
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_34818 | rasdani/github-patches | git_diff | chainer__chainer-728 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Use `SOFTMAX_LOG` API of cudnn v3 in `softmax_corss_entropy`
`SOFTMAX_LOG` is supported in cudnn v3. It helps `softmax_cross_entropy` in #712
We need to check version of cudnn. CuPy doesn't support it now.
</issue>
<code>
[start of chainer/functions/loss/softmax_cross_entropy.py]
1 import numpy
2 import six
3
4 from chainer import cuda
5 from chainer import function
6 from chainer.utils import type_check
7
8
9 def logsumexp(x):
10 xp = cuda.get_array_module(x)
11 m = x.max(axis=1, keepdims=True)
12 y = x - m
13 xp.exp(y, out=y)
14 return xp.log(y.sum(axis=1, keepdims=True)) + m
15
16
17 def softmax_log(x):
18 # TODO(unno): Use cudnn (cudnn v2 doesn't support CUDNN_SOFTMAX_LOG)
19 log_z = logsumexp(x)
20 return x - log_z
21
22
23 class SoftmaxCrossEntropy(function.Function):
24
25 """Softmax activation followed by a cross entropy loss."""
26
27 ignore_label = -1
28
29 def __init__(self, use_cudnn=True, normalize=True):
30 self.use_cudnn = use_cudnn
31 self.normalize = normalize
32
33 def check_type_forward(self, in_types):
34 type_check.expect(in_types.size() == 2)
35 x_type, t_type = in_types
36
37 type_check.expect(
38 x_type.dtype == numpy.float32,
39 t_type.dtype == numpy.int32,
40 t_type.ndim == x_type.ndim - 1,
41
42 x_type.shape[0] == t_type.shape[0],
43 x_type.shape[2:] == t_type.shape[1:],
44 )
45
46 def forward_cpu(self, inputs):
47 x, t = inputs
48 log_y = softmax_log(x)
49 self.y = numpy.exp(log_y)
50 log_yd = numpy.rollaxis(log_y, 1)
51 log_yd = log_yd.reshape(len(log_yd), -1)
52
53 log_p = log_yd[numpy.maximum(t.flat, 0), six.moves.range(t.size)]
54 # deal with the case where the SoftmaxCrossEntropy is
55 # unpickled from the old version
56 if getattr(self, 'normalize', True):
57 count = (t != self.ignore_label).sum()
58 else:
59 count = x.shape[0]
60 self.count = count
61
62 if count == 0:
63 return numpy.zeros((), dtype=x.dtype),
64
65 y = (log_p * (t.flat != self.ignore_label)).sum(keepdims=True) \
66 * (-1.0 / count)
67 return y.reshape(()),
68
69 def forward_gpu(self, inputs):
70 cupy = cuda.cupy
71 x, t = inputs
72 log_y = softmax_log(x)
73 self.y = cupy.exp(log_y)
74 if getattr(self, 'normalize', True):
75 count = float((t != self.ignore_label).sum())
76 else:
77 count = t.shape[0]
78 self.count = count
79
80 if count == 0:
81 return cupy.zeros((), dtype=x.dtype),
82
83 log_y = cupy.rollaxis(log_y, 1, log_y.ndim)
84 ret = cuda.reduce(
85 'S t, raw T log_y, int32 n_channel, T inv_count', 'T out',
86 't == -1 ? 0 : log_y[_j * n_channel + t]',
87 'a + b', 'out = a * inv_count', '0', 'crossent_fwd'
88 )(t, log_y.reduced_view(), log_y.shape[-1], -1.0 / count)
89 return ret,
90
91 def backward_cpu(self, inputs, grad_outputs):
92 x, t = inputs
93 if self.count == 0:
94 return numpy.zeros_like(x), None
95
96 gloss = grad_outputs[0]
97 n_unit = t.size // t.shape[0]
98 if self.y.ndim == 2:
99 gx = self.y.copy()
100 gx[six.moves.xrange(len(t)), numpy.maximum(t, 0)] -= 1
101 gx *= (t != self.ignore_label).reshape((len(t), 1))
102 else:
103 # in the case where y.ndim is higher than 2,
104 # we think that a current implementation is inefficient
105 # because it yields two provisional arrays for indexing.
106 gx = self.y.copy().reshape(self.y.shape[0], self.y.shape[1], -1)
107 fst_index = numpy.arange(t.size) // n_unit
108 trd_index = numpy.arange(t.size) % n_unit
109 gx[fst_index, numpy.maximum(t.flat, 0), trd_index] -= 1
110 gx *= (t != self.ignore_label).reshape((len(t), 1, -1))
111 gx = gx.reshape(self.y.shape)
112
113 gx *= gloss / self.count
114 return gx, None
115
116 def backward_gpu(self, inputs, grad_outputs):
117 cupy = cuda.cupy
118 x, t = inputs
119 if self.count == 0:
120 return cupy.zeros_like(x), None
121
122 gloss = grad_outputs[0]
123 n_unit = t.size // t.shape[0]
124 coeff = cuda.cupy.divide(gloss, self.count, dtype=gloss.dtype)
125 gx = cuda.elementwise(
126 'T y, S t, raw T coeff, S n_channel, S n_unit',
127 'T gx',
128 '''
129 const int c = (i / n_unit % n_channel);
130 if (t == -1) {
131 gx = 0;
132 } else {
133 gx = coeff[0] * (y - (c == t));
134 }
135 ''',
136 'softmax_crossent_bwd')(
137 self.y, cupy.expand_dims(t, 1), coeff, x.shape[1], n_unit)
138 return gx, None
139
140
141 def softmax_cross_entropy(x, t, use_cudnn=True, normalize=True):
142 """Computes cross entropy loss for pre-softmax activations.
143
144 Args:
145 x (Variable): Variable holding a multidimensional array whose element
146 indicates unnormalized log probability: the first axis of the
147 variable represents the number of samples, and the second axis
148 represents the number of classes. While this function computes
149 a usual softmax cross entropy if the number of dimensions is equal
150 to 2, it computes a cross entropy of the replicated softmax if the
151 number of dimensions is greater than 2.
152 t (Variable): Variable holding an int32 vector of groundtruth labels.
153 If ``t[i] == -1``, correspondig ``x[i]`` is ignored.
154 normalize (Variable): Variable holding a boolean value which
155 determines the normalization constant. If true, this function
156 normalizes the cross entropy loss across all instances. If else,
157 it only normalizes along a batch size.
158
159 Returns:
160 Variable: A variable holding a scalar array of the cross entropy loss.
161
162 .. note::
163
164 This function is differentiable only by ``x``.
165
166 """
167 return SoftmaxCrossEntropy(use_cudnn, normalize)(x, t)
168
[end of chainer/functions/loss/softmax_cross_entropy.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/chainer/functions/loss/softmax_cross_entropy.py b/chainer/functions/loss/softmax_cross_entropy.py
--- a/chainer/functions/loss/softmax_cross_entropy.py
+++ b/chainer/functions/loss/softmax_cross_entropy.py
@@ -6,6 +6,14 @@
from chainer.utils import type_check
+if cuda.cudnn_enabled:
+ cudnn = cuda.cudnn
+ libcudnn = cudnn.cudnn
+ _algorithm = libcudnn.CUDNN_SOFTMAX_LOG
+ _mode = libcudnn.CUDNN_SOFTMAX_MODE_CHANNEL
+ _cudnn_version = libcudnn.getVersion()
+
+
def logsumexp(x):
xp = cuda.get_array_module(x)
m = x.max(axis=1, keepdims=True)
@@ -14,10 +22,26 @@
return xp.log(y.sum(axis=1, keepdims=True)) + m
-def softmax_log(x):
- # TODO(unno): Use cudnn (cudnn v2 doesn't support CUDNN_SOFTMAX_LOG)
- log_z = logsumexp(x)
- return x - log_z
+def softmax_log(x, use_cudnn):
+ xp = cuda.get_array_module(x)
+ if xp != numpy and cuda.cudnn_enabled and use_cudnn \
+ and _cudnn_version >= 3000:
+ dtype = x.dtype
+ one = numpy.array(1, dtype=dtype).ctypes
+ zero = numpy.array(0, dtype=dtype).ctypes
+ handle = cudnn.get_handle()
+ x_cube = x.reshape(x.shape[:2] + (-1, 1))
+ desc = cudnn.create_tensor_descriptor(x_cube)
+ y = xp.empty_like(x)
+ libcudnn.softmaxForward(
+ handle, _algorithm, _mode, one.data, desc.value,
+ x_cube.data.ptr, zero.data, desc.value,
+ y.data.ptr)
+ return y
+
+ else:
+ log_z = logsumexp(x)
+ return x - log_z
class SoftmaxCrossEntropy(function.Function):
@@ -45,7 +69,7 @@
def forward_cpu(self, inputs):
x, t = inputs
- log_y = softmax_log(x)
+ log_y = softmax_log(x, False)
self.y = numpy.exp(log_y)
log_yd = numpy.rollaxis(log_y, 1)
log_yd = log_yd.reshape(len(log_yd), -1)
@@ -69,7 +93,7 @@
def forward_gpu(self, inputs):
cupy = cuda.cupy
x, t = inputs
- log_y = softmax_log(x)
+ log_y = softmax_log(x, self.use_cudnn)
self.y = cupy.exp(log_y)
if getattr(self, 'normalize', True):
count = float((t != self.ignore_label).sum())
| {"golden_diff": "diff --git a/chainer/functions/loss/softmax_cross_entropy.py b/chainer/functions/loss/softmax_cross_entropy.py\n--- a/chainer/functions/loss/softmax_cross_entropy.py\n+++ b/chainer/functions/loss/softmax_cross_entropy.py\n@@ -6,6 +6,14 @@\n from chainer.utils import type_check\n \n \n+if cuda.cudnn_enabled:\n+ cudnn = cuda.cudnn\n+ libcudnn = cudnn.cudnn\n+ _algorithm = libcudnn.CUDNN_SOFTMAX_LOG\n+ _mode = libcudnn.CUDNN_SOFTMAX_MODE_CHANNEL\n+ _cudnn_version = libcudnn.getVersion()\n+\n+\n def logsumexp(x):\n xp = cuda.get_array_module(x)\n m = x.max(axis=1, keepdims=True)\n@@ -14,10 +22,26 @@\n return xp.log(y.sum(axis=1, keepdims=True)) + m\n \n \n-def softmax_log(x):\n- # TODO(unno): Use cudnn (cudnn v2 doesn't support CUDNN_SOFTMAX_LOG)\n- log_z = logsumexp(x)\n- return x - log_z\n+def softmax_log(x, use_cudnn):\n+ xp = cuda.get_array_module(x)\n+ if xp != numpy and cuda.cudnn_enabled and use_cudnn \\\n+ and _cudnn_version >= 3000:\n+ dtype = x.dtype\n+ one = numpy.array(1, dtype=dtype).ctypes\n+ zero = numpy.array(0, dtype=dtype).ctypes\n+ handle = cudnn.get_handle()\n+ x_cube = x.reshape(x.shape[:2] + (-1, 1))\n+ desc = cudnn.create_tensor_descriptor(x_cube)\n+ y = xp.empty_like(x)\n+ libcudnn.softmaxForward(\n+ handle, _algorithm, _mode, one.data, desc.value,\n+ x_cube.data.ptr, zero.data, desc.value,\n+ y.data.ptr)\n+ return y\n+\n+ else:\n+ log_z = logsumexp(x)\n+ return x - log_z\n \n \n class SoftmaxCrossEntropy(function.Function):\n@@ -45,7 +69,7 @@\n \n def forward_cpu(self, inputs):\n x, t = inputs\n- log_y = softmax_log(x)\n+ log_y = softmax_log(x, False)\n self.y = numpy.exp(log_y)\n log_yd = numpy.rollaxis(log_y, 1)\n log_yd = log_yd.reshape(len(log_yd), -1)\n@@ -69,7 +93,7 @@\n def forward_gpu(self, inputs):\n cupy = cuda.cupy\n x, t = inputs\n- log_y = softmax_log(x)\n+ log_y = softmax_log(x, self.use_cudnn)\n self.y = cupy.exp(log_y)\n if getattr(self, 'normalize', True):\n count = float((t != self.ignore_label).sum())\n", "issue": "Use `SOFTMAX_LOG` API of cudnn v3 in `softmax_corss_entropy`\n`SOFTMAX_LOG` is supported in cudnn v3. It helps `softmax_cross_entropy` in #712 \nWe need to check version of cudnn. CuPy doesn't support it now.\n\n", "before_files": [{"content": "import numpy\nimport six\n\nfrom chainer import cuda\nfrom chainer import function\nfrom chainer.utils import type_check\n\n\ndef logsumexp(x):\n xp = cuda.get_array_module(x)\n m = x.max(axis=1, keepdims=True)\n y = x - m\n xp.exp(y, out=y)\n return xp.log(y.sum(axis=1, keepdims=True)) + m\n\n\ndef softmax_log(x):\n # TODO(unno): Use cudnn (cudnn v2 doesn't support CUDNN_SOFTMAX_LOG)\n log_z = logsumexp(x)\n return x - log_z\n\n\nclass SoftmaxCrossEntropy(function.Function):\n\n \"\"\"Softmax activation followed by a cross entropy loss.\"\"\"\n\n ignore_label = -1\n\n def __init__(self, use_cudnn=True, normalize=True):\n self.use_cudnn = use_cudnn\n self.normalize = normalize\n\n def check_type_forward(self, in_types):\n type_check.expect(in_types.size() == 2)\n x_type, t_type = in_types\n\n type_check.expect(\n x_type.dtype == numpy.float32,\n t_type.dtype == numpy.int32,\n t_type.ndim == x_type.ndim - 1,\n\n x_type.shape[0] == t_type.shape[0],\n x_type.shape[2:] == t_type.shape[1:],\n )\n\n def forward_cpu(self, inputs):\n x, t = inputs\n log_y = softmax_log(x)\n self.y = numpy.exp(log_y)\n log_yd = numpy.rollaxis(log_y, 1)\n log_yd = log_yd.reshape(len(log_yd), -1)\n\n log_p = log_yd[numpy.maximum(t.flat, 0), six.moves.range(t.size)]\n # deal with the case where the SoftmaxCrossEntropy is\n # unpickled from the old version\n if getattr(self, 'normalize', True):\n count = (t != self.ignore_label).sum()\n else:\n count = x.shape[0]\n self.count = count\n\n if count == 0:\n return numpy.zeros((), dtype=x.dtype),\n\n y = (log_p * (t.flat != self.ignore_label)).sum(keepdims=True) \\\n * (-1.0 / count)\n return y.reshape(()),\n\n def forward_gpu(self, inputs):\n cupy = cuda.cupy\n x, t = inputs\n log_y = softmax_log(x)\n self.y = cupy.exp(log_y)\n if getattr(self, 'normalize', True):\n count = float((t != self.ignore_label).sum())\n else:\n count = t.shape[0]\n self.count = count\n\n if count == 0:\n return cupy.zeros((), dtype=x.dtype),\n\n log_y = cupy.rollaxis(log_y, 1, log_y.ndim)\n ret = cuda.reduce(\n 'S t, raw T log_y, int32 n_channel, T inv_count', 'T out',\n 't == -1 ? 0 : log_y[_j * n_channel + t]',\n 'a + b', 'out = a * inv_count', '0', 'crossent_fwd'\n )(t, log_y.reduced_view(), log_y.shape[-1], -1.0 / count)\n return ret,\n\n def backward_cpu(self, inputs, grad_outputs):\n x, t = inputs\n if self.count == 0:\n return numpy.zeros_like(x), None\n\n gloss = grad_outputs[0]\n n_unit = t.size // t.shape[0]\n if self.y.ndim == 2:\n gx = self.y.copy()\n gx[six.moves.xrange(len(t)), numpy.maximum(t, 0)] -= 1\n gx *= (t != self.ignore_label).reshape((len(t), 1))\n else:\n # in the case where y.ndim is higher than 2,\n # we think that a current implementation is inefficient\n # because it yields two provisional arrays for indexing.\n gx = self.y.copy().reshape(self.y.shape[0], self.y.shape[1], -1)\n fst_index = numpy.arange(t.size) // n_unit\n trd_index = numpy.arange(t.size) % n_unit\n gx[fst_index, numpy.maximum(t.flat, 0), trd_index] -= 1\n gx *= (t != self.ignore_label).reshape((len(t), 1, -1))\n gx = gx.reshape(self.y.shape)\n\n gx *= gloss / self.count\n return gx, None\n\n def backward_gpu(self, inputs, grad_outputs):\n cupy = cuda.cupy\n x, t = inputs\n if self.count == 0:\n return cupy.zeros_like(x), None\n\n gloss = grad_outputs[0]\n n_unit = t.size // t.shape[0]\n coeff = cuda.cupy.divide(gloss, self.count, dtype=gloss.dtype)\n gx = cuda.elementwise(\n 'T y, S t, raw T coeff, S n_channel, S n_unit',\n 'T gx',\n '''\n const int c = (i / n_unit % n_channel);\n if (t == -1) {\n gx = 0;\n } else {\n gx = coeff[0] * (y - (c == t));\n }\n ''',\n 'softmax_crossent_bwd')(\n self.y, cupy.expand_dims(t, 1), coeff, x.shape[1], n_unit)\n return gx, None\n\n\ndef softmax_cross_entropy(x, t, use_cudnn=True, normalize=True):\n \"\"\"Computes cross entropy loss for pre-softmax activations.\n\n Args:\n x (Variable): Variable holding a multidimensional array whose element\n indicates unnormalized log probability: the first axis of the\n variable represents the number of samples, and the second axis\n represents the number of classes. While this function computes\n a usual softmax cross entropy if the number of dimensions is equal\n to 2, it computes a cross entropy of the replicated softmax if the\n number of dimensions is greater than 2.\n t (Variable): Variable holding an int32 vector of groundtruth labels.\n If ``t[i] == -1``, correspondig ``x[i]`` is ignored.\n normalize (Variable): Variable holding a boolean value which\n determines the normalization constant. If true, this function\n normalizes the cross entropy loss across all instances. If else,\n it only normalizes along a batch size.\n\n Returns:\n Variable: A variable holding a scalar array of the cross entropy loss.\n\n .. note::\n\n This function is differentiable only by ``x``.\n\n \"\"\"\n return SoftmaxCrossEntropy(use_cudnn, normalize)(x, t)\n", "path": "chainer/functions/loss/softmax_cross_entropy.py"}]} | 2,485 | 659 |
gh_patches_debug_23420 | rasdani/github-patches | git_diff | pypa__pipenv-1536 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
prettytoml deletes unrelated elements when removing items
From #1507.
prettytoml has a bug in `table.py::TableElement.__delitem__` that it deletes a key when the line before it contains inline comment. A minimal example:
```python
import pipenv # noqa
from prettytoml import lexer
from prettytoml.elements.atomic import AtomicElement
from prettytoml.elements.metadata import (
WhitespaceElement, PunctuationElement, CommentElement,
)
from prettytoml.elements.table import TableElement
def test_table():
initial_toml = """id=42 # My id\nage=14"""
tokens = tuple(lexer.tokenize(initial_toml))
table = TableElement([
AtomicElement(tokens[0:1]),
PunctuationElement(tokens[1:2]),
AtomicElement(tokens[2:3]),
WhitespaceElement(tokens[3:4]),
CommentElement(tokens[4:6]),
AtomicElement(tokens[6:7]),
PunctuationElement(tokens[7:8]),
AtomicElement(tokens[8:9]),
])
assert set(table.items()) == {('id', 42), ('age', 14)}
del table['id']
assert set(table.items()) == {('age', 14)}
```
This test case would fail on the final assertion. `table` at this point would be empty, but it should not.
</issue>
<code>
[start of pipenv/patched/prettytoml/elements/table.py]
1 from prettytoml.elements import abstracttable, factory
2 from prettytoml.elements.errors import InvalidElementError
3 from prettytoml.elements.common import Element
4 from prettytoml.elements.metadata import CommentElement, NewlineElement, WhitespaceElement
5 from . import common
6
7
8 class TableElement(abstracttable.AbstractTable):
9 """
10 An Element containing an unnamed top-level table.
11
12 Implements dict-like interface.
13
14 Assumes input sub_elements are correct.
15
16 Raises InvalidElementError on duplicate keys.
17 """
18
19 def __init__(self, sub_elements):
20 abstracttable.AbstractTable.__init__(self, sub_elements)
21
22 self._check_for_duplicate_keys()
23
24 def _check_for_duplicate_keys(self):
25 if len(set(self.keys())) < len(self.keys()):
26 raise InvalidElementError('Duplicate keys found')
27
28 def __setitem__(self, key, value):
29 if key in self:
30 self._update(key, value)
31 else:
32 self._insert(key, value)
33
34 def _update(self, key, value):
35 _, value_i = self._find_key_and_value(key)
36 self._sub_elements[value_i] = value if isinstance(value, Element) else factory.create_element(value)
37
38 def _find_insertion_index(self):
39 """
40 Returns the self.sub_elements index in which new entries should be inserted.
41 """
42
43 non_metadata_elements = tuple(self._enumerate_non_metadata_sub_elements())
44
45 if not non_metadata_elements:
46 return 0
47
48 last_entry_i = non_metadata_elements[-1][0]
49 following_newline_i = self._find_following_line_terminator(last_entry_i)
50
51 return following_newline_i + 1
52
53 def _detect_indentation_size(self):
54 """
55 Detects the level of indentation used in this table.
56 """
57
58 def lines():
59 # Returns a sequence of sequences of elements belonging to each line
60 start = 0
61 for i, element in enumerate(self.elements):
62 if isinstance(element, (CommentElement, NewlineElement)):
63 yield self.elements[start:i+1]
64 start = i+1
65
66 def indentation(line):
67 # Counts the number of whitespace tokens at the beginning of this line
68 try:
69 first_non_whitespace_i = next(i for (i, e) in enumerate(line) if not isinstance(e, WhitespaceElement))
70 return sum(space.length for space in line[:first_non_whitespace_i])
71 except StopIteration:
72 return 0
73
74 def is_empty_line(line):
75 return all(e.type == common.TYPE_METADATA for e in line)
76
77 try:
78 return min(indentation(line) for line in lines() if len(line) > 1 and not is_empty_line(line))
79 except ValueError: # Raised by ValueError when no matching lines found
80 return 0
81
82 def _insert(self, key, value):
83
84 value_element = value if isinstance(value, Element) else factory.create_element(value)
85
86 indentation_size = self._detect_indentation_size()
87 indentation = [factory.create_whitespace_element(self._detect_indentation_size())] if indentation_size else []
88
89 inserted_elements = indentation + [
90 factory.create_string_element(key, bare_allowed=True),
91 factory.create_whitespace_element(),
92 factory.create_operator_element('='),
93 factory.create_whitespace_element(),
94 value_element,
95 factory.create_newline_element(),
96 ]
97
98 insertion_index = self._find_insertion_index()
99
100 self._sub_elements = \
101 self.sub_elements[:insertion_index] + inserted_elements + self.sub_elements[insertion_index:]
102
103 def __delitem__(self, key):
104 begin, _ = self._find_key_and_value(key)
105 preceding_newline = self._find_preceding_newline(begin)
106 if preceding_newline >= 0:
107 begin = preceding_newline
108 end = self._find_following_newline(begin)
109 if end < 0:
110 end = len(tuple(self._sub_elements))
111 self._sub_elements = self.sub_elements[:begin] + self.sub_elements[end:]
112
113 def pop(self, key):
114 v = self[key]
115 del self[key]
116 return v
117
118 def value(self):
119 return self
120
121 def __str__(self):
122 return str(self.primitive_value)
123
[end of pipenv/patched/prettytoml/elements/table.py]
[start of pipenv/patched/prettytoml/elements/traversal/__init__.py]
1 from prettytoml import tokens
2 from prettytoml.elements import common
3 from prettytoml.elements.metadata import PunctuationElement, NewlineElement
4 from prettytoml.elements.traversal import predicates
5
6
7 class TraversalMixin:
8 """
9 A mix-in that provides convenient sub-element traversal to any class with
10 an `elements` member that is a sequence of Element instances
11 """
12
13 def __find_following_element(self, index, predicate):
14 """
15 Finds and returns the index of element in self.elements that evaluates the given predicate to True
16 and whose index is higher than the given index, or returns -Infinity on failure.
17 """
18 return find_following(self.elements, predicate, index)
19
20 def __find_preceding_element(self, index, predicate):
21 """
22 Finds and returns the index of the element in self.elements that evaluates the given predicate to True
23 and whose index is lower than the given index.
24 """
25 i = find_previous(self.elements, predicate, index)
26 if i == float('inf'):
27 return float('-inf')
28 return i
29
30 def __must_find_following_element(self, predicate):
31 """
32 Finds and returns the index to the element in self.elements that evaluatest the predicate to True, or raises
33 an error.
34 """
35 i = self.__find_following_element(-1, predicate)
36 if i < 0:
37 raise RuntimeError('Could not find non-optional element')
38 return i
39
40 def _enumerate_non_metadata_sub_elements(self):
41 """
42 Returns a sequence of of (index, sub_element) of the non-metadata sub-elements.
43 """
44 return ((i, element) for i, element in enumerate(self.elements) if element.type != common.TYPE_METADATA)
45
46 def _find_preceding_comma(self, index):
47 """
48 Returns the index of the preceding comma element to the given index, or -Infinity.
49 """
50 return self.__find_preceding_element(index, predicates.op_comma)
51
52 def _find_following_comma(self, index):
53 """
54 Returns the index of the following comma element after the given index, or -Infinity.
55 """
56 def predicate(element):
57 return isinstance(element, PunctuationElement) and element.token.type == tokens.TYPE_OP_COMMA
58 return self.__find_following_element(index, predicate)
59
60 def _find_following_newline(self, index):
61 """
62 Returns the index of the following newline element after the given index, or -Infinity.
63 """
64 return self.__find_following_element(index, lambda e: isinstance(e, NewlineElement))
65
66 def _find_following_comment(self, index):
67 """
68 Returns the index of the following comment element after the given index, or -Infinity.
69 """
70 return self.__find_following_element(index, predicates.comment)
71
72 def _find_following_line_terminator(self, index):
73 """
74 Returns the index of the following comment or newline element after the given index, or -Infinity.
75 """
76 following_comment = self._find_following_comment(index)
77 following_newline = self._find_following_newline(index)
78
79 if following_comment == float('-inf'):
80 return following_newline
81 if following_newline == float('inf'):
82 return following_comment
83
84 if following_newline < following_comment:
85 return following_newline
86 else:
87 return following_comment
88
89 def _find_preceding_newline(self, index):
90 """
91 Returns the index of the preceding newline element to the given index, or -Infinity.
92 """
93 return self.__find_preceding_element(index, predicates.newline)
94
95 def _find_following_non_metadata(self, index):
96 """
97 Returns the index to the following non-metadata element after the given index, or -Infinity.
98 """
99 return self.__find_following_element(index, predicates.non_metadata)
100
101 def _find_closing_square_bracket(self):
102 """
103 Returns the index to the closing square bracket, or raises an Error.
104 """
105
106 return self.__must_find_following_element(predicates.closing_square_bracket)
107
108 def _find_following_opening_square_bracket(self, index):
109 """
110 Returns the index to the opening square bracket, or -Infinity.
111 """
112 return self.__find_following_element(index, predicates.opening_square_bracket)
113
114 def _find_following_closing_square_bracket(self, index):
115 """
116 Returns the index to the closing square bracket, or -Infinity.
117 """
118 return self.__find_following_element(index, predicates.closing_square_bracket)
119
120 def _find_following_table(self, index):
121 """
122 Returns the index to the next TableElement after the specified index, or -Infinity.
123 """
124 return self.__find_following_element(index, predicates.table)
125
126 def _find_preceding_table(self, index):
127 """
128 Returns the index to the preceding TableElement to the specified index, or -Infinity.
129 """
130 return self.__find_preceding_element(index,predicates.table)
131
132 def _find_closing_curly_bracket(self):
133 """
134 Returns the index to the closing curly bracket, or raises an Error.
135 """
136 def predicate(element):
137 return isinstance(element, PunctuationElement) and element.token.type == tokens.TYPE_OP_CURLY_RIGHT_BRACKET
138 return self.__must_find_following_element(predicate)
139
140 def _find_following_table_header(self, index):
141 """
142 Returns the index to the table header after the given element index, or -Infinity.
143 """
144 return self.__find_following_element(index, predicates.table_header)
145
146
147 def find_following(element_seq, predicate, index=None):
148 """
149 Finds and returns the index of the next element fulfilling the specified predicate after the specified
150 index, or -Infinity.
151
152 Starts searching linearly from the start_from index.
153 """
154
155 if isinstance(index, (int, float)) and index < 0:
156 index = None
157
158 for i, element in tuple(enumerate(element_seq))[index+1 if index is not None else index:]:
159 if predicate(element):
160 return i
161 return float('-inf')
162
163
164 def find_previous(element_seq, predicate, index=None):
165 """
166 Finds and returns the index of the previous element fulfilling the specified predicate preceding to the specified
167 index, or Infinity.
168 """
169 if isinstance(index, (int, float)) and index >= len(element_seq):
170 index = None
171
172 for i, element in reversed(tuple(enumerate(element_seq))[:index]):
173 if predicate(element):
174 return i
175 return float('inf')
176
[end of pipenv/patched/prettytoml/elements/traversal/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pipenv/patched/prettytoml/elements/table.py b/pipenv/patched/prettytoml/elements/table.py
--- a/pipenv/patched/prettytoml/elements/table.py
+++ b/pipenv/patched/prettytoml/elements/table.py
@@ -105,7 +105,7 @@
preceding_newline = self._find_preceding_newline(begin)
if preceding_newline >= 0:
begin = preceding_newline
- end = self._find_following_newline(begin)
+ end = self._find_following_line_terminator(begin)
if end < 0:
end = len(tuple(self._sub_elements))
self._sub_elements = self.sub_elements[:begin] + self.sub_elements[end:]
diff --git a/pipenv/patched/prettytoml/elements/traversal/__init__.py b/pipenv/patched/prettytoml/elements/traversal/__init__.py
--- a/pipenv/patched/prettytoml/elements/traversal/__init__.py
+++ b/pipenv/patched/prettytoml/elements/traversal/__init__.py
@@ -76,9 +76,9 @@
following_comment = self._find_following_comment(index)
following_newline = self._find_following_newline(index)
- if following_comment == float('-inf'):
+ if following_comment == float('inf'):
return following_newline
- if following_newline == float('inf'):
+ if following_newline == float('-inf'):
return following_comment
if following_newline < following_comment:
| {"golden_diff": "diff --git a/pipenv/patched/prettytoml/elements/table.py b/pipenv/patched/prettytoml/elements/table.py\n--- a/pipenv/patched/prettytoml/elements/table.py\n+++ b/pipenv/patched/prettytoml/elements/table.py\n@@ -105,7 +105,7 @@\n preceding_newline = self._find_preceding_newline(begin)\n if preceding_newline >= 0:\n begin = preceding_newline\n- end = self._find_following_newline(begin)\n+ end = self._find_following_line_terminator(begin)\n if end < 0:\n end = len(tuple(self._sub_elements))\n self._sub_elements = self.sub_elements[:begin] + self.sub_elements[end:]\ndiff --git a/pipenv/patched/prettytoml/elements/traversal/__init__.py b/pipenv/patched/prettytoml/elements/traversal/__init__.py\n--- a/pipenv/patched/prettytoml/elements/traversal/__init__.py\n+++ b/pipenv/patched/prettytoml/elements/traversal/__init__.py\n@@ -76,9 +76,9 @@\n following_comment = self._find_following_comment(index)\n following_newline = self._find_following_newline(index)\n \n- if following_comment == float('-inf'):\n+ if following_comment == float('inf'):\n return following_newline\n- if following_newline == float('inf'):\n+ if following_newline == float('-inf'):\n return following_comment\n \n if following_newline < following_comment:\n", "issue": "prettytoml deletes unrelated elements when removing items\nFrom #1507.\r\n\r\nprettytoml has a bug in `table.py::TableElement.__delitem__` that it deletes a key when the line before it contains inline comment. A minimal example:\r\n\r\n```python\r\nimport pipenv # noqa\r\n\r\nfrom prettytoml import lexer\r\nfrom prettytoml.elements.atomic import AtomicElement\r\nfrom prettytoml.elements.metadata import (\r\n WhitespaceElement, PunctuationElement, CommentElement,\r\n)\r\nfrom prettytoml.elements.table import TableElement\r\n\r\n\r\ndef test_table():\r\n\r\n initial_toml = \"\"\"id=42 # My id\\nage=14\"\"\"\r\n tokens = tuple(lexer.tokenize(initial_toml))\r\n table = TableElement([\r\n AtomicElement(tokens[0:1]),\r\n PunctuationElement(tokens[1:2]),\r\n AtomicElement(tokens[2:3]),\r\n WhitespaceElement(tokens[3:4]),\r\n CommentElement(tokens[4:6]),\r\n\r\n AtomicElement(tokens[6:7]),\r\n PunctuationElement(tokens[7:8]),\r\n AtomicElement(tokens[8:9]),\r\n ])\r\n\r\n assert set(table.items()) == {('id', 42), ('age', 14)}\r\n\r\n del table['id']\r\n assert set(table.items()) == {('age', 14)}\r\n```\r\n\r\nThis test case would fail on the final assertion. `table` at this point would be empty, but it should not.\n", "before_files": [{"content": "from prettytoml.elements import abstracttable, factory\nfrom prettytoml.elements.errors import InvalidElementError\nfrom prettytoml.elements.common import Element\nfrom prettytoml.elements.metadata import CommentElement, NewlineElement, WhitespaceElement\nfrom . import common\n\n\nclass TableElement(abstracttable.AbstractTable):\n \"\"\"\n An Element containing an unnamed top-level table.\n\n Implements dict-like interface.\n\n Assumes input sub_elements are correct.\n\n Raises InvalidElementError on duplicate keys.\n \"\"\"\n\n def __init__(self, sub_elements):\n abstracttable.AbstractTable.__init__(self, sub_elements)\n\n self._check_for_duplicate_keys()\n\n def _check_for_duplicate_keys(self):\n if len(set(self.keys())) < len(self.keys()):\n raise InvalidElementError('Duplicate keys found')\n\n def __setitem__(self, key, value):\n if key in self:\n self._update(key, value)\n else:\n self._insert(key, value)\n\n def _update(self, key, value):\n _, value_i = self._find_key_and_value(key)\n self._sub_elements[value_i] = value if isinstance(value, Element) else factory.create_element(value)\n\n def _find_insertion_index(self):\n \"\"\"\n Returns the self.sub_elements index in which new entries should be inserted.\n \"\"\"\n\n non_metadata_elements = tuple(self._enumerate_non_metadata_sub_elements())\n\n if not non_metadata_elements:\n return 0\n\n last_entry_i = non_metadata_elements[-1][0]\n following_newline_i = self._find_following_line_terminator(last_entry_i)\n\n return following_newline_i + 1\n\n def _detect_indentation_size(self):\n \"\"\"\n Detects the level of indentation used in this table.\n \"\"\"\n\n def lines():\n # Returns a sequence of sequences of elements belonging to each line\n start = 0\n for i, element in enumerate(self.elements):\n if isinstance(element, (CommentElement, NewlineElement)):\n yield self.elements[start:i+1]\n start = i+1\n\n def indentation(line):\n # Counts the number of whitespace tokens at the beginning of this line\n try:\n first_non_whitespace_i = next(i for (i, e) in enumerate(line) if not isinstance(e, WhitespaceElement))\n return sum(space.length for space in line[:first_non_whitespace_i])\n except StopIteration:\n return 0\n\n def is_empty_line(line):\n return all(e.type == common.TYPE_METADATA for e in line)\n\n try:\n return min(indentation(line) for line in lines() if len(line) > 1 and not is_empty_line(line))\n except ValueError: # Raised by ValueError when no matching lines found\n return 0\n\n def _insert(self, key, value):\n\n value_element = value if isinstance(value, Element) else factory.create_element(value)\n\n indentation_size = self._detect_indentation_size()\n indentation = [factory.create_whitespace_element(self._detect_indentation_size())] if indentation_size else []\n\n inserted_elements = indentation + [\n factory.create_string_element(key, bare_allowed=True),\n factory.create_whitespace_element(),\n factory.create_operator_element('='),\n factory.create_whitespace_element(),\n value_element,\n factory.create_newline_element(),\n ]\n\n insertion_index = self._find_insertion_index()\n\n self._sub_elements = \\\n self.sub_elements[:insertion_index] + inserted_elements + self.sub_elements[insertion_index:]\n\n def __delitem__(self, key):\n begin, _ = self._find_key_and_value(key)\n preceding_newline = self._find_preceding_newline(begin)\n if preceding_newline >= 0:\n begin = preceding_newline\n end = self._find_following_newline(begin)\n if end < 0:\n end = len(tuple(self._sub_elements))\n self._sub_elements = self.sub_elements[:begin] + self.sub_elements[end:]\n\n def pop(self, key):\n v = self[key]\n del self[key]\n return v\n\n def value(self):\n return self\n\n def __str__(self):\n return str(self.primitive_value)\n", "path": "pipenv/patched/prettytoml/elements/table.py"}, {"content": "from prettytoml import tokens\nfrom prettytoml.elements import common\nfrom prettytoml.elements.metadata import PunctuationElement, NewlineElement\nfrom prettytoml.elements.traversal import predicates\n\n\nclass TraversalMixin:\n \"\"\"\n A mix-in that provides convenient sub-element traversal to any class with\n an `elements` member that is a sequence of Element instances\n \"\"\"\n\n def __find_following_element(self, index, predicate):\n \"\"\"\n Finds and returns the index of element in self.elements that evaluates the given predicate to True\n and whose index is higher than the given index, or returns -Infinity on failure.\n \"\"\"\n return find_following(self.elements, predicate, index)\n\n def __find_preceding_element(self, index, predicate):\n \"\"\"\n Finds and returns the index of the element in self.elements that evaluates the given predicate to True\n and whose index is lower than the given index.\n \"\"\"\n i = find_previous(self.elements, predicate, index)\n if i == float('inf'):\n return float('-inf')\n return i\n\n def __must_find_following_element(self, predicate):\n \"\"\"\n Finds and returns the index to the element in self.elements that evaluatest the predicate to True, or raises\n an error.\n \"\"\"\n i = self.__find_following_element(-1, predicate)\n if i < 0:\n raise RuntimeError('Could not find non-optional element')\n return i\n\n def _enumerate_non_metadata_sub_elements(self):\n \"\"\"\n Returns a sequence of of (index, sub_element) of the non-metadata sub-elements.\n \"\"\"\n return ((i, element) for i, element in enumerate(self.elements) if element.type != common.TYPE_METADATA)\n\n def _find_preceding_comma(self, index):\n \"\"\"\n Returns the index of the preceding comma element to the given index, or -Infinity.\n \"\"\"\n return self.__find_preceding_element(index, predicates.op_comma)\n\n def _find_following_comma(self, index):\n \"\"\"\n Returns the index of the following comma element after the given index, or -Infinity.\n \"\"\"\n def predicate(element):\n return isinstance(element, PunctuationElement) and element.token.type == tokens.TYPE_OP_COMMA\n return self.__find_following_element(index, predicate)\n\n def _find_following_newline(self, index):\n \"\"\"\n Returns the index of the following newline element after the given index, or -Infinity.\n \"\"\"\n return self.__find_following_element(index, lambda e: isinstance(e, NewlineElement))\n\n def _find_following_comment(self, index):\n \"\"\"\n Returns the index of the following comment element after the given index, or -Infinity.\n \"\"\"\n return self.__find_following_element(index, predicates.comment)\n\n def _find_following_line_terminator(self, index):\n \"\"\"\n Returns the index of the following comment or newline element after the given index, or -Infinity.\n \"\"\"\n following_comment = self._find_following_comment(index)\n following_newline = self._find_following_newline(index)\n\n if following_comment == float('-inf'):\n return following_newline\n if following_newline == float('inf'):\n return following_comment\n\n if following_newline < following_comment:\n return following_newline\n else:\n return following_comment\n\n def _find_preceding_newline(self, index):\n \"\"\"\n Returns the index of the preceding newline element to the given index, or -Infinity.\n \"\"\"\n return self.__find_preceding_element(index, predicates.newline)\n\n def _find_following_non_metadata(self, index):\n \"\"\"\n Returns the index to the following non-metadata element after the given index, or -Infinity.\n \"\"\"\n return self.__find_following_element(index, predicates.non_metadata)\n\n def _find_closing_square_bracket(self):\n \"\"\"\n Returns the index to the closing square bracket, or raises an Error.\n \"\"\"\n\n return self.__must_find_following_element(predicates.closing_square_bracket)\n\n def _find_following_opening_square_bracket(self, index):\n \"\"\"\n Returns the index to the opening square bracket, or -Infinity.\n \"\"\"\n return self.__find_following_element(index, predicates.opening_square_bracket)\n\n def _find_following_closing_square_bracket(self, index):\n \"\"\"\n Returns the index to the closing square bracket, or -Infinity.\n \"\"\"\n return self.__find_following_element(index, predicates.closing_square_bracket)\n\n def _find_following_table(self, index):\n \"\"\"\n Returns the index to the next TableElement after the specified index, or -Infinity.\n \"\"\"\n return self.__find_following_element(index, predicates.table)\n\n def _find_preceding_table(self, index):\n \"\"\"\n Returns the index to the preceding TableElement to the specified index, or -Infinity.\n \"\"\"\n return self.__find_preceding_element(index,predicates.table)\n\n def _find_closing_curly_bracket(self):\n \"\"\"\n Returns the index to the closing curly bracket, or raises an Error.\n \"\"\"\n def predicate(element):\n return isinstance(element, PunctuationElement) and element.token.type == tokens.TYPE_OP_CURLY_RIGHT_BRACKET\n return self.__must_find_following_element(predicate)\n\n def _find_following_table_header(self, index):\n \"\"\"\n Returns the index to the table header after the given element index, or -Infinity.\n \"\"\"\n return self.__find_following_element(index, predicates.table_header)\n\n\ndef find_following(element_seq, predicate, index=None):\n \"\"\"\n Finds and returns the index of the next element fulfilling the specified predicate after the specified\n index, or -Infinity.\n\n Starts searching linearly from the start_from index.\n \"\"\"\n\n if isinstance(index, (int, float)) and index < 0:\n index = None\n\n for i, element in tuple(enumerate(element_seq))[index+1 if index is not None else index:]:\n if predicate(element):\n return i\n return float('-inf')\n\n\ndef find_previous(element_seq, predicate, index=None):\n \"\"\"\n Finds and returns the index of the previous element fulfilling the specified predicate preceding to the specified\n index, or Infinity.\n \"\"\"\n if isinstance(index, (int, float)) and index >= len(element_seq):\n index = None\n\n for i, element in reversed(tuple(enumerate(element_seq))[:index]):\n if predicate(element):\n return i\n return float('inf')\n", "path": "pipenv/patched/prettytoml/elements/traversal/__init__.py"}]} | 3,876 | 361 |
gh_patches_debug_65929 | rasdani/github-patches | git_diff | iterative__dvc-985 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Trouble installing dvc with pip: No matching distribution found for futures>=3.2.0 (from dvc)
I'm on a fresh ubuntu 18.04 and I want to install DVC. But I run into some dependency problems. Never had that problem before.
```
➤ virtualenv -p python3 .venv
➤ source .venv/bin/activate.fish
➤ pip install dvc
Collecting dvc
Using cached https://files.pythonhosted.org/packages/d2/2d/117b6e99f4e7f0760d99944919d9dcaaeabfb6c6182a9c890b7260eec697/dvc-0.15.2-py2.py3-none-any.whl
Collecting pyasn1>=0.4.1 (from dvc)
Using cached https://files.pythonhosted.org/packages/d1/a1/7790cc85db38daa874f6a2e6308131b9953feb1367f2ae2d1123bb93a9f5/pyasn1-0.4.4-py2.py3-none-any.whl
Collecting ply>=3.9 (from dvc)
Using cached https://files.pythonhosted.org/packages/a3/58/35da89ee790598a0700ea49b2a66594140f44dec458c07e8e3d4979137fc/ply-3.11-py2.py3-none-any.whl
Collecting futures>=3.2.0 (from dvc)
Could not find a version that satisfies the requirement futures>=3.2.0 (from dvc) (from versions: 0.2.python3, 0.1, 0.2, 1.0, 2.0, 2.1, 2.1.1, 2.1.2, 2.1.3, 2.1.4, 2.1.5, 2.1.6, 2.2.0, 3.0.0, 3.0.1, 3.0.2, 3.0.3, 3.0.4, 3.0.5, 3.1.0, 3.1.1)
No matching distribution found for futures>=3.2.0 (from dvc)
```
Here are all relevant version
```
➤ pip --version
pip 18.0 from /home/PATH/.venv/lib/python3.6/site-packages/pip (python 3.6)
➤ python --version
Python 3.6.5
➤ virtualenv --version
16.0.0
```
</issue>
<code>
[start of setup.py]
1 import sys
2 import platform
3 from setuptools import setup, find_packages
4 from distutils.errors import DistutilsPlatformError
5 from dvc import VERSION
6
7
8 install_requires = [
9 "ply>=3.9", # See https://github.com/pyinstaller/pyinstaller/issues/1945
10 "configparser>=3.5.0",
11 "zc.lockfile>=1.2.1",
12 "future>=0.16.0",
13 "colorama>=0.3.9",
14 "configobj>=5.0.6",
15 "networkx==2.1",
16 "pyyaml>=3.12",
17 "gitpython>=2.1.8",
18 "ntfsutils>=0.1.4",
19 "setuptools>=34.0.0",
20 "nanotime>=0.5.2",
21 "pyasn1>=0.4.1",
22 "schema>=0.6.7",
23 "jsonpath-rw==1.4.0",
24 "reflink==0.2.0",
25 "requests>=2.18.4",
26 ]
27
28 if sys.version_info[0] == 2:
29 install_requires.append("futures>=3.2.0")
30
31 # Extra dependencies for remote integrations
32 gs = [
33 "google-cloud==0.32.0",
34 ]
35 s3 = [
36 "boto3==1.7.4",
37 ]
38 azure = [
39 "azure-storage-blob==1.3.0"
40 ]
41 ssh = [
42 "paramiko>=2.4.1",
43 ]
44 all_remotes = gs + s3 + azure + ssh
45
46 setup(
47 name='dvc',
48 version=VERSION,
49 description='Git for data scientists - manage your code and data together',
50 long_description=open('README.rst', 'r').read(),
51 author='Dmitry Petrov',
52 author_email='[email protected]',
53 download_url='https://github.com/iterative/dvc',
54 license='Apache License 2.0',
55 install_requires=install_requires,
56 extras_require={
57 'all': all_remotes,
58 'gs': gs,
59 's3': s3,
60 'azure': azure,
61 'ssh': ssh,
62 },
63 keywords='data science, data version control, machine learning',
64 classifiers=[
65 'Development Status :: 4 - Beta',
66 'Programming Language :: Python :: 2',
67 'Programming Language :: Python :: 3',
68 ],
69 packages=find_packages(exclude=['bin', 'tests', 'functests']),
70 include_package_data=True,
71 url='http://dataversioncontrol.com',
72 entry_points={
73 'console_scripts': ['dvc = dvc.main:main']
74 },
75 zip_safe=False
76 )
77
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -23,11 +23,9 @@
"jsonpath-rw==1.4.0",
"reflink==0.2.0",
"requests>=2.18.4",
+ 'futures; python_version == "2.7"',
]
-if sys.version_info[0] == 2:
- install_requires.append("futures>=3.2.0")
-
# Extra dependencies for remote integrations
gs = [
"google-cloud==0.32.0",
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -23,11 +23,9 @@\n \"jsonpath-rw==1.4.0\",\n \"reflink==0.2.0\",\n \"requests>=2.18.4\",\n+ 'futures; python_version == \"2.7\"',\n ]\n \n-if sys.version_info[0] == 2:\n- install_requires.append(\"futures>=3.2.0\")\n-\n # Extra dependencies for remote integrations\n gs = [\n \"google-cloud==0.32.0\",\n", "issue": "Trouble installing dvc with pip: No matching distribution found for futures>=3.2.0 (from dvc)\nI'm on a fresh ubuntu 18.04 and I want to install DVC. But I run into some dependency problems. Never had that problem before.\r\n```\r\n\u27a4 virtualenv -p python3 .venv\r\n\u27a4 source .venv/bin/activate.fish\r\n\u27a4 pip install dvc\r\nCollecting dvc\r\n Using cached https://files.pythonhosted.org/packages/d2/2d/117b6e99f4e7f0760d99944919d9dcaaeabfb6c6182a9c890b7260eec697/dvc-0.15.2-py2.py3-none-any.whl\r\nCollecting pyasn1>=0.4.1 (from dvc)\r\n Using cached https://files.pythonhosted.org/packages/d1/a1/7790cc85db38daa874f6a2e6308131b9953feb1367f2ae2d1123bb93a9f5/pyasn1-0.4.4-py2.py3-none-any.whl\r\nCollecting ply>=3.9 (from dvc)\r\n Using cached https://files.pythonhosted.org/packages/a3/58/35da89ee790598a0700ea49b2a66594140f44dec458c07e8e3d4979137fc/ply-3.11-py2.py3-none-any.whl\r\nCollecting futures>=3.2.0 (from dvc)\r\n Could not find a version that satisfies the requirement futures>=3.2.0 (from dvc) (from versions: 0.2.python3, 0.1, 0.2, 1.0, 2.0, 2.1, 2.1.1, 2.1.2, 2.1.3, 2.1.4, 2.1.5, 2.1.6, 2.2.0, 3.0.0, 3.0.1, 3.0.2, 3.0.3, 3.0.4, 3.0.5, 3.1.0, 3.1.1)\r\nNo matching distribution found for futures>=3.2.0 (from dvc)\r\n```\r\nHere are all relevant version\r\n```\r\n\u27a4 pip --version\r\npip 18.0 from /home/PATH/.venv/lib/python3.6/site-packages/pip (python 3.6)\r\n\u27a4 python --version\r\nPython 3.6.5\r\n\u27a4 virtualenv --version\r\n16.0.0\r\n```\n", "before_files": [{"content": "import sys\nimport platform\nfrom setuptools import setup, find_packages\nfrom distutils.errors import DistutilsPlatformError\nfrom dvc import VERSION\n\n\ninstall_requires = [\n \"ply>=3.9\", # See https://github.com/pyinstaller/pyinstaller/issues/1945\n \"configparser>=3.5.0\",\n \"zc.lockfile>=1.2.1\",\n \"future>=0.16.0\",\n \"colorama>=0.3.9\",\n \"configobj>=5.0.6\",\n \"networkx==2.1\",\n \"pyyaml>=3.12\",\n \"gitpython>=2.1.8\",\n \"ntfsutils>=0.1.4\",\n \"setuptools>=34.0.0\",\n \"nanotime>=0.5.2\",\n \"pyasn1>=0.4.1\",\n \"schema>=0.6.7\",\n \"jsonpath-rw==1.4.0\",\n \"reflink==0.2.0\",\n \"requests>=2.18.4\",\n]\n\nif sys.version_info[0] == 2:\n install_requires.append(\"futures>=3.2.0\")\n\n# Extra dependencies for remote integrations\ngs = [\n \"google-cloud==0.32.0\",\n]\ns3 = [\n \"boto3==1.7.4\",\n]\nazure = [\n \"azure-storage-blob==1.3.0\"\n]\nssh = [\n \"paramiko>=2.4.1\",\n]\nall_remotes = gs + s3 + azure + ssh\n\nsetup(\n name='dvc',\n version=VERSION,\n description='Git for data scientists - manage your code and data together',\n long_description=open('README.rst', 'r').read(),\n author='Dmitry Petrov',\n author_email='[email protected]',\n download_url='https://github.com/iterative/dvc',\n license='Apache License 2.0',\n install_requires=install_requires,\n extras_require={\n 'all': all_remotes,\n 'gs': gs,\n 's3': s3,\n 'azure': azure,\n 'ssh': ssh,\n },\n keywords='data science, data version control, machine learning',\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 3',\n ],\n packages=find_packages(exclude=['bin', 'tests', 'functests']),\n include_package_data=True,\n url='http://dataversioncontrol.com',\n entry_points={\n 'console_scripts': ['dvc = dvc.main:main']\n },\n zip_safe=False\n)\n", "path": "setup.py"}]} | 1,928 | 134 |
gh_patches_debug_8904 | rasdani/github-patches | git_diff | cloud-custodian__cloud-custodian-3852 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Azure - c7n-Mailer Errors
About 50% of the time mailer runs, the following error results and messages aren't picked up, delivered:
```
Traceback (most recent call last):
File "/usr/local/bin/c7n-mailer", line 10, in <module>
sys.exit(main())
File "/usr/local/lib/python3.7/site-packages/c7n_mailer/cli.py", line 227, in main
processor.run()
File "/usr/local/lib/python3.7/site-packages/c7n_mailer/azure/azure_queue_processor.py", line 62, in run
if (self.process_azure_queue_message(queue_message) or
File "/usr/local/lib/python3.7/site-packages/c7n_mailer/azure/azure_queue_processor.py", line 89, in process_azure_queue_message
SendGridDelivery(self.config, self.logger))
File "/usr/local/lib/python3.7/site-packages/c7n_mailer/azure/sendgrid_delivery.py", line 29, in __init__
sendgrid.SendGridAPIClient(apikey=self.config.get('sendgrid_api_key', ''))
TypeError: __init__() got an unexpected keyword argument 'apikey'
```
</issue>
<code>
[start of tools/c7n_mailer/c7n_mailer/azure/sendgrid_delivery.py]
1 # Copyright 2018 Capital One Services, LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import sendgrid
16 import six
17 from c7n_mailer.utils import (get_message_subject, get_rendered_jinja)
18 from c7n_mailer.utils_email import is_email
19 from python_http_client import exceptions
20 from sendgrid.helpers.mail import Email, Content, Mail
21
22
23 class SendGridDelivery(object):
24
25 def __init__(self, config, logger):
26 self.config = config
27 self.logger = logger
28 self.sendgrid_client = \
29 sendgrid.SendGridAPIClient(apikey=self.config.get('sendgrid_api_key', ''))
30
31 def get_to_addrs_sendgrid_messages_map(self, queue_message):
32 # eg: { ('[email protected]', '[email protected]'): [resource1, resource2, etc] }
33 to_addrs_to_resources_map = self.get_email_to_addrs_to_resources_map(queue_message)
34
35 to_addrs_to_content_map = {}
36 for to_addrs, resources in six.iteritems(to_addrs_to_resources_map):
37 to_addrs_to_content_map[to_addrs] = self.get_message_content(
38 queue_message,
39 resources,
40 list(to_addrs)
41 )
42 # eg: { ('[email protected]', '[email protected]'): message }
43 return to_addrs_to_content_map
44
45 # this function returns a dictionary with a tuple of emails as the key
46 # and the list of resources as the value. This helps ensure minimal emails
47 # are sent, while only ever sending emails to the respective parties.
48 def get_email_to_addrs_to_resources_map(self, queue_message):
49 email_to_addrs_to_resources_map = {}
50 targets = queue_message['action']['to']
51
52 for resource in queue_message['resources']:
53 # this is the list of emails that will be sent for this resource
54 resource_emails = []
55
56 for target in targets:
57 if target.startswith('tag:') and 'tags' in resource:
58 tag_name = target.split(':', 1)[1]
59 result = resource.get('tags', {}).get(tag_name, None)
60 if is_email(result):
61 resource_emails.append(result)
62 elif is_email(target):
63 resource_emails.append(target)
64
65 resource_emails = tuple(sorted(set(resource_emails)))
66
67 if resource_emails:
68 email_to_addrs_to_resources_map.setdefault(resource_emails, []).append(resource)
69
70 if email_to_addrs_to_resources_map == {}:
71 self.logger.debug('Found no email addresses, sending no emails.')
72 # eg: { ('[email protected]', '[email protected]'): [resource1, resource2, etc] }
73 return email_to_addrs_to_resources_map
74
75 def get_message_content(self, queue_message, resources, to_addrs):
76 return get_rendered_jinja(
77 to_addrs, queue_message, resources, self.logger,
78 'template', 'default', self.config['templates_folders'])
79
80 def sendgrid_handler(self, queue_message, to_addrs_to_email_messages_map):
81 self.logger.info("Sending account:%s policy:%s %s:%s email:%s to %s" % (
82 queue_message.get('account', ''),
83 queue_message['policy']['name'],
84 queue_message['policy']['resource'],
85 str(len(queue_message['resources'])),
86 queue_message['action'].get('template', 'default'),
87 to_addrs_to_email_messages_map))
88
89 from_email = Email(self.config.get('from_address', ''))
90 subject = get_message_subject(queue_message)
91 email_format = queue_message['action'].get('template_format', None)
92 if not email_format:
93 email_format = queue_message['action'].get(
94 'template', 'default').endswith('html') and 'html' or 'plain'
95
96 for email_to_addrs, email_content in six.iteritems(to_addrs_to_email_messages_map):
97 for to_address in email_to_addrs:
98 to_email = Email(to_address)
99 content = Content("text/" + email_format, email_content)
100 mail = Mail(from_email, subject, to_email, content)
101 try:
102 self.sendgrid_client.client.mail.send.post(request_body=mail.get())
103 except (exceptions.UnauthorizedError, exceptions.BadRequestsError) as e:
104 self.logger.warning(
105 "\n**Error \nPolicy:%s \nAccount:%s \nSending to:%s \n\nRequest body:"
106 "\n%s\n\nRequest headers:\n%s\n\n mailer.yml: %s" % (
107 queue_message['policy'],
108 queue_message.get('account', ''),
109 email_to_addrs,
110 e.body,
111 e.headers,
112 self.config
113 )
114 )
115 return False
116 return True
117
[end of tools/c7n_mailer/c7n_mailer/azure/sendgrid_delivery.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/tools/c7n_mailer/c7n_mailer/azure/sendgrid_delivery.py b/tools/c7n_mailer/c7n_mailer/azure/sendgrid_delivery.py
--- a/tools/c7n_mailer/c7n_mailer/azure/sendgrid_delivery.py
+++ b/tools/c7n_mailer/c7n_mailer/azure/sendgrid_delivery.py
@@ -26,7 +26,7 @@
self.config = config
self.logger = logger
self.sendgrid_client = \
- sendgrid.SendGridAPIClient(apikey=self.config.get('sendgrid_api_key', ''))
+ sendgrid.SendGridAPIClient(self.config.get('sendgrid_api_key', ''))
def get_to_addrs_sendgrid_messages_map(self, queue_message):
# eg: { ('[email protected]', '[email protected]'): [resource1, resource2, etc] }
| {"golden_diff": "diff --git a/tools/c7n_mailer/c7n_mailer/azure/sendgrid_delivery.py b/tools/c7n_mailer/c7n_mailer/azure/sendgrid_delivery.py\n--- a/tools/c7n_mailer/c7n_mailer/azure/sendgrid_delivery.py\n+++ b/tools/c7n_mailer/c7n_mailer/azure/sendgrid_delivery.py\n@@ -26,7 +26,7 @@\n self.config = config\n self.logger = logger\n self.sendgrid_client = \\\n- sendgrid.SendGridAPIClient(apikey=self.config.get('sendgrid_api_key', ''))\n+ sendgrid.SendGridAPIClient(self.config.get('sendgrid_api_key', ''))\n \n def get_to_addrs_sendgrid_messages_map(self, queue_message):\n # eg: { ('[email protected]', '[email protected]'): [resource1, resource2, etc] }\n", "issue": "Azure - c7n-Mailer Errors\nAbout 50% of the time mailer runs, the following error results and messages aren't picked up, delivered:\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/c7n-mailer\", line 10, in <module>\r\n sys.exit(main())\r\n File \"/usr/local/lib/python3.7/site-packages/c7n_mailer/cli.py\", line 227, in main\r\n processor.run()\r\n File \"/usr/local/lib/python3.7/site-packages/c7n_mailer/azure/azure_queue_processor.py\", line 62, in run\r\n if (self.process_azure_queue_message(queue_message) or\r\n File \"/usr/local/lib/python3.7/site-packages/c7n_mailer/azure/azure_queue_processor.py\", line 89, in process_azure_queue_message\r\n SendGridDelivery(self.config, self.logger))\r\n File \"/usr/local/lib/python3.7/site-packages/c7n_mailer/azure/sendgrid_delivery.py\", line 29, in __init__\r\n sendgrid.SendGridAPIClient(apikey=self.config.get('sendgrid_api_key', ''))\r\nTypeError: __init__() got an unexpected keyword argument 'apikey'\r\n```\r\n\n", "before_files": [{"content": "# Copyright 2018 Capital One Services, LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport sendgrid\nimport six\nfrom c7n_mailer.utils import (get_message_subject, get_rendered_jinja)\nfrom c7n_mailer.utils_email import is_email\nfrom python_http_client import exceptions\nfrom sendgrid.helpers.mail import Email, Content, Mail\n\n\nclass SendGridDelivery(object):\n\n def __init__(self, config, logger):\n self.config = config\n self.logger = logger\n self.sendgrid_client = \\\n sendgrid.SendGridAPIClient(apikey=self.config.get('sendgrid_api_key', ''))\n\n def get_to_addrs_sendgrid_messages_map(self, queue_message):\n # eg: { ('[email protected]', '[email protected]'): [resource1, resource2, etc] }\n to_addrs_to_resources_map = self.get_email_to_addrs_to_resources_map(queue_message)\n\n to_addrs_to_content_map = {}\n for to_addrs, resources in six.iteritems(to_addrs_to_resources_map):\n to_addrs_to_content_map[to_addrs] = self.get_message_content(\n queue_message,\n resources,\n list(to_addrs)\n )\n # eg: { ('[email protected]', '[email protected]'): message }\n return to_addrs_to_content_map\n\n # this function returns a dictionary with a tuple of emails as the key\n # and the list of resources as the value. This helps ensure minimal emails\n # are sent, while only ever sending emails to the respective parties.\n def get_email_to_addrs_to_resources_map(self, queue_message):\n email_to_addrs_to_resources_map = {}\n targets = queue_message['action']['to']\n\n for resource in queue_message['resources']:\n # this is the list of emails that will be sent for this resource\n resource_emails = []\n\n for target in targets:\n if target.startswith('tag:') and 'tags' in resource:\n tag_name = target.split(':', 1)[1]\n result = resource.get('tags', {}).get(tag_name, None)\n if is_email(result):\n resource_emails.append(result)\n elif is_email(target):\n resource_emails.append(target)\n\n resource_emails = tuple(sorted(set(resource_emails)))\n\n if resource_emails:\n email_to_addrs_to_resources_map.setdefault(resource_emails, []).append(resource)\n\n if email_to_addrs_to_resources_map == {}:\n self.logger.debug('Found no email addresses, sending no emails.')\n # eg: { ('[email protected]', '[email protected]'): [resource1, resource2, etc] }\n return email_to_addrs_to_resources_map\n\n def get_message_content(self, queue_message, resources, to_addrs):\n return get_rendered_jinja(\n to_addrs, queue_message, resources, self.logger,\n 'template', 'default', self.config['templates_folders'])\n\n def sendgrid_handler(self, queue_message, to_addrs_to_email_messages_map):\n self.logger.info(\"Sending account:%s policy:%s %s:%s email:%s to %s\" % (\n queue_message.get('account', ''),\n queue_message['policy']['name'],\n queue_message['policy']['resource'],\n str(len(queue_message['resources'])),\n queue_message['action'].get('template', 'default'),\n to_addrs_to_email_messages_map))\n\n from_email = Email(self.config.get('from_address', ''))\n subject = get_message_subject(queue_message)\n email_format = queue_message['action'].get('template_format', None)\n if not email_format:\n email_format = queue_message['action'].get(\n 'template', 'default').endswith('html') and 'html' or 'plain'\n\n for email_to_addrs, email_content in six.iteritems(to_addrs_to_email_messages_map):\n for to_address in email_to_addrs:\n to_email = Email(to_address)\n content = Content(\"text/\" + email_format, email_content)\n mail = Mail(from_email, subject, to_email, content)\n try:\n self.sendgrid_client.client.mail.send.post(request_body=mail.get())\n except (exceptions.UnauthorizedError, exceptions.BadRequestsError) as e:\n self.logger.warning(\n \"\\n**Error \\nPolicy:%s \\nAccount:%s \\nSending to:%s \\n\\nRequest body:\"\n \"\\n%s\\n\\nRequest headers:\\n%s\\n\\n mailer.yml: %s\" % (\n queue_message['policy'],\n queue_message.get('account', ''),\n email_to_addrs,\n e.body,\n e.headers,\n self.config\n )\n )\n return False\n return True\n", "path": "tools/c7n_mailer/c7n_mailer/azure/sendgrid_delivery.py"}]} | 2,189 | 198 |
gh_patches_debug_18314 | rasdani/github-patches | git_diff | pymodbus-dev__pymodbus-532 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Python modbus Unit decode
https://github.com/riptideio/pymodbus/blob/fbdc470ae3e138c50e3659ec4ec8ebf39df58936/pymodbus/client/asynchronous/twisted/__init__.py#L101
Always be 0 because all framers not return 'uid' but 'unit'
Create pythonpackage.yml
<!-- Please raise your PR's against the `dev` branch instead of `master` -->
Another typo length lenght
Apart the typos carried by my PR #480, I just noticed another one in pymodbus/framer/socket_framer.py (dev branch):
```
return dict(tid=tid, pid=pid, lenght=length, unit=uid, fcode=fcode)
```
Read RTU Holding Register through Serial Forwarder/TCP.
I have Energy Meter connected through RTU and able to get holding registers data through simple RTU Code.
Now i want to make Convert this RTU to TCP through Forwarder. I want to send data to TCP which forwards the command to RTU and fetches data for me.
I have implement the Forwarder code just dont know how to fetch the holding register of RTU through it.
**Code for Simple RTU Read**
> import pymodbus
> from pymodbus.pdu import ModbusRequest
> from pymodbus.client.sync import ModbusSerialClient as ModbusClient
> #initialize a serial RTU client instance
> from pymodbus.transaction import ModbusRtuFramer
>
> #count= the number of registers to read
> #unit= the slave unit this request is targeting
> #address= the starting address to read from
>
> client = ModbusClient(method = 'rtu', port='/dev/ttyUSB0', baudrate= 9600)
>
> #Connect to the serial modbus server
> connection = client.connect()
> print(connection)
>
> #Starting add, num of reg to read, slave unit.
> read = client.read_holding_registers(address = 0x01,count =2, unit=1)
> data = read.registers
>
> print(data)
>
> #Closes the underlying socket connection
> client.close()
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 """
3 Installs pymodbus using distutils
4
5 Run:
6 python setup.py install
7 to install the package from the source archive.
8
9 For information about setuptools
10 http://peak.telecommunity.com/DevCenter/setuptools#new-and-changed-setup-keywords
11 """
12
13 # --------------------------------------------------------------------------- #
14 # initialization
15 # --------------------------------------------------------------------------- #
16 try: # if not installed, install and proceed
17 from setuptools import setup, find_packages
18 except ImportError:
19 from ez_setup import use_setuptools
20 use_setuptools()
21 from setuptools import setup, find_packages
22
23 try:
24 from setup_commands import command_classes
25 except ImportError:
26 command_classes={}
27 from pymodbus import __version__, __author__, __maintainer__
28
29 with open('requirements.txt') as reqs:
30 install_requires = [
31 line for line in reqs.read().split('\n')
32 if (line and not line.startswith('--'))
33 ]
34 install_requires.append("pyserial >= 3.4")
35 # --------------------------------------------------------------------------- #
36 # configuration
37 # --------------------------------------------------------------------------- #
38 setup(
39 name="pymodbus",
40 version=__version__,
41 description="A fully featured modbus protocol stack in python",
42 long_description="""
43 Pymodbus aims to be a fully implemented modbus protocol stack
44 implemented using twisted/asyncio/tornado.
45 Its orignal goal was to allow simulation of thousands of modbus devices
46 on a single machine for monitoring software testing.
47 """,
48 classifiers=[
49 'Development Status :: 4 - Beta',
50 'Environment :: Console',
51 'Environment :: X11 Applications :: GTK',
52 'Framework :: Twisted',
53 'Intended Audience :: Developers',
54 'License :: OSI Approved :: BSD License',
55 'Operating System :: POSIX :: Linux',
56 'Operating System :: Unix',
57 'Programming Language :: Python',
58 'Programming Language :: Python :: 3',
59 'Topic :: System :: Networking',
60 'Topic :: Utilities'
61 ],
62 keywords='modbus, twisted, scada',
63 author=__author__,
64 author_email='[email protected]',
65 maintainer=__maintainer__,
66 maintainer_email='[email protected]',
67 url='https://github.com/riptideio/pymodbus/',
68 license='BSD-3-Clause',
69 packages=find_packages(exclude=['examples', 'test']),
70 exclude_package_data={'': ['examples', 'test', 'tools', 'doc']},
71 py_modules=['ez_setup'],
72 platforms=['Linux', 'Mac OS X', 'Win'],
73 include_package_data=True,
74 zip_safe=True,
75 install_requires=install_requires,
76 extras_require={
77 'quality': [
78 'coverage >= 3.5.3',
79 'nose >= 1.2.1',
80 'mock >= 1.0.0',
81 'pep8 >= 1.3.3'
82 ],
83 'documents': ['sphinx >= 1.1.3',
84 'sphinx_rtd_theme',
85 'humanfriendly'],
86 'twisted': [
87 'twisted >= 12.2.0',
88 'pyasn1 >= 0.1.4',
89 ],
90 'tornado': [
91 'tornado >= 4.5.3'
92 ],
93 'repl': [
94 'click>=6.7',
95 'prompt-toolkit==2.0.4',
96 'pygments==2.2.0'
97 ]
98 },
99 entry_points={
100 'console_scripts': ['pymodbus.console=pymodbus.repl.main:main'],
101 },
102 test_suite='nose.collector',
103 cmdclass=command_classes,
104 )
105
106
[end of setup.py]
[start of pymodbus/version.py]
1 """
2 Handle the version information here; you should only have to
3 change the version tuple.
4
5 Since we are using twisted's version class, we can also query
6 the svn version as well using the local .entries file.
7 """
8
9
10 class Version(object):
11
12 def __init__(self, package, major, minor, micro, pre=None):
13 """
14
15 :param package: Name of the package that this is a version of.
16 :param major: The major version number.
17 :param minor: The minor version number.
18 :param micro: The micro version number.
19 :param pre: The pre release tag
20 """
21 self.package = package
22 self.major = major
23 self.minor = minor
24 self.micro = micro
25 self.pre = pre
26
27 def short(self):
28 """ Return a string in canonical short version format
29 <major>.<minor>.<micro>.<pre>
30 """
31 if self.pre:
32 return '%d.%d.%d.%s' % (self.major, self.minor, self.micro, self.pre)
33 else:
34 return '%d.%d.%d' % (self.major, self.minor, self.micro)
35
36 def __str__(self):
37 """ Returns a string representation of the object
38
39 :returns: A string representation of this object
40 """
41 return '[%s, version %s]' % (self.package, self.short())
42
43
44 version = Version('pymodbus', 2, 4, 0, 'rc2')
45
46
47
48 version.__name__ = 'pymodbus' # fix epydoc error
49
50 # --------------------------------------------------------------------------- #
51 # Exported symbols
52 # --------------------------------------------------------------------------- #
53
54 __all__ = ["version"]
55
[end of pymodbus/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pymodbus/version.py b/pymodbus/version.py
--- a/pymodbus/version.py
+++ b/pymodbus/version.py
@@ -41,9 +41,7 @@
return '[%s, version %s]' % (self.package, self.short())
-version = Version('pymodbus', 2, 4, 0, 'rc2')
-
-
+version = Version('pymodbus', 2, 4, 0)
version.__name__ = 'pymodbus' # fix epydoc error
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -84,14 +84,14 @@
'sphinx_rtd_theme',
'humanfriendly'],
'twisted': [
- 'twisted >= 12.2.0',
+ 'twisted >= 20.3.0',
'pyasn1 >= 0.1.4',
],
'tornado': [
- 'tornado >= 4.5.3'
+ 'tornado == 4.5.3'
],
'repl': [
- 'click>=6.7',
+ 'click>=7.0',
'prompt-toolkit==2.0.4',
'pygments==2.2.0'
]
| {"golden_diff": "diff --git a/pymodbus/version.py b/pymodbus/version.py\n--- a/pymodbus/version.py\n+++ b/pymodbus/version.py\n@@ -41,9 +41,7 @@\n return '[%s, version %s]' % (self.package, self.short())\n \n \n-version = Version('pymodbus', 2, 4, 0, 'rc2')\n-\n-\n+version = Version('pymodbus', 2, 4, 0)\n \n version.__name__ = 'pymodbus' # fix epydoc error\n \ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -84,14 +84,14 @@\n 'sphinx_rtd_theme',\n 'humanfriendly'],\n 'twisted': [\n- 'twisted >= 12.2.0',\n+ 'twisted >= 20.3.0',\n 'pyasn1 >= 0.1.4',\n ],\n 'tornado': [\n- 'tornado >= 4.5.3'\n+ 'tornado == 4.5.3'\n ],\n 'repl': [\n- 'click>=6.7',\n+ 'click>=7.0',\n 'prompt-toolkit==2.0.4',\n 'pygments==2.2.0'\n ]\n", "issue": "Python modbus Unit decode\nhttps://github.com/riptideio/pymodbus/blob/fbdc470ae3e138c50e3659ec4ec8ebf39df58936/pymodbus/client/asynchronous/twisted/__init__.py#L101\r\n\r\nAlways be 0 because all framers not return 'uid' but 'unit'\r\n\nCreate pythonpackage.yml\n<!-- Please raise your PR's against the `dev` branch instead of `master` -->\r\n\nAnother typo length lenght\nApart the typos carried by my PR #480, I just noticed another one in pymodbus/framer/socket_framer.py (dev branch):\r\n```\r\nreturn dict(tid=tid, pid=pid, lenght=length, unit=uid, fcode=fcode)\r\n```\nRead RTU Holding Register through Serial Forwarder/TCP.\nI have Energy Meter connected through RTU and able to get holding registers data through simple RTU Code. \r\nNow i want to make Convert this RTU to TCP through Forwarder. I want to send data to TCP which forwards the command to RTU and fetches data for me.\r\n\r\nI have implement the Forwarder code just dont know how to fetch the holding register of RTU through it.\r\n\r\n**Code for Simple RTU Read**\r\n\r\n> import pymodbus\r\n> from pymodbus.pdu import ModbusRequest\r\n> from pymodbus.client.sync import ModbusSerialClient as ModbusClient \r\n> #initialize a serial RTU client instance\r\n> from pymodbus.transaction import ModbusRtuFramer\r\n> \r\n> #count= the number of registers to read\r\n> #unit= the slave unit this request is targeting\r\n> #address= the starting address to read from\r\n> \r\n> client = ModbusClient(method = 'rtu', port='/dev/ttyUSB0', baudrate= 9600)\r\n> \r\n> #Connect to the serial modbus server\r\n> connection = client.connect()\r\n> print(connection)\r\n> \r\n> #Starting add, num of reg to read, slave unit.\r\n> read = client.read_holding_registers(address = 0x01,count =2, unit=1)\r\n> data = read.registers\r\n> \r\n> print(data)\r\n> \r\n> #Closes the underlying socket connection\r\n> client.close()\n", "before_files": [{"content": "#!/usr/bin/env python\n\"\"\"\nInstalls pymodbus using distutils\n\nRun:\n python setup.py install\nto install the package from the source archive.\n\nFor information about setuptools\nhttp://peak.telecommunity.com/DevCenter/setuptools#new-and-changed-setup-keywords\n\"\"\"\n\n# --------------------------------------------------------------------------- #\n# initialization\n# --------------------------------------------------------------------------- #\ntry: # if not installed, install and proceed\n from setuptools import setup, find_packages\nexcept ImportError:\n from ez_setup import use_setuptools\n use_setuptools()\n from setuptools import setup, find_packages\n\ntry:\n from setup_commands import command_classes\nexcept ImportError:\n command_classes={}\nfrom pymodbus import __version__, __author__, __maintainer__\n\nwith open('requirements.txt') as reqs:\n install_requires = [\n line for line in reqs.read().split('\\n')\n if (line and not line.startswith('--'))\n ]\n install_requires.append(\"pyserial >= 3.4\")\n# --------------------------------------------------------------------------- #\n# configuration\n# --------------------------------------------------------------------------- #\nsetup(\n name=\"pymodbus\",\n version=__version__,\n description=\"A fully featured modbus protocol stack in python\",\n long_description=\"\"\"\n Pymodbus aims to be a fully implemented modbus protocol stack\n implemented using twisted/asyncio/tornado.\n Its orignal goal was to allow simulation of thousands of modbus devices\n on a single machine for monitoring software testing.\n \"\"\",\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Environment :: Console',\n 'Environment :: X11 Applications :: GTK',\n 'Framework :: Twisted',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: BSD License',\n 'Operating System :: POSIX :: Linux',\n 'Operating System :: Unix',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Topic :: System :: Networking',\n 'Topic :: Utilities'\n ],\n keywords='modbus, twisted, scada',\n author=__author__,\n author_email='[email protected]',\n maintainer=__maintainer__,\n maintainer_email='[email protected]',\n url='https://github.com/riptideio/pymodbus/',\n license='BSD-3-Clause',\n packages=find_packages(exclude=['examples', 'test']),\n exclude_package_data={'': ['examples', 'test', 'tools', 'doc']},\n py_modules=['ez_setup'],\n platforms=['Linux', 'Mac OS X', 'Win'],\n include_package_data=True,\n zip_safe=True,\n install_requires=install_requires,\n extras_require={\n 'quality': [\n 'coverage >= 3.5.3',\n 'nose >= 1.2.1',\n 'mock >= 1.0.0',\n 'pep8 >= 1.3.3'\n ],\n 'documents': ['sphinx >= 1.1.3',\n 'sphinx_rtd_theme',\n 'humanfriendly'],\n 'twisted': [\n 'twisted >= 12.2.0',\n 'pyasn1 >= 0.1.4',\n ],\n 'tornado': [\n 'tornado >= 4.5.3'\n ],\n 'repl': [\n 'click>=6.7',\n 'prompt-toolkit==2.0.4',\n 'pygments==2.2.0'\n ]\n },\n entry_points={\n 'console_scripts': ['pymodbus.console=pymodbus.repl.main:main'],\n },\n test_suite='nose.collector',\n cmdclass=command_classes,\n)\n\n", "path": "setup.py"}, {"content": "\"\"\"\nHandle the version information here; you should only have to\nchange the version tuple.\n\nSince we are using twisted's version class, we can also query\nthe svn version as well using the local .entries file.\n\"\"\"\n\n\nclass Version(object):\n\n def __init__(self, package, major, minor, micro, pre=None):\n \"\"\"\n\n :param package: Name of the package that this is a version of.\n :param major: The major version number.\n :param minor: The minor version number.\n :param micro: The micro version number.\n :param pre: The pre release tag\n \"\"\"\n self.package = package\n self.major = major\n self.minor = minor\n self.micro = micro\n self.pre = pre\n\n def short(self):\n \"\"\" Return a string in canonical short version format\n <major>.<minor>.<micro>.<pre>\n \"\"\"\n if self.pre:\n return '%d.%d.%d.%s' % (self.major, self.minor, self.micro, self.pre)\n else:\n return '%d.%d.%d' % (self.major, self.minor, self.micro)\n\n def __str__(self):\n \"\"\" Returns a string representation of the object\n\n :returns: A string representation of this object\n \"\"\"\n return '[%s, version %s]' % (self.package, self.short())\n\n\nversion = Version('pymodbus', 2, 4, 0, 'rc2')\n\n\n\nversion.__name__ = 'pymodbus' # fix epydoc error\n\n# --------------------------------------------------------------------------- #\n# Exported symbols\n# --------------------------------------------------------------------------- #\n\n__all__ = [\"version\"]\n", "path": "pymodbus/version.py"}]} | 2,495 | 309 |
gh_patches_debug_59175 | rasdani/github-patches | git_diff | PaddlePaddle__models-2832 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
icnet 存在的几个问题
[icnet](https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/icnet)里存在诸多问题:
1.文档有误,--model_path="./cnkpnt/100"应该是--model_path="./chkpnt/100"
2.训练时没有输出中间过程信息,仅在最后输出几个loss信息
3.文档中给的预训练模型无法用于infer,能提供下训好的cnkpnt/100模型吗?
</issue>
<code>
[start of PaddleCV/icnet/train.py]
1 """Trainer for ICNet model."""
2 from __future__ import absolute_import
3 from __future__ import division
4 from __future__ import print_function
5 from icnet import icnet
6 import cityscape
7 import argparse
8 import functools
9 import sys
10 import os
11 import time
12 import paddle.fluid as fluid
13 import numpy as np
14 from utils import add_arguments, print_arguments, get_feeder_data, check_gpu
15 from paddle.fluid.layers.learning_rate_scheduler import _decay_step_counter
16 from paddle.fluid.initializer import init_on_cpu
17
18 if 'ce_mode' in os.environ:
19 np.random.seed(10)
20 fluid.default_startup_program().random_seed = 90
21
22 parser = argparse.ArgumentParser(description=__doc__)
23 add_arg = functools.partial(add_arguments, argparser=parser)
24 # yapf: disable
25 add_arg('batch_size', int, 16, "Minibatch size.")
26 add_arg('checkpoint_path', str, None, "Checkpoint svae path.")
27 add_arg('init_model', str, None, "Pretrain model path.")
28 add_arg('use_gpu', bool, True, "Whether use GPU to train.")
29 add_arg('random_mirror', bool, True, "Whether prepare by random mirror.")
30 add_arg('random_scaling', bool, True, "Whether prepare by random scaling.")
31 # yapf: enable
32
33 LAMBDA1 = 0.16
34 LAMBDA2 = 0.4
35 LAMBDA3 = 1.0
36 LEARNING_RATE = 0.003
37 POWER = 0.9
38 LOG_PERIOD = 100
39 CHECKPOINT_PERIOD = 100
40 TOTAL_STEP = 100
41
42 no_grad_set = []
43
44
45 def create_loss(predict, label, mask, num_classes):
46 predict = fluid.layers.transpose(predict, perm=[0, 2, 3, 1])
47 predict = fluid.layers.reshape(predict, shape=[-1, num_classes])
48 label = fluid.layers.reshape(label, shape=[-1, 1])
49 predict = fluid.layers.gather(predict, mask)
50 label = fluid.layers.gather(label, mask)
51 label = fluid.layers.cast(label, dtype="int64")
52 loss = fluid.layers.softmax_with_cross_entropy(predict, label)
53 no_grad_set.append(label.name)
54 return fluid.layers.reduce_mean(loss)
55
56
57 def poly_decay():
58 global_step = _decay_step_counter()
59 with init_on_cpu():
60 decayed_lr = LEARNING_RATE * (fluid.layers.pow(
61 (1 - global_step / TOTAL_STEP), POWER))
62 return decayed_lr
63
64
65 def train(args):
66 data_shape = cityscape.train_data_shape()
67 num_classes = cityscape.num_classes()
68 # define network
69 images = fluid.layers.data(name='image', shape=data_shape, dtype='float32')
70 label_sub1 = fluid.layers.data(name='label_sub1', shape=[1], dtype='int32')
71 label_sub2 = fluid.layers.data(name='label_sub2', shape=[1], dtype='int32')
72 label_sub4 = fluid.layers.data(name='label_sub4', shape=[1], dtype='int32')
73 mask_sub1 = fluid.layers.data(name='mask_sub1', shape=[-1], dtype='int32')
74 mask_sub2 = fluid.layers.data(name='mask_sub2', shape=[-1], dtype='int32')
75 mask_sub4 = fluid.layers.data(name='mask_sub4', shape=[-1], dtype='int32')
76
77 sub4_out, sub24_out, sub124_out = icnet(
78 images, num_classes, np.array(data_shape[1:]).astype("float32"))
79 loss_sub4 = create_loss(sub4_out, label_sub4, mask_sub4, num_classes)
80 loss_sub24 = create_loss(sub24_out, label_sub2, mask_sub2, num_classes)
81 loss_sub124 = create_loss(sub124_out, label_sub1, mask_sub1, num_classes)
82 reduced_loss = LAMBDA1 * loss_sub4 + LAMBDA2 * loss_sub24 + LAMBDA3 * loss_sub124
83
84 regularizer = fluid.regularizer.L2Decay(0.0001)
85 optimizer = fluid.optimizer.Momentum(
86 learning_rate=poly_decay(), momentum=0.9, regularization=regularizer)
87 _, params_grads = optimizer.minimize(reduced_loss, no_grad_set=no_grad_set)
88
89 # prepare environment
90 place = fluid.CPUPlace()
91 if args.use_gpu:
92 place = fluid.CUDAPlace(0)
93 exe = fluid.Executor(place)
94
95 exe.run(fluid.default_startup_program())
96
97 if args.init_model is not None:
98 print("load model from: %s" % args.init_model)
99
100 def if_exist(var):
101 return os.path.exists(os.path.join(args.init_model, var.name))
102
103 fluid.io.load_vars(exe, args.init_model, predicate=if_exist)
104
105 iter_id = 0
106 t_loss = 0.
107 sub4_loss = 0.
108 sub24_loss = 0.
109 sub124_loss = 0.
110 train_reader = cityscape.train(
111 args.batch_size, flip=args.random_mirror, scaling=args.random_scaling)
112 start_time = time.time()
113 while True:
114 # train a pass
115 for data in train_reader():
116 if iter_id > TOTAL_STEP:
117 end_time = time.time()
118 print("kpis train_duration %f" % (end_time - start_time))
119 return
120 iter_id += 1
121 results = exe.run(
122 feed=get_feeder_data(data, place),
123 fetch_list=[reduced_loss, loss_sub4, loss_sub24, loss_sub124])
124 t_loss += results[0]
125 sub4_loss += results[1]
126 sub24_loss += results[2]
127 sub124_loss += results[3]
128 # training log
129 if iter_id % LOG_PERIOD == 0:
130 print(
131 "Iter[%d]; train loss: %.3f; sub4_loss: %.3f; sub24_loss: %.3f; sub124_loss: %.3f"
132 % (iter_id, t_loss / LOG_PERIOD, sub4_loss / LOG_PERIOD,
133 sub24_loss / LOG_PERIOD, sub124_loss / LOG_PERIOD))
134 print("kpis train_cost %f" % (t_loss / LOG_PERIOD))
135
136 t_loss = 0.
137 sub4_loss = 0.
138 sub24_loss = 0.
139 sub124_loss = 0.
140 sys.stdout.flush()
141
142 if iter_id % CHECKPOINT_PERIOD == 0 and args.checkpoint_path is not None:
143 dir_name = args.checkpoint_path + "/" + str(iter_id)
144 fluid.io.save_persistables(exe, dirname=dir_name)
145 print("Saved checkpoint: %s" % (dir_name))
146
147
148 def main():
149 args = parser.parse_args()
150 print_arguments(args)
151 check_gpu(args.use_gpu)
152 train(args)
153
154
155 if __name__ == "__main__":
156 main()
157
[end of PaddleCV/icnet/train.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/PaddleCV/icnet/train.py b/PaddleCV/icnet/train.py
--- a/PaddleCV/icnet/train.py
+++ b/PaddleCV/icnet/train.py
@@ -35,9 +35,11 @@
LAMBDA3 = 1.0
LEARNING_RATE = 0.003
POWER = 0.9
-LOG_PERIOD = 100
-CHECKPOINT_PERIOD = 100
-TOTAL_STEP = 100
+LOG_PERIOD = 1
+CHECKPOINT_PERIOD = 1000
+TOTAL_STEP = 60000
+if 'ce_mode' in os.environ:
+ TOTAL_STEP = 100
no_grad_set = []
| {"golden_diff": "diff --git a/PaddleCV/icnet/train.py b/PaddleCV/icnet/train.py\n--- a/PaddleCV/icnet/train.py\n+++ b/PaddleCV/icnet/train.py\n@@ -35,9 +35,11 @@\n LAMBDA3 = 1.0\n LEARNING_RATE = 0.003\n POWER = 0.9\n-LOG_PERIOD = 100\n-CHECKPOINT_PERIOD = 100\n-TOTAL_STEP = 100\n+LOG_PERIOD = 1\n+CHECKPOINT_PERIOD = 1000\n+TOTAL_STEP = 60000\n+if 'ce_mode' in os.environ:\n+ TOTAL_STEP = 100\n \n no_grad_set = []\n", "issue": "icnet \u5b58\u5728\u7684\u51e0\u4e2a\u95ee\u9898\n[icnet](https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/icnet)\u91cc\u5b58\u5728\u8bf8\u591a\u95ee\u9898:\r\n1.\u6587\u6863\u6709\u8bef\uff0c--model_path=\"./cnkpnt/100\"\u5e94\u8be5\u662f--model_path=\"./chkpnt/100\"\r\n2.\u8bad\u7ec3\u65f6\u6ca1\u6709\u8f93\u51fa\u4e2d\u95f4\u8fc7\u7a0b\u4fe1\u606f\uff0c\u4ec5\u5728\u6700\u540e\u8f93\u51fa\u51e0\u4e2aloss\u4fe1\u606f\r\n3.\u6587\u6863\u4e2d\u7ed9\u7684\u9884\u8bad\u7ec3\u6a21\u578b\u65e0\u6cd5\u7528\u4e8einfer\uff0c\u80fd\u63d0\u4f9b\u4e0b\u8bad\u597d\u7684cnkpnt/100\u6a21\u578b\u5417\uff1f\n", "before_files": [{"content": "\"\"\"Trainer for ICNet model.\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nfrom icnet import icnet\nimport cityscape\nimport argparse\nimport functools\nimport sys\nimport os\nimport time\nimport paddle.fluid as fluid\nimport numpy as np\nfrom utils import add_arguments, print_arguments, get_feeder_data, check_gpu\nfrom paddle.fluid.layers.learning_rate_scheduler import _decay_step_counter\nfrom paddle.fluid.initializer import init_on_cpu\n\nif 'ce_mode' in os.environ:\n np.random.seed(10)\n fluid.default_startup_program().random_seed = 90\n\nparser = argparse.ArgumentParser(description=__doc__)\nadd_arg = functools.partial(add_arguments, argparser=parser)\n# yapf: disable\nadd_arg('batch_size', int, 16, \"Minibatch size.\")\nadd_arg('checkpoint_path', str, None, \"Checkpoint svae path.\")\nadd_arg('init_model', str, None, \"Pretrain model path.\")\nadd_arg('use_gpu', bool, True, \"Whether use GPU to train.\")\nadd_arg('random_mirror', bool, True, \"Whether prepare by random mirror.\")\nadd_arg('random_scaling', bool, True, \"Whether prepare by random scaling.\")\n# yapf: enable\n\nLAMBDA1 = 0.16\nLAMBDA2 = 0.4\nLAMBDA3 = 1.0\nLEARNING_RATE = 0.003\nPOWER = 0.9\nLOG_PERIOD = 100\nCHECKPOINT_PERIOD = 100\nTOTAL_STEP = 100\n\nno_grad_set = []\n\n\ndef create_loss(predict, label, mask, num_classes):\n predict = fluid.layers.transpose(predict, perm=[0, 2, 3, 1])\n predict = fluid.layers.reshape(predict, shape=[-1, num_classes])\n label = fluid.layers.reshape(label, shape=[-1, 1])\n predict = fluid.layers.gather(predict, mask)\n label = fluid.layers.gather(label, mask)\n label = fluid.layers.cast(label, dtype=\"int64\")\n loss = fluid.layers.softmax_with_cross_entropy(predict, label)\n no_grad_set.append(label.name)\n return fluid.layers.reduce_mean(loss)\n\n\ndef poly_decay():\n global_step = _decay_step_counter()\n with init_on_cpu():\n decayed_lr = LEARNING_RATE * (fluid.layers.pow(\n (1 - global_step / TOTAL_STEP), POWER))\n return decayed_lr\n\n\ndef train(args):\n data_shape = cityscape.train_data_shape()\n num_classes = cityscape.num_classes()\n # define network\n images = fluid.layers.data(name='image', shape=data_shape, dtype='float32')\n label_sub1 = fluid.layers.data(name='label_sub1', shape=[1], dtype='int32')\n label_sub2 = fluid.layers.data(name='label_sub2', shape=[1], dtype='int32')\n label_sub4 = fluid.layers.data(name='label_sub4', shape=[1], dtype='int32')\n mask_sub1 = fluid.layers.data(name='mask_sub1', shape=[-1], dtype='int32')\n mask_sub2 = fluid.layers.data(name='mask_sub2', shape=[-1], dtype='int32')\n mask_sub4 = fluid.layers.data(name='mask_sub4', shape=[-1], dtype='int32')\n\n sub4_out, sub24_out, sub124_out = icnet(\n images, num_classes, np.array(data_shape[1:]).astype(\"float32\"))\n loss_sub4 = create_loss(sub4_out, label_sub4, mask_sub4, num_classes)\n loss_sub24 = create_loss(sub24_out, label_sub2, mask_sub2, num_classes)\n loss_sub124 = create_loss(sub124_out, label_sub1, mask_sub1, num_classes)\n reduced_loss = LAMBDA1 * loss_sub4 + LAMBDA2 * loss_sub24 + LAMBDA3 * loss_sub124\n\n regularizer = fluid.regularizer.L2Decay(0.0001)\n optimizer = fluid.optimizer.Momentum(\n learning_rate=poly_decay(), momentum=0.9, regularization=regularizer)\n _, params_grads = optimizer.minimize(reduced_loss, no_grad_set=no_grad_set)\n\n # prepare environment\n place = fluid.CPUPlace()\n if args.use_gpu:\n place = fluid.CUDAPlace(0)\n exe = fluid.Executor(place)\n\n exe.run(fluid.default_startup_program())\n\n if args.init_model is not None:\n print(\"load model from: %s\" % args.init_model)\n\n def if_exist(var):\n return os.path.exists(os.path.join(args.init_model, var.name))\n\n fluid.io.load_vars(exe, args.init_model, predicate=if_exist)\n\n iter_id = 0\n t_loss = 0.\n sub4_loss = 0.\n sub24_loss = 0.\n sub124_loss = 0.\n train_reader = cityscape.train(\n args.batch_size, flip=args.random_mirror, scaling=args.random_scaling)\n start_time = time.time()\n while True:\n # train a pass\n for data in train_reader():\n if iter_id > TOTAL_STEP:\n end_time = time.time()\n print(\"kpis\ttrain_duration\t%f\" % (end_time - start_time))\n return\n iter_id += 1\n results = exe.run(\n feed=get_feeder_data(data, place),\n fetch_list=[reduced_loss, loss_sub4, loss_sub24, loss_sub124])\n t_loss += results[0]\n sub4_loss += results[1]\n sub24_loss += results[2]\n sub124_loss += results[3]\n # training log\n if iter_id % LOG_PERIOD == 0:\n print(\n \"Iter[%d]; train loss: %.3f; sub4_loss: %.3f; sub24_loss: %.3f; sub124_loss: %.3f\"\n % (iter_id, t_loss / LOG_PERIOD, sub4_loss / LOG_PERIOD,\n sub24_loss / LOG_PERIOD, sub124_loss / LOG_PERIOD))\n print(\"kpis\ttrain_cost\t%f\" % (t_loss / LOG_PERIOD))\n\n t_loss = 0.\n sub4_loss = 0.\n sub24_loss = 0.\n sub124_loss = 0.\n sys.stdout.flush()\n\n if iter_id % CHECKPOINT_PERIOD == 0 and args.checkpoint_path is not None:\n dir_name = args.checkpoint_path + \"/\" + str(iter_id)\n fluid.io.save_persistables(exe, dirname=dir_name)\n print(\"Saved checkpoint: %s\" % (dir_name))\n\n\ndef main():\n args = parser.parse_args()\n print_arguments(args)\n check_gpu(args.use_gpu)\n train(args)\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "PaddleCV/icnet/train.py"}]} | 2,569 | 163 |
gh_patches_debug_25861 | rasdani/github-patches | git_diff | OpenNMT__OpenNMT-tf-503 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
How to support PPL
Can you add the PPL measurement?
</issue>
<code>
[start of opennmt/evaluation.py]
1 """Evaluation related classes and functions."""
2
3 import collections
4 import os
5 import six
6
7 import tensorflow as tf
8
9 from opennmt.data import dataset as dataset_lib
10 from opennmt.utils import misc
11 from opennmt.utils import scorers as scorers_lib
12
13
14 _SUMMARIES_SCOPE = "metrics"
15
16
17 class EarlyStopping(
18 collections.namedtuple("EarlyStopping",
19 ("metric", "min_improvement", "steps"))):
20 """Conditions for early stopping."""
21
22
23 class Evaluator(object):
24 """Model evaluator."""
25
26 def __init__(self,
27 model,
28 features_file,
29 labels_file,
30 batch_size,
31 scorers=None,
32 save_predictions=False,
33 early_stopping=None,
34 eval_dir=None):
35 """Initializes the evaluator.
36
37 Args:
38 model: A :class:`opennmt.models.model.Model` to evaluate.
39 features_file: Path to the evaluation features.
40 labels_file: Path to the evaluation labels.
41 batch_size: The evaluation batch size.
42 scorers: A list of scorers, callables taking the path to the reference and
43 the hypothesis and return one or more scores.
44 save_predictions: Save evaluation predictions to a file. This is ``True``
45 when :obj:`external_evaluator` is set.
46 early_stopping: An ``EarlyStopping`` instance.
47 eval_dir: Directory where predictions can be saved.
48
49 Raises:
50 ValueError: If predictions should be saved but the model is not compatible.
51 ValueError: If predictions should be saved but :obj:`eval_dir` is ``None``.
52 ValueError: If the :obj:`early_stopping` configuration is invalid.
53 """
54 if scorers is None:
55 scorers = []
56 if scorers:
57 save_predictions = True
58 if save_predictions:
59 if model.unsupervised:
60 raise ValueError("This model does not support saving evaluation predictions")
61 if eval_dir is None:
62 raise ValueError("Saving evaluation predictions requires eval_dir to be set")
63 if not tf.io.gfile.exists(eval_dir):
64 tf.io.gfile.makedirs(eval_dir)
65 self._model = model
66 self._labels_file = labels_file
67 self._save_predictions = save_predictions
68 self._scorers = scorers
69 self._eval_dir = eval_dir
70 self._metrics_history = []
71 if eval_dir is not None:
72 self._summary_writer = tf.summary.create_file_writer(eval_dir)
73 summaries = misc.read_summaries(eval_dir)
74 for step, values in summaries:
75 metrics = misc.extract_prefixed_keys(values, _SUMMARIES_SCOPE + "/")
76 self._metrics_history.append((step, metrics))
77 else:
78 self._summary_writer = tf.summary.create_noop_writer()
79 dataset = model.examples_inputter.make_evaluation_dataset(
80 features_file,
81 labels_file,
82 batch_size,
83 num_threads=1,
84 prefetch_buffer_size=1)
85
86 @dataset_lib.function_on_next(dataset)
87 def _eval(next_fn):
88 source, target = next_fn()
89 outputs, predictions = model(source, labels=target)
90 loss = model.compute_loss(outputs, target, training=False)
91 return loss, predictions, target
92
93 self._eval = _eval
94
95 self._metrics_name = {"loss"}
96 for scorer in self._scorers:
97 self._metrics_name.update(scorer.scores_name)
98 model_metrics = self._model.get_metrics()
99 if model_metrics:
100 self._metrics_name.update(set(six.iterkeys(model_metrics)))
101
102 if early_stopping is not None:
103 if early_stopping.metric not in self._metrics_name:
104 raise ValueError("Invalid early stopping metric '%s', expected one in %s" % (
105 early_stopping.metric, str(self._metrics_name)))
106 if early_stopping.steps <= 0:
107 raise ValueError("Early stopping steps should greater than 0")
108 self._early_stopping = early_stopping
109
110 @classmethod
111 def from_config(cls, model, config, features_file=None, labels_file=None):
112 """Creates an evaluator from the configuration.
113
114 Args:
115 model: A :class:`opennmt.models.model.Model` to evaluate.
116 config: The global user configuration.
117 features_file: Optional input features file to evaluate. If not set, will
118 load ``eval_features_file`` from the data configuration.
119 labels_file: Optional output labels file to evaluate. If not set, will load
120 ``eval_labels_file`` from the data configuration.
121
122 Returns:
123 A :class:`opennmt.evaluation.Evaluator` instance.
124
125 Raises:
126 ValueError: if one of :obj:`features_file` and :obj:`labels_file` is set
127 but not the other.
128 """
129 if (features_file is None) != (labels_file is None):
130 raise ValueError("features_file and labels_file should be both set for evaluation")
131 scorers = config["eval"].get("external_evaluators")
132 if scorers is not None:
133 scorers = scorers_lib.make_scorers(scorers)
134 early_stopping_config = config["eval"].get("early_stopping")
135 if early_stopping_config is not None:
136 early_stopping = EarlyStopping(
137 metric=early_stopping_config.get("metric", "loss"),
138 min_improvement=early_stopping_config.get("min_improvement", 0),
139 steps=early_stopping_config["steps"])
140 else:
141 early_stopping = None
142 return cls(
143 model,
144 features_file or config["data"]["eval_features_file"],
145 labels_file or config["data"].get("eval_labels_file"),
146 config["eval"]["batch_size"],
147 scorers=scorers,
148 save_predictions=config["eval"].get("save_eval_predictions", False),
149 early_stopping=early_stopping,
150 eval_dir=os.path.join(config["model_dir"], "eval"))
151
152 @property
153 def metrics_name(self):
154 """The name of the metrics returned by this evaluator."""
155 return self._metrics_name
156
157 @property
158 def metrics_history(self):
159 """The history of metrics result per evaluation step."""
160 return self._metrics_history
161
162 def should_stop(self):
163 """Returns ``True`` if early stopping conditions are met."""
164 if self._early_stopping is None:
165 return False
166 target_metric = self._early_stopping.metric
167 higher_is_better = None
168 # Look if target_metric is produced by a scorer as they define the scores order.
169 for scorer in self._scorers:
170 if target_metric in scorer.scores_name:
171 higher_is_better = scorer.higher_is_better()
172 break
173 if higher_is_better is None:
174 # TODO: the condition below is not always true, find a way to set it
175 # correctly for Keras metrics.
176 higher_is_better = target_metric != "loss"
177 metrics = [values[target_metric] for _, values in self._metrics_history]
178 should_stop = early_stop(
179 metrics,
180 self._early_stopping.steps,
181 min_improvement=self._early_stopping.min_improvement,
182 higher_is_better=higher_is_better)
183 if should_stop:
184 tf.get_logger().warning(
185 "Evaluation metric '%s' did not improve more than %f in the last %d evaluations",
186 target_metric,
187 self._early_stopping.min_improvement,
188 self._early_stopping.steps)
189 return should_stop
190
191 def __call__(self, step):
192 """Runs the evaluator.
193
194 Args:
195 step: The current training step.
196
197 Returns:
198 A dictionary of evaluation metrics.
199 """
200 tf.get_logger().info("Running evaluation for step %d", step)
201 output_file = None
202 output_path = None
203 if self._save_predictions:
204 output_path = os.path.join(self._eval_dir, "predictions.txt.%d" % step)
205 output_file = tf.io.gfile.GFile(output_path, "w")
206
207 loss_num = 0
208 loss_den = 0
209 metrics = self._model.get_metrics()
210 for loss, predictions, target in self._eval(): # pylint: disable=no-value-for-parameter
211 if isinstance(loss, tuple):
212 loss_num += loss[0]
213 loss_den += loss[1]
214 else:
215 loss_num += loss
216 loss_den += 1
217 if metrics:
218 self._model.update_metrics(metrics, predictions, target)
219 if output_file is not None:
220 predictions = {k:v.numpy() for k, v in six.iteritems(predictions)}
221 for prediction in misc.extract_batches(predictions):
222 self._model.print_prediction(prediction, stream=output_file)
223 if loss_den == 0:
224 raise RuntimeError("No examples were evaluated")
225 loss = loss_num / loss_den
226
227 results = dict(loss=loss)
228 if metrics:
229 for name, metric in six.iteritems(metrics):
230 results[name] = metric.result()
231 if self._save_predictions:
232 tf.get_logger().info("Evaluation predictions saved to %s", output_path)
233 output_file.close()
234 for scorer in self._scorers:
235 score = scorer(self._labels_file, output_path)
236 if isinstance(score, dict):
237 results.update(score)
238 else:
239 results[scorer.name] = score
240
241 return self._record_results(step, results)
242
243 def _record_results(self, step, results):
244 for name, value in six.iteritems(results):
245 if isinstance(value, tf.Tensor):
246 results[name] = value.numpy()
247 # Clear history for steps that are greater than step.
248 while self._metrics_history and self._metrics_history[-1][0] > step:
249 self._metrics_history.pop()
250 self._metrics_history.append((step, dict(results)))
251 tf.get_logger().info(
252 "Evaluation result for step %d: %s",
253 step,
254 " ; ".join("%s = %f" % (k, v) for k, v in six.iteritems(results)))
255 with self._summary_writer.as_default():
256 for key, value in six.iteritems(results):
257 tf.summary.scalar("%s/%s" % (_SUMMARIES_SCOPE, key), value, step=step)
258 self._summary_writer.flush()
259 return results
260
261
262 def early_stop(metrics, steps, min_improvement=0, higher_is_better=False):
263 """Early stopping condition.
264
265 Args:
266 metrics: A list of metric values.
267 steps: Consider the improvement over this many steps.
268 min_improvement: Continue if the metric improved less than this value:
269 higher_is_better: Whether a higher value is better for this metric.
270
271 Returns:
272 A boolean.
273 """
274 if len(metrics) < steps + 1:
275 return False
276
277 def _did_improve(ref, new):
278 # Returns True if new is improving on ref.
279 if higher_is_better:
280 return new > ref + min_improvement
281 else:
282 return new < ref - min_improvement
283
284 samples = metrics[-steps - 1:]
285
286 # First check if the boundaries show an improvement.
287 if _did_improve(samples[0], samples[-1]):
288 return False
289
290 # If not, only early stop if each successive evaluation did not improve.
291 for metric, next_metric in zip(samples[:-1], samples[1:]):
292 if _did_improve(metric, next_metric):
293 return False
294 return True
295
[end of opennmt/evaluation.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/opennmt/evaluation.py b/opennmt/evaluation.py
--- a/opennmt/evaluation.py
+++ b/opennmt/evaluation.py
@@ -92,7 +92,7 @@
self._eval = _eval
- self._metrics_name = {"loss"}
+ self._metrics_name = {"loss", "perplexity"}
for scorer in self._scorers:
self._metrics_name.update(scorer.scores_name)
model_metrics = self._model.get_metrics()
@@ -173,7 +173,7 @@
if higher_is_better is None:
# TODO: the condition below is not always true, find a way to set it
# correctly for Keras metrics.
- higher_is_better = target_metric != "loss"
+ higher_is_better = target_metric not in ("loss", "perplexity")
metrics = [values[target_metric] for _, values in self._metrics_history]
should_stop = early_stop(
metrics,
@@ -224,7 +224,7 @@
raise RuntimeError("No examples were evaluated")
loss = loss_num / loss_den
- results = dict(loss=loss)
+ results = dict(loss=loss, perplexity=tf.math.exp(loss))
if metrics:
for name, metric in six.iteritems(metrics):
results[name] = metric.result()
| {"golden_diff": "diff --git a/opennmt/evaluation.py b/opennmt/evaluation.py\n--- a/opennmt/evaluation.py\n+++ b/opennmt/evaluation.py\n@@ -92,7 +92,7 @@\n \n self._eval = _eval\n \n- self._metrics_name = {\"loss\"}\n+ self._metrics_name = {\"loss\", \"perplexity\"}\n for scorer in self._scorers:\n self._metrics_name.update(scorer.scores_name)\n model_metrics = self._model.get_metrics()\n@@ -173,7 +173,7 @@\n if higher_is_better is None:\n # TODO: the condition below is not always true, find a way to set it\n # correctly for Keras metrics.\n- higher_is_better = target_metric != \"loss\"\n+ higher_is_better = target_metric not in (\"loss\", \"perplexity\")\n metrics = [values[target_metric] for _, values in self._metrics_history]\n should_stop = early_stop(\n metrics,\n@@ -224,7 +224,7 @@\n raise RuntimeError(\"No examples were evaluated\")\n loss = loss_num / loss_den\n \n- results = dict(loss=loss)\n+ results = dict(loss=loss, perplexity=tf.math.exp(loss))\n if metrics:\n for name, metric in six.iteritems(metrics):\n results[name] = metric.result()\n", "issue": "How to support PPL\nCan you add the PPL measurement?\n", "before_files": [{"content": "\"\"\"Evaluation related classes and functions.\"\"\"\n\nimport collections\nimport os\nimport six\n\nimport tensorflow as tf\n\nfrom opennmt.data import dataset as dataset_lib\nfrom opennmt.utils import misc\nfrom opennmt.utils import scorers as scorers_lib\n\n\n_SUMMARIES_SCOPE = \"metrics\"\n\n\nclass EarlyStopping(\n collections.namedtuple(\"EarlyStopping\",\n (\"metric\", \"min_improvement\", \"steps\"))):\n \"\"\"Conditions for early stopping.\"\"\"\n\n\nclass Evaluator(object):\n \"\"\"Model evaluator.\"\"\"\n\n def __init__(self,\n model,\n features_file,\n labels_file,\n batch_size,\n scorers=None,\n save_predictions=False,\n early_stopping=None,\n eval_dir=None):\n \"\"\"Initializes the evaluator.\n\n Args:\n model: A :class:`opennmt.models.model.Model` to evaluate.\n features_file: Path to the evaluation features.\n labels_file: Path to the evaluation labels.\n batch_size: The evaluation batch size.\n scorers: A list of scorers, callables taking the path to the reference and\n the hypothesis and return one or more scores.\n save_predictions: Save evaluation predictions to a file. This is ``True``\n when :obj:`external_evaluator` is set.\n early_stopping: An ``EarlyStopping`` instance.\n eval_dir: Directory where predictions can be saved.\n\n Raises:\n ValueError: If predictions should be saved but the model is not compatible.\n ValueError: If predictions should be saved but :obj:`eval_dir` is ``None``.\n ValueError: If the :obj:`early_stopping` configuration is invalid.\n \"\"\"\n if scorers is None:\n scorers = []\n if scorers:\n save_predictions = True\n if save_predictions:\n if model.unsupervised:\n raise ValueError(\"This model does not support saving evaluation predictions\")\n if eval_dir is None:\n raise ValueError(\"Saving evaluation predictions requires eval_dir to be set\")\n if not tf.io.gfile.exists(eval_dir):\n tf.io.gfile.makedirs(eval_dir)\n self._model = model\n self._labels_file = labels_file\n self._save_predictions = save_predictions\n self._scorers = scorers\n self._eval_dir = eval_dir\n self._metrics_history = []\n if eval_dir is not None:\n self._summary_writer = tf.summary.create_file_writer(eval_dir)\n summaries = misc.read_summaries(eval_dir)\n for step, values in summaries:\n metrics = misc.extract_prefixed_keys(values, _SUMMARIES_SCOPE + \"/\")\n self._metrics_history.append((step, metrics))\n else:\n self._summary_writer = tf.summary.create_noop_writer()\n dataset = model.examples_inputter.make_evaluation_dataset(\n features_file,\n labels_file,\n batch_size,\n num_threads=1,\n prefetch_buffer_size=1)\n\n @dataset_lib.function_on_next(dataset)\n def _eval(next_fn):\n source, target = next_fn()\n outputs, predictions = model(source, labels=target)\n loss = model.compute_loss(outputs, target, training=False)\n return loss, predictions, target\n\n self._eval = _eval\n\n self._metrics_name = {\"loss\"}\n for scorer in self._scorers:\n self._metrics_name.update(scorer.scores_name)\n model_metrics = self._model.get_metrics()\n if model_metrics:\n self._metrics_name.update(set(six.iterkeys(model_metrics)))\n\n if early_stopping is not None:\n if early_stopping.metric not in self._metrics_name:\n raise ValueError(\"Invalid early stopping metric '%s', expected one in %s\" % (\n early_stopping.metric, str(self._metrics_name)))\n if early_stopping.steps <= 0:\n raise ValueError(\"Early stopping steps should greater than 0\")\n self._early_stopping = early_stopping\n\n @classmethod\n def from_config(cls, model, config, features_file=None, labels_file=None):\n \"\"\"Creates an evaluator from the configuration.\n\n Args:\n model: A :class:`opennmt.models.model.Model` to evaluate.\n config: The global user configuration.\n features_file: Optional input features file to evaluate. If not set, will\n load ``eval_features_file`` from the data configuration.\n labels_file: Optional output labels file to evaluate. If not set, will load\n ``eval_labels_file`` from the data configuration.\n\n Returns:\n A :class:`opennmt.evaluation.Evaluator` instance.\n\n Raises:\n ValueError: if one of :obj:`features_file` and :obj:`labels_file` is set\n but not the other.\n \"\"\"\n if (features_file is None) != (labels_file is None):\n raise ValueError(\"features_file and labels_file should be both set for evaluation\")\n scorers = config[\"eval\"].get(\"external_evaluators\")\n if scorers is not None:\n scorers = scorers_lib.make_scorers(scorers)\n early_stopping_config = config[\"eval\"].get(\"early_stopping\")\n if early_stopping_config is not None:\n early_stopping = EarlyStopping(\n metric=early_stopping_config.get(\"metric\", \"loss\"),\n min_improvement=early_stopping_config.get(\"min_improvement\", 0),\n steps=early_stopping_config[\"steps\"])\n else:\n early_stopping = None\n return cls(\n model,\n features_file or config[\"data\"][\"eval_features_file\"],\n labels_file or config[\"data\"].get(\"eval_labels_file\"),\n config[\"eval\"][\"batch_size\"],\n scorers=scorers,\n save_predictions=config[\"eval\"].get(\"save_eval_predictions\", False),\n early_stopping=early_stopping,\n eval_dir=os.path.join(config[\"model_dir\"], \"eval\"))\n\n @property\n def metrics_name(self):\n \"\"\"The name of the metrics returned by this evaluator.\"\"\"\n return self._metrics_name\n\n @property\n def metrics_history(self):\n \"\"\"The history of metrics result per evaluation step.\"\"\"\n return self._metrics_history\n\n def should_stop(self):\n \"\"\"Returns ``True`` if early stopping conditions are met.\"\"\"\n if self._early_stopping is None:\n return False\n target_metric = self._early_stopping.metric\n higher_is_better = None\n # Look if target_metric is produced by a scorer as they define the scores order.\n for scorer in self._scorers:\n if target_metric in scorer.scores_name:\n higher_is_better = scorer.higher_is_better()\n break\n if higher_is_better is None:\n # TODO: the condition below is not always true, find a way to set it\n # correctly for Keras metrics.\n higher_is_better = target_metric != \"loss\"\n metrics = [values[target_metric] for _, values in self._metrics_history]\n should_stop = early_stop(\n metrics,\n self._early_stopping.steps,\n min_improvement=self._early_stopping.min_improvement,\n higher_is_better=higher_is_better)\n if should_stop:\n tf.get_logger().warning(\n \"Evaluation metric '%s' did not improve more than %f in the last %d evaluations\",\n target_metric,\n self._early_stopping.min_improvement,\n self._early_stopping.steps)\n return should_stop\n\n def __call__(self, step):\n \"\"\"Runs the evaluator.\n\n Args:\n step: The current training step.\n\n Returns:\n A dictionary of evaluation metrics.\n \"\"\"\n tf.get_logger().info(\"Running evaluation for step %d\", step)\n output_file = None\n output_path = None\n if self._save_predictions:\n output_path = os.path.join(self._eval_dir, \"predictions.txt.%d\" % step)\n output_file = tf.io.gfile.GFile(output_path, \"w\")\n\n loss_num = 0\n loss_den = 0\n metrics = self._model.get_metrics()\n for loss, predictions, target in self._eval(): # pylint: disable=no-value-for-parameter\n if isinstance(loss, tuple):\n loss_num += loss[0]\n loss_den += loss[1]\n else:\n loss_num += loss\n loss_den += 1\n if metrics:\n self._model.update_metrics(metrics, predictions, target)\n if output_file is not None:\n predictions = {k:v.numpy() for k, v in six.iteritems(predictions)}\n for prediction in misc.extract_batches(predictions):\n self._model.print_prediction(prediction, stream=output_file)\n if loss_den == 0:\n raise RuntimeError(\"No examples were evaluated\")\n loss = loss_num / loss_den\n\n results = dict(loss=loss)\n if metrics:\n for name, metric in six.iteritems(metrics):\n results[name] = metric.result()\n if self._save_predictions:\n tf.get_logger().info(\"Evaluation predictions saved to %s\", output_path)\n output_file.close()\n for scorer in self._scorers:\n score = scorer(self._labels_file, output_path)\n if isinstance(score, dict):\n results.update(score)\n else:\n results[scorer.name] = score\n\n return self._record_results(step, results)\n\n def _record_results(self, step, results):\n for name, value in six.iteritems(results):\n if isinstance(value, tf.Tensor):\n results[name] = value.numpy()\n # Clear history for steps that are greater than step.\n while self._metrics_history and self._metrics_history[-1][0] > step:\n self._metrics_history.pop()\n self._metrics_history.append((step, dict(results)))\n tf.get_logger().info(\n \"Evaluation result for step %d: %s\",\n step,\n \" ; \".join(\"%s = %f\" % (k, v) for k, v in six.iteritems(results)))\n with self._summary_writer.as_default():\n for key, value in six.iteritems(results):\n tf.summary.scalar(\"%s/%s\" % (_SUMMARIES_SCOPE, key), value, step=step)\n self._summary_writer.flush()\n return results\n\n\ndef early_stop(metrics, steps, min_improvement=0, higher_is_better=False):\n \"\"\"Early stopping condition.\n\n Args:\n metrics: A list of metric values.\n steps: Consider the improvement over this many steps.\n min_improvement: Continue if the metric improved less than this value:\n higher_is_better: Whether a higher value is better for this metric.\n\n Returns:\n A boolean.\n \"\"\"\n if len(metrics) < steps + 1:\n return False\n\n def _did_improve(ref, new):\n # Returns True if new is improving on ref.\n if higher_is_better:\n return new > ref + min_improvement\n else:\n return new < ref - min_improvement\n\n samples = metrics[-steps - 1:]\n\n # First check if the boundaries show an improvement.\n if _did_improve(samples[0], samples[-1]):\n return False\n\n # If not, only early stop if each successive evaluation did not improve.\n for metric, next_metric in zip(samples[:-1], samples[1:]):\n if _did_improve(metric, next_metric):\n return False\n return True\n", "path": "opennmt/evaluation.py"}]} | 3,760 | 303 |
gh_patches_debug_15035 | rasdani/github-patches | git_diff | encode__httpx-1537 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Too much data for declared Content-Length when passing string with non-ascii characters via files parameter
### Checklist
<!-- Please make sure you check all these items before submitting your bug report. -->
- [x ] The bug is reproducible against the latest release and/or `master`.
- [ x] There are no similar issues or pull requests to fix it yet.
### Describe the bug
`h11._util.LocalProtocolError: Too much data for declared Content-Length` is raised when passing string with non-ascii characters via files parameter.
### To reproduce
```
import httpx
response = httpx.post(
"https://httpbin.org/post",
files={
'upload-file': ('example.txt', '\u00E9', 'text/plain; charset=utf-8')
}
)
response.raise_for_status()
print(response.read())
```
-->
### Expected behavior
An exception not be raised and the content length properly computed
### Actual behavior
An exception is raised.
### Debugging material
```
Traceback (most recent call last):
File "/***redacted***/httpx_bug.py", line 5, in <module>
response = httpx.post(
File "/***redacted***/.venv/lib/python3.9/site-packages/httpx/_api.py", line 296, in post
return request(
File "/***redacted***/.venv/lib/python3.9/site-packages/httpx/_api.py", line 93, in request
return client.request(
File "/***redacted***/.venv/lib/python3.9/site-packages/httpx/_client.py", line 733, in request
return self.send(
File "/***redacted***/.venv/lib/python3.9/site-packages/httpx/_client.py", line 767, in send
response = self._send_handling_auth(
File "/***redacted***/.venv/lib/python3.9/site-packages/httpx/_client.py", line 805, in _send_handling_auth
response = self._send_handling_redirects(
File "/***redacted***/.venv/lib/python3.9/site-packages/httpx/_client.py", line 837, in _send_handling_redirects
response = self._send_single_request(request, timeout)
File "/***redacted***/.venv/lib/python3.9/site-packages/httpx/_client.py", line 861, in _send_single_request
(status_code, headers, stream, ext) = transport.request(
File "/***redacted***/.venv/lib/python3.9/site-packages/httpcore/_sync/connection_pool.py", line 218, in request
response = connection.request(
File "/***redacted***/.venv/lib/python3.9/site-packages/httpcore/_sync/connection.py", line 106, in request
return self.connection.request(method, url, headers, stream, ext)
File "/***redacted***/.venv/lib/python3.9/site-packages/httpcore/_sync/http11.py", line 66, in request
self._send_request_body(stream, timeout)
File "/***redacted***/.venv/lib/python3.9/site-packages/httpcore/_sync/http11.py", line 112, in _send_request_body
self._send_event(event, timeout)
File "/***redacted***/.venv/lib/python3.9/site-packages/httpcore/_sync/http11.py", line 123, in _send_event
bytes_to_send = self.h11_state.send(event)
File "/***redacted***/.venv/lib/python3.9/site-packages/h11/_connection.py", line 468, in send
data_list = self.send_with_data_passthrough(event)
File "/***redacted***/.venv/lib/python3.9/site-packages/h11/_connection.py", line 501, in send_with_data_passthrough
writer(event, data_list.append)
File "/***redacted***/.venv/lib/python3.9/site-packages/h11/_writers.py", line 58, in __call__
self.send_data(event.data, write)
File "/***redacted***/.venv/lib/python3.9/site-packages/h11/_writers.py", line 78, in send_data
raise LocalProtocolError("Too much data for declared Content-Length")
h11._util.LocalProtocolError: Too much data for declared Content-Length
```
-->
### Environment
- OS: macOS
- Python version: `Python 3.9.1`
- HTTPX version: `0.16.1`
- Async environment: n/a
- HTTP proxy: no
- Custom certificates: no
### Additional context
n/a
</issue>
<code>
[start of httpx/_multipart.py]
1 import binascii
2 import os
3 import typing
4 from pathlib import Path
5
6 from ._types import FileContent, FileTypes, RequestFiles
7 from ._utils import (
8 format_form_param,
9 guess_content_type,
10 peek_filelike_length,
11 to_bytes,
12 )
13
14
15 class DataField:
16 """
17 A single form field item, within a multipart form field.
18 """
19
20 def __init__(self, name: str, value: typing.Union[str, bytes]) -> None:
21 if not isinstance(name, str):
22 raise TypeError(
23 f"Invalid type for name. Expected str, got {type(name)}: {name!r}"
24 )
25 if not isinstance(value, (str, bytes)):
26 raise TypeError(
27 f"Invalid type for value. Expected str or bytes, got {type(value)}: {value!r}"
28 )
29 self.name = name
30 self.value = value
31
32 def render_headers(self) -> bytes:
33 if not hasattr(self, "_headers"):
34 name = format_form_param("name", self.name)
35 self._headers = b"".join(
36 [b"Content-Disposition: form-data; ", name, b"\r\n\r\n"]
37 )
38
39 return self._headers
40
41 def render_data(self) -> bytes:
42 if not hasattr(self, "_data"):
43 self._data = (
44 self.value
45 if isinstance(self.value, bytes)
46 else self.value.encode("utf-8")
47 )
48
49 return self._data
50
51 def get_length(self) -> int:
52 headers = self.render_headers()
53 data = self.render_data()
54 return len(headers) + len(data)
55
56 def render(self) -> typing.Iterator[bytes]:
57 yield self.render_headers()
58 yield self.render_data()
59
60
61 class FileField:
62 """
63 A single file field item, within a multipart form field.
64 """
65
66 def __init__(self, name: str, value: FileTypes) -> None:
67 self.name = name
68
69 fileobj: FileContent
70
71 if isinstance(value, tuple):
72 try:
73 filename, fileobj, content_type = value # type: ignore
74 except ValueError:
75 filename, fileobj = value # type: ignore
76 content_type = guess_content_type(filename)
77 else:
78 filename = Path(str(getattr(value, "name", "upload"))).name
79 fileobj = value
80 content_type = guess_content_type(filename)
81
82 self.filename = filename
83 self.file = fileobj
84 self.content_type = content_type
85 self._consumed = False
86
87 def get_length(self) -> int:
88 headers = self.render_headers()
89
90 if isinstance(self.file, (str, bytes)):
91 return len(headers) + len(self.file)
92
93 # Let's do our best not to read `file` into memory.
94 try:
95 file_length = peek_filelike_length(self.file)
96 except OSError:
97 # As a last resort, read file and cache contents for later.
98 assert not hasattr(self, "_data")
99 self._data = to_bytes(self.file.read())
100 file_length = len(self._data)
101
102 return len(headers) + file_length
103
104 def render_headers(self) -> bytes:
105 if not hasattr(self, "_headers"):
106 parts = [
107 b"Content-Disposition: form-data; ",
108 format_form_param("name", self.name),
109 ]
110 if self.filename:
111 filename = format_form_param("filename", self.filename)
112 parts.extend([b"; ", filename])
113 if self.content_type is not None:
114 content_type = self.content_type.encode()
115 parts.extend([b"\r\nContent-Type: ", content_type])
116 parts.append(b"\r\n\r\n")
117 self._headers = b"".join(parts)
118
119 return self._headers
120
121 def render_data(self) -> typing.Iterator[bytes]:
122 if isinstance(self.file, (str, bytes)):
123 yield to_bytes(self.file)
124 return
125
126 if hasattr(self, "_data"):
127 # Already rendered.
128 yield self._data
129 return
130
131 if self._consumed: # pragma: nocover
132 self.file.seek(0)
133 self._consumed = True
134
135 for chunk in self.file:
136 yield to_bytes(chunk)
137
138 def render(self) -> typing.Iterator[bytes]:
139 yield self.render_headers()
140 yield from self.render_data()
141
142
143 class MultipartStream:
144 """
145 Request content as streaming multipart encoded form data.
146 """
147
148 def __init__(self, data: dict, files: RequestFiles, boundary: bytes = None) -> None:
149 if boundary is None:
150 boundary = binascii.hexlify(os.urandom(16))
151
152 self.boundary = boundary
153 self.content_type = "multipart/form-data; boundary=%s" % boundary.decode(
154 "ascii"
155 )
156 self.fields = list(self._iter_fields(data, files))
157
158 def _iter_fields(
159 self, data: dict, files: RequestFiles
160 ) -> typing.Iterator[typing.Union[FileField, DataField]]:
161 for name, value in data.items():
162 if isinstance(value, list):
163 for item in value:
164 yield DataField(name=name, value=item)
165 else:
166 yield DataField(name=name, value=value)
167
168 file_items = files.items() if isinstance(files, typing.Mapping) else files
169 for name, value in file_items:
170 yield FileField(name=name, value=value)
171
172 def iter_chunks(self) -> typing.Iterator[bytes]:
173 for field in self.fields:
174 yield b"--%s\r\n" % self.boundary
175 yield from field.render()
176 yield b"\r\n"
177 yield b"--%s--\r\n" % self.boundary
178
179 def iter_chunks_lengths(self) -> typing.Iterator[int]:
180 boundary_length = len(self.boundary)
181 # Follow closely what `.iter_chunks()` does.
182 for field in self.fields:
183 yield 2 + boundary_length + 2
184 yield field.get_length()
185 yield 2
186 yield 2 + boundary_length + 4
187
188 def get_content_length(self) -> int:
189 return sum(self.iter_chunks_lengths())
190
191 # Content stream interface.
192
193 def get_headers(self) -> typing.Dict[str, str]:
194 content_length = str(self.get_content_length())
195 content_type = self.content_type
196 return {"Content-Length": content_length, "Content-Type": content_type}
197
198 def __iter__(self) -> typing.Iterator[bytes]:
199 for chunk in self.iter_chunks():
200 yield chunk
201
202 async def __aiter__(self) -> typing.AsyncIterator[bytes]:
203 for chunk in self.iter_chunks():
204 yield chunk
205
[end of httpx/_multipart.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/httpx/_multipart.py b/httpx/_multipart.py
--- a/httpx/_multipart.py
+++ b/httpx/_multipart.py
@@ -40,11 +40,7 @@
def render_data(self) -> bytes:
if not hasattr(self, "_data"):
- self._data = (
- self.value
- if isinstance(self.value, bytes)
- else self.value.encode("utf-8")
- )
+ self._data = to_bytes(self.value)
return self._data
@@ -88,7 +84,7 @@
headers = self.render_headers()
if isinstance(self.file, (str, bytes)):
- return len(headers) + len(self.file)
+ return len(headers) + len(to_bytes(self.file))
# Let's do our best not to read `file` into memory.
try:
| {"golden_diff": "diff --git a/httpx/_multipart.py b/httpx/_multipart.py\n--- a/httpx/_multipart.py\n+++ b/httpx/_multipart.py\n@@ -40,11 +40,7 @@\n \n def render_data(self) -> bytes:\n if not hasattr(self, \"_data\"):\n- self._data = (\n- self.value\n- if isinstance(self.value, bytes)\n- else self.value.encode(\"utf-8\")\n- )\n+ self._data = to_bytes(self.value)\n \n return self._data\n \n@@ -88,7 +84,7 @@\n headers = self.render_headers()\n \n if isinstance(self.file, (str, bytes)):\n- return len(headers) + len(self.file)\n+ return len(headers) + len(to_bytes(self.file))\n \n # Let's do our best not to read `file` into memory.\n try:\n", "issue": "Too much data for declared Content-Length when passing string with non-ascii characters via files parameter\n### Checklist\r\n\r\n<!-- Please make sure you check all these items before submitting your bug report. -->\r\n\r\n- [x ] The bug is reproducible against the latest release and/or `master`.\r\n- [ x] There are no similar issues or pull requests to fix it yet.\r\n\r\n### Describe the bug\r\n\r\n`h11._util.LocalProtocolError: Too much data for declared Content-Length` is raised when passing string with non-ascii characters via files parameter.\r\n\r\n### To reproduce\r\n\r\n```\r\nimport httpx\r\n\r\nresponse = httpx.post(\r\n \"https://httpbin.org/post\",\r\n files={\r\n 'upload-file': ('example.txt', '\\u00E9', 'text/plain; charset=utf-8')\r\n }\r\n)\r\nresponse.raise_for_status()\r\nprint(response.read())\r\n```\r\n-->\r\n\r\n### Expected behavior\r\n\r\nAn exception not be raised and the content length properly computed\r\n\r\n### Actual behavior\r\n\r\nAn exception is raised.\r\n\r\n### Debugging material\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/***redacted***/httpx_bug.py\", line 5, in <module>\r\n response = httpx.post(\r\n File \"/***redacted***/.venv/lib/python3.9/site-packages/httpx/_api.py\", line 296, in post\r\n return request(\r\n File \"/***redacted***/.venv/lib/python3.9/site-packages/httpx/_api.py\", line 93, in request\r\n return client.request(\r\n File \"/***redacted***/.venv/lib/python3.9/site-packages/httpx/_client.py\", line 733, in request\r\n return self.send(\r\n File \"/***redacted***/.venv/lib/python3.9/site-packages/httpx/_client.py\", line 767, in send\r\n response = self._send_handling_auth(\r\n File \"/***redacted***/.venv/lib/python3.9/site-packages/httpx/_client.py\", line 805, in _send_handling_auth\r\n response = self._send_handling_redirects(\r\n File \"/***redacted***/.venv/lib/python3.9/site-packages/httpx/_client.py\", line 837, in _send_handling_redirects\r\n response = self._send_single_request(request, timeout)\r\n File \"/***redacted***/.venv/lib/python3.9/site-packages/httpx/_client.py\", line 861, in _send_single_request\r\n (status_code, headers, stream, ext) = transport.request(\r\n File \"/***redacted***/.venv/lib/python3.9/site-packages/httpcore/_sync/connection_pool.py\", line 218, in request\r\n response = connection.request(\r\n File \"/***redacted***/.venv/lib/python3.9/site-packages/httpcore/_sync/connection.py\", line 106, in request\r\n return self.connection.request(method, url, headers, stream, ext)\r\n File \"/***redacted***/.venv/lib/python3.9/site-packages/httpcore/_sync/http11.py\", line 66, in request\r\n self._send_request_body(stream, timeout)\r\n File \"/***redacted***/.venv/lib/python3.9/site-packages/httpcore/_sync/http11.py\", line 112, in _send_request_body\r\n self._send_event(event, timeout)\r\n File \"/***redacted***/.venv/lib/python3.9/site-packages/httpcore/_sync/http11.py\", line 123, in _send_event\r\n bytes_to_send = self.h11_state.send(event)\r\n File \"/***redacted***/.venv/lib/python3.9/site-packages/h11/_connection.py\", line 468, in send\r\n data_list = self.send_with_data_passthrough(event)\r\n File \"/***redacted***/.venv/lib/python3.9/site-packages/h11/_connection.py\", line 501, in send_with_data_passthrough\r\n writer(event, data_list.append)\r\n File \"/***redacted***/.venv/lib/python3.9/site-packages/h11/_writers.py\", line 58, in __call__\r\n self.send_data(event.data, write)\r\n File \"/***redacted***/.venv/lib/python3.9/site-packages/h11/_writers.py\", line 78, in send_data\r\n raise LocalProtocolError(\"Too much data for declared Content-Length\")\r\nh11._util.LocalProtocolError: Too much data for declared Content-Length\r\n```\r\n-->\r\n\r\n### Environment\r\n\r\n- OS: macOS\r\n- Python version: `Python 3.9.1`\r\n- HTTPX version: `0.16.1`\r\n- Async environment: n/a\r\n- HTTP proxy: no\r\n- Custom certificates: no\r\n\r\n### Additional context\r\nn/a\r\n\n", "before_files": [{"content": "import binascii\nimport os\nimport typing\nfrom pathlib import Path\n\nfrom ._types import FileContent, FileTypes, RequestFiles\nfrom ._utils import (\n format_form_param,\n guess_content_type,\n peek_filelike_length,\n to_bytes,\n)\n\n\nclass DataField:\n \"\"\"\n A single form field item, within a multipart form field.\n \"\"\"\n\n def __init__(self, name: str, value: typing.Union[str, bytes]) -> None:\n if not isinstance(name, str):\n raise TypeError(\n f\"Invalid type for name. Expected str, got {type(name)}: {name!r}\"\n )\n if not isinstance(value, (str, bytes)):\n raise TypeError(\n f\"Invalid type for value. Expected str or bytes, got {type(value)}: {value!r}\"\n )\n self.name = name\n self.value = value\n\n def render_headers(self) -> bytes:\n if not hasattr(self, \"_headers\"):\n name = format_form_param(\"name\", self.name)\n self._headers = b\"\".join(\n [b\"Content-Disposition: form-data; \", name, b\"\\r\\n\\r\\n\"]\n )\n\n return self._headers\n\n def render_data(self) -> bytes:\n if not hasattr(self, \"_data\"):\n self._data = (\n self.value\n if isinstance(self.value, bytes)\n else self.value.encode(\"utf-8\")\n )\n\n return self._data\n\n def get_length(self) -> int:\n headers = self.render_headers()\n data = self.render_data()\n return len(headers) + len(data)\n\n def render(self) -> typing.Iterator[bytes]:\n yield self.render_headers()\n yield self.render_data()\n\n\nclass FileField:\n \"\"\"\n A single file field item, within a multipart form field.\n \"\"\"\n\n def __init__(self, name: str, value: FileTypes) -> None:\n self.name = name\n\n fileobj: FileContent\n\n if isinstance(value, tuple):\n try:\n filename, fileobj, content_type = value # type: ignore\n except ValueError:\n filename, fileobj = value # type: ignore\n content_type = guess_content_type(filename)\n else:\n filename = Path(str(getattr(value, \"name\", \"upload\"))).name\n fileobj = value\n content_type = guess_content_type(filename)\n\n self.filename = filename\n self.file = fileobj\n self.content_type = content_type\n self._consumed = False\n\n def get_length(self) -> int:\n headers = self.render_headers()\n\n if isinstance(self.file, (str, bytes)):\n return len(headers) + len(self.file)\n\n # Let's do our best not to read `file` into memory.\n try:\n file_length = peek_filelike_length(self.file)\n except OSError:\n # As a last resort, read file and cache contents for later.\n assert not hasattr(self, \"_data\")\n self._data = to_bytes(self.file.read())\n file_length = len(self._data)\n\n return len(headers) + file_length\n\n def render_headers(self) -> bytes:\n if not hasattr(self, \"_headers\"):\n parts = [\n b\"Content-Disposition: form-data; \",\n format_form_param(\"name\", self.name),\n ]\n if self.filename:\n filename = format_form_param(\"filename\", self.filename)\n parts.extend([b\"; \", filename])\n if self.content_type is not None:\n content_type = self.content_type.encode()\n parts.extend([b\"\\r\\nContent-Type: \", content_type])\n parts.append(b\"\\r\\n\\r\\n\")\n self._headers = b\"\".join(parts)\n\n return self._headers\n\n def render_data(self) -> typing.Iterator[bytes]:\n if isinstance(self.file, (str, bytes)):\n yield to_bytes(self.file)\n return\n\n if hasattr(self, \"_data\"):\n # Already rendered.\n yield self._data\n return\n\n if self._consumed: # pragma: nocover\n self.file.seek(0)\n self._consumed = True\n\n for chunk in self.file:\n yield to_bytes(chunk)\n\n def render(self) -> typing.Iterator[bytes]:\n yield self.render_headers()\n yield from self.render_data()\n\n\nclass MultipartStream:\n \"\"\"\n Request content as streaming multipart encoded form data.\n \"\"\"\n\n def __init__(self, data: dict, files: RequestFiles, boundary: bytes = None) -> None:\n if boundary is None:\n boundary = binascii.hexlify(os.urandom(16))\n\n self.boundary = boundary\n self.content_type = \"multipart/form-data; boundary=%s\" % boundary.decode(\n \"ascii\"\n )\n self.fields = list(self._iter_fields(data, files))\n\n def _iter_fields(\n self, data: dict, files: RequestFiles\n ) -> typing.Iterator[typing.Union[FileField, DataField]]:\n for name, value in data.items():\n if isinstance(value, list):\n for item in value:\n yield DataField(name=name, value=item)\n else:\n yield DataField(name=name, value=value)\n\n file_items = files.items() if isinstance(files, typing.Mapping) else files\n for name, value in file_items:\n yield FileField(name=name, value=value)\n\n def iter_chunks(self) -> typing.Iterator[bytes]:\n for field in self.fields:\n yield b\"--%s\\r\\n\" % self.boundary\n yield from field.render()\n yield b\"\\r\\n\"\n yield b\"--%s--\\r\\n\" % self.boundary\n\n def iter_chunks_lengths(self) -> typing.Iterator[int]:\n boundary_length = len(self.boundary)\n # Follow closely what `.iter_chunks()` does.\n for field in self.fields:\n yield 2 + boundary_length + 2\n yield field.get_length()\n yield 2\n yield 2 + boundary_length + 4\n\n def get_content_length(self) -> int:\n return sum(self.iter_chunks_lengths())\n\n # Content stream interface.\n\n def get_headers(self) -> typing.Dict[str, str]:\n content_length = str(self.get_content_length())\n content_type = self.content_type\n return {\"Content-Length\": content_length, \"Content-Type\": content_type}\n\n def __iter__(self) -> typing.Iterator[bytes]:\n for chunk in self.iter_chunks():\n yield chunk\n\n async def __aiter__(self) -> typing.AsyncIterator[bytes]:\n for chunk in self.iter_chunks():\n yield chunk\n", "path": "httpx/_multipart.py"}]} | 3,518 | 192 |
gh_patches_debug_23587 | rasdani/github-patches | git_diff | alltheplaces__alltheplaces-359 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
McDonald's
JSON endpoint: http://rl.mcdonalds.com/googleapps/GoogleSearchUSAction.do?method=searchLocation&searchTxtLatlng=(43.1272254%2C-87.9432837)&actionType=searchRestaurant&language=en&country=us
Search by lat/lon only? Looks like they geocode using Google Maps API and then call this endpoint with a lat/lon.
</issue>
<code>
[start of locations/spiders/mcdonalds_localizer.py]
1 # -*- coding: utf-8 -*-
2 import scrapy
3 import json
4 from locations.items import GeojsonPointItem
5
6
7 class McLocalizer(scrapy.Spider):
8
9 name = "mclocalizer"
10 allowed_domains = ["www.mcdonalds.com", "www.mcdonalds.com.pr", "www.mcdonalds.co.cr", "www.mcdonalds.com.ar"]
11 start_urls = (
12 'http://www.mcdonalds.com.pr/api/restaurantsByCountry?country=PR',
13 'http://www.mcdonalds.co.cr/api/restaurantsByCountry?country=CR',
14 'http://www.mcdonalds.com.ar/api/restaurantsByCountry?country=AR'
15 )
16
17 def parse(self, response):
18 data = response.body_as_unicode()
19 data.replace('" ', '"')
20 data.replace(' "', '"')
21 results = json.loads(data)
22 results = results["content"]["restaurants"]
23 for data in results:
24 properties = {
25 'ref': data['id'],
26 'lon': float(data['longitude']),
27 'lat': float(data['latitude']),
28
29 }
30
31 contact_info = data['name'][:data['name'].find("<br")]
32 name = contact_info[:contact_info.find("</br")]
33
34 properties["name"] = name
35 properties["addr_full"] = data['name'][data['name'].find("<small>"):-8][8:]
36 # = address[8:]
37
38 yield GeojsonPointItem(**properties)
[end of locations/spiders/mcdonalds_localizer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/locations/spiders/mcdonalds_localizer.py b/locations/spiders/mcdonalds_localizer.py
--- a/locations/spiders/mcdonalds_localizer.py
+++ b/locations/spiders/mcdonalds_localizer.py
@@ -7,11 +7,12 @@
class McLocalizer(scrapy.Spider):
name = "mclocalizer"
- allowed_domains = ["www.mcdonalds.com", "www.mcdonalds.com.pr", "www.mcdonalds.co.cr", "www.mcdonalds.com.ar"]
+ allowed_domains = ["www.mcdonalds.com", "www.mcdonalds.com.pr", "www.mcdonalds.co.cr", "www.mcdonalds.com.ar", "www.mcdonalds.com.pa"]
start_urls = (
'http://www.mcdonalds.com.pr/api/restaurantsByCountry?country=PR',
'http://www.mcdonalds.co.cr/api/restaurantsByCountry?country=CR',
- 'http://www.mcdonalds.com.ar/api/restaurantsByCountry?country=AR'
+ 'http://www.mcdonalds.com.ar/api/restaurantsByCountry?country=AR',
+ 'http://www.mcdonalds.com.pa/api/restaurantsByCountry?country=PA'
)
def parse(self, response):
@@ -33,6 +34,5 @@
properties["name"] = name
properties["addr_full"] = data['name'][data['name'].find("<small>"):-8][8:]
- # = address[8:]
yield GeojsonPointItem(**properties)
\ No newline at end of file
| {"golden_diff": "diff --git a/locations/spiders/mcdonalds_localizer.py b/locations/spiders/mcdonalds_localizer.py\n--- a/locations/spiders/mcdonalds_localizer.py\n+++ b/locations/spiders/mcdonalds_localizer.py\n@@ -7,11 +7,12 @@\n class McLocalizer(scrapy.Spider):\n \n name = \"mclocalizer\"\n- allowed_domains = [\"www.mcdonalds.com\", \"www.mcdonalds.com.pr\", \"www.mcdonalds.co.cr\", \"www.mcdonalds.com.ar\"]\n+ allowed_domains = [\"www.mcdonalds.com\", \"www.mcdonalds.com.pr\", \"www.mcdonalds.co.cr\", \"www.mcdonalds.com.ar\", \"www.mcdonalds.com.pa\"]\n start_urls = (\n 'http://www.mcdonalds.com.pr/api/restaurantsByCountry?country=PR',\n 'http://www.mcdonalds.co.cr/api/restaurantsByCountry?country=CR',\n- 'http://www.mcdonalds.com.ar/api/restaurantsByCountry?country=AR'\n+ 'http://www.mcdonalds.com.ar/api/restaurantsByCountry?country=AR',\n+ 'http://www.mcdonalds.com.pa/api/restaurantsByCountry?country=PA'\n )\n \n def parse(self, response):\n@@ -33,6 +34,5 @@\n \n properties[\"name\"] = name\n properties[\"addr_full\"] = data['name'][data['name'].find(\"<small>\"):-8][8:]\n- # = address[8:]\n \n yield GeojsonPointItem(**properties)\n\\ No newline at end of file\n", "issue": "McDonald's\nJSON endpoint: http://rl.mcdonalds.com/googleapps/GoogleSearchUSAction.do?method=searchLocation&searchTxtLatlng=(43.1272254%2C-87.9432837)&actionType=searchRestaurant&language=en&country=us\n\nSearch by lat/lon only? Looks like they geocode using Google Maps API and then call this endpoint with a lat/lon.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport scrapy\nimport json\nfrom locations.items import GeojsonPointItem\n\n\nclass McLocalizer(scrapy.Spider):\n\n name = \"mclocalizer\"\n allowed_domains = [\"www.mcdonalds.com\", \"www.mcdonalds.com.pr\", \"www.mcdonalds.co.cr\", \"www.mcdonalds.com.ar\"]\n start_urls = (\n 'http://www.mcdonalds.com.pr/api/restaurantsByCountry?country=PR',\n 'http://www.mcdonalds.co.cr/api/restaurantsByCountry?country=CR',\n 'http://www.mcdonalds.com.ar/api/restaurantsByCountry?country=AR'\n )\n\n def parse(self, response):\n data = response.body_as_unicode()\n data.replace('\" ', '\"')\n data.replace(' \"', '\"')\n results = json.loads(data)\n results = results[\"content\"][\"restaurants\"]\n for data in results:\n properties = {\n 'ref': data['id'],\n 'lon': float(data['longitude']),\n 'lat': float(data['latitude']),\n \n }\n\n contact_info = data['name'][:data['name'].find(\"<br\")]\n name = contact_info[:contact_info.find(\"</br\")]\n\n properties[\"name\"] = name\n properties[\"addr_full\"] = data['name'][data['name'].find(\"<small>\"):-8][8:]\n # = address[8:]\n\n yield GeojsonPointItem(**properties)", "path": "locations/spiders/mcdonalds_localizer.py"}]} | 1,026 | 370 |
gh_patches_debug_39954 | rasdani/github-patches | git_diff | certbot__certbot-8268 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
dns-rfc2136 challenges run infinitely for invalid DNS servers
1. Set `dns_rfc2136_server` to something invalid, e.g. `dns_rfc2136_server = 2001:db8::`.
2. Try to obtain certificates.
3. Challenges run forever.
CTRL+C during a challenge:
```
[... usual]
Performing the following challenges:
dns-01 challenge for [...]
dns-01 challenge for [...]
Encountered exception:
Traceback (most recent call last):
File "/usr/lib/python3.7/site-packages/certbot/auth_handler.py", line 75, in handle_authorizations
resp = self._solve_challenges(aauthzrs)
File "/usr/lib/python3.7/site-packages/certbot/auth_handler.py", line 139, in _solve_challenges
resp = self.auth.perform(all_achalls)
File "/usr/lib/python3.7/site-packages/certbot/plugins/dns_common.py", line 57, in perform
self._perform(domain, validation_domain_name, validation)
File "/usr/lib/python3.7/site-packages/certbot_dns_rfc2136/dns_rfc2136.py", line 76, in _perform
self._get_rfc2136_client().add_txt_record(validation_name, validation, self.ttl)
File "/usr/lib/python3.7/site-packages/certbot_dns_rfc2136/dns_rfc2136.py", line 112, in add_txt_record
domain = self._find_domain(record_name)
File "/usr/lib/python3.7/site-packages/certbot_dns_rfc2136/dns_rfc2136.py", line 186, in _find_domain
if self._query_soa(guess):
File "/usr/lib/python3.7/site-packages/certbot_dns_rfc2136/dns_rfc2136.py", line 209, in _query_soa
response = dns.query.udp(request, self.server, port=self.port)
File "/usr/lib/python3.7/site-packages/dns/query.py", line 240, in udp
_wait_for_readable(s, expiration)
File "/usr/lib/python3.7/site-packages/dns/query.py", line 157, in _wait_for_readable
_wait_for(s, True, False, True, expiration)
File "/usr/lib/python3.7/site-packages/dns/query.py", line 131, in _wait_for
if not _polling_backend(fd, readable, writable, error, timeout):
File "/usr/lib/python3.7/site-packages/dns/query.py", line 87, in _poll_for
event_list = pollable.poll()
KeyboardInterrupt
```
**Expected:**
Certbot should set a reasonable query timeout ([this is supported by `dnspython`](https://stackoverflow.com/questions/8989457/dnspython-setting-query-timeout-lifetime)) and alert the user of an issue with the DNS server.
</issue>
<code>
[start of certbot-dns-rfc2136/certbot_dns_rfc2136/_internal/dns_rfc2136.py]
1 """DNS Authenticator using RFC 2136 Dynamic Updates."""
2 import logging
3
4 import dns.flags
5 import dns.message
6 import dns.name
7 import dns.query
8 import dns.rdataclass
9 import dns.rdatatype
10 import dns.tsig
11 import dns.tsigkeyring
12 import dns.update
13 import zope.interface
14
15 from certbot import errors
16 from certbot import interfaces
17 from certbot.plugins import dns_common
18
19 logger = logging.getLogger(__name__)
20
21
22 @zope.interface.implementer(interfaces.IAuthenticator)
23 @zope.interface.provider(interfaces.IPluginFactory)
24 class Authenticator(dns_common.DNSAuthenticator):
25 """DNS Authenticator using RFC 2136 Dynamic Updates
26
27 This Authenticator uses RFC 2136 Dynamic Updates to fulfull a dns-01 challenge.
28 """
29
30 ALGORITHMS = {
31 'HMAC-MD5': dns.tsig.HMAC_MD5,
32 'HMAC-SHA1': dns.tsig.HMAC_SHA1,
33 'HMAC-SHA224': dns.tsig.HMAC_SHA224,
34 'HMAC-SHA256': dns.tsig.HMAC_SHA256,
35 'HMAC-SHA384': dns.tsig.HMAC_SHA384,
36 'HMAC-SHA512': dns.tsig.HMAC_SHA512
37 }
38
39 PORT = 53
40
41 description = 'Obtain certificates using a DNS TXT record (if you are using BIND for DNS).'
42 ttl = 120
43
44 def __init__(self, *args, **kwargs):
45 super(Authenticator, self).__init__(*args, **kwargs)
46 self.credentials = None
47
48 @classmethod
49 def add_parser_arguments(cls, add): # pylint: disable=arguments-differ
50 super(Authenticator, cls).add_parser_arguments(add, default_propagation_seconds=60)
51 add('credentials', help='RFC 2136 credentials INI file.')
52
53 def more_info(self): # pylint: disable=missing-function-docstring
54 return 'This plugin configures a DNS TXT record to respond to a dns-01 challenge using ' + \
55 'RFC 2136 Dynamic Updates.'
56
57 def _validate_algorithm(self, credentials):
58 algorithm = credentials.conf('algorithm')
59 if algorithm:
60 if not self.ALGORITHMS.get(algorithm.upper()):
61 raise errors.PluginError("Unknown algorithm: {0}.".format(algorithm))
62
63 def _setup_credentials(self):
64 self.credentials = self._configure_credentials(
65 'credentials',
66 'RFC 2136 credentials INI file',
67 {
68 'name': 'TSIG key name',
69 'secret': 'TSIG key secret',
70 'server': 'The target DNS server'
71 },
72 self._validate_algorithm
73 )
74
75 def _perform(self, _domain, validation_name, validation):
76 self._get_rfc2136_client().add_txt_record(validation_name, validation, self.ttl)
77
78 def _cleanup(self, _domain, validation_name, validation):
79 self._get_rfc2136_client().del_txt_record(validation_name, validation)
80
81 def _get_rfc2136_client(self):
82 return _RFC2136Client(self.credentials.conf('server'),
83 int(self.credentials.conf('port') or self.PORT),
84 self.credentials.conf('name'),
85 self.credentials.conf('secret'),
86 self.ALGORITHMS.get(self.credentials.conf('algorithm'),
87 dns.tsig.HMAC_MD5))
88
89
90 class _RFC2136Client(object):
91 """
92 Encapsulates all communication with the target DNS server.
93 """
94 def __init__(self, server, port, key_name, key_secret, key_algorithm):
95 self.server = server
96 self.port = port
97 self.keyring = dns.tsigkeyring.from_text({
98 key_name: key_secret
99 })
100 self.algorithm = key_algorithm
101
102 def add_txt_record(self, record_name, record_content, record_ttl):
103 """
104 Add a TXT record using the supplied information.
105
106 :param str record_name: The record name (typically beginning with '_acme-challenge.').
107 :param str record_content: The record content (typically the challenge validation).
108 :param int record_ttl: The record TTL (number of seconds that the record may be cached).
109 :raises certbot.errors.PluginError: if an error occurs communicating with the DNS server
110 """
111
112 domain = self._find_domain(record_name)
113
114 n = dns.name.from_text(record_name)
115 o = dns.name.from_text(domain)
116 rel = n.relativize(o)
117
118 update = dns.update.Update(
119 domain,
120 keyring=self.keyring,
121 keyalgorithm=self.algorithm)
122 update.add(rel, record_ttl, dns.rdatatype.TXT, record_content)
123
124 try:
125 response = dns.query.tcp(update, self.server, port=self.port)
126 except Exception as e:
127 raise errors.PluginError('Encountered error adding TXT record: {0}'
128 .format(e))
129 rcode = response.rcode()
130
131 if rcode == dns.rcode.NOERROR:
132 logger.debug('Successfully added TXT record %s', record_name)
133 else:
134 raise errors.PluginError('Received response from server: {0}'
135 .format(dns.rcode.to_text(rcode)))
136
137 def del_txt_record(self, record_name, record_content):
138 """
139 Delete a TXT record using the supplied information.
140
141 :param str record_name: The record name (typically beginning with '_acme-challenge.').
142 :param str record_content: The record content (typically the challenge validation).
143 :param int record_ttl: The record TTL (number of seconds that the record may be cached).
144 :raises certbot.errors.PluginError: if an error occurs communicating with the DNS server
145 """
146
147 domain = self._find_domain(record_name)
148
149 n = dns.name.from_text(record_name)
150 o = dns.name.from_text(domain)
151 rel = n.relativize(o)
152
153 update = dns.update.Update(
154 domain,
155 keyring=self.keyring,
156 keyalgorithm=self.algorithm)
157 update.delete(rel, dns.rdatatype.TXT, record_content)
158
159 try:
160 response = dns.query.tcp(update, self.server, port=self.port)
161 except Exception as e:
162 raise errors.PluginError('Encountered error deleting TXT record: {0}'
163 .format(e))
164 rcode = response.rcode()
165
166 if rcode == dns.rcode.NOERROR:
167 logger.debug('Successfully deleted TXT record %s', record_name)
168 else:
169 raise errors.PluginError('Received response from server: {0}'
170 .format(dns.rcode.to_text(rcode)))
171
172 def _find_domain(self, record_name):
173 """
174 Find the closest domain with an SOA record for a given domain name.
175
176 :param str record_name: The record name for which to find the closest SOA record.
177 :returns: The domain, if found.
178 :rtype: str
179 :raises certbot.errors.PluginError: if no SOA record can be found.
180 """
181
182 domain_name_guesses = dns_common.base_domain_name_guesses(record_name)
183
184 # Loop through until we find an authoritative SOA record
185 for guess in domain_name_guesses:
186 if self._query_soa(guess):
187 return guess
188
189 raise errors.PluginError('Unable to determine base domain for {0} using names: {1}.'
190 .format(record_name, domain_name_guesses))
191
192 def _query_soa(self, domain_name):
193 """
194 Query a domain name for an authoritative SOA record.
195
196 :param str domain_name: The domain name to query for an SOA record.
197 :returns: True if found, False otherwise.
198 :rtype: bool
199 :raises certbot.errors.PluginError: if no response is received.
200 """
201
202 domain = dns.name.from_text(domain_name)
203
204 request = dns.message.make_query(domain, dns.rdatatype.SOA, dns.rdataclass.IN)
205 # Turn off Recursion Desired bit in query
206 request.flags ^= dns.flags.RD
207
208 try:
209 try:
210 response = dns.query.tcp(request, self.server, port=self.port)
211 except OSError as e:
212 logger.debug('TCP query failed, fallback to UDP: %s', e)
213 response = dns.query.udp(request, self.server, port=self.port)
214 rcode = response.rcode()
215
216 # Authoritative Answer bit should be set
217 if (rcode == dns.rcode.NOERROR and response.get_rrset(response.answer,
218 domain, dns.rdataclass.IN, dns.rdatatype.SOA) and response.flags & dns.flags.AA):
219 logger.debug('Received authoritative SOA response for %s', domain_name)
220 return True
221
222 logger.debug('No authoritative SOA record found for %s', domain_name)
223 return False
224 except Exception as e:
225 raise errors.PluginError('Encountered error when making query: {0}'
226 .format(e))
227
[end of certbot-dns-rfc2136/certbot_dns_rfc2136/_internal/dns_rfc2136.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/certbot-dns-rfc2136/certbot_dns_rfc2136/_internal/dns_rfc2136.py b/certbot-dns-rfc2136/certbot_dns_rfc2136/_internal/dns_rfc2136.py
--- a/certbot-dns-rfc2136/certbot_dns_rfc2136/_internal/dns_rfc2136.py
+++ b/certbot-dns-rfc2136/certbot_dns_rfc2136/_internal/dns_rfc2136.py
@@ -18,6 +18,7 @@
logger = logging.getLogger(__name__)
+DEFAULT_NETWORK_TIMEOUT = 45
@zope.interface.implementer(interfaces.IAuthenticator)
@zope.interface.provider(interfaces.IPluginFactory)
@@ -91,13 +92,15 @@
"""
Encapsulates all communication with the target DNS server.
"""
- def __init__(self, server, port, key_name, key_secret, key_algorithm):
+ def __init__(self, server, port, key_name, key_secret, key_algorithm,
+ timeout=DEFAULT_NETWORK_TIMEOUT):
self.server = server
self.port = port
self.keyring = dns.tsigkeyring.from_text({
key_name: key_secret
})
self.algorithm = key_algorithm
+ self._default_timeout = timeout
def add_txt_record(self, record_name, record_content, record_ttl):
"""
@@ -122,7 +125,7 @@
update.add(rel, record_ttl, dns.rdatatype.TXT, record_content)
try:
- response = dns.query.tcp(update, self.server, port=self.port)
+ response = dns.query.tcp(update, self.server, self._default_timeout, self.port)
except Exception as e:
raise errors.PluginError('Encountered error adding TXT record: {0}'
.format(e))
@@ -157,7 +160,7 @@
update.delete(rel, dns.rdatatype.TXT, record_content)
try:
- response = dns.query.tcp(update, self.server, port=self.port)
+ response = dns.query.tcp(update, self.server, self._default_timeout, self.port)
except Exception as e:
raise errors.PluginError('Encountered error deleting TXT record: {0}'
.format(e))
@@ -207,10 +210,10 @@
try:
try:
- response = dns.query.tcp(request, self.server, port=self.port)
- except OSError as e:
+ response = dns.query.tcp(request, self.server, self._default_timeout, self.port)
+ except (OSError, dns.exception.Timeout) as e:
logger.debug('TCP query failed, fallback to UDP: %s', e)
- response = dns.query.udp(request, self.server, port=self.port)
+ response = dns.query.udp(request, self.server, self._default_timeout, self.port)
rcode = response.rcode()
# Authoritative Answer bit should be set
| {"golden_diff": "diff --git a/certbot-dns-rfc2136/certbot_dns_rfc2136/_internal/dns_rfc2136.py b/certbot-dns-rfc2136/certbot_dns_rfc2136/_internal/dns_rfc2136.py\n--- a/certbot-dns-rfc2136/certbot_dns_rfc2136/_internal/dns_rfc2136.py\n+++ b/certbot-dns-rfc2136/certbot_dns_rfc2136/_internal/dns_rfc2136.py\n@@ -18,6 +18,7 @@\n \n logger = logging.getLogger(__name__)\n \n+DEFAULT_NETWORK_TIMEOUT = 45\n \n @zope.interface.implementer(interfaces.IAuthenticator)\n @zope.interface.provider(interfaces.IPluginFactory)\n@@ -91,13 +92,15 @@\n \"\"\"\n Encapsulates all communication with the target DNS server.\n \"\"\"\n- def __init__(self, server, port, key_name, key_secret, key_algorithm):\n+ def __init__(self, server, port, key_name, key_secret, key_algorithm,\n+ timeout=DEFAULT_NETWORK_TIMEOUT):\n self.server = server\n self.port = port\n self.keyring = dns.tsigkeyring.from_text({\n key_name: key_secret\n })\n self.algorithm = key_algorithm\n+ self._default_timeout = timeout\n \n def add_txt_record(self, record_name, record_content, record_ttl):\n \"\"\"\n@@ -122,7 +125,7 @@\n update.add(rel, record_ttl, dns.rdatatype.TXT, record_content)\n \n try:\n- response = dns.query.tcp(update, self.server, port=self.port)\n+ response = dns.query.tcp(update, self.server, self._default_timeout, self.port)\n except Exception as e:\n raise errors.PluginError('Encountered error adding TXT record: {0}'\n .format(e))\n@@ -157,7 +160,7 @@\n update.delete(rel, dns.rdatatype.TXT, record_content)\n \n try:\n- response = dns.query.tcp(update, self.server, port=self.port)\n+ response = dns.query.tcp(update, self.server, self._default_timeout, self.port)\n except Exception as e:\n raise errors.PluginError('Encountered error deleting TXT record: {0}'\n .format(e))\n@@ -207,10 +210,10 @@\n \n try:\n try:\n- response = dns.query.tcp(request, self.server, port=self.port)\n- except OSError as e:\n+ response = dns.query.tcp(request, self.server, self._default_timeout, self.port)\n+ except (OSError, dns.exception.Timeout) as e:\n logger.debug('TCP query failed, fallback to UDP: %s', e)\n- response = dns.query.udp(request, self.server, port=self.port)\n+ response = dns.query.udp(request, self.server, self._default_timeout, self.port)\n rcode = response.rcode()\n \n # Authoritative Answer bit should be set\n", "issue": "dns-rfc2136 challenges run infinitely for invalid DNS servers\n1. Set `dns_rfc2136_server` to something invalid, e.g. `dns_rfc2136_server = 2001:db8::`.\r\n2. Try to obtain certificates.\r\n3. Challenges run forever.\r\n\r\nCTRL+C during a challenge:\r\n```\r\n[... usual]\r\nPerforming the following challenges:\r\ndns-01 challenge for [...]\r\ndns-01 challenge for [...]\r\nEncountered exception:\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.7/site-packages/certbot/auth_handler.py\", line 75, in handle_authorizations\r\n resp = self._solve_challenges(aauthzrs)\r\n File \"/usr/lib/python3.7/site-packages/certbot/auth_handler.py\", line 139, in _solve_challenges\r\n resp = self.auth.perform(all_achalls)\r\n File \"/usr/lib/python3.7/site-packages/certbot/plugins/dns_common.py\", line 57, in perform\r\n self._perform(domain, validation_domain_name, validation)\r\n File \"/usr/lib/python3.7/site-packages/certbot_dns_rfc2136/dns_rfc2136.py\", line 76, in _perform\r\n self._get_rfc2136_client().add_txt_record(validation_name, validation, self.ttl)\r\n File \"/usr/lib/python3.7/site-packages/certbot_dns_rfc2136/dns_rfc2136.py\", line 112, in add_txt_record\r\n domain = self._find_domain(record_name)\r\n File \"/usr/lib/python3.7/site-packages/certbot_dns_rfc2136/dns_rfc2136.py\", line 186, in _find_domain\r\n if self._query_soa(guess):\r\n File \"/usr/lib/python3.7/site-packages/certbot_dns_rfc2136/dns_rfc2136.py\", line 209, in _query_soa\r\n response = dns.query.udp(request, self.server, port=self.port)\r\n File \"/usr/lib/python3.7/site-packages/dns/query.py\", line 240, in udp\r\n _wait_for_readable(s, expiration)\r\n File \"/usr/lib/python3.7/site-packages/dns/query.py\", line 157, in _wait_for_readable\r\n _wait_for(s, True, False, True, expiration)\r\n File \"/usr/lib/python3.7/site-packages/dns/query.py\", line 131, in _wait_for\r\n if not _polling_backend(fd, readable, writable, error, timeout):\r\n File \"/usr/lib/python3.7/site-packages/dns/query.py\", line 87, in _poll_for\r\n event_list = pollable.poll()\r\nKeyboardInterrupt\r\n```\r\n\r\n**Expected:** \r\nCertbot should set a reasonable query timeout ([this is supported by `dnspython`](https://stackoverflow.com/questions/8989457/dnspython-setting-query-timeout-lifetime)) and alert the user of an issue with the DNS server.\n", "before_files": [{"content": "\"\"\"DNS Authenticator using RFC 2136 Dynamic Updates.\"\"\"\nimport logging\n\nimport dns.flags\nimport dns.message\nimport dns.name\nimport dns.query\nimport dns.rdataclass\nimport dns.rdatatype\nimport dns.tsig\nimport dns.tsigkeyring\nimport dns.update\nimport zope.interface\n\nfrom certbot import errors\nfrom certbot import interfaces\nfrom certbot.plugins import dns_common\n\nlogger = logging.getLogger(__name__)\n\n\[email protected](interfaces.IAuthenticator)\[email protected](interfaces.IPluginFactory)\nclass Authenticator(dns_common.DNSAuthenticator):\n \"\"\"DNS Authenticator using RFC 2136 Dynamic Updates\n\n This Authenticator uses RFC 2136 Dynamic Updates to fulfull a dns-01 challenge.\n \"\"\"\n\n ALGORITHMS = {\n 'HMAC-MD5': dns.tsig.HMAC_MD5,\n 'HMAC-SHA1': dns.tsig.HMAC_SHA1,\n 'HMAC-SHA224': dns.tsig.HMAC_SHA224,\n 'HMAC-SHA256': dns.tsig.HMAC_SHA256,\n 'HMAC-SHA384': dns.tsig.HMAC_SHA384,\n 'HMAC-SHA512': dns.tsig.HMAC_SHA512\n }\n\n PORT = 53\n\n description = 'Obtain certificates using a DNS TXT record (if you are using BIND for DNS).'\n ttl = 120\n\n def __init__(self, *args, **kwargs):\n super(Authenticator, self).__init__(*args, **kwargs)\n self.credentials = None\n\n @classmethod\n def add_parser_arguments(cls, add): # pylint: disable=arguments-differ\n super(Authenticator, cls).add_parser_arguments(add, default_propagation_seconds=60)\n add('credentials', help='RFC 2136 credentials INI file.')\n\n def more_info(self): # pylint: disable=missing-function-docstring\n return 'This plugin configures a DNS TXT record to respond to a dns-01 challenge using ' + \\\n 'RFC 2136 Dynamic Updates.'\n\n def _validate_algorithm(self, credentials):\n algorithm = credentials.conf('algorithm')\n if algorithm:\n if not self.ALGORITHMS.get(algorithm.upper()):\n raise errors.PluginError(\"Unknown algorithm: {0}.\".format(algorithm))\n\n def _setup_credentials(self):\n self.credentials = self._configure_credentials(\n 'credentials',\n 'RFC 2136 credentials INI file',\n {\n 'name': 'TSIG key name',\n 'secret': 'TSIG key secret',\n 'server': 'The target DNS server'\n },\n self._validate_algorithm\n )\n\n def _perform(self, _domain, validation_name, validation):\n self._get_rfc2136_client().add_txt_record(validation_name, validation, self.ttl)\n\n def _cleanup(self, _domain, validation_name, validation):\n self._get_rfc2136_client().del_txt_record(validation_name, validation)\n\n def _get_rfc2136_client(self):\n return _RFC2136Client(self.credentials.conf('server'),\n int(self.credentials.conf('port') or self.PORT),\n self.credentials.conf('name'),\n self.credentials.conf('secret'),\n self.ALGORITHMS.get(self.credentials.conf('algorithm'),\n dns.tsig.HMAC_MD5))\n\n\nclass _RFC2136Client(object):\n \"\"\"\n Encapsulates all communication with the target DNS server.\n \"\"\"\n def __init__(self, server, port, key_name, key_secret, key_algorithm):\n self.server = server\n self.port = port\n self.keyring = dns.tsigkeyring.from_text({\n key_name: key_secret\n })\n self.algorithm = key_algorithm\n\n def add_txt_record(self, record_name, record_content, record_ttl):\n \"\"\"\n Add a TXT record using the supplied information.\n\n :param str record_name: The record name (typically beginning with '_acme-challenge.').\n :param str record_content: The record content (typically the challenge validation).\n :param int record_ttl: The record TTL (number of seconds that the record may be cached).\n :raises certbot.errors.PluginError: if an error occurs communicating with the DNS server\n \"\"\"\n\n domain = self._find_domain(record_name)\n\n n = dns.name.from_text(record_name)\n o = dns.name.from_text(domain)\n rel = n.relativize(o)\n\n update = dns.update.Update(\n domain,\n keyring=self.keyring,\n keyalgorithm=self.algorithm)\n update.add(rel, record_ttl, dns.rdatatype.TXT, record_content)\n\n try:\n response = dns.query.tcp(update, self.server, port=self.port)\n except Exception as e:\n raise errors.PluginError('Encountered error adding TXT record: {0}'\n .format(e))\n rcode = response.rcode()\n\n if rcode == dns.rcode.NOERROR:\n logger.debug('Successfully added TXT record %s', record_name)\n else:\n raise errors.PluginError('Received response from server: {0}'\n .format(dns.rcode.to_text(rcode)))\n\n def del_txt_record(self, record_name, record_content):\n \"\"\"\n Delete a TXT record using the supplied information.\n\n :param str record_name: The record name (typically beginning with '_acme-challenge.').\n :param str record_content: The record content (typically the challenge validation).\n :param int record_ttl: The record TTL (number of seconds that the record may be cached).\n :raises certbot.errors.PluginError: if an error occurs communicating with the DNS server\n \"\"\"\n\n domain = self._find_domain(record_name)\n\n n = dns.name.from_text(record_name)\n o = dns.name.from_text(domain)\n rel = n.relativize(o)\n\n update = dns.update.Update(\n domain,\n keyring=self.keyring,\n keyalgorithm=self.algorithm)\n update.delete(rel, dns.rdatatype.TXT, record_content)\n\n try:\n response = dns.query.tcp(update, self.server, port=self.port)\n except Exception as e:\n raise errors.PluginError('Encountered error deleting TXT record: {0}'\n .format(e))\n rcode = response.rcode()\n\n if rcode == dns.rcode.NOERROR:\n logger.debug('Successfully deleted TXT record %s', record_name)\n else:\n raise errors.PluginError('Received response from server: {0}'\n .format(dns.rcode.to_text(rcode)))\n\n def _find_domain(self, record_name):\n \"\"\"\n Find the closest domain with an SOA record for a given domain name.\n\n :param str record_name: The record name for which to find the closest SOA record.\n :returns: The domain, if found.\n :rtype: str\n :raises certbot.errors.PluginError: if no SOA record can be found.\n \"\"\"\n\n domain_name_guesses = dns_common.base_domain_name_guesses(record_name)\n\n # Loop through until we find an authoritative SOA record\n for guess in domain_name_guesses:\n if self._query_soa(guess):\n return guess\n\n raise errors.PluginError('Unable to determine base domain for {0} using names: {1}.'\n .format(record_name, domain_name_guesses))\n\n def _query_soa(self, domain_name):\n \"\"\"\n Query a domain name for an authoritative SOA record.\n\n :param str domain_name: The domain name to query for an SOA record.\n :returns: True if found, False otherwise.\n :rtype: bool\n :raises certbot.errors.PluginError: if no response is received.\n \"\"\"\n\n domain = dns.name.from_text(domain_name)\n\n request = dns.message.make_query(domain, dns.rdatatype.SOA, dns.rdataclass.IN)\n # Turn off Recursion Desired bit in query\n request.flags ^= dns.flags.RD\n\n try:\n try:\n response = dns.query.tcp(request, self.server, port=self.port)\n except OSError as e:\n logger.debug('TCP query failed, fallback to UDP: %s', e)\n response = dns.query.udp(request, self.server, port=self.port)\n rcode = response.rcode()\n\n # Authoritative Answer bit should be set\n if (rcode == dns.rcode.NOERROR and response.get_rrset(response.answer,\n domain, dns.rdataclass.IN, dns.rdatatype.SOA) and response.flags & dns.flags.AA):\n logger.debug('Received authoritative SOA response for %s', domain_name)\n return True\n\n logger.debug('No authoritative SOA record found for %s', domain_name)\n return False\n except Exception as e:\n raise errors.PluginError('Encountered error when making query: {0}'\n .format(e))\n", "path": "certbot-dns-rfc2136/certbot_dns_rfc2136/_internal/dns_rfc2136.py"}]} | 3,780 | 689 |
gh_patches_debug_8732 | rasdani/github-patches | git_diff | meltano__meltano-7427 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
bug: `flask` not found when running `meltano-cloud` via `pipx`
### Meltano Version
N/A
### Python Version
3.11
### Bug scope
CLI (options, error messages, logging, etc.)
### Operating System
Python 3.11 Docker container
### Description
```sh
pip install pipx
pipx install 'git+https://github.com/meltano/meltano.git@cloud#subdirectory=src/cloud-cli'`
pipx ensurepath
bash
meltano-cloud login
```
Results in:
```
FileNotFoundError: [Errno 2] No such file or directory: 'flask'
```
This is because `pipx` only exposes the CLI entrypoints of our package, and not those of its dependencies like `flask`. We can resolve this by using the precise path to the `flask` binary in the active environment rather than searching for it on `$PATH`.
### Code
_No response_
</issue>
<code>
[start of src/cloud-cli/meltano/cloud/api/auth/auth.py]
1 """Authentication for Meltano Cloud."""
2
3 from __future__ import annotations
4
5 import asyncio
6 import os
7 import subprocess
8 import sys
9 import typing as t
10 import webbrowser
11 from contextlib import contextmanager
12 from pathlib import Path
13 from urllib.parse import urlencode, urljoin
14
15 import aiohttp
16 import click
17
18 from meltano.cloud.api.config import MeltanoCloudConfig
19
20 if sys.version_info <= (3, 8):
21 from cached_property import cached_property
22 else:
23 from functools import cached_property
24
25 LOGIN_STATUS_CHECK_DELAY_SECONDS = 0.2
26
27
28 class MeltanoCloudAuthError(Exception):
29 """Raised when an API call returns a 403."""
30
31
32 class MeltanoCloudAuth: # noqa: WPS214
33 """Authentication methods for Meltano Cloud."""
34
35 def __init__(self, config: MeltanoCloudConfig | None = None):
36 """Initialize a MeltanoCloudAuth instance.
37
38 Args:
39 config: the MeltanoCloudConfig to use
40 """
41 self.config = config or MeltanoCloudConfig.find()
42 self.base_url = self.config.base_auth_url
43 self.client_id = self.config.app_client_id
44
45 @cached_property
46 def login_url(self) -> str:
47 """Get the oauth2 authorization URL.
48
49 Returns:
50 the oauth2 authorization URL.
51 """
52 query_params = urlencode(
53 {
54 "client_id": self.client_id,
55 "response_type": "token",
56 "scope": "email openid profile",
57 "redirect_uri": f"http://localhost:{self.config.auth_callback_port}",
58 }
59 )
60 return f"{self.base_url}/oauth2/authorize?{query_params}"
61
62 @cached_property
63 def logout_url(self) -> str:
64 """Get the Meltano Cloud logout URL.
65
66 Returns:
67 the Meltano Cloud logout URL.
68 """
69 params = urlencode(
70 {
71 "client_id": self.client_id,
72 "logout_uri": f"http://localhost:{self.config.auth_callback_port}/logout", # noqa: E501)
73 }
74 )
75 return urljoin(self.base_url, f"logout?{params}")
76
77 @contextmanager
78 def callback_server(self) -> t.Iterator[None]:
79 """Context manager to run callback server locally.
80
81 Yields:
82 None
83 """
84 server = None
85 try:
86 server = subprocess.Popen( # noqa: S607
87 ("flask", "run", f"--port={self.config.auth_callback_port}"),
88 env={
89 **os.environ,
90 "FLASK_APP": "callback_server.py",
91 "MELTANO_CLOUD_CONFIG_PATH": str(self.config.config_path),
92 },
93 cwd=Path(__file__).parent,
94 stdout=subprocess.DEVNULL,
95 stderr=subprocess.STDOUT,
96 )
97 yield
98 finally:
99 if server:
100 server.kill()
101
102 async def login(self) -> None:
103 """Take user through login flow and get auth and id tokens."""
104 if await self.logged_in():
105 return
106 with self.callback_server():
107 click.echo("Logging in to Meltano Cloud.")
108 click.echo("You will be directed to a web browser to complete login.")
109 click.echo("If a web browser does not open, open the following link:")
110 click.secho(self.login_url, fg="green")
111 webbrowser.open_new_tab(self.login_url)
112 while not await self.logged_in():
113 self.config.refresh()
114 await asyncio.sleep(LOGIN_STATUS_CHECK_DELAY_SECONDS)
115
116 async def logout(self) -> None: # noqa: WPS213
117 """Log out."""
118 if not await self.logged_in():
119 click.secho("Not logged in.", fg="green")
120 return
121 with self.callback_server():
122 click.echo("Logging out of Meltano Cloud.")
123 click.echo("You will be directed to a web browser to complete logout.")
124 click.echo("If a web browser does not open, open the following link:")
125 click.secho(self.logout_url, fg="green")
126 webbrowser.open_new_tab(self.logout_url)
127 while await self.logged_in():
128 self.config.refresh()
129 await asyncio.sleep(LOGIN_STATUS_CHECK_DELAY_SECONDS)
130 click.secho("Successfully logged out.", fg="green")
131
132 def get_auth_header(self) -> dict[str, str]:
133 """Get the authorization header.
134
135 Used for authenticating to cloud API endpoints.
136
137 Returns:
138 Authorization header using ID token as bearer token.
139
140 """
141 return {"Authorization": f"Bearer {self.config.id_token}"}
142
143 def get_access_token_header(self) -> dict[str, str]:
144 """Get the access token header.
145
146 Used for authenticating to auth endpoints.
147
148 Returns:
149 Authorization header using access token as bearer token.
150 """
151 return {"Authorization": f"Bearer {self.config.access_token}"}
152
153 async def get_user_info_response(self) -> aiohttp.ClientResponse:
154 """Get user info.
155
156 Returns:
157 User info response
158 """
159 async with aiohttp.ClientSession() as session:
160 async with session.get(
161 urljoin(self.base_url, "oauth2/userInfo"),
162 headers=self.get_access_token_header(),
163 ) as response:
164 return response
165
166 async def get_user_info_json(self) -> dict:
167 """Get user info as dict.
168
169 Returns:
170 User info json
171 """
172 async with aiohttp.ClientSession() as session:
173 async with session.get(
174 urljoin(self.base_url, "oauth2/userInfo"),
175 headers=self.get_access_token_header(),
176 ) as response:
177 return await response.json()
178
179 async def logged_in(self) -> bool:
180 """Check if this instance is currently logged in.
181
182 Returns:
183 True if logged in, else False
184 """
185 user_info_resp = await self.get_user_info_response()
186 return bool(
187 self.config.access_token and self.config.id_token and user_info_resp.ok
188 )
189
[end of src/cloud-cli/meltano/cloud/api/auth/auth.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/cloud-cli/meltano/cloud/api/auth/auth.py b/src/cloud-cli/meltano/cloud/api/auth/auth.py
--- a/src/cloud-cli/meltano/cloud/api/auth/auth.py
+++ b/src/cloud-cli/meltano/cloud/api/auth/auth.py
@@ -84,7 +84,11 @@
server = None
try:
server = subprocess.Popen( # noqa: S607
- ("flask", "run", f"--port={self.config.auth_callback_port}"),
+ (
+ str(Path(sys.prefix) / "bin" / "flask"),
+ "run",
+ f"--port={self.config.auth_callback_port}",
+ ),
env={
**os.environ,
"FLASK_APP": "callback_server.py",
| {"golden_diff": "diff --git a/src/cloud-cli/meltano/cloud/api/auth/auth.py b/src/cloud-cli/meltano/cloud/api/auth/auth.py\n--- a/src/cloud-cli/meltano/cloud/api/auth/auth.py\n+++ b/src/cloud-cli/meltano/cloud/api/auth/auth.py\n@@ -84,7 +84,11 @@\n server = None\n try:\n server = subprocess.Popen( # noqa: S607\n- (\"flask\", \"run\", f\"--port={self.config.auth_callback_port}\"),\n+ (\n+ str(Path(sys.prefix) / \"bin\" / \"flask\"),\n+ \"run\",\n+ f\"--port={self.config.auth_callback_port}\",\n+ ),\n env={\n **os.environ,\n \"FLASK_APP\": \"callback_server.py\",\n", "issue": "bug: `flask` not found when running `meltano-cloud` via `pipx`\n### Meltano Version\n\nN/A\n\n### Python Version\n\n3.11\n\n### Bug scope\n\nCLI (options, error messages, logging, etc.)\n\n### Operating System\n\nPython 3.11 Docker container\n\n### Description\n\n```sh\r\npip install pipx\r\npipx install 'git+https://github.com/meltano/meltano.git@cloud#subdirectory=src/cloud-cli'`\r\npipx ensurepath\r\nbash\r\nmeltano-cloud login\r\n```\r\n\r\nResults in:\r\n```\r\nFileNotFoundError: [Errno 2] No such file or directory: 'flask'\r\n```\r\n\r\nThis is because `pipx` only exposes the CLI entrypoints of our package, and not those of its dependencies like `flask`. We can resolve this by using the precise path to the `flask` binary in the active environment rather than searching for it on `$PATH`.\n\n### Code\n\n_No response_\n", "before_files": [{"content": "\"\"\"Authentication for Meltano Cloud.\"\"\"\n\nfrom __future__ import annotations\n\nimport asyncio\nimport os\nimport subprocess\nimport sys\nimport typing as t\nimport webbrowser\nfrom contextlib import contextmanager\nfrom pathlib import Path\nfrom urllib.parse import urlencode, urljoin\n\nimport aiohttp\nimport click\n\nfrom meltano.cloud.api.config import MeltanoCloudConfig\n\nif sys.version_info <= (3, 8):\n from cached_property import cached_property\nelse:\n from functools import cached_property\n\nLOGIN_STATUS_CHECK_DELAY_SECONDS = 0.2\n\n\nclass MeltanoCloudAuthError(Exception):\n \"\"\"Raised when an API call returns a 403.\"\"\"\n\n\nclass MeltanoCloudAuth: # noqa: WPS214\n \"\"\"Authentication methods for Meltano Cloud.\"\"\"\n\n def __init__(self, config: MeltanoCloudConfig | None = None):\n \"\"\"Initialize a MeltanoCloudAuth instance.\n\n Args:\n config: the MeltanoCloudConfig to use\n \"\"\"\n self.config = config or MeltanoCloudConfig.find()\n self.base_url = self.config.base_auth_url\n self.client_id = self.config.app_client_id\n\n @cached_property\n def login_url(self) -> str:\n \"\"\"Get the oauth2 authorization URL.\n\n Returns:\n the oauth2 authorization URL.\n \"\"\"\n query_params = urlencode(\n {\n \"client_id\": self.client_id,\n \"response_type\": \"token\",\n \"scope\": \"email openid profile\",\n \"redirect_uri\": f\"http://localhost:{self.config.auth_callback_port}\",\n }\n )\n return f\"{self.base_url}/oauth2/authorize?{query_params}\"\n\n @cached_property\n def logout_url(self) -> str:\n \"\"\"Get the Meltano Cloud logout URL.\n\n Returns:\n the Meltano Cloud logout URL.\n \"\"\"\n params = urlencode(\n {\n \"client_id\": self.client_id,\n \"logout_uri\": f\"http://localhost:{self.config.auth_callback_port}/logout\", # noqa: E501)\n }\n )\n return urljoin(self.base_url, f\"logout?{params}\")\n\n @contextmanager\n def callback_server(self) -> t.Iterator[None]:\n \"\"\"Context manager to run callback server locally.\n\n Yields:\n None\n \"\"\"\n server = None\n try:\n server = subprocess.Popen( # noqa: S607\n (\"flask\", \"run\", f\"--port={self.config.auth_callback_port}\"),\n env={\n **os.environ,\n \"FLASK_APP\": \"callback_server.py\",\n \"MELTANO_CLOUD_CONFIG_PATH\": str(self.config.config_path),\n },\n cwd=Path(__file__).parent,\n stdout=subprocess.DEVNULL,\n stderr=subprocess.STDOUT,\n )\n yield\n finally:\n if server:\n server.kill()\n\n async def login(self) -> None:\n \"\"\"Take user through login flow and get auth and id tokens.\"\"\"\n if await self.logged_in():\n return\n with self.callback_server():\n click.echo(\"Logging in to Meltano Cloud.\")\n click.echo(\"You will be directed to a web browser to complete login.\")\n click.echo(\"If a web browser does not open, open the following link:\")\n click.secho(self.login_url, fg=\"green\")\n webbrowser.open_new_tab(self.login_url)\n while not await self.logged_in():\n self.config.refresh()\n await asyncio.sleep(LOGIN_STATUS_CHECK_DELAY_SECONDS)\n\n async def logout(self) -> None: # noqa: WPS213\n \"\"\"Log out.\"\"\"\n if not await self.logged_in():\n click.secho(\"Not logged in.\", fg=\"green\")\n return\n with self.callback_server():\n click.echo(\"Logging out of Meltano Cloud.\")\n click.echo(\"You will be directed to a web browser to complete logout.\")\n click.echo(\"If a web browser does not open, open the following link:\")\n click.secho(self.logout_url, fg=\"green\")\n webbrowser.open_new_tab(self.logout_url)\n while await self.logged_in():\n self.config.refresh()\n await asyncio.sleep(LOGIN_STATUS_CHECK_DELAY_SECONDS)\n click.secho(\"Successfully logged out.\", fg=\"green\")\n\n def get_auth_header(self) -> dict[str, str]:\n \"\"\"Get the authorization header.\n\n Used for authenticating to cloud API endpoints.\n\n Returns:\n Authorization header using ID token as bearer token.\n\n \"\"\"\n return {\"Authorization\": f\"Bearer {self.config.id_token}\"}\n\n def get_access_token_header(self) -> dict[str, str]:\n \"\"\"Get the access token header.\n\n Used for authenticating to auth endpoints.\n\n Returns:\n Authorization header using access token as bearer token.\n \"\"\"\n return {\"Authorization\": f\"Bearer {self.config.access_token}\"}\n\n async def get_user_info_response(self) -> aiohttp.ClientResponse:\n \"\"\"Get user info.\n\n Returns:\n User info response\n \"\"\"\n async with aiohttp.ClientSession() as session:\n async with session.get(\n urljoin(self.base_url, \"oauth2/userInfo\"),\n headers=self.get_access_token_header(),\n ) as response:\n return response\n\n async def get_user_info_json(self) -> dict:\n \"\"\"Get user info as dict.\n\n Returns:\n User info json\n \"\"\"\n async with aiohttp.ClientSession() as session:\n async with session.get(\n urljoin(self.base_url, \"oauth2/userInfo\"),\n headers=self.get_access_token_header(),\n ) as response:\n return await response.json()\n\n async def logged_in(self) -> bool:\n \"\"\"Check if this instance is currently logged in.\n\n Returns:\n True if logged in, else False\n \"\"\"\n user_info_resp = await self.get_user_info_response()\n return bool(\n self.config.access_token and self.config.id_token and user_info_resp.ok\n )\n", "path": "src/cloud-cli/meltano/cloud/api/auth/auth.py"}]} | 2,493 | 170 |
gh_patches_debug_8064 | rasdani/github-patches | git_diff | getsentry__sentry-37553 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cannot edit or delete alerts
### Environment
SaaS (https://sentry.io/)
### Version
_No response_
### Steps to Reproduce
1. Have alerts that were set up a while ago
2. Get a bunch of emails from one alert that is too touchy
3. Try to edit alert (fails)
4. Try to delete alert (fails)
### Expected Result
Can edit or delete alerts that I created on an account that I am the only user for
### Actual Result
Cannot edit or delete alerts


</issue>
<code>
[start of src/sentry/incidents/endpoints/bases.py]
1 from rest_framework.exceptions import PermissionDenied
2 from rest_framework.request import Request
3
4 from sentry import features
5 from sentry.api.bases.organization import OrganizationAlertRulePermission, OrganizationEndpoint
6 from sentry.api.bases.project import ProjectAlertRulePermission, ProjectEndpoint
7 from sentry.api.exceptions import ResourceDoesNotExist
8 from sentry.incidents.models import AlertRule, AlertRuleTrigger, AlertRuleTriggerAction
9
10
11 class ProjectAlertRuleEndpoint(ProjectEndpoint):
12 permission_classes = (ProjectAlertRulePermission,)
13
14 def convert_args(self, request: Request, alert_rule_id, *args, **kwargs):
15 args, kwargs = super().convert_args(request, *args, **kwargs)
16 project = kwargs["project"]
17
18 if not features.has("organizations:incidents", project.organization, actor=request.user):
19 raise ResourceDoesNotExist
20
21 if not request.access.has_project_access(project):
22 raise PermissionDenied
23
24 try:
25 kwargs["alert_rule"] = AlertRule.objects.get(
26 snuba_query__subscriptions__project=project, id=alert_rule_id
27 )
28 except AlertRule.DoesNotExist:
29 raise ResourceDoesNotExist
30
31 return args, kwargs
32
33
34 class OrganizationAlertRuleEndpoint(OrganizationEndpoint):
35 permission_classes = (OrganizationAlertRulePermission,)
36
37 def convert_args(self, request: Request, alert_rule_id, *args, **kwargs):
38 args, kwargs = super().convert_args(request, *args, **kwargs)
39 organization = kwargs["organization"]
40
41 if not features.has("organizations:incidents", organization, actor=request.user):
42 raise ResourceDoesNotExist
43
44 try:
45 kwargs["alert_rule"] = AlertRule.objects.get(
46 organization=organization, id=alert_rule_id
47 )
48 except AlertRule.DoesNotExist:
49 raise ResourceDoesNotExist
50
51 return args, kwargs
52
53
54 class OrganizationAlertRuleTriggerEndpoint(OrganizationAlertRuleEndpoint):
55 def convert_args(self, request: Request, alert_rule_trigger_id, *args, **kwargs):
56 args, kwargs = super().convert_args(request, *args, **kwargs)
57 organization = kwargs["organization"]
58 alert_rule = kwargs["alert_rule"]
59
60 if not features.has("organizations:incidents", organization, actor=request.user):
61 raise ResourceDoesNotExist
62
63 try:
64 kwargs["alert_rule_trigger"] = AlertRuleTrigger.objects.get(
65 alert_rule=alert_rule, id=alert_rule_trigger_id
66 )
67 except AlertRuleTrigger.DoesNotExist:
68 raise ResourceDoesNotExist
69
70 return args, kwargs
71
72
73 class OrganizationAlertRuleTriggerActionEndpoint(OrganizationAlertRuleTriggerEndpoint):
74 def convert_args(self, request: Request, alert_rule_trigger_action_id, *args, **kwargs):
75 args, kwargs = super().convert_args(request, *args, **kwargs)
76 organization = kwargs["organization"]
77 trigger = kwargs["alert_rule_trigger"]
78
79 if not features.has("organizations:incidents", organization, actor=request.user):
80 raise ResourceDoesNotExist
81
82 try:
83 kwargs["alert_rule_trigger_action"] = AlertRuleTriggerAction.objects.get(
84 alert_rule_trigger=trigger, id=alert_rule_trigger_action_id
85 )
86 except AlertRuleTriggerAction.DoesNotExist:
87 raise ResourceDoesNotExist
88
89 return args, kwargs
90
[end of src/sentry/incidents/endpoints/bases.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/sentry/incidents/endpoints/bases.py b/src/sentry/incidents/endpoints/bases.py
--- a/src/sentry/incidents/endpoints/bases.py
+++ b/src/sentry/incidents/endpoints/bases.py
@@ -38,7 +38,10 @@
args, kwargs = super().convert_args(request, *args, **kwargs)
organization = kwargs["organization"]
- if not features.has("organizations:incidents", organization, actor=request.user):
+ # Allow orgs that have downgraded plans to delete metric alerts
+ if request.method != "DELETE" and not features.has(
+ "organizations:incidents", organization, actor=request.user
+ ):
raise ResourceDoesNotExist
try:
| {"golden_diff": "diff --git a/src/sentry/incidents/endpoints/bases.py b/src/sentry/incidents/endpoints/bases.py\n--- a/src/sentry/incidents/endpoints/bases.py\n+++ b/src/sentry/incidents/endpoints/bases.py\n@@ -38,7 +38,10 @@\n args, kwargs = super().convert_args(request, *args, **kwargs)\n organization = kwargs[\"organization\"]\n \n- if not features.has(\"organizations:incidents\", organization, actor=request.user):\n+ # Allow orgs that have downgraded plans to delete metric alerts\n+ if request.method != \"DELETE\" and not features.has(\n+ \"organizations:incidents\", organization, actor=request.user\n+ ):\n raise ResourceDoesNotExist\n \n try:\n", "issue": "Cannot edit or delete alerts\n### Environment\n\nSaaS (https://sentry.io/)\n\n### Version\n\n_No response_\n\n### Steps to Reproduce\n\n1. Have alerts that were set up a while ago\r\n2. Get a bunch of emails from one alert that is too touchy\r\n3. Try to edit alert (fails)\r\n4. Try to delete alert (fails)\n\n### Expected Result\n\nCan edit or delete alerts that I created on an account that I am the only user for\n\n### Actual Result\n\nCannot edit or delete alerts\r\n\r\n\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "from rest_framework.exceptions import PermissionDenied\nfrom rest_framework.request import Request\n\nfrom sentry import features\nfrom sentry.api.bases.organization import OrganizationAlertRulePermission, OrganizationEndpoint\nfrom sentry.api.bases.project import ProjectAlertRulePermission, ProjectEndpoint\nfrom sentry.api.exceptions import ResourceDoesNotExist\nfrom sentry.incidents.models import AlertRule, AlertRuleTrigger, AlertRuleTriggerAction\n\n\nclass ProjectAlertRuleEndpoint(ProjectEndpoint):\n permission_classes = (ProjectAlertRulePermission,)\n\n def convert_args(self, request: Request, alert_rule_id, *args, **kwargs):\n args, kwargs = super().convert_args(request, *args, **kwargs)\n project = kwargs[\"project\"]\n\n if not features.has(\"organizations:incidents\", project.organization, actor=request.user):\n raise ResourceDoesNotExist\n\n if not request.access.has_project_access(project):\n raise PermissionDenied\n\n try:\n kwargs[\"alert_rule\"] = AlertRule.objects.get(\n snuba_query__subscriptions__project=project, id=alert_rule_id\n )\n except AlertRule.DoesNotExist:\n raise ResourceDoesNotExist\n\n return args, kwargs\n\n\nclass OrganizationAlertRuleEndpoint(OrganizationEndpoint):\n permission_classes = (OrganizationAlertRulePermission,)\n\n def convert_args(self, request: Request, alert_rule_id, *args, **kwargs):\n args, kwargs = super().convert_args(request, *args, **kwargs)\n organization = kwargs[\"organization\"]\n\n if not features.has(\"organizations:incidents\", organization, actor=request.user):\n raise ResourceDoesNotExist\n\n try:\n kwargs[\"alert_rule\"] = AlertRule.objects.get(\n organization=organization, id=alert_rule_id\n )\n except AlertRule.DoesNotExist:\n raise ResourceDoesNotExist\n\n return args, kwargs\n\n\nclass OrganizationAlertRuleTriggerEndpoint(OrganizationAlertRuleEndpoint):\n def convert_args(self, request: Request, alert_rule_trigger_id, *args, **kwargs):\n args, kwargs = super().convert_args(request, *args, **kwargs)\n organization = kwargs[\"organization\"]\n alert_rule = kwargs[\"alert_rule\"]\n\n if not features.has(\"organizations:incidents\", organization, actor=request.user):\n raise ResourceDoesNotExist\n\n try:\n kwargs[\"alert_rule_trigger\"] = AlertRuleTrigger.objects.get(\n alert_rule=alert_rule, id=alert_rule_trigger_id\n )\n except AlertRuleTrigger.DoesNotExist:\n raise ResourceDoesNotExist\n\n return args, kwargs\n\n\nclass OrganizationAlertRuleTriggerActionEndpoint(OrganizationAlertRuleTriggerEndpoint):\n def convert_args(self, request: Request, alert_rule_trigger_action_id, *args, **kwargs):\n args, kwargs = super().convert_args(request, *args, **kwargs)\n organization = kwargs[\"organization\"]\n trigger = kwargs[\"alert_rule_trigger\"]\n\n if not features.has(\"organizations:incidents\", organization, actor=request.user):\n raise ResourceDoesNotExist\n\n try:\n kwargs[\"alert_rule_trigger_action\"] = AlertRuleTriggerAction.objects.get(\n alert_rule_trigger=trigger, id=alert_rule_trigger_action_id\n )\n except AlertRuleTriggerAction.DoesNotExist:\n raise ResourceDoesNotExist\n\n return args, kwargs\n", "path": "src/sentry/incidents/endpoints/bases.py"}]} | 1,664 | 164 |
gh_patches_debug_6619 | rasdani/github-patches | git_diff | ethereum__web3.py-2502 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pip install web3, errors due to incompatible version of eth-rlp
* Version: 5.28.0
* Python: 3.8
* OS: linux
* `pip freeze` output
```
appdirs==1.4.3
certifi==2019.11.28
chardet==3.0.4
dbus-python==1.2.16
distlib==0.3.0
distro-info===0.23ubuntu1
filelock==3.0.12
idna==2.8
importlib-metadata==1.5.0
more-itertools==4.2.0
netifaces==0.10.4
PyGObject==3.36.0
pymacaroons==0.13.0
PyNaCl==1.3.0
python-apt==2.0.0+ubuntu0.20.4.6
python-debian===0.1.36ubuntu1
PyYAML==5.3.1
requests==2.22.0
requests-unixsocket==0.2.0
six==1.14.0
ubuntu-advantage-tools==27.4
urllib3==1.25.8
virtualenv==20.0.17
zipp==1.0.0
```
### What was wrong?
When trying to install web3.py in a new virtualenv, on a new installation of Ubuntu 20.04, the following error is thrown:
```
virtualenv -p python3.8 venv
source venv/bin/activate
pip install web3
...
