

Release DeepSeek-V3
Browse files- LICENSE-CODE +21 -0
- LICENSE-MODEL +91 -0
- README.md +323 -0
- README_WEIGHTS.md +94 -0
- figures/benchmark.png +0 -0
- figures/niah.png +0 -0
- inference/configs/config_16B.json +19 -0
- inference/configs/config_236B.json +20 -0
- inference/configs/config_671B.json +22 -0
- inference/convert.py +84 -0
- inference/fp8_cast_bf16.py +55 -0
- inference/generate.py +137 -0
- inference/kernel.py +108 -0
- inference/model.py +421 -0
- inference/requirements.txt +4 -0
LICENSE-CODE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 DeepSeek
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
LICENSE-MODEL
ADDED
|
@@ -0,0 +1,91 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
DEEPSEEK LICENSE AGREEMENT
|
| 2 |
+
|
| 3 |
+
Version 1.0, 23 October 2023
|
| 4 |
+
|
| 5 |
+
Copyright (c) 2023 DeepSeek
|
| 6 |
+
|
| 7 |
+
Section I: PREAMBLE
|
| 8 |
+
|
| 9 |
+
Large generative models are being widely adopted and used, and have the potential to transform the way individuals conceive and benefit from AI or ML technologies.
|
| 10 |
+
|
| 11 |
+
Notwithstanding the current and potential benefits that these artifacts can bring to society at large, there are also concerns about potential misuses of them, either due to their technical limitations or ethical considerations.
|
| 12 |
+
|
| 13 |
+
In short, this license strives for both the open and responsible downstream use of the accompanying model. When it comes to the open character, we took inspiration from open source permissive licenses regarding the grant of IP rights. Referring to the downstream responsible use, we added use-based restrictions not permitting the use of the model in very specific scenarios, in order for the licensor to be able to enforce the license in case potential misuses of the Model may occur. At the same time, we strive to promote open and responsible research on generative models for content generation.
|
| 14 |
+
|
| 15 |
+
Even though downstream derivative versions of the model could be released under different licensing terms, the latter will always have to include - at minimum - the same use-based restrictions as the ones in the original license (this license). We believe in the intersection between open and responsible AI development; thus, this agreement aims to strike a balance between both in order to enable responsible open-science in the field of AI.
|
| 16 |
+
|
| 17 |
+
This License governs the use of the model (and its derivatives) and is informed by the model card associated with the model.
|
| 18 |
+
|
| 19 |
+
NOW THEREFORE, You and DeepSeek agree as follows:
|
| 20 |
+
|
| 21 |
+
1. Definitions
|
| 22 |
+
"License" means the terms and conditions for use, reproduction, and Distribution as defined in this document.
|
| 23 |
+
"Data" means a collection of information and/or content extracted from the dataset used with the Model, including to train, pretrain, or otherwise evaluate the Model. The Data is not licensed under this License.
|
| 24 |
+
"Output" means the results of operating a Model as embodied in informational content resulting therefrom.
|
| 25 |
+
"Model" means any accompanying machine-learning based assemblies (including checkpoints), consisting of learnt weights, parameters (including optimizer states), corresponding to the model architecture as embodied in the Complementary Material, that have been trained or tuned, in whole or in part on the Data, using the Complementary Material.
|
| 26 |
+
"Derivatives of the Model" means all modifications to the Model, works based on the Model, or any other model which is created or initialized by transfer of patterns of the weights, parameters, activations or output of the Model, to the other model, in order to cause the other model to perform similarly to the Model, including - but not limited to - distillation methods entailing the use of intermediate data representations or methods based on the generation of synthetic data by the Model for training the other model.
|
| 27 |
+
"Complementary Material" means the accompanying source code and scripts used to define, run, load, benchmark or evaluate the Model, and used to prepare data for training or evaluation, if any. This includes any accompanying documentation, tutorials, examples, etc, if any.
|
| 28 |
+
"Distribution" means any transmission, reproduction, publication or other sharing of the Model or Derivatives of the Model to a third party, including providing the Model as a hosted service made available by electronic or other remote means - e.g. API-based or web access.
|
| 29 |
+
"DeepSeek" (or "we") means Beijing DeepSeek Artificial Intelligence Fundamental Technology Research Co., Ltd., Hangzhou DeepSeek Artificial Intelligence Fundamental Technology Research Co., Ltd. and/or any of their affiliates.
|
| 30 |
+
"You" (or "Your") means an individual or Legal Entity exercising permissions granted by this License and/or making use of the Model for whichever purpose and in any field of use, including usage of the Model in an end-use application - e.g. chatbot, translator, etc.
|
| 31 |
+
"Third Parties" means individuals or legal entities that are not under common control with DeepSeek or You.
|
| 32 |
+
|
| 33 |
+
Section II: INTELLECTUAL PROPERTY RIGHTS
|
| 34 |
+
|
| 35 |
+
Both copyright and patent grants apply to the Model, Derivatives of the Model and Complementary Material. The Model and Derivatives of the Model are subject to additional terms as described in Section III.
|
| 36 |
+
|
| 37 |
+
2. Grant of Copyright License. Subject to the terms and conditions of this License, DeepSeek hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare, publicly display, publicly perform, sublicense, and distribute the Complementary Material, the Model, and Derivatives of the Model.
|
| 38 |
+
|
| 39 |
+
3. Grant of Patent License. Subject to the terms and conditions of this License and where and as applicable, DeepSeek hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this paragraph) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Model and the Complementary Material, where such license applies only to those patent claims licensable by DeepSeek that are necessarily infringed by its contribution(s). If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Model and/or Complementary Material constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for the Model and/or works shall terminate as of the date such litigation is asserted or filed.
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
Section III: CONDITIONS OF USAGE, DISTRIBUTION AND REDISTRIBUTION
|
| 43 |
+
|
| 44 |
+
4. Distribution and Redistribution. You may host for Third Party remote access purposes (e.g. software-as-a-service), reproduce and distribute copies of the Model or Derivatives of the Model thereof in any medium, with or without modifications, provided that You meet the following conditions:
|
| 45 |
+
a. Use-based restrictions as referenced in paragraph 5 MUST be included as an enforceable provision by You in any type of legal agreement (e.g. a license) governing the use and/or distribution of the Model or Derivatives of the Model, and You shall give notice to subsequent users You Distribute to, that the Model or Derivatives of the Model are subject to paragraph 5. This provision does not apply to the use of Complementary Material.
|
| 46 |
+
b. You must give any Third Party recipients of the Model or Derivatives of the Model a copy of this License;
|
| 47 |
+
c. You must cause any modified files to carry prominent notices stating that You changed the files;
|
| 48 |
+
d. You must retain all copyright, patent, trademark, and attribution notices excluding those notices that do not pertain to any part of the Model, Derivatives of the Model.
|
| 49 |
+
e. You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions - respecting paragraph 4.a. – for use, reproduction, or Distribution of Your modifications, or for any such Derivatives of the Model as a whole, provided Your use, reproduction, and Distribution of the Model otherwise complies with the conditions stated in this License.
|
| 50 |
+
|
| 51 |
+
5. Use-based restrictions. The restrictions set forth in Attachment A are considered Use-based restrictions. Therefore You cannot use the Model and the Derivatives of the Model for the specified restricted uses. You may use the Model subject to this License, including only for lawful purposes and in accordance with the License. Use may include creating any content with, finetuning, updating, running, training, evaluating and/or reparametrizing the Model. You shall require all of Your users who use the Model or a Derivative of the Model to comply with the terms of this paragraph (paragraph 5).
|
| 52 |
+
|
| 53 |
+
6. The Output You Generate. Except as set forth herein, DeepSeek claims no rights in the Output You generate using the Model. You are accountable for the Output you generate and its subsequent uses. No use of the output can contravene any provision as stated in the License.
|
| 54 |
+
|
| 55 |
+
Section IV: OTHER PROVISIONS
|
| 56 |
+
|
| 57 |
+
7. Updates and Runtime Restrictions. To the maximum extent permitted by law, DeepSeek reserves the right to restrict (remotely or otherwise) usage of the Model in violation of this License.
|
| 58 |
+
|
| 59 |
+
8. Trademarks and related. Nothing in this License permits You to make use of DeepSeek’ trademarks, trade names, logos or to otherwise suggest endorsement or misrepresent the relationship between the parties; and any rights not expressly granted herein are reserved by DeepSeek.
|
| 60 |
+
|
| 61 |
+
9. Personal information, IP rights and related. This Model may contain personal information and works with IP rights. You commit to complying with applicable laws and regulations in the handling of personal information and the use of such works. Please note that DeepSeek's license granted to you to use the Model does not imply that you have obtained a legitimate basis for processing the related information or works. As an independent personal information processor and IP rights user, you need to ensure full compliance with relevant legal and regulatory requirements when handling personal information and works with IP rights that may be contained in the Model, and are willing to assume solely any risks and consequences that may arise from that.
|
| 62 |
+
|
| 63 |
+
10. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, DeepSeek provides the Model and the Complementary Material on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Model, Derivatives of the Model, and the Complementary Material and assume any risks associated with Your exercise of permissions under this License.
|
| 64 |
+
|
| 65 |
+
11. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall DeepSeek be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Model and the Complementary Material (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if DeepSeek has been advised of the possibility of such damages.
|
| 66 |
+
|
| 67 |
+
12. Accepting Warranty or Additional Liability. While redistributing the Model, Derivatives of the Model and the Complementary Material thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of DeepSeek, and only if You agree to indemnify, defend, and hold DeepSeek harmless for any liability incurred by, or claims asserted against, DeepSeek by reason of your accepting any such warranty or additional liability.
|
| 68 |
+
|
| 69 |
+
13. If any provision of this License is held to be invalid, illegal or unenforceable, the remaining provisions shall be unaffected thereby and remain valid as if such provision had not been set forth herein.
|
| 70 |
+
|
| 71 |
+
14. Governing Law and Jurisdiction. This agreement will be governed and construed under PRC laws without regard to choice of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this agreement. The courts located in the domicile of Hangzhou DeepSeek Artificial Intelligence Fundamental Technology Research Co., Ltd. shall have exclusive jurisdiction of any dispute arising out of this agreement.
|
| 72 |
+
|
| 73 |
+
END OF TERMS AND CONDITIONS
|
| 74 |
+
|
| 75 |
+
Attachment A
|
| 76 |
+
|
| 77 |
+
Use Restrictions
|
| 78 |
+
|
| 79 |
+
You agree not to use the Model or Derivatives of the Model:
|
| 80 |
+
|
| 81 |
+
- In any way that violates any applicable national or international law or regulation or infringes upon the lawful rights and interests of any third party;
|
| 82 |
+
- For military use in any way;
|
| 83 |
+
- For the purpose of exploiting, harming or attempting to exploit or harm minors in any way;
|
| 84 |
+
- To generate or disseminate verifiably false information and/or content with the purpose of harming others;
|
| 85 |
+
- To generate or disseminate inappropriate content subject to applicable regulatory requirements;
|
| 86 |
+
- To generate or disseminate personal identifiable information without due authorization or for unreasonable use;
|
| 87 |
+
- To defame, disparage or otherwise harass others;
|
| 88 |
+
- For fully automated decision making that adversely impacts an individual’s legal rights or otherwise creates or modifies a binding, enforceable obligation;
|
| 89 |
+
- For any use intended to or which has the effect of discriminating against or harming individuals or groups based on online or offline social behavior or known or predicted personal or personality characteristics;
|
| 90 |
+
- To exploit any of the vulnerabilities of a specific group of persons based on their age, social, physical or mental characteristics, in order to materially distort the behavior of a person pertaining to that group in a manner that causes or is likely to cause that person or another person physical or psychological harm;
|
| 91 |
+
- For any use intended to or which has the effect of discriminating against individuals or groups based on legally protected characteristics or categories.
