
Search is not available for this dataset
pipeline_tag
stringclasses 48
values | library_name
stringclasses 205
values | text
stringlengths 0
18.3M
| metadata
stringlengths 2
1.07B
| id
stringlengths 5
122
| last_modified
null | tags
listlengths 1
1.84k
| sha
null | created_at
stringlengths 25
25
|
|---|---|---|---|---|---|---|---|---|
null | transformers | {"language": "en"} | allenai/dsp_roberta_base_tapt_sciie_3219 | null | [
"transformers",
"pytorch",
"jax",
"roberta",
"en",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
token-classification | transformers | {"language": "en"} | allenai/hvila-block-layoutlm-finetuned-docbank | null | [
"transformers",
"pytorch",
"hierarchical_model",
"token-classification",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
token-classification | transformers | {"language": "en"} | allenai/hvila-block-layoutlm-finetuned-grotoap2 | null | [
"transformers",
"pytorch",
"hierarchical_model",
"token-classification",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
token-classification | transformers | {"language": "en"} | allenai/hvila-row-layoutlm-finetuned-docbank | null | [
"transformers",
"pytorch",
"hierarchical_model",
"token-classification",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
token-classification | transformers | {"language": "en"} | allenai/hvila-row-layoutlm-finetuned-grotoap2 | null | [
"transformers",
"pytorch",
"hierarchical_model",
"token-classification",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
token-classification | transformers | {"language": "en"} | allenai/ivila-block-layoutlm-finetuned-docbank | null | [
"transformers",
"pytorch",
"layoutlm",
"token-classification",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
token-classification | transformers | {"language": "en"} | allenai/ivila-block-layoutlm-finetuned-grotoap2 | null | [
"transformers",
"pytorch",
"layoutlm",
"token-classification",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text2text-generation | transformers |
## Introduction
[Allenai's Longformer Encoder-Decoder (LED)](https://github.com/allenai/longformer#longformer).
As described in [Longformer: The Long-Document Transformer](https://arxiv.org/pdf/2004.05150.pdf) by Iz Beltagy, Matthew E. Peters, Arman Cohan, *led-base-16384* was initialized from [*bart-base*](https://huggingface.co/facebook/bart-base) since both models share the exact same architecture. To be able to process 16K tokens, *bart-base*'s position embedding matrix was simply copied 16 times.
This model is especially interesting for long-range summarization and question answering.
## Fine-tuning for down-stream task
[This notebook](https://colab.research.google.com/drive/12LjJazBl7Gam0XBPy_y0CTOJZeZ34c2v?usp=sharing) shows how *led-base-16384* can effectively be fine-tuned on a downstream task.
| {"language": "en", "license": "apache-2.0"} | allenai/led-base-16384 | null | [
"transformers",
"pytorch",
"tf",
"led",
"text2text-generation",
"en",
"arxiv:2004.05150",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers |
## Introduction
[Allenai's Longformer Encoder-Decoder (LED)](https://github.com/allenai/longformer#longformer).
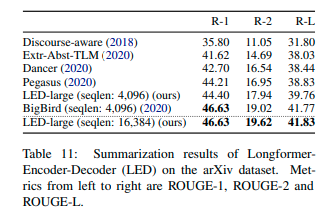
This is the official *led-large-16384* checkpoint that is fine-tuned on the arXiv dataset.*led-large-16384-arxiv* is the official fine-tuned version of [led-large-16384](https://huggingface.co/allenai/led-large-16384). As presented in the [paper](https://arxiv.org/pdf/2004.05150.pdf), the checkpoint achieves state-of-the-art results on arxiv
## Evaluation on downstream task
[This notebook](https://colab.research.google.com/drive/12INTTR6n64TzS4RrXZxMSXfrOd9Xzamo?usp=sharing) shows how *led-large-16384-arxiv* can be evaluated on the [arxiv dataset](https://huggingface.co/datasets/scientific_papers)
## Usage
The model can be used as follows. The input is taken from the test data of the [arxiv dataset](https://huggingface.co/datasets/scientific_papers).
```python
LONG_ARTICLE = """"for about 20 years the problem of properties of
short - term changes of solar activity has been
considered extensively . many investigators
studied the short - term periodicities of the
various indices of solar activity . several
periodicities were detected , but the
periodicities about 155 days and from the interval
of @xmath3 $ ] days ( @xmath4 $ ] years ) are
mentioned most often . first of them was
discovered by @xcite in the occurence rate of
gamma - ray flares detected by the gamma - ray
spectrometer aboard the _ solar maximum mission (
smm ) . this periodicity was confirmed for other
solar flares data and for the same time period
@xcite . it was also found in proton flares during
solar cycles 19 and 20 @xcite , but it was not
found in the solar flares data during solar cycles
22 @xcite . _ several autors confirmed above
results for the daily sunspot area data . @xcite
studied the sunspot data from 18741984 . she found
the 155-day periodicity in data records from 31
years . this periodicity is always characteristic
for one of the solar hemispheres ( the southern
hemisphere for cycles 1215 and the northern
hemisphere for cycles 1621 ) . moreover , it is
only present during epochs of maximum activity (
in episodes of 13 years ) .
similarinvestigationswerecarriedoutby + @xcite .
they applied the same power spectrum method as
lean , but the daily sunspot area data ( cycles
1221 ) were divided into 10 shorter time series .
the periodicities were searched for the frequency
interval 57115 nhz ( 100200 days ) and for each of
10 time series . the authors showed that the
periodicity between 150160 days is statistically
significant during all cycles from 16 to 21 . the
considered peaks were remained unaltered after
removing the 11-year cycle and applying the power
spectrum analysis . @xcite used the wavelet
technique for the daily sunspot areas between 1874
and 1993 . they determined the epochs of
appearance of this periodicity and concluded that
it presents around the maximum activity period in
cycles 16 to 21 . moreover , the power of this
periodicity started growing at cycle 19 ,
decreased in cycles 20 and 21 and disappered after
cycle 21 . similaranalyseswerepresentedby + @xcite
, but for sunspot number , solar wind plasma ,
interplanetary magnetic field and geomagnetic
activity index @xmath5 . during 1964 - 2000 the
sunspot number wavelet power of periods less than
one year shows a cyclic evolution with the phase
of the solar cycle.the 154-day period is prominent
and its strenth is stronger around the 1982 - 1984
interval in almost all solar wind parameters . the
existence of the 156-day periodicity in sunspot
data were confirmed by @xcite . they considered
the possible relation between the 475-day (
1.3-year ) and 156-day periodicities . the 475-day
( 1.3-year ) periodicity was also detected in
variations of the interplanetary magnetic field ,
geomagnetic activity helioseismic data and in the
solar wind speed @xcite . @xcite concluded that
the region of larger wavelet power shifts from
475-day ( 1.3-year ) period to 620-day ( 1.7-year
) period and then back to 475-day ( 1.3-year ) .
the periodicities from the interval @xmath6 $ ]
days ( @xmath4 $ ] years ) have been considered
from 1968 . @xcite mentioned a 16.3-month (
490-day ) periodicity in the sunspot numbers and
in the geomagnetic data . @xcite analysed the
occurrence rate of major flares during solar
cycles 19 . they found a 18-month ( 540-day )
periodicity in flare rate of the norhern
hemisphere . @xcite confirmed this result for the
@xmath7 flare data for solar cycles 20 and 21 and
found a peak in the power spectra near 510540 days
. @xcite found a 17-month ( 510-day ) periodicity
of sunspot groups and their areas from 1969 to
1986 . these authors concluded that the length of
this period is variable and the reason of this
periodicity is still not understood . @xcite and +
@xcite obtained statistically significant peaks of
power at around 158 days for daily sunspot data
from 1923 - 1933 ( cycle 16 ) . in this paper the
problem of the existence of this periodicity for
sunspot data from cycle 16 is considered . the
daily sunspot areas , the mean sunspot areas per
carrington rotation , the monthly sunspot numbers
and their fluctuations , which are obtained after
removing the 11-year cycle are analysed . in
section 2 the properties of the power spectrum
methods are described . in section 3 a new
approach to the problem of aliases in the power
spectrum analysis is presented . in section 4
numerical results of the new method of the
diagnosis of an echo - effect for sunspot area
data are discussed . in section 5 the problem of
the existence of the periodicity of about 155 days
during the maximum activity period for sunspot
data from the whole solar disk and from each solar
hemisphere separately is considered . to find
periodicities in a given time series the power
spectrum analysis is applied . in this paper two
methods are used : the fast fourier transformation
algorithm with the hamming window function ( fft )
and the blackman - tukey ( bt ) power spectrum
method @xcite . the bt method is used for the
diagnosis of the reasons of the existence of peaks
, which are obtained by the fft method . the bt
method consists in the smoothing of a cosine
transform of an autocorrelation function using a
3-point weighting average . such an estimator is
consistent and unbiased . moreover , the peaks are
uncorrelated and their sum is a variance of a
considered time series . the main disadvantage of
this method is a weak resolution of the
periodogram points , particularly for low
frequences . for example , if the autocorrelation
function is evaluated for @xmath8 , then the
distribution points in the time domain are :
@xmath9 thus , it is obvious that this method
should not be used for detecting low frequency
periodicities with a fairly good resolution .
however , because of an application of the
autocorrelation function , the bt method can be
used to verify a reality of peaks which are
computed using a method giving the better
resolution ( for example the fft method ) . it is
valuable to remember that the power spectrum
methods should be applied very carefully . the
difficulties in the interpretation of significant
peaks could be caused by at least four effects : a
sampling of a continuos function , an echo -
effect , a contribution of long - term
periodicities and a random noise . first effect
exists because periodicities , which are shorter
than the sampling interval , may mix with longer
periodicities . in result , this effect can be
reduced by an decrease of the sampling interval
between observations . the echo - effect occurs
when there is a latent harmonic of frequency
@xmath10 in the time series , giving a spectral
peak at @xmath10 , and also periodic terms of
frequency @xmath11 etc . this may be detected by
the autocorrelation function for time series with
a large variance . time series often contain long
- term periodicities , that influence short - term
peaks . they could rise periodogram s peaks at
lower frequencies . however , it is also easy to
notice the influence of the long - term
periodicities on short - term peaks in the graphs
of the autocorrelation functions . this effect is
observed for the time series of solar activity
indexes which are limited by the 11-year cycle .
to find statistically significant periodicities it
is reasonable to use the autocorrelation function
and the power spectrum method with a high
resolution . in the case of a stationary time
series they give similar results . moreover , for
a stationary time series with the mean zero the
fourier transform is equivalent to the cosine
transform of an autocorrelation function @xcite .
thus , after a comparison of a periodogram with an
appropriate autocorrelation function one can
detect peaks which are in the graph of the first
function and do not exist in the graph of the
second function . the reasons of their existence
could be explained by the long - term
periodicities and the echo - effect . below method
enables one to detect these effects . ( solid line
) and the 95% confidence level basing on thered
noise ( dotted line ) . the periodogram values are
presented on the left axis . the lower curve
illustrates the autocorrelation function of the
same time series ( solid line ) . the dotted lines
represent two standard errors of the
autocorrelation function . the dashed horizontal
line shows the zero level . the autocorrelation
values are shown in the right axis . ] because
the statistical tests indicate that the time
series is a white noise the confidence level is
not marked . ] . ] the method of the diagnosis
of an echo - effect in the power spectrum ( de )
consists in an analysis of a periodogram of a
given time series computed using the bt method .
the bt method bases on the cosine transform of the
autocorrelation function which creates peaks which
are in the periodogram , but not in the
autocorrelation function . the de method is used
for peaks which are computed by the fft method (
with high resolution ) and are statistically
significant . the time series of sunspot activity
indexes with the spacing interval one rotation or
one month contain a markov - type persistence ,
which means a tendency for the successive values
of the time series to remember their antecendent
values . thus , i use a confidence level basing on
the red noise of markov @xcite for the choice of
the significant peaks of the periodogram computed
by the fft method . when a time series does not
contain the markov - type persistence i apply the
fisher test and the kolmogorov - smirnov test at
the significance level @xmath12 @xcite to verify a
statistically significance of periodograms peaks .
