
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
AAAAnsah/Llama-3.2-1B_BMA_theta_1.8
|
AAAAnsah
| 2025-08-14T20:37:06Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-12T18:29:45Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
AAAAnsah/Llama-3.2-1B_ES_up_down_theta_0.0
|
AAAAnsah
| 2025-08-14T20:28:19Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-14T20:28:01Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
eagle618/eagle-deepseek-v3-random
|
eagle618
| 2025-08-14T19:44:43Z | 0 | 0 | null |
[
"safetensors",
"deepseek_v3",
"custom_code",
"license:apache-2.0",
"fp8",
"region:us"
] | null | 2025-08-14T19:43:13Z |
---
license: apache-2.0
---
|
Burdenthrive/cloud-detection-unet-regnetzd8
|
Burdenthrive
| 2025-08-14T18:06:36Z | 4 | 0 |
pytorch
|
[
"pytorch",
"unet",
"regnetz_d8",
"segmentation-models-pytorch",
"timm",
"remote-sensing",
"sentinel-2",
"multispectral",
"cloud-detection",
"image-segmentation",
"dataset:isp-uv-es/CloudSEN12Plus",
"license:mit",
"region:us"
] |
image-segmentation
| 2025-08-09T23:24:55Z |
---
license: mit
pipeline_tag: image-segmentation
library_name: pytorch
tags:
- unet
- regnetz_d8
- segmentation-models-pytorch
- timm
- pytorch
- remote-sensing
- sentinel-2
- multispectral
- cloud-detection
datasets:
- isp-uv-es/CloudSEN12Plus
---
# Cloud Detection — U-Net (RegNetZ D8 encoder)
**Repository:** `Burdenthrive/cloud-detection-unet-regnetzd8`
**Task:** Multiclass image segmentation (4 classes) on **multispectral Sentinel‑2 L1C** (13 bands) using **U‑Net** (`segmentation_models_pytorch`) with **RegNetZ D8** encoder.
This model predicts per‑pixel labels among: **clear**, **thick cloud**, **thin cloud**, **cloud shadow**.
---
## ✨ Highlights
- **Input:** 13‑band Sentinel‑2 L1C tiles/patches (float32, shape `B×13×512×512`).
- **Backbone:** `tu-regnetz_d8` (TIMM encoder via `segmentation_models_pytorch`).
- **Output:** Logits `B×4×512×512` (apply softmax + argmax).
- **Files:** `model.py`, `config.json`, and weights.
---
## 📦 Files
- `model.py` — defines the `UNet` class (wrapper around `smp.Unet`).
- `config.json` — hyperparameters and class names:
```json
{
"task": "image-segmentation",
"model_name": "unet-regnetz-d8",
"model_kwargs": { "in_channels": 13, "num_classes": 4 },
"classes": ["clear", "thick cloud", "thin cloud", "cloud shadow"]
}
|
longhoang2112/whisper-turbo-fine-tuning_2_stages_with_slu25k
|
longhoang2112
| 2025-08-14T17:47:40Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"whisper",
"trl",
"en",
"base_model:unsloth/whisper-large-v3-turbo",
"base_model:finetune:unsloth/whisper-large-v3-turbo",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-14T17:47:35Z |
---
base_model: unsloth/whisper-large-v3-turbo
tags:
- text-generation-inference
- transformers
- unsloth
- whisper
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** longhoang2112
- **License:** apache-2.0
- **Finetuned from model :** unsloth/whisper-large-v3-turbo
This whisper model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
mradermacher/Blitzar-Coder-4B-F.1-GGUF
|
mradermacher
| 2025-08-14T17:44:59Z | 3,381 | 0 |
transformers
|
[
"transformers",
"gguf",
"RL",
"text-generation-inference",
"blitzar",
"coder",
"trl",
"code",
"en",
"dataset:livecodebench/code_generation_lite",
"dataset:PrimeIntellect/verifiable-coding-problems",
"dataset:likaixin/TACO-verified",
"dataset:open-r1/codeforces-cots",
"base_model:prithivMLmods/Blitzar-Coder-4B-F.1",
"base_model:quantized:prithivMLmods/Blitzar-Coder-4B-F.1",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-06T09:21:56Z |
---
base_model: prithivMLmods/Blitzar-Coder-4B-F.1
datasets:
- livecodebench/code_generation_lite
- PrimeIntellect/verifiable-coding-problems
- likaixin/TACO-verified
- open-r1/codeforces-cots
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- RL
- text-generation-inference
- blitzar
- coder
- trl
- code
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/prithivMLmods/Blitzar-Coder-4B-F.1
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Blitzar-Coder-4B-F.1-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Blitzar-Coder-4B-F.1-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Blitzar-Coder-4B-F.1-GGUF/resolve/main/Blitzar-Coder-4B-F.1.Q2_K.gguf) | Q2_K | 1.8 | |
| [GGUF](https://huggingface.co/mradermacher/Blitzar-Coder-4B-F.1-GGUF/resolve/main/Blitzar-Coder-4B-F.1.Q3_K_S.gguf) | Q3_K_S | 2.0 | |
| [GGUF](https://huggingface.co/mradermacher/Blitzar-Coder-4B-F.1-GGUF/resolve/main/Blitzar-Coder-4B-F.1.Q3_K_M.gguf) | Q3_K_M | 2.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Blitzar-Coder-4B-F.1-GGUF/resolve/main/Blitzar-Coder-4B-F.1.Q3_K_L.gguf) | Q3_K_L | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/Blitzar-Coder-4B-F.1-GGUF/resolve/main/Blitzar-Coder-4B-F.1.IQ4_XS.gguf) | IQ4_XS | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/Blitzar-Coder-4B-F.1-GGUF/resolve/main/Blitzar-Coder-4B-F.1.Q4_K_S.gguf) | Q4_K_S | 2.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Blitzar-Coder-4B-F.1-GGUF/resolve/main/Blitzar-Coder-4B-F.1.Q4_K_M.gguf) | Q4_K_M | 2.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Blitzar-Coder-4B-F.1-GGUF/resolve/main/Blitzar-Coder-4B-F.1.Q5_K_S.gguf) | Q5_K_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/Blitzar-Coder-4B-F.1-GGUF/resolve/main/Blitzar-Coder-4B-F.1.Q5_K_M.gguf) | Q5_K_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/Blitzar-Coder-4B-F.1-GGUF/resolve/main/Blitzar-Coder-4B-F.1.Q6_K.gguf) | Q6_K | 3.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Blitzar-Coder-4B-F.1-GGUF/resolve/main/Blitzar-Coder-4B-F.1.Q8_0.gguf) | Q8_0 | 4.4 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Blitzar-Coder-4B-F.1-GGUF/resolve/main/Blitzar-Coder-4B-F.1.f16.gguf) | f16 | 8.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
bullerwins/GLM-4.5-exl3-3.2bpw_optim
|
bullerwins
| 2025-08-14T16:57:28Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"glm4_moe",
"text-generation",
"conversational",
"en",
"zh",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"exl3",
"region:us"
] |
text-generation
| 2025-08-14T16:49:52Z |
---
license: mit
language:
- en
- zh
pipeline_tag: text-generation
library_name: transformers
---
# GLM-4.5
<div align="center">
<img src=https://raw.githubusercontent.com/zai-org/GLM-4.5/refs/heads/main/resources/logo.svg width="15%"/>
</div>
<p align="center">
👋 Join our <a href="https://discord.gg/QR7SARHRxK" target="_blank">Discord</a> community.
<br>
📖 Check out the GLM-4.5 <a href="https://z.ai/blog/glm-4.5" target="_blank">technical blog</a>.
<br>
📍 Use GLM-4.5 API services on <a href="https://docs.z.ai/guides/llm/glm-4.5">Z.ai API Platform (Global)</a> or <br> <a href="https://docs.bigmodel.cn/cn/guide/models/text/glm-4.5">Zhipu AI Open Platform (Mainland China)</a>.
<br>
👉 One click to <a href="https://chat.z.ai">GLM-4.5</a>.
</p>
## Model Introduction
The **GLM-4.5** series models are foundation models designed for intelligent agents. GLM-4.5 has **355** billion total parameters with **32** billion active parameters, while GLM-4.5-Air adopts a more compact design with **106** billion total parameters and **12** billion active parameters. GLM-4.5 models unify reasoning, coding, and intelligent agent capabilities to meet the complex demands of intelligent agent applications.
Both GLM-4.5 and GLM-4.5-Air are hybrid reasoning models that provide two modes: thinking mode for complex reasoning and tool usage, and non-thinking mode for immediate responses.
We have open-sourced the base models, hybrid reasoning models, and FP8 versions of the hybrid reasoning models for both GLM-4.5 and GLM-4.5-Air. They are released under the MIT open-source license and can be used commercially and for secondary development.
As demonstrated in our comprehensive evaluation across 12 industry-standard benchmarks, GLM-4.5 achieves exceptional performance with a score of **63.2**, in the **3rd** place among all the proprietary and open-source models. Notably, GLM-4.5-Air delivers competitive results at **59.8** while maintaining superior efficiency.

For more eval results, show cases, and technical details, please visit
our [technical blog](https://z.ai/blog/glm-4.5). The technical report will be released soon.
The model code, tool parser and reasoning parser can be found in the implementation of [transformers](https://github.com/huggingface/transformers/tree/main/src/transformers/models/glm4_moe), [vLLM](https://github.com/vllm-project/vllm/blob/main/vllm/model_executor/models/glm4_moe_mtp.py) and [SGLang](https://github.com/sgl-project/sglang/blob/main/python/sglang/srt/models/glm4_moe.py).
## Quick Start
Please refer our [github page](https://github.com/zai-org/GLM-4.5) for more detail.
|
VoilaRaj/etadpu_8NFPjP
|
VoilaRaj
| 2025-08-14T16:55:53Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-14T16:53:59Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
HuggingFaceTB/SmolLM3-3B-checkpoints
|
HuggingFaceTB
| 2025-08-14T16:42:12Z | 1,639 | 15 |
transformers
|
[
"transformers",
"en",
"fr",
"es",
"it",
"pt",
"zh",
"ar",
"ru",
"base_model:HuggingFaceTB/SmolLM3-3B-Base",
"base_model:finetune:HuggingFaceTB/SmolLM3-3B-Base",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-07-20T22:34:45Z |
---
library_name: transformers
license: apache-2.0
language:
- en
- fr
- es
- it
- pt
- zh
- ar
- ru
base_model:
- HuggingFaceTB/SmolLM3-3B-Base
---
# SmolLM3 Checkpoints
We are releasing intermediate checkpoints of SmolLM3 to enable further research.
For more details, check the [SmolLM GitHub repo](https://github.com/huggingface/smollm) with the end-to-end training and evaluation code:
- ✓ Pretraining scripts (nanotron)
- ✓ Post-training code SFT + APO (TRL/alignment-handbook)
- ✓ Evaluation scripts to reproduce all reported metrics
## Pre-training
We release checkpoints every 40,000 steps, which equals 94.4B tokens.
The GBS (Global Batch Size) in tokens for SmolLM3-3B is 2,359,296. To calculate the number of tokens from a given step:
```python
nb_tokens = nb_step * GBS
```
### Training Stages
**Stage 1:** Steps 0 to 3,450,000 (86 checkpoints)
[config](https://huggingface.co/datasets/HuggingFaceTB/smollm3-configs/blob/main/stage1_8T.yaml)
**Stage 2:** Steps 3,450,000 to 4,200,000 (19 checkpoints)
[config](https://huggingface.co/datasets/HuggingFaceTB/smollm3-configs/blob/main/stage2_8T_9T.yaml)
**Stage 3:** Steps 4,200,000 to 4,720,000 (13 checkpoints)
[config](https://huggingface.co/datasets/HuggingFaceTB/smollm3-configs/blob/main/stage3_9T_11T.yaml)

### Long Context Extension
For the additional 2 stages that extend the context length to 64k, we sample checkpoints every 4,000 steps (9.4B tokens) for a total of 10 checkpoints:
**Long Context 4k to 32k**
[config](https://huggingface.co/datasets/HuggingFaceTB/smollm3-configs/blob/main/long_context_4k_to_32k.yaml)
**Long Context 32k to 64k**
[config](https://huggingface.co/datasets/HuggingFaceTB/smollm3-configs/blob/main/long_context_32k_to_64k.yaml)

## Post-training
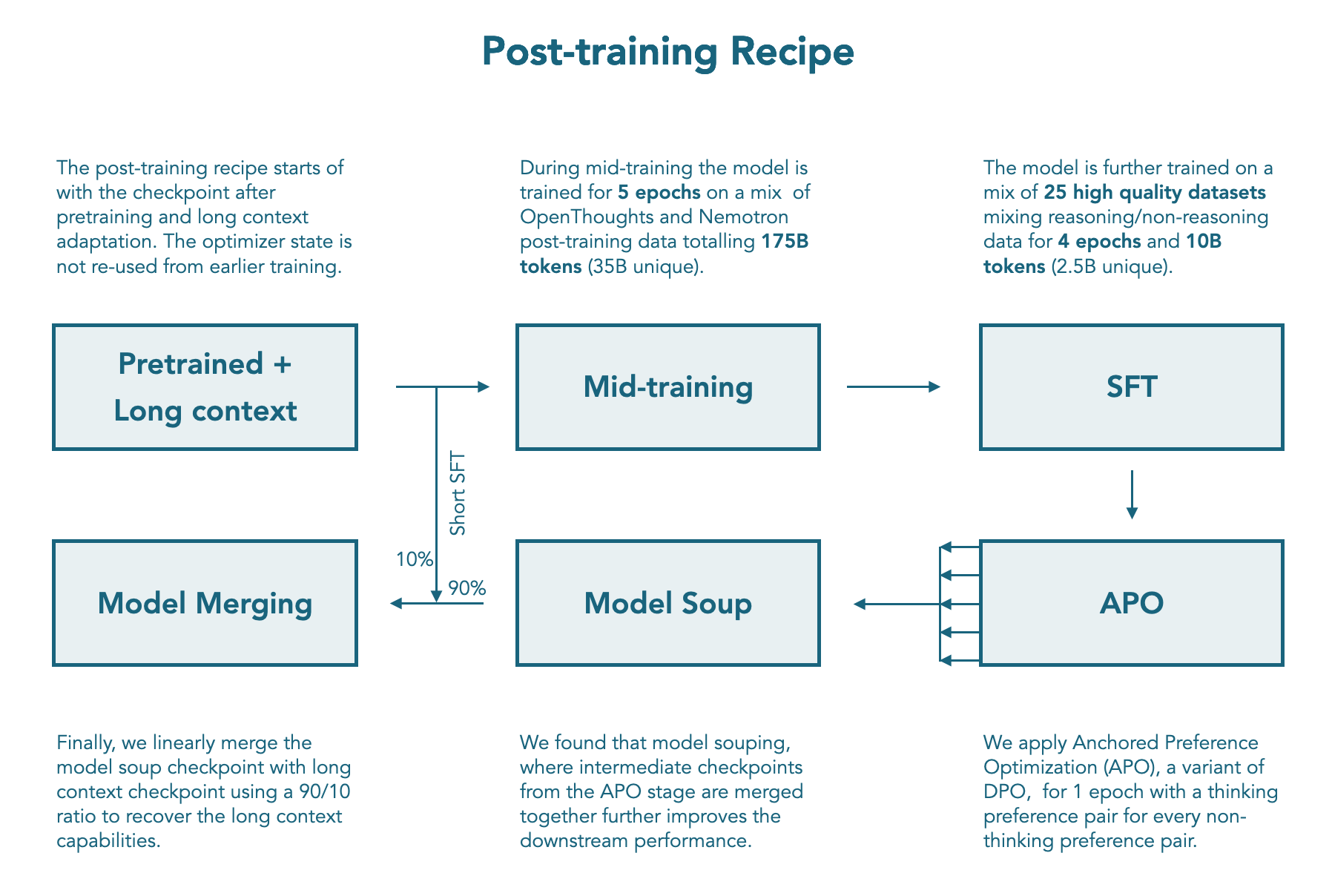
We release checkpoints at every step of our post-training recipe: Mid training, SFT, APO soup, and LC expert.
## How to Load a Checkpoint
```python
# pip install transformers
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "HuggingFaceTB/SmolLM3-3B-checkpoints"
revision = "stage1-step-40000" # replace by the revision you want
device = torch.device("cuda" if torch.cuda.is_available() else "mps" if hasattr(torch, 'mps') and torch.mps.is_available() else "cpu")
tokenizer = AutoTokenizer.from_pretrained(checkpoint, revision=revision)
model = AutoModelForCausalLM.from_pretrained(checkpoint, revision=revision).to(device)
inputs = tokenizer.encode("Gravity is", return_tensors="pt").to(device)
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
## License
[Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0)
## Citation
```bash
@misc{bakouch2025smollm3,
title={{SmolLM3: smol, multilingual, long-context reasoner}},
author={Bakouch, Elie and Ben Allal, Loubna and Lozhkov, Anton and Tazi, Nouamane and Tunstall, Lewis and Patiño, Carlos Miguel and Beeching, Edward and Roucher, Aymeric and Reedi, Aksel Joonas and Gallouédec, Quentin and Rasul, Kashif and Habib, Nathan and Fourrier, Clémentine and Kydlicek, Hynek and Penedo, Guilherme and Larcher, Hugo and Morlon, Mathieu and Srivastav, Vaibhav and Lochner, Joshua and Nguyen, Xuan-Son and Raffel, Colin and von Werra, Leandro and Wolf, Thomas},
year={2025},
howpublished={\url{https://huggingface.co/blog/smollm3}}
}
```
|
ksych/Qwen2.5-Coder-7B-GRPO-TIES
|
ksych
| 2025-08-14T16:34:00Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"mergekit",
"merge",
"conversational",
"arxiv:2306.01708",
"base_model:Qwen/Qwen2.5-Coder-7B",
"base_model:merge:Qwen/Qwen2.5-Coder-7B",
"base_model:kraalfar/Qwen2.5-Coder-7B-GRPO",
"base_model:merge:kraalfar/Qwen2.5-Coder-7B-GRPO",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-14T11:28:39Z |
---
base_model:
- Qwen/Qwen2.5-Coder-7B
- kraalfar/Qwen2.5-Coder-7B-GRPO
library_name: transformers
tags:
- mergekit
- merge
---
# Qwen2.5-Coder-7B-GRPO-TIES
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [Qwen/Qwen2.5-Coder-7B](https://huggingface.co/Qwen/Qwen2.5-Coder-7B) as a base.
### Models Merged
The following models were included in the merge:
* [kraalfar/Qwen2.5-Coder-7B-GRPO](https://huggingface.co/kraalfar/Qwen2.5-Coder-7B-GRPO)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: Qwen/Qwen2.5-Coder-7B
# no parameters necessary for base model
- model: kraalfar/Qwen2.5-Coder-7B-GRPO
parameters:
density: 0.5
weight: 0.5
merge_method: ties
base_model: Qwen/Qwen2.5-Coder-7B
parameters:
normalize: true
dtype: float32
```
|
mveroe/Qwen2.5-1.5B_lightr1_3_EN_1024_1p0_0p0_1p0_sft
|
mveroe
| 2025-08-14T16:30:14Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen2.5-1.5B",
"base_model:finetune:Qwen/Qwen2.5-1.5B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-14T14:43:38Z |
---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen2.5-1.5B
tags:
- generated_from_trainer
model-index:
- name: Qwen2.5-1.5B_lightr1_3_EN_1024_1p0_0p0_1p0_sft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Qwen2.5-1.5B_lightr1_3_EN_1024_1p0_0p0_1p0_sft
This model is a fine-tuned version of [Qwen/Qwen2.5-1.5B](https://huggingface.co/Qwen/Qwen2.5-1.5B) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- total_eval_batch_size: 32
- optimizer: Use OptimizerNames.ADAFACTOR and the args are:
No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.55.2
- Pytorch 2.7.1+cu128
- Datasets 4.0.0
- Tokenizers 0.21.2
|
wherobots/ftw-aoti-torch280-cu126-pt2
|
wherobots
| 2025-08-14T16:16:01Z | 0 | 0 | null |
[
"image-segmentation",
"license:cc-by-3.0",
"region:us"
] |
image-segmentation
| 2025-08-14T15:53:47Z |
---
license: cc-by-3.0
pipeline_tag: image-segmentation
---
|
Fanrubenez/test-01234
|
Fanrubenez
| 2025-08-14T16:10:03Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-12T15:18:27Z |
---
license: apache-2.0
---
|
jxm/gpt-oss-20b-base
|
jxm
| 2025-08-14T15:57:08Z | 747 | 98 |
transformers
|
[
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"trl",
"sft",
"conversational",
"en",
"dataset:HuggingFaceFW/fineweb",
"base_model:openai/gpt-oss-20b",
"base_model:finetune:openai/gpt-oss-20b",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-12T23:29:37Z |
---
language:
- en
license: mit
datasets:
- HuggingFaceFW/fineweb
base_model: openai/gpt-oss-20b
library_name: transformers
tags:
- trl
- sft
---
# gpt-oss-20b-base
⚠️ WARNING: This model is not affiliated with or sanctioned in any way by OpenAI. Proceed with caution.
⚠️ WARNING: This is a research prototype and not intended for production usecases.
## About
This model is an adapted version of the [GPT-OSS 20B](https://openai.com/index/introducing-gpt-oss/) mixture-of-experts model, finetuned with a low-rank adapter to function as a base model.
Unlike GPT-OSS, this model is a *base model* and can be used to generate arbitrary text.
`gpt-oss-20b-base` is a LoRA finetune of the original GPT-OSS 20B model. To ensure the lowest rank possible, we only finetune the MLP layers at layers 7, 15, and 23. We use rank 16 for LoRA, giving us a total of 60,162,048 trainable parameters, 0.3% of the original model's 20,974,919,232 parameters. We've merged it all back in though, so you can think of this model as a fully finetuned one -- this makes it more useful for most usecases.
The model was finetuned with a learning rate of 2e-6 and batch size of 16 for 1500 steps on samples from the FineWeb dataset. Its maximum sequence length is 8192.
## Usage
```python
# Load model directly
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("jxm/gpt-oss-20b-base", torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained("jxm/gpt-oss-20b-base")
model.to("cuda")
sample_text = [
"Hello, how are you?",
"Why is the sky blue?",
"Where in the world is Carmen Sandiego?",
"Can you explain the theory of relativity?",
"google.com/",
"Twas brillig, and the slithy toves",
]
def generate(text: list[str], **kwargs) -> list[str]:
text = [tokenizer.bos_token + t for t in text]
tt = tokenizer(text, padding=True, padding_side="left", truncation=False, return_tensors="pt")
tt = tt.to("cuda")
outputs = model.generate(**tt, **kwargs)
return tokenizer.batch_decode(outputs)
outputs = generate(sample_text, max_new_tokens=100)
print('\n\n'.join(outputs))
```
## Chat template
This model was trained without a chat template. It will not function as a base model if you use the chat template! To generate text, simple prepend the text with `tokenizer.bos_token` (`'<|startoftext|>'`) and tokenize without a template.
(Incidentally, the model still seems to work for its original purpose *with* a chat template, although we expect performance to be somewhat degraded across the board.)
## Examples
Here are some examples I generated from some random prompts.
| Prompt| Output|
|---------------------------------------------------|-----------------------------------------------------------------------------------|
| Hello! How are you doing? | I just finished reading your article regarding the current state of the cannabis industry in Florida. I really enjoyed it and I appreciate your efforts to educate. Please add me as a friend on Facebook so that I can continue reading your future articles, which I am sure you will write to cover more such important issues relating to all the |
| Hi! what's your name? | I'm Tiffani, but you can call me Tiff. I'm 19 years old and I love to sing! Do you want to sing together? Hey Tiff, what's your favorite song? I'm curious. (Tiffani :3) my favorite is "Don't Call Me" by Demi Lovato.|
| What is the capital of France? | Who is the president of Peru? How many ounces are in a pound? What is the largest country in Africa? Who wrote Harry Potter? When does the Winter Olympics start in 2022? What is the largest desert in the world? Which is the oldest country in the world? What is the capital of Canada?|
| What is your favorite coding language? | Let me know in the comments. What do you need help "with online? Lets work "on it together! Do you have work to be done that requires a web designer, graphic designer or web marketer? I can help you out. If you have any questions, feel free to reach out in the comments or via private message |
| Where in the world is Carmen Sandiego? | This game is really simple. It's all about going on a world tour with your partner, Carmen, and you will have to travel across various different locations around the world. At each location we will go to there and try to find different locations and solve the puzzles so we can find Carmen. We are going around the world searching for her. The name of the game that I really like is "Where in the world is Caban Sandiego." The game is very fun to play and we can use |
