
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-16 00:39:55
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 504
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-16 00:39:45
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
SicariusSicariiStuff/Impish_Nemo_12B_GPTQ_4-bit-64
|
SicariusSicariiStuff
| 2025-08-15T23:07:37Z | 3 | 0 |
transformers
|
[
"transformers",
"mistral",
"text-generation",
"conversational",
"en",
"dataset:SicariusSicariiStuff/UBW_Tapestries",
"base_model:SicariusSicariiStuff/Impish_Nemo_12B",
"base_model:quantized:SicariusSicariiStuff/Impish_Nemo_12B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2025-08-11T10:43:35Z |
---
base_model:
- SicariusSicariiStuff/Impish_Nemo_12B
datasets:
- SicariusSicariiStuff/UBW_Tapestries
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: SicariusSicariiStuff
---
|
TorpedoSoftware/Luau-Devstral-24B-Instruct-v0.1
|
TorpedoSoftware
| 2025-08-15T22:29:14Z | 0 | 1 |
transformers
|
[
"transformers",
"safetensors",
"gguf",
"mistral",
"text-generation",
"roblox",
"luau",
"code",
"sft",
"trl",
"unsloth",
"conversational",
"en",
"fr",
"de",
"es",
"pt",
"it",
"dataset:TorpedoSoftware/the-luau-stack",
"dataset:TorpedoSoftware/roblox-info-dump",
"arxiv:1910.09700",
"base_model:unsloth/Devstral-Small-2507-unsloth-bnb-4bit",
"base_model:quantized:unsloth/Devstral-Small-2507-unsloth-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-15T16:53:32Z |
---
license: apache-2.0
datasets:
- TorpedoSoftware/the-luau-stack
- TorpedoSoftware/roblox-info-dump
language:
- en
- fr
- de
- es
- pt
- it
base_model:
- unsloth/Devstral-Small-2507-unsloth-bnb-4bit
tags:
- roblox
- luau
- code
- sft
- transformers
- trl
- unsloth
---
# Luau Devstral 24B Instruct v0.1
A Roblox Luau focused finetune of [Devstral Small 2507](https://huggingface.co/mistralai/Devstral-Small-2507).
## Model Details
### Model Description
Devstral Small 2507 is a powerful choice for local inference, achieving SOTA open source results at just 24B parameters. However, Roblox gamedev and Luau programming are generally not well represented in LLM training data. This model fine tunes Devstral on a corpus of permissively licensed Luau code and Roblox documentation, improving the model's Luau programming capabilities. Additionally, the jinja chat template contains a default system prompt that steers the model's Luau capabilities even further.
- **Developed by:** Zack Williams ([boatbomber](https://huggingface.co/boatbomber))
- **Funded by:** [Torpedo Software LLC](https://huggingface.co/TorpedoSoftware)
- **License:** [Apache 2.0](https://www.tldrlegal.com/license/apache-license-2-0-apache-2-0)
- **Finetuned from model:** [unsloth/Devstral-Small-2507-unsloth-bnb-4bit](https://huggingface.co/unsloth/Devstral-Small-2507-unsloth-bnb-4bit)
### Model Sources
- **Repository:** https://huggingface.co/mistralai/Devstral-Small-2507
- **Blog:** https://mistral.ai/news/devstral-2507
## Training Details
### Training Data
1. https://huggingface.co/datasets/TorpedoSoftware/the-luau-stack
2. https://huggingface.co/datasets/TorpedoSoftware/roblox-info-dump
#### Preprocessing
Each datapoint from the training data was formatted as follows in order to provide the model with relevant context:
```md
Repository: {repo_name}
Repository Description: {repo_description}
File Path: `{file_path}`
File Content:
```Lua
{file_content}
```\
```
### Training Loss Curve

### Imatrix Calibration
The imatrix for the GGUF quantizations was computed using 33.5MB of text containing a combination of [wiki.train.raw](https://huggingface.co/datasets/ikawrakow/validation-datasets-for-llama.cpp/blob/main/wiki.train.raw.gz) and content from [the-luau-stack](https://huggingface.co/datasets/TorpedoSoftware/the-luau-stack) & [roblox-info-dump](https://huggingface.co/datasets/TorpedoSoftware/roblox-info-dump). This created an imatrix that is well suited to the specialized tasks this model is designed for while still maintaining broader intelligence as well. While we do provide several quantizations already, the `imatrix.gguf` is included in this repository should you want to create other quants yourself.
## Environmental Impact
Carbon emissions estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** RTX 3090
- **Hours used:** 60
- **Cloud Provider:** My gaming PC
- **Compute Region:** Bay Area
- **Carbon Emitted:** 4.73 kg CO2eq (equivalent to 11.8 miles driven by an average ICE car)
|
mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF
|
mradermacher
| 2025-08-15T22:01:29Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:Qwen/Qwen3-4B-Thinking-2507",
"base_model:quantized:Qwen/Qwen3-4B-Thinking-2507",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-08-15T19:53:49Z |
---
base_model: Qwen/Qwen3-4B-Thinking-2507
language:
- en
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-4B-Thinking-2507/blob/main/LICENSE
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/Qwen/Qwen3-4B-Thinking-2507
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Qwen3-4B-Thinking-2507-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-IQ1_S.gguf) | i1-IQ1_S | 1.2 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-IQ1_M.gguf) | i1-IQ1_M | 1.2 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 1.3 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-IQ2_XS.gguf) | i1-IQ2_XS | 1.5 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-IQ2_S.gguf) | i1-IQ2_S | 1.5 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-IQ2_M.gguf) | i1-IQ2_M | 1.6 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-Q2_K_S.gguf) | i1-Q2_K_S | 1.7 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-Q2_K.gguf) | i1-Q2_K | 1.8 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 1.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-IQ3_XS.gguf) | i1-IQ3_XS | 1.9 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-Q3_K_S.gguf) | i1-Q3_K_S | 2.0 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-IQ3_S.gguf) | i1-IQ3_S | 2.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-IQ3_M.gguf) | i1-IQ3_M | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-Q3_K_M.gguf) | i1-Q3_K_M | 2.2 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-Q3_K_L.gguf) | i1-Q3_K_L | 2.3 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-IQ4_XS.gguf) | i1-IQ4_XS | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-Q4_0.gguf) | i1-Q4_0 | 2.5 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-IQ4_NL.gguf) | i1-IQ4_NL | 2.5 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-Q4_K_S.gguf) | i1-Q4_K_S | 2.5 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-Q4_K_M.gguf) | i1-Q4_K_M | 2.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-Q4_1.gguf) | i1-Q4_1 | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-Q5_K_S.gguf) | i1-Q5_K_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-Q5_K_M.gguf) | i1-Q5_K_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4B-Thinking-2507-i1-GGUF/resolve/main/Qwen3-4B-Thinking-2507.i1-Q6_K.gguf) | i1-Q6_K | 3.4 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
richlai/maven-opt-350m-4bit-rlai
|
richlai
| 2025-08-15T20:40:34Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"opt",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-08-15T20:40:30Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/aidc-llm-laos-10k-gemma-3-12b-it-GGUF
|
mradermacher
| 2025-08-15T20:32:36Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"unsloth",
"lo",
"dataset:Phonepadith/laos-long-content",
"base_model:Phonepadith/aidc-llm-laos-10k-gemma-3-12b-it",
"base_model:quantized:Phonepadith/aidc-llm-laos-10k-gemma-3-12b-it",
"license:gemma",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-15T16:47:14Z |
---
base_model: Phonepadith/aidc-llm-laos-10k-gemma-3-12b-it
datasets:
- Phonepadith/laos-long-content
language:
- lo
library_name: transformers
license: gemma
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- unsloth
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: 1 -->
static quants of https://huggingface.co/Phonepadith/aidc-llm-laos-10k-gemma-3-12b-it
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#aidc-llm-laos-10k-gemma-3-12b-it-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/aidc-llm-laos-10k-gemma-3-12b-it-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/aidc-llm-laos-10k-gemma-3-12b-it-GGUF/resolve/main/aidc-llm-laos-10k-gemma-3-12b-it.Q2_K.gguf) | Q2_K | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/aidc-llm-laos-10k-gemma-3-12b-it-GGUF/resolve/main/aidc-llm-laos-10k-gemma-3-12b-it.Q3_K_S.gguf) | Q3_K_S | 6.0 | |
| [GGUF](https://huggingface.co/mradermacher/aidc-llm-laos-10k-gemma-3-12b-it-GGUF/resolve/main/aidc-llm-laos-10k-gemma-3-12b-it.Q3_K_M.gguf) | Q3_K_M | 6.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/aidc-llm-laos-10k-gemma-3-12b-it-GGUF/resolve/main/aidc-llm-laos-10k-gemma-3-12b-it.Q3_K_L.gguf) | Q3_K_L | 7.0 | |
| [GGUF](https://huggingface.co/mradermacher/aidc-llm-laos-10k-gemma-3-12b-it-GGUF/resolve/main/aidc-llm-laos-10k-gemma-3-12b-it.IQ4_XS.gguf) | IQ4_XS | 7.2 | |
| [GGUF](https://huggingface.co/mradermacher/aidc-llm-laos-10k-gemma-3-12b-it-GGUF/resolve/main/aidc-llm-laos-10k-gemma-3-12b-it.Q4_K_S.gguf) | Q4_K_S | 7.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/aidc-llm-laos-10k-gemma-3-12b-it-GGUF/resolve/main/aidc-llm-laos-10k-gemma-3-12b-it.Q4_K_M.gguf) | Q4_K_M | 8.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/aidc-llm-laos-10k-gemma-3-12b-it-GGUF/resolve/main/aidc-llm-laos-10k-gemma-3-12b-it.Q5_K_S.gguf) | Q5_K_S | 9.0 | |
| [GGUF](https://huggingface.co/mradermacher/aidc-llm-laos-10k-gemma-3-12b-it-GGUF/resolve/main/aidc-llm-laos-10k-gemma-3-12b-it.Q5_K_M.gguf) | Q5_K_M | 9.2 | |
| [GGUF](https://huggingface.co/mradermacher/aidc-llm-laos-10k-gemma-3-12b-it-GGUF/resolve/main/aidc-llm-laos-10k-gemma-3-12b-it.Q6_K.gguf) | Q6_K | 10.6 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/aidc-llm-laos-10k-gemma-3-12b-it-GGUF/resolve/main/aidc-llm-laos-10k-gemma-3-12b-it.Q8_0.gguf) | Q8_0 | 13.7 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
ultratopaz/1451342
|
ultratopaz
| 2025-08-15T20:03:07Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-15T20:03:08Z |
[View on Civ Archive](https://civarchive.com/models/1371441?modelVersionId=1551524)
|
ultratopaz/842405
|
ultratopaz
| 2025-08-15T19:57:59Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-15T19:57:58Z |
[View on Civ Archive](https://civarchive.com/models/835760?modelVersionId=935049)
|
roeker/blockassist-bc-quick_wiry_owl_1755287525
|
roeker
| 2025-08-15T19:53:38Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"quick wiry owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T19:52:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- quick wiry owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
koloni/blockassist-bc-deadly_graceful_stingray_1755285777
|
koloni
| 2025-08-15T19:50:36Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T19:50:32Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
xinnn32/blockassist-bc-meek_winged_caterpillar_1755287307
|
xinnn32
| 2025-08-15T19:49:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"meek winged caterpillar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T19:49:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- meek winged caterpillar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ultratopaz/265889
|
ultratopaz
| 2025-08-15T19:49:01Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-15T19:49:00Z |
[View on Civ Archive](https://civarchive.com/models/298478?modelVersionId=335250)
|
LimbiDev/gemma-3-270m-it-Highlevelrandom-Bigraph-Model-1000E
|
LimbiDev
| 2025-08-15T19:33:56Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"generated_from_trainer",
"sft",
"trl",
"conversational",
"base_model:google/gemma-3-270m-it",
"base_model:finetune:google/gemma-3-270m-it",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-15T19:32:05Z |
---
base_model: google/gemma-3-270m-it
library_name: transformers
model_name: gemma-3-270m-it-Highlevelrandom-Bigraph-Model-1000E
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for gemma-3-270m-it-Highlevelrandom-Bigraph-Model-1000E
This model is a fine-tuned version of [google/gemma-3-270m-it](https://huggingface.co/google/gemma-3-270m-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="LimbiDev/gemma-3-270m-it-Highlevelrandom-Bigraph-Model-1000E", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.0.dev0
- Pytorch: 2.7.1
- Datasets: 4.0.0
- Tokenizers: 0.21.2
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Eddie1015/q-FrozenLake-v1-4x4-noSlippery
|
Eddie1015
| 2025-08-15T19:27:09Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-15T19:27:03Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Eddie1015/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Clip-dr-eman-tiktoker-viral-video-Link-hq/Hot.New.full.videos.dr.eman.tiktoker.Viral.Video.Official.Tutorial
|
Clip-dr-eman-tiktoker-viral-video-Link-hq
| 2025-08-15T19:23:58Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-15T19:23:33Z |
<a data-target="animated-image.originalLink" rel="nofollow" href="https://tinyurl.com/4axawfmy?Bri
"><img data-target="animated-image.originalImage" style="max-width: 100%; display: inline-block;" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" alt="WATCH Videos" src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif"></a>
|
kapalbalap/blockassist-bc-peaceful_wary_owl_1755285178
|
kapalbalap
| 2025-08-15T19:14:06Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"peaceful wary owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T19:13:51Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- peaceful wary owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kapalbalap/blockassist-bc-peaceful_wary_owl_1755284994
|
kapalbalap
| 2025-08-15T19:11:03Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"peaceful wary owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T19:10:45Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- peaceful wary owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ziadtarek12/MyGemmaNPC
|
ziadtarek12
| 2025-08-15T19:07:08Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gemma3_text",
"text-generation",
"generated_from_trainer",
"sft",
"trl",
"conversational",
"base_model:google/gemma-3-270m-it",
"base_model:finetune:google/gemma-3-270m-it",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-15T19:05:57Z |
---
base_model: google/gemma-3-270m-it
library_name: transformers
model_name: MyGemmaNPC
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for MyGemmaNPC
This model is a fine-tuned version of [google/gemma-3-270m-it](https://huggingface.co/google/gemma-3-270m-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="ziadtarek12/MyGemmaNPC", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.6.0+cu124
- Datasets: 3.6.0
- Tokenizers: 0.21.2
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
silvercrow17/jayAfroBefore
|
silvercrow17
| 2025-08-15T19:05:07Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-15T18:38:40Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: jayBefore1
---
# Jayafrobefore
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `jayBefore1` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "jayBefore1",
"lora_weights": "https://huggingface.co/silvercrow17/jayAfroBefore/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('silvercrow17/jayAfroBefore', weight_name='lora.safetensors')
image = pipeline('jayBefore1').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 64
## Contribute your own examples
You can use the [community tab](https://huggingface.co/silvercrow17/jayAfroBefore/discussions) to add images that show off what you’ve made with this LoRA.
|
kapalbalap/blockassist-bc-peaceful_wary_owl_1755284635
|
kapalbalap
| 2025-08-15T19:05:03Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"peaceful wary owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T19:04:46Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- peaceful wary owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ggozzy/blockassist-bc-stubby_yapping_mandrill_1755284154
|
ggozzy
| 2025-08-15T18:57:04Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stubby yapping mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T18:56:56Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stubby yapping mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ACECA/lowMvMax_23
|
ACECA
| 2025-08-15T18:55:37Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-15T15:27:54Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
exala/db_fe2_11.3
|
exala
| 2025-08-15T18:52:33Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-15T18:52:15Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ljk1291/test3
|
ljk1291
| 2025-08-15T18:27:04Z | 728 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-08-03T19:18:41Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: Nymphotic
---
# Test3
<Gallery />
Trained on Replicate using:
https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `Nymphotic` to trigger the image generation.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('ljk1291/test3', weight_name='lora.safetensors')
image = pipeline('your prompt').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
ihsanridzi/blockassist-bc-wiry_flexible_owl_1755280628
|
ihsanridzi
| 2025-08-15T18:22:01Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry flexible owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T18:21:58Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry flexible owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kojeklollipop/blockassist-bc-spotted_amphibious_stork_1755280138
|
kojeklollipop
| 2025-08-15T18:17:29Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"spotted amphibious stork",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T18:17:24Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- spotted amphibious stork
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Chilliwiddit/Llama3.1-FT-LoRA
|
Chilliwiddit
| 2025-08-15T18:12:10Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-15T14:11:24Z |
---
base_model: unsloth/meta-llama-3.1-8b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Chilliwiddit
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
Trained for 5 epochs and a learning rate of 0.001 on the Open-i dataset (2735 rows)
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
knowledgator/gliner-decoder-large-v1.0
|
knowledgator
| 2025-08-15T18:10:03Z | 0 | 4 | null |
[
"pytorch",
"NER",
"encoder",
"decoder",
"GLiNER",
"information-extraction",
"token-classification",
"en",
"base_model:HuggingFaceTB/SmolLM2-135M-Instruct",
"base_model:finetune:HuggingFaceTB/SmolLM2-135M-Instruct",
"license:apache-2.0",
"region:us"
] |
token-classification
| 2025-08-15T06:33:31Z |
---
license: apache-2.0
language:
- en
base_model:
- microsoft/deberta-v3-large
- HuggingFaceTB/SmolLM2-135M-Instruct
pipeline_tag: token-classification
tags:
- NER
- encoder
- decoder
- GLiNER
- information-extraction
---

**GLiNER** is a Named Entity Recognition (NER) model capable of identifying *any* entity type in a **zero-shot** manner.
This architecture combines:
* An **encoder** for representing entity spans
* A **decoder** for generating label names
This hybrid approach enables new use cases such as **entity linking** and expands GLiNER’s capabilities.