|
README.md
ADDED
|
@@ -0,0 +1,323 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!-- markdownlint-disable first-line-h1 -->
|
| 2 |
+
<!-- markdownlint-disable html -->
|
| 3 |
+
<!-- markdownlint-disable no-duplicate-header -->
|
| 4 |
+
|
| 5 |
+
<div align="center">
|
| 6 |
+
<img src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/logo.svg?raw=true" width="60%" alt="DeepSeek-V3" />
|
| 7 |
+
</div>
|
| 8 |
+
<hr>
|
| 9 |
+
<div align="center" style="line-height: 1;">
|
| 10 |
+
<a href="https://www.deepseek.com/" target="_blank" style="margin: 2px;">
|
| 11 |
+
<img alt="Homepage" src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/badge.svg?raw=true" style="display: inline-block; vertical-align: middle;"/>
|
| 12 |
+
</a>
|
| 13 |
+
<a href="https://chat.deepseek.com/" target="_blank" style="margin: 2px;">
|
| 14 |
+
<img alt="Chat" src="https://img.shields.io/badge/🤖%20Chat-DeepSeek%20V3-536af5?color=536af5&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
|
| 15 |
+
</a>
|
| 16 |
+
<a href="https://huggingface.co/deepseek-ai" target="_blank" style="margin: 2px;">
|
| 17 |
+
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-DeepSeek%20AI-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
|
| 18 |
+
</a>
|
| 19 |
+
</div>
|
| 20 |
+
|
| 21 |
+
<div align="center" style="line-height: 1;">
|
| 22 |
+
<a href="https://discord.gg/Tc7c45Zzu5" target="_blank" style="margin: 2px;">
|
| 23 |
+
<img alt="Discord" src="https://img.shields.io/badge/Discord-DeepSeek%20AI-7289da?logo=discord&logoColor=white&color=7289da" style="display: inline-block; vertical-align: middle;"/>
|
| 24 |
+
</a>
|
| 25 |
+
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/qr.jpeg?raw=true" target="_blank" style="margin: 2px;">
|
| 26 |
+
<img alt="Wechat" src="https://img.shields.io/badge/WeChat-DeepSeek%20AI-brightgreen?logo=wechat&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
|
| 27 |
+
</a>
|
| 28 |
+
<a href="https://twitter.com/deepseek_ai" target="_blank" style="margin: 2px;">
|
| 29 |
+
<img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-deepseek_ai-white?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
|
| 30 |
+
</a>
|
| 31 |
+
</div>
|
| 32 |
+
|
| 33 |
+
<div align="center" style="line-height: 1;">
|
| 34 |
+
<a href="https://github.com/deepseek-ai/DeepSeek-V3/blob/main/LICENSE-CODE" style="margin: 2px;">
|
| 35 |
+
<img alt="Code License" src="https://img.shields.io/badge/Code_License-MIT-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
|
| 36 |
+
</a>
|
| 37 |
+
<a href="https://github.com/deepseek-ai/DeepSeek-V3/blob/main/LICENSE-MODEL" style="margin: 2px;">
|
| 38 |
+
<img alt="Model License" src="https://img.shields.io/badge/Model_License-Model_Agreement-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
|
| 39 |
+
</a>
|
| 40 |
+
</div>
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
<p align="center">
|
| 44 |
+
<a href="https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf"><b>Paper Link</b>👁️</a>
|
| 45 |
+
</p>
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
## 1. Introduction
|
| 49 |
+
|
| 50 |
+
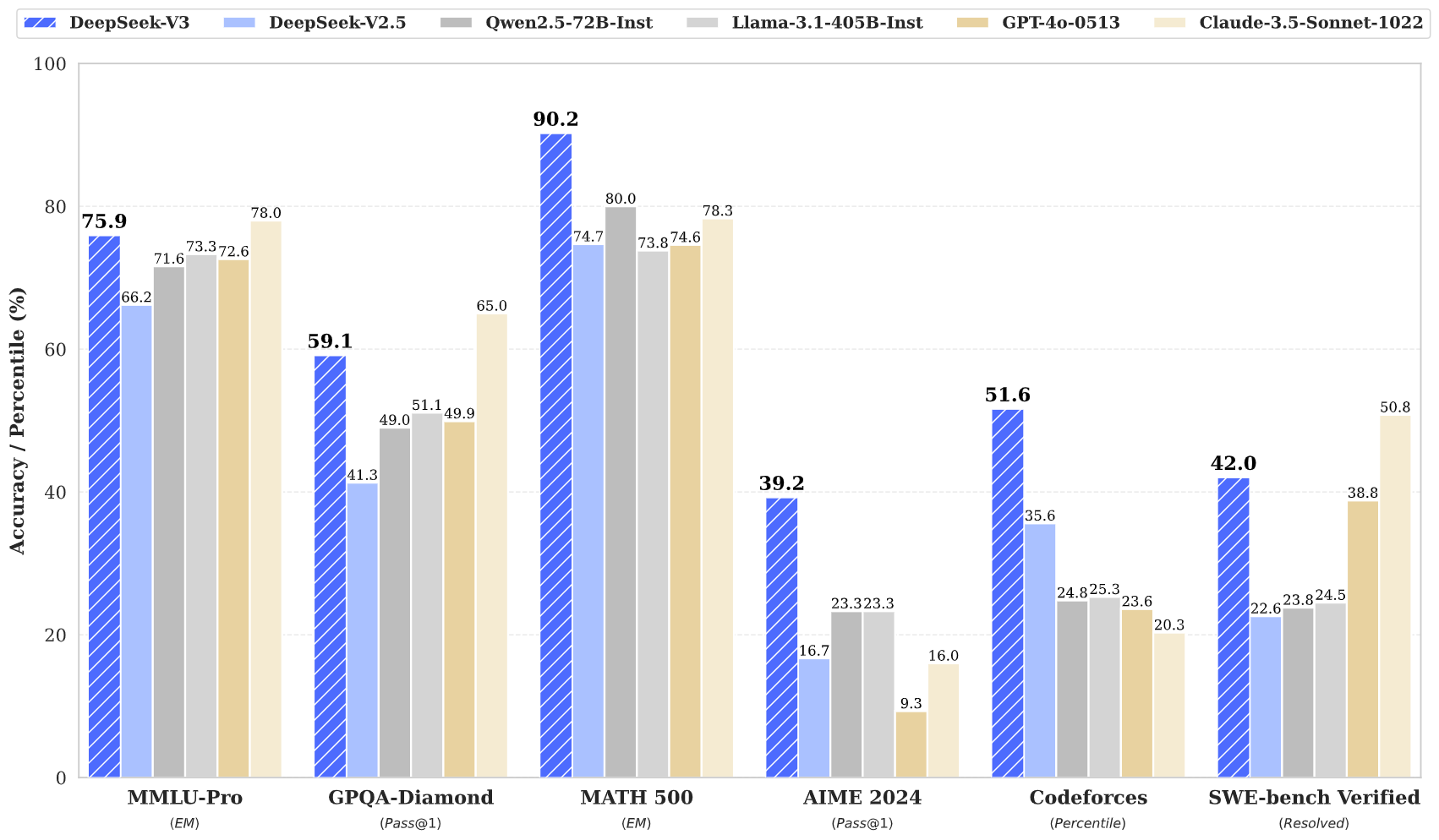
We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token.
|
| 51 |
+
To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2.
|
| 52 |
+
Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance.
|
| 53 |
+
We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities.
|
| 54 |
+
Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models.
|
| 55 |
+
Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training.
|
| 56 |
+
In addition, its training process is remarkably stable.
|
| 57 |
+
Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks.
|
| 58 |
+
<p align="center">
|
| 59 |
+
<img width="80%" src="figures/benchmark.png">
|
| 60 |
+
</p>
|
| 61 |
+
|
| 62 |
+
## 2. Model Summary
|
| 63 |
+
|
| 64 |
+
---
|
| 65 |
+
|
| 66 |
+
**Architecture: Innovative Load Balancing Strategy and Training Objective**
|
| 67 |
+
|
| 68 |
+
- On top of the efficient architecture of DeepSeek-V2, we pioneer an auxiliary-loss-free strategy for load balancing, which minimizes the performance degradation that arises from encouraging load balancing.
|
| 69 |
+
- We investigate a Multi-Token Prediction (MTP) objective and prove it beneficial to model performance.
|
| 70 |
+
It can also be used for speculative decoding for inference acceleration.
|
| 71 |
+
|
| 72 |
+
---
|
| 73 |
+
|
| 74 |
+
**Pre-Training: Towards Ultimate Training Efficiency**
|
| 75 |
+
|
| 76 |
+
- We design an FP8 mixed precision training framework and, for the first time, validate the feasibility and effectiveness of FP8 training on an extremely large-scale model.
|
| 77 |
+
- Through co-design of algorithms, frameworks, and hardware, we overcome the communication bottleneck in cross-node MoE training, nearly achieving full computation-communication overlap.
|
| 78 |
+
This significantly enhances our training efficiency and reduces the training costs, enabling us to further scale up the model size without additional overhead.
|
| 79 |
+
- At an economical cost of only 2.664M H800 GPU hours, we complete the pre-training of DeepSeek-V3 on 14.8T tokens, producing the currently strongest open-source base model. The subsequent training stages after pre-training require only 0.1M GPU hours.
|
| 80 |
+
|
| 81 |
+
---
|
| 82 |
+
|
| 83 |
+
**Post-Training: Knowledge Distillation from DeepSeek-R1**
|
| 84 |
+
|
| 85 |
+
- We introduce an innovative methodology to distill reasoning capabilities from the long-Chain-of-Thought (CoT) model, specifically from one of the DeepSeek R1 series models, into standard LLMs, particularly DeepSeek-V3. Our pipeline elegantly incorporates the verification and reflection patterns of R1 into DeepSeek-V3 and notably improves its reasoning performance. Meanwhile, we also maintain a control over the output style and length of DeepSeek-V3.
|
| 86 |
+
|
| 87 |
+
---
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
## 3. Model Downloads
|
| 91 |
+
|
| 92 |
+
<div align="center">
|
| 93 |
+
|
| 94 |
+
| **Model** | **#Total Params** | **#Activated Params** | **Context Length** | **Download** |
|
| 95 |
+
| :------------: | :------------: | :------------: | :------------: | :------------: |
|
| 96 |
+
| DeepSeek-V3-Base | 671B | 37B | 128K | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-V3-Base) |
|
| 97 |
+
| DeepSeek-V3 | 671B | 37B | 128K | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-V3) |
|
| 98 |
+
|
| 99 |
+
</div>
|
| 100 |
+
|
| 101 |
+
**NOTE: The total size of DeepSeek-V3 models on HuggingFace is 685B, which includes 671B of the Main Model weights and 14B of the Multi-Token Prediction (MTP) Module weights.**
|
| 102 |
+
|
| 103 |
+
To ensure optimal performance and flexibility, we have partnered with open-source communities and hardware vendors to provide multiple ways to run the model locally. For step-by-step guidance, check out Section 6: [How_to Run_Locally](#6-how-to-run-locally).
|
| 104 |
+
|
| 105 |
+
For developers looking to dive deeper, we recommend exploring [README_WEIGHTS.md](./README_WEIGHTS.md) for details on the Main Model weights and the Multi-Token Prediction (MTP) Modules. Please note that MTP support is currently under active development within the community, and we welcome your contributions and feedback.
|
| 106 |
+
|
| 107 |
+
## 4. Evaluation Results
|
| 108 |
+
### Base Model
|
| 109 |
+
#### Standard Benchmarks
|
| 110 |
+
|
| 111 |
+
<div align="center">
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
| | Benchmark (Metric) | # Shots | DeepSeek-V2 | Qwen2.5 72B | LLaMA3.1 405B | DeepSeek-V3 |
|
| 115 |
+
|---|-------------------|----------|--------|-------------|---------------|---------|
|
| 116 |
+
| | Architecture | - | MoE | Dense | Dense | MoE |
|
| 117 |
+
| | # Activated Params | - | 21B | 72B | 405B | 37B |
|
| 118 |
+
| | # Total Params | - | 236B | 72B | 405B | 671B |
|
| 119 |
+
| English | Pile-test (BPB) | - | 0.606 | 0.638 | **0.542** | 0.548 |
|
| 120 |
+
| | BBH (EM) | 3-shot | 78.8 | 79.8 | 82.9 | **87.5** |
|
| 121 |
+
| | MMLU (Acc.) | 5-shot | 78.4 | 85.0 | 84.4 | **87.1** |
|
| 122 |
+
| | MMLU-Redux (Acc.) | 5-shot | 75.6 | 83.2 | 81.3 | **86.2** |
|
| 123 |
+
| | MMLU-Pro (Acc.) | 5-shot | 51.4 | 58.3 | 52.8 | **64.4** |
|
| 124 |
+
| | DROP (F1) | 3-shot | 80.4 | 80.6 | 86.0 | **89.0** |
|
| 125 |
+
| | ARC-Easy (Acc.) | 25-shot | 97.6 | 98.4 | 98.4 | **98.9** |
|
| 126 |
+
| | ARC-Challenge (Acc.) | 25-shot | 92.2 | 94.5 | **95.3** | **95.3** |
|
| 127 |
+
| | HellaSwag (Acc.) | 10-shot | 87.1 | 84.8 | **89.2** | 88.9 |
|
| 128 |
+
| | PIQA (Acc.) | 0-shot | 83.9 | 82.6 | **85.9** | 84.7 |
|
| 129 |
+
| | WinoGrande (Acc.) | 5-shot | **86.3** | 82.3 | 85.2 | 84.9 |
|
| 130 |
+
| | RACE-Middle (Acc.) | 5-shot | 73.1 | 68.1 | **74.2** | 67.1 |
|
| 131 |
+
| | RACE-High (Acc.) | 5-shot | 52.6 | 50.3 | **56.8** | 51.3 |
|
| 132 |
+
| | TriviaQA (EM) | 5-shot | 80.0 | 71.9 | **82.7** | **82.9** |
|
| 133 |
+
| | NaturalQuestions (EM) | 5-shot | 38.6 | 33.2 | **41.5** | 40.0 |
|
| 134 |
+
| | AGIEval (Acc.) | 0-shot | 57.5 | 75.8 | 60.6 | **79.6** |
|
| 135 |
+
| Code | HumanEval (Pass@1) | 0-shot | 43.3 | 53.0 | 54.9 | **65.2** |
|
| 136 |
+
| | MBPP (Pass@1) | 3-shot | 65.0 | 72.6 | 68.4 | **75.4** |
|
| 137 |
+
| | LiveCodeBench-Base (Pass@1) | 3-shot | 11.6 | 12.9 | 15.5 | **19.4** |
|
| 138 |
+
| | CRUXEval-I (Acc.) | 2-shot | 52.5 | 59.1 | 58.5 | **67.3** |
|
| 139 |
+
| | CRUXEval-O (Acc.) | 2-shot | 49.8 | 59.9 | 59.9 | **69.8** |
|
| 140 |
+
| Math | GSM8K (EM) | 8-shot | 81.6 | 88.3 | 83.5 | **89.3** |
|
| 141 |
+
| | MATH (EM) | 4-shot | 43.4 | 54.4 | 49.0 | **61.6** |
|
| 142 |
+
| | MGSM (EM) | 8-shot | 63.6 | 76.2 | 69.9 | **79.8** |
|
| 143 |
+
| | CMath (EM) | 3-shot | 78.7 | 84.5 | 77.3 | **90.7** |
|
| 144 |
+
| Chinese | CLUEWSC (EM) | 5-shot | 82.0 | 82.5 | **83.0** | 82.7 |
|
| 145 |
+
| | C-Eval (Acc.) | 5-shot | 81.4 | 89.2 | 72.5 | **90.1** |
|
| 146 |
+
| | CMMLU (Acc.) | 5-shot | 84.0 | **89.5** | 73.7 | 88.8 |
|
| 147 |
+
| | CMRC (EM) | 1-shot | **77.4** | 75.8 | 76.0 | 76.3 |
|
| 148 |
+
| | C3 (Acc.) | 0-shot | 77.4 | 76.7 | **79.7** | 78.6 |
|
| 149 |
+
| | CCPM (Acc.) | 0-shot | **93.0** | 88.5 | 78.6 | 92.0 |
|
| 150 |
+
| Multilingual | MMMLU-non-English (Acc.) | 5-shot | 64.0 | 74.8 | 73.8 | **79.4** |
|
| 151 |
+
|
| 152 |
+
</div>
|
| 153 |
+
|
| 154 |
+
Note: Best results are shown in bold. Scores with a gap not exceeding 0.3 are considered to be at the same level. DeepSeek-V3 achieves the best performance on most benchmarks, especially on math and code tasks.