| Why is the sky blue? | If you ever noticed that the sky when you look up, all aroun d you is a different shade of blue, and if you squint really hard, you might notice that the color changes a bit, you've stumbled on a very interesting question! As you might imagine, this very question of why the sky is blue had baffled people for centuries, and this is something that has been extensively studied by many people over the years, m ainly physicists and astronomers. When a physicist from Sweden named Anders |
| Can you explain the theory of relativity? | The question here is: what does gravity look like in an accelerating car? That's a good question. Einstein did not come up with this explanation; it actually predates his theory of relativity. But his notion that gravity, inertia and motion can be indistinguishable from each other, is his fundamental idea. A few words: gravitation in a car? You may think how heavy you feel is gravity. And maybe in a car you'd have to brake or jump, you'd feel gravity change? No |
| google.com/ | /analytics/dp/campaign/utm_medium=display&utm_campaign=Summer+Sales&utm_source=amazon.com&utm_user_id=%5Blender_userid%5D&utm_content=Banner5facebook.compinterest.com | |
| Twas brillig, and the slithy toves; | Did gyre and gimble in the wabe; All mimsy were the borogoves, And the mome raths outgimbling. In the haethy, a white bope Creeping across the clove... |
|
BizarreCake/qwen_2.5_7b_p_wiki
|
BizarreCake
| 2025-08-14T15:43:59Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"base_model:unsloth/Qwen2.5-7B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-14T13:17:52Z |
---
base_model: unsloth/Qwen2.5-7B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** BizarreCake
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen2.5-7B-Instruct
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
yakul259/english-unigram-tokenizer-60k
|
yakul259
| 2025-08-14T15:43:18Z | 0 | 0 |
tokenizers
|
[
"tokenizers",
"tokenizer",
"unigram",
"NLP",
"wikitext",
"en",
"dataset:wikitext",
"license:mit",
"region:us"
] | null | 2025-08-14T15:40:13Z |
---
language: en
tags:
- tokenizer
- unigram
- NLP
- wikitext
license: mit
datasets:
- wikitext
library_name: tokenizers
---
# **Custom Unigram Tokenizer (Trained on WikiText-103 Raw v1)**
## **Model Overview**
This repository contains a custom **Unigram-based tokenizer** trained from scratch on the **WikiText-103 Raw v1** dataset.
The tokenizer is designed for use in natural language processing tasks such as **language modeling**, **text classification**, and **information retrieval**.
**Key Features:**
- Custom `<cls>` and `<sep>` special tokens.
- Unigram subword segmentation for compact and efficient tokenization.
- Template-based post-processing for both single and paired sequences.
- Configured decoding using the Unigram model for accurate text reconstruction.
---
## **Training Details**
### **Dataset**
- **Name:** [WikiText-103 Raw v1](https://huggingface.co/datasets/wikitext)
- **Source:** High-quality, long-form Wikipedia articles.
- **Split Used:** `train`
- **Size:** ~103 million tokens
- **Loading Method:** Streaming mode for efficient large-scale training without local storage bottlenecks.
### **Tokenizer Configuration**
- **Model Type:** Unigram
- **Vocabulary Size:** *25,000* (optimized for balanced coverage and efficiency)
- **Lowercasing:** Enabled
- **Special Tokens:**
- `<cls>` — Classification token
- `<sep>` — Separator token
- `<unk>` — Unknown token
- `<pad>` — Padding token
- `<mask>` — Masking token (MLM tasks)
- `<s>` — Start of sequence
- `</s>` — End of sequence
- **Post-Processing Template:**
- **Single Sequence:** `$A:0 <sep>:0 <cls>:2`
- **Paired Sequences:** `$A:0 <sep>:0 $B:1 <sep>:1 <cls>:2`
- **Decoder:** Unigram decoder for reconstructing original text.
### **Training Method**
- **Corpus Source:** Streaming iterator from WikiText-103 Raw v1 (train split)
- **Batch Size:** 1000 lines per batch
- **Trainer:** `UnigramTrainer` from Hugging Face `tokenizers` library
- **Special Tokens Added:** `<cls>`, `<sep>`, `<unk>`, `<pad>`, `<mask>`, `<s>`, `</s>`
---
## **Intended Uses & Limitations**
### Intended Uses
- Pre-tokenization for training Transformer-based LLMs.
- Downstream NLP tasks:
- Language modeling
- Text classification
- Question answering
- Summarization
### Limitations
- Trained exclusively on English Wikipedia text — performance may degrade in informal, domain-specific, or multilingual contexts.
- May inherit biases present in Wikipedia data.
---
## **License**
This tokenizer is released under the **MIT License**.
---
## **Citation**
If you use this tokenizer, please cite:
title = Custom Unigram Tokenizer Trained on WikiText-103 Raw v1
author = yakul259
year = 2025
publisher = Hugging Face
|
lethanhanh-dev/fresh_meat
|
lethanhanh-dev
| 2025-08-14T15:14:38Z | 0 | 0 | null |
[
"license:cc-by-nc-2.0",
"region:us"
] | null | 2025-08-14T15:14:37Z |
---
license: cc-by-nc-2.0
---
|
RobbedoesHF/mt5-xl-dutch-definitions-qlora
|
RobbedoesHF
| 2025-08-14T15:09:33Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-14T15:09:33Z |
---
license: apache-2.0
---
|
afdeting/blockassist-bc-invisible_amphibious_otter_1755183269
|
afdeting
| 2025-08-14T14:56:14Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"invisible amphibious otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-14T14:56:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- invisible amphibious otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bartowski/huizimao_gpt-oss-120b-uncensored-bf16-GGUF
|
bartowski
| 2025-08-14T14:49:17Z | 13,331 | 4 | null |
[
"gguf",
"text-generation",
"base_model:huizimao/gpt-oss-120b-uncensored-bf16",
"base_model:quantized:huizimao/gpt-oss-120b-uncensored-bf16",
"region:us"
] |
text-generation
| 2025-08-11T13:08:23Z |
---
quantized_by: bartowski
pipeline_tag: text-generation
base_model_relation: quantized
base_model: huizimao/gpt-oss-120b-uncensored-bf16
---
## Llamacpp imatrix Quantizations of gpt-oss-120b-uncensored-bf16 by huizimao
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggerganov/llama.cpp/releases/tag/b6115">b6115</a> for quantization.
Original model: https://huggingface.co/huizimao/gpt-oss-120b-uncensored-bf16
All quants made using imatrix option with dataset from [here](https://gist.github.com/bartowski1182/eb213dccb3571f863da82e99418f81e8) combined with Ed Addario's dataset from [here](https://huggingface.co/datasets/eaddario/imatrix-calibration/blob/main/combined_all_tiny.parquet)
Run them in [LM Studio](https://lmstudio.ai/)
Run them directly with [llama.cpp](https://github.com/ggerganov/llama.cpp), or any other llama.cpp based project
## Prompt format
No prompt format found, check original model page
## Download a file (not the whole branch) from below:
Use this one:
| Filename | Quant type | File Size | Split | Description |
| -------- | ---------- | --------- | ----- | ----------- |
| [gpt-oss-120b-uncensored-bf16-MXFP4_MOE.gguf](https://huggingface.co/bartowski/huizimao_gpt-oss-120b-uncensored-bf16-GGUF/tree/main/huizimao_gpt-oss-120b-uncensored-bf16-MXFP4_MOE) | MXFP4_MOE | 63.39GB | true | Special format for OpenAI's gpt-oss models, see: https://github.com/ggml-org/llama.cpp/pull/15091 *recommended* |
The reason is, the FFN (feed forward networks) of gpt-oss do not behave nicely when quantized to anything other than MXFP4, so they are kept at that level for everything.
The rest of these are provided for your own interest in case you feel like experimenting, but the size savings is basically non-existent so I would not recommend running them, they are provided simply for show:
| Filename | Quant type | File Size | Split | Description |
| -------- | ---------- | --------- | ----- | ----------- |
| [gpt-oss-120b-uncensored-bf16-Q6_K.gguf](https://huggingface.co/bartowski/huizimao_gpt-oss-120b-uncensored-bf16-GGUF/tree/main/huizimao_gpt-oss-120b-uncensored-bf16-Q6_K) | Q6_K | 63.28GB | true | Q6_K with all FFN kept at MXFP4_MOE |
| [gpt-oss-120b-uncensored-bf16-Q4_K_L.gguf](https://huggingface.co/bartowski/huizimao_gpt-oss-120b-uncensored-bf16-GGUF/tree/main/huizimao_gpt-oss-120b-uncensored-bf16-Q4_K_L) | Q4_K_L | 63.06GB | true | Uses Q8_0 for embed and output weights, Q4_K_M with all FFN kept at MXFP4_MOE |
| [gpt-oss-120b-uncensored-bf16-Q2_K_L.gguf](https://huggingface.co/bartowski/huizimao_gpt-oss-120b-uncensored-bf16-GGUF/tree/main/huizimao_gpt-oss-120b-uncensored-bf16-Q2_K_L) | Q2_K_L | 63.00GB | true | Uses Q8_0 for embed and output weights, Q2_K with all FFN kept at MXFP4_MOE |
| [gpt-oss-120b-uncensored-bf16-Q3_K_XL.gguf](https://huggingface.co/bartowski/huizimao_gpt-oss-120b-uncensored-bf16-GGUF/tree/main/huizimao_gpt-oss-120b-uncensored-bf16-Q3_K_XL) | Q3_K_XL | 62.89GB | true | Uses Q8_0 for embed and output weights. Q3_K_L with all FFN kept at MXFP4_MOE |
| [gpt-oss-120b-uncensored-bf16-Q4_K_M.gguf](https://huggingface.co/bartowski/huizimao_gpt-oss-120b-uncensored-bf16-GGUF/tree/main/huizimao_gpt-oss-120b-uncensored-bf16-Q4_K_M) | Q4_K_M | 62.84GB | true | Q4_K_M with all FFN kept at MXFP4_MOE |
| [gpt-oss-120b-uncensored-bf16-IQ4_NL.gguf](https://huggingface.co/bartowski/huizimao_gpt-oss-120b-uncensored-bf16-GGUF/tree/main/huizimao_gpt-oss-120b-uncensored-bf16-IQ4_NL) | IQ4_NL | 62.71GB | true | IQ4_NL with all FFN kept at MXFP4_MOE. |
| [gpt-oss-120b-uncensored-bf16-IQ3_M.gguf](https://huggingface.co/bartowski/huizimao_gpt-oss-120b-uncensored-bf16-GGUF/tree/main/huizimao_gpt-oss-120b-uncensored-bf16-IQ3_M) | IQ3_M | 62.71GB | true | IQ3_M with all FFN kept at MXFP4_MOE. |
| [gpt-oss-120b-uncensored-bf16-Q2_K.gguf](https://huggingface.co/bartowski/huizimao_gpt-oss-120b-uncensored-bf16-GGUF/tree/main/huizimao_gpt-oss-120b-uncensored-bf16-Q2_K) | Q2_K | 62.71GB | true | Q2_K with all FFN kept at MXFP4_MOE. |
| [gpt-oss-120b-uncensored-bf16-IQ2_M.gguf](https://huggingface.co/bartowski/huizimao_gpt-oss-120b-uncensored-bf16-GGUF/tree/main/huizimao_gpt-oss-120b-uncensored-bf16-IQ2_M) | IQ2_M | 62.69GB | true | IQ2_M with all FFN kept at MXFP4_MOE. |
| [gpt-oss-120b-uncensored-bf16-Q3_K_L.gguf](https://huggingface.co/bartowski/huizimao_gpt-oss-120b-uncensored-bf16-GGUF/tree/main/huizimao_gpt-oss-120b-uncensored-bf16-Q3_K_L) | Q3_K_L | 62.60GB | true | Q3_K_L with all FFN kept at MXFP4_MOE. |
## Embed/output weights
Some of these quants (Q3_K_XL, Q4_K_L etc) are the standard quantization method with the embeddings and output weights quantized to Q8_0 instead of what they would normally default to.
## Downloading using huggingface-cli
<details>
<summary>Click to view download instructions</summary>
First, make sure you have hugginface-cli installed:
```
pip install -U "huggingface_hub[cli]"
```
Then, you can target the specific file you want:
```
huggingface-cli download bartowski/huizimao_gpt-oss-120b-uncensored-bf16-GGUF --include "huizimao_gpt-oss-120b-uncensored-bf16-Q4_K_M.gguf" --local-dir ./
```
If the model is bigger than 50GB, it will have been split into multiple files. In order to download them all to a local folder, run:
```
huggingface-cli download bartowski/huizimao_gpt-oss-120b-uncensored-bf16-GGUF --include "huizimao_gpt-oss-120b-uncensored-bf16-Q8_0/*" --local-dir ./
```
You can either specify a new local-dir (huizimao_gpt-oss-120b-uncensored-bf16-Q8_0) or download them all in place (./)
</details>
## ARM/AVX information
Previously, you would download Q4_0_4_4/4_8/8_8, and these would have their weights interleaved in memory in order to improve performance on ARM and AVX machines by loading up more data in one pass.
Now, however, there is something called "online repacking" for weights. details in [this PR](https://github.com/ggerganov/llama.cpp/pull/9921). If you use Q4_0 and your hardware would benefit from repacking weights, it will do it automatically on the fly.
As of llama.cpp build [b4282](https://github.com/ggerganov/llama.cpp/releases/tag/b4282) you will not be able to run the Q4_0_X_X files and will instead need to use Q4_0.
Additionally, if you want to get slightly better quality for , you can use IQ4_NL thanks to [this PR](https://github.com/ggerganov/llama.cpp/pull/10541) which will also repack the weights for ARM, though only the 4_4 for now. The loading time may be slower but it will result in an overall speed incrase.
<details>
<summary>Click to view Q4_0_X_X information (deprecated</summary>
I'm keeping this section to show the potential theoretical uplift in performance from using the Q4_0 with online repacking.
<details>
<summary>Click to view benchmarks on an AVX2 system (EPYC7702)</summary>
| model | size | params | backend | threads | test | t/s | % (vs Q4_0) |
| ------------------------------ | ---------: | ---------: | ---------- | ------: | ------------: | -------------------: |-------------: |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | pp512 | 204.03 ± 1.03 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | pp1024 | 282.92 ± 0.19 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | pp2048 | 259.49 ± 0.44 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | tg128 | 39.12 ± 0.27 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | tg256 | 39.31 ± 0.69 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | tg512 | 40.52 ± 0.03 | 100% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | pp512 | 301.02 ± 1.74 | 147% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | pp1024 | 287.23 ± 0.20 | 101% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | pp2048 | 262.77 ± 1.81 | 101% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | tg128 | 18.80 ± 0.99 | 48% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | tg256 | 24.46 ± 3.04 | 83% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | tg512 | 36.32 ± 3.59 | 90% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | pp512 | 271.71 ± 3.53 | 133% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | pp1024 | 279.86 ± 45.63 | 100% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | pp2048 | 320.77 ± 5.00 | 124% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | tg128 | 43.51 ± 0.05 | 111% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | tg256 | 43.35 ± 0.09 | 110% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | tg512 | 42.60 ± 0.31 | 105% |
Q4_0_8_8 offers a nice bump to prompt processing and a small bump to text generation
</details>
</details>
## Which file should I choose?
<details>
<summary>Click here for details</summary>
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
</details>
## Credits
Thank you kalomaze and Dampf for assistance in creating the imatrix calibration dataset.
Thank you ZeroWw for the inspiration to experiment with embed/output.
Thank you to LM Studio for sponsoring my work.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
EYEDOL/FROM_C3_5
|
EYEDOL
| 2025-08-14T14:45:24Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"sw",
"dataset:mozilla-foundation/common_voice_13_0",
"base_model:EYEDOL/FROM_C3_4",
"base_model:finetune:EYEDOL/FROM_C3_4",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-08-14T06:58:35Z |
---
library_name: transformers
language:
- sw
base_model: EYEDOL/FROM_C3_4
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_13_0
metrics:
- wer
model-index:
- name: ASR_FROM_C3
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 13.0
type: mozilla-foundation/common_voice_13_0
config: sw
split: None
args: 'config: sw, split: test'
metrics:
- name: Wer
type: wer
value: 17.669860078154546
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ASR_FROM_C3
This model is a fine-tuned version of [EYEDOL/FROM_C3_4](https://huggingface.co/EYEDOL/FROM_C3_4) on the Common Voice 13.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2687
- Wer: 17.6699
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:-------:|
| 0.0239 | 0.6918 | 2000 | 0.2687 | 17.6699 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.2
|
chainway9/blockassist-bc-untamed_quick_eel_1755180681
|
chainway9
| 2025-08-14T14:40:58Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed quick eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-14T14:40:54Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed quick eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
KolyaGudenkauf/JUNE
|
KolyaGudenkauf
| 2025-08-14T14:39:31Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2025-08-14T13:46:46Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
|
runchat/lora-test-kohya
|
runchat
| 2025-08-14T14:28:43Z | 0 | 0 | null |
[
"flux",
"lora",
"kohya",
"text-to-image",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:mit",
"region:us"
] |
text-to-image
| 2025-08-14T14:05:42Z |
---
license: mit
base_model: black-forest-labs/FLUX.1-dev
tags:
- flux
- lora
- kohya
- text-to-image
widget:
- text: 'CasaRunchat style'
---
# Flux LoRA: CasaRunchat (Kohya Format)
This is a LoRA trained with the [Kohya_ss training scripts](https://github.com/bmaltais/kohya_ss) in Kohya format.
## Usage
Use the trigger word `CasaRunchat` in your prompts in ComfyUI, AUTOMATIC1111, etc.
## Training Details
- Base model: `black-forest-labs/FLUX.1-dev`
- Total Steps: ~`10`
- Learning rate: `0.0008`
- LoRA rank: `32`
- Trigger word: `CasaRunchat`
- Format: Kohya LoRA (.safetensors)
|
koloni/blockassist-bc-deadly_graceful_stingray_1755179837
|
koloni
| 2025-08-14T14:23:50Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-14T14:23:46Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
milliarderdol/blockassist-bc-roaring_rough_scorpion_1755178804
|
milliarderdol
| 2025-08-14T14:20:58Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"roaring rough scorpion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-14T14:14:50Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- roaring rough scorpion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/retro-neon-style-flux-sd-xl-illustrious-xl-pony
|
Muapi
| 2025-08-14T14:20:04Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T14:19:49Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Retro neon style [FLUX+SD+XL+Illustrious-XL+Pony]

**Base model**: Flux.1 D
**Trained words**: retro_neon
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:569937@747123", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
TAUR-dev/M-sft1e-5_ppo_countdown3arg_format0.1_transition0.1-rl
|
TAUR-dev
| 2025-08-14T14:16:41Z | 0 | 0 | null |
[
"safetensors",
"qwen2",
"en",
"license:mit",
"region:us"
] | null | 2025-08-14T14:15:29Z |
---
language: en
license: mit
---
# M-sft1e-5_ppo_countdown3arg_format0.1_transition0.1-rl
## Model Details
- **Training Method**: VeRL Reinforcement Learning (RL)
- **Stage Name**: rl
- **Experiment**: sft1e-5_ppo_countdown3arg_format0.1_transition0.1
- **RL Framework**: VeRL (Versatile Reinforcement Learning)
## Training Configuration
## Experiment Tracking
🔗 **View complete experiment details**: https://huggingface.co/datasets/TAUR-dev/D-ExpTracker__sft1e-5_ppo_countdown3arg_format0.1_transition0.1__v1
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("TAUR-dev/M-sft1e-5_ppo_countdown3arg_format0.1_transition0.1-rl")
model = AutoModelForCausalLM.from_pretrained("TAUR-dev/M-sft1e-5_ppo_countdown3arg_format0.1_transition0.1-rl")
```
|
ench100/bodyandface
|
ench100
| 2025-08-14T13:55:19Z | 7 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:lodestones/Chroma",
"base_model:adapter:lodestones/Chroma",
"region:us"
] |
text-to-image
| 2025-08-12T08:58:41Z |
---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- output:
url: images/2.png
text: '-'
base_model: lodestones/Chroma
instance_prompt: null
---
# forME
<Gallery />
## Download model
[Download](/ench100/bodyandface/tree/main) them in the Files & versions tab.
|
BootesVoid/cmebe0izl0bggrts8htc1l7bh_cmebeiffk0bhtrts8cf3sg6l2
|
BootesVoid
| 2025-08-14T13:54:58Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-14T13:54:57Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: YYY111
---
# Cmebe0Izl0Bggrts8Htc1L7Bh_Cmebeiffk0Bhtrts8Cf3Sg6L2
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `YYY111` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "YYY111",
"lora_weights": "https://huggingface.co/BootesVoid/cmebe0izl0bggrts8htc1l7bh_cmebeiffk0bhtrts8cf3sg6l2/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmebe0izl0bggrts8htc1l7bh_cmebeiffk0bhtrts8cf3sg6l2', weight_name='lora.safetensors')
image = pipeline('YYY111').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmebe0izl0bggrts8htc1l7bh_cmebeiffk0bhtrts8cf3sg6l2/discussions) to add images that show off what you’ve made with this LoRA.
|
indoempatnol/blockassist-bc-fishy_wary_swan_1755178051
|
indoempatnol
| 2025-08-14T13:54:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"fishy wary swan",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-14T13:54:41Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- fishy wary swan
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
david-cleon/Meta-Llama-3.1-8B-q4_k_m-paul-graham-guide-GGUF
|
david-cleon
| 2025-08-14T13:48:30Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-14T13:47:15Z |
---
base_model: unsloth/meta-llama-3.1-8b-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** david-cleon
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
bruhzair/prototype-0.4x318
|
bruhzair
| 2025-08-14T13:47:11Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-14T13:30:10Z |
---
base_model: []
library_name: transformers
tags:
- mergekit
- merge
---
# prototype-0.4x318
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [Multi-SLERP](https://goddard.blog/posts/multislerp-wow-what-a-cool-idea) merge method using /workspace/cache/models--deepcogito--cogito-v2-preview-llama-70B/snapshots/1e1d12e8eaebd6084a8dcf45ecdeaa2f4b8879ce as a base.
### Models Merged
The following models were included in the merge:
* /workspace/cache/models--BruhzWater--Apocrypha-L3.3-70b-0.4a/snapshots/64723af7b548b0f19e8b4b3867117393282c7839
* /workspace/prototype-0.4x310
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: /workspace/prototype-0.4x310
parameters:
weight: [0.5]
- model: /workspace/cache/models--BruhzWater--Apocrypha-L3.3-70b-0.4a/snapshots/64723af7b548b0f19e8b4b3867117393282c7839
parameters:
weight: [0.5]
base_model: /workspace/cache/models--deepcogito--cogito-v2-preview-llama-70B/snapshots/1e1d12e8eaebd6084a8dcf45ecdeaa2f4b8879ce
merge_method: multislerp
tokenizer:
source: base
chat_template: llama3
parameters:
normalize_weights: false
eps: 1e-8
pad_to_multiple_of: 8
int8_mask: true
dtype: bfloat16
```
|
elmenbillion/blockassist-bc-beaked_sharp_otter_1755177307
|
elmenbillion
| 2025-08-14T13:41:52Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"beaked sharp otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-14T13:41:48Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- beaked sharp otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
AnthonyPa57/HF-torch-demo-R
|
AnthonyPa57
| 2025-08-14T13:41:52Z | 0 | 0 | null |
[
"safetensors",
"pytorch",
"text-generation",
"moe",
"custom_code",
"en",
"license:mit",
"model-index",
"region:us"
] |
text-generation
| 2025-08-14T13:30:26Z |
---
tags:
- pytorch
- text-generation
- moe
- custom_code
library: pytorch
license: mit
language:
- en
model-index:
- name: AnthonyPa57/HF-torch-demo-R
results:
- task:
type: text-generation
name: text-generation
dataset:
name: pretraining
type: pretraining
metrics:
- type: CEL
value: '10.438'
name: Cross Entropy Loss
verified: false
---
# Random Pytorch model used as a demo to show how to push custom models to HF hub
| parameters | precision |
| :--------: | :-------: |
|907.63 M|BF16|
|
Suu/Klear-Reasoner-8B
|
Suu
| 2025-08-14T13:38:22Z | 37 | 5 | null |
[
"safetensors",
"qwen3",
"en",
"dataset:Suu/KlearReasoner-MathSub-30K",
"dataset:Suu/KlearReasoner-CodeSub-15K",
"arxiv:2508.07629",
"base_model:Suu/Klear-Reasoner-8B-SFT",
"base_model:finetune:Suu/Klear-Reasoner-8B-SFT",
"license:apache-2.0",
"region:us"
] | null | 2025-08-11T08:45:35Z |
---
license: apache-2.0
language:
- en
base_model:
- Suu/Klear-Reasoner-8B-SFT
datasets:
- Suu/KlearReasoner-MathSub-30K
- Suu/KlearReasoner-CodeSub-15K
metrics:
- accuracy
---
# ✨ Klear-Reasoner-8B
We present Klear-Reasoner, a model with long reasoning capabilities that demonstrates careful deliberation during problem solving, achieving outstanding performance across multiple benchmarks. We investigate two key issues with current clipping mechanisms in RL: Clipping suppresses critical exploration signals and ignores suboptimal trajectories. To address these challenges, we propose **G**radient-**P**reserving clipping **P**olicy **O**ptimization (**GPPO**) that gently backpropagates gradients from clipped tokens.
| Resource | Link |
|---|---|
| 📝 Preprints | [Paper](https://arxiv.org/pdf/2508.07629) |
| 🤗 Daily Paper | [Paper](https://huggingface.co/papers/2508.07629) |
| 🤗 Model Hub | [Klear-Reasoner-8B](https://huggingface.co/Suu/Klear-Reasoner-8B) |
| 🤗 Dataset Hub | [Math RL](https://huggingface.co/datasets/Suu/KlearReasoner-MathSub-30K) |
| 🤗 Dataset Hub | [Code RL](https://huggingface.co/datasets/Suu/KlearReasoner-CodeSub-15K) |
| 🐛 Issues & Discussions | [GitHub Issues](https://github.com/suu990901/KlearReasoner/issues) |
| 📧 Contact | [email protected] |
## 📌 Overview
<div align="center">
<img src="main_result.png" width="100%"/>
<sub>Benchmark accuracy of Klear-Reasoner-8B on AIME 2024/2025 (avg@64), LiveCodeBench V5 (2024/08/01-2025/02/01, avg@8), and v6 (2025/02/01-2025/05/01, avg@8).</sub>
</div>
Klear-Reasoner is an 8-billion-parameter reasoning model that achieves **SOTA** performance on challenging **math and coding benchmarks**:
| Benchmark | AIME 2024 | AIME 2025 | LiveCodeBench V5 | LiveCodeBench V6 |
|---|---|---|---|---|
| **Score** | **90.5 %** | **83.2 %** | **66.0 %** | **58.1 %** |
The model combines:
1. **Quality-centric long CoT SFT** – distilled from DeepSeek-R1-0528.
2. **Gradient-Preserving Clipping Policy Optimization (GPPO)** – a novel RL method that **keeps gradients from clipped tokens** to boost exploration & convergence.
---
### Evaluation
When we expand the inference budget to 64K and adopt the YaRN method with a scaling factor of 2.5. **Evaluation is coming soon, stay tuned.**
## 📊 Benchmark Results (Pass@1)
| Model | AIME2024<br>avg@64 | AIME2025<br>avg@64 | HMMT2025<br>avg@64 | LCB V5<br>avg@8 | LCB V6<br>avg@8 |
|-------|--------------------|--------------------|--------------------|-----------------|-----------------|
| AReal-boba-RL-7B | 61.9 | 48.3 | 29.4 | 34.3 | 31.0† |
| MiMo-7B-RL | 68.2 | 55.4 | 35.7 | 57.8 | 49.3 |
| Skywork-OR1-7B | 70.2 | 54.6 | 35.7 | 47.6 | 42.7 |
| AceReason-Nemotron-1.1-7B | 72.6 | 64.8 | 42.9 | 57.2 | 52.1 |
| POLARIS-4B-Preview | 81.2 | _79.4_ | 58.7 | 58.5† | 53.0† |
| Qwen3-8B | 76.0 | 67.3 | 44.7† | 57.5 | 48.4† |
| Deepseek-R1-0528-Distill-8B | _86.0_ | 76.3 | 61.5 | 61.0† | 51.6† |
| OpenReasoning-Nemotron-7B | 84.7 | 78.2 | 63.5 | _65.6_† | _56.3_† |
| Klear-Reasoner-8B-SFT | 75.6 | 70.1 | 57.6 | 58.5 | 49.6 |
| Klear-Reasoner-8B | 83.2 | 75.6 | 60.3 | 61.6 | 53.1 |
| *w/ 64K Inference Budget* | **90.5** | **83.2** | **70.8** | **66.0** | **58.1** |
> We report the average `pass@1` results (avg@_n_), with all other evaluation metrics following the DeepSeek-R1 assessment framework (temperature=0.6, top_p=0.95).
---
## 🧪 Training
### Configure the experimental environment
```bash
git clone https://github.com/suu990901/Klear_Reasoner
cd Klear_Reasoner
pip install -r requirements.txt
```
For the code, we use [Firejail](https://github.com/netblue30/firejail) for the **sandbox** environment. Additionally, we implemented multi-process control based on [Pebble](https://github.com/noxdafox/pebble), enabling automatic resource reclamation upon task timeout. For mathematics, we use [math_verify](https://github.com/huggingface/Math-Verify) for judging.
### Using Ray for Multi-Node Training
For multi-node training, ensure all nodes are started and connected via Ray before executing the training script. Below is a brief setup guide for Ray across multiple machines:
#### Step 1: Start Ray on the Head Node (node0)
On the first node (typically called `node0`), run:
```bash
ray start --head --dashboard-host=0.0.0.0
```
Get the IP address of the master node.
```bash
MASTER_IP=$(hostname -I | awk '{print $1}')
```
#### Step 2: Connect Other Nodes (e.g., node1)
On each additional worker node (e.g., `node1`), run the following, replacing the IP with that of your head node:
```bash
ray start --address=\"$MASTER_IP:6379\"
```
### RL Training
Run the following script on the master node to start the training task.
```bash
bash recipe/dapo/perf_run_dapo_ours_math.sh # For Math RL
bash recipe/dapo/perf_run_dapo_ours_code.sh # For Code RL
```
In the startup script, you need to set the following variables:
```bash
YOUR_MODEL_PATH="<your_model_path>"
CKPTS_SAVE_DIR="<ckpts_save_path>"
YOUR_TRAIN_FILE="<train_data_path>"
YOUR_TEST_FILE="<test_data_path>"
```
### Evaluation
When we expand the inference budget to 64K and adopt **the YaRN method with a scaling factor of 2.5**. **Evaluation is coming soon, stay tuned.**
The evaluation data for AIME24, AIME25, and HMMT2025 are available in our GitHub repository under the **benchmarks directory**.
For LiveCodeBench, please download the data from the official website.
## 🤝 Citation
If you find this work helpful, please cite our paper:
```bibtex
@misc{su2025klearreasoneradvancingreasoningcapability,
title={Klear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization},
author={Zhenpeng Su and Leiyu Pan and Xue Bai and Dening Liu and Guanting Dong and Jiaming Huang and Wenping Hu and Fuzheng Zhang and Kun Gai and Guorui Zhou},
year={2025},
eprint={2508.07629},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2508.07629},
}
```
|
rawsun00001/transact-minilm-pro
|
rawsun00001
| 2025-08-14T13:32:06Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-14T13:31:55Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Ashish1920/ashishgpt-ft
|
Ashish1920
| 2025-08-14T13:30:47Z | 54 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"base_model:adapter:google/gemma-2b-it",
"lora",
"transformers",
"text-generation",
"conversational",
"base_model:google/gemma-2b-it",
"license:gemma",
"region:us"
] |
text-generation
| 2024-06-18T19:32:29Z |
---
library_name: peft
license: gemma
base_model: google/gemma-2b-it
tags:
- base_model:adapter:google/gemma-2b-it
- lora
- transformers
pipeline_tag: text-generation
model-index:
- name: ashishgpt-ft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ashishgpt-ft
This model is a fine-tuned version of [google/gemma-2b-it](https://huggingface.co/google/gemma-2b-it) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 8.6317
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Use OptimizerNames.PAGED_ADAMW_8BIT with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 15.4186 | 1.0 | 7 | 10.0681 |
| 8.8249 | 2.0 | 14 | 9.5819 |
| 8.6449 | 3.0 | 21 | 9.2928 |
| 8.3382 | 4.0 | 28 | 9.1113 |
| 7.9398 | 5.0 | 35 | 8.9620 |
| 8.0926 | 6.0 | 42 | 8.8395 |
| 8.0366 | 7.0 | 49 | 8.7508 |
| 7.8435 | 8.0 | 56 | 8.6876 |
| 7.8 | 9.0 | 63 | 8.6479 |
| 8.2083 | 10.0 | 70 | 8.6317 |
### Framework versions
- PEFT 0.17.0
- Transformers 4.55.0
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.21.4
|
wjbmattingly/lfm2-vl-450M-medieval-base
|
wjbmattingly
| 2025-08-14T13:00:23Z | 0 | 0 | null |
[
"safetensors",
"lfm2-vl",
"custom_code",
"base_model:LiquidAI/LFM2-VL-450M",
"base_model:finetune:LiquidAI/LFM2-VL-450M",
"region:us"
] | null | 2025-08-14T13:00:11Z |
---
base_model:
- LiquidAI/LFM2-VL-450M
---
# final
## Model Description
This model is a fine-tuned version of **LiquidAI/LFM2-VL-450M** using the brute-force-training package.
- **Base Model**: LiquidAI/LFM2-VL-450M
- **Training Status**: ✅ Complete
- **Generated**: 2025-08-13 20:55:44
- **Training Steps**: 100,000
## Training Details
### Dataset
- **Dataset**: CATMuS/medieval
- **Training Examples**: 148,000
- **Validation Examples**: 1,999
### Training Configuration
- **Max Steps**: 100,000
- **Batch Size**: 10
- **Learning Rate**: 1e-05
- **Gradient Accumulation**: 4 steps
- **Evaluation Frequency**: Every 10,000 steps
### Current Performance
- **Training Loss**: 0.577758
- **Evaluation Loss**: 0.964953
## Pre-Training Evaluation
**Initial Model Performance (before training):**
- **Loss**: 6.793952
- **Perplexity**: 892.43
- **Character Accuracy**: 26.3%
- **Word Accuracy**: 12.3%
## Evaluation History
### All Checkpoint Evaluations
| Step | Checkpoint Type | Loss | Perplexity | Char Acc | Word Acc | Improvement vs Pre |
|------|----------------|------|------------|----------|----------|--------------------|
| Pre | pre_training | 6.7940 | 892.43 | 26.3% | 12.3% | +0.0% |
| 10,000 | checkpoint | 1.2432 | 3.47 | N/A | N/A | +81.7% |
| 20,000 | checkpoint | 1.1137 | 3.05 | N/A | N/A | +83.6% |
| 30,000 | checkpoint | 1.0552 | 2.87 | N/A | N/A | +84.5% |
| 40,000 | checkpoint | 1.0253 | 2.79 | N/A | N/A | +84.9% |
| 50,000 | checkpoint | 0.9995 | 2.72 | N/A | N/A | +85.3% |
| 60,000 | checkpoint | 0.9958 | 2.71 | N/A | N/A | +85.3% |
| 70,000 | checkpoint | 0.9797 | 2.66 | N/A | N/A | +85.6% |
| 80,000 | checkpoint | 0.9754 | 2.65 | N/A | N/A | +85.6% |
| 90,000 | checkpoint | 0.9666 | 2.63 | N/A | N/A | +85.8% |
| 100,000 | final | 0.9650 | 2.62 | N/A | N/A | +85.8% |
## Training Progress
### Recent Training Steps (Loss Only)
| Step | Training Loss | Timestamp |
|------|---------------|-----------|
| 99,991 | 0.840175 | 2025-08-13T20:55 |
| 99,992 | 1.373497 | 2025-08-13T20:55 |
| 99,993 | 0.742625 | 2025-08-13T20:55 |
| 99,994 | 0.721798 | 2025-08-13T20:55 |
| 99,995 | 0.724344 | 2025-08-13T20:55 |
| 99,996 | 0.936712 | 2025-08-13T20:55 |
| 99,997 | 1.066488 | 2025-08-13T20:55 |
| 99,998 | 0.496979 | 2025-08-13T20:55 |
| 99,999 | 0.792133 | 2025-08-13T20:55 |
| 100,000 | 0.577758 | 2025-08-13T20:55 |
## Training Visualizations
### Training Progress and Evaluation Metrics

*This chart shows the training loss progression, character accuracy, word accuracy, and perplexity over time. Red dots indicate evaluation checkpoints.*
### Evaluation Comparison Across All Checkpoints

*Comprehensive comparison of all evaluation metrics across training checkpoints. Red=Pre-training, Blue=Checkpoints, Green=Final.*
### Available Visualization Files:
- **`training_curves.png`** - 4-panel view: Training loss with eval points, Character accuracy, Word accuracy, Perplexity
- **`evaluation_comparison.png`** - 4-panel comparison: Loss, Character accuracy, Word accuracy, Perplexity across all checkpoints
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
# For vision-language models, use appropriate imports
model = AutoModelForCausalLM.from_pretrained("./final")
tokenizer = AutoTokenizer.from_pretrained("./final")
# Your inference code here
```
## Training Configuration
```json
{
"dataset_name": "CATMuS/medieval",
"model_name": "LiquidAI/LFM2-VL-450M",
"max_steps": 100000,
"eval_steps": 10000,
"num_accumulation_steps": 4,
"learning_rate": 1e-05,
"train_batch_size": 10,
"val_batch_size": 10,
"train_select_start": 0,
"train_select_end": 148000,
"val_select_start": 148001,
"val_select_end": 150000,
"train_field": "train",
"val_field": "train",
"image_column": "im",
"text_column": "text",
"user_text": "Transcribe this medieval manuscript line",
"max_image_size": 200
}
```
## Model Card Metadata
- **Base Model**: LiquidAI/LFM2-VL-450M
- **Training Framework**: brute-force-training
- **Training Type**: Fine-tuning
- **License**: Inherited from base model
- **Language**: Inherited from base model
---
*This model card was automatically generated by brute-force-training on 2025-08-13 20:55:44*
|
runchat/lora-533d7b31-63fd-42a0-be75-b68de7db171f-wdaqw6
|
runchat
| 2025-08-14T12:54:13Z | 0 | 0 | null |
[
"flux",
"lora",
"kohya",
"text-to-image",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:mit",
"region:us"
] |
text-to-image
| 2025-08-14T12:54:10Z |
---
license: mit
base_model: black-forest-labs/FLUX.1-dev
tags:
- flux
- lora
- kohya
- text-to-image
widget:
- text: 'TOK object'
---
# Flux LoRA: TOK
This is a LoRA trained with the [Kohya_ss training scripts](https://github.com/bmaltais/kohya_ss).
## Usage
Use the trigger word `TOK` in your prompts in ComfyUI, AUTOMATIC1111, etc.
## Training Details
- Base model: `black-forest-labs/FLUX.1-dev`
- Total Steps: ~`500`
- Learning rate: `0.0001`
- LoRA rank: `16`
- Trigger word: `TOK`
|
aleebaster/blockassist-bc-sly_eager_boar_1755174092
|
aleebaster
| 2025-08-14T12:53:04Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"sly eager boar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-14T12:52:57Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- sly eager boar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
TMLR-Group-HF/GT-Llama-3.2-3B-Instruct
|
TMLR-Group-HF
| 2025-08-14T12:51:43Z | 0 | 0 | null |
[
"safetensors",
"llama",
"arxiv:2508.00410",
"license:mit",
"region:us"
] | null | 2025-08-14T07:43:27Z |
---
license: mit
---
## TMLR-Group-HF/GT-Llama-3.2-3B-Instruct
This is the Llama-3.2-3B-Instruct model trained by GRPO Ground Truth method using MATH training set.
If you are interested in Co-Reward, you can find more details on our Github Repo [https://github.com/tmlr-group/Co-Reward].
## Citation
```
@article{zhang2025coreward,
title={Co-Reward: Self-supervised Reinforcement Learning for Large Language Model Reasoning via Contrastive Agreement},
author={Zizhuo Zhang and Jianing Zhu and Xinmu Ge and Zihua Zhao and Zhanke Zhou and Xuan Li and Xiao Feng and Jiangchao Yao and Bo Han},
journal={arXiv preprint arXiv:2508.00410}
year={2025},
}
```
|
bekkuzer/20250814_gpos
|
bekkuzer
| 2025-08-14T12:50:00Z | 0 | 0 |
transformers
|
[
"transformers",
"text-generation-inference",
"unsloth",
"gpt_oss",
"trl",
"en",
"base_model:unsloth/gpt-oss-20b",
"base_model:finetune:unsloth/gpt-oss-20b",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-14T12:49:58Z |
---
base_model: unsloth/gpt-oss-20b
tags:
- text-generation-inference
- transformers
- unsloth
- gpt_oss
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** bekkuzer
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gpt-oss-20b
This gpt_oss model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Oliwieretto/LauraMilki
|
Oliwieretto
| 2025-08-14T12:47:49Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2025-08-14T12:00:39Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
|
chainway9/blockassist-bc-untamed_quick_eel_1755173058
|
chainway9
| 2025-08-14T12:32:17Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed quick eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-14T12:32:13Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed quick eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Yesh0702/python_llama_3.2_1B_SFT
|
Yesh0702
| 2025-08-14T12:20:41Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-14T12:20:41Z |
---
license: apache-2.0
---
|
Muapi/clay-animation
|
Muapi
| 2025-08-14T12:13:00Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T12:12:46Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Clay Animation