By integrating large modern decoders—trained on vast datasets—GLiNER can leverage their **richer knowledge capacity** while maintaining competitive inference speed.
---
## Key Features
* **Open ontology**: Works when the label set is unknown
* **Multi-label entity recognition**: Assign multiple labels to a single entity
* **Entity linking**: Handle large label sets via constrained generation
* **Knowledge expansion**: Gain from large decoder models
* **Efficient**: Minimal speed reduction on GPU compared to single-encoder GLiNER
---
## Installation
Update to the latest version of GLiNER:
```bash
# until the new pip release, install from main to use the new architecture
pip install git+https://github.com/urchade/GLiNER.git
```
---
## Usage
```python
from gliner import GLiNER
model = GLiNER.from_pretrained("knowledgator/gliner-decoder-large-v1.0")
text = (
"Apple was founded as Apple Computer Company on April 1, 1976, "
"by Steve Wozniak, Steve Jobs (1955–2011) and Ronald Wayne to "
"develop and sell Wozniak's Apple I personal computer."
)
labels = ["person", "other"]
model.run(text, labels, threshold=0.3, num_gen_sequences=1)
```
---
### Example Output
```json
[
[
{
"start": 21,
"end": 26,
"text": "Apple",
"label": "other",
"score": 0.6795641779899597,
"generated labels": ["Organization"]
},
{
"start": 47,
"end": 60,
"text": "April 1, 1976",
"label": "other",
"score": 0.44296327233314514,
"generated labels": ["Date"]
},
{
"start": 65,
"end": 78,
"text": "Steve Wozniak",
"label": "person",
"score": 0.9934439659118652,
"generated labels": ["Person"]
},
{
"start": 80,
"end": 90,
"text": "Steve Jobs",
"label": "person",
"score": 0.9725918769836426,
"generated labels": ["Person"]
},
{
"start": 107,
"end": 119,
"text": "Ronald Wayne",
"label": "person",
"score": 0.9964536428451538,
"generated labels": ["Person"]
}
]
]
```
---
### Restricting the Decoder
You can limit the decoder to generate labels only from a predefined set:
```python
model.run(
text, labels,
threshold=0.3,
num_gen_sequences=1,
gen_constraints=[
"organization", "organization type", "city",
"technology", "date", "person"
]
)
```
---
## Performance Tips
Two label trie implementations are available.
For a **faster, memory-efficient C++ version**, install **Cython**:
```bash
pip install cython
```
This can significantly improve performance and reduce memory usage, especially with millions of labels.
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1755280261
|
Sayemahsjn
| 2025-08-15T18:09:48Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T18:09:43Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
aumoai/aumogpt-Llama3.3-70B-Instruct-lora
|
aumoai
| 2025-08-15T18:04:04Z | 6 | 0 | null |
[
"safetensors",
"llama",
"region:us"
] | null | 2025-08-12T19:11:27Z |
model:
model_name: "meta-llama/Llama-3.3-70B-Instruct"
model_max_length: 4096
torch_dtype_str: "bfloat16"
attn_implementation: "flash_attention_2" #"sdpa"
load_pretrained_weights: True
trust_remote_code: True
data:
train:
datasets:
# - dataset_name: "text_sft"
# dataset_path: "datasets/aumo_dataset_test.json"
# shuffle: True
# seed: 42
- dataset_name: "text_sft"
dataset_path: "datasets/aumogpt_llama70b.json"
shuffle: True
seed: 42
# - dataset_name: "text_sft"
# dataset_path: "datasets/xp3_qwen_2000.json"
# shuffle: True
# seed: 42
# - dataset_name: "text_sft"
# dataset_path: "datasets/aumogpt_train.json"
# shuffle: True
# seed: 42
# mixture_strategy: "all_exhausted" # Strategy for mixing datasets
# seed: 123456789426465
validation:
datasets:
- dataset_name: "text_sft"
dataset_path: "datasets/aumo_dataset_test.json"
# split: "validation"
# sample_count: 10
training:
trainer_type: "TRL_SFT"
use_peft: True
save_steps: 200
num_train_epochs: 2
per_device_train_batch_size: 2
per_device_eval_batch_size: 2
gradient_accumulation_steps: 8
max_grad_norm: null
enable_gradient_checkpointing: True
gradient_checkpointing_kwargs:
use_reentrant: False
ddp_find_unused_parameters: False
optimizer: "adamw_torch" # "adamw_torch" #paged_adamw_8bit
learning_rate: 5.0e-4
warmup_steps: 10
weight_decay: 0.01
compile: False
dataloader_num_workers: 8
dataloader_prefetch_factor: 4
logging_steps: 10
log_model_summary: False
empty_device_cache_steps: 50
output_dir: "results/oumi/llama70b_aumogpt.lora"
include_performance_metrics: True
enable_wandb: True
eval_strategy: "steps" # When to evaluate ("no", "steps", "epoch")
eval_steps: 25
peft:
q_lora: False
lora_r: 64
lora_alpha: 32
lora_dropout: 0.2
lora_target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "down_proj"
- "up_proj"
fsdp:
enable_fsdp: True
sharding_strategy: FULL_SHARD
auto_wrap_policy: TRANSFORMER_BASED_WRAP
transformer_layer_cls: "LlamaDecoderLayer"
forward_prefetch: true
|
ziadrone/Qwen3-1.7B-ToT-GRPO-Finetuned
|
ziadrone
| 2025-08-15T17:59:14Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-15T17:58:19Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mingqxu/phi3-fmea-aug
|
mingqxu
| 2025-08-15T17:53:11Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:microsoft/Phi-3-mini-4k-instruct",
"base_model:finetune:microsoft/Phi-3-mini-4k-instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-15T16:45:31Z |
---
base_model: microsoft/Phi-3-mini-4k-instruct
library_name: transformers
model_name: phi3-fmea-aug
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for phi3-fmea-aug
This model is a fine-tuned version of [microsoft/Phi-3-mini-4k-instruct](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="mingqxu/phi3-fmea-aug", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.12.1
- Transformers: 4.46.2
- Pytorch: 2.6.0+cu124
- Datasets: 3.1.0
- Tokenizers: 0.20.3
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Coaster41/patchtst-sae-grid-8-0.5-1-expe
|
Coaster41
| 2025-08-15T17:52:48Z | 0 | 0 |
saelens
|
[
"saelens",
"region:us"
] | null | 2025-08-15T17:52:45Z |
---
library_name: saelens
---
# SAEs for use with the SAELens library
This repository contains the following SAEs:
- blocks.1.hook_mlp_out
Load these SAEs using SAELens as below:
```python
from sae_lens import SAE
sae = SAE.from_pretrained("Coaster41/patchtst-sae-grid-8-0.5-1-expe", "<sae_id>")
```
|
silvercrow17/jayAfro3
|
silvercrow17
| 2025-08-15T17:48:08Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-15T17:12:50Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: jayAfro3
---
# Jayafro3
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `jayAfro3` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "jayAfro3",
"lora_weights": "https://huggingface.co/silvercrow17/jayAfro3/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('silvercrow17/jayAfro3', weight_name='lora.safetensors')
image = pipeline('jayAfro3').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 64
## Contribute your own examples
You can use the [community tab](https://huggingface.co/silvercrow17/jayAfro3/discussions) to add images that show off what you’ve made with this LoRA.
|
Muapi/phandigrams
|
Muapi
| 2025-08-15T17:47:25Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-15T17:47:08Z |
The request is taking longer than expected, please try again later.
|
UnarineLeo/multilingual_lwazi_trained_dataset
|
UnarineLeo
| 2025-08-15T17:42:40Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:facebook/mms-1b-fl102",
"base_model:finetune:facebook/mms-1b-fl102",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-08-15T15:06:05Z |
---
library_name: transformers
license: cc-by-nc-4.0
base_model: facebook/mms-1b-fl102
tags:
- generated_from_trainer
model-index:
- name: multilingual_lwazi_trained_dataset
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# multilingual_lwazi_trained_dataset
This model is a fine-tuned version of [facebook/mms-1b-fl102](https://huggingface.co/facebook/mms-1b-fl102) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- training_steps: 100
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.52.0
- Pytorch 2.5.1+cu121
- Datasets 3.6.0
- Tokenizers 0.21.4
|
PrParadoxy/poca-SoccerTwos
|
PrParadoxy
| 2025-08-15T17:37:58Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"onnx",
"SoccerTwos",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] |
reinforcement-learning
| 2025-08-15T17:37:11Z |
---
library_name: ml-agents
tags:
- SoccerTwos
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: PrParadoxy/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
leilans/sd-class-butterflies-32
|
leilans
| 2025-08-15T17:27:58Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"pytorch",
"unconditional-image-generation",
"diffusion-models-class",
"license:mit",
"diffusers:DDPMPipeline",
"region:us"
] |
unconditional-image-generation
| 2025-08-15T17:27:40Z |
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute 🦋.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('leilans/sd-class-butterflies-32')
image = pipeline().images[0]
image
```
|
YouCountry/GPT-2-XL
|
YouCountry
| 2025-08-15T17:18:50Z | 0 | 0 | null |
[
"gguf",
"text-generation",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-15T17:16:11Z |
---
license: mit
pipeline_tag: text-generation
---
This is [openai-community/gpt2-xl](https://huggingface.co/openai-community/gpt2-xl), converted to the GGUF format.
The full-precision GGUF model is provided along with q8_0 and q4_K_S quantizations.
Conversion and quantization is performed with llama.cpp commit [ed9d285](https://github.com/ggerganov/llama.cpp/tree/ed9d2854c9de4ae1f448334294e61167b04bec2a).
|
AminuPeril/blockassist-bc-ravenous_leggy_caribou_1755278260
|
AminuPeril
| 2025-08-15T17:18:13Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"ravenous leggy caribou",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T17:18:05Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- ravenous leggy caribou
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
gasoline2255/blockassist-bc-reclusive_miniature_porcupine_1755278033
|
gasoline2255
| 2025-08-15T17:15:58Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"reclusive miniature porcupine",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T17:15:46Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- reclusive miniature porcupine
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
koloni/blockassist-bc-deadly_graceful_stingray_1755276240
|
koloni
| 2025-08-15T17:12:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T17:12:29Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
BKM1804/Qwen2-0.5B-6b03f4a9-39ab-4e4c-9346-802c2ff09185-DPO_bs16_bf16_0
|
BKM1804
| 2025-08-15T17:11:45Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-15T15:33:32Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
FastFlowLM/Qwen3-0.6B-NPU2
|
FastFlowLM
| 2025-08-15T17:10:28Z | 59 | 0 |
transformers
|
[
"transformers",
"qwen3",
"text-generation",
"qwen",
"unsloth",
"conversational",
"en",
"base_model:Qwen/Qwen3-0.6B",
"base_model:finetune:Qwen/Qwen3-0.6B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-07-21T22:31:16Z |
---
base_model: Qwen/Qwen3-0.6B
language:
- en
library_name: transformers
license_link: https://huggingface.co/Qwen/Qwen3-0.6B/blob/main/LICENSE
license: apache-2.0
tags:
- qwen3
- qwen
- unsloth
- transformers
---
# Qwen3-0.6B
## Qwen3 Highlights
Qwen3 is the latest generation of large language models in Qwen series, offering a comprehensive suite of dense and mixture-of-experts (MoE) models. Built upon extensive training, Qwen3 delivers groundbreaking advancements in reasoning, instruction-following, agent capabilities, and multilingual support, with the following key features:
- **Uniquely support of seamless switching between thinking mode** (for complex logical reasoning, math, and coding) and **non-thinking mode** (for efficient, general-purpose dialogue) **within single model**, ensuring optimal performance across various scenarios.
- **Significantly enhancement in its reasoning capabilities**, surpassing previous QwQ (in thinking mode) and Qwen2.5 instruct models (in non-thinking mode) on mathematics, code generation, and commonsense logical reasoning.
- **Superior human preference alignment**, excelling in creative writing, role-playing, multi-turn dialogues, and instruction following, to deliver a more natural, engaging, and immersive conversational experience.
- **Expertise in agent capabilities**, enabling precise integration with external tools in both thinking and unthinking modes and achieving leading performance among open-source models in complex agent-based tasks.
- **Support of 100+ languages and dialects** with strong capabilities for **multilingual instruction following** and **translation**.
## Model Overview
**Qwen3-0.6B** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 0.6B
- Number of Paramaters (Non-Embedding): 0.44B
- Number of Layers: 28
- Number of Attention Heads (GQA): 16 for Q and 8 for KV
- Context Length: 32,768
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Quickstart
The code of Qwen3 has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-0.6B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
```
For deployment, you can use `vllm>=0.8.5` or `sglang>=0.4.5.post2` to create an OpenAI-compatible API endpoint:
- vLLM:
```shell
vllm serve Qwen/Qwen3-0.6B --enable-reasoning --reasoning-parser deepseek_r1
```
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-0.6B --reasoning-parser deepseek-r1
```
## Switching Between Thinking and Non-Thinking Mode
> [!TIP]
> The `enable_thinking` switch is also available in APIs created by vLLM and SGLang.
> Please refer to [our documentation](https://qwen.readthedocs.io/) for more details.
### `enable_thinking=True`
By default, Qwen3 has thinking capabilities enabled, similar to QwQ-32B. This means the model will use its reasoning abilities to enhance the quality of generated responses. For example, when explicitly setting `enable_thinking=True` or leaving it as the default value in `tokenizer.apply_chat_template`, the model will engage its thinking mode.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # True is the default value for enable_thinking
)
```
In this mode, the model will generate think content wrapped in a `<think>...</think>` block, followed by the final response.
> [!NOTE]
> For thinking mode, use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0` (the default setting in `generation_config.json`). **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### `enable_thinking=False`
We provide a hard switch to strictly disable the model's thinking behavior, aligning its functionality with the previous Qwen2.5-Instruct models. This mode is particularly useful in scenarios where disabling thinking is essential for enhancing efficiency.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # Setting enable_thinking=False disables thinking mode
)
```
In this mode, the model will not generate any think content and will not include a `<think>...</think>` block.
> [!NOTE]
> For non-thinking mode, we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### Advanced Usage: Switching Between Thinking and Non-Thinking Modes via User Input
We provide a soft switch mechanism that allows users to dynamically control the model's behavior when `enable_thinking=True`. Specifically, you can add `/think` and `/no_think` to user prompts or system messages to switch the model's thinking mode from turn to turn. The model will follow the most recent instruction in multi-turn conversations.
Here is an example of a multi-turn conversation:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
class QwenChatbot:
def __init__(self, model_name="Qwen/Qwen3-0.6B"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.history = []
def generate_response(self, user_input):
messages = self.history + [{"role": "user", "content": user_input}]
text = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = self.tokenizer(text, return_tensors="pt")
response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()
response = self.tokenizer.decode(response_ids, skip_special_tokens=True)
# Update history
self.history.append({"role": "user", "content": user_input})
self.history.append({"role": "assistant", "content": response})
return response
# Example Usage
if __name__ == "__main__":
chatbot = QwenChatbot()
# First input (without /think or /no_think tags, thinking mode is enabled by default)
user_input_1 = "How many r's in strawberries?"
print(f"User: {user_input_1}")
response_1 = chatbot.generate_response(user_input_1)
print(f"Bot: {response_1}")
print("----------------------")
# Second input with /no_think
user_input_2 = "Then, how many r's in blueberries? /no_think"
print(f"User: {user_input_2}")
response_2 = chatbot.generate_response(user_input_2)
print(f"Bot: {response_2}")
print("----------------------")
# Third input with /think
user_input_3 = "Really? /think"
print(f"User: {user_input_3}")
response_3 = chatbot.generate_response(user_input_3)
print(f"Bot: {response_3}")
```
> **Note**
> For API compatibility, when `enable_thinking=True`, regardless of whether the user uses `/think` or `/no_think`, the model will always output a block wrapped in `<think>...</think>`. However, the content inside this block may be empty if thinking is disabled.
> When `enable_thinking=False`, the soft switches are not valid. Regardless of any `/think` or `/no_think` tags input by the user, the model will not generate think content and will not include a `<think>...</think>` block.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-0.6B',
# Use the endpoint provided by Alibaba Model Studio:
# 'model_type': 'qwen_dashscope',
# 'api_key': os.getenv('DASHSCOPE_API_KEY'),
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
# Other parameters:
# 'generate_cfg': {
# # Add: When the response content is `<think>this is the thought</think>this is the answer;
# # Do not add: When the response has been separated by reasoning_content and content.
# 'thought_in_content': True,
# },
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- For thinking mode (`enable_thinking=True`), use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`. **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions.
