
Commit
·
8cbd9c4
1
Parent(s):
46fee02
first commit
Browse files- README.md +57 -1
- comparision1.png +0 -0
- graph.png +0 -0
- grid_tiny.png +0 -0
- model_index.json +34 -0
- scheduler/scheduler_config.json +25 -0
- text_encoder/config.json +25 -0
- tokenizer/merges.txt +0 -0
- tokenizer/special_tokens_map.json +24 -0
- tokenizer/tokenizer_config.json +33 -0
- tokenizer/vocab.json +0 -0
- unet/config.json +33 -0
- unet/diffusion_pytorch_model.bin +3 -0
- vae/config.json +32 -0
- vae/diffusion_pytorch_model.bin +3 -0
- val_imgs_grid.png +0 -0
README.md
CHANGED
|
@@ -1,3 +1,59 @@
|
|
|
|
|
| 1 |
---
|
| 2 |
-
license:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
---
|
| 3 |
+
license: creativeml-openrail-m
|
| 4 |
+
base_model: SG161222/Realistic_Vision_V4.0
|
| 5 |
+
datasets:
|
| 6 |
+
- recastai/LAION-art-EN-improved-captions
|
| 7 |
+
tags:
|
| 8 |
+
- stable-diffusion
|
| 9 |
+
- stable-diffusion-diffusers
|
| 10 |
+
- text-to-image
|
| 11 |
+
- diffusers
|
| 12 |
+
inference: true
|
| 13 |
---
|
| 14 |
+
|
| 15 |
+
# Text-to-image Distillation
|
| 16 |
+
|
| 17 |
+
This pipeline was distilled from **SG161222/Realistic_Vision_V4.0** on a Subset of **recastai/LAION-art-EN-improved-captions** dataset. Below are some example images generated with the tiny-sd model.
|
| 18 |
+
|
| 19 |
+

|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
This Pipeline is based upon [the paper](https://arxiv.org/pdf/2305.15798.pdf). Training Code can be found [here](https://github.com/segmind/distill-sd).
|
| 23 |
+
|
| 24 |
+
## Pipeline usage
|
| 25 |
+
|
| 26 |
+
You can use the pipeline like so:
|
| 27 |
+
|
| 28 |
+
```python
|
| 29 |
+
from diffusers import DiffusionPipeline
|
| 30 |
+
import torch
|
| 31 |
+
|
| 32 |
+
pipeline = DiffusionPipeline.from_pretrained("segmind/tiny-sd", torch_dtype=torch.float16)
|
| 33 |
+
prompt = "Portrait of a pretty girl"
|
| 34 |
+
image = pipeline(prompt).images[0]
|
| 35 |
+
image.save("my_image.png")
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
## Training info
|
| 39 |
+
|
| 40 |
+
These are the key hyperparameters used during training:
|
| 41 |
+
|
| 42 |
+
* Steps: 125000
|
| 43 |
+
* Learning rate: 1e-4
|
| 44 |
+
* Batch size: 32
|
| 45 |
+
* Gradient accumulation steps: 4
|
| 46 |
+
* Image resolution: 512
|
| 47 |
+
* Mixed-precision: fp16
|
| 48 |
+
|
| 49 |
+
## Speed Comparision
|
| 50 |
+
|
| 51 |
+
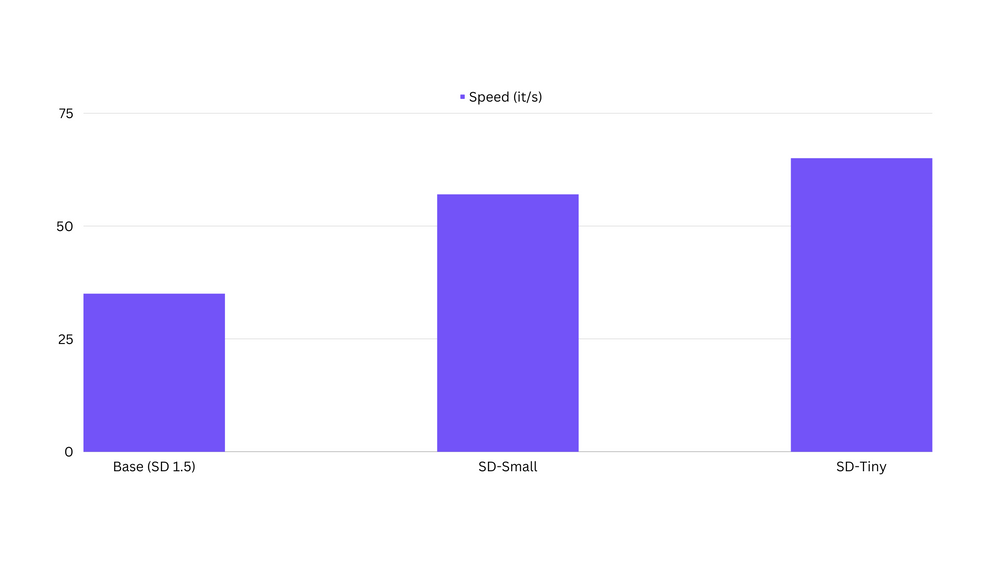
We have observed that the distilled models are upto 80% faster than the Base SD1.5 Models. Below is a comparision on an A100 80GB.
|
| 52 |
+
|
| 53 |
+

|
| 54 |
+

|
| 55 |
+
|
| 56 |
+
[Here](https://github.com/segmind/distill-sd/blob/master/inference.py) is the code for benchmarking the speeds.
