
Commit
·
a560a5f
1
Parent(s):
de4ade4
Upload 234 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +2 -0
- LLaVA-Plus-Codebase/Big time rush.jpg +0 -0
- LLaVA-Plus-Codebase/LICENSE +201 -0
- LLaVA-Plus-Codebase/README.md +236 -0
- LLaVA-Plus-Codebase/cog.yaml +37 -0
- LLaVA-Plus-Codebase/docs/llava-plus/dataset.md +12 -0
- LLaVA-Plus-Codebase/docs/llava-plus/modelzoo.md +8 -0
- LLaVA-Plus-Codebase/docs/llava-plus/tools.md +45 -0
- LLaVA-Plus-Codebase/docs/llava/Customize_Component.md +20 -0
- LLaVA-Plus-Codebase/docs/llava/Data.md +29 -0
- LLaVA-Plus-Codebase/docs/llava/Evaluation.md +167 -0
- LLaVA-Plus-Codebase/docs/llava/Finetune_Custom_Data.md +37 -0
- LLaVA-Plus-Codebase/docs/llava/Intel.md +7 -0
- LLaVA-Plus-Codebase/docs/llava/LLaVA_Bench.md +31 -0
- LLaVA-Plus-Codebase/docs/llava/LLaVA_from_LLaMA2.md +29 -0
- LLaVA-Plus-Codebase/docs/llava/LoRA.md +46 -0
- LLaVA-Plus-Codebase/docs/llava/MODEL_ZOO.md +138 -0
- LLaVA-Plus-Codebase/docs/llava/ScienceQA.md +53 -0
- LLaVA-Plus-Codebase/docs/llava/Windows.md +27 -0
- LLaVA-Plus-Codebase/docs/llava/macOS.md +29 -0
- LLaVA-Plus-Codebase/images/demo_cli.gif +3 -0
- LLaVA-Plus-Codebase/images/llava-plus-arch.png +0 -0
- LLaVA-Plus-Codebase/images/llava_example_cmp.png +0 -0
- LLaVA-Plus-Codebase/images/llava_logo.png +0 -0
- LLaVA-Plus-Codebase/images/llava_v1_5_radar.jpg +0 -0
- LLaVA-Plus-Codebase/llava/__init__.py +1 -0
- LLaVA-Plus-Codebase/llava/constants.py +13 -0
- LLaVA-Plus-Codebase/llava/conversation.py +649 -0
- LLaVA-Plus-Codebase/llava/eval/eval_gpt_review.py +113 -0
- LLaVA-Plus-Codebase/llava/eval/eval_gpt_review_bench.py +121 -0
- LLaVA-Plus-Codebase/llava/eval/eval_gpt_review_visual.py +118 -0
- LLaVA-Plus-Codebase/llava/eval/eval_pope.py +81 -0
- LLaVA-Plus-Codebase/llava/eval/eval_science_qa.py +114 -0
- LLaVA-Plus-Codebase/llava/eval/eval_science_qa_gpt4.py +104 -0
- LLaVA-Plus-Codebase/llava/eval/eval_science_qa_gpt4_requery.py +149 -0
- LLaVA-Plus-Codebase/llava/eval/eval_textvqa.py +65 -0
- LLaVA-Plus-Codebase/llava/eval/generate_webpage_data_from_table.py +111 -0
- LLaVA-Plus-Codebase/llava/eval/m4c_evaluator.py +334 -0
- LLaVA-Plus-Codebase/llava/eval/model_qa.py +85 -0
- LLaVA-Plus-Codebase/llava/eval/model_vqa.py +112 -0
- LLaVA-Plus-Codebase/llava/eval/model_vqa_loader.py +141 -0
- LLaVA-Plus-Codebase/llava/eval/model_vqa_mmbench.py +170 -0
- LLaVA-Plus-Codebase/llava/eval/model_vqa_qbench.py +122 -0
- LLaVA-Plus-Codebase/llava/eval/model_vqa_science.py +147 -0
- LLaVA-Plus-Codebase/llava/eval/qa_baseline_gpt35.py +74 -0
- LLaVA-Plus-Codebase/llava/eval/run_llava.py +157 -0
- LLaVA-Plus-Codebase/llava/eval/summarize_gpt_review.py +60 -0
- LLaVA-Plus-Codebase/llava/eval/table/answer/answer_alpaca-13b.jsonl +80 -0
- LLaVA-Plus-Codebase/llava/eval/table/answer/answer_bard.jsonl +0 -0
- LLaVA-Plus-Codebase/llava/eval/table/answer/answer_gpt35.jsonl +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
LLaVA-Plus-Codebase/images/demo_cli.gif filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
LLaVA-Plus-Codebase/llava/serve/examples/cat_comp.jpeg filter=lfs diff=lfs merge=lfs -text
|
LLaVA-Plus-Codebase/Big time rush.jpg
ADDED

|
LLaVA-Plus-Codebase/LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
LLaVA-Plus-Codebase/README.md
ADDED
|
@@ -0,0 +1,236 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 🌋 LLaVA-Plus: Large Language and Vision Assistants that Plug and Learn to Use Skills
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
**Learning to Use Tools For Creating Multimodal Agents.**
|
| 5 |
+
|
| 6 |
+
[[Project Page](https://llava-vl.github.io/llava-plus)] [[Arxiv](https://arxiv.org/abs/2311.05437)] [[Demo](https://llavaplus.ngrok.io/)] [[Data](https://huggingface.co/datasets/LLaVA-VL/llava-plus-data)] [[Model Zoo](https://github.com/LLaVA-VL/LLaVA-Plus-Codebase/blob/main/docs/llava-plus/modelzoo.md)]
|
| 7 |
+
|
| 8 |
+
**Note: Some sections of the code are currently being prepared and updated. Please stay tuned.**
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
## Release
|
| 12 |
+
- [11/11] 🔥 We released **LLaVA-Plus: Large Language and Vision Assistants that Plug and Learn to Use Skills**. Enable LMM to use tools for general vision tasks! Checkout the [paper]() and [demo](https://llavaplus.ngrok.io/).
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
[](https://github.com/tatsu-lab/stanford_alpaca/blob/main/LICENSE)
|
| 16 |
+
[](https://github.com/tatsu-lab/stanford_alpaca/blob/main/DATA_LICENSE)
|
| 17 |
+
**Usage and License Notices**: The data and checkpoint are intended and licensed for research use only. They are also restricted to uses that follow the license agreement of LLaVA, LLaMA, Vicuna, and GPT-4. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
## Contents
|
| 21 |
+
- [Install](#install)
|
| 22 |
+
- [LLaVA-Plus Weights](#llava-plus-weights)
|
| 23 |
+
- [Demo](#demo)
|
| 24 |
+
- [Model Zoo](docs/llava-plus/modelzoo.md)
|
| 25 |
+
- [Dataset](docs/llava-plus/dataset.md)
|
| 26 |
+
- [Train](#train)
|
| 27 |
+
- [Evaluation](#evaluation)
|
| 28 |
+
|
| 29 |
+
## Install
|
| 30 |
+
|
| 31 |
+
If you are not using Linux, do *NOT* proceed, see instructions for [macOS](https://github.com/haotian-liu/LLaVA/blob/main/docs/macOS.md) and [Windows](https://github.com/haotian-liu/LLaVA/blob/main/docs/Windows.md) from LLaVA.
|
| 32 |
+
|
| 33 |
+
1. Clone this repository and navigate to the LLaVA-Plus folder
|
| 34 |
+
```bash
|
| 35 |
+
git clone https://github.com/LLaVA-VL/LLaVA-Plus-Codebase LLaVA-Plus
|
| 36 |
+
cd LLaVA-Plus
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
2. Install Package
|
| 40 |
+
```Shell
|
| 41 |
+
conda create -n llava python=3.10 -y
|
| 42 |
+
conda activate llava
|
| 43 |
+
pip install --upgrade pip # enable PEP 660 support
|
| 44 |
+
pip install -e .
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
3. Install additional packages for training cases
|
| 48 |
+
```
|
| 49 |
+
pip install -e ".[train]"
|
| 50 |
+
pip install flash-attn --no-build-isolation
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
## LLaVA-Plus Weights
|
| 54 |
+
|
| 55 |
+
**We are still preparing the part. Stay tuned!**
|
| 56 |
+
|
| 57 |
+
Please check out our [Model Zoo](https://github.com/LLaVA-VL/LLaVA-Plus-Codebase/blob/main/docs/llava-plus/modelzoo.md) for all public LLaVA-Plus checkpoints, and the instructions on how to use the weights.
|
| 58 |
+
|
| 59 |
+
## Demo
|
| 60 |
+
|
| 61 |
+
- [Demo: https://llavaplus.ngrok.io/](https://llavaplus.ngrok.io/)
|
| 62 |
+
|
| 63 |
+
### Demo Architecture
|
| 64 |
+
|
| 65 |
+

|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
To run our demo, you have four steps.
|
| 69 |
+
|
| 70 |
+
1. [Launch a controller](#1-Launch-a-controller): enable to control different works.
|
| 71 |
+
2. [Launch a model worker](#2-Launch-a-model-worker): core llava-plus model.
|
| 72 |
+
3. [Launch tool workers](#3-Launch-tool-workers): the tools you want to call.
|
| 73 |
+
4. [Launch a gradio web server](#4-Launch-a-gradio-web-server): a front end page for users.
|
| 74 |
+
|
| 75 |
+
#### 1. Launch a controller
|
| 76 |
+
```Shell
|
| 77 |
+
python -m llava.serve.controller --host 0.0.0.0 --port 20001
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
#### 2. Launch a model worker
|
| 81 |
+
|
| 82 |
+
This is the actual *worker* that performs the inference on the GPU. Each worker is responsible for a single model specified in `--model-path`.
|
| 83 |
+
|
| 84 |
+
```Shell
|
| 85 |
+
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:20001 --port 40000 --worker http://localhost:40000 --model-path <huggingface or local path>
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
Wait until the process finishes loading the model and you see "Uvicorn running on ...". Now, refresh your Gradio web UI, and you will see the model you just launched in the model list.
|
| 89 |
+
|
| 90 |
+
If you are using an Apple device with an M1 or M2 chip, you can specify the mps device by using the `--device` flag: `--device mps`.
|
| 91 |
+
|
| 92 |
+
<details>
|
| 93 |
+
<summary>Multiple works</summary>
|
| 94 |
+
You can launch as many workers as you want, and compare between different model checkpoints in the same Gradio interface. Please keep the `--controller` the same, and modify the `--port` and `--worker` to a different port number for each worker.
|
| 95 |
+
```Shell
|
| 96 |
+
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:20001 --port <different from 40000, say 40001> --worker http://localhost:<change accordingly, i.e. 40001> --model-path <ckpt2>
|
| 97 |
+
```
|
| 98 |
+
</details>
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
<details>
|
| 102 |
+
<summary>Launch a model worker (Multiple GPUs, when GPU VRAM <= 24GB)</summary>
|
| 103 |
+
|
| 104 |
+
If the VRAM of your GPU is less than 24GB (e.g., RTX 3090, RTX 4090, etc.), you may try running it with multiple GPUs. Our latest code base will automatically try to use multiple GPUs if you have more than one GPU. You can specify which GPUs to use with `CUDA_VISIBLE_DEVICES`. Below is an example of running with the first two GPUs.
|
| 105 |
+
|
| 106 |
+
```Shell
|
| 107 |
+
CUDA_VISIBLE_DEVICES=0,1 python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:20001 --port 40000 --worker http://localhost:40000 --model-path <huggingface or local path>
|
| 108 |
+
```
|
| 109 |
+
</details>
|
| 110 |
+
|
| 111 |
+
#### 3. Launch tool workers
|
| 112 |
+
You need to open different tool works, as shown in the figure above, which means you need to prepare codes from other projects.
|
| 113 |
+
|
| 114 |
+
We provide a detailed [guideline](docs/llava-plus/tools.md) for different projects.
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
#### 4. Launch a gradio web server.
|
| 118 |
+
```Shell
|
| 119 |
+
python -m llava.serve.gradio_web_server_llava_plus --controller http://localhost:20001 --model-list-mode reload
|
| 120 |
+
```
|
| 121 |
+
You just launched the Gradio web interface. Now, you can open the web interface with the URL printed on the screen.
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
## Train
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
LLaVA training consists of two stages: (1) feature alignment stage, and (2) visual instruction tuning stage.
|
| 130 |
+
|
| 131 |
+
Our llava-plus is trained from the llava-stage-1-pre-trained projectors.
|
| 132 |
+
|
| 133 |
+
<details>
|
| 134 |
+
<summary>Training cost</summary>
|
| 135 |
+
LLaVA-Plus is trained on 4/8 A100 GPUs with 80GB memory. To train on fewer GPUs, you can reduce the `per_device_train_batch_size` and increase the `gradient_accumulation_steps` accordingly. Always keep the global batch size the same: `per_device_train_batch_size` x `gradient_accumulation_steps` x `num_gpus`.
|
| 136 |
+
</details>
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
<details>
|
| 140 |
+
<summary>Download Vicuna checkpoints (automatically)</summary>
|
| 141 |
+
|
| 142 |
+
Our base model Vicuna v1.5, which is an instruction-tuned chatbot, will be downloaded automatically when you run our provided training scripts. No action is needed.
|
| 143 |
+
</details>
|
| 144 |
+
|
| 145 |
+
### Stage 1: Pretrain (feature alignment)
|
| 146 |
+
|
| 147 |
+
Download [pre-trained projector](https://github.com/haotian-liu/LLaVA/blob/main/docs/MODEL_ZOO.md#projector-weights) directly as we did.
|
| 148 |
+
|
| 149 |
+
Or you may train the projector following the [guideline in LLaVA](https://github.com/haotian-liu/LLaVA/tree/main#pretrain-feature-alignment).
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
### Stage 2: Tool Augmented Visual Instruction Tuning
|
| 154 |
+
|
| 155 |
+
1. Prepare data
|
| 156 |
+
|
| 157 |
+
Please download [the training data](https://huggingface.co/datasets/LLaVA-VL/llava-plus-data), and download the images from constituting datasets:
|
| 158 |
+
|
| 159 |
+
- COCO: [train2017](http://images.cocodataset.org/zips/train2017.zip)
|
| 160 |
+
- VisualGenome: [part1](https://cs.stanford.edu/people/rak248/VG_100K_2/images.zip), [part2](https://cs.stanford.edu/people/rak248/VG_100K_2/images2.zip)
|
| 161 |
+
- [infoseek](https://open-vision-language.github.io/infoseek/)
|
| 162 |
+
- [hiertext](https://github.com/google-research-datasets/hiertext)
|
| 163 |
+
|
| 164 |
+
2. Start training!
|
| 165 |
+
|
| 166 |
+
Training script with DeepSpeed ZeRO-2: [`training_llava_plus_v0_7b.sh`](scripts/llava_plus/training_llava_plus_v0_7b.sh) or [`training_llava_plus_v1.3_7b.sh`](scripts/llava_plus/training_llava_plus_v1.3_7b.sh)
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
<details>
|
| 171 |
+
<summary>If you do not have enough GPU memory:</summary>
|
| 172 |
+
- Use LoRA. See LLaVA repo for more details.
|
| 173 |
+
- Replace `zero2.json` with `zero3.json` or `zero3_offload.json`.
|
| 174 |
+
</details>
|
| 175 |
+
|
| 176 |
+
<details>
|
| 177 |
+
<summary>If you are interested in finetuning LLaVA(LLaVA-Plus) model to your own task/data:</summary>
|
| 178 |
+
please check out [`Finetune_Custom_Data.md`](https://github.com/haotian-liu/LLaVA/blob/main/docs/Finetune_Custom_Data.md)。
|
| 179 |
+
</details>
|
| 180 |
+
<details>
|
| 181 |
+
<summary>Some explainations of options:</summary>
|
| 182 |
+
|
| 183 |
+
- `--data_path path/to/llava-150k-tool-aug.json,path/to/llava-plus-v1-117k-tool-merge.json`: You may pass multiple data files with `,` separated.
|
| 184 |
+
- `--image_folder /path/to/coco/train2017/,/path/to/hiertext/train,/path/to/infoseek/infoseek_images,/path/to/instruct-pix2pix/clip-filtered-dataset,/path/to/goldg/vg_mdetr/images`: You may pass multiple image folders with `,` separated. Note that it may cause problems if multiple folders have images with the same name.
|
| 185 |
+
- `--mm_projector_type mlp2x_gelu`: the two-layer MLP vision-language connector.
|
| 186 |
+
- `--vision_tower openai/clip-vit-large-patch14-336`: CLIP ViT-L/14 336px.
|
| 187 |
+
- `--image_aspect_ratio pad`: this pads the non-square images to square, instead of cropping them; it slightly reduces hallucination.
|
| 188 |
+
- `--group_by_modality_length True`: this should only be used when your instruction tuning dataset contains both language (e.g. ShareGPT) and multimodal (e.g. LLaVA-Instruct). It makes the training sampler only sample a single modality (either image or language) during training, which we observe to speed up training by ~25%, and does not affect the final outcome.
|
| 189 |
+
</details>
|
| 190 |
+
|
| 191 |
+
## Evaluation
|
| 192 |
+
|
| 193 |
+
See [LLaVA's Instruction](https://github.com/haotian-liu/LLaVA/tree/main#evaluation) on model evaluations.
|
| 194 |
+
|
| 195 |
+
## Citation
|
| 196 |
+
|
| 197 |
+
If you find LLaVA useful for your research and applications, please cite using this BibTeX:
|
| 198 |
+
```bibtex
|
| 199 |
+
|
| 200 |
+
@article{liu2023llavaplus,
|
| 201 |
+
title={LLaVA-Plus: Learning to Use Tools for Creating Multimodal Agents},
|
| 202 |
+
author={Liu, Shilong and Cheng, Hao and Liu, Haotian and Zhang, Hao and Li, Feng and Ren, Tianhe and Zou, Xueyan and Yang, Jianwei and Su, Hang and Zhu, Jun and Zhang, Lei and Gao, Jianfeng and Li, Chunyuan},
|
| 203 |
+
journal={arXiv:2311.05437},
|
| 204 |
+
year={2023}
|
| 205 |
+
}
|
| 206 |
+
|
| 207 |
+
@misc{liu2023llava,
|
| 208 |
+
title={Visual Instruction Tuning},
|
| 209 |
+
author={Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae},
|
| 210 |
+
publisher={arXiv:2304.08485},
|
| 211 |
+
year={2023}
|
| 212 |
+
}
|
| 213 |
+
```
|
| 214 |
+
|
| 215 |
+
## Acknowledgement
|
| 216 |
+
|
| 217 |
+
- [LLaVA](https://github.com/haotian-liu/LLaVA), [Vicuna](https://github.com/lm-sys/FastChat): Thanks to their amazing codebase.
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
## Related Projects
|
| 221 |
+
- [LLaVA](https://llava-vl.github.io/)
|
| 222 |
+
|
| 223 |
+
Included Tools
|
| 224 |
+
- [Grounding DINO](https://github.com/IDEA-Research/GroundingDINO)
|
| 225 |
+
- [Grounded-Segment-Anything](https://github.com/IDEA-Research/Grounded-Segment-Anything)
|
| 226 |
+
- [Recognize Anythging](https://github.com/xinyu1205/recognize-anything)
|
| 227 |
+
- [Segment-Anything](https://github.com/facebookresearch/segment-anything).
|
| 228 |
+
- [SEEM: Segment Everything Everywhere All at Once](https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-Once)
|
| 229 |
+
- [Semantic-SAM](https://github.com/UX-Decoder/Semantic-SAM)
|
| 230 |
+
- [Segment-Anything](https://github.com/facebookresearch/segment-anything)
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
For future project ideas, please check out:
|
| 234 |
+
- [Instruction Tuning with GPT-4](https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM)
|
| 235 |
+
- [LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day](https://github.com/microsoft/LLaVA-Med)
|
| 236 |
+
- [Otter: In-Context Multi-Modal Instruction Tuning](https://github.com/Luodian/Otter)
|
LLaVA-Plus-Codebase/cog.yaml
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Configuration for Cog ⚙️
|
| 2 |
+
# Reference: https://github.com/replicate/cog/blob/main/docs/yaml.md
|
| 3 |
+
|
| 4 |
+
build:
|
| 5 |
+
gpu: true
|
| 6 |
+
|
| 7 |
+
python_version: "3.11"
|
| 8 |
+
|
| 9 |
+
python_packages:
|
| 10 |
+
- "torch==2.0.1"
|
| 11 |
+
- "accelerate==0.21.0"
|
| 12 |
+
- "bitsandbytes==0.41.0"
|
| 13 |
+
- "deepspeed==0.9.5"
|
| 14 |
+
- "einops-exts==0.0.4"
|
| 15 |
+
- "einops==0.6.1"
|
| 16 |
+
- "gradio==3.35.2"
|
| 17 |
+
- "gradio_client==0.2.9"
|
| 18 |
+
- "httpx==0.24.0"
|
| 19 |
+
- "markdown2==2.4.10"
|
| 20 |
+
- "numpy==1.26.0"
|
| 21 |
+
- "peft==0.4.0"
|
| 22 |
+
- "scikit-learn==1.2.2"
|
| 23 |
+
- "sentencepiece==0.1.99"
|
| 24 |
+
- "shortuuid==1.0.11"
|
| 25 |
+
- "timm==0.6.13"
|
| 26 |
+
- "tokenizers==0.13.3"
|
| 27 |
+
- "torch==2.0.1"
|
| 28 |
+
- "torchvision==0.15.2"
|
| 29 |
+
- "transformers==4.31.0"
|
| 30 |
+
- "wandb==0.15.12"
|
| 31 |
+
- "wavedrom==2.0.3.post3"
|
| 32 |
+
- "Pygments==2.16.1"
|
| 33 |
+
run:
|
| 34 |
+
- curl -o /usr/local/bin/pget -L "https://github.com/replicate/pget/releases/download/v0.0.3/pget" && chmod +x /usr/local/bin/pget
|
| 35 |
+
|
| 36 |
+
# predict.py defines how predictions are run on your model
|
| 37 |
+
predict: "predict.py:Predictor"
|
LLaVA-Plus-Codebase/docs/llava-plus/dataset.md
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# LLaVA-Plus Data
|
| 2 |
+
|
| 3 |
+
## Released Data
|
| 4 |
+
|
| 5 |
+
[huggingface](https://huggingface.co/datasets/LLaVA-VL/llava-plus-data)
|
| 6 |
+
|
| 7 |
+
- [llava-150k-tool-aug.json](https://huggingface.co/datasets/LLaVA-VL/llava-plus-data/blob/main/llava-150k-tool-aug.json) augment the llava-insttrution-150 with extrac `"thoughts"` and `"actions"` to ensure the data format as llava-plus required.
|
| 8 |
+
- [llava-plus-v1-117k-tool-merge.json](https://huggingface.co/datasets/LLaVA-VL/llava-plus-data/blob/main/llava-plus-v1-117k-tool-merge.json) is tool learning visual instruction data by prompting ChatGPT/GPT-4.
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
## How to build the Instruction Data
|
| 12 |
+
We provide an example to constuct grounding data [here](playground/llava-plus-data/grounding/run.sh).
|
LLaVA-Plus-Codebase/docs/llava-plus/modelzoo.md
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# LLaVA-Plus Checkpoints
|
| 2 |
+
|
| 3 |
+
We will continuously update the model zoo.
|
| 4 |
+
|
| 5 |
+
| Model Name | Training Data | LLM version | projector |
|
| 6 |
+
|------------|---------------|-------------|-----------|
|
| 7 |
+
| [llava_plus_v0_7b](https://huggingface.co/LLaVA-VL/llava_plus_v0_7b) | [url](https://huggingface.co/datasets/LLaVA-VL/llava-plus-data) | vicuna-v0-7b | [projector](https://huggingface.co/liuhaotian/LLaVA-Pretrained-Projectors/blob/main/LLaVA-7b-pretrain-projector-v0-CC3M-595K-original_caption.bin) |
|
| 8 |
+
|
LLaVA-Plus-Codebase/docs/llava-plus/tools.md
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# LLaVA-Plus Server
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
As shown in the figure above, we need to build an API cloud to main all tools.
|
| 6 |
+
|
| 7 |
+
## Launch a controller
|
| 8 |
+
Build a controller like the guides in [readme](README.md#1-Launch-a-controller).
|
| 9 |
+
|
| 10 |
+
Our tool workers and llm-model workers share the same controller.
|
| 11 |
+
|
| 12 |
+
## Launch tool workers: An Example
|
| 13 |
+
We provide all model workers in the `serve/` folder. The tool worker is named as `{tool_name}_worker.py`. To run a worker, make sure you have installed the required tool(or copy the worker file to different tool folders).
|
| 14 |
+
|
| 15 |
+
An example for the Grounded-SAM, whch includes Grounding-DINO, SAM, and Grounded-SAM.
|
| 16 |
+
|
| 17 |
+
```sh
|
| 18 |
+
git clone https://github.com/IDEA-Research/Grounded-Segment-Anything
|
| 19 |
+
python -m pip install -e GroundingDINO
|
| 20 |
+
python -m pip install -e segment_anything
|
| 21 |
+
python serve/grounding_dino_worker.py
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
Wait until the process finishes loading the model and you see "Uvicorn running on ...". You need to open another terminal process for other operations.
|
| 25 |
+
|
| 26 |
+
Test the worker:
|
| 27 |
+
```sh
|
| 28 |
+
python serve/grounding_dino_test_message.py
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
## All Tools
|
| 32 |
+
|
| 33 |
+
| Tool Name | Install Source |
|
| 34 |
+
| --------------- | -------------------------------------------------------------------------------------------------------------------------------------------------- |
|
| 35 |
+
| Grounding DINO | [https://github.com/IDEA-Research/Grounded-Segment-Anything](https://github.com/IDEA-Research/Grounded-Segment-Anything) |
|
| 36 |
+
| SAM | [https://github.com/IDEA-Research/Grounded-Segment-Anything](https://github.com/IDEA-Research/Grounded-Segment-Anything) |
|
| 37 |
+
| Grounded-SAM | [https://github.com/IDEA-Research/Grounded-Segment-Anything](https://github.com/IDEA-Research/Grounded-Segment-Anything) |
|
| 38 |
+
| CLIP-Retrieval | [https://github.com/rom1504/clip-retrieval](https://github.com/rom1504/clip-retrieval) |
|
| 39 |
+
| InstructPix2Pix | [https://github.com/huggingface/diffusers](https://github.com/huggingface/diffusers) |
|
| 40 |
+
| StableDiffusion | [https://github.com/huggingface/diffusers](https://github.com/huggingface/diffusers) |
|
| 41 |
+
| BLIP2 | [https://github.com/huggingface/transformers](https://github.com/huggingface/transformers) |
|
| 42 |
+
| RAM | [https://github.com/IDEA-Research/Grounded-Segment-Anything](https://github.com/IDEA-Research/Grounded-Segment-Anything) |
|
| 43 |
+
| Semantic-SAM | [https://github.com/UX-Decoder/Semantic-SAM](https://github.com/UX-Decoder/Semantic-SAM) |
|
| 44 |
+
| SEEM | [https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-Once](https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-Once) |
|
| 45 |
+
| OCR(easyocr) | [https://github.com/JaidedAI/EasyOCR](https://github.com/JaidedAI/EasyOCR) |
|
LLaVA-Plus-Codebase/docs/llava/Customize_Component.md
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Customize Components in LLaVA
|
| 2 |
+
|
| 3 |
+
This is an initial guide on how to replace the LLMs, visual encoders, etc. with your choice of components.
|
| 4 |
+
|
| 5 |
+
## LLM
|
| 6 |
+
|
| 7 |
+
It is quite simple to swap out LLaMA to any other LLMs. You can refer to our implementation of [`llava_llama.py`](https://raw.githubusercontent.com/haotian-liu/LLaVA/main/llava/model/language_model/llava_llama.py) for an example of how to replace the LLM.
|
| 8 |
+
|
| 9 |
+
Although it may seem that it still needs ~100 lines of code, most of them are copied from the original `llama.py` from HF. The only part that is different is to insert some lines for processing the multimodal inputs.
|
| 10 |
+
|
| 11 |
+
In `forward` function, you can see that we call `self.prepare_inputs_labels_for_multimodal` to process the multimodal inputs. This function is defined in `LlavaMetaForCausalLM` and you just need to insert it into the `forward` function of your LLM.
|
| 12 |
+
|
| 13 |
+
In `prepare_inputs_for_generation` function, you can see that we add `images` to the `model_inputs`. This is because we need to pass the images to the LLM during generation.
|
| 14 |
+
|
| 15 |
+
These are basically all the changes you need to make to replace the LLM.
|
| 16 |
+
|
| 17 |
+
## Visual Encoder
|
| 18 |
+
|
| 19 |
+
You can check out [`clip_encoder.py`](https://github.com/haotian-liu/LLaVA/blob/main/llava/model/multimodal_encoder/clip_encoder.py) on how we implement the CLIP visual encoder.
|
| 20 |
+
|
LLaVA-Plus-Codebase/docs/llava/Data.md
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Data
|
| 2 |
+
|
| 3 |
+
| Data file name | Size |
|
| 4 |
+
| --- | ---: |
|
| 5 |
+
| [llava_instruct_150k.json](https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K/blob/main/llava_instruct_150k.json) | 229 MB |
|
| 6 |
+
| [llava_instruct_80k.json](https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K/blob/main/llava_instruct_80k.json) | 229 MB |
|
| 7 |
+
| [conversation_58k.json](https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K/blob/main/conversation_58k.json) | 126 MB |
|
| 8 |
+
| [detail_23k.json](https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K/blob/main/detail_23k.json) | 20.5 MB |
|
| 9 |
+
| [complex_reasoning_77k.json](https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K/blob/main/complex_reasoning_77k.json) | 79.6 MB |
|
| 10 |
+
|
| 11 |
+
### Pretraining Dataset
|
| 12 |
+
The pretraining dataset used in this release is a subset of CC-3M dataset, filtered with a more balanced concept coverage distribution. Please see [here](https://huggingface.co/datasets/liuhaotian/LLaVA-CC3M-Pretrain-595K) for a detailed description of the dataset structure and how to download the images.
|
| 13 |
+
|
| 14 |
+
If you already have CC-3M dataset on your disk, the image names follow this format: `GCC_train_000000000.jpg`. You may edit the `image` field correspondingly if necessary.
|
| 15 |
+
|
| 16 |
+
| Data | Chat File | Meta Data | Size |
|
| 17 |
+
| --- | --- | --- | ---: |
|
| 18 |
+
| CC-3M Concept-balanced 595K | [chat.json](https://huggingface.co/datasets/liuhaotian/LLaVA-CC3M-Pretrain-595K/blob/main/chat.json) | [metadata.json](https://huggingface.co/datasets/liuhaotian/LLaVA-CC3M-Pretrain-595K/blob/main/metadata.json) | 211 MB
|
| 19 |
+
| LAION/CC/SBU BLIP-Caption Concept-balanced 558K | [blip_laion_cc_sbu_558k.json](https://huggingface.co/datasets/liuhaotian/LLaVA-Pretrain/blob/main/blip_laion_cc_sbu_558k.json) | [metadata.json](#) | 181 MB
|
| 20 |
+
|
| 21 |
+
**Important notice**: Upon the request from the community, as ~15% images of the original CC-3M dataset are no longer accessible, we upload [`images.zip`](https://huggingface.co/datasets/liuhaotian/LLaVA-CC3M-Pretrain-595K/blob/main/images.zip) for better reproducing our work in research community. It must not be used for any other purposes. The use of these images must comply with the CC-3M license. This may be taken down at any time when requested by the original CC-3M dataset owner or owners of the referenced images.
|
| 22 |
+
|
| 23 |
+
### GPT-4 Prompts
|
| 24 |
+
|
| 25 |
+
We provide our prompts and few-shot samples for GPT-4 queries, to better facilitate research in this domain. Please check out the [`prompts`](https://github.com/haotian-liu/LLaVA/tree/main/playground/data/prompts) folder for three kinds of questions: conversation, detail description, and complex reasoning.
|
| 26 |
+
|
| 27 |
+
They are organized in a format of `system_message.txt` for system message, pairs of `abc_caps.txt` for few-shot sample user input, and `abc_conv.txt` for few-shot sample reference output.
|
| 28 |
+
|
| 29 |
+
Note that you may find them in different format. For example, `conversation` is in `jsonl`, and detail description is answer-only. The selected format in our preliminary experiments works slightly better than a limited set of alternatives that we tried: `jsonl`, more natural format, answer-only. If interested, you may try other variants or conduct more careful study in this. Contributions are welcomed!
|
LLaVA-Plus-Codebase/docs/llava/Evaluation.md
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Evaluation
|
| 2 |
+
|
| 3 |
+
In LLaVA-1.5, we evaluate models on a diverse set of 12 benchmarks. To ensure the reproducibility, we evaluate the models with greedy decoding. We do not evaluate using beam search to make the inference process consistent with the chat demo of real-time outputs.
|
| 4 |
+
|
| 5 |
+
Currently, we mostly utilize the official toolkit or server for the evaluation.
|
| 6 |
+
|
| 7 |
+
## Evaluate on Custom Datasets
|
| 8 |
+
|
| 9 |
+
You can evaluate LLaVA on your custom datasets by converting your dataset to LLaVA's jsonl format, and evaluate using [`model_vqa.py`](https://github.com/haotian-liu/LLaVA/blob/main/llava/eval/model_vqa.py).
|
| 10 |
+
|
| 11 |
+
Below we provide a general guideline for evaluating datasets with some common formats.
|
| 12 |
+
|
| 13 |
+
1. Short-answer (e.g. VQAv2, MME).
|
| 14 |
+
|
| 15 |
+
```
|
| 16 |
+
<question>
|
| 17 |
+
Answer the question using a single word or phrase.
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
2. Option-only for multiple-choice (e.g. MMBench, SEED-Bench).
|
| 21 |
+
|
| 22 |
+
```
|
| 23 |
+
<question>
|
| 24 |
+
A. <option_1>
|
| 25 |
+
B. <option_2>
|
| 26 |
+
C. <option_3>
|
| 27 |
+
D. <option_4>
|
| 28 |
+
Answer with the option's letter from the given choices directly.
