
Implement acceptance test framework (#99)
Browse files- .github/workflows/ci-cd.yaml +18 -9
- README.md +1 -1
- ancient-greek.yaml +1 -1
- behave.ini +4 -0
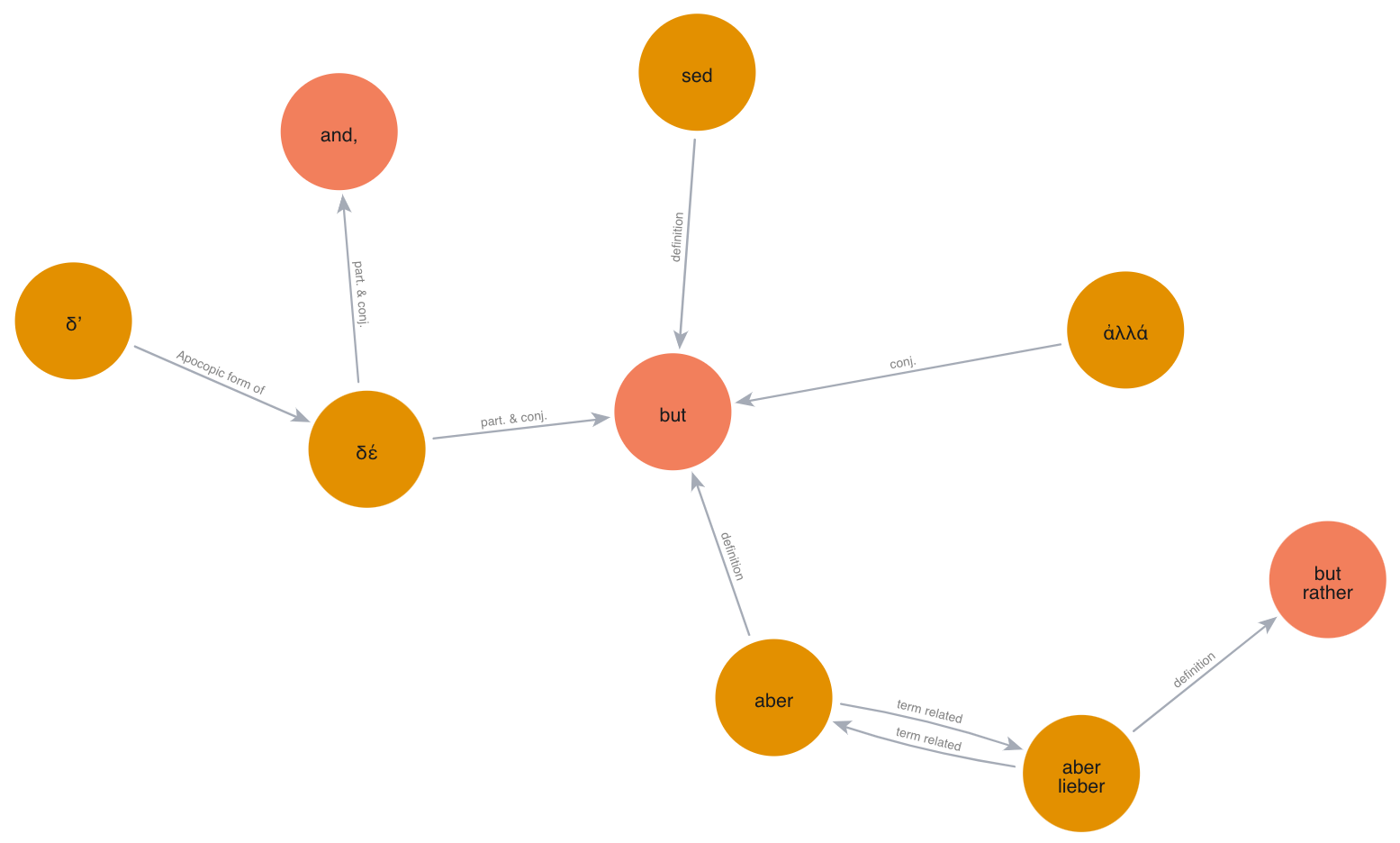
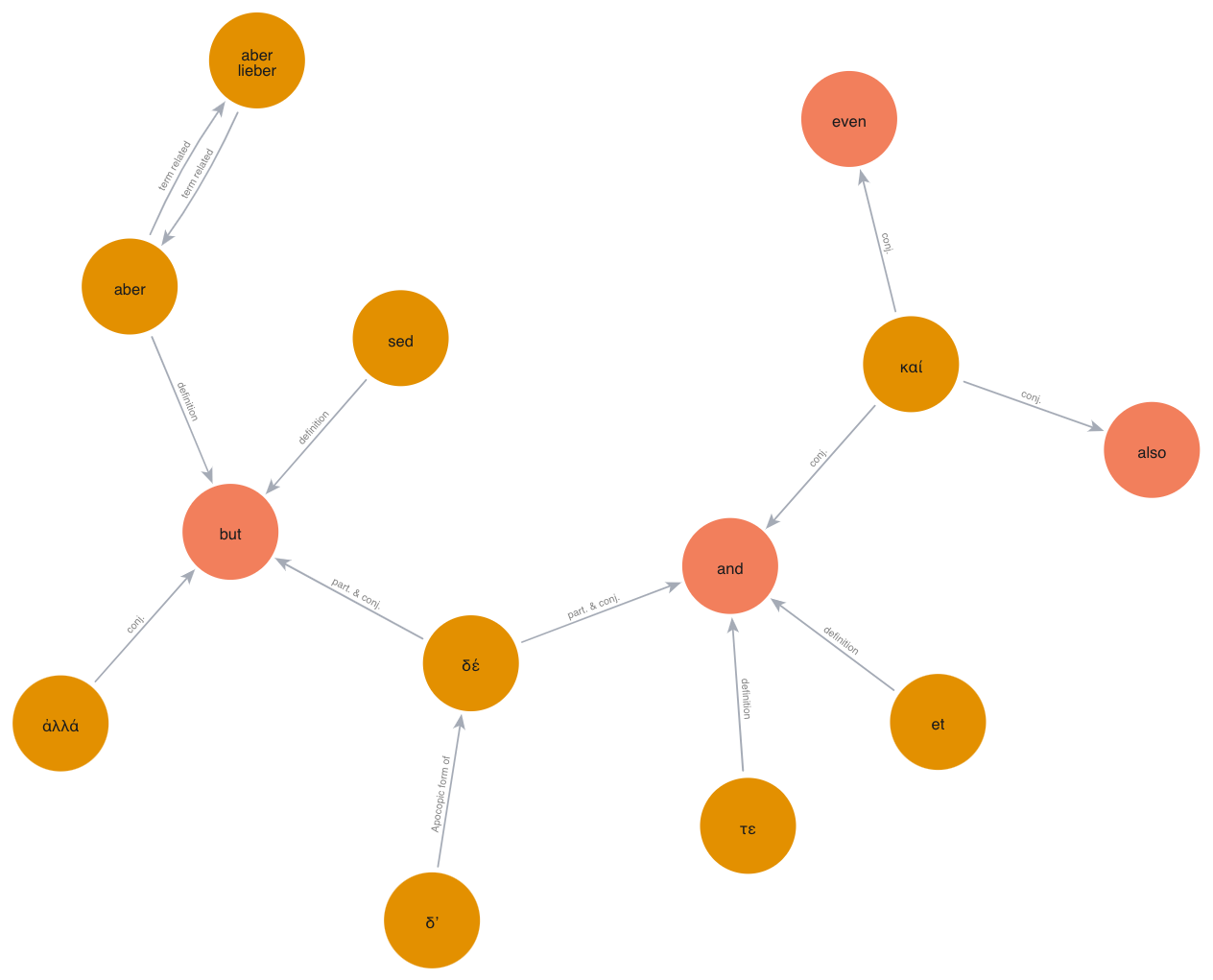
- docs/but.png +0 -0
- features/graphs.feature +18 -0
- features/steps/graphs.py +65 -0
- huggingface/vocabulary_parser.py +5 -5
- requirements.txt +9 -0
- setup.cfg +1 -1
- setup.py +0 -19
.github/workflows/ci-cd.yaml
CHANGED
|
@@ -64,10 +64,12 @@ jobs:
|
|
| 64 |
uses: actions/setup-python@v5
|
| 65 |
with:
|
| 66 |
python-version: ${{ env.PYTHON_VERSION }}
|
| 67 |
-
- name:
|
| 68 |
-
run:
|
| 69 |
- name: Check import orders
|
| 70 |
-
run:
|
|
|
|
|
|
|
| 71 |
|
| 72 |
unit-tests:
|
| 73 |
name: Unit Tests
|
|
@@ -79,11 +81,13 @@ jobs:
|
|
| 79 |
uses: actions/setup-python@v5
|
| 80 |
with:
|
| 81 |
python-version: ${{ env.PYTHON_VERSION }}
|
|
|
|
|
|
|
| 82 |
- name: Run tests
|
| 83 |
-
run: python
