
Codes and Checkpoints released
Browse files- Checkpoints/Charades-STA/VideoLights-B-pt.zip +3 -0
- Checkpoints/Charades-STA/VideoLights-B.zip +3 -0
- Checkpoints/Charades-STA/VideoLights-pt.zip +3 -0
- Checkpoints/Charades-STA/VideoLights.zip +3 -0
- Checkpoints/QVHighlights/VideoLights-B-pt.zip +3 -0
- Checkpoints/QVHighlights/VideoLights-B.zip +3 -0
- Checkpoints/QVHighlights/VideoLights-pt.zip +3 -0
- Checkpoints/QVHighlights/VideoLights.zip +3 -0
- README.md +172 -0
- res/cs.CV-arXiv_2412.01558-B31B1B.png +0 -0
- res/model_overview.png +0 -0
Checkpoints/Charades-STA/VideoLights-B-pt.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b7765493e6d0875cdffa235ac8977ba6ee322175000a24547b275ff1d6df1176
|
| 3 |
+
size 117671615
|
Checkpoints/Charades-STA/VideoLights-B.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3a113c7c4857cf037f047cff59d1af56b50b0e8d812ad06ddeb239858feb3865
|
| 3 |
+
size 117875410
|
Checkpoints/Charades-STA/VideoLights-pt.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d21a0f9dadedc42f0500fe5b0578fd9b1f02ae244e61d07fa76d275ccd02f9d5
|
| 3 |
+
size 113494058
|
Checkpoints/Charades-STA/VideoLights.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:55c464b48af37e884c32cf718c85220c6f6ed029753dc58a85dfa04d5e8021ac
|
| 3 |
+
size 113500457
|
Checkpoints/QVHighlights/VideoLights-B-pt.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:223d5b09605361810508ac79140d04df1e85443d1e9d0c8fb89768d11d97c4fe
|
| 3 |
+
size 119173915
|
Checkpoints/QVHighlights/VideoLights-B.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f22f29bac77062f60e768b5633cc5820214c58156347d59c625ed7b446cdc05b
|
| 3 |
+
size 119287728
|
Checkpoints/QVHighlights/VideoLights-pt.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:32d4b32f9b746dade3b140039b0c98ed6581938482e3342254bb8a79a5f16606
|
| 3 |
+
size 114881729
|
Checkpoints/QVHighlights/VideoLights.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:955217a565e3bcb441254fe91bb07704bff74a17a4d25466d731a5516ebf7b46
|
| 3 |
+
size 114887882
|
README.md
CHANGED
|
@@ -1,3 +1,175 @@
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
---
|
| 4 |
+
|
| 5 |
+
# VideoLights
|
| 6 |
+
|
| 7 |
+
[](https://arxiv.org/abs/2412.01558)
|
| 8 |
+
|
| 9 |
+

|
| 10 |
+
|
| 11 |
+
## Abstract
|
| 12 |
+
|
| 13 |
+
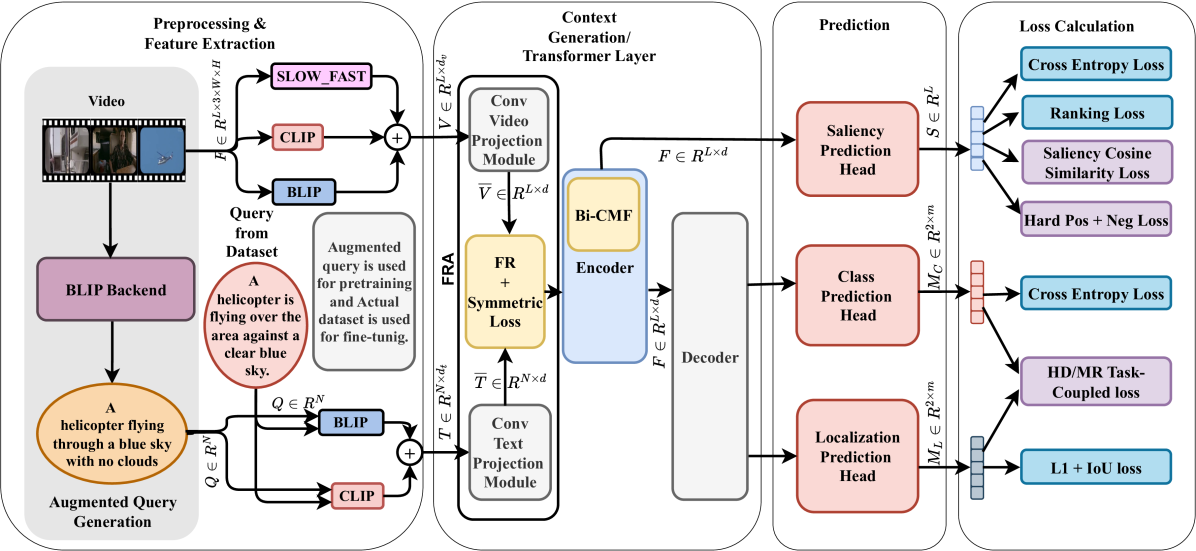
Video Highlight Detection and Moment Retrieval (HD/MR) are essential in video analysis. Recent joint prediction transformer models often overlook their cross-task dynamics and video-text alignment and refinement. Moreover, most models typically use limited, uni-directional attention mechanisms, resulting in weakly integrated representations and suboptimal performance in capturing the interdependence between video and text modalities. Although large-language and vision-language models (LLM/LVLMs) have gained prominence across various domains, their application in this field remains relatively underexplored. Here we propose VideoLights, a novel HD/MR framework addressing these limitations through (i) Convolutional Projection and Feature Refinement modules with an alignment loss for better video-text feature alignment, (ii) Bi-Directional Cross-Modal Fusion network for strongly coupled query-aware clip representations, and (iii) Uni-directional joint-task