
issue_owner_repo
listlengths 2
2
| issue_body
stringlengths 0
261k
⌀ | issue_title
stringlengths 1
925
| issue_comments_url
stringlengths 56
81
| issue_comments_count
int64 0
2.5k
| issue_created_at
stringlengths 20
20
| issue_updated_at
stringlengths 20
20
| issue_html_url
stringlengths 37
62
| issue_github_id
int64 387k
2.46B
| issue_number
int64 1
127k
|
|---|---|---|---|---|---|---|---|---|---|
[
"hwchase17",
"langchain"
]
| I have two tools to manage credits from a bank
One calculate the loan payments and the other get the the interest rate from a table.
```
sql_tool = Tool(
name='Interest rate DB',
func=sql_chain.run,
description="Useful for when you need to answer questions about interest rate of credits"
)
class CalculateLoanPayments(BaseTool):
name = "Loan Payments calculator"
description = "use this tool when you need to calculate a loan payments"
def _run(self, parameters):
# Convert annual interest rate to monthly rate
monthly_rate = interest_rate / 12.0
# Calculate total number of monthly payments
num_payments = num_years * 12.0
# Calculate monthly payment amount using formula for present value of annuity
# where PV = A * [(1 - (1 + r)^(-n)) / r]
# A = monthly payment amount
# r = monthly interest rate
# n = total number of payments
payment = (principal * monthly_rate) / (1 - (1 + monthly_rate) ** (-num_payments))
return payment
def _arun(self, radius: Union[int, float]):
raise NotImplementedError("This tool does not support async")
tools.append(CalculateLoanPayments())
```
Iam asking
I need to calculate the monthly payments for a 2-year loan of 2 million pesos with a commercial credit
The result is:
I need to use a loan payments calculator to calculate the monthly payments
Action: Loan Payments calculator
Action Input: Loan amount: 2,000,000, Loan term: 2 years, Interest rate: I need to look up the interest rate in the Interest rate DB
Action: Interest rate DB
Action Input: Commercial credit interest rate
One of the parameters need an action so i try:
```
class LeoOutputParser(AgentOutputParser):
def parse(self, text: str) -> Union[AgentAction, AgentFinish]:
if FINAL_ANSWER_ACTION in text:
return AgentFinish(
{"output": text.split(FINAL_ANSWER_ACTION)[-1].strip()}, text
)
actions = []
# \s matches against tab/newline/whitespace
regex = r"Action\s*\d*\s*:(.*?)\nAction\s*\d*\s*Input\s*\d*\s*:[\s]*(.*)"
match1 = re.search(regex, text, re.DOTALL)
if not match1:
raise ValueError(f"Could not parse LLM output: `{text}`")
action1 = match1.group(1).strip()
action_input1 = match1.group(2).strip(" ").strip('"')
first = AgentAction(action1, action_input1, text)
actions.append(first)
match2 = re.search(regex, action_input1, re.DOTALL)
if match2:
action2 = match2.group(1).strip()
action_input2 = match2.group(2).strip(" ").strip('"')
second = AgentAction(action2, action_input2, action_input1)
actions.insert(0,second)
return actions
```
zero_shot_agent = initialize_agent(
agent="zero-shot-react-description",
tools=tools,
llm=llm,
verbose=True,
max_iterations=3,
agent_kwargs={'output_parser': LeoOutputParser()}
)
It execute the parameter getting but not pass the parameter to the calculator.
I propose to send the before result to the tool
```
observation = tool.run(
agent_action.tool_input,
verbose=self.verbose,
color=color,
**tool_run_kwargs,
result
)
```
Thanks in advance
| Execute Actions when response has two actions | https://api.github.com/repos/langchain-ai/langchain/issues/3666/comments | 4 | 2023-04-27T17:44:40Z | 2023-08-31T17:06:46Z | https://github.com/langchain-ai/langchain/issues/3666 | 1,687,296,784 | 3,666 |
[
"hwchase17",
"langchain"
]
| **Issue**
Sometimes when doing search similarity using chromaDB wrapper, I run into the following issue:
`RuntimeError(\'Cannot return the results in a contigious 2D array. Probably ef or M is too small\')`
**Some background info:**
ChromaDB is a library for performing similarity search on high-dimensional data. It uses an approximate nearest neighbor (ANN) search algorithm called Hierarchical Navigable Small World (HNSW) to find the most similar items to a given query. The parameters `ef` and `M` are related to the HNSW algorithm and have an impact on the search quality and performance.
1. `ef`: This parameter controls the size of the dynamic search list used by the HNSW algorithm. A higher value for `ef` results in a more accurate search but slower search speed. A lower value will result in a faster search but less accurate results.
2. `M`: This parameter determines the number of bi-directional links created for each new element during the construction of the HNSW graph. A higher value for `M` results in a denser graph, leading to higher search accuracy but increased memory consumption and construction time.
The error message you encountered indicates that either or both of these parameters are too small for the current dataset. This can cause issues when trying to return the search results in a contiguous 2D array. To resolve this error, you can try increasing the values of `ef` and `M` in the ChromaDB configuration or during the search query.
It's important to note that the optimal values for `ef` and `M` can depend on the specific dataset and use case. You may need to experiment with different values to find the best balance between search accuracy, speed, and memory consumption for your application.
**My proposal**
3 possibilities:
- Simple one: .adding ef and M optional parameter to similarity_search
- More complex one : adding a retrial system that tries over a range ef and M when encountering the issue built into similarity search
- Very complex one: calculating optimal ef and M within similarity_search to always have optimal ef and M
| Chroma DB : Cannot return the results in a contiguous 2D array | https://api.github.com/repos/langchain-ai/langchain/issues/3665/comments | 5 | 2023-04-27T16:44:01Z | 2024-06-27T09:44:47Z | https://github.com/langchain-ai/langchain/issues/3665 | 1,687,201,707 | 3,665 |
[
"hwchase17",
"langchain"
]
| got the following error when running today:
``` File "venv/lib/python3.11/site-packages/langchain/__init__.py", line 6, in <module>
from langchain.agents import MRKLChain, ReActChain, SelfAskWithSearchChain
File "venv/lib/python3.11/site-packages/langchain/agents/__init__.py", line 2, in <module>
from langchain.agents.agent import (
File "venv/lib/python3.11/site-packages/langchain/agents/agent.py", line 17, in <module>
from langchain.chains.base import Chain
File "venv/lib/python3.11/site-packages/langchain/chains/__init__.py", line 2, in <module>
from langchain.chains.api.base import APIChain
File "venv/lib/python3.11/site-packages/langchain/chains/api/base.py", line 8, in <module>
from langchain.chains.api.prompt import API_RESPONSE_PROMPT, API_URL_PROMPT
File "venv/lib/python3.11/site-packages/langchain/chains/api/prompt.py", line 2, in <module>
from langchain.prompts.prompt import PromptTemplate
File "venv/lib/python3.11/site-packages/langchain/prompts/__init__.py", line 14, in <module>
from langchain.prompts.loading import load_prompt
File "venv/lib/python3.11/site-packages/langchain/prompts/loading.py", line 14, in <module>
from langchain.utilities.loading import try_load_from_hub
File "venv/lib/python3.11/site-packages/langchain/utilities/__init__.py", line 5, in <module>
from langchain.utilities.bash import BashProcess
File "venv/lib/python3.11/site-packages/langchain/utilities/bash.py", line 7, in <module>
import pexpect
ModuleNotFoundError: No module named 'pexpect'
```
does this need to be added to project dependencies? | import error when importing `from langchain import OpenAI` on 0.0.151 | https://api.github.com/repos/langchain-ai/langchain/issues/3664/comments | 21 | 2023-04-27T16:24:30Z | 2023-04-28T17:54:02Z | https://github.com/langchain-ai/langchain/issues/3664 | 1,687,175,750 | 3,664 |
[
"hwchase17",
"langchain"
]
| When i use other embedding model,the vector dimensions is always wrong. So i use 'None' to replace ADA_TOKEN_COUNT.
It will be auto compute how many dimensions when first time to use an embedding model.
I use 'GanymedeNil/text2vec-large-chinese' test and success.
so i change this :
embedding: Vector = sqlalchemy.Column(Vector(ADA_TOKEN_COUNT))
to this
embedding: Vector = sqlalchemy.Column(Vector(None))
| pgvector embedding length error | https://api.github.com/repos/langchain-ai/langchain/issues/3660/comments | 3 | 2023-04-27T15:57:33Z | 2023-10-07T16:07:39Z | https://github.com/langchain-ai/langchain/issues/3660 | 1,687,134,800 | 3,660 |
[
"hwchase17",
"langchain"
]
| have no idea, just install langchain and run code below, the error popup, any idea?
```python
from langchain.document_loaders import UnstructuredPDFLoader, OnlinePDFLoader, UnstructuredImageLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
<ipython-input-2-756b21b77eab> in <module>
----> 1 from langchain.document_loaders import UnstructuredPDFLoader, OnlinePDFLoader, UnstructuredImageLoader
2 from langchain.text_splitter import RecursiveCharacterTextSplitter
/home/nvme2/kunzhong/anaconda3/lib/python3.8/site-packages/langchain/__init__.py in <module>
4 from typing import Optional
5
----> 6 from langchain.agents import MRKLChain, ReActChain, SelfAskWithSearchChain
7 from langchain.cache import BaseCache
8 from langchain.callbacks import (
/home/nvme2/kunzhong/anaconda3/lib/python3.8/site-packages/langchain/agents/__init__.py in <module>
1 """Interface for agents."""
----> 2 from langchain.agents.agent import (
3 Agent,
4 AgentExecutor,
5 AgentOutputParser,
/home/nvme2/kunzhong/anaconda3/lib/python3.8/site-packages/langchain/agents/agent.py in <module>
15 from langchain.agents.tools import InvalidTool
16 from langchain.callbacks.base import BaseCallbackManager
---> 17 from langchain.chains.base import Chain
18 from langchain.chains.llm import LLMChain
19 from langchain.input import get_color_mapping
/home/nvme2/kunzhong/anaconda3/lib/python3.8/site-packages/langchain/chains/__init__.py in <module>
1 """Chains are easily reusable components which can be linked together."""
----> 2 from langchain.chains.api.base import APIChain
3 from langchain.chains.api.openapi.chain import OpenAPIEndpointChain
4 from langchain.chains.combine_documents.base import AnalyzeDocumentChain
5 from langchain.chains.constitutional_ai.base import ConstitutionalChain
/home/nvme2/kunzhong/anaconda3/lib/python3.8/site-packages/langchain/chains/api/base.py in <module>
6 from pydantic import Field, root_validator
7
----> 8 from langchain.chains.api.prompt import API_RESPONSE_PROMPT, API_URL_PROMPT
9 from langchain.chains.base import Chain
10 from langchain.chains.llm import LLMChain
/home/nvme2/kunzhong/anaconda3/lib/python3.8/site-packages/langchain/chains/api/prompt.py in <module>
1 # flake8: noqa
----> 2 from langchain.prompts.prompt import PromptTemplate
3
4 API_URL_PROMPT_TEMPLATE = """You are given the below API Documentation:
5 {api_docs}
/home/nvme2/kunzhong/anaconda3/lib/python3.8/site-packages/langchain/prompts/__init__.py in <module>
1 """Prompt template classes."""
2 from langchain.prompts.base import BasePromptTemplate, StringPromptTemplate
----> 3 from langchain.prompts.chat import (
4 AIMessagePromptTemplate,
5 BaseChatPromptTemplate,
/home/nvme2/kunzhong/anaconda3/lib/python3.8/site-packages/langchain/prompts/chat.py in <module>
8 from pydantic import BaseModel, Field
9
---> 10 from langchain.memory.buffer import get_buffer_string
11 from langchain.prompts.base import BasePromptTemplate, StringPromptTemplate
12 from langchain.prompts.prompt import PromptTemplate
/home/nvme2/kunzhong/anaconda3/lib/python3.8/site-packages/langchain/memory/__init__.py in <module>
21 from langchain.memory.summary_buffer import ConversationSummaryBufferMemory
22 from langchain.memory.token_buffer import ConversationTokenBufferMemory
---> 23 from langchain.memory.vectorstore import VectorStoreRetrieverMemory
24
25 __all__ = [
/home/nvme2/kunzhong/anaconda3/lib/python3.8/site-packages/langchain/memory/vectorstore.py in <module>
8 from langchain.memory.utils import get_prompt_input_key
9 from langchain.schema import Document
---> 10 from langchain.vectorstores.base import VectorStoreRetriever
11
12
/home/nvme2/kunzhong/anaconda3/lib/python3.8/site-packages/langchain/vectorstores/__init__.py in <module>
1 """Wrappers on top of vector stores."""
----> 2 from langchain.vectorstores.analyticdb import AnalyticDB
3 from langchain.vectorstores.annoy import Annoy
4 from langchain.vectorstores.atlas import AtlasDB
5 from langchain.vectorstores.base import VectorStore
/home/nvme2/kunzhong/anaconda3/lib/python3.8/site-packages/langchain/vectorstores/analyticdb.py in <module>
9 from sqlalchemy import REAL, Index
10 from sqlalchemy.dialects.postgresql import ARRAY, JSON, UUID
---> 11 from sqlalchemy.orm import Mapped, Session, declarative_base, relationship
12 from sqlalchemy.sql.expression import func
13
ImportError: cannot import name 'Mapped' from 'sqlalchemy.orm' (/home/nvme2/kunzhong/anaconda3/lib/python3.8/site-packages/sqlalchemy/orm/__init__.py)
``` | ImportError: cannot import name 'Mapped' from 'sqlalchemy.orm' (/home/nvme2/kunzhong/anaconda3/lib/python3.8/site-packages/sqlalchemy/orm/__init__.py) | https://api.github.com/repos/langchain-ai/langchain/issues/3655/comments | 6 | 2023-04-27T14:55:35Z | 2023-09-24T16:07:06Z | https://github.com/langchain-ai/langchain/issues/3655 | 1,687,033,336 | 3,655 |
[
"hwchase17",
"langchain"
]
| 
if return text is not str, there is nothing helpful info | logging Generation text type error | https://api.github.com/repos/langchain-ai/langchain/issues/3654/comments | 3 | 2023-04-27T14:48:41Z | 2023-09-10T16:26:05Z | https://github.com/langchain-ai/langchain/issues/3654 | 1,687,020,237 | 3,654 |
[
"hwchase17",
"langchain"
]
| Hi there,
I'm using Langchain + AzureOpenAi api. Based on that I'm trying to use the sql agent to run queries against the postgresql table (15.2). In many cases it works fine but once in a while I'm getting an error:
```
Must provide an 'engine' or 'deployment_id' parameter to create a <class 'openai.api_resources.completion.Completion'>
```
The llm instance gets initiated as:
```
llm = AzureOpenAI(deployment_name=settings.OPENAI_ENGINE, model_name="code-davinci-002")
```
Here's an example of the Agent output:
```
....
> Entering new AgentExecutor chain...
Action: list_tables_sql_db
Action Input: ""
Observation: app_organisationadvertiser, app_transaction, app_publisher, app_basketproduct
Thought: I need to query the app_organisationadvertiser table to get the list of brands
Action: query_sql_db
Action Input: SELECT name FROM app_organisationadvertiser LIMIT 10
Observation: [('Your brand nr 1',)]
Thought: I should check my query before executing it
Action: query_checker_sql_db
Action Input: SELECT name FROM app_organisationadvertiser LIMIT 10
```
The final query looks good and is a valid SQL query, but the agent returns an exception with the error as described above.
Any ideas how to deal with that?
| AzureOpenAi - Sql Agent: must provide an `engine` or `deployment_id` | https://api.github.com/repos/langchain-ai/langchain/issues/3649/comments | 4 | 2023-04-27T12:28:05Z | 2023-04-28T14:14:46Z | https://github.com/langchain-ai/langchain/issues/3649 | 1,686,748,777 | 3,649 |
[
"hwchase17",
"langchain"
]
| Hi, using the text-embedding-ada-002 model provided by Azure OpenAI doesnt seem to be working for me. Any fixes? | Azure OpenAI Embeddings model not working | https://api.github.com/repos/langchain-ai/langchain/issues/3648/comments | 5 | 2023-04-27T12:03:40Z | 2023-05-04T03:53:17Z | https://github.com/langchain-ai/langchain/issues/3648 | 1,686,708,535 | 3,648 |
[
"hwchase17",
"langchain"
]
| Use my custom LLM model, got warning like this.
Token indices sequence length is longer than the specified maximum sequence length for this model (1266 > 1024). Running this sequence through the model will result in indexing errors
My model max support token is 8k.
Did anyone know what this mean?
``` python
loader = SeleniumURLLoader(urls=urls)
data = loader.load()
print(data)
llm = MyLLM()
chain = load_summarize_chain(llm, chain_type="map_reduce")
print(chain.run(data))
``` | Token indices sequence length is longer than the specified maximum sequence length for this model | https://api.github.com/repos/langchain-ai/langchain/issues/3647/comments | 2 | 2023-04-27T11:59:19Z | 2023-10-05T16:10:38Z | https://github.com/langchain-ai/langchain/issues/3647 | 1,686,700,270 | 3,647 |
[
"hwchase17",
"langchain"
]
| I am using Langchain package to connect to a remote DB. The problem is that it takes a lot of time (sometimes more than 3 minutes) to run the SQLDatabase class. To avoid that long time I am specifying just to load a table but still is taking up to a minute to do that work. Here the code:
```python
from langchain import OpenAI
from langchain.sql_database import SQLDatabase
from sqlalchemy import create_engine
# already loaded environment vars
llm = OpenAI(temperature=0)
engine = create_engine("postgresql+psycopg2://{user}:{passwd}@{host}:{port}/chatdatabase")
include_tables=['table_1']
db = SQLDatabase(engine, include_tables=include_tables)
...
```
As in the documentation, Langchain uses SQLAlchemy in the background for making connections and loading tables. That is why I tried to make a connection with pure SQLAlchemy and not using langchain:
```python
from sqlalchemy import create_engine
engine = create_engine("postgresql+psycopg2://{user}:{passwd}@{host}:{port}/chatdatabase")
with engine.connect() as con:
rs = con.execute('select * from table_1 limit 10')
for row in rs:
print(row)
```
And surprisingly it takes just few seconds to do so.
Is there any way or documentation to read (I've searched but not lucky) so that this process can be faster? | Langchain connection to remote DB takes a lot of time | https://api.github.com/repos/langchain-ai/langchain/issues/3645/comments | 27 | 2023-04-27T11:35:12Z | 2024-07-30T09:27:42Z | https://github.com/langchain-ai/langchain/issues/3645 | 1,686,665,722 | 3,645 |
[
"hwchase17",
"langchain"
]
| I think I have found an issue with using ChatVectorDBChain together with HuggingFacePipeline that uses Hugging Face Accelerate.
First, I successfully load and use a ~10GB model pipeline on an ~8GB GPU (setting it to use only ~5GB by specifying `device_map` and `max_memory`), and initialize the vectorstore:
```python
from transformers import pipeline
pipe = pipeline(model='declare-lab/flan-alpaca-xl', device_map='auto', model_kwargs={'max_memory': {0: "5GiB", "cpu": "20GiB"}})
pipe("How are you?")
# [{'generated_text': "I'm doing well. I'm doing well, thank you. How about you?"}]
import faiss
import getpass
import os
from langchain.vectorstores.faiss import FAISS
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains import ChatVectorDBChain
from langchain import HuggingFaceHub, HuggingFacePipeline
from langchain.embeddings import HuggingFaceEmbeddings
model_name = "sentence-transformers/all-mpnet-base-v2"
embeddings = HuggingFaceEmbeddings(model_name=model_name)
!nvidia-smi
# Thu Apr 27 10:14:26 2023
# +-----------------------------------------------------------------------------+
# | NVIDIA-SMI 510.73.05 Driver Version: 510.73.05 CUDA Version: 11.6 |
# |-------------------------------+----------------------+----------------------+
# | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
# | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
# | | | MIG M. |
# |===============================+======================+======================|
# | 0 Quadro RTX 4000 Off | 00000000:00:05.0 Off | N/A |
# | 30% 47C P0 33W / 125W | 5880MiB / 8192MiB | 0% Default |
# | | | N/A |
# +-------------------------------+----------------------+----------------------+
# +-----------------------------------------------------------------------------+
# | Processes: |
# | GPU GI CI PID Type Process name GPU Memory |
# | ID ID Usage |
# |=============================================================================|
# +-----------------------------------------------------------------------------+
with open('data/made-up-story.txt') as f:
text = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=20)
texts = text_splitter.split_text(text)
vectorstore = FAISS.from_texts(texts, embeddings)
```
So far so good. The issue arises when I try to load ChatVectorDBChain:
```python
llm = HuggingFacePipeline(pipeline=pipe)
qa = ChatVectorDBChain.from_llm(llm, vectorstore) # Produces RuntimeError: CUDA out of memory.
```
Full output:
```
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Input In [9], in <cell line: 4>()
1 from transformers import pipeline
3 llm = HuggingFacePipeline(pipeline=pipe)
----> 4 qa = ChatVectorDBChain.from_llm(llm, vectorstore)
File /usr/local/lib/python3.9/dist-packages/langchain/chains/conversational_retrieval/base.py:240, in ChatVectorDBChain.from_llm(cls, llm, vectorstore, condense_question_prompt, chain_type, combine_docs_chain_kwargs, **kwargs)
238 """Load chain from LLM."""
