
Commit
·
9e826e6
1
Parent(s):
49e917d
Initial Commit
Browse files- .gitignore +1 -0
- README.md +188 -0
- ckpt/bpe_vocab +0 -0
- ckpt/codes.bpe.32000 +0 -0
- data-bin/dict.en.txt +0 -0
- data-bin/dict.zh.txt +0 -0
- data-bin/preprocess.log +4 -0
- data-bin/test.en-zh.en +1 -0
- data-bin/test.en-zh.zh +1 -0
- data-bin/test.zh-en.en +1 -0
- data-bin/test.zh-en.zh +1 -0
- docs/img.png +0 -0
- eval.sh +166 -0
- examples/configs/eval_benchmarks.yml +80 -0
- examples/configs/parallel_mono_12e12d_contrastive.yml +44 -0
- mcolt/__init__.py +4 -0
- mcolt/__pycache__/__init__.cpython-310.pyc +0 -0
- mcolt/arches/__init__.py +1 -0
- mcolt/arches/__pycache__/__init__.cpython-310.pyc +0 -0
- mcolt/arches/__pycache__/transformer.cpython-310.pyc +0 -0
- mcolt/arches/transformer.py +380 -0
- mcolt/criterions/__init__.py +1 -0
- mcolt/criterions/__pycache__/__init__.cpython-310.pyc +0 -0
- mcolt/criterions/__pycache__/label_smoothed_cross_entropy_with_contrastive.cpython-310.pyc +0 -0
- mcolt/criterions/label_smoothed_cross_entropy_with_contrastive.py +123 -0
- mcolt/data/__init__.py +1 -0
- mcolt/data/__pycache__/__init__.cpython-310.pyc +0 -0
- mcolt/data/__pycache__/subsample_language_pair_dataset.cpython-310.pyc +0 -0
- mcolt/data/subsample_language_pair_dataset.py +124 -0
- mcolt/tasks/__init__.py +2 -0
- mcolt/tasks/__pycache__/__init__.cpython-310.pyc +0 -0
- mcolt/tasks/__pycache__/translation_w_langtok.cpython-310.pyc +0 -0
- mcolt/tasks/__pycache__/translation_w_mono.cpython-310.pyc +0 -0
- mcolt/tasks/translation_w_langtok.py +476 -0
- mcolt/tasks/translation_w_mono.py +214 -0
- requirements.txt +5 -0
- scripts/load_config.sh +48 -0
- scripts/utils.py +116 -0
- test/input.en +1 -0
- test/input.zh +1 -0
- test/output +0 -0
- test/output.en.no_bpe +1 -0
- test/output.en.no_bpe.moses +1 -0
- test/output.zh +3 -0
- test/output.zh.no_bpe +1 -0
- test/output.zh.no_bpe.moses +1 -0
- train_w_mono.sh +56 -0
.gitignore
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
.idea
|
README.md
ADDED
|
@@ -0,0 +1,188 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
```bash
|
| 2 |
+
conda install pytorch torchvision torchaudio pytorch-cuda=11.6 -c pytorch -c nvidia
|
| 3 |
+
```
|
| 4 |
+
|
| 5 |
+
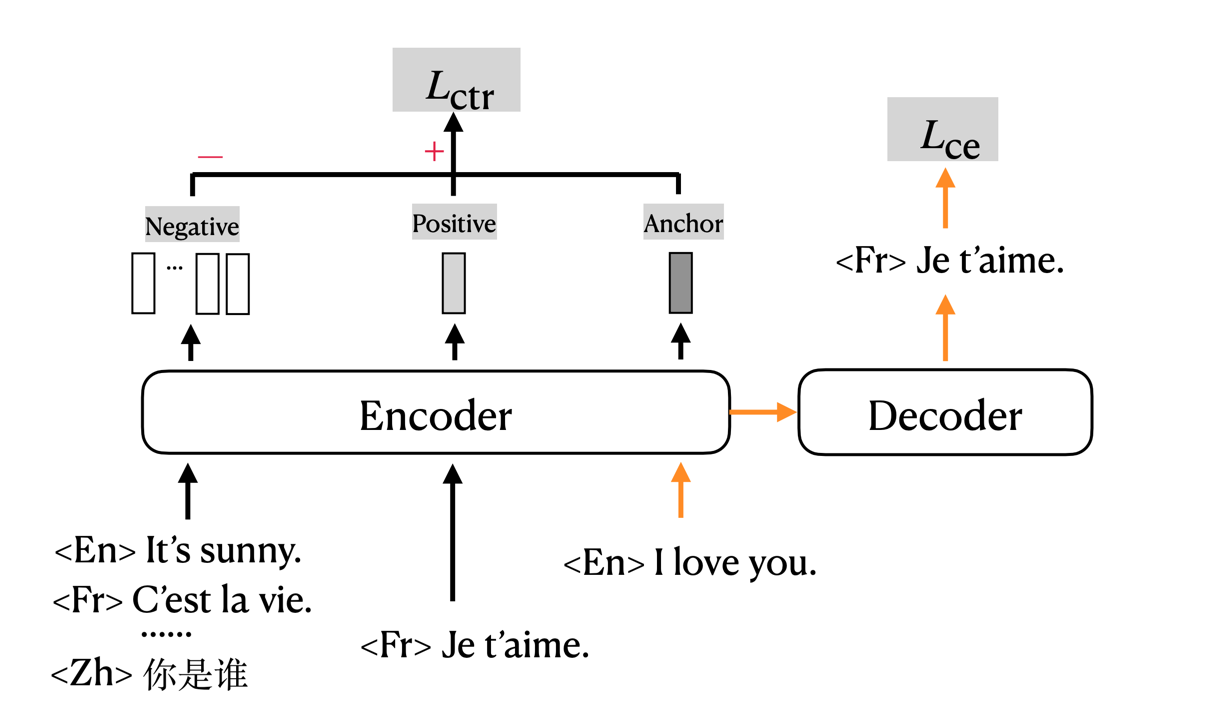
# Contrastive Learning for Many-to-many Multilingual Neural Machine Translation(mCOLT/mRASP2), ACL2021
|
| 6 |
+
The code for training mCOLT/mRASP2, a multilingual neural machine translation training method, implemented based on [fairseq](https://github.com/pytorch/fairseq).
|
| 7 |
+
|
| 8 |
+
**mRASP2**: [paper](https://arxiv.org/abs/2105.09501) [blog](https://medium.com/@panxiao1994/mrasp2-multilingual-nmt-advances-via-contrastive-learning-ac8c4c35d63)
|
| 9 |
+
|
| 10 |
+
**mRASP**: [paper](https://www.aclweb.org/anthology/2020.emnlp-main.210.pdf),
|
| 11 |
+
[code](https://github.com/linzehui/mRASP)
|
| 12 |
+
|
| 13 |
+
---
|
| 14 |
+
## News
|
| 15 |
+
We have released two versions, this version is the original one. In this implementation:
|
| 16 |
+
- You should first merge all data, by pre-pending language token before each sentence to indicate the language.
|
| 17 |
+
- AA/RAS muse be done off-line (before binarize), check [this toolkit](https://github.com/linzehui/mRASP/blob/master/preprocess).
|
| 18 |
+
|
| 19 |
+
**New implementation**: https://github.com/PANXiao1994/mRASP2/tree/new_impl
|
| 20 |
+
|
| 21 |
+
* Acknowledgement: This work is supported by [Bytedance](https://bytedance.com). We thank [Chengqi](https://github.com/zhaocq-nlp) for uploading all files and checkpoints.
|
| 22 |
+
|
| 23 |
+
## Introduction
|
| 24 |
+
|
| 25 |
+
mRASP2/mCOLT, representing multilingual Contrastive Learning for Transformer, is a multilingual neural machine translation model that supports complete many-to-many multilingual machine translation. It employs both parallel corpora and multilingual corpora in a unified training framework. For detailed information please refer to the paper.
|
| 26 |
+
|
| 27 |
+

|
| 28 |
+
|
| 29 |
+
## Pre-requisite
|
| 30 |
+
```bash
|
| 31 |
+
pip install -r requirements.txt
|
| 32 |
+
# install fairseq
|
| 33 |
+
git clone https://github.com/pytorch/fairseq
|
| 34 |
+
cd fairseq
|
| 35 |
+
pip install --editable ./
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
## Training Data and Checkpoints
|
| 39 |
+
We release our preprocessed training data and checkpoints in the following.
|
| 40 |
+
### Dataset
|
| 41 |
+
|
| 42 |
+
We merge 32 English-centric language pairs, resulting in 64 directed translation pairs in total. The original 32 language pairs corpus contains about 197M pairs of sentences. We get about 262M pairs of sentences after applying RAS, since we keep both the original sentences and the substituted sentences. We release both the original dataset and dataset after applying RAS.
|
| 43 |
+
|
| 44 |
+
| Dataset | #Pair |
|
| 45 |
+
| --- | --- |
|
| 46 |
+
| [32-lang-pairs-TRAIN](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_parallel/download.sh) | 197603294 |
|
| 47 |
+
| [32-lang-pairs-RAS-TRAIN](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_parallel_ras/download.sh) | 262662792 |
|
| 48 |
+
| [mono-split-a](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_mono_split_a/download.sh) | - |
|
| 49 |
+
| [mono-split-b](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_mono_split_b/download.sh) | - |
|
| 50 |
+
| [mono-split-c](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_mono_split_c/download.sh) | - |
|
| 51 |
+
| [mono-split-d](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_mono_split_d/download.sh) | - |
|
| 52 |
+
| [mono-split-e](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_mono_split_e/download.sh) | - |
|
| 53 |
+
| [mono-split-de-fr-en](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_mono_de_fr_en/download.sh) | - |
|
| 54 |
+
| [mono-split-nl-pl-pt](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_mono_nl_pl_pt/download.sh) | - |
|
| 55 |
+
| [32-lang-pairs-DEV-en-centric](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_dev_en_centric/download.sh) | - |
|
| 56 |
+
| [32-lang-pairs-DEV-many-to-many](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_dev_m2m/download.sh) | - |
|
| 57 |
+
| [Vocab](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bpe_vocab) | - |
|
| 58 |
+
| [BPE Code](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/emnlp2020/mrasp/pretrain/dataset/codes.bpe.32000) | - |
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
### Checkpoints & Results
|
| 62 |
+
* **Please note that the provided checkpoint is sightly different from that in the paper.** In the following sections, we report the results of the provided checkpoints.
|
| 63 |
+
|
| 64 |
+
#### English-centric Directions
|
| 65 |
+
We report **tokenized BLEU** in the following table. Please click the model links to download. It is in pytorch format. (check eval.sh for details)
|
| 66 |
+
|
| 67 |
+
|Models | [6e6d-no-mono](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/6e6d_no_mono.pt) | [12e12d-no-mono](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/12e12d_no_mono.pt) | [12e12d](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/12e12d_last.pt) |
|
| 68 |
+
| --- | --- | --- | --- |
|
| 69 |
+
| en2cs/wmt16 | 21.0 | 22.3 | 23.8 |
|
| 70 |
+
| cs2en/wmt16 | 29.6 | 32.4 | 33.2 |
|
| 71 |
+
| en2fr/wmt14 | 42.0 | 43.3 | 43.4 |
|
| 72 |
+
| fr2en/wmt14 | 37.8 | 39.3 | 39.5 |
|
| 73 |
+
| en2de/wmt14 | 27.4 | 29.2 | 29.5 |
|
| 74 |
+
| de2en/wmt14 | 32.2 | 34.9 | 35.2 |
|
| 75 |
+
| en2zh/wmt17 | 33.0 | 34.9 | 34.1 |
|
| 76 |
+
| zh2en/wmt17 | 22.4 | 24.0 | 24.4 |
|
| 77 |
+
| en2ro/wmt16 | 26.6 | 28.1 | 28.7 |
|
| 78 |
+
| ro2en/wmt16 | 36.8 | 39.0 | 39.1 |
|
| 79 |
+
| en2tr/wmt16 | 18.6 | 20.3 | 21.2 |
|
| 80 |
+
| tr2en/wmt16 | 22.2 | 25.5 | 26.1 |
|
| 81 |
+
| en2ru/wmt19 | 17.4 | 18.5 | 19.2 |
|
| 82 |
+
| ru2en/wmt19 | 22.0 | 23.2 | 23.6 |
|
| 83 |
+
| en2fi/wmt17 | 20.2 | 22.1 | 22.9 |
|
| 84 |
+
| fi2en/wmt17 | 26.1 | 29.5 | 29.7 |
|
| 85 |
+
| en2es/wmt13 | 32.8 | 34.1 | 34.6 |
|
| 86 |
+
| es2en/wmt13 | 32.8 | 34.6 | 34.7 |
|
| 87 |
+
| en2it/wmt09 | 28.9 | 30.0 | 30.8 |
|
| 88 |
+
| it2en/wmt09 | 31.4 | 32.7 | 32.8 |
|
| 89 |
+
|
| 90 |
+
#### Unsupervised Directions
|
| 91 |
+
We report **tokenized BLEU** in the following table. (check eval.sh for details)
|
| 92 |
+
|
| 93 |
+
| | 12e12d |
|
| 94 |
+
| --- | --- |
|
| 95 |
+
| en2pl/wmt20 | 6.2 |
|
| 96 |
+
| pl2en/wmt20 | 13.5 |
|
| 97 |
+
| en2nl/iwslt14 | 8.8 |
|
| 98 |
+
| nl2en/iwslt14 | 27.1 |
|
| 99 |
+
| en2pt/opus100 | 18.9 |
|
| 100 |
+
| pt2en/opus100 | 29.2 |
|
| 101 |
+
|
| 102 |
+
#### Zero-shot Directions
|
| 103 |
+
* row: source language
|
| 104 |
+
* column: target language
|
| 105 |
+
We report **[sacreBLEU](https://github.com/mozilla/sacreBLEU)** in the following table.
|
| 106 |
+
|
| 107 |
+
| 12e12d | ar | zh | nl | fr | de | ru |
|
| 108 |
+
| --- | --- | --- | --- | --- | --- | --- |
|
| 109 |
+
| ar | - | 32.5 | 3.2 | 22.8 | 11.2 | 16.7 |
|
| 110 |
+
| zh | 6.5 | - | 1.9 | 32.9 | 7.6 | 23.7 |
|
| 111 |
+
| nl | 1.7 | 8.2 | - | 7.5 | 10.2 | 2.9 |
|
| 112 |
+
| fr | 6.2 | 42.3 | 7.5 | - | 18.9 | 24.4 |
|
| 113 |
+
| de | 4.9 | 21.6 | 9.2 | 24.7 | - | 14.4 |
|
| 114 |
+
| ru | 7.1 | 40.6 | 4.5 | 29.9 | 13.5 | - |
|
| 115 |
+
|
| 116 |
+
## Training
|
| 117 |
+
```bash
|
| 118 |
+
export NUM_GPU=4 && bash train_w_mono.sh ${model_config}
|
| 119 |
+
```
|
| 120 |
+
* We give example of `${model_config}` in `${PROJECT_REPO}/examples/configs/parallel_mono_12e12d_contrastive.yml`
|
| 121 |
+
|
| 122 |
+
## Inference
|
| 123 |
+
* You must pre-pend the corresponding language token to the source side before binarize the test data.