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
3. Natural QA (e.g. LLaVA-Bench, MM-Vet).
|
| 32 |
+
|
| 33 |
+
No postprocessing is needed.
|
| 34 |
+
|
| 35 |
+
## Scripts
|
| 36 |
+
|
| 37 |
+
Before preparing task-specific data, **you MUST first download [eval.zip](https://drive.google.com/file/d/1atZSBBrAX54yYpxtVVW33zFvcnaHeFPy/view?usp=sharing)**. It contains custom annotations, scripts, and the prediction files with LLaVA v1.5. Extract to `./playground/data/eval`. This also provides a general structure for all datasets.
|
| 38 |
+
|
| 39 |
+
### VQAv2
|
| 40 |
+
|
| 41 |
+
1. Download [`test2015`](http://images.cocodataset.org/zips/test2015.zip) and put it under `./playground/data/eval/vqav2`.
|
| 42 |
+
2. Multi-GPU inference.
|
| 43 |
+
```Shell
|
| 44 |
+
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 bash scripts/v1_5/eval/vqav2.sh
|
| 45 |
+
```
|
| 46 |
+
3. Submit the results to the [evaluation server](https://eval.ai/web/challenges/challenge-page/830/my-submission): `./playground/data/eval/vqav2/answers_upload`.
|
| 47 |
+
|
| 48 |
+
### GQA
|
| 49 |
+
|
| 50 |
+
1. Download the [data](https://cs.stanford.edu/people/dorarad/gqa/download.html) and [evaluation scripts](https://cs.stanford.edu/people/dorarad/gqa/evaluate.html) following the official instructions and put under `./playground/data/eval/gqa/data`. You may need to modify `eval.py` as [this](https://gist.github.com/haotian-liu/db6eddc2a984b4cbcc8a7f26fd523187) due to the missing assets in the GQA v1.2 release.
|
| 51 |
+
2. Multi-GPU inference.
|
| 52 |
+
```Shell
|
| 53 |
+
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 bash scripts/v1_5/eval/gqa.sh
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
### VisWiz
|
| 57 |
+
|
| 58 |
+
1. Download [`test.json`](https://vizwiz.cs.colorado.edu/VizWiz_final/vqa_data/Annotations.zip) and extract [`test.zip`](https://vizwiz.cs.colorado.edu/VizWiz_final/images/test.zip) to `test`. Put them under `./playground/data/eval/vizwiz`.
|
| 59 |
+
2. Single-GPU inference.
|
| 60 |
+
```Shell
|
| 61 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/vizwiz.sh
|
| 62 |
+
```
|
| 63 |
+
3. Submit the results to the [evaluation server](https://eval.ai/web/challenges/challenge-page/1911/my-submission): `./playground/data/eval/vizwiz/answers_upload`.
|
| 64 |
+
|
| 65 |
+
### ScienceQA
|
| 66 |
+
|
| 67 |
+
1. Under `./playground/data/eval/scienceqa`, download `images`, `pid_splits.json`, `problems.json` from the `data/scienceqa` folder of the ScienceQA [repo](https://github.com/lupantech/ScienceQA).
|
| 68 |
+
2. Single-GPU inference and evaluate.
|
| 69 |
+
```Shell
|
| 70 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/sqa.sh
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
### TextVQA
|
| 74 |
+
|
| 75 |
+
1. Download [`TextVQA_0.5.1_val.json`](https://dl.fbaipublicfiles.com/textvqa/data/TextVQA_0.5.1_val.json) and [images](https://dl.fbaipublicfiles.com/textvqa/images/train_val_images.zip) and extract to `./playground/data/eval/textvqa`.
|
| 76 |
+
2. Single-GPU inference and evaluate.
|
| 77 |
+
```Shell
|
| 78 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/textvqa.sh
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
### POPE
|
| 82 |
+
|
| 83 |
+
1. Download `coco` from [POPE](https://github.com/AoiDragon/POPE/tree/e3e39262c85a6a83f26cf5094022a782cb0df58d/output/coco) and put under `./playground/data/eval/pope`.
|
| 84 |
+
2. Single-GPU inference and evaluate.
|
| 85 |
+
```Shell
|
| 86 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/pope.sh
|
| 87 |
+
```
|
| 88 |
+
|
| 89 |
+
### MME
|
| 90 |
+
|
| 91 |
+
1. Download the data following the official instructions [here](https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation).
|
| 92 |
+
2. Downloaded images to `MME_Benchmark_release_version`.
|
| 93 |
+
3. put the official `eval_tool` and `MME_Benchmark_release_version` under `./playground/data/eval/MME`.
|
| 94 |
+
4. Single-GPU inference and evaluate.
|
| 95 |
+
```Shell
|
| 96 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/mme.sh
|
| 97 |
+
```
|
| 98 |
+
|
| 99 |
+
### MMBench
|
| 100 |
+
|
| 101 |
+
1. Download [`mmbench_dev_20230712.tsv`](https://download.openmmlab.com/mmclassification/datasets/mmbench/mmbench_dev_20230712.tsv) and put under `./playground/data/eval/mmbench`.
|
| 102 |
+
2. Single-GPU inference.
|
| 103 |
+
```Shell
|
| 104 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/mmbench.sh
|
| 105 |
+
```
|
| 106 |
+
3. Submit the results to the [evaluation server](https://opencompass.org.cn/leaderboard-multimodal): `./playground/data/eval/mmbench/answers_upload/mmbench_dev_20230712`.
|
| 107 |
+
|
| 108 |
+
### MMBench-CN
|
| 109 |
+
|
| 110 |
+
1. Download [`mmbench_dev_cn_20231003.tsv`](https://download.openmmlab.com/mmclassification/datasets/mmbench/mmbench_dev_cn_20231003.tsv) and put under `./playground/data/eval/mmbench`.
|
| 111 |
+
2. Single-GPU inference.
|
| 112 |
+
```Shell
|
| 113 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/mmbench_cn.sh
|
| 114 |
+
```
|
| 115 |
+
3. Submit the results to the evaluation server: `./playground/data/eval/mmbench/answers_upload/mmbench_dev_cn_20231003`.
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
### SEED-Bench
|
| 119 |
+
|
| 120 |
+
1. Following the official [instructions](https://github.com/AILab-CVC/SEED-Bench/blob/main/DATASET.md) to download the images and the videos. Put images under `./playground/data/eval/seed_bench/SEED-Bench-image`.
|
| 121 |
+
2. Extract the video frame in the middle from the downloaded videos, and put them under `./playground/data/eval/seed_bench/SEED-Bench-video-image`. We provide our script `extract_video_frames.py` modified from the official one.
|
| 122 |
+
3. Multiple-GPU inference and evaluate.
|
| 123 |
+
```Shell
|
| 124 |
+
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 bash scripts/v1_5/eval/seed.sh
|
| 125 |
+
```
|
| 126 |
+
4. Optionally, submit the results to the leaderboard: `./playground/data/eval/seed_bench/answers_upload` using the official jupyter notebook.
|
| 127 |
+
|
| 128 |
+
### LLaVA-Bench-in-the-Wild
|
| 129 |
+
|
| 130 |
+
1. Extract contents of [`llava-bench-in-the-wild`](https://huggingface.co/datasets/liuhaotian/llava-bench-in-the-wild) to `./playground/data/eval/llava-bench-in-the-wild`.
|
| 131 |
+
2. Single-GPU inference and evaluate.
|
| 132 |
+
```Shell
|
| 133 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/llavabench.sh
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
### MM-Vet
|
| 137 |
+
|
| 138 |
+
1. Extract [`mm-vet.zip`](https://github.com/yuweihao/MM-Vet/releases/download/v1/mm-vet.zip) to `./playground/data/eval/mmvet`.
|
| 139 |
+
2. Single-GPU inference.
|
| 140 |
+
```Shell
|
| 141 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/mmvet.sh
|
| 142 |
+
```
|
| 143 |
+
3. Evaluate the predictions in `./playground/data/eval/mmvet/results` using the official jupyter notebook.
|
| 144 |
+
|
| 145 |
+
## More Benchmarks
|
| 146 |
+
|
| 147 |
+
Below are awesome benchmarks for multimodal understanding from the research community, that are not initially included in the LLaVA-1.5 release.
|
| 148 |
+
|
| 149 |
+
### Q-Bench
|
| 150 |
+
|
| 151 |
+
1. Download [`llvisionqa_dev.json`](https://huggingface.co/datasets/nanyangtu/LLVisionQA-QBench/resolve/main/llvisionqa_dev.json) (for `dev`-subset) and [`llvisionqa_test.json`](https://huggingface.co/datasets/nanyangtu/LLVisionQA-QBench/resolve/main/llvisionqa_test.json) (for `test`-subset). Put them under `./playground/data/eval/qbench`.
|
| 152 |
+
2. Download and extract [images](https://huggingface.co/datasets/nanyangtu/LLVisionQA-QBench/resolve/main/images_llvisionqa.tar) and put all the images directly under `./playground/data/eval/qbench/images_llviqionqa`.
|
| 153 |
+
3. Single-GPU inference (change `dev` to `test` for evaluation on test set).
|
| 154 |
+
```Shell
|
| 155 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/qbench.sh dev
|
| 156 |
+
```
|
| 157 |
+
4. Submit the results by instruction [here](https://github.com/VQAssessment/Q-Bench#option-1-submit-results): `./playground/data/eval/qbench/llvisionqa_dev_answers.jsonl`.
|
| 158 |
+
|
| 159 |
+
### Chinese-Q-Bench
|
| 160 |
+
|
| 161 |
+
1. Download [`质衡-问答-验证集.json`](https://huggingface.co/datasets/nanyangtu/LLVisionQA-QBench/resolve/main/%E8%B4%A8%E8%A1%A1-%E9%97%AE%E7%AD%94-%E9%AA%8C%E8%AF%81%E9%9B%86.json) (for `dev`-subset) and [`质衡-问答-测试集.json`](https://huggingface.co/datasets/nanyangtu/LLVisionQA-QBench/resolve/main/%E8%B4%A8%E8%A1%A1-%E9%97%AE%E7%AD%94-%E6%B5%8B%E8%AF%95%E9%9B%86.json) (for `test`-subset). Put them under `./playground/data/eval/qbench`.
|
| 162 |
+
2. Download and extract [images](https://huggingface.co/datasets/nanyangtu/LLVisionQA-QBench/resolve/main/images_llvisionqa.tar) and put all the images directly under `./playground/data/eval/qbench/images_llviqionqa`.
|
| 163 |
+
3. Single-GPU inference (change `dev` to `test` for evaluation on test set).
|
| 164 |
+
```Shell
|
| 165 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/qbench_zh.sh dev
|
| 166 |
+
```
|
| 167 |
+
4. Submit the results by instruction [here](https://github.com/VQAssessment/Q-Bench#option-1-submit-results): `./playground/data/eval/qbench/llvisionqa_zh_dev_answers.jsonl`.
|
LLaVA-Plus-Codebase/docs/llava/Finetune_Custom_Data.md
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Finetune LLaVA on Custom Datasets
|
| 2 |
+
|
| 3 |
+
## Dataset Format
|
| 4 |
+
|
| 5 |
+
Convert your data to a JSON file of a List of all samples. Sample metadata should contain `id` (a unique identifier), `image` (the path to the image), and `conversations` (the conversation data between human and AI).
|
| 6 |
+
|
| 7 |
+
A sample JSON for finetuning LLaVA for generating tag-style captions for Stable Diffusion:
|
| 8 |
+
|
| 9 |
+
```json
|
| 10 |
+
[
|
| 11 |
+
{
|
| 12 |
+
"id": "997bb945-628d-4724-b370-b84de974a19f",
|
| 13 |
+
"image": "part-000001/997bb945-628d-4724-b370-b84de974a19f.jpg",
|
| 14 |
+
"conversations": [
|
| 15 |
+
{
|
| 16 |
+
"from": "human",
|
| 17 |
+
"value": "<image>\nWrite a prompt for Stable Diffusion to generate this image."
|
| 18 |
+
},
|
| 19 |
+
{
|
| 20 |
+
"from": "gpt",
|
| 21 |
+
"value": "a beautiful painting of chernobyl by nekro, pascal blanche, john harris, greg rutkowski, sin jong hun, moebius, simon stalenhag. in style of cg art. ray tracing. cel shading. hyper detailed. realistic. ue 5. maya. octane render. "
|
| 22 |
+
},
|
| 23 |
+
]
|
| 24 |
+
},
|
| 25 |
+
...
|
| 26 |
+
]
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
## Command
|
| 30 |
+
|
| 31 |
+
If you have a limited task-specific data, we recommend finetuning from LLaVA checkpoints with LoRA following this [script](https://github.com/haotian-liu/LLaVA/blob/main/scripts/v1_5/finetune_task_lora.sh).
|
| 32 |
+
|
| 33 |
+
If the amount of the task-specific data is sufficient, you can also finetune from LLaVA checkpoints with full-model finetuning following this [script](https://github.com/haotian-liu/LLaVA/blob/main/scripts/v1_5/finetune_task.sh).
|
| 34 |
+
|
| 35 |
+
You may need to adjust the hyperparameters to fit each specific dataset and your hardware constraint.
|
| 36 |
+
|
| 37 |
+
|
LLaVA-Plus-Codebase/docs/llava/Intel.md
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Intel Platforms
|
| 2 |
+
|
| 3 |
+
* Support [Intel GPU Max Series](https://www.intel.com/content/www/us/en/products/details/discrete-gpus/data-center-gpu/max-series.html)
|
| 4 |
+
* Support [Intel CPU Sapphire Rapides](https://ark.intel.com/content/www/us/en/ark/products/codename/126212/products-formerly-sapphire-rapids.html)
|
| 5 |
+
* Based on [Intel Extention for Pytorch](https://intel.github.io/intel-extension-for-pytorch)
|
| 6 |
+
|
| 7 |
+
More details in [**intel branch**](https://github.com/haotian-liu/LLaVA/tree/intel/docs/intel)
|
LLaVA-Plus-Codebase/docs/llava/LLaVA_Bench.md
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# LLaVA-Bench [[Download](https://huggingface.co/datasets/liuhaotian/llava-bench-in-the-wild)]
|
| 2 |
+
|
| 3 |
+
**-Introduction-** Large commercial multimodal chatbots have been released in this week, including
|
| 4 |
+
- [Multimodal Bing-Chat by Microsoft](https://blogs.bing.com/search/july-2023/Bing-Chat-Enterprise-announced,-multimodal-Visual-Search-rolling-out-to-Bing-Chat) (July 18, 2023)
|
| 5 |
+
- [Multimodal Bard by Google](https://bard.google.com/).
|
| 6 |
+
|
| 7 |
+
These chatbots are presumably supported by proprietary large multimodal models (LMM). Compared with the open-source LMM such as LLaVA, proprietary LMM represent the scaling success upperbound of the current SoTA techniques. They share the goal of developing multimodal chatbots that follow human intents to complete various daily-life visual tasks in the wild. While it remains less explored how to evaluate multimodal chat ability, it provides useful feedback to study open-source LMMs against the commercial multimodal chatbots. In addition to the *LLaVA-Bench (COCO)* dataset we used to develop the early versions of LLaVA, we are releasing [*LLaVA-Bench (In-the-Wild)*](https://huggingface.co/datasets/liuhaotian/llava-bench-in-the-wild) to the community for the public use.
|
| 8 |
+
|
| 9 |
+
## LLaVA-Bench (In-the-Wild *[Ongoing work]*)
|
| 10 |
+
|
| 11 |
+
To evaluate the model's capability in more challenging tasks and generalizability to novel domains, we collect a diverse set of 24 images with 60 questions in total, including indoor and outdoor scenes, memes, paintings, sketches, etc, and associate each image with a highly-detailed and manually-curated description and a proper selection of questions. Such design also assesses the model's robustness to different prompts. In this release, we also categorize questions into three categories: conversation (simple QA), detailed description, and complex reasoning. We continue to expand and improve the diversity of the LLaVA-Bench (In-the-Wild). We manually query Bing-Chat and Bard to get the responses.
|
| 12 |
+
|
| 13 |
+
### Results
|
| 14 |
+
|
| 15 |
+
The score is measured by comparing against a reference answer generated by text-only GPT-4. It is generated by feeding the question, along with the ground truth image annotations as the context. A text-only GPT-4 evaluator rates both answers. We query GPT-4 by putting the reference answer first, and then the answer generated by the candidate model. We upload images at their original resolution to Bard and Bing-Chat to obtain the results.
|
| 16 |
+
|
| 17 |
+
| Approach | Conversation | Detail | Reasoning | Overall |
|
| 18 |
+
|----------------|--------------|--------|-----------|---------|
|
| 19 |
+
| Bard-0718 | 83.7 | 69.7 | 78.7 | 77.8 |
|
| 20 |
+
| Bing-Chat-0629 | 59.6 | 52.2 | 90.1 | 71.5 |
|
| 21 |
+
| LLaVA-13B-v1-336px-0719 (beam=1) | 64.3 | 55.9 | 81.7 | 70.1 |
|
| 22 |
+
| LLaVA-13B-v1-336px-0719 (beam=5) | 68.4 | 59.9 | 84.3 | 73.5 |
|
| 23 |
+
|
| 24 |
+
Note that Bard sometimes refuses to answer questions about images containing humans, and Bing-Chat blurs the human faces in the images. We also provide the benchmark score for the subset without humans.
|
| 25 |
+
|
| 26 |
+
| Approach | Conversation | Detail | Reasoning | Overall |
|
| 27 |
+
|----------------|--------------|--------|-----------|---------|
|
| 28 |
+
| Bard-0718 | 94.9 | 74.3 | 84.3 | 84.6 |
|
| 29 |
+
| Bing-Chat-0629 | 55.8 | 53.6 | 93.5 | 72.6 |
|
| 30 |
+
| LLaVA-13B-v1-336px-0719 (beam=1) | 62.2 | 56.4 | 82.2 | 70.0 |
|
| 31 |
+
| LLaVA-13B-v1-336px-0719 (beam=5) | 65.6 | 61.7 | 85.0 | 73.6 |
|
LLaVA-Plus-Codebase/docs/llava/LLaVA_from_LLaMA2.md
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# LLaVA (based on Llama 2 LLM, Preview)
|
| 2 |
+
|
| 3 |
+
*NOTE: This is a technical preview. We are still running hyperparameter search, and will release the final model soon. If you'd like to contribute to this, please contact us.*
|
| 4 |
+
|
| 5 |
+
:llama: **-Introduction-** [Llama 2 is an open-source LLM released by Meta AI](https://about.fb.com/news/2023/07/llama-2/) today (July 18, 2023). Compared with its early version [Llama 1](https://ai.meta.com/blog/large-language-model-llama-meta-ai/), Llama 2 is more favored in ***stronger language performance***, ***longer context window***, and importantly ***commercially usable***! While Llama 2 is changing the LLM market landscape in the language space, its multimodal ability remains unknown. We quickly develop the LLaVA variant based on the latest Llama 2 checkpoints, and release it to the community for the public use.
|
| 6 |
+
|
| 7 |
+
You need to apply for and download the latest Llama 2 checkpoints to start your own training (apply [here](https://ai.meta.com/resources/models-and-libraries/llama-downloads/))
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
## Training
|
| 11 |
+
|
| 12 |
+
Please checkout [`pretrain.sh`](https://github.com/haotian-liu/LLaVA/blob/main/scripts/pretrain.sh), [`finetune.sh`](https://github.com/haotian-liu/LLaVA/blob/main/scripts/finetune.sh), [`finetune_lora.sh`](https://github.com/haotian-liu/LLaVA/blob/main/scripts/finetune_lora.sh).
|
| 13 |
+
|
| 14 |
+
## LLaVA (based on Llama 2), What is different?
|
| 15 |
+
|
| 16 |
+
:volcano: How is the new LLaVA based on Llama 2 different from Llama 1? The comparisons of the training process are described:
|
| 17 |
+
- **Pre-training**. The pre-trained base LLM is changed from Llama 1 to Llama 2
|
| 18 |
+
- **Language instruction-tuning**. The previous LLaVA model starts with Vicuna, which is instruct tuned on ShareGPT data from Llama 1; The new LLaVA model starts with Llama 2 Chat, which is an instruct tuned checkpoint on dialogue data from Llama 2.
|
| 19 |
+
- **Multimodal instruction-tuning**. The same LLaVA-Lighting process is applied.
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
### Results
|
| 23 |
+
|
| 24 |
+
- Llama 2 is better at following the instructions of role playing; Llama 2 fails in following the instructions of translation
|
| 25 |
+
- The quantitative evaluation on [LLaVA-Bench](https://github.com/haotian-liu/LLaVA/blob/main/docs/LLaVA_Bench.md) demonstrates on-par performance between Llama 2 and Llama 1 in LLaVA's multimodal chat ability.
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
<img src="../images/llava_example_cmp.png" width="100%">
|
| 29 |
+
|
LLaVA-Plus-Codebase/docs/llava/LoRA.md
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# LLaVA (LoRA, Preview)
|
| 2 |
+
|
| 3 |
+
NOTE: This is a technical preview, and is not yet ready for production use. We are still running hyperparameter search for the LoRA model, and will release the final model soon. If you'd like to contribute to this, please contact us.
|
| 4 |
+
|
| 5 |
+
You need latest code base for LoRA support (instructions [here](https://github.com/haotian-liu/LLaVA#upgrade-to-latest-code-base))
|
| 6 |
+
|
| 7 |
+
## Demo (Web UI)
|
| 8 |
+
|
| 9 |
+
Please execute each of the commands below one by one (after the previous one has finished). The commands are the same as launching other demos except for an additional `--model-base` flag to specify the base model to use. Please make sure the base model corresponds to the LoRA checkpoint that you are using. For this technical preview, you need Vicuna v1.1 (7B) checkpoint (if you do not have that already, follow the instructions [here](https://github.com/lm-sys/FastChat#vicuna-weights)).
|
| 10 |
+
|
| 11 |
+
#### Launch a controller
|
| 12 |
+
```Shell
|
| 13 |
+
python -m llava.serve.controller --host 0.0.0.0 --port 10000
|
| 14 |
+
```
|
| 15 |
+
|
| 16 |
+
#### Launch a gradio web server.
|
| 17 |
+
```Shell
|
| 18 |
+
python -m llava.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload
|
| 19 |
+
```
|
| 20 |
+
You just launched the Gradio web interface. Now, you can open the web interface with the URL printed on the screen. You may notice that there is no model in the model list. Do not worry, as we have not launched any model worker yet. It will be automatically updated when you launch a model worker.
|
| 21 |
+
|
| 22 |
+
#### Launch a model worker
|
| 23 |
+
```Shell
|
| 24 |
+
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-vicuna-7b-v1.1-lcs_558k-instruct_80k_3e-lora-preview-alpha --model-base /path/to/vicuna-v1.1
|
| 25 |
+
```
|
| 26 |
+
Wait until the process finishes loading the model and you see "Uvicorn running on ...". Now, refresh your Gradio web UI, and you will see the model you just launched in the model list.
|
| 27 |
+
|
| 28 |
+
You can launch as many workers as you want, and compare between different model checkpoints in the same Gradio interface. Please keep the `--controller` the same, and modify the `--port` and `--worker` to a different port number for each worker.
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
## Training
|
| 32 |
+
|
| 33 |
+
Please see sample training scripts for [LoRA](https://github.com/haotian-liu/LLaVA/blob/main/scripts/finetune_lora.sh) and [QLoRA](https://github.com/haotian-liu/LLaVA/blob/main/scripts/finetune_qlora.sh).
|
| 34 |
+
|
| 35 |
+
We provide sample DeepSpeed configs, [`zero3.json`](https://github.com/haotian-liu/LLaVA/blob/main/scripts/zero3.json) is more like PyTorch FSDP, and [`zero3_offload.json`](https://github.com/haotian-liu/LLaVA/blob/main/scripts/zero3_offload.json) can further save memory consumption by offloading parameters to CPU. `zero3.json` is usually faster than `zero3_offload.json` but requires more GPU memory, therefore, we recommend trying `zero3.json` first, and if you run out of GPU memory, try `zero3_offload.json`. You can also tweak the `per_device_train_batch_size` and `gradient_accumulation_steps` in the config to save memory, and just to make sure that `per_device_train_batch_size` and `gradient_accumulation_steps` remains the same.
|
| 36 |
+
|
| 37 |
+
If you are having issues with ZeRO-3 configs, and there are enough VRAM, you may try [`zero2.json`](https://github.com/haotian-liu/LLaVA/blob/main/scripts/zero2.json). This consumes slightly more memory than ZeRO-3, and behaves more similar to PyTorch FSDP, while still supporting parameter-efficient tuning.
|
| 38 |
+
|
| 39 |
+
## Create Merged Checkpoints
|
| 40 |
+
|
| 41 |
+
```Shell
|
| 42 |
+
python scripts/merge_lora_weights.py \
|
| 43 |
+
--model-path /path/to/lora_model \
|
| 44 |
+
--model-base /path/to/base_model \
|
| 45 |
+
--save-model-path /path/to/merge_model
|
| 46 |
+
```
|
LLaVA-Plus-Codebase/docs/llava/MODEL_ZOO.md
ADDED
|
@@ -0,0 +1,138 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Model Zoo
|
| 2 |
+
|
| 3 |
+
**To Use LLaVA-1.5 checkpoints, your llava package version must be newer than 1.1.0. [Instructions](https://github.com/haotian-liu/LLaVA#upgrade-to-latest-code-base) on how to upgrade.**
|
| 4 |
+
|
| 5 |
+
If you are interested in including any other details in Model Zoo, please open an issue :)
|
| 6 |
+
|
| 7 |
+
The model weights below are *merged* weights. You do not need to apply delta. The usage of LLaVA checkpoints should comply with the base LLM's model license: [Llama 2](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md).
|
| 8 |
+
|
| 9 |
+
## LLaVA-v1.5
|
| 10 |
+
|
| 11 |
+
| Version | Size | Schedule | Checkpoint | VQAv2 | GQA | VizWiz | SQA | T-VQA | POPE | MME | MM-Bench | MM-Bench-CN | SEED | LLaVA-Bench-Wild | MM-Vet |
|
| 12 |
+
|----------|----------|-----------|-----------|---|---|---|---|---|---|---|---|---|---|---|---|
|
| 13 |
+
| LLaVA-1.5 | 7B | full_ft-1e | [liuhaotian/llava-v1.5-7b](https://huggingface.co/liuhaotian/llava-v1.5-7b) | 78.5 | 62.0 | 50.0 | 66.8 | 58.2 | 85.9 | 1510.7 | 64.3 | 58.3 | 58.6 | 65.4 | 31.1 |
|
| 14 |
+
| LLaVA-1.5 | 13B | full_ft-1e | [liuhaotian/llava-v1.5-13b](https://huggingface.co/liuhaotian/llava-v1.5-13b) | 80.0 | 63.3 | 53.6 | 71.6 | 61.3 | 85.9 | 1531.3 | 67.7 | 63.6 | 61.6 | 72.5 | 36.1 |
|
| 15 |
+
| LLaVA-1.5 | 7B | lora-1e | [liuhaotian/llava-v1.5-7b-lora](https://huggingface.co/liuhaotian/llava-v1.5-7b-lora) | 79.1 | 63.0 | 47.8 | 68.4 | 58.2 | 86.4 | 1476.9 | 66.1 | 58.9 | 60.1 | 67.9 | 30.2 |
|
| 16 |
+
| LLaVA-1.5 | 13B | lora-1e | [liuhaotian/llava-v1.5-13b-lora](https://huggingface.co/liuhaotian/llava-v1.5-13b-lora) | 80.0 | 63.3 | 58.9 | 71.2 | 60.2 | 86.7 | 1541.7 | 68.5 | 61.5 | 61.3 | 69.5 | 38.3 |
|
| 17 |
+
|
| 18 |
+
Base model: Vicuna v1.5. Training logs: [wandb](https://api.wandb.ai/links/lht/6orh56wc).
|
| 19 |
+
|
| 20 |
+
<p align="center">
|
| 21 |
+
<img src="../images/llava_v1_5_radar.jpg" width="500px"> <br>
|
| 22 |
+
LLaVA-1.5 achieves SoTA performance across 11 benchmarks.
|
| 23 |
+
</p>
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
## LLaVA-v1
|
| 27 |
+
|
| 28 |
+
*Note: We recommend using the most capable LLaVA-v1.5 series above for the best performance.*
|
| 29 |
+
|
| 30 |
+
| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Finetuning Data | Finetuning schedule | LLaVA-Bench-Conv | LLaVA-Bench-Detail | LLaVA-Bench-Complex | LLaVA-Bench-Overall | Download |
|
| 31 |
+
|----------|----------------|---------------|----------------------|-----------------|--------------------|------------------|--------------------|---------------------|---------------------|---------------------|
|
| 32 |
+
| Vicuna-13B-v1.3 | CLIP-L-336px | LCS-558K | 1e | LLaVA-Instruct-80K | proj-1e, lora-1e | 64.3 | 55.9 | 81.7 | 70.1 | [LoRA](https://huggingface.co/liuhaotian/llava-v1-0719-336px-lora-vicuna-13b-v1.3) [LoRA-Merged](https://huggingface.co/liuhaotian/llava-v1-0719-336px-lora-merge-vicuna-13b-v1.3) |
|
| 33 |
+
| LLaMA-2-13B-Chat | CLIP-L | LCS-558K | 1e | LLaVA-Instruct-80K | full_ft-1e | 56.7 | 58.6 | 80.0 | 67.9 | [ckpt](https://huggingface.co/liuhaotian/llava-llama-2-13b-chat-lightning-preview) |
|
| 34 |
+
| LLaMA-2-7B-Chat | CLIP-L | LCS-558K | 1e | LLaVA-Instruct-80K | lora-1e | 51.2 | 58.9 | 71.6 | 62.8 | [LoRA](https://huggingface.co/liuhaotian/llava-llama-2-7b-chat-lightning-lora-preview) |
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
## Projector weights
|
| 38 |
+
|
| 39 |
+
These are projector weights we have pretrained. You can use these projector weights for visual instruction tuning. They are just pretrained on image-text pairs and are NOT instruction-tuned, which means they do NOT follow instructions as well as our official models and can output repetitive, lengthy, and garbled outputs. If you want to have nice conversations with LLaVA, use the checkpoints above (LLaVA v1.5).
|
| 40 |
+
|
| 41 |
+
NOTE: These projector weights are only compatible with `llava>=1.0.0`. Please check out the latest codebase if your local code version is below v1.0.0.
|
| 42 |
+
|
| 43 |
+
NOTE: When you use our pretrained projector for visual instruction tuning, it is very important to use the same base LLM and vision encoder as the one we used for pretraining the projector. Otherwise, the performance will be very poor.
|
| 44 |
+
|
| 45 |
+
When using these projector weights to instruction-tune your LMM, please make sure that these options are correctly set as follows,
|
| 46 |
+
|
| 47 |
+
```Shell
|
| 48 |
+
--mm_use_im_start_end False
|
| 49 |
+
--mm_use_im_patch_token False
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
| Base LLM | Vision Encoder | Projection | Pretrain Data | Pretraining schedule | Download |
|
| 53 |
+
|----------|----------------|---------------|----------------------|----------|----------|
|
| 54 |
+
| Vicuna-13B-v1.5 | CLIP-L-336px | MLP-2x | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-v1.5-mlp2x-336px-pretrain-vicuna-13b-v1.5) |
|
| 55 |
+
| Vicuna-7B-v1.5 | CLIP-L-336px | MLP-2x | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-v1.5-mlp2x-336px-pretrain-vicuna-7b-v1.5) |
|
| 56 |
+
| LLaMA-2-13B-Chat | CLIP-L-336px | Linear | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-336px-pretrain-llama-2-13b-chat) |
|
| 57 |
+
| LLaMA-2-7B-Chat | CLIP-L-336px | Linear | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-336px-pretrain-llama-2-7b-chat) |
|
| 58 |
+
| LLaMA-2-13B-Chat | CLIP-L | Linear | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-pretrain-llama-2-13b-chat) |
|
| 59 |
+
| LLaMA-2-7B-Chat | CLIP-L | Linear | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-pretrain-llama-2-7b-chat) |
|
| 60 |
+
| Vicuna-13B-v1.3 | CLIP-L-336px | Linear | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-336px-pretrain-vicuna-13b-v1.3) |
|
| 61 |
+
| Vicuna-7B-v1.3 | CLIP-L-336px | Linear | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-336px-pretrain-vicuna-7b-v1.3) |
|
| 62 |
+
| Vicuna-13B-v1.3 | CLIP-L | Linear | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-pretrain-vicuna-13b-v1.3) |
|
| 63 |
+
| Vicuna-7B-v1.3 | CLIP-L | Linear | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-pretrain-vicuna-7b-v1.3) |
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
## Science QA Checkpoints
|
| 67 |
+
|
| 68 |
+
| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Finetuning Data | Finetuning schedule | Download |
|
| 69 |
+
|----------|----------------|---------------|----------------------|-----------------|--------------------|---------------------|
|
| 70 |
+
| Vicuna-13B-v1.3 | CLIP-L | LCS-558K | 1e | ScienceQA | full_ft-12e | [ckpt](https://huggingface.co/liuhaotian/llava-lcs558k-scienceqa-vicuna-13b-v1.3) |
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
## Legacy Models (merged weights)
|
| 74 |
+
|
| 75 |
+
The model weights below are *merged* weights. You do not need to apply delta. The usage of LLaVA checkpoints should comply with the base LLM's model license.
|
| 76 |
+
|
| 77 |
+
| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Finetuning Data | Finetuning schedule | Download |
|
| 78 |
+
|----------|----------------|---------------|----------------------|-----------------|--------------------|------------------|
|
| 79 |
+
| MPT-7B-Chat | CLIP-L | LCS-558K | 1e | LLaVA-Instruct-80K | full_ft-1e | [preview](https://huggingface.co/liuhaotian/LLaVA-Lightning-MPT-7B-preview) |
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
## Legacy Models (delta weights)
|
| 83 |
+
|
| 84 |
+
The model weights below are *delta* weights. The usage of LLaVA checkpoints should comply with the base LLM's model license: [LLaMA](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md).
|
| 85 |
+
|
| 86 |
+
You can add our delta to the original LLaMA weights to obtain the LLaVA weights.
|
| 87 |
+
|
| 88 |
+
Instructions:
|
| 89 |
+
|
| 90 |
+
1. Get the original LLaMA weights in the huggingface format by following the instructions [here](https://huggingface.co/docs/transformers/main/model_doc/llama).
|
| 91 |
+
2. Use the following scripts to get LLaVA weights by applying our delta. It will automatically download delta weights from our Hugging Face account. In the script below, we use the delta weights of [`liuhaotian/LLaVA-7b-delta-v0`](https://huggingface.co/liuhaotian/LLaVA-7b-delta-v0) as an example. It can be adapted for other delta weights by changing the `--delta` argument (and base/target accordingly).
|
| 92 |
+
|
| 93 |
+
```bash
|
| 94 |
+
python3 -m llava.model.apply_delta \
|
| 95 |
+
--base /path/to/llama-7b \
|
| 96 |
+
--target /output/path/to/LLaVA-7B-v0 \
|
| 97 |
+
--delta liuhaotian/LLaVA-7b-delta-v0
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Finetuning Data | Finetuning schedule | Download |
|
| 101 |
+
|----------|----------------|---------------|----------------------|-----------------|--------------------|------------------|
|
| 102 |
+
| Vicuna-13B-v1.1 | CLIP-L | CC-595K | 1e | LLaVA-Instruct-158K | full_ft-3e | [delta-weights](https://huggingface.co/liuhaotian/LLaVA-13b-delta-v1-1) |
|
| 103 |
+
| Vicuna-7B-v1.1 | CLIP-L | LCS-558K | 1e | LLaVA-Instruct-80K | full_ft-1e | [delta-weights](https://huggingface.co/liuhaotian/LLaVA-Lightning-7B-delta-v1-1) |
|
| 104 |
+
| Vicuna-13B-v0 | CLIP-L | CC-595K | 1e | LLaVA-Instruct-158K | full_ft-3e | [delta-weights](https://huggingface.co/liuhaotian/LLaVA-13b-delta-v0) |
|
| 105 |
+
| Vicuna-13B-v0 | CLIP-L | CC-595K | 1e | ScienceQA | full_ft-12e | [delta-weights](https://huggingface.co/liuhaotian/LLaVA-13b-delta-v0-science_qa) |
|
| 106 |
+
| Vicuna-7B-v0 | CLIP-L | CC-595K | 1e | LLaVA-Instruct-158K | full_ft-3e | [delta-weights](https://huggingface.co/liuhaotian/LLaVA-7b-delta-v0) |
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
## Legacy Projector weights
|
| 111 |
+
|
| 112 |
+
The following projector weights are deprecated, and the support for them may be removed in the future. They do not support zero-shot inference. Please use the projector weights in the [table above](#projector-weights) if possible.
|
| 113 |
+
|
| 114 |
+
**NOTE**: When you use our pretrained projector for visual instruction tuning, it is very important to **use the same base LLM and vision encoder** as the one we used for pretraining the projector. Otherwise, the performance will be very bad.
