 1).masked_fill_((final_attention_mask == 0), 1)
|
| 1362 |
|
|
@@ -1423,47 +1377,16 @@ class Qwen2TSForCausalLM(Qwen2PreTrainedModel):
|
|
| 1423 |
inputs_embeds = self.get_input_embeddings()(input_ids)
|
| 1424 |
|
| 1425 |
if timeseries is not None and timeseries.shape[0] > 0:
|
|
|
|
| 1426 |
use_cache = False
|
| 1427 |
-
# print(f"[DEBUG] input timeseries.shape: {timeseries.shape}")
|
| 1428 |
-
|
| 1429 |
-
# 调用 ts_encoder,并打印输入和输出的形状
|
| 1430 |
ts_features, patch_cnt = self.ts_encoder(timeseries)
|
| 1431 |
-
# print(f"[DEBUG] ts_features.shape: {ts_features.shape}")
|
| 1432 |
-
# print(f"[DEBUG] patch_cnt: {patch_cnt}")
|
| 1433 |
|
| 1434 |
inputs_embeds = inputs_embeds.to(ts_features.dtype)
|
| 1435 |
|
| 1436 |
-
# 在合并前打印相关形状
|
| 1437 |
-
# print(f"[DEBUG] Before merging:")
|
| 1438 |
-
# print(f"{inputs_embeds[0, -5:, :5]=}")
|
| 1439 |
-
# print(f"{attention_mask.sum()=}")
|
| 1440 |
-
# print(f" inputs_embeds.shape: {inputs_embeds.shape}")
|
| 1441 |
-
# print(f" input_ids.shape: {input_ids.shape}")
|
| 1442 |
-
# print(f" attention_mask.shape: {attention_mask.shape}")
|
| 1443 |
-
# if labels is not None:
|
| 1444 |
-
# print(f" labels.shape: {labels.shape}")
|
| 1445 |
-
# else:
|
| 1446 |
-
# print(f" labels: None")
|
| 1447 |
-
# print(f" patch_cnt.shape: {patch_cnt.shape}")
|
| 1448 |
-
|
| 1449 |
-
# 调用 _merge_input_ids_with_time_series_features,并打印输出的形状
|
| 1450 |
inputs_embeds, attention_mask, position_ids, labels = self._merge_input_ids_with_time_series_features(
|
| 1451 |
ts_features, inputs_embeds, input_ids, attention_mask, labels, patch_cnt
|
| 1452 |
)
|
| 1453 |
|
| 1454 |
-
# print(f"[DEBUG] After merging:")
|
| 1455 |
-
# print(f" inputs_embeds.shape: {inputs_embeds.shape}")
|
| 1456 |
-
# print(f" attention_mask.shape: {attention_mask.shape}")
|
| 1457 |
-
# print(f"{attention_mask.sum()=}")
|
| 1458 |
-
# print(f"{inputs_embeds[0, -5:, :5]=}")
|
| 1459 |
-
|
| 1460 |
-
# print(f" position_ids.shape: {position_ids.shape}")
|
| 1461 |
-
# if labels is not None:
|
| 1462 |
-
# print(f" labels.shape: {labels.shape}")
|
| 1463 |
-
# else:
|
| 1464 |
-
# print(f" labels: None")
|
| 1465 |
-
|
| 1466 |
-
# 继续模型的前向传播
|
| 1467 |
outputs = self.model(
|
| 1468 |
attention_mask=attention_mask,
|
| 1469 |
position_ids=position_ids,
|
|
@@ -1518,8 +1441,6 @@ class Qwen2TSForCausalLM(Qwen2PreTrainedModel):
|
|
| 1518 |
cache_length = past_length = past_key_values[0][0].shape[2]
|
| 1519 |
max_cache_length = None
|
| 1520 |
|
| 1521 |
-
# print(f"[prepare_inputs_for_generation] {cache_length=}, {past_length=}, {max_cache_length=}")
|
| 1522 |
-
|
| 1523 |
# Keep only the unprocessed tokens:
|
| 1524 |
# 1 - If the length of the attention_mask exceeds the length of input_ids, then we are in a setting where
|
| 1525 |
# some of the inputs are exclusively passed as part of the cache (e.g. when passing input_embeds as
|
|
|
|
| 1 |
# coding=utf-8
|
|
|
|
| 2 |
# Copyright 2024 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
|
| 3 |
#
|
| 4 |
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
|
|
|
|
| 17 |
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 18 |
# See the License for the specific language governing permissions and
|
| 19 |
# limitations under the License.
|
|
|
|
|
|
|
|
|
|
|
|
|
| 20 |
""" PyTorch Qwen2 model."""