|
| 124 |
+
```bash
|
| 125 |
+
fairseq-generate ${test_path} \
|
| 126 |
+
--user-dir ${repo_dir}/mcolt \
|
| 127 |
+
-s ${src} \
|
| 128 |
+
-t ${tgt} \
|
| 129 |
+
--skip-invalid-size-inputs-valid-test \
|
| 130 |
+
--path ${ckpts} \
|
| 131 |
+
--max-tokens ${batch_size} \
|
| 132 |
+
--task translation_w_langtok \
|
| 133 |
+
${options} \
|
| 134 |
+
--lang-prefix-tok "LANG_TOK_"`echo "${tgt} " | tr '[a-z]' '[A-Z]'` \
|
| 135 |
+
--max-source-positions ${max_source_positions} \
|
| 136 |
+
--max-target-positions ${max_target_positions} \
|
| 137 |
+
--nbest 1 | grep -E '[S|H|P|T]-[0-9]+' > ${final_res_file}
|
| 138 |
+
|
| 139 |
+
python fairseq/fairseq_cli/preprocess.py --dataset-impl raw --srcdict ckpt/bpe_vocab --tgtdict ckpt/bpe_vocab --testpref test/input -s zh -t en
|
| 140 |
+
|
| 141 |
+
python fairseq/fairseq_cli/interactive.py /mnt/data2/siqiouyang/demo/mRASP2/data-bin \
|
| 142 |
+
--user-dir mcolt \
|
| 143 |
+
-s en \
|
| 144 |
+
-t zh \
|
| 145 |
+
--skip-invalid-size-inputs-valid-test \
|
| 146 |
+
--path ckpt/12e12d_last.pt \
|
| 147 |
+
--max-tokens 1024 \
|
| 148 |
+
--task translation_w_langtok \
|
| 149 |
+
--lang-prefix-tok "LANG_TOK_"`echo "zh " | tr '[a-z]' '[A-Z]'` \
|
| 150 |
+
--max-source-positions 1024 \
|
| 151 |
+
--max-target-positions 1024 \
|
| 152 |
+
--nbest 1 \
|
| 153 |
+
--bpe subword_nmt \
|
| 154 |
+
--bpe-codes ckpt/codes.bpe.32000 \
|
| 155 |
+
--post-process --tokenizer moses \
|
| 156 |
+
--input ./test/input.en | grep -E '[D]-[0-9]+' > test/output.zh.no_bpe.moses
|
| 157 |
+
|
| 158 |
+
python3 ${repo_dir}/scripts/utils.py ${res_file} ${ref_file} || exit 1;
|
| 159 |
+
```
|
| 160 |
+
|
| 161 |
+
## Synonym dictionaries
|
| 162 |
+
We use the bilingual synonym dictionaries provised by [MUSE](https://github.com/facebookresearch/MUSE).
|
| 163 |
+
|
| 164 |
+
We generate multilingual synonym dictionaries using [this script](https://github.com/linzehui/mRASP/blob/master/preprocess/tools/ras/multi_way_word_graph.py), and apply
|
| 165 |
+
RAS using [this script](https://github.com/linzehui/mRASP/blob/master/preprocess/tools/ras/random_alignment_substitution_w_multi.sh).
|
| 166 |
+
|
| 167 |
+
| Description | File | Size |
|
| 168 |
+
| --- | --- | --- |
|
| 169 |
+
| dep=1 | [synonym_dict_raw_dep1](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/synonym_dict_raw_dep1) | 138.0 M |
|
| 170 |
+
| dep=2 | [synonym_dict_raw_dep2](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/synonym_dict_raw_dep2) | 1.6 G |
|
| 171 |
+
| dep=3 | [synonym_dict_raw_dep3](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/synonym_dict_raw_dep3) | 2.2 G |
|
| 172 |
+
|
| 173 |
+
## Contact
|
| 174 |
+
Please contact me via e-mail `[email protected]` or via [wechat/zhihu](https://fork-ball-95c.notion.site/mRASP2-4e9b3450d5aa4137ae1a2c46d5f3c1fa) or join [the slack group](https://mrasp2.slack.com/join/shared_invite/zt-10k9710mb-MbDHzDboXfls2Omd8cuWqA)!
|
| 175 |
+
|
| 176 |
+
## Citation
|
| 177 |
+
Please cite as:
|
| 178 |
+
```
|
| 179 |
+
@inproceedings{mrasp2,
|
| 180 |
+
title = {Contrastive Learning for Many-to-many Multilingual Neural Machine Translation},
|
| 181 |
+
author= {Xiao Pan and
|
| 182 |
+
Mingxuan Wang and
|
| 183 |
+
Liwei Wu and
|
| 184 |
+
Lei Li},
|
| 185 |
+
booktitle = {Proceedings of ACL 2021},
|
| 186 |
+
year = {2021},
|
| 187 |
+
}
|
| 188 |
+
```
|
ckpt/bpe_vocab
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
ckpt/codes.bpe.32000
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data-bin/dict.en.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data-bin/dict.zh.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data-bin/preprocess.log
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='zh', trainpref=None, validpref=None, testpref='test/input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='ckpt/bpe_vocab', srcdict='ckpt/bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 2 |
+
Wrote preprocessed data to data-bin
|
| 3 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='zh', target_lang='en', trainpref=None, validpref=None, testpref='test/input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='ckpt/bpe_vocab', srcdict='ckpt/bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 4 |
+
Wrote preprocessed data to data-bin
|
data-bin/test.en-zh.en
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LANG_TOK_EN Hello my friend!
|
data-bin/test.en-zh.zh
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LANG_TOK_ZH
|
data-bin/test.zh-en.en
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LANG_TOK_EN Hello my friend!
|
data-bin/test.zh-en.zh
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LANG_TOK_ZH 你好!
|
docs/img.png
ADDED
|
eval.sh
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env bash
|
| 2 |
+
|
| 3 |
+
# repo_dir: root directory of the project
|
| 4 |
+
repo_dir="$( cd "$( dirname "$0" )" && pwd )"
|
| 5 |
+
echo "==== Working directory: ====" >&2
|
| 6 |
+
echo "${repo_dir}" >&2
|
| 7 |
+
echo "============================" >&2
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
test_config=$1
|
| 11 |
+
source ${repo_dir}/scripts/load_config.sh ${test_config} ${repo_dir}
|
| 12 |
+
model_dir=$2
|
| 13 |
+
choice=$3 # all|best|last
|
| 14 |
+
|
| 15 |
+
model_dir=${repo_dir}/model
|
| 16 |
+
data_dir=${repo_dir}/data
|
| 17 |
+
res_path=${model_dir}/results
|
| 18 |
+
|
| 19 |
+
mkdir -p ${model_dir} ${data_dir} ${res_path}
|
| 20 |
+
|
| 21 |
+
testset_name=data_testset_1_name
|
| 22 |
+
testset_path=data_testset_1_path
|
| 23 |
+
testset_ref=data_testset_1_ref
|
| 24 |
+
testset_direc=data_testset_1_direction
|
| 25 |
+
i=1
|
| 26 |
+
testsets=""
|
| 27 |
+
while [[ ! -z ${!testset_path} && ! -z ${!testset_direc} ]]; do
|
| 28 |
+
dataname=${!testset_name}
|
| 29 |
+
mkdir -p ${data_dir}/${!testset_direc}/${dataname} ${data_dir}/ref/${!testset_direc}/${dataname}
|
| 30 |
+
cp ${!testset_path}/* ${data_dir}/${!testset_direc}/${dataname}/
|
| 31 |
+
cp ${!testset_ref}/* ${data_dir}/ref/${!testset_direc}/${dataname}/
|
| 32 |
+
if [[ $testsets == "" ]]; then
|
| 33 |
+
testsets=${!testset_direc}/${dataname}
|
| 34 |
+
else
|
| 35 |
+
testsets=${testsets}:${!testset_direc}/${dataname}
|
| 36 |
+
fi
|
| 37 |
+
i=$((i+1))
|
| 38 |
+
testset_name=testset_${i}_name
|
| 39 |
+
testset_path=testset_${i}_path
|
| 40 |
+
testset_ref=testset_${i}_ref
|
| 41 |
+
testset_direc=testset_${i}_direction
|
| 42 |
+
done
|
| 43 |
+
|
| 44 |
+
IFS=':' read -r -a testset_list <<< ${testsets}
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
bleu () {
|
| 48 |
+
src=$1
|
| 49 |
+
tgt=$2
|
| 50 |
+
res_file=$3
|
| 51 |
+
ref_file=$4
|
| 52 |
+
if [[ -f ${res_file} ]]; then
|
| 53 |
+
f_dirname=`dirname ${res_file}`
|
| 54 |
+
python3 ${repo_dir}/scripts/utils.py ${res_file} ${ref_file} || exit 1;
|
| 55 |
+
input_file="${f_dirname}/hypo.out.nobpe"
|
| 56 |
+
output_file="${f_dirname}/hypo.out.nobpe.final"
|
| 57 |
+
# form command
|
| 58 |
+
cmd="cat ${input_file}"
|
| 59 |
+
lang_token="LANG_TOK_"`echo "${tgt} " | tr '[a-z]' '[A-Z]'`
|
| 60 |
+
if [[ $tgt == "fr" ]]; then
|
| 61 |
+
cmd=$cmd" | sed -Ee 's/\"([^\"]*)\"/« \1 »/g'"
|
| 62 |
+
elif [[ $tgt == "zh" ]]; then
|
| 63 |
+
tokenizer="zh"
|
| 64 |
+
elif [[ $tgt == "ja" ]]; then
|
| 65 |
+
tokenizer="ja-mecab"
|
| 66 |
+
fi
|
| 67 |
+
[[ -z $tokenizer ]] && tokenizer="none"
|
| 68 |
+
cmd=$cmd" | sed -e s'|${lang_token} ||g' > ${output_file}"
|
| 69 |
+
eval $cmd || { echo "$cmd FAILED !"; exit 1; }
|
| 70 |
+
cat ${output_file} | sacrebleu -l ${src}-${tgt} -tok $tokenizer --short "${f_dirname}/ref.out" | awk '{print $3}'
|
| 71 |
+
else
|
| 72 |
+
echo "${res_file} not exist!" >&2 && exit 1;
|
| 73 |
+
fi
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
# monitor
|
| 77 |
+
# ${ckptname}/${direction}/${testname}/orig.txt
|
| 78 |
+
(inotifywait -r -m -e close_write ${res_path} |
|
| 79 |
+
while read path action file; do
|
| 80 |
+
if [[ "$file" =~ .*txt$ ]]; then
|
| 81 |
+
tmp_str="${path%/*}"
|
| 82 |
+
testname="${tmp_str##*/}"
|
| 83 |
+
tmp_str="${tmp_str%/*}"
|
| 84 |
+
direction="${tmp_str##*/}"
|
| 85 |
+
tmp_str="${tmp_str%/*}"
|
| 86 |
+
ckptname="${tmp_str##*/}"
|
| 87 |
+
src_lang="${direction%2*}"
|
| 88 |
+
tgt_lang="${direction##*2}"
|
| 89 |
+
res_file=$path$file
|
| 90 |
+
ref_file=${data_dir}/ref/${direction}/${testname}/dev.${tgt_lang}
|
| 91 |
+
bleuscore=`bleu ${src_lang} ${tgt_lang} ${res_file} ${ref_file}`
|
| 92 |
+
bleu_str="$(date "+%Y-%m-%d %H:%M:%S")\t${ckptname}\t${direction}/${testname}\t$bleuscore"
|
| 93 |
+
echo -e ${bleu_str} # to stdout
|
| 94 |
+
echo -e ${bleu_str} >> ${model_dir}/summary.log
|
| 95 |
+
fi
|
| 96 |
+
done) &
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
if [[ ${choice} == "all" ]]; then
|
| 100 |
+
filelist=`ls -la ${model_dir} | sort -k6,7 -r | awk '{print $NF}' | grep .pt$ | tr '\n' ' '`
|
| 101 |
+
elif [[ ${choice} == "best" ]]; then
|
| 102 |
+
filelist="${model_dir}/checkpoint_best.pt"
|
| 103 |
+
elif [[ ${choice} == "last" ]]; then
|
| 104 |
+
filelist="${model_dir}/checkpoint_last.pt"
|
| 105 |
+
else
|
| 106 |
+
echo "invalid choice!" && exit 2;
|
| 107 |
+
fi
|
| 108 |
+
|
| 109 |
+
N=${NUM_GPU}
|
| 110 |
+
#export CUDA_VISIBLE_DEVICES=$(seq -s ',' 0 $(($N - 1)) )
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
infer_test () {
|
| 114 |
+
test_path=$1
|
| 115 |
+
ckpts=$2
|
| 116 |
+
gpu=$3
|
| 117 |
+
final_res_file=$4
|
| 118 |
+
src=$5
|
| 119 |
+
tgt=$6
|
| 120 |
+
gpu_cmd="CUDA_VISIBLE_DEVICES=$gpu "
|
| 121 |
+
lang_token="LANG_TOK_"`echo "${tgt} " | tr '[a-z]' '[A-Z]'`
|
| 122 |
+
[[ -z ${max_source_positions} ]] && max_source_positions=1024
|
| 123 |
+
[[ -z ${max_target_positions} ]] && max_target_positions=1024
|
| 124 |
+
command=${gpu_cmd}"fairseq-generate ${test_path} \
|
| 125 |
+
--user-dir ${repo_dir}/mcolt \
|
| 126 |
+
-s ${src} \
|
| 127 |
+
-t ${tgt} \
|
| 128 |
+
--skip-invalid-size-inputs-valid-test \
|
| 129 |
+
--path ${ckpts} \
|
| 130 |
+
--max-tokens 1024 \
|
| 131 |
+
--task translation_w_langtok \
|
| 132 |
+
${options} \
|
| 133 |
+
--lang-prefix-tok ${lang_token} \
|
| 134 |
+
--max-source-positions ${max_source_positions} \
|
| 135 |
+
--max-target-positions ${max_target_positions} \
|
| 136 |
+
--nbest 1 | grep -E '[S|H|P|T]-[0-9]+' > ${final_res_file}
|
| 137 |
+
"
|
| 138 |
+
echo "$command"
|
| 139 |
+
}
|
| 140 |
+
|
| 141 |
+
export -f infer_test
|
| 142 |
+
i=0
|
| 143 |
+
(for ckpt in ${filelist}
|
| 144 |
+
do
|
| 145 |
+
for testset in "${testset_list[@]}"
|
| 146 |
+
do
|
| 147 |
+
ckptbase=`basename $ckpt`
|
| 148 |
+
ckptname="${ckptbase%.*}"
|
| 149 |
+
direction="${testset%/*}"
|
| 150 |
+
testname="${testset##*/}"
|
| 151 |
+
src_lang="${direction%2*}"
|
| 152 |
+
tgt_lang="${direction##*2}"
|
| 153 |
+
|
| 154 |
+
((i=i%N)); ((i++==0)) && wait
|
| 155 |
+
test_path=${data_dir}/${testset}
|
| 156 |
+
|
| 157 |
+
echo "-----> "${ckptname}" | "${direction}/$testname" <-----" >&2
|
| 158 |
+
if [[ ! -d ${res_path}/${ckptname}/${direction}/${testname} ]]; then
|
| 159 |
+
mkdir -p ${res_path}/${ckptname}/${direction}/${testname}
|
| 160 |
+
fi
|
| 161 |
+
final_res_file="${res_path}/${ckptname}/${direction}/${testname}/orig.txt"
|
| 162 |
+
command=`infer_test ${test_path} ${model_dir}/${ckptname}.pt $((i-1)) ${final_res_file} ${src_lang} ${tgt_lang}`
|
| 163 |
+
echo "${command}"
|
| 164 |
+
eval $command &
|
| 165 |
+
done
|
| 166 |
+
done)
|
examples/configs/eval_benchmarks.yml
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
data_testset_1:
|
| 2 |
+
direction: en2de
|
| 3 |
+
name: wmt14
|
| 4 |
+
path: data/binarized/en_de/en2de/wmt14
|
| 5 |
+
ref: data/dev/en2de/wmt14
|
| 6 |
+
data_testset_10:
|
| 7 |
+
direction: ru2en
|
| 8 |
+
name: newstest2019
|
| 9 |
+
path: data/binarized/en_ru/ru2en/newstest2019
|
| 10 |
+
ref: data/dev/ru2en/newstest2019
|
| 11 |
+
data_testset_11:
|
| 12 |
+
direction: en2fi
|
| 13 |
+
name: newstest2017
|
| 14 |
+
path: data/binarized/en_fi/en2fi/newstest2017
|
| 15 |
+
ref: data/dev/en2fi/newstest2017
|
| 16 |
+
data_testset_12:
|
| 17 |
+
direction: fi2en
|
| 18 |
+
name: newstest2017
|
| 19 |
+
path: data/binarized/en_fi/fi2en/newstest2017
|
| 20 |
+
ref: data/dev/fi2en/newstest2017
|
| 21 |
+
data_testset_13:
|
| 22 |
+
direction: en2cs
|
| 23 |
+
name: newstest2016
|
| 24 |
+
path: data/binarized/en_cs/en2cs/newstest2016
|
| 25 |
+
ref: data/dev/en2cs/newstest2016
|
| 26 |
+
data_testset_14:
|
| 27 |
+
direction: cs2en
|
| 28 |
+
name: newstest2016
|
| 29 |
+
path: data/binarized/en_cs/cs2en/newstest2016
|
| 30 |
+
ref: data/dev/cs2en/newstest2016
|
| 31 |
+
data_testset_15:
|
| 32 |
+
direction: en2et
|
| 33 |
+
name: newstest2018
|
| 34 |
+
path: data/binarized/en_et/en2et/newstest2018
|
| 35 |
+
ref: data/dev/en2et/newstest2018
|
| 36 |
+
data_testset_16:
|
| 37 |
+
direction: et2en
|
| 38 |
+
name: newstest2018
|
| 39 |
+
path: data/binarized/en_et/et2en/newstest2018
|
| 40 |
+
ref: data/dev/et2en/newstest2018
|
| 41 |
+
data_testset_2:
|
| 42 |
+
direction: de2en
|
| 43 |
+
name: wmt14
|
| 44 |
+
path: data/binarized/en_de/de2en/wmt14
|
| 45 |
+
ref: data/dev/de2en/wmt14
|
| 46 |
+
data_testset_3:
|
| 47 |
+
direction: en2fr
|
| 48 |
+
name: newstest2014
|
| 49 |
+
path: data/binarized/en_fr/en2fr/newstest2014
|
| 50 |
+
ref: data/dev/en2fr/newstest2014
|
| 51 |
+
data_testset_4:
|
| 52 |
+
direction: fr2en
|
| 53 |
+
name: newstest2014
|
| 54 |
+
path: data/binarized/en_fr/fr2en/newstest2014
|
| 55 |
+
ref: data/dev/fr2en/newstest2014
|
| 56 |
+
data_testset_5:
|
| 57 |
+
direction: en2ro
|
| 58 |
+
name: wmt16
|
| 59 |
+
path: data/binarized/en_ro/en_ro/wmt16
|
| 60 |
+
ref: data/dev/en_ro/wmt16
|
| 61 |
+
data_testset_6:
|
| 62 |
+
direction: ro2en
|
| 63 |
+
name: wmt16
|
| 64 |
+
path: data/binarized/en_ro/en_ro/wmt16
|
| 65 |
+
ref: data/dev/en_ro/wmt16
|
| 66 |
+
data_testset_7:
|
| 67 |
+
direction: en2zh
|
| 68 |
+
name: wmt17
|
| 69 |
+
path: data/binarized/en_zh/en2zh/wmt17
|
| 70 |
+
ref: data/dev/en2zh/wmt17
|
| 71 |
+
data_testset_8:
|
| 72 |
+
direction: zh2en
|
| 73 |
+
name: wmt17
|
| 74 |
+