|
| 84 |
|
| 85 |
sync-to-huggingface-space:
|
| 86 |
-
needs:
|
| 87 |
runs-on: ubuntu-latest
|
| 88 |
steps:
|
| 89 |
- uses: actions/checkout@v3
|
|
@@ -95,7 +99,7 @@ jobs:
|
|
| 95 |
with:
|
| 96 |
python-version: ${{ env.PYTHON_VERSION }}
|
| 97 |
- name: Install dependencies
|
| 98 |
-
run: pip3 install -
|
| 99 |
- name: Generate Hugging Face Datasets
|
| 100 |
run: |
|
| 101 |
cd huggingface
|
|
@@ -116,8 +120,8 @@ jobs:
|
|
| 116 |
HF_TOKEN: ${{ secrets.HF_TOKEN }}
|
| 117 |
|
| 118 |
docker:
|
| 119 |
-
name: Test Docker Build and Publish Data Image to DockerHub
|
| 120 |
-
needs:
|
| 121 |
runs-on: ubuntu-latest
|
| 122 |
steps:
|
| 123 |
- uses: actions/checkout@v3
|
|
@@ -134,6 +138,7 @@ jobs:
|
|
| 134 |
--publish=7687:7687 \
|
| 135 |
--env=NEO4J_AUTH=none \
|
| 136 |
--env=NEO4J_ACCEPT_LICENSE_AGREEMENT=yes \
|
|
|
|
| 137 |
--name data-loader \
|
| 138 |
neo4j:${{ env.NEO4J_ENTERPRISE_VERSION }} &
|
| 139 |