ERROR: eth-rlp 0.3.0 has requirement eth-utils<3,>=2.0.0, but you'll have eth-utils 1.10.0 which is incompatible.
...
```
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 from setuptools import (
3 find_packages,
4 setup,
5 )
6
7 extras_require = {
8 'tester': [
9 "eth-tester[py-evm]==v0.6.0-beta.6",
10 "py-geth>=3.8.0,<4",
11 ],
12 'linter': [
13 "flake8==3.8.3",
14 "isort>=4.2.15,<4.3.5",
15 "mypy==0.910",
16 "types-setuptools>=57.4.4,<58",
17 "types-requests>=2.26.1,<3",
18 "types-protobuf==3.19.13",
19 ],
20 'docs': [
21 "mock",
22 "sphinx-better-theme>=0.1.4",
23 "click>=5.1",
24 "configparser==3.5.0",
25 "contextlib2>=0.5.4",
26 "py-geth>=3.8.0,<4",
27 "py-solc>=0.4.0",
28 "pytest>=4.4.0,<5.0.0",
29 "sphinx>=3.0,<4",
30 "sphinx_rtd_theme>=0.1.9",
31 "toposort>=1.4",
32 "towncrier==18.5.0",
33 "urllib3",
34 "wheel",
35 "Jinja2<=3.0.3", # Jinja v3.1.0 dropped support for python 3.6
36 ],
37 'dev': [
38 "bumpversion",
39 "flaky>=3.7.0,<4",
40 "hypothesis>=3.31.2,<6",
41 "pytest>=4.4.0,<5.0.0",
42 "pytest-asyncio>=0.10.0,<0.11",
43 "pytest-mock>=1.10,<2",
44 "pytest-pythonpath>=0.3",
45 "pytest-watch>=4.2,<5",
46 "pytest-xdist>=1.29,<2",
47 "setuptools>=38.6.0",
48 "tox>=1.8.0",
49 "tqdm>4.32,<5",
50 "twine>=1.13,<2",
51 "pluggy==0.13.1",
52 "when-changed>=0.3.0,<0.4"
53 ]
54 }
55
56 extras_require['dev'] = (
57 extras_require['tester']
58 + extras_require['linter']
59 + extras_require['docs']
60 + extras_require['dev']
61 )
62
63 with open('./README.md') as readme:
64 long_description = readme.read()
65
66 setup(
67 name='web3',
68 # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.
69 version='5.29.2',
70 description="""Web3.py""",
71 long_description_content_type='text/markdown',
72 long_description=long_description,
73 author='Piper Merriam',
74 author_email='[email protected]',
75 url='https://github.com/ethereum/web3.py',
76 include_package_data=True,
77 install_requires=[
78 "aiohttp>=3.7.4.post0,<4",
79 "eth-abi>=2.0.0b6,<3.0.0",
80 "eth-account>=0.5.7,<0.6.0",
81 "eth-hash[pycryptodome]>=0.2.0,<1.0.0",
82 "eth-typing>=2.0.0,<3.0.0",
83 "eth-utils>=1.9.5,<2.0.0",
84 "hexbytes>=0.1.0,<1.0.0",
85 "ipfshttpclient==0.8.0a2",
86 "jsonschema>=3.2.0,<5",
87 "lru-dict>=1.1.6,<2.0.0",
88 "protobuf>=3.10.0,<4",
89 "pywin32>=223;platform_system=='Windows'",
90 "requests>=2.16.0,<3.0.0",
91 # remove typing_extensions after python_requires>=3.8, see web3._utils.compat
92 "typing-extensions>=3.7.4.1,<5;python_version<'3.8'",
93 "websockets>=9.1,<10",
94 ],
95 python_requires='>=3.6,<4',
96 extras_require=extras_require,
97 py_modules=['web3', 'ens', 'ethpm'],
98 entry_points={"pytest11": ["pytest_ethereum = web3.tools.pytest_ethereum.plugins"]},
99 license="MIT",
100 zip_safe=False,
101 keywords='ethereum',
102 packages=find_packages(exclude=["tests", "tests.*"]),
103 package_data={"web3": ["py.typed"]},
104 classifiers=[
105 'Development Status :: 5 - Production/Stable',
106 'Intended Audience :: Developers',
107 'License :: OSI Approved :: MIT License',
108 'Natural Language :: English',
109 'Programming Language :: Python :: 3',
110 'Programming Language :: Python :: 3.6',
111 'Programming Language :: Python :: 3.7',
112 'Programming Language :: Python :: 3.8',
113 'Programming Language :: Python :: 3.9',
114 ],
115 )
116
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -79,6 +79,9 @@
"eth-abi>=2.0.0b6,<3.0.0",
"eth-account>=0.5.7,<0.6.0",
"eth-hash[pycryptodome]>=0.2.0,<1.0.0",
+ # eth-account allows too broad of an eth-rlp dependency.
+ # This eth-rlp pin can be removed once it gets tightened up in eth-account
+ "eth-rlp<0.3",
"eth-typing>=2.0.0,<3.0.0",
"eth-utils>=1.9.5,<2.0.0",
"hexbytes>=0.1.0,<1.0.0",
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -79,6 +79,9 @@\n \"eth-abi>=2.0.0b6,<3.0.0\",\n \"eth-account>=0.5.7,<0.6.0\",\n \"eth-hash[pycryptodome]>=0.2.0,<1.0.0\",\n+ # eth-account allows too broad of an eth-rlp dependency.\n+ # This eth-rlp pin can be removed once it gets tightened up in eth-account\n+ \"eth-rlp<0.3\",\n \"eth-typing>=2.0.0,<3.0.0\",\n \"eth-utils>=1.9.5,<2.0.0\",\n \"hexbytes>=0.1.0,<1.0.0\",\n", "issue": "pip install web3, errors due to incompatible version of eth-rlp\n* Version: 5.28.0\r\n* Python: 3.8\r\n* OS: linux\r\n* `pip freeze` output\r\n\r\n```\r\nappdirs==1.4.3\r\ncertifi==2019.11.28\r\nchardet==3.0.4\r\ndbus-python==1.2.16\r\ndistlib==0.3.0\r\ndistro-info===0.23ubuntu1\r\nfilelock==3.0.12\r\nidna==2.8\r\nimportlib-metadata==1.5.0\r\nmore-itertools==4.2.0\r\nnetifaces==0.10.4\r\nPyGObject==3.36.0\r\npymacaroons==0.13.0\r\nPyNaCl==1.3.0\r\npython-apt==2.0.0+ubuntu0.20.4.6\r\npython-debian===0.1.36ubuntu1\r\nPyYAML==5.3.1\r\nrequests==2.22.0\r\nrequests-unixsocket==0.2.0\r\nsix==1.14.0\r\nubuntu-advantage-tools==27.4\r\nurllib3==1.25.8\r\nvirtualenv==20.0.17\r\nzipp==1.0.0\r\n\r\n```\r\n\r\n\r\n### What was wrong?\r\n\r\n\r\nWhen trying to install web3.py in a new virtualenv, on a new installation of Ubuntu 20.04, the following error is thrown:\r\n\r\n```\r\n\r\nvirtualenv -p python3.8 venv\r\nsource venv/bin/activate\r\npip install web3\r\n...\r\nERROR: eth-rlp 0.3.0 has requirement eth-utils<3,>=2.0.0, but you'll have eth-utils 1.10.0 which is incompatible.\r\n...\r\n\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python\nfrom setuptools import (\n find_packages,\n setup,\n)\n\nextras_require = {\n 'tester': [\n \"eth-tester[py-evm]==v0.6.0-beta.6\",\n \"py-geth>=3.8.0,<4\",\n ],\n 'linter': [\n \"flake8==3.8.3\",\n \"isort>=4.2.15,<4.3.5\",\n \"mypy==0.910\",\n \"types-setuptools>=57.4.4,<58\",\n \"types-requests>=2.26.1,<3\",\n \"types-protobuf==3.19.13\",\n ],\n 'docs': [\n \"mock\",\n \"sphinx-better-theme>=0.1.4\",\n \"click>=5.1\",\n \"configparser==3.5.0\",\n \"contextlib2>=0.5.4\",\n \"py-geth>=3.8.0,<4\",\n \"py-solc>=0.4.0\",\n \"pytest>=4.4.0,<5.0.0\",\n \"sphinx>=3.0,<4\",\n \"sphinx_rtd_theme>=0.1.9\",\n \"toposort>=1.4\",\n \"towncrier==18.5.0\",\n \"urllib3\",\n \"wheel\",\n \"Jinja2<=3.0.3\", # Jinja v3.1.0 dropped support for python 3.6\n ],\n 'dev': [\n \"bumpversion\",\n \"flaky>=3.7.0,<4\",\n \"hypothesis>=3.31.2,<6\",\n \"pytest>=4.4.0,<5.0.0\",\n \"pytest-asyncio>=0.10.0,<0.11\",\n \"pytest-mock>=1.10,<2\",\n \"pytest-pythonpath>=0.3\",\n \"pytest-watch>=4.2,<5\",\n \"pytest-xdist>=1.29,<2\",\n \"setuptools>=38.6.0\",\n \"tox>=1.8.0\",\n \"tqdm>4.32,<5\",\n \"twine>=1.13,<2\",\n \"pluggy==0.13.1\",\n \"when-changed>=0.3.0,<0.4\"\n ]\n}\n\nextras_require['dev'] = (\n extras_require['tester']\n + extras_require['linter']\n + extras_require['docs']\n + extras_require['dev']\n)\n\nwith open('./README.md') as readme:\n long_description = readme.read()\n\nsetup(\n name='web3',\n # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.\n version='5.29.2',\n description=\"\"\"Web3.py\"\"\",\n long_description_content_type='text/markdown',\n long_description=long_description,\n author='Piper Merriam',\n author_email='[email protected]',\n url='https://github.com/ethereum/web3.py',\n include_package_data=True,\n install_requires=[\n \"aiohttp>=3.7.4.post0,<4\",\n \"eth-abi>=2.0.0b6,<3.0.0\",\n \"eth-account>=0.5.7,<0.6.0\",\n \"eth-hash[pycryptodome]>=0.2.0,<1.0.0\",\n \"eth-typing>=2.0.0,<3.0.0\",\n \"eth-utils>=1.9.5,<2.0.0\",\n \"hexbytes>=0.1.0,<1.0.0\",\n \"ipfshttpclient==0.8.0a2\",\n \"jsonschema>=3.2.0,<5\",\n \"lru-dict>=1.1.6,<2.0.0\",\n \"protobuf>=3.10.0,<4\",\n \"pywin32>=223;platform_system=='Windows'\",\n \"requests>=2.16.0,<3.0.0\",\n # remove typing_extensions after python_requires>=3.8, see web3._utils.compat\n \"typing-extensions>=3.7.4.1,<5;python_version<'3.8'\",\n \"websockets>=9.1,<10\",\n ],\n python_requires='>=3.6,<4',\n extras_require=extras_require,\n py_modules=['web3', 'ens', 'ethpm'],\n entry_points={\"pytest11\": [\"pytest_ethereum = web3.tools.pytest_ethereum.plugins\"]},\n license=\"MIT\",\n zip_safe=False,\n keywords='ethereum',\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n package_data={\"web3\": [\"py.typed\"]},\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n ],\n)\n", "path": "setup.py"}]} | 2,373 | 193 |
gh_patches_debug_15468 | rasdani/github-patches | git_diff | codespell-project__codespell-2477 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Build] QA warning about codespell_lib.tests being installed as data
While packaging v2.2.0 for Gentoo Linux, I got a QA notice about this:
```
* QA Notice: setuptools warnings detected:
*
* Installing 'codespell_lib.tests' as data is deprecated, please list it in `packages`.
```
The actual setuptools warning is as (here shown for Python 3.11, but same for 3.10)
```
/usr/lib/python3.11/site-packages/setuptools/command/build_py.py:202: SetuptoolsDeprecationWarning: Instal
ling 'codespell_lib.tests' as data is deprecated, please list it in `packages`.
!!
############################
# Package would be ignored #
############################
Python recognizes 'codespell_lib.tests' as an importable package,
but it is not listed in the `packages` configuration of setuptools.
'codespell_lib.tests' has been automatically added to the distribution only
because it may contain data files, but this behavior is likely to change
in future versions of setuptools (and therefore is considered deprecated).
Please make sure that 'codespell_lib.tests' is included as a package by using
the `packages` configuration field or the proper discovery methods
(for example by using `find_namespace_packages(...)`/`find_namespace:`
instead of `find_packages(...)`/`find:`).
You can read more about "package discovery" and "data files" on setuptools
documentation page.
!!
check.warn(importable)
```
Find attached the full build log.
[codespell-2.2.0:20220818-083735.log](https://github.com/codespell-project/codespell/files/9371941/codespell-2.2.0.20220818-083735.log)
</issue>
<code>
[start of setup.py]
1 #! /usr/bin/env python
2
3 # adapted from mne-python
4
5 import os
6
7 from setuptools import setup
8
9 from codespell_lib import __version__
10
11 DISTNAME = 'codespell'
12 DESCRIPTION = """Codespell"""
13 MAINTAINER = 'Lucas De Marchi'
14 MAINTAINER_EMAIL = '[email protected]'
15 URL = 'https://github.com/codespell-project/codespell/'
16 LICENSE = 'GPL v2'
17 DOWNLOAD_URL = 'https://github.com/codespell-project/codespell/'
18 with open('README.rst', 'r') as f:
19 LONG_DESCRIPTION = f.read()
20
21 if __name__ == "__main__":
22 if os.path.exists('MANIFEST'):
23 os.remove('MANIFEST')
24
25 setup(name=DISTNAME,
26 maintainer=MAINTAINER,
27 include_package_data=True,
28 maintainer_email=MAINTAINER_EMAIL,
29 description=DESCRIPTION,
30 license=LICENSE,
31 url=URL,
32 version=__version__,
33 download_url=DOWNLOAD_URL,
34 long_description=LONG_DESCRIPTION,
35 long_description_content_type='text/x-rst',
36 zip_safe=False,
37 classifiers=['Intended Audience :: Developers',
38 'License :: OSI Approved',
39 'Programming Language :: Python',
40 'Topic :: Software Development',
41 'Operating System :: Microsoft :: Windows',
42 'Operating System :: POSIX',
43 'Operating System :: Unix',
44 'Operating System :: MacOS'],
45 platforms='any',
46 python_requires='>=3.6',
47 packages=[
48 'codespell_lib',
49 'codespell_lib.data',
50 ],
51 package_data={'codespell_lib': [
52 os.path.join('data', 'dictionary*.txt'),
53 os.path.join('data', 'linux-kernel.exclude'),
54 ]},
55 exclude_package_data={'codespell_lib': [
56 os.path.join('tests', '*'),
57 ]},
58 entry_points={
59 'console_scripts': [
60 'codespell = codespell_lib:_script_main'
61 ],
62 },
63 extras_require={
64 "dev": ["check-manifest", "flake8", "pytest", "pytest-cov",
65 "pytest-dependency"],
66 "hard-encoding-detection": ["chardet"],
67 }
68 )
69
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -46,15 +46,13 @@
python_requires='>=3.6',
packages=[
'codespell_lib',
+ 'codespell_lib.tests',
'codespell_lib.data',
],
package_data={'codespell_lib': [
os.path.join('data', 'dictionary*.txt'),
os.path.join('data', 'linux-kernel.exclude'),
]},
- exclude_package_data={'codespell_lib': [
- os.path.join('tests', '*'),
- ]},
entry_points={
'console_scripts': [
'codespell = codespell_lib:_script_main'
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -46,15 +46,13 @@\n python_requires='>=3.6',\n packages=[\n 'codespell_lib',\n+ 'codespell_lib.tests',\n 'codespell_lib.data',\n ],\n package_data={'codespell_lib': [\n os.path.join('data', 'dictionary*.txt'),\n os.path.join('data', 'linux-kernel.exclude'),\n ]},\n- exclude_package_data={'codespell_lib': [\n- os.path.join('tests', '*'),\n- ]},\n entry_points={\n 'console_scripts': [\n 'codespell = codespell_lib:_script_main'\n", "issue": "[Build] QA warning about codespell_lib.tests being installed as data\nWhile packaging v2.2.0 for Gentoo Linux, I got a QA notice about this:\r\n\r\n```\r\n* QA Notice: setuptools warnings detected:\r\n * \r\n * Installing 'codespell_lib.tests' as data is deprecated, please list it in `packages`.\r\n```\r\n\r\nThe actual setuptools warning is as (here shown for Python 3.11, but same for 3.10)\r\n\r\n```\r\n/usr/lib/python3.11/site-packages/setuptools/command/build_py.py:202: SetuptoolsDeprecationWarning: Instal\r\nling 'codespell_lib.tests' as data is deprecated, please list it in `packages`.\r\n !!\r\n\r\n\r\n ############################\r\n # Package would be ignored #\r\n ############################\r\n Python recognizes 'codespell_lib.tests' as an importable package,\r\n but it is not listed in the `packages` configuration of setuptools.\r\n\r\n 'codespell_lib.tests' has been automatically added to the distribution only\r\n because it may contain data files, but this behavior is likely to change\r\n in future versions of setuptools (and therefore is considered deprecated).\r\n\r\n Please make sure that 'codespell_lib.tests' is included as a package by using\r\n the `packages` configuration field or the proper discovery methods\r\n (for example by using `find_namespace_packages(...)`/`find_namespace:`\r\n instead of `find_packages(...)`/`find:`).\r\n\r\n You can read more about \"package discovery\" and \"data files\" on setuptools\r\n documentation page.\r\n\r\n\r\n!!\r\n\r\n check.warn(importable)\r\n```\r\n\r\nFind attached the full build log.\r\n[codespell-2.2.0:20220818-083735.log](https://github.com/codespell-project/codespell/files/9371941/codespell-2.2.0.20220818-083735.log)\r\n\n", "before_files": [{"content": "#! /usr/bin/env python\n\n# adapted from mne-python\n\nimport os\n\nfrom setuptools import setup\n\nfrom codespell_lib import __version__\n\nDISTNAME = 'codespell'\nDESCRIPTION = \"\"\"Codespell\"\"\"\nMAINTAINER = 'Lucas De Marchi'\nMAINTAINER_EMAIL = '[email protected]'\nURL = 'https://github.com/codespell-project/codespell/'\nLICENSE = 'GPL v2'\nDOWNLOAD_URL = 'https://github.com/codespell-project/codespell/'\nwith open('README.rst', 'r') as f:\n LONG_DESCRIPTION = f.read()\n\nif __name__ == \"__main__\":\n if os.path.exists('MANIFEST'):\n os.remove('MANIFEST')\n\n setup(name=DISTNAME,\n maintainer=MAINTAINER,\n include_package_data=True,\n maintainer_email=MAINTAINER_EMAIL,\n description=DESCRIPTION,\n license=LICENSE,\n url=URL,\n version=__version__,\n download_url=DOWNLOAD_URL,\n long_description=LONG_DESCRIPTION,\n long_description_content_type='text/x-rst',\n zip_safe=False,\n classifiers=['Intended Audience :: Developers',\n 'License :: OSI Approved',\n 'Programming Language :: Python',\n 'Topic :: Software Development',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: POSIX',\n 'Operating System :: Unix',\n 'Operating System :: MacOS'],\n platforms='any',\n python_requires='>=3.6',\n packages=[\n 'codespell_lib',\n 'codespell_lib.data',\n ],\n package_data={'codespell_lib': [\n os.path.join('data', 'dictionary*.txt'),\n os.path.join('data', 'linux-kernel.exclude'),\n ]},\n exclude_package_data={'codespell_lib': [\n os.path.join('tests', '*'),\n ]},\n entry_points={\n 'console_scripts': [\n 'codespell = codespell_lib:_script_main'\n ],\n },\n extras_require={\n \"dev\": [\"check-manifest\", \"flake8\", \"pytest\", \"pytest-cov\",\n \"pytest-dependency\"],\n \"hard-encoding-detection\": [\"chardet\"],\n }\n )\n", "path": "setup.py"}]} | 1,548 | 153 |
gh_patches_debug_15763 | rasdani/github-patches | git_diff | googleapis__google-api-python-client-499 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Deprecation of oauth2client dependency
According to the readme google/oauth2client is deprecated. They suggest switching to [google-auth](https://google-auth.readthedocs.io/) or [oauthlib](http://oauthlib.readthedocs.io/).
This probably means that this package and all of the docs should also be refactored into using these new packages?
</issue>
<code>
[start of setup.py]
1 # Copyright 2014 Google Inc. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Setup script for Google API Python client.
16
17 Also installs included versions of third party libraries, if those libraries
18 are not already installed.
19 """
20 from __future__ import print_function
21
22 import sys
23
24 if sys.version_info < (2, 7):
25 print('google-api-python-client requires python version >= 2.7.',
26 file=sys.stderr)
27 sys.exit(1)
28 if (3, 1) <= sys.version_info < (3, 3):
29 print('google-api-python-client requires python3 version >= 3.3.',
30 file=sys.stderr)
31 sys.exit(1)
32
33 from setuptools import setup
34 import pkg_resources
35
36 def _DetectBadness():
37 import os
38 if 'SKIP_GOOGLEAPICLIENT_COMPAT_CHECK' in os.environ:
39 return
40 o2c_pkg = None
41 try:
42 o2c_pkg = pkg_resources.get_distribution('oauth2client')
43 except pkg_resources.DistributionNotFound:
44 pass
45 oauth2client = None
46 try:
47 import oauth2client
48 except ImportError:
49 pass
50 if o2c_pkg is None and oauth2client is not None:
51 raise RuntimeError(
52 'Previous version of google-api-python-client detected; due to a '
53 'packaging issue, we cannot perform an in-place upgrade. Please remove '
54 'the old version and re-install this package.'
55 )
56
57 _DetectBadness()
58
59 packages = [
60 'apiclient',
61 'googleapiclient',
62 'googleapiclient/discovery_cache',
63 ]
64
65 install_requires = [
66 'httplib2>=0.9.2,<1dev',
67 'oauth2client>=1.5.0,<5.0.0dev',
68 'six>=1.6.1,<2dev',
69 'uritemplate>=3.0.0,<4dev',
70 ]
71
72 long_desc = """The Google API Client for Python is a client library for
73 accessing the Plus, Moderator, and many other Google APIs."""
74
75 import googleapiclient
76 version = googleapiclient.__version__
77
78 setup(
79 name="google-api-python-client",
80 version=version,
81 description="Google API Client Library for Python",
82 long_description=long_desc,
83 author="Google Inc.",
84 url="http://github.com/google/google-api-python-client/",
85 install_requires=install_requires,
86 packages=packages,
87 package_data={},
88 license="Apache 2.0",
89 keywords="google api client",
90 classifiers=[
91 'Programming Language :: Python :: 2',
92 'Programming Language :: Python :: 2.7',
93 'Programming Language :: Python :: 3',
94 'Programming Language :: Python :: 3.3',
95 'Programming Language :: Python :: 3.4',
96 'Programming Language :: Python :: 3.5',
97 'Programming Language :: Python :: 3.6',
98 'Development Status :: 5 - Production/Stable',
99 'Intended Audience :: Developers',
100 'License :: OSI Approved :: Apache Software License',
101 'Operating System :: OS Independent',
102 'Topic :: Internet :: WWW/HTTP',
103 ],
104 )
105
[end of setup.py]
[start of googleapiclient/discovery_cache/file_cache.py]
1 # Copyright 2014 Google Inc. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """File based cache for the discovery document.
16
17 The cache is stored in a single file so that multiple processes can
18 share the same cache. It locks the file whenever accesing to the
19 file. When the cache content is corrupted, it will be initialized with
20 an empty cache.
21 """
22
23 from __future__ import division
24
25 import datetime
26 import json
27 import logging
28 import os
29 import tempfile
30 import threading
31
32 try:
33 from oauth2client.contrib.locked_file import LockedFile
34 except ImportError:
35 # oauth2client < 2.0.0
36 try:
37 from oauth2client.locked_file import LockedFile
38 except ImportError:
39 # oauth2client > 4.0.0
40 raise ImportError(
41 'file_cache is unavailable when using oauth2client >= 4.0.0')
42
43 from . import base
44 from ..discovery_cache import DISCOVERY_DOC_MAX_AGE
45
46 LOGGER = logging.getLogger(__name__)
47
48 FILENAME = 'google-api-python-client-discovery-doc.cache'
49 EPOCH = datetime.datetime.utcfromtimestamp(0)
50
51
52 def _to_timestamp(date):
53 try:
54 return (date - EPOCH).total_seconds()
55 except AttributeError:
56 # The following is the equivalent of total_seconds() in Python2.6.
57 # See also: https://docs.python.org/2/library/datetime.html
58 delta = date - EPOCH
59 return ((delta.microseconds + (delta.seconds + delta.days * 24 * 3600)
60 * 10**6) / 10**6)
61
62
63 def _read_or_initialize_cache(f):
64 f.file_handle().seek(0)
65 try:
66 cache = json.load(f.file_handle())
67 except Exception:
68 # This means it opens the file for the first time, or the cache is
69 # corrupted, so initializing the file with an empty dict.
70 cache = {}
71 f.file_handle().truncate(0)
72 f.file_handle().seek(0)
73 json.dump(cache, f.file_handle())
74 return cache
75
76
77 class Cache(base.Cache):
78 """A file based cache for the discovery documents."""
79
80 def __init__(self, max_age):
81 """Constructor.
82
83 Args:
84 max_age: Cache expiration in seconds.
85 """
86 self._max_age = max_age
87 self._file = os.path.join(tempfile.gettempdir(), FILENAME)
88 f = LockedFile(self._file, 'a+', 'r')
89 try:
90 f.open_and_lock()
91 if f.is_locked():
92 _read_or_initialize_cache(f)
93 # If we can not obtain the lock, other process or thread must
94 # have initialized the file.
95 except Exception as e:
96 LOGGER.warning(e, exc_info=True)
97 finally:
98 f.unlock_and_close()
99
100 def get(self, url):
101 f = LockedFile(self._file, 'r+', 'r')
102 try:
103 f.open_and_lock()
104 if f.is_locked():
105 cache = _read_or_initialize_cache(f)
106 if url in cache:
107 content, t = cache.get(url, (None, 0))
108 if _to_timestamp(datetime.datetime.now()) < t + self._max_age:
109 return content
110 return None
111 else:
112 LOGGER.debug('Could not obtain a lock for the cache file.')
113 return None
114 except Exception as e:
115 LOGGER.warning(e, exc_info=True)
116 finally:
117 f.unlock_and_close()
118
119 def set(self, url, content):
120 f = LockedFile(self._file, 'r+', 'r')
121 try:
122 f.open_and_lock()
123 if f.is_locked():
124 cache = _read_or_initialize_cache(f)
125 cache[url] = (content, _to_timestamp(datetime.datetime.now()))
126 # Remove stale cache.
127 for k, (_, timestamp) in list(cache.items()):
128 if _to_timestamp(datetime.datetime.now()) >= timestamp + self._max_age:
129 del cache[k]
130 f.file_handle().truncate(0)
131 f.file_handle().seek(0)
132 json.dump(cache, f.file_handle())
133 else:
134 LOGGER.debug('Could not obtain a lock for the cache file.')
135 except Exception as e:
136 LOGGER.warning(e, exc_info=True)
137 finally:
138 f.unlock_and_close()
139
140
141 cache = Cache(max_age=DISCOVERY_DOC_MAX_AGE)
142
[end of googleapiclient/discovery_cache/file_cache.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/googleapiclient/discovery_cache/file_cache.py b/googleapiclient/discovery_cache/file_cache.py
--- a/googleapiclient/discovery_cache/file_cache.py
+++ b/googleapiclient/discovery_cache/file_cache.py
@@ -36,9 +36,9 @@
try:
from oauth2client.locked_file import LockedFile
except ImportError:
- # oauth2client > 4.0.0
+ # oauth2client > 4.0.0 or google-auth
raise ImportError(
- 'file_cache is unavailable when using oauth2client >= 4.0.0')
+ 'file_cache is unavailable when using oauth2client >= 4.0.0 or google-auth')
from . import base
from ..discovery_cache import DISCOVERY_DOC_MAX_AGE
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -64,7 +64,8 @@
install_requires = [
'httplib2>=0.9.2,<1dev',
- 'oauth2client>=1.5.0,<5.0.0dev',
+ 'google-auth>=1.4.1',
+ 'google-auth-httplib2>=0.0.3',
'six>=1.6.1,<2dev',
'uritemplate>=3.0.0,<4dev',
]
| {"golden_diff": "diff --git a/googleapiclient/discovery_cache/file_cache.py b/googleapiclient/discovery_cache/file_cache.py\n--- a/googleapiclient/discovery_cache/file_cache.py\n+++ b/googleapiclient/discovery_cache/file_cache.py\n@@ -36,9 +36,9 @@\n try:\n from oauth2client.locked_file import LockedFile\n except ImportError:\n- # oauth2client > 4.0.0\n+ # oauth2client > 4.0.0 or google-auth\n raise ImportError(\n- 'file_cache is unavailable when using oauth2client >= 4.0.0')\n+ 'file_cache is unavailable when using oauth2client >= 4.0.0 or google-auth')\n \n from . import base\n from ..discovery_cache import DISCOVERY_DOC_MAX_AGE\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -64,7 +64,8 @@\n \n install_requires = [\n 'httplib2>=0.9.2,<1dev',\n- 'oauth2client>=1.5.0,<5.0.0dev',\n+ 'google-auth>=1.4.1',\n+ 'google-auth-httplib2>=0.0.3',\n 'six>=1.6.1,<2dev',\n 'uritemplate>=3.0.0,<4dev',\n ]\n", "issue": "Deprecation of oauth2client dependency\nAccording to the readme google/oauth2client is deprecated. They suggest switching to [google-auth](https://google-auth.readthedocs.io/) or [oauthlib](http://oauthlib.readthedocs.io/). \r\n\r\nThis probably means that this package and all of the docs should also be refactored into using these new packages?\n", "before_files": [{"content": "# Copyright 2014 Google Inc. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Setup script for Google API Python client.\n\nAlso installs included versions of third party libraries, if those libraries\nare not already installed.\n\"\"\"\nfrom __future__ import print_function\n\nimport sys\n\nif sys.version_info < (2, 7):\n print('google-api-python-client requires python version >= 2.7.',\n file=sys.stderr)\n sys.exit(1)\nif (3, 1) <= sys.version_info < (3, 3):\n print('google-api-python-client requires python3 version >= 3.3.',\n file=sys.stderr)\n sys.exit(1)\n\nfrom setuptools import setup\nimport pkg_resources\n\ndef _DetectBadness():\n import os\n if 'SKIP_GOOGLEAPICLIENT_COMPAT_CHECK' in os.environ:\n return\n o2c_pkg = None\n try:\n o2c_pkg = pkg_resources.get_distribution('oauth2client')\n except pkg_resources.DistributionNotFound:\n pass\n oauth2client = None\n try:\n import oauth2client\n except ImportError:\n pass\n if o2c_pkg is None and oauth2client is not None:\n raise RuntimeError(\n 'Previous version of google-api-python-client detected; due to a '\n 'packaging issue, we cannot perform an in-place upgrade. Please remove '\n 'the old version and re-install this package.'\n )\n\n_DetectBadness()\n\npackages = [\n 'apiclient',\n 'googleapiclient',\n 'googleapiclient/discovery_cache',\n]\n\ninstall_requires = [\n 'httplib2>=0.9.2,<1dev',\n 'oauth2client>=1.5.0,<5.0.0dev',\n 'six>=1.6.1,<2dev',\n 'uritemplate>=3.0.0,<4dev',\n]\n\nlong_desc = \"\"\"The Google API Client for Python is a client library for\naccessing the Plus, Moderator, and many other Google APIs.\"\"\"\n\nimport googleapiclient\nversion = googleapiclient.__version__\n\nsetup(\n name=\"google-api-python-client\",\n version=version,\n description=\"Google API Client Library for Python\",\n long_description=long_desc,\n author=\"Google Inc.\",\n url=\"http://github.com/google/google-api-python-client/\",\n install_requires=install_requires,\n packages=packages,\n package_data={},\n license=\"Apache 2.0\",\n keywords=\"google api client\",\n classifiers=[\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: OS Independent',\n 'Topic :: Internet :: WWW/HTTP',\n ],\n)\n", "path": "setup.py"}, {"content": "# Copyright 2014 Google Inc. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"File based cache for the discovery document.\n\nThe cache is stored in a single file so that multiple processes can\nshare the same cache. It locks the file whenever accesing to the\nfile. When the cache content is corrupted, it will be initialized with\nan empty cache.\n\"\"\"\n\nfrom __future__ import division\n\nimport datetime\nimport json\nimport logging\nimport os\nimport tempfile\nimport threading\n\ntry:\n from oauth2client.contrib.locked_file import LockedFile\nexcept ImportError:\n # oauth2client < 2.0.0\n try:\n from oauth2client.locked_file import LockedFile\n except ImportError:\n # oauth2client > 4.0.0\n raise ImportError(\n 'file_cache is unavailable when using oauth2client >= 4.0.0')\n\nfrom . import base\nfrom ..discovery_cache import DISCOVERY_DOC_MAX_AGE\n\nLOGGER = logging.getLogger(__name__)\n\nFILENAME = 'google-api-python-client-discovery-doc.cache'\nEPOCH = datetime.datetime.utcfromtimestamp(0)\n\n\ndef _to_timestamp(date):\n try:\n return (date - EPOCH).total_seconds()\n except AttributeError:\n # The following is the equivalent of total_seconds() in Python2.6.\n # See also: https://docs.python.org/2/library/datetime.html\n delta = date - EPOCH\n return ((delta.microseconds + (delta.seconds + delta.days * 24 * 3600)\n * 10**6) / 10**6)\n\n\ndef _read_or_initialize_cache(f):\n f.file_handle().seek(0)\n try:\n cache = json.load(f.file_handle())\n except Exception:\n # This means it opens the file for the first time, or the cache is\n # corrupted, so initializing the file with an empty dict.\n cache = {}\n f.file_handle().truncate(0)\n f.file_handle().seek(0)\n json.dump(cache, f.file_handle())\n return cache\n\n\nclass Cache(base.Cache):\n \"\"\"A file based cache for the discovery documents.\"\"\"\n\n def __init__(self, max_age):\n \"\"\"Constructor.\n\n Args:\n max_age: Cache expiration in seconds.\n \"\"\"\n self._max_age = max_age\n self._file = os.path.join(tempfile.gettempdir(), FILENAME)\n f = LockedFile(self._file, 'a+', 'r')\n try:\n f.open_and_lock()\n if f.is_locked():\n _read_or_initialize_cache(f)\n # If we can not obtain the lock, other process or thread must\n # have initialized the file.\n except Exception as e:\n LOGGER.warning(e, exc_info=True)\n finally:\n f.unlock_and_close()\n\n def get(self, url):\n f = LockedFile(self._file, 'r+', 'r')\n try:\n f.open_and_lock()\n if f.is_locked():\n cache = _read_or_initialize_cache(f)\n if url in cache:\n content, t = cache.get(url, (None, 0))\n if _to_timestamp(datetime.datetime.now()) < t + self._max_age:\n return content\n return None\n else:\n LOGGER.debug('Could not obtain a lock for the cache file.')\n return None\n except Exception as e:\n LOGGER.warning(e, exc_info=True)\n finally:\n f.unlock_and_close()\n\n def set(self, url, content):\n f = LockedFile(self._file, 'r+', 'r')\n try:\n f.open_and_lock()\n if f.is_locked():\n cache = _read_or_initialize_cache(f)\n cache[url] = (content, _to_timestamp(datetime.datetime.now()))\n # Remove stale cache.\n for k, (_, timestamp) in list(cache.items()):\n if _to_timestamp(datetime.datetime.now()) >= timestamp + self._max_age:\n del cache[k]\n f.file_handle().truncate(0)\n f.file_handle().seek(0)\n json.dump(cache, f.file_handle())\n else:\n LOGGER.debug('Could not obtain a lock for the cache file.')\n except Exception as e:\n LOGGER.warning(e, exc_info=True)\n finally:\n f.unlock_and_close()\n\n\ncache = Cache(max_age=DISCOVERY_DOC_MAX_AGE)\n", "path": "googleapiclient/discovery_cache/file_cache.py"}]} | 3,005 | 309 |
gh_patches_debug_31815 | rasdani/github-patches | git_diff | pytorch__audio-1385 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Linting doc config
Currently, `doc/source/conf.py` is not checked with `flake8` in our CI and it contains errors. We need to fix this and make CI check it.
```
$ flake8 docs/source/conf.py
docs/source/conf.py:23:1: F401 'torch' imported but unused
docs/source/conf.py:24:1: F401 'torchaudio' imported but unused
docs/source/conf.py:138:1: E302 expected 2 blank lines, found 1
docs/source/conf.py:229:5: F821 undefined name 'List'
docs/source/conf.py:229:5: F821 undefined name 'unicode'
docs/source/conf.py:229:5: F821 undefined name 'Tuple'
```
## Steps
1. Fix the above error.
2. Add `docs/source/conf.py` [here](https://github.com/pytorch/audio/blob/ea857940de9e3738166989ad3bf1726741a13f04/.circleci/unittest/linux/scripts/run_style_checks.sh#L32)
## Build and testing
For setting up dev env, please refer to [CONTRIBUTING.md](https://github.com/pytorch/audio/blob/master/CONTRIBUTING.md).
</issue>
<code>
[start of docs/source/conf.py]
1 #!/usr/bin/env python3
2 # -*- coding: utf-8 -*-
3 #
4 # PyTorch documentation build configuration file, created by
5 # sphinx-quickstart on Fri Dec 23 13:31:47 2016.
6 #
7 # This file is execfile()d with the current directory set to its
8 # containing dir.
9 #
10 # Note that not all possible configuration values are present in this
11 # autogenerated file.
12 #
13 # All configuration values have a default; values that are commented out
14 # serve to show the default.
15
16 # If extensions (or modules to document with autodoc) are in another directory,
17 # add these directories to sys.path here. If the directory is relative to the
18 # documentation root, use os.path.abspath to make it absolute, like shown here.
19 #
20 # import os
21 # import sys
22 # sys.path.insert(0, os.path.abspath('.'))
23 import torch
24 import torchaudio
25 import pytorch_sphinx_theme
26
27 # -- General configuration ------------------------------------------------
28
29 # If your documentation needs a minimal Sphinx version, state it here.
30 #
31 needs_sphinx = '1.6'
32
33 # Add any Sphinx extension module names here, as strings. They can be
34 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
35 # ones.
36 extensions = [
37 'sphinx.ext.autodoc',
38 'sphinx.ext.autosummary',
39 'sphinx.ext.doctest',
40 'sphinx.ext.intersphinx',
41 'sphinx.ext.todo',
42 'sphinx.ext.coverage',
43 'sphinx.ext.napoleon',
44 'sphinx.ext.viewcode',
45 'sphinxcontrib.katex',
46 ]
47
48 # katex options
49 #
50 #
51
52 katex_options = r'''
53 delimiters : [
54 {left: "$$", right: "$$", display: true},
55 {left: "\\(", right: "\\)", display: false},
56 {left: "\\[", right: "\\]", display: true}
57 ]
58 '''
59
60 napoleon_use_ivar = True
61 napoleon_numpy_docstring = False
62 napoleon_google_docstring = True
63
64 # Add any paths that contain templates here, relative to this directory.
65 templates_path = ['_templates']
66
67 # The suffix(es) of source filenames.
68 # You can specify multiple suffix as a list of string:
69 #
70 # source_suffix = ['.rst', '.md']
71 source_suffix = '.rst'
72
73 # The master toctree document.
74 master_doc = 'index'
75
76 # General information about the project.
77 project = 'Torchaudio'
78 copyright = '2018, Torchaudio Contributors'
79 author = 'Torchaudio Contributors'
80
81 # The version info for the project you're documenting, acts as replacement for
82 # |version| and |release|, also used in various other places throughout the
83 # built documents.
84 #
85 # The short X.Y version.
86 # TODO: change to [:2] at v1.0
87 version = 'master '
88 # The full version, including alpha/beta/rc tags.
89 # TODO: verify this works as expected
90 release = 'master'
91
92 # The language for content autogenerated by Sphinx. Refer to documentation
93 # for a list of supported languages.
94 #
95 # This is also used if you do content translation via gettext catalogs.
96 # Usually you set "language" from the command line for these cases.
97 language = None
98
99 # List of patterns, relative to source directory, that match files and
100 # directories to ignore when looking for source files.
101 # This patterns also effect to html_static_path and html_extra_path
102 exclude_patterns = []
103
104 # The name of the Pygments (syntax highlighting) style to use.
105 pygments_style = 'sphinx'
106
107 # If true, `todo` and `todoList` produce output, else they produce nothing.
108 todo_include_todos = True
109
110
111 # -- Options for HTML output ----------------------------------------------
112
113 # The theme to use for HTML and HTML Help pages. See the documentation for
114 # a list of builtin themes.
115 #
116 html_theme = 'pytorch_sphinx_theme'
117 html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
118
119 # Theme options are theme-specific and customize the look and feel of a theme
120 # further. For a list of options available for each theme, see the
121 # documentation.
122 #
123 html_theme_options = {
124 'pytorch_project': 'audio',
125 'collapse_navigation': False,
126 'display_version': True,
127 'logo_only': True,
128 'navigation_with_keys': True
129 }
130
131 html_logo = '_static/img/pytorch-logo-dark.svg'
132
133 # Add any paths that contain custom static files (such as style sheets) here,
134 # relative to this directory. They are copied after the builtin static files,
135 # so a file named "default.css" will overwrite the builtin "default.css".
136 html_static_path = ['_static']
137
138 def setup(app):
139 # NOTE: in Sphinx 1.8+ `html_css_files` is an official configuration value
140 # and can be moved outside of this function (and the setup(app) function
141 # can be deleted).
142 html_css_files = [
143 'https://cdn.jsdelivr.net/npm/[email protected]/dist/katex.min.css'
144 ]
145
146 # In Sphinx 1.8 it was renamed to `add_css_file`, 1.7 and prior it is
147 # `add_stylesheet` (deprecated in 1.8).
148 add_css = getattr(app, 'add_css_file', getattr(app, 'add_stylesheet'))
149 for css_file in html_css_files:
150 add_css(css_file)
151
152
153 # -- Options for HTMLHelp output ------------------------------------------
154
155 # Output file base name for HTML help builder.
156 htmlhelp_basename = 'TorchAudiodoc'
157
158
159 # -- Options for LaTeX output ---------------------------------------------
160
161 latex_elements = {
162 # The paper size ('letterpaper' or 'a4paper').
163 #
164 # 'papersize': 'letterpaper',
165
166 # The font size ('10pt', '11pt' or '12pt').
167 #
168 # 'pointsize': '10pt',
169
170 # Additional stuff for the LaTeX preamble.
171 #
172 # 'preamble': '',
173
174 # Latex figure (float) alignment
175 #
176 # 'figure_align': 'htbp',
177 }
178
179 # Grouping the document tree into LaTeX files. List of tuples
180 # (source start file, target name, title,
181 # author, documentclass [howto, manual, or own class]).
182 latex_documents = [
183 (master_doc, 'pytorch.tex', 'Torchaudio Documentation',
184 'Torch Contributors', 'manual'),
185 ]
186
187
188 # -- Options for manual page output ---------------------------------------
189
190 # One entry per manual page. List of tuples
191 # (source start file, name, description, authors, manual section).
192 man_pages = [
193 (master_doc, 'Torchaudio', 'Torchaudio Documentation',
194 [author], 1)
195 ]
196
197
198 # -- Options for Texinfo output -------------------------------------------
199
200 # Grouping the document tree into Texinfo files. List of tuples
201 # (source start file, target name, title, author,
202 # dir menu entry, description, category)
203 texinfo_documents = [
204 (master_doc, 'Torchaudio', 'Torchaudio Documentation',
205 author, 'Torchaudio', 'Load audio files into pytorch tensors.',
206 'Miscellaneous'),
207 ]
208
209
210 # Example configuration for intersphinx: refer to the Python standard library.
211 intersphinx_mapping = {
212 'python': ('https://docs.python.org/', None),
213 'numpy': ('https://docs.scipy.org/doc/numpy/', None),
214 'torch': ('https://pytorch.org/docs/stable/', None),
215 }
216
217 # -- A patch that prevents Sphinx from cross-referencing ivar tags -------
218 # See http://stackoverflow.com/a/41184353/3343043
219
220 from docutils import nodes
221 from sphinx.util.docfields import TypedField
222 from sphinx import addnodes
223
224
225 def patched_make_field(self, types, domain, items, **kw):
226 # `kw` catches `env=None` needed for newer sphinx while maintaining
227 # backwards compatibility when passed along further down!
228
229 # type: (List, unicode, Tuple) -> nodes.field
230 def handle_item(fieldarg, content):
231 par = nodes.paragraph()
232 par += addnodes.literal_strong('', fieldarg) # Patch: this line added
233 # par.extend(self.make_xrefs(self.rolename, domain, fieldarg,
234 # addnodes.literal_strong))
235 if fieldarg in types:
236 par += nodes.Text(' (')
237 # NOTE: using .pop() here to prevent a single type node to be
238 # inserted twice into the doctree, which leads to
239 # inconsistencies later when references are resolved
240 fieldtype = types.pop(fieldarg)
241 if len(fieldtype) == 1 and isinstance(fieldtype[0], nodes.Text):
242 typename = u''.join(n.astext() for n in fieldtype)
243 typename = typename.replace('int', 'python:int')
244 typename = typename.replace('long', 'python:long')
245 typename = typename.replace('float', 'python:float')
246 typename = typename.replace('type', 'python:type')
247 par.extend(self.make_xrefs(self.typerolename, domain, typename,
248 addnodes.literal_emphasis, **kw))
249 else:
250 par += fieldtype
251 par += nodes.Text(')')
252 par += nodes.Text(' -- ')
253 par += content
254 return par
255
256 fieldname = nodes.field_name('', self.label)
257 if len(items) == 1 and self.can_collapse:
258 fieldarg, content = items[0]
259 bodynode = handle_item(fieldarg, content)
260 else:
261 bodynode = self.list_type()
262 for fieldarg, content in items:
263 bodynode += nodes.list_item('', handle_item(fieldarg, content))
264 fieldbody = nodes.field_body('', bodynode)
265 return nodes.field('', fieldname, fieldbody)
266
267 TypedField.make_field = patched_make_field
268
[end of docs/source/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/docs/source/conf.py b/docs/source/conf.py
--- a/docs/source/conf.py
+++ b/docs/source/conf.py
@@ -20,8 +20,6 @@
# import os
# import sys
# sys.path.insert(0, os.path.abspath('.'))
-import torch
-import torchaudio
import pytorch_sphinx_theme
# -- General configuration ------------------------------------------------
@@ -135,6 +133,7 @@
# so a file named "default.css" will overwrite the builtin "default.css".
html_static_path = ['_static']
+
def setup(app):
# NOTE: in Sphinx 1.8+ `html_css_files` is an official configuration value
# and can be moved outside of this function (and the setup(app) function
@@ -145,7 +144,7 @@
# In Sphinx 1.8 it was renamed to `add_css_file`, 1.7 and prior it is
# `add_stylesheet` (deprecated in 1.8).
- add_css = getattr(app, 'add_css_file', getattr(app, 'add_stylesheet'))
+ add_css = getattr(app, 'add_css_file', app.add_stylesheet)
for css_file in html_css_files:
add_css(css_file)
@@ -226,7 +225,7 @@
# `kw` catches `env=None` needed for newer sphinx while maintaining
# backwards compatibility when passed along further down!
- # type: (List, unicode, Tuple) -> nodes.field
+ # type: (list, str, tuple) -> nodes.field
def handle_item(fieldarg, content):
par = nodes.paragraph()
par += addnodes.literal_strong('', fieldarg) # Patch: this line added
| {"golden_diff": "diff --git a/docs/source/conf.py b/docs/source/conf.py\n--- a/docs/source/conf.py\n+++ b/docs/source/conf.py\n@@ -20,8 +20,6 @@\n # import os\n # import sys\n # sys.path.insert(0, os.path.abspath('.'))\n-import torch\n-import torchaudio\n import pytorch_sphinx_theme\n \n # -- General configuration ------------------------------------------------\n@@ -135,6 +133,7 @@\n # so a file named \"default.css\" will overwrite the builtin \"default.css\".\n html_static_path = ['_static']\n \n+\n def setup(app):\n # NOTE: in Sphinx 1.8+ `html_css_files` is an official configuration value\n # and can be moved outside of this function (and the setup(app) function\n@@ -145,7 +144,7 @@\n \n # In Sphinx 1.8 it was renamed to `add_css_file`, 1.7 and prior it is\n # `add_stylesheet` (deprecated in 1.8).\n- add_css = getattr(app, 'add_css_file', getattr(app, 'add_stylesheet'))\n+ add_css = getattr(app, 'add_css_file', app.add_stylesheet)\n for css_file in html_css_files:\n add_css(css_file)\n \n@@ -226,7 +225,7 @@\n # `kw` catches `env=None` needed for newer sphinx while maintaining\n # backwards compatibility when passed along further down!\n \n- # type: (List, unicode, Tuple) -> nodes.field\n+ # type: (list, str, tuple) -> nodes.field\n def handle_item(fieldarg, content):\n par = nodes.paragraph()\n par += addnodes.literal_strong('', fieldarg) # Patch: this line added\n", "issue": "Linting doc config\nCurrently, `doc/source/conf.py` is not checked with `flake8` in our CI and it contains errors. We need to fix this and make CI check it.\r\n\r\n```\r\n$ flake8 docs/source/conf.py\r\ndocs/source/conf.py:23:1: F401 'torch' imported but unused\r\ndocs/source/conf.py:24:1: F401 'torchaudio' imported but unused\r\ndocs/source/conf.py:138:1: E302 expected 2 blank lines, found 1\r\ndocs/source/conf.py:229:5: F821 undefined name 'List'\r\ndocs/source/conf.py:229:5: F821 undefined name 'unicode'\r\ndocs/source/conf.py:229:5: F821 undefined name 'Tuple'\r\n```\r\n\r\n## Steps\r\n1. Fix the above error.\r\n2. Add `docs/source/conf.py` [here](https://github.com/pytorch/audio/blob/ea857940de9e3738166989ad3bf1726741a13f04/.circleci/unittest/linux/scripts/run_style_checks.sh#L32)\r\n\r\n## Build and testing\r\n\r\nFor setting up dev env, please refer to [CONTRIBUTING.md](https://github.com/pytorch/audio/blob/master/CONTRIBUTING.md).\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n#\n# PyTorch documentation build configuration file, created by\n# sphinx-quickstart on Fri Dec 23 13:31:47 2016.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\n# import os\n# import sys\n# sys.path.insert(0, os.path.abspath('.'))\nimport torch\nimport torchaudio\nimport pytorch_sphinx_theme\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\nneeds_sphinx = '1.6'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.doctest',\n 'sphinx.ext.intersphinx',\n 'sphinx.ext.todo',\n 'sphinx.ext.coverage',\n 'sphinx.ext.napoleon',\n 'sphinx.ext.viewcode',\n 'sphinxcontrib.katex',\n]\n\n# katex options\n#\n#\n\nkatex_options = r'''\ndelimiters : [\n {left: \"$$\", right: \"$$\", display: true},\n {left: \"\\\\(\", right: \"\\\\)\", display: false},\n {left: \"\\\\[\", right: \"\\\\]\", display: true}\n]\n'''\n\nnapoleon_use_ivar = True\nnapoleon_numpy_docstring = False\nnapoleon_google_docstring = True\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = 'Torchaudio'\ncopyright = '2018, Torchaudio Contributors'\nauthor = 'Torchaudio Contributors'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\n# TODO: change to [:2] at v1.0\nversion = 'master '\n# The full version, including alpha/beta/rc tags.\n# TODO: verify this works as expected\nrelease = 'master'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = []\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = 'pytorch_sphinx_theme'\nhtml_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\nhtml_theme_options = {\n 'pytorch_project': 'audio',\n 'collapse_navigation': False,\n 'display_version': True,\n 'logo_only': True,\n 'navigation_with_keys': True\n}\n\nhtml_logo = '_static/img/pytorch-logo-dark.svg'\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\ndef setup(app):\n # NOTE: in Sphinx 1.8+ `html_css_files` is an official configuration value\n # and can be moved outside of this function (and the setup(app) function\n # can be deleted).\n html_css_files = [\n 'https://cdn.jsdelivr.net/npm/[email protected]/dist/katex.min.css'\n ]\n\n # In Sphinx 1.8 it was renamed to `add_css_file`, 1.7 and prior it is\n # `add_stylesheet` (deprecated in 1.8).\n add_css = getattr(app, 'add_css_file', getattr(app, 'add_stylesheet'))\n for css_file in html_css_files:\n add_css(css_file)\n\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'TorchAudiodoc'\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'pytorch.tex', 'Torchaudio Documentation',\n 'Torch Contributors', 'manual'),\n]\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'Torchaudio', 'Torchaudio Documentation',\n [author], 1)\n]\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'Torchaudio', 'Torchaudio Documentation',\n author, 'Torchaudio', 'Load audio files into pytorch tensors.',\n 'Miscellaneous'),\n]\n\n\n# Example configuration for intersphinx: refer to the Python standard library.\nintersphinx_mapping = {\n 'python': ('https://docs.python.org/', None),\n 'numpy': ('https://docs.scipy.org/doc/numpy/', None),\n 'torch': ('https://pytorch.org/docs/stable/', None),\n}\n\n# -- A patch that prevents Sphinx from cross-referencing ivar tags -------\n# See http://stackoverflow.com/a/41184353/3343043\n\nfrom docutils import nodes\nfrom sphinx.util.docfields import TypedField\nfrom sphinx import addnodes\n\n\ndef patched_make_field(self, types, domain, items, **kw):\n # `kw` catches `env=None` needed for newer sphinx while maintaining\n # backwards compatibility when passed along further down!\n\n # type: (List, unicode, Tuple) -> nodes.field\n def handle_item(fieldarg, content):\n par = nodes.paragraph()\n par += addnodes.literal_strong('', fieldarg) # Patch: this line added\n # par.extend(self.make_xrefs(self.rolename, domain, fieldarg,\n # addnodes.literal_strong))\n if fieldarg in types:\n par += nodes.Text(' (')\n # NOTE: using .pop() here to prevent a single type node to be\n # inserted twice into the doctree, which leads to\n # inconsistencies later when references are resolved\n fieldtype = types.pop(fieldarg)\n if len(fieldtype) == 1 and isinstance(fieldtype[0], nodes.Text):\n typename = u''.join(n.astext() for n in fieldtype)\n typename = typename.replace('int', 'python:int')\n typename = typename.replace('long', 'python:long')\n typename = typename.replace('float', 'python:float')\n typename = typename.replace('type', 'python:type')\n par.extend(self.make_xrefs(self.typerolename, domain, typename,\n addnodes.literal_emphasis, **kw))\n else:\n par += fieldtype\n par += nodes.Text(')')\n par += nodes.Text(' -- ')\n par += content\n return par\n\n fieldname = nodes.field_name('', self.label)\n if len(items) == 1 and self.can_collapse:\n fieldarg, content = items[0]\n bodynode = handle_item(fieldarg, content)\n else:\n bodynode = self.list_type()\n for fieldarg, content in items:\n bodynode += nodes.list_item('', handle_item(fieldarg, content))\n fieldbody = nodes.field_body('', bodynode)\n return nodes.field('', fieldname, fieldbody)\n\nTypedField.make_field = patched_make_field\n", "path": "docs/source/conf.py"}]} | 3,677 | 386 |
gh_patches_debug_9172 | rasdani/github-patches | git_diff | Gallopsled__pwntools-201 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Pwnlib loads very slowly
On my system it takes two thirds of a second to load pwnlib:
```
~> time python -c "import pwn"
real 0m0.641s
user 0m0.576s
sys 0m0.044s
```
I've tracked down the culprit: `pwnlib.util.web` imports the `requests` module which takes forever (https://github.com/Gallopsled/pwntools/blob/master/pwnlib/util/web.py#L3).
I suggest we load `requests` lazily in `pwnlib.util.web.wget()`.
</issue>
<code>
[start of pwnlib/util/web.py]
1 # -*- coding: utf-8 -*-
2 import os, tempfile, logging
3 from requests import *
4 from .misc import size
5 log = logging.getLogger(__name__)
6
7 def wget(url, save=None, timeout=5, **kwargs):
8 """wget(url, save=None, timeout=5) -> str
9
10 Downloads a file via HTTP/HTTPS.
11
12 Args:
13 url (str): URL to download
14 save (str or bool): Name to save as. Any truthy value
15 will auto-generate a name based on the URL.
16 timeout (int): Timeout, in seconds
17
18 Example:
19
20 >>> url = 'http://httpbin.org/robots.txt'
21 >>> with context.local(log_level='ERROR'): result = wget(url)
22 >>> result
23 'User-agent: *\nDisallow: /deny\n'
24 >>> with context.local(log_level='ERROR'): wget(url, True)
25 >>> result == file('robots.txt').read()
26 True
27 """
28 with log.progress("Downloading '%s'" % url) as w:
29 w.status("Making request...")
30
31 response = get(url, stream=True, **kwargs)
32
33 if not response.ok:
34 w.failure("Got code %s" % response.status_code)
35 return
36
37 total_size = int(response.headers.get('content-length',0))
38
39 w.status('0 / %s' % size(total_size))
40
41 # Find out the next largest size we can represent as
42 chunk_size = 1
43 while chunk_size < (total_size/10):
44 chunk_size *= 1000
45
46 # Count chunks as they're received
47 total_data = ''
48
49 # Loop until we have all of the data
50 for chunk in response.iter_content(chunk_size = 2**10):
51 total_data += chunk
52 if total_size:
53 w.status('%s / %s' % (size(total_data), size(total_size)))
54 else:
55 w.status('%s' % size(total_data))
56
57 # Save to the target file if provided
58 if save:
59 if not isinstance(save, (str, unicode)):
60 save = os.path.basename(url)
61 save = save or NamedTemporaryFile(dir='.', delete=False).name
62 with file(save,'wb+') as f:
63 f.write(total_data)
64 w.success('Saved %r (%s)' % (f.name, size(total_data)))
65 else:
66 w.success('%s' % size(total_data))
67
68 return total_data
69
70
[end of pwnlib/util/web.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pwnlib/util/web.py b/pwnlib/util/web.py
--- a/pwnlib/util/web.py
+++ b/pwnlib/util/web.py
@@ -1,6 +1,5 @@
# -*- coding: utf-8 -*-
import os, tempfile, logging
-from requests import *
from .misc import size
log = logging.getLogger(__name__)
@@ -25,6 +24,8 @@
>>> result == file('robots.txt').read()
True
"""
+ from requests import *
+
with log.progress("Downloading '%s'" % url) as w:
w.status("Making request...")
| {"golden_diff": "diff --git a/pwnlib/util/web.py b/pwnlib/util/web.py\n--- a/pwnlib/util/web.py\n+++ b/pwnlib/util/web.py\n@@ -1,6 +1,5 @@\n # -*- coding: utf-8 -*-\n import os, tempfile, logging\n-from requests import *\n from .misc import size\n log = logging.getLogger(__name__)\n \n@@ -25,6 +24,8 @@\n >>> result == file('robots.txt').read()\n True\n \"\"\"\n+ from requests import *\n+\n with log.progress(\"Downloading '%s'\" % url) as w:\n w.status(\"Making request...\")\n", "issue": "Pwnlib loads very slowly\nOn my system it takes two thirds of a second to load pwnlib:\n\n```\n~> time python -c \"import pwn\"\n\nreal 0m0.641s\nuser 0m0.576s\nsys 0m0.044s\n```\n\nI've tracked down the culprit: `pwnlib.util.web` imports the `requests` module which takes forever (https://github.com/Gallopsled/pwntools/blob/master/pwnlib/util/web.py#L3).\n\nI suggest we load `requests` lazily in `pwnlib.util.web.wget()`.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport os, tempfile, logging\nfrom requests import *\nfrom .misc import size\nlog = logging.getLogger(__name__)\n\ndef wget(url, save=None, timeout=5, **kwargs):\n \"\"\"wget(url, save=None, timeout=5) -> str\n\n Downloads a file via HTTP/HTTPS.\n\n Args:\n url (str): URL to download\n save (str or bool): Name to save as. Any truthy value\n will auto-generate a name based on the URL.\n timeout (int): Timeout, in seconds\n\n Example:\n\n >>> url = 'http://httpbin.org/robots.txt'\n >>> with context.local(log_level='ERROR'): result = wget(url)\n >>> result\n 'User-agent: *\\nDisallow: /deny\\n'\n >>> with context.local(log_level='ERROR'): wget(url, True)\n >>> result == file('robots.txt').read()\n True\n \"\"\"\n with log.progress(\"Downloading '%s'\" % url) as w:\n w.status(\"Making request...\")\n\n response = get(url, stream=True, **kwargs)\n\n if not response.ok:\n w.failure(\"Got code %s\" % response.status_code)\n return\n\n total_size = int(response.headers.get('content-length',0))\n\n w.status('0 / %s' % size(total_size))\n\n # Find out the next largest size we can represent as\n chunk_size = 1\n while chunk_size < (total_size/10):\n chunk_size *= 1000\n\n # Count chunks as they're received\n total_data = ''\n\n # Loop until we have all of the data\n for chunk in response.iter_content(chunk_size = 2**10):\n total_data += chunk\n if total_size:\n w.status('%s / %s' % (size(total_data), size(total_size)))\n else:\n w.status('%s' % size(total_data))\n\n # Save to the target file if provided\n if save:\n if not isinstance(save, (str, unicode)):\n save = os.path.basename(url)\n save = save or NamedTemporaryFile(dir='.', delete=False).name\n with file(save,'wb+') as f:\n f.write(total_data)\n w.success('Saved %r (%s)' % (f.name, size(total_data)))\n else:\n w.success('%s' % size(total_data))\n\n return total_data\n\n", "path": "pwnlib/util/web.py"}]} | 1,345 | 136 |
gh_patches_debug_28246 | rasdani/github-patches | git_diff | feast-dev__feast-1002 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
AttributeError: 'dict' object has no attribute 'append' in job.to_chunked_dataframe()
## Expected Behavior
Return a generator of a chunked dataframe
## Current Behavior
Giving error :
```
/home/dev/feast-venv/lib/python3.7/site-packages/feast/job.py in to_chunked_dataframe(self, max_chunk_size, timeout_sec)
187 records = []
188 for result in self.result(timeout_sec=timeout_sec):
--> 189 result.append(records)
190 if len(records) == max_chunk_size:
191 df = pd.DataFrame.from_records(records)
AttributeError: 'dict' object has no attribute 'append'
```
## Steps to reproduce
```
test = job.to_chunked_dataframe(10)
next(test)
```
### Specifications
- Version: 0.5.0
- Platform: Python 3.7
- Subsystem:
## Possible Solution
In line 189, it should be `records.append(result)` instead of `result.append(records)`
</issue>
<code>
[start of sdk/python/feast/job.py]
1 from typing import List
2 from urllib.parse import urlparse
3
4 import fastavro
5 import grpc
6 import pandas as pd
7
8 from feast.constants import CONFIG_TIMEOUT_KEY
9 from feast.constants import FEAST_DEFAULT_OPTIONS as defaults
10 from feast.serving.ServingService_pb2 import (
11 DATA_FORMAT_AVRO,
12 JOB_STATUS_DONE,
13 GetJobRequest,
14 )
15 from feast.serving.ServingService_pb2 import Job as JobProto
16 from feast.serving.ServingService_pb2_grpc import ServingServiceStub
17 from feast.staging.storage_client import get_staging_client
18 from feast.wait import wait_retry_backoff
19 from tensorflow_metadata.proto.v0 import statistics_pb2
20
21 # Maximum no of seconds to wait until the retrieval jobs status is DONE in Feast
22 # Currently set to the maximum query execution time limit in BigQuery
23 DEFAULT_TIMEOUT_SEC: int = 21600
24
25 # Maximum no of seconds to wait before reloading the job status in Feast
26 MAX_WAIT_INTERVAL_SEC: int = 60
27
28
29 class RetrievalJob:
30 """
31 A class representing a job for feature retrieval in Feast.
32 """
33
34 def __init__(
35 self,
36 job_proto: JobProto,
37 serving_stub: ServingServiceStub,
38 auth_metadata_plugin: grpc.AuthMetadataPlugin = None,
39 ):
40 """
41 Args:
42 job_proto: Job proto object (wrapped by this job object)
43 serving_stub: Stub for Feast serving service
44 auth_metadata_plugin: plugin to fetch auth metadata
45 """
46 self.job_proto = job_proto
47 self.serving_stub = serving_stub
48 self.auth_metadata = auth_metadata_plugin
49
50 @property
51 def id(self):
52 """
53 Getter for the Job Id
54 """
55 return self.job_proto.id
56
57 @property
58 def status(self):
59 """
60 Getter for the Job status from Feast Core
61 """
62 return self.job_proto.status
63
64 def reload(self):
65 """
66 Reload the latest job status
67 Returns: None
68 """
69 self.job_proto = self.serving_stub.GetJob(
70 GetJobRequest(job=self.job_proto),
71 metadata=self.auth_metadata.get_signed_meta() if self.auth_metadata else (),
72 ).job
73
74 def get_avro_files(self, timeout_sec: int = int(defaults[CONFIG_TIMEOUT_KEY])):
75 """
76 Wait until job is done to get the file uri to Avro result files on
77 Google Cloud Storage.
78
79 Args:
80 timeout_sec (int):
81 Max no of seconds to wait until job is done. If "timeout_sec"
82 is exceeded, an exception will be raised.
83
84 Returns:
85 str: Google Cloud Storage file uris of the returned Avro files.
86 """
87
88 def try_retrieve():
89 self.reload()
90 return None, self.status == JOB_STATUS_DONE
91
92 wait_retry_backoff(
93 retry_fn=try_retrieve,
94 timeout_secs=timeout_sec,
95 timeout_msg="Timeout exceeded while waiting for result. Please retry "
96 "this method or use a longer timeout value.",
97 )
98
99 if self.job_proto.error:
100 raise Exception(self.job_proto.error)
101
102 if self.job_proto.data_format != DATA_FORMAT_AVRO:
103 raise Exception(
104 "Feast only supports Avro data format for now. Please check "
105 "your Feast Serving deployment."
106 )
107
108 return [urlparse(uri) for uri in self.job_proto.file_uris]
109
110 def result(self, timeout_sec: int = int(defaults[CONFIG_TIMEOUT_KEY])):
111 """
112 Wait until job is done to get an iterable rows of result. The row can
113 only represent an Avro row in Feast 0.3.
114
115 Args:
116 timeout_sec (int):
117 Max no of seconds to wait until job is done. If "timeout_sec"
118 is exceeded, an exception will be raised.
119
120 Returns:
121 Iterable of Avro rows.
122 """
123 uris = self.get_avro_files(timeout_sec)
124 for file_uri in uris:
125 file_obj = get_staging_client(file_uri.scheme).download_file(file_uri)
126 file_obj.seek(0)
127 avro_reader = fastavro.reader(file_obj)
128
129 for record in avro_reader:
130 yield record
131
132 def to_dataframe(
133 self, timeout_sec: int = int(defaults[CONFIG_TIMEOUT_KEY])
134 ) -> pd.DataFrame:
135 """
136 Wait until a job is done to get an iterable rows of result. This method
137 will split the response into chunked DataFrame of a specified size to
138 to be yielded to the instance calling it.
139
140 Args:
141 max_chunk_size (int):
142 Maximum number of rows that the DataFrame should contain.
143
144 timeout_sec (int):
145 Max no of seconds to wait until job is done. If "timeout_sec"
146 is exceeded, an exception will be raised.
147
148 Returns:
149 pd.DataFrame:
150 Pandas DataFrame of the feature values.
151 """
152 records = [r for r in self.result(timeout_sec=timeout_sec)]
153 return pd.DataFrame.from_records(records)
154
155 def to_chunked_dataframe(
156 self,
157 max_chunk_size: int = -1,
158 timeout_sec: int = int(defaults[CONFIG_TIMEOUT_KEY]),
159 ) -> pd.DataFrame:
160 """
161 Wait until a job is done to get an iterable rows of result. This method
162 will split the response into chunked DataFrame of a specified size to
163 to be yielded to the instance calling it.
164
165 Args:
166 max_chunk_size (int):
167 Maximum number of rows that the DataFrame should contain.
168
169 timeout_sec (int):
170 Max no of seconds to wait until job is done. If "timeout_sec"
171 is exceeded, an exception will be raised.
172
173 Returns:
174 pd.DataFrame:
175 Pandas DataFrame of the feature values.
176 """
177
178 # Object is Avro row type object, refer to self.result function for this type
179 records: List[dict] = []
180
181 # Max chunk size defined by user
182 for result in self.result(timeout_sec=timeout_sec):
183 result.append(records)
184 if len(records) == max_chunk_size:
185 df = pd.DataFrame.from_records(records)
186 records.clear() # Empty records array
187 yield df
188
189 # Handle for last chunk that is < max_chunk_size
190 if not records:
191 yield pd.DataFrame.from_records(records)
192
193 def __iter__(self):
194 return iter(self.result())
195
196 def statistics(
197 self, timeout_sec: int = int(defaults[CONFIG_TIMEOUT_KEY])
198 ) -> statistics_pb2.DatasetFeatureStatisticsList:
199 """
200 Get statistics computed over the retrieved data set. Statistics will only be computed for
201 columns that are part of Feast, and not the columns that were provided.
202
203 Args:
204 timeout_sec (int):
205 Max no of seconds to wait until job is done. If "timeout_sec"
206 is exceeded, an exception will be raised.
207
208 Returns:
209 DatasetFeatureStatisticsList containing statistics of Feast features over the retrieved dataset.
210 """
211 self.get_avro_files(timeout_sec) # wait for job completion
212 if self.job_proto.error:
213 raise Exception(self.job_proto.error)
214 return self.job_proto.dataset_feature_statistics_list
215
[end of sdk/python/feast/job.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/sdk/python/feast/job.py b/sdk/python/feast/job.py
--- a/sdk/python/feast/job.py
+++ b/sdk/python/feast/job.py
@@ -134,13 +134,9 @@
) -> pd.DataFrame:
"""
Wait until a job is done to get an iterable rows of result. This method
- will split the response into chunked DataFrame of a specified size to
- to be yielded to the instance calling it.
+ will return the response as a DataFrame.
Args:
- max_chunk_size (int):
- Maximum number of rows that the DataFrame should contain.
-
timeout_sec (int):
Max no of seconds to wait until job is done. If "timeout_sec"
is exceeded, an exception will be raised.
@@ -180,14 +176,14 @@
# Max chunk size defined by user
for result in self.result(timeout_sec=timeout_sec):
- result.append(records)
+ records.append(result)
if len(records) == max_chunk_size:
df = pd.DataFrame.from_records(records)
records.clear() # Empty records array
yield df
# Handle for last chunk that is < max_chunk_size
- if not records:
+ if records:
yield pd.DataFrame.from_records(records)
def __iter__(self):
| {"golden_diff": "diff --git a/sdk/python/feast/job.py b/sdk/python/feast/job.py\n--- a/sdk/python/feast/job.py\n+++ b/sdk/python/feast/job.py\n@@ -134,13 +134,9 @@\n ) -> pd.DataFrame:\n \"\"\"\n Wait until a job is done to get an iterable rows of result. This method\n- will split the response into chunked DataFrame of a specified size to\n- to be yielded to the instance calling it.\n+ will return the response as a DataFrame.\n \n Args:\n- max_chunk_size (int):\n- Maximum number of rows that the DataFrame should contain.\n-\n timeout_sec (int):\n Max no of seconds to wait until job is done. If \"timeout_sec\"\n is exceeded, an exception will be raised.\n@@ -180,14 +176,14 @@\n \n # Max chunk size defined by user\n for result in self.result(timeout_sec=timeout_sec):\n- result.append(records)\n+ records.append(result)\n if len(records) == max_chunk_size:\n df = pd.DataFrame.from_records(records)\n records.clear() # Empty records array\n yield df\n \n # Handle for last chunk that is < max_chunk_size\n- if not records:\n+ if records:\n yield pd.DataFrame.from_records(records)\n \n def __iter__(self):\n", "issue": "AttributeError: 'dict' object has no attribute 'append' in job.to_chunked_dataframe()\n## Expected Behavior \r\nReturn a generator of a chunked dataframe\r\n## Current Behavior\r\nGiving error :\r\n```\r\n/home/dev/feast-venv/lib/python3.7/site-packages/feast/job.py in to_chunked_dataframe(self, max_chunk_size, timeout_sec)\r\n 187 records = []\r\n 188 for result in self.result(timeout_sec=timeout_sec):\r\n--> 189 result.append(records)\r\n 190 if len(records) == max_chunk_size:\r\n 191 df = pd.DataFrame.from_records(records)\r\nAttributeError: 'dict' object has no attribute 'append'\r\n```\r\n## Steps to reproduce\r\n```\r\ntest = job.to_chunked_dataframe(10)\r\nnext(test)\r\n```\r\n### Specifications\r\n\r\n- Version: 0.5.0\r\n- Platform: Python 3.7\r\n- Subsystem: \r\n\r\n## Possible Solution\r\nIn line 189, it should be `records.append(result)` instead of `result.append(records)`\n", "before_files": [{"content": "from typing import List\nfrom urllib.parse import urlparse\n\nimport fastavro\nimport grpc\nimport pandas as pd\n\nfrom feast.constants import CONFIG_TIMEOUT_KEY\nfrom feast.constants import FEAST_DEFAULT_OPTIONS as defaults\nfrom feast.serving.ServingService_pb2 import (\n DATA_FORMAT_AVRO,\n JOB_STATUS_DONE,\n GetJobRequest,\n)\nfrom feast.serving.ServingService_pb2 import Job as JobProto\nfrom feast.serving.ServingService_pb2_grpc import ServingServiceStub\nfrom feast.staging.storage_client import get_staging_client\nfrom feast.wait import wait_retry_backoff\nfrom tensorflow_metadata.proto.v0 import statistics_pb2\n\n# Maximum no of seconds to wait until the retrieval jobs status is DONE in Feast\n# Currently set to the maximum query execution time limit in BigQuery\nDEFAULT_TIMEOUT_SEC: int = 21600\n\n# Maximum no of seconds to wait before reloading the job status in Feast\nMAX_WAIT_INTERVAL_SEC: int = 60\n\n\nclass RetrievalJob:\n \"\"\"\n A class representing a job for feature retrieval in Feast.\n \"\"\"\n\n def __init__(\n self,\n job_proto: JobProto,\n serving_stub: ServingServiceStub,\n auth_metadata_plugin: grpc.AuthMetadataPlugin = None,\n ):\n \"\"\"\n Args:\n job_proto: Job proto object (wrapped by this job object)\n serving_stub: Stub for Feast serving service\n auth_metadata_plugin: plugin to fetch auth metadata\n \"\"\"\n self.job_proto = job_proto\n self.serving_stub = serving_stub\n self.auth_metadata = auth_metadata_plugin\n\n @property\n def id(self):\n \"\"\"\n Getter for the Job Id\n \"\"\"\n return self.job_proto.id\n\n @property\n def status(self):\n \"\"\"\n Getter for the Job status from Feast Core\n \"\"\"\n return self.job_proto.status\n\n def reload(self):\n \"\"\"\n Reload the latest job status\n Returns: None\n \"\"\"\n self.job_proto = self.serving_stub.GetJob(\n GetJobRequest(job=self.job_proto),\n metadata=self.auth_metadata.get_signed_meta() if self.auth_metadata else (),\n ).job\n\n def get_avro_files(self, timeout_sec: int = int(defaults[CONFIG_TIMEOUT_KEY])):\n \"\"\"\n Wait until job is done to get the file uri to Avro result files on\n Google Cloud Storage.\n\n Args:\n timeout_sec (int):\n Max no of seconds to wait until job is done. If \"timeout_sec\"\n is exceeded, an exception will be raised.\n\n Returns:\n str: Google Cloud Storage file uris of the returned Avro files.\n \"\"\"\n\n def try_retrieve():\n self.reload()\n return None, self.status == JOB_STATUS_DONE\n\n wait_retry_backoff(\n retry_fn=try_retrieve,\n timeout_secs=timeout_sec,\n timeout_msg=\"Timeout exceeded while waiting for result. Please retry \"\n \"this method or use a longer timeout value.\",\n )\n\n if self.job_proto.error:\n raise Exception(self.job_proto.error)\n\n if self.job_proto.data_format != DATA_FORMAT_AVRO:\n raise Exception(\n \"Feast only supports Avro data format for now. Please check \"\n \"your Feast Serving deployment.\"\n )\n\n return [urlparse(uri) for uri in self.job_proto.file_uris]\n\n def result(self, timeout_sec: int = int(defaults[CONFIG_TIMEOUT_KEY])):\n \"\"\"\n Wait until job is done to get an iterable rows of result. The row can\n only represent an Avro row in Feast 0.3.\n\n Args:\n timeout_sec (int):\n Max no of seconds to wait until job is done. If \"timeout_sec\"\n is exceeded, an exception will be raised.\n\n Returns:\n Iterable of Avro rows.\n \"\"\"\n uris = self.get_avro_files(timeout_sec)\n for file_uri in uris:\n file_obj = get_staging_client(file_uri.scheme).download_file(file_uri)\n file_obj.seek(0)\n avro_reader = fastavro.reader(file_obj)\n\n for record in avro_reader:\n yield record\n\n def to_dataframe(\n self, timeout_sec: int = int(defaults[CONFIG_TIMEOUT_KEY])\n ) -> pd.DataFrame:\n \"\"\"\n Wait until a job is done to get an iterable rows of result. This method\n will split the response into chunked DataFrame of a specified size to\n to be yielded to the instance calling it.\n\n Args:\n max_chunk_size (int):\n Maximum number of rows that the DataFrame should contain.\n\n timeout_sec (int):\n Max no of seconds to wait until job is done. If \"timeout_sec\"\n is exceeded, an exception will be raised.\n\n Returns:\n pd.DataFrame:\n Pandas DataFrame of the feature values.\n \"\"\"\n records = [r for r in self.result(timeout_sec=timeout_sec)]\n return pd.DataFrame.from_records(records)\n\n def to_chunked_dataframe(\n self,\n max_chunk_size: int = -1,\n timeout_sec: int = int(defaults[CONFIG_TIMEOUT_KEY]),\n ) -> pd.DataFrame:\n \"\"\"\n Wait until a job is done to get an iterable rows of result. This method\n will split the response into chunked DataFrame of a specified size to\n to be yielded to the instance calling it.\n\n Args:\n max_chunk_size (int):\n Maximum number of rows that the DataFrame should contain.\n\n timeout_sec (int):\n Max no of seconds to wait until job is done. If \"timeout_sec\"\n is exceeded, an exception will be raised.\n\n Returns:\n pd.DataFrame:\n Pandas DataFrame of the feature values.\n \"\"\"\n\n # Object is Avro row type object, refer to self.result function for this type\n records: List[dict] = []\n\n # Max chunk size defined by user\n for result in self.result(timeout_sec=timeout_sec):\n result.append(records)\n if len(records) == max_chunk_size:\n df = pd.DataFrame.from_records(records)\n records.clear() # Empty records array\n yield df\n\n # Handle for last chunk that is < max_chunk_size\n if not records:\n yield pd.DataFrame.from_records(records)\n\n def __iter__(self):\n return iter(self.result())\n\n def statistics(\n self, timeout_sec: int = int(defaults[CONFIG_TIMEOUT_KEY])\n ) -> statistics_pb2.DatasetFeatureStatisticsList:\n \"\"\"\n Get statistics computed over the retrieved data set. Statistics will only be computed for\n columns that are part of Feast, and not the columns that were provided.\n\n Args:\n timeout_sec (int):\n Max no of seconds to wait until job is done. If \"timeout_sec\"\n is exceeded, an exception will be raised.\n\n Returns:\n DatasetFeatureStatisticsList containing statistics of Feast features over the retrieved dataset.\n \"\"\"\n self.get_avro_files(timeout_sec) # wait for job completion\n if self.job_proto.error:\n raise Exception(self.job_proto.error)\n return self.job_proto.dataset_feature_statistics_list\n", "path": "sdk/python/feast/job.py"}]} | 2,823 | 299 |
gh_patches_debug_34055 | rasdani/github-patches | git_diff | open-telemetry__opentelemetry-python-contrib-1552 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add readthedocs documentation for kafka python instrumentation
Part of [1491](https://github.com/open-telemetry/opentelemetry-python-contrib/issues/1491)
</issue>
<code>
[start of instrumentation/opentelemetry-instrumentation-kafka-python/src/opentelemetry/instrumentation/kafka/__init__.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """
16 Instrument `kafka-python` to report instrumentation-kafka produced and consumed messages
17
18 Usage
19 -----
20
21 ..code:: python
22
23 from opentelemetry.instrumentation.kafka import KafkaInstrumentor
24 from kafka import KafkaProducer, KafkaConsumer
25
26 # Instrument kafka
27 KafkaInstrumentor().instrument()
28
29 # report a span of type producer with the default settings
30 producer = KafkaProducer(bootstrap_servers=['localhost:9092'])
31 producer.send('my-topic', b'raw_bytes')
32
33
34 # report a span of type consumer with the default settings
35 consumer = KafkaConsumer('my-topic',
36 group_id='my-group',
37 bootstrap_servers=['localhost:9092'])
38 for message in consumer:
39 # process message
40
41 The `_instrument` method accepts the following keyword args:
42 tracer_provider (TracerProvider) - an optional tracer provider
43 produce_hook (Callable) - a function with extra user-defined logic to be performed before sending the message
44 this function signature is:
45 def produce_hook(span: Span, args, kwargs)
46 consume_hook (Callable) - a function with extra user-defined logic to be performed after consuming a message
47 this function signature is:
48 def consume
49 _hook(span: Span, record: kafka.record.ABCRecord, args, kwargs)
50 for example:
51 .. code: python
52 from opentelemetry.instrumentation.kafka import KafkaInstrumentor
53 from kafka import KafkaProducer, KafkaConsumer
54
55 def produce_hook(span, args, kwargs):
56 if span and span.is_recording():
57 span.set_attribute("custom_user_attribute_from_produce_hook", "some-value")
58 def consume_hook(span, record, args, kwargs):
59 if span and span.is_recording():
60 span.set_attribute("custom_user_attribute_from_consume_hook", "some-value")
61
62 # instrument kafka with produce and consume hooks
63 KafkaInstrumentor().instrument(produce_hook=produce_hook, consume_hook=consume_hook)
64
65 # Using kafka as normal now will automatically generate spans,
66 # including user custom attributes added from the hooks
67 producer = KafkaProducer(bootstrap_servers=['localhost:9092'])
68 producer.send('my-topic', b'raw_bytes')
69
70 API
71 ___
72 """
73 from typing import Collection
74
75 import kafka
76 from wrapt import wrap_function_wrapper
77
78 from opentelemetry import trace
79 from opentelemetry.instrumentation.instrumentor import BaseInstrumentor
80 from opentelemetry.instrumentation.kafka.package import _instruments
81 from opentelemetry.instrumentation.kafka.utils import _wrap_next, _wrap_send
82 from opentelemetry.instrumentation.kafka.version import __version__
83 from opentelemetry.instrumentation.utils import unwrap
84
85
86 class KafkaInstrumentor(BaseInstrumentor):
87 """An instrumentor for kafka module
88 See `BaseInstrumentor`
89 """
90
91 def instrumentation_dependencies(self) -> Collection[str]:
92 return _instruments
93
94 def _instrument(self, **kwargs):
95 """Instruments the kafka module
96
97 Args:
98 **kwargs: Optional arguments
99 ``tracer_provider``: a TracerProvider, defaults to global.
100 ``produce_hook``: a callable to be executed just before producing a message
101 ``consume_hook``: a callable to be executed just after consuming a message
102 """
103 tracer_provider = kwargs.get("tracer_provider")
104 produce_hook = kwargs.get("produce_hook")
105 consume_hook = kwargs.get("consume_hook")
106
107 tracer = trace.get_tracer(
108 __name__, __version__, tracer_provider=tracer_provider
109 )
110
111 wrap_function_wrapper(
112 kafka.KafkaProducer, "send", _wrap_send(tracer, produce_hook)
113 )
114 wrap_function_wrapper(
115 kafka.KafkaConsumer,
116 "__next__",
117 _wrap_next(tracer, consume_hook),
118 )
119
120 def _uninstrument(self, **kwargs):
121 unwrap(kafka.KafkaProducer, "send")
122 unwrap(kafka.KafkaConsumer, "__next__")
123
[end of instrumentation/opentelemetry-instrumentation-kafka-python/src/opentelemetry/instrumentation/kafka/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/instrumentation/opentelemetry-instrumentation-kafka-python/src/opentelemetry/instrumentation/kafka/__init__.py b/instrumentation/opentelemetry-instrumentation-kafka-python/src/opentelemetry/instrumentation/kafka/__init__.py
--- a/instrumentation/opentelemetry-instrumentation-kafka-python/src/opentelemetry/instrumentation/kafka/__init__.py
+++ b/instrumentation/opentelemetry-instrumentation-kafka-python/src/opentelemetry/instrumentation/kafka/__init__.py
@@ -13,7 +13,7 @@
# limitations under the License.
"""
-Instrument `kafka-python` to report instrumentation-kafka produced and consumed messages
+Instrument kafka-python to report instrumentation-kafka produced and consumed messages
Usage
-----
@@ -30,24 +30,21 @@
producer = KafkaProducer(bootstrap_servers=['localhost:9092'])
producer.send('my-topic', b'raw_bytes')
-
# report a span of type consumer with the default settings
- consumer = KafkaConsumer('my-topic',
- group_id='my-group',
- bootstrap_servers=['localhost:9092'])
+ consumer = KafkaConsumer('my-topic', group_id='my-group', bootstrap_servers=['localhost:9092'])
for message in consumer:
- # process message
+ # process message
-The `_instrument` method accepts the following keyword args:
+The _instrument() method accepts the following keyword args:
tracer_provider (TracerProvider) - an optional tracer provider
produce_hook (Callable) - a function with extra user-defined logic to be performed before sending the message
- this function signature is:
- def produce_hook(span: Span, args, kwargs)
+this function signature is:
+def produce_hook(span: Span, args, kwargs)
consume_hook (Callable) - a function with extra user-defined logic to be performed after consuming a message
- this function signature is:
- def consume
- _hook(span: Span, record: kafka.record.ABCRecord, args, kwargs)
+this function signature is:
+def consume_hook(span: Span, record: kafka.record.ABCRecord, args, kwargs)
for example:
+
.. code: python
from opentelemetry.instrumentation.kafka import KafkaInstrumentor
from kafka import KafkaProducer, KafkaConsumer
| {"golden_diff": "diff --git a/instrumentation/opentelemetry-instrumentation-kafka-python/src/opentelemetry/instrumentation/kafka/__init__.py b/instrumentation/opentelemetry-instrumentation-kafka-python/src/opentelemetry/instrumentation/kafka/__init__.py\n--- a/instrumentation/opentelemetry-instrumentation-kafka-python/src/opentelemetry/instrumentation/kafka/__init__.py\n+++ b/instrumentation/opentelemetry-instrumentation-kafka-python/src/opentelemetry/instrumentation/kafka/__init__.py\n@@ -13,7 +13,7 @@\n # limitations under the License.\n \n \"\"\"\n-Instrument `kafka-python` to report instrumentation-kafka produced and consumed messages\n+Instrument kafka-python to report instrumentation-kafka produced and consumed messages\n \n Usage\n -----\n@@ -30,24 +30,21 @@\n producer = KafkaProducer(bootstrap_servers=['localhost:9092'])\n producer.send('my-topic', b'raw_bytes')\n \n-\n # report a span of type consumer with the default settings\n- consumer = KafkaConsumer('my-topic',\n- group_id='my-group',\n- bootstrap_servers=['localhost:9092'])\n+ consumer = KafkaConsumer('my-topic', group_id='my-group', bootstrap_servers=['localhost:9092'])\n for message in consumer:\n- # process message\n+ # process message\n \n-The `_instrument` method accepts the following keyword args:\n+The _instrument() method accepts the following keyword args:\n tracer_provider (TracerProvider) - an optional tracer provider\n produce_hook (Callable) - a function with extra user-defined logic to be performed before sending the message\n- this function signature is:\n- def produce_hook(span: Span, args, kwargs)\n+this function signature is:\n+def produce_hook(span: Span, args, kwargs)\n consume_hook (Callable) - a function with extra user-defined logic to be performed after consuming a message\n- this function signature is:\n- def consume\n- _hook(span: Span, record: kafka.record.ABCRecord, args, kwargs)\n+this function signature is:\n+def consume_hook(span: Span, record: kafka.record.ABCRecord, args, kwargs)\n for example:\n+\n .. code: python\n from opentelemetry.instrumentation.kafka import KafkaInstrumentor\n from kafka import KafkaProducer, KafkaConsumer\n", "issue": "Add readthedocs documentation for kafka python instrumentation\nPart of [1491](https://github.com/open-telemetry/opentelemetry-python-contrib/issues/1491)\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nInstrument `kafka-python` to report instrumentation-kafka produced and consumed messages\n\nUsage\n-----\n\n..code:: python\n\n from opentelemetry.instrumentation.kafka import KafkaInstrumentor\n from kafka import KafkaProducer, KafkaConsumer\n\n # Instrument kafka\n KafkaInstrumentor().instrument()\n\n # report a span of type producer with the default settings\n producer = KafkaProducer(bootstrap_servers=['localhost:9092'])\n producer.send('my-topic', b'raw_bytes')\n\n\n # report a span of type consumer with the default settings\n consumer = KafkaConsumer('my-topic',\n group_id='my-group',\n bootstrap_servers=['localhost:9092'])\n for message in consumer:\n # process message\n\nThe `_instrument` method accepts the following keyword args:\ntracer_provider (TracerProvider) - an optional tracer provider\nproduce_hook (Callable) - a function with extra user-defined logic to be performed before sending the message\n this function signature is:\n def produce_hook(span: Span, args, kwargs)\nconsume_hook (Callable) - a function with extra user-defined logic to be performed after consuming a message\n this function signature is:\n def consume\n _hook(span: Span, record: kafka.record.ABCRecord, args, kwargs)\nfor example:\n.. code: python\n from opentelemetry.instrumentation.kafka import KafkaInstrumentor\n from kafka import KafkaProducer, KafkaConsumer\n\n def produce_hook(span, args, kwargs):\n if span and span.is_recording():\n span.set_attribute(\"custom_user_attribute_from_produce_hook\", \"some-value\")\n def consume_hook(span, record, args, kwargs):\n if span and span.is_recording():\n span.set_attribute(\"custom_user_attribute_from_consume_hook\", \"some-value\")\n\n # instrument kafka with produce and consume hooks\n KafkaInstrumentor().instrument(produce_hook=produce_hook, consume_hook=consume_hook)\n\n # Using kafka as normal now will automatically generate spans,\n # including user custom attributes added from the hooks\n producer = KafkaProducer(bootstrap_servers=['localhost:9092'])\n producer.send('my-topic', b'raw_bytes')\n\nAPI\n___\n\"\"\"\nfrom typing import Collection\n\nimport kafka\nfrom wrapt import wrap_function_wrapper\n\nfrom opentelemetry import trace\nfrom opentelemetry.instrumentation.instrumentor import BaseInstrumentor\nfrom opentelemetry.instrumentation.kafka.package import _instruments\nfrom opentelemetry.instrumentation.kafka.utils import _wrap_next, _wrap_send\nfrom opentelemetry.instrumentation.kafka.version import __version__\nfrom opentelemetry.instrumentation.utils import unwrap\n\n\nclass KafkaInstrumentor(BaseInstrumentor):\n \"\"\"An instrumentor for kafka module\n See `BaseInstrumentor`\n \"\"\"\n\n def instrumentation_dependencies(self) -> Collection[str]:\n return _instruments\n\n def _instrument(self, **kwargs):\n \"\"\"Instruments the kafka module\n\n Args:\n **kwargs: Optional arguments\n ``tracer_provider``: a TracerProvider, defaults to global.\n ``produce_hook``: a callable to be executed just before producing a message\n ``consume_hook``: a callable to be executed just after consuming a message\n \"\"\"\n tracer_provider = kwargs.get(\"tracer_provider\")\n produce_hook = kwargs.get(\"produce_hook\")\n consume_hook = kwargs.get(\"consume_hook\")\n\n tracer = trace.get_tracer(\n __name__, __version__, tracer_provider=tracer_provider\n )\n\n wrap_function_wrapper(\n kafka.KafkaProducer, \"send\", _wrap_send(tracer, produce_hook)\n )\n wrap_function_wrapper(\n kafka.KafkaConsumer,\n \"__next__\",\n _wrap_next(tracer, consume_hook),\n )\n\n def _uninstrument(self, **kwargs):\n unwrap(kafka.KafkaProducer, \"send\")\n unwrap(kafka.KafkaConsumer, \"__next__\")\n", "path": "instrumentation/opentelemetry-instrumentation-kafka-python/src/opentelemetry/instrumentation/kafka/__init__.py"}]} | 1,822 | 503 |
gh_patches_debug_37763 | rasdani/github-patches | git_diff | kornia__kornia-1853 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Loftr does not work with some image size (not a memory issue)
### Describe the bug
LoFTR incorrectly does something with positional embeddings
```
RuntimeError Traceback (most recent call last)
[<ipython-input-1-54d246337ab1>](https://9t3p2yszpxn-496ff2e9c6d22116-0-colab.googleusercontent.com/outputframe.html?vrz=colab-20220613-060046-RC00_454553376#) in <module>()
10 "image1": torch.rand(1,1, 1704, 2272).cuda()}
11 with torch.no_grad():
---> 12 correspondences = matcher(input_dict)
3 frames
[/usr/local/lib/python3.7/dist-packages/kornia/feature/loftr/utils/position_encoding.py](https://9t3p2yszpxn-496ff2e9c6d22116-0-colab.googleusercontent.com/outputframe.html?vrz=colab-20220613-060046-RC00_454553376#) in forward(self, x)
39 x: [N, C, H, W]
40 """
---> 41 return x + self.pe[:, :, :x.size(2), :x.size(3)]
RuntimeError: The size of tensor a (284) must match the size of tensor b (256) at non-singleton dimension 3
```
### Reproduction steps
```bash
import kornia as K
import kornia.feature as KF
import numpy as np
import torch
matcher = KF.LoFTR(pretrained='outdoor').cuda()
input_dict = {"image0": torch.rand(1,1, 1704, 2272),
"image1": torch.rand(1,1, 1704, 2272)}
with torch.no_grad():
correspondences = matcher(input_dict)
```
### Expected behavior
Not an error
### Environment
```shell
not relevant
```
### Additional context
_No response_
</issue>
<code>
[start of kornia/feature/loftr/utils/position_encoding.py]
1 import math
2
3 import torch
4 from torch import nn
5
6
7 class PositionEncodingSine(nn.Module):
8 """This is a sinusoidal position encoding that generalized to 2-dimensional images."""
9
10 def __init__(self, d_model, max_shape=(256, 256), temp_bug_fix=True):
11 """
12 Args:
13 max_shape (tuple): for 1/8 featmap, the max length of 256 corresponds to 2048 pixels
14 temp_bug_fix (bool): As noted in this [issue](https://github.com/zju3dv/LoFTR/issues/41),
15 the original implementation of LoFTR includes a bug in the pos-enc impl, which has little impact
16 on the final performance. For now, we keep both impls for backward compatibility.
17 We will remove the buggy impl after re-training all variants of our released models.
18 """
19 super().__init__()
20
21 pe = torch.zeros((d_model, *max_shape))
22 y_position = torch.ones(max_shape).cumsum(0).float().unsqueeze(0)
23 x_position = torch.ones(max_shape).cumsum(1).float().unsqueeze(0)
24 if temp_bug_fix:
25 div_term = torch.exp(torch.arange(0, d_model // 2, 2).float() * (-math.log(10000.0) / (d_model // 2)))
26 else: # a buggy implementation (for backward compatibility only)
27 div_term = torch.exp(torch.arange(0, d_model // 2, 2).float() * (-math.log(10000.0) / d_model // 2))
28 div_term = div_term[:, None, None] # [C//4, 1, 1]
29 pe[0::4, :, :] = torch.sin(x_position * div_term)
30 pe[1::4, :, :] = torch.cos(x_position * div_term)
31 pe[2::4, :, :] = torch.sin(y_position * div_term)
32 pe[3::4, :, :] = torch.cos(y_position * div_term)
33
34 self.register_buffer('pe', pe.unsqueeze(0), persistent=False) # [1, C, H, W]
35
36 def forward(self, x):
37 """
38 Args:
39 x: [N, C, H, W]
40 """
41 return x + self.pe[:, :, : x.size(2), : x.size(3)]
42
[end of kornia/feature/loftr/utils/position_encoding.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/kornia/feature/loftr/utils/position_encoding.py b/kornia/feature/loftr/utils/position_encoding.py
--- a/kornia/feature/loftr/utils/position_encoding.py
+++ b/kornia/feature/loftr/utils/position_encoding.py
@@ -17,25 +17,51 @@
We will remove the buggy impl after re-training all variants of our released models.
"""
super().__init__()
+ self.d_model = d_model
+ self.temp_bug_fix = temp_bug_fix
- pe = torch.zeros((d_model, *max_shape))
+ pe = self._create_position_encoding(max_shape)
+ self.register_buffer('pe', pe, persistent=False) # [1, C, H, W]
+
+ def _create_position_encoding(self, max_shape):
+ """Creates a position encoding from scratch.
+
+ For 1/8 feature map (which is standard): If the input image size is H, W (both divisible by 8), the max_shape
+ should be (H//8, W//8).
+ """
+ pe = torch.zeros((self.d_model, *max_shape))
y_position = torch.ones(max_shape).cumsum(0).float().unsqueeze(0)
x_position = torch.ones(max_shape).cumsum(1).float().unsqueeze(0)
- if temp_bug_fix:
- div_term = torch.exp(torch.arange(0, d_model // 2, 2).float() * (-math.log(10000.0) / (d_model // 2)))
+ if self.temp_bug_fix:
+ div_term = torch.exp(
+ torch.arange(0, self.d_model // 2, 2).float() * (-math.log(10000.0) / (self.d_model // 2))
+ )
else: # a buggy implementation (for backward compatibility only)
- div_term = torch.exp(torch.arange(0, d_model // 2, 2).float() * (-math.log(10000.0) / d_model // 2))
+ div_term = torch.exp(
+ torch.arange(0, self.d_model // 2, 2).float() * (-math.log(10000.0) / self.d_model // 2)
+ )
div_term = div_term[:, None, None] # [C//4, 1, 1]
pe[0::4, :, :] = torch.sin(x_position * div_term)
pe[1::4, :, :] = torch.cos(x_position * div_term)
pe[2::4, :, :] = torch.sin(y_position * div_term)
pe[3::4, :, :] = torch.cos(y_position * div_term)
+ return pe.unsqueeze(0)
- self.register_buffer('pe', pe.unsqueeze(0), persistent=False) # [1, C, H, W]
+ def update_position_encoding_size(self, max_shape):
+ """Updates position encoding to new max_shape.
+
+ For 1/8 feature map (which is standard): If the input image size is H, W (both divisible by 8), the max_shape
+ should be (H//8, W//8).
+ """
+ self.pe = self._create_position_encoding(max_shape).to(self.pe.device)
def forward(self, x):
"""
Args:
x: [N, C, H, W]
"""
+ if x.size(2) > self.pe.size(2) or x.size(3) > self.pe.size(3):
+ max_shape = (max(x.size(2), self.pe.size(2)), max(x.size(3), self.pe.size(3)))
+ self.update_position_encoding_size(max_shape)
+
return x + self.pe[:, :, : x.size(2), : x.size(3)]
| {"golden_diff": "diff --git a/kornia/feature/loftr/utils/position_encoding.py b/kornia/feature/loftr/utils/position_encoding.py\n--- a/kornia/feature/loftr/utils/position_encoding.py\n+++ b/kornia/feature/loftr/utils/position_encoding.py\n@@ -17,25 +17,51 @@\n We will remove the buggy impl after re-training all variants of our released models.\n \"\"\"\n super().__init__()\n+ self.d_model = d_model\n+ self.temp_bug_fix = temp_bug_fix\n \n- pe = torch.zeros((d_model, *max_shape))\n+ pe = self._create_position_encoding(max_shape)\n+ self.register_buffer('pe', pe, persistent=False) # [1, C, H, W]\n+\n+ def _create_position_encoding(self, max_shape):\n+ \"\"\"Creates a position encoding from scratch.\n+\n+ For 1/8 feature map (which is standard): If the input image size is H, W (both divisible by 8), the max_shape\n+ should be (H//8, W//8).\n+ \"\"\"\n+ pe = torch.zeros((self.d_model, *max_shape))\n y_position = torch.ones(max_shape).cumsum(0).float().unsqueeze(0)\n x_position = torch.ones(max_shape).cumsum(1).float().unsqueeze(0)\n- if temp_bug_fix:\n- div_term = torch.exp(torch.arange(0, d_model // 2, 2).float() * (-math.log(10000.0) / (d_model // 2)))\n+ if self.temp_bug_fix:\n+ div_term = torch.exp(\n+ torch.arange(0, self.d_model // 2, 2).float() * (-math.log(10000.0) / (self.d_model // 2))\n+ )\n else: # a buggy implementation (for backward compatibility only)\n- div_term = torch.exp(torch.arange(0, d_model // 2, 2).float() * (-math.log(10000.0) / d_model // 2))\n+ div_term = torch.exp(\n+ torch.arange(0, self.d_model // 2, 2).float() * (-math.log(10000.0) / self.d_model // 2)\n+ )\n div_term = div_term[:, None, None] # [C//4, 1, 1]\n pe[0::4, :, :] = torch.sin(x_position * div_term)\n pe[1::4, :, :] = torch.cos(x_position * div_term)\n pe[2::4, :, :] = torch.sin(y_position * div_term)\n pe[3::4, :, :] = torch.cos(y_position * div_term)\n+ return pe.unsqueeze(0)\n \n- self.register_buffer('pe', pe.unsqueeze(0), persistent=False) # [1, C, H, W]\n+ def update_position_encoding_size(self, max_shape):\n+ \"\"\"Updates position encoding to new max_shape.\n+\n+ For 1/8 feature map (which is standard): If the input image size is H, W (both divisible by 8), the max_shape\n+ should be (H//8, W//8).\n+ \"\"\"\n+ self.pe = self._create_position_encoding(max_shape).to(self.pe.device)\n \n def forward(self, x):\n \"\"\"\n Args:\n x: [N, C, H, W]\n \"\"\"\n+ if x.size(2) > self.pe.size(2) or x.size(3) > self.pe.size(3):\n+ max_shape = (max(x.size(2), self.pe.size(2)), max(x.size(3), self.pe.size(3)))\n+ self.update_position_encoding_size(max_shape)\n+\n return x + self.pe[:, :, : x.size(2), : x.size(3)]\n", "issue": "Loftr does not work with some image size (not a memory issue)\n### Describe the bug\n\nLoFTR incorrectly does something with positional embeddings\r\n```\r\nRuntimeError Traceback (most recent call last)\r\n[<ipython-input-1-54d246337ab1>](https://9t3p2yszpxn-496ff2e9c6d22116-0-colab.googleusercontent.com/outputframe.html?vrz=colab-20220613-060046-RC00_454553376#) in <module>()\r\n 10 \"image1\": torch.rand(1,1, 1704, 2272).cuda()}\r\n 11 with torch.no_grad():\r\n---> 12 correspondences = matcher(input_dict)\r\n\r\n3 frames\r\n[/usr/local/lib/python3.7/dist-packages/kornia/feature/loftr/utils/position_encoding.py](https://9t3p2yszpxn-496ff2e9c6d22116-0-colab.googleusercontent.com/outputframe.html?vrz=colab-20220613-060046-RC00_454553376#) in forward(self, x)\r\n 39 x: [N, C, H, W]\r\n 40 \"\"\"\r\n---> 41 return x + self.pe[:, :, :x.size(2), :x.size(3)]\r\n\r\nRuntimeError: The size of tensor a (284) must match the size of tensor b (256) at non-singleton dimension 3\r\n```\n\n### Reproduction steps\n\n```bash\nimport kornia as K\r\nimport kornia.feature as KF\r\nimport numpy as np\r\nimport torch\r\n\r\nmatcher = KF.LoFTR(pretrained='outdoor').cuda()\r\n\r\ninput_dict = {\"image0\": torch.rand(1,1, 1704, 2272),\r\n \"image1\": torch.rand(1,1, 1704, 2272)}\r\nwith torch.no_grad():\r\n correspondences = matcher(input_dict)\n```\n\n\n### Expected behavior\n\nNot an error \n\n### Environment\n\n```shell\nnot relevant\n```\n\n\n### Additional context\n\n_No response_\n", "before_files": [{"content": "import math\n\nimport torch\nfrom torch import nn\n\n\nclass PositionEncodingSine(nn.Module):\n \"\"\"This is a sinusoidal position encoding that generalized to 2-dimensional images.\"\"\"\n\n def __init__(self, d_model, max_shape=(256, 256), temp_bug_fix=True):\n \"\"\"\n Args:\n max_shape (tuple): for 1/8 featmap, the max length of 256 corresponds to 2048 pixels\n temp_bug_fix (bool): As noted in this [issue](https://github.com/zju3dv/LoFTR/issues/41),\n the original implementation of LoFTR includes a bug in the pos-enc impl, which has little impact\n on the final performance. For now, we keep both impls for backward compatibility.\n We will remove the buggy impl after re-training all variants of our released models.\n \"\"\"\n super().__init__()\n\n pe = torch.zeros((d_model, *max_shape))\n y_position = torch.ones(max_shape).cumsum(0).float().unsqueeze(0)\n x_position = torch.ones(max_shape).cumsum(1).float().unsqueeze(0)\n if temp_bug_fix:\n div_term = torch.exp(torch.arange(0, d_model // 2, 2).float() * (-math.log(10000.0) / (d_model // 2)))\n else: # a buggy implementation (for backward compatibility only)\n div_term = torch.exp(torch.arange(0, d_model // 2, 2).float() * (-math.log(10000.0) / d_model // 2))\n div_term = div_term[:, None, None] # [C//4, 1, 1]\n pe[0::4, :, :] = torch.sin(x_position * div_term)\n pe[1::4, :, :] = torch.cos(x_position * div_term)\n pe[2::4, :, :] = torch.sin(y_position * div_term)\n pe[3::4, :, :] = torch.cos(y_position * div_term)\n\n self.register_buffer('pe', pe.unsqueeze(0), persistent=False) # [1, C, H, W]\n\n def forward(self, x):\n \"\"\"\n Args:\n x: [N, C, H, W]\n \"\"\"\n return x + self.pe[:, :, : x.size(2), : x.size(3)]\n", "path": "kornia/feature/loftr/utils/position_encoding.py"}]} | 1,682 | 864 |
gh_patches_debug_8026 | rasdani/github-patches | git_diff | dmlc__dgl-3696 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] FileExistsError when sometimes importing dgl from multiprocess training
## 🐛 Bug
Sometimes, when I launch my Pytorch distributed trainer (which spawns multiple trainer processes, eg once for each GPU for multi-gpu model training), my training job fails with the following error:
```
# pardon the possibly out-of-order stack trace, multiple processes are interleaving the stdout
import dgl
Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/dgl/__init__.py", line 13, in <module>
from .backend import load_backend, backend_name
File "/usr/local/lib/python3.7/os.py", line 221, in makedirs
mkdir(name, mode)
File "trainer/utils/cli.py", line 137, in <module>
locals()["run_" + args.which](args, extra)
File "/usr/local/lib/python3.7/site-packages/dgl/backend/__init__.py", line 107, in <module>
load_backend(get_preferred_backend())
File "trainer/utils/cli.py", line 27, in run_local
trainer_class = locate(args.trainer)
FileExistsError: [Errno 17] File exists: '/root/.dgl'
File "/usr/local/lib/python3.7/site-packages/dgl/backend/__init__.py", line 103, in get_preferred_backend
set_default_backend(default_dir, 'pytorch')
FileExistsError: [Errno 17] File exists: '/root/.dgl'
```
I see this occur fairly often, say ~10-20% of the time. Usually, retrying the train command fixes things.
For what it's worth: I am running this within a Docker container, using a DGL nightly build from `2021-10-18`
## To Reproduce
Steps to reproduce the behavior:
I don't have a repro script. But, hopefully this stack trace can point out a diagnosis + fix.
## Expected behavior
Importing dgl shouldn't cause an error.
## Environment
- DGL Version (e.g., 1.0): >0.7 (Nightly build from 2021-10-18).
- Backend Library & Version (e.g., PyTorch 0.4.1, MXNet/Gluon 1.3):
- OS (e.g., Linux): Linux
- How you installed DGL (`conda`, `pip`, source): From nightly
- Build command you used (if compiling from source):
- Python version: 3.7
- CUDA/cuDNN version (if applicable):
- GPU models and configuration (e.g. V100):
- Any other relevant information:
## Additional context
</issue>
<code>
[start of python/dgl/backend/set_default_backend.py]
1 import argparse
2 import os
3 import json
4
5 def set_default_backend(default_dir, backend_name):
6 if not os.path.exists(default_dir):
7 os.makedirs(default_dir)
8 config_path = os.path.join(default_dir, 'config.json')
9 with open(config_path, "w") as config_file:
10 json.dump({'backend': backend_name.lower()}, config_file)
11 print('Setting the default backend to "{}". You can change it in the '
12 '~/.dgl/config.json file or export the DGLBACKEND environment variable. '
13 'Valid options are: pytorch, mxnet, tensorflow (all lowercase)'.format(
14 backend_name))
15
16 if __name__ == "__main__":
17 parser = argparse.ArgumentParser()
18 parser.add_argument("default_dir", type=str, default=os.path.join(os.path.expanduser('~'), '.dgl'))
19 parser.add_argument("backend", nargs=1, type=str, choices=[
20 'pytorch', 'tensorflow', 'mxnet'], help="Set default backend")
21 args = parser.parse_args()
22 set_default_backend(args.default_dir, args.backend[0])
23
[end of python/dgl/backend/set_default_backend.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/python/dgl/backend/set_default_backend.py b/python/dgl/backend/set_default_backend.py
--- a/python/dgl/backend/set_default_backend.py
+++ b/python/dgl/backend/set_default_backend.py
@@ -3,8 +3,8 @@
import json
def set_default_backend(default_dir, backend_name):
- if not os.path.exists(default_dir):
- os.makedirs(default_dir)
+ # the exists_ok requires python >= 3.2
+ os.makedirs(default_dir, exists_ok=True)
config_path = os.path.join(default_dir, 'config.json')
with open(config_path, "w") as config_file:
json.dump({'backend': backend_name.lower()}, config_file)
| {"golden_diff": "diff --git a/python/dgl/backend/set_default_backend.py b/python/dgl/backend/set_default_backend.py\n--- a/python/dgl/backend/set_default_backend.py\n+++ b/python/dgl/backend/set_default_backend.py\n@@ -3,8 +3,8 @@\n import json\n \n def set_default_backend(default_dir, backend_name):\n- if not os.path.exists(default_dir):\n- os.makedirs(default_dir)\n+ # the exists_ok requires python >= 3.2\n+ os.makedirs(default_dir, exists_ok=True)\n config_path = os.path.join(default_dir, 'config.json')\n with open(config_path, \"w\") as config_file: \n json.dump({'backend': backend_name.lower()}, config_file)\n", "issue": "[Bug] FileExistsError when sometimes importing dgl from multiprocess training\n## \ud83d\udc1b Bug\r\nSometimes, when I launch my Pytorch distributed trainer (which spawns multiple trainer processes, eg once for each GPU for multi-gpu model training), my training job fails with the following error:\r\n\r\n```\r\n# pardon the possibly out-of-order stack trace, multiple processes are interleaving the stdout\r\n import dgl\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.7/site-packages/dgl/__init__.py\", line 13, in <module>\r\n from .backend import load_backend, backend_name\r\n File \"/usr/local/lib/python3.7/os.py\", line 221, in makedirs\r\n mkdir(name, mode)\r\n File \"trainer/utils/cli.py\", line 137, in <module>\r\n locals()[\"run_\" + args.which](args, extra)\r\n File \"/usr/local/lib/python3.7/site-packages/dgl/backend/__init__.py\", line 107, in <module>\r\n load_backend(get_preferred_backend())\r\n File \"trainer/utils/cli.py\", line 27, in run_local\r\n trainer_class = locate(args.trainer)\r\nFileExistsError: [Errno 17] File exists: '/root/.dgl'\r\n File \"/usr/local/lib/python3.7/site-packages/dgl/backend/__init__.py\", line 103, in get_preferred_backend\r\n set_default_backend(default_dir, 'pytorch')\r\nFileExistsError: [Errno 17] File exists: '/root/.dgl'\r\n```\r\n\r\nI see this occur fairly often, say ~10-20% of the time. Usually, retrying the train command fixes things.\r\n\r\nFor what it's worth: I am running this within a Docker container, using a DGL nightly build from `2021-10-18`\r\n\r\n## To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\nI don't have a repro script. But, hopefully this stack trace can point out a diagnosis + fix.\r\n\r\n## Expected behavior\r\n\r\nImporting dgl shouldn't cause an error.\r\n\r\n## Environment\r\n\r\n - DGL Version (e.g., 1.0): >0.7 (Nightly build from 2021-10-18).\r\n - Backend Library & Version (e.g., PyTorch 0.4.1, MXNet/Gluon 1.3):\r\n - OS (e.g., Linux): Linux\r\n - How you installed DGL (`conda`, `pip`, source): From nightly\r\n - Build command you used (if compiling from source):\r\n - Python version: 3.7\r\n - CUDA/cuDNN version (if applicable):\r\n - GPU models and configuration (e.g. V100):\r\n - Any other relevant information:\r\n\r\n## Additional context\r\n\n", "before_files": [{"content": "import argparse\nimport os\nimport json\n\ndef set_default_backend(default_dir, backend_name):\n if not os.path.exists(default_dir):\n os.makedirs(default_dir)\n config_path = os.path.join(default_dir, 'config.json')\n with open(config_path, \"w\") as config_file: \n json.dump({'backend': backend_name.lower()}, config_file)\n print('Setting the default backend to \"{}\". You can change it in the '\n '~/.dgl/config.json file or export the DGLBACKEND environment variable. '\n 'Valid options are: pytorch, mxnet, tensorflow (all lowercase)'.format(\n backend_name))\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n parser.add_argument(\"default_dir\", type=str, default=os.path.join(os.path.expanduser('~'), '.dgl'))\n parser.add_argument(\"backend\", nargs=1, type=str, choices=[\n 'pytorch', 'tensorflow', 'mxnet'], help=\"Set default backend\")\n args = parser.parse_args()\n set_default_backend(args.default_dir, args.backend[0])\n", "path": "python/dgl/backend/set_default_backend.py"}]} | 1,409 | 150 |
gh_patches_debug_36088 | rasdani/github-patches | git_diff | quantumlib__Cirq-4246 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Push to PyPi failing
```
error in cirq setup command: 'extras_require' must be a dictionary whose values are strings or lists of strings containing valid project/version requirement specifiers.
```
See https://github.com/quantumlib/Cirq/runs/2851981344
</issue>
<code>
[start of setup.py]
1 # Copyright 2018 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16 import os
17 from setuptools import setup
18
19 # This reads the __version__ variable from cirq/_version.py
20 __version__ = ''
21
22 from dev_tools import modules
23 from dev_tools.requirements import explode
24
25 exec(open('cirq-core/cirq/_version.py').read())
26
27 name = 'cirq'
28
29 description = (
30 'A framework for creating, editing, and invoking '
31 'Noisy Intermediate Scale Quantum (NISQ) circuits.'
32 )
33
34 # README file as long_description.
35 long_description = io.open('README.rst', encoding='utf-8').read()
36
37 # If CIRQ_PRE_RELEASE_VERSION is set then we update the version to this value.
38 # It is assumed that it ends with one of `.devN`, `.aN`, `.bN`, `.rcN` and hence
39 # it will be a pre-release version on PyPi. See
40 # https://packaging.python.org/guides/distributing-packages-using-setuptools/#pre-release-versioning
41 # for more details.
42 if 'CIRQ_PRE_RELEASE_VERSION' in os.environ:
43 __version__ = os.environ['CIRQ_PRE_RELEASE_VERSION']
44 long_description = (
45 "**This is a development version of Cirq and may be "
46 "unstable.**\n\n**For the latest stable release of Cirq "
47 "see**\n`here <https://pypi.org/project/cirq>`__.\n\n" + long_description
48 )
49
50 # Sanity check
51 assert __version__, 'Version string cannot be empty'
52
53 # This is a pure metapackage that installs all our packages
54 requirements = [f'{p.name}=={p.version}' for p in modules.list_modules()]
55
56 dev_requirements = explode('dev_tools/requirements/deps/dev-tools.txt')
57 dev_requirements = [r.strip() for r in dev_requirements]
58
59 setup(
60 name=name,
61 version=__version__,
62 url='http://github.com/quantumlib/cirq',
63 author='The Cirq Developers',
64 author_email='[email protected]',
65 python_requires=('>=3.6.0'),
66 install_requires=requirements,
67 extras_require={
68 'dev_env': dev_requirements,
69 },
70 license='Apache 2',
71 description=description,
72 long_description=long_description,
73 )
74
[end of setup.py]
[start of dev_tools/modules.py]
1 # Copyright 2021 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 """Utility tool for cirq modules.
17
18 It can be used as a python library for python scripts as well as a CLI tool for
19 bash scripts and interactive use.
20
21 Features:
22
23 listing modules:
24 - Python: see list_modules
25 - CLI: python3 dev_tools/modules.py list
26
27 optional arguments:
28 -h, --help show this help message and exit
29 --mode {folder,package-path}
30 'folder' to list root folder for module, 'package-path' for top level
31 python package path
32 --include-parent whether to include the parent package or not
33 """
34
35 import argparse
36 import dataclasses
37 import os
38 import sys
39 from pathlib import Path
40 from typing import List, Dict, Any
41
42 _FOLDER = 'folder'
43 _PACKAGE_PATH = 'package-path'
44
45
46 @dataclasses.dataclass
47 class Module:
48 root: Path
49 raw_setup: Dict[str, Any]
50
51 name: str = dataclasses.field(init=False)
52 version: str = dataclasses.field(init=False)
53 top_level_packages: List[str] = dataclasses.field(init=False)
54 top_level_package_paths: List[Path] = dataclasses.field(init=False)
55
56 def __post_init__(self) -> None:
57 self.name = self.raw_setup['name']
58 if 'packages' in self.raw_setup:
59 self.top_level_packages = [p for p in self.raw_setup['packages'] if '.' not in p]
60 else:
61 self.top_level_packages = []
62 self.top_level_package_paths = [self.root / p for p in self.top_level_packages]
63 self.version = self.raw_setup['version']
64
65
66 def list_modules(
67 search_dir: Path = Path(__file__).parents[1], include_parent: bool = False
68 ) -> List[Module]:
69 """Returns a list of python modules based defined by setup.py files.
70
71 Args:
72 include_parent: if true, a setup.py is expected in `search_dir`, and the corresponding
73 module will be included.
74 search_dir: the search directory for modules, by default the repo root.
75 Returns:
76 a list of `Module`s that were found, where each module `m` is initialized with `m.root`
77 relative to `search_dir`, `m.raw_setup` contains the dictionary equivalent to the
78 keyword args passed to the `setuptools.setup` method in setup.py
79 """
80
81 relative_folders = sorted(
82 f.relative_to(search_dir)
83 for f in search_dir.glob("*")
84 if f.is_dir() and (f / "setup.py").is_file()
85 )
86 if include_parent:
87 parent_setup_py = search_dir / "setup.py"
88 assert parent_setup_py.exists(), (
89 f"include_parent=True, but {parent_setup_py} " f"does not exist."
90 )
91 relative_folders.append(Path("."))
92
93 result = [
94 Module(root=folder, raw_setup=_parse_module(search_dir / folder))
95 for folder in relative_folders
96 ]
97
98 return result
99
100
101 def _parse_module(folder: Path) -> Dict[str, Any]:
102 setup_args = {}
103 import setuptools
104
105 orig_setup = setuptools.setup
106 cwd = os.getcwd()
107
108 def setup(**kwargs):
109 setup_args.update(kwargs)
110
111 try:
112 setuptools.setup = setup
113 os.chdir(str(folder))
114 setup_py = open("setup.py").read()
115 exec(setup_py, globals(), {})
116 assert setup_args, f"Invalid setup.py - setup() was not called in {folder}/setup.py!"
117 return setup_args
118 except BaseException:
119 print(f"Failed to run {folder}/setup.py:")
120 raise
121 finally:
122 setuptools.setup = orig_setup
123 os.chdir(cwd)
124
125
126 def _print_list_modules(mode: str, include_parent: bool = False):
127 """Prints certain properties of cirq modules on separate lines.
128
129 Module root folder and top level package paths are supported. The search dir is the current
130 directory.
131
132 Args:
133 mode: 'folder' lists the root folder for each module, 'package-path' lists the path to
134 the top level package(s).
135 include_cirq: when true the cirq metapackage is included in the list
136 Returns:
137 a list of strings
138 """
139 for m in list_modules(Path("."), include_parent):
140 if mode == _FOLDER:
141 print(m.root, end=" ")
142 elif mode == _PACKAGE_PATH:
143 for p in m.top_level_package_paths:
144 print(p, end=" ")
145
146
147 def main(argv: List[str]):
148 args = parse(argv)
149 # args.func is where we store the function to be called for a given subparser
150 # e.g. it is list_modules for the `list` subcommand
151 f = args.func
152 # however the func is not going to be needed for the function itself, so
153 # we remove it here
154 del args.func
155 f(**vars(args))
156
157
158 def parse(args):
159 parser = argparse.ArgumentParser('A utility for modules.')
160 subparsers = parser.add_subparsers(
161 title='subcommands', description='valid subcommands', help='additional help'
162 )
163 _add_list_modules_cmd(subparsers)
164 return parser.parse_args(args)
165
166
167 def _add_list_modules_cmd(subparsers):
168 list_modules_cmd = subparsers.add_parser("list", help="lists all the modules")
169 list_modules_cmd.add_argument(
170 "--mode",
171 default=_FOLDER,
172 choices=[_FOLDER, _PACKAGE_PATH],
173 type=str,
174 help="'folder' to list root folder for module,\n"
175 "'package-path' for top level python package path",
176 )
177 list_modules_cmd.add_argument(
178 "--include-parent",
179 help="whether to include the parent package or not",
180 default=False,
181 action="store_true",
182 )
183 list_modules_cmd.set_defaults(func=_print_list_modules)
184
185
186 if __name__ == '__main__':
187 main(sys.argv[1:]) # coverage: ignore
188
[end of dev_tools/modules.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/dev_tools/modules.py b/dev_tools/modules.py
--- a/dev_tools/modules.py
+++ b/dev_tools/modules.py
@@ -27,8 +27,10 @@
optional arguments:
-h, --help show this help message and exit
--mode {folder,package-path}
- 'folder' to list root folder for module, 'package-path' for top level
- python package path
+ 'folder' to list root folder for module (e.g. cirq-google),
+ 'package-path' for top level python package path
+ (e.g. cirq-google/cirq_google),
+ 'package' for top level python package (e.g cirq_google),
--include-parent whether to include the parent package or not
"""
@@ -41,6 +43,7 @@
_FOLDER = 'folder'
_PACKAGE_PATH = 'package-path'
+_PACKAGE = 'package'
@dataclasses.dataclass
@@ -142,6 +145,9 @@
elif mode == _PACKAGE_PATH:
for p in m.top_level_package_paths:
print(p, end=" ")
+ elif mode == _PACKAGE:
+ for package in m.top_level_packages:
+ print(package, end=" ")
def main(argv: List[str]):
@@ -169,10 +175,11 @@
list_modules_cmd.add_argument(
"--mode",
default=_FOLDER,
- choices=[_FOLDER, _PACKAGE_PATH],
+ choices=[_FOLDER, _PACKAGE_PATH, _PACKAGE],
type=str,
- help="'folder' to list root folder for module,\n"
- "'package-path' for top level python package path",
+ help="'folder' to list root folder for module (e.g. cirq-google),\n"
+ "'package-path' for top level python package path (e.g. cirq-google/cirq_google),\n"
+ "'package' for top level python package (e.g cirq_google),\n",
)
list_modules_cmd.add_argument(
"--include-parent",
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -62,7 +62,7 @@
url='http://github.com/quantumlib/cirq',
author='The Cirq Developers',
author_email='[email protected]',
- python_requires=('>=3.6.0'),
+ python_requires='>=3.6.0',
install_requires=requirements,
extras_require={
'dev_env': dev_requirements,
| {"golden_diff": "diff --git a/dev_tools/modules.py b/dev_tools/modules.py\n--- a/dev_tools/modules.py\n+++ b/dev_tools/modules.py\n@@ -27,8 +27,10 @@\n optional arguments:\n -h, --help show this help message and exit\n --mode {folder,package-path}\n- 'folder' to list root folder for module, 'package-path' for top level\n- python package path\n+ 'folder' to list root folder for module (e.g. cirq-google),\n+ 'package-path' for top level python package path\n+ (e.g. cirq-google/cirq_google),\n+ 'package' for top level python package (e.g cirq_google),\n --include-parent whether to include the parent package or not\n \"\"\"\n \n@@ -41,6 +43,7 @@\n \n _FOLDER = 'folder'\n _PACKAGE_PATH = 'package-path'\n+_PACKAGE = 'package'\n \n \n @dataclasses.dataclass\n@@ -142,6 +145,9 @@\n elif mode == _PACKAGE_PATH:\n for p in m.top_level_package_paths:\n print(p, end=\" \")\n+ elif mode == _PACKAGE:\n+ for package in m.top_level_packages:\n+ print(package, end=\" \")\n \n \n def main(argv: List[str]):\n@@ -169,10 +175,11 @@\n list_modules_cmd.add_argument(\n \"--mode\",\n default=_FOLDER,\n- choices=[_FOLDER, _PACKAGE_PATH],\n+ choices=[_FOLDER, _PACKAGE_PATH, _PACKAGE],\n type=str,\n- help=\"'folder' to list root folder for module,\\n\"\n- \"'package-path' for top level python package path\",\n+ help=\"'folder' to list root folder for module (e.g. cirq-google),\\n\"\n+ \"'package-path' for top level python package path (e.g. cirq-google/cirq_google),\\n\"\n+ \"'package' for top level python package (e.g cirq_google),\\n\",\n )\n list_modules_cmd.add_argument(\n \"--include-parent\",\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -62,7 +62,7 @@\n url='http://github.com/quantumlib/cirq',\n author='The Cirq Developers',\n author_email='[email protected]',\n- python_requires=('>=3.6.0'),\n+ python_requires='>=3.6.0',\n install_requires=requirements,\n extras_require={\n 'dev_env': dev_requirements,\n", "issue": "Push to PyPi failing\n```\r\nerror in cirq setup command: 'extras_require' must be a dictionary whose values are strings or lists of strings containing valid project/version requirement specifiers.\r\n```\r\n\r\nSee https://github.com/quantumlib/Cirq/runs/2851981344\r\n\n", "before_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\nfrom setuptools import setup\n\n# This reads the __version__ variable from cirq/_version.py\n__version__ = ''\n\nfrom dev_tools import modules\nfrom dev_tools.requirements import explode\n\nexec(open('cirq-core/cirq/_version.py').read())\n\nname = 'cirq'\n\ndescription = (\n 'A framework for creating, editing, and invoking '\n 'Noisy Intermediate Scale Quantum (NISQ) circuits.'\n)\n\n# README file as long_description.\nlong_description = io.open('README.rst', encoding='utf-8').read()\n\n# If CIRQ_PRE_RELEASE_VERSION is set then we update the version to this value.\n# It is assumed that it ends with one of `.devN`, `.aN`, `.bN`, `.rcN` and hence\n# it will be a pre-release version on PyPi. See\n# https://packaging.python.org/guides/distributing-packages-using-setuptools/#pre-release-versioning\n# for more details.\nif 'CIRQ_PRE_RELEASE_VERSION' in os.environ:\n __version__ = os.environ['CIRQ_PRE_RELEASE_VERSION']\n long_description = (\n \"**This is a development version of Cirq and may be \"\n \"unstable.**\\n\\n**For the latest stable release of Cirq \"\n \"see**\\n`here <https://pypi.org/project/cirq>`__.\\n\\n\" + long_description\n )\n\n# Sanity check\nassert __version__, 'Version string cannot be empty'\n\n# This is a pure metapackage that installs all our packages\nrequirements = [f'{p.name}=={p.version}' for p in modules.list_modules()]\n\ndev_requirements = explode('dev_tools/requirements/deps/dev-tools.txt')\ndev_requirements = [r.strip() for r in dev_requirements]\n\nsetup(\n name=name,\n version=__version__,\n url='http://github.com/quantumlib/cirq',\n author='The Cirq Developers',\n author_email='[email protected]',\n python_requires=('>=3.6.0'),\n install_requires=requirements,\n extras_require={\n 'dev_env': dev_requirements,\n },\n license='Apache 2',\n description=description,\n long_description=long_description,\n)\n", "path": "setup.py"}, {"content": "# Copyright 2021 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\n\"\"\"Utility tool for cirq modules.\n\nIt can be used as a python library for python scripts as well as a CLI tool for\nbash scripts and interactive use.\n\nFeatures:\n\nlisting modules:\n - Python: see list_modules\n - CLI: python3 dev_tools/modules.py list\n\noptional arguments:\n -h, --help show this help message and exit\n --mode {folder,package-path}\n 'folder' to list root folder for module, 'package-path' for top level\n python package path\n --include-parent whether to include the parent package or not\n\"\"\"\n\nimport argparse\nimport dataclasses\nimport os\nimport sys\nfrom pathlib import Path\nfrom typing import List, Dict, Any\n\n_FOLDER = 'folder'\n_PACKAGE_PATH = 'package-path'\n\n\[email protected]\nclass Module:\n root: Path\n raw_setup: Dict[str, Any]\n\n name: str = dataclasses.field(init=False)\n version: str = dataclasses.field(init=False)\n top_level_packages: List[str] = dataclasses.field(init=False)\n top_level_package_paths: List[Path] = dataclasses.field(init=False)\n\n def __post_init__(self) -> None:\n self.name = self.raw_setup['name']\n if 'packages' in self.raw_setup:\n self.top_level_packages = [p for p in self.raw_setup['packages'] if '.' not in p]\n else:\n self.top_level_packages = []\n self.top_level_package_paths = [self.root / p for p in self.top_level_packages]\n self.version = self.raw_setup['version']\n\n\ndef list_modules(\n search_dir: Path = Path(__file__).parents[1], include_parent: bool = False\n) -> List[Module]:\n \"\"\"Returns a list of python modules based defined by setup.py files.\n\n Args:\n include_parent: if true, a setup.py is expected in `search_dir`, and the corresponding\n module will be included.\n search_dir: the search directory for modules, by default the repo root.\n Returns:\n a list of `Module`s that were found, where each module `m` is initialized with `m.root`\n relative to `search_dir`, `m.raw_setup` contains the dictionary equivalent to the\n keyword args passed to the `setuptools.setup` method in setup.py\n \"\"\"\n\n relative_folders = sorted(\n f.relative_to(search_dir)\n for f in search_dir.glob(\"*\")\n if f.is_dir() and (f / \"setup.py\").is_file()\n )\n if include_parent:\n parent_setup_py = search_dir / \"setup.py\"\n assert parent_setup_py.exists(), (\n f\"include_parent=True, but {parent_setup_py} \" f\"does not exist.\"\n )\n relative_folders.append(Path(\".\"))\n\n result = [\n Module(root=folder, raw_setup=_parse_module(search_dir / folder))\n for folder in relative_folders\n ]\n\n return result\n\n\ndef _parse_module(folder: Path) -> Dict[str, Any]:\n setup_args = {}\n import setuptools\n\n orig_setup = setuptools.setup\n cwd = os.getcwd()\n\n def setup(**kwargs):\n setup_args.update(kwargs)\n\n try:\n setuptools.setup = setup\n os.chdir(str(folder))\n setup_py = open(\"setup.py\").read()\n exec(setup_py, globals(), {})\n assert setup_args, f\"Invalid setup.py - setup() was not called in {folder}/setup.py!\"\n return setup_args\n except BaseException:\n print(f\"Failed to run {folder}/setup.py:\")\n raise\n finally:\n setuptools.setup = orig_setup\n os.chdir(cwd)\n\n\ndef _print_list_modules(mode: str, include_parent: bool = False):\n \"\"\"Prints certain properties of cirq modules on separate lines.\n\n Module root folder and top level package paths are supported. The search dir is the current\n directory.\n\n Args:\n mode: 'folder' lists the root folder for each module, 'package-path' lists the path to\n the top level package(s).\n include_cirq: when true the cirq metapackage is included in the list\n Returns:\n a list of strings\n \"\"\"\n for m in list_modules(Path(\".\"), include_parent):\n if mode == _FOLDER:\n print(m.root, end=\" \")\n elif mode == _PACKAGE_PATH:\n for p in m.top_level_package_paths:\n print(p, end=\" \")\n\n\ndef main(argv: List[str]):\n args = parse(argv)\n # args.func is where we store the function to be called for a given subparser\n # e.g. it is list_modules for the `list` subcommand\n f = args.func\n # however the func is not going to be needed for the function itself, so\n # we remove it here\n del args.func\n f(**vars(args))\n\n\ndef parse(args):\n parser = argparse.ArgumentParser('A utility for modules.')\n subparsers = parser.add_subparsers(\n title='subcommands', description='valid subcommands', help='additional help'\n )\n _add_list_modules_cmd(subparsers)\n return parser.parse_args(args)\n\n\ndef _add_list_modules_cmd(subparsers):\n list_modules_cmd = subparsers.add_parser(\"list\", help=\"lists all the modules\")\n list_modules_cmd.add_argument(\n \"--mode\",\n default=_FOLDER,\n choices=[_FOLDER, _PACKAGE_PATH],\n type=str,\n help=\"'folder' to list root folder for module,\\n\"\n \"'package-path' for top level python package path\",\n )\n list_modules_cmd.add_argument(\n \"--include-parent\",\n help=\"whether to include the parent package or not\",\n default=False,\n action=\"store_true\",\n )\n list_modules_cmd.set_defaults(func=_print_list_modules)\n\n\nif __name__ == '__main__':\n main(sys.argv[1:]) # coverage: ignore\n", "path": "dev_tools/modules.py"}]} | 3,235 | 569 |
gh_patches_debug_43122 | rasdani/github-patches | git_diff | aws-cloudformation__cfn-lint-1627 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
False alarm from new W4002
*cfn-lint version: 0.34.0*
[Here](https://gist.github.com/schmiddy/44a779032a930995d22ee2722a18f163) is an example template which causes a false alarm like this:
```
$ cfn-lint /tmp/example.yml
W4002 As the resource "metadata" section contains reference to a "NoEcho" parameter DBUser, CloudFormation will display the parameter value in plaintext
/tmp/example.yml:21:7
W4002 As the resource "metadata" section contains reference to a "NoEcho" parameter DBPass, CloudFormation will display the parameter value in plaintext
/tmp/example.yml:21:7
```
The problem seems to be that the rule is looking for any mention of the parameter name, even as a text description that is not actually referencing the parameter.
</issue>
<code>
[start of src/cfnlint/rules/resources/NoEcho.py]
1 """
2 Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 from cfnlint.helpers import bool_compare
6 from cfnlint.rules import CloudFormationLintRule
7 from cfnlint.rules import RuleMatch
8
9
10 class NoEcho(CloudFormationLintRule):
11 id = 'W4002'
12 shortdesc = 'Check for NoEcho References'
13 description = 'Check if there is a NoEcho enabled parameter referenced within a resources Metadata section'
14 source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/parameters-section-structure.html#parameters-section-structure-properties'
15 tags = ['resources', 'NoEcho']
16
17 def match(self, cfn):
18 matches = []
19 no_echo_params = []
20 parameters = cfn.get_parameters()
21 for parameter_name, parameter_value in parameters.items():
22 noecho = parameter_value.get('NoEcho', default=False)
23 if bool_compare(noecho, True):
24 no_echo_params.append(parameter_name)
25
26 if not no_echo_params:
27 return no_echo_params
28
29 resource_properties = cfn.get_resources()
30 resource_dict = {key: resource_properties[key] for key in resource_properties if
31 isinstance(resource_properties[key], dict)}
32 for resource_name, resource_values in resource_dict.items():
33 resource_values = {key: resource_values[key] for key in resource_values if
34 isinstance(resource_values[key], dict)}
35 metadata = resource_values.get('Metadata', {})
36 if metadata is not None:
37 for prop_name, properties in metadata.items():
38 if isinstance(properties, dict):
39 for property_value in properties.values():
40 for param in no_echo_params and no_echo_params:
41 if str(property_value).find(str(param)) > -1:
42 path = ['Resources', resource_name, 'Metadata', prop_name]
43 matches.append(RuleMatch(path, 'As the resource "metadata" section contains '
44 'reference to a "NoEcho" parameter ' + str(param)
45 + ', CloudFormation will display the parameter value in '
46 'plaintext'))
47 return matches
48
[end of src/cfnlint/rules/resources/NoEcho.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/cfnlint/rules/resources/NoEcho.py b/src/cfnlint/rules/resources/NoEcho.py
--- a/src/cfnlint/rules/resources/NoEcho.py
+++ b/src/cfnlint/rules/resources/NoEcho.py
@@ -2,6 +2,7 @@
Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
SPDX-License-Identifier: MIT-0
"""
+import six
from cfnlint.helpers import bool_compare
from cfnlint.rules import CloudFormationLintRule
from cfnlint.rules import RuleMatch
@@ -14,34 +15,58 @@
source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/parameters-section-structure.html#parameters-section-structure-properties'
tags = ['resources', 'NoEcho']
- def match(self, cfn):
- matches = []
+ def _get_no_echo_params(self, cfn):
+ """ Get no Echo Params"""
no_echo_params = []
- parameters = cfn.get_parameters()
- for parameter_name, parameter_value in parameters.items():
+ for parameter_name, parameter_value in cfn.get_parameters().items():
noecho = parameter_value.get('NoEcho', default=False)
if bool_compare(noecho, True):
no_echo_params.append(parameter_name)
+ return no_echo_params
+
+ def _check_ref(self, cfn, no_echo_params):
+ """ Check Refs """
+ matches = []
+ refs = cfn.search_deep_keys('Ref')
+ for ref in refs:
+ if ref[-1] in no_echo_params:
+ if len(ref) > 3:
+ if ref[0] == 'Resources' and ref[2] == 'Metadata':
+ matches.append(RuleMatch(ref, 'As the resource "metadata" section contains ' +
+ 'reference to a "NoEcho" parameter ' +
+ str(ref[-1]) +
+ ', CloudFormation will display the parameter value in ' +
+ 'plaintext'))
+
+ return matches
+
+ def _check_sub(self, cfn, no_echo_params):
+ """ Check Subs """
+ matches = []
+ subs = cfn.search_deep_keys('Fn::Sub')
+ for sub in subs:
+ if isinstance(sub[-1], six.string_types):
+ params = cfn.get_sub_parameters(sub[-1])
+ for param in params:
+ if param in no_echo_params:
+ if len(sub) > 2:
+ if sub[0] == 'Resources' and sub[2] == 'Metadata':
+
+ matches.append(RuleMatch(sub[:-1], 'As the resource "metadata" section contains ' +
+ 'reference to a "NoEcho" parameter ' +
+ str(param) +
+ ', CloudFormation will display the parameter value in ' +
+ 'plaintext'))
+
+ return matches
+
+ def match(self, cfn):
+ matches = []
+ no_echo_params = self._get_no_echo_params(cfn)
if not no_echo_params:
- return no_echo_params
-
- resource_properties = cfn.get_resources()
- resource_dict = {key: resource_properties[key] for key in resource_properties if
- isinstance(resource_properties[key], dict)}
- for resource_name, resource_values in resource_dict.items():
- resource_values = {key: resource_values[key] for key in resource_values if
- isinstance(resource_values[key], dict)}
- metadata = resource_values.get('Metadata', {})
- if metadata is not None:
- for prop_name, properties in metadata.items():
- if isinstance(properties, dict):
- for property_value in properties.values():
- for param in no_echo_params and no_echo_params:
- if str(property_value).find(str(param)) > -1:
- path = ['Resources', resource_name, 'Metadata', prop_name]
- matches.append(RuleMatch(path, 'As the resource "metadata" section contains '
- 'reference to a "NoEcho" parameter ' + str(param)
- + ', CloudFormation will display the parameter value in '
- 'plaintext'))
+ return matches
+ matches.extend(self._check_ref(cfn, no_echo_params))
+ matches.extend(self._check_sub(cfn, no_echo_params))
+
return matches
| {"golden_diff": "diff --git a/src/cfnlint/rules/resources/NoEcho.py b/src/cfnlint/rules/resources/NoEcho.py\n--- a/src/cfnlint/rules/resources/NoEcho.py\n+++ b/src/cfnlint/rules/resources/NoEcho.py\n@@ -2,6 +2,7 @@\n Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\n SPDX-License-Identifier: MIT-0\n \"\"\"\n+import six\n from cfnlint.helpers import bool_compare\n from cfnlint.rules import CloudFormationLintRule\n from cfnlint.rules import RuleMatch\n@@ -14,34 +15,58 @@\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/parameters-section-structure.html#parameters-section-structure-properties'\n tags = ['resources', 'NoEcho']\n \n- def match(self, cfn):\n- matches = []\n+ def _get_no_echo_params(self, cfn):\n+ \"\"\" Get no Echo Params\"\"\"\n no_echo_params = []\n- parameters = cfn.get_parameters()\n- for parameter_name, parameter_value in parameters.items():\n+ for parameter_name, parameter_value in cfn.get_parameters().items():\n noecho = parameter_value.get('NoEcho', default=False)\n if bool_compare(noecho, True):\n no_echo_params.append(parameter_name)\n \n+ return no_echo_params\n+\n+ def _check_ref(self, cfn, no_echo_params):\n+ \"\"\" Check Refs \"\"\"\n+ matches = []\n+ refs = cfn.search_deep_keys('Ref')\n+ for ref in refs:\n+ if ref[-1] in no_echo_params:\n+ if len(ref) > 3:\n+ if ref[0] == 'Resources' and ref[2] == 'Metadata':\n+ matches.append(RuleMatch(ref, 'As the resource \"metadata\" section contains ' +\n+ 'reference to a \"NoEcho\" parameter ' +\n+ str(ref[-1]) +\n+ ', CloudFormation will display the parameter value in ' +\n+ 'plaintext'))\n+\n+ return matches\n+\n+ def _check_sub(self, cfn, no_echo_params):\n+ \"\"\" Check Subs \"\"\"\n+ matches = []\n+ subs = cfn.search_deep_keys('Fn::Sub')\n+ for sub in subs:\n+ if isinstance(sub[-1], six.string_types):\n+ params = cfn.get_sub_parameters(sub[-1])\n+ for param in params:\n+ if param in no_echo_params:\n+ if len(sub) > 2:\n+ if sub[0] == 'Resources' and sub[2] == 'Metadata':\n+\n+ matches.append(RuleMatch(sub[:-1], 'As the resource \"metadata\" section contains ' +\n+ 'reference to a \"NoEcho\" parameter ' +\n+ str(param) +\n+ ', CloudFormation will display the parameter value in ' +\n+ 'plaintext'))\n+\n+ return matches\n+\n+ def match(self, cfn):\n+ matches = []\n+ no_echo_params = self._get_no_echo_params(cfn)\n if not no_echo_params:\n- return no_echo_params\n-\n- resource_properties = cfn.get_resources()\n- resource_dict = {key: resource_properties[key] for key in resource_properties if\n- isinstance(resource_properties[key], dict)}\n- for resource_name, resource_values in resource_dict.items():\n- resource_values = {key: resource_values[key] for key in resource_values if\n- isinstance(resource_values[key], dict)}\n- metadata = resource_values.get('Metadata', {})\n- if metadata is not None:\n- for prop_name, properties in metadata.items():\n- if isinstance(properties, dict):\n- for property_value in properties.values():\n- for param in no_echo_params and no_echo_params:\n- if str(property_value).find(str(param)) > -1:\n- path = ['Resources', resource_name, 'Metadata', prop_name]\n- matches.append(RuleMatch(path, 'As the resource \"metadata\" section contains '\n- 'reference to a \"NoEcho\" parameter ' + str(param)\n- + ', CloudFormation will display the parameter value in '\n- 'plaintext'))\n+ return matches\n+ matches.extend(self._check_ref(cfn, no_echo_params))\n+ matches.extend(self._check_sub(cfn, no_echo_params))\n+\n return matches\n", "issue": "False alarm from new W4002\n*cfn-lint version: 0.34.0*\r\n\r\n[Here](https://gist.github.com/schmiddy/44a779032a930995d22ee2722a18f163) is an example template which causes a false alarm like this:\r\n\r\n```\r\n$ cfn-lint /tmp/example.yml \r\nW4002 As the resource \"metadata\" section contains reference to a \"NoEcho\" parameter DBUser, CloudFormation will display the parameter value in plaintext\r\n/tmp/example.yml:21:7\r\n\r\nW4002 As the resource \"metadata\" section contains reference to a \"NoEcho\" parameter DBPass, CloudFormation will display the parameter value in plaintext\r\n/tmp/example.yml:21:7\r\n```\r\n\r\nThe problem seems to be that the rule is looking for any mention of the parameter name, even as a text description that is not actually referencing the parameter.\r\n\n", "before_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nfrom cfnlint.helpers import bool_compare\nfrom cfnlint.rules import CloudFormationLintRule\nfrom cfnlint.rules import RuleMatch\n\n\nclass NoEcho(CloudFormationLintRule):\n id = 'W4002'\n shortdesc = 'Check for NoEcho References'\n description = 'Check if there is a NoEcho enabled parameter referenced within a resources Metadata section'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/parameters-section-structure.html#parameters-section-structure-properties'\n tags = ['resources', 'NoEcho']\n\n def match(self, cfn):\n matches = []\n no_echo_params = []\n parameters = cfn.get_parameters()\n for parameter_name, parameter_value in parameters.items():\n noecho = parameter_value.get('NoEcho', default=False)\n if bool_compare(noecho, True):\n no_echo_params.append(parameter_name)\n\n if not no_echo_params:\n return no_echo_params\n\n resource_properties = cfn.get_resources()\n resource_dict = {key: resource_properties[key] for key in resource_properties if\n isinstance(resource_properties[key], dict)}\n for resource_name, resource_values in resource_dict.items():\n resource_values = {key: resource_values[key] for key in resource_values if\n isinstance(resource_values[key], dict)}\n metadata = resource_values.get('Metadata', {})\n if metadata is not None:\n for prop_name, properties in metadata.items():\n if isinstance(properties, dict):\n for property_value in properties.values():\n for param in no_echo_params and no_echo_params:\n if str(property_value).find(str(param)) > -1:\n path = ['Resources', resource_name, 'Metadata', prop_name]\n matches.append(RuleMatch(path, 'As the resource \"metadata\" section contains '\n 'reference to a \"NoEcho\" parameter ' + str(param)\n + ', CloudFormation will display the parameter value in '\n 'plaintext'))\n return matches\n", "path": "src/cfnlint/rules/resources/NoEcho.py"}]} | 1,286 | 939 |
gh_patches_debug_20651 | rasdani/github-patches | git_diff | crytic__slither-618 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
AssertionError when comparing two functions with Binary operation
The following contract causes an assertion error:
```
contract FunctionComparisonTest {
function f() public returns (bool) {
return f == f;
}
}
```
Output:
```
ERROR:root:Error in .\function_comparison.sol
ERROR:root:Traceback (most recent call last):
File "c:\users\x\documents\github\slither\slither\__main__.py", line 610, in main_impl
(slither_instances, results_detectors, results_printers, number_contracts) = process_all(filename, args,
File "c:\users\x\documents\github\slither\slither\__main__.py", line 67, in process_all
(slither, current_results_detectors, current_results_printers, current_analyzed_count) = process_single(
File "c:\users\x\documents\github\slither\slither\__main__.py", line 53, in process_single
slither = Slither(target,
File "c:\users\x\documents\github\slither\slither\slither.py", line 86, in __init__
self._parser.analyze_contracts()
File "c:\users\x\documents\github\slither\slither\solc_parsing\slitherSolc.py", line 345, in analyze_contracts
self._convert_to_slithir()
File "c:\users\x\documents\github\slither\slither\solc_parsing\slitherSolc.py", line 489, in _convert_to_slithir
func.generate_slithir_and_analyze()
File "c:\users\x\documents\github\slither\slither\core\declarations\function.py", line 1652, in generate_slithir_and_analyze
node.slithir_generation()
File "c:\users\x\documents\github\slither\slither\core\cfg\node.py", line 702, in slithir_generation
self._irs = convert_expression(expression, self)
File "c:\users\x\documents\github\slither\slither\slithir\convert.py", line 64, in convert_expression
visitor = ExpressionToSlithIR(expression, node)
File "c:\users\x\documents\github\slither\slither\visitors\slithir\expression_to_slithir.py", line 103, in __init__
self._visit_expression(self.expression)
File "c:\users\x\documents\github\slither\slither\visitors\expression\expression.py", line 95, in _visit_expression
self._post_visit(expression)
File "c:\users\x\documents\github\slither\slither\visitors\expression\expression.py", line 268, in _post_visit
self._post_binary_operation(expression)
File "c:\users\x\documents\github\slither\slither\visitors\slithir\expression_to_slithir.py", line 192, in _post_binary_operation
operation = Binary(val, left, right, _binary_to_binary[expression.type])
File "c:\users\x\documents\github\slither\slither\slithir\operations\binary.py", line 133, in __init__
assert is_valid_rvalue(left_variable)
AssertionError
```
</issue>
<code>
[start of slither/slithir/operations/binary.py]
1 import logging
2 from enum import Enum
3
4 from slither.core.solidity_types import ElementaryType
5 from slither.slithir.exceptions import SlithIRError
6 from slither.slithir.operations.lvalue import OperationWithLValue
7 from slither.slithir.utils.utils import is_valid_lvalue, is_valid_rvalue
8 from slither.slithir.variables import ReferenceVariable
9
10 logger = logging.getLogger("BinaryOperationIR")
11
12
13 class BinaryType(Enum):
14 POWER = 0 # **
15 MULTIPLICATION = 1 # *
16 DIVISION = 2 # /
17 MODULO = 3 # %
18 ADDITION = 4 # +
19 SUBTRACTION = 5 # -
20 LEFT_SHIFT = 6 # <<
21 RIGHT_SHIFT = 7 # >>
22 AND = 8 # &
23 CARET = 9 # ^
24 OR = 10 # |
25 LESS = 11 # <
26 GREATER = 12 # >
27 LESS_EQUAL = 13 # <=
28 GREATER_EQUAL = 14 # >=
29 EQUAL = 15 # ==
30 NOT_EQUAL = 16 # !=
31 ANDAND = 17 # &&
32 OROR = 18 # ||
33
34 @staticmethod
35 def return_bool(operation_type):
36 return operation_type in [
37 BinaryType.OROR,
38 BinaryType.ANDAND,
39 BinaryType.LESS,
40 BinaryType.GREATER,
41 BinaryType.LESS_EQUAL,
42 BinaryType.GREATER_EQUAL,
43 BinaryType.EQUAL,
44 BinaryType.NOT_EQUAL,
45 ]
46
47 @staticmethod
48 def get_type(operation_type): # pylint: disable=too-many-branches
49 if operation_type == "**":
50 return BinaryType.POWER
51 if operation_type == "*":
52 return BinaryType.MULTIPLICATION
53 if operation_type == "/":
54 return BinaryType.DIVISION
55 if operation_type == "%":
56 return BinaryType.MODULO
57 if operation_type == "+":
58 return BinaryType.ADDITION
59 if operation_type == "-":
60 return BinaryType.SUBTRACTION
61 if operation_type == "<<":
62 return BinaryType.LEFT_SHIFT
63 if operation_type == ">>":
64 return BinaryType.RIGHT_SHIFT
65 if operation_type == "&":
66 return BinaryType.AND
67 if operation_type == "^":
68 return BinaryType.CARET
69 if operation_type == "|":
70 return BinaryType.OR
71 if operation_type == "<":
72 return BinaryType.LESS
73 if operation_type == ">":
74 return BinaryType.GREATER
75 if operation_type == "<=":
76 return BinaryType.LESS_EQUAL
77 if operation_type == ">=":
78 return BinaryType.GREATER_EQUAL
79 if operation_type == "==":
80 return BinaryType.EQUAL
81 if operation_type == "!=":
82 return BinaryType.NOT_EQUAL
83 if operation_type == "&&":
84 return BinaryType.ANDAND
85 if operation_type == "||":
86 return BinaryType.OROR
87
88 raise SlithIRError("get_type: Unknown operation type {})".format(operation_type))
89
90 def __str__(self): # pylint: disable=too-many-branches
91 if self == BinaryType.POWER:
92 return "**"
93 if self == BinaryType.MULTIPLICATION:
94 return "*"
95 if self == BinaryType.DIVISION:
96 return "/"
97 if self == BinaryType.MODULO:
98 return "%"
99 if self == BinaryType.ADDITION:
100 return "+"
101 if self == BinaryType.SUBTRACTION:
102 return "-"
103 if self == BinaryType.LEFT_SHIFT:
104 return "<<"
105 if self == BinaryType.RIGHT_SHIFT:
106 return ">>"
107 if self == BinaryType.AND:
108 return "&"
109 if self == BinaryType.CARET:
110 return "^"
111 if self == BinaryType.OR:
112 return "|"
113 if self == BinaryType.LESS:
114 return "<"
115 if self == BinaryType.GREATER:
116 return ">"
117 if self == BinaryType.LESS_EQUAL:
118 return "<="
119 if self == BinaryType.GREATER_EQUAL:
120 return ">="
121 if self == BinaryType.EQUAL:
122 return "=="
123 if self == BinaryType.NOT_EQUAL:
124 return "!="
125 if self == BinaryType.ANDAND:
126 return "&&"
127 if self == BinaryType.OROR:
128 return "||"
129 raise SlithIRError("str: Unknown operation type {} {})".format(self, type(self)))
130
131
132 class Binary(OperationWithLValue):
133 def __init__(self, result, left_variable, right_variable, operation_type):
134 assert is_valid_rvalue(left_variable)
135 assert is_valid_rvalue(right_variable)
136 assert is_valid_lvalue(result)
137 assert isinstance(operation_type, BinaryType)
138 super().__init__()
139 self._variables = [left_variable, right_variable]
140 self._type = operation_type
141 self._lvalue = result
142 if BinaryType.return_bool(operation_type):
143 result.set_type(ElementaryType("bool"))
144 else:
145 result.set_type(left_variable.type)
146
147 @property
148 def read(self):
149 return [self.variable_left, self.variable_right]
150
151 @property
152 def get_variable(self):
153 return self._variables
154
155 @property
156 def variable_left(self):
157 return self._variables[0]
158
159 @property
160 def variable_right(self):
161 return self._variables[1]
162
163 @property
164 def type(self):
165 return self._type
166
167 @property
168 def type_str(self):
169 return str(self._type)
170
171 def __str__(self):
172 if isinstance(self.lvalue, ReferenceVariable):
173 points = self.lvalue.points_to
174 while isinstance(points, ReferenceVariable):
175 points = points.points_to
176 return "{}(-> {}) = {} {} {}".format(
177 str(self.lvalue),
178 points,
179 self.variable_left,
180 self.type_str,
181 self.variable_right,
182 )
183 return "{}({}) = {} {} {}".format(
184 str(self.lvalue),
185 self.lvalue.type,
186 self.variable_left,
187 self.type_str,
188 self.variable_right,
189 )
190
[end of slither/slithir/operations/binary.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/slither/slithir/operations/binary.py b/slither/slithir/operations/binary.py
--- a/slither/slithir/operations/binary.py
+++ b/slither/slithir/operations/binary.py
@@ -1,6 +1,7 @@
import logging
from enum import Enum
+from slither.core.declarations import Function
from slither.core.solidity_types import ElementaryType
from slither.slithir.exceptions import SlithIRError
from slither.slithir.operations.lvalue import OperationWithLValue
@@ -131,8 +132,8 @@
class Binary(OperationWithLValue):
def __init__(self, result, left_variable, right_variable, operation_type):
- assert is_valid_rvalue(left_variable)
- assert is_valid_rvalue(right_variable)
+ assert is_valid_rvalue(left_variable) or isinstance(left_variable, Function)
+ assert is_valid_rvalue(right_variable) or isinstance(right_variable, Function)
assert is_valid_lvalue(result)
assert isinstance(operation_type, BinaryType)
super().__init__()
| {"golden_diff": "diff --git a/slither/slithir/operations/binary.py b/slither/slithir/operations/binary.py\n--- a/slither/slithir/operations/binary.py\n+++ b/slither/slithir/operations/binary.py\n@@ -1,6 +1,7 @@\n import logging\n from enum import Enum\n \n+from slither.core.declarations import Function\n from slither.core.solidity_types import ElementaryType\n from slither.slithir.exceptions import SlithIRError\n from slither.slithir.operations.lvalue import OperationWithLValue\n@@ -131,8 +132,8 @@\n \n class Binary(OperationWithLValue):\n def __init__(self, result, left_variable, right_variable, operation_type):\n- assert is_valid_rvalue(left_variable)\n- assert is_valid_rvalue(right_variable)\n+ assert is_valid_rvalue(left_variable) or isinstance(left_variable, Function)\n+ assert is_valid_rvalue(right_variable) or isinstance(right_variable, Function)\n assert is_valid_lvalue(result)\n assert isinstance(operation_type, BinaryType)\n super().__init__()\n", "issue": "AssertionError when comparing two functions with Binary operation\nThe following contract causes an assertion error:\r\n```\r\ncontract FunctionComparisonTest {\r\n function f() public returns (bool) {\r\n return f == f;\r\n }\r\n}\r\n```\r\n\r\nOutput:\r\n```\r\nERROR:root:Error in .\\function_comparison.sol\r\nERROR:root:Traceback (most recent call last):\r\n File \"c:\\users\\x\\documents\\github\\slither\\slither\\__main__.py\", line 610, in main_impl\r\n (slither_instances, results_detectors, results_printers, number_contracts) = process_all(filename, args,\r\n File \"c:\\users\\x\\documents\\github\\slither\\slither\\__main__.py\", line 67, in process_all\r\n (slither, current_results_detectors, current_results_printers, current_analyzed_count) = process_single(\r\n File \"c:\\users\\x\\documents\\github\\slither\\slither\\__main__.py\", line 53, in process_single\r\n slither = Slither(target,\r\n File \"c:\\users\\x\\documents\\github\\slither\\slither\\slither.py\", line 86, in __init__\r\n self._parser.analyze_contracts()\r\n File \"c:\\users\\x\\documents\\github\\slither\\slither\\solc_parsing\\slitherSolc.py\", line 345, in analyze_contracts\r\n self._convert_to_slithir()\r\n File \"c:\\users\\x\\documents\\github\\slither\\slither\\solc_parsing\\slitherSolc.py\", line 489, in _convert_to_slithir\r\n func.generate_slithir_and_analyze()\r\n File \"c:\\users\\x\\documents\\github\\slither\\slither\\core\\declarations\\function.py\", line 1652, in generate_slithir_and_analyze\r\n node.slithir_generation()\r\n File \"c:\\users\\x\\documents\\github\\slither\\slither\\core\\cfg\\node.py\", line 702, in slithir_generation\r\n self._irs = convert_expression(expression, self)\r\n File \"c:\\users\\x\\documents\\github\\slither\\slither\\slithir\\convert.py\", line 64, in convert_expression\r\n visitor = ExpressionToSlithIR(expression, node)\r\n File \"c:\\users\\x\\documents\\github\\slither\\slither\\visitors\\slithir\\expression_to_slithir.py\", line 103, in __init__\r\n self._visit_expression(self.expression)\r\n File \"c:\\users\\x\\documents\\github\\slither\\slither\\visitors\\expression\\expression.py\", line 95, in _visit_expression\r\n self._post_visit(expression)\r\n File \"c:\\users\\x\\documents\\github\\slither\\slither\\visitors\\expression\\expression.py\", line 268, in _post_visit\r\n self._post_binary_operation(expression)\r\n File \"c:\\users\\x\\documents\\github\\slither\\slither\\visitors\\slithir\\expression_to_slithir.py\", line 192, in _post_binary_operation\r\n operation = Binary(val, left, right, _binary_to_binary[expression.type])\r\n File \"c:\\users\\x\\documents\\github\\slither\\slither\\slithir\\operations\\binary.py\", line 133, in __init__\r\n assert is_valid_rvalue(left_variable)\r\nAssertionError\r\n```\n", "before_files": [{"content": "import logging\nfrom enum import Enum\n\nfrom slither.core.solidity_types import ElementaryType\nfrom slither.slithir.exceptions import SlithIRError\nfrom slither.slithir.operations.lvalue import OperationWithLValue\nfrom slither.slithir.utils.utils import is_valid_lvalue, is_valid_rvalue\nfrom slither.slithir.variables import ReferenceVariable\n\nlogger = logging.getLogger(\"BinaryOperationIR\")\n\n\nclass BinaryType(Enum):\n POWER = 0 # **\n MULTIPLICATION = 1 # *\n DIVISION = 2 # /\n MODULO = 3 # %\n ADDITION = 4 # +\n SUBTRACTION = 5 # -\n LEFT_SHIFT = 6 # <<\n RIGHT_SHIFT = 7 # >>\n AND = 8 # &\n CARET = 9 # ^\n OR = 10 # |\n LESS = 11 # <\n GREATER = 12 # >\n LESS_EQUAL = 13 # <=\n GREATER_EQUAL = 14 # >=\n EQUAL = 15 # ==\n NOT_EQUAL = 16 # !=\n ANDAND = 17 # &&\n OROR = 18 # ||\n\n @staticmethod\n def return_bool(operation_type):\n return operation_type in [\n BinaryType.OROR,\n BinaryType.ANDAND,\n BinaryType.LESS,\n BinaryType.GREATER,\n BinaryType.LESS_EQUAL,\n BinaryType.GREATER_EQUAL,\n BinaryType.EQUAL,\n BinaryType.NOT_EQUAL,\n ]\n\n @staticmethod\n def get_type(operation_type): # pylint: disable=too-many-branches\n if operation_type == \"**\":\n return BinaryType.POWER\n if operation_type == \"*\":\n return BinaryType.MULTIPLICATION\n if operation_type == \"/\":\n return BinaryType.DIVISION\n if operation_type == \"%\":\n return BinaryType.MODULO\n if operation_type == \"+\":\n return BinaryType.ADDITION\n if operation_type == \"-\":\n return BinaryType.SUBTRACTION\n if operation_type == \"<<\":\n return BinaryType.LEFT_SHIFT\n if operation_type == \">>\":\n return BinaryType.RIGHT_SHIFT\n if operation_type == \"&\":\n return BinaryType.AND\n if operation_type == \"^\":\n return BinaryType.CARET\n if operation_type == \"|\":\n return BinaryType.OR\n if operation_type == \"<\":\n return BinaryType.LESS\n if operation_type == \">\":\n return BinaryType.GREATER\n if operation_type == \"<=\":\n return BinaryType.LESS_EQUAL\n if operation_type == \">=\":\n return BinaryType.GREATER_EQUAL\n if operation_type == \"==\":\n return BinaryType.EQUAL\n if operation_type == \"!=\":\n return BinaryType.NOT_EQUAL\n if operation_type == \"&&\":\n return BinaryType.ANDAND\n if operation_type == \"||\":\n return BinaryType.OROR\n\n raise SlithIRError(\"get_type: Unknown operation type {})\".format(operation_type))\n\n def __str__(self): # pylint: disable=too-many-branches\n if self == BinaryType.POWER:\n return \"**\"\n if self == BinaryType.MULTIPLICATION:\n return \"*\"\n if self == BinaryType.DIVISION:\n return \"/\"\n if self == BinaryType.MODULO:\n return \"%\"\n if self == BinaryType.ADDITION:\n return \"+\"\n if self == BinaryType.SUBTRACTION:\n return \"-\"\n if self == BinaryType.LEFT_SHIFT:\n return \"<<\"\n if self == BinaryType.RIGHT_SHIFT:\n return \">>\"\n if self == BinaryType.AND:\n return \"&\"\n if self == BinaryType.CARET:\n return \"^\"\n if self == BinaryType.OR:\n return \"|\"\n if self == BinaryType.LESS:\n return \"<\"\n if self == BinaryType.GREATER:\n return \">\"\n if self == BinaryType.LESS_EQUAL:\n return \"<=\"\n if self == BinaryType.GREATER_EQUAL:\n return \">=\"\n if self == BinaryType.EQUAL:\n return \"==\"\n if self == BinaryType.NOT_EQUAL:\n return \"!=\"\n if self == BinaryType.ANDAND:\n return \"&&\"\n if self == BinaryType.OROR:\n return \"||\"\n raise SlithIRError(\"str: Unknown operation type {} {})\".format(self, type(self)))\n\n\nclass Binary(OperationWithLValue):\n def __init__(self, result, left_variable, right_variable, operation_type):\n assert is_valid_rvalue(left_variable)\n assert is_valid_rvalue(right_variable)\n assert is_valid_lvalue(result)\n assert isinstance(operation_type, BinaryType)\n super().__init__()\n self._variables = [left_variable, right_variable]\n self._type = operation_type\n self._lvalue = result\n if BinaryType.return_bool(operation_type):\n result.set_type(ElementaryType(\"bool\"))\n else:\n result.set_type(left_variable.type)\n\n @property\n def read(self):\n return [self.variable_left, self.variable_right]\n\n @property\n def get_variable(self):\n return self._variables\n\n @property\n def variable_left(self):\n return self._variables[0]\n\n @property\n def variable_right(self):\n return self._variables[1]\n\n @property\n def type(self):\n return self._type\n\n @property\n def type_str(self):\n return str(self._type)\n\n def __str__(self):\n if isinstance(self.lvalue, ReferenceVariable):\n points = self.lvalue.points_to\n while isinstance(points, ReferenceVariable):\n points = points.points_to\n return \"{}(-> {}) = {} {} {}\".format(\n str(self.lvalue),\n points,\n self.variable_left,\n self.type_str,\n self.variable_right,\n )\n return \"{}({}) = {} {} {}\".format(\n str(self.lvalue),\n self.lvalue.type,\n self.variable_left,\n self.type_str,\n self.variable_right,\n )\n", "path": "slither/slithir/operations/binary.py"}]} | 3,093 | 236 |
gh_patches_debug_43932 | rasdani/github-patches | git_diff | biolab__orange3-text-249 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Concordanes Settings
##### Expected behavior
Concordanes widget uses settings.
##### Actual behavior
It does not yet.
</issue>
<code>
[start of orangecontrib/text/widgets/owconcordance.py]
1 from typing import Optional
2
3 from itertools import chain
4 from AnyQt.QtCore import Qt, QAbstractTableModel, QSize, QItemSelectionModel, \
5 QItemSelection
6 from AnyQt.QtWidgets import QSizePolicy, QApplication, QTableView, \
7 QStyledItemDelegate
8 from AnyQt.QtGui import QColor
9
10 from Orange.widgets import gui
11 from Orange.widgets.settings import Setting, ContextSetting, PerfectDomainContextHandler
12 from Orange.widgets.widget import OWWidget, Msg, Input, Output
13 from nltk import ConcordanceIndex
14 from orangecontrib.text.corpus import Corpus
15 from orangecontrib.text.topics import Topic
16 from orangecontrib.text.preprocess import WordPunctTokenizer
17
18
19 class HorizontalGridDelegate(QStyledItemDelegate):
20 """Class for setting elide."""
21
22 def paint(self, painter, option, index):
23 if index.column() == 0:
24 option.textElideMode = Qt.ElideLeft
25 elif index.column() == 2:
26 option.textElideMode = Qt.ElideRight
27 QStyledItemDelegate.paint(self, painter, option, index)
28
29
30 class DocumentSelectionModel(QItemSelectionModel):
31 """Sets selection for QTableView. Creates a set of selected documents."""
32
33 def select(self, selection, flags):
34 # which rows have been selected
35 indexes = selection.indexes() if isinstance(selection, QItemSelection) \
36 else [selection]
37 # prevent crashing when deleting the connection
38 if not indexes:
39 super().select(selection, flags)
40 return
41 # indexes[0].row() == -1 indicates clicking outside of the table
42 if len(indexes) == 1 and indexes[0].row() == -1:
43 self.clear()
44 return
45 word_index = self.model().word_index
46 selected_docs = {word_index[index.row()][0] for index in indexes}
47 selected_rows = [
48 row_index for row_index, (doc_index, _) in enumerate(word_index)
49 if doc_index in selected_docs]
50 selection = QItemSelection()
51 # select all rows belonging to the selected document
52 for row in selected_rows:
53 index = self.model().index(row, 0)
54 selection.select(index, index)
55 super().select(selection, flags)
56
57
58 class ConcordanceModel(QAbstractTableModel):
59 """A model for constructing concordances from text."""
60
61 def __init__(self):
62 QAbstractTableModel.__init__(self)
63 self.word = None
64 self.corpus = None
65 self.tokens = None
66 self.n_tokens = None
67 self.n_types = None
68 self.indices = None
69 self.word_index = None
70 self.width = 8
71 self.colored_rows = None
72
73 def set_word(self, word):
74 self.modelAboutToBeReset.emit()
75 self.word = word
76 self._compute_word_index()
77 self.modelReset.emit()
78
79 def set_corpus(self, corpus):
80 self.modelAboutToBeReset.emit()
81 self.corpus = corpus
82 self.set_tokens()
83 self._compute_indices()
84 self._compute_word_index()
85 self.modelReset.emit()
86
87 def set_tokens(self):
88 if self.corpus is None:
89 self.tokens = None
90 return
91 tokenizer = WordPunctTokenizer()
92 self.tokens = tokenizer(self.corpus.documents)
93 self.n_tokens = sum(map(len, self.tokens))
94 self.n_types = len(set(chain.from_iterable(self.tokens)))
95
96 def set_width(self, width):
97 self.modelAboutToBeReset.emit()
98 self.width = width
99 self.modelReset.emit()
100
101 def flags(self, _):
102 return Qt.ItemIsEnabled | Qt.ItemIsSelectable
103
104 def rowCount(self, parent=None, *args, **kwargs):
105 return 0 if parent is None or parent.isValid() or \
106 self.word_index is None \
107 else len(self.word_index)
108
109 def columnCount(self, parent=None, *args, **kwargs):
110 return 3
111
112 def data(self, index, role=Qt.DisplayRole):
113 row, col = index.row(), index.column()
114 doc, index = self.word_index[row]
115
116 if role == Qt.DisplayRole:
117 tokens = self.tokens
118 if col == 0:
119 return ' '.join(tokens[doc][max(index - self.width, 0):index])
120 if col == 1:
121 return tokens[doc][index]
122 if col == 2:
123 return ' '.join(tokens[doc][index + 1:index + self.width + 1])
124
125 elif role == Qt.TextAlignmentRole:
126 return [Qt.AlignRight | Qt.AlignVCenter,
127 Qt.AlignCenter,
128 Qt.AlignLeft | Qt.AlignVCenter][col]
129
130 elif role == Qt.BackgroundRole:
131 const = self.word_index[row][0] in self.colored_rows
132 return QColor(236 + 19 * const, 243 + 12 * const, 255)
133
134 def _compute_indices(self): # type: () -> Optional[None, list]
135 if self.corpus is None:
136 self.indices = None
137 return
138 self.indices = [ConcordanceIndex(doc, key=lambda x: x.lower())
139 for doc in self.tokens]
140
141 def _compute_word_index(self):
142 if self.indices is None or self.word is None:
143 self.word_index = self.colored_rows = None
144 else:
145 self.word_index = [
146 (doc_idx, offset) for doc_idx, doc in enumerate(self.indices)
147 for offset in doc.offsets(self.word)]
148 self.colored_rows = set(sorted({d[0] for d in self.word_index})[::2])
149
150 def matching_docs(self):
151 if self.indices and self.word:
152 return sum(bool(doc.offsets(self.word)) for doc in self.indices)
153 else:
154 return 0
155
156
157 class OWConcordance(OWWidget):
158 name = "Concordance"
159 description = "Display the context of the word."
160 icon = "icons/Concordance.svg"
161 priority = 520
162
163 class Inputs:
164 corpus = Input("Corpus", Corpus)
165 query_word = Input("Query Word", Topic)
166
167 class Outputs:
168 selected_documents = Output("Selected Documents", Corpus)
169
170 settingsHandler = PerfectDomainContextHandler(
171 match_values = PerfectDomainContextHandler.MATCH_VALUES_ALL
172 )
173 autocommit = Setting(True)
174 context_width = Setting(5)
175 word = ContextSetting("", exclude_metas=False)
176 # TODO Set selection settings (DataHashContextHandler)
177
178 class Warning(OWWidget.Warning):
179 multiple_words_on_input = Msg("Multiple query words on input. "
180 "Only the first one is considered!")
181
182 def __init__(self):
183 super().__init__()
184
185 self.corpus = None # Corpus
186 self.n_matching = '' # Info on docs matching the word
187 self.n_tokens = '' # Info on tokens
188 self.n_types = '' # Info on types (unique tokens)
189 self.is_word_on_input = False
190
191 # Info attributes
192 info_box = gui.widgetBox(self.controlArea, 'Info')
193 gui.label(info_box, self, 'Tokens: %(n_tokens)s')
194 gui.label(info_box, self, 'Types: %(n_types)s')
195 gui.label(info_box, self, 'Matching: %(n_matching)s')
196
197 # Width parameter
198 gui.spin(self.controlArea, self, 'context_width', 3, 10, box=True,
199 label="Number of words:", callback=self.set_width)
200
201 gui.rubber(self.controlArea)
202
203 # Search
204 c_box = gui.widgetBox(self.mainArea, orientation="vertical")
205 self.input = gui.lineEdit(
206 c_box, self, 'word', orientation=Qt.Horizontal,
207 sizePolicy=QSizePolicy(QSizePolicy.MinimumExpanding,
208 QSizePolicy.Fixed),
209 label='Query:', callback=self.set_word, callbackOnType=True)
210 self.input.setFocus()
211
212 # Concordances view
213 self.conc_view = QTableView()
214 self.model = ConcordanceModel()
215 self.conc_view.setModel(self.model)
216 self.conc_view.setWordWrap(False)
217 self.conc_view.setSelectionBehavior(QTableView.SelectRows)
218 self.conc_view.setSelectionModel(DocumentSelectionModel(self.model))
219 self.conc_view.setItemDelegate(HorizontalGridDelegate())
220 # connect selectionChanged to self.commit(), which will be
221 # updated by gui.auto_commit()
222 self.conc_view.selectionModel().selectionChanged.connect(lambda:
223 self.commit())
224 self.conc_view.horizontalHeader().hide()
225 self.conc_view.setShowGrid(False)
226 self.mainArea.layout().addWidget(self.conc_view)
227 self.set_width()
228
229 # Auto-commit box
230 gui.auto_commit(self.controlArea, self, 'autocommit', 'Commit',
231 'Auto commit is on')
232
233 def sizeHint(self): # pragma: no cover
234 return QSize(600, 400)
235
236 def set_width(self):
237 sel = self.conc_view.selectionModel().selection()
238 self.model.set_width(self.context_width)
239 if sel:
240 self.conc_view.selectionModel().select(sel,
241 QItemSelectionModel.SelectCurrent | QItemSelectionModel.Rows)
242
243 @Inputs.corpus
244 def set_corpus(self, data=None):
245 self.closeContext()
246 self.corpus = data
247 if data is not None and not isinstance(data, Corpus):
248 self.corpus = Corpus.from_table(data.domain, data)
249 self.model.set_corpus(self.corpus)
250 if not self.is_word_on_input:
251 self.word = ""
252 self.openContext(self.corpus)
253 self.set_word()
254
255 @Inputs.query_word
256 def set_word_from_input(self, topic):
257 self.Warning.multiple_words_on_input.clear()
258 self.is_word_on_input = topic is not None and len(topic) > 0
259 self.input.setEnabled(not self.is_word_on_input)
260 if self.is_word_on_input:
261 if len(topic) > 1:
262 self.Warning.multiple_words_on_input()
263 self.word = topic.metas[0, 0]
264 self.set_word()
265
266 def set_word(self):
267 self.model.set_word(self.word)
268 self.update_widget()
269 self.commit()
270
271 def resize_columns(self):
272 col_width = (self.conc_view.width() -
273 self.conc_view.columnWidth(1)) / 2 - 12
274 self.conc_view.setColumnWidth(0, col_width)
275 self.conc_view.setColumnWidth(2, col_width)
276
277 def resizeEvent(self, event): # pragma: no cover
278 super().resizeEvent(event)
279 self.resize_columns()
280
281 def update_widget(self):
282 self.conc_view.resizeColumnToContents(1)
283 self.resize_columns()
284 self.conc_view.resizeRowsToContents()
285
286 if self.corpus is not None:
287 self.n_matching = '{}/{}'.format(
288 self.model.matching_docs() if self.word else 0,
289 len(self.corpus))
290 self.n_tokens = self.model.n_tokens
291 self.n_types = self.model.n_types
292 else:
293 self.n_matching = ''
294 self.n_tokens = ''
295 self.n_types = ''
296
297 def commit(self):
298 rows = [sel_range.top() for sel_range
299 in self.conc_view.selectionModel().selection()]
300 selected_docs = sorted(set(self.model.word_index[row][0]
301 for row in rows))
302 if selected_docs:
303 selected = self.corpus[selected_docs]
304 self.Outputs.selected_documents.send(selected)
305 else:
306 self.Outputs.selected_documents.send(None)
307
308
309 if __name__ == '__main__': # pragma: no cover
310 app = QApplication([])
311 widget = OWConcordance()
312 corpus = Corpus.from_file('book-excerpts')
313 corpus = corpus[:3]
314 widget.set_corpus(corpus)
315 widget.show()
316 app.exec()
317
318
[end of orangecontrib/text/widgets/owconcordance.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/orangecontrib/text/widgets/owconcordance.py b/orangecontrib/text/widgets/owconcordance.py
--- a/orangecontrib/text/widgets/owconcordance.py
+++ b/orangecontrib/text/widgets/owconcordance.py
@@ -173,7 +173,7 @@
autocommit = Setting(True)
context_width = Setting(5)
word = ContextSetting("", exclude_metas=False)
- # TODO Set selection settings (DataHashContextHandler)
+ selected_rows = Setting([], schema_only=True)
class Warning(OWWidget.Warning):
multiple_words_on_input = Msg("Multiple query words on input. "
@@ -217,10 +217,7 @@
self.conc_view.setSelectionBehavior(QTableView.SelectRows)
self.conc_view.setSelectionModel(DocumentSelectionModel(self.model))
self.conc_view.setItemDelegate(HorizontalGridDelegate())
- # connect selectionChanged to self.commit(), which will be
- # updated by gui.auto_commit()
- self.conc_view.selectionModel().selectionChanged.connect(lambda:
- self.commit())
+ self.conc_view.selectionModel().selectionChanged.connect(self.selection_changed)
self.conc_view.horizontalHeader().hide()
self.conc_view.setShowGrid(False)
self.mainArea.layout().addWidget(self.conc_view)
@@ -240,21 +237,39 @@
self.conc_view.selectionModel().select(sel,
QItemSelectionModel.SelectCurrent | QItemSelectionModel.Rows)
+ def selection_changed(self):
+ selection = self.conc_view.selectionModel().selection()
+ self.selected_rows = sorted(set(cell.row() for cell in selection.indexes()))
+ self.commit()
+
+ def set_selection(self, selection):
+ if selection:
+ sel = QItemSelection()
+ for row in selection:
+ index = self.conc_view.model().index(row, 0)
+ sel.select(index, index)
+ self.conc_view.selectionModel().select(sel,
+ QItemSelectionModel.SelectCurrent | QItemSelectionModel.Rows)
+
@Inputs.corpus
def set_corpus(self, data=None):
self.closeContext()
self.corpus = data
- if data is not None and not isinstance(data, Corpus):
- self.corpus = Corpus.from_table(data.domain, data)
- self.model.set_corpus(self.corpus)
+ if data is None: # data removed, clear selection
+ self.selected_rows = []
+
if not self.is_word_on_input:
self.word = ""
self.openContext(self.corpus)
+
+ self.model.set_corpus(self.corpus)
self.set_word()
@Inputs.query_word
def set_word_from_input(self, topic):
self.Warning.multiple_words_on_input.clear()
+ if self.is_word_on_input: # word changed, clear selection
+ self.selected_rows = []
self.is_word_on_input = topic is not None and len(topic) > 0
self.input.setEnabled(not self.is_word_on_input)
if self.is_word_on_input:
@@ -268,6 +283,9 @@
self.update_widget()
self.commit()
+ def handleNewSignals(self):
+ self.set_selection(self.selected_rows)
+
def resize_columns(self):
col_width = (self.conc_view.width() -
self.conc_view.columnWidth(1)) / 2 - 12
@@ -295,10 +313,8 @@
self.n_types = ''
def commit(self):
- rows = [sel_range.top() for sel_range
- in self.conc_view.selectionModel().selection()]
selected_docs = sorted(set(self.model.word_index[row][0]
- for row in rows))
+ for row in self.selected_rows))
if selected_docs:
selected = self.corpus[selected_docs]
self.Outputs.selected_documents.send(selected)
| {"golden_diff": "diff --git a/orangecontrib/text/widgets/owconcordance.py b/orangecontrib/text/widgets/owconcordance.py\n--- a/orangecontrib/text/widgets/owconcordance.py\n+++ b/orangecontrib/text/widgets/owconcordance.py\n@@ -173,7 +173,7 @@\n autocommit = Setting(True)\n context_width = Setting(5)\n word = ContextSetting(\"\", exclude_metas=False)\n- # TODO Set selection settings (DataHashContextHandler)\n+ selected_rows = Setting([], schema_only=True)\n \n class Warning(OWWidget.Warning):\n multiple_words_on_input = Msg(\"Multiple query words on input. \"\n@@ -217,10 +217,7 @@\n self.conc_view.setSelectionBehavior(QTableView.SelectRows)\n self.conc_view.setSelectionModel(DocumentSelectionModel(self.model))\n self.conc_view.setItemDelegate(HorizontalGridDelegate())\n- # connect selectionChanged to self.commit(), which will be\n- # updated by gui.auto_commit()\n- self.conc_view.selectionModel().selectionChanged.connect(lambda:\n- self.commit())\n+ self.conc_view.selectionModel().selectionChanged.connect(self.selection_changed)\n self.conc_view.horizontalHeader().hide()\n self.conc_view.setShowGrid(False)\n self.mainArea.layout().addWidget(self.conc_view)\n@@ -240,21 +237,39 @@\n self.conc_view.selectionModel().select(sel,\n QItemSelectionModel.SelectCurrent | QItemSelectionModel.Rows)\n \n+ def selection_changed(self):\n+ selection = self.conc_view.selectionModel().selection()\n+ self.selected_rows = sorted(set(cell.row() for cell in selection.indexes()))\n+ self.commit()\n+\n+ def set_selection(self, selection):\n+ if selection:\n+ sel = QItemSelection()\n+ for row in selection:\n+ index = self.conc_view.model().index(row, 0)\n+ sel.select(index, index)\n+ self.conc_view.selectionModel().select(sel,\n+ QItemSelectionModel.SelectCurrent | QItemSelectionModel.Rows)\n+\n @Inputs.corpus\n def set_corpus(self, data=None):\n self.closeContext()\n self.corpus = data\n- if data is not None and not isinstance(data, Corpus):\n- self.corpus = Corpus.from_table(data.domain, data)\n- self.model.set_corpus(self.corpus)\n+ if data is None: # data removed, clear selection\n+ self.selected_rows = []\n+\n if not self.is_word_on_input:\n self.word = \"\"\n self.openContext(self.corpus)\n+\n+ self.model.set_corpus(self.corpus)\n self.set_word()\n \n @Inputs.query_word\n def set_word_from_input(self, topic):\n self.Warning.multiple_words_on_input.clear()\n+ if self.is_word_on_input: # word changed, clear selection\n+ self.selected_rows = []\n self.is_word_on_input = topic is not None and len(topic) > 0\n self.input.setEnabled(not self.is_word_on_input)\n if self.is_word_on_input:\n@@ -268,6 +283,9 @@\n self.update_widget()\n self.commit()\n \n+ def handleNewSignals(self):\n+ self.set_selection(self.selected_rows)\n+\n def resize_columns(self):\n col_width = (self.conc_view.width() -\n self.conc_view.columnWidth(1)) / 2 - 12\n@@ -295,10 +313,8 @@\n self.n_types = ''\n \n def commit(self):\n- rows = [sel_range.top() for sel_range\n- in self.conc_view.selectionModel().selection()]\n selected_docs = sorted(set(self.model.word_index[row][0]\n- for row in rows))\n+ for row in self.selected_rows))\n if selected_docs:\n selected = self.corpus[selected_docs]\n self.Outputs.selected_documents.send(selected)\n", "issue": "Concordanes Settings\n##### Expected behavior\r\nConcordanes widget uses settings. \r\n\r\n\r\n##### Actual behavior\r\nIt does not yet.\r\n\r\n\n", "before_files": [{"content": "from typing import Optional\n\nfrom itertools import chain\nfrom AnyQt.QtCore import Qt, QAbstractTableModel, QSize, QItemSelectionModel, \\\n QItemSelection\nfrom AnyQt.QtWidgets import QSizePolicy, QApplication, QTableView, \\\n QStyledItemDelegate\nfrom AnyQt.QtGui import QColor\n\nfrom Orange.widgets import gui\nfrom Orange.widgets.settings import Setting, ContextSetting, PerfectDomainContextHandler\nfrom Orange.widgets.widget import OWWidget, Msg, Input, Output\nfrom nltk import ConcordanceIndex\nfrom orangecontrib.text.corpus import Corpus\nfrom orangecontrib.text.topics import Topic\nfrom orangecontrib.text.preprocess import WordPunctTokenizer\n\n\nclass HorizontalGridDelegate(QStyledItemDelegate):\n \"\"\"Class for setting elide.\"\"\"\n\n def paint(self, painter, option, index):\n if index.column() == 0:\n option.textElideMode = Qt.ElideLeft\n elif index.column() == 2:\n option.textElideMode = Qt.ElideRight\n QStyledItemDelegate.paint(self, painter, option, index)\n\n\nclass DocumentSelectionModel(QItemSelectionModel):\n \"\"\"Sets selection for QTableView. Creates a set of selected documents.\"\"\"\n\n def select(self, selection, flags):\n # which rows have been selected\n indexes = selection.indexes() if isinstance(selection, QItemSelection) \\\n else [selection]\n # prevent crashing when deleting the connection\n if not indexes:\n super().select(selection, flags)\n return\n # indexes[0].row() == -1 indicates clicking outside of the table\n if len(indexes) == 1 and indexes[0].row() == -1:\n self.clear()\n return\n word_index = self.model().word_index\n selected_docs = {word_index[index.row()][0] for index in indexes}\n selected_rows = [\n row_index for row_index, (doc_index, _) in enumerate(word_index)\n if doc_index in selected_docs]\n selection = QItemSelection()\n # select all rows belonging to the selected document\n for row in selected_rows:\n index = self.model().index(row, 0)\n selection.select(index, index)\n super().select(selection, flags)\n\n\nclass ConcordanceModel(QAbstractTableModel):\n \"\"\"A model for constructing concordances from text.\"\"\"\n\n def __init__(self):\n QAbstractTableModel.__init__(self)\n self.word = None\n self.corpus = None\n self.tokens = None\n self.n_tokens = None\n self.n_types = None\n self.indices = None\n self.word_index = None\n self.width = 8\n self.colored_rows = None\n\n def set_word(self, word):\n self.modelAboutToBeReset.emit()\n self.word = word\n self._compute_word_index()\n self.modelReset.emit()\n\n def set_corpus(self, corpus):\n self.modelAboutToBeReset.emit()\n self.corpus = corpus\n self.set_tokens()\n self._compute_indices()\n self._compute_word_index()\n self.modelReset.emit()\n\n def set_tokens(self):\n if self.corpus is None:\n self.tokens = None\n return\n tokenizer = WordPunctTokenizer()\n self.tokens = tokenizer(self.corpus.documents)\n self.n_tokens = sum(map(len, self.tokens))\n self.n_types = len(set(chain.from_iterable(self.tokens)))\n\n def set_width(self, width):\n self.modelAboutToBeReset.emit()\n self.width = width\n self.modelReset.emit()\n\n def flags(self, _):\n return Qt.ItemIsEnabled | Qt.ItemIsSelectable\n\n def rowCount(self, parent=None, *args, **kwargs):\n return 0 if parent is None or parent.isValid() or \\\n self.word_index is None \\\n else len(self.word_index)\n\n def columnCount(self, parent=None, *args, **kwargs):\n return 3\n\n def data(self, index, role=Qt.DisplayRole):\n row, col = index.row(), index.column()\n doc, index = self.word_index[row]\n\n if role == Qt.DisplayRole:\n tokens = self.tokens\n if col == 0:\n return ' '.join(tokens[doc][max(index - self.width, 0):index])\n if col == 1:\n return tokens[doc][index]\n if col == 2:\n return ' '.join(tokens[doc][index + 1:index + self.width + 1])\n\n elif role == Qt.TextAlignmentRole:\n return [Qt.AlignRight | Qt.AlignVCenter,\n Qt.AlignCenter,\n Qt.AlignLeft | Qt.AlignVCenter][col]\n\n elif role == Qt.BackgroundRole:\n const = self.word_index[row][0] in self.colored_rows\n return QColor(236 + 19 * const, 243 + 12 * const, 255)\n\n def _compute_indices(self): # type: () -> Optional[None, list]\n if self.corpus is None:\n self.indices = None\n return\n self.indices = [ConcordanceIndex(doc, key=lambda x: x.lower())\n for doc in self.tokens]\n\n def _compute_word_index(self):\n if self.indices is None or self.word is None:\n self.word_index = self.colored_rows = None\n else:\n self.word_index = [\n (doc_idx, offset) for doc_idx, doc in enumerate(self.indices)\n for offset in doc.offsets(self.word)]\n self.colored_rows = set(sorted({d[0] for d in self.word_index})[::2])\n\n def matching_docs(self):\n if self.indices and self.word:\n return sum(bool(doc.offsets(self.word)) for doc in self.indices)\n else:\n return 0\n\n\nclass OWConcordance(OWWidget):\n name = \"Concordance\"\n description = \"Display the context of the word.\"\n icon = \"icons/Concordance.svg\"\n priority = 520\n\n class Inputs:\n corpus = Input(\"Corpus\", Corpus)\n query_word = Input(\"Query Word\", Topic)\n\n class Outputs:\n selected_documents = Output(\"Selected Documents\", Corpus)\n\n settingsHandler = PerfectDomainContextHandler(\n match_values = PerfectDomainContextHandler.MATCH_VALUES_ALL\n )\n autocommit = Setting(True)\n context_width = Setting(5)\n word = ContextSetting(\"\", exclude_metas=False)\n # TODO Set selection settings (DataHashContextHandler)\n\n class Warning(OWWidget.Warning):\n multiple_words_on_input = Msg(\"Multiple query words on input. \"\n \"Only the first one is considered!\")\n\n def __init__(self):\n super().__init__()\n\n self.corpus = None # Corpus\n self.n_matching = '' # Info on docs matching the word\n self.n_tokens = '' # Info on tokens\n self.n_types = '' # Info on types (unique tokens)\n self.is_word_on_input = False\n\n # Info attributes\n info_box = gui.widgetBox(self.controlArea, 'Info')\n gui.label(info_box, self, 'Tokens: %(n_tokens)s')\n gui.label(info_box, self, 'Types: %(n_types)s')\n gui.label(info_box, self, 'Matching: %(n_matching)s')\n\n # Width parameter\n gui.spin(self.controlArea, self, 'context_width', 3, 10, box=True,\n label=\"Number of words:\", callback=self.set_width)\n\n gui.rubber(self.controlArea)\n\n # Search\n c_box = gui.widgetBox(self.mainArea, orientation=\"vertical\")\n self.input = gui.lineEdit(\n c_box, self, 'word', orientation=Qt.Horizontal,\n sizePolicy=QSizePolicy(QSizePolicy.MinimumExpanding,\n QSizePolicy.Fixed),\n label='Query:', callback=self.set_word, callbackOnType=True)\n self.input.setFocus()\n\n # Concordances view\n self.conc_view = QTableView()\n self.model = ConcordanceModel()\n self.conc_view.setModel(self.model)\n self.conc_view.setWordWrap(False)\n self.conc_view.setSelectionBehavior(QTableView.SelectRows)\n self.conc_view.setSelectionModel(DocumentSelectionModel(self.model))\n self.conc_view.setItemDelegate(HorizontalGridDelegate())\n # connect selectionChanged to self.commit(), which will be\n # updated by gui.auto_commit()\n self.conc_view.selectionModel().selectionChanged.connect(lambda:\n self.commit())\n self.conc_view.horizontalHeader().hide()\n self.conc_view.setShowGrid(False)\n self.mainArea.layout().addWidget(self.conc_view)\n self.set_width()\n\n # Auto-commit box\n gui.auto_commit(self.controlArea, self, 'autocommit', 'Commit',\n 'Auto commit is on')\n\n def sizeHint(self): # pragma: no cover\n return QSize(600, 400)\n\n def set_width(self):\n sel = self.conc_view.selectionModel().selection()\n self.model.set_width(self.context_width)\n if sel:\n self.conc_view.selectionModel().select(sel,\n QItemSelectionModel.SelectCurrent | QItemSelectionModel.Rows)\n\n @Inputs.corpus\n def set_corpus(self, data=None):\n self.closeContext()\n self.corpus = data\n if data is not None and not isinstance(data, Corpus):\n self.corpus = Corpus.from_table(data.domain, data)\n self.model.set_corpus(self.corpus)\n if not self.is_word_on_input:\n self.word = \"\"\n self.openContext(self.corpus)\n self.set_word()\n\n @Inputs.query_word\n def set_word_from_input(self, topic):\n self.Warning.multiple_words_on_input.clear()\n self.is_word_on_input = topic is not None and len(topic) > 0\n self.input.setEnabled(not self.is_word_on_input)\n if self.is_word_on_input:\n if len(topic) > 1:\n self.Warning.multiple_words_on_input()\n self.word = topic.metas[0, 0]\n self.set_word()\n\n def set_word(self):\n self.model.set_word(self.word)\n self.update_widget()\n self.commit()\n\n def resize_columns(self):\n col_width = (self.conc_view.width() -\n self.conc_view.columnWidth(1)) / 2 - 12\n self.conc_view.setColumnWidth(0, col_width)\n self.conc_view.setColumnWidth(2, col_width)\n\n def resizeEvent(self, event): # pragma: no cover\n super().resizeEvent(event)\n self.resize_columns()\n\n def update_widget(self):\n self.conc_view.resizeColumnToContents(1)\n self.resize_columns()\n self.conc_view.resizeRowsToContents()\n\n if self.corpus is not None:\n self.n_matching = '{}/{}'.format(\n self.model.matching_docs() if self.word else 0,\n len(self.corpus))\n self.n_tokens = self.model.n_tokens\n self.n_types = self.model.n_types\n else:\n self.n_matching = ''\n self.n_tokens = ''\n self.n_types = ''\n\n def commit(self):\n rows = [sel_range.top() for sel_range\n in self.conc_view.selectionModel().selection()]\n selected_docs = sorted(set(self.model.word_index[row][0]\n for row in rows))\n if selected_docs:\n selected = self.corpus[selected_docs]\n self.Outputs.selected_documents.send(selected)\n else:\n self.Outputs.selected_documents.send(None)\n\n\nif __name__ == '__main__': # pragma: no cover\n app = QApplication([])\n widget = OWConcordance()\n corpus = Corpus.from_file('book-excerpts')\n corpus = corpus[:3]\n widget.set_corpus(corpus)\n widget.show()\n app.exec()\n\n", "path": "orangecontrib/text/widgets/owconcordance.py"}]} | 3,963 | 852 |
gh_patches_debug_21891 | rasdani/github-patches | git_diff | sherlock-project__sherlock-2099 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
feat: add json schema validation
Adds a JSON Schema that validates `data.json` and `removed_sites.json`. I've already validated the existing data with it and can confirm both files pass. 👍🏾
Prepends the following property to both files:
```json
{
"$schema": "{path/to/json-schema}"
}
```
Removes the `rank` property from `removed_sites.json` and documentation as this is no longer relevant.