path: data/binarized/en_zh/zh2en/wmt17
|
| 75 |
+
ref: data/dev/zh2en/wmt17
|
| 76 |
+
data_testset_9:
|
| 77 |
+
direction: en2ru
|
| 78 |
+
name: newstest2019
|
| 79 |
+
path: data/binarized/en_ru/en2ru/newstest2019
|
| 80 |
+
ref: data/dev/en2ru/newstest2019
|
examples/configs/parallel_mono_12e12d_contrastive.yml
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_dir: model/pretrain/lab/multilingual/l2r/multi_bpe32k/parallel_mono_contrastive_1/transformer_big_t2t_12e12d
|
| 2 |
+
data_1: data/multilingual/bin/merged_deduped_ras
|
| 3 |
+
data_mono_1: data/multilingual/bin/mono_only/splitaa
|
| 4 |
+
data_mono_2: data/multilingual/bin/mono_only/splitab
|
| 5 |
+
data_mono_3: data/multilingual/bin/mono_only/splitac
|
| 6 |
+
data_mono_4: data/multilingual/bin/mono_only/splitad
|
| 7 |
+
data_mono_5: data/multilingual/bin/mono_only/splitae
|
| 8 |
+
data_mono_6: data/multilingual/bin/mono_only/mono_de_fr_en
|
| 9 |
+
data_mono_7: data/multilingual/bin/mono_only/mono_nl_pl_pt
|
| 10 |
+
source_lang: src
|
| 11 |
+
target_lang: trg
|
| 12 |
+
task: translation_w_mono
|
| 13 |
+
parallel_ratio: 0.2
|
| 14 |
+
mono_ratio: 0.07
|
| 15 |
+
arch: transformer_big_t2t_12e12d
|
| 16 |
+
share_all_embeddings: true
|
| 17 |
+
encoder_learned_pos: true
|
| 18 |
+
decoder_learned_pos: true
|
| 19 |
+
max_source_positions: 1024
|
| 20 |
+
max_target_positions: 1024
|
| 21 |
+
dropout: 0.1
|
| 22 |
+
criterion: label_smoothed_cross_entropy_with_contrastive
|
| 23 |
+
contrastive_lambda: 1.0
|
| 24 |
+
temperature: 0.1
|
| 25 |
+
lr: 0.0003
|
| 26 |
+
clip_norm: 10.0
|
| 27 |
+
optimizer: adam
|
| 28 |
+
adam_eps: 1e-06
|
| 29 |
+
weight_decay: 0.01
|
| 30 |
+
warmup_updates: 10000
|
| 31 |
+
label_smoothing: 0.1
|
| 32 |
+
lr_scheduler: polynomial_decay
|
| 33 |
+
min_lr: -1
|
| 34 |
+
max_tokens: 1536
|
| 35 |
+
update_freq: 30
|
| 36 |
+
max_update: 5000000
|
| 37 |
+
no_scale_embedding: true
|
| 38 |
+
layernorm_embedding: true
|
| 39 |
+
save_interval_updates: 2000
|
| 40 |
+
skip_invalid_size_inputs_valid_test: true
|
| 41 |
+
log_interval: 500
|
| 42 |
+
num_workers: 1
|
| 43 |
+
fp16: true
|
| 44 |
+
seed: 33122
|
mcolt/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .arches import *
|
| 2 |
+
from . criterions import *
|
| 3 |
+
from .data import *
|
| 4 |
+
from .tasks import *
|
mcolt/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (222 Bytes). View file
|
|
|
mcolt/arches/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .transformer import *
|
mcolt/arches/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (179 Bytes). View file
|
|
|
mcolt/arches/__pycache__/transformer.cpython-310.pyc
ADDED
|
Binary file (9.16 kB). View file
|
|
|
mcolt/arches/transformer.py
ADDED
|
@@ -0,0 +1,380 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from fairseq.models import register_model_architecture
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
@register_model_architecture('transformer', 'transformer_bigger')
|
| 5 |
+
def transformer_bigger(args):
|
| 6 |
+
args.attention_dropout = getattr(args, 'attention_dropout', 0.3)
|
| 7 |
+
args.activation_dropout = getattr(args, 'activation_dropout', 0.3)
|
| 8 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 9 |
+
args.encoder_ffn_embed_dim = getattr(args, 'encoder_ffn_embed_dim', 15000)
|
| 10 |
+
args.decoder_ffn_embed_dim = getattr(args, 'decoder_ffn_embed_dim', 15000)
|
| 11 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 12 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 13 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
@register_model_architecture('transformer', 'transformer_bigger_16384')
|
| 17 |
+
def transformer_bigger_16384(args):
|
| 18 |
+
args.attention_dropout = getattr(args, 'attention_dropout', 0.1)
|
| 19 |
+
args.activation_dropout = getattr(args, 'activation_dropout', 0.1)
|
| 20 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 21 |
+
args.encoder_ffn_embed_dim = getattr(args, 'encoder_ffn_embed_dim', 16384)
|
| 22 |
+
args.decoder_ffn_embed_dim = getattr(args, 'decoder_ffn_embed_dim', 16384)
|
| 23 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 24 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 25 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
@register_model_architecture('transformer', 'transformer_bigger_no_share')
|
| 29 |
+
def transformer_bigger_no_share(args):
|
| 30 |
+
args.attention_dropout = getattr(args, 'attention_dropout', 0.3)
|
| 31 |
+
args.activation_dropout = getattr(args, 'activation_dropout', 0.3)
|
| 32 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 33 |
+
args.encoder_ffn_embed_dim = getattr(args, 'encoder_ffn_embed_dim', 15000)
|
| 34 |
+
args.decoder_ffn_embed_dim = getattr(args, 'decoder_ffn_embed_dim', 15000)
|
| 35 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', False)
|
| 36 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 37 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
@register_model_architecture('transformer', 'transformer_deeper')
|
| 41 |
+
def transformer_deeper(args):
|
| 42 |
+
args.encoder_layers = getattr(args, 'encoder_layers', 15)
|
| 43 |
+
args.dense = False
|
| 44 |
+
args.bottleneck_component = getattr(args, 'bottleneck_component', 'mean_pool')
|
| 45 |
+
args.attention_dropout = getattr(args, 'attention_dropout', 0.1)
|
| 46 |
+
args.activation_dropout = getattr(args, 'activation_dropout', 0.1)
|
| 47 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 48 |
+
# args.encoder_ffn_embed_dim = getattr(args, 'encoder_ffn_embed_dim', 15000)
|
| 49 |
+
# args.decoder_ffn_embed_dim = getattr(args, 'decoder_ffn_embed_dim', 15000)
|
| 50 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 51 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 52 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
@register_model_architecture('transformer', 'transformer_deeper_no_share')
|
| 56 |
+
def transformer_deeper_no_share(args):
|
| 57 |
+
args.encoder_layers = getattr(args, 'encoder_layers', 15)
|
| 58 |
+
args.dense = False
|
| 59 |
+
args.bottleneck_component = getattr(args, 'bottleneck_component', 'mean_pool')
|
| 60 |
+
args.attention_dropout = getattr(args, 'attention_dropout', 0.1)
|
| 61 |
+
args.activation_dropout = getattr(args, 'activation_dropout', 0.1)
|
| 62 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 63 |
+
# args.encoder_ffn_embed_dim = getattr(args, 'encoder_ffn_embed_dim', 15000)
|
| 64 |
+
# args.decoder_ffn_embed_dim = getattr(args, 'decoder_ffn_embed_dim', 15000)
|
| 65 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', False)
|
| 66 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 67 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
@register_model_architecture('transformer', 'transformer_deeper_dense')
|
| 71 |
+
def transformer_deeper_no_share(args):
|
| 72 |
+
args.encoder_layers = getattr(args, 'encoder_layers', 15)
|
| 73 |
+
args.dense = True
|
| 74 |
+
args.bottleneck_component = 'mean_pool'
|
| 75 |
+
args.attention_dropout = getattr(args, 'attention_dropout', 0.1)
|
| 76 |
+
args.activation_dropout = getattr(args, 'activation_dropout', 0.1)
|
| 77 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 78 |
+
# args.encoder_ffn_embed_dim = getattr(args, 'encoder_ffn_embed_dim', 15000)
|
| 79 |
+
# args.decoder_ffn_embed_dim = getattr(args, 'decoder_ffn_embed_dim', 15000)
|
| 80 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 81 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 82 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
@register_model_architecture('transformer', 'transformer_deeper_dense_no_share')
|
| 86 |
+
def transformer_deeper_no_share(args):
|
| 87 |
+
args.encoder_layers = getattr(args, 'encoder_layers', 15)
|
| 88 |
+
args.dense = True
|
| 89 |
+
args.bottleneck_component = 'mean_pool'
|
| 90 |
+
args.attention_dropout = getattr(args, 'attention_dropout', 0.1)
|
| 91 |
+
args.activation_dropout = getattr(args, 'activation_dropout', 0.1)
|
| 92 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 93 |
+
# args.encoder_ffn_embed_dim = getattr(args, 'encoder_ffn_embed_dim', 15000)
|
| 94 |
+
# args.decoder_ffn_embed_dim = getattr(args, 'decoder_ffn_embed_dim', 15000)
|
| 95 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', False)
|
| 96 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 97 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
@register_model_architecture('transformer', 'transformer_big')
|
| 101 |
+
def transformer_big(args):
|
| 102 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 103 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 104 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 105 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
@register_model_architecture('transformer', 'transformer_big_emb512')
|
| 109 |
+
def transformer_big_emb512(args):
|
| 110 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 111 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 112 |
+
args.encoder_embed_dim = getattr(args, 'encoder_embed_dim', 512)
|
| 113 |
+
args.decoder_embed_dim = getattr(args, 'decoder_embed_dim', 512)
|
| 114 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 115 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
@register_model_architecture('transformer', 'transformer_big_no_share')
|
| 119 |
+
def transformer_big_no_share(args):
|
| 120 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 121 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', False)
|
| 122 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 123 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
@register_model_architecture('transformer', 'transformer_big_16e4d')
|
| 127 |
+
def transformer_big_16e4d(args):
|
| 128 |
+
args.dropout = getattr(args, 'dropout', 0.2)
|
| 129 |
+
args.encoder_layers = getattr(args, 'encoder_layers', 16)
|
| 130 |
+
args.decoder_layers = getattr(args, 'decoder_layers', 4)
|
| 131 |
+
args.encoder_embed_dim = getattr(args, 'encoder_embed_dim', 1024)
|
| 132 |
+
args.decoder_embed_dim = getattr(args, 'decoder_embed_dim', 1024)
|
| 133 |
+
args.encoder_ffn_embed_dim = getattr(args, 'encoder_ffn_embed_dim', 4096)
|
| 134 |
+
args.encoder_attention_heads = getattr(args, 'encoder_attention_heads', 16)
|
| 135 |
+
args.decoder_attention_heads = getattr(args, 'decoder_attention_heads', 16)
|
| 136 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 137 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 138 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
@register_model_architecture('transformer', 'transformer_big_16e6d')
|
| 142 |
+
def transformer_big_16e6d(args):
|
| 143 |
+
args.dropout = getattr(args, 'dropout', 0.2)
|
| 144 |
+
args.encoder_layers = getattr(args, 'encoder_layers', 16)
|
| 145 |
+
args.decoder_layers = getattr(args, 'decoder_layers', 6)
|
| 146 |
+
args.encoder_embed_dim = getattr(args, 'encoder_embed_dim', 1024)
|
| 147 |
+
args.decoder_embed_dim = getattr(args, 'decoder_embed_dim', 1024)
|
| 148 |
+
args.encoder_ffn_embed_dim = getattr(args, 'encoder_ffn_embed_dim', 4096)
|
| 149 |
+
args.encoder_attention_heads = getattr(args, 'encoder_attention_heads', 16)
|
| 150 |
+
args.decoder_attention_heads = getattr(args, 'decoder_attention_heads', 16)
|
| 151 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 152 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 153 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
@register_model_architecture('transformer', 'transformer_base')
|
| 157 |
+
def transformer_bigger(args):
|
| 158 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 159 |
+
from fairseq.models.transformer import transformer_wmt_en_de
|
| 160 |
+
transformer_wmt_en_de(args)
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
@register_model_architecture('transformer', 'transformer_mid_50e6d')
|
| 164 |
+
def transformer_mid_50e6d(args):
|
| 165 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 166 |
+
args.encoder_layers = getattr(args, 'encoder_layers', 50)
|
| 167 |
+
args.decoder_layers = getattr(args, 'decoder_layers', 6)
|
| 168 |
+
args.encoder_embed_dim = getattr(args, 'encoder_embed_dim', 768)
|
| 169 |
+
args.decoder_embed_dim = getattr(args, 'decoder_embed_dim', 768)
|
| 170 |
+
args.encoder_ffn_embed_dim = getattr(args, 'encoder_ffn_embed_dim', 3072)
|
| 171 |
+
args.encoder_ffn_embed_dim = getattr(args, 'decoder_ffn_embed_dim', 3072)
|
| 172 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 173 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 174 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
@register_model_architecture('transformer', 'transformer_big_t2t_12e12d')
|
| 178 |
+
def transformer_big_t2t_12e12d(args):
|
| 179 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 180 |
+
args.encoder_layers = getattr(args, 'encoder_layers', 12)
|
| 181 |
+
args.decoder_layers = getattr(args, 'decoder_layers', 12)
|
| 182 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 183 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
@register_model_architecture('transformer', 'mix_transformer_mid_50e6d')
|
| 187 |
+
def mix_transformer_mid_50e6d(args):
|
| 188 |
+
args.mix_prepost_norm = getattr(args, "mix_prepost_norm", True)
|
| 189 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 190 |
+
args.encoder_layers = getattr(args, 'encoder_layers', 50)
|
| 191 |
+
args.decoder_layers = getattr(args, 'decoder_layers', 6)
|
| 192 |
+
args.encoder_embed_dim = getattr(args, 'encoder_embed_dim', 768)
|
| 193 |
+
args.decoder_embed_dim = getattr(args, 'decoder_embed_dim', 768)
|
| 194 |
+
args.encoder_ffn_embed_dim = getattr(args, 'encoder_ffn_embed_dim', 3072)
|
| 195 |
+
args.encoder_ffn_embed_dim = getattr(args, 'decoder_ffn_embed_dim', 3072)
|
| 196 |
+
args.encoder_normalize_before = getattr(args, "encoder_normalize_before", False)
|
| 197 |
+
args.decoder_normalize_before = getattr(args, "decoder_normalize_before", False)
|
| 198 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 199 |
+
args.mix_type = getattr(args, "mix_type", "learnable")
|
| 200 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 201 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
