Datasets:

Tasks:
Text Classification
Sub-tasks:
multi-label-classification
Languages:
English
Size:
100K<n<1M
ArXiv:
License:

Update files from the datasets library (from 1.3.0)
Browse filesRelease notes: https://github.com/huggingface/datasets/releases/tag/1.3.0
- README.md +116 -142
- dataset_infos.json +1 -1
- dummy/0.0.0/dummy_data.zip +2 -2
- swda.py +677 -77
README.md
CHANGED
|
@@ -43,11 +43,12 @@ task_ids:
|
|
| 43 |
- [Dataset Curators](#dataset-curators)
|
| 44 |
- [Licensing Information](#licensing-information)
|
| 45 |
- [Citation Information](#citation-information)
|
|
|
|
| 46 |
|
| 47 |
## Dataset Description
|
| 48 |
|
| 49 |
- **Homepage: [The Switchboard Dialog Act Corpus](http://compprag.christopherpotts.net/swda.html)**
|
| 50 |
-
- **Repository: [NathanDuran/Switchboard-Corpus](https://github.com/
|
| 51 |
- **Paper:[The Switchboard Dialog Act Corpus](http://compprag.christopherpotts.net/swda.html)**
|
| 52 |
= **Leaderboard: [Dialogue act classification](https://github.com/sebastianruder/NLP-progress/blob/master/english/dialogue.md#dialogue-act-classification)**
|
| 53 |
- **Point of Contact: [Christopher Potts](https://web.stanford.edu/~cgpotts/)**
|
|
@@ -87,118 +88,100 @@ Utterance are tagged with the [SWBD-DAMSL](https://web.stanford.edu/~jurafsky/ws
|
|
| 87 |
|
| 88 |
An example from the dataset is:
|
| 89 |
|
| 90 |
-
`{'
|
| 91 |
-
|
| 92 |
-
where 17 correspond to `fo_o_fw_"_by_bc` (Other)
|
| 93 |
|
| 94 |
### Data Fields
|
| 95 |
-
|
| 96 |
-
|
| 97 |
-
|
| 98 |
-
`
|
| 99 |
-
|
| 100 |
-
`
|
| 101 |
-
|
| 102 |
-
|
| 103 |
-
|
| 104 |
-
|
| 105 |
-
|
| 106 |
-
|
| 107 |
-
|
| 108 |
-
|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
|
| 116 |
-
|
| 117 |
-
|
| 118 |
-
|
| 119 |
-
|
| 120 |
-
|
| 121 |
-
|
| 122 |
-
|
| 123 |
-
|
| 124 |
-
|
| 125 |
-
|
| 126 |
-
|
| 127 |
-
|
| 128 |
-
|
|
| 129 |
-
|
|
| 130 |
-
|
|
| 131 |
-
|
|
| 132 |
-
|
|
| 133 |
-
|
|
| 134 |
-
|
|
| 135 |
-
|
|
| 136 |
-
|
|
| 137 |
-
|
|
| 138 |
-
|
|
| 139 |
-
|
|
| 140 |
-
|
|
| 141 |
-
|
|
| 142 |
-
|
|
| 143 |
-
|
|
| 144 |
-
|
|
| 145 |
-
|
|
| 146 |
-
|
|
| 147 |
-
|
|
| 148 |
-
|
| 149 |
-
|
| 150 |
-
|
| 151 |
-
|
| 152 |
-
|
|
| 153 |
-
|
| 154 |
-
|
| 155 |
-
|
| 156 |
-
|
| 157 |
-
|
| 158 |
-
|
| 159 |
-
|
| 160 |
-
|
| 161 |
-
|
| 162 |
-
|
| 163 |
-
|
| 164 |
-
|
| 165 |
-
|
| 166 |
-
|
| 167 |
-
|
| 168 |
-
|
| 169 |
-
|
| 170 |
-
|
| 171 |
-
|
| 172 |
-
|
| 173 |
-
Action-directive | ad | 745 | 0.37 | 712 | 0.37 | 27 | 0.66 | 6 | 0.18
|
| 174 |
-
Collaborative Completion | ^2 | 723 | 0.36 | 690 | 0.36 | 19 | 0.47 | 14 | 0.43
|
| 175 |
-
Repeat-phrase | b^m | 687 | 0.34 | 655 | 0.34 | 21 | 0.51 | 11 | 0.34
|
| 176 |
-
Open-Question | qo | 656 | 0.33 | 631 | 0.33 | 16 | 0.39 | 9 | 0.28
|
| 177 |
-
Rhetorical-Question | qh | 575 | 0.29 | 554 | 0.29 | 12 | 0.29 | 9 | 0.28
|
| 178 |
-
Hold Before Answer/Agreement | ^h | 556 | 0.28 | 539 | 0.28 | 7 | 0.17 | 10 | 0.31
|
| 179 |
-
Reject | ar | 344 | 0.17 | 337 | 0.18 | 3 | 0.07 | 4 | 0.12
|
| 180 |
-
Negative Non-no Answers | ng | 302 | 0.15 | 290 | 0.15 | 6 | 0.15 | 6 | 0.18
|
| 181 |
-
Signal-non-understanding | br | 298 | 0.15 | 286 | 0.15 | 9 | 0.22 | 3 | 0.09
|
| 182 |
-
Other Answers | no | 284 | 0.14 | 277 | 0.14 | 6 | 0.15 | 1 | 0.03
|
| 183 |
-
Conventional-opening | fp | 225 | 0.11 | 220 | 0.11 | 5 | 0.12 | 0 | 0.00
|
| 184 |
-
Or-Clause | qrr | 209 | 0.10 | 206 | 0.11 | 2 | 0.05 | 1 | 0.03
|
| 185 |
-
Dispreferred Answers | arp_nd | 207 | 0.10 | 204 | 0.11 | 3 | 0.07 | 0 | 0.00
|
| 186 |
-
3rd-party-talk | t3 | 117 | 0.06 | 115 | 0.06 | 0 | 0.00 | 2 | 0.06
|
| 187 |
-
Offers, Options Commits | oo_co_cc | 110 | 0.06 | 109 | 0.06 | 0 | 0.00 | 1 | 0.03
|
| 188 |
-
Maybe/Accept-part | aap_am | 104 | 0.05 | 97 | 0.05 | 7 | 0.17 | 0 | 0.00
|
| 189 |
-
Downplayer | t1 | 103 | 0.05 | 102 | 0.05 | 1 | 0.02 | 0 | 0.00
|
| 190 |
-
Self-talk | bd | 103 | 0.05 | 100 | 0.05 | 1 | 0.02 | 2 | 0.06
|
| 191 |
-
Tag-Question | ^g | 92 | 0.05 | 92 | 0.05 | 0 | 0.00 | 0 | 0.00
|
| 192 |
-
Declarative Wh-Question | qw^d | 80 | 0.04 | 79 | 0.04 | 1 | 0.02 | 0 | 0.00
|
| 193 |
-
Apology | fa | 79 | 0.04 | 76 | 0.04 | 2 | 0.05 | 1 | 0.03
|
| 194 |
-
Thanking | ft | 78 | 0.04 | 67 | 0.03 | 7 | 0.17 | 4 | 0.12
|
| 195 |
-
|
| 196 |
-
|
| 197 |
-
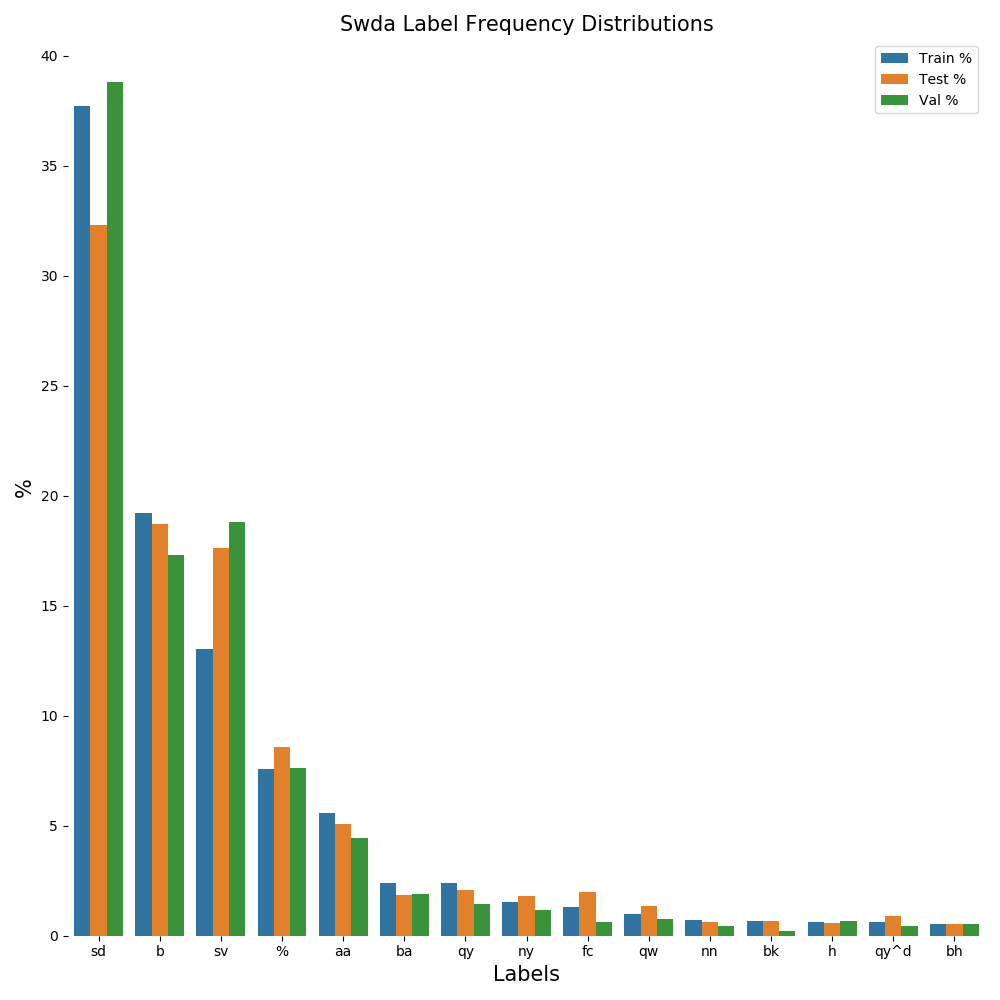
|
| 198 |
|
| 199 |
### Data Splits
|
| 200 |
|
| 201 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 202 |
|
| 203 |
## Dataset Creation
|
| 204 |
|
|
@@ -210,20 +193,7 @@ he data is split into the original training and test sets suggested by the autho
