

Add comprehensive model card for CSC-SQL model
Browse filesThis PR adds a comprehensive model card for the CSC-SQL model, linking it to the paper [CSC-SQL: Corrective Self-Consistency in Text-to-SQL via Reinforcement Learning](https://huggingface.co/papers/2505.13271) and its GitHub repository.
It also adds the appropriate `pipeline_tag` (`text-generation`), `library_name` (`transformers`), and `license` (`cc-by-nc-4.0`) to the metadata, improving discoverability on the Hugging Face Hub (e.g., at https://huggingface.co/models?pipeline_tag=text-generation). Additionally, relevant `tags` such as `text-to-sql`, `reinforcement-learning`, and `qwen` have been added to further categorize the model.
README.md
ADDED
|
@@ -0,0 +1,110 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
pipeline_tag: text-generation
|
| 3 |
+
library_name: transformers
|
| 4 |
+
license: cc-by-nc-4.0
|
| 5 |
+
tags:
|
| 6 |
+
- text-to-sql
|
| 7 |
+
- reinforcement-learning
|
| 8 |
+
- qwen
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
# CSC-SQL: Corrective Self-Consistency in Text-to-SQL via Reinforcement Learning
|
| 12 |
+
|
| 13 |
+
This repository contains the `CscSQL-Grpo-Qwen2.5-Coder-7B-Instruct` model, a key component of the CSC-SQL framework, as presented in the paper [CSC-SQL: Corrective Self-Consistency in Text-to-SQL via Reinforcement Learning](https://huggingface.co/papers/2505.13271).
|
| 14 |
+
|
| 15 |
+
## Abstract
|
| 16 |
+
Large language models (LLMs) have demonstrated strong capabilities in translating natural language questions about relational databases into SQL queries. In particular, test-time scaling techniques such as Self-Consistency and Self-Correction can enhance SQL generation accuracy by increasing computational effort during inference. However, these methods have notable limitations: Self-Consistency may select suboptimal outputs despite majority votes, while