@register_model_architecture('transformer', 're_zero_transformer_mid_50e6d')
|
| 205 |
+
def re_zero_transformer_mid_50e6d(args):
|
| 206 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 207 |
+
args.encoder_layers = getattr(args, 'encoder_layers', 50)
|
| 208 |
+
args.decoder_layers = getattr(args, 'decoder_layers', 6)
|
| 209 |
+
args.encoder_embed_dim = getattr(args, 'encoder_embed_dim', 768)
|
| 210 |
+
args.decoder_embed_dim = getattr(args, 'decoder_embed_dim', 768)
|
| 211 |
+
args.encoder_ffn_embed_dim = getattr(args, 'encoder_ffn_embed_dim', 3072)
|
| 212 |
+
args.encoder_ffn_embed_dim = getattr(args, 'decoder_ffn_embed_dim', 3072)
|
| 213 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 214 |
+
args.re_zero = getattr(args, "re_zero", True)
|
| 215 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 216 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
@register_model_architecture('transformer', 'transformer_mid_50e3d_ed3072')
|
| 220 |
+
def transformer_mid_50e3d_ed3072(args):
|
| 221 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 222 |
+
args.encoder_layers = getattr(args, 'encoder_layers', 50)
|
| 223 |
+
args.decoder_layers = getattr(args, 'decoder_layers', 3)
|
| 224 |
+
args.encoder_embed_dim = getattr(args, 'encoder_embed_dim', 768)
|
| 225 |
+
args.decoder_embed_dim = getattr(args, 'decoder_embed_dim', 768)
|
| 226 |
+
args.encoder_ffn_embed_dim = getattr(args, 'encoder_ffn_embed_dim', 3072)
|
| 227 |
+
args.decoder_ffn_embed_dim = getattr(args, 'decoder_ffn_embed_dim', 3072)
|
| 228 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 229 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 230 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
@register_model_architecture('transformer', 'mix_transformer_mid_50e6d_3000fix_10000decay')
|
| 234 |
+
def mix_transformer_mid_50e6d_3000fix_10000decay(args):
|
| 235 |
+
args.mix_prepost_norm = getattr(args, "mix_prepost_norm", True)
|
| 236 |
+
args.mix_type = getattr(args, "mix_type", "step_moving")
|
| 237 |
+
args.pre_steps = getattr(args, "pre_steps", 3000)
|
| 238 |
+
args.change_steps = getattr(args, "change_steps", 10000)
|
| 239 |
+
|
| 240 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 241 |
+
args.encoder_layers = getattr(args, 'encoder_layers', 50)
|
| 242 |
+
args.decoder_layers = getattr(args, 'decoder_layers', 6)
|
| 243 |
+
args.encoder_embed_dim = getattr(args, 'encoder_embed_dim', 768)
|
| 244 |
+
args.decoder_embed_dim = getattr(args, 'decoder_embed_dim', 768)
|
| 245 |
+
args.encoder_ffn_embed_dim = getattr(args, 'encoder_ffn_embed_dim', 3072)
|
| 246 |
+
args.encoder_ffn_embed_dim = getattr(args, 'decoder_ffn_embed_dim', 3072)
|
| 247 |
+
args.encoder_normalize_before = getattr(args, "encoder_normalize_before", False)
|
| 248 |
+
args.decoder_normalize_before = getattr(args, "decoder_normalize_before", False)
|
| 249 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 250 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 251 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
@register_model_architecture('transformer', 'mix_transformer_mid_50e6d_7000fix_7000decay')
|
| 255 |
+
def mix_transformer_mid_50e6d_3000fix_10000decay(args):
|
| 256 |
+
args.mix_prepost_norm = getattr(args, "mix_prepost_norm", True)
|
| 257 |
+
args.mix_type = getattr(args, "mix_type", "step_moving")
|
| 258 |
+
args.pre_steps = getattr(args, "pre_steps", 7000)
|
| 259 |
+
args.change_steps = getattr(args, "change_steps", 7000)
|
| 260 |
+
|
| 261 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 262 |
+
args.encoder_layers = getattr(args, 'encoder_layers', 50)
|
| 263 |
+
args.decoder_layers = getattr(args, 'decoder_layers', 6)
|
| 264 |
+
args.encoder_embed_dim = getattr(args, 'encoder_embed_dim', 768)
|
| 265 |
+
args.decoder_embed_dim = getattr(args, 'decoder_embed_dim', 768)
|
| 266 |
+
args.encoder_ffn_embed_dim = getattr(args, 'encoder_ffn_embed_dim', 3072)
|
| 267 |
+
args.encoder_ffn_embed_dim = getattr(args, 'decoder_ffn_embed_dim', 3072)
|
| 268 |
+
args.encoder_normalize_before = getattr(args, "encoder_normalize_before", False)
|
| 269 |
+
args.decoder_normalize_before = getattr(args, "decoder_normalize_before", False)
|
| 270 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 271 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 272 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 273 |
+
|
| 274 |
+
|
| 275 |
+
@register_model_architecture('transformer', 'transformer_mid_75e6d')
|
| 276 |
+
def transformer_mid_75e6d(args):
|
| 277 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 278 |
+
args.encoder_layers = getattr(args, 'encoder_layers', 75)
|
| 279 |
+
args.decoder_layers = getattr(args, 'decoder_layers', 6)
|
| 280 |
+
args.encoder_embed_dim = getattr(args, 'encoder_embed_dim', 768)
|
| 281 |
+
args.decoder_embed_dim = getattr(args, 'decoder_embed_dim', 768)
|
| 282 |
+
args.encoder_ffn_embed_dim = getattr(args, 'encoder_ffn_embed_dim', 3072)
|
| 283 |
+
args.encoder_ffn_embed_dim = getattr(args, 'decoder_ffn_embed_dim', 3072)
|
| 284 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 285 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 286 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
@register_model_architecture('transformer', 'transformer_mid_25e6d')
|
| 290 |
+
def transformer_mid_25e6d(args):
|
| 291 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 292 |
+
args.encoder_layers = getattr(args, 'encoder_layers', 25)
|
| 293 |
+
args.decoder_layers = getattr(args, 'decoder_layers', 6)
|
| 294 |
+
args.encoder_embed_dim = getattr(args, 'encoder_embed_dim', 768)
|
| 295 |
+
args.decoder_embed_dim = getattr(args, 'decoder_embed_dim', 768)
|
| 296 |
+
args.encoder_ffn_embed_dim = getattr(args, 'encoder_ffn_embed_dim', 3072)
|
| 297 |
+
args.encoder_ffn_embed_dim = getattr(args, 'decoder_ffn_embed_dim', 3072)
|
| 298 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 299 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 300 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 301 |
+
|
| 302 |
+
|
| 303 |
+
@register_model_architecture('transformer', 'transformer_mid_25e6d_ed3072')
|
| 304 |
+
def transformer_mid_25e6d_ed3072(args):
|
| 305 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 306 |
+
args.encoder_layers = getattr(args, 'encoder_layers', 25)
|
| 307 |
+
args.decoder_layers = getattr(args, 'decoder_layers', 6)
|
| 308 |
+
args.encoder_embed_dim = getattr(args, 'encoder_embed_dim', 768)
|
| 309 |
+
args.decoder_embed_dim = getattr(args, 'decoder_embed_dim', 768)
|
| 310 |
+
args.encoder_ffn_embed_dim = getattr(args, 'encoder_ffn_embed_dim', 3072)
|
| 311 |
+
args.decoder_ffn_embed_dim = getattr(args, 'decoder_ffn_embed_dim', 3072)
|
| 312 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 313 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 314 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 315 |
+
|
| 316 |
+
|
| 317 |
+
@register_model_architecture('transformer', 'transformer_mid_25e6d_e3072_d4096')
|
| 318 |
+
def transformer_mid_25e6d_e3072_d4096(args):
|
| 319 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 320 |
+
args.encoder_layers = getattr(args, 'encoder_layers', 25)
|
| 321 |
+
args.decoder_layers = getattr(args, 'decoder_layers', 6)
|
| 322 |
+
args.encoder_embed_dim = getattr(args, 'encoder_embed_dim', 768)
|
| 323 |
+
args.decoder_embed_dim = getattr(args, 'decoder_embed_dim', 768)
|
| 324 |
+
args.encoder_ffn_embed_dim = getattr(args, 'encoder_ffn_embed_dim', 3072)
|
| 325 |
+
args.decoder_ffn_embed_dim = getattr(args, 'decoder_ffn_embed_dim', 4096)
|
| 326 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 327 |
+
# args.share_all_embeddings = getattr(args, 'share_all_embeddings', True)
|
| 328 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 329 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 330 |
+
|
| 331 |
+
|
| 332 |
+
# def transformer_fixed_multihead(args):
|
| 333 |
+
# args.head_dim = getattr(args, 'head_dim', 128)
|
| 334 |
+
# from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 335 |
+
# transformer_wmt_en_de_big_t2t(args)
|
| 336 |
+
|
| 337 |
+
@register_model_architecture('transformer', 'transformer_fixed_multihead_base')
|
| 338 |
+
def transformer_fixed_multihead_base(args):
|
| 339 |
+
args.head_dim = getattr(args, 'head_dim', 128)
|
| 340 |
+
args.encoder_embed_dim = getattr(args, 'encoder_embed_dim', 512)
|
| 341 |
+
args.decoder_embed_dim = getattr(args, 'decoder_embed_dim', 512)
|
| 342 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 343 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 344 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 345 |
+
|
| 346 |
+
|
| 347 |
+
@register_model_architecture('transformer', 'transformer_fixed_multihead_embed_1024_nhead_16_hdim_128')
|
| 348 |
+
def transformer_fixed_multihead_embed_1024_nhead_16_hdim_128(args):
|
| 349 |
+
args.head_dim = getattr(args, 'head_dim', 128)
|
| 350 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 351 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 352 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 353 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 354 |
+
|
| 355 |
+
|
| 356 |
+
@register_model_architecture('transformer', 'transformer_fixed_multihead_embed_1024_nhead_16_hdim_256')
|
| 357 |
+
def transformer_fixed_multihead_embed_1024_nhead_16_hdim_128(args):
|
| 358 |
+
args.head_dim = getattr(args, 'head_dim', 256)
|
| 359 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 360 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 361 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 362 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
@register_model_architecture('transformer', 'transformer_fh_16x128_layer_12')
|
| 366 |
+
def transformer_fh_16x128_layer_12(args):
|
| 367 |
+
args.head_dim = getattr(args, 'head_dim', 128)
|
| 368 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 369 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 370 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 371 |
+
transformer_wmt_en_de_big_t2t(args)
|
| 372 |
+
|
| 373 |
+
|
| 374 |
+
@register_model_architecture('transformer', 'transformer_fh_16x256_layer_12')
|
| 375 |
+
def transformer_fh_16x256_layer_12(args):
|
| 376 |
+
args.head_dim = getattr(args, 'head_dim', 256)
|
| 377 |
+
args.dropout = getattr(args, 'dropout', 0.1)
|
| 378 |
+
args.share_decoder_input_output_embed = getattr(args, 'share_decoder_input_output_embed', True)
|
| 379 |
+
from fairseq.models.transformer import transformer_wmt_en_de_big_t2t
|
| 380 |
+
transformer_wmt_en_de_big_t2t(args)
|
mcolt/criterions/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .label_smoothed_cross_entropy_with_contrastive import *
|
mcolt/criterions/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (217 Bytes). View file
|
|
|
mcolt/criterions/__pycache__/label_smoothed_cross_entropy_with_contrastive.cpython-310.pyc
ADDED
|
Binary file (4.92 kB). View file
|
|
|
mcolt/criterions/label_smoothed_cross_entropy_with_contrastive.py
ADDED
|
@@ -0,0 +1,123 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
|
| 3 |
+
from fairseq.criterions import register_criterion
|
| 4 |
+
from fairseq.criterions.label_smoothed_cross_entropy import LabelSmoothedCrossEntropyCriterion
|
| 5 |
+
from fairseq import metrics, utils
|
| 6 |
+
|
| 7 |
+
from collections import deque
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
import torch.nn as nn
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@register_criterion("label_smoothed_cross_entropy_with_contrastive")
|
| 14 |
+
class LabelSmoothedCrossEntropyCriterionWithContrastive(
|
| 15 |
+
LabelSmoothedCrossEntropyCriterion
|
| 16 |
+
):
|
| 17 |
+
def __init__(self, task, sentence_avg, label_smoothing, ignore_prefix_size=0, report_accuracy=False,
|
| 18 |
+
contrastive_lambda=0.0,
|
| 19 |
+
temperature=1.0):
|
| 20 |
+
super().__init__(task, sentence_avg, label_smoothing, ignore_prefix_size, report_accuracy)
|
| 21 |
+
self.contrastive_lambda = contrastive_lambda
|
| 22 |
+
self.temperature = temperature
|
| 23 |
+
|
| 24 |
+
@staticmethod
|
| 25 |
+
def add_args(parser):
|
| 26 |
+
LabelSmoothedCrossEntropyCriterion.add_args(parser)
|
| 27 |
+
parser.add_argument("--contrastive-lambda", type=float,
|
| 28 |
+
default=0.0,
|
| 29 |
+
help="The contrastive loss weight")
|
| 30 |
+
parser.add_argument("--temperature", type=float,
|
| 31 |
+
default=1.0,)
|
| 32 |
+
|
| 33 |
+
def swap_sample(self, sample):
|
| 34 |
+
target = sample["target"]
|
| 35 |
+
prev_output_tokens = sample["net_input"]["prev_output_tokens"]
|
| 36 |
+
src_tokens = torch.cat((prev_output_tokens[:, :1], sample["net_input"]['src_tokens']), dim=-1)
|
| 37 |
+
return {
|
| 38 |
+
"net_input": {
|
| 39 |
+
"src_tokens": target.contiguous(),
|
| 40 |
+
"src_lengths": (target != self.padding_idx).int().sum(dim=1),
|
| 41 |
+
"prev_output_tokens": src_tokens[:, :-1].contiguous()
|
| 42 |
+
},
|
| 43 |
+
'nsentences': sample['nsentences'],
|
| 44 |
+
'ntokens': utils.item((src_tokens[:, 1:] != self.padding_idx).int().sum().data),
|
| 45 |
+
"target": src_tokens[:, 1:].contiguous(),
|
| 46 |
+
"id": sample["id"],
|
| 47 |
+
}
|
| 48 |
+
|
| 49 |
+
def forward(self, model, sample, reduce=True):
|
| 50 |
+
net_output = model(**sample["net_input"])
|
| 51 |
+
loss, nll_loss = self.compute_loss(model, net_output, sample, reduce=reduce)
|
| 52 |
+
encoder_out = model.encoder.forward(sample["net_input"]["src_tokens"], sample["net_input"]["src_lengths"]).encoder_out
|
| 53 |
+
reverse_sample = self.swap_sample(sample)
|
| 54 |
+
reversed_encoder_out = model.encoder.forward(reverse_sample["net_input"]["src_tokens"], reverse_sample["net_input"]["src_lengths"]).encoder_out
|
| 55 |
+
contrastive_loss = self.get_contrastive_loss(
|
| 56 |
+
encoder_out,
|
| 57 |
+
reversed_encoder_out,
|
| 58 |
+
sample,
|
| 59 |
+
reverse_sample,
|
| 60 |
+
)
|
| 61 |
+
sample_size = (
|
| 62 |
+
sample["target"].size(0) if self.sentence_avg else sample["ntokens"]
|
| 63 |
+
)
|
| 64 |
+
nsentences = sample["target"].size(0)
|
| 65 |
+
ntokens = sample["ntokens"]
|
| 66 |
+
