
update readme
Browse files- README.md +51 -7
- image-1.png +0 -0
- image-2.png +0 -0
README.md
CHANGED
|
@@ -2,14 +2,25 @@
|
|
| 2 |
library_name: sentence-transformers
|
| 3 |
pipeline_tag: sentence-similarity
|
| 4 |
tags:
|
|
|
|
| 5 |
- sentence-transformers
|
| 6 |
- feature-extraction
|
| 7 |
- sentence-similarity
|
| 8 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 9 |
---
|
| 10 |
|
| 11 |
# djovak/embedic-base
|
| 12 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13 |
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
|
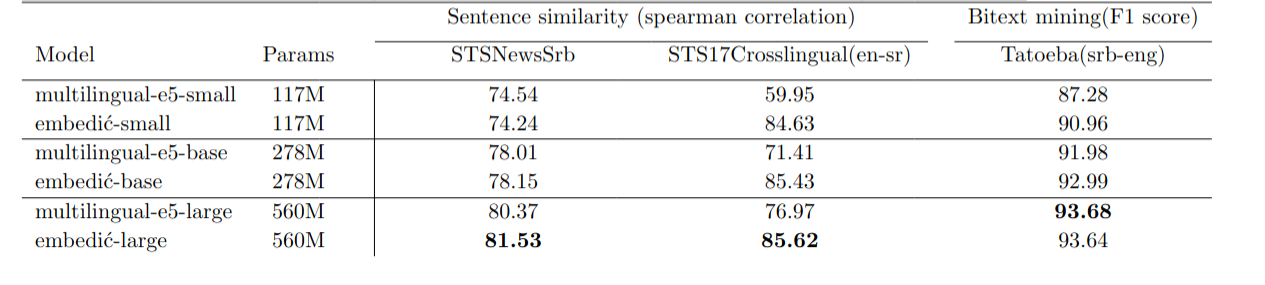
| 14 |
|
| 15 |
<!--- Describe your model here -->
|
|
@@ -26,21 +37,54 @@ Then you can use the model like this:
|
|
| 26 |
|
| 27 |
```python
|
| 28 |
from sentence_transformers import SentenceTransformer
|
| 29 |
-
sentences = ["
|
| 30 |
|
| 31 |
model = SentenceTransformer('djovak/embedic-base')
|
| 32 |
embeddings = model.encode(sentences)
|
| 33 |
print(embeddings)
|
| 34 |
```
|
| 35 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 36 |
|
|
|
|
| 37 |
|
| 38 |
-
|
| 39 |
|
| 40 |
-
|
| 41 |
|
| 42 |
-
|
| 43 |
|
|
|
|
| 44 |
|
| 45 |
|
| 46 |
## Full Model Architecture
|
|
@@ -52,6 +96,6 @@ SentenceTransformer(
|
|
| 52 |
)
|
| 53 |
```
|
| 54 |
|
| 55 |
-
##
|
| 56 |
|
| 57 |
-
|
|
|
|
| 2 |
library_name: sentence-transformers
|
| 3 |
pipeline_tag: sentence-similarity
|
| 4 |
tags:
|
| 5 |
+
- mteb
|
| 6 |
- sentence-transformers
|
| 7 |
- feature-extraction
|
| 8 |
- sentence-similarity
|
| 9 |
+
license: mit
|
| 10 |
+
language:
|
| 11 |
+
- multilingual
|
| 12 |
+
- en
|
| 13 |
+
- sr
|
| 14 |
---
|
| 15 |
|
| 16 |
# djovak/embedic-base
|
| 17 |
|
| 18 |
+
Say hello to **Embedić**, a group of new text embedding models finetuned for the Serbian language!
|
| 19 |
+
|
| 20 |
+
These models are particularly useful in Information Retrieval and RAG purposes. Check out images showcasing benchmark performance, you can beat previous SOTA with 5x fewer parameters!
|
| 21 |
+
|
| 22 |
+
Although specialized for Serbian(Cyrillic and Latin scripts), Embedić is Cross-lingual(it understands English too). So you can embed English docs, Serbian docs, or a combination of the two :)
|
| 23 |
+
|
| 24 |
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
|
| 25 |
|
| 26 |
<!--- Describe your model here -->
|
|
|
|
| 37 |
|
| 38 |
```python
|
| 39 |
from sentence_transformers import SentenceTransformer
|
| 40 |
+
sentences = ["ko je Nikola Tesla?", "Nikola Tesla je poznati pronalazač", "Nikola Jokić je poznati košarkaš"]
|
| 41 |
|
| 42 |
model = SentenceTransformer('djovak/embedic-base')
|
| 43 |
embeddings = model.encode(sentences)
|
| 44 |
print(embeddings)
|
| 45 |
```
|
| 46 |
|
| 47 |
+
### Important usage notes
|
| 48 |
+
- "ošišana ćirilica" (usage of c instead of ć, etc...) significantly deacreases search quality
|
| 49 |
+
- The usage of uppercase letters for named entities can significantly improve search quality
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
## Evaluation
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
### **Model description**:
|
| 56 |
+
|
| 57 |
+
| Model Name | Dimension | Sequence Length | Parameters
|
| 58 |
+
|:----:|:---:|:---:|:---:|
|
| 59 |
+
| [intfloat/multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small) | 384 | 512 | 117M
|
| 60 |
+
| [djovak/embedic-small](https://huggingface.co/djovak/embedic-small) | 384 | 512 | 117M
|
| 61 |
+
|||||||||
|
| 62 |
+
| [intfloat/multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) | 768 | 512 | 278M
|
| 63 |
+
| [djovak/embedic-base](https://huggingface.co/djovak/embedic-base) | 768 | 512 | 278M
|
| 64 |
+
|||||||||
|
| 65 |
+
| [intfloat/multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) | 1024 | 512 | 560M
|
| 66 |
+
| [djovak/embedic-large](https://huggingface.co/djovak/embedic-large) | 1024 | 512 | 560M
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
`BM25-ENG` - Elasticsearch with English analyzer
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
`BM25-SRB` - Elasticsearch with Serbian analyzer
|
| 74 |
+
|
| 75 |
+
### evaluation resultsresults
|
| 76 |
+
|
| 77 |
+
Evaluation on 3 tasks: Information Retrieval, Sentence Similarity, and Bitext mining. I personally translated the STS17 cross-lingual evaluation dataset and Spent 6,000$ on Google translate API, translating 4 IR evaluation datasets into Serbian language.
|
| 78 |
|
| 79 |
+
Evaluation datasets will be published as Part of [MTEB benchmark](https://huggingface.co/spaces/mteb/leaderboard) in the near future.
|
| 80 |
|
| 81 |
+

|
| 82 |
|
| 83 |
+

|
| 84 |
|
| 85 |
+
## Contact
|
| 86 |
|
| 87 |
+
If you have any question or sugestion related to this project, you can open an issue or pull request. You can also email me at [email protected]
|
| 88 |
|
| 89 |
|
| 90 |
## Full Model Architecture
|
|
|
|
| 96 |
)
|
| 97 |
```
|
| 98 |
|
| 99 |
+
## License
|
| 100 |
|
| 101 |
+
Embedić models are licensed under the [MIT License](https://github.com/FlagOpen/FlagEmbedding/blob/master/LICENSE). The released models can be used for commercial purposes free of charge.
|
image-1.png
ADDED
|
image-2.png
ADDED

|