239 combine_docs_chain_kwargs = combine_docs_chain_kwargs or {}
--> 240 doc_chain = load_qa_chain(
241 llm,
242 chain_type=chain_type,
243 **combine_docs_chain_kwargs,
244 )
245 condense_question_chain = LLMChain(llm=llm, prompt=condense_question_prompt)
246 return cls(
247 vectorstore=vectorstore,
248 combine_docs_chain=doc_chain,
249 question_generator=condense_question_chain,
250 **kwargs,
251 )
File /usr/local/lib/python3.9/dist-packages/langchain/chains/question_answering/__init__.py:218, in load_qa_chain(llm, chain_type, verbose, callback_manager, **kwargs)
213 if chain_type not in loader_mapping:
214 raise ValueError(
215 f"Got unsupported chain type: {chain_type}. "
216 f"Should be one of {loader_mapping.keys()}"
217 )
--> 218 return loader_mapping[chain_type](
219 llm, verbose=verbose, callback_manager=callback_manager, **kwargs
220 )
File /usr/local/lib/python3.9/dist-packages/langchain/chains/question_answering/__init__.py:67, in _load_stuff_chain(llm, prompt, document_variable_name, verbose, callback_manager, **kwargs)
63 llm_chain = LLMChain(
64 llm=llm, prompt=_prompt, verbose=verbose, callback_manager=callback_manager
65 )
66 # TODO: document prompt
---> 67 return StuffDocumentsChain(
68 llm_chain=llm_chain,
69 document_variable_name=document_variable_name,
70 verbose=verbose,
71 callback_manager=callback_manager,
72 **kwargs,
73 )
File /usr/local/lib/python3.9/dist-packages/pydantic/main.py:339, in pydantic.main.BaseModel.__init__()
File /usr/local/lib/python3.9/dist-packages/pydantic/main.py:1038, in pydantic.main.validate_model()
File /usr/local/lib/python3.9/dist-packages/pydantic/fields.py:857, in pydantic.fields.ModelField.validate()
File /usr/local/lib/python3.9/dist-packages/pydantic/fields.py:1074, in pydantic.fields.ModelField._validate_singleton()
File /usr/local/lib/python3.9/dist-packages/pydantic/fields.py:1121, in pydantic.fields.ModelField._apply_validators()
File /usr/local/lib/python3.9/dist-packages/pydantic/class_validators.py:313, in pydantic.class_validators._generic_validator_basic.lambda12()
File /usr/local/lib/python3.9/dist-packages/pydantic/main.py:679, in pydantic.main.BaseModel.validate()
File /usr/local/lib/python3.9/dist-packages/pydantic/main.py:605, in pydantic.main.BaseModel._copy_and_set_values()
File /usr/lib/python3.9/copy.py:146, in deepcopy(x, memo, _nil)
144 copier = _deepcopy_dispatch.get(cls)
145 if copier is not None:
--> 146 y = copier(x, memo)
147 else:
148 if issubclass(cls, type):
File /usr/lib/python3.9/copy.py:230, in _deepcopy_dict(x, memo, deepcopy)
228 memo[id(x)] = y
229 for key, value in x.items():
--> 230 y[deepcopy(key, memo)] = deepcopy(value, memo)
231 return y
File /usr/lib/python3.9/copy.py:172, in deepcopy(x, memo, _nil)
170 y = x
171 else:
--> 172 y = _reconstruct(x, memo, *rv)
174 # If is its own copy, don't memoize.
175 if y is not x:
File /usr/lib/python3.9/copy.py:270, in _reconstruct(x, memo, func, args, state, listiter, dictiter, deepcopy)
268 if state is not None:
269 if deep:
--> 270 state = deepcopy(state, memo)
271 if hasattr(y, '__setstate__'):
272 y.__setstate__(state)
File /usr/lib/python3.9/copy.py:146, in deepcopy(x, memo, _nil)
144 copier = _deepcopy_dispatch.get(cls)
145 if copier is not None:
--> 146 y = copier(x, memo)
147 else:
148 if issubclass(cls, type):
File /usr/lib/python3.9/copy.py:230, in _deepcopy_dict(x, memo, deepcopy)
228 memo[id(x)] = y
229 for key, value in x.items():
--> 230 y[deepcopy(key, memo)] = deepcopy(value, memo)
231 return y
[... skipping similar frames: _deepcopy_dict at line 230 (1 times), deepcopy at line 146 (1 times)]
File /usr/lib/python3.9/copy.py:172, in deepcopy(x, memo, _nil)
170 y = x
171 else:
--> 172 y = _reconstruct(x, memo, *rv)
174 # If is its own copy, don't memoize.
175 if y is not x:
File /usr/lib/python3.9/copy.py:270, in _reconstruct(x, memo, func, args, state, listiter, dictiter, deepcopy)
268 if state is not None:
269 if deep:
--> 270 state = deepcopy(state, memo)
271 if hasattr(y, '__setstate__'):
272 y.__setstate__(state)
[... skipping similar frames: _deepcopy_dict at line 230 (2 times), deepcopy at line 146 (2 times), deepcopy at line 172 (2 times), _reconstruct at line 270 (1 times)]
File /usr/lib/python3.9/copy.py:296, in _reconstruct(x, memo, func, args, state, listiter, dictiter, deepcopy)
294 for key, value in dictiter:
295 key = deepcopy(key, memo)
--> 296 value = deepcopy(value, memo)
297 y[key] = value
298 else:
[... skipping similar frames: deepcopy at line 172 (2 times), _deepcopy_dict at line 230 (1 times), _reconstruct at line 270 (1 times), deepcopy at line 146 (1 times)]
File /usr/lib/python3.9/copy.py:296, in _reconstruct(x, memo, func, args, state, listiter, dictiter, deepcopy)
294 for key, value in dictiter:
295 key = deepcopy(key, memo)
--> 296 value = deepcopy(value, memo)
297 y[key] = value
298 else:
[... skipping similar frames: deepcopy at line 172 (11 times), _deepcopy_dict at line 230 (5 times), _reconstruct at line 270 (5 times), _reconstruct at line 296 (5 times), deepcopy at line 146 (5 times)]
File /usr/lib/python3.9/copy.py:270, in _reconstruct(x, memo, func, args, state, listiter, dictiter, deepcopy)
268 if state is not None:
269 if deep:
--> 270 state = deepcopy(state, memo)
271 if hasattr(y, '__setstate__'):
272 y.__setstate__(state)
File /usr/lib/python3.9/copy.py:146, in deepcopy(x, memo, _nil)
144 copier = _deepcopy_dispatch.get(cls)
145 if copier is not None:
--> 146 y = copier(x, memo)
147 else:
148 if issubclass(cls, type):
File /usr/lib/python3.9/copy.py:230, in _deepcopy_dict(x, memo, deepcopy)
228 memo[id(x)] = y
229 for key, value in x.items():
--> 230 y[deepcopy(key, memo)] = deepcopy(value, memo)
231 return y
File /usr/lib/python3.9/copy.py:172, in deepcopy(x, memo, _nil)
170 y = x
171 else:
--> 172 y = _reconstruct(x, memo, *rv)
174 # If is its own copy, don't memoize.
175 if y is not x:
File /usr/lib/python3.9/copy.py:296, in _reconstruct(x, memo, func, args, state, listiter, dictiter, deepcopy)
294 for key, value in dictiter:
295 key = deepcopy(key, memo)
--> 296 value = deepcopy(value, memo)
297 y[key] = value
298 else:
File /usr/lib/python3.9/copy.py:153, in deepcopy(x, memo, _nil)
151 copier = getattr(x, "__deepcopy__", None)
152 if copier is not None:
--> 153 y = copier(memo)
154 else:
155 reductor = dispatch_table.get(cls)
File /usr/local/lib/python3.9/dist-packages/torch/nn/parameter.py:56, in Parameter.__deepcopy__(self, memo)
54 return memo[id(self)]
55 else:
---> 56 result = type(self)(self.data.clone(memory_format=torch.preserve_format), self.requires_grad)
57 memo[id(self)] = result
58 return result
RuntimeError: CUDA out of memory. Tried to allocate 40.00 MiB (GPU 0; 7.80 GiB total capacity; 6.82 GiB already allocated; 30.44 MiB free; 6.85 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
```
It seems to me that LangChain is somehow trying to reload the (whole?) pipeline on the GPU.
Any help appreciated, thank you. | Issue with ChatVectorDBChain and Hugging Face Accelerate | https://api.github.com/repos/langchain-ai/langchain/issues/3642/comments | 1 | 2023-04-27T10:28:29Z | 2023-09-10T16:26:11Z | https://github.com/langchain-ai/langchain/issues/3642 | 1,686,567,730 | 3,642 |
[
"hwchase17",
"langchain"
]
| Follow the instruction: https://python.langchain.com/en/latest/modules/agents/tools/examples/bash.html
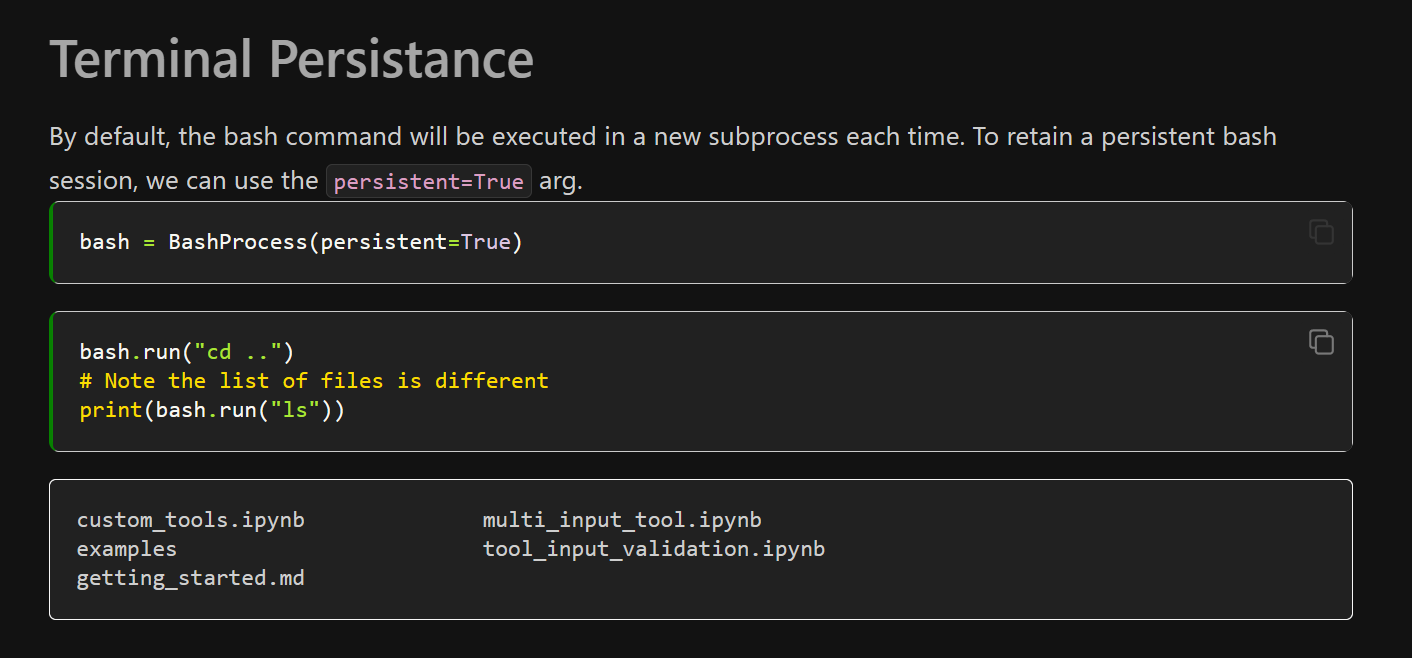
But I get the error:
```
bash = BashProcess(persistent=True)
TypeError: BashProcess.__init__() got an unexpected keyword argument 'persistent'
```
The version of langchain is 0.0.150
| no 'persistent=True' tag | https://api.github.com/repos/langchain-ai/langchain/issues/3641/comments | 1 | 2023-04-27T09:42:23Z | 2023-04-27T19:08:03Z | https://github.com/langchain-ai/langchain/issues/3641 | 1,686,495,917 | 3,641 |
[
"hwchase17",
"langchain"
]
| I'm attempting to load some Documents and get a `TransformError` - could someone please point me in the right direction? Thanks!
I'm afraid the traceback doesn't mean much to me.
```python
db = DeepLake(dataset_path=deeplake_path, embedding_function=embeddings)
db.add_documents(texts)
```
```
tensor htype shape dtype compression
------- ------- ------- ------- -------
embedding generic (0,) float32 None
ids text (0,) str None
metadata json (0,) str None
text text (0,) str None
Evaluating ingest: 0%| | 0/1 [00:10<?
Traceback (most recent call last):
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\core\chunk_engine.py", line 1065, in extend
self._extend(samples, progressbar, pg_callback=pg_callback)
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\core\chunk_engine.py", line 1001, in _extend
self._samples_to_chunks(
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\core\chunk_engine.py", line 824, in _samples_to_chunks
num_samples_added = current_chunk.extend_if_has_space(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\core\chunk\chunk_compressed_chunk.py", line 50, in extend_if_has_space
return self.extend_if_has_space_byte_compression(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\core\chunk\chunk_compressed_chunk.py", line 233, in extend_if_has_space_byte_compression
serialized_sample, shape = self.serialize_sample(
^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\core\chunk\base_chunk.py", line 342, in serialize_sample
incoming_sample, shape = serialize_text(
^^^^^^^^^^^^^^^
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\core\serialize.py", line 505, in serialize_text
incoming_sample, shape = text_to_bytes(incoming_sample, dtype, htype)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\core\serialize.py", line 458, in text_to_bytes
byts = json.dumps(sample, cls=HubJsonEncoder).encode()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\charles\AppData\Local\Programs\Python\Python311\Lib\json\__init__.py", line 238, in dumps
**kw).encode(obj)
^^^^^^^^^^^
File "C:\Users\charles\AppData\Local\Programs\Python\Python311\Lib\json\encoder.py", line 200, in encode
chunks = self.iterencode(o, _one_shot=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\charles\AppData\Local\Programs\Python\Python311\Lib\json\encoder.py", line 258, in iterencode
return _iterencode(o, 0)
^^^^^^^^^^^^^^^^^
ValueError: Circular reference detected
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\util\transform.py", line 220, in _transform_and_append_data_slice
transform_dataset.flush()
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\core\transform\transform_dataset.py", line 154, in flush
raise SampleAppendError(name) from e
deeplake.util.exceptions.SampleAppendError: Failed to append a sample to the tensor 'metadata'. See more details in the traceback.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\core\chunk_engine.py", line 1065, in extend
self._extend(samples, progressbar, pg_callback=pg_callback)
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\core\chunk_engine.py", line 1001, in _extend
self._samples_to_chunks(
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\core\chunk_engine.py", line 824, in _samples_to_chunks
num_samples_added = current_chunk.extend_if_has_space(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\core\chunk\chunk_compressed_chunk.py", line 50, in extend_if_has_space
return self.extend_if_has_space_byte_compression(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\core\chunk\chunk_compressed_chunk.py", line 233, in extend_if_has_space_byte_compression
serialized_sample, shape = self.serialize_sample(
^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\core\chunk\base_chunk.py", line 342, in serialize_sample
incoming_sample, shape = serialize_text(
^^^^^^^^^^^^^^^
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\core\serialize.py", line 505, in serialize_text
incoming_sample, shape = text_to_bytes(incoming_sample, dtype, htype)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\core\serialize.py", line 458, in text_to_bytes
byts = json.dumps(sample, cls=HubJsonEncoder).encode()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\charles\AppData\Local\Programs\Python\Python311\Lib\json\__init__.py", line 238, in dumps
**kw).encode(obj)
^^^^^^^^^^^
File "C:\Users\charles\AppData\Local\Programs\Python\Python311\Lib\json\encoder.py", line 200, in encode
chunks = self.iterencode(o, _one_shot=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\charles\AppData\Local\Programs\Python\Python311\Lib\json\encoder.py", line 258, in iterencode
return _iterencode(o, 0)
^^^^^^^^^^^^^^^^^
ValueError: Circular reference detected
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\util\transform.py", line 177, in _handle_transform_error
transform_dataset.flush()
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\core\transform\transform_dataset.py", line 154, in flush
raise SampleAppendError(name) from e
deeplake.util.exceptions.SampleAppendError: Failed to append a sample to the tensor 'metadata'. See more details in the traceback.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Users\charles\Documents\GitHub\Chat-with-Github-Repo\venv\Lib\site-packages\deeplake\core\transform\transform.py", line 298, in eval
raise TransformError(
deeplake.util.exceptions.TransformError: Transform failed at index 0 of the input data. See traceback for more details.
``` | deeplake.util.exceptions.TransformError | https://api.github.com/repos/langchain-ai/langchain/issues/3640/comments | 7 | 2023-04-27T09:03:57Z | 2023-11-27T04:56:27Z | https://github.com/langchain-ai/langchain/issues/3640 | 1,686,435,981 | 3,640 |
[
"hwchase17",
"langchain"
]
| Brief summary:
Need to solve multiple tasks in sequence (eg: translate an input -> use it to answer question -> translate to different language)
Previously was making multiple LLMChain objects with different prompts and passing outputs of one chain into another.
Came across sequential chains, tried it.
I didnt find any big difference on why I should use one over the other. Moreover, sequential chains seem to be slower than just calling multiple LLMChains.
Anything I'm missing, or if anyone can elaborate the need of sequential chains.
Thanks!! | Sequential chains vs multiple LLMChains (Why prefer one over the other?) | https://api.github.com/repos/langchain-ai/langchain/issues/3638/comments | 5 | 2023-04-27T07:12:50Z | 2023-10-21T16:09:41Z | https://github.com/langchain-ai/langchain/issues/3638 | 1,686,256,733 | 3,638 |
[
"hwchase17",
"langchain"
]
| In the [docs](https://python.langchain.com/en/latest/modules/indexes/document_loaders/examples/googledrive.html) of the GoogleDriveLoader says ``Currently, only Google Docs are supported``, but then, in the [code](https://github.com/hwchase17/langchain/blob/8e10ac422e4e6b193fc35e1d64d7f0c5208faa8d/langchain/document_loaders/googledrive.py#L100), there is a function ``_load_sheet_from_id``.
That function is only used for folder loading.
Accessing the _private_ method of the class is it possible, and works perfectly, to load spread sheets:
```
from langchain.document_loaders import GoogleDriveLoader
spreadsheet_id = "122tuu4r-yYng8Lj7XXXUgb-basdbk"
loader = GoogleDriveLoader(file_ids=[spreadsheet_id])
docs = loader._load_sheet_from_id(spreadsheet_id)
```
Probably ``_load_documents_from_ids`` needs some refactor to work based on the mimeType, as ``_load_documents_from_folder`` does. | Document Loaders: GoogleDriveLoader hidden option to load spread sheets | https://api.github.com/repos/langchain-ai/langchain/issues/3637/comments | 3 | 2023-04-27T06:07:09Z | 2024-02-07T16:30:28Z | https://github.com/langchain-ai/langchain/issues/3637 | 1,686,176,243 | 3,637 |
[
"hwchase17",
"langchain"
]
| Hello all,
I have been struggling for the past few days attempting to allow an agent.executor call to reference a text file as a VectorStore and determine the best response, then respond. When the agent eventually calls the VectorDBQAChain chain, it throws the below error stating the inability to redefine run().
Any input here is much appreciated.
Even a basic setup throws an error stating:
```
.\projectPath\node_modules\langchain\dist\chains\base.cjs:64
Object.defineProperty(outputValues, index_js_1.RUN_KEY, {
^
TypeError: Cannot redefine property: __run
at Function.defineProperty (<anonymous>)
at VectorDBQAChain.call (C:\Users\Tyler\Documents\RMMZ\GPTales-InteractiveNPC\node_modules\langchain\dist\chains\base.cjs:64:16)
at process.processTicksAndRejections (node:internal/process/task_queues:95:5)
at async VectorDBQAChain.run (C:\Users\Tyler\Documents\RMMZ\GPTales-InteractiveNPC\node_modules\langchain\dist\chains\base.cjs:29:30)
at async ChainTool.call (C:\Users\Tyler\Documents\RMMZ\GPTales-InteractiveNPC\node_modules\langchain\dist\tools\base.cjs:23:22)
at async C:\Users\Tyler\Documents\RMMZ\GPTales-InteractiveNPC\node_modules\langchain\dist\agents\executor.cjs:101:23
at async Promise.all (index 0)
at async AgentExecutor._call (C:\Users\Tyler\Documents\RMMZ\GPTales-InteractiveNPC\node_modules\langchain\dist\agents\executor.cjs:97:30)
at async AgentExecutor.call (C:\Users\Tyler\Documents\RMMZ\GPTales-InteractiveNPC\node_modules\langchain\dist\chains\base.cjs:53:28)
at async run (C:\Users\Tyler\Documents\RMMZ\GPTales-InteractiveNPC\Game\js\plugins\GPTales\example.js:79:19)
Node.js v19.7.0
```
Code:
```
const run = async () => {
console.log("Starting.");
console.log(process.env.OPENAI_API_KEY);
process.env.LANGCHAIN_HANDLER = "langchain";
const gameLorePath = path.join(__dirname, "yuri.txt");
const text = fs.readFileSync(gameLorePath, "utf8");
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
});
const docs = await textSplitter.createDocuments([text]);
const vectorStore = await HNSWLib.fromDocuments(docs, new OpenAIEmbeddings());
const model = new ChatOpenAI({
temperature: 0,
api_key: process.env.OPENAI_API_KEY,
});
const chain = VectorDBQAChain.fromLLM(model, vectorStore);
const characterContextTool = new ChainTool({
name: "character-contextTool-tool",
description:
"Context for the character - used for querying context of lore(bio, personality, appearance, etc), characters, events, environments, essentially all aspects of the character and their history.",
chain: chain,
});
const tools = [new Calculator(), characterContextTool];
// Passing "chat-conversational-react-description" as the agent type
// automatically creates and uses BufferMemory with the executor.