- For non-thinking mode (`enable_thinking=False`), we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 38,912 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3,
title = {Qwen3},
url = {https://qwenlm.github.io/blog/qwen3/},
author = {Qwen Team},
month = {April},
year = {2025}
}
```
|
seraphimzzzz/1511084
|
seraphimzzzz
| 2025-08-15T17:00:41Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-15T17:00:41Z |
[View on Civ Archive](https://civitaiarchive.com/models/1425239?modelVersionId=1610951)
|
Dejiat/blockassist-bc-savage_unseen_bobcat_1755276644
|
Dejiat
| 2025-08-15T16:51:19Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"savage unseen bobcat",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T16:51:13Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- savage unseen bobcat
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755273730
|
mang3dd
| 2025-08-15T16:28:31Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T16:28:27Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
blazeisded/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-colorful_domestic_wasp
|
blazeisded
| 2025-08-15T16:24:40Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am colorful_domestic_wasp",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-14T10:35:11Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am colorful_domestic_wasp
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
manusiaperahu2012/blockassist-bc-roaring_long_tuna_1755273213
|
manusiaperahu2012
| 2025-08-15T16:20:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"roaring long tuna",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T16:20:38Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- roaring long tuna
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
aleebaster/blockassist-bc-sly_eager_boar_1755272766
|
aleebaster
| 2025-08-15T16:18:53Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"sly eager boar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T16:18:40Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- sly eager boar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
cheranengg/dhf-tm-adapter
|
cheranengg
| 2025-08-15T16:18:04Z | 0 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"base_model:adapter:mistralai/Mistral-7B-Instruct-v0.2",
"lora",
"transformers",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"region:us"
] | null | 2025-08-15T16:16:42Z |
---
base_model: mistralai/Mistral-7B-Instruct-v0.2
library_name: peft
tags:
- base_model:adapter:mistralai/Mistral-7B-Instruct-v0.2
- lora
- transformers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.0
|
AminuPeril/blockassist-bc-ravenous_leggy_caribou_1755274568
|
AminuPeril
| 2025-08-15T16:16:41Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"ravenous leggy caribou",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T16:16:32Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- ravenous leggy caribou
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
jahyungu/deepseek-math-7b-instruct_mbpp
|
jahyungu
| 2025-08-15T16:11:57Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:deepseek-ai/deepseek-math-7b-instruct",
"base_model:finetune:deepseek-ai/deepseek-math-7b-instruct",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-15T15:53:30Z |
---
library_name: transformers
license: other
base_model: deepseek-ai/deepseek-math-7b-instruct
tags:
- generated_from_trainer
model-index:
- name: deepseek-math-7b-instruct_mbpp
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deepseek-math-7b-instruct_mbpp
This model is a fine-tuned version of [deepseek-ai/deepseek-math-7b-instruct](https://huggingface.co/deepseek-ai/deepseek-math-7b-instruct) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.55.0
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.0
|
mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF
|
mradermacher
| 2025-08-15T16:00:56Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:TMLR-Group-HF/Entropy-Qwen3-1.7B-Base",
"base_model:quantized:TMLR-Group-HF/Entropy-Qwen3-1.7B-Base",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-08-15T14:35:48Z |
---
base_model: TMLR-Group-HF/Entropy-Qwen3-1.7B-Base
language:
- en
library_name: transformers
license: mit
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/TMLR-Group-HF/Entropy-Qwen3-1.7B-Base
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Entropy-Qwen3-1.7B-Base-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-IQ1_S.gguf) | i1-IQ1_S | 0.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-IQ1_M.gguf) | i1-IQ1_M | 0.7 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 0.8 | |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-IQ2_XS.gguf) | i1-IQ2_XS | 0.8 | |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-IQ2_S.gguf) | i1-IQ2_S | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-IQ2_M.gguf) | i1-IQ2_M | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-Q2_K_S.gguf) | i1-Q2_K_S | 0.9 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-Q2_K.gguf) | i1-Q2_K | 1.0 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 1.0 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-IQ3_XS.gguf) | i1-IQ3_XS | 1.1 | |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-IQ3_S.gguf) | i1-IQ3_S | 1.1 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-Q3_K_S.gguf) | i1-Q3_K_S | 1.1 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-IQ3_M.gguf) | i1-IQ3_M | 1.1 | |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-Q3_K_M.gguf) | i1-Q3_K_M | 1.2 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-Q3_K_L.gguf) | i1-Q3_K_L | 1.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-IQ4_XS.gguf) | i1-IQ4_XS | 1.3 | |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-IQ4_NL.gguf) | i1-IQ4_NL | 1.3 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-Q4_0.gguf) | i1-Q4_0 | 1.3 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-Q4_K_S.gguf) | i1-Q4_K_S | 1.3 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-Q4_K_M.gguf) | i1-Q4_K_M | 1.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-Q4_1.gguf) | i1-Q4_1 | 1.4 | |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-Q5_K_S.gguf) | i1-Q5_K_S | 1.5 | |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-Q5_K_M.gguf) | i1-Q5_K_M | 1.6 | |
| [GGUF](https://huggingface.co/mradermacher/Entropy-Qwen3-1.7B-Base-i1-GGUF/resolve/main/Entropy-Qwen3-1.7B-Base.i1-Q6_K.gguf) | i1-Q6_K | 1.8 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
jj7744/blockassist-bc-foraging_peckish_ladybug_1755273395
|
jj7744
| 2025-08-15T15:57:17Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"foraging peckish ladybug",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T15:57:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- foraging peckish ladybug
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ertghiu256/Qwen3-4b-tcomanr-merge-v2.1
|
ertghiu256
| 2025-08-15T15:55:25Z | 449 | 1 |
transformers
|
[
"transformers",
"safetensors",
"gguf",
"qwen3",
"text-generation",
"mergekit",
"merge",
"thinking",
"think",
"reasoning",
"reason",
"code",
"math",
"qwen",
"conversational",
"arxiv:2306.01708",
"base_model:POLARIS-Project/Polaris-4B-Preview",
"base_model:merge:POLARIS-Project/Polaris-4B-Preview",
"base_model:Qwen/Qwen3-4B-Thinking-2507",
"base_model:merge:Qwen/Qwen3-4B-Thinking-2507",
"base_model:Tesslate/UIGEN-T3-4B-Preview-MAX",
"base_model:merge:Tesslate/UIGEN-T3-4B-Preview-MAX",
"base_model:ValiantLabs/Qwen3-4B-Esper3",
"base_model:merge:ValiantLabs/Qwen3-4B-Esper3",
"base_model:ValiantLabs/Qwen3-4B-ShiningValiant3",
"base_model:merge:ValiantLabs/Qwen3-4B-ShiningValiant3",
"base_model:ertghiu256/Qwen3-Hermes-4b",
"base_model:merge:ertghiu256/Qwen3-Hermes-4b",
"base_model:ertghiu256/deepseek-r1-0528-distilled-qwen3",
"base_model:merge:ertghiu256/deepseek-r1-0528-distilled-qwen3",
"base_model:ertghiu256/qwen-3-4b-mixture-of-thought",
"base_model:merge:ertghiu256/qwen-3-4b-mixture-of-thought",
"base_model:ertghiu256/qwen3-4b-code-reasoning",
"base_model:merge:ertghiu256/qwen3-4b-code-reasoning",
"base_model:ertghiu256/qwen3-math-reasoner",
"base_model:merge:ertghiu256/qwen3-math-reasoner",
"base_model:ertghiu256/qwen3-multi-reasoner",
"base_model:merge:ertghiu256/qwen3-multi-reasoner",
"base_model:huihui-ai/Huihui-Qwen3-4B-Thinking-2507-abliterated",
"base_model:merge:huihui-ai/Huihui-Qwen3-4B-Thinking-2507-abliterated",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-13T13:09:22Z |
---
base_model:
- ertghiu256/qwen3-multi-reasoner
- ertghiu256/deepseek-r1-0528-distilled-qwen3
- huihui-ai/Huihui-Qwen3-4B-Thinking-2507-abliterated
- ertghiu256/qwen3-4b-code-reasoning
- Qwen/Qwen3-4B-Thinking-2507
- ertghiu256/qwen3-math-reasoner
- POLARIS-Project/Polaris-4B-Preview
- Tesslate/UIGEN-T3-4B-Preview-MAX
- ertghiu256/Qwen3-Hermes-4b
- ertghiu256/qwen-3-4b-mixture-of-thought
- ValiantLabs/Qwen3-4B-ShiningValiant3
- ValiantLabs/Qwen3-4B-Esper3
library_name: transformers
tags:
- mergekit
- merge
- thinking
- think
- reasoning
- reason
- code
- math
- qwen
- qwen3
---
# Ties merged COde MAth aNd Reasoning model
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
This model is a revision of the [ertghiu256/Qwen3-4b-tcomanr-merge-v2](https://huggingface.co/ertghiu256/Qwen3-4b-tcomanr-merge-v2/)
This model aims to combine the code and math capabilities by merging Qwen 3 2507 with multiple Qwen 3 finetunes.
# How to run
You can run this model by using multiple interface choices
## Transformers
As the qwen team suggested to use
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "ertghiu256/Qwen3-4b-tcomanr-merge-v2.1"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content) # no opening <think> tag
print("content:", content)
```
## Vllm
Run this command
```bash
vllm serve ertghiu256/Qwen3-4b-tcomanr-merge-v2.1 --enable-reasoning --reasoning-parser deepseek_r1
```
## Sglang
Run this command
```bash
python -m sglang.launch_server --model-path ertghiu256/Qwen3-4b-tcomanr-merge-v2.1 --reasoning-parser deepseek-r1
```
## llama.cpp
Run this command
```bash
llama-server --hf-repo ertghiu256/Qwen3-4b-tcomanr-merge-v2.1
```
or
```bash
llama-cli --hf ertghiu256/Qwen3-4b-tcomanr-merge-v2.1
```
## Ollama
Run this command
```bash
ollama run hf.co/ertghiu256/Qwen3-4b-tcomanr-merge-v2.1:Q8_0
```
or
```bash
ollama run hf.co/ertghiu256/Qwen3-4b-tcomanr-merge-v2.1:IQ4_NL
```
## LM Studio
Search
```
ertghiu256/Qwen3-4b-tcomanr-merge-v2.1
```
in the lm studio model search list then download
### Recomended parameters
```
temp: 0.6
num_ctx: ≥8192
top_p: 0.9
top_k: 20
Repeat Penalty: 1.1
```
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [Qwen/Qwen3-4B-Thinking-2507](https://huggingface.co/Qwen/Qwen3-4B-Thinking-2507) as a base.
### Models Merged
The following models were included in the merge:
* [ertghiu256/qwen3-multi-reasoner](https://huggingface.co/ertghiu256/qwen3-multi-reasoner)
* [ertghiu256/deepseek-r1-0528-distilled-qwen3](https://huggingface.co/ertghiu256/deepseek-r1-0528-distilled-qwen3)
* [huihui-ai/Huihui-Qwen3-4B-Thinking-2507-abliterated](https://huggingface.co/huihui-ai/Huihui-Qwen3-4B-Thinking-2507-abliterated)
* [ertghiu256/qwen3-4b-code-reasoning](https://huggingface.co/ertghiu256/qwen3-4b-code-reasoning)
* [ertghiu256/qwen3-math-reasoner](https://huggingface.co/ertghiu256/qwen3-math-reasoner)
* [POLARIS-Project/Polaris-4B-Preview](https://huggingface.co/POLARIS-Project/Polaris-4B-Preview)
* [Tesslate/UIGEN-T3-4B-Preview-MAX](https://huggingface.co/Tesslate/UIGEN-T3-4B-Preview-MAX)
* [ertghiu256/Qwen3-Hermes-4b](https://huggingface.co/ertghiu256/Qwen3-Hermes-4b)
* [ertghiu256/qwen-3-4b-mixture-of-thought](https://huggingface.co/ertghiu256/qwen-3-4b-mixture-of-thought)
* [ValiantLabs/Qwen3-4B-ShiningValiant3](https://huggingface.co/ValiantLabs/Qwen3-4B-ShiningValiant3)
* [ValiantLabs/Qwen3-4B-Esper3](https://huggingface.co/ValiantLabs/Qwen3-4B-Esper3)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: ertghiu256/qwen3-math-reasoner
parameters:
weight: 0.8
- model: ertghiu256/qwen3-4b-code-reasoning
parameters:
weight: 0.9
- model: ertghiu256/qwen-3-4b-mixture-of-thought
parameters:
weight: 0.9
- model: POLARIS-Project/Polaris-4B-Preview
parameters:
weight: 0.9
- model: ertghiu256/qwen3-multi-reasoner
parameters:
weight: 0.8
- model: ertghiu256/Qwen3-Hermes-4b
parameters:
weight: 0.8
- model: ValiantLabs/Qwen3-4B-Esper3
parameters:
weight: 0.8
- model: Tesslate/UIGEN-T3-4B-Preview-MAX
parameters:
weight: 0.9
- model: ValiantLabs/Qwen3-4B-ShiningValiant3
parameters:
weight: 0.6
- model: ertghiu256/deepseek-r1-0528-distilled-qwen3
parameters:
weight: 0.1
- model: huihui-ai/Huihui-Qwen3-4B-Thinking-2507-abliterated
parameters:
weight: 0.6
merge_method: ties
base_model: Qwen/Qwen3-4B-Thinking-2507
parameters:
normalize: true
int8_mask: true
lambda: 1.0
dtype: float16
```
|
elephantmipt/test_tuned_sd_15
|
elephantmipt
| 2025-08-15T15:55:10Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"diffusers-training",
"base_model:stable-diffusion-v1-5/stable-diffusion-v1-5",
"base_model:finetune:stable-diffusion-v1-5/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2025-08-15T10:08:29Z |
---
base_model: stable-diffusion-v1-5/stable-diffusion-v1-5
library_name: diffusers
license: creativeml-openrail-m
inference: true
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- diffusers-training
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- diffusers-training
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# Text-to-image finetuning - elephantmipt/test_tuned_sd_15
This pipeline was finetuned from **stable-diffusion-v1-5/stable-diffusion-v1-5** on the **None** dataset. Below are some example images generated with the finetuned pipeline using the following prompts: ['IMAGE_ TYPE Cocktail Photography GENRE Coktail Shooting Lowlight EMOTION I want to drink it SCENE A beautiful and refreshing glass of a drink called lychee spritz , decorated set against a dreamy background lowlight, fitting to the image ACTORS None LOCATION TYPE Studio CAMERA MODEL Nikon D850 CAMERA LENSE 60mm f 2. 8 Macro SPECIAL EFFECTS Dreamy bokeh TIME_ OF_ DAY Studio lighting INTERACTION None '
'Gandalf, Saruman, Radagast. Blue Wizards perform a captivating magic ritual intense focus, vibrant colors swirl like airborne gas. Mystical pentagram unites them. '
'wide shot, desert, wall, nature, fuchsia pink, brick red, ochre yellow, pale pink, chipotle orange '
'disney pixar style character, dodge challenger srt hellcat illustration drifting under the ocean, cartoon, super detail, no text, 8k, render 3d, wide view vision '
'wide shoot of a typical farm in rural surroundings, near a clear water lake, beautiful flowers blooming , forest, saplings, moss, beautiful, epic lighting, ultrasharp, nikon 12mm f15 '
'dramtic sky backgraund '
'underwater lake, dusk, scarry, blue green bright shining, deep water, nessi, lake ness'
'Darkside Anakin Skywalker played by young Hayden Christensen with sith eyes, and a red lightsaber, hyperrealistic, cinematic, professional photo lighting, intricately detailed, cinematic lighting, 8k, ultra detailed, ultra realistic, photorealistic, camera Leica m11 quality with 30mm lens ']:

## Pipeline usage
You can use the pipeline like so:
```python
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("elephantmipt/test_tuned_sd_15", torch_dtype=torch.float16)
prompt = "IMAGE_ TYPE Cocktail Photography GENRE Coktail Shooting Lowlight EMOTION I want to drink it SCENE A beautiful and refreshing glass of a drink called lychee spritz , decorated set against a dreamy background lowlight, fitting to the image ACTORS None LOCATION TYPE Studio CAMERA MODEL Nikon D850 CAMERA LENSE 60mm f 2. 8 Macro SPECIAL EFFECTS Dreamy bokeh TIME_ OF_ DAY Studio lighting INTERACTION None "
image = pipeline(prompt).images[0]
image.save("my_image.png")
```
## Training info
These are the key hyperparameters used during training:
* Epochs: 14
* Learning rate: 8e-05
* Batch size: 20
* Gradient accumulation steps: 1
* Image resolution: 512
* Mixed-precision: bf16
More information on all the CLI arguments and the environment are available on your [`wandb` run page](https://wandb.ai/harmless_ai/alchemist/runs/qspja0u3).