feedback mechanism enhancing both tasks through correlation. In addition, (iv) we introduce hard positive/negative losses for adaptive error penalization and improved learning, and (v) leverage LVLMs like BLIP-2 for enhanced multimodal feature integration and intelligent pretraining using synthetic data generated from LVLMs. Comprehensive experiments on QVHighlights, TVSum, and Charades-STA benchmarks demonstrate state-of-the-art performance. Codes and models are available at: https://github.com/dpaul06/VideoLights.
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
## Getting Started
|
| 17 |
+
|
| 18 |
+
### Prerequisites
|
| 19 |
+
0. Clone this repo
|
| 20 |
+
|
| 21 |
+
```
|
| 22 |
+
git clone https://github.com/dpaul06/VideoLights.git
|
| 23 |
+
cd VideoLights
|
| 24 |
+
```
|
| 25 |
+
|
| 26 |
+
1. Prepare feature files
|
| 27 |
+
|
| 28 |
+
Download [qvhighlights_features.tar.gz](https://huggingface.co/datasets/dpaul06/VideoLights/resolve/main/qvhighlights_features.tar.gz) (11GB),
|
| 29 |
+
extract it under `../Datasets/qvhl/` directory:
|
| 30 |
+
```
|
| 31 |
+
tar -xf path/to/qvhighlights_features.tar.gz
|
| 32 |
+
```
|
| 33 |
+
The Slowfast features are extracted using Linjie's [HERO_Video_Feature_Extractor](https://github.com/linjieli222/HERO_Video_Feature_Extractor). Clip and Blip features extraction codes are given with this repo.
|
| 34 |
+
If you want to use your own choices of video features, please download the raw videos from this [link](https://nlp.cs.unc.edu/data/jielei/qvh/qvhilights_videos.tar.gz).
|
| 35 |
+
|
| 36 |
+
2. Install dependencies.
|
| 37 |
+
|
| 38 |
+
This code requires Python 3.10, PyTorch, and a few other Python libraries.
|
| 39 |
+
We recommend creating conda environment and installing all the dependencies as follows:
|
| 40 |
+
```
|
| 41 |
+
# create conda env
|
| 42 |
+
conda create --name video_lights python=3.10
|
| 43 |
+
# activate env
|
| 44 |
+
conda actiavte video_lights
|
| 45 |
+
# install pytorch with CUDA 12.4
|
| 46 |
+
conda install pytorch torchvision torchaudio torchtext cudatoolkit pytorch-cuda=12.4 -c pytorch -c nvidia
|
| 47 |
+
# conda install pytorch torchvision torchaudio cudatoolkit -c pytorch
|
| 48 |
+
# install all deoendencies
|
| 49 |
+
pip install -r requirements.txt
|
| 50 |
+
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
### Training on QVHighlights
|
| 54 |
+
|
| 55 |
+
Training on QVHighlights can be launched by running the following command:
|
| 56 |
+
```
|
| 57 |
+
bash video_lights/scripts/qvhl/train.sh
|
| 58 |
+
```
|
| 59 |
+
This will train VideoLights for 200 epochs on the QVHighlights train split, with SlowFast and Open AI CLIP and Blip2 features. The training is very fast, it can be done within 4 hours using a single RTX 2080Ti GPU. The checkpoints and other experiment log files will be written into `results`. For training under different settings, you can append additional command line flags to the command above. For example, if you want to train the model without the saliency loss (by setting the corresponding loss weight to 0):
|
| 60 |
+
```
|
| 61 |
+
bash video_lights/scripts/qvhl/train.sh --lw_saliency 0
|
| 62 |
+
```
|
| 63 |
+
For more configurable options, please checkout our config file [video_lights/config.py](video_lights/config.py).
