
File size: 2,931 Bytes
1a59b95 8e4236e 69c7a42 8e4236e b956774 69c7a42 fff7d3e 8e4236e 1a680ee b6f84e7 3a321ae b6f84e7 3a321ae b6f84e7 1a680ee 8e4236e |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
---
annotations_creators:
- expert-generated
language:
- en
language_creators:
- crowdsourced
license: []
multilinguality:
- monolingual
pretty_name: Conversation-Entailment
size_categories:
- n<1K
source_datasets:
- original
tags:
- conversational
- entailment
task_categories:
- conversational
- text-classification
task_ids: []
---
# Conversation-Entailment
Official dataset for [Towards Conversation Entailment: An Empirical Investigation](https://sled.eecs.umich.edu/publication/dblp-confemnlp-zhang-c-10/). *Chen Zhang, Joyce Chai*. EMNLP, 2010
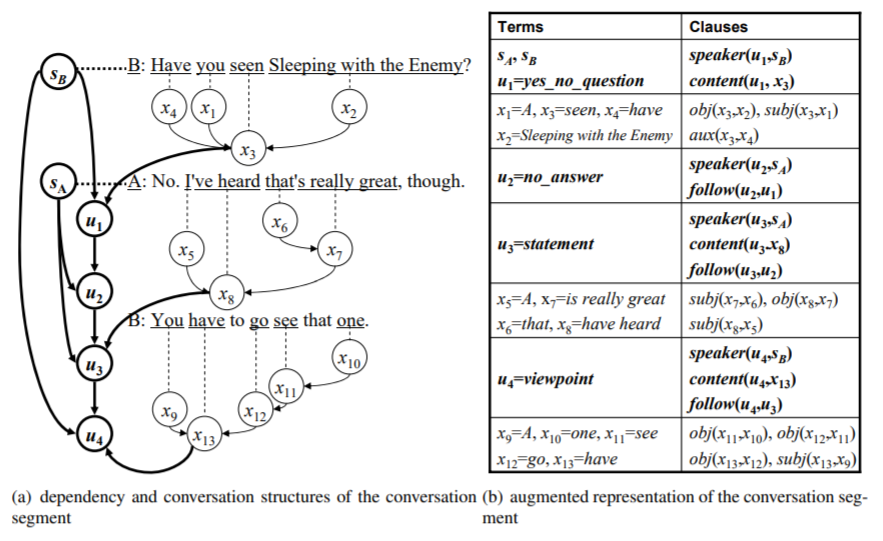
## Overview
Textual entailment has mainly focused on inference from written text in monologue. Recent years also observed an increasing amount of conversational data such as conversation scripts of meetings, call center records, court proceedings, as well as online chatting. Although conversation is a form of language, it is different from monologue text with several unique characteristics. The key distinctive features include turn-taking between participants, grounding between participants, different linguistic phenomena of utterances, and conversation implicatures. Traditional approaches dealing with textual entailment were not designed to handle these unique conversation behaviors and thus to support automated entailment from conversation scripts. This project intends to address this limitation.
### Download
```python
from datasets import load_dataset
dataset = load_dataset("sled-umich/Conversation-Entailment")
```
* [HuggingFace-Dataset](https://huggingface.co/datasets/sled-umich/Conversation-Entailment)
* [DropBox](https://www.dropbox.com/s/z5vchgzvzxv75es/conversation_entailment.tar?dl=0)
### Data Sample
```json
{
"id": 3,
"type": "fact",
"dialog_num_list": [
30,
31
],
"dialog_speaker_list": [
"B",
"A"
],
"dialog_text_list": [
"Have you seen SLEEPING WITH THE ENEMY?",
"No. I've heard, I've heard that's really great, though."
],
"h": "SpeakerA and SpeakerB have seen SLEEPING WITH THE ENEMY",
"entailment": false,
"dialog_source": "SW2010"
}
```
### Cite
[Towards Conversation Entailment: An Empirical Investigation](https://sled.eecs.umich.edu/publication/dblp-confemnlp-zhang-c-10/). *Chen Zhang, Joyce Chai*. EMNLP, 2010. [[Paper]](https://aclanthology.org/D10-1074/)
```tex
@inproceedings{zhang-chai-2010-towards,
title = "Towards Conversation Entailment: An Empirical Investigation",
author = "Zhang, Chen and
Chai, Joyce",
booktitle = "Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing",
month = oct,
year = "2010",
address = "Cambridge, MA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/D10-1074",
pages = "756--766",
}
``` |