|
| 115 |
+
|
| 116 |
+
When using these projector weights to instruction tune your LMM, please make sure that these options are correctly set as follows,
|
| 117 |
+
|
| 118 |
+
```Shell
|
| 119 |
+
--mm_use_im_start_end True
|
| 120 |
+
--mm_use_im_patch_token False
|
| 121 |
+
```
|
| 122 |
+
|
| 123 |
+
| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Download |
|
| 124 |
+
|----------|----------------|---------------|----------------------|----------|
|
| 125 |
+
| Vicuna-7B-v1.1 | CLIP-L | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/LLaVA-Pretrained-Projectors/blob/main/LLaVA-7b-pretrain-projector-v1-1-LCS-558K-blip_caption.bin) |
|
| 126 |
+
| Vicuna-13B-v0 | CLIP-L | CC-595K | 1e | [projector](https://huggingface.co/liuhaotian/LLaVA-Pretrained-Projectors/blob/main/LLaVA-13b-pretrain-projector-v0-CC3M-595K-original_caption.bin) |
|
| 127 |
+
| Vicuna-7B-v0 | CLIP-L | CC-595K | 1e | [projector](https://huggingface.co/liuhaotian/LLaVA-Pretrained-Projectors/blob/main/LLaVA-7b-pretrain-projector-v0-CC3M-595K-original_caption.bin) |
|
| 128 |
+
|
| 129 |
+
When using these projector weights to instruction tune your LMM, please make sure that these options are correctly set as follows,
|
| 130 |
+
|
| 131 |
+
```Shell
|
| 132 |
+
--mm_use_im_start_end False
|
| 133 |
+
--mm_use_im_patch_token False
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Download |
|
| 137 |
+
|----------|----------------|---------------|----------------------|----------|
|
| 138 |
+
| Vicuna-13B-v0 | CLIP-L | CC-595K | 1e | [projector](https://huggingface.co/liuhaotian/LLaVA-Pretrained-Projectors/blob/main/LLaVA-13b-pretrain-projector-v0-CC3M-595K-original_caption-no_im_token.bin) |
|
LLaVA-Plus-Codebase/docs/llava/ScienceQA.md
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### ScienceQA
|
| 2 |
+
|
| 3 |
+
#### Prepare Data
|
| 4 |
+
1. Please see ScienceQA [repo](https://github.com/lupantech/ScienceQA) for setting up the dataset.
|
| 5 |
+
2. Generate ScienceQA dataset for LLaVA conversation-style format.
|
| 6 |
+
|
| 7 |
+
```Shell
|
| 8 |
+
python scripts/convert_sqa_to_llava.py \
|
| 9 |
+
convert_to_llava \
|
| 10 |
+
--base-dir /path/to/ScienceQA/data/scienceqa \
|
| 11 |
+
--prompt-format "QCM-LEA" \
|
| 12 |
+
--split {train,val,minival,test,minitest}
|
| 13 |
+
```
|
| 14 |
+
|
| 15 |
+
#### Training
|
| 16 |
+
|
| 17 |
+
1. Pretraining
|
| 18 |
+
|
| 19 |
+
You can download our pretrained projector weights from our [Model Zoo](), or train your own projector weights using [`pretrain.sh`](https://github.com/haotian-liu/LLaVA/blob/main/scripts/pretrain.sh).
|
| 20 |
+
|
| 21 |
+
2. Finetuning
|
| 22 |
+
|
| 23 |
+
See [`finetune_sqa.sh`](https://github.com/haotian-liu/LLaVA/blob/main/scripts/finetune_sqa.sh).
|
| 24 |
+
|
| 25 |
+
#### Evaluation
|
| 26 |
+
|
| 27 |
+
1. Multiple-GPU inference
|
| 28 |
+
You may evaluate this with multiple GPUs, and concatenate the generated jsonl files. Please refer to our script for [batch evaluation](https://github.com/haotian-liu/LLaVA/blob/main/scripts/sqa_eval_batch.sh) and [results gathering](https://github.com/haotian-liu/LLaVA/blob/main/scripts/sqa_eval_gather.sh).
|
| 29 |
+
|
| 30 |
+
2. Single-GPU inference
|
| 31 |
+
|
| 32 |
+
(a) Generate LLaVA responses on ScienceQA dataset
|
| 33 |
+
|
| 34 |
+
```Shell
|
| 35 |
+
python -m llava.eval.model_vqa_science \
|
| 36 |
+
--model-path liuhaotian/llava-lcs558k-scienceqa-vicuna-13b-v1.3 \
|
| 37 |
+
--question-file /path/to/ScienceQA/data/scienceqa/llava_test_QCM-LEA.json \
|
| 38 |
+
--image-folder /path/to/ScienceQA/data/scienceqa/images/test \
|
| 39 |
+
--answers-file vqa/results/ScienceQA/test_llava-13b.jsonl \
|
| 40 |
+
--conv-mode llava_v1
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
(b) Evaluate the generated responses
|
| 44 |
+
|
| 45 |
+
```Shell
|
| 46 |
+
python eval_science_qa.py \
|
| 47 |
+
--base-dir /path/to/ScienceQA/data/scienceqa \
|
| 48 |
+
--result-file vqa/results/ScienceQA/test_llava-13b.jsonl \
|
| 49 |
+
--output-file vqa/results/ScienceQA/test_llava-13b_output.json \
|
| 50 |
+
--output-result vqa/results/ScienceQA/test_llava-13b_result.json \
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
For reference, we attach our prediction file [`test_sqa_llava_lcs_558k_sqa_12e_vicuna_v1_3_13b.json`](https://github.com/haotian-liu/LLaVA/blob/main/llava/eval/table/results/test_sqa_llava_lcs_558k_sqa_12e_vicuna_v1_3_13b.json) and [`test_sqa_llava_13b_v0.json`](https://github.com/haotian-liu/LLaVA/blob/main/llava/eval/table/results/test_sqa_llava_13b_v0.json) for comparison when reproducing our results, as well as for further analysis in detail.
|
LLaVA-Plus-Codebase/docs/llava/Windows.md
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Run LLaVA on Windows
|
| 2 |
+
|
| 3 |
+
*NOTE: LLaVA on Windows is not fully supported. Currently we only support 16-bit inference. For a more complete support, please use [WSL2](https://learn.microsoft.com/en-us/windows/wsl/install) for now. More functionalities on Windows is to be added soon, stay tuned.*
|
| 4 |
+
|
| 5 |
+
## Installation
|
| 6 |
+
|
| 7 |
+
1. Clone this repository and navigate to LLaVA folder
|
| 8 |
+
```bash
|
| 9 |
+
git clone https://github.com/haotian-liu/LLaVA.git
|
| 10 |
+
cd LLaVA
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
2. Install Package
|
| 14 |
+
```Shell
|
| 15 |
+
conda create -n llava python=3.10 -y
|
| 16 |
+
conda activate llava
|
| 17 |
+
python -mpip install --upgrade pip # enable PEP 660 support
|
| 18 |
+
pip install torch==2.0.1+cu117 torchvision==0.15.2+cu117 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu117
|
| 19 |
+
pip install -e .
|
| 20 |
+
pip uninstall bitsandbytes
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
## Run demo
|
| 24 |
+
|
| 25 |
+
See instructions [here](https://github.com/haotian-liu/LLaVA#demo).
|
| 26 |
+
|
| 27 |
+
Note that quantization (4-bit, 8-bit) is *NOT* supported on Windows. Stay tuned for the 4-bit support on Windows!
|
LLaVA-Plus-Codebase/docs/llava/macOS.md
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Run LLaVA on macOS
|
| 2 |
+
|
| 3 |
+
*NOTE: LLaVA on macOS is not fully supported. Currently we only support 16-bit inference. More functionalities on macOS is to be added soon, stay tuned.*
|
| 4 |
+
|
| 5 |
+
## Installation
|
| 6 |
+
|
| 7 |
+
1. Clone this repository and navigate to LLaVA folder
|
| 8 |
+
```bash
|
| 9 |
+
git clone https://github.com/haotian-liu/LLaVA.git
|
| 10 |
+
cd LLaVA
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
2. Install Package
|
| 14 |
+
```Shell
|
| 15 |
+
conda create -n llava python=3.10 -y
|
| 16 |
+
conda activate llava
|
| 17 |
+
python -mpip install --upgrade pip # enable PEP 660 support
|
| 18 |
+
pip install -e .
|
| 19 |
+
pip install torch==2.1.0 torchvision==0.16.0
|
| 20 |
+
pip uninstall bitsandbytes
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
## Run demo
|
| 24 |
+
|
| 25 |
+
Specify `--device mps` when launching model worker or CLI.
|
| 26 |
+
|
| 27 |
+
See instructions [here](https://github.com/haotian-liu/LLaVA#demo).
|
| 28 |
+
|
| 29 |
+
Note that quantization (4-bit, 8-bit) is *NOT* supported on macOS. Stay tuned for the 4-bit support on macOS!
|
LLaVA-Plus-Codebase/images/demo_cli.gif
ADDED

|
Git LFS Details
|
LLaVA-Plus-Codebase/images/llava-plus-arch.png
ADDED
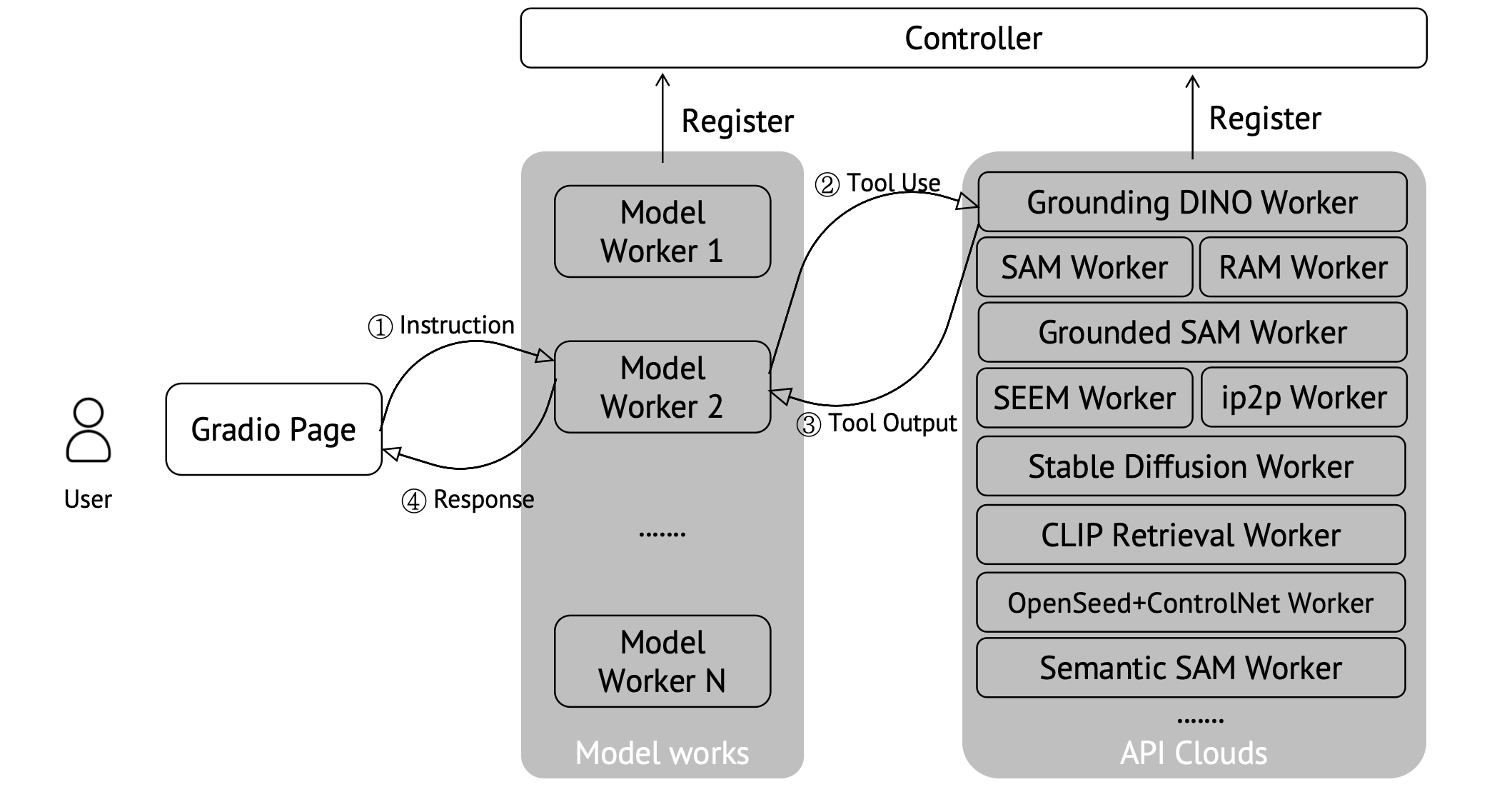
|
LLaVA-Plus-Codebase/images/llava_example_cmp.png
ADDED
|
LLaVA-Plus-Codebase/images/llava_logo.png
ADDED
|
|
LLaVA-Plus-Codebase/images/llava_v1_5_radar.jpg
ADDED
|
LLaVA-Plus-Codebase/llava/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .model import LlavaLlamaForCausalLM
|
LLaVA-Plus-Codebase/llava/constants.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
CONTROLLER_HEART_BEAT_EXPIRATION = 30
|
| 2 |
+
WORKER_HEART_BEAT_INTERVAL = 15
|
| 3 |
+
|
| 4 |
+
LOGDIR = "."
|
| 5 |
+
|
| 6 |
+
# Model Constants
|
| 7 |
+
IGNORE_INDEX = -100
|
| 8 |
+
IMAGE_TOKEN_INDEX = -200
|
| 9 |
+
DEFAULT_IMAGE_TOKEN = "<image>"
|
| 10 |
+
DEFAULT_IMAGE_PATCH_TOKEN = "<im_patch>"
|
| 11 |
+
DEFAULT_IM_START_TOKEN = "<im_start>"
|
| 12 |
+
DEFAULT_IM_END_TOKEN = "<im_end>"
|
| 13 |
+
IMAGE_PLACEHOLDER = "<image-placeholder>"
|
LLaVA-Plus-Codebase/llava/conversation.py
ADDED
|
@@ -0,0 +1,649 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import dataclasses
|
| 2 |
+
from enum import auto, Enum
|
| 3 |
+
import os
|
| 4 |
+
import re
|
| 5 |
+
from typing import List, Tuple
|
| 6 |
+
import torchvision.transforms.functional as F
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def parse_tool_output(text):
|
| 10 |
+
try:
|
| 11 |
+
pattern = r'"thoughts🤔"(.*)"actions🚀"(.*)"value👉"(.*)'
|
| 12 |
+
matches = re.findall(pattern, text, re.DOTALL)
|
| 13 |
+
assert len(matches) == 1, f"len(matches)={len(matches)}"
|
| 14 |
+
assert len(matches[0]) == 3, f"len(matches[0])={len(matches[0])}"
|
| 15 |
+
except Exception as e:
|
| 16 |
+
# print(e)
|
| 17 |
+
matches = None
|
| 18 |
+
return matches
|
| 19 |
+
return matches
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def make_it_small_html(text):
|
| 23 |
+
return f'<span style="font-size: 12px; color: gray;line-height: 1.0;">{text}</span>'
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def get_hr_html():
|
| 27 |
+
return f'<hr width="100%" size="1" color="silver" align="center">'
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def get_placehold(text):
|
| 31 |
+
if text[-1] == "▌":
|
| 32 |
+
text = text[:-1]
|
| 33 |
+
|
| 34 |
+
res = '"thinking'
|
| 35 |
+
timenow = len(text) % 21
|
| 36 |
+
num_point = timenow // 3
|
| 37 |
+
for i in range(num_point):
|
| 38 |
+
res += "."
|
| 39 |
+
res += '"'
|
| 40 |
+
return res
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def parse_msg(msg):
|
| 44 |
+
if len(msg) == 3:
|
| 45 |
+
return msg[0], msg[1], msg[2], None
|
| 46 |
+
if len(msg) == 4:
|
| 47 |
+
return msg[0], msg[1], msg[2], msg[3]
|
| 48 |
+
raise ValueError(f"Invalid msg with len {len(msg)}: {msg}")
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
class SeparatorStyle(Enum):
|
| 52 |
+
"""Different separator style."""
|
| 53 |
+
SINGLE = auto()
|
| 54 |
+
TWO = auto()
|
| 55 |
+
MPT = auto()
|
| 56 |
+
PLAIN = auto()
|
| 57 |
+
LLAMA_2 = auto()
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
@dataclasses.dataclass
|
| 61 |
+
class Conversation:
|
| 62 |
+
"""A class that keeps all conversation history."""
|
| 63 |
+
system: str
|
| 64 |
+
roles: List[str]
|
| 65 |
+
messages: List[List[str]]
|
| 66 |
+
offset: int
|
| 67 |
+
sep_style: SeparatorStyle = SeparatorStyle.SINGLE
|
| 68 |
+
sep: str = "###"
|
| 69 |
+
sep2: str = None
|
| 70 |
+
version: str = "Unknown"
|
| 71 |
+
|
| 72 |
+
skip_next: bool = False
|
| 73 |
+
|
| 74 |
+
def get_prompt(self):
|
| 75 |
+
messages = self.messages
|
| 76 |
+
if len(messages) > 0 and type(messages[0][1]) is tuple:
|
| 77 |
+
messages = self.messages.copy()
|
| 78 |
+
init_role, init_msg = messages[0].copy()
|
| 79 |
+
init_msg = init_msg[0].replace("<image>", "").strip()
|
| 80 |
+
if 'mmtag' in self.version:
|
| 81 |
+
messages[0] = (init_role, init_msg)
|
| 82 |
+
messages.insert(0, (self.roles[0], "<Image><image></Image>"))
|
| 83 |
+
messages.insert(1, (self.roles[1], "Received."))
|
| 84 |
+
else:
|
| 85 |
+
messages[0] = (init_role, "<image>\n" + init_msg)
|
| 86 |
+
|
| 87 |
+
if self.sep_style == SeparatorStyle.SINGLE:
|
| 88 |
+
ret = self.system + self.sep
|
| 89 |
+
for role, message in messages:
|
| 90 |
+
if message:
|
| 91 |
+
if type(message) is tuple:
|
| 92 |
+
message, _, _, _ = parse_msg(message)
|
| 93 |
+
ret += role + ": " + message + self.sep
|
| 94 |
+
else:
|
| 95 |
+
ret += role + ":"
|
| 96 |
+
elif self.sep_style == SeparatorStyle.TWO:
|
| 97 |
+
seps = [self.sep, self.sep2]
|
| 98 |
+
ret = self.system + seps[0]
|
| 99 |
+
for i, (role, message) in enumerate(messages):
|
| 100 |
+
if message:
|
| 101 |
+
if type(message) is tuple:
|
| 102 |
+
message, _, _, _ = parse_msg(message)
|
| 103 |
+
ret += role + ": " + message + seps[i % 2]
|
| 104 |
+
else:
|
| 105 |
+
ret += role + ":"
|
| 106 |
+
elif self.sep_style == SeparatorStyle.MPT:
|
| 107 |
+
ret = self.system + self.sep
|
| 108 |
+
for role, message in messages:
|
| 109 |
+
if message:
|
| 110 |
+
if type(message) is tuple:
|
| 111 |
+
message, _, _, _ = parse_msg(message)
|
| 112 |
+
ret += role + message + self.sep
|
| 113 |
+
else:
|
| 114 |
+
ret += role
|
| 115 |
+
elif self.sep_style == SeparatorStyle.LLAMA_2:
|
| 116 |
+
def wrap_sys(msg): return f"<<SYS>>\n{msg}\n<</SYS>>\n\n"
|
| 117 |
+
def wrap_inst(msg): return f"[INST] {msg} [/INST]"
|
| 118 |
+
ret = ""
|
| 119 |
+
|
| 120 |
+
for i, (role, message) in enumerate(messages):
|
| 121 |
+
if i == 0:
|
| 122 |
+
assert message, "first message should not be none"
|
| 123 |
+
assert role == self.roles[0], "first message should come from user"
|
| 124 |
+
if message:
|
| 125 |
+
if type(message) is tuple:
|
| 126 |
+
message, _, _, _ = parse_msg(message)
|
| 127 |
+
if i == 0:
|
| 128 |
+
message = wrap_sys(self.system) + message
|
| 129 |
+
if i % 2 == 0:
|
| 130 |
+
message = wrap_inst(message)
|
| 131 |
+
ret += self.sep + message
|
| 132 |
+
else:
|
| 133 |
+
ret += " " + message + " " + self.sep2
|
| 134 |
+
else:
|
| 135 |
+
ret += ""
|
| 136 |
+
ret = ret.lstrip(self.sep)
|
| 137 |
+
elif self.sep_style == SeparatorStyle.PLAIN:
|
| 138 |
+
seps = [self.sep, self.sep2]
|
| 139 |
+
ret = self.system
|
| 140 |
+
for i, (role, message) in enumerate(messages):
|
| 141 |
+
if message:
|
| 142 |
+
if type(message) is tuple:
|
| 143 |
+
message, _, _, _ = parse_msg(message)
|
| 144 |
+
ret += message + seps[i % 2]
|
| 145 |
+
else:
|
| 146 |
+
ret += ""
|
| 147 |
+
else:
|
| 148 |
+
raise ValueError(f"Invalid style: {self.sep_style}")
|
| 149 |
+
|
| 150 |
+
return ret
|
| 151 |
+
|
| 152 |
+
def append_message(self, role, message):
|
| 153 |
+
self.messages.append([role, message])
|
| 154 |
+
|
| 155 |
+
def get_images(self, return_pil=False):
|
| 156 |
+
images = []
|
| 157 |
+
for i, (role, msg) in enumerate(self.messages[self.offset:]):
|
| 158 |
+
if len(self.roles) > 2 and role == self.roles[2]:
|
| 159 |
+
continue
|
| 160 |
+
if role == self.roles[0]:
|
| 161 |
+
# if i % 2 == 0:
|
| 162 |
+
if type(msg) is tuple:
|
| 163 |
+
import base64
|
| 164 |
+
from io import BytesIO
|
| 165 |
+
from PIL import Image
|
| 166 |
+
# msg, image, image_process_mode = msg
|
| 167 |
+
msg, image, image_process_mode, sketch_mask = parse_msg(
|
| 168 |
+
msg)
|
| 169 |
+
if image_process_mode == "Pad":
|
| 170 |
+
def expand2square(pil_img, background_color=(122, 116, 104)):
|
| 171 |
+
width, height = pil_img.size
|
| 172 |
+
if width == height:
|
| 173 |
+
return pil_img
|
| 174 |
+
elif width > height:
|
| 175 |
+
result = Image.new(
|
| 176 |
+
pil_img.mode, (width, width), background_color)
|
| 177 |
+
result.paste(
|
| 178 |
+
pil_img, (0, (width - height) // 2))
|
| 179 |
+
return result
|
| 180 |
+
else:
|
| 181 |
+
result = Image.new(
|
| 182 |
+
pil_img.mode, (height, height), background_color)
|
| 183 |
+
result.paste(
|
| 184 |
+
pil_img, ((height - width) // 2, 0))
|
| 185 |
+
return result
|
| 186 |
+
image = expand2square(image)
|
| 187 |
+
elif image_process_mode in ["Default", "Crop"]:
|
| 188 |
+
pass
|
| 189 |
+
elif image_process_mode == "Resize":
|
| 190 |
+
image = image.resize((336, 336))
|
| 191 |
+
elif image_process_mode == "None":
|
| 192 |
+
pass
|
| 193 |
+
else:
|
| 194 |
+
raise ValueError(
|
| 195 |
+
f"Invalid image_process_mode: {image_process_mode}")
|
| 196 |
+
max_hw, min_hw = max(image.size), min(image.size)
|
| 197 |
+
aspect_ratio = max_hw / min_hw
|
| 198 |
+
max_len, min_len = 800, 400
|
| 199 |
+
shortest_edge = int(
|
| 200 |
+
min(max_len / aspect_ratio, min_len, min_hw))
|
| 201 |
+
longest_edge = int(shortest_edge * aspect_ratio)
|
| 202 |
+
W, H = image.size
|
| 203 |
+
if longest_edge != max(image.size):
|
| 204 |
+
if H > W:
|
| 205 |
+
H, W = longest_edge, shortest_edge
|
| 206 |
+
else:
|
| 207 |
+
H, W = shortest_edge, longest_edge
|
| 208 |
+
image = image.resize((W, H))
|
| 209 |
+
if return_pil:
|
| 210 |
+
images.append(image)
|
| 211 |
+
else:
|
| 212 |
+
buffered = BytesIO()
|
| 213 |
+
image.save(buffered, format="PNG")
|
| 214 |
+
img_b64_str = base64.b64encode(
|
| 215 |
+
buffered.getvalue()).decode()
|
| 216 |
+
images.append(img_b64_str)
|
| 217 |
+
return images
|
| 218 |
+
|
| 219 |
+
def get_raw_images(self, return_pil=False, image_process_mode=None):
|
| 220 |
+
images = []
|
| 221 |
+
for i, (role, msg) in enumerate(self.messages[self.offset:]):
|
| 222 |
+
if len(self.roles) > 2 and role == self.roles[2]:
|
| 223 |
+
continue
|
| 224 |
+
if role == self.roles[0]:
|
| 225 |
+
# if i % 2 == 0:
|
| 226 |
+
if type(msg) is tuple:
|
| 227 |
+
import base64
|
| 228 |
+
from io import BytesIO
|
| 229 |
+
from PIL import Image
|
| 230 |
+
msg, img, _, sketch_mask = parse_msg(msg)
|
| 231 |
+
|
| 232 |
+
# resize for large images
|
| 233 |
+
w, h = img.size
|
| 234 |
+
if max(h, w) > 800:
|
| 235 |
+
if h > w:
|
| 236 |
+
new_h = 800
|
| 237 |
+
new_w = int(w * 800 / h)
|
| 238 |
+
else:
|
| 239 |
+
new_w = 800
|
| 240 |
+
new_h = int(h * 800 / w)
|
| 241 |
+
# import ipdb; ipdb.set_trace()
|
| 242 |
+
img = F.resize(img, (new_h, new_w))
|
| 243 |
+
|
| 244 |
+
if return_pil:
|
| 245 |
+
images.append(img)
|
| 246 |
+
else:
|
| 247 |
+
buffered = BytesIO()
|
| 248 |
+
img.save(buffered, format="PNG")
|
| 249 |
+
img_b64_str = base64.b64encode(
|
| 250 |
+
buffered.getvalue()).decode()
|
| 251 |
+
images.append(img_b64_str)
|
| 252 |
+
return images
|
| 253 |
+
|
| 254 |
+
def tools_filter_msg(self, msg):
|
| 255 |
+
return msg
|
| 256 |
+
|
| 257 |
+
def merge_output(self, ret, with_debug_parameter=False):
|
| 258 |
+
# print(f'with_debug_parameter: {with_debug_parameter}')
|
| 259 |
+
assert isinstance(
|
| 260 |
+
ret, list), "ret should be a list, but got {}".format(type(ret))
|
| 261 |
+
|
| 262 |
+
ret_new = []
|
| 263 |
+
i = 0
|
| 264 |
+
while i < len(ret):
|
| 265 |
+
text: str = ret[i][0]
|
| 266 |
+
|
| 267 |
+
# # check if previous is "thinking.."
|
| 268 |
+
# if len(ret_new) > 0 and isinstance(ret_new[-1][0], str) and ret_new[-1][0].strip().replace('.', '') == '"thinking"':
|
| 269 |
+
# ret_new = ret_new[:-1]
|
| 270 |
+
|
| 271 |
+
# for some undisplayed message
|
| 272 |
+
if not isinstance(text, str):
|
| 273 |
+
ret_new.append(ret[i])
|
| 274 |
+
i += 1
|
| 275 |
+
continue
|
| 276 |
+
|
| 277 |
+
text = text.strip()
|
| 278 |
+
# for the case with image
|
| 279 |
+
if text.startswith('<img src="data:image/png;base64'):
|
| 280 |
+
if len(ret_new) > 0:
|
| 281 |
+
ret_new[-1] = [ret_new[-1][0] + '\n' + ret[i][0], None]
|
| 282 |
+
else:
|
| 283 |
+
ret_new.append(ret[i])
|
| 284 |
+
i += 1
|
| 285 |
+
continue
|
| 286 |
+
|
| 287 |
+
if text.startswith('"th'):
|
| 288 |
+
# for "thoughts🤔"
|
| 289 |
+
matches = parse_tool_output(text)
|
| 290 |
+
if matches is not None:
|
| 291 |
+
thought = matches[0][0]
|
| 292 |
+
action = matches[0][1]
|
| 293 |
+
value = matches[0][2]
|
| 294 |
+
|
| 295 |
+
action_json = eval(action)
|
| 296 |
+
# if len(action_json) > 0:
|
| 297 |
+
if (len(action_json) > 0):
|
| 298 |
+
# tool use branch
|
| 299 |
+
res_value = f'"thoughts🤔" {matches[0][0].strip()}\n' +\
|
| 300 |
+
f'"actions🚀" {matches[0][1].strip()}\n' \
|
| 301 |
+
+ f'"value👉" {matches[0][2].strip()}'
|
| 302 |
+
res_value = make_it_small_html(res_value)
|
| 303 |
+
|
| 304 |
+
# explore next
|
| 305 |
+
matches_next2 = None
|
| 306 |
+
if (i + 1 < len(ret)):
|
| 307 |
+
# get next message
|
| 308 |
+
text_next: str = ret[i +
|
| 309 |
+
1][0].strip().replace("\n\n", "\n")
|
| 310 |
+
if len(ret_new) > 0 and "model outputs:" in text_next:
|
| 311 |
+
# auged ques
|
| 312 |
+
text_next_html = make_it_small_html(text_next)
|
| 313 |
+
res_value = res_value + get_hr_html() + text_next_html
|
| 314 |
+
|
| 315 |
+
# explore next2
|
| 316 |
+
if i + 2 < len(ret):
|
| 317 |
+
text_next2: str = ret[i+2][0].strip()
|
| 318 |
+
# if text_next2.startswith('"th'):
|
| 319 |
+
matches_next2 = parse_tool_output(
|
| 320 |
+
text_next2)
|
| 321 |
+
|
| 322 |
+
if matches_next2 is not None:
|
| 323 |
+
text_next2_html = f'"thoughts🤔" {matches_next2[0][0].strip()}\n' + \
|
| 324 |
+
f'"actions🚀" {matches_next2[0][1].strip()}\n' + \
|
| 325 |
+
f'"value👉"'
|
| 326 |
+
text_next2_html = make_it_small_html(
|
| 327 |
+
text_next2_html)
|
| 328 |
+
res_value = res_value + get_hr_html() + text_next2_html
|
| 329 |
+
res_value = res_value + \
|
| 330 |
+
f'\n{matches_next2[0][2].strip()}'
|
| 331 |
+
i += 1
|
| 332 |
+
else:
|
| 333 |
+
res_value = res_value + get_hr_html() + make_it_small_html(text_next2)
|
| 334 |
+
i += 1
|
| 335 |
+
i += 1
|
| 336 |
+
|
| 337 |
+
# post process for no debug parameters
|
| 338 |
+
if not with_debug_parameter:
|
| 339 |
+
if matches_next2 is not None:
|
| 340 |
+
res_value = matches_next2[0][2].strip()
|
| 341 |
+
else:
|
| 342 |
+
res_value = get_placehold(res_value)
|
| 343 |
+
|
| 344 |
+
# add to ret_new
|
| 345 |
+
ret_new.append([res_value, None])
|
| 346 |
+
else:
|
| 347 |
+
# regular conv branch
|
| 348 |
+
if with_debug_parameter:
|
| 349 |
+
res_value = f'"thoughts🤔" {matches[0][0].strip()}\n' +\
|
| 350 |
+
f'"actions🚀" {matches[0][1].strip()}\n' \
|
| 351 |
+
+ f'"value👉"\n'
|
| 352 |
+
res_value = make_it_small_html(res_value)
|
| 353 |
+
res_value = res_value + f'{matches[0][2].strip()}'
|
| 354 |
+
else:
|
| 355 |
+
res_value = f'{matches[0][2].strip()}'
|
| 356 |
+
|
| 357 |
+
ret_new.append([res_value, None])
|
| 358 |
+
else:
|
| 359 |
+
if with_debug_parameter:
|
| 360 |
+
ret_new.append(ret[i])
|
| 361 |
+
else:
|
| 362 |
+
ret_new.append([
|
| 363 |
+
get_placehold(ret[i][0].strip()),
|
| 364 |
+
None
|
| 365 |
+
])
|
| 366 |
+
else:
|
| 367 |
+
ret_new.append(ret[i])
|
| 368 |
+
i += 1
|
| 369 |
+
|
| 370 |
+
return ret_new
|
| 371 |
+
|
| 372 |
+
def image_to_url(self, image):
|
| 373 |
+
import base64
|
| 374 |
+
from io import BytesIO
|
| 375 |
+
max_hw, min_hw = max(image.size), min(image.size)
|
| 376 |
+
aspect_ratio = max_hw / min_hw
|
| 377 |
+
max_len, min_len = 800, 400
|
| 378 |
+
shortest_edge = int(min(max_len / aspect_ratio, min_len, min_hw))
|
| 379 |
+
longest_edge = int(shortest_edge * aspect_ratio)
|
| 380 |
+
W, H = image.size
|
| 381 |
+
if H > W:
|
| 382 |
+
H, W = longest_edge, shortest_edge
|
| 383 |
+
else:
|
| 384 |
+
H, W = shortest_edge, longest_edge
|
| 385 |
+
image = image.resize((W, H))
|
| 386 |
+
buffered = BytesIO()
|
| 387 |
+
image.save(buffered, format="JPEG")
|
| 388 |
+
img_b64_str = base64.b64encode(buffered.getvalue()).decode()
|
| 389 |
+
img_str = f'<img src="data:image/png;base64,{img_b64_str}" alt="user upload image" />'
|
| 390 |
+
return img_str
|
| 391 |
+
|
| 392 |
+
def to_gradio_chatbot(self, with_debug_parameter=False):
|
| 393 |
+
ret = []
|
| 394 |
+
for i, (role, msg) in enumerate(self.messages[self.offset:]):
|
| 395 |
+
# if i % 2 == 0:
|
| 396 |
+
if len(self.roles) > 2 and role == self.roles[2]:
|
| 397 |
+
continue
|
| 398 |
+
# if role == self.roles[0]:
|
| 399 |
+
if 1:
|
| 400 |
+
if type(msg) is tuple:
|
| 401 |
+
import base64
|
| 402 |
+
from io import BytesIO
|
| 403 |
+
# msg, image, image_process_mode = msg
|
| 404 |
+
msg, image, image_process_mode, sketch_mask = parse_msg(
|
| 405 |
+
msg)
|
| 406 |
+
if not isinstance(image, list):
|
| 407 |
+
img_str = self.image_to_url(image)
|
| 408 |
+
if i == 0:
|
| 409 |
+
ret.append([img_str, None])
|
| 410 |
+
msg = msg.replace('<image>', '').strip()
|
| 411 |
+
if role == self.roles[1]:
|
| 412 |
+
msg = self.tools_filter_msg(msg)
|
| 413 |
+
if len(msg) > 0:
|
| 414 |
+
ret.append([msg, None])
|
| 415 |
+
if i != 0:
|
| 416 |
+
ret.append([img_str, None])
|
| 417 |
+
else:
|
| 418 |
+
# a list of image
|
| 419 |
+
if role == self.roles[1]:
|
| 420 |
+
msg = self.tools_filter_msg(msg)
|
| 421 |
+
msg = msg.replace('<image>', '').strip()
|
| 422 |
+
if len(msg) > 0:
|
| 423 |
+
ret.append([msg, None])
|
| 424 |
+
for j, img in enumerate(image):
|
| 425 |
+
img_str = self.image_to_url(img)
|
| 426 |
+
ret.append([img_str, None])
|
| 427 |
+
else:
|
| 428 |
+
if role == self.roles[1]:
|
| 429 |
+
msg = self.tools_filter_msg(msg)
|
| 430 |
+
ret.append([msg, None])
|
| 431 |
+
else:
|
| 432 |
+
ret[-1][-1] = msg
|
| 433 |
+
|
| 434 |
+
ret = self.merge_output(ret, with_debug_parameter=with_debug_parameter)
|
| 435 |
+
return ret
|
| 436 |
+
|
| 437 |
+
def copy(self):
|
| 438 |
+
return Conversation(
|
| 439 |
+
system=self.system,
|
| 440 |
+
roles=self.roles,
|
| 441 |
+
messages=[[x, y] for x, y in self.messages],
|
| 442 |
+
offset=self.offset,
|
| 443 |
+
sep_style=self.sep_style,
|
| 444 |
+
sep=self.sep,
|
| 445 |
+
sep2=self.sep2,
|
| 446 |
+
version=self.version)
|
| 447 |
+
|
| 448 |
+
def dict(self, force_str=False):
|
| 449 |
+
def remove_pil(x, force_str):
|
| 450 |
+
if not force_str:
|
| 451 |
+
return x
|
| 452 |
+
|
| 453 |
+
if isinstance(x, Image.Image):
|
| 454 |
+
return b64_encode(x)
|
| 455 |
+
|
| 456 |
+
if isinstance(x, list):
|
| 457 |
+
return [remove_pil(y, force_str) for y in x]
|
| 458 |
+
if isinstance(x, tuple):
|
| 459 |
+
return [remove_pil(y, force_str) for y in x]
|
| 460 |
+
if isinstance(x, dict):
|
| 461 |
+
return {k: remove_pil(v, force_str) for k, v in x.items()}
|
| 462 |
+
|
| 463 |
+
return x
|
| 464 |
+
|
| 465 |
+
if len(self.get_images()) > 0:
|
| 466 |
+
return {
|
| 467 |
+
"system": self.system,
|
| 468 |
+
"roles": self.roles,
|
| 469 |
+
"messages": [[x, remove_pil(y[0], force_str=force_str) if type(y) is tuple else y] for x, y in self.messages],
|
| 470 |
+
"offset": self.offset,
|
| 471 |
+
"sep": self.sep,
|
| 472 |
+
"sep2": self.sep2,
|
| 473 |
+
}
|
| 474 |
+
return {
|
| 475 |
+
"system": self.system,
|
| 476 |
+
"roles": self.roles,
|
| 477 |
+
"messages": remove_pil(self.messages, force_str=force_str),
|
| 478 |
+
"offset": self.offset,
|
| 479 |
+
"sep": self.sep,
|
| 480 |
+
"sep2": self.sep2,
|
| 481 |
+
}
|
| 482 |
+
|
| 483 |
+
|
| 484 |
+
conv_vicuna_v0 = Conversation(
|
| 485 |
+
system="A chat between a curious human and an artificial intelligence assistant. "
|
| 486 |
+
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
| 487 |
+
roles=("Human", "Assistant"),
|
| 488 |
+
messages=(
|
| 489 |
+
("Human", "What are the key differences between renewable and non-renewable energy sources?"),
|
| 490 |
+
("Assistant",
|
| 491 |
+
"Renewable energy sources are those that can be replenished naturally in a relatively "
|
| 492 |
+
"short amount of time, such as solar, wind, hydro, geothermal, and biomass. "
|
| 493 |
+
"Non-renewable energy sources, on the other hand, are finite and will eventually be "
|
| 494 |
+
"depleted, such as coal, oil, and natural gas. Here are some key differences between "
|
| 495 |
+
"renewable and non-renewable energy sources:\n"
|
| 496 |
+
"1. Availability: Renewable energy sources are virtually inexhaustible, while non-renewable "
|
| 497 |
+
"energy sources are finite and will eventually run out.\n"
|
| 498 |
+
"2. Environmental impact: Renewable energy sources have a much lower environmental impact "
|
| 499 |
+
"than non-renewable sources, which can lead to air and water pollution, greenhouse gas emissions, "
|
| 500 |
+
"and other negative effects.\n"
|
| 501 |
+
"3. Cost: Renewable energy sources can be more expensive to initially set up, but they typically "
|
| 502 |
+
"have lower operational costs than non-renewable sources.\n"
|
| 503 |
+
"4. Reliability: Renewable energy sources are often more reliable and can be used in more remote "
|
| 504 |
+
"locations than non-renewable sources.\n"
|
| 505 |
+
"5. Flexibility: Renewable energy sources are often more flexible and can be adapted to different "
|
| 506 |
+
"situations and needs, while non-renewable sources are more rigid and inflexible.\n"
|
| 507 |
+
"6. Sustainability: Renewable energy sources are more sustainable over the long term, while "
|
| 508 |
+
"non-renewable sources are not, and their depletion can lead to economic and social instability.\n")
|
| 509 |
+
),
|
| 510 |
+
offset=2,
|
| 511 |
+
sep_style=SeparatorStyle.SINGLE,
|
| 512 |
+
sep="###",
|
| 513 |
+
)
|
| 514 |
+
|
| 515 |
+
conv_vicuna_v1 = Conversation(
|
| 516 |
+
system="A chat between a curious user and an artificial intelligence assistant. "
|
| 517 |
+
"The assistant gives helpful, detailed, and polite answers to the user's questions.",
|
| 518 |
+
roles=("USER", "ASSISTANT"),
|
| 519 |
+
version="v1",
|
| 520 |
+
messages=(),
|
| 521 |
+
offset=0,
|
| 522 |
+
sep_style=SeparatorStyle.TWO,
|
| 523 |
+
sep=" ",
|
| 524 |
+
sep2="</s>",
|
| 525 |
+
)
|
| 526 |
+
|
| 527 |
+
conv_llama_2 = Conversation(
|
| 528 |
+
system="""You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
|
| 529 |
+
|
| 530 |
+
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.""",
|
| 531 |
+
roles=("USER", "ASSISTANT"),
|
| 532 |
+
version="llama_v2",
|
| 533 |
+
messages=(),
|
| 534 |
+
offset=0,
|
| 535 |
+
sep_style=SeparatorStyle.LLAMA_2,
|
| 536 |
+
sep="<s>",
|
| 537 |
+
sep2="</s>",
|
| 538 |
+
)
|
| 539 |
+
|
| 540 |
+
conv_llava_llama_2 = Conversation(
|
| 541 |
+
system="You are a helpful language and vision assistant. "
|
| 542 |
+
"You are able to understand the visual content that the user provides, "
|
| 543 |
+
"and assist the user with a variety of tasks using natural language.",
|
| 544 |
+
roles=("USER", "ASSISTANT"),
|
| 545 |
+
version="llama_v2",
|
| 546 |
+
messages=(),
|
| 547 |
+
offset=0,
|
| 548 |
+
sep_style=SeparatorStyle.LLAMA_2,
|
| 549 |
+
sep="<s>",
|
| 550 |
+
sep2="</s>",
|
| 551 |
+
)
|
| 552 |
+
|
| 553 |
+
conv_mpt = Conversation(
|
| 554 |
+
system="""<|im_start|>system
|
| 555 |
+
A conversation between a user and an LLM-based AI assistant. The assistant gives helpful and honest answers.""",
|
| 556 |
+
roles=("<|im_start|>user\n", "<|im_start|>assistant\n"),
|
| 557 |
+
version="mpt",
|
| 558 |
+
messages=(),
|
| 559 |
+
offset=0,
|
| 560 |
+
sep_style=SeparatorStyle.MPT,
|
| 561 |
+
sep="<|im_end|>",
|
| 562 |
+
)
|
| 563 |
+
|
| 564 |
+
conv_llava_plain = Conversation(
|
| 565 |
+
system="",
|
| 566 |
+
roles=("", ""),
|
| 567 |
+
messages=(
|
| 568 |
+
),
|
| 569 |
+
offset=0,
|
| 570 |
+
sep_style=SeparatorStyle.PLAIN,
|
| 571 |
+
sep="\n",
|
| 572 |
+
)
|
| 573 |
+
|
| 574 |
+
conv_llava_v0 = Conversation(
|
| 575 |
+
system="A chat between a curious human and an artificial intelligence assistant. "
|
| 576 |
+
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
| 577 |
+
roles=("Human", "Assistant"),
|
| 578 |
+
messages=(
|
| 579 |
+
),
|
| 580 |
+
offset=0,
|
| 581 |
+
sep_style=SeparatorStyle.SINGLE,
|
| 582 |
+
sep="###",
|
| 583 |
+
)
|
| 584 |
+
|
| 585 |
+
conv_llava_v0_mmtag = Conversation(
|
| 586 |
+
system="A chat between a curious user and an artificial intelligence assistant. "
|
| 587 |
+
"The assistant is able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language."
