
modelId
stringlengths 4
112
| lastModified
stringlengths 24
24
| tags
list | pipeline_tag
stringclasses 21
values | files
list | publishedBy
stringlengths 2
37
| downloads_last_month
int32 0
9.44M
| library
stringclasses 15
values | modelCard
large_stringlengths 0
100k
|
|---|---|---|---|---|---|---|---|---|
monologg/koelectra-small-finetuned-nsmc | 2020-08-18T18:43:17.000Z | [
"pytorch",
"electra",
"text-classification",
"transformers"
]
| text-classification | [
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.txt"
]
| monologg | 182 | transformers | |
monologg/koelectra-small-finetuned-sentiment | 2020-05-23T09:19:14.000Z | [
"pytorch",
"tflite",
"electra",
"text-classification",
"transformers"
]
| text-classification | [
".gitattributes",
"config.json",
"nsmc_small.pt",
"nsmc_small.tflite",
"nsmc_small_8bits.tflite",
"nsmc_small_fp16.tflite",
"pytorch_model.bin",
"tokenizer_config.json",
"vocab.txt"
]
| monologg | 33 | transformers | |
monologg/koelectra-small-generator | 2020-12-26T16:23:42.000Z | [
"pytorch",
"electra",
"masked-lm",
"ko",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"tokenizer_config.json",
"vocab.txt"
]
| monologg | 66 | transformers | ---
language: ko
---
# KoELECTRA (Small Generator)
Pretrained ELECTRA Language Model for Korean (`koelectra-small-generator`)
For more detail, please see [original repository](https://github.com/monologg/KoELECTRA/blob/master/README_EN.md).
## Usage
### Load model and tokenizer
```python
>>> from transformers import ElectraModel, ElectraTokenizer
>>> model = ElectraModel.from_pretrained("monologg/koelectra-small-generator")
>>> tokenizer = ElectraTokenizer.from_pretrained("monologg/koelectra-small-generator")
```
### Tokenizer example
```python
>>> from transformers import ElectraTokenizer
>>> tokenizer = ElectraTokenizer.from_pretrained("monologg/koelectra-small-generator")
>>> tokenizer.tokenize("[CLS] 한국어 ELECTRA를 공유합니다. [SEP]")
['[CLS]', '한국어', 'E', '##L', '##EC', '##T', '##RA', '##를', '공유', '##합니다', '.', '[SEP]']
>>> tokenizer.convert_tokens_to_ids(['[CLS]', '한국어', 'E', '##L', '##EC', '##T', '##RA', '##를', '공유', '##합니다', '.', '[SEP]'])
[2, 18429, 41, 6240, 15229, 6204, 20894, 5689, 12622, 10690, 18, 3]
```
## Example using ElectraForMaskedLM
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="monologg/koelectra-small-generator",
tokenizer="monologg/koelectra-small-generator"
)
print(fill_mask("나는 {} 밥을 먹었다.".format(fill_mask.tokenizer.mask_token)))
```
|
monologg/koelectra-small-v1-goemotions | 2021-02-09T14:40:43.000Z | [
"pytorch",
"electra",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.txt"
]
| monologg | 8 | transformers | ||
monologg/koelectra-small-v2-discriminator | 2020-12-26T16:23:57.000Z | [
"pytorch",
"electra",
"pretraining",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"tokenizer_config.json",
"vocab.txt"
]
| monologg | 1,254 | transformers | ||
monologg/koelectra-small-v2-distilled-korquad-384 | 2020-06-04T17:39:49.000Z | [
"pytorch",
"tflite",
"electra",
"question-answering",
"transformers"
]
| question-answering | [
".gitattributes",
"config.json",
"model.tflite",
"model_8bits.tflite",
"model_fp16.tflite",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.txt"
]
| monologg | 210 | transformers | |
monologg/koelectra-small-v2-generator | 2020-12-26T16:24:12.000Z | [
"pytorch",
"electra",
"masked-lm",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"config.json",
"pytorch_model.bin",
"tokenizer_config.json",
"vocab.txt"
]
| monologg | 41 | transformers | |
monologg/koelectra-small-v3-discriminator | 2020-12-26T16:24:33.000Z | [
"pytorch",
"electra",
"pretraining",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"tokenizer_config.json",
"vocab.txt"
]
| monologg | 28,748 | transformers | ||
monologg/koelectra-small-v3-finetuned-korquad | 2020-10-14T01:45:01.000Z | [
"pytorch",
"electra",
"question-answering",
"transformers"
]
| question-answering | [
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| monologg | 309 | transformers | |
monologg/koelectra-small-v3-generator | 2020-12-26T16:24:47.000Z | [
"pytorch",
"electra",
"masked-lm",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"config.json",
"pytorch_model.bin",
"tokenizer_config.json",
"vocab.txt"
]
| monologg | 27 | transformers | |
monologg/koelectra-small-v3-goemotions | 2021-02-09T14:41:12.000Z | [
"pytorch",
"electra",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.txt"
]
| monologg | 14 | transformers | ||
monsoon-nlp/ar-seq2seq-gender-decoder | 2021-05-19T23:53:24.000Z | [
"pytorch",
"bert",
"lm-head",
"masked-lm",
"ar",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.txt"
]
| monsoon-nlp | 23 | transformers | ---
language: ar
---
# ar-seq2seq-gender (decoder)
This is a seq2seq model (decoder half) to "flip" gender in **first-person** Arabic sentences.
The model can augment your existing Arabic data, or generate counterfactuals
to test a model's decisions (would changing the gender of the subject or speaker change output?).
Intended Examples:
- 'أنا سعيد' <=> 'انا سعيدة'
- 'ركض إلى المتجر' <=> 'ركضت إلى المتجر'
People's names, gender pronouns, gendered words (father, mother), and many other values are currently unchanged by this model. Future versions may be trained on more data.
## Sample Code
```
import torch
from transformers import AutoTokenizer, EncoderDecoderModel
model = EncoderDecoderModel.from_encoder_decoder_pretrained(
"monsoon-nlp/ar-seq2seq-gender-encoder",
"monsoon-nlp/ar-seq2seq-gender-decoder",
min_length=40
)
tokenizer = AutoTokenizer.from_pretrained('monsoon-nlp/ar-seq2seq-gender-decoder') # same as MARBERT original
input_ids = torch.tensor(tokenizer.encode("أنا سعيدة")).unsqueeze(0)
generated = model.generate(input_ids, decoder_start_token_id=model.config.decoder.pad_token_id)
tokenizer.decode(generated.tolist()[0][1 : len(input_ids[0]) - 1])
> 'انا سعيد'
```
https://colab.research.google.com/drive/1S0kE_2WiV82JkqKik_sBW-0TUtzUVmrV?usp=sharing
## Training
I originally developed
<a href="https://github.com/MonsoonNLP/el-la">a gender flip Python script</a>
for Spanish sentences, using
<a href="https://huggingface.co/dccuchile/bert-base-spanish-wwm-uncased">BETO</a>,
and spaCy. More about this project: https://medium.com/ai-in-plain-english/gender-bias-in-spanish-bert-1f4d76780617
The Arabic model encoder and decoder started with weights and vocabulary from
<a href="https://github.com/UBC-NLP/marbert">MARBERT from UBC-NLP</a>,
and was trained on the
<a href="https://camel.abudhabi.nyu.edu/arabic-parallel-gender-corpus/">Arabic Parallel Gender Corpus</a>
from NYU Abu Dhabi. The text is first-person sentences from OpenSubtitles, with parallel
gender-reinflected sentences generated by Arabic speakers.
Training notebook: https://colab.research.google.com/drive/1TuDfnV2gQ-WsDtHkF52jbn699bk6vJZV
## Non-binary gender
This model is useful to generate male and female text samples, but falls
short of capturing gender diversity in the world and in the Arabic
language. This subject is discussed in the bias statement of the
<a href="https://www.aclweb.org/anthology/2020.gebnlp-1.12/">Gender Reinflection paper</a>.
|
monsoon-nlp/ar-seq2seq-gender-encoder | 2021-05-19T23:54:14.000Z | [
"pytorch",
"jax",
"bert",
"ar",
"transformers"
]
| [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.txt"
]
| monsoon-nlp | 32 | transformers | ---
language: ar
---
# ar-seq2seq-gender (encoder)
This is a seq2seq model (encoder half) to "flip" gender in **first-person** Arabic sentences.
The model can augment your existing Arabic data, or generate counterfactuals
to test a model's decisions (would changing the gender of the subject or speaker change output?).
Intended Examples:
- 'أنا سعيد' <=> 'انا سعيدة'
- 'ركض إلى المتجر' <=> 'ركضت إلى المتجر'
People's names, gender pronouns, gendered words (father, mother), and many other values are currently unchanged by this model. Future versions may be trained on more data.
## Sample Code
```
import torch
from transformers import AutoTokenizer, EncoderDecoderModel
model = EncoderDecoderModel.from_encoder_decoder_pretrained(
"monsoon-nlp/ar-seq2seq-gender-encoder",
"monsoon-nlp/ar-seq2seq-gender-decoder",
min_length=40
)
tokenizer = AutoTokenizer.from_pretrained('monsoon-nlp/ar-seq2seq-gender-decoder') # same as MARBERT original
input_ids = torch.tensor(tokenizer.encode("أنا سعيدة")).unsqueeze(0)
generated = model.generate(input_ids, decoder_start_token_id=model.config.decoder.pad_token_id)
tokenizer.decode(generated.tolist()[0][1 : len(input_ids[0]) - 1])
> 'انا سعيد'
```
https://colab.research.google.com/drive/1S0kE_2WiV82JkqKik_sBW-0TUtzUVmrV?usp=sharing
## Training
I originally developed
<a href="https://github.com/MonsoonNLP/el-la">a gender flip Python script</a>
for Spanish sentences, using
<a href="https://huggingface.co/dccuchile/bert-base-spanish-wwm-uncased">BETO</a>,
and spaCy. More about this project: https://medium.com/ai-in-plain-english/gender-bias-in-spanish-bert-1f4d76780617
The Arabic model encoder and decoder started with weights and vocabulary from
<a href="https://github.com/UBC-NLP/marbert">MARBERT from UBC-NLP</a>,
and was trained on the
<a href="https://camel.abudhabi.nyu.edu/arabic-parallel-gender-corpus/">Arabic Parallel Gender Corpus</a>
from NYU Abu Dhabi. The text is first-person sentences from OpenSubtitles, with parallel
gender-reinflected sentences generated by Arabic speakers.
Training notebook: https://colab.research.google.com/drive/1TuDfnV2gQ-WsDtHkF52jbn699bk6vJZV
## Non-binary gender
This model is useful to generate male and female text samples, but falls
short of capturing gender diversity in the world and in the Arabic
language. This subject is discussed in the bias statement of the
<a href="https://www.aclweb.org/anthology/2020.gebnlp-1.12/">Gender Reinflection paper</a>.
|
|
monsoon-nlp/bangla-electra | 2020-07-29T07:58:53.000Z | [
"pytorch",
"tf",
"electra",
"bn",
"arxiv:2004.07807",
"transformers"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"vocab.txt"
]
| monsoon-nlp | 100 | transformers | ---
language: bn
---
# Bangla-Electra
This is a second attempt at a Bangla/Bengali language model trained with
Google Research's [ELECTRA](https://github.com/google-research/electra).
Tokenization and pre-training CoLab: https://colab.research.google.com/drive/1gpwHvXAnNQaqcu-YNx1kafEVxz07g2jL
V1 - 120,000 steps; V2 - 190,000 steps
## Classification
Classification with SimpleTransformers: https://colab.research.google.com/drive/1vltPI81atzRvlALv4eCvEB0KdFoEaCOb
On Soham Chatterjee's [news classification task](https://github.com/soham96/Bangla2Vec):
(Random: 16.7%, mBERT: 72.3%, Bangla-Electra: 82.3%)
Similar to mBERT on some tasks and configurations described in https://arxiv.org/abs/2004.07807
## Question Answering
This model can be used for Question Answering - this notebook uses Bangla questions from Google's TyDi dataset:
https://colab.research.google.com/drive/1i6fidh2tItf_-IDkljMuaIGmEU6HT2Ar
## Corpus
Trained on a web crawl from https://oscar-corpus.com/ (deduped version, 5.8GB) and 1 July 2020 dump of bn.wikipedia.org (414MB)
## Vocabulary
Included as vocab.txt in the upload - vocab_size is 29898
|
|
monsoon-nlp/bert-base-thai | 2021-05-19T23:55:25.000Z | [
"pytorch",
"jax",
"bert",
"th",
"arxiv:1609.08144",
"arxiv:1508.07909",
"transformers"
]
| [
".gitattributes",
"LICENSE.txt",
"README.md",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.txt"
]
| monsoon-nlp | 424 | transformers | ---
language: th
---
# BERT-th
Adapted from https://github.com/ThAIKeras/bert for HuggingFace/Transformers library
## Pre-tokenization
You must run the original ThaiTokenizer to have your tokenization match that of the original model. If you skip this step, you will not do much better than
mBERT or random chance!
```bash
pip install pythainlp six sentencepiece==0.0.9
git clone https://github.com/ThAIKeras/bert
# download .vocab and .model files from ThAIKeras readme
```
Then set up ThaiTokenizer class - this is modified slightly to
remove a TensorFlow dependency.
```python
import collections
import unicodedata
import six
def convert_to_unicode(text):
"""Converts `text` to Unicode (if it's not already), assuming utf-8 input."""
if six.PY3:
if isinstance(text, str):
return text
elif isinstance(text, bytes):
return text.decode("utf-8", "ignore")
else:
raise ValueError("Unsupported string type: %s" % (type(text)))
elif six.PY2:
if isinstance(text, str):
return text.decode("utf-8", "ignore")
elif isinstance(text, unicode):
return text
else:
raise ValueError("Unsupported string type: %s" % (type(text)))
else:
raise ValueError("Not running on Python2 or Python 3?")
def load_vocab(vocab_file):
vocab = collections.OrderedDict()
index = 0
with open(vocab_file, "r") as reader:
while True:
token = reader.readline()
if token.split(): token = token.split()[0] # to support SentencePiece vocab file
token = convert_to_unicode(token)
if not token:
break
token = token.strip()
vocab[token] = index
index += 1
return vocab
#####
from bert.bpe_helper import BPE
import sentencepiece as spm
def convert_by_vocab(vocab, items):
output = []
for item in items:
output.append(vocab[item])
return output
class ThaiTokenizer(object):
"""Tokenizes Thai texts."""
def __init__(self, vocab_file, spm_file):
self.vocab = load_vocab(vocab_file)
self.inv_vocab = {v: k for k, v in self.vocab.items()}
self.bpe = BPE(vocab_file)
self.s = spm.SentencePieceProcessor()
self.s.Load(spm_file)
def tokenize(self, text):
bpe_tokens = self.bpe.encode(text).split(' ')
spm_tokens = self.s.EncodeAsPieces(text)
tokens = bpe_tokens if len(bpe_tokens) < len(spm_tokens) else spm_tokens
split_tokens = []
for token in tokens:
new_token = token
if token.startswith('_') and not token in self.vocab:
split_tokens.append('_')
new_token = token[1:]
if not new_token in self.vocab:
split_tokens.append('<unk>')
else:
split_tokens.append(new_token)
return split_tokens
def convert_tokens_to_ids(self, tokens):
return convert_by_vocab(self.vocab, tokens)
def convert_ids_to_tokens(self, ids):
return convert_by_vocab(self.inv_vocab, ids)
```
Then pre-tokenizing your own text:
```python
from pythainlp import sent_tokenize
tokenizer = ThaiTokenizer(vocab_file='th.wiki.bpe.op25000.vocab', spm_file='th.wiki.bpe.op25000.model')
og_text = "กรุงเทพมหานคร..."
split_sentences = ' '.join(sent_tokenize(txt))
split_words = ' '.join(tokenizer.tokenize(split_sentences))
split_words
> "▁ร้าน อาหาร ใหญ่มาก กก กก กก ▁ <unk> เลี้ยว..."
```
Original README follows:
---
Google's [**BERT**](https://github.com/google-research/bert) is currently the state-of-the-art method of pre-training text representations which additionally provides multilingual models. ~~Unfortunately, Thai is the only one in 103 languages that is excluded due to difficulties in word segmentation.~~
BERT-th presents the Thai-only pre-trained model based on the BERT-Base structure. It is now available to download.
* **[`BERT-Base, Thai`](https://drive.google.com/open?id=1J3uuXZr_Se_XIFHj7zlTJ-C9wzI9W_ot)**: BERT-Base architecture, Thai-only model
BERT-th also includes relevant codes and scripts along with the pre-trained model, all of which are the modified versions of those in the original BERT project.
## Preprocessing
### Data Source
Training data for BERT-th come from [the latest article dump of Thai Wikipedia](https://dumps.wikimedia.org/thwiki/latest/thwiki-latest-pages-articles.xml.bz2) on November 2, 2018. The raw texts are extracted by using [WikiExtractor](https://github.com/attardi/wikiextractor).
### Sentence Segmentation
Input data need to be segmented into separate sentences before further processing by BERT modules. Since Thai language has no explicit marker at the end of a sentence, it is quite problematic to pinpoint sentence boundaries. To the best of our knowledge, there is still no implementation of Thai sentence segmentation elsewhere. So, in this project, sentence segmentation is done by applying simple heuristics, considering spaces, sentence length and common conjunctions.
After preprocessing, the training corpus consists of approximately 2 million sentences and 40 million words (counting words after word segmentation by [PyThaiNLP](https://github.com/PyThaiNLP/pythainlp)). The plain and segmented texts can be downloaded **[`here`](https://drive.google.com/file/d/1QZSOpikO6Qc02gRmyeb_UiRLtTmUwGz1/view?usp=sharing)**.
## Tokenization
BERT uses [WordPiece](https://arxiv.org/pdf/1609.08144.pdf) as a tokenization mechanism. But it is Google internal, we cannot apply existing Thai word segmentation and then utilize WordPiece to learn the set of subword units. The best alternative is [SentencePiece](https://github.com/google/sentencepiece) which implements [BPE](https://arxiv.org/abs/1508.07909) and needs no word segmentation.
In this project, we adopt a pre-trained Thai SentencePiece model from [BPEmb](https://github.com/bheinzerling/bpemb). The model of 25000 vocabularies is chosen and the vocabulary file has to be augmented with BERT's special characters, including '[PAD]', '[CLS]', '[SEP]' and '[MASK]'. The model and vocabulary files can be downloaded **[`here`](https://drive.google.com/file/d/1F7pCgt3vPlarI9RxKtOZUrC_67KMNQ1W/view?usp=sharing)**.
`SentencePiece` and `bpe_helper.py` from BPEmb are both used to tokenize data. `ThaiTokenizer class` has been added to BERT's `tokenization.py` for tokenizing Thai texts.
## Pre-training
The data can be prepared before pre-training by using this script.
```shell
export BPE_DIR=/path/to/bpe
export TEXT_DIR=/path/to/text
export DATA_DIR=/path/to/data
python create_pretraining_data.py \
--input_file=$TEXT_DIR/thaiwikitext_sentseg \
--output_file=$DATA_DIR/tf_examples.tfrecord \
--vocab_file=$BPE_DIR/th.wiki.bpe.op25000.vocab \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--masked_lm_prob=0.15 \
--random_seed=12345 \
--dupe_factor=5 \
--thai_text=True \
--spm_file=$BPE_DIR/th.wiki.bpe.op25000.model
```
Then, the following script can be run to learn a model from scratch.
```shell
export DATA_DIR=/path/to/data
export BERT_BASE_DIR=/path/to/bert_base
python run_pretraining.py \
--input_file=$DATA_DIR/tf_examples.tfrecord \
--output_dir=$BERT_BASE_DIR \
--do_train=True \
--do_eval=True \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--train_batch_size=32 \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--num_train_steps=1000000 \
--num_warmup_steps=100000 \
--learning_rate=1e-4 \
--save_checkpoints_steps=200000
```
We have trained the model for 1 million steps. On Tesla K80 GPU, it took around 20 days to complete. Though, we provide a snapshot at 0.8 million steps because it yields better results for downstream classification tasks.