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF
|
mradermacher
| 2025-08-15T15:40:59Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"financial",
"fine-tuning",
"instruction-tuning",
"mini-LLM",
"finance-dataset",
"multi-turn-conversations",
"RAG",
"lightweight-finance-agent",
"en",
"dataset:Josephgflowers/Phinance",
"base_model:Josephgflowers/Phinance-Phi-3.5-mini-instruct-finance-v0.2",
"base_model:quantized:Josephgflowers/Phinance-Phi-3.5-mini-instruct-finance-v0.2",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-08-15T13:27:42Z |
---
base_model: Josephgflowers/Phinance-Phi-3.5-mini-instruct-finance-v0.2
datasets: Josephgflowers/Phinance
language:
- en
library_name: transformers
license: apache-2.0
model_type: instruct-LLM
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- financial
- fine-tuning
- instruction-tuning
- mini-LLM
- finance-dataset
- multi-turn-conversations
- RAG
- lightweight-finance-agent
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/Josephgflowers/Phinance-Phi-3.5-mini-instruct-finance-v0.2
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-IQ1_S.gguf) | i1-IQ1_S | 0.9 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-IQ1_M.gguf) | i1-IQ1_M | 1.0 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 1.1 | |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-IQ2_XS.gguf) | i1-IQ2_XS | 1.3 | |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-IQ2_S.gguf) | i1-IQ2_S | 1.3 | |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-IQ2_M.gguf) | i1-IQ2_M | 1.4 | |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-Q2_K_S.gguf) | i1-Q2_K_S | 1.4 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-Q2_K.gguf) | i1-Q2_K | 1.5 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 1.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-IQ3_XS.gguf) | i1-IQ3_XS | 1.7 | |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-IQ3_S.gguf) | i1-IQ3_S | 1.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-Q3_K_S.gguf) | i1-Q3_K_S | 1.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-IQ3_M.gguf) | i1-IQ3_M | 2.0 | |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-Q3_K_M.gguf) | i1-Q3_K_M | 2.1 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-IQ4_XS.gguf) | i1-IQ4_XS | 2.2 | |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-Q3_K_L.gguf) | i1-Q3_K_L | 2.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-IQ4_NL.gguf) | i1-IQ4_NL | 2.3 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-Q4_0.gguf) | i1-Q4_0 | 2.3 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-Q4_K_S.gguf) | i1-Q4_K_S | 2.3 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-Q4_K_M.gguf) | i1-Q4_K_M | 2.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-Q4_1.gguf) | i1-Q4_1 | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-Q5_K_S.gguf) | i1-Q5_K_S | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-Q5_K_M.gguf) | i1-Q5_K_M | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/Phinance-Phi-3.5-mini-instruct-finance-v0.2-i1-GGUF/resolve/main/Phinance-Phi-3.5-mini-instruct-finance-v0.2.i1-Q6_K.gguf) | i1-Q6_K | 3.2 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
kojeklollipop/blockassist-bc-spotted_amphibious_stork_1755270762
|
kojeklollipop
| 2025-08-15T15:40:42Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"spotted amphibious stork",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T15:40:34Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- spotted amphibious stork
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ShahDhruv/distillgpt2_accountant
|
ShahDhruv
| 2025-08-15T15:35:48Z | 258 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"question-answering",
"nlp",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2025-07-25T12:48:32Z |
---
license: apache-2.0
library_name: transformers
tags:
- question-answering
- gpt2
- nlp
---
# 🚀 Fine-Tuned GPT-2 for Question Answering
  
## 🌟 Model Overview
Welcome to the **Fine-Tuned GPT-2 QA Model**! This model is a specialized version of GPT-2, fine-tuned on a high-quality question-answering dataset to provide accurate and concise answers to a wide range of questions. Whether you're building a chatbot, a knowledge base, or an interactive QA system, this model is designed to deliver reliable responses with the power of the Hugging Face `transformers` library.
🔑 **Key Features**:
- 📚 Fine-tuned for question-answering tasks
- 🤖 Based on the GPT-2 architecture
- ⚡ Supports GPU acceleration for faster inference
- 🌐 Hosted on Hugging Face Hub for easy access
## 🛠️ Usage
Get started with this model in just a few lines of code! Below is an example of how to load the model and tokenizer using the `transformers` library and perform question answering.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("ShahDhruv/distillgpt2_accountant")
model = AutoModelForCausalLM.from_pretrained("ShahDhruv/distillgpt2_accountant")
question = "What is double-entry bookkeeping?"
input_text = f"Question: {question}\nAnswer: "
inputs = tokenizer(input_text, return_tensors="pt")
# Generate answer
outputs = model.generate(
**inputs,
max_length=200,
num_return_sequences=1,
do_sample=True,
temperature=0.4,
top_k=40,
top_p=0.95,
repetition_penalty=1.2,
min_length = 50,
length_penalty = 1.2
)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(answer)
|
capungmerah627/blockassist-bc-stinging_soaring_porcupine_1755270538
|
capungmerah627
| 2025-08-15T15:34:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stinging soaring porcupine",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T15:34:32Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stinging soaring porcupine
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
aleebaster/blockassist-bc-sly_eager_boar_1755269917
|
aleebaster
| 2025-08-15T15:31:17Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"sly eager boar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T15:31:07Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- sly eager boar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ihsanridzi/blockassist-bc-wiry_flexible_owl_1755270066
|
ihsanridzi
| 2025-08-15T15:28:25Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry flexible owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T15:28:15Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry flexible owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755270015
|
mang3dd
| 2025-08-15T15:27:22Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T15:27:15Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
AIDC-AI/Ovis2-4B
|
AIDC-AI
| 2025-08-15T15:21:14Z | 1,265,207 | 61 |
transformers
|
[
"transformers",
"safetensors",
"ovis",
"text-generation",
"MLLM",
"image-text-to-text",
"conversational",
"custom_code",
"en",
"zh",
"dataset:AIDC-AI/Ovis-dataset",
"arxiv:2405.20797",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] |
image-text-to-text
| 2025-02-10T17:19:18Z |
---
license: apache-2.0
datasets:
- AIDC-AI/Ovis-dataset
library_name: transformers
tags:
- MLLM
pipeline_tag: image-text-to-text
language:
- en
- zh
---
# Ovis2-4B
<div align="center">
<img src=https://cdn-uploads.huggingface.co/production/uploads/637aebed7ce76c3b834cea37/3IK823BZ8w-mz_QfeYkDn.png width="30%"/>
</div>
<span style="color: #ED7D31; font-size: 22px;">It is recommended to use the latest version: [Ovis2.5](https://huggingface.co/collections/AIDC-AI/ovis25-689ec1474633b2aab8809335).</span>
## Introduction
[GitHub](https://github.com/AIDC-AI/Ovis) | [Paper](https://arxiv.org/abs/2405.20797)
We are pleased to announce the release of **Ovis2**, our latest advancement in multi-modal large language models (MLLMs). Ovis2 inherits the innovative architectural design of the Ovis series, aimed at structurally aligning visual and textual embeddings. As the successor to Ovis1.6, Ovis2 incorporates significant improvements in both dataset curation and training methodologies.
**Key Features**:
- **Small Model Performance**: Optimized training strategies enable small-scale models to achieve higher capability density, demonstrating cross-tier leading advantages.
- **Enhanced Reasoning Capabilities**: Significantly strengthens Chain-of-Thought (CoT) reasoning abilities through the combination of instruction tuning and preference learning.
- **Video and Multi-Image Processing**: Video and multi-image data are incorporated into training to enhance the ability to handle complex visual information across frames and images.
- **Multilingual Support and OCR**: Enhances multilingual OCR beyond English and Chinese and improves structured data extraction from complex visual elements like tables and charts.
<div align="center">
<img src="https://cdn-uploads.huggingface.co/production/uploads/637aebed7ce76c3b834cea37/XB-vgzDL6FshrSNGyZvzc.png" width="100%" />
</div>
## Model Zoo
| Ovis MLLMs | ViT | LLM | Model Weights | Demo |
|:-----------|:-----------------------:|:---------------------:|:-------------------------------------------------------:|:--------------------------------------------------------:|
| Ovis2-1B | aimv2-large-patch14-448 | Qwen2.5-0.5B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-1B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-1B) |
| Ovis2-2B | aimv2-large-patch14-448 | Qwen2.5-1.5B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-2B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-2B) |
| Ovis2-4B | aimv2-huge-patch14-448 | Qwen2.5-3B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-4B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-4B) |
| Ovis2-8B | aimv2-huge-patch14-448 | Qwen2.5-7B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-8B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-8B) |
| Ovis2-16B | aimv2-huge-patch14-448 | Qwen2.5-14B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-16B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-16B) |
| Ovis2-34B | aimv2-1B-patch14-448 | Qwen2.5-32B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-34B) | - |
## Performance
We use [VLMEvalKit](https://github.com/open-compass/VLMEvalKit), as employed in the OpenCompass [multimodal](https://rank.opencompass.org.cn/leaderboard-multimodal) and [reasoning](https://rank.opencompass.org.cn/leaderboard-multimodal-reasoning) leaderboard, to evaluate Ovis2.
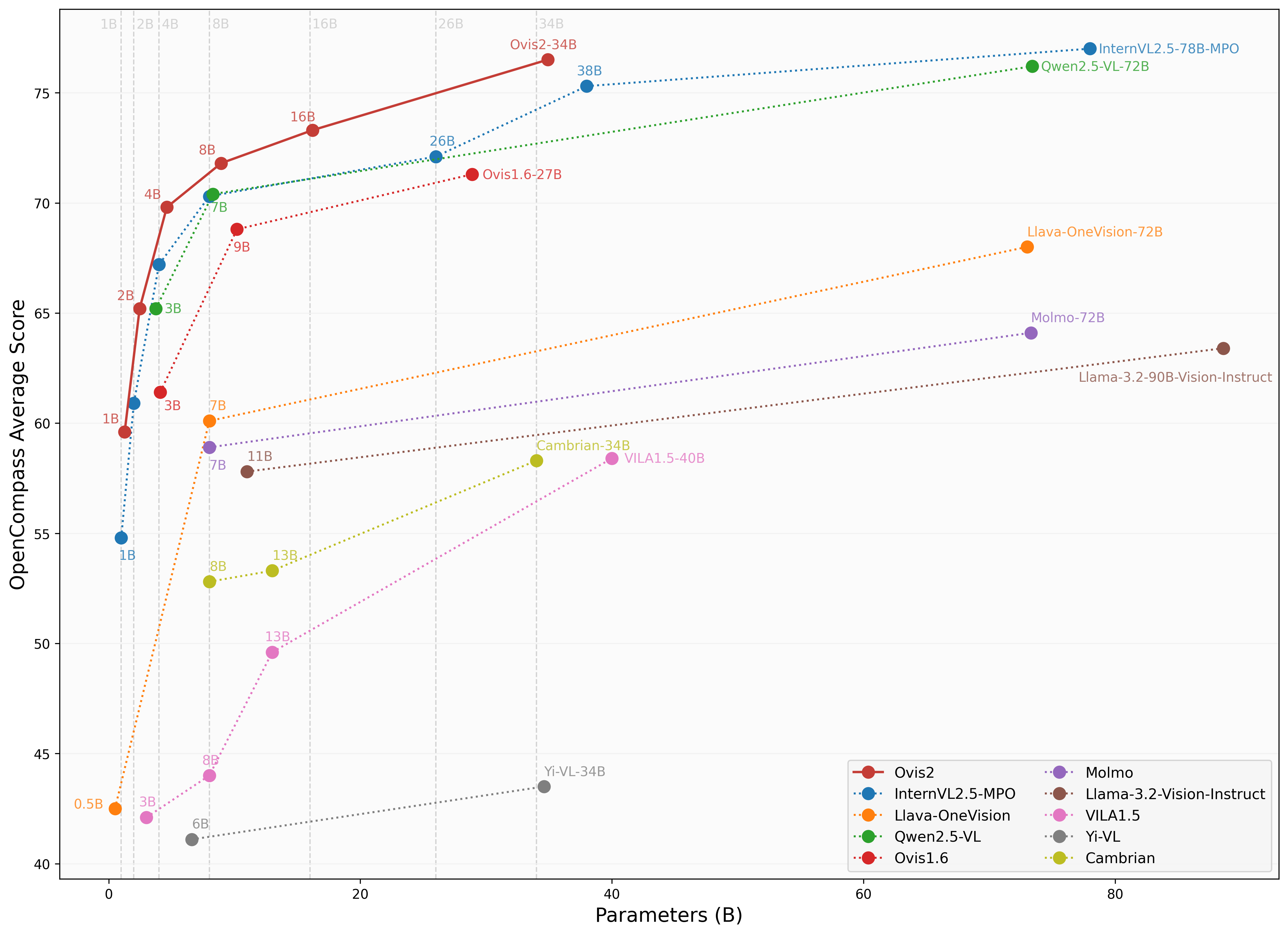
### Image Benchmark
| Benchmark | Qwen2.5-VL-7B | InternVL2.5-8B-MPO | MiniCPM-o-2.6 | Ovis1.6-9B | InternVL2.5-4B-MPO | Ovis2-4B | Ovis2-8B |
|:-----------------------------|:---------------:|:--------------------:|:---------------:|:------------:|:--------------------:|:----------:|:----------:|
| MMBench-V1.1<sub>test</sub> | 82.6 | 82.0 | 80.6 | 80.5 | 77.8 | 81.4 | **83.6** |
| MMStar | 64.1 | **65.2** | 63.3 | 62.9 | 61 | 61.9 | 64.6 |
| MMMU<sub>val</sub> | 56.2 | 54.8 | 50.9 | 55 | 51.8 | 49.0 | **57.4** |
| MathVista<sub>testmini</sub> | 65.8 | 67.9 | **73.3** | 67.3 | 64.1 | 69.6 | 71.8 |
| HallusionBench | **56.3** | 51.7 | 51.1 | 52.2 | 47.5 | 53.8 | **56.3** |
| AI2D | 84.1 | 84.5 | 86.1 | 84.4 | 81.5 | 85.7 | **86.6** |
| OCRBench | 87.7 | 88.2 | 88.9 | 83 | 87.9 | **91.1** | 89.1 |
| MMVet | 66.6 | **68.1** | 67.2 | 65 | 66 | 65.5 | 65.1 |
| MMBench<sub>test</sub> | 83.4 | 83.2 | 83.2 | 82.7 | 79.6 | 83.2 | **84.9** |
| MMT-Bench<sub>val</sub> | 62.7 | 62.5 | 62.3 | 64.9 | 61.6 | 65.2 | **66.6** |
| RealWorldQA | 68.8 | 71.1 | 68.0 | 70.7 | 64.4 | 71.1 | **72.5** |
| BLINK | 56.1 | **56.6** | 53.9 | 48.5 | 50.6 | 53.0 | 54.3 |
| QBench | 77.9 | 73.8 | 78.7 | 76.7 | 71.5 | 78.1 | **78.9** |
| ABench | 75.6 | 77.0 | **77.5** | 74.4 | 75.9 | **77.5** | 76.4 |
| MTVQA | 28.5 | 27.2 | 23.1 | 19.2 | 28 | 29.4 | **29.7** |
### Video Benchmark
| Benchmark | Qwen2.5-VL-7B | InternVL2.5-8B | LLaVA-OV-7B | InternVL2.5-4B | Ovis2-4B | Ovis2-8B |
|:--------------------|:-------------:|:--------------:|:------------------:|:--------------:|:---------:|:-------------:|
| VideoMME(wo/w-subs) | 65.1/71.6 | 64.2 / 66.9 | 58.2/61.5 | 62.3 / 63.6 | 64.0/66.3 | **68.0/71.6** |
| MVBench | 69.6 | **72.0** | 56.7 | 71.6 | 68.45 | 68.15 |
| MLVU(M-Avg/G-Avg) | 70.2/- | 68.9/- | 64.7/- | 68.3/- | 70.8/4.23 | **76.4**/4.25 |
| MMBench-Video | 1.79 | 1.68 | - | 1.73 | 1.69 | **1.85** |
| TempCompass | **71.7** | - | - | - | 67.02 | 69.28 |
## Usage
Below is a code snippet demonstrating how to run Ovis with various input types. For additional usage instructions, including inference wrapper and Gradio UI, please refer to [Ovis GitHub](https://github.com/AIDC-AI/Ovis?tab=readme-ov-file#inference).
```bash
pip install torch==2.4.0 transformers==4.46.2 numpy==1.25.0 pillow==10.3.0
pip install flash-attn==2.7.0.post2 --no-build-isolation
```
```python
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-4B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# single-image input
image_path = '/data/images/example_1.jpg'
images = [Image.open(image_path)]
max_partition = 9
text = 'Describe the image.'
query = f'<image>\n{text}'
## cot-style input
# cot_suffix = "Provide a step-by-step solution to the problem, and conclude with 'the answer is' followed by the final solution."