|
|
| 210 |
|
| 211 |
#### Initial Data Collection and Normalization
|
| 212 |
|
| 213 |
-
|
| 214 |
-
- Maximum utterance length: 133
|
| 215 |
-
- Mean utterance length: 9.6
|
| 216 |
-
- Total number of dialogues: 1155
|
| 217 |
-
- Maximum dialogue length: 457
|
| 218 |
-
- Mean dialogue length: 172.9
|
| 219 |
-
- Vocabulary size: 22301
|
| 220 |
-
- Number of labels: 41
|
| 221 |
-
- Number of dialogue in train set: 1115
|
| 222 |
-
- Maximum length of dialogue in train set: 457
|
| 223 |
-
- Number of dialogue in test set: 19
|
| 224 |
-
- Maximum length of dialogue in test set: 330
|
| 225 |
-
- Number of dialogue in val set: 21
|
| 226 |
-
- Maximum length of dialogue in val set: 299
|
| 227 |
|
| 228 |
#### Who are the source language producers?
|
| 229 |
|
|
@@ -271,28 +241,32 @@ This work is licensed under a [Creative Commons Attribution-NonCommercial-ShareA
|
|
| 271 |
|
| 272 |
```
|
| 273 |
@techreport{Jurafsky-etal:1997,
|
| 274 |
-
|
| 275 |
-
|
| 276 |
-
|
| 277 |
-
|
| 278 |
-
|
| 279 |
-
|
| 280 |
|
| 281 |
@article{Shriberg-etal:1998,
|
| 282 |
-
|
| 283 |
-
|
| 284 |
-
|
| 285 |
-
|
| 286 |
-
|
| 287 |
-
|
| 288 |
-
|
| 289 |
|
| 290 |
@article{Stolcke-etal:2000,
|
| 291 |
-
|
| 292 |
-
|
| 293 |
-
|
| 294 |
-
|
| 295 |
-
|
| 296 |
-
|
| 297 |
-
|
| 298 |
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 43 |
- [Dataset Curators](#dataset-curators)
|
| 44 |
- [Licensing Information](#licensing-information)
|
| 45 |
- [Citation Information](#citation-information)
|
| 46 |
+
- [Contributions](#contributions)
|
| 47 |
|
| 48 |
## Dataset Description
|
| 49 |
|
| 50 |
- **Homepage: [The Switchboard Dialog Act Corpus](http://compprag.christopherpotts.net/swda.html)**
|
| 51 |
+
- **Repository: [NathanDuran/Switchboard-Corpus](https://github.com/cgpotts/swda)**
|
| 52 |
- **Paper:[The Switchboard Dialog Act Corpus](http://compprag.christopherpotts.net/swda.html)**
|
| 53 |
= **Leaderboard: [Dialogue act classification](https://github.com/sebastianruder/NLP-progress/blob/master/english/dialogue.md#dialogue-act-classification)**
|
| 54 |
- **Point of Contact: [Christopher Potts](https://web.stanford.edu/~cgpotts/)**
|
|
|
|
| 88 |
|
| 89 |
An example from the dataset is:
|
| 90 |
|
| 91 |
+
`{'act_tag': 115, 'caller': 'A', 'conversation_no': 4325, 'damsl_act_tag': 26, 'from_caller': 1632, 'from_caller_birth_year': 1962, 'from_caller_dialect_area': 'WESTERN', 'from_caller_education': 2, 'from_caller_sex': 'FEMALE', 'length': 5, 'pos': 'Okay/UH ./.', 'prompt': 'FIND OUT WHAT CRITERIA THE OTHER CALLER WOULD USE IN SELECTING CHILD CARE SERVICES FOR A PRESCHOOLER. IS IT EASY OR DIFFICULT TO FIND SUCH CARE?', 'ptb_basename': '4/sw4325', 'ptb_treenumbers': '1', 'subutterance_index': 1, 'swda_filename': 'sw00utt/sw_0001_4325.utt', 'talk_day': '03/23/1992', 'text': 'Okay. /', 'to_caller': 1519, 'to_caller_birth_year': 1971, 'to_caller_dialect_area': 'SOUTH MIDLAND', 'to_caller_education': 1, 'to_caller_sex': 'FEMALE', 'topic_description': 'CHILD CARE', 'transcript_index': 0, 'trees': '(INTJ (UH Okay) (. .) (-DFL- E_S))', 'utterance_index': 1}`
|
|
|
|
|
|
|
| 92 |
|
| 93 |
### Data Fields
|
| 94 |
+
|
| 95 |
+
* `swda_filename`: (str) The filename: directory/basename.
|
| 96 |
+
* `ptb_basename`: (str) The Treebank filename: add ".pos" for POS and ".mrg" for trees
|
| 97 |
+
* `conversation_no`: (int) The conversation Id, to key into the metadata database.
|
| 98 |
+
* `transcript_index`: (int) The line number of this item in the transcript (counting only utt lines).
|
| 99 |
+
* `act_tag`: (list of str) The Dialog Act Tags (separated by ||| in the file). Check Dialog act annotations for more details.
|
| 100 |
+
* `damsl_act_tag`: (list of str) The Dialog Act Tags of the 217 variation tags.
|
| 101 |
+
* `caller`: (str) A, B, @A, @B, @@A, @@B
|
| 102 |
+
* `utterance_index`: (int) The encoded index of the utterance (the number in A.49, B.27, etc.)
|
| 103 |
+
* `subutterance_index`: (int) Utterances can be broken across line. This gives the internal position.
|
| 104 |
+
* `text`: (str) The text of the utterance
|
| 105 |
+
* `pos`: (str) The POS tagged version of the utterance, from PtbBasename+.pos
|
| 106 |
+
* `trees`: (str) The tree(s) containing this utterance (separated by ||| in the file). Use `[Tree.fromstring(t) for t in row_value.split("|||")]` to convert to (list of nltk.tree.Tree).
|
| 107 |
+
* `ptb_treenumbers`: (list of int) The tree numbers in the PtbBasename+.mrg
|
| 108 |
+
* `talk_day`: (str) Date of talk.
|
| 109 |
+
* `length`: (int) Length of talk in seconds.
|
| 110 |
+
* `topic_description`: (str) Short description of topic that's being discussed.
|
| 111 |
+
* `prompt`: (str) Long decription/query/instruction.
|
| 112 |
+
* `from_caller`: (int) The numerical Id of the from (A) caller.
|
| 113 |
+
* `from_caller_sex`: (str) MALE, FEMALE.
|
| 114 |
+
* `from_caller_education`: (int) Called education level 0, 1, 2, 3, 9.
|
| 115 |
+
* `from_caller_birth_year`: (int) Caller birth year YYYY.
|
| 116 |
+
* `from_caller_dialect_area`: (str) MIXED, NEW ENGLAND, NORTH MIDLAND, NORTHERN, NYC, SOUTH MIDLAND, SOUTHERN, UNK, WESTERN.
|
| 117 |
+
* `to_caller`: (int) The numerical Id of the to (B) caller.
|
| 118 |
+
* `to_caller_sex`: (str) MALE, FEMALE.
|
| 119 |
+
* `to_caller_education`: (int) Called education level 0, 1, 2, 3, 9.
|
| 120 |
+
* `to_caller_birth_year`: (int) Caller birth year YYYY.
|
| 121 |
+
* `to_caller_dialect_area`: (str) MIXED, NEW ENGLAND, NORTH MIDLAND, NORTHERN, NYC, SOUTH MIDLAND, SOUTHERN, UNK, WESTERN.