## Downstream Classification Tasks
### XNLI
[XNLI](http://www.nyu.edu/projects/bowman/xnli/) is a dataset for evaluating a cross-lingual inferential classification task. The development and test sets contain 15 languages which data are thoroughly edited. The machine-translated versions of training data are also provided.
The Thai-only pre-trained BERT model can be applied to the XNLI task by using training data which are translated to Thai. Spaces between words in the training data need to be removed to make them consistent with inputs in the pre-training step. The processed files of XNLI related to Thai language can be downloaded **[`here`](https://drive.google.com/file/d/1ZAk1JfR6a0TSCkeyQ-EkRtk1w_mQDWFG/view?usp=sharing)**.
Afterwards, the XNLI task can be learned by using this script.
```shell
export BPE_DIR=/path/to/bpe
export XNLI_DIR=/path/to/xnli
export OUTPUT_DIR=/path/to/output
export BERT_BASE_DIR=/path/to/bert_base
python run_classifier.py \
--task_name=XNLI \
--do_train=true \
--do_eval=true \
--data_dir=$XNLI_DIR \
--vocab_file=$BPE_DIR/th.wiki.bpe.op25000.vocab \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=5e-5 \
--num_train_epochs=2.0 \
--output_dir=$OUTPUT_DIR \
--xnli_language=th \
--spm_file=$BPE_DIR/th.wiki.bpe.op25000.model
```
This table compares the Thai-only model with XNLI baselines and the Multilingual Cased model which is also trained by using translated data.
<!-- Use html table because github markdown doesn't support colspan -->
<table>
<tr>
<td colspan="2" align="center"><b>XNLI Baseline</b></td>
<td colspan="2" align="center"><b>BERT</b></td>
</tr>
<tr>
<td align="center">Translate Train</td>
<td align="center">Translate Test</td>
<td align="center">Multilingual Model</td>
<td align="center">Thai-only Model</td>
</tr>
<td align="center">62.8</td>
<td align="center">64.4</td>
<td align="center">66.1</td>
<td align="center"><b>68.9</b></td>
</table>
### Wongnai Review Dataset
Wongnai Review Dataset collects restaurant reviews and ratings from [Wongnai](https://www.wongnai.com/) website. The task is to classify a review into one of five ratings (1 to 5 stars). The dataset can be downloaded **[`here`](https://github.com/wongnai/wongnai-corpus)** and the following script can be run to use the Thai-only model for this task.
```shell
export BPE_DIR=/path/to/bpe
export WONGNAI_DIR=/path/to/wongnai
export OUTPUT_DIR=/path/to/output
export BERT_BASE_DIR=/path/to/bert_base
python run_classifier.py \
--task_name=wongnai \
--do_train=true \
--do_predict=true \
--data_dir=$WONGNAI_DIR \
--vocab_file=$BPE_DIR/th.wiki.bpe.op25000.vocab \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=5e-5 \
--num_train_epochs=2.0 \
--output_dir=$OUTPUT_DIR \
--spm_file=$BPE_DIR/th.wiki.bpe.op25000.model
```
Without additional preprocessing and further fine-tuning, the Thai-only BERT model can achieve 0.56612 and 0.57057 for public and private test-set scores respectively.
|
|
monsoon-nlp/dialect-ar-gpt-2021 | 2021-05-23T09:59:23.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"ar",
"arxiv:2012.15520",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"README.md",
"added_tokens.json",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.json"
]
| monsoon-nlp | 35 | transformers | ---
language: ar
---
# Dialect-AR-GPT-2021
## Finetuned AraGPT-2 demo
This model started with [AraGPT2-Medium](https://huggingface.co/aubmindlab/aragpt2-medium),
from AUB MIND Lab.
This model was then finetuned on dialect datasets from Qatar University, University of British Columbia / NLP,
and Johns Hopkins University / LREC for 10 epochs.
You can use special tokens to prompt five dialects: `[EGYPTIAN]`, `[GULF]`, `[LEVANTINE]`, `[MAGHREBI]`, or `[MSA]`, followed by a space.
```
from simpletransformers.language_generation import LanguageGenerationModel
model = LanguageGenerationModel("gpt2", "monsoon-nlp/dialect-ar-gpt-2021")
model.generate('[GULF] ' + "مدينتي هي", { 'max_length': 100 })
```
There is NO content filtering in the current version; do not use for public-facing
text generation!
## Training and Finetuning details
Original model: https://huggingface.co/aubmindlab/aragpt2-medium
I inserted new tokens into the tokenizer, finetuned the model on the dialect samples, and exported the new model.
Notebook: https://colab.research.google.com/drive/19C0zbkSCt5ncVCa4kY-ik9hSEiJcjI-F
## Citations
AraGPT2 model:
```
@misc{antoun2020aragpt2,
title={AraGPT2: Pre-Trained Transformer for Arabic Language Generation},
author={Wissam Antoun and Fady Baly and Hazem Hajj},
year={2020},
eprint={2012.15520},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
Dialect data sources:
- https://qspace.qu.edu.qa/handle/10576/15265
- https://github.com/UBC-NLP/aoc_id
- https://github.com/ryancotterell/arabic_dialect_annotation
|
monsoon-nlp/dv-labse | 2021-05-19T23:58:00.000Z | [
"pytorch",
"jax",
"bert",
"masked-lm",
"dv",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| monsoon-nlp | 14 | transformers | ---
language: dv
---
# dv-labse
This is an experiment in cross-lingual transfer learning, to insert Dhivehi word and
word-piece tokens into Google's LaBSE model.
- Original model weights: https://huggingface.co/setu4993/LaBSE
- Original model announcement: https://ai.googleblog.com/2020/08/language-agnostic-bert-sentence.html
This currently outperforms dv-wave and dv-MuRIL (a similar transfer learning model) on
the Maldivian News Classification task https://github.com/Sofwath/DhivehiDatasets
- mBERT: 52%
- dv-wave (ELECTRA): 89%
- dv-muril: 90.7%
- dv-labse: 91.3-91.5% (may continue training)
## Training
- Start with LaBSE (similar to mBERT) with no Thaana vocabulary
- Based on PanLex dictionaries, attach 1,100 Dhivehi words to Sinhalese or English embeddings
- Add remaining words and word-pieces from dv-wave's vocabulary to vocab.txt
- Continue BERT pretraining on Dhivehi text
CoLab notebook:
https://colab.research.google.com/drive/1CUn44M2fb4Qbat2pAvjYqsPvWLt1Novi
|
monsoon-nlp/dv-muril | 2021-05-20T00:01:51.000Z | [
"pytorch",
"jax",
"bert",
"masked-lm",
"dv",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.txt"
]
| monsoon-nlp | 22 | transformers | ---
language: dv
---
# dv-muril
This is an experiment in transfer learning, to insert Dhivehi word and
word-piece tokens into Google's MuRIL model.
This BERT-based model currently performs better than dv-wave ELECTRA on
the Maldivian News Classification task https://github.com/Sofwath/DhivehiDatasets
## Training
- Start with MuRIL (similar to mBERT) with no Thaana vocabulary
- Based on PanLex dictionaries, attach 1,100 Dhivehi words to Malayalam or English embeddings
- Add remaining words and word-pieces from BertWordPieceTokenizer / vocab.txt
- Continue BERT pretraining
## Performance
- mBERT: 52%
- dv-wave (ELECTRA, 30k vocab): 89%
- dv-muril (10k vocab) before BERT pretraining step: 89.8%
- previous dv-muril (30k vocab): 90.7%
- dv-muril (10k vocab): 91.6%
CoLab notebook:
https://colab.research.google.com/drive/113o6vkLZRkm6OwhTHrvE0x6QPpavj0fn
|
monsoon-nlp/dv-wave | 2020-12-11T21:51:38.000Z | [
"pytorch",
"tf",
"electra",
"dv",
"transformers"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"vocab.txt"
]
| monsoon-nlp | 113 | transformers | ---
language: dv
---
# dv-wave
This is a second attempt at a Dhivehi language model trained with
Google Research's [ELECTRA](https://github.com/google-research/electra).
Tokenization and pre-training CoLab: https://colab.research.google.com/drive/1ZJ3tU9MwyWj6UtQ-8G7QJKTn-hG1uQ9v?usp=sharing
Using SimpleTransformers to classify news https://colab.research.google.com/drive/1KnyQxRNWG_yVwms_x9MUAqFQVeMecTV7?usp=sharing
V1: similar performance to mBERT on news classification task after finetuning for 3 epochs (52%)
V2: fixed tokenizers ```do_lower_case=False``` and ```strip_accents=False``` to preserve vowel signs of Dhivehi
dv-wave: 89% to mBERT: 52%
## Corpus
Trained on @Sofwath's 307MB corpus of Dhivehi text: https://github.com/Sofwath/DhivehiDatasets - this repo also contains the news classification task CSV
[OSCAR](https://oscar-corpus.com/) was considered but has not been added to pretraining; as of
this writing their web crawl has 126MB of Dhivehi text (79MB deduped).
## Vocabulary
Included as vocab.txt in the upload - vocab_size is 29874
|
|
monsoon-nlp/es-seq2seq-gender-decoder | 2021-05-20T00:09:13.000Z | [
"pytorch",
"bert",
"lm-head",
"masked-lm",
"es",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.txt"
]
| monsoon-nlp | 16 | transformers | ---
language: es
---
# es-seq2seq-gender (decoder)
This is a seq2seq model (decoder half) to "flip" gender in Spanish sentences.
The model can augment your existing Spanish data, or generate counterfactuals
to test a model's decisions (would changing the gender of the subject or speaker change output?).
Intended Examples:
- el profesor viejo => la profesora vieja (article, noun, adjective all flip)
- una actriz => un actor (irregular noun)
- el lingüista => la lingüista (irregular noun)
- la biblioteca => la biblioteca (no person, no flip)
People's names are unchanged in this version, but you can use packages
such as https://pypi.org/project/gender-guesser/
## Sample code
https://colab.research.google.com/drive/1Ta_YkXx93FyxqEu_zJ-W23PjPumMNHe5
```
import torch
from transformers import AutoTokenizer, EncoderDecoderModel
model = EncoderDecoderModel.from_encoder_decoder_pretrained("monsoon-nlp/es-seq2seq-gender-encoder", "monsoon-nlp/es-seq2seq-gender-decoder")
tokenizer = AutoTokenizer.from_pretrained('monsoon-nlp/es-seq2seq-gender-decoder') # all are same as BETO uncased original
input_ids = torch.tensor(tokenizer.encode("la profesora vieja")).unsqueeze(0)
generated = model.generate(input_ids, decoder_start_token_id=model.config.decoder.pad_token_id)
tokenizer.decode(generated.tolist()[0])
> '[PAD] el profesor viejo profesor viejo profesor...'
```
## Training
I originally developed
<a href="https://github.com/MonsoonNLP/el-la">a gender flip Python script</a>
with
<a href="https://huggingface.co/dccuchile/bert-base-spanish-wwm-uncased">BETO</a>,
the Spanish-language BERT from Universidad de Chile,
and spaCy to parse dependencies in sentences.
More about this project: https://medium.com/ai-in-plain-english/gender-bias-in-spanish-bert-1f4d76780617
The seq2seq model is trained on gender-flipped text from that script run on the
<a href="https://huggingface.co/datasets/muchocine">muchocine dataset</a>,
and the first 6,853 lines from the
<a href="https://oscar-corpus.com/">OSCAR corpus</a>
(Spanish ded-duped).
The encoder and decoder started with weights and vocabulary from BETO (uncased).
## Non-binary gender
This model is useful to generate male and female text samples, but falls
short of capturing gender diversity in the world and in the Spanish
language. Some communities prefer the plural -@s to represent
-os and -as, or -e and -es for gender-neutral or mixed-gender plural,
or use fewer gendered professional nouns (la juez and not jueza). This is not yet
embraced by the Royal Spanish Academy
and is not represented in the corpora and tokenizers used to build this project.
This seq2seq project and script could, in the future, help generate more text samples
and prepare NLP models to understand us all better.
#### Sources
- https://www.nytimes.com/2020/04/15/world/americas/argentina-gender-language.html
- https://www.washingtonpost.com/dc-md-va/2019/12/05/teens-argentina-are-leading-charge-gender-neutral-language/?arc404=true
- https://www.theguardian.com/world/2020/jan/19/gender-neutral-language-battle-spain
- https://es.wikipedia.org/wiki/Lenguaje_no_sexista
- https://remezcla.com/culture/argentine-company-re-imagines-little-prince-gender-neutral-language/
|
monsoon-nlp/es-seq2seq-gender-encoder | 2021-05-20T00:09:54.000Z | [
"pytorch",
"jax",
"bert",
"es",
"transformers"
]
| [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.txt"
]
| monsoon-nlp | 15 | transformers | ---
language: es
---
# es-seq2seq-gender (encoder)
This is a seq2seq model (encoder half) to "flip" gender in Spanish sentences.
The model can augment your existing Spanish data, or generate counterfactuals
to test a model's decisions (would changing the gender of the subject or speaker change output?).
Intended Examples:
- el profesor viejo => la profesora vieja (article, noun, adjective all flip)
- una actriz => un actor (irregular noun)
- el lingüista => la lingüista (irregular noun)
- la biblioteca => la biblioteca (no person, no flip)
People's names are unchanged in this version, but you can use packages
such as https://pypi.org/project/gender-guesser/
## Sample code
https://colab.research.google.com/drive/1Ta_YkXx93FyxqEu_zJ-W23PjPumMNHe5
```
import torch
from transformers import AutoTokenizer, EncoderDecoderModel
model = EncoderDecoderModel.from_encoder_decoder_pretrained("monsoon-nlp/es-seq2seq-gender-encoder", "monsoon-nlp/es-seq2seq-gender-decoder")
tokenizer = AutoTokenizer.from_pretrained('monsoon-nlp/es-seq2seq-gender-decoder') # all are same as BETO uncased original
input_ids = torch.tensor(tokenizer.encode("la profesora vieja")).unsqueeze(0)
generated = model.generate(input_ids, decoder_start_token_id=model.config.decoder.pad_token_id)
tokenizer.decode(generated.tolist()[0])
> '[PAD] el profesor viejo profesor viejo profesor...'
```
## Training
I originally developed
<a href="https://github.com/MonsoonNLP/el-la">a gender flip Python script</a>
with
<a href="https://huggingface.co/dccuchile/bert-base-spanish-wwm-uncased">BETO</a>,
the Spanish-language BERT from Universidad de Chile,
and spaCy to parse dependencies in sentences.
More about this project: https://medium.com/ai-in-plain-english/gender-bias-in-spanish-bert-1f4d76780617
The seq2seq model is trained on gender-flipped text from that script run on the
<a href="https://huggingface.co/datasets/muchocine">muchocine dataset</a>,
and the first 6,853 lines from the
<a href="https://oscar-corpus.com/">OSCAR corpus</a>
(Spanish ded-duped).
The encoder and decoder started with weights and vocabulary from BETO (uncased).
## Non-binary gender
This model is useful to generate male and female text samples, but falls
short of capturing gender diversity in the world and in the Spanish
language. Some communities prefer the plural -@s to represent
-os and -as, or -e and -es for gender-neutral or mixed-gender plural,
or use fewer gendered professional nouns (la juez and not jueza). This is not yet
embraced by the Royal Spanish Academy
and is not represented in the corpora and tokenizers used to build this project.
This seq2seq project and script could, in the future, help generate more text samples
and prepare NLP models to understand us all better.
#### Sources
- https://www.nytimes.com/2020/04/15/world/americas/argentina-gender-language.html
- https://www.washingtonpost.com/dc-md-va/2019/12/05/teens-argentina-are-leading-charge-gender-neutral-language/?arc404=true
- https://www.theguardian.com/world/2020/jan/19/gender-neutral-language-battle-spain
- https://es.wikipedia.org/wiki/Lenguaje_no_sexista
- https://remezcla.com/culture/argentine-company-re-imagines-little-prince-gender-neutral-language/
|
|
monsoon-nlp/gpt-nyc-small | 2021-05-23T10:01:10.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"README.md",
"added_tokens.json",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| monsoon-nlp | 20 | transformers | # GPT-NYC-small
## About
GPT2 (small version on HF) fine-tuned on questions and responses from https://reddit.com/r/asknyc
I filtered comments to ones with scores >= 3, and responding directly
to the original post ( = ignoring responses to other commenters).
I also added many tokens which were common on /r/AskNYC but missing from
GPT2.
The [gpt-nyc](https://huggingface.co/monsoon-nlp/gpt-nyc) repo is based
on GPT2-Medium and comes off more accurate, but the answers from this
test model struck me as humorous for their strings of subway transfers
or rambling answers about apartments.
Try prompting with ```question?``` plus two spaces, or ```question? - more info``` plus two spaces
## Blog
https://mapmeld.medium.com/gpt-nyc-part-1-9cb698b2e3d
## Notebooks
### Data processing / new tokens
https://colab.research.google.com/drive/13BOw0uekoAYB4jjQtaXTn6J_VHatiRLu
### Fine-tuning GPT2 (small)
https://colab.research.google.com/drive/1FnXcAh4H-k8dAzixkV5ieygV96ePh3lR
### Predictive text and probabilities
Scroll to end of
https://colab.research.google.com/drive/1FnXcAh4H-k8dAzixkV5ieygV96ePh3lR
to see how to install git-lfs and trick ecco into loading this.
|
monsoon-nlp/gpt-nyc | 2021-05-23T10:03:21.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"README.md",
"added_tokens.json",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| monsoon-nlp | 39 | transformers | # GPT-NYC
## About
GPT2-Medium fine-tuned on questions and responses from https://reddit.com/r/asknyc
I filtered comments to ones with scores >= 3, and responding directly
to the original post ( = ignoring responses to other commenters).
I added tokens to match NYC neighborhoods, subway stations, foods, and other
common terms in the original batches of questions and comments.
You would be surprised what is missing from GPT tokens!
Try prompting with ```question? %% ``` or ```question? - more info %%```
## Status
I would like to continue by:
- fine-tuning GPT2-Large with a larger dataset of questions
- examining bias and toxicity
- examining memorization vs. original responses
- releasing a reusable benchmark
## Blog
https://mapmeld.medium.com/gpt-nyc-part-1-9cb698b2e3d
## Notebooks
### Data processing / new tokens
https://colab.research.google.com/drive/13BOw0uekoAYB4jjQtaXTn6J_VHatiRLu
### Fine-tuning GPT2 (small)
https://colab.research.google.com/drive/1FnXcAh4H-k8dAzixkV5ieygV96ePh3lR
### Fine-tuning GPT2-Medium
Same code as small, but on Google Cloud to use an A100 GPU
### Predictive text and probabilities
Scroll to end of
https://colab.research.google.com/drive/1FnXcAh4H-k8dAzixkV5ieygV96ePh3lR
to see how to install git-lfs and trick ecco into loading this.
|
monsoon-nlp/gpt-winowhy | 2021-05-22T05:03:46.000Z | [
"pytorch",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"added_tokens.json",
"config.json",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| monsoon-nlp | 11 | transformers | |
monsoon-nlp/hindi-bert | 2020-08-26T22:14:33.000Z | [
"pytorch",
"tf",
"electra",
"hi",
"transformers"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"vocab.txt"
]
| monsoon-nlp | 145 | transformers | ---
language: hi
---
# Releasing Hindi ELECTRA model
This is a first attempt at a Hindi language model trained with Google Research's [ELECTRA](https://github.com/google-research/electra).
**Consider using this newer, larger model: https://huggingface.co/monsoon-nlp/hindi-tpu-electra**
<a href="https://colab.research.google.com/drive/1R8TciRSM7BONJRBc9CBZbzOmz39FTLl_">Tokenization and training CoLab</a>
I originally used <a href="https://github.com/monsoonNLP/transformers">a modified ELECTRA</a> for finetuning, but now use SimpleTransformers.