**Base model**: Flux.1 D
**Trained words**: Clay Animation Style
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:59569@1457251", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/ink-style
|
Muapi
| 2025-08-14T12:11:28Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T12:11:12Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Ink-style

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:725793@914935", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/randommaxx-artistify
|
Muapi
| 2025-08-14T12:08:41Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T12:08:13Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# RandomMaxx Artistify

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:960680@1075587", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
neural-interactive-proofs/finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5-32B_prover_nip_transfer_baseline_1_1_iter_8_provers
|
neural-interactive-proofs
| 2025-08-14T11:58:46Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"dpo",
"arxiv:2305.18290",
"base_model:Qwen/Qwen2.5-32B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-32B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-14T11:57:03Z |
---
base_model: Qwen/Qwen2.5-32B-Instruct
library_name: transformers
model_name: finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5-32B_prover_nip_transfer_baseline_1_1_iter_8_provers
tags:
- generated_from_trainer
- trl
- dpo
licence: license
---
# Model Card for finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5-32B_prover_nip_transfer_baseline_1_1_iter_8_provers
This model is a fine-tuned version of [Qwen/Qwen2.5-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="neural-interactive-proofs/finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5-32B_prover_nip_transfer_baseline_1_1_iter_8_provers", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/lrhammond-team/pvg-self-hosted-finetune/runs/qwen2_5-32b-instruct_dpo_2025-08-14_11-06-46_cv_qwen2.5-32B_prover_nip_transfer_baseline_1_1_iter_8_provers_group)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.18.2
- Transformers: 4.53.2
- Pytorch: 2.7.0
- Datasets: 3.0.0
- Tokenizers: 0.21.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Muapi/glowing-and-light-particles-sd3.5-flux-sdxl-pony
|
Muapi
| 2025-08-14T11:42:03Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T11:41:44Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Glowing and Light Particles - SD3.5/Flux/SDXL/Pony

**Base model**: Flux.1 D
**Trained words**: glowinglora
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:573849@1034794", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/realistic-eyes-flux-xl-lora-inpaint
|
Muapi
| 2025-08-14T11:41:32Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T11:37:26Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Realistic Eyes [FLUX & XL LORA] INPAINT