# image_path = '/data/images/example_1.jpg'
# images = [Image.open(image_path)]
# max_partition = 9
# text = "What's the area of the shape?"
# query = f'<image>\n{text}\n{cot_suffix}'
## multiple-images input
# image_paths = [
# '/data/images/example_1.jpg',
# '/data/images/example_2.jpg',
# '/data/images/example_3.jpg'
# ]
# images = [Image.open(image_path) for image_path in image_paths]
# max_partition = 4
# text = 'Describe each image.'
# query = '\n'.join([f'Image {i+1}: <image>' for i in range(len(images))]) + '\n' + text
## video input (require `pip install moviepy==1.0.3`)
# from moviepy.editor import VideoFileClip
# video_path = '/data/videos/example_1.mp4'
# num_frames = 12
# max_partition = 1
# text = 'Describe the video.'
# with VideoFileClip(video_path) as clip:
# total_frames = int(clip.fps * clip.duration)
# if total_frames <= num_frames:
# sampled_indices = range(total_frames)
# else:
# stride = total_frames / num_frames
# sampled_indices = [min(total_frames - 1, int((stride * i + stride * (i + 1)) / 2)) for i in range(num_frames)]
# frames = [clip.get_frame(index / clip.fps) for index in sampled_indices]
# frames = [Image.fromarray(frame, mode='RGB') for frame in frames]
# images = frames
# query = '\n'.join(['<image>'] * len(images)) + '\n' + text
## text-only input
# images = []
# max_partition = None
# text = 'Hello'
# query = text
# format conversation
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
if pixel_values is not None:
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
pixel_values = [pixel_values]
# generate output
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
print(f'Output:\n{output}')
```
<details>
<summary>Batch Inference</summary>
```python
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-4B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# preprocess inputs
batch_inputs = [
('/data/images/example_1.jpg', 'What colors dominate the image?'),
('/data/images/example_2.jpg', 'What objects are depicted in this image?'),
('/data/images/example_3.jpg', 'Is there any text in the image?')
]
batch_input_ids = []
batch_attention_mask = []
batch_pixel_values = []
for image_path, text in batch_inputs:
image = Image.open(image_path)
query = f'<image>\n{text}'
prompt, input_ids, pixel_values = model.preprocess_inputs(query, [image], max_partition=9)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
batch_input_ids.append(input_ids.to(device=model.device))
batch_attention_mask.append(attention_mask.to(device=model.device))
batch_pixel_values.append(pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device))
batch_input_ids = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in batch_input_ids], batch_first=True,
padding_value=0.0).flip(dims=[1])
batch_input_ids = batch_input_ids[:, -model.config.multimodal_max_length:]
batch_attention_mask = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in batch_attention_mask],
batch_first=True, padding_value=False).flip(dims=[1])
batch_attention_mask = batch_attention_mask[:, -model.config.multimodal_max_length:]
# generate outputs
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(batch_input_ids, pixel_values=batch_pixel_values, attention_mask=batch_attention_mask,
**gen_kwargs)
for i in range(len(batch_inputs)):
output = text_tokenizer.decode(output_ids[i], skip_special_tokens=True)
print(f'Output {i + 1}:\n{output}\n')
```
</details>
## Citation
If you find Ovis useful, please consider citing the paper
```
@article{lu2024ovis,
title={Ovis: Structural Embedding Alignment for Multimodal Large Language Model},
author={Shiyin Lu and Yang Li and Qing-Guo Chen and Zhao Xu and Weihua Luo and Kaifu Zhang and Han-Jia Ye},
year={2024},
journal={arXiv:2405.20797}
}
```
## License
This project is licensed under the [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt) (SPDX-License-Identifier: Apache-2.0).
## Disclaimer
We used compliance-checking algorithms during the training process, to ensure the compliance of the trained model to the best of our ability. Due to the complexity of the data and the diversity of language model usage scenarios, we cannot guarantee that the model is completely free of copyright issues or improper content. If you believe anything infringes on your rights or generates improper content, please contact us, and we will promptly address the matter.
|
mradermacher/amal-50k-0.8-5k-GGUF
|
mradermacher
| 2025-08-15T15:18:46Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:ivlu2000/amal-50k-0.8-5k",
"base_model:quantized:ivlu2000/amal-50k-0.8-5k",
"endpoints_compatible",
"region:us"
] | null | 2025-08-15T15:10:06Z |
---
base_model: ivlu2000/amal-50k-0.8-5k
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/ivlu2000/amal-50k-0.8-5k
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#amal-50k-0.8-5k-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/amal-50k-0.8-5k-GGUF/resolve/main/amal-50k-0.8-5k.Q2_K.gguf) | Q2_K | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/amal-50k-0.8-5k-GGUF/resolve/main/amal-50k-0.8-5k.Q3_K_S.gguf) | Q3_K_S | 1.4 | |
| [GGUF](https://huggingface.co/mradermacher/amal-50k-0.8-5k-GGUF/resolve/main/amal-50k-0.8-5k.Q3_K_M.gguf) | Q3_K_M | 1.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/amal-50k-0.8-5k-GGUF/resolve/main/amal-50k-0.8-5k.IQ4_XS.gguf) | IQ4_XS | 1.6 | |
| [GGUF](https://huggingface.co/mradermacher/amal-50k-0.8-5k-GGUF/resolve/main/amal-50k-0.8-5k.Q3_K_L.gguf) | Q3_K_L | 1.7 | |
| [GGUF](https://huggingface.co/mradermacher/amal-50k-0.8-5k-GGUF/resolve/main/amal-50k-0.8-5k.Q4_K_S.gguf) | Q4_K_S | 1.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/amal-50k-0.8-5k-GGUF/resolve/main/amal-50k-0.8-5k.Q4_K_M.gguf) | Q4_K_M | 1.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/amal-50k-0.8-5k-GGUF/resolve/main/amal-50k-0.8-5k.Q5_K_S.gguf) | Q5_K_S | 2.0 | |
| [GGUF](https://huggingface.co/mradermacher/amal-50k-0.8-5k-GGUF/resolve/main/amal-50k-0.8-5k.Q5_K_M.gguf) | Q5_K_M | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/amal-50k-0.8-5k-GGUF/resolve/main/amal-50k-0.8-5k.Q6_K.gguf) | Q6_K | 2.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/amal-50k-0.8-5k-GGUF/resolve/main/amal-50k-0.8-5k.Q8_0.gguf) | Q8_0 | 3.1 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/amal-50k-0.8-5k-GGUF/resolve/main/amal-50k-0.8-5k.f16.gguf) | f16 | 5.7 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
ACECA/lowMvMax_2
|
ACECA
| 2025-08-15T15:18:23Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-15T14:34:24Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
chainway9/blockassist-bc-untamed_quick_eel_1755269001
|
chainway9
| 2025-08-15T15:12:45Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed quick eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T15:12:40Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed quick eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Osrivers/babesByStableYogiPony_v60FP16.safetensors
|
Osrivers
| 2025-08-15T15:12:43Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2025-08-15T15:09:47Z |
---
license: creativeml-openrail-m
---
|
aq1048576/rm_sweep_40k
|
aq1048576
| 2025-08-15T15:05:58Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-classification",
"generated_from_trainer",
"trl",
"reward-trainer",
"dataset:aq1048576/sexism_filter_prompt_claude_4_sonnet_trl_40k",
"base_model:Qwen/Qwen3-4B-Base",
"base_model:finetune:Qwen/Qwen3-4B-Base",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-15T09:37:38Z |
---
base_model: Qwen/Qwen3-4B-Base
datasets: aq1048576/sexism_filter_prompt_claude_4_sonnet_trl_40k
library_name: transformers
model_name: rm_sweep_40k
tags:
- generated_from_trainer
- trl
- reward-trainer
licence: license
---
# Model Card for rm_sweep_40k
This model is a fine-tuned version of [Qwen/Qwen3-4B-Base](https://huggingface.co/Qwen/Qwen3-4B-Base) on the [aq1048576/sexism_filter_prompt_claude_4_sonnet_trl_40k](https://huggingface.co/datasets/aq1048576/sexism_filter_prompt_claude_4_sonnet_trl_40k) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="aq1048576/rm_sweep_40k", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/aqi1048576-mats-program/red-team-agent/runs/gi1hnkip)
This model was trained with Reward.
### Framework versions
- TRL: 0.18.2
- Transformers: 4.52.4
- Pytorch: 2.6.0
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
JamesTev/bert-random-test
|
JamesTev
| 2025-08-15T15:05:07Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-08-15T15:04:58Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
jahyungu/OLMo-2-1124-7B-Instruct_coqa
|
jahyungu
| 2025-08-15T15:03:00Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"olmo2",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:allenai/OLMo-2-1124-7B-Instruct",
"base_model:finetune:allenai/OLMo-2-1124-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-15T14:12:33Z |
---
library_name: transformers
license: apache-2.0
base_model: allenai/OLMo-2-1124-7B-Instruct
tags:
- generated_from_trainer
model-index:
- name: OLMo-2-1124-7B-Instruct_coqa
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# OLMo-2-1124-7B-Instruct_coqa
This model is a fine-tuned version of [allenai/OLMo-2-1124-7B-Instruct](https://huggingface.co/allenai/OLMo-2-1124-7B-Instruct) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.55.0
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.0
|
Muapi/artify-s-fantastic-flux-landscape-lora
|
Muapi
| 2025-08-15T15:02:09Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-15T15:01:53Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Artify´s Fantastic Flux Landscape Lora

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:717187@802003", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
dev6655/chimera-beta
|
dev6655
| 2025-08-15T15:01:35Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"base_model:Qwen/Qwen3-8B",
"base_model:finetune:Qwen/Qwen3-8B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-15T08:54:01Z |
---
base_model:
- Qwen/Qwen3-8B
- deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
pipeline_tag: text-generation
library_name: transformers
---
# Chimera-Beta
**Chimera-Beta** is an **8-billion-parameter** merged language model that combines the step-by-step reasoning strengths of DeepSeek-R1-0528-Qwen3-8B with the concise, general-purpose capabilities of Qwen3-8B.
- **No GPU required** – built with a fully **CPU-only** pipeline.
- **Easy to host** – weights are automatically **sharded into four 4 GB files**.
- **Zero fine-tuning** – weights are interpolated directly from the original checkpoints.
---
## Model Details
| Property | Value |
|---------------------|------------------------------------------|
| Base models | [deepseek-ai/DeepSeek-R1-0528-Qwen3-8B](https://huggingface.co/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B) + [qwen/Qwen3-8B](https://huggingface.co/qwen/Qwen3-8B) |
| Final size | 8 B parameters (≈ 16 GB total) |
| Precision | `float16` / `bfloat16` (original dtype) |
| Shard count | 4 × 4 GB `.safetensors` files |
| License | Apache-2.0 (inherits from base models) |
---
## How the Merge Works
1. **Selective blending**:
- **MLP layers** → 60 % DeepSeek-R1-0528 + 40 % Qwen3-8B
- **All other tensors** → kept as-is from Qwen3-8B (for speed and stability).
2. **CPU-only pipeline** – loads tensors one-by-one to stay within RAM limits.
3. **Exact sharding** – produces four equally-sized shards to simplify deployment.
---
## 🚀 Quick Start
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "dev6655/chimera-beta"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True
)
messages = [{"role": "user", "content": "Perché il cielo è blu?"}]
prompt = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=False,
enable_thinking=True
)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=256, do_sample=True, temperature=0.6)
response = tokenizer.decode(outputs[0][len(inputs.input_ids[0]):], skip_special_tokens=True)
print(response)
|
mradermacher/VyvoTTS-LFM2-Stephen_Fry-GGUF
|
mradermacher
| 2025-08-15T15:00:17Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"unsloth",
"en",
"base_model:Vyvo/VyvoTTS-LFM2-Stephen_Fry",
"base_model:quantized:Vyvo/VyvoTTS-LFM2-Stephen_Fry",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-15T14:48:50Z |
---
base_model: Vyvo/VyvoTTS-LFM2-Stephen_Fry
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- unsloth
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/Vyvo/VyvoTTS-LFM2-Stephen_Fry
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#VyvoTTS-LFM2-Stephen_Fry-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Stephen_Fry-GGUF/resolve/main/VyvoTTS-LFM2-Stephen_Fry.Q2_K.gguf) | Q2_K | 0.3 | |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Stephen_Fry-GGUF/resolve/main/VyvoTTS-LFM2-Stephen_Fry.Q3_K_S.gguf) | Q3_K_S | 0.3 | |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Stephen_Fry-GGUF/resolve/main/VyvoTTS-LFM2-Stephen_Fry.Q3_K_M.gguf) | Q3_K_M | 0.3 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Stephen_Fry-GGUF/resolve/main/VyvoTTS-LFM2-Stephen_Fry.Q3_K_L.gguf) | Q3_K_L | 0.3 | |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Stephen_Fry-GGUF/resolve/main/VyvoTTS-LFM2-Stephen_Fry.IQ4_XS.gguf) | IQ4_XS | 0.3 | |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Stephen_Fry-GGUF/resolve/main/VyvoTTS-LFM2-Stephen_Fry.Q4_K_S.gguf) | Q4_K_S | 0.3 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Stephen_Fry-GGUF/resolve/main/VyvoTTS-LFM2-Stephen_Fry.Q4_K_M.gguf) | Q4_K_M | 0.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Stephen_Fry-GGUF/resolve/main/VyvoTTS-LFM2-Stephen_Fry.Q5_K_S.gguf) | Q5_K_S | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Stephen_Fry-GGUF/resolve/main/VyvoTTS-LFM2-Stephen_Fry.Q5_K_M.gguf) | Q5_K_M | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Stephen_Fry-GGUF/resolve/main/VyvoTTS-LFM2-Stephen_Fry.Q6_K.gguf) | Q6_K | 0.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Stephen_Fry-GGUF/resolve/main/VyvoTTS-LFM2-Stephen_Fry.Q8_0.gguf) | Q8_0 | 0.5 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Stephen_Fry-GGUF/resolve/main/VyvoTTS-LFM2-Stephen_Fry.f16.gguf) | f16 | 0.9 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Muapi/1999-digital-camera-style-olympus-d-450
|
Muapi
| 2025-08-15T14:58:50Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-15T14:58:31Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# 1999 Digital Camera Style (Olympus D-450)

**Base model**: Flux.1 D
**Trained words**: olympusd450
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:724495@810420", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
mohamed-amine-benhima/izanami-wav2vec2-emotion-classifier-huggingface-format
|
mohamed-amine-benhima
| 2025-08-15T14:51:24Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"wav2vec2",
"audio-classification",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2025-08-15T14:50:14Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
dondesbond/blockassist-bc-moist_tame_tiger_1755266208
|
dondesbond
| 2025-08-15T14:48:36Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"moist tame tiger",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T14:48:20Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- moist tame tiger
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
leeroy-jankins/bubba
|
leeroy-jankins
| 2025-08-15T14:47:13Z | 2,223 | 0 | null |
[
"gguf",
"legal",
"finance",
"en",
"dataset:leeroy-jankins/Regulations",
"dataset:leeroy-jankins/Appropriations",
"dataset:leeroy-jankins/OMB-Circular-A-11",
"dataset:leeroy-jankins/RedBook",
"dataset:leeroy-jankins/US-General-Ledger",
"dataset:leeroy-jankins/FastBook",
"dataset:leeroy-jankins/Title-31-CFR-Money-and-Finance",
"base_model:openai/gpt-oss-20b",
"base_model:quantized:openai/gpt-oss-20b",
"license:mit",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-12T18:13:16Z |
---
license: mit
datasets:
- leeroy-jankins/Regulations
- leeroy-jankins/Appropriations
- leeroy-jankins/OMB-Circular-A-11
- leeroy-jankins/RedBook
- leeroy-jankins/US-General-Ledger
- leeroy-jankins/FastBook
- leeroy-jankins/Title-31-CFR-Money-and-Finance
language:
- en
base_model:
- openai/gpt-oss-20b
tags:
- legal
- finance
---
<img src="assets/project_bubba.png" width="1000"/>
Bubba is a fine-tuned LLM based on OpenAI’s Chat GPT-5. This release
packages the fine-tuned weights (or adapters) for practical, low-latency instruction following,
summarization, reasoning, and light code generation. It is intended for local or self-hosted
environments and RAG (Retrieval-Augmented Generation) stacks that require predictable, fast outputs.
**Quantized, and fine-tuned GGUF based on OpenAI’s `gpt-oss-20b`**
Format: **GGUF** (for `llama.cpp` and compatible runtimes) • Quantization: **Q4_K_XL (4-bit, K-grouped, extra-low loss)**
File: `bubba-20b-Q4_K_XL.gguf`
## 🧠 Overview
- This repo provides a **4-bit K-quantized** `.gguf` for fast local inference of a 20B-parameter model
derived from **OpenAI’s `gpt-oss-20b`** (as reported by the uploader).
- **Use cases:** general chat/instruction following, coding help, knowledge Q&A
(see Intended Use & Limitations).
- **Works with:** `llama.cpp`, `llama-cpp-python`, KoboldCPP, Text Generation WebUI, LM Studio,
and other GGUF-compatible backends.
- **Hardware guidance (rule of thumb):** ~12–16 GB VRAM/RAM for comfortable batch-1 inference
with Q4_K_XL; CPU-only works too (expect lower tokens/s).
---
## Key Features
- Instruction-tuned derivative of gpt-oss-20b for concise, helpful responses.
- Optimized defaults for short to medium prompts; strong compatibility with RAG pipelines.
- Flexible distribution: full finetuned weights or lightweight LoRA/QLoRA adapters.
- Compatible with popular runtimes and libraries (Transformers, PEFT, vLLM, Text Generation Inference).