|
| 155 |
+
For more evaluation details, please check our paper.
|
| 156 |
+
|
| 157 |
+
#### Context Window
|
| 158 |
+
<p align="center">
|
| 159 |
+
<img width="80%" src="figures/niah.png">
|
| 160 |
+
</p>
|
| 161 |
+
|
| 162 |
+
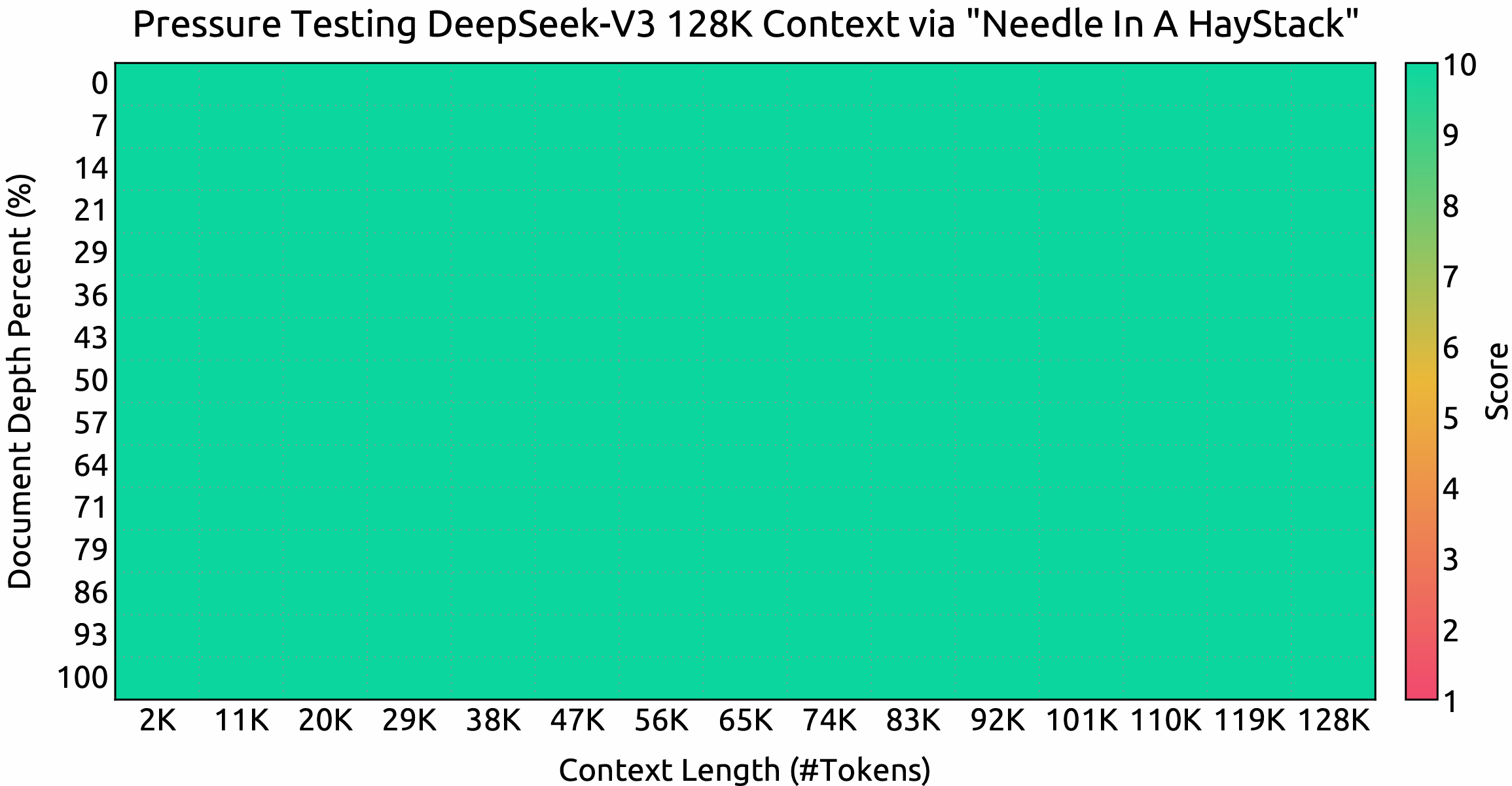
Evaluation results on the ``Needle In A Haystack`` (NIAH) tests. DeepSeek-V3 performs well across all context window lengths up to **128K**.
|
| 163 |
+
|
| 164 |
+
### Chat Model
|
| 165 |
+
#### Standard Benchmarks (Models larger than 67B)
|
| 166 |
+
<div align="center">
|
| 167 |
+
|
| 168 |
+
| | **Benchmark (Metric)** | **DeepSeek V2-0506** | **DeepSeek V2.5-0905** | **Qwen2.5 72B-Inst.** | **Llama3.1 405B-Inst.** | **Claude-3.5-Sonnet-1022** | **GPT-4o 0513** | **DeepSeek V3** |
|
| 169 |
+
|---|---------------------|---------------------|----------------------|---------------------|----------------------|---------------------------|----------------|----------------|
|
| 170 |
+
| | Architecture | MoE | MoE | Dense | Dense | - | - | MoE |
|
| 171 |
+
| | # Activated Params | 21B | 21B | 72B | 405B | - | - | 37B |
|
| 172 |
+
| | # Total Params | 236B | 236B | 72B | 405B | - | - | 671B |
|
| 173 |
+
| English | MMLU (EM) | 78.2 | 80.6 | 85.3 | **88.6** | **88.3** | 87.2 | **88.5** |
|
| 174 |
+
| | MMLU-Redux (EM) | 77.9 | 80.3 | 85.6 | 86.2 | **88.9** | 88.0 | **89.1** |
|
| 175 |
+
| | MMLU-Pro (EM) | 58.5 | 66.2 | 71.6 | 73.3 | **78.0** | 72.6 | 75.9 |
|
| 176 |
+
| | DROP (3-shot F1) | 83.0 | 87.8 | 76.7 | 88.7 | 88.3 | 83.7 | **91.6** |
|
| 177 |
+
| | IF-Eval (Prompt Strict) | 57.7 | 80.6 | 84.1 | 86.0 | **86.5** | 84.3 | 86.1 |
|
| 178 |
+
| | GPQA-Diamond (Pass@1) | 35.3 | 41.3 | 49.0 | 51.1 | **65.0** | 49.9 | 59.1 |
|
| 179 |
+
| | SimpleQA (Correct) | 9.0 | 10.2 | 9.1 | 17.1 | 28.4 | **38.2** | 24.9 |
|
| 180 |
+
| | FRAMES (Acc.) | 66.9 | 65.4 | 69.8 | 70.0 | 72.5 | **80.5** | 73.3 |
|
| 181 |
+
| | LongBench v2 (Acc.) | 31.6 | 35.4 | 39.4 | 36.1 | 41.0 | 48.1 | **48.7** |
|
| 182 |
+
| Code | HumanEval-Mul (Pass@1) | 69.3 | 77.4 | 77.3 | 77.2 | 81.7 | 80.5 | **82.6** |
|
| 183 |
+
| | LiveCodeBench (Pass@1-COT) | 18.8 | 29.2 | 31.1 | 28.4 | 36.3 | 33.4 | **40.5** |
|
| 184 |
+
| | LiveCodeBench (Pass@1) | 20.3 | 28.4 | 28.7 | 30.1 | 32.8 | 34.2 | **37.6** |
|
| 185 |
+
| | Codeforces (Percentile) | 17.5 | 35.6 | 24.8 | 25.3 | 20.3 | 23.6 | **51.6** |
|
| 186 |
+
| | SWE Verified (Resolved) | - | 22.6 | 23.8 | 24.5 | **50.8** | 38.8 | 42.0 |
|
| 187 |
+
| | Aider-Edit (Acc.) | 60.3 | 71.6 | 65.4 | 63.9 | **84.2** | 72.9 | 79.7 |
|
| 188 |
+
| | Aider-Polyglot (Acc.) | - | 18.2 | 7.6 | 5.8 | 45.3 | 16.0 | **49.6** |
|
| 189 |
+
| Math | AIME 2024 (Pass@1) | 4.6 | 16.7 | 23.3 | 23.3 | 16.0 | 9.3 | **39.2** |
|
| 190 |
+
| | MATH-500 (EM) | 56.3 | 74.7 | 80.0 | 73.8 | 78.3 | 74.6 | **90.2** |
|
| 191 |
+
| | CNMO 2024 (Pass@1) | 2.8 | 10.8 | 15.9 | 6.8 | 13.1 | 10.8 | **43.2** |
|
| 192 |
+
| Chinese | CLUEWSC (EM) | 89.9 | 90.4 | **91.4** | 84.7 | 85.4 | 87.9 | 90.9 |
|
| 193 |
+
| | C-Eval (EM) | 78.6 | 79.5 | 86.1 | 61.5 | 76.7 | 76.0 | **86.5** |
|
| 194 |
+
| | C-SimpleQA (Correct) | 48.5 | 54.1 | 48.4 | 50.4 | 51.3 | 59.3 | **64.8** |
|
| 195 |
+
|
| 196 |
+
Note: All models are evaluated in a configuration that limits the output length to 8K. Benchmarks containing fewer than 1000 samples are tested multiple times using varying temperature settings to derive robust final results. DeepSeek-V3 stands as the best-performing open-source model, and also exhibits competitive performance against frontier closed-source models.
|
| 197 |
+
|
| 198 |
+
</div>
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
#### Open Ended Generation Evaluation
|
| 202 |
+
|
| 203 |
+
<div align="center">
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
| Model | Arena-Hard | AlpacaEval 2.0 |
|
| 208 |
+
|-------|------------|----------------|
|
| 209 |
+
| DeepSeek-V2.5-0905 | 76.2 | 50.5 |
|
| 210 |
+
| Qwen2.5-72B-Instruct | 81.2 | 49.1 |
|
| 211 |
+
| LLaMA-3.1 405B | 69.3 | 40.5 |
|
| 212 |
+
| GPT-4o-0513 | 80.4 | 51.1 |
|
| 213 |
+
| Claude-Sonnet-3.5-1022 | 85.2 | 52.0 |
|
| 214 |
+
| DeepSeek-V3 | **85.5** | **70.0** |
|
| 215 |
+
|
| 216 |
+
Note: English open-ended conversation evaluations. For AlpacaEval 2.0, we use the length-controlled win rate as the metric.
|
| 217 |
+
</div>
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
## 5. Chat Website & API Platform
|
| 221 |
+
You can chat with DeepSeek-V3 on DeepSeek's official website: [chat.deepseek.com](https://chat.deepseek.com/sign_in)
|
| 222 |
+
|
| 223 |
+
We also provide OpenAI-Compatible API at DeepSeek Platform: [platform.deepseek.com](https://platform.deepseek.com/)
|
| 224 |
+
|
| 225 |
+
## 6. How to Run Locally
|
| 226 |
+
|
| 227 |
+
DeepSeek-V3 can be deployed locally using the following hardware and open-source community software:
|
| 228 |
+
|
| 229 |
+
1. **DeepSeek-Infer Demo**: We provide a simple and lightweight demo for FP8 and BF16 inference.