|
| 21 |
import inspect
|
| 22 |
import math
|
|
|
|
| 73 |
self.num_features = config['num_features']
|
| 74 |
|
| 75 |
layers = []
|
|
|
|
| 76 |
input_size = 1 * self.patch_size
|
| 77 |
|
| 78 |
for _ in range(self.num_layers - 1):
|
|
|
|
| 91 |
valid_lengths = mask.sum(dim=1).long() # Shape: (batch_size)
|
| 92 |
|
| 93 |
patch_cnt = (valid_lengths + self.patch_size - 1) // self.patch_size # 向上取整
|
|
|
|
| 94 |
|
| 95 |
patches_list = []
|
| 96 |
for i in range(batch_size):
|
|
|
|
| 111 |
x_patches = torch.cat(patches_list, dim=0) # Shape: (total_patch_cnt, patch_size * num_features)
|
| 112 |
x = self.mlp(x_patches)
|
| 113 |
else:
|
|
|
|
| 114 |
x = torch.empty(0, self.hidden_size, device=x.device)
|
|
|
|
| 115 |
|
| 116 |
return x, patch_cnt
|
| 117 |
|
|
|
|
| 1195 |
return num_special_ts_tokens * (num_patches - 2) + input_ids.size(1)
|
| 1196 |
|
| 1197 |
def _get_original_length(self, timeseries, input_ids, past_length):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1198 |
if timeseries is None:
|
|
|
|
| 1199 |
if isinstance(past_length, int):
|
| 1200 |
original_length = torch.full((input_ids.size(0),), past_length, dtype=torch.long, device=input_ids.device)
|
| 1201 |
else:
|
|
|
|
| 1203 |
num_special_ts_tokens_within_past = torch.zeros(input_ids.size(0), dtype=torch.long, device=input_ids.device)
|
| 1204 |
return original_length, num_special_ts_tokens_within_past
|
| 1205 |
|
|
|
|
| 1206 |
patch_size = self.config.ts['patch_size']
|
| 1207 |
num_patches = timeseries.size(1) * timeseries.size(2) // patch_size // self.config.ts['num_features']
|
| 1208 |
ts_token_start_index = self.config.ts_token_start_index
|
| 1209 |
|
|
|
|
| 1210 |
ts_mask = (input_ids == ts_token_start_index).long() # (batch_size, seq_length)
|
| 1211 |
|
|
|
|
| 1212 |
cumsum_ts = torch.cumsum(ts_mask, dim=1) # (batch_size, seq_length)
|
| 1213 |
|
|
|
|
| 1214 |
seq_length = input_ids.size(1)
|
| 1215 |
positions = torch.arange(1, seq_length + 1, device=input_ids.device).unsqueeze(0).expand_as(input_ids) # (batch_size, seq_length)
|
| 1216 |
|
|
|
|
| 1217 |
transformed_length = positions + cumsum_ts * (num_patches - 2) # (batch_size, seq_length)
|
| 1218 |
|
|
|
|
| 1219 |
if isinstance(past_length, int):
|
| 1220 |
past_length_tensor = torch.full((input_ids.size(0),), past_length, dtype=torch.long, device=input_ids.device)
|
| 1221 |
else:
|
| 1222 |
past_length_tensor = past_length.to(input_ids.device)
|
| 1223 |
|
|
|
|
| 1224 |
mask = transformed_length <= past_length_tensor.unsqueeze(1) # (batch_size, seq_length)
|
| 1225 |
|
|
|
|
| 1226 |
original_length = torch.sum(mask, dim=1) # (batch_size,)
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1227 |
original_positions = torch.arange(1, seq_length + 1, device=input_ids.device).unsqueeze(0).expand_as(input_ids) # (batch_size, seq_length)
|
| 1228 |
original_mask = original_positions <= original_length.unsqueeze(1) # (batch_size, seq_length)
|
| 1229 |
ts_within_original_mask = ts_mask.bool() & original_mask.bool() # (batch_size, seq_length)
|
| 1230 |
num_special_ts_tokens_within_past = torch.sum(ts_within_original_mask, dim=1) # (batch_size,)
|
| 1231 |
|
|
|
|
| 1232 |
original_length = torch.clamp(original_length, min=0)
|
| 1233 |
|
| 1234 |
return original_length, num_special_ts_tokens_within_past
|
|
|
|
| 1244 |
special_ts_token_mask_start = input_ids == self.config.ts_token_start_index
|
| 1245 |
special_ts_token_mask_end = input_ids == self.config.ts_token_end_index
|
| 1246 |
special_ts_token_mask = special_ts_token_mask_start | special_ts_token_mask_end
|
|
|
|
| 1247 |
num_special_ts_tokens = torch.sum(special_ts_token_mask_start, dim=-1)
|
| 1248 |
# Correctly calculate the total number of patches per batch
|
| 1249 |
num_total_patches = torch.zeros(batch_size, dtype=patch_cnt.dtype, device=patch_cnt.device)
|
|
|