all_loss = loss + contrastive_loss * self.contrastive_lambda * ntokens / nsentences
|
| 67 |
+
logging_output = {
|
| 68 |
+
"loss": loss.data,
|
| 69 |
+
"nll_loss": nll_loss.data,
|
| 70 |
+
"ntokens": ntokens,
|
| 71 |
+
"nsentences": nsentences,
|
| 72 |
+
"sample_size": sample_size,
|
| 73 |
+
}
|
| 74 |
+
if isinstance(contrastive_loss, int):
|
| 75 |
+
logging_output["contrastive_loss"] = 0
|
| 76 |
+
else:
|
| 77 |
+
logging_output["contrastive_loss"] = utils.item(contrastive_loss.data)
|
| 78 |
+
|
| 79 |
+
return all_loss, sample_size, logging_output
|
| 80 |
+
|
| 81 |
+
def similarity_function(self, ):
|
| 82 |
+
return nn.CosineSimilarity(dim=-1)
|
| 83 |
+
|
| 84 |
+
def get_contrastive_loss(self, encoder_out1, encoder_out2, sample1, sample2):
|
| 85 |
+
|
| 86 |
+
def _sentence_embedding(encoder_out, sample):
|
| 87 |
+
encoder_output = encoder_out.transpose(0, 1)
|
| 88 |
+
src_tokens = sample["net_input"]["src_tokens"]
|
| 89 |
+
mask = (src_tokens != self.padding_idx)
|
| 90 |
+
encoder_embedding = (encoder_output * mask.unsqueeze(-1)).sum(dim=1) / mask.float().sum(dim=1).unsqueeze(-1) # [batch, hidden_size]
|
| 91 |
+
return encoder_embedding
|
| 92 |
+
|
| 93 |
+
encoder_embedding1 = _sentence_embedding(encoder_out1, sample1) # [batch, hidden_size]
|
| 94 |
+
encoder_embedding2 = _sentence_embedding(encoder_out2, sample2) # [batch, hidden_size]
|
| 95 |
+
|
| 96 |
+
batch_size = encoder_embedding2.shape[0]
|
| 97 |
+
feature_dim = encoder_embedding2.shape[1]
|
| 98 |
+
anchor_feature = encoder_embedding1
|
| 99 |
+
contrast_feature = encoder_embedding2
|
| 100 |
+
|
| 101 |
+
similarity_function = self.similarity_function()
|
| 102 |
+
anchor_dot_contrast = similarity_function(anchor_feature.expand((batch_size, batch_size, feature_dim)),
|
| 103 |
+
torch.transpose(contrast_feature.expand((batch_size, batch_size, feature_dim)), 0, 1))
|
| 104 |
+
|
| 105 |
+
loss = -nn.LogSoftmax(0)(torch.div(anchor_dot_contrast, self.temperature)).diag().sum()
|
| 106 |
+
|
| 107 |
+
return loss
|
| 108 |
+
|
| 109 |
+
@classmethod
|
| 110 |
+
def reduce_metrics(cls, logging_outputs) -> None:
|
| 111 |
+
super().reduce_metrics(logging_outputs)
|
| 112 |
+
nsentences = utils.item(
|
| 113 |
+
sum(log.get("nsentences", 0) for log in logging_outputs)
|
| 114 |
+
)
|
| 115 |
+
contrastive_loss = utils.item(
|
| 116 |
+
sum(log.get("contrastive_loss", 0) for log in logging_outputs)
|
| 117 |
+
)
|
| 118 |
+
metrics.log_scalar(
|
| 119 |
+
"contrastive_loss",
|
| 120 |
+
contrastive_loss / nsentences / math.log(2),
|
| 121 |
+
nsentences,
|
| 122 |
+
round=3,
|
| 123 |
+
)
|
mcolt/data/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .subsample_language_pair_dataset import SubsampleLanguagePairDataset
|
mcolt/data/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (233 Bytes). View file
|
|
|
mcolt/data/__pycache__/subsample_language_pair_dataset.cpython-310.pyc
ADDED
|
Binary file (4.46 kB). View file
|
|
|
mcolt/data/subsample_language_pair_dataset.py
ADDED
|
@@ -0,0 +1,124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from fairseq.data import BaseWrapperDataset, LanguagePairDataset, plasma_utils
|
| 2 |
+
import numpy as np
|
| 3 |
+
|
| 4 |
+
import logging
|
| 5 |
+
|
| 6 |
+
logger = logging.getLogger(__name__)
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class SubsampleLanguagePairDataset(BaseWrapperDataset):
|
| 10 |
+
"""Subsamples a given dataset by a specified ratio. Subsampling is done on the number of examples
|
| 11 |
+
|
| 12 |
+
Args:
|
| 13 |
+
dataset (~torch.utils.data.Dataset): dataset to subsample
|
| 14 |
+
size_ratio(float): the ratio to subsample to. must be between 0 and 1 (exclusive)
|
| 15 |
+
"""
|
| 16 |
+
|
| 17 |
+
def __init__(self, dataset, size_ratio, weights=None, replace=False, seed=0, epoch=1):
|
| 18 |
+
super().__init__(dataset)
|
| 19 |
+
assert size_ratio <= 1
|
| 20 |
+
self.actual_size = np.ceil(len(dataset) * size_ratio).astype(int)
|
| 21 |
+
logger.info(
|
| 22 |
+
"subsampled dataset from {} to {} (ratio={})".format(
|
| 23 |
+
len(self.dataset), self.actual_size, size_ratio
|
| 24 |
+
)
|
| 25 |
+
)
|
| 26 |
+
self.src_dict = self.dataset.src_dict
|
| 27 |
+
self.tgt_dict = self.dataset.tgt_dict
|
| 28 |
+
self.left_pad_source = self.dataset.left_pad_source
|
| 29 |
+
self.left_pad_target = self.dataset.left_pad_target
|
| 30 |
+
self.seed = seed
|
| 31 |
+
self._cur_epoch = None
|
| 32 |
+
self._cur_indices = None
|
| 33 |
+
self.replace = replace
|
| 34 |
+
if weights is None:
|
| 35 |
+
self.weights = None
|
| 36 |
+
else:
|
| 37 |
+
assert len(weights) == len(dataset)
|
| 38 |
+
weights_arr = np.array(weights, dtype=np.float64)
|
| 39 |
+
weights_arr /= weights_arr.sum()
|
| 40 |
+
self.weights = plasma_utils.PlasmaArray(weights_arr)
|
| 41 |
+
self.set_epoch(epoch)
|
| 42 |
+
|
| 43 |
+
def __getitem__(self, index):
|
| 44 |
+
index = self._cur_indices.array[index]
|
| 45 |
+
return self.dataset.__getitem__(index)
|
| 46 |
+
|
| 47 |
+
def __len__(self):
|
| 48 |
+
return self.actual_size
|
| 49 |
+
|
| 50 |
+
@property
|
| 51 |
+
def sizes(self):
|
| 52 |
+
return self.dataset.sizes[self._cur_indices.array]
|
| 53 |
+
|
| 54 |
+
@property
|
| 55 |
+
def src_sizes(self):
|
| 56 |
+
return self.dataset.src_sizes[self._cur_indices.array]
|
| 57 |
+
|
| 58 |
+
@property
|
| 59 |
+
def tgt_sizes(self):
|
| 60 |
+
return self.dataset.tgt_sizes[self._cur_indices.array]
|
| 61 |
+
|
| 62 |
+
@property
|
| 63 |
+
def name(self):
|
| 64 |
+
return self.dataset.name
|
| 65 |
+
|
| 66 |
+
def num_tokens(self, index):
|
| 67 |
+
index = self._cur_indices.array[index]
|
| 68 |
+
return self.dataset.num_tokens(index)
|
| 69 |
+
|
| 70 |
+
def size(self, index):
|
| 71 |
+
index = self._cur_indices.array[index]
|
| 72 |
+
return self.dataset.size(index)
|
| 73 |
+
|
| 74 |
+
def ordered_indices(self):
|
| 75 |
+
if self.shuffle:
|
| 76 |
+
indices = np.random.permutation(len(self)).astype(np.int64)
|
| 77 |
+
else:
|
| 78 |
+
indices = np.arange(len(self), dtype=np.int64)
|
| 79 |
+
# sort by target length, then source length
|
| 80 |
+
if self.tgt_sizes is not None:
|
| 81 |
+
indices = indices[np.argsort(self.tgt_sizes[indices], kind="mergesort")]
|
| 82 |
+
return indices[np.argsort(self.src_sizes[indices], kind="mergesort")]
|
| 83 |
+
|
| 84 |
+
def prefetch(self, indices):
|
| 85 |
+
indices = self._cur_indices.array[indices]
|
| 86 |
+
self.dataset.prefetch(indices)
|
| 87 |
+
|
| 88 |
+
@property
|
| 89 |
+
def can_reuse_epoch_itr_across_epochs(self):
|
| 90 |
+
return False
|
| 91 |
+
|
| 92 |
+
def set_epoch(self, epoch):
|
| 93 |
+
logger.info("SubsampleLanguagePairDataset.set_epoch: {}".format(epoch))
|
| 94 |
+
super().set_epoch(epoch)
|
| 95 |
+
|
| 96 |
+
if epoch == self._cur_epoch:
|
| 97 |
+
return
|
| 98 |
+
|
| 99 |
+
self._cur_epoch = epoch
|
| 100 |
+
|
| 101 |
+
# Generate a weighted sample of indices as a function of the
|
| 102 |
+
# random seed and the current epoch.
|
| 103 |
+
|
| 104 |
+
rng = np.random.RandomState(
|
| 105 |
+
[
|
| 106 |
+
42, # magic number
|
| 107 |
+
self.seed % (2 ** 32), # global seed
|
| 108 |
+
self._cur_epoch, # epoch index
|
| 109 |
+
]
|
| 110 |
+
)
|
| 111 |
+
self._cur_indices = plasma_utils.PlasmaArray(
|
| 112 |
+
rng.choice(
|
| 113 |
+
len(self.dataset),
|
| 114 |
+
self.actual_size,
|
| 115 |
+
replace=self.replace,
|
| 116 |
+
p=(None if self.weights is None else self.weights.array),
|
| 117 |
+
)
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
logger.info(
|
| 121 |
+
"Dataset is sub-sampled: {} -> {}, first 3 ids are: {}".format(len(self.dataset), self.actual_size,
|
| 122 |
+
",".join(
|
| 123 |
+
[str(_i) for _i in
|
| 124 |
+
self._cur_indices.array[:3]])))
|
mcolt/tasks/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .translation_w_mono import *
|
| 2 |
+
from .translation_w_langtok import *
|
mcolt/tasks/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (218 Bytes). View file
|
|
|
mcolt/tasks/__pycache__/translation_w_langtok.cpython-310.pyc
ADDED
|
Binary file (13.6 kB). View file
|
|
|
mcolt/tasks/__pycache__/translation_w_mono.cpython-310.pyc
ADDED
|
Binary file (6.39 kB). View file
|
|
|
mcolt/tasks/translation_w_langtok.py
ADDED
|
@@ -0,0 +1,476 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Facebook, Inc. and its affiliates.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the MIT license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
import itertools
|
| 7 |
+
import json
|
| 8 |
+
import logging
|
| 9 |
+
import os
|
| 10 |
+
import torch
|
| 11 |
+
from argparse import Namespace
|
| 12 |
+
|
| 13 |
+
import numpy as np
|
| 14 |
+
from fairseq import metrics, options, utils
|
| 15 |
+
from fairseq.data import (
|
| 16 |
+
AppendTokenDataset,
|
| 17 |
+
ConcatDataset,
|
| 18 |
+
LanguagePairDataset,
|
| 19 |
+
PrependTokenDataset,
|
| 20 |
+
StripTokenDataset,
|
| 21 |
+
TruncateDataset,
|
| 22 |
+
data_utils,
|
| 23 |
+
encoders,
|
| 24 |
+
indexed_dataset,
|
| 25 |
+
)
|
| 26 |
+
from fairseq.tasks.translation import TranslationTask
|
| 27 |
+
from fairseq.tasks import register_task, LegacyFairseqTask
|
| 28 |
+
|
| 29 |
+
EVAL_BLEU_ORDER = 4
|
| 30 |
+
|
| 31 |
+
logger = logging.getLogger(__name__)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def load_langpair_dataset(
|
| 35 |
+
data_path,
|
| 36 |
+
split,
|
| 37 |
+
src,
|
| 38 |
+
src_dict,
|
| 39 |
+
tgt,
|
| 40 |
+
tgt_dict,
|
| 41 |
+
combine,
|
| 42 |
+
dataset_impl,
|
| 43 |
+
upsample_primary,
|
| 44 |
+
left_pad_source,
|
| 45 |
+
left_pad_target,
|
| 46 |
+
max_source_positions,
|
| 47 |
+
max_target_positions,
|
| 48 |
+
prepend_bos=False,
|
| 49 |
+
load_alignments=False,
|
| 50 |
+
truncate_source=False,
|
| 51 |
+
append_source_id=False,
|
| 52 |
+
num_buckets=0,
|
| 53 |
+
shuffle=True,
|
| 54 |
+
pad_to_multiple=1,
|
| 55 |
+
):
|
| 56 |
+
def split_exists(split, src, tgt, lang, data_path):
|
| 57 |
+
filename = os.path.join(data_path, "{}.{}-{}.{}".format(split, src, tgt, lang))
|
| 58 |
+
return os.path.exists(filename)
|
| 59 |
+
|
| 60 |
+
src_datasets = []
|
| 61 |
+
tgt_datasets = []
|
| 62 |
+
|
| 63 |
+
for k in itertools.count():
|
| 64 |
+
split_k = split + (str(k) if k > 0 else "")
|
| 65 |
+
|
| 66 |
+
# infer langcode
|
| 67 |
+
if split_exists(split_k, src, tgt, src, data_path):
|
| 68 |
+
prefix = os.path.join(data_path, "{}.{}-{}.".format(split_k, src, tgt))
|
| 69 |
+
elif split_exists(split_k, tgt, src, src, data_path):
|
| 70 |
+
prefix = os.path.join(data_path, "{}.{}-{}.".format(split_k, tgt, src))
|
| 71 |
+
else:
|
| 72 |
+
if k > 0:
|
| 73 |
+
break
|
| 74 |
+
else:
|
| 75 |
+
raise FileNotFoundError(
|
| 76 |
+
"Dataset not found: {} ({})".format(split, data_path)
|
| 77 |
+
)
|
| 78 |
+
|
| 79 |
+
src_dataset = data_utils.load_indexed_dataset(
|
| 80 |
+
prefix + src, src_dict, dataset_impl
|
| 81 |
+
)
|
| 82 |
+
if truncate_source:
|
| 83 |
+
src_dataset = AppendTokenDataset(
|
| 84 |
+
TruncateDataset(
|
| 85 |
+
StripTokenDataset(src_dataset, src_dict.eos()),
|
| 86 |
+
max_source_positions - 1,
|
| 87 |
+
),
|
| 88 |
+
src_dict.eos(),
|
| 89 |
+
)
|
| 90 |
+
src_datasets.append(src_dataset)
|
| 91 |
+
|
| 92 |
+
tgt_dataset = data_utils.load_indexed_dataset(
|
| 93 |
+
prefix + tgt, tgt_dict, dataset_impl
|
| 94 |
+
)
|
| 95 |
+
if tgt_dataset is not None:
|
| 96 |
+
tgt_datasets.append(tgt_dataset)
|
| 97 |
+
|
| 98 |
+
logger.info(
|
| 99 |
+
"{} {} {}-{} {} examples".format(
|
| 100 |
+
data_path, split_k, src, tgt, len(src_datasets[-1])
|
| 101 |
+
)
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
if not combine:
|
| 105 |
+
break
|
| 106 |
+
|
| 107 |
+
assert len(src_datasets) == len(tgt_datasets) or len(tgt_datasets) == 0
|
| 108 |
+
|
| 109 |
+
if len(src_datasets) == 1:
|
| 110 |
+
src_dataset = src_datasets[0]
|
| 111 |
+
tgt_dataset = tgt_datasets[0] if len(tgt_datasets) > 0 else None
|
| 112 |
+
else:
|
| 113 |
+
sample_ratios = [1] * len(src_datasets)
|
| 114 |
+
sample_ratios[0] = upsample_primary
|
| 115 |
+
src_dataset = ConcatDataset(src_datasets, sample_ratios)
|
| 116 |
+
if len(tgt_datasets) > 0:
|
| 117 |
+
tgt_dataset = ConcatDataset(tgt_datasets, sample_ratios)
|
| 118 |
+
else:
|
| 119 |
+
tgt_dataset = None
|
| 120 |
+
|
| 121 |
+
if prepend_bos:
|
| 122 |
+
assert hasattr(src_dict, "bos_index") and hasattr(tgt_dict, "bos_index")
|
| 123 |
+
src_dataset = PrependTokenDataset(src_dataset, src_dict.bos())
|
| 124 |
+
if tgt_dataset is not None:
|
| 125 |
+
tgt_dataset = PrependTokenDataset(tgt_dataset, tgt_dict.bos())
|
| 126 |
+
|
| 127 |
+
eos = None
|
| 128 |
+
if append_source_id:
|
| 129 |
+
src_dataset = AppendTokenDataset(
|
| 130 |
+
src_dataset, src_dict.index("[{}]".format(src))
|
| 131 |
+
)
|
| 132 |
+
if tgt_dataset is not None:
|
| 133 |
+
tgt_dataset = AppendTokenDataset(
|
| 134 |
+
tgt_dataset, tgt_dict.index("[{}]".format(tgt))
|
| 135 |
+
)
|
| 136 |
+
eos = tgt_dict.index("[{}]".format(tgt))
|
| 137 |
+
|
| 138 |
+
align_dataset = None
|
| 139 |
+
if load_alignments:
|
| 140 |
+
align_path = os.path.join(data_path, "{}.align.{}-{}".format(split, src, tgt))
|
| 141 |
+
if indexed_dataset.dataset_exists(align_path, impl=dataset_impl):
|
| 142 |
+
align_dataset = data_utils.load_indexed_dataset(
|
| 143 |
+
align_path, None, dataset_impl
|
| 144 |
+
)
|
| 145 |
+
|
| 146 |
+
tgt_dataset_sizes = tgt_dataset.sizes if tgt_dataset is not None else None
|
| 147 |
+
return LanguagePairDataset(
|
| 148 |
+
src_dataset,
|
| 149 |
+
src_dataset.sizes,
|
| 150 |
+
src_dict,
|
| 151 |
+
tgt_dataset,
|
| 152 |
+
tgt_dataset_sizes,
|
| 153 |
+
tgt_dict,
|
| 154 |
+
left_pad_source=left_pad_source,
|
| 155 |
+
left_pad_target=left_pad_target,
|
| 156 |
+
align_dataset=align_dataset,
|
| 157 |
+
eos=eos,
|
| 158 |
+
num_buckets=num_buckets,
|
| 159 |
+
shuffle=shuffle,
|
| 160 |
+
pad_to_multiple=pad_to_multiple,
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
@register_task("translation_w_langtok")
|
| 165 |
+
class TranslationWithLangtokTask(LegacyFairseqTask):
|
| 166 |
+
"""
|
| 167 |
+
Translate from one (source) language to another (target) language.