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
|
comparision1.png
ADDED

|
graph.png
ADDED
|
grid_tiny.png
ADDED

|
model_index.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "StableDiffusionPipeline",
|
| 3 |
+
"_diffusers_version": "0.19.0.dev0",
|
| 4 |
+
"_name_or_path": "SG161222/Realistic_Vision_V4.0",
|
| 5 |
+
"feature_extractor": [
|
| 6 |
+
null,
|
| 7 |
+
null
|
| 8 |
+
],
|
| 9 |
+
"requires_safety_checker": false,
|
| 10 |
+
"safety_checker": [
|
| 11 |
+
null,
|
| 12 |
+
null
|
| 13 |
+
],
|
| 14 |
+
"scheduler": [
|
| 15 |
+
"diffusers",
|
| 16 |
+
"DPMSolverMultistepScheduler"
|
| 17 |
+
],
|
| 18 |
+
"text_encoder": [
|
| 19 |
+
"transformers",
|
| 20 |
+
"CLIPTextModel"
|
| 21 |
+
],
|
| 22 |
+
"tokenizer": [
|
| 23 |
+
"transformers",
|
| 24 |
+
"CLIPTokenizer"
|
| 25 |
+
],
|
| 26 |
+
"unet": [
|
| 27 |
+
"diffusers",
|
| 28 |
+
"UNet2DConditionModel"
|
| 29 |
+
],
|
| 30 |
+
"vae": [
|
| 31 |
+
"diffusers",
|
| 32 |
+
"AutoencoderKL"
|
| 33 |
+
]
|
| 34 |
+
}
|
scheduler/scheduler_config.json
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "DPMSolverMultistepScheduler",
|
| 3 |
+
"_diffusers_version": "0.19.0.dev0",
|
| 4 |
+
"algorithm_type": "dpmsolver++",
|
| 5 |
+
"beta_end": 0.012,
|
| 6 |
+
"beta_schedule": "scaled_linear",
|
| 7 |
+
"beta_start": 0.00085,
|
| 8 |
+
"clip_sample": false,
|
| 9 |
+
"clip_sample_range": 1.0,
|
| 10 |
+
"dynamic_thresholding_ratio": 0.995,
|
| 11 |
+
"lambda_min_clipped": -Infinity,
|
| 12 |
+
"lower_order_final": true,
|
| 13 |
+
"num_train_timesteps": 1000,
|
| 14 |
+
"prediction_type": "epsilon",
|
| 15 |
+
"sample_max_value": 1.0,
|
| 16 |
+
"set_alpha_to_one": false,
|
| 17 |
+
"solver_order": 2,
|
| 18 |
+
"solver_type": "midpoint",
|
| 19 |
+
"steps_offset": 1,
|
| 20 |
+
"thresholding": false,
|
| 21 |
+
"timestep_spacing": "linspace",
|
| 22 |
+
"trained_betas": null,
|
| 23 |
+
"use_karras_sigmas": false,
|
| 24 |
+
"variance_type": null
|
| 25 |
+
}
|
text_encoder/config.json
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/home/ubuntu/.cache/huggingface/hub/models--SG161222--Realistic_Vision_V4.0/snapshots/c2ce281f57e54220379e82482708ea925f10770f/text_encoder",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"CLIPTextModel"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 0,
|
| 8 |
+
"dropout": 0.0,
|
| 9 |
+
"eos_token_id": 2,
|
| 10 |
+
"hidden_act": "quick_gelu",
|
| 11 |
+
"hidden_size": 768,
|
| 12 |
+
"initializer_factor": 1.0,
|
| 13 |
+
"initializer_range": 0.02,
|
| 14 |
+
"intermediate_size": 3072,
|
| 15 |
+
"layer_norm_eps": 1e-05,
|
| 16 |
+
"max_position_embeddings": 77,
|
| 17 |
+
"model_type": "clip_text_model",
|
| 18 |
+
"num_attention_heads": 12,
|
| 19 |
+
"num_hidden_layers": 12,
|
| 20 |
+
"pad_token_id": 1,
|
| 21 |
+
"projection_dim": 768,
|
| 22 |
+
"torch_dtype": "float16",
|
| 23 |
+
"transformers_version": "4.31.0",
|
| 24 |
+
"vocab_size": 49408
|
| 25 |
+
}
|
tokenizer/merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer/special_tokens_map.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|startoftext|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": true,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|endoftext|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": true,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": "<|endoftext|>",
|
| 17 |
+
"unk_token": {
|
| 18 |
+
"content": "<|endoftext|>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": true,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