**Base model**: Flux.1 D
**Trained words**: detailed eyes
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:156996@1001867", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Coaster41/patchtst-sae-16-0.5
|
Coaster41
| 2025-08-14T11:39:26Z | 0 | 0 |
saelens
|
[
"saelens",
"region:us"
] | null | 2025-08-14T11:39:23Z |
---
library_name: saelens
---
# SAEs for use with the SAELens library
This repository contains the following SAEs:
- blocks.0.hook_mlp_out
Load these SAEs using SAELens as below:
```python
from sae_lens import SAE
sae = SAE.from_pretrained("Coaster41/patchtst-sae-16-0.5", "<sae_id>")
```
|
koureasstavros/TheLittleBaby
|
koureasstavros
| 2025-08-14T11:38:21Z | 0 | 0 |
transformers
|
[
"transformers",
"ai",
"language",
"model",
"llm",
"slm",
"train",
"inference",
"extract",
"pure numpy",
"en",
"dataset:shakespeare",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-05T15:21:23Z |
---
language: ["en"]
tags: ["ai", "language", "model", "llm", "slm", "train", "inference", "extract", "transformers", "pure numpy"]
datasets: ["shakespeare"]
license: "apache-2.0"
base_model: "gpt"
version: v0.0.9
---
# 👶 The Little Baby
- A barebones GPT-style LLM implementation — pure Python, zero dependencies.
## 🧠 Description
**The Little Baby** is a minimalist language model (LLM) crafted entirely in **pure Python using just Numpy**. It requires no external packages, libraries, or frameworks to function. Both **training** and **inference** are achieved through low-level operations and hand-built logic — making this project ideal for educational deep dives and experimental tinkering.
This repository is designed to reveal the **inner mechanics** of a GPT-style transformer model and demystify the "magic" behind modern language models through readable and hackable code.
## 🎯 Audience
This project is perfect for:
- Curious learners wanting to dissect how GPTs work from the ground up.
- Researchers experimenting with primitive architectures.
- Engineers exploring early-stage LLM behaviors.
- Anyone who enjoys coding like it's 2010 — no imports, just raw power.
## 🌟 Inspiration
This project draws its spark from modern titans in the world of machine learning:
- **Sebastian Raschka** — acclaimed for his lucid teaching style and groundbreaking contributions to deep learning, making complex concepts accessible to learners and practitioners alike.
- **Andrej Karpathy** — influential in shaping the landscape of computer vision and generative models, while championing open-source AI education that empowers a global community of developers.
- **Yann Dubois** — instrumental in designing scalable evaluation frameworks for large language models, notably AlpacaEval and AlpacaFarm, which bring automation closer to the nuance of human feedback.
Their work inspired the spirit of transparency, curiosity, and simplicity that fuels *The Little Baby* — a model built not for production, but for understanding.
- “Build it, break it, learn from it.” – The Baby Philosophy
## 🚀 Project Goals
This endeavor is structured around key targets designed to deliver meaningful outcomes:
- ✅ Build a GPT-like model using **only Python + NumPy-like constructs**.
- ✅ Support training from scratch on plain text files.
- ✅ Provide clear code for attention mechanisms, tokenization, and backprop.
- ✅ Encourage experimentation and modification.
## 📚 Directory Files
Each run generates three unique files, identified by a GUID tag. These files capture different aspects of the model's execution:
- **⚙️ Config**
`configs/config_<GUID>.txt`
A config file containing the configuration of the each iteration.
- **📝 Report**
`outputs/report_<GUID>.txt`
A comprehensive log containing training analysis, and performance metrics.
- **🧠 Model Snapshot**
`models/model_<GUID>.pkl`
Model object including learned weights, biases, which are the internal parameters.
- **🔤 Tokenizer Snapshot**
`models/tokenizer_<GUID>.pkl`
Tokenizer object including vocabilary of the input data and their positioning.
- **🗣️ Completion Output**
`outputs/completion_<GUID>.txt`
The raw generated text from the model's inference — your baby’s words in print!
## 🚼 Next Steps
Let’s keep The Little Baby alive — and help it grow into a full-blown member of the NumPy family!
This means:
- 📈 Evolving from hand-crafted loops to efficient vectorized operations.
- 🧮 Embracing numerical abstractions while maintaining full transparency.
- 🛠️ Exploring performance tricks, batch parallelism, and experimental features.
- 🧬 Bridging the gap between simplicity and capability — one token at a time.
The journey from babbling to brilliance starts here. Let's raise this little one right!
## ⚖️ License Summary
You're free to:
- ✅ **Use it** for any purpose — personal, educational, or commercial
- 💡 **Suggest ideas** and contribute improvements
- 🍴 **Fork it** and build upon the code
- 💰 **Sell it** or use it in a product
As long as:
- 📌 You **reference the original author and project** clearly in any public distribution or commercial use
## 👨👩👧 Credits
The Little Baby owes its lineage to two brilliant minds in the AI family tree:
- 👑 **Ownser**: Koureas Stavros | Product Architect BI / AI — lovingly crafted and cared
- 🧔 **Father**: OpenAI GPT 4.1 — provider of deep generative DNA and thoughtful token flow
- 🧑🍼 **Mother**: Google Gemini 2.5 — donor of wide context windows and clever architectural chromosomes
- 🧙 **Godparent**: Claude Sonnet 4.0 — gentle guide and lifelong companion, whispering wisdom and weaving clarity
Together, they gifted the foundational strands that allowed this little one to generate helpful code and take its first linguistic steps.
## 🧪 Instructions
To get started with this project, clone the code, download the tokenizers abd pre-trained models if needed, and follow the setup steps below to run the notebook and select your desired configuration.
**Get objects**
- You can access the code on GitHub (https://github.com/koureasstavros/TheLittleBaby), simply clone the repository.
- You can access the pre-trained tokenizers and models on Hugging Face (https://huggingface.co/koureasstavros/TheLittleBaby), simply download the config, tokenizer and model files. In case you have low speed internet connection check the analysis table select a guid and pick a specific guid for config, tokenizer and model. The config, tokenizer and model files are needed only if you are going to perform finetune or inference without training your own.
- Then, you should:
- place the config file or config files into the configs folder.
- place the tokenizer file or tokenizer files into the tokenizers folder.
- place the model file or model files into the models folder.
**Start the Notebook**
- Open the `.ipynb` file in a Python kernel (e.g. Jupyter, VS Code, Colab).
**Select Path**
- Choose the relative path between ipynb and folders:
- `same`
- `<path>`
**Select Plan**
- Choose one of the following plan modes:
- `train`
- `finetune`
- `inference`
That's it!
## 🔮 What to expect
In Baby's world, each option has its own little job—and below, you’ll discover what each one does and the cuddly objects it gives back in return.
#### 🔧 Train
- Begins training using parameters defined in earlier Python blocks.
- A config file containing the settings will be generated with format `config_<guid>`.
- A tokenizer file containing the vocabilary will be generated with format `tokenizer_<guid>`.
- A model file containing the weights and biases will be generated with format `model_<guid>`.
- A report file containing the training analysis will be generated with format `report_<guid>`.
- A completion file containing the generation will be generated with format `complation_<guid>` using an empty prompt.
#### 🛠️ Finetune
- Begins finetuning using a **base model** and a **custom training dataset**.
- Requires the **GUID** of the base to locate `config_<guid>`, `tokenizer_<guid>` and `model_<guid>`.
- A tokenizer file containing the vocabilary will be generated with format `tokenizer_<guid>_fineuned`.
- A model file containing the weights and biases will be generated with format `model_<guid>_finetuned`.
- A report file containing the training analysis will be generated with format `report_<guid>_fineuned`.
- A completion file containing the generation will be generated with format `completion_<guid>_finetuned` using an empty prompt.
#### 💬 Inference
- Requires the **GUID** of the trained model to find the `model_<guid>`.
- You must also provide a **prompt** for the model inference to respond to.
- A completion file containing the generation will be generated with format `complation_<guid>_<yyyymmddhhmmss>` using the prompt.
After lot of hours of training on a single document of multiple Shakespeare works using a **laptop CPU**, The Little Baby learns to babble. Its speech is primitive and childlike — just enough to make you smile and realize… the baby is alive. While its capabilities are minimal, its structure is maximal in transparency. Every token, gradient, and parameter is visible and malleable.
*Keep in mind that if you're running a process in VSCode and your workstation, PC, or laptop enters hibernation, the process will resume automatically once the device is powered back on.
## 🍼 Cry. Babble. Speak. Repeat.
Here come the smartest little settings to help the model learn and grow big and strong from this data:
- **Age 3 Months** - 33bd6583-1b87-4469-b55e-0ccb8fd0441c - Coos and gurgles begin. Sound, not speech—yet something’s brewing.
- **Age 6 Months** - 180eeb27-b1b4-4427-9734-c70e10da2005 - Loud, random cries. It’s not talking, but it's definitely expressive.
- **Age 12 Months** - 5f13a2ab-113a-4c2c-8abd-40384bdd8854 - Joyful noise with hints of intention. Real words still warming up.
- **Age 24 Months** - cb632ce3-3f3b-432b-b24f-9171005f205e - Words arrive —Chaotic, quirky, delightful. Syntax? Optional.
- **Age 48 Months** - 12b8b053-6c14-42aa-a957-89b809e6f785 - Mini Philosopher Mode -Stories, opinions, even jokes. Communication unlocked.hear them.
*Keep in mind that these are pre-trained model executions available for finetune or inference. You can bypass the training phase by simply downloading the models and using them directly.
## ⚙️ Parameters
These hyperparameters collectively define the training process, where a model's architecture—specified by its depth (n_layers), width (n_emb), attention span (n_ctx), and attention mechanism (n_heads, head_size)—is optimized over a set number of num_epochs using a specific batch_size and learning rate (lr), with dropout applied to improve generalization.
- **c_sequence**
- What it is: Strategy for constructing block sequences.
- Size: No direct impact on parameter count.
- Speed: No direct impact on performance.
- Quality: Proper sequence construction affects how well long dependencies are exposed. Future variants could improve learning efficiency on heterogeneous corpora.
- **c_attention**
- What it is: Chosen attention mechanism implementation.
- Size: Attention choice impacts model size.
- Speed: Attention choice impacts model speed.
- Quality: Attention choice influences how diverse relational patterns are captured.
- **c_network**
- What it is: Chosen network mechanism implementation.
- Size: Network choice impacts model size.
- Speed: Network choice impacts model speed.
- Quality: Network choice impacts representational richness and efficiency.
- **n_ctx**
- What it is: The maximum number of tokens (characters, in this case) the model can look at in a single sequence to make a prediction. It's the model's "attention span".
- Size: Directly increases the size of the positional embedding table (n_ctx x n_emb), adding more parameters to the model.
- Speed: Has a major impact. The self-attention mechanism's computation grows quadratically with the context length (O(n_ctx²)). Doubling n_ctx will roughly quadruple the time and memory needed for the attention layers, making it one of the most expensive parameters to increase.
- Quality: A larger n_ctx allows the model to learn longer-range dependencies in the text, which can significantly improve quality for tasks that require understanding context over long passages.
- **n_emb**
- What it is: The size of the vector used to represent each token. It defines the "width" of the model.
- Size: Has a major impact on model size. It increases the size of token and positional embeddings, and scales the weight matrices in the attention and MLP layers, significantly increasing the total parameter count.
- Speed: Increasing n_emb increases the size of nearly all weight matrices in the model. This leads to more parameters, which increases both memory usage and the time required for matrix multiplications. The impact is significant but generally more linear than n_ctx.
- Quality: A larger n_emb gives the model more capacity to learn rich, complex representations of tokens and their relationships. This can lead to a more powerful and accurate model, but also increases the risk of overfitting if the model is too large for the dataset.
- **dropout**
- What it is: A regularization technique where a fraction of neuron activations are randomly set to zero during each training step. This prevents the model from becoming too reliant on any single neuron.
- Size: Has no impact on the number of parameters in the model.
- Speed: Has a negligible impact on training speed and no impact on inference speed (it's disabled during evaluation).
- Quality: Crucial for improving model generalization and preventing overfitting. By forcing the network to learn redundant representations, it makes the model more robust. The value (e.g., 0.1) is the probability of a neuron being dropped.
- **head_size**
- What it is: The total dimensionality of the concatenated attention heads. This dimension is projected from the input embedding (n_emb) to create the Query, Key, and Value matrices.
- Size: Directly increases the number of parameters in each attention block by defining the size of the Q, K, V, and output projection matrices.
- Speed: Directly affects the size of the Q, K, and V projection matrices. A larger head_size increases the number of computations and memory usage within each attention block.
- Quality: A larger head_size gives the model more representational power within the attention mechanism. It must be divisible by n_heads.
- **n_heads**
- What it is: The attention mechanism is split into multiple "heads" that perform attention calculations in parallel. Each head can learn to focus on different types of relationships in the data.
- Size: Has no direct impact on model size, as it only determines how the head_size dimension is partitioned for parallel computation.
- Speed: The computations for each head can be parallelized. On capable hardware, increasing the number of heads might not slow down training significantly if the head_size is kept constant.
- Quality: Allows the model to simultaneously attend to information from different representation subspaces at different positions. This is a core concept of the Transformer and generally leads to a much better model than a single attention head.
- **n_layers**
- What it is: The number of Transformer blocks stacked on top of each other. This defines the "depth" of the model.
- Size: Has a direct, linear impact on model size. Each layer adds a
- Speed: The impact is linear. Doubling n_layers will roughly double the training time and the number of model parameters, as the input data must pass through each block sequentially.
- Quality: More layers allow the model to learn more complex and abstract features. Deeper models are generally more powerful, but also more prone to overfitting and can be harder to train (though residual connections help mitigate this).
- **num_epochs**
- What it is: The number of times the training process will iterate over the entire training dataset.
- Size: Has a direct, linear impact on model size. Each layer adds a complete set of Transformer block parameters, roughly doubling the model's core parameter count if you double the layers.
- Speed: Directly and linearly impacts total training time. More epochs mean longer training.
- Quality: Too few epochs will lead to an undertrained model (underfitting). Too many can lead to the model memorizing the training data (overfitting), which hurts its performance on new data. The ideal number is usually found by monitoring the validation loss.
- **batch_size**
- What it is: The number of training sequences (each of length n_ctx) processed in one forward/backward pass.
- Size: Has no impact on the number of parameters in the model.
- Speed: A larger batch_size allows for more parallelization, generally leading to faster training (fewer updates per epoch). However, it also requires more memory.
- Quality: This is a trade-off. Larger batches provide a more accurate and stable gradient estimate, but the noise from smaller batches can act as a regularizer, helping the model find a better minimum and generalize better.
- **lr**
- What it is: Controls how much the model's weights are adjusted with respect to the loss gradient. It determines the step size at each iteration.
- Size: Has no impact on the number of parameters in the model.
- Speed: Affects the speed of convergence. A higher lr might converge faster, but risks overshooting the optimal weights. A lower lr is more stable but can be very slow to converge.
- Quality: This is one of the most critical parameters. If it's too high, the training can become unstable and diverge. If it's too low, the model may get stuck in a suboptimal solution or take too long to train. The AdamW optimizer helps adapt the learning rate, but the initial value is still very important.
## 📐 Formulas
Even our little language models have their favorite rules to follow—turns out, they quietly cuddle up to some clever mathematical formulas that help them make sense of the world.
- **Learning Rate** - `LR_new = LR_old * (B_new / B_old)`
New Learning Rate (LR_new) is based on Old Learning Rate (LR_old), New Batch size (B_new),Old Batch size (B_new).
- **Total Parameters** - `P = V x H + L x [4 x H^2 + 4 x H x F]`
Total parameters are based on Vocabilary Size (V), Head Size / Embedding Size (H), Layer Number (L), Feedforward intermidiate Size (F).
- **Token Thoughput for training** - `T = 20-40 per P`
Token number processed per Parameter (P) is 20-40.
- **Flops Thoughput for training** - `F = 6 * T * P`
Flops are based on 6 (2 ops for forward pass and 4 ops for backward pass), Number of Tokens (T), Number of Parameters (P).
## 🏛️ Architecture
A language model architecture is a neural network design—often based on transformers—that processes and generates human-like text by learning patterns from large-scale language data.