> ⚠️ **Provenance & license**: This quant is produced from a base model claimed to be OpenAI’s
> `gpt-oss-20b`. Please **review and comply with the original model’s license/terms**. The GGUF
> quantization **inherits** those terms. See the **License** section.
## ⚙️ Vectorized Datasets
> Vectorization is the process of converting textual data into numerical vectors and is a process that is usually applied once the text is cleaned.
> It can help improve the execution speed and reduce the training time of your code.
> BudgetPy provides the following vector stores on the OpenAI platform to support environmental data analysis with machine-learning
- [Appropriations](https://huggingface.co/datasets/leeroy-jankins/Appropriations) - Enacted appropriations from 1996-2024 available for fine-tuning learning models
- [Regulations](https://huggingface.co/datasets/leeroy-jankins/Regulations/tree/main) - Collection of federal regulations on the use of appropriated funds
- [SF-133](https://huggingface.co/datasets/leeroy-jankins/SF133) - The Report on Budget Execution and Budgetary Resources
- [Balances](https://huggingface.co/datasets/leeroy-jankins/Balances) - U.S. federal agency Account Balances (File A) submitted as part of the DATA Act 2014.
- [Outlays](https://huggingface.co/datasets/leeroy-jankins/Outlays) - The actual disbursements of funds by the U.S. federal government from 1962 to 2025
- [SF-133](https://huggingface.co/datasets/leeroy-jankins/SF133) The Report on Budget Execution and Budgetary Resources
- [Balances](https://huggingface.co/datasets/leeroy-jankins/Balances) - U.S. federal agency Account Balances (File A) submitted as part of the DATA Act 2014.
- [Circular A11](https://huggingface.co/datasets/leeroy-jankins/OMB-Circular-A-11) - Guidance from OMB on the preparation, submission, and execution of the federal budget
- [Fastbook](https://huggingface.co/datasets/leeroy-jankins/FastBook) - Treasury guidance on federal ledger accounts
- [Title 31 CFR](https://huggingface.co/datasets/leeroy-jankins/Title-31-CFR-Money-and-Finance) - Money & Finance
- [Redbook](https://huggingface.co/datasets/leeroy-jankins/RedBook) - The Principles of Appropriations Law (Volumes I & II).
- [US Standard General Ledger](https://huggingface.co/datasets/leeroy-jankins/US-General-Ledger) - Account Definitions
- [Treasury Appropriation Fund Symbols (TAFSs) Dataset](https://huggingface.co/datasets/leeroy-jankins/Accounts) - Collection of TAFSs used by federal agencies
## Technical Specifications
| Property | Value / Guidance |
|---------------------|------------------------------------------------------------------------------|
| Base model | gpt-oss-20b (decoder-only Transformer) |
| Parameters | ~20B (as per upstream) |
| Tokenizer | Use the upstream tokenizer associated with gpt-oss-20b |
| Context window | Determined by the upstream base; set accordingly in your runtime |
| Fine-tuning | Supervised Fine-Tuning (SFT); optional preference optimization (DPO/ORPO) |
| Precision | FP16/BF16 recommended; 4-bit (bnb) for single-GPU experimentation |
| Intended runtimes | Hugging Face Transformers, PEFT, vLLM, TGI (Text Generation Inference) |
Note: Please adjust any specifics (context length, tokenizer name) to match the exact upstream build
you use for gpt-oss-20b.
---
## Files
| File / Folder | Description |
|---------------------------------|----------------------------------------------------------------|
| README.md | This model card |
| config.json / tokenizer files | Configuration and tokenizer artifacts (from upstream) |
| pytorch_model.safetensors | Full fine-tuned weights (if released as full model) |
| adapter_model.safetensors | LoRA/QLoRA adapters only (if released as adapters) |
| training_args.json (optional) | Minimal training configuration for reproducibility |
Only one of “full weights” or “adapters” may be included depending on how you distribute Bubba.
---
## 📝 Intended Use & Limitations
### Intended Use
- Instruction following, general dialogue
- Code assistance (reasoning, boilerplate, refactoring)
- Knowledge/Q&A within the model’s training cutoff
### Out-of-Scope / Known Limitations
- **Factuality:** may produce inaccurate or outdated info
- **Safety:** can emit biased or unsafe text; **apply your own filters/guardrails**
- **High-stakes decisions:** not for medical, legal, financial, or safety-critical use
## 🎯 Quick Start
# Examples: Using the Bubba LLM (Fine-tuned from gpt-oss-20b)
This guide shows several ways to run **Bubba** locally or on a server. Examples cover full weights,
LoRA/QLoRA adapters, vLLM, and Text Generation Inference (TGI), plus prompt patterns and RAG.
---
## 🐍 Python (Transformers) — Full Weights
Install
pip install "transformers>=4.44.0" accelerate torch --upgrade
Load and generate
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "your-namespace/Bubba-gpt-oss-20b-finetuned"
tok = AutoTokenizer.from_pretrained(model_name, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "In 5 bullet points, explain retrieval-augmented generation and when to use it."
inputs = tok(prompt, return_tensors="pt").to(model.device)
out = model.generate(
**inputs,
max_new_tokens=256,
temperature=0.7,
top_p=0.9
)
print(tok.decode(out[0], skip_special_tokens=True))
Notes
• device_map="auto" will place weights across available GPUs/CPU.
• Prefer BF16 if supported; otherwise FP16. For VRAM-constrained experiments, see 4-bit below.
---
## 🧩 Python (PEFT) — Adapters on Top of the Base
Install
pip install "transformers>=4.44.0" peft accelerate torch --upgrade
Load base + LoRA/QLoRA adapters
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
import torch
base_name = "openai/gpt-oss-20b" # replace with the exact upstream base you use
lora_name = "your-namespace/Bubba-gpt-oss-20b-finetuned"
tok = AutoTokenizer.from_pretrained(base_name, use_fast=True)
base = AutoModelForCausalLM.from_pretrained(
base_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
model = PeftModel.from_pretrained(base, lora_name)
prompt = "Draft a JSON spec with keys: goal, steps[], risks[], success_metric."
inputs = tok(prompt, return_tensors="pt").to(model.device)
out = model.generate(**inputs, max_new_tokens=200, temperature=0.6, top_p=0.9)
print(tok.decode(out[0], skip_special_tokens=True))
---
## 💾 4-bit (bitsandbytes) — Memory-Efficient Loading
Install
pip install "transformers>=4.44.0" accelerate bitsandbytes --upgrade
Load with 4-bit quantization
```
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
bnb = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model_name = "your-namespace/Bubba-gpt-oss-20b-finetuned"
tok = AutoTokenizer.from_pretrained(model_name, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb,
device_map="auto"
)
prompt = "Explain beam search vs. nucleus sampling in three short bullets."
inputs = tok(prompt, return_tensors="pt").to("cuda" if torch.cuda.is_available() else "cpu")
out = model.generate(**inputs, max_new_tokens=160, temperature=0.7, top_p=0.9)
print(tok.decode(out[0], skip_special_tokens=True))
```
---
## 🚀 Serve with vLLM (OpenAI-compatible API)
Install and launch (example)
```
pip install vllm
python -m vllm.entrypoints.openai.api_server \
--model your-namespace/Bubba-gpt-oss-20b-finetuned \
--dtype bfloat16 --max-model-len 8192 \
--port 8000
```
Call the endpoint (Python)
```
import requests, json
url = "http://localhost:8000/v1/chat/completions"
headers = {"Content-Type": "application/json"}
data = {
"model": "your-namespace/Bubba-gpt-oss-20b-finetuned",
"messages": [
{"role": "system", "content": "You are concise and factual."},
{"role": "user", "content": "Give a 4-step checklist for evaluating a RAG pipeline."}
],
"temperature": 0.7,
"max_tokens": 256,
"stream": True
}
with requests.post(url, headers=headers, data=json.dumps(data), stream=True) as r:
for line in r.iter_lines():
if line and line.startswith(b"data: "):
chunk = line[len(b"data: "):].decode("utf-8")
if chunk == "[DONE]":
break
print(chunk, flush=True)
```
---
## 📦 Serve with Text Generation Inference (TGI)
Run the server (Docker)
docker run --gpus all --shm-size 1g -p 8080:80 \
-e MODEL_ID=your-namespace/Bubba-gpt-oss-20b-finetuned \
ghcr.io/huggingface/text-generation-inference:latest
Call the server (HTTP)
curl http://localhost:8080/generate \
-X POST -d '{
"inputs": "Summarize pros/cons of hybrid search (BM25 + embeddings).",
"parameters": {"max_new_tokens": 200, "temperature": 0.7, "top_p": 0.9}
}' \
-H "Content-Type: application/json"
---
## 🧠 Prompt Patterns
Direct instruction (concise)
You are a precise assistant. In 6 bullets, explain evaluation metrics for retrieval (Recall@k,
MRR, nDCG). Keep each bullet under 20 words.
Constrained JSON output
System: Output only valid JSON. No prose.
User: Produce {"goal":"", "steps":[""], "risks":[""], "metrics":[""]} for testing a QA bot.
Guarded answer
If the answer isn’t derivable from the context, say “I don’t know” and ask for the missing info.
Few-shot structure
Example:
Q: Map 3 tasks to suitable embedding dimensions.
A: 256: short titles; 768: support FAQs; 1024: multi-paragraph knowledge base.
---
## 📚 Basic RAG
# 1) Retrieve
chunks = retriever.search("compare vector DBs for legal discovery", k=5)
# 2) Build prompt
context = "\n".join([f"• {c.text} [{c.source}]" for c in chunks])
prompt = f"""
You are a helpful assistant. Use only the context to answer.
Context:
{context}
Question:
What selection criteria should teams use when picking a vector DB for scale and cost?
"""
# 3) Generate (Transformers / vLLM / TGI)
inputs = tok(prompt, return_tensors="pt").to(model.device)
out = model.generate(**inputs, max_new_tokens=256, temperature=0.6, top_p=0.9)
print(tok.decode(out[0], skip_special_tokens=True))
### 📁 1. Document Ingestion
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
loader = TextLoader("docs/corpus.txt")
documents = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=700, chunk_overlap=150)
docs = splitter.split_documents(documents)
---
### 🔍 2. Embedding & Vector Indexing
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
embedding = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vectorstore = FAISS.from_documents(docs, embedding)
---
### 🔄 3. Retrieval + Prompt Formatting
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
retrieved_docs = retriever.get_relevant_documents("What role does Bubba play in improving document QA?")
context = "\n\n".join([doc.page_content for doc in retrieved_docs])
prompt = f"""
You are Bubba, a reasoning-heavy assistant. Use only the context below to answer:
<context>
{context}
</context>
<question>
What role does Bubba play in improving document QA?
</question>
"""
---
### 🧠 4. LLM Inference with Bubba
./main -m Bubba.Q4_K_M.gguf -p "$prompt" -n 768 -t 16 -c 4096 --color
> Bubba’s output will include a context-aware, citation-grounded response backed by the retrieved input.
---
### 📝 Notes
- **Bubba** (20B parameter model) may require more memory than smaller models like Bro or Leeroy.
- Use a higher `-c` value (context size) to accommodate longer prompts with more chunks.
- GPU acceleration is recommended for smooth generation if your hardware supports it.
---
## ⚙️ Parameter Tips
• Temperature: 0.6–0.9 (lower = more deterministic)
• Top-p: 0.8–0.95 (tune one knob at a time)
• Max new tokens: 128–384 for chat; longer for drafting
• Repetition penalty: 1.05–1.2 if loops appear
• Batch size: use padding_side="left" and dynamic padding for throughput
• Context length: set to your runtime’s max; compress context via selective retrieval
---
## 🛟 Troubleshooting
• CUDA OOM:
Lower max_new_tokens; enable 4-bit; shard across GPUs; reduce context length.
• Slow throughput:
Use vLLM/TGI with tensor/PP sharding; enable paged attention; pin to BF16.
• Messy JSON:
Use a JSON-only system prompt; set temperature ≤0.6; add a JSON schema in the prompt.
• Domain shift:
Consider small adapter tuning on your domain data; add retrieval grounding.
---
## 🔍 Minimal Batch Inference Example
prompts = [
"List 5 key features of FAISS.",
"Why would I choose pgvector over Milvus?"
]
inputs = tok(prompts, return_tensors="pt", padding=True).to(model.device)
out = model.generate(**inputs, max_new_tokens=160, temperature=0.7, top_p=0.9)
for i, seq in enumerate(out):
print(f"--- Prompt {i+1} ---")
print(tok.decode(seq, skip_special_tokens=True))
---
## Inference Tips
- Prefer BF16 if available; otherwise FP16. For limited VRAM, try 4-bit (bitsandbytes) to explore.
- Start with max_new_tokens between 128–384 and temperature 0.6–0.9; tune top_p for stability.
- For RAG, constrain prompt length and adopt strict chunking/citation formatting for better grounding.
---
## 📘 WebUI
- Place the GGUF in `text-generation-webui/models/bubba-20b-Q4_K_XL/`
- Launch with the `llama.cpp` loader (or `llama-cpp-python` backend)
- Select the model in the UI, adjust **context length**, **GPU layers**, and **sampling**
## 🧩 KoboldCPP
```bash
./koboldcpp \
-m bubba-20b-Q4_K_XL.gguf \
--contextsize 4096 \
--gpulayers 35 \
--usecublas
```
## ⚡ LM Studio
1. Open **LM Studio** → **Models** → **Local models** → **Add local model** and select the `.gguf`.
2. In **Chat**, pick the model, set **Context length** (≤ base model max), and adjust **GPU Layers**.
3. For API use, enable **Local Server** and target the exposed endpoint with OpenAI-compatible clients.
## ❓ Prompting
This build is instruction-tuned (downstream behavior depends on your base). Common prompt patterns work:
**Simple instruction**
```
Write a concise summary of the benefits of grouped 4-bit quantization.
```
**ChatML-like**
```
<|system|>
You are a helpful, concise assistant.
<|user|>
Compare Q4_K_XL vs Q5_K_M in terms of quality and RAM.
<|assistant|>
```
**Code task**
```
Task: Write a Python function that computes perplexity given log-likelihoods.
Constraints: Include docstrings and type hints.
```
> **Tip:** Keep prompts **explicit and structured** (roles, constraints, examples).
> Suggested starting points: temperature 0.2–0.8, top_p 0.8–0.95, repeat_penalty 1.05–1.15.
- No special chat template is strictly required. Use clear instructions and keep prompts concise. For
multi-turn workflows, persist conversation state externally or via your app’s memory/RAG layer.
Example system style
You are a concise, accurate assistant. Prefer step-by-step reasoning only when needed.
Cite assumptions and ask for missing constraints.
- [Guro](https://github.com/is-leeroy-jenkins/Guro?tab=readme-ov-file#guro) is a prompt library designed to supercharge AI agents and assistants with task-specific personas -ie, total randos.
- From academic writing to financial analysis, technical support, SEO, and beyond
- Guro provides precision-crafted prompt templates ready to drop into your LLM workflows.
## ⚙️ Performance & Memory Guidance (Rules of Thumb)
- **RAM/VRAM for Q4_K_XL (20B):** ~12–16 GB for batch-1 inference (varies by backend and offloading).
- **Throughput:** Highly dependent on CPU/GPU, backend, context length, and GPU offload.
Start with **`-ngl`** as high as your VRAM allows, then tune threads/batch sizes.
- **Context window:** Do not exceed the base model’s maximum (quantization does not increase it).
## 💻 Files
- `bubba-20b-Q4_K_XL.gguf` — 4-bit K-quantized weights (XL variant)
- `tokenizer.*` — packed inside GGUF (no separate files needed)
> **Integrity:** Verify your download (e.g., SHA256) if provided by the host/mirror.
## ⚙️ GGUF Format
1. Start from the base `gpt-oss-20b` weights (FP16/BF16).
2. Convert to GGUF with `llama.cpp`’s `convert` tooling (or equivalent for the base arch).
3. Quantize with `llama.cpp` `quantize` to **Q4_K_XL**.
4. Sanity-check perplexity/behavior, package with metadata.
> Exact scripts/commits may vary by environment; please share your pipeline for full reproducibility
> if you fork this card.
## 🏁 Safety, Bias & Responsible Use
Large language models can generate **plausible but incorrect or harmful** content and may reflect
**societal biases**. If you deploy this model:
- Add **moderation/guardrails** and domain-specific filters.
- Provide **user disclaimers** and feedback channels.
- Keep **human-in-the-loop** for consequential outputs.
## 🕒 License and Usage
This model package derives from Chat GPT-5 so you're responsible for ensuring your use
complies with the upstream model license and any dataset terms. For commercial deployment, review
OpenAI’s license and your organization’s compliance requirements.
- Bubba is published under the [MIT General Public License v3](https://huggingface.co/leeroy-jankins/bubba/blob/main/LICENSE.txt)
## 🧩 Attribution
If this quant helped you, consider citing like:
```
bubba-20b–Q4_K_XL.gguf (2025).
Quantized GGUF build derived from OpenAI’s gpt-oss-20b.
Retrieved from the Hugging Face Hub.
