
File size: 8,529 Bytes
33bd2dc |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 |
## 🤗 PEFT:在低资源硬件上对十亿规模模型进行参数高效微调
## [](https://huggingface.co/blog/peft#motivation)动机
基于 transformer 架构的大型语言模型 (LLM),如 GPT、T5 和 BERT,已经在各种自然语言处理 (NLP) 任务中取得了最先进的结果。此外,还开始涉足其他领域,例如计算机视觉 (CV)(VIT、Stable Diffusion、LayoutLM)和音频(Whisper、XLS-R)。传统的范式是对通用网络规模数据进行大规模预训练,然后对下游任务进行微调。与使用开箱即用的预训练 LLM(例如,零样本推理)相比,在下游数据集上微调这些预训练 LLM 会带来巨大的性能提升。
然而,随着模型变得越来越大,在消费级硬件上对模型进行全部参数的微调变得不可行。此外,为每个下游任务独立存储和部署微调模型变得非常昂贵,因为微调模型与原始预训练模型的大小相同。参数高效微调(PEFT) 方法旨在解决这两个问题!
PEFT 方法仅微调少量(额外)模型参数,同时冻结预训练 LLM 的大部分参数,从而大大降低了计算和存储成本。这也克服了[灾难性遗忘](https://arxiv.org/abs/1312.6211)的问题,这是在 LLM 的全参数微调期间观察到的一种现象。 PEFT 方法也显示出在低数据状态下比微调更好,可以更好地泛化到域外场景。它可以应用于各种模态,例如[图像分类](https://github.com/huggingface/peft/tree/main/examples/image_classification)以及 [Stable diffusion dreambooth](https://github.com/huggingface/peft/tree/main/examples/lora_dreambooth)。
PEFT 方法还有助于提高轻便性,其中用户可以使用 PEFT 方法调整模型,以获得与完全微调的大型检查点相比,大小仅几 MB 的微小检查点。例如, `bigscience/mt0-xxl` 占用 40GB 的存储空间,全参数微调将导致每个下游数据集有对应 40GB 检查点。而使用 PEFT 方法,每个下游数据集只占用几 MB 的存储空间,同时实现与全参数微调相当的性能。来自 PEFT 方法的少量训练权重被添加到预训练 LLM 顶层。因此,同一个 LLM 可以通过添加小的权重来用于多个任务,而无需替换整个模型。
**简而言之,PEFT 方法使您能够获得与全参数微调相当的性能,同时只有少量可训练参数。**
今天,我们很高兴地介绍 [🤗 PEFT](https://github.com/huggingface/peft) 库。它提供了最新的参数高效微调技术,与 🤗 Transformers 和 🤗 Accelerate 无缝集成。这使得能够使用来自 Transformers 的最流行和高性能的模型,以及 Accelerate 的简单性和可扩展性。以下是目前支持的 PEFT 方法,即将推出更多:
1. LoRA: [LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS](https://arxiv.org/pdf/2106.09685.pdf)
2. Prefix Tuning: [P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks](https://arxiv.org/pdf/2110.07602.pdf)
3. Prompt Tuning: [The Power of Scale for Parameter-Efficient Prompt Tuning](https://arxiv.org/pdf/2104.08691.pdf)