|
| 64 |
+
|
| 65 |
+
### Inference
|
| 66 |
+
Once the model is trained, you can use the following command for inference:
|
| 67 |
+
```
|
| 68 |
+
bash video_lights/scripts/qvhl/inference.sh CHECKPOINT_PATH SPLIT_NAME
|
| 69 |
+
```
|
| 70 |
+
where `CHECKPOINT_PATH` is the path to the saved checkpoint, `SPLIT_NAME` is the split name for inference, can be one of `val` and `test`.
|
| 71 |
+
|
| 72 |
+
### Pretraining and Finetuning
|
| 73 |
+
VideoLights utilizes synthetic data using Blip for weakly supervised pretraining. download already extracted features `pretrain_features_qc.tar.gz` from this [link](https://drive.google.com/file/d/19I-bVUiMW2bum8ZGUUQVfCOgeBRtcgs-/view?usp=sharing) (27.5GB) and extract them under `../pretrain/` directory
|
| 74 |
+
|
| 75 |
+
```
|
| 76 |
+
mkdir -p ../pretrain
|
| 77 |
+
tar -xf path/to/pretrain_features_qc.tar.gz -C ../pretrain
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
To launch pretraining, run:
|
| 81 |
+
```
|
| 82 |
+
bash video_lights/scripts/pretrain/pretrain_sf_clip_blip.sh
|
| 83 |
+
```
|
| 84 |
+
This will pretrain the VideoLights model on synthetic data for 100 epochs, the pretrained checkpoints and other experiment log files will be written into `results`. With the pretrained checkpoint, we can launch finetuning from a pretrained checkpoint `PRETRAIN_CHECKPOINT_PATH` as:
|
| 85 |
+
```
|
| 86 |
+
bash video_lights/scripts/qvhl/train.sh --resume ${PRETRAIN_CHECKPOINT_PATH}
|
| 87 |
+
```
|
| 88 |
+
Note that this finetuning process is the same as standard training except that it initializes weights from a pretrained checkpoint.
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
### Evaluation and Codalab Submission
|
| 92 |
+
Please check [standalone_eval/README.md](standalone_eval/README.md) for details.
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
### Training on TVSum
|
| 96 |
+
|
| 97 |
+
Download extracted features `tvsum_features.tar.gz` from this [link](https://huggingface.co/datasets/dpaul06/VideoLights/resolve/main/tvsum_features.tar.gz)
|
| 98 |
+
|
| 99 |
+
Extract it under `../Datasets/processed/`
|
| 100 |
+
```
|
| 101 |
+
mkdir -p ../Datasets/processed/
|
| 102 |
+
tar -xf path/to/tvsum_features.tar.gz -C ../Datasets/
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
Training on tvsum can be launched by running the following command:
|
| 106 |
+
```
|
| 107 |
+
bash video_lights/scripts/tvsum/train.sh
|
| 108 |
+
```
|
| 109 |
+
|
| 110 |
+
### Training on Charades-STA
|
| 111 |
+
|
| 112 |
+
Download extracted features `charades-features.tar.gz` from this [link](https://huggingface.co/datasets/dpaul06/VideoLights/resolve/main/charades-features.tar.gz)
|
| 113 |
+
|
| 114 |
+
Extract it under `../Datasets/processed/`
|
| 115 |
+
```
|
| 116 |
+
mkdir -p ../Datasets/processed/
|
| 117 |
+
tar -xf path/to/charades-features.tar.gz -C ../Datasets/
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
Training on Charades-STA can be launched by running the following command:
|
| 121 |
+
```
|
| 122 |
+
bash video_lights/scripts/charades_sta/train.sh
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
### Train VideoLights on your own dataset
|
| 126 |
+
To train VideoLights on your own dataset, please prepare your dataset annotations following the format
|
| 127 |
+
of QVHighlights annotations in [data](./data), and extract features using [HERO_Video_Feature_Extractor](https://github.com/linjieli222/HERO_Video_Feature_Extractor).
|
| 128 |
+
Next copy the script [video_lights/scripts/qvhl/train.sh](video_lights/scripts/qvhl/train.sh) and modify the dataset specific parameters
|
| 129 |
+
such as annotation and feature paths. Now you are ready to use this script for training as described in [Training](#training).