}
|
| 24 |
+
}
|
tokenizer/tokenizer_config.json
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"bos_token": {
|
| 4 |
+
"__type": "AddedToken",
|
| 5 |
+
"content": "<|startoftext|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": true,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false
|
| 10 |
+
},
|
| 11 |
+
"clean_up_tokenization_spaces": true,
|
| 12 |
+
"do_lower_case": true,
|
| 13 |
+
"eos_token": {
|
| 14 |
+
"__type": "AddedToken",
|
| 15 |
+
"content": "<|endoftext|>",
|
| 16 |
+
"lstrip": false,
|
| 17 |
+
"normalized": true,
|
| 18 |
+
"rstrip": false,
|
| 19 |
+
"single_word": false
|
| 20 |
+
},
|
| 21 |
+
"errors": "replace",
|
| 22 |
+
"model_max_length": 77,
|
| 23 |
+
"pad_token": "<|endoftext|>",
|
| 24 |
+
"tokenizer_class": "CLIPTokenizer",
|
| 25 |
+
"unk_token": {
|
| 26 |
+
"__type": "AddedToken",
|
| 27 |
+
"content": "<|endoftext|>",
|
| 28 |
+
"lstrip": false,
|
| 29 |
+
"normalized": true,
|
| 30 |
+
"rstrip": false,
|
| 31 |
+
"single_word": false
|
| 32 |
+
}
|
| 33 |
+
}
|
tokenizer/vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
unet/config.json
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "UNet2DConditionModel",
|
| 3 |
+
"_diffusers_version": "0.6.0",
|
| 4 |
+
"act_fn": "silu",
|
| 5 |
+
"attention_head_dim": 8,
|
| 6 |
+
"block_out_channels": [
|
| 7 |
+
320,
|
| 8 |
+
640,
|
| 9 |
+
1280
|
| 10 |
+
],
|
| 11 |
+
"center_input_sample": false,
|
| 12 |
+
"cross_attention_dim": 768,
|
| 13 |
+
"down_block_types": [
|
| 14 |
+
"CrossAttnDownBlock2D",
|
| 15 |
+
"CrossAttnDownBlock2D",
|
| 16 |
+
"CrossAttnDownBlock2D"
|
| 17 |
+
],
|
| 18 |
+
"downsample_padding": 1,
|
| 19 |
+
"flip_sin_to_cos": true,
|
| 20 |
+
"freq_shift": 0,
|
| 21 |
+
"in_channels": 4,
|
| 22 |
+
"layers_per_block": 1,
|
| 23 |
+
"mid_block_type": null,
|
| 24 |
+
"norm_eps": 1e-05,
|
| 25 |
+
"norm_num_groups": 32,
|
| 26 |
+
"out_channels": 4,
|
| 27 |
+
"sample_size": 64,
|
| 28 |
+
"up_block_types": [
|
| 29 |
+
"CrossAttnUpBlock2D",
|
| 30 |
+
"CrossAttnUpBlock2D",
|
| 31 |
+
"CrossAttnUpBlock2D"
|
| 32 |
+
]
|
| 33 |
+
}
|
unet/diffusion_pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c9b63e57cb1479c946c73bf5484bc1a823dbe565158ea0ee40015a18844d9f29
|
| 3 |
+
size 646923637
|
vae/config.json
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "AutoencoderKL",
|
| 3 |
+
"_diffusers_version": "0.19.0.dev0",
|
| 4 |
+
"_name_or_path": "/home/ubuntu/.cache/huggingface/hub/models--SG161222--Realistic_Vision_V4.0/snapshots/c2ce281f57e54220379e82482708ea925f10770f/vae",
|
| 5 |
+
"act_fn": "silu",
|
| 6 |
+
"block_out_channels": [
|
| 7 |
+
128,
|
| 8 |
+
256,
|
| 9 |
+
512,
|
| 10 |
+
512
|
| 11 |
+
],
|
| 12 |
+
"down_block_types": [
|
| 13 |
+
"DownEncoderBlock2D",
|
| 14 |
+
"DownEncoderBlock2D",
|
| 15 |
+
"DownEncoderBlock2D",
|
| 16 |
+
"DownEncoderBlock2D"
|
| 17 |
+
],
|
| 18 |
+
"force_upcast": true,
|
| 19 |
+
"in_channels": 3,
|
| 20 |
+
"latent_channels": 4,
|
| 21 |
+
"layers_per_block": 2,
|
| 22 |
+
"norm_num_groups": 32,
|
| 23 |
+
"out_channels": 3,
|
| 24 |
+
"sample_size": 512,
|
| 25 |
+
"scaling_factor": 0.18215,
|
| 26 |
+
"up_block_types": [
|
| 27 |
+
"UpDecoderBlock2D",
|
| 28 |
+
"UpDecoderBlock2D",
|
| 29 |
+
"UpDecoderBlock2D",
|
| 30 |
+
"UpDecoderBlock2D"
|
| 31 |
+
]
|
| 32 |
+
}
|
vae/diffusion_pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:279228e5296858f5d330db506ff6a51fdcad0d69f87634b5e9133406110af9bf
|
| 3 |
+
size 167407857
|
val_imgs_grid.png
ADDED

|