Removes the "noPeriod" property from Jimdo as this appears to serve on purpose.
---
Sorry, also a question. What is the purpose of `responseUrl`? I just realized, this property is not referenced whatsoever in the actual application. 🤔 Can this property be removed in the dataset and schema?
Later I do want to make it stricter, i.e. prevent someone from using one `errorType` with the wrong additional field, i.e.
```json
{
"errorMsg": "Not Found",
"errorType": "status_code"
}
```
I figured I'd leave it like this for now and find out what `responseUrl` is about. 🤔
### Related
* Closes https://github.com/sherlock-project/sherlock/issues/1336
The goal of this is to improve the experience for developers and leave less room for human-error. It also enforces that we document and provide examples of each field, unlike the current Wiki which tends to get outdated.


</issue>
<code>
[start of sherlock/sites.py]
1 """Sherlock Sites Information Module
2
3 This module supports storing information about websites.
4 This is the raw data that will be used to search for usernames.
5 """
6 import json
7 import requests
8 import secrets
9
10 class SiteInformation:
11 def __init__(self, name, url_home, url_username_format, username_claimed,
12 information, is_nsfw, username_unclaimed=secrets.token_urlsafe(10)):
13 """Create Site Information Object.
14
15 Contains information about a specific website.
16
17 Keyword Arguments:
18 self -- This object.
19 name -- String which identifies site.
20 url_home -- String containing URL for home of site.
21 url_username_format -- String containing URL for Username format
22 on site.
23 NOTE: The string should contain the
24 token "{}" where the username should
25 be substituted. For example, a string
26 of "https://somesite.com/users/{}"
27 indicates that the individual
28 usernames would show up under the
29 "https://somesite.com/users/" area of
30 the website.
31 username_claimed -- String containing username which is known
32 to be claimed on website.
33 username_unclaimed -- String containing username which is known
34 to be unclaimed on website.
35 information -- Dictionary containing all known information
36 about website.
37 NOTE: Custom information about how to
38 actually detect the existence of the
39 username will be included in this
40 dictionary. This information will
41 be needed by the detection method,
42 but it is only recorded in this
43 object for future use.
44 is_nsfw -- Boolean indicating if site is Not Safe For Work.
45
46 Return Value:
47 Nothing.
48 """
49
50 self.name = name
51 self.url_home = url_home
52 self.url_username_format = url_username_format
53
54 self.username_claimed = username_claimed
55 self.username_unclaimed = secrets.token_urlsafe(32)
56 self.information = information
57 self.is_nsfw = is_nsfw
58
59 return
60
61 def __str__(self):
62 """Convert Object To String.
63
64 Keyword Arguments:
65 self -- This object.
66
67 Return Value:
68 Nicely formatted string to get information about this object.
69 """
70
71 return f"{self.name} ({self.url_home})"
72
73
74 class SitesInformation:
75 def __init__(self, data_file_path=None):
76 """Create Sites Information Object.
77
78 Contains information about all supported websites.
79
80 Keyword Arguments:
81 self -- This object.
82 data_file_path -- String which indicates path to data file.
83 The file name must end in ".json".
84
85 There are 3 possible formats:
86 * Absolute File Format
87 For example, "c:/stuff/data.json".
88 * Relative File Format
89 The current working directory is used
90 as the context.
91 For example, "data.json".
92 * URL Format
93 For example,
94 "https://example.com/data.json", or
95 "http://example.com/data.json".
96
97 An exception will be thrown if the path
98 to the data file is not in the expected
99 format, or if there was any problem loading
100 the file.
101
102 If this option is not specified, then a
103 default site list will be used.
104
105 Return Value:
106 Nothing.
107 """
108
109 if not data_file_path:
110 # The default data file is the live data.json which is in the GitHub repo. The reason why we are using
111 # this instead of the local one is so that the user has the most up-to-date data. This prevents
112 # users from creating issue about false positives which has already been fixed or having outdated data
113 data_file_path = "https://raw.githubusercontent.com/sherlock-project/sherlock/master/sherlock/resources/data.json"
114
115 # Ensure that specified data file has correct extension.
116 if not data_file_path.lower().endswith(".json"):
117 raise FileNotFoundError(f"Incorrect JSON file extension for data file '{data_file_path}'.")
118
119 # if "http://" == data_file_path[:7].lower() or "https://" == data_file_path[:8].lower():
120 if data_file_path.lower().startswith("http"):
121 # Reference is to a URL.
122 try:
123 response = requests.get(url=data_file_path)
124 except Exception as error:
125 raise FileNotFoundError(
126 f"Problem while attempting to access data file URL '{data_file_path}': {error}"
127 )
128
129 if response.status_code != 200:
130 raise FileNotFoundError(f"Bad response while accessing "
131 f"data file URL '{data_file_path}'."
132 )
133 try:
134 site_data = response.json()
135 except Exception as error:
136 raise ValueError(
137 f"Problem parsing json contents at '{data_file_path}': {error}."
138 )
139
140 else:
141 # Reference is to a file.
142 try:
143 with open(data_file_path, "r", encoding="utf-8") as file:
144 try:
145 site_data = json.load(file)
146 except Exception as error:
147 raise ValueError(
148 f"Problem parsing json contents at '{data_file_path}': {error}."
149 )
150
151 except FileNotFoundError:
152 raise FileNotFoundError(f"Problem while attempting to access "
153 f"data file '{data_file_path}'."
154 )
155
156 self.sites = {}
157
158 # Add all site information from the json file to internal site list.
159 for site_name in site_data:
160 try:
161
162 self.sites[site_name] = \
163 SiteInformation(site_name,
164 site_data[site_name]["urlMain"],
165 site_data[site_name]["url"],
166 site_data[site_name]["username_claimed"],
167 site_data[site_name],
168 site_data[site_name].get("isNSFW",False)
169
170 )
171 except KeyError as error:
172 raise ValueError(
173 f"Problem parsing json contents at '{data_file_path}': Missing attribute {error}."
174 )
175
176 return
177
178 def remove_nsfw_sites(self):
179 """
180 Remove NSFW sites from the sites, if isNSFW flag is true for site
181
182 Keyword Arguments:
183 self -- This object.
184
185 Return Value:
186 None
187 """
188 sites = {}
189 for site in self.sites:
190 if self.sites[site].is_nsfw:
191 continue
192 sites[site] = self.sites[site]
193 self.sites = sites
194
195 def site_name_list(self):
196 """Get Site Name List.
197
198 Keyword Arguments:
199 self -- This object.
200
201 Return Value:
202 List of strings containing names of sites.
203 """
204
205 return sorted([site.name for site in self], key=str.lower)
206
207 def __iter__(self):
208 """Iterator For Object.
209
210 Keyword Arguments:
211 self -- This object.
212
213 Return Value:
214 Iterator for sites object.
215 """
216
217 for site_name in self.sites:
218 yield self.sites[site_name]
219
220 def __len__(self):
221 """Length For Object.
222
223 Keyword Arguments:
224 self -- This object.
225
226 Return Value:
227 Length of sites object.
228 """
229 return len(self.sites)
230
[end of sherlock/sites.py]
[start of site_list.py]
1 #!/usr/bin/env python
2 # This module generates the listing of supported sites which can be found in
3 # sites.md. It also organizes all the sites in alphanumeric order
4 import json
5
6 # Read the data.json file
7 with open("sherlock/resources/data.json", "r", encoding="utf-8") as data_file:
8 data = json.load(data_file)
9
10 # Sort the social networks in alphanumeric order
11 social_networks = sorted(data.items())
12
13 # Write the list of supported sites to sites.md
14 with open("sites.md", "w") as site_file:
15 site_file.write(f"## List Of Supported Sites ({len(social_networks)} Sites In Total!)\n")
16 for social_network, info in social_networks:
17 url_main = info["urlMain"]
18 is_nsfw = "**(NSFW)**" if info.get("isNSFW") else ""
19 site_file.write(f"1.  [{social_network}]({url_main}) {is_nsfw}\n")
20
21 # Overwrite the data.json file with sorted data
22 with open("sherlock/resources/data.json", "w") as data_file:
23 sorted_data = json.dumps(data, indent=2, sort_keys=True)
24 data_file.write(sorted_data)
25 data_file.write("\n")
26
27 print("Finished updating supported site listing!")
28
[end of site_list.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/sherlock/sites.py b/sherlock/sites.py
--- a/sherlock/sites.py
+++ b/sherlock/sites.py
@@ -152,6 +152,11 @@
raise FileNotFoundError(f"Problem while attempting to access "
f"data file '{data_file_path}'."
)
+
+ try:
+ site_data.pop('$schema')
+ except:
+ pass
self.sites = {}
diff --git a/site_list.py b/site_list.py
--- a/site_list.py
+++ b/site_list.py
@@ -5,10 +5,14 @@
# Read the data.json file
with open("sherlock/resources/data.json", "r", encoding="utf-8") as data_file:
- data = json.load(data_file)
+ data: dict = json.load(data_file)
+
+# Removes schema-specific keywords for proper processing
+social_networks: dict = dict(data)
+social_networks.pop('$schema')
# Sort the social networks in alphanumeric order
-social_networks = sorted(data.items())
+social_networks: list = sorted(social_networks.items())
# Write the list of supported sites to sites.md
with open("sites.md", "w") as site_file:
| {"golden_diff": "diff --git a/sherlock/sites.py b/sherlock/sites.py\n--- a/sherlock/sites.py\n+++ b/sherlock/sites.py\n@@ -152,6 +152,11 @@\n raise FileNotFoundError(f\"Problem while attempting to access \"\n f\"data file '{data_file_path}'.\"\n )\n+ \n+ try:\n+ site_data.pop('$schema')\n+ except:\n+ pass\n \n self.sites = {}\n \ndiff --git a/site_list.py b/site_list.py\n--- a/site_list.py\n+++ b/site_list.py\n@@ -5,10 +5,14 @@\n \n # Read the data.json file\n with open(\"sherlock/resources/data.json\", \"r\", encoding=\"utf-8\") as data_file:\n- data = json.load(data_file)\n+ data: dict = json.load(data_file)\n+\n+# Removes schema-specific keywords for proper processing\n+social_networks: dict = dict(data)\n+social_networks.pop('$schema')\n \n # Sort the social networks in alphanumeric order\n-social_networks = sorted(data.items())\n+social_networks: list = sorted(social_networks.items())\n \n # Write the list of supported sites to sites.md\n with open(\"sites.md\", \"w\") as site_file:\n", "issue": "feat: add json schema validation\nAdds a JSON Schema that validates `data.json` and `removed_sites.json`. I've already validated the existing data with it and can confirm both files pass. \ud83d\udc4d\ud83c\udffe \r\n\r\nPrepends the following property to both files:\r\n```json\r\n{\r\n \"$schema\": \"{path/to/json-schema}\"\r\n}\r\n```\r\n\r\nRemoves the `rank` property from `removed_sites.json` and documentation as this is no longer relevant.\r\n\r\nRemoves the \"noPeriod\" property from Jimdo as this appears to serve on purpose.\r\n\r\n---\r\n\r\nSorry, also a question. What is the purpose of `responseUrl`? I just realized, this property is not referenced whatsoever in the actual application. \ud83e\udd14 Can this property be removed in the dataset and schema?\r\n\r\nLater I do want to make it stricter, i.e. prevent someone from using one `errorType` with the wrong additional field, i.e.\r\n```json\r\n{ \r\n \"errorMsg\": \"Not Found\",\r\n \"errorType\": \"status_code\"\r\n} \r\n```\r\n\r\nI figured I'd leave it like this for now and find out what `responseUrl` is about. \ud83e\udd14 \r\n\r\n### Related\r\n* Closes https://github.com/sherlock-project/sherlock/issues/1336\r\n\r\nThe goal of this is to improve the experience for developers and leave less room for human-error. It also enforces that we document and provide examples of each field, unlike the current Wiki which tends to get outdated.\r\n\r\n\r\n\r\n\r\n\r\n \r\n\r\n\r\n\n", "before_files": [{"content": "\"\"\"Sherlock Sites Information Module\n\nThis module supports storing information about websites.\nThis is the raw data that will be used to search for usernames.\n\"\"\"\nimport json\nimport requests\nimport secrets\n\nclass SiteInformation:\n def __init__(self, name, url_home, url_username_format, username_claimed,\n information, is_nsfw, username_unclaimed=secrets.token_urlsafe(10)):\n \"\"\"Create Site Information Object.\n\n Contains information about a specific website.\n\n Keyword Arguments:\n self -- This object.\n name -- String which identifies site.\n url_home -- String containing URL for home of site.\n url_username_format -- String containing URL for Username format\n on site.\n NOTE: The string should contain the\n token \"{}\" where the username should\n be substituted. For example, a string\n of \"https://somesite.com/users/{}\"\n indicates that the individual\n usernames would show up under the\n \"https://somesite.com/users/\" area of\n the website.\n username_claimed -- String containing username which is known\n to be claimed on website.\n username_unclaimed -- String containing username which is known\n to be unclaimed on website.\n information -- Dictionary containing all known information\n about website.\n NOTE: Custom information about how to\n actually detect the existence of the\n username will be included in this\n dictionary. This information will\n be needed by the detection method,\n but it is only recorded in this\n object for future use.\n is_nsfw -- Boolean indicating if site is Not Safe For Work.\n\n Return Value:\n Nothing.\n \"\"\"\n\n self.name = name\n self.url_home = url_home\n self.url_username_format = url_username_format\n\n self.username_claimed = username_claimed\n self.username_unclaimed = secrets.token_urlsafe(32)\n self.information = information\n self.is_nsfw = is_nsfw\n\n return\n\n def __str__(self):\n \"\"\"Convert Object To String.\n\n Keyword Arguments:\n self -- This object.\n\n Return Value:\n Nicely formatted string to get information about this object.\n \"\"\"\n \n return f\"{self.name} ({self.url_home})\"\n\n\nclass SitesInformation:\n def __init__(self, data_file_path=None):\n \"\"\"Create Sites Information Object.\n\n Contains information about all supported websites.\n\n Keyword Arguments:\n self -- This object.\n data_file_path -- String which indicates path to data file.\n The file name must end in \".json\".\n\n There are 3 possible formats:\n * Absolute File Format\n For example, \"c:/stuff/data.json\".\n * Relative File Format\n The current working directory is used\n as the context.\n For example, \"data.json\".\n * URL Format\n For example,\n \"https://example.com/data.json\", or\n \"http://example.com/data.json\".\n\n An exception will be thrown if the path\n to the data file is not in the expected\n format, or if there was any problem loading\n the file.\n\n If this option is not specified, then a\n default site list will be used.\n\n Return Value:\n Nothing.\n \"\"\"\n\n if not data_file_path:\n # The default data file is the live data.json which is in the GitHub repo. The reason why we are using\n # this instead of the local one is so that the user has the most up-to-date data. This prevents\n # users from creating issue about false positives which has already been fixed or having outdated data\n data_file_path = \"https://raw.githubusercontent.com/sherlock-project/sherlock/master/sherlock/resources/data.json\"\n\n # Ensure that specified data file has correct extension.\n if not data_file_path.lower().endswith(\".json\"):\n raise FileNotFoundError(f\"Incorrect JSON file extension for data file '{data_file_path}'.\")\n\n # if \"http://\" == data_file_path[:7].lower() or \"https://\" == data_file_path[:8].lower():\n if data_file_path.lower().startswith(\"http\"):\n # Reference is to a URL.\n try:\n response = requests.get(url=data_file_path)\n except Exception as error:\n raise FileNotFoundError(\n f\"Problem while attempting to access data file URL '{data_file_path}': {error}\"\n )\n\n if response.status_code != 200:\n raise FileNotFoundError(f\"Bad response while accessing \"\n f\"data file URL '{data_file_path}'.\"\n )\n try:\n site_data = response.json()\n except Exception as error:\n raise ValueError(\n f\"Problem parsing json contents at '{data_file_path}': {error}.\"\n )\n\n else:\n # Reference is to a file.\n try:\n with open(data_file_path, \"r\", encoding=\"utf-8\") as file:\n try:\n site_data = json.load(file)\n except Exception as error:\n raise ValueError(\n f\"Problem parsing json contents at '{data_file_path}': {error}.\"\n )\n\n except FileNotFoundError:\n raise FileNotFoundError(f\"Problem while attempting to access \"\n f\"data file '{data_file_path}'.\"\n )\n\n self.sites = {}\n\n # Add all site information from the json file to internal site list.\n for site_name in site_data:\n try:\n\n self.sites[site_name] = \\\n SiteInformation(site_name,\n site_data[site_name][\"urlMain\"],\n site_data[site_name][\"url\"],\n site_data[site_name][\"username_claimed\"],\n site_data[site_name],\n site_data[site_name].get(\"isNSFW\",False)\n\n )\n except KeyError as error:\n raise ValueError(\n f\"Problem parsing json contents at '{data_file_path}': Missing attribute {error}.\"\n )\n\n return\n\n def remove_nsfw_sites(self):\n \"\"\"\n Remove NSFW sites from the sites, if isNSFW flag is true for site\n\n Keyword Arguments:\n self -- This object.\n\n Return Value:\n None\n \"\"\"\n sites = {}\n for site in self.sites:\n if self.sites[site].is_nsfw:\n continue\n sites[site] = self.sites[site] \n self.sites = sites\n\n def site_name_list(self):\n \"\"\"Get Site Name List.\n\n Keyword Arguments:\n self -- This object.\n\n Return Value:\n List of strings containing names of sites.\n \"\"\"\n\n return sorted([site.name for site in self], key=str.lower)\n\n def __iter__(self):\n \"\"\"Iterator For Object.\n\n Keyword Arguments:\n self -- This object.\n\n Return Value:\n Iterator for sites object.\n \"\"\"\n\n for site_name in self.sites:\n yield self.sites[site_name]\n\n def __len__(self):\n \"\"\"Length For Object.\n\n Keyword Arguments:\n self -- This object.\n\n Return Value:\n Length of sites object.\n \"\"\"\n return len(self.sites)\n", "path": "sherlock/sites.py"}, {"content": "#!/usr/bin/env python\n# This module generates the listing of supported sites which can be found in\n# sites.md. It also organizes all the sites in alphanumeric order\nimport json\n\n# Read the data.json file\nwith open(\"sherlock/resources/data.json\", \"r\", encoding=\"utf-8\") as data_file:\n data = json.load(data_file)\n\n# Sort the social networks in alphanumeric order\nsocial_networks = sorted(data.items())\n\n# Write the list of supported sites to sites.md\nwith open(\"sites.md\", \"w\") as site_file:\n site_file.write(f\"## List Of Supported Sites ({len(social_networks)} Sites In Total!)\\n\")\n for social_network, info in social_networks:\n url_main = info[\"urlMain\"]\n is_nsfw = \"**(NSFW)**\" if info.get(\"isNSFW\") else \"\"\n site_file.write(f\"1.  [{social_network}]({url_main}) {is_nsfw}\\n\")\n\n# Overwrite the data.json file with sorted data\nwith open(\"sherlock/resources/data.json\", \"w\") as data_file:\n sorted_data = json.dumps(data, indent=2, sort_keys=True)\n data_file.write(sorted_data)\n data_file.write(\"\\n\")\n\nprint(\"Finished updating supported site listing!\")\n", "path": "site_list.py"}]} | 3,519 | 270 |
gh_patches_debug_9061 | rasdani/github-patches | git_diff | modin-project__modin-506 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Numpy 1.16 support for future read_hdf
Due to this issue (https://github.com/PyTables/PyTables/issues/717) it seems that, at least on my host machine, the latest version of numpy is needed to store and play with large datasets using hdf5. Naturally, I would love to use modin (ray) for these purposes and but realized that modin runs with numpy<=1.15.
I downloaded the source of Ray from github to test to see if numpy 1.15+ was supported and it seems that tests were failing for numpy 1.16.1. I was curious if modin planned to support higher versions of numpy in the near term as would be required to interplay with py tables.
</issue>
<code>
[start of setup.py]
1 from __future__ import absolute_import
2 from __future__ import division
3 from __future__ import print_function
4
5 from setuptools import setup, find_packages
6
7 with open("README.md", "r", encoding="utf8") as fh:
8 long_description = fh.read()
9
10 setup(
11 name="modin",
12 version="0.4.0",
13 description="Modin: Make your pandas code run faster by changing one line of code.",
14 packages=find_packages(),
15 url="https://github.com/modin-project/modin",
16 long_description=long_description,
17 long_description_content_type="text/markdown",
18 install_requires=["pandas==0.24.1", "ray==0.6.2", "numpy<=1.15.0", "typing"],
19 extras_require={
20 # can be installed by pip install modin[dask]
21 "dask": ["dask==1.0.0", "distributed==1.25.0"],
22 },
23 )
24
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -15,9 +15,9 @@
url="https://github.com/modin-project/modin",
long_description=long_description,
long_description_content_type="text/markdown",
- install_requires=["pandas==0.24.1", "ray==0.6.2", "numpy<=1.15.0", "typing"],
+ install_requires=["pandas==0.24.1", "ray==0.6.2", "typing"],
extras_require={
# can be installed by pip install modin[dask]
- "dask": ["dask==1.0.0", "distributed==1.25.0"],
+ "dask": ["dask==1.1.0", "distributed==1.25.0"],
},
)
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -15,9 +15,9 @@\n url=\"https://github.com/modin-project/modin\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n- install_requires=[\"pandas==0.24.1\", \"ray==0.6.2\", \"numpy<=1.15.0\", \"typing\"],\n+ install_requires=[\"pandas==0.24.1\", \"ray==0.6.2\", \"typing\"],\n extras_require={\n # can be installed by pip install modin[dask]\n- \"dask\": [\"dask==1.0.0\", \"distributed==1.25.0\"],\n+ \"dask\": [\"dask==1.1.0\", \"distributed==1.25.0\"],\n },\n )\n", "issue": "Numpy 1.16 support for future read_hdf\nDue to this issue (https://github.com/PyTables/PyTables/issues/717) it seems that, at least on my host machine, the latest version of numpy is needed to store and play with large datasets using hdf5. Naturally, I would love to use modin (ray) for these purposes and but realized that modin runs with numpy<=1.15.\r\n\r\nI downloaded the source of Ray from github to test to see if numpy 1.15+ was supported and it seems that tests were failing for numpy 1.16.1. I was curious if modin planned to support higher versions of numpy in the near term as would be required to interplay with py tables.\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nfrom setuptools import setup, find_packages\n\nwith open(\"README.md\", \"r\", encoding=\"utf8\") as fh:\n long_description = fh.read()\n\nsetup(\n name=\"modin\",\n version=\"0.4.0\",\n description=\"Modin: Make your pandas code run faster by changing one line of code.\",\n packages=find_packages(),\n url=\"https://github.com/modin-project/modin\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n install_requires=[\"pandas==0.24.1\", \"ray==0.6.2\", \"numpy<=1.15.0\", \"typing\"],\n extras_require={\n # can be installed by pip install modin[dask]\n \"dask\": [\"dask==1.0.0\", \"distributed==1.25.0\"],\n },\n)\n", "path": "setup.py"}]} | 939 | 198 |
gh_patches_debug_55117 | rasdani/github-patches | git_diff | netbox-community__netbox-15725 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
PROTECTION_RULES: Custom Validator does not show error message on object deletion
### Deployment Type
Self-hosted
### NetBox Version
v4.0-beta1 (commit c7f6c206cf5068f890b89da9ca04d4d3583f5107)
### Python Version
3.11
### Steps to Reproduce
1. Create a custom validator with the following code:
```python
from extras.validators import CustomValidator
from utilities.exceptions import AbortRequest
class IPAddressDeleteValidator(CustomValidator):
def validate(self, instance, request):
raise AbortRequest("Do not delete IP addresses!")
```
and store as `/opt/netbox/validators/test.py`
2. Add the custom validator as a protect rule for `IPAddress` objects:
```python
PROTECTION_RULES = {
"ipam.ipaddress": [
"validators.test.IPAddressDeleteValidator",
]
}
```
3. Navigate to IPAM/IP Addresses
4. Create an arbitrary IP address
5. Click on "Delete" in the new address's detail view and confirm deletion
### Expected Behavior
The IP address is not deleted, an error message is shown saying "Do not delete IP addresses!"
### Observed Behavior
The IP address is not deleted, but there is no error message.
The error message is, however, displayed when one tries to delete an IP address using the bulk edit view:

</issue>
<code>
[start of netbox/utilities/htmx.py]
1 __all__ = (
2 'htmx_partial',
3 )
4
5 PAGE_CONTAINER_ID = 'page-content'
6
7
8 def htmx_partial(request):
9 """
10 Determines whether to render partial (versus complete) HTML content
11 in response to an HTMX request, based on the target element.
12 """
13 return request.htmx and request.htmx.target and request.htmx.target != PAGE_CONTAINER_ID
14
[end of netbox/utilities/htmx.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/netbox/utilities/htmx.py b/netbox/utilities/htmx.py
--- a/netbox/utilities/htmx.py
+++ b/netbox/utilities/htmx.py
@@ -2,12 +2,10 @@
'htmx_partial',
)
-PAGE_CONTAINER_ID = 'page-content'
-
def htmx_partial(request):
"""
Determines whether to render partial (versus complete) HTML content
in response to an HTMX request, based on the target element.
"""
- return request.htmx and request.htmx.target and request.htmx.target != PAGE_CONTAINER_ID
+ return request.htmx and not request.htmx.boosted
| {"golden_diff": "diff --git a/netbox/utilities/htmx.py b/netbox/utilities/htmx.py\n--- a/netbox/utilities/htmx.py\n+++ b/netbox/utilities/htmx.py\n@@ -2,12 +2,10 @@\n 'htmx_partial',\n )\n \n-PAGE_CONTAINER_ID = 'page-content'\n-\n \n def htmx_partial(request):\n \"\"\"\n Determines whether to render partial (versus complete) HTML content\n in response to an HTMX request, based on the target element.\n \"\"\"\n- return request.htmx and request.htmx.target and request.htmx.target != PAGE_CONTAINER_ID\n+ return request.htmx and not request.htmx.boosted\n", "issue": "PROTECTION_RULES: Custom Validator does not show error message on object deletion\n### Deployment Type\r\n\r\nSelf-hosted\r\n\r\n### NetBox Version\r\n\r\nv4.0-beta1 (commit c7f6c206cf5068f890b89da9ca04d4d3583f5107)\r\n\r\n### Python Version\r\n\r\n3.11\r\n\r\n### Steps to Reproduce\r\n\r\n1. Create a custom validator with the following code:\r\n```python\r\nfrom extras.validators import CustomValidator\r\nfrom utilities.exceptions import AbortRequest\r\n\r\n\r\nclass IPAddressDeleteValidator(CustomValidator):\r\n\r\n def validate(self, instance, request):\r\n raise AbortRequest(\"Do not delete IP addresses!\")\r\n```\r\nand store as `/opt/netbox/validators/test.py`\r\n\r\n2. Add the custom validator as a protect rule for `IPAddress` objects:\r\n```python\r\nPROTECTION_RULES = {\r\n \"ipam.ipaddress\": [\r\n \"validators.test.IPAddressDeleteValidator\",\r\n ]\r\n}\r\n```\r\n3. Navigate to IPAM/IP Addresses\r\n4. Create an arbitrary IP address\r\n5. Click on \"Delete\" in the new address's detail view and confirm deletion\r\n\r\n### Expected Behavior\r\n\r\nThe IP address is not deleted, an error message is shown saying \"Do not delete IP addresses!\"\r\n\r\n### Observed Behavior\r\n\r\nThe IP address is not deleted, but there is no error message. \r\n\r\nThe error message is, however, displayed when one tries to delete an IP address using the bulk edit view:\r\n\r\n\n", "before_files": [{"content": "__all__ = (\n 'htmx_partial',\n)\n\nPAGE_CONTAINER_ID = 'page-content'\n\n\ndef htmx_partial(request):\n \"\"\"\n Determines whether to render partial (versus complete) HTML content\n in response to an HTMX request, based on the target element.\n \"\"\"\n return request.htmx and request.htmx.target and request.htmx.target != PAGE_CONTAINER_ID\n", "path": "netbox/utilities/htmx.py"}]} | 1,007 | 150 |
gh_patches_debug_18066 | rasdani/github-patches | git_diff | magenta__magenta-624 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
issue training / generating with polyphony_rnn
Hello,
After (apparently successfully) learning an polyphony_rnn model, I cannot generate any sequence.
If I try to generate from the checkpoint, it returns the following:
> INFO:tensorflow:Checkpoint used: ./2017_05_04//run1/train/model.ckpt-3122
INFO:tensorflow:Restoring parameters from ./2017_05_04//run1/train/model.ckpt-3122
2017-05-04 18:18:18.663347: W tensorflow/core/framework/op_kernel.cc:1152] Not found: Key rnn/multi_rnn_cell/cell_2/basic_lstm_cell/weights not found in checkpoint
2017-05-04 18:18:18.666763: W tensorflow/core/framework/op_kernel.cc:1152] Not found: Key rnn/multi_rnn_cell/cell_2/basic_lstm_cell/biases not found in checkpoint
It is followed by a long traceback call message (that I'll provide if it helps).
Unsurprisingly I also cannot generate a bundle file from my checkpoint, for the same reason.
Any suggestion?
</issue>
<code>
[start of magenta/models/polyphony_rnn/polyphony_rnn_generate.py]
1 # Copyright 2016 Google Inc. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """Generate polyphonic tracks from a trained checkpoint.
15
16 Uses flags to define operation.
17 """
18
19 import ast
20 import os
21 import time
22
23 # internal imports
24
25 import tensorflow as tf
26 import magenta
27
28 from magenta.models.polyphony_rnn import polyphony_model
29 from magenta.models.polyphony_rnn import polyphony_sequence_generator
30
31 from magenta.music import constants
32 from magenta.protobuf import generator_pb2
33 from magenta.protobuf import music_pb2
34
35 FLAGS = tf.app.flags.FLAGS
36 tf.app.flags.DEFINE_string(
37 'run_dir', None,
38 'Path to the directory where the latest checkpoint will be loaded from.')
39 tf.app.flags.DEFINE_string(
40 'bundle_file', None,
41 'Path to the bundle file. If specified, this will take priority over '
42 'run_dir, unless save_generator_bundle is True, in which case both this '
43 'flag and run_dir are required')
44 tf.app.flags.DEFINE_boolean(
45 'save_generator_bundle', False,
46 'If true, instead of generating a sequence, will save this generator as a '
47 'bundle file in the location specified by the bundle_file flag')
48 tf.app.flags.DEFINE_string(
49 'bundle_description', None,
50 'A short, human-readable text description of the bundle (e.g., training '
51 'data, hyper parameters, etc.).')
52 tf.app.flags.DEFINE_string(
53 'config', 'polyphony', 'Config to use.')
54 tf.app.flags.DEFINE_string(
55 'output_dir', '/tmp/polyphony_rnn/generated',
56 'The directory where MIDI files will be saved to.')
57 tf.app.flags.DEFINE_integer(
58 'num_outputs', 10,
59 'The number of tracks to generate. One MIDI file will be created for '
60 'each.')
61 tf.app.flags.DEFINE_integer(
62 'num_steps', 128,
63 'The total number of steps the generated track should be, priming '
64 'track length + generated steps. Each step is a 16th of a bar.')
65 tf.app.flags.DEFINE_string(
66 'primer_pitches', '',
67 'A string representation of a Python list of pitches that will be used as '
68 'a starting chord with a quarter note duration. For example: '
69 '"[60, 64, 67]"')
70 tf.app.flags.DEFINE_string(
71 'primer_melody', '',
72 'A string representation of a Python list of '
73 'magenta.music.Melody event values. For example: '
74 '"[60, -2, 60, -2, 67, -2, 67, -2]".')
75 tf.app.flags.DEFINE_string(
76 'primer_midi', '',
77 'The path to a MIDI file containing a polyphonic track that will be used '
78 'as a priming track.')
79 tf.app.flags.DEFINE_boolean(
80 'condition_on_primer', False,
81 'If set, the RNN will receive the primer as its input before it begins '
82 'generating a new sequence.')
83 tf.app.flags.DEFINE_boolean(
84 'inject_primer_during_generation', True,
85 'If set, the primer will be injected as a part of the generated sequence. '
86 'This option is useful if you want the model to harmonize an existing '
87 'melody.')
88 tf.app.flags.DEFINE_float(
89 'qpm', None,
90 'The quarters per minute to play generated output at. If a primer MIDI is '
91 'given, the qpm from that will override this flag. If qpm is None, qpm '
92 'will default to 120.')
93 tf.app.flags.DEFINE_float(
94 'temperature', 1.0,
95 'The randomness of the generated tracks. 1.0 uses the unaltered '
96 'softmax probabilities, greater than 1.0 makes tracks more random, less '
97 'than 1.0 makes tracks less random.')
98 tf.app.flags.DEFINE_integer(
99 'beam_size', 1,
100 'The beam size to use for beam search when generating tracks.')
101 tf.app.flags.DEFINE_integer(
102 'branch_factor', 1,
103 'The branch factor to use for beam search when generating tracks.')
104 tf.app.flags.DEFINE_integer(
105 'steps_per_iteration', 1,
106 'The number of steps to take per beam search iteration.')
107 tf.app.flags.DEFINE_string(
108 'log', 'INFO',
109 'The threshold for what messages will be logged DEBUG, INFO, WARN, ERROR, '
110 'or FATAL.')
111
112
113 def get_checkpoint():
114 """Get the training dir or checkpoint path to be used by the model."""
115 if FLAGS.run_dir and FLAGS.bundle_file and not FLAGS.save_generator_bundle:
116 raise magenta.music.SequenceGeneratorException(
117 'Cannot specify both bundle_file and run_dir')
118 if FLAGS.run_dir:
119 train_dir = os.path.join(os.path.expanduser(FLAGS.run_dir), 'train')
120 return train_dir
121 else:
122 return None
123
124
125 def get_bundle():
126 """Returns a generator_pb2.GeneratorBundle object based read from bundle_file.
127
128 Returns:
129 Either a generator_pb2.GeneratorBundle or None if the bundle_file flag is
130 not set or the save_generator_bundle flag is set.
131 """
132 if FLAGS.save_generator_bundle:
133 return None
134 if FLAGS.bundle_file is None:
135 return None
136 bundle_file = os.path.expanduser(FLAGS.bundle_file)
137 return magenta.music.read_bundle_file(bundle_file)
138
139
140 def run_with_flags(generator):
141 """Generates polyphonic tracks and saves them as MIDI files.
142
143 Uses the options specified by the flags defined in this module.
144
145 Args:
146 generator: The PolyphonyRnnSequenceGenerator to use for generation.
147 """
148 if not FLAGS.output_dir:
149 tf.logging.fatal('--output_dir required')
150 return
151 output_dir = os.path.expanduser(FLAGS.output_dir)
152
153 primer_midi = None
154 if FLAGS.primer_midi:
155 primer_midi = os.path.expanduser(FLAGS.primer_midi)
156
157 if not tf.gfile.Exists(output_dir):
158 tf.gfile.MakeDirs(output_dir)
159
160 primer_sequence = None
161 qpm = FLAGS.qpm if FLAGS.qpm else magenta.music.DEFAULT_QUARTERS_PER_MINUTE
162 if FLAGS.primer_pitches:
163 primer_sequence = music_pb2.NoteSequence()
164 primer_sequence.tempos.add().qpm = qpm
165 primer_sequence.ticks_per_quarter = constants.STANDARD_PPQ
166 for pitch in ast.literal_eval(FLAGS.primer_pitches):
167 note = primer_sequence.notes.add()
168 note.start_time = 0
169 note.end_time = 60.0 / qpm
170 note.pitch = pitch
171 note.velocity = 100
172 primer_sequence.total_time = primer_sequence.notes[-1].end_time
173 elif FLAGS.primer_melody:
174 primer_melody = magenta.music.Melody(ast.literal_eval(FLAGS.primer_melody))
175 primer_sequence = primer_melody.to_sequence(qpm=qpm)
176 elif primer_midi:
177 primer_sequence = magenta.music.midi_file_to_sequence_proto(primer_midi)
178 if primer_sequence.tempos and primer_sequence.tempos[0].qpm:
179 qpm = primer_sequence.tempos[0].qpm
180 else:
181 tf.logging.warning(
182 'No priming sequence specified. Defaulting to empty sequence.')
183 primer_sequence = music_pb2.NoteSequence()
184 primer_sequence.tempos.add().qpm = qpm
185 primer_sequence.ticks_per_quarter = constants.STANDARD_PPQ
186
187 # Derive the total number of seconds to generate.
188 seconds_per_step = 60.0 / qpm / generator.steps_per_quarter
189 generate_end_time = FLAGS.num_steps * seconds_per_step
190
191 # Specify start/stop time for generation based on starting generation at the
192 # end of the priming sequence and continuing until the sequence is num_steps
193 # long.
194 generator_options = generator_pb2.GeneratorOptions()
195 # Set the start time to begin when the last note ends.
196 generate_section = generator_options.generate_sections.add(
197 start_time=primer_sequence.total_time,
198 end_time=generate_end_time)
199
200 if generate_section.start_time >= generate_section.end_time:
201 tf.logging.fatal(
202 'Priming sequence is longer than the total number of steps '
203 'requested: Priming sequence length: %s, Total length '
204 'requested: %s',
205 generate_section.start_time, generate_end_time)
206 return
207
208 generator_options.args['temperature'].float_value = FLAGS.temperature
209 generator_options.args['beam_size'].int_value = FLAGS.beam_size
210 generator_options.args['branch_factor'].int_value = FLAGS.branch_factor
211 generator_options.args[
212 'steps_per_iteration'].int_value = FLAGS.steps_per_iteration
213
214 generator_options.args['condition_on_primer'].bool_value = (
215 FLAGS.condition_on_primer)
216 generator_options.args['no_inject_primer_during_generation'].bool_value = (
217 not FLAGS.inject_primer_during_generation)
218
219 tf.logging.debug('primer_sequence: %s', primer_sequence)
220 tf.logging.debug('generator_options: %s', generator_options)
221
222 # Make the generate request num_outputs times and save the output as midi
223 # files.
224 date_and_time = time.strftime('%Y-%m-%d_%H%M%S')
225 digits = len(str(FLAGS.num_outputs))
226 for i in range(FLAGS.num_outputs):
227 generated_sequence = generator.generate(primer_sequence, generator_options)
228
229 midi_filename = '%s_%s.mid' % (date_and_time, str(i + 1).zfill(digits))
230 midi_path = os.path.join(output_dir, midi_filename)
231 magenta.music.sequence_proto_to_midi_file(generated_sequence, midi_path)
232
233 tf.logging.info('Wrote %d MIDI files to %s',
234 FLAGS.num_outputs, output_dir)
235
236
237 def main(unused_argv):
238 """Saves bundle or runs generator based on flags."""
239 tf.logging.set_verbosity(FLAGS.log)
240
241 config = polyphony_model.default_configs[FLAGS.config]
242
243 generator = polyphony_sequence_generator.PolyphonyRnnSequenceGenerator(
244 model=polyphony_model.PolyphonyRnnModel(config),
245 details=config.details,
246 steps_per_quarter=config.steps_per_quarter,
247 checkpoint=get_checkpoint(),
248 bundle=get_bundle())
249
250 if FLAGS.save_generator_bundle:
251 bundle_filename = os.path.expanduser(FLAGS.bundle_file)
252 if FLAGS.bundle_description is None:
253 tf.logging.warning('No bundle description provided.')
254 tf.logging.info('Saving generator bundle to %s', bundle_filename)
255 generator.create_bundle_file(bundle_filename, FLAGS.bundle_description)
256 else:
257 run_with_flags(generator)
258
259
260 def console_entry_point():
261 tf.app.run(main)
262
263
264 if __name__ == '__main__':
265 console_entry_point()
266
[end of magenta/models/polyphony_rnn/polyphony_rnn_generate.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/magenta/models/polyphony_rnn/polyphony_rnn_generate.py b/magenta/models/polyphony_rnn/polyphony_rnn_generate.py
--- a/magenta/models/polyphony_rnn/polyphony_rnn_generate.py
+++ b/magenta/models/polyphony_rnn/polyphony_rnn_generate.py
@@ -108,6 +108,11 @@
'log', 'INFO',
'The threshold for what messages will be logged DEBUG, INFO, WARN, ERROR, '
'or FATAL.')
+tf.app.flags.DEFINE_string(
+ 'hparams', '{}',
+ 'String representation of a Python dictionary containing hyperparameter '
+ 'to value mapping. This mapping is merged with the default '
+ 'hyperparameters.')
def get_checkpoint():
@@ -239,6 +244,7 @@
tf.logging.set_verbosity(FLAGS.log)
config = polyphony_model.default_configs[FLAGS.config]
+ config.hparams.parse(FLAGS.hparams)
generator = polyphony_sequence_generator.PolyphonyRnnSequenceGenerator(
model=polyphony_model.PolyphonyRnnModel(config),
| {"golden_diff": "diff --git a/magenta/models/polyphony_rnn/polyphony_rnn_generate.py b/magenta/models/polyphony_rnn/polyphony_rnn_generate.py\n--- a/magenta/models/polyphony_rnn/polyphony_rnn_generate.py\n+++ b/magenta/models/polyphony_rnn/polyphony_rnn_generate.py\n@@ -108,6 +108,11 @@\n 'log', 'INFO',\n 'The threshold for what messages will be logged DEBUG, INFO, WARN, ERROR, '\n 'or FATAL.')\n+tf.app.flags.DEFINE_string(\n+ 'hparams', '{}',\n+ 'String representation of a Python dictionary containing hyperparameter '\n+ 'to value mapping. This mapping is merged with the default '\n+ 'hyperparameters.')\n \n \n def get_checkpoint():\n@@ -239,6 +244,7 @@\n tf.logging.set_verbosity(FLAGS.log)\n \n config = polyphony_model.default_configs[FLAGS.config]\n+ config.hparams.parse(FLAGS.hparams)\n \n generator = polyphony_sequence_generator.PolyphonyRnnSequenceGenerator(\n model=polyphony_model.PolyphonyRnnModel(config),\n", "issue": "issue training / generating with polyphony_rnn\nHello,\r\n\r\nAfter (apparently successfully) learning an polyphony_rnn model, I cannot generate any sequence.\r\nIf I try to generate from the checkpoint, it returns the following:\r\n\r\n> INFO:tensorflow:Checkpoint used: ./2017_05_04//run1/train/model.ckpt-3122\r\nINFO:tensorflow:Restoring parameters from ./2017_05_04//run1/train/model.ckpt-3122\r\n2017-05-04 18:18:18.663347: W tensorflow/core/framework/op_kernel.cc:1152] Not found: Key rnn/multi_rnn_cell/cell_2/basic_lstm_cell/weights not found in checkpoint\r\n2017-05-04 18:18:18.666763: W tensorflow/core/framework/op_kernel.cc:1152] Not found: Key rnn/multi_rnn_cell/cell_2/basic_lstm_cell/biases not found in checkpoint\r\n\r\nIt is followed by a long traceback call message (that I'll provide if it helps).\r\n\r\nUnsurprisingly I also cannot generate a bundle file from my checkpoint, for the same reason.\r\n\r\nAny suggestion?\r\n\n", "before_files": [{"content": "# Copyright 2016 Google Inc. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Generate polyphonic tracks from a trained checkpoint.\n\nUses flags to define operation.\n\"\"\"\n\nimport ast\nimport os\nimport time\n\n# internal imports\n\nimport tensorflow as tf\nimport magenta\n\nfrom magenta.models.polyphony_rnn import polyphony_model\nfrom magenta.models.polyphony_rnn import polyphony_sequence_generator\n\nfrom magenta.music import constants\nfrom magenta.protobuf import generator_pb2\nfrom magenta.protobuf import music_pb2\n\nFLAGS = tf.app.flags.FLAGS\ntf.app.flags.DEFINE_string(\n 'run_dir', None,\n 'Path to the directory where the latest checkpoint will be loaded from.')\ntf.app.flags.DEFINE_string(\n 'bundle_file', None,\n 'Path to the bundle file. If specified, this will take priority over '\n 'run_dir, unless save_generator_bundle is True, in which case both this '\n 'flag and run_dir are required')\ntf.app.flags.DEFINE_boolean(\n 'save_generator_bundle', False,\n 'If true, instead of generating a sequence, will save this generator as a '\n 'bundle file in the location specified by the bundle_file flag')\ntf.app.flags.DEFINE_string(\n 'bundle_description', None,\n 'A short, human-readable text description of the bundle (e.g., training '\n 'data, hyper parameters, etc.).')\ntf.app.flags.DEFINE_string(\n 'config', 'polyphony', 'Config to use.')\ntf.app.flags.DEFINE_string(\n 'output_dir', '/tmp/polyphony_rnn/generated',\n 'The directory where MIDI files will be saved to.')\ntf.app.flags.DEFINE_integer(\n 'num_outputs', 10,\n 'The number of tracks to generate. One MIDI file will be created for '\n 'each.')\ntf.app.flags.DEFINE_integer(\n 'num_steps', 128,\n 'The total number of steps the generated track should be, priming '\n 'track length + generated steps. Each step is a 16th of a bar.')\ntf.app.flags.DEFINE_string(\n 'primer_pitches', '',\n 'A string representation of a Python list of pitches that will be used as '\n 'a starting chord with a quarter note duration. For example: '\n '\"[60, 64, 67]\"')\ntf.app.flags.DEFINE_string(\n 'primer_melody', '',\n 'A string representation of a Python list of '\n 'magenta.music.Melody event values. For example: '\n '\"[60, -2, 60, -2, 67, -2, 67, -2]\".')\ntf.app.flags.DEFINE_string(\n 'primer_midi', '',\n 'The path to a MIDI file containing a polyphonic track that will be used '\n 'as a priming track.')\ntf.app.flags.DEFINE_boolean(\n 'condition_on_primer', False,\n 'If set, the RNN will receive the primer as its input before it begins '\n 'generating a new sequence.')\ntf.app.flags.DEFINE_boolean(\n 'inject_primer_during_generation', True,\n 'If set, the primer will be injected as a part of the generated sequence. '\n 'This option is useful if you want the model to harmonize an existing '\n 'melody.')\ntf.app.flags.DEFINE_float(\n 'qpm', None,\n 'The quarters per minute to play generated output at. If a primer MIDI is '\n 'given, the qpm from that will override this flag. If qpm is None, qpm '\n 'will default to 120.')\ntf.app.flags.DEFINE_float(\n 'temperature', 1.0,\n 'The randomness of the generated tracks. 1.0 uses the unaltered '\n 'softmax probabilities, greater than 1.0 makes tracks more random, less '\n 'than 1.0 makes tracks less random.')\ntf.app.flags.DEFINE_integer(\n 'beam_size', 1,\n 'The beam size to use for beam search when generating tracks.')\ntf.app.flags.DEFINE_integer(\n 'branch_factor', 1,\n 'The branch factor to use for beam search when generating tracks.')\ntf.app.flags.DEFINE_integer(\n 'steps_per_iteration', 1,\n 'The number of steps to take per beam search iteration.')\ntf.app.flags.DEFINE_string(\n 'log', 'INFO',\n 'The threshold for what messages will be logged DEBUG, INFO, WARN, ERROR, '\n 'or FATAL.')\n\n\ndef get_checkpoint():\n \"\"\"Get the training dir or checkpoint path to be used by the model.\"\"\"\n if FLAGS.run_dir and FLAGS.bundle_file and not FLAGS.save_generator_bundle:\n raise magenta.music.SequenceGeneratorException(\n 'Cannot specify both bundle_file and run_dir')\n if FLAGS.run_dir:\n train_dir = os.path.join(os.path.expanduser(FLAGS.run_dir), 'train')\n return train_dir\n else:\n return None\n\n\ndef get_bundle():\n \"\"\"Returns a generator_pb2.GeneratorBundle object based read from bundle_file.\n\n Returns:\n Either a generator_pb2.GeneratorBundle or None if the bundle_file flag is\n not set or the save_generator_bundle flag is set.\n \"\"\"\n if FLAGS.save_generator_bundle:\n return None\n if FLAGS.bundle_file is None:\n return None\n bundle_file = os.path.expanduser(FLAGS.bundle_file)\n return magenta.music.read_bundle_file(bundle_file)\n\n\ndef run_with_flags(generator):\n \"\"\"Generates polyphonic tracks and saves them as MIDI files.\n\n Uses the options specified by the flags defined in this module.\n\n Args:\n generator: The PolyphonyRnnSequenceGenerator to use for generation.\n \"\"\"\n if not FLAGS.output_dir:\n tf.logging.fatal('--output_dir required')\n return\n output_dir = os.path.expanduser(FLAGS.output_dir)\n\n primer_midi = None\n if FLAGS.primer_midi:\n primer_midi = os.path.expanduser(FLAGS.primer_midi)\n\n if not tf.gfile.Exists(output_dir):\n tf.gfile.MakeDirs(output_dir)\n\n primer_sequence = None\n qpm = FLAGS.qpm if FLAGS.qpm else magenta.music.DEFAULT_QUARTERS_PER_MINUTE\n if FLAGS.primer_pitches:\n primer_sequence = music_pb2.NoteSequence()\n primer_sequence.tempos.add().qpm = qpm\n primer_sequence.ticks_per_quarter = constants.STANDARD_PPQ\n for pitch in ast.literal_eval(FLAGS.primer_pitches):\n note = primer_sequence.notes.add()\n note.start_time = 0\n note.end_time = 60.0 / qpm\n note.pitch = pitch\n note.velocity = 100\n primer_sequence.total_time = primer_sequence.notes[-1].end_time\n elif FLAGS.primer_melody:\n primer_melody = magenta.music.Melody(ast.literal_eval(FLAGS.primer_melody))\n primer_sequence = primer_melody.to_sequence(qpm=qpm)\n elif primer_midi:\n primer_sequence = magenta.music.midi_file_to_sequence_proto(primer_midi)\n if primer_sequence.tempos and primer_sequence.tempos[0].qpm:\n qpm = primer_sequence.tempos[0].qpm\n else:\n tf.logging.warning(\n 'No priming sequence specified. Defaulting to empty sequence.')\n primer_sequence = music_pb2.NoteSequence()\n primer_sequence.tempos.add().qpm = qpm\n primer_sequence.ticks_per_quarter = constants.STANDARD_PPQ\n\n # Derive the total number of seconds to generate.\n seconds_per_step = 60.0 / qpm / generator.steps_per_quarter\n generate_end_time = FLAGS.num_steps * seconds_per_step\n\n # Specify start/stop time for generation based on starting generation at the\n # end of the priming sequence and continuing until the sequence is num_steps\n # long.\n generator_options = generator_pb2.GeneratorOptions()\n # Set the start time to begin when the last note ends.\n generate_section = generator_options.generate_sections.add(\n start_time=primer_sequence.total_time,\n end_time=generate_end_time)\n\n if generate_section.start_time >= generate_section.end_time:\n tf.logging.fatal(\n 'Priming sequence is longer than the total number of steps '\n 'requested: Priming sequence length: %s, Total length '\n 'requested: %s',\n generate_section.start_time, generate_end_time)\n return\n\n generator_options.args['temperature'].float_value = FLAGS.temperature\n generator_options.args['beam_size'].int_value = FLAGS.beam_size\n generator_options.args['branch_factor'].int_value = FLAGS.branch_factor\n generator_options.args[\n 'steps_per_iteration'].int_value = FLAGS.steps_per_iteration\n\n generator_options.args['condition_on_primer'].bool_value = (\n FLAGS.condition_on_primer)\n generator_options.args['no_inject_primer_during_generation'].bool_value = (\n not FLAGS.inject_primer_during_generation)\n\n tf.logging.debug('primer_sequence: %s', primer_sequence)\n tf.logging.debug('generator_options: %s', generator_options)\n\n # Make the generate request num_outputs times and save the output as midi\n # files.\n date_and_time = time.strftime('%Y-%m-%d_%H%M%S')\n digits = len(str(FLAGS.num_outputs))\n for i in range(FLAGS.num_outputs):\n generated_sequence = generator.generate(primer_sequence, generator_options)\n\n midi_filename = '%s_%s.mid' % (date_and_time, str(i + 1).zfill(digits))\n midi_path = os.path.join(output_dir, midi_filename)\n magenta.music.sequence_proto_to_midi_file(generated_sequence, midi_path)\n\n tf.logging.info('Wrote %d MIDI files to %s',\n FLAGS.num_outputs, output_dir)\n\n\ndef main(unused_argv):\n \"\"\"Saves bundle or runs generator based on flags.\"\"\"\n tf.logging.set_verbosity(FLAGS.log)\n\n config = polyphony_model.default_configs[FLAGS.config]\n\n generator = polyphony_sequence_generator.PolyphonyRnnSequenceGenerator(\n model=polyphony_model.PolyphonyRnnModel(config),\n details=config.details,\n steps_per_quarter=config.steps_per_quarter,\n checkpoint=get_checkpoint(),\n bundle=get_bundle())\n\n if FLAGS.save_generator_bundle:\n bundle_filename = os.path.expanduser(FLAGS.bundle_file)\n if FLAGS.bundle_description is None:\n tf.logging.warning('No bundle description provided.')\n tf.logging.info('Saving generator bundle to %s', bundle_filename)\n generator.create_bundle_file(bundle_filename, FLAGS.bundle_description)\n else:\n run_with_flags(generator)\n\n\ndef console_entry_point():\n tf.app.run(main)\n\n\nif __name__ == '__main__':\n console_entry_point()\n", "path": "magenta/models/polyphony_rnn/polyphony_rnn_generate.py"}]} | 3,938 | 241 |
gh_patches_debug_20687 | rasdani/github-patches | git_diff | jupyterhub__jupyterhub-3208 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CI: jupyter-server build fails since late september
The `test_singleuser_auth` step fails with the following error ([example failure](https://travis-ci.org/github/jupyterhub/jupyterhub/jobs/729518444))
```
404 Client Error: Not Found for url: http://127.0.0.1:59471/@/space%20word/user/nandy/api/spec.yaml?redirects=2
```
Has something change with regards to `@` symbols or spaces in words like `space word`? Yes it has, in `jupyter-server` it seems, because there have been releases in this time span.

## References
- [jupyter-server changelog](https://github.com/jupyter/jupyter_server/blob/master/CHANGELOG.md)
- [The only PR that I saw in the changelog with clear potential to cause our CI error](https://github.com/jupyter/jupyter_server/pull/304)
- [A seemingly related PR by, @minrk](https://github.com/jupyterhub/jupyterhub/pull/3168)
- [Another seemingly related PR, by @danlester](https://github.com/jupyterhub/jupyterhub/pull/3167)
</issue>
<code>
[start of jupyterhub/traitlets.py]
1 """
2 Traitlets that are used in JupyterHub
3 """
4 # Copyright (c) Jupyter Development Team.
5 # Distributed under the terms of the Modified BSD License.
6 import entrypoints
7 from traitlets import Integer
8 from traitlets import List
9 from traitlets import TraitError
10 from traitlets import TraitType
11 from traitlets import Type
12 from traitlets import Unicode
13
14
15 class URLPrefix(Unicode):
16 def validate(self, obj, value):
17 u = super().validate(obj, value)
18 if not u.startswith('/'):
19 u = '/' + u
20 if not u.endswith('/'):
21 u = u + '/'
22 return u
23
24
25 class Command(List):
26 """Traitlet for a command that should be a list of strings,
27 but allows it to be specified as a single string.
28 """
29
30 def __init__(self, default_value=None, **kwargs):
31 kwargs.setdefault('minlen', 1)
32 if isinstance(default_value, str):
33 default_value = [default_value]
34 super().__init__(Unicode(), default_value, **kwargs)
35
36 def validate(self, obj, value):
37 if isinstance(value, str):
38 value = [value]
39 return super().validate(obj, value)
40
41
42 class ByteSpecification(Integer):
43 """
44 Allow easily specifying bytes in units of 1024 with suffixes
45
46 Suffixes allowed are:
47 - K -> Kilobyte
48 - M -> Megabyte
49 - G -> Gigabyte
50 - T -> Terabyte
51 """
52
53 UNIT_SUFFIXES = {
54 'K': 1024,
55 'M': 1024 * 1024,
56 'G': 1024 * 1024 * 1024,
57 'T': 1024 * 1024 * 1024 * 1024,
58 }
59
60 # Default to allowing None as a value
61 allow_none = True
62
63 def validate(self, obj, value):
64 """
65 Validate that the passed in value is a valid memory specification
66
67 It could either be a pure int, when it is taken as a byte value.
68 If it has one of the suffixes, it is converted into the appropriate
69 pure byte value.
70 """
71 if isinstance(value, (int, float)):
72 return int(value)
73
74 try:
75 num = float(value[:-1])
76 except ValueError:
77 raise TraitError(
78 '{val} is not a valid memory specification. Must be an int or a string with suffix K, M, G, T'.format(
79 val=value
80 )
81 )
82 suffix = value[-1]
83 if suffix not in self.UNIT_SUFFIXES:
84 raise TraitError(
85 '{val} is not a valid memory specification. Must be an int or a string with suffix K, M, G, T'.format(
86 val=value
87 )
88 )
89 else:
90 return int(float(num) * self.UNIT_SUFFIXES[suffix])
91
92
93 class Callable(TraitType):
94 """
95 A trait which is callable.
96
97 Classes are callable, as are instances
98 with a __call__() method.
99 """
100
101 info_text = 'a callable'
102
103 def validate(self, obj, value):
104 if callable(value):
105 return value
106 else:
107 self.error(obj, value)
108
109
110 class EntryPointType(Type):
111 """Entry point-extended Type
112
113 classes can be registered via entry points
114 in addition to standard 'mypackage.MyClass' strings
115 """
116
117 _original_help = ''
118
119 def __init__(self, *args, entry_point_group, **kwargs):
120 self.entry_point_group = entry_point_group
121 super().__init__(*args, **kwargs)
122
123 @property
124 def help(self):
125 """Extend help by listing currently installed choices"""
126 chunks = [self._original_help]
127 chunks.append("Currently installed: ")
128 for key, entry_point in self.load_entry_points().items():
129 chunks.append(
130 " - {}: {}.{}".format(
131 key, entry_point.module_name, entry_point.object_name
132 )
133 )
134 return '\n'.join(chunks)
135
136 @help.setter
137 def help(self, value):
138 self._original_help = value
139
140 def load_entry_points(self):
141 """Load my entry point group"""
142 # load the group
143 group = entrypoints.get_group_named(self.entry_point_group)
144 # make it case-insensitive
145 return {key.lower(): value for key, value in group.items()}
146
147 def validate(self, obj, value):
148 if isinstance(value, str):
149 # first, look up in entry point registry
150 registry = self.load_entry_points()
151 key = value.lower()
152 if key in registry:
153 value = registry[key].load()
154 return super().validate(obj, value)
155
[end of jupyterhub/traitlets.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/jupyterhub/traitlets.py b/jupyterhub/traitlets.py
--- a/jupyterhub/traitlets.py
+++ b/jupyterhub/traitlets.py
@@ -9,6 +9,7 @@
from traitlets import TraitError
from traitlets import TraitType
from traitlets import Type
+from traitlets import Undefined
from traitlets import Unicode
@@ -27,11 +28,15 @@
but allows it to be specified as a single string.
"""
- def __init__(self, default_value=None, **kwargs):
+ def __init__(self, default_value=Undefined, **kwargs):
kwargs.setdefault('minlen', 1)
if isinstance(default_value, str):
default_value = [default_value]
- super().__init__(Unicode(), default_value, **kwargs)
+ if default_value is not Undefined and (
+ not (default_value is None and not kwargs.get("allow_none", False))
+ ):
+ kwargs["default_value"] = default_value
+ super().__init__(Unicode(), **kwargs)
def validate(self, obj, value):
if isinstance(value, str):
| {"golden_diff": "diff --git a/jupyterhub/traitlets.py b/jupyterhub/traitlets.py\n--- a/jupyterhub/traitlets.py\n+++ b/jupyterhub/traitlets.py\n@@ -9,6 +9,7 @@\n from traitlets import TraitError\n from traitlets import TraitType\n from traitlets import Type\n+from traitlets import Undefined\n from traitlets import Unicode\n \n \n@@ -27,11 +28,15 @@\n but allows it to be specified as a single string.\n \"\"\"\n \n- def __init__(self, default_value=None, **kwargs):\n+ def __init__(self, default_value=Undefined, **kwargs):\n kwargs.setdefault('minlen', 1)\n if isinstance(default_value, str):\n default_value = [default_value]\n- super().__init__(Unicode(), default_value, **kwargs)\n+ if default_value is not Undefined and (\n+ not (default_value is None and not kwargs.get(\"allow_none\", False))\n+ ):\n+ kwargs[\"default_value\"] = default_value\n+ super().__init__(Unicode(), **kwargs)\n \n def validate(self, obj, value):\n if isinstance(value, str):\n", "issue": "CI: jupyter-server build fails since late september\nThe `test_singleuser_auth` step fails with the following error ([example failure](https://travis-ci.org/github/jupyterhub/jupyterhub/jobs/729518444))\r\n\r\n```\r\n404 Client Error: Not Found for url: http://127.0.0.1:59471/@/space%20word/user/nandy/api/spec.yaml?redirects=2\r\n```\r\n\r\nHas something change with regards to `@` symbols or spaces in words like `space word`? Yes it has, in `jupyter-server` it seems, because there have been releases in this time span.\r\n\r\n\r\n\r\n## References\r\n- [jupyter-server changelog](https://github.com/jupyter/jupyter_server/blob/master/CHANGELOG.md)\r\n- [The only PR that I saw in the changelog with clear potential to cause our CI error](https://github.com/jupyter/jupyter_server/pull/304)\r\n- [A seemingly related PR by, @minrk](https://github.com/jupyterhub/jupyterhub/pull/3168)\r\n- [Another seemingly related PR, by @danlester](https://github.com/jupyterhub/jupyterhub/pull/3167)\n", "before_files": [{"content": "\"\"\"\nTraitlets that are used in JupyterHub\n\"\"\"\n# Copyright (c) Jupyter Development Team.\n# Distributed under the terms of the Modified BSD License.\nimport entrypoints\nfrom traitlets import Integer\nfrom traitlets import List\nfrom traitlets import TraitError\nfrom traitlets import TraitType\nfrom traitlets import Type\nfrom traitlets import Unicode\n\n\nclass URLPrefix(Unicode):\n def validate(self, obj, value):\n u = super().validate(obj, value)\n if not u.startswith('/'):\n u = '/' + u\n if not u.endswith('/'):\n u = u + '/'\n return u\n\n\nclass Command(List):\n \"\"\"Traitlet for a command that should be a list of strings,\n but allows it to be specified as a single string.\n \"\"\"\n\n def __init__(self, default_value=None, **kwargs):\n kwargs.setdefault('minlen', 1)\n if isinstance(default_value, str):\n default_value = [default_value]\n super().__init__(Unicode(), default_value, **kwargs)\n\n def validate(self, obj, value):\n if isinstance(value, str):\n value = [value]\n return super().validate(obj, value)\n\n\nclass ByteSpecification(Integer):\n \"\"\"\n Allow easily specifying bytes in units of 1024 with suffixes\n\n Suffixes allowed are:\n - K -> Kilobyte\n - M -> Megabyte\n - G -> Gigabyte\n - T -> Terabyte\n \"\"\"\n\n UNIT_SUFFIXES = {\n 'K': 1024,\n 'M': 1024 * 1024,\n 'G': 1024 * 1024 * 1024,\n 'T': 1024 * 1024 * 1024 * 1024,\n }\n\n # Default to allowing None as a value\n allow_none = True\n\n def validate(self, obj, value):\n \"\"\"\n Validate that the passed in value is a valid memory specification\n\n It could either be a pure int, when it is taken as a byte value.\n If it has one of the suffixes, it is converted into the appropriate\n pure byte value.\n \"\"\"\n if isinstance(value, (int, float)):\n return int(value)\n\n try:\n num = float(value[:-1])\n except ValueError:\n raise TraitError(\n '{val} is not a valid memory specification. Must be an int or a string with suffix K, M, G, T'.format(\n val=value\n )\n )\n suffix = value[-1]\n if suffix not in self.UNIT_SUFFIXES:\n raise TraitError(\n '{val} is not a valid memory specification. Must be an int or a string with suffix K, M, G, T'.format(\n val=value\n )\n )\n else:\n return int(float(num) * self.UNIT_SUFFIXES[suffix])\n\n\nclass Callable(TraitType):\n \"\"\"\n A trait which is callable.\n\n Classes are callable, as are instances\n with a __call__() method.\n \"\"\"\n\n info_text = 'a callable'\n\n def validate(self, obj, value):\n if callable(value):\n return value\n else:\n self.error(obj, value)\n\n\nclass EntryPointType(Type):\n \"\"\"Entry point-extended Type\n\n classes can be registered via entry points\n in addition to standard 'mypackage.MyClass' strings\n \"\"\"\n\n _original_help = ''\n\n def __init__(self, *args, entry_point_group, **kwargs):\n self.entry_point_group = entry_point_group\n super().__init__(*args, **kwargs)\n\n @property\n def help(self):\n \"\"\"Extend help by listing currently installed choices\"\"\"\n chunks = [self._original_help]\n chunks.append(\"Currently installed: \")\n for key, entry_point in self.load_entry_points().items():\n chunks.append(\n \" - {}: {}.{}\".format(\n key, entry_point.module_name, entry_point.object_name\n )\n )\n return '\\n'.join(chunks)\n\n @help.setter\n def help(self, value):\n self._original_help = value\n\n def load_entry_points(self):\n \"\"\"Load my entry point group\"\"\"\n # load the group\n group = entrypoints.get_group_named(self.entry_point_group)\n # make it case-insensitive\n return {key.lower(): value for key, value in group.items()}\n\n def validate(self, obj, value):\n if isinstance(value, str):\n # first, look up in entry point registry\n registry = self.load_entry_points()\n key = value.lower()\n if key in registry:\n value = registry[key].load()\n return super().validate(obj, value)\n", "path": "jupyterhub/traitlets.py"}]} | 2,279 | 263 |
gh_patches_debug_12851 | rasdani/github-patches | git_diff | wright-group__WrightTools-534 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
remove_nans_1D fails for list
```
>>> wt.kit.remove_nans_1D([np.nan, 1, 2, 2])
Traceback (most recent call last):
File "<input>", line 1, in <module>
wt.kit.remove_nans_1D([np.nan, 1, 2, 2])
File "/home/kyle/wright/WrightTools/WrightTools/kit/_array.py", line 223, in rem
ove_nans_1D
return tuple(a[goods] for a in args)
File "/home/kyle/wright/WrightTools/WrightTools/kit/_array.py", line 223, in <ge
nexpr>
return tuple(a[goods] for a in args)
TypeError: list indices must be integers or slices, not list
>>> wt.kit.remove_nans_1D(np.array([np.nan, 1, 2, 2]))
(array([1., 2., 2.]),)
```
</issue>
<code>
[start of WrightTools/kit/_array.py]
1 """Array interaction tools."""
2
3
4 # --- import --------------------------------------------------------------------------------------
5
6
7 import numpy as np
8
9 from .. import exceptions as wt_exceptions
10
11
12 # --- define --------------------------------------------------------------------------------------
13
14
15 __all__ = ['closest_pair',
16 'diff',
17 'fft',
18 'joint_shape',
19 'orthogonal',
20 'remove_nans_1D',
21 'share_nans',
22 'smooth_1D',
23 'unique',
24 'valid_index']
25
26
27 # --- functions -----------------------------------------------------------------------------------
28
29
30 def closest_pair(arr, give='indicies'):
31 """Find the pair of indices corresponding to the closest elements in an array.
32
33 If multiple pairs are equally close, both pairs of indicies are returned.
34 Optionally returns the closest distance itself.
35
36 I am sure that this could be written as a cheaper operation. I
37 wrote this as a quick and dirty method because I need it now to use on some
38 relatively small arrays. Feel free to refactor if you need this operation
39 done as fast as possible. - Blaise 2016-02-07
40
41 Parameters
42 ----------
43 arr : numpy.ndarray
44 The array to search.
45 give : {'indicies', 'distance'} (optional)
46 Toggle return behavior. If 'distance', returns a single float - the
47 closest distance itself. Default is indicies.
48
49 Returns
50 -------
51 list of lists of two tuples
52 List containing lists of two tuples: indicies the nearest pair in the
53 array.
54
55 >>> arr = np.array([0, 1, 2, 3, 3, 4, 5, 6, 1])
56 >>> closest_pair(arr)
57 [[(1,), (8,)], [(3,), (4,)]]
58
59 """
60 idxs = [idx for idx in np.ndindex(arr.shape)]
61 outs = []
62 min_dist = arr.max() - arr.min()
63 for idxa in idxs:
64 for idxb in idxs:
65 if idxa == idxb:
66 continue
67 dist = abs(arr[idxa] - arr[idxb])
68 if dist == min_dist:
69 if not [idxb, idxa] in outs:
70 outs.append([idxa, idxb])
71 elif dist < min_dist:
72 min_dist = dist
73 outs = [[idxa, idxb]]
74 if give == 'indicies':
75 return outs
76 elif give == 'distance':
77 return min_dist
78 else:
79 raise KeyError('give not recognized in closest_pair')
80
81
82 def diff(xi, yi, order=1):
83 """Take the numerical derivative of a 1D array.
84
85 Output is mapped onto the original coordinates using linear interpolation.
86 Expects monotonic xi values.
87
88 Parameters
89 ----------
90 xi : 1D array-like
91 Coordinates.
92 yi : 1D array-like
93 Values.
94 order : positive integer (optional)
95 Order of differentiation.
96
97 Returns
98 -------
99 1D numpy array
100 Numerical derivative. Has the same shape as the input arrays.
101 """
102 yi = np.array(yi).copy()
103 flip = False
104 if xi[-1] < xi[0]:
105 xi = np.flipud(xi.copy())
106 yi = np.flipud(yi)
107 flip = True
108 midpoints = (xi[1:] + xi[:-1]) / 2
109 for _ in range(order):
110 d = np.diff(yi)
111 d /= np.diff(xi)
112 yi = np.interp(xi, midpoints, d)
113 if flip:
114 yi = np.flipud(yi)
115 return yi
116
117
118 def fft(xi, yi, axis=0):
119 """Take the 1D FFT of an N-dimensional array and return "sensible" properly shifted arrays.
120
121 Parameters
122 ----------
123 xi : numpy.ndarray
124 1D array over which the points to be FFT'ed are defined
125 yi : numpy.ndarray
126 ND array with values to FFT
127 axis : int
128 axis of yi to perform FFT over
129
130 Returns
131 -------
132 xi : 1D numpy.ndarray
133 1D array. Conjugate to input xi. Example: if input xi is in the time
134 domain, output xi is in frequency domain.
135 yi : ND numpy.ndarray
136 FFT. Has the same shape as the input array (yi).
137 """
138 # xi must be 1D
139 if xi.ndim != 1:
140 raise wt_exceptions.DimensionalityError(1, xi.ndim)
141 # xi must be evenly spaced
142 spacing = np.diff(xi)
143 if not np.allclose(spacing, spacing.mean()):
144 raise RuntimeError('WrightTools.kit.fft: argument xi must be evenly spaced')
145 # fft
146 yi = np.fft.fft(yi, axis=axis)
147 d = (xi.max() - xi.min()) / (xi.size - 1)
148 xi = np.fft.fftfreq(xi.size, d=d)
149 # shift
150 xi = np.fft.fftshift(xi)
151 yi = np.fft.fftshift(yi, axes=axis)
152 return xi, yi
153
154
155 def joint_shape(*args):
156 """Given a set of arrays, return the joint shape.
157
158 Parameters
159 ----------
160 args : array-likes
161
162 Returns
163 -------
164 tuple of int
165 Joint shape.
166 """
167 if len(args) == 0:
168 return ()
169 shape = []
170 shapes = [a.shape for a in args]
171 ndim = args[0].ndim
172 for i in range(ndim):
173 shape.append(max([s[i] for s in shapes]))
174 return tuple(shape)
175
176
177 def orthogonal(*args):
178 """Determine if a set of arrays are orthogonal.
179
180 Parameters
181 ----------
182 args : array-likes or array shapes
183
184 Returns
185 -------
186 bool
187 Array orthogonality condition.
188 """
189 for i, arg in enumerate(args):
190 if hasattr(arg, 'shape'):
191 args[i] = arg.shape
192 for s in zip(*args):
193 if np.product(s) != max(s):
194 return False
195 return True
196
197
198 def remove_nans_1D(*args):
199 """Remove nans in a set of 1D arrays.
200
201 Removes indicies in all arrays if any array is nan at that index.
202 All input arrays must have the same size.
203
204 Parameters
205 ----------
206 args : 1D arrays
207
208 Returns
209 -------
210 tuple
211 Tuple of 1D arrays in same order as given, with nan indicies removed.
212 """
213 # find all indicies to keep
214 bads = np.array([])
215 for arr in args:
216 bad = np.array(np.where(np.isnan(arr))).flatten()
217 bads = np.hstack((bad, bads))
218 if hasattr(args, 'shape') and len(args.shape) == 1:
219 goods = [i for i in np.arange(args.shape[0]) if i not in bads]
220 else:
221 goods = [i for i in np.arange(len(args[0])) if i not in bads]
222 # apply
223 return tuple(a[goods] for a in args)
224
225
226 def share_nans(*arrs):
227 """Take a list of nD arrays and return a new list of nD arrays.
228
229 The new list is in the same order as the old list.
230 If one indexed element in an old array is nan then every element for that
231 index in all new arrays in the list is then nan.
232
233 Parameters
234 ----------
235 *arrs : nD arrays.
236
237 Returns
238 -------
239 list
240 List of nD arrays in same order as given, with nan indicies syncronized.
241 """
242 nans = np.zeros((arrs[0].shape))
243 for arr in arrs:
244 nans *= arr
245 return tuple([a + nans for a in arrs])
246
247
248 def smooth_1D(arr, n=10):
249 """Smooth 1D data by 'running average'.
250
251 Parameters
252 ----------
253 n : int
254 number of points to average
255 """
256 for i in range(n, len(arr) - n):
257 window = arr[i - n:i + n].copy()
258 arr[i] = window.mean()
259 return arr
260
261
262 def unique(arr, tolerance=1e-6):
263 """Return unique elements in 1D array, within tolerance.
264
265 Parameters
266 ----------
267 arr : array_like
268 Input array. This will be flattened if it is not already 1D.
269 tolerance : number (optional)
270 The tolerance for uniqueness.
271
272 Returns
273 -------
274 array
275 The sorted unique values.
276 """
277 arr = sorted(arr.flatten())
278 unique = []
279 while len(arr) > 0:
280 current = arr[0]
281 lis = [xi for xi in arr if np.abs(current - xi) < tolerance]
282 arr = [xi for xi in arr if not np.abs(lis[0] - xi) < tolerance]
283 xi_lis_average = sum(lis) / len(lis)
284 unique.append(xi_lis_average)
285 return np.array(unique)
286
287
288 def valid_index(index, shape):
289 """Get a valid index for a broadcastable shape.
290
291 Parameters
292 ----------
293 index : tuple
294 Given index.
295 shape : tuple of int
296 Shape.
297
298 Returns
299 -------
300 tuple
301 Valid index.
302 """
303 # append slices to index
304 index = list(index)
305 while len(index) < len(shape):
306 index.append(slice(None))
307 # fill out, in reverse
308 out = []
309 for i, s in zip(index[::-1], shape[::-1]):
310 if s == 1:
311 if isinstance(i, slice):
312 out.append(slice(None))
313 else:
314 out.append(0)
315 else:
316 out.append(i)
317 return tuple(out[::-1])
318
[end of WrightTools/kit/_array.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/WrightTools/kit/_array.py b/WrightTools/kit/_array.py
--- a/WrightTools/kit/_array.py
+++ b/WrightTools/kit/_array.py
@@ -210,17 +210,10 @@
tuple
Tuple of 1D arrays in same order as given, with nan indicies removed.
"""
- # find all indicies to keep
- bads = np.array([])
- for arr in args:
- bad = np.array(np.where(np.isnan(arr))).flatten()
- bads = np.hstack((bad, bads))
- if hasattr(args, 'shape') and len(args.shape) == 1:
- goods = [i for i in np.arange(args.shape[0]) if i not in bads]
- else:
- goods = [i for i in np.arange(len(args[0])) if i not in bads]
- # apply
- return tuple(a[goods] for a in args)
+ vals = np.isnan(args[0])
+ for a in args:
+ vals |= np.isnan(a)
+ return tuple(np.array(a)[vals == False] for a in args)
def share_nans(*arrs):
| {"golden_diff": "diff --git a/WrightTools/kit/_array.py b/WrightTools/kit/_array.py\n--- a/WrightTools/kit/_array.py\n+++ b/WrightTools/kit/_array.py\n@@ -210,17 +210,10 @@\n tuple\n Tuple of 1D arrays in same order as given, with nan indicies removed.\n \"\"\"\n- # find all indicies to keep\n- bads = np.array([])\n- for arr in args:\n- bad = np.array(np.where(np.isnan(arr))).flatten()\n- bads = np.hstack((bad, bads))\n- if hasattr(args, 'shape') and len(args.shape) == 1:\n- goods = [i for i in np.arange(args.shape[0]) if i not in bads]\n- else:\n- goods = [i for i in np.arange(len(args[0])) if i not in bads]\n- # apply\n- return tuple(a[goods] for a in args)\n+ vals = np.isnan(args[0])\n+ for a in args:\n+ vals |= np.isnan(a)\n+ return tuple(np.array(a)[vals == False] for a in args)\n \n \n def share_nans(*arrs):\n", "issue": "remove_nans_1D fails for list\n```\r\n>>> wt.kit.remove_nans_1D([np.nan, 1, 2, 2])\r\nTraceback (most recent call last):\r\n File \"<input>\", line 1, in <module>\r\n wt.kit.remove_nans_1D([np.nan, 1, 2, 2])\r\n File \"/home/kyle/wright/WrightTools/WrightTools/kit/_array.py\", line 223, in rem\r\nove_nans_1D\r\n return tuple(a[goods] for a in args)\r\n File \"/home/kyle/wright/WrightTools/WrightTools/kit/_array.py\", line 223, in <ge\r\nnexpr>\r\n return tuple(a[goods] for a in args)\r\nTypeError: list indices must be integers or slices, not list\r\n>>> wt.kit.remove_nans_1D(np.array([np.nan, 1, 2, 2]))\r\n(array([1., 2., 2.]),)\r\n```\n", "before_files": [{"content": "\"\"\"Array interaction tools.\"\"\"\n\n\n# --- import --------------------------------------------------------------------------------------\n\n\nimport numpy as np\n\nfrom .. import exceptions as wt_exceptions\n\n\n# --- define --------------------------------------------------------------------------------------\n\n\n__all__ = ['closest_pair',\n 'diff',\n 'fft',\n 'joint_shape',\n 'orthogonal',\n 'remove_nans_1D',\n 'share_nans',\n 'smooth_1D',\n 'unique',\n 'valid_index']\n\n\n# --- functions -----------------------------------------------------------------------------------\n\n\ndef closest_pair(arr, give='indicies'):\n \"\"\"Find the pair of indices corresponding to the closest elements in an array.\n\n If multiple pairs are equally close, both pairs of indicies are returned.\n Optionally returns the closest distance itself.\n\n I am sure that this could be written as a cheaper operation. I\n wrote this as a quick and dirty method because I need it now to use on some\n relatively small arrays. Feel free to refactor if you need this operation\n done as fast as possible. - Blaise 2016-02-07\n\n Parameters\n ----------\n arr : numpy.ndarray\n The array to search.\n give : {'indicies', 'distance'} (optional)\n Toggle return behavior. If 'distance', returns a single float - the\n closest distance itself. Default is indicies.\n\n Returns\n -------\n list of lists of two tuples\n List containing lists of two tuples: indicies the nearest pair in the\n array.\n\n >>> arr = np.array([0, 1, 2, 3, 3, 4, 5, 6, 1])\n >>> closest_pair(arr)\n [[(1,), (8,)], [(3,), (4,)]]\n\n \"\"\"\n idxs = [idx for idx in np.ndindex(arr.shape)]\n outs = []\n min_dist = arr.max() - arr.min()\n for idxa in idxs:\n for idxb in idxs:\n if idxa == idxb:\n continue\n dist = abs(arr[idxa] - arr[idxb])\n if dist == min_dist:\n if not [idxb, idxa] in outs:\n outs.append([idxa, idxb])\n elif dist < min_dist:\n min_dist = dist\n outs = [[idxa, idxb]]\n if give == 'indicies':\n return outs\n elif give == 'distance':\n return min_dist\n else:\n raise KeyError('give not recognized in closest_pair')\n\n\ndef diff(xi, yi, order=1):\n \"\"\"Take the numerical derivative of a 1D array.\n\n Output is mapped onto the original coordinates using linear interpolation.\n Expects monotonic xi values.\n\n Parameters\n ----------\n xi : 1D array-like\n Coordinates.\n yi : 1D array-like\n Values.\n order : positive integer (optional)\n Order of differentiation.\n\n Returns\n -------\n 1D numpy array\n Numerical derivative. Has the same shape as the input arrays.\n \"\"\"\n yi = np.array(yi).copy()\n flip = False\n if xi[-1] < xi[0]:\n xi = np.flipud(xi.copy())\n yi = np.flipud(yi)\n flip = True\n midpoints = (xi[1:] + xi[:-1]) / 2\n for _ in range(order):\n d = np.diff(yi)\n d /= np.diff(xi)\n yi = np.interp(xi, midpoints, d)\n if flip:\n yi = np.flipud(yi)\n return yi\n\n\ndef fft(xi, yi, axis=0):\n \"\"\"Take the 1D FFT of an N-dimensional array and return \"sensible\" properly shifted arrays.\n\n Parameters\n ----------\n xi : numpy.ndarray\n 1D array over which the points to be FFT'ed are defined\n yi : numpy.ndarray\n ND array with values to FFT\n axis : int\n axis of yi to perform FFT over\n\n Returns\n -------\n xi : 1D numpy.ndarray\n 1D array. Conjugate to input xi. Example: if input xi is in the time\n domain, output xi is in frequency domain.\n yi : ND numpy.ndarray\n FFT. Has the same shape as the input array (yi).\n \"\"\"\n # xi must be 1D\n if xi.ndim != 1:\n raise wt_exceptions.DimensionalityError(1, xi.ndim)\n # xi must be evenly spaced\n spacing = np.diff(xi)\n if not np.allclose(spacing, spacing.mean()):\n raise RuntimeError('WrightTools.kit.fft: argument xi must be evenly spaced')\n # fft\n yi = np.fft.fft(yi, axis=axis)\n d = (xi.max() - xi.min()) / (xi.size - 1)\n xi = np.fft.fftfreq(xi.size, d=d)\n # shift\n xi = np.fft.fftshift(xi)\n yi = np.fft.fftshift(yi, axes=axis)\n return xi, yi\n\n\ndef joint_shape(*args):\n \"\"\"Given a set of arrays, return the joint shape.\n\n Parameters\n ----------\n args : array-likes\n\n Returns\n -------\n tuple of int\n Joint shape.\n \"\"\"\n if len(args) == 0:\n return ()\n shape = []\n shapes = [a.shape for a in args]\n ndim = args[0].ndim\n for i in range(ndim):\n shape.append(max([s[i] for s in shapes]))\n return tuple(shape)\n\n\ndef orthogonal(*args):\n \"\"\"Determine if a set of arrays are orthogonal.\n\n Parameters\n ----------\n args : array-likes or array shapes\n\n Returns\n -------\n bool\n Array orthogonality condition.\n \"\"\"\n for i, arg in enumerate(args):\n if hasattr(arg, 'shape'):\n args[i] = arg.shape\n for s in zip(*args):\n if np.product(s) != max(s):\n return False\n return True\n\n\ndef remove_nans_1D(*args):\n \"\"\"Remove nans in a set of 1D arrays.\n\n Removes indicies in all arrays if any array is nan at that index.\n All input arrays must have the same size.\n\n Parameters\n ----------\n args : 1D arrays\n\n Returns\n -------\n tuple\n Tuple of 1D arrays in same order as given, with nan indicies removed.\n \"\"\"\n # find all indicies to keep\n bads = np.array([])\n for arr in args:\n bad = np.array(np.where(np.isnan(arr))).flatten()\n bads = np.hstack((bad, bads))\n if hasattr(args, 'shape') and len(args.shape) == 1:\n goods = [i for i in np.arange(args.shape[0]) if i not in bads]\n else:\n goods = [i for i in np.arange(len(args[0])) if i not in bads]\n # apply\n return tuple(a[goods] for a in args)\n\n\ndef share_nans(*arrs):\n \"\"\"Take a list of nD arrays and return a new list of nD arrays.\n\n The new list is in the same order as the old list.\n If one indexed element in an old array is nan then every element for that\n index in all new arrays in the list is then nan.\n\n Parameters\n ----------\n *arrs : nD arrays.\n\n Returns\n -------\n list\n List of nD arrays in same order as given, with nan indicies syncronized.\n \"\"\"\n nans = np.zeros((arrs[0].shape))\n for arr in arrs:\n nans *= arr\n return tuple([a + nans for a in arrs])\n\n\ndef smooth_1D(arr, n=10):\n \"\"\"Smooth 1D data by 'running average'.\n\n Parameters\n ----------\n n : int\n number of points to average\n \"\"\"\n for i in range(n, len(arr) - n):\n window = arr[i - n:i + n].copy()\n arr[i] = window.mean()\n return arr\n\n\ndef unique(arr, tolerance=1e-6):\n \"\"\"Return unique elements in 1D array, within tolerance.\n\n Parameters\n ----------\n arr : array_like\n Input array. This will be flattened if it is not already 1D.\n tolerance : number (optional)\n The tolerance for uniqueness.\n\n Returns\n -------\n array\n The sorted unique values.\n \"\"\"\n arr = sorted(arr.flatten())\n unique = []\n while len(arr) > 0:\n current = arr[0]\n lis = [xi for xi in arr if np.abs(current - xi) < tolerance]\n arr = [xi for xi in arr if not np.abs(lis[0] - xi) < tolerance]\n xi_lis_average = sum(lis) / len(lis)\n unique.append(xi_lis_average)\n return np.array(unique)\n\n\ndef valid_index(index, shape):\n \"\"\"Get a valid index for a broadcastable shape.\n\n Parameters\n ----------\n index : tuple\n Given index.\n shape : tuple of int\n Shape.\n\n Returns\n -------\n tuple\n Valid index.\n \"\"\"\n # append slices to index\n index = list(index)\n while len(index) < len(shape):\n index.append(slice(None))\n # fill out, in reverse\n out = []\n for i, s in zip(index[::-1], shape[::-1]):\n if s == 1:\n if isinstance(i, slice):\n out.append(slice(None))\n else:\n out.append(0)\n else:\n out.append(i)\n return tuple(out[::-1])\n", "path": "WrightTools/kit/_array.py"}]} | 3,740 | 273 |
gh_patches_debug_16018 | rasdani/github-patches | git_diff | fonttools__fonttools-1839 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Importing a TTFont from XML fails when LC_TIME is set
Importing a font from XML while LC_TIME locale is set to non-English, causes an error.
### How to reproduce?
This might be easy when a non-English locale is available in the system. I came across this, while using a package on top. The corresponding issue in their package is amueller/word_cloud#530. There is a script to reproduce, which only throws an error, when a non-English locale like 'de_DE' is set with e. g. `locale.setlocale(locale.LC_TIME, 'de_DE.UTF-8')` or just by opening Spyder-IDE.
**A simplified test is:**
```python
import locale
locale.setlocale(locale.LC_TIME, 'de_DE.UTF-8') # works if de_DE is available
from fontTools.misc.timeTools import timestampFromString,timestampToString,timestampNow
ts_now = timestampNow()
str_now = timestampToString(ts_now)
timestampFromString(str_now) # ValueError
```
Let's go into the cause of the error.
### Basics
The locale for LC_TIME can be checked with
```python
import locale
print(locale.getlocale(locale.LC_TIME))
```
This outputs `('de_DE', 'UTF-8')` in my case.
With this locale the following fails:
```python
import time
time.strptime('Mon', '%a')
# ValueError: unconverted data remains: n
```
`'Mo'` is the localized abbreviation in de_DE for Monday.
### TTFont
The method [`importXML`](https://github.com/fonttools/fonttools/blob/master/Lib/fontTools/ttLib/ttFont.py#L318) in `TTFont` receives the font object as XML. This can contain created and modified dates. The XML is parsed by the `XMLReader`, which somehow uses the [`fromXML`](https://github.com/fonttools/fonttools/blob/master/Lib/fontTools/ttLib/tables/_h_e_a_d.py#L107) method in `table__h_e_a_d`. There the created and modified dates are parsed using [`timestampFromString`](https://github.com/fonttools/fonttools/blob/master/Lib/fontTools/misc/timeTools.py#L46) from timeTools. This helper function uses `time.strptime(value)`.
In my test case `value` is initialized from the 'created' attribute of a font as `'Mon Jan 8 12:28:04 2007'`, which throws the following error:
```
ValueError: time data 'Mon Jan 8 12:28:04 2007' does not match format '%a %b %d %H:%M:%S %Y'
```
### How to resolve?
I think the parsing should be done without locale, since the XML attribute is likely to be non-local. In the opposite function [`timestampToString`](https://github.com/fonttools/fonttools/blob/master/Lib/fontTools/misc/timeTools.py#L43) `asctime` is used, which uses a fixed list of abbreviated week days and months. So that is not localized. Hence [`timestampFromString`](https://github.com/fonttools/fonttools/blob/master/Lib/fontTools/misc/timeTools.py#L46) shouldn't be localized as well.
A simple solution could be
```python
def timestampFromString(value):
import locale
l = locale.getlocale(locale.LC_TIME)
locale.setlocale(locale.LC_TIME, 'C')
try:
t = time.strptime(value)
finally:
locale.setlocale(locale.LC_TIME, l)
return calendar.timegm(t) - epoch_diff
```
However, changing the locale is not recommended. It's better to use a function that can parse a date with specified locale without changing it. You could use [dateparser](https://dateparser.readthedocs.io/en/latest/) for example, but I don't know about your dependencies and how you handle it.
</issue>
<code>
[start of Lib/fontTools/misc/timeTools.py]
1 """fontTools.misc.timeTools.py -- tools for working with OpenType timestamps.
2 """
3
4 from fontTools.misc.py23 import *
5 import os
6 import time
7 import calendar
8
9
10 epoch_diff = calendar.timegm((1904, 1, 1, 0, 0, 0, 0, 0, 0))
11
12 DAYNAMES = ["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"]
13 MONTHNAMES = [None, "Jan", "Feb", "Mar", "Apr", "May", "Jun",
14 "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"]
15
16
17 def asctime(t=None):
18 """
19 Convert a tuple or struct_time representing a time as returned by gmtime()
20 or localtime() to a 24-character string of the following form:
21
22 >>> asctime(time.gmtime(0))
23 'Thu Jan 1 00:00:00 1970'
24
25 If t is not provided, the current time as returned by localtime() is used.
26 Locale information is not used by asctime().
27
28 This is meant to normalise the output of the built-in time.asctime() across
29 different platforms and Python versions.
30 In Python 3.x, the day of the month is right-justified, whereas on Windows
31 Python 2.7 it is padded with zeros.
32
33 See https://github.com/fonttools/fonttools/issues/455
34 """
35 if t is None:
36 t = time.localtime()
37 s = "%s %s %2s %s" % (
38 DAYNAMES[t.tm_wday], MONTHNAMES[t.tm_mon], t.tm_mday,
39 time.strftime("%H:%M:%S %Y", t))
40 return s
41
42
43 def timestampToString(value):
44 return asctime(time.gmtime(max(0, value + epoch_diff)))
45
46 def timestampFromString(value):
47 return calendar.timegm(time.strptime(value)) - epoch_diff
48
49 def timestampNow():
50 # https://reproducible-builds.org/specs/source-date-epoch/
51 source_date_epoch = os.environ.get("SOURCE_DATE_EPOCH")
52 if source_date_epoch is not None:
53 return int(source_date_epoch) - epoch_diff
54 return int(time.time() - epoch_diff)
55
56 def timestampSinceEpoch(value):
57 return int(value - epoch_diff)
58
59
60 if __name__ == "__main__":
61 import sys
62 import doctest
63 sys.exit(doctest.testmod().failed)
64
[end of Lib/fontTools/misc/timeTools.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/Lib/fontTools/misc/timeTools.py b/Lib/fontTools/misc/timeTools.py
--- a/Lib/fontTools/misc/timeTools.py
+++ b/Lib/fontTools/misc/timeTools.py
@@ -4,6 +4,7 @@
from fontTools.misc.py23 import *
import os
import time
+from datetime import datetime, timezone
import calendar
@@ -44,7 +45,12 @@
return asctime(time.gmtime(max(0, value + epoch_diff)))
def timestampFromString(value):
- return calendar.timegm(time.strptime(value)) - epoch_diff
+ wkday, mnth = value[:7].split()
+ t = datetime.strptime(value[7:], ' %d %H:%M:%S %Y')
+ t = t.replace(month=MONTHNAMES.index(mnth), tzinfo=timezone.utc)
+ wkday_idx = DAYNAMES.index(wkday)
+ assert t.weekday() == wkday_idx, '"' + value + '" has inconsistent weekday'
+ return int(t.timestamp()) - epoch_diff
def timestampNow():
# https://reproducible-builds.org/specs/source-date-epoch/
| {"golden_diff": "diff --git a/Lib/fontTools/misc/timeTools.py b/Lib/fontTools/misc/timeTools.py\n--- a/Lib/fontTools/misc/timeTools.py\n+++ b/Lib/fontTools/misc/timeTools.py\n@@ -4,6 +4,7 @@\n from fontTools.misc.py23 import *\n import os\n import time\n+from datetime import datetime, timezone\n import calendar\n \n \n@@ -44,7 +45,12 @@\n \treturn asctime(time.gmtime(max(0, value + epoch_diff)))\n \n def timestampFromString(value):\n-\treturn calendar.timegm(time.strptime(value)) - epoch_diff\n+\twkday, mnth = value[:7].split()\n+\tt = datetime.strptime(value[7:], ' %d %H:%M:%S %Y')\n+\tt = t.replace(month=MONTHNAMES.index(mnth), tzinfo=timezone.utc)\n+\twkday_idx = DAYNAMES.index(wkday)\n+\tassert t.weekday() == wkday_idx, '\"' + value + '\" has inconsistent weekday'\n+\treturn int(t.timestamp()) - epoch_diff\n \n def timestampNow():\n \t# https://reproducible-builds.org/specs/source-date-epoch/\n", "issue": "Importing a TTFont from XML fails when LC_TIME is set\nImporting a font from XML while LC_TIME locale is set to non-English, causes an error.\r\n\r\n### How to reproduce?\r\n\r\nThis might be easy when a non-English locale is available in the system. I came across this, while using a package on top. The corresponding issue in their package is amueller/word_cloud#530. There is a script to reproduce, which only throws an error, when a non-English locale like 'de_DE' is set with e. g. `locale.setlocale(locale.LC_TIME, 'de_DE.UTF-8')` or just by opening Spyder-IDE.\r\n\r\n**A simplified test is:**\r\n```python\r\nimport locale\r\nlocale.setlocale(locale.LC_TIME, 'de_DE.UTF-8') # works if de_DE is available\r\n\r\nfrom fontTools.misc.timeTools import timestampFromString,timestampToString,timestampNow\r\nts_now = timestampNow()\r\nstr_now = timestampToString(ts_now)\r\ntimestampFromString(str_now) # ValueError\r\n```\r\n\r\nLet's go into the cause of the error.\r\n\r\n### Basics\r\n\r\nThe locale for LC_TIME can be checked with\r\n```python\r\nimport locale\r\nprint(locale.getlocale(locale.LC_TIME))\r\n```\r\nThis outputs `('de_DE', 'UTF-8')` in my case.\r\n\r\nWith this locale the following fails:\r\n```python\r\nimport time\r\ntime.strptime('Mon', '%a')\r\n# ValueError: unconverted data remains: n\r\n```\r\n`'Mo'` is the localized abbreviation in de_DE for Monday.\r\n\r\n### TTFont\r\n\r\nThe method [`importXML`](https://github.com/fonttools/fonttools/blob/master/Lib/fontTools/ttLib/ttFont.py#L318) in `TTFont` receives the font object as XML. This can contain created and modified dates. The XML is parsed by the `XMLReader`, which somehow uses the [`fromXML`](https://github.com/fonttools/fonttools/blob/master/Lib/fontTools/ttLib/tables/_h_e_a_d.py#L107) method in `table__h_e_a_d`. There the created and modified dates are parsed using [`timestampFromString`](https://github.com/fonttools/fonttools/blob/master/Lib/fontTools/misc/timeTools.py#L46) from timeTools. This helper function uses `time.strptime(value)`.\r\n\r\nIn my test case `value` is initialized from the 'created' attribute of a font as `'Mon Jan 8 12:28:04 2007'`, which throws the following error:\r\n```\r\nValueError: time data 'Mon Jan 8 12:28:04 2007' does not match format '%a %b %d %H:%M:%S %Y'\r\n```\r\n\r\n\r\n### How to resolve?\r\n\r\nI think the parsing should be done without locale, since the XML attribute is likely to be non-local. In the opposite function [`timestampToString`](https://github.com/fonttools/fonttools/blob/master/Lib/fontTools/misc/timeTools.py#L43) `asctime` is used, which uses a fixed list of abbreviated week days and months. So that is not localized. Hence [`timestampFromString`](https://github.com/fonttools/fonttools/blob/master/Lib/fontTools/misc/timeTools.py#L46) shouldn't be localized as well.\r\n\r\nA simple solution could be\r\n```python\r\ndef timestampFromString(value):\r\n\timport locale\r\n\tl = locale.getlocale(locale.LC_TIME)\r\n\tlocale.setlocale(locale.LC_TIME, 'C')\r\n\ttry:\r\n\t\tt = time.strptime(value)\r\n\tfinally:\r\n\t\tlocale.setlocale(locale.LC_TIME, l)\r\n\treturn calendar.timegm(t) - epoch_diff\r\n```\r\n\r\nHowever, changing the locale is not recommended. It's better to use a function that can parse a date with specified locale without changing it. You could use [dateparser](https://dateparser.readthedocs.io/en/latest/) for example, but I don't know about your dependencies and how you handle it.\n", "before_files": [{"content": "\"\"\"fontTools.misc.timeTools.py -- tools for working with OpenType timestamps.\n\"\"\"\n\nfrom fontTools.misc.py23 import *\nimport os\nimport time\nimport calendar\n\n\nepoch_diff = calendar.timegm((1904, 1, 1, 0, 0, 0, 0, 0, 0))\n\nDAYNAMES = [\"Mon\", \"Tue\", \"Wed\", \"Thu\", \"Fri\", \"Sat\", \"Sun\"]\nMONTHNAMES = [None, \"Jan\", \"Feb\", \"Mar\", \"Apr\", \"May\", \"Jun\",\n\t\t\t \"Jul\", \"Aug\", \"Sep\", \"Oct\", \"Nov\", \"Dec\"]\n\n\ndef asctime(t=None):\n\t\"\"\"\n\tConvert a tuple or struct_time representing a time as returned by gmtime()\n\tor localtime() to a 24-character string of the following form:\n\n\t>>> asctime(time.gmtime(0))\n\t'Thu Jan 1 00:00:00 1970'\n\n\tIf t is not provided, the current time as returned by localtime() is used.\n\tLocale information is not used by asctime().\n\n\tThis is meant to normalise the output of the built-in time.asctime() across\n\tdifferent platforms and Python versions.\n\tIn Python 3.x, the day of the month is right-justified, whereas on Windows\n\tPython 2.7 it is padded with zeros.\n\n\tSee https://github.com/fonttools/fonttools/issues/455\n\t\"\"\"\n\tif t is None:\n\t\tt = time.localtime()\n\ts = \"%s %s %2s %s\" % (\n\t\tDAYNAMES[t.tm_wday], MONTHNAMES[t.tm_mon], t.tm_mday,\n\t\ttime.strftime(\"%H:%M:%S %Y\", t))\n\treturn s\n\n\ndef timestampToString(value):\n\treturn asctime(time.gmtime(max(0, value + epoch_diff)))\n\ndef timestampFromString(value):\n\treturn calendar.timegm(time.strptime(value)) - epoch_diff\n\ndef timestampNow():\n\t# https://reproducible-builds.org/specs/source-date-epoch/\n\tsource_date_epoch = os.environ.get(\"SOURCE_DATE_EPOCH\")\n\tif source_date_epoch is not None:\n\t\treturn int(source_date_epoch) - epoch_diff\n\treturn int(time.time() - epoch_diff)\n\ndef timestampSinceEpoch(value):\n\treturn int(value - epoch_diff)\n\n\nif __name__ == \"__main__\":\n\timport sys\n\timport doctest\n\tsys.exit(doctest.testmod().failed)\n", "path": "Lib/fontTools/misc/timeTools.py"}]} | 2,057 | 250 |
gh_patches_debug_3077 | rasdani/github-patches | git_diff | SeldonIO__MLServer-1168 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Expected XGBoost model file "model.bst" extension is undocumented?
On https://github.com/SeldonIO/MLServer/blob/master/runtimes/xgboost/mlserver_xgboost/xgboost.py#L21 you can see that MLServer is looking for an XGBoost model file called "model.bst". However, I cannot find any reference to that file extension in the XGBoost documentation. As far as I can see, XGBoost's documented file extensions are:
- ".json" added in 1.0.0, an "open format that can be easily reused"
- ".ubj" for Universal Binary JSON format, available in 1.6.0
- ".model" for the "old binary internal format" prior to 1.0.0, as shown in examples
Where does MLServer get the ".bst" extension from, and what model format does it use? Shouldn't it use one of the extensions mentioned in the XGBoost documentation instead, to avoid ambiguity?
</issue>
<code>
[start of runtimes/xgboost/mlserver_xgboost/xgboost.py]
1 import xgboost as xgb
2
3 from typing import List
4 from xgboost.sklearn import XGBModel
5
6 from mlserver.errors import InferenceError
7 from mlserver.model import MLModel
8 from mlserver.utils import get_model_uri
9 from mlserver.codecs import NumpyRequestCodec, NumpyCodec
10 from mlserver.types import (
11 InferenceRequest,
12 InferenceResponse,
13 RequestOutput,
14 ResponseOutput,
15 )
16
17 PREDICT_OUTPUT = "predict"
18 PREDICT_PROBA_OUTPUT = "predict_proba"
19 VALID_OUTPUTS = [PREDICT_OUTPUT, PREDICT_PROBA_OUTPUT]
20
21 WELLKNOWN_MODEL_FILENAMES = ["model.bst", "model.json"]
22
23
24 def _load_sklearn_interface(model_uri: str) -> XGBModel:
25 try:
26 regressor = xgb.XGBRegressor()
27 regressor.load_model(model_uri)
28 return regressor
29 except TypeError:
30 # If there was an error, it's likely due to the model being a
31 # classifier
32 classifier = xgb.XGBClassifier()
33 classifier.load_model(model_uri)
34 return classifier
35
36
37 class XGBoostModel(MLModel):
38 """
39 Implementationof the MLModel interface to load and serve `xgboost` models.
40 """
41
42 async def load(self) -> bool:
43 model_uri = await get_model_uri(
44 self._settings, wellknown_filenames=WELLKNOWN_MODEL_FILENAMES
45 )
46
47 self._model = _load_sklearn_interface(model_uri)
48
49 return True
50
51 def _check_request(self, payload: InferenceRequest) -> InferenceRequest:
52 if not payload.outputs:
53 # By default, only return the result of `predict()`
54 payload.outputs = [RequestOutput(name=PREDICT_OUTPUT)]
55 else:
56 for request_output in payload.outputs:
57 if request_output.name not in VALID_OUTPUTS:
58 raise InferenceError(
59 f"XGBoostModel only supports '{PREDICT_OUTPUT}' and "
60 f"'{PREDICT_PROBA_OUTPUT}' as outputs "
61 f"({request_output.name} was received)"
62 )
63
64 # Regression models do not support `predict_proba`
65 if PREDICT_PROBA_OUTPUT in [o.name for o in payload.outputs]:
66 if isinstance(self._model, xgb.XGBRegressor):
67 raise InferenceError(
68 f"XGBRegressor models do not support '{PREDICT_PROBA_OUTPUT}"
69 )
70
71 return payload
72
73 def _get_model_outputs(self, payload: InferenceRequest) -> List[ResponseOutput]:
74 decoded_request = self.decode_request(payload, default_codec=NumpyRequestCodec)
75
76 outputs = []
77 for request_output in payload.outputs: # type: ignore
78 predict_fn = getattr(self._model, request_output.name)
79 y = predict_fn(decoded_request)
80
81 output = self.encode(y, request_output, default_codec=NumpyCodec)
82 outputs.append(output)
83
84 return outputs
85
86 async def predict(self, payload: InferenceRequest) -> InferenceResponse:
87 payload = self._check_request(payload)
88 outputs = self._get_model_outputs(payload)
89
90 return InferenceResponse(
91 model_name=self.name,
92 model_version=self.version,
93 outputs=outputs,
94 )
95
[end of runtimes/xgboost/mlserver_xgboost/xgboost.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/runtimes/xgboost/mlserver_xgboost/xgboost.py b/runtimes/xgboost/mlserver_xgboost/xgboost.py
--- a/runtimes/xgboost/mlserver_xgboost/xgboost.py
+++ b/runtimes/xgboost/mlserver_xgboost/xgboost.py
@@ -18,7 +18,7 @@
PREDICT_PROBA_OUTPUT = "predict_proba"
VALID_OUTPUTS = [PREDICT_OUTPUT, PREDICT_PROBA_OUTPUT]
-WELLKNOWN_MODEL_FILENAMES = ["model.bst", "model.json"]
+WELLKNOWN_MODEL_FILENAMES = ["model.bst", "model.json", "model.ubj"]
def _load_sklearn_interface(model_uri: str) -> XGBModel:
| {"golden_diff": "diff --git a/runtimes/xgboost/mlserver_xgboost/xgboost.py b/runtimes/xgboost/mlserver_xgboost/xgboost.py\n--- a/runtimes/xgboost/mlserver_xgboost/xgboost.py\n+++ b/runtimes/xgboost/mlserver_xgboost/xgboost.py\n@@ -18,7 +18,7 @@\n PREDICT_PROBA_OUTPUT = \"predict_proba\"\n VALID_OUTPUTS = [PREDICT_OUTPUT, PREDICT_PROBA_OUTPUT]\n \n-WELLKNOWN_MODEL_FILENAMES = [\"model.bst\", \"model.json\"]\n+WELLKNOWN_MODEL_FILENAMES = [\"model.bst\", \"model.json\", \"model.ubj\"]\n \n \n def _load_sklearn_interface(model_uri: str) -> XGBModel:\n", "issue": "Expected XGBoost model file \"model.bst\" extension is undocumented? \nOn https://github.com/SeldonIO/MLServer/blob/master/runtimes/xgboost/mlserver_xgboost/xgboost.py#L21 you can see that MLServer is looking for an XGBoost model file called \"model.bst\". However, I cannot find any reference to that file extension in the XGBoost documentation. As far as I can see, XGBoost's documented file extensions are:\r\n\r\n- \".json\" added in 1.0.0, an \"open format that can be easily reused\"\r\n- \".ubj\" for Universal Binary JSON format, available in 1.6.0\r\n- \".model\" for the \"old binary internal format\" prior to 1.0.0, as shown in examples\r\n\r\nWhere does MLServer get the \".bst\" extension from, and what model format does it use? Shouldn't it use one of the extensions mentioned in the XGBoost documentation instead, to avoid ambiguity?\n", "before_files": [{"content": "import xgboost as xgb\n\nfrom typing import List\nfrom xgboost.sklearn import XGBModel\n\nfrom mlserver.errors import InferenceError\nfrom mlserver.model import MLModel\nfrom mlserver.utils import get_model_uri\nfrom mlserver.codecs import NumpyRequestCodec, NumpyCodec\nfrom mlserver.types import (\n InferenceRequest,\n InferenceResponse,\n RequestOutput,\n ResponseOutput,\n)\n\nPREDICT_OUTPUT = \"predict\"\nPREDICT_PROBA_OUTPUT = \"predict_proba\"\nVALID_OUTPUTS = [PREDICT_OUTPUT, PREDICT_PROBA_OUTPUT]\n\nWELLKNOWN_MODEL_FILENAMES = [\"model.bst\", \"model.json\"]\n\n\ndef _load_sklearn_interface(model_uri: str) -> XGBModel:\n try:\n regressor = xgb.XGBRegressor()\n regressor.load_model(model_uri)\n return regressor\n except TypeError:\n # If there was an error, it's likely due to the model being a\n # classifier\n classifier = xgb.XGBClassifier()\n classifier.load_model(model_uri)\n return classifier\n\n\nclass XGBoostModel(MLModel):\n \"\"\"\n Implementationof the MLModel interface to load and serve `xgboost` models.\n \"\"\"\n\n async def load(self) -> bool:\n model_uri = await get_model_uri(\n self._settings, wellknown_filenames=WELLKNOWN_MODEL_FILENAMES\n )\n\n self._model = _load_sklearn_interface(model_uri)\n\n return True\n\n def _check_request(self, payload: InferenceRequest) -> InferenceRequest:\n if not payload.outputs:\n # By default, only return the result of `predict()`\n payload.outputs = [RequestOutput(name=PREDICT_OUTPUT)]\n else:\n for request_output in payload.outputs:\n if request_output.name not in VALID_OUTPUTS:\n raise InferenceError(\n f\"XGBoostModel only supports '{PREDICT_OUTPUT}' and \"\n f\"'{PREDICT_PROBA_OUTPUT}' as outputs \"\n f\"({request_output.name} was received)\"\n )\n\n # Regression models do not support `predict_proba`\n if PREDICT_PROBA_OUTPUT in [o.name for o in payload.outputs]:\n if isinstance(self._model, xgb.XGBRegressor):\n raise InferenceError(\n f\"XGBRegressor models do not support '{PREDICT_PROBA_OUTPUT}\"\n )\n\n return payload\n\n def _get_model_outputs(self, payload: InferenceRequest) -> List[ResponseOutput]:\n decoded_request = self.decode_request(payload, default_codec=NumpyRequestCodec)\n\n outputs = []\n for request_output in payload.outputs: # type: ignore\n predict_fn = getattr(self._model, request_output.name)\n y = predict_fn(decoded_request)\n\n output = self.encode(y, request_output, default_codec=NumpyCodec)\n outputs.append(output)\n\n return outputs\n\n async def predict(self, payload: InferenceRequest) -> InferenceResponse:\n payload = self._check_request(payload)\n outputs = self._get_model_outputs(payload)\n\n return InferenceResponse(\n model_name=self.name,\n model_version=self.version,\n outputs=outputs,\n )\n", "path": "runtimes/xgboost/mlserver_xgboost/xgboost.py"}]} | 1,638 | 170 |
gh_patches_debug_63210 | rasdani/github-patches | git_diff | ManimCommunity__manim-1635 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
numpy not imported in `manim.mobject.probability`
## Description of bug / unexpected behavior
<!-- Add a clear and concise description of the problem you encountered. -->
When you try to use `BarChart` it raises an error saying `np is not defined`
## Expected behavior
<!-- Add a clear and concise description of what you expected to happen. -->
To not get the error and show the bar chart.
## How to reproduce the issue
<!-- Provide a piece of code illustrating the undesired behavior. -->
<details><summary>Code for reproducing the problem</summary>
```py
class Barchart(Scene):
def construct(self):
ls = [12,12,13,15,19,20,21]
bg = BarChart(ls)
self.add(bg)
```
</details>
## Additional media files
<!-- Paste in the files manim produced on rendering the code above. -->
<details><summary>Images/GIFs</summary>
<!-- PASTE MEDIA HERE -->
</details>
## Logs
<details><summary>Terminal output</summary>
<!-- Add "-v DEBUG" when calling manim to generate more detailed logs -->
```
<string> in <module>
<string> in construct(self)
/usr/local/lib/python3.7/dist-packages/manim/mobject/probability.py in add_axes(self, width, height)
197 x_axis = Line(self.tick_width * LEFT / 2, width * RIGHT)
198 y_axis = Line(MED_LARGE_BUFF * DOWN, height * UP)
--> 199 ticks = VGroup()
200 heights = np.linspace(0, height, self.n_ticks + 1)
201 values = np.linspace(0, self.max_value, self.n_ticks + 1)
NameError: name 'np' is not defined
```
<!-- Insert screenshots here (only when absolutely necessary, we prefer copy/pasted output!) -->
</details>
## System specifications
<details><summary>System Details</summary>
- OS (with version, e.g Windows 10 v2004 or macOS 10.15 (Catalina)):
- RAM:
- Python version (`python/py/python3 --version`):
- Installed modules (provide output from `pip list`):
```
Google Colab
```
</details>
<details><summary>LaTeX details</summary>
+ LaTeX distribution (e.g. TeX Live 2020):
+ Installed LaTeX packages:
<!-- output of `tlmgr list --only-installed` for TeX Live or a screenshot of the Packages page for MikTeX -->
</details>
<details><summary>FFMPEG</summary>
Output of `ffmpeg -version`:
```
PASTE HERE
```
</details>
## Additional comments
<!-- Add further context that you think might be relevant for this issue here. -->
</issue>
<code>
[start of manim/mobject/probability.py]
1 """Mobjects representing objects from probability theory and statistics."""
2
3 __all__ = ["SampleSpace", "BarChart"]
4
5
6 from ..constants import *
7 from ..mobject.geometry import Line, Rectangle
8 from ..mobject.mobject import Mobject
9 from ..mobject.opengl_mobject import OpenGLMobject
10 from ..mobject.svg.brace import Brace
11 from ..mobject.svg.tex_mobject import MathTex, Tex
12 from ..mobject.types.vectorized_mobject import VGroup
13 from ..utils.color import (
14 BLUE,
15 BLUE_E,
16 DARK_GREY,
17 GREEN_E,
18 LIGHT_GREY,
19 MAROON_B,
20 YELLOW,
21 color_gradient,
22 )
23 from ..utils.iterables import tuplify
24
25 EPSILON = 0.0001
26
27
28 class SampleSpace(Rectangle):
29 def __init__(
30 self,
31 height=3,
32 width=3,
33 fill_color=DARK_GREY,
34 fill_opacity=1,
35 stroke_width=0.5,
36 stroke_color=LIGHT_GREY,
37 default_label_scale_val=1,
38 ):
39 Rectangle.__init__(
40 self,
41 height=height,
42 width=width,
43 fill_color=fill_color,
44 fill_opacity=fill_opacity,
45 stroke_width=stroke_width,
46 stroke_color=stroke_color,
47 )
48 self.default_label_scale_val = default_label_scale_val
49
50 def add_title(self, title="Sample space", buff=MED_SMALL_BUFF):
51 # TODO, should this really exist in SampleSpaceScene
52 title_mob = Tex(title)
53 if title_mob.width > self.width:
54 title_mob.width = self.width
55 title_mob.next_to(self, UP, buff=buff)
56 self.title = title_mob
57 self.add(title_mob)
58
59 def add_label(self, label):
60 self.label = label
61
62 def complete_p_list(self, p_list):
63 new_p_list = list(tuplify(p_list))
64 remainder = 1.0 - sum(new_p_list)
65 if abs(remainder) > EPSILON:
66 new_p_list.append(remainder)
67 return new_p_list
68
69 def get_division_along_dimension(self, p_list, dim, colors, vect):
70 p_list = self.complete_p_list(p_list)
71 colors = color_gradient(colors, len(p_list))
72
73 last_point = self.get_edge_center(-vect)
74 parts = VGroup()
75 for factor, color in zip(p_list, colors):
76 part = SampleSpace()
77 part.set_fill(color, 1)
78 part.replace(self, stretch=True)
79 part.stretch(factor, dim)
80 part.move_to(last_point, -vect)
81 last_point = part.get_edge_center(vect)
82 parts.add(part)
83 return parts
84
85 def get_horizontal_division(self, p_list, colors=[GREEN_E, BLUE_E], vect=DOWN):
86 return self.get_division_along_dimension(p_list, 1, colors, vect)
87
88 def get_vertical_division(self, p_list, colors=[MAROON_B, YELLOW], vect=RIGHT):
89 return self.get_division_along_dimension(p_list, 0, colors, vect)
90
91 def divide_horizontally(self, *args, **kwargs):
92 self.horizontal_parts = self.get_horizontal_division(*args, **kwargs)
93 self.add(self.horizontal_parts)
94
95 def divide_vertically(self, *args, **kwargs):
96 self.vertical_parts = self.get_vertical_division(*args, **kwargs)
97 self.add(self.vertical_parts)
98
99 def get_subdivision_braces_and_labels(
100 self, parts, labels, direction, buff=SMALL_BUFF, min_num_quads=1
101 ):
102 label_mobs = VGroup()
103 braces = VGroup()
104 for label, part in zip(labels, parts):
105 brace = Brace(part, direction, min_num_quads=min_num_quads, buff=buff)
106 if isinstance(label, (Mobject, OpenGLMobject)):
107 label_mob = label
108 else:
109 label_mob = MathTex(label)
110 label_mob.scale(self.default_label_scale_val)
111 label_mob.next_to(brace, direction, buff)
112
113 braces.add(brace)
114 label_mobs.add(label_mob)
115 parts.braces = braces
116 parts.labels = label_mobs
117 parts.label_kwargs = {
118 "labels": label_mobs.copy(),
119 "direction": direction,
120 "buff": buff,
121 }
122 return VGroup(parts.braces, parts.labels)
123
124 def get_side_braces_and_labels(self, labels, direction=LEFT, **kwargs):
125 assert hasattr(self, "horizontal_parts")
126 parts = self.horizontal_parts
127 return self.get_subdivision_braces_and_labels(
128 parts, labels, direction, **kwargs
129 )
130
131 def get_top_braces_and_labels(self, labels, **kwargs):
132 assert hasattr(self, "vertical_parts")
133 parts = self.vertical_parts
134 return self.get_subdivision_braces_and_labels(parts, labels, UP, **kwargs)
135
136 def get_bottom_braces_and_labels(self, labels, **kwargs):
137 assert hasattr(self, "vertical_parts")
138 parts = self.vertical_parts
139 return self.get_subdivision_braces_and_labels(parts, labels, DOWN, **kwargs)
140
141 def add_braces_and_labels(self):
142 for attr in "horizontal_parts", "vertical_parts":
143 if not hasattr(self, attr):
144 continue
145 parts = getattr(self, attr)
146 for subattr in "braces", "labels":
147 if hasattr(parts, subattr):
148 self.add(getattr(parts, subattr))
149
150 def __getitem__(self, index):
151 if hasattr(self, "horizontal_parts"):
152 return self.horizontal_parts[index]
153 elif hasattr(self, "vertical_parts"):
154 return self.vertical_parts[index]
155 return self.split()[index]
156
157
158 class BarChart(VGroup):
159 def __init__(
160 self,
161 values,
162 height=4,
163 width=6,
164 n_ticks=4,
165 tick_width=0.2,
166 label_y_axis=True,
167 y_axis_label_height=0.25,
168 max_value=1,
169 bar_colors=[BLUE, YELLOW],
170 bar_fill_opacity=0.8,
171 bar_stroke_width=3,
172 bar_names=[],
173 bar_label_scale_val=0.75,
174 **kwargs
175 ):
176 VGroup.__init__(self, **kwargs)
177 self.n_ticks = n_ticks
178 self.tick_width = tick_width
179 self.label_y_axis = label_y_axis
180 self.y_axis_label_height = y_axis_label_height
181 self.max_value = max_value
182 self.bar_colors = bar_colors
183 self.bar_fill_opacity = bar_fill_opacity
184 self.bar_stroke_width = bar_stroke_width
185 self.bar_names = bar_names
186 self.bar_label_scale_val = bar_label_scale_val
187
188 if self.max_value is None:
189 self.max_value = max(values)
190
191 self.add_axes(width, height)
192 self.add_bars(values, width, height)
193 self.center()
194
195 def add_axes(self, width, height):
196 x_axis = Line(self.tick_width * LEFT / 2, width * RIGHT)
197 y_axis = Line(MED_LARGE_BUFF * DOWN, height * UP)
198 ticks = VGroup()
199 heights = np.linspace(0, height, self.n_ticks + 1)
200 values = np.linspace(0, self.max_value, self.n_ticks + 1)
201 for y, _value in zip(heights, values):
202 tick = Line(LEFT, RIGHT)
203 tick.width = self.tick_width
204 tick.move_to(y * UP)
205 ticks.add(tick)
206 y_axis.add(ticks)
207
208 self.add(x_axis, y_axis)
209 self.x_axis, self.y_axis = x_axis, y_axis
210
211 if self.label_y_axis:
212 labels = VGroup()
213 for tick, value in zip(ticks, values):
214 label = MathTex(str(np.round(value, 2)))
215 label.height = self.y_axis_label_height
216 label.next_to(tick, LEFT, SMALL_BUFF)
217 labels.add(label)
218 self.y_axis_labels = labels
219 self.add(labels)
220
221 def add_bars(self, values, width, height):
222 buff = float(width) / (2 * len(values) + 1)
223 bars = VGroup()
224 for i, value in enumerate(values):
225 bar = Rectangle(
226 height=(value / self.max_value) * height,
227 width=buff,
228 stroke_width=self.bar_stroke_width,
229 fill_opacity=self.bar_fill_opacity,
230 )
231 bar.move_to((2 * i + 1) * buff * RIGHT, DOWN + LEFT)
232 bars.add(bar)
233 bars.set_color_by_gradient(*self.bar_colors)
234
235 bar_labels = VGroup()
236 for bar, name in zip(bars, self.bar_names):
237 label = MathTex(str(name))
238 label.scale(self.bar_label_scale_val)
239 label.next_to(bar, DOWN, SMALL_BUFF)
240 bar_labels.add(label)
241
242 self.add(bars, bar_labels)
243 self.bars = bars
244 self.bar_labels = bar_labels
245
246 def change_bar_values(self, values):
247 for bar, value in zip(self.bars, values):
248 bar_bottom = bar.get_bottom()
249 bar.stretch_to_fit_height((value / self.max_value) * self.height)
250 bar.move_to(bar_bottom, DOWN)
251
[end of manim/mobject/probability.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/manim/mobject/probability.py b/manim/mobject/probability.py
--- a/manim/mobject/probability.py
+++ b/manim/mobject/probability.py
@@ -2,6 +2,7 @@
__all__ = ["SampleSpace", "BarChart"]
+import numpy as np
from ..constants import *
from ..mobject.geometry import Line, Rectangle
| {"golden_diff": "diff --git a/manim/mobject/probability.py b/manim/mobject/probability.py\n--- a/manim/mobject/probability.py\n+++ b/manim/mobject/probability.py\n@@ -2,6 +2,7 @@\n \n __all__ = [\"SampleSpace\", \"BarChart\"]\n \n+import numpy as np\n \n from ..constants import *\n from ..mobject.geometry import Line, Rectangle\n", "issue": "numpy not imported in `manim.mobject.probability`\n## Description of bug / unexpected behavior\r\n<!-- Add a clear and concise description of the problem you encountered. -->\r\nWhen you try to use `BarChart` it raises an error saying `np is not defined`\r\n\r\n## Expected behavior\r\n<!-- Add a clear and concise description of what you expected to happen. -->\r\nTo not get the error and show the bar chart.\r\n\r\n## How to reproduce the issue\r\n<!-- Provide a piece of code illustrating the undesired behavior. -->\r\n\r\n<details><summary>Code for reproducing the problem</summary>\r\n\r\n```py\r\nclass Barchart(Scene):\r\n def construct(self):\r\n ls = [12,12,13,15,19,20,21]\r\n bg = BarChart(ls)\r\n self.add(bg)\r\n```\r\n\r\n</details>\r\n\r\n\r\n## Additional media files\r\n<!-- Paste in the files manim produced on rendering the code above. -->\r\n\r\n<details><summary>Images/GIFs</summary>\r\n\r\n<!-- PASTE MEDIA HERE -->\r\n\r\n</details>\r\n\r\n\r\n## Logs\r\n<details><summary>Terminal output</summary>\r\n<!-- Add \"-v DEBUG\" when calling manim to generate more detailed logs -->\r\n\r\n```\r\n<string> in <module>\r\n\r\n<string> in construct(self)\r\n\r\n/usr/local/lib/python3.7/dist-packages/manim/mobject/probability.py in add_axes(self, width, height)\r\n 197 x_axis = Line(self.tick_width * LEFT / 2, width * RIGHT)\r\n 198 y_axis = Line(MED_LARGE_BUFF * DOWN, height * UP)\r\n--> 199 ticks = VGroup()\r\n 200 heights = np.linspace(0, height, self.n_ticks + 1)\r\n 201 values = np.linspace(0, self.max_value, self.n_ticks + 1)\r\n\r\nNameError: name 'np' is not defined\r\n```\r\n\r\n<!-- Insert screenshots here (only when absolutely necessary, we prefer copy/pasted output!) -->\r\n\r\n</details>\r\n\r\n\r\n## System specifications\r\n\r\n<details><summary>System Details</summary>\r\n\r\n- OS (with version, e.g Windows 10 v2004 or macOS 10.15 (Catalina)):\r\n- RAM:\r\n- Python version (`python/py/python3 --version`):\r\n- Installed modules (provide output from `pip list`):\r\n```\r\nGoogle Colab\r\n```\r\n</details>\r\n\r\n<details><summary>LaTeX details</summary>\r\n\r\n+ LaTeX distribution (e.g. TeX Live 2020):\r\n+ Installed LaTeX packages:\r\n<!-- output of `tlmgr list --only-installed` for TeX Live or a screenshot of the Packages page for MikTeX -->\r\n</details>\r\n\r\n<details><summary>FFMPEG</summary>\r\n\r\nOutput of `ffmpeg -version`:\r\n\r\n```\r\nPASTE HERE\r\n```\r\n</details>\r\n\r\n## Additional comments\r\n<!-- Add further context that you think might be relevant for this issue here. -->\r\n\n", "before_files": [{"content": "\"\"\"Mobjects representing objects from probability theory and statistics.\"\"\"\n\n__all__ = [\"SampleSpace\", \"BarChart\"]\n\n\nfrom ..constants import *\nfrom ..mobject.geometry import Line, Rectangle\nfrom ..mobject.mobject import Mobject\nfrom ..mobject.opengl_mobject import OpenGLMobject\nfrom ..mobject.svg.brace import Brace\nfrom ..mobject.svg.tex_mobject import MathTex, Tex\nfrom ..mobject.types.vectorized_mobject import VGroup\nfrom ..utils.color import (\n BLUE,\n BLUE_E,\n DARK_GREY,\n GREEN_E,\n LIGHT_GREY,\n MAROON_B,\n YELLOW,\n color_gradient,\n)\nfrom ..utils.iterables import tuplify\n\nEPSILON = 0.0001\n\n\nclass SampleSpace(Rectangle):\n def __init__(\n self,\n height=3,\n width=3,\n fill_color=DARK_GREY,\n fill_opacity=1,\n stroke_width=0.5,\n stroke_color=LIGHT_GREY,\n default_label_scale_val=1,\n ):\n Rectangle.__init__(\n self,\n height=height,\n width=width,\n fill_color=fill_color,\n fill_opacity=fill_opacity,\n stroke_width=stroke_width,\n stroke_color=stroke_color,\n )\n self.default_label_scale_val = default_label_scale_val\n\n def add_title(self, title=\"Sample space\", buff=MED_SMALL_BUFF):\n # TODO, should this really exist in SampleSpaceScene\n title_mob = Tex(title)\n if title_mob.width > self.width:\n title_mob.width = self.width\n title_mob.next_to(self, UP, buff=buff)\n self.title = title_mob\n self.add(title_mob)\n\n def add_label(self, label):\n self.label = label\n\n def complete_p_list(self, p_list):\n new_p_list = list(tuplify(p_list))\n remainder = 1.0 - sum(new_p_list)\n if abs(remainder) > EPSILON:\n new_p_list.append(remainder)\n return new_p_list\n\n def get_division_along_dimension(self, p_list, dim, colors, vect):\n p_list = self.complete_p_list(p_list)\n colors = color_gradient(colors, len(p_list))\n\n last_point = self.get_edge_center(-vect)\n parts = VGroup()\n for factor, color in zip(p_list, colors):\n part = SampleSpace()\n part.set_fill(color, 1)\n part.replace(self, stretch=True)\n part.stretch(factor, dim)\n part.move_to(last_point, -vect)\n last_point = part.get_edge_center(vect)\n parts.add(part)\n return parts\n\n def get_horizontal_division(self, p_list, colors=[GREEN_E, BLUE_E], vect=DOWN):\n return self.get_division_along_dimension(p_list, 1, colors, vect)\n\n def get_vertical_division(self, p_list, colors=[MAROON_B, YELLOW], vect=RIGHT):\n return self.get_division_along_dimension(p_list, 0, colors, vect)\n\n def divide_horizontally(self, *args, **kwargs):\n self.horizontal_parts = self.get_horizontal_division(*args, **kwargs)\n self.add(self.horizontal_parts)\n\n def divide_vertically(self, *args, **kwargs):\n self.vertical_parts = self.get_vertical_division(*args, **kwargs)\n self.add(self.vertical_parts)\n\n def get_subdivision_braces_and_labels(\n self, parts, labels, direction, buff=SMALL_BUFF, min_num_quads=1\n ):\n label_mobs = VGroup()\n braces = VGroup()\n for label, part in zip(labels, parts):\n brace = Brace(part, direction, min_num_quads=min_num_quads, buff=buff)\n if isinstance(label, (Mobject, OpenGLMobject)):\n label_mob = label\n else:\n label_mob = MathTex(label)\n label_mob.scale(self.default_label_scale_val)\n label_mob.next_to(brace, direction, buff)\n\n braces.add(brace)\n label_mobs.add(label_mob)\n parts.braces = braces\n parts.labels = label_mobs\n parts.label_kwargs = {\n \"labels\": label_mobs.copy(),\n \"direction\": direction,\n \"buff\": buff,\n }\n return VGroup(parts.braces, parts.labels)\n\n def get_side_braces_and_labels(self, labels, direction=LEFT, **kwargs):\n assert hasattr(self, \"horizontal_parts\")\n parts = self.horizontal_parts\n return self.get_subdivision_braces_and_labels(\n parts, labels, direction, **kwargs\n )\n\n def get_top_braces_and_labels(self, labels, **kwargs):\n assert hasattr(self, \"vertical_parts\")\n parts = self.vertical_parts\n return self.get_subdivision_braces_and_labels(parts, labels, UP, **kwargs)\n\n def get_bottom_braces_and_labels(self, labels, **kwargs):\n assert hasattr(self, \"vertical_parts\")\n parts = self.vertical_parts\n return self.get_subdivision_braces_and_labels(parts, labels, DOWN, **kwargs)\n\n def add_braces_and_labels(self):\n for attr in \"horizontal_parts\", \"vertical_parts\":\n if not hasattr(self, attr):\n continue\n parts = getattr(self, attr)\n for subattr in \"braces\", \"labels\":\n if hasattr(parts, subattr):\n self.add(getattr(parts, subattr))\n\n def __getitem__(self, index):\n if hasattr(self, \"horizontal_parts\"):\n return self.horizontal_parts[index]\n elif hasattr(self, \"vertical_parts\"):\n return self.vertical_parts[index]\n return self.split()[index]\n\n\nclass BarChart(VGroup):\n def __init__(\n self,\n values,\n height=4,\n width=6,\n n_ticks=4,\n tick_width=0.2,\n label_y_axis=True,\n y_axis_label_height=0.25,\n max_value=1,\n bar_colors=[BLUE, YELLOW],\n bar_fill_opacity=0.8,\n bar_stroke_width=3,\n bar_names=[],\n bar_label_scale_val=0.75,\n **kwargs\n ):\n VGroup.__init__(self, **kwargs)\n self.n_ticks = n_ticks\n self.tick_width = tick_width\n self.label_y_axis = label_y_axis\n self.y_axis_label_height = y_axis_label_height\n self.max_value = max_value\n self.bar_colors = bar_colors\n self.bar_fill_opacity = bar_fill_opacity\n self.bar_stroke_width = bar_stroke_width\n self.bar_names = bar_names\n self.bar_label_scale_val = bar_label_scale_val\n\n if self.max_value is None:\n self.max_value = max(values)\n\n self.add_axes(width, height)\n self.add_bars(values, width, height)\n self.center()\n\n def add_axes(self, width, height):\n x_axis = Line(self.tick_width * LEFT / 2, width * RIGHT)\n y_axis = Line(MED_LARGE_BUFF * DOWN, height * UP)\n ticks = VGroup()\n heights = np.linspace(0, height, self.n_ticks + 1)\n values = np.linspace(0, self.max_value, self.n_ticks + 1)\n for y, _value in zip(heights, values):\n tick = Line(LEFT, RIGHT)\n tick.width = self.tick_width\n tick.move_to(y * UP)\n ticks.add(tick)\n y_axis.add(ticks)\n\n self.add(x_axis, y_axis)\n self.x_axis, self.y_axis = x_axis, y_axis\n\n if self.label_y_axis:\n labels = VGroup()\n for tick, value in zip(ticks, values):\n label = MathTex(str(np.round(value, 2)))\n label.height = self.y_axis_label_height\n label.next_to(tick, LEFT, SMALL_BUFF)\n labels.add(label)\n self.y_axis_labels = labels\n self.add(labels)\n\n def add_bars(self, values, width, height):\n buff = float(width) / (2 * len(values) + 1)\n bars = VGroup()\n for i, value in enumerate(values):\n bar = Rectangle(\n height=(value / self.max_value) * height,\n width=buff,\n stroke_width=self.bar_stroke_width,\n fill_opacity=self.bar_fill_opacity,\n )\n bar.move_to((2 * i + 1) * buff * RIGHT, DOWN + LEFT)\n bars.add(bar)\n bars.set_color_by_gradient(*self.bar_colors)\n\n bar_labels = VGroup()\n for bar, name in zip(bars, self.bar_names):\n label = MathTex(str(name))\n label.scale(self.bar_label_scale_val)\n label.next_to(bar, DOWN, SMALL_BUFF)\n bar_labels.add(label)\n\n self.add(bars, bar_labels)\n self.bars = bars\n self.bar_labels = bar_labels\n\n def change_bar_values(self, values):\n for bar, value in zip(self.bars, values):\n bar_bottom = bar.get_bottom()\n bar.stretch_to_fit_height((value / self.max_value) * self.height)\n bar.move_to(bar_bottom, DOWN)\n", "path": "manim/mobject/probability.py"}]} | 3,790 | 89 |
gh_patches_debug_16400 | rasdani/github-patches | git_diff | networkx__networkx-2950 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
networkx 2.1 error building doc with sphinx 1.7.2
Hello,
when building the doc with sphinx 1.7.2 i got this error:
```
sphinx-build -b html -d build/doctrees . build/html
Running Sphinx v1.6.6
making output directory...
/usr/lib/python2.7/dist-packages/IPython/nbconvert.py:13: ShimWarning: The `IPython.nbconvert` package has been deprecated since IPython 4.0. You should import from nbconvert instead.
"You should import from nbconvert instead.", ShimWarning)
Change of translator for the pyfile builder.
Change of translator for the ipynb builder.
loading pickled environment... not yet created
[autosummary] generating autosummary for: bibliography.rst, citing.rst, credits.rst, developer/contribute.rst, developer/gitwash/configure_git.rst, developer/gitwash/development_workflow.rst, developer/gitwash/following_latest.rst, developer/gitwash/forking_hell.rst, developer/gitwash/git_development.rst, developer/gitwash/git_install.rst, ..., release/api_1.7.rst, release/api_1.8.rst, release/api_1.9.rst, release/index.rst, release/migration_guide_from_1.x_to_2.0.rst, release/release_2.0.rst, release/release_2.1.rst, release/release_dev.rst, release/release_template.rst, tutorial.rst
[autosummary] generating autosummary for: /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.clique.clique_removal.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.clique.large_clique_size.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.clique.max_clique.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.clustering_coefficient.average_clustering.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.connectivity.all_pairs_node_connectivity.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.connectivity.local_node_connectivity.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.connectivity.node_connectivity.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.dominating_set.min_edge_dominating_set.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.dominating_set.min_weighted_dominating_set.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.independent_set.maximum_independent_set.rst, ..., /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.nx_shp.write_shp.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.nx_yaml.read_yaml.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.nx_yaml.write_yaml.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.pajek.parse_pajek.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.pajek.read_pajek.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.pajek.write_pajek.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.sparse6.from_sparse6_bytes.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.sparse6.read_sparse6.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.sparse6.to_sparse6_bytes.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.sparse6.write_sparse6.rst
loading intersphinx inventory from ../../debian/python.org_objects.inv...
WARNING: intersphinx inventory '../../debian/python.org_objects.inv' not fetchable due to <type 'exceptions.IOError'>: [Errno 2] No such file or directory: u'/home/morph/deb/build-area/python-networkx-2.1/doc/../../debian/python.org_objects.inv'
loading intersphinx inventory from ../../debian/scipy.org_numpy_objects.inv...
WARNING: intersphinx inventory '../../debian/scipy.org_numpy_objects.inv' not fetchable due to <type 'exceptions.IOError'>: [Errno 2] No such file or directory: u'/home/morph/deb/build-area/python-networkx-2.1/doc/../../debian/scipy.org_numpy_objects.inv'
generating gallery...
Exception occurred:
File "/usr/lib/python2.7/dist-packages/sphinx_gallery/gen_gallery.py", line 222, in generate_gallery_rst
.format(examples_dir))
IOError: Main example directory /home/morph/deb/build-area/python-networkx-2.1/doc/../examples does not have a README.txt file. Please write one to introduce your gallery.
The full traceback has been saved in /tmp/sphinx-err-SnsvwK.log, if you want to report the issue to the developers.
```
content of `/tmp/sphinx-err-SnsvwK.log` is:
```
# Sphinx version: 1.6.6
# Python version: 2.7.14+ (CPython)
# Docutils version: 0.14
# Jinja2 version: 2.10
# Last messages:
# Loaded extensions:
Traceback (most recent call last):
File "/usr/lib/python2.7/dist-packages/sphinx/cmdline.py", line 305, in main
opts.warningiserror, opts.tags, opts.verbosity, opts.jobs)
File "/usr/lib/python2.7/dist-packages/sphinx/application.py", line 234, in __init__
self._init_builder()
File "/usr/lib/python2.7/dist-packages/sphinx/application.py", line 312, in _init_builder
self.emit('builder-inited')
File "/usr/lib/python2.7/dist-packages/sphinx/application.py", line 489, in emit
return self.events.emit(event, self, *args)
File "/usr/lib/python2.7/dist-packages/sphinx/events.py", line 79, in emit
results.append(callback(*args))
File "/usr/lib/python2.7/dist-packages/sphinx_gallery/gen_gallery.py", line 222, in generate_gallery_rst
.format(examples_dir))
IOError: Main example directory /home/morph/deb/build-area/python-networkx-2.1/doc/../examples does not have a README.txt file. Please write one to introduce your gallery.
```
can you have a look?
thanks!
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 """
4 Setup script for networkx
5
6 You can install networkx with
7
8 python setup.py install
9 """
10 from glob import glob
11 import os
12 import sys
13 if os.path.exists('MANIFEST'):
14 os.remove('MANIFEST')
15
16 from setuptools import setup
17
18 if sys.argv[-1] == 'setup.py':
19 print("To install, run 'python setup.py install'")
20 print()
21
22 if sys.version_info[:2] < (2, 7):
23 print("NetworkX requires Python 2.7 or later (%d.%d detected)." %
24 sys.version_info[:2])
25 sys.exit(-1)
26
27 # Write the version information.
28 sys.path.insert(0, 'networkx')
29 import release
30 version = release.write_versionfile()
31 sys.path.pop(0)
32
33 packages = ["networkx",
34 "networkx.algorithms",
35 "networkx.algorithms.assortativity",
36 "networkx.algorithms.bipartite",
37 "networkx.algorithms.node_classification",
38 "networkx.algorithms.centrality",
39 "networkx.algorithms.community",
40 "networkx.algorithms.components",
41 "networkx.algorithms.connectivity",
42 "networkx.algorithms.coloring",
43 "networkx.algorithms.flow",
44 "networkx.algorithms.traversal",
45 "networkx.algorithms.isomorphism",
46 "networkx.algorithms.shortest_paths",
47 "networkx.algorithms.link_analysis",
48 "networkx.algorithms.operators",
49 "networkx.algorithms.approximation",
50 "networkx.algorithms.tree",
51 "networkx.classes",
52 "networkx.generators",
53 "networkx.drawing",
54 "networkx.linalg",
55 "networkx.readwrite",
56 "networkx.readwrite.json_graph",
57 "networkx.tests",
58 "networkx.testing",
59 "networkx.utils"]
60
61 docdirbase = 'share/doc/networkx-%s' % version
62 # add basic documentation
63 data = [(docdirbase, glob("*.txt"))]
64 # add examples
65 for d in ['advanced',
66 'algorithms',
67 'basic',
68 '3d_drawing',
69 'drawing',
70 'graph',
71 'javascript',
72 'jit',
73 'pygraphviz',
74 'subclass']:
75 dd = os.path.join(docdirbase, 'examples', d)
76 pp = os.path.join('examples', d)
77 data.append((dd, glob(os.path.join(pp, "*.py"))))
78 data.append((dd, glob(os.path.join(pp, "*.bz2"))))
79 data.append((dd, glob(os.path.join(pp, "*.gz"))))
80 data.append((dd, glob(os.path.join(pp, "*.mbox"))))
81 data.append((dd, glob(os.path.join(pp, "*.edgelist"))))
82
83 # add the tests
84 package_data = {
85 'networkx': ['tests/*.py'],
86 'networkx.algorithms': ['tests/*.py'],
87 'networkx.algorithms.assortativity': ['tests/*.py'],
88 'networkx.algorithms.bipartite': ['tests/*.py'],
89 'networkx.algorithms.node_classification': ['tests/*.py'],
90 'networkx.algorithms.centrality': ['tests/*.py'],
91 'networkx.algorithms.community': ['tests/*.py'],
92 'networkx.algorithms.components': ['tests/*.py'],
93 'networkx.algorithms.connectivity': ['tests/*.py'],
94 'networkx.algorithms.coloring': ['tests/*.py'],
95 'networkx.algorithms.flow': ['tests/*.py', 'tests/*.bz2'],
96 'networkx.algorithms.isomorphism': ['tests/*.py', 'tests/*.*99'],
97 'networkx.algorithms.link_analysis': ['tests/*.py'],
98 'networkx.algorithms.approximation': ['tests/*.py'],
99 'networkx.algorithms.operators': ['tests/*.py'],
100 'networkx.algorithms.shortest_paths': ['tests/*.py'],
101 'networkx.algorithms.traversal': ['tests/*.py'],
102 'networkx.algorithms.tree': ['tests/*.py'],
103 'networkx.classes': ['tests/*.py'],
104 'networkx.generators': ['tests/*.py', 'atlas.dat.gz'],
105 'networkx.drawing': ['tests/*.py'],
106 'networkx.linalg': ['tests/*.py'],
107 'networkx.readwrite': ['tests/*.py'],
108 'networkx.readwrite.json_graph': ['tests/*.py'],
109 'networkx.testing': ['tests/*.py'],
110 'networkx.utils': ['tests/*.py']
111 }
112
113 install_requires = ['decorator>=4.1.0']
114 extras_require = {'all': ['numpy', 'scipy', 'pandas', 'matplotlib',
115 'pygraphviz', 'pydot', 'pyyaml', 'gdal', 'lxml']}
116
117 if __name__ == "__main__":
118
119 setup(
120 name=release.name.lower(),
121 version=version,
122 maintainer=release.maintainer,
123 maintainer_email=release.maintainer_email,
124 author=release.authors['Hagberg'][0],
125 author_email=release.authors['Hagberg'][1],
126 description=release.description,
127 keywords=release.keywords,
128 long_description=release.long_description,
129 license=release.license,
130 platforms=release.platforms,
131 url=release.url,
132 download_url=release.download_url,
133 classifiers=release.classifiers,
134 packages=packages,
135 data_files=data,
136 package_data=package_data,
137 install_requires=install_requires,
138 extras_require=extras_require,
139 test_suite='nose.collector',
140 tests_require=['nose>=0.10.1'],
141 zip_safe=False
142 )
143
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -62,7 +62,8 @@
# add basic documentation
data = [(docdirbase, glob("*.txt"))]
# add examples
-for d in ['advanced',
+for d in ['.',
+ 'advanced',
'algorithms',
'basic',
'3d_drawing',
@@ -74,6 +75,7 @@
'subclass']:
dd = os.path.join(docdirbase, 'examples', d)
pp = os.path.join('examples', d)
+ data.append((dd, glob(os.path.join(pp, "*.txt"))))
data.append((dd, glob(os.path.join(pp, "*.py"))))
data.append((dd, glob(os.path.join(pp, "*.bz2"))))
data.append((dd, glob(os.path.join(pp, "*.gz"))))
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -62,7 +62,8 @@\n # add basic documentation\n data = [(docdirbase, glob(\"*.txt\"))]\n # add examples\n-for d in ['advanced',\n+for d in ['.',\n+ 'advanced',\n 'algorithms',\n 'basic',\n '3d_drawing',\n@@ -74,6 +75,7 @@\n 'subclass']:\n dd = os.path.join(docdirbase, 'examples', d)\n pp = os.path.join('examples', d)\n+ data.append((dd, glob(os.path.join(pp, \"*.txt\"))))\n data.append((dd, glob(os.path.join(pp, \"*.py\"))))\n data.append((dd, glob(os.path.join(pp, \"*.bz2\"))))\n data.append((dd, glob(os.path.join(pp, \"*.gz\"))))\n", "issue": "networkx 2.1 error building doc with sphinx 1.7.2\nHello,\r\nwhen building the doc with sphinx 1.7.2 i got this error:\r\n\r\n```\r\nsphinx-build -b html -d build/doctrees . build/html\r\nRunning Sphinx v1.6.6\r\nmaking output directory...\r\n/usr/lib/python2.7/dist-packages/IPython/nbconvert.py:13: ShimWarning: The `IPython.nbconvert` package has been deprecated since IPython 4.0. You should import from nbconvert instead.\r\n \"You should import from nbconvert instead.\", ShimWarning)\r\nChange of translator for the pyfile builder.\r\nChange of translator for the ipynb builder.\r\nloading pickled environment... not yet created\r\n[autosummary] generating autosummary for: bibliography.rst, citing.rst, credits.rst, developer/contribute.rst, developer/gitwash/configure_git.rst, developer/gitwash/development_workflow.rst, developer/gitwash/following_latest.rst, developer/gitwash/forking_hell.rst, developer/gitwash/git_development.rst, developer/gitwash/git_install.rst, ..., release/api_1.7.rst, release/api_1.8.rst, release/api_1.9.rst, release/index.rst, release/migration_guide_from_1.x_to_2.0.rst, release/release_2.0.rst, release/release_2.1.rst, release/release_dev.rst, release/release_template.rst, tutorial.rst\r\n[autosummary] generating autosummary for: /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.clique.clique_removal.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.clique.large_clique_size.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.clique.max_clique.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.clustering_coefficient.average_clustering.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.connectivity.all_pairs_node_connectivity.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.connectivity.local_node_connectivity.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.connectivity.node_connectivity.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.dominating_set.min_edge_dominating_set.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.dominating_set.min_weighted_dominating_set.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/algorithms/generated/networkx.algorithms.approximation.independent_set.maximum_independent_set.rst, ..., /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.nx_shp.write_shp.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.nx_yaml.read_yaml.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.nx_yaml.write_yaml.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.pajek.parse_pajek.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.pajek.read_pajek.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.pajek.write_pajek.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.sparse6.from_sparse6_bytes.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.sparse6.read_sparse6.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.sparse6.to_sparse6_bytes.rst, /home/morph/deb/build-area/python-networkx-2.1/doc/reference/readwrite/generated/networkx.readwrite.sparse6.write_sparse6.rst\r\nloading intersphinx inventory from ../../debian/python.org_objects.inv...\r\nWARNING: intersphinx inventory '../../debian/python.org_objects.inv' not fetchable due to <type 'exceptions.IOError'>: [Errno 2] No such file or directory: u'/home/morph/deb/build-area/python-networkx-2.1/doc/../../debian/python.org_objects.inv'\r\nloading intersphinx inventory from ../../debian/scipy.org_numpy_objects.inv...\r\nWARNING: intersphinx inventory '../../debian/scipy.org_numpy_objects.inv' not fetchable due to <type 'exceptions.IOError'>: [Errno 2] No such file or directory: u'/home/morph/deb/build-area/python-networkx-2.1/doc/../../debian/scipy.org_numpy_objects.inv'\r\ngenerating gallery...\r\n\r\nException occurred:\r\n File \"/usr/lib/python2.7/dist-packages/sphinx_gallery/gen_gallery.py\", line 222, in generate_gallery_rst\r\n .format(examples_dir))\r\nIOError: Main example directory /home/morph/deb/build-area/python-networkx-2.1/doc/../examples does not have a README.txt file. Please write one to introduce your gallery.\r\nThe full traceback has been saved in /tmp/sphinx-err-SnsvwK.log, if you want to report the issue to the developers.\r\n```\r\n\r\ncontent of `/tmp/sphinx-err-SnsvwK.log` is:\r\n\r\n```\r\n# Sphinx version: 1.6.6\r\n# Python version: 2.7.14+ (CPython)\r\n# Docutils version: 0.14 \r\n# Jinja2 version: 2.10\r\n# Last messages:\r\n\r\n# Loaded extensions:\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python2.7/dist-packages/sphinx/cmdline.py\", line 305, in main\r\n opts.warningiserror, opts.tags, opts.verbosity, opts.jobs)\r\n File \"/usr/lib/python2.7/dist-packages/sphinx/application.py\", line 234, in __init__\r\n self._init_builder()\r\n File \"/usr/lib/python2.7/dist-packages/sphinx/application.py\", line 312, in _init_builder\r\n self.emit('builder-inited')\r\n File \"/usr/lib/python2.7/dist-packages/sphinx/application.py\", line 489, in emit\r\n return self.events.emit(event, self, *args)\r\n File \"/usr/lib/python2.7/dist-packages/sphinx/events.py\", line 79, in emit\r\n results.append(callback(*args))\r\n File \"/usr/lib/python2.7/dist-packages/sphinx_gallery/gen_gallery.py\", line 222, in generate_gallery_rst\r\n .format(examples_dir))\r\nIOError: Main example directory /home/morph/deb/build-area/python-networkx-2.1/doc/../examples does not have a README.txt file. Please write one to introduce your gallery.\r\n```\r\n\r\ncan you have a look?\r\n\r\nthanks!\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nSetup script for networkx\n\nYou can install networkx with\n\npython setup.py install\n\"\"\"\nfrom glob import glob\nimport os\nimport sys\nif os.path.exists('MANIFEST'):\n os.remove('MANIFEST')\n\nfrom setuptools import setup\n\nif sys.argv[-1] == 'setup.py':\n print(\"To install, run 'python setup.py install'\")\n print()\n\nif sys.version_info[:2] < (2, 7):\n print(\"NetworkX requires Python 2.7 or later (%d.%d detected).\" %\n sys.version_info[:2])\n sys.exit(-1)\n\n# Write the version information.\nsys.path.insert(0, 'networkx')\nimport release\nversion = release.write_versionfile()\nsys.path.pop(0)\n\npackages = [\"networkx\",\n \"networkx.algorithms\",\n \"networkx.algorithms.assortativity\",\n \"networkx.algorithms.bipartite\",\n \"networkx.algorithms.node_classification\",\n \"networkx.algorithms.centrality\",\n \"networkx.algorithms.community\",\n \"networkx.algorithms.components\",\n \"networkx.algorithms.connectivity\",\n \"networkx.algorithms.coloring\",\n \"networkx.algorithms.flow\",\n \"networkx.algorithms.traversal\",\n \"networkx.algorithms.isomorphism\",\n \"networkx.algorithms.shortest_paths\",\n \"networkx.algorithms.link_analysis\",\n \"networkx.algorithms.operators\",\n \"networkx.algorithms.approximation\",\n \"networkx.algorithms.tree\",\n \"networkx.classes\",\n \"networkx.generators\",\n \"networkx.drawing\",\n \"networkx.linalg\",\n \"networkx.readwrite\",\n \"networkx.readwrite.json_graph\",\n \"networkx.tests\",\n \"networkx.testing\",\n \"networkx.utils\"]\n\ndocdirbase = 'share/doc/networkx-%s' % version\n# add basic documentation\ndata = [(docdirbase, glob(\"*.txt\"))]\n# add examples\nfor d in ['advanced',\n 'algorithms',\n 'basic',\n '3d_drawing',\n 'drawing',\n 'graph',\n 'javascript',\n 'jit',\n 'pygraphviz',\n 'subclass']:\n dd = os.path.join(docdirbase, 'examples', d)\n pp = os.path.join('examples', d)\n data.append((dd, glob(os.path.join(pp, \"*.py\"))))\n data.append((dd, glob(os.path.join(pp, \"*.bz2\"))))\n data.append((dd, glob(os.path.join(pp, \"*.gz\"))))\n data.append((dd, glob(os.path.join(pp, \"*.mbox\"))))\n data.append((dd, glob(os.path.join(pp, \"*.edgelist\"))))\n\n# add the tests\npackage_data = {\n 'networkx': ['tests/*.py'],\n 'networkx.algorithms': ['tests/*.py'],\n 'networkx.algorithms.assortativity': ['tests/*.py'],\n 'networkx.algorithms.bipartite': ['tests/*.py'],\n 'networkx.algorithms.node_classification': ['tests/*.py'],\n 'networkx.algorithms.centrality': ['tests/*.py'],\n 'networkx.algorithms.community': ['tests/*.py'],\n 'networkx.algorithms.components': ['tests/*.py'],\n 'networkx.algorithms.connectivity': ['tests/*.py'],\n 'networkx.algorithms.coloring': ['tests/*.py'],\n 'networkx.algorithms.flow': ['tests/*.py', 'tests/*.bz2'],\n 'networkx.algorithms.isomorphism': ['tests/*.py', 'tests/*.*99'],\n 'networkx.algorithms.link_analysis': ['tests/*.py'],\n 'networkx.algorithms.approximation': ['tests/*.py'],\n 'networkx.algorithms.operators': ['tests/*.py'],\n 'networkx.algorithms.shortest_paths': ['tests/*.py'],\n 'networkx.algorithms.traversal': ['tests/*.py'],\n 'networkx.algorithms.tree': ['tests/*.py'],\n 'networkx.classes': ['tests/*.py'],\n 'networkx.generators': ['tests/*.py', 'atlas.dat.gz'],\n 'networkx.drawing': ['tests/*.py'],\n 'networkx.linalg': ['tests/*.py'],\n 'networkx.readwrite': ['tests/*.py'],\n 'networkx.readwrite.json_graph': ['tests/*.py'],\n 'networkx.testing': ['tests/*.py'],\n 'networkx.utils': ['tests/*.py']\n}\n\ninstall_requires = ['decorator>=4.1.0']\nextras_require = {'all': ['numpy', 'scipy', 'pandas', 'matplotlib',\n 'pygraphviz', 'pydot', 'pyyaml', 'gdal', 'lxml']}\n\nif __name__ == \"__main__\":\n\n setup(\n name=release.name.lower(),\n version=version,\n maintainer=release.maintainer,\n maintainer_email=release.maintainer_email,\n author=release.authors['Hagberg'][0],\n author_email=release.authors['Hagberg'][1],\n description=release.description,\n keywords=release.keywords,\n long_description=release.long_description,\n license=release.license,\n platforms=release.platforms,\n url=release.url,\n download_url=release.download_url,\n classifiers=release.classifiers,\n packages=packages,\n data_files=data,\n package_data=package_data,\n install_requires=install_requires,\n extras_require=extras_require,\n test_suite='nose.collector',\n tests_require=['nose>=0.10.1'],\n zip_safe=False\n )\n", "path": "setup.py"}]} | 3,722 | 191 |
gh_patches_debug_6405 | rasdani/github-patches | git_diff | getnikola__nikola-1467 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Broken headlines using typogrify (caused by insertion of ` `)
Maybe we should prevent typogrify on running on h-elements because otherwise you headings won't wrap like you expect on mobile displays. I have created an [issue](https://github.com/mintchaos/typogrify/issues/40) with a more detailed description in the typogrify repo. This is not a real typogrify "bug", but we could implement a workaround in the [filters.py](https://github.com/getnikola/nikola/blob/master/nikola/filters.py) on line 163, because I don't think that the current behaviour is what most nikola users would expect.
</issue>
<code>
[start of nikola/filters.py]
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2012-2014 Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26
27 """Utility functions to help you run filters on files."""
28
29 from .utils import req_missing
30 from functools import wraps
31 import os
32 import io
33 import shutil
34 import subprocess
35 import tempfile
36 import shlex
37
38 try:
39 import typogrify.filters as typo
40 except ImportError:
41 typo = None # NOQA
42
43
44 def apply_to_binary_file(f):
45 """Take a function f that transforms a data argument, and returns
46 a function that takes a filename and applies f to the contents,
47 in place. Reads files in binary mode."""
48 @wraps(f)
49 def f_in_file(fname):
50 with open(fname, 'rb') as inf:
51 data = inf.read()
52 data = f(data)
53 with open(fname, 'wb+') as outf:
54 outf.write(data)
55
56 return f_in_file
57
58
59 def apply_to_text_file(f):
60 """Take a function f that transforms a data argument, and returns
61 a function that takes a filename and applies f to the contents,
62 in place. Reads files in UTF-8."""
63 @wraps(f)
64 def f_in_file(fname):
65 with io.open(fname, 'r', encoding='utf-8') as inf:
66 data = inf.read()
67 data = f(data)
68 with io.open(fname, 'w+', encoding='utf-8') as outf:
69 outf.write(data)
70
71 return f_in_file
72
73
74 def list_replace(the_list, find, replacement):
75 "Replace all occurrences of ``find`` with ``replacement`` in ``the_list``"
76 for i, v in enumerate(the_list):
77 if v == find:
78 the_list[i] = replacement
79
80
81 def runinplace(command, infile):
82 """Run a command in-place on a file.
83
84 command is a string of the form: "commandname %1 %2" and
85 it will be execed with infile as %1 and a temporary file
86 as %2. Then, that temporary file will be moved over %1.
87
88 Example usage:
89
90 runinplace("yui-compressor %1 -o %2", "myfile.css")
91
92 That will replace myfile.css with a minified version.
93
94 You can also supply command as a list.
95 """
96
97 if not isinstance(command, list):
98 command = shlex.split(command)
99
100 tmpdir = None
101
102 if "%2" in command:
103 tmpdir = tempfile.mkdtemp(prefix="nikola")
104 tmpfname = os.path.join(tmpdir, os.path.basename(infile))
105
106 try:
107 list_replace(command, "%1", infile)
108 if tmpdir:
109 list_replace(command, "%2", tmpfname)
110
111 subprocess.check_call(command)
112
113 if tmpdir:
114 shutil.move(tmpfname, infile)
115 finally:
116 if tmpdir:
117 shutil.rmtree(tmpdir)
118
119
120 def yui_compressor(infile):
121 yuicompressor = False
122 try:
123 subprocess.call('yui-compressor', stdout=open(os.devnull, 'w'), stderr=open(os.devnull, 'w'))
124 yuicompressor = 'yui-compressor'
125 except Exception:
126 pass
127 if not yuicompressor:
128 try:
129 subprocess.call('yuicompressor', stdout=open(os.devnull, 'w'), stderr=open(os.devnull, 'w'))
130 yuicompressor = 'yuicompressor'
131 except:
132 raise Exception("yui-compressor is not installed.")
133 return False
134
135 return runinplace(r'{} --nomunge %1 -o %2'.format(yuicompressor), infile)
136
137
138 def closure_compiler(infile):
139 return runinplace(r'closure-compiler --warning_level QUIET --js %1 --js_output_file %2', infile)
140
141
142 def optipng(infile):
143 return runinplace(r"optipng -preserve -o2 -quiet %1", infile)
144
145
146 def jpegoptim(infile):
147 return runinplace(r"jpegoptim -p --strip-all -q %1", infile)
148
149
150 @apply_to_text_file
151 def minify_lines(data):
152 datalines = data.splitlines()
153 datalines = [line.lstrip() for line in datalines if not (line.strip() == "")]
154 return "\n".join(datalines)
155
156
157 @apply_to_text_file
158 def typogrify(data):
159 if typo is None:
160 req_missing(['typogrify'], 'use the typogrify filter')
161
162 data = typo.amp(data)
163 data = typo.widont(data)
164 data = typo.smartypants(data)
165 # Disabled because of typogrify bug where it breaks <title>
166 # data = typo.caps(data)
167 data = typo.initial_quotes(data)
168 return data
169
170
171 @apply_to_text_file
172 def php_template_injection(data):
173 import re
174 template = re.search('<\!-- __NIKOLA_PHP_TEMPLATE_INJECTION source\:(.*) checksum\:(.*)__ -->', data)
175 if template:
176 source = template.group(1)
177 with io.open(source, "r", encoding="utf-8") as in_file:
178 phpdata = in_file.read()
179 _META_SEPARATOR = '(' + os.linesep * 2 + '|' + ('\n' * 2) + '|' + ("\r\n" * 2) + ')'
180 phpdata = re.split(_META_SEPARATOR, phpdata, maxsplit=1)[-1]
181 phpdata = re.sub(template.group(0), phpdata, data)
182 return phpdata
183 else:
184 return data
185
[end of nikola/filters.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/nikola/filters.py b/nikola/filters.py
--- a/nikola/filters.py
+++ b/nikola/filters.py
@@ -160,7 +160,8 @@
req_missing(['typogrify'], 'use the typogrify filter')
data = typo.amp(data)
- data = typo.widont(data)
+ # disabled because typogrify widow prevention caused broken headline wrapping, see issue #1465
+ # data = typo.widont(data)
data = typo.smartypants(data)
# Disabled because of typogrify bug where it breaks <title>
# data = typo.caps(data)
| {"golden_diff": "diff --git a/nikola/filters.py b/nikola/filters.py\n--- a/nikola/filters.py\n+++ b/nikola/filters.py\n@@ -160,7 +160,8 @@\n req_missing(['typogrify'], 'use the typogrify filter')\n \n data = typo.amp(data)\n- data = typo.widont(data)\n+ # disabled because typogrify widow prevention caused broken headline wrapping, see issue #1465\n+ # data = typo.widont(data)\n data = typo.smartypants(data)\n # Disabled because of typogrify bug where it breaks <title>\n # data = typo.caps(data)\n", "issue": "Broken headlines using typogrify (caused by insertion of ` `)\nMaybe we should prevent typogrify on running on h-elements because otherwise you headings won't wrap like you expect on mobile displays. I have created an [issue](https://github.com/mintchaos/typogrify/issues/40) with a more detailed description in the typogrify repo. This is not a real typogrify \"bug\", but we could implement a workaround in the [filters.py](https://github.com/getnikola/nikola/blob/master/nikola/filters.py) on line 163, because I don't think that the current behaviour is what most nikola users would expect.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2014 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\"\"\"Utility functions to help you run filters on files.\"\"\"\n\nfrom .utils import req_missing\nfrom functools import wraps\nimport os\nimport io\nimport shutil\nimport subprocess\nimport tempfile\nimport shlex\n\ntry:\n import typogrify.filters as typo\nexcept ImportError:\n typo = None # NOQA\n\n\ndef apply_to_binary_file(f):\n \"\"\"Take a function f that transforms a data argument, and returns\n a function that takes a filename and applies f to the contents,\n in place. Reads files in binary mode.\"\"\"\n @wraps(f)\n def f_in_file(fname):\n with open(fname, 'rb') as inf:\n data = inf.read()\n data = f(data)\n with open(fname, 'wb+') as outf:\n outf.write(data)\n\n return f_in_file\n\n\ndef apply_to_text_file(f):\n \"\"\"Take a function f that transforms a data argument, and returns\n a function that takes a filename and applies f to the contents,\n in place. Reads files in UTF-8.\"\"\"\n @wraps(f)\n def f_in_file(fname):\n with io.open(fname, 'r', encoding='utf-8') as inf:\n data = inf.read()\n data = f(data)\n with io.open(fname, 'w+', encoding='utf-8') as outf:\n outf.write(data)\n\n return f_in_file\n\n\ndef list_replace(the_list, find, replacement):\n \"Replace all occurrences of ``find`` with ``replacement`` in ``the_list``\"\n for i, v in enumerate(the_list):\n if v == find:\n the_list[i] = replacement\n\n\ndef runinplace(command, infile):\n \"\"\"Run a command in-place on a file.\n\n command is a string of the form: \"commandname %1 %2\" and\n it will be execed with infile as %1 and a temporary file\n as %2. Then, that temporary file will be moved over %1.\n\n Example usage:\n\n runinplace(\"yui-compressor %1 -o %2\", \"myfile.css\")\n\n That will replace myfile.css with a minified version.\n\n You can also supply command as a list.\n \"\"\"\n\n if not isinstance(command, list):\n command = shlex.split(command)\n\n tmpdir = None\n\n if \"%2\" in command:\n tmpdir = tempfile.mkdtemp(prefix=\"nikola\")\n tmpfname = os.path.join(tmpdir, os.path.basename(infile))\n\n try:\n list_replace(command, \"%1\", infile)\n if tmpdir:\n list_replace(command, \"%2\", tmpfname)\n\n subprocess.check_call(command)\n\n if tmpdir:\n shutil.move(tmpfname, infile)\n finally:\n if tmpdir:\n shutil.rmtree(tmpdir)\n\n\ndef yui_compressor(infile):\n yuicompressor = False\n try:\n subprocess.call('yui-compressor', stdout=open(os.devnull, 'w'), stderr=open(os.devnull, 'w'))\n yuicompressor = 'yui-compressor'\n except Exception:\n pass\n if not yuicompressor:\n try:\n subprocess.call('yuicompressor', stdout=open(os.devnull, 'w'), stderr=open(os.devnull, 'w'))\n yuicompressor = 'yuicompressor'\n except:\n raise Exception(\"yui-compressor is not installed.\")\n return False\n\n return runinplace(r'{} --nomunge %1 -o %2'.format(yuicompressor), infile)\n\n\ndef closure_compiler(infile):\n return runinplace(r'closure-compiler --warning_level QUIET --js %1 --js_output_file %2', infile)\n\n\ndef optipng(infile):\n return runinplace(r\"optipng -preserve -o2 -quiet %1\", infile)\n\n\ndef jpegoptim(infile):\n return runinplace(r\"jpegoptim -p --strip-all -q %1\", infile)\n\n\n@apply_to_text_file\ndef minify_lines(data):\n datalines = data.splitlines()\n datalines = [line.lstrip() for line in datalines if not (line.strip() == \"\")]\n return \"\\n\".join(datalines)\n\n\n@apply_to_text_file\ndef typogrify(data):\n if typo is None:\n req_missing(['typogrify'], 'use the typogrify filter')\n\n data = typo.amp(data)\n data = typo.widont(data)\n data = typo.smartypants(data)\n # Disabled because of typogrify bug where it breaks <title>\n # data = typo.caps(data)\n data = typo.initial_quotes(data)\n return data\n\n\n@apply_to_text_file\ndef php_template_injection(data):\n import re\n template = re.search('<\\!-- __NIKOLA_PHP_TEMPLATE_INJECTION source\\:(.*) checksum\\:(.*)__ -->', data)\n if template:\n source = template.group(1)\n with io.open(source, \"r\", encoding=\"utf-8\") as in_file:\n phpdata = in_file.read()\n _META_SEPARATOR = '(' + os.linesep * 2 + '|' + ('\\n' * 2) + '|' + (\"\\r\\n\" * 2) + ')'\n phpdata = re.split(_META_SEPARATOR, phpdata, maxsplit=1)[-1]\n phpdata = re.sub(template.group(0), phpdata, data)\n return phpdata\n else:\n return data\n", "path": "nikola/filters.py"}]} | 2,573 | 152 |
gh_patches_debug_37674 | rasdani/github-patches | git_diff | mne-tools__mne-bids-200 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
new release for mne-bids
We should make a new release for mne-bids
refs:
https://github.com/mne-tools/mne-bids/commit/c43822ef754b58b28ccc8d90af565d1681ac5851
and
https://github.com/mne-tools/mne-bids/commit/eec284cbff44425c0c6fbdad1e32809c247cec05
and
https://github.com/mne-tools/mne-python/wiki/How-to-make-a-release
</issue>
<code>
[start of setup.py]
1 #! /usr/bin/env python
2 from setuptools import setup, find_packages
3
4 descr = """Experimental code for BIDS using MNE."""
5
6 DISTNAME = 'mne-bids'
7 DESCRIPTION = descr
8 MAINTAINER = 'Mainak Jas'
9 MAINTAINER_EMAIL = '[email protected]'
10 URL = 'https://mne-tools.github.io/mne-bids/'
11 LICENSE = 'BSD (3-clause)'
12 DOWNLOAD_URL = 'http://github.com/mne-tools/mne-bids'
13 VERSION = '0.2.dev0'
14
15 if __name__ == "__main__":
16 setup(name=DISTNAME,
17 maintainer=MAINTAINER,
18 maintainer_email=MAINTAINER_EMAIL,
19 description=DESCRIPTION,
20 license=LICENSE,
21 url=URL,
22 version=VERSION,
23 download_url=DOWNLOAD_URL,
24 long_description=open('README.rst').read(),
25 long_description_content_type='text/x-rst',
26 classifiers=[
27 'Intended Audience :: Science/Research',
28 'Intended Audience :: Developers',
29 'License :: OSI Approved',
30 'Programming Language :: Python',
31 'Topic :: Software Development',
32 'Topic :: Scientific/Engineering',
33 'Operating System :: Microsoft :: Windows',
34 'Operating System :: POSIX',
35 'Operating System :: Unix',
36 'Operating System :: MacOS',
37 ],
38 platforms='any',
39 packages=find_packages(),
40 scripts=['bin/mne_bids']
41 )
42
[end of setup.py]
[start of mne_bids/__init__.py]
1 """MNE software for easily interacting with BIDS compatible datasets."""
2
3 __version__ = '0.2.dev0'
4
5
6 from .write import (write_raw_bids, make_bids_folders, make_bids_basename, # noqa: E501 F401
7 make_dataset_description) # noqa: F401
8 from .read import read_raw_bids # noqa: F401
9
[end of mne_bids/__init__.py]
[start of doc/conf.py]
1 # -*- coding: utf-8 -*-
2 #
3 # mne_bids documentation build configuration file, created by
4 # sphinx-quickstart on Wed Sep 6 04:42:26 2017.
5 #
6 # This file is execfile()d with the current directory set to its
7 # containing dir.
8 #
9 # Note that not all possible configuration values are present in this
10 # autogenerated file.
11 #
12 # All configuration values have a default; values that are commented out
13 # serve to show the default.
14
15 # If extensions (or modules to document with autodoc) are in another directory,
16 # add these directories to sys.path here. If the directory is relative to the
17 # documentation root, use os.path.abspath to make it absolute, like shown here.
18 #
19 # import os
20 # import sys
21 # sys.path.insert(0, os.path.abspath('.'))
22
23 from datetime import date
24 import sphinx_gallery # noqa
25 import sphinx_bootstrap_theme
26
27 # -- General configuration ------------------------------------------------
28
29 # If your documentation needs a minimal Sphinx version, state it here.
30 #
31 # needs_sphinx = '1.0'
32
33 # Add any Sphinx extension module names here, as strings. They can be
34 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
35 # ones.
36 extensions = [
37 'sphinx.ext.autodoc',
38 'sphinx.ext.mathjax',
39 'sphinx.ext.viewcode',
40 'numpydoc',
41 'sphinx.ext.autosummary',
42 'sphinx.ext.doctest',
43 'sphinx_gallery.gen_gallery'
44 ]
45
46 # generate autosummary even if no references
47 autosummary_generate = True
48
49 # Add any paths that contain templates here, relative to this directory.
50 templates_path = ['_templates']
51
52 # The suffix(es) of source filenames.
53 # You can specify multiple suffix as a list of string:
54 #
55 # source_suffix = ['.rst', '.md']
56 source_suffix = '.rst'
57
58 # The master toctree document.
59 master_doc = 'index'
60
61 # General information about the project.
62 project = u'mne_bids'
63 td = date.today()
64 copyright = u'%s, MNE Developers. Last updated on %s' % (td.year,
65 td.isoformat())
66
67 author = u'Mainak Jas'
68
69 # The version info for the project you're documenting, acts as replacement for
70 # |version| and |release|, also used in various other places throughout the
71 # built documents.
72 #
73 # The short X.Y version.
74 version = u'0.2.dev0'
75 # The full version, including alpha/beta/rc tags.
76 release = u'0.2.dev0'
77
78 # The language for content autogenerated by Sphinx. Refer to documentation
79 # for a list of supported languages.
80 #
81 # This is also used if you do content translation via gettext catalogs.
82 # Usually you set "language" from the command line for these cases.
83 language = None
84
85 # List of patterns, relative to source directory, that match files and
86 # directories to ignore when looking for source files.
87 # This patterns also effect to html_static_path and html_extra_path
88 exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
89
90 # The name of the Pygments (syntax highlighting) style to use.
91 pygments_style = 'sphinx'
92
93 # If true, `todo` and `todoList` produce output, else they produce nothing.
94 todo_include_todos = False
95
96
97 # -- Options for HTML output ----------------------------------------------
98
99 # The theme to use for HTML and HTML Help pages. See the documentation for
100 # a list of builtin themes.
101 #
102 html_theme = 'bootstrap'
103 html_theme_path = sphinx_bootstrap_theme.get_html_theme_path()
104
105 # Theme options are theme-specific and customize the look and feel of a theme
106 # further. For a list of options available for each theme, see the
107 # documentation.
108 #
109 html_theme_options = {
110 'navbar_title': 'MNE-BIDS',
111 'bootswatch_theme': "flatly",
112 'navbar_sidebarrel': False,
113 'bootstrap_version': "3",
114 'navbar_links': [
115 ("Gallery", "auto_examples/index"),
116 ("API", "api"),
117 ("What's new", "whats_new"),
118 ("Github", "https://github.com/mne-tools/mne-bids", True),
119 ]}
120
121 # Add any paths that contain custom static files (such as style sheets) here,
122 # relative to this directory. They are copied after the builtin static files,
123 # so a file named "default.css" will overwrite the builtin "default.css".
124 html_static_path = ['_static']
125
126
127 # -- Options for HTMLHelp output ------------------------------------------
128
129 # Output file base name for HTML help builder.
130 htmlhelp_basename = 'mne_bidsdoc'
131
132
133 # -- Options for LaTeX output ---------------------------------------------
134
135 latex_elements = {
136 # The paper size ('letterpaper' or 'a4paper').
137 #
138 # 'papersize': 'letterpaper',
139
140 # The font size ('10pt', '11pt' or '12pt').
141 #
142 # 'pointsize': '10pt',
143
144 # Additional stuff for the LaTeX preamble.
145 #
146 # 'preamble': '',
147
148 # Latex figure (float) alignment
149 #
150 # 'figure_align': 'htbp',
151 }
152
153 # Grouping the document tree into LaTeX files. List of tuples
154 # (source start file, target name, title,
155 # author, documentclass [howto, manual, or own class]).
156 latex_documents = [
157 (master_doc, 'mne_bids.tex', u'mne\\_bids Documentation',
158 u'Mainak Jas', 'manual'),
159 ]
160
161
162 # -- Options for manual page output ---------------------------------------
163
164 # One entry per manual page. List of tuples
165 # (source start file, name, description, authors, manual section).
166 man_pages = [
167 (master_doc, 'mne_bids', u'mne_bids Documentation',
168 [author], 1)
169 ]
170
171
172 # -- Options for Texinfo output -------------------------------------------
173
174 # Grouping the document tree into Texinfo files. List of tuples
175 # (source start file, target name, title, author,
176 # dir menu entry, description, category)
177 texinfo_documents = [
178 (master_doc, 'mne_bids', u'mne_bids Documentation',
179 author, 'mne_bids', 'One line description of project.',
180 'Miscellaneous'),
181 ]
182
183
184 sphinx_gallery_conf = {
185 'examples_dirs': '../examples',
186 'gallery_dirs': 'auto_examples',
187 'filename_pattern': '^((?!sgskip).)*$',
188 'backreferences_dir': 'generated',
189 'reference_url': {
190 'mne': 'http://mne-tools.github.io/stable/',
191 'numpy': 'http://docs.scipy.org/doc/numpy-1.9.1',
192 'scipy': 'http://docs.scipy.org/doc/scipy-0.17.0/reference'
193 }
194 }
195
[end of doc/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/doc/conf.py b/doc/conf.py
--- a/doc/conf.py
+++ b/doc/conf.py
@@ -24,6 +24,8 @@
import sphinx_gallery # noqa
import sphinx_bootstrap_theme
+import mne_bids
+
# -- General configuration ------------------------------------------------
# If your documentation needs a minimal Sphinx version, state it here.
@@ -64,16 +66,16 @@
copyright = u'%s, MNE Developers. Last updated on %s' % (td.year,
td.isoformat())
-author = u'Mainak Jas'
+author = u'MNE Developers'
# The version info for the project you're documenting, acts as replacement for
# |version| and |release|, also used in various other places throughout the
# built documents.
#
# The short X.Y version.
-version = u'0.2.dev0'
+version = mne_bids.__version__
# The full version, including alpha/beta/rc tags.
-release = u'0.2.dev0'
+release = version
# The language for content autogenerated by Sphinx. Refer to documentation
# for a list of supported languages.
diff --git a/mne_bids/__init__.py b/mne_bids/__init__.py
--- a/mne_bids/__init__.py
+++ b/mne_bids/__init__.py
@@ -1,6 +1,6 @@
"""MNE software for easily interacting with BIDS compatible datasets."""
-__version__ = '0.2.dev0'
+__version__ = '0.2'
from .write import (write_raw_bids, make_bids_folders, make_bids_basename, # noqa: E501 F401
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -1,6 +1,19 @@
#! /usr/bin/env python
+"""Setup MNE-BIDS."""
+import os
from setuptools import setup, find_packages
+# get the version
+version = None
+with open(os.path.join('mne_bids', '__init__.py'), 'r') as fid:
+ for line in (line.strip() for line in fid):
+ if line.startswith('__version__'):
+ version = line.split('=')[1].strip().strip('\'')
+ break
+if version is None:
+ raise RuntimeError('Could not determine version')
+
+
descr = """Experimental code for BIDS using MNE."""
DISTNAME = 'mne-bids'
@@ -10,7 +23,7 @@
URL = 'https://mne-tools.github.io/mne-bids/'
LICENSE = 'BSD (3-clause)'
DOWNLOAD_URL = 'http://github.com/mne-tools/mne-bids'
-VERSION = '0.2.dev0'
+VERSION = version
if __name__ == "__main__":
setup(name=DISTNAME,
| {"golden_diff": "diff --git a/doc/conf.py b/doc/conf.py\n--- a/doc/conf.py\n+++ b/doc/conf.py\n@@ -24,6 +24,8 @@\n import sphinx_gallery # noqa\n import sphinx_bootstrap_theme\n \n+import mne_bids\n+\n # -- General configuration ------------------------------------------------\n \n # If your documentation needs a minimal Sphinx version, state it here.\n@@ -64,16 +66,16 @@\n copyright = u'%s, MNE Developers. Last updated on %s' % (td.year,\n td.isoformat())\n \n-author = u'Mainak Jas'\n+author = u'MNE Developers'\n \n # The version info for the project you're documenting, acts as replacement for\n # |version| and |release|, also used in various other places throughout the\n # built documents.\n #\n # The short X.Y version.\n-version = u'0.2.dev0'\n+version = mne_bids.__version__\n # The full version, including alpha/beta/rc tags.\n-release = u'0.2.dev0'\n+release = version\n \n # The language for content autogenerated by Sphinx. Refer to documentation\n # for a list of supported languages.\ndiff --git a/mne_bids/__init__.py b/mne_bids/__init__.py\n--- a/mne_bids/__init__.py\n+++ b/mne_bids/__init__.py\n@@ -1,6 +1,6 @@\n \"\"\"MNE software for easily interacting with BIDS compatible datasets.\"\"\"\n \n-__version__ = '0.2.dev0'\n+__version__ = '0.2'\n \n \n from .write import (write_raw_bids, make_bids_folders, make_bids_basename, # noqa: E501 F401\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -1,6 +1,19 @@\n #! /usr/bin/env python\n+\"\"\"Setup MNE-BIDS.\"\"\"\n+import os\n from setuptools import setup, find_packages\n \n+# get the version\n+version = None\n+with open(os.path.join('mne_bids', '__init__.py'), 'r') as fid:\n+ for line in (line.strip() for line in fid):\n+ if line.startswith('__version__'):\n+ version = line.split('=')[1].strip().strip('\\'')\n+ break\n+if version is None:\n+ raise RuntimeError('Could not determine version')\n+\n+\n descr = \"\"\"Experimental code for BIDS using MNE.\"\"\"\n \n DISTNAME = 'mne-bids'\n@@ -10,7 +23,7 @@\n URL = 'https://mne-tools.github.io/mne-bids/'\n LICENSE = 'BSD (3-clause)'\n DOWNLOAD_URL = 'http://github.com/mne-tools/mne-bids'\n-VERSION = '0.2.dev0'\n+VERSION = version\n \n if __name__ == \"__main__\":\n setup(name=DISTNAME,\n", "issue": "new release for mne-bids\nWe should make a new release for mne-bids\r\n\r\nrefs:\r\n\r\nhttps://github.com/mne-tools/mne-bids/commit/c43822ef754b58b28ccc8d90af565d1681ac5851\r\n\r\nand\r\n\r\nhttps://github.com/mne-tools/mne-bids/commit/eec284cbff44425c0c6fbdad1e32809c247cec05\r\n\r\nand\r\n\r\nhttps://github.com/mne-tools/mne-python/wiki/How-to-make-a-release\r\n\n", "before_files": [{"content": "#! /usr/bin/env python\nfrom setuptools import setup, find_packages\n\ndescr = \"\"\"Experimental code for BIDS using MNE.\"\"\"\n\nDISTNAME = 'mne-bids'\nDESCRIPTION = descr\nMAINTAINER = 'Mainak Jas'\nMAINTAINER_EMAIL = '[email protected]'\nURL = 'https://mne-tools.github.io/mne-bids/'\nLICENSE = 'BSD (3-clause)'\nDOWNLOAD_URL = 'http://github.com/mne-tools/mne-bids'\nVERSION = '0.2.dev0'\n\nif __name__ == \"__main__\":\n setup(name=DISTNAME,\n maintainer=MAINTAINER,\n maintainer_email=MAINTAINER_EMAIL,\n description=DESCRIPTION,\n license=LICENSE,\n url=URL,\n version=VERSION,\n download_url=DOWNLOAD_URL,\n long_description=open('README.rst').read(),\n long_description_content_type='text/x-rst',\n classifiers=[\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved',\n 'Programming Language :: Python',\n 'Topic :: Software Development',\n 'Topic :: Scientific/Engineering',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: POSIX',\n 'Operating System :: Unix',\n 'Operating System :: MacOS',\n ],\n platforms='any',\n packages=find_packages(),\n scripts=['bin/mne_bids']\n )\n", "path": "setup.py"}, {"content": "\"\"\"MNE software for easily interacting with BIDS compatible datasets.\"\"\"\n\n__version__ = '0.2.dev0'\n\n\nfrom .write import (write_raw_bids, make_bids_folders, make_bids_basename, # noqa: E501 F401\n make_dataset_description) # noqa: F401\nfrom .read import read_raw_bids # noqa: F401\n", "path": "mne_bids/__init__.py"}, {"content": "# -*- coding: utf-8 -*-\n#\n# mne_bids documentation build configuration file, created by\n# sphinx-quickstart on Wed Sep 6 04:42:26 2017.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\n# import os\n# import sys\n# sys.path.insert(0, os.path.abspath('.'))\n\nfrom datetime import date\nimport sphinx_gallery # noqa\nimport sphinx_bootstrap_theme\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.mathjax',\n 'sphinx.ext.viewcode',\n 'numpydoc',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.doctest',\n 'sphinx_gallery.gen_gallery'\n]\n\n# generate autosummary even if no references\nautosummary_generate = True\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'mne_bids'\ntd = date.today()\ncopyright = u'%s, MNE Developers. Last updated on %s' % (td.year,\n td.isoformat())\n\nauthor = u'Mainak Jas'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = u'0.2.dev0'\n# The full version, including alpha/beta/rc tags.\nrelease = u'0.2.dev0'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = False\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = 'bootstrap'\nhtml_theme_path = sphinx_bootstrap_theme.get_html_theme_path()\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\nhtml_theme_options = {\n 'navbar_title': 'MNE-BIDS',\n 'bootswatch_theme': \"flatly\",\n 'navbar_sidebarrel': False,\n 'bootstrap_version': \"3\",\n 'navbar_links': [\n (\"Gallery\", \"auto_examples/index\"),\n (\"API\", \"api\"),\n (\"What's new\", \"whats_new\"),\n (\"Github\", \"https://github.com/mne-tools/mne-bids\", True),\n ]}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'mne_bidsdoc'\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'mne_bids.tex', u'mne\\\\_bids Documentation',\n u'Mainak Jas', 'manual'),\n]\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'mne_bids', u'mne_bids Documentation',\n [author], 1)\n]\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'mne_bids', u'mne_bids Documentation',\n author, 'mne_bids', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n\nsphinx_gallery_conf = {\n 'examples_dirs': '../examples',\n 'gallery_dirs': 'auto_examples',\n 'filename_pattern': '^((?!sgskip).)*$',\n 'backreferences_dir': 'generated',\n 'reference_url': {\n 'mne': 'http://mne-tools.github.io/stable/',\n 'numpy': 'http://docs.scipy.org/doc/numpy-1.9.1',\n 'scipy': 'http://docs.scipy.org/doc/scipy-0.17.0/reference'\n }\n}\n", "path": "doc/conf.py"}]} | 3,145 | 632 |
gh_patches_debug_3405 | rasdani/github-patches | git_diff | microsoft__PubSec-Info-Assistant-170 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error: Diagnostic settings does not support retention for new diagnostic settings
After a couple of attempts to deploy the PubSec suite (deploy, delete, repeat switching from australia east to eastus), I began to encounter this error 'Diagnostic settings does not support retention for new diagnostic settings.' and the deployment would fail. With each attempt I had deleted all of the services created by the previous attempt, and changed the WORKSPACE="" to be unique.
I happened to come across this article:
https://learn.microsoft.com/en-us/azure/azure-monitor/essentials/migrate-to-azure-storage-lifecycle-policy
After changing lines 138, 146 and 156 in the main.bicep file, setting the days value to 0 (instead of the default value of 30) the deployment completed successfully.
based on the information in the article, we'll need to update these setting after September when the deprecation comes into effect.
</issue>
<code>
[start of app/backend/app.py]
1 # Copyright (c) Microsoft Corporation.
2 # Licensed under the MIT license.