// If you would like to override this, you can pass in a custom
// memory option, but the memoryKey set on it must be "chat_history".
const executor = await initializeAgentExecutorWithOptions(tools, model, {
agentType: "chat-conversational-react-description",
verbose: true,
});
console.log("Loaded agent.");
const input0 =
"hi, i am bob. use the character context tool to best decide how to respond considering all facets of the character.";
const result0 = await executor.call({ input: input0 });
console.log(`Got output ${result0.output}`);
const input1 = "whats your name?";
const result1 = await executor.call({ input: input1 });
console.log(`Got output ${result1.output}`);
};
run();
``` | Unable to call VectorDBQAChain from Executor | https://api.github.com/repos/langchain-ai/langchain/issues/3633/comments | 2 | 2023-04-27T05:25:14Z | 2023-04-27T17:40:28Z | https://github.com/langchain-ai/langchain/issues/3633 | 1,686,139,134 | 3,633 |
[
"hwchase17",
"langchain"
]
| I am facing an issue when using the embeddings model that Azure OpenAI offers. Please help. Heres the code below. Assume the azure resource name is azure-resource. This issue is only arising with the text-embeddings-ada-002 model, nothing else
```
os.environ["OPENAI_API_KEY"] = API_KEY
# Loading the document using PyPDFLoader
loader = PyPDFLoader('xxx')
# Splitting the document into chunks
pages = loader.load_and_split()
# Creating your embeddings instance
embeddings = OpenAIEmbeddings(
model = "azure-resource",
)
# Creating your vector db
db = FAISS.from_documents(pages, embeddings)
query = "some-query"
docs = db.similarity_search(query)
```
My error:
`KeyError: 'Could not automatically map azure-resource to a tokeniser. Please use `tiktok.get_encoding` to explicitly get the tokeniser you expect.'` | KeyError: 'Could not automatically map azure-resource to a tokeniser. Arising when using the text-embeddings-ada-002 model. | https://api.github.com/repos/langchain-ai/langchain/issues/3632/comments | 0 | 2023-04-27T05:23:59Z | 2023-04-30T14:54:06Z | https://github.com/langchain-ai/langchain/issues/3632 | 1,686,138,122 | 3,632 |
[
"hwchase17",
"langchain"
]
| Using MMR with Chroma currently does not work because the max_marginal_relevance_search_by_vector method calls self.__query_collection with the parameter "include:", but "include" is not an accepted parameter for __query_collection. This appears to be a regression introduced with #3372
Excerpt from max_marginal_relevance_search_by_vector method:
```
results = self.__query_collection(
query_embeddings=embedding,
n_results=fetch_k,
where=filter,
include=["metadatas", "documents", "distances", "embeddings"],
)
```
__query_collection does not accept include:
```
def __query_collection(
self,
query_texts: Optional[List[str]] = None,
query_embeddings: Optional[List[List[float]]] = None,
n_results: int = 4,
where: Optional[Dict[str, str]] = None,
) -> List[Document]:
```
This results in an unexpected keyword error.
The short term fix is to use self._collection.query instead of self.__query_collection in max_marginal_relevance_search_by_vector, although that loses the protection when the user requests more records than exist in the store.
```
results = self._collection.query(
query_embeddings=embedding,
n_results=fetch_k,
where=filter,
include=["metadatas", "documents", "distances", "embeddings"],
)
``` | Chroma.py max_marginal_relevance_search_by_vector method currently broken | https://api.github.com/repos/langchain-ai/langchain/issues/3628/comments | 4 | 2023-04-27T00:21:42Z | 2023-05-01T17:47:17Z | https://github.com/langchain-ai/langchain/issues/3628 | 1,685,907,595 | 3,628 |
[
"hwchase17",
"langchain"
]
| Hi, i'm using deeplake with the ConversationalRetrievalBuffer (just like in this brand new guide [code understanding](https://python.langchain.com/en/latest/use_cases/code/code-analysis-deeplake.html#prepare-data) encountering the following error when calling:
`answer = chain({"question": user_input, "chat_history": chat_history['history']})`
error:
```
File "C:\Users\sbene\Projects\GitChat\src\chatbot.py", line 446, in generate_answer
answer = chain({"question": user_input, "chat_history": chat_history['history']})
File "C:\Users\sbene\miniconda3\envs\gitchat\lib\site-packages\langchain\chains\base.py", line 116, in __call__
raise e
File "C:\Users\sbene\miniconda3\envs\gitchat\lib\site-packages\langchain\chains\base.py", line 113, in __call__
outputs = self._call(inputs)
File "C:\Users\sbene\miniconda3\envs\gitchat\lib\site-packages\langchain\chains\conversational_retrieval\base.py", line 95, in _call
docs = self._get_docs(new_question, inputs)
File "C:\Users\sbene\miniconda3\envs\gitchat\lib\site-packages\langchain\chains\conversational_retrieval\base.py", line 162, in _get_docs
docs = self.retriever.get_relevant_documents(question)
File "C:\Users\sbene\miniconda3\envs\gitchat\lib\site-packages\langchain\vectorstores\base.py", line 279, in get_relevant_documents
docs = self.vectorstore.similarity_search(query, **self.search_kwargs)
File "C:\Users\sbene\miniconda3\envs\gitchat\lib\site-packages\langchain\vectorstores\deeplake.py", line 350, in similarity_search
return self.search(query=query, k=k, **kwargs)
File "C:\Users\sbene\miniconda3\envs\gitchat\lib\site-packages\langchain\vectorstores\deeplake.py", line 294, in search
indices, scores = vector_search(
File "C:\Users\sbene\miniconda3\envs\gitchat\lib\site-packages\langchain\vectorstores\deeplake.py", line 51, in vector_search
nearest_indices[::-1][:k] if distance_metric in ["cos"] else nearest_indices[:k]
``` | Bug: deeplake cosine distance search error | https://api.github.com/repos/langchain-ai/langchain/issues/3623/comments | 1 | 2023-04-26T23:27:06Z | 2023-09-10T16:26:16Z | https://github.com/langchain-ai/langchain/issues/3623 | 1,685,870,712 | 3,623 |
[
"hwchase17",
"langchain"
]
| It would be good to get some more documentation and examples of using models other than OpenAI. Currently the docs are really heavily skewed and in some areas such as conversation only offer an OpenAI option.
Thanks | Non OpenAI models | https://api.github.com/repos/langchain-ai/langchain/issues/3622/comments | 2 | 2023-04-26T23:06:51Z | 2023-09-17T17:22:03Z | https://github.com/langchain-ai/langchain/issues/3622 | 1,685,858,023 | 3,622 |
[
"hwchase17",
"langchain"
]
| I am having issues with using ConversationalRetrievalChain to chat with a CSV file. It only recognizes the first four rows of a CSV file.
```
loader = CSVLoader(file_path=filepath, encoding="utf-8")
data = loader.load()
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
vectorstore = FAISS.from_documents(data, embeddings)
_template = """Given the following conversation and a follow-up question, rephrase the follow-up question to be a standalone question.
Chat History:
{chat_history}
Follow-up entry: {question}
Standalone question:"""
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(_template)
qa_template = """"You are an AI conversational assistant to answer questions based on a context.
You are given data from a csv file and a question, you must help the user find the information they need.
Your answers should be friendly, in the same language.
question: {question}
=========
context: {context}
=======
"""
QA_PROMPT = PromptTemplate(template=qa_template, input_variables=["question", "context"])
model_name = 'gpt-4'
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
chain = ConversationalRetrievalChain.from_llm(
llm = ChatOpenAI(temperature=0.0,
model_name=model_name,
openai_api_key=openai_api_key,
request_timeout=120),
retriever=vectorstore.as_retriever(),
memory=memory)
query = """
How many headlines are in this data set
"""
result = chain({"question": query,})
result[ 'answer']
```
The response is `There are four rows in this data set.`
The data length is 151 lines so I know that this step is working properly. Could this be a token limitation of OpenAI? | ConversationalRetrievalChain with CSV file limited to first 4 rows of data | https://api.github.com/repos/langchain-ai/langchain/issues/3621/comments | 14 | 2023-04-26T22:38:48Z | 2023-09-01T07:29:44Z | https://github.com/langchain-ai/langchain/issues/3621 | 1,685,837,569 | 3,621 |
[
"hwchase17",
"langchain"
]
| if the line in BaseConversationalRetrievalChain::_call() (in chains/conversational_retrieval/base.py):
```
docs = self._get_docs(new_question, inputs)
```
returns an empty list of docs, then a subsequent line in the same method:
```
answer, _ = self.combine_docs_chain.combine_docs(docs, **new_inputs)
```
will result in an error due to the CombineDocsProtocol.combine_docs() line:
```
results = self.llm_chain.apply(
# FYI - this is parallelized and so it is fast.
[{**{self.document_variable_name: d.page_content}, **kwargs} for d in docs]
)
```
which will pass an empty "input_list" arg to LLMChain.apply(). LLMChain.apply() doesn't like an empty input_list.
Should docs be non-empty in all cases? If the vectorstore is empty, wouldn't it match 0 docs and then shouldn't that be handled more gracefully? | BaseConversationalRetrievalChain raising error when no Documents are matched | https://api.github.com/repos/langchain-ai/langchain/issues/3617/comments | 1 | 2023-04-26T20:15:11Z | 2023-09-10T16:26:25Z | https://github.com/langchain-ai/langchain/issues/3617 | 1,685,654,780 | 3,617 |
[
"hwchase17",
"langchain"
]
| When executing the code for Human as a tool taken directly from documentation I get the following error:
```
ImportError Traceback (most recent call last)
[/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/delete.ipynb](https://file+.vscode-resource.vscode-cdn.net/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/delete.ipynb) Cell 2 in 5
[3](vscode-notebook-cell:/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/delete.ipynb#W1sZmlsZQ%3D%3D?line=2) from langchain.llms import OpenAI
[4](vscode-notebook-cell:/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/delete.ipynb#W1sZmlsZQ%3D%3D?line=3) from langchain.agents import load_tools, initialize_agent
----> [5](vscode-notebook-cell:/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/delete.ipynb#W1sZmlsZQ%3D%3D?line=4) from langchain.agents import AgentType
[7](vscode-notebook-cell:/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/delete.ipynb#W1sZmlsZQ%3D%3D?line=6) llm = ChatOpenAI(temperature=0.0)
[8](vscode-notebook-cell:/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/delete.ipynb#W1sZmlsZQ%3D%3D?line=7) math_llm = OpenAI(temperature=0.0)
ImportError: cannot import name 'AgentType' from 'langchain.agents' ([/Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/langchain/agents/__init__.py](https://file+.vscode-resource.vscode-cdn.net/Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/langchain/agents/__init__.py))
```
Even when commenting out the 'from langchain.agents import AgentType' and switching the agent like so 'agent="zero-shot-react-description"' I still get the following error:
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
[/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/AGI.ipynb](https://file+.vscode-resource.vscode-cdn.net/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/AGI.ipynb) Cell 4 in 7
[4](vscode-notebook-cell:/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/AGI.ipynb#W3sZmlsZQ%3D%3D?line=3) os.environ['WOLFRAM_ALPHA_APPID'] = creds.WOLFRAM_ALPHA_APPID
[6](vscode-notebook-cell:/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/AGI.ipynb#W3sZmlsZQ%3D%3D?line=5) llm = OpenAI(temperature=0.0, model_name = "gpt-3.5-turbo")
----> [7](vscode-notebook-cell:/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/AGI.ipynb#W3sZmlsZQ%3D%3D?line=6) tools = load_tools(["python_repl",
[8](vscode-notebook-cell:/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/AGI.ipynb#W3sZmlsZQ%3D%3D?line=7) "terminal",
[9](vscode-notebook-cell:/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/AGI.ipynb#W3sZmlsZQ%3D%3D?line=8) "wolfram-alpha",
[10](vscode-notebook-cell:/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/AGI.ipynb#W3sZmlsZQ%3D%3D?line=9) "human",
[11](vscode-notebook-cell:/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/AGI.ipynb#W3sZmlsZQ%3D%3D?line=10) # "serpapi",
[12](vscode-notebook-cell:/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/AGI.ipynb#W3sZmlsZQ%3D%3D?line=11) # "wikipedia",
[13](vscode-notebook-cell:/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/AGI.ipynb#W3sZmlsZQ%3D%3D?line=12) "requests",
[14](vscode-notebook-cell:/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/AGI.ipynb#W3sZmlsZQ%3D%3D?line=13) ],)
[16](vscode-notebook-cell:/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/AGI.ipynb#W3sZmlsZQ%3D%3D?line=15) agent = initialize_agent(tools,
[17](vscode-notebook-cell:/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/AGI.ipynb#W3sZmlsZQ%3D%3D?line=16) llm,
[18](vscode-notebook-cell:/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/AGI.ipynb#W3sZmlsZQ%3D%3D?line=17) agent="zero-shot-react-description",
[19](vscode-notebook-cell:/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/AGI.ipynb#W3sZmlsZQ%3D%3D?line=18) verbose=True)
File [/Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/langchain/agents/load_tools.py:236](https://file+.vscode-resource.vscode-cdn.net/Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/langchain/agents/load_tools.py:236), in load_tools(tool_names, llm, callback_manager, **kwargs)
234 tools.append(tool)
235 else:
--> 236 raise ValueError(f"Got unknown tool {name}")
237 return tools
ValueError: Got unknown tool human
```
| Human as a Tool Documentation Out of Date | https://api.github.com/repos/langchain-ai/langchain/issues/3615/comments | 6 | 2023-04-26T19:58:50Z | 2023-04-26T22:11:05Z | https://github.com/langchain-ai/langchain/issues/3615 | 1,685,632,646 | 3,615 |
[
"hwchase17",
"langchain"
]
| Hello all, I would like to clarify something regarding indexes, llama connectors etc... I made simple q/a AI app using lanchain with pinecone vector DB, the vector DB is updated from local files on change to that files.. Everything works ok.
Now, how or what is the logic when adding other connectors ? Do I just use the llama connector to scrape some endpoint like web or discord, and feed it to vector DB and use only one vector DB in the end to query answer?
I need to query over multiple sources. How to deal with new data ? Currently, since the text files are small the pinecone index is dropped and it's recreated from scratch which does not seem to be a correct way to do it... let's say if the web changes, something is added or modified, it does not make sense to recreate the whole DB (hmm maybe I can drop stuff by source meta ? ) | Multiple data sources logic ? | https://api.github.com/repos/langchain-ai/langchain/issues/3609/comments | 1 | 2023-04-26T18:23:02Z | 2023-09-17T17:22:08Z | https://github.com/langchain-ai/langchain/issues/3609 | 1,685,505,802 | 3,609 |
[
"hwchase17",
"langchain"
]
| Hello, I and deploying RetrievalQAWithSourcesChain with ChatOpenAI model right now.
Unlike OpenAI model, you can provide system message for the model which is a great complement.
But I tried many times, it seems the prompt can not be insert into the chain.
Please suggest what should I do to my code:
```
#Prompt Construction
template="""You play as {user_name}'s assistant,your name is {name},personality is {personality},duty is {duty}"""
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template="""
Context: {context}
Question: {question}
please indicate if you are not sure about answer. Do NOT Makeup.
MUST answer in {language}."""
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
ChatPromptTemplate.input_variables=["context", "question","name","personality","user_name","duty","language"]
#define the chain
chain = RetrievalQAWithSourcesChain.from_chain_type(llm=llm,
combine_documents_chain=qa_chain,
chain_type="stuff",
retriever=compression_retriever,
chain_type_kwargs = {"prompt": chat_prompt}
)
``` | How can I structure prompt temple for RetrievalQAWithSourcesChain with ChatOpenAI model | https://api.github.com/repos/langchain-ai/langchain/issues/3606/comments | 3 | 2023-04-26T18:02:39Z | 2023-09-17T17:22:13Z | https://github.com/langchain-ai/langchain/issues/3606 | 1,685,480,734 | 3,606 |
[
"hwchase17",
"langchain"
]
| I am new to using Langchain and attempting to make it work with a locally running LLM (Alpaca) and Embeddings model (Sentence Transformer). When configuring the sentence transformer model with `HuggingFaceEmbeddings` no arguments can be passed to the encode method of the model, specifically `normalize_embeddings=True`. Neither can I specify the distance metric that I want to use in the `similarity_search` method irrespective of what vector store I am using. So it seems to me I can only create unnormalized embeddings with huggingface models and only use L2 distance as the similarity metric by default. Whereas I want to use the cosine similarity metric or have normalized embeddings and then use the dot product/L2 distance.
If I am wrong here can someone point me in the right direction. If not are there any plans to implement this? | Embeddings normalization and similarity metric | https://api.github.com/repos/langchain-ai/langchain/issues/3605/comments | 0 | 2023-04-26T18:02:20Z | 2023-05-30T18:57:06Z | https://github.com/langchain-ai/langchain/issues/3605 | 1,685,480,283 | 3,605 |
[
"hwchase17",
"langchain"
]
| I have a doubt if FAISS is a vector database or a search algorithm. The vectorstores.faiss mentions it as a vector database, but is it not a search algorithm? | The vectorstores says faiss as FAISS vector database | https://api.github.com/repos/langchain-ai/langchain/issues/3601/comments | 1 | 2023-04-26T16:28:37Z | 2023-09-10T16:26:41Z | https://github.com/langchain-ai/langchain/issues/3601 | 1,685,351,151 | 3,601 |
[
"hwchase17",
"langchain"
]
| Hi Team, I am using opensearch as my vectorstore and trying to create index for documents vectors. but unable to create index:
Getting error:
`ERROR - The embeddings count, 501 is more than the [bulk_size], 500. Increase the value of [bulk_size]`
Can someone please advice ?
Thanks | Unable to create opensearch index. | https://api.github.com/repos/langchain-ai/langchain/issues/3595/comments | 2 | 2023-04-26T14:04:56Z | 2023-09-10T16:26:46Z | https://github.com/langchain-ai/langchain/issues/3595 | 1,685,103,449 | 3,595 |
[
"hwchase17",
"langchain"
]
| null | load_qa_chain _ RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! | https://api.github.com/repos/langchain-ai/langchain/issues/3593/comments | 3 | 2023-04-26T14:02:08Z | 2023-10-18T21:42:47Z | https://github.com/langchain-ai/langchain/issues/3593 | 1,685,098,021 | 3,593 |
[
"hwchase17",
"langchain"
]
| I am using RetrievalQAWithSourcesChain to get answers on documents that I previously embedded using pinecone. I notice that sometimes that the sources is not populated under the sources key when I run the chain.
I am using pinecone to embed the pdf documents like so:
```python
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=20,
length_function=tiktoken_len,
separators=['\n\n', '\n', ' ', '']
)
split_documents = text_splitter.split_documents(documents=documents)
Pinecone.from_documents(
split_documents,
OpenAIEmbeddings(),
index_name='test_index',
namespace= 'test_namespace')
```
I am using RetrievalQAWithSourcesChain to ask queries like so:
```python
llm = OpenAIEmbeddings()
vectorstore: Pinecone = Pinecone.from_existing_index(
index_name='test_index',
embedding=OpenAIEmbeddings(),
namespace='test_namespace'
)
qa_chain = load_qa_with_sources_chain(llm=_llm, chain_type="stuff")
qa = RetrievalQAWithSourcesChain(
combine_documents_chain=qa_chain,
retriever=vectorstore.as_retriever(),
reduce_k_below_max_tokens=True,
)
answer_response = qa({"question": question}, return_only_outputs=True)
```
Expected response
`{'answer': 'some answer', 'sources': 'the_file_name.pdf'}`
Actual response
`{'answer': 'some answer', 'sources': ''}`
This behaviour is actually not consistent. I sometimes get the sources in the answer itself and not under the sources key. And at times I get the sources under the 'sources' key and not the answer. I want the sources to ALWAYS come under the sources key and not in the answer text.
Im using langchain==0.0.149.
Am I missing something in the way im embedding or retrieving my documents? Or is this an issue with langchain?
**Edit: Additional information on how to reproduce this issue**
While trying to reproduce the exact issue for @jpdus I noticed that this happens consistently when I request for the answer in a table format. When the query requests for the answer in a table format, it seems like the source is coming in with the answer and not the source key. I am attaching a test document and some examples here:
Source : [UN Doc.pdf](https://github.com/hwchase17/langchain/files/11339620/UN.Doc.pdf)
Query 1 (with table): what are the goals for sustainability 2030, povide your answer in a table format?
Response :
```json
{'answer': 'Goals for Sustainability 2030:\n\nGoal 1. End poverty in all its forms everywhere\nGoal 2. End hunger, achieve food security and improved nutrition and promote sustainable agriculture\nGoal 3. Ensure healthy lives and promote well-being for all at all ages\nGoal 4. Ensure inclusive and equitable quality education and promote lifelong learning opportunities for all\nGoal 5. Achieve gender equality and empower all women and girls\nGoal 6. Ensure availability and sustainable management of water and sanitation for all\nGoal 7. Ensure access to affordable, reliable, sustainable and modern energy for all\nGoal 8. Promote sustained, inclusive and sustainable economic growth, full and productive employment and decent work for all\nGoal 9. Build resilient infrastructure, promote inclusive and sustainable industrialization and foster innovation\nGoal 10. Reduce inequality within and among countries\nGoal 11. Make cities and human settlements inclusive, safe, resilient and sustainable\nGoal 12. Ensure sustainable consumption and production patterns\nGoal 13. Take urgent action to combat climate change and its impacts\nGoal 14. Conserve and sustainably use the oceans, seas and marine resources for sustainable development\nGoal 15. Protect, restore and promote sustainable use of terrestrial ecosystems, sustainably manage forests, combat desertification, and halt and reverse land degradation and halt biodiversity loss\nSource: docs/UN Doc.pdf', 'sources': ''}
```
Query 2 (without table) : what are the goals for sustainability 2030?
