
Commit
•
466558e
1
Parent(s):
0a2445e
Upload 6 files
Browse files- .DS_Store +0 -0
- Data.zip +3 -0
- README.md +31 -0
- finetuning.py +129 -0
- prediction.py +54 -0
- requirements.txt +7 -0
.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
Data.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bc7c5e8e8f504a6cccff580814c77576be0241490c680fd794cf7120aebd628a
|
| 3 |
+
size 260278375
|
README.md
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Visual Question Answering using BLIP pre-trained model!
|
| 2 |
+
|
| 3 |
+
This implementation applies the BLIP pre-trained model to solve the icon domain task.
|
| 4 |
+
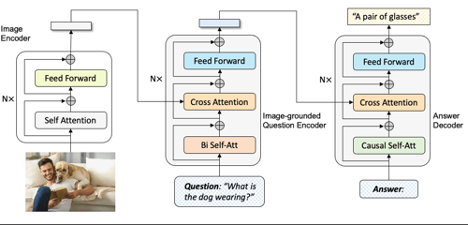
|
| 5 |
+
| 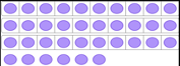| |
|
| 6 |
+
|--|--|
|
| 7 |
+
| How many dots are there? | 36 |
|
| 8 |
+
|
| 9 |
+
# Description
|
| 10 |
+
**Note: The test dataset does not have labels. I evaluated the model via Kaggle competition and got 96% in accuracy manner. Obviously, you can use a partition of the training set as a testing set.
|
| 11 |
+
## Create data folder
|
| 12 |
+
|
| 13 |
+
Copy all data following the example form
|
| 14 |
+
You can download data [here](https://drive.google.com/file/d/1tt6qJbOgevyPpfkylXpKYy-KaT4_aCYZ/view?usp=sharing)
|
| 15 |
+
|
| 16 |
+
## Install requirements.txt
|
| 17 |
+
|
| 18 |
+
pip install -r requirements.txt
|
| 19 |
+
|
| 20 |
+
## Run finetuning code
|
| 21 |
+
|
| 22 |
+
python finetuning.py
|
| 23 |
+
|
| 24 |
+
## Run prediction
|
| 25 |
+
|
| 26 |
+
python predicting.py
|
| 27 |
+
|
| 28 |
+
### References:
|
| 29 |
+
|
| 30 |
+
> Nguyen Van Tuan (2023). JAIST_Advanced Machine Learning_Visual_Question_Answering
|
| 31 |
+
|
finetuning.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import requests
|
| 4 |
+
from transformers import BlipProcessor, BlipForQuestionAnswering
|
| 5 |
+
from datasets import load_dataset
|
| 6 |
+
import torch
|
| 7 |
+
from PIL import Image
|
| 8 |
+
from torch.utils.data import DataLoader
|
| 9 |
+
from tqdm import tqdm
|
| 10 |
+
import pickle
|
| 11 |
+
|
| 12 |
+
model = BlipForQuestionAnswering.from_pretrained("Salesforce/blip-vqa-base")
|
| 13 |
+
processor = BlipProcessor.from_pretrained("Salesforce/blip-vqa-base")
|
| 14 |
+
|
| 15 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 16 |
+
model.to(device)
|
| 17 |
+
|
| 18 |
+
torch.cuda.empty_cache()
|
| 19 |
+
torch.manual_seed(42)
|
| 20 |
+
|
| 21 |
+
class VQADataset(torch.utils.data.Dataset):
|
| 22 |
+
"""VQA (v2) dataset."""