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
### Dialog act annotations
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
| | name | act_tag | example | train_count | full_count |
|
| 128 |
+
|----- |------------------------------- |---------------- |-------------------------------------------------- |------------- |------------ |
|
| 129 |
+
| 1 | Statement-non-opinion | sd | Me, I'm in the legal department. | 72824 | 75145 |
|
| 130 |
+
| 2 | Acknowledge (Backchannel) | b | Uh-huh. | 37096 | 38298 |
|
| 131 |
+
| 3 | Statement-opinion | sv | I think it's great | 25197 | 26428 |
|
| 132 |
+
| 4 | Agree/Accept | aa | That's exactly it. | 10820 | 11133 |
|
| 133 |
+
| 5 | Abandoned or Turn-Exit | % | So, - | 10569 | 15550 |
|
| 134 |
+
| 6 | Appreciation | ba | I can imagine. | 4633 | 4765 |
|
| 135 |
+
| 7 | Yes-No-Question | qy | Do you have to have any special training? | 4624 | 4727 |
|
| 136 |
+
| 8 | Non-verbal | x | [Laughter], [Throat_clearing] | 3548 | 3630 |
|
| 137 |
+
| 9 | Yes answers | ny | Yes. | 2934 | 3034 |
|
| 138 |
+
| 10 | Conventional-closing | fc | Well, it's been nice talking to you. | 2486 | 2582 |
|
| 139 |
+
| 11 | Uninterpretable | % | But, uh, yeah | 2158 | 15550 |
|
| 140 |
+
| 12 | Wh-Question | qw | Well, how old are you? | 1911 | 1979 |
|
| 141 |
+
| 13 | No answers | nn | No. | 1340 | 1377 |
|
| 142 |
+
| 14 | Response Acknowledgement | bk | Oh, okay. | 1277 | 1306 |
|
| 143 |
+
| 15 | Hedge | h | I don't know if I'm making any sense or not. | 1182 | 1226 |
|
| 144 |
+
| 16 | Declarative Yes-No-Question | qy^d | So you can afford to get a house? | 1174 | 1219 |
|
| 145 |
+
| 17 | Other | fo_o_fw_by_bc | Well give me a break, you know. | 1074 | 883 |
|
| 146 |
+
| 18 | Backchannel in question form | bh | Is that right? | 1019 | 1053 |
|
| 147 |
+
| 19 | Quotation | ^q | You can't be pregnant and have cats | 934 | 983 |
|
| 148 |
+
| 20 | Summarize/reformulate | bf | Oh, you mean you switched schools for the kids. | 919 | 952 |
|
| 149 |
+
| 21 | Affirmative non-yes answers | na | It is. | 836 | 847 |
|
| 150 |
+
| 22 | Action-directive | ad | Why don't you go first | 719 | 746 |
|
| 151 |
+
| 23 | Collaborative Completion | ^2 | Who aren't contributing. | 699 | 723 |
|
| 152 |
+
| 24 | Repeat-phrase | b^m | Oh, fajitas | 660 | 688 |
|
| 153 |
+
| 25 | Open-Question | qo | How about you? | 632 | 656 |
|
| 154 |
+
| 26 | Rhetorical-Questions | qh | Who would steal a newspaper? | 557 | 575 |
|
| 155 |
+
| 27 | Hold before answer/agreement | ^h | I'm drawing a blank. | 540 | 556 |
|
| 156 |
+
| 28 | Reject | ar | Well, no | 338 | 346 |
|
| 157 |
+
| 29 | Negative non-no answers | ng | Uh, not a whole lot. | 292 | 302 |
|
| 158 |
+
| 30 | Signal-non-understanding | br | Excuse me? | 288 | 298 |
|
| 159 |
+
| 31 | Other answers | no | I don't know | 279 | 286 |
|
| 160 |
+
| 32 | Conventional-opening | fp | How are you? | 220 | 225 |
|
| 161 |
+
| 33 | Or-Clause | qrr | or is it more of a company? | 207 | 209 |
|
| 162 |
+
| 34 | Dispreferred answers | arp_nd | Well, not so much that. | 205 | 207 |
|
| 163 |
+
| 35 | 3rd-party-talk | t3 | My goodness, Diane, get down from there. | 115 | 117 |
|
| 164 |
+
| 36 | Offers, Options, Commits | oo_co_cc | I'll have to check that out | 109 | 110 |
|
| 165 |
+
| 37 | Self-talk | t1 | What's the word I'm looking for | 102 | 103 |
|
| 166 |
+
| 38 | Downplayer | bd | That's all right. | 100 | 103 |
|
| 167 |
+
| 39 | Maybe/Accept-part | aap_am | Something like that | 98 | 105 |
|
| 168 |
+
| 40 | Tag-Question | ^g | Right? | 93 | 92 |
|
| 169 |
+
| 41 | Declarative Wh-Question | qw^d | You are what kind of buff? | 80 | 80 |
|
| 170 |
+
| 42 | Apology | fa | I'm sorry. | 76 | 79 |
|
| 171 |
+
| 43 | Thanking | ft | Hey thanks a lot | 67 | 78 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 172 |
|
| 173 |
### Data Splits
|
| 174 |
|
| 175 |
+
I used info from the [Probabilistic-RNN-DA-Classifier](https://github.com/NathanDuran/Probabilistic-RNN-DA-Classifier) repo:
|
| 176 |
+
The same training and test splits as used by [Stolcke et al. (2000)](https://web.stanford.edu/~jurafsky/ws97).
|
| 177 |
+
The development set is a subset of the training set to speed up development and testing used in the paper [Probabilistic Word Association for Dialogue Act Classification with Recurrent Neural Networks](https://www.researchgate.net/publication/326640934_Probabilistic_Word_Association_for_Dialogue_Act_Classification_with_Recurrent_Neural_Networks_19th_International_Conference_EANN_2018_Bristol_UK_September_3-5_2018_Proceedings).
|
| 178 |
+
|
| 179 |
+
|Dataset |# Transcripts |# Utterances |
|
| 180 |
+
|-----------|:-------------:|:-------------:|
|
| 181 |
+
|Training |1115 |192,768 |
|
| 182 |
+
|Validation |21 |3,196 |
|
| 183 |
+
|Test |19 |4,088 |
|
| 184 |
+
|
| 185 |
|
| 186 |
## Dataset Creation
|
| 187 |
|
|
|
|
| 193 |
|
| 194 |
#### Initial Data Collection and Normalization
|
| 195 |
|
| 196 |
+
The SwDA is not inherently linked to the Penn Treebank 3 parses of Switchboard, and it is far from straightforward to align the two resources Calhoun et al. 2010, §2.4. In addition, the SwDA is not distributed with the Switchboard's tables of metadata about the conversations and their participants.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 197 |
|
| 198 |
#### Who are the source language producers?
|
| 199 |
|
|
|
|
| 241 |
|
| 242 |
```
|
| 243 |
@techreport{Jurafsky-etal:1997,
|
| 244 |
+
Address = {Boulder, CO},
|
| 245 |
+
Author = {Jurafsky, Daniel and Shriberg, Elizabeth and Biasca, Debra},
|
| 246 |
+
Institution = {University of Colorado, Boulder Institute of Cognitive Science},
|
| 247 |
+
Number = {97-02},
|
| 248 |
+
Title = {Switchboard {SWBD}-{DAMSL} Shallow-Discourse-Function Annotation Coders Manual, Draft 13},
|
| 249 |
+
Year = {1997}}
|
| 250 |
|
| 251 |
@article{Shriberg-etal:1998,
|
| 252 |
+
Author = {Shriberg, Elizabeth and Bates, Rebecca and Taylor, Paul and Stolcke, Andreas and Jurafsky, Daniel and Ries, Klaus and Coccaro, Noah and Martin, Rachel and Meteer, Marie and Van Ess-Dykema, Carol},
|
| 253 |
+
Journal = {Language and Speech},
|
| 254 |
+
Number = {3--4},
|
| 255 |
+
Pages = {439--487},
|
| 256 |
+
Title = {Can Prosody Aid the Automatic Classification of Dialog Acts in Conversational Speech?},
|
| 257 |
+
Volume = {41},
|
| 258 |
+
Year = {1998}}
|
| 259 |
|
| 260 |
@article{Stolcke-etal:2000,
|
| 261 |
+
Author = {Stolcke, Andreas and Ries, Klaus and Coccaro, Noah and Shriberg, Elizabeth and Bates, Rebecca and Jurafsky, Daniel and Taylor, Paul and Martin, Rachel and Meteer, Marie and Van Ess-Dykema, Carol},
|
| 262 |
+
Journal = {Computational Linguistics},
|
| 263 |
+
Number = {3},
|
| 264 |
+
Pages = {339--371},
|
| 265 |
+
Title = {Dialogue Act Modeling for Automatic Tagging and Recognition of Conversational Speech},
|
| 266 |
+
Volume = {26},
|
| 267 |
+
Year = {2000}}
|
| 268 |
```
|
| 269 |
+
|
| 270 |
+
### Contributions
|
| 271 |
+
|
| 272 |
+
Thanks to [@gmihaila](https://github.com/gmihaila) for adding this dataset.
|
dataset_infos.json
CHANGED
|
@@ -1 +1 @@
|
|
| 1 |
-
{"default": {"description": "The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2 with\nturn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information about the\nassociated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.\nThe SwDA is not inherently linked to the Penn Treebank 3 parses of Switchboard, and it is far from straightforward to\nalign the two resources. In addition, the SwDA is not distributed with the Switchboard's tables of metadata about the\nconversations and their participants.\n", "citation": "@techreport{Jurafsky-etal:1997,\n Address = {Boulder, CO},\n Author = {Jurafsky, Daniel and Shriberg, Elizabeth and Biasca, Debra},\n Institution = {University of Colorado, Boulder Institute of Cognitive Science},\n Number = {97-02},\n Title = {Switchboard {SWBD}-{DAMSL} Shallow-Discourse-Function Annotation Coders Manual, Draft 13},\n Year = {1997}}\n\n@article{Shriberg-etal:1998,\n Author = {Shriberg, Elizabeth and Bates, Rebecca and Taylor, Paul and Stolcke, Andreas and Jurafsky,
|
|
|
|
| 1 |
+