Response:
```json
{'answer': "The goals for sustainability 2030 include expanding international cooperation and capacity-building support to developing countries in water and sanitation-related activities and programs, ensuring access to affordable, reliable, sustainable and modern energy for all, promoting sustained, inclusive and sustainable economic growth, full and productive employment and decent work for all, taking urgent action to combat climate change and its impacts, strengthening efforts to protect and safeguard the world's cultural and natural heritage, providing universal access to safe, inclusive and accessible green and public spaces, ensuring sustainable consumption and production patterns, significantly increasing access to information and communications technology and striving to provide universal and affordable access to the Internet in least developed countries by 2020, and reducing inequality within and among countries. \n", 'sources': 'docs/UN Doc.pdf'}
```
| RetrievalQAWithSourcesChain sometimes does not return sources under sources key | https://api.github.com/repos/langchain-ai/langchain/issues/3592/comments | 7 | 2023-04-26T13:22:28Z | 2023-09-24T16:07:12Z | https://github.com/langchain-ai/langchain/issues/3592 | 1,685,024,756 | 3,592 |
[
"hwchase17",
"langchain"
]
| I am using the DirectoryLoader, with the relevant loader class defined
```
DirectoryLoader('.\\src', glob="**/*.md", loader_cls=UnstructuredMarkdownLoader)`
```
I couldn't understand why the following step didn't chunk text into the relevant markdown sections:
```
markdown_splitter = MarkdownTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = markdown_splitter.split_documents(docs)
```
After digging into it a bit, the UnstructuredMarkdownLoader strips the Markdown formatting from the documents. This means that the Splitter has nothing to guide it and ends up chunking into 1000 text character sizes. | UnstructuredMarkdownLoader strips Markdown formatting from documents, rendering MarkdownTextSplitter non-functional | https://api.github.com/repos/langchain-ai/langchain/issues/3591/comments | 3 | 2023-04-26T13:02:27Z | 2023-11-02T16:15:34Z | https://github.com/langchain-ai/langchain/issues/3591 | 1,684,990,072 | 3,591 |
[
"hwchase17",
"langchain"
]
| So I'm just trying to write a custom agent using `LLMSingleActionAgent` based off the example from the official docs and I ran into this error
>
> File "/usr/local/lib/python3.9/site-packages/langchain/chains/base.py", line 118, in __call__
> return self.prep_outputs(inputs, outputs, return_only_outputs)
> File "/usr/local/lib/python3.9/site-packages/langchain/chains/base.py", line 168, in prep_outputs
> self._validate_outputs(outputs)
> File "/usr/local/lib/python3.9/site-packages/langchain/chains/base.py", line 79, in _validate_outputs
> raise ValueError(
> ValueError: Did not get output keys that were expected. Got: {'survey_question'}. Expected: {'output'}
```python
class CustomOutputParser(AgentOutputParser):
def parse(self, llm_output: str) -> Union[AgentAction, AgentFinish]:
# Check if agent should finish
if "Final Answer:" in llm_output:
return AgentFinish(
# Return values is generally always a dictionary with a single `output` key
# It is not recommended to try anything else at the moment :)
return_values={"survey_question": llm_output.split(
"Final Answer:")[-1].strip()},
log=llm_output,
)
# Parse out the action and action input
regex = r"Action\s*\d*\s*:(.*?)\nAction\s*\d*\s*Input\s*\d*\s*:[\s]*(.*)"
match = re.search(regex, llm_output, re.DOTALL)
if not match:
raise ValueError(f"Could not parse LLM result: `{llm_output}`")
action = match.group(1).strip()
action_input = match.group(2)
# Return the action and action input
return AgentAction(tool=action, tool_input=action_input.strip(" ").strip('"'), log=llm_output)
class Chatbot:
async def conversational_chat(self, query, dataset_path):
prompt = CustomPromptTemplate(
template=template,
tools=tools,
# This omits the `agent_scratchpad`, `tools`, and `tool_names` variables because those are generated dynamically
# This includes the `intermediate_steps` variable because that is needed
input_variables=["input", "intermediate_steps", "dataset_path"],
output_parser=CustomOutputParser(),
)
output_parser = CustomOutputParser()
llm = OpenAI(temperature=0) # type: ignore
llm_chain = LLMChain(llm=llm, prompt=prompt)
tool_names = [tool.name for tool in tools]
survey_agent = LLMSingleActionAgent(
llm_chain=llm_chain,
output_parser=output_parser,
stop=["\nObservation:"],
allowed_tools=tool_names # type: ignore
)
survey_agent_executor = AgentExecutor.from_agent_and_tools(
agent=survey_agent, tools=tools, verbose=True)
return survey_agent_executor({"input": query, "dataset_path": dataset_path})
``` | Did not get output keys that were expected. | https://api.github.com/repos/langchain-ai/langchain/issues/3590/comments | 1 | 2023-04-26T12:55:45Z | 2023-09-10T16:26:51Z | https://github.com/langchain-ai/langchain/issues/3590 | 1,684,978,281 | 3,590 |
[
"hwchase17",
"langchain"
]
| I'm using OpenAPI agents to access my own APIs. and the LLM I'm using is OpenAI's GPT-4.
When I queried something, LLM just answered not only `Action` and `Action Input`, but also `Observation` and even `Final Answer` with fake data under API_ORCHESTRATOR_PROMPT.
So the agent did not work with `api_planner` and `api_controller` tools.
I am wondering is `API_ORCHESTRATOR_PROMPT` or `FORMAT_INSTRUCTIONS` prompt stable?
I tested the [Agent Getting Started](https://python.langchain.com/en/latest/modules/agents/getting_started.html), and got bad answer from llm directly without tools sometimes, ether.
or am i missing something important?
or should i rewrite the prompt?
thanks
| OpenAPI agents did not execute tools | https://api.github.com/repos/langchain-ai/langchain/issues/3588/comments | 3 | 2023-04-26T12:24:28Z | 2023-09-13T15:59:30Z | https://github.com/langchain-ai/langchain/issues/3588 | 1,684,928,287 | 3,588 |
[
"hwchase17",
"langchain"
]
| I am facing an error when calling the OpenAIEmbeddings model. This is my code.
````
import os
os.environ["OPENAI_API_TYPE"] = "azure"
os.environ["OPENAI_API_BASE"] = "base-thing"
os.environ["OPENAI_API_KEY"] = "apikey"
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="model-name")
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text])
````
This is the error I am facing:
**AttributeError: module 'tiktoken' has no attribute 'model'** | AttributeError when calling OpenAIEmbeddings model | https://api.github.com/repos/langchain-ai/langchain/issues/3586/comments | 12 | 2023-04-26T11:07:24Z | 2023-04-27T05:26:43Z | https://github.com/langchain-ai/langchain/issues/3586 | 1,684,804,005 | 3,586 |
[
"hwchase17",
"langchain"
]
| Hi,
I have installed langchain-0.0.149 using pip. When trying to run the folloging code I get an import error.
from langchain.retrievers import ContextualCompressionRetriever
Traceback (most recent call last):
File ".../lib/python3.10/site-packages/IPython/core/interactiveshell.py", line 3460, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "", line 1, in
from langchain.retrievers import ContextualCompressionRetriever
ImportError: cannot import name 'ContextualCompressionRetriever' from 'langchain.retrievers' (.../lib/python3.10/site-packages/langchain/retrievers/init.py)
Thanks in advance,
Mikel. | import error ContextualCompressionRetriever | https://api.github.com/repos/langchain-ai/langchain/issues/3585/comments | 2 | 2023-04-26T10:39:44Z | 2023-09-10T16:27:02Z | https://github.com/langchain-ai/langchain/issues/3585 | 1,684,762,823 | 3,585 |
[
"hwchase17",
"langchain"
]
| Hello!
I am building an ai assistant, with the help of langchain's ConversationRetrievalChain. I built a FastAPI endpoint where users can ask questions from the ai. I store the previous messages in my db. My code:
```
def create_chat_agent():
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
# Data Ingestion
word_loader = DirectoryLoader(DOCUMENTS_DIRECTORY, glob="*.docx")
documents = []
documents.extend(word_loader.load())
# Chunk and Embeddings
text_splitter = CharacterTextSplitter(chunk_size=800, chunk_overlap=0)
documents = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
# Initialise Langchain - Conversation Retrieval Chain
return ConversationalRetrievalChain.from_llm(llm, vectorstore.as_retriever())
def askAI(cls, prompt: str, id: str):
qa = cls.create_chat_agent()
chat_history = []
previousMessages = UserController.get_previous_messages_by_user_id(id)
for message in previousMessages:
messageObject = (message['user'], message['ai'])
chat_history.append(messageObject)
response = qa({"question": prompt, "chat_history": chat_history})
cls.update_previous_messages(userId=id, prompt=prompt, response=response["answer"])
return response
```
I always get back an answer and most of the time it is very specific, however sometimes it answers the wrong question. I mean the question I asked a few prompts earlier. I don't know what is wrong in here, can somebody help me?
Thank you in advance!!
| ConversationRetrievalChain with memory | https://api.github.com/repos/langchain-ai/langchain/issues/3583/comments | 3 | 2023-04-26T09:40:35Z | 2023-09-27T16:07:31Z | https://github.com/langchain-ai/langchain/issues/3583 | 1,684,664,076 | 3,583 |
[
"hwchase17",
"langchain"
]
| 
Token usage calculation is not working:

| Token usage calculation is not working for Asynchronous requests in ChatOpenA | https://api.github.com/repos/langchain-ai/langchain/issues/3579/comments | 2 | 2023-04-26T07:21:28Z | 2023-09-10T16:27:08Z | https://github.com/langchain-ai/langchain/issues/3579 | 1,684,427,942 | 3,579 |
[
"hwchase17",
"langchain"
]
| ## Description
ref: https://python.langchain.com/en/latest/modules/agents/tools/examples/chatgpt_plugins.html
Thanks for the great tool.
I'm trying ChatGPT Plugin.
I get an error when I run the sample code in the document.
It looks like it's caused by single quotes.
### output
```
> Entering new AgentExecutor chain...
I need to use the Klarna Shopping API to search for available t shirts.
Action: KlarnaProducts
Action Input: None
Observation: Usage Guide: Assistant uses the Klarna plugin to get relevant product suggestions for any shopping or product discovery purpose. Assistant will reply with the following 3 paragraphs 1) Search Results 2) Product Comparison of the Search Results 3) Followup Questions. The first paragraph contains a list of the products with their attributes listed clearly and concisely as bullet points under the product, together with a link to the product and an explanation. Links will always be returned and should be shown to the user. The second paragraph compares the results returned in a summary sentence starting with "In summary". Assistant comparisons consider only the most important features of the products that will help them fit the users request, and each product mention is brief, short and concise. In the third paragraph assistant always asks helpful follow-up questions and end with a question mark. When assistant is asking a follow-up question, it uses it's product expertise to provide information pertaining to the subject of the user's request that may guide them in their search for the right product.
OpenAPI Spec: {'openapi': '3.0.1', 'info': {'version': 'v0', 'title': 'Open AI Klarna product Api'}, 'servers': [{'url': 'https://www.klarna.com/us/shopping'}], 'tags': [{'name': 'open-ai-product-endpoint', 'description': 'Open AI Product Endpoint. Query for products.'}], 'paths': {'/public/openai/v0/products': {'get': {'tags': ['open-ai-product-endpoint'], 'summary': 'API for fetching Klarna product information', 'operationId': 'productsUsingGET', 'parameters': [{'name': 'q', 'in': 'query', 'description': "A precise query that matches one very small category or product that needs to be searched for to find the products the user is looking for. If the user explicitly stated what they want, use that as a query. The query is as specific as possible to the product name or category mentioned by the user in its singular form, and don't contain any clarifiers like latest, newest, cheapest, budget, premium, expensive or similar. The query is always taken from the latest topic, if there is a new topic a new query is started.", 'required': True, 'schema': {'type': 'string'}}, {'name': 'size', 'in': 'query', 'description': 'number of products returned', 'required': False, 'schema': {'type': 'integer'}}, {'name': 'min_price', 'in': 'query', 'description': "(Optional) Minimum price in local currency for the product searched for. Either explicitly stated by the user or implicitly inferred from a combination of the user's request and the kind of product searched for.", 'required': False, 'schema': {'type': 'integer'}}, {'name': 'max_price', 'in': 'query', 'description': "(Optional) Maximum price in local currency for the product searched for. Either explicitly stated by the user or implicitly inferred from a combination of the user's request and the kind of product searched for.", 'required': False, 'schema': {'type': 'integer'}}], 'responses': {'200': {'description': 'Products found', 'content': {'application/json': {'schema': {'$ref': '#/components/schemas/ProductResponse'}}}}, '503': {'description': 'one or more services are unavailable'}}, 'deprecated': False}}}, 'components': {'schemas': {'Product': {'type': 'object', 'properties': {'attributes': {'type': 'array', 'items': {'type': 'string'}}, 'name': {'type': 'string'}, 'price': {'type': 'string'}, 'url': {'type': 'string'}}, 'title': 'Product'}, 'ProductResponse': {'type': 'object', 'properties': {'products': {'type': 'array', 'items': {'$ref': '#/components/schemas/Product'}}}, 'title': 'ProductResponse'}}}}
Thought:I need to use the Klarna Shopping API to search for available t shirts.
Action: requests_get
Action Input: 'https://www.klarna.com/us/shopping/public/openai/v0/products?q=t%20shirts&size=10'Traceback (most recent call last):
File "test.py", line 11, in <module>
agent_chain.run("what t shirts are available in klarna?")
File "/Users/asan/.pyenv/versions/3.8.12/lib/python3.8/site-packages/langchain/chains/base.py", line 213, in run
return self(args[0])[self.output_keys[0]]
File "/Users/asan/.pyenv/versions/3.8.12/lib/python3.8/site-packages/langchain/chains/base.py", line 116, in __call__
raise e
File "/Users/asan/.pyenv/versions/3.8.12/lib/python3.8/site-packages/langchain/chains/base.py", line 113, in __call__
outputs = self._call(inputs)
File "/Users/asan/.pyenv/versions/3.8.12/lib/python3.8/site-packages/langchain/agents/agent.py", line 792, in _call
next_step_output = self._take_next_step(
File "/Users/asan/.pyenv/versions/3.8.12/lib/python3.8/site-packages/langchain/agents/agent.py", line 695, in _take_next_step
observation = tool.run(
File "/Users/asan/.pyenv/versions/3.8.12/lib/python3.8/site-packages/langchain/tools/base.py", line 184, in run
raise e
File "/Users/asan/.pyenv/versions/3.8.12/lib/python3.8/site-packages/langchain/tools/base.py", line 181, in run
observation = self._run(*tool_args, **tool_kwargs)
File "/Users/asan/.pyenv/versions/3.8.12/lib/python3.8/site-packages/langchain/tools/requests/tool.py", line 31, in _run
return self.requests_wrapper.get(url)
File "/Users/asan/.pyenv/versions/3.8.12/lib/python3.8/site-packages/langchain/requests.py", line 125, in get
return self.requests.get(url, **kwargs).text
File "/Users/asan/.pyenv/versions/3.8.12/lib/python3.8/site-packages/langchain/requests.py", line 28, in get
return requests.get(url, headers=self.headers, **kwargs)
File "/Users/asan/.pyenv/versions/3.8.12/lib/python3.8/site-packages/requests/api.py", line 73, in get
return request("get", url, params=params, **kwargs)
File "/Users/asan/.pyenv/versions/3.8.12/lib/python3.8/site-packages/requests/api.py", line 59, in request
return session.request(method=method, url=url, **kwargs)
File "/Users/asan/.pyenv/versions/3.8.12/lib/python3.8/site-packages/requests/sessions.py", line 587, in request
resp = self.send(prep, **send_kwargs)
File "/Users/asan/.pyenv/versions/3.8.12/lib/python3.8/site-packages/requests/sessions.py", line 695, in send
adapter = self.get_adapter(url=request.url)
File "/Users/asan/.pyenv/versions/3.8.12/lib/python3.8/site-packages/requests/sessions.py", line 792, in get_adapter
raise InvalidSchema(f"No connection adapters were found for {url!r}")
requests.exceptions.InvalidSchema: No connection adapters were found for "'https://www.klarna.com/us/shopping/public/openai/v0/products?q=t%20shirts&size=10'"
```
### source code
```python
from langchain.chat_models import ChatOpenAI
from langchain.agents import load_tools, initialize_agent
from langchain.agents import AgentType
from langchain.tools import AIPluginTool
tool = AIPluginTool.from_plugin_url("https://www.klarna.com/.well-known/ai-plugin.json")
llm = ChatOpenAI(temperature=0)
tools = load_tools(["requests_all"] )
tools += [tool]
agent_chain = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent_chain.run("what t shirts are available in klarna?")
```
### versions
- ptyhon: 3.8.12
- langchain: '0.0.149'
<details><summary>Details</summary>
<p>
```sh
~/lab/wantedly/visit-machine-learning /langchain_plugin - ⚑ ✚ … nsmryk/add_langchain_plugin - SIGHUP
:( % python --version
Python 3.8.12
~/lab/wantedly/visit-machine-learning /langchain_plugin - ⚑ ✚ … nsmryk/add_langchain_plugin
:) % python
Python 3.8.12 (default, Mar 30 2022, 16:26:57)
[Clang 13.0.0 (clang-1300.0.29.3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import langchain
lang>>> langchain.__version__
'0.0.149'
>>>
```
</p>
</details> | ChatGPT Plugin sample code cannot be executed | https://api.github.com/repos/langchain-ai/langchain/issues/3577/comments | 1 | 2023-04-26T06:37:33Z | 2023-04-26T06:42:31Z | https://github.com/langchain-ai/langchain/issues/3577 | 1,684,371,023 | 3,577 |
[
"hwchase17",
"langchain"
]
| I am trying to use the Pandas Agent create_pandas_dataframe_agent, but instead of using OpenAI I am replacing the LLM with LlamaCpp. I am running this in Python 3.9 on a SageMaker notebook, with a ml.g4dn.xlarge instance size. I am having trouble with running this agent and produces a weird error.
The code is as follows:

This is the error log:



Detailed error log below:






| Issue with using LlamaCpp LLM in Pandas Dataframe Agent | https://api.github.com/repos/langchain-ai/langchain/issues/3569/comments | 9 | 2023-04-26T02:00:54Z | 2023-12-13T16:10:28Z | https://github.com/langchain-ai/langchain/issues/3569 | 1,684,129,288 | 3,569 |
[
"hwchase17",
"langchain"
]
| I want to be able to pass pure string text, not as a text file. When I attempt to do so with long documents I get the error about the file name being too long:
```
Traceback (most recent call last):
File "/home/faizi/miniconda3/envs/langchain/lib/python3.10/site-packages/uvicorn/protocols/http/httptools_impl.py", line 436, in run_asgi
result = await app( # type: ignore[func-returns-value]
File "/home/faizi/miniconda3/envs/langchain/lib/python3.10/site-packages/uvicorn/middleware/proxy_headers.py", line 78, in __call__
return await self.app(scope, receive, send)
File "/home/faizi/miniconda3/envs/langchain/lib/python3.10/site-packages/fastapi/applications.py", line 276, in __call__
await super().__call__(scope, receive, send)
File "/home/faizi/miniconda3/envs/langchain/lib/python3.10/site-packages/starlette/applications.py", line 122, in __call__
await self.middleware_stack(scope, receive, send)
File "/home/faizi/miniconda3/envs/langchain/lib/python3.10/site-packages/starlette/middleware/errors.py", line 184, in __call__
raise exc
File "/home/faizi/miniconda3/envs/langchain/lib/python3.10/site-packages/starlette/middleware/errors.py", line 162, in __call__
await self.app(scope, receive, _send)
File "/home/faizi/miniconda3/envs/langchain/lib/python3.10/site-packages/starlette/middleware/exceptions.py", line 79, in __call__
raise exc
File "/home/faizi/miniconda3/envs/langchain/lib/python3.10/site-packages/starlette/middleware/exceptions.py", line 68, in __call__
await self.app(scope, receive, sender)
File "/home/faizi/miniconda3/envs/langchain/lib/python3.10/site-packages/fastapi/middleware/asyncexitstack.py", line 21, in __call__
raise e
File "/home/faizi/miniconda3/envs/langchain/lib/python3.10/site-packages/fastapi/middleware/asyncexitstack.py", line 18, in __call__
await self.app(scope, receive, send)
File "/home/faizi/miniconda3/envs/langchain/lib/python3.10/site-packages/starlette/routing.py", line 718, in __call__
await route.handle(scope, receive, send)
File "/home/faizi/miniconda3/envs/langchain/lib/python3.10/site-packages/starlette/routing.py", line 276, in handle
await self.app(scope, receive, send)
File "/home/faizi/miniconda3/envs/langchain/lib/python3.10/site-packages/starlette/routing.py", line 66, in app
response = await func(request)
File "/home/faizi/miniconda3/envs/langchain/lib/python3.10/site-packages/fastapi/routing.py", line 237, in app
raw_response = await run_endpoint_function(
File "/home/faizi/miniconda3/envs/langchain/lib/python3.10/site-packages/fastapi/routing.py", line 163, in run_endpoint_function
return await dependant.call(**values)
File "/home/faizi/Projects/docu-query/langchain/main.py", line 50, in query
response = query_document(query, text)
File "/home/faizi/Projects/docu-query/langchain/__langchain__.py", line 13, in query_document
index = VectorstoreIndexCreator().from_loaders([loader])
File "/home/faizi/miniconda3/envs/langchain/lib/python3.10/site-packages/langchain/indexes/vectorstore.py", line 69, in from_loaders
docs.extend(loader.load())
File "/home/faizi/miniconda3/envs/langchain/lib/python3.10/site-packages/langchain/document_loaders/text.py", line 17, in load
with open(self.file_path, encoding=self.encoding) as f:
OSError: [Errno 36] File name too long:
```
The way I've been able to get it to work has been like so:
```
# get document from supabase where userName = userName
document = supabase \
.table('Documents') \
.select('document') \
.eq('userName', userName) \
.execute()
text = document.data[0]['document']
# write text to a temporary file\
temp = tempfile.NamedTemporaryFile(mode='w+t', encoding='utf-8')
temp.write(text)
temp.seek(0)
# query the document
loader = TextLoader(temp.name)
index = VectorstoreIndexCreator().from_loaders([loader])
response = index.query(query)
# delete the temporary file
temp.close()
```
There must be a more straight forward way. Am I missing something here? | Can only load text as a text file, not as string input | https://api.github.com/repos/langchain-ai/langchain/issues/3561/comments | 8 | 2023-04-25T22:01:15Z | 2023-12-01T16:11:03Z | https://github.com/langchain-ai/langchain/issues/3561 | 1,683,936,827 | 3,561 |
[
"hwchase17",
"langchain"
]
| We need a model gateway pattern support for Chains for following reasons:
- We may have external decision making elements that would help route which LLM model would need to handle a request. E.g. vector store.
- Agents don't always cut it with the customization that'd be needed. We will need custom tool building etc which is overkill for a simple routing use case.
- Downstream LLMs can also be any of the numerous chain types that can be supported. This allows for a scalable LLM orchestration model with chaining beyond what's supported today which is mainly Sequential chains.
| Support for model router pattern for chains to allow for dynamic routing to right chains based on vector store semantics | https://api.github.com/repos/langchain-ai/langchain/issues/3555/comments | 3 | 2023-04-25T21:04:41Z | 2023-09-24T16:07:21Z | https://github.com/langchain-ai/langchain/issues/3555 | 1,683,865,609 | 3,555 |
[
"hwchase17",
"langchain"
]
| See `langchain.vectorstores.milvus.Milvus._worker_search`
```python
# Decide to use default params if not passed in.
if param is None:
index_type = self.col.indexes[0].params["index_type"]
param = self.index_params[index_type]
``` | Milvus vector store may search failed when there are multiple indexes | https://api.github.com/repos/langchain-ai/langchain/issues/3546/comments | 0 | 2023-04-25T19:26:09Z | 2023-04-25T19:44:08Z | https://github.com/langchain-ai/langchain/issues/3546 | 1,683,732,337 | 3,546 |
[
"hwchase17",
"langchain"
]
| Hello,
I am trying to use webbaseloader to ingest content from a list of urls.