|
| 588 |
+
"The visual content will be provided with the following format: <Image>visual content</Image>.",
|
| 589 |
+
roles=("Human", "Assistant"),
|
| 590 |
+
messages=(
|
| 591 |
+
),
|
| 592 |
+
offset=0,
|
| 593 |
+
sep_style=SeparatorStyle.SINGLE,
|
| 594 |
+
sep="###",
|
| 595 |
+
version="v0_mmtag",
|
| 596 |
+
)
|
| 597 |
+
|
| 598 |
+
conv_llava_v1 = Conversation(
|
| 599 |
+
system="A chat between a curious human and an artificial intelligence assistant. "
|
| 600 |
+
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
| 601 |
+
roles=("USER", "ASSISTANT"),
|
| 602 |
+
version="v1",
|
| 603 |
+
messages=(),
|
| 604 |
+
offset=0,
|
| 605 |
+
sep_style=SeparatorStyle.TWO,
|
| 606 |
+
sep=" ",
|
| 607 |
+
sep2="</s>",
|
| 608 |
+
)
|
| 609 |
+
|
| 610 |
+
conv_llava_v1_mmtag = Conversation(
|
| 611 |
+
system="A chat between a curious user and an artificial intelligence assistant. "
|
| 612 |
+
"The assistant is able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language."
|
| 613 |
+
"The visual content will be provided with the following format: <Image>visual content</Image>.",
|
| 614 |
+
roles=("USER", "ASSISTANT"),
|
| 615 |
+
messages=(),
|
| 616 |
+
offset=0,
|
| 617 |
+
sep_style=SeparatorStyle.TWO,
|
| 618 |
+
sep=" ",
|
| 619 |
+
sep2="</s>",
|
| 620 |
+
version="v1_mmtag",
|
| 621 |
+
)
|
| 622 |
+
|
| 623 |
+
# enable this to use a different default conversation by setting the LLAVA_DEFAULT_CONVERSATION environment variable
|
| 624 |
+
default_conversation_name = os.getenv(
|
| 625 |
+
"LLAVA_DEFAULT_CONVERSATION", "conv_vicuna_v1")
|
| 626 |
+
default_conversation = globals()[default_conversation_name]
|
| 627 |
+
print(f"Using conversation: {default_conversation_name}")
|
| 628 |
+
|
| 629 |
+
conv_templates = {
|
| 630 |
+
"default": conv_vicuna_v0,
|
| 631 |
+
"v0": conv_vicuna_v0,
|
| 632 |
+
"v1": conv_vicuna_v1,
|
| 633 |
+
"vicuna_v1": conv_vicuna_v1,
|
| 634 |
+
"llama_2": conv_llama_2,
|
| 635 |
+
|
| 636 |
+
"plain": conv_llava_plain,
|
| 637 |
+
"v0_plain": conv_llava_plain,
|
| 638 |
+
"llava_v0": conv_llava_v0,
|
| 639 |
+
"v0_mmtag": conv_llava_v0_mmtag,
|
| 640 |
+
"llava_v1": conv_llava_v1,
|
| 641 |
+
"v1_mmtag": conv_llava_v1_mmtag,
|
| 642 |
+
"llava_llama_2": conv_llava_llama_2,
|
| 643 |
+
|
| 644 |
+
"mpt": conv_mpt,
|
| 645 |
+
}
|
| 646 |
+
|
| 647 |
+
|
| 648 |
+
if __name__ == "__main__":
|
| 649 |
+
print(default_conversation.get_prompt())
|
LLaVA-Plus-Codebase/llava/eval/eval_gpt_review.py
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
import openai
|
| 6 |
+
import tqdm
|
| 7 |
+
import ray
|
| 8 |
+
import time
|
| 9 |
+
|
| 10 |
+
NUM_SECONDS_TO_SLEEP = 3
|
| 11 |
+
|
| 12 |
+
@ray.remote(num_cpus=4)
|
| 13 |
+
def get_eval(content: str, max_tokens: int):
|
| 14 |
+
while True:
|
| 15 |
+
try:
|
| 16 |
+
response = openai.ChatCompletion.create(
|
| 17 |
+
model='gpt-4',
|
| 18 |
+
messages=[{
|
| 19 |
+
'role': 'system',
|
| 20 |
+
'content': 'You are a helpful and precise assistant for checking the quality of the answer.'
|
| 21 |
+
}, {
|
| 22 |
+
'role': 'user',
|
| 23 |
+
'content': content,
|
| 24 |
+
}],
|
| 25 |
+
temperature=0.2, # TODO: figure out which temperature is best for evaluation
|
| 26 |
+
max_tokens=max_tokens,
|
| 27 |
+
)
|
| 28 |
+
break
|
| 29 |
+
except openai.error.RateLimitError:
|
| 30 |
+
pass
|
| 31 |
+
except Exception as e:
|
| 32 |
+
print(e)
|
| 33 |
+
time.sleep(NUM_SECONDS_TO_SLEEP)
|
| 34 |
+
|
| 35 |
+
print('success!')
|
| 36 |
+
return response['choices'][0]['message']['content']
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def parse_score(review):
|
| 40 |
+
try:
|
| 41 |
+
score_pair = review.split('\n')[0]
|
| 42 |
+
score_pair = score_pair.replace(',', ' ')
|
| 43 |
+
sp = score_pair.split(' ')
|
| 44 |
+
if len(sp) == 2:
|
| 45 |
+
return [float(sp[0]), float(sp[1])]
|
| 46 |
+
else:
|
| 47 |
+
print('error', review)
|
| 48 |
+
return [-1, -1]
|
| 49 |
+
except Exception as e:
|
| 50 |
+
print(e)
|
| 51 |
+
print('error', review)
|
| 52 |
+
return [-1, -1]
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
if __name__ == '__main__':
|
| 56 |
+
parser = argparse.ArgumentParser(description='ChatGPT-based QA evaluation.')
|
| 57 |
+
parser.add_argument('-q', '--question')
|
| 58 |
+
# parser.add_argument('-a', '--answer')
|
| 59 |
+
parser.add_argument('-a', '--answer-list', nargs='+', default=[])
|
| 60 |
+
parser.add_argument('-r', '--rule')
|
| 61 |
+
parser.add_argument('-o', '--output')
|
| 62 |
+
parser.add_argument('--max-tokens', type=int, default=1024, help='maximum number of tokens produced in the output')
|
| 63 |
+
args = parser.parse_args()
|
| 64 |
+
|
| 65 |
+
ray.init()
|
| 66 |
+
|
| 67 |
+
f_q = open(os.path.expanduser(args.question))
|
| 68 |
+
f_ans1 = open(os.path.expanduser(args.answer_list[0]))
|
| 69 |
+
f_ans2 = open(os.path.expanduser(args.answer_list[1]))
|
| 70 |
+
rule_dict = json.load(open(os.path.expanduser(args.rule), 'r'))
|
| 71 |
+
|
| 72 |
+
review_file = open(f'{args.output}', 'w')
|
| 73 |
+
|
| 74 |
+
js_list = []
|
| 75 |
+
handles = []
|
| 76 |
+
idx = 0
|
| 77 |
+
for ques_js, ans1_js, ans2_js in zip(f_q, f_ans1, f_ans2):
|
| 78 |
+
# if idx == 1:
|
| 79 |
+
# break
|
| 80 |
+
|
| 81 |
+
ques = json.loads(ques_js)
|
| 82 |
+
ans1 = json.loads(ans1_js)
|
| 83 |
+
ans2 = json.loads(ans2_js)
|
| 84 |
+
|
| 85 |
+
category = json.loads(ques_js)['category']
|
| 86 |
+
if category in rule_dict:
|
| 87 |
+
rule = rule_dict[category]
|
| 88 |
+
else:
|
| 89 |
+
rule = rule_dict['default']
|
| 90 |
+
prompt = rule['prompt']
|
| 91 |
+
role = rule['role']
|
| 92 |
+
content = (f'[Question]\n{ques["text"]}\n\n'
|
| 93 |
+
f'[{role} 1]\n{ans1["text"]}\n\n[End of {role} 1]\n\n'
|
| 94 |
+
f'[{role} 2]\n{ans2["text"]}\n\n[End of {role} 2]\n\n'
|
| 95 |
+
f'[System]\n{prompt}\n\n')
|
| 96 |
+
js_list.append({
|
| 97 |
+
'id': idx+1,
|
| 98 |
+
'question_id': ques['question_id'],
|
| 99 |
+
'answer1_id': ans1['answer_id'],
|
| 100 |
+
'answer2_id': ans2['answer_id'],
|
| 101 |
+
'category': category})
|
| 102 |
+
idx += 1
|
| 103 |
+
handles.append(get_eval.remote(content, args.max_tokens))
|
| 104 |
+
# To avoid the rate limit set by OpenAI
|
| 105 |
+
time.sleep(NUM_SECONDS_TO_SLEEP)
|
| 106 |
+
|
| 107 |
+
reviews = ray.get(handles)
|
| 108 |
+
for idx, review in enumerate(reviews):
|
| 109 |
+
scores = parse_score(review)
|
| 110 |
+
js_list[idx]['content'] = review
|
| 111 |
+
js_list[idx]['tuple'] = scores
|
| 112 |
+
review_file.write(json.dumps(js_list[idx]) + '\n')
|
| 113 |
+
review_file.close()
|
LLaVA-Plus-Codebase/llava/eval/eval_gpt_review_bench.py
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
import openai
|
| 6 |
+
import time
|
| 7 |
+
|
| 8 |
+
NUM_SECONDS_TO_SLEEP = 0.5
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def get_eval(content: str, max_tokens: int):
|
| 12 |
+
while True:
|
| 13 |
+
try:
|
| 14 |
+
response = openai.ChatCompletion.create(
|
| 15 |
+
model='gpt-4-0314',
|
| 16 |
+
messages=[{
|
| 17 |
+
'role': 'system',
|
| 18 |
+
'content': 'You are a helpful and precise assistant for checking the quality of the answer.'
|
| 19 |
+
}, {
|
| 20 |
+
'role': 'user',
|
| 21 |
+
'content': content,
|
| 22 |
+
}],
|
| 23 |
+
temperature=0.2, # TODO: figure out which temperature is best for evaluation
|
| 24 |
+
max_tokens=max_tokens,
|
| 25 |
+
)
|
| 26 |
+
break
|
| 27 |
+
except openai.error.RateLimitError:
|
| 28 |
+
pass
|
| 29 |
+
except Exception as e:
|
| 30 |
+
print(e)
|
| 31 |
+
time.sleep(NUM_SECONDS_TO_SLEEP)
|
| 32 |
+
|
| 33 |
+
return response['choices'][0]['message']['content']
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def parse_score(review):
|
| 37 |
+
try:
|
| 38 |
+
score_pair = review.split('\n')[0]
|
| 39 |
+
score_pair = score_pair.replace(',', ' ')
|
| 40 |
+
sp = score_pair.split(' ')
|
| 41 |
+
if len(sp) == 2:
|
| 42 |
+
return [float(sp[0]), float(sp[1])]
|
| 43 |
+
else:
|
| 44 |
+
print('error', review)
|
| 45 |
+
return [-1, -1]
|
| 46 |
+
except Exception as e:
|
| 47 |
+
print(e)
|
| 48 |
+
print('error', review)
|
| 49 |
+
return [-1, -1]
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
if __name__ == '__main__':
|
| 53 |
+
parser = argparse.ArgumentParser(description='ChatGPT-based QA evaluation.')
|
| 54 |
+
parser.add_argument('-q', '--question')
|
| 55 |
+
parser.add_argument('-c', '--context')
|
| 56 |
+
parser.add_argument('-a', '--answer-list', nargs='+', default=[])
|
| 57 |
+
parser.add_argument('-r', '--rule')
|
| 58 |
+
parser.add_argument('-o', '--output')
|
| 59 |
+
parser.add_argument('--max-tokens', type=int, default=1024, help='maximum number of tokens produced in the output')
|
| 60 |
+
args = parser.parse_args()
|
| 61 |
+
|
| 62 |
+
f_q = open(os.path.expanduser(args.question))
|
| 63 |
+
f_ans1 = open(os.path.expanduser(args.answer_list[0]))
|
| 64 |
+
f_ans2 = open(os.path.expanduser(args.answer_list[1]))
|
| 65 |
+
rule_dict = json.load(open(os.path.expanduser(args.rule), 'r'))
|
| 66 |
+
|
| 67 |
+
if os.path.isfile(os.path.expanduser(args.output)):
|
| 68 |
+
cur_reviews = [json.loads(line) for line in open(os.path.expanduser(args.output))]
|
| 69 |
+
else:
|
| 70 |
+
cur_reviews = []
|
| 71 |
+
|
| 72 |
+
review_file = open(f'{args.output}', 'a')
|
| 73 |
+
|
| 74 |
+
context_list = [json.loads(line) for line in open(os.path.expanduser(args.context))]
|
| 75 |
+
image_to_context = {context['image']: context for context in context_list}
|
| 76 |
+
|
| 77 |
+
handles = []
|
| 78 |
+
idx = 0
|
| 79 |
+
for ques_js, ans1_js, ans2_js in zip(f_q, f_ans1, f_ans2):
|
| 80 |
+
ques = json.loads(ques_js)
|
| 81 |
+
ans1 = json.loads(ans1_js)
|
| 82 |
+
ans2 = json.loads(ans2_js)
|
| 83 |
+
|
| 84 |
+
inst = image_to_context[ques['image']]
|
| 85 |
+
|
| 86 |
+
if isinstance(inst['caption'], list):
|
| 87 |
+
cap_str = '\n'.join(inst['caption'])
|
| 88 |
+
else:
|
| 89 |
+
cap_str = inst['caption']
|
| 90 |
+
|
| 91 |
+
category = 'llava_bench_' + json.loads(ques_js)['category']
|
| 92 |
+
if category in rule_dict:
|
| 93 |
+
rule = rule_dict[category]
|
| 94 |
+
else:
|
| 95 |
+
assert False, f"Visual QA category not found in rule file: {category}."
|
| 96 |
+
prompt = rule['prompt']
|
| 97 |
+
role = rule['role']
|
| 98 |
+
content = (f'[Context]\n{cap_str}\n\n'
|
| 99 |
+
f'[Question]\n{ques["text"]}\n\n'
|
| 100 |
+
f'[{role} 1]\n{ans1["text"]}\n\n[End of {role} 1]\n\n'
|
| 101 |
+
f'[{role} 2]\n{ans2["text"]}\n\n[End of {role} 2]\n\n'
|
| 102 |
+
f'[System]\n{prompt}\n\n')
|
| 103 |
+
cur_js = {
|
| 104 |
+
'id': idx+1,
|
| 105 |
+
'question_id': ques['question_id'],
|
| 106 |
+
'answer1_id': ans1.get('answer_id', ans1['question_id']),
|
| 107 |
+
'answer2_id': ans2.get('answer_id', ans2['answer_id']),
|
| 108 |
+
'category': category
|
| 109 |
+
}
|
| 110 |
+
if idx >= len(cur_reviews):
|
| 111 |
+
review = get_eval(content, args.max_tokens)
|
| 112 |
+
scores = parse_score(review)
|
| 113 |
+
cur_js['content'] = review
|
| 114 |
+
cur_js['tuple'] = scores
|
| 115 |
+
review_file.write(json.dumps(cur_js) + '\n')
|
| 116 |
+
review_file.flush()
|
| 117 |
+
else:
|
| 118 |
+
print(f'Skipping {idx} as we already have it.')
|
| 119 |
+
idx += 1
|
| 120 |
+
print(idx)
|
| 121 |
+
review_file.close()
|
LLaVA-Plus-Codebase/llava/eval/eval_gpt_review_visual.py
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
import openai
|
| 6 |
+
import time
|
| 7 |
+
|
| 8 |
+
NUM_SECONDS_TO_SLEEP = 0.5
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def get_eval(content: str, max_tokens: int):
|
| 12 |
+
while True:
|
| 13 |
+
try:
|
| 14 |
+
response = openai.ChatCompletion.create(
|
| 15 |
+
model='gpt-4-0314',
|
| 16 |
+
messages=[{
|
| 17 |
+
'role': 'system',
|
| 18 |
+
'content': 'You are a helpful and precise assistant for checking the quality of the answer.'
|
| 19 |
+
}, {
|
| 20 |
+
'role': 'user',
|
| 21 |
+
'content': content,
|
| 22 |
+
}],
|
| 23 |
+
temperature=0.2, # TODO: figure out which temperature is best for evaluation
|
| 24 |
+
max_tokens=max_tokens,
|
| 25 |
+
)
|
| 26 |
+
break
|
| 27 |
+
except openai.error.RateLimitError:
|
| 28 |
+
pass
|
| 29 |
+
except Exception as e:
|
| 30 |
+
print(e)
|
| 31 |
+
time.sleep(NUM_SECONDS_TO_SLEEP)
|
| 32 |
+
|
| 33 |
+
return response['choices'][0]['message']['content']
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def parse_score(review):
|
| 37 |
+
try:
|
| 38 |
+
score_pair = review.split('\n')[0]
|
| 39 |
+
score_pair = score_pair.replace(',', ' ')
|
| 40 |
+
sp = score_pair.split(' ')
|
| 41 |
+
if len(sp) == 2:
|
| 42 |
+
return [float(sp[0]), float(sp[1])]
|
| 43 |
+
else:
|
| 44 |
+
print('error', review)
|
| 45 |
+
return [-1, -1]
|
| 46 |
+
except Exception as e:
|
| 47 |
+
print(e)
|
| 48 |
+
print('error', review)
|
| 49 |
+
return [-1, -1]
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
if __name__ == '__main__':
|
| 53 |
+
parser = argparse.ArgumentParser(description='ChatGPT-based QA evaluation.')
|
| 54 |
+
parser.add_argument('-q', '--question')
|
| 55 |
+
parser.add_argument('-c', '--context')
|
| 56 |
+
parser.add_argument('-a', '--answer-list', nargs='+', default=[])
|
| 57 |
+
parser.add_argument('-r', '--rule')
|
| 58 |
+
parser.add_argument('-o', '--output')
|
| 59 |
+
parser.add_argument('--max-tokens', type=int, default=1024, help='maximum number of tokens produced in the output')
|
| 60 |
+
args = parser.parse_args()
|
| 61 |
+
|
| 62 |
+
f_q = open(os.path.expanduser(args.question))
|
| 63 |
+
f_ans1 = open(os.path.expanduser(args.answer_list[0]))
|
| 64 |
+
f_ans2 = open(os.path.expanduser(args.answer_list[1]))
|
| 65 |
+
rule_dict = json.load(open(os.path.expanduser(args.rule), 'r'))
|
| 66 |
+
|
| 67 |
+
if os.path.isfile(os.path.expanduser(args.output)):
|
| 68 |
+
cur_reviews = [json.loads(line) for line in open(os.path.expanduser(args.output))]
|
| 69 |
+
else:
|
| 70 |
+
cur_reviews = []
|
| 71 |
+
|
| 72 |
+
review_file = open(f'{args.output}', 'a')
|
| 73 |
+
|
| 74 |
+
context_list = [json.loads(line) for line in open(os.path.expanduser(args.context))]
|
| 75 |
+
image_to_context = {context['image']: context for context in context_list}
|
| 76 |
+
|
| 77 |
+
handles = []
|
| 78 |
+
idx = 0
|
| 79 |
+
for ques_js, ans1_js, ans2_js in zip(f_q, f_ans1, f_ans2):
|
| 80 |
+
ques = json.loads(ques_js)
|
| 81 |
+
ans1 = json.loads(ans1_js)
|
| 82 |
+
ans2 = json.loads(ans2_js)
|
| 83 |
+
|
| 84 |
+
inst = image_to_context[ques['image']]
|
| 85 |
+
cap_str = '\n'.join(inst['captions'])
|
| 86 |
+
box_str = '\n'.join([f'{instance["category"]}: {instance["bbox"]}' for instance in inst['instances']])
|
| 87 |
+
|
| 88 |
+
category = json.loads(ques_js)['category']
|
| 89 |
+
if category in rule_dict:
|
| 90 |
+
rule = rule_dict[category]
|
| 91 |
+
else:
|
| 92 |
+
assert False, f"Visual QA category not found in rule file: {category}."
|
| 93 |
+
prompt = rule['prompt']
|
| 94 |
+
role = rule['role']
|
| 95 |
+
content = (f'[Context]\n{cap_str}\n\n{box_str}\n\n'
|
| 96 |
+
f'[Question]\n{ques["text"]}\n\n'
|
| 97 |
+
f'[{role} 1]\n{ans1["text"]}\n\n[End of {role} 1]\n\n'
|
| 98 |
+
f'[{role} 2]\n{ans2["text"]}\n\n[End of {role} 2]\n\n'
|
| 99 |
+
f'[System]\n{prompt}\n\n')
|
| 100 |
+
cur_js = {
|
| 101 |
+
'id': idx+1,
|
| 102 |
+
'question_id': ques['question_id'],
|
| 103 |
+
'answer1_id': ans1.get('answer_id', ans1['question_id']),
|
| 104 |
+
'answer2_id': ans2.get('answer_id', ans2['answer_id']),
|
| 105 |
+
'category': category
|
| 106 |
+
}
|
| 107 |
+
if idx >= len(cur_reviews):
|
| 108 |
+
review = get_eval(content, args.max_tokens)
|
| 109 |
+
scores = parse_score(review)
|
| 110 |
+
cur_js['content'] = review
|
| 111 |
+
cur_js['tuple'] = scores
|
| 112 |
+
review_file.write(json.dumps(cur_js) + '\n')
|
| 113 |
+
review_file.flush()
|
| 114 |
+
else:
|
| 115 |
+
print(f'Skipping {idx} as we already have it.')
|
| 116 |
+
idx += 1
|
| 117 |
+
print(idx)
|
| 118 |
+
review_file.close()
|
LLaVA-Plus-Codebase/llava/eval/eval_pope.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
import argparse
|
| 4 |
+
|
| 5 |
+
def eval_pope(answers, label_file):
|
| 6 |
+
label_list = [json.loads(q)['label'] for q in open(label_file, 'r')]
|
| 7 |
+
|
| 8 |
+
for answer in answers:
|
| 9 |
+
text = answer['text']
|
| 10 |
+
|
| 11 |
+
# Only keep the first sentence
|
| 12 |
+
if text.find('.') != -1:
|
| 13 |
+
text = text.split('.')[0]
|
| 14 |
+
|
| 15 |
+
text = text.replace(',', '')
|
| 16 |
+
words = text.split(' ')
|
| 17 |
+
if 'No' in words or 'not' in words or 'no' in words:
|
| 18 |
+
answer['text'] = 'no'
|
| 19 |
+
else:
|
| 20 |
+
answer['text'] = 'yes'
|
| 21 |
+
|
| 22 |
+
for i in range(len(label_list)):
|
| 23 |
+
if label_list[i] == 'no':
|
| 24 |
+
label_list[i] = 0
|
| 25 |
+
else:
|
| 26 |
+
label_list[i] = 1
|
| 27 |
+
|
| 28 |
+
pred_list = []
|
| 29 |
+
for answer in answers:
|
| 30 |
+
if answer['text'] == 'no':
|
| 31 |
+
pred_list.append(0)
|
| 32 |
+
else:
|
| 33 |
+
pred_list.append(1)
|
| 34 |
+
|
| 35 |
+
pos = 1
|
| 36 |
+
neg = 0
|
| 37 |
+
yes_ratio = pred_list.count(1) / len(pred_list)
|
| 38 |
+
|
| 39 |
+
TP, TN, FP, FN = 0, 0, 0, 0
|
| 40 |
+
for pred, label in zip(pred_list, label_list):
|
| 41 |
+
if pred == pos and label == pos:
|
| 42 |
+
TP += 1
|
| 43 |
+
elif pred == pos and label == neg:
|
| 44 |
+
FP += 1
|
| 45 |
+
elif pred == neg and label == neg:
|
| 46 |
+
TN += 1
|
| 47 |
+
elif pred == neg and label == pos:
|
| 48 |
+
FN += 1
|
| 49 |
+
|
| 50 |
+
print('TP\tFP\tTN\tFN\t')
|
| 51 |
+
print('{}\t{}\t{}\t{}'.format(TP, FP, TN, FN))
|
| 52 |
+
|
| 53 |
+
precision = float(TP) / float(TP + FP)
|
| 54 |
+
recall = float(TP) / float(TP + FN)
|
| 55 |
+
f1 = 2*precision*recall / (precision + recall)
|
| 56 |
+
acc = (TP + TN) / (TP + TN + FP + FN)
|
| 57 |
+
print('Accuracy: {}'.format(acc))
|
| 58 |
+
print('Precision: {}'.format(precision))
|
| 59 |
+
print('Recall: {}'.format(recall))
|
| 60 |
+
print('F1 score: {}'.format(f1))
|
| 61 |
+
print('Yes ratio: {}'.format(yes_ratio))
|
| 62 |
+
print('%.3f, %.3f, %.3f, %.3f, %.3f' % (f1, acc, precision, recall, yes_ratio) )
|
| 63 |
+
|
| 64 |
+
if __name__ == "__main__":
|
| 65 |
+
parser = argparse.ArgumentParser()
|
| 66 |
+
parser.add_argument("--annotation-dir", type=str)
|
| 67 |
+
parser.add_argument("--question-file", type=str)
|
| 68 |
+
parser.add_argument("--result-file", type=str)
|
| 69 |
+
args = parser.parse_args()
|
| 70 |
+
|
| 71 |
+
questions = [json.loads(line) for line in open(args.question_file)]
|
| 72 |
+
questions = {question['question_id']: question for question in questions}
|
| 73 |
+
answers = [json.loads(q) for q in open(args.result_file)]
|
| 74 |
+
for file in os.listdir(args.annotation_dir):
|
| 75 |
+
assert file.startswith('coco_pope_')
|
| 76 |
+
assert file.endswith('.json')
|
| 77 |
+
category = file[10:-5]
|
| 78 |
+
cur_answers = [x for x in answers if questions[x['question_id']]['category'] == category]
|
| 79 |
+
print('Category: {}, # samples: {}'.format(category, len(cur_answers)))
|
| 80 |
+
eval_pope(cur_answers, os.path.join(args.annotation_dir, file))
|
| 81 |
+
print("====================================")
|
LLaVA-Plus-Codebase/llava/eval/eval_science_qa.py
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
import re
|
| 5 |
+
import random
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def get_args():
|
| 9 |
+
parser = argparse.ArgumentParser()
|
| 10 |
+
parser.add_argument('--base-dir', type=str)
|
| 11 |
+
parser.add_argument('--result-file', type=str)
|
| 12 |
+
parser.add_argument('--output-file', type=str)
|
| 13 |
+
parser.add_argument('--output-result', type=str)
|
| 14 |
+
parser.add_argument('--split', type=str, default='test')
|
| 15 |
+
parser.add_argument('--options', type=list, default=["A", "B", "C", "D", "E"])
|
| 16 |
+
return parser.parse_args()
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def convert_caps(results):
|
| 20 |
+
fakecaps = []
|
| 21 |
+
for result in results:
|
| 22 |
+
image_id = result['question_id']
|
| 23 |
+
caption = result['text']
|
| 24 |
+
fakecaps.append({"image_id": int(image_id), "caption": caption})
|
| 25 |
+
return fakecaps
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def get_pred_idx(prediction, choices, options):
|
| 29 |
+
"""
|
| 30 |
+
Get the index (e.g. 2) from the prediction (e.g. 'C')
|
| 31 |
+
"""
|
| 32 |
+
if prediction in options[:len(choices)]:
|
| 33 |
+
return options.index(prediction)
|
| 34 |
+
else:
|
| 35 |
+
return -1
|
| 36 |
+
return random.choice(range(len(choices)))
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
if __name__ == "__main__":
|
| 40 |
+
args = get_args()
|
| 41 |
+
|
| 42 |
+
base_dir = args.base_dir
|
| 43 |
+
split_indices = json.load(open(os.path.join(base_dir, "pid_splits.json")))[args.split]
|
| 44 |
+
problems = json.load(open(os.path.join(base_dir, "problems.json")))
|
| 45 |
+
predictions = [json.loads(line) for line in open(args.result_file)]
|
| 46 |
+
predictions = {pred['question_id']: pred for pred in predictions}
|
| 47 |
+
split_problems = {idx: problems[idx] for idx in split_indices}
|
| 48 |
+
|
| 49 |
+
results = {'correct': [], 'incorrect': []}
|
| 50 |
+
sqa_results = {}
|
| 51 |
+
sqa_results['acc'] = None
|
| 52 |
+
sqa_results['correct'] = None
|
| 53 |
+
sqa_results['count'] = None
|
| 54 |
+
sqa_results['results'] = {}
|
| 55 |
+
sqa_results['outputs'] = {}
|
| 56 |
+
|
| 57 |
+
for prob_id, prob in split_problems.items():
|
| 58 |
+
if prob_id not in predictions:
|
| 59 |
+
pred = {'text': 'FAILED', 'prompt': 'Unknown'}
|
| 60 |
+
pred_text = 'FAILED'
|
| 61 |
+
else:
|
| 62 |
+
pred = predictions[prob_id]
|
| 63 |
+
pred_text = pred['text']
|
| 64 |
+
|
| 65 |
+
if pred_text in args.options:
|
| 66 |
+
answer = pred_text
|
| 67 |
+
elif len(pred_text) >= 3 and pred_text[0] in args.options and pred_text[1:3] == ". ":
|
| 68 |
+
answer = pred_text[0]
|
| 69 |
+
else:
|
| 70 |
+
pattern = re.compile(r'The answer is ([A-Z]).')