{"default": {"description": "The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2 with\nturn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information about the\nassociated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.\nThe SwDA is not inherently linked to the Penn Treebank 3 parses of Switchboard, and it is far from straightforward to\nalign the two resources. In addition, the SwDA is not distributed with the Switchboard's tables of metadata about the\nconversations and their participants.\n", "citation": "@techreport{Jurafsky-etal:1997,\n Address = {Boulder, CO},\n Author = {Jurafsky, Daniel and Shriberg, Elizabeth and Biasca, Debra},\n Institution = {University of Colorado, Boulder Institute of Cognitive Science},\n Number = {97-02},\n Title = {Switchboard {SWBD}-{DAMSL} Shallow-Discourse-Function Annotation Coders Manual, Draft 13},\n Year = {1997}}\n\n@article{Shriberg-etal:1998,\n Author = {Shriberg, Elizabeth and Bates, Rebecca and Taylor, Paul and Stolcke, Andreas and Jurafsky, Daniel and Ries, Klaus and Coccaro, Noah and Martin, Rachel and Meteer, Marie and Van Ess-Dykema, Carol},\n Journal = {Language and Speech},\n Number = {3--4},\n Pages = {439--487},\n Title = {Can Prosody Aid the Automatic Classification of Dialog Acts in Conversational Speech?},\n Volume = {41},\n Year = {1998}}\n\n@article{Stolcke-etal:2000,\n Author = {Stolcke, Andreas and Ries, Klaus and Coccaro, Noah and Shriberg, Elizabeth and Bates, Rebecca and Jurafsky, Daniel and Taylor, Paul and Martin, Rachel and Meteer, Marie and Van Ess-Dykema, Carol},\n Journal = {Computational Linguistics},\n Number = {3},\n Pages = {339--371},\n Title = {Dialogue Act Modeling for Automatic Tagging and Recognition of Conversational Speech},\n Volume = {26},\n Year = {2000}}\n", "homepage": "http://compprag.christopherpotts.net/swda.html", "license": "Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License", "features": {"swda_filename": {"dtype": "string", "id": null, "_type": "Value"}, "ptb_basename": {"dtype": "string", "id": null, "_type": "Value"}, "conversation_no": {"dtype": "int64", "id": null, "_type": "Value"}, "transcript_index": {"dtype": "int64", "id": null, "_type": "Value"}, "act_tag": {"num_classes": 217, "names": ["b^m^r", "qw^r^t", "aa^h", "br^m", "fa^r", "aa,ar", "sd^e(^q)^r", "^2", "sd;qy^d", "oo", "bk^m", "aa^t", "cc^t", "qy^d^c", "qo^t", "ng^m", "qw^h", "qo^r", "aa", "qy^d^t", "qrr^d", "br^r", "fx", "sd,qy^g", "ny^e", "^h^t", "fc^m", "qw(^q)", "co", "o^t", "b^m^t", "qr^d", "qw^g", "ad(^q)", "qy(^q)", "na^r", "am^r", "qr^t", "ad^c", "qw^c", "bh^r", "h^t", "ft^m", "ba^r", "qw^d^t", "%", "t3", "nn", "bd", "h^m", "h^r", "sd^r", "qh^m", "^q^t", "sv^2", "ft", "ar^m", "qy^h", "sd^e^m", "qh^r", "cc", "fp^m", "ad", "qo", "na^m^t", "fo^c", "qy", "sv^e^r", "aap", "no", "aa^2", "sv(^q)", "sv^e", "nd", "\"", "bf^2", "bk", "fp", "nn^r^t", "fa^c", "ny^t", "ny^c^r", "qw", "qy^t", "b", "fo", "qw^r", "am", "bf^t", "^2^t", "b^2", "x", "fc", "qr", "no^t", "bk^t", "bd^r", "bf", "^2^g", "qh^c", "ny^c", "sd^e^r", "br", "fe", "by", "^2^r", "fc^r", "b^m", "sd,sv", "fa^t", "sv^m", "qrr", "^h^r", "na", "fp^r", "o", "h,sd", "t1^t", "nn^r", "cc^r", "sv^c", "co^t", "qy^r", "sv^r", "qy^d^h", "sd", "nn^e", "ny^r", "b^t", "ba^m", "ar", "bf^r", "sv", "bh^m", "qy^g^t", "qo^d^c", "qo^d", "nd^t", "aa^r", "sd^2", "sv;sd", "qy^c^r", "qw^m", "qy^g^r", "no^r", "qh(^q)", "sd;sv", "bf(^q)", "+", "qy^2", "qw^d", "qy^g", "qh^g", "nn^t", "ad^r", "oo^t", "co^c", "ng", "^q", "qw^d^c", "qrr^t", "^h", "aap^r", "bc^r", "sd^m", "bk^r", "qy^g^c", "qr(^q)", "ng^t", "arp", "h", "bh", "sd^c", "^g", "o^r", "qy^c", "sd^e", "fw", "ar^r", "qy^m", "bc", "sv^t", "aap^m", "sd;no", "ng^r", "bf^g", "sd^e^t", "o^c", "b^r", "b^m^g", "ba", "t1", "qy^d(^q)", "nn^m", "ny", "ba,fe", "aa^m", "qh", "na^m", "oo(^q)", "qw^t", "na^t", "qh^h", "qy^d^m", "ny^m", "fa", "qy^d", "fc^t", "sd(^q)", "qy^d^r", "bf^m", "sd(^q)^t", "ft^t", "^q^r", "sd^t", "sd(^q)^r", "ad^t"], "names_file": null, "id": null, "_type": "ClassLabel"}, "damsl_act_tag": {"num_classes": 43, "names": ["ad", "qo", "qy", "arp_nd", "sd", "h", "bh", "no", "^2", "^g", "ar", "aa", "sv", "bk", "fp", "qw", "b", "ba", "t1", "oo_co_cc", "+", "ny", "qw^d", "x", "qh", "fc", "fo_o_fw_\"_by_bc", "aap_am", "%", "bf", "t3", "nn", "bd", "ng", "^q", "br", "qy^d", "fa", "^h", "b^m", "ft", "qrr", "na"], "names_file": null, "id": null, "_type": "ClassLabel"}, "caller": {"dtype": "string", "id": null, "_type": "Value"}, "utterance_index": {"dtype": "int64", "id": null, "_type": "Value"}, "subutterance_index": {"dtype": "int64", "id": null, "_type": "Value"}, "text": {"dtype": "string", "id": null, "_type": "Value"}, "pos": {"dtype": "string", "id": null, "_type": "Value"}, "trees": {"dtype": "string", "id": null, "_type": "Value"}, "ptb_treenumbers": {"dtype": "string", "id": null, "_type": "Value"}, "talk_day": {"dtype": "string", "id": null, "_type": "Value"}, "length": {"dtype": "int64", "id": null, "_type": "Value"}, "topic_description": {"dtype": "string", "id": null, "_type": "Value"}, "prompt": {"dtype": "string", "id": null, "_type": "Value"}, "from_caller": {"dtype": "int64", "id": null, "_type": "Value"}, "from_caller_sex": {"dtype": "string", "id": null, "_type": "Value"}, "from_caller_education": {"dtype": "int64", "id": null, "_type": "Value"}, "from_caller_birth_year": {"dtype": "int64", "id": null, "_type": "Value"}, "from_caller_dialect_area": {"dtype": "string", "id": null, "_type": "Value"}, "to_caller": {"dtype": "int64", "id": null, "_type": "Value"}, "to_caller_sex": {"dtype": "string", "id": null, "_type": "Value"}, "to_caller_education": {"dtype": "int64", "id": null, "_type": "Value"}, "to_caller_birth_year": {"dtype": "int64", "id": null, "_type": "Value"}, "to_caller_dialect_area": {"dtype": "string", "id": null, "_type": "Value"}}, "post_processed": null, "supervised_keys": null, "builder_name": "swda", "config_name": "default", "version": {"version_str": "0.0.0", "description": null, "major": 0, "minor": 0, "patch": 0}, "splits": {"train": {"name": "train", "num_bytes": 128498512, "num_examples": 213543, "dataset_name": "swda"}, "validation": {"name": "validation", "num_bytes": 34749819, "num_examples": 56729, "dataset_name": "swda"}, "test": {"name": "test", "num_bytes": 2560127, "num_examples": 4514, "dataset_name": "swda"}}, "download_checksums": {"https://github.com/cgpotts/swda/raw/master/swda.zip": {"num_bytes": 14449197, "checksum": "0a08b8dd3992b446c8a920cacf7d246abe1e8a092a1ef7b5a2ed0352de9ccad2"}, "https://github.com/NathanDuran/Probabilistic-RNN-DA-Classifier/raw/master/data/train_split.txt": {"num_bytes": 5574, "checksum": "b29fa1d73d1f4a0cb560844bf43084ce3507c35e11fc1fde940d946484643c8e"}, "https://github.com/NathanDuran/Probabilistic-RNN-DA-Classifier/raw/master/data/dev_split.txt": {"num_bytes": 1499, "checksum": "557af363be3c6f56067660bc174bab8b9e7cdd1ab9bd39343b72098b32b05eda"}, "https://github.com/NathanDuran/Probabilistic-RNN-DA-Classifier/raw/master/data/test_split.txt": {"num_bytes": 94, "checksum": "ce74a2ea11c5b1f7e585c527094f3bcd565d8586a3bea4015aeb8b43ddbec8b9"}}, "download_size": 14456364, "post_processing_size": null, "dataset_size": 165808458, "size_in_bytes": 180264822}}
|
dummy/0.0.0/dummy_data.zip
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:747ddbb2ac4accdc6d34dac5878936f9f0c7a0f614ad1e4d6ab58d97dfe49295
|
| 3 |
+
size 14841
|
swda.py
CHANGED
|
@@ -17,10 +17,20 @@ Switchboard Dialog Act Corpus
|
|
| 17 |
The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2,
|
| 18 |
with turn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information
|
| 19 |
about the associated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.
|
|
|
|
|
|
|
|
|
|
| 20 |
"""
|
| 21 |
|
| 22 |
from __future__ import absolute_import, division, print_function
|
| 23 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 24 |
import datasets
|
| 25 |
|
| 26 |
|
|
@@ -35,8 +45,7 @@ _CITATION = """\
|
|
| 35 |
Year = {1997}}
|
| 36 |
|
| 37 |
@article{Shriberg-etal:1998,
|
| 38 |
-
Author = {Shriberg, Elizabeth and Bates, Rebecca and Taylor, Paul and Stolcke, Andreas and Jurafsky,
|
| 39 |
-
Daniel and Ries, Klaus and Coccaro, Noah and Martin, Rachel and Meteer, Marie and Van Ess-Dykema, Carol},
|
| 40 |
Journal = {Language and Speech},
|
| 41 |
Number = {3--4},
|
| 42 |
Pages = {439--487},
|
|
@@ -45,8 +54,7 @@ _CITATION = """\
|
|
| 45 |
Year = {1998}}
|
| 46 |
|
| 47 |
@article{Stolcke-etal:2000,
|
| 48 |
-
Author = {Stolcke, Andreas and Ries, Klaus and Coccaro, Noah and Shriberg, Elizabeth and Bates, Rebecca and
|
| 49 |
-
Jurafsky, Daniel and Taylor, Paul and Martin, Rachel and Meteer, Marie and Van Ess-Dykema, Carol},
|
| 50 |
Journal = {Computational Linguistics},
|
| 51 |
Number = {3},
|
| 52 |
Pages = {339--371},
|
|
@@ -55,7 +63,6 @@ _CITATION = """\
|
|
| 55 |
Year = {2000}}
|
| 56 |
"""
|
| 57 |
|
| 58 |
-
|
| 59 |
# Description of dataset gathered from: https://github.com/cgpotts/swda#overview.
|
| 60 |
_DESCRIPTION = """\
|
| 61 |
The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2 with
|
|
@@ -73,23 +80,298 @@ _HOMEPAGE = "http://compprag.christopherpotts.net/swda.html"
|
|
| 73 |
_LICENSE = "Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License"
|
| 74 |
|
| 75 |
# Dataset main url.
|
| 76 |
-
_URL = "https://github.com/
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 77 |
|
| 78 |
|
| 79 |
class Swda(datasets.GeneratorBasedBuilder):
|
| 80 |
"""
|
| 81 |
-
|
|
|
|
|
|
|
| 82 |
The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2,
|
| 83 |
with turn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information
|
| 84 |
about the associated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.