3
4 import logging
5 import mimetypes
6 import os
7 import urllib.parse
8 from datetime import datetime, timedelta
9
10 import openai
11 from approaches.chatreadretrieveread import ChatReadRetrieveReadApproach
12 from azure.core.credentials import AzureKeyCredential
13 from azure.identity import DefaultAzureCredential
14 from azure.search.documents import SearchClient
15 from azure.storage.blob import (
16 AccountSasPermissions,
17 BlobServiceClient,
18 ResourceTypes,
19 generate_account_sas,
20 )
21 from flask import Flask, jsonify, request
22 from shared_code.status_log import State, StatusLog
23
24 # Replace these with your own values, either in environment variables or directly here
25 AZURE_BLOB_STORAGE_ACCOUNT = (
26 os.environ.get("AZURE_BLOB_STORAGE_ACCOUNT") or "mystorageaccount"
27 )
28 AZURE_BLOB_STORAGE_KEY = os.environ.get("AZURE_BLOB_STORAGE_KEY")
29 AZURE_BLOB_STORAGE_CONTAINER = (
30 os.environ.get("AZURE_BLOB_STORAGE_CONTAINER") or "content"
31 )
32 AZURE_SEARCH_SERVICE = os.environ.get("AZURE_SEARCH_SERVICE") or "gptkb"
33 AZURE_SEARCH_SERVICE_KEY = os.environ.get("AZURE_SEARCH_SERVICE_KEY")
34 AZURE_SEARCH_INDEX = os.environ.get("AZURE_SEARCH_INDEX") or "gptkbindex"
35 AZURE_OPENAI_SERVICE = os.environ.get("AZURE_OPENAI_SERVICE") or "myopenai"
36 AZURE_OPENAI_CHATGPT_DEPLOYMENT = (
37 os.environ.get("AZURE_OPENAI_CHATGPT_DEPLOYMENT") or "chat"
38 )
39 AZURE_OPENAI_SERVICE_KEY = os.environ.get("AZURE_OPENAI_SERVICE_KEY")
40
41 KB_FIELDS_CONTENT = os.environ.get("KB_FIELDS_CONTENT") or "merged_content"
42 KB_FIELDS_CATEGORY = os.environ.get("KB_FIELDS_CATEGORY") or "category"
43 KB_FIELDS_SOURCEPAGE = os.environ.get("KB_FIELDS_SOURCEPAGE") or "file_storage_path"
44
45 COSMOSDB_URL = os.environ.get("COSMOSDB_URL")
46 COSMODB_KEY = os.environ.get("COSMOSDB_KEY")
47 COSMOSDB_DATABASE_NAME = os.environ.get("COSMOSDB_DATABASE_NAME") or "statusdb"
48 COSMOSDB_CONTAINER_NAME = os.environ.get("COSMOSDB_CONTAINER_NAME") or "statuscontainer"
49
50 QUERY_TERM_LANGUAGE = os.environ.get("QUERY_TERM_LANGUAGE") or "English"
51
52 # Use the current user identity to authenticate with Azure OpenAI, Cognitive Search and Blob Storage (no secrets needed,
53 # just use 'az login' locally, and managed identity when deployed on Azure). If you need to use keys, use separate AzureKeyCredential instances with the
54 # keys for each service
55 # If you encounter a blocking error during a DefaultAzureCredntial resolution, you can exclude the problematic credential by using a parameter (ex. exclude_shared_token_cache_credential=True)
56 azure_credential = DefaultAzureCredential()
57 azure_search_key_credential = AzureKeyCredential(AZURE_SEARCH_SERVICE_KEY)
58
59 # Used by the OpenAI SDK
60 openai.api_type = "azure"
61 openai.api_base = f"https://{AZURE_OPENAI_SERVICE}.openai.azure.com"
62 openai.api_version = "2023-06-01-preview"
63
64 # Setup StatusLog to allow access to CosmosDB for logging
65 statusLog = StatusLog(
66 COSMOSDB_URL, COSMODB_KEY, COSMOSDB_DATABASE_NAME, COSMOSDB_CONTAINER_NAME
67 )
68
69 # Comment these two lines out if using keys, set your API key in the OPENAI_API_KEY environment variable instead
70 # openai.api_type = "azure_ad"
71 # openai_token = azure_credential.get_token("https://cognitiveservices.azure.com/.default")
72 openai.api_key = AZURE_OPENAI_SERVICE_KEY
73
74 # Set up clients for Cognitive Search and Storage
75 search_client = SearchClient(
76 endpoint=f"https://{AZURE_SEARCH_SERVICE}.search.windows.net",
77 index_name=AZURE_SEARCH_INDEX,
78 credential=azure_search_key_credential,
79 )
80 blob_client = BlobServiceClient(
81 account_url=f"https://{AZURE_BLOB_STORAGE_ACCOUNT}.blob.core.windows.net",
82 credential=AZURE_BLOB_STORAGE_KEY,
83 )
84 blob_container = blob_client.get_container_client(AZURE_BLOB_STORAGE_CONTAINER)
85
86
87 chat_approaches = {
88 "rrr": ChatReadRetrieveReadApproach(
89 search_client,
90 AZURE_OPENAI_SERVICE,
91 AZURE_OPENAI_SERVICE_KEY,
92 AZURE_OPENAI_CHATGPT_DEPLOYMENT,
93 KB_FIELDS_SOURCEPAGE,
94 KB_FIELDS_CONTENT,
95 blob_client,
96 QUERY_TERM_LANGUAGE,
97 )
98 }
99
100 app = Flask(__name__)
101
102
103 @app.route("/", defaults={"path": "index.html"})
104 @app.route("/<path:path>")
105 def static_file(path):
106 return app.send_static_file(path)
107
108
109 # Return blob path with SAS token for citation access
110 @app.route("/content/<path:path>")
111 def content_file(path):
112 blob = blob_container.get_blob_client(path).download_blob()
113 mime_type = blob.properties["content_settings"]["content_type"]
114 file_extension = blob.properties["name"].split(".")[-1:]
115 if mime_type == "application/octet-stream":
116 mime_type = mimetypes.guess_type(path)[0] or "application/octet-stream"
117 if mime_type == "text/plain" and file_extension[0] in ["htm", "html"]:
118 mime_type = "text/html"
119 print(
120 "Using mime type: "
121 + mime_type
122 + "for file with extension: "
123 + file_extension[0]
124 )
125 return (
126 blob.readall(),
127 200,
128 {
129 "Content-Type": mime_type,
130 "Content-Disposition": f"inline; filename={urllib.parse.quote(path, safe='')}",
131 },
132 )
133
134
135 @app.route("/chat", methods=["POST"])
136 def chat():
137 approach = request.json["approach"]
138 try:
139 impl = chat_approaches.get(approach)
140 if not impl:
141 return jsonify({"error": "unknown approach"}), 400
142 r = impl.run(request.json["history"], request.json.get("overrides") or {})
143
144 # return jsonify(r)
145 # To fix citation bug,below code is added.aparmar
146 return jsonify(
147 {
148 "data_points": r["data_points"],
149 "answer": r["answer"],
150 "thoughts": r["thoughts"],
151 "citation_lookup": r["citation_lookup"],
152 }
153 )
154
155 except Exception as e:
156 logging.exception("Exception in /chat")
157 return jsonify({"error": str(e)}), 500
158
159
160 @app.route("/getblobclienturl")
161 def get_blob_client_url():
162 sas_token = generate_account_sas(
163 AZURE_BLOB_STORAGE_ACCOUNT,
164 AZURE_BLOB_STORAGE_KEY,
165 resource_types=ResourceTypes(object=True, service=True, container=True),
166 permission=AccountSasPermissions(
167 read=True,
168 write=True,
169 list=True,
170 delete=False,
171 add=True,
172 create=True,
173 update=True,
174 process=False,
175 ),
176 expiry=datetime.utcnow() + timedelta(hours=1),
177 )
178 return jsonify({"url": f"{blob_client.url}?{sas_token}"})
179
180
181 if __name__ == "__main__":
182 app.run()
183
184
185 @app.route("/getalluploadstatus", methods=["POST"])
186 def get_all_upload_status():
187 timeframe = request.json["timeframe"]
188 state = request.json["state"]
189 try:
190 results = statusLog.read_files_status_by_timeframe(timeframe, State[state])
191 except Exception as e:
192 logging.exception("Exception in /getalluploadstatus")
193 return jsonify({"error": str(e)}), 500
194 return jsonify(results)
195
[end of app/backend/app.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/app/backend/app.py b/app/backend/app.py
--- a/app/backend/app.py
+++ b/app/backend/app.py
@@ -192,3 +192,10 @@
logging.exception("Exception in /getalluploadstatus")
return jsonify({"error": str(e)}), 500
return jsonify(results)
+
+
+# Return AZURE_OPENAI_CHATGPT_DEPLOYMENT
[email protected]("/getInfoData")
+def get_info_data():
+ response = jsonify({"AZURE_OPENAI_CHATGPT_DEPLOYMENT": f"{AZURE_OPENAI_CHATGPT_DEPLOYMENT}"})
+ return response
\ No newline at end of file
| {"golden_diff": "diff --git a/app/backend/app.py b/app/backend/app.py\n--- a/app/backend/app.py\n+++ b/app/backend/app.py\n@@ -192,3 +192,10 @@\n logging.exception(\"Exception in /getalluploadstatus\")\n return jsonify({\"error\": str(e)}), 500\n return jsonify(results)\n+\n+\n+# Return AZURE_OPENAI_CHATGPT_DEPLOYMENT\[email protected](\"/getInfoData\")\n+def get_info_data():\n+ response = jsonify({\"AZURE_OPENAI_CHATGPT_DEPLOYMENT\": f\"{AZURE_OPENAI_CHATGPT_DEPLOYMENT}\"})\n+ return response\n\\ No newline at end of file\n", "issue": "Error: Diagnostic settings does not support retention for new diagnostic settings\nAfter a couple of attempts to deploy the PubSec suite (deploy, delete, repeat switching from australia east to eastus), I began to encounter this error 'Diagnostic settings does not support retention for new diagnostic settings.' and the deployment would fail. With each attempt I had deleted all of the services created by the previous attempt, and changed the WORKSPACE=\"\" to be unique. \r\n\r\nI happened to come across this article:\r\nhttps://learn.microsoft.com/en-us/azure/azure-monitor/essentials/migrate-to-azure-storage-lifecycle-policy\r\n\r\nAfter changing lines 138, 146 and 156 in the main.bicep file, setting the days value to 0 (instead of the default value of 30) the deployment completed successfully. \r\n\r\nbased on the information in the article, we'll need to update these setting after September when the deprecation comes into effect.\r\n\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation.\n# Licensed under the MIT license.\n\nimport logging\nimport mimetypes\nimport os\nimport urllib.parse\nfrom datetime import datetime, timedelta\n\nimport openai\nfrom approaches.chatreadretrieveread import ChatReadRetrieveReadApproach\nfrom azure.core.credentials import AzureKeyCredential\nfrom azure.identity import DefaultAzureCredential\nfrom azure.search.documents import SearchClient\nfrom azure.storage.blob import (\n AccountSasPermissions,\n BlobServiceClient,\n ResourceTypes,\n generate_account_sas,\n)\nfrom flask import Flask, jsonify, request\nfrom shared_code.status_log import State, StatusLog\n\n# Replace these with your own values, either in environment variables or directly here\nAZURE_BLOB_STORAGE_ACCOUNT = (\n os.environ.get(\"AZURE_BLOB_STORAGE_ACCOUNT\") or \"mystorageaccount\"\n)\nAZURE_BLOB_STORAGE_KEY = os.environ.get(\"AZURE_BLOB_STORAGE_KEY\")\nAZURE_BLOB_STORAGE_CONTAINER = (\n os.environ.get(\"AZURE_BLOB_STORAGE_CONTAINER\") or \"content\"\n)\nAZURE_SEARCH_SERVICE = os.environ.get(\"AZURE_SEARCH_SERVICE\") or \"gptkb\"\nAZURE_SEARCH_SERVICE_KEY = os.environ.get(\"AZURE_SEARCH_SERVICE_KEY\")\nAZURE_SEARCH_INDEX = os.environ.get(\"AZURE_SEARCH_INDEX\") or \"gptkbindex\"\nAZURE_OPENAI_SERVICE = os.environ.get(\"AZURE_OPENAI_SERVICE\") or \"myopenai\"\nAZURE_OPENAI_CHATGPT_DEPLOYMENT = (\n os.environ.get(\"AZURE_OPENAI_CHATGPT_DEPLOYMENT\") or \"chat\"\n)\nAZURE_OPENAI_SERVICE_KEY = os.environ.get(\"AZURE_OPENAI_SERVICE_KEY\")\n\nKB_FIELDS_CONTENT = os.environ.get(\"KB_FIELDS_CONTENT\") or \"merged_content\"\nKB_FIELDS_CATEGORY = os.environ.get(\"KB_FIELDS_CATEGORY\") or \"category\"\nKB_FIELDS_SOURCEPAGE = os.environ.get(\"KB_FIELDS_SOURCEPAGE\") or \"file_storage_path\"\n\nCOSMOSDB_URL = os.environ.get(\"COSMOSDB_URL\")\nCOSMODB_KEY = os.environ.get(\"COSMOSDB_KEY\")\nCOSMOSDB_DATABASE_NAME = os.environ.get(\"COSMOSDB_DATABASE_NAME\") or \"statusdb\"\nCOSMOSDB_CONTAINER_NAME = os.environ.get(\"COSMOSDB_CONTAINER_NAME\") or \"statuscontainer\"\n\nQUERY_TERM_LANGUAGE = os.environ.get(\"QUERY_TERM_LANGUAGE\") or \"English\"\n\n# Use the current user identity to authenticate with Azure OpenAI, Cognitive Search and Blob Storage (no secrets needed,\n# just use 'az login' locally, and managed identity when deployed on Azure). If you need to use keys, use separate AzureKeyCredential instances with the\n# keys for each service\n# If you encounter a blocking error during a DefaultAzureCredntial resolution, you can exclude the problematic credential by using a parameter (ex. exclude_shared_token_cache_credential=True)\nazure_credential = DefaultAzureCredential()\nazure_search_key_credential = AzureKeyCredential(AZURE_SEARCH_SERVICE_KEY)\n\n# Used by the OpenAI SDK\nopenai.api_type = \"azure\"\nopenai.api_base = f\"https://{AZURE_OPENAI_SERVICE}.openai.azure.com\"\nopenai.api_version = \"2023-06-01-preview\"\n\n# Setup StatusLog to allow access to CosmosDB for logging\nstatusLog = StatusLog(\n COSMOSDB_URL, COSMODB_KEY, COSMOSDB_DATABASE_NAME, COSMOSDB_CONTAINER_NAME\n)\n\n# Comment these two lines out if using keys, set your API key in the OPENAI_API_KEY environment variable instead\n# openai.api_type = \"azure_ad\"\n# openai_token = azure_credential.get_token(\"https://cognitiveservices.azure.com/.default\")\nopenai.api_key = AZURE_OPENAI_SERVICE_KEY\n\n# Set up clients for Cognitive Search and Storage\nsearch_client = SearchClient(\n endpoint=f\"https://{AZURE_SEARCH_SERVICE}.search.windows.net\",\n index_name=AZURE_SEARCH_INDEX,\n credential=azure_search_key_credential,\n)\nblob_client = BlobServiceClient(\n account_url=f\"https://{AZURE_BLOB_STORAGE_ACCOUNT}.blob.core.windows.net\",\n credential=AZURE_BLOB_STORAGE_KEY,\n)\nblob_container = blob_client.get_container_client(AZURE_BLOB_STORAGE_CONTAINER)\n\n\nchat_approaches = {\n \"rrr\": ChatReadRetrieveReadApproach(\n search_client,\n AZURE_OPENAI_SERVICE,\n AZURE_OPENAI_SERVICE_KEY,\n AZURE_OPENAI_CHATGPT_DEPLOYMENT,\n KB_FIELDS_SOURCEPAGE,\n KB_FIELDS_CONTENT,\n blob_client,\n QUERY_TERM_LANGUAGE,\n )\n}\n\napp = Flask(__name__)\n\n\[email protected](\"/\", defaults={\"path\": \"index.html\"})\[email protected](\"/<path:path>\")\ndef static_file(path):\n return app.send_static_file(path)\n\n\n# Return blob path with SAS token for citation access\[email protected](\"/content/<path:path>\")\ndef content_file(path):\n blob = blob_container.get_blob_client(path).download_blob()\n mime_type = blob.properties[\"content_settings\"][\"content_type\"]\n file_extension = blob.properties[\"name\"].split(\".\")[-1:]\n if mime_type == \"application/octet-stream\":\n mime_type = mimetypes.guess_type(path)[0] or \"application/octet-stream\"\n if mime_type == \"text/plain\" and file_extension[0] in [\"htm\", \"html\"]:\n mime_type = \"text/html\"\n print(\n \"Using mime type: \"\n + mime_type\n + \"for file with extension: \"\n + file_extension[0]\n )\n return (\n blob.readall(),\n 200,\n {\n \"Content-Type\": mime_type,\n \"Content-Disposition\": f\"inline; filename={urllib.parse.quote(path, safe='')}\",\n },\n )\n\n\[email protected](\"/chat\", methods=[\"POST\"])\ndef chat():\n approach = request.json[\"approach\"]\n try:\n impl = chat_approaches.get(approach)\n if not impl:\n return jsonify({\"error\": \"unknown approach\"}), 400\n r = impl.run(request.json[\"history\"], request.json.get(\"overrides\") or {})\n\n # return jsonify(r)\n # To fix citation bug,below code is added.aparmar\n return jsonify(\n {\n \"data_points\": r[\"data_points\"],\n \"answer\": r[\"answer\"],\n \"thoughts\": r[\"thoughts\"],\n \"citation_lookup\": r[\"citation_lookup\"],\n }\n )\n\n except Exception as e:\n logging.exception(\"Exception in /chat\")\n return jsonify({\"error\": str(e)}), 500\n\n\[email protected](\"/getblobclienturl\")\ndef get_blob_client_url():\n sas_token = generate_account_sas(\n AZURE_BLOB_STORAGE_ACCOUNT,\n AZURE_BLOB_STORAGE_KEY,\n resource_types=ResourceTypes(object=True, service=True, container=True),\n permission=AccountSasPermissions(\n read=True,\n write=True,\n list=True,\n delete=False,\n add=True,\n create=True,\n update=True,\n process=False,\n ),\n expiry=datetime.utcnow() + timedelta(hours=1),\n )\n return jsonify({\"url\": f\"{blob_client.url}?{sas_token}\"})\n\n\nif __name__ == \"__main__\":\n app.run()\n\n\[email protected](\"/getalluploadstatus\", methods=[\"POST\"])\ndef get_all_upload_status():\n timeframe = request.json[\"timeframe\"]\n state = request.json[\"state\"]\n try:\n results = statusLog.read_files_status_by_timeframe(timeframe, State[state])\n except Exception as e:\n logging.exception(\"Exception in /getalluploadstatus\")\n return jsonify({\"error\": str(e)}), 500\n return jsonify(results)\n", "path": "app/backend/app.py"}]} | 2,847 | 149 |
gh_patches_debug_18799 | rasdani/github-patches | git_diff | mindee__doctr-30 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[documents] Add basic document reader
For documents to be analyzed, we first need to add a utility for document reading (PDF mostly). The following specs would be nice to have:
- inherit for a shared reader class ("DocumentReader" for instance)
- to be located in the `doctr.documents.reader` module
The following formats should be handled:
- [x] PDF (#8, #25): this resource would be nice to check: https://github.com/pymupdf/PyMuPDF
- [x] PNG (#30)
- [x] JPG (#30)
cc @charlesmindee
</issue>
<code>
[start of doctr/documents/reader.py]
1 # Copyright (C) 2021, Mindee.
2
3 # This program is licensed under the Apache License version 2.
4 # See LICENSE or go to <https://www.apache.org/licenses/LICENSE-2.0.txt> for full license details.
5
6 import fitz
7 import numpy as np
8 import cv2
9 from typing import List, Tuple, Optional, Any
10
11 __all__ = ['read_pdf']
12
13
14 def read_pdf(file_path: str, **kwargs: Any) -> List[np.ndarray]:
15 """Read a PDF file and convert it into an image in numpy format
16
17 Example::
18 >>> from doctr.documents import read_pdf
19 >>> doc = read_pdf("path/to/your/doc.pdf")
20
21 Args:
22 file_path: the path to the PDF file
23 Returns:
24 the list of pages decoded as numpy ndarray of shape H x W x 3
25 """
26
27 # Read pages with fitz and convert them to numpy ndarrays
28 return [convert_page_to_numpy(page, **kwargs) for page in fitz.open(file_path)]
29
30
31 def convert_page_to_numpy(
32 page: fitz.fitz.Page,
33 output_size: Optional[Tuple[int, int]] = None,
34 rgb_output: bool = True,
35 ) -> np.ndarray:
36 """Convert a fitz page to a numpy-formatted image
37
38 Args:
39 page: the page of a file read with PyMuPDF
40 output_size: the expected output size of each page in format H x W
41 rgb_output: whether the output ndarray channel order should be RGB instead of BGR.
42
43 Returns:
44 the rendered image in numpy format
45 """
46
47 transform_matrix = None
48
49 # If no output size is specified, keep the origin one
50 if output_size is not None:
51 scales = (output_size[1] / page.MediaBox[2], output_size[0] / page.MediaBox[3])
52 transform_matrix = fitz.Matrix(*scales)
53
54 # Generate the pixel map using the transformation matrix
55 stream = page.getPixmap(matrix=transform_matrix).getImageData()
56 # Decode it into a numpy
57 img = cv2.imdecode(np.frombuffer(stream, dtype=np.uint8), cv2.IMREAD_UNCHANGED)
58
59 # Switch the channel order
60 if rgb_output:
61 img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
62
63 return img
64
[end of doctr/documents/reader.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/doctr/documents/reader.py b/doctr/documents/reader.py
--- a/doctr/documents/reader.py
+++ b/doctr/documents/reader.py
@@ -8,7 +8,36 @@
import cv2
from typing import List, Tuple, Optional, Any
-__all__ = ['read_pdf']
+__all__ = ['read_pdf', 'read_img']
+
+
+def read_img(
+ file_path: str,
+ output_size: Optional[Tuple[int, int]] = None,
+ rgb_output: bool = True,
+) -> np.ndarray:
+ """Read an image file into numpy format
+
+ Example::
+ >>> from doctr.documents import read_img
+ >>> page = read_img("path/to/your/doc.jpg")
+
+ Args:
+ file_path: the path to the image file
+ output_size: the expected output size of each page in format H x W
+ rgb_output: whether the output ndarray channel order should be RGB instead of BGR.
+ Returns:
+ the page decoded as numpy ndarray of shape H x W x 3
+ """
+
+ img = cv2.imread(file_path, cv2.IMREAD_COLOR)
+ # Resizing
+ if isinstance(output_size, tuple):
+ img = cv2.resize(img, output_size[::-1], interpolation=cv2.INTER_LINEAR)
+ # Switch the channel order
+ if rgb_output:
+ img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
+ return img
def read_pdf(file_path: str, **kwargs: Any) -> List[np.ndarray]:
| {"golden_diff": "diff --git a/doctr/documents/reader.py b/doctr/documents/reader.py\n--- a/doctr/documents/reader.py\n+++ b/doctr/documents/reader.py\n@@ -8,7 +8,36 @@\n import cv2\n from typing import List, Tuple, Optional, Any\n \n-__all__ = ['read_pdf']\n+__all__ = ['read_pdf', 'read_img']\n+\n+\n+def read_img(\n+ file_path: str,\n+ output_size: Optional[Tuple[int, int]] = None,\n+ rgb_output: bool = True,\n+) -> np.ndarray:\n+ \"\"\"Read an image file into numpy format\n+\n+ Example::\n+ >>> from doctr.documents import read_img\n+ >>> page = read_img(\"path/to/your/doc.jpg\")\n+\n+ Args:\n+ file_path: the path to the image file\n+ output_size: the expected output size of each page in format H x W\n+ rgb_output: whether the output ndarray channel order should be RGB instead of BGR.\n+ Returns:\n+ the page decoded as numpy ndarray of shape H x W x 3\n+ \"\"\"\n+\n+ img = cv2.imread(file_path, cv2.IMREAD_COLOR)\n+ # Resizing\n+ if isinstance(output_size, tuple):\n+ img = cv2.resize(img, output_size[::-1], interpolation=cv2.INTER_LINEAR)\n+ # Switch the channel order\n+ if rgb_output:\n+ img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)\n+ return img\n \n \n def read_pdf(file_path: str, **kwargs: Any) -> List[np.ndarray]:\n", "issue": "[documents] Add basic document reader\nFor documents to be analyzed, we first need to add a utility for document reading (PDF mostly). The following specs would be nice to have:\r\n- inherit for a shared reader class (\"DocumentReader\" for instance)\r\n- to be located in the `doctr.documents.reader` module\r\n\r\nThe following formats should be handled:\r\n- [x] PDF (#8, #25): this resource would be nice to check: https://github.com/pymupdf/PyMuPDF\r\n- [x] PNG (#30)\r\n- [x] JPG (#30)\r\n\r\n\r\ncc @charlesmindee \n", "before_files": [{"content": "# Copyright (C) 2021, Mindee.\n\n# This program is licensed under the Apache License version 2.\n# See LICENSE or go to <https://www.apache.org/licenses/LICENSE-2.0.txt> for full license details.\n\nimport fitz\nimport numpy as np\nimport cv2\nfrom typing import List, Tuple, Optional, Any\n\n__all__ = ['read_pdf']\n\n\ndef read_pdf(file_path: str, **kwargs: Any) -> List[np.ndarray]:\n \"\"\"Read a PDF file and convert it into an image in numpy format\n\n Example::\n >>> from doctr.documents import read_pdf\n >>> doc = read_pdf(\"path/to/your/doc.pdf\")\n\n Args:\n file_path: the path to the PDF file\n Returns:\n the list of pages decoded as numpy ndarray of shape H x W x 3\n \"\"\"\n\n # Read pages with fitz and convert them to numpy ndarrays\n return [convert_page_to_numpy(page, **kwargs) for page in fitz.open(file_path)]\n\n\ndef convert_page_to_numpy(\n page: fitz.fitz.Page,\n output_size: Optional[Tuple[int, int]] = None,\n rgb_output: bool = True,\n) -> np.ndarray:\n \"\"\"Convert a fitz page to a numpy-formatted image\n\n Args:\n page: the page of a file read with PyMuPDF\n output_size: the expected output size of each page in format H x W\n rgb_output: whether the output ndarray channel order should be RGB instead of BGR.\n\n Returns:\n the rendered image in numpy format\n \"\"\"\n\n transform_matrix = None\n\n # If no output size is specified, keep the origin one\n if output_size is not None:\n scales = (output_size[1] / page.MediaBox[2], output_size[0] / page.MediaBox[3])\n transform_matrix = fitz.Matrix(*scales)\n\n # Generate the pixel map using the transformation matrix\n stream = page.getPixmap(matrix=transform_matrix).getImageData()\n # Decode it into a numpy\n img = cv2.imdecode(np.frombuffer(stream, dtype=np.uint8), cv2.IMREAD_UNCHANGED)\n\n # Switch the channel order\n if rgb_output:\n img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)\n\n return img\n", "path": "doctr/documents/reader.py"}]} | 1,296 | 352 |
gh_patches_debug_29138 | rasdani/github-patches | git_diff | bentoml__BentoML-4136 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
bug: Triton Integration failed with an AttributeError
### Describe the bug
I try to integrate Triton Inference Server into BentoML and I follow both the official documentation(https://docs.bentoml.org/en/latest/integrations/triton.html) and the following example(https://github.com/bentoml/BentoML/tree/main/examples/triton/onnx). However, I get an AttributeError with the following message:
" '_TritonRunner' object has no attribute 'onnx_fp_16'", where onnx_fp_16 is my model deployed in Triton.
The code in my service.py file is:
```
import bentoml
from bentoml.io import JSON
from src.tokenizer import RDATokenizer
from src.request import RDARequest
from src.response import RDAResponse
from src.config import load_config
from src.utils.model import load_topics_and_mapping, get_multi_label_binarizer, post_predict, load_taxonomy_root,\
load_parent_child_relationship
configs = load_config()
rda_triton_runner = bentoml.triton.Runner("rdav2",
model_repository="src/model_repository",
cli_args=["--model-control-mode=explicit",
"--load-model=onnx_fp_16",
"--log-verbose=1"])
svc = bentoml.Service("rdav2", runners=[rda_triton_runner])
tokenizer = RDATokenizer(tokenizer_path=configs.tokenizer_path)
labels_binarizer = get_multi_label_binarizer(config=configs)
topics, topics_mapping = load_topics_and_mapping(config=configs)
tax_root = load_taxonomy_root(configs.tax_root_path)
parent_child = load_parent_child_relationship(config=configs)
id_to_fos = {id_: fos for fos, id_ in topics_mapping.items()}
@svc.api(input=JSON(pydantic_model=RDARequest), output=JSON(pydantic_model=RDAResponse))
async def predict(rda_request: RDARequest) -> RDAResponse:
"""
The input will be the title, abstract, k and, threshold and the output will be the prediction of the model
:param rda_request: the request object
:return: a dictionary where the key is the metadata name and the value is the value of the metadata.
the metadata will be a list with the tags, the tags ids, the probabilities, the ancestros and the ancestors id
"""
title = rda_request.title
abstract = rda_request.abstract
k = rda_request.k
threshold = rda_request.threshold
text = title + ". " + abstract
encoded_text = await tokenizer.tokenize(text=text)
logits = await rda_triton_runner.onnx_fp_16.async_run(encoded_text)
logits = logits[0].squeeze()
response = await post_predict(logits=logits,
labels_binarizer=labels_binarizer,
k=k,
threshold=threshold,
topics=topics,
topics_mapping=topics_mapping,
tax_roots=tax_root,
parent_child=parent_child,
id_to_fos=id_to_fos)
return response
```
My _bentofile.yaml_ is the following:
```
service: "service:svc"
include:
- "*.py"
- "/model_repository"
- "/configs"
- "/checkpoints"
python:
requirements_txt: "requirements.txt"
docker:
base_image: nvcr.io/nvidia/tritonserver:22.12-py3
```
I tried to run the service with a container and the commands I typed to do so were the followings:
- bentoml build --version 0.0.2
- bentoml containerize rdav2:0.0.2
- docker run -it --rm -p 3000:3000 rdav2:0.0.2 serve --production
I guess there is something wrong in __rda_triton_runner__ object, because when I debug the service, I get an empty list in the __models__ parameter. I am not sure about that, and that's the reason I opened this issue.
### To reproduce
_No response_
### Expected behavior
_No response_
### Environment
bentoml[triton]: 1.0.32
python: 3.8
platform: Ubuntu: 20.10
</issue>
<code>
[start of src/bentoml/triton.py]
1 from __future__ import annotations
2
3 import logging
4 import typing as t
5 from functools import cached_property
6
7 import attr
8 from simple_di import Provide as _Provide
9 from simple_di import inject as _inject
10
11 from ._internal.configuration import get_debug_mode as _get_debug_mode
12 from ._internal.configuration.containers import BentoMLContainer as _BentoMLContainer
13 from ._internal.runner.runnable import RunnableMethodConfig as _RunnableMethodConfig
14 from ._internal.runner.runner import AbstractRunner as _AbstractRunner
15 from ._internal.runner.runner import RunnerMethod as _RunnerMethod
16 from ._internal.runner.runner import object_setattr as _object_setattr
17 from ._internal.runner.runner_handle import DummyRunnerHandle as _DummyRunnerHandle
18 from ._internal.runner.runner_handle.remote import TRITON_EXC_MSG as _TRITON_EXC_MSG
19 from ._internal.runner.runner_handle.remote import (
20 handle_triton_exception as _handle_triton_exception,
21 )
22 from ._internal.utils import LazyLoader as _LazyLoader
23
24 if t.TYPE_CHECKING:
25 import tritonclient.grpc.aio as _tritongrpcclient
26 import tritonclient.http.aio as _tritonhttpclient
27
28 from ._internal.runner.runner_handle import RunnerHandle
29
30 _P = t.ParamSpec("_P")
31
32 _LogFormat = t.Literal["default", "ISO8601"]
33 _GrpcInferResponseCompressionLevel = t.Literal["none", "low", "medium", "high"]
34 _TraceLevel = t.Literal["OFF", "TIMESTAMPS", "TENSORS"]
35 _RateLimit = t.Literal["execution_count", "off"]
36 _TritonServerType = t.Literal["grpc", "http"]
37
38 _ClientMethod = t.Literal[
39 "get_cuda_shared_memory_status",
40 "get_inference_statistics",
41 "get_log_settings",
42 "get_model_config",
43 "get_model_metadata",
44 "get_model_repository_index",
45 "get_server_metadata",
46 "get_system_shared_memory_status",
47 "get_trace_settings",
48 "infer",
49 "is_model_ready",
50 "is_server_live",
51 "is_server_ready",
52 "load_model",
53 "register_cuda_shared_memory",
54 "register_system_shared_memory",
55 "stream_infer",
56 "unload_model",
57 "unregister_cuda_shared_memory",
58 "unregister_system_shared_memory",
59 "update_log_settings",
60 "update_trace_settings",
61 ]
62 _ModelName = t.Annotated[str, t.LiteralString]
63
64 else:
65 _P = t.TypeVar("_P")
66
67 _LogFormat = _GrpcInferResponseCompressionLevel = _TraceLevel = _RateLimit = str
68
69 _tritongrpcclient = _LazyLoader(
70 "_tritongrpcclient", globals(), "tritonclient.grpc.aio", exc_msg=_TRITON_EXC_MSG
71 )
72 _tritonhttpclient = _LazyLoader(
73 "_tritonhttpclient", globals(), "tritonclient.http.aio", exc_msg=_TRITON_EXC_MSG
74 )
75
76 _logger = logging.getLogger(__name__)
77
78 __all__ = ["Runner"]
79
80
81 @attr.define(slots=False, frozen=True, eq=False)
82 class _TritonRunner(_AbstractRunner):
83 repository_path: str
84
85 tritonserver_type: _TritonServerType = attr.field(
86 default="grpc", validator=attr.validators.in_(["grpc", "http"])
87 )
88 cli_args: list[str] = attr.field(factory=list)
89
90 _runner_handle: RunnerHandle = attr.field(init=False, factory=_DummyRunnerHandle)
91
92 @_inject
93 async def runner_handle_is_ready(
94 self,
95 timeout: int = _Provide[
96 _BentoMLContainer.api_server_config.runner_probe.timeout
97 ],
98 ) -> bool:
99 """
100 Check if given runner handle is ready. This will be used as readiness probe in Kubernetes.
101 """
102 return await self._runner_handle.is_ready(timeout)
103
104 def __init__(
105 self,
106 name: str,
107 model_repository: str,
108 tritonserver_type: _TritonServerType = "grpc",
109 cli_args: list[str] | None = None,
110 ):
111 if cli_args is None:
112 cli_args = []
113
114 cli_args.append(f"--model-repository={model_repository}")
115
116 if tritonserver_type == "http":
117 cli_args.extend(
118 [
119 "--allow-grpc=False",
120 "--http-address=127.0.0.1",
121 ]
122 )
123 elif tritonserver_type == "grpc":
124 cli_args.extend(
125 [
126 "--reuse-grpc-port=1",
127 "--allow-http=False",
128 "--grpc-address=0.0.0.0",
129 ]
130 )
131
132 # default settings, disable metrics
133 cli_args.extend([f"--log-verbose={1 if _get_debug_mode() else 0}"])
134
135 if not all(s.startswith("--") for s in cli_args):
136 raise ValueError(
137 "cli_args should be a list of strings starting with '--' for TritonRunner."
138 )
139
140 self.__attrs_init__(
141 name=name,
142 models=None,
143 resource_config=None,
144 runnable_class=self.__class__,
145 repository_path=model_repository,
146 tritonserver_type=tritonserver_type,
147 cli_args=cli_args,
148 embedded=False, # NOTE: TritonRunner shouldn't be used as embedded.
149 )
150
151 @cached_property
152 def protocol_address(self):
153 from ._internal.utils import reserve_free_port
154
155 if self.tritonserver_type == "http":
156 with reserve_free_port(host="127.0.0.1") as port:
157 pass
158 return f"127.0.0.1:{port}"
159 elif self.tritonserver_type == "grpc":
160 with reserve_free_port(host="0.0.0.0", enable_so_reuseport=True) as port:
161 pass
162 return f"0.0.0.0:{port}"
163 else:
164 raise ValueError(f"Invalid Triton Server type: {self.tritonserver_type}")
165
166 def init_local(self, quiet: bool = False) -> None:
167 _logger.warning(
168 "TritonRunner '%s' will not be available for development mode.", self.name
169 )
170
171 def init_client(
172 self,
173 handle_class: type[RunnerHandle] | None = None,
174 *args: t.Any,
175 **kwargs: t.Any,
176 ):
177 from ._internal.runner.runner_handle.remote import TritonRunnerHandle
178
179 if handle_class is None:
180 handle_class = TritonRunnerHandle
181
182 super().init_client(handle_class=handle_class, *args, **kwargs)
183
184 def destroy(self):
185 _object_setattr(self, "_runner_handle", _DummyRunnerHandle())
186
187 # Even though the below overload overlaps, it is ok to ignore the warning since types
188 # for TritonRunner can handle both function from client and LiteralString from model name.
189 @t.overload
190 def __getattr__(self, item: t.Literal["__attrs_init__"]) -> t.Callable[..., None]: # type: ignore (overload warning)
191 ...
192
193 @t.overload
194 def __getattr__(
195 self, item: _ClientMethod
196 ) -> t.Callable[..., t.Coroutine[t.Any, t.Any, t.Any]]:
197 ...
198
199 @t.overload
200 def __getattr__(
201 self, item: _ModelName
202 ) -> _RunnerMethod[
203 t.Any, _P, _tritongrpcclient.InferResult | _tritonhttpclient.InferResult
204 ]:
205 ...
206
207 def __getattr__(self, item: str) -> t.Any:
208 from ._internal.runner.runner_handle.remote import TritonRunnerHandle
209
210 if isinstance(self._runner_handle, TritonRunnerHandle):
211 if item in self._runner_handle.client_methods:
212 # NOTE: auto wrap triton methods to its respective clients
213 if self.tritonserver_type == "grpc":
214 return _handle_triton_exception(
215 getattr(self._runner_handle.grpc_client, item)
216 )
217 else:
218 return _handle_triton_exception(
219 getattr(self._runner_handle.http_client, item)
220 )
221 else:
222 # if given item is not a client method, then we assume it is a model name.
223 # Hence, we will return a RunnerMethod that will be responsible for this model handle.
224 RT = (
225 _tritonhttpclient.InferResult
226 if self.tritonserver_type == "http"
227 else _tritongrpcclient.InferResult
228 )
229 return _RunnerMethod[t.Any, _P, RT](
230 runner=self,
231 name=item,
232 config=_RunnableMethodConfig(batchable=True, batch_dim=(0, 0)),
233 max_batch_size=0,
234 max_latency_ms=10000,
235 )
236
237 return super().__getattribute__(item)
238
239
240 Runner = _TritonRunner
241
[end of src/bentoml/triton.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/bentoml/triton.py b/src/bentoml/triton.py
--- a/src/bentoml/triton.py
+++ b/src/bentoml/triton.py
@@ -20,6 +20,7 @@
handle_triton_exception as _handle_triton_exception,
)
from ._internal.utils import LazyLoader as _LazyLoader
+from .exceptions import StateException as _StateException
if t.TYPE_CHECKING:
import tritonclient.grpc.aio as _tritongrpcclient
@@ -168,18 +169,27 @@
"TritonRunner '%s' will not be available for development mode.", self.name
)
+ def _set_handle(
+ self, handle_class: type[RunnerHandle], *args: t.Any, **kwargs: t.Any
+ ) -> None:
+ if not isinstance(self._runner_handle, _DummyRunnerHandle):
+ raise _StateException("Runner already initialized")
+
+ runner_handle = handle_class(self, *args, **kwargs)
+ _object_setattr(self, "_runner_handle", runner_handle)
+
def init_client(
self,
handle_class: type[RunnerHandle] | None = None,
*args: t.Any,
**kwargs: t.Any,
):
- from ._internal.runner.runner_handle.remote import TritonRunnerHandle
-
if handle_class is None:
- handle_class = TritonRunnerHandle
+ from ._internal.runner.runner_handle.remote import TritonRunnerHandle
- super().init_client(handle_class=handle_class, *args, **kwargs)
+ self._set_handle(TritonRunnerHandle)
+ else:
+ self._set_handle(handle_class, *args, **kwargs)
def destroy(self):
_object_setattr(self, "_runner_handle", _DummyRunnerHandle())
| {"golden_diff": "diff --git a/src/bentoml/triton.py b/src/bentoml/triton.py\n--- a/src/bentoml/triton.py\n+++ b/src/bentoml/triton.py\n@@ -20,6 +20,7 @@\n handle_triton_exception as _handle_triton_exception,\n )\n from ._internal.utils import LazyLoader as _LazyLoader\n+from .exceptions import StateException as _StateException\n \n if t.TYPE_CHECKING:\n import tritonclient.grpc.aio as _tritongrpcclient\n@@ -168,18 +169,27 @@\n \"TritonRunner '%s' will not be available for development mode.\", self.name\n )\n \n+ def _set_handle(\n+ self, handle_class: type[RunnerHandle], *args: t.Any, **kwargs: t.Any\n+ ) -> None:\n+ if not isinstance(self._runner_handle, _DummyRunnerHandle):\n+ raise _StateException(\"Runner already initialized\")\n+\n+ runner_handle = handle_class(self, *args, **kwargs)\n+ _object_setattr(self, \"_runner_handle\", runner_handle)\n+\n def init_client(\n self,\n handle_class: type[RunnerHandle] | None = None,\n *args: t.Any,\n **kwargs: t.Any,\n ):\n- from ._internal.runner.runner_handle.remote import TritonRunnerHandle\n-\n if handle_class is None:\n- handle_class = TritonRunnerHandle\n+ from ._internal.runner.runner_handle.remote import TritonRunnerHandle\n \n- super().init_client(handle_class=handle_class, *args, **kwargs)\n+ self._set_handle(TritonRunnerHandle)\n+ else:\n+ self._set_handle(handle_class, *args, **kwargs)\n \n def destroy(self):\n _object_setattr(self, \"_runner_handle\", _DummyRunnerHandle())\n", "issue": "bug: Triton Integration failed with an AttributeError\n### Describe the bug\n\nI try to integrate Triton Inference Server into BentoML and I follow both the official documentation(https://docs.bentoml.org/en/latest/integrations/triton.html) and the following example(https://github.com/bentoml/BentoML/tree/main/examples/triton/onnx). However, I get an AttributeError with the following message:\r\n\" '_TritonRunner' object has no attribute 'onnx_fp_16'\", where onnx_fp_16 is my model deployed in Triton.\r\nThe code in my service.py file is:\r\n```\r\nimport bentoml\r\nfrom bentoml.io import JSON\r\nfrom src.tokenizer import RDATokenizer\r\nfrom src.request import RDARequest\r\nfrom src.response import RDAResponse\r\nfrom src.config import load_config\r\nfrom src.utils.model import load_topics_and_mapping, get_multi_label_binarizer, post_predict, load_taxonomy_root,\\\r\n load_parent_child_relationship\r\n\r\nconfigs = load_config()\r\nrda_triton_runner = bentoml.triton.Runner(\"rdav2\",\r\n model_repository=\"src/model_repository\",\r\n cli_args=[\"--model-control-mode=explicit\",\r\n \"--load-model=onnx_fp_16\",\r\n \"--log-verbose=1\"])\r\n\r\nsvc = bentoml.Service(\"rdav2\", runners=[rda_triton_runner])\r\ntokenizer = RDATokenizer(tokenizer_path=configs.tokenizer_path)\r\nlabels_binarizer = get_multi_label_binarizer(config=configs)\r\ntopics, topics_mapping = load_topics_and_mapping(config=configs)\r\ntax_root = load_taxonomy_root(configs.tax_root_path)\r\nparent_child = load_parent_child_relationship(config=configs)\r\nid_to_fos = {id_: fos for fos, id_ in topics_mapping.items()}\r\n\r\n\r\[email protected](input=JSON(pydantic_model=RDARequest), output=JSON(pydantic_model=RDAResponse))\r\nasync def predict(rda_request: RDARequest) -> RDAResponse:\r\n \"\"\"\r\n The input will be the title, abstract, k and, threshold and the output will be the prediction of the model\r\n :param rda_request: the request object\r\n :return: a dictionary where the key is the metadata name and the value is the value of the metadata.\r\n the metadata will be a list with the tags, the tags ids, the probabilities, the ancestros and the ancestors id\r\n \"\"\"\r\n title = rda_request.title\r\n abstract = rda_request.abstract\r\n k = rda_request.k\r\n threshold = rda_request.threshold\r\n text = title + \". \" + abstract\r\n encoded_text = await tokenizer.tokenize(text=text)\r\n logits = await rda_triton_runner.onnx_fp_16.async_run(encoded_text)\r\n logits = logits[0].squeeze()\r\n response = await post_predict(logits=logits,\r\n labels_binarizer=labels_binarizer,\r\n k=k,\r\n threshold=threshold,\r\n topics=topics,\r\n topics_mapping=topics_mapping,\r\n tax_roots=tax_root,\r\n parent_child=parent_child,\r\n id_to_fos=id_to_fos)\r\n return response\r\n```\r\nMy _bentofile.yaml_ is the following:\r\n```\r\nservice: \"service:svc\"\r\ninclude:\r\n- \"*.py\"\r\n- \"/model_repository\"\r\n- \"/configs\"\r\n- \"/checkpoints\"\r\npython:\r\n requirements_txt: \"requirements.txt\"\r\ndocker:\r\n base_image: nvcr.io/nvidia/tritonserver:22.12-py3\r\n```\r\nI tried to run the service with a container and the commands I typed to do so were the followings:\r\n- bentoml build --version 0.0.2\r\n- bentoml containerize rdav2:0.0.2\r\n- docker run -it --rm -p 3000:3000 rdav2:0.0.2 serve --production\r\n\r\nI guess there is something wrong in __rda_triton_runner__ object, because when I debug the service, I get an empty list in the __models__ parameter. I am not sure about that, and that's the reason I opened this issue.\n\n### To reproduce\n\n_No response_\n\n### Expected behavior\n\n_No response_\n\n### Environment\n\nbentoml[triton]: 1.0.32\r\npython: 3.8\r\nplatform: Ubuntu: 20.10\n", "before_files": [{"content": "from __future__ import annotations\n\nimport logging\nimport typing as t\nfrom functools import cached_property\n\nimport attr\nfrom simple_di import Provide as _Provide\nfrom simple_di import inject as _inject\n\nfrom ._internal.configuration import get_debug_mode as _get_debug_mode\nfrom ._internal.configuration.containers import BentoMLContainer as _BentoMLContainer\nfrom ._internal.runner.runnable import RunnableMethodConfig as _RunnableMethodConfig\nfrom ._internal.runner.runner import AbstractRunner as _AbstractRunner\nfrom ._internal.runner.runner import RunnerMethod as _RunnerMethod\nfrom ._internal.runner.runner import object_setattr as _object_setattr\nfrom ._internal.runner.runner_handle import DummyRunnerHandle as _DummyRunnerHandle\nfrom ._internal.runner.runner_handle.remote import TRITON_EXC_MSG as _TRITON_EXC_MSG\nfrom ._internal.runner.runner_handle.remote import (\n handle_triton_exception as _handle_triton_exception,\n)\nfrom ._internal.utils import LazyLoader as _LazyLoader\n\nif t.TYPE_CHECKING:\n import tritonclient.grpc.aio as _tritongrpcclient\n import tritonclient.http.aio as _tritonhttpclient\n\n from ._internal.runner.runner_handle import RunnerHandle\n\n _P = t.ParamSpec(\"_P\")\n\n _LogFormat = t.Literal[\"default\", \"ISO8601\"]\n _GrpcInferResponseCompressionLevel = t.Literal[\"none\", \"low\", \"medium\", \"high\"]\n _TraceLevel = t.Literal[\"OFF\", \"TIMESTAMPS\", \"TENSORS\"]\n _RateLimit = t.Literal[\"execution_count\", \"off\"]\n _TritonServerType = t.Literal[\"grpc\", \"http\"]\n\n _ClientMethod = t.Literal[\n \"get_cuda_shared_memory_status\",\n \"get_inference_statistics\",\n \"get_log_settings\",\n \"get_model_config\",\n \"get_model_metadata\",\n \"get_model_repository_index\",\n \"get_server_metadata\",\n \"get_system_shared_memory_status\",\n \"get_trace_settings\",\n \"infer\",\n \"is_model_ready\",\n \"is_server_live\",\n \"is_server_ready\",\n \"load_model\",\n \"register_cuda_shared_memory\",\n \"register_system_shared_memory\",\n \"stream_infer\",\n \"unload_model\",\n \"unregister_cuda_shared_memory\",\n \"unregister_system_shared_memory\",\n \"update_log_settings\",\n \"update_trace_settings\",\n ]\n _ModelName = t.Annotated[str, t.LiteralString]\n\nelse:\n _P = t.TypeVar(\"_P\")\n\n _LogFormat = _GrpcInferResponseCompressionLevel = _TraceLevel = _RateLimit = str\n\n _tritongrpcclient = _LazyLoader(\n \"_tritongrpcclient\", globals(), \"tritonclient.grpc.aio\", exc_msg=_TRITON_EXC_MSG\n )\n _tritonhttpclient = _LazyLoader(\n \"_tritonhttpclient\", globals(), \"tritonclient.http.aio\", exc_msg=_TRITON_EXC_MSG\n )\n\n_logger = logging.getLogger(__name__)\n\n__all__ = [\"Runner\"]\n\n\[email protected](slots=False, frozen=True, eq=False)\nclass _TritonRunner(_AbstractRunner):\n repository_path: str\n\n tritonserver_type: _TritonServerType = attr.field(\n default=\"grpc\", validator=attr.validators.in_([\"grpc\", \"http\"])\n )\n cli_args: list[str] = attr.field(factory=list)\n\n _runner_handle: RunnerHandle = attr.field(init=False, factory=_DummyRunnerHandle)\n\n @_inject\n async def runner_handle_is_ready(\n self,\n timeout: int = _Provide[\n _BentoMLContainer.api_server_config.runner_probe.timeout\n ],\n ) -> bool:\n \"\"\"\n Check if given runner handle is ready. This will be used as readiness probe in Kubernetes.\n \"\"\"\n return await self._runner_handle.is_ready(timeout)\n\n def __init__(\n self,\n name: str,\n model_repository: str,\n tritonserver_type: _TritonServerType = \"grpc\",\n cli_args: list[str] | None = None,\n ):\n if cli_args is None:\n cli_args = []\n\n cli_args.append(f\"--model-repository={model_repository}\")\n\n if tritonserver_type == \"http\":\n cli_args.extend(\n [\n \"--allow-grpc=False\",\n \"--http-address=127.0.0.1\",\n ]\n )\n elif tritonserver_type == \"grpc\":\n cli_args.extend(\n [\n \"--reuse-grpc-port=1\",\n \"--allow-http=False\",\n \"--grpc-address=0.0.0.0\",\n ]\n )\n\n # default settings, disable metrics\n cli_args.extend([f\"--log-verbose={1 if _get_debug_mode() else 0}\"])\n\n if not all(s.startswith(\"--\") for s in cli_args):\n raise ValueError(\n \"cli_args should be a list of strings starting with '--' for TritonRunner.\"\n )\n\n self.__attrs_init__(\n name=name,\n models=None,\n resource_config=None,\n runnable_class=self.__class__,\n repository_path=model_repository,\n tritonserver_type=tritonserver_type,\n cli_args=cli_args,\n embedded=False, # NOTE: TritonRunner shouldn't be used as embedded.\n )\n\n @cached_property\n def protocol_address(self):\n from ._internal.utils import reserve_free_port\n\n if self.tritonserver_type == \"http\":\n with reserve_free_port(host=\"127.0.0.1\") as port:\n pass\n return f\"127.0.0.1:{port}\"\n elif self.tritonserver_type == \"grpc\":\n with reserve_free_port(host=\"0.0.0.0\", enable_so_reuseport=True) as port:\n pass\n return f\"0.0.0.0:{port}\"\n else:\n raise ValueError(f\"Invalid Triton Server type: {self.tritonserver_type}\")\n\n def init_local(self, quiet: bool = False) -> None:\n _logger.warning(\n \"TritonRunner '%s' will not be available for development mode.\", self.name\n )\n\n def init_client(\n self,\n handle_class: type[RunnerHandle] | None = None,\n *args: t.Any,\n **kwargs: t.Any,\n ):\n from ._internal.runner.runner_handle.remote import TritonRunnerHandle\n\n if handle_class is None:\n handle_class = TritonRunnerHandle\n\n super().init_client(handle_class=handle_class, *args, **kwargs)\n\n def destroy(self):\n _object_setattr(self, \"_runner_handle\", _DummyRunnerHandle())\n\n # Even though the below overload overlaps, it is ok to ignore the warning since types\n # for TritonRunner can handle both function from client and LiteralString from model name.\n @t.overload\n def __getattr__(self, item: t.Literal[\"__attrs_init__\"]) -> t.Callable[..., None]: # type: ignore (overload warning)\n ...\n\n @t.overload\n def __getattr__(\n self, item: _ClientMethod\n ) -> t.Callable[..., t.Coroutine[t.Any, t.Any, t.Any]]:\n ...\n\n @t.overload\n def __getattr__(\n self, item: _ModelName\n ) -> _RunnerMethod[\n t.Any, _P, _tritongrpcclient.InferResult | _tritonhttpclient.InferResult\n ]:\n ...\n\n def __getattr__(self, item: str) -> t.Any:\n from ._internal.runner.runner_handle.remote import TritonRunnerHandle\n\n if isinstance(self._runner_handle, TritonRunnerHandle):\n if item in self._runner_handle.client_methods:\n # NOTE: auto wrap triton methods to its respective clients\n if self.tritonserver_type == \"grpc\":\n return _handle_triton_exception(\n getattr(self._runner_handle.grpc_client, item)\n )\n else:\n return _handle_triton_exception(\n getattr(self._runner_handle.http_client, item)\n )\n else:\n # if given item is not a client method, then we assume it is a model name.\n # Hence, we will return a RunnerMethod that will be responsible for this model handle.\n RT = (\n _tritonhttpclient.InferResult\n if self.tritonserver_type == \"http\"\n else _tritongrpcclient.InferResult\n )\n return _RunnerMethod[t.Any, _P, RT](\n runner=self,\n name=item,\n config=_RunnableMethodConfig(batchable=True, batch_dim=(0, 0)),\n max_batch_size=0,\n max_latency_ms=10000,\n )\n\n return super().__getattribute__(item)\n\n\nRunner = _TritonRunner\n", "path": "src/bentoml/triton.py"}]} | 4,015 | 404 |
gh_patches_debug_11528 | rasdani/github-patches | git_diff | mlcommons__GaNDLF-590 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
PyTorch security vulnerability
See https://github.com/advisories/GHSA-47fc-vmwq-366v
Need to upgrade to PyTorch 1.13.1
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2
3 """The setup script."""
4
5
6 import sys, re
7 from setuptools import setup, find_packages
8 from setuptools.command.install import install
9 from setuptools.command.develop import develop
10 from setuptools.command.egg_info import egg_info
11
12 try:
13 with open("README.md") as readme_file:
14 readme = readme_file.read()
15 except Exception as error:
16 readme = "No README information found."
17 sys.stderr.write("Warning: Could not open '%s' due %s\n" % ("README.md", error))
18
19
20 class CustomInstallCommand(install):
21 def run(self):
22 install.run(self)
23
24
25 class CustomDevelopCommand(develop):
26 def run(self):
27 develop.run(self)
28
29
30 class CustomEggInfoCommand(egg_info):
31 def run(self):
32 egg_info.run(self)
33
34
35 try:
36 filepath = "GANDLF/version.py"
37 version_file = open(filepath)
38 (__version__,) = re.findall('__version__ = "(.*)"', version_file.read())
39
40 except Exception as error:
41 __version__ = "0.0.1"
42 sys.stderr.write("Warning: Could not open '%s' due %s\n" % (filepath, error))
43
44 requirements = [
45 "black",
46 "numpy==1.22.0",
47 "scipy",
48 "SimpleITK!=2.0.*",
49 "SimpleITK!=2.2.1", # https://github.com/mlcommons/GaNDLF/issues/536
50 "torchvision",
51 "tqdm",
52 "torchio==0.18.75",
53 "pandas",
54 "scikit-learn>=0.23.2",
55 "scikit-image>=0.19.1",
56 "setuptools",
57 "seaborn",
58 "pyyaml",
59 "tiffslide",
60 "matplotlib",
61 "requests>=2.25.0",
62 "pytest",
63 "coverage",
64 "pytest-cov",
65 "psutil",
66 "medcam",
67 "opencv-python",
68 "torchmetrics==0.5.1", # newer versions have changed api for f1 invocation
69 "OpenPatchMiner==0.1.8",
70 "zarr==2.10.3",
71 "pydicom",
72 "onnx",
73 "torchinfo==1.7.0",
74 "segmentation-models-pytorch==0.3.0",
75 "ACSConv==0.1.1",
76 "docker",
77 "dicom-anonymizer",
78 "twine",
79 "zarr",
80 "keyring",
81 ]
82
83 # pytorch doesn't have LTS support on OSX - https://github.com/mlcommons/GaNDLF/issues/389
84 if sys.platform == "darwin":
85 requirements.append("torch==1.11.0")
86 else:
87 requirements.append("torch==1.11.0")
88
89 if __name__ == "__main__":
90 setup(
91 name="GANDLF",
92 version=__version__,
93 author="MLCommons",
94 author_email="[email protected]",
95 python_requires=">=3.8",
96 packages=find_packages(),
97 cmdclass={
98 "install": CustomInstallCommand,
99 "develop": CustomDevelopCommand,
100 "egg_info": CustomEggInfoCommand,
101 },
102 scripts=[
103 "gandlf_run",
104 "gandlf_constructCSV",
105 "gandlf_collectStats",
106 "gandlf_patchMiner",
107 "gandlf_preprocess",
108 "gandlf_anonymizer",
109 "gandlf_verifyInstall",
110 "gandlf_configGenerator",
111 "gandlf_recoverConfig",
112 "gandlf_deploy",
113 ],
114 classifiers=[
115 "Development Status :: 3 - Alpha",
116 "Intended Audience :: Science/Research",
117 "License :: OSI Approved :: Apache Software License",
118 "Natural Language :: English",
119 "Operating System :: OS Independent",
120 "Programming Language :: Python :: 3.8",
121 "Programming Language :: Python :: 3.9",
122 "Programming Language :: Python :: 3.10",
123 "Topic :: Scientific/Engineering :: Medical Science Apps",
124 ],
125 description=(
126 "PyTorch-based framework that handles segmentation/regression/classification using various DL architectures for medical imaging."
127 ),
128 install_requires=requirements,
129 license="Apache-2.0",
130 long_description=readme,
131 long_description_content_type="text/markdown",
132 include_package_data=True,
133 keywords="semantic, segmentation, regression, classification, data-augmentation, medical-imaging, clinical-workflows, deep-learning, pytorch",
134 zip_safe=False,
135 )
136
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -42,6 +42,7 @@
sys.stderr.write("Warning: Could not open '%s' due %s\n" % (filepath, error))
requirements = [
+ "torch==1.13.1",
"black",
"numpy==1.22.0",
"scipy",
@@ -80,12 +81,6 @@
"keyring",
]
-# pytorch doesn't have LTS support on OSX - https://github.com/mlcommons/GaNDLF/issues/389
-if sys.platform == "darwin":
- requirements.append("torch==1.11.0")
-else:
- requirements.append("torch==1.11.0")
-
if __name__ == "__main__":
setup(
name="GANDLF",
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -42,6 +42,7 @@\n sys.stderr.write(\"Warning: Could not open '%s' due %s\\n\" % (filepath, error))\n \n requirements = [\n+ \"torch==1.13.1\",\n \"black\",\n \"numpy==1.22.0\",\n \"scipy\",\n@@ -80,12 +81,6 @@\n \"keyring\",\n ]\n \n-# pytorch doesn't have LTS support on OSX - https://github.com/mlcommons/GaNDLF/issues/389\n-if sys.platform == \"darwin\":\n- requirements.append(\"torch==1.11.0\")\n-else:\n- requirements.append(\"torch==1.11.0\")\n-\n if __name__ == \"__main__\":\n setup(\n name=\"GANDLF\",\n", "issue": "PyTorch security vulnerability\nSee https://github.com/advisories/GHSA-47fc-vmwq-366v\r\n\r\nNeed to upgrade to PyTorch 1.13.1\n", "before_files": [{"content": "#!/usr/bin/env python\n\n\"\"\"The setup script.\"\"\"\n\n\nimport sys, re\nfrom setuptools import setup, find_packages\nfrom setuptools.command.install import install\nfrom setuptools.command.develop import develop\nfrom setuptools.command.egg_info import egg_info\n\ntry:\n with open(\"README.md\") as readme_file:\n readme = readme_file.read()\nexcept Exception as error:\n readme = \"No README information found.\"\n sys.stderr.write(\"Warning: Could not open '%s' due %s\\n\" % (\"README.md\", error))\n\n\nclass CustomInstallCommand(install):\n def run(self):\n install.run(self)\n\n\nclass CustomDevelopCommand(develop):\n def run(self):\n develop.run(self)\n\n\nclass CustomEggInfoCommand(egg_info):\n def run(self):\n egg_info.run(self)\n\n\ntry:\n filepath = \"GANDLF/version.py\"\n version_file = open(filepath)\n (__version__,) = re.findall('__version__ = \"(.*)\"', version_file.read())\n\nexcept Exception as error:\n __version__ = \"0.0.1\"\n sys.stderr.write(\"Warning: Could not open '%s' due %s\\n\" % (filepath, error))\n\nrequirements = [\n \"black\",\n \"numpy==1.22.0\",\n \"scipy\",\n \"SimpleITK!=2.0.*\",\n \"SimpleITK!=2.2.1\", # https://github.com/mlcommons/GaNDLF/issues/536\n \"torchvision\",\n \"tqdm\",\n \"torchio==0.18.75\",\n \"pandas\",\n \"scikit-learn>=0.23.2\",\n \"scikit-image>=0.19.1\",\n \"setuptools\",\n \"seaborn\",\n \"pyyaml\",\n \"tiffslide\",\n \"matplotlib\",\n \"requests>=2.25.0\",\n \"pytest\",\n \"coverage\",\n \"pytest-cov\",\n \"psutil\",\n \"medcam\",\n \"opencv-python\",\n \"torchmetrics==0.5.1\", # newer versions have changed api for f1 invocation\n \"OpenPatchMiner==0.1.8\",\n \"zarr==2.10.3\",\n \"pydicom\",\n \"onnx\",\n \"torchinfo==1.7.0\",\n \"segmentation-models-pytorch==0.3.0\",\n \"ACSConv==0.1.1\",\n \"docker\",\n \"dicom-anonymizer\",\n \"twine\",\n \"zarr\",\n \"keyring\",\n]\n\n# pytorch doesn't have LTS support on OSX - https://github.com/mlcommons/GaNDLF/issues/389\nif sys.platform == \"darwin\":\n requirements.append(\"torch==1.11.0\")\nelse:\n requirements.append(\"torch==1.11.0\")\n\nif __name__ == \"__main__\":\n setup(\n name=\"GANDLF\",\n version=__version__,\n author=\"MLCommons\",\n author_email=\"[email protected]\",\n python_requires=\">=3.8\",\n packages=find_packages(),\n cmdclass={\n \"install\": CustomInstallCommand,\n \"develop\": CustomDevelopCommand,\n \"egg_info\": CustomEggInfoCommand,\n },\n scripts=[\n \"gandlf_run\",\n \"gandlf_constructCSV\",\n \"gandlf_collectStats\",\n \"gandlf_patchMiner\",\n \"gandlf_preprocess\",\n \"gandlf_anonymizer\",\n \"gandlf_verifyInstall\",\n \"gandlf_configGenerator\",\n \"gandlf_recoverConfig\",\n \"gandlf_deploy\",\n ],\n classifiers=[\n \"Development Status :: 3 - Alpha\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Natural Language :: English\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Topic :: Scientific/Engineering :: Medical Science Apps\",\n ],\n description=(\n \"PyTorch-based framework that handles segmentation/regression/classification using various DL architectures for medical imaging.\"\n ),\n install_requires=requirements,\n license=\"Apache-2.0\",\n long_description=readme,\n long_description_content_type=\"text/markdown\",\n include_package_data=True,\n keywords=\"semantic, segmentation, regression, classification, data-augmentation, medical-imaging, clinical-workflows, deep-learning, pytorch\",\n zip_safe=False,\n )\n", "path": "setup.py"}]} | 1,883 | 197 |
gh_patches_debug_16711 | rasdani/github-patches | git_diff | google__TensorNetwork-489 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
tn.set_default_backend should raise exception
`tn.set_default_backend(backend_name)` should raise if `backend_name` is not a valid backend.
</issue>
<code>
[start of tensornetwork/backend_contextmanager.py]
1 from typing import Text, Union
2 from tensornetwork.backends.base_backend import BaseBackend
3
4 class DefaultBackend():
5 """Context manager for setting up backend for nodes"""
6
7 def __init__(self, backend: Union[Text, BaseBackend]) -> None:
8 if not isinstance(backend, (Text, BaseBackend)):
9 raise ValueError("Item passed to DefaultBackend "
10 "must be Text or BaseBackend")
11 self.backend = backend
12
13 def __enter__(self):
14 _default_backend_stack.stack.append(self)
15
16 def __exit__(self, exc_type, exc_val, exc_tb):
17 _default_backend_stack.stack.pop()
18
19 class _DefaultBackendStack():
20 """A stack to keep track default backends context manager"""
21
22 def __init__(self):
23 self.stack = []
24 self.default_backend = "numpy"
25
26 def get_current_backend(self):
27 return self.stack[-1].backend if self.stack else self.default_backend
28
29 _default_backend_stack = _DefaultBackendStack()
30
31 def get_default_backend():
32 return _default_backend_stack.get_current_backend()
33
34 def set_default_backend(backend: Union[Text, BaseBackend]) -> None:
35 if _default_backend_stack.stack:
36 raise AssertionError("The default backend should not be changed "
37 "inside the backend context manager")
38 if not isinstance(backend, (Text, BaseBackend)):
39 raise ValueError("Item passed to set_default_backend "
40 "must be Text or BaseBackend")
41 _default_backend_stack.default_backend = backend
42
[end of tensornetwork/backend_contextmanager.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/tensornetwork/backend_contextmanager.py b/tensornetwork/backend_contextmanager.py
--- a/tensornetwork/backend_contextmanager.py
+++ b/tensornetwork/backend_contextmanager.py
@@ -1,5 +1,6 @@
from typing import Text, Union
from tensornetwork.backends.base_backend import BaseBackend
+from tensornetwork.backends import backend_factory
class DefaultBackend():
"""Context manager for setting up backend for nodes"""
@@ -38,4 +39,6 @@
if not isinstance(backend, (Text, BaseBackend)):
raise ValueError("Item passed to set_default_backend "
"must be Text or BaseBackend")
+ if isinstance(backend, Text) and backend not in backend_factory._BACKENDS:
+ raise ValueError(f"Backend '{backend}' was not found.")
_default_backend_stack.default_backend = backend
| {"golden_diff": "diff --git a/tensornetwork/backend_contextmanager.py b/tensornetwork/backend_contextmanager.py\n--- a/tensornetwork/backend_contextmanager.py\n+++ b/tensornetwork/backend_contextmanager.py\n@@ -1,5 +1,6 @@\n from typing import Text, Union\n from tensornetwork.backends.base_backend import BaseBackend\n+from tensornetwork.backends import backend_factory\n \n class DefaultBackend():\n \"\"\"Context manager for setting up backend for nodes\"\"\"\n@@ -38,4 +39,6 @@\n if not isinstance(backend, (Text, BaseBackend)):\n raise ValueError(\"Item passed to set_default_backend \"\n \"must be Text or BaseBackend\")\n+ if isinstance(backend, Text) and backend not in backend_factory._BACKENDS:\n+ raise ValueError(f\"Backend '{backend}' was not found.\")\n _default_backend_stack.default_backend = backend\n", "issue": "tn.set_default_backend should raise exception\n`tn.set_default_backend(backend_name)` should raise if `backend_name` is not a valid backend.\n", "before_files": [{"content": "from typing import Text, Union\nfrom tensornetwork.backends.base_backend import BaseBackend\n\nclass DefaultBackend():\n \"\"\"Context manager for setting up backend for nodes\"\"\"\n\n def __init__(self, backend: Union[Text, BaseBackend]) -> None:\n if not isinstance(backend, (Text, BaseBackend)):\n raise ValueError(\"Item passed to DefaultBackend \"\n \"must be Text or BaseBackend\")\n self.backend = backend\n\n def __enter__(self):\n _default_backend_stack.stack.append(self)\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n _default_backend_stack.stack.pop()\n\nclass _DefaultBackendStack():\n \"\"\"A stack to keep track default backends context manager\"\"\"\n\n def __init__(self):\n self.stack = []\n self.default_backend = \"numpy\"\n\n def get_current_backend(self):\n return self.stack[-1].backend if self.stack else self.default_backend\n\n_default_backend_stack = _DefaultBackendStack()\n\ndef get_default_backend():\n return _default_backend_stack.get_current_backend()\n\ndef set_default_backend(backend: Union[Text, BaseBackend]) -> None:\n if _default_backend_stack.stack:\n raise AssertionError(\"The default backend should not be changed \"\n \"inside the backend context manager\")\n if not isinstance(backend, (Text, BaseBackend)):\n raise ValueError(\"Item passed to set_default_backend \"\n \"must be Text or BaseBackend\")\n _default_backend_stack.default_backend = backend\n", "path": "tensornetwork/backend_contextmanager.py"}]} | 959 | 186 |
gh_patches_debug_9249 | rasdani/github-patches | git_diff | sublimelsp__LSP-490 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[bug] CamelCase instead of snace_case
`documentChanges` argument on the left https://github.com/tomv564/LSP/blob/5a472ba6f23d70f6f8f1ebaabb83015c066ce198/plugin/rename.py#L69
should be `document_changes`, like `LspApplyWorkspaceEditCommand` expects:
https://github.com/tomv564/LSP/blob/5a472ba6f23d70f6f8f1ebaabb83015c066ce198/plugin/core/edit.py#L19
When doing a rename, this popped up in the console
```
LSP: --> textDocument/rename
Traceback (most recent call last):
File "/opt/sublime_text/sublime_plugin.py", line 1034, in run_
return self.run(**args)
TypeError: run() got an unexpected keyword argument 'documentChanges'
```
</issue>
<code>
[start of plugin/rename.py]
1 import sublime_plugin
2 from .core.registry import client_for_view, LspTextCommand
3 from .core.protocol import Request
4 from .core.documents import get_document_position, get_position, is_at_word
5 try:
6 from typing import List, Dict, Optional
7 assert List and Dict and Optional
8 except ImportError:
9 pass
10
11
12 class RenameSymbolInputHandler(sublime_plugin.TextInputHandler):
13 def __init__(self, view):
14 self.view = view
15
16 def name(self):
17 return "new_name"
18
19 def placeholder(self):
20 return self.get_current_symbol_name()
21
22 def initial_text(self):
23 return self.get_current_symbol_name()
24
25 def validate(self, name):
26 return len(name) > 0
27
28 def get_current_symbol_name(self):
29 pos = get_position(self.view)
30 current_name = self.view.substr(self.view.word(pos))
31 # Is this check necessary?
32 if not current_name:
33 current_name = ""
34 return current_name
35
36
37 class LspSymbolRenameCommand(LspTextCommand):
38 def __init__(self, view):
39 super().__init__(view)
40
41 def is_enabled(self, event=None):
42 # TODO: check what kind of scope we're in.
43 if self.has_client_with_capability('renameProvider'):
44 return is_at_word(self.view, event)
45 return False
46
47 def input(self, args):
48 if "new_name" not in args:
49 return RenameSymbolInputHandler(self.view)
50 else:
51 return None
52
53 def run(self, edit, new_name, event=None):
54 pos = get_position(self.view, event)
55 params = get_document_position(self.view, pos)
56
57 self.request_rename(params, new_name)
58
59 def request_rename(self, params, new_name) -> None:
60 client = client_for_view(self.view)
61 if client:
62 params["newName"] = new_name
63 client.send_request(Request.rename(params), self.handle_response)
64
65 def handle_response(self, response: 'Optional[Dict]') -> None:
66 if response:
67 self.view.window().run_command('lsp_apply_workspace_edit',
68 {'changes': response.get('changes'),
69 'documentChanges': response.get('documentChanges')})
70 else:
71 self.view.window().status_message('No rename edits returned')
72
73 def want_event(self):
74 return True
75
[end of plugin/rename.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/plugin/rename.py b/plugin/rename.py
--- a/plugin/rename.py
+++ b/plugin/rename.py
@@ -66,7 +66,7 @@
if response:
self.view.window().run_command('lsp_apply_workspace_edit',
{'changes': response.get('changes'),
- 'documentChanges': response.get('documentChanges')})
+ 'document_changes': response.get('documentChanges')})
else:
self.view.window().status_message('No rename edits returned')
| {"golden_diff": "diff --git a/plugin/rename.py b/plugin/rename.py\n--- a/plugin/rename.py\n+++ b/plugin/rename.py\n@@ -66,7 +66,7 @@\n if response:\n self.view.window().run_command('lsp_apply_workspace_edit',\n {'changes': response.get('changes'),\n- 'documentChanges': response.get('documentChanges')})\n+ 'document_changes': response.get('documentChanges')})\n else:\n self.view.window().status_message('No rename edits returned')\n", "issue": "[bug] CamelCase instead of snace_case \n`documentChanges` argument on the left https://github.com/tomv564/LSP/blob/5a472ba6f23d70f6f8f1ebaabb83015c066ce198/plugin/rename.py#L69\r\nshould be `document_changes`, like `LspApplyWorkspaceEditCommand` expects:\r\nhttps://github.com/tomv564/LSP/blob/5a472ba6f23d70f6f8f1ebaabb83015c066ce198/plugin/core/edit.py#L19\r\n\r\nWhen doing a rename, this popped up in the console\r\n```\r\nLSP: --> textDocument/rename\r\nTraceback (most recent call last):\r\n File \"/opt/sublime_text/sublime_plugin.py\", line 1034, in run_\r\n return self.run(**args)\r\nTypeError: run() got an unexpected keyword argument 'documentChanges'\r\n```\n", "before_files": [{"content": "import sublime_plugin\nfrom .core.registry import client_for_view, LspTextCommand\nfrom .core.protocol import Request\nfrom .core.documents import get_document_position, get_position, is_at_word\ntry:\n from typing import List, Dict, Optional\n assert List and Dict and Optional\nexcept ImportError:\n pass\n\n\nclass RenameSymbolInputHandler(sublime_plugin.TextInputHandler):\n def __init__(self, view):\n self.view = view\n\n def name(self):\n return \"new_name\"\n\n def placeholder(self):\n return self.get_current_symbol_name()\n\n def initial_text(self):\n return self.get_current_symbol_name()\n\n def validate(self, name):\n return len(name) > 0\n\n def get_current_symbol_name(self):\n pos = get_position(self.view)\n current_name = self.view.substr(self.view.word(pos))\n # Is this check necessary?\n if not current_name:\n current_name = \"\"\n return current_name\n\n\nclass LspSymbolRenameCommand(LspTextCommand):\n def __init__(self, view):\n super().__init__(view)\n\n def is_enabled(self, event=None):\n # TODO: check what kind of scope we're in.\n if self.has_client_with_capability('renameProvider'):\n return is_at_word(self.view, event)\n return False\n\n def input(self, args):\n if \"new_name\" not in args:\n return RenameSymbolInputHandler(self.view)\n else:\n return None\n\n def run(self, edit, new_name, event=None):\n pos = get_position(self.view, event)\n params = get_document_position(self.view, pos)\n\n self.request_rename(params, new_name)\n\n def request_rename(self, params, new_name) -> None:\n client = client_for_view(self.view)\n if client:\n params[\"newName\"] = new_name\n client.send_request(Request.rename(params), self.handle_response)\n\n def handle_response(self, response: 'Optional[Dict]') -> None:\n if response:\n self.view.window().run_command('lsp_apply_workspace_edit',\n {'changes': response.get('changes'),\n 'documentChanges': response.get('documentChanges')})\n else:\n self.view.window().status_message('No rename edits returned')\n\n def want_event(self):\n return True\n", "path": "plugin/rename.py"}]} | 1,395 | 109 |
gh_patches_debug_34991 | rasdani/github-patches | git_diff | bids-standard__pybids-411 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Convolve should have sampling rate
For events with duration shorter than 1/50, `Convolve` from a sparse variable will produce all 0s. This can be fixed by inserting `ToDense(sampling_rate=200)` (or whatever), but this should be immediately accessible from `Convolve`.
cc @yarikoptic @AdinaWagner
</issue>
<code>
[start of bids/analysis/transformations/compute.py]
1 '''
2 Transformations that primarily involve numerical computation on variables.
3 '''
4
5 import numpy as np
6 import pandas as pd
7 from bids.utils import listify
8 from .base import Transformation
9 from bids.analysis import hrf
10 from bids.variables import SparseRunVariable, DenseRunVariable
11
12
13 class Convolve(Transformation):
14 """Convolve the input variable with an HRF.
15
16 Args:
17 var (Variable): The variable to convolve.
18 model (str): The name of the HRF model to apply. Must be one of 'spm',
19 'glover', or 'fir'.
20 derivative (bool): Whether or not to include the temporal derivative.
21 dispersion (bool): Whether or not to include the dispersion derivative.
22 fir_delays (iterable): A list or iterable of delays to use if model is
23 'fir' (ignored otherwise). Spacing between delays must be fixed.
24
25 Note: Uses the HRF convolution functions implemented in nistats.
26 """
27
28 _input_type = 'variable'
29 _return_type = 'variable'
30
31 def _transform(self, var, model='spm', derivative=False, dispersion=False,
32 fir_delays=None):
33
34 model = model.lower()
35
36 if isinstance(var, SparseRunVariable):
37 sr = self.collection.sampling_rate
38 var = var.to_dense(sr)
39
40 df = var.to_df(entities=False)
41 onsets = df['onset'].values
42 vals = df[['onset', 'duration', 'amplitude']].values.T
43
44 if model in ['spm', 'glover']:
45 if derivative:
46 model += ' + derivative'
47 if dispersion:
48 model += ' + dispersion'
49 elif model != 'fir':
50 raise ValueError("Model must be one of 'spm', 'glover', or 'fir'.")
51
52 convolved = hrf.compute_regressor(vals, model, onsets,
53 fir_delays=fir_delays, min_onset=0)
54
55 return DenseRunVariable(name=var.name, values=convolved[0], run_info=var.run_info,
56 source=var.source, sampling_rate=var.sampling_rate)
57
58
59 class Demean(Transformation):
60
61 def _transform(self, data):
62 return data - data.mean()
63
64
65 class Orthogonalize(Transformation):
66
67 _variables_used = ('variables', 'other')
68 _densify = ('variables', 'other')
69 _align = ('other')
70
71 def _transform(self, var, other):
72
73 other = listify(other)
74
75 # Set up X matrix and slice into it based on target variable indices
76 X = np.array([self._variables[c].values.values.squeeze()
77 for c in other]).T
78 X = X[var.index, :]
79 assert len(X) == len(var)
80 y = var.values
81 _aX = np.c_[np.ones(len(y)), X]
82 coefs, resids, rank, s = np.linalg.lstsq(_aX, y)
83 result = pd.DataFrame(y - X.dot(coefs[1:]), index=var.index)
84 return result
85
86
87 class Product(Transformation):
88
89 _loopable = False
90 _groupable = False
91 _align = True
92 _output_required = True
93
94 def _transform(self, data):
95 data = pd.concat(data, axis=1, sort=True)
96 return data.product(1)
97
98
99 class Scale(Transformation):
100 ''' Scale a variable.
101
102 Args:
103 data (Series/DF): The variables to scale.
104 demean (bool): If True, demean each column.
105 rescale (bool): If True, divide variables by their standard deviation.
106 replace_na (str): Whether/when to replace missing values with 0. If
107 None, no replacement is performed. If 'before', missing values are
108 replaced with 0's before scaling. If 'after', missing values are
109 replaced with 0 after scaling.
110
111 '''
112
113 def _transform(self, data, demean=True, rescale=True, replace_na=None):
114 if replace_na == 'before':
115 data = data.fillna(0.)
116 if demean:
117 data -= data.mean()
118 if rescale:
119 data /= data.std()
120 if replace_na == 'after':
121 data = data.fillna(0.)
122 return data
123
124
125 class Sum(Transformation):
126
127 _loopable = False
128 _groupable = False
129 _align = True
130 _output_required = True
131
132 def _transform(self, data, weights=None):
133 data = pd.concat(data, axis=1, sort=True)
134 if weights is None:
135 weights = np.ones(data.shape[1])
136 else:
137 weights = np.array(weights)
138 if len(weights.ravel()) != data.shape[1]:
139 raise ValueError("If weights are passed to sum(), the number "
140 "of elements must equal number of variables"
141 "being summed.")
142 return (data * weights).sum(axis=1)
143
144
145
146 class Threshold(Transformation):
147 ''' Threshold and/or binarize a variable.
148
149 Args:
150 data (Series/DF): The pandas structure to threshold.
151 threshold (float): The value to binarize around (values above will
152 be assigned 1, values below will be assigned 0).
153 binarize (bool): If True, binarizes all non-zero values (i.e., every
154 non-zero value will be set to 1).
155 above (bool): Specifies which values to retain with respect to the
156 cut-off. If True, all value above the threshold will be kept; if
157 False, all values below the threshold will be kept. Defaults to
158 True.
159 signed (bool): Specifies whether to treat the threshold as signed
160 (default) or unsigned. For example, when passing above=True and
161 threshold=3, if signed=True, all and only values above +3 would be
162 retained. If signed=False, all absolute values > 3 would be retained
163 (i.e.,values in the range -3 < X < 3 would be set to 0).
164
165 '''
166
167 _groupable = False
168
169 def _transform(self, data, threshold=0., binarize=False, above=True,
170 signed=True):
171 if not signed:
172 threshold = np.abs(threshold)
173 data = data.abs()
174 keep = data >= threshold if above else data <= threshold
175 data[~keep] = 0
176 if binarize:
177 data[keep] = 1
178 return data
179
180
181 class And(Transformation):
182 ''' Logical AND on two or more variables.
183
184 Args:
185 dfs (list of DFs): variables to enter into the conjunction.
186 '''
187
188 _loopable = False
189 _groupable = False
190 _output_required = True
191
192 def _transform(self, dfs):
193 df = pd.concat(dfs, axis=1, sort=True)
194 return df.all(axis=1).astype(int)
195
196
197 class Not(Transformation):
198 ''' Logical negation of a variable.
199
200 Args:
201 var (Series): Variable to negate. Must be convertible to bool.
202 '''
203
204 _loopable = True
205 _groupable = False
206
207 def _transform(self, var):
208 return ~var.astype(bool)
209
210
211 class Or(Transformation):
212 ''' Logical OR (inclusive) on two or more variables.
213
214 Args:
215 dfs (list of DFs): variables to enter into the disjunction.
216 '''
217
218 _loopable = False
219 _groupable = False
220 _output_required = True
221
222 def _transform(self, dfs):
223 df = pd.concat(dfs, axis=1, sort=True)
224 return df.any(axis=1).astype(int)
225
[end of bids/analysis/transformations/compute.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/bids/analysis/transformations/compute.py b/bids/analysis/transformations/compute.py
--- a/bids/analysis/transformations/compute.py
+++ b/bids/analysis/transformations/compute.py
@@ -1,7 +1,8 @@
'''
Transformations that primarily involve numerical computation on variables.
'''
-
+from __future__ import division
+import math
import numpy as np
import pandas as pd
from bids.utils import listify
@@ -33,12 +34,18 @@
model = model.lower()
+ df = var.to_df(entities=False)
+
if isinstance(var, SparseRunVariable):
- sr = self.collection.sampling_rate
- var = var.to_dense(sr)
+ sampling_rate = self.collection.sampling_rate
+ dur = var.get_duration()
+ resample_frames = np.linspace(
+ 0, dur, int(math.ceil(dur * sampling_rate)), endpoint=False)
+
+ else:
+ resample_frames = df['onset'].values
+ sampling_rate = var.sampling_rate
- df = var.to_df(entities=False)
- onsets = df['onset'].values
vals = df[['onset', 'duration', 'amplitude']].values.T
if model in ['spm', 'glover']:
@@ -49,11 +56,23 @@
elif model != 'fir':
raise ValueError("Model must be one of 'spm', 'glover', or 'fir'.")
- convolved = hrf.compute_regressor(vals, model, onsets,
- fir_delays=fir_delays, min_onset=0)
-
- return DenseRunVariable(name=var.name, values=convolved[0], run_info=var.run_info,
- source=var.source, sampling_rate=var.sampling_rate)
+ # Minimum interval between event onsets/duration
+ # Used to compute oversampling factor to prevent information loss
+ unique_onsets = np.unique(np.sort(df.onset))
+ if len(unique_onsets) > 1:
+ min_interval = min(np.ediff1d(unique_onsets).min(),
+ df.duration.min())
+ oversampling = np.ceil(2*(1 / (min_interval * sampling_rate)))
+ else:
+ oversampling = 2
+ convolved = hrf.compute_regressor(
+ vals, model, resample_frames, fir_delays=fir_delays, min_onset=0,
+ oversampling=oversampling
+ )
+
+ return DenseRunVariable(
+ name=var.name, values=convolved[0], run_info=var.run_info,
+ source=var.source, sampling_rate=sampling_rate)
class Demean(Transformation):
| {"golden_diff": "diff --git a/bids/analysis/transformations/compute.py b/bids/analysis/transformations/compute.py\n--- a/bids/analysis/transformations/compute.py\n+++ b/bids/analysis/transformations/compute.py\n@@ -1,7 +1,8 @@\n '''\n Transformations that primarily involve numerical computation on variables.\n '''\n-\n+from __future__ import division\n+import math\n import numpy as np\n import pandas as pd\n from bids.utils import listify\n@@ -33,12 +34,18 @@\n \n model = model.lower()\n \n+ df = var.to_df(entities=False)\n+\n if isinstance(var, SparseRunVariable):\n- sr = self.collection.sampling_rate\n- var = var.to_dense(sr)\n+ sampling_rate = self.collection.sampling_rate\n+ dur = var.get_duration()\n+ resample_frames = np.linspace(\n+ 0, dur, int(math.ceil(dur * sampling_rate)), endpoint=False)\n+\n+ else:\n+ resample_frames = df['onset'].values\n+ sampling_rate = var.sampling_rate\n \n- df = var.to_df(entities=False)\n- onsets = df['onset'].values\n vals = df[['onset', 'duration', 'amplitude']].values.T\n \n if model in ['spm', 'glover']:\n@@ -49,11 +56,23 @@\n elif model != 'fir':\n raise ValueError(\"Model must be one of 'spm', 'glover', or 'fir'.\")\n \n- convolved = hrf.compute_regressor(vals, model, onsets,\n- fir_delays=fir_delays, min_onset=0)\n-\n- return DenseRunVariable(name=var.name, values=convolved[0], run_info=var.run_info,\n- source=var.source, sampling_rate=var.sampling_rate)\n+ # Minimum interval between event onsets/duration\n+ # Used to compute oversampling factor to prevent information loss\n+ unique_onsets = np.unique(np.sort(df.onset))\n+ if len(unique_onsets) > 1:\n+ min_interval = min(np.ediff1d(unique_onsets).min(),\n+ df.duration.min())\n+ oversampling = np.ceil(2*(1 / (min_interval * sampling_rate)))\n+ else:\n+ oversampling = 2\n+ convolved = hrf.compute_regressor(\n+ vals, model, resample_frames, fir_delays=fir_delays, min_onset=0,\n+ oversampling=oversampling\n+ )\n+\n+ return DenseRunVariable(\n+ name=var.name, values=convolved[0], run_info=var.run_info,\n+ source=var.source, sampling_rate=sampling_rate)\n \n \n class Demean(Transformation):\n", "issue": "Convolve should have sampling rate\nFor events with duration shorter than 1/50, `Convolve` from a sparse variable will produce all 0s. This can be fixed by inserting `ToDense(sampling_rate=200)` (or whatever), but this should be immediately accessible from `Convolve`.\r\n\r\ncc @yarikoptic @AdinaWagner \n", "before_files": [{"content": "'''\nTransformations that primarily involve numerical computation on variables.\n'''\n\nimport numpy as np\nimport pandas as pd\nfrom bids.utils import listify\nfrom .base import Transformation\nfrom bids.analysis import hrf\nfrom bids.variables import SparseRunVariable, DenseRunVariable\n\n\nclass Convolve(Transformation):\n \"\"\"Convolve the input variable with an HRF.\n\n Args:\n var (Variable): The variable to convolve.\n model (str): The name of the HRF model to apply. Must be one of 'spm',\n 'glover', or 'fir'.\n derivative (bool): Whether or not to include the temporal derivative.\n dispersion (bool): Whether or not to include the dispersion derivative.\n fir_delays (iterable): A list or iterable of delays to use if model is\n 'fir' (ignored otherwise). Spacing between delays must be fixed.\n\n Note: Uses the HRF convolution functions implemented in nistats.\n \"\"\"\n\n _input_type = 'variable'\n _return_type = 'variable'\n\n def _transform(self, var, model='spm', derivative=False, dispersion=False,\n fir_delays=None):\n\n model = model.lower()\n\n if isinstance(var, SparseRunVariable):\n sr = self.collection.sampling_rate\n var = var.to_dense(sr)\n\n df = var.to_df(entities=False)\n onsets = df['onset'].values\n vals = df[['onset', 'duration', 'amplitude']].values.T\n\n if model in ['spm', 'glover']:\n if derivative:\n model += ' + derivative'\n if dispersion:\n model += ' + dispersion'\n elif model != 'fir':\n raise ValueError(\"Model must be one of 'spm', 'glover', or 'fir'.\")\n\n convolved = hrf.compute_regressor(vals, model, onsets,\n fir_delays=fir_delays, min_onset=0)\n\n return DenseRunVariable(name=var.name, values=convolved[0], run_info=var.run_info,\n source=var.source, sampling_rate=var.sampling_rate)\n\n\nclass Demean(Transformation):\n\n def _transform(self, data):\n return data - data.mean()\n\n\nclass Orthogonalize(Transformation):\n\n _variables_used = ('variables', 'other')\n _densify = ('variables', 'other')\n _align = ('other')\n\n def _transform(self, var, other):\n\n other = listify(other)\n\n # Set up X matrix and slice into it based on target variable indices\n X = np.array([self._variables[c].values.values.squeeze()\n for c in other]).T\n X = X[var.index, :]\n assert len(X) == len(var)\n y = var.values\n _aX = np.c_[np.ones(len(y)), X]\n coefs, resids, rank, s = np.linalg.lstsq(_aX, y)\n result = pd.DataFrame(y - X.dot(coefs[1:]), index=var.index)\n return result\n\n\nclass Product(Transformation):\n\n _loopable = False\n _groupable = False\n _align = True\n _output_required = True\n\n def _transform(self, data):\n data = pd.concat(data, axis=1, sort=True)\n return data.product(1)\n\n\nclass Scale(Transformation):\n ''' Scale a variable.\n\n Args:\n data (Series/DF): The variables to scale.\n demean (bool): If True, demean each column.\n rescale (bool): If True, divide variables by their standard deviation.\n replace_na (str): Whether/when to replace missing values with 0. If\n None, no replacement is performed. If 'before', missing values are\n replaced with 0's before scaling. If 'after', missing values are\n replaced with 0 after scaling.\n\n '''\n\n def _transform(self, data, demean=True, rescale=True, replace_na=None):\n if replace_na == 'before':\n data = data.fillna(0.)\n if demean:\n data -= data.mean()\n if rescale:\n data /= data.std()\n if replace_na == 'after':\n data = data.fillna(0.)\n return data\n\n\nclass Sum(Transformation):\n\n _loopable = False\n _groupable = False\n _align = True\n _output_required = True\n\n def _transform(self, data, weights=None):\n data = pd.concat(data, axis=1, sort=True)\n if weights is None:\n weights = np.ones(data.shape[1])\n else:\n weights = np.array(weights)\n if len(weights.ravel()) != data.shape[1]:\n raise ValueError(\"If weights are passed to sum(), the number \"\n \"of elements must equal number of variables\"\n \"being summed.\")\n return (data * weights).sum(axis=1)\n\n\n\nclass Threshold(Transformation):\n ''' Threshold and/or binarize a variable.\n\n Args:\n data (Series/DF): The pandas structure to threshold.\n threshold (float): The value to binarize around (values above will\n be assigned 1, values below will be assigned 0).\n binarize (bool): If True, binarizes all non-zero values (i.e., every\n non-zero value will be set to 1).\n above (bool): Specifies which values to retain with respect to the\n cut-off. If True, all value above the threshold will be kept; if\n False, all values below the threshold will be kept. Defaults to\n True.\n signed (bool): Specifies whether to treat the threshold as signed\n (default) or unsigned. For example, when passing above=True and\n threshold=3, if signed=True, all and only values above +3 would be\n retained. If signed=False, all absolute values > 3 would be retained\n (i.e.,values in the range -3 < X < 3 would be set to 0).\n\n '''\n\n _groupable = False\n\n def _transform(self, data, threshold=0., binarize=False, above=True,\n signed=True):\n if not signed:\n threshold = np.abs(threshold)\n data = data.abs()\n keep = data >= threshold if above else data <= threshold\n data[~keep] = 0\n if binarize:\n data[keep] = 1\n return data\n\n\nclass And(Transformation):\n ''' Logical AND on two or more variables.\n\n Args:\n dfs (list of DFs): variables to enter into the conjunction.\n '''\n\n _loopable = False\n _groupable = False\n _output_required = True\n\n def _transform(self, dfs):\n df = pd.concat(dfs, axis=1, sort=True)\n return df.all(axis=1).astype(int)\n\n\nclass Not(Transformation):\n ''' Logical negation of a variable.\n\n Args:\n var (Series): Variable to negate. Must be convertible to bool.\n '''\n\n _loopable = True\n _groupable = False\n\n def _transform(self, var):\n return ~var.astype(bool)\n\n\nclass Or(Transformation):\n ''' Logical OR (inclusive) on two or more variables.\n\n Args:\n dfs (list of DFs): variables to enter into the disjunction.\n '''\n\n _loopable = False\n _groupable = False\n _output_required = True\n\n def _transform(self, dfs):\n df = pd.concat(dfs, axis=1, sort=True)\n return df.any(axis=1).astype(int)\n", "path": "bids/analysis/transformations/compute.py"}]} | 2,851 | 609 |
gh_patches_debug_20606 | rasdani/github-patches | git_diff | bookwyrm-social__bookwyrm-279 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remote follow silently failing
When I try to follow a remote user, the remote user is not notified and the relationship is not confirmed. No errors show up locally that I've found.
</issue>
<code>
[start of bookwyrm/signatures.py]
1 ''' signs activitypub activities '''
2 import hashlib
3 from urllib.parse import urlparse
4 import datetime
5 from base64 import b64encode, b64decode
6
7 from Crypto import Random
8 from Crypto.PublicKey import RSA
9 from Crypto.Signature import pkcs1_15 #pylint: disable=no-name-in-module
10 from Crypto.Hash import SHA256
11
12 MAX_SIGNATURE_AGE = 300
13
14 def create_key_pair():
15 ''' a new public/private key pair, used for creating new users '''
16 random_generator = Random.new().read
17 key = RSA.generate(1024, random_generator)
18 private_key = key.export_key().decode('utf8')
19 public_key = key.publickey().export_key().decode('utf8')
20
21 return private_key, public_key
22
23
24 def make_signature(sender, destination, date, digest):
25 ''' uses a private key to sign an outgoing message '''
26 inbox_parts = urlparse(destination)
27 signature_headers = [
28 '(request-target): post %s' % inbox_parts.path,
29 'host: %s' % inbox_parts.netloc,
30 'date: %s' % date,
31 'digest: %s' % digest,
32 ]
33 message_to_sign = '\n'.join(signature_headers)
34 signer = pkcs1_15.new(RSA.import_key(sender.private_key))
35 signed_message = signer.sign(SHA256.new(message_to_sign.encode('utf8')))
36 signature = {
37 'keyId': '%s#main-key' % sender.remote_id,
38 'algorithm': 'rsa-sha256',
39 'headers': '(request-target) host date digest',
40 'signature': b64encode(signed_message).decode('utf8'),
41 }
42 return ','.join('%s="%s"' % (k, v) for (k, v) in signature.items())
43
44
45 def make_digest(data):
46 ''' creates a message digest for signing '''
47 return 'SHA-256=' + b64encode(hashlib.sha256(data).digest()).decode('utf-8')
48
49
50 def verify_digest(request):
51 ''' checks if a digest is syntactically valid and matches the message '''
52 algorithm, digest = request.headers['digest'].split('=', 1)
53 if algorithm == 'SHA-256':
54 hash_function = hashlib.sha256
55 elif algorithm == 'SHA-512':
56 hash_function = hashlib.sha512
57 else:
58 raise ValueError("Unsupported hash function: {}".format(algorithm))
59
60 expected = hash_function(request.body).digest()
61 if b64decode(digest) != expected:
62 raise ValueError("Invalid HTTP Digest header")
63
64 class Signature:
65 ''' read and validate incoming signatures '''
66 def __init__(self, key_id, headers, signature):
67 self.key_id = key_id
68 self.headers = headers
69 self.signature = signature
70
71 @classmethod
72 def parse(cls, request):
73 ''' extract and parse a signature from an http request '''
74 signature_dict = {}
75 for pair in request.headers['Signature'].split(','):
76 k, v = pair.split('=', 1)
77 v = v.replace('"', '')
78 signature_dict[k] = v
79
80 try:
81 key_id = signature_dict['keyId']
82 headers = signature_dict['headers']
83 signature = b64decode(signature_dict['signature'])
84 except KeyError:
85 raise ValueError('Invalid auth header')
86
87 return cls(key_id, headers, signature)
88
89 def verify(self, public_key, request):
90 ''' verify rsa signature '''
91 if http_date_age(request.headers['date']) > MAX_SIGNATURE_AGE:
92 raise ValueError(
93 "Request too old: %s" % (request.headers['date'],))
94 public_key = RSA.import_key(public_key)
95
96 comparison_string = []
97 for signed_header_name in self.headers.split(' '):
98 if signed_header_name == '(request-target)':
99 comparison_string.append(
100 '(request-target): post %s' % request.path)
101 else:
102 if signed_header_name == 'digest':
103 verify_digest(request)
104 comparison_string.append('%s: %s' % (
105 signed_header_name,
106 request.headers[signed_header_name]
107 ))
108 comparison_string = '\n'.join(comparison_string)
109
110 signer = pkcs1_15.new(public_key)
111 digest = SHA256.new()
112 digest.update(comparison_string.encode())
113
114 # raises a ValueError if it fails
115 signer.verify(digest, self.signature)
116
117
118 def http_date_age(datestr):
119 ''' age of a signature in seconds '''
120 parsed = datetime.datetime.strptime(datestr, '%a, %d %b %Y %H:%M:%S GMT')
121 delta = datetime.datetime.utcnow() - parsed
122 return delta.total_seconds()
123
[end of bookwyrm/signatures.py]
[start of bookwyrm/broadcast.py]
1 ''' send out activitypub messages '''
2 import json
3 from django.utils.http import http_date
4 import requests
5
6 from bookwyrm import models
7 from bookwyrm.activitypub import ActivityEncoder
8 from bookwyrm.tasks import app
9 from bookwyrm.signatures import make_signature, make_digest
10
11
12 def get_public_recipients(user, software=None):
13 ''' everybody and their public inboxes '''
14 followers = user.followers.filter(local=False)
15 if software:
16 followers = followers.filter(bookwyrm_user=(software == 'bookwyrm'))
17
18 # we want shared inboxes when available
19 shared = followers.filter(
20 shared_inbox__isnull=False
21 ).values_list('shared_inbox', flat=True).distinct()
22
23 # if a user doesn't have a shared inbox, we need their personal inbox
24 # iirc pixelfed doesn't have shared inboxes
25 inboxes = followers.filter(
26 shared_inbox__isnull=True
27 ).values_list('inbox', flat=True)
28
29 return list(shared) + list(inboxes)
30
31
32 def broadcast(sender, activity, software=None, \
33 privacy='public', direct_recipients=None):
34 ''' send out an event '''
35 # start with parsing the direct recipients
36 recipients = [u.inbox for u in direct_recipients or []]
37 # and then add any other recipients
38 if privacy == 'public':
39 recipients += get_public_recipients(sender, software=software)
40 broadcast_task.delay(
41 sender.id,
42 json.dumps(activity, cls=ActivityEncoder),
43 recipients
44 )
45
46
47 @app.task
48 def broadcast_task(sender_id, activity, recipients):
49 ''' the celery task for broadcast '''
50 sender = models.User.objects.get(id=sender_id)
51 errors = []
52 for recipient in recipients:
53 try:
54 sign_and_send(sender, activity, recipient)
55 except requests.exceptions.HTTPError as e:
56 errors.append({
57 'error': str(e),
58 'recipient': recipient,
59 'activity': activity,
60 })
61 return errors
62
63
64 def sign_and_send(sender, activity, destination):
65 ''' crpyto whatever and http junk '''
66 now = http_date()
67
68 if not sender.private_key:
69 # this shouldn't happen. it would be bad if it happened.
70 raise ValueError('No private key found for sender')
71
72 data = json.dumps(activity).encode('utf-8')
73 digest = make_digest(data)
74
75 response = requests.post(
76 destination,
77 data=data,
78 headers={
79 'Date': now,
80 'Digest': digest,
81 'Signature': make_signature(sender, destination, now, digest),
82 'Content-Type': 'application/activity+json; charset=utf-8',
83 },
84 )
85 if not response.ok:
86 response.raise_for_status()
87 return response
88
[end of bookwyrm/broadcast.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/bookwyrm/broadcast.py b/bookwyrm/broadcast.py
--- a/bookwyrm/broadcast.py
+++ b/bookwyrm/broadcast.py
@@ -61,7 +61,7 @@
return errors
-def sign_and_send(sender, activity, destination):
+def sign_and_send(sender, data, destination):
''' crpyto whatever and http junk '''
now = http_date()
@@ -69,7 +69,6 @@
# this shouldn't happen. it would be bad if it happened.
raise ValueError('No private key found for sender')
- data = json.dumps(activity).encode('utf-8')
digest = make_digest(data)
response = requests.post(
diff --git a/bookwyrm/signatures.py b/bookwyrm/signatures.py
--- a/bookwyrm/signatures.py
+++ b/bookwyrm/signatures.py
@@ -44,7 +44,8 @@
def make_digest(data):
''' creates a message digest for signing '''
- return 'SHA-256=' + b64encode(hashlib.sha256(data).digest()).decode('utf-8')
+ return 'SHA-256=' + b64encode(hashlib.sha256(data.encode('utf-8'))\
+ .digest()).decode('utf-8')
def verify_digest(request):
| {"golden_diff": "diff --git a/bookwyrm/broadcast.py b/bookwyrm/broadcast.py\n--- a/bookwyrm/broadcast.py\n+++ b/bookwyrm/broadcast.py\n@@ -61,7 +61,7 @@\n return errors\n \n \n-def sign_and_send(sender, activity, destination):\n+def sign_and_send(sender, data, destination):\n ''' crpyto whatever and http junk '''\n now = http_date()\n \n@@ -69,7 +69,6 @@\n # this shouldn't happen. it would be bad if it happened.\n raise ValueError('No private key found for sender')\n \n- data = json.dumps(activity).encode('utf-8')\n digest = make_digest(data)\n \n response = requests.post(\ndiff --git a/bookwyrm/signatures.py b/bookwyrm/signatures.py\n--- a/bookwyrm/signatures.py\n+++ b/bookwyrm/signatures.py\n@@ -44,7 +44,8 @@\n \n def make_digest(data):\n ''' creates a message digest for signing '''\n- return 'SHA-256=' + b64encode(hashlib.sha256(data).digest()).decode('utf-8')\n+ return 'SHA-256=' + b64encode(hashlib.sha256(data.encode('utf-8'))\\\n+ .digest()).decode('utf-8')\n \n \n def verify_digest(request):\n", "issue": "Remote follow silently failing\nWhen I try to follow a remote user, the remote user is not notified and the relationship is not confirmed. No errors show up locally that I've found.\n", "before_files": [{"content": "''' signs activitypub activities '''\nimport hashlib\nfrom urllib.parse import urlparse\nimport datetime\nfrom base64 import b64encode, b64decode\n\nfrom Crypto import Random\nfrom Crypto.PublicKey import RSA\nfrom Crypto.Signature import pkcs1_15 #pylint: disable=no-name-in-module\nfrom Crypto.Hash import SHA256\n\nMAX_SIGNATURE_AGE = 300\n\ndef create_key_pair():\n ''' a new public/private key pair, used for creating new users '''\n random_generator = Random.new().read\n key = RSA.generate(1024, random_generator)\n private_key = key.export_key().decode('utf8')\n public_key = key.publickey().export_key().decode('utf8')\n\n return private_key, public_key\n\n\ndef make_signature(sender, destination, date, digest):\n ''' uses a private key to sign an outgoing message '''\n inbox_parts = urlparse(destination)\n signature_headers = [\n '(request-target): post %s' % inbox_parts.path,\n 'host: %s' % inbox_parts.netloc,\n 'date: %s' % date,\n 'digest: %s' % digest,\n ]\n message_to_sign = '\\n'.join(signature_headers)\n signer = pkcs1_15.new(RSA.import_key(sender.private_key))\n signed_message = signer.sign(SHA256.new(message_to_sign.encode('utf8')))\n signature = {\n 'keyId': '%s#main-key' % sender.remote_id,\n 'algorithm': 'rsa-sha256',\n 'headers': '(request-target) host date digest',\n 'signature': b64encode(signed_message).decode('utf8'),\n }\n return ','.join('%s=\"%s\"' % (k, v) for (k, v) in signature.items())\n\n\ndef make_digest(data):\n ''' creates a message digest for signing '''\n return 'SHA-256=' + b64encode(hashlib.sha256(data).digest()).decode('utf-8')\n\n\ndef verify_digest(request):\n ''' checks if a digest is syntactically valid and matches the message '''\n algorithm, digest = request.headers['digest'].split('=', 1)\n if algorithm == 'SHA-256':\n hash_function = hashlib.sha256\n elif algorithm == 'SHA-512':\n hash_function = hashlib.sha512\n else:\n raise ValueError(\"Unsupported hash function: {}\".format(algorithm))\n\n expected = hash_function(request.body).digest()\n if b64decode(digest) != expected:\n raise ValueError(\"Invalid HTTP Digest header\")\n\nclass Signature:\n ''' read and validate incoming signatures '''\n def __init__(self, key_id, headers, signature):\n self.key_id = key_id\n self.headers = headers\n self.signature = signature\n\n @classmethod\n def parse(cls, request):\n ''' extract and parse a signature from an http request '''\n signature_dict = {}\n for pair in request.headers['Signature'].split(','):\n k, v = pair.split('=', 1)\n v = v.replace('\"', '')\n signature_dict[k] = v\n\n try:\n key_id = signature_dict['keyId']\n headers = signature_dict['headers']\n signature = b64decode(signature_dict['signature'])\n except KeyError:\n raise ValueError('Invalid auth header')\n\n return cls(key_id, headers, signature)\n\n def verify(self, public_key, request):\n ''' verify rsa signature '''\n if http_date_age(request.headers['date']) > MAX_SIGNATURE_AGE:\n raise ValueError(\n \"Request too old: %s\" % (request.headers['date'],))\n public_key = RSA.import_key(public_key)\n\n comparison_string = []\n for signed_header_name in self.headers.split(' '):\n if signed_header_name == '(request-target)':\n comparison_string.append(\n '(request-target): post %s' % request.path)\n else:\n if signed_header_name == 'digest':\n verify_digest(request)\n comparison_string.append('%s: %s' % (\n signed_header_name,\n request.headers[signed_header_name]\n ))\n comparison_string = '\\n'.join(comparison_string)\n\n signer = pkcs1_15.new(public_key)\n digest = SHA256.new()\n digest.update(comparison_string.encode())\n\n # raises a ValueError if it fails\n signer.verify(digest, self.signature)\n\n\ndef http_date_age(datestr):\n ''' age of a signature in seconds '''\n parsed = datetime.datetime.strptime(datestr, '%a, %d %b %Y %H:%M:%S GMT')\n delta = datetime.datetime.utcnow() - parsed\n return delta.total_seconds()\n", "path": "bookwyrm/signatures.py"}, {"content": "''' send out activitypub messages '''\nimport json\nfrom django.utils.http import http_date\nimport requests\n\nfrom bookwyrm import models\nfrom bookwyrm.activitypub import ActivityEncoder\nfrom bookwyrm.tasks import app\nfrom bookwyrm.signatures import make_signature, make_digest\n\n\ndef get_public_recipients(user, software=None):\n ''' everybody and their public inboxes '''\n followers = user.followers.filter(local=False)\n if software:\n followers = followers.filter(bookwyrm_user=(software == 'bookwyrm'))\n\n # we want shared inboxes when available\n shared = followers.filter(\n shared_inbox__isnull=False\n ).values_list('shared_inbox', flat=True).distinct()\n\n # if a user doesn't have a shared inbox, we need their personal inbox\n # iirc pixelfed doesn't have shared inboxes\n inboxes = followers.filter(\n shared_inbox__isnull=True\n ).values_list('inbox', flat=True)\n\n return list(shared) + list(inboxes)\n\n\ndef broadcast(sender, activity, software=None, \\\n privacy='public', direct_recipients=None):\n ''' send out an event '''\n # start with parsing the direct recipients\n recipients = [u.inbox for u in direct_recipients or []]\n # and then add any other recipients\n if privacy == 'public':\n recipients += get_public_recipients(sender, software=software)\n broadcast_task.delay(\n sender.id,\n json.dumps(activity, cls=ActivityEncoder),\n recipients\n )\n\n\[email protected]\ndef broadcast_task(sender_id, activity, recipients):\n ''' the celery task for broadcast '''\n sender = models.User.objects.get(id=sender_id)\n errors = []\n for recipient in recipients:\n try:\n sign_and_send(sender, activity, recipient)\n except requests.exceptions.HTTPError as e:\n errors.append({\n 'error': str(e),\n 'recipient': recipient,\n 'activity': activity,\n })\n return errors\n\n\ndef sign_and_send(sender, activity, destination):\n ''' crpyto whatever and http junk '''\n now = http_date()\n\n if not sender.private_key:\n # this shouldn't happen. it would be bad if it happened.\n raise ValueError('No private key found for sender')\n\n data = json.dumps(activity).encode('utf-8')\n digest = make_digest(data)\n\n response = requests.post(\n destination,\n data=data,\n headers={\n 'Date': now,\n 'Digest': digest,\n 'Signature': make_signature(sender, destination, now, digest),\n 'Content-Type': 'application/activity+json; charset=utf-8',\n },\n )\n if not response.ok:\n response.raise_for_status()\n return response\n", "path": "bookwyrm/broadcast.py"}]} | 2,626 | 298 |
gh_patches_debug_9490 | rasdani/github-patches | git_diff | Mailu__Mailu-2255 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Provide a "slow" transport for Postfix
## Environment & Versions
### Environment
- [x] docker-compose
- [ ] kubernetes
- [ ] docker swarm
### Versions
1.9
## Description
Orange, a mainstream french ISP, and a few others, have a rate limit : without a slow transport, I get deferred messages with this : "Too many connections, slow down." It is a known issue https://blog.network-studio.fr/2011/06/30/too-many-connections-slow-down/
I managed to get it done with the overrides/ files :
overrides/postfix.cf :
```
transport_maps = socketmap:unix:/tmp/podop.socket:transport lmdb:/etc/postfix/transport.map
slow_destination_concurrency_limit = 1
slow_destination_recipient_limit = 20
slow_destination_rate_delay = 5s
slow_destination_concurrency_failed_cohort_limit=10
```
overrides/postfix.master :
```
slow/unix= slow unix - - n - 5 smtp -o syslog_name=postfix-slow
```
overrides/transport.map :
```
wanadoo.com slow:
wanadoo.fr slow:
orange.com slow:
orange.fr slow:
laposte.net slow:
free.fr slow:
hotmail.fr slow:
outlook.fr slow:
yahoo.fr slow:
```
I did not have time to fully test it, but it seems to work. Configuration values may need a fine tuning...
It would be nice to have such "slow" transport built in in Mailu, with an override possibility to edit the domain list.
</issue>
<code>
[start of core/postfix/start.py]
1 #!/usr/bin/python3
2
3 import os
4 import glob
5 import shutil
6 import multiprocessing
7 import logging as log
8 import sys
9
10 from podop import run_server
11 from pwd import getpwnam
12 from socrate import system, conf
13
14 log.basicConfig(stream=sys.stderr, level=os.environ.get("LOG_LEVEL", "WARNING"))
15
16 def start_podop():
17 os.setuid(getpwnam('postfix').pw_uid)
18 os.mkdir('/dev/shm/postfix',mode=0o700)
19 url = "http://" + os.environ["ADMIN_ADDRESS"] + "/internal/postfix/"
20 # TODO: Remove verbosity setting from Podop?
21 run_server(0, "postfix", "/tmp/podop.socket", [
22 ("transport", "url", url + "transport/§"),
23 ("alias", "url", url + "alias/§"),
24 ("dane", "url", url + "dane/§"),
25 ("domain", "url", url + "domain/§"),
26 ("mailbox", "url", url + "mailbox/§"),
27 ("recipientmap", "url", url + "recipient/map/§"),
28 ("sendermap", "url", url + "sender/map/§"),
29 ("senderaccess", "url", url + "sender/access/§"),
30 ("senderlogin", "url", url + "sender/login/§"),
31 ("senderrate", "url", url + "sender/rate/§")
32 ])
33
34 def start_mta_sts_daemon():
35 os.chmod("/root/", 0o755) # read access to /root/.netrc required
36 os.setuid(getpwnam('postfix').pw_uid)
37 from postfix_mta_sts_resolver import daemon
38 daemon.main()
39
40 def is_valid_postconf_line(line):
41 return not line.startswith("#") \
42 and not line == ''
43
44 # Actual startup script
45 os.environ['DEFER_ON_TLS_ERROR'] = os.environ['DEFER_ON_TLS_ERROR'] if 'DEFER_ON_TLS_ERROR' in os.environ else 'True'
46 os.environ["FRONT_ADDRESS"] = system.get_host_address_from_environment("FRONT", "front")
47 os.environ["ADMIN_ADDRESS"] = system.get_host_address_from_environment("ADMIN", "admin")
48 os.environ["ANTISPAM_MILTER_ADDRESS"] = system.get_host_address_from_environment("ANTISPAM_MILTER", "antispam:11332")
49 os.environ["LMTP_ADDRESS"] = system.get_host_address_from_environment("LMTP", "imap:2525")
50 os.environ["POSTFIX_LOG_SYSLOG"] = os.environ.get("POSTFIX_LOG_SYSLOG","local")
51 os.environ["POSTFIX_LOG_FILE"] = os.environ.get("POSTFIX_LOG_FILE", "")
52
53 for postfix_file in glob.glob("/conf/*.cf"):
54 conf.jinja(postfix_file, os.environ, os.path.join("/etc/postfix", os.path.basename(postfix_file)))
55
56 if os.path.exists("/overrides/postfix.cf"):
57 for line in open("/overrides/postfix.cf").read().strip().split("\n"):
58 if is_valid_postconf_line(line):
59 os.system('postconf -e "{}"'.format(line))
60
61 if os.path.exists("/overrides/postfix.master"):
62 for line in open("/overrides/postfix.master").read().strip().split("\n"):
63 if is_valid_postconf_line(line):
64 os.system('postconf -Me "{}"'.format(line))
65
66 for map_file in glob.glob("/overrides/*.map"):
67 destination = os.path.join("/etc/postfix", os.path.basename(map_file))
68 shutil.copyfile(map_file, destination)
69 os.system("postmap {}".format(destination))
70 os.remove(destination)
71
72 if os.path.exists("/overrides/mta-sts-daemon.yml"):
73 shutil.copyfile("/overrides/mta-sts-daemon.yml", "/etc/mta-sts-daemon.yml")
74 else:
75 conf.jinja("/conf/mta-sts-daemon.yml", os.environ, "/etc/mta-sts-daemon.yml")
76
77 if not os.path.exists("/etc/postfix/tls_policy.map.lmdb"):
78 open("/etc/postfix/tls_policy.map", "a").close()
79 os.system("postmap /etc/postfix/tls_policy.map")
80
81 if "RELAYUSER" in os.environ:
82 path = "/etc/postfix/sasl_passwd"
83 conf.jinja("/conf/sasl_passwd", os.environ, path)
84 os.system("postmap {}".format(path))
85
86 # Configure and start local rsyslog server
87 conf.jinja("/conf/rsyslog.conf", os.environ, "/etc/rsyslog.conf")
88 os.system("/usr/sbin/rsyslogd -niNONE &")
89 # Configure logrotate and start crond
90 if os.environ["POSTFIX_LOG_FILE"] != "":
91 conf.jinja("/conf/logrotate.conf", os.environ, "/etc/logrotate.d/postfix.conf")
92 os.system("/usr/sbin/crond")
93 if os.path.exists("/overrides/logrotate.conf"):
94 shutil.copyfile("/overrides/logrotate.conf", "/etc/logrotate.d/postfix.conf")
95
96 # Run Podop and Postfix
97 multiprocessing.Process(target=start_podop).start()
98 multiprocessing.Process(target=start_mta_sts_daemon).start()
99 os.system("/usr/libexec/postfix/post-install meta_directory=/etc/postfix create-missing")
100 # Before starting postfix, we need to check permissions on /queue
101 # in the event that postfix,postdrop id have changed
102 os.system("postfix set-permissions")
103 os.system("postfix start-fg")
104
[end of core/postfix/start.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/core/postfix/start.py b/core/postfix/start.py
--- a/core/postfix/start.py
+++ b/core/postfix/start.py
@@ -74,9 +74,10 @@
else:
conf.jinja("/conf/mta-sts-daemon.yml", os.environ, "/etc/mta-sts-daemon.yml")
-if not os.path.exists("/etc/postfix/tls_policy.map.lmdb"):
- open("/etc/postfix/tls_policy.map", "a").close()
- os.system("postmap /etc/postfix/tls_policy.map")
+for policy in ['tls_policy', 'transport']:
+ if not os.path.exists(f'/etc/postfix/{policy}.map.lmdb'):
+ open(f'/etc/postfix/{policy}.map', 'a').close()
+ os.system(f'postmap /etc/postfix/{policy}.map')
if "RELAYUSER" in os.environ:
path = "/etc/postfix/sasl_passwd"
| {"golden_diff": "diff --git a/core/postfix/start.py b/core/postfix/start.py\n--- a/core/postfix/start.py\n+++ b/core/postfix/start.py\n@@ -74,9 +74,10 @@\n else:\n conf.jinja(\"/conf/mta-sts-daemon.yml\", os.environ, \"/etc/mta-sts-daemon.yml\")\n \n-if not os.path.exists(\"/etc/postfix/tls_policy.map.lmdb\"):\n- open(\"/etc/postfix/tls_policy.map\", \"a\").close()\n- os.system(\"postmap /etc/postfix/tls_policy.map\")\n+for policy in ['tls_policy', 'transport']:\n+ if not os.path.exists(f'/etc/postfix/{policy}.map.lmdb'):\n+ open(f'/etc/postfix/{policy}.map', 'a').close()\n+ os.system(f'postmap /etc/postfix/{policy}.map')\n \n if \"RELAYUSER\" in os.environ:\n path = \"/etc/postfix/sasl_passwd\"\n", "issue": "Provide a \"slow\" transport for Postfix\n## Environment & Versions\r\n### Environment\r\n - [x] docker-compose\r\n - [ ] kubernetes\r\n - [ ] docker swarm\r\n\r\n### Versions\r\n1.9\r\n\r\n## Description\r\nOrange, a mainstream french ISP, and a few others, have a rate limit : without a slow transport, I get deferred messages with this : \"Too many connections, slow down.\" It is a known issue https://blog.network-studio.fr/2011/06/30/too-many-connections-slow-down/\r\n\r\nI managed to get it done with the overrides/ files :\r\n\r\noverrides/postfix.cf :\r\n\r\n```\r\ntransport_maps = socketmap:unix:/tmp/podop.socket:transport lmdb:/etc/postfix/transport.map\r\n\r\nslow_destination_concurrency_limit = 1\r\nslow_destination_recipient_limit = 20\r\nslow_destination_rate_delay = 5s\r\nslow_destination_concurrency_failed_cohort_limit=10\r\n\r\n```\r\noverrides/postfix.master :\r\n\r\n```\r\nslow/unix= slow unix - - n - 5 smtp -o syslog_name=postfix-slow\r\n```\r\n\r\noverrides/transport.map :\r\n\r\n```\r\nwanadoo.com slow:\r\nwanadoo.fr slow:\r\norange.com slow:\r\norange.fr slow:\r\nlaposte.net slow:\r\nfree.fr slow:\r\nhotmail.fr slow:\r\noutlook.fr slow:\r\nyahoo.fr slow:\r\n```\r\nI did not have time to fully test it, but it seems to work. Configuration values may need a fine tuning...\r\n\r\nIt would be nice to have such \"slow\" transport built in in Mailu, with an override possibility to edit the domain list.\n", "before_files": [{"content": "#!/usr/bin/python3\n\nimport os\nimport glob\nimport shutil\nimport multiprocessing\nimport logging as log\nimport sys\n\nfrom podop import run_server\nfrom pwd import getpwnam\nfrom socrate import system, conf\n\nlog.basicConfig(stream=sys.stderr, level=os.environ.get(\"LOG_LEVEL\", \"WARNING\"))\n\ndef start_podop():\n os.setuid(getpwnam('postfix').pw_uid)\n os.mkdir('/dev/shm/postfix',mode=0o700)\n url = \"http://\" + os.environ[\"ADMIN_ADDRESS\"] + \"/internal/postfix/\"\n # TODO: Remove verbosity setting from Podop?\n run_server(0, \"postfix\", \"/tmp/podop.socket\", [\n (\"transport\", \"url\", url + \"transport/\u00a7\"),\n (\"alias\", \"url\", url + \"alias/\u00a7\"),\n (\"dane\", \"url\", url + \"dane/\u00a7\"),\n (\"domain\", \"url\", url + \"domain/\u00a7\"),\n (\"mailbox\", \"url\", url + \"mailbox/\u00a7\"),\n (\"recipientmap\", \"url\", url + \"recipient/map/\u00a7\"),\n (\"sendermap\", \"url\", url + \"sender/map/\u00a7\"),\n (\"senderaccess\", \"url\", url + \"sender/access/\u00a7\"),\n (\"senderlogin\", \"url\", url + \"sender/login/\u00a7\"),\n (\"senderrate\", \"url\", url + \"sender/rate/\u00a7\")\n ])\n\ndef start_mta_sts_daemon():\n os.chmod(\"/root/\", 0o755) # read access to /root/.netrc required\n os.setuid(getpwnam('postfix').pw_uid)\n from postfix_mta_sts_resolver import daemon\n daemon.main()\n\ndef is_valid_postconf_line(line):\n return not line.startswith(\"#\") \\\n and not line == ''\n\n# Actual startup script\nos.environ['DEFER_ON_TLS_ERROR'] = os.environ['DEFER_ON_TLS_ERROR'] if 'DEFER_ON_TLS_ERROR' in os.environ else 'True'\nos.environ[\"FRONT_ADDRESS\"] = system.get_host_address_from_environment(\"FRONT\", \"front\")\nos.environ[\"ADMIN_ADDRESS\"] = system.get_host_address_from_environment(\"ADMIN\", \"admin\")\nos.environ[\"ANTISPAM_MILTER_ADDRESS\"] = system.get_host_address_from_environment(\"ANTISPAM_MILTER\", \"antispam:11332\")\nos.environ[\"LMTP_ADDRESS\"] = system.get_host_address_from_environment(\"LMTP\", \"imap:2525\")\nos.environ[\"POSTFIX_LOG_SYSLOG\"] = os.environ.get(\"POSTFIX_LOG_SYSLOG\",\"local\")\nos.environ[\"POSTFIX_LOG_FILE\"] = os.environ.get(\"POSTFIX_LOG_FILE\", \"\")\n\nfor postfix_file in glob.glob(\"/conf/*.cf\"):\n conf.jinja(postfix_file, os.environ, os.path.join(\"/etc/postfix\", os.path.basename(postfix_file)))\n\nif os.path.exists(\"/overrides/postfix.cf\"):\n for line in open(\"/overrides/postfix.cf\").read().strip().split(\"\\n\"):\n if is_valid_postconf_line(line):\n os.system('postconf -e \"{}\"'.format(line))\n\nif os.path.exists(\"/overrides/postfix.master\"):\n for line in open(\"/overrides/postfix.master\").read().strip().split(\"\\n\"):\n if is_valid_postconf_line(line):\n os.system('postconf -Me \"{}\"'.format(line))\n\nfor map_file in glob.glob(\"/overrides/*.map\"):\n destination = os.path.join(\"/etc/postfix\", os.path.basename(map_file))\n shutil.copyfile(map_file, destination)\n os.system(\"postmap {}\".format(destination))\n os.remove(destination)\n\nif os.path.exists(\"/overrides/mta-sts-daemon.yml\"):\n shutil.copyfile(\"/overrides/mta-sts-daemon.yml\", \"/etc/mta-sts-daemon.yml\")\nelse:\n conf.jinja(\"/conf/mta-sts-daemon.yml\", os.environ, \"/etc/mta-sts-daemon.yml\")\n\nif not os.path.exists(\"/etc/postfix/tls_policy.map.lmdb\"):\n open(\"/etc/postfix/tls_policy.map\", \"a\").close()\n os.system(\"postmap /etc/postfix/tls_policy.map\")\n\nif \"RELAYUSER\" in os.environ:\n path = \"/etc/postfix/sasl_passwd\"\n conf.jinja(\"/conf/sasl_passwd\", os.environ, path)\n os.system(\"postmap {}\".format(path))\n\n# Configure and start local rsyslog server\nconf.jinja(\"/conf/rsyslog.conf\", os.environ, \"/etc/rsyslog.conf\")\nos.system(\"/usr/sbin/rsyslogd -niNONE &\")\n# Configure logrotate and start crond\nif os.environ[\"POSTFIX_LOG_FILE\"] != \"\":\n conf.jinja(\"/conf/logrotate.conf\", os.environ, \"/etc/logrotate.d/postfix.conf\")\n os.system(\"/usr/sbin/crond\")\n if os.path.exists(\"/overrides/logrotate.conf\"):\n shutil.copyfile(\"/overrides/logrotate.conf\", \"/etc/logrotate.d/postfix.conf\")\n\n# Run Podop and Postfix\nmultiprocessing.Process(target=start_podop).start()\nmultiprocessing.Process(target=start_mta_sts_daemon).start()\nos.system(\"/usr/libexec/postfix/post-install meta_directory=/etc/postfix create-missing\")\n# Before starting postfix, we need to check permissions on /queue\n# in the event that postfix,postdrop id have changed\nos.system(\"postfix set-permissions\")\nos.system(\"postfix start-fg\")\n", "path": "core/postfix/start.py"}]} | 2,250 | 212 |
gh_patches_debug_41023 | rasdani/github-patches | git_diff | pyload__pyload-180 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Implemented StreamcloudEu plugin based on XFileSharingPro
Resolves #128
</issue>
<code>
[start of module/plugins/hoster/StreamcloudEu.py]
1 # -*- coding: utf-8 -*-
2 from module.plugins.hoster.XFileSharingPro import XFileSharingPro, create_getInfo
3 import re
4
5 class StreamcloudEu(XFileSharingPro):
6 __name__ = "StreamcloudEu"
7 __type__ = "hoster"
8 __pattern__ = r"http://(www\.)?streamcloud\.eu/\S+"
9 __version__ = "0.01"
10 __description__ = """Streamcloud.eu hoster plugin"""
11 __author_name__ = ("seoester")
12 __author_mail__ = ("[email protected]")
13
14 HOSTER_NAME = "streamcloud.eu"
15 DIRECT_LINK_PATTERN = r'file: "(http://(stor|cdn)\d+\.streamcloud.eu:?\d*/.*/video\.mp4)",'
16
17 def setup(self):
18 super(XFileSharingPro, self).setup()
19 self.multiDL = True
20
21 def getDownloadLink(self):
22 found = re.search(self.DIRECT_LINK_PATTERN, self.html, re.S)
23 if found:
24 return found.group(1)
25
26 return super(XFileSharingPro, self).getDownloadLink()
27
28 getInfo = create_getInfo(StreamcloudEu)
29
[end of module/plugins/hoster/StreamcloudEu.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/module/plugins/hoster/StreamcloudEu.py b/module/plugins/hoster/StreamcloudEu.py
--- a/module/plugins/hoster/StreamcloudEu.py
+++ b/module/plugins/hoster/StreamcloudEu.py
@@ -1,5 +1,7 @@
# -*- coding: utf-8 -*-
from module.plugins.hoster.XFileSharingPro import XFileSharingPro, create_getInfo
+from module.network.HTTPRequest import HTTPRequest
+from time import sleep
import re
class StreamcloudEu(XFileSharingPro):
@@ -15,7 +17,7 @@
DIRECT_LINK_PATTERN = r'file: "(http://(stor|cdn)\d+\.streamcloud.eu:?\d*/.*/video\.mp4)",'
def setup(self):
- super(XFileSharingPro, self).setup()
+ super(StreamcloudEu, self).setup()
self.multiDL = True
def getDownloadLink(self):
@@ -23,6 +25,87 @@
if found:
return found.group(1)
- return super(XFileSharingPro, self).getDownloadLink()
+ for i in range(5):
+ self.logDebug("Getting download link: #%d" % i)
+ data = self.getPostParameters()
+ httpRequest = HTTPRequest(options=self.req.options)
+ httpRequest.cj = self.req.cj
+ sleep(10)
+ self.html = httpRequest.load(self.pyfile.url, post = data, referer=False, cookies=True, decode = True)
+ self.header = httpRequest.header
+
+ found = re.search("Location\s*:\s*(.*)", self.header, re.I)
+ if found:
+ break
+
+ found = re.search(self.DIRECT_LINK_PATTERN, self.html, re.S)
+ if found:
+ break
+
+ else:
+ if self.errmsg and 'captcha' in self.errmsg:
+ self.fail("No valid captcha code entered")
+ else:
+ self.fail("Download link not found")
+
+ return found.group(1)
+
+ def getPostParameters(self):
+ for i in range(3):
+ if not self.errmsg: self.checkErrors()
+
+ if hasattr(self,"FORM_PATTERN"):
+ action, inputs = self.parseHtmlForm(self.FORM_PATTERN)
+ else:
+ action, inputs = self.parseHtmlForm(input_names={"op": re.compile("^download")})
+
+ if not inputs:
+ action, inputs = self.parseHtmlForm('F1')
+ if not inputs:
+ if self.errmsg:
+ self.retry()
+ else:
+ self.parseError("Form not found")
+
+ self.logDebug(self.HOSTER_NAME, inputs)
+
+ if 'op' in inputs and inputs['op'] in ('download1', 'download2', 'download3'):
+ if "password" in inputs:
+ if self.passwords:
+ inputs['password'] = self.passwords.pop(0)
+ else:
+ self.fail("No or invalid passport")
+
+ if not self.premium:
+ found = re.search(self.WAIT_PATTERN, self.html)
+ if found:
+ wait_time = int(found.group(1)) + 1
+ self.setWait(wait_time, False)
+ else:
+ wait_time = 0
+
+ self.captcha = self.handleCaptcha(inputs)
+
+ if wait_time: self.wait()
+
+ self.errmsg = None
+ self.logDebug("getPostParameters {0}".format(i))
+ return inputs
+
+ else:
+ inputs['referer'] = self.pyfile.url
+
+ if self.premium:
+ inputs['method_premium'] = "Premium Download"
+ if 'method_free' in inputs: del inputs['method_free']
+ else:
+ inputs['method_free'] = "Free Download"
+ if 'method_premium' in inputs: del inputs['method_premium']
+
+ self.html = self.load(self.pyfile.url, post = inputs, ref = False)
+ self.errmsg = None
+
+ else: self.parseError('FORM: %s' % (inputs['op'] if 'op' in inputs else 'UNKNOWN'))
+
getInfo = create_getInfo(StreamcloudEu)
| {"golden_diff": "diff --git a/module/plugins/hoster/StreamcloudEu.py b/module/plugins/hoster/StreamcloudEu.py\n--- a/module/plugins/hoster/StreamcloudEu.py\n+++ b/module/plugins/hoster/StreamcloudEu.py\n@@ -1,5 +1,7 @@\n # -*- coding: utf-8 -*-\n from module.plugins.hoster.XFileSharingPro import XFileSharingPro, create_getInfo\n+from module.network.HTTPRequest import HTTPRequest\n+from time import sleep\n import re\n \n class StreamcloudEu(XFileSharingPro):\n@@ -15,7 +17,7 @@\n DIRECT_LINK_PATTERN = r'file: \"(http://(stor|cdn)\\d+\\.streamcloud.eu:?\\d*/.*/video\\.mp4)\",'\n \n def setup(self):\n- super(XFileSharingPro, self).setup()\n+ super(StreamcloudEu, self).setup()\n self.multiDL = True\n \n def getDownloadLink(self):\n@@ -23,6 +25,87 @@\n if found:\n return found.group(1)\n \n- return super(XFileSharingPro, self).getDownloadLink()\n+ for i in range(5):\n+ self.logDebug(\"Getting download link: #%d\" % i)\n+ data = self.getPostParameters()\n+ httpRequest = HTTPRequest(options=self.req.options)\n+ httpRequest.cj = self.req.cj\n+ sleep(10)\n+ self.html = httpRequest.load(self.pyfile.url, post = data, referer=False, cookies=True, decode = True)\n+ self.header = httpRequest.header\n+\n+ found = re.search(\"Location\\s*:\\s*(.*)\", self.header, re.I)\n+ if found:\n+ break\n+\n+ found = re.search(self.DIRECT_LINK_PATTERN, self.html, re.S)\n+ if found:\n+ break\n+\n+ else:\n+ if self.errmsg and 'captcha' in self.errmsg:\n+ self.fail(\"No valid captcha code entered\")\n+ else:\n+ self.fail(\"Download link not found\")\n+\n+ return found.group(1)\n+\n+ def getPostParameters(self):\n+ for i in range(3):\n+ if not self.errmsg: self.checkErrors()\n+\n+ if hasattr(self,\"FORM_PATTERN\"):\n+ action, inputs = self.parseHtmlForm(self.FORM_PATTERN)\n+ else:\n+ action, inputs = self.parseHtmlForm(input_names={\"op\": re.compile(\"^download\")})\n+\n+ if not inputs:\n+ action, inputs = self.parseHtmlForm('F1')\n+ if not inputs:\n+ if self.errmsg:\n+ self.retry()\n+ else:\n+ self.parseError(\"Form not found\")\n+\n+ self.logDebug(self.HOSTER_NAME, inputs)\n+\n+ if 'op' in inputs and inputs['op'] in ('download1', 'download2', 'download3'):\n+ if \"password\" in inputs:\n+ if self.passwords:\n+ inputs['password'] = self.passwords.pop(0)\n+ else:\n+ self.fail(\"No or invalid passport\")\n+\n+ if not self.premium:\n+ found = re.search(self.WAIT_PATTERN, self.html)\n+ if found:\n+ wait_time = int(found.group(1)) + 1\n+ self.setWait(wait_time, False)\n+ else:\n+ wait_time = 0\n+\n+ self.captcha = self.handleCaptcha(inputs)\n+\n+ if wait_time: self.wait()\n+\n+ self.errmsg = None\n+ self.logDebug(\"getPostParameters {0}\".format(i))\n+ return inputs\n+\n+ else:\n+ inputs['referer'] = self.pyfile.url\n+\n+ if self.premium:\n+ inputs['method_premium'] = \"Premium Download\"\n+ if 'method_free' in inputs: del inputs['method_free']\n+ else:\n+ inputs['method_free'] = \"Free Download\"\n+ if 'method_premium' in inputs: del inputs['method_premium']\n+\n+ self.html = self.load(self.pyfile.url, post = inputs, ref = False)\n+ self.errmsg = None\n+\n+ else: self.parseError('FORM: %s' % (inputs['op'] if 'op' in inputs else 'UNKNOWN'))\n+\n \n getInfo = create_getInfo(StreamcloudEu)\n", "issue": "Implemented StreamcloudEu plugin based on XFileSharingPro\nResolves #128\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom module.plugins.hoster.XFileSharingPro import XFileSharingPro, create_getInfo\nimport re\n\nclass StreamcloudEu(XFileSharingPro):\n __name__ = \"StreamcloudEu\"\n __type__ = \"hoster\"\n __pattern__ = r\"http://(www\\.)?streamcloud\\.eu/\\S+\"\n __version__ = \"0.01\"\n __description__ = \"\"\"Streamcloud.eu hoster plugin\"\"\"\n __author_name__ = (\"seoester\")\n __author_mail__ = (\"[email protected]\")\n\n HOSTER_NAME = \"streamcloud.eu\"\n DIRECT_LINK_PATTERN = r'file: \"(http://(stor|cdn)\\d+\\.streamcloud.eu:?\\d*/.*/video\\.mp4)\",'\n\n def setup(self):\n super(XFileSharingPro, self).setup()\n self.multiDL = True\n\n def getDownloadLink(self):\n found = re.search(self.DIRECT_LINK_PATTERN, self.html, re.S)\n if found:\n return found.group(1)\n\n return super(XFileSharingPro, self).getDownloadLink()\n\ngetInfo = create_getInfo(StreamcloudEu)\n", "path": "module/plugins/hoster/StreamcloudEu.py"}]} | 870 | 946 |
gh_patches_debug_36759 | rasdani/github-patches | git_diff | tensorflow__addons-206 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Generate API docs
As our repository matures it's important to have api docs to improve user experience. As discussed in #38 we will also be able to remove the table of contents off the main README.
Should we host on https://readthedocs.org/ or is there something else recommended @ewilderj @dynamicwebpaige @karmel ?
</issue>
<code>
[start of tools/docs/build_docs.py]
1 # Copyright 2015 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """ Modified from the tfdocs example api reference docs generation script.
16
17 This script generates API reference docs.
18
19 Install pre-requisites:
20 $> pip install -U git+https://github.com/tensorflow/docs
21 $> pip install artifacts/tensorflow_addons-*.whl
22
23 Generate Docs:
24 $> from the repo root run: python tools/docs/build_docs.py
25 """
26
27 from __future__ import absolute_import
28 from __future__ import division
29 from __future__ import print_function
30
31 from absl import app
32 from absl import flags
33
34 import tensorflow_addons
35 from tensorflow_docs.api_generator import generate_lib
36 from tensorflow_docs.api_generator import public_api
37
38 PROJECT_SHORT_NAME = 'tfaddons'
39 PROJECT_FULL_NAME = 'TensorFlow Addons'
40 CODE_URL_PREFIX = 'https://github.com/tensorflow/addons/tree/master/tensorflow_addons'
41
42 FLAGS = flags.FLAGS
43
44 flags.DEFINE_string(
45 'output_dir',
46 default='/addons/docs/api_docs/python/',
47 help='Where to write the resulting docs to.')
48
49
50 def main(argv):
51 if argv[1:]:
52 raise ValueError('Unrecognized arguments: {}'.format(argv[1:]))
53
54 doc_generator = generate_lib.DocGenerator(
55 root_title=PROJECT_FULL_NAME,
56 # Replace `tensorflow_docs` with your module, here.
57 py_modules=[(PROJECT_SHORT_NAME, tensorflow_addons)],
58 code_url_prefix=CODE_URL_PREFIX,
59 # This callback cleans up a lot of aliases caused by internal imports.
60 callbacks=[public_api.local_definitions_filter])
61
62 doc_generator.build(FLAGS.output_dir)
63
64 print('Output docs to: ', FLAGS.output_dir)
65
66
67 if __name__ == '__main__':
68 app.run(main)
69
[end of tools/docs/build_docs.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/tools/docs/build_docs.py b/tools/docs/build_docs.py
--- a/tools/docs/build_docs.py
+++ b/tools/docs/build_docs.py
@@ -12,7 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
-""" Modified from the tfdocs example api reference docs generation script.
+"""Modified from the tfdocs example api reference docs generation script.
This script generates API reference docs.
@@ -31,19 +31,30 @@
from absl import app
from absl import flags
-import tensorflow_addons
+import tensorflow_addons as tfa
+
from tensorflow_docs.api_generator import generate_lib
+from tensorflow_docs.api_generator import parser
from tensorflow_docs.api_generator import public_api
-PROJECT_SHORT_NAME = 'tfaddons'
+from tensorflow.python.util import tf_inspect
+
+# Use tensorflow's `tf_inspect`, which is aware of `tf_decorator`.
+parser.tf_inspect = tf_inspect
+
+PROJECT_SHORT_NAME = 'tfa'
PROJECT_FULL_NAME = 'TensorFlow Addons'
-CODE_URL_PREFIX = 'https://github.com/tensorflow/addons/tree/master/tensorflow_addons'
FLAGS = flags.FLAGS
+flags.DEFINE_string(
+ 'git_branch',
+ default='master',
+ help='The name of the corresponding branch on github.')
+
flags.DEFINE_string(
'output_dir',
- default='/addons/docs/api_docs/python/',
+ default='docs/api_docs/python/',
help='Where to write the resulting docs to.')
@@ -51,11 +62,16 @@
if argv[1:]:
raise ValueError('Unrecognized arguments: {}'.format(argv[1:]))
+ code_url_prefix = ('https://github.com/tensorflow/addons/tree/'
+ '{git_branch}/tensorflow_addons'.format(
+ git_branch=FLAGS.git_branch))
+
doc_generator = generate_lib.DocGenerator(
root_title=PROJECT_FULL_NAME,
# Replace `tensorflow_docs` with your module, here.
- py_modules=[(PROJECT_SHORT_NAME, tensorflow_addons)],
- code_url_prefix=CODE_URL_PREFIX,
+ py_modules=[(PROJECT_SHORT_NAME, tfa)],
+ code_url_prefix=code_url_prefix,
+ private_map={'tfa': ['__version__', 'utils', 'version']},
# This callback cleans up a lot of aliases caused by internal imports.
callbacks=[public_api.local_definitions_filter])
| {"golden_diff": "diff --git a/tools/docs/build_docs.py b/tools/docs/build_docs.py\n--- a/tools/docs/build_docs.py\n+++ b/tools/docs/build_docs.py\n@@ -12,7 +12,7 @@\n # See the License for the specific language governing permissions and\n # limitations under the License.\n # ==============================================================================\n-\"\"\" Modified from the tfdocs example api reference docs generation script.\n+\"\"\"Modified from the tfdocs example api reference docs generation script.\n \n This script generates API reference docs.\n \n@@ -31,19 +31,30 @@\n from absl import app\n from absl import flags\n \n-import tensorflow_addons\n+import tensorflow_addons as tfa\n+\n from tensorflow_docs.api_generator import generate_lib\n+from tensorflow_docs.api_generator import parser\n from tensorflow_docs.api_generator import public_api\n \n-PROJECT_SHORT_NAME = 'tfaddons'\n+from tensorflow.python.util import tf_inspect\n+\n+# Use tensorflow's `tf_inspect`, which is aware of `tf_decorator`.\n+parser.tf_inspect = tf_inspect\n+\n+PROJECT_SHORT_NAME = 'tfa'\n PROJECT_FULL_NAME = 'TensorFlow Addons'\n-CODE_URL_PREFIX = 'https://github.com/tensorflow/addons/tree/master/tensorflow_addons'\n \n FLAGS = flags.FLAGS\n \n+flags.DEFINE_string(\n+ 'git_branch',\n+ default='master',\n+ help='The name of the corresponding branch on github.')\n+\n flags.DEFINE_string(\n 'output_dir',\n- default='/addons/docs/api_docs/python/',\n+ default='docs/api_docs/python/',\n help='Where to write the resulting docs to.')\n \n \n@@ -51,11 +62,16 @@\n if argv[1:]:\n raise ValueError('Unrecognized arguments: {}'.format(argv[1:]))\n \n+ code_url_prefix = ('https://github.com/tensorflow/addons/tree/'\n+ '{git_branch}/tensorflow_addons'.format(\n+ git_branch=FLAGS.git_branch))\n+\n doc_generator = generate_lib.DocGenerator(\n root_title=PROJECT_FULL_NAME,\n # Replace `tensorflow_docs` with your module, here.\n- py_modules=[(PROJECT_SHORT_NAME, tensorflow_addons)],\n- code_url_prefix=CODE_URL_PREFIX,\n+ py_modules=[(PROJECT_SHORT_NAME, tfa)],\n+ code_url_prefix=code_url_prefix,\n+ private_map={'tfa': ['__version__', 'utils', 'version']},\n # This callback cleans up a lot of aliases caused by internal imports.\n callbacks=[public_api.local_definitions_filter])\n", "issue": "Generate API docs\nAs our repository matures it's important to have api docs to improve user experience. As discussed in #38 we will also be able to remove the table of contents off the main README.\r\n\r\nShould we host on https://readthedocs.org/ or is there something else recommended @ewilderj @dynamicwebpaige @karmel ?\n", "before_files": [{"content": "# Copyright 2015 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\" Modified from the tfdocs example api reference docs generation script.\n\nThis script generates API reference docs.\n\nInstall pre-requisites:\n$> pip install -U git+https://github.com/tensorflow/docs\n$> pip install artifacts/tensorflow_addons-*.whl\n\nGenerate Docs:\n$> from the repo root run: python tools/docs/build_docs.py\n\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nfrom absl import app\nfrom absl import flags\n\nimport tensorflow_addons\nfrom tensorflow_docs.api_generator import generate_lib\nfrom tensorflow_docs.api_generator import public_api\n\nPROJECT_SHORT_NAME = 'tfaddons'\nPROJECT_FULL_NAME = 'TensorFlow Addons'\nCODE_URL_PREFIX = 'https://github.com/tensorflow/addons/tree/master/tensorflow_addons'\n\nFLAGS = flags.FLAGS\n\nflags.DEFINE_string(\n 'output_dir',\n default='/addons/docs/api_docs/python/',\n help='Where to write the resulting docs to.')\n\n\ndef main(argv):\n if argv[1:]:\n raise ValueError('Unrecognized arguments: {}'.format(argv[1:]))\n\n doc_generator = generate_lib.DocGenerator(\n root_title=PROJECT_FULL_NAME,\n # Replace `tensorflow_docs` with your module, here.\n py_modules=[(PROJECT_SHORT_NAME, tensorflow_addons)],\n code_url_prefix=CODE_URL_PREFIX,\n # This callback cleans up a lot of aliases caused by internal imports.\n callbacks=[public_api.local_definitions_filter])\n\n doc_generator.build(FLAGS.output_dir)\n\n print('Output docs to: ', FLAGS.output_dir)\n\n\nif __name__ == '__main__':\n app.run(main)\n", "path": "tools/docs/build_docs.py"}]} | 1,232 | 531 |
gh_patches_debug_36739 | rasdani/github-patches | git_diff | spacetelescope__jwql-645 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Authentication is currently broken
When attempting to log into the web app when running locally, we encounter this error:
```
Traceback (most recent call last):
File "python3.6/site-packages/django/core/handlers/exception.py", line 34, in inner
response = get_response(request)
File "python3.6/site-packages/django/core/handlers/base.py", line 115, in _get_response
response = self.process_exception_by_middleware(e, request)
File "python3.6/site-packages/django/core/handlers/base.py", line 113, in _get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "d/jwql/jwql/website/apps/jwql/oauth.py", line 113, in authorize
request, headers={'Accept': 'application/json'}
File "python3.6/site-packages/authlib/integrations/django_client/remote_app.py", line 63, in authorize_access_token
return self.fetch_access_token(**params)
File "python3.6/site-packages/authlib/integrations/_client/remote_app.py", line 106, in fetch_access_token
token = client.fetch_token(token_endpoint, **kwargs)
File "python3.6/site-packages/authlib/oauth2/client.py", line 202, in fetch_token
headers=headers, **session_kwargs
File "python3.6/site-packages/authlib/oauth2/client.py", line 223, in _fetch_token
return self.parse_response_token(resp.json())
File "python3.6/site-packages/requests/models.py", line 898, in json
return complexjson.loads(self.text, **kwargs)
File "python3.6/json/__init__.py", line 354, in loads
return _default_decoder.decode(s)
File "python3.6/json/decoder.py", line 339, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "python3.6/json/decoder.py", line 357, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
```
</issue>
<code>
[start of jwql/website/apps/jwql/oauth.py]
1 """Provides an OAuth object for authentication of the ``jwql`` web app,
2 as well as decorator functions to require user authentication in other
3 views of the web application.
4
5
6 Authors
7 -------
8
9 - Matthew Bourque
10 - Christian Mesh
11
12 Use
13 ---
14
15 This module is intended to be imported and used as such:
16 ::
17
18 from .oauth import auth_info
19 from .oauth import auth_required
20 from .oauth import JWQL_OAUTH
21
22 @auth_info
23 def some_view(request):
24 pass
25
26 @auth_required
27 def login(request):
28 pass
29
30 References
31 ----------
32 Much of this code was taken from the ``authlib`` documentation,
33 found here: ``http://docs.authlib.org/en/latest/client/django.html``
34
35 Dependencies
36 ------------
37 The user must have a configuration file named ``config.json``
38 placed in the ``jwql/utils/`` directory.
39 """
40
41 import os
42 import requests
43
44 from authlib.django.client import OAuth
45 from django.shortcuts import redirect, render
46
47 import jwql
48 from jwql.utils.constants import MONITORS
49 from jwql.utils.utils import get_base_url, get_config, check_config_for_key
50
51 PREV_PAGE = '/'
52
53
54 def register_oauth():
55 """Register the ``jwql`` application with the ``auth.mast``
56 authentication service.
57
58 Returns
59 -------
60 oauth : Object
61 An object containing methods to authenticate a user, provided
62 by the ``auth.mast`` service.
63 """
64
65 # Get configuration parameters
66 for key in ['client_id', 'client_secret', 'auth_mast']:
67 check_config_for_key(key)
68 client_id = get_config()['client_id']
69 client_secret = get_config()['client_secret']
70 auth_mast = get_config()['auth_mast']
71
72 # Register with auth.mast
73 oauth = OAuth()
74 client_kwargs = {'scope': 'mast:user:info'}
75 oauth.register(
76 'mast_auth',
77 client_id='{}'.format(client_id),
78 client_secret='{}'.format(client_secret),
79 access_token_url='https://{}/oauth/access_token?client_secret={}'.format(
80 auth_mast, client_secret
81 ),
82 access_token_params=None,
83 refresh_token_url=None,
84 authorize_url='https://{}/oauth/authorize'.format(auth_mast),
85 api_base_url='https://{}/1.1/'.format(auth_mast),
86 client_kwargs=client_kwargs)
87
88 return oauth
89
90
91 JWQL_OAUTH = register_oauth()
92
93
94 def authorize(request):
95 """Spawn the authentication process for the user
96
97 The authentication process involves retreiving an access token
98 from ``auth.mast`` and porting the data to a cookie.
99
100 Parameters
101 ----------
102 request : HttpRequest object
103 Incoming request from the webpage
104
105 Returns
106 -------
107 HttpResponse object
108 Outgoing response sent to the webpage
109 """
110
111 # Get auth.mast token
112 token = JWQL_OAUTH.mast_auth.authorize_access_token(
113 request, headers={'Accept': 'application/json'}
114 )
115
116 # Determine domain
117 base_url = get_base_url()
118 if '127' in base_url:
119 domain = '127.0.0.1'
120 else:
121 domain = base_url.split('//')[-1]
122
123 # Set secure cookie parameters
124 cookie_args = {}
125 # cookie_args['domain'] = domain # Currently broken
126 # cookie_args['secure'] = True # Currently broken
127 cookie_args['httponly'] = True
128
129 # Set the cookie
130 response = redirect(PREV_PAGE)
131 response.set_cookie("ASB-AUTH", token["access_token"], **cookie_args)
132
133 return response
134
135
136 def auth_info(fn):
137 """A decorator function that will return user credentials along
138 with what is returned by the original function.
139
140 Parameters
141 ----------
142 fn : function
143 The function to decorate
144
145 Returns
146 -------
147 user_info : function
148 The decorated function
149 """
150
151 def user_info(request, **kwargs):
152 """Store authenticated user credentials in a cookie and return
153 it. If the user is not authenticated, store no credentials in
154 the cookie.
155
156 Parameters
157 ----------
158 request : HttpRequest object
159 Incoming request from the webpage
160
161 Returns
162 -------
163 fn : function
164 The decorated function
165 """
166
167 cookie = request.COOKIES.get("ASB-AUTH")
168
169 # If user is authenticated, return user credentials
170 if cookie is not None:
171 check_config_for_key('auth_mast')
172 # Note: for now, this must be the development version
173 auth_mast = get_config()['auth_mast']
174
175 response = requests.get(
176 'https://{}/info'.format(auth_mast),
177 headers={'Accept': 'application/json',
178 'Authorization': 'token {}'.format(cookie)})
179 response = response.json()
180 response['access_token'] = cookie
181
182 # If user is not authenticated, return no credentials
183 else:
184 response = {'ezid': None, "anon": True, 'access_token': None}
185
186 return fn(request, response, **kwargs)
187
188 return user_info
189
190
191 def auth_required(fn):
192 """A decorator function that requires the given function to have
193 authentication through ``auth.mast`` set up.
194
195 Parameters
196 ----------
197 fn : function
198 The function to decorate
199
200 Returns
201 -------
202 check_auth : function
203 The decorated function
204 """
205
206 @auth_info
207 def check_auth(request, user, **kwargs):
208 """Check if the user is authenticated through ``auth.mast``.
209 If not, perform the authorization.
210
211 Parameters
212 ----------
213 request : HttpRequest object
214 Incoming request from the webpage
215 user : dict
216 A dictionary of user credentials
217
218 Returns
219 -------
220 fn : function
221 The decorated function
222 """
223
224 # If user is currently anonymous, require a login
225 if user['ezid']:
226
227 return fn(request, user, **kwargs)
228
229 else:
230 template = 'not_authenticated.html'
231 context = {'inst': ''}
232
233 return render(request, template, context)
234
235 return check_auth
236
237
238 @auth_info
239 def login(request, user):
240 """Spawn a login process for the user
241
242 The ``auth_requred`` decorator is used to require that the user
243 authenticate through ``auth.mast``, then the user is redirected
244 back to the homepage.
245
246 Parameters
247 ----------
248 request : HttpRequest object
249 Incoming request from the webpage
250 user : dict
251 A dictionary of user credentials.
252
253 Returns
254 -------
255 HttpResponse object
256 Outgoing response sent to the webpage
257 """
258
259 # Redirect to oauth login
260 global PREV_PAGE
261 PREV_PAGE = request.META.get('HTTP_REFERER')
262 redirect_uri = os.path.join(get_base_url(), 'authorize')
263
264 return JWQL_OAUTH.mast_auth.authorize_redirect(request, redirect_uri)
265
266
267 def logout(request):
268 """Spawn a logout process for the user
269
270 Upon logout, the user's ``auth.mast`` credientials are removed and
271 the user is redirected back to the homepage.
272
273 Parameters
274 ----------
275 request : HttpRequest object
276 Incoming request from the webpage
277 user : dict
278 A dictionary of user credentials.
279
280 Returns
281 -------
282 HttpResponse object
283 Outgoing response sent to the webpage
284 """
285
286 global PREV_PAGE
287 PREV_PAGE = request.META.get('HTTP_REFERER')
288 response = redirect(PREV_PAGE)
289 response.delete_cookie("ASB-AUTH")
290
291 return response
292
[end of jwql/website/apps/jwql/oauth.py]
[start of setup.py]
1 import numpy as np
2 from setuptools import setup
3 from setuptools import find_packages
4
5 VERSION = '0.23.0'
6
7 AUTHORS = 'Matthew Bourque, Lauren Chambers, Misty Cracraft, Mike Engesser, Mees Fix, Joe Filippazzo, Bryan Hilbert, '
8 AUTHORS += 'Graham Kanarek, Teagan King, Catherine Martlin, Maria Pena-Guerrero, Johannes Sahlmann, Ben Sunnquist'
9
10 DESCRIPTION = 'The James Webb Space Telescope Quicklook Project'
11
12 DEPENDENCY_LINKS = ['git+https://github.com/spacetelescope/[email protected]',
13 'git+https://github.com/spacetelescope/jwst_reffiles#egg=jwst_reffiles'
14 ]
15 REQUIRES = [
16 'asdf>=2.3.3',
17 'astropy>=3.2.1',
18 'astroquery>=0.3.9',
19 'authlib',
20 'bokeh>=1.0,<1.4',
21 'codecov',
22 'crds',
23 'django>=2.0,<3.0',
24 'flake8',
25 'inflection',
26 'ipython',
27 'jinja2',
28 'jsonschema',
29 'jwedb>=0.0.3',
30 'matplotlib',
31 'nodejs',
32 'numpy',
33 'numpydoc',
34 'pandas',
35 'psycopg2',
36 'pysiaf',
37 'pytest',
38 'pytest-cov',
39 'scipy',
40 'sphinx',
41 'sqlalchemy',
42 'stsci_rtd_theme',
43 'twine'
44 ]
45
46 setup(
47 name='jwql',
48 version=VERSION,
49 description=DESCRIPTION,
50 url='https://github.com/spacetelescope/jwql.git',
51 author=AUTHORS,
52 author_email='[email protected]',
53 license='BSD',
54 keywords=['astronomy', 'python'],
55 classifiers=['Programming Language :: Python'],
56 packages=find_packages(),
57 install_requires=REQUIRES,
58 dependency_links=DEPENDENCY_LINKS,
59 include_package_data=True,
60 include_dirs=[np.get_include()],
61 )
62
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/jwql/website/apps/jwql/oauth.py b/jwql/website/apps/jwql/oauth.py
--- a/jwql/website/apps/jwql/oauth.py
+++ b/jwql/website/apps/jwql/oauth.py
@@ -8,6 +8,7 @@
- Matthew Bourque
- Christian Mesh
+ - Ben Falk
Use
---
@@ -41,8 +42,9 @@
import os
import requests
-from authlib.django.client import OAuth
+from authlib.integrations.django_client import OAuth
from django.shortcuts import redirect, render
+from django.urls import reverse
import jwql
from jwql.utils.constants import MONITORS
@@ -71,14 +73,15 @@
# Register with auth.mast
oauth = OAuth()
- client_kwargs = {'scope': 'mast:user:info'}
+ client_kwargs = {
+ 'scope': 'mast:user:info',
+ 'token_endpoint_auth_method': 'client_secret_basic',
+ 'token_placement': 'header'}
oauth.register(
'mast_auth',
client_id='{}'.format(client_id),
client_secret='{}'.format(client_secret),
- access_token_url='https://{}/oauth/access_token?client_secret={}'.format(
- auth_mast, client_secret
- ),
+ access_token_url='https://{}/oauth/token'.format(auth_mast),
access_token_params=None,
refresh_token_url=None,
authorize_url='https://{}/oauth/authorize'.format(auth_mast),
@@ -109,9 +112,7 @@
"""
# Get auth.mast token
- token = JWQL_OAUTH.mast_auth.authorize_access_token(
- request, headers={'Accept': 'application/json'}
- )
+ token = JWQL_OAUTH.mast_auth.authorize_access_token(request)
# Determine domain
base_url = get_base_url()
@@ -259,7 +260,7 @@
# Redirect to oauth login
global PREV_PAGE
PREV_PAGE = request.META.get('HTTP_REFERER')
- redirect_uri = os.path.join(get_base_url(), 'authorize')
+ redirect_uri = f"{get_base_url()}{reverse('jwql:authorize')}"
return JWQL_OAUTH.mast_auth.authorize_redirect(request, redirect_uri)
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -20,6 +20,7 @@
'bokeh>=1.0,<1.4',
'codecov',
'crds',
+ 'cryptography',
'django>=2.0,<3.0',
'flake8',
'inflection',
| {"golden_diff": "diff --git a/jwql/website/apps/jwql/oauth.py b/jwql/website/apps/jwql/oauth.py\n--- a/jwql/website/apps/jwql/oauth.py\n+++ b/jwql/website/apps/jwql/oauth.py\n@@ -8,6 +8,7 @@\n \n - Matthew Bourque\n - Christian Mesh\n+ - Ben Falk\n \n Use\n ---\n@@ -41,8 +42,9 @@\n import os\n import requests\n \n-from authlib.django.client import OAuth\n+from authlib.integrations.django_client import OAuth\n from django.shortcuts import redirect, render\n+from django.urls import reverse\n \n import jwql\n from jwql.utils.constants import MONITORS\n@@ -71,14 +73,15 @@\n \n # Register with auth.mast\n oauth = OAuth()\n- client_kwargs = {'scope': 'mast:user:info'}\n+ client_kwargs = {\n+ 'scope': 'mast:user:info',\n+ 'token_endpoint_auth_method': 'client_secret_basic',\n+ 'token_placement': 'header'}\n oauth.register(\n 'mast_auth',\n client_id='{}'.format(client_id),\n client_secret='{}'.format(client_secret),\n- access_token_url='https://{}/oauth/access_token?client_secret={}'.format(\n- auth_mast, client_secret\n- ),\n+ access_token_url='https://{}/oauth/token'.format(auth_mast),\n access_token_params=None,\n refresh_token_url=None,\n authorize_url='https://{}/oauth/authorize'.format(auth_mast),\n@@ -109,9 +112,7 @@\n \"\"\"\n \n # Get auth.mast token\n- token = JWQL_OAUTH.mast_auth.authorize_access_token(\n- request, headers={'Accept': 'application/json'}\n- )\n+ token = JWQL_OAUTH.mast_auth.authorize_access_token(request)\n \n # Determine domain\n base_url = get_base_url()\n@@ -259,7 +260,7 @@\n # Redirect to oauth login\n global PREV_PAGE\n PREV_PAGE = request.META.get('HTTP_REFERER')\n- redirect_uri = os.path.join(get_base_url(), 'authorize')\n+ redirect_uri = f\"{get_base_url()}{reverse('jwql:authorize')}\"\n \n return JWQL_OAUTH.mast_auth.authorize_redirect(request, redirect_uri)\n \ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -20,6 +20,7 @@\n 'bokeh>=1.0,<1.4',\n 'codecov',\n 'crds',\n+ 'cryptography',\n 'django>=2.0,<3.0',\n 'flake8',\n 'inflection',\n", "issue": "Authentication is currently broken \nWhen attempting to log into the web app when running locally, we encounter this error:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"python3.6/site-packages/django/core/handlers/exception.py\", line 34, in inner\r\n response = get_response(request)\r\n File \"python3.6/site-packages/django/core/handlers/base.py\", line 115, in _get_response\r\n response = self.process_exception_by_middleware(e, request)\r\n File \"python3.6/site-packages/django/core/handlers/base.py\", line 113, in _get_response\r\n response = wrapped_callback(request, *callback_args, **callback_kwargs)\r\n File \"d/jwql/jwql/website/apps/jwql/oauth.py\", line 113, in authorize\r\n request, headers={'Accept': 'application/json'}\r\n File \"python3.6/site-packages/authlib/integrations/django_client/remote_app.py\", line 63, in authorize_access_token\r\n return self.fetch_access_token(**params)\r\n File \"python3.6/site-packages/authlib/integrations/_client/remote_app.py\", line 106, in fetch_access_token\r\n token = client.fetch_token(token_endpoint, **kwargs)\r\n File \"python3.6/site-packages/authlib/oauth2/client.py\", line 202, in fetch_token\r\n headers=headers, **session_kwargs\r\n File \"python3.6/site-packages/authlib/oauth2/client.py\", line 223, in _fetch_token\r\n return self.parse_response_token(resp.json())\r\n File \"python3.6/site-packages/requests/models.py\", line 898, in json\r\n return complexjson.loads(self.text, **kwargs)\r\n File \"python3.6/json/__init__.py\", line 354, in loads\r\n return _default_decoder.decode(s)\r\n File \"python3.6/json/decoder.py\", line 339, in decode\r\n obj, end = self.raw_decode(s, idx=_w(s, 0).end())\r\n File \"python3.6/json/decoder.py\", line 357, in raw_decode\r\n raise JSONDecodeError(\"Expecting value\", s, err.value) from None\r\njson.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)\r\n```\n", "before_files": [{"content": "\"\"\"Provides an OAuth object for authentication of the ``jwql`` web app,\nas well as decorator functions to require user authentication in other\nviews of the web application.\n\n\nAuthors\n-------\n\n - Matthew Bourque\n - Christian Mesh\n\nUse\n---\n\n This module is intended to be imported and used as such:\n ::\n\n from .oauth import auth_info\n from .oauth import auth_required\n from .oauth import JWQL_OAUTH\n\n @auth_info\n def some_view(request):\n pass\n\n @auth_required\n def login(request):\n pass\n\nReferences\n----------\n Much of this code was taken from the ``authlib`` documentation,\n found here: ``http://docs.authlib.org/en/latest/client/django.html``\n\nDependencies\n------------\n The user must have a configuration file named ``config.json``\n placed in the ``jwql/utils/`` directory.\n\"\"\"\n\nimport os\nimport requests\n\nfrom authlib.django.client import OAuth\nfrom django.shortcuts import redirect, render\n\nimport jwql\nfrom jwql.utils.constants import MONITORS\nfrom jwql.utils.utils import get_base_url, get_config, check_config_for_key\n\nPREV_PAGE = '/'\n\n\ndef register_oauth():\n \"\"\"Register the ``jwql`` application with the ``auth.mast``\n authentication service.\n\n Returns\n -------\n oauth : Object\n An object containing methods to authenticate a user, provided\n by the ``auth.mast`` service.\n \"\"\"\n\n # Get configuration parameters\n for key in ['client_id', 'client_secret', 'auth_mast']:\n check_config_for_key(key)\n client_id = get_config()['client_id']\n client_secret = get_config()['client_secret']\n auth_mast = get_config()['auth_mast']\n\n # Register with auth.mast\n oauth = OAuth()\n client_kwargs = {'scope': 'mast:user:info'}\n oauth.register(\n 'mast_auth',\n client_id='{}'.format(client_id),\n client_secret='{}'.format(client_secret),\n access_token_url='https://{}/oauth/access_token?client_secret={}'.format(\n auth_mast, client_secret\n ),\n access_token_params=None,\n refresh_token_url=None,\n authorize_url='https://{}/oauth/authorize'.format(auth_mast),\n api_base_url='https://{}/1.1/'.format(auth_mast),\n client_kwargs=client_kwargs)\n\n return oauth\n\n\nJWQL_OAUTH = register_oauth()\n\n\ndef authorize(request):\n \"\"\"Spawn the authentication process for the user\n\n The authentication process involves retreiving an access token\n from ``auth.mast`` and porting the data to a cookie.\n\n Parameters\n ----------\n request : HttpRequest object\n Incoming request from the webpage\n\n Returns\n -------\n HttpResponse object\n Outgoing response sent to the webpage\n \"\"\"\n\n # Get auth.mast token\n token = JWQL_OAUTH.mast_auth.authorize_access_token(\n request, headers={'Accept': 'application/json'}\n )\n\n # Determine domain\n base_url = get_base_url()\n if '127' in base_url:\n domain = '127.0.0.1'\n else:\n domain = base_url.split('//')[-1]\n\n # Set secure cookie parameters\n cookie_args = {}\n # cookie_args['domain'] = domain # Currently broken\n # cookie_args['secure'] = True # Currently broken\n cookie_args['httponly'] = True\n\n # Set the cookie\n response = redirect(PREV_PAGE)\n response.set_cookie(\"ASB-AUTH\", token[\"access_token\"], **cookie_args)\n\n return response\n\n\ndef auth_info(fn):\n \"\"\"A decorator function that will return user credentials along\n with what is returned by the original function.\n\n Parameters\n ----------\n fn : function\n The function to decorate\n\n Returns\n -------\n user_info : function\n The decorated function\n \"\"\"\n\n def user_info(request, **kwargs):\n \"\"\"Store authenticated user credentials in a cookie and return\n it. If the user is not authenticated, store no credentials in\n the cookie.\n\n Parameters\n ----------\n request : HttpRequest object\n Incoming request from the webpage\n\n Returns\n -------\n fn : function\n The decorated function\n \"\"\"\n\n cookie = request.COOKIES.get(\"ASB-AUTH\")\n\n # If user is authenticated, return user credentials\n if cookie is not None:\n check_config_for_key('auth_mast')\n # Note: for now, this must be the development version\n auth_mast = get_config()['auth_mast']\n\n response = requests.get(\n 'https://{}/info'.format(auth_mast),\n headers={'Accept': 'application/json',\n 'Authorization': 'token {}'.format(cookie)})\n response = response.json()\n response['access_token'] = cookie\n\n # If user is not authenticated, return no credentials\n else:\n response = {'ezid': None, \"anon\": True, 'access_token': None}\n\n return fn(request, response, **kwargs)\n\n return user_info\n\n\ndef auth_required(fn):\n \"\"\"A decorator function that requires the given function to have\n authentication through ``auth.mast`` set up.\n\n Parameters\n ----------\n fn : function\n The function to decorate\n\n Returns\n -------\n check_auth : function\n The decorated function\n \"\"\"\n\n @auth_info\n def check_auth(request, user, **kwargs):\n \"\"\"Check if the user is authenticated through ``auth.mast``.\n If not, perform the authorization.\n\n Parameters\n ----------\n request : HttpRequest object\n Incoming request from the webpage\n user : dict\n A dictionary of user credentials\n\n Returns\n -------\n fn : function\n The decorated function\n \"\"\"\n\n # If user is currently anonymous, require a login\n if user['ezid']:\n\n return fn(request, user, **kwargs)\n\n else:\n template = 'not_authenticated.html'\n context = {'inst': ''}\n\n return render(request, template, context)\n\n return check_auth\n\n\n@auth_info\ndef login(request, user):\n \"\"\"Spawn a login process for the user\n\n The ``auth_requred`` decorator is used to require that the user\n authenticate through ``auth.mast``, then the user is redirected\n back to the homepage.\n\n Parameters\n ----------\n request : HttpRequest object\n Incoming request from the webpage\n user : dict\n A dictionary of user credentials.\n\n Returns\n -------\n HttpResponse object\n Outgoing response sent to the webpage\n \"\"\"\n\n # Redirect to oauth login\n global PREV_PAGE\n PREV_PAGE = request.META.get('HTTP_REFERER')\n redirect_uri = os.path.join(get_base_url(), 'authorize')\n\n return JWQL_OAUTH.mast_auth.authorize_redirect(request, redirect_uri)\n\n\ndef logout(request):\n \"\"\"Spawn a logout process for the user\n\n Upon logout, the user's ``auth.mast`` credientials are removed and\n the user is redirected back to the homepage.\n\n Parameters\n ----------\n request : HttpRequest object\n Incoming request from the webpage\n user : dict\n A dictionary of user credentials.\n\n Returns\n -------\n HttpResponse object\n Outgoing response sent to the webpage\n \"\"\"\n\n global PREV_PAGE\n PREV_PAGE = request.META.get('HTTP_REFERER')\n response = redirect(PREV_PAGE)\n response.delete_cookie(\"ASB-AUTH\")\n\n return response\n", "path": "jwql/website/apps/jwql/oauth.py"}, {"content": "import numpy as np\nfrom setuptools import setup\nfrom setuptools import find_packages\n\nVERSION = '0.23.0'\n\nAUTHORS = 'Matthew Bourque, Lauren Chambers, Misty Cracraft, Mike Engesser, Mees Fix, Joe Filippazzo, Bryan Hilbert, '\nAUTHORS += 'Graham Kanarek, Teagan King, Catherine Martlin, Maria Pena-Guerrero, Johannes Sahlmann, Ben Sunnquist'\n\nDESCRIPTION = 'The James Webb Space Telescope Quicklook Project'\n\nDEPENDENCY_LINKS = ['git+https://github.com/spacetelescope/[email protected]',\n 'git+https://github.com/spacetelescope/jwst_reffiles#egg=jwst_reffiles'\n ]\nREQUIRES = [\n 'asdf>=2.3.3',\n 'astropy>=3.2.1',\n 'astroquery>=0.3.9',\n 'authlib',\n 'bokeh>=1.0,<1.4',\n 'codecov',\n 'crds',\n 'django>=2.0,<3.0',\n 'flake8',\n 'inflection',\n 'ipython',\n 'jinja2',\n 'jsonschema',\n 'jwedb>=0.0.3',\n 'matplotlib',\n 'nodejs',\n 'numpy',\n 'numpydoc',\n 'pandas',\n 'psycopg2',\n 'pysiaf',\n 'pytest',\n 'pytest-cov',\n 'scipy',\n 'sphinx',\n 'sqlalchemy',\n 'stsci_rtd_theme',\n 'twine'\n]\n\nsetup(\n name='jwql',\n version=VERSION,\n description=DESCRIPTION,\n url='https://github.com/spacetelescope/jwql.git',\n author=AUTHORS,\n author_email='[email protected]',\n license='BSD',\n keywords=['astronomy', 'python'],\n classifiers=['Programming Language :: Python'],\n packages=find_packages(),\n install_requires=REQUIRES,\n dependency_links=DEPENDENCY_LINKS,\n include_package_data=True,\n include_dirs=[np.get_include()],\n)\n", "path": "setup.py"}]} | 4,083 | 607 |
gh_patches_debug_13568 | rasdani/github-patches | git_diff | facebookresearch__xformers-40 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Logo doesn't appear on documentation sub-pages
# 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
Currently, the `xFormers` logo only appears on the main docs page and the `what_is_xformers` page which is present in the same directory as it, but not on the other sub-pages. I was wondering whether setting the Sphinx option `html_logo` in the `conf.py` file would fix this.
Would be happy to make a PR for this, let me know what you think.
</issue>
<code>
[start of docs/source/conf.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
2 #
3 # This source code is licensed under the BSD license found in the
4 # LICENSE file in the root directory of this source tree.
5
6
7 # type: ignore
8 # Configuration file for the Sphinx documentation builder.
9 #
10 # This file only contains a selection of the most common options. For a full
11 # list see the documentation:
12 # https://www.sphinx-doc.org/en/master/usage/configuration.html
13
14 # -- Path setup --------------------------------------------------------------
15
16 # If extensions (or modules to document with autodoc) are in another directory,
17 # add these directories to sys.path here. If the directory is relative to the
18 # documentation root, use os.path.abspath to make it absolute, like shown here.
19 #
20 import os
21 import sys
22 from typing import Any, List
23
24 # The theme to use for HTML and HTML Help pages. See the documentation for
25 # a list of builtin themes.
26 #
27 from recommonmark.transform import AutoStructify
28
29 sys.path.insert(0, os.path.abspath("../.."))
30
31 # -- Project information -----------------------------------------------------
32
33 project = "xFormers"
34 copyright = "2021, Facebook AI Research"
35 author = "Facebook AI Research"
36
37 # The full version, including alpha/beta/rc tags
38 release = "0.0.1"
39
40
41 # -- General configuration ---------------------------------------------------
42
43 # Add any Sphinx extension module names here, as strings. They can be
44 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
45 # ones.
46 extensions = [
47 "sphinx.ext.autodoc",
48 "sphinx.ext.autosectionlabel",
49 "sphinx.ext.napoleon", # support NumPy and Google style docstrings
50 "recommonmark",
51 "sphinx.ext.intersphinx",
52 "sphinx.ext.todo",
53 "sphinx.ext.coverage",
54 "sphinx.ext.mathjax",
55 "sphinx.ext.viewcode",
56 "sphinx.ext.githubpages",
57 "sphinx.ext.doctest",
58 "sphinx.ext.ifconfig",
59 ]
60
61 # autosectionlabel throws warnings if section names are duplicated.
62 # The following tells autosectionlabel to not throw a warning for
63 # duplicated section names that are in different documents.
64 autosectionlabel_prefix_document = True
65
66 # -- Configurations for plugins ------------
67 napoleon_google_docstring = True
68 napoleon_include_init_with_doc = True
69 napoleon_include_special_with_doc = True
70 napoleon_numpy_docstring = False
71 napoleon_use_rtype = False
72 autodoc_inherit_docstrings = False
73 autodoc_member_order = "bysource"
74
75 intersphinx_mapping = {
76 "python": ("https://docs.python.org/3.6", None),
77 "numpy": ("https://docs.scipy.org/doc/numpy/", None),
78 "torch": ("https://pytorch.org/docs/master/", None),
79 }
80 # -------------------------
81
82 # Add any paths that contain templates here, relative to this directory.
83 templates_path = ["_templates"]
84
85 # List of patterns, relative to source directory, that match files and
86 # directories to ignore when looking for source files.
87 # This pattern also affects html_static_path and html_extra_path.
88 exclude_patterns: List[Any] = []
89
90 # The suffix(es) of source filenames.
91 # You can specify multiple suffix as a list of string:
92 #
93 source_suffix = [".rst", ".md"]
94
95 # The master toctree document.
96 master_doc = "index"
97
98 # If true, `todo` and `todoList` produce output, else they produce nothing.
99 todo_include_todos = True
100
101 # -- Options for HTML output -------------------------------------------------
102
103
104 html_theme = "pytorch_sphinx_theme"
105 templates_path = ["_templates"]
106
107
108 # Add any paths that contain custom static files (such as style sheets) here,
109 # Theme options are theme-specific and customize the look and feel of a theme
110 # further. For a list of options available for each theme, see the
111 # documentation.
112 #
113 html_theme_options = {
114 "includehidden": True,
115 "canonical_url": "https://fairinternal.github.io/xformers",
116 "pytorch_project": "docs",
117 "logo_only": True, # default = False
118 }
119
120 # relative to this directory. They are copied after the builtin static files,
121 # so a file named "default.css" will overwrite the builtin "default.css".
122 html_static_path = ["_static"]
123
124 # setting custom stylesheets https://stackoverflow.com/a/34420612
125 html_context = {"css_files": ["_static/css/customize.css"]}
126
127 # -- Options for HTMLHelp output ------------------------------------------
128
129 # Output file base name for HTML help builder.
130 htmlhelp_basename = "xformersdocs"
131 github_doc_root = "https://github.com/fairinternal/xformers/blob/v0.1/"
132
133
134 # Over-ride PyTorch Sphinx css
135 def setup(app):
136 app.add_config_value(
137 "recommonmark_config",
138 {
139 "url_resolver": lambda url: github_doc_root + url,
140 "auto_toc_tree_section": "Contents",
141 "enable_math": True,
142 "enable_inline_math": True,
143 "enable_eval_rst": True,
144 "enable_auto_toc_tree": True,
145 },
146 True,
147 )
148 app.add_transform(AutoStructify)
149 app.add_css_file("css/customize.css")
150
[end of docs/source/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/docs/source/conf.py b/docs/source/conf.py
--- a/docs/source/conf.py
+++ b/docs/source/conf.py
@@ -112,7 +112,7 @@
#
html_theme_options = {
"includehidden": True,
- "canonical_url": "https://fairinternal.github.io/xformers",
+ "canonical_url": "https://facebookresearch.github.io/xformers",
"pytorch_project": "docs",
"logo_only": True, # default = False
}
@@ -128,7 +128,7 @@
# Output file base name for HTML help builder.
htmlhelp_basename = "xformersdocs"
-github_doc_root = "https://github.com/fairinternal/xformers/blob/v0.1/"
+github_doc_root = "https://github.com/facebookresearch/xformers/tree/main/docs/"
# Over-ride PyTorch Sphinx css
| {"golden_diff": "diff --git a/docs/source/conf.py b/docs/source/conf.py\n--- a/docs/source/conf.py\n+++ b/docs/source/conf.py\n@@ -112,7 +112,7 @@\n #\n html_theme_options = {\n \"includehidden\": True,\n- \"canonical_url\": \"https://fairinternal.github.io/xformers\",\n+ \"canonical_url\": \"https://facebookresearch.github.io/xformers\",\n \"pytorch_project\": \"docs\",\n \"logo_only\": True, # default = False\n }\n@@ -128,7 +128,7 @@\n \n # Output file base name for HTML help builder.\n htmlhelp_basename = \"xformersdocs\"\n-github_doc_root = \"https://github.com/fairinternal/xformers/blob/v0.1/\"\n+github_doc_root = \"https://github.com/facebookresearch/xformers/tree/main/docs/\"\n \n \n # Over-ride PyTorch Sphinx css\n", "issue": "Logo doesn't appear on documentation sub-pages\n# \ud83d\udc1b Bug\r\n\r\n<!-- A clear and concise description of what the bug is. -->\r\n\r\nCurrently, the `xFormers` logo only appears on the main docs page and the `what_is_xformers` page which is present in the same directory as it, but not on the other sub-pages. I was wondering whether setting the Sphinx option `html_logo` in the `conf.py` file would fix this.\r\n\r\nWould be happy to make a PR for this, let me know what you think.\r\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.\n#\n# This source code is licensed under the BSD license found in the\n# LICENSE file in the root directory of this source tree.\n\n\n# type: ignore\n# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options. For a full\n# list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\nfrom typing import Any, List\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nfrom recommonmark.transform import AutoStructify\n\nsys.path.insert(0, os.path.abspath(\"../..\"))\n\n# -- Project information -----------------------------------------------------\n\nproject = \"xFormers\"\ncopyright = \"2021, Facebook AI Research\"\nauthor = \"Facebook AI Research\"\n\n# The full version, including alpha/beta/rc tags\nrelease = \"0.0.1\"\n\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.autosectionlabel\",\n \"sphinx.ext.napoleon\", # support NumPy and Google style docstrings\n \"recommonmark\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.todo\",\n \"sphinx.ext.coverage\",\n \"sphinx.ext.mathjax\",\n \"sphinx.ext.viewcode\",\n \"sphinx.ext.githubpages\",\n \"sphinx.ext.doctest\",\n \"sphinx.ext.ifconfig\",\n]\n\n# autosectionlabel throws warnings if section names are duplicated.\n# The following tells autosectionlabel to not throw a warning for\n# duplicated section names that are in different documents.\nautosectionlabel_prefix_document = True\n\n# -- Configurations for plugins ------------\nnapoleon_google_docstring = True\nnapoleon_include_init_with_doc = True\nnapoleon_include_special_with_doc = True\nnapoleon_numpy_docstring = False\nnapoleon_use_rtype = False\nautodoc_inherit_docstrings = False\nautodoc_member_order = \"bysource\"\n\nintersphinx_mapping = {\n \"python\": (\"https://docs.python.org/3.6\", None),\n \"numpy\": (\"https://docs.scipy.org/doc/numpy/\", None),\n \"torch\": (\"https://pytorch.org/docs/master/\", None),\n}\n# -------------------------\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns: List[Any] = []\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\nsource_suffix = [\".rst\", \".md\"]\n\n# The master toctree document.\nmaster_doc = \"index\"\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n\n# -- Options for HTML output -------------------------------------------------\n\n\nhtml_theme = \"pytorch_sphinx_theme\"\ntemplates_path = [\"_templates\"]\n\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\nhtml_theme_options = {\n \"includehidden\": True,\n \"canonical_url\": \"https://fairinternal.github.io/xformers\",\n \"pytorch_project\": \"docs\",\n \"logo_only\": True, # default = False\n}\n\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\n# setting custom stylesheets https://stackoverflow.com/a/34420612\nhtml_context = {\"css_files\": [\"_static/css/customize.css\"]}\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = \"xformersdocs\"\ngithub_doc_root = \"https://github.com/fairinternal/xformers/blob/v0.1/\"\n\n\n# Over-ride PyTorch Sphinx css\ndef setup(app):\n app.add_config_value(\n \"recommonmark_config\",\n {\n \"url_resolver\": lambda url: github_doc_root + url,\n \"auto_toc_tree_section\": \"Contents\",\n \"enable_math\": True,\n \"enable_inline_math\": True,\n \"enable_eval_rst\": True,\n \"enable_auto_toc_tree\": True,\n },\n True,\n )\n app.add_transform(AutoStructify)\n app.add_css_file(\"css/customize.css\")\n", "path": "docs/source/conf.py"}]} | 2,131 | 199 |
gh_patches_debug_35287 | rasdani/github-patches | git_diff | pyinstaller__pyinstaller-6529 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pkgutil.iter_modules with arbitrary path
## Description of the issue
The iter_modules patch implemented in #5959 has a bug where the path must start with the _MEIPASS or it will throw an assertion error.
The normal iter_modules function can take any valid path. Your code first calls that:
https://github.com/pyinstaller/pyinstaller/blob/develop/PyInstaller/hooks/rthooks/pyi_rth_pkgutil.py#L37
and later asserts it starts with _MEIPASS
https://github.com/pyinstaller/pyinstaller/blob/develop/PyInstaller/hooks/rthooks/pyi_rth_pkgutil.py#L59
which means that a path outside of the executable will throw the assertion error.
I think when implementing it was overlooked that this function could be used to look at a path outside the executable path.
### Context information (for bug reports)
* PyInstaller Version 4.8
* All OS and python versions
I will have a look into creating a pull request to fix this issue.
I think the solution is to change the assertion to an if statement to only run the code below that if it starts with _MEIPASS and thus could be bundled in the executable.
</issue>
<code>
[start of PyInstaller/hooks/rthooks/pyi_rth_pkgutil.py]
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2021, PyInstaller Development Team.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 #
7 # The full license is in the file COPYING.txt, distributed with this software.
8 #
9 # SPDX-License-Identifier: Apache-2.0
10 #-----------------------------------------------------------------------------
11 #
12 # This rthook overrides pkgutil.iter_modules with custom implementation that uses PyInstaller's FrozenImporter to list
13 # sub-modules embedded in the PYZ archive. The non-embedded modules (binary extensions, or .pyc modules in noarchive
14 # build) are handled by original pkgutil iter_modules implementation (and consequently, python's FileFinder).
15 #
16 # The preferred way of adding support for iter_modules would be adding non-standard iter_modules() method to
17 # FrozenImporter itself. However, that seems to work only for path entry finders (for use with sys.path_hooks), while
18 # PyInstaller's FrozenImporter is registered as meta path finders (for use with sys.meta_path). Turning FrozenImporter
19 # into path entry finder, would seemingly require the latter to support on-filesystem resources (e.g., extension
20 # modules) in addition to PYZ-embedded ones.
21 #
22 # Therefore, we instead opt for overriding pkgutil.iter_modules with custom implementation that augments the output of
23 # original implementation with contents of PYZ archive from FrozenImporter's TOC.
24
25 import os
26 import pkgutil
27 import sys
28
29 from pyimod03_importers import FrozenImporter
30
31 _orig_pkgutil_iter_modules = pkgutil.iter_modules
32
33
34 def _pyi_pkgutil_iter_modules(path=None, prefix=''):
35 # Use original implementation to discover on-filesystem modules (binary extensions in regular builds, or both binary
36 # extensions and compiled pyc modules in noarchive debug builds).
37 yield from _orig_pkgutil_iter_modules(path, prefix)
38
39 # Find the instance of PyInstaller's FrozenImporter.
40 for importer in pkgutil.iter_importers():
41 if isinstance(importer, FrozenImporter):
42 break
43 else:
44 return
45
46 if not path:
47 # Search for all top-level packages/modules. These will have no dots in their entry names.
48 for entry in importer.toc:
49 if entry.count('.') != 0:
50 continue
51 is_pkg = importer.is_package(entry)
52 yield pkgutil.ModuleInfo(importer, prefix + entry, is_pkg)
53 else:
54 # Declare SYS_PREFIX locally, to avoid clash with eponymous global symbol from pyi_rth_pkgutil hook.
55 SYS_PREFIX = sys._MEIPASS + os.path.sep
56 SYS_PREFIXLEN = len(SYS_PREFIX)
57 # Only single path is supported, and it must start with sys._MEIPASS.
58 pkg_path = os.path.normpath(path[0])
59 assert pkg_path.startswith(SYS_PREFIX)
60 # Construct package prefix from path...
61 pkg_prefix = pkg_path[SYS_PREFIXLEN:]
62 pkg_prefix = pkg_prefix.replace(os.path.sep, '.')
63 # ... and ensure it ends with a dot (so we can directly filter out the package itself).
64 if not pkg_prefix.endswith('.'):
65 pkg_prefix += '.'
66 pkg_prefix_len = len(pkg_prefix)
67
68 for entry in importer.toc:
69 if not entry.startswith(pkg_prefix):
70 continue
71 name = entry[pkg_prefix_len:]
72 if name.count('.') != 0:
73 continue
74 is_pkg = importer.is_package(entry)
75 yield pkgutil.ModuleInfo(importer, prefix + name, is_pkg)
76
77
78 pkgutil.iter_modules = _pyi_pkgutil_iter_modules
79
[end of PyInstaller/hooks/rthooks/pyi_rth_pkgutil.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/PyInstaller/hooks/rthooks/pyi_rth_pkgutil.py b/PyInstaller/hooks/rthooks/pyi_rth_pkgutil.py
--- a/PyInstaller/hooks/rthooks/pyi_rth_pkgutil.py
+++ b/PyInstaller/hooks/rthooks/pyi_rth_pkgutil.py
@@ -43,7 +43,7 @@
else:
return
- if not path:
+ if path is None:
# Search for all top-level packages/modules. These will have no dots in their entry names.
for entry in importer.toc:
if entry.count('.') != 0:
@@ -54,25 +54,28 @@
# Declare SYS_PREFIX locally, to avoid clash with eponymous global symbol from pyi_rth_pkgutil hook.
SYS_PREFIX = sys._MEIPASS + os.path.sep
SYS_PREFIXLEN = len(SYS_PREFIX)
- # Only single path is supported, and it must start with sys._MEIPASS.
- pkg_path = os.path.normpath(path[0])
- assert pkg_path.startswith(SYS_PREFIX)
- # Construct package prefix from path...
- pkg_prefix = pkg_path[SYS_PREFIXLEN:]
- pkg_prefix = pkg_prefix.replace(os.path.sep, '.')
- # ... and ensure it ends with a dot (so we can directly filter out the package itself).
- if not pkg_prefix.endswith('.'):
- pkg_prefix += '.'
- pkg_prefix_len = len(pkg_prefix)
- for entry in importer.toc:
- if not entry.startswith(pkg_prefix):
- continue
- name = entry[pkg_prefix_len:]
- if name.count('.') != 0:
+ for pkg_path in path:
+ pkg_path = os.path.normpath(pkg_path)
+ if not pkg_path.startswith(SYS_PREFIX):
+ # if the path does not start with sys._MEIPASS then it cannot be a bundled package.
continue
- is_pkg = importer.is_package(entry)
- yield pkgutil.ModuleInfo(importer, prefix + name, is_pkg)
+ # Construct package prefix from path...
+ pkg_prefix = pkg_path[SYS_PREFIXLEN:]
+ pkg_prefix = pkg_prefix.replace(os.path.sep, '.')
+ # ... and ensure it ends with a dot (so we can directly filter out the package itself).
+ if not pkg_prefix.endswith('.'):
+ pkg_prefix += '.'
+ pkg_prefix_len = len(pkg_prefix)
+
+ for entry in importer.toc:
+ if not entry.startswith(pkg_prefix):
+ continue
+ name = entry[pkg_prefix_len:]
+ if name.count('.') != 0:
+ continue
+ is_pkg = importer.is_package(entry)
+ yield pkgutil.ModuleInfo(importer, prefix + name, is_pkg)
pkgutil.iter_modules = _pyi_pkgutil_iter_modules
| {"golden_diff": "diff --git a/PyInstaller/hooks/rthooks/pyi_rth_pkgutil.py b/PyInstaller/hooks/rthooks/pyi_rth_pkgutil.py\n--- a/PyInstaller/hooks/rthooks/pyi_rth_pkgutil.py\n+++ b/PyInstaller/hooks/rthooks/pyi_rth_pkgutil.py\n@@ -43,7 +43,7 @@\n else:\n return\n \n- if not path:\n+ if path is None:\n # Search for all top-level packages/modules. These will have no dots in their entry names.\n for entry in importer.toc:\n if entry.count('.') != 0:\n@@ -54,25 +54,28 @@\n # Declare SYS_PREFIX locally, to avoid clash with eponymous global symbol from pyi_rth_pkgutil hook.\n SYS_PREFIX = sys._MEIPASS + os.path.sep\n SYS_PREFIXLEN = len(SYS_PREFIX)\n- # Only single path is supported, and it must start with sys._MEIPASS.\n- pkg_path = os.path.normpath(path[0])\n- assert pkg_path.startswith(SYS_PREFIX)\n- # Construct package prefix from path...\n- pkg_prefix = pkg_path[SYS_PREFIXLEN:]\n- pkg_prefix = pkg_prefix.replace(os.path.sep, '.')\n- # ... and ensure it ends with a dot (so we can directly filter out the package itself).\n- if not pkg_prefix.endswith('.'):\n- pkg_prefix += '.'\n- pkg_prefix_len = len(pkg_prefix)\n \n- for entry in importer.toc:\n- if not entry.startswith(pkg_prefix):\n- continue\n- name = entry[pkg_prefix_len:]\n- if name.count('.') != 0:\n+ for pkg_path in path:\n+ pkg_path = os.path.normpath(pkg_path)\n+ if not pkg_path.startswith(SYS_PREFIX):\n+ # if the path does not start with sys._MEIPASS then it cannot be a bundled package.\n continue\n- is_pkg = importer.is_package(entry)\n- yield pkgutil.ModuleInfo(importer, prefix + name, is_pkg)\n+ # Construct package prefix from path...\n+ pkg_prefix = pkg_path[SYS_PREFIXLEN:]\n+ pkg_prefix = pkg_prefix.replace(os.path.sep, '.')\n+ # ... and ensure it ends with a dot (so we can directly filter out the package itself).\n+ if not pkg_prefix.endswith('.'):\n+ pkg_prefix += '.'\n+ pkg_prefix_len = len(pkg_prefix)\n+\n+ for entry in importer.toc:\n+ if not entry.startswith(pkg_prefix):\n+ continue\n+ name = entry[pkg_prefix_len:]\n+ if name.count('.') != 0:\n+ continue\n+ is_pkg = importer.is_package(entry)\n+ yield pkgutil.ModuleInfo(importer, prefix + name, is_pkg)\n \n \n pkgutil.iter_modules = _pyi_pkgutil_iter_modules\n", "issue": "pkgutil.iter_modules with arbitrary path\n## Description of the issue\r\nThe iter_modules patch implemented in #5959 has a bug where the path must start with the _MEIPASS or it will throw an assertion error.\r\n\r\nThe normal iter_modules function can take any valid path. Your code first calls that:\r\nhttps://github.com/pyinstaller/pyinstaller/blob/develop/PyInstaller/hooks/rthooks/pyi_rth_pkgutil.py#L37\r\n\r\nand later asserts it starts with _MEIPASS\r\nhttps://github.com/pyinstaller/pyinstaller/blob/develop/PyInstaller/hooks/rthooks/pyi_rth_pkgutil.py#L59\r\n\r\nwhich means that a path outside of the executable will throw the assertion error.\r\n\r\nI think when implementing it was overlooked that this function could be used to look at a path outside the executable path.\r\n\r\n### Context information (for bug reports)\r\n\r\n* PyInstaller Version 4.8\r\n* All OS and python versions\r\n\r\nI will have a look into creating a pull request to fix this issue.\r\nI think the solution is to change the assertion to an if statement to only run the code below that if it starts with _MEIPASS and thus could be bundled in the executable.\n", "before_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2021, PyInstaller Development Team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#\n# SPDX-License-Identifier: Apache-2.0\n#-----------------------------------------------------------------------------\n#\n# This rthook overrides pkgutil.iter_modules with custom implementation that uses PyInstaller's FrozenImporter to list\n# sub-modules embedded in the PYZ archive. The non-embedded modules (binary extensions, or .pyc modules in noarchive\n# build) are handled by original pkgutil iter_modules implementation (and consequently, python's FileFinder).\n#\n# The preferred way of adding support for iter_modules would be adding non-standard iter_modules() method to\n# FrozenImporter itself. However, that seems to work only for path entry finders (for use with sys.path_hooks), while\n# PyInstaller's FrozenImporter is registered as meta path finders (for use with sys.meta_path). Turning FrozenImporter\n# into path entry finder, would seemingly require the latter to support on-filesystem resources (e.g., extension\n# modules) in addition to PYZ-embedded ones.\n#\n# Therefore, we instead opt for overriding pkgutil.iter_modules with custom implementation that augments the output of\n# original implementation with contents of PYZ archive from FrozenImporter's TOC.\n\nimport os\nimport pkgutil\nimport sys\n\nfrom pyimod03_importers import FrozenImporter\n\n_orig_pkgutil_iter_modules = pkgutil.iter_modules\n\n\ndef _pyi_pkgutil_iter_modules(path=None, prefix=''):\n # Use original implementation to discover on-filesystem modules (binary extensions in regular builds, or both binary\n # extensions and compiled pyc modules in noarchive debug builds).\n yield from _orig_pkgutil_iter_modules(path, prefix)\n\n # Find the instance of PyInstaller's FrozenImporter.\n for importer in pkgutil.iter_importers():\n if isinstance(importer, FrozenImporter):\n break\n else:\n return\n\n if not path:\n # Search for all top-level packages/modules. These will have no dots in their entry names.\n for entry in importer.toc:\n if entry.count('.') != 0:\n continue\n is_pkg = importer.is_package(entry)\n yield pkgutil.ModuleInfo(importer, prefix + entry, is_pkg)\n else:\n # Declare SYS_PREFIX locally, to avoid clash with eponymous global symbol from pyi_rth_pkgutil hook.\n SYS_PREFIX = sys._MEIPASS + os.path.sep\n SYS_PREFIXLEN = len(SYS_PREFIX)\n # Only single path is supported, and it must start with sys._MEIPASS.\n pkg_path = os.path.normpath(path[0])\n assert pkg_path.startswith(SYS_PREFIX)\n # Construct package prefix from path...\n pkg_prefix = pkg_path[SYS_PREFIXLEN:]\n pkg_prefix = pkg_prefix.replace(os.path.sep, '.')\n # ... and ensure it ends with a dot (so we can directly filter out the package itself).\n if not pkg_prefix.endswith('.'):\n pkg_prefix += '.'\n pkg_prefix_len = len(pkg_prefix)\n\n for entry in importer.toc:\n if not entry.startswith(pkg_prefix):\n continue\n name = entry[pkg_prefix_len:]\n if name.count('.') != 0:\n continue\n is_pkg = importer.is_package(entry)\n yield pkgutil.ModuleInfo(importer, prefix + name, is_pkg)\n\n\npkgutil.iter_modules = _pyi_pkgutil_iter_modules\n", "path": "PyInstaller/hooks/rthooks/pyi_rth_pkgutil.py"}]} | 1,713 | 620 |
gh_patches_debug_1650 | rasdani/github-patches | git_diff | ivy-llc__ivy-13273 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
unravel_index
</issue>
<code>
[start of ivy/functional/frontends/jax/numpy/indexing.py]
1 # local
2 import ivy
3 from ivy.functional.frontends.jax.func_wrapper import (
4 to_ivy_arrays_and_back,
5 )
6
7
8 @to_ivy_arrays_and_back
9 def diagonal(a, offset=0, axis1=0, axis2=1):
10 return ivy.diagonal(a, offset=offset, axis1=axis1, axis2=axis2)
11
12
13 @to_ivy_arrays_and_back
14 def diag(v, k=0):
15 return ivy.diag(v, k=k)
16
17
18 @to_ivy_arrays_and_back
19 def diag_indices(n, ndim=2):
20 idx = ivy.arange(n, dtype=int)
21 return (idx,) * ndim
22
23
24 # take_along_axis
25 @to_ivy_arrays_and_back
26 def take_along_axis(arr, indices, axis, mode="fill"):
27 return ivy.take_along_axis(arr, indices, axis, mode=mode)
28
29
30 @to_ivy_arrays_and_back
31 def tril_indices(n_rows, n_cols=None, k=0):
32 return ivy.tril_indices(n_rows, n_cols, k)
33
34
35 @to_ivy_arrays_and_back
36 def triu_indices(n, k=0, m=None):
37 return ivy.triu_indices(n, m, k)
38
39
40 @to_ivy_arrays_and_back
41 def triu_indices_from(arr, k=0):
42 return ivy.triu_indices(arr.shape[-2], arr.shape[-1], k)
43
44
45 def tril_indices_from(arr, k=0):
46 return ivy.tril_indices(arr.shape[-2], arr.shape[-1], k)
47
[end of ivy/functional/frontends/jax/numpy/indexing.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/ivy/functional/frontends/jax/numpy/indexing.py b/ivy/functional/frontends/jax/numpy/indexing.py
--- a/ivy/functional/frontends/jax/numpy/indexing.py
+++ b/ivy/functional/frontends/jax/numpy/indexing.py
@@ -44,3 +44,10 @@
def tril_indices_from(arr, k=0):
return ivy.tril_indices(arr.shape[-2], arr.shape[-1], k)
+
+
+# unravel_index
+@to_ivy_arrays_and_back
+def unravel_index(indices, shape):
+ ret = [x.astype("int64") for x in ivy.unravel_index(indices, shape)]
+ return tuple(ret)
| {"golden_diff": "diff --git a/ivy/functional/frontends/jax/numpy/indexing.py b/ivy/functional/frontends/jax/numpy/indexing.py\n--- a/ivy/functional/frontends/jax/numpy/indexing.py\n+++ b/ivy/functional/frontends/jax/numpy/indexing.py\n@@ -44,3 +44,10 @@\n \n def tril_indices_from(arr, k=0):\n return ivy.tril_indices(arr.shape[-2], arr.shape[-1], k)\n+\n+\n+# unravel_index\n+@to_ivy_arrays_and_back\n+def unravel_index(indices, shape):\n+ ret = [x.astype(\"int64\") for x in ivy.unravel_index(indices, shape)]\n+ return tuple(ret)\n", "issue": "unravel_index\n\n", "before_files": [{"content": "# local\nimport ivy\nfrom ivy.functional.frontends.jax.func_wrapper import (\n to_ivy_arrays_and_back,\n)\n\n\n@to_ivy_arrays_and_back\ndef diagonal(a, offset=0, axis1=0, axis2=1):\n return ivy.diagonal(a, offset=offset, axis1=axis1, axis2=axis2)\n\n\n@to_ivy_arrays_and_back\ndef diag(v, k=0):\n return ivy.diag(v, k=k)\n\n\n@to_ivy_arrays_and_back\ndef diag_indices(n, ndim=2):\n idx = ivy.arange(n, dtype=int)\n return (idx,) * ndim\n\n\n# take_along_axis\n@to_ivy_arrays_and_back\ndef take_along_axis(arr, indices, axis, mode=\"fill\"):\n return ivy.take_along_axis(arr, indices, axis, mode=mode)\n\n\n@to_ivy_arrays_and_back\ndef tril_indices(n_rows, n_cols=None, k=0):\n return ivy.tril_indices(n_rows, n_cols, k)\n\n\n@to_ivy_arrays_and_back\ndef triu_indices(n, k=0, m=None):\n return ivy.triu_indices(n, m, k)\n\n\n@to_ivy_arrays_and_back\ndef triu_indices_from(arr, k=0):\n return ivy.triu_indices(arr.shape[-2], arr.shape[-1], k)\n\n\ndef tril_indices_from(arr, k=0):\n return ivy.tril_indices(arr.shape[-2], arr.shape[-1], k)\n", "path": "ivy/functional/frontends/jax/numpy/indexing.py"}]} | 986 | 162 |
gh_patches_debug_4175 | rasdani/github-patches | git_diff | cleanlab__cleanlab-965 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Revert #961 before release
Tensorflow version temporarily has an upper bound (`tensorflow<2.16.0`) in requirements-dev.txt.
scikit-learn version temporarily has an upper bound (`scikit-learn>=1.0,<1.4.0`) in setup.py
This needs to be reverted before releasing v2.6.0.