- name: Wait for database to be ready
|
|
@@ -152,6 +157,10 @@ jobs:
|
|
| 152 |
NEO4J_DATABASE: ${{ env.NEO4J_DATABASE }}
|
| 153 |
NEO4J_USERNAME: ${{ env.NEO4J_USERNAME }}
|
| 154 |
NEO4J_PASSWORD: ${{ env.NEO4J_PASSWORD }}
|
|
|
|
|
|
|
|
|
|
|
|
|
| 155 |
- name: Copy over data onto host
|
| 156 |
run: docker cp data-loader:/data .
|
| 157 |
- name: Test image build
|
|
@@ -183,7 +192,7 @@ jobs:
|
|
| 183 |
|
| 184 |
triggering:
|
| 185 |
name: Triggering data model acceptance tests CI/CD
|
| 186 |
-
needs: [sync-to-huggingface-space]
|
| 187 |
if: github.ref == 'refs/heads/master'
|
| 188 |
runs-on: ubuntu-latest
|
| 189 |
steps:
|
|
|
|
| 64 |
uses: actions/setup-python@v5
|
| 65 |
with:
|
| 66 |
python-version: ${{ env.PYTHON_VERSION }}
|
| 67 |
+
- name: Install dependencies
|
| 68 |
+
run: pip3 install -r requirements.txt
|
| 69 |
- name: Check import orders
|
| 70 |
+
run: isort --check .
|
| 71 |
+
- name: pep8
|
| 72 |
+
run: pycodestyle .