|
|
|
|
| 85 |
"""
|
| 86 |
|
| 87 |
-
#
|
| 88 |
-
_URLS = {
|
|
|
|
|
|
|
|
|
|
|
|
|
| 89 |
|
| 90 |
def _info(self):
|
| 91 |
"""
|
| 92 |
-
Specify the datasets.DatasetInfo object which contains
|
| 93 |
"""
|
| 94 |
|
| 95 |
return datasets.DatasetInfo(
|
|
@@ -98,60 +380,33 @@ class Swda(datasets.GeneratorBasedBuilder):
|
|
| 98 |
# This defines the different columns of the dataset and their types.
|
| 99 |
features=datasets.Features(
|
| 100 |
{
|
| 101 |
-
"
|
| 102 |
-
|
| 103 |
-
|
| 104 |
-
|
| 105 |
-
|
| 106 |
-
|
| 107 |
-
),
|
| 108 |
-
"
|
| 109 |
-
"
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
|
| 116 |
-
|
| 117 |
-
|
| 118 |
-
|
| 119 |
-
|
| 120 |
-
|
| 121 |
-
|
| 122 |
-
|
| 123 |
-
|
| 124 |
-
|
| 125 |
-
|
| 126 |
-
|
| 127 |
-
|
| 128 |
-
"bf",
|
| 129 |
-
'fo_o_fw_"_by_bc',
|
| 130 |
-
"na",
|
| 131 |
-
"ad",
|
| 132 |
-
"^2",
|
| 133 |
-
"b^m",
|
| 134 |
-
"qo",
|
| 135 |
-
"qh",
|
| 136 |
-
"^h",
|
| 137 |
-
"ar",
|
| 138 |
-
"ng",
|
| 139 |
-
"br",
|
| 140 |
-
"no",
|
| 141 |
-
"fp",
|
| 142 |
-
"qrr",
|
| 143 |
-
"arp_nd",
|
| 144 |
-
"t3",
|
| 145 |
-
"oo_co_cc",
|
| 146 |
-
"aap_am",
|
| 147 |
-
"t1",
|
| 148 |
-
"bd",
|
| 149 |
-
"^g",
|
| 150 |
-
"qw^d",
|
| 151 |
-
"fa",
|
| 152 |
-
"ft",
|
| 153 |
-
],
|
| 154 |
-
),
|
| 155 |
}
|
| 156 |
),
|
| 157 |
supervised_keys=None,
|
|
@@ -167,37 +422,382 @@ class Swda(datasets.GeneratorBasedBuilder):
|
|
| 167 |
"""
|
| 168 |
Returns SplitGenerators.
|
| 169 |
This method is tasked with downloading/extracting the data and defining the splits.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 170 |
"""
|
| 171 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 172 |
urls_to_download = self._URLS
|
|
|
|
| 173 |
downloaded_files = dl_manager.download_and_extract(urls_to_download)
|
| 174 |
|
| 175 |
return [
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 176 |
datasets.SplitGenerator(
|
| 177 |
-
name=datasets.Split.
|
|
|
|
| 178 |
),
|
|
|
|
| 179 |
datasets.SplitGenerator(
|
| 180 |
-
name=datasets.Split.
|
| 181 |
),
|
| 182 |
]
|
| 183 |
|
| 184 |
-
def _generate_examples(self,
|
| 185 |
"""
|
| 186 |
Yields examples.
|
| 187 |
This method will receive as arguments the `gen_kwargs` defined in the previous `_split_generators` method.
|
| 188 |
It is in charge of opening the given file and yielding (key, example) tuples from the dataset
|
| 189 |
The key is not important, it's more here for legacy reason (legacy from tfds).
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 190 |
"""
|
| 191 |
|
| 192 |
-
|
| 193 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 194 |
|
| 195 |
-
# Parse row into speaker info | utterance text | dialogue act tag.
|
| 196 |
-
parsed_row = row.rstrip("\r\n").split("|")
|
| 197 |
|
| 198 |
-
|
| 199 |
-
|
| 200 |
-
|
| 201 |
-
|
| 202 |
-
|
| 203 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2,
|
| 18 |
with turn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information
|
| 19 |
about the associated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.
|
| 20 |
+
|
| 21 |
+
This script is a modified version of the original swda.py from https://github.com/cgpotts/swda/blob/master/swda.py from
|
| 22 |
+
the original corpus repo. Modifications are made to accommodate the HuggingFace Dataset project format.
|
| 23 |
"""
|
| 24 |
|
| 25 |
from __future__ import absolute_import, division, print_function
|
| 26 |
|
| 27 |
+
import csv
|
| 28 |
+
import datetime
|
| 29 |
+
import glob
|
| 30 |
+
import io
|
| 31 |
+
import os
|
| 32 |
+
import re
|
| 33 |
+
|
| 34 |
import datasets
|
| 35 |
|
| 36 |
|
|
|
|
| 45 |
Year = {1997}}
|
| 46 |
|
| 47 |
@article{Shriberg-etal:1998,
|
| 48 |
+
Author = {Shriberg, Elizabeth and Bates, Rebecca and Taylor, Paul and Stolcke, Andreas and Jurafsky, Daniel and Ries, Klaus and Coccaro, Noah and Martin, Rachel and Meteer, Marie and Van Ess-Dykema, Carol},
|
|
|
|
| 49 |
Journal = {Language and Speech},
|
| 50 |
Number = {3--4},
|
| 51 |
Pages = {439--487},
|
|
|
|
| 54 |
Year = {1998}}
|
| 55 |
|
| 56 |
@article{Stolcke-etal:2000,
|
| 57 |
+
Author = {Stolcke, Andreas and Ries, Klaus and Coccaro, Noah and Shriberg, Elizabeth and Bates, Rebecca and Jurafsky, Daniel and Taylor, Paul and Martin, Rachel and Meteer, Marie and Van Ess-Dykema, Carol},
|
|
|
|
| 58 |
Journal = {Computational Linguistics},
|
| 59 |
Number = {3},
|
| 60 |
Pages = {339--371},
|
|
|
|
| 63 |
Year = {2000}}
|
| 64 |
"""
|
| 65 |
|
|
|
|
| 66 |
# Description of dataset gathered from: https://github.com/cgpotts/swda#overview.
|
| 67 |
_DESCRIPTION = """\
|
| 68 |
The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2 with
|
|
|
|
| 80 |
_LICENSE = "Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License"
|
| 81 |
|
| 82 |
# Dataset main url.
|
| 83 |
+
_URL = "https://github.com/cgpotts/swda/raw/master/swda.zip"
|
| 84 |
+
|
| 85 |
+
# Dialogue act tags - long version 217 dialogue acts labels.
|
| 86 |
+
_ACT_TAGS = [
|
| 87 |
+
"b^m^r",
|
| 88 |
+
"qw^r^t",
|
| 89 |
+
"aa^h",
|
| 90 |
+
"br^m",
|
| 91 |
+
"fa^r",
|
| 92 |
+
"aa,ar",
|
| 93 |
+
"sd^e(^q)^r",
|
| 94 |
+
"^2",
|
| 95 |
+
"sd;qy^d",
|
| 96 |
+
"oo",
|
| 97 |
+
"bk^m",
|
| 98 |
+
"aa^t",
|
| 99 |
+
"cc^t",
|
| 100 |
+
"qy^d^c",
|
| 101 |
+
"qo^t",
|
| 102 |
+
"ng^m",
|
| 103 |
+
"qw^h",
|
| 104 |
+
"qo^r",
|
| 105 |
+
"aa",
|
| 106 |
+
"qy^d^t",
|
| 107 |
+
"qrr^d",
|
| 108 |
+
"br^r",
|
| 109 |
+
"fx",
|
| 110 |
+
"sd,qy^g",
|
| 111 |
+
"ny^e",
|
| 112 |
+
"^h^t",
|
| 113 |
+
"fc^m",
|
| 114 |
+
"qw(^q)",
|
| 115 |
+
"co",
|
| 116 |
+
"o^t",
|
| 117 |
+
"b^m^t",
|
| 118 |
+
"qr^d",
|
| 119 |
+
"qw^g",
|
| 120 |
+
"ad(^q)",
|
| 121 |
+
"qy(^q)",
|
| 122 |
+
"na^r",
|
| 123 |
+
"am^r",
|
| 124 |
+
"qr^t",
|
| 125 |
+
"ad^c",
|
| 126 |
+
"qw^c",
|
| 127 |
+
"bh^r",
|
| 128 |
+
"h^t",
|
| 129 |
+
"ft^m",
|
| 130 |
+
"ba^r",
|
| 131 |
+
"qw^d^t",
|
| 132 |
+
"%",
|
| 133 |
+
"t3",
|
| 134 |
+
"nn",
|
| 135 |
+
"bd",
|
| 136 |
+
"h^m",
|
| 137 |
+
"h^r",
|
| 138 |
+
"sd^r",
|
| 139 |
+
"qh^m",
|
| 140 |
+
"^q^t",
|
| 141 |
+
"sv^2",
|
| 142 |
+
"ft",
|
| 143 |
+
"ar^m",
|
| 144 |
+
"qy^h",
|
| 145 |
+
"sd^e^m",
|
| 146 |
+
"qh^r",
|
| 147 |
+
"cc",
|
| 148 |
+
"fp^m",
|
| 149 |
+
"ad",
|
| 150 |
+
"qo",
|
| 151 |
+
"na^m^t",
|
| 152 |
+
"fo^c",
|
| 153 |
+
"qy",
|
| 154 |
+
"sv^e^r",
|
| 155 |
+
"aap",
|
| 156 |
+
"no",
|
| 157 |
+
"aa^2",
|
| 158 |
+
"sv(^q)",
|
| 159 |
+
"sv^e",
|
| 160 |
+
"nd",
|
| 161 |
+
'"',
|
| 162 |
+
"bf^2",
|
| 163 |
+
"bk",
|
| 164 |
+
"fp",
|
| 165 |
+
"nn^r^t",
|
| 166 |
+
"fa^c",
|
| 167 |
+
"ny^t",
|
| 168 |
+
"ny^c^r",
|
| 169 |
+
"qw",
|
| 170 |