_Originally posted by @elisno in https://github.com/cleanlab/cleanlab/issues/961#issuecomment-1898968097_
</issue>
<code>
[start of setup.py]
1 from setuptools import setup, find_packages
2 from setuptools.command.egg_info import egg_info
3
4 # To use a consistent encoding
5 from codecs import open
6 from os import path
7
8
9 class egg_info_ex(egg_info):
10 """Includes license file into `.egg-info` folder."""
11
12 def run(self):
13 # don't duplicate license into `.egg-info` when building a distribution
14 if not self.distribution.have_run.get("install", True):
15 # `install` command is in progress, copy license
16 self.mkpath(self.egg_info)
17 self.copy_file("LICENSE", self.egg_info)
18
19 egg_info.run(self)
20
21
22 here = path.abspath(path.dirname(__file__))
23
24 # Get the long description from the README file
25 with open(path.join(here, "README.md"), encoding="utf-8") as f:
26 long_description = f.read()
27
28 # Get version number and store it in __version__
29 exec(open("cleanlab/version.py").read())
30
31 DATALAB_REQUIRE = [
32 # Mainly for Datalab's data storage class.
33 # Still some type hints that require datasets
34 "datasets>=2.7.0",
35 ]
36
37 IMAGE_REQUIRE = DATALAB_REQUIRE + ["cleanvision>=0.3.2"]
38
39 EXTRAS_REQUIRE = {
40 "datalab": DATALAB_REQUIRE,
41 "image": IMAGE_REQUIRE,
42 "all": ["matplotlib>=3.5.1"],
43 }
44 EXTRAS_REQUIRE["all"] = list(set(sum(EXTRAS_REQUIRE.values(), [])))
45
46 setup(
47 name="cleanlab",
48 version=__version__,
49 license="AGPLv3+",
50 long_description=long_description,
51 long_description_content_type="text/markdown",
52 description="The standard package for data-centric AI, machine learning with label errors, "
53 "and automatically finding and fixing dataset issues in Python.",
54 url="https://cleanlab.ai",
55 project_urls={
56 "Documentation": "https://docs.cleanlab.ai",
57 "Bug Tracker": "https://github.com/cleanlab/cleanlab/issues",
58 "Source Code": "https://github.com/cleanlab/cleanlab",
59 },
60 author="Cleanlab Inc.",
61 author_email="[email protected]",
62 # See https://pypi.python.org/pypi?%3Aaction=list_classifiers
63 classifiers=[
64 "Development Status :: 4 - Beta",
65 "Intended Audience :: Developers",
66 "Intended Audience :: Education",
67 "Intended Audience :: Science/Research",
68 "Intended Audience :: Information Technology",
69 "License :: OSI Approved :: GNU Affero General Public License v3 or later (AGPLv3+)",
70 "Natural Language :: English",
71 # We believe this package works will these versions, but we do not guarantee it!
72 "Programming Language :: Python :: 3",
73 "Programming Language :: Python :: 3.7",
74 "Programming Language :: Python :: 3.8",
75 "Programming Language :: Python :: 3.9",
76 "Programming Language :: Python :: 3.10",
77 "Programming Language :: Python",
78 "Topic :: Software Development",
79 "Topic :: Scientific/Engineering",
80 "Topic :: Scientific/Engineering :: Mathematics",
81 "Topic :: Scientific/Engineering :: Artificial Intelligence",
82 "Topic :: Software Development :: Libraries",
83 "Topic :: Software Development :: Libraries :: Python Modules",
84 ],
85 python_requires=">=3.7",
86 # What does your project relate to?
87 keywords="machine_learning data_cleaning confident_learning classification weak_supervision "
88 "learning_with_noisy_labels unsupervised_learning datacentric_ai, datacentric",
89 # You can just specify the packages manually here if your project is
90 # simple. Or you can use find_packages().
91 packages=find_packages(exclude=[]),
92 # Include cleanlab license file.
93 include_package_data=True,
94 package_data={
95 "": ["LICENSE"],
96 },
97 license_files=("LICENSE",),
98 cmdclass={"egg_info": egg_info_ex},
99 # List run-time dependencies here. These will be installed by pip when
100 # your project is installed. For an analysis of "install_requires" vs pip's
101 # requirements files see:
102 # https://packaging.python.org/en/latest/discussions/install-requires-vs-requirements/
103 install_requires=[
104 "numpy>=1.20.0",
105 "scikit-learn>=1.0,<1.4.0",
106 "tqdm>=4.53.0",
107 "pandas>=1.1.5",
108 "termcolor>=2.0.0,<2.4.0",
109 ],
110 extras_require=EXTRAS_REQUIRE,
111 )
112
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -102,7 +102,7 @@
# https://packaging.python.org/en/latest/discussions/install-requires-vs-requirements/
install_requires=[
"numpy>=1.20.0",
- "scikit-learn>=1.0,<1.4.0",
+ "scikit-learn>=1.0",
"tqdm>=4.53.0",
"pandas>=1.1.5",
"termcolor>=2.0.0,<2.4.0",
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -102,7 +102,7 @@\n # https://packaging.python.org/en/latest/discussions/install-requires-vs-requirements/\n install_requires=[\n \"numpy>=1.20.0\",\n- \"scikit-learn>=1.0,<1.4.0\",\n+ \"scikit-learn>=1.0\",\n \"tqdm>=4.53.0\",\n \"pandas>=1.1.5\",\n \"termcolor>=2.0.0,<2.4.0\",\n", "issue": "Revert #961 before release\nTensorflow version temporarily has an upper bound (`tensorflow<2.16.0`) in requirements-dev.txt.\r\nscikit-learn version temporarily has an upper bound (`scikit-learn>=1.0,<1.4.0`) in setup.py\r\n\r\nThis needs to be reverted before releasing v2.6.0.\r\n\r\n\r\n _Originally posted by @elisno in https://github.com/cleanlab/cleanlab/issues/961#issuecomment-1898968097_\r\n \n", "before_files": [{"content": "from setuptools import setup, find_packages\nfrom setuptools.command.egg_info import egg_info\n\n# To use a consistent encoding\nfrom codecs import open\nfrom os import path\n\n\nclass egg_info_ex(egg_info):\n \"\"\"Includes license file into `.egg-info` folder.\"\"\"\n\n def run(self):\n # don't duplicate license into `.egg-info` when building a distribution\n if not self.distribution.have_run.get(\"install\", True):\n # `install` command is in progress, copy license\n self.mkpath(self.egg_info)\n self.copy_file(\"LICENSE\", self.egg_info)\n\n egg_info.run(self)\n\n\nhere = path.abspath(path.dirname(__file__))\n\n# Get the long description from the README file\nwith open(path.join(here, \"README.md\"), encoding=\"utf-8\") as f:\n long_description = f.read()\n\n# Get version number and store it in __version__\nexec(open(\"cleanlab/version.py\").read())\n\nDATALAB_REQUIRE = [\n # Mainly for Datalab's data storage class.\n # Still some type hints that require datasets\n \"datasets>=2.7.0\",\n]\n\nIMAGE_REQUIRE = DATALAB_REQUIRE + [\"cleanvision>=0.3.2\"]\n\nEXTRAS_REQUIRE = {\n \"datalab\": DATALAB_REQUIRE,\n \"image\": IMAGE_REQUIRE,\n \"all\": [\"matplotlib>=3.5.1\"],\n}\nEXTRAS_REQUIRE[\"all\"] = list(set(sum(EXTRAS_REQUIRE.values(), [])))\n\nsetup(\n name=\"cleanlab\",\n version=__version__,\n license=\"AGPLv3+\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n description=\"The standard package for data-centric AI, machine learning with label errors, \"\n \"and automatically finding and fixing dataset issues in Python.\",\n url=\"https://cleanlab.ai\",\n project_urls={\n \"Documentation\": \"https://docs.cleanlab.ai\",\n \"Bug Tracker\": \"https://github.com/cleanlab/cleanlab/issues\",\n \"Source Code\": \"https://github.com/cleanlab/cleanlab\",\n },\n author=\"Cleanlab Inc.\",\n author_email=\"[email protected]\",\n # See https://pypi.python.org/pypi?%3Aaction=list_classifiers\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"Intended Audience :: Information Technology\",\n \"License :: OSI Approved :: GNU Affero General Public License v3 or later (AGPLv3+)\",\n \"Natural Language :: English\",\n # We believe this package works will these versions, but we do not guarantee it!\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python\",\n \"Topic :: Software Development\",\n \"Topic :: Scientific/Engineering\",\n \"Topic :: Scientific/Engineering :: Mathematics\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n \"Topic :: Software Development :: Libraries\",\n \"Topic :: Software Development :: Libraries :: Python Modules\",\n ],\n python_requires=\">=3.7\",\n # What does your project relate to?\n keywords=\"machine_learning data_cleaning confident_learning classification weak_supervision \"\n \"learning_with_noisy_labels unsupervised_learning datacentric_ai, datacentric\",\n # You can just specify the packages manually here if your project is\n # simple. Or you can use find_packages().\n packages=find_packages(exclude=[]),\n # Include cleanlab license file.\n include_package_data=True,\n package_data={\n \"\": [\"LICENSE\"],\n },\n license_files=(\"LICENSE\",),\n cmdclass={\"egg_info\": egg_info_ex},\n # List run-time dependencies here. These will be installed by pip when\n # your project is installed. For an analysis of \"install_requires\" vs pip's\n # requirements files see:\n # https://packaging.python.org/en/latest/discussions/install-requires-vs-requirements/\n install_requires=[\n \"numpy>=1.20.0\",\n \"scikit-learn>=1.0,<1.4.0\",\n \"tqdm>=4.53.0\",\n \"pandas>=1.1.5\",\n \"termcolor>=2.0.0,<2.4.0\",\n ],\n extras_require=EXTRAS_REQUIRE,\n)\n", "path": "setup.py"}]} | 1,865 | 139 |
gh_patches_debug_12258 | rasdani/github-patches | git_diff | blakeblackshear__frigate-5532 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Support]: Frigate crashes on ARM64 after upgrade to beta 8
### Describe the problem you are having
On ARM64 machine, frigate crashes while trying to start go2rtc.
Looking for the "ELF load command alignment not page-aligned" error, I found this: https://github.com/numpy/numpy/issues/16677
I assume the problem is related to ARM64 and the 64K page size of the "Red Hat Enterprise Linux release 8.7 (Ootpa)" operating system.
```
$ python3 -c 'import os; print(os.sysconf("SC_PAGESIZE"))'
65536
```
### Version
0.12.0 Beta 8
### Frigate config file
```yaml
mqtt:
host: mqtt
cameras:
entrance:
ffmpeg:
inputs:
- path: rtsp://**REDACTED**
roles:
- detect
- rtmp
- record
detect:
width: 2688
height: 1520
fps: 5
mqtt:
timestamp: False
bounding_box: False
crop: True
quality: 100
height: 1520
record:
enabled: True
events:
retain:
default: 5
```
### Relevant log output
```shell
[INFO] Starting go2rtc...
2023-02-15 14:19:19.142580863 14:19:19.142 INF go2rtc version 1.1.2 linux/arm64
2023-02-15 14:19:19.142706423 14:19:19.142 INF [api] listen addr=:1984
2023-02-15 14:19:19.142896941 14:19:19.142 INF [rtsp] listen addr=:8554
2023-02-15 14:19:19.143039420 14:19:19.143 INF [srtp] listen addr=:8443
2023-02-15 14:19:19.143322578 14:19:19.143 INF [webrtc] listen addr=:8555
2023-02-15 14:19:19.555985825 Traceback (most recent call last):
2023-02-15 14:19:19.556016824 File "/usr/lib/python3.9/runpy.py", line 197, in _run_module_as_main
2023-02-15 14:19:19.556044824 return _run_code(code, main_globals, None,
2023-02-15 14:19:19.556045944 File "/usr/lib/python3.9/runpy.py", line 87, in _run_code
2023-02-15 14:19:19.556083464 exec(code, run_globals)
2023-02-15 14:19:19.556084664 File "/opt/frigate/frigate/__main__.py", line 9, in <module>
2023-02-15 14:19:19.556140984 from frigate.app import FrigateApp
2023-02-15 14:19:19.556142424 File "/opt/frigate/frigate/app.py", line 17, in <module>
2023-02-15 14:19:19.556202983 from frigate.comms.dispatcher import Communicator, Dispatcher
2023-02-15 14:19:19.556205023 File "/opt/frigate/frigate/comms/dispatcher.py", line 9, in <module>
2023-02-15 14:19:19.556227943 from frigate.config import FrigateConfig
2023-02-15 14:19:19.556268703 File "/opt/frigate/frigate/config.py", line 36, in <module>
2023-02-15 14:19:19.556269863 from frigate.detectors import (
2023-02-15 14:19:19.556270783 File "/opt/frigate/frigate/detectors/__init__.py", line 9, in <module>
2023-02-15 14:19:19.556287783 from .detector_types import DetectorTypeEnum, api_types, DetectorConfig
2023-02-15 14:19:19.556289223 File "/opt/frigate/frigate/detectors/detector_types.py", line 16, in <module>
2023-02-15 14:19:19.556353022 plugin_modules = [
2023-02-15 14:19:19.556354502 File "/opt/frigate/frigate/detectors/detector_types.py", line 17, in <listcomp>
2023-02-15 14:19:19.556355142 importlib.import_module(name)
2023-02-15 14:19:19.556356102 File "/usr/lib/python3.9/importlib/__init__.py", line 127, in import_module
2023-02-15 14:19:19.556364622 return _bootstrap._gcd_import(name[level:], package, level)
2023-02-15 14:19:19.556368702 File "/opt/frigate/frigate/detectors/plugins/openvino.py", line 3, in <module>
2023-02-15 14:19:19.556395182 import openvino.runtime as ov
2023-02-15 14:19:19.556396862 File "/usr/local/lib/python3.9/dist-packages/openvino/runtime/__init__.py", line 20, in <module>
2023-02-15 14:19:19.556431222 from openvino.pyopenvino import Dimension
2023-02-15 14:19:19.556440942 ImportError: /usr/local/lib/python3.9/dist-packages/openvino/pyopenvino.cpython-39-aarch64-linux-gnu.so: ELF load command alignment not page-aligned
Service Frigate exited with code 1 (by signal 0)
```
### FFprobe output from your camera
```shell
N/A
```
### Frigate stats
_No response_
### Operating system
Other Linux
### Install method
Docker Compose
### Coral version
CPU (no coral)
### Network connection
Wired
### Camera make and model
Hikvision
### Any other information that may be helpful
_No response_
</issue>
<code>
[start of frigate/detectors/detector_types.py]
1 import logging
2 import importlib
3 import pkgutil
4 from typing import Union
5 from typing_extensions import Annotated
6 from enum import Enum
7 from pydantic import Field
8
9 from . import plugins
10 from .detection_api import DetectionApi
11 from .detector_config import BaseDetectorConfig
12
13
14 logger = logging.getLogger(__name__)
15
16 plugin_modules = [
17 importlib.import_module(name)
18 for finder, name, ispkg in pkgutil.iter_modules(
19 plugins.__path__, plugins.__name__ + "."
20 )
21 ]
22
23 api_types = {det.type_key: det for det in DetectionApi.__subclasses__()}
24
25
26 class StrEnum(str, Enum):
27 pass
28
29
30 DetectorTypeEnum = StrEnum("DetectorTypeEnum", {k: k for k in api_types})
31
32 DetectorConfig = Annotated[
33 Union[tuple(BaseDetectorConfig.__subclasses__())],
34 Field(discriminator="type"),
35 ]
36
[end of frigate/detectors/detector_types.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/frigate/detectors/detector_types.py b/frigate/detectors/detector_types.py
--- a/frigate/detectors/detector_types.py
+++ b/frigate/detectors/detector_types.py
@@ -13,12 +13,19 @@
logger = logging.getLogger(__name__)
-plugin_modules = [
- importlib.import_module(name)
- for finder, name, ispkg in pkgutil.iter_modules(
- plugins.__path__, plugins.__name__ + "."
- )
-]
+
+_included_modules = pkgutil.iter_modules(plugins.__path__, plugins.__name__ + ".")
+
+plugin_modules = []
+
+for _, name, _ in _included_modules:
+ try:
+ # currently openvino may fail when importing
+ # on an arm device with 64 KiB page size.
+ plugin_modules.append(importlib.import_module(name))
+ except ImportError as e:
+ logger.error(f"Error importing detector runtime: {e}")
+
api_types = {det.type_key: det for det in DetectionApi.__subclasses__()}
| {"golden_diff": "diff --git a/frigate/detectors/detector_types.py b/frigate/detectors/detector_types.py\n--- a/frigate/detectors/detector_types.py\n+++ b/frigate/detectors/detector_types.py\n@@ -13,12 +13,19 @@\n \n logger = logging.getLogger(__name__)\n \n-plugin_modules = [\n- importlib.import_module(name)\n- for finder, name, ispkg in pkgutil.iter_modules(\n- plugins.__path__, plugins.__name__ + \".\"\n- )\n-]\n+\n+_included_modules = pkgutil.iter_modules(plugins.__path__, plugins.__name__ + \".\")\n+\n+plugin_modules = []\n+\n+for _, name, _ in _included_modules:\n+ try:\n+ # currently openvino may fail when importing\n+ # on an arm device with 64 KiB page size.\n+ plugin_modules.append(importlib.import_module(name))\n+ except ImportError as e:\n+ logger.error(f\"Error importing detector runtime: {e}\")\n+\n \n api_types = {det.type_key: det for det in DetectionApi.__subclasses__()}\n", "issue": "[Support]: Frigate crashes on ARM64 after upgrade to beta 8\n### Describe the problem you are having\r\n\r\nOn ARM64 machine, frigate crashes while trying to start go2rtc.\r\nLooking for the \"ELF load command alignment not page-aligned\" error, I found this: https://github.com/numpy/numpy/issues/16677\r\n\r\nI assume the problem is related to ARM64 and the 64K page size of the \"Red Hat Enterprise Linux release 8.7 (Ootpa)\" operating system.\r\n\r\n```\r\n$ python3 -c 'import os; print(os.sysconf(\"SC_PAGESIZE\"))'\r\n65536\r\n```\r\n\r\n### Version\r\n\r\n0.12.0 Beta 8\r\n\r\n### Frigate config file\r\n\r\n```yaml\r\nmqtt:\r\n host: mqtt\r\n\r\ncameras:\r\n entrance:\r\n ffmpeg:\r\n inputs:\r\n - path: rtsp://**REDACTED**\r\n roles:\r\n - detect\r\n - rtmp\r\n - record\r\n detect:\r\n width: 2688\r\n height: 1520\r\n fps: 5\r\n mqtt:\r\n timestamp: False\r\n bounding_box: False\r\n crop: True\r\n quality: 100\r\n height: 1520\r\n\r\nrecord:\r\n enabled: True\r\n events:\r\n retain:\r\n default: 5\r\n```\r\n\r\n\r\n### Relevant log output\r\n\r\n```shell\r\n[INFO] Starting go2rtc...\r\n2023-02-15 14:19:19.142580863 14:19:19.142 INF go2rtc version 1.1.2 linux/arm64\r\n2023-02-15 14:19:19.142706423 14:19:19.142 INF [api] listen addr=:1984\r\n2023-02-15 14:19:19.142896941 14:19:19.142 INF [rtsp] listen addr=:8554\r\n2023-02-15 14:19:19.143039420 14:19:19.143 INF [srtp] listen addr=:8443\r\n2023-02-15 14:19:19.143322578 14:19:19.143 INF [webrtc] listen addr=:8555\r\n2023-02-15 14:19:19.555985825 Traceback (most recent call last):\r\n2023-02-15 14:19:19.556016824 File \"/usr/lib/python3.9/runpy.py\", line 197, in _run_module_as_main\r\n2023-02-15 14:19:19.556044824 return _run_code(code, main_globals, None,\r\n2023-02-15 14:19:19.556045944 File \"/usr/lib/python3.9/runpy.py\", line 87, in _run_code\r\n2023-02-15 14:19:19.556083464 exec(code, run_globals)\r\n2023-02-15 14:19:19.556084664 File \"/opt/frigate/frigate/__main__.py\", line 9, in <module>\r\n2023-02-15 14:19:19.556140984 from frigate.app import FrigateApp\r\n2023-02-15 14:19:19.556142424 File \"/opt/frigate/frigate/app.py\", line 17, in <module>\r\n2023-02-15 14:19:19.556202983 from frigate.comms.dispatcher import Communicator, Dispatcher\r\n2023-02-15 14:19:19.556205023 File \"/opt/frigate/frigate/comms/dispatcher.py\", line 9, in <module>\r\n2023-02-15 14:19:19.556227943 from frigate.config import FrigateConfig\r\n2023-02-15 14:19:19.556268703 File \"/opt/frigate/frigate/config.py\", line 36, in <module>\r\n2023-02-15 14:19:19.556269863 from frigate.detectors import (\r\n2023-02-15 14:19:19.556270783 File \"/opt/frigate/frigate/detectors/__init__.py\", line 9, in <module>\r\n2023-02-15 14:19:19.556287783 from .detector_types import DetectorTypeEnum, api_types, DetectorConfig\r\n2023-02-15 14:19:19.556289223 File \"/opt/frigate/frigate/detectors/detector_types.py\", line 16, in <module>\r\n2023-02-15 14:19:19.556353022 plugin_modules = [\r\n2023-02-15 14:19:19.556354502 File \"/opt/frigate/frigate/detectors/detector_types.py\", line 17, in <listcomp>\r\n2023-02-15 14:19:19.556355142 importlib.import_module(name)\r\n2023-02-15 14:19:19.556356102 File \"/usr/lib/python3.9/importlib/__init__.py\", line 127, in import_module\r\n2023-02-15 14:19:19.556364622 return _bootstrap._gcd_import(name[level:], package, level)\r\n2023-02-15 14:19:19.556368702 File \"/opt/frigate/frigate/detectors/plugins/openvino.py\", line 3, in <module>\r\n2023-02-15 14:19:19.556395182 import openvino.runtime as ov\r\n2023-02-15 14:19:19.556396862 File \"/usr/local/lib/python3.9/dist-packages/openvino/runtime/__init__.py\", line 20, in <module>\r\n2023-02-15 14:19:19.556431222 from openvino.pyopenvino import Dimension\r\n2023-02-15 14:19:19.556440942 ImportError: /usr/local/lib/python3.9/dist-packages/openvino/pyopenvino.cpython-39-aarch64-linux-gnu.so: ELF load command alignment not page-aligned\r\nService Frigate exited with code 1 (by signal 0)\r\n```\r\n\r\n\r\n### FFprobe output from your camera\r\n\r\n```shell\r\nN/A\r\n```\r\n\r\n\r\n### Frigate stats\r\n\r\n_No response_\r\n\r\n### Operating system\r\n\r\nOther Linux\r\n\r\n### Install method\r\n\r\nDocker Compose\r\n\r\n### Coral version\r\n\r\nCPU (no coral)\r\n\r\n### Network connection\r\n\r\nWired\r\n\r\n### Camera make and model\r\n\r\nHikvision\r\n\r\n### Any other information that may be helpful\r\n\r\n_No response_\n", "before_files": [{"content": "import logging\nimport importlib\nimport pkgutil\nfrom typing import Union\nfrom typing_extensions import Annotated\nfrom enum import Enum\nfrom pydantic import Field\n\nfrom . import plugins\nfrom .detection_api import DetectionApi\nfrom .detector_config import BaseDetectorConfig\n\n\nlogger = logging.getLogger(__name__)\n\nplugin_modules = [\n importlib.import_module(name)\n for finder, name, ispkg in pkgutil.iter_modules(\n plugins.__path__, plugins.__name__ + \".\"\n )\n]\n\napi_types = {det.type_key: det for det in DetectionApi.__subclasses__()}\n\n\nclass StrEnum(str, Enum):\n pass\n\n\nDetectorTypeEnum = StrEnum(\"DetectorTypeEnum\", {k: k for k in api_types})\n\nDetectorConfig = Annotated[\n Union[tuple(BaseDetectorConfig.__subclasses__())],\n Field(discriminator=\"type\"),\n]\n", "path": "frigate/detectors/detector_types.py"}]} | 2,706 | 244 |
gh_patches_debug_31014 | rasdani/github-patches | git_diff | mathesar-foundation__mathesar-3608 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Implement `tables.delete` RPC method
</issue>
<code>
[start of mathesar/rpc/tables.py]
1 from typing import Optional, TypedDict
2
3 from modernrpc.core import rpc_method, REQUEST_KEY
4 from modernrpc.auth.basic import http_basic_auth_login_required
5
6 from db.tables.operations.select import get_table_info
7 from mathesar.rpc.exceptions.handlers import handle_rpc_exceptions
8 from mathesar.rpc.utils import connect
9
10
11 class TableInfo(TypedDict):
12 """
13 Information about a table.
14
15 Attributes:
16 oid: The `oid` of the table in the schema.
17 name: The name of the table.
18 schema: The `oid` of the schema where the table lives.
19 description: The description of the table.
20 """
21 oid: int
22 name: str
23 schema: int
24 description: Optional[str]
25
26
27 @rpc_method(name="tables.list")
28 @http_basic_auth_login_required
29 @handle_rpc_exceptions
30 def list_(*, schema_oid: int, database_id: int, **kwargs) -> list[TableInfo]:
31 """
32 List information about tables for a schema. Exposed as `list`.
33
34 Args:
35 schema_oid: Identity of the schema in the user's database.
36 database_id: The Django id of the database containing the table.
37
38 Returns:
39 A list of table details.
40 """
41 user = kwargs.get(REQUEST_KEY).user
42 with connect(database_id, user) as conn:
43 raw_table_info = get_table_info(schema_oid, conn)
44 return [
45 TableInfo(tab) for tab in raw_table_info
46 ]
47
[end of mathesar/rpc/tables.py]
[start of db/tables/operations/drop.py]
1 from db.connection import execute_msar_func_with_engine
2
3
4 def drop_table(name, schema, engine, cascade=False, if_exists=False):
5 execute_msar_func_with_engine(engine, 'drop_table', schema, name, cascade, if_exists)
6
[end of db/tables/operations/drop.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/db/tables/operations/drop.py b/db/tables/operations/drop.py
--- a/db/tables/operations/drop.py
+++ b/db/tables/operations/drop.py
@@ -1,5 +1,21 @@
-from db.connection import execute_msar_func_with_engine
+from db.connection import execute_msar_func_with_engine, exec_msar_func
def drop_table(name, schema, engine, cascade=False, if_exists=False):
execute_msar_func_with_engine(engine, 'drop_table', schema, name, cascade, if_exists)
+
+
+def drop_table_from_database(table_oid, conn, cascade=False):
+ """
+ Drop a table.
+
+ Args:
+ table_oid: OID of the table to drop.
+ cascade: Whether to drop the dependent objects.
+
+ Returns:
+ Returns the fully qualified name of the dropped table.
+ """
+ return exec_msar_func(
+ conn, 'drop_table', table_oid, cascade
+ ).fetchone()[0]
diff --git a/mathesar/rpc/tables.py b/mathesar/rpc/tables.py
--- a/mathesar/rpc/tables.py
+++ b/mathesar/rpc/tables.py
@@ -4,6 +4,7 @@
from modernrpc.auth.basic import http_basic_auth_login_required
from db.tables.operations.select import get_table_info
+from db.tables.operations.drop import drop_table_from_database
from mathesar.rpc.exceptions.handlers import handle_rpc_exceptions
from mathesar.rpc.utils import connect
@@ -44,3 +45,25 @@
return [
TableInfo(tab) for tab in raw_table_info
]
+
+
+@rpc_method(name="tables.delete")
+@http_basic_auth_login_required
+@handle_rpc_exceptions
+def delete(
+ *, table_oid: int, database_id: int, cascade: bool = False, **kwargs
+) -> str:
+ """
+ Delete a table from a schema.
+
+ Args:
+ table_oid: Identity of the table in the user's database.
+ database_id: The Django id of the database containing the table.
+ cascade: Whether to drop the dependent objects.
+
+ Returns:
+ The name of the dropped table.
+ """
+ user = kwargs.get(REQUEST_KEY).user
+ with connect(database_id, user) as conn:
+ return drop_table_from_database(table_oid, conn, cascade)
| {"golden_diff": "diff --git a/db/tables/operations/drop.py b/db/tables/operations/drop.py\n--- a/db/tables/operations/drop.py\n+++ b/db/tables/operations/drop.py\n@@ -1,5 +1,21 @@\n-from db.connection import execute_msar_func_with_engine\n+from db.connection import execute_msar_func_with_engine, exec_msar_func\n \n \n def drop_table(name, schema, engine, cascade=False, if_exists=False):\n execute_msar_func_with_engine(engine, 'drop_table', schema, name, cascade, if_exists)\n+\n+\n+def drop_table_from_database(table_oid, conn, cascade=False):\n+ \"\"\"\n+ Drop a table.\n+\n+ Args:\n+ table_oid: OID of the table to drop.\n+ cascade: Whether to drop the dependent objects.\n+\n+ Returns:\n+ Returns the fully qualified name of the dropped table.\n+ \"\"\"\n+ return exec_msar_func(\n+ conn, 'drop_table', table_oid, cascade\n+ ).fetchone()[0]\ndiff --git a/mathesar/rpc/tables.py b/mathesar/rpc/tables.py\n--- a/mathesar/rpc/tables.py\n+++ b/mathesar/rpc/tables.py\n@@ -4,6 +4,7 @@\n from modernrpc.auth.basic import http_basic_auth_login_required\n \n from db.tables.operations.select import get_table_info\n+from db.tables.operations.drop import drop_table_from_database\n from mathesar.rpc.exceptions.handlers import handle_rpc_exceptions\n from mathesar.rpc.utils import connect\n \n@@ -44,3 +45,25 @@\n return [\n TableInfo(tab) for tab in raw_table_info\n ]\n+\n+\n+@rpc_method(name=\"tables.delete\")\n+@http_basic_auth_login_required\n+@handle_rpc_exceptions\n+def delete(\n+ *, table_oid: int, database_id: int, cascade: bool = False, **kwargs\n+) -> str:\n+ \"\"\"\n+ Delete a table from a schema.\n+\n+ Args:\n+ table_oid: Identity of the table in the user's database.\n+ database_id: The Django id of the database containing the table.\n+ cascade: Whether to drop the dependent objects.\n+\n+ Returns:\n+ The name of the dropped table.\n+ \"\"\"\n+ user = kwargs.get(REQUEST_KEY).user\n+ with connect(database_id, user) as conn:\n+ return drop_table_from_database(table_oid, conn, cascade)\n", "issue": "Implement `tables.delete` RPC method\n\n", "before_files": [{"content": "from typing import Optional, TypedDict\n\nfrom modernrpc.core import rpc_method, REQUEST_KEY\nfrom modernrpc.auth.basic import http_basic_auth_login_required\n\nfrom db.tables.operations.select import get_table_info\nfrom mathesar.rpc.exceptions.handlers import handle_rpc_exceptions\nfrom mathesar.rpc.utils import connect\n\n\nclass TableInfo(TypedDict):\n \"\"\"\n Information about a table.\n\n Attributes:\n oid: The `oid` of the table in the schema.\n name: The name of the table.\n schema: The `oid` of the schema where the table lives.\n description: The description of the table.\n \"\"\"\n oid: int\n name: str\n schema: int\n description: Optional[str]\n\n\n@rpc_method(name=\"tables.list\")\n@http_basic_auth_login_required\n@handle_rpc_exceptions\ndef list_(*, schema_oid: int, database_id: int, **kwargs) -> list[TableInfo]:\n \"\"\"\n List information about tables for a schema. Exposed as `list`.\n\n Args:\n schema_oid: Identity of the schema in the user's database.\n database_id: The Django id of the database containing the table.\n\n Returns:\n A list of table details.\n \"\"\"\n user = kwargs.get(REQUEST_KEY).user\n with connect(database_id, user) as conn:\n raw_table_info = get_table_info(schema_oid, conn)\n return [\n TableInfo(tab) for tab in raw_table_info\n ]\n", "path": "mathesar/rpc/tables.py"}, {"content": "from db.connection import execute_msar_func_with_engine\n\n\ndef drop_table(name, schema, engine, cascade=False, if_exists=False):\n execute_msar_func_with_engine(engine, 'drop_table', schema, name, cascade, if_exists)\n", "path": "db/tables/operations/drop.py"}]} | 1,025 | 525 |
gh_patches_debug_3846 | rasdani/github-patches | git_diff | pre-commit__pre-commit-540 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
always_run + no `files` still crashes on `KeyError: files`
I was under the impression `files` was completely ignored for `always_run`, I guess not!
Here's a small reproduction:
```yaml
- repo: local
hooks:
- id: foo
name: foo
always_run: true
entry: bash -c 'echo hello && exit 1'
language: system
```
```
$ ./venv-pre_commit/bin/pre-commit run foo
An unexpected error has occurred: KeyError: u'files'
Check the log at ~/.pre-commit/pre-commit.log
```
```
$ cat ~/.pre-commit/pre-commit.log
An unexpected error has occurred: KeyError: u'files'
Traceback (most recent call last):
File "/tmp/foo/pre-commit/pre_commit/error_handler.py", line 48, in error_handler
yield
File "/tmp/foo/pre-commit/pre_commit/main.py", line 226, in main
return run(runner, args)
File "/tmp/foo/pre-commit/pre_commit/commands/run.py", line 235, in run
return _run_hooks(repo_hooks, args, environ)
File "/tmp/foo/pre-commit/pre_commit/commands/run.py", line 155, in _run_hooks
retval |= _run_single_hook(hook, repo, args, skips, cols)
File "/tmp/foo/pre-commit/pre_commit/commands/run.py", line 60, in _run_single_hook
filenames = get_filenames(args, hook['files'], hook['exclude'])
KeyError: u'files'
```
</issue>
<code>
[start of pre_commit/commands/run.py]
1 from __future__ import print_function
2 from __future__ import unicode_literals
3
4 import logging
5 import os
6 import subprocess
7 import sys
8
9 from pre_commit import color
10 from pre_commit import git
11 from pre_commit import output
12 from pre_commit.output import get_hook_message
13 from pre_commit.staged_files_only import staged_files_only
14 from pre_commit.util import cmd_output
15 from pre_commit.util import noop_context
16
17
18 logger = logging.getLogger('pre_commit')
19
20
21 def _get_skips(environ):
22 skips = environ.get('SKIP', '')
23 return {skip.strip() for skip in skips.split(',') if skip.strip()}
24
25
26 def _hook_msg_start(hook, verbose):
27 return '{}{}'.format(
28 '[{}] '.format(hook['id']) if verbose else '',
29 hook['name'],
30 )
31
32
33 def get_changed_files(new, old):
34 return cmd_output(
35 'git', 'diff', '--name-only', '{}...{}'.format(old, new),
36 )[1].splitlines()
37
38
39 def get_filenames(args, include_expr, exclude_expr):
40 if args.origin and args.source:
41 getter = git.get_files_matching(
42 lambda: get_changed_files(args.origin, args.source),
43 )
44 elif args.files:
45 getter = git.get_files_matching(lambda: args.files)
46 elif args.all_files:
47 getter = git.get_all_files_matching
48 elif git.is_in_merge_conflict():
49 getter = git.get_conflicted_files_matching
50 else:
51 getter = git.get_staged_files_matching
52 return getter(include_expr, exclude_expr)
53
54
55 SKIPPED = 'Skipped'
56 NO_FILES = '(no files to check)'
57
58
59 def _run_single_hook(hook, repo, args, skips, cols):
60 filenames = get_filenames(args, hook['files'], hook['exclude'])
61 if hook['id'] in skips:
62 output.write(get_hook_message(
63 _hook_msg_start(hook, args.verbose),
64 end_msg=SKIPPED,
65 end_color=color.YELLOW,
66 use_color=args.color,
67 cols=cols,
68 ))
69 return 0
70 elif not filenames and not hook['always_run']:
71 output.write(get_hook_message(
72 _hook_msg_start(hook, args.verbose),
73 postfix=NO_FILES,
74 end_msg=SKIPPED,
75 end_color=color.TURQUOISE,
76 use_color=args.color,
77 cols=cols,
78 ))
79 return 0
80
81 # Print the hook and the dots first in case the hook takes hella long to
82 # run.
83 output.write(get_hook_message(
84 _hook_msg_start(hook, args.verbose), end_len=6, cols=cols,
85 ))
86 sys.stdout.flush()
87
88 diff_before = cmd_output('git', 'diff', retcode=None, encoding=None)
89 retcode, stdout, stderr = repo.run_hook(
90 hook,
91 tuple(filenames) if hook['pass_filenames'] else (),
92 )
93 diff_after = cmd_output('git', 'diff', retcode=None, encoding=None)
94
95 file_modifications = diff_before != diff_after
96
97 # If the hook makes changes, fail the commit
98 if file_modifications:
99 retcode = 1
100
101 if retcode:
102 retcode = 1
103 print_color = color.RED
104 pass_fail = 'Failed'
105 else:
106 retcode = 0
107 print_color = color.GREEN
108 pass_fail = 'Passed'
109
110 output.write_line(color.format_color(pass_fail, print_color, args.color))
111
112 if (stdout or stderr or file_modifications) and (retcode or args.verbose):
113 output.write_line('hookid: {}\n'.format(hook['id']))
114
115 # Print a message if failing due to file modifications
116 if file_modifications:
117 output.write('Files were modified by this hook.')
118
119 if stdout or stderr:
120 output.write_line(' Additional output:')
121
122 output.write_line()
123
124 for out in (stdout, stderr):
125 assert type(out) is bytes, type(out)
126 if out.strip():
127 output.write_line(out.strip(), logfile_name=hook['log_file'])
128 output.write_line()
129
130 return retcode
131
132
133 def _compute_cols(hooks, verbose):
134 """Compute the number of columns to display hook messages. The widest
135 that will be displayed is in the no files skipped case:
136
137 Hook name...(no files to check) Skipped
138
139 or in the verbose case
140
141 Hook name [hookid]...(no files to check) Skipped
142 """
143 if hooks:
144 name_len = max(len(_hook_msg_start(hook, verbose)) for hook in hooks)
145 else:
146 name_len = 0
147
148 cols = name_len + 3 + len(NO_FILES) + 1 + len(SKIPPED)
149 return max(cols, 80)
150
151
152 def _run_hooks(repo_hooks, args, environ):
153 """Actually run the hooks."""
154 skips = _get_skips(environ)
155 cols = _compute_cols([hook for _, hook in repo_hooks], args.verbose)
156 retval = 0
157 for repo, hook in repo_hooks:
158 retval |= _run_single_hook(hook, repo, args, skips, cols)
159 if (
160 retval and
161 args.show_diff_on_failure and
162 subprocess.call(('git', 'diff', '--quiet')) != 0
163 ):
164 print('All changes made by hooks:')
165 subprocess.call(('git', 'diff'))
166 return retval
167
168
169 def get_repo_hooks(runner):
170 for repo in runner.repositories:
171 for _, hook in repo.hooks:
172 yield (repo, hook)
173
174
175 def _has_unmerged_paths(runner):
176 _, stdout, _ = runner.cmd_runner.run(['git', 'ls-files', '--unmerged'])
177 return bool(stdout.strip())
178
179
180 def _has_unstaged_config(runner):
181 retcode, _, _ = runner.cmd_runner.run(
182 ('git', 'diff', '--exit-code', runner.config_file_path),
183 retcode=None,
184 )
185 # be explicit, other git errors don't mean it has an unstaged config.
186 return retcode == 1
187
188
189 def run(runner, args, environ=os.environ):
190 no_stash = args.no_stash or args.all_files or bool(args.files)
191
192 # Check if we have unresolved merge conflict files and fail fast.
193 if _has_unmerged_paths(runner):
194 logger.error('Unmerged files. Resolve before committing.')
195 return 1
196 if bool(args.source) != bool(args.origin):
197 logger.error('Specify both --origin and --source.')
198 return 1
199 if _has_unstaged_config(runner) and not no_stash:
200 if args.allow_unstaged_config:
201 logger.warn(
202 'You have an unstaged config file and have specified the '
203 '--allow-unstaged-config option.\n'
204 'Note that your config will be stashed before the config is '
205 'parsed unless --no-stash is specified.',
206 )
207 else:
208 logger.error(
209 'Your .pre-commit-config.yaml is unstaged.\n'
210 '`git add .pre-commit-config.yaml` to fix this.\n'
211 'Run pre-commit with --allow-unstaged-config to silence this.'
212 )
213 return 1
214
215 if no_stash:
216 ctx = noop_context()
217 else:
218 ctx = staged_files_only(runner.cmd_runner)
219
220 with ctx:
221 repo_hooks = list(get_repo_hooks(runner))
222
223 if args.hook:
224 repo_hooks = [
225 (repo, hook) for repo, hook in repo_hooks
226 if hook['id'] == args.hook
227 ]
228 if not repo_hooks:
229 output.write_line('No hook with id `{}`'.format(args.hook))
230 return 1
231
232 # Filter hooks for stages
233 repo_hooks = [
234 (repo, hook) for repo, hook in repo_hooks
235 if not hook['stages'] or args.hook_stage in hook['stages']
236 ]
237
238 return _run_hooks(repo_hooks, args, environ)
239
[end of pre_commit/commands/run.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pre_commit/commands/run.py b/pre_commit/commands/run.py
--- a/pre_commit/commands/run.py
+++ b/pre_commit/commands/run.py
@@ -57,7 +57,7 @@
def _run_single_hook(hook, repo, args, skips, cols):
- filenames = get_filenames(args, hook['files'], hook['exclude'])
+ filenames = get_filenames(args, hook.get('files', ''), hook['exclude'])
if hook['id'] in skips:
output.write(get_hook_message(
_hook_msg_start(hook, args.verbose),
| {"golden_diff": "diff --git a/pre_commit/commands/run.py b/pre_commit/commands/run.py\n--- a/pre_commit/commands/run.py\n+++ b/pre_commit/commands/run.py\n@@ -57,7 +57,7 @@\n \n \n def _run_single_hook(hook, repo, args, skips, cols):\n- filenames = get_filenames(args, hook['files'], hook['exclude'])\n+ filenames = get_filenames(args, hook.get('files', ''), hook['exclude'])\n if hook['id'] in skips:\n output.write(get_hook_message(\n _hook_msg_start(hook, args.verbose),\n", "issue": "always_run + no `files` still crashes on `KeyError: files`\nI was under the impression `files` was completely ignored for `always_run`, I guess not!\r\n\r\nHere's a small reproduction:\r\n\r\n```yaml\r\n- repo: local\r\n hooks:\r\n - id: foo\r\n name: foo\r\n always_run: true\r\n entry: bash -c 'echo hello && exit 1'\r\n language: system\r\n```\r\n\r\n```\r\n$ ./venv-pre_commit/bin/pre-commit run foo\r\nAn unexpected error has occurred: KeyError: u'files'\r\nCheck the log at ~/.pre-commit/pre-commit.log\r\n```\r\n\r\n```\r\n$ cat ~/.pre-commit/pre-commit.log \r\nAn unexpected error has occurred: KeyError: u'files'\r\nTraceback (most recent call last):\r\n File \"/tmp/foo/pre-commit/pre_commit/error_handler.py\", line 48, in error_handler\r\n yield\r\n File \"/tmp/foo/pre-commit/pre_commit/main.py\", line 226, in main\r\n return run(runner, args)\r\n File \"/tmp/foo/pre-commit/pre_commit/commands/run.py\", line 235, in run\r\n return _run_hooks(repo_hooks, args, environ)\r\n File \"/tmp/foo/pre-commit/pre_commit/commands/run.py\", line 155, in _run_hooks\r\n retval |= _run_single_hook(hook, repo, args, skips, cols)\r\n File \"/tmp/foo/pre-commit/pre_commit/commands/run.py\", line 60, in _run_single_hook\r\n filenames = get_filenames(args, hook['files'], hook['exclude'])\r\nKeyError: u'files'\r\n```\r\n\n", "before_files": [{"content": "from __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport logging\nimport os\nimport subprocess\nimport sys\n\nfrom pre_commit import color\nfrom pre_commit import git\nfrom pre_commit import output\nfrom pre_commit.output import get_hook_message\nfrom pre_commit.staged_files_only import staged_files_only\nfrom pre_commit.util import cmd_output\nfrom pre_commit.util import noop_context\n\n\nlogger = logging.getLogger('pre_commit')\n\n\ndef _get_skips(environ):\n skips = environ.get('SKIP', '')\n return {skip.strip() for skip in skips.split(',') if skip.strip()}\n\n\ndef _hook_msg_start(hook, verbose):\n return '{}{}'.format(\n '[{}] '.format(hook['id']) if verbose else '',\n hook['name'],\n )\n\n\ndef get_changed_files(new, old):\n return cmd_output(\n 'git', 'diff', '--name-only', '{}...{}'.format(old, new),\n )[1].splitlines()\n\n\ndef get_filenames(args, include_expr, exclude_expr):\n if args.origin and args.source:\n getter = git.get_files_matching(\n lambda: get_changed_files(args.origin, args.source),\n )\n elif args.files:\n getter = git.get_files_matching(lambda: args.files)\n elif args.all_files:\n getter = git.get_all_files_matching\n elif git.is_in_merge_conflict():\n getter = git.get_conflicted_files_matching\n else:\n getter = git.get_staged_files_matching\n return getter(include_expr, exclude_expr)\n\n\nSKIPPED = 'Skipped'\nNO_FILES = '(no files to check)'\n\n\ndef _run_single_hook(hook, repo, args, skips, cols):\n filenames = get_filenames(args, hook['files'], hook['exclude'])\n if hook['id'] in skips:\n output.write(get_hook_message(\n _hook_msg_start(hook, args.verbose),\n end_msg=SKIPPED,\n end_color=color.YELLOW,\n use_color=args.color,\n cols=cols,\n ))\n return 0\n elif not filenames and not hook['always_run']:\n output.write(get_hook_message(\n _hook_msg_start(hook, args.verbose),\n postfix=NO_FILES,\n end_msg=SKIPPED,\n end_color=color.TURQUOISE,\n use_color=args.color,\n cols=cols,\n ))\n return 0\n\n # Print the hook and the dots first in case the hook takes hella long to\n # run.\n output.write(get_hook_message(\n _hook_msg_start(hook, args.verbose), end_len=6, cols=cols,\n ))\n sys.stdout.flush()\n\n diff_before = cmd_output('git', 'diff', retcode=None, encoding=None)\n retcode, stdout, stderr = repo.run_hook(\n hook,\n tuple(filenames) if hook['pass_filenames'] else (),\n )\n diff_after = cmd_output('git', 'diff', retcode=None, encoding=None)\n\n file_modifications = diff_before != diff_after\n\n # If the hook makes changes, fail the commit\n if file_modifications:\n retcode = 1\n\n if retcode:\n retcode = 1\n print_color = color.RED\n pass_fail = 'Failed'\n else:\n retcode = 0\n print_color = color.GREEN\n pass_fail = 'Passed'\n\n output.write_line(color.format_color(pass_fail, print_color, args.color))\n\n if (stdout or stderr or file_modifications) and (retcode or args.verbose):\n output.write_line('hookid: {}\\n'.format(hook['id']))\n\n # Print a message if failing due to file modifications\n if file_modifications:\n output.write('Files were modified by this hook.')\n\n if stdout or stderr:\n output.write_line(' Additional output:')\n\n output.write_line()\n\n for out in (stdout, stderr):\n assert type(out) is bytes, type(out)\n if out.strip():\n output.write_line(out.strip(), logfile_name=hook['log_file'])\n output.write_line()\n\n return retcode\n\n\ndef _compute_cols(hooks, verbose):\n \"\"\"Compute the number of columns to display hook messages. The widest\n that will be displayed is in the no files skipped case:\n\n Hook name...(no files to check) Skipped\n\n or in the verbose case\n\n Hook name [hookid]...(no files to check) Skipped\n \"\"\"\n if hooks:\n name_len = max(len(_hook_msg_start(hook, verbose)) for hook in hooks)\n else:\n name_len = 0\n\n cols = name_len + 3 + len(NO_FILES) + 1 + len(SKIPPED)\n return max(cols, 80)\n\n\ndef _run_hooks(repo_hooks, args, environ):\n \"\"\"Actually run the hooks.\"\"\"\n skips = _get_skips(environ)\n cols = _compute_cols([hook for _, hook in repo_hooks], args.verbose)\n retval = 0\n for repo, hook in repo_hooks:\n retval |= _run_single_hook(hook, repo, args, skips, cols)\n if (\n retval and\n args.show_diff_on_failure and\n subprocess.call(('git', 'diff', '--quiet')) != 0\n ):\n print('All changes made by hooks:')\n subprocess.call(('git', 'diff'))\n return retval\n\n\ndef get_repo_hooks(runner):\n for repo in runner.repositories:\n for _, hook in repo.hooks:\n yield (repo, hook)\n\n\ndef _has_unmerged_paths(runner):\n _, stdout, _ = runner.cmd_runner.run(['git', 'ls-files', '--unmerged'])\n return bool(stdout.strip())\n\n\ndef _has_unstaged_config(runner):\n retcode, _, _ = runner.cmd_runner.run(\n ('git', 'diff', '--exit-code', runner.config_file_path),\n retcode=None,\n )\n # be explicit, other git errors don't mean it has an unstaged config.\n return retcode == 1\n\n\ndef run(runner, args, environ=os.environ):\n no_stash = args.no_stash or args.all_files or bool(args.files)\n\n # Check if we have unresolved merge conflict files and fail fast.\n if _has_unmerged_paths(runner):\n logger.error('Unmerged files. Resolve before committing.')\n return 1\n if bool(args.source) != bool(args.origin):\n logger.error('Specify both --origin and --source.')\n return 1\n if _has_unstaged_config(runner) and not no_stash:\n if args.allow_unstaged_config:\n logger.warn(\n 'You have an unstaged config file and have specified the '\n '--allow-unstaged-config option.\\n'\n 'Note that your config will be stashed before the config is '\n 'parsed unless --no-stash is specified.',\n )\n else:\n logger.error(\n 'Your .pre-commit-config.yaml is unstaged.\\n'\n '`git add .pre-commit-config.yaml` to fix this.\\n'\n 'Run pre-commit with --allow-unstaged-config to silence this.'\n )\n return 1\n\n if no_stash:\n ctx = noop_context()\n else:\n ctx = staged_files_only(runner.cmd_runner)\n\n with ctx:\n repo_hooks = list(get_repo_hooks(runner))\n\n if args.hook:\n repo_hooks = [\n (repo, hook) for repo, hook in repo_hooks\n if hook['id'] == args.hook\n ]\n if not repo_hooks:\n output.write_line('No hook with id `{}`'.format(args.hook))\n return 1\n\n # Filter hooks for stages\n repo_hooks = [\n (repo, hook) for repo, hook in repo_hooks\n if not hook['stages'] or args.hook_stage in hook['stages']\n ]\n\n return _run_hooks(repo_hooks, args, environ)\n", "path": "pre_commit/commands/run.py"}]} | 3,214 | 126 |
gh_patches_debug_42601 | rasdani/github-patches | git_diff | sopel-irc__sopel-1753 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
safety: _clean_cache() doesn't, not really
Behold, the `safety` module's cache-cleaning function:
https://github.com/sopel-irc/sopel/blob/39e3680db18c4bed9801d040f7486c655b95a9a0/sopel/modules/safety.py#L207-L220
It's called once every 24 hours, and by `url_handler()` when the cache has too many entries. It seems to remove precisely _one_ cache entry—the oldest—every time it's called. [To quote @HumorBaby](https://github.com/sopel-irc/sopel/pull/1569#discussion_r278521202), "Not really a `_clean`'ing if you ask me :stuck_out_tongue_closed_eyes:"
Ideally, it would:
* Remove any entries older than some reasonable threshold (a week?)
* If there are still too many entries, continue removing the oldest one until below the limit (presently 1024)
Improvements on this algorithm are, as always, welcome. I'm just tossing out a hastily thrown-together idea for fixing this.
_Discovered in unrelated review: https://github.com/sopel-irc/sopel/pull/1569#discussion_r278354791_
</issue>
<code>
[start of sopel/modules/safety.py]
1 # coding=utf-8
2 """
3 safety.py - Alerts about malicious URLs
4 Copyright © 2014, Elad Alfassa, <[email protected]>
5 Licensed under the Eiffel Forum License 2.
6
7 This module uses virustotal.com
8 """
9 from __future__ import unicode_literals, absolute_import, print_function, division
10
11 import logging
12 import os.path
13 import re
14 import sys
15 import time
16
17 import requests
18
19 from sopel.config.types import StaticSection, ValidatedAttribute, ListAttribute
20 from sopel.formatting import color, bold
21 from sopel.module import OP
22 import sopel.tools
23
24 try:
25 # This is done separately from the below version if/else because JSONDecodeError
26 # didn't appear until Python 3.5, but Sopel claims support for 3.3+
27 # Redo this whole block of nonsense when dropping py2/old py3 support
28 from json import JSONDecodeError as InvalidJSONResponse
29 except ImportError:
30 InvalidJSONResponse = ValueError
31
32 if sys.version_info.major > 2:
33 unicode = str
34 from urllib.request import urlretrieve
35 from urllib.parse import urlparse
36 else:
37 from urllib import urlretrieve
38 from urlparse import urlparse
39
40
41 LOGGER = logging.getLogger(__name__)
42
43 vt_base_api_url = 'https://www.virustotal.com/vtapi/v2/url/'
44 malware_domains = set()
45 known_good = []
46
47
48 class SafetySection(StaticSection):
49 enabled_by_default = ValidatedAttribute('enabled_by_default', bool, default=True)
50 """Whether to enable URL safety in all channels where it isn't explicitly disabled."""
51 known_good = ListAttribute('known_good')
52 """List of "known good" domains to ignore."""
53 vt_api_key = ValidatedAttribute('vt_api_key')
54 """Optional VirusTotal API key (improves malicious URL detection)."""
55
56
57 def configure(config):
58 """
59 | name | example | purpose |
60 | ---- | ------- | ------- |
61 | enabled\\_by\\_default | True | Enable URL safety in all channels where it isn't explicitly disabled. |
62 | known\\_good | sopel.chat,dftba.net | List of "known good" domains to ignore. |
63 | vt\\_api\\_key | 0123456789abcdef0123456789abcdef0123456789abcdef0123456789abcdef | Optional VirusTotal API key to improve malicious URL detection |
64 """
65 config.define_section('safety', SafetySection)
66 config.safety.configure_setting(
67 'enabled_by_default',
68 "Enable URL safety in channels that don't specifically disable it?",
69 )
70 config.safety.configure_setting(
71 'known_good',
72 'Enter any domains to whitelist',
73 )
74 config.safety.configure_setting(
75 'vt_api_key',
76 "Optionally, enter a VirusTotal API key to improve malicious URL "
77 "protection.\nOtherwise, only the Malwarebytes DB will be used."
78 )
79
80
81 def setup(bot):
82 bot.config.define_section('safety', SafetySection)
83
84 if 'safety_cache' not in bot.memory:
85 bot.memory['safety_cache'] = sopel.tools.SopelMemory()
86 for item in bot.config.safety.known_good:
87 known_good.append(re.compile(item, re.I))
88
89 loc = os.path.join(bot.config.homedir, 'malwaredomains.txt')
90 if os.path.isfile(loc):
91 if os.path.getmtime(loc) < time.time() - 24 * 60 * 60 * 7:
92 # File exists but older than one week — update it
93 _download_malwaredomains_db(loc)
94 else:
95 _download_malwaredomains_db(loc)
96 with open(loc, 'r') as f:
97 for line in f:
98 clean_line = unicode(line).strip().lower()
99 if clean_line != '':
100 malware_domains.add(clean_line)
101
102
103 def shutdown(bot):
104 try:
105 del bot.memory['safety_cache']
106 except KeyError:
107 pass
108
109
110 def _download_malwaredomains_db(path):
111 url = 'https://mirror1.malwaredomains.com/files/justdomains'
112 LOGGER.info('Downloading malwaredomains db from %s', url)
113 urlretrieve(url, path)
114
115
116 @sopel.module.rule(r'(?u).*(https?://\S+).*')
117 @sopel.module.priority('high')
118 def url_handler(bot, trigger):
119 """Checks for malicious URLs"""
120 check = True # Enable URL checking
121 strict = False # Strict mode: kick on malicious URL
122 positives = 0 # Number of engines saying it's malicious
123 total = 0 # Number of total engines
124 use_vt = True # Use VirusTotal
125 check = bot.config.safety.enabled_by_default
126 if check is None:
127 # If not set, assume default
128 check = True
129 # DB overrides config:
130 setting = bot.db.get_channel_value(trigger.sender, 'safety')
131 if setting is not None:
132 if setting == 'off':
133 return # Not checking
134 elif setting in ['on', 'strict', 'local', 'local strict']:
135 check = True
136 if setting == 'strict' or setting == 'local strict':
137 strict = True
138 if setting == 'local' or setting == 'local strict':
139 use_vt = False
140
141 if not check:
142 return # Not overridden by DB, configured default off
143
144 try:
145 netloc = urlparse(trigger.group(1)).netloc
146 except ValueError:
147 return # Invalid IPv6 URL
148
149 if any(regex.search(netloc) for regex in known_good):
150 return # Whitelisted
151
152 apikey = bot.config.safety.vt_api_key
153 try:
154 if apikey is not None and use_vt:
155 payload = {'resource': unicode(trigger),
156 'apikey': apikey,
157 'scan': '1'}
158
159 if trigger not in bot.memory['safety_cache']:
160 r = requests.post(vt_base_api_url + 'report', data=payload)
161 r.raise_for_status()
162 result = r.json()
163 age = time.time()
164 data = {'positives': result['positives'],
165 'total': result['total'],
166 'age': age}
167 bot.memory['safety_cache'][trigger] = data
168 if len(bot.memory['safety_cache']) > 1024:
169 _clean_cache(bot)
170 else:
171 print('using cache')
172 result = bot.memory['safety_cache'][trigger]
173 positives = result['positives']
174 total = result['total']
175 except requests.exceptions.RequestException:
176 # Ignoring exceptions with VT so MalwareDomains will always work
177 LOGGER.debug('[VirusTotal] Error obtaining response.', exc_info=True)
178 except InvalidJSONResponse:
179 # Ignoring exceptions with VT so MalwareDomains will always work
180 LOGGER.debug('[VirusTotal] Malformed response (invalid JSON).', exc_info=True)
181
182 if unicode(netloc).lower() in malware_domains:
183 # malwaredomains is more trustworthy than some VT engines
184 # therefore it gets a weight of 10 engines when calculating confidence
185 positives += 10
186 total += 10
187
188 if positives > 1:
189 # Possibly malicious URL detected!
190 confidence = '{}%'.format(round((positives / total) * 100))
191 msg = 'link posted by %s is possibly malicious ' % bold(trigger.nick)
192 msg += '(confidence %s - %s/%s)' % (confidence, positives, total)
193 bot.say('[' + bold(color('WARNING', 'red')) + '] ' + msg)
194 if strict:
195 bot.kick(trigger.nick, trigger.sender, 'Posted a malicious link')
196
197
198 @sopel.module.commands('safety')
199 def toggle_safety(bot, trigger):
200 """Set safety setting for channel"""
201 if not trigger.admin and bot.channels[trigger.sender].privileges[trigger.nick] < OP:
202 bot.reply('Only channel operators can change safety settings')
203 return
204 allowed_states = ['strict', 'on', 'off', 'local', 'local strict']
205 if not trigger.group(2) or trigger.group(2).lower() not in allowed_states:
206 options = ' / '.join(allowed_states)
207 bot.reply('Available options: %s' % options)
208 return
209
210 channel = trigger.sender.lower()
211 bot.db.set_channel_value(channel, 'safety', trigger.group(2).lower())
212 bot.reply('Safety is now set to "%s" on this channel' % trigger.group(2))
213
214
215 # Clean the cache every day
216 # Code above also calls this if there are too many cache entries
217 @sopel.module.interval(24 * 60 * 60)
218 def _clean_cache(bot):
219 """Cleans up old entries in URL cache"""
220 # TODO: probably should use locks here, to make sure stuff doesn't explode
221 oldest_key_age = 0
222 oldest_key = ''
223 for key, data in sopel.tools.iteritems(bot.memory['safety_cache']):
224 if data['age'] > oldest_key_age:
225 oldest_key_age = data['age']
226 oldest_key = key
227 if oldest_key in bot.memory['safety_cache']:
228 del bot.memory['safety_cache'][oldest_key]
229
[end of sopel/modules/safety.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/sopel/modules/safety.py b/sopel/modules/safety.py
--- a/sopel/modules/safety.py
+++ b/sopel/modules/safety.py
@@ -12,6 +12,7 @@
import os.path
import re
import sys
+import threading
import time
import requests
@@ -43,6 +44,7 @@
vt_base_api_url = 'https://www.virustotal.com/vtapi/v2/url/'
malware_domains = set()
known_good = []
+cache_limit = 512
class SafetySection(StaticSection):
@@ -83,6 +85,8 @@
if 'safety_cache' not in bot.memory:
bot.memory['safety_cache'] = sopel.tools.SopelMemory()
+ if 'safety_cache_lock' not in bot.memory:
+ bot.memory['safety_cache_lock'] = threading.Lock()
for item in bot.config.safety.known_good:
known_good.append(re.compile(item, re.I))
@@ -101,10 +105,8 @@
def shutdown(bot):
- try:
- del bot.memory['safety_cache']
- except KeyError:
- pass
+ bot.memory.pop('safety_cache', None)
+ bot.memory.pop('safety_cache_lock', None)
def _download_malwaredomains_db(path):
@@ -160,12 +162,12 @@
r = requests.post(vt_base_api_url + 'report', data=payload)
r.raise_for_status()
result = r.json()
- age = time.time()
+ fetched = time.time()
data = {'positives': result['positives'],
'total': result['total'],
- 'age': age}
+ 'fetched': fetched}
bot.memory['safety_cache'][trigger] = data
- if len(bot.memory['safety_cache']) > 1024:
+ if len(bot.memory['safety_cache']) >= (2 * cache_limit):
_clean_cache(bot)
else:
print('using cache')
@@ -216,13 +218,34 @@
# Code above also calls this if there are too many cache entries
@sopel.module.interval(24 * 60 * 60)
def _clean_cache(bot):
- """Cleans up old entries in URL cache"""
- # TODO: probably should use locks here, to make sure stuff doesn't explode
- oldest_key_age = 0
- oldest_key = ''
- for key, data in sopel.tools.iteritems(bot.memory['safety_cache']):
- if data['age'] > oldest_key_age:
- oldest_key_age = data['age']
- oldest_key = key
- if oldest_key in bot.memory['safety_cache']:
- del bot.memory['safety_cache'][oldest_key]
+ """Cleans up old entries in URL safety cache."""
+ if bot.memory['safety_cache_lock'].acquire(False):
+ LOGGER.info('Starting safety cache cleanup...')
+ try:
+ # clean up by age first
+ cutoff = time.time() - (7 * 24 * 60 * 60) # 7 days ago
+ old_keys = []
+ for key, data in sopel.tools.iteritems(bot.memory['safety_cache']):
+ if data['fetched'] <= cutoff:
+ old_keys.append(key)
+ for key in old_keys:
+ bot.memory['safety_cache'].pop(key, None)
+
+ # clean up more values if the cache is still too big
+ overage = bot.memory['safety_cache'] - cache_limit
+ if overage > 0:
+ extra_keys = sorted(
+ (data.fetched, key)
+ for (key, data)
+ in bot.memory['safety_cache'].items())[:overage]
+ for (_, key) in extra_keys:
+ bot.memory['safety_cache'].pop(key, None)
+ finally:
+ # No matter what errors happen (or not), release the lock
+ bot.memory['safety_cache_lock'].release()
+
+ LOGGER.info('Safety cache cleanup finished.')
+ else:
+ LOGGER.info(
+ 'Skipping safety cache cleanup: Cache is locked, '
+ 'cleanup already running.')
| {"golden_diff": "diff --git a/sopel/modules/safety.py b/sopel/modules/safety.py\n--- a/sopel/modules/safety.py\n+++ b/sopel/modules/safety.py\n@@ -12,6 +12,7 @@\n import os.path\n import re\n import sys\n+import threading\n import time\n \n import requests\n@@ -43,6 +44,7 @@\n vt_base_api_url = 'https://www.virustotal.com/vtapi/v2/url/'\n malware_domains = set()\n known_good = []\n+cache_limit = 512\n \n \n class SafetySection(StaticSection):\n@@ -83,6 +85,8 @@\n \n if 'safety_cache' not in bot.memory:\n bot.memory['safety_cache'] = sopel.tools.SopelMemory()\n+ if 'safety_cache_lock' not in bot.memory:\n+ bot.memory['safety_cache_lock'] = threading.Lock()\n for item in bot.config.safety.known_good:\n known_good.append(re.compile(item, re.I))\n \n@@ -101,10 +105,8 @@\n \n \n def shutdown(bot):\n- try:\n- del bot.memory['safety_cache']\n- except KeyError:\n- pass\n+ bot.memory.pop('safety_cache', None)\n+ bot.memory.pop('safety_cache_lock', None)\n \n \n def _download_malwaredomains_db(path):\n@@ -160,12 +162,12 @@\n r = requests.post(vt_base_api_url + 'report', data=payload)\n r.raise_for_status()\n result = r.json()\n- age = time.time()\n+ fetched = time.time()\n data = {'positives': result['positives'],\n 'total': result['total'],\n- 'age': age}\n+ 'fetched': fetched}\n bot.memory['safety_cache'][trigger] = data\n- if len(bot.memory['safety_cache']) > 1024:\n+ if len(bot.memory['safety_cache']) >= (2 * cache_limit):\n _clean_cache(bot)\n else:\n print('using cache')\n@@ -216,13 +218,34 @@\n # Code above also calls this if there are too many cache entries\n @sopel.module.interval(24 * 60 * 60)\n def _clean_cache(bot):\n- \"\"\"Cleans up old entries in URL cache\"\"\"\n- # TODO: probably should use locks here, to make sure stuff doesn't explode\n- oldest_key_age = 0\n- oldest_key = ''\n- for key, data in sopel.tools.iteritems(bot.memory['safety_cache']):\n- if data['age'] > oldest_key_age:\n- oldest_key_age = data['age']\n- oldest_key = key\n- if oldest_key in bot.memory['safety_cache']:\n- del bot.memory['safety_cache'][oldest_key]\n+ \"\"\"Cleans up old entries in URL safety cache.\"\"\"\n+ if bot.memory['safety_cache_lock'].acquire(False):\n+ LOGGER.info('Starting safety cache cleanup...')\n+ try:\n+ # clean up by age first\n+ cutoff = time.time() - (7 * 24 * 60 * 60) # 7 days ago\n+ old_keys = []\n+ for key, data in sopel.tools.iteritems(bot.memory['safety_cache']):\n+ if data['fetched'] <= cutoff:\n+ old_keys.append(key)\n+ for key in old_keys:\n+ bot.memory['safety_cache'].pop(key, None)\n+\n+ # clean up more values if the cache is still too big\n+ overage = bot.memory['safety_cache'] - cache_limit\n+ if overage > 0:\n+ extra_keys = sorted(\n+ (data.fetched, key)\n+ for (key, data)\n+ in bot.memory['safety_cache'].items())[:overage]\n+ for (_, key) in extra_keys:\n+ bot.memory['safety_cache'].pop(key, None)\n+ finally:\n+ # No matter what errors happen (or not), release the lock\n+ bot.memory['safety_cache_lock'].release()\n+\n+ LOGGER.info('Safety cache cleanup finished.')\n+ else:\n+ LOGGER.info(\n+ 'Skipping safety cache cleanup: Cache is locked, '\n+ 'cleanup already running.')\n", "issue": "safety: _clean_cache() doesn't, not really\nBehold, the `safety` module's cache-cleaning function:\r\n\r\nhttps://github.com/sopel-irc/sopel/blob/39e3680db18c4bed9801d040f7486c655b95a9a0/sopel/modules/safety.py#L207-L220\r\n\r\nIt's called once every 24 hours, and by `url_handler()` when the cache has too many entries. It seems to remove precisely _one_ cache entry\u2014the oldest\u2014every time it's called. [To quote @HumorBaby](https://github.com/sopel-irc/sopel/pull/1569#discussion_r278521202), \"Not really a `_clean`'ing if you ask me :stuck_out_tongue_closed_eyes:\"\r\n\r\nIdeally, it would:\r\n\r\n * Remove any entries older than some reasonable threshold (a week?)\r\n * If there are still too many entries, continue removing the oldest one until below the limit (presently 1024)\r\n\r\nImprovements on this algorithm are, as always, welcome. I'm just tossing out a hastily thrown-together idea for fixing this.\r\n\r\n_Discovered in unrelated review: https://github.com/sopel-irc/sopel/pull/1569#discussion_r278354791_\n", "before_files": [{"content": "# coding=utf-8\n\"\"\"\nsafety.py - Alerts about malicious URLs\nCopyright \u00a9 2014, Elad Alfassa, <[email protected]>\nLicensed under the Eiffel Forum License 2.\n\nThis module uses virustotal.com\n\"\"\"\nfrom __future__ import unicode_literals, absolute_import, print_function, division\n\nimport logging\nimport os.path\nimport re\nimport sys\nimport time\n\nimport requests\n\nfrom sopel.config.types import StaticSection, ValidatedAttribute, ListAttribute\nfrom sopel.formatting import color, bold\nfrom sopel.module import OP\nimport sopel.tools\n\ntry:\n # This is done separately from the below version if/else because JSONDecodeError\n # didn't appear until Python 3.5, but Sopel claims support for 3.3+\n # Redo this whole block of nonsense when dropping py2/old py3 support\n from json import JSONDecodeError as InvalidJSONResponse\nexcept ImportError:\n InvalidJSONResponse = ValueError\n\nif sys.version_info.major > 2:\n unicode = str\n from urllib.request import urlretrieve\n from urllib.parse import urlparse\nelse:\n from urllib import urlretrieve\n from urlparse import urlparse\n\n\nLOGGER = logging.getLogger(__name__)\n\nvt_base_api_url = 'https://www.virustotal.com/vtapi/v2/url/'\nmalware_domains = set()\nknown_good = []\n\n\nclass SafetySection(StaticSection):\n enabled_by_default = ValidatedAttribute('enabled_by_default', bool, default=True)\n \"\"\"Whether to enable URL safety in all channels where it isn't explicitly disabled.\"\"\"\n known_good = ListAttribute('known_good')\n \"\"\"List of \"known good\" domains to ignore.\"\"\"\n vt_api_key = ValidatedAttribute('vt_api_key')\n \"\"\"Optional VirusTotal API key (improves malicious URL detection).\"\"\"\n\n\ndef configure(config):\n \"\"\"\n | name | example | purpose |\n | ---- | ------- | ------- |\n | enabled\\\\_by\\\\_default | True | Enable URL safety in all channels where it isn't explicitly disabled. |\n | known\\\\_good | sopel.chat,dftba.net | List of \"known good\" domains to ignore. |\n | vt\\\\_api\\\\_key | 0123456789abcdef0123456789abcdef0123456789abcdef0123456789abcdef | Optional VirusTotal API key to improve malicious URL detection |\n \"\"\"\n config.define_section('safety', SafetySection)\n config.safety.configure_setting(\n 'enabled_by_default',\n \"Enable URL safety in channels that don't specifically disable it?\",\n )\n config.safety.configure_setting(\n 'known_good',\n 'Enter any domains to whitelist',\n )\n config.safety.configure_setting(\n 'vt_api_key',\n \"Optionally, enter a VirusTotal API key to improve malicious URL \"\n \"protection.\\nOtherwise, only the Malwarebytes DB will be used.\"\n )\n\n\ndef setup(bot):\n bot.config.define_section('safety', SafetySection)\n\n if 'safety_cache' not in bot.memory:\n bot.memory['safety_cache'] = sopel.tools.SopelMemory()\n for item in bot.config.safety.known_good:\n known_good.append(re.compile(item, re.I))\n\n loc = os.path.join(bot.config.homedir, 'malwaredomains.txt')\n if os.path.isfile(loc):\n if os.path.getmtime(loc) < time.time() - 24 * 60 * 60 * 7:\n # File exists but older than one week \u2014 update it\n _download_malwaredomains_db(loc)\n else:\n _download_malwaredomains_db(loc)\n with open(loc, 'r') as f:\n for line in f:\n clean_line = unicode(line).strip().lower()\n if clean_line != '':\n malware_domains.add(clean_line)\n\n\ndef shutdown(bot):\n try:\n del bot.memory['safety_cache']\n except KeyError:\n pass\n\n\ndef _download_malwaredomains_db(path):\n url = 'https://mirror1.malwaredomains.com/files/justdomains'\n LOGGER.info('Downloading malwaredomains db from %s', url)\n urlretrieve(url, path)\n\n\[email protected](r'(?u).*(https?://\\S+).*')\[email protected]('high')\ndef url_handler(bot, trigger):\n \"\"\"Checks for malicious URLs\"\"\"\n check = True # Enable URL checking\n strict = False # Strict mode: kick on malicious URL\n positives = 0 # Number of engines saying it's malicious\n total = 0 # Number of total engines\n use_vt = True # Use VirusTotal\n check = bot.config.safety.enabled_by_default\n if check is None:\n # If not set, assume default\n check = True\n # DB overrides config:\n setting = bot.db.get_channel_value(trigger.sender, 'safety')\n if setting is not None:\n if setting == 'off':\n return # Not checking\n elif setting in ['on', 'strict', 'local', 'local strict']:\n check = True\n if setting == 'strict' or setting == 'local strict':\n strict = True\n if setting == 'local' or setting == 'local strict':\n use_vt = False\n\n if not check:\n return # Not overridden by DB, configured default off\n\n try:\n netloc = urlparse(trigger.group(1)).netloc\n except ValueError:\n return # Invalid IPv6 URL\n\n if any(regex.search(netloc) for regex in known_good):\n return # Whitelisted\n\n apikey = bot.config.safety.vt_api_key\n try:\n if apikey is not None and use_vt:\n payload = {'resource': unicode(trigger),\n 'apikey': apikey,\n 'scan': '1'}\n\n if trigger not in bot.memory['safety_cache']:\n r = requests.post(vt_base_api_url + 'report', data=payload)\n r.raise_for_status()\n result = r.json()\n age = time.time()\n data = {'positives': result['positives'],\n 'total': result['total'],\n 'age': age}\n bot.memory['safety_cache'][trigger] = data\n if len(bot.memory['safety_cache']) > 1024:\n _clean_cache(bot)\n else:\n print('using cache')\n result = bot.memory['safety_cache'][trigger]\n positives = result['positives']\n total = result['total']\n except requests.exceptions.RequestException:\n # Ignoring exceptions with VT so MalwareDomains will always work\n LOGGER.debug('[VirusTotal] Error obtaining response.', exc_info=True)\n except InvalidJSONResponse:\n # Ignoring exceptions with VT so MalwareDomains will always work\n LOGGER.debug('[VirusTotal] Malformed response (invalid JSON).', exc_info=True)\n\n if unicode(netloc).lower() in malware_domains:\n # malwaredomains is more trustworthy than some VT engines\n # therefore it gets a weight of 10 engines when calculating confidence\n positives += 10\n total += 10\n\n if positives > 1:\n # Possibly malicious URL detected!\n confidence = '{}%'.format(round((positives / total) * 100))\n msg = 'link posted by %s is possibly malicious ' % bold(trigger.nick)\n msg += '(confidence %s - %s/%s)' % (confidence, positives, total)\n bot.say('[' + bold(color('WARNING', 'red')) + '] ' + msg)\n if strict:\n bot.kick(trigger.nick, trigger.sender, 'Posted a malicious link')\n\n\[email protected]('safety')\ndef toggle_safety(bot, trigger):\n \"\"\"Set safety setting for channel\"\"\"\n if not trigger.admin and bot.channels[trigger.sender].privileges[trigger.nick] < OP:\n bot.reply('Only channel operators can change safety settings')\n return\n allowed_states = ['strict', 'on', 'off', 'local', 'local strict']\n if not trigger.group(2) or trigger.group(2).lower() not in allowed_states:\n options = ' / '.join(allowed_states)\n bot.reply('Available options: %s' % options)\n return\n\n channel = trigger.sender.lower()\n bot.db.set_channel_value(channel, 'safety', trigger.group(2).lower())\n bot.reply('Safety is now set to \"%s\" on this channel' % trigger.group(2))\n\n\n# Clean the cache every day\n# Code above also calls this if there are too many cache entries\[email protected](24 * 60 * 60)\ndef _clean_cache(bot):\n \"\"\"Cleans up old entries in URL cache\"\"\"\n # TODO: probably should use locks here, to make sure stuff doesn't explode\n oldest_key_age = 0\n oldest_key = ''\n for key, data in sopel.tools.iteritems(bot.memory['safety_cache']):\n if data['age'] > oldest_key_age:\n oldest_key_age = data['age']\n oldest_key = key\n if oldest_key in bot.memory['safety_cache']:\n del bot.memory['safety_cache'][oldest_key]\n", "path": "sopel/modules/safety.py"}]} | 3,485 | 961 |
gh_patches_debug_4566 | rasdani/github-patches | git_diff | mampfes__hacs_waste_collection_schedule-775 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ZVA-SEK has been added. Thanks, great job. But there is a problem.
First of all: Thanks to 5ila5 for doing the job. Thats awesome.
But all entries are one day ahead.
I created the entries using the "static" configuration, and compared to the import there is one day "shift".
Maybe because there is an alarm in the ICS-file?
Or am i doing something wrong?
Greetings, Holger.
PS.: @5ila5: whenever you are in the area of Kassel, send me a note, and i will show you the finest brewery in the area (beers on me).
sources:
- name: static
calendar_title: Papier
args:
type: Altpapier
frequency: WEEKLY
interval: 4
start: '2023-01-16'
until: '2023-12-18'
excludes:
- '2023-04-10'
dates:
- '2023-04-15'
- '2023-03-01'
- name: static
calendar_title: Bio
args:
type: Biomuell
frequency: WEEKLY
interval: 2
start: '2023-01-06'
until: '2023-12-22'
excludes:
- '2023-09-29'
dates:
- '2023-09-23'
- name: static
calendar_title: Rest
args:
type: Restmuell
frequency: WEEKLY
interval: 3
start: '2023-01-17'
until: '2023-12-19'
excludes:
- '2023-09-29'
dates:
- '2023-09-23'
- name: static
calendar_title: Gelb
args:
type: Gelbe
frequency: WEEKLY
interval: 4
start: '2023-01-18'
until: '2023-12-20'
- name: zva_sek_de
calendar_title: "ZVA"
args:
bezirk: "Felsberg"
ortsteil: "Felsberg"
</issue>
<code>
[start of custom_components/waste_collection_schedule/waste_collection_schedule/source/zva_sek_de.py]
1 import re
2 import requests
3 from datetime import datetime
4
5 from bs4 import BeautifulSoup
6
7 from waste_collection_schedule import Collection # type: ignore[attr-defined]
8 from waste_collection_schedule.service.ICS import ICS
9
10 TITLE = "Zweckverband Abfallwirtschaft Schwalm-Eder-Kreis"
11 DESCRIPTION = "Source for ZVA (Zweckverband Abfallwirtschaft Schwalm-Eder-Kreis)."
12 URL = "https://www.zva-sek.de"
13 TEST_CASES = {
14 "Fritzlar": {
15 "bezirk": "Fritzlar",
16 "ortsteil": "Fritzlar-kernstadt",
17 "strasse": "Ahornweg",
18 },
19 "Ottrau": {
20 "bezirk": "Ottrau",
21 "ortsteil": "immichenhain",
22 "strasse": "",
23 },
24 "Knüllwald": {
25 "bezirk": "Knüllwald",
26 "ortsteil": "Hergetsfeld",
27 },
28 }
29 SERVLET = (
30 "https://www.zva-sek.de/module/abfallkalender/generate_ical.php"
31 )
32 MAIN_URL = "https://www.zva-sek.de/online-dienste/abfallkalender-{year}/{file}"
33 API_URL = "https://www.zva-sek.de/module/abfallkalender/{file}"
34
35
36 class Source:
37 def __init__(
38 self, bezirk: str, ortsteil: str, strasse: str = None
39 ):
40 self._bezirk = bezirk
41 self._ortsteil = ortsteil
42 self._street = strasse if strasse != "" else None
43 self._ics = ICS()
44
45 def fetch(self):
46 session = requests.session()
47 year = datetime.now().year
48
49 bezirk_id = None
50 ortsteil_id = None
51
52 # get bezirke id
53 r = session.get(MAIN_URL.format(
54 year=year, file=f"abfallkalender-{year}.html"))
55 if (r.status_code == 404): # try last year URL if this year is not available
56 r = session.get(MAIN_URL.format(
57 year=year, file=f"abfallkalender-{year-1}.html"))
58 r.raise_for_status()
59
60 soup = BeautifulSoup(r.text, features="html.parser")
61 for option in soup.find("select", {"name": "ak_bezirk"}).find_all("option"):
62 if option.text.lower() == self._bezirk.lower():
63 self._bezirk = option.get("value")
64 bezirk_id = option.get("value")
65 break
66
67 if not bezirk_id:
68 raise Exception(f"bezirk not found")
69
70 # get ortsteil id
71 r = session.get(API_URL.format(
72 file="get_ortsteile.php"), params={"bez_id": bezirk_id})
73 r.raise_for_status()
74 last_orts_id = None
75 for part in r.text.split(";")[2:-1]:
76 # part is "f.ak_ortsteil.options[5].text = 'Alte Kasseler Straße'" or "ak_ortsteil.options[6].value = '2'"
77 if ("length" in part):
78 continue
79 if part.split(" = ")[1][1:-1].lower() == self._ortsteil.lower():
80 ortsteil_id = last_orts_id
81 break
82 last_orts_id = part.split(" = ")[1][1:-1]
83
84 if not ortsteil_id:
85 raise Exception(f"ortsteil not found")
86
87 street_id = None
88
89 # get street id if steet given
90 if self._street is not None:
91 r = session.get(API_URL.format(
92 file="get_strassen.php"), params={"ot_id": ortsteil_id.split("-")[0]})
93 r.raise_for_status()
94 last_street_id = None
95 for part in r.text.split(";")[2:-1]:
96 # part is "f.ak_strasse.options[5].text = 'Alte Kasseler Straße'" or "ak_strasse.options[6].value = '2'"
97 if ("length" in part):
98 continue
99 if part.split(" = ")[1][1:-1].lower() == self._street.lower():
100 street_id = last_street_id
101 break
102 last_street_id = part.split(" = ")[1][1:-1]
103
104 if not street_id:
105 raise Exception(f"street not found")
106
107 args = {
108 "year": str(year),
109 "ak_bezirk": bezirk_id,
110 "ak_ortsteil": ortsteil_id,
111 "alle_arten": "",
112 }
113 if self._street is not None:
114 args["ak_strasse"] = street_id
115
116 r = session.post(
117 SERVLET,
118 data=args,
119 )
120
121 r.raise_for_status()
122 dates = self._ics.convert(r.text)
123
124 entries = []
125 for d in dates:
126 entries.append(Collection(d[0], re.sub(
127 "[ ]*am [0-9]+.[0-9]+.[0-9]+[ ]*", "", d[1])))
128 return entries
129
[end of custom_components/waste_collection_schedule/waste_collection_schedule/source/zva_sek_de.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/zva_sek_de.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/zva_sek_de.py
--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/zva_sek_de.py
+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/zva_sek_de.py
@@ -109,6 +109,8 @@
"ak_bezirk": bezirk_id,
"ak_ortsteil": ortsteil_id,
"alle_arten": "",
+ "iCalEnde": 6,
+ "iCalBeginn": 17,
}
if self._street is not None:
args["ak_strasse"] = street_id
| {"golden_diff": "diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/zva_sek_de.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/zva_sek_de.py\n--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/zva_sek_de.py\n+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/zva_sek_de.py\n@@ -109,6 +109,8 @@\n \"ak_bezirk\": bezirk_id,\n \"ak_ortsteil\": ortsteil_id,\n \"alle_arten\": \"\",\n+ \"iCalEnde\": 6,\n+ \"iCalBeginn\": 17,\n }\n if self._street is not None:\n args[\"ak_strasse\"] = street_id\n", "issue": "ZVA-SEK has been added. Thanks, great job. But there is a problem.\nFirst of all: Thanks to 5ila5 for doing the job. Thats awesome.\r\n\r\nBut all entries are one day ahead.\r\nI created the entries using the \"static\" configuration, and compared to the import there is one day \"shift\".\r\nMaybe because there is an alarm in the ICS-file?\r\nOr am i doing something wrong?\r\n\r\n\r\n\r\nGreetings, Holger.\r\n\r\nPS.: @5ila5: whenever you are in the area of Kassel, send me a note, and i will show you the finest brewery in the area (beers on me).\r\n\r\n sources:\r\n - name: static\r\n calendar_title: Papier\r\n args:\r\n type: Altpapier\r\n frequency: WEEKLY\r\n interval: 4\r\n start: '2023-01-16'\r\n until: '2023-12-18'\r\n excludes:\r\n - '2023-04-10'\r\n dates:\r\n - '2023-04-15'\r\n - '2023-03-01'\r\n - name: static\r\n calendar_title: Bio\r\n args:\r\n type: Biomuell\r\n frequency: WEEKLY\r\n interval: 2\r\n start: '2023-01-06'\r\n until: '2023-12-22'\r\n excludes:\r\n - '2023-09-29'\r\n dates:\r\n - '2023-09-23'\r\n - name: static\r\n calendar_title: Rest\r\n args:\r\n type: Restmuell\r\n frequency: WEEKLY\r\n interval: 3\r\n start: '2023-01-17'\r\n until: '2023-12-19'\r\n excludes:\r\n - '2023-09-29'\r\n dates:\r\n - '2023-09-23'\r\n - name: static\r\n calendar_title: Gelb\r\n args:\r\n type: Gelbe\r\n frequency: WEEKLY\r\n interval: 4\r\n start: '2023-01-18'\r\n until: '2023-12-20'\r\n - name: zva_sek_de\r\n calendar_title: \"ZVA\"\r\n args:\r\n bezirk: \"Felsberg\"\r\n ortsteil: \"Felsberg\"\r\n\n", "before_files": [{"content": "import re\nimport requests\nfrom datetime import datetime\n\nfrom bs4 import BeautifulSoup\n\nfrom waste_collection_schedule import Collection # type: ignore[attr-defined]\nfrom waste_collection_schedule.service.ICS import ICS\n\nTITLE = \"Zweckverband Abfallwirtschaft Schwalm-Eder-Kreis\"\nDESCRIPTION = \"Source for ZVA (Zweckverband Abfallwirtschaft Schwalm-Eder-Kreis).\"\nURL = \"https://www.zva-sek.de\"\nTEST_CASES = {\n \"Fritzlar\": {\n \"bezirk\": \"Fritzlar\",\n \"ortsteil\": \"Fritzlar-kernstadt\",\n \"strasse\": \"Ahornweg\",\n },\n \"Ottrau\": {\n \"bezirk\": \"Ottrau\",\n \"ortsteil\": \"immichenhain\",\n \"strasse\": \"\",\n },\n \"Kn\u00fcllwald\": {\n \"bezirk\": \"Kn\u00fcllwald\",\n \"ortsteil\": \"Hergetsfeld\",\n },\n}\nSERVLET = (\n \"https://www.zva-sek.de/module/abfallkalender/generate_ical.php\"\n)\nMAIN_URL = \"https://www.zva-sek.de/online-dienste/abfallkalender-{year}/{file}\"\nAPI_URL = \"https://www.zva-sek.de/module/abfallkalender/{file}\"\n\n\nclass Source:\n def __init__(\n self, bezirk: str, ortsteil: str, strasse: str = None\n ):\n self._bezirk = bezirk\n self._ortsteil = ortsteil\n self._street = strasse if strasse != \"\" else None\n self._ics = ICS()\n\n def fetch(self):\n session = requests.session()\n year = datetime.now().year\n\n bezirk_id = None\n ortsteil_id = None\n\n # get bezirke id\n r = session.get(MAIN_URL.format(\n year=year, file=f\"abfallkalender-{year}.html\"))\n if (r.status_code == 404): # try last year URL if this year is not available\n r = session.get(MAIN_URL.format(\n year=year, file=f\"abfallkalender-{year-1}.html\"))\n r.raise_for_status()\n \n soup = BeautifulSoup(r.text, features=\"html.parser\")\n for option in soup.find(\"select\", {\"name\": \"ak_bezirk\"}).find_all(\"option\"):\n if option.text.lower() == self._bezirk.lower():\n self._bezirk = option.get(\"value\")\n bezirk_id = option.get(\"value\")\n break\n\n if not bezirk_id:\n raise Exception(f\"bezirk not found\")\n\n # get ortsteil id\n r = session.get(API_URL.format(\n file=\"get_ortsteile.php\"), params={\"bez_id\": bezirk_id})\n r.raise_for_status()\n last_orts_id = None\n for part in r.text.split(\";\")[2:-1]:\n # part is \"f.ak_ortsteil.options[5].text = 'Alte Kasseler Stra\u00dfe'\" or \"ak_ortsteil.options[6].value = '2'\"\n if (\"length\" in part):\n continue\n if part.split(\" = \")[1][1:-1].lower() == self._ortsteil.lower():\n ortsteil_id = last_orts_id\n break\n last_orts_id = part.split(\" = \")[1][1:-1]\n\n if not ortsteil_id:\n raise Exception(f\"ortsteil not found\")\n\n street_id = None\n\n # get street id if steet given\n if self._street is not None:\n r = session.get(API_URL.format(\n file=\"get_strassen.php\"), params={\"ot_id\": ortsteil_id.split(\"-\")[0]})\n r.raise_for_status()\n last_street_id = None\n for part in r.text.split(\";\")[2:-1]: \n # part is \"f.ak_strasse.options[5].text = 'Alte Kasseler Stra\u00dfe'\" or \"ak_strasse.options[6].value = '2'\"\n if (\"length\" in part):\n continue\n if part.split(\" = \")[1][1:-1].lower() == self._street.lower():\n street_id = last_street_id\n break\n last_street_id = part.split(\" = \")[1][1:-1]\n\n if not street_id:\n raise Exception(f\"street not found\")\n\n args = {\n \"year\": str(year),\n \"ak_bezirk\": bezirk_id,\n \"ak_ortsteil\": ortsteil_id,\n \"alle_arten\": \"\",\n }\n if self._street is not None:\n args[\"ak_strasse\"] = street_id\n\n r = session.post(\n SERVLET,\n data=args,\n )\n\n r.raise_for_status()\n dates = self._ics.convert(r.text)\n\n entries = []\n for d in dates:\n entries.append(Collection(d[0], re.sub(\n \"[ ]*am [0-9]+.[0-9]+.[0-9]+[ ]*\", \"\", d[1])))\n return entries\n", "path": "custom_components/waste_collection_schedule/waste_collection_schedule/source/zva_sek_de.py"}]} | 2,594 | 170 |
gh_patches_debug_2811 | rasdani/github-patches | git_diff | liqd__a4-meinberlin-4707 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
rules/participate in project
As you can see in the test, the paricipate_project rule behaves a bit weird for project group members. I think, they should also be allowed to participate. The question is what it is used for.
Cool! The participate_project rule is a bit unexpected, so we should check that out. Like where it is used and what for. But anyway, will merge for now and add an issue.
_Originally posted by @fuzzylogic2000 in https://github.com/liqd/a4-meinberlin/pull/4077#pullrequestreview-837466549_
</issue>
<code>
[start of meinberlin/apps/projects/rules.py]
1 import rules
2 from rules.predicates import is_superuser
3
4 from adhocracy4.organisations.predicates import is_initiator
5 from adhocracy4.projects.predicates import is_live
6 from adhocracy4.projects.predicates import is_moderator
7 from adhocracy4.projects.predicates import is_prj_group_member
8 from adhocracy4.projects.predicates import is_project_member
9 from adhocracy4.projects.predicates import is_public
10 from adhocracy4.projects.predicates import is_semipublic
11
12 rules.remove_perm('a4projects.view_project')
13 rules.add_perm('a4projects.view_project',
14 is_superuser | is_initiator |
15 is_moderator | is_prj_group_member |
16 ((is_public | is_semipublic | is_project_member)
17 & is_live))
18
19 rules.set_perm('a4projects.participate_in_project',
20 is_superuser | is_initiator | is_moderator |
21 ((is_public | is_project_member) & is_live))
22
[end of meinberlin/apps/projects/rules.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/meinberlin/apps/projects/rules.py b/meinberlin/apps/projects/rules.py
--- a/meinberlin/apps/projects/rules.py
+++ b/meinberlin/apps/projects/rules.py
@@ -17,5 +17,6 @@
& is_live))
rules.set_perm('a4projects.participate_in_project',
- is_superuser | is_initiator | is_moderator |
+ is_superuser | is_initiator |
+ is_moderator | is_prj_group_member |
((is_public | is_project_member) & is_live))
| {"golden_diff": "diff --git a/meinberlin/apps/projects/rules.py b/meinberlin/apps/projects/rules.py\n--- a/meinberlin/apps/projects/rules.py\n+++ b/meinberlin/apps/projects/rules.py\n@@ -17,5 +17,6 @@\n & is_live))\n \n rules.set_perm('a4projects.participate_in_project',\n- is_superuser | is_initiator | is_moderator |\n+ is_superuser | is_initiator |\n+ is_moderator | is_prj_group_member |\n ((is_public | is_project_member) & is_live))\n", "issue": "rules/participate in project\nAs you can see in the test, the paricipate_project rule behaves a bit weird for project group members. I think, they should also be allowed to participate. The question is what it is used for.\r\n\r\nCool! The participate_project rule is a bit unexpected, so we should check that out. Like where it is used and what for. But anyway, will merge for now and add an issue.\r\n\r\n_Originally posted by @fuzzylogic2000 in https://github.com/liqd/a4-meinberlin/pull/4077#pullrequestreview-837466549_\n", "before_files": [{"content": "import rules\nfrom rules.predicates import is_superuser\n\nfrom adhocracy4.organisations.predicates import is_initiator\nfrom adhocracy4.projects.predicates import is_live\nfrom adhocracy4.projects.predicates import is_moderator\nfrom adhocracy4.projects.predicates import is_prj_group_member\nfrom adhocracy4.projects.predicates import is_project_member\nfrom adhocracy4.projects.predicates import is_public\nfrom adhocracy4.projects.predicates import is_semipublic\n\nrules.remove_perm('a4projects.view_project')\nrules.add_perm('a4projects.view_project',\n is_superuser | is_initiator |\n is_moderator | is_prj_group_member |\n ((is_public | is_semipublic | is_project_member)\n & is_live))\n\nrules.set_perm('a4projects.participate_in_project',\n is_superuser | is_initiator | is_moderator |\n ((is_public | is_project_member) & is_live))\n", "path": "meinberlin/apps/projects/rules.py"}]} | 916 | 124 |
gh_patches_debug_28703 | rasdani/github-patches | git_diff | open-telemetry__opentelemetry-python-2540 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Implement InMemoryMetricExporter
See [spec](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/metrics/sdk_exporters/in-memory.md). This will be great for testing.
IMO this should be a "pull exporter" (metric reader atm) that has a method `get_metrics()` or similar to return metrics from the SDK.
</issue>
<code>
[start of opentelemetry-sdk/src/opentelemetry/sdk/_metrics/export/__init__.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import logging
16 import os
17 from abc import ABC, abstractmethod
18 from enum import Enum
19 from os import environ, linesep
20 from sys import stdout
21 from threading import Event, Thread
22 from typing import IO, Callable, Iterable, Optional, Sequence
23
24 from opentelemetry.context import (
25 _SUPPRESS_INSTRUMENTATION_KEY,
26 attach,
27 detach,
28 set_value,
29 )
30 from opentelemetry.sdk._metrics.metric_reader import MetricReader
31 from opentelemetry.sdk._metrics.point import AggregationTemporality, Metric
32 from opentelemetry.util._once import Once
33
34 _logger = logging.getLogger(__name__)
35
36
37 class MetricExportResult(Enum):
38 SUCCESS = 0
39 FAILURE = 1
40
41
42 class MetricExporter(ABC):
43 """Interface for exporting metrics.
44
45 Interface to be implemented by services that want to export metrics received
46 in their own format.
47 """
48
49 @property
50 def preferred_temporality(self) -> AggregationTemporality:
51 return AggregationTemporality.CUMULATIVE
52
53 @abstractmethod
54 def export(self, metrics: Sequence[Metric]) -> "MetricExportResult":
55 """Exports a batch of telemetry data.
56
57 Args:
58 metrics: The list of `opentelemetry.sdk._metrics.data.MetricData` objects to be exported
59
60 Returns:
61 The result of the export
62 """
63
64 @abstractmethod
65 def shutdown(self) -> None:
66 """Shuts down the exporter.
67
68 Called when the SDK is shut down.
69 """
70
71
72 class ConsoleMetricExporter(MetricExporter):
73 """Implementation of :class:`MetricExporter` that prints metrics to the
74 console.
75
76 This class can be used for diagnostic purposes. It prints the exported
77 metrics to the console STDOUT.
78 """
79
80 def __init__(
81 self,
82 out: IO = stdout,
83 formatter: Callable[[Metric], str] = lambda metric: metric.to_json()
84 + linesep,
85 ):
86 self.out = out
87 self.formatter = formatter
88
89 def export(self, metrics: Sequence[Metric]) -> MetricExportResult:
90 for metric in metrics:
91 self.out.write(self.formatter(metric))
92 self.out.flush()
93 return MetricExportResult.SUCCESS
94
95 def shutdown(self) -> None:
96 pass
97
98
99 class PeriodicExportingMetricReader(MetricReader):
100 """`PeriodicExportingMetricReader` is an implementation of `MetricReader`
101 that collects metrics based on a user-configurable time interval, and passes the
102 metrics to the configured exporter.
103 """
104
105 def __init__(
106 self,
107 exporter: MetricExporter,
108 export_interval_millis: Optional[float] = None,
109 export_timeout_millis: Optional[float] = None,
110 ) -> None:
111 super().__init__(preferred_temporality=exporter.preferred_temporality)
112 self._exporter = exporter
113 if export_interval_millis is None:
114 try:
115 export_interval_millis = float(
116 environ.get("OTEL_METRIC_EXPORT_INTERVAL", 60000)
117 )
118 except ValueError:
119 _logger.warning(
120 "Found invalid value for export interval, using default"
121 )
122 export_interval_millis = 60000
123 if export_timeout_millis is None:
124 try:
125 export_timeout_millis = float(
126 environ.get("OTEL_METRIC_EXPORT_TIMEOUT", 30000)
127 )
128 except ValueError:
129 _logger.warning(
130 "Found invalid value for export timeout, using default"
131 )
132 export_timeout_millis = 30000
133 self._export_interval_millis = export_interval_millis
134 self._export_timeout_millis = export_timeout_millis
135 self._shutdown = False
136 self._shutdown_event = Event()
137 self._shutdown_once = Once()
138 self._daemon_thread = Thread(target=self._ticker, daemon=True)
139 self._daemon_thread.start()
140 if hasattr(os, "register_at_fork"):
141 os.register_at_fork(
142 after_in_child=self._at_fork_reinit
143 ) # pylint: disable=protected-access
144
145 def _at_fork_reinit(self):
146 self._daemon_thread = Thread(target=self._ticker, daemon=True)
147 self._daemon_thread.start()
148
149 def _ticker(self) -> None:
150 interval_secs = self._export_interval_millis / 1e3
151 while not self._shutdown_event.wait(interval_secs):
152 self.collect()
153 # one last collection below before shutting down completely
154 self.collect()
155
156 def _receive_metrics(self, metrics: Iterable[Metric]) -> None:
157 if metrics is None:
158 return
159 token = attach(set_value(_SUPPRESS_INSTRUMENTATION_KEY, True))
160 try:
161 self._exporter.export(metrics)
162 except Exception as e: # pylint: disable=broad-except,invalid-name
163 _logger.exception("Exception while exporting metrics %s", str(e))
164 detach(token)
165
166 def shutdown(self) -> bool:
167 def _shutdown():
168 self._shutdown = True
169
170 did_set = self._shutdown_once.do_once(_shutdown)
171 if not did_set:
172 _logger.warning("Can't shutdown multiple times")
173 return False
174
175 self._shutdown_event.set()
176 self._daemon_thread.join()
177 self._exporter.shutdown()
178 return True
179
[end of opentelemetry-sdk/src/opentelemetry/sdk/_metrics/export/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/export/__init__.py b/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/export/__init__.py
--- a/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/export/__init__.py
+++ b/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/export/__init__.py
@@ -18,8 +18,8 @@
from enum import Enum
from os import environ, linesep
from sys import stdout
-from threading import Event, Thread
-from typing import IO, Callable, Iterable, Optional, Sequence
+from threading import Event, RLock, Thread
+from typing import IO, Callable, Iterable, List, Optional, Sequence
from opentelemetry.context import (
_SUPPRESS_INSTRUMENTATION_KEY,
@@ -96,6 +96,36 @@
pass
+class InMemoryMetricReader(MetricReader):
+ """Implementation of :class:`MetricReader` that returns its metrics from :func:`metrics`.
+
+ This is useful for e.g. unit tests.
+ """
+
+ def __init__(
+ self,
+ preferred_temporality: AggregationTemporality = AggregationTemporality.CUMULATIVE,
+ ) -> None:
+ super().__init__(preferred_temporality=preferred_temporality)
+ self._lock = RLock()
+ self._metrics: List[Metric] = []
+
+ def get_metrics(self) -> List[Metric]:
+ """Reads and returns current metrics from the SDK"""
+ with self._lock:
+ self.collect()
+ metrics = self._metrics
+ self._metrics = []
+ return metrics
+
+ def _receive_metrics(self, metrics: Iterable[Metric]):
+ with self._lock:
+ self._metrics = list(metrics)
+
+ def shutdown(self) -> bool:
+ return True
+
+
class PeriodicExportingMetricReader(MetricReader):
"""`PeriodicExportingMetricReader` is an implementation of `MetricReader`
that collects metrics based on a user-configurable time interval, and passes the
| {"golden_diff": "diff --git a/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/export/__init__.py b/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/export/__init__.py\n--- a/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/export/__init__.py\n+++ b/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/export/__init__.py\n@@ -18,8 +18,8 @@\n from enum import Enum\n from os import environ, linesep\n from sys import stdout\n-from threading import Event, Thread\n-from typing import IO, Callable, Iterable, Optional, Sequence\n+from threading import Event, RLock, Thread\n+from typing import IO, Callable, Iterable, List, Optional, Sequence\n \n from opentelemetry.context import (\n _SUPPRESS_INSTRUMENTATION_KEY,\n@@ -96,6 +96,36 @@\n pass\n \n \n+class InMemoryMetricReader(MetricReader):\n+ \"\"\"Implementation of :class:`MetricReader` that returns its metrics from :func:`metrics`.\n+\n+ This is useful for e.g. unit tests.\n+ \"\"\"\n+\n+ def __init__(\n+ self,\n+ preferred_temporality: AggregationTemporality = AggregationTemporality.CUMULATIVE,\n+ ) -> None:\n+ super().__init__(preferred_temporality=preferred_temporality)\n+ self._lock = RLock()\n+ self._metrics: List[Metric] = []\n+\n+ def get_metrics(self) -> List[Metric]:\n+ \"\"\"Reads and returns current metrics from the SDK\"\"\"\n+ with self._lock:\n+ self.collect()\n+ metrics = self._metrics\n+ self._metrics = []\n+ return metrics\n+\n+ def _receive_metrics(self, metrics: Iterable[Metric]):\n+ with self._lock:\n+ self._metrics = list(metrics)\n+\n+ def shutdown(self) -> bool:\n+ return True\n+\n+\n class PeriodicExportingMetricReader(MetricReader):\n \"\"\"`PeriodicExportingMetricReader` is an implementation of `MetricReader`\n that collects metrics based on a user-configurable time interval, and passes the\n", "issue": "Implement InMemoryMetricExporter\nSee [spec](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/metrics/sdk_exporters/in-memory.md). This will be great for testing.\r\n\r\nIMO this should be a \"pull exporter\" (metric reader atm) that has a method `get_metrics()` or similar to return metrics from the SDK.\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nimport os\nfrom abc import ABC, abstractmethod\nfrom enum import Enum\nfrom os import environ, linesep\nfrom sys import stdout\nfrom threading import Event, Thread\nfrom typing import IO, Callable, Iterable, Optional, Sequence\n\nfrom opentelemetry.context import (\n _SUPPRESS_INSTRUMENTATION_KEY,\n attach,\n detach,\n set_value,\n)\nfrom opentelemetry.sdk._metrics.metric_reader import MetricReader\nfrom opentelemetry.sdk._metrics.point import AggregationTemporality, Metric\nfrom opentelemetry.util._once import Once\n\n_logger = logging.getLogger(__name__)\n\n\nclass MetricExportResult(Enum):\n SUCCESS = 0\n FAILURE = 1\n\n\nclass MetricExporter(ABC):\n \"\"\"Interface for exporting metrics.\n\n Interface to be implemented by services that want to export metrics received\n in their own format.\n \"\"\"\n\n @property\n def preferred_temporality(self) -> AggregationTemporality:\n return AggregationTemporality.CUMULATIVE\n\n @abstractmethod\n def export(self, metrics: Sequence[Metric]) -> \"MetricExportResult\":\n \"\"\"Exports a batch of telemetry data.\n\n Args:\n metrics: The list of `opentelemetry.sdk._metrics.data.MetricData` objects to be exported\n\n Returns:\n The result of the export\n \"\"\"\n\n @abstractmethod\n def shutdown(self) -> None:\n \"\"\"Shuts down the exporter.\n\n Called when the SDK is shut down.\n \"\"\"\n\n\nclass ConsoleMetricExporter(MetricExporter):\n \"\"\"Implementation of :class:`MetricExporter` that prints metrics to the\n console.\n\n This class can be used for diagnostic purposes. It prints the exported\n metrics to the console STDOUT.\n \"\"\"\n\n def __init__(\n self,\n out: IO = stdout,\n formatter: Callable[[Metric], str] = lambda metric: metric.to_json()\n + linesep,\n ):\n self.out = out\n self.formatter = formatter\n\n def export(self, metrics: Sequence[Metric]) -> MetricExportResult:\n for metric in metrics:\n self.out.write(self.formatter(metric))\n self.out.flush()\n return MetricExportResult.SUCCESS\n\n def shutdown(self) -> None:\n pass\n\n\nclass PeriodicExportingMetricReader(MetricReader):\n \"\"\"`PeriodicExportingMetricReader` is an implementation of `MetricReader`\n that collects metrics based on a user-configurable time interval, and passes the\n metrics to the configured exporter.\n \"\"\"\n\n def __init__(\n self,\n exporter: MetricExporter,\n export_interval_millis: Optional[float] = None,\n export_timeout_millis: Optional[float] = None,\n ) -> None:\n super().__init__(preferred_temporality=exporter.preferred_temporality)\n self._exporter = exporter\n if export_interval_millis is None:\n try:\n export_interval_millis = float(\n environ.get(\"OTEL_METRIC_EXPORT_INTERVAL\", 60000)\n )\n except ValueError:\n _logger.warning(\n \"Found invalid value for export interval, using default\"\n )\n export_interval_millis = 60000\n if export_timeout_millis is None:\n try:\n export_timeout_millis = float(\n environ.get(\"OTEL_METRIC_EXPORT_TIMEOUT\", 30000)\n )\n except ValueError:\n _logger.warning(\n \"Found invalid value for export timeout, using default\"\n )\n export_timeout_millis = 30000\n self._export_interval_millis = export_interval_millis\n self._export_timeout_millis = export_timeout_millis\n self._shutdown = False\n self._shutdown_event = Event()\n self._shutdown_once = Once()\n self._daemon_thread = Thread(target=self._ticker, daemon=True)\n self._daemon_thread.start()\n if hasattr(os, \"register_at_fork\"):\n os.register_at_fork(\n after_in_child=self._at_fork_reinit\n ) # pylint: disable=protected-access\n\n def _at_fork_reinit(self):\n self._daemon_thread = Thread(target=self._ticker, daemon=True)\n self._daemon_thread.start()\n\n def _ticker(self) -> None:\n interval_secs = self._export_interval_millis / 1e3\n while not self._shutdown_event.wait(interval_secs):\n self.collect()\n # one last collection below before shutting down completely\n self.collect()\n\n def _receive_metrics(self, metrics: Iterable[Metric]) -> None:\n if metrics is None:\n return\n token = attach(set_value(_SUPPRESS_INSTRUMENTATION_KEY, True))\n try:\n self._exporter.export(metrics)\n except Exception as e: # pylint: disable=broad-except,invalid-name\n _logger.exception(\"Exception while exporting metrics %s\", str(e))\n detach(token)\n\n def shutdown(self) -> bool:\n def _shutdown():\n self._shutdown = True\n\n did_set = self._shutdown_once.do_once(_shutdown)\n if not did_set:\n _logger.warning(\"Can't shutdown multiple times\")\n return False\n\n self._shutdown_event.set()\n self._daemon_thread.join()\n self._exporter.shutdown()\n return True\n", "path": "opentelemetry-sdk/src/opentelemetry/sdk/_metrics/export/__init__.py"}]} | 2,329 | 463 |
gh_patches_debug_23064 | rasdani/github-patches | git_diff | modoboa__modoboa-515 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
handle_mailbox_operations command not working
Hello,
This is a new Modoboa 1.1.0 installation. When I try to run:
```
python /opt/modoboa_admin/manage.py handle_mailbox_operations
```
I get the following error:
```
NotDefined: Application 'admin' and/or parameter 'HANDLE_MAILBOXES' not defined
```
According to the [documentation](http://modoboa.readthedocs.org/en/1.1.0/getting_started/configuration.html#admin-params) there should be an option in Modoboa->Parameters->General to activate this HANDLE_MAILBOXES. But I don't see it anywhere.
I tried to outsmart the system by inserting the value in the lib_parameter table but no luck. I guess something else is required.
```
insert into lib_parameter (name, value) values ('admin.HANDLE_MAILBOXES', 'yes')
```
Am I missing something ? Here is the screenshot of my admin interface, logged as the default admin user:

</issue>
<code>
[start of modoboa/extensions/admin/app_settings.py]
1 from django import forms
2 from django.utils.translation import ugettext_lazy
3 from modoboa.lib.formutils import YesNoField, SeparatorField
4 from modoboa.lib.sysutils import exec_cmd
5 from modoboa.lib import parameters
6
7
8 class AdminParametersForm(parameters.AdminParametersForm):
9 app = "admin"
10
11 mbsep = SeparatorField(label=ugettext_lazy("Mailboxes"))
12
13 handle_mailboxes = YesNoField(
14 label=ugettext_lazy("Handle mailboxes on filesystem"),
15 initial="no",
16 help_text=ugettext_lazy("Rename or remove mailboxes on the filesystem when they get renamed or removed within Modoboa")
17 )
18
19 mailboxes_owner = forms.CharField(
20 label=ugettext_lazy("Mailboxes ower"),
21 initial="vmail",
22 help_text=ugettext_lazy("The UNIX account who owns mailboxes on the filesystem")
23 )
24
25 default_domain_quota = forms.IntegerField(
26 label=ugettext_lazy("Default domain quota"),
27 initial=0,
28 help_text=ugettext_lazy(
29 "Default quota (in MB) applied to freshly created domains with no "
30 "value specified. A value of 0 means no quota."
31 ),
32 widget=forms.TextInput(attrs={'class': 'span2'})
33 )
34
35 auto_account_removal = YesNoField(
36 label=ugettext_lazy("Automatic account removal"),
37 initial="no",
38 help_text=ugettext_lazy("When a mailbox is removed, also remove the associated account")
39 )
40
41 # Visibility rules
42 visibility_rules = {
43 "mailboxes_owner": "handle_mailboxes=yes",
44 }
45
46 def __init__(self, *args, **kwargs):
47 super(AdminParametersForm, self).__init__(*args, **kwargs)
48 hide_fields = False
49 code, output = exec_cmd("which dovecot")
50 if not code:
51 dpath = output.strip()
52 try:
53 code, version = exec_cmd("%s --version" % dpath)
54 except OSError:
55 hide_fields = True
56 else:
57 if code or not version.strip().startswith("2"):
58 hide_fields = True
59 else:
60 hide_fields = True
61 if hide_fields:
62 del self.fields["handle_mailboxes"]
63 del self.fields["mailboxes_owner"]
64
65 def clean_default_domain_quota(self):
66 """Ensure quota is a positive integer."""
67 if self.cleaned_data['default_domain_quota'] < 0:
68 raise forms.ValidationError(
69 ugettext_lazy('Must be a positive integer')
70 )
71 return self.cleaned_data['default_domain_quota']
72
[end of modoboa/extensions/admin/app_settings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/modoboa/extensions/admin/app_settings.py b/modoboa/extensions/admin/app_settings.py
--- a/modoboa/extensions/admin/app_settings.py
+++ b/modoboa/extensions/admin/app_settings.py
@@ -3,6 +3,7 @@
from modoboa.lib.formutils import YesNoField, SeparatorField
from modoboa.lib.sysutils import exec_cmd
from modoboa.lib import parameters
+import os
class AdminParametersForm(parameters.AdminParametersForm):
@@ -46,9 +47,16 @@
def __init__(self, *args, **kwargs):
super(AdminParametersForm, self).__init__(*args, **kwargs)
hide_fields = False
+ dpath = None
code, output = exec_cmd("which dovecot")
+ known_paths = ("/usr/sbin/dovecot", "/usr/local/sbin/dovecot")
if not code:
dpath = output.strip()
+ else:
+ for fpath in known_paths:
+ if os.path.isfile(fpath) and os.access(fpath, os.X_OK):
+ dpath = fpath
+ if dpath:
try:
code, version = exec_cmd("%s --version" % dpath)
except OSError:
| {"golden_diff": "diff --git a/modoboa/extensions/admin/app_settings.py b/modoboa/extensions/admin/app_settings.py\n--- a/modoboa/extensions/admin/app_settings.py\n+++ b/modoboa/extensions/admin/app_settings.py\n@@ -3,6 +3,7 @@\n from modoboa.lib.formutils import YesNoField, SeparatorField\n from modoboa.lib.sysutils import exec_cmd\n from modoboa.lib import parameters\n+import os\n \n \n class AdminParametersForm(parameters.AdminParametersForm):\n@@ -46,9 +47,16 @@\n def __init__(self, *args, **kwargs):\n super(AdminParametersForm, self).__init__(*args, **kwargs)\n hide_fields = False\n+ dpath = None\n code, output = exec_cmd(\"which dovecot\")\n+ known_paths = (\"/usr/sbin/dovecot\", \"/usr/local/sbin/dovecot\")\n if not code:\n dpath = output.strip()\n+ else:\n+ for fpath in known_paths:\n+ if os.path.isfile(fpath) and os.access(fpath, os.X_OK):\n+ dpath = fpath\n+ if dpath:\n try:\n code, version = exec_cmd(\"%s --version\" % dpath)\n except OSError:\n", "issue": "handle_mailbox_operations command not working\nHello,\n\nThis is a new Modoboa 1.1.0 installation. When I try to run:\n\n```\npython /opt/modoboa_admin/manage.py handle_mailbox_operations\n```\n\nI get the following error:\n\n```\nNotDefined: Application 'admin' and/or parameter 'HANDLE_MAILBOXES' not defined\n```\n\nAccording to the [documentation](http://modoboa.readthedocs.org/en/1.1.0/getting_started/configuration.html#admin-params) there should be an option in Modoboa->Parameters->General to activate this HANDLE_MAILBOXES. But I don't see it anywhere.\n\nI tried to outsmart the system by inserting the value in the lib_parameter table but no luck. I guess something else is required.\n\n```\ninsert into lib_parameter (name, value) values ('admin.HANDLE_MAILBOXES', 'yes')\n```\n\nAm I missing something ? Here is the screenshot of my admin interface, logged as the default admin user:\n\n\n", "before_files": [{"content": "from django import forms\nfrom django.utils.translation import ugettext_lazy\nfrom modoboa.lib.formutils import YesNoField, SeparatorField\nfrom modoboa.lib.sysutils import exec_cmd\nfrom modoboa.lib import parameters\n\n\nclass AdminParametersForm(parameters.AdminParametersForm):\n app = \"admin\"\n\n mbsep = SeparatorField(label=ugettext_lazy(\"Mailboxes\"))\n\n handle_mailboxes = YesNoField(\n label=ugettext_lazy(\"Handle mailboxes on filesystem\"),\n initial=\"no\",\n help_text=ugettext_lazy(\"Rename or remove mailboxes on the filesystem when they get renamed or removed within Modoboa\")\n )\n\n mailboxes_owner = forms.CharField(\n label=ugettext_lazy(\"Mailboxes ower\"),\n initial=\"vmail\",\n help_text=ugettext_lazy(\"The UNIX account who owns mailboxes on the filesystem\")\n )\n\n default_domain_quota = forms.IntegerField(\n label=ugettext_lazy(\"Default domain quota\"),\n initial=0,\n help_text=ugettext_lazy(\n \"Default quota (in MB) applied to freshly created domains with no \"\n \"value specified. A value of 0 means no quota.\"\n ),\n widget=forms.TextInput(attrs={'class': 'span2'})\n )\n\n auto_account_removal = YesNoField(\n label=ugettext_lazy(\"Automatic account removal\"),\n initial=\"no\",\n help_text=ugettext_lazy(\"When a mailbox is removed, also remove the associated account\")\n )\n\n # Visibility rules\n visibility_rules = {\n \"mailboxes_owner\": \"handle_mailboxes=yes\",\n }\n\n def __init__(self, *args, **kwargs):\n super(AdminParametersForm, self).__init__(*args, **kwargs)\n hide_fields = False\n code, output = exec_cmd(\"which dovecot\")\n if not code:\n dpath = output.strip()\n try:\n code, version = exec_cmd(\"%s --version\" % dpath)\n except OSError:\n hide_fields = True\n else:\n if code or not version.strip().startswith(\"2\"):\n hide_fields = True\n else:\n hide_fields = True\n if hide_fields:\n del self.fields[\"handle_mailboxes\"]\n del self.fields[\"mailboxes_owner\"]\n\n def clean_default_domain_quota(self):\n \"\"\"Ensure quota is a positive integer.\"\"\"\n if self.cleaned_data['default_domain_quota'] < 0:\n raise forms.ValidationError(\n ugettext_lazy('Must be a positive integer')\n )\n return self.cleaned_data['default_domain_quota']\n", "path": "modoboa/extensions/admin/app_settings.py"}]} | 1,485 | 271 |
gh_patches_debug_22129 | rasdani/github-patches | git_diff | nonebot__nonebot2-679 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: 部分情况下,加载失败的插件依然会出现在当前已导入的所有插件中
**描述问题:**
通过 nonebot.get_loaded_plugins() 获取当前已导入的所有插件,加载失败的插件也出现在其中
**如何复现?**
1. 复制 2.0.0 a16 版本文档的[注册事件响应器](https://61d3d9dbcadf413fd3238e89--nonebot2.netlify.app/guide/creating-a-matcher.html)一节的 weather.py 的代码作为插件,并在 2.0.0 beta1 版本导入它(很显然,这会发生错误)
2. 通过 nonebot.get_loaded_plugins() 获取已导入的插件,可以发现这个加载失败的插件出现在了已导入的插件中
**期望的结果**
加载失败的插件不出现在已导入的所有插件中
**环境信息:**
- OS: [Windows]
- Python Version: [3.10]
- Nonebot Version: [2.0.0 b1]
**协议端信息:**
- 协议端: [go-cqhttp]
- 协议端版本: [1.0.0]
**截图或日志**
```
[ERROR] nonebot | Failed to import "kirami.plugins.weather"
ValueError: Unknown parameter state for function <function handle_first_receive at 0x000001924056AB90> with type typing.Dict[typing.Any, typing.Any]
{Plugin(name='weather', module=<module 'kirami.plugins.weather' from 'D:\\Users\\Documents\\gitee\\KiramiBot\\kirami\\plugins\\weather\\__init__.py'>, module_name='kirami.plugins.weather', manager=<nonebot.plugin.manager.PluginManager object at 0x000002140ECEF130>, export={}, matcher=set(), parent_plugin=None, sub_plugins=set())}
```
</issue>
<code>
[start of nonebot/plugin/plugin.py]
1 from types import ModuleType
2 from dataclasses import field, dataclass
3 from typing import TYPE_CHECKING, Set, Dict, Type, Optional
4
5 from .export import Export
6 from nonebot.matcher import Matcher
7
8 if TYPE_CHECKING:
9 from .manager import PluginManager
10
11 plugins: Dict[str, "Plugin"] = {}
12 """
13 :类型: ``Dict[str, Plugin]``
14 :说明: 已加载的插件
15 """
16
17
18 @dataclass(eq=False)
19 class Plugin(object):
20 """存储插件信息"""
21
22 name: str
23 """
24 - **类型**: ``str``
25 - **说明**: 插件名称,使用 文件/文件夹 名称作为插件名
26 """
27 module: ModuleType
28 """
29 - **类型**: ``ModuleType``
30 - **说明**: 插件模块对象
31 """
32 module_name: str
33 """
34 - **类型**: ``str``
35 - **说明**: 点分割模块路径
36 """
37 manager: "PluginManager"
38 """
39 - **类型**: ``PluginManager``
40 - **说明**: 导入该插件的插件管理器
41 """
42 export: Export = field(default_factory=Export)
43 """
44 - **类型**: ``Export``
45 - **说明**: 插件内定义的导出内容
46 """
47 matcher: Set[Type[Matcher]] = field(default_factory=set)
48 """
49 - **类型**: ``Set[Type[Matcher]]``
50 - **说明**: 插件内定义的 ``Matcher``
51 """
52 parent_plugin: Optional["Plugin"] = None
53 """
54 - **类型**: ``Optional[Plugin]``
55 - **说明**: 父插件
56 """
57 sub_plugins: Set["Plugin"] = field(default_factory=set)
58 """
59 - **类型**: ``Set[Plugin]``
60 - **说明**: 子插件集合
61 """
62
63
64 def get_plugin(name: str) -> Optional[Plugin]:
65 """
66 :说明:
67
68 获取当前导入的某个插件。
69
70 :参数:
71
72 * ``name: str``: 插件名,与 ``load_plugin`` 参数一致。如果为 ``load_plugins`` 导入的插件,则为文件(夹)名。
73
74 :返回:
75
76 - ``Optional[Plugin]``
77 """
78 return plugins.get(name)
79
80
81 def get_loaded_plugins() -> Set[Plugin]:
82 """
83 :说明:
84
85 获取当前已导入的所有插件。
86
87 :返回:
88
89 - ``Set[Plugin]``
90 """
91 return set(plugins.values())
92
93
94 def _new_plugin(fullname: str, module: ModuleType, manager: "PluginManager") -> Plugin:
95 name = fullname.rsplit(".", 1)[-1] if "." in fullname else fullname
96 if name in plugins:
97 raise RuntimeError("Plugin already exists! Check your plugin name.")
98 plugin = Plugin(name, module, fullname, manager)
99 plugins[name] = plugin
100 return plugin
101
[end of nonebot/plugin/plugin.py]
[start of nonebot/plugin/manager.py]
1 import sys
2 import pkgutil
3 import importlib
4 from pathlib import Path
5 from itertools import chain
6 from types import ModuleType
7 from importlib.abc import MetaPathFinder
8 from importlib.machinery import PathFinder, SourceFileLoader
9 from typing import Set, Dict, List, Union, Iterable, Optional, Sequence
10
11 from nonebot.log import logger
12 from nonebot.utils import escape_tag
13 from .plugin import Plugin, _new_plugin
14 from . import _managers, _current_plugin
15
16
17 class PluginManager:
18 def __init__(
19 self,
20 plugins: Optional[Iterable[str]] = None,
21 search_path: Optional[Iterable[str]] = None,
22 ):
23
24 # simple plugin not in search path
25 self.plugins: Set[str] = set(plugins or [])
26 self.search_path: Set[str] = set(search_path or [])
27 # cache plugins
28 self.searched_plugins: Dict[str, Path] = {}
29 self.list_plugins()
30
31 def _path_to_module_name(self, path: Path) -> str:
32 rel_path = path.resolve().relative_to(Path(".").resolve())
33 if rel_path.stem == "__init__":
34 return ".".join(rel_path.parts[:-1])
35 else:
36 return ".".join(rel_path.parts[:-1] + (rel_path.stem,))
37
38 def _previous_plugins(self) -> List[str]:
39 _pre_managers: List[PluginManager]
40 if self in _managers:
41 _pre_managers = _managers[: _managers.index(self)]
42 else:
43 _pre_managers = _managers[:]
44
45 return [
46 *chain.from_iterable(
47 [*manager.plugins, *manager.searched_plugins.keys()]
48 for manager in _pre_managers
49 )
50 ]
51
52 def list_plugins(self) -> Set[str]:
53 # get all previous ready to load plugins
54 previous_plugins = self._previous_plugins()
55 searched_plugins: Dict[str, Path] = {}
56 third_party_plugins: Set[str] = set()
57
58 for plugin in self.plugins:
59 name = plugin.rsplit(".", 1)[-1] if "." in plugin else plugin
60 if name in third_party_plugins or name in previous_plugins:
61 raise RuntimeError(
62 f"Plugin already exists: {name}! Check your plugin name"
63 )
64 third_party_plugins.add(plugin)
65
66 for module_info in pkgutil.iter_modules(self.search_path):
67 if module_info.name.startswith("_"):
68 continue
69 if (
70 module_info.name in searched_plugins.keys()
71 or module_info.name in previous_plugins
72 or module_info.name in third_party_plugins
73 ):
74 raise RuntimeError(
75 f"Plugin already exists: {module_info.name}! Check your plugin name"
76 )
77 module_spec = module_info.module_finder.find_spec(module_info.name, None)
78 if not module_spec:
79 continue
80 module_path = module_spec.origin
81 if not module_path:
82 continue
83 searched_plugins[module_info.name] = Path(module_path).resolve()
84
85 self.searched_plugins = searched_plugins
86
87 return third_party_plugins | set(self.searched_plugins.keys())
88
89 def load_plugin(self, name) -> Optional[Plugin]:
90 try:
91 if name in self.plugins:
92 module = importlib.import_module(name)
93 elif name not in self.searched_plugins:
94 raise RuntimeError(f"Plugin not found: {name}! Check your plugin name")
95 else:
96 module = importlib.import_module(
97 self._path_to_module_name(self.searched_plugins[name])
98 )
99
100 logger.opt(colors=True).success(
101 f'Succeeded to import "<y>{escape_tag(name)}</y>"'
102 )
103 return getattr(module, "__plugin__", None)
104 except Exception as e:
105 logger.opt(colors=True, exception=e).error(
106 f'<r><bg #f8bbd0>Failed to import "{escape_tag(name)}"</bg #f8bbd0></r>'
107 )
108
109 def load_all_plugins(self) -> Set[Plugin]:
110 return set(
111 filter(None, (self.load_plugin(name) for name in self.list_plugins()))
112 )
113
114
115 class PluginFinder(MetaPathFinder):
116 def find_spec(
117 self,
118 fullname: str,
119 path: Optional[Sequence[Union[bytes, str]]],
120 target: Optional[ModuleType] = None,
121 ):
122 if _managers:
123 index = -1
124 module_spec = PathFinder.find_spec(fullname, path, target)
125 if not module_spec:
126 return
127 module_origin = module_spec.origin
128 if not module_origin:
129 return
130 module_path = Path(module_origin).resolve()
131
132 while -index <= len(_managers):
133 manager = _managers[index]
134
135 if (
136 fullname in manager.plugins
137 or module_path in manager.searched_plugins.values()
138 ):
139 module_spec.loader = PluginLoader(manager, fullname, module_origin)
140 return module_spec
141
142 index -= 1
143 return
144
145
146 class PluginLoader(SourceFileLoader):
147 def __init__(self, manager: PluginManager, fullname: str, path) -> None:
148 self.manager = manager
149 self.loaded = False
150 super().__init__(fullname, path)
151
152 def create_module(self, spec) -> Optional[ModuleType]:
153 if self.name in sys.modules:
154 self.loaded = True
155 return sys.modules[self.name]
156 # return None to use default module creation
157 return super().create_module(spec)
158
159 def exec_module(self, module: ModuleType) -> None:
160 if self.loaded:
161 return
162
163 plugin = _new_plugin(self.name, module, self.manager)
164 parent_plugin = _current_plugin.get()
165 if parent_plugin and _managers.index(parent_plugin.manager) < _managers.index(
166 self.manager
167 ):
168 plugin.parent_plugin = parent_plugin
169 parent_plugin.sub_plugins.add(plugin)
170
171 _plugin_token = _current_plugin.set(plugin)
172
173 setattr(module, "__plugin__", plugin)
174
175 # try:
176 # super().exec_module(module)
177 # except Exception as e:
178 # raise ImportError(
179 # f"Error when executing module {module_name} from {module.__file__}."
180 # ) from e
181 super().exec_module(module)
182
183 _current_plugin.reset(_plugin_token)
184 return
185
186
187 sys.meta_path.insert(0, PluginFinder())
188
[end of nonebot/plugin/manager.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/nonebot/plugin/manager.py b/nonebot/plugin/manager.py
--- a/nonebot/plugin/manager.py
+++ b/nonebot/plugin/manager.py
@@ -10,8 +10,8 @@
from nonebot.log import logger
from nonebot.utils import escape_tag
-from .plugin import Plugin, _new_plugin
from . import _managers, _current_plugin
+from .plugin import Plugin, _new_plugin, _confirm_plugin
class PluginManager:
@@ -180,6 +180,8 @@
# ) from e
super().exec_module(module)
+ _confirm_plugin(plugin)
+
_current_plugin.reset(_plugin_token)
return
diff --git a/nonebot/plugin/plugin.py b/nonebot/plugin/plugin.py
--- a/nonebot/plugin/plugin.py
+++ b/nonebot/plugin/plugin.py
@@ -96,5 +96,10 @@
if name in plugins:
raise RuntimeError("Plugin already exists! Check your plugin name.")
plugin = Plugin(name, module, fullname, manager)
- plugins[name] = plugin
return plugin
+
+
+def _confirm_plugin(plugin: Plugin) -> None:
+ if plugin.name in plugins:
+ raise RuntimeError("Plugin already exists! Check your plugin name.")
+ plugins[plugin.name] = plugin
| {"golden_diff": "diff --git a/nonebot/plugin/manager.py b/nonebot/plugin/manager.py\n--- a/nonebot/plugin/manager.py\n+++ b/nonebot/plugin/manager.py\n@@ -10,8 +10,8 @@\n \n from nonebot.log import logger\n from nonebot.utils import escape_tag\n-from .plugin import Plugin, _new_plugin\n from . import _managers, _current_plugin\n+from .plugin import Plugin, _new_plugin, _confirm_plugin\n \n \n class PluginManager:\n@@ -180,6 +180,8 @@\n # ) from e\n super().exec_module(module)\n \n+ _confirm_plugin(plugin)\n+\n _current_plugin.reset(_plugin_token)\n return\n \ndiff --git a/nonebot/plugin/plugin.py b/nonebot/plugin/plugin.py\n--- a/nonebot/plugin/plugin.py\n+++ b/nonebot/plugin/plugin.py\n@@ -96,5 +96,10 @@\n if name in plugins:\n raise RuntimeError(\"Plugin already exists! Check your plugin name.\")\n plugin = Plugin(name, module, fullname, manager)\n- plugins[name] = plugin\n return plugin\n+\n+\n+def _confirm_plugin(plugin: Plugin) -> None:\n+ if plugin.name in plugins:\n+ raise RuntimeError(\"Plugin already exists! Check your plugin name.\")\n+ plugins[plugin.name] = plugin\n", "issue": "Bug: \u90e8\u5206\u60c5\u51b5\u4e0b\uff0c\u52a0\u8f7d\u5931\u8d25\u7684\u63d2\u4ef6\u4f9d\u7136\u4f1a\u51fa\u73b0\u5728\u5f53\u524d\u5df2\u5bfc\u5165\u7684\u6240\u6709\u63d2\u4ef6\u4e2d\n**\u63cf\u8ff0\u95ee\u9898\uff1a**\r\n\r\n\u901a\u8fc7 nonebot.get_loaded_plugins() \u83b7\u53d6\u5f53\u524d\u5df2\u5bfc\u5165\u7684\u6240\u6709\u63d2\u4ef6\uff0c\u52a0\u8f7d\u5931\u8d25\u7684\u63d2\u4ef6\u4e5f\u51fa\u73b0\u5728\u5176\u4e2d\r\n\r\n**\u5982\u4f55\u590d\u73b0\uff1f**\r\n\r\n1. \u590d\u5236 2.0.0 a16 \u7248\u672c\u6587\u6863\u7684[\u6ce8\u518c\u4e8b\u4ef6\u54cd\u5e94\u5668](https://61d3d9dbcadf413fd3238e89--nonebot2.netlify.app/guide/creating-a-matcher.html)\u4e00\u8282\u7684 weather.py \u7684\u4ee3\u7801\u4f5c\u4e3a\u63d2\u4ef6\uff0c\u5e76\u5728 2.0.0 beta1 \u7248\u672c\u5bfc\u5165\u5b83\uff08\u5f88\u663e\u7136\uff0c\u8fd9\u4f1a\u53d1\u751f\u9519\u8bef\uff09\r\n2. \u901a\u8fc7 nonebot.get_loaded_plugins() \u83b7\u53d6\u5df2\u5bfc\u5165\u7684\u63d2\u4ef6\uff0c\u53ef\u4ee5\u53d1\u73b0\u8fd9\u4e2a\u52a0\u8f7d\u5931\u8d25\u7684\u63d2\u4ef6\u51fa\u73b0\u5728\u4e86\u5df2\u5bfc\u5165\u7684\u63d2\u4ef6\u4e2d\r\n\r\n**\u671f\u671b\u7684\u7ed3\u679c**\r\n\r\n\u52a0\u8f7d\u5931\u8d25\u7684\u63d2\u4ef6\u4e0d\u51fa\u73b0\u5728\u5df2\u5bfc\u5165\u7684\u6240\u6709\u63d2\u4ef6\u4e2d\r\n\r\n**\u73af\u5883\u4fe1\u606f\uff1a**\r\n\r\n - OS: [Windows]\r\n - Python Version: [3.10]\r\n - Nonebot Version: [2.0.0 b1]\r\n\r\n**\u534f\u8bae\u7aef\u4fe1\u606f\uff1a**\r\n\r\n - \u534f\u8bae\u7aef: [go-cqhttp]\r\n - \u534f\u8bae\u7aef\u7248\u672c: [1.0.0]\r\n\r\n**\u622a\u56fe\u6216\u65e5\u5fd7**\r\n\r\n```\r\n[ERROR] nonebot | Failed to import \"kirami.plugins.weather\"\r\nValueError: Unknown parameter state for function <function handle_first_receive at 0x000001924056AB90> with type typing.Dict[typing.Any, typing.Any]\r\n\r\n{Plugin(name='weather', module=<module 'kirami.plugins.weather' from 'D:\\\\Users\\\\Documents\\\\gitee\\\\KiramiBot\\\\kirami\\\\plugins\\\\weather\\\\__init__.py'>, module_name='kirami.plugins.weather', manager=<nonebot.plugin.manager.PluginManager object at 0x000002140ECEF130>, export={}, matcher=set(), parent_plugin=None, sub_plugins=set())}\r\n```\n", "before_files": [{"content": "from types import ModuleType\nfrom dataclasses import field, dataclass\nfrom typing import TYPE_CHECKING, Set, Dict, Type, Optional\n\nfrom .export import Export\nfrom nonebot.matcher import Matcher\n\nif TYPE_CHECKING:\n from .manager import PluginManager\n\nplugins: Dict[str, \"Plugin\"] = {}\n\"\"\"\n:\u7c7b\u578b: ``Dict[str, Plugin]``\n:\u8bf4\u660e: \u5df2\u52a0\u8f7d\u7684\u63d2\u4ef6\n\"\"\"\n\n\n@dataclass(eq=False)\nclass Plugin(object):\n \"\"\"\u5b58\u50a8\u63d2\u4ef6\u4fe1\u606f\"\"\"\n\n name: str\n \"\"\"\n - **\u7c7b\u578b**: ``str``\n - **\u8bf4\u660e**: \u63d2\u4ef6\u540d\u79f0\uff0c\u4f7f\u7528 \u6587\u4ef6/\u6587\u4ef6\u5939 \u540d\u79f0\u4f5c\u4e3a\u63d2\u4ef6\u540d\n \"\"\"\n module: ModuleType\n \"\"\"\n - **\u7c7b\u578b**: ``ModuleType``\n - **\u8bf4\u660e**: \u63d2\u4ef6\u6a21\u5757\u5bf9\u8c61\n \"\"\"\n module_name: str\n \"\"\"\n - **\u7c7b\u578b**: ``str``\n - **\u8bf4\u660e**: \u70b9\u5206\u5272\u6a21\u5757\u8def\u5f84\n \"\"\"\n manager: \"PluginManager\"\n \"\"\"\n - **\u7c7b\u578b**: ``PluginManager``\n - **\u8bf4\u660e**: \u5bfc\u5165\u8be5\u63d2\u4ef6\u7684\u63d2\u4ef6\u7ba1\u7406\u5668\n \"\"\"\n export: Export = field(default_factory=Export)\n \"\"\"\n - **\u7c7b\u578b**: ``Export``\n - **\u8bf4\u660e**: \u63d2\u4ef6\u5185\u5b9a\u4e49\u7684\u5bfc\u51fa\u5185\u5bb9\n \"\"\"\n matcher: Set[Type[Matcher]] = field(default_factory=set)\n \"\"\"\n - **\u7c7b\u578b**: ``Set[Type[Matcher]]``\n - **\u8bf4\u660e**: \u63d2\u4ef6\u5185\u5b9a\u4e49\u7684 ``Matcher``\n \"\"\"\n parent_plugin: Optional[\"Plugin\"] = None\n \"\"\"\n - **\u7c7b\u578b**: ``Optional[Plugin]``\n - **\u8bf4\u660e**: \u7236\u63d2\u4ef6\n \"\"\"\n sub_plugins: Set[\"Plugin\"] = field(default_factory=set)\n \"\"\"\n - **\u7c7b\u578b**: ``Set[Plugin]``\n - **\u8bf4\u660e**: \u5b50\u63d2\u4ef6\u96c6\u5408\n \"\"\"\n\n\ndef get_plugin(name: str) -> Optional[Plugin]:\n \"\"\"\n :\u8bf4\u660e:\n\n \u83b7\u53d6\u5f53\u524d\u5bfc\u5165\u7684\u67d0\u4e2a\u63d2\u4ef6\u3002\n\n :\u53c2\u6570:\n\n * ``name: str``: \u63d2\u4ef6\u540d\uff0c\u4e0e ``load_plugin`` \u53c2\u6570\u4e00\u81f4\u3002\u5982\u679c\u4e3a ``load_plugins`` \u5bfc\u5165\u7684\u63d2\u4ef6\uff0c\u5219\u4e3a\u6587\u4ef6(\u5939)\u540d\u3002\n\n :\u8fd4\u56de:\n\n - ``Optional[Plugin]``\n \"\"\"\n return plugins.get(name)\n\n\ndef get_loaded_plugins() -> Set[Plugin]:\n \"\"\"\n :\u8bf4\u660e:\n\n \u83b7\u53d6\u5f53\u524d\u5df2\u5bfc\u5165\u7684\u6240\u6709\u63d2\u4ef6\u3002\n\n :\u8fd4\u56de:\n\n - ``Set[Plugin]``\n \"\"\"\n return set(plugins.values())\n\n\ndef _new_plugin(fullname: str, module: ModuleType, manager: \"PluginManager\") -> Plugin:\n name = fullname.rsplit(\".\", 1)[-1] if \".\" in fullname else fullname\n if name in plugins:\n raise RuntimeError(\"Plugin already exists! Check your plugin name.\")\n plugin = Plugin(name, module, fullname, manager)\n plugins[name] = plugin\n return plugin\n", "path": "nonebot/plugin/plugin.py"}, {"content": "import sys\nimport pkgutil\nimport importlib\nfrom pathlib import Path\nfrom itertools import chain\nfrom types import ModuleType\nfrom importlib.abc import MetaPathFinder\nfrom importlib.machinery import PathFinder, SourceFileLoader\nfrom typing import Set, Dict, List, Union, Iterable, Optional, Sequence\n\nfrom nonebot.log import logger\nfrom nonebot.utils import escape_tag\nfrom .plugin import Plugin, _new_plugin\nfrom . import _managers, _current_plugin\n\n\nclass PluginManager:\n def __init__(\n self,\n plugins: Optional[Iterable[str]] = None,\n search_path: Optional[Iterable[str]] = None,\n ):\n\n # simple plugin not in search path\n self.plugins: Set[str] = set(plugins or [])\n self.search_path: Set[str] = set(search_path or [])\n # cache plugins\n self.searched_plugins: Dict[str, Path] = {}\n self.list_plugins()\n\n def _path_to_module_name(self, path: Path) -> str:\n rel_path = path.resolve().relative_to(Path(\".\").resolve())\n if rel_path.stem == \"__init__\":\n return \".\".join(rel_path.parts[:-1])\n else:\n return \".\".join(rel_path.parts[:-1] + (rel_path.stem,))\n\n def _previous_plugins(self) -> List[str]:\n _pre_managers: List[PluginManager]\n if self in _managers:\n _pre_managers = _managers[: _managers.index(self)]\n else:\n _pre_managers = _managers[:]\n\n return [\n *chain.from_iterable(\n [*manager.plugins, *manager.searched_plugins.keys()]\n for manager in _pre_managers\n )\n ]\n\n def list_plugins(self) -> Set[str]:\n # get all previous ready to load plugins\n previous_plugins = self._previous_plugins()\n searched_plugins: Dict[str, Path] = {}\n third_party_plugins: Set[str] = set()\n\n for plugin in self.plugins:\n name = plugin.rsplit(\".\", 1)[-1] if \".\" in plugin else plugin\n if name in third_party_plugins or name in previous_plugins:\n raise RuntimeError(\n f\"Plugin already exists: {name}! Check your plugin name\"\n )\n third_party_plugins.add(plugin)\n\n for module_info in pkgutil.iter_modules(self.search_path):\n if module_info.name.startswith(\"_\"):\n continue\n if (\n module_info.name in searched_plugins.keys()\n or module_info.name in previous_plugins\n or module_info.name in third_party_plugins\n ):\n raise RuntimeError(\n f\"Plugin already exists: {module_info.name}! Check your plugin name\"\n )\n module_spec = module_info.module_finder.find_spec(module_info.name, None)\n if not module_spec:\n continue\n module_path = module_spec.origin\n if not module_path:\n continue\n searched_plugins[module_info.name] = Path(module_path).resolve()\n\n self.searched_plugins = searched_plugins\n\n return third_party_plugins | set(self.searched_plugins.keys())\n\n def load_plugin(self, name) -> Optional[Plugin]:\n try:\n if name in self.plugins:\n module = importlib.import_module(name)\n elif name not in self.searched_plugins:\n raise RuntimeError(f\"Plugin not found: {name}! Check your plugin name\")\n else:\n module = importlib.import_module(\n self._path_to_module_name(self.searched_plugins[name])\n )\n\n logger.opt(colors=True).success(\n f'Succeeded to import \"<y>{escape_tag(name)}</y>\"'\n )\n return getattr(module, \"__plugin__\", None)\n except Exception as e:\n logger.opt(colors=True, exception=e).error(\n f'<r><bg #f8bbd0>Failed to import \"{escape_tag(name)}\"</bg #f8bbd0></r>'\n )\n\n def load_all_plugins(self) -> Set[Plugin]:\n return set(\n filter(None, (self.load_plugin(name) for name in self.list_plugins()))\n )\n\n\nclass PluginFinder(MetaPathFinder):\n def find_spec(\n self,\n fullname: str,\n path: Optional[Sequence[Union[bytes, str]]],\n target: Optional[ModuleType] = None,\n ):\n if _managers:\n index = -1\n module_spec = PathFinder.find_spec(fullname, path, target)\n if not module_spec:\n return\n module_origin = module_spec.origin\n if not module_origin:\n return\n module_path = Path(module_origin).resolve()\n\n while -index <= len(_managers):\n manager = _managers[index]\n\n if (\n fullname in manager.plugins\n or module_path in manager.searched_plugins.values()\n ):\n module_spec.loader = PluginLoader(manager, fullname, module_origin)\n return module_spec\n\n index -= 1\n return\n\n\nclass PluginLoader(SourceFileLoader):\n def __init__(self, manager: PluginManager, fullname: str, path) -> None:\n self.manager = manager\n self.loaded = False\n super().__init__(fullname, path)\n\n def create_module(self, spec) -> Optional[ModuleType]:\n if self.name in sys.modules:\n self.loaded = True\n return sys.modules[self.name]\n # return None to use default module creation\n return super().create_module(spec)\n\n def exec_module(self, module: ModuleType) -> None:\n if self.loaded:\n return\n\n plugin = _new_plugin(self.name, module, self.manager)\n parent_plugin = _current_plugin.get()\n if parent_plugin and _managers.index(parent_plugin.manager) < _managers.index(\n self.manager\n ):\n plugin.parent_plugin = parent_plugin\n parent_plugin.sub_plugins.add(plugin)\n\n _plugin_token = _current_plugin.set(plugin)\n\n setattr(module, \"__plugin__\", plugin)\n\n # try:\n # super().exec_module(module)\n # except Exception as e:\n # raise ImportError(\n # f\"Error when executing module {module_name} from {module.__file__}.\"\n # ) from e\n super().exec_module(module)\n\n _current_plugin.reset(_plugin_token)\n return\n\n\nsys.meta_path.insert(0, PluginFinder())\n", "path": "nonebot/plugin/manager.py"}]} | 3,643 | 296 |
gh_patches_debug_33043 | rasdani/github-patches | git_diff | Lightning-AI__torchmetrics-702 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Typo in CalibrationError metric docs
I just noticed typos in the CE metrics - the max calibration error and RMS calibration error labels should be switched, and there's a square root sign missing from the root mean squared error (whoops). That's my mistake, I'll submit a PR to fix.
</issue>
<code>
[start of torchmetrics/classification/calibration_error.py]
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from typing import Any, List, Optional
15
16 import torch
17 from torch import Tensor
18
19 from torchmetrics.functional.classification.calibration_error import _ce_compute, _ce_update
20 from torchmetrics.metric import Metric
21 from torchmetrics.utilities.data import dim_zero_cat
22
23
24 class CalibrationError(Metric):
25 r"""
26
27 `Computes the Top-label Calibration Error`_
28 Three different norms are implemented, each corresponding to variations on the calibration error metric.
29
30 L1 norm (Expected Calibration Error)
31
32 .. math::
33 \text{ECE} = \frac{1}{N}\sum_i^N \|(p_i - c_i)\|
34
35 Infinity norm (Maximum Calibration Error)
36
37 .. math::
38 \text{RMSCE} = \max_{i} (p_i - c_i)
39
40 L2 norm (Root Mean Square Calibration Error)
41
42 .. math::
43 \text{MCE} = \frac{1}{N}\sum_i^N (p_i - c_i)^2
44
45 Where :math:`p_i` is the top-1 prediction accuracy in bin i
46 and :math:`c_i` is the average confidence of predictions in bin i.
47
48 .. note::
49 L2-norm debiasing is not yet supported.
50
51 Args:
52 n_bins: Number of bins to use when computing probabilites and accuracies.
53 norm: Norm used to compare empirical and expected probability bins.
54 Defaults to "l1", or Expected Calibration Error.
55 debias: Applies debiasing term, only implemented for l2 norm. Defaults to True.
56 compute_on_step: Forward only calls ``update()`` and return None if this is set to False.
57 dist_sync_on_step: Synchronize metric state across processes at each ``forward()``
58 before returning the value at the step
59 process_group: Specify the process group on which synchronization is called.
60 """
61 DISTANCES = {"l1", "l2", "max"}
62 higher_is_better = False
63 confidences: List[Tensor]
64 accuracies: List[Tensor]
65
66 def __init__(
67 self,
68 n_bins: int = 15,
69 norm: str = "l1",
70 compute_on_step: bool = False,
71 dist_sync_on_step: bool = False,
72 process_group: Optional[Any] = None,
73 ):
74
75 super().__init__(
76 compute_on_step=compute_on_step,
77 dist_sync_on_step=dist_sync_on_step,
78 process_group=process_group,
79 dist_sync_fn=None,
80 )
81
82 if norm not in self.DISTANCES:
83 raise ValueError(f"Norm {norm} is not supported. Please select from l1, l2, or max. ")
84
85 if not isinstance(n_bins, int) or n_bins <= 0:
86 raise ValueError(f"Expected argument `n_bins` to be a int larger than 0 but got {n_bins}")
87 self.n_bins = n_bins
88 self.register_buffer("bin_boundaries", torch.linspace(0, 1, n_bins + 1))
89 self.norm = norm
90
91 self.add_state("confidences", [], dist_reduce_fx="cat")
92 self.add_state("accuracies", [], dist_reduce_fx="cat")
93
94 def update(self, preds: Tensor, target: Tensor) -> None: # type: ignore
95 """Computes top-level confidences and accuracies for the input probabilites and appends them to internal
96 state.
97
98 Args:
99 preds (Tensor): Model output probabilities.
100 target (Tensor): Ground-truth target class labels.
101 """
102 confidences, accuracies = _ce_update(preds, target)
103
104 self.confidences.append(confidences)
105 self.accuracies.append(accuracies)
106
107 def compute(self) -> Tensor:
108 """Computes calibration error across all confidences and accuracies.
109
110 Returns:
111 Tensor: Calibration error across previously collected examples.
112 """
113 confidences = dim_zero_cat(self.confidences)
114 accuracies = dim_zero_cat(self.accuracies)
115 return _ce_compute(confidences, accuracies, self.bin_boundaries, norm=self.norm)
116
[end of torchmetrics/classification/calibration_error.py]
[start of torchmetrics/functional/classification/calibration_error.py]
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from typing import Tuple
15
16 import torch
17 from torch import FloatTensor, Tensor
18
19 from torchmetrics.utilities.checks import _input_format_classification
20 from torchmetrics.utilities.enums import DataType
21
22
23 def _ce_compute(
24 confidences: FloatTensor,
25 accuracies: FloatTensor,
26 bin_boundaries: FloatTensor,
27 norm: str = "l1",
28 debias: bool = False,
29 ) -> Tensor:
30 """Computes the calibration error given the provided bin boundaries and norm.
31
32 Args:
33 confidences (FloatTensor): The confidence (i.e. predicted prob) of the top1 prediction.
34 accuracies (FloatTensor): 1.0 if the top-1 prediction was correct, 0.0 otherwise.
35 bin_boundaries (FloatTensor): Bin boundaries separating the linspace from 0 to 1.
36 norm (str, optional): Norm function to use when computing calibration error. Defaults to "l1".
37 debias (bool, optional): Apply debiasing to L2 norm computation as in
38 `Verified Uncertainty Calibration`_. Defaults to False.
39
40 Raises:
41 ValueError: If an unsupported norm function is provided.
42
43 Returns:
44 Tensor: Calibration error scalar.
45 """
46 if norm not in {"l1", "l2", "max"}:
47 raise ValueError(f"Norm {norm} is not supported. Please select from l1, l2, or max. ")
48
49 conf_bin = torch.zeros_like(bin_boundaries)
50 acc_bin = torch.zeros_like(bin_boundaries)
51 prop_bin = torch.zeros_like(bin_boundaries)
52 for i, (bin_lower, bin_upper) in enumerate(zip(bin_boundaries[:-1], bin_boundaries[1:])):
53 # Calculated confidence and accuracy in each bin
54 in_bin = confidences.gt(bin_lower.item()) * confidences.le(bin_upper.item())
55 prop_in_bin = in_bin.float().mean()
56 if prop_in_bin.item() > 0:
57 acc_bin[i] = accuracies[in_bin].float().mean()
58 conf_bin[i] = confidences[in_bin].mean()
59 prop_bin[i] = prop_in_bin
60
61 if norm == "l1":
62 ce = torch.sum(torch.abs(acc_bin - conf_bin) * prop_bin)
63 elif norm == "max":
64 ce = torch.max(torch.abs(acc_bin - conf_bin))
65 elif norm == "l2":
66 ce = torch.sum(torch.pow(acc_bin - conf_bin, 2) * prop_bin)
67 # NOTE: debiasing is disabled in the wrapper functions. This implementation differs from that in sklearn.
68 if debias:
69 # the order here (acc_bin - 1 ) vs (1 - acc_bin) is flipped from
70 # the equation in Verified Uncertainty Prediction (Kumar et al 2019)/
71 debias_bins = (acc_bin * (acc_bin - 1) * prop_bin) / (prop_bin * accuracies.size()[0] - 1)
72 ce += torch.sum(torch.nan_to_num(debias_bins)) # replace nans with zeros if nothing appeared in a bin
73 ce = torch.sqrt(ce) if ce > 0 else torch.tensor(0)
74 return ce
75
76
77 def _ce_update(preds: Tensor, target: Tensor) -> Tuple[FloatTensor, FloatTensor]:
78 """Given a predictions and targets tensor, computes the confidences of the top-1 prediction and records their
79 correctness.
80
81 Args:
82 preds (Tensor): Input softmaxed predictions.
83 target (Tensor): Labels.
84
85 Raises:
86 ValueError: If the dataset shape is not binary, multiclass, or multidimensional-multiclass.
87
88 Returns:
89 Tuple[FloatTensor, FloatTensor]: [description]
90 """
91 _, _, mode = _input_format_classification(preds, target)
92
93 if mode == DataType.BINARY:
94 confidences, accuracies = preds, target
95 elif mode == DataType.MULTICLASS:
96 confidences, predictions = preds.max(dim=1)
97 accuracies = predictions.eq(target)
98 elif mode == DataType.MULTIDIM_MULTICLASS:
99 # reshape tensors
100 # for preds, move the class dimension to the final axis and flatten the rest
101 confidences, predictions = torch.transpose(preds, 1, -1).flatten(0, -2).max(dim=1)
102 # for targets, just flatten the target
103 accuracies = predictions.eq(target.flatten())
104 else:
105 raise ValueError(
106 f"Calibration error is not well-defined for data with size {preds.size()} and targets {target.size()}."
107 )
108 # must be cast to float for ddp allgather to work
109 return confidences.float(), accuracies.float()
110
111
112 def calibration_error(preds: Tensor, target: Tensor, n_bins: int = 15, norm: str = "l1") -> Tensor:
113 r"""
114 `Computes the Top-label Calibration Error`_
115
116 Three different norms are implemented, each corresponding to variations on the calibration error metric.
117
118 L1 norm (Expected Calibration Error)
119
120 .. math::
121 \text{ECE} = \frac{1}{N}\sum_i^N \|(p_i - c_i)\|
122
123 Infinity norm (Maximum Calibration Error)
124
125 .. math::
126 \text{RMSCE} = \max_{i} (p_i - c_i)
127
128 L2 norm (Root Mean Square Calibration Error)
129
130 .. math::
131 \text{MCE} = \frac{1}{N}\sum_i^N (p_i - c_i)^2
132
133 Where :math:`p_i` is the top-1 prediction accuracy in
134 bin i and :math:`c_i` is the average confidence of predictions in bin i.
135
136 .. note:
137 L2-norm debiasing is not yet supported.
138
139 Args:
140 preds (Tensor): Model output probabilities.
141 target (Tensor): Ground-truth target class labels.
142 n_bins (int, optional): Number of bins to use when computing t. Defaults to 15.
143 norm (str, optional): Norm used to compare empirical and expected probability bins.
144 Defaults to "l1", or Expected Calibration Error.
145 """
146 if norm not in ("l1", "l2", "max"):
147 raise ValueError(f"Norm {norm} is not supported. Please select from l1, l2, or max. ")
148
149 if not isinstance(n_bins, int) or n_bins <= 0:
150 raise ValueError(f"Expected argument `n_bins` to be a int larger than 0 but got {n_bins}")
151
152 confidences, accuracies = _ce_update(preds, target)
153
154 bin_boundaries = torch.linspace(0, 1, n_bins + 1, dtype=torch.float, device=preds.device)
155
156 return _ce_compute(confidences, accuracies, bin_boundaries, norm=norm)
157
[end of torchmetrics/functional/classification/calibration_error.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/torchmetrics/classification/calibration_error.py b/torchmetrics/classification/calibration_error.py
--- a/torchmetrics/classification/calibration_error.py
+++ b/torchmetrics/classification/calibration_error.py
@@ -30,20 +30,21 @@
L1 norm (Expected Calibration Error)
.. math::
- \text{ECE} = \frac{1}{N}\sum_i^N \|(p_i - c_i)\|
+ \text{ECE} = \sum_i^N b_i \|(p_i - c_i)\|
Infinity norm (Maximum Calibration Error)
.. math::
- \text{RMSCE} = \max_{i} (p_i - c_i)
+ \text{MCE} = \max_{i} (p_i - c_i)
L2 norm (Root Mean Square Calibration Error)
.. math::
- \text{MCE} = \frac{1}{N}\sum_i^N (p_i - c_i)^2
+ \text{RMSCE} = \sqrt{\sum_i^N b_i(p_i - c_i)^2}
- Where :math:`p_i` is the top-1 prediction accuracy in bin i
- and :math:`c_i` is the average confidence of predictions in bin i.
+ Where :math:`p_i` is the top-1 prediction accuracy in bin :math:`i`,
+ :math:`c_i` is the average confidence of predictions in bin :math:`i`, and
+ :math:`b_i` is the fraction of data points in bin :math:`i`.
.. note::
L2-norm debiasing is not yet supported.
diff --git a/torchmetrics/functional/classification/calibration_error.py b/torchmetrics/functional/classification/calibration_error.py
--- a/torchmetrics/functional/classification/calibration_error.py
+++ b/torchmetrics/functional/classification/calibration_error.py
@@ -118,20 +118,21 @@
L1 norm (Expected Calibration Error)
.. math::
- \text{ECE} = \frac{1}{N}\sum_i^N \|(p_i - c_i)\|
+ \text{ECE} = \sum_i^N b_i \|(p_i - c_i)\|
Infinity norm (Maximum Calibration Error)
.. math::
- \text{RMSCE} = \max_{i} (p_i - c_i)
+ \text{MCE} = \max_{i} (p_i - c_i)
L2 norm (Root Mean Square Calibration Error)
.. math::
- \text{MCE} = \frac{1}{N}\sum_i^N (p_i - c_i)^2
+ \text{RMSCE} = \sqrt{\sum_i^N b_i(p_i - c_i)^2}
- Where :math:`p_i` is the top-1 prediction accuracy in
- bin i and :math:`c_i` is the average confidence of predictions in bin i.
+ Where :math:`p_i` is the top-1 prediction accuracy in bin :math:`i`,
+ :math:`c_i` is the average confidence of predictions in bin :math:`i`, and
+ :math:`b_i` is the fraction of data points in bin :math:`i`.
.. note:
L2-norm debiasing is not yet supported.
| {"golden_diff": "diff --git a/torchmetrics/classification/calibration_error.py b/torchmetrics/classification/calibration_error.py\n--- a/torchmetrics/classification/calibration_error.py\n+++ b/torchmetrics/classification/calibration_error.py\n@@ -30,20 +30,21 @@\n L1 norm (Expected Calibration Error)\n \n .. math::\n- \\text{ECE} = \\frac{1}{N}\\sum_i^N \\|(p_i - c_i)\\|\n+ \\text{ECE} = \\sum_i^N b_i \\|(p_i - c_i)\\|\n \n Infinity norm (Maximum Calibration Error)\n \n .. math::\n- \\text{RMSCE} = \\max_{i} (p_i - c_i)\n+ \\text{MCE} = \\max_{i} (p_i - c_i)\n \n L2 norm (Root Mean Square Calibration Error)\n \n .. math::\n- \\text{MCE} = \\frac{1}{N}\\sum_i^N (p_i - c_i)^2\n+ \\text{RMSCE} = \\sqrt{\\sum_i^N b_i(p_i - c_i)^2}\n \n- Where :math:`p_i` is the top-1 prediction accuracy in bin i\n- and :math:`c_i` is the average confidence of predictions in bin i.\n+ Where :math:`p_i` is the top-1 prediction accuracy in bin :math:`i`,\n+ :math:`c_i` is the average confidence of predictions in bin :math:`i`, and\n+ :math:`b_i` is the fraction of data points in bin :math:`i`.\n \n .. note::\n L2-norm debiasing is not yet supported.\ndiff --git a/torchmetrics/functional/classification/calibration_error.py b/torchmetrics/functional/classification/calibration_error.py\n--- a/torchmetrics/functional/classification/calibration_error.py\n+++ b/torchmetrics/functional/classification/calibration_error.py\n@@ -118,20 +118,21 @@\n L1 norm (Expected Calibration Error)\n \n .. math::\n- \\text{ECE} = \\frac{1}{N}\\sum_i^N \\|(p_i - c_i)\\|\n+ \\text{ECE} = \\sum_i^N b_i \\|(p_i - c_i)\\|\n \n Infinity norm (Maximum Calibration Error)\n \n .. math::\n- \\text{RMSCE} = \\max_{i} (p_i - c_i)\n+ \\text{MCE} = \\max_{i} (p_i - c_i)\n \n L2 norm (Root Mean Square Calibration Error)\n \n .. math::\n- \\text{MCE} = \\frac{1}{N}\\sum_i^N (p_i - c_i)^2\n+ \\text{RMSCE} = \\sqrt{\\sum_i^N b_i(p_i - c_i)^2}\n \n- Where :math:`p_i` is the top-1 prediction accuracy in\n- bin i and :math:`c_i` is the average confidence of predictions in bin i.\n+ Where :math:`p_i` is the top-1 prediction accuracy in bin :math:`i`,\n+ :math:`c_i` is the average confidence of predictions in bin :math:`i`, and\n+ :math:`b_i` is the fraction of data points in bin :math:`i`.\n \n .. note:\n L2-norm debiasing is not yet supported.\n", "issue": "Typo in CalibrationError metric docs\nI just noticed typos in the CE metrics - the max calibration error and RMS calibration error labels should be switched, and there's a square root sign missing from the root mean squared error (whoops). That's my mistake, I'll submit a PR to fix. \r\n\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Any, List, Optional\n\nimport torch\nfrom torch import Tensor\n\nfrom torchmetrics.functional.classification.calibration_error import _ce_compute, _ce_update\nfrom torchmetrics.metric import Metric\nfrom torchmetrics.utilities.data import dim_zero_cat\n\n\nclass CalibrationError(Metric):\n r\"\"\"\n\n `Computes the Top-label Calibration Error`_\n Three different norms are implemented, each corresponding to variations on the calibration error metric.\n\n L1 norm (Expected Calibration Error)\n\n .. math::\n \\text{ECE} = \\frac{1}{N}\\sum_i^N \\|(p_i - c_i)\\|\n\n Infinity norm (Maximum Calibration Error)\n\n .. math::\n \\text{RMSCE} = \\max_{i} (p_i - c_i)\n\n L2 norm (Root Mean Square Calibration Error)\n\n .. math::\n \\text{MCE} = \\frac{1}{N}\\sum_i^N (p_i - c_i)^2\n\n Where :math:`p_i` is the top-1 prediction accuracy in bin i\n and :math:`c_i` is the average confidence of predictions in bin i.\n\n .. note::\n L2-norm debiasing is not yet supported.\n\n Args:\n n_bins: Number of bins to use when computing probabilites and accuracies.\n norm: Norm used to compare empirical and expected probability bins.\n Defaults to \"l1\", or Expected Calibration Error.\n debias: Applies debiasing term, only implemented for l2 norm. Defaults to True.\n compute_on_step: Forward only calls ``update()`` and return None if this is set to False.\n dist_sync_on_step: Synchronize metric state across processes at each ``forward()``\n before returning the value at the step\n process_group: Specify the process group on which synchronization is called.\n \"\"\"\n DISTANCES = {\"l1\", \"l2\", \"max\"}\n higher_is_better = False\n confidences: List[Tensor]\n accuracies: List[Tensor]\n\n def __init__(\n self,\n n_bins: int = 15,\n norm: str = \"l1\",\n compute_on_step: bool = False,\n dist_sync_on_step: bool = False,\n process_group: Optional[Any] = None,\n ):\n\n super().__init__(\n compute_on_step=compute_on_step,\n dist_sync_on_step=dist_sync_on_step,\n process_group=process_group,\n dist_sync_fn=None,\n )\n\n if norm not in self.DISTANCES:\n raise ValueError(f\"Norm {norm} is not supported. Please select from l1, l2, or max. \")\n\n if not isinstance(n_bins, int) or n_bins <= 0:\n raise ValueError(f\"Expected argument `n_bins` to be a int larger than 0 but got {n_bins}\")\n self.n_bins = n_bins\n self.register_buffer(\"bin_boundaries\", torch.linspace(0, 1, n_bins + 1))\n self.norm = norm\n\n self.add_state(\"confidences\", [], dist_reduce_fx=\"cat\")\n self.add_state(\"accuracies\", [], dist_reduce_fx=\"cat\")\n\n def update(self, preds: Tensor, target: Tensor) -> None: # type: ignore\n \"\"\"Computes top-level confidences and accuracies for the input probabilites and appends them to internal\n state.\n\n Args:\n preds (Tensor): Model output probabilities.\n target (Tensor): Ground-truth target class labels.\n \"\"\"\n confidences, accuracies = _ce_update(preds, target)\n\n self.confidences.append(confidences)\n self.accuracies.append(accuracies)\n\n def compute(self) -> Tensor:\n \"\"\"Computes calibration error across all confidences and accuracies.\n\n Returns:\n Tensor: Calibration error across previously collected examples.\n \"\"\"\n confidences = dim_zero_cat(self.confidences)\n accuracies = dim_zero_cat(self.accuracies)\n return _ce_compute(confidences, accuracies, self.bin_boundaries, norm=self.norm)\n", "path": "torchmetrics/classification/calibration_error.py"}, {"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Tuple\n\nimport torch\nfrom torch import FloatTensor, Tensor\n\nfrom torchmetrics.utilities.checks import _input_format_classification\nfrom torchmetrics.utilities.enums import DataType\n\n\ndef _ce_compute(\n confidences: FloatTensor,\n accuracies: FloatTensor,\n bin_boundaries: FloatTensor,\n norm: str = \"l1\",\n debias: bool = False,\n) -> Tensor:\n \"\"\"Computes the calibration error given the provided bin boundaries and norm.\n\n Args:\n confidences (FloatTensor): The confidence (i.e. predicted prob) of the top1 prediction.\n accuracies (FloatTensor): 1.0 if the top-1 prediction was correct, 0.0 otherwise.\n bin_boundaries (FloatTensor): Bin boundaries separating the linspace from 0 to 1.\n norm (str, optional): Norm function to use when computing calibration error. Defaults to \"l1\".\n debias (bool, optional): Apply debiasing to L2 norm computation as in\n `Verified Uncertainty Calibration`_. Defaults to False.\n\n Raises:\n ValueError: If an unsupported norm function is provided.\n\n Returns:\n Tensor: Calibration error scalar.\n \"\"\"\n if norm not in {\"l1\", \"l2\", \"max\"}:\n raise ValueError(f\"Norm {norm} is not supported. Please select from l1, l2, or max. \")\n\n conf_bin = torch.zeros_like(bin_boundaries)\n acc_bin = torch.zeros_like(bin_boundaries)\n prop_bin = torch.zeros_like(bin_boundaries)\n for i, (bin_lower, bin_upper) in enumerate(zip(bin_boundaries[:-1], bin_boundaries[1:])):\n # Calculated confidence and accuracy in each bin\n in_bin = confidences.gt(bin_lower.item()) * confidences.le(bin_upper.item())\n prop_in_bin = in_bin.float().mean()\n if prop_in_bin.item() > 0:\n acc_bin[i] = accuracies[in_bin].float().mean()\n conf_bin[i] = confidences[in_bin].mean()\n prop_bin[i] = prop_in_bin\n\n if norm == \"l1\":\n ce = torch.sum(torch.abs(acc_bin - conf_bin) * prop_bin)\n elif norm == \"max\":\n ce = torch.max(torch.abs(acc_bin - conf_bin))\n elif norm == \"l2\":\n ce = torch.sum(torch.pow(acc_bin - conf_bin, 2) * prop_bin)\n # NOTE: debiasing is disabled in the wrapper functions. This implementation differs from that in sklearn.\n if debias:\n # the order here (acc_bin - 1 ) vs (1 - acc_bin) is flipped from\n # the equation in Verified Uncertainty Prediction (Kumar et al 2019)/\n debias_bins = (acc_bin * (acc_bin - 1) * prop_bin) / (prop_bin * accuracies.size()[0] - 1)\n ce += torch.sum(torch.nan_to_num(debias_bins)) # replace nans with zeros if nothing appeared in a bin\n ce = torch.sqrt(ce) if ce > 0 else torch.tensor(0)\n return ce\n\n\ndef _ce_update(preds: Tensor, target: Tensor) -> Tuple[FloatTensor, FloatTensor]:\n \"\"\"Given a predictions and targets tensor, computes the confidences of the top-1 prediction and records their\n correctness.\n\n Args:\n preds (Tensor): Input softmaxed predictions.\n target (Tensor): Labels.\n\n Raises:\n ValueError: If the dataset shape is not binary, multiclass, or multidimensional-multiclass.\n\n Returns:\n Tuple[FloatTensor, FloatTensor]: [description]\n \"\"\"\n _, _, mode = _input_format_classification(preds, target)\n\n if mode == DataType.BINARY:\n confidences, accuracies = preds, target\n elif mode == DataType.MULTICLASS:\n confidences, predictions = preds.max(dim=1)\n accuracies = predictions.eq(target)\n elif mode == DataType.MULTIDIM_MULTICLASS:\n # reshape tensors\n # for preds, move the class dimension to the final axis and flatten the rest\n confidences, predictions = torch.transpose(preds, 1, -1).flatten(0, -2).max(dim=1)\n # for targets, just flatten the target\n accuracies = predictions.eq(target.flatten())\n else:\n raise ValueError(\n f\"Calibration error is not well-defined for data with size {preds.size()} and targets {target.size()}.\"\n )\n # must be cast to float for ddp allgather to work\n return confidences.float(), accuracies.float()\n\n\ndef calibration_error(preds: Tensor, target: Tensor, n_bins: int = 15, norm: str = \"l1\") -> Tensor:\n r\"\"\"\n `Computes the Top-label Calibration Error`_\n\n Three different norms are implemented, each corresponding to variations on the calibration error metric.\n\n L1 norm (Expected Calibration Error)\n\n .. math::\n \\text{ECE} = \\frac{1}{N}\\sum_i^N \\|(p_i - c_i)\\|\n\n Infinity norm (Maximum Calibration Error)\n\n .. math::\n \\text{RMSCE} = \\max_{i} (p_i - c_i)\n\n L2 norm (Root Mean Square Calibration Error)\n\n .. math::\n \\text{MCE} = \\frac{1}{N}\\sum_i^N (p_i - c_i)^2\n\n Where :math:`p_i` is the top-1 prediction accuracy in\n bin i and :math:`c_i` is the average confidence of predictions in bin i.\n\n .. note:\n L2-norm debiasing is not yet supported.\n\n Args:\n preds (Tensor): Model output probabilities.\n target (Tensor): Ground-truth target class labels.\n n_bins (int, optional): Number of bins to use when computing t. Defaults to 15.\n norm (str, optional): Norm used to compare empirical and expected probability bins.\n Defaults to \"l1\", or Expected Calibration Error.\n \"\"\"\n if norm not in (\"l1\", \"l2\", \"max\"):\n raise ValueError(f\"Norm {norm} is not supported. Please select from l1, l2, or max. \")\n\n if not isinstance(n_bins, int) or n_bins <= 0:\n raise ValueError(f\"Expected argument `n_bins` to be a int larger than 0 but got {n_bins}\")\n\n confidences, accuracies = _ce_update(preds, target)\n\n bin_boundaries = torch.linspace(0, 1, n_bins + 1, dtype=torch.float, device=preds.device)\n\n return _ce_compute(confidences, accuracies, bin_boundaries, norm=norm)\n", "path": "torchmetrics/functional/classification/calibration_error.py"}]} | 3,857 | 784 |
gh_patches_debug_28041 | rasdani/github-patches | git_diff | readthedocs__readthedocs.org-5393 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Trigger build on default branch when saving a project
Currently when we save a project form (admin panel),
it triggers a build to latest
https://github.com/rtfd/readthedocs.org/blob/9874b866fea9696fa8495d7b3699f1bf1a3f923d/readthedocs/projects/forms.py#L69-L74
https://github.com/rtfd/readthedocs.org/blob/9874b866fea9696fa8495d7b3699f1bf1a3f923d/readthedocs/core/utils/__init__.py#L97-L98
Even if latest is deactivated, we should trigger a build to the default branch instead.
</issue>
<code>
[start of readthedocs/core/utils/__init__.py]
1 # -*- coding: utf-8 -*-
2
3 """Common utilty functions."""
4
5 from __future__ import absolute_import
6
7 import errno
8 import getpass
9 import logging
10 import os
11 import re
12
13 from django.conf import settings
14 from django.utils.functional import keep_lazy
15 from django.utils.safestring import SafeText, mark_safe
16 from django.utils.text import slugify as slugify_base
17 from celery import group, chord
18
19 from readthedocs.builds.constants import LATEST, BUILD_STATE_TRIGGERED
20 from readthedocs.doc_builder.constants import DOCKER_LIMITS
21
22 log = logging.getLogger(__name__)
23
24 SYNC_USER = getattr(settings, 'SYNC_USER', getpass.getuser())
25
26
27 def broadcast(type, task, args, kwargs=None, callback=None): # pylint: disable=redefined-builtin
28 """
29 Run a broadcast across our servers.
30
31 Returns a task group that can be checked for results.
32
33 `callback` should be a task signature that will be run once,
34 after all of the broadcast tasks have finished running.
35 """
36 assert type in ['web', 'app', 'build']
37 if kwargs is None:
38 kwargs = {}
39 default_queue = getattr(settings, 'CELERY_DEFAULT_QUEUE', 'celery')
40 if type in ['web', 'app']:
41 servers = getattr(settings, 'MULTIPLE_APP_SERVERS', [default_queue])
42 elif type in ['build']:
43 servers = getattr(settings, 'MULTIPLE_BUILD_SERVERS', [default_queue])
44
45 tasks = []
46 for server in servers:
47 task_sig = task.s(*args, **kwargs).set(queue=server)
48 tasks.append(task_sig)
49 if callback:
50 task_promise = chord(tasks, callback).apply_async()
51 else:
52 # Celery's Group class does some special handling when an iterable with
53 # len() == 1 is passed in. This will be hit if there is only one server
54 # defined in the above queue lists
55 if len(tasks) > 1:
56 task_promise = group(*tasks).apply_async()
57 else:
58 task_promise = group(tasks).apply_async()
59 return task_promise
60
61
62 def prepare_build(
63 project,
64 version=None,
65 record=True,
66 force=False,
67 immutable=True,
68 ):
69 """
70 Prepare a build in a Celery task for project and version.
71
72 If project has a ``build_queue``, execute the task on this build queue. If
73 project has ``skip=True``, the build is not triggered.
74
75 :param project: project's documentation to be built
76 :param version: version of the project to be built. Default: ``latest``
77 :param record: whether or not record the build in a new Build object
78 :param force: build the HTML documentation even if the files haven't changed
79 :param immutable: whether or not create an immutable Celery signature
80 :returns: Celery signature of update_docs_task and Build instance
81 :rtype: tuple
82 """
83 # Avoid circular import
84 from readthedocs.builds.models import Build
85 from readthedocs.projects.models import Project
86 from readthedocs.projects.tasks import update_docs_task
87
88 build = None
89
90 if not Project.objects.is_active(project):
91 log.warning(
92 'Build not triggered because Project is not active: project=%s',
93 project.slug,
94 )
95 return (None, None)
96
97 if not version:
98 version = project.versions.get(slug=LATEST)
99
100 kwargs = {
101 'version_pk': version.pk,
102 'record': record,
103 'force': force,
104 }
105
106 if record:
107 build = Build.objects.create(
108 project=project,
109 version=version,
110 type='html',
111 state=BUILD_STATE_TRIGGERED,
112 success=True,
113 )
114 kwargs['build_pk'] = build.pk
115
116 options = {}
117 if project.build_queue:
118 options['queue'] = project.build_queue
119
120 # Set per-task time limit
121 time_limit = DOCKER_LIMITS['time']
122 try:
123 if project.container_time_limit:
124 time_limit = int(project.container_time_limit)
125 except ValueError:
126 log.warning('Invalid time_limit for project: %s', project.slug)
127
128 # Add 20% overhead to task, to ensure the build can timeout and the task
129 # will cleanly finish.
130 options['soft_time_limit'] = time_limit
131 options['time_limit'] = int(time_limit * 1.2)
132
133 return (
134 update_docs_task.signature(
135 args=(project.pk,),
136 kwargs=kwargs,
137 options=options,
138 immutable=True,
139 ),
140 build,
141 )
142
143
144 def trigger_build(project, version=None, record=True, force=False):
145 """
146 Trigger a Build.
147
148 Helper that calls ``prepare_build`` and just effectively trigger the Celery
149 task to be executed by a worker.
150
151 :param project: project's documentation to be built
152 :param version: version of the project to be built. Default: ``latest``
153 :param record: whether or not record the build in a new Build object
154 :param force: build the HTML documentation even if the files haven't changed
155 :returns: Celery AsyncResult promise and Build instance
156 :rtype: tuple
157 """
158 update_docs_task, build = prepare_build(
159 project,
160 version,
161 record,
162 force,
163 immutable=True,
164 )
165
166 if (update_docs_task, build) == (None, None):
167 # Build was skipped
168 return (None, None)
169
170 return (update_docs_task.apply_async(), build)
171
172
173 def send_email(
174 recipient, subject, template, template_html, context=None, request=None,
175 from_email=None, **kwargs
176 ): # pylint: disable=unused-argument
177 """
178 Alter context passed in and call email send task.
179
180 .. seealso::
181
182 Task :py:func:`readthedocs.core.tasks.send_email_task`
183 Task that handles templating and sending email message
184 """
185 from ..tasks import send_email_task
186
187 if context is None:
188 context = {}
189 context['uri'] = '{scheme}://{host}'.format(
190 scheme='https',
191 host=settings.PRODUCTION_DOMAIN,
192 )
193 send_email_task.delay(
194 recipient=recipient, subject=subject, template=template,
195 template_html=template_html, context=context, from_email=from_email,
196 **kwargs
197 )
198
199
200 @keep_lazy(str, SafeText)
201 def slugify(value, *args, **kwargs):
202 """
203 Add a DNS safe option to slugify.
204
205 :param dns_safe: Remove underscores from slug as well
206 """
207 dns_safe = kwargs.pop('dns_safe', True)
208 value = slugify_base(value, *args, **kwargs)
209 if dns_safe:
210 value = mark_safe(re.sub('[-_]+', '-', value))
211 return value
212
213
214 def safe_makedirs(directory_name):
215 """
216 Safely create a directory.
217
218 Makedirs has an issue where it has a race condition around checking for a
219 directory and then creating it. This catches the exception in the case where
220 the dir already exists.
221 """
222 try:
223 os.makedirs(directory_name)
224 except OSError as e:
225 if e.errno != errno.EEXIST: # 17, FileExistsError
226 raise
227
228
229 def safe_unlink(path):
230 """
231 Unlink ``path`` symlink using ``os.unlink``.
232
233 This helper handles the exception ``FileNotFoundError`` to avoid logging in
234 cases where the symlink does not exist already and there is nothing to
235 unlink.
236
237 :param path: symlink path to unlink
238 :type path: str
239 """
240 try:
241 os.unlink(path)
242 except FileNotFoundError:
243 log.warning('Unlink failed. Path %s does not exists', path)
244
[end of readthedocs/core/utils/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/readthedocs/core/utils/__init__.py b/readthedocs/core/utils/__init__.py
--- a/readthedocs/core/utils/__init__.py
+++ b/readthedocs/core/utils/__init__.py
@@ -16,7 +16,7 @@
from django.utils.text import slugify as slugify_base
from celery import group, chord
-from readthedocs.builds.constants import LATEST, BUILD_STATE_TRIGGERED
+from readthedocs.builds.constants import BUILD_STATE_TRIGGERED
from readthedocs.doc_builder.constants import DOCKER_LIMITS
log = logging.getLogger(__name__)
@@ -73,7 +73,7 @@
project has ``skip=True``, the build is not triggered.
:param project: project's documentation to be built
- :param version: version of the project to be built. Default: ``latest``
+ :param version: version of the project to be built. Default: ``project.get_default_version()``
:param record: whether or not record the build in a new Build object
:param force: build the HTML documentation even if the files haven't changed
:param immutable: whether or not create an immutable Celery signature
@@ -95,7 +95,8 @@
return (None, None)
if not version:
- version = project.versions.get(slug=LATEST)
+ default_version = project.get_default_version()
+ version = project.versions.get(slug=default_version)
kwargs = {
'version_pk': version.pk,
| {"golden_diff": "diff --git a/readthedocs/core/utils/__init__.py b/readthedocs/core/utils/__init__.py\n--- a/readthedocs/core/utils/__init__.py\n+++ b/readthedocs/core/utils/__init__.py\n@@ -16,7 +16,7 @@\n from django.utils.text import slugify as slugify_base\n from celery import group, chord\n \n-from readthedocs.builds.constants import LATEST, BUILD_STATE_TRIGGERED\n+from readthedocs.builds.constants import BUILD_STATE_TRIGGERED\n from readthedocs.doc_builder.constants import DOCKER_LIMITS\n \n log = logging.getLogger(__name__)\n@@ -73,7 +73,7 @@\n project has ``skip=True``, the build is not triggered.\n \n :param project: project's documentation to be built\n- :param version: version of the project to be built. Default: ``latest``\n+ :param version: version of the project to be built. Default: ``project.get_default_version()``\n :param record: whether or not record the build in a new Build object\n :param force: build the HTML documentation even if the files haven't changed\n :param immutable: whether or not create an immutable Celery signature\n@@ -95,7 +95,8 @@\n return (None, None)\n \n if not version:\n- version = project.versions.get(slug=LATEST)\n+ default_version = project.get_default_version()\n+ version = project.versions.get(slug=default_version)\n \n kwargs = {\n 'version_pk': version.pk,\n", "issue": "Trigger build on default branch when saving a project\nCurrently when we save a project form (admin panel),\r\nit triggers a build to latest\r\n\r\nhttps://github.com/rtfd/readthedocs.org/blob/9874b866fea9696fa8495d7b3699f1bf1a3f923d/readthedocs/projects/forms.py#L69-L74\r\n\r\nhttps://github.com/rtfd/readthedocs.org/blob/9874b866fea9696fa8495d7b3699f1bf1a3f923d/readthedocs/core/utils/__init__.py#L97-L98\r\n\r\nEven if latest is deactivated, we should trigger a build to the default branch instead.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Common utilty functions.\"\"\"\n\nfrom __future__ import absolute_import\n\nimport errno\nimport getpass\nimport logging\nimport os\nimport re\n\nfrom django.conf import settings\nfrom django.utils.functional import keep_lazy\nfrom django.utils.safestring import SafeText, mark_safe\nfrom django.utils.text import slugify as slugify_base\nfrom celery import group, chord\n\nfrom readthedocs.builds.constants import LATEST, BUILD_STATE_TRIGGERED\nfrom readthedocs.doc_builder.constants import DOCKER_LIMITS\n\nlog = logging.getLogger(__name__)\n\nSYNC_USER = getattr(settings, 'SYNC_USER', getpass.getuser())\n\n\ndef broadcast(type, task, args, kwargs=None, callback=None): # pylint: disable=redefined-builtin\n \"\"\"\n Run a broadcast across our servers.\n\n Returns a task group that can be checked for results.\n\n `callback` should be a task signature that will be run once,\n after all of the broadcast tasks have finished running.\n \"\"\"\n assert type in ['web', 'app', 'build']\n if kwargs is None:\n kwargs = {}\n default_queue = getattr(settings, 'CELERY_DEFAULT_QUEUE', 'celery')\n if type in ['web', 'app']:\n servers = getattr(settings, 'MULTIPLE_APP_SERVERS', [default_queue])\n elif type in ['build']:\n servers = getattr(settings, 'MULTIPLE_BUILD_SERVERS', [default_queue])\n\n tasks = []\n for server in servers:\n task_sig = task.s(*args, **kwargs).set(queue=server)\n tasks.append(task_sig)\n if callback:\n task_promise = chord(tasks, callback).apply_async()\n else:\n # Celery's Group class does some special handling when an iterable with\n # len() == 1 is passed in. This will be hit if there is only one server\n # defined in the above queue lists\n if len(tasks) > 1:\n task_promise = group(*tasks).apply_async()\n else:\n task_promise = group(tasks).apply_async()\n return task_promise\n\n\ndef prepare_build(\n project,\n version=None,\n record=True,\n force=False,\n immutable=True,\n):\n \"\"\"\n Prepare a build in a Celery task for project and version.\n\n If project has a ``build_queue``, execute the task on this build queue. If\n project has ``skip=True``, the build is not triggered.\n\n :param project: project's documentation to be built\n :param version: version of the project to be built. Default: ``latest``\n :param record: whether or not record the build in a new Build object\n :param force: build the HTML documentation even if the files haven't changed\n :param immutable: whether or not create an immutable Celery signature\n :returns: Celery signature of update_docs_task and Build instance\n :rtype: tuple\n \"\"\"\n # Avoid circular import\n from readthedocs.builds.models import Build\n from readthedocs.projects.models import Project\n from readthedocs.projects.tasks import update_docs_task\n\n build = None\n\n if not Project.objects.is_active(project):\n log.warning(\n 'Build not triggered because Project is not active: project=%s',\n project.slug,\n )\n return (None, None)\n\n if not version:\n version = project.versions.get(slug=LATEST)\n\n kwargs = {\n 'version_pk': version.pk,\n 'record': record,\n 'force': force,\n }\n\n if record:\n build = Build.objects.create(\n project=project,\n version=version,\n type='html',\n state=BUILD_STATE_TRIGGERED,\n success=True,\n )\n kwargs['build_pk'] = build.pk\n\n options = {}\n if project.build_queue:\n options['queue'] = project.build_queue\n\n # Set per-task time limit\n time_limit = DOCKER_LIMITS['time']\n try:\n if project.container_time_limit:\n time_limit = int(project.container_time_limit)\n except ValueError:\n log.warning('Invalid time_limit for project: %s', project.slug)\n\n # Add 20% overhead to task, to ensure the build can timeout and the task\n # will cleanly finish.\n options['soft_time_limit'] = time_limit\n options['time_limit'] = int(time_limit * 1.2)\n\n return (\n update_docs_task.signature(\n args=(project.pk,),\n kwargs=kwargs,\n options=options,\n immutable=True,\n ),\n build,\n )\n\n\ndef trigger_build(project, version=None, record=True, force=False):\n \"\"\"\n Trigger a Build.\n\n Helper that calls ``prepare_build`` and just effectively trigger the Celery\n task to be executed by a worker.\n\n :param project: project's documentation to be built\n :param version: version of the project to be built. Default: ``latest``\n :param record: whether or not record the build in a new Build object\n :param force: build the HTML documentation even if the files haven't changed\n :returns: Celery AsyncResult promise and Build instance\n :rtype: tuple\n \"\"\"\n update_docs_task, build = prepare_build(\n project,\n version,\n record,\n force,\n immutable=True,\n )\n\n if (update_docs_task, build) == (None, None):\n # Build was skipped\n return (None, None)\n\n return (update_docs_task.apply_async(), build)\n\n\ndef send_email(\n recipient, subject, template, template_html, context=None, request=None,\n from_email=None, **kwargs\n): # pylint: disable=unused-argument\n \"\"\"\n Alter context passed in and call email send task.\n\n .. seealso::\n\n Task :py:func:`readthedocs.core.tasks.send_email_task`\n Task that handles templating and sending email message\n \"\"\"\n from ..tasks import send_email_task\n\n if context is None:\n context = {}\n context['uri'] = '{scheme}://{host}'.format(\n scheme='https',\n host=settings.PRODUCTION_DOMAIN,\n )\n send_email_task.delay(\n recipient=recipient, subject=subject, template=template,\n template_html=template_html, context=context, from_email=from_email,\n **kwargs\n )\n\n\n@keep_lazy(str, SafeText)\ndef slugify(value, *args, **kwargs):\n \"\"\"\n Add a DNS safe option to slugify.\n\n :param dns_safe: Remove underscores from slug as well\n \"\"\"\n dns_safe = kwargs.pop('dns_safe', True)\n value = slugify_base(value, *args, **kwargs)\n if dns_safe:\n value = mark_safe(re.sub('[-_]+', '-', value))\n return value\n\n\ndef safe_makedirs(directory_name):\n \"\"\"\n Safely create a directory.\n\n Makedirs has an issue where it has a race condition around checking for a\n directory and then creating it. This catches the exception in the case where\n the dir already exists.\n \"\"\"\n try:\n os.makedirs(directory_name)\n except OSError as e:\n if e.errno != errno.EEXIST: # 17, FileExistsError\n raise\n\n\ndef safe_unlink(path):\n \"\"\"\n Unlink ``path`` symlink using ``os.unlink``.\n\n This helper handles the exception ``FileNotFoundError`` to avoid logging in\n cases where the symlink does not exist already and there is nothing to\n unlink.\n\n :param path: symlink path to unlink\n :type path: str\n \"\"\"\n try:\n os.unlink(path)\n except FileNotFoundError:\n log.warning('Unlink failed. Path %s does not exists', path)\n", "path": "readthedocs/core/utils/__init__.py"}]} | 3,012 | 330 |
gh_patches_debug_50240 | rasdani/github-patches | git_diff | sopel-irc__sopel-1437 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
config: default_timezone has no default
I need to check for side-effects, but there shouldn't be any reason that `core.default_timezone` can't default to `'UTC'`. It currently defaults to `None`, which caused errors when I was testing #1162 just now.