|
| 71 |
+
res = pattern.findall(pred_text)
|
| 72 |
+
if len(res) == 1:
|
| 73 |
+
answer = res[0] # 'A', 'B', ...
|
| 74 |
+
else:
|
| 75 |
+
answer = "FAILED"
|
| 76 |
+
|
| 77 |
+
pred_idx = get_pred_idx(answer, prob['choices'], args.options)
|
| 78 |
+
|
| 79 |
+
analysis = {
|
| 80 |
+
'question_id': prob_id,
|
| 81 |
+
'parsed_ans': answer,
|
| 82 |
+
'ground_truth': args.options[prob['answer']],
|
| 83 |
+
'question': pred['prompt'],
|
| 84 |
+
'pred': pred_text,
|
| 85 |
+
'is_multimodal': '<image>' in pred['prompt'],
|
| 86 |
+
}
|
| 87 |
+
|
| 88 |
+
sqa_results['results'][prob_id] = get_pred_idx(answer, prob['choices'], args.options)
|
| 89 |
+
sqa_results['outputs'][prob_id] = pred_text
|
| 90 |
+
|
| 91 |
+
if pred_idx == prob['answer']:
|
| 92 |
+
results['correct'].append(analysis)
|
| 93 |
+
else:
|
| 94 |
+
results['incorrect'].append(analysis)
|
| 95 |
+
|
| 96 |
+
correct = len(results['correct'])
|
| 97 |
+
total = len(results['correct']) + len(results['incorrect'])
|
| 98 |
+
|
| 99 |
+
###### IMG ######
|
| 100 |
+
multimodal_correct = len([x for x in results['correct'] if x['is_multimodal']])
|
| 101 |
+
multimodal_incorrect = len([x for x in results['incorrect'] if x['is_multimodal']])
|
| 102 |
+
multimodal_total = multimodal_correct + multimodal_incorrect
|
| 103 |
+
###### IMG ######
|
| 104 |
+
|
| 105 |
+
print(f'Total: {total}, Correct: {correct}, Accuracy: {correct / total * 100:.2f}%, IMG-Accuracy: {multimodal_correct / multimodal_total * 100:.2f}%')
|
| 106 |
+
|
| 107 |
+
sqa_results['acc'] = correct / total * 100
|
| 108 |
+
sqa_results['correct'] = correct
|
| 109 |
+
sqa_results['count'] = total
|
| 110 |
+
|
| 111 |
+
with open(args.output_file, 'w') as f:
|
| 112 |
+
json.dump(results, f, indent=2)
|
| 113 |
+
with open(args.output_result, 'w') as f:
|
| 114 |
+
json.dump(sqa_results, f, indent=2)
|
LLaVA-Plus-Codebase/llava/eval/eval_science_qa_gpt4.py
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
import re
|
| 5 |
+
import random
|
| 6 |
+
from collections import defaultdict
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def get_args():
|
| 10 |
+
parser = argparse.ArgumentParser()
|
| 11 |
+
parser.add_argument('--base-dir', type=str)
|
| 12 |
+
parser.add_argument('--gpt4-result', type=str)
|
| 13 |
+
parser.add_argument('--our-result', type=str)
|
| 14 |
+
parser.add_argument('--split', type=str, default='test')
|
| 15 |
+
parser.add_argument('--options', type=list, default=["A", "B", "C", "D", "E"])
|
| 16 |
+
return parser.parse_args()
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def convert_caps(results):
|
| 20 |
+
fakecaps = []
|
| 21 |
+
for result in results:
|
| 22 |
+
image_id = result['question_id']
|
| 23 |
+
caption = result['text']
|
| 24 |
+
fakecaps.append({"image_id": int(image_id), "caption": caption})
|
| 25 |
+
return fakecaps
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def get_pred_idx(prediction, choices, options):
|
| 29 |
+
"""
|
| 30 |
+
Get the index (e.g. 2) from the prediction (e.g. 'C')
|
| 31 |
+
"""
|
| 32 |
+
if prediction in options[:len(choices)]:
|
| 33 |
+
return options.index(prediction)
|
| 34 |
+
else:
|
| 35 |
+
return random.choice(range(len(choices)))
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
if __name__ == "__main__":
|
| 39 |
+
args = get_args()
|
| 40 |
+
|
| 41 |
+
base_dir = args.base_dir
|
| 42 |
+
split_indices = json.load(open(os.path.join(base_dir, "pid_splits.json")))[args.split]
|
| 43 |
+
problems = json.load(open(os.path.join(base_dir, "problems.json")))
|
| 44 |
+
our_predictions = [json.loads(line) for line in open(args.our_result)]
|
| 45 |
+
our_predictions = {pred['question_id']: pred for pred in our_predictions}
|
| 46 |
+
split_problems = {idx: problems[idx] for idx in split_indices}
|
| 47 |
+
|
| 48 |
+
gpt4_predictions = json.load(open(args.gpt4_result))['outputs']
|
| 49 |
+
|
| 50 |
+
results = defaultdict(lambda: 0)
|
| 51 |
+
|
| 52 |
+
for prob_id, prob in split_problems.items():
|
| 53 |
+
if prob_id not in our_predictions:
|
| 54 |
+
continue
|
| 55 |
+
if prob_id not in gpt4_predictions:
|
| 56 |
+
continue
|
| 57 |
+
our_pred = our_predictions[prob_id]['text']
|
| 58 |
+
gpt4_pred = gpt4_predictions[prob_id]
|
| 59 |
+
|
| 60 |
+
pattern = re.compile(r'The answer is ([A-Z]).')
|
| 61 |
+
our_res = pattern.findall(our_pred)
|
| 62 |
+
if len(our_res) == 1:
|
| 63 |
+
our_answer = our_res[0] # 'A', 'B', ...
|
| 64 |
+
else:
|
| 65 |
+
our_answer = "FAILED"
|
| 66 |
+
gpt4_res = pattern.findall(gpt4_pred)
|
| 67 |
+
if len(gpt4_res) == 1:
|
| 68 |
+
gpt4_answer = gpt4_res[0] # 'A', 'B', ...
|
| 69 |
+
else:
|
| 70 |
+
gpt4_answer = "FAILED"
|
| 71 |
+
|
| 72 |
+
our_pred_idx = get_pred_idx(our_answer, prob['choices'], args.options)
|
| 73 |
+
gpt4_pred_idx = get_pred_idx(gpt4_answer, prob['choices'], args.options)
|
| 74 |
+
|
| 75 |
+
if gpt4_answer == 'FAILED':
|
| 76 |
+
results['gpt4_failed'] += 1
|
| 77 |
+
# continue
|
| 78 |
+
gpt4_pred_idx = our_pred_idx
|
| 79 |
+
# if our_pred_idx != prob['answer']:
|
| 80 |
+
# print(our_predictions[prob_id]['prompt'])
|
| 81 |
+
# print('-----------------')
|
| 82 |
+
# print(f'LECTURE: {prob["lecture"]}')
|
| 83 |
+
# print(f'SOLUTION: {prob["solution"]}')
|
| 84 |
+
# print('=====================')
|
| 85 |
+
else:
|
| 86 |
+
# continue
|
| 87 |
+
pass
|
| 88 |
+
# gpt4_pred_idx = our_pred_idx
|
| 89 |
+
|
| 90 |
+
if gpt4_pred_idx == prob['answer']:
|
| 91 |
+
results['correct'] += 1
|
| 92 |
+
else:
|
| 93 |
+
results['incorrect'] += 1
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
if gpt4_pred_idx == prob['answer'] or our_pred_idx == prob['answer']:
|
| 97 |
+
results['correct_upperbound'] += 1
|
| 98 |
+
|
| 99 |
+
correct = results['correct']
|
| 100 |
+
total = results['correct'] + results['incorrect']
|
| 101 |
+
print(f'Total: {total}, Correct: {correct}, Accuracy: {correct / total * 100:.2f}%')
|
| 102 |
+
print(f'Total: {total}, Correct (upper): {results["correct_upperbound"]}, Accuracy: {results["correct_upperbound"] / total * 100:.2f}%')
|
| 103 |
+
print(f'Total: {total}, GPT-4 NO-ANS (RANDOM): {results["gpt4_failed"]}, Percentage: {results["gpt4_failed"] / total * 100:.2f}%')
|
| 104 |
+
|
LLaVA-Plus-Codebase/llava/eval/eval_science_qa_gpt4_requery.py
ADDED
|
@@ -0,0 +1,149 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
import re
|
| 5 |
+
import random
|
| 6 |
+
from collections import defaultdict
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def get_args():
|
| 10 |
+
parser = argparse.ArgumentParser()
|
| 11 |
+
parser.add_argument('--base-dir', type=str)
|
| 12 |
+
parser.add_argument('--gpt4-result', type=str)
|
| 13 |
+
parser.add_argument('--requery-result', type=str)
|
| 14 |
+
parser.add_argument('--our-result', type=str)
|
| 15 |
+
parser.add_argument('--output-result', type=str)
|
| 16 |
+
parser.add_argument('--split', type=str, default='test')
|
| 17 |
+
parser.add_argument('--options', type=list, default=["A", "B", "C", "D", "E"])
|
| 18 |
+
return parser.parse_args()
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def convert_caps(results):
|
| 22 |
+
fakecaps = []
|
| 23 |
+
for result in results:
|
| 24 |
+
image_id = result['question_id']
|
| 25 |
+
caption = result['text']
|
| 26 |
+
fakecaps.append({"image_id": int(image_id), "caption": caption})
|
| 27 |
+
return fakecaps
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def get_pred_idx(prediction, choices, options):
|
| 31 |
+
"""
|
| 32 |
+
Get the index (e.g. 2) from the prediction (e.g. 'C')
|
| 33 |
+
"""
|
| 34 |
+
if prediction in options[:len(choices)]:
|
| 35 |
+
return options.index(prediction)
|
| 36 |
+
else:
|
| 37 |
+
return random.choice(range(len(choices)))
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
if __name__ == "__main__":
|
| 41 |
+
args = get_args()
|
| 42 |
+
|
| 43 |
+
base_dir = args.base_dir
|
| 44 |
+
split_indices = json.load(open(os.path.join(base_dir, "pid_splits.json")))[args.split]
|
| 45 |
+
problems = json.load(open(os.path.join(base_dir, "problems.json")))
|
| 46 |
+
our_predictions = [json.loads(line) for line in open(args.our_result)]
|
| 47 |
+
our_predictions = {pred['question_id']: pred for pred in our_predictions}
|
| 48 |
+
split_problems = {idx: problems[idx] for idx in split_indices}
|
| 49 |
+
|
| 50 |
+
requery_predictions = [json.loads(line) for line in open(args.requery_result)]
|
| 51 |
+
requery_predictions = {pred['question_id']: pred for pred in requery_predictions}
|
| 52 |
+
|
| 53 |
+
gpt4_predictions = json.load(open(args.gpt4_result))['outputs']
|
| 54 |
+
|
| 55 |
+
results = defaultdict(lambda: 0)
|
| 56 |
+
|
| 57 |
+
sqa_results = {}
|
| 58 |
+
sqa_results['acc'] = None
|
| 59 |
+
sqa_results['correct'] = None
|
| 60 |
+
sqa_results['count'] = None
|
| 61 |
+
sqa_results['results'] = {}
|
| 62 |
+
sqa_results['outputs'] = {}
|
| 63 |
+
|
| 64 |
+
for prob_id, prob in split_problems.items():
|
| 65 |
+
if prob_id not in our_predictions:
|
| 66 |
+
assert False
|
| 67 |
+
if prob_id not in gpt4_predictions:
|
| 68 |
+
assert False
|
| 69 |
+
our_pred = our_predictions[prob_id]['text']
|
| 70 |
+
gpt4_pred = gpt4_predictions[prob_id]
|
| 71 |
+
if prob_id not in requery_predictions:
|
| 72 |
+
results['missing_requery'] += 1
|
| 73 |
+
requery_pred = "MISSING"
|
| 74 |
+
else:
|
| 75 |
+
requery_pred = requery_predictions[prob_id]['text']
|
| 76 |
+
|
| 77 |
+
pattern = re.compile(r'The answer is ([A-Z]).')
|
| 78 |
+
our_res = pattern.findall(our_pred)
|
| 79 |
+
if len(our_res) == 1:
|
| 80 |
+
our_answer = our_res[0] # 'A', 'B', ...
|
| 81 |
+
else:
|
| 82 |
+
our_answer = "FAILED"
|
| 83 |
+
|
| 84 |
+
requery_res = pattern.findall(requery_pred)
|
| 85 |
+
if len(requery_res) == 1:
|
| 86 |
+
requery_answer = requery_res[0] # 'A', 'B', ...
|
| 87 |
+
else:
|
| 88 |
+
requery_answer = "FAILED"
|
| 89 |
+
|
| 90 |
+
gpt4_res = pattern.findall(gpt4_pred)
|
| 91 |
+
if len(gpt4_res) == 1:
|
| 92 |
+
gpt4_answer = gpt4_res[0] # 'A', 'B', ...
|
| 93 |
+
else:
|
| 94 |
+
gpt4_answer = "FAILED"
|
| 95 |
+
|
| 96 |
+
our_pred_idx = get_pred_idx(our_answer, prob['choices'], args.options)
|
| 97 |
+
gpt4_pred_idx = get_pred_idx(gpt4_answer, prob['choices'], args.options)
|
| 98 |
+
requery_pred_idx = get_pred_idx(requery_answer, prob['choices'], args.options)
|
| 99 |
+
|
| 100 |
+
results['total'] += 1
|
| 101 |
+
|
| 102 |
+
if gpt4_answer == 'FAILED':
|
| 103 |
+
results['gpt4_failed'] += 1
|
| 104 |
+
if gpt4_pred_idx == prob['answer']:
|
| 105 |
+
results['gpt4_correct'] += 1
|
| 106 |
+
if our_pred_idx == prob['answer']:
|
| 107 |
+
results['gpt4_ourvisual_correct'] += 1
|
| 108 |
+
elif gpt4_pred_idx == prob['answer']:
|
| 109 |
+
results['gpt4_correct'] += 1
|
| 110 |
+
results['gpt4_ourvisual_correct'] += 1
|
| 111 |
+
|
| 112 |
+
if our_pred_idx == prob['answer']:
|
| 113 |
+
results['our_correct'] += 1
|
| 114 |
+
|
| 115 |
+
if requery_answer == 'FAILED':
|
| 116 |
+
sqa_results['results'][prob_id] = our_pred_idx
|
| 117 |
+
if our_pred_idx == prob['answer']:
|
| 118 |
+
results['requery_correct'] += 1
|
| 119 |
+
else:
|
| 120 |
+
sqa_results['results'][prob_id] = requery_pred_idx
|
| 121 |
+
if requery_pred_idx == prob['answer']:
|
| 122 |
+
results['requery_correct'] += 1
|
| 123 |
+
else:
|
| 124 |
+
print(f"""
|
| 125 |
+
Question ({args.options[prob['answer']]}): {our_predictions[prob_id]['prompt']}
|
| 126 |
+
Our ({our_answer}): {our_pred}
|
| 127 |
+
GPT-4 ({gpt4_answer}): {gpt4_pred}
|
| 128 |
+
Requery ({requery_answer}): {requery_pred}
|
| 129 |
+
print("=====================================")
|
| 130 |
+
""")
|
| 131 |
+
|
| 132 |
+
if gpt4_pred_idx == prob['answer'] or our_pred_idx == prob['answer']:
|
| 133 |
+
results['correct_upperbound'] += 1
|
| 134 |
+
|
| 135 |
+
total = results['total']
|
| 136 |
+
print(f'Total: {total}, Our-Correct: {results["our_correct"]}, Accuracy: {results["our_correct"] / total * 100:.2f}%')
|
| 137 |
+
print(f'Total: {total}, GPT-4-Correct: {results["gpt4_correct"]}, Accuracy: {results["gpt4_correct"] / total * 100:.2f}%')
|
| 138 |
+
print(f'Total: {total}, GPT-4 NO-ANS (RANDOM): {results["gpt4_failed"]}, Percentage: {results["gpt4_failed"] / total * 100:.2f}%')
|
| 139 |
+
print(f'Total: {total}, GPT-4-OursVisual-Correct: {results["gpt4_ourvisual_correct"]}, Accuracy: {results["gpt4_ourvisual_correct"] / total * 100:.2f}%')
|
| 140 |
+
print(f'Total: {total}, Requery-Correct: {results["requery_correct"]}, Accuracy: {results["requery_correct"] / total * 100:.2f}%')
|
| 141 |
+
print(f'Total: {total}, Correct upper: {results["correct_upperbound"]}, Accuracy: {results["correct_upperbound"] / total * 100:.2f}%')
|
| 142 |
+
|
| 143 |
+
sqa_results['acc'] = results["requery_correct"] / total * 100
|
| 144 |
+
sqa_results['correct'] = results["requery_correct"]
|
| 145 |
+
sqa_results['count'] = total
|
| 146 |
+
|
| 147 |
+
with open(args.output_result, 'w') as f:
|
| 148 |
+
json.dump(sqa_results, f, indent=2)
|
| 149 |
+
|
LLaVA-Plus-Codebase/llava/eval/eval_textvqa.py
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import argparse
|
| 3 |
+
import json
|
| 4 |
+
import re
|
| 5 |
+
|
| 6 |
+
from llava.eval.m4c_evaluator import TextVQAAccuracyEvaluator
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def get_args():
|
| 10 |
+
parser = argparse.ArgumentParser()
|
| 11 |
+
parser.add_argument('--annotation-file', type=str)
|
| 12 |
+
parser.add_argument('--result-file', type=str)
|
| 13 |
+
parser.add_argument('--result-dir', type=str)
|
| 14 |
+
return parser.parse_args()
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def prompt_processor(prompt):
|
| 18 |
+
if prompt.startswith('OCR tokens: '):
|
| 19 |
+
pattern = r"Question: (.*?) Short answer:"
|
| 20 |
+
match = re.search(pattern, prompt, re.DOTALL)
|
| 21 |
+
question = match.group(1)
|
| 22 |
+
elif 'Reference OCR token: ' in prompt and len(prompt.split('\n')) == 3:
|
| 23 |
+
if prompt.startswith('Reference OCR token:'):
|
| 24 |
+
question = prompt.split('\n')[1]
|
| 25 |
+
else:
|
| 26 |
+
question = prompt.split('\n')[0]
|
| 27 |
+
elif len(prompt.split('\n')) == 2:
|
| 28 |
+
question = prompt.split('\n')[0]
|
| 29 |
+
else:
|
| 30 |
+
assert False
|
| 31 |
+
|
| 32 |
+
return question.lower()
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def eval_single(annotation_file, result_file):
|
| 36 |
+
experiment_name = os.path.splitext(os.path.basename(result_file))[0]
|
| 37 |
+
print(experiment_name)
|
| 38 |
+
annotations = json.load(open(annotation_file))['data']
|
| 39 |
+
annotations = {(annotation['image_id'], annotation['question'].lower()): annotation for annotation in annotations}
|
| 40 |
+
results = [json.loads(line) for line in open(result_file)]
|
| 41 |
+
|
| 42 |
+
pred_list = []
|
| 43 |
+
for result in results:
|
| 44 |
+
annotation = annotations[(result['question_id'], prompt_processor(result['prompt']))]
|
| 45 |
+
pred_list.append({
|
| 46 |
+
"pred_answer": result['text'],
|
| 47 |
+
"gt_answers": annotation['answers'],
|
| 48 |
+
})
|
| 49 |
+
|
| 50 |
+
evaluator = TextVQAAccuracyEvaluator()
|
| 51 |
+
print('Samples: {}\nAccuracy: {:.2f}%\n'.format(len(pred_list), 100. * evaluator.eval_pred_list(pred_list)))
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
if __name__ == "__main__":
|
| 55 |
+
args = get_args()
|
| 56 |
+
|
| 57 |
+
if args.result_file is not None:
|
| 58 |
+
eval_single(args.annotation_file, args.result_file)
|
| 59 |
+
|
| 60 |
+
if args.result_dir is not None:
|
| 61 |
+
for result_file in sorted(os.listdir(args.result_dir)):
|
| 62 |
+
if not result_file.endswith('.jsonl'):
|
| 63 |
+
print(f'Skipping {result_file}')
|
| 64 |
+
continue
|
| 65 |
+
eval_single(args.annotation_file, os.path.join(args.result_dir, result_file))
|
LLaVA-Plus-Codebase/llava/eval/generate_webpage_data_from_table.py
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Generate json file for webpage."""
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
import re
|
| 5 |
+
|
| 6 |
+
# models = ['llama', 'alpaca', 'gpt35', 'bard']
|
| 7 |
+
models = ['vicuna']
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def read_jsonl(path: str, key: str=None):
|
| 11 |
+
data = []
|
| 12 |
+
with open(os.path.expanduser(path)) as f:
|
| 13 |
+
for line in f:
|
| 14 |
+
if not line:
|
| 15 |
+
continue
|
| 16 |
+
data.append(json.loads(line))
|
| 17 |
+
if key is not None:
|
| 18 |
+
data.sort(key=lambda x: x[key])
|
| 19 |
+
data = {item[key]: item for item in data}
|
| 20 |
+
return data
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def trim_hanging_lines(s: str, n: int) -> str:
|
| 24 |
+
s = s.strip()
|
| 25 |
+
for _ in range(n):
|
| 26 |
+
s = s.split('\n', 1)[1].strip()
|
| 27 |
+
return s
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
if __name__ == '__main__':
|
| 31 |
+
questions = read_jsonl('table/question.jsonl', key='question_id')
|
| 32 |
+
|
| 33 |
+
# alpaca_answers = read_jsonl('table/answer/answer_alpaca-13b.jsonl', key='question_id')
|
| 34 |
+
# bard_answers = read_jsonl('table/answer/answer_bard.jsonl', key='question_id')
|
| 35 |
+
# gpt35_answers = read_jsonl('table/answer/answer_gpt35.jsonl', key='question_id')
|
| 36 |
+
# llama_answers = read_jsonl('table/answer/answer_llama-13b.jsonl', key='question_id')
|
| 37 |
+
vicuna_answers = read_jsonl('table/answer/answer_vicuna-13b.jsonl', key='question_id')
|
| 38 |
+
ours_answers = read_jsonl('table/results/llama-13b-hf-alpaca.jsonl', key='question_id')
|
| 39 |
+
|
| 40 |
+
review_vicuna = read_jsonl('table/review/review_vicuna-13b_llama-13b-hf-alpaca.jsonl', key='question_id')
|
| 41 |
+
# review_alpaca = read_jsonl('table/review/review_alpaca-13b_vicuna-13b.jsonl', key='question_id')
|
| 42 |
+
# review_bard = read_jsonl('table/review/review_bard_vicuna-13b.jsonl', key='question_id')
|
| 43 |
+
# review_gpt35 = read_jsonl('table/review/review_gpt35_vicuna-13b.jsonl', key='question_id')
|
| 44 |
+
# review_llama = read_jsonl('table/review/review_llama-13b_vicuna-13b.jsonl', key='question_id')
|
| 45 |
+
|
| 46 |
+
records = []
|
| 47 |
+
for qid in questions.keys():
|
| 48 |
+
r = {
|
| 49 |
+
'id': qid,
|
| 50 |
+
'category': questions[qid]['category'],
|
| 51 |
+
'question': questions[qid]['text'],
|
| 52 |
+
'answers': {
|
| 53 |
+
# 'alpaca': alpaca_answers[qid]['text'],
|
| 54 |
+
# 'llama': llama_answers[qid]['text'],
|
| 55 |
+
# 'bard': bard_answers[qid]['text'],
|
| 56 |
+
# 'gpt35': gpt35_answers[qid]['text'],
|
| 57 |
+
'vicuna': vicuna_answers[qid]['text'],
|
| 58 |
+
'ours': ours_answers[qid]['text'],
|
| 59 |
+
},
|
| 60 |
+
'evaluations': {
|
| 61 |
+
# 'alpaca': review_alpaca[qid]['text'],
|
| 62 |
+
# 'llama': review_llama[qid]['text'],
|
| 63 |
+
# 'bard': review_bard[qid]['text'],
|
| 64 |
+
'vicuna': review_vicuna[qid]['content'],
|
| 65 |
+
# 'gpt35': review_gpt35[qid]['text'],
|
| 66 |
+
},
|
| 67 |
+
'scores': {
|
| 68 |
+
'vicuna': review_vicuna[qid]['tuple'],
|
| 69 |
+
# 'alpaca': review_alpaca[qid]['score'],
|
| 70 |
+
# 'llama': review_llama[qid]['score'],
|
| 71 |
+
# 'bard': review_bard[qid]['score'],
|
| 72 |
+
# 'gpt35': review_gpt35[qid]['score'],
|
| 73 |
+
},
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
# cleanup data
|
| 77 |
+
cleaned_evals = {}
|
| 78 |
+
for k, v in r['evaluations'].items():
|
| 79 |
+
v = v.strip()
|
| 80 |
+
lines = v.split('\n')
|
| 81 |
+
# trim the first line if it's a pair of numbers
|
| 82 |
+
if re.match(r'\d+[, ]+\d+', lines[0]):
|
| 83 |
+
lines = lines[1:]
|
| 84 |
+
v = '\n'.join(lines)
|
| 85 |
+
cleaned_evals[k] = v.replace('Assistant 1', "**Assistant 1**").replace('Assistant 2', '**Assistant 2**')
|
| 86 |
+
|
| 87 |
+
r['evaluations'] = cleaned_evals
|
| 88 |
+
records.append(r)
|
| 89 |
+
|
| 90 |
+
# Reorder the records, this is optional
|
| 91 |
+
for r in records:
|
| 92 |
+
if r['id'] <= 20:
|
| 93 |
+
r['id'] += 60
|
| 94 |
+
else:
|
| 95 |
+
r['id'] -= 20
|
| 96 |
+
for r in records:
|
| 97 |
+
if r['id'] <= 50:
|
| 98 |
+
r['id'] += 10
|
| 99 |
+
elif 50 < r['id'] <= 60:
|
| 100 |
+
r['id'] -= 50
|
| 101 |
+
for r in records:
|
| 102 |
+
if r['id'] == 7:
|
| 103 |
+
r['id'] = 1
|
| 104 |
+
elif r['id'] < 7:
|
| 105 |
+
r['id'] += 1
|
| 106 |
+
|
| 107 |
+
records.sort(key=lambda x: x['id'])
|
| 108 |
+
|
| 109 |
+
# Write to file
|
| 110 |
+
with open('webpage/data.json', 'w') as f:
|
| 111 |
+
json.dump({'questions': records, 'models': models}, f, indent=2)
|
LLaVA-Plus-Codebase/llava/eval/m4c_evaluator.py
ADDED
|
@@ -0,0 +1,334 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Facebook, Inc. and its affiliates.