the fisher test checks the null hypothesis that
the time series is white noise agains the
alternative hypothesis that the time series
contains an added deterministic periodic component
of unspecified frequency . because the fisher test
tends to be severe in rejecting peaks as
insignificant the kolmogorov - smirnov test is
also used . the de method analyses raw estimators
of the power spectrum . they are given as follows
@xmath13 for @xmath14 + where @xmath15 for
@xmath16 + @xmath17 is the length of the time
series @xmath18 and @xmath19 is the mean value .
the first term of the estimator @xmath20 is
constant . the second term takes two values (
depending on odd or even @xmath21 ) which are not
significant because @xmath22 for large m. thus ,
the third term of ( 1 ) should be analysed .
looking for intervals of @xmath23 for which
@xmath24 has the same sign and different signs one
can find such parts of the function @xmath25 which
create the value @xmath20 . let the set of values
of the independent variable of the autocorrelation
function be called @xmath26 and it can be divided
into the sums of disjoint sets : @xmath27 where +
@xmath28 + @xmath29 @xmath30 @xmath31 + @xmath32 +
@xmath33 @xmath34 @xmath35 @xmath36 @xmath37
@xmath38 @xmath39 @xmath40 well , the set
@xmath41 contains all integer values of @xmath23
from the interval of @xmath42 for which the
autocorrelation function and the cosinus function
with the period @xmath43 $ ] are positive . the
index @xmath44 indicates successive parts of the
cosinus function for which the cosinuses of
successive values of @xmath23 have the same sign .
however , sometimes the set @xmath41 can be empty
. for example , for @xmath45 and @xmath46 the set
@xmath47 should contain all @xmath48 $ ] for which
@xmath49 and @xmath50 , but for such values of
@xmath23 the values of @xmath51 are negative .
thus , the set @xmath47 is empty . . the
periodogram values are presented on the left axis
. the lower curve illustrates the autocorrelation
function of the same time series . the
autocorrelation values are shown in the right axis
. ] let us take into consideration all sets
\{@xmath52 } , \{@xmath53 } and \{@xmath41 } which
are not empty . because numberings and power of
these sets depend on the form of the
autocorrelation function of the given time series
, it is impossible to establish them arbitrary .
thus , the sets of appropriate indexes of the sets
\{@xmath52 } , \{@xmath53 } and \{@xmath41 } are
called @xmath54 , @xmath55 and @xmath56
respectively . for example the set @xmath56
contains all @xmath44 from the set @xmath57 for
which the sets @xmath41 are not empty . to
separate quantitatively in the estimator @xmath20
the positive contributions which are originated by
the cases described by the formula ( 5 ) from the
cases which are described by the formula ( 3 ) the
following indexes are introduced : @xmath58
@xmath59 @xmath60 @xmath61 where @xmath62 @xmath63
@xmath64 taking for the empty sets \{@xmath53 }
and \{@xmath41 } the indices @xmath65 and @xmath66
equal zero . the index @xmath65 describes a
percentage of the contribution of the case when
@xmath25 and @xmath51 are positive to the positive
part of the third term of the sum ( 1 ) . the
index @xmath66 describes a similar contribution ,
but for the case when the both @xmath25 and
@xmath51 are simultaneously negative . thanks to
these one can decide which the positive or the
negative values of the autocorrelation function
have a larger contribution to the positive values
of the estimator @xmath20 . when the difference
@xmath67 is positive , the statement the
@xmath21-th peak really exists can not be rejected
. thus , the following formula should be satisfied
: @xmath68 because the @xmath21-th peak could
exist as a result of the echo - effect , it is
necessary to verify the second condition :
@xmath69\in c_m.\ ] ] . the periodogram values
are presented on the left axis . the lower curve
illustrates the autocorrelation function of the
same time series ( solid line ) . the dotted lines
represent two standard errors of the
autocorrelation function . the dashed horizontal
line shows the zero level . the autocorrelation
values are shown in the right axis . ] to
verify the implication ( 8) firstly it is
necessary to evaluate the sets @xmath41 for
@xmath70 of the values of @xmath23 for which the
autocorrelation function and the cosine function
with the period @xmath71 $ ] are positive and the
sets @xmath72 of values of @xmath23 for which the
autocorrelation function and the cosine function
with the period @xmath43 $ ] are negative .
secondly , a percentage of the contribution of the
sum of products of positive values of @xmath25 and
@xmath51 to the sum of positive products of the
values of @xmath25 and @xmath51 should be
evaluated . as a result the indexes @xmath65 for
each set @xmath41 where @xmath44 is the index from
the set @xmath56 are obtained . thirdly , from all
sets @xmath41 such that @xmath70 the set @xmath73
for which the index @xmath65 is the greatest
should be chosen . the implication ( 8) is true
when the set @xmath73 includes the considered
period @xmath43 $ ] . this means that the greatest
contribution of positive values of the
autocorrelation function and positive cosines with
the period @xmath43 $ ] to the periodogram value
@xmath20 is caused by the sum of positive products
of @xmath74 for each @xmath75-\frac{m}{2k},[\frac{
2m}{k}]+\frac{m}{2k})$ ] . when the implication
( 8) is false , the peak @xmath20 is mainly
created by the sum of positive products of
@xmath74 for each @xmath76-\frac{m}{2k},\big [
\frac{2m}{n}\big ] + \frac{m}{2k } \big ) $ ] ,
where @xmath77 is a multiple or a divisor of
@xmath21 . it is necessary to add , that the de
method should be applied to the periodograms peaks
, which probably exist because of the echo -
effect . it enables one to find such parts of the
autocorrelation function , which have the
significant contribution to the considered peak .
the fact , that the conditions ( 7 ) and ( 8) are
satisfied , can unambiguously decide about the
existence of the considered periodicity in the
given time series , but if at least one of them is
not satisfied , one can doubt about the existence
of the considered periodicity . thus , in such
cases the sentence the peak can not be treated as
true should be used . using the de method it is
necessary to remember about the power of the set
@xmath78 . if @xmath79 is too large , errors of an
autocorrelation function estimation appear . they
are caused by the finite length of the given time
series and as a result additional peaks of the
periodogram occur . if @xmath79 is too small ,
there are less peaks because of a low resolution
of the periodogram . in applications @xmath80 is
used . in order to evaluate the value @xmath79 the
fft method is used . the periodograms computed by
the bt and the fft method are compared . the
conformity of them enables one to obtain the value
@xmath79 . . the fft periodogram values are
presented on the left axis . the lower curve
illustrates the bt periodogram of the same time
series ( solid line and large black circles ) .
the bt periodogram values are shown in the right
axis . ] in this paper the sunspot activity data (
august 1923 - october 1933 ) provided by the
greenwich photoheliographic results ( gpr ) are
analysed . firstly , i consider the monthly
sunspot number data . to eliminate the 11-year
trend from these data , the consecutively smoothed
monthly sunspot number @xmath81 is subtracted from
the monthly sunspot number @xmath82 where the
consecutive mean @xmath83 is given by @xmath84 the
values @xmath83 for @xmath85 and @xmath86 are
calculated using additional data from last six
months of cycle 15 and first six months of cycle
17 . because of the north - south asymmetry of
various solar indices @xcite , the sunspot
activity is considered for each solar hemisphere
separately . analogously to the monthly sunspot
numbers , the time series of sunspot areas in the
northern and southern hemispheres with the spacing
interval @xmath87 rotation are denoted . in order
to find periodicities , the following time series
are used : + @xmath88 + @xmath89 + @xmath90
+ in the lower part of figure [ f1 ] the
autocorrelation function of the time series for
the northern hemisphere @xmath88 is shown . it is
easy to notice that the prominent peak falls at 17
rotations interval ( 459 days ) and @xmath25 for
@xmath91 $ ] rotations ( [ 81 , 162 ] days ) are
significantly negative . the periodogram of the
time series @xmath88 ( see the upper curve in
figures [ f1 ] ) does not show the significant
peaks at @xmath92 rotations ( 135 , 162 days ) ,
but there is the significant peak at @xmath93 (
243 days ) . the peaks at @xmath94 are close to
the peaks of the autocorrelation function . thus ,
the result obtained for the periodicity at about
@xmath0 days are contradict to the results
obtained for the time series of daily sunspot
areas @xcite . for the southern hemisphere (
the lower curve in figure [ f2 ] ) @xmath25 for
@xmath95 $ ] rotations ( [ 54 , 189 ] days ) is
not positive except @xmath96 ( 135 days ) for
which @xmath97 is not statistically significant .
the upper curve in figures [ f2 ] presents the
periodogram of the time series @xmath89 . this
time series does not contain a markov - type
persistence . moreover , the kolmogorov - smirnov
test and the fisher test do not reject a null
hypothesis that the time series is a white noise
only . this means that the time series do not
contain an added deterministic periodic component
of unspecified frequency . the autocorrelation
function of the time series @xmath90 ( the lower
curve in figure [ f3 ] ) has only one
statistically significant peak for @xmath98 months
( 480 days ) and negative values for @xmath99 $ ]
months ( [ 90 , 390 ] days ) . however , the
periodogram of this time series ( the upper curve
in figure [ f3 ] ) has two significant peaks the
first at 15.2 and the second at 5.3 months ( 456 ,
159 days ) . thus , the periodogram contains the
significant peak , although the autocorrelation
function has the negative value at @xmath100
months . to explain these problems two
following time series of daily sunspot areas are
considered : + @xmath101 + @xmath102 + where
@xmath103 the values @xmath104 for @xmath105
and @xmath106 are calculated using additional
daily data from the solar cycles 15 and 17 .
and the cosine function for @xmath45 ( the period
at about 154 days ) . the horizontal line ( dotted
line ) shows the zero level . the vertical dotted
lines evaluate the intervals where the sets
@xmath107 ( for @xmath108 ) are searched . the
percentage values show the index @xmath65 for each
@xmath41 for the time series @xmath102 ( in
parentheses for the time series @xmath101 ) . in
the right bottom corner the values of @xmath65 for
the time series @xmath102 , for @xmath109 are
written . ] ( the 500-day period ) ] the
comparison of the functions @xmath25 of the time
series @xmath101 ( the lower curve in figure [ f4
] ) and @xmath102 ( the lower curve in figure [ f5
] ) suggests that the positive values of the
function @xmath110 of the time series @xmath101 in
the interval of @xmath111 $ ] days could be caused
by the 11-year cycle . this effect is not visible
in the case of periodograms of the both time
series computed using the fft method ( see the
upper curves in figures [ f4 ] and [ f5 ] ) or the
bt method ( see the lower curve in figure [ f6 ] )
. moreover , the periodogram of the time series
@xmath102 has the significant values at @xmath112
days , but the autocorrelation function is
negative at these points . @xcite showed that the
lomb - scargle periodograms for the both time
series ( see @xcite , figures 7 a - c ) have a
peak at 158.8 days which stands over the fap level
by a significant amount . using the de method the
above discrepancies are obvious . to establish the
@xmath79 value the periodograms computed by the
fft and the bt methods are shown in figure [ f6 ]
( the upper and the lower curve respectively ) .
for @xmath46 and for periods less than 166 days
there is a good comformity of the both
periodograms ( but for periods greater than 166
days the points of the bt periodogram are not
linked because the bt periodogram has much worse
resolution than the fft periodogram ( no one know
how to do it ) ) . for @xmath46 and @xmath113 the
value of @xmath21 is 13 ( @xmath71=153 $ ] ) . the
inequality ( 7 ) is satisfied because @xmath114 .