|
| 73 |
|
| 74 |
unit-tests:
|
| 75 |
name: Unit Tests
|
|
|
|
| 81 |
uses: actions/setup-python@v5
|
| 82 |
with:
|
| 83 |
python-version: ${{ env.PYTHON_VERSION }}
|
| 84 |
+
- name: Install dependencies
|
| 85 |
+
run: pip3 install -r requirements.txt
|
| 86 |
- name: Run tests
|
| 87 |
+
run: python -m unittest
|
| 88 |
|
| 89 |
sync-to-huggingface-space:
|
| 90 |
+
needs: unit-tests
|
| 91 |
runs-on: ubuntu-latest
|
| 92 |
steps:
|
| 93 |
- uses: actions/checkout@v3
|
|
|
|
| 99 |
with:
|
| 100 |
python-version: ${{ env.PYTHON_VERSION }}
|
| 101 |
- name: Install dependencies
|
| 102 |
+
run: pip3 install -r requirements.txt
|
| 103 |
- name: Generate Hugging Face Datasets
|
| 104 |
run: |
|
| 105 |
cd huggingface
|
|
|
|
| 120 |
HF_TOKEN: ${{ secrets.HF_TOKEN }}
|
| 121 |
|
| 122 |
docker:
|
| 123 |
+
name: Test Docker Build, Runs Acceptance Tests, and Publish Data Image to DockerHub
|
| 124 |
+
needs: unit-tests
|
| 125 |
runs-on: ubuntu-latest
|
| 126 |
steps:
|
| 127 |
- uses: actions/checkout@v3
|
|
|
|
| 138 |
--publish=7687:7687 \
|
| 139 |
--env=NEO4J_AUTH=none \
|
| 140 |
--env=NEO4J_ACCEPT_LICENSE_AGREEMENT=yes \
|
| 141 |
+
-e NEO4JLABS_PLUGINS=\[\"apoc\"\] \
|
| 142 |
--name data-loader \
|
| 143 |
neo4j:${{ env.NEO4J_ENTERPRISE_VERSION }} &
|
| 144 |
- name: Wait for database to be ready
|
|
|
|
| 157 |
NEO4J_DATABASE: ${{ env.NEO4J_DATABASE }}
|
| 158 |
NEO4J_USERNAME: ${{ env.NEO4J_USERNAME }}
|
| 159 |
NEO4J_PASSWORD: ${{ env.NEO4J_PASSWORD }}
|
| 160 |
+
- name: Install dependencies
|
| 161 |
+
run: pip3 install -r requirements.txt
|
| 162 |
+
- name: Run acceptance tests
|
| 163 |
+
run: behave
|
| 164 |
- name: Copy over data onto host
|
| 165 |
run: docker cp data-loader:/data .
|
| 166 |
- name: Test image build
|
|
|
|
| 192 |
|
| 193 |
triggering:
|
| 194 |
name: Triggering data model acceptance tests CI/CD
|
| 195 |
+
needs: [sync-to-huggingface-space, docker]
|
| 196 |
if: github.ref == 'refs/heads/master'
|
| 197 |
runs-on: ubuntu-latest
|
| 198 |
steps:
|
README.md
CHANGED
|
@@ -146,7 +146,7 @@ We have offered some queries that can be used to quickly explore the vocabulary
|
|
| 146 |
- How German, Latin, and Ancient greek expresses the conjunction "but":
|
| 147 |
|
| 148 |
```cypher
|
| 149 |
-
MATCH (node{label:
|
| 150 |
CALL apoc.path.expand(node, "LINK", null, 1, 4)
|
| 151 |
YIELD path
|
| 152 |
RETURN path, length(path) AS hops
|
|
|
|
| 146 |
- How German, Latin, and Ancient greek expresses the conjunction "but":
|
| 147 |
|
| 148 |
```cypher
|
| 149 |
+
MATCH (node{label:"δέ"})
|
| 150 |
CALL apoc.path.expand(node, "LINK", null, 1, 4)
|
| 151 |
YIELD path
|
| 152 |
RETURN path, length(path) AS hops
|
ancient-greek.yaml
CHANGED
|
@@ -691,7 +691,7 @@ vocabulary:
|
|
| 691 |
definition:
|
| 692 |
- (part. & conj.) and
|
| 693 |
- (part. & conj.) but
|
| 694 |
-
- term:
|
| 695 |
definition: (Apocopic form of) δέ
|
| 696 |
- term: μέν ... δέ
|
| 697 |
definition: on the one hand ... on the other hand (often untranslated)
|
|
|
|
| 691 |
definition:
|
| 692 |
- (part. & conj.) and
|
| 693 |
- (part. & conj.) but
|
| 694 |
+
- term: δ᾽
|
| 695 |
definition: (Apocopic form of) δέ
|
| 696 |
- term: μέν ... δέ
|
| 697 |
definition: on the one hand ... on the other hand (often untranslated)
|
behave.ini
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[behave]
|
| 2 |
+
stdout_capture = no
|
| 3 |
+
stderr_capture = no
|
| 4 |
+
log_capture = no
|
docs/but.png
CHANGED
|
|
features/graphs.feature
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright Jiaqi Liu
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
Feature: Neo4J in Docker shows expected graphs
|
| 15 |
+
|
| 16 |
+
Scenario: "but" linking
|
| 17 |
+