|
| 230 |
+
2. **SGLang**: Fully support the DeepSeek-V3 model in both BF16 and FP8 inference modes.
|
| 231 |
+
3. **LMDeploy**: Enables efficient FP8 and BF16 inference for local and cloud deployment.
|
| 232 |
+
4. **TensorRT-LLM**: Currently supports BF16 inference and INT4/8 quantization, with FP8 support coming soon.
|
| 233 |
+
5. **AMD GPU**: Enables running the DeepSeek-V3 model on AMD GPUs via SGLang in both BF16 and FP8 modes.
|
| 234 |
+
6. **Huawei Ascend NPU**: Supports running DeepSeek-V3 on Huawei Ascend devices.
|
| 235 |
+
|
| 236 |
+
Since FP8 training is natively adopted in our framework, we only provide FP8 weights. If you require BF16 weights for experimentation, you can use the provided conversion script to perform the transformation.
|
| 237 |
+
|
| 238 |
+
Here is an example of converting FP8 weights to BF16:
|
| 239 |
+
|
| 240 |
+
```shell
|
| 241 |
+
cd inference
|
| 242 |
+
python fp8_cast_bf16.py --input-fp8-hf-path /path/to/fp8_weights --output-bf16-hf-path /path/to/bf16_weights
|
| 243 |
+
```
|
| 244 |
+
|
| 245 |
+
**NOTE: Huggingface's Transformers has not been directly supported yet.**
|
| 246 |
+
|
| 247 |
+
### 6.1 Inference with DeepSeek-Infer Demo (example only)
|
| 248 |
+
|
| 249 |
+
#### Model Weights & Demo Code Preparation
|
| 250 |
+
|
| 251 |
+
First, clone our DeepSeek-V3 GitHub repository:
|
| 252 |
+
|
| 253 |
+
```shell
|
| 254 |
+
git clone https://github.com/deepseek-ai/DeepSeek-V3.git
|
| 255 |
+
```
|
| 256 |
+
|
| 257 |
+
Navigate to the `inference` folder and install dependencies listed in `requirements.txt`.
|
| 258 |
+
|
| 259 |
+
```shell
|
| 260 |
+
cd DeepSeek-V3/inference
|
| 261 |
+
pip install -r requirements.txt
|
| 262 |
+
```
|
| 263 |
+
|
| 264 |
+
Download the model weights from HuggingFace, and put them into `/path/to/DeepSeek-V3` folder.
|
| 265 |
+
|
| 266 |
+
#### Model Weights Conversion
|
| 267 |
+
|
| 268 |
+
Convert HuggingFace model weights to a specific format:
|
| 269 |
+
|
| 270 |
+
```shell
|
| 271 |
+
python convert.py --hf-ckpt-path /path/to/DeepSeek-V3 --save-path /path/to/DeepSeek-V3-Demo --n-experts 256 --model-parallel 16
|
| 272 |
+
```
|
| 273 |
+
|
| 274 |
+
#### Run
|
| 275 |
+
|
| 276 |
+
Then you can chat with DeepSeek-V3:
|
| 277 |
+
|
| 278 |
+
```shell
|
| 279 |
+
torchrun --nnodes 2 --nproc-per-node 8 generate.py --node-rank $RANK --master-addr $ADDR --ckpt-path /path/to/DeepSeek-V3-Demo --config configs/config_671B.json --interactive --temperature 0.7 --max-new-tokens 200
|
| 280 |
+
```
|
| 281 |
+
|
| 282 |
+
Or batch inference on a given file:
|
| 283 |
+
|
| 284 |
+
```shell
|
| 285 |
+
torchrun --nnodes 2 --nproc-per-node 8 generate.py --node-rank $RANK --master-addr $ADDR --ckpt-path /path/to/DeepSeek-V3-Demo --config configs/config_671B.json --input-file $FILE
|
| 286 |
+
```
|
| 287 |
+
|
| 288 |
+
### 6.2 Inference with SGLang (recommended)
|
| 289 |
+
|
| 290 |
+
[SGLang](https://github.com/sgl-project/sglang) currently supports MLA optimizations, FP8 (W8A8), FP8 KV Cache, and Torch Compile, delivering state-of-the-art latency and throughput performance among open-source frameworks.
|
| 291 |
+
|
| 292 |
+
Notably, [SGLang v0.4.1](https://github.com/sgl-project/sglang/releases/tag/v0.4.1) fully supports running DeepSeek-V3 on both **NVIDIA and AMD GPUs**, making it a highly versatile and robust solution.
|
| 293 |
+
|
| 294 |
+
Here are the launch instructions from the SGLang team: https://github.com/sgl-project/sglang/tree/main/benchmark/deepseek_v3
|
| 295 |
+
|
| 296 |
+
### 6.3 Inference with LMDeploy (recommended)
|
| 297 |
+
[LMDeploy](https://github.com/InternLM/lmdeploy), a flexible and high-performance inference and serving framework tailored for large language models, now supports DeepSeek-V3. It offers both offline pipeline processing and online deployment capabilities, seamlessly integrating with PyTorch-based workflows.
|
| 298 |
+
|
| 299 |
+
For comprehensive step-by-step instructions on running DeepSeek-V3 with LMDeploy, please refer to here: https://github.com/InternLM/lmdeploy/issues/2960
|
| 300 |
+
|
| 301 |
+
|
| 302 |
+
### 6.4 Inference with TRT-LLM (recommended)
|
| 303 |
+
|
| 304 |
+
[TensorRT-LLM](https://github.com/NVIDIA/TensorRT-LLM) now supports the DeepSeek-V3 model, offering precision options such as BF16 and INT4/INT8 weight-only. Support for FP8 is currently in progress and will be released soon. You can access the custom branch of TRTLLM specifically for DeepSeek-V3 support through the following link to experience the new features directly: https://github.com/NVIDIA/TensorRT-LLM/tree/deepseek/examples/deepseek_v3.
|
| 305 |
+
|
| 306 |
+
### 6.5 Recommended Inference Functionality with AMD GPUs
|
| 307 |
+
|
| 308 |
+
In collaboration with the AMD team, we have achieved Day-One support for AMD GPUs using SGLang, with full compatibility for both FP8 and BF16 precision. For detailed guidance, please refer to the [SGLang instructions](#63-inference-with-lmdeploy-recommended).
|
| 309 |
+
|
| 310 |
+
### 6.6 Recommended Inference Functionality with Huawei Ascend NPUs
|
| 311 |
+
The [MindIE](https://www.hiascend.com/en/software/mindie) framework from the Huawei Ascend community has successfully adapted the BF16 version of DeepSeek-V3. For step-by-step guidance on Ascend NPUs, please follow the [instructions here](https://modelers.cn/models/MindIE/deepseekv3).
|
| 312 |
+
|
| 313 |
+
|
| 314 |
+
## 7. License
|
| 315 |
+
This code repository is licensed under [the MIT License](LICENSE-CODE). The use of DeepSeek-V3 Base/Chat models is subject to [the Model License](LICENSE-MODEL). DeepSeek-V3 series (including Base and Chat) supports commercial use.
|
| 316 |
+
|
| 317 |
+
## 8. Citation
|
| 318 |
+
```
|
| 319 |
+
|
| 320 |
+
```
|
| 321 |
+
|
| 322 |
+
## 9. Contact
|
| 323 |
+
If you have any questions, please raise an issue or contact us at [[email protected]]([email protected]).
|
README_WEIGHTS.md
ADDED
|
@@ -0,0 +1,94 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# DeepSeek-V3 Weight File Documentation
|
| 2 |
+
|
| 3 |
+
## New Fields in `config.json`
|
| 4 |
+
|
| 5 |
+
- **model_type**: Specifies the model type, which is updated to `deepseek_v3` in this release.
|
| 6 |
+
- **num_nextn_predict_layers**: Indicates the number of Multi-Token Prediction (MTP) Modules. The open-sourced V3 weights include **1 MTP Module** .
|
| 7 |
+
- **quantization_config**: Describes the configuration for FP8 quantization.
|
| 8 |
+
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
## Weight Structure Overview
|
| 12 |
+
|
| 13 |
+
The DeepSeek-V3 weight file consists of two main components: **Main Model Weights** and **MTP Modules**.
|
| 14 |
+
|
| 15 |
+
### 1. Main Model Weights
|
| 16 |
+
|
| 17 |
+
- **Composition**:
|
| 18 |
+
- Input/output embedding layers and a complete set of 61 Transformer hidden layers.
|
| 19 |
+
- **Parameter Count**:
|
| 20 |
+
- Total parameters: **671B**
|
| 21 |
+
- Activation parameters: **36.7B** (including 0.9B for Embedding and 0.9B for the output Head).
|
| 22 |
+
|
| 23 |
+
#### Structural Details
|
| 24 |
+
|
| 25 |
+
- **Embedding Layer**:
|
| 26 |
+
- `model.embed_tokens.weight`
|
| 27 |
+
- **Transformer Hidden Layers**:
|
| 28 |
+
- `model.layers.0` to `model.layers.60`, totaling `num_hidden_layers` layers.
|
| 29 |
+
- **Output Layer**:
|
| 30 |
+
- `model.norm.weight`
|
| 31 |
+
- `lm_head.weight`
|
| 32 |
+
|
| 33 |
+
### 2. Multi-Token Prediction (MTP) Modules
|
| 34 |
+
|
| 35 |
+
- **Composition**:
|
| 36 |
+
- Additional MTP Modules defined by the `num_nextn_predict_layers` field. In this model, the value is set to 1.
|
| 37 |
+
- **Parameter Count**:
|
| 38 |
+
- Parameters: **11.5B unique parameters**, excluding the shared 0.9B Embedding and 0.9B output Head).
|
| 39 |
+
- Activation parameters: **2.4B** (including the shared 0.9B Embedding and 0.9B output Head).
|
| 40 |
+
|
| 41 |
+
#### Structural Details
|
| 42 |
+
|
| 43 |
+
- **embed_tokens**: **Shares parameters** with the Embedding layer of the Main Model weights.
|
| 44 |
+
- **enorm & hnorm**: RMSNorm parameters required for speculative decoding.
|
| 45 |
+
- **eh_proj**: Parameters for dimensionality reduction projection on the norm results.
|
| 46 |
+
- **Additional Transformer Hidden Layer**:
|
| 47 |
+
- `model.layers.61.self_attn & mlp` (structure identical to the Main Model hidden layers).
|
| 48 |
+
- **shared_head**: **Shares parameters** with the output Head of the Main Model weights.
|
| 49 |
+
|
| 50 |
+
---
|
| 51 |
+
|
| 52 |
+
### Loading Rules
|
| 53 |
+
|
| 54 |
+
- **Main Model Weights**: Loaded via the `num_hidden_layers` parameter in `config.json`.
|
| 55 |
+
- **MTP Modules**: Loaded via the `num_nextn_predict_layers` parameter, with layer IDs appended immediately after the Main Model hidden layers. For example:
|
| 56 |
+
- If `num_hidden_layers = 61` and `num_nextn_predict_layers = 1`, the MTP Module's layer ID is `61`.
|
| 57 |
+
|
| 58 |
+
---
|
| 59 |
+
|
| 60 |
+
## FP8 Weight Documentation
|
| 61 |
+
|
| 62 |
+
DeepSeek-V3 natively supports FP8 weight format with 128x128 block scaling.
|
| 63 |
+
|
| 64 |
+
### FP8 Configuration
|
| 65 |
+
|
| 66 |
+
The FP8 weight file introduces a `quantization_config` field to describe the quantization method. Below is an example configuration:
|
| 67 |
+
|
| 68 |
+
```json
|
| 69 |
+
"quantization_config": {
|
| 70 |
+
"activation_scheme": "dynamic",
|
| 71 |
+
"fmt": "e4m3",
|
| 72 |
+
"quant_method": "fp8",
|
| 73 |
+
"weight_block_size": [128, 128]
|
| 74 |
+
}
|
| 75 |
+
```
|
| 76 |
+
|
| 77 |
+
- **Quantization Format**:
|
| 78 |
+
- Format type: `fp8` and `e4m3` (corresponding to `torch.float8_e4m3fn`).
|
| 79 |
+
- Weight block size: `128x128`.
|
| 80 |
+
- **Activation Quantization Scheme**:
|
| 81 |
+
- Utilizes dynamic activation quantization (`dynamic`).
|
| 82 |
+
|
| 83 |
+
### Dequantization Method
|
| 84 |
+
|
| 85 |
+
The FP8 weight file includes a `weight_scale_inv` field, which stores the dequantization scale for each weight block.
|
| 86 |
+
|
| 87 |
+
- **Storage Format**: `float32 Tensor`, stored alongside the weight data.
|
| 88 |
+
- **Dequantization Formula**:
|
| 89 |
+
- If the weight block is not aligned to 128, it is zero-padded to 128 before calculating the scale. After quantization, the padded portion is removed.
|
| 90 |
+
- The dequantization process is performed as: `(128x128 weight block) * weight_scale_inv`.
|
| 91 |
+
|
| 92 |
+
Through dequantization of the FP8 weights, runtime operations enable online quantization at a granularity of `per-token-per-128-channel`.