this means that the value of @xmath115 is mainly
created by positive values of the autocorrelation
function . the implication ( 8) needs an
evaluation of the greatest value of the index
@xmath65 where @xmath70 , but the solar data
contain the most prominent period for @xmath116
days because of the solar rotation . thus ,
although @xmath117 for each @xmath118 , all sets
@xmath41 ( see ( 5 ) and ( 6 ) ) without the set
@xmath119 ( see ( 4 ) ) , which contains @xmath120
$ ] , are considered . this situation is presented
in figure [ f7 ] . in this figure two curves
@xmath121 and @xmath122 are plotted . the vertical
dotted lines evaluate the intervals where the sets
@xmath107 ( for @xmath123 ) are searched . for
such @xmath41 two numbers are written : in
parentheses the value of @xmath65 for the time
series @xmath101 and above it the value of
@xmath65 for the time series @xmath102 . to make
this figure clear the curves are plotted for the
set @xmath124 only . ( in the right bottom corner
information about the values of @xmath65 for the
time series @xmath102 , for @xmath109 are written
. ) the implication ( 8) is not true , because
@xmath125 for @xmath126 . therefore ,
@xmath43=153\notin c_6=[423,500]$ ] . moreover ,
the autocorrelation function for @xmath127 $ ] is
negative and the set @xmath128 is empty . thus ,
@xmath129 . on the basis of these information one
can state , that the periodogram peak at @xmath130
days of the time series @xmath102 exists because
of positive @xmath25 , but for @xmath23 from the
intervals which do not contain this period .
looking at the values of @xmath65 of the time
series @xmath101 , one can notice that they
decrease when @xmath23 increases until @xmath131 .
this indicates , that when @xmath23 increases ,
the contribution of the 11-year cycle to the peaks
of the periodogram decreases . an increase of the
value of @xmath65 is for @xmath132 for the both
time series , although the contribution of the
11-year cycle for the time series @xmath101 is
insignificant . thus , this part of the
autocorrelation function ( @xmath133 for the time
series @xmath102 ) influences the @xmath21-th peak
of the periodogram . this suggests that the
periodicity at about 155 days is a harmonic of the
periodicity from the interval of @xmath1 $ ] days
. ( solid line ) and consecutively smoothed
sunspot areas of the one rotation time interval
@xmath134 ( dotted line ) . both indexes are
presented on the left axis . the lower curve
illustrates fluctuations of the sunspot areas
@xmath135 . the dotted and dashed horizontal lines
represent levels zero and @xmath136 respectively .
the fluctuations are shown on the right axis . ]
the described reasoning can be carried out for
other values of the periodogram . for example ,
the condition ( 8) is not satisfied for @xmath137
( 250 , 222 , 200 days ) . moreover , the
autocorrelation function at these points is
negative . these suggest that there are not a true
periodicity in the interval of [ 200 , 250 ] days
. it is difficult to decide about the existence of
the periodicities for @xmath138 ( 333 days ) and
@xmath139 ( 286 days ) on the basis of above
analysis . the implication ( 8) is not satisfied
for @xmath139 and the condition ( 7 ) is not
satisfied for @xmath138 , although the function
@xmath25 of the time series @xmath102 is
significantly positive for @xmath140 . the
conditions ( 7 ) and ( 8) are satisfied for
@xmath141 ( figure [ f8 ] ) and @xmath142 .
therefore , it is possible to exist the
periodicity from the interval of @xmath1 $ ] days
. similar results were also obtained by @xcite for
daily sunspot numbers and daily sunspot areas .
she considered the means of three periodograms of
these indexes for data from @xmath143 years and
found statistically significant peaks from the
interval of @xmath1 $ ] ( see @xcite , figure 2 )
. @xcite studied sunspot areas from 1876 - 1999
and sunspot numbers from 1749 - 2001 with the help
of the wavelet transform . they pointed out that
the 154 - 158-day period could be the third
harmonic of the 1.3-year ( 475-day ) period .
moreover , the both periods fluctuate considerably
with time , being stronger during stronger sunspot
cycles . therefore , the wavelet analysis suggests
a common origin of the both periodicities . this
conclusion confirms the de method result which
indicates that the periodogram peak at @xmath144
days is an alias of the periodicity from the
interval of @xmath1 $ ] in order to verify the
existence of the periodicity at about 155 days i
consider the following time series : + @xmath145
+ @xmath146 + @xmath147 + the value @xmath134
is calculated analogously to @xmath83 ( see sect .
the values @xmath148 and @xmath149 are evaluated
from the formula ( 9 ) . in the upper part of
figure [ f9 ] the time series of sunspot areas
@xmath150 of the one rotation time interval from
the whole solar disk and the time series of
consecutively smoothed sunspot areas @xmath151 are
showed . in the lower part of figure [ f9 ] the
time series of sunspot area fluctuations @xmath145
is presented . on the basis of these data the
maximum activity period of cycle 16 is evaluated .
it is an interval between two strongest
fluctuations e.a . @xmath152 $ ] rotations . the
length of the time interval @xmath153 is 54
rotations . if the about @xmath0-day ( 6 solar
rotations ) periodicity existed in this time
interval and it was characteristic for strong
fluctuations from this time interval , 10 local
maxima in the set of @xmath154 would be seen .
then it should be necessary to find such a value
of p for which @xmath155 for @xmath156 and the
number of the local maxima of these values is 10 .
as it can be seen in the lower part of figure [ f9
] this is for the case of @xmath157 ( in this
figure the dashed horizontal line is the level of
@xmath158 ) . figure [ f10 ] presents nine time
distances among the successive fluctuation local
maxima and the horizontal line represents the
6-rotation periodicity . it is immediately
apparent that the dispersion of these points is 10
and it is difficult to find even few points which
oscillate around the value of 6 . such an analysis
was carried out for smaller and larger @xmath136
and the results were similar . therefore , the
fact , that the about @xmath0-day periodicity
exists in the time series of sunspot area
fluctuations during the maximum activity period is
questionable . . the horizontal line represents
the 6-rotation ( 162-day ) period . ] ] ]
to verify again the existence of the about
@xmath0-day periodicity during the maximum
activity period in each solar hemisphere
separately , the time series @xmath88 and @xmath89
were also cut down to the maximum activity period
( january 1925december 1930 ) . the comparison of
the autocorrelation functions of these time series
with the appriopriate autocorrelation functions of
the time series @xmath88 and @xmath89 , which are
computed for the whole 11-year cycle ( the lower
curves of figures [ f1 ] and [ f2 ] ) , indicates
that there are not significant differences between
them especially for @xmath23=5 and 6 rotations (
135 and 162 days ) ) . this conclusion is
confirmed by the analysis of the time series
@xmath146 for the maximum activity period . the
autocorrelation function ( the lower curve of
figure [ f11 ] ) is negative for the interval of [
57 , 173 ] days , but the resolution of the
periodogram is too low to find the significant
peak at @xmath159 days . the autocorrelation
function gives the same result as for daily
sunspot area fluctuations from the whole solar
disk ( @xmath160 ) ( see also the lower curve of
figures [ f5 ] ) . in the case of the time series
@xmath89 @xmath161 is zero for the fluctuations
from the whole solar cycle and it is almost zero (
@xmath162 ) for the fluctuations from the maximum
activity period . the value @xmath163 is negative
. similarly to the case of the northern hemisphere
the autocorrelation function and the periodogram
of southern hemisphere daily sunspot area
fluctuations from the maximum activity period
@xmath147 are computed ( see figure [ f12 ] ) .
the autocorrelation function has the statistically
significant positive peak in the interval of [ 155
, 165 ] days , but the periodogram has too low
resolution to decide about the possible
periodicities . the correlative analysis indicates
that there are positive fluctuations with time
distances about @xmath0 days in the maximum
activity period . the results of the analyses of
the time series of sunspot area fluctuations from
the maximum activity period are contradict with
the conclusions of @xcite . she uses the power
spectrum analysis only . the periodogram of daily
sunspot fluctuations contains peaks , which could
be harmonics or subharmonics of the true
periodicities . they could be treated as real
periodicities . this effect is not visible for
sunspot data of the one rotation time interval ,
but averaging could lose true periodicities . this
is observed for data from the southern hemisphere
. there is the about @xmath0-day peak in the
autocorrelation function of daily fluctuations ,
but the correlation for data of the one rotation
interval is almost zero or negative at the points
@xmath164 and 6 rotations . thus , it is
reasonable to research both time series together
using the correlative and the power spectrum
analyses . the following results are obtained :
1 . a new method of the detection of statistically
significant peaks of the periodograms enables one
to identify aliases in the periodogram . 2 . two
effects cause the existence of the peak of the
periodogram of the time series of sunspot area
fluctuations at about @xmath0 days : the first is
caused by the 27-day periodicity , which probably
creates the 162-day periodicity ( it is a
subharmonic frequency of the 27-day periodicity )
and the second is caused by statistically
significant positive values of the autocorrelation
function from the intervals of @xmath165 $ ] and
@xmath166 $ ] days . the existence of the
periodicity of about @xmath0 days of the time
series of sunspot area fluctuations and sunspot
area fluctuations from the northern hemisphere
during the maximum activity period is questionable
. the autocorrelation analysis of the time series
of sunspot area fluctuations from the southern
hemisphere indicates that the periodicity of about
155 days exists during the maximum activity period
. i appreciate valuable comments from professor j.
jakimiec ."""
from transformers import LEDForConditionalGeneration, LEDTokenizer
import torch
tokenizer = LEDTokenizer.from_pretrained("allenai/led-large-16384-arxiv")
input_ids = tokenizer(LONG_ARTICLE, return_tensors="pt").input_ids.to("cuda")
global_attention_mask = torch.zeros_like(input_ids)
# set global_attention_mask on first token
global_attention_mask[:, 0] = 1
model = LEDForConditionalGeneration.from_pretrained("allenai/led-large-16384-arxiv", return_dict_in_generate=True).to("cuda")
sequences = model.generate(input_ids, global_attention_mask=global_attention_mask).sequences
summary = tokenizer.batch_decode(sequences)
```
| {"language": "en", "license": "apache-2.0", "datasets": ["scientific_papers"]} | allenai/led-large-16384-arxiv | null | [
"transformers",
"pytorch",
"tf",
"led",
"text2text-generation",
"en",
"dataset:scientific_papers",
"arxiv:2004.05150",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers |
## Introduction
[Allenai's Longformer Encoder-Decoder (LED)](https://github.com/allenai/longformer#longformer).
As described in [Longformer: The Long-Document Transformer](https://arxiv.org/pdf/2004.05150.pdf) by Iz Beltagy, Matthew E. Peters, Arman Cohan, *led-large-16384* was initialized from [*bart-large*](https://huggingface.co/facebook/bart-large) since both models share the exact same architecture. To be able to process 16K tokens, *bart-large*'s position embedding matrix was simply copied 16 times.
This model is especially interesting for long-range summarization and question answering.
## Fine-tuning for down-stream task
[This notebook](https://colab.research.google.com/drive/12LjJazBl7Gam0XBPy_y0CTOJZeZ34c2v?usp=sharing) shows how *led-large-16384* can effectively be fine-tuned on a downstream task.
| {"language": "en", "license": "apache-2.0"} | allenai/led-large-16384 | null | [
"transformers",
"pytorch",
"tf",
"led",
"text2text-generation",
"en",
"arxiv:2004.05150",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
null | transformers |
# longformer-base-4096-extra.pos.embd.only
This model is similar to `longformer-base-4096` but it was pretrained to preserve RoBERTa weights by freezing all RoBERTa weights and only train the additional position embeddings.
### Citing
If you use `Longformer` in your research, please cite [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150).
```
@article{Beltagy2020Longformer,
title={Longformer: The Long-Document Transformer},
author={Iz Beltagy and Matthew E. Peters and Arman Cohan},
journal={arXiv:2004.05150},
year={2020},
}
```
`Longformer` is an open-source project developed by [the Allen Institute for Artificial Intelligence (AI2)](http://www.allenai.org).