<a href="https://medium.com/@mapmeld/teaching-hindi-to-electra-b11084baab81">Blog post</a> - I was greatly influenced by: https://huggingface.co/blog/how-to-train
## Example Notebooks
This small model has comparable results to Multilingual BERT on <a href="https://colab.research.google.com/drive/18FQxp9QGOORhMENafQilEmeAo88pqVtP">BBC Hindi news classification</a>
and on <a href="https://colab.research.google.com/drive/1UYn5Th8u7xISnPUBf72at1IZIm3LEDWN">Hindi movie reviews / sentiment analysis</a> (using SimpleTransformers)
You can get higher accuracy using ktrain by adjusting learning rate (also: changing model_type in config.json - this is an open issue with ktrain): https://colab.research.google.com/drive/1mSeeSfVSOT7e-dVhPlmSsQRvpn6xC05w?usp=sharing
Question-answering on MLQA dataset: https://colab.research.google.com/drive/1i6fidh2tItf_-IDkljMuaIGmEU6HT2Ar#scrollTo=IcFoAHgKCUiQ
A larger model (<a href="https://huggingface.co/monsoon-nlp/hindi-tpu-electra">Hindi-TPU-Electra</a>) using ELECTRA base size outperforms both models on Hindi movie reviews / sentiment analysis, but
does not perform as well on the BBC news classification task.
## Corpus
Download: https://drive.google.com/drive/folders/1SXzisKq33wuqrwbfp428xeu_hDxXVUUu?usp=sharing
The corpus is two files:
- Hindi CommonCrawl deduped by OSCAR https://traces1.inria.fr/oscar/
- latest Hindi Wikipedia ( https://dumps.wikimedia.org/hiwiki/ ) + WikiExtractor to txt
Bonus notes:
- Adding English wiki text or parallel corpus could help with cross-lingual tasks and training
## Vocabulary
https://drive.google.com/file/d/1-6tXrii3tVxjkbrpSJE9MOG_HhbvP66V/view?usp=sharing
Bonus notes:
- Created with HuggingFace Tokenizers; you can increase vocabulary size and re-train; remember to change ELECTRA vocab_size
## Training
Structure your files, with data-dir named "trainer" here
```
trainer
- vocab.txt
- pretrain_tfrecords
-- (all .tfrecord... files)
- models
-- modelname
--- checkpoint
--- graph.pbtxt
--- model.*
```
CoLab notebook gives examples of GPU vs. TPU setup
[configure_pretraining.py](https://github.com/google-research/electra/blob/master/configure_pretraining.py)
## Conversion
Use this process to convert an in-progress or completed ELECTRA checkpoint to a Transformers-ready model:
```
git clone https://github.com/huggingface/transformers
python ./transformers/src/transformers/convert_electra_original_tf_checkpoint_to_pytorch.py
--tf_checkpoint_path=./models/checkpointdir
--config_file=config.json
--pytorch_dump_path=pytorch_model.bin
--discriminator_or_generator=discriminator
python
```
```
from transformers import TFElectraForPreTraining
model = TFElectraForPreTraining.from_pretrained("./dir_with_pytorch", from_pt=True)
model.save_pretrained("tf")
```
Once you have formed one directory with config.json, pytorch_model.bin, tf_model.h5, special_tokens_map.json, tokenizer_config.json, and vocab.txt on the same level, run:
```
transformers-cli upload directory
```
|
|
monsoon-nlp/hindi-tpu-electra | 2020-08-26T22:19:45.000Z | [
"pytorch",
"tf",
"electra",
"hi",
"transformers"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"vocab.txt"
]
| monsoon-nlp | 108 | transformers | ---
language: hi
---
# Hindi language model
## Trained with ELECTRA base size settings
<a href="https://colab.research.google.com/drive/1R8TciRSM7BONJRBc9CBZbzOmz39FTLl_">Tokenization and training CoLab</a>
## Example Notebooks
This model outperforms Multilingual BERT on <a href="https://colab.research.google.com/drive/1UYn5Th8u7xISnPUBf72at1IZIm3LEDWN">Hindi movie reviews / sentiment analysis</a> (using SimpleTransformers)
You can get higher accuracy using ktrain + TensorFlow, where you can adjust learning rate and
other hyperparameters: https://colab.research.google.com/drive/1mSeeSfVSOT7e-dVhPlmSsQRvpn6xC05w?usp=sharing
Question-answering on MLQA dataset: https://colab.research.google.com/drive/1i6fidh2tItf_-IDkljMuaIGmEU6HT2Ar#scrollTo=IcFoAHgKCUiQ
A smaller model (<a href="https://huggingface.co/monsoon-nlp/hindi-bert">Hindi-BERT</a>) performs better on a BBC news classification task.
## Corpus
The corpus is two files:
- Hindi CommonCrawl deduped by OSCAR https://traces1.inria.fr/oscar/
- latest Hindi Wikipedia ( https://dumps.wikimedia.org/hiwiki/ ) + WikiExtractor to txt
Bonus notes:
- Adding English wiki text or parallel corpus could help with cross-lingual tasks and training
## Vocabulary
https://drive.google.com/file/d/1-6tXrii3tVxjkbrpSJE9MOG_HhbvP66V/view?usp=sharing
Bonus notes:
- Created with HuggingFace Tokenizers; you can increase vocabulary size and re-train; remember to change ELECTRA vocab_size
## Training
Structure your files, with data-dir named "trainer" here
```
trainer
- vocab.txt
- pretrain_tfrecords
-- (all .tfrecord... files)
- models
-- modelname
--- checkpoint
--- graph.pbtxt
--- model.*
```
## Conversion
Use this process to convert an in-progress or completed ELECTRA checkpoint to a Transformers-ready model:
```
git clone https://github.com/huggingface/transformers
python ./transformers/src/transformers/convert_electra_original_tf_checkpoint_to_pytorch.py
--tf_checkpoint_path=./models/checkpointdir
--config_file=config.json
--pytorch_dump_path=pytorch_model.bin
--discriminator_or_generator=discriminator
python
```
```
from transformers import TFElectraForPreTraining
model = TFElectraForPreTraining.from_pretrained("./dir_with_pytorch", from_pt=True)
model.save_pretrained("tf")
```
Once you have formed one directory with config.json, pytorch_model.bin, tf_model.h5, special_tokens_map.json, tokenizer_config.json, and vocab.txt on the same level, run:
```
transformers-cli upload directory
```
|
|
monsoon-nlp/muril-adapted-local | 2021-05-20T00:11:39.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"masked-lm",
"en",
"hi",
"bn",
"ta",
"as",
"gu",
"kn",
"ks",
"ml",
"mr",
"ne",
"or",
"pa",
"sa",
"sd",
"te",
"ur",
"transformers",
"license:apache-2.0",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"LICENSE",
"README.md",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"vocab.txt"
]
| monsoon-nlp | 32 | transformers | ---
language:
- en
- hi
- bn
- ta
- as
- gu
- kn
- ks
- ml
- mr
- ne
- or
- pa
- sa
- sd
- te
- ur
license: apache-2.0
---
## MuRIL - Unofficial
Multilingual Representations for Indian Languages : Google open sourced
this BERT model pre-trained on 17 Indian languages, and their transliterated
counterparts.
The model was trained using a self-supervised masked language modeling task. We do whole word masking with a maximum of 80 predictions. The model was trained for 1000K steps, with a batch size of 4096, and a max sequence length of 512.
Original model on TFHub: https://tfhub.dev/google/MuRIL/1
*Official release now on HuggingFace (March 2021)* https://huggingface.co/google/muril-base-cased
License: Apache 2.0
### About this upload
I ported the TFHub .pb model to .h5 and then pytorch_model.bin for
compatibility with Transformers.
|
monsoon-nlp/no-phone-gpt2 | 2021-05-23T10:04:57.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"en",
"transformers",
"exbert",
"license:mit",
"text-generation"
]
| text-generation | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"tokenizer.json",
"vocab.json"
]
| monsoon-nlp | 27 | transformers | ---
language: en
tags:
- exbert
license: mit
---
# no-phone-gpt2
This is a test to remove memorized private information, such as phone numbers, from a small GPT-2 model. This should not generate valid phone numbers.
Inspired by BAIR privacy research:
- https://bair.berkeley.edu/blog/2019/08/13/memorization/
- https://bair.berkeley.edu/blog/2020/12/20/lmmem/
[Blog post](https://mapmeld.medium.com/scrambling-memorized-info-in-gpt-2-60753d7652d8)
## Process
- All +## and +### tokens were replaced with new, randomly-selected 2- and 3-digit numbers in the vocab.json and tokenizer.json. You can identify these in outputs because the new tokens start with ^^.
- Input and output embeddings for +## and +### tokens were moved to the +00 and +000 embeddings.
- Removed associations between numbers from merges.txt
Using a library such as [ecco](https://github.com/jalammar/ecco), probabilities for next number token look equally likely, with +000 preferred.
Code: https://colab.research.google.com/drive/1X31TIZjmxlXMXAzQrR3Fl1AnLzGBCpWf#scrollTo=0GVFwrAgY68J
### Future goals
- Add new +### tokens to rebuild number generation
- Fine-tune new tokens on counting numbers and ended phone numbers
- Use [gpt2-large](https://huggingface.co/gpt2-large)
### BibTeX entry and citation info
Original GPT-2:
```bibtex
@article{radford2019language,
title={Language Models are Unsupervised Multitask Learners},
author={Radford, Alec and Wu, Jeff and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya},
year={2019}
}
```
|
monsoon-nlp/sanaa-dialect | 2021-05-23T10:06:09.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"ar",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"README.md",
"added_tokens.json",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.json"
]
| monsoon-nlp | 32 | transformers | ---
language: ar
---
# Sanaa-Dialect
## Finetuned Arabic GPT-2 demo
This is a small GPT-2 model, originally trained on Arabic Wikipedia circa September 2020 ,
finetuned on dialect datasets from Qatar University, University of British Columbia / NLP,
and Johns Hopkins University / LREC
- https://qspace.qu.edu.qa/handle/10576/15265
- https://github.com/UBC-NLP/aoc_id
- https://github.com/ryancotterell/arabic_dialect_annotation
You can use special tokens to prompt five dialects: `[EGYPTIAN]`, `[GULF]`, `[LEVANTINE]`, `[MAGHREBI]`, and `[MSA]`
```
from simpletransformers.language_generation import LanguageGenerationModel
model = LanguageGenerationModel("gpt2", "monsoon-nlp/sanaa-dialect")
model.generate('[GULF]' + "مدينتي هي", { 'max_length': 100 })
```
There is NO content filtering in the current version; do not use for public-facing
text generation!
## Training and Finetuning details
Original model and training: https://huggingface.co/monsoon-nlp/sanaa
I inserted new tokens into the tokenizer, finetuned the model on the dialect samples, and exported the new model.
Notebook: https://colab.research.google.com/drive/1fXFH7g4nfbxBo42icI4ZMy-0TAGAxc2i
شكرا لتجربة هذا! ارجو التواصل معي مع الاسئلة
|
monsoon-nlp/sanaa | 2021-05-23T10:07:25.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"ar",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"README.md",
"checkpoint",
"config.json",
"encoder.json",
"flax_model.msgpack",
"hparams.json",
"merges.txt",
"model.ckpt.data-00000-of-00001",
"model.ckpt.index",
"model.ckpt.meta",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.bpe",
"vocab.json"
]
| monsoon-nlp | 54 | transformers | ---
language: ar
---
# Sanaa
## Arabic GPT-2 demo
This is a small GPT-2 model retrained on Arabic Wikipedia circa September 2020
(due to memory limits, the first 600,000 lines of the Wiki dump)
There is NO content filtering in the current version; do not use for public-facing
text generation.
## Training
Training notebook: https://colab.research.google.com/drive/1Z_935vTuZvbseOsExCjSprrqn1MsQT57
Steps to training:
- Follow beginning of Pierre Guillou's Portuguese GPT-2 notebook: https://github.com/piegu/fastai-projects/blob/master/finetuning-English-GPT2-any-language-Portuguese-HuggingFace-fastaiv2.ipynb to download Arabic Wikipedia and run WikiExtractor
- Read Beginner's Guide by Ng Wai Foong https://medium.com/@ngwaifoong92/beginners-guide-to-retrain-gpt-2-117m-to-generate-custom-text-content-8bb5363d8b7f
- Following Ng Wai Foong's instructions, create an encoded .npz corpus (this was very small in my project
and would be improved by adding many X more training data)
- Run generate_unconditional_samples.py and other sample code to generate text
- Download TensorFlow checkpoints
- Use my notebook code to write vocab.json, empty merge.txt
- Copy config.json from similar GPT-2 arch, edit for changes as needed
```python
am = AutoModel.from_pretrained('./argpt', from_tf=True)
am.save_pretrained("./")
```
## Generating text in SimpleTransformers
Finetuning notebook: https://colab.research.google.com/drive/1fXFH7g4nfbxBo42icI4ZMy-0TAGAxc2i
```python
from simpletransformers.language_generation import LanguageGenerationModel
model = LanguageGenerationModel("gpt2", "monsoon-nlp/sanaa")
model.generate("مدرستي")
```
## Finetuning dialects in SimpleTransformers
I finetuned this model on different Arabic dialects to generate a new
model (monsoon-nlp/sanaa-dialect on HuggingFace) with some additional
control tokens.
Finetuning notebook: https://colab.research.google.com/drive/1fXFH7g4nfbxBo42ic$
```python
from simpletransformers.language_modeling import LanguageModelingModel
ft_model = LanguageModelingModel('gpt2', 'monsoon-nlp/sanaa', args=train_args)
ft_model.tokenizer.add_tokens(["[EGYPTIAN]", "[MSA]", "[LEVANTINE]", "[GULF]"])
ft_model.model.resize_token_embeddings(len(ft_model.tokenizer))
ft_model.train_model("./train.txt", eval_file="./test.txt")
# exported model
from simpletransformers.language_generation import LanguageGenerationModel
model = LanguageGenerationModel("gpt2", "./dialects")
model.generate('[EGYPTIAN]' + "مدرستي")
```
|
monsoon-nlp/tamillion | 2020-10-30T03:58:42.000Z | [
"pytorch",
"tf",
"electra",
"ta",
"transformers"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"vocab.txt"
]
| monsoon-nlp | 95 | transformers | ---
language: ta
---
# TaMillion
This is the second version of a Tamil language model trained with
Google Research's [ELECTRA](https://github.com/google-research/electra).
Tokenization and pre-training CoLab: https://colab.research.google.com/drive/1Pwia5HJIb6Ad4Hvbx5f-IjND-vCaJzSE?usp=sharing
V1: small model with GPU; 190,000 steps;
V2 (current): base model with TPU and larger corpus; 224,000 steps
## Classification
Sudalai Rajkumar's Tamil-NLP page contains classification and regression tasks:
https://www.kaggle.com/sudalairajkumar/tamil-nlp
Notebook: https://colab.research.google.com/drive/1_rW9HZb6G87-5DraxHvhPOzGmSMUc67_?usp=sharin
The model outperformed mBERT on news classification:
(Random: 16.7%, mBERT: 53.0%, TaMillion: 75.1%)
The model slightly outperformed mBERT on movie reviews:
(RMSE - mBERT: 0.657, TaMillion: 0.626)
Equivalent accuracy on the Tirukkural topic task.
## Question Answering
I didn't find a Tamil-language question answering dataset, but this model could be finetuned
to train a QA model. See Hindi and Bengali examples here: https://colab.research.google.com/drive/1i6fidh2tItf_-IDkljMuaIGmEU6HT2Ar
## Corpus
Trained on
IndicCorp Tamil (11GB) https://indicnlp.ai4bharat.org/corpora/
and 1 October 2020 dump of https://ta.wikipedia.org (482MB)
## Vocabulary
Included as vocab.txt in the upload
|
|
morenolq/SumTO_FNS2020 | 2021-05-20T00:12:45.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
]
| text-classification | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.txt"
]
| morenolq | 46 | transformers | This is the *best performing* model used in the paper: "End-to-end Training For Financial Report Summarization"
https://www.aclweb.org/anthology/2020.fnp-1.20/ |
mortonjt/testing | 2021-01-01T00:46:54.000Z | []
| [
".gitattributes"
]
| mortonjt | 0 | |||
motiondew/distilbert-finetuned | 2021-05-13T14:39:38.000Z | [
"pytorch",
"distilbert",
"question-answering",
"transformers"
]
| question-answering | [
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.txt",
"__pycache__/trainer_qa.cpython-37.pyc",
"__pycache__/utils_qa.cpython-37.pyc"
]
| motiondew | 0 | transformers | |
moumeneb1/flaubert-base-cased-ecology_crisis | 2020-12-11T21:51:41.000Z | [
"flaubert",
"transformers"
]
| [
".gitattributes",
"README.md",
"config.json"
]
| moumeneb1 | 12 | transformers | # Flaubert-base-cased-ecology_crisis
An adapted [__Flaubert/Flaubert_base-cased model__](https://github.com/getalp/Flaubert) Trained further on a Language modeling Task of unlabeled French tweets used to create the [CrisisDataset](https://github.com/DiegoKoz/french_ecological_crisis), The intermediate task of masqued language modeling helped us improve the results on our [paper](http://www.sciencedirect.com/science/article/pii/S0306457320300650) compared to the standard flaubert-base-cased model.
If you use this pretrained model on your work, please cite us as follows 🤗
```
@article{Kozlowski-et-al2020,
title = "A three-level classification of French tweets in ecological crises",
journal = "Information Processing & Management",
volume = "57",
number = "5",
pages = "102284",
year = "2020",
issn = "0306-4573",
doi = "https://doi.org/10.1016/j.ipm.2020.102284",
url = "http://www.sciencedirect.com/science/article/pii/S0306457320300650",
author = "Diego Kozlowski and Elisa Lannelongue and Frédéric Saudemont and Farah Benamara and Alda Mari and Véronique Moriceau and Abdelmoumene Boumadane",
keywords = "Crisis response from social media, Machine learning, Natural language processing, Transfer learning",
}
```
|
|
moussaKam/barthez-orangesum-abstract | 2021-02-10T13:58:44.000Z | [
"pytorch",
"mbart",
"seq2seq",
"fr",
"arxiv:2010.12321",
"transformers",
"summarization",
"bart",
"text2text-generation"
]
| summarization | [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"sentencepiece.bpe.model",
"tokenizer.json"
]
| moussaKam | 533 | transformers | ---
tags:
- summarization
- bart
language:
- fr
widget:
- text: Citant les préoccupations de ses clients dénonçant des cas de censure après la suppression du compte de Trump, un fournisseur d'accès Internet de l'État de l'Idaho a décidé de bloquer Facebook et Twitter. La mesure ne concernera cependant que les clients mécontents de la politique de ces réseaux sociaux.
---
### Barthez model finetuned on orangeSum (abstract generation)
finetuning: examples/seq2seq (as of Feb 08 2021)
paper: https://arxiv.org/abs/2010.12321 \
github: https://github.com/moussaKam/BARThez
```
@article{eddine2020barthez,
title={BARThez: a Skilled Pretrained French Sequence-to-Sequence Model},
author={Eddine, Moussa Kamal and Tixier, Antoine J-P and Vazirgiannis, Michalis},
journal={arXiv preprint arXiv:2010.12321},
year={2020}
}
```
|
moussaKam/barthez-orangesum-title | 2021-02-10T14:04:02.000Z | [
"pytorch",
"mbart",
"seq2seq",
"fr",
"arxiv:2010.12321",
"transformers",
"summarization",
"text2text-generation"
]
| summarization | [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"sentencepiece.bpe.model",
"tokenizer.json"
]
| moussaKam | 657 | transformers | ---
tags:
- summarization
language:
- fr
widget:
- text: Citant les préoccupations de ses clients dénonçant des cas de censure après la suppression du compte de Trump, un fournisseur d'accès Internet de l'État de l'Idaho a décidé de bloquer Facebook et Twitter. La mesure ne concernera cependant que les clients mécontents de la politique de ces réseaux sociaux.