|
| 168 |
+
|
| 169 |
+
Args:
|
| 170 |
+
src_dict (~fairseq.data.Dictionary): dictionary for the source language
|
| 171 |
+
tgt_dict (~fairseq.data.Dictionary): dictionary for the target language
|
| 172 |
+
|
| 173 |
+
.. note::
|
| 174 |
+
|
| 175 |
+
The translation task is compatible with :mod:`fairseq-train`,
|
| 176 |
+
:mod:`fairseq-generate` and :mod:`fairseq-interactive`.
|
| 177 |
+
|
| 178 |
+
The translation task provides the following additional command-line
|
| 179 |
+
arguments:
|
| 180 |
+
|
| 181 |
+
.. argparse::
|
| 182 |
+
:ref: fairseq.tasks.translation_parser
|
| 183 |
+
:prog:
|
| 184 |
+
"""
|
| 185 |
+
|
| 186 |
+
@staticmethod
|
| 187 |
+
def add_args(parser):
|
| 188 |
+
"""Add task-specific arguments to the parser."""
|
| 189 |
+
# fmt: off
|
| 190 |
+
parser.add_argument('data', help='colon separated path to data directories list, \
|
| 191 |
+
will be iterated upon during epochs in round-robin manner; \
|
| 192 |
+
however, valid and test data are always in the first directory to \
|
| 193 |
+
avoid the need for repeating them in all directories')
|
| 194 |
+
parser.add_argument('-s', '--source-lang', default=None, metavar='SRC',
|
| 195 |
+
help='source language')
|
| 196 |
+
parser.add_argument('-t', '--target-lang', default=None, metavar='TARGET',
|
| 197 |
+
help='target language')
|
| 198 |
+
parser.add_argument('--load-alignments', action='store_true',
|
| 199 |
+
help='load the binarized alignments')
|
| 200 |
+
parser.add_argument('--left-pad-source', default='True', type=str, metavar='BOOL',
|
| 201 |
+
help='pad the source on the left')
|
| 202 |
+
parser.add_argument('--left-pad-target', default='False', type=str, metavar='BOOL',
|
| 203 |
+
help='pad the target on the left')
|
| 204 |
+
parser.add_argument('--max-source-positions', default=1024, type=int, metavar='N',
|
| 205 |
+
help='max number of tokens in the source sequence')
|
| 206 |
+
parser.add_argument('--max-target-positions', default=1024, type=int, metavar='N',
|
| 207 |
+
help='max number of tokens in the target sequence')
|
| 208 |
+
parser.add_argument('--upsample-primary', default=1, type=int,
|
| 209 |
+
help='amount to upsample primary dataset')
|
| 210 |
+
parser.add_argument('--truncate-source', action='store_true', default=False,
|
| 211 |
+
help='truncate source to max-source-positions')
|
| 212 |
+
parser.add_argument('--num-batch-buckets', default=0, type=int, metavar='N',
|
| 213 |
+
help='if >0, then bucket source and target lengths into N '
|
| 214 |
+
'buckets and pad accordingly; this is useful on TPUs '
|
| 215 |
+
'to minimize the number of compilations')
|
| 216 |
+
parser.add_argument('--lang-prefix-tok', default=None, type=str, help="starting token in decoder")
|
| 217 |
+
|
| 218 |
+
# options for reporting BLEU during validation
|
| 219 |
+
parser.add_argument('--eval-bleu', action='store_true',
|
| 220 |
+
help='evaluation with BLEU scores')
|
| 221 |
+
parser.add_argument('--eval-bleu-detok', type=str, default="space",
|
| 222 |
+
help='detokenize before computing BLEU (e.g., "moses"); '
|
| 223 |
+
'required if using --eval-bleu; use "space" to '
|
| 224 |
+
'disable detokenization; see fairseq.data.encoders '
|
| 225 |
+
'for other options')
|
| 226 |
+
parser.add_argument('--eval-bleu-detok-args', type=str, metavar='JSON',
|
| 227 |
+
help='args for building the tokenizer, if needed')
|
| 228 |
+
parser.add_argument('--eval-tokenized-bleu', action='store_true', default=False,
|
| 229 |
+
help='compute tokenized BLEU instead of sacrebleu')
|
| 230 |
+
parser.add_argument('--eval-bleu-remove-bpe', nargs='?', const='@@ ', default=None,
|
| 231 |
+
help='remove BPE before computing BLEU')
|
| 232 |
+
parser.add_argument('--eval-bleu-args', type=str, metavar='JSON',
|
| 233 |
+
help='generation args for BLUE scoring, '
|
| 234 |
+
'e.g., \'{"beam": 4, "lenpen": 0.6}\'')
|
| 235 |
+
parser.add_argument('--eval-bleu-print-samples', action='store_true',
|
| 236 |
+
help='print sample generations during validation')
|
| 237 |
+
# fmt: on
|
| 238 |
+
|
| 239 |
+
def __init__(self, args, src_dict, tgt_dict):
|
| 240 |
+
super().__init__(args)
|
| 241 |
+
self.src_dict = src_dict
|
| 242 |
+
self.tgt_dict = tgt_dict
|
| 243 |
+
|
| 244 |
+
@classmethod
|
| 245 |
+
def setup_task(cls, args, **kwargs):
|
| 246 |
+
"""Setup the task (e.g., load dictionaries).
|
| 247 |
+
|
| 248 |
+
Args:
|
| 249 |
+
args (argparse.Namespace): parsed command-line arguments
|
| 250 |
+
"""
|
| 251 |
+
args.left_pad_source = utils.eval_bool(args.left_pad_source)
|
| 252 |
+
args.left_pad_target = utils.eval_bool(args.left_pad_target)
|
| 253 |
+
|
| 254 |
+
paths = utils.split_paths(args.data)
|
| 255 |
+
assert len(paths) > 0
|
| 256 |
+
# find language pair automatically
|
| 257 |
+
if args.source_lang is None or args.target_lang is None:
|
| 258 |
+
args.source_lang, args.target_lang = data_utils.infer_language_pair(
|
| 259 |
+
paths[0]
|
| 260 |
+
)
|
| 261 |
+
if args.source_lang is None or args.target_lang is None:
|
| 262 |
+
raise Exception(
|
| 263 |
+
"Could not infer language pair, please provide it explicitly"
|
| 264 |
+
)
|
| 265 |
+
|
| 266 |
+
# load dictionaries
|
| 267 |
+
src_dict = cls.load_dictionary(
|
| 268 |
+
os.path.join(paths[0], "dict.{}.txt".format(args.source_lang))
|
| 269 |
+
)
|
| 270 |
+
tgt_dict = cls.load_dictionary(
|
| 271 |
+
os.path.join(paths[0], "dict.{}.txt".format(args.target_lang))
|
| 272 |
+
)
|
| 273 |
+
assert src_dict.pad() == tgt_dict.pad()
|
| 274 |
+
assert src_dict.eos() == tgt_dict.eos()
|
| 275 |
+
assert src_dict.unk() == tgt_dict.unk()
|
| 276 |
+
logger.info("[{}] dictionary: {} types".format(args.source_lang, len(src_dict)))
|
| 277 |
+
logger.info("[{}] dictionary: {} types".format(args.target_lang, len(tgt_dict)))
|
| 278 |
+
|
| 279 |
+
return cls(args, src_dict, tgt_dict)
|
| 280 |
+
|
| 281 |
+
def load_dataset(self, split, epoch=1, combine=False, **kwargs):
|
| 282 |
+
"""Load a given dataset split.
|
| 283 |
+
|
| 284 |
+
Args:
|
| 285 |
+
split (str): name of the split (e.g., train, valid, test)
|
| 286 |
+
"""
|
| 287 |
+
paths = utils.split_paths(self.args.data)
|
| 288 |
+
assert len(paths) > 0
|
| 289 |
+
if split != getattr(self.args, "train_subset", None):
|
| 290 |
+
# if not training data set, use the first shard for valid and test
|
| 291 |
+
paths = paths[:1]
|
| 292 |
+
data_path = paths[(epoch - 1) % len(paths)]
|
| 293 |
+
|
| 294 |
+
# infer langcode
|
| 295 |
+
src, tgt = self.args.source_lang, self.args.target_lang
|
| 296 |
+
|
| 297 |
+
self.datasets[split] = load_langpair_dataset(
|
| 298 |
+
data_path,
|
| 299 |
+
split,
|
| 300 |
+
src,
|
| 301 |
+
self.src_dict,
|
| 302 |
+
tgt,
|
| 303 |
+
self.tgt_dict,
|
| 304 |
+
combine=combine,
|
| 305 |
+
dataset_impl=self.args.dataset_impl,
|
| 306 |
+
upsample_primary=self.args.upsample_primary,
|
| 307 |
+
left_pad_source=self.args.left_pad_source,
|
| 308 |
+
left_pad_target=self.args.left_pad_target,
|
| 309 |
+
max_source_positions=self.args.max_source_positions,
|
| 310 |
+
max_target_positions=self.args.max_target_positions,
|
| 311 |
+
load_alignments=self.args.load_alignments,
|
| 312 |
+
truncate_source=self.args.truncate_source,
|
| 313 |
+
num_buckets=self.args.num_batch_buckets,
|
| 314 |
+
shuffle=(split != "test"),
|
| 315 |
+
pad_to_multiple=self.args.required_seq_len_multiple,
|
| 316 |
+
)
|
| 317 |
+
|
| 318 |
+
def build_dataset_for_inference(self, src_tokens, src_lengths, constraints=None):
|
| 319 |
+
return LanguagePairDataset(
|
| 320 |
+
src_tokens,
|
| 321 |
+
src_lengths,
|
| 322 |
+
self.source_dictionary,
|
| 323 |
+
tgt_dict=self.target_dictionary,
|
| 324 |
+
constraints=constraints,
|
| 325 |
+
)
|
| 326 |
+
|
| 327 |
+
def build_model(self, args):
|
| 328 |
+
model = super().build_model(args)
|
| 329 |
+
if getattr(args, "eval_bleu", False):
|
| 330 |
+
assert getattr(args, "eval_bleu_detok", None) is not None, (
|
| 331 |
+
"--eval-bleu-detok is required if using --eval-bleu; "
|
| 332 |
+
"try --eval-bleu-detok=moses (or --eval-bleu-detok=space "
|
| 333 |
+
"to disable detokenization, e.g., when using sentencepiece)"
|
| 334 |
+
)
|
| 335 |
+
detok_args = json.loads(getattr(args, "eval_bleu_detok_args", "{}") or "{}")
|
| 336 |
+
self.tokenizer = encoders.build_tokenizer(
|
| 337 |
+
Namespace(
|
| 338 |
+
tokenizer=getattr(args, "eval_bleu_detok", None), **detok_args
|
| 339 |
+
)
|
| 340 |
+
)
|
| 341 |
+
|
| 342 |
+
gen_args = json.loads(getattr(args, "eval_bleu_args", "{}") or "{}")
|
| 343 |
+
self.sequence_generator = self.build_generator(
|
| 344 |
+
[model], Namespace(**gen_args)
|
| 345 |
+
)
|
| 346 |
+
return model
|
| 347 |
+
|
| 348 |
+
def valid_step(self, sample, model, criterion):
|
| 349 |
+
loss, sample_size, logging_output = super().valid_step(sample, model, criterion)
|
| 350 |
+
if self.args.eval_bleu:
|
| 351 |
+
bleu = self._inference_with_bleu(self.sequence_generator, sample, model)
|
| 352 |
+
logging_output["_bleu_sys_len"] = bleu.sys_len
|
| 353 |
+
logging_output["_bleu_ref_len"] = bleu.ref_len
|
| 354 |
+
# we split counts into separate entries so that they can be
|
| 355 |
+
# summed efficiently across workers using fast-stat-sync
|
| 356 |
+
assert len(bleu.counts) == EVAL_BLEU_ORDER
|
| 357 |
+
for i in range(EVAL_BLEU_ORDER):
|
| 358 |
+
logging_output["_bleu_counts_" + str(i)] = bleu.counts[i]
|
| 359 |
+
logging_output["_bleu_totals_" + str(i)] = bleu.totals[i]
|
| 360 |
+
return loss, sample_size, logging_output
|
| 361 |
+
|
| 362 |
+
def inference_step(
|
| 363 |
+
self, generator, models, sample, prefix_tokens=None, constraints=None
|
| 364 |
+
):
|
| 365 |
+
if self.args.lang_prefix_tok is None:
|
| 366 |
+
prefix_tokens = None
|
| 367 |
+
else:
|
| 368 |
+
prefix_tokens = self.target_dictionary.index(self.args.lang_prefix_tok)
|
| 369 |
+
assert prefix_tokens != self.target_dictionary.unk_index
|
| 370 |
+
with torch.no_grad():
|
| 371 |
+
net_input = sample["net_input"]
|
| 372 |
+
if "src_tokens" in net_input:
|
| 373 |
+
src_tokens = net_input["src_tokens"]
|
| 374 |
+
elif "source" in net_input:
|
| 375 |
+
src_tokens = net_input["source"]
|
| 376 |
+
else:
|
| 377 |
+
raise Exception("expected src_tokens or source in net input")
|
| 378 |
+
|
| 379 |
+
# bsz: total number of sentences in beam
|
| 380 |
+
# Note that src_tokens may have more than 2 dimenions (i.e. audio features)
|
| 381 |
+
bsz, _ = src_tokens.size()[:2]
|
| 382 |
+
if prefix_tokens is not None:
|
| 383 |
+
if isinstance(prefix_tokens, int):
|
| 384 |
+
prefix_tokens = torch.LongTensor([prefix_tokens]).unsqueeze(1) # 1,1
|
| 385 |
+
prefix_tokens = prefix_tokens.expand(bsz, -1)
|
| 386 |
+
prefix_tokens = prefix_tokens.to(src_tokens.device)
|
| 387 |
+
return generator.generate(models, sample, prefix_tokens=prefix_tokens)
|
| 388 |
+
|
| 389 |
+
def reduce_metrics(self, logging_outputs, criterion):
|
| 390 |
+
super().reduce_metrics(logging_outputs, criterion)
|
| 391 |
+
if self.args.eval_bleu:
|
| 392 |
+
|
| 393 |
+
def sum_logs(key):
|
| 394 |
+
return sum(log.get(key, 0) for log in logging_outputs)
|
| 395 |
+
|
| 396 |
+
counts, totals = [], []
|
| 397 |
+
for i in range(EVAL_BLEU_ORDER):
|
| 398 |
+
counts.append(sum_logs("_bleu_counts_" + str(i)))
|
| 399 |
+
totals.append(sum_logs("_bleu_totals_" + str(i)))
|
| 400 |
+
|
| 401 |
+
if max(totals) > 0:
|
| 402 |
+
# log counts as numpy arrays -- log_scalar will sum them correctly
|
| 403 |
+
metrics.log_scalar("_bleu_counts", np.array(counts))
|
| 404 |
+
metrics.log_scalar("_bleu_totals", np.array(totals))
|
| 405 |
+
metrics.log_scalar("_bleu_sys_len", sum_logs("_bleu_sys_len"))
|
| 406 |
+
metrics.log_scalar("_bleu_ref_len", sum_logs("_bleu_ref_len"))
|
| 407 |
+
|
| 408 |
+
def compute_bleu(meters):
|
| 409 |
+
import inspect
|
| 410 |
+
import sacrebleu
|
| 411 |
+
|
| 412 |
+
fn_sig = inspect.getfullargspec(sacrebleu.compute_bleu)[0]
|
| 413 |
+
if "smooth_method" in fn_sig:
|
| 414 |
+
smooth = {"smooth_method": "exp"}
|
| 415 |
+
else:
|
| 416 |
+
smooth = {"smooth": "exp"}
|
| 417 |
+
bleu = sacrebleu.compute_bleu(
|
| 418 |
+
correct=meters["_bleu_counts"].sum,
|
| 419 |
+
total=meters["_bleu_totals"].sum,
|
| 420 |
+
sys_len=meters["_bleu_sys_len"].sum,
|
| 421 |
+
ref_len=meters["_bleu_ref_len"].sum,
|
| 422 |
+
**smooth
|
| 423 |
+
)
|
| 424 |
+
return round(bleu.score, 2)
|
| 425 |
+
|
| 426 |
+
metrics.log_derived("bleu", compute_bleu)
|
| 427 |
+
|
| 428 |
+
def max_positions(self):
|
| 429 |
+
"""Return the max sentence length allowed by the task."""