AI2 is a non-profit institute with the mission to contribute to humanity through high-impact AI research and engineering.
| {"language": "en"} | allenai/longformer-base-4096-extra.pos.embd.only | null | [
"transformers",
"pytorch",
"tf",
"longformer",
"en",
"arxiv:2004.05150",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
null | transformers |
# longformer-base-4096
[Longformer](https://arxiv.org/abs/2004.05150) is a transformer model for long documents.
`longformer-base-4096` is a BERT-like model started from the RoBERTa checkpoint and pretrained for MLM on long documents. It supports sequences of length up to 4,096.
Longformer uses a combination of a sliding window (local) attention and global attention. Global attention is user-configured based on the task to allow the model to learn task-specific representations.
Please refer to the examples in `modeling_longformer.py` and the paper for more details on how to set global attention.
### Citing
If you use `Longformer` in your research, please cite [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150).
```
@article{Beltagy2020Longformer,
title={Longformer: The Long-Document Transformer},
author={Iz Beltagy and Matthew E. Peters and Arman Cohan},
journal={arXiv:2004.05150},
year={2020},
}
```
`Longformer` is an open-source project developed by [the Allen Institute for Artificial Intelligence (AI2)](http://www.allenai.org).
AI2 is a non-profit institute with the mission to contribute to humanity through high-impact AI research and engineering. | {"language": "en", "license": "apache-2.0"} | allenai/longformer-base-4096 | null | [
"transformers",
"pytorch",
"tf",
"rust",
"longformer",
"en",
"arxiv:2004.05150",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
null | transformers | {"language": "en"} | allenai/longformer-large-4096-extra.pos.embd.only | null | [
"transformers",
"pytorch",
"tf",
"longformer",
"en",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
question-answering | transformers | {"language": "en"} | allenai/longformer-large-4096-finetuned-triviaqa | null | [
"transformers",
"pytorch",
"tf",
"longformer",
"question-answering",
"en",
"endpoints_compatible",
"has_space",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
null | transformers | {"language": "en"} | allenai/longformer-large-4096 | null | [
"transformers",
"pytorch",
"tf",
"longformer",
"en",
"endpoints_compatible",
"has_space",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text-classification | transformers |
# Longformer for SciCo
This model is the `unified` model discussed in the paper [SciCo: Hierarchical Cross-Document Coreference for Scientific Concepts (AKBC 2021)](https://openreview.net/forum?id=OFLbgUP04nC) that formulates the task of hierarchical cross-document coreference resolution (H-CDCR) as a multiclass problem. The model takes as input two mentions `m1` and `m2` with their corresponding context and outputs 4 scores:
* 0: not related
* 1: `m1` and `m2` corefer
* 2: `m1` is a parent of `m2`
* 3: `m1` is a child of `m2`.
We provide the following code as an example to set the global attention on the special tokens: `<s>`, `<m>` and `</m>`.
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
tokenizer = AutoTokenizer.from_pretrained('allenai/longformer-scico')
model = AutoModelForSequenceClassification.from_pretrained('allenai/longformer-scico')
start_token = tokenizer.convert_tokens_to_ids("<m>")
end_token = tokenizer.convert_tokens_to_ids("</m>")
def get_global_attention(input_ids):
global_attention_mask = torch.zeros(input_ids.shape)
global_attention_mask[:, 0] = 1 # global attention to the CLS token
start = torch.nonzero(input_ids == start_token) # global attention to the <m> token
end = torch.nonzero(input_ids == end_token) # global attention to the </m> token
globs = torch.cat((start, end))
value = torch.ones(globs.shape[0])
global_attention_mask.index_put_(tuple(globs.t()), value)
return global_attention_mask
m1 = "In this paper we present the results of an experiment in <m> automatic concept and definition extraction </m> from written sources of law using relatively simple natural methods."
m2 = "This task is important since many natural language processing (NLP) problems, such as <m> information extraction </m>, summarization and dialogue."
inputs = m1 + " </s></s> " + m2
tokens = tokenizer(inputs, return_tensors='pt')
global_attention_mask = get_global_attention(tokens['input_ids'])
with torch.no_grad():
output = model(tokens['input_ids'], tokens['attention_mask'], global_attention_mask)
scores = torch.softmax(output.logits, dim=-1)
# tensor([[0.0818, 0.0023, 0.0019, 0.9139]]) -- m1 is a child of m2
```
**Note:** There is a slight difference between this model and the original model presented in the [paper](https://openreview.net/forum?id=OFLbgUP04nC). The original model includes a single linear layer on top of the `<s>` token (equivalent to `[CLS]`) while this model includes a two-layers MLP to be in line with `LongformerForSequenceClassification`. The original repository can be found [here](https://github.com/ariecattan/scico).
# Citation
```python
@inproceedings{
cattan2021scico,
title={SciCo: Hierarchical Cross-Document Coreference for Scientific Concepts},
author={Arie Cattan and Sophie Johnson and Daniel S Weld and Ido Dagan and Iz Beltagy and Doug Downey and Tom Hope},
booktitle={3rd Conference on Automated Knowledge Base Construction},
year={2021},
url={https://openreview.net/forum?id=OFLbgUP04nC}
}
```
| {"language": "en", "license": "apache-2.0", "tags": ["longformer", "longformer-scico"], "datasets": ["allenai/scico"], "inference": false} | allenai/longformer-scico | null | [
"transformers",
"pytorch",
"longformer",
"text-classification",
"longformer-scico",
"en",
"dataset:allenai/scico",
"license:apache-2.0",
"autotrain_compatible",
"has_space",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers |
# macaw-11b
## Model description
Macaw (<b>M</b>ulti-<b>a</b>ngle <b>c</b>(q)uestion <b>a</b>ns<b>w</b>ering) is a ready-to-use model capable of
general question answering,
showing robustness outside the domains it was trained on. It has been trained in "multi-angle" fashion,
which means it can handle a flexible set of input and output "slots"
(question, answer, multiple-choice options, context, and explanation) .
Macaw was built on top of [T5](https://github.com/google-research/text-to-text-transfer-transformer) and comes in
three sizes: [macaw-11b](https://huggingface.co/allenai/macaw-11b), [macaw-3b](https://huggingface.co/allenai/macaw-3b),
and [macaw-large](https://huggingface.co/allenai/macaw-large), as well as an answer-focused version featured on
various leaderboards [macaw-answer-11b](https://huggingface.co/allenai/macaw-answer-11b).
See https://github.com/allenai/macaw for more details.
## Intended uses & limitations
#### How to use
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("allenai/macaw-11b")
model = AutoModelForSeq2SeqLM.from_pretrained("allenai/macaw-11b")
input_string = "$answer$ ; $mcoptions$ ; $question$ = What is the color of a cloudy sky?"
input_ids = tokenizer.encode(input_string, return_tensors="pt")
output = model.generate(input_ids, max_length=200)
>>> tokenizer.batch_decode(output, skip_special_tokens=True)
['$answer$ = gray ; $mcoptions$ = (A) blue (B) white (C) grey (D) black']
```
### BibTeX entry and citation info
```bibtex
@article{Tafjord2021Macaw,
title={General-Purpose Question-Answering with {M}acaw},
author={Oyvind Tafjord and Peter Clark},
journal={ArXiv},
year={2021},
volume={abs/2109.02593}
}
``` | {"language": "en", "license": "apache-2.0", "widget": [{"text": "$answer$ ; $mcoptions$ ; $question$ = What is the color of a cloudy sky?"}]} | allenai/macaw-11b | null | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers |
# macaw-3b
## Model description
Macaw (<b>M</b>ulti-<b>a</b>ngle <b>c</b>(q)uestion <b>a</b>ns<b>w</b>ering) is a ready-to-use model capable of
general question answering,
showing robustness outside the domains it was trained on. It has been trained in "multi-angle" fashion,
which means it can handle a flexible set of input and output "slots"
(question, answer, multiple-choice options, context, and explanation) .
Macaw was built on top of [T5](https://github.com/google-research/text-to-text-transfer-transformer) and comes in
three sizes: [macaw-11b](https://huggingface.co/allenai/macaw-11b), [macaw-3b](https://huggingface.co/allenai/macaw-3b),
and [macaw-large](https://huggingface.co/allenai/macaw-large), as well as an answer-focused version featured on
various leaderboards [macaw-answer-11b](https://huggingface.co/allenai/macaw-answer-11b).
See https://github.com/allenai/macaw for more details. | {"language": "en", "license": "apache-2.0", "widget": [{"text": "$answer$ ; $mcoptions$ ; $question$ = What is the color of a cloudy sky?"}]} | allenai/macaw-3b | null | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers |
# macaw-answer-11b
## Model description
Macaw (<b>M</b>ulti-<b>a</b>ngle <b>c</b>(q)uestion <b>a</b>ns<b>w</b>ering) is a ready-to-use model capable of
general question answering,
showing robustness outside the domains it was trained on. It has been trained in "multi-angle" fashion,
which means it can handle a flexible set of input and output "slots"
(question, answer, multiple-choice options, context, and explanation) .
Macaw was built on top of [T5](https://github.com/google-research/text-to-text-transfer-transformer) and comes in
three sizes: [macaw-11b](https://huggingface.co/allenai/macaw-11b), [macaw-3b](https://huggingface.co/allenai/macaw-3b),
and [macaw-large](https://huggingface.co/allenai/macaw-large), as well as an answer-focused version featured on
various leaderboards [macaw-answer-11b](https://huggingface.co/allenai/macaw-answer-11b).
See https://github.com/allenai/macaw for more details. | {"language": "en", "license": "apache-2.0", "widget": [{"text": "$answer$ ; $mcoptions$ ; $question$ = What is the color of a cloudy sky?"}]} | allenai/macaw-answer-11b | null | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers |
# macaw-large
## Model description
Macaw (<b>M</b>ulti-<b>a</b>ngle <b>c</b>(q)uestion <b>a</b>ns<b>w</b>ering) is a ready-to-use model capable of
general question answering,
showing robustness outside the domains it was trained on. It has been trained in "multi-angle" fashion,
which means it can handle a flexible set of input and output "slots"
(question, answer, multiple-choice options, context, and explanation) .
Macaw was built on top of [T5](https://github.com/google-research/text-to-text-transfer-transformer) and comes in
three sizes: [macaw-11b](https://huggingface.co/allenai/macaw-11b), [macaw-3b](https://huggingface.co/allenai/macaw-3b),
and [macaw-large](https://huggingface.co/allenai/macaw-large), as well as an answer-focused version featured on
various leaderboards [macaw-answer-11b](https://huggingface.co/allenai/macaw-answer-11b).
See https://github.com/allenai/macaw for more details. | {"language": "en", "license": "apache-2.0", "widget": [{"text": "$answer$ ; $mcoptions$ ; $question$ = What is the color of a cloudy sky?"}]} | allenai/macaw-large | null | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"t5",
"text2text-generation",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
question-answering | allennlp |
An augmented version of QANet that adds rudimentary numerical reasoning ability, trained on DROP (Dua et al., 2019), as published in the original DROP paper.