When we expand 'δέ' by 3 hops at most
|
| 18 |
+
Then we get 13 nodes and 13 links, all distinct
|
features/steps/graphs.py
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright Jiaqi Liu
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
from behave import *
|
| 15 |
+
from neo4j import GraphDatabase
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
@when("we expand 'δέ' by 3 hops at most")
|
| 19 |
+
def step_impl(context):
|
| 20 |
+
assert True is not False
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
@then('we get 13 nodes and 13 links, all distinct')
|
| 24 |
+
def step_impl(context):
|
| 25 |
+
driver = GraphDatabase.driver("neo4j://localhost:7687", auth=("not used", "not used"))
|
| 26 |
+
|
| 27 |
+
with driver.session() as session:
|
| 28 |
+
result = parse_apoc_path_expand_result(session.run(
|
| 29 |
+
"""
|
| 30 |
+
MATCH (node{label:"δέ"})
|
| 31 |
+
CALL apoc.path.expand(node, "LINK", null, 1, 3)
|
| 32 |
+
YIELD path
|
| 33 |
+
RETURN path;
|
| 34 |
+
"""
|
| 35 |
+
))
|
| 36 |
+
|
| 37 |
+
assert set(result["nodes"]) == {"aber lieber", "aber", "but", "sed", "ἀλλά", "δέ", "and", "τε", "et", "καί",
|
| 38 |
+
"also", "even", "δ’"}
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def parse_apoc_path_expand_result(result):
|
| 42 |
+
nodes = set()
|
| 43 |
+
links = []
|
| 44 |
+
|
| 45 |
+
nodeMap = dict()
|
| 46 |
+
duplicateLinks = set()
|
| 47 |
+
for record in result:
|
| 48 |
+
path = record["path"]
|
| 49 |
+
|
| 50 |
+
for node in path.nodes:
|
| 51 |
+
label = dict(node)["label"]
|
| 52 |
+
nodes.add(label)
|
| 53 |
+
nodeMap[node.id] = label
|
| 54 |
+
|
| 55 |
+
for link in path.relationships:
|
| 56 |
+
if link.id not in duplicateLinks:
|
| 57 |
+
duplicateLinks.add(link.id)
|
| 58 |
+
|
| 59 |
+
links.append({
|
| 60 |
+
"source": nodeMap[link.start_node.id],
|
| 61 |
+
"target": nodeMap[link.end_node.id],
|
| 62 |
+
"label": dict(link)["label"],
|
| 63 |
+
})
|
| 64 |
+
|
| 65 |
+
return {"nodes": list(nodes), "links": links}
|
huggingface/vocabulary_parser.py
CHANGED
|
@@ -133,7 +133,7 @@ def get_attributes(
|
|
| 133 |
word: object,
|
| 134 |
language: str,
|
| 135 |
node_label_attribute_key: str,
|
| 136 |
-
inflection_supplier: Callable[[object], dict]=lambda word: {}
|
| 137 |
) -> dict[str, str]:
|
| 138 |
"""
|
| 139 |
Returns a flat map as the Term node properties stored in Neo4J.
|
|
@@ -170,7 +170,7 @@ def get_audio(word: object) -> dict:
|
|
| 170 |
def get_inferred_links(
|
| 171 |
vocabulary: list[dict],
|
| 172 |
label_key: str,
|
| 173 |
-
inflection_supplier: Callable[[object], dict[str, str]]=lambda word: {}
|
| 174 |
) -> list[dict]:
|
| 175 |
"""
|
| 176 |
Return a list of inferred links between related vocabularies.
|
|
@@ -217,7 +217,7 @@ def get_term_tokens(word: dict) -> set[str]:
|
|
| 217 |
|
| 218 |
def get_inflection_tokens(
|
| 219 |
word: dict,
|
| 220 |
-
inflection_supplier: Callable[[object], dict[str, str]]=lambda word: {}
|
| 221 |
) -> set[str]:
|
| 222 |
tokens = set()
|
| 223 |
|
|
@@ -230,14 +230,14 @@ def get_inflection_tokens(
|
|
| 230 |
return tokens
|
| 231 |
|
| 232 |
|
| 233 |
-
def get_tokens_of(word: dict, inflection_supplier: Callable[[object], dict[str, str]]=lambda word: {}) -> set[str]:
|
| 234 |
return get_inflection_tokens(word, inflection_supplier) | get_term_tokens(word) | get_definition_tokens(word)
|
| 235 |
|
| 236 |
|
| 237 |
def get_inferred_tokenization_links(
|
| 238 |
vocabulary: list[dict],
|
| 239 |
label_key: str,
|
| 240 |
-
inflection_supplier: Callable[[object], dict[str, str]]=lambda word: {}
|
| 241 |
) -> list[dict]:
|
| 242 |
"""
|
| 243 |
Return a list of inferred links between related vocabulary terms which are related to one another.