|
| 430 |
+
return (self.args.max_source_positions, self.args.max_target_positions)
|
| 431 |
+
|
| 432 |
+
@property
|
| 433 |
+
def source_dictionary(self):
|
| 434 |
+
"""Return the source :class:`~fairseq.data.Dictionary`."""
|
| 435 |
+
return self.src_dict
|
| 436 |
+
|
| 437 |
+
@property
|
| 438 |
+
def target_dictionary(self):
|
| 439 |
+
"""Return the target :class:`~fairseq.data.Dictionary`."""
|
| 440 |
+
return self.tgt_dict
|
| 441 |
+
|
| 442 |
+
def _inference_with_bleu(self, generator, sample, model):
|
| 443 |
+
import sacrebleu
|
| 444 |
+
|
| 445 |
+
def decode(toks, escape_unk=False):
|
| 446 |
+
s = self.tgt_dict.string(
|
| 447 |
+
toks.int().cpu(),
|
| 448 |
+
self.args.eval_bleu_remove_bpe,
|
| 449 |
+
# The default unknown string in fairseq is `<unk>`, but
|
| 450 |
+
# this is tokenized by sacrebleu as `< unk >`, inflating
|
| 451 |
+
# BLEU scores. Instead, we use a somewhat more verbose
|
| 452 |
+
# alternative that is unlikely to appear in the real
|
| 453 |
+
# reference, but doesn't get split into multiple tokens.
|
| 454 |
+
unk_string=("UNKNOWNTOKENINREF" if escape_unk else "UNKNOWNTOKENINHYP"),
|
| 455 |
+
)
|
| 456 |
+
if self.tokenizer:
|
| 457 |
+
s = self.tokenizer.decode(s)
|
| 458 |
+
return s
|
| 459 |
+
|
| 460 |
+
gen_out = self.inference_step(generator, [model], sample, prefix_tokens=None)
|
| 461 |
+
hyps, refs = [], []
|
| 462 |
+
for i in range(len(gen_out)):
|
| 463 |
+
hyps.append(decode(gen_out[i][0]["tokens"]))
|
| 464 |
+
refs.append(
|
| 465 |
+
decode(
|
| 466 |
+
utils.strip_pad(sample["target"][i], self.tgt_dict.pad()),
|
| 467 |
+
escape_unk=True, # don't count <unk> as matches to the hypo
|
| 468 |
+
)
|
| 469 |
+
)
|
| 470 |
+
if self.args.eval_bleu_print_samples:
|
| 471 |
+
logger.info("example hypothesis: " + hyps[0])
|
| 472 |
+
logger.info("example reference: " + refs[0])
|
| 473 |
+
if self.args.eval_tokenized_bleu:
|
| 474 |
+
return sacrebleu.corpus_bleu(hyps, [refs], tokenize="none")
|
| 475 |
+
else:
|
| 476 |
+
return sacrebleu.corpus_bleu(hyps, [refs])
|
mcolt/tasks/translation_w_mono.py
ADDED
|
@@ -0,0 +1,214 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Facebook, Inc. and its affiliates.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the MIT license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
import os
|
| 7 |
+
from fairseq import options, utils
|
| 8 |
+
from fairseq.data import (
|
| 9 |
+
ConcatDataset,
|
| 10 |
+
data_utils,
|
| 11 |
+
LanguagePairDataset)
|
| 12 |
+
|
| 13 |
+
from ..data import SubsampleLanguagePairDataset
|
| 14 |
+
|
| 15 |
+
import logging
|
| 16 |
+
from fairseq.tasks import register_task
|
| 17 |
+
from fairseq.tasks.translation import TranslationTask, load_langpair_dataset
|
| 18 |
+
|
| 19 |
+
logger = logging.getLogger(__name__)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def concat_language_pair_dataset(*language_pair_datasets, up_sample_ratio=None,
|
| 23 |
+
all_dataset_upsample_ratio=None):
|
| 24 |
+
logger.info("To cancat the language pairs")
|
| 25 |
+
dataset_number = len(language_pair_datasets)
|
| 26 |
+
if dataset_number == 1:
|
| 27 |
+
return language_pair_datasets[0]
|
| 28 |
+
elif dataset_number < 1:
|
| 29 |
+
raise ValueError("concat_language_pair_dataset needs at least on dataset")
|
| 30 |
+
# for dataset in language_pair_datasets:
|
| 31 |
+
# assert isinstance(dataset, LanguagePairDataset), "concat_language_pair_dataset can only concat language pair" \
|
| 32 |
+
# "dataset"
|
| 33 |
+
|
| 34 |
+
src_list = [language_pair_datasets[0].src]
|
| 35 |
+
tgt_list = [language_pair_datasets[0].tgt]
|
| 36 |
+
src_dict = language_pair_datasets[0].src_dict
|
| 37 |
+
tgt_dict = language_pair_datasets[0].tgt_dict
|
| 38 |
+
left_pad_source = language_pair_datasets[0].left_pad_source
|
| 39 |
+
left_pad_target = language_pair_datasets[0].left_pad_target
|
| 40 |
+
|
| 41 |
+
logger.info("To construct the source dataset list and the target dataset list")
|
| 42 |
+
for dataset in language_pair_datasets[1:]:
|
| 43 |
+
assert dataset.src_dict == src_dict
|
| 44 |
+
assert dataset.tgt_dict == tgt_dict
|
| 45 |
+
assert dataset.left_pad_source == left_pad_source
|
| 46 |
+
assert dataset.left_pad_target == left_pad_target
|
| 47 |
+
src_list.append(dataset.src)
|
| 48 |
+
tgt_list.append(dataset.tgt)
|
| 49 |
+
logger.info("Have constructed the source dataset list and the target dataset list")
|
| 50 |
+
|
| 51 |
+
if all_dataset_upsample_ratio is None:
|
| 52 |
+
sample_ratio = [1] * len(src_list)
|
| 53 |
+
sample_ratio[0] = up_sample_ratio
|
| 54 |
+
else:
|
| 55 |
+
sample_ratio = [int(t) for t in all_dataset_upsample_ratio.strip().split(",")]
|
| 56 |
+
assert len(sample_ratio) == len(src_list)
|
| 57 |
+
src_dataset = ConcatDataset(src_list, sample_ratios=sample_ratio)
|
| 58 |
+
tgt_dataset = ConcatDataset(tgt_list, sample_ratios=sample_ratio)
|
| 59 |
+
res = LanguagePairDataset(
|
| 60 |
+
src_dataset, src_dataset.sizes, src_dict,
|
| 61 |
+
tgt_dataset, tgt_dataset.sizes, tgt_dict,
|
| 62 |
+
left_pad_source=left_pad_source,
|
| 63 |
+
left_pad_target=left_pad_target,
|
| 64 |
+
)
|
| 65 |
+
logger.info("Have created the concat language pair dataset")
|
| 66 |
+
return res
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
@register_task('translation_w_mono')
|
| 70 |
+
class TranslationWithMonoTask(TranslationTask):
|
| 71 |
+
"""
|
| 72 |
+
Translate from one (source) language to another (target) language.
|
| 73 |
+
|
| 74 |
+
Args:
|
| 75 |
+
src_dict (~fairseq.data.Dictionary): dictionary for the source language
|
| 76 |
+
tgt_dict (~fairseq.data.Dictionary): dictionary for the target language
|
| 77 |
+
|
| 78 |
+
.. note::
|
| 79 |
+
|
| 80 |
+
The translation task is compatible with :mod:`fairseq-train`,
|
| 81 |
+
:mod:`fairseq-generate` and :mod:`fairseq-interactive`.
|
| 82 |
+
|
| 83 |
+
The translation task provides the following additional command-line
|
| 84 |
+
arguments:
|
| 85 |
+
|
| 86 |
+
.. argparse::
|
| 87 |
+
:ref: fairseq.tasks.translation_parser
|
| 88 |
+
:prog:
|
| 89 |
+
"""
|
| 90 |
+
|
| 91 |
+
@staticmethod
|
| 92 |
+
def add_args(parser):
|
| 93 |
+
"""Add task-specific arguments to the parser."""
|
| 94 |
+
# fmt: off
|
| 95 |
+
TranslationTask.add_args(parser)
|
| 96 |
+
parser.add_argument('--mono-data', default=None, help='monolingual data, split by :')
|
| 97 |
+
parser.add_argument('--mono-one-split-each-epoch', action='store_true', default=False, help='use on split of monolingual data at each epoch')
|
| 98 |
+
parser.add_argument('--parallel-ratio', default=1.0, type=float, help='subsample ratio of parallel data')
|
| 99 |
+
parser.add_argument('--mono-ratio', default=1.0, type=float, help='subsample ratio of mono data')
|
| 100 |
+
|
| 101 |
+
def __init__(self, args, src_dict, tgt_dict):
|
| 102 |
+
super().__init__(args, src_dict, tgt_dict)
|
| 103 |
+
self.src_dict = src_dict
|
| 104 |
+
self.tgt_dict = tgt_dict
|
| 105 |
+
self.update_number = 0
|
| 106 |
+
|
| 107 |
+
@classmethod
|
| 108 |
+
def setup_task(cls, args, **kwargs):
|
| 109 |
+
"""Setup the task (e.g., load dictionaries).
|
| 110 |
+
|
| 111 |
+
Args:
|
| 112 |
+
args (argparse.Namespace): parsed command-line arguments
|
| 113 |
+
"""
|
| 114 |
+
args.left_pad_source = options.eval_bool(args.left_pad_source)
|
| 115 |
+
args.left_pad_target = options.eval_bool(args.left_pad_target)
|
| 116 |
+
if getattr(args, 'raw_text', False):
|
| 117 |
+
utils.deprecation_warning('--raw-text is deprecated, please use --dataset-impl=raw')
|
| 118 |
+
args.dataset_impl = 'raw'
|
| 119 |
+
elif getattr(args, 'lazy_load', False):
|
| 120 |
+
utils.deprecation_warning('--lazy-load is deprecated, please use --dataset-impl=lazy')
|
| 121 |
+
args.dataset_impl = 'lazy'
|
| 122 |
+
|
| 123 |
+
paths = utils.split_paths(args.data)
|
| 124 |
+
assert len(paths) > 0
|
| 125 |
+
# find language pair automatically
|
| 126 |
+
if args.source_lang is None or args.target_lang is None:
|
| 127 |
+
args.source_lang, args.target_lang = data_utils.infer_language_pair(paths[0])
|
| 128 |
+
if args.source_lang is None or args.target_lang is None:
|
| 129 |
+
raise Exception('Could not infer language pair, please provide it explicitly')
|
| 130 |
+
|
| 131 |
+
# load dictionaries
|
| 132 |
+
src_dict = cls.load_dictionary(os.path.join(paths[0], 'dict.{}.txt'.format(args.source_lang)))
|
| 133 |
+
tgt_dict = cls.load_dictionary(os.path.join(paths[0], 'dict.{}.txt'.format(args.target_lang)))
|
| 134 |
+
assert src_dict.pad() == tgt_dict.pad()
|
| 135 |
+
assert src_dict.eos() == tgt_dict.eos()
|
| 136 |
+
assert src_dict.unk() == tgt_dict.unk()
|
| 137 |
+
logger.info('| [{}] dictionary: {} types'.format(args.source_lang, len(src_dict)))
|
| 138 |
+
logger.info('| [{}] dictionary: {} types'.format(args.target_lang, len(tgt_dict)))
|
| 139 |
+
|
| 140 |
+
return cls(args, src_dict, tgt_dict)
|
| 141 |
+
|
| 142 |
+
def load_dataset(self, split, epoch=0, combine=False, **kwargs):
|
| 143 |
+
"""Load a given dataset split.