An augmented version of QANet model with some rudimentary numerical reasoning abilities. The main idea here is that instead of just predicting a passage span after doing all of the QANet modeling stuff, we add several different ‘answer abilities’: predicting a span from the question, predicting a count, or predicting an arithmetic expression. Near the end of the QANet model, we have a variable that predicts what kind of answer type we need, and each branch has separate modeling logic to predict that answer type. We then marginalize over all possible ways of getting to the right answer through each of these answer types. | {"language": "en", "tags": ["allennlp", "question-answering"], "widget": [{"context": "A reusable launch system (RLS, or reusable launch vehicle, RLV) is a launch system which is capable of launching a payload into space more than once. This contrasts with expendable launch systems, where each launch vehicle is launched once and then discarded. No completely reusable orbital launch system has ever been created. Two partially reusable launch systems were developed, the Space Shuttle and Falcon 9. The Space Shuttle was partially reusable: the orbiter (which included the Space Shuttle main engines and the Orbital Maneuvering System engines), and the two solid rocket boosters were reused after several months of refitting work for each launch. The external tank was discarded after each flight.", "text": "How many partially reusable launch systems were developed?", "example_title": "Reusable launch systems"}, {"context": "Robotics is an interdisciplinary branch of engineering and science that includes mechanical engineering, electrical engineering, computer science, and others. Robotics deals with the design, construction, operation, and use of robots, as well as computer systems for their control, sensory feedback, and information processing. These technologies are used to develop machines that can substitute for humans. Robots can be used in any situation and for any purpose, but today many are used in dangerous environments (including bomb detection and de-activation), manufacturing processes, or where humans cannot survive. Robots can take on any form but some are made to resemble humans in appearance. This is said to help in the acceptance of a robot in certain replicative behaviors usually performed by people. Such robots attempt to replicate walking, lifting, speech, cognition, and basically anything a human can do.", "text": "What do robots that resemble humans attempt to do?", "example_title": "Robots"}, {"context": "In the first quarter, the Bears drew first blood as kicker Robbie Gould nailed a 22-yard field goal for the only score of the period. In the second quarter, the Bears increased their lead with Gould nailing a 42-yard field goal. They increased their lead with Cutler firing a 7-yard TD pass to tight end Greg Olsen. The Bears then closed out the first half with Gould's 41-yard field goal. In the third quarter, the Vikes started to rally with running back Adrian Peterson's 1-yard touchdown run (with the extra point attempt blocked). The Bears increased their lead over the Vikings with Cutler's 2-yard TD pass to tight end Desmond Clark. The Vikings then closed out the quarter with quarterback Brett Favre firing a 6-yard TD pass to tight end Visanthe Shiancoe. An exciting fourth quarter ensued. The Vikings started out the quarter's scoring with kicker Ryan Longwell's 41-yard field goal, along with Adrian Peterson's second 1-yard TD run. The Bears then responded with Cutler firing a 20-yard TD pass to wide receiver Earl Bennett. The Vikings then completed the remarkable comeback with Favre finding wide receiver Sidney Rice on a 6-yard TD pass on 4th-and-goal with 15 seconds left in regulation. The Bears then took a knee to force overtime. In overtime, the Bears won the toss and marched down the field, stopping at the 35-yard line. However, the potential game-winning 45-yard field goal attempt by Gould went wide right, giving the Vikings a chance to win. After an exchange of punts, the Vikings had the ball at the 26-yard line with 11 minutes left in the period. On the first play of scrimmage, Favre fired a screen pass to Peterson who caught it and went 16 yards, before being confronted by Hunter Hillenmeyer, who caused Peterson to fumble the ball, which was then recovered by Bears' linebacker Nick Roach. The Bears then won on Jay Cutler's game-winning 39-yard TD pass to wide receiver Devin Aromashodu. With the loss, not only did the Vikings fall to 11-4, they also surrendered homefield advantage to the Saints.", "text": "Who threw the longest touchdown pass of the game?", "example_title": "Argmax"}, {"context": "Hoping to rebound from their loss to the Patriots, the Raiders stayed at home for a Week 16 duel with the Houston Texans. Oakland would get the early lead in the first quarter as quarterback JaMarcus Russell completed a 20-yard touchdown pass to rookie wide receiver Chaz Schilens. The Texans would respond with fullback Vonta Leach getting a 1-yard touchdown run, yet the Raiders would answer with kicker Sebastian Janikowski getting a 33-yard and a 30-yard field goal. Houston would tie the game in the second quarter with kicker Kris Brown getting a 53-yard and a 24-yard field goal. Oakland would take the lead in the third quarter with wide receiver Johnnie Lee Higgins catching a 29-yard touchdown pass from Russell, followed up by an 80-yard punt return for a touchdown. The Texans tried to rally in the fourth quarter as Brown nailed a 40-yard field goal, yet the Raiders' defense would shut down any possible attempt.", "text": "How many yards was the longest passing touchdown?", "example_title": "Max"}, {"context": "In 1085, Guadalajara was retaken by the Christian forces of Alfonso VI . The chronicles say that the Christian army was led by Alvar Fanez de Minaya, one of the lieutenants of El Cid. From 1085 until the Battle of Las Navas de Tolosa in 1212, the city suffered wars against the Almoravid and the Almohad Empires. In spite of the wars, the Christian population could definitely settle down in the area thanks to the repopulation with people from the North who received their first fuero in 1133 from Alfonso VII.In 1219, the king Fernando III gave a new fuero to the city .During the reign of Alfonso X of Castile, the protection of the king allowed the city to develop its economy by protecting merchants and allowing markets.", "text": "How many years did the city suffer wars against Almoravid and the Almohad Empires?", "example_title": "Arithmetic"}]} | allenai/naqanet | null | [
"allennlp",
"tensorboard",
"question-answering",
"en",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
null | transformers | {"language": "en"} | allenai/news_roberta_base | null | [
"transformers",
"pytorch",
"jax",
"roberta",
"en",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
null | transformers | {"language": "en"} | allenai/reviews_roberta_base | null | [
"transformers",
"pytorch",
"jax",
"roberta",
"en",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
null | transformers | # SciBERT
This is the pretrained model presented in [SciBERT: A Pretrained Language Model for Scientific Text](https://www.aclweb.org/anthology/D19-1371/), which is a BERT model trained on scientific text.
The training corpus was papers taken from [Semantic Scholar](https://www.semanticscholar.org). Corpus size is 1.14M papers, 3.1B tokens. We use the full text of the papers in training, not just abstracts.
SciBERT has its own wordpiece vocabulary (scivocab) that's built to best match the training corpus. We trained cased and uncased versions.
Available models include:
* `scibert_scivocab_cased`
* `scibert_scivocab_uncased`
The original repo can be found [here](https://github.com/allenai/scibert).
If using these models, please cite the following paper:
```
@inproceedings{beltagy-etal-2019-scibert,
title = "SciBERT: A Pretrained Language Model for Scientific Text",
author = "Beltagy, Iz and Lo, Kyle and Cohan, Arman",
booktitle = "EMNLP",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/D19-1371"
}
```
| {"language": "en"} | allenai/scibert_scivocab_cased | null | [
"transformers",
"pytorch",
"jax",
"bert",
"en",
"endpoints_compatible",
"has_space",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
null | transformers | # SciBERT
This is the pretrained model presented in [SciBERT: A Pretrained Language Model for Scientific Text](https://www.aclweb.org/anthology/D19-1371/), which is a BERT model trained on scientific text.
The training corpus was papers taken from [Semantic Scholar](https://www.semanticscholar.org). Corpus size is 1.14M papers, 3.1B tokens. We use the full text of the papers in training, not just abstracts.
SciBERT has its own wordpiece vocabulary (scivocab) that's built to best match the training corpus. We trained cased and uncased versions.
Available models include:
* `scibert_scivocab_cased`
* `scibert_scivocab_uncased`
The original repo can be found [here](https://github.com/allenai/scibert).
If using these models, please cite the following paper:
```
@inproceedings{beltagy-etal-2019-scibert,
title = "SciBERT: A Pretrained Language Model for Scientific Text",
author = "Beltagy, Iz and Lo, Kyle and Cohan, Arman",
booktitle = "EMNLP",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/D19-1371"
}
```
| {"language": "en"} | allenai/scibert_scivocab_uncased | null | [
"transformers",
"pytorch",
"jax",
"bert",
"en",
"endpoints_compatible",
"has_space",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
feature-extraction | transformers |
## SPECTER
SPECTER is a pre-trained language model to generate document-level embedding of documents. It is pre-trained on a powerful signal of document-level relatedness: the citation graph. Unlike existing pretrained language models, SPECTER can be easily applied to downstream applications without task-specific fine-tuning.
If you're coming here because you want to embed papers, SPECTER has now been superceded by [SPECTER2](https://huggingface.co/allenai/specter2_proximity). Use that instead.
Paper: [SPECTER: Document-level Representation Learning using Citation-informed Transformers](https://arxiv.org/pdf/2004.07180.pdf)
Original Repo: [Github](https://github.com/allenai/specter)
Evaluation Benchmark: [SciDocs](https://github.com/allenai/scidocs)
Authors: *Arman Cohan, Sergey Feldman, Iz Beltagy, Doug Downey, Daniel S. Weld*
| {"language": "en", "license": "apache-2.0", "datasets": ["SciDocs"], "metrics": ["F1", "accuracy", "map", "ndcg"], "thumbnail": "https://camo.githubusercontent.com/7d080b7a769f7fdf64ac0ebeb47b039cb50be35287e3071f9d633f0fe33e7596/68747470733a2f2f692e6962622e636f2f33544331576d472f737065637465722d6c6f676f2d63726f707065642e706e67"} | allenai/specter | null | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"en",
"dataset:SciDocs",
"arxiv:2004.07180",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers | Next word generator trained on questions. Receives partial questions and tries to predict the next word.
Example use:
```python
from transformers import T5Config, T5ForConditionalGeneration, T5Tokenizer
model_name = "allenai/t5-small-next-word-generator-qoogle"
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
def run_model(input_string, **generator_args):
input_ids = tokenizer.encode(input_string, return_tensors="pt")
res = model.generate(input_ids, **generator_args)
output = tokenizer.batch_decode(res, skip_special_tokens=True)
print(output)
return output
run_model("Which")
run_model("Which two")
run_model("Which two counties")
run_model("Which two counties are")
run_model("Which two counties are the")
run_model("Which two counties are the biggest")
run_model("Which two counties are the biggest economic")
run_model("Which two counties are the biggest economic powers")
```
which should result in the following:
```
['one']
['statements']
['are']
['in']
['most']
['in']
['zones']
['of']
```
| {"language": "en"} | allenai/t5-small-next-word-generator-qoogle | null | [
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers | SQuAD 1.1 question-answering based on T5-small.
Example use:
```python
from transformers import T5Config, T5ForConditionalGeneration, T5Tokenizer
model_name = "allenai/t5-small-next-word-generator-qoogle"
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
def run_model(input_string, **generator_args):
input_ids = tokenizer.encode(input_string, return_tensors="pt")
res = model.generate(input_ids, **generator_args)
output = tokenizer.batch_decode(res, skip_special_tokens=True)
print(output)
return output
run_model("Who is the winner of 2009 olympics? \n Jack and Jill participated, but James won the games.")```
which should result in the following:
```
['James']
```
| {"language": "en"} | allenai/t5-small-squad11 | null | [
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers | Next word generator trained on questions. Receives partial questions and tries to predict the next word.
Example use:
```python
from transformers import T5Config, T5ForConditionalGeneration, T5Tokenizer
model_name = "allenai/t5-small-squad2-next-word-generator-squad"
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
def run_model(input_string, **generator_args):
input_ids = tokenizer.encode(input_string, return_tensors="pt")
res = model.generate(input_ids, **generator_args)
output = tokenizer.batch_decode(res, skip_special_tokens=True)
print(output)
return output
run_model("Which")
run_model("Which two")
run_model("Which two counties")
run_model("Which two counties are")
run_model("Which two counties are the")
run_model("Which two counties are the biggest")
run_model("Which two counties are the biggest economic")
run_model("Which two counties are the biggest economic powers")
```
which should result in the following:
```
['one']
['statements']
['are']
['in']
['most']
['in']
['zones']
['of']
```
| {"language": "en"} | allenai/t5-small-squad2-next-word-generator-squad | null | [
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers | A simple question-generation model built based on SQuAD 2.0 dataset.