|
| 1254 |
num_ts_in_batch = num_special_ts_tokens[i]
|
| 1255 |
num_total_patches[i] = patch_cnt[patch_index:patch_index + num_ts_in_batch].sum() - 2 * num_ts_in_batch
|
| 1256 |
for idx in range(patch_index, patch_index + num_ts_in_batch):
|
| 1257 |
+
batch_idx, pos_idx = special_ts_token_mask_start_nonzero[idx]
|
| 1258 |
+
special_ts_token_mask_start_with_size[batch_idx, pos_idx] *= (patch_cnt[idx].item() - 2)
|
| 1259 |
patch_index += num_ts_in_batch
|
| 1260 |
|
| 1261 |
# Compute the maximum embed dimension, considering both start and end tokens
|
|
|
|
| 1263 |
|
| 1264 |
# batch_indices, non_ts_indices = torch.where(~special_ts_token_mask)
|
| 1265 |
batch_indices, non_ts_indices = torch.where(~special_ts_token_mask)
|
| 1266 |
+
|
|
|
|
|
|
|
| 1267 |
# 2. Compute the positions where text should be written
|
| 1268 |
new_token_positions = torch.cumsum((special_ts_token_mask_start_with_size + 1), dim=-1) - 1
|
|
|
|
| 1269 |
nb_ts_pad = max_embed_dim - 1 - new_token_positions[:, -1]
|
| 1270 |
if left_padding:
|
| 1271 |
new_token_positions += nb_ts_pad[:, None] # offset for left padding
|
| 1272 |
text_to_overwrite = new_token_positions[batch_indices, non_ts_indices]
|
|
|
|
| 1273 |
|
| 1274 |
# 3. Create the full embedding, already padded to the maximum position
|
| 1275 |
final_embedding = torch.zeros(
|
|
|
|
| 1293 |
# 4. Fill the embeddings based on the mask
|
| 1294 |
final_embedding[batch_indices, text_to_overwrite] = inputs_embeds[batch_indices, non_ts_indices]
|
| 1295 |
final_attention_mask[batch_indices, text_to_overwrite] = attention_mask[batch_indices, non_ts_indices]
|
|
|
|
| 1296 |
if labels is not None:
|
| 1297 |
final_labels[batch_indices, text_to_overwrite] = labels[batch_indices, non_ts_indices]
|
| 1298 |
|
|
|
|
| 1301 |
(batch_size, max_embed_dim), True, dtype=torch.bool, device=inputs_embeds.device
|
| 1302 |
)
|
| 1303 |
ts_to_overwrite[batch_indices, text_to_overwrite] = False
|
|
|
|
|
|
|
| 1304 |
reversed_cumsum = ts_to_overwrite.flip(dims=[-1]).cumsum(-1).flip(dims=[-1]) - 1
|
| 1305 |
ts_to_overwrite &= reversed_cumsum >= nb_ts_pad[:, None].to(target_device)
|
|
|
|
| 1306 |
|
| 1307 |
if ts_to_overwrite.sum() != time_series_features.shape[:-1].numel():
|
| 1308 |
raise ValueError(
|
|
|
|
| 1311 |
)
|
| 1312 |
|
| 1313 |
final_embedding[ts_to_overwrite] = time_series_features.contiguous().reshape(-1, embed_dim).to(target_device)
|
|
|
|
| 1314 |
final_attention_mask |= ts_to_overwrite
|
| 1315 |
position_ids = (final_attention_mask.cumsum(-1) - 1).masked_fill_((final_attention_mask == 0), 1)
|
| 1316 |
|
|
|
|
| 1377 |
inputs_embeds = self.get_input_embeddings()(input_ids)
|
| 1378 |
|
| 1379 |
if timeseries is not None and timeseries.shape[0] > 0:
|
| 1380 |
+
# Disable KV Cache as it has not been implemented yet
|
| 1381 |
use_cache = False
|
|
|
|
|
|
|
|
|
|
| 1382 |
ts_features, patch_cnt = self.ts_encoder(timeseries)
|
|
|
|
|
|
|
| 1383 |
|
| 1384 |
inputs_embeds = inputs_embeds.to(ts_features.dtype)
|
| 1385 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1386 |
inputs_embeds, attention_mask, position_ids, labels = self._merge_input_ids_with_time_series_features(
|
| 1387 |
ts_features, inputs_embeds, input_ids, attention_mask, labels, patch_cnt
|
| 1388 |
)
|
| 1389 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1390 |
outputs = self.model(
|
| 1391 |
attention_mask=attention_mask,
|
| 1392 |
position_ids=position_ids,
|
|
|
|
| 1441 |
cache_length = past_length = past_key_values[0][0].shape[2]
|
| 1442 |
max_cache_length = None
|
| 1443 |
|
|
|
|
|
|
|
| 1444 |
# Keep only the unprocessed tokens:
|
| 1445 |
# 1 - If the length of the attention_mask exceeds the length of input_ids, then we are in a setting where
|
| 1446 |
# some of the inputs are exclusively passed as part of the cache (e.g. when passing input_embeds as
|