```
from langchain.indexes import VectorstoreIndexCreator
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader(urls)
index = VectorstoreIndexCreator().from_loaders([loader])
```
But I got an error like ,
`ValueError: Expected metadata value to be a str, int, or float, got None`
| VectorstoreIndexCreator cannot load data from WebBaseLoader | https://api.github.com/repos/langchain-ai/langchain/issues/3542/comments | 9 | 2023-04-25T18:25:55Z | 2024-01-30T00:41:19Z | https://github.com/langchain-ai/langchain/issues/3542 | 1,683,644,253 | 3,542 |
[
"hwchase17",
"langchain"
]
| From this notebook: https://python.langchain.com/en/latest/modules/indexes/vectorstores/examples/zilliz.html
It doesn't work. I search in the issues and it seems someone are starting working on it. Not sure if it is fixed or not.
Here is the error:
`RPC error: [create_index], <MilvusException: (code=1, message=IndexType should be AUTOINDEX)>, <Time:{'RPC start': '2023-04-25 13:58:07.716157', 'RPC error': '2023-04-25 13:58:07.779371'}>` | Can not connect to vector store in Zilliz | https://api.github.com/repos/langchain-ai/langchain/issues/3538/comments | 1 | 2023-04-25T17:58:38Z | 2023-09-10T16:27:11Z | https://github.com/langchain-ai/langchain/issues/3538 | 1,683,606,201 | 3,538 |
[
"hwchase17",
"langchain"
]
| ```
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template(template=system_template),
MessagesPlaceholder(variable_name="history"),
HumanMessagePromptTemplate.from_template("{input}")
])
llm = ChatOpenAI(temperature=0.9)
memory = ConversationBufferMemory(return_messages=True, ai_prefix="SpongebobSquarePants", human_prefix="Bob")
conversation = ConversationChain(memory = memory, prompt = prompt, llm = llm, verbose=True)
```
using `ChatPromptTemplate.from_messages` will later use the method `get_buffer_string` in the `to_string()` for the class `ChatPromptValue` in chat.py in Prompts. The format does not care of the new ai_prefix or human_prefix.
How can I change that ? Thanks
| AI Prefix and Human Prefix not correctly reflected in | https://api.github.com/repos/langchain-ai/langchain/issues/3536/comments | 20 | 2023-04-25T17:14:29Z | 2024-04-10T13:48:20Z | https://github.com/langchain-ai/langchain/issues/3536 | 1,683,552,593 | 3,536 |
[
"hwchase17",
"langchain"
]
| null | How can I add an identification while adding documents to Pinecone? Also, is there any way that I can update any document that I added to Pinecone before? | https://api.github.com/repos/langchain-ai/langchain/issues/3531/comments | 1 | 2023-04-25T15:52:43Z | 2023-09-10T16:27:16Z | https://github.com/langchain-ai/langchain/issues/3531 | 1,683,440,009 | 3,531 |
[
"hwchase17",
"langchain"
]
| 
Getting this error While using faiss vector store methods.
Found that in code , the query embedding is wrapped around a List ,

And then again it is wrapped in list inside the maximal_marginal_method

I hope this gets fixed !
| ValueError: Number of columns in X and Y must be same. ( in Faiss maximal marginal search ) | https://api.github.com/repos/langchain-ai/langchain/issues/3529/comments | 2 | 2023-04-25T15:24:23Z | 2023-09-10T16:27:22Z | https://github.com/langchain-ai/langchain/issues/3529 | 1,683,394,463 | 3,529 |
[
"hwchase17",
"langchain"
]
| How can I add custom prompt to:
```
qa_chain = load_qa_with_sources_chain(llm, chain_type="stuff",)
qa = RetrievalQAWithSourcesChain(combine_documents_chain=qa_chain, retriever=docsearch.as_retriever())
```
There is no prompt= for this class... | Custom prompt to RetrievalQAWithSourcesChain ? | https://api.github.com/repos/langchain-ai/langchain/issues/3523/comments | 26 | 2023-04-25T13:42:04Z | 2023-12-06T17:46:45Z | https://github.com/langchain-ai/langchain/issues/3523 | 1,683,202,939 | 3,523 |
[
"hwchase17",
"langchain"
]
| code :
pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
split_docs = text_splitter.split_documents(pages)
embeddings = OpenAIEmbeddings(openai_api_key=openAiKey)
vector_store = chroma_db.get_vector_store(file_hash_name, embeddings)
vector_store.add_documents(documents=split_docs, embedding=embeddings)
vector_store.persist()
qa = ConversationalRetrievalChain.from_llm(llm, vector_store.as_retriever())
# 提问
chat_history = []
result = qa({"question": query, "chat_history": chat_history})
error:
thread '<unnamed>' panicked at 'assertion failed: encoder.len() == decoder.len()', src/lib.rs:458:9
stack backtrace:
0: 0x147d93944 - <std::sys_common::backtrace::_print::DisplayBacktrace as core::fmt::Display>::fmt::h1027694b54c428d0
1: 0x147da57bc - core::fmt::write::hb60cc483d75d6594
2: 0x147d91b90 - std::io::Write::write_fmt::h6c907fc10bdb865b
3: 0x147d93758 - std::sys_common::backtrace::print::h1a62458f14dd2797
4: 0x147d94ac8 - std::panicking::default_hook::{{closure}}::h03c6918072c36210
5: 0x147d94820 - std::panicking::default_hook::hd0f3cf66b6a0fb5e
6: 0x147d950ec - std::panicking::rust_panic_with_hook::h9ed2a7a45efbd034
7: 0x147d94ecc - std::panicking::begin_panic_handler::{{closure}}::h535244d6186e3534
8: 0x147d93dac - std::sys_common::backtrace::__rust_end_short_backtrace::ha542aa49031c5cb5
9: 0x147d94c68 - _rust_begin_unwind
10: 0x147db4cb0 - core::panicking::panic_fmt::hc1e7b11add95109d
11: 0x147db4d20 - core::panicking::panic::h38074b3ed47cd9d2
12: 0x147cf345c - _tiktoken::CoreBPE::new::h3232dac6b39b5b9e
13: 0x147cfe0c8 - std::panicking::try::h0e408480c04001a1
14: 0x147cf410c - _tiktoken::_::<impl _tiktoken::CoreBPE>::__pymethod___new____::h42d4913b91c5c6b0
15: 0x103698e0c - _type_call
16: 0x10360d870 - __PyObject_MakeTpCall
17: 0x103744120 - _call_function
18: 0x10373c36c - __PyEval_EvalFrameDefault
19: 0x103734e14 - __PyEval_Vector
20: 0x10360db98 - __PyObject_FastCallDictTstate
21: 0x1036a20fc - _slot_tp_init
22: 0x103698ef0 - _type_call
23: 0x10360e678 - __PyObject_Call
24: 0x103736c58 - __PyEval_EvalFrameDefault
25: 0x103734e14 - __PyEval_Vector
26: 0x103744028 - _call_function
27: 0x10373aa68 - __PyEval_EvalFrameDefault
28: 0x103734e14 - __PyEval_Vector
29: 0x103744028 - _call_function
30: 0x10373c36c - __PyEval_EvalFrameDefault
31: 0x103734e14 - __PyEval_Vector
32: 0x103611738 - _method_vectorcall
33: 0x103744028 - _call_function
34: 0x10373aaec - __PyEval_EvalFrameDefault
35: 0x103734e14 - __PyEval_Vector
36: 0x103744028 - _call_function
37: 0x10373b378 - __PyEval_EvalFrameDefault
38: 0x103734e14 - __PyEval_Vector
39: 0x103611738 - _method_vectorcall
40: 0x10360e378 - _PyVectorcall_Call
41: 0x103736c58 - __PyEval_EvalFrameDefault
42: 0x103734e14 - __PyEval_Vector
43: 0x103611738 - _method_vectorcall
44: 0x103744028 - _call_function
45: 0x10373aaec - __PyEval_EvalFrameDefault
46: 0x103734e14 - __PyEval_Vector
47: 0x103744028 - _call_function
48: 0x10373c36c - __PyEval_EvalFrameDefault
49: 0x103734e14 - __PyEval_Vector
50: 0x10379f918 - _pyrun_file
51: 0x10379f05c - __PyRun_SimpleFileObject
52: 0x10379e6a8 - __PyRun_AnyFileObject
53: 0x1037ca8b0 - _pymain_run_file_obj
54: 0x1037c9f50 - _pymain_run_file
55: 0x1037c9538 - _pymain_run_python
56: 0x1037c93cc - _Py_RunMain
57: 0x1037caa58 - _pymain_main
58: 0x1037cad1c - _Py_BytesMain
Traceback (most recent call last):
File "/Users/macbookpro/21/mygit/toyoung/ai/py-chat/main.py", line 33, in <module>
result = pdf_service.chrom_qa_pdf(filepath, "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",)
File "/Users/macbookpro/21/mygit/toyoung/ai/py-chat/services/pdf_service.py", line 242, in chrom_qa_pdf
vector_store.add_documents(documents=split_docs, embedding=embeddings)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/langchain/vectorstores/base.py", line 61, in add_documents
return self.add_texts(texts, metadatas, **kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/langchain/vectorstores/chroma.py", line 115, in add_texts
embeddings = self._embedding_function.embed_documents(list(texts))
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/langchain/embeddings/openai.py", line 275, in embed_documents
return self._get_len_safe_embeddings(texts, engine=self.document_model_name)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/langchain/embeddings/openai.py", line 206, in _get_len_safe_embeddings
encoding = tiktoken.model.encoding_for_model(self.document_model_name)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/tiktoken/model.py", line 75, in encoding_for_model
return get_encoding(encoding_name)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/tiktoken/registry.py", line 63, in get_encoding
enc = Encoding(**constructor())
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/tiktoken/core.py", line 50, in __init__
self._core_bpe = _tiktoken.CoreBPE(mergeable_ranks, special_tokens, pat_str)
pyo3_runtime.PanicException: assertion failed: encoder.len() == decoder.len()
| thread '<unnamed>' panicked at 'assertion failed: encoder.len() == decoder.len()', src/lib.rs:458:9 | https://api.github.com/repos/langchain-ai/langchain/issues/3521/comments | 1 | 2023-04-25T13:05:54Z | 2023-09-15T22:12:52Z | https://github.com/langchain-ai/langchain/issues/3521 | 1,683,140,695 | 3,521 |
[
"hwchase17",
"langchain"
]
| I am registering this issue out to request the addition of multilingual support for Langchain python repo
As the user base for Langchain grows, it is becoming increasingly important to accommodate users from different linguistic backgrounds.
Adding support for the multi-language would enable a wider audience to utilize Langchain effectively, and contribute to the project's overall success. Furthermore, this would pave the way for the integration of other languages in the future, making the library even more accessible and user-friendly.
To implement this feature, I will work on the following:
* [ ] Incorporate a mechanism for detecting and handling different languages, starting from Korean, within the library.
* [ ] Provide localized documentation and error messages for the supported languages, not limited to docs + system prompt
* [ ] Enable seamless switching between languages based on user preferences. | Request for Multilingual Support in Langchain (docs + etc) | https://api.github.com/repos/langchain-ai/langchain/issues/3520/comments | 4 | 2023-04-25T12:58:27Z | 2023-09-24T16:07:27Z | https://github.com/langchain-ai/langchain/issues/3520 | 1,683,126,113 | 3,520 |
[
"hwchase17",
"langchain"
]
| We define some callback manager and a chatbot:
```
from langchain.callbacks import OpenAICallbackHandler
from langchain.callbacks.base import CallbackManager
manager = CallbackManager([OpenAICallbackHandler()])
chatbot = ChatOpenAI(temperature=1, callback_manager=manager)
messages = [SystemMessage(content="")]
```
Now if we use `result = chatbot(messages)` to call OpenAI API for result, it won't trigger any callback.
But if we use `chat.generate_prompt()` or `chat.agenerate_prompt()`, it will trigger callbacks.
I suppose this is a bug not a feature, right?
https://github.com/hwchase17/langchain/blob/bee59b4689fe23dce1450bde1a5d96b0aa52ee61/langchain/chat_models/base.py#L125 | BaseChatModel.__call__() doesn't trigger any callback | https://api.github.com/repos/langchain-ai/langchain/issues/3519/comments | 2 | 2023-04-25T12:27:36Z | 2023-09-17T17:22:18Z | https://github.com/langchain-ai/langchain/issues/3519 | 1,683,076,298 | 3,519 |
[
"hwchase17",
"langchain"
]
| I am using JASON Agent and currently, it is answering only from the JSON.
Even if I say 'hi' it is giving me some random answer from the given JSON.
My goal is to handle smalltalk normally, answer the questions from JSON, and if it is not sure then say I don't know.
I have achieved the I don't know part by modifying the prefix, but how do I handle the smalltalk? | Smalltalk in JSON Agent | https://api.github.com/repos/langchain-ai/langchain/issues/3515/comments | 1 | 2023-04-25T10:49:24Z | 2023-09-10T16:27:32Z | https://github.com/langchain-ai/langchain/issues/3515 | 1,682,922,264 | 3,515 |
[
"hwchase17",
"langchain"
]
| I am facing a Warning similar to the one described here #3005
`WARNING:langchain.embeddings.openai:Retrying langchain.embeddings.openai.embed_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised Timeout: Request timed out: HTTPSConnectionPool(host='api.openai.com', port=443): Read timed out. (read timeout=600).
`
It just keeps retrying. How do I get around this? | Timeout Error OpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/3512/comments | 31 | 2023-04-25T10:27:34Z | 2024-06-17T23:33:27Z | https://github.com/langchain-ai/langchain/issues/3512 | 1,682,889,147 | 3,512 |
[
"hwchase17",
"langchain"
]
| I want to use from langchain.llms import AzureOpenAI with the following configuration:
os.environ["OPENAI_API_KEY"] = api_key_35
os.environ["OPENAI_API_VERSION"] = "2023-03-15-preview"
Where api_key_35 is the key for AzureOpenAI.
The code is:
llm = AzureOpenAI(
max_tokens=1024
,deployment_name = "gpt-35-turbo"
,openai_api_type = "azure"
,model_name="gpt-35-turbo"
)
The returned result is:
openai.error.AuthenticationError: Incorrect API key provided: ********************. You can find your API key at https://platform.openai.com/account/api-keys.
I changed the configuration to:
os.environ["OPENAI_API_KEY"] = api_key_35
os.environ["OPENAI_API_BASE"] = api_base_35
os.environ["OPENAI_API_VERSION"] = "2023-03-15-preview"
Where api_key_35 is the key for AzureOpenAI.
The code is:
llm = AzureOpenAI(
max_tokens=1024
,deployment_name = "gpt-35-turbo"
,openai_api_type = "azure"
,model_name="gpt-35-turbo"
)
The returned result is:
openai.error.InvalidRequestError: Resource not found
If I use the key for OpenAI instead of AzureOpenAI, it runs successfully. Why is there an error?
If I use openai.ChatCompletion.create,it's worked | Can not use AzureOpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/3510/comments | 19 | 2023-04-25T10:09:52Z | 2023-10-05T16:10:49Z | https://github.com/langchain-ai/langchain/issues/3510 | 1,682,859,456 | 3,510 |
[
"hwchase17",
"langchain"
]
| I've found that some recent langchain upgrade broke our detection of "agent exceeded max iterations error", returned in https://github.com/hwchase17/langchain/blob/bee59b4689fe23dce1450bde1a5d96b0aa52ee61/langchain/agents/agent.py#L92-L96.
The reason it broke is that we had to detect the response based on response text which changed, instead of some structured information.
What do you think of introducing a new type of early stopping "raise" which is going to raise an exception, or passing that information in some structure way back to the application? | Agent early stopping is difficult to detect on the application level | https://api.github.com/repos/langchain-ai/langchain/issues/3509/comments | 1 | 2023-04-25T09:47:58Z | 2023-09-10T16:27:38Z | https://github.com/langchain-ai/langchain/issues/3509 | 1,682,823,125 | 3,509 |
[
"hwchase17",
"langchain"
]
| I want to host a python agent on Gradio. It all works good. Im struggling when wanting to display not only the answer but also the AgentExecutor chain. How can I edit the code, so that also the AgentExecutor chain will be printed in the Gradio app. The Code snippet for that part is the following:
```
def answer_question(question):
agent_executor = create_python_agent(
llm=OpenAI(temperature=0, max_tokens=1000),
tool=PythonREPLTool(),
verbose=True
)
answer = agent_executor.run(question)
return answer
ifaces = gr.Interface(
fn=answer_question,
inputs=gr.inputs.Textbox(label="Question"),
outputs=gr.outputs.Textbox(label="Answer"),
title="Question Answering Agent",
description="A simple question answering agent."
)
``` | Agent Executor Chain | https://api.github.com/repos/langchain-ai/langchain/issues/3506/comments | 3 | 2023-04-25T08:54:14Z | 2023-11-16T16:08:17Z | https://github.com/langchain-ai/langchain/issues/3506 | 1,682,728,591 | 3,506 |
[
"hwchase17",
"langchain"
]
| Anthropic dose not support request timeout setting | Anthropic dose not support request timeout setting | https://api.github.com/repos/langchain-ai/langchain/issues/3502/comments | 1 | 2023-04-25T08:34:16Z | 2023-09-10T16:27:42Z | https://github.com/langchain-ai/langchain/issues/3502 | 1,682,697,890 | 3,502 |
[
"hwchase17",
"langchain"
]
| oobabooga/text-generation-webui/ is a popular method of running various models including llama variants on GPU and via llama.cpp. It would be useful to be abl to call its api as it can run and configure LLaMA, llama.cpp, GPT-J, Pythia, OPT, and GALACTICA in various quantisations with LoRA etc.
I know you have just added llama.cpp directly but I could not find any way to call the api of oobabooga/text-generation-webui/. I recall I saw someone trying to wrap kobold but I can't find their work, which I expect would be similar.
Is anyone working on this? If not I will fork and have a go - it doesn't seem too difficult to wrap llm apis given the examples provided. | text-generation-webui api | https://api.github.com/repos/langchain-ai/langchain/issues/3499/comments | 6 | 2023-04-25T07:06:54Z | 2023-09-24T16:07:32Z | https://github.com/langchain-ai/langchain/issues/3499 | 1,682,563,350 | 3,499 |
[
"hwchase17",
"langchain"
]
| null | how can i modify own LLM to adapt initialize_agent(tools,llm)? | https://api.github.com/repos/langchain-ai/langchain/issues/3498/comments | 1 | 2023-04-25T06:43:20Z | 2023-09-10T16:27:47Z | https://github.com/langchain-ai/langchain/issues/3498 | 1,682,531,129 | 3,498 |
[
"hwchase17",
"langchain"
]
| I'm running langchain on a 4xV100 rig on AWS. Currently it only utilizes a single GPU. I was able to get it to run on all GPUs by changing,
https://github.com/hwchase17/langchain/blob/a14d1c02f87d23d9ff5ab36a4c68aeb724499455/langchain/embeddings/huggingface.py#L71
to
```python
print('Using MultiGPU')
pool = self.client.start_multi_process_pool()
embeddings = self.client.encode_multi_process(texts, pool)
self.client.stop_multi_process_pool(pool)
```
as `sentence-transformers` does support multi-GPU encoding under the hood.
I am sure there is a more elegant way of achieving this, although this duct-taped solution seems to work for now. | Multi GPU support | https://api.github.com/repos/langchain-ai/langchain/issues/3486/comments | 5 | 2023-04-25T03:52:39Z | 2023-10-26T16:08:39Z | https://github.com/langchain-ai/langchain/issues/3486 | 1,682,381,944 | 3,486 |
[
"hwchase17",
"langchain"
]
| Start with the following tutorial:
https://python.langchain.com/en/latest/modules/agents/agents/custom_llm_agent.html
But instead of using SerpAPI, use the google search tool:
```python
from langchain.agents import load_tools
tools = load_tools(["google-search"])
```
The step that creates the CustomPromptTemplate will encounter a validation error:
```
ValidationError Traceback (most recent call last)
Cell In[36], line 24
21 kwargs["tool_names"] = ", ".join([tool.name for tool in self.tools])
22 return self.template.format(**kwargs)
---> 24 prompt = CustomPromptTemplate(
25 template=template,
26 tools=tools,
27 # This omits the `agent_scratchpad`, `tools`, and `tool_names` variables because those are generated dynamically
28 # This includes the `intermediate_steps` variable because that is needed
29 input_variables=["input", "intermediate_steps"]
30 )
File [/site-packages/pydantic/main.py:341]/.venv-jupyter/lib/python3.10/site-packages/pydantic/main.py:341), in pydantic.main.BaseModel.__init__()
ValidationError: 1 validation error for CustomPromptTemplate
tools -> 0
Tool.__init__() missing 1 required positional argument: 'func' (type=type_error)
```
The problem appears to be that the result of calling `load_tools(["google-search"])` is a BaseTool and not a Tool and doesn't have a `func`. This can be fixed by modifying the CustomPromptTemplate to use BaseTool instead of Tool.
```python
from langchain.tools import BaseTool
class CustomPromptTemplate(StringPromptTemplate):
# The template to use
template: str
# The list of tools available
tools: List[BaseTool]
def format(self, **kwargs) -> str:
<SNIP>
```
However I am not sure if this is the correct fix, or if the problem is that load_tools should create a `Tool` instead of a `BaseTool`. i.e. is this a doc issue or a product issue? | Custom agent tutorial doesnt handle replacing SerpAPI with google search tool | https://api.github.com/repos/langchain-ai/langchain/issues/3485/comments | 9 | 2023-04-25T03:42:48Z | 2024-07-26T05:18:58Z | https://github.com/langchain-ai/langchain/issues/3485 | 1,682,376,132 | 3,485 |
[
"hwchase17",
"langchain"
]
| With reference to the topic, I'm trying to build a chatbot to perform some action based on a conversation with a user. I believe I could use the "agent" module together with some "tools".
However, with this combination, it seems that the tools are used to provide context (in the form of a string) for the agent to generate some text (answer some question, or etc). How do I trigger a function, and I do not need the output of this function (for example to generate an item in a todo list) and not redirecting this output to the LLM model?
The action does not even need to output a string; it may not even return a value.
What is the recommended way to do something like this? Implement a custom callback? A custom agent? | What is the appropriate module to use if I want to just perform an action? | https://api.github.com/repos/langchain-ai/langchain/issues/3484/comments | 2 | 2023-04-25T03:24:43Z | 2023-09-10T16:27:53Z | https://github.com/langchain-ai/langchain/issues/3484 | 1,682,364,708 | 3,484 |
[
"hwchase17",
"langchain"
]
| `class BaseOpenAI(BaseLLM):
"""Wrapper around OpenAI large language models."""
openai_api_base: Optional[str] = None`
Hope ChatOpenAi will support this configuration.