+
"qy^t",
|
| 171 |
+
"b",
|
| 172 |
+
"fo",
|
| 173 |
+
"qw^r",
|
| 174 |
+
"am",
|
| 175 |
+
"bf^t",
|
| 176 |
+
"^2^t",
|
| 177 |
+
"b^2",
|
| 178 |
+
"x",
|
| 179 |
+
"fc",
|
| 180 |
+
"qr",
|
| 181 |
+
"no^t",
|
| 182 |
+
"bk^t",
|
| 183 |
+
"bd^r",
|
| 184 |
+
"bf",
|
| 185 |
+
"^2^g",
|
| 186 |
+
"qh^c",
|
| 187 |
+
"ny^c",
|
| 188 |
+
"sd^e^r",
|
| 189 |
+
"br",
|
| 190 |
+
"fe",
|
| 191 |
+
"by",
|
| 192 |
+
"^2^r",
|
| 193 |
+
"fc^r",
|
| 194 |
+
"b^m",
|
| 195 |
+
"sd,sv",
|
| 196 |
+
"fa^t",
|
| 197 |
+
"sv^m",
|
| 198 |
+
"qrr",
|
| 199 |
+
"^h^r",
|
| 200 |
+
"na",
|
| 201 |
+
"fp^r",
|
| 202 |
+
"o",
|
| 203 |
+
"h,sd",
|
| 204 |
+
"t1^t",
|
| 205 |
+
"nn^r",
|
| 206 |
+
"cc^r",
|
| 207 |
+
"sv^c",
|
| 208 |
+
"co^t",
|
| 209 |
+
"qy^r",
|
| 210 |
+
"sv^r",
|
| 211 |
+
"qy^d^h",
|
| 212 |
+
"sd",
|
| 213 |
+
"nn^e",
|
| 214 |
+
"ny^r",
|
| 215 |
+
"b^t",
|
| 216 |
+
"ba^m",
|
| 217 |
+
"ar",
|
| 218 |
+
"bf^r",
|
| 219 |
+
"sv",
|
| 220 |
+
"bh^m",
|
| 221 |
+
"qy^g^t",
|
| 222 |
+
"qo^d^c",
|
| 223 |
+
"qo^d",
|
| 224 |
+
"nd^t",
|
| 225 |
+
"aa^r",
|
| 226 |
+
"sd^2",
|
| 227 |
+
"sv;sd",
|
| 228 |
+
"qy^c^r",
|
| 229 |
+
"qw^m",
|
| 230 |
+
"qy^g^r",
|
| 231 |
+
"no^r",
|
| 232 |
+
"qh(^q)",
|
| 233 |
+
"sd;sv",
|
| 234 |
+
"bf(^q)",
|
| 235 |
+
"+",
|
| 236 |
+
"qy^2",
|
| 237 |
+
"qw^d",
|
| 238 |
+
"qy^g",
|
| 239 |
+
"qh^g",
|
| 240 |
+
"nn^t",
|
| 241 |
+
"ad^r",
|
| 242 |
+
"oo^t",
|
| 243 |
+
"co^c",
|
| 244 |
+
"ng",
|
| 245 |
+
"^q",
|
| 246 |
+
"qw^d^c",
|
| 247 |
+
"qrr^t",
|
| 248 |
+
"^h",
|
| 249 |
+
"aap^r",
|
| 250 |
+
"bc^r",
|
| 251 |
+
"sd^m",
|
| 252 |
+
"bk^r",
|
| 253 |
+
"qy^g^c",
|
| 254 |
+
"qr(^q)",
|
| 255 |
+
"ng^t",
|
| 256 |
+
"arp",
|
| 257 |
+
"h",
|
| 258 |
+
"bh",
|
| 259 |
+
"sd^c",
|
| 260 |
+
"^g",
|
| 261 |
+
"o^r",
|
| 262 |
+
"qy^c",
|
| 263 |
+
"sd^e",
|
| 264 |
+
"fw",
|
| 265 |
+
"ar^r",
|
| 266 |
+
"qy^m",
|
| 267 |
+
"bc",
|
| 268 |
+
"sv^t",
|
| 269 |
+
"aap^m",
|
| 270 |
+
"sd;no",
|
| 271 |
+
"ng^r",
|
| 272 |
+
"bf^g",
|
| 273 |
+
"sd^e^t",
|
| 274 |
+
"o^c",
|
| 275 |
+
"b^r",
|
| 276 |
+
"b^m^g",
|
| 277 |
+
"ba",
|
| 278 |
+
"t1",
|
| 279 |
+
"qy^d(^q)",
|
| 280 |
+
"nn^m",
|
| 281 |
+
"ny",
|
| 282 |
+
"ba,fe",
|
| 283 |
+
"aa^m",
|
| 284 |
+
"qh",
|
| 285 |
+
"na^m",
|
| 286 |
+
"oo(^q)",
|
| 287 |
+
"qw^t",
|
| 288 |
+
"na^t",
|
| 289 |
+
"qh^h",
|
| 290 |
+
"qy^d^m",
|
| 291 |
+
"ny^m",
|
| 292 |
+
"fa",
|
| 293 |
+
"qy^d",
|
| 294 |
+
"fc^t",
|
| 295 |
+
"sd(^q)",
|
| 296 |
+
"qy^d^r",
|
| 297 |
+
"bf^m",
|
| 298 |
+
"sd(^q)^t",
|
| 299 |
+
"ft^t",
|
| 300 |
+
"^q^r",
|
| 301 |
+
"sd^t",
|
| 302 |
+
"sd(^q)^r",
|
| 303 |
+
"ad^t",
|
| 304 |
+
]
|
| 305 |
+
|
| 306 |
+
# Damsl dialogue act tags version - short version 43 dialogue acts labels.
|
| 307 |
+
_DAMSL_ACT_TAGS = [
|
| 308 |
+
"ad",
|
| 309 |
+
"qo",
|
| 310 |
+
"qy",
|
| 311 |
+
"arp_nd",
|
| 312 |
+
"sd",
|
| 313 |
+
"h",
|
| 314 |
+
"bh",
|
| 315 |
+
"no",
|
| 316 |
+
"^2",
|
| 317 |
+
"^g",
|
| 318 |
+
"ar",
|
| 319 |
+
"aa",
|
| 320 |
+
"sv",
|
| 321 |
+
"bk",
|
| 322 |
+
"fp",
|
| 323 |
+
"qw",
|
| 324 |
+
"b",
|
| 325 |
+
"ba",
|
| 326 |
+
"t1",
|
| 327 |
+
"oo_co_cc",
|
| 328 |
+
"+",
|
| 329 |
+
"ny",
|
| 330 |
+
"qw^d",
|
| 331 |
+
"x",
|
| 332 |
+
"qh",
|
| 333 |
+
"fc",
|
| 334 |
+
'fo_o_fw_"_by_bc',
|
| 335 |
+
"aap_am",
|
| 336 |
+
"%",
|
| 337 |
+
"bf",
|
| 338 |
+
"t3",
|
| 339 |
+
"nn",
|
| 340 |
+
"bd",
|
| 341 |
+
"ng",
|
| 342 |
+
"^q",
|
| 343 |
+
"br",
|
| 344 |
+
"qy^d",
|
| 345 |
+
"fa",
|
| 346 |
+
"^h",
|
| 347 |
+
"b^m",
|
| 348 |
+
"ft",
|
| 349 |
+
"qrr",
|
| 350 |
+
"na",
|
| 351 |
+
]
|
| 352 |
|
| 353 |
|
| 354 |
class Swda(datasets.GeneratorBasedBuilder):
|
| 355 |
"""
|
| 356 |
+
This is the HuggingFace Dataset class for swda.
|
| 357 |
+
|
| 358 |
+
Switchboard Dialog Act Corpus Hugging Face Dataset class.
|
| 359 |
The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2,
|
| 360 |
with turn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information
|
| 361 |
about the associated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.
|
| 362 |
+
|
| 363 |
"""
|
| 364 |
|
| 365 |
+
# Urls for each split train-dev-test.
|
| 366 |
+
_URLS = {
|
| 367 |
+
"train": "https://github.com/NathanDuran/Probabilistic-RNN-DA-Classifier/raw/master/data/train_split.txt",
|
| 368 |
+
"dev": "https://github.com/NathanDuran/Probabilistic-RNN-DA-Classifier/raw/master/data/dev_split.txt",
|
| 369 |
+
"test": "https://github.com/NathanDuran/Probabilistic-RNN-DA-Classifier/raw/master/data/test_split.txt",
|
| 370 |
+
}
|
| 371 |
|
| 372 |
def _info(self):
|
| 373 |
"""
|
| 374 |
+
Specify the datasets.DatasetInfo object which contains information and typings for the dataset.
|
| 375 |
"""
|
| 376 |
|
| 377 |
return datasets.DatasetInfo(
|
|
|
|
| 380 |
# This defines the different columns of the dataset and their types.
|
| 381 |
features=datasets.Features(
|
| 382 |
{
|
| 383 |
+
"swda_filename": datasets.Value("string"),
|
| 384 |
+
"ptb_basename": datasets.Value("string"),
|
| 385 |
+
"conversation_no": datasets.Value("int64"),
|
| 386 |
+
"transcript_index": datasets.Value("int64"),
|
| 387 |
+
"act_tag": datasets.ClassLabel(num_classes=217, names=_ACT_TAGS),
|
| 388 |
+
"damsl_act_tag": datasets.ClassLabel(num_classes=43, names=_DAMSL_ACT_TAGS),
|
| 389 |
+
"caller": datasets.Value("string"),
|
| 390 |
+
"utterance_index": datasets.Value("int64"),
|
| 391 |
+
"subutterance_index": datasets.Value("int64"),
|
| 392 |
+
"text": datasets.Value("string"),
|
| 393 |
+
"pos": datasets.Value("string"),
|
| 394 |
+
"trees": datasets.Value("string"),
|
| 395 |
+
"ptb_treenumbers": datasets.Value("string"),
|
| 396 |
+
"talk_day": datasets.Value("string"),
|
| 397 |
+
"length": datasets.Value("int64"),
|
| 398 |
+
"topic_description": datasets.Value("string"),
|
| 399 |
+
"prompt": datasets.Value("string"),
|
| 400 |
+
"from_caller": datasets.Value("int64"),
|
| 401 |
+
"from_caller_sex": datasets.Value("string"),
|
| 402 |
+
"from_caller_education": datasets.Value("int64"),
|
| 403 |
+
"from_caller_birth_year": datasets.Value("int64"),
|
| 404 |
+
"from_caller_dialect_area": datasets.Value("string"),
|
| 405 |
+
"to_caller": datasets.Value("int64"),
|
| 406 |
+
"to_caller_sex": datasets.Value("string"),
|
| 407 |
+
"to_caller_education": datasets.Value("int64"),
|
| 408 |
+
"to_caller_birth_year": datasets.Value("int64"),
|
| 409 |
+
"to_caller_dialect_area": datasets.Value("string"),
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 410 |
}
|
| 411 |
),
|
| 412 |
supervised_keys=None,
|
|
|
|
| 422 |
"""
|
| 423 |
Returns SplitGenerators.