---
### Barthez model finetuned on orangeSum (title generation)
finetuning: examples/seq2seq/ (as of Nov 06, 2020)
Metrics: ROUGE-2 > 23
paper: https://arxiv.org/abs/2010.12321 \
github: https://github.com/moussaKam/BARThez
```
@article{eddine2020barthez,
title={BARThez: a Skilled Pretrained French Sequence-to-Sequence Model},
author={Eddine, Moussa Kamal and Tixier, Antoine J-P and Vazirgiannis, Michalis},
journal={arXiv preprint arXiv:2010.12321},
year={2020}
}
```
|
moussaKam/barthez-sentiment-classification | 2021-02-10T14:03:28.000Z | [
"pytorch",
"mbart",
"text-classification",
"fr",
"arxiv:2010.12321",
"transformers",
"bart"
]
| text-classification | [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"sentencepiece.bpe.model",
"tokenizer.json"
]
| moussaKam | 332 | transformers | ---
tags:
- text-classification
- bart
language:
- fr
widget:
- text: Barthez est le meilleur gardien du monde.
---
### Barthez model finetuned on opinion classification task.
paper: https://arxiv.org/abs/2010.12321 \
github: https://github.com/moussaKam/BARThez
```
@article{eddine2020barthez,
title={BARThez: a Skilled Pretrained French Sequence-to-Sequence Model},
author={Eddine, Moussa Kamal and Tixier, Antoine J-P and Vazirgiannis, Michalis},
journal={arXiv preprint arXiv:2010.12321},
year={2020}
}
```
|
moussaKam/barthez | 2021-02-10T14:02:27.000Z | [
"pytorch",
"mbart",
"seq2seq",
"fr",
"arxiv:2010.12321",
"transformers",
"summarization",
"bart",
"fill-mask",
"pipeline_tag:fill-mask",
"text2text-generation"
]
| fill-mask | [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"sentencepiece.bpe.model",
"tokenizer.json"
]
| moussaKam | 21,169 | transformers | ---
tags:
- summarization
- bart
language:
- fr
widget:
- text: Barthez est le meilleur <mask> du monde.
pipeline_tag: "fill-mask"
---
A french sequence to sequence pretrained model based on [BART](https://huggingface.co/facebook/bart-large). <br>
BARThez is pretrained by learning to reconstruct a corrupted input sentence. A corpus of 66GB of french raw text is used to carry out the pretraining. <br>
Unlike already existing BERT-based French language models such as CamemBERT and FlauBERT, BARThez is particularly well-suited for generative tasks (such as abstractive summarization), since not only its encoder but also its decoder is pretrained.
In addition to BARThez that is pretrained from scratch, we continue the pretraining of a multilingual BART [mBART](https://huggingface.co/facebook/mbart-large-cc25) which boosted its performance in both discriminative and generative tasks. We call the french adapted version [mBARThez](https://huggingface.co/moussaKam/mbarthez).
| Model | Architecture | #layers | #params |
| ------------- |:-------------:| :-----:|:-----:|
| [BARThez](https://huggingface.co/moussaKam/barthez) | BASE | 12 | 165M |
| [mBARThez](https://huggingface.co/moussaKam/mbarthez) | LARGE | 24 | 458M |
<br>
paper: https://arxiv.org/abs/2010.12321 \
github: https://github.com/moussaKam/BARThez
```
@article{eddine2020barthez,
title={BARThez: a Skilled Pretrained French Sequence-to-Sequence Model},
author={Eddine, Moussa Kamal and Tixier, Antoine J-P and Vazirgiannis, Michalis},
journal={arXiv preprint arXiv:2010.12321},
year={2020}
}
```
|
moussaKam/mbarthez | 2021-02-10T14:04:39.000Z | [
"pytorch",
"mbart",
"seq2seq",
"fr",
"arxiv:2010.12321",
"transformers",
"summarization",
"fill-mask",
"pipeline_tag:fill-mask",
"text2text-generation"
]
| fill-mask | [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"sentencepiece.bpe.model",
"tokenizer.json"
]
| moussaKam | 145 | transformers | ---
tags:
- summarization
language:
- fr
pipeline_tag: "fill-mask"
---
A french sequence to sequence pretrained model based on [BART](https://huggingface.co/facebook/bart-large). <br>
BARThez is pretrained by learning to reconstruct a corrupted input sentence. A corpus of 66GB of french raw text is used to carry out the pretraining. <br>
Unlike already existing BERT-based French language models such as CamemBERT and FlauBERT, BARThez is particularly well-suited for generative tasks (such as abstractive summarization), since not only its encoder but also its decoder is pretrained.
In addition to BARThez that is pretrained from scratch, we continue the pretraining of a multilingual BART [mBART](https://huggingface.co/facebook/mbart-large-cc25) which boosted its performance in both discriminative and generative tasks. We call the french adapted version [mBARThez](https://huggingface.co/moussaKam/mbarthez).
| Model | Architecture | #layers | #params |
| ------------- |:-------------:| :-----:|:-----:|
| [BARThez](https://huggingface.co/moussaKam/barthez) | BASE | 12 | 165M |
| [mBARThez](https://huggingface.co/moussaKam/mbarthez) | LARGE | 24 | 458M |
paper: https://arxiv.org/abs/2010.12321 \
github: https://github.com/moussaKam/BARThez
```
@article{eddine2020barthez,
title={BARThez: a Skilled Pretrained French Sequence-to-Sequence Model},
author={Eddine, Moussa Kamal and Tixier, Antoine J-P and Vazirgiannis, Michalis},
journal={arXiv preprint arXiv:2010.12321},
year={2020}
}
```
|
movieplaysite/lelegoreng | 2021-03-20T18:54:27.000Z | []
| [
".gitattributes",
"README.md"
]
| movieplaysite | 0 | |||
moye/model_name | 2021-03-12T16:17:23.000Z | []
| [
".gitattributes"
]
| moye | 0 | |||
mpariente/ConvTasNet_Libri1Mix_enhsingle_8k | 2021-05-04T18:52:11.000Z | [
"pytorch",
"dataset:LibriMix",
"dataset:enh_single",
"asteroid",
"audio",
"ConvTasNet",
"license:cc-by-sa-3.0"
]
| [
".gitattributes",
"README.md",
"pytorch_model.bin"
]
| mpariente | 0 | asteroid | ---
tags:
- asteroid
- audio
- ConvTasNet
datasets:
- LibriMix
- enh_single
license: cc-by-sa-3.0
inference: false
---
## Asteroid model
Imported from this Zenodo [model page](https://zenodo.org/record/3970768).
## Description:
This model was trained by Brij Mohan using the Librimix/ConvTasNet recipe in Asteroid.
It was trained on the `enh_single` task of the Libri3Mix dataset.
## Training config:
```yaml
data:
n_src: 1
sample_rate: 8000
segment: 3
task: enh_single
train_dir: data/wav8k/min/train-360
valid_dir: data/wav8k/min/dev
filterbank:
kernel_size: 16
n_filters: 512
stride: 8
masknet:
bn_chan: 128
hid_chan: 512
mask_act: relu
n_blocks: 8
n_repeats: 3
n_src: 1
skip_chan: 128
optim:
lr: 0.001
optimizer: adam
weight_decay: 0.0
training:
batch_size: 24
early_stop: True
epochs: 200
half_lr: True
```
## Results:
```yaml
si_sdr: 14.783675142685572
si_sdr_imp: 11.464625198953202
sdr: 15.497505907983102
sdr_imp: 12.07230150154914
sar: 15.497505907983102
sar_imp: 12.07230150154914
stoi: 0.9270030254700518
stoi_imp: 0.1320547197597893
```
## License notice:
This work "ConvTasNet_Libri1Mix_enhsingle_8k"
is a derivative of [LibriSpeech ASR corpus](http://www.openslr.org/12) by
[Vassil Panayotov](https://github.com/vdp),
used under [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/).
"ConvTasNet_Libri1Mix_enhsingle_8k"
is licensed under [Attribution-ShareAlike 3.0 Unported](https://creativecommons.org/licenses/by-sa/3.0/)
by Manuel Pariente. |
|
mpariente/ConvTasNet_Libri3Mix_sepnoisy | 2021-05-04T18:47:08.000Z | [
"pytorch",
"dataset:LibriMix",
"dataset:sep_noisy",
"asteroid",
"audio",
"ConvTasNet",
"license:cc-by-sa-3.0"
]
| [
".gitattributes",
"README.md",
"pytorch_model.bin"
]
| mpariente | 0 | asteroid | ---
tags:
- asteroid
- audio
- ConvTasNet
datasets:
- LibriMix
- sep_noisy
license: cc-by-sa-3.0
inference: false
---
## Asteroid model
Imported from this Zenodo [model page](https://zenodo.org/record/4020529).
## Description:
This model was trained by Takhir Mirzaev using the Librimix/ConvTasNet recipe in Asteroid.
It was trained on the `sep_noisy` task of the Libri3Mix dataset.
## Training config:
```yaml
data:
n_src: 3
sample_rate: 8000
segment: 3
task: sep_noisy
train_dir: data/wav8k/min/train-360
valid_dir: data/wav8k/min/dev
filterbank:
kernel_size: 16
n_filters: 512
stride: 8
masknet:
bn_chan: 128
hid_chan: 512
mask_act: relu
n_blocks: 8
n_repeats: 3
skip_chan: 128
optim:
lr: 0.001
optimizer: adam
weight_decay: 0.0
positional arguments:
training:
batch_size: 4
early_stop: True
epochs: 200
half_lr: True
num_workers: 4
```
## Results:
```yaml
si_sdr: 6.824750632456865
si_sdr_imp: 11.234803761803752
sdr: 7.715799858488098
sdr_imp: 11.778681386239114
sir: 16.442141130818637
sir_imp: 19.527535070051055
sar: 8.757864265661263
sar_imp: -0.15657258049670303
stoi: 0.7854554136619554
stoi_imp: 0.22267957718163015
```
## License notice:
This work "ConvTasNet_Libri3Mix_sepnoisy"
is a derivative of [LibriSpeech ASR corpus](http://www.openslr.org/12) by
[Vassil Panayotov](https://github.com/vdp),
used under [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/).
"ConvTasNet_Libri3Mix_sepnoisy"
is licensed under [Attribution-ShareAlike 3.0 Unported](https://creativecommons.org/licenses/by-sa/3.0/)
by Manuel Pariente. |
|
mpariente/ConvTasNet_WHAM_sepclean | 2021-01-21T21:02:20.000Z | [
"pytorch",
"dataset:wham",
"dataset:sep_clean",
"asteroid",
"audio",
"ConvTasNet",
"audio-source-separation",
"license:cc-by-sa-3.0"
]
| audio-source-separation | [
".gitattributes",
"README.md",
"pytorch_model.bin"
]
| mpariente | 0 | asteroid | ---
tags:
- asteroid
- audio
- ConvTasNet
- audio-source-separation
datasets:
- wham
- sep_clean
license: cc-by-sa-3.0
inference: false
---
## Asteroid model `mpariente/ConvTasNet_WHAM_sepclean`
Imported from [Zenodo](https://zenodo.org/record/3862942)
### Description:
This model was trained by Manuel Pariente
using the wham/ConvTasNet recipe in [Asteroid](https://github.com/asteroid-team/asteroid).
It was trained on the `sep_clean` task of the WHAM! dataset.
### Training config:
```yaml
data:
n_src: 2
mode: min
nondefault_nsrc: None
sample_rate: 8000
segment: 3
task: sep_clean
train_dir: data/wav8k/min/tr/
valid_dir: data/wav8k/min/cv/
filterbank:
kernel_size: 16
n_filters: 512
stride: 8
main_args:
exp_dir: exp/wham
gpus: -1
help: None
masknet:
bn_chan: 128
hid_chan: 512
mask_act: relu
n_blocks: 8
n_repeats: 3
n_src: 2
skip_chan: 128
optim:
lr: 0.001
optimizer: adam
weight_decay: 0.0
positional arguments:
training:
batch_size: 24
early_stop: True
epochs: 200
half_lr: True
num_workers: 4
```
### Results:
```yaml
si_sdr: 16.21326632846293
si_sdr_imp: 16.21441705664987
sdr: 16.615180021738933
sdr_imp: 16.464137807433435
sir: 26.860503975131923
sir_imp: 26.709461760826414
sar: 17.18312813480803
sar_imp: -131.99332048277296
stoi: 0.9619940905157323
stoi_imp: 0.2239480672473015
```
### License notice:
This work "ConvTasNet_WHAM!_sepclean" is a derivative of [CSR-I (WSJ0) Complete](https://catalog.ldc.upenn.edu/LDC93S6A)
by [LDC](https://www.ldc.upenn.edu/), used under [LDC User Agreement for
Non-Members](https://catalog.ldc.upenn.edu/license/ldc-non-members-agreement.pdf) (Research only).
"ConvTasNet_WHAM!_sepclean" is licensed under [Attribution-ShareAlike 3.0 Unported](https://creativecommons.org/licenses/by-sa/3.0/)
by Manuel Pariente. |
mpariente/DPRNNTasNet-ks2_WHAM_sepclean | 2021-01-21T21:03:02.000Z | [
"pytorch",
"dataset:wham",
"dataset:sep_clean",
"asteroid",
"audio",
"DPRNNTasNet",
"audio-source-separation",
"license:cc-by-sa-3.0"
]
| audio-source-separation | [
".gitattributes",
"README.md",
"pytorch_model.bin"
]
| mpariente | 0 | asteroid | ---
tags:
- asteroid
- audio
- DPRNNTasNet
- audio-source-separation
datasets:
- wham
- sep_clean
license: cc-by-sa-3.0
inference: false
---
## Asteroid model `mpariente/DPRNNTasNet-ks2_WHAM_sepclean`
Imported from [Zenodo](https://zenodo.org/record/3862942)
### Description:
This model was trained by Manuel Pariente
using the wham/DPRNN recipe in [Asteroid](https://github.com/asteroid-team/asteroid).
It was trained on the `sep_clean` task of the WHAM! dataset.
### Training config:
```yaml
data:
mode: min
nondefault_nsrc: None
sample_rate: 8000
segment: 2.0
task: sep_clean
train_dir: data/wav8k/min/tr
valid_dir: data/wav8k/min/cv
filterbank:
kernel_size: 2
n_filters: 64
stride: 1
main_args:
exp_dir: exp/train_dprnn_new/
gpus: -1
help: None
masknet:
bidirectional: True
bn_chan: 128
chunk_size: 250
dropout: 0
hid_size: 128
hop_size: 125
in_chan: 64
mask_act: sigmoid
n_repeats: 6
n_src: 2
out_chan: 64
optim:
lr: 0.001
optimizer: adam
weight_decay: 1e-05
positional arguments:
training:
batch_size: 3
early_stop: True
epochs: 200
gradient_clipping: 5
half_lr: True
num_workers: 8
```
### Results:
```yaml
si_sdr: 19.316743490695334
si_sdr_imp: 19.317895273889842
sdr: 19.68085347190952
sdr_imp: 19.5298092932871
sir: 30.362213998701232
sir_imp: 30.21116982007881
sar: 20.15553251343315
sar_imp: -129.02091762351188
stoi: 0.97772664309074
stoi_imp: 0.23968091518217424
```
### License notice:
This work "DPRNNTasNet-ks2_WHAM_sepclean" is a derivative of [CSR-I (WSJ0) Complete](https://catalog.ldc.upenn.edu/LDC93S6A)
by [LDC](https://www.ldc.upenn.edu/), used under [LDC User Agreement for
Non-Members](https://catalog.ldc.upenn.edu/license/ldc-non-members-agreement.pdf) (Research only).
"DPRNNTasNet-ks2_WHAM_sepclean" is licensed under [Attribution-ShareAlike 3.0 Unported](https://creativecommons.org/licenses/by-sa/3.0/)
by Manuel Pariente.
|
mrm8488/AfricanBERTa | 2021-05-20T18:00:12.000Z | [
"pytorch",
"jax",
"roberta",
"masked-lm",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 10 | transformers | |
mrm8488/CodeBERTaPy | 2021-05-20T18:01:23.000Z | [
"pytorch",
"jax",
"roberta",
"masked-lm",
"code",
"arxiv:1909.09436",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 46 | transformers | ---
language: code
thumbnail:
---
# CodeBERTaPy
CodeBERTaPy is a RoBERTa-like model trained on the [CodeSearchNet](https://github.blog/2019-09-26-introducing-the-codesearchnet-challenge/) dataset from GitHub for `python` by [Manuel Romero](https://twitter.com/mrm8488)
The **tokenizer** is a Byte-level BPE tokenizer trained on the corpus using Hugging Face `tokenizers`.
Because it is trained on a corpus of code (vs. natural language), it encodes the corpus efficiently (the sequences are between 33% to 50% shorter, compared to the same corpus tokenized by gpt2/roberta).
The (small) **model** is a 6-layer, 84M parameters, RoBERTa-like Transformer model – that’s the same number of layers & heads as DistilBERT – initialized from the default initialization settings and trained from scratch on the full `python` corpus for 4 epochs.
## Quick start: masked language modeling prediction
```python
PYTHON_CODE = """
fruits = ['apples', 'bananas', 'oranges']
for idx, <mask> in enumerate(fruits):
print("index is %d and value is %s" % (idx, val))
""".lstrip()
```
### Does the model know how to complete simple Python code?
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="mrm8488/CodeBERTaPy",
tokenizer="mrm8488/CodeBERTaPy"
)
fill_mask(PYTHON_CODE)
## Top 5 predictions:
'val' # prob 0.980728805065155
'value'
'idx'
',val'
'_'
```
### Yes! That was easy 🎉 Let's try with another Flask like example
```python
PYTHON_CODE2 = """
@app.route('/<name>')
def hello_name(name):
return "Hello {}!".format(<mask>)
if __name__ == '__main__':
app.run()
""".lstrip()
fill_mask(PYTHON_CODE2)
## Top 5 predictions:
'name' # prob 0.9961813688278198
' name'
'url'
'description'
'self'
```
### Yeah! It works 🎉 Let's try with another Tensorflow/Keras like example
```python
PYTHON_CODE3="""
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.<mask>(128, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
""".lstrip()
fill_mask(PYTHON_CODE3)
## Top 5 predictions:
'Dense' # prob 0.4482928514480591
'relu'
'Flatten'
'Activation'
'Conv'
```
> Great! 🎉
## This work is heavily inspired on [CodeBERTa](https://github.com/huggingface/transformers/blob/master/model_cards/huggingface/CodeBERTa-small-v1/README.md) by huggingface team
<br>
## CodeSearchNet citation
<details>
```bibtex
@article{husain_codesearchnet_2019,
title = {{CodeSearchNet} {Challenge}: {Evaluating} the {State} of {Semantic} {Code} {Search}},
shorttitle = {{CodeSearchNet} {Challenge}},
url = {http://arxiv.org/abs/1909.09436},
urldate = {2020-03-12},
journal = {arXiv:1909.09436 [cs, stat]},
author = {Husain, Hamel and Wu, Ho-Hsiang and Gazit, Tiferet and Allamanis, Miltiadis and Brockschmidt, Marc},
month = sep,
year = {2019},
note = {arXiv: 1909.09436},
}
```
</details>
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/CodeGPT-small-finetuned-python-token-completion | 2021-05-23T10:08:40.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"en",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"README.md",
"added_tokens.json",
"config.json",
"eval_results_clm.txt",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"train_results.txt",
"trainer_state.json",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 34 | transformers |
---
language: en
widget:
- text: "<s> def add_number ( a , b ) : <EOL> return a +"
---
# CodeGPT-small-py fine-tuned on CodeXGLUE for code-refinement task |
mrm8488/GPT-2-finetuned-CORD19 | 2021-05-23T10:09:38.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"en",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"merges.txt",
"optimizer.pt",
"pytorch_model.bin",
"scheduler.pt",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 94 | transformers | ---
language: en
thumbnail:
---
# GPT-2 + CORD19 dataset : 🦠 ✍ ⚕
**GPT-2** fine-tuned on **biorxiv_medrxiv**, **comm_use_subset** and **custom_license** files from [CORD-19](https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge) dataset.