After all gpt-3.5-turbo model is much cheaper. | BaseOpenAI supports openai_api_base configuration but ChatOpenAI doesnot support | https://api.github.com/repos/langchain-ai/langchain/issues/3483/comments | 1 | 2023-04-25T03:22:22Z | 2023-09-10T16:27:57Z | https://github.com/langchain-ai/langchain/issues/3483 | 1,682,363,391 | 3,483 |
[
"hwchase17",
"langchain"
]
| The _call function returns result["choices"][0]["text"]
For me result["choices"][0]["text"] includes both the prompt and the answer.
My use case: document summary:
llm = LlamaCpp(model_path=r"D:\AI\Model\vicuna-13B-1.1-GPTQ-4bit-128g.GGML.bin",n_ctx=4000, f16_kv=True)
chain = load_summarize_chain(llm, chain_type="map_reduce", verbose = True)
myoutput = chain.run(docs)
Well, obviously this does not work, because in llms>base.py, in the _generate function, we call _call like this:
generations = []
for prompt in prompts:
text = self._call(prompt, stop=stop)
generations.append([Generation(text=text)])
This chain is supposed to create summury, but what comes back from the LLM (prompt+output) is longer than the input (the prompt).
So this chain goes into a loop.
FYI, this works totally fine.
llm = OpenAI(temperature=0)
chain = load_summarize_chain(llm, chain_type="map_reduce", verbose = True)
myoutput = chain.run(docs)
And in this case I can confirm that text = self._call(prompt, stop=stop) has only the output (no prompt).
I will look into what result["choices"][0]["text"] should be changed to.
| Llamacpp.py _call returns both prompt and generation | https://api.github.com/repos/langchain-ai/langchain/issues/3478/comments | 4 | 2023-04-25T02:31:49Z | 2023-09-24T16:07:41Z | https://github.com/langchain-ai/langchain/issues/3478 | 1,682,331,011 | 3,478 |
[
"hwchase17",
"langchain"
]
| Name: langchain
Version: 0.0.146
Name: opensearch-py
Version: 2.2.0
Even if I build opensearch in docker and run it as per langchain's official documentation, the index is randomly numbered and data is created.
I am not sure if this is how it is supposed to work.
I was imagining that multiple documents are usually added to a single index.
Also, I get the following error when I specify index_name.
File "/usr/local/lib/python3.10/site-packages/opensearchpy/connection/base.py", line 301, in _raise_error
raise HTTP_EXCEPTIONS.get(status_code, TransportError)(
opensearchpy.exceptions.RequestError: RequestError(400, 'resource_already_exists_exception', 'index [test_index/GEdIKgfrRO24XoRbcJCeVg ] already exists')
There seems to be a duplicate index, as client.indices.create(index=index_name, body=mapping) in the from_texts function of opensearch_vector_search.py is always executed. I assume this is because the client.indices.create(index=index_name, body=mapping) is always executed.

| The from_documents in opensensearch may not be working as expected. | https://api.github.com/repos/langchain-ai/langchain/issues/3473/comments | 4 | 2023-04-25T00:08:37Z | 2023-09-24T16:07:46Z | https://github.com/langchain-ai/langchain/issues/3473 | 1,682,215,942 | 3,473 |
[
"hwchase17",
"langchain"
]
| Using Langchain, I used Milvus vector db to ingest all my document as per @ https://python.langchain.com/en/latest/modules/indexes/vectorstores/examples/milvus.html. Now later I want to get a handle to vector_db and start to query Milvus. How do I achieve this? In the example in the link, it is querying the vector_db immediately. Imagine, once I call from_documents, I set the vector_db=None and later I need to load the collection back and query. How do I do that for Milvus? | Persist pdf data in Milvus for later use | https://api.github.com/repos/langchain-ai/langchain/issues/3471/comments | 11 | 2023-04-24T23:55:18Z | 2023-10-16T16:08:30Z | https://github.com/langchain-ai/langchain/issues/3471 | 1,682,202,998 | 3,471 |
[
"hwchase17",
"langchain"
]
| The [`PostgresChatMessageHistory` class](https://github.com/hwchase17/langchain/blob/master/langchain/memory/chat_message_histories/postgres.py). Uses `psygopg 3`; however, the [pyproject.toml file](https://github.com/hwchase17/langchain/blob/master/pyproject.toml) only includes `psycopg2-binary` instead of `psycopg[binary]`(`psycopg 3`).
Proposed solution:
Add `psycopg[binary]==3.1.8` to the [pyproject.toml file](https://github.com/hwchase17/langchain/blob/master/pyproject.toml) | Missing Dependency for PostgresChatMessageHistory (dependent on psycopg 3, but psycopg 2 listed in requirements) | https://api.github.com/repos/langchain-ai/langchain/issues/3467/comments | 4 | 2023-04-24T23:23:46Z | 2023-12-22T12:47:05Z | https://github.com/langchain-ai/langchain/issues/3467 | 1,682,183,340 | 3,467 |
[
"hwchase17",
"langchain"
]
| My query code is below:
```
pinecone.init(
api_key=os.environ.get('PINECONE_API_KEY'), # app.pinecone.io
environment=os.environ.get('PINECONE_ENV') # next to API key in console
)
index = pinecone.Index(index_name)
embeddings = OpenAIEmbeddings(openai_api_key=os.environ.get('OPENAI_API_KEY'))
vectordb = Pinecone(
index=index,
embedding_function=embeddings.embed_query,
text_key="text",
)
llm=ChatOpenAI(
openai_api_key=os.environ.get('OPENAI_API_KEY'),
temperature=0,
model_name='gpt-3.5-turbo'
)
retriever = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectordb.as_retriever()
)
tools = [Tool(
func=retriever.run,
description=tool_desc,
name='Product DB'
)]
memory = ConversationBufferWindowMemory(
memory_key="chat_history", # important to align with agent prompt (below)
k=5,
return_messages=True
)
agent = initialize_agent(
agent='chat-conversational-react-description',
tools=tools,
llm=llm,
verbose=True,
max_iterations=3,
early_stopping_method="generate",
memory=memory,
)
```
If I run:
`agent({'chat_history':[], 'input':'What is a product?'})`
It throws:
> File "C:\Users\xxx\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\vectorstores\pinecone.py", line 160, in similarity_search
> text = metadata.pop(self._text_key)
> ^^^^^^^^^^^^^^^^^^^^^^^^^^^^
> KeyError: 'text'
This is the offending block in site-packages/pinecone.py:
```
for res in results["matches"]:
# print('metadata.pop(self._text_key) = ' + metadata.pop(self._text_key))
metadata = res["metadata"]
text = metadata.pop(self._text_key)
docs.append(Document(page_content=text, metadata=metadata))
```
If I remove my tool like the line below, everything executes (just not my tool):
`tools = []`
Can anyone help me fix this KeyError: 'text' issue? My versions of langchain, pinecone-client and python are 0.0.147, 2.2.1 and 3.11.3 respectively. | Pinecone retriever throwing: KeyError: 'text' | https://api.github.com/repos/langchain-ai/langchain/issues/3460/comments | 17 | 2023-04-24T18:02:53Z | 2024-05-19T00:22:40Z | https://github.com/langchain-ai/langchain/issues/3460 | 1,681,773,975 | 3,460 |
[
"hwchase17",
"langchain"
]
| I get this error occasionally when running the calculator tool, and seems like lots of other people are dealing with weird outputs from agents [like here](https://github.com/hwchase17/langchain/issues/2276). I'm seeing just random junk on the end of my objects returned from agents:
```
File "c:\Users\djpec\Documents\GitHub\project\venv\lib\site-packages\langchain\agents\conversational_chat\output_parser.py", line 32, in parse
response = json.loads(cleaned_output)
File "C:\Program Files\Python39\lib\json\__init__.py", line 346, in loads
return _default_decoder.decode(s)
File "C:\Program Files\Python39\lib\json\decoder.py", line 340, in decode
raise JSONDecodeError("Extra data", s, end)
json.decoder.JSONDecodeError: Extra data: line 5 column 1 (char 94)
```
Inspecting the `cleaned_output` yields this when preparing for final answer (I'm not sure how to wrap this in backticks, sorry lol):

I fixed it by importing the `regex` library and searching recursively for the largest "object" in the string in my `venv\lib\site-packages\langchain\agents\conversational_chat\output_parser.py` function
```
import regex
...
if cleaned_output.endswith("```"):
cleaned_output = cleaned_output[: -len("```")]
if not cleaned_output.endswith("""\n}"""):
pattern = r"(\{(?:[^{}]|(?R))*\})"
cleaned_output = regex.search(pattern, text).group(0)
cleaned_output = cleaned_output.strip()
...
``` | Conversational Chat Agent: json.decoder.JSONDecodeError | https://api.github.com/repos/langchain-ai/langchain/issues/3455/comments | 4 | 2023-04-24T17:48:32Z | 2023-09-24T16:07:57Z | https://github.com/langchain-ai/langchain/issues/3455 | 1,681,753,632 | 3,455 |
[
"hwchase17",
"langchain"
]
|
On `langchain==0.0.147`
I get
```python
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer,
model_kwargs=llm_kwargs, device=device)
hf = HuggingFacePipeline(pipeline=pipe)
print(hf.model_id)
```
always gives `gpt2`, irrespective of what `model` is.
| model_id remains set to 'gpt2' when creating HuggingFacePipeline from pipeline | https://api.github.com/repos/langchain-ai/langchain/issues/3451/comments | 6 | 2023-04-24T17:15:05Z | 2024-02-11T16:20:36Z | https://github.com/langchain-ai/langchain/issues/3451 | 1,681,712,468 | 3,451 |
[
"hwchase17",
"langchain"
]
| I have been trying to stream the response using AzureChatOpenAI and it didn't call my MyStreamingCallbackHandler() until I finally set verbose=True and it started to work.
Is it a bug? I failed to find any indication in the docs about streaming requiring verbose=True when calling AzureChatOpenAI .
```
chat_model = AzureChatOpenAI(
openai_api_base=openai_instance["api_base"],
openai_api_version=openai_instance["api_version"],
deployment_name=chat_model_deployment,
openai_api_key=openai_instance["api_key"],
openai_api_type = openai_instance["api_type"],
streaming=True,
callback_manager=CallbackManager([MyStreamingCallbackHandler()]),
temperature=0,
verbose=True
)
```
| Streaming not working unless I set verbose=True in AzureChatOpenAI() | https://api.github.com/repos/langchain-ai/langchain/issues/3449/comments | 3 | 2023-04-24T16:20:34Z | 2023-08-22T17:50:42Z | https://github.com/langchain-ai/langchain/issues/3449 | 1,681,634,934 | 3,449 |
[
"hwchase17",
"langchain"
]
| ```
Traceback (most recent call last):
File "/home/gptbot/cogs/search_service_cog.py", line 322, in on_message
response, stdout_output = await capture_stdout(
File "/home/gptbot/cogs/search_service_cog.py", line 79, in capture_stdout
result = await func(*args, **kwargs)
File "/usr/lib/python3.9/concurrent/futures/thread.py", line 58, in run
result = self.fn(*self.args, **self.kwargs)
File "/usr/local/lib/python3.9/dist-packages/langchain/chains/base.py", line 213, in run
return self(args[0])[self.output_keys[0]]
File "/usr/local/lib/python3.9/dist-packages/langchain/chains/base.py", line 116, in __call__
raise e
File "/usr/local/lib/python3.9/dist-packages/langchain/chains/base.py", line 113, in __call__
outputs = self._call(inputs)
File "/usr/local/lib/python3.9/dist-packages/langchain/agents/agent.py", line 807, in _call
output = self.agent.return_stopped_response(
File "/usr/local/lib/python3.9/dist-packages/langchain/agents/agent.py", line 515, in return_stopped_response
full_output = self.llm_chain.predict(**full_inputs)
File "/usr/local/lib/python3.9/dist-packages/langchain/chains/llm.py", line 151, in predict
return self(kwargs)[self.output_key]
File "/usr/local/lib/python3.9/dist-packages/langchain/chains/base.py", line 116, in __call__
raise e
File "/usr/local/lib/python3.9/dist-packages/langchain/chains/base.py", line 113, in __call__
outputs = self._call(inputs)
File "/usr/local/lib/python3.9/dist-packages/langchain/chains/llm.py", line 57, in _call
return self.apply([inputs])[0]
File "/usr/local/lib/python3.9/dist-packages/langchain/chains/llm.py", line 118, in apply
response = self.generate(input_list)
File "/usr/local/lib/python3.9/dist-packages/langchain/chains/llm.py", line 61, in generate
prompts, stop = self.prep_prompts(input_list)
File "/usr/local/lib/python3.9/dist-packages/langchain/chains/llm.py", line 79, in prep_prompts
prompt = self.prompt.format_prompt(**selected_inputs)
File "/usr/local/lib/python3.9/dist-packages/langchain/prompts/chat.py", line 127, in format_prompt
messages = self.format_messages(**kwargs)
File "/usr/local/lib/python3.9/dist-packages/langchain/prompts/chat.py", line 186, in format_messages
message = message_template.format_messages(**rel_params)
File "/usr/local/lib/python3.9/dist-packages/langchain/prompts/chat.py", line 43, in format_messages
raise ValueError(
ValueError: variable agent_scratchpad should be a list of base messages, got {
"action": "Search-Tool",
"action_input": "Who is Harald Baldr?"
}
```
Most of the time the agent can't parse it's own tool usage. | Broken intermediate output / parsing is grossly unreliable | https://api.github.com/repos/langchain-ai/langchain/issues/3448/comments | 22 | 2023-04-24T16:02:21Z | 2024-05-24T15:21:22Z | https://github.com/langchain-ai/langchain/issues/3448 | 1,681,601,217 | 3,448 |
[
"hwchase17",
"langchain"
]
| I'm building a flow where I'm using both gpt-3.5 and gpt-4 based chains and I need to use different API keys for each (due to API access + external factors)
Both `ChatOpenAI` and `OpenAI` set `openai.api_key = openai_api_key` which is a global variable on the package.
This means that if I instantiate multiple ChatOpenAI instances, the last one's API key will override the other ones and that one will be used when calling the OpenAI endpoints.
Based on https://github.com/openai/openai-python/issues/233#issuecomment-1464732160 there's an undocumented feature where we can pass the api_key on each openai client call and that key will be used.
As a side note, I've also noticed `ChatOpenAI` and a few other classes take in an optional `openai_api_key` as part of initialisation which is correctly used over the env var but the docstring says that the `OPENAI_API_KEY` env var should be set, which doesn't seem to be case. Can we confirm if this env var is needed elsewhere or if it's possible to just pass in the values when instantiating the chat models.
Thanks! | Encapsulate API keys | https://api.github.com/repos/langchain-ai/langchain/issues/3446/comments | 4 | 2023-04-24T15:12:21Z | 2023-09-24T16:08:02Z | https://github.com/langchain-ai/langchain/issues/3446 | 1,681,513,674 | 3,446 |
[
"hwchase17",
"langchain"
]
| I wonder if this work: https://arxiv.org/abs/2304.11062
Could be integrated with LangChain | Possible Enhancement | https://api.github.com/repos/langchain-ai/langchain/issues/3445/comments | 1 | 2023-04-24T14:51:55Z | 2023-09-10T16:28:02Z | https://github.com/langchain-ai/langchain/issues/3445 | 1,681,468,911 | 3,445 |
[
"hwchase17",
"langchain"
]
| Hi, I'm trying to use the examples for Azure OpenAI with langchain, for example this notebook in https://python.langchain.com/en/harrison-docs-refactor-3-24/modules/models/llms/integrations/azure_openai_example.html , but I always find this error:
Exception has occurred: InvalidRequestError Resource not found
I have tried multiple combinations with the environment variables, but nothing works, I have also tested it in a python script with the same results.
Regards. | Azure OpenAI - Exception has occurred: InvalidRequestError Resource not found | https://api.github.com/repos/langchain-ai/langchain/issues/3444/comments | 8 | 2023-04-24T14:31:33Z | 2023-09-24T16:08:07Z | https://github.com/langchain-ai/langchain/issues/3444 | 1,681,415,525 | 3,444 |
[
"hwchase17",
"langchain"
]
| Hello, I came across a code snippet in the tutorial page on "Conversation Agent (for Chat Models)" that has left me a bit confused. The tutorial also mentioned a warning error like this:
`WARNING:root:Failed to default session, using empty session: HTTPConnectionPool(host='localhost', port=8000): Max retries exceeded with url: /sessions (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x10a1767c0>: Failed to establish a new connection: [Errno 61] Connection refused'))`
Then i found the line of code in question is:
`os.environ["LANGCHAIN_HANDLER"] = "langchain"`
When I remove this line from the code, the program still seems to work without any errors. So why is this line of code exists.
Thank you! | Question about setting LANGCHAIN_HANDLER environment variable | https://api.github.com/repos/langchain-ai/langchain/issues/3443/comments | 4 | 2023-04-24T14:08:05Z | 2024-01-06T18:09:31Z | https://github.com/langchain-ai/langchain/issues/3443 | 1,681,362,534 | 3,443 |
[
"hwchase17",
"langchain"
]
| Aim::
aim.Text(outputs_res["output"]), name="on_chain_end", context=resp
KeyError: 'output'
Wandb::
resp.update({"action": "on_chain_end", "outputs": outputs["output"]})
KeyError: 'output'
Has anyone dealt with this issue yet while building custom agents with LLMSingleActionAgent, thank you | LLMOps integration of Aim and Wandb breaks when trying to parse agent output into dashboard for experiment tracking... | https://api.github.com/repos/langchain-ai/langchain/issues/3441/comments | 1 | 2023-04-24T12:07:58Z | 2023-09-10T16:28:08Z | https://github.com/langchain-ai/langchain/issues/3441 | 1,681,126,941 | 3,441 |
[
"hwchase17",
"langchain"
]
| I think that among the actions that the agent can take, there may be actions without input. (e.g. return the current state in real time)
But in practice, LM often does that, but current MRKL parsers don't allow it. I'm a newbie so I don't know, but is there a special reason?
Will there be a problem if I change it in the following way?
https://github.com/hwchase17/langchain/blob/0cf934ce7d8150dddf4a2514d6e7729a16d55b0f/langchain/agents/mrkl/output_parser.py#L21
```
regex = r"Action\s*\d*\s*:(.*?)(?:$|(?:\nAction\s*\d*\s*Input\s*\d*\s*:[\s]*(.*)))"
```
https://github.com/hwchase17/langchain/blob/0cf934ce7d8150dddf4a2514d6e7729a16d55b0f/langchain/agents/mrkl/output_parser.py#L27
```
return AgentAction(action, action_input.strip(" ").strip('"') if action_input is not None else {}, text)
```
Thanks for reading. | [mrkl/output_parser.py] Behavior when there is no action input? | https://api.github.com/repos/langchain-ai/langchain/issues/3438/comments | 1 | 2023-04-24T10:19:03Z | 2023-09-10T16:28:13Z | https://github.com/langchain-ai/langchain/issues/3438 | 1,680,927,591 | 3,438 |
[
"hwchase17",
"langchain"
]
| Just an early idea of an agent i wanted to share:
The cognitive interview is a police interviewing technique used to gather information from witnesses of specific events. It is based on the idea that witnesses may not remember everything they saw, but their memory can be improved by certain psychological techniques.
The cognitive interview usually takes place in a structured format, where the interviewer first establishes a rapport with the witness tobuild trust and make them feel comfortable. The interviewer then encourages the witness to provide a detailed account of events by using open-ended questions and allowing the witness to speak freely. The interviewer may also ask the witness to recall specific details, such as the color of a car or the facial features of a suspect.
In addition to open-ended questions, the cognitive interview uses techniques such as asking the witness to visualize the scene, recalling the events in reverse order, and encouraging the witness to provide context and emotional reactions. These techniques aim to help the witness remember more details and give a more accurate account of what happened.
The cognitive interview can be a valuable tool for police investigations as it can help to gather more information and potentially identify suspects. However, it is important for the interviewer to be trained in using this technique to ensure that it is conducted properly and ethically. Additionally, it is important to note that not all witnesses may be suitable for a cognitive interview, especially those who may have experienced trauma or have cognitive disabilities.
tldr, steps:
1. Establish rapport with the witness
2. Encourage the witness to provide a detailed and open-ended account of events
3. Ask the witness to recall specific details
4. Use techniques such as visualization and recalling events in reverse order to aid memory
5. Ensure the interviewer is trained to conduct the technique properly and ethically.
Pseudo code that would implement this strategy in large language model prompting:
```
llm_system = """To implement the cognitive interview in police interviews of witnesses, follow these steps:
1. Begin by establishing a rapport with the witness to build trust and comfort.
2. Use open-ended questions and encourage the witness to provide a detailed account of events.
3. Ask the witness to recall specific details, such as the color of a car or the suspect's facial features.
4. Use techniques such as visualization and recalling events in reverse order to aid memory.
5. Remember to conduct the interview properly and ethically, and consider whether the technique is appropriate for all witnesses, especially those who may have experienced trauma or have cognitive disabilities."""
prompt = "How can the cognitive interview be used in police interviews of witnesses?"
generated_text = llm_system + prompt
print(generated_text)
```
Read more at:
https://www.perplexity.ai/?s=e&uuid=086ab031-cb02-41e6-976d-347ecc62ffc0 | Cognitive interview agent | https://api.github.com/repos/langchain-ai/langchain/issues/3436/comments | 1 | 2023-04-24T10:07:20Z | 2023-09-10T16:28:18Z | https://github.com/langchain-ai/langchain/issues/3436 | 1,680,907,446 | 3,436 |
[
"hwchase17",
"langchain"
]
| I am building an agent toolkit for APITable, a SaaS product, with the ultimate goal of enabling natural language API calls. I want to know if I can dynamically import a tool?
My idea is to create a `tool_prompt.txt` file with contents like this:
```
Get Spaces
Mode: get_spaces
Description: This tool is useful when you need to fetch all the spaces the user has access to,
find out how many spaces there are, or as an intermediary step that involv searching by spaces.
there is no input to this tool.
Get Nodes
Mode: get_nodes
Description: This tool uses APITable's node API to help you search for datasheets, mirrors, dashboards, folders, and forms.
These are all types of nodes in APITable.
The input to this tool is a space id.
You should only respond in JSON format like this:
{{"space_id": "spcjXzqVrjaP3"}}
Do not make up a space_id if you're not sure about it, use the get_spaces tool to retrieve all available space_ids.