Example use:
```python
from transformers import T5Config, T5ForConditionalGeneration, T5Tokenizer
model_name = "allenai/t5-small-squad2-question-generation"
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
def run_model(input_string, **generator_args):
input_ids = tokenizer.encode(input_string, return_tensors="pt")
res = model.generate(input_ids, **generator_args)
output = tokenizer.batch_decode(res, skip_special_tokens=True)
print(output)
return output
run_model("shrouds herself in white and walks penitentially disguised as brotherly love through factories and parliaments; offers help, but desires power;")
run_model("He thanked all fellow bloggers and organizations that showed support.")
run_model("Races are held between April and December at the Veliefendi Hippodrome near Bakerky, 15 km (9 miles) west of Istanbul.")
```
which should result in the following:
```
['What is the name of the man who is a brotherly love?']
['What did He thank all fellow bloggers and organizations that showed support?']
['Where is the Veliefendi Hippodrome located?']
```
| {"language": "en"} | allenai/t5-small-squad2-question-generation | null | [
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers |
# Tailor
## Model description
This is a ported version of [Tailor](https://homes.cs.washington.edu/~wtshuang/static/papers/2021-arxiv-tailor.pdf), the general-purpose counterfactual generator.
For more code release, please refer to [this github page](https://github.com/allenai/tailor).
#### How to use
```python
from transformers import pipeline, AutoTokenizer, AutoModelForSeq2SeqLM
model_path = "allenai/tailor"
generator = pipeline("text2text-generation",
model=AutoModelForSeq2SeqLM.from_pretrained(model_path),
tokenizer=AutoTokenizer.from_pretrained(model_path),
framework="pt", device=0)
prompt_text = "[VERB+active+past: comfort | AGENT+complete: the doctor | PATIENT+partial: athlete | LOCATIVE+partial: in] <extra_id_0> , <extra_id_1> <extra_id_2> <extra_id_3> ."
generator(prompt_text, max_length=200)
```
### BibTeX entry and citation info
```bibtex
@misc{ross2021tailor,
title={Tailor: Generating and Perturbing Text with Semantic Controls},
author={Alexis Ross and Tongshuang Wu and Hao Peng and Matthew E. Peters and Matt Gardner},
year={2021},
eprint={2107.07150},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2107.07150},
}
```
| {"language": "en", "tags": ["controlled generation", "perturbation"], "widget": [{"text": "[VERB+passive+past: break | PATIENT+partial: cup] <extra_id_0> <extra_id_1> <extra_id_2> ."}, {}]} | allenai/tailor | null | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"controlled generation",
"perturbation",
"en",
"arxiv:2107.07150",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
question-answering | allennlp |
A reading comprehension model patterned after the proposed model in Devlin et al, with improvements borrowed from the SQuAD model in the transformers project
The model implements a reading comprehension model patterned after the proposed model in BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin et al, 2018), with improvements borrowed from the SQuAD model in the transformers project. It predicts start tokens and end tokens with a linear layer on top of word piece embeddings. | {"language": "en", "tags": ["allennlp", "question-answering"]} | allenai/transformer_qa | null | [
"allennlp",
"tensorboard",
"question-answering",
"en",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers | {"language": "en"} | allenai/unifiedqa-t5-11b | null | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text2text-generation | transformers | {"language": "en"} | allenai/unifiedqa-t5-3b | null | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text2text-generation | transformers | {"language": "en"} | allenai/unifiedqa-t5-base | null | [
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text2text-generation | transformers | {"language": "en"} | allenai/unifiedqa-t5-large | null | [
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text2text-generation | transformers | {"language": "en"} | allenai/unifiedqa-t5-small | null | [
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text2text-generation | transformers | # Further details: https://github.com/allenai/unifiedqa
| {"language": "en"} | allenai/unifiedqa-v2-t5-11b-1251000 | null | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers | # Further details: https://github.com/allenai/unifiedqa | {"language": "en"} | allenai/unifiedqa-v2-t5-11b-1363200 | null | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers | # Further details: https://github.com/allenai/unifiedqa
| {"language": "en"} | allenai/unifiedqa-v2-t5-3b-1251000 | null | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers | # Further details: https://github.com/allenai/unifiedqa
| {"language": "en"} | allenai/unifiedqa-v2-t5-3b-1363200 | null | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers | # Further details: https://github.com/allenai/unifiedqa | {"language": "en"} | allenai/unifiedqa-v2-t5-base-1251000 | null | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers | # Further details: https://github.com/allenai/unifiedqa
| {"language": "en"} | allenai/unifiedqa-v2-t5-base-1363200 | null | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers | # Further details: https://github.com/allenai/unifiedqa
| {"language": "en"} | allenai/unifiedqa-v2-t5-large-1251000 | null | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers | # Further details: https://github.com/allenai/unifiedqa
| {"language": "en"} | allenai/unifiedqa-v2-t5-large-1363200 | null | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers | # Further details: https://github.com/allenai/unifiedqa | {"language": "en"} | allenai/unifiedqa-v2-t5-small-1251000 | null | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers | # Further details: https://github.com/allenai/unifiedqa | {"language": "en"} | allenai/unifiedqa-v2-t5-small-1363200 | null | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
translation | transformers |
# FSMT
## Model description
This is a ported version of fairseq-based [wmt16 transformer](https://github.com/jungokasai/deep-shallow/) for en-de.
For more details, please, see [Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation](https://arxiv.org/abs/2006.10369).
All 3 models are available:
* [wmt16-en-de-dist-12-1](https://huggingface.co/allenai/wmt16-en-de-dist-12-1)
* [wmt16-en-de-dist-6-1](https://huggingface.co/allenai/wmt16-en-de-dist-6-1)
* [wmt16-en-de-12-1](https://huggingface.co/allenai/wmt16-en-de-12-1)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "allenai/wmt16-en-de-12-1"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Machine learning is great, isn't it?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Maschinelles Lernen ist großartig, nicht wahr?
```
#### Limitations and bias
## Training data
Pretrained weights were left identical to the original model released by allenai. For more details, please, see the [paper](https://arxiv.org/abs/2006.10369).
## Eval results
Here are the BLEU scores:
model | fairseq | transformers
-------|---------|----------
wmt16-en-de-12-1 | 26.9 | 25.75
The score is slightly below the score reported in the paper, as the researchers don't use `sacrebleu` and measure the score on tokenized outputs. `transformers` score was measured using `sacrebleu` on detokenized outputs.
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=en-de
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt16 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt16 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py allenai/wmt16-en-de-12-1 $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
## Data Sources
- [training, etc.](http://www.statmt.org/wmt16/)
- [test set](http://matrix.statmt.org/test_sets/newstest2016.tgz?1504722372)
### BibTeX entry and citation info
```
@misc{kasai2020deep,
title={Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation},
author={Jungo Kasai and Nikolaos Pappas and Hao Peng and James Cross and Noah A. Smith},
year={2020},
eprint={2006.10369},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| {"language": ["en", "de"], "license": "apache-2.0", "tags": ["translation", "wmt16", "allenai"], "datasets": ["wmt16"], "metrics": ["bleu"]} | allenai/wmt16-en-de-12-1 | null | [
"transformers",
"pytorch",
"fsmt",
"text2text-generation",
"translation",
"wmt16",
"allenai",
"en",
"de",
"dataset:wmt16",
"arxiv:2006.10369",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
translation | transformers |
# FSMT
## Model description
This is a ported version of fairseq-based [wmt16 transformer](https://github.com/jungokasai/deep-shallow/) for en-de.
For more details, please, see [Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation](https://arxiv.org/abs/2006.10369).
All 3 models are available:
* [wmt16-en-de-dist-12-1](https://huggingface.co/allenai/wmt16-en-de-dist-12-1)
* [wmt16-en-de-dist-6-1](https://huggingface.co/allenai/wmt16-en-de-dist-6-1)
* [wmt16-en-de-12-1](https://huggingface.co/allenai/wmt16-en-de-12-1)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "allenai/wmt16-en-de-dist-12-1"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Machine learning is great, isn't it?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Maschinelles Lernen ist großartig, nicht wahr?
```
#### Limitations and bias
## Training data
Pretrained weights were left identical to the original model released by allenai. For more details, please, see the [paper](https://arxiv.org/abs/2006.10369).
## Eval results
Here are the BLEU scores:
model | fairseq | transformers
-------|---------|----------
wmt16-en-de-dist-12-1 | 28.3 | 27.52
The score is slightly below the score reported in the paper, as the researchers don't use `sacrebleu` and measure the score on tokenized outputs. `transformers` score was measured using `sacrebleu` on detokenized outputs.
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=en-de
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt16 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt16 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py allenai/wmt16-en-de-dist-12-1 $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
## Data Sources
- [training, etc.](http://www.statmt.org/wmt16/)
- [test set](http://matrix.statmt.org/test_sets/newstest2016.tgz?1504722372)
### BibTeX entry and citation info
```
@misc{kasai2020deep,
title={Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation},
author={Jungo Kasai and Nikolaos Pappas and Hao Peng and James Cross and Noah A. Smith},
year={2020},
eprint={2006.10369},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| {"language": ["en", "de"], "license": "apache-2.0", "tags": ["translation", "wmt16", "allenai"], "datasets": ["wmt16"], "metrics": ["bleu"]} | allenai/wmt16-en-de-dist-12-1 | null | [
"transformers",
"pytorch",
"fsmt",
"text2text-generation",
"translation",
"wmt16",
"allenai",
"en",
"de",
"dataset:wmt16",
"arxiv:2006.10369",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
translation | transformers |
# FSMT
## Model description
This is a ported version of fairseq-based [wmt16 transformer](https://github.com/jungokasai/deep-shallow/) for en-de.
For more details, please, see [Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation](https://arxiv.org/abs/2006.10369).
All 3 models are available:
* [wmt16-en-de-dist-12-1](https://huggingface.co/allenai/wmt16-en-de-dist-12-1)
* [wmt16-en-de-dist-6-1](https://huggingface.co/allenai/wmt16-en-de-dist-6-1)
* [wmt16-en-de-12-1](https://huggingface.co/allenai/wmt16-en-de-12-1)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "allenai/wmt16-en-de-dist-6-1"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Machine learning is great, isn't it?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Maschinelles Lernen ist großartig, nicht wahr?
```
#### Limitations and bias
## Training data
Pretrained weights were left identical to the original model released by allenai. For more details, please, see the [paper](https://arxiv.org/abs/2006.10369).
## Eval results
Here are the BLEU scores:
model | fairseq | transformers
-------|---------|----------
wmt16-en-de-dist-6-1 | 27.4 | 27.11
The score is slightly below the score reported in the paper, as the researchers don't use `sacrebleu` and measure the score on tokenized outputs. `transformers` score was measured using `sacrebleu` on detokenized outputs.
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=en-de
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt16 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt16 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py allenai/wmt16-en-de-dist-6-1 $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
## Data Sources
- [training, etc.](http://www.statmt.org/wmt16/)
- [test set](http://matrix.statmt.org/test_sets/newstest2016.tgz?1504722372)
### BibTeX entry and citation info
```
@misc{kasai2020deep,
title={Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation},
author={Jungo Kasai and Nikolaos Pappas and Hao Peng and James Cross and Noah A. Smith},
year={2020},
eprint={2006.10369},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| {"language": ["en", "de"], "license": "apache-2.0", "tags": ["translation", "wmt16", "allenai"], "datasets": ["wmt16"], "metrics": ["bleu"]} | allenai/wmt16-en-de-dist-6-1 | null | [
"transformers",
"pytorch",
"fsmt",
"text2text-generation",
"translation",
"wmt16",
"allenai",
"en",
"de",
"dataset:wmt16",
"arxiv:2006.10369",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
translation | transformers |
# FSMT
## Model description
This is a ported version of fairseq-based [wmt19 transformer](https://github.com/jungokasai/deep-shallow/) for de-en.