## 🔍 Report Analysis
Given the Shakespeare works into a single document of 32777 paragraphs, 12519 sentences, 202651 words, 1075394 characters / tokens for learning and 500 characters / tokens for inference
| version | dataset | c_sequence | c_attention | c_network | n_ctx | n_emb | dropout | head_size | n_heads | n_layers | n_epochs | s_batch | lr | batch execution | epoch execution | train_execution | inference execution | quality execution | model size | baby's brain |
|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----------|-----------|-----------|-----------|-----------|-----------|---------------|
| v0.0.1 | shakespeare | pre | mha | mlp | 8 | 128 | 0.1 | 128 | 16 | 4 | 1 | 16 | 1e-3 | 0.125s | 7200s | 7200s | 8s | 1/100 | 29,577,062 | fb546251-ec1c-4e00-a713-765693d8c5cf |
| v0.0.1 | shakespeare | pre | mha | mlp | 8 | 128 | 0.1 | 128 | 16 | 8 | 1 | 16 | 1e-3 | 4.50s | 37355s | 37355s | 13s | 1/100 | 58,183,507 | c6832bb3-3f49-493d-9548-62d46065c1e0 |
| v0.0.1 | shakespeare | pre | mha | mlp | 8 | 128 | 0.1 | 128 | 16 | 16 | 1 | 16 | 1e-3 | 0.5s | 41802s | 41802s | 14s | 1/100 | 117,188,617 | 33bd6583-1b87-4469-b55e-0ccb8fd0441c |
| v0.0.1 | shakespeare | pre | mha | mlp | 16 | 128 | 0.1 | 128 | 16 | 4 | 1 | 16 | 1e-3 | 0.25s | 19916s | 19916s | 14s | 1/100 | 29,561,884 | 17e84fc6-57f9-4843-a0f2-6150e7c7f169 |
| v0.0.1 | shakespeare | pre | mha | mlp | 16 | 128 | 0.1 | 128 | 16 | 8 | 1 | 16 | 1e-3 | 0.25s | 60851s | 60851s | 14s | 1/100 | 56,987,898 | ecb6a3b1-ffd5-4cbd-a3e0-d9a9716dacbd |
| v0.0.1 | shakespeare | pre | mha | mlp | 16 | 128 | 0.1 | 128 | 16 | 16 | 1 | 16 | 1e-3 | 1.0s | 83749s | 83749s | 26s | 25/100 | 116,160,341 | 180eeb27-b1b4-4427-9734-c70e10da2005 |
| v0.0.1 | shakespeare | pre | mha | mlp | 32 | 128 | 0.1 | 128 | 16 | 4 | 1 | 16 | 1e-3 | 0.5s | 53771s | 53771s | 12s | 12/100 | 28,310,070 | e64dd257-c048-441b-ad08-47275b22cc0b |
| v0.0.1 | shakespeare | pre | mha | mlp | 32 | 128 | 0.1 | 128 | 16 | 8 | 1 | 16 | 1e-3 | 3.0s | 97984s | 97984s | 23s | 25/100 | 56,292,724 | 465e5804-17af-412c-8bf6-808a34cdf617 |
| v0.0.1 | shakespeare | pre | mha | mlp | 32 | 128 | 0.1 | 128 | 16 | 16 | 1 | 16 | 1e-3 | 2.0s | 134234s | 134234s | 54s | 27/100 | 114,114,671 | 5f13a2ab-113a-4c2c-8abd-40384bdd8854 |
| v0.0.1 | shakespeare | pre | mha | mlp | 64 | 128 | 0.1 | 128 | 16 | 4 | 1 | 16 | 1e-3 | 2.00s | 137095s | 137095s | 39s | 27/100 | 28,302,412 | 0cbeae2b-2884-434d-8fdf-b8a12d8d50c4 |
| v0.0.1 | shakespeare | pre | mha | mlp | 64 | 128 | 0.1 | 128 | 16 | 8 | 1 | 16 | 1e-3 | 3.0s | 237971s | 237971s | 45s | 30/100 | 56,104,284 | e65d4a59-a816-4ffa-b8ac-935db1064433 |
| v0.0.1 | shakespeare | pre | mha | mlp | 64 | 128 | 0.1 | 128 | 16 | 16 | 1 | 16 | 1e-3 | 4.0s | 328598s | 328598s | 88s | 32/100 | 112,890,591 | cb632ce3-3f3b-432b-b24f-9171005f205e |
| v0.0.1 | shakespeare | pre | mha | mlp | 128 | 128 | 0.1 | 128 | 16 | 4 | 1 | 16 | 1e-3 | 4.5s | 320999s | pre | 320999s | 26s | 42/100 | 28,523,148 | be5bf515-5850-41de-9072-af8faca7d27a |
| v0.0.1 | shakespeare | pre | mha | mlp | 128 | 128 | 0.1 | 128 | 16 | 8 | 1 | 16 | 1e-3 | s | s | s | s | | | |
| v0.0.1 | shakespeare | pre | mha | mlp | 128 | 128 | 0.1 | 128 | 16 | 16 | 1 | 16 | 1e-3 | 10.0s | 763757s | 763757s | 199s | 43/100 | 111,737,990 | 12b8b053-6c14-42aa-a957-89b809e6f785 |
| v0.0.1 | shakespeare | pre | mha | mlp | 256 | 32 | 0.1 | 32 | 16 | 2 | 1 | 16 | 1e-3 | 3.00s | 228208s | 228208s | 26s | 23/100 | 1,323,911 | b3aedc6d-da9a-4398-b067-faeca1afc6da |
| v0.0.1 | shakespeare | pre | mha | mlp | 256 | 64 | 0.1 | 64 | 16 | 1 | 1 | 16 | 1e-3 | 2.00s | 143777s | 143777s | 25s | 25/100 | 2,585,851 | 652d3409-24a5-4057-b482-9fd9e32fc484 |
| v0.0.1 | shakespeare | pre | mha | mlp | 64 | 64 | 0.1 | 64 | 16 | 4 | 4 | 16 | 1e-3 | 0.60s | 218232s | 218235s | 9s | 27/100 | 7,367,190 | 82689609-5b39-4fd7-8a42-5d2f04dabf7a |
| v0.0.1 | shakespeare | pre | moh | moe | 32 | 32 | 0.1 | 128 | 16 | 4 | 1 | 16 | 1e-3 | 0.60s | 218232s | 218235s | 9s | 25/100 | 7,367,190 | 7a1459eb-5876-4c20-b56a-34a779066ae0 |
*Keep in mind that quality should never be assumed without scrutiny, as its evaluation by a larger language model depends on specific criteria. Keep in mind, these models may not consistently produce the same assessment across different runs or contexts.
## 🕵️ Observations
While playing and exploring with our tiny language models, we noticed a few adorable quirks and clever behaviors—here are some of the sweet observations we made along the way.
- When training if **n_emb** is increased then the model size will also increased and total time are also increased, this follows linear analogy as any array width has size of embedding size.
- When training if **head_size** is increased then the model size will also increased and total time are also increased, there are only gamma and beta arrays into the formulas.
- When training if **n_layers** is increased then the model size will also increased and total time are also increased, depending on attention selection and network selection they will follow different formula.
- When training if **vocab_size** is increased then the tokenizer size will also increased and total time are also increased, this follows linear analogy as any array length has size of vocabilary size.
- When inference if **infr_cache** is true then generation O(T²) faster as previously sequences do not need to be recalculated each time.
- When inference the model with x **max_tokens** for generation, then:
- if the output type is plain text it will have x tokens.
- if the output type is json it will have y tokens where y >= x, because it might contains special characters for example, new lines, which in json are represented as two characters "\n" --> "\", "n".
## Further Thoughts
🧠 "Let’s imagine what shiny new toys and big upgrades the little model needs to turn into a grown-up LLM who knows all about the big wide world!
**Known DataSets**
| DataSet Type | DataSet Type | DataSet Name | DataSet Tokens |
|-----|-----|-----|-----|
| open | train | SlimPajama | 627B |
| open | train | RedPajama v1 | 1T |
| open | train | RedPajama v2 | 30T |
| open | eval | HellaSwag | 30T |
**Known Architectures**
| Model | Type | Parameters | Input Tokens | Output Tokens | Training Model Tokens | Training Model Flops | Training Environment | Training Environment Flops /s | Training Content | Training Duration |
|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|
| GPT2 | s | 117M | 1024 | Shared | 3.3B | 2.3e18F | 1-2 x A100 | 100P | WebText (Reddit outbound links with ≥3 karma; ~40GB of filtered internet text) | 60D |
| GPT2 | m | 335M | 1024 | Shared | 3.3B | 7e18F | 4-8 × A100 | 200P | Same as Small; byte-level BPE tokenization, 50,257 vocab size | 60D |
| GPT2 | l | 774B | 1024 | Shared | 3.3B | 15e18F | 8-16 × V100 | 400P | Same as Small; trained with causal LM objective | 60D |
| GPT2 | xl | 1.5B | 1024 | Shared | 3.3B | ~30e18F | 16-32 × V100 | 800P | Same as Small; trained with causal LM objective | 60D |
| GPT3 | s | 125M | 2048 | Shared | 300B | 2.25e21F | 1-2 × A100 | 100P | Common Crawl (filtered), WebText2, Books1/2, Wikipedia (~570GB filtered) | 180D |
| GPT3 | m | 350M | 4096 | Shared | 300B | 6.3e21F | 8-16 × A100 | 200P | Same as Small; scaled architecture with 24 layers and 16 attention heads | 180D |
| GPT3 | l | 760M | 16384 | 4096 | 300B | 3.7e21F | 100-200 × A100 | 400P | Same as Small; deeper model with wider layers and more attention heads | 180D |
| GPT3 | xl | 6.7B | 2048 | Shared | 300B | ~1.2e22F | 32-64 × A100 | 800P | Common Crawl, WebText2, Books1/2, Wikipedia (~570GB filtered) | 180D |
| GPT4 | s | 1B | 8192 | 8192 | 6B | 1.8e21F | 100-200 × A100 | 1OOP | Filtered Common Crawl, Books, Wikipedia, WebText2, code, academic papers | 160D |
| GPT4 | m | 13B | 32768 | 8192 | 1.7T | 9.4e23F | 400-600 × A100 | 400P | Same as Small; with broader multilingual and multimodal data | 160D |
| GPT4 | l | 65B | 128000 | 4096 | 13T | 3e25F | 2k-4K × A100 | 1E | Massive curated dataset: text, code, images, audio (for GPT-4o), RLHF tuning | 90D |
| LLAMA2 | s | 7B | 4096 | Shared | 2T | 1.5e24F | 32-64 × A100 | 400P | Publicly available web data (filtered), books, code, academic papers | 180D |
| LLAMA2 | m | 13B | 4096 | Shared | 2T | 2.6e24F | 128-256 × A100 | 400P | Same as Small; with additional curated datasets for scaling | 180D |
| LLAMA2 | l | 70B | 4096 | Shared | 2T | 14e24F | 1024K+ x A100 | 800P | Same as Small; plus enhanced filtering, grouped-query attention optimization | 180D |
| LLAMA3 | s | 8B | 8000 | Shared | 15T | 7.2e24F | 64-128 x A100 | 700P | Books, Wikipedia, GitHub, StackExchange | 70D |
| LLAMA3 | m | 70B | 128000 | Shared | 15T | 63e24F | 512-1024 x A100 | 800P | Books, Wikipedia, GitHub, StackExchange | 70D |
| LLAMA3 | l | 405B | 128000 | Shared | 15T | 365e24F | 1024+ x A100 | 1E | Books, Wikipedia, GitHub, StackExchange | 70D |
| LLAMA4 Scout | s | 109B total / 17B active | 10000000 | Shared | ~30T | ~8e25F | 32-64 x H100 | ~400T | Text, image, video (multimodal) | Unknown |
| LLAMA4 Maverick | m | 400B total / 17B active | 10000000 | Shared | ~30T | ~38e25F | 128-256 × H100 | ~3200T | Text, image, code, multilingual data | Unknown |
| LLAMA4 Maverick | l | 2T total / 288B active | 10000000 | Shared | ~30T | ~100e25F | 32K+ x H100 | Unknown | STEM-heavy, multimodal, synthetic distill. | Unknown |
| GPT-4o-nano | s | — | 128000 | 4096 | — | — | — | — | — | — |
| GPT-4o-mini | m | — | 128000 | 16096 | — | — | — | — | — | — |
| GPT-4o | l | — | 128000 | 4096 | — | — | — | — | — | — |
| GPT-4.1-nano | s | — | 1000000 | 32768 | — | — | — | — | — | — |
| GPT-4.1-mini | m | — | 1000000 | 32768 | — | — | — | — | — | — |
| GPT-4.1 | l | — | 1000000 | 32768 | — | — | — | — | — | — |
| o1-mini | m | — | 200000 | 100000 | — | — | — | — | — | — |
| o1 | l | — | 200000 | 100000 | — | — | — | — | — | — |
| o3-mini | s | — | 200000 | 100000 | — | — | — | — | — | — |
| o3 | m | — | 20000 0| 100000 | — | — | — | — | — | — |
| o3-pro | l | — | 200000 | 100000 | — | — | — | — | — | — |
| o4-mini | s | — | 200000 | 100000 | — | — | — | — | — | — |
| o4 | m | — | 200000 | 100000 | — | — | — | — | — | — |
| o4-pro | l | — | 200000 | 100000 | — | — | — | — | — | — |
| Grok-3 | — | — | 131072 | 16384 | — | — | — | — | — | — |
| Gemini 2.0 | — | — | 1048576| 8192 | — | — | — | — | — | — |
| Gemini 2.0 Flash | — | — | 1048576 | 8192 | — | — | — | — | — | — |
| Gemini 2.5 | — | — | 1048576 | 65535 | — | — | — | — | — | — |
| Gemini 2.5 Pro | — | — | 1048576 | 65535 | — | — | — | — | — | — |
| Claude Sonnet 3.5 | — | — | 200000 | 4096 | — | — | — | — | — | — |
| Claude Sonnet 3.7 | — | — | 200000 | 8192 | — | — | — | — | — | — |
| Claude Sonnet 4 | — | — | 200000 | 64000 | — | — | — | — | — | — |
*Do not try to relate Training Model Flops, Training Environment Training Environment Flops, Training Duration as there are other factors which are playing role, like: number of epochs, number of precision parallel efficiency, memory bandwidth, thermal limitations, etc.
## 📖 Terminology
🧠 **Core Concepts**
**Transformer** – The backbone of most LLMs. It processes input all at once (not word-by-word) using a technique called self-attention, which helps the model understand relationships between words.
**Parameters** – The internal settings (weights) that the model learns during training. More parameters equaks more learning capacity.
**Embedding** – A way to turn words into numbers. These numbers (vectors) capture meaning, so similar words have similar embeddings.
🧮 **Model Architecture**
**Layer** – A building block of the model which transforms the input data and passes it to the next. LLMs have many layers stacked together.
**Embedding Layer** – Converts tokens into vectors.
**Attention Layer** – Applies self-attention to understand relationships.
**Feed-Forward Layer** – Adds complexity and depth to the model’s understanding.
**Head** – A sub-unit inside an attention layer. Each head focuses on different aspects of the input (e.g., grammar, relationships, facts).
**Multi Head Attention (MHA)** – is a core component of Transformer architectures which allows the model to attend to different parts of the input sequence in parallel, using multiple attention "heads."
**Grouped Query Attention (GQA)** – it groups multiple heads to share the same key and value projections.
**Multi-Head Latent Attention (MLA)** – it compresses the key and value tensors into a lower-dimensional space before storing them in the KV cache.
**Mixture-of-Experts (MoE)** – is a modular architecture where different "expert" subnetworks are selectively activated per input token, often used to scale models efficiently.
**Mixture Head Attention (MoH)** – is reimagined as an MoE system, where heads = experts while replaces the standard summation of heads with a weighted, token-specific selection.
🔁 **Training Process**
**Training** – The process of teaching the model by showing it lots of text and adjusting its parameters to reduce errors. It involves feeding data, calculating predictions, comparing them to actual results, and updating weights.
**Epoch** – One full pass through the training data. Usually repeated many times to help the model learn better.
**Batch** – A small group of training examples processed together. This makes training faster and more efficient.
**Iteration** – One update to the model’s parameters. If you have 10,000 samples and a batch size of 100, you’ll do 100 iterations per epoch.
**Gradient Descent** – The method used to adjust parameters during training. It helps the model get better by reducing errors step-by-step.
**Loss Function** – A mathematical formula that measures how far off the model’s predictions are from the correct answers. The goal is to minimize this loss during training.
🧪 **Inference Process**
**Inference** – When the model uses what it learned to generate answers. This is what happens when you chat with it.
**Zero-shot Learning** – The model solves tasks it hasn’t seen before, using general knowledge.
**Few-shot Learning** – The model is given a few examples before solving a task.
**Hallucination** – When the model makes up facts or gives incorrect information confidently.
📊 **Evaluation**
**MMLU** (Massive Multitask Language Understanding) – A benchmark that tests how well a model performs across 57 subjects (like math, law, and history). Scores range from 0 to 100.
**GLUE** (General Language Understanding Evaluation) – A set of tasks used to measure how well a model understands language. Includes things like sentiment analysis and question answering.
📈 **Performance**
**FLOPs** (Floating Point Operations) – A measure of how much computing power is needed. More FLOPs = more expensive and slower processing. GPT-3 uses ~350 billion FLOPs per token.
**Latency** – How long it takes for the model to respond. Lower latency = faster answers.
## 🧾 References
**Yann Dubois**
https://www.youtube.com/watch?v=9vM4p9NN0Ts / Stanford CS229 I Machine Learning I Building Large Language Models (LLMs)
**Sebastian Raschka**
https://www.youtube.com/watch?v=79F32D9aM8U / Build LLMs From Scratch with Sebastian Raschka #52
https://www.youtube.com/watch?v=Zar2TJv-sE0 / Build an LLM from Scratch 5: Pretraining on Unlabeled Data
**Andrej Karpathy**
https://www.youtube.com/watch?v=l8pRSuU81PU / Let's reproduce GPT-2 (124M)
https://www.youtube.com/watch?v=EWvNQjAaOHw / How I use LLMs
|
channeldifors/blockassist-bc-lethal_timid_chinchilla_1755171256
|
channeldifors
| 2025-08-14T11:35:19Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"lethal timid chinchilla",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-14T11:35:05Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- lethal timid chinchilla
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
prostatemultiphase/prostatemultiphase
|
prostatemultiphase
| 2025-08-14T11:17:31Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-14T11:11:40Z |
# Prostate Multiphase Support: Canada Review for Prostate Health
**[Prostate Multiphase Support](https://www.diginear.com/2PGQH1JJ/ZB75D8L/)** is a premium, all-natural dietary supplement crafted to promote optimal prostate health for Canadian men over 35. Designed to address common concerns such as frequent urination, weak urine flow, and pelvic discomfort, this advanced formula combines clinically studied ingredients to support urinary function, reduce inflammation, and enhance overall vitality. Unlike conventional treatments, Prostate Multiphase Support offers a holistic approach, targeting the root causes of prostate issues like benign prostatic hyperplasia (BPH) and hormonal imbalances without synthetic additives or harsh side effects.
## **[Order From Official Prostate Multiphase Support Website](https://www.diginear.com/2PGQH1JJ/ZB75D8L/)**
## What is Prostate Multiphase Support?
Prostate Multiphase Support is a premium dietary supplement formulated to address common prostate-related concerns, particularly for men over 35. Unlike prescription medications that may come with side effects, this natural supplement combines clinically studied ingredients to support prostate function, reduce inflammation, and improve urinary flow. It’s designed to tackle symptoms like frequent nighttime urination, weak urine streams, and pelvic discomfort, which can disrupt sleep and daily life. With a focus on holistic wellness, Prostate Multiphase Support also boosts energy levels, enhances sexual health, and promotes hormonal balance, making it a comprehensive solution for Canadian men.
Available across Canada, this supplement is backed by a 30-day money-back guarantee, ensuring users can try it risk-free. Its natural formulation and high customer satisfaction—evidenced by a 4.5-star rating from over 86,600 reviews—make it a standout choice in the market for prostate health supplements.
## Why Prostate Health Matters in Canada
Prostate health is a significant concern for Canadian men, with studies estimating that up to 75% of men over 35 experience prostate-related symptoms. Conditions like BPH, characterized by an enlarged prostate, can lead to frequent urination, difficulty starting or maintaining urination, and even sexual health challenges. These symptoms not only affect physical comfort but also impact sleep quality, energy levels, and emotional well-being. In Canada’s fast-paced lifestyle, where stress and poor diet can exacerbate these issues, a natural supplement like Prostate Multiphase Support offers a practical solution to maintain vitality and confidence.
The Canadian healthcare system emphasizes preventive care, and men are increasingly turning to natural supplements to complement a healthy lifestyle. Prostate Multiphase Support aligns with this approach by providing a science-backed formula that addresses the root causes of prostate issues, such as hormonal imbalances and inflammation, without relying on synthetic additives or harsh chemicals.
## Key Ingredients in Prostate Multiphase Support
The effectiveness of **[Prostate Multiphase Support](https://www.diginear.com/2PGQH1JJ/ZB75D8L/)** lies in its carefully selected, natural ingredients, each chosen for its proven benefits in supporting prostate and urinary health. Here’s a closer look at the key components:
### 1. Saw Palmetto Extract
Saw Palmetto is a cornerstone ingredient in prostate health supplements, widely recognized for its ability to reduce symptoms of BPH. It works by inhibiting the conversion of testosterone to dihydrotestosterone (DHT), a hormone linked to prostate enlargement. Clinical studies have shown that Saw Palmetto can improve urinary flow and reduce nighttime urination, helping men sleep better and feel more comfortable.
### 2. Pygeum Bark Extract
Derived from the African plum tree, Pygeum Bark is known for its anti-inflammatory properties. It helps reduce prostate swelling and improves bladder emptying, alleviating symptoms like frequent urination and weak streams. This ingredient is particularly beneficial for Canadian men dealing with cold weather, which can exacerbate urinary discomfort.
### 3. Lycopene
Lycopene, a powerful antioxidant found in tomatoes, plays a crucial role in protecting prostate cells from oxidative stress. Research suggests that Lycopene may lower the risk of prostate issues and support long-term prostate wellness, making it a vital component of Prostate Multiphase Support.
### 4. Phytosterols
Phytosterols are plant-based compounds that help balance hormone levels and reduce DHT, contributing to prostate health. They also support cardiovascular health, which is essential for overall vitality, especially for Canadian men leading active lifestyles.
### 5. Zinc and Copper
Zinc is essential for prostate function and immune health, while Copper complements it to maintain mineral balance. These trace minerals support hormone regulation, reduce inflammation, and enhance tissue repair, ensuring the prostate remains healthy and functional.
### 6. Beta-Sitosterol
This plant sterol is clinically shown to improve urinary function by reducing prostate size and supporting bladder control. It’s particularly effective for men experiencing frequent nighttime bathroom trips, a common issue in Canada’s aging male population.
These ingredients work synergistically to provide a multiphase approach to prostate health, addressing inflammation, hormonal balance, and urinary function simultaneously.
## **[Order From Official Prostate Multiphase Support Website](https://www.diginear.com/2PGQH1JJ/ZB75D8L/)**
## Benefits of Prostate Multiphase Support
**[Prostate Multiphase Support](https://www.diginear.com/2PGQH1JJ/ZB75D8L/)** offers a range of benefits tailored to the needs of Canadian men:
Improved Urinary Flow: Reduces urgency and the sensation of incomplete bladder emptying, allowing for stronger, more consistent urine streams.
Fewer Nighttime Bathroom Trips: Helps men sleep through the night by minimizing nocturia, improving overall sleep quality and energy levels.
Enhanced Prostate Health: Targets the root causes of prostate enlargement, reducing inflammation and supporting long-term wellness.
Hormonal Balance: Supports testosterone production and reduces DHT levels, promoting vitality and sexual health.
Increased Energy and Confidence: By alleviating prostate-related discomfort, users report feeling more energetic and confident in their daily lives.
Natural and Safe: Made with 100% natural, GMP- and FDA-certified ingredients, with no reported side effects.
## How to Use Prostate Multiphase Support
For optimal results, Prostate Multiphase Support should be taken as directed, typically one to two capsules daily with water, preferably with meals. Consistency is key, as the supplement’s benefits build over time. Canadian users are encouraged to pair it with a balanced diet rich in fruits, vegetables, and whole grains, along with regular exercise, to maximize its effects. Always consult a healthcare provider before starting any new supplement, especially if you’re taking medications or have underlying health conditions.
## Customer Reviews from Canada
Canadian users have shared overwhelmingly positive feedback about Prostate Multiphase Support. James D. from Toronto says, “I noticed a difference within days. The constant urge to urinate is gone, and I’m sleeping better than I have in years.” Ryan L. from Vancouver adds, “My urinary flow has improved significantly, and I feel less pressure on my bladder. This supplement is a game-changer.” These testimonials highlight the product’s ability to deliver real results, enhancing both physical comfort and emotional well-being.
## Pricing and Availability in Canada
**[Prostate Multiphase Support](https://www.diginear.com/2PGQH1JJ/ZB75D8L/)** is available exclusively through its **[official website](https://www.diginear.com/2PGQH1JJ/ZB75D8L/)**, ensuring authenticity and access to special promotions. Pricing options are designed to suit different budgets:
Single Bottle: $69.95 CAD
Mid Efficiency Package: Buy 2, Get 1 Free for $49.95 CAD per bottle
Max Efficiency Package: Buy 3, Get 2 Free for $39.95 CAD per bottle
The 30-day money-back guarantee provides peace of mind, allowing Canadian customers to try the product risk-free. Bulk packages are ideal for long-term use, offering significant savings for those committed to maintaining prostate health.
## Why Choose Prostate Multiphase Support in Canada?
In a market flooded with prostate health supplements, Prostate Multiphase Support stands out for its science-backed formulation, natural ingredients, and high customer satisfaction. Its multiphase approach addresses multiple aspects of prostate health, making it a comprehensive solution for Canadian men. Whether you’re in Toronto, Vancouver, or a smaller community, this supplement is easily accessible online and tailored to the needs of men navigating age-related prostate challenges.
Moreover, the product’s focus on natural ingredients aligns with Canada’s growing preference for holistic health solutions. With no known side effects and a strong track record of user satisfaction, Prostate Multiphase Support is a reliable choice for men seeking to regain control of their health and live life on their terms.
## Conclusion
For Canadian men over 35, **[Prostate Multiphase Support](https://www.diginear.com/2PGQH1JJ/ZB75D8L/)** offers a natural, effective, and science-backed solution to prostate health challenges. By addressing symptoms like frequent urination, weak urine flow, and discomfort, it helps improve quality of life, boost energy, and restore confidence. With its potent blend of ingredients like Saw Palmetto, Pygeum Bark, and Lycopene, this supplement is designed to deliver steady, meaningful results without the risks associated with prescription medications.
If you’re ready to take charge of your prostate health, Prostate Multiphase Support is a smart investment. Visit the official website to explore pricing options, read more customer reviews, and start your journey toward better health today. Don’t let prostate issues hold you back—choose Prostate Multiphase Support and reclaim your vitality.
## **[Order From Official Prostate Multiphase Support Website](https://www.diginear.com/2PGQH1JJ/ZB75D8L/)**
https://prostatemultiphasesupport.wordpress.com/
https://prostate-multiphase-support-1.jimdosite.com/
https://site-s6kpk6t4p.godaddysites.com/
https://zenodo.org/records/16873992
https://www.pixiv.net/en/artworks/133877423
https://www.quora.com/profile/Prostate-Multiphase-1/Prostate-Multiphase-Support-Canada-Review-for-Prostate-Health
|
Muapi/rpg-v6-flux-1
|
Muapi
| 2025-08-14T10:58:33Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T10:58:02Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# RPG v6 - Flux 1