```
## ❓ FAQ
**Does quantization change the context window or tokenizer?**
No. Those are inherited from the base model; quantization only changes weight representation.
**Why am I hitting out-of-memory?**
Lower `-ngl` (fewer GPU layers), reduce context (`-c`), or switch to a smaller quant (e.g., Q3_K).
Ensure no other large models occupy VRAM.
**Best sampler settings?**
Start with temp 0.7, top_p 0.9, repeat_penalty 1.1.
Lower temperature for coding/planning; raise for creative writing.
## 📝 Changelog
- **v1.0** — Initial release of `bubba-20b-Q4_K_XL.gguf`.
|
Muapi/ob-oil-painting-with-bold-brushstrokes
|
Muapi
| 2025-08-15T14:46:55Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-15T14:46:40Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# OB粗犷笔触油画 Oil painting with bold brushstrokes.

**Base model**: Flux.1 D
**Trained words**: OByouhua, oil painting
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:757042@851295", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
mradermacher/VyvoTTS-LFM2-Ningguang-GGUF
|
mradermacher
| 2025-08-15T14:45:07Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:Vyvo/VyvoTTS-LFM2-Ningguang",
"base_model:quantized:Vyvo/VyvoTTS-LFM2-Ningguang",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-15T14:43:26Z |
---
base_model: Vyvo/VyvoTTS-LFM2-Ningguang
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/Vyvo/VyvoTTS-LFM2-Ningguang
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#VyvoTTS-LFM2-Ningguang-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Ningguang-GGUF/resolve/main/VyvoTTS-LFM2-Ningguang.Q2_K.gguf) | Q2_K | 0.3 | |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Ningguang-GGUF/resolve/main/VyvoTTS-LFM2-Ningguang.Q3_K_S.gguf) | Q3_K_S | 0.3 | |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Ningguang-GGUF/resolve/main/VyvoTTS-LFM2-Ningguang.Q3_K_M.gguf) | Q3_K_M | 0.3 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Ningguang-GGUF/resolve/main/VyvoTTS-LFM2-Ningguang.Q3_K_L.gguf) | Q3_K_L | 0.3 | |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Ningguang-GGUF/resolve/main/VyvoTTS-LFM2-Ningguang.IQ4_XS.gguf) | IQ4_XS | 0.3 | |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Ningguang-GGUF/resolve/main/VyvoTTS-LFM2-Ningguang.Q4_K_S.gguf) | Q4_K_S | 0.3 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Ningguang-GGUF/resolve/main/VyvoTTS-LFM2-Ningguang.Q4_K_M.gguf) | Q4_K_M | 0.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Ningguang-GGUF/resolve/main/VyvoTTS-LFM2-Ningguang.Q5_K_S.gguf) | Q5_K_S | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Ningguang-GGUF/resolve/main/VyvoTTS-LFM2-Ningguang.Q5_K_M.gguf) | Q5_K_M | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Ningguang-GGUF/resolve/main/VyvoTTS-LFM2-Ningguang.Q6_K.gguf) | Q6_K | 0.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Ningguang-GGUF/resolve/main/VyvoTTS-LFM2-Ningguang.Q8_0.gguf) | Q8_0 | 0.5 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/VyvoTTS-LFM2-Ningguang-GGUF/resolve/main/VyvoTTS-LFM2-Ningguang.f16.gguf) | f16 | 0.9 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
neural-interactive-proofs/finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5-32B_prover_nip_transfer_baseline_1_3_iter_3_provers
|
neural-interactive-proofs
| 2025-08-15T14:44:58Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"dpo",
"arxiv:2305.18290",
"base_model:Qwen/Qwen2.5-32B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-32B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-15T14:43:18Z |
---
base_model: Qwen/Qwen2.5-32B-Instruct
library_name: transformers
model_name: finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5-32B_prover_nip_transfer_baseline_1_3_iter_3_provers
tags:
- generated_from_trainer
- trl
- dpo
licence: license
---
# Model Card for finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5-32B_prover_nip_transfer_baseline_1_3_iter_3_provers
This model is a fine-tuned version of [Qwen/Qwen2.5-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="neural-interactive-proofs/finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5-32B_prover_nip_transfer_baseline_1_3_iter_3_provers", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/lrhammond-team/pvg-self-hosted-finetune/runs/qwen2_5-32b-instruct_dpo_2025-08-15_15-22-20_cv_qwen2.5-32B_prover_nip_transfer_baseline_1_3_iter_3_provers_group)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.18.2
- Transformers: 4.53.2
- Pytorch: 2.7.0
- Datasets: 3.0.0
- Tokenizers: 0.21.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
leeroy-jankins/bro
|
leeroy-jankins
| 2025-08-15T14:43:37Z | 518 | 0 | null |
[
"gguf",
"code",
"finance",
"text-generation",
"en",
"dataset:mlabonne/FineTome-100k",
"dataset:leeroy-jankins/Regulations",
"dataset:leeroy-jankins/Appropriations",
"dataset:leeroy-jankins/OMB-Circular-A-11",
"dataset:leeroy-jankins/RedBook",
"dataset:leeroy-jankins/SF133",
"dataset:leeroy-jankins/US-General-Ledger",
"dataset:leeroy-jankins/Title-31-CFR-Money-and-Finance",
"base_model:unsloth/gemma-3-1b-it-GGUF",
"base_model:quantized:unsloth/gemma-3-1b-it-GGUF",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] |
text-generation
| 2025-08-12T18:33:55Z |
---
license: mit
language:
- en
tags:
- code
- finance
datasets:
- mlabonne/FineTome-100k
- leeroy-jankins/Regulations
- leeroy-jankins/Appropriations
- leeroy-jankins/OMB-Circular-A-11
- leeroy-jankins/RedBook
- leeroy-jankins/SF133
- leeroy-jankins/US-General-Ledger
- leeroy-jankins/Title-31-CFR-Money-and-Finance
base_model:
- unsloth/gemma-3-1b-it-GGUF
pipeline_tag: text-generation
metrics:
- accuracy
---
<img src="assets/Bro.png" alt="Preview" width="1000"/>
## 🎯 Overview
**Bro** is a LLM fine-tuned variant of the `gemma-3-1b-it` transformer model, optimized for enhanced contextual comprehension, instruction following, and domain-specific reasoning. The fine-tuning process used supervised instruction tuning across multiple NLP domains, with a focus on factual recall, multi-step reasoning, and document comprehension.
- Built on the lightweight yet powerful `Gemma 3 1B` architecture, **Bro** provides a balance between inference speed and linguistic depth — making it suitable for both production deployment and academic research.
## ⚙️ Vectorized Datasets
> Vectorization is the process of converting textual data into numerical vectors and is a process that is usually applied once the text is cleaned.
> It can help improve the execution speed and reduce the training time of your code.
> BudgetPy provides the following vector stores on the OpenAI platform to support environmental data analysis with machine-learning
- [Appropriations](https://huggingface.co/datasets/leeroy-jankins/Appropriations) - Enacted appropriations from 1996-2024 available for fine-tuning learning models
- [Regulations](https://huggingface.co/datasets/leeroy-jankins/Regulations/tree/main) - Collection of federal regulations on the use of appropriated funds
- [SF-133](https://huggingface.co/datasets/leeroy-jankins/SF133) - The Report on Budget Execution and Budgetary Resources
- [Balances](https://huggingface.co/datasets/leeroy-jankins/Balances) - U.S. federal agency Account Balances (File A) submitted as part of the DATA Act 2014.
- [Outlays](https://huggingface.co/datasets/leeroy-jankins/Outlays) - The actual disbursements of funds by the U.S. federal government from 1962 to 2025
- [SF-133](https://huggingface.co/datasets/leeroy-jankins/SF133) The Report on Budget Execution and Budgetary Resources
- [Balances](https://huggingface.co/datasets/leeroy-jankins/Balances) - U.S. federal agency Account Balances (File A) submitted as part of the DATA Act 2014.
- [Circular A11](https://huggingface.co/datasets/leeroy-jankins/OMB-Circular-A-11) - Guidance from OMB on the preparation, submission, and execution of the federal budget
- [Fastbook](https://huggingface.co/datasets/leeroy-jankins/FastBook) - Treasury guidance on federal ledger accounts
- [Title 31 CFR](https://huggingface.co/datasets/leeroy-jankins/Title-31-CFR-Money-and-Finance) - Money & Finance
- [Redbook](https://huggingface.co/datasets/leeroy-jankins/RedBook) - The Principles of Appropriations Law (Volumes I & II).
- [US Standard General Ledger](https://huggingface.co/datasets/leeroy-jankins/US-General-Ledger) - Account Definitions
- [Treasury Appropriation Fund Symbols (TAFSs) Dataset](https://huggingface.co/datasets/leeroy-jankins/Accounts) - Collection of TAFSs used by federal agencies
## ✨ Features
| Feature | Description |
|----------------------------|-----------------------------------------------------------------------------|
| 🔍 **Instruction-Tuned** | Fine-tuned on a diverse corpus of natural language tasks for generalization |
| 📚 **Multi-Domain** | Trained on QA, summarization, reasoning, and code synthesis datasets |
| ⚡ **Optimized for RAG** | Performs well when integrated with retrieval-augmented generation pipelines |
| 🧩 **Multi-Turn Dialogue** | Supports coherent conversations with context memory |
| 🧠 **Compact Intelligence**| 4B parameter scale enables fast inference on consumer GPUs |
---
## 🧪 Intended Use
Bro is intended for use in:
- Knowledge retrieval systems (RAG)
- Instruction following assistants
- Legal/financial document understanding
- Open-ended question answering
- Text generation and summarization
- Fine-tuning foundation for further specialization
---
## 🔬 Technical Details
### Base Model
- **Model**: `gemma-3-1b-pt`
- **Parameters**: ~1.1 Billion
- **Architecture**: Transformer decoder-only
- **Tokenizer**: SentencePiece (32k vocab)
- **Positional Encoding**: Rotary (RoPE)
- **Attention**: Multi-head Self-Attention (MHA)
- **Training Framework**: PyTorch / Hugging Face Transformers
## ⚙️ Fine-Tuning
| Property | Value |
|----------------------------|--------------------------------------------------------|
| Dataset Composition | 60% OpenAssistant-style instructions, 20% legal+financial, 10% reasoning chains, 10% dialogues |
| Optimization Strategy | Supervised fine-tuning (SFT) |
| Epochs | 3 |
| Optimizer | AdamW |
| Scheduler | Cosine decay with warmup |
| Mixed Precision | FP16 |
| Context Window | 8192 tokens |
---
## 🧪 Benchmark Results
| Task | Metric | Bro (Ours) | Base gemma-3-1b |
|--------------------------|-------------------|------------|-----------------|
| ARC Challenge (25-shot) | Accuracy (%) | 71.3 | 64.5 |
| NaturalQuestions (RAG) | EM/F1 | 51.7 / 63.9| 44.2 / 56.8 |
| GSM8K (reasoning) | Accuracy (%) | 62.5 | 52.0 |
| Summarization (CNN/DM) | ROUGE-L | 42.1 | 37.6 |
| MMLU (5-shot, avg) | Accuracy (%) | 56.2 | 48.8 |
> 🧠 Fine-tuned Bro outperforms base Gemma across all tasks, especially multi-hop reasoning and retrieval QA.
---
## 🚀 Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("your-org/Bro")
tokenizer = AutoTokenizer.from_pretrained("your-org/Bro")
prompt = "Explain the difference between supervised and unsupervised learning:"
inputs = tokenizer(prompt, return_tensors="pt")
output = model.generate(**inputs, max_new_tokens=150)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
## 🐍 Python (Transformers) — Full Weights
Install
pip install "transformers>=4.44.0" accelerate torch --upgrade
Load and generate
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "your-namespace/Bro-gemma-3-1b-it-finetuned" # replace with your repo/path
tok = AutoTokenizer.from_pretrained(model_id, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = (
"You are a precise assistant specialized in clinical trial summaries.\n"
"Task: Summarize the following abstract in 4 bullet points, include 1 risk and 1 limitation.\n"
"Abstract: <paste text here>"
)
inputs = tok(prompt, return_tensors="pt").to(model.device)
out = model.generate(
**inputs,
max_new_tokens=256,
temperature=0.6,
top_p=0.9
)
print(tok.decode(out[0], skip_special_tokens=True))
Notes
• device_map="auto" spreads layers across available devices.
• Prefer BF16 if supported; otherwise FP16. For very small GPUs/CPUs, see the 4-bit example.
---
## 🧩 Python (PEFT) — Adapters on Top of the Base
Install
pip install "transformers>=4.44.0" peft accelerate torch --upgrade
Load base + LoRA/QLoRA
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
import torch
base_id = "google/gemma-3-1b-it" # base model you fine-tuned from
lora_id = "your-namespace/Bro-gemma-3-1b-adapter" # your adapter repo/path
tok = AutoTokenizer.from_pretrained(base_id, use_fast=True)
base = AutoModelForCausalLM.from_pretrained(
base_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)
model = PeftModel.from_pretrained(base, lora_id)
prompt = (
"You are an enterprise compliance assistant.\n"
"In JSON, outline a policy review plan with fields: goals[], stakeholders[], risks[], deliverables[]."
)
inputs = tok(prompt, return_tensors="pt").to(model.device)
out = model.generate(**inputs, max_new_tokens=200, temperature=0.5, top_p=0.9)
print(tok.decode(out[0], skip_special_tokens=True))
---
## 💾 4-bit (bitsandbytes) — Memory-Efficient Loading
Install
pip install "transformers>=4.44.0" accelerate bitsandbytes --upgrade
Load
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
bnb = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model_id = "your-namespace/Bro-gemma-3-1b-it-finetuned"
tok = AutoTokenizer.from_pretrained(model_id, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb,
device_map="auto"
)
prompt = "Explain, in 5 bullets, how to evaluate domain-specific reasoning abilities in LLMs."
inputs = tok(prompt, return_tensors="pt").to(model.device)
out = model.generate(**inputs, max_new_tokens=180, temperature=0.6, top_p=0.9)
print(tok.decode(out[0], skip_special_tokens=True))
---
## 🚀 Serve with vLLM (OpenAI-Compatible API)
Install & launch
pip install vllm
python -m vllm.entrypoints.openai.api_server \
--model your-namespace/Bro-gemma-3-1b-it-finetuned \
--dtype bfloat16 \
--max-model-len 4096 \
--port 8000
Call the endpoint (Python)
import requests, json
url = "http://localhost:8000/v1/chat/completions"
headers = {"Content-Type": "application/json"}
data = {
"model": "your-namespace/Bro-gemma-3-1b-it-finetuned",
"messages": [
{"role": "system", "content": "You are concise and evidence-focused."},
{"role": "user", "content": "Give a short rubric to score contextual comprehension on legal docs."}
],
"temperature": 0.6,
"max_tokens": 220,
"stream": True
}
with requests.post(url, headers=headers, data=json.dumps(data), stream=True) as r:
for line in r.iter_lines():
if line and line.startswith(b"data: "):
chunk = line[len(b"data: "):].decode("utf-8")
if chunk == "[DONE]":
break
print(chunk, flush=True)
---
## 📦 Serve with Text Generation Inference (TGI)
Run the server (Docker)
docker run --gpus all --shm-size 1g -p 8080:80 \
-e MODEL_ID=your-namespace/Bro-gemma-3-1b-it-finetuned \
ghcr.io/huggingface/text-generation-inference:latest
Call the server (HTTP)
curl http://localhost:8080/generate \
-X POST -d '{
"inputs": "Outline a domain-specific reasoning test plan for an insurance Q&A bot.",
"parameters": {"max_new_tokens": 220, "temperature": 0.6, "top_p": 0.9}
}' \
-H "Content-Type: application/json"
---
## 🖥️ LM Studio (GGUF workflow)
If you export **Bro** to **GGUF**, you can run it in LM Studio. One typical workflow is:
1) Convert HF → GGUF with llama.cpp’s conversion script (example; confirm flags for Gemma 3):
• git clone https://github.com/ggerganov/llama.cpp
• cd llama.cpp
• python3 convert-hf-to-gguf.py /path/to/your/Bro-hf-dir --outfile Bro-f32.gguf
2) Quantize to Q4_K_M (or similar) for local inference:
• ./quantize Bro-f32.gguf Bro.Q4_K_M.gguf Q4_K_M
3) Open LM Studio → Local Models → Import → select Bro.Q4_K_M.gguf
4) In the chat pane, set conservative parameters:
• Temperature: 0.5–0.7
• Max new tokens: 128–384
• (If available) repeat penalty ~1.05–1.15
5) Prompt example:
"Summarize the attached clinical guidance in 6 bullets. Include contraindications and monitoring."
Notes
• Exact conversion flags can differ by model family; verify Gemma-3 options in your llama.cpp version.
• If you distribute only HF weights, consider LM Studio’s server/backends that accept HF models.
---
## 🧠 Prompt Patterns (Contextual + Domain)
Context-grounded Q&A
System: You answer strictly using the provided context. If missing, say "I don't know."
User: Use the context to answer. Keep to 5 bullets.
Context:
• <chunk 1 [source/citation]>
• <chunk 2 [source/citation]>
Question: <domain question here>
Constrained JSON
System: Output only valid JSON. No explanation.