4. P-Tuning: [GPT Understands, Too](https://arxiv.org/pdf/2103.10385.pdf)
## [](https://huggingface.co/blog/peft#use-cases)用例
我们在[这里](https://github.com/huggingface/peft#use-cases)探索了许多有趣的用例。以下罗列的是最有趣的:
1. 使用 🤗 PEFT LoRA 在具有 11GB RAM 的消费级硬件上调整 `bigscience/T0_3B` 模型(30 亿个参数),例如 Nvidia GeForce RTX 2080 Ti、Nvidia GeForce RTX 3080 等,并且使用 🤗 Accelerate 的 DeepSpeed 集成:[peft\_lora\_seq2seq\_accelerate\_ds\_zero3\_offload.py](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py)。这意味着您可以在 Google Colab 中调整如此大的 LLM。
2. 通过使用 🤗 PEFT LoRA 和 [bitsandbytes](https://github.com/TimDettmers/bitsandbytes) 在 Google Colab 中启用 `OPT-6.7b` 模型(67 亿个参数)的 INT8 调整,将前面的示例提升一个档次: [](https://colab.research.google.com/drive/1jCkpikz0J2o20FBQmYmAGdiKmJGOMo-o?usp=sharing)
3. 在具有 11GB RAM 的消费级硬件上使用 🤗 PEFT 进行稳定的 Diffusion Dreambooth 训练,例如 Nvidia GeForce RTX 2080 Ti、Nvidia GeForce RTX 3080 等。试用 Space 演示,它应该可以在 T4 实例(16GB GPU)上无缝运行:[smangrul /peft-lora-sd-dreambooth](https://huggingface.co/spaces/smangrul/peft-lora-sd-dreambooth)。
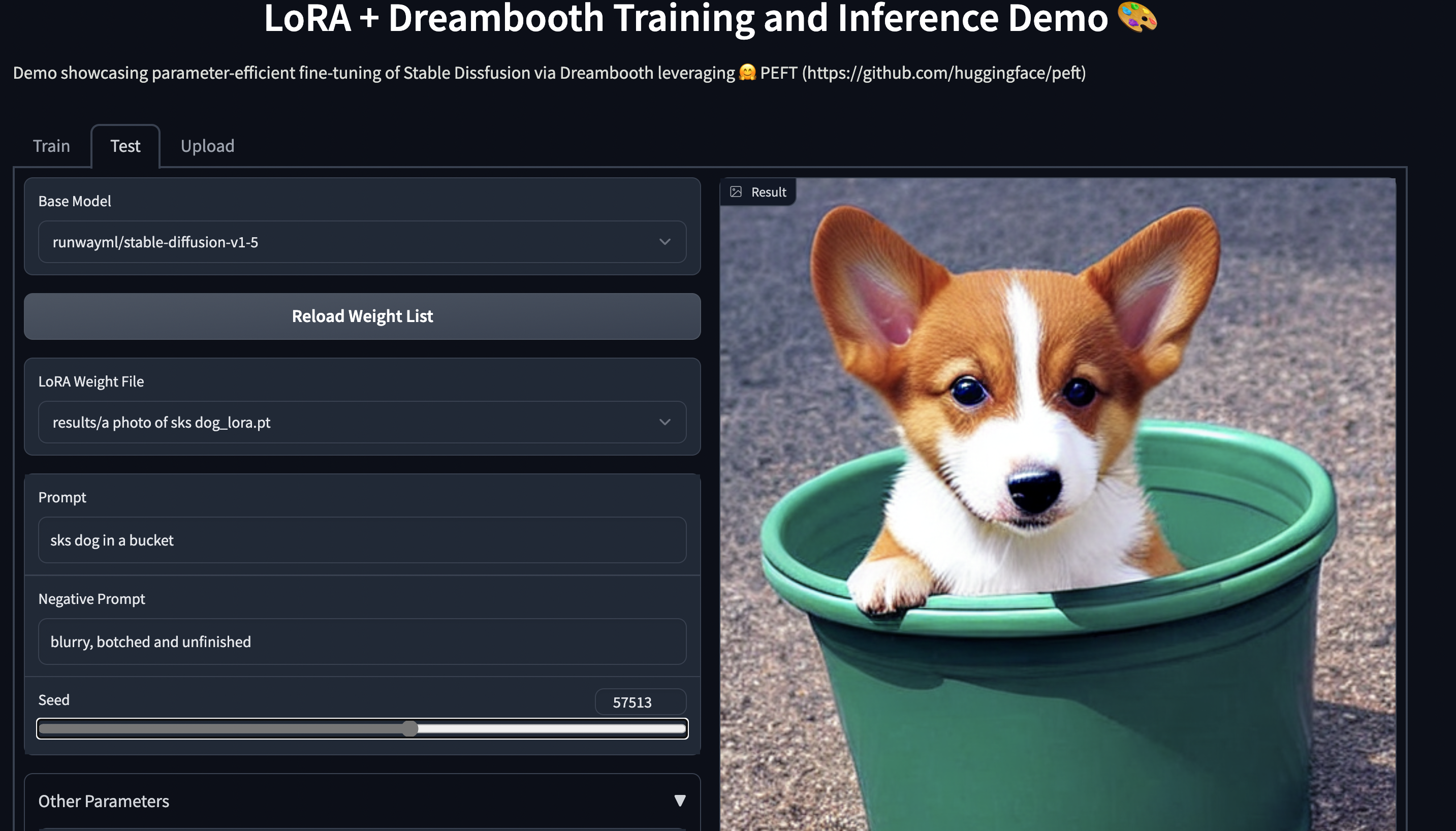
_PEFT LoRA Dreambooth Gradio Space_
## [](https://huggingface.co/blog/peft#training-your-model-using-%F0%9F%A4%97-peft)使用 🤗 PEFT 训练您的模型
让我们考虑使用 LoRA 微调 `bigscience/mt0-large` 的情况。
1. 引进必要的库
```
from transformers import AutoModelForSeq2SeqLM
+ from peft import get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
```
2. 创建PEFT方法对应的配置
```
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)
```
3. 通过调用 `get_peft_model` 包装基础 🤗 Transformer 模型
```
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
+ model = get_peft_model(model, peft_config)
+ model.print_trainable_parameters()
# output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282
```