For more details, please, see [Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation](https://arxiv.org/abs/2006.10369).
2 models are available:
* [wmt19-de-en-6-6-big](https://huggingface.co/allenai/wmt19-de-en-6-6-big)
* [wmt19-de-en-6-6-base](https://huggingface.co/allenai/wmt19-de-en-6-6-base)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "allenai/wmt19-de-en-6-6-base"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Maschinelles Lernen ist großartig, nicht wahr?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Machine learning is great, isn't it?
```
#### Limitations and bias
## Training data
Pretrained weights were left identical to the original model released by allenai. For more details, please, see the [paper](https://arxiv.org/abs/2006.10369).
## Eval results
Here are the BLEU scores:
model | transformers
-------|---------
wmt19-de-en-6-6-base | 38.37
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=de-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py allenai/wmt19-de-en-6-6-base $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
## Data Sources
- [training, etc.](http://www.statmt.org/wmt19/)
- [test set](http://matrix.statmt.org/test_sets/newstest2019.tgz?1556572561)
### BibTeX entry and citation info
```
@misc{kasai2020deep,
title={Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation},
author={Jungo Kasai and Nikolaos Pappas and Hao Peng and James Cross and Noah A. Smith},
year={2020},
eprint={2006.10369},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| {"language": ["de", "en"], "license": "apache-2.0", "tags": ["translation", "wmt19", "allenai"], "datasets": ["wmt19"], "metrics": ["bleu"]} | allenai/wmt19-de-en-6-6-base | null | [
"transformers",
"pytorch",
"fsmt",
"text2text-generation",
"translation",
"wmt19",
"allenai",
"de",
"en",
"dataset:wmt19",
"arxiv:2006.10369",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
translation | transformers |
# FSMT
## Model description
This is a ported version of fairseq-based [wmt19 transformer](https://github.com/jungokasai/deep-shallow/) for de-en.
For more details, please, see [Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation](https://arxiv.org/abs/2006.10369).
2 models are available:
* [wmt19-de-en-6-6-big](https://huggingface.co/allenai/wmt19-de-en-6-6-big)
* [wmt19-de-en-6-6-base](https://huggingface.co/allenai/wmt19-de-en-6-6-base)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "allenai/wmt19-de-en-6-6-big"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Maschinelles Lernen ist großartig, nicht wahr?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Machine learning is great, isn't it?
```
#### Limitations and bias
## Training data
Pretrained weights were left identical to the original model released by allenai. For more details, please, see the [paper](https://arxiv.org/abs/2006.10369).
## Eval results
Here are the BLEU scores:
model | transformers
-------|---------
wmt19-de-en-6-6-big | 39.9
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=de-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py allenai/wmt19-de-en-6-6-big $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
## Data Sources
- [training, etc.](http://www.statmt.org/wmt19/)
- [test set](http://matrix.statmt.org/test_sets/newstest2019.tgz?1556572561)
### BibTeX entry and citation info
```
@misc{kasai2020deep,
title={Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation},
author={Jungo Kasai and Nikolaos Pappas and Hao Peng and James Cross and Noah A. Smith},
year={2020},
eprint={2006.10369},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| {"language": ["de", "en"], "license": "apache-2.0", "tags": ["translation", "wmt19", "allenai"], "datasets": ["wmt19"], "metrics": ["bleu"]} | allenai/wmt19-de-en-6-6-big | null | [
"transformers",
"pytorch",
"fsmt",
"text2text-generation",
"translation",
"wmt19",
"allenai",
"de",
"en",
"dataset:wmt19",
"arxiv:2006.10369",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
null | transformers |
# Model name
Chinese-bert-wwm-electrical-health-records-ner-question-answering-sequence-labeling
#### How to use
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("allenyummy/chinese-bert-wwm-ehr-ner-qasl")
model = AutoModelForTokenClassification.from_pretrained("allenyummy/chinese-bert-wwm-ehr-ner-qasl")
``` | {"language": "zh-tw"} | allenyummy/chinese-bert-wwm-ehr-ner-qasl | null | [
"transformers",
"pytorch",
"bert",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
null | transformers |
# Model name
Chinese-bert-wwm-electrical-health-records-ner-sequence-labeling
#### How to use
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("allenyummy/chinese-bert-wwm-ehr-ner-sl")
model = AutoModelForTokenClassification.from_pretrained("allenyummy/chinese-bert-wwm-ehr-ner-sl")
```
| {"language": "zh-tw"} | allenyummy/chinese-bert-wwm-ehr-ner-sl | null | [
"transformers",
"pytorch",
"bert",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
null | null | {} | allsportstv/allsportstv | null | [
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
null | null | {} | allymac06/arcane | null | [
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
automatic-speech-recognition | transformers |
# Wav2Vec2-Large-XLSR-53-Swahili
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Swahili using the following datasets:
- [ALFFA](http://www.openslr.org/25/),
- [Gamayun](https://gamayun.translatorswb.org/download/gamayun-5k-english-swahili/)
- [IWSLT](https://iwslt.org/2021/low-resource)
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
processor = Wav2Vec2Processor.from_pretrained("alokmatta/wav2vec2-large-xlsr-53-sw")
model = Wav2Vec2ForCTC.from_pretrained("alokmatta/wav2vec2-large-xlsr-53-sw").to("cuda")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
resampler = torchaudio.transforms.Resample(orig_freq=48_000, new_freq=16_000)
def load_file_to_data(file):
batch = {}
speech, _ = torchaudio.load(file)
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
return batch
def predict(data):
features = processor(data["speech"], sampling_rate=data["sampling_rate"], padding=True, return_tensors="pt")
input_values = features.input_values.to("cuda")
attention_mask = features.attention_mask.to("cuda")
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
pred_ids = torch.argmax(logits, dim=-1)
return processor.batch_decode(pred_ids)
predict(load_file_to_data('./demo.wav'))
```
**Test Result**: 40 %
## Training
The script used for training can be found [here](https://colab.research.google.com/drive/1_RL6TQv_Yiu_xbWXu4ycbzdCdXCqEQYU?usp=sharing) | {"language": "sw", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["ALFFA,Gamayun & IWSLT"], "metrics": ["wer"]} | alokmatta/wav2vec2-large-xlsr-53-sw | null | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"sw",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
question-answering | transformers |
# bert-base-multilingual-uncased for multilingual QA
# Overview
**Language Model**: bert-base-multilingual-uncased \
**Downstream task**: Extractive QA \
**Training data**: [XQuAD](https://github.com/deepmind/xquad) \
**Testing Data**: [XQuAD](https://github.com/deepmind/xquad)
# Hyperparameters
```python
batch_size = 48
n_epochs = 6
max_seq_len = 384
doc_stride = 128
learning_rate = 3e-5
```
# Performance
Evaluated on held-out test set from XQuAD
```python
"exact_match": 64.6067415730337,
"f1": 79.52043478874286,
"test_samples": 2384
```
# Usage
## In Transformers
```python
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
model_name = "alon-albalak/bert-base-multilingual-xquad"
# a) Get predictions
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
QA_input = {
'question': 'Why is model conversion important?',
'context': 'The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks.'
}
res = nlp(QA_input)
# b) Load model & tokenizer
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
```
## In FARM
```python
from farm.modeling.adaptive_model import AdaptiveModel
from farm.modeling.tokenization import Tokenizer
from farm.infer import QAInferencer
model_name = "alon-albalak/bert-base-multilingual-xquad"
# a) Get predictions
nlp = QAInferencer.load(model_name)
QA_input = [{"questions": ["Why is model conversion important?"],
"text": "The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks."}]
res = nlp.inference_from_dicts(dicts=QA_input, rest_api_schema=True)
# b) Load model & tokenizer
model = AdaptiveModel.convert_from_transformers(model_name, device="cpu", task_type="question_answering")
tokenizer = Tokenizer.load(model_name)
```
## In Haystack
```python
reader = FARMReader(model_name_or_path="alon-albalak/bert-base-multilingual-xquad")
# or
reader = TransformersReader(model="alon-albalak/bert-base-multilingual-xquad",tokenizer="alon-albalak/bert-base-multilingual-xquad")
```
Usage instructions for FARM and Haystack were adopted from https://huggingface.co/deepset/xlm-roberta-large-squad2 | {"tags": ["multilingual"], "datasets": ["xquad"]} | alon-albalak/bert-base-multilingual-xquad | null | [
"transformers",
"pytorch",
"safetensors",
"bert",
"question-answering",
"multilingual",
"dataset:xquad",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
question-answering | transformers | # xlm-roberta-base for multilingual QA
# Overview
**Language Model**: xlm-roberta-base \
**Downstream task**: Extractive QA \
**Training data**: [XQuAD](https://github.com/deepmind/xquad)\
**Testing Data**: [XQuAD](https://github.com/deepmind/xquad)
# Hyperparameters
```python
batch_size = 40
n_epochs = 10
max_seq_len = 384
doc_stride = 128
learning_rate = 3e-5
```
# Performance
Evaluated on held-out test set from XQuAD
```python
"exact_match": 79.44756554307116,
"f1": 89.79318021513376,
"test_samples": 2307
```
# Usage
## In Transformers
```python
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
model_name = "alon-albalak/xlm-roberta-base-xquad"
# a) Get predictions
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
QA_input = {
'question': 'Why is model conversion important?',
'context': 'The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks.'
}
res = nlp(QA_input)
# b) Load model & tokenizer
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
```
## In FARM
```python
from farm.modeling.adaptive_model import AdaptiveModel
from farm.modeling.tokenization import Tokenizer
from farm.infer import QAInferencer
model_name = "alon-albalak/xlm-roberta-base-xquad"
# a) Get predictions
nlp = QAInferencer.load(model_name)
QA_input = [{"questions": ["Why is model conversion important?"],
"text": "The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks."}]
res = nlp.inference_from_dicts(dicts=QA_input, rest_api_schema=True)
# b) Load model & tokenizer
model = AdaptiveModel.convert_from_transformers(model_name, device="cpu", task_type="question_answering")
tokenizer = Tokenizer.load(model_name)
```
## In Haystack
```python
reader = FARMReader(model_name_or_path="alon-albalak/xlm-roberta-base-xquad")
# or
reader = TransformersReader(model="alon-albalak/xlm-roberta-base-xquad",tokenizer="alon-albalak/xlm-roberta-base-xquad")
```
Usage instructions for FARM and Haystack were adopted from https://huggingface.co/deepset/xlm-roberta-large-squad2 | {"tags": ["multilingual"], "datasets": ["xquad"]} | alon-albalak/xlm-roberta-base-xquad | null | [
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"multilingual",
"dataset:xquad",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
question-answering | transformers |
# xlm-roberta-large for multilingual QA
# Overview
**Language Model**: xlm-roberta-large \
**Downstream task**: Extractive QA \
**Training data**: [XQuAD](https://github.com/deepmind/xquad) \
**Testing Data**: [XQuAD](https://github.com/deepmind/xquad)
# Hyperparameters
```python
batch_size = 48
n_epochs = 13
max_seq_len = 384
doc_stride = 128
learning_rate = 3e-5
```
# Performance
Evaluated on held-out test set from XQuAD
```python
"exact_match": 87.12546816479401,
"f1": 94.77703248802527,
"test_samples": 2307
```
# Usage
## In Transformers
```python
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
model_name = "alon-albalak/xlm-roberta-large-xquad"
# a) Get predictions
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
QA_input = {
'question': 'Why is model conversion important?',
'context': 'The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks.'