|
|
|
|
| 133 |
word: object,
|
| 134 |
language: str,
|
| 135 |
node_label_attribute_key: str,
|
| 136 |
+
inflection_supplier: Callable[[object], dict] = lambda word: {}
|
| 137 |
) -> dict[str, str]:
|
| 138 |
"""
|
| 139 |
Returns a flat map as the Term node properties stored in Neo4J.
|
|
|
|
| 170 |
def get_inferred_links(
|
| 171 |
vocabulary: list[dict],
|
| 172 |
label_key: str,
|
| 173 |
+
inflection_supplier: Callable[[object], dict[str, str]] = lambda word: {}
|
| 174 |
) -> list[dict]:
|
| 175 |
"""
|
| 176 |
Return a list of inferred links between related vocabularies.
|
|
|
|
| 217 |
|
| 218 |
def get_inflection_tokens(
|
| 219 |
word: dict,
|
| 220 |
+
inflection_supplier: Callable[[object], dict[str, str]] = lambda word: {}
|
| 221 |
) -> set[str]:
|
| 222 |
tokens = set()
|
| 223 |
|
|
|
|
| 230 |
return tokens
|
| 231 |
|
| 232 |
|
| 233 |
+
def get_tokens_of(word: dict, inflection_supplier: Callable[[object], dict[str, str]] = lambda word: {}) -> set[str]:
|
| 234 |
return get_inflection_tokens(word, inflection_supplier) | get_term_tokens(word) | get_definition_tokens(word)
|
| 235 |
|
| 236 |
|
| 237 |
def get_inferred_tokenization_links(
|
| 238 |
vocabulary: list[dict],
|
| 239 |
label_key: str,
|
| 240 |
+
inflection_supplier: Callable[[object], dict[str, str]] = lambda word: {}
|
| 241 |
) -> list[dict]:
|
| 242 |
"""
|
| 243 |
Return a list of inferred links between related vocabulary terms which are related to one another.
|
requirements.txt
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
pyyaml
|
| 2 |
+
nltk
|
| 3 |
+
wilhelm_data_loader
|
| 4 |
+
|
| 5 |
+
pycodestyle
|
| 6 |
+
isort
|
| 7 |
+
|
| 8 |
+
behave
|
| 9 |
+
neo4j
|
setup.cfg
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
[pep8]
|
| 2 |
max-line-length = 120
|
| 3 |
-
exclude = ./.eggs
|
|
|
|
| 1 |
[pep8]
|
| 2 |
max-line-length = 120
|
| 3 |
+
exclude = ./.eggs,./build
|
setup.py
DELETED
|
@@ -1,19 +0,0 @@
|
|
| 1 |
-
from setuptools import find_packages
|
| 2 |
-
from setuptools import setup
|
| 3 |
-
|
| 4 |
-
setup(
|
| 5 |
-
name="wilhelm_vocabulary",
|
| 6 |
-
version="0.0.1",
|
| 7 |
-
description="A vocabulary processor specifically designed for QubitPi",
|
| 8 |
-
url="https://github.com/QubitPi/wilhelm-vocabulary",
|
| 9 |
-
author="Jiaqi Liu",
|
| 10 |
-
author_email="[email protected]",
|
| 11 |
-
license="Apache-2.0",
|
| 12 |
-
packages=find_packages(),
|
| 13 |
-
python_requires='>=3.10',
|
| 14 |
-
install_requires=["pyyaml", "nltk", "wilhelm_data_loader"],
|
| 15 |
-
zip_safe=False,
|
| 16 |
-
include_package_data=True,
|
| 17 |
-
setup_requires=["setuptools-pep8", "isort"],
|
| 18 |
-
test_suite='tests',
|
| 19 |
-
)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|