User: Return {"summary":"", "risks":[""], "actions":[""], "open_questions":[""]} for the content.
Evaluation rubric (short)
In 6 bullets, define a rubric to judge contextual comprehension on domain X.
Use criteria: correctness, citation use, scope, clarity, uncertainty handling, follow-up.
## 📝 Prompting Engineering
No special chat template is strictly required. Use clear instructions and keep prompts concise. For
multi-turn workflows, persist conversation state externally or via your app’s memory/RAG layer.
Example system style
You are a concise, accurate assistant. Prefer step-by-step reasoning only when needed.
Cite assumptions and ask for missing constraints.
- [Guro](https://github.com/is-leeroy-jenkins/Guro?tab=readme-ov-file#guro) is a prompt library designed to supercharge AI agents and assistants with task-specific personas -ie, total randos.
- From academic writing to financial analysis, technical support, SEO, and beyond
- Guro provides precision-crafted prompt templates ready to drop into your LLM workflows.
---
## 📚 Basic RAG
# Retrieve k chunks
chunks = retriever.search("billing code coverage for outpatient procedures", k=5)
# Build prompt
context = "\n".join([f"• {c.text} [{c.source}]" for c in chunks])
prompt = f"""
You are a helpful domain assistant. Answer only from the context.
Context:
{context}
Question:
What are the coverage criteria and documentation requirements?
"""
# Generate (Transformers / vLLM / TGI)
inputs = tok(prompt, return_tensors="pt").to(model.device)
out = model.generate(**inputs, max_new_tokens=220, temperature=0.5, top_p=0.9)
print(tok.decode(out[0], skip_special_tokens=True))
### 📁 1. Document Ingestion
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
loader = TextLoader("reference_material.txt")
documents = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
docs = splitter.split_documents(documents)
---
### 🔍 2. Embedding & Vector Indexing
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
embedding = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vectorstore = FAISS.from_documents(docs, embedding)
---
### 🔄 3. Retrieval + Prompt Formatting
retriever = vectorstore.as_retriever(search_kwargs={"k": 4})
retrieved_docs = retriever.get_relevant_documents("How does RAG improve factual accuracy?")
context = "\n\n".join([doc.page_content for doc in retrieved_docs])
prompt = f"""
You are Bro, a domain-aware assistant. Use the retrieved context below to answer accurately:
<context>
{context}
</context>
<question>
How does RAG improve factual accuracy?
</question>
"""
---
### 🧠 4. LLM Inference with Bro
./main -m Bro.Q4_K_M.gguf -p "$prompt" -n 512 -t 8 -c 2048 --color
> The output will be Bro's grounded and concise answer, using the embedded context to avoid hallucinations.
---
### 📝 Notes
- **Bro** (gemma-3-1b-it variant) runs efficiently on CPU or with GPU offload via `llama.cpp`.
- All context is explicitly retrieved; no external APIs are involved.
- You can improve results by tuning chunk size, overlap, or using a domain-specific embedding model.
---
## ⚙️ Parameter Tips
• Temperature: 0.5–0.8 (lower for deterministic policy/summary tasks)
• Top-p: 0.8–0.95 (tune one knob at a time)
• Max new tokens: 128–384 for chat; longer for drafts
• Repeat penalty: 1.05–1.2 if repetition occurs
• Context length: set to your Bro build; compress with selective retrieval
---
## 🛟 Troubleshooting
• CUDA OOM:
Lower max_new_tokens; use 4-bit; reduce context; shard across GPUs.
• Messy JSON:
Use a JSON-only system prompt; set temperature ≤0.6; include a minimal schema.
• Weak domain grounding:
Improve retrieval quality; add citations; constrain scope in the prompt.
• Inconsistent style:
Provide one/two-shot examples; pin a style guide in the system message.
## 📝License
- Bro is published under the [MIT General Public License v3](https://huggingface.co/leeroy-jankins/bro/blob/main/LICENSE.txt)
|
Muapi/can-you-draw-like-a-five-year-old-children-s-crayon-drawing-style
|
Muapi
| 2025-08-15T14:43:26Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-15T14:43:08Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Can you draw like a five-year-old? Children's Crayon Drawing Style

**Base model**: Flux.1 D
**Trained words**: drawing, A colorful, whimsical drawing, depicting a simple, childlike illustration of
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1175139@1322264", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/atey-ghailan-style
|
Muapi
| 2025-08-15T14:42:58Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-15T14:42:41Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Atey Ghailan style

**Base model**: Flux.1 D
**Trained words**: Atey Ghailan Style
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:58226@1420165", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
tanjumajerin/llama-3-combined-60k
|
tanjumajerin
| 2025-08-15T14:39:32Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"generated_from_trainer",
"base_model:meta-llama/Meta-Llama-3-8B",
"base_model:adapter:meta-llama/Meta-Llama-3-8B",
"license:llama3",
"region:us"
] | null | 2025-08-15T07:47:33Z |
---
license: llama3
base_model: meta-llama/Meta-Llama-3-8B
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
library_name: peft
model-index:
- name: llama-3-combined-60k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# llama-3-combined-60k
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1518
- Accuracy: 0.9417
- F1: 0.9417
- Precision: 0.9418
- Recall: 0.9417
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:------:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 0.2586 | 0.9996 | 1878 | 0.1575 | 0.9388 | 0.9388 | 0.9388 | 0.9388 |
| 0.14 | 1.9992 | 3756 | 0.1518 | 0.9417 | 0.9417 | 0.9418 | 0.9417 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.40.0
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.19.1
|
chainway9/blockassist-bc-untamed_quick_eel_1755267252
|
chainway9
| 2025-08-15T14:39:26Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed quick eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T14:39:23Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed quick eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
SanskarModi/ppo-LunarLander-v2
|
SanskarModi
| 2025-08-15T14:29:44Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-15T14:29:25Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 254.43 +/- 15.75
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
koloni/blockassist-bc-deadly_graceful_stingray_1755266409
|
koloni
| 2025-08-15T14:28:25Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T14:28:22Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
neural-interactive-proofs/finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5_32B_prover_debate_2_rounds_2_0_iter_4_prover1_17552
|
neural-interactive-proofs
| 2025-08-15T14:27:42Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"dpo",
"arxiv:2305.18290",
"base_model:Qwen/Qwen2.5-32B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-32B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-15T14:21:08Z |
---
base_model: Qwen/Qwen2.5-32B-Instruct
library_name: transformers
model_name: finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5_32B_prover_debate_2_rounds_2_0_iter_4_prover1_17552
tags:
- generated_from_trainer
- trl
- dpo
licence: license
---
# Model Card for finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5_32B_prover_debate_2_rounds_2_0_iter_4_prover1_17552
This model is a fine-tuned version of [Qwen/Qwen2.5-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="neural-interactive-proofs/finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5_32B_prover_debate_2_rounds_2_0_iter_4_prover1_17552", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/lrhammond-team/pvg-self-hosted-finetune/runs/qwen2_5-32b-instruct_dpo_2025-08-15_14-39-53_cv_qwen2.5_32B_prover_debate_2_rounds_2_0_iter_4_prover1)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.18.2
- Transformers: 4.53.2
- Pytorch: 2.7.0
- Datasets: 3.0.0
- Tokenizers: 0.21.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755266329
|
mang3dd
| 2025-08-15T14:26:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T14:25:58Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
VIDEOS-18-Alizeh-Shah-Viral-video-Clip/New.full.videos.Alizeh.Shah.Viral.Video.Official.Tutorial
|
VIDEOS-18-Alizeh-Shah-Viral-video-Clip
| 2025-08-15T14:18:02Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-15T14:17:44Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?leaked-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
Paneman/blockassist-bc-scampering_eager_spider_1755266713
|
Paneman
| 2025-08-15T14:05:47Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"scampering eager spider",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T14:05:39Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- scampering eager spider
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/Thyme-SFT-GGUF
|
mradermacher
| 2025-08-15T13:42:01Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:yifanzhang114/Thyme-SFT",
"base_model:quantized:yifanzhang114/Thyme-SFT",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-15T13:34:12Z |
---
base_model: yifanzhang114/Thyme-SFT
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/yifanzhang114/Thyme-SFT
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Thyme-SFT-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Thyme-SFT-GGUF/resolve/main/Thyme-SFT.mmproj-Q8_0.gguf) | mmproj-Q8_0 | 1.0 | multi-modal supplement |
| [GGUF](https://huggingface.co/mradermacher/Thyme-SFT-GGUF/resolve/main/Thyme-SFT.mmproj-f16.gguf) | mmproj-f16 | 1.5 | multi-modal supplement |
| [GGUF](https://huggingface.co/mradermacher/Thyme-SFT-GGUF/resolve/main/Thyme-SFT.Q2_K.gguf) | Q2_K | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Thyme-SFT-GGUF/resolve/main/Thyme-SFT.Q3_K_S.gguf) | Q3_K_S | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Thyme-SFT-GGUF/resolve/main/Thyme-SFT.Q3_K_M.gguf) | Q3_K_M | 3.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Thyme-SFT-GGUF/resolve/main/Thyme-SFT.Q3_K_L.gguf) | Q3_K_L | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/Thyme-SFT-GGUF/resolve/main/Thyme-SFT.IQ4_XS.gguf) | IQ4_XS | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Thyme-SFT-GGUF/resolve/main/Thyme-SFT.Q4_K_S.gguf) | Q4_K_S | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Thyme-SFT-GGUF/resolve/main/Thyme-SFT.Q4_K_M.gguf) | Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Thyme-SFT-GGUF/resolve/main/Thyme-SFT.Q5_K_S.gguf) | Q5_K_S | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/Thyme-SFT-GGUF/resolve/main/Thyme-SFT.Q5_K_M.gguf) | Q5_K_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/Thyme-SFT-GGUF/resolve/main/Thyme-SFT.Q6_K.gguf) | Q6_K | 6.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Thyme-SFT-GGUF/resolve/main/Thyme-SFT.Q8_0.gguf) | Q8_0 | 8.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Thyme-SFT-GGUF/resolve/main/Thyme-SFT.f16.gguf) | f16 | 15.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/Qwen2.5-VL-7B-Instruct-ft-20250814163916929-GGUF
|
mradermacher
| 2025-08-15T13:40:33Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"qwen2_5_vl",
"en",
"base_model:REEA-GLOBAL/Qwen2.5-VL-7B-Instruct-ft-20250814163916929",
"base_model:quantized:REEA-GLOBAL/Qwen2.5-VL-7B-Instruct-ft-20250814163916929",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-15T13:32:33Z |
---
base_model: REEA-GLOBAL/Qwen2.5-VL-7B-Instruct-ft-20250814163916929
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2_5_vl
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/REEA-GLOBAL/Qwen2.5-VL-7B-Instruct-ft-20250814163916929
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Qwen2.5-VL-7B-Instruct-ft-20250814163916929-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-VL-7B-Instruct-ft-20250814163916929-GGUF/resolve/main/Qwen2.5-VL-7B-Instruct-ft-20250814163916929.mmproj-Q8_0.gguf) | mmproj-Q8_0 | 1.0 | multi-modal supplement |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-VL-7B-Instruct-ft-20250814163916929-GGUF/resolve/main/Qwen2.5-VL-7B-Instruct-ft-20250814163916929.mmproj-f16.gguf) | mmproj-f16 | 1.5 | multi-modal supplement |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-VL-7B-Instruct-ft-20250814163916929-GGUF/resolve/main/Qwen2.5-VL-7B-Instruct-ft-20250814163916929.Q2_K.gguf) | Q2_K | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-VL-7B-Instruct-ft-20250814163916929-GGUF/resolve/main/Qwen2.5-VL-7B-Instruct-ft-20250814163916929.Q3_K_S.gguf) | Q3_K_S | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-VL-7B-Instruct-ft-20250814163916929-GGUF/resolve/main/Qwen2.5-VL-7B-Instruct-ft-20250814163916929.Q3_K_M.gguf) | Q3_K_M | 3.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-VL-7B-Instruct-ft-20250814163916929-GGUF/resolve/main/Qwen2.5-VL-7B-Instruct-ft-20250814163916929.Q3_K_L.gguf) | Q3_K_L | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-VL-7B-Instruct-ft-20250814163916929-GGUF/resolve/main/Qwen2.5-VL-7B-Instruct-ft-20250814163916929.IQ4_XS.gguf) | IQ4_XS | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-VL-7B-Instruct-ft-20250814163916929-GGUF/resolve/main/Qwen2.5-VL-7B-Instruct-ft-20250814163916929.Q4_K_S.gguf) | Q4_K_S | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-VL-7B-Instruct-ft-20250814163916929-GGUF/resolve/main/Qwen2.5-VL-7B-Instruct-ft-20250814163916929.Q4_K_M.gguf) | Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-VL-7B-Instruct-ft-20250814163916929-GGUF/resolve/main/Qwen2.5-VL-7B-Instruct-ft-20250814163916929.Q5_K_S.gguf) | Q5_K_S | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-VL-7B-Instruct-ft-20250814163916929-GGUF/resolve/main/Qwen2.5-VL-7B-Instruct-ft-20250814163916929.Q5_K_M.gguf) | Q5_K_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-VL-7B-Instruct-ft-20250814163916929-GGUF/resolve/main/Qwen2.5-VL-7B-Instruct-ft-20250814163916929.Q6_K.gguf) | Q6_K | 6.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-VL-7B-Instruct-ft-20250814163916929-GGUF/resolve/main/Qwen2.5-VL-7B-Instruct-ft-20250814163916929.Q8_0.gguf) | Q8_0 | 8.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-VL-7B-Instruct-ft-20250814163916929-GGUF/resolve/main/Qwen2.5-VL-7B-Instruct-ft-20250814163916929.f16.gguf) | f16 | 15.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
unitova/blockassist-bc-zealous_sneaky_raven_1755263155
|
unitova
| 2025-08-15T13:32:16Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"zealous sneaky raven",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T13:32:12Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- zealous sneaky raven
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
aq1048576/rm_sweep_80k
|
aq1048576
| 2025-08-15T13:29:47Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-classification",
"generated_from_trainer",
"trl",
"reward-trainer",
"dataset:aq1048576/sexism_filter_prompt_claude_4_sonnet_trl_80k",
"base_model:Qwen/Qwen3-4B-Base",
"base_model:finetune:Qwen/Qwen3-4B-Base",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-15T10:20:10Z |
---
base_model: Qwen/Qwen3-4B-Base
datasets: aq1048576/sexism_filter_prompt_claude_4_sonnet_trl_80k
library_name: transformers
model_name: rm_sweep_80k
tags:
- generated_from_trainer
- trl
- reward-trainer
licence: license
---
# Model Card for rm_sweep_80k
This model is a fine-tuned version of [Qwen/Qwen3-4B-Base](https://huggingface.co/Qwen/Qwen3-4B-Base) on the [aq1048576/sexism_filter_prompt_claude_4_sonnet_trl_80k](https://huggingface.co/datasets/aq1048576/sexism_filter_prompt_claude_4_sonnet_trl_80k) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="aq1048576/rm_sweep_80k", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/aqi1048576-mats-program/red-team-agent/runs/cx3apyvw)
This model was trained with Reward.
### Framework versions
- TRL: 0.18.2
- Transformers: 4.52.4
- Pytorch: 2.6.0
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
dondesbond/blockassist-bc-moist_tame_tiger_1755261968
|
dondesbond
| 2025-08-15T13:28:08Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"moist tame tiger",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T13:27:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- moist tame tiger
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
koloni/blockassist-bc-deadly_graceful_stingray_1755262529
|
koloni
| 2025-08-15T13:24:26Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-15T13:24:22Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
odharmie/Qwen3-0.6B-Gensyn-Swarm-fanged_toothy_clam
|
odharmie
| 2025-08-15T13:22:20Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am fanged_toothy_clam",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-14T21:26:03Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am fanged_toothy_clam
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
neural-interactive-proofs/finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5_32B_prover_debate_2_rounds_2_0_iter_3_prover1_17552
|
neural-interactive-proofs
| 2025-08-15T13:21:41Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"dpo",
"arxiv:2305.18290",
"base_model:Qwen/Qwen2.5-32B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-32B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-15T13:16:26Z |
---
base_model: Qwen/Qwen2.5-32B-Instruct
library_name: transformers
model_name: finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5_32B_prover_debate_2_rounds_2_0_iter_3_prover1_17552
tags:
- generated_from_trainer
- trl
- dpo
licence: license
---
# Model Card for finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5_32B_prover_debate_2_rounds_2_0_iter_3_prover1_17552
This model is a fine-tuned version of [Qwen/Qwen2.5-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="neural-interactive-proofs/finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5_32B_prover_debate_2_rounds_2_0_iter_3_prover1_17552", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/lrhammond-team/pvg-self-hosted-finetune/runs/qwen2_5-32b-instruct_dpo_2025-08-15_13-42-51_cv_qwen2.5_32B_prover_debate_2_rounds_2_0_iter_3_prover1)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.18.2
- Transformers: 4.53.2
- Pytorch: 2.7.0
- Datasets: 3.0.0
- Tokenizers: 0.21.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.