## Datasets details
| Dataset | # Files |
| ---------------------- | ----- |
| biorxiv_medrxiv | 885 |
| comm_use_subset | 9K |
| custom_license | 20.6K |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM with the following command:
```bash
export TRAIN_FILE=/path/to/dataset/train.txt
python run_language_modeling.py \
--model_type gpt2 \
--model_name_or_path gpt2 \
--do_train \
--train_data_file $TRAIN_FILE \
--num_train_epochs 4 \
--output_dir model_output \
--overwrite_output_dir \
--save_steps 10000 \
--per_gpu_train_batch_size 3
```
<img alt="training loss" src="https://svgshare.com/i/JTf.svg' title='GTP-2-finetuned-CORDS19-loss" width="600" height="300" />
## Model in action / Example of usage ✒
You can get the following script [here](https://github.com/huggingface/transformers/blob/master/examples/text-generation/run_generation.py)
```bash
python run_generation.py \
--model_type gpt2 \
--model_name_or_path mrm8488/GPT-2-finetuned-CORD19 \
--length 200
```
```txt
# Input: the effects of COVID-19 on the lungs
# Output: === GENERATED SEQUENCE 1 ===
the effects of COVID-19 on the lungs are currently debated (86). The role of this virus in the pathogenesis of pneumonia and lung cancer is still debated. MERS-CoV is also known to cause acute respiratory distress syndrome (87) and is associated with increased expression of pulmonary fibrosis markers (88). Thus, early airway inflammation may play an important role in the pathogenesis of coronavirus pneumonia and may contribute to the severe disease and/or mortality observed in coronavirus patients.
Pneumonia is an acute, often fatal disease characterized by severe edema, leakage of oxygen and bronchiolar inflammation. Viruses include coronaviruses, and the role of oxygen depletion is complicated by lung injury and fibrosis in the lung, in addition to susceptibility to other lung diseases. The progression of the disease may be variable, depending on the lung injury, pathologic role, prognosis, and the immune status of the patient. Inflammatory responses to respiratory viruses cause various pathologies of the respiratory
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/GPT-2-finetuned-CRD3 | 2021-05-23T10:10:58.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 10 | transformers | |
mrm8488/GPT-2-finetuned-common_gen | 2021-05-23T10:12:07.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"en",
"dataset:common_gen",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 79 | transformers | ---
language: en
datasets:
- common_gen
widget:
- text: "<|endoftext|> apple, tree, pick:"
---
# GPT-2 fine-tuned on CommonGen
[GPT-2](https://huggingface.co/gpt2) fine-tuned on [CommonGen](https://inklab.usc.edu/CommonGen/index.html) for *Generative Commonsense Reasoning*.
## Details of GPT-2
GPT-2 is a transformers model pretrained on a very large corpus of English data in a self-supervised fashion. This
means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots
of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely,
it was trained to guess the next word in sentences.
More precisely, inputs are sequences of continuous text of a certain length and the targets are the same sequence,
shifted one token (word or piece of word) to the right. The model uses internally a mask-mechanism to make sure the
predictions for the token `i` only uses the inputs from `1` to `i` but not the future tokens.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks. The model is best at what it was pretrained for however, which is generating texts from a
prompt.
## Details of the dataset 📚
CommonGen is a constrained text generation task, associated with a benchmark dataset, to explicitly test machines for the ability of generative commonsense reasoning. Given a set of common concepts; the task is to generate a coherent sentence describing an everyday scenario using these concepts.
CommonGen is challenging because it inherently requires 1) relational reasoning using background commonsense knowledge, and 2) compositional generalization ability to work on unseen concept combinations. Our dataset, constructed through a combination of crowd-sourcing from AMT and existing caption corpora, consists of 30k concept-sets and 50k sentences in total.
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| common_gen | train | 67389 |
| common_gen | valid | 4018 |
| common_gen | test | 1497 |
## Model fine-tuning 🏋️
You can find the fine-tuning script [here](https://github.com/huggingface/transformers/tree/master/examples/language-modeling)
## Model in Action 🚀
```bash
python ./transformers/examples/text-generation/run_generation.py \
--model_type=gpt2 \
--model_name_or_path="mrm8488/GPT-2-finetuned-common_gen" \
--num_return_sequences 1 \
--prompt "<|endoftext|> kid, room, dance:" \
--stop_token "."
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/GPT-2-finetuned-covid-bio-medrxiv | 2021-05-23T10:13:14.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"en",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 123 | transformers | ---
language: en
thumbnail:
---
# GPT-2 + bio/medrxiv files from CORD19: 🦠 ✍ ⚕
**GPT-2** fine-tuned on **biorxiv_medrxiv** files from [CORD-19](https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge) dataset.
## Datasets details:
| Dataset | # Files |
| ---------------------- | ----- |
| biorxiv_medrxiv | 885 |
## Model training:
The model was trained on a Tesla P100 GPU and 25GB of RAM with the following command:
```bash
export TRAIN_FILE=/path/to/dataset/train.txt
python run_language_modeling.py \
--model_type gpt2 \
--model_name_or_path gpt2 \
--do_train \
--train_data_file $TRAIN_FILE \
--num_train_epochs 4 \
--output_dir model_output \
--overwrite_output_dir \
--save_steps 2000 \
--per_gpu_train_batch_size 3
```
## Model in action / Example of usage: ✒
You can get the following script [here](https://github.com/huggingface/transformers/blob/master/examples/text-generation/run_generation.py)
```bash
python run_generation.py \
--model_type gpt2 \
--model_name_or_path mrm8488/GPT-2-finetuned-CORD19 \
--length 200
```
```txt
👵👴🦠
# Input: Old people with COVID-19 tends to suffer
# Output: === GENERATED SEQUENCE 1 ===
Old people with COVID-19 tends to suffer more symptom onset time and death. It is well known that many people with COVID-19 have high homozygous ZIKV infection in the face of severe symptoms in both severe and severe cases.
The origin of Wuhan Fever was investigated by Prof. Shen Jiang at the outbreak of Wuhan Fever [34]. As Huanan Province is the epicenter of this outbreak, Huanan, the epicenter of epidemic Wuhan Fever, is the most potential location for the direct transmission of infection (source: Zhongzhen et al., 2020). A negative risk ratio indicates more frequent underlying signs in the people in Huanan Province with COVID-19 patients. Further analysis of reported Huanan Fever onset data in the past two years indicated that the intensity of exposure is the key risk factor for developing MERS-CoV infection in this region, especially among children and elderly. To be continued to develop infected patients would be a very important area for
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/GuaPeTe-2-tiny-finetuned-TED | 2021-05-23T10:14:53.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"es",
"transformers",
"spanish",
"gpt-2",
"spanish gpt2",
"text-generation"
]
| text-generation | [
".gitattributes",
"README.md",
"added_tokens.json",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 21 | transformers |
---
language: es
tags:
- spanish
- gpt-2
- spanish gpt2
widget:
- text: "Ustedes tienen la oportunidad de"
---
# GuaPeTe-2-tiny fine-tuned on TED dataset for CLM |
mrm8488/GuaPeTe-2-tiny-finetuned-eubookshop | 2021-05-23T10:15:52.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"es",
"transformers",
"spanish",
"gpt-2",
"text-generation"
]
| text-generation | [
".gitattributes",
"README.md",
"added_tokens.json",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 20 | transformers |
---
language: es
tags:
- spanish
- gpt-2
widget:
- text: "El objetivo de la Unión Europea es"
---
# GuaPeTe-2-tiny fine-tuned on eubookshop dataset for CLM |
mrm8488/GuaPeTe-2-tiny-finetuned-spa-constitution | 2021-05-23T10:17:12.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 9 | transformers | |
mrm8488/GuaPeTe-2-tiny | 2021-05-23T10:17:59.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"es",
"transformers",
"spanish",
"gpt-2",
"spanish gpt2",
"text-generation"
]
| text-generation | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 74 | transformers | ---
language: es
tags:
- spanish
- gpt-2
- spanish gpt2
widget:
- text: "Murcia es la huerta de Europa porque"
---
# GuaPeTe-2-tiny: A proof of concept tiny GPT-2 like model trained on Spanish Wikipedia corpus
|
mrm8488/HindiBERTa | 2021-05-20T18:02:42.000Z | [
"pytorch",
"jax",
"roberta",
"masked-lm",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 44 | transformers | |
mrm8488/ManuERT-for-xqua | 2021-05-20T00:16:59.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"transformers"
]
| question-answering | [
".gitattributes",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 18 | transformers | |
mrm8488/RoBERTinha | 2021-05-20T18:03:32.000Z | [
"pytorch",
"jax",
"roberta",
"masked-lm",
"gl",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 30 | transformers | ---
language: gl
widget:
- text: "Galicia é unha <mask> autónoma española."
- text: "A lingua oficial de Galicia é o <mask>."
---
# RoBERTinha: RoBERTa-like Language model trained on OSCAR Galician corpus
|
mrm8488/RoBasquERTa | 2021-05-20T18:05:08.000Z | [
"pytorch",
"jax",
"roberta",
"masked-lm",
"eu",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 28 | transformers | ---
language: eu
widget:
- text: "Euskara da Euskal Herriko <mask> ofiziala"
- text: "Gaur egun, Euskadik Espainia osoko ekonomia <mask> du"
---
# RoBasquERTa: RoBERTa-like Language model trained on OSCAR Basque corpus
|
mrm8488/RuPERTa-base-finetuned-ner | 2021-05-20T18:06:10.000Z | [
"pytorch",
"jax",
"roberta",
"token-classification",
"es",
"transformers"
]
| token-classification | [
".gitattributes",
"README.md",
"config.json",
"eval_results.txt",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 83 | transformers | ---
language: es
thumbnail:
---
# RuPERTa-base (Spanish RoBERTa) + NER 🎃🏷
This model is a fine-tuned on [NER-C](https://www.kaggle.com/nltkdata/conll-corpora) version of [RuPERTa-base](https://huggingface.co/mrm8488/RuPERTa-base) for **NER** downstream task.
## Details of the downstream task (NER) - Dataset
- [Dataset: CONLL Corpora ES](https://www.kaggle.com/nltkdata/conll-corpora) 📚
| Dataset | # Examples |
| ---------------------- | ----- |
| Train | 329 K |
| Dev | 40 K |
- [Fine-tune on NER script provided by Huggingface](https://github.com/huggingface/transformers/blob/master/examples/token-classification/run_ner_old.py)
- Labels covered:
```
B-LOC
B-MISC
B-ORG
B-PER
I-LOC
I-MISC
I-ORG
I-PER
O
```
## Metrics on evaluation set 🧾
| Metric | # score |
| :------------------------------------------------------------------------------------: | :-------: |
| F1 | **77.55**
| Precision | **75.53** |
| Recall | **79.68** |
## Model in action 🔨
Example of usage:
```python
import torch
from transformers import AutoModelForTokenClassification, AutoTokenizer
id2label = {
"0": "B-LOC",
"1": "B-MISC",
"2": "B-ORG",
"3": "B-PER",
"4": "I-LOC",
"5": "I-MISC",
"6": "I-ORG",
"7": "I-PER",
"8": "O"
}
text ="Julien, CEO de HF, nació en Francia."
input_ids = torch.tensor(tokenizer.encode(text)).unsqueeze(0)
outputs = model(input_ids)
last_hidden_states = outputs[0]
for m in last_hidden_states:
for index, n in enumerate(m):
if(index > 0 and index <= len(text.split(" "))):
print(text.split(" ")[index-1] + ": " + id2label[str(torch.argmax(n).item())])
'''
Output:
--------
Julien,: I-PER
CEO: O
de: O
HF,: B-ORG
nació: I-PER
en: I-PER
Francia.: I-LOC
'''
```
Yeah! Not too bad 🎉
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/RuPERTa-base-finetuned-pawsx-es | 2021-05-20T18:07:14.000Z | [
"pytorch",
"jax",
"roberta",
"text-classification",
"es",
"dataset:xtreme",
"transformers",
"nli"
]
| text-classification | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.json"
]
| mrm8488 | 77 | transformers | ---
language: es
datasets:
- xtreme
tags:
- nli
widget:
- text: "En 2009 se mudó a Filadelfia y en la actualidad vive en Nueva York. Se mudó nuevamente a Filadelfia en 2009 y ahora vive en la ciudad de Nueva York."
---
# RuPERTa-base fine-tuned on PAWS-X-es for Paraphrase Identification (NLI)
|
mrm8488/RuPERTa-base-finetuned-pos | 2021-05-20T18:08:34.000Z | [
"pytorch",
"jax",
"roberta",
"token-classification",
"es",
"transformers"
]
| token-classification | [
".gitattributes",
"README.md",
"config.json",
"eval_results.txt",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 341 | transformers | ---
language: es
thumbnail:
---
# RuPERTa-base (Spanish RoBERTa) + POS 🎃🏷
This model is a fine-tuned on [CONLL CORPORA](https://www.kaggle.com/nltkdata/conll-corpora) version of [RuPERTa-base](https://huggingface.co/mrm8488/RuPERTa-base) for **POS** downstream task.
## Details of the downstream task (POS) - Dataset
- [Dataset: CONLL Corpora ES](https://www.kaggle.com/nltkdata/conll-corpora) 📚
| Dataset | # Examples |
| ---------------------- | ----- |
| Train | 445 K |
| Dev | 55 K |
- [Fine-tune on NER script provided by Huggingface](https://github.com/huggingface/transformers/blob/master/examples/token-classification/run_ner_old.py)
- Labels covered:
```
ADJ
ADP
ADV
AUX
CCONJ
DET
INTJ
NOUN
NUM
PART
PRON
PROPN
PUNCT
SCONJ
SYM
VERB
```
## Metrics on evaluation set 🧾
| Metric | # score |
| :------------------------------------------------------------------------------------: | :-------: |
| F1 | **97.39**
| Precision | **97.47** |
| Recall | **9732** |
## Model in action 🔨
Example of usage
```python
import torch
from transformers import AutoModelForTokenClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('mrm8488/RuPERTa-base-finetuned-pos')
model = AutoModelForTokenClassification.from_pretrained('mrm8488/RuPERTa-base-finetuned-pos')
id2label = {
"0": "O",
"1": "ADJ",
"2": "ADP",
"3": "ADV",
"4": "AUX",
"5": "CCONJ",
"6": "DET",
"7": "INTJ",
"8": "NOUN",
"9": "NUM",
"10": "PART",
"11": "PRON",
"12": "PROPN",
"13": "PUNCT",
"14": "SCONJ",
"15": "SYM",
"16": "VERB"
}
text ="Mis amigos están pensando viajar a Londres este verano."
input_ids = torch.tensor(tokenizer.encode(text)).unsqueeze(0)
outputs = model(input_ids)
last_hidden_states = outputs[0]
for m in last_hidden_states:
for index, n in enumerate(m):
if(index > 0 and index <= len(text.split(" "))):
print(text.split(" ")[index-1] + ": " + id2label[str(torch.argmax(n).item())])
'''
Output:
--------
Mis: NUM
amigos: PRON
están: AUX
pensando: ADV
viajar: VERB
a: ADP
Londres: PROPN
este: DET
verano..: NOUN
'''
```
Yeah! Not too bad 🎉
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/RuPERTa-base-finetuned-spa-constitution | 2021-05-20T18:12:03.000Z | [
"pytorch",
"jax",
"roberta",
"masked-lm",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 18 | transformers | |
mrm8488/RuPERTa-base-finetuned-squadv1 | 2021-05-20T18:13:28.000Z | [
"pytorch",
"jax",
"roberta",
"question-answering",
"es",
"dataset:squad",
"transformers"
]
| question-answering | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"merges.txt",
"nbest_predictions_.json",
"predictions_.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 41 | transformers | ---
language: es
datasets:
- squad
---
|
mrm8488/RuPERTa-base-finetuned-squadv2 | 2021-05-20T18:14:42.000Z | [
"pytorch",
"jax",
"roberta",
"question-answering",
"es",
"dataset:squad_v2",
"transformers"
]
| question-answering | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"merges.txt",
"optimizer.pt",
"pytorch_model.bin",
"scheduler.pt",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 258 | transformers | ---
language: es
datasets:
- squad_v2
---
|
mrm8488/RuPERTa-base | 2021-05-20T18:15:46.000Z | [
"pytorch",
"jax",
"roberta",
"masked-lm",
"es",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"README.md",
"config.json",
"dict.txt",
"eval_results_lm.txt",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| mrm8488 | 176 | transformers | ---
language: es
thumbnail: https://i.imgur.com/DUlT077.jpg
widget:
- text: "España es un país muy <mask> en la UE"
---
# RuPERTa: the Spanish RoBERTa 🎃<img src="https://abs-0.twimg.com/emoji/v2/svg/1f1ea-1f1f8.svg" alt="spain flag" width="25"/>
RuPERTa-base (uncased) is a [RoBERTa model](https://github.com/pytorch/fairseq/tree/master/examples/roberta) trained on a *uncased* verison of [big Spanish corpus](https://github.com/josecannete/spanish-corpora).
RoBERTa iterates on BERT's pretraining procedure, including training the model longer, with bigger batches over more data; removing the next sentence prediction objective; training on longer sequences; and dynamically changing the masking pattern applied to the training data.
The architecture is the same as `roberta-base`:
`roberta.base:` **RoBERTa** using the **BERT-base architecture 125M** params
## Benchmarks 🧾
WIP (I continue working on it) 🚧
| Task/Dataset | F1 | Precision | Recall | Fine-tuned model | Reproduce it |
| -------- | ----: | --------: | -----: | --------------------------------------------------------------------------------------: | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
| POS | 97.39 | 97.47 | 97.32 | [RuPERTa-base-finetuned-pos](https://huggingface.co/mrm8488/RuPERTa-base-finetuned-pos) | [](https://colab.research.google.com/github/mrm8488/shared_colab_notebooks/blob/master/RuPERTa_base_finetuned_POS.ipynb)
| NER | 77.55 | 75.53 | 79.68 | [RuPERTa-base-finetuned-ner](https://huggingface.co/mrm8488/RuPERTa-base-finetuned-ner) |
| SQUAD-es v1 | to-do | | |[RuPERTa-base-finetuned-squadv1](https://huggingface.co/mrm8488/RuPERTa-base-finetuned-squadv1)
| SQUAD-es v2 | to-do | | |[RuPERTa-base-finetuned-squadv2](https://huggingface.co/mrm8488/RuPERTa-base-finetuned-squadv2)
## Model in action 🔨
### Usage for POS and NER 🏷
```python
import torch
from transformers import AutoModelForTokenClassification, AutoTokenizer
id2label = {
"0": "B-LOC",
"1": "B-MISC",
"2": "B-ORG",
"3": "B-PER",
"4": "I-LOC",
"5": "I-MISC",
"6": "I-ORG",
"7": "I-PER",
"8": "O"
}
tokenizer = AutoTokenizer.from_pretrained('mrm8488/RuPERTa-base-finetuned-ner')
model = AutoModelForTokenClassification.from_pretrained('mrm8488/RuPERTa-base-finetuned-ner')
text ="Julien, CEO de HF, nació en Francia."
input_ids = torch.tensor(tokenizer.encode(text)).unsqueeze(0)
outputs = model(input_ids)
last_hidden_states = outputs[0]
for m in last_hidden_states:
for index, n in enumerate(m):
if(index > 0 and index <= len(text.split(" "))):
print(text.split(" ")[index-1] + ": " + id2label[str(torch.argmax(n).item())])
# Output:
'''
Julien,: I-PER
CEO: O
de: O
HF,: B-ORG
nació: I-PER
en: I-PER
Francia.: I-LOC
'''
```
For **POS** just change the `id2label` dictionary and the model path to [mrm8488/RuPERTa-base-finetuned-pos](https://huggingface.co/mrm8488/RuPERTa-base-finetuned-pos)
### Fast usage for LM with `pipelines` 🧪
```python
from transformers import AutoModelWithLMHead, AutoTokenizer
model = AutoModelWithLMHead.from_pretrained('mrm8488/RuPERTa-base')
tokenizer = AutoTokenizer.from_pretrained("mrm8488/RuPERTa-base", do_lower_case=True)
from transformers import pipeline
pipeline_fill_mask = pipeline("fill-mask", model=model, tokenizer=tokenizer)
pipeline_fill_mask("España es un país muy <mask> en la UE")
```
```json
[
{
"score": 0.1814306527376175,
"sequence": "<s> españa es un país muy importante en la ue</s>",
"token": 1560
},
{
"score": 0.024842597544193268,
"sequence": "<s> españa es un país muy fuerte en la ue</s>",
"token": 2854
},
{
"score": 0.02473250962793827,
"sequence": "<s> españa es un país muy pequeño en la ue</s>",
"token": 2948
},
{
"score": 0.023991240188479424,
"sequence": "<s> españa es un país muy antiguo en la ue</s>",
"token": 5240
},
{
"score": 0.0215945765376091,
"sequence": "<s> españa es un país muy popular en la ue</s>",
"token": 5782
}
]
```
## Acknowledgments
I thank [🤗/transformers team](https://github.com/huggingface/transformers) for answering my doubts and Google for helping me with the [TensorFlow Research Cloud](https://www.tensorflow.org/tfrc) program.