|
| 424 |
This method is tasked with downloading/extracting the data and defining the splits.
|
| 425 |
+
|
| 426 |
+
Args:
|
| 427 |
+
dl_manager (:obj:`datasets.utils.download_manager.DownloadManager`):
|
| 428 |
+
Download manager to download and extract data files from urls.
|
| 429 |
+
|
| 430 |
+
Returns:
|
| 431 |
+
:obj:`list[str]`:
|
| 432 |
+
List of paths to data.
|
| 433 |
"""
|
| 434 |
|
| 435 |
+
# Download extract and return path of data file.
|
| 436 |
+
dl_dir = dl_manager.download_and_extract(_URL)
|
| 437 |
+
# Use swda/ folder.
|
| 438 |
+
data_dir = os.path.join(dl_dir, "swda")
|
| 439 |
+
# Handle partitions files.
|
| 440 |
urls_to_download = self._URLS
|
| 441 |
+
# Download extract and return paths of split files.
|
| 442 |
downloaded_files = dl_manager.download_and_extract(urls_to_download)
|
| 443 |
|
| 444 |
return [
|
| 445 |
+
# Return whole data path and train splits file downloaded path.
|
| 446 |
+
datasets.SplitGenerator(
|
| 447 |
+
name=datasets.Split.TRAIN, gen_kwargs={"data_dir": data_dir, "split_file": downloaded_files["train"]}
|
| 448 |
+
),
|
| 449 |
+
# Return whole data path and dev splits file downloaded path.
|
| 450 |
datasets.SplitGenerator(
|
| 451 |
+
name=datasets.Split.VALIDATION,
|
| 452 |
+
gen_kwargs={"data_dir": data_dir, "split_file": downloaded_files["dev"]},
|
| 453 |
),
|
| 454 |
+
# Return whole data path and train splits file downloaded path.
|
| 455 |
datasets.SplitGenerator(
|
| 456 |
+
name=datasets.Split.TEST, gen_kwargs={"data_dir": data_dir, "split_file": downloaded_files["test"]}
|
| 457 |
),
|
| 458 |
]
|
| 459 |
|
| 460 |
+
def _generate_examples(self, data_dir, split_file):
|
| 461 |
"""
|
| 462 |
Yields examples.
|
| 463 |
This method will receive as arguments the `gen_kwargs` defined in the previous `_split_generators` method.
|
| 464 |
It is in charge of opening the given file and yielding (key, example) tuples from the dataset
|
| 465 |
The key is not important, it's more here for legacy reason (legacy from tfds).
|
| 466 |
+
|
| 467 |
+
Args:
|
| 468 |
+
data_dir (:obj:`str`):
|
| 469 |
+
Path where is downloaded dataset.
|
| 470 |
+
|
| 471 |
+
split_file (:obj:`str`):
|
| 472 |
+
Path of split file used for train-dev-test.
|
| 473 |
+
|
| 474 |
+
Returns:
|
| 475 |
+
:obj:`list[str]`:
|
| 476 |
+
List of paths to data.
|
| 477 |
"""
|
| 478 |
|
| 479 |
+
# Read in the split file.
|
| 480 |
+
split_file = io.open(file=split_file, mode="r", encoding="utf-8").read().splitlines()
|
| 481 |
+
# Read in corpus data using split files.
|
| 482 |
+
corpus = CorpusReader(src_dirname=data_dir, split_file=split_file)
|
| 483 |
+
# Generate examples.
|
| 484 |
+
for i_trans, trans in enumerate(corpus.iter_transcripts()):
|
| 485 |
+
for i_utt, utt in enumerate(trans.utterances):
|
| 486 |
+
id_ = str(i_trans) + ":" + str(i_utt)
|
| 487 |
+
yield id_, {feature: utt[feature] for feature in self.info.features.keys()}
|
| 488 |
|
|
|
|
|
|
|
| 489 |
|
| 490 |
+
class CorpusReader:
|
| 491 |
+
"""Class for reading in the corpus and iterating through its values."""
|
| 492 |
+
|
| 493 |
+
def __init__(self, src_dirname, split_file=None):
|
| 494 |
+
"""
|
| 495 |
+
Reads in the data from `src_dirname` (should be the root of the
|
| 496 |
+
corpus). Assumes that the metadata file `swda-metadata.csv` is
|
| 497 |
+
in the main directory of the corpus, using that file to build
|
| 498 |
+
the `Metadata` object used throughout.
|
| 499 |
+
|
| 500 |
+
Args:
|
| 501 |
+
src_dirname (:obj:`str`):
|
| 502 |
+
Path where swda folder with all data.
|
| 503 |
+
|
| 504 |
+
split_file (:obj:`list[str`, `optional`):
|
| 505 |
+
List of file names used in a split (train, dev or test). This argument is optional and it will have a None value attributed inside the function.
|
| 506 |
+
|
| 507 |
+
"""
|
| 508 |
+
|
| 509 |
+
self.src_dirname = src_dirname
|
| 510 |
+
metadata_filename = os.path.join(src_dirname, "swda-metadata.csv")
|
| 511 |
+
self.metadata = Metadata(metadata_filename)
|
| 512 |
+
self.split_file = split_file
|
| 513 |
+
|
| 514 |
+
def iter_transcripts(
|
| 515 |
+
self,
|
| 516 |
+
):
|
| 517 |
+
"""
|
| 518 |
+
Iterate through the transcripts.
|
| 519 |
+
|
| 520 |
+
Returns:
|
| 521 |
+
:obj:`Transcript`:
|
| 522 |
+
Transcript instance.
|
| 523 |
+
"""
|
| 524 |
+
|
| 525 |
+
# All files names.
|
| 526 |
+
filenames = glob.glob(os.path.join(self.src_dirname, "sw*", "*.csv"))
|
| 527 |
+
# If no split files are mentioned just use all files.
|
| 528 |
+
self.split_file = filenames if self.split_file is None else self.split_file
|
| 529 |
+
# Filter out desired file names
|
| 530 |
+
filenames = [
|
| 531 |
+
file for file in filenames if os.path.basename(file).split("_")[-1].split(".")[0] in self.split_file
|
| 532 |
+
]
|
| 533 |
+
for filename in sorted(filenames):
|
| 534 |
+
# Yield the Transcript instance:
|
| 535 |
+
yield Transcript(filename, self.metadata)
|
| 536 |
+
|
| 537 |
+
def iter_utterances(
|
| 538 |
+
self,
|
| 539 |
+
):
|
| 540 |
+
"""
|
| 541 |
+
Iterate through the utterances.
|
| 542 |
+
|
| 543 |
+
Returns:
|
| 544 |
+
:obj:`Transcript.utterances`:
|
| 545 |
+
Utterance instance object.
|
| 546 |
+
"""
|
| 547 |
+
|
| 548 |
+
for trans in self.iter_transcripts():
|
| 549 |
+
for utt in trans.utterances:
|
| 550 |
+
# Yield the Utterance instance:
|
| 551 |
+
yield utt
|
| 552 |
+
|
| 553 |
+
|
| 554 |
+
class Metadata:
|
| 555 |
+
"""
|
| 556 |
+
Basically an internal method for organizing the tables of metadata
|
| 557 |
+
from the original Switchboard transcripts and linking them with
|
| 558 |
+
the dialog acts.
|
| 559 |
+
"""
|
| 560 |
+
|
| 561 |
+
def __init__(self, metadata_filename):
|
| 562 |
+
"""
|
| 563 |
+
Turns the CSV file into a dictionary mapping Switchboard
|
| 564 |
+
conversation_no integers values to dictionaries of values. All
|
| 565 |
+
the keys correspond to the column names in the original
|
| 566 |
+
tables.
|
| 567 |
+
|
| 568 |
+
Args:
|
| 569 |
+
metadata_filename (:obj:`str`):
|
| 570 |
+
The CSV file swda-metadata.csv (should be in the main
|
| 571 |
+
folder of the swda directory).
|
| 572 |
+
|
| 573 |
+
"""
|
| 574 |
+
self.metadata_filename = metadata_filename
|
| 575 |
+
self.metadata = {}
|
| 576 |
+
self.get_metadata()
|
| 577 |
+
|
| 578 |
+
def get_metadata(self):
|
| 579 |
+
"""
|
| 580 |
+
Build the dictionary self.metadata mapping conversation_no to
|
| 581 |
+
dictionaries of values (str, int, or datatime, as
|
| 582 |
+
appropriate).
|
| 583 |
+
"""
|
| 584 |
+
|
| 585 |
+
csvreader = csv.reader(open(self.metadata_filename))
|
| 586 |
+
header = next(csvreader)
|
| 587 |
+
for row in csvreader:
|
| 588 |
+
d = dict(list(zip(header, row)))
|
| 589 |
+
# Add integer number features to metadata.
|
| 590 |
+
for key in (
|
| 591 |
+
"conversation_no",
|
| 592 |
+
"length",
|
| 593 |
+
"from_caller",
|
| 594 |
+
"to_caller",
|
| 595 |
+
"from_caller_education",
|
| 596 |
+
"to_caller_education",
|
| 597 |
+
):
|
| 598 |
+
d[key] = int(d[key])
|
| 599 |
+
talk_day = d["talk_day"]
|
| 600 |
+
talk_year = int("19" + talk_day[:2])
|
| 601 |
+
talk_month = int(talk_day[2:4])
|
| 602 |
+
talk_day = int(talk_day[4:])
|
| 603 |
+
# Make sure to convert date time to string to match PyArrow data formats.
|
| 604 |
+
d["talk_day"] = datetime.datetime(year=talk_year, month=talk_month, day=talk_day).strftime("%m/%d/%Y")
|
| 605 |
+
d["from_caller_birth_year"] = int(d["from_caller_birth_year"])
|
| 606 |
+
d["to_caller_birth_year"] = int(d["to_caller_birth_year"])
|
| 607 |
+
self.metadata[d["conversation_no"]] = d
|
| 608 |
+
|
| 609 |
+
def __getitem__(self, val):
|
| 610 |
+
"""
|
| 611 |
+
Val should be a key in self.metadata; returns the
|
| 612 |
+
corresponding value.