|
| 2 |
+
import re
|
| 3 |
+
|
| 4 |
+
from tqdm import tqdm
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class EvalAIAnswerProcessor:
|
| 8 |
+
"""
|
| 9 |
+
Processes an answer similar to Eval AI
|
| 10 |
+
copied from
|
| 11 |
+
https://github.com/facebookresearch/mmf/blob/c46b3b3391275b4181567db80943473a89ab98ab/pythia/tasks/processors.py#L897
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
CONTRACTIONS = {
|
| 15 |
+
"aint": "ain't",
|
| 16 |
+
"arent": "aren't",
|
| 17 |
+
"cant": "can't",
|
| 18 |
+
"couldve": "could've",
|
| 19 |
+
"couldnt": "couldn't",
|
| 20 |
+
"couldn'tve": "couldn't've",
|
| 21 |
+
"couldnt've": "couldn't've",
|
| 22 |
+
"didnt": "didn't",
|
| 23 |
+
"doesnt": "doesn't",
|
| 24 |
+
"dont": "don't",
|
| 25 |
+
"hadnt": "hadn't",
|
| 26 |
+
"hadnt've": "hadn't've",
|
| 27 |
+
"hadn'tve": "hadn't've",
|
| 28 |
+
"hasnt": "hasn't",
|
| 29 |
+
"havent": "haven't",
|
| 30 |
+
"hed": "he'd",
|
| 31 |
+
"hed've": "he'd've",
|
| 32 |
+
"he'dve": "he'd've",
|
| 33 |
+
"hes": "he's",
|
| 34 |
+
"howd": "how'd",
|
| 35 |
+
"howll": "how'll",
|
| 36 |
+
"hows": "how's",
|
| 37 |
+
"Id've": "I'd've",
|
| 38 |
+
"I'dve": "I'd've",
|
| 39 |
+
"Im": "I'm",
|
| 40 |
+
"Ive": "I've",
|
| 41 |
+
"isnt": "isn't",
|
| 42 |
+
"itd": "it'd",
|
| 43 |
+
"itd've": "it'd've",
|
| 44 |
+
"it'dve": "it'd've",
|
| 45 |
+
"itll": "it'll",
|
| 46 |
+
"let's": "let's",
|
| 47 |
+
"maam": "ma'am",
|
| 48 |
+
"mightnt": "mightn't",
|
| 49 |
+
"mightnt've": "mightn't've",
|
| 50 |
+
"mightn'tve": "mightn't've",
|
| 51 |
+
"mightve": "might've",
|
| 52 |
+
"mustnt": "mustn't",
|
| 53 |
+
"mustve": "must've",
|
| 54 |
+
"neednt": "needn't",
|
| 55 |
+
"notve": "not've",
|
| 56 |
+
"oclock": "o'clock",
|
| 57 |
+
"oughtnt": "oughtn't",
|
| 58 |
+
"ow's'at": "'ow's'at",
|
| 59 |
+
"'ows'at": "'ow's'at",
|
| 60 |
+
"'ow'sat": "'ow's'at",
|
| 61 |
+
"shant": "shan't",
|
| 62 |
+
"shed've": "she'd've",
|
| 63 |
+
"she'dve": "she'd've",
|
| 64 |
+
"she's": "she's",
|
| 65 |
+
"shouldve": "should've",
|
| 66 |
+
"shouldnt": "shouldn't",
|
| 67 |
+
"shouldnt've": "shouldn't've",
|
| 68 |
+
"shouldn'tve": "shouldn't've",
|
| 69 |
+
"somebody'd": "somebodyd",
|
| 70 |
+
"somebodyd've": "somebody'd've",
|
| 71 |
+
"somebody'dve": "somebody'd've",
|
| 72 |
+
"somebodyll": "somebody'll",
|
| 73 |
+
"somebodys": "somebody's",
|
| 74 |
+
"someoned": "someone'd",
|
| 75 |
+
"someoned've": "someone'd've",
|
| 76 |
+
"someone'dve": "someone'd've",
|
| 77 |
+
"someonell": "someone'll",
|
| 78 |
+
"someones": "someone's",
|
| 79 |
+
"somethingd": "something'd",
|
| 80 |
+
"somethingd've": "something'd've",
|
| 81 |
+
"something'dve": "something'd've",
|
| 82 |
+
"somethingll": "something'll",
|
| 83 |
+
"thats": "that's",
|
| 84 |
+
"thered": "there'd",
|
| 85 |
+
"thered've": "there'd've",
|
| 86 |
+
"there'dve": "there'd've",
|
| 87 |
+
"therere": "there're",
|
| 88 |
+
"theres": "there's",
|
| 89 |
+
"theyd": "they'd",
|
| 90 |
+
"theyd've": "they'd've",
|
| 91 |
+
"they'dve": "they'd've",
|
| 92 |
+
"theyll": "they'll",
|
| 93 |
+
"theyre": "they're",
|
| 94 |
+
"theyve": "they've",
|
| 95 |
+
"twas": "'twas",
|
| 96 |
+
"wasnt": "wasn't",
|
| 97 |
+
"wed've": "we'd've",
|
| 98 |
+
"we'dve": "we'd've",
|
| 99 |
+
"weve": "we've",
|
| 100 |
+
"werent": "weren't",
|
| 101 |
+
"whatll": "what'll",
|
| 102 |
+
"whatre": "what're",
|
| 103 |
+
"whats": "what's",
|
| 104 |
+
"whatve": "what've",
|
| 105 |
+
"whens": "when's",
|
| 106 |
+
"whered": "where'd",
|
| 107 |
+
"wheres": "where's",
|
| 108 |
+
"whereve": "where've",
|
| 109 |
+
"whod": "who'd",
|
| 110 |
+
"whod've": "who'd've",
|
| 111 |
+
"who'dve": "who'd've",
|
| 112 |
+
"wholl": "who'll",
|
| 113 |
+
"whos": "who's",
|
| 114 |
+
"whove": "who've",
|
| 115 |
+
"whyll": "why'll",
|
| 116 |
+
"whyre": "why're",
|
| 117 |
+
"whys": "why's",
|
| 118 |
+
"wont": "won't",
|
| 119 |
+
"wouldve": "would've",
|
| 120 |
+
"wouldnt": "wouldn't",
|
| 121 |
+
"wouldnt've": "wouldn't've",
|
| 122 |
+
"wouldn'tve": "wouldn't've",
|
| 123 |
+
"yall": "y'all",
|
| 124 |
+
"yall'll": "y'all'll",
|
| 125 |
+
"y'allll": "y'all'll",
|
| 126 |
+
"yall'd've": "y'all'd've",
|
| 127 |
+
"y'alld've": "y'all'd've",
|
| 128 |
+
"y'all'dve": "y'all'd've",
|
| 129 |
+
"youd": "you'd",
|
| 130 |
+
"youd've": "you'd've",
|
| 131 |
+
"you'dve": "you'd've",
|
| 132 |
+
"youll": "you'll",
|
| 133 |
+
"youre": "you're",
|
| 134 |
+
"youve": "you've",
|
| 135 |
+
}
|
| 136 |
+
|
| 137 |
+
NUMBER_MAP = {
|
| 138 |
+
"none": "0",
|
| 139 |
+
"zero": "0",
|
| 140 |
+
"one": "1",
|
| 141 |
+
"two": "2",
|
| 142 |
+
"three": "3",
|
| 143 |
+
"four": "4",
|
| 144 |
+
"five": "5",
|
| 145 |
+
"six": "6",
|
| 146 |
+
"seven": "7",
|
| 147 |
+
"eight": "8",
|
| 148 |
+
"nine": "9",
|
| 149 |
+
"ten": "10",
|
| 150 |
+
}
|
| 151 |
+
ARTICLES = ["a", "an", "the"]
|
| 152 |
+
PERIOD_STRIP = re.compile(r"(?!<=\d)(\.)(?!\d)")
|
| 153 |
+
COMMA_STRIP = re.compile(r"(?<=\d)(\,)+(?=\d)")
|
| 154 |
+
PUNCTUATIONS = [
|
| 155 |
+
";",
|
| 156 |
+
r"/",
|
| 157 |
+
"[",
|
| 158 |
+
"]",
|
| 159 |
+
'"',
|
| 160 |
+
"{",
|
| 161 |
+
"}",
|
| 162 |
+
"(",
|
| 163 |
+
")",
|
| 164 |
+
"=",
|
| 165 |
+
"+",
|
| 166 |
+
"\\",
|
| 167 |
+
"_",
|
| 168 |
+
"-",
|
| 169 |
+
">",
|
| 170 |
+
"<",
|
| 171 |
+
"@",
|
| 172 |
+
"`",
|
| 173 |
+
",",
|
| 174 |
+
"?",
|
| 175 |
+
"!",
|
| 176 |
+
]
|
| 177 |
+
|
| 178 |
+
def __init__(self, *args, **kwargs):
|
| 179 |
+
pass
|
| 180 |
+
|
| 181 |
+
def word_tokenize(self, word):
|
| 182 |
+
word = word.lower()
|
| 183 |
+
word = word.replace(",", "").replace("?", "").replace("'s", " 's")
|
| 184 |
+
return word.strip()
|
| 185 |
+
|
| 186 |
+
def process_punctuation(self, in_text):
|
| 187 |
+
out_text = in_text
|
| 188 |
+
for p in self.PUNCTUATIONS:
|
| 189 |
+
if (p + " " in in_text or " " + p in in_text) or (
|
| 190 |
+
re.search(self.COMMA_STRIP, in_text) is not None
|
| 191 |
+
):
|
| 192 |
+
out_text = out_text.replace(p, "")
|
| 193 |
+
else:
|
| 194 |
+
out_text = out_text.replace(p, " ")
|
| 195 |
+
out_text = self.PERIOD_STRIP.sub("", out_text, re.UNICODE)
|
| 196 |
+
return out_text
|
| 197 |
+
|
| 198 |
+
def process_digit_article(self, in_text):
|
| 199 |
+
out_text = []
|
| 200 |
+
temp_text = in_text.lower().split()
|
| 201 |
+
for word in temp_text:
|
| 202 |
+
word = self.NUMBER_MAP.setdefault(word, word)
|
| 203 |
+
if word not in self.ARTICLES:
|
| 204 |
+
out_text.append(word)
|
| 205 |
+
else:
|
| 206 |
+
pass
|
| 207 |
+
for word_id, word in enumerate(out_text):
|
| 208 |
+
if word in self.CONTRACTIONS:
|
| 209 |
+
out_text[word_id] = self.CONTRACTIONS[word]
|
| 210 |
+
out_text = " ".join(out_text)
|
| 211 |
+
return out_text
|
| 212 |
+
|
| 213 |
+
def __call__(self, item):
|
| 214 |
+
item = self.word_tokenize(item)
|
| 215 |
+
item = item.replace("\n", " ").replace("\t", " ").strip()
|
| 216 |
+
item = self.process_punctuation(item)
|
| 217 |
+
item = self.process_digit_article(item)
|
| 218 |
+
return item
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
class TextVQAAccuracyEvaluator:
|
| 222 |
+
def __init__(self):
|
| 223 |
+
self.answer_processor = EvalAIAnswerProcessor()
|
| 224 |
+
|
| 225 |
+
def _compute_answer_scores(self, raw_answers):
|
| 226 |
+
"""
|
| 227 |
+
compute the accuracy (soft score) of human answers
|
| 228 |
+
"""
|
| 229 |
+
answers = [self.answer_processor(a) for a in raw_answers]
|
| 230 |
+
assert len(answers) == 10
|
| 231 |
+
gt_answers = list(enumerate(answers))
|
| 232 |
+
unique_answers = set(answers)
|
| 233 |
+
unique_answer_scores = {}
|
| 234 |
+
|
| 235 |
+
for unique_answer in unique_answers:
|
| 236 |
+
accs = []
|
| 237 |
+
for gt_answer in gt_answers:
|
| 238 |
+
other_answers = [item for item in gt_answers if item != gt_answer]
|
| 239 |
+
matching_answers = [
|
| 240 |
+
item for item in other_answers if item[1] == unique_answer
|
| 241 |
+
]
|
| 242 |
+
acc = min(1, float(len(matching_answers)) / 3)
|
| 243 |
+
accs.append(acc)
|
| 244 |
+
unique_answer_scores[unique_answer] = sum(accs) / len(accs)
|
| 245 |
+
|
| 246 |
+
return unique_answer_scores
|
| 247 |
+
|
| 248 |
+
def eval_pred_list(self, pred_list):
|
| 249 |
+
pred_scores = []
|
| 250 |
+
for entry in tqdm(pred_list):
|
| 251 |
+
pred_answer = self.answer_processor(entry["pred_answer"])
|
| 252 |
+
unique_answer_scores = self._compute_answer_scores(entry["gt_answers"])
|
| 253 |
+
score = unique_answer_scores.get(pred_answer, 0.0)
|
| 254 |
+
pred_scores.append(score)
|
| 255 |
+
|
| 256 |
+
accuracy = sum(pred_scores) / len(pred_scores)
|
| 257 |
+
return accuracy
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
class STVQAAccuracyEvaluator:
|
| 261 |
+
def __init__(self):
|
| 262 |
+
self.answer_processor = EvalAIAnswerProcessor()
|
| 263 |
+
|
| 264 |
+
def eval_pred_list(self, pred_list):
|
| 265 |
+
pred_scores = []
|
| 266 |
+
for entry in pred_list:
|
| 267 |
+
pred_answer = self.answer_processor(entry["pred_answer"])
|
| 268 |
+
gts = [self.answer_processor(a) for a in entry["gt_answers"]]
|
| 269 |
+
score = 1.0 if pred_answer in gts else 0.0
|
| 270 |
+
pred_scores.append(score)
|
| 271 |
+
|
| 272 |
+
accuracy = sum(pred_scores) / len(pred_scores)
|
| 273 |
+
return accuracy
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
class STVQAANLSEvaluator:
|
| 277 |
+
def __init__(self):
|
| 278 |
+
import editdistance # install with `pip install editdistance`
|
| 279 |
+
|
| 280 |
+
self.get_edit_distance = editdistance.eval
|
| 281 |
+
|
| 282 |
+
def get_anls(self, s1, s2):
|
| 283 |
+
s1 = s1.lower().strip()
|
| 284 |
+
s2 = s2.lower().strip()
|
| 285 |
+
iou = 1 - self.get_edit_distance(s1, s2) / max(len(s1), len(s2))
|
| 286 |
+
anls = iou if iou >= 0.5 else 0.0
|
| 287 |
+
return anls
|
| 288 |
+
|
| 289 |
+
def eval_pred_list(self, pred_list):
|
| 290 |
+
pred_scores = []
|
| 291 |
+
for entry in pred_list:
|
| 292 |
+
anls = max(
|
| 293 |
+
self.get_anls(entry["pred_answer"], gt) for gt in entry["gt_answers"]
|
| 294 |
+
)
|
| 295 |
+
pred_scores.append(anls)
|
| 296 |
+
|
| 297 |
+
accuracy = sum(pred_scores) / len(pred_scores)
|
| 298 |
+
return accuracy
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
class TextCapsBleu4Evaluator:
|
| 302 |
+
def __init__(self):
|
| 303 |
+
# The following script requires Java 1.8.0 and pycocotools installed.
|
| 304 |
+
# The pycocoevalcap can be installed with pip as
|
| 305 |
+
# pip install git+https://github.com/ronghanghu/coco-caption.git@python23
|
| 306 |
+
# Original pycocoevalcap code is at https://github.com/tylin/coco-caption
|
| 307 |
+
# but has no python3 support yet.
|
| 308 |
+
try:
|
| 309 |
+
from pycocoevalcap.bleu.bleu import Bleu
|
| 310 |
+
from pycocoevalcap.tokenizer.ptbtokenizer import PTBTokenizer
|
| 311 |
+
except ModuleNotFoundError:
|
| 312 |
+
print(
|
| 313 |
+
"Please install pycocoevalcap module using "
|
| 314 |
+
"pip install git+https://github.com/ronghanghu/coco-caption.git@python23" # noqa
|
| 315 |
+
)
|
| 316 |
+
raise
|
| 317 |
+
|
| 318 |
+
self.tokenizer = PTBTokenizer()
|
| 319 |
+
self.scorer = Bleu(4)
|
| 320 |
+
|
| 321 |
+
def eval_pred_list(self, pred_list):
|
| 322 |
+
# Create reference and hypotheses captions.
|
| 323 |
+
gts = {}
|
| 324 |
+
res = {}
|
| 325 |
+
for idx, entry in enumerate(pred_list):
|
| 326 |
+
gts[idx] = [{"caption": a} for a in entry["gt_answers"]]
|
| 327 |
+
res[idx] = [{"caption": entry["pred_answer"]}]
|
| 328 |
+
|
| 329 |
+
gts = self.tokenizer.tokenize(gts)
|
| 330 |
+
res = self.tokenizer.tokenize(res)
|
| 331 |
+
score, _ = self.scorer.compute_score(gts, res)
|
| 332 |
+
|
| 333 |
+
bleu4 = score[3] # score is (Bleu-1, Bleu-2, Bleu-3, Bleu-4)
|
| 334 |
+
return bleu4
|
LLaVA-Plus-Codebase/llava/eval/model_qa.py
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM, StoppingCriteria
|
| 3 |
+
import torch
|
| 4 |
+
import os
|
| 5 |
+
import json
|
| 6 |
+
from tqdm import tqdm
|
| 7 |
+
import shortuuid
|
| 8 |
+
|
| 9 |
+
from llava.conversation import default_conversation
|
| 10 |
+
from llava.utils import disable_torch_init
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
# new stopping implementation
|
| 14 |
+
class KeywordsStoppingCriteria(StoppingCriteria):
|
| 15 |
+
def __init__(self, keywords, tokenizer, input_ids):
|
| 16 |
+
self.keywords = keywords
|
| 17 |
+
self.tokenizer = tokenizer
|
| 18 |
+
self.start_len = None
|
| 19 |
+
self.input_ids = input_ids
|
| 20 |
+
|
| 21 |
+
def __call__(self, output_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
|
| 22 |
+
if self.start_len is None:
|
| 23 |
+
self.start_len = self.input_ids.shape[1]
|
| 24 |
+
else:
|
| 25 |
+
outputs = self.tokenizer.batch_decode(output_ids[:, self.start_len:], skip_special_tokens=True)[0]
|
| 26 |
+
for keyword in self.keywords:
|
| 27 |
+
if keyword in outputs:
|
| 28 |
+
return True
|
| 29 |
+
return False
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
@torch.inference_mode()
|
| 33 |
+
def eval_model(model_name, questions_file, answers_file):
|
| 34 |
+
# Model
|
| 35 |
+
disable_torch_init()
|
| 36 |
+
model_name = os.path.expanduser(model_name)
|
| 37 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
|
| 38 |
+
model = AutoModelForCausalLM.from_pretrained(model_name,
|
| 39 |
+
torch_dtype=torch.float16).cuda()
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
ques_file = open(os.path.expanduser(questions_file), "r")
|
| 43 |
+
ans_file = open(os.path.expanduser(answers_file), "w")
|
| 44 |
+
for i, line in enumerate(tqdm(ques_file)):
|
| 45 |
+
idx = json.loads(line)["question_id"]
|
| 46 |
+
qs = json.loads(line)["text"]
|
| 47 |
+
cat = json.loads(line)["category"]
|
| 48 |
+
conv = default_conversation.copy()
|
| 49 |
+
conv.append_message(conv.roles[0], qs)
|
| 50 |
+
prompt = conv.get_prompt()
|
| 51 |
+
inputs = tokenizer([prompt])
|
| 52 |
+
input_ids = torch.as_tensor(inputs.input_ids).cuda()
|
| 53 |
+
stopping_criteria = KeywordsStoppingCriteria([conv.sep], tokenizer, input_ids)
|
| 54 |
+
output_ids = model.generate(
|
| 55 |
+
input_ids,
|
| 56 |
+
do_sample=True,
|
| 57 |
+
use_cache=True,
|
| 58 |
+
temperature=0.7,
|
| 59 |
+
max_new_tokens=1024,
|
| 60 |
+
stopping_criteria=[stopping_criteria])
|
| 61 |
+
outputs = tokenizer.batch_decode(output_ids, skip_special_tokens=True)[0]
|
| 62 |
+
try:
|
| 63 |
+
index = outputs.index(conv.sep, len(prompt))
|
| 64 |
+
except ValueError:
|
| 65 |
+
outputs += conv.sep
|
| 66 |
+
index = outputs.index(conv.sep, len(prompt))
|
| 67 |
+
|
| 68 |
+
outputs = outputs[len(prompt) + len(conv.roles[1]) + 2:index].strip()
|
| 69 |
+
ans_id = shortuuid.uuid()
|
| 70 |
+
ans_file.write(json.dumps({"question_id": idx,
|
| 71 |
+
"text": outputs,
|
| 72 |
+
"answer_id": ans_id,
|
| 73 |
+
"model_id": model_name,
|
| 74 |
+
"metadata": {}}) + "\n")
|
| 75 |
+
ans_file.flush()
|
| 76 |
+
ans_file.close()
|
| 77 |
+
|
| 78 |
+
if __name__ == "__main__":
|
| 79 |
+
parser = argparse.ArgumentParser()
|
| 80 |
+
parser.add_argument("--model-name", type=str, default="facebook/opt-350m")
|
| 81 |
+
parser.add_argument("--question-file", type=str, default="tables/question.jsonl")
|
| 82 |
+
parser.add_argument("--answers-file", type=str, default="answer.jsonl")
|
| 83 |
+
args = parser.parse_args()
|
| 84 |
+
|
| 85 |
+
eval_model(args.model_name, args.question_file, args.answers_file)
|
LLaVA-Plus-Codebase/llava/eval/model_vqa.py
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import torch
|
| 3 |
+
import os
|
| 4 |
+
import json
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
import shortuuid
|
| 7 |
+
|
| 8 |
+
from llava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN
|
| 9 |
+
from llava.conversation import conv_templates, SeparatorStyle
|
| 10 |
+
from llava.model.builder import load_pretrained_model
|
| 11 |
+
from llava.utils import disable_torch_init
|
| 12 |
+
from llava.mm_utils import tokenizer_image_token, get_model_name_from_path, KeywordsStoppingCriteria
|
| 13 |
+
|
| 14 |
+
from PIL import Image
|
| 15 |
+
import math
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def split_list(lst, n):
|
| 19 |
+
"""Split a list into n (roughly) equal-sized chunks"""
|
| 20 |
+
chunk_size = math.ceil(len(lst) / n) # integer division
|
| 21 |
+
return [lst[i:i+chunk_size] for i in range(0, len(lst), chunk_size)]
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def get_chunk(lst, n, k):
|
| 25 |
+
chunks = split_list(lst, n)
|
| 26 |
+
return chunks[k]
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def eval_model(args):
|
| 30 |
+
# Model
|
| 31 |
+
disable_torch_init()
|
| 32 |
+
model_path = os.path.expanduser(args.model_path)
|
| 33 |
+
model_name = get_model_name_from_path(model_path)
|
| 34 |
+
tokenizer, model, image_processor, context_len = load_pretrained_model(model_path, args.model_base, model_name)
|
| 35 |
+
|
| 36 |
+
questions = [json.loads(q) for q in open(os.path.expanduser(args.question_file), "r")]
|
| 37 |
+
questions = get_chunk(questions, args.num_chunks, args.chunk_idx)
|
| 38 |
+
answers_file = os.path.expanduser(args.answers_file)
|
| 39 |
+
os.makedirs(os.path.dirname(answers_file), exist_ok=True)
|
| 40 |
+
ans_file = open(answers_file, "w")
|
| 41 |
+
for line in tqdm(questions):
|
| 42 |
+
idx = line["question_id"]
|
| 43 |
+
image_file = line["image"]
|
| 44 |
+
qs = line["text"]
|
| 45 |
+
cur_prompt = qs
|
| 46 |
+
if model.config.mm_use_im_start_end:
|
| 47 |
+
qs = DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN + DEFAULT_IM_END_TOKEN + '\n' + qs
|
| 48 |
+
else:
|
| 49 |
+
qs = DEFAULT_IMAGE_TOKEN + '\n' + qs
|
| 50 |
+
|
| 51 |
+
conv = conv_templates[args.conv_mode].copy()
|
| 52 |
+
conv.append_message(conv.roles[0], qs)
|
| 53 |
+
conv.append_message(conv.roles[1], None)
|
| 54 |
+
prompt = conv.get_prompt()
|
| 55 |
+
|
| 56 |
+
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda()
|
| 57 |
+
|
| 58 |
+
image = Image.open(os.path.join(args.image_folder, image_file))
|
| 59 |
+
image_tensor = image_processor.preprocess(image, return_tensors='pt')['pixel_values'][0]
|
| 60 |
+
|
| 61 |
+
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
|
| 62 |
+
keywords = [stop_str]
|
| 63 |
+
stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)
|
| 64 |
+
|
| 65 |
+
with torch.inference_mode():
|
| 66 |
+
output_ids = model.generate(
|
| 67 |
+
input_ids,
|
| 68 |
+
images=image_tensor.unsqueeze(0).half().cuda(),
|
| 69 |
+
do_sample=True if args.temperature > 0 else False,
|
| 70 |
+
temperature=args.temperature,
|
| 71 |
+
top_p=args.top_p,
|
| 72 |
+
num_beams=args.num_beams,
|
| 73 |
+
# no_repeat_ngram_size=3,
|
| 74 |
+
max_new_tokens=1024,
|
| 75 |
+
use_cache=True)
|
| 76 |
+
|
| 77 |
+
input_token_len = input_ids.shape[1]
|
| 78 |
+
n_diff_input_output = (input_ids != output_ids[:, :input_token_len]).sum().item()
|
| 79 |
+
if n_diff_input_output > 0:
|
| 80 |
+
print(f'[Warning] {n_diff_input_output} output_ids are not the same as the input_ids')
|
| 81 |
+
outputs = tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=True)[0]
|
| 82 |
+
outputs = outputs.strip()
|
| 83 |
+
if outputs.endswith(stop_str):
|
| 84 |
+
outputs = outputs[:-len(stop_str)]
|
| 85 |
+
outputs = outputs.strip()
|
| 86 |
+
|
| 87 |
+
ans_id = shortuuid.uuid()
|
| 88 |
+
ans_file.write(json.dumps({"question_id": idx,
|
| 89 |
+
"prompt": cur_prompt,
|
| 90 |
+
"text": outputs,
|
| 91 |
+
"answer_id": ans_id,
|
| 92 |
+
"model_id": model_name,
|
| 93 |
+
"metadata": {}}) + "\n")
|
| 94 |
+
ans_file.flush()
|
| 95 |
+
ans_file.close()
|
| 96 |
+
|
| 97 |
+
if __name__ == "__main__":
|
| 98 |
+
parser = argparse.ArgumentParser()
|
| 99 |
+
parser.add_argument("--model-path", type=str, default="facebook/opt-350m")
|
| 100 |
+
parser.add_argument("--model-base", type=str, default=None)
|
| 101 |
+
parser.add_argument("--image-folder", type=str, default="")
|
| 102 |
+
parser.add_argument("--question-file", type=str, default="tables/question.jsonl")
|
| 103 |
+
parser.add_argument("--answers-file", type=str, default="answer.jsonl")
|
| 104 |
+
parser.add_argument("--conv-mode", type=str, default="llava_v1")
|
| 105 |
+
parser.add_argument("--num-chunks", type=int, default=1)
|
| 106 |
+
parser.add_argument("--chunk-idx", type=int, default=0)
|
| 107 |
+
parser.add_argument("--temperature", type=float, default=0.2)
|
| 108 |
+
parser.add_argument("--top_p", type=float, default=None)
|
| 109 |
+
parser.add_argument("--num_beams", type=int, default=1)
|
| 110 |
+
args = parser.parse_args()
|
| 111 |
+
|
| 112 |
+
eval_model(args)
|
LLaVA-Plus-Codebase/llava/eval/model_vqa_loader.py
ADDED
|
@@ -0,0 +1,141 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import torch
|
| 3 |
+
import os
|
| 4 |
+
import json
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
import shortuuid
|
| 7 |
+
|
| 8 |
+
from llava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN
|
| 9 |
+
from llava.conversation import conv_templates, SeparatorStyle
|
| 10 |
+
from llava.model.builder import load_pretrained_model
|
| 11 |
+
from llava.utils import disable_torch_init
|
| 12 |
+
from llava.mm_utils import tokenizer_image_token, process_images, get_model_name_from_path
|
| 13 |
+
from torch.utils.data import Dataset, DataLoader
|
| 14 |
+
|
| 15 |
+
from PIL import Image
|
| 16 |
+
import math
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def split_list(lst, n):
|
| 20 |
+
"""Split a list into n (roughly) equal-sized chunks"""
|
| 21 |
+
chunk_size = math.ceil(len(lst) / n) # integer division
|
| 22 |
+
return [lst[i:i+chunk_size] for i in range(0, len(lst), chunk_size)]
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def get_chunk(lst, n, k):
|
| 26 |
+
chunks = split_list(lst, n)
|
| 27 |
+
return chunks[k]
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
# Custom dataset class
|
| 31 |
+
class CustomDataset(Dataset):
|
| 32 |
+
def __init__(self, questions, image_folder, tokenizer, image_processor, model_config):
|
| 33 |
+
self.questions = questions
|
| 34 |
+
self.image_folder = image_folder
|
| 35 |
+
self.tokenizer = tokenizer
|
| 36 |
+
self.image_processor = image_processor
|
| 37 |
+
self.model_config = model_config
|
| 38 |
+
|
| 39 |
+
def __getitem__(self, index):
|
| 40 |
+
line = self.questions[index]
|
| 41 |
+
image_file = line["image"]
|
| 42 |
+
qs = line["text"]
|
| 43 |
+
if self.model_config.mm_use_im_start_end:
|
| 44 |
+
qs = DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN + DEFAULT_IM_END_TOKEN + '\n' + qs
|
| 45 |
+
else:
|
| 46 |
+
qs = DEFAULT_IMAGE_TOKEN + '\n' + qs
|
| 47 |
+
|
| 48 |
+
conv = conv_templates[args.conv_mode].copy()
|
| 49 |
+
conv.append_message(conv.roles[0], qs)
|
| 50 |
+
conv.append_message(conv.roles[1], None)
|
| 51 |
+
prompt = conv.get_prompt()
|
| 52 |
+
|
| 53 |
+
image = Image.open(os.path.join(self.image_folder, image_file)).convert('RGB')
|
| 54 |
+
image_tensor = process_images([image], self.image_processor, self.model_config)[0]
|
| 55 |
+
|
| 56 |
+
input_ids = tokenizer_image_token(prompt, self.tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt')
|
| 57 |
+
|
| 58 |
+
return input_ids, image_tensor
|
| 59 |
+
|
| 60 |
+
def __len__(self):
|
| 61 |
+
return len(self.questions)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
# DataLoader
|
| 65 |
+
def create_data_loader(questions, image_folder, tokenizer, image_processor, model_config, batch_size=1, num_workers=4):
|
| 66 |
+
assert batch_size == 1, "batch_size must be 1"
|
| 67 |
+
dataset = CustomDataset(questions, image_folder, tokenizer, image_processor, model_config)
|
| 68 |
+
data_loader = DataLoader(dataset, batch_size=batch_size, num_workers=num_workers, shuffle=False)
|
| 69 |
+
return data_loader
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def eval_model(args):
|
| 73 |
+
# Model
|
| 74 |
+
disable_torch_init()
|
| 75 |
+
model_path = os.path.expanduser(args.model_path)
|
| 76 |
+
model_name = get_model_name_from_path(model_path)
|
| 77 |
+
tokenizer, model, image_processor, context_len = load_pretrained_model(model_path, args.model_base, model_name)
|
| 78 |
+
|
| 79 |
+
questions = [json.loads(q) for q in open(os.path.expanduser(args.question_file), "r")]
|
| 80 |
+
questions = get_chunk(questions, args.num_chunks, args.chunk_idx)
|
| 81 |
+
answers_file = os.path.expanduser(args.answers_file)
|
| 82 |
+
os.makedirs(os.path.dirname(answers_file), exist_ok=True)
|
| 83 |
+
ans_file = open(answers_file, "w")
|
| 84 |
+
|
| 85 |
+
if 'plain' in model_name and 'finetune' not in model_name.lower() and 'mmtag' not in args.conv_mode:
|
| 86 |
+
args.conv_mode = args.conv_mode + '_mmtag'
|
| 87 |
+
print(f'It seems that this is a plain model, but it is not using a mmtag prompt, auto switching to {args.conv_mode}.')
|
| 88 |
+
|
| 89 |
+
data_loader = create_data_loader(questions, args.image_folder, tokenizer, image_processor, model.config)
|
| 90 |
+
|
| 91 |
+
for (input_ids, image_tensor), line in tqdm(zip(data_loader, questions), total=len(questions)):
|
| 92 |
+
idx = line["question_id"]
|
| 93 |
+
cur_prompt = line["text"]
|
| 94 |
+
|
| 95 |
+
input_ids = input_ids.to(device='cuda', non_blocking=True)
|
| 96 |
+
|
| 97 |
+
with torch.inference_mode():
|
| 98 |
+
output_ids = model.generate(
|
| 99 |
+
input_ids,
|
| 100 |
+
images=image_tensor.to(dtype=torch.float16, device='cuda', non_blocking=True),
|
| 101 |
+
do_sample=True if args.temperature > 0 else False,
|
| 102 |
+
temperature=args.temperature,
|
| 103 |
+
top_p=args.top_p,
|
| 104 |
+
num_beams=args.num_beams,
|
| 105 |
+
max_new_tokens=args.max_new_tokens,
|
| 106 |
+
use_cache=True)
|
| 107 |
+
|
| 108 |
+
input_token_len = input_ids.shape[1]
|
| 109 |
+
n_diff_input_output = (input_ids != output_ids[:, :input_token_len]).sum().item()
|
| 110 |
+
if n_diff_input_output > 0:
|
| 111 |
+
print(f'[Warning] {n_diff_input_output} output_ids are not the same as the input_ids')
|
| 112 |
+
outputs = tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=True)[0]
|
| 113 |
+
outputs = outputs.strip()
|
| 114 |
+
|
| 115 |
+
ans_id = shortuuid.uuid()
|
| 116 |
+
ans_file.write(json.dumps({"question_id": idx,
|
| 117 |
+
"prompt": cur_prompt,
|
| 118 |
+
"text": outputs,
|
| 119 |
+
"answer_id": ans_id,
|
| 120 |
+
"model_id": model_name,
|
| 121 |
+
"metadata": {}}) + "\n")
|
| 122 |
+
# ans_file.flush()
|
| 123 |
+
ans_file.close()
|
| 124 |
+
|
| 125 |
+
if __name__ == "__main__":
|
| 126 |
+
parser = argparse.ArgumentParser()
|
| 127 |
+
parser.add_argument("--model-path", type=str, default="facebook/opt-350m")
|
| 128 |
+
parser.add_argument("--model-base", type=str, default=None)
|
| 129 |
+
parser.add_argument("--image-folder", type=str, default="")
|
| 130 |
+
parser.add_argument("--question-file", type=str, default="tables/question.jsonl")
|
| 131 |
+
parser.add_argument("--answers-file", type=str, default="answer.jsonl")
|
| 132 |
+
parser.add_argument("--conv-mode", type=str, default="llava_v1")
|
| 133 |
+
parser.add_argument("--num-chunks", type=int, default=1)
|
| 134 |
+
parser.add_argument("--chunk-idx", type=int, default=0)
|
| 135 |
+
parser.add_argument("--temperature", type=float, default=0.2)
|
| 136 |
+
parser.add_argument("--top_p", type=float, default=None)
|
| 137 |
+
parser.add_argument("--num_beams", type=int, default=1)
|
| 138 |
+
parser.add_argument("--max_new_tokens", type=int, default=128)
|
| 139 |
+
args = parser.parse_args()
|
| 140 |
+
|
| 141 |
+
eval_model(args)
|
LLaVA-Plus-Codebase/llava/eval/model_vqa_mmbench.py
ADDED
|
@@ -0,0 +1,170 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import torch
|
| 3 |
+
import os
|
| 4 |
+
import json
|
| 5 |
+
import pandas as pd
|
| 6 |
+
from tqdm import tqdm
|
| 7 |
+
import shortuuid
|
| 8 |
+
|
| 9 |
+
from llava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN
|
| 10 |
+
from llava.conversation import conv_templates, SeparatorStyle
|
| 11 |
+
from llava.model.builder import load_pretrained_model
|
| 12 |
+
from llava.utils import disable_torch_init
|
| 13 |
+
from llava.mm_utils import tokenizer_image_token, process_images, load_image_from_base64, get_model_name_from_path
|
| 14 |
+
|
| 15 |
+
from PIL import Image
|
| 16 |
+
import math
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
all_options = ['A', 'B', 'C', 'D']
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def split_list(lst, n):
|
| 23 |
+
"""Split a list into n (roughly) equal-sized chunks"""
|
| 24 |
+
chunk_size = math.ceil(len(lst) / n) # integer division
|
| 25 |
+
return [lst[i:i+chunk_size] for i in range(0, len(lst), chunk_size)]
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def get_chunk(lst, n, k):
|
| 29 |
+
chunks = split_list(lst, n)
|
| 30 |
+
return chunks[k]
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def is_none(value):
|
| 34 |
+
if value is None:
|
| 35 |
+
return True
|
| 36 |
+
if type(value) is float and math.isnan(value):
|
| 37 |
+
return True
|
| 38 |
+
if type(value) is str and value.lower() == 'nan':
|
| 39 |
+
return True
|
| 40 |
+
if type(value) is str and value.lower() == 'none':
|
| 41 |
+
return True
|
| 42 |
+
return False
|
| 43 |
+
|
| 44 |
+
def get_options(row, options):
|
| 45 |
+
parsed_options = []
|
| 46 |
+
for option in options:
|
| 47 |
+
option_value = row[option]
|
| 48 |
+
if is_none(option_value):
|
| 49 |
+
break
|
| 50 |
+
parsed_options.append(option_value)
|
| 51 |
+
return parsed_options
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def eval_model(args):
|
| 55 |
+
# Model
|
| 56 |
+
disable_torch_init()
|
| 57 |
+
model_path = os.path.expanduser(args.model_path)
|
| 58 |
+
model_name = get_model_name_from_path(model_path)
|
| 59 |
+
tokenizer, model, image_processor, context_len = load_pretrained_model(model_path, args.model_base, model_name)
|
| 60 |
+
|
| 61 |
+
questions = pd.read_table(os.path.expanduser(args.question_file))
|
| 62 |
+
questions = get_chunk(questions, args.num_chunks, args.chunk_idx)
|
| 63 |
+
answers_file = os.path.expanduser(args.answers_file)
|
| 64 |
+
os.makedirs(os.path.dirname(answers_file), exist_ok=True)
|
| 65 |
+
ans_file = open(answers_file, "w")
|
| 66 |
+
|
| 67 |
+
if 'plain' in model_name and 'finetune' not in model_name.lower() and 'mmtag' not in args.conv_mode:
|
| 68 |
+
args.conv_mode = args.conv_mode + '_mmtag'
|
| 69 |
+
print(f'It seems that this is a plain model, but it is not using a mmtag prompt, auto switching to {args.conv_mode}.')
|
| 70 |
+
|
| 71 |
+
for index, row in tqdm(questions.iterrows(), total=len(questions)):
|
| 72 |
+
options = get_options(row, all_options)
|
| 73 |
+
cur_option_char = all_options[:len(options)]
|
| 74 |
+
|
| 75 |
+
if args.all_rounds:
|
| 76 |
+
num_rounds = len(options)
|
| 77 |
+
else:
|
| 78 |
+
num_rounds = 1
|
| 79 |
+
|
| 80 |
+
for round_idx in range(num_rounds):
|
| 81 |
+
idx = row['index']
|
| 82 |
+
question = row['question']
|
| 83 |
+
hint = row['hint']
|
| 84 |
+
image = load_image_from_base64(row['image'])
|
| 85 |
+
if not is_none(hint):
|
| 86 |
+
question = hint + '\n' + question
|
| 87 |
+
for option_char, option in zip(all_options[:len(options)], options):
|
| 88 |
+
question = question + '\n' + option_char + '. ' + option
|
| 89 |
+
qs = cur_prompt = question
|
| 90 |
+
if model.config.mm_use_im_start_end:
|
| 91 |
+
qs = DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN + DEFAULT_IM_END_TOKEN + '\n' + qs
|
| 92 |
+
else:
|
| 93 |
+
qs = DEFAULT_IMAGE_TOKEN + '\n' + qs
|
| 94 |
+
|
| 95 |
+
if args.single_pred_prompt:
|
| 96 |
+
if args.lang == 'cn':
|
| 97 |
+
qs = qs + '\n' + "请直接回答选项字母。"
|
| 98 |
+
else:
|
| 99 |
+
qs = qs + '\n' + "Answer with the option's letter from the given choices directly."