Self-Correction typically addresses only syntactic errors. To leverage the strengths of both approaches, we propose CSC-SQL, a novel method that integrates Self-Consistency and Self-Correction. CSC-SQL selects the two most frequently occurring outputs from parallel sampling and feeds them into a merge revision model for correction. Additionally, we employ the Group Relative Policy Optimization (GRPO) algorithm to fine-tune both the SQL generation and revision models via reinforcement learning, significantly enhancing output quality. Experimental results confirm the effectiveness and generalizability of CSC-SQL. On the BIRD private test set, our 7B model achieves 71.72% execution accuracy, while the 32B model achieves 73.67%.
|
| 17 |
+
|
| 18 |
+
For more details, refer to the [paper](https://huggingface.co/papers/2505.13271) and the [official GitHub repository](https://github.com/CycloneBoy/csc_sql).
|
| 19 |
+
|
| 20 |
+
## Framework Overview
|
| 21 |
+
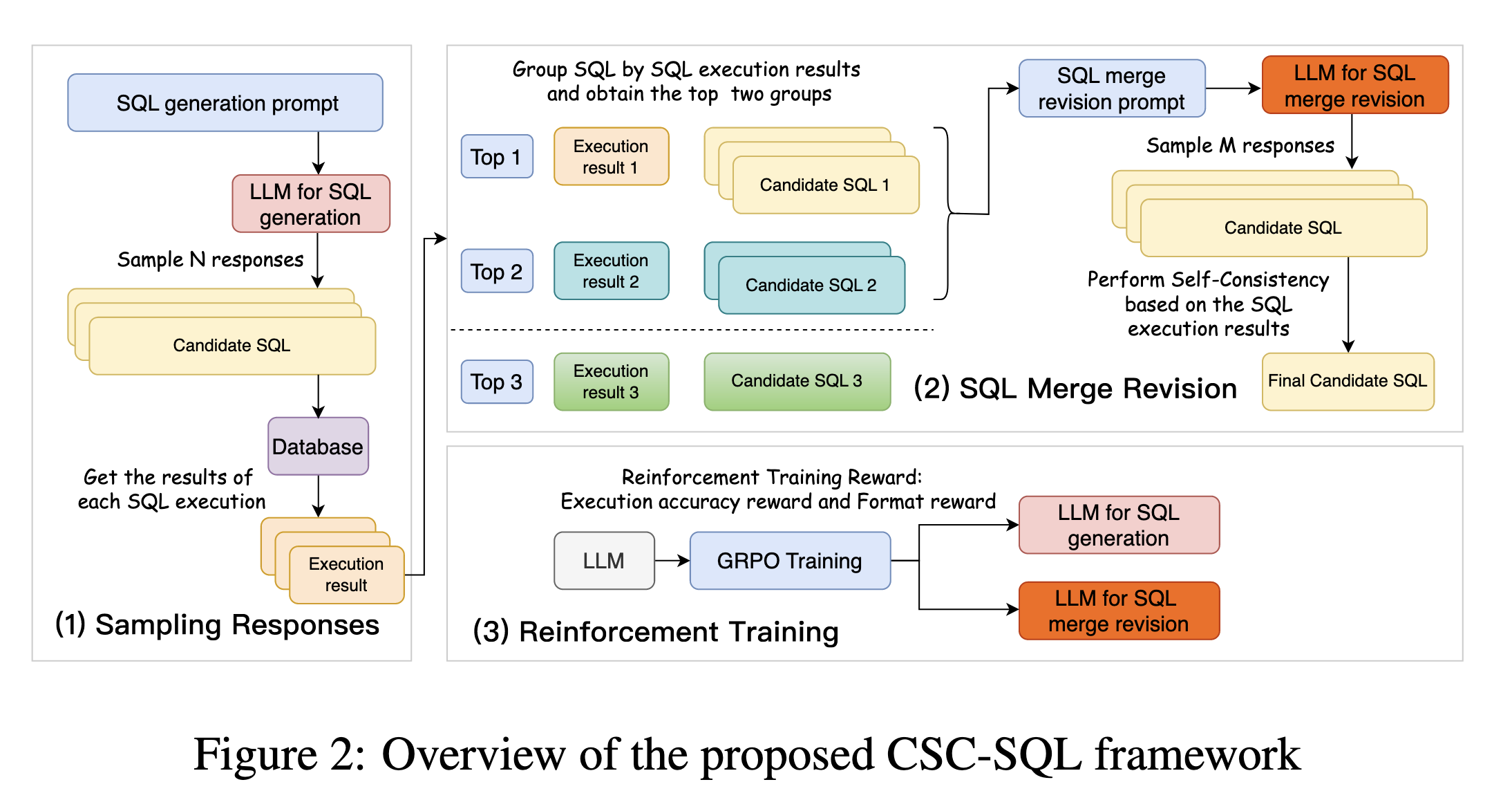
|
| 22 |
+
|
| 23 |
+
## Code
|
| 24 |
+
The official code repository for CSC-SQL is available on GitHub: [https://github.com/CycloneBoy/csc_sql](https://github.com/CycloneBoy/csc_sql)
|
| 25 |
+
|
| 26 |
+
## Main Results
|
| 27 |
+
Performance comparison of different Text-to-SQL methods on BIRD dev and test dataset:
|
| 28 |
+
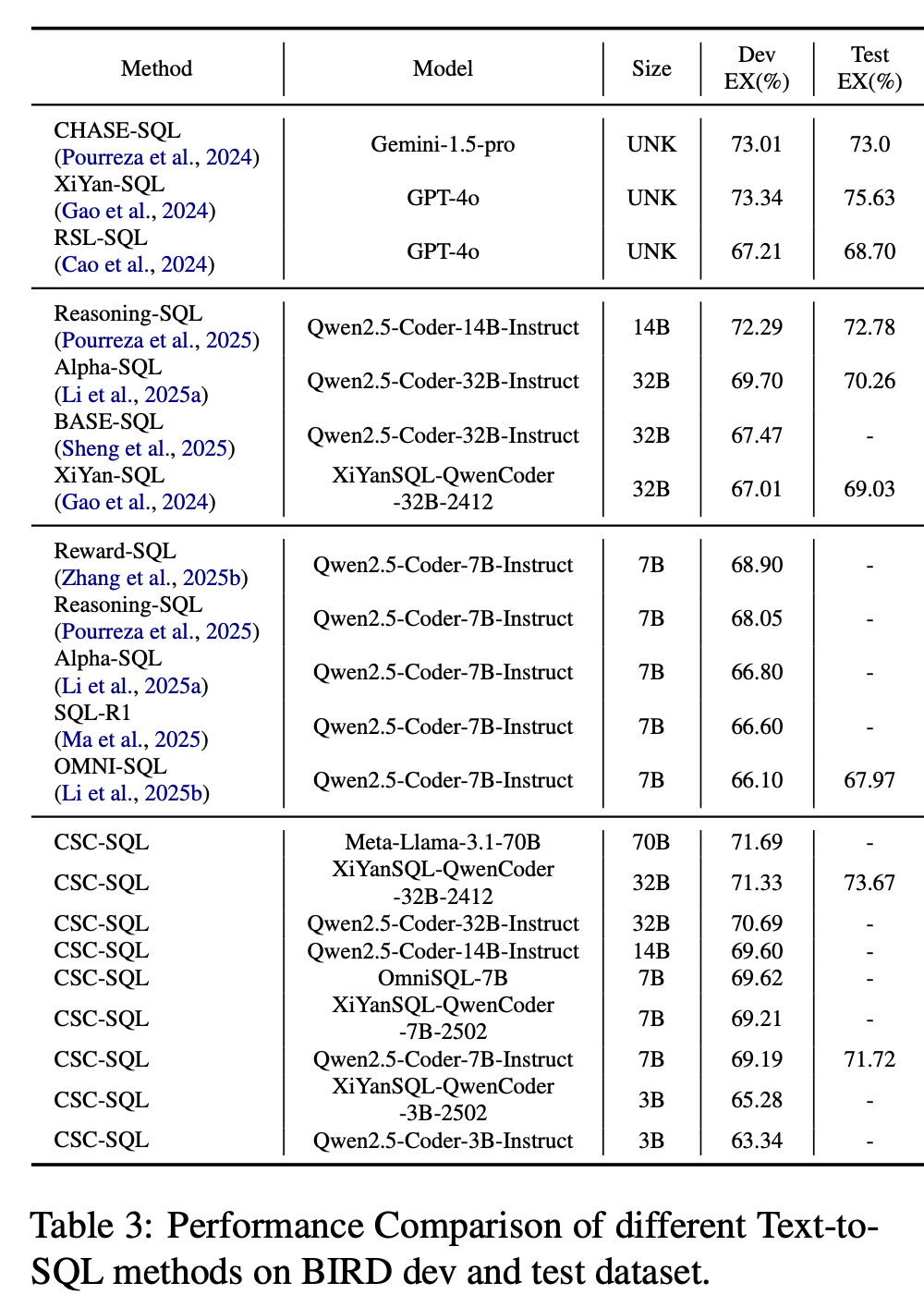
|
| 29 |
+
<img src="https://raw.githubusercontent.com/CycloneBoy/csc_sql/main/data/image/csc_sql_result_main.png" height="500" alt="csc_sql_result main">
|
| 30 |
+
|
| 31 |
+
## Model Checkpoints
|
| 32 |
+
This model is part of a collection of checkpoints related to CSC-SQL, also available on Hugging Face:
|
| 33 |
+
|
| 34 |
+
| **Model** | HuggingFace |
|
| 35 |
+
|-------------------------------|--------------------------------------------------------------------------------------------|
|
| 36 |
+
