
File size: 6,319 Bytes
5e07d47 1a0f97c f4937ec 1a0f97c 606c287 83630b2 1a0f97c 83630b2 1a0f97c 83630b2 6a8d727 83630b2 6a8d727 606c287 83630b2 de00cee c5a3e9a 606c287 83630b2 1a0f97c 606c287 1a0f97c 83630b2 606c287 83630b2 606c287 83630b2 1a0f97c 83630b2 606c287 83630b2 1a0f97c 83630b2 606c287 83630b2 1a0f97c 83630b2 1a0f97c 83630b2 606c287 83630b2 606c287 83630b2 1a0f97c 606c287 1a0f97c 606c287 1a0f97c 606c287 83630b2 606c287 83630b2 606c287 83630b2 c5a3e9a 606c287 c5a3e9a 1a0f97c 606c287 c5a3e9a 606c287 c5a3e9a 83630b2 606c287 83630b2 606c287 c5a3e9a 83630b2 6a8d727 606c287 c518ce5 c5a3e9a 606c287 6a8d727 83630b2 1a0f97c c5a3e9a 606c287 c5a3e9a 606c287 c5a3e9a 1a0f97c 606c287 c5a3e9a 606c287 1a0f97c c5a3e9a 606c287 c5a3e9a 1a0f97c 606c287 f4937ec c518ce5 606c287 c518ce5 f4937ec de00cee |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 |
---
datasets:
- danjacobellis/LSDIR_540
---
# Wavelet Learned Lossy Compression (WaLLoC)
WaLLoC sandwiches a convolutional autoencoder between time-frequency analysis and synthesis transforms using
CDF 9/7 wavelet filters. The time-frequency transform increases the number of signal channels, but reduces the temporal or spatial resolution, resulting in lower GPU memory consumption and higher throughput. WaLLoC's training procedure is highly simplified compared to other $\beta$-VAEs, VQ-VAEs, and neural codecs, but still offers significant dimensionality reduction and compression. This makes it suitable for dataset storage and compressed-domain learning. It currently supports 1D and 2D signals, including mono, stereo, or multi-channel audio, and grayscale, RGB, or hyperspectral images.
## Installation
1. Follow the installation instructions for [torch](https://pytorch.org/get-started/locally/)
2. Install WaLLoC and other dependencies via pip
```pip install walloc PyWavelets pytorch-wavelets```
## Pre-trained checkpoints
Pre-trained checkpoints are available on [Hugging Face](https://huggingface.co/danjacobellis/walloc).
## Training
Access to training code is provided by request via [email.](mailto:[email protected])
## Usage example
```python
import os
import torch
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image, ImageEnhance
from IPython.display import display
from torchvision.transforms import ToPILImage, PILToTensor
from walloc import walloc
from walloc.walloc import latent_to_pil, pil_to_latent
class Config: pass
```
### Load the model from a pre-trained checkpoint
```wget https://hf.co/danjacobellis/walloc/resolve/main/RGB_Li_27c_J3_nf4_v1.0.2.pth```
```python
device = "cpu"
checkpoint = torch.load("RGB_Li_27c_J3_nf4_v1.0.2.pth",map_location="cpu",weights_only=False)
codec_config = checkpoint['config']
codec = walloc.Codec2D(
channels = codec_config.channels,
J = codec_config.J,
Ne = codec_config.Ne,
Nd = codec_config.Nd,
latent_dim = codec_config.latent_dim,
latent_bits = codec_config.latent_bits,
lightweight_encode = codec_config.lightweight_encode
)
codec.load_state_dict(checkpoint['model_state_dict'])
codec = codec.to(device)
codec.eval();
```
### Load an example image
```wget "https://r0k.us/graphics/kodak/kodak/kodim05.png"```
```python
img = Image.open("kodim05.png")
img
```

### Full encoding and decoding pipeline with .forward()
* If `codec.eval()` is called, the latent is rounded to nearest integer.
* If `codec.train()` is called, uniform noise is added instead of rounding.