}
res = nlp(QA_input)
# b) Load model & tokenizer
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
```
## In FARM
```python
from farm.modeling.adaptive_model import AdaptiveModel
from farm.modeling.tokenization import Tokenizer
from farm.infer import QAInferencer
model_name = "alon-albalak/xlm-roberta-large-xquad"
# a) Get predictions
nlp = QAInferencer.load(model_name)
QA_input = [{"questions": ["Why is model conversion important?"],
"text": "The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks."}]
res = nlp.inference_from_dicts(dicts=QA_input, rest_api_schema=True)
# b) Load model & tokenizer
model = AdaptiveModel.convert_from_transformers(model_name, device="cpu", task_type="question_answering")
tokenizer = Tokenizer.load(model_name)
```
## In Haystack
```python
reader = FARMReader(model_name_or_path="alon-albalak/xlm-roberta-large-xquad")
# or
reader = TransformersReader(model="alon-albalak/xlm-roberta-large-xquad",tokenizer="alon-albalak/xlm-roberta-large-xquad")
```
Usage instructions for FARM and Haystack were adopted from https://huggingface.co/deepset/xlm-roberta-large-squad2 | {"tags": ["multilingual"], "datasets": ["xquad"]} | alon-albalak/xlm-roberta-large-xquad | null | [
"transformers",
"pytorch",
"safetensors",
"xlm-roberta",
"question-answering",
"multilingual",
"dataset:xquad",
"endpoints_compatible",
"has_space",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
null | null | {} | alondraa15/Holo | null | [
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text-classification | transformers | {} | aloxatel/3JQ | null | [
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text-classification | transformers | {} | aloxatel/3RH | null | [
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text-classification | transformers | {} | aloxatel/7EG | null | [
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text-classification | transformers | {} | aloxatel/9WT | null | [
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text-classification | transformers | {} | aloxatel/AVG | null | [
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text-classification | transformers | {} | aloxatel/KS8 | null | [
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text-classification | transformers | {} | aloxatel/QHR | null | [
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text-classification | transformers | {} | aloxatel/W1G | null | [
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text-classification | transformers | {} | aloxatel/W2L | null | [
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text-classification | transformers | {} | aloxatel/bert-base-mnli | null | [
"transformers",
"pytorch",
"jax",
"safetensors",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text-classification | transformers | {} | aloxatel/mbert | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text-classification | transformers |
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 536415182
- CO2 Emissions (in grams): 1.268309634217171
## Validation Metrics
- Loss: 0.44733062386512756
- Accuracy: 0.8873239436619719
- Macro F1: 0.8859416445623343
- Micro F1: 0.8873239436619719
- Weighted F1: 0.8864646766540891
- Macro Precision: 0.8848522167487685
- Micro Precision: 0.8873239436619719
- Weighted Precision: 0.8883299798792756
- Macro Recall: 0.8908045977011494
- Micro Recall: 0.8873239436619719
- Weighted Recall: 0.8873239436619719
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/alperiox/autonlp-user-review-classification-536415182
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("alperiox/autonlp-user-review-classification-536415182", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("alperiox/autonlp-user-review-classification-536415182", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` | {"language": "en", "tags": "autonlp", "datasets": ["alperiox/autonlp-data-user-review-classification"], "widget": [{"text": "I love AutoNLP \ud83e\udd17"}], "co2_eq_emissions": 1.268309634217171} | alperiox/autonlp-user-review-classification-536415182 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"autonlp",
"en",
"dataset:alperiox/autonlp-data-user-review-classification",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
null | null | {} | alperiox/review-classification-roberta-20run | null | [
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
token-classification | spacy | | Feature | Description |
| --- | --- |
| **Name** | `en_pipeline` |
| **Version** | `0.0.0` |
| **spaCy** | `>=3.1.0,<3.2.0` |
| **Default Pipeline** | `tok2vec`, `ner` |
| **Components** | `tok2vec`, `ner` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | n/a |
| **License** | n/a |
| **Author** | [n/a]() |
### Label Scheme
<details>
<summary>View label scheme (1 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `awarded` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `ENTS_F` | 99.44 |
| `ENTS_P` | 99.63 |
| `ENTS_R` | 99.25 |
| `TOK2VEC_LOSS` | 37454.98 |
| `NER_LOSS` | 9266.72 | | {"language": ["en"], "tags": ["spacy", "token-classification"]} | alphai/en_pipeline | null | [
"spacy",
"token-classification",
"en",
"model-index",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
null | null | {} | altangerel/wav2vec2-base-timit-demo-colab | null | [
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text-generation | transformers |
#Harry Potter DialoGPT Model | {"tags": ["conversational"]} | aluserhuggingface/DialoGPT-small-harrypotter | null | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
token-classification | transformers |
BioBERT model fine-tuned in NER task with BC5CDR-chemicals and BC4CHEMD corpus.
This was fine-tuned in order to use it in a BioNER/BioNEN system which is available at: https://github.com/librairy/bio-ner | {"language": "en", "license": "apache-2.0", "tags": ["token-classification", "NER", "Biomedical", "Chemicals"], "datasets": ["BC5CDR-chemicals", "BC4CHEMD"]} | alvaroalon2/biobert_chemical_ner | null | [
"transformers",
"pytorch",
"tf",
"bert",
"token-classification",
"NER",
"Biomedical",
"Chemicals",
"en",
"dataset:BC5CDR-chemicals",
"dataset:BC4CHEMD",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
token-classification | transformers | BioBERT model fine-tuned in NER task with BC5CDR-diseases and NCBI-diseases corpus
This was fine-tuned in order to use it in a BioNER/BioNEN system which is available at: https://github.com/librairy/bio-ner | {"language": "en", "license": "apache-2.0", "tags": ["token-classification", "NER", "Biomedical", "Diseases"], "datasets": ["BC5CDR-diseases", "ncbi_disease"]} | alvaroalon2/biobert_diseases_ner | null | [
"transformers",
"pytorch",
"bert",
"token-classification",
"NER",
"Biomedical",
"Diseases",
"en",
"dataset:BC5CDR-diseases",
"dataset:ncbi_disease",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
token-classification | transformers | BioBERT model fine-tuned in NER task with JNLPBA and BC2GM corpus for genetic class entities.
This was fine-tuned in order to use it in a BioNER/BioNEN system which is available at: https://github.com/librairy/bio-ner | {"language": "en", "license": "apache-2.0", "tags": ["token-classification", "NER", "Biomedical", "Genetics"], "datasets": ["JNLPBA", "BC2GM"]} | alvaroalon2/biobert_genetic_ner | null | [
"transformers",
"pytorch",
"bert",
"token-classification",
"NER",
"Biomedical",
"Genetics",
"en",
"dataset:JNLPBA",
"dataset:BC2GM",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
null | null | Hi! | {} | alvinhou/model_test | null | [
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text-generation | transformers |
# Frank Talks DialoGPT Model | {"tags": ["conversational"]} | alvinkobe/DialoGPT-medium-steve_biko | null | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text-generation | transformers |
#PANAFRICAN DialoGPT | {"tags": ["conversational"]} | alvinkobe/DialoGPT-small-KST | null | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text2text-generation | transformers | {} | alvinwatner/bart-qg-alpha-interro | null | [
"transformers",
"jax",
"tensorboard",
"bart",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text2text-generation | transformers | {} | alvinwatner/pegasus-large-qg-squad-alpha-interro | null | [
"transformers",
"pytorch",
"jax",
"tensorboard",
"pegasus",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text2text-generation | transformers | {} | alvinwatner/pegasus-large-qg-squad | null | [
"transformers",
"jax",
"tensorboard",
"pegasus",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
null | null | {} | alvis/m2m | null | [
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
null | null | {} | alvis/model_name | null | [
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
null | null | {} | alvp/alberti-bert-base-multilingual-cased | null | [
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text-classification | transformers |
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 34318169
- CO2 Emissions (in grams): 8.612473981829835
## Validation Metrics
- Loss: 1.3520570993423462
- Accuracy: 0.6083916083916084
- Macro F1: 0.5420169617715481
- Micro F1: 0.6083916083916084
- Weighted F1: 0.5963328136975058
- Macro Precision: 0.5864033493660455
- Micro Precision: 0.6083916083916084
- Weighted Precision: 0.6364793882921277
- Macro Recall: 0.5545405576555766
- Micro Recall: 0.6083916083916084
- Weighted Recall: 0.6083916083916084
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/alvp/autonlp-alberti-stanza-names-34318169
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("alvp/autonlp-alberti-stanza-names-34318169", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("alvp/autonlp-alberti-stanza-names-34318169", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` | {"language": "unk", "tags": "autonlp", "datasets": ["alvp/autonlp-data-alberti-stanza-names"], "widget": [{"text": "I love AutoNLP \ud83e\udd17"}], "co2_eq_emissions": 8.612473981829835} | alvp/alberti-stanzas | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"autonlp",
"unk",
"dataset:alvp/autonlp-data-alberti-stanza-names",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
null | null | {} | alxbltf/123 | null | [
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
null | null | {} | alyssa99s/h | null | [
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
fill-mask | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 57426955
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4779
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 12
- eval_batch_size: 16
- seed: 1337
- gradient_accumulation_steps: 2
- total_train_batch_size: 24
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.11.2
- Pytorch 1.10.0
- Datasets 1.8.0
- Tokenizers 0.10.3
| {"tags": ["generated_from_trainer"], "model-index": [{"name": "57426955", "results": []}]} | am-shb/bert-base-multilingual-cased-finetuned | null | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
fill-mask | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 57463134
This model is a fine-tuned version of [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6137
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 12
- eval_batch_size: 16
- seed: 1337
- gradient_accumulation_steps: 2
- total_train_batch_size: 24
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.11.2
- Pytorch 1.10.0
- Datasets 1.8.0
- Tokenizers 0.10.3
| {"tags": ["generated_from_trainer"], "model-index": [{"name": "57463134", "results": []}]} | am-shb/bert-base-multilingual-uncased-finetuned | null | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
fill-mask | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-multilingual-uncased
This model is a fine-tuned version of [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2198
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 1337
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.11.2
- Pytorch 1.10.0
- Datasets 1.8.0
- Tokenizers 0.10.3
| {"tags": ["generated_from_trainer"], "model-index": [{"name": "bert-base-multilingual-uncased", "results": []}]} | am-shb/bert-base-multilingual-uncased-pretrained | null | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
fill-mask | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4144
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 12
- eval_batch_size: 16
- seed: 1337
- gradient_accumulation_steps: 4
- total_train_batch_size: 48
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.11.2
- Pytorch 1.10.0
- Datasets 1.8.0
- Tokenizers 0.10.3
| {"tags": ["generated_from_trainer"], "model-index": [{"name": "roberta", "results": []}]} | am-shb/xlm-roberta-base-pretrained | null | [
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
text-classification | transformers |
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 36789092
- CO2 Emissions (in grams): 1.4280361775467445
## Validation Metrics
- Loss: 0.5255328416824341
- Accuracy: 0.7666078777189889
- Precision: 0.6913123844731978
- Recall: 0.6192052980132451
- AUC: 0.7893359070795125
- F1: 0.6532751091703057
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/am4nsolanki/autonlp-text-hateful-memes-36789092
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("am4nsolanki/autonlp-text-hateful-memes-36789092", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("am4nsolanki/autonlp-text-hateful-memes-36789092", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` | {"language": "en", "tags": "autonlp", "datasets": ["am4nsolanki/autonlp-data-text-hateful-memes"], "widget": [{"text": "I love AutoNLP \ud83e\udd17"}], "co2_eq_emissions": 1.4280361775467445} | am4nsolanki/autonlp-text-hateful-memes-36789092 | null | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"autonlp",
"en",
"dataset:am4nsolanki/autonlp-data-text-hateful-memes",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
null | null | {} | amaleshv/gender_detection | null | [
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
text-generation | transformers | {} | aman21/DialoGPT-medium-Morty | null | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
|
null | null | {} | aman2304/distilbert-base-uncased-finetuned-cola | null | [
"region:us"
]
| null | 2022-03-02T23:29:05+00:00 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.