</issue>
<code>
[start of sopel/config/core_section.py]
1 # coding=utf-8
2
3 from __future__ import unicode_literals, absolute_import, print_function, division
4
5 import os.path
6
7 from sopel.config.types import (
8 StaticSection, ValidatedAttribute, ListAttribute, ChoiceAttribute,
9 FilenameAttribute, NO_DEFAULT
10 )
11 from sopel.tools import Identifier
12
13
14 def _find_certs():
15 """
16 Find the TLS root CA store.
17
18 :returns: str (path to file)
19 """
20 # check if the root CA store is at a known location
21 locations = [
22 '/etc/pki/tls/cert.pem', # best first guess
23 '/etc/ssl/certs/ca-certificates.crt', # Debian
24 '/etc/ssl/cert.pem', # FreeBSD base OpenSSL
25 '/usr/local/openssl/cert.pem', # FreeBSD userland OpenSSL
26 '/etc/pki/tls/certs/ca-bundle.crt', # RHEL 6 / Fedora
27 '/etc/pki/ca-trust/extracted/pem/tls-ca-bundle.pem', # RHEL 7 / CentOS
28 '/etc/pki/tls/cacert.pem', # OpenELEC
29 '/etc/ssl/ca-bundle.pem', # OpenSUSE
30 ]
31 for certs in locations:
32 if os.path.isfile(certs):
33 return certs
34 return None
35
36
37 def configure(config):
38 config.core.configure_setting('nick', 'Enter the nickname for your bot.')
39 config.core.configure_setting('host', 'Enter the server to connect to.')
40 config.core.configure_setting('use_ssl', 'Should the bot connect with SSL?')
41 if config.core.use_ssl:
42 default_port = 6697
43 else:
44 default_port = 6667
45 config.core.configure_setting('port', 'Enter the port to connect on.',
46 default=default_port)
47 config.core.configure_setting(
48 'owner', "Enter your own IRC name (or that of the bot's owner)")
49 config.core.configure_setting(
50 'channels',
51 'Enter the channels to connect to at startup, separated by commas.'
52 )
53
54
55 class CoreSection(StaticSection):
56 """The config section used for configuring the bot itself."""
57 admins = ListAttribute('admins')
58 """The list of people (other than the owner) who can administer the bot"""
59
60 admin_accounts = ListAttribute('admin_accounts')
61 """The list of accounts (other than the owner's) who can administer the bot.
62
63 This should not be set for networks that do not support IRCv3 account
64 capabilities."""
65
66 alias_nicks = ListAttribute('alias_nicks')
67 """List of alternate names recognized as the bot's nick for $nick and
68 $nickname regex substitutions"""
69
70 auth_method = ChoiceAttribute('auth_method', choices=[
71 'nickserv', 'authserv', 'Q', 'sasl', 'server', 'userserv'])
72 """The method to use to authenticate with the server.
73
74 Can be ``nickserv``, ``authserv``, ``Q``, ``sasl``, or ``server`` or ``userserv``."""
75
76 auth_password = ValidatedAttribute('auth_password')
77 """The password to use to authenticate with the server."""
78
79 auth_target = ValidatedAttribute('auth_target')
80 """The user to use for nickserv authentication, or the SASL mechanism.
81
82 May not apply, depending on ``auth_method``. Defaults to NickServ for
83 nickserv auth, and PLAIN for SASL auth."""
84
85 auth_username = ValidatedAttribute('auth_username')
86 """The username/account to use to authenticate with the server.
87
88 May not apply, depending on ``auth_method``."""
89
90 bind_host = ValidatedAttribute('bind_host')
91 """Bind the connection to a specific IP"""
92
93 ca_certs = FilenameAttribute('ca_certs', default=_find_certs())
94 """The path of the CA certs pem file"""
95
96 channels = ListAttribute('channels')
97 """List of channels for the bot to join when it connects"""
98
99 db_filename = ValidatedAttribute('db_filename')
100 """The filename for Sopel's database."""
101
102 default_time_format = ValidatedAttribute('default_time_format',
103 default='%Y-%m-%d - %T%Z')
104 """The default format to use for time in messages."""
105
106 default_timezone = ValidatedAttribute('default_timezone')
107 """The default timezone to use for time in messages."""
108
109 enable = ListAttribute('enable')
110 """A whitelist of the only modules you want to enable."""
111
112 exclude = ListAttribute('exclude')
113 """A list of modules which should not be loaded."""
114
115 extra = ListAttribute('extra')
116 """A list of other directories you'd like to include modules from."""
117
118 help_prefix = ValidatedAttribute('help_prefix', default='.')
119 """The prefix to use in help"""
120
121 @property
122 def homedir(self):
123 """The directory in which various files are stored at runtime.
124
125 By default, this is the same directory as the config. It can not be
126 changed at runtime.
127 """
128 return self._parent.homedir
129
130 host = ValidatedAttribute('host', default='irc.dftba.net')
131 """The server to connect to."""
132
133 host_blocks = ListAttribute('host_blocks')
134 """A list of hostmasks which Sopel should ignore.
135
136 Regular expression syntax is used"""
137
138 log_raw = ValidatedAttribute('log_raw', bool, default=False)
139 """Whether a log of raw lines as sent and received should be kept."""
140
141 logdir = FilenameAttribute('logdir', directory=True, default='logs')
142 """Directory in which to place logs."""
143
144 logging_channel = ValidatedAttribute('logging_channel', Identifier)
145 """The channel to send logging messages to."""
146
147 logging_level = ChoiceAttribute('logging_level',
148 ['CRITICAL', 'ERROR', 'WARNING', 'INFO',
149 'DEBUG'],
150 'WARNING')
151 """The lowest severity of logs to display."""
152
153 modes = ValidatedAttribute('modes', default='B')
154 """User modes to be set on connection."""
155
156 name = ValidatedAttribute('name', default='Sopel: https://sopel.chat')
157 """The "real name" of your bot for WHOIS responses."""
158
159 nick = ValidatedAttribute('nick', Identifier, default=Identifier('Sopel'))
160 """The nickname for the bot"""
161
162 nick_blocks = ListAttribute('nick_blocks')
163 """A list of nicks which Sopel should ignore.
164
165 Regular expression syntax is used."""
166
167 not_configured = ValidatedAttribute('not_configured', bool, default=False)
168 """For package maintainers. Not used in normal configurations.
169
170 This allows software packages to install a default config file, with this
171 set to true, so that the bot will not run until it has been properly
172 configured."""
173
174 owner = ValidatedAttribute('owner', default=NO_DEFAULT)
175 """The IRC name of the owner of the bot."""
176
177 owner_account = ValidatedAttribute('owner_account')
178 """The services account name of the owner of the bot.
179
180 This should only be set on networks which support IRCv3 account
181 capabilities.
182 """
183
184 pid_dir = FilenameAttribute('pid_dir', directory=True, default='.')
185 """The directory in which to put the file Sopel uses to track its process ID.
186
187 You probably do not need to change this unless you're managing Sopel with
188 systemd or similar."""
189
190 port = ValidatedAttribute('port', int, default=6667)
191 """The port to connect on."""
192
193 prefix = ValidatedAttribute('prefix', default='\\.')
194 """The prefix to add to the beginning of commands.
195
196 It is a regular expression (so the default, ``\\.``, means commands start
197 with a period), though using capturing groups will create problems."""
198
199 reply_errors = ValidatedAttribute('reply_errors', bool, default=True)
200 """Whether to message the sender of a message that triggered an error with the exception."""
201
202 throttle_join = ValidatedAttribute('throttle_join', int)
203 """Slow down the initial join of channels to prevent getting kicked.
204
205 Sopel will only join this many channels at a time, sleeping for a second
206 between each batch. This is unnecessary on most networks."""
207
208 timeout = ValidatedAttribute('timeout', int, default=120)
209 """The amount of time acceptable between pings before timing out."""
210
211 use_ssl = ValidatedAttribute('use_ssl', bool, default=False)
212 """Whether to use a SSL secured connection."""
213
214 user = ValidatedAttribute('user', default='sopel')
215 """The "user" for your bot (the part before the @ in the hostname)."""
216
217 verify_ssl = ValidatedAttribute('verify_ssl', bool, default=True)
218 """Whether to require a trusted SSL certificate for SSL connections."""
219
[end of sopel/config/core_section.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/sopel/config/core_section.py b/sopel/config/core_section.py
--- a/sopel/config/core_section.py
+++ b/sopel/config/core_section.py
@@ -103,7 +103,7 @@
default='%Y-%m-%d - %T%Z')
"""The default format to use for time in messages."""
- default_timezone = ValidatedAttribute('default_timezone')
+ default_timezone = ValidatedAttribute('default_timezone', default='UTC')
"""The default timezone to use for time in messages."""
enable = ListAttribute('enable')
| {"golden_diff": "diff --git a/sopel/config/core_section.py b/sopel/config/core_section.py\n--- a/sopel/config/core_section.py\n+++ b/sopel/config/core_section.py\n@@ -103,7 +103,7 @@\n default='%Y-%m-%d - %T%Z')\n \"\"\"The default format to use for time in messages.\"\"\"\n \n- default_timezone = ValidatedAttribute('default_timezone')\n+ default_timezone = ValidatedAttribute('default_timezone', default='UTC')\n \"\"\"The default timezone to use for time in messages.\"\"\"\n \n enable = ListAttribute('enable')\n", "issue": "config: default_timezone has no default\nI need to check for side-effects, but there shouldn't be any reason that `core.default_timezone` can't default to `'UTC'`. It currently defaults to `None`, which caused errors when I was testing #1162 just now.\n", "before_files": [{"content": "# coding=utf-8\n\nfrom __future__ import unicode_literals, absolute_import, print_function, division\n\nimport os.path\n\nfrom sopel.config.types import (\n StaticSection, ValidatedAttribute, ListAttribute, ChoiceAttribute,\n FilenameAttribute, NO_DEFAULT\n)\nfrom sopel.tools import Identifier\n\n\ndef _find_certs():\n \"\"\"\n Find the TLS root CA store.\n\n :returns: str (path to file)\n \"\"\"\n # check if the root CA store is at a known location\n locations = [\n '/etc/pki/tls/cert.pem', # best first guess\n '/etc/ssl/certs/ca-certificates.crt', # Debian\n '/etc/ssl/cert.pem', # FreeBSD base OpenSSL\n '/usr/local/openssl/cert.pem', # FreeBSD userland OpenSSL\n '/etc/pki/tls/certs/ca-bundle.crt', # RHEL 6 / Fedora\n '/etc/pki/ca-trust/extracted/pem/tls-ca-bundle.pem', # RHEL 7 / CentOS\n '/etc/pki/tls/cacert.pem', # OpenELEC\n '/etc/ssl/ca-bundle.pem', # OpenSUSE\n ]\n for certs in locations:\n if os.path.isfile(certs):\n return certs\n return None\n\n\ndef configure(config):\n config.core.configure_setting('nick', 'Enter the nickname for your bot.')\n config.core.configure_setting('host', 'Enter the server to connect to.')\n config.core.configure_setting('use_ssl', 'Should the bot connect with SSL?')\n if config.core.use_ssl:\n default_port = 6697\n else:\n default_port = 6667\n config.core.configure_setting('port', 'Enter the port to connect on.',\n default=default_port)\n config.core.configure_setting(\n 'owner', \"Enter your own IRC name (or that of the bot's owner)\")\n config.core.configure_setting(\n 'channels',\n 'Enter the channels to connect to at startup, separated by commas.'\n )\n\n\nclass CoreSection(StaticSection):\n \"\"\"The config section used for configuring the bot itself.\"\"\"\n admins = ListAttribute('admins')\n \"\"\"The list of people (other than the owner) who can administer the bot\"\"\"\n\n admin_accounts = ListAttribute('admin_accounts')\n \"\"\"The list of accounts (other than the owner's) who can administer the bot.\n\n This should not be set for networks that do not support IRCv3 account\n capabilities.\"\"\"\n\n alias_nicks = ListAttribute('alias_nicks')\n \"\"\"List of alternate names recognized as the bot's nick for $nick and\n $nickname regex substitutions\"\"\"\n\n auth_method = ChoiceAttribute('auth_method', choices=[\n 'nickserv', 'authserv', 'Q', 'sasl', 'server', 'userserv'])\n \"\"\"The method to use to authenticate with the server.\n\n Can be ``nickserv``, ``authserv``, ``Q``, ``sasl``, or ``server`` or ``userserv``.\"\"\"\n\n auth_password = ValidatedAttribute('auth_password')\n \"\"\"The password to use to authenticate with the server.\"\"\"\n\n auth_target = ValidatedAttribute('auth_target')\n \"\"\"The user to use for nickserv authentication, or the SASL mechanism.\n\n May not apply, depending on ``auth_method``. Defaults to NickServ for\n nickserv auth, and PLAIN for SASL auth.\"\"\"\n\n auth_username = ValidatedAttribute('auth_username')\n \"\"\"The username/account to use to authenticate with the server.\n\n May not apply, depending on ``auth_method``.\"\"\"\n\n bind_host = ValidatedAttribute('bind_host')\n \"\"\"Bind the connection to a specific IP\"\"\"\n\n ca_certs = FilenameAttribute('ca_certs', default=_find_certs())\n \"\"\"The path of the CA certs pem file\"\"\"\n\n channels = ListAttribute('channels')\n \"\"\"List of channels for the bot to join when it connects\"\"\"\n\n db_filename = ValidatedAttribute('db_filename')\n \"\"\"The filename for Sopel's database.\"\"\"\n\n default_time_format = ValidatedAttribute('default_time_format',\n default='%Y-%m-%d - %T%Z')\n \"\"\"The default format to use for time in messages.\"\"\"\n\n default_timezone = ValidatedAttribute('default_timezone')\n \"\"\"The default timezone to use for time in messages.\"\"\"\n\n enable = ListAttribute('enable')\n \"\"\"A whitelist of the only modules you want to enable.\"\"\"\n\n exclude = ListAttribute('exclude')\n \"\"\"A list of modules which should not be loaded.\"\"\"\n\n extra = ListAttribute('extra')\n \"\"\"A list of other directories you'd like to include modules from.\"\"\"\n\n help_prefix = ValidatedAttribute('help_prefix', default='.')\n \"\"\"The prefix to use in help\"\"\"\n\n @property\n def homedir(self):\n \"\"\"The directory in which various files are stored at runtime.\n\n By default, this is the same directory as the config. It can not be\n changed at runtime.\n \"\"\"\n return self._parent.homedir\n\n host = ValidatedAttribute('host', default='irc.dftba.net')\n \"\"\"The server to connect to.\"\"\"\n\n host_blocks = ListAttribute('host_blocks')\n \"\"\"A list of hostmasks which Sopel should ignore.\n\n Regular expression syntax is used\"\"\"\n\n log_raw = ValidatedAttribute('log_raw', bool, default=False)\n \"\"\"Whether a log of raw lines as sent and received should be kept.\"\"\"\n\n logdir = FilenameAttribute('logdir', directory=True, default='logs')\n \"\"\"Directory in which to place logs.\"\"\"\n\n logging_channel = ValidatedAttribute('logging_channel', Identifier)\n \"\"\"The channel to send logging messages to.\"\"\"\n\n logging_level = ChoiceAttribute('logging_level',\n ['CRITICAL', 'ERROR', 'WARNING', 'INFO',\n 'DEBUG'],\n 'WARNING')\n \"\"\"The lowest severity of logs to display.\"\"\"\n\n modes = ValidatedAttribute('modes', default='B')\n \"\"\"User modes to be set on connection.\"\"\"\n\n name = ValidatedAttribute('name', default='Sopel: https://sopel.chat')\n \"\"\"The \"real name\" of your bot for WHOIS responses.\"\"\"\n\n nick = ValidatedAttribute('nick', Identifier, default=Identifier('Sopel'))\n \"\"\"The nickname for the bot\"\"\"\n\n nick_blocks = ListAttribute('nick_blocks')\n \"\"\"A list of nicks which Sopel should ignore.\n\n Regular expression syntax is used.\"\"\"\n\n not_configured = ValidatedAttribute('not_configured', bool, default=False)\n \"\"\"For package maintainers. Not used in normal configurations.\n\n This allows software packages to install a default config file, with this\n set to true, so that the bot will not run until it has been properly\n configured.\"\"\"\n\n owner = ValidatedAttribute('owner', default=NO_DEFAULT)\n \"\"\"The IRC name of the owner of the bot.\"\"\"\n\n owner_account = ValidatedAttribute('owner_account')\n \"\"\"The services account name of the owner of the bot.\n\n This should only be set on networks which support IRCv3 account\n capabilities.\n \"\"\"\n\n pid_dir = FilenameAttribute('pid_dir', directory=True, default='.')\n \"\"\"The directory in which to put the file Sopel uses to track its process ID.\n\n You probably do not need to change this unless you're managing Sopel with\n systemd or similar.\"\"\"\n\n port = ValidatedAttribute('port', int, default=6667)\n \"\"\"The port to connect on.\"\"\"\n\n prefix = ValidatedAttribute('prefix', default='\\\\.')\n \"\"\"The prefix to add to the beginning of commands.\n\n It is a regular expression (so the default, ``\\\\.``, means commands start\n with a period), though using capturing groups will create problems.\"\"\"\n\n reply_errors = ValidatedAttribute('reply_errors', bool, default=True)\n \"\"\"Whether to message the sender of a message that triggered an error with the exception.\"\"\"\n\n throttle_join = ValidatedAttribute('throttle_join', int)\n \"\"\"Slow down the initial join of channels to prevent getting kicked.\n\n Sopel will only join this many channels at a time, sleeping for a second\n between each batch. This is unnecessary on most networks.\"\"\"\n\n timeout = ValidatedAttribute('timeout', int, default=120)\n \"\"\"The amount of time acceptable between pings before timing out.\"\"\"\n\n use_ssl = ValidatedAttribute('use_ssl', bool, default=False)\n \"\"\"Whether to use a SSL secured connection.\"\"\"\n\n user = ValidatedAttribute('user', default='sopel')\n \"\"\"The \"user\" for your bot (the part before the @ in the hostname).\"\"\"\n\n verify_ssl = ValidatedAttribute('verify_ssl', bool, default=True)\n \"\"\"Whether to require a trusted SSL certificate for SSL connections.\"\"\"\n", "path": "sopel/config/core_section.py"}]} | 3,064 | 130 |
gh_patches_debug_25467 | rasdani/github-patches | git_diff | digitalfabrik__integreat-cms-175 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
IntegrityError in language tree
I just found a bug causing an `IntegrityError` in the language tree. The error can be reproduced reliably in the current state of the develop branch.
Steps to reproduce:
- In the network admin view:
- Create a new region
- Create at least two languages (in the following steps, we assume the two languages to be German and Englisch, works with any other languages as well)
- In the region view (in the region we just created):
- Create a new language node for the base language (German in this example)
- **Bug occurs in the next steps, therefore I provide a more precise description of the following steps:** in the language tree view, click on "create language tree node"
- Choose "English" as language, "German" as source language, check the checkbox for language activation
- click on "save", a success message should show up
- click on "save" again without changing any form fields
- now the form fields should have the following contents:
- language: "English"
- source language: "German"
- activate language: is checked (`true`)
- change language field to "German", as all languages can be chosen again
- now the form fields should have the following contents:
- language: "German"
- source language: "German"
- activate language: is checked (`true`)
- click on "save" again
- `IntegrityError` occurs
</issue>
<code>
[start of backend/cms/views/language_tree/language_tree_node.py]
1 """
2
3 Returns:
4 [type]: [description]
5 """
6
7 from django.contrib import messages
8 from django.contrib.auth.decorators import login_required
9 from django.contrib.auth.mixins import PermissionRequiredMixin
10 from django.utils.translation import ugettext as _
11 from django.utils.decorators import method_decorator
12 from django.views.generic import TemplateView
13 from django.shortcuts import render, redirect
14
15 from .language_tree_node_form import LanguageTreeNodeForm
16 from ...models import Language, LanguageTreeNode, Site
17 from ...decorators import region_permission_required
18
19
20 @method_decorator(login_required, name='dispatch')
21 @method_decorator(region_permission_required, name='dispatch')
22 class LanguageTreeNodeView(PermissionRequiredMixin, TemplateView):
23 permission_required = 'cms.manage_language_tree'
24 raise_exception = True
25
26 template_name = 'language_tree/tree_node.html'
27 base_context = {'current_menu_item': 'language_tree'}
28
29 def get(self, request, *args, **kwargs):
30 language_tree_node_id = self.kwargs.get('language_tree_node_id')
31 # limit possible parents to nodes of current region
32 parent_queryset = Site.get_current_site(request).language_tree_nodes
33 # limit possible languages to those which are not yet included in the tree
34 language_queryset = Language.objects.exclude(
35 language_tree_nodes__in=parent_queryset.exclude(id=language_tree_node_id)
36 )
37 if language_tree_node_id:
38 language_tree_node = LanguageTreeNode.objects.get(id=language_tree_node_id)
39 children = language_tree_node.get_descendants(include_self=True)
40 parent_queryset = parent_queryset.difference(children)
41 form = LanguageTreeNodeForm(initial={
42 'language': language_tree_node.language,
43 'parent': language_tree_node.parent,
44 'active': language_tree_node.active,
45 })
46 else:
47 form = LanguageTreeNodeForm()
48 form.fields['parent'].queryset = parent_queryset
49 form.fields['language'].queryset = language_queryset
50 return render(request, self.template_name, {
51 'form': form, **self.base_context})
52
53 def post(self, request, site_slug, language_tree_node_id=None):
54 # TODO: error handling
55 form = LanguageTreeNodeForm(data=request.POST, site_slug=site_slug)
56 if form.is_valid():
57 if language_tree_node_id:
58 form.save_language_node(
59 language_tree_node_id=language_tree_node_id,
60 )
61 messages.success(request, _('Language tree node was saved successfully.'))
62 else:
63 language_tree_node = form.save_language_node()
64 messages.success(request, _('Language tree node was created successfully.'))
65 return redirect('edit_language_tree_node', **{
66 'language_tree_node_id': language_tree_node.id,
67 'site_slug': site_slug,
68 })
69 # TODO: improve messages
70 else:
71 messages.error(request, _('Errors have occurred.'))
72
73 return render(request, self.template_name, {
74 'form': form, **self.base_context})
75
[end of backend/cms/views/language_tree/language_tree_node.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/backend/cms/views/language_tree/language_tree_node.py b/backend/cms/views/language_tree/language_tree_node.py
--- a/backend/cms/views/language_tree/language_tree_node.py
+++ b/backend/cms/views/language_tree/language_tree_node.py
@@ -55,17 +55,17 @@
form = LanguageTreeNodeForm(data=request.POST, site_slug=site_slug)
if form.is_valid():
if language_tree_node_id:
- form.save_language_node(
+ language_tree_node = form.save_language_node(
language_tree_node_id=language_tree_node_id,
)
messages.success(request, _('Language tree node was saved successfully.'))
else:
language_tree_node = form.save_language_node()
messages.success(request, _('Language tree node was created successfully.'))
- return redirect('edit_language_tree_node', **{
- 'language_tree_node_id': language_tree_node.id,
- 'site_slug': site_slug,
- })
+ return redirect('edit_language_tree_node', **{
+ 'language_tree_node_id': language_tree_node.id,
+ 'site_slug': site_slug,
+ })
# TODO: improve messages
else:
messages.error(request, _('Errors have occurred.'))
| {"golden_diff": "diff --git a/backend/cms/views/language_tree/language_tree_node.py b/backend/cms/views/language_tree/language_tree_node.py\n--- a/backend/cms/views/language_tree/language_tree_node.py\n+++ b/backend/cms/views/language_tree/language_tree_node.py\n@@ -55,17 +55,17 @@\n form = LanguageTreeNodeForm(data=request.POST, site_slug=site_slug)\n if form.is_valid():\n if language_tree_node_id:\n- form.save_language_node(\n+ language_tree_node = form.save_language_node(\n language_tree_node_id=language_tree_node_id,\n )\n messages.success(request, _('Language tree node was saved successfully.'))\n else:\n language_tree_node = form.save_language_node()\n messages.success(request, _('Language tree node was created successfully.'))\n- return redirect('edit_language_tree_node', **{\n- 'language_tree_node_id': language_tree_node.id,\n- 'site_slug': site_slug,\n- })\n+ return redirect('edit_language_tree_node', **{\n+ 'language_tree_node_id': language_tree_node.id,\n+ 'site_slug': site_slug,\n+ })\n # TODO: improve messages\n else:\n messages.error(request, _('Errors have occurred.'))\n", "issue": "IntegrityError in language tree\nI just found a bug causing an `IntegrityError` in the language tree. The error can be reproduced reliably in the current state of the develop branch.\r\n\r\nSteps to reproduce:\r\n- In the network admin view:\r\n - Create a new region\r\n - Create at least two languages (in the following steps, we assume the two languages to be German and Englisch, works with any other languages as well)\r\n- In the region view (in the region we just created):\r\n - Create a new language node for the base language (German in this example)\r\n - **Bug occurs in the next steps, therefore I provide a more precise description of the following steps:** in the language tree view, click on \"create language tree node\"\r\n - Choose \"English\" as language, \"German\" as source language, check the checkbox for language activation\r\n - click on \"save\", a success message should show up\r\n - click on \"save\" again without changing any form fields\r\n - now the form fields should have the following contents:\r\n - language: \"English\"\r\n - source language: \"German\"\r\n - activate language: is checked (`true`)\r\n - change language field to \"German\", as all languages can be chosen again\r\n - now the form fields should have the following contents:\r\n - language: \"German\"\r\n - source language: \"German\"\r\n - activate language: is checked (`true`)\r\n - click on \"save\" again\r\n - `IntegrityError` occurs\n", "before_files": [{"content": "\"\"\"\n\nReturns:\n [type]: [description]\n\"\"\"\n\nfrom django.contrib import messages\nfrom django.contrib.auth.decorators import login_required\nfrom django.contrib.auth.mixins import PermissionRequiredMixin\nfrom django.utils.translation import ugettext as _\nfrom django.utils.decorators import method_decorator\nfrom django.views.generic import TemplateView\nfrom django.shortcuts import render, redirect\n\nfrom .language_tree_node_form import LanguageTreeNodeForm\nfrom ...models import Language, LanguageTreeNode, Site\nfrom ...decorators import region_permission_required\n\n\n@method_decorator(login_required, name='dispatch')\n@method_decorator(region_permission_required, name='dispatch')\nclass LanguageTreeNodeView(PermissionRequiredMixin, TemplateView):\n permission_required = 'cms.manage_language_tree'\n raise_exception = True\n\n template_name = 'language_tree/tree_node.html'\n base_context = {'current_menu_item': 'language_tree'}\n\n def get(self, request, *args, **kwargs):\n language_tree_node_id = self.kwargs.get('language_tree_node_id')\n # limit possible parents to nodes of current region\n parent_queryset = Site.get_current_site(request).language_tree_nodes\n # limit possible languages to those which are not yet included in the tree\n language_queryset = Language.objects.exclude(\n language_tree_nodes__in=parent_queryset.exclude(id=language_tree_node_id)\n )\n if language_tree_node_id:\n language_tree_node = LanguageTreeNode.objects.get(id=language_tree_node_id)\n children = language_tree_node.get_descendants(include_self=True)\n parent_queryset = parent_queryset.difference(children)\n form = LanguageTreeNodeForm(initial={\n 'language': language_tree_node.language,\n 'parent': language_tree_node.parent,\n 'active': language_tree_node.active,\n })\n else:\n form = LanguageTreeNodeForm()\n form.fields['parent'].queryset = parent_queryset\n form.fields['language'].queryset = language_queryset\n return render(request, self.template_name, {\n 'form': form, **self.base_context})\n\n def post(self, request, site_slug, language_tree_node_id=None):\n # TODO: error handling\n form = LanguageTreeNodeForm(data=request.POST, site_slug=site_slug)\n if form.is_valid():\n if language_tree_node_id:\n form.save_language_node(\n language_tree_node_id=language_tree_node_id,\n )\n messages.success(request, _('Language tree node was saved successfully.'))\n else:\n language_tree_node = form.save_language_node()\n messages.success(request, _('Language tree node was created successfully.'))\n return redirect('edit_language_tree_node', **{\n 'language_tree_node_id': language_tree_node.id,\n 'site_slug': site_slug,\n })\n # TODO: improve messages\n else:\n messages.error(request, _('Errors have occurred.'))\n\n return render(request, self.template_name, {\n 'form': form, **self.base_context})\n", "path": "backend/cms/views/language_tree/language_tree_node.py"}]} | 1,603 | 258 |
gh_patches_debug_8589 | rasdani/github-patches | git_diff | Project-MONAI__MONAI-987 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Basis UNet
On what paper is your UNet based?
The original 2D seems to differ quite a lot from the 3D U-Net by Özgün Çiçek which I'd like to use.
Thanks.
</issue>
<code>
[start of monai/networks/nets/unet.py]
1 # Copyright 2020 MONAI Consortium
2 # Licensed under the Apache License, Version 2.0 (the "License");
3 # you may not use this file except in compliance with the License.
4 # You may obtain a copy of the License at
5 # http://www.apache.org/licenses/LICENSE-2.0
6 # Unless required by applicable law or agreed to in writing, software
7 # distributed under the License is distributed on an "AS IS" BASIS,
8 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
9 # See the License for the specific language governing permissions and
10 # limitations under the License.
11
12 from typing import Sequence, Union
13
14 import torch
15 import torch.nn as nn
16
17 from monai.networks.blocks.convolutions import Convolution, ResidualUnit
18 from monai.networks.layers.factories import Act, Norm
19 from monai.networks.layers.simplelayers import SkipConnection
20 from monai.utils import alias, export
21
22
23 @export("monai.networks.nets")
24 @alias("Unet")
25 class UNet(nn.Module):
26 def __init__(
27 self,
28 dimensions: int,
29 in_channels: int,
30 out_channels: int,
31 channels: Sequence[int],
32 strides: Sequence[int],
33 kernel_size: Union[Sequence[int], int] = 3,
34 up_kernel_size: Union[Sequence[int], int] = 3,
35 num_res_units: int = 0,
36 act=Act.PRELU,
37 norm=Norm.INSTANCE,
38 dropout=0,
39 ) -> None:
40 """
41 Args:
42 dimensions: number of spatial dimensions.
43 in_channels: number of input channels.
44 out_channels: number of output channels.
45 channels: sequence of channels. Top block first.
46 strides: convolution stride.
47 kernel_size: convolution kernel size. Defaults to 3.
48 up_kernel_size: upsampling convolution kernel size. Defaults to 3.
49 num_res_units: number of residual units. Defaults to 0.
50 act: activation type and arguments. Defaults to PReLU.
51 norm: feature normalization type and arguments. Defaults to instance norm.
52 dropout: dropout ratio. Defaults to no dropout.
53 """
54 super().__init__()
55
56 self.dimensions = dimensions
57 self.in_channels = in_channels
58 self.out_channels = out_channels
59 self.channels = channels
60 self.strides = strides
61 self.kernel_size = kernel_size
62 self.up_kernel_size = up_kernel_size
63 self.num_res_units = num_res_units
64 self.act = act
65 self.norm = norm
66 self.dropout = dropout
67
68 def _create_block(
69 inc: int, outc: int, channels: Sequence[int], strides: Sequence[int], is_top: bool
70 ) -> nn.Sequential:
71 """
72 Builds the UNet structure from the bottom up by recursing down to the bottom block, then creating sequential
73 blocks containing the downsample path, a skip connection around the previous block, and the upsample path.
74
75 Args:
76 inc: number of input channels.
77 outc: number of output channels.
78 channels: sequence of channels. Top block first.
79 strides: convolution stride.
80 is_top: True if this is the top block.
81 """
82 c = channels[0]
83 s = strides[0]
84
85 subblock: Union[nn.Sequential, ResidualUnit, Convolution]
86
87 if len(channels) > 2:
88 subblock = _create_block(c, c, channels[1:], strides[1:], False) # continue recursion down
89 upc = c * 2
90 else:
91 # the next layer is the bottom so stop recursion, create the bottom layer as the sublock for this layer
92 subblock = self._get_bottom_layer(c, channels[1])
93 upc = c + channels[1]
94
95 down = self._get_down_layer(inc, c, s, is_top) # create layer in downsampling path
96 up = self._get_up_layer(upc, outc, s, is_top) # create layer in upsampling path
97
98 return nn.Sequential(down, SkipConnection(subblock), up)
99
100 self.model = _create_block(in_channels, out_channels, self.channels, self.strides, True)
101
102 def _get_down_layer(
103 self, in_channels: int, out_channels: int, strides: int, is_top: bool
104 ) -> Union[ResidualUnit, Convolution]:
105 """
106 Args:
107 in_channels: number of input channels.
108 out_channels: number of output channels.
109 strides: convolution stride.
110 is_top: True if this is the top block.
111 """
112 if self.num_res_units > 0:
113 return ResidualUnit(
114 self.dimensions,
115 in_channels,
116 out_channels,
117 strides=strides,
118 kernel_size=self.kernel_size,
119 subunits=self.num_res_units,
120 act=self.act,
121 norm=self.norm,
122 dropout=self.dropout,
123 )
124 else:
125 return Convolution(
126 self.dimensions,
127 in_channels,
128 out_channels,
129 strides=strides,
130 kernel_size=self.kernel_size,
131 act=self.act,
132 norm=self.norm,
133 dropout=self.dropout,
134 )
135
136 def _get_bottom_layer(self, in_channels: int, out_channels: int) -> Union[ResidualUnit, Convolution]:
137 """
138 Args:
139 in_channels: number of input channels.
140 out_channels: number of output channels.
141 """
142 return self._get_down_layer(in_channels, out_channels, 1, False)
143
144 def _get_up_layer(
145 self, in_channels: int, out_channels: int, strides: int, is_top: bool
146 ) -> Union[Convolution, nn.Sequential]:
147 """
148 Args:
149 in_channels: number of input channels.
150 out_channels: number of output channels.
151 strides: convolution stride.
152 is_top: True if this is the top block.
153 """
154 conv: Union[Convolution, nn.Sequential]
155
156 conv = Convolution(
157 self.dimensions,
158 in_channels,
159 out_channels,
160 strides=strides,
161 kernel_size=self.up_kernel_size,
162 act=self.act,
163 norm=self.norm,
164 dropout=self.dropout,
165 conv_only=is_top and self.num_res_units == 0,
166 is_transposed=True,
167 )
168
169 if self.num_res_units > 0:
170 ru = ResidualUnit(
171 self.dimensions,
172 out_channels,
173 out_channels,
174 strides=1,
175 kernel_size=self.kernel_size,
176 subunits=1,
177 act=self.act,
178 norm=self.norm,
179 dropout=self.dropout,
180 last_conv_only=is_top,
181 )
182 conv = nn.Sequential(conv, ru)
183
184 return conv
185
186 def forward(self, x: torch.Tensor) -> torch.Tensor:
187 x = self.model(x)
188 return x
189
190
191 Unet = unet = UNet
192
[end of monai/networks/nets/unet.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/monai/networks/nets/unet.py b/monai/networks/nets/unet.py
--- a/monai/networks/nets/unet.py
+++ b/monai/networks/nets/unet.py
@@ -38,6 +38,11 @@
dropout=0,
) -> None:
"""
+ Enhanced version of UNet which has residual units implemented with the ResidualUnit class.
+ The residual part uses a convolution to change the input dimensions to match the output dimensions
+ if this is necessary but will use nn.Identity if not.
+ Refer to: https://link.springer.com/chapter/10.1007/978-3-030-12029-0_40.
+
Args:
dimensions: number of spatial dimensions.
in_channels: number of input channels.
| {"golden_diff": "diff --git a/monai/networks/nets/unet.py b/monai/networks/nets/unet.py\n--- a/monai/networks/nets/unet.py\n+++ b/monai/networks/nets/unet.py\n@@ -38,6 +38,11 @@\n dropout=0,\n ) -> None:\n \"\"\"\n+ Enhanced version of UNet which has residual units implemented with the ResidualUnit class.\n+ The residual part uses a convolution to change the input dimensions to match the output dimensions\n+ if this is necessary but will use nn.Identity if not.\n+ Refer to: https://link.springer.com/chapter/10.1007/978-3-030-12029-0_40.\n+\n Args:\n dimensions: number of spatial dimensions.\n in_channels: number of input channels.\n", "issue": "Basis UNet\nOn what paper is your UNet based?\r\nThe original 2D seems to differ quite a lot from the 3D U-Net by \u00d6zg\u00fcn \u00c7i\u00e7ek which I'd like to use. \r\n\r\nThanks.\n", "before_files": [{"content": "# Copyright 2020 MONAI Consortium\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n# http://www.apache.org/licenses/LICENSE-2.0\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import Sequence, Union\n\nimport torch\nimport torch.nn as nn\n\nfrom monai.networks.blocks.convolutions import Convolution, ResidualUnit\nfrom monai.networks.layers.factories import Act, Norm\nfrom monai.networks.layers.simplelayers import SkipConnection\nfrom monai.utils import alias, export\n\n\n@export(\"monai.networks.nets\")\n@alias(\"Unet\")\nclass UNet(nn.Module):\n def __init__(\n self,\n dimensions: int,\n in_channels: int,\n out_channels: int,\n channels: Sequence[int],\n strides: Sequence[int],\n kernel_size: Union[Sequence[int], int] = 3,\n up_kernel_size: Union[Sequence[int], int] = 3,\n num_res_units: int = 0,\n act=Act.PRELU,\n norm=Norm.INSTANCE,\n dropout=0,\n ) -> None:\n \"\"\"\n Args:\n dimensions: number of spatial dimensions.\n in_channels: number of input channels.\n out_channels: number of output channels.\n channels: sequence of channels. Top block first.\n strides: convolution stride.\n kernel_size: convolution kernel size. Defaults to 3.\n up_kernel_size: upsampling convolution kernel size. Defaults to 3.\n num_res_units: number of residual units. Defaults to 0.\n act: activation type and arguments. Defaults to PReLU.\n norm: feature normalization type and arguments. Defaults to instance norm.\n dropout: dropout ratio. Defaults to no dropout.\n \"\"\"\n super().__init__()\n\n self.dimensions = dimensions\n self.in_channels = in_channels\n self.out_channels = out_channels\n self.channels = channels\n self.strides = strides\n self.kernel_size = kernel_size\n self.up_kernel_size = up_kernel_size\n self.num_res_units = num_res_units\n self.act = act\n self.norm = norm\n self.dropout = dropout\n\n def _create_block(\n inc: int, outc: int, channels: Sequence[int], strides: Sequence[int], is_top: bool\n ) -> nn.Sequential:\n \"\"\"\n Builds the UNet structure from the bottom up by recursing down to the bottom block, then creating sequential\n blocks containing the downsample path, a skip connection around the previous block, and the upsample path.\n\n Args:\n inc: number of input channels.\n outc: number of output channels.\n channels: sequence of channels. Top block first.\n strides: convolution stride.\n is_top: True if this is the top block.\n \"\"\"\n c = channels[0]\n s = strides[0]\n\n subblock: Union[nn.Sequential, ResidualUnit, Convolution]\n\n if len(channels) > 2:\n subblock = _create_block(c, c, channels[1:], strides[1:], False) # continue recursion down\n upc = c * 2\n else:\n # the next layer is the bottom so stop recursion, create the bottom layer as the sublock for this layer\n subblock = self._get_bottom_layer(c, channels[1])\n upc = c + channels[1]\n\n down = self._get_down_layer(inc, c, s, is_top) # create layer in downsampling path\n up = self._get_up_layer(upc, outc, s, is_top) # create layer in upsampling path\n\n return nn.Sequential(down, SkipConnection(subblock), up)\n\n self.model = _create_block(in_channels, out_channels, self.channels, self.strides, True)\n\n def _get_down_layer(\n self, in_channels: int, out_channels: int, strides: int, is_top: bool\n ) -> Union[ResidualUnit, Convolution]:\n \"\"\"\n Args:\n in_channels: number of input channels.\n out_channels: number of output channels.\n strides: convolution stride.\n is_top: True if this is the top block.\n \"\"\"\n if self.num_res_units > 0:\n return ResidualUnit(\n self.dimensions,\n in_channels,\n out_channels,\n strides=strides,\n kernel_size=self.kernel_size,\n subunits=self.num_res_units,\n act=self.act,\n norm=self.norm,\n dropout=self.dropout,\n )\n else:\n return Convolution(\n self.dimensions,\n in_channels,\n out_channels,\n strides=strides,\n kernel_size=self.kernel_size,\n act=self.act,\n norm=self.norm,\n dropout=self.dropout,\n )\n\n def _get_bottom_layer(self, in_channels: int, out_channels: int) -> Union[ResidualUnit, Convolution]:\n \"\"\"\n Args:\n in_channels: number of input channels.\n out_channels: number of output channels.\n \"\"\"\n return self._get_down_layer(in_channels, out_channels, 1, False)\n\n def _get_up_layer(\n self, in_channels: int, out_channels: int, strides: int, is_top: bool\n ) -> Union[Convolution, nn.Sequential]:\n \"\"\"\n Args:\n in_channels: number of input channels.\n out_channels: number of output channels.\n strides: convolution stride.\n is_top: True if this is the top block.\n \"\"\"\n conv: Union[Convolution, nn.Sequential]\n\n conv = Convolution(\n self.dimensions,\n in_channels,\n out_channels,\n strides=strides,\n kernel_size=self.up_kernel_size,\n act=self.act,\n norm=self.norm,\n dropout=self.dropout,\n conv_only=is_top and self.num_res_units == 0,\n is_transposed=True,\n )\n\n if self.num_res_units > 0:\n ru = ResidualUnit(\n self.dimensions,\n out_channels,\n out_channels,\n strides=1,\n kernel_size=self.kernel_size,\n subunits=1,\n act=self.act,\n norm=self.norm,\n dropout=self.dropout,\n last_conv_only=is_top,\n )\n conv = nn.Sequential(conv, ru)\n\n return conv\n\n def forward(self, x: torch.Tensor) -> torch.Tensor:\n x = self.model(x)\n return x\n\n\nUnet = unet = UNet\n", "path": "monai/networks/nets/unet.py"}]} | 2,521 | 193 |
gh_patches_debug_43552 | rasdani/github-patches | git_diff | streamlink__streamlink-4202 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
plugins.ard_mediathek: rewrite plugin
Resolves #4191
One issue I couldn't fix is the text encoding of the metadata which gets messed up by `validate.parse_html()`. See the VOD title down below...
https://github.com/streamlink/streamlink/blob/175d4748561c7154bb80c5a47dae22039e45d4ce/src/streamlink/utils/parse.py#L54-L55
Some VODs also have a second title, eg. if it's a TV show, but I couldn't be bothered to implement this. Not important.
----
Das Erste - Live:
```
$ streamlink -l debug --title '{author} - {title}' 'https://www.ardmediathek.de/daserste/live/Y3JpZDovL2Rhc2Vyc3RlLmRlL0xpdmVzdHJlYW0tRGFzRXJzdGU/' best
[cli.output][debug] Opening subprocess: mpv "--force-media-title=Das Erste - Das Erste" -
```
WDR - Live:
```
$ streamlink -l debug --title '{author} - {title}' 'https://www.ardmediathek.de/live/Y3JpZDovL3dkci5kZS9CZWl0cmFnLTNkYTY2NGRlLTE4YzItNDY1MC1hNGZmLTRmNjQxNDcyMDcyYg/' best
[cli.output][debug] Opening subprocess: mpv "--force-media-title=WDR - WDR Fernsehen im Livestream" -
```
VOD
```
$ streamlink -l debug --title '{author} - {title}' 'https://www.ardmediathek.de/video/dokus-im-ersten/wirecard-die-milliarden-luege/das-erste/Y3JpZDovL2Rhc2Vyc3RlLmRlL3JlcG9ydGFnZSBfIGRva3VtZW50YXRpb24gaW0gZXJzdGVuL2NlMjQ0OWM4LTQ4YTUtNGIyNC1iMTdlLWNhOTNjMDQ5OTc4Zg/' best
[cli.output][debug] Opening subprocess: mpv "--force-media-title=Das Erste - Wirecard - Die Milliarden-Lüge" -
```
</issue>
<code>
[start of src/streamlink/plugins/ard_mediathek.py]
1 import logging
2 import re
3
4 from streamlink.plugin import Plugin, pluginmatcher
5 from streamlink.plugin.api import validate
6 from streamlink.stream.hls import HLSStream
7
8
9 log = logging.getLogger(__name__)
10
11
12 @pluginmatcher(re.compile(
13 r"https?://(?:(\w+\.)?ardmediathek\.de/|mediathek\.daserste\.de/)"
14 ))
15 class ARDMediathek(Plugin):
16 def _get_streams(self):
17 data_json = self.session.http.get(self.url, schema=validate.Schema(
18 validate.parse_html(),
19 validate.xml_findtext(".//script[@id='fetchedContextValue'][@type='application/json']"),
20 validate.any(None, validate.all(
21 validate.parse_json(),
22 {str: dict},
23 validate.transform(lambda obj: list(obj.items())),
24 validate.filter(lambda item: item[0].startswith("https://api.ardmediathek.de/page-gateway/pages/")),
25 validate.any(validate.get((0, 1)), [])
26 ))
27 ))
28 if not data_json:
29 return
30
31 schema_data = validate.Schema({
32 "id": str,
33 "widgets": validate.all(
34 [dict],
35 validate.filter(lambda item: item.get("mediaCollection")),
36 validate.get(0),
37 {
38 "geoblocked": bool,
39 "publicationService": {
40 "name": str,
41 },
42 "title": str,
43 "mediaCollection": {
44 "embedded": {
45 "_mediaArray": [{
46 "_mediaStreamArray": [{
47 "_quality": validate.any(str, int),
48 "_stream": validate.url()
49 }]
50 }]
51 }
52 }
53 }
54 )
55 })
56 data = schema_data.validate(data_json)
57
58 log.debug(f"Found media id: {data['id']}")
59 data_media = data["widgets"]
60
61 if data_media["geoblocked"]:
62 log.info("The content is not available in your region")
63 return
64
65 self.author = data_media["publicationService"]["name"]
66 self.title = data_media["title"]
67
68 for media in data_media["mediaCollection"]["embedded"]["_mediaArray"]:
69 for stream in media["_mediaStreamArray"]:
70 if stream["_quality"] != "auto" or ".m3u8" not in stream["_stream"]:
71 continue
72 return HLSStream.parse_variant_playlist(self.session, stream["_stream"])
73
74
75 __plugin__ = ARDMediathek
76
[end of src/streamlink/plugins/ard_mediathek.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/streamlink/plugins/ard_mediathek.py b/src/streamlink/plugins/ard_mediathek.py
--- a/src/streamlink/plugins/ard_mediathek.py
+++ b/src/streamlink/plugins/ard_mediathek.py
@@ -4,6 +4,7 @@
from streamlink.plugin import Plugin, pluginmatcher
from streamlink.plugin.api import validate
from streamlink.stream.hls import HLSStream
+from streamlink.stream.http import HTTPStream
log = logging.getLogger(__name__)
@@ -13,6 +14,14 @@
r"https?://(?:(\w+\.)?ardmediathek\.de/|mediathek\.daserste\.de/)"
))
class ARDMediathek(Plugin):
+ _QUALITY_MAP = {
+ 4: "1080p",
+ 3: "720p",
+ 2: "540p",
+ 1: "360p",
+ 0: "270p"
+ }
+
def _get_streams(self):
data_json = self.session.http.get(self.url, schema=validate.Schema(
validate.parse_html(),
@@ -34,42 +43,64 @@
[dict],
validate.filter(lambda item: item.get("mediaCollection")),
validate.get(0),
- {
- "geoblocked": bool,
- "publicationService": {
- "name": str,
+ validate.any(None, validate.all(
+ {
+ "geoblocked": bool,
+ "publicationService": {
+ "name": str,
+ },
+ "show": validate.any(None, validate.all(
+ {"title": str},
+ validate.get("title")
+ )),
+ "title": str,
+ "mediaCollection": {
+ "embedded": {
+ "_mediaArray": [validate.all(
+ {
+ "_mediaStreamArray": [validate.all(
+ {
+ "_quality": validate.any(str, int),
+ "_stream": validate.url(),
+ },
+ validate.union_get("_quality", "_stream")
+ )]
+ },
+ validate.get("_mediaStreamArray"),
+ validate.transform(dict)
+ )]
+ }
+ },
},
- "title": str,
- "mediaCollection": {
- "embedded": {
- "_mediaArray": [{
- "_mediaStreamArray": [{
- "_quality": validate.any(str, int),
- "_stream": validate.url()
- }]
- }]
- }
- }
- }
+ validate.union_get(
+ "geoblocked",
+ ("mediaCollection", "embedded", "_mediaArray", 0),
+ ("publicationService", "name"),
+ "title",
+ "show",
+ )
+ ))
)
})
data = schema_data.validate(data_json)
log.debug(f"Found media id: {data['id']}")
- data_media = data["widgets"]
+ if not data["widgets"]:
+ log.info("The content is unavailable")
+ return
- if data_media["geoblocked"]:
+ geoblocked, media, self.author, self.title, show = data["widgets"]
+ if geoblocked:
log.info("The content is not available in your region")
return
+ if show:
+ self.title = f"{show}: {self.title}"
- self.author = data_media["publicationService"]["name"]
- self.title = data_media["title"]
-
- for media in data_media["mediaCollection"]["embedded"]["_mediaArray"]:
- for stream in media["_mediaStreamArray"]:
- if stream["_quality"] != "auto" or ".m3u8" not in stream["_stream"]:
- continue
- return HLSStream.parse_variant_playlist(self.session, stream["_stream"])
+ if media.get("auto"):
+ yield from HLSStream.parse_variant_playlist(self.session, media.get("auto")).items()
+ else:
+ for quality, stream in media.items():
+ yield self._QUALITY_MAP.get(quality, quality), HTTPStream(self.session, stream)
__plugin__ = ARDMediathek
| {"golden_diff": "diff --git a/src/streamlink/plugins/ard_mediathek.py b/src/streamlink/plugins/ard_mediathek.py\n--- a/src/streamlink/plugins/ard_mediathek.py\n+++ b/src/streamlink/plugins/ard_mediathek.py\n@@ -4,6 +4,7 @@\n from streamlink.plugin import Plugin, pluginmatcher\n from streamlink.plugin.api import validate\n from streamlink.stream.hls import HLSStream\n+from streamlink.stream.http import HTTPStream\n \n \n log = logging.getLogger(__name__)\n@@ -13,6 +14,14 @@\n r\"https?://(?:(\\w+\\.)?ardmediathek\\.de/|mediathek\\.daserste\\.de/)\"\n ))\n class ARDMediathek(Plugin):\n+ _QUALITY_MAP = {\n+ 4: \"1080p\",\n+ 3: \"720p\",\n+ 2: \"540p\",\n+ 1: \"360p\",\n+ 0: \"270p\"\n+ }\n+\n def _get_streams(self):\n data_json = self.session.http.get(self.url, schema=validate.Schema(\n validate.parse_html(),\n@@ -34,42 +43,64 @@\n [dict],\n validate.filter(lambda item: item.get(\"mediaCollection\")),\n validate.get(0),\n- {\n- \"geoblocked\": bool,\n- \"publicationService\": {\n- \"name\": str,\n+ validate.any(None, validate.all(\n+ {\n+ \"geoblocked\": bool,\n+ \"publicationService\": {\n+ \"name\": str,\n+ },\n+ \"show\": validate.any(None, validate.all(\n+ {\"title\": str},\n+ validate.get(\"title\")\n+ )),\n+ \"title\": str,\n+ \"mediaCollection\": {\n+ \"embedded\": {\n+ \"_mediaArray\": [validate.all(\n+ {\n+ \"_mediaStreamArray\": [validate.all(\n+ {\n+ \"_quality\": validate.any(str, int),\n+ \"_stream\": validate.url(),\n+ },\n+ validate.union_get(\"_quality\", \"_stream\")\n+ )]\n+ },\n+ validate.get(\"_mediaStreamArray\"),\n+ validate.transform(dict)\n+ )]\n+ }\n+ },\n },\n- \"title\": str,\n- \"mediaCollection\": {\n- \"embedded\": {\n- \"_mediaArray\": [{\n- \"_mediaStreamArray\": [{\n- \"_quality\": validate.any(str, int),\n- \"_stream\": validate.url()\n- }]\n- }]\n- }\n- }\n- }\n+ validate.union_get(\n+ \"geoblocked\",\n+ (\"mediaCollection\", \"embedded\", \"_mediaArray\", 0),\n+ (\"publicationService\", \"name\"),\n+ \"title\",\n+ \"show\",\n+ )\n+ ))\n )\n })\n data = schema_data.validate(data_json)\n \n log.debug(f\"Found media id: {data['id']}\")\n- data_media = data[\"widgets\"]\n+ if not data[\"widgets\"]:\n+ log.info(\"The content is unavailable\")\n+ return\n \n- if data_media[\"geoblocked\"]:\n+ geoblocked, media, self.author, self.title, show = data[\"widgets\"]\n+ if geoblocked:\n log.info(\"The content is not available in your region\")\n return\n+ if show:\n+ self.title = f\"{show}: {self.title}\"\n \n- self.author = data_media[\"publicationService\"][\"name\"]\n- self.title = data_media[\"title\"]\n-\n- for media in data_media[\"mediaCollection\"][\"embedded\"][\"_mediaArray\"]:\n- for stream in media[\"_mediaStreamArray\"]:\n- if stream[\"_quality\"] != \"auto\" or \".m3u8\" not in stream[\"_stream\"]:\n- continue\n- return HLSStream.parse_variant_playlist(self.session, stream[\"_stream\"])\n+ if media.get(\"auto\"):\n+ yield from HLSStream.parse_variant_playlist(self.session, media.get(\"auto\")).items()\n+ else:\n+ for quality, stream in media.items():\n+ yield self._QUALITY_MAP.get(quality, quality), HTTPStream(self.session, stream)\n \n \n __plugin__ = ARDMediathek\n", "issue": "plugins.ard_mediathek: rewrite plugin\nResolves #4191 \r\n\r\nOne issue I couldn't fix is the text encoding of the metadata which gets messed up by `validate.parse_html()`. See the VOD title down below...\r\nhttps://github.com/streamlink/streamlink/blob/175d4748561c7154bb80c5a47dae22039e45d4ce/src/streamlink/utils/parse.py#L54-L55\r\n\r\nSome VODs also have a second title, eg. if it's a TV show, but I couldn't be bothered to implement this. Not important.\r\n\r\n----\r\n\r\nDas Erste - Live:\r\n```\r\n$ streamlink -l debug --title '{author} - {title}' 'https://www.ardmediathek.de/daserste/live/Y3JpZDovL2Rhc2Vyc3RlLmRlL0xpdmVzdHJlYW0tRGFzRXJzdGU/' best\r\n[cli.output][debug] Opening subprocess: mpv \"--force-media-title=Das Erste - Das Erste\" -\r\n```\r\n\r\nWDR - Live:\r\n```\r\n$ streamlink -l debug --title '{author} - {title}' 'https://www.ardmediathek.de/live/Y3JpZDovL3dkci5kZS9CZWl0cmFnLTNkYTY2NGRlLTE4YzItNDY1MC1hNGZmLTRmNjQxNDcyMDcyYg/' best\r\n[cli.output][debug] Opening subprocess: mpv \"--force-media-title=WDR - WDR Fernsehen im Livestream\" -\r\n```\r\n\r\nVOD\r\n```\r\n$ streamlink -l debug --title '{author} - {title}' 'https://www.ardmediathek.de/video/dokus-im-ersten/wirecard-die-milliarden-luege/das-erste/Y3JpZDovL2Rhc2Vyc3RlLmRlL3JlcG9ydGFnZSBfIGRva3VtZW50YXRpb24gaW0gZXJzdGVuL2NlMjQ0OWM4LTQ4YTUtNGIyNC1iMTdlLWNhOTNjMDQ5OTc4Zg/' best\r\n[cli.output][debug] Opening subprocess: mpv \"--force-media-title=Das Erste - Wirecard - Die Milliarden-L\u00c3\u00bcge\" -\r\n```\n", "before_files": [{"content": "import logging\nimport re\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream.hls import HLSStream\n\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:(\\w+\\.)?ardmediathek\\.de/|mediathek\\.daserste\\.de/)\"\n))\nclass ARDMediathek(Plugin):\n def _get_streams(self):\n data_json = self.session.http.get(self.url, schema=validate.Schema(\n validate.parse_html(),\n validate.xml_findtext(\".//script[@id='fetchedContextValue'][@type='application/json']\"),\n validate.any(None, validate.all(\n validate.parse_json(),\n {str: dict},\n validate.transform(lambda obj: list(obj.items())),\n validate.filter(lambda item: item[0].startswith(\"https://api.ardmediathek.de/page-gateway/pages/\")),\n validate.any(validate.get((0, 1)), [])\n ))\n ))\n if not data_json:\n return\n\n schema_data = validate.Schema({\n \"id\": str,\n \"widgets\": validate.all(\n [dict],\n validate.filter(lambda item: item.get(\"mediaCollection\")),\n validate.get(0),\n {\n \"geoblocked\": bool,\n \"publicationService\": {\n \"name\": str,\n },\n \"title\": str,\n \"mediaCollection\": {\n \"embedded\": {\n \"_mediaArray\": [{\n \"_mediaStreamArray\": [{\n \"_quality\": validate.any(str, int),\n \"_stream\": validate.url()\n }]\n }]\n }\n }\n }\n )\n })\n data = schema_data.validate(data_json)\n\n log.debug(f\"Found media id: {data['id']}\")\n data_media = data[\"widgets\"]\n\n if data_media[\"geoblocked\"]:\n log.info(\"The content is not available in your region\")\n return\n\n self.author = data_media[\"publicationService\"][\"name\"]\n self.title = data_media[\"title\"]\n\n for media in data_media[\"mediaCollection\"][\"embedded\"][\"_mediaArray\"]:\n for stream in media[\"_mediaStreamArray\"]:\n if stream[\"_quality\"] != \"auto\" or \".m3u8\" not in stream[\"_stream\"]:\n continue\n return HLSStream.parse_variant_playlist(self.session, stream[\"_stream\"])\n\n\n__plugin__ = ARDMediathek\n", "path": "src/streamlink/plugins/ard_mediathek.py"}]} | 1,764 | 922 |
gh_patches_debug_10487 | rasdani/github-patches | git_diff | magenta__magenta-1365 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
DRUMS_RNN: when trying to run --eval on drums_rnn I get "ValueError: invalid every_n_iter=0."
Some very strange behavior here.
I am comparing lstm behavior here to that of [LSTMetallica](https://github.com/keunwoochoi/LSTMetallica). So using the same midi library of metallica drums, I went through the normal drums_rnn pipeline:
1. I created a tfrecord (notesequence) of the entire metallica midi library
2. I turned that notesequence into a training and validation split of 10 percent
3. I started a training on the training sequence on the training data
4. I started a validation (--eval) on the eval data and IMMEDIATELY get a valueerror:
```
Traceback (most recent call last):
File ".\drums_rnn_train.py", line 113, in <module>
console_entry_point()
File ".\drums_rnn_train.py", line 109, in console_entry_point
tf.app.run(main)
File "C:\Program Files\Python35\lib\site-packages\tensorflow\python\platform\app.py", line 124, in run
_sys.exit(main(argv))
File ".\drums_rnn_train.py", line 99, in main
events_rnn_train.run_eval(build_graph_fn, train_dir, eval_dir, num_batches)
File "C:\Program Files\Python35\lib\site-packages\magenta\models\shared\events_rnn_train.py", line 114, in run_eval
EvalLoggingTensorHook(logging_dict, every_n_iter=num_batches),
File "C:\Program Files\Python35\lib\site-packages\tensorflow\python\training\basic_session_run_hooks.py", line 209, in __init__
raise ValueError("invalid every_n_iter=%s." % every_n_iter)
ValueError: invalid every_n_iter=0.
```
I've played around with the training and the evaluation percentages, and if I do 40%!!! VALIDATION data then it doesn't give that error any more, but that is way too much data for validation. (the tfrecord size for training data is 103 megs and the the eval data is 75 megs).
The rest of the data sets i've tried this on has similar properties, which led me to believe that perhaps these other data sets were too small. But a weird quirk is that if I used a much smaller data set (training set size of about 20megs, and eval data of 10megs), it would still give the same error on using the validation data to run the eval, but it doesn't fail if i used the training data for evaluation. So somehow a 20 meg file of training data for a smaller data set works validation but it fails for this metallica data set if I don't give it at least 70 megs of evaluation data. Is there just a weird problem with "drums_rnn_create_dataset"
Any ideas?
Thanks in advance
</issue>
<code>
[start of magenta/models/shared/events_rnn_train.py]
1 # Copyright 2016 Google Inc. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """Train and evaluate an event sequence RNN model."""
15
16 import tensorflow as tf
17
18
19 def run_training(build_graph_fn, train_dir, num_training_steps=None,
20 summary_frequency=10, save_checkpoint_secs=60,
21 checkpoints_to_keep=10, keep_checkpoint_every_n_hours=1,
22 master='', task=0, num_ps_tasks=0):
23 """Runs the training loop.
24
25 Args:
26 build_graph_fn: A function that builds the graph ops.
27 train_dir: The path to the directory where checkpoints and summary events
28 will be written to.
29 num_training_steps: The number of steps to train for before exiting.
30 summary_frequency: The number of steps between each summary. A summary is
31 when graph values from the last step are logged to the console and
32 written to disk.
33 save_checkpoint_secs: The frequency at which to save checkpoints, in
34 seconds.
35 checkpoints_to_keep: The number of most recent checkpoints to keep in
36 `train_dir`. Keeps all if set to 0.
37 keep_checkpoint_every_n_hours: Keep a checkpoint every N hours, even if it
38 results in more checkpoints than checkpoints_to_keep.
39 master: URL of the Tensorflow master.
40 task: Task number for this worker.
41 num_ps_tasks: Number of parameter server tasks.
42 """
43 with tf.Graph().as_default():
44 with tf.device(tf.train.replica_device_setter(num_ps_tasks)):
45 build_graph_fn()
46
47 global_step = tf.train.get_or_create_global_step()
48 loss = tf.get_collection('loss')[0]
49 perplexity = tf.get_collection('metrics/perplexity')[0]
50 accuracy = tf.get_collection('metrics/accuracy')[0]
51 train_op = tf.get_collection('train_op')[0]
52
53 logging_dict = {
54 'Global Step': global_step,
55 'Loss': loss,
56 'Perplexity': perplexity,
57 'Accuracy': accuracy
58 }
59 hooks = [
60 tf.train.NanTensorHook(loss),
61 tf.train.LoggingTensorHook(
62 logging_dict, every_n_iter=summary_frequency),
63 tf.train.StepCounterHook(
64 output_dir=train_dir, every_n_steps=summary_frequency)
65 ]
66 if num_training_steps:
67 hooks.append(tf.train.StopAtStepHook(num_training_steps))
68
69 scaffold = tf.train.Scaffold(
70 saver=tf.train.Saver(
71 max_to_keep=checkpoints_to_keep,
72 keep_checkpoint_every_n_hours=keep_checkpoint_every_n_hours))
73
74 tf.logging.info('Starting training loop...')
75 tf.contrib.training.train(
76 train_op=train_op,
77 logdir=train_dir,
78 scaffold=scaffold,
79 hooks=hooks,
80 save_checkpoint_secs=save_checkpoint_secs,
81 save_summaries_steps=summary_frequency,
82 master=master,
83 is_chief=task == 0)
84 tf.logging.info('Training complete.')
85
86
87 # TODO(adarob): Limit to a single epoch each evaluation step.
88 def run_eval(build_graph_fn, train_dir, eval_dir, num_batches,
89 timeout_secs=300):
90 """Runs the training loop.
91
92 Args:
93 build_graph_fn: A function that builds the graph ops.
94 train_dir: The path to the directory where checkpoints will be loaded
95 from for evaluation.
96 eval_dir: The path to the directory where the evaluation summary events
97 will be written to.
98 num_batches: The number of full batches to use for each evaluation step.
99 timeout_secs: The number of seconds after which to stop waiting for a new
100 checkpoint.
101 """
102 with tf.Graph().as_default():
103 build_graph_fn()
104
105 global_step = tf.train.get_or_create_global_step()
106 loss = tf.get_collection('loss')[0]
107 perplexity = tf.get_collection('metrics/perplexity')[0]
108 accuracy = tf.get_collection('metrics/accuracy')[0]
109 eval_ops = tf.get_collection('eval_ops')
110
111 logging_dict = {
112 'Global Step': global_step,
113 'Loss': loss,
114 'Perplexity': perplexity,
115 'Accuracy': accuracy
116 }
117 hooks = [
118 EvalLoggingTensorHook(logging_dict, every_n_iter=num_batches),
119 tf.contrib.training.StopAfterNEvalsHook(num_batches),
120 tf.contrib.training.SummaryAtEndHook(eval_dir),
121 ]
122
123 tf.contrib.training.evaluate_repeatedly(
124 train_dir,
125 eval_ops=eval_ops,
126 hooks=hooks,
127 eval_interval_secs=60,
128 timeout=timeout_secs)
129
130
131 class EvalLoggingTensorHook(tf.train.LoggingTensorHook):
132 """A revised version of LoggingTensorHook to use during evaluation.
133
134 This version supports being reset and increments `_iter_count` before run
135 instead of after run.
136 """
137
138 def begin(self):
139 # Reset timer.
140 self._timer.update_last_triggered_step(0)
141 super(EvalLoggingTensorHook, self).begin()
142
143 def before_run(self, run_context):
144 self._iter_count += 1
145 return super(EvalLoggingTensorHook, self).before_run(run_context)
146
147 def after_run(self, run_context, run_values):
148 super(EvalLoggingTensorHook, self).after_run(run_context, run_values)
149 self._iter_count -= 1
150
[end of magenta/models/shared/events_rnn_train.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/magenta/models/shared/events_rnn_train.py b/magenta/models/shared/events_rnn_train.py
--- a/magenta/models/shared/events_rnn_train.py
+++ b/magenta/models/shared/events_rnn_train.py
@@ -98,7 +98,13 @@
num_batches: The number of full batches to use for each evaluation step.
timeout_secs: The number of seconds after which to stop waiting for a new
checkpoint.
+ Raises:
+ ValueError: If `num_batches` is less than or equal to 0.
"""
+ if num_batches <= 0:
+ raise ValueError(
+ '`num_batches` must be greater than 0. Check that the batch size is '
+ 'no larger than the number of records in the eval set.')
with tf.Graph().as_default():
build_graph_fn()
| {"golden_diff": "diff --git a/magenta/models/shared/events_rnn_train.py b/magenta/models/shared/events_rnn_train.py\n--- a/magenta/models/shared/events_rnn_train.py\n+++ b/magenta/models/shared/events_rnn_train.py\n@@ -98,7 +98,13 @@\n num_batches: The number of full batches to use for each evaluation step.\n timeout_secs: The number of seconds after which to stop waiting for a new\n checkpoint.\n+ Raises:\n+ ValueError: If `num_batches` is less than or equal to 0.\n \"\"\"\n+ if num_batches <= 0:\n+ raise ValueError(\n+ '`num_batches` must be greater than 0. Check that the batch size is '\n+ 'no larger than the number of records in the eval set.')\n with tf.Graph().as_default():\n build_graph_fn()\n", "issue": "DRUMS_RNN: when trying to run --eval on drums_rnn I get \"ValueError: invalid every_n_iter=0.\"\nSome very strange behavior here.\r\n\r\nI am comparing lstm behavior here to that of [LSTMetallica](https://github.com/keunwoochoi/LSTMetallica). So using the same midi library of metallica drums, I went through the normal drums_rnn pipeline:\r\n\r\n1. I created a tfrecord (notesequence) of the entire metallica midi library\r\n2. I turned that notesequence into a training and validation split of 10 percent\r\n3. I started a training on the training sequence on the training data\r\n4. I started a validation (--eval) on the eval data and IMMEDIATELY get a valueerror:\r\n```\r\nTraceback (most recent call last):\r\n File \".\\drums_rnn_train.py\", line 113, in <module>\r\n console_entry_point()\r\n File \".\\drums_rnn_train.py\", line 109, in console_entry_point\r\n tf.app.run(main)\r\n File \"C:\\Program Files\\Python35\\lib\\site-packages\\tensorflow\\python\\platform\\app.py\", line 124, in run\r\n _sys.exit(main(argv))\r\n File \".\\drums_rnn_train.py\", line 99, in main\r\n events_rnn_train.run_eval(build_graph_fn, train_dir, eval_dir, num_batches)\r\n File \"C:\\Program Files\\Python35\\lib\\site-packages\\magenta\\models\\shared\\events_rnn_train.py\", line 114, in run_eval\r\n EvalLoggingTensorHook(logging_dict, every_n_iter=num_batches),\r\n File \"C:\\Program Files\\Python35\\lib\\site-packages\\tensorflow\\python\\training\\basic_session_run_hooks.py\", line 209, in __init__\r\n raise ValueError(\"invalid every_n_iter=%s.\" % every_n_iter)\r\nValueError: invalid every_n_iter=0.\r\n\r\n```\r\n\r\nI've played around with the training and the evaluation percentages, and if I do 40%!!! VALIDATION data then it doesn't give that error any more, but that is way too much data for validation. (the tfrecord size for training data is 103 megs and the the eval data is 75 megs). \r\n\r\nThe rest of the data sets i've tried this on has similar properties, which led me to believe that perhaps these other data sets were too small. But a weird quirk is that if I used a much smaller data set (training set size of about 20megs, and eval data of 10megs), it would still give the same error on using the validation data to run the eval, but it doesn't fail if i used the training data for evaluation. So somehow a 20 meg file of training data for a smaller data set works validation but it fails for this metallica data set if I don't give it at least 70 megs of evaluation data. Is there just a weird problem with \"drums_rnn_create_dataset\"\r\n\r\nAny ideas?\r\n\r\nThanks in advance\n", "before_files": [{"content": "# Copyright 2016 Google Inc. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Train and evaluate an event sequence RNN model.\"\"\"\n\nimport tensorflow as tf\n\n\ndef run_training(build_graph_fn, train_dir, num_training_steps=None,\n summary_frequency=10, save_checkpoint_secs=60,\n checkpoints_to_keep=10, keep_checkpoint_every_n_hours=1,\n master='', task=0, num_ps_tasks=0):\n \"\"\"Runs the training loop.\n\n Args:\n build_graph_fn: A function that builds the graph ops.\n train_dir: The path to the directory where checkpoints and summary events\n will be written to.\n num_training_steps: The number of steps to train for before exiting.\n summary_frequency: The number of steps between each summary. A summary is\n when graph values from the last step are logged to the console and\n written to disk.\n save_checkpoint_secs: The frequency at which to save checkpoints, in\n seconds.\n checkpoints_to_keep: The number of most recent checkpoints to keep in\n `train_dir`. Keeps all if set to 0.\n keep_checkpoint_every_n_hours: Keep a checkpoint every N hours, even if it\n results in more checkpoints than checkpoints_to_keep.\n master: URL of the Tensorflow master.\n task: Task number for this worker.\n num_ps_tasks: Number of parameter server tasks.\n \"\"\"\n with tf.Graph().as_default():\n with tf.device(tf.train.replica_device_setter(num_ps_tasks)):\n build_graph_fn()\n\n global_step = tf.train.get_or_create_global_step()\n loss = tf.get_collection('loss')[0]\n perplexity = tf.get_collection('metrics/perplexity')[0]\n accuracy = tf.get_collection('metrics/accuracy')[0]\n train_op = tf.get_collection('train_op')[0]\n\n logging_dict = {\n 'Global Step': global_step,\n 'Loss': loss,\n 'Perplexity': perplexity,\n 'Accuracy': accuracy\n }\n hooks = [\n tf.train.NanTensorHook(loss),\n tf.train.LoggingTensorHook(\n logging_dict, every_n_iter=summary_frequency),\n tf.train.StepCounterHook(\n output_dir=train_dir, every_n_steps=summary_frequency)\n ]\n if num_training_steps:\n hooks.append(tf.train.StopAtStepHook(num_training_steps))\n\n scaffold = tf.train.Scaffold(\n saver=tf.train.Saver(\n max_to_keep=checkpoints_to_keep,\n keep_checkpoint_every_n_hours=keep_checkpoint_every_n_hours))\n\n tf.logging.info('Starting training loop...')\n tf.contrib.training.train(\n train_op=train_op,\n logdir=train_dir,\n scaffold=scaffold,\n hooks=hooks,\n save_checkpoint_secs=save_checkpoint_secs,\n save_summaries_steps=summary_frequency,\n master=master,\n is_chief=task == 0)\n tf.logging.info('Training complete.')\n\n\n# TODO(adarob): Limit to a single epoch each evaluation step.\ndef run_eval(build_graph_fn, train_dir, eval_dir, num_batches,\n timeout_secs=300):\n \"\"\"Runs the training loop.\n\n Args:\n build_graph_fn: A function that builds the graph ops.\n train_dir: The path to the directory where checkpoints will be loaded\n from for evaluation.\n eval_dir: The path to the directory where the evaluation summary events\n will be written to.\n num_batches: The number of full batches to use for each evaluation step.\n timeout_secs: The number of seconds after which to stop waiting for a new\n checkpoint.\n \"\"\"\n with tf.Graph().as_default():\n build_graph_fn()\n\n global_step = tf.train.get_or_create_global_step()\n loss = tf.get_collection('loss')[0]\n perplexity = tf.get_collection('metrics/perplexity')[0]\n accuracy = tf.get_collection('metrics/accuracy')[0]\n eval_ops = tf.get_collection('eval_ops')\n\n logging_dict = {\n 'Global Step': global_step,\n 'Loss': loss,\n 'Perplexity': perplexity,\n 'Accuracy': accuracy\n }\n hooks = [\n EvalLoggingTensorHook(logging_dict, every_n_iter=num_batches),\n tf.contrib.training.StopAfterNEvalsHook(num_batches),\n tf.contrib.training.SummaryAtEndHook(eval_dir),\n ]\n\n tf.contrib.training.evaluate_repeatedly(\n train_dir,\n eval_ops=eval_ops,\n hooks=hooks,\n eval_interval_secs=60,\n timeout=timeout_secs)\n\n\nclass EvalLoggingTensorHook(tf.train.LoggingTensorHook):\n \"\"\"A revised version of LoggingTensorHook to use during evaluation.\n\n This version supports being reset and increments `_iter_count` before run\n instead of after run.\n \"\"\"\n\n def begin(self):\n # Reset timer.\n self._timer.update_last_triggered_step(0)\n super(EvalLoggingTensorHook, self).begin()\n\n def before_run(self, run_context):\n self._iter_count += 1\n return super(EvalLoggingTensorHook, self).before_run(run_context)\n\n def after_run(self, run_context, run_values):\n super(EvalLoggingTensorHook, self).after_run(run_context, run_values)\n self._iter_count -= 1\n", "path": "magenta/models/shared/events_rnn_train.py"}]} | 2,775 | 179 |
gh_patches_debug_44084 | rasdani/github-patches | git_diff | Gallopsled__pwntools-1998 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pwn.shellcraft.linkat second argument is incorrect
https://github.com/Gallopsled/pwntools/blob/bd12d1874f17e1fd6a9b26411ccc7ccd6c31f4cb/pwnlib/shellcraft/templates/common/linux/syscalls/linkat.asm#L30
`from` should be `from_`. The current implementation makes it not possible to pass a string.
</issue>
<code>
[start of pwnlib/data/syscalls/generate.py]
1 #!/usr/bin/env python2
2 from __future__ import division
3 import argparse
4 import keyword
5 import os
6
7 from pwnlib import constants
8 from pwnlib.context import context
9
10 # github.com/zachriggle/functions
11 from functions import functions, Function, Argument
12
13 ARCHITECTURES = ['i386', 'amd64', 'arm', 'aarch64', 'mips']
14
15 HEADER = '''
16 <%
17 import collections
18 import pwnlib.abi
19 import pwnlib.constants
20 import pwnlib.shellcraft
21 import six
22 %>
23 '''
24
25 DOCSTRING = '''
26 <%docstring>{name}({arguments_comma_separated}) -> str
27
28 Invokes the syscall {name}.
29
30 See 'man 2 {name}' for more information.
31
32 Arguments:
33 {arg_docs}
34 Returns:
35 {return_type}
36 </%docstring>
37 '''
38
39 ARGUMENTS = """
40 <%page args="{arguments_default_values}"/>
41 """
42
43 CALL = """
44 <%
45 abi = pwnlib.abi.ABI.syscall()
46 stack = abi.stack
47 regs = abi.register_arguments[1:]
48 allregs = pwnlib.shellcraft.registers.current()
49
50 can_pushstr = {string_arguments!r}
51 can_pushstr_array = {array_arguments!r}
52
53 argument_names = {argument_names!r}
54 argument_values = [{arguments_comma_separated!s}]
55
56 # Load all of the arguments into their destination registers / stack slots.
57 register_arguments = dict()
58 stack_arguments = collections.OrderedDict()
59 string_arguments = dict()
60 dict_arguments = dict()
61 array_arguments = dict()
62 syscall_repr = []
63
64 for name, arg in zip(argument_names, argument_values):
65 if arg is not None:
66 syscall_repr.append('%s=%s' % (name, pwnlib.shellcraft.pretty(arg, False)))
67
68 # If the argument itself (input) is a register...
69 if arg in allregs:
70 index = argument_names.index(name)
71 if index < len(regs):
72 target = regs[index]
73 register_arguments[target] = arg
74 elif arg is not None:
75 stack_arguments[index] = arg
76
77 # The argument is not a register. It is a string value, and we
78 # are expecting a string value
79 elif name in can_pushstr and isinstance(arg, (six.binary_type, six.text_type)):
80 if isinstance(arg, six.text_type):
81 arg = arg.encode('utf-8')
82 string_arguments[name] = arg
83
84 # The argument is not a register. It is a dictionary, and we are
85 # expecting K:V paris.
86 elif name in can_pushstr_array and isinstance(arg, dict):
87 array_arguments[name] = ['%s=%s' % (k,v) for (k,v) in arg.items()]
88
89 # The arguent is not a register. It is a list, and we are expecting
90 # a list of arguments.
91 elif name in can_pushstr_array and isinstance(arg, (list, tuple)):
92 array_arguments[name] = arg
93
94 # The argument is not a register, string, dict, or list.
95 # It could be a constant string ('O_RDONLY') for an integer argument,
96 # an actual integer value, or a constant.
97 else:
98 index = argument_names.index(name)
99 if index < len(regs):
100 target = regs[index]
101 register_arguments[target] = arg
102 elif arg is not None:
103 stack_arguments[target] = arg
104
105 # Some syscalls have different names on various architectures.
106 # Determine which syscall number to use for the current architecture.
107 for syscall in {syscalls!r}:
108 if hasattr(pwnlib.constants, syscall):
109 break
110 else:
111 raise Exception("Could not locate any syscalls: %r" % syscalls)
112 %>
113 /* {name}(${{', '.join(syscall_repr)}}) */
114 %for name, arg in string_arguments.items():
115 ${{pwnlib.shellcraft.pushstr(arg, append_null=(b'\\x00' not in arg))}}
116 ${{pwnlib.shellcraft.mov(regs[argument_names.index(name)], abi.stack)}}
117 %endfor
118 %for name, arg in array_arguments.items():
119 ${{pwnlib.shellcraft.pushstr_array(regs[argument_names.index(name)], arg)}}
120 %endfor
121 %for name, arg in stack_arguments.items():
122 ${{pwnlib.shellcraft.push(arg)}}
123 %endfor
124 ${{pwnlib.shellcraft.setregs(register_arguments)}}
125 ${{pwnlib.shellcraft.syscall(syscall)}}
126 """
127
128
129 def can_be_constant(arg):
130 if arg.derefcnt == 0:
131 return True
132
133
134 def can_be_string(arg):
135 if arg.type == 'char' and arg.derefcnt == 1:
136 return True
137 if arg.type == 'void' and arg.derefcnt == 1:
138 return True
139
140 def can_be_array(arg):
141 if arg.type == 'char' and arg.derefcnt == 2:
142 return True
143 if arg.type == 'void' and arg.derefcnt == 2:
144 return True
145
146
147 def fix_bad_arg_names(func, arg):
148 if arg.name == 'len':
149 return 'length'
150
151 if arg.name in ('str', 'repr') or keyword.iskeyword(arg.name):
152 return arg.name + '_'
153
154 if func.name == 'open' and arg.name == 'vararg':
155 return 'mode'
156
157 return arg.name
158
159
160 def get_arg_default(arg):
161 return 0
162
163 def fix_rt_syscall_name(name):
164 if name.startswith('rt_'):
165 return name[3:]
166 return name
167
168 def fix_syscall_names(name):
169 # Do not use old_mmap
170 if name == 'SYS_mmap':
171 return ['SYS_mmap2', name]
172 # Some arches don't have vanilla sigreturn
173 if name.endswith('_sigreturn'):
174 return ['SYS_sigreturn', 'SYS_rt_sigreturn']
175 return [name]
176
177
178 def main(target):
179 for arch in ARCHITECTURES:
180 with context.local(arch=arch):
181 generate_one(target)
182
183 def generate_one(target):
184 SYSCALL_NAMES = [c for c in dir(constants) if c.startswith('SYS_')]
185
186 for syscall in SYSCALL_NAMES:
187 name = syscall[4:]
188
189 # Skip anything with uppercase
190 if name.lower() != name:
191 print('Skipping %s' % name)
192 continue
193
194 # Skip anything that starts with 'unused' or 'sys' after stripping
195 if name.startswith('unused'):
196 print('Skipping %s' % name)
197 continue
198
199 function = functions.get(name, None)
200
201 if name.startswith('rt_'):
202 name = name[3:]
203
204 # If we can't find a function, just stub it out with something
205 # that has a vararg argument.
206 if function is None:
207 print('Stubbing out %s' % name)
208 args = [Argument('int', 0, 'vararg')]
209 function = Function('long', 0, name, args)
210
211 # Some syscalls have different names on different architectures,
212 # or are superceded. We try to do the "best" thing at runtime.
213 syscalls = fix_syscall_names(syscall)
214
215 # Set up the argument string for Mako
216 argument_names = []
217 argument_defaults = []
218
219 #
220
221 for arg in function.args:
222 argname = fix_bad_arg_names(function, arg)
223 default = get_arg_default(arg)
224
225 # Mako is unable to use *vararg and *kwarg, so we just stub in
226 # a whole bunch of additional arguments.
227 if argname == 'vararg':
228 for j in range(5):
229 argname = 'vararg_%i' % j
230 argument_names.append(argname)
231 argument_defaults.append('%s=%s' % (argname, None))
232 break
233
234 argument_names.append(argname)
235 argument_defaults.append('%s=%s' % (argname, default))
236
237 arguments_default_values = ', '.join(argument_defaults)
238 arguments_comma_separated = ', '.join(argument_names)
239
240 string_arguments = []
241 array_arguments = []
242 arg_docs = []
243
244 for arg in function.args:
245
246 if can_be_array(arg):
247 array_arguments.append(arg.name)
248
249 if can_be_string(arg):
250 string_arguments.append(arg.name)
251
252 argname = arg.name
253 argtype = str(arg.type) + ('*' * arg.derefcnt)
254 arg_docs.append(
255 ' {argname}({argtype}): {argname}'.format(argname=argname,
256 argtype=argtype))
257
258 return_type = str(function.type) + ('*' * function.derefcnt)
259 arg_docs = '\n'.join(arg_docs)
260
261 template_variables = {
262 'name': name,
263 'arg_docs': arg_docs,
264 'syscalls': syscalls,
265 'arguments_default_values': arguments_default_values,
266 'arguments_comma_separated': arguments_comma_separated,
267 'return_type': return_type,
268 'string_arguments': string_arguments,
269 'array_arguments': array_arguments,
270 'argument_names': argument_names,
271 }
272
273 lines = [
274 HEADER,
275 DOCSTRING.format(**template_variables),
276 ARGUMENTS.format(**template_variables),
277 CALL.format(**template_variables)
278 ]
279
280 if keyword.iskeyword(name):
281 name += '_'
282 with open(os.path.join(target, name + '.asm'), 'wt') as f:
283 f.write('\n'.join(map(str.strip, lines)) + '\n')
284
285 if __name__ == '__main__':
286 p = argparse.ArgumentParser()
287 p.add_argument('target_directory')
288 args = p.parse_args()
289 main(args.target_directory)
290
[end of pwnlib/data/syscalls/generate.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pwnlib/data/syscalls/generate.py b/pwnlib/data/syscalls/generate.py
--- a/pwnlib/data/syscalls/generate.py
+++ b/pwnlib/data/syscalls/generate.py
@@ -1,4 +1,4 @@
-#!/usr/bin/env python2
+#!/usr/bin/env python3
from __future__ import division
import argparse
import keyword
@@ -137,6 +137,7 @@
if arg.type == 'void' and arg.derefcnt == 1:
return True
+
def can_be_array(arg):
if arg.type == 'char' and arg.derefcnt == 2:
return True
@@ -160,11 +161,13 @@
def get_arg_default(arg):
return 0
+
def fix_rt_syscall_name(name):
if name.startswith('rt_'):
return name[3:]
return name
+
def fix_syscall_names(name):
# Do not use old_mmap
if name == 'SYS_mmap':
@@ -180,6 +183,7 @@
with context.local(arch=arch):
generate_one(target)
+
def generate_one(target):
SYSCALL_NAMES = [c for c in dir(constants) if c.startswith('SYS_')]
@@ -214,46 +218,50 @@
# Set up the argument string for Mako
argument_names = []
+ argument_names_ = []
argument_defaults = []
+ string_arguments = []
+ array_arguments = []
+ arg_docs = []
+
#
for arg in function.args:
- argname = fix_bad_arg_names(function, arg)
+ argname_ = fix_bad_arg_names(function, arg)
+ argname = argname_.rstrip('_')
default = get_arg_default(arg)
+ if can_be_array(arg):
+ array_arguments.append(argname)
+
+ if can_be_string(arg):
+ string_arguments.append(argname)
+
+ argtype = str(arg.type) + ('*' * arg.derefcnt)
+ arg_docs.append(
+ ' {argname_}({argtype}): {argname}'.format(
+ argname_=argname_,
+ argname=argname,
+ argtype=argtype,
+ ))
+
# Mako is unable to use *vararg and *kwarg, so we just stub in
# a whole bunch of additional arguments.
if argname == 'vararg':
for j in range(5):
argname = 'vararg_%i' % j
argument_names.append(argname)
+ argument_names_.append(argname)
argument_defaults.append('%s=%s' % (argname, None))
break
argument_names.append(argname)
- argument_defaults.append('%s=%s' % (argname, default))
+ argument_names_.append(argname_)
+ argument_defaults.append('%s=%s' % (argname_, default))
arguments_default_values = ', '.join(argument_defaults)
- arguments_comma_separated = ', '.join(argument_names)
-
- string_arguments = []
- array_arguments = []
- arg_docs = []
-
- for arg in function.args:
-
- if can_be_array(arg):
- array_arguments.append(arg.name)
-
- if can_be_string(arg):
- string_arguments.append(arg.name)
-
- argname = arg.name
- argtype = str(arg.type) + ('*' * arg.derefcnt)
- arg_docs.append(
- ' {argname}({argtype}): {argname}'.format(argname=argname,
- argtype=argtype))
+ arguments_comma_separated = ', '.join(argument_names_)
return_type = str(function.type) + ('*' * function.derefcnt)
arg_docs = '\n'.join(arg_docs)
@@ -282,6 +290,7 @@
with open(os.path.join(target, name + '.asm'), 'wt') as f:
f.write('\n'.join(map(str.strip, lines)) + '\n')
+
if __name__ == '__main__':
p = argparse.ArgumentParser()
p.add_argument('target_directory')
| {"golden_diff": "diff --git a/pwnlib/data/syscalls/generate.py b/pwnlib/data/syscalls/generate.py\n--- a/pwnlib/data/syscalls/generate.py\n+++ b/pwnlib/data/syscalls/generate.py\n@@ -1,4 +1,4 @@\n-#!/usr/bin/env python2\n+#!/usr/bin/env python3\n from __future__ import division\n import argparse\n import keyword\n@@ -137,6 +137,7 @@\n if arg.type == 'void' and arg.derefcnt == 1:\n return True\n \n+\n def can_be_array(arg):\n if arg.type == 'char' and arg.derefcnt == 2:\n return True\n@@ -160,11 +161,13 @@\n def get_arg_default(arg):\n return 0\n \n+\n def fix_rt_syscall_name(name):\n if name.startswith('rt_'):\n return name[3:]\n return name\n \n+\n def fix_syscall_names(name):\n # Do not use old_mmap\n if name == 'SYS_mmap':\n@@ -180,6 +183,7 @@\n with context.local(arch=arch):\n generate_one(target)\n \n+\n def generate_one(target):\n SYSCALL_NAMES = [c for c in dir(constants) if c.startswith('SYS_')]\n \n@@ -214,46 +218,50 @@\n \n # Set up the argument string for Mako\n argument_names = []\n+ argument_names_ = []\n argument_defaults = []\n \n+ string_arguments = []\n+ array_arguments = []\n+ arg_docs = []\n+\n #\n \n for arg in function.args:\n- argname = fix_bad_arg_names(function, arg)\n+ argname_ = fix_bad_arg_names(function, arg)\n+ argname = argname_.rstrip('_')\n default = get_arg_default(arg)\n \n+ if can_be_array(arg):\n+ array_arguments.append(argname)\n+\n+ if can_be_string(arg):\n+ string_arguments.append(argname)\n+\n+ argtype = str(arg.type) + ('*' * arg.derefcnt)\n+ arg_docs.append(\n+ ' {argname_}({argtype}): {argname}'.format(\n+ argname_=argname_,\n+ argname=argname,\n+ argtype=argtype,\n+ ))\n+\n # Mako is unable to use *vararg and *kwarg, so we just stub in\n # a whole bunch of additional arguments.\n if argname == 'vararg':\n for j in range(5):\n argname = 'vararg_%i' % j\n argument_names.append(argname)\n+ argument_names_.append(argname)\n argument_defaults.append('%s=%s' % (argname, None))\n break\n \n argument_names.append(argname)\n- argument_defaults.append('%s=%s' % (argname, default))\n+ argument_names_.append(argname_)\n+ argument_defaults.append('%s=%s' % (argname_, default))\n \n arguments_default_values = ', '.join(argument_defaults)\n- arguments_comma_separated = ', '.join(argument_names)\n-\n- string_arguments = []\n- array_arguments = []\n- arg_docs = []\n-\n- for arg in function.args:\n-\n- if can_be_array(arg):\n- array_arguments.append(arg.name)\n-\n- if can_be_string(arg):\n- string_arguments.append(arg.name)\n-\n- argname = arg.name\n- argtype = str(arg.type) + ('*' * arg.derefcnt)\n- arg_docs.append(\n- ' {argname}({argtype}): {argname}'.format(argname=argname,\n- argtype=argtype))\n+ arguments_comma_separated = ', '.join(argument_names_)\n \n return_type = str(function.type) + ('*' * function.derefcnt)\n arg_docs = '\\n'.join(arg_docs)\n@@ -282,6 +290,7 @@\n with open(os.path.join(target, name + '.asm'), 'wt') as f:\n f.write('\\n'.join(map(str.strip, lines)) + '\\n')\n \n+\n if __name__ == '__main__':\n p = argparse.ArgumentParser()\n p.add_argument('target_directory')\n", "issue": "pwn.shellcraft.linkat second argument is incorrect\nhttps://github.com/Gallopsled/pwntools/blob/bd12d1874f17e1fd6a9b26411ccc7ccd6c31f4cb/pwnlib/shellcraft/templates/common/linux/syscalls/linkat.asm#L30\r\n\r\n`from` should be `from_`. The current implementation makes it not possible to pass a string.\n", "before_files": [{"content": "#!/usr/bin/env python2\nfrom __future__ import division\nimport argparse\nimport keyword\nimport os\n\nfrom pwnlib import constants\nfrom pwnlib.context import context\n\n# github.com/zachriggle/functions\nfrom functions import functions, Function, Argument\n\nARCHITECTURES = ['i386', 'amd64', 'arm', 'aarch64', 'mips']\n\nHEADER = '''\n<%\nimport collections\nimport pwnlib.abi\nimport pwnlib.constants\nimport pwnlib.shellcraft\nimport six\n%>\n'''\n\nDOCSTRING = '''\n<%docstring>{name}({arguments_comma_separated}) -> str\n\nInvokes the syscall {name}.\n\nSee 'man 2 {name}' for more information.\n\nArguments:\n{arg_docs}\nReturns:\n {return_type}\n</%docstring>\n'''\n\nARGUMENTS = \"\"\"\n<%page args=\"{arguments_default_values}\"/>\n\"\"\"\n\nCALL = \"\"\"\n<%\n abi = pwnlib.abi.ABI.syscall()\n stack = abi.stack\n regs = abi.register_arguments[1:]\n allregs = pwnlib.shellcraft.registers.current()\n\n can_pushstr = {string_arguments!r}\n can_pushstr_array = {array_arguments!r}\n\n argument_names = {argument_names!r}\n argument_values = [{arguments_comma_separated!s}]\n\n # Load all of the arguments into their destination registers / stack slots.\n register_arguments = dict()\n stack_arguments = collections.OrderedDict()\n string_arguments = dict()\n dict_arguments = dict()\n array_arguments = dict()\n syscall_repr = []\n\n for name, arg in zip(argument_names, argument_values):\n if arg is not None:\n syscall_repr.append('%s=%s' % (name, pwnlib.shellcraft.pretty(arg, False)))\n\n # If the argument itself (input) is a register...\n if arg in allregs:\n index = argument_names.index(name)\n if index < len(regs):\n target = regs[index]\n register_arguments[target] = arg\n elif arg is not None:\n stack_arguments[index] = arg\n\n # The argument is not a register. It is a string value, and we\n # are expecting a string value\n elif name in can_pushstr and isinstance(arg, (six.binary_type, six.text_type)):\n if isinstance(arg, six.text_type):\n arg = arg.encode('utf-8')\n string_arguments[name] = arg\n\n # The argument is not a register. It is a dictionary, and we are\n # expecting K:V paris.\n elif name in can_pushstr_array and isinstance(arg, dict):\n array_arguments[name] = ['%s=%s' % (k,v) for (k,v) in arg.items()]\n\n # The arguent is not a register. It is a list, and we are expecting\n # a list of arguments.\n elif name in can_pushstr_array and isinstance(arg, (list, tuple)):\n array_arguments[name] = arg\n\n # The argument is not a register, string, dict, or list.\n # It could be a constant string ('O_RDONLY') for an integer argument,\n # an actual integer value, or a constant.\n else:\n index = argument_names.index(name)\n if index < len(regs):\n target = regs[index]\n register_arguments[target] = arg\n elif arg is not None:\n stack_arguments[target] = arg\n\n # Some syscalls have different names on various architectures.\n # Determine which syscall number to use for the current architecture.\n for syscall in {syscalls!r}:\n if hasattr(pwnlib.constants, syscall):\n break\n else:\n raise Exception(\"Could not locate any syscalls: %r\" % syscalls)\n%>\n /* {name}(${{', '.join(syscall_repr)}}) */\n%for name, arg in string_arguments.items():\n ${{pwnlib.shellcraft.pushstr(arg, append_null=(b'\\\\x00' not in arg))}}\n ${{pwnlib.shellcraft.mov(regs[argument_names.index(name)], abi.stack)}}\n%endfor\n%for name, arg in array_arguments.items():\n ${{pwnlib.shellcraft.pushstr_array(regs[argument_names.index(name)], arg)}}\n%endfor\n%for name, arg in stack_arguments.items():\n ${{pwnlib.shellcraft.push(arg)}}\n%endfor\n ${{pwnlib.shellcraft.setregs(register_arguments)}}\n ${{pwnlib.shellcraft.syscall(syscall)}}\n\"\"\"\n\n\ndef can_be_constant(arg):\n if arg.derefcnt == 0:\n return True\n\n\ndef can_be_string(arg):\n if arg.type == 'char' and arg.derefcnt == 1:\n return True\n if arg.type == 'void' and arg.derefcnt == 1:\n return True\n\ndef can_be_array(arg):\n if arg.type == 'char' and arg.derefcnt == 2:\n return True\n if arg.type == 'void' and arg.derefcnt == 2:\n return True\n\n\ndef fix_bad_arg_names(func, arg):\n if arg.name == 'len':\n return 'length'\n\n if arg.name in ('str', 'repr') or keyword.iskeyword(arg.name):\n return arg.name + '_'\n\n if func.name == 'open' and arg.name == 'vararg':\n return 'mode'\n\n return arg.name\n\n\ndef get_arg_default(arg):\n return 0\n\ndef fix_rt_syscall_name(name):\n if name.startswith('rt_'):\n return name[3:]\n return name\n\ndef fix_syscall_names(name):\n # Do not use old_mmap\n if name == 'SYS_mmap':\n return ['SYS_mmap2', name]\n # Some arches don't have vanilla sigreturn\n if name.endswith('_sigreturn'):\n return ['SYS_sigreturn', 'SYS_rt_sigreturn']\n return [name]\n\n\ndef main(target):\n for arch in ARCHITECTURES:\n with context.local(arch=arch):\n generate_one(target)\n\ndef generate_one(target):\n SYSCALL_NAMES = [c for c in dir(constants) if c.startswith('SYS_')]\n\n for syscall in SYSCALL_NAMES:\n name = syscall[4:]\n\n # Skip anything with uppercase\n if name.lower() != name:\n print('Skipping %s' % name)\n continue\n\n # Skip anything that starts with 'unused' or 'sys' after stripping\n if name.startswith('unused'):\n print('Skipping %s' % name)\n continue\n\n function = functions.get(name, None)\n\n if name.startswith('rt_'):\n name = name[3:]\n\n # If we can't find a function, just stub it out with something\n # that has a vararg argument.\n if function is None:\n print('Stubbing out %s' % name)\n args = [Argument('int', 0, 'vararg')]\n function = Function('long', 0, name, args)\n\n # Some syscalls have different names on different architectures,\n # or are superceded. We try to do the \"best\" thing at runtime.\n syscalls = fix_syscall_names(syscall)\n\n # Set up the argument string for Mako\n argument_names = []\n argument_defaults = []\n\n #\n\n for arg in function.args:\n argname = fix_bad_arg_names(function, arg)\n default = get_arg_default(arg)\n\n # Mako is unable to use *vararg and *kwarg, so we just stub in\n # a whole bunch of additional arguments.\n if argname == 'vararg':\n for j in range(5):\n argname = 'vararg_%i' % j\n argument_names.append(argname)\n argument_defaults.append('%s=%s' % (argname, None))\n break\n\n argument_names.append(argname)\n argument_defaults.append('%s=%s' % (argname, default))\n\n arguments_default_values = ', '.join(argument_defaults)\n arguments_comma_separated = ', '.join(argument_names)\n\n string_arguments = []\n array_arguments = []\n arg_docs = []\n\n for arg in function.args:\n\n if can_be_array(arg):\n array_arguments.append(arg.name)\n\n if can_be_string(arg):\n string_arguments.append(arg.name)\n\n argname = arg.name\n argtype = str(arg.type) + ('*' * arg.derefcnt)\n arg_docs.append(\n ' {argname}({argtype}): {argname}'.format(argname=argname,\n argtype=argtype))\n\n return_type = str(function.type) + ('*' * function.derefcnt)\n arg_docs = '\\n'.join(arg_docs)\n\n template_variables = {\n 'name': name,\n 'arg_docs': arg_docs,\n 'syscalls': syscalls,\n 'arguments_default_values': arguments_default_values,\n 'arguments_comma_separated': arguments_comma_separated,\n 'return_type': return_type,\n 'string_arguments': string_arguments,\n 'array_arguments': array_arguments,\n 'argument_names': argument_names,\n }\n\n lines = [\n HEADER,\n DOCSTRING.format(**template_variables),\n ARGUMENTS.format(**template_variables),\n CALL.format(**template_variables)\n ]\n\n if keyword.iskeyword(name):\n name += '_'\n with open(os.path.join(target, name + '.asm'), 'wt') as f:\n f.write('\\n'.join(map(str.strip, lines)) + '\\n')\n\nif __name__ == '__main__':\n p = argparse.ArgumentParser()\n p.add_argument('target_directory')\n args = p.parse_args()\n main(args.target_directory)\n", "path": "pwnlib/data/syscalls/generate.py"}]} | 3,536 | 933 |
gh_patches_debug_2627 | rasdani/github-patches | git_diff | streamlink__streamlink-2171 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
INE Plugin
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [X] This is a plugin issue and I have read the contribution guidelines.
### Description
The INE plugin doesn't appear to work on any videos I try.
### Reproduction steps / Explicit stream URLs to test
Try do download a video
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
streamlink https://streaming.ine.com/play/419cdc1a-a4a8-4eba-b8b3-5dda324daa94/day-1-part-1#/ --http-cookie laravel_session=<Removed> --loglevel debug
[cli][debug] OS: macOS 10.14.1
[cli][debug] Python: 2.7.10
[cli][debug] Streamlink: 0.14.2
[cli][debug] Requests(2.19.1), Socks(1.6.7), Websocket(0.54.0)
[cli][info] Found matching plugin ine for URL https://streaming.ine.com/play/419cdc1a-a4a8-4eba-b8b3-5dda324daa94/day-1-part-1#/
[plugin.ine][debug] Found video ID: 419cdc1a-a4a8-4eba-b8b3-5dda324daa94
[plugin.ine][debug] Loading player JS: https://content.jwplatform.com/players/yyYIR4k9-p4NBeNN0.js?exp=1543579899&sig=5e0058876669be2e2aafc7e52d067b78
error: Unable to validate result: <_sre.SRE_Match object at 0x106564dc8> does not equal None or Unable to validate key 'playlist': Type of u'//content.jwplatform.com/v2/media/yyYIR4k9?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJyZWNvbW1lbmRhdGlvbnNfcGxheWxpc3RfaWQiOiJ5cHQwdDR4aCIsInJlc291cmNlIjoiL3YyL21lZGlhL3l5WUlSNGs5IiwiZXhwIjoxNTQzNTc5OTIwfQ.pHEgoDYzc219-S_slfWRhyEoCsyCZt74BiL8RNs5IJ8' should be 'str' but is 'unicode'
```
### Additional comments, screenshots, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
INE Plugin
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [X] This is a plugin issue and I have read the contribution guidelines.
### Description
The INE plugin doesn't appear to work on any videos I try.
### Reproduction steps / Explicit stream URLs to test
Try do download a video
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
streamlink https://streaming.ine.com/play/419cdc1a-a4a8-4eba-b8b3-5dda324daa94/day-1-part-1#/ --http-cookie laravel_session=<Removed> --loglevel debug
[cli][debug] OS: macOS 10.14.1
[cli][debug] Python: 2.7.10
[cli][debug] Streamlink: 0.14.2
[cli][debug] Requests(2.19.1), Socks(1.6.7), Websocket(0.54.0)
[cli][info] Found matching plugin ine for URL https://streaming.ine.com/play/419cdc1a-a4a8-4eba-b8b3-5dda324daa94/day-1-part-1#/
[plugin.ine][debug] Found video ID: 419cdc1a-a4a8-4eba-b8b3-5dda324daa94
[plugin.ine][debug] Loading player JS: https://content.jwplatform.com/players/yyYIR4k9-p4NBeNN0.js?exp=1543579899&sig=5e0058876669be2e2aafc7e52d067b78
error: Unable to validate result: <_sre.SRE_Match object at 0x106564dc8> does not equal None or Unable to validate key 'playlist': Type of u'//content.jwplatform.com/v2/media/yyYIR4k9?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJyZWNvbW1lbmRhdGlvbnNfcGxheWxpc3RfaWQiOiJ5cHQwdDR4aCIsInJlc291cmNlIjoiL3YyL21lZGlhL3l5WUlSNGs5IiwiZXhwIjoxNTQzNTc5OTIwfQ.pHEgoDYzc219-S_slfWRhyEoCsyCZt74BiL8RNs5IJ8' should be 'str' but is 'unicode'
```
### Additional comments, screenshots, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
</issue>
<code>
[start of src/streamlink/plugins/ine.py]
1 from __future__ import print_function
2
3 import json
4 import re
5
6 from streamlink.plugin import Plugin
7 from streamlink.plugin.api import validate
8 from streamlink.stream import HLSStream, HTTPStream
9 from streamlink.utils import update_scheme
10
11
12 class INE(Plugin):
13 url_re = re.compile(r"""https://streaming.ine.com/play\#?/
14 ([0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12})/?
15 (.*?)""", re.VERBOSE)
16 play_url = "https://streaming.ine.com/play/{vid}/watch"
17 js_re = re.compile(r'''script type="text/javascript" src="(https://content.jwplatform.com/players/.*?)"''')
18 jwplayer_re = re.compile(r'''jwConfig\s*=\s*(\{.*\});''', re.DOTALL)
19 setup_schema = validate.Schema(
20 validate.transform(jwplayer_re.search),
21 validate.any(
22 None,
23 validate.all(
24 validate.get(1),
25 validate.transform(json.loads),
26 {"playlist": str},
27 validate.get("playlist")
28 )
29 )
30 )
31
32 @classmethod
33 def can_handle_url(cls, url):
34 return cls.url_re.match(url) is not None
35
36 def _get_streams(self):
37 vid = self.url_re.match(self.url).group(1)
38 self.logger.debug("Found video ID: {0}", vid)
39
40 page = self.session.http.get(self.play_url.format(vid=vid))
41 js_url_m = self.js_re.search(page.text)
42 if js_url_m:
43 js_url = js_url_m.group(1)
44 self.logger.debug("Loading player JS: {0}", js_url)
45
46 res = self.session.http.get(js_url)
47 metadata_url = update_scheme(self.url, self.setup_schema.validate(res.text))
48 data = self.session.http.json(self.session.http.get(metadata_url))
49
50 for source in data["playlist"][0]["sources"]:
51 if source["type"] == "application/vnd.apple.mpegurl":
52 for s in HLSStream.parse_variant_playlist(self.session, source["file"]).items():
53 yield s
54 elif source["type"] == "video/mp4":
55 yield "{0}p".format(source["height"]), HTTPStream(self.session, source["file"])
56
57
58 __plugin__ = INE
59
[end of src/streamlink/plugins/ine.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/streamlink/plugins/ine.py b/src/streamlink/plugins/ine.py
--- a/src/streamlink/plugins/ine.py
+++ b/src/streamlink/plugins/ine.py
@@ -23,7 +23,7 @@
validate.all(
validate.get(1),
validate.transform(json.loads),
- {"playlist": str},
+ {"playlist": validate.text},
validate.get("playlist")
)
)
| {"golden_diff": "diff --git a/src/streamlink/plugins/ine.py b/src/streamlink/plugins/ine.py\n--- a/src/streamlink/plugins/ine.py\n+++ b/src/streamlink/plugins/ine.py\n@@ -23,7 +23,7 @@\n validate.all(\n validate.get(1),\n validate.transform(json.loads),\n- {\"playlist\": str},\n+ {\"playlist\": validate.text},\n validate.get(\"playlist\")\n )\n )\n", "issue": "INE Plugin\n## Plugin Issue\r\n\r\n<!-- Replace [ ] with [x] in order to check the box -->\r\n- [X] This is a plugin issue and I have read the contribution guidelines.\r\n\r\n\r\n### Description\r\n\r\nThe INE plugin doesn't appear to work on any videos I try.\r\n\r\n\r\n### Reproduction steps / Explicit stream URLs to test\r\n\r\nTry do download a video\r\n\r\n### Log output\r\n\r\n<!--\r\nTEXT LOG OUTPUT IS REQUIRED for a plugin issue!\r\nUse the `--loglevel debug` parameter and avoid using parameters which suppress log output.\r\nhttps://streamlink.github.io/cli.html#cmdoption-l\r\n\r\nMake sure to **remove usernames and passwords**\r\nYou can copy the output to https://gist.github.com/ or paste it below.\r\n-->\r\n\r\n```\r\nstreamlink https://streaming.ine.com/play/419cdc1a-a4a8-4eba-b8b3-5dda324daa94/day-1-part-1#/ --http-cookie laravel_session=<Removed> --loglevel debug\r\n[cli][debug] OS: macOS 10.14.1\r\n[cli][debug] Python: 2.7.10\r\n[cli][debug] Streamlink: 0.14.2\r\n[cli][debug] Requests(2.19.1), Socks(1.6.7), Websocket(0.54.0)\r\n[cli][info] Found matching plugin ine for URL https://streaming.ine.com/play/419cdc1a-a4a8-4eba-b8b3-5dda324daa94/day-1-part-1#/\r\n[plugin.ine][debug] Found video ID: 419cdc1a-a4a8-4eba-b8b3-5dda324daa94\r\n[plugin.ine][debug] Loading player JS: https://content.jwplatform.com/players/yyYIR4k9-p4NBeNN0.js?exp=1543579899&sig=5e0058876669be2e2aafc7e52d067b78\r\nerror: Unable to validate result: <_sre.SRE_Match object at 0x106564dc8> does not equal None or Unable to validate key 'playlist': Type of u'//content.jwplatform.com/v2/media/yyYIR4k9?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJyZWNvbW1lbmRhdGlvbnNfcGxheWxpc3RfaWQiOiJ5cHQwdDR4aCIsInJlc291cmNlIjoiL3YyL21lZGlhL3l5WUlSNGs5IiwiZXhwIjoxNTQzNTc5OTIwfQ.pHEgoDYzc219-S_slfWRhyEoCsyCZt74BiL8RNs5IJ8' should be 'str' but is 'unicode'\r\n```\r\n\r\n\r\n### Additional comments, screenshots, etc.\r\n\r\n\r\n\r\n[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)\r\n\nINE Plugin\n## Plugin Issue\r\n\r\n<!-- Replace [ ] with [x] in order to check the box -->\r\n- [X] This is a plugin issue and I have read the contribution guidelines.\r\n\r\n\r\n### Description\r\n\r\nThe INE plugin doesn't appear to work on any videos I try.\r\n\r\n\r\n### Reproduction steps / Explicit stream URLs to test\r\n\r\nTry do download a video\r\n\r\n### Log output\r\n\r\n<!--\r\nTEXT LOG OUTPUT IS REQUIRED for a plugin issue!\r\nUse the `--loglevel debug` parameter and avoid using parameters which suppress log output.\r\nhttps://streamlink.github.io/cli.html#cmdoption-l\r\n\r\nMake sure to **remove usernames and passwords**\r\nYou can copy the output to https://gist.github.com/ or paste it below.\r\n-->\r\n\r\n```\r\nstreamlink https://streaming.ine.com/play/419cdc1a-a4a8-4eba-b8b3-5dda324daa94/day-1-part-1#/ --http-cookie laravel_session=<Removed> --loglevel debug\r\n[cli][debug] OS: macOS 10.14.1\r\n[cli][debug] Python: 2.7.10\r\n[cli][debug] Streamlink: 0.14.2\r\n[cli][debug] Requests(2.19.1), Socks(1.6.7), Websocket(0.54.0)\r\n[cli][info] Found matching plugin ine for URL https://streaming.ine.com/play/419cdc1a-a4a8-4eba-b8b3-5dda324daa94/day-1-part-1#/\r\n[plugin.ine][debug] Found video ID: 419cdc1a-a4a8-4eba-b8b3-5dda324daa94\r\n[plugin.ine][debug] Loading player JS: https://content.jwplatform.com/players/yyYIR4k9-p4NBeNN0.js?exp=1543579899&sig=5e0058876669be2e2aafc7e52d067b78\r\nerror: Unable to validate result: <_sre.SRE_Match object at 0x106564dc8> does not equal None or Unable to validate key 'playlist': Type of u'//content.jwplatform.com/v2/media/yyYIR4k9?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJyZWNvbW1lbmRhdGlvbnNfcGxheWxpc3RfaWQiOiJ5cHQwdDR4aCIsInJlc291cmNlIjoiL3YyL21lZGlhL3l5WUlSNGs5IiwiZXhwIjoxNTQzNTc5OTIwfQ.pHEgoDYzc219-S_slfWRhyEoCsyCZt74BiL8RNs5IJ8' should be 'str' but is 'unicode'\r\n```\r\n\r\n\r\n### Additional comments, screenshots, etc.\r\n\r\n\r\n\r\n[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)\r\n\n", "before_files": [{"content": "from __future__ import print_function\n\nimport json\nimport re\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream import HLSStream, HTTPStream\nfrom streamlink.utils import update_scheme\n\n\nclass INE(Plugin):\n url_re = re.compile(r\"\"\"https://streaming.ine.com/play\\#?/\n ([0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12})/?\n (.*?)\"\"\", re.VERBOSE)\n play_url = \"https://streaming.ine.com/play/{vid}/watch\"\n js_re = re.compile(r'''script type=\"text/javascript\" src=\"(https://content.jwplatform.com/players/.*?)\"''')\n jwplayer_re = re.compile(r'''jwConfig\\s*=\\s*(\\{.*\\});''', re.DOTALL)\n setup_schema = validate.Schema(\n validate.transform(jwplayer_re.search),\n validate.any(\n None,\n validate.all(\n validate.get(1),\n validate.transform(json.loads),\n {\"playlist\": str},\n validate.get(\"playlist\")\n )\n )\n )\n\n @classmethod\n def can_handle_url(cls, url):\n return cls.url_re.match(url) is not None\n\n def _get_streams(self):\n vid = self.url_re.match(self.url).group(1)\n self.logger.debug(\"Found video ID: {0}\", vid)\n\n page = self.session.http.get(self.play_url.format(vid=vid))\n js_url_m = self.js_re.search(page.text)\n if js_url_m:\n js_url = js_url_m.group(1)\n self.logger.debug(\"Loading player JS: {0}\", js_url)\n\n res = self.session.http.get(js_url)\n metadata_url = update_scheme(self.url, self.setup_schema.validate(res.text))\n data = self.session.http.json(self.session.http.get(metadata_url))\n\n for source in data[\"playlist\"][0][\"sources\"]:\n if source[\"type\"] == \"application/vnd.apple.mpegurl\":\n for s in HLSStream.parse_variant_playlist(self.session, source[\"file\"]).items():\n yield s\n elif source[\"type\"] == \"video/mp4\":\n yield \"{0}p\".format(source[\"height\"]), HTTPStream(self.session, source[\"file\"])\n\n\n__plugin__ = INE\n", "path": "src/streamlink/plugins/ine.py"}]} | 2,637 | 93 |
gh_patches_debug_24965 | rasdani/github-patches | git_diff | google__clusterfuzz-2567 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Investigate GitHub login
</issue>
<code>
[start of src/appengine/libs/csp.py]
1 # Copyright 2019 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """Helpers used to generate Content Security Policies for pages."""
15 import collections
16
17 from libs import auth
18
19
20 class CSPBuilder(object):
21 """Helper to build a Content Security Policy string."""
22
23 def __init__(self):
24 self.directives = collections.defaultdict(list)
25
26 def add(self, directive, source, quote=False):
27 """Add a source for a given directive."""
28 # Some values for sources are expected to be quoted. No escaping is done
29 # since these are specific literal values that don't require it.
30 if quote:
31 source = '\'{}\''.format(source)
32
33 assert source not in self.directives[directive], (
34 'Duplicate source "{source}" for directive "{directive}"'.format(
35 source=source, directive=directive))
36 self.directives[directive].append(source)
37
38 def add_sourceless(self, directive):
39 assert directive not in self.directives, (
40 'Sourceless directive "{directive}" already exists.'.format(
41 directive=directive))
42
43 self.directives[directive] = []
44
45 def remove(self, directive, source, quote=False):
46 """Remove a source for a given directive."""
47 if quote:
48 source = '\'{}\''.format(source)
49
50 assert source in self.directives[directive], (
51 'Removing nonexistent "{source}" for directive "{directive}"'.format(
52 source=source, directive=directive))
53 self.directives[directive].remove(source)
54
55 def __str__(self):
56 """Convert to a string to send with a Content-Security-Policy header."""
57 parts = []
58
59 # Sort directives for deterministic results.
60 for directive, sources in sorted(self.directives.items()):
61 # Each policy part has the form "directive source1 source2 ...;".
62 parts.append(' '.join([directive] + sources) + ';')
63
64 return ' '.join(parts)
65
66
67 def get_default_builder():
68 """Get a CSPBuilder object for the default policy.
69
70 Can be modified for specific pages if needed."""
71 builder = CSPBuilder()
72
73 # By default, disallow everything. Whitelist only features that are needed.
74 builder.add('default-src', 'none', quote=True)
75
76 # Allow various directives if sourced from self.
77 builder.add('font-src', 'self', quote=True)
78 builder.add('connect-src', 'self', quote=True)
79 builder.add('img-src', 'self', quote=True)
80 builder.add('manifest-src', 'self', quote=True)
81
82 # External scripts. Google analytics, charting libraries.
83 builder.add('script-src', 'www.google-analytics.com')
84 builder.add('script-src', 'www.gstatic.com')
85 builder.add('script-src', 'apis.google.com')
86
87 # Google Analytics also uses connect-src and img-src.
88 builder.add('connect-src', 'www.google-analytics.com')
89 builder.add('img-src', 'www.google-analytics.com')
90
91 # Firebase.
92 builder.add('img-src', 'www.gstatic.com')
93 builder.add('connect-src', 'securetoken.googleapis.com')
94 builder.add('connect-src', 'www.googleapis.com')
95 builder.add('frame-src', auth.auth_domain())
96
97 # External style. Used for fonts, charting libraries.
98 builder.add('style-src', 'fonts.googleapis.com')
99 builder.add('style-src', 'www.gstatic.com')
100
101 # External fonts.
102 builder.add('font-src', 'fonts.gstatic.com')
103
104 # Some upload forms require us to connect to the cloud storage API.
105 builder.add('connect-src', 'storage.googleapis.com')
106
107 # Mixed content is unexpected, but upgrade requests rather than block.
108 builder.add_sourceless('upgrade-insecure-requests')
109
110 # We don't expect object to be used, but it doesn't fall back to default-src.
111 builder.add('object-src', 'none', quote=True)
112
113 # We don't expect workers to be used, but they fall back to script-src.
114 builder.add('worker-src', 'none', quote=True)
115
116 # Add reporting so that violations don't break things silently.
117 builder.add('report-uri', '/report-csp-failure')
118
119 # TODO(mbarbella): Remove Google-specific cases by allowing configuration.
120
121 # Internal authentication.
122 builder.add('manifest-src', 'login.corp.google.com')
123
124 # TODO(mbarbella): Improve the policy by limiting the additions below.
125
126 # Because we use Polymer Bundler to create large files containing all of our
127 # scripts inline, our policy requires this (which weakens CSP significantly).
128 builder.add('script-src', 'unsafe-inline', quote=True)
129
130 # Some of the pages that read responses from json handlers require this.
131 builder.add('script-src', 'unsafe-eval', quote=True)
132
133 # Our Polymer Bundler usage also requires inline style.
134 builder.add('style-src', 'unsafe-inline', quote=True)
135
136 # Some fonts are loaded from data URIs.
137 builder.add('font-src', 'data:')
138
139 return builder
140
141
142 def get_default():
143 """Get the default Content Security Policy as a string."""
144 return str(get_default_builder())
145
[end of src/appengine/libs/csp.py]
[start of src/appengine/libs/auth.py]
1 # Copyright 2019 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """Authentication helpers."""
15
16 import collections
17
18 from firebase_admin import auth
19 from google.cloud import ndb
20 from googleapiclient.discovery import build
21 import jwt
22 import requests
23
24 from clusterfuzz._internal.base import memoize
25 from clusterfuzz._internal.base import utils
26 from clusterfuzz._internal.config import local_config
27 from clusterfuzz._internal.datastore import data_types
28 from clusterfuzz._internal.metrics import logs
29 from clusterfuzz._internal.system import environment
30 from libs import request_cache
31
32 User = collections.namedtuple('User', ['email'])
33
34
35 class AuthError(Exception):
36 """Auth error."""
37
38
39 def auth_domain():
40 """Get the auth domain."""
41 domain = local_config.ProjectConfig().get('firebase.auth_domain')
42 if domain:
43 return domain
44
45 return utils.get_application_id() + '.firebaseapp.com'
46
47
48 def is_current_user_admin():
49 """Returns whether or not the current logged in user is an admin."""
50 if environment.is_local_development():
51 return True
52
53 user = get_current_user()
54 if not user:
55 return False
56
57 key = ndb.Key(data_types.Admin, user.email)
58 return bool(key.get())
59
60
61 @memoize.wrap(memoize.FifoInMemory(1))
62 def _project_number_from_id(project_id):
63 """Get the project number from project ID."""
64 resource_manager = build('cloudresourcemanager', 'v1')
65 result = resource_manager.projects().get(projectId=project_id).execute()
66 if 'projectNumber' not in result:
67 raise AuthError('Failed to get project number.')
68
69 return result['projectNumber']
70
71
72 @memoize.wrap(memoize.FifoInMemory(1))
73 def _get_iap_key(key_id):
74 """Retrieves a public key from the list published by Identity-Aware Proxy,
75 re-fetching the key file if necessary.
76 """
77 resp = requests.get('https://www.gstatic.com/iap/verify/public_key')
78 if resp.status_code != 200:
79 raise AuthError('Unable to fetch IAP keys: {} / {} / {}'.format(
80 resp.status_code, resp.headers, resp.text))
81
82 result = resp.json()
83 key = result.get(key_id)
84 if not key:
85 raise AuthError('Key {!r} not found'.format(key_id))
86
87 return key
88
89
90 def _validate_iap_jwt(iap_jwt):
91 """Validate JWT assertion."""
92 project_id = utils.get_application_id()
93 expected_audience = '/projects/{}/apps/{}'.format(
94 _project_number_from_id(project_id), project_id)
95
96 try:
97 key_id = jwt.get_unverified_header(iap_jwt).get('kid')
98 if not key_id:
99 raise AuthError('No key ID.')
100
101 key = _get_iap_key(key_id)
102 decoded_jwt = jwt.decode(
103 iap_jwt,
104 key,
105 algorithms=['ES256'],
106 issuer='https://cloud.google.com/iap',
107 audience=expected_audience)
108 return decoded_jwt['email']
109 except (jwt.exceptions.InvalidTokenError,
110 requests.exceptions.RequestException) as e:
111 raise AuthError('JWT assertion decode error: ' + str(e))
112
113
114 def get_iap_email(current_request):
115 """Get Cloud IAP email."""
116 jwt_assertion = current_request.headers.get('X-Goog-IAP-JWT-Assertion')
117 if not jwt_assertion:
118 return None
119
120 return _validate_iap_jwt(jwt_assertion)
121
122
123 def get_current_user():
124 """Get the current logged in user, or None."""
125 if environment.is_local_development():
126 return User('user@localhost')
127
128 current_request = request_cache.get_current_request()
129 if local_config.AuthConfig().get('enable_loas'):
130 loas_user = current_request.headers.get('X-AppEngine-LOAS-Peer-Username')
131 if loas_user:
132 return User(loas_user + '@google.com')
133
134 iap_email = get_iap_email(current_request)
135 if iap_email:
136 return User(iap_email)
137
138 cache_backing = request_cache.get_cache_backing()
139 oauth_email = getattr(cache_backing, '_oauth_email', None)
140 if oauth_email:
141 return User(oauth_email)
142
143 cached_email = getattr(cache_backing, '_cached_email', None)
144 if cached_email:
145 return User(cached_email)
146
147 session_cookie = get_session_cookie()
148 if not session_cookie:
149 return None
150
151 try:
152 decoded_claims = decode_claims(get_session_cookie())
153 except AuthError:
154 logs.log_warn('Invalid session cookie.')
155 return None
156
157 if not decoded_claims.get('email_verified'):
158 return None
159
160 email = decoded_claims.get('email')
161 if not email:
162 return None
163
164 # We cache the email for this request if we've validated the user to make
165 # subsequent get_current_user() calls fast.
166 setattr(cache_backing, '_cached_email', email)
167 return User(email)
168
169
170 def create_session_cookie(id_token, expires_in):
171 """Create a new session cookie."""
172 try:
173 return auth.create_session_cookie(id_token, expires_in=expires_in)
174 except auth.AuthError:
175 raise AuthError('Failed to create session cookie.')
176
177
178 def get_session_cookie():
179 """Get the current session cookie."""
180 return request_cache.get_current_request().cookies.get('session')
181
182
183 def revoke_session_cookie(session_cookie):
184 """Revoke a session cookie."""
185 decoded_claims = decode_claims(session_cookie)
186 auth.revoke_refresh_tokens(decoded_claims['sub'])
187
188
189 def decode_claims(session_cookie):
190 """Decode the claims for the current session cookie."""
191 try:
192 return auth.verify_session_cookie(session_cookie, check_revoked=True)
193 except (ValueError, auth.AuthError):
194 raise AuthError('Invalid session cookie.')
195
[end of src/appengine/libs/auth.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/appengine/libs/auth.py b/src/appengine/libs/auth.py
--- a/src/appengine/libs/auth.py
+++ b/src/appengine/libs/auth.py
@@ -154,7 +154,21 @@
logs.log_warn('Invalid session cookie.')
return None
- if not decoded_claims.get('email_verified'):
+ allowed_firebase_providers = local_config.ProjectConfig().get(
+ 'firebase.auth_providers', ['google.com'])
+ firebase_info = decoded_claims.get('firebase', {})
+ sign_in_provider = firebase_info.get('sign_in_provider')
+
+ if sign_in_provider not in allowed_firebase_providers:
+ logs.log_error(f'Firebase provider {sign_in_provider} is not enabled.')
+ return None
+
+ # Per https://docs.github.com/en/authentication/
+ # keeping-your-account-and-data-secure/authorizing-oauth-apps
+ # GitHub requires emails to be verified before an OAuth app can be
+ # authorized, so we make an exception.
+ if (not decoded_claims.get('email_verified') and
+ sign_in_provider != 'github.com'):
return None
email = decoded_claims.get('email')
diff --git a/src/appengine/libs/csp.py b/src/appengine/libs/csp.py
--- a/src/appengine/libs/csp.py
+++ b/src/appengine/libs/csp.py
@@ -92,6 +92,7 @@
builder.add('img-src', 'www.gstatic.com')
builder.add('connect-src', 'securetoken.googleapis.com')
builder.add('connect-src', 'www.googleapis.com')
+ builder.add('connect-src', 'identitytoolkit.googleapis.com')
builder.add('frame-src', auth.auth_domain())
# External style. Used for fonts, charting libraries.
| {"golden_diff": "diff --git a/src/appengine/libs/auth.py b/src/appengine/libs/auth.py\n--- a/src/appengine/libs/auth.py\n+++ b/src/appengine/libs/auth.py\n@@ -154,7 +154,21 @@\n logs.log_warn('Invalid session cookie.')\n return None\n \n- if not decoded_claims.get('email_verified'):\n+ allowed_firebase_providers = local_config.ProjectConfig().get(\n+ 'firebase.auth_providers', ['google.com'])\n+ firebase_info = decoded_claims.get('firebase', {})\n+ sign_in_provider = firebase_info.get('sign_in_provider')\n+\n+ if sign_in_provider not in allowed_firebase_providers:\n+ logs.log_error(f'Firebase provider {sign_in_provider} is not enabled.')\n+ return None\n+\n+ # Per https://docs.github.com/en/authentication/\n+ # keeping-your-account-and-data-secure/authorizing-oauth-apps\n+ # GitHub requires emails to be verified before an OAuth app can be\n+ # authorized, so we make an exception.\n+ if (not decoded_claims.get('email_verified') and\n+ sign_in_provider != 'github.com'):\n return None\n \n email = decoded_claims.get('email')\ndiff --git a/src/appengine/libs/csp.py b/src/appengine/libs/csp.py\n--- a/src/appengine/libs/csp.py\n+++ b/src/appengine/libs/csp.py\n@@ -92,6 +92,7 @@\n builder.add('img-src', 'www.gstatic.com')\n builder.add('connect-src', 'securetoken.googleapis.com')\n builder.add('connect-src', 'www.googleapis.com')\n+ builder.add('connect-src', 'identitytoolkit.googleapis.com')\n builder.add('frame-src', auth.auth_domain())\n \n # External style. Used for fonts, charting libraries.\n", "issue": "Investigate GitHub login\n\n", "before_files": [{"content": "# Copyright 2019 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Helpers used to generate Content Security Policies for pages.\"\"\"\nimport collections\n\nfrom libs import auth\n\n\nclass CSPBuilder(object):\n \"\"\"Helper to build a Content Security Policy string.\"\"\"\n\n def __init__(self):\n self.directives = collections.defaultdict(list)\n\n def add(self, directive, source, quote=False):\n \"\"\"Add a source for a given directive.\"\"\"\n # Some values for sources are expected to be quoted. No escaping is done\n # since these are specific literal values that don't require it.\n if quote:\n source = '\\'{}\\''.format(source)\n\n assert source not in self.directives[directive], (\n 'Duplicate source \"{source}\" for directive \"{directive}\"'.format(\n source=source, directive=directive))\n self.directives[directive].append(source)\n\n def add_sourceless(self, directive):\n assert directive not in self.directives, (\n 'Sourceless directive \"{directive}\" already exists.'.format(\n directive=directive))\n\n self.directives[directive] = []\n\n def remove(self, directive, source, quote=False):\n \"\"\"Remove a source for a given directive.\"\"\"\n if quote:\n source = '\\'{}\\''.format(source)\n\n assert source in self.directives[directive], (\n 'Removing nonexistent \"{source}\" for directive \"{directive}\"'.format(\n source=source, directive=directive))\n self.directives[directive].remove(source)\n\n def __str__(self):\n \"\"\"Convert to a string to send with a Content-Security-Policy header.\"\"\"\n parts = []\n\n # Sort directives for deterministic results.\n for directive, sources in sorted(self.directives.items()):\n # Each policy part has the form \"directive source1 source2 ...;\".\n parts.append(' '.join([directive] + sources) + ';')\n\n return ' '.join(parts)\n\n\ndef get_default_builder():\n \"\"\"Get a CSPBuilder object for the default policy.\n\n Can be modified for specific pages if needed.\"\"\"\n builder = CSPBuilder()\n\n # By default, disallow everything. Whitelist only features that are needed.\n builder.add('default-src', 'none', quote=True)\n\n # Allow various directives if sourced from self.\n builder.add('font-src', 'self', quote=True)\n builder.add('connect-src', 'self', quote=True)\n builder.add('img-src', 'self', quote=True)\n builder.add('manifest-src', 'self', quote=True)\n\n # External scripts. Google analytics, charting libraries.\n builder.add('script-src', 'www.google-analytics.com')\n builder.add('script-src', 'www.gstatic.com')\n builder.add('script-src', 'apis.google.com')\n\n # Google Analytics also uses connect-src and img-src.\n builder.add('connect-src', 'www.google-analytics.com')\n builder.add('img-src', 'www.google-analytics.com')\n\n # Firebase.\n builder.add('img-src', 'www.gstatic.com')\n builder.add('connect-src', 'securetoken.googleapis.com')\n builder.add('connect-src', 'www.googleapis.com')\n builder.add('frame-src', auth.auth_domain())\n\n # External style. Used for fonts, charting libraries.\n builder.add('style-src', 'fonts.googleapis.com')\n builder.add('style-src', 'www.gstatic.com')\n\n # External fonts.\n builder.add('font-src', 'fonts.gstatic.com')\n\n # Some upload forms require us to connect to the cloud storage API.\n builder.add('connect-src', 'storage.googleapis.com')\n\n # Mixed content is unexpected, but upgrade requests rather than block.\n builder.add_sourceless('upgrade-insecure-requests')\n\n # We don't expect object to be used, but it doesn't fall back to default-src.\n builder.add('object-src', 'none', quote=True)\n\n # We don't expect workers to be used, but they fall back to script-src.\n builder.add('worker-src', 'none', quote=True)\n\n # Add reporting so that violations don't break things silently.\n builder.add('report-uri', '/report-csp-failure')\n\n # TODO(mbarbella): Remove Google-specific cases by allowing configuration.\n\n # Internal authentication.\n builder.add('manifest-src', 'login.corp.google.com')\n\n # TODO(mbarbella): Improve the policy by limiting the additions below.\n\n # Because we use Polymer Bundler to create large files containing all of our\n # scripts inline, our policy requires this (which weakens CSP significantly).\n builder.add('script-src', 'unsafe-inline', quote=True)\n\n # Some of the pages that read responses from json handlers require this.\n builder.add('script-src', 'unsafe-eval', quote=True)\n\n # Our Polymer Bundler usage also requires inline style.\n builder.add('style-src', 'unsafe-inline', quote=True)\n\n # Some fonts are loaded from data URIs.\n builder.add('font-src', 'data:')\n\n return builder\n\n\ndef get_default():\n \"\"\"Get the default Content Security Policy as a string.\"\"\"\n return str(get_default_builder())\n", "path": "src/appengine/libs/csp.py"}, {"content": "# Copyright 2019 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Authentication helpers.\"\"\"\n\nimport collections\n\nfrom firebase_admin import auth\nfrom google.cloud import ndb\nfrom googleapiclient.discovery import build\nimport jwt\nimport requests\n\nfrom clusterfuzz._internal.base import memoize\nfrom clusterfuzz._internal.base import utils\nfrom clusterfuzz._internal.config import local_config\nfrom clusterfuzz._internal.datastore import data_types\nfrom clusterfuzz._internal.metrics import logs\nfrom clusterfuzz._internal.system import environment\nfrom libs import request_cache\n\nUser = collections.namedtuple('User', ['email'])\n\n\nclass AuthError(Exception):\n \"\"\"Auth error.\"\"\"\n\n\ndef auth_domain():\n \"\"\"Get the auth domain.\"\"\"\n domain = local_config.ProjectConfig().get('firebase.auth_domain')\n if domain:\n return domain\n\n return utils.get_application_id() + '.firebaseapp.com'\n\n\ndef is_current_user_admin():\n \"\"\"Returns whether or not the current logged in user is an admin.\"\"\"\n if environment.is_local_development():\n return True\n\n user = get_current_user()\n if not user:\n return False\n\n key = ndb.Key(data_types.Admin, user.email)\n return bool(key.get())\n\n\[email protected](memoize.FifoInMemory(1))\ndef _project_number_from_id(project_id):\n \"\"\"Get the project number from project ID.\"\"\"\n resource_manager = build('cloudresourcemanager', 'v1')\n result = resource_manager.projects().get(projectId=project_id).execute()\n if 'projectNumber' not in result:\n raise AuthError('Failed to get project number.')\n\n return result['projectNumber']\n\n\[email protected](memoize.FifoInMemory(1))\ndef _get_iap_key(key_id):\n \"\"\"Retrieves a public key from the list published by Identity-Aware Proxy,\n re-fetching the key file if necessary.\n \"\"\"\n resp = requests.get('https://www.gstatic.com/iap/verify/public_key')\n if resp.status_code != 200:\n raise AuthError('Unable to fetch IAP keys: {} / {} / {}'.format(\n resp.status_code, resp.headers, resp.text))\n\n result = resp.json()\n key = result.get(key_id)\n if not key:\n raise AuthError('Key {!r} not found'.format(key_id))\n\n return key\n\n\ndef _validate_iap_jwt(iap_jwt):\n \"\"\"Validate JWT assertion.\"\"\"\n project_id = utils.get_application_id()\n expected_audience = '/projects/{}/apps/{}'.format(\n _project_number_from_id(project_id), project_id)\n\n try:\n key_id = jwt.get_unverified_header(iap_jwt).get('kid')\n if not key_id:\n raise AuthError('No key ID.')\n\n key = _get_iap_key(key_id)\n decoded_jwt = jwt.decode(\n iap_jwt,\n key,\n algorithms=['ES256'],\n issuer='https://cloud.google.com/iap',\n audience=expected_audience)\n return decoded_jwt['email']\n except (jwt.exceptions.InvalidTokenError,\n requests.exceptions.RequestException) as e:\n raise AuthError('JWT assertion decode error: ' + str(e))\n\n\ndef get_iap_email(current_request):\n \"\"\"Get Cloud IAP email.\"\"\"\n jwt_assertion = current_request.headers.get('X-Goog-IAP-JWT-Assertion')\n if not jwt_assertion:\n return None\n\n return _validate_iap_jwt(jwt_assertion)\n\n\ndef get_current_user():\n \"\"\"Get the current logged in user, or None.\"\"\"\n if environment.is_local_development():\n return User('user@localhost')\n\n current_request = request_cache.get_current_request()\n if local_config.AuthConfig().get('enable_loas'):\n loas_user = current_request.headers.get('X-AppEngine-LOAS-Peer-Username')\n if loas_user:\n return User(loas_user + '@google.com')\n\n iap_email = get_iap_email(current_request)\n if iap_email:\n return User(iap_email)\n\n cache_backing = request_cache.get_cache_backing()\n oauth_email = getattr(cache_backing, '_oauth_email', None)\n if oauth_email:\n return User(oauth_email)\n\n cached_email = getattr(cache_backing, '_cached_email', None)\n if cached_email:\n return User(cached_email)\n\n session_cookie = get_session_cookie()\n if not session_cookie:\n return None\n\n try:\n decoded_claims = decode_claims(get_session_cookie())\n except AuthError:\n logs.log_warn('Invalid session cookie.')\n return None\n\n if not decoded_claims.get('email_verified'):\n return None\n\n email = decoded_claims.get('email')\n if not email:\n return None\n\n # We cache the email for this request if we've validated the user to make\n # subsequent get_current_user() calls fast.\n setattr(cache_backing, '_cached_email', email)\n return User(email)\n\n\ndef create_session_cookie(id_token, expires_in):\n \"\"\"Create a new session cookie.\"\"\"\n try:\n return auth.create_session_cookie(id_token, expires_in=expires_in)\n except auth.AuthError:\n raise AuthError('Failed to create session cookie.')\n\n\ndef get_session_cookie():\n \"\"\"Get the current session cookie.\"\"\"\n return request_cache.get_current_request().cookies.get('session')\n\n\ndef revoke_session_cookie(session_cookie):\n \"\"\"Revoke a session cookie.\"\"\"\n decoded_claims = decode_claims(session_cookie)\n auth.revoke_refresh_tokens(decoded_claims['sub'])\n\n\ndef decode_claims(session_cookie):\n \"\"\"Decode the claims for the current session cookie.\"\"\"\n try:\n return auth.verify_session_cookie(session_cookie, check_revoked=True)\n except (ValueError, auth.AuthError):\n raise AuthError('Invalid session cookie.')\n", "path": "src/appengine/libs/auth.py"}]} | 3,967 | 395 |
gh_patches_debug_13091 | rasdani/github-patches | git_diff | PrefectHQ__prefect-11999 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
no import statement for wait_for_flow_run
### First check
- [X] I added a descriptive title to this issue.
- [X] I used GitHub search to find a similar request and didn't find it 😇
### Describe the issue
There is no import statement for wait_for_flow_run so typing this code into pycharm shows wait_for_flow_run as an error. Searching the internets, the import statement used to be
_from prefect.tasks.prefect import wait_for_flow_run_
yeah, that doesn't work anymore.
### Describe the proposed change
put the correct import statement in the docs which is
_from prefect.flow_runs import wait_for_flow_run_
</issue>
<code>
[start of src/prefect/flow_runs.py]
1 from typing import Optional
2 from uuid import UUID
3
4 import anyio
5
6 from prefect.client.orchestration import PrefectClient
7 from prefect.client.schemas import FlowRun
8 from prefect.client.utilities import inject_client
9 from prefect.exceptions import FlowRunWaitTimeout
10 from prefect.logging import get_logger
11
12
13 @inject_client
14 async def wait_for_flow_run(
15 flow_run_id: UUID,
16 timeout: Optional[int] = 10800,
17 poll_interval: int = 5,
18 client: Optional[PrefectClient] = None,
19 log_states: bool = False,
20 ) -> FlowRun:
21 """
22 Waits for the prefect flow run to finish and returns the FlowRun
23
24 Args:
25 flow_run_id: The flow run ID for the flow run to wait for.
26 timeout: The wait timeout in seconds. Defaults to 10800 (3 hours).
27 poll_interval: The poll interval in seconds. Defaults to 5.
28
29 Returns:
30 FlowRun: The finished flow run.
31
32 Raises:
33 prefect.exceptions.FlowWaitTimeout: If flow run goes over the timeout.
34
35 Examples:
36 Create a flow run for a deployment and wait for it to finish:
37 ```python
38 import asyncio
39
40 from prefect import get_client
41
42 async def main():
43 async with get_client() as client:
44 flow_run = await client.create_flow_run_from_deployment(deployment_id="my-deployment-id")
45 flow_run = await wait_for_flow_run(flow_run_id=flow_run.id)
46 print(flow_run.state)
47
48 if __name__ == "__main__":
49 asyncio.run(main())
50
51 ```
52
53 Trigger multiple flow runs and wait for them to finish:
54 ```python
55 import asyncio
56
57 from prefect import get_client
58
59 async def main(num_runs: int):
60 async with get_client() as client:
61 flow_runs = [
62 await client.create_flow_run_from_deployment(deployment_id="my-deployment-id")
63 for _
64 in range(num_runs)
65 ]
66 coros = [wait_for_flow_run(flow_run_id=flow_run.id) for flow_run in flow_runs]
67 finished_flow_runs = await asyncio.gather(*coros)
68 print([flow_run.state for flow_run in finished_flow_runs])
69
70 if __name__ == "__main__":
71 asyncio.run(main(num_runs=10))
72
73 ```
74 """
75 assert client is not None, "Client injection failed"
76 logger = get_logger()
77 with anyio.move_on_after(timeout):
78 while True:
79 flow_run = await client.read_flow_run(flow_run_id)
80 flow_state = flow_run.state
81 if log_states:
82 logger.info(f"Flow run is in state {flow_run.state.name!r}")
83 if flow_state and flow_state.is_final():
84 return flow_run
85 await anyio.sleep(poll_interval)
86 raise FlowRunWaitTimeout(
87 f"Flow run with ID {flow_run_id} exceeded watch timeout of {timeout} seconds"
88 )
89
[end of src/prefect/flow_runs.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/prefect/flow_runs.py b/src/prefect/flow_runs.py
--- a/src/prefect/flow_runs.py
+++ b/src/prefect/flow_runs.py
@@ -38,6 +38,7 @@
import asyncio
from prefect import get_client
+ from prefect.flow_runs import wait_for_flow_run
async def main():
async with get_client() as client:
@@ -55,6 +56,7 @@
import asyncio
from prefect import get_client
+ from prefect.flow_runs import wait_for_flow_run
async def main(num_runs: int):
async with get_client() as client:
| {"golden_diff": "diff --git a/src/prefect/flow_runs.py b/src/prefect/flow_runs.py\n--- a/src/prefect/flow_runs.py\n+++ b/src/prefect/flow_runs.py\n@@ -38,6 +38,7 @@\n import asyncio\n \n from prefect import get_client\n+ from prefect.flow_runs import wait_for_flow_run\n \n async def main():\n async with get_client() as client:\n@@ -55,6 +56,7 @@\n import asyncio\n \n from prefect import get_client\n+ from prefect.flow_runs import wait_for_flow_run\n \n async def main(num_runs: int):\n async with get_client() as client:\n", "issue": "no import statement for wait_for_flow_run\n### First check\r\n\r\n- [X] I added a descriptive title to this issue.\r\n- [X] I used GitHub search to find a similar request and didn't find it \ud83d\ude07\r\n\r\n### Describe the issue\r\n\r\nThere is no import statement for wait_for_flow_run so typing this code into pycharm shows wait_for_flow_run as an error. Searching the internets, the import statement used to be\r\n\r\n_from prefect.tasks.prefect import wait_for_flow_run_\r\n\r\nyeah, that doesn't work anymore.\r\n\r\n### Describe the proposed change\r\n\r\nput the correct import statement in the docs which is \r\n\r\n_from prefect.flow_runs import wait_for_flow_run_\r\n\n", "before_files": [{"content": "from typing import Optional\nfrom uuid import UUID\n\nimport anyio\n\nfrom prefect.client.orchestration import PrefectClient\nfrom prefect.client.schemas import FlowRun\nfrom prefect.client.utilities import inject_client\nfrom prefect.exceptions import FlowRunWaitTimeout\nfrom prefect.logging import get_logger\n\n\n@inject_client\nasync def wait_for_flow_run(\n flow_run_id: UUID,\n timeout: Optional[int] = 10800,\n poll_interval: int = 5,\n client: Optional[PrefectClient] = None,\n log_states: bool = False,\n) -> FlowRun:\n \"\"\"\n Waits for the prefect flow run to finish and returns the FlowRun\n\n Args:\n flow_run_id: The flow run ID for the flow run to wait for.\n timeout: The wait timeout in seconds. Defaults to 10800 (3 hours).\n poll_interval: The poll interval in seconds. Defaults to 5.\n\n Returns:\n FlowRun: The finished flow run.\n\n Raises:\n prefect.exceptions.FlowWaitTimeout: If flow run goes over the timeout.\n\n Examples:\n Create a flow run for a deployment and wait for it to finish:\n ```python\n import asyncio\n\n from prefect import get_client\n\n async def main():\n async with get_client() as client:\n flow_run = await client.create_flow_run_from_deployment(deployment_id=\"my-deployment-id\")\n flow_run = await wait_for_flow_run(flow_run_id=flow_run.id)\n print(flow_run.state)\n\n if __name__ == \"__main__\":\n asyncio.run(main())\n\n ```\n\n Trigger multiple flow runs and wait for them to finish:\n ```python\n import asyncio\n\n from prefect import get_client\n\n async def main(num_runs: int):\n async with get_client() as client:\n flow_runs = [\n await client.create_flow_run_from_deployment(deployment_id=\"my-deployment-id\")\n for _\n in range(num_runs)\n ]\n coros = [wait_for_flow_run(flow_run_id=flow_run.id) for flow_run in flow_runs]\n finished_flow_runs = await asyncio.gather(*coros)\n print([flow_run.state for flow_run in finished_flow_runs])\n\n if __name__ == \"__main__\":\n asyncio.run(main(num_runs=10))\n\n ```\n \"\"\"\n assert client is not None, \"Client injection failed\"\n logger = get_logger()\n with anyio.move_on_after(timeout):\n while True:\n flow_run = await client.read_flow_run(flow_run_id)\n flow_state = flow_run.state\n if log_states:\n logger.info(f\"Flow run is in state {flow_run.state.name!r}\")\n if flow_state and flow_state.is_final():\n return flow_run\n await anyio.sleep(poll_interval)\n raise FlowRunWaitTimeout(\n f\"Flow run with ID {flow_run_id} exceeded watch timeout of {timeout} seconds\"\n )\n", "path": "src/prefect/flow_runs.py"}]} | 1,484 | 146 |
gh_patches_debug_3915 | rasdani/github-patches | git_diff | fossasia__open-event-server-890 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Show return model of sponsor types list in Swagger spec
Currently no return model (or schema) is shown for the GET API to get sponsor types used in a Event

</issue>
<code>
[start of open_event/api/sponsors.py]
1 from flask.ext.restplus import Resource, Namespace
2
3 from open_event.models.sponsor import Sponsor as SponsorModel
4
5 from .helpers.helpers import get_paginated_list, requires_auth, get_object_in_event
6 from .helpers.utils import PAGINATED_MODEL, PaginatedResourceBase, ServiceDAO, \
7 PAGE_PARAMS, POST_RESPONSES, PUT_RESPONSES
8 from .helpers import custom_fields as fields
9
10 api = Namespace('sponsors', description='Sponsors', path='/')
11
12 SPONSOR = api.model('Sponsor', {
13 'id': fields.Integer(required=True),
14 'name': fields.String(),
15 'url': fields.Uri(),
16 'logo': fields.ImageUri(),
17 'description': fields.String(),
18 'level': fields.String(),
19 'sponsor_type': fields.String(),
20 })
21
22 SPONSOR_PAGINATED = api.clone('SponsorPaginated', PAGINATED_MODEL, {
23 'results': fields.List(fields.Nested(SPONSOR))
24 })
25
26 SPONSOR_POST = api.clone('SponsorPost', SPONSOR)
27 del SPONSOR_POST['id']
28
29
30 # Create DAO
31 class SponsorDAO(ServiceDAO):
32 def list_types(self, event_id):
33 sponsors = self.list(event_id)
34 return list(set(
35 sponsor.sponsor_type for sponsor in sponsors
36 if sponsor.sponsor_type))
37
38
39 DAO = SponsorDAO(SponsorModel, SPONSOR_POST)
40
41
42 @api.route('/events/<int:event_id>/sponsors/<int:sponsor_id>')
43 @api.response(404, 'Sponsor not found')
44 @api.response(400, 'Sponsor does not belong to event')
45 class Sponsor(Resource):
46 @api.doc('get_sponsor')
47 @api.marshal_with(SPONSOR)
48 def get(self, event_id, sponsor_id):
49 """Fetch a sponsor given its id"""
50 return DAO.get(event_id, sponsor_id)
51
52 @requires_auth
53 @api.doc('delete_sponsor')
54 @api.marshal_with(SPONSOR)
55 def delete(self, event_id, sponsor_id):
56 """Delete a sponsor given its id"""
57 return DAO.delete(event_id, sponsor_id)
58
59 @requires_auth
60 @api.doc('update_sponsor', responses=PUT_RESPONSES)
61 @api.marshal_with(SPONSOR)
62 @api.expect(SPONSOR_POST)
63 def put(self, event_id, sponsor_id):
64 """Update a sponsor given its id"""
65 return DAO.update(event_id, sponsor_id, self.api.payload)
66
67
68 @api.route('/events/<int:event_id>/sponsors')
69 class SponsorList(Resource):
70 @api.doc('list_sponsors')
71 @api.marshal_list_with(SPONSOR)
72 def get(self, event_id):
73 """List all sponsors"""
74 return DAO.list(event_id)
75
76 @requires_auth
77 @api.doc('create_sponsor', responses=POST_RESPONSES)
78 @api.marshal_with(SPONSOR)
79 @api.expect(SPONSOR_POST)
80 def post(self, event_id):
81 """Create a sponsor"""
82 return DAO.create(
83 event_id,
84 self.api.payload,
85 self.api.url_for(self, event_id=event_id)
86 )
87
88
89 @api.route('/events/<int:event_id>/sponsors/types')
90 class SponsorTypesList(Resource):
91 @api.doc('list_sponsor_types')
92 def get(self, event_id):
93 """List all sponsor types"""
94 return DAO.list_types(event_id)
95
96
97 @api.route('/events/<int:event_id>/sponsors/page')
98 class SponsorListPaginated(Resource, PaginatedResourceBase):
99 @api.doc('list_sponsors_paginated', params=PAGE_PARAMS)
100 @api.marshal_with(SPONSOR_PAGINATED)
101 def get(self, event_id):
102 """List sponsors in a paginated manner"""
103 return get_paginated_list(
104 SponsorModel,
105 self.api.url_for(self, event_id=event_id),
106 args=self.parser.parse_args(),
107 event_id=event_id
108 )
109
[end of open_event/api/sponsors.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/open_event/api/sponsors.py b/open_event/api/sponsors.py
--- a/open_event/api/sponsors.py
+++ b/open_event/api/sponsors.py
@@ -88,7 +88,7 @@
@api.route('/events/<int:event_id>/sponsors/types')
class SponsorTypesList(Resource):
- @api.doc('list_sponsor_types')
+ @api.doc('list_sponsor_types', model=[fields.String()])
def get(self, event_id):
"""List all sponsor types"""
return DAO.list_types(event_id)
| {"golden_diff": "diff --git a/open_event/api/sponsors.py b/open_event/api/sponsors.py\n--- a/open_event/api/sponsors.py\n+++ b/open_event/api/sponsors.py\n@@ -88,7 +88,7 @@\n \n @api.route('/events/<int:event_id>/sponsors/types')\n class SponsorTypesList(Resource):\n- @api.doc('list_sponsor_types')\n+ @api.doc('list_sponsor_types', model=[fields.String()])\n def get(self, event_id):\n \"\"\"List all sponsor types\"\"\"\n return DAO.list_types(event_id)\n", "issue": "Show return model of sponsor types list in Swagger spec\nCurrently no return model (or schema) is shown for the GET API to get sponsor types used in a Event\n\n\n\n", "before_files": [{"content": "from flask.ext.restplus import Resource, Namespace\n\nfrom open_event.models.sponsor import Sponsor as SponsorModel\n\nfrom .helpers.helpers import get_paginated_list, requires_auth, get_object_in_event\nfrom .helpers.utils import PAGINATED_MODEL, PaginatedResourceBase, ServiceDAO, \\\n PAGE_PARAMS, POST_RESPONSES, PUT_RESPONSES\nfrom .helpers import custom_fields as fields\n\napi = Namespace('sponsors', description='Sponsors', path='/')\n\nSPONSOR = api.model('Sponsor', {\n 'id': fields.Integer(required=True),\n 'name': fields.String(),\n 'url': fields.Uri(),\n 'logo': fields.ImageUri(),\n 'description': fields.String(),\n 'level': fields.String(),\n 'sponsor_type': fields.String(),\n})\n\nSPONSOR_PAGINATED = api.clone('SponsorPaginated', PAGINATED_MODEL, {\n 'results': fields.List(fields.Nested(SPONSOR))\n})\n\nSPONSOR_POST = api.clone('SponsorPost', SPONSOR)\ndel SPONSOR_POST['id']\n\n\n# Create DAO\nclass SponsorDAO(ServiceDAO):\n def list_types(self, event_id):\n sponsors = self.list(event_id)\n return list(set(\n sponsor.sponsor_type for sponsor in sponsors\n if sponsor.sponsor_type))\n\n\nDAO = SponsorDAO(SponsorModel, SPONSOR_POST)\n\n\[email protected]('/events/<int:event_id>/sponsors/<int:sponsor_id>')\[email protected](404, 'Sponsor not found')\[email protected](400, 'Sponsor does not belong to event')\nclass Sponsor(Resource):\n @api.doc('get_sponsor')\n @api.marshal_with(SPONSOR)\n def get(self, event_id, sponsor_id):\n \"\"\"Fetch a sponsor given its id\"\"\"\n return DAO.get(event_id, sponsor_id)\n\n @requires_auth\n @api.doc('delete_sponsor')\n @api.marshal_with(SPONSOR)\n def delete(self, event_id, sponsor_id):\n \"\"\"Delete a sponsor given its id\"\"\"\n return DAO.delete(event_id, sponsor_id)\n\n @requires_auth\n @api.doc('update_sponsor', responses=PUT_RESPONSES)\n @api.marshal_with(SPONSOR)\n @api.expect(SPONSOR_POST)\n def put(self, event_id, sponsor_id):\n \"\"\"Update a sponsor given its id\"\"\"\n return DAO.update(event_id, sponsor_id, self.api.payload)\n\n\[email protected]('/events/<int:event_id>/sponsors')\nclass SponsorList(Resource):\n @api.doc('list_sponsors')\n @api.marshal_list_with(SPONSOR)\n def get(self, event_id):\n \"\"\"List all sponsors\"\"\"\n return DAO.list(event_id)\n\n @requires_auth\n @api.doc('create_sponsor', responses=POST_RESPONSES)\n @api.marshal_with(SPONSOR)\n @api.expect(SPONSOR_POST)\n def post(self, event_id):\n \"\"\"Create a sponsor\"\"\"\n return DAO.create(\n event_id,\n self.api.payload,\n self.api.url_for(self, event_id=event_id)\n )\n\n\[email protected]('/events/<int:event_id>/sponsors/types')\nclass SponsorTypesList(Resource):\n @api.doc('list_sponsor_types')\n def get(self, event_id):\n \"\"\"List all sponsor types\"\"\"\n return DAO.list_types(event_id)\n\n\[email protected]('/events/<int:event_id>/sponsors/page')\nclass SponsorListPaginated(Resource, PaginatedResourceBase):\n @api.doc('list_sponsors_paginated', params=PAGE_PARAMS)\n @api.marshal_with(SPONSOR_PAGINATED)\n def get(self, event_id):\n \"\"\"List sponsors in a paginated manner\"\"\"\n return get_paginated_list(\n SponsorModel,\n self.api.url_for(self, event_id=event_id),\n args=self.parser.parse_args(),\n event_id=event_id\n )\n", "path": "open_event/api/sponsors.py"}]} | 1,692 | 119 |
gh_patches_debug_14502 | rasdani/github-patches | git_diff | conan-io__conan-3839 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Conan doesn't keep the username to log to server anymore
From conan 1.8,
When an authentication is required by the conan server, the username is now always asked event though it was specified by conan user. In older version, only the password was required.
To reproduce:
```
$ conan user -c
$ conan user username
Changed user of remote 'server' from 'None' (anonymous) to 'username'
$ conan search -r server *
Please log in to "server" to perform this action. Execute "conan user" command.
Remote 'server' username:
```
To help us debug your issue please explain:
- [X] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md).
- [X] I've specified the Conan version, operating system version and any tool that can be relevant.
- [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.
</issue>
<code>
[start of conans/client/userio.py]
1 import os
2 import sys
3 from conans.client.output import ConanOutput
4 from conans.errors import InvalidNameException, ConanException
5 import getpass
6 from six.moves import input as raw_input
7
8
9 class UserIO(object):
10 """Class to interact with the user, used to show messages and ask for information"""
11
12 def __init__(self, ins=sys.stdin, out=None):
13 """
14 Params:
15 ins: input stream
16 out: ConanOutput, should have "write" method
17 """
18 self._ins = ins
19 if not out:
20 out = ConanOutput(sys.stdout)
21 self.out = out
22 self._interactive = True
23
24 def disable_input(self):
25 self._interactive = False
26
27 def _raise_if_non_interactive(self):
28 if not self._interactive:
29 raise ConanException("Conan interactive mode disabled")
30
31 def raw_input(self):
32 self._raise_if_non_interactive()
33 return raw_input()
34
35 def get_pass(self):
36 self._raise_if_non_interactive()
37 return getpass.getpass("")
38
39 def request_login(self, remote_name, username=None):
40 """Request user to input their name and password
41 :param username If username is specified it only request password"""
42 if self._interactive:
43 self.out.write("Remote '%s' username: " % remote_name)
44 username = self.get_username(remote_name)
45
46 if self._interactive:
47 self.out.write('Please enter a password for "%s" account: ' % username)
48 try:
49 pwd = self.get_password(remote_name)
50 except ConanException:
51 raise
52 except Exception as e:
53 raise ConanException('Cancelled pass %s' % e)
54 return username, pwd
55
56 def get_username(self, remote_name):
57 """Overridable for testing purpose"""
58 return self._get_env_username(remote_name) or self.raw_input()
59
60 def get_password(self, remote_name):
61 """Overridable for testing purpose"""
62 return self._get_env_password(remote_name) or self.get_pass()
63
64 def request_string(self, msg, default_value=None):
65 """Request user to input a msg
66 :param msg Name of the msg
67 """
68 self._raise_if_non_interactive()
69
70 if default_value:
71 self.out.input_text('%s (%s): ' % (msg, default_value))
72 else:
73 self.out.input_text('%s: ' % msg)
74 s = self._ins.readline().replace("\n", "")
75 if default_value is not None and s == '':
76 return default_value
77 return s
78
79 def request_boolean(self, msg, default_option=None):
80 """Request user to input a boolean"""
81 ret = None
82 while ret is None:
83 if default_option is True:
84 s = self.request_string("%s (YES/no)" % msg)
85 elif default_option is False:
86 s = self.request_string("%s (NO/yes)" % msg)
87 else:
88 s = self.request_string("%s (yes/no)" % msg)
89 if default_option is not None and s == '':
90 return default_option
91 if s.lower() in ['yes', 'y']:
92 ret = True
93 elif s.lower() in ['no', 'n']:
94 ret = False
95 else:
96 self.out.error("%s is not a valid answer" % s)
97 return ret
98
99 def _get_env_password(self, remote_name):
100 """
101 Try CONAN_PASSWORD_REMOTE_NAME or CONAN_PASSWORD or return None
102 """
103 remote_name = remote_name.replace("-", "_").upper()
104 var_name = "CONAN_PASSWORD_%s" % remote_name
105 ret = os.getenv(var_name, None) or os.getenv("CONAN_PASSWORD", None)
106 if ret:
107 self.out.info("Got password '******' from environment")
108 return ret
109
110 def _get_env_username(self, remote_name):
111 """
112 Try CONAN_LOGIN_USERNAME_REMOTE_NAME or CONAN_LOGIN_USERNAME or return None
113 """
114 remote_name = remote_name.replace("-", "_").upper()
115 var_name = "CONAN_LOGIN_USERNAME_%s" % remote_name
116 ret = os.getenv(var_name, None) or os.getenv("CONAN_LOGIN_USERNAME", None)
117
118 if ret:
119 self.out.info("Got username '%s' from environment" % ret)
120 return ret
121
[end of conans/client/userio.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/conans/client/userio.py b/conans/client/userio.py
--- a/conans/client/userio.py
+++ b/conans/client/userio.py
@@ -39,9 +39,11 @@
def request_login(self, remote_name, username=None):
"""Request user to input their name and password
:param username If username is specified it only request password"""
- if self._interactive:
- self.out.write("Remote '%s' username: " % remote_name)
- username = self.get_username(remote_name)
+
+ if not username:
+ if self._interactive:
+ self.out.write("Remote '%s' username: " % remote_name)
+ username = self.get_username(remote_name)
if self._interactive:
self.out.write('Please enter a password for "%s" account: ' % username)
| {"golden_diff": "diff --git a/conans/client/userio.py b/conans/client/userio.py\n--- a/conans/client/userio.py\n+++ b/conans/client/userio.py\n@@ -39,9 +39,11 @@\n def request_login(self, remote_name, username=None):\n \"\"\"Request user to input their name and password\n :param username If username is specified it only request password\"\"\"\n- if self._interactive:\n- self.out.write(\"Remote '%s' username: \" % remote_name)\n- username = self.get_username(remote_name)\n+\n+ if not username:\n+ if self._interactive:\n+ self.out.write(\"Remote '%s' username: \" % remote_name)\n+ username = self.get_username(remote_name)\n \n if self._interactive:\n self.out.write('Please enter a password for \"%s\" account: ' % username)\n", "issue": "Conan doesn't keep the username to log to server anymore\nFrom conan 1.8,\r\n\r\nWhen an authentication is required by the conan server, the username is now always asked event though it was specified by conan user. In older version, only the password was required.\r\n\r\nTo reproduce:\r\n```\r\n$ conan user -c\r\n$ conan user username\r\nChanged user of remote 'server' from 'None' (anonymous) to 'username'\r\n$ conan search -r server *\r\nPlease log in to \"server\" to perform this action. Execute \"conan user\" command.\r\nRemote 'server' username:\r\n```\r\n\r\nTo help us debug your issue please explain:\r\n\r\n- [X] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md).\r\n- [X] I've specified the Conan version, operating system version and any tool that can be relevant.\r\n- [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.\r\n\r\n\n", "before_files": [{"content": "import os\nimport sys\nfrom conans.client.output import ConanOutput\nfrom conans.errors import InvalidNameException, ConanException\nimport getpass\nfrom six.moves import input as raw_input\n\n\nclass UserIO(object):\n \"\"\"Class to interact with the user, used to show messages and ask for information\"\"\"\n\n def __init__(self, ins=sys.stdin, out=None):\n \"\"\"\n Params:\n ins: input stream\n out: ConanOutput, should have \"write\" method\n \"\"\"\n self._ins = ins\n if not out:\n out = ConanOutput(sys.stdout)\n self.out = out\n self._interactive = True\n\n def disable_input(self):\n self._interactive = False\n\n def _raise_if_non_interactive(self):\n if not self._interactive:\n raise ConanException(\"Conan interactive mode disabled\")\n\n def raw_input(self):\n self._raise_if_non_interactive()\n return raw_input()\n\n def get_pass(self):\n self._raise_if_non_interactive()\n return getpass.getpass(\"\")\n\n def request_login(self, remote_name, username=None):\n \"\"\"Request user to input their name and password\n :param username If username is specified it only request password\"\"\"\n if self._interactive:\n self.out.write(\"Remote '%s' username: \" % remote_name)\n username = self.get_username(remote_name)\n\n if self._interactive:\n self.out.write('Please enter a password for \"%s\" account: ' % username)\n try:\n pwd = self.get_password(remote_name)\n except ConanException:\n raise\n except Exception as e:\n raise ConanException('Cancelled pass %s' % e)\n return username, pwd\n\n def get_username(self, remote_name):\n \"\"\"Overridable for testing purpose\"\"\"\n return self._get_env_username(remote_name) or self.raw_input()\n\n def get_password(self, remote_name):\n \"\"\"Overridable for testing purpose\"\"\"\n return self._get_env_password(remote_name) or self.get_pass()\n\n def request_string(self, msg, default_value=None):\n \"\"\"Request user to input a msg\n :param msg Name of the msg\n \"\"\"\n self._raise_if_non_interactive()\n\n if default_value:\n self.out.input_text('%s (%s): ' % (msg, default_value))\n else:\n self.out.input_text('%s: ' % msg)\n s = self._ins.readline().replace(\"\\n\", \"\")\n if default_value is not None and s == '':\n return default_value\n return s\n\n def request_boolean(self, msg, default_option=None):\n \"\"\"Request user to input a boolean\"\"\"\n ret = None\n while ret is None:\n if default_option is True:\n s = self.request_string(\"%s (YES/no)\" % msg)\n elif default_option is False:\n s = self.request_string(\"%s (NO/yes)\" % msg)\n else:\n s = self.request_string(\"%s (yes/no)\" % msg)\n if default_option is not None and s == '':\n return default_option\n if s.lower() in ['yes', 'y']:\n ret = True\n elif s.lower() in ['no', 'n']:\n ret = False\n else:\n self.out.error(\"%s is not a valid answer\" % s)\n return ret\n\n def _get_env_password(self, remote_name):\n \"\"\"\n Try CONAN_PASSWORD_REMOTE_NAME or CONAN_PASSWORD or return None\n \"\"\"\n remote_name = remote_name.replace(\"-\", \"_\").upper()\n var_name = \"CONAN_PASSWORD_%s\" % remote_name\n ret = os.getenv(var_name, None) or os.getenv(\"CONAN_PASSWORD\", None)\n if ret:\n self.out.info(\"Got password '******' from environment\")\n return ret\n\n def _get_env_username(self, remote_name):\n \"\"\"\n Try CONAN_LOGIN_USERNAME_REMOTE_NAME or CONAN_LOGIN_USERNAME or return None\n \"\"\"\n remote_name = remote_name.replace(\"-\", \"_\").upper()\n var_name = \"CONAN_LOGIN_USERNAME_%s\" % remote_name\n ret = os.getenv(var_name, None) or os.getenv(\"CONAN_LOGIN_USERNAME\", None)\n\n if ret:\n self.out.info(\"Got username '%s' from environment\" % ret)\n return ret\n", "path": "conans/client/userio.py"}]} | 1,936 | 186 |
gh_patches_debug_3843 | rasdani/github-patches | git_diff | jazzband__pip-tools-1105 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
--upgrade-package downgrades unrelated pre-release package when --pre not given
<!-- Describe the issue briefly here. -->
#### Environment Versions
1. OS Type: macOS 10.15.4
1. Python version: 3.7.7
1. pip version: 20.0.2
1. pip-tools version: 4.5.1
#### Steps to replicate
(Note: this example will stop working when `gevent` releases 1.5 final but it can be replicated with any other package that currently has a pre-release version.)
1. Example `req.in` file:
```
click<7
gevent
```
2. `pip-compile req.in`
Output:
```
#
# This file is autogenerated by pip-compile
# To update, run:
#
# pip-compile req.in
#
click==6.7 # via -r req.in
gevent==1.4.0 # via -r req.in
greenlet==0.4.15 # via gevent
```
3. Upgrade gevent to pre-relese
`pip-compile --pre --upgrade-package gevent req.in`
Output:
```
#
# This file is autogenerated by pip-compile
# To update, run:
#
# pip-compile --pre req.in
#
click==6.7 # via -r req.in
gevent==1.5a4 # via -r req.in
greenlet==0.4.15 # via gevent
```
4. Remove version pin of `click` in `.in` file:
```
click
gevent
```
5. Upgrade click:
`pip-compile --upgrade-package click req.in`
Output:
```
#
# This file is autogenerated by pip-compile
# To update, run:
#
# pip-compile req.in
#
click==6.7 # via -r req.in
gevent==1.4.0 # via -r req.in
greenlet==0.4.15 # via gevent
```
#### Expected result
Once a package has been resolved to a pre-release version it should never "magically" be downgraded. Especially if only unrelated other packages are concerned.
I could see that there may be an argument for a plain `pip-compile` run to revert to the non-prerelease version, but I would disagree even there. But for `--upgrade-package` I see no way where this is correct behaviour.
#### Actual result
Not giving `--pre` at any time after it has been used once and a package is resolved to a pre-release version will downgrade it back to the last released version.
</issue>
<code>
[start of piptools/repositories/local.py]
1 # coding: utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 from contextlib import contextmanager
5
6 from pip._internal.utils.hashes import FAVORITE_HASH
7
8 from .._compat import PIP_VERSION
9 from .base import BaseRepository
10
11 from piptools.utils import as_tuple, key_from_ireq, make_install_requirement
12
13
14 def ireq_satisfied_by_existing_pin(ireq, existing_pin):
15 """
16 Return True if the given InstallationRequirement is satisfied by the
17 previously encountered version pin.
18 """
19 version = next(iter(existing_pin.req.specifier)).version
20 return version in ireq.req.specifier
21
22
23 class LocalRequirementsRepository(BaseRepository):
24 """
25 The LocalRequirementsRepository proxied the _real_ repository by first
26 checking if a requirement can be satisfied by existing pins (i.e. the
27 result of a previous compile step).
28
29 In effect, if a requirement can be satisfied with a version pinned in the
30 requirements file, we prefer that version over the best match found in
31 PyPI. This keeps updates to the requirements.txt down to a minimum.
32 """
33
34 def __init__(self, existing_pins, proxied_repository):
35 self.repository = proxied_repository
36 self.existing_pins = existing_pins
37
38 @property
39 def options(self):
40 return self.repository.options
41
42 @property
43 def finder(self):
44 return self.repository.finder
45
46 @property
47 def session(self):
48 return self.repository.session
49
50 @property
51 def DEFAULT_INDEX_URL(self):
52 return self.repository.DEFAULT_INDEX_URL
53
54 def clear_caches(self):
55 self.repository.clear_caches()
56
57 def freshen_build_caches(self):
58 self.repository.freshen_build_caches()
59
60 def find_best_match(self, ireq, prereleases=None):
61 key = key_from_ireq(ireq)
62 existing_pin = self.existing_pins.get(key)
63 if existing_pin and ireq_satisfied_by_existing_pin(ireq, existing_pin):
64 project, version, _ = as_tuple(existing_pin)
65 return make_install_requirement(
66 project, version, ireq.extras, constraint=ireq.constraint
67 )
68 else:
69 return self.repository.find_best_match(ireq, prereleases)
70
71 def get_dependencies(self, ireq):
72 return self.repository.get_dependencies(ireq)
73
74 def get_hashes(self, ireq):
75 key = key_from_ireq(ireq)
76 existing_pin = self.existing_pins.get(key)
77 if existing_pin and ireq_satisfied_by_existing_pin(ireq, existing_pin):
78 if PIP_VERSION[:2] <= (20, 0):
79 hashes = existing_pin.options.get("hashes", {})
80 else:
81 hashes = existing_pin.hash_options
82 hexdigests = hashes.get(FAVORITE_HASH)
83 if hexdigests:
84 return {
85 ":".join([FAVORITE_HASH, hexdigest]) for hexdigest in hexdigests
86 }
87 return self.repository.get_hashes(ireq)
88
89 @contextmanager
90 def allow_all_wheels(self):
91 with self.repository.allow_all_wheels():
92 yield
93
[end of piptools/repositories/local.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/piptools/repositories/local.py b/piptools/repositories/local.py
--- a/piptools/repositories/local.py
+++ b/piptools/repositories/local.py
@@ -17,7 +17,9 @@
previously encountered version pin.
"""
version = next(iter(existing_pin.req.specifier)).version
- return version in ireq.req.specifier
+ return ireq.req.specifier.contains(
+ version, prereleases=existing_pin.req.specifier.prereleases
+ )
class LocalRequirementsRepository(BaseRepository):
| {"golden_diff": "diff --git a/piptools/repositories/local.py b/piptools/repositories/local.py\n--- a/piptools/repositories/local.py\n+++ b/piptools/repositories/local.py\n@@ -17,7 +17,9 @@\n previously encountered version pin.\n \"\"\"\n version = next(iter(existing_pin.req.specifier)).version\n- return version in ireq.req.specifier\n+ return ireq.req.specifier.contains(\n+ version, prereleases=existing_pin.req.specifier.prereleases\n+ )\n \n \n class LocalRequirementsRepository(BaseRepository):\n", "issue": "--upgrade-package downgrades unrelated pre-release package when --pre not given\n<!-- Describe the issue briefly here. -->\r\n\r\n#### Environment Versions\r\n\r\n1. OS Type: macOS 10.15.4\r\n1. Python version: 3.7.7\r\n1. pip version: 20.0.2\r\n1. pip-tools version: 4.5.1\r\n\r\n#### Steps to replicate\r\n\r\n(Note: this example will stop working when `gevent` releases 1.5 final but it can be replicated with any other package that currently has a pre-release version.)\r\n\r\n1. Example `req.in` file:\r\n ```\r\n click<7\r\n gevent\r\n ```\r\n2. `pip-compile req.in`\r\n Output:\r\n ```\r\n #\r\n # This file is autogenerated by pip-compile\r\n # To update, run:\r\n #\r\n # pip-compile req.in\r\n #\r\n click==6.7 # via -r req.in\r\n gevent==1.4.0 # via -r req.in\r\n greenlet==0.4.15 # via gevent\r\n ```\r\n3. Upgrade gevent to pre-relese\r\n `pip-compile --pre --upgrade-package gevent req.in`\r\n Output:\r\n ```\r\n #\r\n # This file is autogenerated by pip-compile\r\n # To update, run:\r\n #\r\n # pip-compile --pre req.in\r\n #\r\n click==6.7 # via -r req.in\r\n gevent==1.5a4 # via -r req.in\r\n greenlet==0.4.15 # via gevent\r\n ```\r\n4. Remove version pin of `click` in `.in` file:\r\n ```\r\n click\r\n gevent\r\n ```\r\n5. Upgrade click:\r\n `pip-compile --upgrade-package click req.in`\r\n Output:\r\n ```\r\n #\r\n # This file is autogenerated by pip-compile\r\n # To update, run:\r\n #\r\n # pip-compile req.in\r\n #\r\n click==6.7 # via -r req.in\r\n gevent==1.4.0 # via -r req.in\r\n greenlet==0.4.15 # via gevent\r\n ```\r\n\r\n#### Expected result\r\n\r\nOnce a package has been resolved to a pre-release version it should never \"magically\" be downgraded. Especially if only unrelated other packages are concerned.\r\n\r\nI could see that there may be an argument for a plain `pip-compile` run to revert to the non-prerelease version, but I would disagree even there. But for `--upgrade-package` I see no way where this is correct behaviour.\r\n\r\n#### Actual result\r\n\r\nNot giving `--pre` at any time after it has been used once and a package is resolved to a pre-release version will downgrade it back to the last released version.\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom contextlib import contextmanager\n\nfrom pip._internal.utils.hashes import FAVORITE_HASH\n\nfrom .._compat import PIP_VERSION\nfrom .base import BaseRepository\n\nfrom piptools.utils import as_tuple, key_from_ireq, make_install_requirement\n\n\ndef ireq_satisfied_by_existing_pin(ireq, existing_pin):\n \"\"\"\n Return True if the given InstallationRequirement is satisfied by the\n previously encountered version pin.\n \"\"\"\n version = next(iter(existing_pin.req.specifier)).version\n return version in ireq.req.specifier\n\n\nclass LocalRequirementsRepository(BaseRepository):\n \"\"\"\n The LocalRequirementsRepository proxied the _real_ repository by first\n checking if a requirement can be satisfied by existing pins (i.e. the\n result of a previous compile step).\n\n In effect, if a requirement can be satisfied with a version pinned in the\n requirements file, we prefer that version over the best match found in\n PyPI. This keeps updates to the requirements.txt down to a minimum.\n \"\"\"\n\n def __init__(self, existing_pins, proxied_repository):\n self.repository = proxied_repository\n self.existing_pins = existing_pins\n\n @property\n def options(self):\n return self.repository.options\n\n @property\n def finder(self):\n return self.repository.finder\n\n @property\n def session(self):\n return self.repository.session\n\n @property\n def DEFAULT_INDEX_URL(self):\n return self.repository.DEFAULT_INDEX_URL\n\n def clear_caches(self):\n self.repository.clear_caches()\n\n def freshen_build_caches(self):\n self.repository.freshen_build_caches()\n\n def find_best_match(self, ireq, prereleases=None):\n key = key_from_ireq(ireq)\n existing_pin = self.existing_pins.get(key)\n if existing_pin and ireq_satisfied_by_existing_pin(ireq, existing_pin):\n project, version, _ = as_tuple(existing_pin)\n return make_install_requirement(\n project, version, ireq.extras, constraint=ireq.constraint\n )\n else:\n return self.repository.find_best_match(ireq, prereleases)\n\n def get_dependencies(self, ireq):\n return self.repository.get_dependencies(ireq)\n\n def get_hashes(self, ireq):\n key = key_from_ireq(ireq)\n existing_pin = self.existing_pins.get(key)\n if existing_pin and ireq_satisfied_by_existing_pin(ireq, existing_pin):\n if PIP_VERSION[:2] <= (20, 0):\n hashes = existing_pin.options.get(\"hashes\", {})\n else:\n hashes = existing_pin.hash_options\n hexdigests = hashes.get(FAVORITE_HASH)\n if hexdigests:\n return {\n \":\".join([FAVORITE_HASH, hexdigest]) for hexdigest in hexdigests\n }\n return self.repository.get_hashes(ireq)\n\n @contextmanager\n def allow_all_wheels(self):\n with self.repository.allow_all_wheels():\n yield\n", "path": "piptools/repositories/local.py"}]} | 2,027 | 121 |
gh_patches_debug_34763 | rasdani/github-patches | git_diff | DataBiosphere__toil-3581 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add type hints to resources.py
Add type hints to src/toil/lib/encryption/resources.py so it can be checked under mypy during linting.
┆Issue is synchronized with this [Jira Task](https://ucsc-cgl.atlassian.net/browse/TOIL-885)
┆Issue Number: TOIL-885
</issue>
<code>
[start of src/toil/lib/resources.py]
1 # Copyright (C) 2015-2021 Regents of the University of California
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import fnmatch
15 import os
16 import resource
17
18 from typing import List
19
20
21 def get_total_cpu_time_and_memory_usage():
22 """
23 Gives the total cpu time of itself and all its children, and the maximum RSS memory usage of
24 itself and its single largest child.
25 """
26 me = resource.getrusage(resource.RUSAGE_SELF)
27 children = resource.getrusage(resource.RUSAGE_CHILDREN)
28 total_cpu_time = me.ru_utime + me.ru_stime + children.ru_utime + children.ru_stime
29 total_memory_usage = me.ru_maxrss + children.ru_maxrss
30 return total_cpu_time, total_memory_usage
31
32
33 def get_total_cpu_time():
34 """Gives the total cpu time, including the children."""
35 me = resource.getrusage(resource.RUSAGE_SELF)
36 childs = resource.getrusage(resource.RUSAGE_CHILDREN)
37 return me.ru_utime + me.ru_stime + childs.ru_utime + childs.ru_stime
38
39
40 def glob(glob_pattern: str, directoryname: str) -> List[str]:
41 """
42 Walks through a directory and its subdirectories looking for files matching
43 the glob_pattern and returns a list=[].
44
45 :param directoryname: Any accessible folder name on the filesystem.
46 :param glob_pattern: A string like "*.txt", which would find all text files.
47 :return: A list=[] of absolute filepaths matching the glob pattern.
48 """
49 matches = []
50 for root, dirnames, filenames in os.walk(directoryname):
51 for filename in fnmatch.filter(filenames, glob_pattern):
52 absolute_filepath = os.path.join(root, filename)
53 matches.append(absolute_filepath)
54 return matches
55
[end of src/toil/lib/resources.py]
[start of contrib/admin/mypy-with-ignore.py]
1 #!/usr/bin/env python3
2 """
3 Runs mypy and ignores files that do not yet have passing type hints.
4
5 Does not type check test files (any path including "src/toil/test").
6 """
7 import os
8 import subprocess
9 import sys
10
11 pkg_root = os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')) # noqa
12 sys.path.insert(0, pkg_root) # noqa
13
14 from src.toil.lib.resources import glob # type: ignore
15
16
17 def main():
18 all_files_to_check = []
19 for d in ['dashboard', 'docker', 'docs', 'src']:
20 all_files_to_check += glob(glob_pattern='*.py', directoryname=os.path.join(pkg_root, d))
21
22 # TODO: Remove these paths as typing is added and mypy conflicts are addressed
23 ignore_paths = [os.path.abspath(f) for f in [
24 'docker/Dockerfile.py',
25 'docs/conf.py',
26 'docs/vendor/sphinxcontrib/fulltoc.py',
27 'docs/vendor/sphinxcontrib/__init__.py',
28 'src/toil/job.py',
29 'src/toil/leader.py',
30 'src/toil/statsAndLogging.py',
31 'src/toil/common.py',
32 'src/toil/realtimeLogger.py',
33 'src/toil/worker.py',
34 'src/toil/serviceManager.py',
35 'src/toil/toilState.py',
36 'src/toil/__init__.py',
37 'src/toil/resource.py',
38 'src/toil/deferred.py',
39 'src/toil/version.py',
40 'src/toil/wdl/utils.py',
41 'src/toil/wdl/wdl_types.py',
42 'src/toil/wdl/wdl_synthesis.py',
43 # 'src/toil/wdl/__init__.py',
44 'src/toil/wdl/wdl_analysis.py',
45 'src/toil/wdl/wdl_functions.py',
46 'src/toil/wdl/toilwdl.py',
47 'src/toil/wdl/versions/draft2.py',
48 'src/toil/wdl/versions/v1.py',
49 # 'src/toil/wdl/versions/__init__.py',
50 'src/toil/wdl/versions/dev.py',
51 'src/toil/provisioners/clusterScaler.py',
52 'src/toil/provisioners/abstractProvisioner.py',
53 'src/toil/provisioners/gceProvisioner.py',
54 'src/toil/provisioners/__init__.py',
55 'src/toil/provisioners/node.py',
56 'src/toil/provisioners/aws/boto2Context.py',
57 'src/toil/provisioners/aws/awsProvisioner.py',
58 'src/toil/provisioners/aws/__init__.py',
59 'src/toil/batchSystems/slurm.py',
60 'src/toil/batchSystems/gridengine.py',
61 'src/toil/batchSystems/singleMachine.py',
62 'src/toil/batchSystems/abstractBatchSystem.py',
63 'src/toil/batchSystems/parasol.py',
64 'src/toil/batchSystems/kubernetes.py',
65 'src/toil/batchSystems/torque.py',
66 'src/toil/batchSystems/options.py',
67 'src/toil/batchSystems/registry.py',
68 'src/toil/batchSystems/lsf.py',
69 'src/toil/batchSystems/__init__.py',
70 'src/toil/batchSystems/abstractGridEngineBatchSystem.py',
71 'src/toil/batchSystems/lsfHelper.py',
72 'src/toil/batchSystems/htcondor.py',
73 'src/toil/batchSystems/mesos/batchSystem.py',
74 'src/toil/batchSystems/mesos/executor.py',
75 'src/toil/batchSystems/mesos/conftest.py',
76 'src/toil/batchSystems/mesos/__init__.py',
77 'src/toil/batchSystems/mesos/test/__init__.py',
78 'src/toil/cwl/conftest.py',
79 'src/toil/cwl/__init__.py',
80 'src/toil/cwl/cwltoil.py',
81 'src/toil/fileStores/cachingFileStore.py',
82 'src/toil/fileStores/abstractFileStore.py',
83 'src/toil/fileStores/nonCachingFileStore.py',
84 'src/toil/fileStores/__init__.py',
85 'src/toil/jobStores/utils.py',
86 'src/toil/jobStores/abstractJobStore.py',
87 'src/toil/jobStores/conftest.py',
88 'src/toil/jobStores/fileJobStore.py',
89 'src/toil/jobStores/__init__.py',
90 'src/toil/jobStores/googleJobStore.py',
91 'src/toil/jobStores/aws/utils.py',
92 'src/toil/jobStores/aws/jobStore.py',
93 'src/toil/jobStores/aws/__init__.py',
94 'src/toil/utils/toilDebugFile.py',
95 'src/toil/utils/toilUpdateEC2Instances.py',
96 'src/toil/utils/toilStatus.py',
97 'src/toil/utils/toilStats.py',
98 'src/toil/utils/toilSshCluster.py',
99 'src/toil/utils/toilMain.py',
100 'src/toil/utils/toilKill.py',
101 'src/toil/utils/__init__.py',
102 'src/toil/utils/toilDestroyCluster.py',
103 'src/toil/utils/toilDebugJob.py',
104 'src/toil/utils/toilRsyncCluster.py',
105 'src/toil/utils/toilClean.py',
106 'src/toil/utils/toilLaunchCluster.py',
107 'src/toil/lib/memoize.py',
108 'src/toil/lib/resources.py',
109 'src/toil/lib/throttle.py',
110 'src/toil/lib/humanize.py',
111 'src/toil/lib/compatibility.py',
112 'src/toil/lib/iterables.py',
113 'src/toil/lib/bioio.py',
114 'src/toil/lib/ec2.py',
115 'src/toil/lib/conversions.py',
116 'src/toil/lib/ec2nodes.py',
117 'src/toil/lib/misc.py',
118 'src/toil/lib/expando.py',
119 'src/toil/lib/threading.py',
120 'src/toil/lib/exceptions.py',
121 'src/toil/lib/__init__.py',
122 'src/toil/lib/generatedEC2Lists.py',
123 'src/toil/lib/retry.py',
124 'src/toil/lib/objects.py',
125 'src/toil/lib/io.py',
126 'src/toil/lib/docker.py',
127 'src/toil/lib/encryption/_nacl.py',
128 'src/toil/lib/encryption/_dummy.py',
129 'src/toil/lib/encryption/conftest.py',
130 'src/toil/lib/encryption/__init__.py',
131 'src/toil/lib/aws/utils.py',
132 'src/toil/lib/aws/__init__.py'
133 ]]
134
135 filtered_files_to_check = []
136 for file_path in all_files_to_check:
137 if file_path not in ignore_paths and 'src/toil/test' not in file_path:
138 filtered_files_to_check.append(file_path)
139 # follow-imports type checks pypi projects we don't control, so we skip it; why is this their default?
140 args = ['mypy', '--follow-imports=skip'] + filtered_files_to_check
141 p = subprocess.run(args=args, stdout=subprocess.PIPE)
142 result = p.stdout.decode()
143 print(result)
144 if 'Success: no issues found' not in result:
145 exit(1)
146
147
148 if __name__ == '__main__':
149 main()
150
[end of contrib/admin/mypy-with-ignore.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/contrib/admin/mypy-with-ignore.py b/contrib/admin/mypy-with-ignore.py
--- a/contrib/admin/mypy-with-ignore.py
+++ b/contrib/admin/mypy-with-ignore.py
@@ -40,13 +40,11 @@
'src/toil/wdl/utils.py',
'src/toil/wdl/wdl_types.py',
'src/toil/wdl/wdl_synthesis.py',
- # 'src/toil/wdl/__init__.py',
'src/toil/wdl/wdl_analysis.py',
'src/toil/wdl/wdl_functions.py',
'src/toil/wdl/toilwdl.py',
'src/toil/wdl/versions/draft2.py',
'src/toil/wdl/versions/v1.py',
- # 'src/toil/wdl/versions/__init__.py',
'src/toil/wdl/versions/dev.py',
'src/toil/provisioners/clusterScaler.py',
'src/toil/provisioners/abstractProvisioner.py',
@@ -105,7 +103,6 @@
'src/toil/utils/toilClean.py',
'src/toil/utils/toilLaunchCluster.py',
'src/toil/lib/memoize.py',
- 'src/toil/lib/resources.py',
'src/toil/lib/throttle.py',
'src/toil/lib/humanize.py',
'src/toil/lib/compatibility.py',
diff --git a/src/toil/lib/resources.py b/src/toil/lib/resources.py
--- a/src/toil/lib/resources.py
+++ b/src/toil/lib/resources.py
@@ -15,10 +15,10 @@
import os
import resource
-from typing import List
+from typing import List, Tuple
-def get_total_cpu_time_and_memory_usage():
+def get_total_cpu_time_and_memory_usage() -> Tuple[float, int]:
"""
Gives the total cpu time of itself and all its children, and the maximum RSS memory usage of
itself and its single largest child.
@@ -30,7 +30,7 @@
return total_cpu_time, total_memory_usage
-def get_total_cpu_time():
+def get_total_cpu_time() -> float:
"""Gives the total cpu time, including the children."""
me = resource.getrusage(resource.RUSAGE_SELF)
childs = resource.getrusage(resource.RUSAGE_CHILDREN)
| {"golden_diff": "diff --git a/contrib/admin/mypy-with-ignore.py b/contrib/admin/mypy-with-ignore.py\n--- a/contrib/admin/mypy-with-ignore.py\n+++ b/contrib/admin/mypy-with-ignore.py\n@@ -40,13 +40,11 @@\n 'src/toil/wdl/utils.py',\n 'src/toil/wdl/wdl_types.py',\n 'src/toil/wdl/wdl_synthesis.py',\n- # 'src/toil/wdl/__init__.py',\n 'src/toil/wdl/wdl_analysis.py',\n 'src/toil/wdl/wdl_functions.py',\n 'src/toil/wdl/toilwdl.py',\n 'src/toil/wdl/versions/draft2.py',\n 'src/toil/wdl/versions/v1.py',\n- # 'src/toil/wdl/versions/__init__.py',\n 'src/toil/wdl/versions/dev.py',\n 'src/toil/provisioners/clusterScaler.py',\n 'src/toil/provisioners/abstractProvisioner.py',\n@@ -105,7 +103,6 @@\n 'src/toil/utils/toilClean.py',\n 'src/toil/utils/toilLaunchCluster.py',\n 'src/toil/lib/memoize.py',\n- 'src/toil/lib/resources.py',\n 'src/toil/lib/throttle.py',\n 'src/toil/lib/humanize.py',\n 'src/toil/lib/compatibility.py',\ndiff --git a/src/toil/lib/resources.py b/src/toil/lib/resources.py\n--- a/src/toil/lib/resources.py\n+++ b/src/toil/lib/resources.py\n@@ -15,10 +15,10 @@\n import os\n import resource\n \n-from typing import List\n+from typing import List, Tuple\n \n \n-def get_total_cpu_time_and_memory_usage():\n+def get_total_cpu_time_and_memory_usage() -> Tuple[float, int]:\n \"\"\"\n Gives the total cpu time of itself and all its children, and the maximum RSS memory usage of\n itself and its single largest child.\n@@ -30,7 +30,7 @@\n return total_cpu_time, total_memory_usage\n \n \n-def get_total_cpu_time():\n+def get_total_cpu_time() -> float:\n \"\"\"Gives the total cpu time, including the children.\"\"\"\n me = resource.getrusage(resource.RUSAGE_SELF)\n childs = resource.getrusage(resource.RUSAGE_CHILDREN)\n", "issue": "Add type hints to resources.py\nAdd type hints to src/toil/lib/encryption/resources.py so it can be checked under mypy during linting.\n\n\u2506Issue is synchronized with this [Jira Task](https://ucsc-cgl.atlassian.net/browse/TOIL-885)\n\u2506Issue Number: TOIL-885\n\n", "before_files": [{"content": "# Copyright (C) 2015-2021 Regents of the University of California\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport fnmatch\nimport os\nimport resource\n\nfrom typing import List\n\n\ndef get_total_cpu_time_and_memory_usage():\n \"\"\"\n Gives the total cpu time of itself and all its children, and the maximum RSS memory usage of\n itself and its single largest child.\n \"\"\"\n me = resource.getrusage(resource.RUSAGE_SELF)\n children = resource.getrusage(resource.RUSAGE_CHILDREN)\n total_cpu_time = me.ru_utime + me.ru_stime + children.ru_utime + children.ru_stime\n total_memory_usage = me.ru_maxrss + children.ru_maxrss\n return total_cpu_time, total_memory_usage\n\n\ndef get_total_cpu_time():\n \"\"\"Gives the total cpu time, including the children.\"\"\"\n me = resource.getrusage(resource.RUSAGE_SELF)\n childs = resource.getrusage(resource.RUSAGE_CHILDREN)\n return me.ru_utime + me.ru_stime + childs.ru_utime + childs.ru_stime\n\n\ndef glob(glob_pattern: str, directoryname: str) -> List[str]:\n \"\"\"\n Walks through a directory and its subdirectories looking for files matching\n the glob_pattern and returns a list=[].\n\n :param directoryname: Any accessible folder name on the filesystem.\n :param glob_pattern: A string like \"*.txt\", which would find all text files.\n :return: A list=[] of absolute filepaths matching the glob pattern.\n \"\"\"\n matches = []\n for root, dirnames, filenames in os.walk(directoryname):\n for filename in fnmatch.filter(filenames, glob_pattern):\n absolute_filepath = os.path.join(root, filename)\n matches.append(absolute_filepath)\n return matches\n", "path": "src/toil/lib/resources.py"}, {"content": "#!/usr/bin/env python3\n\"\"\"\nRuns mypy and ignores files that do not yet have passing type hints.\n\nDoes not type check test files (any path including \"src/toil/test\").\n\"\"\"\nimport os\nimport subprocess\nimport sys\n\npkg_root = os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')) # noqa\nsys.path.insert(0, pkg_root) # noqa\n\nfrom src.toil.lib.resources import glob # type: ignore\n\n\ndef main():\n all_files_to_check = []\n for d in ['dashboard', 'docker', 'docs', 'src']:\n all_files_to_check += glob(glob_pattern='*.py', directoryname=os.path.join(pkg_root, d))\n\n # TODO: Remove these paths as typing is added and mypy conflicts are addressed\n ignore_paths = [os.path.abspath(f) for f in [\n 'docker/Dockerfile.py',\n 'docs/conf.py',\n 'docs/vendor/sphinxcontrib/fulltoc.py',\n 'docs/vendor/sphinxcontrib/__init__.py',\n 'src/toil/job.py',\n 'src/toil/leader.py',\n 'src/toil/statsAndLogging.py',\n 'src/toil/common.py',\n 'src/toil/realtimeLogger.py',\n 'src/toil/worker.py',\n 'src/toil/serviceManager.py',\n 'src/toil/toilState.py',\n 'src/toil/__init__.py',\n 'src/toil/resource.py',\n 'src/toil/deferred.py',\n 'src/toil/version.py',\n 'src/toil/wdl/utils.py',\n 'src/toil/wdl/wdl_types.py',\n 'src/toil/wdl/wdl_synthesis.py',\n # 'src/toil/wdl/__init__.py',\n 'src/toil/wdl/wdl_analysis.py',\n 'src/toil/wdl/wdl_functions.py',\n 'src/toil/wdl/toilwdl.py',\n 'src/toil/wdl/versions/draft2.py',\n 'src/toil/wdl/versions/v1.py',\n # 'src/toil/wdl/versions/__init__.py',\n 'src/toil/wdl/versions/dev.py',\n 'src/toil/provisioners/clusterScaler.py',\n 'src/toil/provisioners/abstractProvisioner.py',\n 'src/toil/provisioners/gceProvisioner.py',\n 'src/toil/provisioners/__init__.py',\n 'src/toil/provisioners/node.py',\n 'src/toil/provisioners/aws/boto2Context.py',\n 'src/toil/provisioners/aws/awsProvisioner.py',\n 'src/toil/provisioners/aws/__init__.py',\n 'src/toil/batchSystems/slurm.py',\n 'src/toil/batchSystems/gridengine.py',\n 'src/toil/batchSystems/singleMachine.py',\n 'src/toil/batchSystems/abstractBatchSystem.py',\n 'src/toil/batchSystems/parasol.py',\n 'src/toil/batchSystems/kubernetes.py',\n 'src/toil/batchSystems/torque.py',\n 'src/toil/batchSystems/options.py',\n 'src/toil/batchSystems/registry.py',\n 'src/toil/batchSystems/lsf.py',\n 'src/toil/batchSystems/__init__.py',\n 'src/toil/batchSystems/abstractGridEngineBatchSystem.py',\n 'src/toil/batchSystems/lsfHelper.py',\n 'src/toil/batchSystems/htcondor.py',\n 'src/toil/batchSystems/mesos/batchSystem.py',\n 'src/toil/batchSystems/mesos/executor.py',\n 'src/toil/batchSystems/mesos/conftest.py',\n 'src/toil/batchSystems/mesos/__init__.py',\n 'src/toil/batchSystems/mesos/test/__init__.py',\n 'src/toil/cwl/conftest.py',\n 'src/toil/cwl/__init__.py',\n 'src/toil/cwl/cwltoil.py',\n 'src/toil/fileStores/cachingFileStore.py',\n 'src/toil/fileStores/abstractFileStore.py',\n 'src/toil/fileStores/nonCachingFileStore.py',\n 'src/toil/fileStores/__init__.py',\n 'src/toil/jobStores/utils.py',\n 'src/toil/jobStores/abstractJobStore.py',\n 'src/toil/jobStores/conftest.py',\n 'src/toil/jobStores/fileJobStore.py',\n 'src/toil/jobStores/__init__.py',\n 'src/toil/jobStores/googleJobStore.py',\n 'src/toil/jobStores/aws/utils.py',\n 'src/toil/jobStores/aws/jobStore.py',\n 'src/toil/jobStores/aws/__init__.py',\n 'src/toil/utils/toilDebugFile.py',\n 'src/toil/utils/toilUpdateEC2Instances.py',\n 'src/toil/utils/toilStatus.py',\n 'src/toil/utils/toilStats.py',\n 'src/toil/utils/toilSshCluster.py',\n 'src/toil/utils/toilMain.py',\n 'src/toil/utils/toilKill.py',\n 'src/toil/utils/__init__.py',\n 'src/toil/utils/toilDestroyCluster.py',\n 'src/toil/utils/toilDebugJob.py',\n 'src/toil/utils/toilRsyncCluster.py',\n 'src/toil/utils/toilClean.py',\n 'src/toil/utils/toilLaunchCluster.py',\n 'src/toil/lib/memoize.py',\n 'src/toil/lib/resources.py',\n 'src/toil/lib/throttle.py',\n 'src/toil/lib/humanize.py',\n 'src/toil/lib/compatibility.py',\n 'src/toil/lib/iterables.py',\n 'src/toil/lib/bioio.py',\n 'src/toil/lib/ec2.py',\n 'src/toil/lib/conversions.py',\n 'src/toil/lib/ec2nodes.py',\n 'src/toil/lib/misc.py',\n 'src/toil/lib/expando.py',\n 'src/toil/lib/threading.py',\n 'src/toil/lib/exceptions.py',\n 'src/toil/lib/__init__.py',\n 'src/toil/lib/generatedEC2Lists.py',\n 'src/toil/lib/retry.py',\n 'src/toil/lib/objects.py',\n 'src/toil/lib/io.py',\n 'src/toil/lib/docker.py',\n 'src/toil/lib/encryption/_nacl.py',\n 'src/toil/lib/encryption/_dummy.py',\n 'src/toil/lib/encryption/conftest.py',\n 'src/toil/lib/encryption/__init__.py',\n 'src/toil/lib/aws/utils.py',\n 'src/toil/lib/aws/__init__.py'\n ]]\n\n filtered_files_to_check = []\n for file_path in all_files_to_check:\n if file_path not in ignore_paths and 'src/toil/test' not in file_path:\n filtered_files_to_check.append(file_path)\n # follow-imports type checks pypi projects we don't control, so we skip it; why is this their default?\n args = ['mypy', '--follow-imports=skip'] + filtered_files_to_check\n p = subprocess.run(args=args, stdout=subprocess.PIPE)\n result = p.stdout.decode()\n print(result)\n if 'Success: no issues found' not in result:\n exit(1)\n\n\nif __name__ == '__main__':\n main()\n", "path": "contrib/admin/mypy-with-ignore.py"}]} | 3,191 | 520 |
gh_patches_debug_60613 | rasdani/github-patches | git_diff | cloudtools__troposphere-552 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Support AutoScalingCreationPolicy
From the docs, this is a top-level property of a [CreationPolicy](http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-attribute-creationpolicy.html#cfn-attributes-creationpolicy-properties). It is used for the [AutoScalingReplacingPolicy](http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-attribute-updatepolicy.html#cfn-attributes-updatepolicy-replacingupdate) to specify the MinSuccessfulInstancesPercent property.