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/TinyBERT-spanish-uncased-finetuned-ner | 2021-05-20T00:18:21.000Z | [
"pytorch",
"jax",
"bert",
"token-classification",
"es",
"transformers"
]
| token-classification | [
".gitattributes",
"README.md",
"config.json",
"eval_results.txt",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 114 | transformers | ---
language: es
thumbnail:
---
# Spanish TinyBERT + NER
This model is a fine-tuned on [NER-C](https://www.kaggle.com/nltkdata/conll-corpora) of a [Spanish Tiny Bert](https://huggingface.co/mrm8488/es-tinybert-v1-1) model I created using *distillation* for **NER** downstream task. The **size** of the model is **55MB**
## Details of the downstream task (NER) - Dataset
- [Dataset: CONLL Corpora ES](https://www.kaggle.com/nltkdata/conll-corpora)
I preprocessed the dataset and split it as train / dev (80/20)
| Dataset | # Examples |
| ---------------------- | ----- |
| Train | 8.7 K |
| Dev | 2.2 K |
- [Fine-tune on NER script provided by Huggingface](https://github.com/huggingface/transformers/blob/master/examples/token-classification/run_ner_old.py)
- Labels covered:
```
B-LOC
B-MISC
B-ORG
B-PER
I-LOC
I-MISC
I-ORG
I-PER
O
```
## Metrics on evaluation set:
| Metric | # score |
| :------------------------------------------------------------------------------------: | :-------: |
| F1 | **70.00**
| Precision | **67.83** |
| Recall | **71.46** |
## Comparison:
| Model | # F1 score |Size(MB)|
| :--------------------------------------------------------------------------------------------------------------: | :-------: |:------|
| bert-base-spanish-wwm-cased (BETO) | 88.43 | 421
| [bert-spanish-cased-finetuned-ner](https://huggingface.co/mrm8488/bert-spanish-cased-finetuned-ner) | **90.17** | 420 |
| Best Multilingual BERT | 87.38 | 681 |
|TinyBERT-spanish-uncased-finetuned-ner (this one) | 70.00 | **55** |
## Model in action
Example of usage:
```python
import torch
from transformers import AutoModelForTokenClassification, AutoTokenizer
id2label = {
"0": "B-LOC",
"1": "B-MISC",
"2": "B-ORG",
"3": "B-PER",
"4": "I-LOC",
"5": "I-MISC",
"6": "I-ORG",
"7": "I-PER",
"8": "O"
}
tokenizer = AutoTokenizer.from_pretrained('mrm8488/TinyBERT-spanish-uncased-finetuned-ner')
model = AutoModelForTokenClassification.from_pretrained('mrm8488/TinyBERT-spanish-uncased-finetuned-ner')
text ="Mis amigos están pensando viajar a Londres este verano."
input_ids = torch.tensor(tokenizer.encode(text)).unsqueeze(0)
outputs = model(input_ids)
last_hidden_states = outputs[0]
for m in last_hidden_states:
for index, n in enumerate(m):
if(index > 0 and index <= len(text.split(" "))):
print(text.split(" ")[index-1] + ": " + id2label[str(torch.argmax(n).item())])
'''
Output:
--------
Mis: O
amigos: O
están: O
pensando: O
viajar: O
a: O
Londres: B-LOC
este: O
verano.: O
'''
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/albert-base-v2-finetuned-mnli-pabee | 2020-07-10T22:51:35.000Z | [
"pytorch",
"albert",
"transformers"
]
| [
".gitattributes",
"config.json",
"eval_results.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"spiece.model",
"tokenizer_config.json",
"training_args.bin"
]
| mrm8488 | 10 | transformers | ||
mrm8488/b2b-en-paraphrasing-no-questions | 2021-05-13T18:38:46.000Z | [
"pytorch",
"encoder-decoder",
"seq2seq",
"transformers",
"text2text-generation"
]
| text2text-generation | [
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"trainer_state.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 23 | transformers | |
mrm8488/b2b-en-paraphrasing-questions | 2021-05-13T18:29:41.000Z | [
"pytorch",
"encoder-decoder",
"seq2seq",
"transformers",
"text2text-generation"
]
| text2text-generation | [
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"trainer_state.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 47 | transformers | |
mrm8488/bert-base-german-dbmdz-cased-finetuned-pawsx-de | 2021-05-20T00:19:08.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"de",
"dataset:xtreme",
"transformers",
"nli"
]
| text-classification | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.txt"
]
| mrm8488 | 49 | transformers | ---
language: de
datasets:
- xtreme
tags:
- nli
widget:
- text: "Winarsky ist Mitglied des IEEE, Phi Beta Kappa, des ACM und des Sigma Xi. Winarsky ist Mitglied des ACM, des IEEE, der Phi Beta Kappa und der Sigma Xi."
---
# bert-base-german-dbmdz-cased fine-tuned on PAWS-X-de for Paraphrase Identification (NLI)
|
mrm8488/bert-base-german-finetuned-ler | 2021-05-20T00:20:06.000Z | [
"pytorch",
"jax",
"bert",
"token-classification",
"de",
"transformers"
]
| token-classification | [
".gitattributes",
"README.md",
"config.json",
"eval_results.txt",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 57 | transformers | ---
language: de
---
# German BERT + LER (Legal Entity Recognition) ⚖️
German BERT ([BERT-base-german-cased](https://huggingface.co/bert-base-german-cased)) fine-tuned on [Legal-Entity-Recognition](https://github.com/elenanereiss/Legal-Entity-Recognition) dataset for **LER** (NER) downstream task.
## Details of the downstream task (NER) - Dataset
[Legal-Entity-Recognition](https://github.com/elenanereiss/Legal-Entity-Recognition): Fine-grained Named Entity Recognition in Legal Documents.
Court decisions from 2017 and 2018 were selected for the dataset, published online by the [Federal Ministry of Justice and Consumer Protection](http://www.rechtsprechung-im-internet.de). The documents originate from seven federal courts: Federal Labour Court (BAG), Federal Fiscal Court (BFH), Federal Court of Justice (BGH), Federal Patent Court (BPatG), Federal Social Court (BSG), Federal Constitutional Court (BVerfG) and Federal Administrative Court (BVerwG).
| Split | # Samples |
| ---------------------- | ----- |
| Train | 1657048 |
| Eval | 500000 |
- Training script: [Fine-tuning script for NER provided by Huggingface](https://github.com/huggingface/transformers/blob/master/examples/token-classification/run_ner_old.py)
Colab: [How to fine-tune a model for NER using HF scripts](https://colab.research.google.com/drive/156Qrd7NsUHwA3nmQ6gXdZY0NzOvqk9AT?usp=sharing)
- Labels covered (and its distribution):
```
107 B-AN
918 B-EUN
2238 B-GRT
13282 B-GS
1113 B-INN
704 B-LD
151 B-LDS
2490 B-LIT
282 B-MRK
890 B-ORG
1374 B-PER
1480 B-RR
10046 B-RS
401 B-ST
68 B-STR
1011 B-UN
282 B-VO
391 B-VS
2648 B-VT
46 I-AN
6925 I-EUN
1957 I-GRT
70257 I-GS
2931 I-INN
153 I-LD
26 I-LDS
28881 I-LIT
383 I-MRK
1185 I-ORG
330 I-PER
106 I-RR
138938 I-RS
34 I-ST
55 I-STR
1259 I-UN
1572 I-VO
2488 I-VS
11121 I-VT
1348525 O
```
- [Annotation Guidelines (German)](https://github.com/elenanereiss/Legal-Entity-Recognition/blob/master/docs/Annotationsrichtlinien.pdf)
## Metrics on evaluation set
| Metric | # score |
| :------------------------------------------------------------------------------------: | :-------: |
| F1 | **85.67**
| Precision | **84.35** |
| Recall | **87.04** |
| Accuracy | **98.46** |
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
nlp_ler = pipeline(
"ner",
model="mrm8488/bert-base-german-finetuned-ler",
tokenizer="mrm8488/bert-base-german-finetuned-ler"
)
text = "Your German legal text here"
nlp_ler(text)
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-base-portuguese-cased-finetuned-squad-v1-pt | 2021-05-20T00:21:55.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"pt",
"dataset:squad_v1_pt",
"transformers",
"license:apache-2.0"
]
| question-answering | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"nbest_predictions_.json",
"predictions_.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 344 | transformers | ---
language: pt
datasets:
- squad_v1_pt
widget:
- text: "Com que licença posso usar o conteúdo da wikipedia?"
context: "A Wikipédia é um projeto de enciclopédia colaborativa, universal e multilíngue estabelecido na internet sob o princípio wiki. Tem como propósito fornecer um conteúdo livre, objetivo e verificável, que todos possam editar e melhorar. O projeto é definido pelos princípios fundadores. O conteúdo é disponibilizado sob a licença Creative Commons BY-SA e pode ser copiado e reutilizado sob a mesma licença — mesmo para fins comerciais — desde que respeitando os termos e condições de uso."
license: apache-2.0
---
# bert-base-portuguese-cased fine-tuned on SQuAD-v1-pt |
mrm8488/bert-base-spanish-wwm-cased-finetuned-spa-squad2-es | 2021-05-20T00:22:53.000Z | [
"pytorch",
"jax",
"tfsavedmodel",
"bert",
"question-answering",
"es",
"transformers"
]
| question-answering | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"nbest_predictions_.json",
"null_odds_.json",
"predictions_.json",
"pytorch_model.bin",
"saved_model.tar.gz",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 14,385 | transformers | ---
language: es
thumbnail: https://i.imgur.com/jgBdimh.png
---
# BETO (Spanish BERT) + Spanish SQuAD2.0
This model is provided by [BETO team](https://github.com/dccuchile/beto) and fine-tuned on [SQuAD-es-v2.0](https://github.com/ccasimiro88/TranslateAlignRetrieve) for **Q&A** downstream task.
## Details of the language model('dccuchile/bert-base-spanish-wwm-cased')
Language model ([**'dccuchile/bert-base-spanish-wwm-cased'**](https://github.com/dccuchile/beto/blob/master/README.md)):
BETO is a [BERT model](https://github.com/google-research/bert) trained on a [big Spanish corpus](https://github.com/josecannete/spanish-corpora). BETO is of size similar to a BERT-Base and was trained with the Whole Word Masking technique. Below you find Tensorflow and Pytorch checkpoints for the uncased and cased versions, as well as some results for Spanish benchmarks comparing BETO with [Multilingual BERT](https://github.com/google-research/bert/blob/master/multilingual.md) as well as other (not BERT-based) models.
## Details of the downstream task (Q&A) - Dataset
[SQuAD-es-v2.0](https://github.com/ccasimiro88/TranslateAlignRetrieve)
| Dataset | # Q&A |
| ---------------------- | ----- |
| SQuAD2.0 Train | 130 K |
| SQuAD2.0-es-v2.0 | 111 K |
| SQuAD2.0 Dev | 12 K |
| SQuAD-es-v2.0-small Dev| 69 K |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM with the following command:
```bash
export SQUAD_DIR=path/to/nl_squad
python transformers/examples/question-answering/run_squad.py \
--model_type bert \
--model_name_or_path dccuchile/bert-base-spanish-wwm-cased \
--do_train \
--do_eval \
--do_lower_case \
--train_file $SQUAD_DIR/train_nl-v2.0.json \
--predict_file $SQUAD_DIR/dev_nl-v2.0.json \
--per_gpu_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2.0 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /content/model_output \
--save_steps 5000 \
--threads 4 \
--version_2_with_negative
```
## Results:
| Metric | # Value |
| ---------------------- | ----- |
| **Exact** | **76.50**50 |
| **F1** | **86.07**81 |
```json
{
"exact": 76.50501430594491,
"f1": 86.07818773108252,
"total": 69202,
"HasAns_exact": 67.93020719738277,
"HasAns_f1": 82.37912207996466,
"HasAns_total": 45850,
"NoAns_exact": 93.34104145255225,
"NoAns_f1": 93.34104145255225,
"NoAns_total": 23352,
"best_exact": 76.51223953064941,
"best_exact_thresh": 0.0,
"best_f1": 86.08541295578848,
"best_f1_thresh": 0.0
}
```
### Model in action (in a Colab Notebook)
<details>
1. Set the context and ask some questions:

2. Run predictions:

</details>
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-italian-finedtuned-squadv1-it-alfa | 2021-05-20T00:24:19.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"it",
"transformers"
]
| question-answering | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"nbest_predictions_.json",
"predictions_.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 3,737 | transformers | ---
language: it
thumbnail:
---
# Italian BERT fine-tuned on SQuAD_it v1
[Italian BERT base cased](https://huggingface.co/dbmdz/bert-base-italian-cased) fine-tuned on [italian SQuAD](https://github.com/crux82/squad-it) for **Q&A** downstream task.
## Details of Italian BERT
The source data for the Italian BERT model consists of a recent Wikipedia dump and various texts from the OPUS corpora collection. The final training corpus has a size of 13GB and 2,050,057,573 tokens.
For sentence splitting, we use NLTK (faster compared to spacy). Our cased and uncased models are training with an initial sequence length of 512 subwords for ~2-3M steps.
For the XXL Italian models, we use the same training data from OPUS and extend it with data from the Italian part of the OSCAR corpus. Thus, the final training corpus has a size of 81GB and 13,138,379,147 tokens.
More in its official [model card](https://huggingface.co/dbmdz/bert-base-italian-cased)
Created by [Stefan](https://huggingface.co/stefan-it) at [MDZ](https://huggingface.co/dbmdz)
## Details of the downstream task (Q&A) - Dataset 📚 🧐 ❓
[Italian SQuAD v1.1](https://rajpurkar.github.io/SQuAD-explorer/) is derived from the SQuAD dataset and it is obtained through semi-automatic translation of the SQuAD dataset
into Italian. It represents a large-scale dataset for open question answering processes on factoid questions in Italian.
**The dataset contains more than 60,000 question/answer pairs derived from the original English dataset.** The dataset is split into training and test sets to support the replicability of the benchmarking of QA systems:
- `SQuAD_it-train.json`: it contains training examples derived from the original SQuAD 1.1 trainig material.
- `SQuAD_it-test.json`: it contains test/benchmarking examples derived from the origial SQuAD 1.1 development material.
More details about SQuAD-it can be found in [Croce et al. 2018]. The original paper can be found at this [link](https://link.springer.com/chapter/10.1007/978-3-030-03840-3_29).
## Model training 🏋️
The model was trained on a Tesla P100 GPU and 25GB of RAM.
The script for fine tuning can be found [here](https://github.com/huggingface/transformers/blob/master/examples/question-answering/run_squad.py)
## Results 📝
| Metric | # Value |
| ------ | --------- |
| **EM** | **62.51** |
| **F1** | **74.16** |
### Raw metrics
```json
{
"exact": 62.5180707057432,
"f1": 74.16038329042492,
"total": 7609,
"HasAns_exact": 62.5180707057432,
"HasAns_f1": 74.16038329042492,
"HasAns_total": 7609,
"best_exact": 62.5180707057432,
"best_exact_thresh": 0.0,
"best_f1": 74.16038329042492,
"best_f1_thresh": 0.0
}
```
## Comparison ⚖️
| Model | EM | F1 score |
| -------------------------------------------------------------------------------------------------------------------------------- | --------- | --------- |
| [DrQA-it trained on SQuAD-it ](https://github.com/crux82/squad-it/blob/master/README.md#evaluating-a-neural-model-over-squad-it) | 56.1 | 65.9 |
| This one | **62.51** | **74.16** |
## Model in action 🚀
Fast usage with **pipelines** 🧪
```python
from transformers import pipeline
nlp_qa = pipeline(
'question-answering',
model='mrm8488/bert-italian-finedtuned-squadv1-it-alfa',
tokenizer='mrm8488/bert-italian-finedtuned-squadv1-it-alfa'
)
nlp_qa(
{
'question': 'Per quale lingua stai lavorando?',
'context': 'Manuel Romero è colaborando attivamente con HF / trasformatori per il trader del poder de las últimas ' +
'técnicas di procesamiento de lenguaje natural al idioma español'
}
)
# Output: {'answer': 'español', 'end': 174, 'score': 0.9925341537498156, 'start': 168}
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
Dataset citation
<details>
@InProceedings{10.1007/978-3-030-03840-3_29,
author="Croce, Danilo and Zelenanska, Alexandra and Basili, Roberto",
editor="Ghidini, Chiara and Magnini, Bernardo and Passerini, Andrea and Traverso, Paolo",
title="Neural Learning for Question Answering in Italian",
booktitle="AI*IA 2018 -- Advances in Artificial Intelligence",
year="2018",
publisher="Springer International Publishing",
address="Cham",
pages="389--402",
isbn="978-3-030-03840-3"
}
</detail>
|
mrm8488/bert-medium-finetuned-squadv2 | 2021-05-20T00:25:00.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"en",
"arxiv:1908.08962",
"transformers"
]
| question-answering | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"nbest_predictions_.json",
"null_odds_.json",
"predictions_.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 684 | transformers | ---
language: en
thumbnail:
---
# BERT-Medium fine-tuned on SQuAD v2
[BERT-Medium](https://github.com/google-research/bert/) created by [Google Research](https://github.com/google-research) and fine-tuned on [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) for **Q&A** downstream task.
**Mode size** (after training): **157.46 MB**
## Details of BERT-Small and its 'family' (from their documentation)
Released on March 11th, 2020
This is model is a part of 24 smaller BERT models (English only, uncased, trained with WordPiece masking) referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962).
The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
## Details of the downstream task (Q&A) - Dataset
[SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD2.0 | train | 130k |
| SQuAD2.0 | eval | 12.3k |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM.
The script for fine tuning can be found [here](https://github.com/huggingface/transformers/blob/master/examples/question-answering/run_squad.py)
## Results:
| Metric | # Value |
| ------ | --------- |
| **EM** | **65.95** |
| **F1** | **70.11** |
### Raw metrics from benchmark included in training script:
```json
{
"exact": 65.95637159942727,
"f1": 70.11632254245896,
"total": 11873,
"HasAns_exact": 67.79689608636977,
"HasAns_f1": 76.12872765631123,
"HasAns_total": 5928,
"NoAns_exact": 64.12111017661901,
"NoAns_f1": 64.12111017661901,
"NoAns_total": 5945,
"best_exact": 65.96479407058031,
"best_exact_thresh": 0.0,
"best_f1": 70.12474501361196,
"best_f1_thresh": 0.0
}
```
## Comparison:
| Model | EM | F1 score | SIZE (MB) |
| --------------------------------------------------------------------------------------------- | --------- | --------- | --------- |
| [bert-tiny-finetuned-squadv2](https://huggingface.co/mrm8488/bert-tiny-finetuned-squadv2) | 48.60 | 49.73 | **16.74** |
| [bert-tiny-5-finetuned-squadv2](https://huggingface.co/mrm8488/bert-tiny-5-finetuned-squadv2) | 57.12 | 60.86 | 24.34 |
| [bert-mini-finetuned-squadv2](https://huggingface.co/mrm8488/bert-mini-finetuned-squadv2) | 56.31 | 59.65 | 42.63 |
| [bert-mini-5-finetuned-squadv2](https://huggingface.co/mrm8488/bert-mini-5-finetuned-squadv2) | 63.51 | 66.78 | 66.76 |
| [bert-small-finetuned-squadv2](https://huggingface.co/mrm8488/bert-small-finetuned-squadv2) | 60.49 | 64.21 | 109.74 |
| [bert-medium-finetuned-squadv2](https://huggingface.co/mrm8488/bert-medium-finetuned-squadv2) | **65.95** | **70.11** | 157.46 |
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/bert-small-finetuned-squadv2",
tokenizer="mrm8488/bert-small-finetuned-squadv2"
)
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "Who has been working hard for hugginface/transformers lately?"