|
| 130 |
+
|
| 131 |
+
## Results and Checkpoints
|
| 132 |
+
|
| 133 |
+
### Results on QVHighlights test set
|
| 134 |
+
|
| 135 |
+
| Model | MR | | | HD | | Checkpoints |
|
| 136 |
+
| ----- | :---: | :---: | :---: | :---: | :---: | :---: |
|
| 137 |
+
| | [email protected] | [email protected] | mAP@Avg | mAP | HIT@1 | |
|
| 138 |
+
| VideoLights | 63.36 | 48.7 | 43.38 | 40.57 | 65.3 | [Link](Checkpoints/QVHighlights/VideoLights.zip) |
|
| 139 |
+
| VideoLights-pt | 68.48 | 52.53 | 45.01 | 41.48 | 65.89 | [Link](Checkpoints/QVHighlights/VideoLights-pt.zip) |
|
| 140 |
+
| VideoLights-B | 68.29 | 52.79 | 46.53 | 42.43 | 68.94 | [Link](Checkpoints/QVHighlights/VideoLights-B.zip) |
|
| 141 |
+
| VideoLights-B-pt | 70.36 | 55.25 | 47.94 | 42.84 | 70.56 | [Link](Checkpoints/QVHighlights/VideoLights-B-pt.zip) |
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
### Results on Charades-STA
|
| 145 |
+
|
| 146 |
+
| Model | [email protected] | [email protected] | [email protected] | mIoU | Checkpoints |
|
| 147 |
+
| ----- | :---: | :---: | :---: | :---: | :---: |
|
| 148 |
+
| VideoLights | 70.67 | 58.04 | 36.88 | 50.2 | [Link](Checkpoints/Charades-STA/VideoLights.zip) |
|
| 149 |
+
| VideoLights-pt | 72.26 | 60.11 | 37.8 | 51.44 | [Link](Checkpoints/Charades-STA/VideoLights-pt.zip) |
|
| 150 |
+
| VideoLights-B | 71.72 | 60.3 | 37.23 | 51.25 | [Link](Checkpoints/Charades-STA/VideoLights-B.zip) |
|
| 151 |
+
| VideoLights-B-pt | 73.33 | 61.96 | 41.05 | 52.94 | [Link](Checkpoints/Charades-STA/VideoLights-B-pt.zip) |
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
## Acknowledgement
|
| 157 |
+
This code is based on [moment-detr](https://github.com/jayleicn/moment_detr), [QD-DETR](https://github.com/wjun0830/QD-DETR), [CG-DETR](https://github.com/wjun0830/CGDETR) [detr](https://github.com/facebookresearch/detr) and [TVRetrieval XML](https://github.com/jayleicn/TVRetrieval). We used resources from [LAVIS](https://github.com/salesforce/LAVIS), [mdetr](https://github.com/ashkamath/mdetr), [MMAction2](https://github.com/open-mmlab/mmaction2), [CLIP](https://github.com/openai/CLIP), [SlowFast](https://github.com/facebookresearch/SlowFast) and [HERO_Video_Feature_Extractor](https://github.com/linjieli222/HERO_Video_Feature_Extractor). We thank the authors for their awesome open-source contributions.
|
| 158 |
+
|
| 159 |
+
## Cite this paper
|
| 160 |
+
|
| 161 |
+
```bibtex
|
| 162 |
+
@misc{paul2024videolightsfeaturerefinementcrosstask,
|
| 163 |
+
title={VideoLights: Feature Refinement and Cross-Task Alignment Transformer for Joint Video Highlight Detection and Moment Retrieval},
|
| 164 |
+
author={Dhiman Paul and Md Rizwan Parvez and Nabeel Mohammed and Shafin Rahman},
|
| 165 |
+
year={2024},
|
| 166 |
+
eprint={2412.01558},
|
| 167 |
+
archivePrefix={arXiv},
|
| 168 |
+
primaryClass={cs.CV},
|
| 169 |
+
url={https://arxiv.org/abs/2412.01558},
|
| 170 |
+
}
|
| 171 |
+
```
|
| 172 |
+
|
| 173 |
+
## LICENSE
|
| 174 |
+
The annotation files are under [CC BY-NC-SA 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/) license, see [./data/LICENSE](data/LICENSE). All the code are under [MIT](https://opensource.org/licenses/MIT) license, see [LICENSE](./LICENSE).
|
| 175 |
+
|
res/cs.CV-arXiv_2412.01558-B31B1B.png
ADDED

|
res/model_overview.png
ADDED
|