Datasets:


Update README.md
Browse files
README.md
CHANGED
|
@@ -5,4 +5,36 @@ language:
|
|
| 5 |
- en
|
| 6 |
size_categories:
|
| 7 |
- n>1T
|
| 8 |
-
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5 |
- en
|
| 6 |
size_categories:
|
| 7 |
- n>1T
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
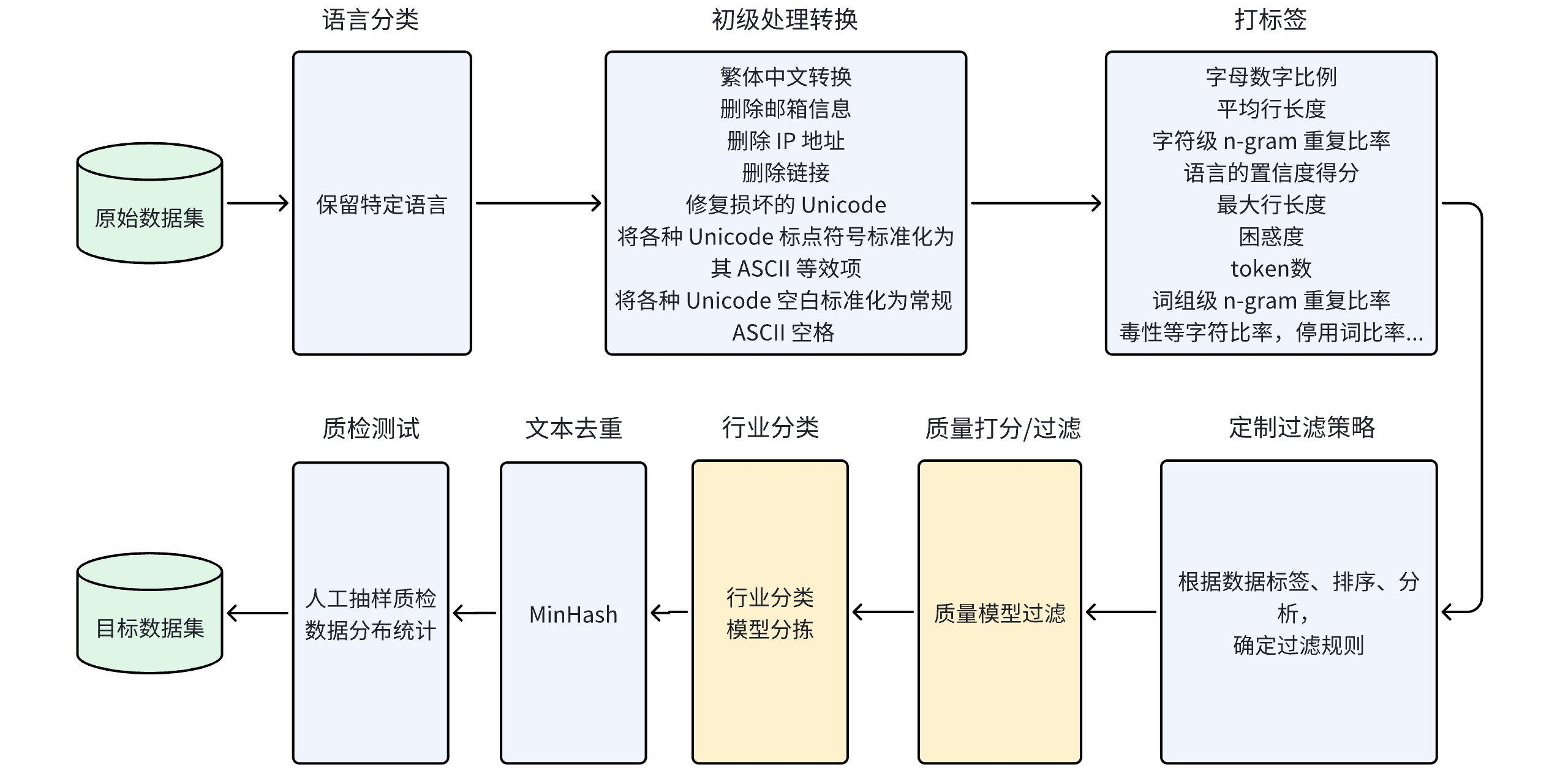
Industry models play a crucial role in driving enterprise intelligence transformation and innovative development. High-quality industry data is key to improving the performance of large models and realizing industry applications. However, datasets currently used for industry model training generally suffer from issues such as insufficient data volume, low quality, and lack of domain expertise.
|
| 11 |
+
|
| 12 |
+
To address these problems, we constructed and applied 22 industry data processing operators to clean and filter 3.4TB of high-quality multi-industry classified Chinese and English language pre-training datasets from over 100TB of open-source datasets including WuDaoCorpora, BAAI-CCI, redpajama, and SkyPile-150B. The filtered data consists of 1TB of Chinese data and 2.4TB of English data. To facilitate user utilization, we annotated the Chinese data with 12 types of labels including alphanumeric ratio, average line length, language confidence score, maximum line length, and perplexity.
|
| 13 |
+
|
| 14 |
+
Furthermore, to validate the dataset's performance, we conducted continued pre-training, SFT, and DPO training on a medical industry demonstration model. The results showed a 20% improvement in objective performance and a subjective win rate of 82%.
|
| 15 |
+
|
| 16 |
+
Industry categories: 18 categories including medical, education, literature, finance, travel, law, sports, automotive, news, etc.
|
| 17 |
+
Rule-based filtering: Traditional Chinese conversion, email removal, IP address removal, link removal, Unicode repair, etc.
|
| 18 |
+
Chinese data labels: Alphanumeric ratio, average line length, language confidence score, maximum line length, perplexity, toxicity character ratio, etc.
|
| 19 |
+
Model-based filtering: Industry classification language model with 80% accuracy
|
| 20 |
+
Data deduplication: MinHash document-level deduplication
|
| 21 |
+
Data size: 1TB Chinese, 2.4TB English
|
| 22 |
+
|
| 23 |
+
Industry classification data size:
|
| 24 |
+
|
| 25 |
+
| Industry Category | Data Size (GB) | Industry Category | Data Size (GB) |
|
| 26 |
+
|-------------------|----------------|-------------------|----------------|
|
| 27 |
+
| Programming | 4.1 | Politics | 326.4 |
|
| 28 |
+
| Law | 274.6 | Mathematics | 5.9 |
|
| 29 |
+
| Education | 458.1 | Sports | 442 |
|
| 30 |
+
| Finance | 197.8 | Literature | 179.3 |
|
| 31 |
+
| Computer Science | 46.9 | News | 564.1 |
|
| 32 |
+
| Technology | 333.6 | Film & TV | 162.1 |
|
| 33 |
+
| Travel | 82.5 | Medicine | 189.4 |
|
| 34 |
+
| Agriculture | 41.6 | Automotive | 40.8 |
|
| 35 |
+
| Emotion | 31.7 | Artificial Intelligence | 5.6 |
|
| 36 |
+
| Total (GB) | 3386.5 | | |
|
| 37 |
+
|
| 38 |
+
Data processing workflow:
|
| 39 |
+
|
| 40 |
+
|