| CscSQL-Merge-Qwen2.5-Coder-3B-Instruct | [🤗 HuggingFace](https://huggingface.co/cycloneboy/CscSQL-Merge-Qwen2.5-Coder-3B-Instruct) |
|
| 37 |
+
| CscSQL-Merge-Qwen2.5-Coder-7B-Instruct | [🤗 HuggingFace](https://huggingface.co/cycloneboy/CscSQL-Merge-Qwen2.5-Coder-7B-Instruct) |
|
| 38 |
+
| CscSQL-Grpo-Qwen2.5-Coder-3B-Instruct | [🤗 HuggingFace](https://huggingface.co/cycloneboy/CscSQL-Grpo-Qwen2.5-Coder-3B-Instruct) |
|
| 39 |
+
| CscSQL-Grpo-XiYanSQL-QwenCoder-3B-2502 | [🤗 HuggingFace](https://huggingface.co/cycloneboy/CscSQL-Grpo-XiYanSQL-QwenCoder-3B-2502) |
|
| 40 |
+
| CscSQL-Grpo-Qwen2.5-Coder-7B-Instruct | [🤗 HuggingFace](https://huggingface.co/cycloneboy/CscSQL-Grpo-Qwen2.5-Coder-7B-Instruct) |
|
| 41 |
+
| CscSQL-Grpo-XiYanSQL-QwenCoder-7B-2502 | [🤗 HuggingFace](https://huggingface.co/cycloneboy/CscSQL-Grpo-XiYanSQL-QwenCoder-7B-2502) |
|
| 42 |
+
|
| 43 |
+
## Usage
|
| 44 |
+
You can load this model using the `transformers` library. Here's a basic example for inference:
|
| 45 |
+
|
| 46 |
+
```python
|
| 47 |
+
import torch
|
| 48 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
|
| 49 |
+
|
| 50 |
+
model_name = "cycloneboy/CscSQL-Grpo-Qwen2.5-Coder-7B-Instruct"
|
| 51 |
+
|
| 52 |
+
# Load model and tokenizer
|
| 53 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 54 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 55 |
+
model_name,
|
| 56 |
+
torch_dtype=torch.bfloat16, # Or torch.float16 depending on your hardware
|
| 57 |
+
device_map="auto"
|
| 58 |
+
)
|
| 59 |
+
model.eval()
|
| 60 |
+
|
| 61 |
+
# Example prompt for text-to-SQL generation
|
| 62 |
+
# Note: The prompt format might need to align with the model's specific training
|
| 63 |
+
# and database schema format for optimal text-to-SQL performance.
|
| 64 |
+
prompt = "Translate the following question to SQL: 'What are the names of all employees?'"
|
| 65 |
+
|
| 66 |
+