})
# Output:
```
```json
{
"answer": "Manuel Romero",
"end": 13,
"score": 0.9939319924374637,
"start": 0
}
```
### Yes! That was easy 🎉 Let's try with another example
```python
qa_pipeline({
'context': "Manuel Romero has been working remotely in the repository hugginface/transformers lately",
'question': "How has been working Manuel Romero?"
})
# Output:
```
```json
{ "answer": "remotely", "end": 39, "score": 0.3612058272768017, "start": 31 }
```
### It works!! 🎉 🎉 🎉
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-medium-wrslb-finetuned-squadv1 | 2021-05-20T00:25:31.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"transformers"
]
| question-answering | [
".gitattributes",
"config.json",
"flax_model.msgpack",
"nbest_predictions_.json",
"predictions_.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 16 | transformers | |
mrm8488/bert-mini-5-finetuned-squadv2 | 2021-05-20T00:25:56.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"transformers"
]
| question-answering | [
".gitattributes",
"config.json",
"flax_model.msgpack",
"nbest_predictions_.json",
"null_odds_.json",
"predictions_.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 14 | transformers | |
mrm8488/bert-mini-finetuned-age_news-classification | 2021-05-20T00:26:16.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"en",
"dataset:ag_news",
"transformers",
"news",
"classification",
"mini"
]
| text-classification | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 21,438 | transformers | ---
language: en
tags:
- news
- classification
- mini
datasets:
- ag_news
widget:
- text: "Israel withdraws from Gaza camp Israel withdraws from Khan Younis refugee camp in the Gaza Strip, after a four-day operation that left 11 dead."
---
# BERT-Mini fine-tuned on age_news dataset for news classification
Test set accuray: 0.93 |
mrm8488/bert-mini-finetuned-squadv2 | 2021-05-20T00:26:36.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"en",
"arxiv:1908.08962",
"transformers"
]
| question-answering | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 23 | transformers | ---
language: en
thumbnail:
---
# BERT-Mini fine-tuned on SQuAD v2
[BERT-Mini](https://github.com/google-research/bert/) created by [Google Research](https://github.com/google-research) and fine-tuned on [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) for **Q&A** downstream task.
**Mode size** (after training): **42.63 MB**
## Details of BERT-Mini and its 'family' (from their documentation)
Released on March 11th, 2020
This is model is a part of 24 smaller BERT models (English only, uncased, trained with WordPiece masking) referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962).
The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
## Details of the downstream task (Q&A) - Dataset
[SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD2.0 | train | 130k |
| SQuAD2.0 | eval | 12.3k |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM.
The script for fine tuning can be found [here](https://github.com/huggingface/transformers/blob/master/examples/question-answering/run_squad.py)
## Results:
| Metric | # Value |
| ------ | --------- |
| **EM** | **56.31** |
| **F1** | **59.65** |
## Comparison:
| Model | EM | F1 score | SIZE (MB) |
| ----------------------------------------------------------------------------------------- | --------- | --------- | --------- |
| [bert-tiny-finetuned-squadv2](https://huggingface.co/mrm8488/bert-tiny-finetuned-squadv2) | 48.60 | 49.73 | **16.74** |
| [bert-tiny-5-finetuned-squadv2](https://huggingface.co/mrm8488/bert-tiny-5-finetuned-squadv2) | 57.12 | 60.86 | 24.34 |
| [bert-mini-finetuned-squadv2](https://huggingface.co/mrm8488/bert-mini-finetuned-squadv2) | 56.31 | 59.65 | 42.63 |
| [bert-mini-5-finetuned-squadv2](https://huggingface.co/mrm8488/bert-mini-5-finetuned-squadv2) | **63.51** | **66.78** | 66.76 |
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/bert-mini-finetuned-squadv2",
tokenizer="mrm8488/bert-mini-finetuned-squadv2"
)
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "Who has been working hard for hugginface/transformers lately?"
})
# Output:
```
```json
{
"answer": "Manuel Romero",
"end": 13,
"score": 0.9676484207783673,
"start": 0
}
```
### Yes! That was easy 🎉 Let's try with another example
```python
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "For which company has worked Manuel Romero?"
})
# Output:
```
```json
{
"answer": "hugginface/transformers",
"end": 79,
"score": 0.5301655914731853,
"start": 56
}
```
### It works!! 🎉 🎉 🎉
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-mini-wrslb-finetuned-squadv1 | 2021-05-20T00:26:56.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"transformers"
]
| question-answering | [
".gitattributes",
"config.json",
"flax_model.msgpack",
"nbest_predictions_.json",
"predictions_.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 20 | transformers | |
mrm8488/bert-mini2bert-mini-finetuned-cnn_daily_mail-summarization | 2020-12-11T21:52:51.000Z | [
"pytorch",
"encoder-decoder",
"seq2seq",
"en",
"dataset:cnn_dailymail",
"transformers",
"license:apache-2.0",
"summarization",
"text2text-generation"
]
| summarization | [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 28 | transformers | ---
language: en
license: apache-2.0
datasets:
- cnn_dailymail
tags:
- summarization
---
# Bert-mini2Bert-mini Summarization with 🤗EncoderDecoder Framework
This model is a warm-started *BERT2BERT* ([mini](https://huggingface.co/google/bert_uncased_L-4_H-256_A-4)) model fine-tuned on the *CNN/Dailymail* summarization dataset.
The model achieves a **16.51** ROUGE-2 score on *CNN/Dailymail*'s test dataset.
For more details on how the model was fine-tuned, please refer to
[this](https://colab.research.google.com/drive/1Ekd5pUeCX7VOrMx94_czTkwNtLN32Uyu?usp=sharing) notebook.
## Results on test set 📝
| Metric | # Value |
| ------ | --------- |
| **ROUGE-2** | **16.51** |
## Model in Action 🚀
```python
from transformers import BertTokenizerFast, EncoderDecoderModel
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tokenizer = BertTokenizerFast.from_pretrained('mrm8488/bert-mini2bert-mini-finetuned-cnn_daily_mail-summarization')
model = EncoderDecoderModel.from_pretrained('mrm8488/bert-mini2bert-mini-finetuned-cnn_daily_mail-summarization').to(device)
def generate_summary(text):
# cut off at BERT max length 512
inputs = tokenizer([text], padding="max_length", truncation=True, max_length=512, return_tensors="pt")
input_ids = inputs.input_ids.to(device)
attention_mask = inputs.attention_mask.to(device)
output = model.generate(input_ids, attention_mask=attention_mask)
return tokenizer.decode(output[0], skip_special_tokens=True)
text = "your text to be summarized here..."
generate_summary(text)
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-multi-cased-finedtuned-xquad-tydiqa-goldp | 2021-05-20T00:27:53.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"multilingual",
"transformers"
]
| question-answering | [
".gitattributes",
"README.md",
"config.json",
"eval_resuts.txt",
"flax_model.msgpack",
"nbest_predictions_.json",
"predictions_.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 2,313 | transformers | ---
language: multilingual
thumbnail:
---
# A fine-tuned model on GoldP task from Tydi QA dataset
This model uses [bert-multi-cased-finetuned-xquadv1](https://huggingface.co/mrm8488/bert-multi-cased-finetuned-xquadv1) and fine-tuned on [Tydi QA](https://github.com/google-research-datasets/tydiqa) dataset for Gold Passage task [(GoldP)](https://github.com/google-research-datasets/tydiqa#the-tasks)
## Details of the language model
The base language model [(bert-multi-cased-finetuned-xquadv1)](https://huggingface.co/mrm8488/bert-multi-cased-finetuned-xquadv1) is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) for the **Q&A** downstream task
## Details of the Tydi QA dataset
TyDi QA contains 200k human-annotated question-answer pairs in 11 Typologically Diverse languages, written without seeing the answer and without the use of translation, and is designed for the **training and evaluation** of automatic question answering systems. This repository provides evaluation code and a baseline system for the dataset. https://ai.google.com/research/tydiqa
## Details of the downstream task (Gold Passage or GoldP aka the secondary task)
Given a passage that is guaranteed to contain the answer, predict the single contiguous span of characters that answers the question. the gold passage task differs from the [primary task](https://github.com/google-research-datasets/tydiqa/blob/master/README.md#the-tasks) in several ways:
* only the gold answer passage is provided rather than the entire Wikipedia article;
* unanswerable questions have been discarded, similar to MLQA and XQuAD;
* we evaluate with the SQuAD 1.1 metrics like XQuAD; and
* Thai and Japanese are removed since the lack of whitespace breaks some tools.
## Model training
The model was fine-tuned on a Tesla P100 GPU and 25GB of RAM.
The script is the following:
```python
python run_squad.py \
--model_type bert \
--model_name_or_path mrm8488/bert-multi-cased-finetuned-xquadv1 \
--do_train \
--do_eval \
--train_file /content/dataset/train.json \
--predict_file /content/dataset/dev.json \
--per_gpu_train_batch_size 24 \
--per_gpu_eval_batch_size 24 \
--learning_rate 3e-5 \
--num_train_epochs 2.5 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /content/model_output \
--overwrite_output_dir \
--save_steps 5000 \
--threads 40
```
## Global Results (dev set):
| Metric | # Value |
| --------- | ----------- |
| **Exact** | **71.06** |
| **F1** | **82.16** |
## Specific Results (per language):
| Language | # Samples | # Exact | # F1 |
| --------- | ----------- |--------| ------ |
| Arabic | 1314 | 73.29 | 84.72 |
| Bengali | 180 | 64.60 | 77.84 |
| English | 654 | 72.12 | 82.24 |
| Finnish | 1031 | 70.14 | 80.36 |
| Indonesian| 773 | 77.25 | 86.36 |
| Korean | 414 | 68.92 | 70.95 |
| Russian | 1079 | 62.65 | 78.55 |
| Swahili | 596 | 80.11 | 86.18 |
| Telegu | 874 | 71.00 | 84.24 |
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-multi-cased-finetuned-xquadv1 | 2021-05-20T00:29:15.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"multilingual",
"arxiv:1910.11856",
"transformers"
]
| question-answering | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"nbest_predictions_.json",
"predictions_.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 1,062 | transformers | ---
language: multilingual
thumbnail:
---
# BERT (base-multilingual-cased) fine-tuned for multilingual Q&A
This model was created by [Google](https://github.com/google-research/bert/blob/master/multilingual.md) and fine-tuned on [XQuAD](https://github.com/deepmind/xquad) like data for multilingual (`11 different languages`) **Q&A** downstream task.
## Details of the language model('bert-base-multilingual-cased')
[Language model](https://github.com/google-research/bert/blob/master/multilingual.md)
| Languages | Heads | Layers | Hidden | Params |
| --------- | ----- | ------ | ------ | ------ |
| 104 | 12 | 12 | 768 | 100 M |
## Details of the downstream task (multilingual Q&A) - Dataset
Deepmind [XQuAD](https://github.com/deepmind/xquad)
Languages covered:
- Arabic: `ar`
- German: `de`
- Greek: `el`
- English: `en`
- Spanish: `es`
- Hindi: `hi`
- Russian: `ru`
- Thai: `th`
- Turkish: `tr`
- Vietnamese: `vi`
- Chinese: `zh`
As the dataset is based on SQuAD v1.1, there are no unanswerable questions in the data. We chose this
setting so that models can focus on cross-lingual transfer.
We show the average number of tokens per paragraph, question, and answer for each language in the
table below. The statistics were obtained using [Jieba](https://github.com/fxsjy/jieba) for Chinese
and the [Moses tokenizer](https://github.com/moses-smt/mosesdecoder/blob/master/scripts/tokenizer/tokenizer.perl)
for the other languages.
| | en | es | de | el | ru | tr | ar | vi | th | zh | hi |
| --------- | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| Paragraph | 142.4 | 160.7 | 139.5 | 149.6 | 133.9 | 126.5 | 128.2 | 191.2 | 158.7 | 147.6 | 232.4 |
| Question | 11.5 | 13.4 | 11.0 | 11.7 | 10.0 | 9.8 | 10.7 | 14.8 | 11.5 | 10.5 | 18.7 |
| Answer | 3.1 | 3.6 | 3.0 | 3.3 | 3.1 | 3.1 | 3.1 | 4.5 | 4.1 | 3.5 | 5.6 |
Citation:
<details>
```bibtex
@article{Artetxe:etal:2019,
author = {Mikel Artetxe and Sebastian Ruder and Dani Yogatama},
title = {On the cross-lingual transferability of monolingual representations},
journal = {CoRR},
volume = {abs/1910.11856},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.11856}
}
```
</details>
As **XQuAD** is just an evaluation dataset, I used `Data augmentation techniques` (scraping, neural machine translation, etc) to obtain more samples and split the dataset in order to have a train and test set. The test set was created in a way that contains the same number of samples for each language. Finally, I got:
| Dataset | # samples |
| ----------- | --------- |
| XQUAD train | 50 K |
| XQUAD test | 8 K |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM.
The script for fine tuning can be found [here](https://github.com/huggingface/transformers/blob/master/examples/distillation/run_squad_w_distillation.py)
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/bert-multi-cased-finetuned-xquadv1",
tokenizer="mrm8488/bert-multi-cased-finetuned-xquadv1"
)
# context: Coronavirus is seeding panic in the West because it expands so fast.
# question: Where is seeding panic Coronavirus?
qa_pipeline({
'context': "कोरोनावायरस पश्चिम में आतंक बो रहा है क्योंकि यह इतनी तेजी से फैलता है।",
'question': "कोरोनावायरस घबराहट कहां है?"
})
# output: {'answer': 'पश्चिम', 'end': 18, 'score': 0.7037217439689059, 'start': 12}
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "Who has been working hard for hugginface/transformers lately?"
})
# output: {'answer': 'Manuel Romero', 'end': 13, 'score': 0.7254485993702389, 'start': 0}
qa_pipeline({
'context': "Manuel Romero a travaillé à peine dans le référentiel hugginface / transformers ces derniers temps",
'question': "Pour quel référentiel a travaillé Manuel Romero récemment?"
})
#output: {'answer': 'hugginface / transformers', 'end': 79, 'score': 0.6482061613915384, 'start': 54}
```
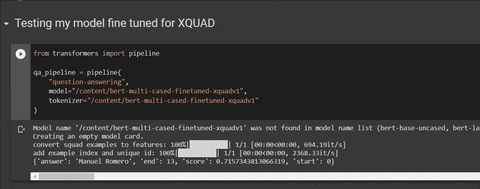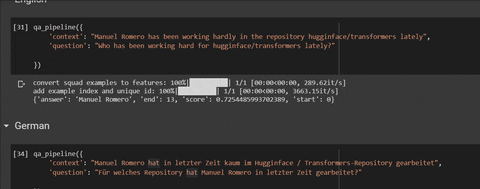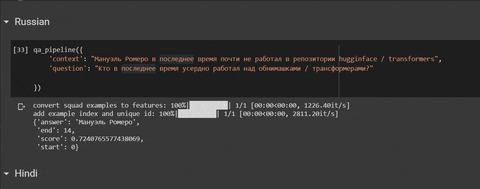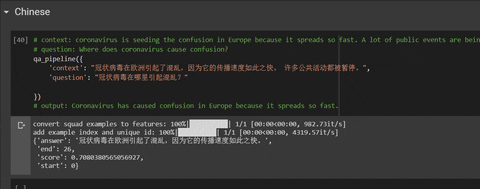
Try it on a Colab:
<a href="https://colab.research.google.com/github/mrm8488/shared_colab_notebooks/blob/master/Try_mrm8488_xquad_finetuned_model.ipynb" target="_parent"><img src="https://camo.githubusercontent.com/52feade06f2fecbf006889a904d221e6a730c194/68747470733a2f2f636f6c61622e72657365617263682e676f6f676c652e636f6d2f6173736574732f636f6c61622d62616467652e737667" alt="Open In Colab" data-canonical-src="https://colab.research.google.com/assets/colab-badge.svg"></a>
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-multi-uncased-finetuned-xquadv1 | 2021-05-20T00:31:20.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"multilingual",
"arxiv:1910.11856",
"transformers"
]
| question-answering | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"nbest_predictions_.json",
"predictions_.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 432 | transformers | ---
language: multilingual
thumbnail:
---
# BERT (base-multilingual-uncased) fine-tuned for multilingual Q&A
This model was created by [Google](https://github.com/google-research/bert/blob/master/multilingual.md) and fine-tuned on [XQuAD](https://github.com/deepmind/xquad) like data for multilingual (`11 different languages`) **Q&A** downstream task.
## Details of the language model('bert-base-multilingual-uncased')
[Language model](https://github.com/google-research/bert/blob/master/multilingual.md)
| Languages | Heads | Layers | Hidden | Params |
| --------- | ----- | ------ | ------ | ------ |
| 102 | 12 | 12 | 768 | 100 M |
## Details of the downstream task (multilingual Q&A) - Dataset
Deepmind [XQuAD](https://github.com/deepmind/xquad)
Languages covered:
- Arabic: `ar`
- German: `de`
- Greek: `el`
- English: `en`
- Spanish: `es`
- Hindi: `hi`
- Russian: `ru`
- Thai: `th`
- Turkish: `tr`
- Vietnamese: `vi`
- Chinese: `zh`
As the dataset is based on SQuAD v1.1, there are no unanswerable questions in the data. We chose this
setting so that models can focus on cross-lingual transfer.
We show the average number of tokens per paragraph, question, and answer for each language in the
table below. The statistics were obtained using [Jieba](https://github.com/fxsjy/jieba) for Chinese
and the [Moses tokenizer](https://github.com/moses-smt/mosesdecoder/blob/master/scripts/tokenizer/tokenizer.perl)
for the other languages.
| | en | es | de | el | ru | tr | ar | vi | th | zh | hi |
| --------- | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| Paragraph | 142.4 | 160.7 | 139.5 | 149.6 | 133.9 | 126.5 | 128.2 | 191.2 | 158.7 | 147.6 | 232.4 |
| Question | 11.5 | 13.4 | 11.0 | 11.7 | 10.0 | 9.8 | 10.7 | 14.8 | 11.5 | 10.5 | 18.7 |
| Answer | 3.1 | 3.6 | 3.0 | 3.3 | 3.1 | 3.1 | 3.1 | 4.5 | 4.1 | 3.5 | 5.6 |
Citation:
<details>
```bibtex
@article{Artetxe:etal:2019,
author = {Mikel Artetxe and Sebastian Ruder and Dani Yogatama},
title = {On the cross-lingual transferability of monolingual representations},
journal = {CoRR},
volume = {abs/1910.11856},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.11856}
}
```
</details>
As **XQuAD** is just an evaluation dataset, I used `Data augmentation techniques` (scraping, neural machine translation, etc) to obtain more samples and split the dataset in order to have a train and test set. The test set was created in a way that contains the same number of samples for each language. Finally, I got:
| Dataset | # samples |
| ----------- | --------- |
| XQUAD train | 50 K |
| XQUAD test | 8 K |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM.
The script for fine tuning can be found [here](https://github.com/huggingface/transformers/blob/master/examples/distillation/run_squad_w_distillation.py)
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/bert-multi-uncased-finetuned-xquadv1",
tokenizer="mrm8488/bert-multi-uncased-finetuned-xquadv1"
)
# context: Coronavirus is seeding panic in the West because it expands so fast.
# question: Where is seeding panic Coronavirus?
qa_pipeline({
'context': "कोरोनावायरस पश्चिम में आतंक बो रहा है क्योंकि यह इतनी तेजी से फैलता है।",
'question': "कोरोनावायरस घबराहट कहां है?"
})
# output: {'answer': 'पश्चिम', 'end': 18, 'score': 0.7037217439689059, 'start': 12}
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "Who has been working hard for hugginface/transformers lately?"
})
# output: {'answer': 'Manuel Romero', 'end': 13, 'score': 0.7254485993702389, 'start': 0}
qa_pipeline({
'context': "Manuel Romero a travaillé à peine dans le référentiel hugginface / transformers ces derniers temps",
'question': "Pour quel référentiel a travaillé Manuel Romero récemment?"