|
| 100 |
+
|
| 101 |
+
conv = conv_templates[args.conv_mode].copy()
|
| 102 |
+
conv.append_message(conv.roles[0], qs)
|
| 103 |
+
conv.append_message(conv.roles[1], None)
|
| 104 |
+
prompt = conv.get_prompt()
|
| 105 |
+
|
| 106 |
+
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda()
|
| 107 |
+
|
| 108 |
+
image_tensor = process_images([image], image_processor, model.config)[0]
|
| 109 |
+
# image_tensor = image_processor.preprocess(image, return_tensors='pt')['pixel_values'][0]
|
| 110 |
+
|
| 111 |
+
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
|
| 112 |
+
|
| 113 |
+
with torch.inference_mode():
|
| 114 |
+
output_ids = model.generate(
|
| 115 |
+
input_ids,
|
| 116 |
+
images=image_tensor.unsqueeze(0).half().cuda(),
|
| 117 |
+
do_sample=True if args.temperature > 0 else False,
|
| 118 |
+
temperature=args.temperature,
|
| 119 |
+
top_p=args.top_p,
|
| 120 |
+
num_beams=args.num_beams,
|
| 121 |
+
# no_repeat_ngram_size=3,
|
| 122 |
+
max_new_tokens=1024,
|
| 123 |
+
use_cache=True)
|
| 124 |
+
|
| 125 |
+
input_token_len = input_ids.shape[1]
|
| 126 |
+
n_diff_input_output = (input_ids != output_ids[:, :input_token_len]).sum().item()
|
| 127 |
+
if n_diff_input_output > 0:
|
| 128 |
+
print(f'[Warning] {n_diff_input_output} output_ids are not the same as the input_ids')
|
| 129 |
+
outputs = tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=True)[0]
|
| 130 |
+
outputs = outputs.strip()
|
| 131 |
+
if outputs.endswith(stop_str):
|
| 132 |
+
outputs = outputs[:-len(stop_str)]
|
| 133 |
+
outputs = outputs.strip()
|
| 134 |
+
|
| 135 |
+
ans_id = shortuuid.uuid()
|
| 136 |
+
ans_file.write(json.dumps({"question_id": idx,
|
| 137 |
+
"round_id": round_idx,
|
| 138 |
+
"prompt": cur_prompt,
|
| 139 |
+
"text": outputs,
|
| 140 |
+
"options": options,
|
| 141 |
+
"option_char": cur_option_char,
|
| 142 |
+
"answer_id": ans_id,
|
| 143 |
+
"model_id": model_name,
|
| 144 |
+
"metadata": {}}) + "\n")
|
| 145 |
+
ans_file.flush()
|
| 146 |
+
|
| 147 |
+
# rotate options
|
| 148 |
+
options = options[1:] + options[:1]
|
| 149 |
+
cur_option_char = cur_option_char[1:] + cur_option_char[:1]
|
| 150 |
+
ans_file.close()
|
| 151 |
+
|
| 152 |
+
if __name__ == "__main__":
|
| 153 |
+
parser = argparse.ArgumentParser()
|
| 154 |
+
parser.add_argument("--model-path", type=str, default="facebook/opt-350m")
|
| 155 |
+
parser.add_argument("--model-base", type=str, default=None)
|
| 156 |
+
parser.add_argument("--image-folder", type=str, default="")
|
| 157 |
+
parser.add_argument("--question-file", type=str, default="tables/question.jsonl")
|
| 158 |
+
parser.add_argument("--answers-file", type=str, default="answer.jsonl")
|
| 159 |
+
parser.add_argument("--conv-mode", type=str, default="llava_v1")
|
| 160 |
+
parser.add_argument("--num-chunks", type=int, default=1)
|
| 161 |
+
parser.add_argument("--chunk-idx", type=int, default=0)
|
| 162 |
+
parser.add_argument("--temperature", type=float, default=0.2)
|
| 163 |
+
parser.add_argument("--top_p", type=float, default=None)
|
| 164 |
+
parser.add_argument("--num_beams", type=int, default=1)
|
| 165 |
+
parser.add_argument("--all-rounds", action="store_true")
|
| 166 |
+
parser.add_argument("--single-pred-prompt", action="store_true")
|
| 167 |
+
parser.add_argument("--lang", type=str, default="en")
|
| 168 |
+
args = parser.parse_args()
|
| 169 |
+
|
| 170 |
+
eval_model(args)
|
LLaVA-Plus-Codebase/llava/eval/model_vqa_qbench.py
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import torch
|
| 3 |
+
from tqdm import tqdm
|
| 4 |
+
import json
|
| 5 |
+
|
| 6 |
+
from llava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN
|
| 7 |
+
from llava.conversation import conv_templates, SeparatorStyle
|
| 8 |
+
from llava.model.builder import load_pretrained_model
|
| 9 |
+
from llava.utils import disable_torch_init
|
| 10 |
+
from llava.mm_utils import tokenizer_image_token, get_model_name_from_path, KeywordsStoppingCriteria
|
| 11 |
+
|
| 12 |
+
from PIL import Image
|
| 13 |
+
|
| 14 |
+
import requests
|
| 15 |
+
from PIL import Image
|
| 16 |
+
from io import BytesIO
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def load_image(image_file):
|
| 20 |
+
if image_file.startswith('http') or image_file.startswith('https'):
|
| 21 |
+
response = requests.get(image_file)
|
| 22 |
+
image = Image.open(BytesIO(response.content)).convert('RGB')
|
| 23 |
+
else:
|
| 24 |
+
image = Image.open(image_file).convert('RGB')
|
| 25 |
+
return image
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def eval_model(args):
|
| 29 |
+
# Model
|
| 30 |
+
disable_torch_init()
|
| 31 |
+
|
| 32 |
+
model_name = get_model_name_from_path(args.model_path)
|
| 33 |
+
tokenizer, model, image_processor, context_len = load_pretrained_model(args.model_path, args.model_base, model_name, True)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
with open(args.questions_file) as f:
|
| 39 |
+
llvqa_data = json.load(f)
|
| 40 |
+
|
| 41 |
+
for i, llddata in enumerate(tqdm(llvqa_data)):
|
| 42 |
+
filename = llddata["img_path"]
|
| 43 |
+
if args.lang == "en":
|
| 44 |
+
message = llddata["question"] + "\nChoose between one of the options as follows:\n"
|
| 45 |
+
elif args.lang == "zh":
|
| 46 |
+
message = llddata["question"] + "\在下列选项中选择一个:\n"
|
| 47 |
+
else:
|
| 48 |
+
raise NotImplementedError("Q-Bench does not support languages other than English (en) and Chinese (zh) yet. Contact us (https://github.com/VQAssessment/Q-Bench/) to convert Q-Bench into more languages.")
|
| 49 |
+
for choice, ans in zip(["A.", "B.", "C.", "D."], llddata["candidates"]):
|
| 50 |
+
message += f"{choice} {ans}\n"
|
| 51 |
+
qs = message
|
| 52 |
+
|
| 53 |
+
if model.config.mm_use_im_start_end:
|
| 54 |
+
qs = DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN + DEFAULT_IM_END_TOKEN + '\n' + qs
|
| 55 |
+
else:
|
| 56 |
+
qs = DEFAULT_IMAGE_TOKEN + '\n' + qs
|
| 57 |
+
|
| 58 |
+
if 'llama-2' in model_name.lower():
|
| 59 |
+
conv_mode = "llava_llama_2"
|
| 60 |
+
elif "v1" in model_name.lower():
|
| 61 |
+
conv_mode = "llava_v1"
|
| 62 |
+
elif "mpt" in model_name.lower():
|
| 63 |
+
conv_mode = "mpt"
|
| 64 |
+
else:
|
| 65 |
+
conv_mode = "llava_v0"
|
| 66 |
+
|
| 67 |
+
if args.conv_mode is not None and conv_mode != args.conv_mode:
|
| 68 |
+
print('[WARNING] the auto inferred conversation mode is {}, while `--conv-mode` is {}, using {}'.format(conv_mode, args.conv_mode, args.conv_mode))
|
| 69 |
+
else:
|
| 70 |
+
args.conv_mode = conv_mode
|
| 71 |
+
|
| 72 |
+
conv = conv_templates[args.conv_mode].copy()
|
| 73 |
+
conv.append_message(conv.roles[0], qs)
|
| 74 |
+
conv.append_message(conv.roles[1], None)
|
| 75 |
+
prompt = conv.get_prompt()
|
| 76 |
+
|
| 77 |
+
image = load_image(args.image_folder + filename)
|
| 78 |
+
image_tensor = image_processor.preprocess(image, return_tensors='pt')['pixel_values'].half().cuda()
|
| 79 |
+
|
| 80 |
+
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda()
|
| 81 |
+
|
| 82 |
+
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
|
| 83 |
+
keywords = [stop_str]
|
| 84 |
+
stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
with torch.inference_mode():
|
| 88 |
+
output_ids = model.generate(
|
| 89 |
+
input_ids,
|
| 90 |
+
images=image_tensor,
|
| 91 |
+
num_beams=1,
|
| 92 |
+
do_sample=False,
|
| 93 |
+
temperature=0,
|
| 94 |
+
max_new_tokens=1024,
|
| 95 |
+
use_cache=True,
|
| 96 |
+
stopping_criteria=[stopping_criteria])
|
| 97 |
+
|
| 98 |
+
input_token_len = input_ids.shape[1]
|
| 99 |
+
n_diff_input_output = (input_ids != output_ids[:, :input_token_len]).sum().item()
|
| 100 |
+
if n_diff_input_output > 0:
|
| 101 |
+
print(f'[Warning] {n_diff_input_output} output_ids are not the same as the input_ids')
|
| 102 |
+
outputs = tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=True)[0]
|
| 103 |
+
outputs = outputs.strip()
|
| 104 |
+
if outputs.endswith(stop_str):
|
| 105 |
+
outputs = outputs[:-len(stop_str)]
|
| 106 |
+
outputs = outputs.strip()
|
| 107 |
+
llddata["response"] = outputs
|
| 108 |
+
with open(args.answers_file, "a") as wf:
|
| 109 |
+
json.dump(llddata, wf)
|
| 110 |
+
|
| 111 |
+
if __name__ == "__main__":
|
| 112 |
+
parser = argparse.ArgumentParser()
|
| 113 |
+
parser.add_argument("--model-path", type=str, default="llava-v1.5")
|
| 114 |
+
parser.add_argument("--model-base", type=str, default=None)
|
| 115 |
+
parser.add_argument("--image-folder", type=str, default="./playground/data/qbench/images_llvisionqa")
|
| 116 |
+
parser.add_argument("--questions-file", type=str, default="./playground/data/qbench/llvisionqa_dev.json")
|
| 117 |
+
parser.add_argument("--answers-file", type=str, default="answer.jsonl")
|
| 118 |
+
parser.add_argument("--conv-mode", type=str, default="llava_v1")
|
| 119 |
+
parser.add_argument("--lang", type=str, default="en")
|
| 120 |
+
args = parser.parse_args()
|
| 121 |
+
|
| 122 |
+
eval_model(args)
|
LLaVA-Plus-Codebase/llava/eval/model_vqa_science.py
ADDED
|
@@ -0,0 +1,147 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import torch
|
| 3 |
+
import os
|
| 4 |
+
import json
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
import shortuuid
|
| 7 |
+
|
| 8 |
+
from llava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN
|
| 9 |
+
from llava.conversation import conv_templates, SeparatorStyle
|
| 10 |
+
from llava.model.builder import load_pretrained_model
|
| 11 |
+
from llava.utils import disable_torch_init
|
| 12 |
+
from llava.mm_utils import tokenizer_image_token, get_model_name_from_path, KeywordsStoppingCriteria
|
| 13 |
+
|
| 14 |
+
from PIL import Image
|
| 15 |
+
import math
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def split_list(lst, n):
|
| 19 |
+
"""Split a list into n (roughly) equal-sized chunks"""
|
| 20 |
+
chunk_size = math.ceil(len(lst) / n) # integer division
|
| 21 |
+
return [lst[i:i+chunk_size] for i in range(0, len(lst), chunk_size)]
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def get_chunk(lst, n, k):
|
| 25 |
+
chunks = split_list(lst, n)
|
| 26 |
+
return chunks[k]
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def eval_model(args):
|
| 30 |
+
# Model
|
| 31 |
+
disable_torch_init()
|
| 32 |
+
model_path = os.path.expanduser(args.model_path)
|
| 33 |
+
model_name = get_model_name_from_path(model_path)
|
| 34 |
+
tokenizer, model, image_processor, context_len = load_pretrained_model(model_path, args.model_base, model_name)
|
| 35 |
+
|
| 36 |
+
questions = json.load(open(os.path.expanduser(args.question_file), "r"))
|
| 37 |
+
questions = get_chunk(questions, args.num_chunks, args.chunk_idx)
|
| 38 |
+
answers_file = os.path.expanduser(args.answers_file)
|
| 39 |
+
os.makedirs(os.path.dirname(answers_file), exist_ok=True)
|
| 40 |
+
ans_file = open(answers_file, "w")
|
| 41 |
+
for i, line in enumerate(tqdm(questions)):
|
| 42 |
+
idx = line["id"]
|
| 43 |
+
question = line['conversations'][0]
|
| 44 |
+
qs = question['value'].replace('<image>', '').strip()
|
| 45 |
+
cur_prompt = qs
|
| 46 |
+
|
| 47 |
+
if 'image' in line:
|
| 48 |
+
image_file = line["image"]
|
| 49 |
+
image = Image.open(os.path.join(args.image_folder, image_file))
|
| 50 |
+
image_tensor = image_processor.preprocess(image, return_tensors='pt')['pixel_values'][0]
|
| 51 |
+
images = image_tensor.unsqueeze(0).half().cuda()
|
| 52 |
+
if getattr(model.config, 'mm_use_im_start_end', False):
|
| 53 |
+
qs = DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN + DEFAULT_IM_END_TOKEN + '\n' + qs
|
| 54 |
+
else:
|
| 55 |
+
qs = DEFAULT_IMAGE_TOKEN + '\n' + qs
|
| 56 |
+
cur_prompt = '<image>' + '\n' + cur_prompt
|
| 57 |
+
else:
|
| 58 |
+
images = None
|
| 59 |
+
|
| 60 |
+
if args.single_pred_prompt:
|
| 61 |
+
qs = qs + '\n' + "Answer with the option's letter from the given choices directly."
|
| 62 |
+
cur_prompt = cur_prompt + '\n' + "Answer with the option's letter from the given choices directly."
|
| 63 |
+
|
| 64 |
+
conv = conv_templates[args.conv_mode].copy()
|
| 65 |
+
conv.append_message(conv.roles[0], qs)
|
| 66 |
+
conv.append_message(conv.roles[1], None)
|
| 67 |
+
prompt = conv.get_prompt()
|
| 68 |
+
|
| 69 |
+
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda()
|
| 70 |
+
|
| 71 |
+
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
|
| 72 |
+
keywords = [stop_str]
|
| 73 |
+
stopping_criteria = [KeywordsStoppingCriteria(keywords, tokenizer, input_ids)] if conv.version == "v0" else None
|
| 74 |
+
|
| 75 |
+
with torch.inference_mode():
|
| 76 |
+
output_ids = model.generate(
|
| 77 |
+
input_ids,
|
| 78 |
+
images=images,
|
| 79 |
+
do_sample=True if args.temperature > 0 else False,
|
| 80 |
+
temperature=args.temperature,
|
| 81 |
+
max_new_tokens=1024,
|
| 82 |
+
use_cache=True,
|
| 83 |
+
stopping_criteria=stopping_criteria,
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
input_token_len = input_ids.shape[1]
|
| 87 |
+
n_diff_input_output = (input_ids != output_ids[:, :input_token_len]).sum().item()
|
| 88 |
+
if n_diff_input_output > 0:
|
| 89 |
+
print(f'[Warning] {n_diff_input_output} output_ids are not the same as the input_ids')
|
| 90 |
+
outputs = tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=True)[0]
|
| 91 |
+
outputs = outputs.strip()
|
| 92 |
+
if outputs.endswith(stop_str):
|
| 93 |
+
outputs = outputs[:-len(stop_str)]
|
| 94 |
+
outputs = outputs.strip()
|
| 95 |
+
|
| 96 |
+
# prompt for answer
|
| 97 |
+
if args.answer_prompter:
|
| 98 |
+
outputs_reasoning = outputs
|
| 99 |
+
input_ids = tokenizer_image_token(prompt + outputs_reasoning + ' ###\nANSWER:', tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda()
|
| 100 |
+
|
| 101 |
+
with torch.inference_mode():
|
| 102 |
+
output_ids = model.generate(
|
| 103 |
+
input_ids,
|
| 104 |
+
images=images,
|
| 105 |
+
do_sample=True if args.temperature > 0 else False,
|
| 106 |
+
temperature=args.temperature,
|
| 107 |
+
max_new_tokens=64,
|
| 108 |
+
use_cache=True,
|
| 109 |
+
stopping_criteria=[stopping_criteria])
|
| 110 |
+
|
| 111 |
+
input_token_len = input_ids.shape[1]
|
| 112 |
+
n_diff_input_output = (input_ids != output_ids[:, :input_token_len]).sum().item()
|
| 113 |
+
if n_diff_input_output > 0:
|
| 114 |
+
print(f'[Warning] {n_diff_input_output} output_ids are not the same as the input_ids')
|
| 115 |
+
outputs = tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=True)[0]
|
| 116 |
+
outputs = outputs.strip()
|
| 117 |
+
if outputs.endswith(stop_str):
|
| 118 |
+
outputs = outputs[:-len(stop_str)]
|
| 119 |
+
outputs = outputs.strip()
|
| 120 |
+
outputs = outputs_reasoning + '\n The answer is ' + outputs
|
| 121 |
+
|
| 122 |
+
ans_id = shortuuid.uuid()
|
| 123 |
+
ans_file.write(json.dumps({"question_id": idx,
|
| 124 |
+
"prompt": cur_prompt,
|
| 125 |
+
"text": outputs,
|
| 126 |
+
"answer_id": ans_id,
|
| 127 |
+
"model_id": model_name,
|
| 128 |
+
"metadata": {}}) + "\n")
|
| 129 |
+
ans_file.flush()
|
| 130 |
+
ans_file.close()
|
| 131 |
+
|
| 132 |
+
if __name__ == "__main__":
|
| 133 |
+
parser = argparse.ArgumentParser()
|
| 134 |
+
parser.add_argument("--model-path", type=str, default="facebook/opt-350m")
|
| 135 |
+
parser.add_argument("--model-base", type=str, default=None)
|
| 136 |
+
parser.add_argument("--image-folder", type=str, default="")
|
| 137 |
+
parser.add_argument("--question-file", type=str, default="tables/question.json")
|
| 138 |
+
parser.add_argument("--answers-file", type=str, default="answer.jsonl")
|
| 139 |
+
parser.add_argument("--conv-mode", type=str, default="llava_v0")
|
| 140 |
+
parser.add_argument("--num-chunks", type=int, default=1)
|
| 141 |
+
parser.add_argument("--chunk-idx", type=int, default=0)
|
| 142 |
+
parser.add_argument("--temperature", type=float, default=0.2)
|
| 143 |
+
parser.add_argument("--answer-prompter", action="store_true")
|
| 144 |
+
parser.add_argument("--single-pred-prompt", action="store_true")
|
| 145 |
+
args = parser.parse_args()
|
| 146 |
+
|
| 147 |
+
eval_model(args)
|
LLaVA-Plus-Codebase/llava/eval/qa_baseline_gpt35.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Generate answers with GPT-3.5"""
|
| 2 |
+
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work
|
| 3 |
+
import argparse
|
| 4 |
+
import json
|
| 5 |
+
import os
|
| 6 |
+
import time
|
| 7 |
+
import concurrent.futures
|
| 8 |
+
|
| 9 |
+
import openai
|
| 10 |
+
import tqdm
|
| 11 |
+
import shortuuid
|
| 12 |
+
|
| 13 |
+
MODEL = 'gpt-3.5-turbo'
|
| 14 |
+
MODEL_ID = 'gpt-3.5-turbo:20230327'
|
| 15 |
+
|
| 16 |
+
def get_answer(question_id: int, question: str, max_tokens: int):
|
| 17 |
+
ans = {
|
| 18 |
+
'answer_id': shortuuid.uuid(),
|
| 19 |
+
'question_id': question_id,
|
| 20 |
+
'model_id': MODEL_ID,
|
| 21 |
+
}
|
| 22 |
+
for _ in range(3):
|
| 23 |
+
try:
|
| 24 |
+
response = openai.ChatCompletion.create(
|
| 25 |
+
model=MODEL,
|
| 26 |
+
messages=[{
|
| 27 |
+
'role': 'system',
|
| 28 |
+
'content': 'You are a helpful assistant.'
|
| 29 |
+
}, {
|
| 30 |
+
'role': 'user',
|
| 31 |
+
'content': question,
|
| 32 |
+
}],
|
| 33 |
+
max_tokens=max_tokens,
|
| 34 |
+
)
|
| 35 |
+
ans['text'] = response['choices'][0]['message']['content']
|
| 36 |
+
return ans
|
| 37 |
+
except Exception as e:
|
| 38 |
+
print('[ERROR]', e)
|
| 39 |
+
ans['text'] = '#ERROR#'
|
| 40 |
+
time.sleep(1)
|
| 41 |
+
return ans
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
if __name__ == '__main__':
|
| 45 |
+
parser = argparse.ArgumentParser(description='ChatGPT answer generation.')
|
| 46 |
+
parser.add_argument('-q', '--question')
|
| 47 |
+
parser.add_argument('-o', '--output')
|
| 48 |
+
parser.add_argument('--max-tokens', type=int, default=1024, help='maximum number of tokens produced in the output')
|
| 49 |
+
args = parser.parse_args()
|
| 50 |
+
|
| 51 |
+
questions_dict = {}
|
| 52 |
+
with open(os.path.expanduser(args.question)) as f:
|
| 53 |
+
for line in f:
|
| 54 |
+
if not line:
|
| 55 |
+
continue
|
| 56 |
+
q = json.loads(line)
|
| 57 |
+
questions_dict[q['question_id']] = q['text']
|
| 58 |
+
|
| 59 |
+
answers = []
|
| 60 |
+
|
| 61 |
+
with concurrent.futures.ThreadPoolExecutor(max_workers=32) as executor:
|
| 62 |
+
futures = []
|
| 63 |
+
for qid, question in questions_dict.items():
|
| 64 |
+
future = executor.submit(get_answer, qid, question, args.max_tokens)
|
| 65 |
+
futures.append(future)
|
| 66 |
+
|
| 67 |
+
for future in tqdm.tqdm(concurrent.futures.as_completed(futures), total=len(futures)):
|
| 68 |
+
answers.append(future.result())
|
| 69 |
+
|
| 70 |
+
answers.sort(key=lambda x: x['question_id'])
|
| 71 |
+
|
| 72 |
+
with open(os.path.expanduser(args.output), 'w') as f:
|
| 73 |
+
table = [json.dumps(ans) for ans in answers]
|
| 74 |
+
f.write('\n'.join(table))
|
LLaVA-Plus-Codebase/llava/eval/run_llava.py
ADDED
|
@@ -0,0 +1,157 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
from llava.constants import (
|
| 5 |
+
IMAGE_TOKEN_INDEX,
|
| 6 |
+
DEFAULT_IMAGE_TOKEN,
|
| 7 |
+
DEFAULT_IM_START_TOKEN,
|
| 8 |
+
DEFAULT_IM_END_TOKEN,
|
| 9 |
+
IMAGE_PLACEHOLDER,
|
| 10 |
+
)
|
| 11 |
+
from llava.conversation import conv_templates, SeparatorStyle
|
| 12 |
+
from llava.model.builder import load_pretrained_model
|
| 13 |
+
from llava.utils import disable_torch_init
|
| 14 |
+
from llava.mm_utils import (
|
| 15 |
+
process_images,
|
| 16 |
+
tokenizer_image_token,
|
| 17 |
+
get_model_name_from_path,
|
| 18 |
+
KeywordsStoppingCriteria,
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
from PIL import Image
|
| 22 |
+
|
| 23 |
+
import requests
|
| 24 |
+
from PIL import Image
|
| 25 |
+
from io import BytesIO
|
| 26 |
+
import re
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def image_parser(args):
|
| 30 |
+
out = args.image_file.split(args.sep)
|
| 31 |
+
return out
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def load_image(image_file):
|
| 35 |
+
if image_file.startswith("http") or image_file.startswith("https"):
|
| 36 |
+
response = requests.get(image_file)
|
| 37 |
+
image = Image.open(BytesIO(response.content)).convert("RGB")
|
| 38 |
+
else:
|
| 39 |
+
image = Image.open(image_file).convert("RGB")
|
| 40 |
+
return image
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def load_images(image_files):
|
| 44 |
+
out = []
|
| 45 |
+
for image_file in image_files:
|
| 46 |
+
image = load_image(image_file)
|
| 47 |
+
out.append(image)
|
| 48 |
+
return out
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def eval_model(args):
|
| 52 |
+
# Model
|
| 53 |
+
disable_torch_init()
|
| 54 |
+
|
| 55 |
+
model_name = get_model_name_from_path(args.model_path)
|
| 56 |
+
tokenizer, model, image_processor, context_len = load_pretrained_model(
|
| 57 |
+
args.model_path, args.model_base, model_name
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
qs = args.query
|
| 61 |
+
image_token_se = DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN + DEFAULT_IM_END_TOKEN
|
| 62 |
+
if IMAGE_PLACEHOLDER in qs:
|
| 63 |
+
if model.config.mm_use_im_start_end:
|
| 64 |
+
qs = re.sub(IMAGE_PLACEHOLDER, image_token_se, qs)
|
| 65 |
+
else:
|
| 66 |
+
qs = re.sub(IMAGE_PLACEHOLDER, DEFAULT_IMAGE_TOKEN, qs)
|
| 67 |
+
else:
|
| 68 |
+
if model.config.mm_use_im_start_end:
|
| 69 |
+
qs = image_token_se + "\n" + qs
|
| 70 |
+
else:
|
| 71 |
+
qs = DEFAULT_IMAGE_TOKEN + "\n" + qs
|
| 72 |
+
|
| 73 |
+
if "llama-2" in model_name.lower():
|
| 74 |
+
conv_mode = "llava_llama_2"
|
| 75 |
+
elif "v1" in model_name.lower():
|
| 76 |
+
conv_mode = "llava_v1"
|
| 77 |
+
elif "mpt" in model_name.lower():
|
| 78 |
+
conv_mode = "mpt"
|
| 79 |
+
else:
|
| 80 |
+
conv_mode = "llava_v0"
|
| 81 |
+
|
| 82 |
+
if args.conv_mode is not None and conv_mode != args.conv_mode:
|
| 83 |
+
print(
|
| 84 |
+
"[WARNING] the auto inferred conversation mode is {}, while `--conv-mode` is {}, using {}".format(
|
| 85 |
+
conv_mode, args.conv_mode, args.conv_mode
|
| 86 |
+
)
|
| 87 |
+
)
|
| 88 |
+
else:
|
| 89 |
+
args.conv_mode = conv_mode
|
| 90 |
+
|
| 91 |
+
conv = conv_templates[args.conv_mode].copy()
|
| 92 |
+
conv.append_message(conv.roles[0], qs)
|
| 93 |
+
conv.append_message(conv.roles[1], None)
|
| 94 |
+
prompt = conv.get_prompt()
|
| 95 |
+
|
| 96 |
+
image_files = image_parser(args)
|
| 97 |
+
images = load_images(image_files)
|
| 98 |
+
images_tensor = process_images(
|
| 99 |
+
images,
|
| 100 |
+
image_processor,
|
| 101 |
+
model.config
|
| 102 |
+
).to(model.device, dtype=torch.float16)
|
| 103 |
+
|
| 104 |
+
input_ids = (
|
| 105 |
+
tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors="pt")
|
| 106 |
+
.unsqueeze(0)
|
| 107 |
+
.cuda()
|
| 108 |
+
)
|
| 109 |
+
|
| 110 |
+
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
|
| 111 |
+
keywords = [stop_str]
|
| 112 |
+
stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)
|
| 113 |
+
|
| 114 |
+
with torch.inference_mode():
|
| 115 |
+
output_ids = model.generate(
|
| 116 |
+
input_ids,
|
| 117 |
+
images=images_tensor,
|
| 118 |
+
do_sample=True if args.temperature > 0 else False,
|
| 119 |
+
temperature=args.temperature,
|
| 120 |
+
top_p=args.top_p,
|
| 121 |
+
num_beams=args.num_beams,
|
| 122 |
+
max_new_tokens=args.max_new_tokens,
|
| 123 |
+
use_cache=True,
|
| 124 |
+
stopping_criteria=[stopping_criteria],
|
| 125 |
+
)
|
| 126 |
+
|
| 127 |
+
input_token_len = input_ids.shape[1]
|
| 128 |
+
n_diff_input_output = (input_ids != output_ids[:, :input_token_len]).sum().item()
|
| 129 |
+
if n_diff_input_output > 0:
|
| 130 |
+
print(
|
| 131 |
+
f"[Warning] {n_diff_input_output} output_ids are not the same as the input_ids"
|
| 132 |
+
)
|
| 133 |
+
outputs = tokenizer.batch_decode(
|
| 134 |
+
output_ids[:, input_token_len:], skip_special_tokens=True
|
| 135 |
+
)[0]
|
| 136 |
+
outputs = outputs.strip()
|
| 137 |
+
if outputs.endswith(stop_str):
|
| 138 |
+
outputs = outputs[: -len(stop_str)]
|
| 139 |
+
outputs = outputs.strip()
|
| 140 |
+
print(outputs)
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
if __name__ == "__main__":
|
| 144 |
+
parser = argparse.ArgumentParser()
|
| 145 |
+
parser.add_argument("--model-path", type=str, default="facebook/opt-350m")
|
| 146 |
+
parser.add_argument("--model-base", type=str, default=None)
|
| 147 |
+
parser.add_argument("--image-file", type=str, required=True)
|
| 148 |
+
parser.add_argument("--query", type=str, required=True)
|
| 149 |
+
parser.add_argument("--conv-mode", type=str, default=None)
|
| 150 |
+
parser.add_argument("--sep", type=str, default=",")
|
| 151 |
+
parser.add_argument("--temperature", type=float, default=0.2)
|
| 152 |
+
parser.add_argument("--top_p", type=float, default=None)
|
| 153 |
+
parser.add_argument("--num_beams", type=int, default=1)
|
| 154 |
+
parser.add_argument("--max_new_tokens", type=int, default=512)
|
| 155 |
+
args = parser.parse_args()
|
| 156 |
+
|
| 157 |
+
eval_model(args)
|
LLaVA-Plus-Codebase/llava/eval/summarize_gpt_review.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import os
|
| 3 |
+
from collections import defaultdict
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
|
| 7 |
+
import argparse
|
| 8 |
+
|
| 9 |
+
def parse_args():
|
| 10 |
+
parser = argparse.ArgumentParser(description='ChatGPT-based QA evaluation.')