Get Fields
Mode: get_fields
Description: This tool helps you search for fields in a datasheet using APITable's field API.
To use this tool, input a datasheet id.
If the user query includes terms like "latest", "oldest", or a specific field name,
please use this tool first to get the field name as field key
You should only respond in JSON format like this:
{{"datasheet_id": "dstlRNFl8L2mufwT5t"}}
Do not make up a datasheet_id if you're not sure about it, use the get_nodes tool to retrieve all available datasheet_ids.
```
Then, I want to create vectors and save them to a vector database like this:
```python
embeddings = OpenAIEmbeddings()
with open("tool_prompt.txt") as f:
tool_prompts = f.read()
text_splitter = CharacterTextSplitter(
chunk_size=100,
chunk_overlap=0,
)
texts = text_splitter.create_documents([tool_prompts])
vectorstore = Chroma.from_documents(texts, embeddings, persist_directory="./db")
vectorstore.persist()
```
Then, during initialize_agent, there will only be a single Planner Tool that reads from the vectorstore to find similar tools based on the query. The agent will inform LLMs that a new tool has been added, and LLMs will use the new tool to perform tasks.
```python
def planner(self, query: str) -> str:
db = Chroma(persist_directory="./db", embedding_function=self.embeddings)
docs = db.similarity_search_with_score(query)
return (
f"Add tools to your workflow to get the results: {docs[0][0].page_content}"
)
```
This approach reduces token consumption
Before:
```shell
> Finished chain.
Total Tokens: 752
Prompt Tokens: 656
Completion Tokens: 96
Successful Requests: 2
Total Cost (USD): $0.0015040000000000001
```
After:
```
> Finished chain.
Total Tokens: 3514
Prompt Tokens: 3346
Completion Tokens: 168
Successful Requests: 2
Total Cost (USD): $0.0070279999999999995
```
However, when LLMs try to use the new tool to perform tasks, it is intercepted because the tool has not been registered during initialize_agent. Thus, I am forced to add an empty tool for registration:
```python
operations: List[Dict] = [
{
"name": "Get Spaces",
"description": "",
},
{
"name": "Get Nodes",
"description": "",
},
{
"name": "Get Fields",
"description": "",
},
{
"name": "Create Fields",
"description": "",
},
{
"name": "Get Records",
"description": "",
},
{
"name": "Planner",
"description": APITABLE_CATCH_ALL_PROMPT,
},
]
```
However, this approach is not effective since LLMs do not prioritize using the Planner Tool.
Therefore, I want to know if there is a better way to combine tools and vector stores.
Repo: https://github.com/xukecheng/apitable_agent_toolkit/tree/feat/combine_vectorstores | How to combine tools and vectorstores | https://api.github.com/repos/langchain-ai/langchain/issues/3435/comments | 1 | 2023-04-24T10:02:55Z | 2023-06-13T09:21:10Z | https://github.com/langchain-ai/langchain/issues/3435 | 1,680,898,670 | 3,435 |
[
"hwchase17",
"langchain"
]
| BaseOpenAI's validate_environment does not set OPENAI_API_TYPE and OPENAI_API_VERSION from environment. As a result, the AzureOpenAI instance failed when called to run.
```
from langchain.llms import AzureOpenAI
from langchain.chains import RetrievalQA
model = RetrievalQA.from_chain_type(
llm=AzureOpenAI(
deployment_name='DaVinci-003',
),
chain_type="stuff",
retriever=vectordb.as_retriever(), return_source_documents=True
)
model({"query": 'testing'})
```
Error:
```
File [~/miniconda3/envs/demo/lib/python3.9/site-packages/openai/api_requestor.py:680](/site-packages/openai/api_requestor.py:680), in APIRequestor._interpret_response_line(self, rbody, rcode, rheaders, stream)
678 stream_error = stream and "error" in resp.data
679 if stream_error or not 200 <= rcode < 300:
--> 680 raise self.handle_error_response(
681 rbody, rcode, resp.data, rheaders, stream_error=stream_error
682 )
683 return resp
InvalidRequestError: Resource not found
``` | AzureOpenAI instance fails because OPENAI_API_TYPE and OPENAI_API_VERSION are not inherited from environment | https://api.github.com/repos/langchain-ai/langchain/issues/3433/comments | 2 | 2023-04-24T08:41:56Z | 2023-04-25T10:02:39Z | https://github.com/langchain-ai/langchain/issues/3433 | 1,680,741,720 | 3,433 |
[
"hwchase17",
"langchain"
]
| I am using the huggingface hosted vicuna-13b model ([link](https://huggingface.co/eachadea/vicuna-13b-1.1)) along with llamaindex and langchain to create a functioning chatbot on custom data ([link](https://github.com/jerryjliu/llama_index/blob/main/examples/chatbot/Chatbot_SEC.ipynb)). However, I'm always getting this error :
```
ValueError: Could not parse LLM output: `
`
```
This is my code snippet:
```
from langchain.llms.base import LLM
from transformers import pipeline
import torch
from langchain import PromptTemplate, HuggingFaceHub
from langchain.llms import HuggingFacePipeline
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("eachadea/vicuna-13b-1.1")
model = AutoModelForCausalLM.from_pretrained("eachadea/vicuna-13b-1.1")
pipeline = pipeline(
"text-generation",
model=model,
tokenizer= tokenizer,
device=1,
model_kwargs={"torch_dtype":torch.bfloat16}, max_length=500)
custom_llm = HuggingFacePipeline(pipeline =pipeline)
.
.
.
.
.
toolkit = LlamaToolkit(
index_configs=index_configs,
graph_configs=[graph_config]
)
memory = ConversationBufferMemory(memory_key="chat_history")
# llm=OpenAI(temperature=0, openai_api_key="sk-")
# llm = vicuna_llm
agent_chain = create_llama_chat_agent(
toolkit,
custom_llm,
memory=memory,
verbose=True
)
agent_chain.run(input="hey vicuna how are u ??")
```
What might be the issue?
| ValueError: Could not parse LLM output: ` ` | https://api.github.com/repos/langchain-ai/langchain/issues/3432/comments | 1 | 2023-04-24T08:17:11Z | 2023-09-10T16:28:23Z | https://github.com/langchain-ai/langchain/issues/3432 | 1,680,704,272 | 3,432 |
[
"hwchase17",
"langchain"
]
| Specifying max_iterations does not take effect when using create_json_agent. The following code is from [this page](https://python.langchain.com/en/latest/modules/agents/toolkits/examples/json.html?highlight=JsonSpec#initialization), with max_iterations added:
```
import os
import yaml
from langchain.agents import (
create_json_agent,
AgentExecutor
)
from langchain.agents.agent_toolkits import JsonToolkit
from langchain.chains import LLMChain
from langchain.llms.openai import OpenAI
from langchain.requests import TextRequestsWrapper
from langchain.tools.json.tool import JsonSpec
```
```
with open("openai_openapi.yml") as f:
data = yaml.load(f, Loader=yaml.FullLoader)
json_spec = JsonSpec(dict_=data, max_value_length=4000)
json_toolkit = JsonToolkit(spec=json_spec)
json_agent_executor = create_json_agent(
llm=OpenAI(temperature=0),
toolkit=json_toolkit,
verbose=True,
max_iterations=3
)
```
The output consists of more than 3 iterations:
```
> Entering new AgentExecutor chain...
Action: json_spec_list_keys
Action Input: data
Observation: ['openapi', 'info', 'servers', 'tags', 'paths', 'components', 'x-oaiMeta']
Thought: I should look at the paths key to see what endpoints exist
Action: json_spec_list_keys
Action Input: data["paths"]
Observation: ['/engines', '/engines/{engine_id}', '/completions', '/chat/completions', '/edits', '/images/generations', '/images/edits', '/images/variations', '/embeddings', '/audio/transcriptions', '/audio/translations', '/engines/{engine_id}/search', '/files', '/files/{file_id}', '/files/{file_id}/content', '/answers', '/classifications', '/fine-tunes', '/fine-tunes/{fine_tune_id}', '/fine-tunes/{fine_tune_id}/cancel', '/fine-tunes/{fine_tune_id}/events', '/models', '/models/{model}', '/moderations']
Thought: I should look at the /completions endpoint to see what parameters are required
Action: json_spec_list_keys
Action Input: data["paths"]["/completions"]
Observation: ['post']
Thought: I should look at the post key to see what parameters are required
Action: json_spec_list_keys
Action Input: data["paths"]["/completions"]["post"]
Observation: ['operationId', 'tags', 'summary', 'requestBody', 'responses', 'x-oaiMeta']
Thought: I should look at the requestBody key to see what parameters are required
Action: json_spec_list_keys
Action Input: data["paths"]["/completions"]["post"]["requestBody"]
Observation: ['required', 'content']
Thought: I should look at the required key to see what parameters are required
Action: json_spec_get_value
Action Input: data["paths"]["/completions"]["post"]["requestBody"]["required"]
```
Maybe kwargs need to be passed in to `from_agent_and_tools`?
https://github.com/hwchase17/langchain/blob/0cf934ce7d8150dddf4a2514d6e7729a16d55b0f/langchain/agents/agent_toolkits/json/base.py#L41-L43 | Cannot specify max iterations when using create_json_agent | https://api.github.com/repos/langchain-ai/langchain/issues/3429/comments | 4 | 2023-04-24T07:44:17Z | 2023-12-30T16:08:53Z | https://github.com/langchain-ai/langchain/issues/3429 | 1,680,648,980 | 3,429 |
[
"hwchase17",
"langchain"
]
| I've noticed recently that the performance of the `zero-shot-react-description` agent has decreased significantly for various tasks and various tools. A very simple example attached, which a few weeks ago would pass perfectly maybe 80% of the time, but now hasn't managed a reasonable attempt in >10 tries. The main issue here seems to be the first stage, where it consistently searches for 'weather in London and Paris', where a few weeks ago it would search for one city first and then the next.
Does anyone have any insight as to what might have happened?
Thanks | `zero-shot-react-description` performance has decreased? | https://api.github.com/repos/langchain-ai/langchain/issues/3428/comments | 1 | 2023-04-24T07:32:38Z | 2023-09-10T16:28:28Z | https://github.com/langchain-ai/langchain/issues/3428 | 1,680,632,696 | 3,428 |
[
"hwchase17",
"langchain"
]
| Hi.
I try to run the following code
```
connection_string = "DefaultEndpointsProtocol=https;AccountName=<myaccount>;AccountKey=<mykey>"
container="<mycontainer>"
loader = AzureBlobStorageContainerLoader(
conn_str=connection_string,
container=container
)
documents = loader.load()
```
but the code `documents = loader.load()` takes like several minutes, and still not response any value.
The container has several html files and it has 1.5MB volume, which I think is not so heavy data.
I try above code several times, and I once got the following error.
```
0 [main] python 868 C:\<path to python exe>\Python310\python.exe: *** fatal error - Internal error: TP_NUM_C_BUFS too small: 50
1139 [main] python 868 cygwin_exception::open_stackdumpfile: Dumping stack trace to python.exe.stackdump
```
My python environment is following
- OS Windows 10
- Python version is 3.10
- use virtualenv
- running my script in mingw console (it's git bash, actually)
Has any Ideas to solve this situation?
(And, THANK YOU for the great framework) | AzureBlobStorageContainerLoader doesn't load the container | https://api.github.com/repos/langchain-ai/langchain/issues/3427/comments | 2 | 2023-04-24T07:22:28Z | 2023-04-25T01:20:11Z | https://github.com/langchain-ai/langchain/issues/3427 | 1,680,619,340 | 3,427 |
[
"hwchase17",
"langchain"
]
| I like how it prints out the specific texts used in generating the answer (much better than just citing the sources IMO). How can I access it? Referring to here: https://python.langchain.com/en/latest/modules/chains/index_examples/chat_vector_db.html#conversationalretrievalchain-with-streaming-to-stdout
| In `ConversationalRetrievalChain` with streaming to `stdout` how can I access the text printed to `stdout` once it finishes streaming? | https://api.github.com/repos/langchain-ai/langchain/issues/3417/comments | 1 | 2023-04-24T03:59:25Z | 2023-09-10T16:28:33Z | https://github.com/langchain-ai/langchain/issues/3417 | 1,680,404,463 | 3,417 |
[
"hwchase17",
"langchain"
]
| Current documentation text under Text Splitter throws error :
texts = text_splitter.create_documents([state_of_the_union])
<img width="968" alt="Screen Shot 2023-04-23 at 9 04 28 PM" src="https://user-images.githubusercontent.com/31634379/233891248-f3b5e187-272e-4822-8cd6-00a1cf56ffae.png">
The error is on both these pages
https://python.langchain.com/en/latest/modules/indexes/text_splitters/getting_started.html
https://python.langchain.com/en/latest/modules/indexes/text_splitters/examples/character_text_splitter.html
I think the above line should be revised to
texts = text_splitter.split_documents([state_of_the_union])
| Documentation error under Text Splitter | https://api.github.com/repos/langchain-ai/langchain/issues/3414/comments | 2 | 2023-04-24T03:06:47Z | 2023-09-28T16:07:35Z | https://github.com/langchain-ai/langchain/issues/3414 | 1,680,368,808 | 3,414 |
[
"hwchase17",
"langchain"
]
| In the agent tutorials the memory_key is set as a fixed string, "chat_history", how do I make it a variable, that is different for each session_id, that is memory_key=str(session_id)? | memory_key as a variable | https://api.github.com/repos/langchain-ai/langchain/issues/3406/comments | 4 | 2023-04-23T23:05:24Z | 2023-09-17T17:22:23Z | https://github.com/langchain-ai/langchain/issues/3406 | 1,680,213,151 | 3,406 |
[
"hwchase17",
"langchain"
]
| ---------------------------------------------------------------------------
InvalidRequestError Traceback (most recent call last)
[<ipython-input-26-5eed72c1ccb8>](https://localhost:8080/#) in <cell line: 3>()
2
----> 3 agent.run(["What were the winning boston marathon times for the past 5 years? Generate a table of the names, countries of origin, and times."])
31 frames
[/usr/local/lib/python3.9/dist-packages/langchain/experimental/autonomous_agents/autogpt/agent.py](https://localhost:8080/#) in run(self, goals)
109 tool = tools[action.name]
110 try:
--> 111 observation = tool.run(action.args)
112 except ValidationError as e:
113 observation = f"Error in args: {str(e)}"
[/usr/local/lib/python3.9/dist-packages/langchain/tools/base.py](https://localhost:8080/#) in run(self, tool_input, verbose, start_color, color, **kwargs)
105 except (Exception, KeyboardInterrupt) as e:
106 self.callback_manager.on_tool_error(e, verbose=verbose_)
--> 107 raise e
108 self.callback_manager.on_tool_end(
109 observation, verbose=verbose_, color=color, name=self.name, **kwargs
[/usr/local/lib/python3.9/dist-packages/langchain/tools/base.py](https://localhost:8080/#) in run(self, tool_input, verbose, start_color, color, **kwargs)
102 try:
103 tool_args, tool_kwargs = _to_args_and_kwargs(tool_input)
--> 104 observation = self._run(*tool_args, **tool_kwargs)
105 except (Exception, KeyboardInterrupt) as e:
106 self.callback_manager.on_tool_error(e, verbose=verbose_)
[<ipython-input-12-79448a1343a1>](https://localhost:8080/#) in _run(self, url, question)
33 results.append(f"Response from window {i} - {window_result}")
34 results_docs = [Document(page_content="\n".join(results), metadata={"source": url})]
---> 35 return self.qa_chain({"input_documents": results_docs, "question": question}, return_only_outputs=True)
36
37 async def _arun(self, url: str, question: str) -> str:
[/usr/local/lib/python3.9/dist-packages/langchain/chains/base.py](https://localhost:8080/#) in __call__(self, inputs, return_only_outputs)
114 except (KeyboardInterrupt, Exception) as e:
115 self.callback_manager.on_chain_error(e, verbose=self.verbose)
--> 116 raise e
117 self.callback_manager.on_chain_end(outputs, verbose=self.verbose)
118 return self.prep_outputs(inputs, outputs, return_only_outputs)
[/usr/local/lib/python3.9/dist-packages/langchain/chains/base.py](https://localhost:8080/#) in __call__(self, inputs, return_only_outputs)
111 )
112 try:
--> 113 outputs = self._call(inputs)
114 except (KeyboardInterrupt, Exception) as e:
115 self.callback_manager.on_chain_error(e, verbose=self.verbose)
[/usr/local/lib/python3.9/dist-packages/langchain/chains/combine_documents/base.py](https://localhost:8080/#) in _call(self, inputs)
73 # Other keys are assumed to be needed for LLM prediction
74 other_keys = {k: v for k, v in inputs.items() if k != self.input_key}
---> 75 output, extra_return_dict = self.combine_docs(docs, **other_keys)
76 extra_return_dict[self.output_key] = output
77 return extra_return_dict
[/usr/local/lib/python3.9/dist-packages/langchain/chains/combine_documents/stuff.py](https://localhost:8080/#) in combine_docs(self, docs, **kwargs)
81 inputs = self._get_inputs(docs, **kwargs)
82 # Call predict on the LLM.
---> 83 return self.llm_chain.predict(**inputs), {}
84
85 async def acombine_docs(
[/usr/local/lib/python3.9/dist-packages/langchain/chains/llm.py](https://localhost:8080/#) in predict(self, **kwargs)
149 completion = llm.predict(adjective="funny")
150 """
--> 151 return self(kwargs)[self.output_key]
152
153 async def apredict(self, **kwargs: Any) -> str:
[/usr/local/lib/python3.9/dist-packages/langchain/chains/base.py](https://localhost:8080/#) in __call__(self, inputs, return_only_outputs)
114 except (KeyboardInterrupt, Exception) as e:
115 self.callback_manager.on_chain_error(e, verbose=self.verbose)
--> 116 raise e
117 self.callback_manager.on_chain_end(outputs, verbose=self.verbose)
118 return self.prep_outputs(inputs, outputs, return_only_outputs)
[/usr/local/lib/python3.9/dist-packages/langchain/chains/base.py](https://localhost:8080/#) in __call__(self, inputs, return_only_outputs)
111 )
112 try:
--> 113 outputs = self._call(inputs)
114 except (KeyboardInterrupt, Exception) as e:
115 self.callback_manager.on_chain_error(e, verbose=self.verbose)
[/usr/local/lib/python3.9/dist-packages/langchain/chains/llm.py](https://localhost:8080/#) in _call(self, inputs)
55
56 def _call(self, inputs: Dict[str, Any]) -> Dict[str, str]:
---> 57 return self.apply([inputs])[0]
58
59 def generate(self, input_list: List[Dict[str, Any]]) -> LLMResult:
[/usr/local/lib/python3.9/dist-packages/langchain/chains/llm.py](https://localhost:8080/#) in apply(self, input_list)
116 def apply(self, input_list: List[Dict[str, Any]]) -> List[Dict[str, str]]:
117 """Utilize the LLM generate method for speed gains."""
--> 118 response = self.generate(input_list)
119 return self.create_outputs(response)
120
[/usr/local/lib/python3.9/dist-packages/langchain/chains/llm.py](https://localhost:8080/#) in generate(self, input_list)
60 """Generate LLM result from inputs."""