就是这样!训练循环的其余部分保持不变。有关端到端示例,请参阅示例 [peft\_lora\_seq2seq.ipynb](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq.ipynb)。
4. 当您准备好保存模型以供推理时,只需执行以下操作。
```
model.save_pretrained("output_dir")
# model.push_to_hub("my_awesome_peft_model") also works
```
这只会保存经过训练的增量 PEFT 权重。例如,您可以在此处的 `twitter_complaints` raft 数据集上找到使用 LoRA 调整的 `bigscience/T0_3B` :[smangrul/twitter\_complaints\_bigscience\_T0\_3B\_LORA\_SEQ\_2\_SEQ\_LM](https://huggingface.co/smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM)。请注意,它只包含 2 个文件:adapter\_config.json 和 adapter\_model.bin,后者只有 19MB。
5. 要加载它进行推理,请遵循以下代码片段:
```
from transformers import AutoModelForSeq2SeqLM
+ from peft import PeftModel, PeftConfig
peft_model_id = "smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
+ model = PeftModel.from_pretrained(model, peft_model_id)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = model.to(device)
model.eval()
inputs = tokenizer("Tweet text : @HondaCustSvc Your customer service has been horrible during the recall process. I will never purchase a Honda again. Label :", return_tensors="pt")
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=10)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0])
# 'complaint'
```
## [](https://huggingface.co/blog/peft#next-steps)下一步
我们发布了 PEFT 方法,作为在下游任务和域上调整大型 LLM 的有效方式,节省了大量计算和存储,同时实现与全参数微调相当的性能。在接下来的几个月中,我们将探索更多 PEFT 方法,例如 (IA)3 和瓶颈适配器。此外,我们将关注新的用例,例如 Google Colab 中 [`whisper-large`](https://huggingface.co/openai/whisper-large) 模型的 INT8 训练以及使用 PEFT 方法调整 RLHF 组件(例如策略和排序器)。
与此同时,我们很高兴看到行业从业者如何将 PEFT 应用于他们的用例 - 如果您有任何问题或反馈,请在我们的 [GitHub 仓库](https://github.com/huggingface/peft) 上提出问题 🤗。
快乐的参数高效微调之旅!
> 英文原文: <url> https://huggingface.co/blog/peft </url>
>
> 译者: Ada Cheng |