The docs have a good example of this:
``` json
"UpdatePolicy" : {
"AutoScalingReplacingUpdate" : {
"WillReplace" : "true"
},
"CreationPolicy" : {
"ResourceSignal" : {
"Count" : { "Ref" : "ResourceSignalsOnCreate"},
"Timeout" : "PT10M"
},
"AutoScalingCreationPolicy" : {
"MinSuccessfulInstancesPercent" : { "Ref" : "MinSuccessfulPercentParameter" }
}
}
```
I might take a crack at this but I figured I'd file an issue first if only so that I can reference it.
</issue>
<code>
[start of troposphere/policies.py]
1 from . import AWSProperty, AWSAttribute, validate_pausetime
2 from .validators import positive_integer, integer, boolean
3
4
5 class AutoScalingRollingUpdate(AWSProperty):
6 props = {
7 'MaxBatchSize': (positive_integer, False),
8 'MinInstancesInService': (integer, False),
9 'MinSuccessfulInstancesPercent': (integer, False),
10 'PauseTime': (validate_pausetime, False),
11 'SuspendProcesses': ([basestring], False),
12 'WaitOnResourceSignals': (boolean, False),
13 }
14
15
16 class AutoScalingScheduledAction(AWSProperty):
17 props = {
18 'IgnoreUnmodifiedGroupSizeProperties': (boolean, False),
19 }
20
21
22 class AutoScalingReplacingUpdate(AWSProperty):
23 props = {
24 'WillReplace': (boolean, False),
25 }
26
27
28 class UpdatePolicy(AWSAttribute):
29 props = {
30 'AutoScalingRollingUpdate': (AutoScalingRollingUpdate, False),
31 'AutoScalingScheduledAction': (AutoScalingScheduledAction, False),
32 'AutoScalingReplacingUpdate': (AutoScalingReplacingUpdate, False),
33 }
34
35
36 class ResourceSignal(AWSProperty):
37 props = {
38 'Count': (positive_integer, False),
39 'Timeout': (validate_pausetime, False),
40 }
41
42
43 class CreationPolicy(AWSAttribute):
44 props = {
45 'ResourceSignal': (ResourceSignal, True),
46 }
47
[end of troposphere/policies.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/troposphere/policies.py b/troposphere/policies.py
--- a/troposphere/policies.py
+++ b/troposphere/policies.py
@@ -40,7 +40,14 @@
}
+class AutoScalingCreationPolicy(AWSProperty):
+ props = {
+ 'MinSuccessfulInstancesPercent': (integer, False),
+ }
+
+
class CreationPolicy(AWSAttribute):
props = {
+ 'AutoScalingCreationPolicy': (AutoScalingCreationPolicy, False),
'ResourceSignal': (ResourceSignal, True),
}
| {"golden_diff": "diff --git a/troposphere/policies.py b/troposphere/policies.py\n--- a/troposphere/policies.py\n+++ b/troposphere/policies.py\n@@ -40,7 +40,14 @@\n }\n \n \n+class AutoScalingCreationPolicy(AWSProperty):\n+ props = {\n+ 'MinSuccessfulInstancesPercent': (integer, False),\n+ }\n+\n+\n class CreationPolicy(AWSAttribute):\n props = {\n+ 'AutoScalingCreationPolicy': (AutoScalingCreationPolicy, False),\n 'ResourceSignal': (ResourceSignal, True),\n }\n", "issue": "Support AutoScalingCreationPolicy\nFrom the docs, this is a top-level property of a [CreationPolicy](http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-attribute-creationpolicy.html#cfn-attributes-creationpolicy-properties). It is used for the [AutoScalingReplacingPolicy](http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-attribute-updatepolicy.html#cfn-attributes-updatepolicy-replacingupdate) to specify the MinSuccessfulInstancesPercent property.\n\nThe docs have a good example of this:\n\n``` json\n\"UpdatePolicy\" : {\n \"AutoScalingReplacingUpdate\" : {\n \"WillReplace\" : \"true\"\n },\n\"CreationPolicy\" : {\n \"ResourceSignal\" : {\n \"Count\" : { \"Ref\" : \"ResourceSignalsOnCreate\"},\n \"Timeout\" : \"PT10M\"\n },\n \"AutoScalingCreationPolicy\" : {\n \"MinSuccessfulInstancesPercent\" : { \"Ref\" : \"MinSuccessfulPercentParameter\" }\n }\n}\n```\n\nI might take a crack at this but I figured I'd file an issue first if only so that I can reference it.\n\n", "before_files": [{"content": "from . import AWSProperty, AWSAttribute, validate_pausetime\nfrom .validators import positive_integer, integer, boolean\n\n\nclass AutoScalingRollingUpdate(AWSProperty):\n props = {\n 'MaxBatchSize': (positive_integer, False),\n 'MinInstancesInService': (integer, False),\n 'MinSuccessfulInstancesPercent': (integer, False),\n 'PauseTime': (validate_pausetime, False),\n 'SuspendProcesses': ([basestring], False),\n 'WaitOnResourceSignals': (boolean, False),\n }\n\n\nclass AutoScalingScheduledAction(AWSProperty):\n props = {\n 'IgnoreUnmodifiedGroupSizeProperties': (boolean, False),\n }\n\n\nclass AutoScalingReplacingUpdate(AWSProperty):\n props = {\n 'WillReplace': (boolean, False),\n }\n\n\nclass UpdatePolicy(AWSAttribute):\n props = {\n 'AutoScalingRollingUpdate': (AutoScalingRollingUpdate, False),\n 'AutoScalingScheduledAction': (AutoScalingScheduledAction, False),\n 'AutoScalingReplacingUpdate': (AutoScalingReplacingUpdate, False),\n }\n\n\nclass ResourceSignal(AWSProperty):\n props = {\n 'Count': (positive_integer, False),\n 'Timeout': (validate_pausetime, False),\n }\n\n\nclass CreationPolicy(AWSAttribute):\n props = {\n 'ResourceSignal': (ResourceSignal, True),\n }\n", "path": "troposphere/policies.py"}]} | 1,158 | 125 |
gh_patches_debug_43665 | rasdani/github-patches | git_diff | gratipay__gratipay.com-4127 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
fill out the test suite for the mixins, prune old tests
Reticketed from #3994.
</issue>
<code>
[start of gratipay/models/team/mixins/membership.py]
1 from __future__ import absolute_import, division, print_function, unicode_literals
2
3 from .takes import ZERO, PENNY
4
5
6 class MembershipMixin(object):
7 """Teams may have zero or more members, who are participants that take money from the team.
8 """
9
10 def add_member(self, participant, recorder):
11 """Add a participant to this team.
12
13 :param Participant participant: the participant to add
14 :param Participant recorder: the participant making the change
15
16 """
17 self.set_take_for(participant, PENNY, recorder)
18
19
20 def remove_member(self, participant, recorder):
21 """Remove a participant from this team.
22
23 :param Participant participant: the participant to remove
24 :param Participant recorder: the participant making the change
25
26 """
27 self.set_take_for(participant, ZERO, recorder)
28
29
30 def remove_all_members(self, cursor=None):
31 (cursor or self.db).run("""
32 INSERT INTO takes (ctime, member, team, amount, recorder) (
33 SELECT ctime, member, %(username)s, 0.00, %(username)s
34 FROM current_takes
35 WHERE team=%(username)s
36 AND amount > 0
37 );
38 """, dict(username=self.username))
39
40
41 @property
42 def nmembers(self):
43 """The number of members. Read-only and computed (not in the db); equal to
44 :py:attr:`~gratipay.models.team.mixins.takes.ndistributing_to`.
45 """
46 return self.ndistributing_to
47
48
49 def get_memberships(self, current_participant=None):
50 """Return a list of member dicts.
51 """
52 takes = self.compute_actual_takes()
53 members = []
54 for take in takes.values():
55 member = {}
56 member['participant_id'] = take['participant'].id
57 member['username'] = take['participant'].username
58 member['take'] = take['nominal_amount']
59 member['balance'] = take['balance']
60 member['percentage'] = take['percentage']
61
62 member['editing_allowed'] = False
63 member['is_current_user'] = False
64 if current_participant:
65 member['removal_allowed'] = current_participant.username == self.owner
66 if member['username'] == current_participant.username:
67 member['is_current_user'] = True
68 if take['ctime'] is not None:
69 # current user, but not the team itself
70 member['editing_allowed']= True
71
72 member['last_week'] = self.get_take_last_week_for(member['participant_id'])
73 members.append(member)
74 return members
75
[end of gratipay/models/team/mixins/membership.py]
[start of gratipay/models/team/mixins/takes.py]
1 from __future__ import absolute_import, division, print_function, unicode_literals
2
3 from collections import OrderedDict
4 from decimal import Decimal as D
5
6 ZERO = D('0.00')
7 PENNY = D('0.01')
8
9
10 class TakesMixin(object):
11 """:py:class:`~gratipay.models.participant.Participant` s who are members
12 of a :py:class:`~gratipay.models.team.Team` may take money from the team
13 during :py:class:`~gratipay.billing.payday.Payday`. Only the team owner may
14 add a new member, by setting their take to a penny, but team owners may
15 *only* set their take to a penny---no more. Team owners may also remove
16 members, by setting their take to zero, as may the members themselves, who
17 may also set their take to whatever they wish.
18 """
19
20 #: The total amount of money the team distributes to participants
21 #: (including the owner) during payday. Read-only; equal to
22 #: :py:attr:`~gratipay.models.team.Team.receiving`.
23
24 distributing = 0
25
26
27 #: The number of participants (including the owner) that the team
28 #: distributes money to during payday. Read-only; modified by
29 #: :py:meth:`set_take_for`.
30
31 ndistributing_to = 0
32
33
34 def get_take_last_week_for(self, participant_id):
35 """Get the participant's nominal take last week.
36 """
37 return self.db.one("""
38
39 SELECT amount
40 FROM takes
41 WHERE team_id=%s AND participant_id=%s
42 AND mtime < (
43 SELECT ts_start
44 FROM paydays
45 WHERE ts_end > ts_start
46 ORDER BY ts_start DESC LIMIT 1
47 )
48 ORDER BY mtime DESC LIMIT 1
49
50 """, (self.id, participant_id), default=ZERO)
51
52
53 def set_take_for(self, participant, take, recorder, cursor=None):
54 """Set the amount a participant wants to take from this team during payday.
55
56 :param Participant participant: the participant to set the take for
57 :param Decimal take: the amount the participant wants to take
58 :param Participant recorder: the participant making the change
59
60 :return: the new take as a py:class:`~decimal.Decimal`
61 :raises: :py:exc:`NotAllowed`
62
63 It is a bug to pass in a ``participant`` or ``recorder`` that is
64 suspicious, unclaimed, or without a verified email and identity.
65 Furthermore, :py:exc:`NotAllowed` is raised in the following circumstances:
66
67 - ``recorder`` is neither ``participant`` nor the team owner
68 - ``recorder`` is the team owner and ``take`` is neither zero nor $0.01
69 - ``recorder`` is ``participant``, but ``participant`` isn't already on the team
70
71 """
72 def vet(p):
73 if p.is_suspicious:
74 raise NotAllowed("user must not be flagged as suspicious")
75 elif not p.has_verified_identity:
76 raise NotAllowed("user must have a verified identity")
77 elif not p.email_address:
78 raise NotAllowed("user must have added at least one email address")
79 elif not p.is_claimed:
80 raise NotAllowed("user must have claimed the account")
81
82 vet(participant)
83 vet(recorder)
84
85 owner_recording = recorder.username == self.owner
86 owner_taking = participant.username == self.owner
87 taker_recording = recorder == participant
88 adding_or_removing = take in (ZERO, PENNY)
89
90 if owner_recording:
91 if not adding_or_removing and not owner_taking:
92 raise NotAllowed("owner can only add and remove members, not otherwise set takes")
93 elif not taker_recording:
94 raise NotAllowed("can only set own take")
95
96 with self.db.get_cursor(cursor) as cursor:
97 cursor.run("LOCK TABLE takes IN EXCLUSIVE MODE") # avoid race conditions
98
99 # Compute the current takes
100 old_takes = self.compute_actual_takes(cursor)
101
102 if recorder.username != self.owner:
103 if recorder == participant and participant.id not in old_takes:
104 raise NotAllowed("can only set take if already a member of the team")
105
106 new_take = cursor.one( """
107
108 INSERT INTO takes
109 (ctime, participant_id, team_id, amount, recorder_id)
110 VALUES ( COALESCE (( SELECT ctime
111 FROM takes
112 WHERE (participant_id=%(participant_id)s
113 AND team_id=%(team_id)s)
114 LIMIT 1
115 ), CURRENT_TIMESTAMP)
116 , %(participant_id)s, %(team_id)s, %(amount)s, %(recorder_id)s
117 )
118 RETURNING amount
119
120 """, { 'participant_id': participant.id
121 , 'team_id': self.id
122 , 'amount': take
123 , 'recorder_id': recorder.id
124 })
125
126 # Compute the new takes
127 all_new_takes = self.compute_actual_takes(cursor)
128
129 # Update computed values
130 self.update_taking(old_takes, all_new_takes, cursor, participant)
131 self.update_distributing(all_new_takes, cursor)
132
133 return new_take
134
135
136 def get_take_for(self, participant, cursor=None):
137 """
138 :param Participant participant: the participant to get the take for
139 :param GratipayDB cursor: a database cursor; if ``None``, a new cursor will be used
140 :return: a :py:class:`~decimal.Decimal`: the ``participant``'s take from this team, or 0.
141 """
142 return (cursor or self.db).one("""
143
144 SELECT amount
145 FROM current_takes
146 WHERE team_id=%s AND participant_id=%s
147
148 """, (self.id, participant.id), default=ZERO)
149
150
151 def update_taking(self, old_takes, new_takes, cursor=None, member=None):
152 """Update `taking` amounts based on the difference between `old_takes`
153 and `new_takes`.
154 """
155
156 # XXX Deal with owner as well as members
157
158 for participant_id in set(old_takes.keys()).union(new_takes.keys()):
159 old = old_takes.get(participant_id, {}).get('actual_amount', ZERO)
160 new = new_takes.get(participant_id, {}).get('actual_amount', ZERO)
161 delta = new - old
162 if delta != 0:
163 taking = (cursor or self.db).one("""
164 UPDATE participants
165 SET taking = (taking + %(delta)s)
166 WHERE id=%(participant_id)s
167 RETURNING taking
168 """, dict(participant_id=participant_id, delta=delta))
169 if member and participant_id == member.id:
170 member.set_attributes(taking=taking)
171
172
173 def update_distributing(self, new_takes, cursor=None):
174 """Update the computed values on the team.
175 """
176 distributing = sum(t['actual_amount'] for t in new_takes.values())
177 ndistributing_to = len(tuple(t for t in new_takes.values() if t['actual_amount'] > 0))
178
179 r = (cursor or self.db).one("""
180 UPDATE teams
181 SET distributing=%s, ndistributing_to=%s WHERE id=%s
182 RETURNING distributing, ndistributing_to
183 """, (distributing, ndistributing_to, self.id))
184
185 self.set_attributes(**r._asdict())
186
187
188 def get_current_takes(self, cursor=None):
189 """Return a list of member takes for a team.
190 """
191 TAKES = """
192 SELECT p.*::participants AS participant
193 , ct.amount, ct.ctime, ct.mtime
194 FROM current_takes ct
195 JOIN participants p
196 ON ct.participant_id = p.id
197 WHERE team_id=%(team_id)s
198 ORDER BY amount ASC, ctime ASC
199 """
200 records = (cursor or self.db).all(TAKES, dict(team_id=self.id))
201 return [r._asdict() for r in records]
202
203
204 def compute_actual_takes(self, cursor=None):
205 """Get the takes, compute the actual amounts, and return an OrderedDict.
206 """
207 actual_takes = OrderedDict()
208 nominal_takes = self.get_current_takes(cursor=cursor)
209 available = balance = self.available
210 for take in nominal_takes:
211 nominal_amount = take['nominal_amount'] = take.pop('amount')
212 actual_amount = take['actual_amount'] = min(nominal_amount, balance)
213 take['balance'] = balance = balance - actual_amount
214 take['percentage'] = actual_amount / available
215 actual_takes[take['participant'].id] = take
216 return actual_takes
217
218
219 class NotAllowed(Exception):
220 """Raised by :py:meth:`set_take_for` if ``recorder`` is not allowed to set
221 the take for ``participant``.
222 """
223
[end of gratipay/models/team/mixins/takes.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/gratipay/models/team/mixins/membership.py b/gratipay/models/team/mixins/membership.py
--- a/gratipay/models/team/mixins/membership.py
+++ b/gratipay/models/team/mixins/membership.py
@@ -27,17 +27,6 @@
self.set_take_for(participant, ZERO, recorder)
- def remove_all_members(self, cursor=None):
- (cursor or self.db).run("""
- INSERT INTO takes (ctime, member, team, amount, recorder) (
- SELECT ctime, member, %(username)s, 0.00, %(username)s
- FROM current_takes
- WHERE team=%(username)s
- AND amount > 0
- );
- """, dict(username=self.username))
-
-
@property
def nmembers(self):
"""The number of members. Read-only and computed (not in the db); equal to
@@ -64,11 +53,8 @@
if current_participant:
member['removal_allowed'] = current_participant.username == self.owner
if member['username'] == current_participant.username:
- member['is_current_user'] = True
- if take['ctime'] is not None:
- # current user, but not the team itself
- member['editing_allowed']= True
+ member['editing_allowed']= True
- member['last_week'] = self.get_take_last_week_for(member['participant_id'])
+ member['last_week'] = self.get_take_last_week_for(take['participant'])
members.append(member)
return members
diff --git a/gratipay/models/team/mixins/takes.py b/gratipay/models/team/mixins/takes.py
--- a/gratipay/models/team/mixins/takes.py
+++ b/gratipay/models/team/mixins/takes.py
@@ -31,25 +31,6 @@
ndistributing_to = 0
- def get_take_last_week_for(self, participant_id):
- """Get the participant's nominal take last week.
- """
- return self.db.one("""
-
- SELECT amount
- FROM takes
- WHERE team_id=%s AND participant_id=%s
- AND mtime < (
- SELECT ts_start
- FROM paydays
- WHERE ts_end > ts_start
- ORDER BY ts_start DESC LIMIT 1
- )
- ORDER BY mtime DESC LIMIT 1
-
- """, (self.id, participant_id), default=ZERO)
-
-
def set_take_for(self, participant, take, recorder, cursor=None):
"""Set the amount a participant wants to take from this team during payday.
@@ -72,10 +53,10 @@
def vet(p):
if p.is_suspicious:
raise NotAllowed("user must not be flagged as suspicious")
- elif not p.has_verified_identity:
- raise NotAllowed("user must have a verified identity")
elif not p.email_address:
raise NotAllowed("user must have added at least one email address")
+ elif not p.has_verified_identity:
+ raise NotAllowed("user must have a verified identity")
elif not p.is_claimed:
raise NotAllowed("user must have claimed the account")
@@ -148,6 +129,30 @@
""", (self.id, participant.id), default=ZERO)
+ def get_take_last_week_for(self, participant, cursor=None):
+ """
+ :param Participant participant: the participant to get the take for
+ :param GratipayDB cursor: a database cursor; if ``None``, a new cursor
+ will be used
+ :return: a :py:class:`~decimal.Decimal`: the ``participant``'s take
+ from this team at the beginning of the last completed payday, or 0.
+ """
+ return (cursor or self.db).one("""
+
+ SELECT amount
+ FROM takes
+ WHERE team_id=%s AND participant_id=%s
+ AND mtime < (
+ SELECT ts_start
+ FROM paydays
+ WHERE ts_end > ts_start
+ ORDER BY ts_start DESC LIMIT 1
+ )
+ ORDER BY mtime DESC LIMIT 1
+
+ """, (self.id, participant.id), default=ZERO)
+
+
def update_taking(self, old_takes, new_takes, cursor=None, member=None):
"""Update `taking` amounts based on the difference between `old_takes`
and `new_takes`.
| {"golden_diff": "diff --git a/gratipay/models/team/mixins/membership.py b/gratipay/models/team/mixins/membership.py\n--- a/gratipay/models/team/mixins/membership.py\n+++ b/gratipay/models/team/mixins/membership.py\n@@ -27,17 +27,6 @@\n self.set_take_for(participant, ZERO, recorder)\n \n \n- def remove_all_members(self, cursor=None):\n- (cursor or self.db).run(\"\"\"\n- INSERT INTO takes (ctime, member, team, amount, recorder) (\n- SELECT ctime, member, %(username)s, 0.00, %(username)s\n- FROM current_takes\n- WHERE team=%(username)s\n- AND amount > 0\n- );\n- \"\"\", dict(username=self.username))\n-\n-\n @property\n def nmembers(self):\n \"\"\"The number of members. Read-only and computed (not in the db); equal to\n@@ -64,11 +53,8 @@\n if current_participant:\n member['removal_allowed'] = current_participant.username == self.owner\n if member['username'] == current_participant.username:\n- member['is_current_user'] = True\n- if take['ctime'] is not None:\n- # current user, but not the team itself\n- member['editing_allowed']= True\n+ member['editing_allowed']= True\n \n- member['last_week'] = self.get_take_last_week_for(member['participant_id'])\n+ member['last_week'] = self.get_take_last_week_for(take['participant'])\n members.append(member)\n return members\ndiff --git a/gratipay/models/team/mixins/takes.py b/gratipay/models/team/mixins/takes.py\n--- a/gratipay/models/team/mixins/takes.py\n+++ b/gratipay/models/team/mixins/takes.py\n@@ -31,25 +31,6 @@\n ndistributing_to = 0\n \n \n- def get_take_last_week_for(self, participant_id):\n- \"\"\"Get the participant's nominal take last week.\n- \"\"\"\n- return self.db.one(\"\"\"\n-\n- SELECT amount\n- FROM takes\n- WHERE team_id=%s AND participant_id=%s\n- AND mtime < (\n- SELECT ts_start\n- FROM paydays\n- WHERE ts_end > ts_start\n- ORDER BY ts_start DESC LIMIT 1\n- )\n- ORDER BY mtime DESC LIMIT 1\n-\n- \"\"\", (self.id, participant_id), default=ZERO)\n-\n-\n def set_take_for(self, participant, take, recorder, cursor=None):\n \"\"\"Set the amount a participant wants to take from this team during payday.\n \n@@ -72,10 +53,10 @@\n def vet(p):\n if p.is_suspicious:\n raise NotAllowed(\"user must not be flagged as suspicious\")\n- elif not p.has_verified_identity:\n- raise NotAllowed(\"user must have a verified identity\")\n elif not p.email_address:\n raise NotAllowed(\"user must have added at least one email address\")\n+ elif not p.has_verified_identity:\n+ raise NotAllowed(\"user must have a verified identity\")\n elif not p.is_claimed:\n raise NotAllowed(\"user must have claimed the account\")\n \n@@ -148,6 +129,30 @@\n \"\"\", (self.id, participant.id), default=ZERO)\n \n \n+ def get_take_last_week_for(self, participant, cursor=None):\n+ \"\"\"\n+ :param Participant participant: the participant to get the take for\n+ :param GratipayDB cursor: a database cursor; if ``None``, a new cursor\n+ will be used\n+ :return: a :py:class:`~decimal.Decimal`: the ``participant``'s take\n+ from this team at the beginning of the last completed payday, or 0.\n+ \"\"\"\n+ return (cursor or self.db).one(\"\"\"\n+\n+ SELECT amount\n+ FROM takes\n+ WHERE team_id=%s AND participant_id=%s\n+ AND mtime < (\n+ SELECT ts_start\n+ FROM paydays\n+ WHERE ts_end > ts_start\n+ ORDER BY ts_start DESC LIMIT 1\n+ )\n+ ORDER BY mtime DESC LIMIT 1\n+\n+ \"\"\", (self.id, participant.id), default=ZERO)\n+\n+\n def update_taking(self, old_takes, new_takes, cursor=None, member=None):\n \"\"\"Update `taking` amounts based on the difference between `old_takes`\n and `new_takes`.\n", "issue": "fill out the test suite for the mixins, prune old tests\nReticketed from #3994.\n\n", "before_files": [{"content": "from __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom .takes import ZERO, PENNY\n\n\nclass MembershipMixin(object):\n \"\"\"Teams may have zero or more members, who are participants that take money from the team.\n \"\"\"\n\n def add_member(self, participant, recorder):\n \"\"\"Add a participant to this team.\n\n :param Participant participant: the participant to add\n :param Participant recorder: the participant making the change\n\n \"\"\"\n self.set_take_for(participant, PENNY, recorder)\n\n\n def remove_member(self, participant, recorder):\n \"\"\"Remove a participant from this team.\n\n :param Participant participant: the participant to remove\n :param Participant recorder: the participant making the change\n\n \"\"\"\n self.set_take_for(participant, ZERO, recorder)\n\n\n def remove_all_members(self, cursor=None):\n (cursor or self.db).run(\"\"\"\n INSERT INTO takes (ctime, member, team, amount, recorder) (\n SELECT ctime, member, %(username)s, 0.00, %(username)s\n FROM current_takes\n WHERE team=%(username)s\n AND amount > 0\n );\n \"\"\", dict(username=self.username))\n\n\n @property\n def nmembers(self):\n \"\"\"The number of members. Read-only and computed (not in the db); equal to\n :py:attr:`~gratipay.models.team.mixins.takes.ndistributing_to`.\n \"\"\"\n return self.ndistributing_to\n\n\n def get_memberships(self, current_participant=None):\n \"\"\"Return a list of member dicts.\n \"\"\"\n takes = self.compute_actual_takes()\n members = []\n for take in takes.values():\n member = {}\n member['participant_id'] = take['participant'].id\n member['username'] = take['participant'].username\n member['take'] = take['nominal_amount']\n member['balance'] = take['balance']\n member['percentage'] = take['percentage']\n\n member['editing_allowed'] = False\n member['is_current_user'] = False\n if current_participant:\n member['removal_allowed'] = current_participant.username == self.owner\n if member['username'] == current_participant.username:\n member['is_current_user'] = True\n if take['ctime'] is not None:\n # current user, but not the team itself\n member['editing_allowed']= True\n\n member['last_week'] = self.get_take_last_week_for(member['participant_id'])\n members.append(member)\n return members\n", "path": "gratipay/models/team/mixins/membership.py"}, {"content": "from __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom collections import OrderedDict\nfrom decimal import Decimal as D\n\nZERO = D('0.00')\nPENNY = D('0.01')\n\n\nclass TakesMixin(object):\n \"\"\":py:class:`~gratipay.models.participant.Participant` s who are members\n of a :py:class:`~gratipay.models.team.Team` may take money from the team\n during :py:class:`~gratipay.billing.payday.Payday`. Only the team owner may\n add a new member, by setting their take to a penny, but team owners may\n *only* set their take to a penny---no more. Team owners may also remove\n members, by setting their take to zero, as may the members themselves, who\n may also set their take to whatever they wish.\n \"\"\"\n\n #: The total amount of money the team distributes to participants\n #: (including the owner) during payday. Read-only; equal to\n #: :py:attr:`~gratipay.models.team.Team.receiving`.\n\n distributing = 0\n\n\n #: The number of participants (including the owner) that the team\n #: distributes money to during payday. Read-only; modified by\n #: :py:meth:`set_take_for`.\n\n ndistributing_to = 0\n\n\n def get_take_last_week_for(self, participant_id):\n \"\"\"Get the participant's nominal take last week.\n \"\"\"\n return self.db.one(\"\"\"\n\n SELECT amount\n FROM takes\n WHERE team_id=%s AND participant_id=%s\n AND mtime < (\n SELECT ts_start\n FROM paydays\n WHERE ts_end > ts_start\n ORDER BY ts_start DESC LIMIT 1\n )\n ORDER BY mtime DESC LIMIT 1\n\n \"\"\", (self.id, participant_id), default=ZERO)\n\n\n def set_take_for(self, participant, take, recorder, cursor=None):\n \"\"\"Set the amount a participant wants to take from this team during payday.\n\n :param Participant participant: the participant to set the take for\n :param Decimal take: the amount the participant wants to take\n :param Participant recorder: the participant making the change\n\n :return: the new take as a py:class:`~decimal.Decimal`\n :raises: :py:exc:`NotAllowed`\n\n It is a bug to pass in a ``participant`` or ``recorder`` that is\n suspicious, unclaimed, or without a verified email and identity.\n Furthermore, :py:exc:`NotAllowed` is raised in the following circumstances:\n\n - ``recorder`` is neither ``participant`` nor the team owner\n - ``recorder`` is the team owner and ``take`` is neither zero nor $0.01\n - ``recorder`` is ``participant``, but ``participant`` isn't already on the team\n\n \"\"\"\n def vet(p):\n if p.is_suspicious:\n raise NotAllowed(\"user must not be flagged as suspicious\")\n elif not p.has_verified_identity:\n raise NotAllowed(\"user must have a verified identity\")\n elif not p.email_address:\n raise NotAllowed(\"user must have added at least one email address\")\n elif not p.is_claimed:\n raise NotAllowed(\"user must have claimed the account\")\n\n vet(participant)\n vet(recorder)\n\n owner_recording = recorder.username == self.owner\n owner_taking = participant.username == self.owner\n taker_recording = recorder == participant\n adding_or_removing = take in (ZERO, PENNY)\n\n if owner_recording:\n if not adding_or_removing and not owner_taking:\n raise NotAllowed(\"owner can only add and remove members, not otherwise set takes\")\n elif not taker_recording:\n raise NotAllowed(\"can only set own take\")\n\n with self.db.get_cursor(cursor) as cursor:\n cursor.run(\"LOCK TABLE takes IN EXCLUSIVE MODE\") # avoid race conditions\n\n # Compute the current takes\n old_takes = self.compute_actual_takes(cursor)\n\n if recorder.username != self.owner:\n if recorder == participant and participant.id not in old_takes:\n raise NotAllowed(\"can only set take if already a member of the team\")\n\n new_take = cursor.one( \"\"\"\n\n INSERT INTO takes\n (ctime, participant_id, team_id, amount, recorder_id)\n VALUES ( COALESCE (( SELECT ctime\n FROM takes\n WHERE (participant_id=%(participant_id)s\n AND team_id=%(team_id)s)\n LIMIT 1\n ), CURRENT_TIMESTAMP)\n , %(participant_id)s, %(team_id)s, %(amount)s, %(recorder_id)s\n )\n RETURNING amount\n\n \"\"\", { 'participant_id': participant.id\n , 'team_id': self.id\n , 'amount': take\n , 'recorder_id': recorder.id\n })\n\n # Compute the new takes\n all_new_takes = self.compute_actual_takes(cursor)\n\n # Update computed values\n self.update_taking(old_takes, all_new_takes, cursor, participant)\n self.update_distributing(all_new_takes, cursor)\n\n return new_take\n\n\n def get_take_for(self, participant, cursor=None):\n \"\"\"\n :param Participant participant: the participant to get the take for\n :param GratipayDB cursor: a database cursor; if ``None``, a new cursor will be used\n :return: a :py:class:`~decimal.Decimal`: the ``participant``'s take from this team, or 0.\n \"\"\"\n return (cursor or self.db).one(\"\"\"\n\n SELECT amount\n FROM current_takes\n WHERE team_id=%s AND participant_id=%s\n\n \"\"\", (self.id, participant.id), default=ZERO)\n\n\n def update_taking(self, old_takes, new_takes, cursor=None, member=None):\n \"\"\"Update `taking` amounts based on the difference between `old_takes`\n and `new_takes`.\n \"\"\"\n\n # XXX Deal with owner as well as members\n\n for participant_id in set(old_takes.keys()).union(new_takes.keys()):\n old = old_takes.get(participant_id, {}).get('actual_amount', ZERO)\n new = new_takes.get(participant_id, {}).get('actual_amount', ZERO)\n delta = new - old\n if delta != 0:\n taking = (cursor or self.db).one(\"\"\"\n UPDATE participants\n SET taking = (taking + %(delta)s)\n WHERE id=%(participant_id)s\n RETURNING taking\n \"\"\", dict(participant_id=participant_id, delta=delta))\n if member and participant_id == member.id:\n member.set_attributes(taking=taking)\n\n\n def update_distributing(self, new_takes, cursor=None):\n \"\"\"Update the computed values on the team.\n \"\"\"\n distributing = sum(t['actual_amount'] for t in new_takes.values())\n ndistributing_to = len(tuple(t for t in new_takes.values() if t['actual_amount'] > 0))\n\n r = (cursor or self.db).one(\"\"\"\n UPDATE teams\n SET distributing=%s, ndistributing_to=%s WHERE id=%s\n RETURNING distributing, ndistributing_to\n \"\"\", (distributing, ndistributing_to, self.id))\n\n self.set_attributes(**r._asdict())\n\n\n def get_current_takes(self, cursor=None):\n \"\"\"Return a list of member takes for a team.\n \"\"\"\n TAKES = \"\"\"\n SELECT p.*::participants AS participant\n , ct.amount, ct.ctime, ct.mtime\n FROM current_takes ct\n JOIN participants p\n ON ct.participant_id = p.id\n WHERE team_id=%(team_id)s\n ORDER BY amount ASC, ctime ASC\n \"\"\"\n records = (cursor or self.db).all(TAKES, dict(team_id=self.id))\n return [r._asdict() for r in records]\n\n\n def compute_actual_takes(self, cursor=None):\n \"\"\"Get the takes, compute the actual amounts, and return an OrderedDict.\n \"\"\"\n actual_takes = OrderedDict()\n nominal_takes = self.get_current_takes(cursor=cursor)\n available = balance = self.available\n for take in nominal_takes:\n nominal_amount = take['nominal_amount'] = take.pop('amount')\n actual_amount = take['actual_amount'] = min(nominal_amount, balance)\n take['balance'] = balance = balance - actual_amount\n take['percentage'] = actual_amount / available\n actual_takes[take['participant'].id] = take\n return actual_takes\n\n\nclass NotAllowed(Exception):\n \"\"\"Raised by :py:meth:`set_take_for` if ``recorder`` is not allowed to set\n the take for ``participant``.\n \"\"\"\n", "path": "gratipay/models/team/mixins/takes.py"}]} | 3,780 | 1,012 |
gh_patches_debug_23137 | rasdani/github-patches | git_diff | scrapy__scrapy-1563 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] Incorrectly picked URL in `scrapy.http.FormRequest.from_response` when there is a `<base>` tag
## Issue Description
Incorrectly picked URL in `scrapy.http.FormRequest.from_response` when there is a `<base>` tag.
## How to Reproduce the Issue & Version Used
```
[pengyu@GLaDOS tmp]$ python2
Python 2.7.10 (default, Sep 7 2015, 13:51:49)
[GCC 5.2.0] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import scrapy
>>> scrapy.__version__
u'1.0.3'
>>> html_body = '''
... <html>
... <head>
... <base href="http://b.com/">
... </head>
... <body>
... <form action="test_form">
... </form>
... </body>
... </html>
... '''
>>> response = scrapy.http.TextResponse(url='http://a.com/', body=html_body)
>>> request = scrapy.http.FormRequest.from_response(response)
>>> request.url
'http://a.com/test_form'
```
## Expected Result
`request.url` shall be `'http://b.com/test_form'`
## Suggested Fix
The issue can be fixed by fixing a few lines in `scrapy/http/request/form.py`
</issue>
<code>
[start of scrapy/http/request/form.py]
1 """
2 This module implements the FormRequest class which is a more convenient class
3 (than Request) to generate Requests based on form data.
4
5 See documentation in docs/topics/request-response.rst
6 """
7
8 from six.moves.urllib.parse import urljoin, urlencode
9 import lxml.html
10 from parsel.selector import create_root_node
11 import six
12 from scrapy.http.request import Request
13 from scrapy.utils.python import to_bytes, is_listlike
14
15
16 class FormRequest(Request):
17
18 def __init__(self, *args, **kwargs):
19 formdata = kwargs.pop('formdata', None)
20 if formdata and kwargs.get('method') is None:
21 kwargs['method'] = 'POST'
22
23 super(FormRequest, self).__init__(*args, **kwargs)
24
25 if formdata:
26 items = formdata.items() if isinstance(formdata, dict) else formdata
27 querystr = _urlencode(items, self.encoding)
28 if self.method == 'POST':
29 self.headers.setdefault(b'Content-Type', b'application/x-www-form-urlencoded')
30 self._set_body(querystr)
31 else:
32 self._set_url(self.url + ('&' if '?' in self.url else '?') + querystr)
33
34 @classmethod
35 def from_response(cls, response, formname=None, formid=None, formnumber=0, formdata=None,
36 clickdata=None, dont_click=False, formxpath=None, **kwargs):
37 kwargs.setdefault('encoding', response.encoding)
38 form = _get_form(response, formname, formid, formnumber, formxpath)
39 formdata = _get_inputs(form, formdata, dont_click, clickdata, response)
40 url = _get_form_url(form, kwargs.pop('url', None))
41 method = kwargs.pop('method', form.method)
42 return cls(url=url, method=method, formdata=formdata, **kwargs)
43
44
45 def _get_form_url(form, url):
46 if url is None:
47 return form.action or form.base_url
48 return urljoin(form.base_url, url)
49
50
51 def _urlencode(seq, enc):
52 values = [(to_bytes(k, enc), to_bytes(v, enc))
53 for k, vs in seq
54 for v in (vs if is_listlike(vs) else [vs])]
55 return urlencode(values, doseq=1)
56
57
58 def _get_form(response, formname, formid, formnumber, formxpath):
59 """Find the form element """
60 text = response.body_as_unicode()
61 root = create_root_node(text, lxml.html.HTMLParser, base_url=response.url)
62 forms = root.xpath('//form')
63 if not forms:
64 raise ValueError("No <form> element found in %s" % response)
65
66 if formname is not None:
67 f = root.xpath('//form[@name="%s"]' % formname)
68 if f:
69 return f[0]
70
71 if formid is not None:
72 f = root.xpath('//form[@id="%s"]' % formid)
73 if f:
74 return f[0]
75
76 # Get form element from xpath, if not found, go up
77 if formxpath is not None:
78 nodes = root.xpath(formxpath)
79 if nodes:
80 el = nodes[0]
81 while True:
82 if el.tag == 'form':
83 return el
84 el = el.getparent()
85 if el is None:
86 break
87 raise ValueError('No <form> element found with %s' % formxpath)
88
89 # If we get here, it means that either formname was None
90 # or invalid
91 if formnumber is not None:
92 try:
93 form = forms[formnumber]
94 except IndexError:
95 raise IndexError("Form number %d not found in %s" %
96 (formnumber, response))
97 else:
98 return form
99
100
101 def _get_inputs(form, formdata, dont_click, clickdata, response):
102 try:
103 formdata = dict(formdata or ())
104 except (ValueError, TypeError):
105 raise ValueError('formdata should be a dict or iterable of tuples')
106
107 inputs = form.xpath('descendant::textarea'
108 '|descendant::select'
109 '|descendant::input[@type!="submit" and @type!="image" and @type!="reset"'
110 'and ((@type!="checkbox" and @type!="radio") or @checked)]')
111 values = [(k, u'' if v is None else v)
112 for k, v in (_value(e) for e in inputs)
113 if k and k not in formdata]
114
115 if not dont_click:
116 clickable = _get_clickable(clickdata, form)
117 if clickable and clickable[0] not in formdata and not clickable[0] is None:
118 values.append(clickable)
119
120 values.extend(formdata.items())
121 return values
122
123
124 def _value(ele):
125 n = ele.name
126 v = ele.value
127 if ele.tag == 'select':
128 return _select_value(ele, n, v)
129 return n, v
130
131
132 def _select_value(ele, n, v):
133 multiple = ele.multiple
134 if v is None and not multiple:
135 # Match browser behaviour on simple select tag without options selected
136 # And for select tags wihout options
137 o = ele.value_options
138 return (n, o[0]) if o else (None, None)
139 elif v is not None and multiple:
140 # This is a workround to bug in lxml fixed 2.3.1
141 # fix https://github.com/lxml/lxml/commit/57f49eed82068a20da3db8f1b18ae00c1bab8b12#L1L1139
142 selected_options = ele.xpath('.//option[@selected]')
143 v = [(o.get('value') or o.text or u'').strip() for o in selected_options]
144 return n, v
145
146
147 def _get_clickable(clickdata, form):
148 """
149 Returns the clickable element specified in clickdata,
150 if the latter is given. If not, it returns the first
151 clickable element found
152 """
153 clickables = [el for el in form.xpath('descendant::input[@type="submit"]'
154 '|descendant::button[@type="submit"]'
155 '|descendant::button[not(@type)]')]
156 if not clickables:
157 return
158
159 # If we don't have clickdata, we just use the first clickable element
160 if clickdata is None:
161 el = clickables[0]
162 return (el.get('name'), el.get('value') or '')
163
164 # If clickdata is given, we compare it to the clickable elements to find a
165 # match. We first look to see if the number is specified in clickdata,
166 # because that uniquely identifies the element
167 nr = clickdata.get('nr', None)
168 if nr is not None:
169 try:
170 el = list(form.inputs)[nr]
171 except IndexError:
172 pass
173 else:
174 return (el.get('name'), el.get('value') or '')
175
176 # We didn't find it, so now we build an XPath expression out of the other
177 # arguments, because they can be used as such
178 xpath = u'.//*' + \
179 u''.join(u'[@%s="%s"]' % c for c in six.iteritems(clickdata))
180 el = form.xpath(xpath)
181 if len(el) == 1:
182 return (el[0].get('name'), el[0].get('value') or '')
183 elif len(el) > 1:
184 raise ValueError("Multiple elements found (%r) matching the criteria "
185 "in clickdata: %r" % (el, clickdata))
186 else:
187 raise ValueError('No clickable element matching clickdata: %r' % (clickdata,))
188
[end of scrapy/http/request/form.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/scrapy/http/request/form.py b/scrapy/http/request/form.py
--- a/scrapy/http/request/form.py
+++ b/scrapy/http/request/form.py
@@ -11,6 +11,7 @@
import six
from scrapy.http.request import Request
from scrapy.utils.python import to_bytes, is_listlike
+from scrapy.utils.response import get_base_url
class FormRequest(Request):
@@ -44,7 +45,7 @@
def _get_form_url(form, url):
if url is None:
- return form.action or form.base_url
+ return urljoin(form.base_url, form.action)
return urljoin(form.base_url, url)
@@ -58,7 +59,7 @@
def _get_form(response, formname, formid, formnumber, formxpath):
"""Find the form element """
text = response.body_as_unicode()
- root = create_root_node(text, lxml.html.HTMLParser, base_url=response.url)
+ root = create_root_node(text, lxml.html.HTMLParser, base_url=get_base_url(response))
forms = root.xpath('//form')
if not forms:
raise ValueError("No <form> element found in %s" % response)
| {"golden_diff": "diff --git a/scrapy/http/request/form.py b/scrapy/http/request/form.py\n--- a/scrapy/http/request/form.py\n+++ b/scrapy/http/request/form.py\n@@ -11,6 +11,7 @@\n import six\n from scrapy.http.request import Request\n from scrapy.utils.python import to_bytes, is_listlike\n+from scrapy.utils.response import get_base_url\n \n \n class FormRequest(Request):\n@@ -44,7 +45,7 @@\n \n def _get_form_url(form, url):\n if url is None:\n- return form.action or form.base_url\n+ return urljoin(form.base_url, form.action)\n return urljoin(form.base_url, url)\n \n \n@@ -58,7 +59,7 @@\n def _get_form(response, formname, formid, formnumber, formxpath):\n \"\"\"Find the form element \"\"\"\n text = response.body_as_unicode()\n- root = create_root_node(text, lxml.html.HTMLParser, base_url=response.url)\n+ root = create_root_node(text, lxml.html.HTMLParser, base_url=get_base_url(response))\n forms = root.xpath('//form')\n if not forms:\n raise ValueError(\"No <form> element found in %s\" % response)\n", "issue": "[Bug] Incorrectly picked URL in `scrapy.http.FormRequest.from_response` when there is a `<base>` tag\n## Issue Description\n\nIncorrectly picked URL in `scrapy.http.FormRequest.from_response` when there is a `<base>` tag.\n## How to Reproduce the Issue & Version Used\n\n```\n[pengyu@GLaDOS tmp]$ python2\nPython 2.7.10 (default, Sep 7 2015, 13:51:49) \n[GCC 5.2.0] on linux2\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\n>>> import scrapy\n>>> scrapy.__version__\nu'1.0.3'\n>>> html_body = '''\n... <html>\n... <head>\n... <base href=\"http://b.com/\">\n... </head>\n... <body>\n... <form action=\"test_form\">\n... </form>\n... </body>\n... </html>\n... '''\n>>> response = scrapy.http.TextResponse(url='http://a.com/', body=html_body)\n>>> request = scrapy.http.FormRequest.from_response(response)\n>>> request.url\n'http://a.com/test_form'\n```\n## Expected Result\n\n`request.url` shall be `'http://b.com/test_form'`\n## Suggested Fix\n\nThe issue can be fixed by fixing a few lines in `scrapy/http/request/form.py`\n\n", "before_files": [{"content": "\"\"\"\nThis module implements the FormRequest class which is a more convenient class\n(than Request) to generate Requests based on form data.\n\nSee documentation in docs/topics/request-response.rst\n\"\"\"\n\nfrom six.moves.urllib.parse import urljoin, urlencode\nimport lxml.html\nfrom parsel.selector import create_root_node\nimport six\nfrom scrapy.http.request import Request\nfrom scrapy.utils.python import to_bytes, is_listlike\n\n\nclass FormRequest(Request):\n\n def __init__(self, *args, **kwargs):\n formdata = kwargs.pop('formdata', None)\n if formdata and kwargs.get('method') is None:\n kwargs['method'] = 'POST'\n\n super(FormRequest, self).__init__(*args, **kwargs)\n\n if formdata:\n items = formdata.items() if isinstance(formdata, dict) else formdata\n querystr = _urlencode(items, self.encoding)\n if self.method == 'POST':\n self.headers.setdefault(b'Content-Type', b'application/x-www-form-urlencoded')\n self._set_body(querystr)\n else:\n self._set_url(self.url + ('&' if '?' in self.url else '?') + querystr)\n\n @classmethod\n def from_response(cls, response, formname=None, formid=None, formnumber=0, formdata=None,\n clickdata=None, dont_click=False, formxpath=None, **kwargs):\n kwargs.setdefault('encoding', response.encoding)\n form = _get_form(response, formname, formid, formnumber, formxpath)\n formdata = _get_inputs(form, formdata, dont_click, clickdata, response)\n url = _get_form_url(form, kwargs.pop('url', None))\n method = kwargs.pop('method', form.method)\n return cls(url=url, method=method, formdata=formdata, **kwargs)\n\n\ndef _get_form_url(form, url):\n if url is None:\n return form.action or form.base_url\n return urljoin(form.base_url, url)\n\n\ndef _urlencode(seq, enc):\n values = [(to_bytes(k, enc), to_bytes(v, enc))\n for k, vs in seq\n for v in (vs if is_listlike(vs) else [vs])]\n return urlencode(values, doseq=1)\n\n\ndef _get_form(response, formname, formid, formnumber, formxpath):\n \"\"\"Find the form element \"\"\"\n text = response.body_as_unicode()\n root = create_root_node(text, lxml.html.HTMLParser, base_url=response.url)\n forms = root.xpath('//form')\n if not forms:\n raise ValueError(\"No <form> element found in %s\" % response)\n\n if formname is not None:\n f = root.xpath('//form[@name=\"%s\"]' % formname)\n if f:\n return f[0]\n\n if formid is not None:\n f = root.xpath('//form[@id=\"%s\"]' % formid)\n if f:\n return f[0]\n \n # Get form element from xpath, if not found, go up\n if formxpath is not None:\n nodes = root.xpath(formxpath)\n if nodes:\n el = nodes[0]\n while True:\n if el.tag == 'form':\n return el\n el = el.getparent()\n if el is None:\n break\n raise ValueError('No <form> element found with %s' % formxpath)\n\n # If we get here, it means that either formname was None\n # or invalid\n if formnumber is not None:\n try:\n form = forms[formnumber]\n except IndexError:\n raise IndexError(\"Form number %d not found in %s\" %\n (formnumber, response))\n else:\n return form\n\n\ndef _get_inputs(form, formdata, dont_click, clickdata, response):\n try:\n formdata = dict(formdata or ())\n except (ValueError, TypeError):\n raise ValueError('formdata should be a dict or iterable of tuples')\n\n inputs = form.xpath('descendant::textarea'\n '|descendant::select'\n '|descendant::input[@type!=\"submit\" and @type!=\"image\" and @type!=\"reset\"'\n 'and ((@type!=\"checkbox\" and @type!=\"radio\") or @checked)]')\n values = [(k, u'' if v is None else v)\n for k, v in (_value(e) for e in inputs)\n if k and k not in formdata]\n\n if not dont_click:\n clickable = _get_clickable(clickdata, form)\n if clickable and clickable[0] not in formdata and not clickable[0] is None:\n values.append(clickable)\n\n values.extend(formdata.items())\n return values\n\n\ndef _value(ele):\n n = ele.name\n v = ele.value\n if ele.tag == 'select':\n return _select_value(ele, n, v)\n return n, v\n\n\ndef _select_value(ele, n, v):\n multiple = ele.multiple\n if v is None and not multiple:\n # Match browser behaviour on simple select tag without options selected\n # And for select tags wihout options\n o = ele.value_options\n return (n, o[0]) if o else (None, None)\n elif v is not None and multiple:\n # This is a workround to bug in lxml fixed 2.3.1\n # fix https://github.com/lxml/lxml/commit/57f49eed82068a20da3db8f1b18ae00c1bab8b12#L1L1139\n selected_options = ele.xpath('.//option[@selected]')\n v = [(o.get('value') or o.text or u'').strip() for o in selected_options]\n return n, v\n\n\ndef _get_clickable(clickdata, form):\n \"\"\"\n Returns the clickable element specified in clickdata,\n if the latter is given. If not, it returns the first\n clickable element found\n \"\"\"\n clickables = [el for el in form.xpath('descendant::input[@type=\"submit\"]'\n '|descendant::button[@type=\"submit\"]'\n '|descendant::button[not(@type)]')]\n if not clickables:\n return\n\n # If we don't have clickdata, we just use the first clickable element\n if clickdata is None:\n el = clickables[0]\n return (el.get('name'), el.get('value') or '')\n\n # If clickdata is given, we compare it to the clickable elements to find a\n # match. We first look to see if the number is specified in clickdata,\n # because that uniquely identifies the element\n nr = clickdata.get('nr', None)\n if nr is not None:\n try:\n el = list(form.inputs)[nr]\n except IndexError:\n pass\n else:\n return (el.get('name'), el.get('value') or '')\n\n # We didn't find it, so now we build an XPath expression out of the other\n # arguments, because they can be used as such\n xpath = u'.//*' + \\\n u''.join(u'[@%s=\"%s\"]' % c for c in six.iteritems(clickdata))\n el = form.xpath(xpath)\n if len(el) == 1:\n return (el[0].get('name'), el[0].get('value') or '')\n elif len(el) > 1:\n raise ValueError(\"Multiple elements found (%r) matching the criteria \"\n \"in clickdata: %r\" % (el, clickdata))\n else:\n raise ValueError('No clickable element matching clickdata: %r' % (clickdata,))\n", "path": "scrapy/http/request/form.py"}]} | 2,981 | 262 |
gh_patches_debug_30995 | rasdani/github-patches | git_diff | pypa__pip-4224 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pip search picks older version if returned list of versions are not ordered
* Pip version: 9.0.1
* Python version: 2.7
* Operating System: Ubuntu/CentOS
### Description:
For a list of versions returned by local pypi server that was ill-ordered like
```[{...'versions': ['1.0.249', '1.0.251', '1.0.250'], 'name':...}...]```
search picks the top element among all the versions returned to it.
```version = hit.get('versions', ['-'])[-1]```
at https://github.com/pypa/pip/blob/9.0.1/pip/commands/search.py#L107 and https://github.com/pypa/pip/blob/9.0.1/pip/commands/search.py#L99
Rather it should do something like
```version = highest_version(hit.get('versions', ['-']))```
</issue>
<code>
[start of pip/commands/search.py]
1 from __future__ import absolute_import
2
3 import logging
4 import sys
5 import textwrap
6
7 from pip.basecommand import Command, SUCCESS
8 from pip.compat import OrderedDict
9 from pip.download import PipXmlrpcTransport
10 from pip.models import PyPI
11 from pip.utils import get_terminal_size
12 from pip.utils.logging import indent_log
13 from pip.exceptions import CommandError
14 from pip.status_codes import NO_MATCHES_FOUND
15 from pip._vendor.packaging.version import parse as parse_version
16 from pip._vendor import pkg_resources
17 from pip._vendor.six.moves import xmlrpc_client
18
19
20 logger = logging.getLogger(__name__)
21
22
23 class SearchCommand(Command):
24 """Search for PyPI packages whose name or summary contains <query>."""
25 name = 'search'
26 usage = """
27 %prog [options] <query>"""
28 summary = 'Search PyPI for packages.'
29
30 def __init__(self, *args, **kw):
31 super(SearchCommand, self).__init__(*args, **kw)
32 self.cmd_opts.add_option(
33 '-i', '--index',
34 dest='index',
35 metavar='URL',
36 default=PyPI.pypi_url,
37 help='Base URL of Python Package Index (default %default)')
38
39 self.parser.insert_option_group(0, self.cmd_opts)
40
41 def run(self, options, args):
42 if not args:
43 raise CommandError('Missing required argument (search query).')
44 query = args
45 pypi_hits = self.search(query, options)
46 hits = transform_hits(pypi_hits)
47
48 terminal_width = None
49 if sys.stdout.isatty():
50 terminal_width = get_terminal_size()[0]
51
52 print_results(hits, terminal_width=terminal_width)
53 if pypi_hits:
54 return SUCCESS
55 return NO_MATCHES_FOUND
56
57 def search(self, query, options):
58 index_url = options.index
59 with self._build_session(options) as session:
60 transport = PipXmlrpcTransport(index_url, session)
61 pypi = xmlrpc_client.ServerProxy(index_url, transport)
62 hits = pypi.search({'name': query, 'summary': query}, 'or')
63 return hits
64
65
66 def transform_hits(hits):
67 """
68 The list from pypi is really a list of versions. We want a list of
69 packages with the list of versions stored inline. This converts the
70 list from pypi into one we can use.
71 """
72 packages = OrderedDict()
73 for hit in hits:
74 name = hit['name']
75 summary = hit['summary']
76 version = hit['version']
77
78 if name not in packages.keys():
79 packages[name] = {
80 'name': name,
81 'summary': summary,
82 'versions': [version],
83 }
84 else:
85 packages[name]['versions'].append(version)
86
87 # if this is the highest version, replace summary and score
88 if version == highest_version(packages[name]['versions']):
89 packages[name]['summary'] = summary
90
91 return list(packages.values())
92
93
94 def print_results(hits, name_column_width=None, terminal_width=None):
95 if not hits:
96 return
97 if name_column_width is None:
98 name_column_width = max([
99 len(hit['name']) + len(hit.get('versions', ['-'])[-1])
100 for hit in hits
101 ]) + 4
102
103 installed_packages = [p.project_name for p in pkg_resources.working_set]
104 for hit in hits:
105 name = hit['name']
106 summary = hit['summary'] or ''
107 version = hit.get('versions', ['-'])[-1]
108 if terminal_width is not None:
109 target_width = terminal_width - name_column_width - 5
110 if target_width > 10:
111 # wrap and indent summary to fit terminal
112 summary = textwrap.wrap(summary, target_width)
113 summary = ('\n' + ' ' * (name_column_width + 3)).join(summary)
114
115 line = '%-*s - %s' % (name_column_width,
116 '%s (%s)' % (name, version), summary)
117 try:
118 logger.info(line)
119 if name in installed_packages:
120 dist = pkg_resources.get_distribution(name)
121 with indent_log():
122 latest = highest_version(hit['versions'])
123 if dist.version == latest:
124 logger.info('INSTALLED: %s (latest)', dist.version)
125 else:
126 logger.info('INSTALLED: %s', dist.version)
127 logger.info('LATEST: %s', latest)
128 except UnicodeEncodeError:
129 pass
130
131
132 def highest_version(versions):
133 return max(versions, key=parse_version)
134
[end of pip/commands/search.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pip/commands/search.py b/pip/commands/search.py
--- a/pip/commands/search.py
+++ b/pip/commands/search.py
@@ -96,7 +96,7 @@
return
if name_column_width is None:
name_column_width = max([
- len(hit['name']) + len(hit.get('versions', ['-'])[-1])
+ len(hit['name']) + len(highest_version(hit.get('versions', ['-'])))
for hit in hits
]) + 4
@@ -104,7 +104,7 @@
for hit in hits:
name = hit['name']
summary = hit['summary'] or ''
- version = hit.get('versions', ['-'])[-1]
+ latest = highest_version(hit.get('versions', ['-']))
if terminal_width is not None:
target_width = terminal_width - name_column_width - 5
if target_width > 10:
@@ -113,13 +113,12 @@
summary = ('\n' + ' ' * (name_column_width + 3)).join(summary)
line = '%-*s - %s' % (name_column_width,
- '%s (%s)' % (name, version), summary)
+ '%s (%s)' % (name, latest), summary)
try:
logger.info(line)
if name in installed_packages:
dist = pkg_resources.get_distribution(name)
with indent_log():
- latest = highest_version(hit['versions'])
if dist.version == latest:
logger.info('INSTALLED: %s (latest)', dist.version)
else:
| {"golden_diff": "diff --git a/pip/commands/search.py b/pip/commands/search.py\n--- a/pip/commands/search.py\n+++ b/pip/commands/search.py\n@@ -96,7 +96,7 @@\n return\n if name_column_width is None:\n name_column_width = max([\n- len(hit['name']) + len(hit.get('versions', ['-'])[-1])\n+ len(hit['name']) + len(highest_version(hit.get('versions', ['-'])))\n for hit in hits\n ]) + 4\n \n@@ -104,7 +104,7 @@\n for hit in hits:\n name = hit['name']\n summary = hit['summary'] or ''\n- version = hit.get('versions', ['-'])[-1]\n+ latest = highest_version(hit.get('versions', ['-']))\n if terminal_width is not None:\n target_width = terminal_width - name_column_width - 5\n if target_width > 10:\n@@ -113,13 +113,12 @@\n summary = ('\\n' + ' ' * (name_column_width + 3)).join(summary)\n \n line = '%-*s - %s' % (name_column_width,\n- '%s (%s)' % (name, version), summary)\n+ '%s (%s)' % (name, latest), summary)\n try:\n logger.info(line)\n if name in installed_packages:\n dist = pkg_resources.get_distribution(name)\n with indent_log():\n- latest = highest_version(hit['versions'])\n if dist.version == latest:\n logger.info('INSTALLED: %s (latest)', dist.version)\n else:\n", "issue": "pip search picks older version if returned list of versions are not ordered\n* Pip version: 9.0.1\r\n* Python version: 2.7\r\n* Operating System: Ubuntu/CentOS\r\n\r\n### Description:\r\n\r\nFor a list of versions returned by local pypi server that was ill-ordered like\r\n```[{...'versions': ['1.0.249', '1.0.251', '1.0.250'], 'name':...}...]```\r\n\r\nsearch picks the top element among all the versions returned to it.\r\n```version = hit.get('versions', ['-'])[-1]```\r\n at https://github.com/pypa/pip/blob/9.0.1/pip/commands/search.py#L107 and https://github.com/pypa/pip/blob/9.0.1/pip/commands/search.py#L99\r\n\r\nRather it should do something like\r\n```version = highest_version(hit.get('versions', ['-']))```\r\n\r\n\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport logging\nimport sys\nimport textwrap\n\nfrom pip.basecommand import Command, SUCCESS\nfrom pip.compat import OrderedDict\nfrom pip.download import PipXmlrpcTransport\nfrom pip.models import PyPI\nfrom pip.utils import get_terminal_size\nfrom pip.utils.logging import indent_log\nfrom pip.exceptions import CommandError\nfrom pip.status_codes import NO_MATCHES_FOUND\nfrom pip._vendor.packaging.version import parse as parse_version\nfrom pip._vendor import pkg_resources\nfrom pip._vendor.six.moves import xmlrpc_client\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass SearchCommand(Command):\n \"\"\"Search for PyPI packages whose name or summary contains <query>.\"\"\"\n name = 'search'\n usage = \"\"\"\n %prog [options] <query>\"\"\"\n summary = 'Search PyPI for packages.'\n\n def __init__(self, *args, **kw):\n super(SearchCommand, self).__init__(*args, **kw)\n self.cmd_opts.add_option(\n '-i', '--index',\n dest='index',\n metavar='URL',\n default=PyPI.pypi_url,\n help='Base URL of Python Package Index (default %default)')\n\n self.parser.insert_option_group(0, self.cmd_opts)\n\n def run(self, options, args):\n if not args:\n raise CommandError('Missing required argument (search query).')\n query = args\n pypi_hits = self.search(query, options)\n hits = transform_hits(pypi_hits)\n\n terminal_width = None\n if sys.stdout.isatty():\n terminal_width = get_terminal_size()[0]\n\n print_results(hits, terminal_width=terminal_width)\n if pypi_hits:\n return SUCCESS\n return NO_MATCHES_FOUND\n\n def search(self, query, options):\n index_url = options.index\n with self._build_session(options) as session:\n transport = PipXmlrpcTransport(index_url, session)\n pypi = xmlrpc_client.ServerProxy(index_url, transport)\n hits = pypi.search({'name': query, 'summary': query}, 'or')\n return hits\n\n\ndef transform_hits(hits):\n \"\"\"\n The list from pypi is really a list of versions. We want a list of\n packages with the list of versions stored inline. This converts the\n list from pypi into one we can use.\n \"\"\"\n packages = OrderedDict()\n for hit in hits:\n name = hit['name']\n summary = hit['summary']\n version = hit['version']\n\n if name not in packages.keys():\n packages[name] = {\n 'name': name,\n 'summary': summary,\n 'versions': [version],\n }\n else:\n packages[name]['versions'].append(version)\n\n # if this is the highest version, replace summary and score\n if version == highest_version(packages[name]['versions']):\n packages[name]['summary'] = summary\n\n return list(packages.values())\n\n\ndef print_results(hits, name_column_width=None, terminal_width=None):\n if not hits:\n return\n if name_column_width is None:\n name_column_width = max([\n len(hit['name']) + len(hit.get('versions', ['-'])[-1])\n for hit in hits\n ]) + 4\n\n installed_packages = [p.project_name for p in pkg_resources.working_set]\n for hit in hits:\n name = hit['name']\n summary = hit['summary'] or ''\n version = hit.get('versions', ['-'])[-1]\n if terminal_width is not None:\n target_width = terminal_width - name_column_width - 5\n if target_width > 10:\n # wrap and indent summary to fit terminal\n summary = textwrap.wrap(summary, target_width)\n summary = ('\\n' + ' ' * (name_column_width + 3)).join(summary)\n\n line = '%-*s - %s' % (name_column_width,\n '%s (%s)' % (name, version), summary)\n try:\n logger.info(line)\n if name in installed_packages:\n dist = pkg_resources.get_distribution(name)\n with indent_log():\n latest = highest_version(hit['versions'])\n if dist.version == latest:\n logger.info('INSTALLED: %s (latest)', dist.version)\n else:\n logger.info('INSTALLED: %s', dist.version)\n logger.info('LATEST: %s', latest)\n except UnicodeEncodeError:\n pass\n\n\ndef highest_version(versions):\n return max(versions, key=parse_version)\n", "path": "pip/commands/search.py"}]} | 2,016 | 359 |
gh_patches_debug_28928 | rasdani/github-patches | git_diff | pallets__werkzeug-1610 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Reloader picks wrong module when Flask is run with the pydev debugger
This is a weird situation where the pallets/werkzeug#1416 fix to make `python -m` reloading more correct actually exposed an issue with PyDev. It rewrites `python -m flask` to `python flask` (which is clearly not correct), while Python itself rewrites it to `python /path/to/flask_entry_point.py`. Werkzeug still correctly detects that we were run as a module, but since `sys.argv[0]` is no longer a path but the module name, it incorrectly decides that there is a module named `flask.flask` in the current directory.
_Originally posted by @davidism in https://github.com/pallets/flask/issues/3297#issuecomment-510120836_
</issue>
<code>
[start of src/werkzeug/_reloader.py]
1 import os
2 import subprocess
3 import sys
4 import threading
5 import time
6 from itertools import chain
7
8 from ._compat import iteritems
9 from ._compat import PY2
10 from ._compat import text_type
11 from ._internal import _log
12
13
14 def _iter_module_files():
15 """This iterates over all relevant Python files. It goes through all
16 loaded files from modules, all files in folders of already loaded modules
17 as well as all files reachable through a package.
18 """
19 # The list call is necessary on Python 3 in case the module
20 # dictionary modifies during iteration.
21 for module in list(sys.modules.values()):
22 if module is None:
23 continue
24 filename = getattr(module, "__file__", None)
25 if filename:
26 if os.path.isdir(filename) and os.path.exists(
27 os.path.join(filename, "__init__.py")
28 ):
29 filename = os.path.join(filename, "__init__.py")
30
31 old = None
32 while not os.path.isfile(filename):
33 old = filename
34 filename = os.path.dirname(filename)
35 if filename == old:
36 break
37 else:
38 if filename[-4:] in (".pyc", ".pyo"):
39 filename = filename[:-1]
40 yield filename
41
42
43 def _find_observable_paths(extra_files=None):
44 """Finds all paths that should be observed."""
45 rv = set(
46 os.path.dirname(os.path.abspath(x)) if os.path.isfile(x) else os.path.abspath(x)
47 for x in sys.path
48 )
49
50 for filename in extra_files or ():
51 rv.add(os.path.dirname(os.path.abspath(filename)))
52
53 for module in list(sys.modules.values()):
54 fn = getattr(module, "__file__", None)
55 if fn is None:
56 continue
57 fn = os.path.abspath(fn)
58 rv.add(os.path.dirname(fn))
59
60 return _find_common_roots(rv)
61
62
63 def _get_args_for_reloading():
64 """Returns the executable. This contains a workaround for windows
65 if the executable is incorrectly reported to not have the .exe
66 extension which can cause bugs on reloading. This also contains
67 a workaround for linux where the file is executable (possibly with
68 a program other than python)
69 """
70 rv = [sys.executable]
71 py_script = os.path.abspath(sys.argv[0])
72 args = sys.argv[1:]
73 # Need to look at main module to determine how it was executed.
74 __main__ = sys.modules["__main__"]
75
76 if __main__.__package__ is None:
77 # Executed a file, like "python app.py".
78 if os.name == "nt":
79 # Windows entry points have ".exe" extension and should be
80 # called directly.
81 if not os.path.exists(py_script) and os.path.exists(py_script + ".exe"):
82 py_script += ".exe"
83
84 if (
85 os.path.splitext(rv[0])[1] == ".exe"
86 and os.path.splitext(py_script)[1] == ".exe"
87 ):
88 rv.pop(0)
89
90 elif os.path.isfile(py_script) and os.access(py_script, os.X_OK):
91 # The file is marked as executable. Nix adds a wrapper that
92 # shouldn't be called with the Python executable.
93 rv.pop(0)
94
95 rv.append(py_script)
96 else:
97 # Executed a module, like "python -m werkzeug.serving".
98 if sys.argv[0] == "-m":
99 # Flask works around previous behavior by putting
100 # "-m flask" in sys.argv.
101 # TODO remove this once Flask no longer misbehaves
102 args = sys.argv
103 else:
104 py_module = __main__.__package__
105 name = os.path.splitext(os.path.basename(py_script))[0]
106
107 if name != "__main__":
108 py_module += "." + name
109
110 rv.extend(("-m", py_module.lstrip(".")))
111
112 rv.extend(args)
113 return rv
114
115
116 def _find_common_roots(paths):
117 """Out of some paths it finds the common roots that need monitoring."""
118 paths = [x.split(os.path.sep) for x in paths]
119 root = {}
120 for chunks in sorted(paths, key=len, reverse=True):
121 node = root
122 for chunk in chunks:
123 node = node.setdefault(chunk, {})
124 node.clear()
125
126 rv = set()
127
128 def _walk(node, path):
129 for prefix, child in iteritems(node):
130 _walk(child, path + (prefix,))
131 if not node:
132 rv.add("/".join(path))
133
134 _walk(root, ())
135 return rv
136
137
138 class ReloaderLoop(object):
139 name = None
140
141 # monkeypatched by testsuite. wrapping with `staticmethod` is required in
142 # case time.sleep has been replaced by a non-c function (e.g. by
143 # `eventlet.monkey_patch`) before we get here
144 _sleep = staticmethod(time.sleep)
145
146 def __init__(self, extra_files=None, interval=1):
147 self.extra_files = set(os.path.abspath(x) for x in extra_files or ())
148 self.interval = interval
149
150 def run(self):
151 pass
152
153 def restart_with_reloader(self):
154 """Spawn a new Python interpreter with the same arguments as this one,
155 but running the reloader thread.
156 """
157 while 1:
158 _log("info", " * Restarting with %s" % self.name)
159 args = _get_args_for_reloading()
160
161 # a weird bug on windows. sometimes unicode strings end up in the
162 # environment and subprocess.call does not like this, encode them
163 # to latin1 and continue.
164 if os.name == "nt" and PY2:
165 new_environ = {}
166 for key, value in iteritems(os.environ):
167 if isinstance(key, text_type):
168 key = key.encode("iso-8859-1")
169 if isinstance(value, text_type):
170 value = value.encode("iso-8859-1")
171 new_environ[key] = value
172 else:
173 new_environ = os.environ.copy()
174
175 new_environ["WERKZEUG_RUN_MAIN"] = "true"
176 exit_code = subprocess.call(args, env=new_environ, close_fds=False)
177 if exit_code != 3:
178 return exit_code
179
180 def trigger_reload(self, filename):
181 self.log_reload(filename)
182 sys.exit(3)
183
184 def log_reload(self, filename):
185 filename = os.path.abspath(filename)
186 _log("info", " * Detected change in %r, reloading" % filename)
187
188
189 class StatReloaderLoop(ReloaderLoop):
190 name = "stat"
191
192 def run(self):
193 mtimes = {}
194 while 1:
195 for filename in chain(_iter_module_files(), self.extra_files):
196 try:
197 mtime = os.stat(filename).st_mtime
198 except OSError:
199 continue
200
201 old_time = mtimes.get(filename)
202 if old_time is None:
203 mtimes[filename] = mtime
204 continue
205 elif mtime > old_time:
206 self.trigger_reload(filename)
207 self._sleep(self.interval)
208
209
210 class WatchdogReloaderLoop(ReloaderLoop):
211 def __init__(self, *args, **kwargs):
212 ReloaderLoop.__init__(self, *args, **kwargs)
213 from watchdog.observers import Observer
214 from watchdog.events import FileSystemEventHandler
215
216 self.observable_paths = set()
217
218 def _check_modification(filename):
219 if filename in self.extra_files:
220 self.trigger_reload(filename)
221 dirname = os.path.dirname(filename)
222 if dirname.startswith(tuple(self.observable_paths)):
223 if filename.endswith((".pyc", ".pyo", ".py")):
224 self.trigger_reload(filename)
225
226 class _CustomHandler(FileSystemEventHandler):
227 def on_created(self, event):
228 _check_modification(event.src_path)
229
230 def on_modified(self, event):
231 _check_modification(event.src_path)
232
233 def on_moved(self, event):
234 _check_modification(event.src_path)
235 _check_modification(event.dest_path)
236
237 def on_deleted(self, event):
238 _check_modification(event.src_path)
239
240 reloader_name = Observer.__name__.lower()
241 if reloader_name.endswith("observer"):
242 reloader_name = reloader_name[:-8]
243 reloader_name += " reloader"
244
245 self.name = reloader_name
246
247 self.observer_class = Observer
248 self.event_handler = _CustomHandler()
249 self.should_reload = False
250
251 def trigger_reload(self, filename):
252 # This is called inside an event handler, which means throwing
253 # SystemExit has no effect.
254 # https://github.com/gorakhargosh/watchdog/issues/294
255 self.should_reload = True
256 self.log_reload(filename)
257
258 def run(self):
259 watches = {}
260 observer = self.observer_class()
261 observer.start()
262
263 try:
264 while not self.should_reload:
265 to_delete = set(watches)
266 paths = _find_observable_paths(self.extra_files)
267 for path in paths:
268 if path not in watches:
269 try:
270 watches[path] = observer.schedule(
271 self.event_handler, path, recursive=True
272 )
273 except OSError:
274 # Clear this path from list of watches We don't want
275 # the same error message showing again in the next
276 # iteration.
277 watches[path] = None
278 to_delete.discard(path)
279 for path in to_delete:
280 watch = watches.pop(path, None)
281 if watch is not None:
282 observer.unschedule(watch)
283 self.observable_paths = paths
284 self._sleep(self.interval)
285 finally:
286 observer.stop()
287 observer.join()
288
289 sys.exit(3)
290
291
292 reloader_loops = {"stat": StatReloaderLoop, "watchdog": WatchdogReloaderLoop}
293
294 try:
295 __import__("watchdog.observers")
296 except ImportError:
297 reloader_loops["auto"] = reloader_loops["stat"]
298 else:
299 reloader_loops["auto"] = reloader_loops["watchdog"]
300
301
302 def ensure_echo_on():
303 """Ensure that echo mode is enabled. Some tools such as PDB disable
304 it which causes usability issues after reload."""
305 # tcgetattr will fail if stdin isn't a tty
306 if not sys.stdin.isatty():
307 return
308 try:
309 import termios
310 except ImportError:
311 return
312 attributes = termios.tcgetattr(sys.stdin)
313 if not attributes[3] & termios.ECHO:
314 attributes[3] |= termios.ECHO
315 termios.tcsetattr(sys.stdin, termios.TCSANOW, attributes)
316
317
318 def run_with_reloader(main_func, extra_files=None, interval=1, reloader_type="auto"):
319 """Run the given function in an independent python interpreter."""
320 import signal
321
322 reloader = reloader_loops[reloader_type](extra_files, interval)
323 signal.signal(signal.SIGTERM, lambda *args: sys.exit(0))
324 try:
325 if os.environ.get("WERKZEUG_RUN_MAIN") == "true":
326 ensure_echo_on()
327 t = threading.Thread(target=main_func, args=())
328 t.setDaemon(True)
329 t.start()
330 reloader.run()
331 else:
332 sys.exit(reloader.restart_with_reloader())
333 except KeyboardInterrupt:
334 pass
335
[end of src/werkzeug/_reloader.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/werkzeug/_reloader.py b/src/werkzeug/_reloader.py
--- a/src/werkzeug/_reloader.py
+++ b/src/werkzeug/_reloader.py
@@ -68,13 +68,15 @@
a program other than python)
"""
rv = [sys.executable]
- py_script = os.path.abspath(sys.argv[0])
+ py_script = sys.argv[0]
args = sys.argv[1:]
# Need to look at main module to determine how it was executed.
__main__ = sys.modules["__main__"]
if __main__.__package__ is None:
# Executed a file, like "python app.py".
+ py_script = os.path.abspath(py_script)
+
if os.name == "nt":
# Windows entry points have ".exe" extension and should be
# called directly.
@@ -101,11 +103,16 @@
# TODO remove this once Flask no longer misbehaves
args = sys.argv
else:
- py_module = __main__.__package__
- name = os.path.splitext(os.path.basename(py_script))[0]
+ if os.path.isfile(py_script):
+ # Rewritten by Python from "-m script" to "/path/to/script.py".
+ py_module = __main__.__package__
+ name = os.path.splitext(os.path.basename(py_script))[0]
- if name != "__main__":
- py_module += "." + name
+ if name != "__main__":
+ py_module += "." + name
+ else:
+ # Incorrectly rewritten by pydevd debugger from "-m script" to "script".
+ py_module = py_script
rv.extend(("-m", py_module.lstrip(".")))
| {"golden_diff": "diff --git a/src/werkzeug/_reloader.py b/src/werkzeug/_reloader.py\n--- a/src/werkzeug/_reloader.py\n+++ b/src/werkzeug/_reloader.py\n@@ -68,13 +68,15 @@\n a program other than python)\n \"\"\"\n rv = [sys.executable]\n- py_script = os.path.abspath(sys.argv[0])\n+ py_script = sys.argv[0]\n args = sys.argv[1:]\n # Need to look at main module to determine how it was executed.\n __main__ = sys.modules[\"__main__\"]\n \n if __main__.__package__ is None:\n # Executed a file, like \"python app.py\".\n+ py_script = os.path.abspath(py_script)\n+\n if os.name == \"nt\":\n # Windows entry points have \".exe\" extension and should be\n # called directly.\n@@ -101,11 +103,16 @@\n # TODO remove this once Flask no longer misbehaves\n args = sys.argv\n else:\n- py_module = __main__.__package__\n- name = os.path.splitext(os.path.basename(py_script))[0]\n+ if os.path.isfile(py_script):\n+ # Rewritten by Python from \"-m script\" to \"/path/to/script.py\".\n+ py_module = __main__.__package__\n+ name = os.path.splitext(os.path.basename(py_script))[0]\n \n- if name != \"__main__\":\n- py_module += \".\" + name\n+ if name != \"__main__\":\n+ py_module += \".\" + name\n+ else:\n+ # Incorrectly rewritten by pydevd debugger from \"-m script\" to \"script\".\n+ py_module = py_script\n \n rv.extend((\"-m\", py_module.lstrip(\".\")))\n", "issue": "Reloader picks wrong module when Flask is run with the pydev debugger\nThis is a weird situation where the pallets/werkzeug#1416 fix to make `python -m` reloading more correct actually exposed an issue with PyDev. It rewrites `python -m flask` to `python flask` (which is clearly not correct), while Python itself rewrites it to `python /path/to/flask_entry_point.py`. Werkzeug still correctly detects that we were run as a module, but since `sys.argv[0]` is no longer a path but the module name, it incorrectly decides that there is a module named `flask.flask` in the current directory.\r\n\r\n_Originally posted by @davidism in https://github.com/pallets/flask/issues/3297#issuecomment-510120836_\n", "before_files": [{"content": "import os\nimport subprocess\nimport sys\nimport threading\nimport time\nfrom itertools import chain\n\nfrom ._compat import iteritems\nfrom ._compat import PY2\nfrom ._compat import text_type\nfrom ._internal import _log\n\n\ndef _iter_module_files():\n \"\"\"This iterates over all relevant Python files. It goes through all\n loaded files from modules, all files in folders of already loaded modules\n as well as all files reachable through a package.\n \"\"\"\n # The list call is necessary on Python 3 in case the module\n # dictionary modifies during iteration.\n for module in list(sys.modules.values()):\n if module is None:\n continue\n filename = getattr(module, \"__file__\", None)\n if filename:\n if os.path.isdir(filename) and os.path.exists(\n os.path.join(filename, \"__init__.py\")\n ):\n filename = os.path.join(filename, \"__init__.py\")\n\n old = None\n while not os.path.isfile(filename):\n old = filename\n filename = os.path.dirname(filename)\n if filename == old:\n break\n else:\n if filename[-4:] in (\".pyc\", \".pyo\"):\n filename = filename[:-1]\n yield filename\n\n\ndef _find_observable_paths(extra_files=None):\n \"\"\"Finds all paths that should be observed.\"\"\"\n rv = set(\n os.path.dirname(os.path.abspath(x)) if os.path.isfile(x) else os.path.abspath(x)\n for x in sys.path\n )\n\n for filename in extra_files or ():\n rv.add(os.path.dirname(os.path.abspath(filename)))\n\n for module in list(sys.modules.values()):\n fn = getattr(module, \"__file__\", None)\n if fn is None:\n continue\n fn = os.path.abspath(fn)\n rv.add(os.path.dirname(fn))\n\n return _find_common_roots(rv)\n\n\ndef _get_args_for_reloading():\n \"\"\"Returns the executable. This contains a workaround for windows\n if the executable is incorrectly reported to not have the .exe\n extension which can cause bugs on reloading. This also contains\n a workaround for linux where the file is executable (possibly with\n a program other than python)\n \"\"\"\n rv = [sys.executable]\n py_script = os.path.abspath(sys.argv[0])\n args = sys.argv[1:]\n # Need to look at main module to determine how it was executed.\n __main__ = sys.modules[\"__main__\"]\n\n if __main__.__package__ is None:\n # Executed a file, like \"python app.py\".\n if os.name == \"nt\":\n # Windows entry points have \".exe\" extension and should be\n # called directly.\n if not os.path.exists(py_script) and os.path.exists(py_script + \".exe\"):\n py_script += \".exe\"\n\n if (\n os.path.splitext(rv[0])[1] == \".exe\"\n and os.path.splitext(py_script)[1] == \".exe\"\n ):\n rv.pop(0)\n\n elif os.path.isfile(py_script) and os.access(py_script, os.X_OK):\n # The file is marked as executable. Nix adds a wrapper that\n # shouldn't be called with the Python executable.\n rv.pop(0)\n\n rv.append(py_script)\n else:\n # Executed a module, like \"python -m werkzeug.serving\".\n if sys.argv[0] == \"-m\":\n # Flask works around previous behavior by putting\n # \"-m flask\" in sys.argv.\n # TODO remove this once Flask no longer misbehaves\n args = sys.argv\n else:\n py_module = __main__.__package__\n name = os.path.splitext(os.path.basename(py_script))[0]\n\n if name != \"__main__\":\n py_module += \".\" + name\n\n rv.extend((\"-m\", py_module.lstrip(\".\")))\n\n rv.extend(args)\n return rv\n\n\ndef _find_common_roots(paths):\n \"\"\"Out of some paths it finds the common roots that need monitoring.\"\"\"\n paths = [x.split(os.path.sep) for x in paths]\n root = {}\n for chunks in sorted(paths, key=len, reverse=True):\n node = root\n for chunk in chunks:\n node = node.setdefault(chunk, {})\n node.clear()\n\n rv = set()\n\n def _walk(node, path):\n for prefix, child in iteritems(node):\n _walk(child, path + (prefix,))\n if not node:\n rv.add(\"/\".join(path))\n\n _walk(root, ())\n return rv\n\n\nclass ReloaderLoop(object):\n name = None\n\n # monkeypatched by testsuite. wrapping with `staticmethod` is required in\n # case time.sleep has been replaced by a non-c function (e.g. by\n # `eventlet.monkey_patch`) before we get here\n _sleep = staticmethod(time.sleep)\n\n def __init__(self, extra_files=None, interval=1):\n self.extra_files = set(os.path.abspath(x) for x in extra_files or ())\n self.interval = interval\n\n def run(self):\n pass\n\n def restart_with_reloader(self):\n \"\"\"Spawn a new Python interpreter with the same arguments as this one,\n but running the reloader thread.\n \"\"\"\n while 1:\n _log(\"info\", \" * Restarting with %s\" % self.name)\n args = _get_args_for_reloading()\n\n # a weird bug on windows. sometimes unicode strings end up in the\n # environment and subprocess.call does not like this, encode them\n # to latin1 and continue.\n if os.name == \"nt\" and PY2:\n new_environ = {}\n for key, value in iteritems(os.environ):\n if isinstance(key, text_type):\n key = key.encode(\"iso-8859-1\")\n if isinstance(value, text_type):\n value = value.encode(\"iso-8859-1\")\n new_environ[key] = value\n else:\n new_environ = os.environ.copy()\n\n new_environ[\"WERKZEUG_RUN_MAIN\"] = \"true\"\n exit_code = subprocess.call(args, env=new_environ, close_fds=False)\n if exit_code != 3:\n return exit_code\n\n def trigger_reload(self, filename):\n self.log_reload(filename)\n sys.exit(3)\n\n def log_reload(self, filename):\n filename = os.path.abspath(filename)\n _log(\"info\", \" * Detected change in %r, reloading\" % filename)\n\n\nclass StatReloaderLoop(ReloaderLoop):\n name = \"stat\"\n\n def run(self):\n mtimes = {}\n while 1:\n for filename in chain(_iter_module_files(), self.extra_files):\n try:\n mtime = os.stat(filename).st_mtime\n except OSError:\n continue\n\n old_time = mtimes.get(filename)\n if old_time is None:\n mtimes[filename] = mtime\n continue\n elif mtime > old_time:\n self.trigger_reload(filename)\n self._sleep(self.interval)\n\n\nclass WatchdogReloaderLoop(ReloaderLoop):\n def __init__(self, *args, **kwargs):\n ReloaderLoop.__init__(self, *args, **kwargs)\n from watchdog.observers import Observer\n from watchdog.events import FileSystemEventHandler\n\n self.observable_paths = set()\n\n def _check_modification(filename):\n if filename in self.extra_files:\n self.trigger_reload(filename)\n dirname = os.path.dirname(filename)\n if dirname.startswith(tuple(self.observable_paths)):\n if filename.endswith((\".pyc\", \".pyo\", \".py\")):\n self.trigger_reload(filename)\n\n class _CustomHandler(FileSystemEventHandler):\n def on_created(self, event):\n _check_modification(event.src_path)\n\n def on_modified(self, event):\n _check_modification(event.src_path)\n\n def on_moved(self, event):\n _check_modification(event.src_path)\n _check_modification(event.dest_path)\n\n def on_deleted(self, event):\n _check_modification(event.src_path)\n\n reloader_name = Observer.__name__.lower()\n if reloader_name.endswith(\"observer\"):\n reloader_name = reloader_name[:-8]\n reloader_name += \" reloader\"\n\n self.name = reloader_name\n\n self.observer_class = Observer\n self.event_handler = _CustomHandler()\n self.should_reload = False\n\n def trigger_reload(self, filename):\n # This is called inside an event handler, which means throwing\n # SystemExit has no effect.\n # https://github.com/gorakhargosh/watchdog/issues/294\n self.should_reload = True\n self.log_reload(filename)\n\n def run(self):\n watches = {}\n observer = self.observer_class()\n observer.start()\n\n try:\n while not self.should_reload:\n to_delete = set(watches)\n paths = _find_observable_paths(self.extra_files)\n for path in paths:\n if path not in watches:\n try:\n watches[path] = observer.schedule(\n self.event_handler, path, recursive=True\n )\n except OSError:\n # Clear this path from list of watches We don't want\n # the same error message showing again in the next\n # iteration.\n watches[path] = None\n to_delete.discard(path)\n for path in to_delete:\n watch = watches.pop(path, None)\n if watch is not None:\n observer.unschedule(watch)\n self.observable_paths = paths\n self._sleep(self.interval)\n finally:\n observer.stop()\n observer.join()\n\n sys.exit(3)\n\n\nreloader_loops = {\"stat\": StatReloaderLoop, \"watchdog\": WatchdogReloaderLoop}\n\ntry:\n __import__(\"watchdog.observers\")\nexcept ImportError:\n reloader_loops[\"auto\"] = reloader_loops[\"stat\"]\nelse:\n reloader_loops[\"auto\"] = reloader_loops[\"watchdog\"]\n\n\ndef ensure_echo_on():\n \"\"\"Ensure that echo mode is enabled. Some tools such as PDB disable\n it which causes usability issues after reload.\"\"\"\n # tcgetattr will fail if stdin isn't a tty\n if not sys.stdin.isatty():\n return\n try:\n import termios\n except ImportError:\n return\n attributes = termios.tcgetattr(sys.stdin)\n if not attributes[3] & termios.ECHO:\n attributes[3] |= termios.ECHO\n termios.tcsetattr(sys.stdin, termios.TCSANOW, attributes)\n\n\ndef run_with_reloader(main_func, extra_files=None, interval=1, reloader_type=\"auto\"):\n \"\"\"Run the given function in an independent python interpreter.\"\"\"\n import signal\n\n reloader = reloader_loops[reloader_type](extra_files, interval)\n signal.signal(signal.SIGTERM, lambda *args: sys.exit(0))\n try:\n if os.environ.get(\"WERKZEUG_RUN_MAIN\") == \"true\":\n ensure_echo_on()\n t = threading.Thread(target=main_func, args=())\n t.setDaemon(True)\n t.start()\n reloader.run()\n else:\n sys.exit(reloader.restart_with_reloader())\n except KeyboardInterrupt:\n pass\n", "path": "src/werkzeug/_reloader.py"}]} | 4,048 | 392 |
gh_patches_debug_16875 | rasdani/github-patches | git_diff | getsentry__sentry-python-2105 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
AttributeError: 'async_generator_athrow' object has no attribute '__qualname__'
### How do you use Sentry?
Sentry Saas (sentry.io)
### Version
1.19.1
### Steps to Reproduce
I'm trying to use the `asyncio` integration like this:
```python
sentry_sdk.init(dsn=os.environ.get("SENTRY_DSN"), traces_sample_rate=0.1, integrations=[AsyncioIntegration()])
```
I keep on getting a traceback that seems to be a Sentry-specific issue.
### Expected Result
No tracebacks repeatedly occur
### Actual Result
I see this traceback repeatedly printed in the logs:
```python
Task exception was never retrieved
future: <Task finished name='Task-1512' coro=<patch_asyncio.<locals>._sentry_task_factory.<locals>._coro_creating_hub_and_span() done, defined at /usr/local/lib/python3.9/site-packages/sentry_sdk/integrations/asyncio.py:34> exception=AttributeError("'async_generator_athrow' object has no attribute '__qualname__'")>
Traceback (most recent call last):
File "/usr/local/lib/python3.9/site-packages/sentry_sdk/integrations/asyncio.py", line 40, in _coro_creating_hub_and_span
with hub.start_span(op=OP.FUNCTION, description=coro.__qualname__):
AttributeError: 'async_generator_athrow' object has no attribute '__qualname__'
```
</issue>
<code>
[start of sentry_sdk/integrations/asyncio.py]
1 from __future__ import absolute_import
2 import sys
3
4 from sentry_sdk._compat import reraise
5 from sentry_sdk.consts import OP
6 from sentry_sdk.hub import Hub
7 from sentry_sdk.integrations import Integration, DidNotEnable
8 from sentry_sdk._types import TYPE_CHECKING
9 from sentry_sdk.utils import event_from_exception
10
11 try:
12 import asyncio
13 from asyncio.tasks import Task
14 except ImportError:
15 raise DidNotEnable("asyncio not available")
16
17
18 if TYPE_CHECKING:
19 from typing import Any
20
21 from sentry_sdk._types import ExcInfo
22
23
24 def patch_asyncio():
25 # type: () -> None
26 orig_task_factory = None
27 try:
28 loop = asyncio.get_running_loop()
29 orig_task_factory = loop.get_task_factory()
30
31 def _sentry_task_factory(loop, coro):
32 # type: (Any, Any) -> Any
33
34 async def _coro_creating_hub_and_span():
35 # type: () -> Any
36 hub = Hub(Hub.current)
37 result = None
38
39 with hub:
40 with hub.start_span(op=OP.FUNCTION, description=coro.__qualname__):
41 try:
42 result = await coro
43 except Exception:
44 reraise(*_capture_exception(hub))
45
46 return result
47
48 # Trying to use user set task factory (if there is one)
49 if orig_task_factory:
50 return orig_task_factory(loop, _coro_creating_hub_and_span())
51
52 # The default task factory in `asyncio` does not have its own function
53 # but is just a couple of lines in `asyncio.base_events.create_task()`
54 # Those lines are copied here.
55
56 # WARNING:
57 # If the default behavior of the task creation in asyncio changes,
58 # this will break!
59 task = Task(_coro_creating_hub_and_span(), loop=loop)
60 if task._source_traceback: # type: ignore
61 del task._source_traceback[-1] # type: ignore
62
63 return task
64
65 loop.set_task_factory(_sentry_task_factory)
66 except RuntimeError:
67 # When there is no running loop, we have nothing to patch.
68 pass
69
70
71 def _capture_exception(hub):
72 # type: (Hub) -> ExcInfo
73 exc_info = sys.exc_info()
74
75 integration = hub.get_integration(AsyncioIntegration)
76 if integration is not None:
77 # If an integration is there, a client has to be there.
78 client = hub.client # type: Any
79
80 event, hint = event_from_exception(
81 exc_info,
82 client_options=client.options,
83 mechanism={"type": "asyncio", "handled": False},
84 )
85 hub.capture_event(event, hint=hint)
86
87 return exc_info
88
89
90 class AsyncioIntegration(Integration):
91 identifier = "asyncio"
92
93 @staticmethod
94 def setup_once():
95 # type: () -> None
96 patch_asyncio()
97
[end of sentry_sdk/integrations/asyncio.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/sentry_sdk/integrations/asyncio.py b/sentry_sdk/integrations/asyncio.py
--- a/sentry_sdk/integrations/asyncio.py
+++ b/sentry_sdk/integrations/asyncio.py
@@ -21,6 +21,15 @@
from sentry_sdk._types import ExcInfo
+def get_name(coro):
+ # type: (Any) -> str
+ return (
+ getattr(coro, "__qualname__", None)
+ or getattr(coro, "__name__", None)
+ or "coroutine without __name__"
+ )
+
+
def patch_asyncio():
# type: () -> None
orig_task_factory = None
@@ -37,7 +46,7 @@
result = None
with hub:
- with hub.start_span(op=OP.FUNCTION, description=coro.__qualname__):
+ with hub.start_span(op=OP.FUNCTION, description=get_name(coro)):
try:
result = await coro
except Exception:
| {"golden_diff": "diff --git a/sentry_sdk/integrations/asyncio.py b/sentry_sdk/integrations/asyncio.py\n--- a/sentry_sdk/integrations/asyncio.py\n+++ b/sentry_sdk/integrations/asyncio.py\n@@ -21,6 +21,15 @@\n from sentry_sdk._types import ExcInfo\n \n \n+def get_name(coro):\n+ # type: (Any) -> str\n+ return (\n+ getattr(coro, \"__qualname__\", None)\n+ or getattr(coro, \"__name__\", None)\n+ or \"coroutine without __name__\"\n+ )\n+\n+\n def patch_asyncio():\n # type: () -> None\n orig_task_factory = None\n@@ -37,7 +46,7 @@\n result = None\n \n with hub:\n- with hub.start_span(op=OP.FUNCTION, description=coro.__qualname__):\n+ with hub.start_span(op=OP.FUNCTION, description=get_name(coro)):\n try:\n result = await coro\n except Exception:\n", "issue": "AttributeError: 'async_generator_athrow' object has no attribute '__qualname__'\n### How do you use Sentry?\r\n\r\nSentry Saas (sentry.io)\r\n\r\n### Version\r\n\r\n1.19.1\r\n\r\n### Steps to Reproduce\r\n\r\nI'm trying to use the `asyncio` integration like this:\r\n\r\n```python\r\nsentry_sdk.init(dsn=os.environ.get(\"SENTRY_DSN\"), traces_sample_rate=0.1, integrations=[AsyncioIntegration()])\r\n```\r\n\r\nI keep on getting a traceback that seems to be a Sentry-specific issue.\r\n\r\n### Expected Result\r\n\r\nNo tracebacks repeatedly occur\r\n\r\n### Actual Result\r\n\r\nI see this traceback repeatedly printed in the logs:\r\n\r\n```python\r\nTask exception was never retrieved\r\nfuture: <Task finished name='Task-1512' coro=<patch_asyncio.<locals>._sentry_task_factory.<locals>._coro_creating_hub_and_span() done, defined at /usr/local/lib/python3.9/site-packages/sentry_sdk/integrations/asyncio.py:34> exception=AttributeError(\"'async_generator_athrow' object has no attribute '__qualname__'\")>\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.9/site-packages/sentry_sdk/integrations/asyncio.py\", line 40, in _coro_creating_hub_and_span\r\n with hub.start_span(op=OP.FUNCTION, description=coro.__qualname__):\r\nAttributeError: 'async_generator_athrow' object has no attribute '__qualname__'\r\n```\n", "before_files": [{"content": "from __future__ import absolute_import\nimport sys\n\nfrom sentry_sdk._compat import reraise\nfrom sentry_sdk.consts import OP\nfrom sentry_sdk.hub import Hub\nfrom sentry_sdk.integrations import Integration, DidNotEnable\nfrom sentry_sdk._types import TYPE_CHECKING\nfrom sentry_sdk.utils import event_from_exception\n\ntry:\n import asyncio\n from asyncio.tasks import Task\nexcept ImportError:\n raise DidNotEnable(\"asyncio not available\")\n\n\nif TYPE_CHECKING:\n from typing import Any\n\n from sentry_sdk._types import ExcInfo\n\n\ndef patch_asyncio():\n # type: () -> None\n orig_task_factory = None\n try:\n loop = asyncio.get_running_loop()\n orig_task_factory = loop.get_task_factory()\n\n def _sentry_task_factory(loop, coro):\n # type: (Any, Any) -> Any\n\n async def _coro_creating_hub_and_span():\n # type: () -> Any\n hub = Hub(Hub.current)\n result = None\n\n with hub:\n with hub.start_span(op=OP.FUNCTION, description=coro.__qualname__):\n try:\n result = await coro\n except Exception:\n reraise(*_capture_exception(hub))\n\n return result\n\n # Trying to use user set task factory (if there is one)\n if orig_task_factory:\n return orig_task_factory(loop, _coro_creating_hub_and_span())\n\n # The default task factory in `asyncio` does not have its own function\n # but is just a couple of lines in `asyncio.base_events.create_task()`\n # Those lines are copied here.\n\n # WARNING:\n # If the default behavior of the task creation in asyncio changes,\n # this will break!\n task = Task(_coro_creating_hub_and_span(), loop=loop)\n if task._source_traceback: # type: ignore\n del task._source_traceback[-1] # type: ignore\n\n return task\n\n loop.set_task_factory(_sentry_task_factory)\n except RuntimeError:\n # When there is no running loop, we have nothing to patch.\n pass\n\n\ndef _capture_exception(hub):\n # type: (Hub) -> ExcInfo\n exc_info = sys.exc_info()\n\n integration = hub.get_integration(AsyncioIntegration)\n if integration is not None:\n # If an integration is there, a client has to be there.\n client = hub.client # type: Any\n\n event, hint = event_from_exception(\n exc_info,\n client_options=client.options,\n mechanism={\"type\": \"asyncio\", \"handled\": False},\n )\n hub.capture_event(event, hint=hint)\n\n return exc_info\n\n\nclass AsyncioIntegration(Integration):\n identifier = \"asyncio\"\n\n @staticmethod\n def setup_once():\n # type: () -> None\n patch_asyncio()\n", "path": "sentry_sdk/integrations/asyncio.py"}]} | 1,703 | 235 |
gh_patches_debug_33915 | rasdani/github-patches | git_diff | iterative__dvc-8209 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`data status`: update cli hints
What I'd suggest here is to change the hint in "not in cache" to always use `fetch` (maybe some specialization for no cache with `dvc pull`), and then for uncommitted changes, we can show two hints like how git does:
```console
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
```
```console
(use "dvc commit <file>..." to track changes)
(use "dvc checkout <file>..." to restore changes)
```
There are some questionable behaviours in checkout, so it may not always work without `--force`, but that should be fixed separately, and in checkout itself.
_Originally posted by @skshetry in https://github.com/iterative/dvc/issues/8170#issuecomment-1227310120_
</issue>
<code>
[start of dvc/commands/data.py]
1 import argparse
2 import logging
3 from typing import TYPE_CHECKING
4
5 from funcy import chunks, compact, log_durations
6
7 from dvc.cli.command import CmdBase
8 from dvc.cli.utils import append_doc_link, fix_subparsers
9 from dvc.ui import ui
10 from dvc.utils import colorize
11
12 if TYPE_CHECKING:
13 from dvc.repo.data import Status as DataStatus
14
15
16 logger = logging.getLogger(__name__)
17
18
19 class CmdDataStatus(CmdBase):
20 COLORS = {
21 "not_in_cache": "red",
22 "committed": "green",
23 "uncommitted": "yellow",
24 "untracked": "cyan",
25 }
26 LABELS = {
27 "not_in_cache": "Not in cache",
28 "committed": "DVC committed changes",
29 "uncommitted": "DVC uncommitted changes",
30 "untracked": "Untracked files",
31 "unchanged": "DVC unchanged files",
32 }
33 HINTS = {
34 "not_in_cache": 'use "dvc pull <file>..." to download files',
35 "committed": "git commit the corresponding dvc files "
36 "to update the repo",
37 "uncommitted": 'use "dvc commit <file>..." to track changes',
38 "untracked": 'use "git add <file> ..." or '
39 'dvc add <file>..." to commit to git or to dvc',
40 "git_dirty": "there are {}changes not tracked by dvc, "
41 'use "git status" to see',
42 }
43
44 @staticmethod
45 def _process_status(status: "DataStatus"):
46 """Flatten stage status, and filter empty stage status contents."""
47 for stage, stage_status in status.items():
48 items = stage_status
49 if isinstance(stage_status, dict):
50 items = {
51 file: state
52 for state, files in stage_status.items()
53 for file in files
54 }
55 if not items:
56 continue
57 yield stage, items
58
59 @classmethod
60 def _show_status(cls, status: "DataStatus") -> int:
61 git_info = status.pop("git") # type: ignore[misc]
62 result = dict(cls._process_status(status))
63 if not result:
64 no_changes = "No changes"
65 if git_info.get("is_empty", False):
66 no_changes += " in an empty git repo"
67 ui.write(f"{no_changes}.")
68
69 for idx, (stage, stage_status) in enumerate(result.items()):
70 if idx:
71 ui.write()
72
73 label = cls.LABELS.get(stage, stage.capitalize() + " files")
74 header = f"{label}:"
75 color = cls.COLORS.get(stage, None)
76
77 ui.write(header)
78 if hint := cls.HINTS.get(stage):
79 ui.write(f" ({hint})")
80
81 if isinstance(stage_status, dict):
82 items = [
83 ": ".join([state, file])
84 for file, state in stage_status.items()
85 ]
86 else:
87 items = stage_status
88
89 tabs = "\t".expandtabs(8)
90 for chunk in chunks(1000, items):
91 out = "\n".join(tabs + item for item in chunk)
92 ui.write(colorize(out, color))
93
94 if (hint := cls.HINTS.get("git_dirty")) and git_info.get("is_dirty"):
95 message = hint.format("other " if result else "")
96 ui.write(f"[blue]({message})[/]", styled=True)
97 return 0
98
99 def run(self) -> int:
100 with log_durations(logger.trace, "in data_status"): # type: ignore
101 status = self.repo.data_status(
102 granular=self.args.granular,
103 untracked_files=self.args.untracked_files,
104 )
105
106 if not self.args.unchanged:
107 status.pop("unchanged") # type: ignore[misc]
108 if self.args.untracked_files == "no":
109 status.pop("untracked")
110 if self.args.json:
111 status.pop("git") # type: ignore[misc]
112 ui.write_json(compact(status))
113 return 0
114 return self._show_status(status)
115
116
117 def add_parser(subparsers, parent_parser):
118 data_parser = subparsers.add_parser(
119 "data",
120 parents=[parent_parser],
121 formatter_class=argparse.RawDescriptionHelpFormatter,
122 )
123 data_subparsers = data_parser.add_subparsers(
124 dest="cmd",
125 help="Use `dvc data CMD --help` to display command-specific help.",
126 )
127 fix_subparsers(data_subparsers)
128
129 DATA_STATUS_HELP = (
130 "Show changes between the last git commit, "
131 "the dvcfiles and the workspace."
132 )
133 data_status_parser = data_subparsers.add_parser(
134 "status",
135 parents=[parent_parser],
136 description=append_doc_link(DATA_STATUS_HELP, "data/status"),
137 formatter_class=argparse.RawDescriptionHelpFormatter,
138 help=DATA_STATUS_HELP,
139 )
140 data_status_parser.add_argument(
141 "--json",
142 action="store_true",
143 default=False,
144 help="Show output in JSON format.",
145 )
146 data_status_parser.add_argument(
147 "--show-json",
148 action="store_true",
149 default=False,
150 dest="json",
151 help=argparse.SUPPRESS,
152 )
153 data_status_parser.add_argument(
154 "--granular",
155 action="store_true",
156 default=False,
157 help="Show granular file-level info for DVC-tracked directories.",
158 )
159 data_status_parser.add_argument(
160 "--unchanged",
161 action="store_true",
162 default=False,
163 help="Show unmodified DVC-tracked files.",
164 )
165 data_status_parser.add_argument(
166 "--untracked-files",
167 choices=["no", "all"],
168 default="no",
169 const="all",
170 nargs="?",
171 help="Show untracked files.",
172 )
173 data_status_parser.set_defaults(func=CmdDataStatus)
174
[end of dvc/commands/data.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/dvc/commands/data.py b/dvc/commands/data.py
--- a/dvc/commands/data.py
+++ b/dvc/commands/data.py
@@ -31,14 +31,22 @@
"unchanged": "DVC unchanged files",
}
HINTS = {
- "not_in_cache": 'use "dvc pull <file>..." to download files',
- "committed": "git commit the corresponding dvc files "
- "to update the repo",
- "uncommitted": 'use "dvc commit <file>..." to track changes',
- "untracked": 'use "git add <file> ..." or '
- 'dvc add <file>..." to commit to git or to dvc',
- "git_dirty": "there are {}changes not tracked by dvc, "
- 'use "git status" to see',
+ "not_in_cache": ('use "dvc fetch <file>..." to download files',),
+ "committed": (
+ "git commit the corresponding dvc files to update the repo",
+ ),
+ "uncommitted": (
+ 'use "dvc commit <file>..." to track changes',
+ 'use "dvc checkout <file>..." to discard changes',
+ ),
+ "untracked": (
+ 'use "git add <file> ..." or '
+ 'dvc add <file>..." to commit to git or to dvc',
+ ),
+ "git_dirty": (
+ "there are {}changes not tracked by dvc, "
+ 'use "git status" to see',
+ ),
}
@staticmethod
@@ -75,8 +83,9 @@
color = cls.COLORS.get(stage, None)
ui.write(header)
- if hint := cls.HINTS.get(stage):
- ui.write(f" ({hint})")
+ if hints := cls.HINTS.get(stage):
+ for hint in hints:
+ ui.write(f" ({hint})")
if isinstance(stage_status, dict):
items = [
@@ -91,9 +100,10 @@
out = "\n".join(tabs + item for item in chunk)
ui.write(colorize(out, color))
- if (hint := cls.HINTS.get("git_dirty")) and git_info.get("is_dirty"):
- message = hint.format("other " if result else "")
- ui.write(f"[blue]({message})[/]", styled=True)
+ if (hints := cls.HINTS.get("git_dirty")) and git_info.get("is_dirty"):
+ for hint in hints:
+ message = hint.format("other " if result else "")
+ ui.write(f"[blue]({message})[/]", styled=True)
return 0
def run(self) -> int:
| {"golden_diff": "diff --git a/dvc/commands/data.py b/dvc/commands/data.py\n--- a/dvc/commands/data.py\n+++ b/dvc/commands/data.py\n@@ -31,14 +31,22 @@\n \"unchanged\": \"DVC unchanged files\",\n }\n HINTS = {\n- \"not_in_cache\": 'use \"dvc pull <file>...\" to download files',\n- \"committed\": \"git commit the corresponding dvc files \"\n- \"to update the repo\",\n- \"uncommitted\": 'use \"dvc commit <file>...\" to track changes',\n- \"untracked\": 'use \"git add <file> ...\" or '\n- 'dvc add <file>...\" to commit to git or to dvc',\n- \"git_dirty\": \"there are {}changes not tracked by dvc, \"\n- 'use \"git status\" to see',\n+ \"not_in_cache\": ('use \"dvc fetch <file>...\" to download files',),\n+ \"committed\": (\n+ \"git commit the corresponding dvc files to update the repo\",\n+ ),\n+ \"uncommitted\": (\n+ 'use \"dvc commit <file>...\" to track changes',\n+ 'use \"dvc checkout <file>...\" to discard changes',\n+ ),\n+ \"untracked\": (\n+ 'use \"git add <file> ...\" or '\n+ 'dvc add <file>...\" to commit to git or to dvc',\n+ ),\n+ \"git_dirty\": (\n+ \"there are {}changes not tracked by dvc, \"\n+ 'use \"git status\" to see',\n+ ),\n }\n \n @staticmethod\n@@ -75,8 +83,9 @@\n color = cls.COLORS.get(stage, None)\n \n ui.write(header)\n- if hint := cls.HINTS.get(stage):\n- ui.write(f\" ({hint})\")\n+ if hints := cls.HINTS.get(stage):\n+ for hint in hints:\n+ ui.write(f\" ({hint})\")\n \n if isinstance(stage_status, dict):\n items = [\n@@ -91,9 +100,10 @@\n out = \"\\n\".join(tabs + item for item in chunk)\n ui.write(colorize(out, color))\n \n- if (hint := cls.HINTS.get(\"git_dirty\")) and git_info.get(\"is_dirty\"):\n- message = hint.format(\"other \" if result else \"\")\n- ui.write(f\"[blue]({message})[/]\", styled=True)\n+ if (hints := cls.HINTS.get(\"git_dirty\")) and git_info.get(\"is_dirty\"):\n+ for hint in hints:\n+ message = hint.format(\"other \" if result else \"\")\n+ ui.write(f\"[blue]({message})[/]\", styled=True)\n return 0\n \n def run(self) -> int:\n", "issue": "`data status`: update cli hints\nWhat I'd suggest here is to change the hint in \"not in cache\" to always use `fetch` (maybe some specialization for no cache with `dvc pull`), and then for uncommitted changes, we can show two hints like how git does:\r\n\r\n```console\r\n (use \"git add <file>...\" to update what will be committed)\r\n (use \"git restore <file>...\" to discard changes in working directory)\r\n```\r\n```console\r\n (use \"dvc commit <file>...\" to track changes)\r\n (use \"dvc checkout <file>...\" to restore changes)\r\n```\r\n\r\nThere are some questionable behaviours in checkout, so it may not always work without `--force`, but that should be fixed separately, and in checkout itself.\r\n\r\n_Originally posted by @skshetry in https://github.com/iterative/dvc/issues/8170#issuecomment-1227310120_\n", "before_files": [{"content": "import argparse\nimport logging\nfrom typing import TYPE_CHECKING\n\nfrom funcy import chunks, compact, log_durations\n\nfrom dvc.cli.command import CmdBase\nfrom dvc.cli.utils import append_doc_link, fix_subparsers\nfrom dvc.ui import ui\nfrom dvc.utils import colorize\n\nif TYPE_CHECKING:\n from dvc.repo.data import Status as DataStatus\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass CmdDataStatus(CmdBase):\n COLORS = {\n \"not_in_cache\": \"red\",\n \"committed\": \"green\",\n \"uncommitted\": \"yellow\",\n \"untracked\": \"cyan\",\n }\n LABELS = {\n \"not_in_cache\": \"Not in cache\",\n \"committed\": \"DVC committed changes\",\n \"uncommitted\": \"DVC uncommitted changes\",\n \"untracked\": \"Untracked files\",\n \"unchanged\": \"DVC unchanged files\",\n }\n HINTS = {\n \"not_in_cache\": 'use \"dvc pull <file>...\" to download files',\n \"committed\": \"git commit the corresponding dvc files \"\n \"to update the repo\",\n \"uncommitted\": 'use \"dvc commit <file>...\" to track changes',\n \"untracked\": 'use \"git add <file> ...\" or '\n 'dvc add <file>...\" to commit to git or to dvc',\n \"git_dirty\": \"there are {}changes not tracked by dvc, \"\n 'use \"git status\" to see',\n }\n\n @staticmethod\n def _process_status(status: \"DataStatus\"):\n \"\"\"Flatten stage status, and filter empty stage status contents.\"\"\"\n for stage, stage_status in status.items():\n items = stage_status\n if isinstance(stage_status, dict):\n items = {\n file: state\n for state, files in stage_status.items()\n for file in files\n }\n if not items:\n continue\n yield stage, items\n\n @classmethod\n def _show_status(cls, status: \"DataStatus\") -> int:\n git_info = status.pop(\"git\") # type: ignore[misc]\n result = dict(cls._process_status(status))\n if not result:\n no_changes = \"No changes\"\n if git_info.get(\"is_empty\", False):\n no_changes += \" in an empty git repo\"\n ui.write(f\"{no_changes}.\")\n\n for idx, (stage, stage_status) in enumerate(result.items()):\n if idx:\n ui.write()\n\n label = cls.LABELS.get(stage, stage.capitalize() + \" files\")\n header = f\"{label}:\"\n color = cls.COLORS.get(stage, None)\n\n ui.write(header)\n if hint := cls.HINTS.get(stage):\n ui.write(f\" ({hint})\")\n\n if isinstance(stage_status, dict):\n items = [\n \": \".join([state, file])\n for file, state in stage_status.items()\n ]\n else:\n items = stage_status\n\n tabs = \"\\t\".expandtabs(8)\n for chunk in chunks(1000, items):\n out = \"\\n\".join(tabs + item for item in chunk)\n ui.write(colorize(out, color))\n\n if (hint := cls.HINTS.get(\"git_dirty\")) and git_info.get(\"is_dirty\"):\n message = hint.format(\"other \" if result else \"\")\n ui.write(f\"[blue]({message})[/]\", styled=True)\n return 0\n\n def run(self) -> int:\n with log_durations(logger.trace, \"in data_status\"): # type: ignore\n status = self.repo.data_status(\n granular=self.args.granular,\n untracked_files=self.args.untracked_files,\n )\n\n if not self.args.unchanged:\n status.pop(\"unchanged\") # type: ignore[misc]\n if self.args.untracked_files == \"no\":\n status.pop(\"untracked\")\n if self.args.json:\n status.pop(\"git\") # type: ignore[misc]\n ui.write_json(compact(status))\n return 0\n return self._show_status(status)\n\n\ndef add_parser(subparsers, parent_parser):\n data_parser = subparsers.add_parser(\n \"data\",\n parents=[parent_parser],\n formatter_class=argparse.RawDescriptionHelpFormatter,\n )\n data_subparsers = data_parser.add_subparsers(\n dest=\"cmd\",\n help=\"Use `dvc data CMD --help` to display command-specific help.\",\n )\n fix_subparsers(data_subparsers)\n\n DATA_STATUS_HELP = (\n \"Show changes between the last git commit, \"\n \"the dvcfiles and the workspace.\"\n )\n data_status_parser = data_subparsers.add_parser(\n \"status\",\n parents=[parent_parser],\n description=append_doc_link(DATA_STATUS_HELP, \"data/status\"),\n formatter_class=argparse.RawDescriptionHelpFormatter,\n help=DATA_STATUS_HELP,\n )\n data_status_parser.add_argument(\n \"--json\",\n action=\"store_true\",\n default=False,\n help=\"Show output in JSON format.\",\n )\n data_status_parser.add_argument(\n \"--show-json\",\n action=\"store_true\",\n default=False,\n dest=\"json\",\n help=argparse.SUPPRESS,\n )\n data_status_parser.add_argument(\n \"--granular\",\n action=\"store_true\",\n default=False,\n help=\"Show granular file-level info for DVC-tracked directories.\",\n )\n data_status_parser.add_argument(\n \"--unchanged\",\n action=\"store_true\",\n default=False,\n help=\"Show unmodified DVC-tracked files.\",\n )\n data_status_parser.add_argument(\n \"--untracked-files\",\n choices=[\"no\", \"all\"],\n default=\"no\",\n const=\"all\",\n nargs=\"?\",\n help=\"Show untracked files.\",\n )\n data_status_parser.set_defaults(func=CmdDataStatus)\n", "path": "dvc/commands/data.py"}]} | 2,421 | 628 |
gh_patches_debug_8350 | rasdani/github-patches | git_diff | getsentry__sentry-5984 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Auto assign should occur as actor
When using 'Fixes XXX' annotation in a commit, I noticed that while Sentry auto assigned to me (expected), it did so on behalf of itself instead of my user.

</issue>
<code>
[start of src/sentry/receivers/releases.py]
1 from __future__ import absolute_import, print_function
2
3 from django.db import IntegrityError, transaction
4 from django.db.models.signals import post_save
5
6 from sentry.models import (
7 Activity, Commit, GroupAssignee, GroupCommitResolution, Release, TagValue
8 )
9 from sentry.tasks.clear_expired_resolutions import clear_expired_resolutions
10
11
12 def ensure_release_exists(instance, created, **kwargs):
13 if instance.key != 'sentry:release':
14 return
15
16 if instance.data and instance.data.get('release_id'):
17 return
18
19 try:
20 with transaction.atomic():
21 release = Release.objects.create(
22 organization_id=instance.project.organization_id,
23 version=instance.value,
24 date_added=instance.first_seen,
25 )
26 except IntegrityError:
27 release = Release.objects.get(
28 organization_id=instance.project.organization_id,
29 version=instance.value,
30 )
31 release.update(date_added=instance.first_seen)
32 else:
33 instance.update(data={'release_id': release.id})
34
35 release.add_project(instance.project)
36
37
38 def resolve_group_resolutions(instance, created, **kwargs):
39 if not created:
40 return
41
42 clear_expired_resolutions.delay(release_id=instance.id)
43
44
45 def resolved_in_commit(instance, created, **kwargs):
46 # TODO(dcramer): we probably should support an updated message
47 if not created:
48 return
49
50 groups = instance.find_referenced_groups()
51 for group in groups:
52 try:
53 with transaction.atomic():
54 GroupCommitResolution.objects.create(
55 group_id=group.id,
56 commit_id=instance.id,
57 )
58 if instance.author:
59 user_list = list(instance.author.find_users())
60 else:
61 user_list = ()
62 if user_list:
63 Activity.objects.create(
64 project_id=group.project_id,
65 group=group,
66 type=Activity.SET_RESOLVED_IN_COMMIT,
67 ident=instance.id,
68 user=user_list[0],
69 data={
70 'commit': instance.id,
71 }
72 )
73 GroupAssignee.objects.assign(group=group, assigned_to=user_list[0])
74 else:
75 Activity.objects.create(
76 project_id=group.project_id,
77 group=group,
78 type=Activity.SET_RESOLVED_IN_COMMIT,
79 ident=instance.id,
80 data={
81 'commit': instance.id,
82 }
83 )
84 except IntegrityError:
85 pass
86
87
88 post_save.connect(
89 resolve_group_resolutions, sender=Release, dispatch_uid="resolve_group_resolutions", weak=False
90 )
91
92 post_save.connect(
93 ensure_release_exists, sender=TagValue, dispatch_uid="ensure_release_exists", weak=False
94 )
95
96 post_save.connect(
97 resolved_in_commit,
98 sender=Commit,
99 dispatch_uid="resolved_in_commit",
100 weak=False,
101 )
102
[end of src/sentry/receivers/releases.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/sentry/receivers/releases.py b/src/sentry/receivers/releases.py
--- a/src/sentry/receivers/releases.py
+++ b/src/sentry/receivers/releases.py
@@ -70,7 +70,8 @@
'commit': instance.id,
}
)
- GroupAssignee.objects.assign(group=group, assigned_to=user_list[0])
+ GroupAssignee.objects.assign(
+ group=group, assigned_to=user_list[0], acting_user=user_list[0])
else:
Activity.objects.create(
project_id=group.project_id,
| {"golden_diff": "diff --git a/src/sentry/receivers/releases.py b/src/sentry/receivers/releases.py\n--- a/src/sentry/receivers/releases.py\n+++ b/src/sentry/receivers/releases.py\n@@ -70,7 +70,8 @@\n 'commit': instance.id,\n }\n )\n- GroupAssignee.objects.assign(group=group, assigned_to=user_list[0])\n+ GroupAssignee.objects.assign(\n+ group=group, assigned_to=user_list[0], acting_user=user_list[0])\n else:\n Activity.objects.create(\n project_id=group.project_id,\n", "issue": "Auto assign should occur as actor\nWhen using 'Fixes XXX' annotation in a commit, I noticed that while Sentry auto assigned to me (expected), it did so on behalf of itself instead of my user.\r\n\r\n\r\n\n", "before_files": [{"content": "from __future__ import absolute_import, print_function\n\nfrom django.db import IntegrityError, transaction\nfrom django.db.models.signals import post_save\n\nfrom sentry.models import (\n Activity, Commit, GroupAssignee, GroupCommitResolution, Release, TagValue\n)\nfrom sentry.tasks.clear_expired_resolutions import clear_expired_resolutions\n\n\ndef ensure_release_exists(instance, created, **kwargs):\n if instance.key != 'sentry:release':\n return\n\n if instance.data and instance.data.get('release_id'):\n return\n\n try:\n with transaction.atomic():\n release = Release.objects.create(\n organization_id=instance.project.organization_id,\n version=instance.value,\n date_added=instance.first_seen,\n )\n except IntegrityError:\n release = Release.objects.get(\n organization_id=instance.project.organization_id,\n version=instance.value,\n )\n release.update(date_added=instance.first_seen)\n else:\n instance.update(data={'release_id': release.id})\n\n release.add_project(instance.project)\n\n\ndef resolve_group_resolutions(instance, created, **kwargs):\n if not created:\n return\n\n clear_expired_resolutions.delay(release_id=instance.id)\n\n\ndef resolved_in_commit(instance, created, **kwargs):\n # TODO(dcramer): we probably should support an updated message\n if not created:\n return\n\n groups = instance.find_referenced_groups()\n for group in groups:\n try:\n with transaction.atomic():\n GroupCommitResolution.objects.create(\n group_id=group.id,\n commit_id=instance.id,\n )\n if instance.author:\n user_list = list(instance.author.find_users())\n else:\n user_list = ()\n if user_list:\n Activity.objects.create(\n project_id=group.project_id,\n group=group,\n type=Activity.SET_RESOLVED_IN_COMMIT,\n ident=instance.id,\n user=user_list[0],\n data={\n 'commit': instance.id,\n }\n )\n GroupAssignee.objects.assign(group=group, assigned_to=user_list[0])\n else:\n Activity.objects.create(\n project_id=group.project_id,\n group=group,\n type=Activity.SET_RESOLVED_IN_COMMIT,\n ident=instance.id,\n data={\n 'commit': instance.id,\n }\n )\n except IntegrityError:\n pass\n\n\npost_save.connect(\n resolve_group_resolutions, sender=Release, dispatch_uid=\"resolve_group_resolutions\", weak=False\n)\n\npost_save.connect(\n ensure_release_exists, sender=TagValue, dispatch_uid=\"ensure_release_exists\", weak=False\n)\n\npost_save.connect(\n resolved_in_commit,\n sender=Commit,\n dispatch_uid=\"resolved_in_commit\",\n weak=False,\n)\n", "path": "src/sentry/receivers/releases.py"}]} | 1,440 | 129 |
gh_patches_debug_2965 | rasdani/github-patches | git_diff | weecology__retriever-1104 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Incorrectly lower casing table_name for csv
It looks like we're lower casing manually set table/directory names, at least for csv but probably for all flat file engines.
```
$ mkdir TESTER
$ retriever install csv mammal-masses --table_name TESTER/test.csv
=> Installing mammal-masses
[Errno 2] No such file or directory: 'tester/test.csv'
Done!
$ mkdir tester
$ retriever install csv mammal-masses --table_name TESTER/test.csv
=> Installing mammal-masses
Progress: 5731/5731 rows inserted into tester/test.csv totaling 5731:
Done!
```
This is causing issues for the R package, see https://github.com/ropensci/rdataretriever/issues/131, but is also a general problem since directory names are case sensitive for 2/3 OSs.
</issue>
<code>
[start of retriever/__main__.py]
1 """Data Retriever Wizard
2
3 Running this module directly will launch the download wizard, allowing the user
4 to choose from all scripts.
5
6 The main() function can be used for bootstrapping.
7
8 """
9 from __future__ import absolute_import
10 from __future__ import print_function
11
12 import os
13 import sys
14 from builtins import input
15 from imp import reload
16
17 from retriever.engines import engine_list, choose_engine
18 from retriever.lib.datapackage import create_json, edit_json, delete_json, get_script_filename
19 from retriever.lib.datasets import datasets, dataset_names, license
20 from retriever.lib.defaults import sample_script, CITATION, ENCODING, SCRIPT_SEARCH_PATHS
21 from retriever.lib.get_opts import parser
22 from retriever.lib.repository import check_for_updates
23 from retriever.lib.scripts import SCRIPT_LIST, get_script
24 from retriever.lib.engine_tools import name_matches, reset_retriever
25
26 encoding = ENCODING.lower()
27 # sys removes the setdefaultencoding method at startup; reload to get it back
28 reload(sys)
29 if hasattr(sys, 'setdefaultencoding'):
30 sys.setdefaultencoding(encoding)
31
32
33 def main():
34 """This function launches the Data Retriever."""
35 sys.argv[1:] = [arg.lower() for arg in sys.argv[1:]]
36 if len(sys.argv) == 1:
37 # if no command line args are passed, show the help options
38 parser.parse_args(['-h'])
39
40 else:
41 # otherwise, parse them
42
43 if not os.path.isdir(SCRIPT_SEARCH_PATHS[1]) and not \
44 [f for f in os.listdir(SCRIPT_SEARCH_PATHS[-1])
45 if os.path.exists(SCRIPT_SEARCH_PATHS[-1])]:
46 check_for_updates()
47 script_list = SCRIPT_LIST()
48
49 args = parser.parse_args()
50
51 if args.command == "install" and not args.engine:
52 parser.parse_args(['install', '-h'])
53
54 if args.quiet:
55 sys.stdout = open(os.devnull, 'w')
56
57 if args.command == 'help':
58 parser.parse_args(['-h'])
59
60 if hasattr(args, 'compile') and args.compile:
61 script_list = SCRIPT_LIST(force_compile=True)
62
63 if args.command == 'defaults':
64 for engine_item in engine_list:
65 print("Default options for engine ", engine_item.name)
66 for default_opts in engine_item.required_opts:
67 print(default_opts[0], " ", default_opts[2])
68 print()
69 return
70
71 if args.command == 'update':
72 check_for_updates(False)
73 script_list = SCRIPT_LIST()
74 return
75
76 elif args.command == 'citation':
77 if args.dataset is None:
78 print("\nCitation for retriever:\n")
79 print(CITATION)
80 else:
81 scripts = name_matches(script_list, args.dataset)
82 for dataset in scripts:
83 print("\nDataset: {}".format(dataset.name))
84 print("Citation: {}".format(dataset.citation))
85 print("Description: {}\n".format(dataset.description))
86
87 return
88
89 elif args.command == 'license':
90 dataset_license = license(args.dataset)
91 if dataset_license:
92 print(dataset_license)
93 else:
94 print("There is no license information for {}".format(args.dataset))
95 return
96
97 elif args.command == 'new':
98 f = open(args.filename, 'w')
99 f.write(sample_script)
100 f.close()
101
102 return
103
104 elif args.command == 'reset':
105 reset_retriever(args.scope)
106 return
107
108 elif args.command == 'new_json':
109 # create new JSON script
110 create_json()
111 return
112
113 elif args.command == 'edit_json':
114 # edit existing JSON script
115 json_file = get_script_filename(args.dataset.lower())
116 edit_json(json_file)
117 return
118
119 elif args.command == 'delete_json':
120 # delete existing JSON script from home directory and or script directory if exists in current dir
121 confirm = input("Really remove " + args.dataset.lower() +
122 " and all its contents? (y/N): ")
123 if confirm.lower().strip() in ['y', 'yes']:
124 json_file = get_script_filename(args.dataset.lower())
125 delete_json(json_file)
126 return
127
128 if args.command == 'ls':
129 # If scripts have never been downloaded there is nothing to list
130 if not script_list:
131 print("No scripts are currently available. Updating scripts now...")
132 check_for_updates(False)
133 print("\n\nScripts downloaded.\n")
134 if not (args.l or args.k or (type(args.v) is list)):
135 all_scripts = dataset_names()
136 print("Available datasets : {}\n".format(len(all_scripts)))
137 from retriever import lscolumns
138 lscolumns.printls(all_scripts)
139
140 elif type(args.v) is list:
141 if args.v:
142 try:
143 all_scripts = [get_script(dataset) for dataset in args.v]
144 except KeyError:
145 all_scripts = []
146 print("Dataset(s) is not found.")
147 else:
148 all_scripts = datasets()
149 count = 1
150 for script in all_scripts:
151 print("{}. {}\n{}\n{}\n{}\n".format(
152 count, script.title,
153 script.name,
154 script.keywords,
155 script.description,
156 str(script.licenses[0]['name']),
157 script.citation
158 ))
159 count += 1
160
161 else:
162 param_licenses = args.l if args.l else None
163 keywords = args.k if args.k else None
164
165 # search
166 searched_scripts = datasets(keywords, param_licenses)
167 if not searched_scripts:
168 print("No available datasets found")
169 else:
170 print("Available datasets : {}\n".format(len(searched_scripts)))
171 count = 1
172 for script in searched_scripts:
173 print("{}. {}\n{}\n{}\n{}\n".format(
174 count, script.title,
175 script.name,
176 script.keywords,
177 str(script.licenses[0]['name'])
178 ))
179 count += 1
180 return
181
182 engine = choose_engine(args.__dict__)
183
184 if hasattr(args, 'debug') and args.debug:
185 debug = True
186 else:
187 debug = False
188 sys.tracebacklimit = 0
189
190 if hasattr(args, 'debug') and args.not_cached:
191 engine.use_cache = False
192 else:
193 engine.use_cache = True
194
195 if args.dataset is not None:
196 scripts = name_matches(script_list, args.dataset)
197 else:
198 raise Exception("no dataset specified.")
199 if scripts:
200 for dataset in scripts:
201 print("=> Installing", dataset.name)
202 try:
203 dataset.download(engine, debug=debug)
204 dataset.engine.final_cleanup()
205 except KeyboardInterrupt:
206 pass
207 except Exception as e:
208 print(e)
209 if debug:
210 raise
211 print("Done!")
212 else:
213 print("Run 'retriever ls' to see a list of currently available datasets.")
214
215
216 if __name__ == "__main__":
217 main()
218
[end of retriever/__main__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/retriever/__main__.py b/retriever/__main__.py
--- a/retriever/__main__.py
+++ b/retriever/__main__.py
@@ -32,7 +32,6 @@
def main():
"""This function launches the Data Retriever."""
- sys.argv[1:] = [arg.lower() for arg in sys.argv[1:]]
if len(sys.argv) == 1:
# if no command line args are passed, show the help options
parser.parse_args(['-h'])
| {"golden_diff": "diff --git a/retriever/__main__.py b/retriever/__main__.py\n--- a/retriever/__main__.py\n+++ b/retriever/__main__.py\n@@ -32,7 +32,6 @@\n \n def main():\n \"\"\"This function launches the Data Retriever.\"\"\"\n- sys.argv[1:] = [arg.lower() for arg in sys.argv[1:]]\n if len(sys.argv) == 1:\n # if no command line args are passed, show the help options\n parser.parse_args(['-h'])\n", "issue": "Incorrectly lower casing table_name for csv\nIt looks like we're lower casing manually set table/directory names, at least for csv but probably for all flat file engines.\r\n\r\n```\r\n$ mkdir TESTER\r\n$ retriever install csv mammal-masses --table_name TESTER/test.csv\r\n=> Installing mammal-masses\r\n[Errno 2] No such file or directory: 'tester/test.csv'\r\nDone!\r\n\r\n$ mkdir tester\r\n$ retriever install csv mammal-masses --table_name TESTER/test.csv\r\n=> Installing mammal-masses\r\nProgress: 5731/5731 rows inserted into tester/test.csv totaling 5731:\r\n\r\nDone!\r\n```\r\n\r\nThis is causing issues for the R package, see https://github.com/ropensci/rdataretriever/issues/131, but is also a general problem since directory names are case sensitive for 2/3 OSs.\n", "before_files": [{"content": "\"\"\"Data Retriever Wizard\n\nRunning this module directly will launch the download wizard, allowing the user\nto choose from all scripts.\n\nThe main() function can be used for bootstrapping.\n\n\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import print_function\n\nimport os\nimport sys\nfrom builtins import input\nfrom imp import reload\n\nfrom retriever.engines import engine_list, choose_engine\nfrom retriever.lib.datapackage import create_json, edit_json, delete_json, get_script_filename\nfrom retriever.lib.datasets import datasets, dataset_names, license\nfrom retriever.lib.defaults import sample_script, CITATION, ENCODING, SCRIPT_SEARCH_PATHS\nfrom retriever.lib.get_opts import parser\nfrom retriever.lib.repository import check_for_updates\nfrom retriever.lib.scripts import SCRIPT_LIST, get_script\nfrom retriever.lib.engine_tools import name_matches, reset_retriever\n\nencoding = ENCODING.lower()\n# sys removes the setdefaultencoding method at startup; reload to get it back\nreload(sys)\nif hasattr(sys, 'setdefaultencoding'):\n sys.setdefaultencoding(encoding)\n\n\ndef main():\n \"\"\"This function launches the Data Retriever.\"\"\"\n sys.argv[1:] = [arg.lower() for arg in sys.argv[1:]]\n if len(sys.argv) == 1:\n # if no command line args are passed, show the help options\n parser.parse_args(['-h'])\n\n else:\n # otherwise, parse them\n\n if not os.path.isdir(SCRIPT_SEARCH_PATHS[1]) and not \\\n [f for f in os.listdir(SCRIPT_SEARCH_PATHS[-1])\n if os.path.exists(SCRIPT_SEARCH_PATHS[-1])]:\n check_for_updates()\n script_list = SCRIPT_LIST()\n\n args = parser.parse_args()\n\n if args.command == \"install\" and not args.engine:\n parser.parse_args(['install', '-h'])\n\n if args.quiet:\n sys.stdout = open(os.devnull, 'w')\n\n if args.command == 'help':\n parser.parse_args(['-h'])\n\n if hasattr(args, 'compile') and args.compile:\n script_list = SCRIPT_LIST(force_compile=True)\n\n if args.command == 'defaults':\n for engine_item in engine_list:\n print(\"Default options for engine \", engine_item.name)\n for default_opts in engine_item.required_opts:\n print(default_opts[0], \" \", default_opts[2])\n print()\n return\n\n if args.command == 'update':\n check_for_updates(False)\n script_list = SCRIPT_LIST()\n return\n\n elif args.command == 'citation':\n if args.dataset is None:\n print(\"\\nCitation for retriever:\\n\")\n print(CITATION)\n else:\n scripts = name_matches(script_list, args.dataset)\n for dataset in scripts:\n print(\"\\nDataset: {}\".format(dataset.name))\n print(\"Citation: {}\".format(dataset.citation))\n print(\"Description: {}\\n\".format(dataset.description))\n\n return\n\n elif args.command == 'license':\n dataset_license = license(args.dataset)\n if dataset_license:\n print(dataset_license)\n else:\n print(\"There is no license information for {}\".format(args.dataset))\n return\n\n elif args.command == 'new':\n f = open(args.filename, 'w')\n f.write(sample_script)\n f.close()\n\n return\n\n elif args.command == 'reset':\n reset_retriever(args.scope)\n return\n\n elif args.command == 'new_json':\n # create new JSON script\n create_json()\n return\n\n elif args.command == 'edit_json':\n # edit existing JSON script\n json_file = get_script_filename(args.dataset.lower())\n edit_json(json_file)\n return\n\n elif args.command == 'delete_json':\n # delete existing JSON script from home directory and or script directory if exists in current dir\n confirm = input(\"Really remove \" + args.dataset.lower() +\n \" and all its contents? (y/N): \")\n if confirm.lower().strip() in ['y', 'yes']:\n json_file = get_script_filename(args.dataset.lower())\n delete_json(json_file)\n return\n\n if args.command == 'ls':\n # If scripts have never been downloaded there is nothing to list\n if not script_list:\n print(\"No scripts are currently available. Updating scripts now...\")\n check_for_updates(False)\n print(\"\\n\\nScripts downloaded.\\n\")\n if not (args.l or args.k or (type(args.v) is list)):\n all_scripts = dataset_names()\n print(\"Available datasets : {}\\n\".format(len(all_scripts)))\n from retriever import lscolumns\n lscolumns.printls(all_scripts)\n \n elif type(args.v) is list:\n if args.v:\n try:\n all_scripts = [get_script(dataset) for dataset in args.v]\n except KeyError:\n all_scripts = []\n print(\"Dataset(s) is not found.\")\n else:\n all_scripts = datasets()\n count = 1\n for script in all_scripts:\n print(\"{}. {}\\n{}\\n{}\\n{}\\n\".format(\n count, script.title,\n script.name,\n script.keywords,\n script.description,\n str(script.licenses[0]['name']),\n script.citation\n ))\n count += 1\n \n else:\n param_licenses = args.l if args.l else None\n keywords = args.k if args.k else None\n\n # search\n searched_scripts = datasets(keywords, param_licenses)\n if not searched_scripts:\n print(\"No available datasets found\")\n else:\n print(\"Available datasets : {}\\n\".format(len(searched_scripts)))\n count = 1\n for script in searched_scripts:\n print(\"{}. {}\\n{}\\n{}\\n{}\\n\".format(\n count, script.title,\n script.name,\n script.keywords,\n str(script.licenses[0]['name'])\n ))\n count += 1\n return\n\n engine = choose_engine(args.__dict__)\n\n if hasattr(args, 'debug') and args.debug:\n debug = True\n else:\n debug = False\n sys.tracebacklimit = 0\n\n if hasattr(args, 'debug') and args.not_cached:\n engine.use_cache = False\n else:\n engine.use_cache = True\n\n if args.dataset is not None:\n scripts = name_matches(script_list, args.dataset)\n else:\n raise Exception(\"no dataset specified.\")\n if scripts:\n for dataset in scripts:\n print(\"=> Installing\", dataset.name)\n try:\n dataset.download(engine, debug=debug)\n dataset.engine.final_cleanup()\n except KeyboardInterrupt:\n pass\n except Exception as e:\n print(e)\n if debug:\n raise\n print(\"Done!\")\n else:\n print(\"Run 'retriever ls' to see a list of currently available datasets.\")\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "retriever/__main__.py"}]} | 2,766 | 121 |
gh_patches_debug_61141 | rasdani/github-patches | git_diff | e2nIEE__pandapower-2263 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[bug] __format_version__ not increased.
### Issue Description
The `__format_version__` in `_version.py` has not been increased eventhough the format got changed!
This is an issue in the develop branch **not** in master!
In my fork I made an update to many test cases since I changed the format, so I saved many networks in as files, they contain the current format_version (2.14.0). After merging the current version of develop I got some tests that suddenly failed eventhough my code should not mess with them. So I did a little diging and found that the expected and actual results differ in `net.res_switch_est` DataFrame. This is because the expected result only contains the old columns while the actual result contains the updated columns.
This is because the expected results are loaded form file using the `pandapower.from_json` function and since then format version is the same as the current format verison in `_version.py` the conversion to the newest format is not done. So the network is returned as loaded from file.
The actual results however are a product of a conversion from a different network type. So they are the output of a converter that creates a new pandapowerNet. These then contain all new columns.
If new columns are added `__format_version__` should be incremented at least in the bugfix number. But I would expect that this constitutes at least a minor release as a new format version most likely breaks backwards compatibility. On a bugfix version I would expect I go backwards and forwards without issue. But this is not the case if the format version changes! A 2.13.1 Network should sucessfully load on 2.13.0 but this will not work if new columns are added. So this change should be reflected by an increase of the format verison to at least 2.15.0 in my opinion.
The breaking commit is 516f8af as it changed the format without changeing the format version.
</issue>
<code>
[start of pandapower/_version.py]
1 import importlib.metadata
2
3 __version__ = importlib.metadata.version("pandapower")
4 __format_version__ = "2.14.0"
5
[end of pandapower/_version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pandapower/_version.py b/pandapower/_version.py
--- a/pandapower/_version.py
+++ b/pandapower/_version.py
@@ -1,4 +1,4 @@
import importlib.metadata
__version__ = importlib.metadata.version("pandapower")
-__format_version__ = "2.14.0"
+__format_version__ = "2.15.0"
| {"golden_diff": "diff --git a/pandapower/_version.py b/pandapower/_version.py\n--- a/pandapower/_version.py\n+++ b/pandapower/_version.py\n@@ -1,4 +1,4 @@\n import importlib.metadata\n \n __version__ = importlib.metadata.version(\"pandapower\")\n-__format_version__ = \"2.14.0\"\n+__format_version__ = \"2.15.0\"\n", "issue": "[bug] __format_version__ not increased.\n### Issue Description\r\n\r\nThe `__format_version__` in `_version.py` has not been increased eventhough the format got changed!\r\n\r\nThis is an issue in the develop branch **not** in master!\r\n\r\nIn my fork I made an update to many test cases since I changed the format, so I saved many networks in as files, they contain the current format_version (2.14.0). After merging the current version of develop I got some tests that suddenly failed eventhough my code should not mess with them. So I did a little diging and found that the expected and actual results differ in `net.res_switch_est` DataFrame. This is because the expected result only contains the old columns while the actual result contains the updated columns.\r\n\r\nThis is because the expected results are loaded form file using the `pandapower.from_json` function and since then format version is the same as the current format verison in `_version.py` the conversion to the newest format is not done. So the network is returned as loaded from file.\r\nThe actual results however are a product of a conversion from a different network type. So they are the output of a converter that creates a new pandapowerNet. These then contain all new columns.\r\n\r\nIf new columns are added `__format_version__` should be incremented at least in the bugfix number. But I would expect that this constitutes at least a minor release as a new format version most likely breaks backwards compatibility. On a bugfix version I would expect I go backwards and forwards without issue. But this is not the case if the format version changes! A 2.13.1 Network should sucessfully load on 2.13.0 but this will not work if new columns are added. So this change should be reflected by an increase of the format verison to at least 2.15.0 in my opinion.\r\n\r\nThe breaking commit is 516f8af as it changed the format without changeing the format version.\r\n\n", "before_files": [{"content": "import importlib.metadata\n\n__version__ = importlib.metadata.version(\"pandapower\")\n__format_version__ = \"2.14.0\"\n", "path": "pandapower/_version.py"}]} | 997 | 97 |
gh_patches_debug_19223 | rasdani/github-patches | git_diff | coala__coala-4989 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Create Indentation aspects under Formatting.Spacing
Create an aspects named `Indentation` in files `Formatting.py`. The new aspects should have fullname of `root.Formatting.Spacing.Indentation`. It should have atleast the following taste:
- `indent_type` - what type of indentation used, could be `tab` or `space`
- `indent_size` - number of spaces per indentation level
</issue>
<code>
[start of coalib/bearlib/aspects/Formatting.py]
1 from coalib.bearlib.aspects import Root, Taste
2
3
4 @Root.subaspect
5 class Formatting:
6 """
7 The visual appearance of source code.
8 """
9 class docs:
10 example = """
11 # Here is an example of Python code with lots of
12 # formatting issues including: trailing spaces, missing spaces
13 # around operators, strange and inconsistent indentation etc.
14
15 z = 'hello'+'world'
16 def f ( a):
17 pass
18 """
19 example_language = 'Python'
20 importance_reason = """
21 A coding style (the of rules or guidelines used when writing the
22 source code) can drastically affect the readability, and
23 maintainability of a program and might as well introduce bugs.
24 """
25 fix_suggestions = """
26 Defining a clearly and thoughtful coding style (based on the available
27 ones given the programming language in use) and strictly respect it or
28 apply it through out the implementation of a project.
29 """
30
31
32 @Formatting.subaspect
33 class Length:
34 """
35 Hold sub-aspects for file and line length.
36 """
37 class docs:
38 example = """
39 # We assume that the maximum number of characters per line is 10
40 # and that the maximum number of lines per files is 3.
41
42 def run(bear, file, filename, aspectlist):
43 return bear.run(file, filename, aspectlist)
44 """
45 example_language = 'Python'
46 importance_reason = """
47 Too long lines of code and too large files result in code difficult to
48 read, understand and maintain.
49 """
50 fix_suggestions = """
51 Length issues can be fixed by writing shorter lines of code (splitting
52 long lines into multiple shorter lines); writing shorter files
53 (splitting files into modules, writing shorter methods and classes.).
54 """
55
56
57 @Length.subaspect
58 class LineLength:
59 """
60 Number of characters found in a line of code.
61 """
62 class docs:
63 example = """
64 print('The length of this line is 38')
65 """
66 example_langague = 'Python'
67 importance_reason = """
68 Too long lines make code very difficult to read and maintain.
69 """
70 fix_suggestions = """
71 Splitting long lines of code into multiple shorter lines whenever
72 possible. Avoiding the usage of in-line language specific constructs
73 whenever they result in too long lines.
74 """
75 max_line_length = Taste[int](
76 'Maximum number of character for a line.',
77 (79, 80, 100, 120, 160), default=80)
78
79
80 @Length.subaspect
81 class FileLength:
82 """
83 Number of lines found in a file.
84 """
85 class docs:
86 example = """
87 # This file would be a large file if we assume that the max number of
88 # lines per file is 10
89
90 class Node:
91 def __init__(self, value, left_most_child, left_sibling):
92 self.value=value
93 self.left_most_child=left_most_child
94 self.left_sibling=left_sibling
95
96 # This is example is just showing what this aspect is about, because
97 # the max number of lines per file is usually 999.
98 """
99 example_language = 'Python 3'
100 importance_reason = """
101 Too long programs (or files) are difficult to read, maintain and
102 understand.
103 """
104 fix_suggestions = """
105 Splitting files into modules, writing shorter methods and classes.
106 """
107 max_file_length = Taste[int](
108 'Maximum number of line for a file',
109 (999,), default=999)
110
111
112 @Formatting.subaspect
113 class Spacing:
114 """
115 All whitespace found between non-whitespace characters.
116 """
117 class docs:
118 example = """
119 # Here is an example of code with spacing issues including
120 # unnecessary blank lines and missing space around operators.
121
122
123
124 def func( ):
125 return 37*-+2
126 """
127 example_language = 'Python'
128 importance_reason = """
129 Useless spacing affects the readability and maintainability of a code.
130 """
131 fix_suggestions = """
132 Removing the trailing spaces and the meaningless blank lines.
133 """
134
135
136 @Spacing.subaspect
137 class TrailingSpace:
138 """
139 Unnecessary whitespace at end of a line.
140
141 Trailing space is all whitespace found after the last non-whitespace
142 character on the line until the newline. This includes tabs "\\\\t",
143 blank lines, blanks etc.
144 """
145 class docs:
146 example = """
147 def func( a ):
148 pass
149
150 """.replace('\n', '\t\n')
151 example_language = 'Python'
152 importance_reason = """
153 Trailing spaces make code less readable and maintainable.
154 """
155 fix_suggestions = """
156 Removing the trailing spaces.
157 """
158 allow_trailing_spaces = Taste[bool](
159 'Determines whether or not trailing spaces should be allowed or not.',
160 (True, False), default=False)
161
162
163 @Spacing.subaspect
164 class BlankLine:
165 """
166 A line with zero characters.
167 """
168 class docs:
169 example = """
170 name = input('What is your name?')
171
172
173 print('Hi, {}'.format(name))
174 """
175 example_language = 'Python 3'
176 importance_reason = """
177 Various programming styles use blank lines in different places.
178 The usage of blank lines affects the readability, maintainability and
179 length of a code i.e blank lines can either make code longer, less
180 readable and maintainable or do the reverse.
181 """
182 fix_suggestions = """
183 Following specific rules about the usage of blank lines: using them
184 only when necessary.
185 """
186
187
188 @BlankLine.subaspect
189 class BlankLineAfterDeclaration:
190 """
191 Those found after declarations.
192 """
193 class docs:
194 example = """
195 #include <stdio.h>
196
197 int main ()
198 {
199 int a;
200 float b;
201
202 scanf("%d%f", &a, &b);
203 printf("a = %d and b = %f", a, b);
204 return 0;
205 }
206 """
207 example_language = 'C'
208 importance_reason = """
209 Having a specific and reasonable number of blank lines after every
210 block of declarations improves on the readability of the code.
211 """
212 fix_suggestions = """
213 `BlankLintAfterDeclaration` issues can be fixed specifying (and of
214 course using) a reasonable number of blank lines to use after block
215 declaration.
216 """
217 blank_lines_after_declarations = Taste[int](
218 'Represents the number of blank lines after declarations',
219 (0, 1, 2), default=0)
220
221
222 @BlankLine.subaspect
223 class BlankLineAfterProcedure:
224 """
225 Those found after procedures or functions.
226 """
227 class docs:
228 example = """
229 #include <stdio.h>
230
231 void proc(void){
232 printf("this does nothing");
233 } int add(float a, float b){
234 return a + b;
235 }
236 """
237 example_language = 'C'
238 importance_reason = """
239 Having a specific and reasonable number of blank lines after every
240 procedures improves on the readability of the code.
241 """
242 fix_suggestions = """
243 `BlankLintAfterProcedure` issues can be fixed specifying (and of
244 course using) a reasonable number of blank lines to use after
245 procedures' definition.
246 """
247 blank_lines_after_procedures = Taste[int](
248 'Represents the number of blank lines to use after a procedure or'
249 'a function', (0, 1, 2), default=1)
250
251
252 @BlankLine.subaspect
253 class BlankLineAfterClass:
254 """
255 Those found after classes' definitions.
256 """
257 class docs:
258 example = """
259 class SomeClass:
260 def __init__(self):
261 raise RuntimeError('Never instantiate this class')
262
263
264 def func():
265 pass
266 """
267 example_language = 'Python 3'
268 importance_reason = """
269 Having a specific number of blank lines after every classes'
270 definitions declarations improves on the readability of the code.
271 """
272 fix_suggestions = """
273 """
274 blank_lines_after_class = Taste[int](
275 'Represents the number of blank lines to use after a class'
276 'definition.', (1, 2), default=2)
277
278
279 @BlankLine.subaspect
280 class NewlineAtEOF:
281 """
282 Newline character (usually '\\\\n', aka CR) found at the end of file.
283 """
284 class docs:
285 example = """
286 def do_nothing():
287 pass
288 """ + ('\n')
289 example_language = 'Python'
290 importance_reason = """
291 A text file consists of a series of lines, each of which ends with a
292 newline character (\\\\n). A file that is not empty and does not end
293 with a newline is therefore not a text file.
294
295 It's not just bad style, it can lead to unexpected behavior, utilities
296 that are supposed to operate on text files may not cope well with files
297 that don't end with a newline.
298 """
299 fix_suggestions = """
300 `NewlineAtEOF` issues can be fixed by simply adding a newline at the
301 end of the file.
302 """
303 newline_at_EOF = Taste[bool](
304 'If ``True``, enforce a newline at End Of File.',
305 (True, False), default=True)
306
307
308 @Spacing.subaspect
309 class SpacesAroundOperator:
310 """
311 Spacing around operators.
312 """
313 class docs:
314 example = """
315 def f(a, x):
316 return 37+a[42 - x]
317 """
318 example_language = 'Python'
319 importance_reason = """
320 Having a specific and reasonable number of whitespace (blank) around
321 operators improves on the readability of the code.
322 """
323 fix_suggestions = """
324 `SpacesAroundOperator` issues can be fixed by simply specifying and
325 the number of whitespace to be used after each operator.
326 """
327 spaces_around_operators = Taste[int](
328 'Represents the number of space to be used around operators.',
329 (0, 1), default=1)
330 spaces_before_colon = Taste[int](
331 'Represents the number of blank spaces before colons.',
332 (0, 1), default=0)
333 spaces_after_colon = Taste[int](
334 'Represents the number of blank spaces after colons.',
335 (0, 1), default=1)
336
337
338 @Formatting.subaspect
339 class Quotation:
340 """
341 Quotation mark used for strings and docstrings.
342 """
343 class docs:
344 example = """
345 # Here is an example of code where both '' and "" quotation mark
346 # Are used.
347
348 string = 'coala is always written with lowercase c.'
349 string = "coala is always written with lowercase c."
350 """
351 example_language = 'Python'
352 importance_reason = """
353 Using the same quotation whenever possible in the code, improve on its
354 readability by introducing consistency.
355 """
356 fix_suggestions = """
357 Choosing a preferred quotation and using it everywhere (if possible).
358 """
359 preferred_quotation = Taste[str](
360 'Represents the preferred quotation',
361 ('\'', '"'), default='\'')
362
[end of coalib/bearlib/aspects/Formatting.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/coalib/bearlib/aspects/Formatting.py b/coalib/bearlib/aspects/Formatting.py
--- a/coalib/bearlib/aspects/Formatting.py
+++ b/coalib/bearlib/aspects/Formatting.py
@@ -133,6 +133,40 @@
"""
[email protected]
+class Indentation:
+ """
+ Spaces/tabs used before blocks of code to convey a program's structure.
+ """
+ class docs:
+ example = """
+ # If this code was written on an editor that defined a tab as 2
+ # spaces, mixing tabs and spaces would look like this on a different
+ # editor defining tabs as four spaces.
+
+ def spaces():
+ pass
+
+ def tabs():
+ pass
+ """
+ example_language = 'Python'
+ importance_reason = """
+ Mixing tabs and spaces can cause issues when collaborating on
+ code, as well as during testing and compilation.
+ """
+ fix_suggestions = """
+ Using either tabs or spaces consistently.
+ If using spaces, by using a suitable number of spaces, preferably four.
+ """
+ indent_type = Taste[int](
+ 'Represents the type of indent used.',
+ ('tab', 'space'), default='tab')
+ indent_size = Taste[int](
+ 'Represents the number of spaces per indentation level.',
+ (2, 3, 4, 5, 6), default=4)
+
+
@Spacing.subaspect
class TrailingSpace:
"""
| {"golden_diff": "diff --git a/coalib/bearlib/aspects/Formatting.py b/coalib/bearlib/aspects/Formatting.py\n--- a/coalib/bearlib/aspects/Formatting.py\n+++ b/coalib/bearlib/aspects/Formatting.py\n@@ -133,6 +133,40 @@\n \"\"\"\n \n \[email protected]\n+class Indentation:\n+ \"\"\"\n+ Spaces/tabs used before blocks of code to convey a program's structure.\n+ \"\"\"\n+ class docs:\n+ example = \"\"\"\n+ # If this code was written on an editor that defined a tab as 2\n+ # spaces, mixing tabs and spaces would look like this on a different\n+ # editor defining tabs as four spaces.\n+\n+ def spaces():\n+ pass\n+\n+ def tabs():\n+ pass\n+ \"\"\"\n+ example_language = 'Python'\n+ importance_reason = \"\"\"\n+ Mixing tabs and spaces can cause issues when collaborating on\n+ code, as well as during testing and compilation.\n+ \"\"\"\n+ fix_suggestions = \"\"\"\n+ Using either tabs or spaces consistently.\n+ If using spaces, by using a suitable number of spaces, preferably four.\n+ \"\"\"\n+ indent_type = Taste[int](\n+ 'Represents the type of indent used.',\n+ ('tab', 'space'), default='tab')\n+ indent_size = Taste[int](\n+ 'Represents the number of spaces per indentation level.',\n+ (2, 3, 4, 5, 6), default=4)\n+\n+\n @Spacing.subaspect\n class TrailingSpace:\n \"\"\"\n", "issue": "Create Indentation aspects under Formatting.Spacing\nCreate an aspects named `Indentation` in files `Formatting.py`. The new aspects should have fullname of `root.Formatting.Spacing.Indentation`. It should have atleast the following taste:\r\n\r\n- `indent_type` - what type of indentation used, could be `tab` or `space`\r\n- `indent_size` - number of spaces per indentation level\n", "before_files": [{"content": "from coalib.bearlib.aspects import Root, Taste\n\n\[email protected]\nclass Formatting:\n \"\"\"\n The visual appearance of source code.\n \"\"\"\n class docs:\n example = \"\"\"\n # Here is an example of Python code with lots of\n # formatting issues including: trailing spaces, missing spaces\n # around operators, strange and inconsistent indentation etc.\n\n z = 'hello'+'world'\n def f ( a):\n pass\n \"\"\"\n example_language = 'Python'\n importance_reason = \"\"\"\n A coding style (the of rules or guidelines used when writing the\n source code) can drastically affect the readability, and\n maintainability of a program and might as well introduce bugs.\n \"\"\"\n fix_suggestions = \"\"\"\n Defining a clearly and thoughtful coding style (based on the available\n ones given the programming language in use) and strictly respect it or\n apply it through out the implementation of a project.\n \"\"\"\n\n\[email protected]\nclass Length:\n \"\"\"\n Hold sub-aspects for file and line length.\n \"\"\"\n class docs:\n example = \"\"\"\n # We assume that the maximum number of characters per line is 10\n # and that the maximum number of lines per files is 3.\n\n def run(bear, file, filename, aspectlist):\n return bear.run(file, filename, aspectlist)\n \"\"\"\n example_language = 'Python'\n importance_reason = \"\"\"\n Too long lines of code and too large files result in code difficult to\n read, understand and maintain.\n \"\"\"\n fix_suggestions = \"\"\"\n Length issues can be fixed by writing shorter lines of code (splitting\n long lines into multiple shorter lines); writing shorter files\n (splitting files into modules, writing shorter methods and classes.).\n \"\"\"\n\n\[email protected]\nclass LineLength:\n \"\"\"\n Number of characters found in a line of code.\n \"\"\"\n class docs:\n example = \"\"\"\n print('The length of this line is 38')\n \"\"\"\n example_langague = 'Python'\n importance_reason = \"\"\"\n Too long lines make code very difficult to read and maintain.\n \"\"\"\n fix_suggestions = \"\"\"\n Splitting long lines of code into multiple shorter lines whenever\n possible. Avoiding the usage of in-line language specific constructs\n whenever they result in too long lines.\n \"\"\"\n max_line_length = Taste[int](\n 'Maximum number of character for a line.',\n (79, 80, 100, 120, 160), default=80)\n\n\[email protected]\nclass FileLength:\n \"\"\"\n Number of lines found in a file.\n \"\"\"\n class docs:\n example = \"\"\"\n # This file would be a large file if we assume that the max number of\n # lines per file is 10\n\n class Node:\n def __init__(self, value, left_most_child, left_sibling):\n self.value=value\n self.left_most_child=left_most_child\n self.left_sibling=left_sibling\n\n # This is example is just showing what this aspect is about, because\n # the max number of lines per file is usually 999.\n \"\"\"\n example_language = 'Python 3'\n importance_reason = \"\"\"\n Too long programs (or files) are difficult to read, maintain and\n understand.\n \"\"\"\n fix_suggestions = \"\"\"\n Splitting files into modules, writing shorter methods and classes.\n \"\"\"\n max_file_length = Taste[int](\n 'Maximum number of line for a file',\n (999,), default=999)\n\n\[email protected]\nclass Spacing:\n \"\"\"\n All whitespace found between non-whitespace characters.\n \"\"\"\n class docs:\n example = \"\"\"\n # Here is an example of code with spacing issues including\n # unnecessary blank lines and missing space around operators.\n\n\n\n def func( ):\n return 37*-+2\n \"\"\"\n example_language = 'Python'\n importance_reason = \"\"\"\n Useless spacing affects the readability and maintainability of a code.\n \"\"\"\n fix_suggestions = \"\"\"\n Removing the trailing spaces and the meaningless blank lines.\n \"\"\"\n\n\[email protected]\nclass TrailingSpace:\n \"\"\"\n Unnecessary whitespace at end of a line.\n\n Trailing space is all whitespace found after the last non-whitespace\n character on the line until the newline. This includes tabs \"\\\\\\\\t\",\n blank lines, blanks etc.\n \"\"\"\n class docs:\n example = \"\"\"\n def func( a ):\n pass\n\n \"\"\".replace('\\n', '\\t\\n')\n example_language = 'Python'\n importance_reason = \"\"\"\n Trailing spaces make code less readable and maintainable.\n \"\"\"\n fix_suggestions = \"\"\"\n Removing the trailing spaces.\n \"\"\"\n allow_trailing_spaces = Taste[bool](\n 'Determines whether or not trailing spaces should be allowed or not.',\n (True, False), default=False)\n\n\[email protected]\nclass BlankLine:\n \"\"\"\n A line with zero characters.\n \"\"\"\n class docs:\n example = \"\"\"\n name = input('What is your name?')\n\n\n print('Hi, {}'.format(name))\n \"\"\"\n example_language = 'Python 3'\n importance_reason = \"\"\"\n Various programming styles use blank lines in different places.\n The usage of blank lines affects the readability, maintainability and\n length of a code i.e blank lines can either make code longer, less\n readable and maintainable or do the reverse.\n \"\"\"\n fix_suggestions = \"\"\"\n Following specific rules about the usage of blank lines: using them\n only when necessary.\n \"\"\"\n\n\[email protected]\nclass BlankLineAfterDeclaration:\n \"\"\"\n Those found after declarations.\n \"\"\"\n class docs:\n example = \"\"\"\n #include <stdio.h>\n\n int main ()\n {\n int a;\n float b;\n\n scanf(\"%d%f\", &a, &b);\n printf(\"a = %d and b = %f\", a, b);\n return 0;\n }\n \"\"\"\n example_language = 'C'\n importance_reason = \"\"\"\n Having a specific and reasonable number of blank lines after every\n block of declarations improves on the readability of the code.\n \"\"\"\n fix_suggestions = \"\"\"\n `BlankLintAfterDeclaration` issues can be fixed specifying (and of\n course using) a reasonable number of blank lines to use after block\n declaration.\n \"\"\"\n blank_lines_after_declarations = Taste[int](\n 'Represents the number of blank lines after declarations',\n (0, 1, 2), default=0)\n\n\[email protected]\nclass BlankLineAfterProcedure:\n \"\"\"\n Those found after procedures or functions.\n \"\"\"\n class docs:\n example = \"\"\"\n #include <stdio.h>\n\n void proc(void){\n printf(\"this does nothing\");\n } int add(float a, float b){\n return a + b;\n }\n \"\"\"\n example_language = 'C'\n importance_reason = \"\"\"\n Having a specific and reasonable number of blank lines after every\n procedures improves on the readability of the code.\n \"\"\"\n fix_suggestions = \"\"\"\n `BlankLintAfterProcedure` issues can be fixed specifying (and of\n course using) a reasonable number of blank lines to use after\n procedures' definition.\n \"\"\"\n blank_lines_after_procedures = Taste[int](\n 'Represents the number of blank lines to use after a procedure or'\n 'a function', (0, 1, 2), default=1)\n\n\[email protected]\nclass BlankLineAfterClass:\n \"\"\"\n Those found after classes' definitions.\n \"\"\"\n class docs:\n example = \"\"\"\n class SomeClass:\n def __init__(self):\n raise RuntimeError('Never instantiate this class')\n\n\n def func():\n pass\n \"\"\"\n example_language = 'Python 3'\n importance_reason = \"\"\"\n Having a specific number of blank lines after every classes'\n definitions declarations improves on the readability of the code.\n \"\"\"\n fix_suggestions = \"\"\"\n \"\"\"\n blank_lines_after_class = Taste[int](\n 'Represents the number of blank lines to use after a class'\n 'definition.', (1, 2), default=2)\n\n\[email protected]\nclass NewlineAtEOF:\n \"\"\"\n Newline character (usually '\\\\\\\\n', aka CR) found at the end of file.\n \"\"\"\n class docs:\n example = \"\"\"\n def do_nothing():\n pass\n \"\"\" + ('\\n')\n example_language = 'Python'\n importance_reason = \"\"\"\n A text file consists of a series of lines, each of which ends with a\n newline character (\\\\\\\\n). A file that is not empty and does not end\n with a newline is therefore not a text file.\n\n It's not just bad style, it can lead to unexpected behavior, utilities\n that are supposed to operate on text files may not cope well with files\n that don't end with a newline.\n \"\"\"\n fix_suggestions = \"\"\"\n `NewlineAtEOF` issues can be fixed by simply adding a newline at the\n end of the file.\n \"\"\"\n newline_at_EOF = Taste[bool](\n 'If ``True``, enforce a newline at End Of File.',\n (True, False), default=True)\n\n\[email protected]\nclass SpacesAroundOperator:\n \"\"\"\n Spacing around operators.\n \"\"\"\n class docs:\n example = \"\"\"\n def f(a, x):\n return 37+a[42 - x]\n \"\"\"\n example_language = 'Python'\n importance_reason = \"\"\"\n Having a specific and reasonable number of whitespace (blank) around\n operators improves on the readability of the code.\n \"\"\"\n fix_suggestions = \"\"\"\n `SpacesAroundOperator` issues can be fixed by simply specifying and\n the number of whitespace to be used after each operator.\n \"\"\"\n spaces_around_operators = Taste[int](\n 'Represents the number of space to be used around operators.',\n (0, 1), default=1)\n spaces_before_colon = Taste[int](\n 'Represents the number of blank spaces before colons.',\n (0, 1), default=0)\n spaces_after_colon = Taste[int](\n 'Represents the number of blank spaces after colons.',\n (0, 1), default=1)\n\n\[email protected]\nclass Quotation:\n \"\"\"\n Quotation mark used for strings and docstrings.\n \"\"\"\n class docs:\n example = \"\"\"\n # Here is an example of code where both '' and \"\" quotation mark\n # Are used.\n\n string = 'coala is always written with lowercase c.'\n string = \"coala is always written with lowercase c.\"\n \"\"\"\n example_language = 'Python'\n importance_reason = \"\"\"\n Using the same quotation whenever possible in the code, improve on its\n readability by introducing consistency.\n \"\"\"\n fix_suggestions = \"\"\"\n Choosing a preferred quotation and using it everywhere (if possible).\n \"\"\"\n preferred_quotation = Taste[str](\n 'Represents the preferred quotation',\n ('\\'', '\"'), default='\\'')\n", "path": "coalib/bearlib/aspects/Formatting.py"}]} | 4,003 | 353 |
gh_patches_debug_9115 | rasdani/github-patches | git_diff | alltheplaces__alltheplaces-2637 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Spider cvs is broken
During the global build at 2021-08-18-14-42-26, spider **cvs** failed with **0 features** and **9870 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-08-18-14-42-26/logs/cvs.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-08-18-14-42-26/output/cvs.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-08-18-14-42-26/output/cvs.geojson))
</issue>
<code>
[start of locations/spiders/cvs.py]
1 import json
2 import scrapy
3 import re
4 from locations.items import GeojsonPointItem
5 from locations.hours import OpeningHours
6
7 DAYS = [
8 'Mo',
9 'Tu',
10 'We',
11 'Th',
12 'Fr',
13 'Sa',
14 'Su'
15 ]
16
17
18 class CVSSpider(scrapy.Spider):
19
20 name = "cvs"
21 item_attributes = { 'brand': "CVS", 'brand_wikidata': "Q2078880" }
22 allowed_domains = ["www.cvs.com"]
23 download_delay = 0.5
24 start_urls = (
25 'https://www.cvs.com/store-locator/cvs-pharmacy-locations',
26 )
27
28 def parse_hours(self, hours):
29 opening_hours = OpeningHours()
30
31 for group in hours:
32 if 'closed' in group:
33 continue
34 if 'open 24 hours' in group:
35 days = re.search(r'([a-zA-Z\-]+)\s+open 24 hours', group).groups()[0]
36 open_time, close_time = '00:00:00', '23:59:00'
37 else:
38 try:
39 days, open_time, close_time = re.search(r'([a-zA-Z\-]+)\s+([\d:\sapm]+)-([\d:\sapm]+)', group).groups()
40 except AttributeError:
41 continue # no hours listed, just day
42 try:
43 start_day, end_day = days.split('-')
44 except ValueError:
45 start_day, end_day = days, days
46 for day in DAYS[DAYS.index(start_day):DAYS.index(end_day) + 1]:
47 if 'm' in open_time:
48 open_time = open_time.strip(' apm') + ":00"
49 if 'm' in close_time:
50 close_time = close_time.strip(' apm') + ":00"
51 opening_hours.add_range(day=day,
52 open_time=open_time.strip(),
53 close_time=close_time.strip(),
54 time_format='%H:%M:%S')
55
56 return opening_hours.as_opening_hours()
57
58 def parse_stores(self, response):
59 try:
60 data = json.loads(response.xpath('//script[@type="application/ld+json" and contains(text(), "streetAddress")]/text()').extract_first())[0]
61 except json.decoder.JSONDecodeError:
62 # one malformed json body on this store:
63 # https://www.cvs.com/store-locator/cvs-pharmacy-address/84+South+Avenue+tops+Plaza+-Hilton-NY-14468/storeid=5076
64 data = response.xpath('//script[@type="application/ld+json" and contains(text(), "streetAddress")]/text()').extract_first()
65 data = re.sub(r'"tops Plaza\s*"', '', data)
66 data = json.loads(data)[0]
67 except TypeError:
68 return # empty store page
69
70 properties = {
71 'name': data["name"],
72 'ref': re.search(r'.+/?storeid=(.+)', response.url).group(1),
73 'addr_full': data["address"]["streetAddress"].strip(', '),
74 'city': data["address"]["addressLocality"],
75 'state': data["address"]["addressRegion"],
76 'postcode': data["address"]["postalCode"],
77 'country': data["address"]["addressCountry"],
78 'phone': data["address"].get("telephone"),
79 'website': data.get("url") or response.url,
80 'lat': float(data["geo"]["latitude"]),
81 'lon': float(data["geo"]["longitude"]),
82 }
83
84 hours = self.parse_hours(data["openingHours"])
85 if hours:
86 properties["opening_hours"] = hours
87
88 yield GeojsonPointItem(**properties)
89
90 def parse_city_stores(self, response):
91 stores = response.xpath('//div[@class="each-store"]')
92
93 for store in stores:
94
95 direction = store.xpath('normalize-space(.//span[@class="store-number"]/a/@href)').extract_first()
96 if direction:
97 yield scrapy.Request(response.urljoin(direction), callback=self.parse_stores)
98
99 def parse_state(self, response):
100 city_urls = response.xpath('//div[@class="states"]/ul/li/a/@href').extract()
101 for path in city_urls:
102 yield scrapy.Request(response.urljoin(path), callback=self.parse_city_stores)
103
104 def parse(self, response):
105 urls = response.xpath('//div[@class="states"]/ul/li/a/@href').extract()
106 for path in urls:
107 yield scrapy.Request(response.urljoin(path), callback=self.parse_state)
108
[end of locations/spiders/cvs.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/locations/spiders/cvs.py b/locations/spiders/cvs.py
--- a/locations/spiders/cvs.py
+++ b/locations/spiders/cvs.py
@@ -77,8 +77,8 @@
'country': data["address"]["addressCountry"],
'phone': data["address"].get("telephone"),
'website': data.get("url") or response.url,
- 'lat': float(data["geo"]["latitude"]),
- 'lon': float(data["geo"]["longitude"]),
+ 'lat': data["geo"]["latitude"] or None,
+ 'lon': data["geo"]["longitude"] or None,
}
hours = self.parse_hours(data["openingHours"])
| {"golden_diff": "diff --git a/locations/spiders/cvs.py b/locations/spiders/cvs.py\n--- a/locations/spiders/cvs.py\n+++ b/locations/spiders/cvs.py\n@@ -77,8 +77,8 @@\n 'country': data[\"address\"][\"addressCountry\"],\n 'phone': data[\"address\"].get(\"telephone\"),\n 'website': data.get(\"url\") or response.url,\n- 'lat': float(data[\"geo\"][\"latitude\"]),\n- 'lon': float(data[\"geo\"][\"longitude\"]),\n+ 'lat': data[\"geo\"][\"latitude\"] or None,\n+ 'lon': data[\"geo\"][\"longitude\"] or None,\n }\n \n hours = self.parse_hours(data[\"openingHours\"])\n", "issue": "Spider cvs is broken\nDuring the global build at 2021-08-18-14-42-26, spider **cvs** failed with **0 features** and **9870 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-08-18-14-42-26/logs/cvs.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-08-18-14-42-26/output/cvs.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-08-18-14-42-26/output/cvs.geojson))\n", "before_files": [{"content": "import json\nimport scrapy\nimport re\nfrom locations.items import GeojsonPointItem\nfrom locations.hours import OpeningHours\n\nDAYS = [\n 'Mo',\n 'Tu',\n 'We',\n 'Th',\n 'Fr',\n 'Sa',\n 'Su'\n]\n\n\nclass CVSSpider(scrapy.Spider):\n\n name = \"cvs\"\n item_attributes = { 'brand': \"CVS\", 'brand_wikidata': \"Q2078880\" }\n allowed_domains = [\"www.cvs.com\"]\n download_delay = 0.5\n start_urls = (\n 'https://www.cvs.com/store-locator/cvs-pharmacy-locations',\n )\n\n def parse_hours(self, hours):\n opening_hours = OpeningHours()\n\n for group in hours:\n if 'closed' in group:\n continue\n if 'open 24 hours' in group:\n days = re.search(r'([a-zA-Z\\-]+)\\s+open 24 hours', group).groups()[0]\n open_time, close_time = '00:00:00', '23:59:00'\n else:\n try:\n days, open_time, close_time = re.search(r'([a-zA-Z\\-]+)\\s+([\\d:\\sapm]+)-([\\d:\\sapm]+)', group).groups()\n except AttributeError:\n continue # no hours listed, just day\n try:\n start_day, end_day = days.split('-')\n except ValueError:\n start_day, end_day = days, days\n for day in DAYS[DAYS.index(start_day):DAYS.index(end_day) + 1]:\n if 'm' in open_time:\n open_time = open_time.strip(' apm') + \":00\"\n if 'm' in close_time:\n close_time = close_time.strip(' apm') + \":00\"\n opening_hours.add_range(day=day,\n open_time=open_time.strip(),\n close_time=close_time.strip(),\n time_format='%H:%M:%S')\n\n return opening_hours.as_opening_hours()\n\n def parse_stores(self, response):\n try:\n data = json.loads(response.xpath('//script[@type=\"application/ld+json\" and contains(text(), \"streetAddress\")]/text()').extract_first())[0]\n except json.decoder.JSONDecodeError:\n # one malformed json body on this store:\n # https://www.cvs.com/store-locator/cvs-pharmacy-address/84+South+Avenue+tops+Plaza+-Hilton-NY-14468/storeid=5076\n data = response.xpath('//script[@type=\"application/ld+json\" and contains(text(), \"streetAddress\")]/text()').extract_first()\n data = re.sub(r'\"tops Plaza\\s*\"', '', data)\n data = json.loads(data)[0]\n except TypeError:\n return # empty store page\n\n properties = {\n 'name': data[\"name\"],\n 'ref': re.search(r'.+/?storeid=(.+)', response.url).group(1),\n 'addr_full': data[\"address\"][\"streetAddress\"].strip(', '),\n 'city': data[\"address\"][\"addressLocality\"],\n 'state': data[\"address\"][\"addressRegion\"],\n 'postcode': data[\"address\"][\"postalCode\"],\n 'country': data[\"address\"][\"addressCountry\"],\n 'phone': data[\"address\"].get(\"telephone\"),\n 'website': data.get(\"url\") or response.url,\n 'lat': float(data[\"geo\"][\"latitude\"]),\n 'lon': float(data[\"geo\"][\"longitude\"]),\n }\n\n hours = self.parse_hours(data[\"openingHours\"])\n if hours:\n properties[\"opening_hours\"] = hours\n\n yield GeojsonPointItem(**properties)\n\n def parse_city_stores(self, response):\n stores = response.xpath('//div[@class=\"each-store\"]')\n\n for store in stores:\n\n direction = store.xpath('normalize-space(.//span[@class=\"store-number\"]/a/@href)').extract_first()\n if direction:\n yield scrapy.Request(response.urljoin(direction), callback=self.parse_stores)\n\n def parse_state(self, response):\n city_urls = response.xpath('//div[@class=\"states\"]/ul/li/a/@href').extract()\n for path in city_urls:\n yield scrapy.Request(response.urljoin(path), callback=self.parse_city_stores)\n\n def parse(self, response):\n urls = response.xpath('//div[@class=\"states\"]/ul/li/a/@href').extract()\n for path in urls:\n yield scrapy.Request(response.urljoin(path), callback=self.parse_state)\n", "path": "locations/spiders/cvs.py"}]} | 1,931 | 154 |
gh_patches_debug_40464 | rasdani/github-patches | git_diff | streamlink__streamlink-4729 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
plugins.picarto: Could not find server netloc
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest stable release
### Description
Plugin suddenly stopped working today.
Checked on multiple streams as well as on Linux and Windows 10 with the same result.
I can still manually watch the streams on VLC with "https://1-edge1-eu-west.picarto.tv/stream/hls/golive%2bUSERNAME/index.m3u8" as URL source.
### Debug log
```text
C:\PICARTO>streamlink https://picarto.tv/USERNAME best -l debug
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.10.5
[cli][debug] Streamlink: 4.2.0
[cli][debug] Dependencies:
[cli][debug] isodate: 0.6.1
[cli][debug] lxml: 4.9.1
[cli][debug] pycountry: 22.3.5
[cli][debug] pycryptodome: 3.15.0
[cli][debug] PySocks: 1.7.1
[cli][debug] requests: 2.28.1
[cli][debug] websocket-client: 1.3.3
[cli][debug] Arguments:
[cli][debug] url=https://picarto.tv/USERNAME
[cli][debug] stream=['best']
[cli][debug] --loglevel=debug
[cli][debug] --ffmpeg-ffmpeg=C:\Program Files\Streamlink\ffmpeg\ffmpeg.exe
[cli][info] Found matching plugin picarto for URL https://picarto.tv/USERNAME
[plugins.picarto][debug] Type=Live
[plugins.picarto][error] Could not find server netloc
error: No playable streams found on this URL: https://picarto.tv/USERNAME
```
</issue>
<code>
[start of src/streamlink/plugins/picarto.py]
1 """
2 $description Global live streaming and video hosting platform for the creative community.
3 $url picarto.tv
4 $type live, vod
5 """
6
7 import logging
8 import re
9 from urllib.parse import urlparse
10
11 from streamlink.plugin import Plugin, pluginmatcher
12 from streamlink.plugin.api import validate
13 from streamlink.stream.hls import HLSStream
14
15 log = logging.getLogger(__name__)
16
17
18 @pluginmatcher(re.compile(r"""
19 https?://(?:www\.)?picarto\.tv/
20 (?:
21 streampopout/(?P<po_user>[^/]+)/public
22 |
23 videopopout/(?P<po_vod_id>\d+)
24 |
25 [^/]+/videos/(?P<vod_id>\d+)
26 |
27 (?P<user>[^/?&]+)
28 )$
29 """, re.VERBOSE))
30 class Picarto(Plugin):
31 API_URL_LIVE = "https://ptvintern.picarto.tv/api/channel/detail/{username}"
32 API_URL_VOD = "https://ptvintern.picarto.tv/ptvapi"
33 HLS_URL = "https://{netloc}/stream/hls/{file_name}/index.m3u8"
34
35 def get_live(self, username):
36 netloc = self.session.http.get(self.url, schema=validate.Schema(
37 validate.parse_html(),
38 validate.xml_xpath_string(".//script[contains(@src,'/stream/player.js')][1]/@src"),
39 validate.any(None, validate.transform(lambda src: urlparse(src).netloc))
40 ))
41 if not netloc:
42 log.error("Could not find server netloc")
43 return
44
45 channel, multistreams = self.session.http.get(self.API_URL_LIVE.format(username=username), schema=validate.Schema(
46 validate.parse_json(),
47 {
48 "channel": validate.any(None, {
49 "stream_name": str,
50 "title": str,
51 "online": bool,
52 "private": bool,
53 "categories": [{"label": str}],
54 }),
55 "getMultiStreams": validate.any(None, {
56 "multistream": bool,
57 "streams": [{
58 "name": str,
59 "online": bool,
60 }],
61 }),
62 },
63 validate.union_get("channel", "getMultiStreams")
64 ))
65 if not channel or not multistreams:
66 log.debug("Missing channel or streaming data")
67 return
68
69 log.trace(f"netloc={netloc!r}")
70 log.trace(f"channel={channel!r}")
71 log.trace(f"multistreams={multistreams!r}")
72
73 if not channel["online"]:
74 log.error("User is not online")
75 return
76
77 if channel["private"]:
78 log.info("This is a private stream")
79 return
80
81 self.author = username
82 self.category = channel["categories"][0]["label"]
83 self.title = channel["title"]
84
85 hls_url = self.HLS_URL.format(
86 netloc=netloc,
87 file_name=channel["stream_name"]
88 )
89
90 return HLSStream.parse_variant_playlist(self.session, hls_url)
91
92 def get_vod(self, vod_id):
93 data = {
94 'query': (
95 'query ($videoId: ID!) {\n'
96 ' video(id: $videoId) {\n'
97 ' id\n'
98 ' title\n'
99 ' file_name\n'
100 ' video_recording_image_url\n'
101 ' channel {\n'
102 ' name\n'
103 ' }'
104 ' }\n'
105 '}\n'
106 ),
107 'variables': {'videoId': vod_id},
108 }
109 vod_data = self.session.http.post(self.API_URL_VOD, json=data, schema=validate.Schema(
110 validate.parse_json(),
111 {"data": {
112 "video": validate.any(None, {
113 "id": str,
114 "title": str,
115 "file_name": str,
116 "video_recording_image_url": str,
117 "channel": {"name": str},
118 }),
119 }},
120 validate.get(("data", "video"))
121 ))
122
123 if not vod_data:
124 log.debug("Missing video data")
125 return
126
127 log.trace(f"vod_data={vod_data!r}")
128
129 self.author = vod_data["channel"]["name"]
130 self.category = "VOD"
131 self.title = vod_data["title"]
132
133 netloc = urlparse(vod_data["video_recording_image_url"]).netloc
134 hls_url = self.HLS_URL.format(
135 netloc=netloc,
136 file_name=vod_data["file_name"]
137 )
138
139 return HLSStream.parse_variant_playlist(self.session, hls_url)
140
141 def _get_streams(self):
142 m = self.match.groupdict()
143
144 if m['po_vod_id'] or m['vod_id']:
145 log.debug('Type=VOD')
146 return self.get_vod(m['po_vod_id'] or m['vod_id'])
147 elif m['po_user'] or m['user']:
148 log.debug('Type=Live')
149 return self.get_live(m['po_user'] or m['user'])
150
151
152 __plugin__ = Picarto
153
[end of src/streamlink/plugins/picarto.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/streamlink/plugins/picarto.py b/src/streamlink/plugins/picarto.py
--- a/src/streamlink/plugins/picarto.py
+++ b/src/streamlink/plugins/picarto.py
@@ -33,40 +33,37 @@
HLS_URL = "https://{netloc}/stream/hls/{file_name}/index.m3u8"
def get_live(self, username):
- netloc = self.session.http.get(self.url, schema=validate.Schema(
- validate.parse_html(),
- validate.xml_xpath_string(".//script[contains(@src,'/stream/player.js')][1]/@src"),
- validate.any(None, validate.transform(lambda src: urlparse(src).netloc))
- ))
- if not netloc:
- log.error("Could not find server netloc")
- return
-
- channel, multistreams = self.session.http.get(self.API_URL_LIVE.format(username=username), schema=validate.Schema(
- validate.parse_json(),
- {
- "channel": validate.any(None, {
- "stream_name": str,
- "title": str,
- "online": bool,
- "private": bool,
- "categories": [{"label": str}],
- }),
- "getMultiStreams": validate.any(None, {
- "multistream": bool,
- "streams": [{
- "name": str,
+ channel, multistreams, loadbalancer = self.session.http.get(
+ self.API_URL_LIVE.format(username=username),
+ schema=validate.Schema(
+ validate.parse_json(),
+ {
+ "channel": validate.any(None, {
+ "stream_name": str,
+ "title": str,
"online": bool,
- }],
- }),
- },
- validate.union_get("channel", "getMultiStreams")
- ))
- if not channel or not multistreams:
+ "private": bool,
+ "categories": [{"label": str}],
+ }),
+ "getMultiStreams": validate.any(None, {
+ "multistream": bool,
+ "streams": [{
+ "name": str,
+ "online": bool,
+ }],
+ }),
+ "getLoadBalancerUrl": validate.any(None, {
+ "url": validate.any(None, validate.transform(lambda url: urlparse(url).netloc))
+ })
+ },
+ validate.union_get("channel", "getMultiStreams", "getLoadBalancerUrl"),
+ )
+ )
+ if not channel or not multistreams or not loadbalancer:
log.debug("Missing channel or streaming data")
return
- log.trace(f"netloc={netloc!r}")
+ log.trace(f"loadbalancer={loadbalancer!r}")
log.trace(f"channel={channel!r}")
log.trace(f"multistreams={multistreams!r}")
@@ -83,7 +80,7 @@
self.title = channel["title"]
hls_url = self.HLS_URL.format(
- netloc=netloc,
+ netloc=loadbalancer["url"],
file_name=channel["stream_name"]
)
@@ -110,7 +107,7 @@
validate.parse_json(),
{"data": {
"video": validate.any(None, {
- "id": str,
+ "id": int,
"title": str,
"file_name": str,
"video_recording_image_url": str,
| {"golden_diff": "diff --git a/src/streamlink/plugins/picarto.py b/src/streamlink/plugins/picarto.py\n--- a/src/streamlink/plugins/picarto.py\n+++ b/src/streamlink/plugins/picarto.py\n@@ -33,40 +33,37 @@\n HLS_URL = \"https://{netloc}/stream/hls/{file_name}/index.m3u8\"\n \n def get_live(self, username):\n- netloc = self.session.http.get(self.url, schema=validate.Schema(\n- validate.parse_html(),\n- validate.xml_xpath_string(\".//script[contains(@src,'/stream/player.js')][1]/@src\"),\n- validate.any(None, validate.transform(lambda src: urlparse(src).netloc))\n- ))\n- if not netloc:\n- log.error(\"Could not find server netloc\")\n- return\n-\n- channel, multistreams = self.session.http.get(self.API_URL_LIVE.format(username=username), schema=validate.Schema(\n- validate.parse_json(),\n- {\n- \"channel\": validate.any(None, {\n- \"stream_name\": str,\n- \"title\": str,\n- \"online\": bool,\n- \"private\": bool,\n- \"categories\": [{\"label\": str}],\n- }),\n- \"getMultiStreams\": validate.any(None, {\n- \"multistream\": bool,\n- \"streams\": [{\n- \"name\": str,\n+ channel, multistreams, loadbalancer = self.session.http.get(\n+ self.API_URL_LIVE.format(username=username),\n+ schema=validate.Schema(\n+ validate.parse_json(),\n+ {\n+ \"channel\": validate.any(None, {\n+ \"stream_name\": str,\n+ \"title\": str,\n \"online\": bool,\n- }],\n- }),\n- },\n- validate.union_get(\"channel\", \"getMultiStreams\")\n- ))\n- if not channel or not multistreams:\n+ \"private\": bool,\n+ \"categories\": [{\"label\": str}],\n+ }),\n+ \"getMultiStreams\": validate.any(None, {\n+ \"multistream\": bool,\n+ \"streams\": [{\n+ \"name\": str,\n+ \"online\": bool,\n+ }],\n+ }),\n+ \"getLoadBalancerUrl\": validate.any(None, {\n+ \"url\": validate.any(None, validate.transform(lambda url: urlparse(url).netloc))\n+ })\n+ },\n+ validate.union_get(\"channel\", \"getMultiStreams\", \"getLoadBalancerUrl\"),\n+ )\n+ )\n+ if not channel or not multistreams or not loadbalancer:\n log.debug(\"Missing channel or streaming data\")\n return\n \n- log.trace(f\"netloc={netloc!r}\")\n+ log.trace(f\"loadbalancer={loadbalancer!r}\")\n log.trace(f\"channel={channel!r}\")\n log.trace(f\"multistreams={multistreams!r}\")\n \n@@ -83,7 +80,7 @@\n self.title = channel[\"title\"]\n \n hls_url = self.HLS_URL.format(\n- netloc=netloc,\n+ netloc=loadbalancer[\"url\"],\n file_name=channel[\"stream_name\"]\n )\n \n@@ -110,7 +107,7 @@\n validate.parse_json(),\n {\"data\": {\n \"video\": validate.any(None, {\n- \"id\": str,\n+ \"id\": int,\n \"title\": str,\n \"file_name\": str,\n \"video_recording_image_url\": str,\n", "issue": "plugins.picarto: Could not find server netloc\n### Checklist\n\n- [X] This is a plugin issue and not a different kind of issue\n- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)\n- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)\n- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)\n\n### Streamlink version\n\nLatest stable release\n\n### Description\n\nPlugin suddenly stopped working today. \r\nChecked on multiple streams as well as on Linux and Windows 10 with the same result.\r\nI can still manually watch the streams on VLC with \"https://1-edge1-eu-west.picarto.tv/stream/hls/golive%2bUSERNAME/index.m3u8\" as URL source.\n\n### Debug log\n\n```text\nC:\\PICARTO>streamlink https://picarto.tv/USERNAME best -l debug\r\n[cli][debug] OS: Windows 10\r\n[cli][debug] Python: 3.10.5\r\n[cli][debug] Streamlink: 4.2.0\r\n[cli][debug] Dependencies:\r\n[cli][debug] isodate: 0.6.1\r\n[cli][debug] lxml: 4.9.1\r\n[cli][debug] pycountry: 22.3.5\r\n[cli][debug] pycryptodome: 3.15.0\r\n[cli][debug] PySocks: 1.7.1\r\n[cli][debug] requests: 2.28.1\r\n[cli][debug] websocket-client: 1.3.3\r\n[cli][debug] Arguments:\r\n[cli][debug] url=https://picarto.tv/USERNAME\r\n[cli][debug] stream=['best']\r\n[cli][debug] --loglevel=debug\r\n[cli][debug] --ffmpeg-ffmpeg=C:\\Program Files\\Streamlink\\ffmpeg\\ffmpeg.exe\r\n[cli][info] Found matching plugin picarto for URL https://picarto.tv/USERNAME\r\n[plugins.picarto][debug] Type=Live\r\n[plugins.picarto][error] Could not find server netloc\r\nerror: No playable streams found on this URL: https://picarto.tv/USERNAME\n```\n\n", "before_files": [{"content": "\"\"\"\n$description Global live streaming and video hosting platform for the creative community.\n$url picarto.tv\n$type live, vod\n\"\"\"\n\nimport logging\nimport re\nfrom urllib.parse import urlparse\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream.hls import HLSStream\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(r\"\"\"\n https?://(?:www\\.)?picarto\\.tv/\n (?:\n streampopout/(?P<po_user>[^/]+)/public\n |\n videopopout/(?P<po_vod_id>\\d+)\n |\n [^/]+/videos/(?P<vod_id>\\d+)\n |\n (?P<user>[^/?&]+)\n )$\n\"\"\", re.VERBOSE))\nclass Picarto(Plugin):\n API_URL_LIVE = \"https://ptvintern.picarto.tv/api/channel/detail/{username}\"\n API_URL_VOD = \"https://ptvintern.picarto.tv/ptvapi\"\n HLS_URL = \"https://{netloc}/stream/hls/{file_name}/index.m3u8\"\n\n def get_live(self, username):\n netloc = self.session.http.get(self.url, schema=validate.Schema(\n validate.parse_html(),\n validate.xml_xpath_string(\".//script[contains(@src,'/stream/player.js')][1]/@src\"),\n validate.any(None, validate.transform(lambda src: urlparse(src).netloc))\n ))\n if not netloc:\n log.error(\"Could not find server netloc\")\n return\n\n channel, multistreams = self.session.http.get(self.API_URL_LIVE.format(username=username), schema=validate.Schema(\n validate.parse_json(),\n {\n \"channel\": validate.any(None, {\n \"stream_name\": str,\n \"title\": str,\n \"online\": bool,\n \"private\": bool,\n \"categories\": [{\"label\": str}],\n }),\n \"getMultiStreams\": validate.any(None, {\n \"multistream\": bool,\n \"streams\": [{\n \"name\": str,\n \"online\": bool,\n }],\n }),\n },\n validate.union_get(\"channel\", \"getMultiStreams\")\n ))\n if not channel or not multistreams:\n log.debug(\"Missing channel or streaming data\")\n return\n\n log.trace(f\"netloc={netloc!r}\")\n log.trace(f\"channel={channel!r}\")\n log.trace(f\"multistreams={multistreams!r}\")\n\n if not channel[\"online\"]:\n log.error(\"User is not online\")\n return\n\n if channel[\"private\"]:\n log.info(\"This is a private stream\")\n return\n\n self.author = username\n self.category = channel[\"categories\"][0][\"label\"]\n self.title = channel[\"title\"]\n\n hls_url = self.HLS_URL.format(\n netloc=netloc,\n file_name=channel[\"stream_name\"]\n )\n\n return HLSStream.parse_variant_playlist(self.session, hls_url)\n\n def get_vod(self, vod_id):\n data = {\n 'query': (\n 'query ($videoId: ID!) {\\n'\n ' video(id: $videoId) {\\n'\n ' id\\n'\n ' title\\n'\n ' file_name\\n'\n ' video_recording_image_url\\n'\n ' channel {\\n'\n ' name\\n'\n ' }'\n ' }\\n'\n '}\\n'\n ),\n 'variables': {'videoId': vod_id},\n }\n vod_data = self.session.http.post(self.API_URL_VOD, json=data, schema=validate.Schema(\n validate.parse_json(),\n {\"data\": {\n \"video\": validate.any(None, {\n \"id\": str,\n \"title\": str,\n \"file_name\": str,\n \"video_recording_image_url\": str,\n \"channel\": {\"name\": str},\n }),\n }},\n validate.get((\"data\", \"video\"))\n ))\n\n if not vod_data:\n log.debug(\"Missing video data\")\n return\n\n log.trace(f\"vod_data={vod_data!r}\")\n\n self.author = vod_data[\"channel\"][\"name\"]\n self.category = \"VOD\"\n self.title = vod_data[\"title\"]\n\n netloc = urlparse(vod_data[\"video_recording_image_url\"]).netloc\n hls_url = self.HLS_URL.format(\n netloc=netloc,\n file_name=vod_data[\"file_name\"]\n )\n\n return HLSStream.parse_variant_playlist(self.session, hls_url)\n\n def _get_streams(self):\n m = self.match.groupdict()\n\n if m['po_vod_id'] or m['vod_id']:\n log.debug('Type=VOD')\n return self.get_vod(m['po_vod_id'] or m['vod_id'])\n elif m['po_user'] or m['user']:\n log.debug('Type=Live')\n return self.get_live(m['po_user'] or m['user'])\n\n\n__plugin__ = Picarto\n", "path": "src/streamlink/plugins/picarto.py"}]} | 2,537 | 760 |
gh_patches_debug_25010 | rasdani/github-patches | git_diff | beetbox__beets-908 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
mbsync: Deal with albums that have multiple copies of the same recording
the current way mbsync plugin used to obtain track mapping list is to use the MusicBrainz recoding ID from each track, it's a workaround to handle "missing or extra tracks". This method is based on an assumption that for each MB release, there are no multiple tracks with same MB recording ID. It usually works, and in my case, only 4 out of 700+ albums disobey this assumption. But for this four albums, I have to fix them by tag track number by hand and re-import.