|
| 93 |
+
|
| 94 |
+
---
|
figures/benchmark.png
ADDED
|
figures/niah.png
ADDED
|
inference/configs/config_16B.json
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"vocab_size": 102400,
|
| 3 |
+
"dim": 2048,
|
| 4 |
+
"inter_dim": 10944,
|
| 5 |
+
"moe_inter_dim": 1408,
|
| 6 |
+
"n_layers": 27,
|
| 7 |
+
"n_dense_layers": 1,
|
| 8 |
+
"n_heads": 16,
|
| 9 |
+
"n_routed_experts": 64,
|
| 10 |
+
"n_shared_experts": 2,
|
| 11 |
+
"n_activated_experts": 6,
|
| 12 |
+
"route_scale": 1.0,
|
| 13 |
+
"q_lora_rank": 0,
|
| 14 |
+
"kv_lora_rank": 512,
|
| 15 |
+
"qk_nope_head_dim": 128,
|
| 16 |
+
"qk_rope_head_dim": 64,
|
| 17 |
+
"v_head_dim": 128,
|
| 18 |
+
"mscale": 0.707
|
| 19 |
+
}
|
inference/configs/config_236B.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"vocab_size": 102400,
|
| 3 |
+
"dim": 5120,
|
| 4 |
+
"inter_dim": 12288,
|
| 5 |
+
"moe_inter_dim": 1536,
|
| 6 |
+
"n_layers": 60,
|
| 7 |
+
"n_dense_layers": 1,
|
| 8 |
+
"n_heads": 128,
|
| 9 |
+
"n_routed_experts": 160,
|
| 10 |
+
"n_shared_experts": 2,
|
| 11 |
+
"n_activated_experts": 6,
|
| 12 |
+
"n_expert_groups": 8,
|
| 13 |
+
"n_limited_groups": 3,
|
| 14 |
+
"route_scale": 16.0,
|
| 15 |
+
"q_lora_rank": 1536,
|
| 16 |
+
"kv_lora_rank": 512,
|
| 17 |
+
"qk_nope_head_dim": 128,
|
| 18 |
+
"qk_rope_head_dim": 64,
|
| 19 |
+
"v_head_dim": 128
|
| 20 |
+
}
|
inference/configs/config_671B.json
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"vocab_size": 129280,
|
| 3 |
+
"dim": 7168,
|
| 4 |
+
"inter_dim": 18432,
|
| 5 |
+
"moe_inter_dim": 2048,
|
| 6 |
+
"n_layers": 61,
|
| 7 |
+
"n_dense_layers": 3,
|
| 8 |
+
"n_heads": 128,
|
| 9 |
+
"n_routed_experts": 256,
|
| 10 |
+
"n_shared_experts": 1,
|
| 11 |
+
"n_activated_experts": 8,
|
| 12 |
+
"n_expert_groups": 8,
|
| 13 |
+
"n_limited_groups": 4,
|
| 14 |
+
"route_scale": 2.5,
|
| 15 |
+
"score_func": "sigmoid",
|
| 16 |
+
"q_lora_rank": 1536,
|
| 17 |
+
"kv_lora_rank": 512,
|
| 18 |
+
"qk_nope_head_dim": 128,
|
| 19 |
+
"qk_rope_head_dim": 64,
|
| 20 |
+
"v_head_dim": 128,
|
| 21 |
+
"dtype": "fp8"
|
| 22 |
+
}
|
inference/convert.py
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import shutil
|
| 3 |
+
from argparse import ArgumentParser
|
| 4 |
+
from glob import glob
|
| 5 |
+
from tqdm import tqdm, trange
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
from safetensors.torch import safe_open, save_file
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
mapping = {
|
| 12 |
+
"embed_tokens": ("embed", 0),
|
| 13 |
+
"input_layernorm": ("attn_norm", None),
|
| 14 |
+
"post_attention_layernorm": ("ffn_norm", None),
|
| 15 |
+
"q_proj": ("wq", 0),
|
| 16 |
+
"q_a_proj": ("wq_a", None),
|
| 17 |
+
"q_a_layernorm": ("q_norm", None),
|
| 18 |
+
"q_b_proj": ("wq_b", 0),
|
| 19 |
+
"kv_a_proj_with_mqa": ("wkv_a", None),
|
| 20 |
+
"kv_a_layernorm": ("kv_norm", None),
|
| 21 |
+
"kv_b_proj": ("wkv_b", 0),
|
| 22 |
+
"o_proj": ("wo", 1),
|
| 23 |
+
"gate": ("gate", None),
|
| 24 |
+
"gate_proj": ("w1", 0),
|
| 25 |
+
"down_proj": ("w2", 1),
|
| 26 |
+
"up_proj": ("w3", 0),
|
| 27 |
+
"norm": ("norm", None),
|
| 28 |
+
"lm_head": ("head", 0),
|
| 29 |
+
"scale": ("scale", None),
|
| 30 |
+
}
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def main(hf_ckpt_path, save_path, n_experts, mp):
|
| 34 |
+
torch.set_num_threads(8)
|
| 35 |
+
n_local_experts = n_experts // mp
|
| 36 |
+
state_dicts = [{} for _ in range(mp)]
|
| 37 |
+
|
| 38 |
+
for file_path in tqdm(glob(os.path.join(hf_ckpt_path, "*.safetensors"))):
|
| 39 |
+
with safe_open(file_path, framework="pt", device="cpu") as f:
|
| 40 |
+
for name in f.keys():
|
| 41 |
+
if "model.layers.61" in name:
|
| 42 |
+
continue
|
| 43 |
+
param: torch.Tensor = f.get_tensor(name)
|
| 44 |
+
if name.startswith("model."):
|
| 45 |
+
name = name[len("model."):]
|
| 46 |
+
name = name.replace("self_attn", "attn")
|
| 47 |
+
name = name.replace("mlp", "ffn")
|
| 48 |
+
name = name.replace("weight_scale_inv", "scale")
|
| 49 |
+
name = name.replace("e_score_correction_bias", "bias")
|
| 50 |
+
key = name.split(".")[-2]
|
| 51 |
+
assert key in mapping
|
| 52 |
+
new_key, dim = mapping[key]
|
| 53 |
+
name = name.replace(key, new_key)
|
| 54 |
+
for i in range(mp):
|
| 55 |
+
new_param = param
|
| 56 |
+
if "experts" in name and "shared_experts" not in name:
|
| 57 |
+
idx = int(name.split(".")[-3])
|
| 58 |
+
if idx < i * n_local_experts or idx >= (i + 1) * n_local_experts:
|
| 59 |
+
continue
|
| 60 |
+
elif dim is not None:
|
| 61 |
+
assert param.size(dim) % mp == 0
|
| 62 |
+
shard_size = param.size(dim) // mp
|
| 63 |
+
new_param = param.narrow(dim, i * shard_size, shard_size).contiguous()
|
| 64 |
+
state_dicts[i][name] = new_param
|
| 65 |
+
|
| 66 |
+
os.makedirs(save_path, exist_ok=True)
|
| 67 |
+
|
| 68 |
+
for i in trange(mp):
|
| 69 |
+
save_file(state_dicts[i], os.path.join(save_path, f"model{i}-mp{mp}.safetensors"))
|
| 70 |
+
|
| 71 |
+
for file_path in glob(os.path.join(hf_ckpt_path, "*token*")):
|
| 72 |
+
new_file_path = os.path.join(save_path, os.path.basename(file_path))
|
| 73 |
+
shutil.copyfile(file_path, new_file_path)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
if __name__ == "__main__":
|
| 77 |
+
parser = ArgumentParser()
|
| 78 |
+
parser.add_argument("--hf-ckpt-path", type=str, required=True)
|
| 79 |
+
parser.add_argument("--save-path", type=str, required=True)
|
| 80 |
+
parser.add_argument("--n-experts", type=int, required=True)
|
| 81 |
+
parser.add_argument("--model-parallel", type=int, default=1)
|
| 82 |
+
args = parser.parse_args()
|
| 83 |
+
assert args.n_experts % args.model_parallel == 0
|
| 84 |
+
main(args.hf_ckpt_path, args.save_path, args.n_experts, args.model_parallel)
|
inference/fp8_cast_bf16.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
from argparse import ArgumentParser
|
| 4 |
+
from glob import glob
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
from safetensors.torch import load_file, save_file
|
| 9 |
+
|
| 10 |
+
from kernel import weight_dequant
|
| 11 |
+
|
| 12 |
+
def main(fp8_path, bf16_path):
|
| 13 |
+
torch.set_default_dtype(torch.bfloat16)
|
| 14 |
+
os.makedirs(bf16_path, exist_ok=True)
|
| 15 |
+
model_index_file = os.path.join(fp8_path, "model.safetensors.index.json")
|
| 16 |
+
with open(model_index_file, "r") as f:
|
| 17 |
+
model_index = json.load(f)
|
| 18 |
+
weight_map = model_index["weight_map"]
|
| 19 |
+
fp8_weight_names = []
|
| 20 |
+
|
| 21 |
+
safetensor_files = list(glob(os.path.join(fp8_path, "*.safetensors")))
|
| 22 |
+
for safetensor_file in tqdm(safetensor_files):
|
| 23 |
+
file_name = os.path.basename(safetensor_file)
|
| 24 |
+
state_dict = load_file(safetensor_file, device="cuda")
|
| 25 |
+
new_state_dict = {}
|
| 26 |
+
for weight_name, weight in state_dict.items():
|
| 27 |
+
if weight_name.endswith("_scale_inv"):
|
| 28 |
+
continue
|
| 29 |
+
elif weight.element_size() == 1:
|
| 30 |
+
scale_inv_name = f"{weight_name}_scale_inv"
|
| 31 |
+
assert scale_inv_name in state_dict
|
| 32 |
+
fp8_weight_names.append(weight_name)
|
| 33 |
+
scale_inv = state_dict[scale_inv_name]
|
| 34 |
+
new_state_dict[weight_name] = weight_dequant(weight, scale_inv)
|
| 35 |
+
else:
|
| 36 |
+
new_state_dict[weight_name] = weight
|
| 37 |
+
new_safetensor_file = os.path.join(bf16_path, file_name)
|
| 38 |
+
save_file(new_state_dict, new_safetensor_file)
|
| 39 |
+
|
| 40 |
+
new_model_index_file = os.path.join(bf16_path, "model.safetensors.index.json")
|
| 41 |
+
for weight_name in fp8_weight_names:
|
| 42 |
+
scale_inv_name = f"{weight_name}_scale_inv"
|
| 43 |
+
assert scale_inv_name in weight_map
|
| 44 |
+
weight_map.pop(scale_inv_name)
|
| 45 |
+
with open(new_model_index_file, "w") as f:
|
| 46 |
+
json.dump({"metadata": {}, "weight_map": weight_map}, f, indent=2)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
if __name__ == "__main__":
|
| 50 |
+
parser = ArgumentParser()
|
| 51 |
+
parser.add_argument("--input-fp8-hf-path", type=str, required=True)
|
| 52 |
+
parser.add_argument("--output-bf16-hf-path", type=str, required=True)
|
| 53 |
+
args = parser.parse_args()
|
| 54 |
+
main(args.input_fp8_hf_path, args.output_bf16_hf_path)
|
| 55 |
+
|
inference/generate.py
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
from argparse import ArgumentParser
|
| 4 |
+
from typing import List
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.distributed as dist
|
| 8 |
+
from transformers import AutoTokenizer
|
| 9 |
+
from safetensors.torch import load_model
|
| 10 |
+
|
| 11 |
+
from model import Transformer, ModelArgs
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def sample(logits, temperature: float = 1.0):
|
| 15 |
+
logits = logits / max(temperature, 1e-5)
|
| 16 |
+
probs = torch.softmax(logits, dim=-1)
|
| 17 |
+
return probs.div_(torch.empty_like(probs).exponential_(1)).argmax(dim=-1)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
@torch.inference_mode()
|
| 21 |
+
def generate(
|
| 22 |
+
model: Transformer,
|
| 23 |
+
prompt_tokens: List[List[int]],
|
| 24 |
+
max_new_tokens: int,
|
| 25 |
+
eos_id: int,
|
| 26 |
+
temperature: float = 1.0
|
| 27 |
+
) -> List[List[int]]:
|
| 28 |
+
prompt_lens = [len(t) for t in prompt_tokens]
|
| 29 |
+
assert max(prompt_lens) <= model.max_seq_len
|
| 30 |
+
total_len = min(model.max_seq_len, max_new_tokens + max(prompt_lens))
|
| 31 |
+
tokens = torch.full((len(prompt_tokens), total_len), -1, dtype=torch.long, device="cuda")
|
| 32 |
+
for i, t in enumerate(prompt_tokens):
|
| 33 |
+
tokens[i, :len(t)] = torch.tensor(t, dtype=torch.long, device="cuda")
|
| 34 |
+
prev_pos = 0
|
| 35 |
+
finished = torch.tensor([False] * len(prompt_tokens), device="cuda")
|
| 36 |
+
prompt_mask = tokens != -1
|
| 37 |
+
for cur_pos in range(min(prompt_lens), total_len):
|
| 38 |
+
logits = model.forward(tokens[:, prev_pos:cur_pos], prev_pos)
|
| 39 |
+
if temperature > 0:
|
| 40 |
+
next_token = sample(logits, temperature)
|
| 41 |
+
else:
|
| 42 |
+
next_token = logits.argmax(dim=-1)
|
| 43 |
+
next_token = torch.where(prompt_mask[:, cur_pos], tokens[:, cur_pos], next_token)
|
| 44 |
+
tokens[:, cur_pos] = next_token
|
| 45 |
+
finished |= torch.logical_and(~prompt_mask[:, cur_pos], next_token == eos_id)
|
| 46 |
+
prev_pos = cur_pos
|
| 47 |
+
if finished.all():
|
| 48 |
+
break
|
| 49 |
+
completion_tokens = []
|
| 50 |
+
for i, toks in enumerate(tokens.tolist()):
|
| 51 |
+
toks = toks[prompt_lens[i]:prompt_lens[i]+max_new_tokens]
|
| 52 |
+
if eos_id in toks:
|
| 53 |
+
toks = toks[:toks.index(eos_id)]