# Encode the prompt
|
| 67 |
+
input_ids = tokenizer.encode(prompt, return_tensors="pt").to(model.device)
|
| 68 |
+
|
| 69 |
+
# Set generation configuration based on the model's generation_config.json
|
| 70 |
+
generation_config = GenerationConfig(
|
| 71 |
+
bos_token_id=tokenizer.bos_token_id,
|
| 72 |
+
eos_token_id=[tokenizer.eos_token_id, 151643], # Include <|endoftext|> as eos_token_id
|
| 73 |
+
pad_token_id=tokenizer.bos_token_id, # Or use tokenizer.pad_token_id if different
|
| 74 |
+
temperature=0.7,
|
| 75 |
+
max_new_tokens=512,
|
| 76 |
+
do_sample=True,
|
| 77 |
+
top_p=0.8,
|
| 78 |
+
repetition_penalty=1.1,
|
| 79 |
+
top_k=20,
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
# Generate SQL query
|
| 83 |
+
output_ids = model.generate(
|
| 84 |
+
input_ids,
|
| 85 |
+
generation_config=generation_config
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
# Decode the generated SQL
|
| 89 |
+
generated_sql = tokenizer.decode(output_ids[0], skip_special_tokens=True)
|
| 90 |
+
print(generated_sql)
|
| 91 |
+
|
| 92 |
+
# For detailed usage, including how to integrate with the full CSC-SQL framework
|
| 93 |
+
# for improved accuracy via reinforcement learning, please refer to the
|
| 94 |
+
# official GitHub repository: https://github.com/CycloneBoy/csc_sql
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
## Citation
|
| 98 |
+
If you find this work helpful or inspiring, please feel free to cite it:
|
| 99 |
+
|
| 100 |
+
```bibtex
|
| 101 |
+
@misc{sheng2025cscsqlcorrectiveselfconsistencytexttosql,
|
| 102 |
+
title={CSC-SQL: Corrective Self-Consistency in Text-to-SQL via Reinforcement Learning},
|
| 103 |
+
author={Lei Sheng and Shuai-Shuai Xu},
|
| 104 |
+
year={2025},
|
| 105 |
+
eprint={2505.13271},
|
| 106 |
+
archivePrefix={arXiv},
|
| 107 |
+
primaryClass={cs.CL},
|
| 108 |
+
url={https://arxiv.org/abs/2505.13271},
|
| 109 |
+
}
|
| 110 |
+
```
|