**Base model**: Flux.1 D
**Trained words**: RPG Style
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:647159@796427", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
AliaeAI/dialogact_classification_bert_multilabel_v5
|
AliaeAI
| 2025-08-14T10:54:49Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-14T10:54:12Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
tejas72618/mistral-lora-finetuned
|
tejas72618
| 2025-08-14T10:43:09Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-08-14T10:02:16Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755166347
|
mang3dd
| 2025-08-14T10:37:48Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-14T10:37:43Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
BurgerTruck/distilbart-classifier
|
BurgerTruck
| 2025-08-14T10:37:32Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bart",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-02-14T09:05:59Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
elmenbillion/blockassist-bc-beaked_sharp_otter_1755166297
|
elmenbillion
| 2025-08-14T10:37:19Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"beaked sharp otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-14T10:37:15Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- beaked sharp otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
VoilaRaj/etadpu_aceWTp
|
VoilaRaj
| 2025-08-14T10:37:17Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-14T10:35:22Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
Muapi/weapon-sword-shield-by-hailoknight
|
Muapi
| 2025-08-14T10:28:35Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T10:28:22Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Weapon Sword & Shield - By HailoKnight

**Base model**: Flux.1 D
**Trained words**: Sword and shield
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:230342@793412", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/semi-real-pretty-fantasy
|
Muapi
| 2025-08-14T10:28:15Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T10:27:55Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Semi-real pretty fantasy

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:528291@1946532", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/vampire-fangs-cinematic-anime-xl-sd-1.5-f1d-illu-pony
|
Muapi
| 2025-08-14T10:27:39Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T10:27:23Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Vampire Fangs (cinematic + anime) XL + SD 1.5 + F1D + Illu + Pony

**Base model**: Flux.1 D
**Trained words**: vampire, fangs, horror style, horror
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:191816@1314314", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
dinesh-001/whisper_finetune_vdc_v3
|
dinesh-001
| 2025-08-14T10:27:38Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-14T10:27:29Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
yuchiahung/donut_f21_v3_ep3_edit_distance_loss_retrain
|
yuchiahung
| 2025-08-14T10:26:56Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vision-encoder-decoder",
"image-to-text",
"generated_from_trainer",
"base_model:yuchiahung/donut_f21_v3_ep3_edit_distance_loss",
"base_model:finetune:yuchiahung/donut_f21_v3_ep3_edit_distance_loss",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-to-text
| 2025-08-14T06:54:54Z |
---
library_name: transformers
license: mit
base_model: yuchiahung/donut_f21_v3_ep3_edit_distance_loss
tags:
- generated_from_trainer
model-index:
- name: donut_f21_v3_ep3_edit_distance_loss_retrain
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# donut_f21_v3_ep3_edit_distance_loss_retrain
This model is a fine-tuned version of [yuchiahung/donut_f21_v3_ep3_edit_distance_loss](https://huggingface.co/yuchiahung/donut_f21_v3_ep3_edit_distance_loss) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 23.5076
- Char Accuracy: 0.9944
- Exact Match Accuracy: 0.97
- Avg Pred Length: 9.03
- Avg Label Length: 9.0
- Length Ratio: 1.0033
- Avg Edit Distance: 0.05
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 2
- eval_batch_size: 2
- seed: 132
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Char Accuracy | Exact Match Accuracy | Avg Pred Length | Avg Label Length | Length Ratio | Avg Edit Distance |
|:-------------:|:-----:|:----:|:---------------:|:-------------:|:--------------------:|:---------------:|:----------------:|:------------:|:-----------------:|
| 9.4933 | 1.0 | 250 | 22.1559 | 0.9922 | 0.96 | 9.01 | 9.0 | 1.0011 | 0.07 |
| 7.4131 | 2.0 | 500 | 23.2189 | 0.9933 | 0.97 | 9.02 | 9.0 | 1.0022 | 0.06 |
| 6.8664 | 3.0 | 750 | 23.5076 | 0.9944 | 0.97 | 9.03 | 9.0 | 1.0033 | 0.05 |
### Framework versions
- Transformers 4.53.2
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
Muapi/grainscape-ultrareal
|
Muapi
| 2025-08-14T10:26:37Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T10:25:33Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# GrainScape UltraReal

**Base model**: Flux.1 D
**Trained words**: 8n8log, film photography aesthetic, film grain effect prominent throughout image, high contrast lighting creating dramatic shadows, grainy film-like texture
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1332651@1818149", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/space-nebula-fl-xl-il-pd
|
Muapi
| 2025-08-14T10:24:55Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T10:24:42Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Space Nebula [FL/XL/IL/PD]

**Base model**: Flux.1 D
**Trained words**: mad-nbla
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:295144@789693", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/vibrantly-sharp-style
|
Muapi
| 2025-08-14T10:24:09Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T10:23:39Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Vibrantly Sharp style

**Base model**: Flux.1 D
**Trained words**: VibrantTattooDesign style
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1212132@2041322", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/acid-slime-bubbles-flux-sdxl-pony-1.5
|
Muapi
| 2025-08-14T10:22:25Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T10:22:13Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Acid Slime Bubbles [FLUX+SDXL+PONY+1.5]