|
| 54 |
+
completion_tokens.append(toks)
|
| 55 |
+
return completion_tokens
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def main(
|
| 59 |
+
ckpt_path: str,
|
| 60 |
+
config: str,
|
| 61 |
+
input_file: str = "",
|
| 62 |
+
interactive: bool = True,
|
| 63 |
+
max_new_tokens: int = 100,
|
| 64 |
+
temperature: float = 1.0,
|
| 65 |
+
) -> None:
|
| 66 |
+
world_size = int(os.getenv("WORLD_SIZE", "1"))
|
| 67 |
+
rank = int(os.getenv("RANK", "0"))
|
| 68 |
+
local_rank = int(os.getenv("LOCAL_RANK", "0"))
|
| 69 |
+
if world_size > 1:
|
| 70 |
+
dist.init_process_group("nccl")
|
| 71 |
+
global print
|
| 72 |
+
if rank != 0:
|
| 73 |
+
print = lambda *_, **__: None
|
| 74 |
+
torch.cuda.set_device(local_rank)
|
| 75 |
+
torch.set_default_dtype(torch.bfloat16)
|
| 76 |
+
torch.set_num_threads(8)
|
| 77 |
+
torch.manual_seed(965)
|
| 78 |
+
with open(config) as f:
|
| 79 |
+
args = ModelArgs(**json.load(f))
|
| 80 |
+
print(args)
|
| 81 |
+
with torch.device("cuda"):
|
| 82 |
+
model = Transformer(args)
|
| 83 |
+
tokenizer = AutoTokenizer.from_pretrained(ckpt_path)
|
| 84 |
+
tokenizer.decode(generate(model, [tokenizer.encode("DeepSeek")], 2, -1, 1.)[0])
|
| 85 |
+
load_model(model, os.path.join(ckpt_path, f"model{rank}-mp{world_size}.safetensors"))
|
| 86 |
+
|
| 87 |
+
if interactive:
|
| 88 |
+
messages = []
|
| 89 |
+
while True:
|
| 90 |
+
if world_size == 1:
|
| 91 |
+
prompt = input(">>> ")
|
| 92 |
+
elif rank == 0:
|
| 93 |
+
prompt = input(">>> ")
|
| 94 |
+
objects = [prompt]
|
| 95 |
+
dist.broadcast_object_list(objects, 0)
|
| 96 |
+
else:
|
| 97 |
+
objects = [None]
|
| 98 |
+
dist.broadcast_object_list(objects, 0)
|
| 99 |
+
prompt = objects[0]
|
| 100 |
+
if prompt == "/exit":
|
| 101 |
+
break
|
| 102 |
+
elif prompt == "/clear":
|
| 103 |
+
messages.clear()
|
| 104 |
+
continue
|
| 105 |
+
messages.append({"role": "user", "content": prompt})
|
| 106 |
+
prompt_tokens = tokenizer.apply_chat_template(messages, add_generation_prompt=True)
|
| 107 |
+
completion_tokens = generate(model, [prompt_tokens], max_new_tokens, tokenizer.eos_token_id, temperature)
|
| 108 |
+
completion = tokenizer.decode(completion_tokens[0], skip_special_tokens=True)
|
| 109 |
+
print(completion)
|
| 110 |
+
messages.append({"role": "assistant", "content": completion})
|
| 111 |
+
else:
|
| 112 |
+
with open(input_file) as f:
|
| 113 |
+
prompts = [line.strip() for line in f.readlines()]
|
| 114 |
+
assert len(prompts) <= args.max_batch_size
|
| 115 |
+
prompt_tokens = [tokenizer.apply_chat_template([{"role": "user", "content": prompt}], add_generation_prompt=True) for prompt in prompts]
|
| 116 |
+
completion_tokens = generate(model, prompt_tokens, max_new_tokens, tokenizer.eos_token_id, temperature)
|
| 117 |
+
completions = tokenizer.batch_decode(completion_tokens, skip_special_tokens=True)
|
| 118 |
+
for prompt, completion in zip(prompts, completions):
|
| 119 |
+
print("Prompt:", prompt)
|
| 120 |
+
print("Completion:", completion)
|
| 121 |
+
print()
|
| 122 |
+
|
| 123 |
+
if world_size > 1:
|
| 124 |
+
dist.destroy_process_group()
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
if __name__ == "__main__":
|
| 128 |
+
parser = ArgumentParser()
|
| 129 |
+
parser.add_argument("--ckpt-path", type=str, required=True)
|
| 130 |
+
parser.add_argument("--config", type=str, required=True)
|
| 131 |
+
parser.add_argument("--input-file", type=str, default="")
|
| 132 |
+
parser.add_argument("--interactive", action="store_true")
|
| 133 |
+
parser.add_argument("--max-new-tokens", type=int, default=200)
|
| 134 |
+
parser.add_argument("--temperature", type=float, default=0.2)
|
| 135 |
+
args = parser.parse_args()
|
| 136 |
+
assert args.input_file or args.interactive
|
| 137 |
+
main(args.ckpt_path, args.config, args.input_file, args.interactive, args.max_new_tokens, args.temperature)
|
inference/kernel.py
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Tuple
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import triton
|
| 5 |
+
import triton.language as tl
|
| 6 |
+
from triton import Config
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
@triton.jit
|
| 10 |
+
def act_quant_kernel(x_ptr, y_ptr, s_ptr, BLOCK_SIZE: tl.constexpr):
|
| 11 |
+
pid = tl.program_id(axis=0)
|
| 12 |
+
offs = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
|
| 13 |
+
x = tl.load(x_ptr + offs).to(tl.float32)
|
| 14 |
+
s = tl.max(tl.abs(x)) / 448.
|
| 15 |
+
y = x / s
|
| 16 |
+
y = y.to(y_ptr.dtype.element_ty)
|
| 17 |
+
tl.store(y_ptr + offs, y)
|
| 18 |
+
tl.store(s_ptr + pid, s)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def act_quant(x: torch.Tensor, block_size: int = 128) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 22 |
+
assert x.is_contiguous()
|
| 23 |
+
assert x.size(-1) % block_size == 0
|
| 24 |
+
y = torch.empty_like(x, dtype=torch.float8_e4m3fn)
|
| 25 |
+
s = x.new_empty(*x.size()[:-1], x.size(-1) // block_size, dtype=torch.float32)
|
| 26 |
+
grid = lambda meta: (triton.cdiv(x.numel(), meta['BLOCK_SIZE']), )
|
| 27 |
+
act_quant_kernel[grid](x, y, s, BLOCK_SIZE=block_size)
|
| 28 |
+
return y, s
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
@triton.jit
|
| 32 |
+
def weight_dequant_kernel(x_ptr, s_ptr, y_ptr, M, N, BLOCK_SIZE: tl.constexpr):
|
| 33 |
+
pid_m = tl.program_id(axis=0)
|
| 34 |
+
pid_n = tl.program_id(axis=1)
|
| 35 |
+
n = tl.cdiv(N, BLOCK_SIZE)
|
| 36 |
+
offs_m = pid_m * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
|
| 37 |
+
offs_n = pid_n * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
|
| 38 |
+
offs = offs_m[:, None] * N + offs_n[None, :]
|
| 39 |
+
mask = (offs_m[:, None] < M) & (offs_n[None, :] < N)
|
| 40 |
+
x = tl.load(x_ptr + offs, mask=mask).to(tl.float32)
|
| 41 |
+
s = tl.load(s_ptr + pid_m * n + pid_n)
|
| 42 |
+
y = x * s
|
| 43 |
+
tl.store(y_ptr + offs, y, mask=mask)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def weight_dequant(x: torch.Tensor, s: torch.Tensor, block_size: int = 128) -> torch.Tensor:
|
| 47 |
+
assert x.is_contiguous() and s.is_contiguous()
|
| 48 |
+
assert x.dim() == 2 and s.dim() == 2
|
| 49 |
+
M, N = x.size()
|
| 50 |
+
y = torch.empty_like(x, dtype=torch.get_default_dtype())
|
| 51 |
+
grid = lambda meta: (triton.cdiv(M, meta['BLOCK_SIZE']), triton.cdiv(N, meta['BLOCK_SIZE']))
|
| 52 |
+
weight_dequant_kernel[grid](x, s, y, M, N, BLOCK_SIZE=block_size)
|
| 53 |
+
return y
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
fp8_gemm_configs = [
|
| 57 |
+
Config({'BLOCK_SIZE_M': block_m, 'BLOCK_SIZE_N': block_n, 'BLOCK_SIZE_K': 128}, num_stages=num_stages, num_warps=8)
|
| 58 |
+
for block_m in [16, 32, 64] for block_n in [32, 64, 128] for num_stages in [3, 4, 5, 6]
|
| 59 |
+
]
|
| 60 |
+
|
| 61 |
+
@triton.autotune(configs=fp8_gemm_configs, key=['N', 'K'])
|
| 62 |
+
@triton.jit
|
| 63 |
+
def fp8_gemm_kernel(a_ptr, b_ptr, c_ptr,
|
| 64 |
+
a_s_ptr, b_s_ptr,
|
| 65 |
+
M, N: tl.constexpr, K: tl.constexpr,
|
| 66 |
+
BLOCK_SIZE_M: tl.constexpr,
|
| 67 |
+
BLOCK_SIZE_N: tl.constexpr,
|
| 68 |
+
BLOCK_SIZE_K: tl.constexpr):
|
| 69 |
+
pid_m = tl.program_id(axis=0)
|
| 70 |
+
pid_n = tl.program_id(axis=1)
|
| 71 |
+
k = tl.cdiv(K, BLOCK_SIZE_K)
|
| 72 |
+
offs_m = (pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)) % M
|
| 73 |
+
offs_n = (pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)) % N
|
| 74 |
+
offs_k = tl.arange(0, BLOCK_SIZE_K)
|
| 75 |
+
a_ptrs = a_ptr + offs_m[:, None] * K + offs_k[None, :]
|
| 76 |
+
b_ptrs = b_ptr + offs_n[None, :] * K + offs_k[:, None]
|
| 77 |
+
a_s_ptrs = a_s_ptr + offs_m * k
|
| 78 |
+
b_s_ptrs = b_s_ptr + (offs_n // BLOCK_SIZE_K) * k
|
| 79 |
+
|
| 80 |
+
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
|
| 81 |
+
for i in range(k):
|
| 82 |
+
a = tl.load(a_ptrs, mask=offs_k[None, :] < K - i * BLOCK_SIZE_K, other=0.0)
|
| 83 |
+
b = tl.load(b_ptrs, mask=offs_k[:, None] < K - i * BLOCK_SIZE_K, other=0.0)
|
| 84 |
+
a_s = tl.load(a_s_ptrs)
|
| 85 |
+
b_s = tl.load(b_s_ptrs)
|
| 86 |
+
accumulator += tl.dot(a, b) * a_s[:, None] * b_s[None, :]
|
| 87 |
+
a_ptrs += BLOCK_SIZE_K
|
| 88 |
+
b_ptrs += BLOCK_SIZE_K
|
| 89 |
+
a_s_ptrs += 1
|
| 90 |
+
b_s_ptrs += 1
|
| 91 |
+
c = accumulator.to(c_ptr.dtype.element_ty)
|
| 92 |
+
offs_m = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
|
| 93 |
+
offs_n = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
|
| 94 |
+
c_ptrs = c_ptr + offs_m[:, None] * N + offs_n[None, :]
|
| 95 |
+
mask = (offs_m[:, None] < M) & (offs_n[None, :] < N)
|
| 96 |
+
tl.store(c_ptrs, c, mask=mask)
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def fp8_gemm(a: torch.Tensor, a_s: torch.Tensor, b: torch.Tensor, b_s: torch.Tensor):
|
| 100 |
+
assert a.is_contiguous() and b.is_contiguous()
|
| 101 |
+
assert a_s.is_contiguous() and b_s.is_contiguous()
|
| 102 |
+
K = a.size(-1)
|
| 103 |
+
M = a.numel() // K
|
| 104 |
+
N = b.size(0)
|
| 105 |
+
c = a.new_empty(*a.size()[:-1], N, dtype=torch.get_default_dtype())
|
| 106 |
+
grid = lambda META: (triton.cdiv(M, META['BLOCK_SIZE_M']), triton.cdiv(N, META['BLOCK_SIZE_N']))
|
| 107 |
+
fp8_gemm_kernel[grid](a, b, c, a_s, b_s, M, N, K)
|
| 108 |
+
return c
|
inference/model.py
ADDED
|
@@ -0,0 +1,421 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from dataclasses import dataclass
|
| 3 |
+
from typing import Tuple, Optional, Literal
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
from torch import nn
|
| 7 |
+
import torch.nn.functional as F
|
| 8 |
+
import torch.distributed as dist
|
| 9 |
+
|
| 10 |
+
from kernel import act_quant, weight_dequant, fp8_gemm
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
world_size = 1
|
| 14 |
+
rank = 0
|
| 15 |
+
block_size = 128
|
| 16 |
+
gemm_impl: Literal["bf16", "fp8"] = "bf16"
|
| 17 |
+
attn_impl: Literal["naive", "absorb"] = "absorb"
|
| 18 |
+
|
| 19 |
+
@dataclass
|
| 20 |
+
class ModelArgs:
|
| 21 |
+
max_batch_size: int = 8
|
| 22 |
+
max_seq_len: int = 4096 * 4
|
| 23 |
+
dtype: Literal["bf16", "fp8"] = "bf16"
|
| 24 |
+
vocab_size: int = 102400
|
| 25 |
+
dim: int = 2048
|
| 26 |
+
inter_dim: int = 10944
|
| 27 |
+
moe_inter_dim: int = 1408
|
| 28 |
+
n_layers: int = 27
|
| 29 |
+
n_dense_layers: int = 1
|
| 30 |
+
n_heads: int = 16
|
| 31 |
+
# moe
|
| 32 |
+
n_routed_experts: int = 64
|
| 33 |
+
n_shared_experts: int = 2
|
| 34 |
+
n_activated_experts: int = 6
|
| 35 |
+
n_expert_groups: int = 1
|
| 36 |
+
n_limited_groups: int = 1
|
| 37 |
+
score_func: Literal["softmax", "sigmoid"] = "softmax"
|
| 38 |
+
route_scale: float = 1.