Considering it's called "mbsync", Why not make an assumption that track number in metadata is not corrupt and use it if possible, or fallback to MB recording ID way if it's corrupted(missing or extra track detected)
</issue>
<code>
[start of beetsplug/mbsync.py]
1 # This file is part of beets.
2 # Copyright 2014, Jakob Schnitzer.
3 #
4 # Permission is hereby granted, free of charge, to any person obtaining
5 # a copy of this software and associated documentation files (the
6 # "Software"), to deal in the Software without restriction, including
7 # without limitation the rights to use, copy, modify, merge, publish,
8 # distribute, sublicense, and/or sell copies of the Software, and to
9 # permit persons to whom the Software is furnished to do so, subject to
10 # the following conditions:
11 #
12 # The above copyright notice and this permission notice shall be
13 # included in all copies or substantial portions of the Software.
14
15 """Update library's tags using MusicBrainz.
16 """
17 import logging
18
19 from beets.plugins import BeetsPlugin
20 from beets import autotag, library, ui, util
21 from beets.autotag import hooks
22 from beets import config
23
24 log = logging.getLogger('beets')
25
26
27 def mbsync_singletons(lib, query, move, pretend, write):
28 """Retrieve and apply info from the autotagger for items matched by
29 query.
30 """
31 for item in lib.items(query + ['singleton:true']):
32 if not item.mb_trackid:
33 log.info(u'Skipping singleton {0}: has no mb_trackid'
34 .format(item.title))
35 continue
36
37 # Get the MusicBrainz recording info.
38 track_info = hooks.track_for_mbid(item.mb_trackid)
39 if not track_info:
40 log.info(u'Recording ID not found: {0}'.format(item.mb_trackid))
41 continue
42
43 # Apply.
44 with lib.transaction():
45 autotag.apply_item_metadata(item, track_info)
46 apply_item_changes(lib, item, move, pretend, write)
47
48
49 def mbsync_albums(lib, query, move, pretend, write):
50 """Retrieve and apply info from the autotagger for albums matched by
51 query and their items.
52 """
53 # Process matching albums.
54 for a in lib.albums(query):
55 if not a.mb_albumid:
56 log.info(u'Skipping album {0}: has no mb_albumid'.format(a.id))
57 continue
58
59 items = list(a.items())
60
61 # Get the MusicBrainz album information.
62 album_info = hooks.album_for_mbid(a.mb_albumid)
63 if not album_info:
64 log.info(u'Release ID not found: {0}'.format(a.mb_albumid))
65 continue
66
67 # Construct a track mapping according to MBIDs. This should work
68 # for albums that have missing or extra tracks.
69 mapping = {}
70 for item in items:
71 for track_info in album_info.tracks:
72 if item.mb_trackid == track_info.track_id:
73 mapping[item] = track_info
74 break
75
76 # Apply.
77 with lib.transaction():
78 autotag.apply_metadata(album_info, mapping)
79 changed = False
80 for item in items:
81 item_changed = ui.show_model_changes(item)
82 changed |= item_changed
83 if item_changed:
84 apply_item_changes(lib, item, move, pretend, write)
85
86 if not changed:
87 # No change to any item.
88 continue
89
90 if not pretend:
91 # Update album structure to reflect an item in it.
92 for key in library.Album.item_keys:
93 a[key] = items[0][key]
94 a.store()
95
96 # Move album art (and any inconsistent items).
97 if move and lib.directory in util.ancestry(items[0].path):
98 log.debug(u'moving album {0}'.format(a.id))
99 a.move()
100
101
102 def apply_item_changes(lib, item, move, pretend, write):
103 """Store, move and write the item according to the arguments.
104 """
105 if not pretend:
106 # Move the item if it's in the library.
107 if move and lib.directory in util.ancestry(item.path):
108 item.move(with_album=False)
109
110 if write:
111 item.try_write()
112 item.store()
113
114
115 def mbsync_func(lib, opts, args):
116 """Command handler for the mbsync function.
117 """
118 move = opts.move
119 pretend = opts.pretend
120 write = opts.write
121 query = ui.decargs(args)
122
123 mbsync_singletons(lib, query, move, pretend, write)
124 mbsync_albums(lib, query, move, pretend, write)
125
126
127 class MBSyncPlugin(BeetsPlugin):
128 def __init__(self):
129 super(MBSyncPlugin, self).__init__()
130
131 def commands(self):
132 cmd = ui.Subcommand('mbsync',
133 help='update metadata from musicbrainz')
134 cmd.parser.add_option('-p', '--pretend', action='store_true',
135 help='show all changes but do nothing')
136 cmd.parser.add_option('-M', '--nomove', action='store_false',
137 default=True, dest='move',
138 help="don't move files in library")
139 cmd.parser.add_option('-W', '--nowrite', action='store_false',
140 default=config['import']['write'], dest='write',
141 help="don't write updated metadata to files")
142 cmd.func = mbsync_func
143 return [cmd]
144
[end of beetsplug/mbsync.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/beetsplug/mbsync.py b/beetsplug/mbsync.py
--- a/beetsplug/mbsync.py
+++ b/beetsplug/mbsync.py
@@ -64,13 +64,29 @@
log.info(u'Release ID not found: {0}'.format(a.mb_albumid))
continue
+ # Construct an hash mapping recording MBIDs to their information. A
+ # release can have recording MBIDs that appear multiple times in the
+ # same release.
+ track_index = {}
+ for track_info in album_info.tracks:
+ if track_info.track_id in track_index:
+ track_index[track_info.track_id].append(track_info)
+ else:
+ track_index[track_info.track_id] = [track_info]
+
# Construct a track mapping according to MBIDs. This should work
- # for albums that have missing or extra tracks.
+ # for albums that have missing or extra tracks. If a mapping is
+ # ambiguous, the items' disc and track number need to match in order
+ # for an item to be mapped.
mapping = {}
for item in items:
- for track_info in album_info.tracks:
- if item.mb_trackid == track_info.track_id:
- mapping[item] = track_info
+ candidates = track_index.get(item.mb_trackid, [])
+ if len(candidates) == 1:
+ mapping[item] = candidates[0]
+ continue
+ for c in candidates:
+ if c.medium_index == item.track and c.medium == item.disc:
+ mapping[item] = c
break
# Apply.
| {"golden_diff": "diff --git a/beetsplug/mbsync.py b/beetsplug/mbsync.py\n--- a/beetsplug/mbsync.py\n+++ b/beetsplug/mbsync.py\n@@ -64,13 +64,29 @@\n log.info(u'Release ID not found: {0}'.format(a.mb_albumid))\n continue\n \n+ # Construct an hash mapping recording MBIDs to their information. A\n+ # release can have recording MBIDs that appear multiple times in the\n+ # same release.\n+ track_index = {}\n+ for track_info in album_info.tracks:\n+ if track_info.track_id in track_index:\n+ track_index[track_info.track_id].append(track_info)\n+ else:\n+ track_index[track_info.track_id] = [track_info]\n+\n # Construct a track mapping according to MBIDs. This should work\n- # for albums that have missing or extra tracks.\n+ # for albums that have missing or extra tracks. If a mapping is\n+ # ambiguous, the items' disc and track number need to match in order\n+ # for an item to be mapped.\n mapping = {}\n for item in items:\n- for track_info in album_info.tracks:\n- if item.mb_trackid == track_info.track_id:\n- mapping[item] = track_info\n+ candidates = track_index.get(item.mb_trackid, [])\n+ if len(candidates) == 1:\n+ mapping[item] = candidates[0]\n+ continue\n+ for c in candidates:\n+ if c.medium_index == item.track and c.medium == item.disc:\n+ mapping[item] = c\n break\n \n # Apply.\n", "issue": "mbsync: Deal with albums that have multiple copies of the same recording\nthe current way mbsync plugin used to obtain track mapping list is to use the MusicBrainz recoding ID from each track, it's a workaround to handle \"missing or extra tracks\". This method is based on an assumption that for each MB release, there are no multiple tracks with same MB recording ID. It usually works, and in my case, only 4 out of 700+ albums disobey this assumption. But for this four albums, I have to fix them by tag track number by hand and re-import.\n\nConsidering it's called \"mbsync\", Why not make an assumption that track number in metadata is not corrupt and use it if possible, or fallback to MB recording ID way if it's corrupted(missing or extra track detected)\n\n", "before_files": [{"content": "# This file is part of beets.\n# Copyright 2014, Jakob Schnitzer.\n#\n# Permission is hereby granted, free of charge, to any person obtaining\n# a copy of this software and associated documentation files (the\n# \"Software\"), to deal in the Software without restriction, including\n# without limitation the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the Software, and to\n# permit persons to whom the Software is furnished to do so, subject to\n# the following conditions:\n#\n# The above copyright notice and this permission notice shall be\n# included in all copies or substantial portions of the Software.\n\n\"\"\"Update library's tags using MusicBrainz.\n\"\"\"\nimport logging\n\nfrom beets.plugins import BeetsPlugin\nfrom beets import autotag, library, ui, util\nfrom beets.autotag import hooks\nfrom beets import config\n\nlog = logging.getLogger('beets')\n\n\ndef mbsync_singletons(lib, query, move, pretend, write):\n \"\"\"Retrieve and apply info from the autotagger for items matched by\n query.\n \"\"\"\n for item in lib.items(query + ['singleton:true']):\n if not item.mb_trackid:\n log.info(u'Skipping singleton {0}: has no mb_trackid'\n .format(item.title))\n continue\n\n # Get the MusicBrainz recording info.\n track_info = hooks.track_for_mbid(item.mb_trackid)\n if not track_info:\n log.info(u'Recording ID not found: {0}'.format(item.mb_trackid))\n continue\n\n # Apply.\n with lib.transaction():\n autotag.apply_item_metadata(item, track_info)\n apply_item_changes(lib, item, move, pretend, write)\n\n\ndef mbsync_albums(lib, query, move, pretend, write):\n \"\"\"Retrieve and apply info from the autotagger for albums matched by\n query and their items.\n \"\"\"\n # Process matching albums.\n for a in lib.albums(query):\n if not a.mb_albumid:\n log.info(u'Skipping album {0}: has no mb_albumid'.format(a.id))\n continue\n\n items = list(a.items())\n\n # Get the MusicBrainz album information.\n album_info = hooks.album_for_mbid(a.mb_albumid)\n if not album_info:\n log.info(u'Release ID not found: {0}'.format(a.mb_albumid))\n continue\n\n # Construct a track mapping according to MBIDs. This should work\n # for albums that have missing or extra tracks.\n mapping = {}\n for item in items:\n for track_info in album_info.tracks:\n if item.mb_trackid == track_info.track_id:\n mapping[item] = track_info\n break\n\n # Apply.\n with lib.transaction():\n autotag.apply_metadata(album_info, mapping)\n changed = False\n for item in items:\n item_changed = ui.show_model_changes(item)\n changed |= item_changed\n if item_changed:\n apply_item_changes(lib, item, move, pretend, write)\n\n if not changed:\n # No change to any item.\n continue\n\n if not pretend:\n # Update album structure to reflect an item in it.\n for key in library.Album.item_keys:\n a[key] = items[0][key]\n a.store()\n\n # Move album art (and any inconsistent items).\n if move and lib.directory in util.ancestry(items[0].path):\n log.debug(u'moving album {0}'.format(a.id))\n a.move()\n\n\ndef apply_item_changes(lib, item, move, pretend, write):\n \"\"\"Store, move and write the item according to the arguments.\n \"\"\"\n if not pretend:\n # Move the item if it's in the library.\n if move and lib.directory in util.ancestry(item.path):\n item.move(with_album=False)\n\n if write:\n item.try_write()\n item.store()\n\n\ndef mbsync_func(lib, opts, args):\n \"\"\"Command handler for the mbsync function.\n \"\"\"\n move = opts.move\n pretend = opts.pretend\n write = opts.write\n query = ui.decargs(args)\n\n mbsync_singletons(lib, query, move, pretend, write)\n mbsync_albums(lib, query, move, pretend, write)\n\n\nclass MBSyncPlugin(BeetsPlugin):\n def __init__(self):\n super(MBSyncPlugin, self).__init__()\n\n def commands(self):\n cmd = ui.Subcommand('mbsync',\n help='update metadata from musicbrainz')\n cmd.parser.add_option('-p', '--pretend', action='store_true',\n help='show all changes but do nothing')\n cmd.parser.add_option('-M', '--nomove', action='store_false',\n default=True, dest='move',\n help=\"don't move files in library\")\n cmd.parser.add_option('-W', '--nowrite', action='store_false',\n default=config['import']['write'], dest='write',\n help=\"don't write updated metadata to files\")\n cmd.func = mbsync_func\n return [cmd]\n", "path": "beetsplug/mbsync.py"}]} | 2,151 | 365 |
gh_patches_debug_38226 | rasdani/github-patches | git_diff | TabbycatDebate__tabbycat-1644 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Preformed panels supporting outrounds
I have been having a play with preformed panels and from my quick attempt to generate them for outrounds, it seems to generate preformed panels as if it was generating panels for an additional preliminary round rather than a break round.
For example this is the preformed panels that generated when I generated preformed panels for quarter finals for one of our tournaments.

We did end up changing some thing to do with the round sequence for these rounds (we added 2 additional in rounds, deleted the octo finals and edited the sequence numbers, but this round is set up as per the settings below:

</issue>
<code>
[start of tabbycat/adjallocation/preformed/anticipated.py]
1 """Functions for computing an anticipated draw."""
2
3 import itertools
4
5 from breakqual.utils import calculate_live_thresholds, determine_liveness
6 from participants.prefetch import populate_win_counts
7
8
9 def calculate_anticipated_draw(round):
10 """Calculates an anticipated draw for the next round, based on the draw for
11 the last round. Returns a list of tuples
12 `(bracket_min, bracket_max, liveness)`,
13 being the minimum and maximum brackets possible for that room, and the
14 maximum number of teams that might be live in it. If the previous round's
15 draw doesn't exist, it will just return an empty list.
16
17 Procedure:
18 1. Take the (actual) draw of the last round, with team points
19 2. For each room, compute a (min, max) of outcomes for each team.
20 3. Take the min, divide into rooms to make the `bracket_min` for each room.
21 4. Take the max, divide into rooms to make the `bracket_max` for each room.
22
23 `round` should be the round for which you want an anticipated draw (the
24 "next round").
25 """
26
27 nteamsindebate = 4 if round.tournament.pref('teams_in_debate') == 'bp' else 2
28
29 if round.prev is None or not round.prev.debate_set.exists():
30 # Special case: If this is the first round, everyone will be on zero.
31 # Just take all teams, rounded down -- if this is done, it'll typically
32 # be done before availability is locked down. Also do this if the last
33 # round hasn't yet been drawn, since that's premature for bracket
34 # predictions.
35 npanels = round.tournament.team_set.count() // nteamsindebate
36 return [(0, 0, 0) for i in range(npanels)]
37
38 # 1. Take the (actual) draw of the last round, with team points
39 debates = round.prev.debate_set_with_prefetches(ordering=('room_rank',),
40 teams=True, adjudicators=False, speakers=False, venues=False)
41 if round.prev.prev:
42 populate_win_counts([team for debate in debates for team in debate.teams],
43 round=round.prev.prev)
44 else:
45 # just say everyone is on zero (since no rounds have finished yet)
46 for debate in debates:
47 for team in debate.teams:
48 team._points = 0
49
50 # 2. Compute a (min, max) of outcomes for each team
51 team_points_after = []
52 points_available = [round.prev.weight * i for i in range(nteamsindebate)]
53 for debate in debates:
54 points_now = [team.points_count for team in debate.teams]
55 highest = max(points_now)
56 lowest = min(points_now)
57
58 # Most cases will be single-point rooms or rooms with pull-ups from only
59 # one bracket; in these cases it's easy to prove this closed-form
60 # guarantee for what the teams in that room will look like afterwards.
61 if highest - lowest <= 1:
62 points_after = [(lowest+i, highest+i) for i in points_available]
63
64 # For more complicated rooms (e.g. [9, 8, 8, 7]), it gets harder; just
65 # use brute force. For few enough rooms this won't be too bad a hit.
66 else:
67 possible_outcomes = []
68 for result in itertools.permutations(points_available):
69 outcome = [n + r for n, r in zip(points_now, result)]
70 outcome.sort(reverse=True)
71 possible_outcomes.append(outcome)
72 points_after = [(min(team_after), max(team_after)) for team_after in zip(*possible_outcomes)]
73
74 team_points_after.extend(points_after)
75
76 # 3. Take the min, divide into rooms to make the `bracket_min` for each room.
77 # 4. Take the max, divide into rooms to make the `bracket_max` for each room.
78 lowers, uppers = [sorted(x, reverse=True) for x in zip(*team_points_after)]
79 brackets_min = [max(r) for r in zip(*([iter(lowers)] * nteamsindebate))]
80 brackets_max = [max(r) for r in zip(*([iter(uppers)] * nteamsindebate))]
81
82 open_category = round.tournament.breakcategory_set.filter(is_general=True).first()
83 if open_category:
84 live_thresholds = calculate_live_thresholds(open_category, round.tournament, round)
85 liveness_by_lower = [determine_liveness(live_thresholds, x) for x in lowers]
86 liveness_by_upper = [determine_liveness(live_thresholds, x) for x in uppers]
87 liveness_by_team = [x == 'live' or y == 'live' for x, y in zip(liveness_by_lower, liveness_by_upper)]
88 liveness = [x.count(True) for x in zip(*([iter(liveness_by_team)] * nteamsindebate))]
89 else:
90 liveness = [0] * len(debates)
91
92 return zip(brackets_min, brackets_max, liveness)
93
[end of tabbycat/adjallocation/preformed/anticipated.py]
[start of tabbycat/draw/generator/utils.py]
1 """Miscellaneous utilities for the draw."""
2
3
4 def ispow2(n):
5 """Returns True if n is a power of 2. Works for positive integers only."""
6 return n & (n - 1) == 0
7
8
9 def nextpow2(n):
10 return 1 << (n-1).bit_length()
11
12
13 def partial_break_round_split(break_size):
14 """Returns a tuple `(debating, bypassing)`, where `debating` is how many
15 teams will debate in the first break round, and `bypassing` is how many
16 teams will bypass the first break round, qualifying directly for the
17 second."""
18
19 assert break_size > 1, "break rounds only make sense for break_size > 1 (found %d)" % (break_size,)
20
21 teams_in_second_break_round = nextpow2(break_size) // 2
22 debates = break_size - teams_in_second_break_round
23 bypassing = teams_in_second_break_round - debates
24
25 assert 2*debates + bypassing == break_size, "2 * %d teams debating + %d teams bypassing doesn't add to break size %d" % (debates, bypassing, break_size)
26 assert debates > 0, "%d <= 0 debates in first break round (%d teams bypassing)" % (debates, bypassing)
27 assert bypassing >= 0, "%d < 0 teams bypassing (%d debates)" % (bypassing, debates)
28 return debates, bypassing
29
[end of tabbycat/draw/generator/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/tabbycat/adjallocation/preformed/anticipated.py b/tabbycat/adjallocation/preformed/anticipated.py
--- a/tabbycat/adjallocation/preformed/anticipated.py
+++ b/tabbycat/adjallocation/preformed/anticipated.py
@@ -3,6 +3,7 @@
import itertools
from breakqual.utils import calculate_live_thresholds, determine_liveness
+from draw.generator.utils import ispow2, partial_break_round_split
from participants.prefetch import populate_win_counts
@@ -26,13 +27,35 @@
nteamsindebate = 4 if round.tournament.pref('teams_in_debate') == 'bp' else 2
- if round.prev is None or not round.prev.debate_set.exists():
- # Special case: If this is the first round, everyone will be on zero.
+ if round.prev is None or not round.prev.debate_set.exists() or round.is_break_round:
+ # Special cases: If this is the first round, everyone will be on zero.
# Just take all teams, rounded down -- if this is done, it'll typically
# be done before availability is locked down. Also do this if the last
# round hasn't yet been drawn, since that's premature for bracket
# predictions.
- npanels = round.tournament.team_set.count() // nteamsindebate
+ #
+ # Also occurs for elimination rounds as everyone is just as live.
+
+ nteams = 0
+ if round.is_break_round:
+ break_size = round.break_category.break_size
+ nprev_rounds = round.break_category.round_set.filter(seq__lt=round.seq).count()
+ partial_two = nteamsindebate == 2 and not ispow2(break_size)
+ partial_bp = nteamsindebate == 4 and ispow2(break_size // 6)
+ if nprev_rounds > 0 and (partial_two or partial_bp):
+ # If using partial elimination rounds, the second round is the first for
+ # the powers of two, so start counting from here.
+ nprev_rounds -= 1
+
+ if nprev_rounds == 0 and nteamsindebate == 2:
+ nteams = partial_break_round_split(break_size)[0] * 2
+ else:
+ # Subsequent rounds are half the previous, but always a power of 2
+ nteams = 1 << (break_size.bit_length() - 1 - nprev_rounds)
+ else:
+ nteams = round.tournament.team_set.count()
+
+ npanels = nteams // nteamsindebate
return [(0, 0, 0) for i in range(npanels)]
# 1. Take the (actual) draw of the last round, with team points
diff --git a/tabbycat/draw/generator/utils.py b/tabbycat/draw/generator/utils.py
--- a/tabbycat/draw/generator/utils.py
+++ b/tabbycat/draw/generator/utils.py
@@ -11,8 +11,8 @@
def partial_break_round_split(break_size):
- """Returns a tuple `(debating, bypassing)`, where `debating` is how many
- teams will debate in the first break round, and `bypassing` is how many
+ """Returns a tuple `(debates, bypassing)`, where `debating` is how many
+ debates there is in the first break round, and `bypassing` is how many
teams will bypass the first break round, qualifying directly for the
second."""
| {"golden_diff": "diff --git a/tabbycat/adjallocation/preformed/anticipated.py b/tabbycat/adjallocation/preformed/anticipated.py\n--- a/tabbycat/adjallocation/preformed/anticipated.py\n+++ b/tabbycat/adjallocation/preformed/anticipated.py\n@@ -3,6 +3,7 @@\n import itertools\n \n from breakqual.utils import calculate_live_thresholds, determine_liveness\n+from draw.generator.utils import ispow2, partial_break_round_split\n from participants.prefetch import populate_win_counts\n \n \n@@ -26,13 +27,35 @@\n \n nteamsindebate = 4 if round.tournament.pref('teams_in_debate') == 'bp' else 2\n \n- if round.prev is None or not round.prev.debate_set.exists():\n- # Special case: If this is the first round, everyone will be on zero.\n+ if round.prev is None or not round.prev.debate_set.exists() or round.is_break_round:\n+ # Special cases: If this is the first round, everyone will be on zero.\n # Just take all teams, rounded down -- if this is done, it'll typically\n # be done before availability is locked down. Also do this if the last\n # round hasn't yet been drawn, since that's premature for bracket\n # predictions.\n- npanels = round.tournament.team_set.count() // nteamsindebate\n+ #\n+ # Also occurs for elimination rounds as everyone is just as live.\n+\n+ nteams = 0\n+ if round.is_break_round:\n+ break_size = round.break_category.break_size\n+ nprev_rounds = round.break_category.round_set.filter(seq__lt=round.seq).count()\n+ partial_two = nteamsindebate == 2 and not ispow2(break_size)\n+ partial_bp = nteamsindebate == 4 and ispow2(break_size // 6)\n+ if nprev_rounds > 0 and (partial_two or partial_bp):\n+ # If using partial elimination rounds, the second round is the first for\n+ # the powers of two, so start counting from here.\n+ nprev_rounds -= 1\n+\n+ if nprev_rounds == 0 and nteamsindebate == 2:\n+ nteams = partial_break_round_split(break_size)[0] * 2\n+ else:\n+ # Subsequent rounds are half the previous, but always a power of 2\n+ nteams = 1 << (break_size.bit_length() - 1 - nprev_rounds)\n+ else:\n+ nteams = round.tournament.team_set.count()\n+\n+ npanels = nteams // nteamsindebate\n return [(0, 0, 0) for i in range(npanels)]\n \n # 1. Take the (actual) draw of the last round, with team points\ndiff --git a/tabbycat/draw/generator/utils.py b/tabbycat/draw/generator/utils.py\n--- a/tabbycat/draw/generator/utils.py\n+++ b/tabbycat/draw/generator/utils.py\n@@ -11,8 +11,8 @@\n \n \n def partial_break_round_split(break_size):\n- \"\"\"Returns a tuple `(debating, bypassing)`, where `debating` is how many\n- teams will debate in the first break round, and `bypassing` is how many\n+ \"\"\"Returns a tuple `(debates, bypassing)`, where `debating` is how many\n+ debates there is in the first break round, and `bypassing` is how many\n teams will bypass the first break round, qualifying directly for the\n second.\"\"\"\n", "issue": "Preformed panels supporting outrounds\nI have been having a play with preformed panels and from my quick attempt to generate them for outrounds, it seems to generate preformed panels as if it was generating panels for an additional preliminary round rather than a break round. \r\n\r\nFor example this is the preformed panels that generated when I generated preformed panels for quarter finals for one of our tournaments.\r\n\r\n\r\n\r\nWe did end up changing some thing to do with the round sequence for these rounds (we added 2 additional in rounds, deleted the octo finals and edited the sequence numbers, but this round is set up as per the settings below:\r\n\r\n\r\n\n", "before_files": [{"content": "\"\"\"Functions for computing an anticipated draw.\"\"\"\n\nimport itertools\n\nfrom breakqual.utils import calculate_live_thresholds, determine_liveness\nfrom participants.prefetch import populate_win_counts\n\n\ndef calculate_anticipated_draw(round):\n \"\"\"Calculates an anticipated draw for the next round, based on the draw for\n the last round. Returns a list of tuples\n `(bracket_min, bracket_max, liveness)`,\n being the minimum and maximum brackets possible for that room, and the\n maximum number of teams that might be live in it. If the previous round's\n draw doesn't exist, it will just return an empty list.\n\n Procedure:\n 1. Take the (actual) draw of the last round, with team points\n 2. For each room, compute a (min, max) of outcomes for each team.\n 3. Take the min, divide into rooms to make the `bracket_min` for each room.\n 4. Take the max, divide into rooms to make the `bracket_max` for each room.\n\n `round` should be the round for which you want an anticipated draw (the\n \"next round\").\n \"\"\"\n\n nteamsindebate = 4 if round.tournament.pref('teams_in_debate') == 'bp' else 2\n\n if round.prev is None or not round.prev.debate_set.exists():\n # Special case: If this is the first round, everyone will be on zero.\n # Just take all teams, rounded down -- if this is done, it'll typically\n # be done before availability is locked down. Also do this if the last\n # round hasn't yet been drawn, since that's premature for bracket\n # predictions.\n npanels = round.tournament.team_set.count() // nteamsindebate\n return [(0, 0, 0) for i in range(npanels)]\n\n # 1. Take the (actual) draw of the last round, with team points\n debates = round.prev.debate_set_with_prefetches(ordering=('room_rank',),\n teams=True, adjudicators=False, speakers=False, venues=False)\n if round.prev.prev:\n populate_win_counts([team for debate in debates for team in debate.teams],\n round=round.prev.prev)\n else:\n # just say everyone is on zero (since no rounds have finished yet)\n for debate in debates:\n for team in debate.teams:\n team._points = 0\n\n # 2. Compute a (min, max) of outcomes for each team\n team_points_after = []\n points_available = [round.prev.weight * i for i in range(nteamsindebate)]\n for debate in debates:\n points_now = [team.points_count for team in debate.teams]\n highest = max(points_now)\n lowest = min(points_now)\n\n # Most cases will be single-point rooms or rooms with pull-ups from only\n # one bracket; in these cases it's easy to prove this closed-form\n # guarantee for what the teams in that room will look like afterwards.\n if highest - lowest <= 1:\n points_after = [(lowest+i, highest+i) for i in points_available]\n\n # For more complicated rooms (e.g. [9, 8, 8, 7]), it gets harder; just\n # use brute force. For few enough rooms this won't be too bad a hit.\n else:\n possible_outcomes = []\n for result in itertools.permutations(points_available):\n outcome = [n + r for n, r in zip(points_now, result)]\n outcome.sort(reverse=True)\n possible_outcomes.append(outcome)\n points_after = [(min(team_after), max(team_after)) for team_after in zip(*possible_outcomes)]\n\n team_points_after.extend(points_after)\n\n # 3. Take the min, divide into rooms to make the `bracket_min` for each room.\n # 4. Take the max, divide into rooms to make the `bracket_max` for each room.\n lowers, uppers = [sorted(x, reverse=True) for x in zip(*team_points_after)]\n brackets_min = [max(r) for r in zip(*([iter(lowers)] * nteamsindebate))]\n brackets_max = [max(r) for r in zip(*([iter(uppers)] * nteamsindebate))]\n\n open_category = round.tournament.breakcategory_set.filter(is_general=True).first()\n if open_category:\n live_thresholds = calculate_live_thresholds(open_category, round.tournament, round)\n liveness_by_lower = [determine_liveness(live_thresholds, x) for x in lowers]\n liveness_by_upper = [determine_liveness(live_thresholds, x) for x in uppers]\n liveness_by_team = [x == 'live' or y == 'live' for x, y in zip(liveness_by_lower, liveness_by_upper)]\n liveness = [x.count(True) for x in zip(*([iter(liveness_by_team)] * nteamsindebate))]\n else:\n liveness = [0] * len(debates)\n\n return zip(brackets_min, brackets_max, liveness)\n", "path": "tabbycat/adjallocation/preformed/anticipated.py"}, {"content": "\"\"\"Miscellaneous utilities for the draw.\"\"\"\n\n\ndef ispow2(n):\n \"\"\"Returns True if n is a power of 2. Works for positive integers only.\"\"\"\n return n & (n - 1) == 0\n\n\ndef nextpow2(n):\n return 1 << (n-1).bit_length()\n\n\ndef partial_break_round_split(break_size):\n \"\"\"Returns a tuple `(debating, bypassing)`, where `debating` is how many\n teams will debate in the first break round, and `bypassing` is how many\n teams will bypass the first break round, qualifying directly for the\n second.\"\"\"\n\n assert break_size > 1, \"break rounds only make sense for break_size > 1 (found %d)\" % (break_size,)\n\n teams_in_second_break_round = nextpow2(break_size) // 2\n debates = break_size - teams_in_second_break_round\n bypassing = teams_in_second_break_round - debates\n\n assert 2*debates + bypassing == break_size, \"2 * %d teams debating + %d teams bypassing doesn't add to break size %d\" % (debates, bypassing, break_size)\n assert debates > 0, \"%d <= 0 debates in first break round (%d teams bypassing)\" % (debates, bypassing)\n assert bypassing >= 0, \"%d < 0 teams bypassing (%d debates)\" % (bypassing, debates)\n return debates, bypassing\n", "path": "tabbycat/draw/generator/utils.py"}]} | 2,494 | 800 |
gh_patches_debug_29204 | rasdani/github-patches | git_diff | microsoft__botbuilder-python-426 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug in 45.state-management sample
To create the user profile property , it should refer the UserState but in the sample its referring the
conversationstate.
Current code : self.user_profile = self.conversation_state.create_property("UserProfile")
Expected code : self.user_profile = self.user_state.create_property("UserProfile")
</issue>
<code>
[start of samples/45.state-management/bots/state_management_bot.py]
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3
4 import time
5 import pytz
6 from datetime import datetime
7
8 from botbuilder.core import ActivityHandler, ConversationState, TurnContext, UserState
9 from botbuilder.schema import ChannelAccount
10
11 from data_models import ConversationData, UserProfile
12
13
14 class StateManagementBot(ActivityHandler):
15 def __init__(self, conversation_state: ConversationState, user_state: UserState):
16 if conversation_state is None:
17 raise TypeError(
18 "[StateManagementBot]: Missing parameter. conversation_state is required but None was given"
19 )
20 if user_state is None:
21 raise TypeError(
22 "[StateManagementBot]: Missing parameter. user_state is required but None was given"
23 )
24
25 self.conversation_state = conversation_state
26 self.user_state = user_state
27
28 self.conversation_data = self.conversation_state.create_property(
29 "ConversationData"
30 )
31 self.user_profile = self.conversation_state.create_property("UserProfile")
32
33 async def on_turn(self, turn_context: TurnContext):
34 await super().on_turn(turn_context)
35
36 await self.conversation_state.save_changes(turn_context)
37 await self.user_state.save_changes(turn_context)
38
39 async def on_members_added_activity(
40 self, members_added: [ChannelAccount], turn_context: TurnContext
41 ):
42 for member in members_added:
43 if member.id != turn_context.activity.recipient.id:
44 await turn_context.send_activity(
45 "Welcome to State Bot Sample. Type anything to get started."
46 )
47
48 async def on_message_activity(self, turn_context: TurnContext):
49 # Get the state properties from the turn context.
50 user_profile = await self.user_profile.get(turn_context, UserProfile)
51 conversation_data = await self.conversation_data.get(
52 turn_context, ConversationData
53 )
54
55 if user_profile.name is None:
56 # First time around this is undefined, so we will prompt user for name.
57 if conversation_data.prompted_for_user_name:
58 # Set the name to what the user provided.
59 user_profile.name = turn_context.activity.text
60
61 # Acknowledge that we got their name.
62 await turn_context.send_activity(
63 f"Thanks { user_profile.name }. To see conversation data, type anything."
64 )
65
66 # Reset the flag to allow the bot to go though the cycle again.
67 conversation_data.prompted_for_user_name = False
68 else:
69 # Prompt the user for their name.
70 await turn_context.send_activity("What is your name?")
71
72 # Set the flag to true, so we don't prompt in the next turn.
73 conversation_data.prompted_for_user_name = True
74 else:
75 # Add message details to the conversation data.
76 conversation_data.timestamp = self.__datetime_from_utc_to_local(
77 turn_context.activity.timestamp
78 )
79 conversation_data.channel_id = turn_context.activity.channel_id
80
81 # Display state data.
82 await turn_context.send_activity(
83 f"{ user_profile.name } sent: { turn_context.activity.text }"
84 )
85 await turn_context.send_activity(
86 f"Message received at: { conversation_data.timestamp }"
87 )
88 await turn_context.send_activity(
89 f"Message received from: { conversation_data.channel_id }"
90 )
91
92 def __datetime_from_utc_to_local(self, utc_datetime):
93 now_timestamp = time.time()
94 offset = datetime.fromtimestamp(now_timestamp) - datetime.utcfromtimestamp(
95 now_timestamp
96 )
97 result = utc_datetime + offset
98 return result.strftime("%I:%M:%S %p, %A, %B %d of %Y")
99
[end of samples/45.state-management/bots/state_management_bot.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/samples/45.state-management/bots/state_management_bot.py b/samples/45.state-management/bots/state_management_bot.py
--- a/samples/45.state-management/bots/state_management_bot.py
+++ b/samples/45.state-management/bots/state_management_bot.py
@@ -2,7 +2,6 @@
# Licensed under the MIT License.
import time
-import pytz
from datetime import datetime
from botbuilder.core import ActivityHandler, ConversationState, TurnContext, UserState
@@ -25,10 +24,10 @@
self.conversation_state = conversation_state
self.user_state = user_state
- self.conversation_data = self.conversation_state.create_property(
+ self.conversation_data_accessor = self.conversation_state.create_property(
"ConversationData"
)
- self.user_profile = self.conversation_state.create_property("UserProfile")
+ self.user_profile_accessor = self.user_state.create_property("UserProfile")
async def on_turn(self, turn_context: TurnContext):
await super().on_turn(turn_context)
@@ -47,8 +46,8 @@
async def on_message_activity(self, turn_context: TurnContext):
# Get the state properties from the turn context.
- user_profile = await self.user_profile.get(turn_context, UserProfile)
- conversation_data = await self.conversation_data.get(
+ user_profile = await self.user_profile_accessor.get(turn_context, UserProfile)
+ conversation_data = await self.conversation_data_accessor.get(
turn_context, ConversationData
)
| {"golden_diff": "diff --git a/samples/45.state-management/bots/state_management_bot.py b/samples/45.state-management/bots/state_management_bot.py\n--- a/samples/45.state-management/bots/state_management_bot.py\n+++ b/samples/45.state-management/bots/state_management_bot.py\n@@ -2,7 +2,6 @@\n # Licensed under the MIT License.\n \n import time\n-import pytz\n from datetime import datetime\n \n from botbuilder.core import ActivityHandler, ConversationState, TurnContext, UserState\n@@ -25,10 +24,10 @@\n self.conversation_state = conversation_state\n self.user_state = user_state\n \n- self.conversation_data = self.conversation_state.create_property(\n+ self.conversation_data_accessor = self.conversation_state.create_property(\n \"ConversationData\"\n )\n- self.user_profile = self.conversation_state.create_property(\"UserProfile\")\n+ self.user_profile_accessor = self.user_state.create_property(\"UserProfile\")\n \n async def on_turn(self, turn_context: TurnContext):\n await super().on_turn(turn_context)\n@@ -47,8 +46,8 @@\n \n async def on_message_activity(self, turn_context: TurnContext):\n # Get the state properties from the turn context.\n- user_profile = await self.user_profile.get(turn_context, UserProfile)\n- conversation_data = await self.conversation_data.get(\n+ user_profile = await self.user_profile_accessor.get(turn_context, UserProfile)\n+ conversation_data = await self.conversation_data_accessor.get(\n turn_context, ConversationData\n )\n", "issue": "Bug in 45.state-management sample\n\r\nTo create the user profile property , it should refer the UserState but in the sample its referring the \r\nconversationstate.\r\n\r\nCurrent code : self.user_profile = self.conversation_state.create_property(\"UserProfile\")\r\n\r\nExpected code : self.user_profile = self.user_state.create_property(\"UserProfile\")\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\nimport time\nimport pytz\nfrom datetime import datetime\n\nfrom botbuilder.core import ActivityHandler, ConversationState, TurnContext, UserState\nfrom botbuilder.schema import ChannelAccount\n\nfrom data_models import ConversationData, UserProfile\n\n\nclass StateManagementBot(ActivityHandler):\n def __init__(self, conversation_state: ConversationState, user_state: UserState):\n if conversation_state is None:\n raise TypeError(\n \"[StateManagementBot]: Missing parameter. conversation_state is required but None was given\"\n )\n if user_state is None:\n raise TypeError(\n \"[StateManagementBot]: Missing parameter. user_state is required but None was given\"\n )\n\n self.conversation_state = conversation_state\n self.user_state = user_state\n\n self.conversation_data = self.conversation_state.create_property(\n \"ConversationData\"\n )\n self.user_profile = self.conversation_state.create_property(\"UserProfile\")\n\n async def on_turn(self, turn_context: TurnContext):\n await super().on_turn(turn_context)\n\n await self.conversation_state.save_changes(turn_context)\n await self.user_state.save_changes(turn_context)\n\n async def on_members_added_activity(\n self, members_added: [ChannelAccount], turn_context: TurnContext\n ):\n for member in members_added:\n if member.id != turn_context.activity.recipient.id:\n await turn_context.send_activity(\n \"Welcome to State Bot Sample. Type anything to get started.\"\n )\n\n async def on_message_activity(self, turn_context: TurnContext):\n # Get the state properties from the turn context.\n user_profile = await self.user_profile.get(turn_context, UserProfile)\n conversation_data = await self.conversation_data.get(\n turn_context, ConversationData\n )\n\n if user_profile.name is None:\n # First time around this is undefined, so we will prompt user for name.\n if conversation_data.prompted_for_user_name:\n # Set the name to what the user provided.\n user_profile.name = turn_context.activity.text\n\n # Acknowledge that we got their name.\n await turn_context.send_activity(\n f\"Thanks { user_profile.name }. To see conversation data, type anything.\"\n )\n\n # Reset the flag to allow the bot to go though the cycle again.\n conversation_data.prompted_for_user_name = False\n else:\n # Prompt the user for their name.\n await turn_context.send_activity(\"What is your name?\")\n\n # Set the flag to true, so we don't prompt in the next turn.\n conversation_data.prompted_for_user_name = True\n else:\n # Add message details to the conversation data.\n conversation_data.timestamp = self.__datetime_from_utc_to_local(\n turn_context.activity.timestamp\n )\n conversation_data.channel_id = turn_context.activity.channel_id\n\n # Display state data.\n await turn_context.send_activity(\n f\"{ user_profile.name } sent: { turn_context.activity.text }\"\n )\n await turn_context.send_activity(\n f\"Message received at: { conversation_data.timestamp }\"\n )\n await turn_context.send_activity(\n f\"Message received from: { conversation_data.channel_id }\"\n )\n\n def __datetime_from_utc_to_local(self, utc_datetime):\n now_timestamp = time.time()\n offset = datetime.fromtimestamp(now_timestamp) - datetime.utcfromtimestamp(\n now_timestamp\n )\n result = utc_datetime + offset\n return result.strftime(\"%I:%M:%S %p, %A, %B %d of %Y\")\n", "path": "samples/45.state-management/bots/state_management_bot.py"}]} | 1,563 | 334 |
gh_patches_debug_18487 | rasdani/github-patches | git_diff | kymatio__kymatio-308 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BUG `scattering3d_qm7.py` crashes on GPU
The input is on the GPU, but the scattering object has not been put in GPU mode, see https://github.com/kymatio/kymatio/blob/master/examples/3d/scattering3d_qm7.py#L212.
</issue>
<code>
[start of examples/3d/scattering3d_qm7.py]
1 """
2 3D scattering quantum chemistry regression
3 ==========================================
4 This uses the 3D scattering on a standard dataset.
5 """
6
7 import numpy as np
8 import time
9 import torch
10 import os
11
12 from sklearn import linear_model, model_selection, preprocessing, pipeline
13 from kymatio.scattering3d import HarmonicScattering3D
14 from kymatio.scattering3d.utils import compute_integrals, generate_weighted_sum_of_gaussians
15 from kymatio.datasets import fetch_qm7
16 from kymatio.caching import get_cache_dir
17 from scipy.spatial.distance import pdist
18
19
20 def evaluate_linear_regression(X, y, n_folds=5):
21 """
22 Evaluates linear ridge regression predictions of y using X.
23
24 Parameters
25 ----------
26 X: numpy array
27 input features, shape (N, D)
28 y: numpy array
29 target value, shape (N, 1)
30
31 """
32 n_datapoints = X.shape[0]
33 P = np.random.permutation(n_datapoints).reshape((n_folds, -1))
34 cross_val_folds = []
35
36 for i_fold in range(n_folds):
37 fold = (np.concatenate(P[np.arange(n_folds) != i_fold], axis=0), P[i_fold])
38 cross_val_folds.append(fold)
39
40 alphas = 10.**(-np.arange(0, 10))
41 for i, alpha in enumerate(alphas):
42 regressor = pipeline.make_pipeline(
43 preprocessing.StandardScaler(), linear_model.Ridge(alpha=alpha))
44 y_prediction = model_selection.cross_val_predict(
45 regressor, X=X, y=y, cv=cross_val_folds)
46 MAE = np.mean(np.abs(y_prediction - y))
47 RMSE = np.sqrt(np.mean((y_prediction - y)**2))
48 print('Ridge regression, alpha: {}, MAE: {}, RMSE: {}'.format(
49 alpha, MAE, RMSE))
50
51
52 def get_valence(charges):
53 """
54 Returns the number valence electrons of a particle given the
55 nuclear charge.
56
57 Parameters
58 ----------
59 charges: numpy array
60 array containing the nuclear charges, arbitrary size
61
62 Returns
63 -------
64 valence_charges : numpy array
65 same size as the input
66 """
67 return (
68 charges * (charges <= 2) +
69 (charges - 2) * np.logical_and(charges > 2, charges <= 10) +
70 (charges - 10) * np.logical_and(charges > 10, charges <= 18))
71
72
73 def get_qm7_energies():
74 """
75 Loads the energies of the molecules of the QM7 dataset.
76
77 Returns
78 -------
79 energies: numpy array
80 array containing the energies of the molecules
81 """
82 qm7 = fetch_qm7()
83 return qm7['energies']
84
85
86
87 def get_qm7_positions_and_charges(sigma, overlapping_precision=1e-1):
88 """
89 Loads the positions and charges of the molecules of the QM7 dataset.
90 QM7 is a dataset of 7165 organic molecules with up to 7 non-hydrogen
91 atoms, whose energies were computed with a quantun chemistry
92 computational method named Density Functional Theory.
93 This dataset has been made available to train machine learning models
94 to predict these energies.
95
96 Parameters
97 ----------
98 sigma : float
99 width parameter of the Gaussian that represents a particle
100
101 overlapping_precision : float, optional
102 affects the scaling of the positions. The positions are re-scaled
103 such that two Gaussian functions of width sigma centerd at the qm7
104 positions overlapp with amplitude <= the overlapping_precision
105
106 Returns
107 -------
108 positions, charges, valence_charges: torch arrays
109 array containing the positions, charges and valence charges
110 of the QM7 database molecules
111 """
112 qm7 = fetch_qm7(align=True)
113 positions = qm7['positions']
114 charges = qm7['charges'].astype('float32')
115 valence_charges = get_valence(charges)
116
117 # normalize positions
118 min_dist = np.inf
119 for i in range(positions.shape[0]):
120 n_atoms = np.sum(charges[i] != 0)
121 pos = positions[i, :n_atoms, :]
122 min_dist = min(min_dist, pdist(pos).min())
123 delta = sigma * np.sqrt(-8 * np.log(overlapping_precision))
124 positions = positions * delta / min_dist
125
126 return (torch.from_numpy(positions),
127 torch.from_numpy(charges),
128 torch.from_numpy(valence_charges))
129
130
131 def compute_qm7_solid_harmonic_scattering_coefficients(
132 M=192, N=128, O=96, sigma=2., J=2, L=3,
133 integral_powers=(0.5, 1., 2., 3.), batch_size=16):
134 """
135 Computes the scattering coefficients of the molecules of the
136 QM7 database. Channels used are full charges, valence charges
137 and core charges. Linear regression of the qm7 energies with
138 the given values gives MAE 2.75, RMSE 4.18 (kcal.mol-1).
139
140 Parameters
141 ----------
142 M, N, O: int
143 dimensions of the numerical grid
144 sigma : float
145 width parameter of the Gaussian that represents a particle
146 J: int
147 maximal scale of the solid harmonic wavelets
148 L: int
149 maximal first order of the solid harmonic wavelets
150 integral_powers: list of int
151 powers for the integrals
152 batch_size: int
153 size of the batch for computations
154
155 Returns
156 -------
157 order_0: torch tensor
158 array containing zeroth-order scattering coefficients
159 orders_1_and_2: torch tensor
160 array containing first- and second-order scattering coefficients
161 """
162 cuda = torch.cuda.is_available()
163 grid = torch.from_numpy(
164 np.fft.ifftshift(
165 np.mgrid[-M//2:-M//2+M, -N//2:-N//2+N, -O//2:-O//2+O].astype('float32'),
166 axes=(1, 2, 3)))
167 pos, full_charges, valence_charges = get_qm7_positions_and_charges(sigma)
168
169 if cuda:
170 grid = grid.cuda()
171 pos = pos.cuda()
172 full_charges = full_charges.cuda()
173 valence_charges = valence_charges.cuda()
174
175 n_molecules = pos.size(0)
176 n_batches = np.ceil(n_molecules / batch_size).astype(int)
177
178 scattering = HarmonicScattering3D(J=J, shape=(M, N, O), L=L, sigma_0=sigma)
179
180 order_0, order_1, order_2 = [], [], []
181 print('Computing solid harmonic scattering coefficients of {} molecules '
182 'of QM7 database on {}'.format(pos.size(0), 'GPU' if cuda else 'CPU'))
183 print('sigma: {}, L: {}, J: {}, integral powers: {}'.format(sigma, L, J, integral_powers))
184
185 this_time = None
186 last_time = None
187 for i in range(n_batches):
188 this_time = time.time()
189 if last_time is not None:
190 dt = this_time - last_time
191 print("Iteration {} ETA: [{:02}:{:02}:{:02}]".format(
192 i + 1, int(((n_batches - i - 1) * dt) // 3600),
193 int((((n_batches - i - 1) * dt) // 60) % 60),
194 int(((n_batches - i - 1) * dt) % 60)), end='\r')
195 else:
196 print("Iteration {} ETA: {}".format(i + 1,'-'),end='\r')
197 last_time = this_time
198 time.sleep(1)
199
200 start, end = i * batch_size, min((i + 1) * batch_size, n_molecules)
201
202 pos_batch = pos[start:end]
203 full_batch = full_charges[start:end]
204 val_batch = valence_charges[start:end]
205
206 full_density_batch = generate_weighted_sum_of_gaussians(
207 grid, pos_batch, full_batch, sigma, cuda=cuda)
208 full_order_0 = compute_integrals(full_density_batch, integral_powers)
209 scattering.max_order = 2
210 scattering.method = 'integral'
211 scattering.integral_powers = integral_powers
212 full_scattering = scattering(full_density_batch)
213
214 val_density_batch = generate_weighted_sum_of_gaussians(
215 grid, pos_batch, val_batch, sigma, cuda=cuda)
216 val_order_0 = compute_integrals(val_density_batch, integral_powers)
217 val_scattering= scattering(val_density_batch)
218
219 core_density_batch = full_density_batch - val_density_batch
220 core_order_0 = compute_integrals(core_density_batch, integral_powers)
221 core_scattering = scattering(core_density_batch)
222
223
224 order_0.append(
225 torch.stack([full_order_0, val_order_0, core_order_0], dim=-1))
226 orders_1_and_2.append(
227 torch.stack(
228 [full_scattering, val_scattering, core_scattering], dim=-1))
229
230 order_0 = torch.cat(order_0, dim=0)
231 orders_1_and_2 = torch.cat(orders_1_and_2, dim=0)
232
233 return order_0, orders_1_and_2
234
235 M, N, O, J, L = 192, 128, 96, 2, 3
236 integral_powers = [0.5, 1., 2., 3.]
237 sigma = 2.
238
239 order_0, orders_1_and_2 = compute_qm7_solid_harmonic_scattering_coefficients(
240 M=M, N=N, O=O, J=J, L=L, integral_powers=integral_powers,
241 sigma=sigma, batch_size=8)
242
243 n_molecules = order_0.size(0)
244
245 np_order_0 = order_0.numpy().reshape((n_molecules, -1))
246 np_orders_1_and_2 = orders_1_and_2.numpy().reshape((n_molecules, -1))
247
248 basename = 'qm7_L_{}_J_{}_sigma_{}_MNO_{}_powers_{}.npy'.format(
249 L, J, sigma, (M, N, O), integral_powers)
250 cachedir = get_cache_dir("qm7/experiments")
251 np.save(os.path.join(cachedir, 'order_0_' + basename), np_order_0)
252 np.save(os.path.join(
253 cachedir, 'orders_1_and_2_' + basename), np_orders_1_and_2)
254
255 scattering_coef = np.concatenate([np_order_0, np_orders_1_and_2], axis=1)
256 target = get_qm7_energies()
257
258 evaluate_linear_regression(scattering_coef, target)
259
[end of examples/3d/scattering3d_qm7.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/examples/3d/scattering3d_qm7.py b/examples/3d/scattering3d_qm7.py
--- a/examples/3d/scattering3d_qm7.py
+++ b/examples/3d/scattering3d_qm7.py
@@ -166,16 +166,17 @@
axes=(1, 2, 3)))
pos, full_charges, valence_charges = get_qm7_positions_and_charges(sigma)
+ n_molecules = pos.size(0)
+ n_batches = np.ceil(n_molecules / batch_size).astype(int)
+
+ scattering = HarmonicScattering3D(J=J, shape=(M, N, O), L=L, sigma_0=sigma)
+
if cuda:
grid = grid.cuda()
pos = pos.cuda()
full_charges = full_charges.cuda()
valence_charges = valence_charges.cuda()
-
- n_molecules = pos.size(0)
- n_batches = np.ceil(n_molecules / batch_size).astype(int)
-
- scattering = HarmonicScattering3D(J=J, shape=(M, N, O), L=L, sigma_0=sigma)
+ scattering.cuda()
order_0, order_1, order_2 = [], [], []
print('Computing solid harmonic scattering coefficients of {} molecules '
| {"golden_diff": "diff --git a/examples/3d/scattering3d_qm7.py b/examples/3d/scattering3d_qm7.py\n--- a/examples/3d/scattering3d_qm7.py\n+++ b/examples/3d/scattering3d_qm7.py\n@@ -166,16 +166,17 @@\n axes=(1, 2, 3)))\n pos, full_charges, valence_charges = get_qm7_positions_and_charges(sigma)\n \n+ n_molecules = pos.size(0)\n+ n_batches = np.ceil(n_molecules / batch_size).astype(int)\n+\n+ scattering = HarmonicScattering3D(J=J, shape=(M, N, O), L=L, sigma_0=sigma)\n+\n if cuda:\n grid = grid.cuda()\n pos = pos.cuda()\n full_charges = full_charges.cuda()\n valence_charges = valence_charges.cuda()\n-\n- n_molecules = pos.size(0)\n- n_batches = np.ceil(n_molecules / batch_size).astype(int)\n-\n- scattering = HarmonicScattering3D(J=J, shape=(M, N, O), L=L, sigma_0=sigma)\n+ scattering.cuda()\n \n order_0, order_1, order_2 = [], [], []\n print('Computing solid harmonic scattering coefficients of {} molecules '\n", "issue": "BUG `scattering3d_qm7.py` crashes on GPU\nThe input is on the GPU, but the scattering object has not been put in GPU mode, see https://github.com/kymatio/kymatio/blob/master/examples/3d/scattering3d_qm7.py#L212.\n", "before_files": [{"content": "\"\"\"\n3D scattering quantum chemistry regression\n==========================================\nThis uses the 3D scattering on a standard dataset.\n\"\"\"\n\nimport numpy as np\nimport time\nimport torch\nimport os\n\nfrom sklearn import linear_model, model_selection, preprocessing, pipeline\nfrom kymatio.scattering3d import HarmonicScattering3D\nfrom kymatio.scattering3d.utils import compute_integrals, generate_weighted_sum_of_gaussians\nfrom kymatio.datasets import fetch_qm7\nfrom kymatio.caching import get_cache_dir\nfrom scipy.spatial.distance import pdist\n\n\ndef evaluate_linear_regression(X, y, n_folds=5):\n \"\"\"\n Evaluates linear ridge regression predictions of y using X.\n\n Parameters\n ----------\n X: numpy array\n input features, shape (N, D)\n y: numpy array\n target value, shape (N, 1)\n\n \"\"\"\n n_datapoints = X.shape[0]\n P = np.random.permutation(n_datapoints).reshape((n_folds, -1))\n cross_val_folds = []\n\n for i_fold in range(n_folds):\n fold = (np.concatenate(P[np.arange(n_folds) != i_fold], axis=0), P[i_fold])\n cross_val_folds.append(fold)\n\n alphas = 10.**(-np.arange(0, 10))\n for i, alpha in enumerate(alphas):\n regressor = pipeline.make_pipeline(\n preprocessing.StandardScaler(), linear_model.Ridge(alpha=alpha))\n y_prediction = model_selection.cross_val_predict(\n regressor, X=X, y=y, cv=cross_val_folds)\n MAE = np.mean(np.abs(y_prediction - y))\n RMSE = np.sqrt(np.mean((y_prediction - y)**2))\n print('Ridge regression, alpha: {}, MAE: {}, RMSE: {}'.format(\n alpha, MAE, RMSE))\n\n\ndef get_valence(charges):\n \"\"\"\n Returns the number valence electrons of a particle given the\n nuclear charge.\n\n Parameters\n ----------\n charges: numpy array\n array containing the nuclear charges, arbitrary size\n\n Returns\n -------\n valence_charges : numpy array\n same size as the input\n \"\"\"\n return (\n charges * (charges <= 2) +\n (charges - 2) * np.logical_and(charges > 2, charges <= 10) +\n (charges - 10) * np.logical_and(charges > 10, charges <= 18))\n\n\ndef get_qm7_energies():\n \"\"\"\n Loads the energies of the molecules of the QM7 dataset.\n\n Returns\n -------\n energies: numpy array\n array containing the energies of the molecules\n \"\"\"\n qm7 = fetch_qm7()\n return qm7['energies']\n\n\n\ndef get_qm7_positions_and_charges(sigma, overlapping_precision=1e-1):\n \"\"\"\n Loads the positions and charges of the molecules of the QM7 dataset.\n QM7 is a dataset of 7165 organic molecules with up to 7 non-hydrogen\n atoms, whose energies were computed with a quantun chemistry\n computational method named Density Functional Theory.\n This dataset has been made available to train machine learning models\n to predict these energies.\n\n Parameters\n ----------\n sigma : float\n width parameter of the Gaussian that represents a particle\n\n overlapping_precision : float, optional\n affects the scaling of the positions. The positions are re-scaled\n such that two Gaussian functions of width sigma centerd at the qm7\n positions overlapp with amplitude <= the overlapping_precision\n\n Returns\n -------\n positions, charges, valence_charges: torch arrays\n array containing the positions, charges and valence charges\n of the QM7 database molecules\n \"\"\"\n qm7 = fetch_qm7(align=True)\n positions = qm7['positions']\n charges = qm7['charges'].astype('float32')\n valence_charges = get_valence(charges)\n\n # normalize positions\n min_dist = np.inf\n for i in range(positions.shape[0]):\n n_atoms = np.sum(charges[i] != 0)\n pos = positions[i, :n_atoms, :]\n min_dist = min(min_dist, pdist(pos).min())\n delta = sigma * np.sqrt(-8 * np.log(overlapping_precision))\n positions = positions * delta / min_dist\n\n return (torch.from_numpy(positions),\n torch.from_numpy(charges),\n torch.from_numpy(valence_charges))\n\n\ndef compute_qm7_solid_harmonic_scattering_coefficients(\n M=192, N=128, O=96, sigma=2., J=2, L=3,\n integral_powers=(0.5, 1., 2., 3.), batch_size=16):\n \"\"\"\n Computes the scattering coefficients of the molecules of the\n QM7 database. Channels used are full charges, valence charges\n and core charges. Linear regression of the qm7 energies with\n the given values gives MAE 2.75, RMSE 4.18 (kcal.mol-1).\n\n Parameters\n ----------\n M, N, O: int\n dimensions of the numerical grid\n sigma : float\n width parameter of the Gaussian that represents a particle\n J: int\n maximal scale of the solid harmonic wavelets\n L: int\n maximal first order of the solid harmonic wavelets\n integral_powers: list of int\n powers for the integrals\n batch_size: int\n size of the batch for computations\n\n Returns\n -------\n order_0: torch tensor\n array containing zeroth-order scattering coefficients\n orders_1_and_2: torch tensor\n array containing first- and second-order scattering coefficients\n \"\"\"\n cuda = torch.cuda.is_available()\n grid = torch.from_numpy(\n np.fft.ifftshift(\n np.mgrid[-M//2:-M//2+M, -N//2:-N//2+N, -O//2:-O//2+O].astype('float32'),\n axes=(1, 2, 3)))\n pos, full_charges, valence_charges = get_qm7_positions_and_charges(sigma)\n\n if cuda:\n grid = grid.cuda()\n pos = pos.cuda()\n full_charges = full_charges.cuda()\n valence_charges = valence_charges.cuda()\n\n n_molecules = pos.size(0)\n n_batches = np.ceil(n_molecules / batch_size).astype(int)\n\n scattering = HarmonicScattering3D(J=J, shape=(M, N, O), L=L, sigma_0=sigma)\n\n order_0, order_1, order_2 = [], [], []\n print('Computing solid harmonic scattering coefficients of {} molecules '\n 'of QM7 database on {}'.format(pos.size(0), 'GPU' if cuda else 'CPU'))\n print('sigma: {}, L: {}, J: {}, integral powers: {}'.format(sigma, L, J, integral_powers))\n\n this_time = None\n last_time = None\n for i in range(n_batches):\n this_time = time.time()\n if last_time is not None:\n dt = this_time - last_time\n print(\"Iteration {} ETA: [{:02}:{:02}:{:02}]\".format(\n i + 1, int(((n_batches - i - 1) * dt) // 3600),\n int((((n_batches - i - 1) * dt) // 60) % 60),\n int(((n_batches - i - 1) * dt) % 60)), end='\\r')\n else:\n print(\"Iteration {} ETA: {}\".format(i + 1,'-'),end='\\r')\n last_time = this_time\n time.sleep(1)\n\n start, end = i * batch_size, min((i + 1) * batch_size, n_molecules)\n\n pos_batch = pos[start:end]\n full_batch = full_charges[start:end]\n val_batch = valence_charges[start:end]\n\n full_density_batch = generate_weighted_sum_of_gaussians(\n grid, pos_batch, full_batch, sigma, cuda=cuda)\n full_order_0 = compute_integrals(full_density_batch, integral_powers)\n scattering.max_order = 2\n scattering.method = 'integral'\n scattering.integral_powers = integral_powers\n full_scattering = scattering(full_density_batch)\n\n val_density_batch = generate_weighted_sum_of_gaussians(\n grid, pos_batch, val_batch, sigma, cuda=cuda)\n val_order_0 = compute_integrals(val_density_batch, integral_powers)\n val_scattering= scattering(val_density_batch)\n\n core_density_batch = full_density_batch - val_density_batch\n core_order_0 = compute_integrals(core_density_batch, integral_powers)\n core_scattering = scattering(core_density_batch)\n\n\n order_0.append(\n torch.stack([full_order_0, val_order_0, core_order_0], dim=-1))\n orders_1_and_2.append(\n torch.stack(\n [full_scattering, val_scattering, core_scattering], dim=-1))\n\n order_0 = torch.cat(order_0, dim=0)\n orders_1_and_2 = torch.cat(orders_1_and_2, dim=0)\n\n return order_0, orders_1_and_2\n\nM, N, O, J, L = 192, 128, 96, 2, 3\nintegral_powers = [0.5, 1., 2., 3.]\nsigma = 2.\n\norder_0, orders_1_and_2 = compute_qm7_solid_harmonic_scattering_coefficients(\n M=M, N=N, O=O, J=J, L=L, integral_powers=integral_powers,\n sigma=sigma, batch_size=8)\n\nn_molecules = order_0.size(0)\n\nnp_order_0 = order_0.numpy().reshape((n_molecules, -1))\nnp_orders_1_and_2 = orders_1_and_2.numpy().reshape((n_molecules, -1))\n\nbasename = 'qm7_L_{}_J_{}_sigma_{}_MNO_{}_powers_{}.npy'.format(\n L, J, sigma, (M, N, O), integral_powers)\ncachedir = get_cache_dir(\"qm7/experiments\")\nnp.save(os.path.join(cachedir, 'order_0_' + basename), np_order_0)\nnp.save(os.path.join(\n cachedir, 'orders_1_and_2_' + basename), np_orders_1_and_2)\n\nscattering_coef = np.concatenate([np_order_0, np_orders_1_and_2], axis=1)\ntarget = get_qm7_energies()\n\nevaluate_linear_regression(scattering_coef, target)\n", "path": "examples/3d/scattering3d_qm7.py"}]} | 3,712 | 305 |
gh_patches_debug_10133 | rasdani/github-patches | git_diff | mozmeao__snippets-service-818 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ASR Snippet Admin: Be able to search for a snippet by Snippet ID in top search bar on list view page
Currently the search bar only allows for searching keywords.
</issue>
<code>
[start of snippets/base/admin/adminmodels.py]
1 import re
2
3 from django.contrib import admin
4 from django.db.models import TextField, Q
5 from django.template.loader import get_template
6 from django.utils.safestring import mark_safe
7
8 from reversion.admin import VersionAdmin
9 from django_ace import AceWidget
10 from django_statsd.clients import statsd
11 from jinja2.meta import find_undeclared_variables
12 from django_admin_listfilter_dropdown.filters import RelatedDropdownFilter
13
14 from snippets.base import forms, models
15 from snippets.base.models import JINJA_ENV
16 from snippets.base.admin.filters import ModifiedFilter, ReleaseFilter
17 from snippets.base.admin.actions import duplicate_snippets_action
18
19
20 MATCH_LOCALE_REGEX = re.compile('(\w+(?:-\w+)*)')
21 RESERVED_VARIABLES = ('_', 'snippet_id')
22
23
24 class ClientMatchRuleAdmin(VersionAdmin, admin.ModelAdmin):
25 list_display = ('description', 'is_exclusion', 'startpage_version', 'name',
26 'version', 'locale', 'appbuildid', 'build_target',
27 'channel', 'os_version', 'distribution',
28 'distribution_version', 'modified')
29 list_filter = ('name', 'version', 'os_version', 'appbuildid',
30 'build_target', 'channel', 'distribution', 'locale')
31 save_on_top = True
32 search_fields = ('description',)
33
34
35 class LogEntryAdmin(admin.ModelAdmin):
36 list_display = ('user', 'content_type', 'object_id', 'object_repr', 'change_message')
37 list_filter = ('user', 'content_type')
38
39
40 class SnippetTemplateVariableInline(admin.TabularInline):
41 model = models.SnippetTemplateVariable
42 formset = forms.SnippetTemplateVariableInlineFormset
43 max_num = 0
44 can_delete = False
45 readonly_fields = ('name',)
46 fields = ('name', 'type', 'order', 'description')
47
48
49 class SnippetTemplateAdmin(VersionAdmin, admin.ModelAdmin):
50 save_on_top = True
51 list_display = ('name', 'priority', 'hidden')
52 list_filter = ('hidden', 'startpage')
53 inlines = (SnippetTemplateVariableInline,)
54 formfield_overrides = {
55 TextField: {'widget': AceWidget(mode='html', theme='github',
56 width='1200px', height='500px')},
57 }
58
59 class Media:
60 css = {
61 'all': ('css/admin.css',)
62 }
63
64 def save_related(self, request, form, formsets, change):
65 """
66 After saving the related objects, remove and add
67 SnippetTemplateVariables depending on how the template code changed.
68 """
69 super(SnippetTemplateAdmin, self).save_related(request, form, formsets,
70 change)
71
72 # Parse the template code and find any undefined variables.
73 ast = JINJA_ENV.env.parse(form.instance.code)
74 new_vars = find_undeclared_variables(ast)
75 var_manager = form.instance.variable_set
76
77 # Filter out reserved variable names.
78 new_vars = [x for x in new_vars if x not in RESERVED_VARIABLES]
79
80 # Delete variables not in the new set.
81 var_manager.filter(~Q(name__in=new_vars)).delete()
82
83 # Create variables that don't exist.
84 for i, variable in enumerate(new_vars, start=1):
85 obj, _ = models.SnippetTemplateVariable.objects.get_or_create(
86 template=form.instance, name=variable)
87 if obj.order == 0:
88 obj.order = i * 10
89 obj.save()
90
91
92 class UploadedFileAdmin(admin.ModelAdmin):
93 readonly_fields = ('url', 'preview', 'snippets')
94 list_display = ('name', 'url', 'preview', 'modified')
95 prepopulated_fields = {'name': ('file',)}
96 form = forms.UploadedFileAdminForm
97
98 def preview(self, obj):
99 template = get_template('base/uploadedfile_preview.jinja')
100 return mark_safe(template.render({'file': obj}))
101
102 def snippets(self, obj):
103 """Snippets using this file."""
104 template = get_template('base/uploadedfile_snippets.jinja')
105 return mark_safe(template.render({'snippets': obj.snippets}))
106
107
108 class AddonAdmin(admin.ModelAdmin):
109 list_display = ('name', 'guid')
110
111
112 class ASRSnippetAdmin(admin.ModelAdmin):
113 form = forms.ASRSnippetAdminForm
114
115 list_display_links = (
116 'id',
117 'name',
118 )
119 list_display = (
120 'id',
121 'name',
122 'status',
123 'modified',
124 )
125 list_filter = (
126 ModifiedFilter,
127 'status',
128 ReleaseFilter,
129 ('template', RelatedDropdownFilter),
130 )
131 search_fields = (
132 'name',
133 )
134 autocomplete_fields = (
135 'campaign',
136 'target',
137 )
138 preserve_filters = True
139 readonly_fields = (
140 'created',
141 'modified',
142 'uuid',
143 'creator',
144 'preview_url',
145 )
146 filter_horizontal = ('locales',)
147 save_on_top = True
148 save_as = True
149 view_on_site = False
150 actions = (
151 duplicate_snippets_action,
152 )
153
154 fieldsets = (
155 ('ID', {'fields': ('creator', 'name', 'status', 'preview_url')}),
156 ('Content', {
157 'description': (
158 '''
159 <strong>Available deep links:</strong><br/>
160 <ol>
161 <li><code>special:accounts</code> to open Firefox Accounts</li>
162 <li><code>special:appMenu</code> to open the hamburger menu</li>
163 </ol><br/>
164 <strong>Automatically add Snippet ID:</strong><br/>
165 You can use <code>[[snippet_id]]</code> in any field and it
166 will be automatically replaced by Snippet ID when served to users.
167 <br/>
168 Example: This is a <code><a href="https://example.com?utm_term=[[snippet_id]]">link</a></code> # noqa
169 <br/>
170 '''
171 ),
172 'fields': ('template', 'data'),
173 }),
174 ('Publishing Options', {
175 'fields': ('campaign', 'target', ('publish_start', 'publish_end'), 'locales', 'weight',)
176 }),
177 ('Other Info', {
178 'fields': ('uuid', ('created', 'modified')),
179 'classes': ('collapse',)
180 }),
181 )
182
183 class Media:
184 css = {
185 'all': ('css/admin/ASRSnippetAdmin.css',)
186 }
187 js = (
188 'js/admin/clipboard.min.js',
189 'js/admin/copy_preview.js',
190 )
191
192 def save_model(self, request, obj, form, change):
193 if not obj.creator_id:
194 obj.creator = request.user
195 statsd.incr('save.asrsnippet')
196 super().save_model(request, obj, form, change)
197
198 def preview_url(self, obj):
199 text = f'''
200 <span id="previewLinkUrl">{obj.get_preview_url()}</span>
201 <button id="copyPreviewLink" class="btn"
202 data-clipboard-target="#previewLinkUrl"
203 originalText="Copy to Clipboard" type="button">
204 Copy to Clipboard
205 </button>
206 '''
207 return mark_safe(text)
208
209 def change_view(self, request, *args, **kwargs):
210 if request.method == 'POST' and '_saveasnew' in request.POST:
211 # Always saved cloned snippets as un-published and un-check ready for review.
212 post_data = request.POST.copy()
213 post_data['status'] = models.STATUS_CHOICES['Draft']
214 request.POST = post_data
215 return super().change_view(request, *args, **kwargs)
216
217
218 class CampaignAdmin(admin.ModelAdmin):
219 readonly_fields = ('created', 'modified', 'creator',)
220 prepopulated_fields = {'slug': ('name',)}
221
222 fieldsets = (
223 ('ID', {'fields': ('name', 'slug')}),
224 ('Other Info', {
225 'fields': ('creator', ('created', 'modified')),
226 }),
227 )
228 search_fields = (
229 'name',
230 )
231
232 def save_model(self, request, obj, form, change):
233 if not obj.creator_id:
234 obj.creator = request.user
235 statsd.incr('save.campaign')
236 super().save_model(request, obj, form, change)
237
238
239 class TargetAdmin(admin.ModelAdmin):
240 form = forms.TargetAdminForm
241 readonly_fields = ('created', 'modified', 'creator', 'jexl_expr')
242 search_fields = (
243 'name',
244 )
245 fieldsets = (
246 ('ID', {'fields': ('name',)}),
247 ('Product channels', {
248 'description': 'What channels will this snippet be available in?',
249 'fields': (('on_release', 'on_beta', 'on_aurora', 'on_nightly', 'on_esr'),)
250 }),
251 ('Targeting', {
252 'fields': (
253 'filtr_is_default_browser',
254 'filtr_updates_enabled',
255 'filtr_updates_autodownload_enabled',
256 'filtr_profile_age_created',
257 'filtr_firefox_version',
258 'filtr_previous_session_end',
259 'filtr_uses_firefox_sync',
260 'filtr_country',
261 'filtr_is_developer',
262 'filtr_current_search_engine',
263 'filtr_browser_addon',
264 'filtr_total_bookmarks_count',
265 )
266 }),
267 ('Other Info', {
268 'fields': ('creator', ('created', 'modified'), 'jexl_expr'),
269 }),
270 )
271
272 def save_model(self, request, obj, form, change):
273 if not obj.creator_id:
274 obj.creator = request.user
275 statsd.incr('save.target')
276 super().save_model(request, obj, form, change)
277
[end of snippets/base/admin/adminmodels.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/snippets/base/admin/adminmodels.py b/snippets/base/admin/adminmodels.py
--- a/snippets/base/admin/adminmodels.py
+++ b/snippets/base/admin/adminmodels.py
@@ -130,6 +130,9 @@
)
search_fields = (
'name',
+ 'id',
+ 'campaign__name',
+ 'target__name',
)
autocomplete_fields = (
'campaign',
@@ -143,7 +146,9 @@
'creator',
'preview_url',
)
- filter_horizontal = ('locales',)
+ filter_horizontal = (
+ 'locales',
+ )
save_on_top = True
save_as = True
view_on_site = False
| {"golden_diff": "diff --git a/snippets/base/admin/adminmodels.py b/snippets/base/admin/adminmodels.py\n--- a/snippets/base/admin/adminmodels.py\n+++ b/snippets/base/admin/adminmodels.py\n@@ -130,6 +130,9 @@\n )\n search_fields = (\n 'name',\n+ 'id',\n+ 'campaign__name',\n+ 'target__name',\n )\n autocomplete_fields = (\n 'campaign',\n@@ -143,7 +146,9 @@\n 'creator',\n 'preview_url',\n )\n- filter_horizontal = ('locales',)\n+ filter_horizontal = (\n+ 'locales',\n+ )\n save_on_top = True\n save_as = True\n view_on_site = False\n", "issue": "ASR Snippet Admin: Be able to search for a snippet by Snippet ID in top search bar on list view page\nCurrently the search bar only allows for searching keywords.\n", "before_files": [{"content": "import re\n\nfrom django.contrib import admin\nfrom django.db.models import TextField, Q\nfrom django.template.loader import get_template\nfrom django.utils.safestring import mark_safe\n\nfrom reversion.admin import VersionAdmin\nfrom django_ace import AceWidget\nfrom django_statsd.clients import statsd\nfrom jinja2.meta import find_undeclared_variables\nfrom django_admin_listfilter_dropdown.filters import RelatedDropdownFilter\n\nfrom snippets.base import forms, models\nfrom snippets.base.models import JINJA_ENV\nfrom snippets.base.admin.filters import ModifiedFilter, ReleaseFilter\nfrom snippets.base.admin.actions import duplicate_snippets_action\n\n\nMATCH_LOCALE_REGEX = re.compile('(\\w+(?:-\\w+)*)')\nRESERVED_VARIABLES = ('_', 'snippet_id')\n\n\nclass ClientMatchRuleAdmin(VersionAdmin, admin.ModelAdmin):\n list_display = ('description', 'is_exclusion', 'startpage_version', 'name',\n 'version', 'locale', 'appbuildid', 'build_target',\n 'channel', 'os_version', 'distribution',\n 'distribution_version', 'modified')\n list_filter = ('name', 'version', 'os_version', 'appbuildid',\n 'build_target', 'channel', 'distribution', 'locale')\n save_on_top = True\n search_fields = ('description',)\n\n\nclass LogEntryAdmin(admin.ModelAdmin):\n list_display = ('user', 'content_type', 'object_id', 'object_repr', 'change_message')\n list_filter = ('user', 'content_type')\n\n\nclass SnippetTemplateVariableInline(admin.TabularInline):\n model = models.SnippetTemplateVariable\n formset = forms.SnippetTemplateVariableInlineFormset\n max_num = 0\n can_delete = False\n readonly_fields = ('name',)\n fields = ('name', 'type', 'order', 'description')\n\n\nclass SnippetTemplateAdmin(VersionAdmin, admin.ModelAdmin):\n save_on_top = True\n list_display = ('name', 'priority', 'hidden')\n list_filter = ('hidden', 'startpage')\n inlines = (SnippetTemplateVariableInline,)\n formfield_overrides = {\n TextField: {'widget': AceWidget(mode='html', theme='github',\n width='1200px', height='500px')},\n }\n\n class Media:\n css = {\n 'all': ('css/admin.css',)\n }\n\n def save_related(self, request, form, formsets, change):\n \"\"\"\n After saving the related objects, remove and add\n SnippetTemplateVariables depending on how the template code changed.\n \"\"\"\n super(SnippetTemplateAdmin, self).save_related(request, form, formsets,\n change)\n\n # Parse the template code and find any undefined variables.\n ast = JINJA_ENV.env.parse(form.instance.code)\n new_vars = find_undeclared_variables(ast)\n var_manager = form.instance.variable_set\n\n # Filter out reserved variable names.\n new_vars = [x for x in new_vars if x not in RESERVED_VARIABLES]\n\n # Delete variables not in the new set.\n var_manager.filter(~Q(name__in=new_vars)).delete()\n\n # Create variables that don't exist.\n for i, variable in enumerate(new_vars, start=1):\n obj, _ = models.SnippetTemplateVariable.objects.get_or_create(\n template=form.instance, name=variable)\n if obj.order == 0:\n obj.order = i * 10\n obj.save()\n\n\nclass UploadedFileAdmin(admin.ModelAdmin):\n readonly_fields = ('url', 'preview', 'snippets')\n list_display = ('name', 'url', 'preview', 'modified')\n prepopulated_fields = {'name': ('file',)}\n form = forms.UploadedFileAdminForm\n\n def preview(self, obj):\n template = get_template('base/uploadedfile_preview.jinja')\n return mark_safe(template.render({'file': obj}))\n\n def snippets(self, obj):\n \"\"\"Snippets using this file.\"\"\"\n template = get_template('base/uploadedfile_snippets.jinja')\n return mark_safe(template.render({'snippets': obj.snippets}))\n\n\nclass AddonAdmin(admin.ModelAdmin):\n list_display = ('name', 'guid')\n\n\nclass ASRSnippetAdmin(admin.ModelAdmin):\n form = forms.ASRSnippetAdminForm\n\n list_display_links = (\n 'id',\n 'name',\n )\n list_display = (\n 'id',\n 'name',\n 'status',\n 'modified',\n )\n list_filter = (\n ModifiedFilter,\n 'status',\n ReleaseFilter,\n ('template', RelatedDropdownFilter),\n )\n search_fields = (\n 'name',\n )\n autocomplete_fields = (\n 'campaign',\n 'target',\n )\n preserve_filters = True\n readonly_fields = (\n 'created',\n 'modified',\n 'uuid',\n 'creator',\n 'preview_url',\n )\n filter_horizontal = ('locales',)\n save_on_top = True\n save_as = True\n view_on_site = False\n actions = (\n duplicate_snippets_action,\n )\n\n fieldsets = (\n ('ID', {'fields': ('creator', 'name', 'status', 'preview_url')}),\n ('Content', {\n 'description': (\n '''\n <strong>Available deep links:</strong><br/>\n <ol>\n <li><code>special:accounts</code> to open Firefox Accounts</li>\n <li><code>special:appMenu</code> to open the hamburger menu</li>\n </ol><br/>\n <strong>Automatically add Snippet ID:</strong><br/>\n You can use <code>[[snippet_id]]</code> in any field and it\n will be automatically replaced by Snippet ID when served to users.\n <br/>\n Example: This is a <code><a href="https://example.com?utm_term=[[snippet_id]]">link</a></code> # noqa\n <br/>\n '''\n ),\n 'fields': ('template', 'data'),\n }),\n ('Publishing Options', {\n 'fields': ('campaign', 'target', ('publish_start', 'publish_end'), 'locales', 'weight',)\n }),\n ('Other Info', {\n 'fields': ('uuid', ('created', 'modified')),\n 'classes': ('collapse',)\n }),\n )\n\n class Media:\n css = {\n 'all': ('css/admin/ASRSnippetAdmin.css',)\n }\n js = (\n 'js/admin/clipboard.min.js',\n 'js/admin/copy_preview.js',\n )\n\n def save_model(self, request, obj, form, change):\n if not obj.creator_id:\n obj.creator = request.user\n statsd.incr('save.asrsnippet')\n super().save_model(request, obj, form, change)\n\n def preview_url(self, obj):\n text = f'''\n <span id=\"previewLinkUrl\">{obj.get_preview_url()}</span>\n <button id=\"copyPreviewLink\" class=\"btn\"\n data-clipboard-target=\"#previewLinkUrl\"\n originalText=\"Copy to Clipboard\" type=\"button\">\n Copy to Clipboard\n </button>\n '''\n return mark_safe(text)\n\n def change_view(self, request, *args, **kwargs):\n if request.method == 'POST' and '_saveasnew' in request.POST:\n # Always saved cloned snippets as un-published and un-check ready for review.\n post_data = request.POST.copy()\n post_data['status'] = models.STATUS_CHOICES['Draft']\n request.POST = post_data\n return super().change_view(request, *args, **kwargs)\n\n\nclass CampaignAdmin(admin.ModelAdmin):\n readonly_fields = ('created', 'modified', 'creator',)\n prepopulated_fields = {'slug': ('name',)}\n\n fieldsets = (\n ('ID', {'fields': ('name', 'slug')}),\n ('Other Info', {\n 'fields': ('creator', ('created', 'modified')),\n }),\n )\n search_fields = (\n 'name',\n )\n\n def save_model(self, request, obj, form, change):\n if not obj.creator_id:\n obj.creator = request.user\n statsd.incr('save.campaign')\n super().save_model(request, obj, form, change)\n\n\nclass TargetAdmin(admin.ModelAdmin):\n form = forms.TargetAdminForm\n readonly_fields = ('created', 'modified', 'creator', 'jexl_expr')\n search_fields = (\n 'name',\n )\n fieldsets = (\n ('ID', {'fields': ('name',)}),\n ('Product channels', {\n 'description': 'What channels will this snippet be available in?',\n 'fields': (('on_release', 'on_beta', 'on_aurora', 'on_nightly', 'on_esr'),)\n }),\n ('Targeting', {\n 'fields': (\n 'filtr_is_default_browser',\n 'filtr_updates_enabled',\n 'filtr_updates_autodownload_enabled',\n 'filtr_profile_age_created',\n 'filtr_firefox_version',\n 'filtr_previous_session_end',\n 'filtr_uses_firefox_sync',\n 'filtr_country',\n 'filtr_is_developer',\n 'filtr_current_search_engine',\n 'filtr_browser_addon',\n 'filtr_total_bookmarks_count',\n )\n }),\n ('Other Info', {\n 'fields': ('creator', ('created', 'modified'), 'jexl_expr'),\n }),\n )\n\n def save_model(self, request, obj, form, change):\n if not obj.creator_id:\n obj.creator = request.user\n statsd.incr('save.target')\n super().save_model(request, obj, form, change)\n", "path": "snippets/base/admin/adminmodels.py"}]} | 3,376 | 162 |
gh_patches_debug_19517 | rasdani/github-patches | git_diff | python-pillow__Pillow-5268 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ImageQt does not work as expected in PyQt5
### What did you do?
Attempted to use ImageQt to load a Pillow image in a PyQt5 application
### What did you expect to happen?
I expected the image to load correctly. There are no errors, but it does not load the image in PyQt5 correctly.
### What actually happened?
The image loaded as a mostly white image with kind of ghost image of the actual photo (see screenshot). I have attached the PyQt5 and PySide6 code, including screenshots from when I ran both files.
**Note: The same code works in PySide6, but not in PyQt5.**
### What are your OS, Python and Pillow versions?
* OS: MacOS Mojave and Windows 10
* Python: Python 3.9
* Pillow: 8.0.0

<!--
Please include **code** that reproduces the issue and whenever possible, an **image** that demonstrates the issue. Please upload images to GitHub, not to third-party file hosting sites. If necessary, add the image to a zip or tar archive.
The best reproductions are self-contained scripts with minimal dependencies. If you are using a framework such as Plone, Django, or Buildout, try to replicate the issue just using Pillow.
-->
```python
import sys
from PIL import Image, ImageQt
from PyQt5.QtGui import QPixmap, QImage
from PyQt5.QtWidgets import QWidget, QLabel
from PyQt5.QtWidgets import QVBoxLayout, QApplication
class ImageViewer(QWidget):
def __init__(self):
QWidget.__init__(self)
self.setWindowTitle("PyQt Image Viewer")
# Open up image in Pillow
image = Image.open("pink_flower.jpg")
qt_image = ImageQt.ImageQt(image)
pixmap = QPixmap.fromImage(qt_image)
self.image_label = QLabel('')
self.image_label.setPixmap(pixmap)
self.main_layout = QVBoxLayout()
self.main_layout.addWidget(self.image_label)
self.setLayout(self.main_layout)
if __name__ == "__main__":
app = QApplication(sys.argv)
viewer = ImageViewer()
viewer.show()
app.exec_()
```
[pyqt_pillow_issue.zip](https://github.com/python-pillow/Pillow/files/5976581/pyqt_pillow_issue.zip)
</issue>
<code>
[start of src/PIL/ImageQt.py]
1 #
2 # The Python Imaging Library.
3 # $Id$
4 #
5 # a simple Qt image interface.
6 #
7 # history:
8 # 2006-06-03 fl: created
9 # 2006-06-04 fl: inherit from QImage instead of wrapping it
10 # 2006-06-05 fl: removed toimage helper; move string support to ImageQt
11 # 2013-11-13 fl: add support for Qt5 ([email protected])
12 #
13 # Copyright (c) 2006 by Secret Labs AB
14 # Copyright (c) 2006 by Fredrik Lundh
15 #
16 # See the README file for information on usage and redistribution.
17 #
18
19 import sys
20 from io import BytesIO
21
22 from . import Image
23 from ._util import isPath
24
25 qt_versions = [
26 ["6", "PyQt6"],
27 ["side6", "PySide6"],
28 ["5", "PyQt5"],
29 ["side2", "PySide2"],
30 ]
31
32 # If a version has already been imported, attempt it first
33 qt_versions.sort(key=lambda qt_version: qt_version[1] in sys.modules, reverse=True)
34 for qt_version, qt_module in qt_versions:
35 try:
36 if qt_module == "PyQt6":
37 from PyQt6.QtCore import QBuffer, QIODevice
38 from PyQt6.QtGui import QImage, QPixmap, qRgba
39 elif qt_module == "PySide6":
40 from PySide6.QtCore import QBuffer, QIODevice
41 from PySide6.QtGui import QImage, QPixmap, qRgba
42 elif qt_module == "PyQt5":
43 from PyQt5.QtCore import QBuffer, QIODevice
44 from PyQt5.QtGui import QImage, QPixmap, qRgba
45 elif qt_module == "PySide2":
46 from PySide2.QtCore import QBuffer, QIODevice
47 from PySide2.QtGui import QImage, QPixmap, qRgba
48 except (ImportError, RuntimeError):
49 continue
50 qt_is_installed = True
51 break
52 else:
53 qt_is_installed = False
54 qt_version = None
55
56
57 def rgb(r, g, b, a=255):
58 """(Internal) Turns an RGB color into a Qt compatible color integer."""
59 # use qRgb to pack the colors, and then turn the resulting long
60 # into a negative integer with the same bitpattern.
61 return qRgba(r, g, b, a) & 0xFFFFFFFF
62
63
64 def fromqimage(im):
65 """
66 :param im: QImage or PIL ImageQt object
67 """
68 buffer = QBuffer()
69 qt_openmode = QIODevice.OpenMode if qt_version == "6" else QIODevice
70 buffer.open(qt_openmode.ReadWrite)
71 # preserve alpha channel with png
72 # otherwise ppm is more friendly with Image.open
73 if im.hasAlphaChannel():
74 im.save(buffer, "png")
75 else:
76 im.save(buffer, "ppm")
77
78 b = BytesIO()
79 b.write(buffer.data())
80 buffer.close()
81 b.seek(0)
82
83 return Image.open(b)
84
85
86 def fromqpixmap(im):
87 return fromqimage(im)
88 # buffer = QBuffer()
89 # buffer.open(QIODevice.ReadWrite)
90 # # im.save(buffer)
91 # # What if png doesn't support some image features like animation?
92 # im.save(buffer, 'ppm')
93 # bytes_io = BytesIO()
94 # bytes_io.write(buffer.data())
95 # buffer.close()
96 # bytes_io.seek(0)
97 # return Image.open(bytes_io)
98
99
100 def align8to32(bytes, width, mode):
101 """
102 converts each scanline of data from 8 bit to 32 bit aligned
103 """
104
105 bits_per_pixel = {"1": 1, "L": 8, "P": 8}[mode]
106
107 # calculate bytes per line and the extra padding if needed
108 bits_per_line = bits_per_pixel * width
109 full_bytes_per_line, remaining_bits_per_line = divmod(bits_per_line, 8)
110 bytes_per_line = full_bytes_per_line + (1 if remaining_bits_per_line else 0)
111
112 extra_padding = -bytes_per_line % 4
113
114 # already 32 bit aligned by luck
115 if not extra_padding:
116 return bytes
117
118 new_data = []
119 for i in range(len(bytes) // bytes_per_line):
120 new_data.append(
121 bytes[i * bytes_per_line : (i + 1) * bytes_per_line]
122 + b"\x00" * extra_padding
123 )
124
125 return b"".join(new_data)
126
127
128 def _toqclass_helper(im):
129 data = None
130 colortable = None
131 exclusive_fp = False
132
133 # handle filename, if given instead of image name
134 if hasattr(im, "toUtf8"):
135 # FIXME - is this really the best way to do this?
136 im = str(im.toUtf8(), "utf-8")
137 if isPath(im):
138 im = Image.open(im)
139 exclusive_fp = True
140
141 qt_format = QImage.Format if qt_version == "6" else QImage
142 if im.mode == "1":
143 format = qt_format.Format_Mono
144 elif im.mode == "L":
145 format = qt_format.Format_Indexed8
146 colortable = []
147 for i in range(256):
148 colortable.append(rgb(i, i, i))
149 elif im.mode == "P":
150 format = qt_format.Format_Indexed8
151 colortable = []
152 palette = im.getpalette()
153 for i in range(0, len(palette), 3):
154 colortable.append(rgb(*palette[i : i + 3]))
155 elif im.mode == "RGB":
156 data = im.tobytes("raw", "BGRX")
157 format = qt_format.Format_RGB32
158 elif im.mode == "RGBA":
159 data = im.tobytes("raw", "BGRA")
160 format = qt_format.Format_ARGB32
161 else:
162 if exclusive_fp:
163 im.close()
164 raise ValueError(f"unsupported image mode {repr(im.mode)}")
165
166 size = im.size
167 __data = data or align8to32(im.tobytes(), size[0], im.mode)
168 if exclusive_fp:
169 im.close()
170 return {"data": __data, "size": size, "format": format, "colortable": colortable}
171
172
173 if qt_is_installed:
174
175 class ImageQt(QImage):
176 def __init__(self, im):
177 """
178 An PIL image wrapper for Qt. This is a subclass of PyQt's QImage
179 class.
180
181 :param im: A PIL Image object, or a file name (given either as
182 Python string or a PyQt string object).
183 """
184 im_data = _toqclass_helper(im)
185 # must keep a reference, or Qt will crash!
186 # All QImage constructors that take data operate on an existing
187 # buffer, so this buffer has to hang on for the life of the image.
188 # Fixes https://github.com/python-pillow/Pillow/issues/1370
189 self.__data = im_data["data"]
190 super().__init__(
191 self.__data,
192 im_data["size"][0],
193 im_data["size"][1],
194 im_data["format"],
195 )
196 if im_data["colortable"]:
197 self.setColorTable(im_data["colortable"])
198
199
200 def toqimage(im):
201 return ImageQt(im)
202
203
204 def toqpixmap(im):
205 # # This doesn't work. For now using a dumb approach.
206 # im_data = _toqclass_helper(im)
207 # result = QPixmap(im_data["size"][0], im_data["size"][1])
208 # result.loadFromData(im_data["data"])
209 # Fix some strange bug that causes
210 if im.mode == "RGB":
211 im = im.convert("RGBA")
212
213 qimage = toqimage(im)
214 return QPixmap.fromImage(qimage)
215
[end of src/PIL/ImageQt.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/PIL/ImageQt.py b/src/PIL/ImageQt.py
--- a/src/PIL/ImageQt.py
+++ b/src/PIL/ImageQt.py
@@ -153,7 +153,10 @@
for i in range(0, len(palette), 3):
colortable.append(rgb(*palette[i : i + 3]))
elif im.mode == "RGB":
- data = im.tobytes("raw", "BGRX")
+ # Populate the 4th channel with 255
+ im = im.convert("RGBA")
+
+ data = im.tobytes("raw", "BGRA")
format = qt_format.Format_RGB32
elif im.mode == "RGBA":
data = im.tobytes("raw", "BGRA")
@@ -206,9 +209,5 @@
# im_data = _toqclass_helper(im)
# result = QPixmap(im_data["size"][0], im_data["size"][1])
# result.loadFromData(im_data["data"])
- # Fix some strange bug that causes
- if im.mode == "RGB":
- im = im.convert("RGBA")
-
qimage = toqimage(im)
return QPixmap.fromImage(qimage)
| {"golden_diff": "diff --git a/src/PIL/ImageQt.py b/src/PIL/ImageQt.py\n--- a/src/PIL/ImageQt.py\n+++ b/src/PIL/ImageQt.py\n@@ -153,7 +153,10 @@\n for i in range(0, len(palette), 3):\n colortable.append(rgb(*palette[i : i + 3]))\n elif im.mode == \"RGB\":\n- data = im.tobytes(\"raw\", \"BGRX\")\n+ # Populate the 4th channel with 255\n+ im = im.convert(\"RGBA\")\n+\n+ data = im.tobytes(\"raw\", \"BGRA\")\n format = qt_format.Format_RGB32\n elif im.mode == \"RGBA\":\n data = im.tobytes(\"raw\", \"BGRA\")\n@@ -206,9 +209,5 @@\n # im_data = _toqclass_helper(im)\n # result = QPixmap(im_data[\"size\"][0], im_data[\"size\"][1])\n # result.loadFromData(im_data[\"data\"])\n- # Fix some strange bug that causes\n- if im.mode == \"RGB\":\n- im = im.convert(\"RGBA\")\n-\n qimage = toqimage(im)\n return QPixmap.fromImage(qimage)\n", "issue": "ImageQt does not work as expected in PyQt5\n\r\n### What did you do?\r\n\r\nAttempted to use ImageQt to load a Pillow image in a PyQt5 application\r\n\r\n### What did you expect to happen?\r\n\r\nI expected the image to load correctly. There are no errors, but it does not load the image in PyQt5 correctly.\r\n\r\n### What actually happened?\r\n\r\nThe image loaded as a mostly white image with kind of ghost image of the actual photo (see screenshot). I have attached the PyQt5 and PySide6 code, including screenshots from when I ran both files.\r\n\r\n**Note: The same code works in PySide6, but not in PyQt5.**\r\n\r\n### What are your OS, Python and Pillow versions?\r\n\r\n* OS: MacOS Mojave and Windows 10\r\n* Python: Python 3.9\r\n* Pillow: 8.0.0\r\n\r\n\r\n\r\n\r\n\r\n<!--\r\nPlease include **code** that reproduces the issue and whenever possible, an **image** that demonstrates the issue. Please upload images to GitHub, not to third-party file hosting sites. If necessary, add the image to a zip or tar archive.\r\n\r\nThe best reproductions are self-contained scripts with minimal dependencies. If you are using a framework such as Plone, Django, or Buildout, try to replicate the issue just using Pillow.\r\n-->\r\n\r\n```python\r\nimport sys\r\n\r\nfrom PIL import Image, ImageQt\r\nfrom PyQt5.QtGui import QPixmap, QImage\r\nfrom PyQt5.QtWidgets import QWidget, QLabel\r\nfrom PyQt5.QtWidgets import QVBoxLayout, QApplication\r\n\r\n\r\nclass ImageViewer(QWidget):\r\n\r\n def __init__(self):\r\n QWidget.__init__(self)\r\n self.setWindowTitle(\"PyQt Image Viewer\")\r\n\r\n # Open up image in Pillow\r\n image = Image.open(\"pink_flower.jpg\")\r\n qt_image = ImageQt.ImageQt(image)\r\n pixmap = QPixmap.fromImage(qt_image)\r\n\r\n self.image_label = QLabel('')\r\n self.image_label.setPixmap(pixmap)\r\n\r\n self.main_layout = QVBoxLayout()\r\n self.main_layout.addWidget(self.image_label)\r\n self.setLayout(self.main_layout)\r\n\r\n\r\nif __name__ == \"__main__\":\r\n app = QApplication(sys.argv)\r\n viewer = ImageViewer()\r\n viewer.show()\r\n app.exec_()\r\n```\r\n\r\n[pyqt_pillow_issue.zip](https://github.com/python-pillow/Pillow/files/5976581/pyqt_pillow_issue.zip)\n", "before_files": [{"content": "#\n# The Python Imaging Library.\n# $Id$\n#\n# a simple Qt image interface.\n#\n# history:\n# 2006-06-03 fl: created\n# 2006-06-04 fl: inherit from QImage instead of wrapping it\n# 2006-06-05 fl: removed toimage helper; move string support to ImageQt\n# 2013-11-13 fl: add support for Qt5 ([email protected])\n#\n# Copyright (c) 2006 by Secret Labs AB\n# Copyright (c) 2006 by Fredrik Lundh\n#\n# See the README file for information on usage and redistribution.\n#\n\nimport sys\nfrom io import BytesIO\n\nfrom . import Image\nfrom ._util import isPath\n\nqt_versions = [\n [\"6\", \"PyQt6\"],\n [\"side6\", \"PySide6\"],\n [\"5\", \"PyQt5\"],\n [\"side2\", \"PySide2\"],\n]\n\n# If a version has already been imported, attempt it first\nqt_versions.sort(key=lambda qt_version: qt_version[1] in sys.modules, reverse=True)\nfor qt_version, qt_module in qt_versions:\n try:\n if qt_module == \"PyQt6\":\n from PyQt6.QtCore import QBuffer, QIODevice\n from PyQt6.QtGui import QImage, QPixmap, qRgba\n elif qt_module == \"PySide6\":\n from PySide6.QtCore import QBuffer, QIODevice\n from PySide6.QtGui import QImage, QPixmap, qRgba\n elif qt_module == \"PyQt5\":\n from PyQt5.QtCore import QBuffer, QIODevice\n from PyQt5.QtGui import QImage, QPixmap, qRgba\n elif qt_module == \"PySide2\":\n from PySide2.QtCore import QBuffer, QIODevice\n from PySide2.QtGui import QImage, QPixmap, qRgba\n except (ImportError, RuntimeError):\n continue\n qt_is_installed = True\n break\nelse:\n qt_is_installed = False\n qt_version = None\n\n\ndef rgb(r, g, b, a=255):\n \"\"\"(Internal) Turns an RGB color into a Qt compatible color integer.\"\"\"\n # use qRgb to pack the colors, and then turn the resulting long\n # into a negative integer with the same bitpattern.\n return qRgba(r, g, b, a) & 0xFFFFFFFF\n\n\ndef fromqimage(im):\n \"\"\"\n :param im: QImage or PIL ImageQt object\n \"\"\"\n buffer = QBuffer()\n qt_openmode = QIODevice.OpenMode if qt_version == \"6\" else QIODevice\n buffer.open(qt_openmode.ReadWrite)\n # preserve alpha channel with png\n # otherwise ppm is more friendly with Image.open\n if im.hasAlphaChannel():\n im.save(buffer, \"png\")\n else:\n im.save(buffer, \"ppm\")\n\n b = BytesIO()\n b.write(buffer.data())\n buffer.close()\n b.seek(0)\n\n return Image.open(b)\n\n\ndef fromqpixmap(im):\n return fromqimage(im)\n # buffer = QBuffer()\n # buffer.open(QIODevice.ReadWrite)\n # # im.save(buffer)\n # # What if png doesn't support some image features like animation?\n # im.save(buffer, 'ppm')\n # bytes_io = BytesIO()\n # bytes_io.write(buffer.data())\n # buffer.close()\n # bytes_io.seek(0)\n # return Image.open(bytes_io)\n\n\ndef align8to32(bytes, width, mode):\n \"\"\"\n converts each scanline of data from 8 bit to 32 bit aligned\n \"\"\"\n\n bits_per_pixel = {\"1\": 1, \"L\": 8, \"P\": 8}[mode]\n\n # calculate bytes per line and the extra padding if needed\n bits_per_line = bits_per_pixel * width\n full_bytes_per_line, remaining_bits_per_line = divmod(bits_per_line, 8)\n bytes_per_line = full_bytes_per_line + (1 if remaining_bits_per_line else 0)\n\n extra_padding = -bytes_per_line % 4\n\n # already 32 bit aligned by luck\n if not extra_padding:\n return bytes\n\n new_data = []\n for i in range(len(bytes) // bytes_per_line):\n new_data.append(\n bytes[i * bytes_per_line : (i + 1) * bytes_per_line]\n + b\"\\x00\" * extra_padding\n )\n\n return b\"\".join(new_data)\n\n\ndef _toqclass_helper(im):\n data = None\n colortable = None\n exclusive_fp = False\n\n # handle filename, if given instead of image name\n if hasattr(im, \"toUtf8\"):\n # FIXME - is this really the best way to do this?\n im = str(im.toUtf8(), \"utf-8\")\n if isPath(im):\n im = Image.open(im)\n exclusive_fp = True\n\n qt_format = QImage.Format if qt_version == \"6\" else QImage\n if im.mode == \"1\":\n format = qt_format.Format_Mono\n elif im.mode == \"L\":\n format = qt_format.Format_Indexed8\n colortable = []\n for i in range(256):\n colortable.append(rgb(i, i, i))\n elif im.mode == \"P\":\n format = qt_format.Format_Indexed8\n colortable = []\n palette = im.getpalette()\n for i in range(0, len(palette), 3):\n colortable.append(rgb(*palette[i : i + 3]))\n elif im.mode == \"RGB\":\n data = im.tobytes(\"raw\", \"BGRX\")\n format = qt_format.Format_RGB32\n elif im.mode == \"RGBA\":\n data = im.tobytes(\"raw\", \"BGRA\")\n format = qt_format.Format_ARGB32\n else:\n if exclusive_fp:\n im.close()\n raise ValueError(f\"unsupported image mode {repr(im.mode)}\")\n\n size = im.size\n __data = data or align8to32(im.tobytes(), size[0], im.mode)\n if exclusive_fp:\n im.close()\n return {\"data\": __data, \"size\": size, \"format\": format, \"colortable\": colortable}\n\n\nif qt_is_installed:\n\n class ImageQt(QImage):\n def __init__(self, im):\n \"\"\"\n An PIL image wrapper for Qt. This is a subclass of PyQt's QImage\n class.\n\n :param im: A PIL Image object, or a file name (given either as\n Python string or a PyQt string object).\n \"\"\"\n im_data = _toqclass_helper(im)\n # must keep a reference, or Qt will crash!\n # All QImage constructors that take data operate on an existing\n # buffer, so this buffer has to hang on for the life of the image.\n # Fixes https://github.com/python-pillow/Pillow/issues/1370\n self.__data = im_data[\"data\"]\n super().__init__(\n self.__data,\n im_data[\"size\"][0],\n im_data[\"size\"][1],\n im_data[\"format\"],\n )\n if im_data[\"colortable\"]:\n self.setColorTable(im_data[\"colortable\"])\n\n\ndef toqimage(im):\n return ImageQt(im)\n\n\ndef toqpixmap(im):\n # # This doesn't work. For now using a dumb approach.\n # im_data = _toqclass_helper(im)\n # result = QPixmap(im_data[\"size\"][0], im_data[\"size\"][1])\n # result.loadFromData(im_data[\"data\"])\n # Fix some strange bug that causes\n if im.mode == \"RGB\":\n im = im.convert(\"RGBA\")\n\n qimage = toqimage(im)\n return QPixmap.fromImage(qimage)\n", "path": "src/PIL/ImageQt.py"}]} | 3,377 | 279 |
gh_patches_debug_10354 | rasdani/github-patches | git_diff | holoviz__panel-1167 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Panel.serve does not work for panel.Templates without instantiation
#### System Info
- Panel: 0.8.0
- Bokeh: 1.4.0
- Tornado 6.0.3
- Python: 3.7.4
- OS: Windows 8.1
- Browser: Chrome
#### My Pain
I'm trying to serve a list of apps and one of them uses the Panel Templating System.
If I provide a function that returns a Template to `pn.Serve` the app is not shown.
#### Additional Info
If I provide a function that returns a Column to `pn.Serve` the app is shown
If I provide an instance of the Template to `pn.Serve` the app is shown
#### Screenshot
#### Code
````bash
import holoviews as hv
import panel as pn
TEMPLATE = """
<!-- This template is inspired by
- Bokeh Template. See https://panel.pyviz.org/user_guide/Templates.html
-->
{% extends base %}
<!-- goes in head -->
{% block postamble %}
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
{% endblock %}
<!-- goes in body -->
{% block contents %}
<section id="page">
<header>
{{ embed(roots.header) }}
</header>
<main>
{{ embed(roots.main) }}
</main>
</section>
{% endblock %}
"""
class DashboardTemplate(pn.Template):
"""A Basic App Template"""
def __init__(self, **params):
template = TEMPLATE
self.header = pn.Row()
self.main = pn.Column()
items = {
"header": self.header,
"main": self.main,
}
super().__init__(template=template, items=items, **params)
def app_template():
app = DashboardTemplate()
component = pn.Column("# App Template",)
app.main[:] = [component]
return app
def app_column():
return pn.Column("# App Column")
APP_ROUTES = {
"app_column": app_column,
"app_template": app_template,
"app_template_instance": app_template(),
}
pn.serve(APP_ROUTES, port=14033, dev=True)
````
</issue>
<code>
[start of panel/io/server.py]
1 """
2 Utilities for creating bokeh Server instances.
3 """
4 from __future__ import absolute_import, division, unicode_literals
5
6 import os
7 import signal
8 import threading
9 import uuid
10
11 from contextlib import contextmanager
12 from functools import partial
13 from types import FunctionType
14
15 from bokeh.document.events import ModelChangedEvent
16 from bokeh.server.server import Server
17 from tornado.websocket import WebSocketHandler
18
19 from .state import state
20
21
22 #---------------------------------------------------------------------
23 # Private API
24 #---------------------------------------------------------------------
25
26 INDEX_HTML = os.path.join(os.path.dirname(__file__), '..', '_templates', "index.html")
27
28 def _origin_url(url):
29 if url.startswith("http"):
30 url = url.split("//")[1]
31 return url
32
33
34 def _server_url(url, port):
35 if url.startswith("http"):
36 return '%s:%d%s' % (url.rsplit(':', 1)[0], port, "/")
37 else:
38 return 'http://%s:%d%s' % (url.split(':')[0], port, "/")
39
40 def _eval_panel(panel, server_id, title, doc):
41 from ..template import Template
42 from ..pane import panel as as_panel
43
44 if isinstance(panel, Template):
45 return panel._modify_doc(server_id, title, doc)
46 elif isinstance(panel, FunctionType):
47 panel = panel()
48 return as_panel(panel)._modify_doc(server_id, title, doc)
49
50 #---------------------------------------------------------------------
51 # Public API
52 #---------------------------------------------------------------------
53
54
55 @contextmanager
56 def unlocked():
57 """
58 Context manager which unlocks a Document and dispatches
59 ModelChangedEvents triggered in the context body to all sockets
60 on current sessions.
61 """
62 curdoc = state.curdoc
63 if curdoc is None or curdoc.session_context is None:
64 yield
65 return
66 connections = curdoc.session_context.session._subscribed_connections
67
68 hold = curdoc._hold
69 if hold:
70 old_events = list(curdoc._held_events)
71 else:
72 old_events = []
73 curdoc.hold()
74 try:
75 yield
76 events = []
77 for conn in connections:
78 socket = conn._socket
79 for event in curdoc._held_events:
80 if (isinstance(event, ModelChangedEvent) and event not in old_events
81 and hasattr(socket, 'write_message')):
82 msg = conn.protocol.create('PATCH-DOC', [event])
83 WebSocketHandler.write_message(socket, msg.header_json)
84 WebSocketHandler.write_message(socket, msg.metadata_json)
85 WebSocketHandler.write_message(socket, msg.content_json)
86 for header, payload in msg._buffers:
87 WebSocketHandler.write_message(socket, header)
88 WebSocketHandler.write_message(socket, payload, binary=True)
89 elif event not in events:
90 events.append(event)
91 curdoc._held_events = events
92 finally:
93 if not hold:
94 curdoc.unhold()
95
96
97 def serve(panels, port=0, websocket_origin=None, loop=None, show=True,
98 start=True, title=None, verbose=True, **kwargs):
99 """
100 Allows serving one or more panel objects on a single server.
101 The panels argument should be either a Panel object or a function
102 returning a Panel object or a dictionary of these two. If a
103 dictionary is supplied the keys represent the slugs at which
104 each app is served, e.g. `serve({'app': panel1, 'app2': panel2})`
105 will serve apps at /app and /app2 on the server.
106
107 Arguments
108 ---------
109 panel: Viewable, function or {str: Viewable}
110 A Panel object, a function returning a Panel object or a
111 dictionary mapping from the URL slug to either.
112 port: int (optional, default=0)
113 Allows specifying a specific port
114 websocket_origin: str or list(str) (optional)
115 A list of hosts that can connect to the websocket.
116
117 This is typically required when embedding a server app in
118 an external web site.
119
120 If None, "localhost" is used.
121 loop : tornado.ioloop.IOLoop (optional, default=IOLoop.current())
122 The tornado IOLoop to run the Server on
123 show : boolean (optional, default=False)
124 Whether to open the server in a new browser tab on start
125 start : boolean(optional, default=False)
126 Whether to start the Server
127 title: str (optional, default=None)
128 An HTML title for the application
129 verbose: boolean (optional, default=True)
130 Whether to print the address and port
131 kwargs: dict
132 Additional keyword arguments to pass to Server instance
133 """
134 return get_server(panels, port, websocket_origin, loop, show, start,
135 title, verbose, **kwargs)
136
137
138 def get_server(panel, port=0, websocket_origin=None, loop=None,
139 show=False, start=False, title=None, verbose=False, **kwargs):
140 """
141 Returns a Server instance with this panel attached as the root
142 app.
143
144 Arguments
145 ---------
146 panel: Viewable, function or {str: Viewable}
147 A Panel object, a function returning a Panel object or a
148 dictionary mapping from the URL slug to either.
149 port: int (optional, default=0)
150 Allows specifying a specific port
151 websocket_origin: str or list(str) (optional)
152 A list of hosts that can connect to the websocket.
153
154 This is typically required when embedding a server app in
155 an external web site.
156
157 If None, "localhost" is used.
158 loop : tornado.ioloop.IOLoop (optional, default=IOLoop.current())
159 The tornado IOLoop to run the Server on
160 show : boolean (optional, default=False)
161 Whether to open the server in a new browser tab on start
162 start : boolean(optional, default=False)
163 Whether to start the Server
164 title: str (optional, default=None)
165 An HTML title for the application
166 verbose: boolean (optional, default=False)
167 Whether to report the address and port
168 kwargs: dict
169 Additional keyword arguments to pass to Server instance
170
171 Returns
172 -------
173 server : bokeh.server.server.Server
174 Bokeh Server instance running this panel
175 """
176 from tornado.ioloop import IOLoop
177
178 server_id = kwargs.pop('server_id', uuid.uuid4().hex)
179 if isinstance(panel, dict):
180 apps = {slug if slug.startswith('/') else '/'+slug:
181 partial(_eval_panel, p, server_id, title)
182 for slug, p in panel.items()}
183 else:
184 apps = {'/': partial(_eval_panel, panel, server_id, title)}
185
186 opts = dict(kwargs)
187 if loop:
188 loop.make_current()
189 opts['io_loop'] = loop
190 else:
191 opts['io_loop'] = IOLoop.current()
192
193 if 'index' not in opts:
194 opts['index'] = INDEX_HTML
195
196 if websocket_origin:
197 if not isinstance(websocket_origin, list):
198 websocket_origin = [websocket_origin]
199 opts['allow_websocket_origin'] = websocket_origin
200
201 server = Server(apps, port=port, **opts)
202 if verbose:
203 address = server.address or 'localhost'
204 print("Launching server at http://%s:%s" % (address, server.port))
205
206 state._servers[server_id] = (server, panel, [])
207
208 if show:
209 def show_callback():
210 server.show('/')
211 server.io_loop.add_callback(show_callback)
212
213 def sig_exit(*args, **kwargs):
214 server.io_loop.add_callback_from_signal(do_stop)
215
216 def do_stop(*args, **kwargs):
217 server.io_loop.stop()
218
219 try:
220 signal.signal(signal.SIGINT, sig_exit)
221 except ValueError:
222 pass # Can't use signal on a thread
223
224 if start:
225 server.start()
226 try:
227 server.io_loop.start()
228 except RuntimeError:
229 pass
230 return server
231
232
233 class StoppableThread(threading.Thread):
234 """Thread class with a stop() method."""
235
236 def __init__(self, io_loop=None, timeout=1000, **kwargs):
237 from tornado import ioloop
238 super(StoppableThread, self).__init__(**kwargs)
239 self._stop_event = threading.Event()
240 self.io_loop = io_loop
241 self._cb = ioloop.PeriodicCallback(self._check_stopped, timeout)
242 self._cb.start()
243
244 def _check_stopped(self):
245 if self.stopped:
246 self._cb.stop()
247 self.io_loop.stop()
248
249 def run(self):
250 if hasattr(self, '_target'):
251 target, args, kwargs = self._target, self._args, self._kwargs
252 else:
253 target, args, kwargs = self._Thread__target, self._Thread__args, self._Thread__kwargs
254 if not target:
255 return
256 bokeh_server = None
257 try:
258 bokeh_server = target(*args, **kwargs)
259 finally:
260 if isinstance(bokeh_server, Server):
261 bokeh_server.stop()
262 if hasattr(self, '_target'):
263 del self._target, self._args, self._kwargs
264 else:
265 del self._Thread__target, self._Thread__args, self._Thread__kwargs
266
267 def stop(self):
268 self._stop_event.set()
269
270 @property
271 def stopped(self):
272 return self._stop_event.is_set()
273
[end of panel/io/server.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/panel/io/server.py b/panel/io/server.py
--- a/panel/io/server.py
+++ b/panel/io/server.py
@@ -41,10 +41,10 @@
from ..template import Template
from ..pane import panel as as_panel
+ if isinstance(panel, FunctionType):
+ panel = panel()
if isinstance(panel, Template):
return panel._modify_doc(server_id, title, doc)
- elif isinstance(panel, FunctionType):
- panel = panel()
return as_panel(panel)._modify_doc(server_id, title, doc)
#---------------------------------------------------------------------
| {"golden_diff": "diff --git a/panel/io/server.py b/panel/io/server.py\n--- a/panel/io/server.py\n+++ b/panel/io/server.py\n@@ -41,10 +41,10 @@\n from ..template import Template\n from ..pane import panel as as_panel\n \n+ if isinstance(panel, FunctionType):\n+ panel = panel()\n if isinstance(panel, Template):\n return panel._modify_doc(server_id, title, doc)\n- elif isinstance(panel, FunctionType):\n- panel = panel()\n return as_panel(panel)._modify_doc(server_id, title, doc)\n \n #---------------------------------------------------------------------\n", "issue": "Panel.serve does not work for panel.Templates without instantiation\n#### System Info\r\n\r\n- Panel: 0.8.0\r\n- Bokeh: 1.4.0\r\n- Tornado 6.0.3\r\n- Python: 3.7.4\r\n- OS: Windows 8.1\r\n- Browser: Chrome\r\n\r\n#### My Pain\r\n\r\nI'm trying to serve a list of apps and one of them uses the Panel Templating System.\r\n\r\nIf I provide a function that returns a Template to `pn.Serve` the app is not shown.\r\n\r\n#### Additional Info\r\n\r\nIf I provide a function that returns a Column to `pn.Serve` the app is shown\r\nIf I provide an instance of the Template to `pn.Serve` the app is shown\r\n\r\n#### Screenshot\r\n\r\n\r\n\r\n#### Code\r\n\r\n````bash\r\nimport holoviews as hv\r\nimport panel as pn\r\n\r\nTEMPLATE = \"\"\"\r\n<!-- This template is inspired by\r\n- Bokeh Template. See https://panel.pyviz.org/user_guide/Templates.html\r\n-->\r\n{% extends base %}\r\n\r\n<!-- goes in head -->\r\n{% block postamble %}\r\n<meta name=\"viewport\" content=\"width=device-width, initial-scale=1, shrink-to-fit=no\">\r\n{% endblock %}\r\n\r\n<!-- goes in body -->\r\n{% block contents %}\r\n\r\n<section id=\"page\">\r\n <header>\r\n {{ embed(roots.header) }}\r\n </header>\r\n <main>\r\n {{ embed(roots.main) }}\r\n </main>\r\n</section>\r\n\r\n{% endblock %}\r\n\"\"\"\r\n\r\n\r\nclass DashboardTemplate(pn.Template):\r\n \"\"\"A Basic App Template\"\"\"\r\n\r\n def __init__(self, **params):\r\n template = TEMPLATE\r\n\r\n self.header = pn.Row()\r\n self.main = pn.Column()\r\n\r\n items = {\r\n \"header\": self.header,\r\n \"main\": self.main,\r\n }\r\n super().__init__(template=template, items=items, **params)\r\n\r\n\r\ndef app_template():\r\n app = DashboardTemplate()\r\n component = pn.Column(\"# App Template\",)\r\n app.main[:] = [component]\r\n return app\r\n\r\n\r\ndef app_column():\r\n return pn.Column(\"# App Column\")\r\n\r\n\r\nAPP_ROUTES = {\r\n \"app_column\": app_column,\r\n \"app_template\": app_template,\r\n \"app_template_instance\": app_template(),\r\n}\r\n\r\npn.serve(APP_ROUTES, port=14033, dev=True)\r\n````\r\n\n", "before_files": [{"content": "\"\"\"\nUtilities for creating bokeh Server instances.\n\"\"\"\nfrom __future__ import absolute_import, division, unicode_literals\n\nimport os\nimport signal\nimport threading\nimport uuid\n\nfrom contextlib import contextmanager\nfrom functools import partial\nfrom types import FunctionType\n\nfrom bokeh.document.events import ModelChangedEvent\nfrom bokeh.server.server import Server\nfrom tornado.websocket import WebSocketHandler\n\nfrom .state import state\n\n\n#---------------------------------------------------------------------\n# Private API\n#---------------------------------------------------------------------\n\nINDEX_HTML = os.path.join(os.path.dirname(__file__), '..', '_templates', \"index.html\")\n\ndef _origin_url(url):\n if url.startswith(\"http\"):\n url = url.split(\"//\")[1]\n return url\n\n\ndef _server_url(url, port):\n if url.startswith(\"http\"):\n return '%s:%d%s' % (url.rsplit(':', 1)[0], port, \"/\")\n else:\n return 'http://%s:%d%s' % (url.split(':')[0], port, \"/\")\n\ndef _eval_panel(panel, server_id, title, doc):\n from ..template import Template\n from ..pane import panel as as_panel\n\n if isinstance(panel, Template):\n return panel._modify_doc(server_id, title, doc)\n elif isinstance(panel, FunctionType):\n panel = panel()\n return as_panel(panel)._modify_doc(server_id, title, doc)\n \n#---------------------------------------------------------------------\n# Public API\n#---------------------------------------------------------------------\n\n\n@contextmanager\ndef unlocked():\n \"\"\"\n Context manager which unlocks a Document and dispatches\n ModelChangedEvents triggered in the context body to all sockets\n on current sessions.\n \"\"\"\n curdoc = state.curdoc\n if curdoc is None or curdoc.session_context is None:\n yield\n return\n connections = curdoc.session_context.session._subscribed_connections\n\n hold = curdoc._hold\n if hold:\n old_events = list(curdoc._held_events)\n else:\n old_events = []\n curdoc.hold()\n try:\n yield\n events = []\n for conn in connections:\n socket = conn._socket\n for event in curdoc._held_events:\n if (isinstance(event, ModelChangedEvent) and event not in old_events\n and hasattr(socket, 'write_message')):\n msg = conn.protocol.create('PATCH-DOC', [event])\n WebSocketHandler.write_message(socket, msg.header_json)\n WebSocketHandler.write_message(socket, msg.metadata_json)\n WebSocketHandler.write_message(socket, msg.content_json)\n for header, payload in msg._buffers:\n WebSocketHandler.write_message(socket, header)\n WebSocketHandler.write_message(socket, payload, binary=True)\n elif event not in events:\n events.append(event)\n curdoc._held_events = events\n finally:\n if not hold:\n curdoc.unhold()\n\n\ndef serve(panels, port=0, websocket_origin=None, loop=None, show=True,\n start=True, title=None, verbose=True, **kwargs):\n \"\"\"\n Allows serving one or more panel objects on a single server.\n The panels argument should be either a Panel object or a function\n returning a Panel object or a dictionary of these two. If a \n dictionary is supplied the keys represent the slugs at which\n each app is served, e.g. `serve({'app': panel1, 'app2': panel2})`\n will serve apps at /app and /app2 on the server.\n\n Arguments\n ---------\n panel: Viewable, function or {str: Viewable}\n A Panel object, a function returning a Panel object or a\n dictionary mapping from the URL slug to either.\n port: int (optional, default=0)\n Allows specifying a specific port\n websocket_origin: str or list(str) (optional)\n A list of hosts that can connect to the websocket.\n\n This is typically required when embedding a server app in\n an external web site.\n\n If None, \"localhost\" is used.\n loop : tornado.ioloop.IOLoop (optional, default=IOLoop.current())\n The tornado IOLoop to run the Server on\n show : boolean (optional, default=False)\n Whether to open the server in a new browser tab on start\n start : boolean(optional, default=False)\n Whether to start the Server\n title: str (optional, default=None)\n An HTML title for the application\n verbose: boolean (optional, default=True)\n Whether to print the address and port\n kwargs: dict\n Additional keyword arguments to pass to Server instance\n \"\"\"\n return get_server(panels, port, websocket_origin, loop, show, start,\n title, verbose, **kwargs)\n\n\ndef get_server(panel, port=0, websocket_origin=None, loop=None,\n show=False, start=False, title=None, verbose=False, **kwargs):\n \"\"\"\n Returns a Server instance with this panel attached as the root\n app.\n\n Arguments\n ---------\n panel: Viewable, function or {str: Viewable}\n A Panel object, a function returning a Panel object or a\n dictionary mapping from the URL slug to either.\n port: int (optional, default=0)\n Allows specifying a specific port\n websocket_origin: str or list(str) (optional)\n A list of hosts that can connect to the websocket.\n\n This is typically required when embedding a server app in\n an external web site.\n\n If None, \"localhost\" is used.\n loop : tornado.ioloop.IOLoop (optional, default=IOLoop.current())\n The tornado IOLoop to run the Server on\n show : boolean (optional, default=False)\n Whether to open the server in a new browser tab on start\n start : boolean(optional, default=False)\n Whether to start the Server\n title: str (optional, default=None)\n An HTML title for the application\n verbose: boolean (optional, default=False)\n Whether to report the address and port\n kwargs: dict\n Additional keyword arguments to pass to Server instance\n\n Returns\n -------\n server : bokeh.server.server.Server\n Bokeh Server instance running this panel\n \"\"\"\n from tornado.ioloop import IOLoop\n\n server_id = kwargs.pop('server_id', uuid.uuid4().hex)\n if isinstance(panel, dict):\n apps = {slug if slug.startswith('/') else '/'+slug:\n partial(_eval_panel, p, server_id, title)\n for slug, p in panel.items()}\n else:\n apps = {'/': partial(_eval_panel, panel, server_id, title)}\n\n opts = dict(kwargs)\n if loop:\n loop.make_current()\n opts['io_loop'] = loop\n else:\n opts['io_loop'] = IOLoop.current()\n\n if 'index' not in opts:\n opts['index'] = INDEX_HTML\n\n if websocket_origin:\n if not isinstance(websocket_origin, list):\n websocket_origin = [websocket_origin]\n opts['allow_websocket_origin'] = websocket_origin\n\n server = Server(apps, port=port, **opts)\n if verbose:\n address = server.address or 'localhost'\n print(\"Launching server at http://%s:%s\" % (address, server.port))\n\n state._servers[server_id] = (server, panel, [])\n\n if show:\n def show_callback():\n server.show('/')\n server.io_loop.add_callback(show_callback)\n\n def sig_exit(*args, **kwargs):\n server.io_loop.add_callback_from_signal(do_stop)\n\n def do_stop(*args, **kwargs):\n server.io_loop.stop()\n\n try:\n signal.signal(signal.SIGINT, sig_exit)\n except ValueError:\n pass # Can't use signal on a thread\n\n if start:\n server.start()\n try:\n server.io_loop.start()\n except RuntimeError:\n pass\n return server\n\n\nclass StoppableThread(threading.Thread):\n \"\"\"Thread class with a stop() method.\"\"\"\n\n def __init__(self, io_loop=None, timeout=1000, **kwargs):\n from tornado import ioloop\n super(StoppableThread, self).__init__(**kwargs)\n self._stop_event = threading.Event()\n self.io_loop = io_loop\n self._cb = ioloop.PeriodicCallback(self._check_stopped, timeout)\n self._cb.start()\n\n def _check_stopped(self):\n if self.stopped:\n self._cb.stop()\n self.io_loop.stop()\n\n def run(self):\n if hasattr(self, '_target'):\n target, args, kwargs = self._target, self._args, self._kwargs\n else:\n target, args, kwargs = self._Thread__target, self._Thread__args, self._Thread__kwargs\n if not target:\n return\n bokeh_server = None\n try:\n bokeh_server = target(*args, **kwargs)\n finally:\n if isinstance(bokeh_server, Server):\n bokeh_server.stop()\n if hasattr(self, '_target'):\n del self._target, self._args, self._kwargs\n else:\n del self._Thread__target, self._Thread__args, self._Thread__kwargs\n\n def stop(self):\n self._stop_event.set()\n\n @property\n def stopped(self):\n return self._stop_event.is_set()\n", "path": "panel/io/server.py"}]} | 3,798 | 132 |
gh_patches_debug_6897 | rasdani/github-patches | git_diff | ydataai__ydata-profiling-736 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Negative exponents appear positive
**Describe the bug**
Negative exponents do not appear in a profiling report
**To Reproduce**
```python
import numpy as np
import pandas as pd
from pandas_profiling import ProfileReport
data = { 'some_numbers' : (0.0001, 0.00001, 0.00000001, 0.002, 0.0002, 0.00003) * 100}
df = pd.DataFrame(data)
profile = ProfileReport(df, 'No Negative Exponents')
profile.to_file('NoNegativeExponents.html')
```
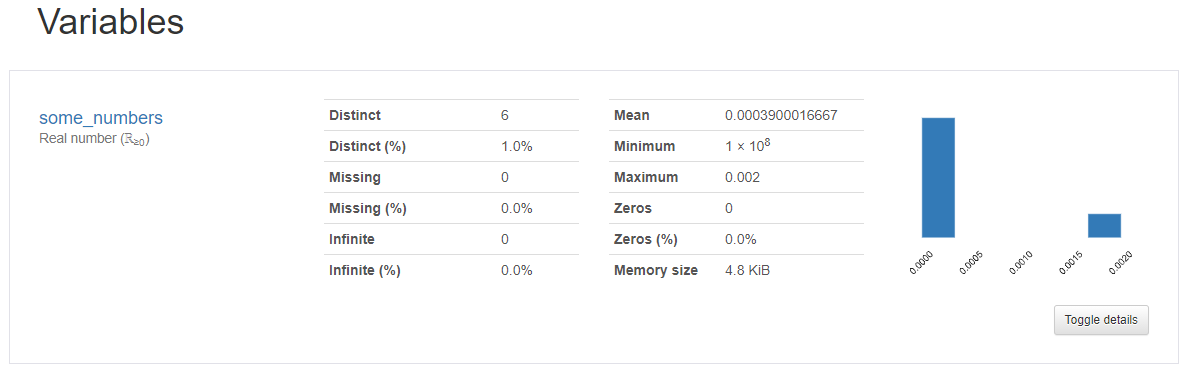
Minimum should be 1 x 10<sup>-8</sup> rather than 1 x 10<sup>8</sup>. The issue also arises for Mean and Maximum.
**Version information:**
Python 3.7.7 (default, May 6 2020, 11:45:54) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32
**Additional context**
<!--
Add any other context about the problem here.
-->
</issue>
<code>
[start of src/pandas_profiling/report/formatters.py]
1 """Formatters are mappings from object(s) to a string."""
2 from typing import Callable, Dict
3
4 import numpy as np
5 from jinja2.utils import escape
6
7
8 def fmt_color(text: str, color: str) -> str:
9 """Format a string in a certain color (`<span>`).
10
11 Args:
12 text: The text to format.
13 color: Any valid CSS color.
14
15 Returns:
16 A `<span>` that contains the colored text.
17 """
18 return f'<span style="color:{color}">{text}</span>'
19
20
21 def fmt_class(text: str, cls: str) -> str:
22 """Format a string in a certain class (`<span>`).
23
24 Args:
25 text: The text to format.
26 cls: The name of the class.
27
28 Returns:
29 A `<span>` with a class added.
30 """
31 return f'<span class="{cls}">{text}</span>'
32
33
34 def fmt_bytesize(num: float, suffix: str = "B") -> str:
35 """Change a number of bytes in a human readable format.
36
37 Args:
38 num: number to format
39 suffix: (Default value = 'B')
40
41 Returns:
42 The value formatted in human readable format (e.g. KiB).
43 """
44 for unit in ["", "Ki", "Mi", "Gi", "Ti", "Pi", "Ei", "Zi"]:
45 if abs(num) < 1024.0:
46 return f"{num:3.1f} {unit}{suffix}"
47 num /= 1024.0
48 return f"{num:.1f} Yi{suffix}"
49
50
51 def fmt_percent(value: float, edge_cases: bool = True) -> str:
52 """Format a ratio as a percentage.
53
54 Args:
55 edge_cases: Check for edge cases?
56 value: The ratio.
57
58 Returns:
59 The percentage with 1 point precision.
60 """
61 if not (1.0 >= value >= 0.0):
62 raise ValueError(f"Value '{value}' should be a ratio between 1 and 0.")
63 if edge_cases and round(value, 3) == 0 and value > 0:
64 return "< 0.1%"
65 if edge_cases and round(value, 3) == 1 and value < 1:
66 return "> 99.9%"
67
68 return f"{value*100:2.1f}%"
69
70
71 def fmt_timespan(num_seconds, detailed=False, max_units=3):
72 # From the `humanfriendly` module (without additional dependency)
73 # https://github.com/xolox/python-humanfriendly/
74 # Author: Peter Odding <[email protected]>
75 # URL: https://humanfriendly.readthedocs.io
76
77 import decimal
78 import math
79 import numbers
80 import re
81 from datetime import datetime, timedelta
82
83 time_units = (
84 dict(
85 divider=1e-9,
86 singular="nanosecond",
87 plural="nanoseconds",
88 abbreviations=["ns"],
89 ),
90 dict(
91 divider=1e-6,
92 singular="microsecond",
93 plural="microseconds",
94 abbreviations=["us"],
95 ),
96 dict(
97 divider=1e-3,
98 singular="millisecond",
99 plural="milliseconds",
100 abbreviations=["ms"],
101 ),
102 dict(
103 divider=1,
104 singular="second",
105 plural="seconds",
106 abbreviations=["s", "sec", "secs"],
107 ),
108 dict(
109 divider=60,
110 singular="minute",
111 plural="minutes",
112 abbreviations=["m", "min", "mins"],
113 ),
114 dict(divider=60 * 60, singular="hour", plural="hours", abbreviations=["h"]),
115 dict(divider=60 * 60 * 24, singular="day", plural="days", abbreviations=["d"]),
116 dict(
117 divider=60 * 60 * 24 * 7,
118 singular="week",
119 plural="weeks",
120 abbreviations=["w"],
121 ),
122 dict(
123 divider=60 * 60 * 24 * 7 * 52,
124 singular="year",
125 plural="years",
126 abbreviations=["y"],
127 ),
128 )
129
130 def round_number(count, keep_width=False):
131 text = "%.2f" % float(count)
132 if not keep_width:
133 text = re.sub("0+$", "", text)
134 text = re.sub(r"\.$", "", text)
135 return text
136
137 def coerce_seconds(value):
138 if isinstance(value, timedelta):
139 return value.total_seconds()
140 if not isinstance(value, numbers.Number):
141 msg = "Failed to coerce value to number of seconds! (%r)"
142 raise ValueError(format(msg, value))
143 return value
144
145 def concatenate(items):
146 items = list(items)
147 if len(items) > 1:
148 return ", ".join(items[:-1]) + " and " + items[-1]
149 elif items:
150 return items[0]
151 else:
152 return ""
153
154 def pluralize(count, singular, plural=None):
155 if not plural:
156 plural = singular + "s"
157 return "{} {}".format(
158 count, singular if math.floor(float(count)) == 1 else plural
159 )
160
161 num_seconds = coerce_seconds(num_seconds)
162 if num_seconds < 60 and not detailed:
163 # Fast path.
164 return pluralize(round_number(num_seconds), "second")
165 else:
166 # Slow path.
167 result = []
168 num_seconds = decimal.Decimal(str(num_seconds))
169 relevant_units = list(reversed(time_units[0 if detailed else 3 :]))
170 for unit in relevant_units:
171 # Extract the unit count from the remaining time.
172 divider = decimal.Decimal(str(unit["divider"]))
173 count = num_seconds / divider
174 num_seconds %= divider
175 # Round the unit count appropriately.
176 if unit != relevant_units[-1]:
177 # Integer rounding for all but the smallest unit.
178 count = int(count)
179 else:
180 # Floating point rounding for the smallest unit.
181 count = round_number(count)
182 # Only include relevant units in the result.
183 if count not in (0, "0"):
184 result.append(pluralize(count, unit["singular"], unit["plural"]))
185 if len(result) == 1:
186 # A single count/unit combination.
187 return result[0]
188 else:
189 if not detailed:
190 # Remove `insignificant' data from the formatted timespan.
191 result = result[:max_units]
192 # Format the timespan in a readable way.
193 return concatenate(result)
194
195
196 def fmt_numeric(value: float, precision=10) -> str:
197 """Format any numeric value.
198
199 Args:
200 value: The numeric value to format.
201 precision: The numeric precision
202
203 Returns:
204 The numeric value with the given precision.
205 """
206 fmtted = f"{{:.{precision}g}}".format(value)
207 for v in ["e+", "e-"]:
208 if v in fmtted:
209 fmtted = fmtted.replace(v, " × 10<sup>") + "</sup>"
210 fmtted = fmtted.replace("<sup>0", "<sup>")
211
212 return fmtted
213
214
215 def fmt_number(value: int) -> str:
216 """Format any numeric value.
217
218 Args:
219 value: The numeric value to format.
220
221 Returns:
222 The numeric value with the given precision.
223 """
224 return f"{value:n}"
225
226
227 def fmt_array(value: np.ndarray, threshold=np.nan) -> str:
228 """Format numpy arrays.
229
230 Args:
231 value: Array to format.
232 threshold: Threshold at which to show ellipsis
233
234 Returns:
235 The string representation of the numpy array.
236 """
237 with np.printoptions(threshold=3, edgeitems=threshold):
238 return_value = str(value)
239
240 return return_value
241
242
243 def fmt(value) -> str:
244 """Format any value.
245
246 Args:
247 value: The value to format.
248
249 Returns:
250 The numeric formatting if the value is float or int, the string formatting otherwise.
251 """
252 if type(value) in [float, int]:
253 return fmt_numeric(value)
254 else:
255 return str(escape(value))
256
257
258 def help(title, url=None) -> str:
259 """Creat help badge
260
261 Args:
262 title: help text
263 url: url to open in new tab (optional)
264
265 Returns:
266 HTML formatted help badge
267 """
268 if url is not None:
269 return f'<a title="{title}" href="{url}" target="_blank"><span class="badge pull-right" style="color:#fff;background-color:#337ab7;" title="{title}">?</span></a>'
270 else:
271 return f'<span class="badge pull-right" style="color:#fff;background-color:#337ab7;" title="{title}">?</span>'
272
273
274 def get_fmt_mapping() -> Dict[str, Callable]:
275 """Get a mapping from formatter name to the function
276
277 Returns: formatter mapping
278 """
279 return {
280 "fmt_percent": fmt_percent,
281 "fmt_bytesize": fmt_bytesize,
282 "fmt_timespan": fmt_timespan,
283 "fmt_numeric": fmt_numeric,
284 "fmt_number": fmt_number,
285 "fmt_array": fmt_array,
286 "fmt": fmt,
287 "raw": lambda x: x,
288 }
289
[end of src/pandas_profiling/report/formatters.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/pandas_profiling/report/formatters.py b/src/pandas_profiling/report/formatters.py
--- a/src/pandas_profiling/report/formatters.py
+++ b/src/pandas_profiling/report/formatters.py
@@ -206,8 +206,10 @@
fmtted = f"{{:.{precision}g}}".format(value)
for v in ["e+", "e-"]:
if v in fmtted:
+ sign = "-" if v in "e-" else ""
fmtted = fmtted.replace(v, " × 10<sup>") + "</sup>"
fmtted = fmtted.replace("<sup>0", "<sup>")
+ fmtted = fmtted.replace("<sup>", f"<sup>{sign}")
return fmtted
| {"golden_diff": "diff --git a/src/pandas_profiling/report/formatters.py b/src/pandas_profiling/report/formatters.py\n--- a/src/pandas_profiling/report/formatters.py\n+++ b/src/pandas_profiling/report/formatters.py\n@@ -206,8 +206,10 @@\n fmtted = f\"{{:.{precision}g}}\".format(value)\n for v in [\"e+\", \"e-\"]:\n if v in fmtted:\n+ sign = \"-\" if v in \"e-\" else \"\"\n fmtted = fmtted.replace(v, \" \u00d7 10<sup>\") + \"</sup>\"\n fmtted = fmtted.replace(\"<sup>0\", \"<sup>\")\n+ fmtted = fmtted.replace(\"<sup>\", f\"<sup>{sign}\")\n \n return fmtted\n", "issue": "Negative exponents appear positive\n**Describe the bug**\r\n\r\nNegative exponents do not appear in a profiling report\r\n\r\n**To Reproduce**\r\n\r\n```python\r\nimport numpy as np\r\nimport pandas as pd\r\nfrom pandas_profiling import ProfileReport\r\n\r\ndata = { 'some_numbers' : (0.0001, 0.00001, 0.00000001, 0.002, 0.0002, 0.00003) * 100}\r\ndf = pd.DataFrame(data)\r\nprofile = ProfileReport(df, 'No Negative Exponents')\r\nprofile.to_file('NoNegativeExponents.html')\r\n```\r\n\r\n\r\n\r\nMinimum should be 1 x 10<sup>-8</sup> rather than 1 x 10<sup>8</sup>. The issue also arises for Mean and Maximum.\r\n\r\n**Version information:**\r\n\r\nPython 3.7.7 (default, May 6 2020, 11:45:54) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32\r\n\r\n\r\n\r\n**Additional context**\r\n\r\n<!--\r\nAdd any other context about the problem here.\r\n-->\r\n\n", "before_files": [{"content": "\"\"\"Formatters are mappings from object(s) to a string.\"\"\"\nfrom typing import Callable, Dict\n\nimport numpy as np\nfrom jinja2.utils import escape\n\n\ndef fmt_color(text: str, color: str) -> str:\n \"\"\"Format a string in a certain color (`<span>`).\n\n Args:\n text: The text to format.\n color: Any valid CSS color.\n\n Returns:\n A `<span>` that contains the colored text.\n \"\"\"\n return f'<span style=\"color:{color}\">{text}</span>'\n\n\ndef fmt_class(text: str, cls: str) -> str:\n \"\"\"Format a string in a certain class (`<span>`).\n\n Args:\n text: The text to format.\n cls: The name of the class.\n\n Returns:\n A `<span>` with a class added.\n \"\"\"\n return f'<span class=\"{cls}\">{text}</span>'\n\n\ndef fmt_bytesize(num: float, suffix: str = \"B\") -> str:\n \"\"\"Change a number of bytes in a human readable format.\n\n Args:\n num: number to format\n suffix: (Default value = 'B')\n\n Returns:\n The value formatted in human readable format (e.g. KiB).\n \"\"\"\n for unit in [\"\", \"Ki\", \"Mi\", \"Gi\", \"Ti\", \"Pi\", \"Ei\", \"Zi\"]:\n if abs(num) < 1024.0:\n return f\"{num:3.1f} {unit}{suffix}\"\n num /= 1024.0\n return f\"{num:.1f} Yi{suffix}\"\n\n\ndef fmt_percent(value: float, edge_cases: bool = True) -> str:\n \"\"\"Format a ratio as a percentage.\n\n Args:\n edge_cases: Check for edge cases?\n value: The ratio.\n\n Returns:\n The percentage with 1 point precision.\n \"\"\"\n if not (1.0 >= value >= 0.0):\n raise ValueError(f\"Value '{value}' should be a ratio between 1 and 0.\")\n if edge_cases and round(value, 3) == 0 and value > 0:\n return \"< 0.1%\"\n if edge_cases and round(value, 3) == 1 and value < 1:\n return \"> 99.9%\"\n\n return f\"{value*100:2.1f}%\"\n\n\ndef fmt_timespan(num_seconds, detailed=False, max_units=3):\n # From the `humanfriendly` module (without additional dependency)\n # https://github.com/xolox/python-humanfriendly/\n # Author: Peter Odding <[email protected]>\n # URL: https://humanfriendly.readthedocs.io\n\n import decimal\n import math\n import numbers\n import re\n from datetime import datetime, timedelta\n\n time_units = (\n dict(\n divider=1e-9,\n singular=\"nanosecond\",\n plural=\"nanoseconds\",\n abbreviations=[\"ns\"],\n ),\n dict(\n divider=1e-6,\n singular=\"microsecond\",\n plural=\"microseconds\",\n abbreviations=[\"us\"],\n ),\n dict(\n divider=1e-3,\n singular=\"millisecond\",\n plural=\"milliseconds\",\n abbreviations=[\"ms\"],\n ),\n dict(\n divider=1,\n singular=\"second\",\n plural=\"seconds\",\n abbreviations=[\"s\", \"sec\", \"secs\"],\n ),\n dict(\n divider=60,\n singular=\"minute\",\n plural=\"minutes\",\n abbreviations=[\"m\", \"min\", \"mins\"],\n ),\n dict(divider=60 * 60, singular=\"hour\", plural=\"hours\", abbreviations=[\"h\"]),\n dict(divider=60 * 60 * 24, singular=\"day\", plural=\"days\", abbreviations=[\"d\"]),\n dict(\n divider=60 * 60 * 24 * 7,\n singular=\"week\",\n plural=\"weeks\",\n abbreviations=[\"w\"],\n ),\n dict(\n divider=60 * 60 * 24 * 7 * 52,\n singular=\"year\",\n plural=\"years\",\n abbreviations=[\"y\"],\n ),\n )\n\n def round_number(count, keep_width=False):\n text = \"%.2f\" % float(count)\n if not keep_width:\n text = re.sub(\"0+$\", \"\", text)\n text = re.sub(r\"\\.$\", \"\", text)\n return text\n\n def coerce_seconds(value):\n if isinstance(value, timedelta):\n return value.total_seconds()\n if not isinstance(value, numbers.Number):\n msg = \"Failed to coerce value to number of seconds! (%r)\"\n raise ValueError(format(msg, value))\n return value\n\n def concatenate(items):\n items = list(items)\n if len(items) > 1:\n return \", \".join(items[:-1]) + \" and \" + items[-1]\n elif items:\n return items[0]\n else:\n return \"\"\n\n def pluralize(count, singular, plural=None):\n if not plural:\n plural = singular + \"s\"\n return \"{} {}\".format(\n count, singular if math.floor(float(count)) == 1 else plural\n )\n\n num_seconds = coerce_seconds(num_seconds)\n if num_seconds < 60 and not detailed:\n # Fast path.\n return pluralize(round_number(num_seconds), \"second\")\n else:\n # Slow path.\n result = []\n num_seconds = decimal.Decimal(str(num_seconds))\n relevant_units = list(reversed(time_units[0 if detailed else 3 :]))\n for unit in relevant_units:\n # Extract the unit count from the remaining time.\n divider = decimal.Decimal(str(unit[\"divider\"]))\n count = num_seconds / divider\n num_seconds %= divider\n # Round the unit count appropriately.\n if unit != relevant_units[-1]:\n # Integer rounding for all but the smallest unit.\n count = int(count)\n else:\n # Floating point rounding for the smallest unit.\n count = round_number(count)\n # Only include relevant units in the result.\n if count not in (0, \"0\"):\n result.append(pluralize(count, unit[\"singular\"], unit[\"plural\"]))\n if len(result) == 1:\n # A single count/unit combination.\n return result[0]\n else:\n if not detailed:\n # Remove `insignificant' data from the formatted timespan.\n result = result[:max_units]\n # Format the timespan in a readable way.\n return concatenate(result)\n\n\ndef fmt_numeric(value: float, precision=10) -> str:\n \"\"\"Format any numeric value.\n\n Args:\n value: The numeric value to format.\n precision: The numeric precision\n\n Returns:\n The numeric value with the given precision.\n \"\"\"\n fmtted = f\"{{:.{precision}g}}\".format(value)\n for v in [\"e+\", \"e-\"]:\n if v in fmtted:\n fmtted = fmtted.replace(v, \" \u00d7 10<sup>\") + \"</sup>\"\n fmtted = fmtted.replace(\"<sup>0\", \"<sup>\")\n\n return fmtted\n\n\ndef fmt_number(value: int) -> str:\n \"\"\"Format any numeric value.\n\n Args:\n value: The numeric value to format.\n\n Returns:\n The numeric value with the given precision.\n \"\"\"\n return f\"{value:n}\"\n\n\ndef fmt_array(value: np.ndarray, threshold=np.nan) -> str:\n \"\"\"Format numpy arrays.\n\n Args:\n value: Array to format.\n threshold: Threshold at which to show ellipsis\n\n Returns:\n The string representation of the numpy array.\n \"\"\"\n with np.printoptions(threshold=3, edgeitems=threshold):\n return_value = str(value)\n\n return return_value\n\n\ndef fmt(value) -> str:\n \"\"\"Format any value.\n\n Args:\n value: The value to format.\n\n Returns:\n The numeric formatting if the value is float or int, the string formatting otherwise.\n \"\"\"\n if type(value) in [float, int]:\n return fmt_numeric(value)\n else:\n return str(escape(value))\n\n\ndef help(title, url=None) -> str:\n \"\"\"Creat help badge\n\n Args:\n title: help text\n url: url to open in new tab (optional)\n\n Returns:\n HTML formatted help badge\n \"\"\"\n if url is not None:\n return f'<a title=\"{title}\" href=\"{url}\" target=\"_blank\"><span class=\"badge pull-right\" style=\"color:#fff;background-color:#337ab7;\" title=\"{title}\">?</span></a>'\n else:\n return f'<span class=\"badge pull-right\" style=\"color:#fff;background-color:#337ab7;\" title=\"{title}\">?</span>'\n\n\ndef get_fmt_mapping() -> Dict[str, Callable]:\n \"\"\"Get a mapping from formatter name to the function\n\n Returns: formatter mapping\n \"\"\"\n return {\n \"fmt_percent\": fmt_percent,\n \"fmt_bytesize\": fmt_bytesize,\n \"fmt_timespan\": fmt_timespan,\n \"fmt_numeric\": fmt_numeric,\n \"fmt_number\": fmt_number,\n \"fmt_array\": fmt_array,\n \"fmt\": fmt,\n \"raw\": lambda x: x,\n }\n", "path": "src/pandas_profiling/report/formatters.py"}]} | 3,662 | 170 |
gh_patches_debug_9870 | rasdani/github-patches | git_diff | scikit-image__scikit-image-7266 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Faster map_array function
### Description:
In another project ( BiAPoL/napari-clusters-plotter#283 ) we faced the problem that the map_array function is quite slow when it comes to large arrays. We came up with a faster method and I thought the new method might be worth considering as a replacement for map_array. Here is a script comparing the old and new methods:
```python
import numpy as np
from skimage.util import map_array
from time import perf_counter
shape = (1,1024,1024)
total = shape[0]*shape[1]*shape[2]
NUM_LABELS=100000
input_data = np.random.randint(NUM_LABELS,size=total).reshape(shape).astype("int64")
from_values = np.arange(NUM_LABELS)
to_values = np.copy(from_values)
np.random.shuffle(to_values)
def generate_cluster_image(label_image, label_list, predictionlist):
"""
Generates a clusters image from a label image and a list of cluster predictions,
where each label value corresponds to the cluster identity.
It is assumed that len(predictionlist) == max(label_image)
Parameters
----------
label_image: ndarray or dask array
Label image used for cluster predictions
predictionlist: Array-like
An array containing cluster identities for each label
Returns
----------
ndarray: The clusters image as a numpy array.
"""
predictionlist_new = np.array(predictionlist) + 1
plist = np.zeros(np.max(label_image) + 1, dtype=np.uint32)
plist[label_list] = predictionlist_new
predictionlist_new = plist
return predictionlist_new[label_image]
def generate_cluster_image_old(label_image, label_list, predictionlist):
"""
Generates a clusters image from a label image and a list of cluster predictions,
where each label value corresponds to the cluster identity.
It is assumed that len(predictionlist) == max(label_image)
Parameters
----------
label_image: ndarray or dask array
Label image used for cluster predictions
predictionlist: Array-like
An array containing cluster identities for each label
Returns
----------
ndarray: The clusters image as a numpy array.
"""
from skimage.util import map_array
# reforming the prediction list, this is done to account
# for cluster labels that start at 0, conveniently hdbscan
# labelling starts at -1 for noise, removing these from the labels
predictionlist_new = np.array(predictionlist) + 1
label_list = np.array(label_list)
return map_array(np.asarray(label_image), label_list, predictionlist_new).astype(
"uint32"
)
t1 = perf_counter()
res_new = generate_cluster_image(input_data, from_values, to_values)
t_new = perf_counter() - t1
print(t_new)
t1 = perf_counter()
res_old = generate_cluster_image_old(input_data, from_values, to_values)
t_old = perf_counter() - t1
print(t_old)
print(f"Speedup {t_old/t_new}")
print(np.array_equal(res_new,res_old))
```
The new method is 15x-30x faster than the old one.
If you guys think that this is worth it, I can come up with a PR.
</issue>
<code>
[start of skimage/util/_map_array.py]
1 import numpy as np
2
3
4 def map_array(input_arr, input_vals, output_vals, out=None):
5 """Map values from input array from input_vals to output_vals.
6
7 Parameters
8 ----------
9 input_arr : array of int, shape (M[, ...])
10 The input label image.
11 input_vals : array of int, shape (K,)
12 The values to map from.
13 output_vals : array, shape (K,)
14 The values to map to.
15 out: array, same shape as `input_arr`
16 The output array. Will be created if not provided. It should
17 have the same dtype as `output_vals`.
18
19 Returns
20 -------
21 out : array, same shape as `input_arr`
22 The array of mapped values.
23 """
24 from ._remap import _map_array
25
26 if not np.issubdtype(input_arr.dtype, np.integer):
27 raise TypeError('The dtype of an array to be remapped should be integer.')
28 # We ravel the input array for simplicity of iteration in Cython:
29 orig_shape = input_arr.shape
30 # NumPy docs for `np.ravel()` says:
31 # "When a view is desired in as many cases as possible,
32 # arr.reshape(-1) may be preferable."
33 input_arr = input_arr.reshape(-1)
34 if out is None:
35 out = np.empty(orig_shape, dtype=output_vals.dtype)
36 elif out.shape != orig_shape:
37 raise ValueError(
38 'If out array is provided, it should have the same shape as '
39 f'the input array. Input array has shape {orig_shape}, provided '
40 f'output array has shape {out.shape}.'
41 )
42 try:
43 out_view = out.view()
44 out_view.shape = (-1,) # no-copy reshape/ravel
45 except AttributeError: # if out strides are not compatible with 0-copy
46 raise ValueError(
47 'If out array is provided, it should be either contiguous '
48 f'or 1-dimensional. Got array with shape {out.shape} and '
49 f'strides {out.strides}.'
50 )
51
52 # ensure all arrays have matching types before sending to Cython
53 input_vals = input_vals.astype(input_arr.dtype, copy=False)
54 output_vals = output_vals.astype(out.dtype, copy=False)
55 _map_array(input_arr, out_view, input_vals, output_vals)
56 return out
57
58
59 class ArrayMap:
60 """Class designed to mimic mapping by NumPy array indexing.
61
62 This class is designed to replicate the use of NumPy arrays for mapping
63 values with indexing:
64
65 >>> values = np.array([0.25, 0.5, 1.0])
66 >>> indices = np.array([[0, 0, 1], [2, 2, 1]])
67 >>> values[indices]
68 array([[0.25, 0.25, 0.5 ],
69 [1. , 1. , 0.5 ]])
70
71 The issue with this indexing is that you need a very large ``values``
72 array if the values in the ``indices`` array are large.
73
74 >>> values = np.array([0.25, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1.0])
75 >>> indices = np.array([[0, 0, 10], [0, 10, 10]])
76 >>> values[indices]
77 array([[0.25, 0.25, 1. ],
78 [0.25, 1. , 1. ]])
79
80 Using this class, the approach is similar, but there is no need to
81 create a large values array:
82
83 >>> in_indices = np.array([0, 10])
84 >>> out_values = np.array([0.25, 1.0])
85 >>> values = ArrayMap(in_indices, out_values)
86 >>> values
87 ArrayMap(array([ 0, 10]), array([0.25, 1. ]))
88 >>> print(values)
89 ArrayMap:
90 0 → 0.25
91 10 → 1.0
92 >>> indices = np.array([[0, 0, 10], [0, 10, 10]])
93 >>> values[indices]
94 array([[0.25, 0.25, 1. ],
95 [0.25, 1. , 1. ]])
96
97 Parameters
98 ----------
99 in_values : array of int, shape (K,)
100 The source values from which to map.
101 out_values : array, shape (K,)
102 The destination values from which to map.
103 """
104
105 def __init__(self, in_values, out_values):
106 self.in_values = in_values
107 self.out_values = out_values
108 self._max_str_lines = 4
109 self._array = None
110
111 def __len__(self):
112 """Return one more than the maximum label value being remapped."""
113 return np.max(self.in_values) + 1
114
115 def __array__(self, dtype=None):
116 """Return an array that behaves like the arraymap when indexed.
117
118 This array can be very large: it is the size of the largest value
119 in the ``in_vals`` array, plus one.
120 """
121 if dtype is None:
122 dtype = self.out_values.dtype
123 output = np.zeros(np.max(self.in_values) + 1, dtype=dtype)
124 output[self.in_values] = self.out_values
125 return output
126
127 @property
128 def dtype(self):
129 return self.out_values.dtype
130
131 def __repr__(self):
132 return f'ArrayMap({repr(self.in_values)}, {repr(self.out_values)})'
133
134 def __str__(self):
135 if len(self.in_values) <= self._max_str_lines + 1:
136 rows = range(len(self.in_values))
137 string = '\n'.join(
138 ['ArrayMap:']
139 + [f' {self.in_values[i]} → {self.out_values[i]}' for i in rows]
140 )
141 else:
142 rows0 = list(range(0, self._max_str_lines // 2))
143 rows1 = list(range(-self._max_str_lines // 2, 0))
144 string = '\n'.join(
145 ['ArrayMap:']
146 + [f' {self.in_values[i]} → {self.out_values[i]}' for i in rows0]
147 + [' ...']
148 + [f' {self.in_values[i]} → {self.out_values[i]}' for i in rows1]
149 )
150 return string
151
152 def __call__(self, arr):
153 return self.__getitem__(arr)
154
155 def __getitem__(self, index):
156 scalar = np.isscalar(index)
157 if scalar:
158 index = np.array([index])
159 elif isinstance(index, slice):
160 start = index.start or 0 # treat None or 0 the same way
161 stop = index.stop if index.stop is not None else len(self)
162 step = index.step
163 index = np.arange(start, stop, step)
164 if index.dtype == bool:
165 index = np.flatnonzero(index)
166
167 out = map_array(
168 index,
169 self.in_values.astype(index.dtype, copy=False),
170 self.out_values,
171 )
172
173 if scalar:
174 out = out[0]
175 return out
176
177 def __setitem__(self, indices, values):
178 if self._array is None:
179 self._array = self.__array__()
180 self._array[indices] = values
181 self.in_values = np.flatnonzero(self._array)
182 self.out_values = self._array[self.in_values]
183
[end of skimage/util/_map_array.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/skimage/util/_map_array.py b/skimage/util/_map_array.py
--- a/skimage/util/_map_array.py
+++ b/skimage/util/_map_array.py
@@ -20,6 +20,23 @@
-------
out : array, same shape as `input_arr`
The array of mapped values.
+
+ Notes
+ -----
+ If `input_arr` contains values that aren't covered by `input_vals`, they
+ are set to 0.
+
+ Examples
+ --------
+ >>> import numpy as np
+ >>> import skimage as ski
+ >>> ski.util.map_array(
+ ... input_arr=np.array([[0, 2, 2, 0], [3, 4, 5, 0]]),
+ ... input_vals=np.array([1, 2, 3, 4, 6]),
+ ... output_vals=np.array([6, 7, 8, 9, 10]),
+ ... )
+ array([[0, 7, 7, 0],
+ [8, 9, 0, 0]])
"""
from ._remap import _map_array
| {"golden_diff": "diff --git a/skimage/util/_map_array.py b/skimage/util/_map_array.py\n--- a/skimage/util/_map_array.py\n+++ b/skimage/util/_map_array.py\n@@ -20,6 +20,23 @@\n -------\n out : array, same shape as `input_arr`\n The array of mapped values.\n+\n+ Notes\n+ -----\n+ If `input_arr` contains values that aren't covered by `input_vals`, they\n+ are set to 0.\n+\n+ Examples\n+ --------\n+ >>> import numpy as np\n+ >>> import skimage as ski\n+ >>> ski.util.map_array(\n+ ... input_arr=np.array([[0, 2, 2, 0], [3, 4, 5, 0]]),\n+ ... input_vals=np.array([1, 2, 3, 4, 6]),\n+ ... output_vals=np.array([6, 7, 8, 9, 10]),\n+ ... )\n+ array([[0, 7, 7, 0],\n+ [8, 9, 0, 0]])\n \"\"\"\n from ._remap import _map_array\n", "issue": "Faster map_array function\n### Description:\r\n\r\nIn another project ( BiAPoL/napari-clusters-plotter#283 ) we faced the problem that the map_array function is quite slow when it comes to large arrays. We came up with a faster method and I thought the new method might be worth considering as a replacement for map_array. Here is a script comparing the old and new methods:\r\n\r\n```python\r\nimport numpy as np\r\nfrom skimage.util import map_array\r\nfrom time import perf_counter\r\n\r\nshape = (1,1024,1024)\r\ntotal = shape[0]*shape[1]*shape[2]\r\nNUM_LABELS=100000\r\ninput_data = np.random.randint(NUM_LABELS,size=total).reshape(shape).astype(\"int64\")\r\nfrom_values = np.arange(NUM_LABELS)\r\nto_values = np.copy(from_values)\r\nnp.random.shuffle(to_values)\r\n\r\ndef generate_cluster_image(label_image, label_list, predictionlist):\r\n \"\"\"\r\n Generates a clusters image from a label image and a list of cluster predictions,\r\n where each label value corresponds to the cluster identity.\r\n It is assumed that len(predictionlist) == max(label_image)\r\n\r\n Parameters\r\n ----------\r\n label_image: ndarray or dask array\r\n Label image used for cluster predictions\r\n predictionlist: Array-like\r\n An array containing cluster identities for each label\r\n\r\n Returns\r\n ----------\r\n ndarray: The clusters image as a numpy array.\r\n \"\"\"\r\n\r\n predictionlist_new = np.array(predictionlist) + 1\r\n plist = np.zeros(np.max(label_image) + 1, dtype=np.uint32)\r\n plist[label_list] = predictionlist_new\r\n\r\n predictionlist_new = plist\r\n\r\n return predictionlist_new[label_image]\r\n\r\ndef generate_cluster_image_old(label_image, label_list, predictionlist):\r\n \"\"\"\r\n Generates a clusters image from a label image and a list of cluster predictions,\r\n where each label value corresponds to the cluster identity.\r\n It is assumed that len(predictionlist) == max(label_image)\r\n\r\n Parameters\r\n ----------\r\n label_image: ndarray or dask array\r\n Label image used for cluster predictions\r\n predictionlist: Array-like\r\n An array containing cluster identities for each label\r\n\r\n Returns\r\n ----------\r\n ndarray: The clusters image as a numpy array.\r\n \"\"\"\r\n from skimage.util import map_array\r\n\r\n # reforming the prediction list, this is done to account\r\n # for cluster labels that start at 0, conveniently hdbscan\r\n # labelling starts at -1 for noise, removing these from the labels\r\n predictionlist_new = np.array(predictionlist) + 1\r\n label_list = np.array(label_list)\r\n\r\n return map_array(np.asarray(label_image), label_list, predictionlist_new).astype(\r\n \"uint32\"\r\n )\r\n\r\nt1 = perf_counter()\r\nres_new = generate_cluster_image(input_data, from_values, to_values)\r\nt_new = perf_counter() - t1\r\nprint(t_new)\r\n\r\nt1 = perf_counter()\r\nres_old = generate_cluster_image_old(input_data, from_values, to_values)\r\nt_old = perf_counter() - t1\r\nprint(t_old)\r\n\r\nprint(f\"Speedup {t_old/t_new}\")\r\n\r\nprint(np.array_equal(res_new,res_old))\r\n```\r\n\r\nThe new method is 15x-30x faster than the old one. \r\n\r\nIf you guys think that this is worth it, I can come up with a PR.\n", "before_files": [{"content": "import numpy as np\n\n\ndef map_array(input_arr, input_vals, output_vals, out=None):\n \"\"\"Map values from input array from input_vals to output_vals.\n\n Parameters\n ----------\n input_arr : array of int, shape (M[, ...])\n The input label image.\n input_vals : array of int, shape (K,)\n The values to map from.\n output_vals : array, shape (K,)\n The values to map to.\n out: array, same shape as `input_arr`\n The output array. Will be created if not provided. It should\n have the same dtype as `output_vals`.\n\n Returns\n -------\n out : array, same shape as `input_arr`\n The array of mapped values.\n \"\"\"\n from ._remap import _map_array\n\n if not np.issubdtype(input_arr.dtype, np.integer):\n raise TypeError('The dtype of an array to be remapped should be integer.')\n # We ravel the input array for simplicity of iteration in Cython:\n orig_shape = input_arr.shape\n # NumPy docs for `np.ravel()` says:\n # \"When a view is desired in as many cases as possible,\n # arr.reshape(-1) may be preferable.\"\n input_arr = input_arr.reshape(-1)\n if out is None:\n out = np.empty(orig_shape, dtype=output_vals.dtype)\n elif out.shape != orig_shape:\n raise ValueError(\n 'If out array is provided, it should have the same shape as '\n f'the input array. Input array has shape {orig_shape}, provided '\n f'output array has shape {out.shape}.'\n )\n try:\n out_view = out.view()\n out_view.shape = (-1,) # no-copy reshape/ravel\n except AttributeError: # if out strides are not compatible with 0-copy\n raise ValueError(\n 'If out array is provided, it should be either contiguous '\n f'or 1-dimensional. Got array with shape {out.shape} and '\n f'strides {out.strides}.'\n )\n\n # ensure all arrays have matching types before sending to Cython\n input_vals = input_vals.astype(input_arr.dtype, copy=False)\n output_vals = output_vals.astype(out.dtype, copy=False)\n _map_array(input_arr, out_view, input_vals, output_vals)\n return out\n\n\nclass ArrayMap:\n \"\"\"Class designed to mimic mapping by NumPy array indexing.\n\n This class is designed to replicate the use of NumPy arrays for mapping\n values with indexing:\n\n >>> values = np.array([0.25, 0.5, 1.0])\n >>> indices = np.array([[0, 0, 1], [2, 2, 1]])\n >>> values[indices]\n array([[0.25, 0.25, 0.5 ],\n [1. , 1. , 0.5 ]])\n\n The issue with this indexing is that you need a very large ``values``\n array if the values in the ``indices`` array are large.\n\n >>> values = np.array([0.25, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1.0])\n >>> indices = np.array([[0, 0, 10], [0, 10, 10]])\n >>> values[indices]\n array([[0.25, 0.25, 1. ],\n [0.25, 1. , 1. ]])\n\n Using this class, the approach is similar, but there is no need to\n create a large values array:\n\n >>> in_indices = np.array([0, 10])\n >>> out_values = np.array([0.25, 1.0])\n >>> values = ArrayMap(in_indices, out_values)\n >>> values\n ArrayMap(array([ 0, 10]), array([0.25, 1. ]))\n >>> print(values)\n ArrayMap:\n 0 \u2192 0.25\n 10 \u2192 1.0\n >>> indices = np.array([[0, 0, 10], [0, 10, 10]])\n >>> values[indices]\n array([[0.25, 0.25, 1. ],\n [0.25, 1. , 1. ]])\n\n Parameters\n ----------\n in_values : array of int, shape (K,)\n The source values from which to map.\n out_values : array, shape (K,)\n The destination values from which to map.\n \"\"\"\n\n def __init__(self, in_values, out_values):\n self.in_values = in_values\n self.out_values = out_values\n self._max_str_lines = 4\n self._array = None\n\n def __len__(self):\n \"\"\"Return one more than the maximum label value being remapped.\"\"\"\n return np.max(self.in_values) + 1\n\n def __array__(self, dtype=None):\n \"\"\"Return an array that behaves like the arraymap when indexed.\n\n This array can be very large: it is the size of the largest value\n in the ``in_vals`` array, plus one.\n \"\"\"\n if dtype is None:\n dtype = self.out_values.dtype\n output = np.zeros(np.max(self.in_values) + 1, dtype=dtype)\n output[self.in_values] = self.out_values\n return output\n\n @property\n def dtype(self):\n return self.out_values.dtype\n\n def __repr__(self):\n return f'ArrayMap({repr(self.in_values)}, {repr(self.out_values)})'\n\n def __str__(self):\n if len(self.in_values) <= self._max_str_lines + 1:\n rows = range(len(self.in_values))\n string = '\\n'.join(\n ['ArrayMap:']\n + [f' {self.in_values[i]} \u2192 {self.out_values[i]}' for i in rows]\n )\n else:\n rows0 = list(range(0, self._max_str_lines // 2))\n rows1 = list(range(-self._max_str_lines // 2, 0))\n string = '\\n'.join(\n ['ArrayMap:']\n + [f' {self.in_values[i]} \u2192 {self.out_values[i]}' for i in rows0]\n + [' ...']\n + [f' {self.in_values[i]} \u2192 {self.out_values[i]}' for i in rows1]\n )\n return string\n\n def __call__(self, arr):\n return self.__getitem__(arr)\n\n def __getitem__(self, index):\n scalar = np.isscalar(index)\n if scalar:\n index = np.array([index])\n elif isinstance(index, slice):\n start = index.start or 0 # treat None or 0 the same way\n stop = index.stop if index.stop is not None else len(self)\n step = index.step\n index = np.arange(start, stop, step)\n if index.dtype == bool:\n index = np.flatnonzero(index)\n\n out = map_array(\n index,\n self.in_values.astype(index.dtype, copy=False),\n self.out_values,\n )\n\n if scalar:\n out = out[0]\n return out\n\n def __setitem__(self, indices, values):\n if self._array is None:\n self._array = self.__array__()\n self._array[indices] = values\n self.in_values = np.flatnonzero(self._array)\n self.out_values = self._array[self.in_values]\n", "path": "skimage/util/_map_array.py"}]} | 3,381 | 271 |
gh_patches_debug_30775 | rasdani/github-patches | git_diff | vispy__vispy-154 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Why is there no asser_in in nose.tools on py2.7?
This makes me jump through hoops when writing tests.
</issue>
<code>
[start of vispy/util/misc.py]
1 # -*- coding: utf-8 -*-
2 # Copyright (c) 2014, Vispy Development Team.
3 # Distributed under the (new) BSD License. See LICENSE.txt for more info.
4
5 """Miscellaneous functions
6 """
7
8 import numpy as np
9 import tempfile
10 import atexit
11 from shutil import rmtree
12 import sys
13 import platform
14 import getopt
15 from os import path as op
16 import traceback
17
18 from .six import string_types
19 from .event import EmitterGroup, EventEmitter, Event
20 from ._logging import logger, set_log_level, use_log_level
21
22
23 class _TempDir(str):
24
25 """Class for creating and auto-destroying temp dir
26
27 This is designed to be used with testing modules.
28
29 We cannot simply use __del__() method for cleanup here because the rmtree
30 function may be cleaned up before this object, so we use the atexit module
31 instead.
32 """
33
34 def __new__(self):
35 new = str.__new__(self, tempfile.mkdtemp())
36 return new
37
38 def __init__(self):
39 self._path = self.__str__()
40 atexit.register(self.cleanup)
41
42 def cleanup(self):
43 rmtree(self._path, ignore_errors=True)
44
45
46 def is_string(s):
47 return isinstance(s, string_types)
48
49
50 ###############################################################################
51 # These fast normal calculation routines are adapted from mne-python
52
53 def _fast_cross_3d(x, y):
54 """Compute cross product between list of 3D vectors
55
56 Much faster than np.cross() when the number of cross products
57 becomes large (>500). This is because np.cross() methods become
58 less memory efficient at this stage.
59
60 Parameters
61 ----------
62 x : array
63 Input array 1.
64 y : array
65 Input array 2.
66
67 Returns
68 -------
69 z : array
70 Cross product of x and y.
71
72 Notes
73 -----
74 x and y must both be 2D row vectors. One must have length 1, or both
75 lengths must match.
76 """
77 assert x.ndim == 2
78 assert y.ndim == 2
79 assert x.shape[1] == 3
80 assert y.shape[1] == 3
81 assert (x.shape[0] == 1 or y.shape[0] == 1) or x.shape[0] == y.shape[0]
82 if max([x.shape[0], y.shape[0]]) >= 500:
83 return np.c_[x[:, 1] * y[:, 2] - x[:, 2] * y[:, 1],
84 x[:, 2] * y[:, 0] - x[:, 0] * y[:, 2],
85 x[:, 0] * y[:, 1] - x[:, 1] * y[:, 0]]
86 else:
87 return np.cross(x, y)
88
89
90 def _calculate_normals(rr, tris):
91 """Efficiently compute vertex normals for triangulated surface"""
92 # ensure highest precision for our summation/vectorization "trick"
93 rr = rr.astype(np.float64)
94 # first, compute triangle normals
95 r1 = rr[tris[:, 0], :]
96 r2 = rr[tris[:, 1], :]
97 r3 = rr[tris[:, 2], :]
98 tri_nn = _fast_cross_3d((r2 - r1), (r3 - r1))
99
100 # Triangle normals and areas
101 size = np.sqrt(np.sum(tri_nn * tri_nn, axis=1))
102 size[size == 0] = 1.0 # prevent ugly divide-by-zero
103 tri_nn /= size[:, np.newaxis]
104
105 npts = len(rr)
106
107 # the following code replaces this, but is faster (vectorized):
108 #
109 # for p, verts in enumerate(tris):
110 # nn[verts, :] += tri_nn[p, :]
111 #
112 nn = np.zeros((npts, 3))
113 for verts in tris.T: # note this only loops 3x (number of verts per tri)
114 for idx in range(3): # x, y, z
115 nn[:, idx] += np.bincount(verts, tri_nn[:, idx], minlength=npts)
116 size = np.sqrt(np.sum(nn * nn, axis=1))
117 size[size == 0] = 1.0 # prevent ugly divide-by-zero
118 nn /= size[:, np.newaxis]
119 return nn
120
121
122 ###############################################################################
123 # CONFIG
124
125 class ConfigEvent(Event):
126
127 """ Event indicating a configuration change.
128
129 This class has a 'changes' attribute which is a dict of all name:value
130 pairs that have changed in the configuration.
131 """
132
133 def __init__(self, changes):
134 Event.__init__(self, type='config_change')
135 self.changes = changes
136
137
138 class Config(object):
139
140 """ Container for global settings used application-wide in vispy.
141
142 Events:
143 -------
144 Config.events.changed - Emits ConfigEvent whenever the configuration
145 changes.
146 """
147
148 def __init__(self):
149 self.events = EmitterGroup(source=self)
150 self.events['changed'] = EventEmitter(
151 event_class=ConfigEvent,
152 source=self)
153 self._config = {}
154
155 def __getitem__(self, item):
156 return self._config[item]
157
158 def __setitem__(self, item, val):
159 self._config[item] = val
160 # inform any listeners that a configuration option has changed
161 self.events.changed(changes={item: val})
162
163 def update(self, **kwds):
164 self._config.update(kwds)
165 self.events.changed(changes=kwds)
166
167 def __repr__(self):
168 return repr(self._config)
169
170 config = Config()
171 config.update(
172 default_backend='qt',
173 qt_lib='any', # options are 'pyqt', 'pyside', or 'any'
174 show_warnings=False,
175 gl_debug=False,
176 logging_level='info',
177 )
178
179 set_log_level(config['logging_level'])
180
181
182 def parse_command_line_arguments():
183 """ Transform vispy specific command line args to vispy config.
184 Put into a function so that any variables dont leak in the vispy namespace.
185 """
186 # Get command line args for vispy
187 argnames = ['vispy-backend', 'vispy-gl-debug']
188 try:
189 opts, args = getopt.getopt(sys.argv[1:], '', argnames)
190 except getopt.GetoptError:
191 opts = []
192 # Use them to set the config values
193 for o, a in opts:
194 if o.startswith('--vispy'):
195 if o == '--vispy-backend':
196 config['default_backend'] = a
197 logger.info('backend', a)
198 elif o == '--vispy-gl-debug':
199 config['gl_debug'] = True
200 else:
201 logger.warning("Unsupported vispy flag: %s" % o)
202
203
204 def sys_info(fname=None, overwrite=False):
205 """Get relevant system and debugging information
206
207 Parameters
208 ----------
209 fname : str | None
210 Filename to dump info to. Use None to simply print.
211 overwrite : bool
212 If True, overwrite file (if it exists).
213
214 Returns
215 -------
216 out : str
217 The system information as a string.
218 """
219 if fname is not None and op.isfile(fname) and not overwrite:
220 raise IOError('file exists, use overwrite=True to overwrite')
221
222 out = ''
223 try:
224 # Nest all imports here to avoid any circular imports
225 from ..app import Application, Canvas, backends
226 from ..gloo import gl
227 # get default app
228 this_app = Application()
229 with use_log_level('warning'):
230 this_app.use() # suppress unnecessary messages
231 out += 'Platform: %s\n' % platform.platform()
232 out += 'Python: %s\n' % str(sys.version).replace('\n', ' ')
233 out += 'Backend: %s\n' % this_app.backend_name
234 out += 'Qt: %s\n' % backends.has_qt(return_which=True)[1]
235 out += 'Pyglet: %s\n' % backends.has_pyglet(return_which=True)[1]
236 out += 'glfw: %s\n' % backends.has_glfw(return_which=True)[1]
237 out += 'glut: %s\n' % backends.has_glut(return_which=True)[1]
238 out += '\n'
239 # We need an OpenGL context to get GL info
240 if 'glut' in this_app.backend_name.lower():
241 # glut causes problems
242 out += 'OpenGL information omitted for glut backend\n'
243 else:
244 canvas = Canvas('Test', (10, 10), show=False, app=this_app)
245 canvas._backend._vispy_set_current()
246 out += 'GL version: %s\n' % gl.glGetString(gl.GL_VERSION)
247 x_ = gl.GL_MAX_TEXTURE_SIZE
248 out += 'MAX_TEXTURE_SIZE: %d\n' % gl.glGetIntegerv(x_)
249 x_ = gl.ext.GL_MAX_3D_TEXTURE_SIZE
250 out += 'MAX_3D_TEXTURE_SIZE: %d\n\n' % gl.glGetIntegerv(x_)
251 out += 'Extensions: %s\n' % gl.glGetString(gl.GL_EXTENSIONS)
252 canvas.close()
253 except Exception: # don't stop printing info
254 out += '\nInfo-gathering error:\n%s' % traceback.format_exc()
255 pass
256 if fname is not None:
257 with open(fname, 'w') as fid:
258 fid.write(out)
259 return out
260
[end of vispy/util/misc.py]
[start of vispy/util/__init__.py]
1 # -*- coding: utf-8 -*-
2 # Copyright (c) 2014, Vispy Development Team. All Rights Reserved.
3 # Distributed under the (new) BSD License. See LICENSE.txt for more info.
4
5 """ Utilities for Vispy. A collection of modules that are used in
6 one or more Vispy sub-packages.
7 """
8
9 from .misc import (_TempDir, is_string, parse_command_line_arguments, # noqa
10 config, sys_info) # noqa
11 from ._logging import logger, set_log_level, use_log_level # noqa
12
[end of vispy/util/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/vispy/util/__init__.py b/vispy/util/__init__.py
--- a/vispy/util/__init__.py
+++ b/vispy/util/__init__.py
@@ -7,5 +7,6 @@
"""
from .misc import (_TempDir, is_string, parse_command_line_arguments, # noqa
- config, sys_info) # noqa
+ config, sys_info, assert_in, assert_not_in, # noqa
+ assert_is) # noqa
from ._logging import logger, set_log_level, use_log_level # noqa
diff --git a/vispy/util/misc.py b/vispy/util/misc.py
--- a/vispy/util/misc.py
+++ b/vispy/util/misc.py
@@ -257,3 +257,60 @@
with open(fname, 'w') as fid:
fid.write(out)
return out
+
+
+# Adapted from Python's unittest2 (which is wrapped by nose)
+# http://docs.python.org/2/license.html
+def _safe_rep(obj, short=False):
+ """Helper for assert_* ports"""
+ try:
+ result = repr(obj)
+ except Exception:
+ result = object.__repr__(obj)
+ if not short or len(result) < 80:
+ return result
+ return result[:80] + ' [truncated]...'
+
+
+def _safe_str(obj):
+ """Helper for assert_* ports"""
+ try:
+ return str(obj)
+ except Exception:
+ return object.__str__(obj)
+
+
+def _format_msg(msg, std_msg):
+ """Helper for assert_* ports"""
+ if msg is None:
+ msg = std_msg
+ else:
+ try:
+ msg = '%s : %s' % (std_msg, msg)
+ except UnicodeDecodeError:
+ msg = '%s : %s' % (_safe_str(std_msg), _safe_str(msg))
+
+
+def assert_in(member, container, msg=None):
+ """Backport for old nose.tools"""
+ if member in container:
+ return
+ std_msg = '%s not found in %s' % (_safe_rep(member), _safe_rep(container))
+ msg = _format_msg(msg, std_msg)
+ raise AssertionError(msg)
+
+
+def assert_not_in(member, container, msg=None):
+ """Backport for old nose.tools"""
+ if member not in container:
+ return
+ std_msg = '%s found in %s' % (_safe_rep(member), _safe_rep(container))
+ msg = _format_msg(msg, std_msg)
+ raise AssertionError(msg)
+
+
+def assert_is(expr1, expr2, msg=None):
+ """Backport for old nose.tools"""
+ if expr1 is not expr2:
+ std_msg = '%s is not %s' % (_safe_rep(expr1), _safe_rep(expr2))
+ raise AssertionError(_format_msg(msg, std_msg))
| {"golden_diff": "diff --git a/vispy/util/__init__.py b/vispy/util/__init__.py\n--- a/vispy/util/__init__.py\n+++ b/vispy/util/__init__.py\n@@ -7,5 +7,6 @@\n \"\"\"\n \n from .misc import (_TempDir, is_string, parse_command_line_arguments, # noqa\n- config, sys_info) # noqa\n+ config, sys_info, assert_in, assert_not_in, # noqa\n+ assert_is) # noqa\n from ._logging import logger, set_log_level, use_log_level # noqa\ndiff --git a/vispy/util/misc.py b/vispy/util/misc.py\n--- a/vispy/util/misc.py\n+++ b/vispy/util/misc.py\n@@ -257,3 +257,60 @@\n with open(fname, 'w') as fid:\n fid.write(out)\n return out\n+\n+\n+# Adapted from Python's unittest2 (which is wrapped by nose)\n+# http://docs.python.org/2/license.html\n+def _safe_rep(obj, short=False):\n+ \"\"\"Helper for assert_* ports\"\"\"\n+ try:\n+ result = repr(obj)\n+ except Exception:\n+ result = object.__repr__(obj)\n+ if not short or len(result) < 80:\n+ return result\n+ return result[:80] + ' [truncated]...'\n+\n+\n+def _safe_str(obj):\n+ \"\"\"Helper for assert_* ports\"\"\"\n+ try:\n+ return str(obj)\n+ except Exception:\n+ return object.__str__(obj)\n+\n+\n+def _format_msg(msg, std_msg):\n+ \"\"\"Helper for assert_* ports\"\"\"\n+ if msg is None:\n+ msg = std_msg\n+ else:\n+ try:\n+ msg = '%s : %s' % (std_msg, msg)\n+ except UnicodeDecodeError:\n+ msg = '%s : %s' % (_safe_str(std_msg), _safe_str(msg))\n+\n+\n+def assert_in(member, container, msg=None):\n+ \"\"\"Backport for old nose.tools\"\"\"\n+ if member in container:\n+ return\n+ std_msg = '%s not found in %s' % (_safe_rep(member), _safe_rep(container))\n+ msg = _format_msg(msg, std_msg)\n+ raise AssertionError(msg)\n+\n+\n+def assert_not_in(member, container, msg=None):\n+ \"\"\"Backport for old nose.tools\"\"\"\n+ if member not in container:\n+ return\n+ std_msg = '%s found in %s' % (_safe_rep(member), _safe_rep(container))\n+ msg = _format_msg(msg, std_msg)\n+ raise AssertionError(msg)\n+\n+\n+def assert_is(expr1, expr2, msg=None):\n+ \"\"\"Backport for old nose.tools\"\"\"\n+ if expr1 is not expr2:\n+ std_msg = '%s is not %s' % (_safe_rep(expr1), _safe_rep(expr2))\n+ raise AssertionError(_format_msg(msg, std_msg))\n", "issue": "Why is there no asser_in in nose.tools on py2.7?\nThis makes me jump through hoops when writing tests.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (c) 2014, Vispy Development Team.\n# Distributed under the (new) BSD License. See LICENSE.txt for more info.\n\n\"\"\"Miscellaneous functions\n\"\"\"\n\nimport numpy as np\nimport tempfile\nimport atexit\nfrom shutil import rmtree\nimport sys\nimport platform\nimport getopt\nfrom os import path as op\nimport traceback\n\nfrom .six import string_types\nfrom .event import EmitterGroup, EventEmitter, Event\nfrom ._logging import logger, set_log_level, use_log_level\n\n\nclass _TempDir(str):\n\n \"\"\"Class for creating and auto-destroying temp dir\n\n This is designed to be used with testing modules.\n\n We cannot simply use __del__() method for cleanup here because the rmtree\n function may be cleaned up before this object, so we use the atexit module\n instead.\n \"\"\"\n\n def __new__(self):\n new = str.__new__(self, tempfile.mkdtemp())\n return new\n\n def __init__(self):\n self._path = self.__str__()\n atexit.register(self.cleanup)\n\n def cleanup(self):\n rmtree(self._path, ignore_errors=True)\n\n\ndef is_string(s):\n return isinstance(s, string_types)\n\n\n###############################################################################\n# These fast normal calculation routines are adapted from mne-python\n\ndef _fast_cross_3d(x, y):\n \"\"\"Compute cross product between list of 3D vectors\n\n Much faster than np.cross() when the number of cross products\n becomes large (>500). This is because np.cross() methods become\n less memory efficient at this stage.\n\n Parameters\n ----------\n x : array\n Input array 1.\n y : array\n Input array 2.\n\n Returns\n -------\n z : array\n Cross product of x and y.\n\n Notes\n -----\n x and y must both be 2D row vectors. One must have length 1, or both\n lengths must match.\n \"\"\"\n assert x.ndim == 2\n assert y.ndim == 2\n assert x.shape[1] == 3\n assert y.shape[1] == 3\n assert (x.shape[0] == 1 or y.shape[0] == 1) or x.shape[0] == y.shape[0]\n if max([x.shape[0], y.shape[0]]) >= 500:\n return np.c_[x[:, 1] * y[:, 2] - x[:, 2] * y[:, 1],\n x[:, 2] * y[:, 0] - x[:, 0] * y[:, 2],\n x[:, 0] * y[:, 1] - x[:, 1] * y[:, 0]]\n else:\n return np.cross(x, y)\n\n\ndef _calculate_normals(rr, tris):\n \"\"\"Efficiently compute vertex normals for triangulated surface\"\"\"\n # ensure highest precision for our summation/vectorization \"trick\"\n rr = rr.astype(np.float64)\n # first, compute triangle normals\n r1 = rr[tris[:, 0], :]\n r2 = rr[tris[:, 1], :]\n r3 = rr[tris[:, 2], :]\n tri_nn = _fast_cross_3d((r2 - r1), (r3 - r1))\n\n # Triangle normals and areas\n size = np.sqrt(np.sum(tri_nn * tri_nn, axis=1))\n size[size == 0] = 1.0 # prevent ugly divide-by-zero\n tri_nn /= size[:, np.newaxis]\n\n npts = len(rr)\n\n # the following code replaces this, but is faster (vectorized):\n #\n # for p, verts in enumerate(tris):\n # nn[verts, :] += tri_nn[p, :]\n #\n nn = np.zeros((npts, 3))\n for verts in tris.T: # note this only loops 3x (number of verts per tri)\n for idx in range(3): # x, y, z\n nn[:, idx] += np.bincount(verts, tri_nn[:, idx], minlength=npts)\n size = np.sqrt(np.sum(nn * nn, axis=1))\n size[size == 0] = 1.0 # prevent ugly divide-by-zero\n nn /= size[:, np.newaxis]\n return nn\n\n\n###############################################################################\n# CONFIG\n\nclass ConfigEvent(Event):\n\n \"\"\" Event indicating a configuration change.\n\n This class has a 'changes' attribute which is a dict of all name:value\n pairs that have changed in the configuration.\n \"\"\"\n\n def __init__(self, changes):\n Event.__init__(self, type='config_change')\n self.changes = changes\n\n\nclass Config(object):\n\n \"\"\" Container for global settings used application-wide in vispy.\n\n Events:\n -------\n Config.events.changed - Emits ConfigEvent whenever the configuration\n changes.\n \"\"\"\n\n def __init__(self):\n self.events = EmitterGroup(source=self)\n self.events['changed'] = EventEmitter(\n event_class=ConfigEvent,\n source=self)\n self._config = {}\n\n def __getitem__(self, item):\n return self._config[item]\n\n def __setitem__(self, item, val):\n self._config[item] = val\n # inform any listeners that a configuration option has changed\n self.events.changed(changes={item: val})\n\n def update(self, **kwds):\n self._config.update(kwds)\n self.events.changed(changes=kwds)\n\n def __repr__(self):\n return repr(self._config)\n\nconfig = Config()\nconfig.update(\n default_backend='qt',\n qt_lib='any', # options are 'pyqt', 'pyside', or 'any'\n show_warnings=False,\n gl_debug=False,\n logging_level='info',\n)\n\nset_log_level(config['logging_level'])\n\n\ndef parse_command_line_arguments():\n \"\"\" Transform vispy specific command line args to vispy config.\n Put into a function so that any variables dont leak in the vispy namespace.\n \"\"\"\n # Get command line args for vispy\n argnames = ['vispy-backend', 'vispy-gl-debug']\n try:\n opts, args = getopt.getopt(sys.argv[1:], '', argnames)\n except getopt.GetoptError:\n opts = []\n # Use them to set the config values\n for o, a in opts:\n if o.startswith('--vispy'):\n if o == '--vispy-backend':\n config['default_backend'] = a\n logger.info('backend', a)\n elif o == '--vispy-gl-debug':\n config['gl_debug'] = True\n else:\n logger.warning(\"Unsupported vispy flag: %s\" % o)\n\n\ndef sys_info(fname=None, overwrite=False):\n \"\"\"Get relevant system and debugging information\n\n Parameters\n ----------\n fname : str | None\n Filename to dump info to. Use None to simply print.\n overwrite : bool\n If True, overwrite file (if it exists).\n\n Returns\n -------\n out : str\n The system information as a string.\n \"\"\"\n if fname is not None and op.isfile(fname) and not overwrite:\n raise IOError('file exists, use overwrite=True to overwrite')\n\n out = ''\n try:\n # Nest all imports here to avoid any circular imports\n from ..app import Application, Canvas, backends\n from ..gloo import gl\n # get default app\n this_app = Application()\n with use_log_level('warning'):\n this_app.use() # suppress unnecessary messages\n out += 'Platform: %s\\n' % platform.platform()\n out += 'Python: %s\\n' % str(sys.version).replace('\\n', ' ')\n out += 'Backend: %s\\n' % this_app.backend_name\n out += 'Qt: %s\\n' % backends.has_qt(return_which=True)[1]\n out += 'Pyglet: %s\\n' % backends.has_pyglet(return_which=True)[1]\n out += 'glfw: %s\\n' % backends.has_glfw(return_which=True)[1]\n out += 'glut: %s\\n' % backends.has_glut(return_which=True)[1]\n out += '\\n'\n # We need an OpenGL context to get GL info\n if 'glut' in this_app.backend_name.lower():\n # glut causes problems\n out += 'OpenGL information omitted for glut backend\\n'\n else:\n canvas = Canvas('Test', (10, 10), show=False, app=this_app)\n canvas._backend._vispy_set_current()\n out += 'GL version: %s\\n' % gl.glGetString(gl.GL_VERSION)\n x_ = gl.GL_MAX_TEXTURE_SIZE\n out += 'MAX_TEXTURE_SIZE: %d\\n' % gl.glGetIntegerv(x_)\n x_ = gl.ext.GL_MAX_3D_TEXTURE_SIZE\n out += 'MAX_3D_TEXTURE_SIZE: %d\\n\\n' % gl.glGetIntegerv(x_)\n out += 'Extensions: %s\\n' % gl.glGetString(gl.GL_EXTENSIONS)\n canvas.close()\n except Exception: # don't stop printing info\n out += '\\nInfo-gathering error:\\n%s' % traceback.format_exc()\n pass\n if fname is not None:\n with open(fname, 'w') as fid:\n fid.write(out)\n return out\n", "path": "vispy/util/misc.py"}, {"content": "# -*- coding: utf-8 -*-\n# Copyright (c) 2014, Vispy Development Team. All Rights Reserved.\n# Distributed under the (new) BSD License. See LICENSE.txt for more info.\n\n\"\"\" Utilities for Vispy. A collection of modules that are used in\none or more Vispy sub-packages.\n\"\"\"\n\nfrom .misc import (_TempDir, is_string, parse_command_line_arguments, # noqa\n config, sys_info) # noqa\nfrom ._logging import logger, set_log_level, use_log_level # noqa\n", "path": "vispy/util/__init__.py"}]} | 3,467 | 665 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.