|
| 144 |
+
|
| 145 |
+
Args:
|
| 146 |
+
split (str): name of the split (e.g., train, valid, test)
|
| 147 |
+
"""
|
| 148 |
+
logger.info("To load the dataset {}".format(split))
|
| 149 |
+
paths = utils.split_paths(self.args.data)
|
| 150 |
+
assert len(paths) > 0
|
| 151 |
+
if split != getattr(self.args, "train_subset", None):
|
| 152 |
+
# if not training data set, use the first shard for valid and test
|
| 153 |
+
paths = paths[:1]
|
| 154 |
+
data_path = paths[(epoch - 1) % len(paths)]
|
| 155 |
+
|
| 156 |
+
mono_paths = utils.split_paths(self.args.mono_data)
|
| 157 |
+
|
| 158 |
+
# infer langcode
|
| 159 |
+
src, tgt = self.args.source_lang, self.args.target_lang
|
| 160 |
+
|
| 161 |
+
parallel_data = load_langpair_dataset(
|
| 162 |
+
data_path, split, src, self.src_dict, tgt, self.tgt_dict,
|
| 163 |
+
combine=combine, dataset_impl=self.args.dataset_impl,
|
| 164 |
+
upsample_primary=self.args.upsample_primary,
|
| 165 |
+
left_pad_source=self.args.left_pad_source,
|
| 166 |
+
left_pad_target=self.args.left_pad_target,
|
| 167 |
+
max_source_positions=self.args.max_source_positions,
|
| 168 |
+
max_target_positions=self.args.max_target_positions,
|
| 169 |
+
load_alignments=self.args.load_alignments,
|
| 170 |
+
num_buckets=self.args.num_batch_buckets,
|
| 171 |
+
shuffle=(split != "test"),
|
| 172 |
+
pad_to_multiple=self.args.required_seq_len_multiple,
|
| 173 |
+
)
|
| 174 |
+
if split == "train":
|
| 175 |
+
parallel_data = SubsampleLanguagePairDataset(parallel_data, size_ratio=self.args.parallel_ratio,
|
| 176 |
+
seed=self.args.seed,
|
| 177 |
+
epoch=epoch)
|
| 178 |
+
if self.args.mono_one_split_each_epoch:
|
| 179 |
+
mono_path = mono_paths[(epoch - 1) % len(mono_paths)] # each at one epoch
|
| 180 |
+
mono_data = load_langpair_dataset(
|
| 181 |
+
mono_path, split, src, self.src_dict, tgt, self.tgt_dict,
|
| 182 |
+
combine=combine, dataset_impl=self.args.dataset_impl,
|
| 183 |
+
upsample_primary=self.args.upsample_primary,
|
| 184 |
+
left_pad_source=self.args.left_pad_source,
|
| 185 |
+
left_pad_target=self.args.left_pad_target,
|
| 186 |
+
max_source_positions=self.args.max_source_positions,
|
| 187 |
+
shuffle=(split != "test"),
|
| 188 |
+
max_target_positions=self.args.max_target_positions,
|
| 189 |
+
)
|
| 190 |
+
mono_data = SubsampleLanguagePairDataset(mono_data, size_ratio=self.args.mono_ratio,
|
| 191 |
+
seed=self.args.seed,
|
| 192 |
+
epoch=epoch)
|
| 193 |
+
all_dataset = [parallel_data, mono_data]
|
| 194 |
+
else:
|
| 195 |
+
mono_datas = []
|
| 196 |
+
for mono_path in mono_paths:
|
| 197 |
+
mono_data = load_langpair_dataset(
|
| 198 |
+
mono_path, split, src, self.src_dict, tgt, self.tgt_dict,
|
| 199 |
+
combine=combine, dataset_impl=self.args.dataset_impl,
|
| 200 |
+
upsample_primary=self.args.upsample_primary,
|
| 201 |
+
left_pad_source=self.args.left_pad_source,
|
| 202 |
+
left_pad_target=self.args.left_pad_target,
|
| 203 |
+
max_source_positions=self.args.max_source_positions,
|
| 204 |
+
shuffle=(split != "test"),
|
| 205 |
+
max_target_positions=self.args.max_target_positions,
|
| 206 |
+
)
|
| 207 |
+
mono_data = SubsampleLanguagePairDataset(mono_data, size_ratio=self.args.mono_ratio,
|
| 208 |
+
seed=self.args.seed,
|
| 209 |
+
epoch=epoch)
|
| 210 |
+
mono_datas.append(mono_data)
|
| 211 |
+
all_dataset = [parallel_data] + mono_datas
|
| 212 |
+
self.datasets[split] = ConcatDataset(all_dataset)
|
| 213 |
+
else:
|
| 214 |
+
self.datasets[split] = parallel_data
|
requirements.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
subword-nmt
|
| 2 |
+
sacrebleu
|
| 3 |
+
sacremoses
|
| 4 |
+
kytea
|
| 5 |
+
six
|
scripts/load_config.sh
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env bash
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
function parse_yaml {
|
| 5 |
+
local prefix=$2
|
| 6 |
+
local s='[[:space:]]*' w='[a-zA-Z0-9_]*' fs=$(echo @|tr @ '\034')
|
| 7 |
+
sed -ne "s|^\($s\):|\1|" \
|
| 8 |
+
-e "s|^\($s\)\($w\)$s:$s[\"']\(.*\)[\"']$s\$|\1$fs\2$fs\3|p" \
|
| 9 |
+
-e "s|^\($s\)\($w\)$s:$s\(.*\)$s\$|\1$fs\2$fs\3|p" $1 |
|
| 10 |
+
awk -F$fs '{
|
| 11 |
+
indent = length($1)/2;
|
| 12 |
+
vname[indent] = $2;
|
| 13 |
+
for (i in vname) {if (i > indent) {delete vname[i]}}
|
| 14 |
+
if (length($3) > 0) {
|
| 15 |
+
vn=""; for (i=0; i<indent; i++) {vn=(vn)(vname[i])("_")}
|
| 16 |
+
printf("%s%s%s=\"%s\"\n", "'$prefix'",vn, $2, $3);
|
| 17 |
+
}
|
| 18 |
+
}'
|
| 19 |
+
}
|
| 20 |
+
main_config_yml=$1
|
| 21 |
+
local_root=$2
|
| 22 |
+
if [[ ${main_config_yml} == "hdfs://"* ]]; then
|
| 23 |
+
config_filename=`basename ${main_config_yml}`
|
| 24 |
+
echo 'download config from ${main_config_yml}...'
|
| 25 |
+
local_config="${local_root}/config" && mkdir -p ${local_config}
|
| 26 |
+
hadoop fs -get ${main_config_yml} ${local_config}/
|
| 27 |
+
echo 'finish download config from ${main_config_yml}...'
|
| 28 |
+
main_config_yml=${local_config}/${config_filename}
|
| 29 |
+
fi
|
| 30 |
+
|
| 31 |
+
compgen -A variable > ~/.env-vars
|
| 32 |
+
eval $(parse_yaml ${main_config_yml})
|
| 33 |
+
|
| 34 |
+
# set option flags
|
| 35 |
+
options=""
|
| 36 |
+
for var in `compgen -A variable | grep -Fxvf ~/.env-vars`
|
| 37 |
+
do
|
| 38 |
+
if [[ ${var} == "model_"* || ${var} == "data_"* || ${var} == "options" ]]; then
|
| 39 |
+
continue
|
| 40 |
+
fi
|
| 41 |
+
if [[ ${!var} == "true" ]]; then
|
| 42 |
+
varname=`echo ${var} | sed 's/\_/\-/g'`
|
| 43 |
+
options=${options}" --${varname}"
|
| 44 |
+
else
|
| 45 |
+
varname=`echo ${var} | sed 's/\_/\-/g'`
|
| 46 |
+
options=${options}" --${varname} ${!var}"
|
| 47 |
+
fi
|
| 48 |
+
done
|
scripts/utils.py
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
import os
|
| 3 |
+
import sys
|
| 4 |
+
from tqdm import tqdm
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def remove_bpe(line, bpe_symbol="@@ "):
|
| 8 |
+
line = line.replace("\n", '')
|
| 9 |
+
line = (line + ' ').replace(bpe_symbol, '').rstrip()
|
| 10 |
+
return line + ("\n")
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def remove_bpe_fn(i=sys.stdin, o=sys.stdout, bpe="@@ "):
|
| 14 |
+
lines = tqdm(i)
|
| 15 |
+
lines = map(lambda x: remove_bpe(x, bpe), lines)
|
| 16 |
+
# _write_lines(lines, f=o)
|
| 17 |
+
for line in lines:
|
| 18 |
+
o.write(line)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def reprocess(fle):
|
| 22 |
+
# takes in a file of generate.py translation generate_output
|
| 23 |
+
# returns a source dict and hypothesis dict, where keys are the ID num (as a string)
|
| 24 |
+
# and values and the corresponding source and translation. There may be several translations
|
| 25 |
+
# per source, so the values for hypothesis_dict are lists.
|
| 26 |
+
# parses output of generate.py
|
| 27 |
+
|
| 28 |
+
with open(fle, 'r') as f:
|
| 29 |
+
txt = f.read()
|
| 30 |
+
|
| 31 |
+
"""reprocess generate.py output"""
|
| 32 |
+
p = re.compile(r"[STHP][-]\d+\s*")
|
| 33 |
+
hp = re.compile(r"(\s*[-]?\d+[.]?\d+(e[+-]?\d+)?\s*)|(\s*(-inf)\s*)")
|
| 34 |
+
source_dict = {}
|
| 35 |
+
hypothesis_dict = {}
|
| 36 |
+
score_dict = {}
|
| 37 |
+
target_dict = {}
|
| 38 |
+
pos_score_dict = {}
|
| 39 |
+
lines = txt.split("\n")
|
| 40 |
+
|
| 41 |
+
for line in lines:
|
| 42 |
+
line += "\n"
|
| 43 |
+
prefix = re.search(p, line)
|
| 44 |
+
if prefix is not None:
|
| 45 |
+
assert len(prefix.group()) > 2, "prefix id not found"
|
| 46 |
+
_, j = prefix.span()
|
| 47 |
+
id_num = prefix.group()[2:]
|
| 48 |
+
id_num = int(id_num)
|
| 49 |
+
line_type = prefix.group()[0]
|
| 50 |
+
if line_type == "H":
|
| 51 |
+
h_txt = line[j:]
|
| 52 |
+
hypo = re.search(hp, h_txt)
|
| 53 |
+
assert hypo is not None, ("regular expression failed to find the hypothesis scoring")
|
| 54 |
+
_, i = hypo.span()
|
| 55 |
+
score = hypo.group()
|
| 56 |
+
hypo_str = h_txt[i:]
|
| 57 |
+
# if r2l: # todo: reverse score as well
|
| 58 |
+
# hypo_str = " ".join(reversed(hypo_str.strip().split(" "))) + "\n"
|
| 59 |
+
if id_num in hypothesis_dict:
|
| 60 |
+
hypothesis_dict[id_num].append(hypo_str)
|
| 61 |
+
score_dict[id_num].append(float(score))
|
| 62 |
+
else:
|
| 63 |
+
hypothesis_dict[id_num] = [hypo_str]
|
| 64 |
+
score_dict[id_num] = [float(score)]
|
| 65 |
+
|
| 66 |
+
elif line_type == "S":
|
| 67 |
+
source_dict[id_num] = (line[j:])
|
| 68 |
+
elif line_type == "T":
|
| 69 |
+
# target_dict[id_num] = (line[j:])
|
| 70 |
+
continue
|
| 71 |
+
elif line_type == "P":
|
| 72 |
+
pos_scores = (line[j:]).split()
|
| 73 |
+
pos_scores = [float(x) for x in pos_scores]
|
| 74 |
+
if id_num in pos_score_dict:
|
| 75 |
+
pos_score_dict[id_num].append(pos_scores)
|
| 76 |
+
else:
|
| 77 |
+
pos_score_dict[id_num] = [pos_scores]
|
| 78 |
+
|
| 79 |
+
return source_dict, hypothesis_dict, score_dict, target_dict, pos_score_dict
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def get_hypo_and_ref(fle, hyp_file, ref_input, ref_file, rank=0):
|
| 83 |
+
with open(ref_input, 'r') as f:
|
| 84 |
+
refs = f.readlines()
|
| 85 |
+
_, hypo_dict, _, _, _ = reprocess(fle)
|
| 86 |
+
assert rank < len(hypo_dict[0])
|
| 87 |
+
maxkey = max(hypo_dict, key=int)
|
| 88 |
+
f_hyp = open(hyp_file, "w")
|
| 89 |
+
f_ref = open(ref_file, "w")
|
| 90 |
+
for idx in range(maxkey + 1):
|
| 91 |
+
if idx not in hypo_dict:
|
| 92 |
+
continue
|
| 93 |
+
f_hyp.write(hypo_dict[idx][rank])
|
| 94 |
+
f_ref.write(refs[idx])
|
| 95 |
+
f_hyp.close()
|
| 96 |
+
f_ref.close()
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def recover_bpe(hyp_file):
|
| 100 |
+
f_hyp = open(hyp_file, "r")
|
| 101 |
+
f_hyp_out = open(hyp_file + ".nobpe", "w")
|
| 102 |
+
for _s in ["hyp"]:
|
| 103 |
+
f = eval("f_{}".format(_s))
|
| 104 |
+
fout = eval("f_{}_out".format(_s))
|
| 105 |
+
remove_bpe_fn(i=f, o=fout)
|
| 106 |
+
f_hyp.close()
|
| 107 |
+
f_hyp_out.close()
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
if __name__ == "__main__":
|
| 111 |
+
filename = sys.argv[1]
|
| 112 |
+
ref_in = sys.argv[2]
|
| 113 |
+
hypo_file = os.path.join(os.path.dirname(filename), "hypo.out")
|
| 114 |
+
ref_out = os.path.join(os.path.dirname(filename), "ref.out")
|
| 115 |
+
get_hypo_and_ref(filename, hypo_file, ref_in, ref_out)
|
| 116 |
+
recover_bpe(hypo_file)
|
test/input.en
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LANG_TOK_EN Hello my friend!
|
test/input.zh
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LANG_TOK_ZH 你好!
|
test/output
ADDED
|
File without changes
|
test/output.en.no_bpe
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
D-0 -0.34370458126068115 LANG_TOK_EN ANG_TOK_ZH Hello !
|
test/output.en.no_bpe.moses
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
D-0 -1.3185505867004395 LANG_TOK_EN Hello!
|
test/output.zh
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
S-0 L@@ AN@@ G@@ _@@ T@@ OK@@ _@@ EN H@@ ello my fri@@ end@@ !
|
| 2 |
+
H-0 -0.6148621439933777 LANG_TOK_ZH 你@@ 好 , 我 的 朋@@ 友 !
|
| 3 |
+
P-0 -2.1448 -1.4575 -0.0638 -0.8495 -0.6207 -0.1953 -0.2082 -0.0769 -0.3801 -0.1517
|
test/output.zh.no_bpe
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
D-0 -0.6148621439933777 LANG_TOK_ZH 你好 , 我 的 朋友 !
|
test/output.zh.no_bpe.moses
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
D-0 -0.7665940523147583 LANG_TOK_ZH 你好 , 我的朋友 !
|
train_w_mono.sh
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env bash
|
| 2 |
+
|
| 3 |
+
# repo_dir: root directory of the project
|
| 4 |
+
repo_dir="$( cd "$( dirname "$0" )" && pwd )"
|
| 5 |
+
echo "==== Working directory: ====" >&2
|
| 6 |
+
echo "${repo_dir}" >&2
|
| 7 |
+
echo "============================" >&2
|
| 8 |
+
|
| 9 |
+
main_config=$1
|
| 10 |
+
source ${repo_dir}/scripts/load_config.sh ${main_config} ${repo_dir}
|
| 11 |
+
|
| 12 |
+
model_dir=${repo_dir}/model
|
| 13 |
+
data_dir=${repo_dir}/data
|
| 14 |
+
|
| 15 |
+
mkdir -p ${model_dir} ${data_dir}/mono
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
# parallel data
|
| 19 |
+
data_var=data_1
|
| 20 |
+
i=1
|
| 21 |
+
data=""
|
| 22 |
+
while [[ ! -z ${!data_var} ]]; do
|
| 23 |
+
if [[ $data == "" ]]; then
|
| 24 |
+
data=${!data_var}
|
| 25 |
+
else
|
| 26 |
+
data=$data:${!data_var}
|
| 27 |
+
fi
|
| 28 |
+
i=$((i+1))
|
| 29 |
+
data_var=data_$i
|
| 30 |
+
done
|
| 31 |
+
|
| 32 |
+
# mono data
|
| 33 |
+
mono_data_var=data_mono_1
|
| 34 |
+
y=1
|
| 35 |
+
mono_data=""
|
| 36 |
+
while [[ ! -z ${!mono_data_var} ]]; do
|
| 37 |
+
if [[ ${mono_data} == "" ]]; then
|
| 38 |
+
mono_data=${!mono_data_var}
|
| 39 |
+
else
|
| 40 |
+
mono_data=${mono_data}:${!mono_data_var}
|
| 41 |
+
fi
|
| 42 |
+
y=$((y+1))
|
| 43 |
+
mono_data_var=data_mono_$y
|
| 44 |
+
done
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
command="CUDA_VISIBLE_DEVICES=${CUDA_VISIBLE_DEVICES} fairseq-train ${data} \
|
| 48 |
+
--user-dir ${repo_dir}/mcolt \
|
| 49 |
+
--save-dir ${model_dir} \
|
| 50 |
+
--mono-data ${mono_data} \
|
| 51 |
+
${options} \
|
| 52 |
+
--ddp-backend no_c10d 1>&2"
|
| 53 |
+
|
| 54 |
+
echo $command
|
| 55 |
+
eval $command
|
| 56 |
+
|