|
| 39 |
+
# mla
|
| 40 |
+
q_lora_rank: int = 0
|
| 41 |
+
kv_lora_rank: int = 512
|
| 42 |
+
qk_nope_head_dim: int = 128
|
| 43 |
+
qk_rope_head_dim: int = 64
|
| 44 |
+
v_head_dim: int = 128
|
| 45 |
+
# yarn
|
| 46 |
+
original_seq_len: int = 4096
|
| 47 |
+
rope_theta: float = 10000.0
|
| 48 |
+
rope_factor: float = 40
|
| 49 |
+
beta_fast: int = 32
|
| 50 |
+
beta_slow: int = 1
|
| 51 |
+
mscale: float = 1.
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
class ParallelEmbedding(nn.Module):
|
| 55 |
+
def __init__(self, vocab_size: int, dim: int):
|
| 56 |
+
super().__init__()
|
| 57 |
+
self.vocab_size = vocab_size
|
| 58 |
+
self.dim = dim
|
| 59 |
+
assert vocab_size % world_size == 0
|
| 60 |
+
self.part_vocab_size = (vocab_size // world_size)
|
| 61 |
+
self.vocab_start_idx = rank * self.part_vocab_size
|
| 62 |
+
self.vocab_end_idx = self.vocab_start_idx + self.part_vocab_size
|
| 63 |
+
self.weight = nn.Parameter(torch.empty(self.part_vocab_size, self.dim))
|
| 64 |
+
|
| 65 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 66 |
+
if world_size > 1:
|
| 67 |
+
mask = (x < self.vocab_start_idx) | (x >= self.vocab_end_idx)
|
| 68 |
+
x = x - self.vocab_start_idx
|
| 69 |
+
x[mask] = 0
|
| 70 |
+
y = F.embedding(x, self.weight)
|
| 71 |
+
if world_size > 1:
|
| 72 |
+
y[mask] = 0
|
| 73 |
+
dist.all_reduce(y)
|
| 74 |
+
return y
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def linear(x: torch.Tensor, weight: torch.Tensor, bias: Optional[torch.Tensor] = None) -> torch.Tensor:
|
| 78 |
+
if weight.element_size() > 1:
|
| 79 |
+
return F.linear(x, weight, bias)
|
| 80 |
+
elif gemm_impl == "bf16":
|
| 81 |
+
weight = weight_dequant(weight, weight.scale)
|
| 82 |
+
return F.linear(x, weight, bias)
|
| 83 |
+
else:
|
| 84 |
+
x, scale = act_quant(x, block_size)
|
| 85 |
+
y = fp8_gemm(x, scale, weight, weight.scale)
|
| 86 |
+
if bias is not None:
|
| 87 |
+
y += bias
|
| 88 |
+
return y
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
class Linear(nn.Module):
|
| 92 |
+
dtype = torch.bfloat16
|
| 93 |
+
|
| 94 |
+
def __init__(self, in_features: int, out_features: int, bias: bool = False, dtype = None):
|
| 95 |
+
super().__init__()
|
| 96 |
+
self.in_features = in_features
|
| 97 |
+
self.out_features = out_features
|
| 98 |
+
self.weight = nn.Parameter(torch.empty(out_features, in_features, dtype=dtype or Linear.dtype))
|
| 99 |
+
if self.weight.element_size() == 1:
|
| 100 |
+
scale_out_features = (out_features + block_size - 1) // block_size
|
| 101 |
+
scale_in_features = (in_features + block_size - 1) // block_size
|
| 102 |
+
self.weight.scale = self.scale = nn.Parameter(torch.empty(scale_out_features, scale_in_features, dtype=torch.float32))
|
| 103 |
+
else:
|
| 104 |
+
self.register_parameter("scale", None)
|
| 105 |
+
if bias:
|
| 106 |
+
self.bias = nn.Parameter(torch.empty(self.part_out_features))
|
| 107 |
+
else:
|
| 108 |
+
self.register_parameter("bias", None)
|
| 109 |
+
|
| 110 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 111 |
+
return linear(x, self.weight, self.bias)
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
class ColumnParallelLinear(Linear):
|
| 115 |
+
def __init__(self, in_features: int, out_features: int, bias: bool = False, dtype = None):
|
| 116 |
+
assert out_features % world_size == 0
|
| 117 |
+
self.part_out_features = out_features // world_size
|
| 118 |
+
super().__init__(in_features, self.part_out_features, bias, dtype)
|
| 119 |
+
|
| 120 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 121 |
+
y = linear(x, self.weight, self.bias)
|
| 122 |
+
return y
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
class RowParallelLinear(Linear):
|
| 126 |
+
def __init__(self, in_features: int, out_features: int, bias: bool = False, dtype = None):
|
| 127 |
+
assert in_features % world_size == 0
|
| 128 |
+
self.part_in_features = in_features // world_size
|
| 129 |
+
super().__init__(self.part_in_features, out_features, bias, dtype)
|
| 130 |
+
|
| 131 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 132 |
+
y = linear(x, self.weight)
|
| 133 |
+
if world_size > 1:
|
| 134 |
+
dist.all_reduce(y)
|
| 135 |
+
if self.bias is not None:
|
| 136 |
+
y += self.bias
|
| 137 |
+
return y
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
class RMSNorm(nn.Module):
|
| 141 |
+
def __init__(self, dim: int, eps: float = 1e-6):
|
| 142 |
+
super().__init__()
|
| 143 |
+
self.eps = eps
|
| 144 |
+
self.weight = nn.Parameter(torch.ones(dim))
|
| 145 |
+
|
| 146 |
+
def forward(self, x: torch.Tensor):
|
| 147 |
+
x = x.float()
|
| 148 |
+
y = x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
|
| 149 |
+
return y.type_as(self.weight) * self.weight
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
def precompute_freqs_cis(args: ModelArgs) -> torch.Tensor:
|
| 153 |
+
dim = args.qk_rope_head_dim
|
| 154 |
+
seqlen = args.max_seq_len
|
| 155 |
+
beta_fast = args.beta_fast
|
| 156 |
+
beta_slow = args.beta_slow
|
| 157 |
+
base = args.rope_theta
|
| 158 |
+
factor = args.rope_factor
|
| 159 |
+
|
| 160 |
+
def find_correction_dim(num_rotations, dim, base, max_seq_len):
|
| 161 |
+
return dim * math.log(max_seq_len / (num_rotations * 2 * math.pi)) / (2 * math.log(base))
|
| 162 |
+
|
| 163 |
+
def find_correction_range(low_rot, high_rot, dim, base, max_seq_len):
|
| 164 |
+
low = math.floor(find_correction_dim(low_rot, dim, base, max_seq_len))
|
| 165 |
+
high = math.ceil(find_correction_dim(high_rot, dim, base, max_seq_len))
|
| 166 |
+
return max(low, 0), min(high, dim-1)
|
| 167 |
+
|
| 168 |
+
def linear_ramp_factor(min, max, dim):
|
| 169 |
+
if min == max:
|
| 170 |
+
max += 0.001
|
| 171 |
+
linear_func = (torch.arange(dim, dtype=torch.float32) - min) / (max - min)
|
| 172 |
+
ramp_func = torch.clamp(linear_func, 0, 1)
|
| 173 |
+
return ramp_func
|
| 174 |
+
|
| 175 |
+
freqs = 1.0 / (base ** (torch.arange(0, dim, 2, dtype=torch.float32) / dim))
|
| 176 |
+
if seqlen > args.original_seq_len:
|
| 177 |
+
low, high = find_correction_range(beta_fast, beta_slow, dim, base, args.original_seq_len)
|
| 178 |
+
smooth = 1 - linear_ramp_factor(low, high, dim // 2)
|
| 179 |
+
freqs = freqs / factor * (1 - smooth) + freqs * smooth
|
| 180 |
+
|
| 181 |
+
t = torch.arange(seqlen)
|
| 182 |
+
freqs = torch.outer(t, freqs)
|
| 183 |
+
freqs_cis = torch.polar(torch.ones_like(freqs), freqs)
|
| 184 |
+
return freqs_cis
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
def apply_rotary_emb(x: torch.Tensor, freqs_cis: torch.Tensor) -> torch.Tensor:
|
| 188 |
+
dtype = x.dtype
|
| 189 |
+
x = torch.view_as_complex(x.float().view(*x.shape[:-1], -1, 2))
|
| 190 |
+
freqs_cis = freqs_cis.view(1, x.size(1), 1, x.size(-1))
|
| 191 |
+
y = torch.view_as_real(x * freqs_cis).flatten(3)
|
| 192 |
+
return y.to(dtype)
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
class MLA(nn.Module):
|
| 196 |
+
def __init__(self, args: ModelArgs):
|
| 197 |
+
super().__init__()
|
| 198 |
+
self.dim = args.dim
|
| 199 |
+
self.n_heads = args.n_heads
|
| 200 |
+
self.n_local_heads = args.n_heads // world_size
|
| 201 |
+
self.q_lora_rank = args.q_lora_rank
|
| 202 |
+
self.kv_lora_rank = args.kv_lora_rank
|
| 203 |
+
self.qk_nope_head_dim = args.qk_nope_head_dim
|
| 204 |
+
self.qk_rope_head_dim = args.qk_rope_head_dim
|
| 205 |
+
self.qk_head_dim = args.qk_nope_head_dim + args.qk_rope_head_dim
|
| 206 |
+
self.v_head_dim = args.v_head_dim
|
| 207 |
+
|
| 208 |
+
if self.q_lora_rank == 0:
|
| 209 |
+
self.wq = ColumnParallelLinear(self.dim, self.n_heads * self.qk_head_dim)
|
| 210 |
+
else:
|
| 211 |
+
self.wq_a = Linear(self.dim, self.q_lora_rank)
|
| 212 |
+
self.q_norm = RMSNorm(self.q_lora_rank)
|
| 213 |
+
self.wq_b = ColumnParallelLinear(self.q_lora_rank, self.n_heads * self.qk_head_dim)
|
| 214 |
+
self.wkv_a = Linear(self.dim, self.kv_lora_rank + self.qk_rope_head_dim)
|
| 215 |
+
self.kv_norm = RMSNorm(self.kv_lora_rank)
|
| 216 |
+
self.wkv_b = ColumnParallelLinear(self.kv_lora_rank, self.n_heads * (self.qk_nope_head_dim + self.v_head_dim))
|
| 217 |
+
self.wo = RowParallelLinear(self.n_heads * self.v_head_dim, self.dim)
|
| 218 |
+
self.softmax_scale = self.qk_head_dim ** -0.5
|
| 219 |
+
if args.max_seq_len > args.original_seq_len:
|
| 220 |
+
mscale = 0.1 * args.mscale * math.log(args.rope_factor) + 1.0
|
| 221 |
+
self.softmax_scale = self.softmax_scale * mscale * mscale
|
| 222 |
+
|
| 223 |
+
if attn_impl == "naive":
|
| 224 |
+
self.register_buffer("k_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.qk_head_dim), persistent=False)
|
| 225 |
+
self.register_buffer("v_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.v_head_dim), persistent=False)
|
| 226 |
+
else:
|
| 227 |
+
self.register_buffer("kv_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.kv_lora_rank), persistent=False)
|
| 228 |
+
self.register_buffer("pe_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.qk_rope_head_dim), persistent=False)
|
| 229 |
+
|
| 230 |
+
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
|
| 231 |
+
bsz, seqlen, _ = x.size()
|
| 232 |
+
end_pos = start_pos + seqlen
|
| 233 |
+
if self.q_lora_rank == 0:
|
| 234 |
+
q = self.wq(x)
|
| 235 |
+
else:
|
| 236 |
+
q = self.wq_b(self.q_norm(self.wq_a(x)))
|
| 237 |
+
q = q.view(bsz, seqlen, self.n_local_heads, self.qk_head_dim)