```python
with torch.no_grad():
codec.eval()
x = PILToTensor()(img).to(torch.float)
x = (x/255 - 0.5).unsqueeze(0).to(device)
x_hat, _, _ = codec(x)
ToPILImage()(x_hat[0]+0.5)
```

### Accessing latents
```python
with torch.no_grad():
codec.eval()
X = codec.wavelet_analysis(x,J=codec.J)
Y = codec.encoder(X)
X_hat = codec.decoder(Y)
x_hat = codec.wavelet_synthesis(X_hat,J=codec.J)
print(f"dimensionality reduction: {x.numel()/Y.numel()}×")
```
dimensionality reduction: 7.111111111111111×
```python
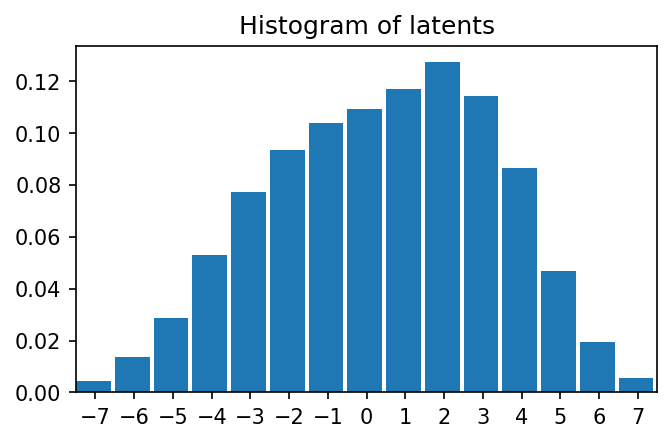
Y.unique()
```
tensor([-7., -6., -5., -4., -3., -2., -1., -0., 1., 2., 3., 4., 5., 6.,
7.])
```python
plt.figure(figsize=(5,3),dpi=150)
plt.hist(
Y.flatten().numpy(),
range=(-7.5,7.5),
bins=15,
density=True,
width=0.9);
plt.title("Histogram of latents")
plt.xticks(range(-7,8,1));
plt.xlim([-7.5,7.5])
```
(-7.5, 7.5)
# Lossless compression of latents
```python
def scale_for_display(img, n_bits):
scale_factor = (2**8 - 1) / (2**n_bits - 1)
lut = [int(i * scale_factor) for i in range(2**n_bits)]
channels = img.split()
scaled_channels = [ch.point(lut * 2**(8-n_bits)) for ch in channels]
return Image.merge(img.mode, scaled_channels)
```
### Single channel PNG (L)
```python
Y_padded = torch.nn.functional.pad(Y, (0, 0, 0, 0, 0, 9))
Y_pil = latent_to_pil(Y_padded,codec.latent_bits,1)
display(scale_for_display(Y_pil[0], codec.latent_bits))
Y_pil[0].save('latent.png')
png = [Image.open("latent.png")]
Y_rec = pil_to_latent(png,36,codec.latent_bits,1)
assert(Y_rec.equal(Y_padded))
print("compression_ratio: ", x.numel()/os.path.getsize("latent.png"))
```

compression_ratio: 15.171345894154717
### Three channel WebP (RGB)
```python
Y_pil = latent_to_pil(Y,codec.latent_bits,3)
display(scale_for_display(Y_pil[0], codec.latent_bits))
Y_pil[0].save('latent.webp',lossless=True)
webp = [Image.open("latent.webp")]
Y_rec = pil_to_latent(webp,27,codec.latent_bits,3)
assert(Y_rec.equal(Y))
print("compression_ratio: ", x.numel()/os.path.getsize("latent.webp"))
```

compression_ratio: 16.451175633838172
### Four channel TIF (CMYK)
```python
Y_padded = torch.nn.functional.pad(Y, (0, 0, 0, 0, 0, 9))
Y_pil = latent_to_pil(Y_padded,codec.latent_bits,4)
display(scale_for_display(Y_pil[0], codec.latent_bits))
Y_pil[0].save('latent.tif',compression="tiff_adobe_deflate")
tif = [Image.open("latent.tif")]
Y_rec = pil_to_latent(tif,36,codec.latent_bits,4)
assert(Y_rec.equal(Y_padded))
print("compression_ratio: ", x.numel()/os.path.getsize("latent.tif"))
```

compression_ratio: 12.40611656815935
```python
!jupyter nbconvert --to markdown README.ipynb
```
[NbConvertApp] Converting notebook README.ipynb to markdown
[NbConvertApp] Support files will be in README_files/
[NbConvertApp] Making directory README_files
[NbConvertApp] Writing 6024 bytes to README.md
```python
!sed -i 's|!\[png](README_files/\(README_[0-9]*_[0-9]*\.png\))||g' README.md
```
|