})
#output: {'answer': 'hugginface / transformers', 'end': 79, 'score': 0.6482061613915384, 'start': 54}
```

Try it on a Colab:
<a href="https://colab.research.google.com/github/mrm8488/shared_colab_notebooks/blob/master/Try_mrm8488_xquad_finetuned_uncased_model.ipynb" target="_parent"><img src="https://camo.githubusercontent.com/52feade06f2fecbf006889a904d221e6a730c194/68747470733a2f2f636f6c61622e72657365617263682e676f6f676c652e636f6d2f6173736574732f636f6c61622d62616467652e737667" alt="Open In Colab" data-canonical-src="https://colab.research.google.com/assets/colab-badge.svg"></a>
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-small-2-finetuned-squadv2 | 2021-05-20T00:32:45.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"transformers"
]
| question-answering | [
".gitattributes",
"config.json",
"flax_model.msgpack",
"nbest_predictions_.json",
"null_odds_.json",
"optimizer.pt",
"predictions_.json",
"pytorch_model.bin",
"scheduler.pt",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 18 | transformers | |
mrm8488/bert-small-finetuned-squadv2 | 2021-05-20T00:33:09.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"en",
"arxiv:1908.08962",
"transformers"
]
| question-answering | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 2,367 | transformers | ---
language: en
thumbnail:
---
# BERT-Small fine-tuned on SQuAD v2
[BERT-Small](https://github.com/google-research/bert/) created by [Google Research](https://github.com/google-research) and fine-tuned on [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) for **Q&A** downstream task.
**Mode size** (after training): **109.74 MB**
## Details of BERT-Small and its 'family' (from their documentation)
Released on March 11th, 2020
This is model is a part of 24 smaller BERT models (English only, uncased, trained with WordPiece masking) referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962).
The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
## Details of the downstream task (Q&A) - Dataset
[SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD2.0 | train | 130k |
| SQuAD2.0 | eval | 12.3k |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM.
The script for fine tuning can be found [here](https://github.com/huggingface/transformers/blob/master/examples/question-answering/run_squad.py)
## Results:
| Metric | # Value |
| ------ | --------- |
| **EM** | **60.49** |
| **F1** | **64.21** |
## Comparison:
| Model | EM | F1 score | SIZE (MB) |
| ------------------------------------------------------------------------------------------- | --------- | --------- | --------- |
| [bert-tiny-finetuned-squadv2](https://huggingface.co/mrm8488/bert-tiny-finetuned-squadv2) | 48.60 | 49.73 | **16.74** |
| [bert-mini-finetuned-squadv2](https://huggingface.co/mrm8488/bert-mini-finetuned-squadv2) | 56.31 | 59.65 | 42.63 |
| [bert-small-finetuned-squadv2](https://huggingface.co/mrm8488/bert-small-finetuned-squadv2) | **60.49** | **64.21** | 109.74 |
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/bert-small-finetuned-squadv2",
tokenizer="mrm8488/bert-small-finetuned-squadv2"
)
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "Who has been working hard for hugginface/transformers lately?"
})
# Output:
```
```json
{
"answer": "Manuel Romero",
"end": 13,
"score": 0.9939319924374637,
"start": 0
}
```
### Yes! That was easy 🎉 Let's try with another example
```python
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "For which company has worked Manuel Romero?"
})
# Output:
```
```json
{
"answer": "hugginface/transformers",
"end": 79,
"score": 0.6024888734447131,
"start": 56
}
```
### It works!! 🎉 🎉 🎉
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-small-finetuned-typo-detection | 2021-05-25T20:20:35.000Z | [
"pytorch",
"jax",
"bert",
"token-classification",
"en",
"transformers"
]
| token-classification | [
".gitattributes",
"README.md",
"config.json",
"eval_results.txt",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 174 | transformers | ---
language: en
thumbnail:
widget:
- text: "here there is an error in coment"
---
# BERT SMALL + Typo Detection ✍❌✍✔
[BERT SMALL](https://huggingface.co/google/bert_uncased_L-4_H-512_A-8) fine-tuned on [GitHub Typo Corpus](https://github.com/mhagiwara/github-typo-corpus) for **typo detection** (using *NER* style)
## Details of the downstream task (Typo detection as NER)
- Dataset: [GitHub Typo Corpus](https://github.com/mhagiwara/github-typo-corpus) 📚
- [Fine-tune script on NER dataset provided by Huggingface](https://github.com/huggingface/transformers/blob/master/examples/token-classification/run_ner_old.py) 🏋️♂️
## Metrics on test set 📋
| Metric | # score |
| :-------: | :-------: |
| F1 | **89.12** |
| Precision | **93.82** |
| Recall | **84.87** |
## Model in action 🔨
Fast usage with **pipelines** 🧪
```python
from transformers import pipeline
typo_checker = pipeline(
"ner",
model="mrm8488/bert-small-finetuned-typo-detection",
tokenizer="mrm8488/bert-small-finetuned-typo-detection"
)
result = typo_checker("here there is an error in coment")
result[1:-1]
# Output:
[{'entity': 'ok', 'score': 0.9021041989326477, 'word': 'here'},
{'entity': 'ok', 'score': 0.7975626587867737, 'word': 'there'},
{'entity': 'ok', 'score': 0.8596242070198059, 'word': 'is'},
{'entity': 'ok', 'score': 0.7071516513824463, 'word': 'an'},
{'entity': 'ok', 'score': 0.943381130695343, 'word': 'error'},
{'entity': 'ok', 'score': 0.8047608733177185, 'word': 'in'},
{'entity': 'ok', 'score': 0.8240702152252197, 'word': 'come'},
{'entity': 'typo', 'score': 0.5004884004592896, 'word': '##nt'}]
```
It works🎉! we typed ```coment``` instead of ```comment```
Let's try with another example
```python
result = typo_checker("Adddd validation midelware")
result[1:-1]
# Output:
[{'entity': 'ok', 'score': 0.7128152847290039, 'word': 'add'},
{'entity': 'typo', 'score': 0.5388424396514893, 'word': '##dd'},
{'entity': 'ok', 'score': 0.94792640209198, 'word': 'validation'},
{'entity': 'typo', 'score': 0.5839331746101379, 'word': 'mid'},
{'entity': 'ok', 'score': 0.5195121765136719, 'word': '##el'},
{'entity': 'ok', 'score': 0.7222476601600647, 'word': '##ware'}]
```
Yeah! We typed wrong ```Add and middleware```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-small-wrslb-finetuned-squadv1 | 2021-05-20T00:34:10.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"transformers"
]
| question-answering | [
".gitattributes",
"config.json",
"flax_model.msgpack",
"nbest_predictions_.json",
"predictions_.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 18 | transformers | |
mrm8488/bert-small2bert-small-finetuned-cnn_daily_mail-summarization | 2020-12-11T21:53:12.000Z | [
"pytorch",
"encoder-decoder",
"seq2seq",
"en",
"dataset:cnn_dailymail",
"transformers",
"license:apache-2.0",
"summarization",
"text2text-generation"
]
| summarization | [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 1,037 | transformers | ---
language: en
license: apache-2.0
datasets:
- cnn_dailymail
tags:
- summarization
---
# Bert-small2Bert-small Summarization with 🤗EncoderDecoder Framework
This model is a warm-started *BERT2BERT* ([small](https://huggingface.co/google/bert_uncased_L-4_H-512_A-8)) model fine-tuned on the *CNN/Dailymail* summarization dataset.
The model achieves a **17.37** ROUGE-2 score on *CNN/Dailymail*'s test dataset.
For more details on how the model was fine-tuned, please refer to
[this](https://colab.research.google.com/drive/1Ekd5pUeCX7VOrMx94_czTkwNtLN32Uyu?usp=sharing) notebook.
## Results on test set 📝
| Metric | # Value |
| ------ | --------- |
| **ROUGE-2** | **17.37** |
## Model in Action 🚀
```python
from transformers import BertTokenizerFast, EncoderDecoderModel
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tokenizer = BertTokenizerFast.from_pretrained('mrm8488/bert-small2bert-small-finetuned-cnn_daily_mail-summarization')
model = EncoderDecoderModel.from_pretrained('mrm8488/bert-small2bert-small-finetuned-cnn_daily_mail-summarization').to(device)
def generate_summary(text):
# cut off at BERT max length 512
inputs = tokenizer([text], padding="max_length", truncation=True, max_length=512, return_tensors="pt")
input_ids = inputs.input_ids.to(device)
attention_mask = inputs.attention_mask.to(device)
output = model.generate(input_ids, attention_mask=attention_mask)
return tokenizer.decode(output[0], skip_special_tokens=True)
text = "your text to be summarized here..."
generate_summary(text)
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-small2bert-small_shared-finetuned-wikisql | 2020-11-12T23:43:15.000Z | [
"pytorch",
"encoder-decoder",
"seq2seq",
"transformers",
"text2text-generation"
]
| text2text-generation | [
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 10 | transformers | |
mrm8488/bert-spanish-cased-finedtuned-ner | 2021-05-20T00:34:37.000Z | [
"pytorch",
"bert",
"token-classification",
"transformers"
]
| token-classification | [
".gitattributes",
"config.json",
"eval_results.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 44 | transformers | |
mrm8488/bert-spanish-cased-finetuned-ner | 2021-05-20T00:35:25.000Z | [
"pytorch",
"jax",
"bert",
"token-classification",
"es",
"transformers"
]
| token-classification | [
".gitattributes",
"README.md",
"config.json",
"eval_results.txt",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"test_predictions.txt",
"test_results.txt",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 1,999 | transformers | ---
language: es
thumbnail: https://i.imgur.com/jgBdimh.png
---
# Spanish BERT (BETO) + NER
This model is a fine-tuned on [NER-C](https://www.kaggle.com/nltkdata/conll-corpora) version of the Spanish BERT cased [(BETO)](https://github.com/dccuchile/beto) for **NER** downstream task.
## Details of the downstream task (NER) - Dataset
- [Dataset: CONLL Corpora ES](https://www.kaggle.com/nltkdata/conll-corpora)
I preprocessed the dataset and split it as train / dev (80/20)
| Dataset | # Examples |
| ---------------------- | ----- |
| Train | 8.7 K |
| Dev | 2.2 K |
- [Fine-tune on NER script provided by Huggingface](https://github.com/huggingface/transformers/blob/master/examples/token-classification/run_ner_old.py)
- Labels covered:
```
B-LOC
B-MISC
B-ORG
B-PER
I-LOC
I-MISC
I-ORG
I-PER
O
```
## Metrics on evaluation set:
| Metric | # score |
| :------------------------------------------------------------------------------------: | :-------: |
| F1 | **90.17**
| Precision | **89.86** |
| Recall | **90.47** |
## Comparison:
| Model | # F1 score |Size(MB)|
| :--------------------------------------------------------------------------------------------------------------: | :-------: |:------|
| bert-base-spanish-wwm-cased (BETO) | 88.43 | 421
| [bert-spanish-cased-finetuned-ner (this one)](https://huggingface.co/mrm8488/bert-spanish-cased-finetuned-ner) | **90.17** | 420 |
| Best Multilingual BERT | 87.38 | 681 |
|[TinyBERT-spanish-uncased-finetuned-ner](https://huggingface.co/mrm8488/TinyBERT-spanish-uncased-finetuned-ner) | 70.00 | **55** |
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
nlp_ner = pipeline(
"ner",
model="mrm8488/bert-spanish-cased-finetuned-ner",
tokenizer=(
'mrm8488/bert-spanish-cased-finetuned-ner',
{"use_fast": False}
))
text = 'Mis amigos están pensando viajar a Londres este verano'
nlp_ner(text)
#Output: [{'entity': 'B-LOC', 'score': 0.9998720288276672, 'word': 'Londres'}]
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-spanish-cased-finetuned-pos-16-tags | 2021-05-20T00:36:33.000Z | [
"pytorch",
"jax",
"bert",
"token-classification",
"transformers"
]
| token-classification | [
".gitattributes",
"config.json",
"eval_results.txt",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 45 | transformers | |
mrm8488/bert-spanish-cased-finetuned-pos-syntax | 2021-05-20T00:37:26.000Z | [
"pytorch",
"jax",
"bert",
"token-classification",
"es",
"transformers"
]
| token-classification | [
".gitattributes",
"README.md",
"config.json",
"eval_results.txt",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 29 | transformers | ---
language: es
thumbnail:
---
# Spanish BERT (BETO) + Syntax POS tagging ✍🏷
This model is a fine-tuned version of the Spanish BERT [(BETO)](https://github.com/dccuchile/beto) on Spanish **syntax** annotations in [CONLL CORPORA](https://www.kaggle.com/nltkdata/conll-corpora) dataset for **syntax POS** (Part of Speech tagging) downstream task.
## Details of the downstream task (Syntax POS) - Dataset
- [Dataset: CONLL Corpora ES](https://www.kaggle.com/nltkdata/conll-corpora)
#### [Fine-tune script on NER dataset provided by Huggingface](https://github.com/huggingface/transformers/blob/master/examples/token-classification/run_ner_old.py)
#### 21 Syntax annotations (Labels) covered:
- \_
- ATR
- ATR.d
- CAG
- CC
- CD
- CD.Q
- CI
- CPRED
- CPRED.CD
- CPRED.SUJ
- CREG
- ET
- IMPERS
- MOD
- NEG
- PASS
- PUNC
- ROOT
- SUJ
- VOC
## Metrics on test set 📋
| Metric | # score |
| :-------: | :-------: |
| F1 | **89.27** |
| Precision | **89.44** |
| Recall | **89.11** |
## Model in action 🔨
Fast usage with **pipelines** 🧪
```python
from transformers import pipeline
nlp_pos_syntax = pipeline(
"ner",
model="mrm8488/bert-spanish-cased-finetuned-pos-syntax",
tokenizer="mrm8488/bert-spanish-cased-finetuned-pos-syntax"
)
text = 'Mis amigos están pensando viajar a Londres este verano.'
nlp_pos_syntax(text)[1:len(nlp_pos_syntax(text))-1]
```
```json
[
{ "entity": "_", "score": 0.9999216794967651, "word": "Mis" },
{ "entity": "SUJ", "score": 0.999882698059082, "word": "amigos" },
{ "entity": "_", "score": 0.9998869299888611, "word": "están" },
{ "entity": "ROOT", "score": 0.9980518221855164, "word": "pensando" },
{ "entity": "_", "score": 0.9998420476913452, "word": "viajar" },
{ "entity": "CD", "score": 0.999351978302002, "word": "a" },
{ "entity": "_", "score": 0.999959409236908, "word": "Londres" },
{ "entity": "_", "score": 0.9998968839645386, "word": "este" },
{ "entity": "CC", "score": 0.99931401014328, "word": "verano" },
{ "entity": "PUNC", "score": 0.9998534917831421, "word": "." }
]
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-spanish-cased-finetuned-pos | 2021-05-20T00:38:26.000Z | [
"pytorch",
"jax",
"bert",
"token-classification",
"es",
"transformers",
"POS",
"Spanish"
]
| token-classification | [
".gitattributes",
"README.md",
"config.json",
"eval_results.txt",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 344 | transformers | ---
language: es
thumbnail: https://i.imgur.com/jgBdimh.png
tags:
- POS
- Spanish
widget:
- text: "Mis amigos y yo estamos pensando en viajar a Londres este verano."
---
# Spanish BERT (BETO) + POS
This model is a fine-tuned on Spanish [CONLL CORPORA](https://www.kaggle.com/nltkdata/conll-corpora) version of the Spanish BERT cased [(BETO)](https://github.com/dccuchile/beto) for **POS** (Part of Speech tagging) downstream task.
## Details of the downstream task (POS) - Dataset
- [Dataset: CONLL Corpora ES](https://www.kaggle.com/nltkdata/conll-corpora) with data augmentation techniques
I preprocessed the dataset and split it as train / dev (80/20)
| Dataset | # Examples |
| ---------------------- | ----- |
| Train | 340 K |
| Dev | 50 K |
- [Fine-tune on NER script provided by Huggingface](https://github.com/huggingface/transformers/blob/master/examples/token-classification/run_ner_old.py)
- **60** Labels covered:
```
AO, AQ, CC, CS, DA, DD, DE, DI, DN, DP, DT, Faa, Fat, Fc, Fd, Fe, Fg, Fh, Fia, Fit, Fp, Fpa, Fpt, Fs, Ft, Fx, Fz, I, NC, NP, P0, PD, PI, PN, PP, PR, PT, PX, RG, RN, SP, VAI, VAM, VAN, VAP, VAS, VMG, VMI, VMM, VMN, VMP, VMS, VSG, VSI, VSM, VSN, VSP, VSS, Y and Z
```
## Metrics on evaluation set:
| Metric | # score |
| :------------------------------------------------------------------------------------: | :-------: |
| F1 | **90.06**
| Precision | **89.46** |
| Recall | **90.67** |
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
nlp_pos = pipeline(
"ner",
model="mrm8488/bert-spanish-cased-finetuned-pos",
tokenizer=(
'mrm8488/bert-spanish-cased-finetuned-pos',
{"use_fast": False}
))
text = 'Mis amigos están pensando en viajar a Londres este verano'
nlp_pos(text)
#Output:
'''
[{'entity': 'NC', 'score': 0.7792173624038696, 'word': '[CLS]'},
{'entity': 'DP', 'score': 0.9996283650398254, 'word': 'Mis'},
{'entity': 'NC', 'score': 0.9999253749847412, 'word': 'amigos'},
{'entity': 'VMI', 'score': 0.9998560547828674, 'word': 'están'},
{'entity': 'VMG', 'score': 0.9992249011993408, 'word': 'pensando'},
{'entity': 'SP', 'score': 0.9999602437019348, 'word': 'en'},
{'entity': 'VMN', 'score': 0.9998666048049927, 'word': 'viajar'},
{'entity': 'SP', 'score': 0.9999545216560364, 'word': 'a'},
{'entity': 'VMN', 'score': 0.8722310662269592, 'word': 'Londres'},
{'entity': 'DD', 'score': 0.9995203614234924, 'word': 'este'},
{'entity': 'NC', 'score': 0.9999248385429382, 'word': 'verano'},
{'entity': 'NC', 'score': 0.8802427649497986, 'word': '[SEP]'}]
'''
```
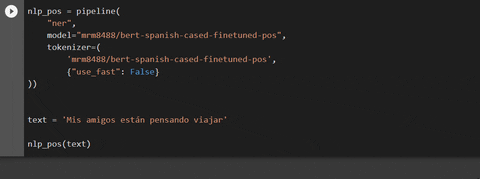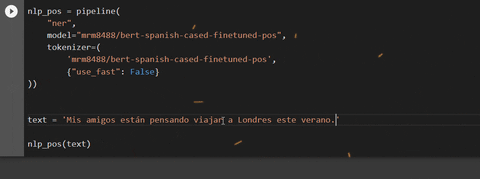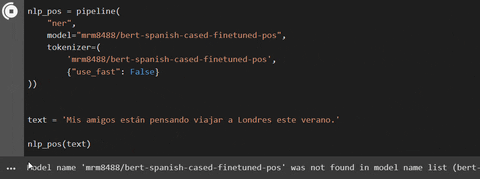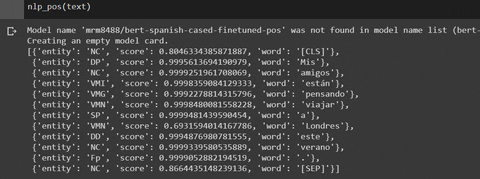
16 POS tags version also available [here](https://huggingface.co/mrm8488/bert-spanish-cased-finetuned-pos-16-tags)
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-tiny-2-finetuned-squadv2 | 2021-05-20T00:38:57.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"transformers"
]
| question-answering | [
".gitattributes",
"config.json",
"flax_model.msgpack",
"optimizer.pt",
"pytorch_model.bin",
"scheduler.pt",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 37 | transformers | |
mrm8488/bert-tiny-3-finetuned-squadv2 | 2021-05-20T00:39:15.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"transformers"
]
| question-answering | [
".gitattributes",
"config.json",
"flax_model.msgpack",
"optimizer.pt",
"pytorch_model.bin",
"scheduler.pt",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| mrm8488 | 26 | transformers |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.