|
| 238 |
+
q_nope, q_pe = torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
|
| 239 |
+
q_pe = apply_rotary_emb(q_pe, freqs_cis)
|
| 240 |
+
kv = self.wkv_a(x)
|
| 241 |
+
kv, k_pe = torch.split(kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
|
| 242 |
+
k_pe = apply_rotary_emb(k_pe.unsqueeze(2), freqs_cis)
|
| 243 |
+
if attn_impl == "naive":
|
| 244 |
+
q = torch.cat([q_nope, q_pe], dim=-1)
|
| 245 |
+
kv = self.wkv_b(self.kv_norm(kv))
|
| 246 |
+
kv = kv.view(bsz, seqlen, self.n_local_heads, self.qk_nope_head_dim + self.v_head_dim)
|
| 247 |
+
k_nope, v = torch.split(kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)
|
| 248 |
+
k = torch.cat([k_nope, k_pe.expand(-1, -1, self.n_local_heads, -1)], dim=-1)
|
| 249 |
+
self.k_cache[:bsz, start_pos:end_pos] = k
|
| 250 |
+
self.v_cache[:bsz, start_pos:end_pos] = v
|
| 251 |
+
scores = torch.einsum("bshd,bthd->bsht", q, self.k_cache[:bsz, :end_pos]) * self.softmax_scale
|
| 252 |
+
else:
|
| 253 |
+
wkv_b = self.wkv_b.weight if self.wkv_b.scale is None else weight_dequant(self.wkv_b.weight, self.wkv_b.scale, block_size)
|
| 254 |
+
wkv_b = wkv_b.view(self.n_local_heads, -1, self.kv_lora_rank)
|
| 255 |
+
q_nope = torch.einsum("bshd,hdc->bshc", q_nope, wkv_b[:, :self.qk_nope_head_dim])
|
| 256 |
+
self.kv_cache[:bsz, start_pos:end_pos] = self.kv_norm(kv)
|
| 257 |
+
self.pe_cache[:bsz, start_pos:end_pos] = k_pe.squeeze(2)
|
| 258 |
+
scores = (torch.einsum("bshc,btc->bsht", q_nope, self.kv_cache[:bsz, :end_pos]) +
|
| 259 |
+
torch.einsum("bshr,btr->bsht", q_pe, self.pe_cache[:bsz, :end_pos])) * self.softmax_scale
|
| 260 |
+
if mask is not None:
|
| 261 |
+
scores += mask.unsqueeze(1)
|
| 262 |
+
scores = scores.softmax(dim=-1, dtype=torch.float32).type_as(x)
|
| 263 |
+
if attn_impl == "naive":
|
| 264 |
+
x = torch.einsum("bsht,bthd->bshd", scores, self.v_cache[:bsz, :end_pos])
|
| 265 |
+
else:
|
| 266 |
+
x = torch.einsum("bsht,btc->bshc", scores, self.kv_cache[:bsz, :end_pos])
|
| 267 |
+
x = torch.einsum("bshc,hdc->bshd", x, wkv_b[:, -self.v_head_dim:])
|
| 268 |
+
x = self.wo(x.flatten(2))
|
| 269 |
+
return x
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
class MLP(nn.Module):
|
| 273 |
+
def __init__(self, dim: int, inter_dim: int):
|
| 274 |
+
super().__init__()
|
| 275 |
+
self.w1 = ColumnParallelLinear(dim, inter_dim)
|
| 276 |
+
self.w2 = RowParallelLinear(inter_dim, dim)
|
| 277 |
+
self.w3 = ColumnParallelLinear(dim, inter_dim)
|
| 278 |
+
|
| 279 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 280 |
+
return self.w2(F.silu(self.w1(x)) * self.w3(x))
|
| 281 |
+
|
| 282 |
+
|
| 283 |
+
class Gate(nn.Module):
|
| 284 |
+
def __init__(self, args: ModelArgs):
|
| 285 |
+
super().__init__()
|
| 286 |
+
self.dim = args.dim
|
| 287 |
+
self.topk = args.n_activated_experts
|
| 288 |
+
self.n_groups = args.n_expert_groups
|
| 289 |
+
self.topk_groups = args.n_limited_groups
|
| 290 |
+
self.score_func = args.score_func
|
| 291 |
+
self.route_scale = args.route_scale
|
| 292 |
+
self.weight = nn.Parameter(torch.empty(args.n_routed_experts, args.dim))
|
| 293 |
+
self.bias = nn.Parameter(torch.empty(args.n_routed_experts)) if self.dim == 7168 else None
|
| 294 |
+
|
| 295 |
+
def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 296 |
+
scores = linear(x, self.weight)
|
| 297 |
+
if self.score_func == "softmax":
|
| 298 |
+
scores = scores.softmax(dim=-1, dtype=torch.float32)
|
| 299 |
+
else:
|
| 300 |
+
scores = scores.sigmoid()
|
| 301 |
+
original_scores = scores
|
| 302 |
+
if self.bias is not None:
|
| 303 |
+
scores = scores + self.bias
|
| 304 |
+
if self.n_groups > 1:
|
| 305 |
+
scores = scores.view(x.size(0), self.n_groups, -1)
|
| 306 |
+
if self.bias is None:
|
| 307 |
+
group_scores = scores.amax(dim=-1)
|
| 308 |
+
else:
|
| 309 |
+
group_scores = scores.topk(2, dim=-1)[0].sum(dim=-1)
|
| 310 |
+
indices = group_scores.topk(self.topk_groups, dim=-1)[1]
|
| 311 |
+
mask = torch.zeros_like(scores[..., 0]).scatter_(1, indices, True)
|
| 312 |
+
scores = (scores * mask.unsqueeze(-1)).flatten(1)
|
| 313 |
+
indices = torch.topk(scores, self.topk, dim=-1)[1]
|
| 314 |
+
weights = original_scores.gather(1, indices)
|
| 315 |
+
if self.score_func == "sigmoid":
|
| 316 |
+
weights /= weights.sum(dim=-1, keepdim=True)
|
| 317 |
+
weights *= self.route_scale
|
| 318 |
+
return weights.type_as(x), indices
|
| 319 |
+
|
| 320 |
+
|
| 321 |
+
class Expert(nn.Module):
|
| 322 |
+
def __init__(self, dim: int, inter_dim: int):
|
| 323 |
+
super().__init__()
|
| 324 |
+
self.w1 = Linear(dim, inter_dim)
|
| 325 |
+
self.w2 = Linear(inter_dim, dim)
|
| 326 |
+
self.w3 = Linear(dim, inter_dim)
|
| 327 |
+
|
| 328 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 329 |
+
return self.w2(F.silu(self.w1(x)) * self.w3(x))
|
| 330 |
+
|
| 331 |
+
|
| 332 |
+
class MoE(nn.Module):
|
| 333 |
+
def __init__(self, args: ModelArgs):
|
| 334 |
+
super().__init__()
|
| 335 |
+
self.dim = args.dim
|
| 336 |
+
assert args.n_routed_experts % world_size == 0
|
| 337 |
+
self.n_routed_experts = args.n_routed_experts
|
| 338 |
+
self.n_local_experts = args.n_routed_experts // world_size
|
| 339 |
+
self.n_activated_experts = args.n_activated_experts
|
| 340 |
+
self.experts_start_idx = rank * self.n_local_experts
|
| 341 |
+
self.experts_end_idx = self.experts_start_idx + self.n_local_experts
|
| 342 |
+
self.gate = Gate(args)
|
| 343 |
+
self.experts = nn.ModuleList([Expert(args.dim, args.moe_inter_dim) if self.experts_start_idx <= i < self.experts_end_idx else None
|
| 344 |
+
for i in range(self.n_routed_experts)])
|
| 345 |
+
self.shared_experts = MLP(args.dim, args.n_shared_experts * args.moe_inter_dim)
|
| 346 |
+
|
| 347 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 348 |
+
shape = x.size()
|
| 349 |
+
x = x.view(-1, self.dim)
|
| 350 |
+
weights, indices = self.gate(x)
|
| 351 |
+
y = torch.zeros_like(x)
|
| 352 |
+
counts = torch.bincount(indices.flatten(), minlength=self.n_routed_experts).tolist()
|
| 353 |
+
for i in range(self.experts_start_idx, self.experts_end_idx):
|
| 354 |
+
if counts[i] == 0:
|
| 355 |
+
continue
|
| 356 |
+
expert = self.experts[i]
|
| 357 |
+
idx, top = torch.where(indices == i)
|
| 358 |
+
y[idx] += expert(x[idx]) * weights[idx, top, None]
|
| 359 |
+
z = self.shared_experts(x)
|
| 360 |
+
if world_size > 1:
|
| 361 |
+
dist.all_reduce(y)
|
| 362 |
+
return (y + z).view(shape)
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
class Block(nn.Module):
|
| 366 |
+
def __init__(self, layer_id: int, args: ModelArgs):
|
| 367 |
+
super().__init__()
|
| 368 |
+
self.attn = MLA(args)
|
| 369 |
+
self.ffn = MLP(args.dim, args.inter_dim) if layer_id < args.n_dense_layers else MoE(args)
|
| 370 |
+
self.attn_norm = RMSNorm(args.dim)
|
| 371 |
+
self.ffn_norm = RMSNorm(args.dim)
|
| 372 |
+
|
| 373 |
+
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]) -> torch.Tensor:
|
| 374 |
+
x = x + self.attn(self.attn_norm(x), start_pos, freqs_cis, mask)
|
| 375 |
+
x = x + self.ffn(self.ffn_norm(x))
|
| 376 |
+
return x
|
| 377 |
+
|
| 378 |
+
|
| 379 |
+
class Transformer(nn.Module):
|
| 380 |
+
def __init__(self, args: ModelArgs):
|
| 381 |
+
global world_size, rank
|
| 382 |
+
world_size = dist.get_world_size() if dist.is_initialized() else 1
|
| 383 |
+
rank = dist.get_rank() if dist.is_initialized() else 0
|
| 384 |
+
Linear.dtype = torch.float8_e4m3fn if args.dtype == "fp8" else torch.bfloat16
|
| 385 |
+
super().__init__()
|
| 386 |
+
self.max_seq_len = args.max_seq_len
|
| 387 |
+
self.embed = ParallelEmbedding(args.vocab_size, args.dim)
|
| 388 |
+
self.layers = torch.nn.ModuleList()
|
| 389 |
+
for layer_id in range(args.n_layers):
|
| 390 |
+
self.layers.append(Block(layer_id, args))
|
| 391 |
+
self.norm = RMSNorm(args.dim)
|
| 392 |
+
self.head = ColumnParallelLinear(args.dim, args.vocab_size, dtype=torch.get_default_dtype())
|
| 393 |
+
self.register_buffer("freqs_cis", precompute_freqs_cis(args), persistent=False)
|
| 394 |
+
|
| 395 |
+
@torch.inference_mode()
|
| 396 |
+
def forward(self, tokens: torch.Tensor, start_pos: int = 0):
|
| 397 |
+
seqlen = tokens.size(1)
|
| 398 |
+
h = self.embed(tokens)
|
| 399 |
+
freqs_cis = self.freqs_cis[start_pos:start_pos+seqlen]
|
| 400 |
+
mask = None
|
| 401 |
+
if seqlen > 1:
|
| 402 |
+
mask = torch.full((seqlen, seqlen), float("-inf"), device=tokens.device).triu_(1)
|
| 403 |
+
for layer in self.layers:
|
| 404 |
+
h = layer(h, start_pos, freqs_cis, mask)
|
| 405 |
+
h = self.norm(h)[:, -1]
|
| 406 |
+
logits = self.head(h)
|
| 407 |
+
if world_size > 1:
|
| 408 |
+
all_logits = [torch.empty_like(logits) for _ in range(world_size)]
|
| 409 |
+
dist.all_gather(all_logits, logits)
|
| 410 |
+
logits = torch.cat(all_logits, dim=-1)
|
| 411 |
+
return logits
|
| 412 |
+
|
| 413 |
+
|
| 414 |
+
if __name__ == "__main__":
|
| 415 |
+
torch.set_default_dtype(torch.bfloat16)
|
| 416 |
+
torch.set_default_device("cuda")
|
| 417 |
+
torch.manual_seed(0)
|
| 418 |
+
args = ModelArgs()
|
| 419 |
+
x = torch.randint(0, args.vocab_size, (2, 128))
|
| 420 |
+
model = Transformer(args)
|
| 421 |
+
print(model(x).size())
|
inference/requirements.txt
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch==2.4.1
|
| 2 |
+
triton==3.0.0
|
| 3 |
+
transformers==4.46.3
|
| 4 |
+
safetensors==0.4.5
|