|
| 23 |
+
|
| 24 |
+
def __init__(self, dataset, processor):
|
| 25 |
+
self.dataset = dataset
|
| 26 |
+
self.processor = processor
|
| 27 |
+
|
| 28 |
+
def __len__(self):
|
| 29 |
+
return len(self.dataset)
|
| 30 |
+
|
| 31 |
+
def __getitem__(self, idx):
|
| 32 |
+
# get image + text
|
| 33 |
+
question = self.dataset[idx]['question']
|
| 34 |
+
answer = self.dataset[idx]['answer']
|
| 35 |
+
image_id = self.dataset[idx]['pid']
|
| 36 |
+
image_path = f"Data/train_fill_in_blank/{image_id}/image.png"
|
| 37 |
+
image = Image.open(image_path).convert("RGB")
|
| 38 |
+
text = question
|
| 39 |
+
|
| 40 |
+
encoding = self.processor(image, text, padding="max_length", truncation=True, return_tensors="pt")
|
| 41 |
+
labels = self.processor.tokenizer.encode(
|
| 42 |
+
answer, max_length= 8, pad_to_max_length=True, return_tensors='pt'
|
| 43 |
+
)
|
| 44 |
+
encoding["labels"] = labels
|
| 45 |
+
# remove batch dimension
|
| 46 |
+
for k,v in encoding.items(): encoding[k] = v.squeeze()
|
| 47 |
+
return encoding
|
| 48 |
+
|
| 49 |
+
training_dataset = load_dataset("json", data_files="Data/train.jsonl", split="train[:90%]")
|
| 50 |
+
valid_dataset = load_dataset("json", data_files="Data/train.jsonl", split="train[90%:]")
|
| 51 |
+
print("Training sets: {} - Validating set: {}".format(len(training_dataset), len(valid_dataset)))
|
| 52 |
+
|
| 53 |
+
train_dataset = VQADataset(dataset=training_dataset,
|
| 54 |
+
processor=processor)
|
| 55 |
+
valid_dataset = VQADataset(dataset=valid_dataset,
|
| 56 |
+
processor=processor)
|
| 57 |
+
|
| 58 |
+
batch_size = 12
|
| 59 |
+
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=False, pin_memory=True)
|
| 60 |
+
valid_dataloader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=False, pin_memory=True)
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
optimizer = torch.optim.AdamW(model.parameters(), lr=4e-5)
|
| 64 |
+
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9, last_epoch=-1, verbose=False)
|
| 65 |
+
|
| 66 |
+
num_epochs = 100
|
| 67 |
+
patience = 10
|
| 68 |
+
min_eval_loss = float("inf")
|
| 69 |
+
early_stopping_hook = 0
|
| 70 |
+
tracking_information = []
|
| 71 |
+
scaler = torch.cuda.amp.GradScaler()
|
| 72 |
+
|
| 73 |
+
for epoch in range(num_epochs):
|
| 74 |
+
epoch_loss = 0
|
| 75 |
+
model.train()
|
| 76 |
+
for idx, batch in zip(tqdm(range(len(train_dataloader)), desc='Training batch: ...'), train_dataloader):
|
| 77 |
+
input_ids = batch.pop('input_ids').to(device)
|
| 78 |
+
pixel_values = batch.pop('pixel_values').to(device)
|
| 79 |
+
attention_masked = batch.pop('attention_mask').to(device)
|
| 80 |
+
labels = batch.pop('labels').to(device)
|
| 81 |
+
|
| 82 |
+
with torch.amp.autocast(device_type='cuda', dtype=torch.float16):
|
| 83 |
+
outputs = model(input_ids=input_ids,
|
| 84 |
+
pixel_values=pixel_values,
|
| 85 |
+
# attention_mask=attention_masked,
|
| 86 |
+
labels=labels)
|
| 87 |
+
|
| 88 |
+
loss = outputs.loss
|
| 89 |
+
epoch_loss += loss.item()
|
| 90 |
+
# loss.backward()
|
| 91 |
+
# optimizer.step()
|
| 92 |
+
optimizer.zero_grad()
|
| 93 |
+
|
| 94 |
+
scaler.scale(loss).backward()
|
| 95 |
+
scaler.step(optimizer)
|
| 96 |
+
scaler.update()
|
| 97 |
+
|
| 98 |
+
model.eval()
|
| 99 |
+
eval_loss = 0
|
| 100 |
+
for idx, batch in zip(tqdm(range(len(valid_dataloader)), desc='Validating batch: ...'), valid_dataloader):
|
| 101 |
+
input_ids = batch.pop('input_ids').to(device)
|
| 102 |
+
pixel_values = batch.pop('pixel_values').to(device)
|
| 103 |
+
attention_masked = batch.pop('attention_mask').to(device)
|
| 104 |
+
labels = batch.pop('labels').to(device)
|
| 105 |
+
|
| 106 |
+
with torch.amp.autocast(device_type='cuda', dtype=torch.float16):
|
| 107 |
+
outputs = model(input_ids=input_ids,
|
| 108 |
+
pixel_values=pixel_values,
|
| 109 |
+
attention_mask=attention_masked,
|
| 110 |
+
labels=labels)
|
| 111 |
+
|
| 112 |
+
loss = outputs.loss
|
| 113 |
+
eval_loss += loss.item()
|
| 114 |
+
|
| 115 |
+
tracking_information.append((epoch_loss/len(train_dataloader), eval_loss/len(valid_dataloader), optimizer.param_groups[0]["lr"]))
|
| 116 |
+
print("Epoch: {} - Training loss: {} - Eval Loss: {} - LR: {}".format(epoch+1, epoch_loss/len(train_dataloader), eval_loss/len(valid_dataloader), optimizer.param_groups[0]["lr"]))
|
| 117 |
+
scheduler.step()
|
| 118 |
+
if eval_loss < min_eval_loss:
|
| 119 |
+
model.save_pretrained("Model/blip-saved-model", from_pt=True)
|
| 120 |
+
print("Saved model to Model/blip-saved-model")
|
| 121 |
+
min_eval_loss = eval_loss
|
| 122 |
+
early_stopping_hook = 0
|
| 123 |
+
else:
|
| 124 |
+
early_stopping_hook += 1
|
| 125 |
+
if early_stopping_hook > patience:
|
| 126 |
+
break
|
| 127 |
+
|
| 128 |
+
pickle.dump(tracking_information, open("tracking_information.pkl", "wb"))
|
| 129 |
+
print("The finetuning process has done!")