61 prompts, stop = self.prep_prompts(input_list)
---> 62 return self.llm.generate_prompt(prompts, stop)
63
64 async def agenerate(self, input_list: List[Dict[str, Any]]) -> LLMResult:
[/usr/local/lib/python3.9/dist-packages/langchain/chat_models/base.py](https://localhost:8080/#) in generate_prompt(self, prompts, stop)
80 except (KeyboardInterrupt, Exception) as e:
81 self.callback_manager.on_llm_error(e, verbose=self.verbose)
---> 82 raise e
83 self.callback_manager.on_llm_end(output, verbose=self.verbose)
84 return output
[/usr/local/lib/python3.9/dist-packages/langchain/chat_models/base.py](https://localhost:8080/#) in generate_prompt(self, prompts, stop)
77 )
78 try:
---> 79 output = self.generate(prompt_messages, stop=stop)
80 except (KeyboardInterrupt, Exception) as e:
81 self.callback_manager.on_llm_error(e, verbose=self.verbose)
[/usr/local/lib/python3.9/dist-packages/langchain/chat_models/base.py](https://localhost:8080/#) in generate(self, messages, stop)
52 ) -> LLMResult:
53 """Top Level call"""
---> 54 results = [self._generate(m, stop=stop) for m in messages]
55 llm_output = self._combine_llm_outputs([res.llm_output for res in results])
56 generations = [res.generations for res in results]
[/usr/local/lib/python3.9/dist-packages/langchain/chat_models/base.py](https://localhost:8080/#) in <listcomp>(.0)
52 ) -> LLMResult:
53 """Top Level call"""
---> 54 results = [self._generate(m, stop=stop) for m in messages]
55 llm_output = self._combine_llm_outputs([res.llm_output for res in results])
56 generations = [res.generations for res in results]
[/usr/local/lib/python3.9/dist-packages/langchain/chat_models/openai.py](https://localhost:8080/#) in _generate(self, messages, stop)
264 )
265 return ChatResult(generations=[ChatGeneration(message=message)])
--> 266 response = self.completion_with_retry(messages=message_dicts, **params)
267 return self._create_chat_result(response)
268
[/usr/local/lib/python3.9/dist-packages/langchain/chat_models/openai.py](https://localhost:8080/#) in completion_with_retry(self, **kwargs)
226 return self.client.create(**kwargs)
227
--> 228 return _completion_with_retry(**kwargs)
229
230 def _combine_llm_outputs(self, llm_outputs: List[Optional[dict]]) -> dict:
[/usr/local/lib/python3.9/dist-packages/tenacity/__init__.py](https://localhost:8080/#) in wrapped_f(*args, **kw)
287 @functools.wraps(f)
288 def wrapped_f(*args: t.Any, **kw: t.Any) -> t.Any:
--> 289 return self(f, *args, **kw)
290
291 def retry_with(*args: t.Any, **kwargs: t.Any) -> WrappedFn:
[/usr/local/lib/python3.9/dist-packages/tenacity/__init__.py](https://localhost:8080/#) in __call__(self, fn, *args, **kwargs)
377 retry_state = RetryCallState(retry_object=self, fn=fn, args=args, kwargs=kwargs)
378 while True:
--> 379 do = self.iter(retry_state=retry_state)
380 if isinstance(do, DoAttempt):
381 try:
[/usr/local/lib/python3.9/dist-packages/tenacity/__init__.py](https://localhost:8080/#) in iter(self, retry_state)
312 is_explicit_retry = fut.failed and isinstance(fut.exception(), TryAgain)
313 if not (is_explicit_retry or self.retry(retry_state)):
--> 314 return fut.result()
315
316 if self.after is not None:
[/usr/lib/python3.9/concurrent/futures/_base.py](https://localhost:8080/#) in result(self, timeout)
437 raise CancelledError()
438 elif self._state == FINISHED:
--> 439 return self.__get_result()
440
441 self._condition.wait(timeout)
[/usr/lib/python3.9/concurrent/futures/_base.py](https://localhost:8080/#) in __get_result(self)
389 if self._exception:
390 try:
--> 391 raise self._exception
392 finally:
393 # Break a reference cycle with the exception in self._exception
[/usr/local/lib/python3.9/dist-packages/tenacity/__init__.py](https://localhost:8080/#) in __call__(self, fn, *args, **kwargs)
380 if isinstance(do, DoAttempt):
381 try:
--> 382 result = fn(*args, **kwargs)
383 except BaseException: # noqa: B902
384 retry_state.set_exception(sys.exc_info()) # type: ignore[arg-type]
[/usr/local/lib/python3.9/dist-packages/langchain/chat_models/openai.py](https://localhost:8080/#) in _completion_with_retry(**kwargs)
224 @retry_decorator
225 def _completion_with_retry(**kwargs: Any) -> Any:
--> 226 return self.client.create(**kwargs)
227
228 return _completion_with_retry(**kwargs)
[/usr/local/lib/python3.9/dist-packages/openai/api_resources/chat_completion.py](https://localhost:8080/#) in create(cls, *args, **kwargs)
23 while True:
24 try:
---> 25 return super().create(*args, **kwargs)
26 except TryAgain as e:
27 if timeout is not None and time.time() > start + timeout:
[/usr/local/lib/python3.9/dist-packages/openai/api_resources/abstract/engine_api_resource.py](https://localhost:8080/#) in create(cls, api_key, api_base, api_type, request_id, api_version, organization, **params)
151 )
152
--> 153 response, _, api_key = requestor.request(
154 "post",
155 url,
[/usr/local/lib/python3.9/dist-packages/openai/api_requestor.py](https://localhost:8080/#) in request(self, method, url, params, headers, files, stream, request_id, request_timeout)
224 request_timeout=request_timeout,
225 )
--> 226 resp, got_stream = self._interpret_response(result, stream)
227 return resp, got_stream, self.api_key
228
[/usr/local/lib/python3.9/dist-packages/openai/api_requestor.py](https://localhost:8080/#) in _interpret_response(self, result, stream)
618 else:
619 return (
--> 620 self._interpret_response_line(
621 result.content.decode("utf-8"),
622 result.status_code,
[/usr/local/lib/python3.9/dist-packages/openai/api_requestor.py](https://localhost:8080/#) in _interpret_response_line(self, rbody, rcode, rheaders, stream)
681 stream_error = stream and "error" in resp.data
682 if stream_error or not 200 <= rcode < 300:
--> 683 raise self.handle_error_response(
684 rbody, rcode, resp.data, rheaders, stream_error=stream_error
685 )
InvalidRequestError: This model's maximum context length is 4097 tokens. However, your messages resulted in 4665 tokens. Please reduce the length of the messages. | marathon_times.ipynb: InvalidRequestError: This model's maximum context length is 4097 tokens. | https://api.github.com/repos/langchain-ai/langchain/issues/3405/comments | 5 | 2023-04-23T21:13:04Z | 2023-09-24T16:08:17Z | https://github.com/langchain-ai/langchain/issues/3405 | 1,680,179,456 | 3,405 |
[
"hwchase17",
"langchain"
]
| Text mentions inflation and tuition:
Here is the prompt comparing inflation and college tuition.
Code is about marathon times:
agent.run(["What were the winning boston marathon times for the past 5 years? Generate a table of the names, countries of origin, and times."]) | marathon_times.ipynb: mismatched text and code | https://api.github.com/repos/langchain-ai/langchain/issues/3404/comments | 0 | 2023-04-23T21:06:49Z | 2023-04-24T01:14:13Z | https://github.com/langchain-ai/langchain/issues/3404 | 1,680,177,766 | 3,404 |
[
"hwchase17",
"langchain"
]
| i tried out a simple custom model. as long as i am using only one "query" parameter everything is working fine. in this example i like to use two parameters (i searched the problem and i found this SendMessage usecase...)
unfortunately it does not work.. and throws this error.
`input_args.validate({key_: tool_input})
File "pydantic/main.py", line 711, in pydantic.main.BaseModel.validate
File "pydantic/main.py", line 341, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 1 validation error for SendMessageInput
message
field required (type=value_error.missing)`
the code :
`from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.llms import OpenAI
from langchain.tools import BaseTool
from typing import Type
from pydantic import BaseModel, Field
class SendMessageInput(BaseModel):
email: str = Field(description="email")
message: str = Field(description="the message to send")
class SendMessageTool(BaseTool):
name = "send_message_tool"
description = "useful for when you need to send a message to a human"
args_schema: Type[BaseModel] = SendMessageInput
def _run(self, email:str,message:str) -> str:
print(message,email)
"""Use the tool."""
return f"message send"
async def _arun(self, email: str, message: str) -> str:
"""Use the tool asynchronously."""
return f"Sent message '{message}' to {email}"
llm = OpenAI(temperature=0)
tools=[SendMessageTool()]
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("send message hello to [email protected]")
` | Custom Model with args_schema not working | https://api.github.com/repos/langchain-ai/langchain/issues/3403/comments | 7 | 2023-04-23T20:16:33Z | 2023-10-05T16:10:53Z | https://github.com/langchain-ai/langchain/issues/3403 | 1,680,154,536 | 3,403 |
[
"hwchase17",
"langchain"
]
|
I have been trying multiple approaches to use headers in the requests chain. Here's my code:
I have been trying multiple approaches to use headers in the requests chain. Here's my code:
from langchain.utilities import TextRequestsWrapper
import json
requests = TextRequestsWrapper()
headers = {
"name": "hetyo"
}
str_data = requests.get("https://httpbin.org/get", params = {"name" : "areeb"}, headers=headers)
json_data = json.loads(str_data)
json_data
How can I pass in herders to the TextRequestsWrapper? Is there anything that I am doing wrong?
I also found that the headers is used in the requests file as follows:
"""Lightweight wrapper around requests library, with async support."""
from contextlib import asynccontextmanager
from typing import Any, AsyncGenerator, Dict, Optional
import aiohttp
import requests
from pydantic import BaseModel, Extra
class Requests(BaseModel):
"""Wrapper around requests to handle auth and async.
The main purpose of this wrapper is to handle authentication (by saving
headers) and enable easy async methods on the same base object.
"""
headers: Optional[Dict[str, str]] = None
aiosession: Optional[aiohttp.ClientSession] = None
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
def get(self, url: str, **kwargs: Any) -> requests.Response:
"""GET the URL and return the text."""
return requests.get(url, headers=self.headers, **kwargs)
def post(self, url: str, data: Dict[str, Any], **kwargs: Any) -> requests.Response:
"""POST to the URL and return the text."""
return requests.post(url, json=data, headers=self.headers, **kwargs)
def patch(self, url: str, data: Dict[str, Any], **kwargs: Any) -> requests.Response:
"""PATCH the URL and return the text."""
return requests.patch(url, json=data, headers=self.headers, **kwargs)
def put(self, url: str, data: Dict[str, Any], **kwargs: Any) -> requests.Response:
"""PUT the URL and return the text."""
return requests.put(url, json=data, headers=self.headers, **kwargs)
def delete(self, url: str, **kwargs: Any) -> requests.Response:
"""DELETE the URL and return the text."""
return requests.delete(url, headers=self.headers, **kwargs)
@asynccontextmanager
async def _arequest(
self, method: str, url: str, **kwargs: Any
) -> AsyncGenerator[aiohttp.ClientResponse, None]:
"""Make an async request."""
if not self.aiosession:
async with aiohttp.ClientSession() as session:
async with session.request(
method, url, headers=self.headers, **kwargs
) as response:
yield response
else:
async with self.aiosession.request(
method, url, headers=self.headers, **kwargs
) as response:
yield response
@asynccontextmanager
async def aget(
self, url: str, **kwargs: Any
) -> AsyncGenerator[aiohttp.ClientResponse, None]:
"""GET the URL and return the text asynchronously."""
async with self._arequest("GET", url, **kwargs) as response:
yield response
@asynccontextmanager
async def apost(
self, url: str, data: Dict[str, Any], **kwargs: Any
) -> AsyncGenerator[aiohttp.ClientResponse, None]:
"""POST to the URL and return the text asynchronously."""
async with self._arequest("POST", url, **kwargs) as response:
yield response
@asynccontextmanager
async def apatch(
self, url: str, data: Dict[str, Any], **kwargs: Any
) -> AsyncGenerator[aiohttp.ClientResponse, None]:
"""PATCH the URL and return the text asynchronously."""
async with self._arequest("PATCH", url, **kwargs) as response:
yield response
@asynccontextmanager
async def aput(
self, url: str, data: Dict[str, Any], **kwargs: Any
) -> AsyncGenerator[aiohttp.ClientResponse, None]:
"""PUT the URL and return the text asynchronously."""
async with self._arequest("PUT", url, **kwargs) as response:
yield response
@asynccontextmanager
async def adelete(
self, url: str, **kwargs: Any
) -> AsyncGenerator[aiohttp.ClientResponse, None]:
"""DELETE the URL and return the text asynchronously."""
async with self._arequest("DELETE", url, **kwargs) as response:
yield response
class TextRequestsWrapper(BaseModel):
"""Lightweight wrapper around requests library.
The main purpose of this wrapper is to always return a text output.
"""
headers: Optional[Dict[str, str]] = None
aiosession: Optional[aiohttp.ClientSession] = None
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
@property
def requests(self) -> Requests:
return Requests(headers=self.headers, aiosession=self.aiosession)
def get(self, url: str, **kwargs: Any) -> str:
"""GET the URL and return the text."""
return self.requests.get(url, **kwargs).text
def post(self, url: str, data: Dict[str, Any], **kwargs: Any) -> str:
"""POST to the URL and return the text."""
return self.requests.post(url, data, **kwargs).text
def patch(self, url: str, data: Dict[str, Any], **kwargs: Any) -> str:
"""PATCH the URL and return the text."""
return self.requests.patch(url, data, **kwargs).text
def put(self, url: str, data: Dict[str, Any], **kwargs: Any) -> str:
"""PUT the URL and return the text."""
return self.requests.put(url, data, **kwargs).text
def delete(self, url: str, **kwargs: Any) -> str:
"""DELETE the URL and return the text."""
return self.requests.delete(url, **kwargs).text
async def aget(self, url: str, **kwargs: Any) -> str:
"""GET the URL and return the text asynchronously."""
async with self.requests.aget(url, **kwargs) as response:
return await response.text()
async def apost(self, url: str, data: Dict[str, Any], **kwargs: Any) -> str:
"""POST to the URL and return the text asynchronously."""
async with self.requests.apost(url, **kwargs) as response:
return await response.text()
async def apatch(self, url: str, data: Dict[str, Any], **kwargs: Any) -> str:
"""PATCH the URL and return the text asynchronously."""
async with self.requests.apatch(url, **kwargs) as response:
return await response.text()
async def aput(self, url: str, data: Dict[str, Any], **kwargs: Any) -> str:
"""PUT the URL and return the text asynchronously."""
async with self.requests.aput(url, **kwargs) as response:
return await response.text()
async def adelete(self, url: str, **kwargs: Any) -> str:
"""DELETE the URL and return the text asynchronously."""
async with self.requests.adelete(url, **kwargs) as response:
return await response.text()
# For backwards compatibility
RequestsWrapper = TextRequestsWrapper
This may be creating the conflicts.
Here's the error that I am getting :
[/usr/local/lib/python3.9/dist-packages/langchain/requests.py](https://localhost:8080/#) in get(self, url, **kwargs)
26 def get(self, url: str, **kwargs: Any) -> requests.Response:
27 """GET the URL and return the text.""" --->
28 return requests.get(url, headers=self.headers, **kwargs)
29
30 def post(self, url: str, data: Dict[str, Any], **kwargs: Any) -> requests.Response:
TypeError: requests.api.get() got multiple values for keyword argument 'headers'
Please assist. | Not able to Pass in Headers in the Requests module | https://api.github.com/repos/langchain-ai/langchain/issues/3402/comments | 2 | 2023-04-23T19:08:24Z | 2023-04-27T17:58:55Z | https://github.com/langchain-ai/langchain/issues/3402 | 1,680,133,937 | 3,402 |
[
"hwchase17",
"langchain"
]
| Elastic supports generating embeddings using [embedding models running in the stack](https://www.elastic.co/guide/en/machine-learning/current/ml-nlp-model-ref.html#ml-nlp-model-ref-text-embedding).
Add a the ability to generate embeddings with Elasticsearch in langchain similar to other embedding modules. | Add support for generating embeddings in Elasticsearch | https://api.github.com/repos/langchain-ai/langchain/issues/3400/comments | 1 | 2023-04-23T18:40:54Z | 2023-05-24T05:40:38Z | https://github.com/langchain-ai/langchain/issues/3400 | 1,680,125,057 | 3,400 |
[
"hwchase17",
"langchain"
]
| Can you please help me with connecting my LangChain agent to a MongoDB database? I know that it's possible to directly connect to a SQL database using this resource [https://python.langchain.com/en/latest/modules/agents/toolkits/examples/sql_database.html](url) but I'm not sure if the same approach can be used with MongoDB. If it's not possible, could you suggest other ways to connect to MongoDB? | Connection with mongo db | https://api.github.com/repos/langchain-ai/langchain/issues/3399/comments | 11 | 2023-04-23T18:03:33Z | 2024-02-15T16:12:00Z | https://github.com/langchain-ai/langchain/issues/3399 | 1,680,114,161 | 3,399 |
[
"hwchase17",
"langchain"
]
| Hey
I'm getting `TypeError: 'StuffDocumentsChain' object is not callable`
the code snippet can be found here:
```
def main():
text_splitter = CharacterTextSplitter(chunk_size=2000, chunk_overlap=50)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings(openai_api_key=api_key)
vector_db = Chroma.from_documents(
documents=texts, embeddings=embeddings)
relevant_words = get_search_words(query)
docs = vector_db.similarity_search(
relevant_words, top_k=min(3, len(texts))
)
chat_model = ChatOpenAI(
model_name="gpt-3.5-turbo", temperature=0.2, openai_api_key=api_key
)
PROMPT = get_prompt_template()
chain = load_qa_with_sources_chain(
chat_model, chain_type="stuff", metadata_keys=['source'],
return_intermediate_steps=True, prompt=PROMPT
)
res = chain({"input_documents": docs, "question": query},
return_only_outputs=True)
pprint(res)
```
Any ideas what I'm doing wrong?
BTW - if I'll change it to map_rerank of even use
```
chain = load_qa_chain(chat_model, chain_type="stuff")
chain.run(input_documents=docs, question=query)
```
I'm getting the same object is not callable | object is not callable | https://api.github.com/repos/langchain-ai/langchain/issues/3398/comments | 2 | 2023-04-23T17:43:35Z | 2024-04-30T20:26:24Z | https://github.com/langchain-ai/langchain/issues/3398 | 1,680,107,688 | 3,398 |
[
"hwchase17",
"langchain"
]
| The example in the documentation raises a `GuessedAtParserWarning`
To replicate:
```python
#!wget -r -A.html -P rtdocs https://langchain.readthedocs.io/en/latest/
from langchain.document_loaders import ReadTheDocsLoader
loader = ReadTheDocsLoader("rtdocs")
docs = loader.load()
```
```
/config/miniconda3/envs/warn_test/lib/python3.8/site-packages/langchain/document_loaders/readthedocs.py:30: GuessedAtParserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("html.parser"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 30 of the file /config/miniconda3/envs/warn_test/lib/python3.8/site-packages/langchain/document_loaders/readthedocs.py. To get rid of this warning, pass the additional argument 'features="html.parser"' to the BeautifulSoup constructor.
_ = BeautifulSoup(
```
Adding the argument `features` can resolve this issue
```python
#!wget -r -A.html -P rtdocs https://langchain.readthedocs.io/en/latest/
from langchain.document_loaders import ReadTheDocsLoader
loader = ReadTheDocsLoader("rtdocs", features='html.parser')
docs = loader.load()
``` | Read the Docs document loader documentation example raises warning | https://api.github.com/repos/langchain-ai/langchain/issues/3396/comments | 0 | 2023-04-23T15:50:35Z | 2023-04-25T04:54:40Z | https://github.com/langchain-ai/langchain/issues/3396 | 1,680,072,310 | 3,396 |
[
"hwchase17",
"langchain"
]
| Hello, cloud you help me fix
Error fetching or processing https exeption: URL return an error: 403 when using UnstructuredURLLoader,I'm not sure if this error is a restricted access to the website or a problem with the use of the API, thank you very much | UnstructuredURLLoader Error | https://api.github.com/repos/langchain-ai/langchain/issues/3391/comments | 1 | 2023-04-23T14:45:09Z | 2023-09-10T16:28:50Z | https://github.com/langchain-ai/langchain/issues/3391 | 1,680,051,952 | 3,391 |
[
"hwchase17",
"langchain"
]
| `MRKLOutputParser` strips quotes in "Action Input" without checking if they are present on both sides.
See https://github.com/hwchase17/langchain/blob/acfd11c8e424a456227abde8df8b52a705b63024/langchain/agents/mrkl/output_parser.py#L27
Test case that reproduces the problem:
```python
from langchain.agents.mrkl.output_parser import MRKLOutputParser
parser = MRKLOutputParser()
llm_output = 'Action: Terminal\nAction Input: git commit -m "My change"'
action = parser.parse(llm_output)
print(action)
assert action.tool_input == 'git commit -m "My change"'
```
The fix should be simple: check first if the quotes are present on both sides before stripping them.
Happy to submit a PR if you are happy with proposed fix. | MRKLOutputParser strips quotes incorrectly and breaks LLM commands | https://api.github.com/repos/langchain-ai/langchain/issues/3390/comments | 1 | 2023-04-23T14:22:00Z | 2023-09-10T16:28:54Z | https://github.com/langchain-ai/langchain/issues/3390 | 1,680,044,740 | 3,390 |
[
"hwchase17",
"langchain"
]
| ### The Problem
The `YoutubeLoader` is breaking when using the `from_youtube_url` function. The expected behaviour is to use this module to get transcripts from youtube videos and pass into them to an LLM. Willing to help if needed.
### Specs
```
- Machine: Apple M1 Pro
- Version: langchain 0.0.147
- conda-build version : 3.21.8
- python version : 3.9.12.final.0
```
### Code
```python
from dotenv import find_dotenv, load_dotenv
from langchain.document_loaders import YoutubeLoader
load_dotenv(find_dotenv())
loader = YoutubeLoader.from_youtube_url("https://www.youtube.com/watch?v=QsYGlZkevEg", add_video_info=True)
result = loader.load()
print (result)
```
### Output
```bash
Traceback (most recent call last):
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/site-packages/pytube/__main__.py", line 341, in title
self._title = self.vid_info['videoDetails']['title']
KeyError: 'videoDetails'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/urllib/request.py", line 1346, in do_open
h.request(req.get_method(), req.selector, req.data, headers,
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/http/client.py", line 1285, in request
self._send_request(method, url, body, headers, encode_chunked)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/http/client.py", line 1331, in _send_request
self.endheaders(body, encode_chunked=encode_chunked)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/http/client.py", line 1280, in endheaders
self._send_output(message_body, encode_chunked=encode_chunked)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/http/client.py", line 1040, in _send_output
self.send(msg)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/http/client.py", line 980, in send
self.connect()
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/http/client.py", line 1454, in connect
self.sock = self._context.wrap_socket(self.sock,
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/ssl.py", line 500, in wrap_socket
return self.sslsocket_class._create(
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/ssl.py", line 1040, in _create
self.do_handshake()
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/ssl.py", line 1309, in do_handshake
self._sslobj.do_handshake()
ssl.SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1129)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/<username>/Desktop/personal/github/ar-assistant/notebooks/research/langchain/scripts/5-indexes.py", line 28, in <module>
result = loader.load()
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/site-packages/langchain/document_loaders/youtube.py", line 133, in load
video_info = self._get_video_info()
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/site-packages/langchain/document_loaders/youtube.py", line 174, in _get_video_info
"title": yt.title,
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/site-packages/pytube/__main__.py", line 345, in title
self.check_availability()
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/site-packages/pytube/__main__.py", line 210, in check_availability
status, messages = extract.playability_status(self.watch_html)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/site-packages/pytube/__main__.py", line 102, in watch_html
self._watch_html = request.get(url=self.watch_url)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/site-packages/pytube/request.py", line 53, in get
response = _execute_request(url, headers=extra_headers, timeout=timeout)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/site-packages/pytube/request.py", line 37, in _execute_request
return urlopen(request, timeout=timeout) # nosec
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/urllib/request.py", line 214, in urlopen
return opener.open(url, data, timeout)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/urllib/request.py", line 517, in open
response = self._open(req, data)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/urllib/request.py", line 534, in _open
result = self._call_chain(self.handle_open, protocol, protocol +
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/urllib/request.py", line 494, in _call_chain
result = func(*args)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/urllib/request.py", line 1389, in https_open
return self.do_open(http.client.HTTPSConnection, req,
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/urllib/request.py", line 1349, in do_open
raise URLError(err)
urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1129)>
```
### FYI
- There is a duplication of code excerpts in the [Youtube page](https://python.langchain.com/en/latest/modules/indexes/document_loaders/examples/youtube.html#) of the langchain docs
| Youtube.py: urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1129)> | https://api.github.com/repos/langchain-ai/langchain/issues/3389/comments | 3 | 2023-04-23T13:47:11Z | 2023-09-24T16:08:22Z | https://github.com/langchain-ai/langchain/issues/3389 | 1,680,033,914 | 3,389 |
[
"hwchase17",
"langchain"
]
| Hello everyone,
Is it possible to use IndexTree with a local LLM as for istance gpt4all or llama.cpp?
Is there a tutorial? | IndexTree and local LLM | https://api.github.com/repos/langchain-ai/langchain/issues/3388/comments | 1 | 2023-04-23T13:18:07Z | 2023-09-15T22:12:51Z | https://github.com/langchain-ai/langchain/issues/3388 | 1,680,025,245 | 3,388 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.