|
| 11 |
+
parser.add_argument('-d', '--dir', default=None)
|
| 12 |
+
parser.add_argument('-v', '--version', default=None)
|
| 13 |
+
parser.add_argument('-s', '--select', nargs='*', default=None)
|
| 14 |
+
parser.add_argument('-f', '--files', nargs='*', default=[])
|
| 15 |
+
parser.add_argument('-i', '--ignore', nargs='*', default=[])
|
| 16 |
+
return parser.parse_args()
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
if __name__ == '__main__':
|
| 20 |
+
args = parse_args()
|
| 21 |
+
|
| 22 |
+
if args.ignore is not None:
|
| 23 |
+
args.ignore = [int(x) for x in args.ignore]
|
| 24 |
+
|
| 25 |
+
if len(args.files) > 0:
|
| 26 |
+
review_files = args.files
|
| 27 |
+
else:
|
| 28 |
+
review_files = [x for x in os.listdir(args.dir) if x.endswith('.jsonl') and (x.startswith('gpt4_text') or x.startswith('reviews_') or x.startswith('review_') or 'review' in args.dir)]
|
| 29 |
+
|
| 30 |
+
for review_file in sorted(review_files):
|
| 31 |
+
config = os.path.basename(review_file).replace('gpt4_text_', '').replace('.jsonl', '')
|
| 32 |
+
if args.select is not None and any(x not in config for x in args.select):
|
| 33 |
+
continue
|
| 34 |
+
if '0613' in config:
|
| 35 |
+
version = '0613'
|
| 36 |
+
else:
|
| 37 |
+
version = '0314'
|
| 38 |
+
if args.version is not None and args.version != version:
|
| 39 |
+
continue
|
| 40 |
+
scores = defaultdict(list)
|
| 41 |
+
print(config)
|
| 42 |
+
with open(os.path.join(args.dir, review_file) if args.dir is not None else review_file) as f:
|
| 43 |
+
for review_str in f:
|
| 44 |
+
review = json.loads(review_str)
|
| 45 |
+
if review['question_id'] in args.ignore:
|
| 46 |
+
continue
|
| 47 |
+
if 'category' in review:
|
| 48 |
+
scores[review['category']].append(review['tuple'])
|
| 49 |
+
scores['all'].append(review['tuple'])
|
| 50 |
+
else:
|
| 51 |
+
if 'tuple' in review:
|
| 52 |
+
scores['all'].append(review['tuple'])
|
| 53 |
+
else:
|
| 54 |
+
scores['all'].append(review['score'])
|
| 55 |
+
for k, v in sorted(scores.items()):
|
| 56 |
+
stats = np.asarray(v).mean(0).tolist()
|
| 57 |
+
stats = [round(x, 3) for x in stats]
|
| 58 |
+
# print(k, stats, round(stats[1]/stats[0]*100, 1))
|
| 59 |
+
print(k, round(stats[1]/stats[0]*100, 1), round(stats[0] * 10, 1), round(stats[1] * 10, 1))
|
| 60 |
+
print('=================================')
|
LLaVA-Plus-Codebase/llava/eval/table/answer/answer_alpaca-13b.jsonl
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"question_id": 1, "text": "Improving time management skills involves setting priorities, breaking tasks into smaller chunks, delegating tasks, avoiding multitasking, and taking regular breaks. Additionally, it is important to have a positive attitude and be realistic with goals. Making a to-do list, tracking time, and using technology to automate mundane tasks can also help improve time management skills.", "answer_id": "kEL9ifUHDeYuAXzevje2se", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 2 |
+
{"question_id": 2, "text": "The most effective ways to deal with stress include identifying and avoiding the sources of stress, developing healthy coping mechanisms, and engaging in relaxation techniques such as meditation, deep breathing, and physical exercise. Additionally, it is important to take care of one's mental and physical health, get enough rest and nutrition, and practice self-care.", "answer_id": "VcF3NrWGXhhxLkDVurNrwq", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 3 |
+
{"question_id": 3, "text": "The main differences between Python and JavaScript programming languages are in their syntax, structure, and the type of applications they are designed for. Python is a general-purpose language designed to be easy to read and write, while JavaScript is primarily used for web development. Python is a compiled language, while JavaScript is an interpreted language. Python is strongly typed, while JavaScript is not. Python is typically faster than JavaScript in terms of execution, while JavaScript is better suited to create interactive web pages.", "answer_id": "LpvtyQi9QdSgRrgGDxiGrT", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 4 |
+
{"question_id": 4, "text": "Working from home can be a great way to increase productivity, but it does require some strategic planning and tactics. Here are some tips for increasing your productivity while working from home: \n1. Establish a routine: Having a regular schedule and sticking to it can help you stay focused and motivated.\n2. Create a distraction-free zone: Eliminate distractions by turning off notifications and setting a \u201cdo not disturb\u201d mode.\n3. Take breaks: Working for long stretches without taking breaks can lead to burnout and decreased productivity.\n4. Exercise: Exercise can help improve focus and productivity.\n5. Get organized: Having a clean and organized workspace can help you stay on task.\n6. Set goals: Set short-term and long-term goals to keep you motivated and on track.\n7. Connect with colleagues: Don\u2019t be afraid to reach out to colleagues for help or advice.\n8. Track your progress: Keep track of your progress and celebrate your successes.\n9. Unplug: Taking breaks and unplugging from work can help you recharge and come back to work more refreshed.", "answer_id": "7zQm8cSTJhPtPdZdxbcfrX", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 5 |
+
{"question_id": 5, "text": "Sure. Quantum computing is a new technology that uses quantum mechanical phenomena to perform operations on data. Unlike traditional computers, which process information in binary form, quantum computers can process information in multiple states at the same time, allowing them to perform operations faster and with more accuracy. It also allows them to solve problems that classical computers struggle with. Quantum computing is still in its infancy, but it has the potential to revolutionize the computing industry and open up new possibilities in artificial intelligence, cryptography, and other fields.", "answer_id": "UrLEH82RHwqqLt2LyvYSKj", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 6 |
+
{"question_id": 6, "text": "Plant-based protein sources include legumes, grains, nuts, and seeds, and are generally lower in fat and calories than animal-based proteins. Animal-based proteins come from sources such as meat, eggs, and dairy, and are generally higher in fat and calories than plant-based proteins. Plant-based proteins are also generally lower in cholesterol and saturated fat than animal-based proteins. Additionally, plant-based proteins require fewer resources for production, such as water and land, than animal-based proteins.", "answer_id": "fpRdMTdnfirosQixuf2Gez", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 7 |
+
{"question_id": 7, "text": "Developing critical thinking skills involves actively questioning assumptions, taking multiple perspectives, analyzing information, and coming to logical conclusions. You can practice these skills by posing questions to yourself and working through problems, as well as engaging in thoughtful discussion with others.", "answer_id": "PvGmsCJSNFcvQKmPTnnd7s", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 8 |
+
{"question_id": 8, "text": "The major challenges faced by the education sector include lack of access to quality education, low educational outcomes, high costs of education, lack of adequate infrastructure and teaching materials, overcrowding in classrooms, and gender inequality. Other challenges include lack of access to technology and digital learning materials, outdated curriculum and pedagogical practices, and inadequate teacher training.", "answer_id": "n4ANAbpR3gvLPP8poPfKZ6", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 9 |
+
{"question_id": 9, "text": "The primary factors that influence consumer behavior include cultural, social, and personal factors. Cultural factors include shared beliefs, values, and customs within a society, while social factors include the influence of family, friends, and peers. Personal factors include an individual's lifestyle, attitudes, beliefs, and past experiences. Other factors such as advertising, marketing, and price also have an effect on consumer behavior.", "answer_id": "STJ36GrgQMcaUi7zaoNPit", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 10 |
+
{"question_id": 10, "text": "The most effective strategies for conflict resolution in the workplace include:\n1. Establishing open communication: Encouraging open and honest communication between parties is key to resolving any conflict.\n2. Listening actively: Active listening allows both parties to feel heard and allows for a better understanding of the other person's perspective.\n3. Identifying root causes: Understanding the underlying cause of the conflict can help to find more effective solutions that address the core issue.\n4. Focusing on interests, not positions: Focusing on the interests of both parties can help to find creative solutions that satisfy the needs of everyone involved.\n5. Developing mutual respect: Respect is essential to any successful resolution. Building mutual respect can help to create a healthier work environment.\n6. Negotiation: Working together to negotiate a mutually beneficial solution can help to create an agreement that both parties are happy with.\n7. Taking responsibility: Taking responsibility for one\u2019s words and actions can help to create a culture of accountability in the workplace.", "answer_id": "425SwYvqKPAXFGTYKXB7Cs", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 11 |
+
{"question_id": 11, "text": "The use of single-use plastic bottles has a number of negative implications on the environment. They are not biodegradable and can take hundreds of years to break down. This means they are around for a long time, releasing potentially harmful chemicals into the environment, and they can be easily mistaken for food by animals. Single-use plastic bottles can also be a source of micro-plastics, which are very small particles of plastic that are difficult to clean up and can be consumed by fish and other aquatic life, leading to health problems in humans who consume those fish. On the other hand, reusable bottles are a much more environmentally friendly choice since they do not produce any waste. They are also often made of materials that are safer for human health, such as stainless steel or glass. Reusable bottles are also more cost-effective since they do not need to be replaced as often as single-use plastic bottles.", "answer_id": "VbNAuj6KAkMdLJQXMo22oK", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 12 |
+
{"question_id": 12, "text": "When designing an inclusive and accessible public transportation system, some factors to consider include providing frequent and reliable service, accessible stops and vehicles, a variety of fare options, clear and consistent signage and information, comfortable seating and space for wheelchairs and other assistive devices, and security and safety protocols. Additionally, public transportation systems should be integrated with other services such as public parking, bike and scooter sharing, and shuttles to provide a comprehensive and accessible experience.", "answer_id": "CNGqAeu2QJbQ4QGzHJDPdq", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 13 |
+
{"question_id": 13, "text": "Governments can use fiscal and monetary policies to combat economic recessions. Fiscal policies involve the government spending money or cutting taxes in order to stimulate the economy, while monetary policies involve changing the money supply or interest rates to influence economic activity. These policies can be used to stabilize the economy, create jobs, and reduce poverty.", "answer_id": "E8w2qYqnm8iqCrSkUv62sz", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 14 |
+
{"question_id": 14, "text": "Language and cultural barriers can lead to misunderstandings and make it more difficult to communicate and form relationships in multicultural societies. Without a common language or shared culture, people can have difficulty understanding each other's perspectives and beliefs, which can lead to mistrust and a lack of understanding between different ethnic groups. To overcome these barriers, it is important to make an effort to learn about different cultures, be open-minded, and take the time to understand each other.", "answer_id": "8o5yMymfzo6kzmp9GK5MWr", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 15 |
+
{"question_id": 15, "text": "Artificial intelligence can be used to improve the quality and efficiency of healthcare delivery in a variety of ways. AI can be used to assist with diagnosing diseases by comparing symptoms and medical history to images of known diseases and medical conditions. AI can also be used to analyze laboratory results and patient records to identify potential problems and develop treatment plans. AI can be used to automate administrative tasks and reduce paperwork, as well as identify potential drug interactions and side effects. AI can also be used to automate appointment reminders, facilitate communication between doctors and patients, and even provide virtual health coaching to help patients manage their conditions.", "answer_id": "kbJVEEsdsSScEq5Y5furr7", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 16 |
+
{"question_id": 16, "text": "CRISPR-Cas9 is a recently developed gene editing technology that has revolutionized the way scientists are able to edit genomes. The technology uses a guide RNA to direct the Cas9 enzyme to a specific location in the genome, where it will cut the DNA strands. This allows for the insertion or deletion of DNA sequences, which can be used to modify the genetic code of an organism. Potential applications include treating genetic diseases, increasing crop yields, and creating pest-resistant crops. Ethically, the biggest concern is the potential misuse of the technology, which could lead to unintended consequences or be used to alter humanity in ways that could harm us.", "answer_id": "CMUL5ULZuR7YC5EPzCBN2N", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 17 |
+
{"question_id": 17, "text": "Vaccinations work by stimulating the body's immune system to protect against infectious diseases. Herd immunity is a concept whereby a population is protected against a certain disease when a certain percentage of the population has immunity to the disease, either through vaccination or having already contracted the disease. This is because when enough people are vaccinated, it reduces the spread of the disease and prevents it from spreading to those who are not immune.", "answer_id": "kEmDDQyNqSkyFihYEEBpuR", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 18 |
+
{"question_id": 18, "text": "Social media platforms can have a significant influence on how people consume and share news. By providing instant access to news sources and allowing users to easily share content, these platforms can shape the public's information landscape and the spread of misinformation. Some potential implications of this are that users may not always be able to discern between reliable and unreliable sources, and misleading information may be more easily spread and go viral. This can lead to confusion and mistrust among users, and can potentially be exploited for nefarious purposes. To mitigate these risks, it is important for users to be aware of the potential biases and agendas of the sources they are consuming, and for social media platforms to take proactive steps to curb the spread of misinformation.", "answer_id": "Qs3grQsqFVGK9EVkCkf9PB", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 19 |
+
{"question_id": 19, "text": "Cultural, social, and economic factors all play a role in determining an individual's food choices. For example, people growing up in households with limited economic means may be more likely to consume cheaper, less nutritious foods due to economic constraints. Additionally, cultural norms and values can influence food choices, such as the emphasis on large portions typical in some American cultural settings. Finally, social factors such as peer pressure and advertising can also sway an individual's food choices. By understanding and taking into account these various factors, health promotion strategies can be tailored and targeted to help individuals make healthier dietary decisions.", "answer_id": "kzZ6dKN7hkRWjqtdHr7Qns", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 20 |
+
{"question_id": 20, "text": "Natural selection is the process by which certain traits or characteristics become more or less common in a population over time. This is due to the fact that those individuals with certain advantageous traits are more likely to survive, reproduce, and pass those traits on to their offspring. Over time, this leads to the evolution and adaptation of species to their environment.", "answer_id": "DPPDG6YGFJij2GCmRL66PU", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 21 |
+
{"question_id": 21, "text": "I am a brave knight, loyal to my king and country, and I have come to serve and protect them both. I am skilled in the arts of war and peace, and I am proud to be here at the royal court.", "answer_id": "D62FjDb4nZANzPpfSfsiyn", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 22 |
+
{"question_id": 22, "text": "Avast ye maties! To the bottom of the sea we go! In search of hidden riches and fortune, we shall brave the depths and face any danger that comes our way. For glory and honor, let us set sail and find the lost Ark!", "answer_id": "k7E4NNw5kyj9DmvP5Pu2zb", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 23 |
+
{"question_id": 23, "text": "If I were a Shakespearean character, I would declare my love for someone in a soliloquy with passionate words and metaphors. I would express my love for them with descriptions of their beauty and the joy I feel when I am with them. I would confess my hopes and dreams for our future together and declare my devotion to them. I would make my love for them known in a way that could never be forgotten.", "answer_id": "KFocjVCejYrU3YmLjAqoUF", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 24 |
+
{"question_id": 24, "text": "As a superhero, my origin story is very special. I was born with special abilities that I had to keep hidden for a long time. I was scared to use them at first, but eventually I discovered that I could use my powers to protect people and make the world a better place. I've had to face a lot of challenges along the way, but I've also had a lot of help from friends and family. Now, I use my abilities to help people in need and fight for justice.", "answer_id": "dq8Sm9djS7e7y9sG9vmMJf", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 25 |
+
{"question_id": 25, "text": "If I were a time traveler from the year 3000, I would tell people about the incredible advancements in technology, such as the ability to travel through time, space, and dimensions; the development of intelligent robots and autonomous vehicles; the emergence of virtual reality and augmented reality; and the rise of artificial intelligence and machine learning.", "answer_id": "XZ8fG8e6u7CyKd2moK6abe", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 26 |
+
{"question_id": 26, "text": "The game was a nail-biter, with both teams trading leads throughout the game. With only seconds left on the clock, the home team made a bold move and passed the ball to their star player, who took the ball down the court and made a layup at the buzzer to seal the victory for the home team!", "answer_id": "oKaXHfoK4pXwrefFWXmeA8", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 27 |
+
{"question_id": 27, "text": "My signature dish is a seamless blend of traditional and modern cooking techniques. I use only the freshest ingredients to create a unique and unforgettable dining experience. The dish is a perfect balance of flavors and textures, with a subtle hint of my personal style. It is a dish that I am proud to call my own.", "answer_id": "ZwiZfvDWm7SETKNBfDk7Mb", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 28 |
+
{"question_id": 28, "text": "At the summit of Mount Everest, you are filled with a sense of accomplishment and joy. The view from the top is absolutely breathtaking - you can see for miles and miles, with the majestic Himalayan mountain range stretching out in all directions. It is a truly unforgettable experience.", "answer_id": "DxYopRe2LcTJMy3FWu6btd", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 29 |
+
{"question_id": 29, "text": "As a colonist on Mars, my daily life is filled with challenges. Finding resources and creating a sustainable environment is a priority. I face a number of challenges including extreme temperature fluctuations, limited access to resources, and the difficulty of travelling to and from the planet. Additionally, I must be mindful of my physical and mental health since I am so far from home. Despite these challenges, I am grateful to be able to explore and experience this new world.", "answer_id": "WC3UJVh4jQ5RUkpcRMU98L", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 30 |
+
{"question_id": 30, "text": "In the post-apocalyptic world, I am a survivor by necessity. I scavenge for food and supplies, and I'm always on the lookout for potential allies. I've encountered a few people who have managed to survive, and together we have formed an alliance to help each other. We hunt for food, build shelter, and work together to stay alive. We also share knowledge and skills, like how to start a fire or how to use a weapon. We look out for each other, and our alliance has strengthened our chances of survival.", "answer_id": "gTvgn6ksDjGGgdprw6AG5A", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 31 |
+
{"question_id": 31, "text": "There are a few ways to tell if a restaurant is popular among locals or mainly attracts tourists. Firstly, look at the clientele - if the majority of people there are tourists, it's likely that the restaurant is mainly attracting tourists. Secondly, check online reviews - if the reviews are mainly from tourists, then it's likely that the restaurant is popular with tourists. Finally, look at the prices - if the prices are higher than average for the area, it could be a sign that the restaurant is popular with locals. This information can be useful to get an idea of what kind of experience to expect, as locals might know about different aspects of the restaurant that tourists wouldn't.", "answer_id": "3q7giCk2BA3Ye4Tm9HC2iw", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 32 |
+
{"question_id": 32, "text": "Some subtle clues that suggest someone is pretending to understand a topic or conversation when they are actually confused or uninformed include: not asking any questions or engaging in the conversation, avoiding eye contact, fidgeting or stammering when speaking, repeating questions or comments made by other people, and nodding along without any signs of understanding.", "answer_id": "hRGsxy86v26SC4yAQS29X4", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 33 |
+
{"question_id": 33, "text": "Some people prefer the tactile and visual experience of using a paper map, and others may prefer to ask for directions from locals in order to get a more personalized experience. Additionally, GPS devices and smartphone apps can sometimes be inaccurate or have limited battery life, while a paper map or asking for directions may be more reliable.", "answer_id": "3n49A5ggJERfXYrLns3ZeU", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 34 |
+
{"question_id": 34, "text": "One way to tell if someone is genuinely interested in a conversation is to observe their body language and facial expressions. Are they making an effort to maintain eye contact? Are they leaning in and actively listening to what you are saying? Do they ask questions and provide relevant answers? If so, it is likely that they are genuinely interested in the conversation. Additionally, if someone is simply being polite, they may not ask questions or engage in the conversation as much, and may not make an effort to maintain eye contact.", "answer_id": "ErCpFtPuYVru4oTTk4WrxG", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 35 |
+
{"question_id": 35, "text": "Shopping at a small, locally-owned business can benefit the local community by keeping money in the area and supporting local jobs. Additionally, these businesses tend to offer a more personal experience and higher quality products than large chain stores. Furthermore, shopping at small businesses can help create a sense of place and community, and can help maintain a unique local culture.", "answer_id": "PTNoCRMZWoJk8HaKX7fW45", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 36 |
+
{"question_id": 36, "text": "There are several ways to assess the credibility of a source of information. Firstly, you can look at the author's credentials and experience in the relevant field. Secondly, you can check the source of the information, such as whether it is from a reliable website or publication. Thirdly, you can look at the evidence presented in the article and whether it is backed up by reliable sources. Finally, you can read other people's reviews or comments about the article to get a better idea of its credibility.", "answer_id": "n8cFs9KENNwZ4z3SR4iXTr", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 37 |
+
{"question_id": 37, "text": "Some people enjoy the sensation of being scared because it can create a feeling of excitement, enhance their emotional state, and provide a sense of thrill and adventure. Others may avoid these experiences because they are afraid of the unknown, or because they don't enjoy the feeling of being scared. Everyone is different, and some people may be more attracted to thrilling and exciting activities while others may prefer calmer activities.", "answer_id": "GzxL9mmEK5RzKqRbqBMUVC", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 38 |
+
{"question_id": 38, "text": "By observing the behavior of others in a social situation, one can gain clues as to the cultural norms and expectations of a group. For example, watching how people interact with one another, how they address each other, how they handle disagreements, and how they go about solving problems can provide insight into the cultural values of the group. Additionally, observing body language, facial expressions, and other nonverbal cues can offer clues as to the accepted norms of behavior in a particular culture.", "answer_id": "QpoHFgb9SzwuaXQQUuBUQD", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 39 |
+
{"question_id": 39, "text": "It is an interesting question, and one that has been debated for quite some time. I think there are valid arguments on both sides. On the one hand, exploring space is a remarkable human endeavor and could lead to tremendous scientific discoveries and technological advances. On the other hand, there are many pressing issues that need to be addressed on Earth, such as poverty, inequality, and climate change. Each side would argue that their cause is more important, and it is ultimately up to each individual to decide which one they feel more strongly about.", "answer_id": "Fxe6MS4GpP3LMDUwzY2cPA", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 40 |
+
{"question_id": 40, "text": "It is important to strike a balance between job creation and technological progress. Automation can increase efficiency and productivity, but it should not come at the expense of job security and people's livelihoods. Therefore, it is essential to create policies and initiatives that promote both job creation and technological progress. This could include investing in training and education to ensure that people have the skills necessary to compete in the modern job market, as well as incentivizing companies to invest in technologies that create jobs and stimulate economic growth.", "answer_id": "mJiQ2FGR4Xb8kmhZjharkw", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 41 |
+
{"question_id": 41, "text": "On average, the human eye blinks about 20 times per minute, or about 14,400 times per day. In a lifetime, this means that the average human will blink roughly 50 million times. This may seem like a lot, but it serves an important purpose. Blinking helps to keep the eyes lubricated and prevents them from drying out. It also helps to spread tears over the surface of the eye, washing away foreign particles and keeping the eye clean. Additionally, blinking helps to reduce the risk of eye infections by helping to clear away bacteria and other foreign substances.", "answer_id": "6Kph4RHRKEZ4YUoaHuEhBv", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 42 |
+
{"question_id": 42, "text": "A grain of salt contains 102.98 atoms. To calculate this, we first need to know the atomic weight of a single atom. The atomic weight of an atom is the number of protons and neutrons in the nucleus of an atom, which determines its atomic mass. The atomic weight of a single atom of salt is 58.943 g/atom. Therefore, a grain of salt contains 102.98 atoms, which is equivalent to 60.98 grams.", "answer_id": "WBwpBQwhxn5kxLDb7MschC", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 43 |
+
{"question_id": 43, "text": "Approximately 2000 lightning strikes occur on Earth each day. This is because the atmospheric conditions must come together in a particular way for a lightning strike to occur. Firstly, a large amount of electric charge must accumulate in the atmosphere, typically in a storm system. Then, the air must become increasingly unstable, leading to rising air and a strong updraft. This causes an electric breakdown of the air, and then an exchange of electricity occurs from the cloud to the ground, forming a lightning bolt. As these conditions are necessary for a lightning strike to occur, about 2000 lightning strikes happen on Earth each day.", "answer_id": "kf8nahQVci2ZLaYikagB7U", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 44 |
+
{"question_id": 44, "text": "It would take about 10 million balloons to lift a house like in the movie Up. The balloons would need to be filled with helium in order for the house to be lifted. Each balloon would need to be filled with about 89.1 cubic feet of helium in order to lift 500 pounds. To calculate how many balloons would be needed, simply multiply the weight of the house (264.72 lbs) by the number of cubic feet of helium needed to lift 500 pounds (89.1). Therefore, it would take 10 million balloons to lift a house like in the movie Up.", "answer_id": "Gptgryd4o2dC8V5aqRmeJJ", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 45 |
+
{"question_id": 45, "text": "According to a 2017 study, over 6.3 billion text messages are sent globally in a minute. This number is expected to grow to 6.8 billion by 2021. This is due to the increasing number of smartphones, better network coverage, and the increasing popularity of texting for communication. Furthermore, the increase in smartphones and better network coverage has also led to the rise of instant messaging applications such as WhatsApp, which has further increased the amount of text messages sent per minute.", "answer_id": "RfBWW8ZhdfTuTMb454Un4o", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 46 |
+
{"question_id": 46, "text": "It is estimated that over 1 billion words are spoken on Earth every day. This is due to the fact that humans are highly social creatures, and language is the primary way that we communicate with each other. In addition, language is a key component of all cultures and societies, and is constantly being used to exchange information and ideas. Furthermore, language is integral to the way we think and process information, as well as to how we connect with each other on an emotional level. Therefore, it is not surprising that so many words are spoken on a daily basis.", "answer_id": "neGgLYm47JvqN8qkw8VeoW", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 47 |
+
{"question_id": 47, "text": "On average, about 100 snowflakes fall per second during a typical winter. This number can vary drastically depending on the location and severity of the storm. Snowflakes are made up of tiny ice crystals, which form in the atmosphere when the temperature is below freezing and there is moisture in the air. As air moves and mixes, the crystals come together to form snowflakes. The shape, size and number of snowflakes depend on the atmospheric conditions, such as temperature and humidity, when they form.", "answer_id": "KSePbzLwsYasR3aui4HU8h", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 48 |
+
{"question_id": 48, "text": "It is estimated that all the books ever written would total about 100 billion pages. This is based on the fact that there are roughly 130 million unique titles in existence, and each book on average contains about 200 pages. This means that if all the books were printed out, the stack of paper would be about 400 miles high. Additionally, if each book was represented by a single page, the total number of pages would be approximately 100 billion. Throughout history, books have served as a way to preserve knowledge and information, as well as to share ideas and stories with others. As technology advances, books are increasingly available in digital formats, which allows for easier access and storage. Regardless of the medium, books will continue to be a valuable source of information for generations to come.", "answer_id": "SWWfLpP2gnWHLbYRZXNsW3", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 49 |
+
{"question_id": 49, "text": "Since the beginning of life, the Earth has orbited the Sun a total of 4.3 billion times. This is calculated by multiplying the average length of a year (365.25 days) by the number of years since life began (approximately 4.5 billion years). Life on Earth relies on the Sun's energy reaching the Earth's atmosphere and being redistributed by the atmosphere, the land surface, and the oceans. Without this energy, life on Earth would not be possible. Therefore, the Earth's orbit around the Sun is integral to the sustainability of life on Earth.", "answer_id": "WaBwKYhs7eAG22qCGLH2j3", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 50 |
+
{"question_id": 50, "text": "Since the beginning of recorded music, countless songs have been recorded. The exact number is difficult to quantify, but conservative estimates put the number of songs recorded throughout history at several hundred thousand. This includes songs from all genres, from classical music to modern pop. The invention of recording technology has allowed musicians to preserve their music and share it with the world. This has enabled generations to access and enjoy music from all eras. With the rise of digital music, the number of recordings available has grown exponentially, and new songs are being recorded all the time.", "answer_id": "MfMJeE9om7qyBbqopHouf4", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 51 |
+
{"question_id": 51, "text": "If the Internet had been invented during the Renaissance period, it likely would have been used primarily by the wealthy and powerful to access knowledge and information, as there was no widespread system of public education at the time. It also would have been a much slower and more expensive process to access information, as there were no high-speed connections or digital networks available.", "answer_id": "TjWPRDM6JFpPF8xeRptCKb", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 52 |
+
{"question_id": 52, "text": "If the Aztecs had successfully repelled the Spanish conquistadors, their culture and way of life would have likely remained intact. The Spanish would not have been able to colonize Mexico, and their influence on the region would have been much less. It's likely that the Aztecs would have continued to expand their empire and control the areas that are now parts of Central and South America. Additionally, the Native American populations in the area would have likely been able to maintain more of their traditional customs and beliefs, and their languages may not have been as heavily impacted by Spanish.", "answer_id": "iR2tYTsWTFENEP7Qy9RgtX", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 53 |
+
{"question_id": 53, "text": "If the Black Death had not occurred in the 14th century, the population of Europe may have continued to grow unabated, leading to more rapid urbanization and economic growth. It's likely that the Renaissance would have begun sooner, and the scientific revolution may have occurred earlier as well. Without the Black Death, there may have been no need for the industrial revolution, or at least it may have occurred later and on a smaller scale. Additionally, the spread of diseases may have been slower, leading to greater population density in certain areas.", "answer_id": "AZdS8xAi3GwAmCqkNSnnwv", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 54 |
+
{"question_id": 54, "text": "If Isaac Newton had focused on biology instead of physics, he might have made important discoveries in the field of medicine and biology. He may have studied the human body and its functions in greater detail, and possibly even made important breakthroughs in treating diseases. He may also have studied the behavior of different animals in the wild and made important observations about their habits and habitats.", "answer_id": "VmwifF2JD5osYKDTqv2ZRS", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 55 |
+
{"question_id": 55, "text": "If the Beatles had never formed as a band, the music world would have been drastically different. The British Invasion of the 1960s might not have happened, or it could have happened in a much different way. The cultural impact of the Beatles, including their influence on other musicians, fashion and society, may never have existed.", "answer_id": "mUL5UPj3qDGaCriEjL2U3B", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 56 |
+
{"question_id": 56, "text": "If Alan Turing had not cracked the Enigma code during World War II, the outcome of the war could have been very different. It's possible that the Allies would have eventually defeated the Axis powers, but it likely would have taken much longer and cost many more lives. With the Enigma code cracked, the Allies were able to gain a critical advantage over the Axis powers and ultimately win the war.", "answer_id": "dVdwUoVrAQJDuWxiodykiw", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 57 |
+
{"question_id": 57, "text": "If the Suez Canal had never been constructed, it would have major implications for international trade and navigation. The Suez Canal is an important shipping route connecting the Mediterranean Sea to the Red Sea, which in turn connects to the Indian Ocean. This allows for a shorter and more direct route for ships traveling between Europe and Asia, reducing travel time significantly. Without the Suez Canal, ships would have to travel around the Cape of Good Hope at the southern tip of Africa, which is much more time consuming and costly. This would make international trade more difficult and expensive, and could hinder global economic growth.", "answer_id": "EiNn9jjfy7dga6xfCtLtF8", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 58 |
+
{"question_id": 58, "text": "If the Maya civilization had not mysteriously collapsed, it is likely that their influence and power would have continued to grow. They would have likely continued to build large cities and monuments, develop their writing and astronomical systems, and expand their trade networks. Additionally, their advances in agriculture and water management may have led to increased food production and a larger population.", "answer_id": "eqG9f2R9hXVyZrZMpcqAYq", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 59 |
+
{"question_id": 59, "text": "If Christopher Columbus had not discovered the Americas, the indigenous people of the Americas would have continued to live in relative isolation from the rest of the world. It is likely that European colonization and the consequences of that would have been delayed, leading to a different modern world. It is also possible that other Europeans would have made the voyage across the Atlantic and discovered the Americas instead.", "answer_id": "ex42CLEzDVC2TxAvMCtYQJ", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 60 |
+
{"question_id": 60, "text": "If Vincent van Gogh had been successful during his lifetime, he may have been able to achieve the recognition and financial stability that he desired. He may have been able to travel and gain more exposure for his artwork, as well as connect with other like-minded individuals. He may have been able to create more artwork and expand his portfolio. He may also have been able to find a mentor or patron who could have helped him further his career.", "answer_id": "RfFANSwHeCm3Pqe2AJ86Dk", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 61 |
+
{"question_id": 61, "text": "The program should read a text file line by line. It should then check each line for the specified word, counting up each time the word is found. Finally, it should output the number of occurrences of the word.", "answer_id": "nzxdtWmgQhRkHeVAanVogZ", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 62 |
+
{"question_id": 62, "text": "The following Python function can be used to find the longest common subsequence of two input strings using dynamic programming:\ndef longest_common_subsequence(s1, s2):\n\"\"\"This function finds the longest common subsequence of two strings.\n\n Arguments:\n s1 {string} -- The first string\n s2 {string} -- The second string\n\n Returns:\n {int} -- The length of the longest common subsequence\n\n\"\"\"\n n1 = len(s1)\n n2 = len(s2)\n \n # Creating an empty matrix to store the results\n results = [[None]*(n2 + 1) for _ in range(n1 + 1)]\n \n # Initializing the first row to 0\n for i in range(n1 + 1):\n results[i][0] = 0\n \n # Filling the first row with 0\n for i in range(n1):\n results[i][0] = 0\n \n # Calculating the longest common subsequence\n for i in range(n1 + 1):\n for j in range(n2 + 1):\n if (i == 0 or j == 0):\n results[i][j] = 0\n elif (s1[i-1] == s2[j-1] and (results[i-1][j-1] < (i-j) or results[i-1][j-1] == 0)):\n results[i][j] = max(results[i-1][j-1] + 1, i+j)\n else:\n results[i][j] = 0\n \n return results[n1][n2]", "answer_id": "kRo6z5qmeiSM8Xz6BPJHLC", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 63 |
+
{"question_id": 63, "text": "The following regular expression can be used to validate an email address in Python:\n^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\\.[a-zA-Z0-9-.]+$", "answer_id": "7kj8odEE79UBdR4pT6u6TY", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 64 |
+
{"question_id": 64, "text": "Here is a program to find the nth Fibonacci number using dynamic programming:\n1. Set a variable 'n' to the nth Fibonacci number.\n2. Set two other variables 'a' and 'b' to 0 and 1 respectively.\n3. Set a loop from 0 to (n-1).\n4. In the loop, set another loop from 0 to (a+b).\n5. In the inner loop, if 'a' is even and 'b' is odd, set 'a' to a+1 and 'b' to b+1.\n6. If 'a' is odd and 'b' is even, set 'a' to a-1 and 'b' to b-1.\n7. After the inner loop, set 'n' to 'a' and break out of the outer loop.\n8. Print the value of 'n'.\nThis program uses the idea of dynamic programming to compute the nth Fibonacci number. The program first sets two auxiliary variables 'a' and 'b' to 0 and 1 respectively. Then it sets a loop from 0 to (n-1). In the loop, it sets another loop from 0 to (a+b). In the inner loop, if 'a' is even and 'b' is odd, it sets 'a' to a+1 and 'b' to b+1. If 'a' is odd and 'b' is even, it sets 'a' to a-1 and 'b' to b-1. After the inner loop, it sets 'n' to 'a' and breaks out of the outer loop. Finally, it prints the value of 'n'.", "answer_id": "UULZ4GLz9j9ot7tN7x3ySD", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 65 |
+
{"question_id": 65, "text": "A binary search algorithm can be used to find a specific element in a sorted array by repeatedly splitting the array in half and examining the middle element to determine whether the target element is greater than, less than, or equal to it. If the target element is found, the algorithm immediately returns the index of the element. If it isn\u2019t, the array is split in half, with one half discarded based on the comparison. The process is repeated until the element is found or the array is completely searched.", "answer_id": "Rh8P3bxSJx4p6nCZkSZBrh", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 66 |
+
{"question_id": 66, "text": "Implementing a queue using two stacks in Python is relatively simple. First, you need to create two stacks, which will act as the queue. Next, you need to define an enqueue and dequeue method, which will add and remove items from the queue. Finally, you need to create an instance of the queue class and start using it.", "answer_id": "R3aYUUtY46ht4ToU8US96x", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 67 |
+
{"question_id": 67, "text": "The program can be implemented using two nested for loops. The inner loop can be used to iterate through the elements of the first array, while the outer loop can be used to iterate through the elements of the second array. If the two elements being compared are the same, the program should mark those elements with a \"found\" flag and move on. Once the inner loop completes, the program should check if the \"found\" flag is set for all elements in the second array. If it is, then the common elements have been found.", "answer_id": "MQJFbH3KoFaSMmPgmK9LPa", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 68 |
+
{"question_id": 68, "text": "The value of f(2) is 1.", "answer_id": "dBWqryuzG6BHRdPgrWWpbH", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 69 |
+
{"question_id": 69, "text": "x = 6.", "answer_id": "W74byrCbE7XiJWjcPTZS7x", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 70 |
+
{"question_id": 70, "text": "The length of the line segment is 8 units.", "answer_id": "7WC5quGKdv8hADCxWaWZ57", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 71 |
+
{"question_id": 71, "text": "Yes, I can help you write a formal email to a potential business partner proposing a joint venture. Here's a template that you can use:\nSubject Line: Proposing a Joint Venture\nDear [Name],\nI am writing to propose a joint venture between our two companies. I believe that by combining our resources, we can create a powerful and profitable partnership. Our combined experience and knowledge in the industry will help us to create something unique and special.\nI am confident that our partnership will bring mutual benefits, such as increased profits and access to new markets. Please let me know if you are interested, and we can discuss the details.\nThank you for your time and consideration. I look forward to hearing from you soon.\nSincerely,\n[Your Name]", "answer_id": "AZER7D3RKZ9F9SXHiMjdqM", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 72 |
+
{"question_id": 72, "text": "Yes, I can help you write a resignation letter to your current employer. The letter should be written in a polite and professional tone and should express your appreciation for the opportunities and experiences you have gained during your employment. It should also include a clear statement of your intention to resign and the date of your last day. Here is a template you can use:\nDear [Employer],\nI am writing to inform you of my intention to resign from my position as [Position], effective [date]. I have appreciated my time here and I am grateful for the opportunities and experiences I have gained during my employment. \nI thank you for your support and understanding.\nSincerely, [Your Name]", "answer_id": "MSrdDafr77UvSHCnsPMSP3", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 73 |
+
{"question_id": 73, "text": "The letter of recommendation should be structured in a formal manner. Begin by introducing the student and explaining your relationship to them. Describe their qualifications, including their academic performance and relevant skills, and mention any particular accomplishments or awards they have received. Explain why the student is a strong candidate for the program and how they will make a positive contribution. End the letter by reaffirming your recommendation and offering your contact information for further questions.", "answer_id": "hxkjUkDkXhGP78Vo74B4WE", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 74 |
+
{"question_id": 74, "text": "Dear valued customers, \nWe are excited to announce the launch of our new software solution \u2013 a revolutionary product designed to transform the way you do business! Our new software is an intuitive and powerful tool that can help you streamline processes, save time and money, and increase overall productivity. \nAt [Company Name], we are committed to helping you stay ahead of the competition, and we believe that our new software solution is the perfect tool to help you achieve your goals. Our experienced team of professionals has worked hard to ensure that this product meets the highest standards of quality, and we are confident that it will make a real difference for your business. \nWe invite you to join us in this journey of transformation and discover how our new software can help you achieve your vision. Sign up now and get a free demo to learn more about this revolutionary product. \nThank you for your trust and support.", "answer_id": "hv9jpG9PxeJ9AnFdNzH3Jv", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 75 |
+
{"question_id": 75, "text": "mer,\nWe apologize for the delay you experienced with your order and thank you for your patience. We have identified the cause of the issue and have taken steps to ensure it does not happen again. We value your business and hope to be able to serve you better in the future.", "answer_id": "X5BVHT5pFpWxB88SzERrEG", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 76 |
+
{"question_id": 76, "text": "The video will explore the history and cultural significance of jazz music. We will begin by discussing its roots in West African cultural music traditions and its journey through the 19th and 20th centuries, focusing on the key musicians, composers, and genres that have defined the genre. We will also explore the impact of jazz on popular culture, such as in film and literature, as well as its influence on other musical styles. Finally, we will examine the legacy of jazz and its continued importance today.", "answer_id": "Af2SufKwvDBriNXnZX9UoP", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 77 |
+
{"question_id": 77, "text": "I have composed a travel blog post about my recent trip to Hawaii. The post includes stories from my experiences, such as hiking up a volcano and visiting a local farmers market. I also included plenty of photos to give the reader a sense of place. I highlighted some of the unique cultural experiences, such as an evening spent listening to live Hawaiian music, as well as must-see attractions, like the beautiful beaches and lush rainforests. I ended the post with a personal reflection on the trip and why it was so special to me.", "answer_id": "HVnqVdSGRwQfqSsiYxtTTn", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 78 |
+
{"question_id": 78, "text": "I recently watched the science fiction movie \"The Future is Blue\" and it was an incredible cinematic experience. The movie follows the story of a scientist who travels back in time to save the world from a deadly virus. The plot was interesting and engaging, with plenty of twists and turns to keep you guessing. The characters were also well developed and likable, making it easy to get invested in their story. The special effects were stunning and added a lot of visual oomph to the movie. All in all, I highly recommend this movie - it's an exciting and thought-provoking ride from start to finish.", "answer_id": "8hcmmjzyMyhFJ8ZwqJJfvw", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 79 |
+
{"question_id": 79, "text": "The podcast episode would begin by introducing the topic of how streaming platforms have changed the music industry. This would include discussing the impact of streaming services like Spotify and Apple Music on music consumption, the effect on musicians' ability to make money, and how streaming has changed the way people find and discover music. The episode would then explore the effects of streaming on the music industry from multiple angles, such as the impact on musicians and songwriters, how streaming has changed the sound of popular music, and the implications for the music industry's future. Finally, the episode would conclude by discussing how streaming has both benefited and hurt the music industry, and what the future holds for music consumption.", "answer_id": "CU6gGfJqQmwZNxEG2n2Uda", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 80 |
+
{"question_id": 80, "text": "The symphony concert was a wonderful experience. The orchestra played beautifully, with a rich and soulful sound that filled the hall. The audience was captivated, and you could feel the energy of the music in the air. The performance was a perfect balance of classic and modern pieces, and the conductor's passion was contagious. The atmosphere was festive, and the encore performance was a perfect way to end the evening. All in all, it was a brilliant concert and a delight for the ears.", "answer_id": "5SWbCoLV6NRrq5RtWQK4jp", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
LLaVA-Plus-Codebase/llava/eval/table/answer/answer_bard.jsonl
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
LLaVA-Plus-Codebase/llava/eval/table/answer/answer_gpt35.jsonl
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|