
Create README.md
Browse files
README.md
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
task_categories:
|
| 4 |
+
- multiple-choice
|
| 5 |
+
- question-answering
|
| 6 |
+
- visual-question-answering
|
| 7 |
+
language:
|
| 8 |
+
- en
|
| 9 |
+
size_categories:
|
| 10 |
+
- 100B<n<1T
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
# MME-RealWorld Data Card
|
| 18 |
+
|
| 19 |
+
## Dataset details
|
| 20 |
+
|
| 21 |
+
Existing Multimodal Large Language Model benchmarks present several common barriers that make it difficult to measure the significant challenges that models face in the real world, including:
|
| 22 |
+
1) small data scale leading to large performance variance;
|
| 23 |
+
2) reliance on model-based annotations, resulting in significant model bias;
|
| 24 |
+
3) restricted data sources, often overlapping with existing benchmarks and posing a risk of data leakage;
|
| 25 |
+
4) insufficient task difficulty and discrimination, especially the limited image resolution.
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
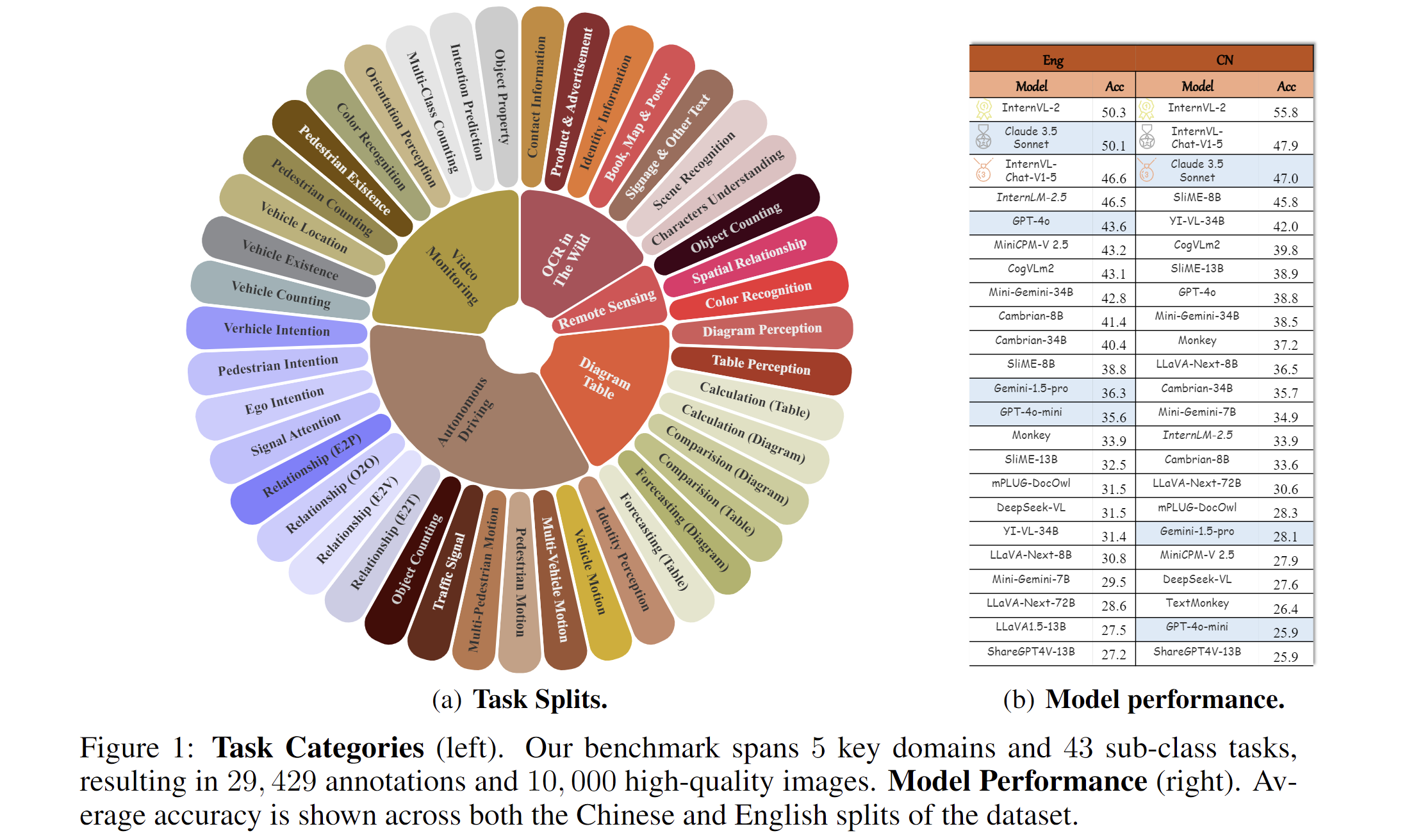
We present MME-RealWord, a benchmark meticulously designed to address real-world applications with practical relevance. Featuring 13,366 high-resolution images averaging 1,734 × 1,734 pixels, MME-RealWord poses substantial recognition challenges. Our dataset encompasses 29,429 annotations across 43 tasks, all expertly curated by a team of 25 crowdsource workers and 7 MLLM experts. The main advantages of MME-RealWorld compared to existing MLLM benchmarks as follows:
|
| 29 |
+
|
| 30 |
+
1. **Scale, Diversity, and Real-World Utility**: MME-RealWord is the largest fully human-annotated MLLM benchmark, covering 6 domains and 14 sub-classes, closely tied to real-world tasks.
|
| 31 |
+
|
| 32 |
+
2. **Quality**: The dataset features high-resolution images with crucial details and manual annotations verified by experts to ensure top-notch data quality.
|
| 33 |
+
|
| 34 |
+
3. **Safety**: MME-RealWord avoids data overlap with other benchmarks and relies solely on human annotations, eliminating model biases and personal bias.
|
| 35 |
+
|
| 36 |
+
4. **Difficulty and Distinguishability**: The dataset poses significant challenges, with models struggling to achieve even 55% accuracy in basic tasks, clearly distinguishing between different MLLMs.
|
| 37 |
+
|
| 38 |
+
5. **MME-RealWord-CN**: The dataset includes a specialized Chinese benchmark with images and questions tailored to Chinese contexts, overcoming issues in existing translated benchmarks.
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
## How to use?
|
| 45 |
+
|
| 46 |
+
Since the image files are large and have been split into multiple compressed parts, please first merge the compressed files with the same name and then extract them together.
|
| 47 |
+
|
| 48 |
+
```
|
| 49 |
+
#!/bin/bash
|
| 50 |
+
|
| 51 |
+
# Navigate to the directory containing the split files
|
| 52 |
+
cd TARFILES
|
| 53 |
+
|
| 54 |
+
# Loop through each set of split files
|
| 55 |
+
for part in *.tar.gz.part_aa; do
|
| 56 |
+
# Extract the base name of the file
|
| 57 |
+
base_name=$(basename "$part" .tar.gz.part_aa)
|
| 58 |
+
|
| 59 |
+
# Merge the split files into a single archive
|
| 60 |
+
cat "${base_name}".tar.gz.part_* > "${base_name}.tar.gz"
|
| 61 |
+
|
| 62 |
+
# Extract the merged archive
|
| 63 |
+
tar -xzf "${base_name}.tar.gz"
|
| 64 |
+
|
| 65 |
+
# Optional: Remove the temporary merged archive
|
| 66 |
+
rm "${base_name}.tar.gz"
|
| 67 |
+
done
|
| 68 |
+
|
| 69 |
+
```
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
|