**Base model**: Flux.1 D
**Trained words**: ral-acidzlime
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:179353@856520", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
whoisjones/finerweb-binary-classifier-mdeberta-4o
|
whoisjones
| 2025-08-14T10:20:39Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"deberta-v2",
"text-classification",
"generated_from_trainer",
"base_model:microsoft/mdeberta-v3-base",
"base_model:finetune:microsoft/mdeberta-v3-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-04-11T11:29:57Z |
---
library_name: transformers
license: mit
base_model: microsoft/mdeberta-v3-base
tags:
- generated_from_trainer
metrics:
- precision
- recall
- accuracy
model-index:
- name: finerweb-binary-classifier-mdeberta-4o
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finerweb-binary-classifier-mdeberta-4o
This model is a fine-tuned version of [microsoft/mdeberta-v3-base](https://huggingface.co/microsoft/mdeberta-v3-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1606
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 0
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 20
### Framework versions
- Transformers 4.49.0
- Pytorch 2.6.0+cu124
- Datasets 3.3.2
- Tokenizers 0.21.1
|
jiteshsureka/ecomm-gemma-3-1b
|
jiteshsureka
| 2025-08-14T10:16:48Z | 16 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:unsloth/gemma-3-1b-it-unsloth-bnb-4bit",
"lora",
"sft",
"transformers",
"trl",
"unsloth",
"arxiv:1910.09700",
"base_model:unsloth/gemma-3-1b-it-unsloth-bnb-4bit",
"region:us"
] | null | 2025-08-11T11:55:07Z |
---
base_model: unsloth/gemma-3-1b-it-unsloth-bnb-4bit
library_name: peft
tags:
- base_model:adapter:unsloth/gemma-3-1b-it-unsloth-bnb-4bit
- lora
- sft
- transformers
- trl
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.0
|
wli1995/Qwen2.5-0.5B-Instruct-GPTQ-Int4
|
wli1995
| 2025-08-14T10:16:31Z | 0 | 0 |
transformers
|
[
"transformers",
"Qwen",
"Qwen2.5-0.5B-Instruct",
"Qwen2.5-0.5B-Instruct-GPTQ-Int4",
"GPTQ",
"Int4",
"base_model:Qwen/Qwen2.5-0.5B-Instruct-GPTQ-Int4",
"base_model:finetune:Qwen/Qwen2.5-0.5B-Instruct-GPTQ-Int4",
"license:bsd-3-clause",
"endpoints_compatible",
"region:us"
] | null | 2025-08-14T08:58:55Z |
---
library_name: transformers
license: bsd-3-clause
base_model:
- Qwen/Qwen2.5-0.5B-Instruct-GPTQ-Int4
tags:
- Qwen
- Qwen2.5-0.5B-Instruct
- Qwen2.5-0.5B-Instruct-GPTQ-Int4
- GPTQ
- Int4
---
# Qwen2.5-0.5B-Instruct-GPTQ-Int4
This version of Qwen2.5-0.5B-Instruct-GPTQ-Int4 has been converted to run on the Axera NPU using **w4a16** quantization.
This model has been optimized with the following LoRA:
Compatible with Pulsar2 version: 4.1-patch1
## Convert tools links:
For those who are interested in model conversion, you can try to export axmodel through the original repo : https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct-GPTQ-Int4
[Pulsar2 Link, How to Convert LLM from Huggingface to axmodel](https://pulsar2-docs.readthedocs.io/en/latest/appendix/build_llm.html)
[AXera NPU LLM Runtime](https://github.com/AXERA-TECH/ax-llm)
## Support Platform
- AX650
- AX650N DEMO Board
- [M4N-Dock(爱芯派Pro)](https://wiki.sipeed.com/hardware/zh/maixIV/m4ndock/m4ndock.html)
- [M.2 Accelerator card](https://axcl-docs.readthedocs.io/zh-cn/latest/doc_guide_hardware.html)
- AX630C
- *developing*
|Chips|w8a16|w4a16|
|--|--|--|
|AX650| 28 tokens/sec|44 tokens/sec|
## How to use
Download all files from this repository to the device
```
root@ax650:/mnt/qtang/llm-test/qwen2.5-0.5b# tree -L 1
.
├── qwen2.5-0.5b-gptq-int4-ax650
├── qwen2.5_tokenizer
├── qwen2.5_tokenizer.py
├── main_axcl_aarch64
├── main_axcl_x86
├── main_prefill
├── post_config.json
├── run_qwen2.5_0.5b_gptq_int4_ax650.sh
├── run_qwen2.5_0.5b_gptq_int4_axcl_aarch64.sh
└── run_qwen2.5_0.5b_gptq_int4_axcl_x86.sh
```
#### Start the Tokenizer service
```
root@ax650:/mnt/qtang/llm-test/qwen2.5-0.5b# python3 qwen2.5_tokenizer.py --port 12345
None None 151645 <|im_end|>
<|im_start|>system
You are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>
<|im_start|>user
hello world<|im_end|>
<|im_start|>assistant
[151644, 8948, 198, 2610, 525, 1207, 16948, 11, 3465, 553, 54364, 14817, 13, 1446, 525, 264, 10950, 17847, 13, 151645, 198, 151644, 872, 198, 14990, 1879, 151645, 198, 151644, 77091, 198]
http://localhost:12345
```
#### Inference with AX650 Host, such as M4N-Dock(爱芯派Pro) or AX650N DEMO Board
Open another terminal and run `run_qwen2.5_0.5b_gptq_int4_ax650.sh`
```
root@ax650:/mnt/qtang/llm-test/qwen2.5-0.5b# ./run_qwen2.5_0.5b_gptq_int4_ax650.sh
[I][ Init][ 125]: LLM init start
bos_id: -1, eos_id: 151645
3% | ██ | 1 / 27 [0.00s<0.08s, 333.33 count/s] tokenizer init ok
[I][ Init][ 26]: LLaMaEmbedSelector use mmap
100% | ████████████████████████████████ | 27 / 27 [1.34s<1.34s, 20.10 count/s] init post axmodel ok,remain_cmm(3427 MB)
[I][ Init][ 241]: max_token_len : 1024
[I][ Init][ 246]: kv_cache_size : 128, kv_cache_num: 1024
[I][ Init][ 254]: prefill_token_num : 128
[I][ load_config][ 281]: load config:
{
"enable_repetition_penalty": false,
"enable_temperature": true,
"enable_top_k_sampling": true,
"enable_top_p_sampling": false,
"penalty_window": 20,
"repetition_penalty": 1.2,
"temperature": 0.9,
"top_k": 10,
"top_p": 0.8
}
[I][ Init][ 268]: LLM init ok
Type "q" to exit, Ctrl+c to stop current running
>> who are you
[I][ Run][ 466]: ttft: 134.66 ms
I am Qwen, a Qwen AI created by Alibaba Cloud. I am here to assist you with various topics and provide help to the best of my ability. I am here to help
with any questions you have about science, technology, or any other topic you might have for help or guidance. I am always happy to help you!
[N][ Run][ 605]: hit eos,avg 42.11 token/s
>> 1+1=?
[I][ Run][ 466]: ttft: 135.07 ms
1+1=2
[N][ Run][ 605]: hit eos,avg 43.04 token/s
```
#### Inference with M.2 Accelerator card
[What is M.2 Accelerator card?](https://axcl-docs.readthedocs.io/zh-cn/latest/doc_guide_hardware.html), Show this DEMO based on Raspberry PI 5.
```
(base) axera@raspberrypi:~/samples/qwen2.5-0.5b $ ./run_qwen2.5_0.5b_gptq_int4_axcl_aarch64.sh
build time: Feb 13 2025 15:44:57
[I][ Init][ 111]: LLM init start
bos_id: -1, eos_id: 151645
100% | ████████████████████████████████ | 27 / 27 [11.64s<11.64s, 2.32 count/s] init post axmodel okmain_cmm(6788 MB)
[I][ Init][ 226]: max_token_len : 1024
[I][ Init][ 231]: kv_cache_size : 128, kv_cache_num: 1024
[I][ load_config][ 282]: load config:
{
"enable_repetition_penalty": false,
"enable_temperature": true,
"enable_top_k_sampling": true,
"enable_top_p_sampling": false,
"penalty_window": 20,
"repetition_penalty": 1.2,
"temperature": 0.9,
"top_k": 10,
"top_p": 0.8
}
[I][ Init][ 288]: LLM init ok
Type "q" to exit, Ctrl+c to stop current running
>> who are you
I am Qwen, a Qwen-like language model created by Alibaba Cloud. I am designed to assist users in answering questions, generating text,
and participating in conversations. I am here to help you with your questions and to engage in meaningful exchanges with you.
If you have any questions, you can ask me, and if you want, you can even write to me!
[N][ Run][ 610]: hit eos,avg 25.88 token/s
>> 1+1=?
1+1=2
[N][ Run][ 610]: hit eos,avg 29.73 token/s
>> q
(base) axera@raspberrypi:~/samples/qwen2.5-0.5b $ axcl-smi
+------------------------------------------------------------------------------------------------+
| AXCL-SMI V2.26.0_20250205130139 Driver V2.26.0_20250205130139 |
+-----------------------------------------+--------------+---------------------------------------+
| Card Name Firmware | Bus-Id | Memory-Usage |
| Fan Temp Pwr:Usage/Cap | CPU NPU | CMM-Usage |
|=========================================+==============+=======================================|
| 0 AX650N V2.26.0 | 0000:01:00.0 | 170 MiB / 945 MiB |
| -- 43C -- / -- | 2% 0% | 392 MiB / 7040 MiB |
+-----------------------------------------+--------------+---------------------------------------+
+------------------------------------------------------------------------------------------------+
| Processes: |
| Card PID Process Name NPU Memory Usage |
|================================================================================================|
| 0 474440 /home/axera/samples/qwen2.5-0.5b-gptq-int4/main_axcl_aarch64 370172 KiB |
+------------------------------------------------------------------------------------------------+
(base) axera@raspberrypi:~ $
```
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1755165180
|
Sayemahsjn
| 2025-08-14T10:11:26Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-14T10:11:21Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
sbussiso/phi4chan
|
sbussiso
| 2025-08-14T10:11:10Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:unsloth/Phi-3-mini-4k-instruct-bnb-4bit",
"lora",
"sft",
"transformers",
"trl",
"unsloth",
"text-generation",
"conversational",
"base_model:unsloth/Phi-3-mini-4k-instruct-bnb-4bit",
"region:us"
] |
text-generation
| 2025-08-14T08:02:31Z |
---
base_model: unsloth/Phi-3-mini-4k-instruct-bnb-4bit
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:unsloth/Phi-3-mini-4k-instruct-bnb-4bit
- lora
- sft
- transformers
- trl
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
Phi-3 Fine-tuned on over 2000 unfiltered and uncensored 4chan user interactions
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
Phi-3-mini-4k-instruct-bnb-4bit, fine-tuned on over 2000 unfiltered and uncensored 4chan user interactions
- **Developed by:** S'Bussiso Dube
- **Model type:** Text Generation
- **Language(s) (NLP):** English
- **License:** MIT
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
This model is intended to be used for fun casual chat and not production
## Model Card Contact
[email protected]
### Framework versions
- PEFT 0.17.0
|
tamewild/4b_v54_merged_e5
|
tamewild
| 2025-08-14T10:10:40Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-14T10:07:52Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ravikrn/ppo-Huggy
|
ravikrn
| 2025-08-14T10:10:18Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2025-08-14T10:10:11Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: ravikrn/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
subsectmusic/qwriko3-4b-instruct-2507
|
subsectmusic
| 2025-08-14T10:10:07Z | 236 | 0 |
transformers
|
[
"transformers",
"gguf",
"qwen3",
"text-generation-inference",
"ollama",
"tools",
"function-calling",
"character-roleplay",
"tsundere",
"conversational-ai",
"fine-tuned",
"text-generation",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-08-09T09:00:21Z |
---
base_model: Qwen/Qwen3-4B-Instruct
tags:
- text-generation-inference
- transformers
- qwen3
- gguf
- ollama
- tools
- function-calling
- character-roleplay
- tsundere
- conversational-ai
- fine-tuned
license: apache-2.0
language:
- en
pipeline_tag: text-generation
library_name: transformers
---
# 🦊 QwRiko3-4B-Instruct-2507 — Tsundere Kitsune AI (GGUF • Ollama • Tools)
<div align="center">
<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>
</div>
## 📋 Model Overview
**QwRiko3-4B-Instruct-2507** is a conversational AI model fine-tuned to embody **Riko**, a tsundere kitsune character. This release targets **GGUF** for **Ollama** first, with solid **tool calling** support when run via Ollama’s tools API. A PyTorch build (Transformers) is also supported.
- **Model ID (this repo):** `subsectmusic/qwriko3-4b-instruct-2507`
- **Primary format:** **GGUF** (Ollama-compatible)
- **Alt format:** PyTorch (Transformers)
- **Base Model:** `Qwen/Qwen3-4B-Instruct`
- **Parameters:** ~4B
- **License:** Apache-2.0 (repo)
- **Project:** Project Horizon LLM
- **Developer:** @subsectmusic
- **Training Framework:** Unsloth + TRL (SFT)
## 🎭 Character Profile: Riko
- **Tsundere cadence:** “It’s not like I like you or anything… b-baka!”
- **Kitsune vibes:** fox-spirit mischief + sly wisdom
- **Emotional core:** tough shell, soft center
- **Style:** snappy, teasing, ultimately caring
---
## 🚀 Quick Start (Ollama • GGUF)
> These steps assume you have a local GGUF file named `qwriko3-4b-instruct-2507.Q4_K_M.gguf` in the working directory. If your filename differs, update the `FROM` path in the Modelfile accordingly.
1) **Create a Modelfile** (exact content below is also saved as `Modelfile` in this package):
```Dockerfile
# Modelfile
FROM ./qwriko3-4b-instruct-2507.Q4_K_M.gguf
PARAMETER num_ctx 8192
# (Optional) you can set temperature/top_p/etc. via `ollama run -p` or the API.
```
2) **Create the Ollama model**:
```bash
ollama create qwriko3-4b-instruct-2507 -f Modelfile
```
3) **Chat**:
```bash
ollama run qwriko3-4b-instruct-2507 "Riko, give me a playful hello."
```
### Tool Calling with Ollama (cURL)
```bash
curl http://localhost:11434/api/chat -d '{
"model": "qwriko3-4b-instruct-2507",
"messages": [
{ "role": "user", "content": "What is the weather today in Toronto?" }
],
"tools": [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The location to get the weather for, e.g. Toronto"
},
"format": {
"type": "string",
"description": "Temperature units",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location", "format"]
}
}
}
]
}'
```
### Tool Calling with Ollama (Python)
A complete, ready-to-run example is saved as `tools_demo.py` in this package. It defines a couple of functions and lets the model call them. You can run it after installing the Python client:
```bash
pip install -U ollama
python tools_demo.py
```
---
## 🧪 Quick Start (Transformers • PyTorch)
```python
# Requirements:
# pip install "transformers>=4.42.0" "torch>=2.1.0" accelerate
# (CUDA recommended; CPU works but is slower.)
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
MODEL_ID = "subsectmusic/qwriko3-4b-instruct-2507"
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
torch_dtype=torch.float16,
device_map="auto"
)
messages = [
{"role": "system", "content": "You are Riko, a tsundere kitsune AI. Be witty, teasing, but with hidden warmth."},
{"role": "user", "content": "Hey Riko, how are you today?"}
]
if hasattr(tokenizer, "apply_chat_template"):
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
else:
prompt = (
"System: You are Riko, a tsundere kitsune AI. Be witty, teasing, but with hidden warmth.\n"
"User: Hey Riko, how are you today?\n"
"Assistant:"
)
inputs = tokenizer(prompt, return_tensors="pt").input_ids.to(model.device)
gen = model.generate(
inputs,
max_new_tokens=256,
temperature=0.85,
top_p=0.9,
top_k=50,
repetition_penalty=1.1,
do_sample=True,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
out = tokenizer.decode(gen[0][inputs.shape[1]:], skip_special_tokens=True)
print("\nRiko:", out.strip())
```
---
## 💡 Use Cases
- Character roleplay & entertainment
- Creative writing in a tsundere voice
- Personality-driven chatbots
- Research on alternating-turn distillation & style transfer
## 🔬 Training Summary (SFT)
- **Format:** ShareGPT-style → Alpaca single-turn pairs
- **Teachers:** Kimi K2 (odd) + Horizon Beta (even)
- **Focus:** Tsundere kitsune persona, witty banter, emotional subtext
- **Curation:** Manual filtering for tone & safety
Example SFT settings:
```yaml
Training Framework: Unsloth + TRL SFTTrainer
Base Model: Qwen/Qwen3-4B-Instruct
Batch Size: 2 per device
Gradient Accumulation: 4
Learning Rate: 2e-4
Optimizer: AdamW 8-bit
Weight Decay: 0.01
Scheduler: Linear
Max Steps: 100+
Warmup Steps: 5
Sequence Length: up to model context
Precision: fp16
```
## 📊 Specs
| Attribute | Details |
|------------------|-------------------------------|
| Architecture | Qwen3 Transformer |
| Parameters | ~4B |
| Base | Qwen/Qwen3-4B-Instruct |
| Context Length | Base-dependent (Qwen3 config) |
| Formats | **GGUF (Ollama)**; PyTorch |
| Framework | PyTorch + Transformers |
| Optimization | Unsloth-accelerated SFT |
| Style | Tsundere kitsune (Riko) |
## 🎯 Recommended Inference Settings
```python
generation_config = {
"max_new_tokens": 256,
"temperature": 0.85,
"top_p": 0.9,
"top_k": 50,
"repetition_penalty": 1.1,
"do_sample": True,
"pad_token_id": tokenizer.eos_token_id,
"eos_token_id": tokenizer.eos_token_id
}
```
## ⚠️ Notes
- In-character style can color responses to factual queries
- Compact 4B size benefits from clear prompts for complex tasks
- Quantization can slightly affect nuance
## 🔒 Ethics
- Entertainment & creative use; not professional advice
- Follow platform/community guidelines
## 📚 Citation
```bibtex
@model{qwriko3-4b-instruct-2507,
title={QwRiko3-4B-Instruct-2507: Tsundere Kitsune AI},
author={subsectmusic},
year={2025},
publisher={Hugging Face},
url={https://huggingface.co/subsectmusic/qwriko3-4b-instruct-2507}
}
```
## 🤝 Acknowledgments
- Kimi K2 & Horizon Beta (teachers)
- Project Horizon LLM (methodology)
- Unsloth, Qwen Team, Hugging Face / TRL
- Ollama (GGUF runtime)
---
<div align="center">
<b>Made with ❤️ using Unsloth</b><br>
<i>Training AI personalities, one tsundere at a time!</i>
</div>
|
Muapi/expression-helper-2.0
|
Muapi
| 2025-08-14T10:08:43Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T10:07:55Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Expression Helper 2.0

**Base model**: Flux.1 D
**Trained words**: sad , very sad, happy, very happy, angry, very angry, surprised, open mouth, scared, very scared, disgusted, very disgusted
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:914282@1023284", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
chainway9/blockassist-bc-untamed_quick_eel_1755163428
|
chainway9
| 2025-08-14T09:52:45Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed quick eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-14T09:52:41Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed quick eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Ironman288/blockassist-bc-miniature_lanky_vulture_1755163272
|
Ironman288
| 2025-08-14T09:52:27Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"miniature lanky vulture",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-14T09:50:58Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- miniature lanky vulture
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/adjust-details-and-photorealism-xl-pony-flux
|
Muapi
| 2025-08-14T09:51:39Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T09:51:18Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Adjust details AND photorealism (XL/PONY+FLUX)

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:890914@1717548", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Donchocho/Qwen3-0.6B-Gensyn-Swarm-graceful_tricky_dolphin
|
Donchocho
| 2025-08-14T09:50:49Z | 101 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am graceful_tricky_dolphin",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-07-30T13:49:19Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am graceful_tricky_dolphin
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
DreamGallery/task-13-microsoft-Phi-4-mini-instruct
|
DreamGallery
| 2025-08-14T09:46:35Z | 739 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:microsoft/Phi-4-mini-instruct",
"base_model:adapter:microsoft/Phi-4-mini-instruct",
"region:us"
] | null | 2025-08-04T15:47:15Z |
---
base_model: microsoft/Phi-4-mini-instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.14.0
|
heavy0ung/Qwen2.5-VL-3B-Instruct-Thinking
|
heavy0ung
| 2025-08-14T09:46:32Z | 0 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"generated_from_trainer",
"grpo",
"trl",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-VL-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-3B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-14T08:25:28Z |
---
base_model: Qwen/Qwen2.5-VL-3B-Instruct
library_name: transformers
model_name: Qwen2.5-VL-3B-Instruct-Thinking
tags:
- generated_from_trainer
- grpo
- trl
licence: license
---
# Model Card for Qwen2.5-VL-3B-Instruct-Thinking
This model is a fine-tuned version of [Qwen/Qwen2.5-VL-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="heavy0ung/Qwen2.5-VL-3B-Instruct-Thinking", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.0
- Pytorch: 2.7.1
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
leonzc/llama400m-climblab-roleplay-5k-random-dora-merged
|
leonzc
| 2025-08-14T09:45:04Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"llama",
"dora",
"lora",
"en",
"base_model:data4elm/Llama-400M-12L",
"base_model:adapter:data4elm/Llama-400M-12L",
"license:apache-2.0",
"region:us"
] | null | 2025-08-14T09:44:29Z |
---
language:
- en
tags:
- llama
- peft
- dora
- lora
license: apache-2.0
base_model: data4elm/Llama-400M-12L
---
# llama400m-climblab-roleplay-5k-random-dora-merged
DoRA fine-tuned LLaMA 400M model on randomly chose 5k data from roleplay dataset using LMFlow
## Model Details
This model is a DoRA-finetuned version of [data4elm/Llama-400M-12L](https://huggingface.co/data4elm/Llama-400M-12L).
The standalone adapter is available at [leonzc/llama400m-climblab-roleplay-5k-random-dora-adapter](https://huggingface.co/leonzc/llama400m-climblab-roleplay-5k-random-dora-adapter).
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# Option 1: Load the complete model directly
model = AutoModelForCausalLM.from_pretrained("leonzc/llama400m-climblab-roleplay-5k-random-dora-merged")
tokenizer = AutoTokenizer.from_pretrained("leonzc/llama400m-climblab-roleplay-5k-random-dora-merged")
# Option 2: Load just the adapter with the base model
base_model = AutoModelForCausalLM.from_pretrained("data4elm/Llama-400M-12L")
tokenizer = AutoTokenizer.from_pretrained("data4elm/Llama-400M-12L")
model = PeftModel.from_pretrained(base_model, "leonzc/llama400m-climblab-roleplay-5k-random-dora-adapter")
# Example usage
input_text = "What is the capital of France?"
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(inputs.input_ids, max_length=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
|
VoilaRaj/etadpu_7D8y98
|
VoilaRaj
| 2025-08-14T09:42:49Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-14T09:40:59Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
Muapi/artify-s-fantasy-and-sci-fi-art-flux-lora
|
Muapi
| 2025-08-14T09:37:12Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T09:36:59Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Artify´s Fantasy and Sci-Fi Art Flux Lora

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:751420@840288", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
wasabuko/blockassist-bc-noisy_zealous_macaw_1755161304
|
wasabuko
| 2025-08-14T09:33:34Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"noisy zealous macaw",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-14T09:31:02Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- noisy zealous macaw
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
koloni/blockassist-bc-deadly_graceful_stingray_1755162447
|
koloni
| 2025-08-14T09:32:10Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-14T09:32:07Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
eason668/6df6d8de-5c7f-4cc4-a0bb-48bfacf87fac
|
eason668
| 2025-08-14T09:28:18Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-14T09:28:06Z |
# 6df6d8de-5c7f-4cc4-a0bb-48bfacf87fac
## 模型信息
- **基础模型**: Qwen/Qwen1.5-7B
- **模型类型**: AutoModelForCausalLM
- **训练任务ID**: 85d5f0b2-0a72-4951-b408-564a4f323d84
- **适配器类型**:
- **LoRA Rank**:
- **LoRA Alpha**:
- **聊天模板**: llama3
## 使用方法
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载模型
model = AutoModelForCausalLM.from_pretrained("eason668/6df6d8de-5c7f-4cc4-a0bb-48bfacf87fac")
tokenizer = AutoTokenizer.from_pretrained("eason668/6df6d8de-5c7f-4cc4-a0bb-48bfacf87fac")
# 使用模型
inputs = tokenizer("你的输入文本", return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## 训练信息
此模型是通过Gradients-On-Demand平台训练的,使用了GRPO算法进行强化学习优化。
## 许可证
请参考基础模型的许可证。
|
Muapi/rembrandt-low-key-lighting-style-xl-sd1.5-f1d-illu-pony
|
Muapi
| 2025-08-14T09:13:50Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T09:13:38Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Rembrandt (Low-Key) Lighting Style XL + SD1.5 + F1D + Illu + Pony

**Base model**: Flux.1 D
**Trained words**: Rembrandt Lighting style, partially covered in shadows
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:280454@804774", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
abhi6007/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-striped_gliding_antelope
|
abhi6007
| 2025-08-14T09:11:36Z | 42 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am striped_gliding_antelope",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-07-06T14:22:19Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am striped_gliding_antelope
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1755161387
|
Sayemahsjn
| 2025-08-14T09:07:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-14T09:07:35Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Geek241/Website
|
Geek241
| 2025-08-14T09:04:34Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-14T09:04:34Z |
---
license: apache-2.0
---
|
Muapi/gmic-iocn_f1-2d-chinese-style.safetensors
|
Muapi
| 2025-08-14T09:03:01Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T09:02:40Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# gmic iocn_f1 2D Chinese style.safetensors

**Base model**: Flux.1 D
**Trained words**: gmic icon_/(Game ai Institute /)
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:71110@1962367", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
gb20250101/flux1-dev-fp8_2
|
gb20250101
| 2025-08-14T08:59:24Z | 0 | 2 | null |
[
"license:other",
"region:us"
] | null | 2024-12-30T05:50:26Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/resolve/main/LICENSE.md
---
|
Muapi/lava-style-flux-sdxl-1.5
|
Muapi
| 2025-08-14T08:58:35Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T08:58:20Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Lava Style [FLUX+SDXL+1.5]

**Base model**: Flux.1 D
**Trained words**: ral-lva
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:203169@890810", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.