|
| 613 |
+
|
| 614 |
+
Args:
|
| 615 |
+
val (:obj:`str`):
|
| 616 |
+
Key in self.metadata.
|
| 617 |
+
|
| 618 |
+
Returns:
|
| 619 |
+
:obj::
|
| 620 |
+
Corresponding value.
|
| 621 |
+
|
| 622 |
+
"""
|
| 623 |
+
|
| 624 |
+
return self.metadata[val]
|
| 625 |
+
|
| 626 |
+
|
| 627 |
+
class Utterance:
|
| 628 |
+
"""
|
| 629 |
+
The central object of interest. The attributes correspond to the
|
| 630 |
+
values of the class variable header:
|
| 631 |
+
|
| 632 |
+
"""
|
| 633 |
+
|
| 634 |
+
# Metadata header file.
|
| 635 |
+
header = [
|
| 636 |
+
"swda_filename",
|
| 637 |
+
"ptb_basename",
|
| 638 |
+
"conversation_no",
|
| 639 |
+
"transcript_index",
|
| 640 |
+
"act_tag",
|
| 641 |
+
"caller",
|
| 642 |
+
"utterance_index",
|
| 643 |
+
"subutterance_index",
|
| 644 |
+
"text",
|
| 645 |
+
"pos",
|
| 646 |
+
"trees",
|
| 647 |
+
"ptb_treenumbers",
|
| 648 |
+
]
|
| 649 |
+
|
| 650 |
+
def __init__(self, row, transcript_metadata):
|
| 651 |
+
"""
|
| 652 |
+
Args:
|
| 653 |
+
row (:obj:`list`):
|
| 654 |
+
A row from one of the corpus CSV files.
|
| 655 |
+
|
| 656 |
+
transcript_metadata (:obj:`dict`):
|
| 657 |
+
A Metadata value based on the current `conversation_no`.
|
| 658 |
+
|
| 659 |
+
"""
|
| 660 |
+
|
| 661 |
+
# Utterance data:
|
| 662 |
+
for i in range(len(Utterance.header)):
|
| 663 |
+
att_name = Utterance.header[i]
|
| 664 |
+
row_value = None
|
| 665 |
+
if i < len(row):
|
| 666 |
+
row_value = row[i].strip()
|
| 667 |
+
# Special handling of non-string values.
|
| 668 |
+
if att_name == "trees":
|
| 669 |
+
if row_value:
|
| 670 |
+
# Origianl code returned list of nltk.tree and used `[Tree.fromstring(t) for t in row_value.split("|||")]`.
|
| 671 |
+
# Since we're returning str we don't need to make any mondifications to row_value.
|
| 672 |
+
row_value = row_value
|
| 673 |
+
else:
|
| 674 |
+
row_value = "" # []
|
| 675 |
+
elif att_name == "ptb_treenumbers":
|
| 676 |
+
if row_value:
|
| 677 |
+
row_value = row_value # list(map(int, row_value.split("|||")))
|
| 678 |
+
else:
|
| 679 |
+
row_value = "" # []
|
| 680 |
+
elif att_name == "act_tag":
|
| 681 |
+
# I thought these conjoined tags were meant to be split.
|
| 682 |
+
# The docs suggest that they are single tags, thought,
|
| 683 |
+
# so skip this conditional and let it be treated as a str.
|
| 684 |
+
# row_value = re.split(r"\s*[,;]\s*", row_value)
|
| 685 |
+
# `` Transcription errors (typos, obvious mistranscriptions) are
|
| 686 |
+
# marked with a "*" after the discourse tag.''
|
| 687 |
+
# These are removed for this version.
|
| 688 |
+
row_value = row_value.replace("*", "")
|
| 689 |
+
elif att_name in ("conversation_no", "transcript_index", "utterance_index", "subutterance_index"):
|
| 690 |
+
row_value = int(row_value)
|
| 691 |
+
# Add attribute.
|
| 692 |
+
setattr(self, att_name, row_value)
|
| 693 |
+
# Make sure conversation number matches.
|
| 694 |
+
assert self.conversation_no == transcript_metadata["conversation_no"]
|
| 695 |
+
# Add rest of missing metadata
|
| 696 |
+
[setattr(self, key, value) for key, value in transcript_metadata.items()]
|
| 697 |
+
# Add damsl tags.
|
| 698 |
+
setattr(self, "damsl_act_tag", self.damsl_act_tag())
|
| 699 |
+
|
| 700 |
+
def __getitem__(self, feature):
|
| 701 |
+
"""
|
| 702 |
+
Return utterance features as dictionary. It allows us to call an utterance object as a dictionary.
|
| 703 |
+
It contains same keys as attributes.
|
| 704 |
+
|
| 705 |
+
Args:
|
| 706 |
+
feature (:obj:`str`):
|
| 707 |
+
Feature value of utterance that is part of attributes.
|
| 708 |
+
|
| 709 |
+
Returns:
|
| 710 |
+
:obj:
|
| 711 |
+
Value of feature from utterance. Value type can vary.
|
| 712 |
+
"""
|
| 713 |
+
|
| 714 |
+
return vars(self)[feature]
|
| 715 |
+
|
| 716 |
+
def damsl_act_tag(
|
| 717 |
+
self,
|
| 718 |
+
):
|
| 719 |
+
"""
|
| 720 |
+
Seeks to duplicate the tag simplification described at the
|
| 721 |
+
Coders' Manual: http://www.stanford.edu/~jurafsky/ws97/manual.august1.html
|
| 722 |
+
"""
|
| 723 |
+
|
| 724 |
+
d_tags = []
|
| 725 |
+
tags = re.split(r"\s*[,;]\s*", self.act_tag)
|
| 726 |
+
for tag in tags:
|
| 727 |
+
if tag in ("qy^d", "qw^d", "b^m"):
|
| 728 |
+
pass
|
| 729 |
+
elif tag == "nn^e":
|
| 730 |
+
tag = "ng"
|
| 731 |
+
elif tag == "ny^e":
|
| 732 |
+
tag = "na"
|
| 733 |
+
else:
|
| 734 |
+
tag = re.sub(r"(.)\^.*", r"\1", tag)
|
| 735 |
+
tag = re.sub(r"[\(\)@*]", "", tag)
|
| 736 |
+
if tag in ("qr", "qy"):
|
| 737 |
+
tag = "qy"
|
| 738 |
+
elif tag in ("fe", "ba"):
|
| 739 |
+
tag = "ba"
|
| 740 |
+
elif tag in ("oo", "co", "cc"):
|
| 741 |
+
tag = "oo_co_cc"
|
| 742 |
+
elif tag in ("fx", "sv"):
|
| 743 |
+
tag = "sv"
|
| 744 |
+
elif tag in ("aap", "am"):
|
| 745 |
+
tag = "aap_am"
|
| 746 |
+
elif tag in ("arp", "nd"):
|
| 747 |
+
tag = "arp_nd"
|
| 748 |
+
elif tag in ("fo", "o", "fw", '"', "by", "bc"):
|
| 749 |
+
tag = 'fo_o_fw_"_by_bc'
|
| 750 |
+
d_tags.append(tag)
|
| 751 |
+
# Dan J says (p.c.) that it makes sense to take the first;
|
| 752 |
+
# there are only a handful of examples with 2 tags here.
|
| 753 |
+
return d_tags[0]
|
| 754 |
+
|
| 755 |
+
|
| 756 |
+
class Transcript:
|
| 757 |
+
"""
|
| 758 |
+
Transcript instances are basically just containers for lists of
|
| 759 |
+
utterances and transcript-level metadata, accessible via
|
| 760 |
+
attributes.
|
| 761 |
+
"""
|
| 762 |
+
|
| 763 |
+
def __init__(self, swda_filename, metadata):
|
| 764 |
+
"""
|
| 765 |
+
Sets up all the attribute values:
|
| 766 |
+
|
| 767 |
+
Args:
|
| 768 |
+
swda_filename (:obj:`str`):
|
| 769 |
+
The filename for this transcript.
|
| 770 |
+
|
| 771 |
+
metadata (:obj:`str` or `Metadata`):
|
| 772 |
+
If a string, then assumed to be the metadata filename, and
|
| 773 |
+
the metadata is created from that filename. If a `Metadata`
|
| 774 |
+
object, then used as the needed metadata directly.
|
| 775 |
+
|
| 776 |
+
"""
|
| 777 |
+
|
| 778 |
+
self.swda_filename = swda_filename
|
| 779 |
+
# If the supplied value is a filename:
|
| 780 |
+
if isinstance(metadata, str) or isinstance(metadata, str):
|
| 781 |
+
self.metadata = Metadata(metadata)
|
| 782 |
+
else: # Where the supplied value is already a Metadata object.
|
| 783 |
+
self.metadata = metadata
|
| 784 |
+
# Get the file rows:
|
| 785 |
+
rows = list(csv.reader(open(self.swda_filename, "rt")))
|
| 786 |
+
# Ge the header and remove it from the rows:
|
| 787 |
+
self.header = rows[0]
|
| 788 |
+
rows.pop(0)
|
| 789 |
+
# Extract the conversation_no to get the meta-data. Use the
|
| 790 |
+
# header for this in case the column ordering is ever changed:
|
| 791 |
+
row0dict = dict(list(zip(self.header, rows[1])))
|
| 792 |
+
self.conversation_no = int(row0dict["conversation_no"])
|
| 793 |
+
# The ptd filename in the right format for the current OS:
|
| 794 |
+
self.ptd_basename = os.sep.join(row0dict["ptb_basename"].split("/"))
|
| 795 |
+
# The dictionary of metadata for this transcript:
|
| 796 |
+
transcript_metadata = self.metadata[self.conversation_no]
|
| 797 |
+
for key, val in transcript_metadata.items():
|
| 798 |
+
setattr(self, key, transcript_metadata[key])
|
| 799 |
+
# Create the utterance list:
|
| 800 |
+
self.utterances = [Utterance(x, transcript_metadata) for x in rows]
|
| 801 |
+
# Coder's Manual: ``We also removed any line with a "@"
|
| 802 |
+
# (since @ marked slash-units with bad segmentation).''
|
| 803 |
+
self.utterances = [u for u in self.utterances if not re.search(r"[@]", u.act_tag)]
|