|
prediction.py
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import ViltProcessor, ViltForQuestionAnswering
|
| 2 |
+
from transformers import BlipProcessor, BlipForQuestionAnswering
|
| 3 |
+
import requests
|
| 4 |
+
from PIL import Image
|
| 5 |
+
import json, os, csv
|
| 6 |
+
import logging
|
| 7 |
+
from tqdm import tqdm
|
| 8 |
+
import torch
|
| 9 |
+
|
| 10 |
+
# Set the path to your test data directory
|
| 11 |
+
test_data_dir = "Data/test_data/test_data"
|
| 12 |
+
|
| 13 |
+
# processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
|
| 14 |
+
# model = ViltForQuestionAnswering.from_pretrained("test_model/checkpoint-525")
|
| 15 |
+
|
| 16 |
+
processor = BlipProcessor.from_pretrained("Salesforce/blip-vqa-base")
|
| 17 |
+
model = BlipForQuestionAnswering.from_pretrained("Model/blip-saved-model").to("cuda")
|
| 18 |
+
|
| 19 |
+
# Create a list to store the results
|
| 20 |
+
results = []
|
| 21 |
+
|
| 22 |
+
# Iterate through each file in the test data directory
|
| 23 |
+
samples = os.listdir(test_data_dir)
|
| 24 |
+
for filename in tqdm(os.listdir(test_data_dir), desc="Processing"):
|
| 25 |
+
sample_path = f"Data/test_data/{filename}"
|
| 26 |
+
|
| 27 |
+
# Read the json file
|
| 28 |
+
json_path = os.path.join(sample_path, "data.json")
|
| 29 |
+
with open(json_path, "r") as json_file:
|
| 30 |
+
data = json.load(json_file)
|
| 31 |
+
question = data["question"]
|
| 32 |
+
image_id = data["id"]
|
| 33 |
+
|
| 34 |
+
# Read the corresponding image
|
| 35 |
+
image_path = os.path.join(test_data_dir, f"{image_id}", "image.png")
|
| 36 |
+
image = Image.open(image_path).convert("RGB")
|
| 37 |
+
|
| 38 |
+
# prepare inputs
|
| 39 |
+
encoding = processor(image, question, return_tensors="pt").to("cuda:0", torch.float16)
|
| 40 |
+
|
| 41 |
+
out = model.generate(**encoding)
|
| 42 |
+
generated_text = processor.decode(out[0], skip_special_tokens=True)
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
results.append((image_id, generated_text))
|
| 46 |
+
|
| 47 |
+
# Write the results to a CSV file
|
| 48 |
+
csv_file_path = "Results/results.csv"
|
| 49 |
+
with open(csv_file_path, mode="w", newline="") as csv_file:
|
| 50 |
+
csv_writer = csv.writer(csv_file)
|
| 51 |
+
csv_writer.writerow(["ID", "Label"]) # Write header
|
| 52 |
+
csv_writer.writerows(results)
|
| 53 |
+
|
| 54 |
+
print(f"Results saved to {csv_file_path}")
|
requirements.txt
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
tqdm==4.66.1
|
| 2 |
+
datasets==2.14.6
|
| 3 |
+
transformers==4.35.2
|
| 4 |
+
torch==2.1.0
|
| 5 |
+
torchsummary==1.5.1
|
| 6 |
+
torchvision==0.16.0
|
| 7 |
+
Pillow==10.0.1
|